WO2021218470A1 - 一种神经网络优化方法以及装置 - Google Patents
一种神经网络优化方法以及装置 Download PDFInfo
- Publication number
- WO2021218470A1 WO2021218470A1 PCT/CN2021/081234 CN2021081234W WO2021218470A1 WO 2021218470 A1 WO2021218470 A1 WO 2021218470A1 CN 2021081234 W CN2021081234 W CN 2021081234W WO 2021218470 A1 WO2021218470 A1 WO 2021218470A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- hyperparameter
- combination
- neural network
- combinations
- hyperparameter combination
- Prior art date
Links
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/776—Validation; Performance evaluation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/047—Probabilistic or stochastic networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/048—Activation functions
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/082—Learning methods modifying the architecture, e.g. adding, deleting or silencing nodes or connections
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/0985—Hyperparameter optimisation; Meta-learning; Learning-to-learn
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
Definitions
- This application relates to the field of artificial intelligence, and in particular to a neural network optimization method and device.
- the parameters that are not obtained through training are called hyperparameters.
- a lot of practical experience is used to adjust the hyperparameters to make the neural network model perform better (for example, the image classification accuracy rate is higher).
- a deep neural network is composed of many neurons, and the input data is transmitted to the output neuron through the middle layer neuron through the input neuron.
- the weight of each neuron will be optimized according to the value of the loss function, thereby reducing the value of the loss function output by the updated model. Therefore, the model can be obtained by optimizing parameters through algorithms.
- the hyperparameters are used to adjust the entire network training process, such as the number of hidden layers of the neural network, the size and number of kernel functions, and so on.
- Hyperparameters are not directly involved in the training process. In the training process, the hyperparameters are often unchanged, but the hyperparameters are crucial to the final performance of the neural network. Therefore, it is particularly important to select a suitable set of hyperparameters. .
- the Successive Halving method is used to evaluate valuable hyper-parameter combinations.
- half of the poor performance results are discarded each time when multiple hyper-parameters are evaluated.
- Hyper-parameter combinations so that there are fewer effective hyper-parameter combinations, and because the number of evaluations of the hyper-parameter combinations is less, the evaluation results of the hyper-parameter combinations may be inaccurate due to partial evaluation errors, which leads to the use of inaccurate evaluation results
- the final optimal hyperparameter combination is also not accurate.
- This application discloses a neural network optimization method and device in the field of artificial intelligence, which are used to efficiently and accurately determine the hyperparameter combination of the neural network.
- this application provides a neural network optimization method, including: sampling a hyperparameter search space to obtain multiple hyperparameter combinations, the hyperparameter search space includes the hyperparameters of the neural network, and the hyperparameters include the non-passing in the neural network.
- Parameters obtained by training; multiple iterations of multiple hyperparameter combinations are evaluated to obtain multiple performance results of each hyperparameter combination in multiple hyperparameter combinations, and multiple performance results are based on substituting into each hyperparameter combination
- the result of the neural network output is determined, wherein in any one of the multiple iterative evaluations, at least one performance result of each hyperparameter combination evaluated before the current evaluation is obtained, and at least one of each hyperparameter combination
- the performance result is included in the multiple performance results of each hyper-parameter combination.
- the performance result determines the optimal hyperparameter combination from multiple hyperparameter combinations; if the optimal hyperparameter combination does not meet the second preset condition, the preset model is updated based on the multiple performance results of each hyperparameter combination, and the preset The model is used to fit the probability distribution, and the probability distribution is used to resample the hyperparameter search space; if the optimal hyperparameter combination meets the second preset condition, the optimal hyperparameter combination is used as the hyperparameter combination of the neural network.
- the hyperparameter combination that meets the first preset condition can be re-evaluated, instead of focusing on the best performance among multiple hyperparameter combinations.
- the performance results of the hyperparameters can obtain more performance results of the hyperparameter combinations whose performance is not optimal, and the accuracy of the overall performance results of the obtained multiple hyperparameter combinations can be improved. Therefore, the probability distribution corresponding to the preset model updated based on the overall more accurate performance results of multiple hyperparameter combinations is also more reliable, so that the hyperparameter combination obtained by re-sampling according to the preset model is also closer to the optimal combination.
- the performance of the determined optimal hyperparameter combination is also better.
- updating the model with the overall more accurate performance results of multiple hyperparameter combinations can quickly converge the preset model, improve convergence efficiency, and accurately and efficiently determine a better hyperparameter combination.
- any one of the foregoing iterations may further include: selecting a second hyperparameter combination from a plurality of hyperparameter combinations according to at least one performance result of each hyperparameter combination, and the second hyperparameter combination is The hyperparameter combination with the best performance among the multiple hyperparameter combinations, or the second hyperparameter combination is the hyperparameter combination with the most evaluation times among the multiple hyperparameter combinations.
- the first preset condition may include: the first superparameter combination The evaluation times of the parameter combination are not higher than the preset times, and the evaluation times of the first hyperparameter combination are not higher than the evaluation times of the second hyperparameter combination; or, the evaluation times of the first hyperparameter combination are higher than the preset times, and The evaluation times of the first hyperparameter combination are not higher than the evaluation times of the second hyperparameter combination, and the partial performance results of the second hyperparameter combination are worse than at least one performance result of the first hyperparameter combination.
- the second hyperparameter combination is also selected from the multiple hyperparameter combinations, and
- the first preset condition is determined according to at least one performance result of the second hyperparameter.
- the hyperparameter combination whose performance result is better than the partial performance result of the second hyperparameter combination can also be evaluated again, or the hyperparameter combination whose evaluation frequency is too low can also be evaluated again.
- the number of performance results of some hyperparameter combinations whose performance is not optimal or the number of evaluations is increased, and the accuracy of the overall performance results of multiple hyperparameters is improved.
- any one of the foregoing multiple iterations of evaluation may further include: if there is no first hyperparameter combination that satisfies the first preset condition among the multiple hyperparameter combinations, performing the evaluation on the first hyperparameter The two hyperparameter combinations are re-evaluated to obtain the performance result of the second hyperparameter combination re-evaluation, and the performance result of the second hyper-parameter combination re-evaluation is included in the multiple performance results of the second hyperparameter combination.
- the hyperparameter combination when iteratively evaluates multiple hyperparameter combinations, it is possible to determine the second hyperparameter combination that performs the best or has been evaluated the most times among the multiple hyperparameter combinations. If the hyperparameter combination meets the first preset condition, the hyperparameter combination that meets the first preset condition is evaluated again, and if there is no hyperparameter combination that meets the first preset condition, the second hyperparameter combination is evaluated.
- the embodiments of the present application are not limited to focusing on the second hyperparameter combination that performs best among multiple hyperparameter combinations, but also re-evaluate other hyperparameter combinations that satisfy the first preset condition among the multiple hyperparameter combinations, thereby
- the overall performance of multiple hyperparameter combinations is more accurate, so that the preset model updated based on the performance results of multiple hyperparameters with more accurate overall performance is also more reliable, and the hyperparameter combination obtained by re-sampling is also more inclined to the optimal combination.
- determining the second hyperparameter combination from the multiple hyperparameter combinations may include: determining the hyperparameter combination with the most evaluation times from the multiple hyperparameter combinations as the second hyperparameter combination; Or, if there are multiple hyperparameter combinations with the most evaluation times in the multiple hyperparameter combinations, at least one hyperparameter combination with the best performance is determined from the plurality of hyperparameter combinations with the most evaluation times as the second hyperparameter combination .
- the hyperparameter combination with the most evaluation times or the hyperparameter combination with the best performance can be selected from a plurality of hyperparameter combinations as the optimal second hyperparameter combination, and multiple selection methods are provided.
- each hyperparameter combination in each iteration evaluation, may be evaluated, and a result obtained by evaluating each hyperparameter combination before the current evaluation may be obtained. Or multiple performance results to obtain at least one performance result of each hyperparameter combination, or directly obtain all the evaluation results obtained before this iterative evaluation, to obtain at least one performance result of each hyperparameter combination. Therefore, the present application provides a variety of iterative evaluation methods, which increases the data volume of the performance result of the hyperparameter combination, and improves the accuracy of the overall performance result of the multiple hyperparameter combination.
- the preset model includes a first probability density function and a second probability density function
- updating the preset model through multiple performance results of each hyperparameter combination may include: according to each hyperparameter combination
- the performance results of the multiple hyperparameter combinations are divided into the first type of hyperparameter combination and the second type of hyperparameter combination.
- the performance of the first type of hyperparameter combination is better than that of the second type of hyperparameter combination.
- the performance of the parameter combination is determined based on the multiple performances of the first type of hyperparameter combination
- the performance of the second type of hyperparameter combination is determined based on the multiple performance results of the second type of hyperparameter
- the first type of hyperparameter combination is updated by the first type of hyperparameter combination.
- the probability density function is used to update the second probability density function through a combination of the second type of hyperparameters.
- the first probability density function may be updated by the first-type hyperparameter combination with better performance
- the second probability density function may be updated by the second-type hyperparameter combination with poor performance.
- the probability of re-sampling the hyperparameter search space obeys the probability distribution determined by the preset model. Therefore, the first probability density function is updated through the hyperparameter combination with excellent performance to make the probability corresponding to the first probability density function more accurate, so that The performance results of the hyperparameter combinations collected again are also better, which improves the convergence speed of the model and improves the accuracy of the overall performance results of multiple hyperparameter combinations.
- the type of the first probability density function or the second probability density function may include one or more of the following: normal distribution, discrete distribution, truncated normal distribution, or lognormal distribution.
- the probability density function can be a variety of models, so that the probability density function can be selected according to different scenarios.
- the neural network is a convolutional neural network for recognizing pictures
- the types of hyperparameters in the hyperparameter search space include one or more of the following: the number of convolutional layers, the number of convolution kernels, The expansion size, the position of the rectified linear unit (ReLU) function in the neural network, the size of the anchor frame, or the ratio of the length to the width of the anchor frame, the anchor frame is used to identify the object in the picture that needs to be recognized.
- the optimal hyperparameter combination of the convolutional neural network can be determined, so that a convolutional neural network with higher accuracy can be obtained.
- the neural network is obtained by combining one or more building units, and the types of hyperparameters in the hyperparameter search space include one or more of the following: the number of network layers of a building unit, the building unit The number of neurons in each layer of the network or the operator of each neuron in the construction unit. Therefore, through the neural network optimization method provided in the present application, a better building unit can be searched for, and a neural network with better realization can be obtained.
- the multiple performance results include classification accuracy or loss value
- the classification accuracy is used to indicate the accuracy of the neural network in recognizing the picture
- the loss value is the value of the loss function corresponding to the neural network
- the second preset condition Including: the classification accuracy of any one of the multiple performance results is greater than the first threshold, or the average value of the classification accuracy included in the multiple performance results is greater than the second threshold, or the loss value is not greater than the third threshold, and so on.
- the performance result of the hyperparameter can be measured by the classification accuracy or the loss value
- the optimal hyperparameter combination can be determined by the performance of the classification accuracy or the loss value
- sampling the hyper-parameter search space to obtain multiple hyper-parameter combinations may include: randomly sampling the hyper-parameter search space to obtain multiple hyper-parameter combinations; or, based on the pre-update The probability distribution determined by the model is assumed to sample the hyperparameter search space, and multiple hyperparameter combinations are obtained.
- the hyperparameter search space can be randomly sampled.
- the hyperparameter search space can be sampled for the first time, or the hyperparameter search space can be sampled based on the probability distribution determined by the preset model. Ways to get multiple hyperparameter combinations.
- this application provides a schematic structural diagram of a neural network optimization device.
- the neural network optimization device includes:
- the sampling module is used to sample the hyperparameter search space to obtain multiple hyperparameter combinations.
- the hyperparameter search space includes the hyperparameters of the neural network, and the hyperparameters include the parameters obtained without training in the neural network;
- the evaluation module is used to perform multiple iterative evaluations on multiple hyperparameter combinations to obtain multiple performance results of each hyperparameter combination in the multiple hyperparameter combinations.
- the multiple performance results are based on substituting into each hyperparameter combination.
- the result of the neural network output is determined, where in any one of the multiple iterative evaluations, at least one performance result of each hyperparameter combination evaluated before the current evaluation is obtained, if multiple hyperparameter combinations exist.
- the first hyperparameter combination of the first preset condition is evaluated again for the first hyperparameter combination to obtain the re-evaluated performance result of the first hyperparameter combination, and the re-evaluated performance result is included in the multiple of the first hyperparameter combination Performance results;
- the determination module is used to determine the optimal hyperparameter combination from multiple hyperparameter combinations according to the multiple performance results of each hyperparameter combination;
- the update module is used to update the preset model through multiple performance results of each hyperparameter combination if the optimal hyperparameter combination does not meet the second preset condition.
- the preset model is used to fit the probability distribution, and the probability distribution is used to Re-sample the hyperparameter search space;
- the selection module is configured to use the optimal hyperparameter combination as the hyperparameter combination of the neural network if the optimal hyperparameter combination satisfies the second preset condition.
- the first preset condition includes: the number of evaluations of the first hyperparameter combination is not higher than the preset number, and the number of evaluations of the first hyperparameter combination is not higher than the evaluation of the second hyperparameter combination
- the second hyperparameter combination is the hyperparameter combination that performs the best among multiple hyperparameter combinations selected in any one iteration, or the hyperparameter combination that has the most evaluation times among multiple hyperparameter combinations, that is, in any one iteration In the iteration, before judging whether there is a first hyperparameter combination that satisfies the first preset condition, the second hyperparameter combination is also selected; or, the evaluation times of the first hyperparameter combination are higher than the preset times, and the first hyperparameter combination
- the number of evaluations of is not higher than the number of evaluations of the second hyperparameter combination, and a part of the performance results of the second hyperparameter combination is worse than at least one performance result of the first hyperparameter combination.
- the evaluation module may further include: if there is no first hyperparameter combination satisfying the first preset condition among the multiple hyperparameter combinations, re-evaluate the second hyperparameter combination to obtain The performance result of the second hyperparameter combination re-evaluation.
- the preset model includes a first probability density function and a second probability density function
- the update module is specifically configured to: divide multiple hyperparameter combinations into at least one performance result of each hyperparameter combination For the first type of hyperparameter combination and the second type of hyperparameter combination, the performance of the first type of hyperparameter combination is better than that of the second type of hyperparameter combination, and the performance of the first type of hyperparameter combination is based on the first type of hyperparameter combination
- the performance of the second type of hyperparameter combination is determined based on the multiple performance results of the second type of hyperparameter, the first probability density function is updated through the first type of hyperparameter combination, and the second type of hyperparameter combination is used Update the second probability density function.
- the type of the first probability density function or the second probability density function may include one or more of the following: normal distribution, discrete distribution, truncated normal distribution, or lognormal distribution.
- the neural network is a convolutional neural network for recognizing pictures
- the types of hyperparameters in the hyperparameter search space include one or more of the following: the number of convolutional layers, the number of convolution kernels, The expansion size, the position of the ReLU function in the neural network, the size of the anchor frame or the ratio of the length and width of the anchor frame, the anchor frame is used to identify the object in the picture that needs to be recognized.
- the neural network is obtained by combining one or more building units, and the types of hyperparameters in the hyperparameter search space include one or more of the following: the number of network layers of a building unit, the building unit The number of neurons in each layer of the network or the operator of each neuron in the construction unit.
- the multiple performance results include classification accuracy or loss value
- the classification accuracy is used to indicate the accuracy of the neural network in recognizing pictures
- the loss value is the value of the loss function corresponding to the neural network
- the second preset The condition includes: the classification accuracy of any one of the multiple performance results is greater than the first threshold, or the average of the classification accuracy included in the multiple performance results is greater than the second threshold, or the loss value is not greater than the third threshold.
- the sampling module is specifically used to: randomly sample the hyperparameter search space to obtain multiple hyperparameter combinations; or, sample the hyperparameter search space based on the probability distribution determined by the preset model, Get multiple hyperparameter combinations.
- the present application provides a neural network optimization device, including: a processor and a memory, wherein the processor and the memory are interconnected by wires, and the processor calls the program code in the memory to execute any one of the above-mentioned first aspects.
- the neural network optimization device may be a chip.
- the embodiments of the present application provide a neural network optimization device.
- the neural network optimization device may also be called a digital processing chip or a chip.
- the chip includes a processing unit and a communication interface.
- the processing unit obtains program instructions through the communication interface.
- the instructions are executed by the processing unit, and the processing unit is configured to perform processing-related functions as in the foregoing first aspect or any optional implementation of the first aspect.
- an embodiment of the present application provides a computer-readable storage medium, including instructions, which when run on a computer, cause the computer to execute the method in the first aspect or any optional implementation of the first aspect.
- the embodiments of the present application provide a computer program product containing instructions, which when run on a computer, cause the computer to execute the method in the first aspect or any optional implementation of the first aspect.
- Figure 1 A schematic diagram of the main body framework of artificial intelligence applied in this application
- FIG. 2 is a schematic diagram of a convolutional neural network structure provided by an embodiment of the application.
- FIG. 3 is a schematic diagram of another convolutional neural network structure provided by an embodiment of the application.
- FIG. 4 is a schematic flowchart of a neural network optimization method provided by an embodiment of this application.
- FIG. 5 is a schematic flowchart of another neural network optimization method provided by an embodiment of the application.
- FIG. 6 is a schematic diagram of an application scenario provided by an embodiment of the application.
- FIG. 7 is a schematic diagram of another application scenario provided by an embodiment of the application.
- FIG. 8 is a schematic diagram of the accuracy of a neural network optimization method provided by an embodiment of this application.
- FIG. 9 is a schematic structural diagram of a neural network optimization device provided by an embodiment of this application.
- FIG. 10 is a schematic structural diagram of a neural network optimization device provided by an embodiment of the application.
- FIG. 11 is a schematic structural diagram of a chip provided by an embodiment of the application.
- AI artificial intelligence
- AI is a theory, method, technology and application system that uses digital computers or machines controlled by digital computers to simulate, extend and expand human intelligence, perceive the environment, acquire knowledge, and use knowledge to obtain the best results.
- artificial intelligence is a branch of computer science that attempts to understand the essence of intelligence and produce a new kind of intelligent machine that can react in a similar way to human intelligence.
- Artificial intelligence is to study the design principles and implementation methods of various intelligent machines, so that the machines have the functions of perception, reasoning and decision-making.
- Research in the field of artificial intelligence includes robotics, natural language processing, computer vision, decision-making and reasoning, human-computer interaction, recommendation and search, and basic AI theories.
- Figure 1 shows a schematic diagram of an artificial intelligence main framework, which describes the overall workflow of the artificial intelligence system and is suitable for general artificial intelligence field requirements.
- Intelligent Information Chain reflects a series of processes from data acquisition to processing. For example, it can be the general process of intelligent information perception, intelligent information representation and formation, intelligent reasoning, intelligent decision-making, intelligent execution and output. In this process, the data has gone through the condensing process of "data-information-knowledge-wisdom".
- the infrastructure provides computing power support for the artificial intelligence system, realizes communication with the outside world, and realizes support through the basic platform.
- computing power is provided by smart chips, such as central processing unit (CPU), network processor (neural-network processing unit, NPU), graphics processing unit (English: graphics processing unit, GPU), Hardware acceleration chips such as application specific integrated circuit (ASIC) or field programmable gate array (FPGA) are provided;
- the basic platform includes distributed computing framework and network related platform guarantee and support, It can include cloud storage and computing, interconnection networks, etc.
- sensors communicate with the outside to obtain data, and these data are provided to the smart chip in the distributed computing system provided by the basic platform for calculation.
- the data in the upper layer of the infrastructure is used to represent the data source in the field of artificial intelligence.
- the data involves graphics, images, voice, and text, as well as the Internet of Things data of traditional devices, including business data of existing systems and sensory data such as force, displacement, liquid level, temperature, and humidity.
- Data processing usually includes data training, machine learning, deep learning, search, reasoning, decision-making and other methods.
- machine learning and deep learning can symbolize and formalize data for intelligent information modeling, extraction, preprocessing, training, etc.
- Reasoning refers to the process of simulating human intelligent reasoning in a computer or intelligent system, using formal information to conduct machine thinking and solving problems based on reasoning control strategies.
- the typical function is search and matching.
- Decision-making refers to the process of making decisions after intelligent information is reasoned, and usually provides functions such as classification, ranking, and prediction.
- some general capabilities can be formed based on the results of the data processing, such as an algorithm or a general system, for example, translation, text analysis, computer vision processing, speech recognition, image Recognition and so on.
- Intelligent products and industry applications refer to the products and applications of artificial intelligence systems in various fields. It is an encapsulation of the overall solution of artificial intelligence, productizing intelligent information decision-making and realizing landing applications. Its application fields mainly include: intelligent manufacturing, intelligent transportation, Smart home, smart medical, smart security, autonomous driving, safe city, smart terminal, etc.
- the neural network is used as an important node to implement machine learning, deep learning, search, reasoning, decision making, etc.
- the neural networks mentioned in this application can include multiple types, such as deep neural networks (DNN), convolutional neural networks (convolutional neural networks, CNN), recurrent neural networks (RNN), residuals Network or other neural network, etc.
- DNN deep neural networks
- CNN convolutional neural networks
- RNN recurrent neural networks
- residuals Network residuals Network or other neural network
- a neural network can be composed of neural units, which can refer to an arithmetic unit that takes x S and intercept 1 as inputs.
- the output of the arithmetic unit can be:
- s 1, 2,...n, n is a natural number greater than 1
- W S is the weight of x S
- b is the bias of the neural unit.
- f is the activation function of the neural unit, which is used to introduce nonlinear characteristics into the neural network to convert the input signal in the neural unit into an output signal.
- the output signal of the activation function can be used as the input of the next convolutional layer.
- the activation function can be sigmoid, rectified linear unit (ReLU), tanh and other functions.
- a neural network is a network formed by connecting many of the above-mentioned single neural units together, that is, the output of one neural unit can be the input of another neural unit.
- the input of each neural unit can be connected with the local receptive field of the previous layer to extract the characteristics of the local receptive field.
- the local receptive field can be a region composed of several neural units.
- Convolutional neural networks (convolutional neural networks, CNN) is a deep neural network with a convolutional structure.
- the convolutional neural network contains a feature extractor composed of a convolutional layer and a sub-sampling layer.
- the feature extractor can be seen as a filter, and the convolution process can be seen as using a trainable filter to convolve with an input image or convolution feature map.
- the convolutional layer refers to the neuron layer that performs convolution processing on the input signal in the convolutional neural network.
- a neuron can be connected to only part of the neighboring neurons.
- a convolutional layer usually contains several feature planes, and each feature plane can be composed of some rectangularly arranged neural units.
- Neural units in the same feature plane share weights, and the shared weights here are the convolution kernels. Sharing weight can be understood as the way of extracting image information has nothing to do with location. The underlying principle is that the statistical information of a certain part of the image is the same as that of other parts. This means that the image information learned in one part can also be used in another part. So for all positions on the image, we can use the same learning image information. In the same convolution layer, multiple convolution kernels can be used to extract different image information. Generally, the more the number of convolution kernels, the richer the image information reflected by the convolution operation.
- the convolution kernel can be initialized in the form of a matrix of random size.
- the convolution kernel can obtain reasonable weights through learning.
- the direct benefit of sharing weights is to reduce the connections between the layers of the convolutional neural network, and at the same time reduce the risk of overfitting.
- Convolutional neural networks can use backpropagation (BP) algorithms to modify the size of the parameters in the initial super-resolution model during the training process, so that the reconstruction error loss of the super-resolution model becomes smaller and smaller. Specifically, forwarding the input signal to the output will cause error loss, and the parameters in the initial super-resolution model are updated by backpropagating the error loss information, so that the error loss is converged.
- the backpropagation algorithm is a backpropagation motion dominated by error loss, and aims to obtain the optimal super-resolution model parameters, such as a weight matrix.
- CNN convolutional neural networks
- CNN is a deep neural network with a convolutional structure. It is a deep learning architecture.
- the deep learning architecture refers to the use of machine learning algorithms to perform multiple levels of learning at different abstract levels.
- CNN is a feed-forward artificial neural network. Each neuron in the feed-forward artificial neural network responds to overlapping regions in the input image.
- a convolutional neural network (CNN) 100 may include an input layer 110, a convolutional layer/pooling layer 120, where the pooling layer is optional, and a neural network layer 130.
- the convolutional layer/pooling layer 120 may include layers 121-126 as in the example.
- layer 121 is a convolutional layer
- layer 122 is a pooling layer
- layer 123 is a convolutional layer
- 124 is a pooling layer
- 121 and 122 are convolutional layers
- 123 is a pooling layer
- 124 and 125 are convolutional layers
- 126 is a convolutional layer.
- Pooling layer That is, the output of the convolutional layer can be used as the input of the subsequent pooling layer, or as the input of another convolutional layer to continue the convolution operation.
- the convolutional layer 121 can include many convolution operators.
- the convolution operator is also called a kernel. Its role in image processing is equivalent to a filter that extracts specific information from the input image matrix.
- the convolution operator can essentially be a weight matrix, which is usually predefined. In the process of image convolution operation, the weight matrix is usually along the horizontal direction of the input image one pixel after another pixel (or two pixels then two pixels...It depends on the value of stride). Processing, so as to complete the work of extracting specific features from the image.
- the size of the weight matrix should be related to the size of the image. It should be noted that the depth dimension of the weight matrix and the depth dimension of the input image are the same.
- the weight matrix will extend to the entire depth of the input image. Therefore, convolution with a single weight matrix will produce a convolution output with a single depth dimension, but in most cases, a single weight matrix is not used, but multiple weight matrices with the same dimension are applied.
- the output of each weight matrix is stacked to form the depth dimension of the convolutional image.
- Different weight matrices can be used to extract different features in the image. For example, one weight matrix is used to extract edge information of the image, another weight matrix is used to extract specific colors of the image, and another weight matrix is used to eliminate unwanted noise in the image. Perform obfuscation and so on.
- the multiple weight matrices have the same dimensions, and the feature maps extracted by the multiple weight matrices with the same dimensions have the same dimensions, and the extracted feature maps with the same dimensions are combined to form the output of the convolution operation.
- weight values in these weight matrices need to be obtained through a lot of training in practical applications, and each weight matrix formed by the weight values obtained through training can extract information from the input image, thereby helping the convolutional neural network 100 to make correct predictions.
- the initial convolutional layer (such as 121) often extracts more general features, which can also be called low-level features; with the convolutional neural network
- the subsequent convolutional layers for example, 126
- features such as high-level semantics
- the pooling layer can also be a multi-layer convolutional layer followed by one or more pooling layers.
- the sole purpose of the pooling layer is to reduce the size of the image space.
- the pooling layer may include an average pooling operator and/or a maximum pooling operator for sampling the input image to obtain an image with a smaller size.
- the average pooling operator can calculate the pixel values in the image within a specific range to generate an average value.
- the maximum pooling operator can take the pixel with the largest value within a specific range as the result of the maximum pooling.
- the operators in the pooling layer should also be related to the image size.
- the size of the image output after processing by the pooling layer can be smaller than the size of the image of the input pooling layer, and each pixel in the image output by the pooling layer represents the average value or the maximum value of the corresponding sub-region of the image input to the pooling layer.
- the convolutional neural network 100 After processing by the convolutional layer/pooling layer 120, the convolutional neural network 100 is not enough to output the required output information. Because as mentioned above, the convolutional layer/pooling layer 120 only extracts features and reduces the parameters brought by the input image. However, in order to generate the final output information (required class information or other related information), the convolutional neural network 100 needs to use the neural network layer 130 to generate one or a group of required classes of output. Therefore, the neural network layer 130 may include multiple hidden layers (131, 132 to 13n as shown in FIG. 2) and an output layer 140.
- the convolutional neural network is: searching for the super unit with the output of the delay prediction model as a constraint condition to obtain at least one first building unit, and stacking the at least one first building unit to obtain.
- the convolutional neural network can be used for image recognition, image classification, image super-resolution reconstruction and so on.
- the output layer 140 After the multiple hidden layers in the neural network layer 130, that is, the final layer of the entire convolutional neural network 100 is the output layer 140.
- the output layer 140 has a loss function similar to the classification cross entropy, which is specifically used to calculate the prediction error.
- the convolutional neural network 100 shown in FIG. 2 is only used as an example of a convolutional neural network.
- the convolutional neural network may also exist in the form of other network models, such as
- the multiple convolutional layers/pooling layers shown in FIG. 3 are in parallel, and the respectively extracted features are input to the full neural network layer 130 for processing.
- a neural network In a neural network, some parameters need to be determined through training, and some parameters need to be determined before training. The following describes some of the parameters involved in the neural network.
- Hyper-parameter It is a parameter that is set to a value before starting the learning process, and is a parameter that is not obtained through training. Hyperparameters are used to adjust the training process of neural networks, such as the number of hidden layers of convolutional neural networks, the size and number of kernel functions, and so on. Hyperparameters are not directly involved in the training process, but only configuration variables. It should be noted that in the training process, the hyperparameters are often constant. The various neural networks currently in use are trained through data and a certain learning algorithm, and then a model that can be used for prediction and estimation is obtained. If this model does not perform well, experienced workers will adjust it.
- Parameters that are not obtained through training such as the network structure, the learning rate in the algorithm, or the number of samples processed in each batch, are generally called hyperparameters. It is usually through a lot of practical experience to adjust the hyperparameters to make the neural network model perform better, until the output of the neural network meets the demand.
- the set of hyperparameter combinations mentioned in this application includes all or part of the hyperparameter values of the neural network.
- a neural network consists of many neurons, and the input data is transmitted to the output through these neurons.
- the weight of each neuron will be optimized with the value of the loss function to reduce the value of the loss function. In this way, the model can be obtained by optimizing the parameters through the algorithm.
- the hyperparameters are used to adjust the entire network training process, such as the number of hidden layers of the aforementioned convolutional neural network, the size or number of kernel functions, and so on. Hyperparameters are not directly involved in the training process, but only as configuration variables.
- Optimizer Used to optimize the parameters of machine learning algorithms, such as network weights. Optimization algorithms such as gradient descent, stochastic gradient descent, or momentum gradient descent (adaptive momentum estimation, Adam) can be used to optimize the parameters.
- optimization algorithms such as gradient descent, stochastic gradient descent, or momentum gradient descent (adaptive momentum estimation, Adam) can be used to optimize the parameters.
- Learning rate refers to the amplitude of updating parameters in each iteration in the optimization algorithm, also called step size.
- step size refers to the amplitude of updating parameters in each iteration in the optimization algorithm, also called step size.
- Activation function refers to the non-linear function added to each neuron, which is the key to the non-linear nature of the neural network. Commonly used activation functions can include sigmoid, rectified linear unit (ReLU), tanh And other functions.
- ReLU rectified linear unit
- Loss function that is, the objective function in the parameter optimization process. Generally, the smaller the value of the loss function, the more accurate the output result of the model is. The process of model training is the process of minimizing the loss function. Commonly used loss functions can include logarithmic loss function, square loss function, exponential loss function and so on.
- Bayesian optimization can be used to select the optimal hyperparameters suitable for the neural network from multiple sets of hyperparameters.
- the Bayesian optimization process may include: first setting the initial model, and then selecting the hyper-parameter combination most likely to meet the preset conditions under the model, and detecting whether the hyper-parameter combination meets the preset conditions, and if the preset conditions are met The process is terminated, and the hyperparameter combination that meets the preset conditions is output; if not, the new set of data is used to modify the model, and the next iteration is continued.
- Commonly used Bayesian process for example, sample multiple hyperparameter combinations from the hyperparameter search space, evaluate each hyperparameter combination, then discard half of the performance results, continue to evaluate the half of the performance results, and then again Half of the poor performance is discarded until the computing resources are exhausted, and the optimal hyperparameter combination is determined from multiple hyperparameter combinations. If the hyper-parameter combination does not meet the requirements, the evaluation results of multiple hyper-parameter combinations are used to continue to modify the model, and multiple hyper-parameter combinations are sampled from the hyper-parameter search space again according to the model, and then evaluated again, etc., until the selected The performance result meets the required hyperparameter combination.
- this method is referred to as Bayesian optimization and hyperband (BOHB), which will not be described in detail below.
- BOHB Bayesian optimization and hyperband
- this application provides a neural network optimization method for efficiently and accurately determining the hyperparameter combination of the neural network.
- FIG. 4 a schematic flowchart of a neural network optimization method provided by the present application is as follows.
- the hyperparameter search space includes the hyperparameters of the neural network, and the hyperparameters can be collected from the hyperparameter search space to obtain multiple hyperparameter combinations. Among them, a set of hyperparameter combinations may include one or more hyperparameter values.
- the hyperparameter search space may include multiple hyperparameters, and the value of each hyperparameter may be a continuously distributed value or a discretely distributed value.
- the hyperparameter search space may include the value range of the hyperparameter A in [0, 10], and the value of the hyperparameter B may include: 1, 5, 8, 9, and so on. Therefore, when sampling in the hyperparameter search space, you can take any value from the values of the continuous distribution, or take any value from the values of the discrete distribution, to obtain a set of hyperparameter combinations.
- the hyperparameter combination can be collected through an initial probability distribution or randomly. For example, if it is the first time that the hyperparameter search space is sampled, the hyperparameter search space can be sampled according to the initial probability distribution to obtain multiple hyperparameter combinations.
- the hyperparameter search space may also be sampled through the probability distribution determined by the updated preset model in the following step 405. For example, if the preset model is updated, the hyperparameters can be sampled according to the probability distribution determined by the preset model to obtain multiple hyperparameter combinations.
- the preset model can be obtained, and the specific collection function may include: Among them, x is the hyperparameter combination, p(y
- the convolutional neural network can refer to the related description of the aforementioned FIG. 2 and FIG. 3.
- the hyperparameters of the convolutional neural network included in the hyperparameter search space may include one or more of the following: the number of convolutional layers, the number of convolution kernels, the expansion size, the position of the ReLU function in the neural network, the anchor box The size of the anchor frame or the ratio of the length to the width of the anchor frame, etc., where the anchor frame is used to identify the object that needs to be recognized in the picture.
- the hyperparameter combination mentioned in this application may include one or more of the aforementioned hyperparameters.
- Object detection can be understood as using one or more anchor frames to find the location of an object in a picture.
- anchor frame usually, multiple types can be defined in advance.
- the type of anchor frame including how many anchor frames are used in a picture, the aspect ratio of each anchor frame, etc.
- the hyperparameters included in the hyperparameter search space may include: building units The number of network layers, the number of neurons in each layer of the network in the construction unit, or the operation operators on each neuron in the construction unit, etc.
- the hyperparameter combination mentioned in this application may include one or more of them.
- the hyperparameters included in the hyperparameter search space may include the number of network layers of the construction unit of the face recognition neural network, the number of neurons in each layer of the network in the construction unit, and The operation operator of each neuron in the construction unit, etc.
- the hyperparameter combination is used to construct a face recognition neural network.
- the hyperparameter search space may include multiple transformation methods, and the multiple transformation methods are used to transform the data, thereby increasing the amount of data.
- the transformation method may include operations such as rotation, translation, or folding in half to increase the number of pictures.
- a learning strategy needs to be determined.
- the adjustable variables included in the learning strategy are the hyperparameters of the neural network, so that the neural network can learn according to the learning strategy, thereby adjusting the neural network's performance. Some parameters. For example, if the input of a neuron in the neural network is x1 and x2, the weight of x1 is w1, and the output of the neuron is: w1*x1+w2*x2, the learning strategy that needs to be determined is how to update w1 or w2 , Such as determining the adjustment step length, the adjustment calculation method, etc.
- multiple iterative evaluations are performed on the multiple hyperparameter combinations to obtain multiple performance results for each hyperparameter combination.
- any one iterative evaluation at least one performance result of each hyper-parameter combination is obtained, and if there is a hyper-parameter combination that meets the first preset condition among the multiple hyper-parameter combinations, The hyper-parameter combination is re-evaluated, and the performance result of the re-evaluation of the hyper-parameter combination that meets the first preset condition is obtained.
- the first preset condition is for example: the number of evaluations is the least or the performance result is better than a certain performance result. Therefore, in the embodiments of the present application, the hyperparameter combination that meets the first preset condition is re-evaluated, instead of focusing on the best performing hyperparameter combination, the accuracy of the overall performance results of multiple hyperparameter combinations is improved. When the model is subsequently updated, the model can be quickly converged.
- any one of the multiple iterative evaluations may include: obtaining at least one performance result of each hyper-parameter combination in the multiple hyper-parameters, and obtaining at least one performance result of each hyper-parameter combination from the multiple hyper-parameters
- a second hyperparameter combination is determined from the combinations, and the second hyperparameter combination is the hyperparameter combination with the most evaluation times or the best performance.
- the first preset condition may be determined according to at least one performance result of the second hyperparameter combination. Then it is determined whether there is a hyper-parameter combination that meets the first preset condition in the at least one hyper-parameter combination.
- the first hyperparameter combination is re-evaluated to obtain the performance result of the re-evaluation of the first hyperparameter combination, and the second superparameter combination
- the parameter combination and the first hyperparameter combination are not the same. If there is no first hyper-parameter combination that meets the first preset condition among the multiple hyper-parameter combinations, the second hyper-parameter combination is re-evaluated to obtain the re-evaluated performance result of the second hyper-parameter combination.
- the multiple hyper-parameter combinations can be evaluated to obtain at least one performance result of each hyper-parameter combination, or to obtain the previous iteration evaluation , At least one performance result obtained by evaluating each of the hyperparameters. For example, in the first evaluation, each hyperparameter combination in the multiple hyperparameter combinations is evaluated, and at least one performance result of each hyperparameter combination is obtained.
- N is a positive integer greater than 1.
- the aforementioned first preset condition is associated with at least one performance result of the second hyperparameter combination, and it can be understood that the first preset condition is determined according to at least one performance result of the second hyperparameter combination.
- the first preset condition determined according to at least one performance result of the second hyperparameter combination may include one of the following: the number of evaluations of the first hyperparameter combination is not higher than the preset number, and the first hyperparameter combination The evaluation times of the second hyperparameter combination are not higher than the evaluation times of the second hyperparameter combination; or, the evaluation times of the first hyperparameter combination are higher than the preset times, but not higher than the evaluation times of the second hyperparameter combination, and the second hyperparameter combination At least one of the performance results of has some results that are worse than the performance results of the first hyperparameter combination.
- the hyperparameter combination can be re-evaluated to obtain the re-evaluated performance result.
- the hyper-parameter combination can be re-evaluated.
- the performance result obtained by the evaluation further confirms whether the performance result of the hyperparameter combination can be better. Therefore, the implementation of the present application can re-evaluate the hyperparameter combination with few evaluation times or some good performance results. If the performance result of a certain hyperparameter combination is poor, it can also be evaluated again, so that the hyperparameter combination Performance results are more accurate.
- the first preset condition may be specifically expressed as:
- n k ⁇ n k′ and n k ⁇ c n , where n k is the number of evaluations of the first hyperparameter combination, n k′ is the number of evaluations of the second hyperparameter combination, and c n is the preset number;
- Y (k) is the performance result of the k-th hyperparameter combination
- Y (k′) is the performance result of the second hyperparameter combination.
- the first hyper-parameter combination has 10 performance results and the second hyper-parameter combination has 50 performance results
- the evaluation result includes the loss value
- the hyperparameter combination with the least number of evaluations is taken as The first hyperparameter combination, or each hyperparameter combination whose evaluation times are less than the threshold and not higher than the evaluation times of the second hyperparameter combination is regarded as the first hyperparameter combination, that is, the multiple evaluation times may be less than the threshold , And the hyperparameter combination that is not higher than the evaluation times of the second hyperparameter combination is evaluated again.
- the hyper-parameter combination that performs better is selected from the multiple hyper-parameter combinations as the first hyper-parameter combination, or each of the multiple hyper-parameter combinations that meets the condition 2 As the first hyper-parameter combination, one hyper-parameter combination can be evaluated again for the multiple hyper-parameter combinations that satisfy the condition 2.
- the hyperparameter combination to be evaluated again can be selected from the multiple hyperparameter combinations through the first preset condition, so that the number of evaluations is less, or the hyperparameter combination whose performance result is better than the partial result of the second hyperparameter combination Perform re-evaluation to improve the accuracy of the performance result of the hyperparameter combination, and further improve the accuracy of the overall performance result of the multiple hyperparameter combinations.
- the specific method for evaluating the hyperparameter combination to obtain the performance result of the hyperparameter combination may include: substituting the hyperparameters included in the hyperparameter combination into the neural network, and then determining the performance result of the hyperparameter combination according to the output of the neural network .
- the performance result may be the classification accuracy, loss value, precision, recall, or number of epochs of the results output by the neural network.
- the classification accuracy represents the accuracy of the neural network to recognize the picture
- the loss value is the value of the loss function of the neural network
- the accuracy rate is used to represent the output result of the neural network.
- the proportion of the sum of the false samples indicates how many of the samples predicted to be positive are correct; the recall rate is used to indicate the results of the neural network output, the samples judged to be true, accounting for the actual samples
- Proportion means how many positive samples in the predicted samples are predicted correctly; one epoch means that in the scenario of reinforcement learning, all samples in the training set are trained once.
- the optimal hyperparameter combination is determined from the multiple hyperparameter combinations according to the multiple performance results of each hyperparameter combination.
- the hyperparameter combination with the most evaluation times may be used as the optimal hyperparameter combination.
- the hyperparameter combination with the best performance can be determined from the multiple hyperparameter combinations with the largest number of evaluations as the second hyperparameter combination.
- the performance result may include the parameters included in the performance result for determination.
- the parameters included in the performance result of the hyperparameter combination are different, and the performance result is measured.
- the optimal way may be different.
- the hyperparameter combination with the best performance result may be: the hyperparameter combination with the highest classification accuracy, or the highest average classification accuracy, or the hyperparameter combination with the lowest loss value, or the like.
- the optimal hyperparameter combination After the optimal hyperparameter combination is determined, it is determined whether the optimal hyperparameter combination satisfies the second preset condition. If the optimal hyperparameter combination satisfies the second preset condition, the hyperparameters included in the optimal hyperparameter combination are used as the hyperparameters of the neural network, that is, step 406 is executed. If the optimal hyperparameter combination does not meet the second preset condition, the preset model is updated based on the multiple performance results of each hyperparameter combination, that is, step 405 is executed.
- the second preset condition may change with different performance results of the hyperparameter combination.
- the second preset condition may correspond to different conditions in different scenarios. Illustratively, some specific scenarios are taken as examples below. Give an illustrative description.
- the performance result of the hyperparameter combination includes classification accuracy
- the second preset condition may include: the classification accuracy in any one of the performance results of the optimal hyperparameter combination is greater than the first threshold, or the optimal The multiple performance results of the hyperparameter combination include an average value of classification accuracy greater than the second threshold.
- the second preset condition may include that the loss value is not greater than the third threshold.
- the second preset condition may include: any accuracy rate is greater than the fourth threshold, or the average value of multiple accuracy rates is greater than the fifth threshold, or, The recall rate is greater than the sixth threshold and so on.
- the second preset condition may include that the number of epochs is not greater than the seventh threshold.
- step 401 can be continued.
- the first preset model includes a first probability density function and a second probability density function.
- the first probability density function is denoted as l(x) and the second probability density function is denoted as g(x) below.
- the probability density function is a continuous function used to express the probability that the output value of a random variable is near a certain value point. The probability that the value of a random variable falls within a certain region is the integral of the probability density function in this region.
- the cumulative distribution function is the integral of the probability density function.
- the types of the first probability density function and the second probability density function may include but are not limited to one or more of the following: normal distribution, discrete distribution, truncated normal distribution, lognormal distribution, exponential distribution, Gamma distribution, Beta distribution or Bernoulli distribution, etc.
- the specific type of the probability density function can be adjusted according to actual application scenarios, which is not limited in this application.
- the multiple hyperparameter combinations are divided into two types, including the first type of hyperparameter combination and the second type of hyperparameter combination.
- the performance of the first type of hyperparameter combination is better than that of the second type of hyperparameter combination.
- the performance of the first type of hyperparameter is determined based on multiple performance results of the first type of hyperparameter, and the performance of the second type of hyperparameter combination is based on the performance of the first type of hyperparameter.
- the performance result of the two-type hyperparameter combination is determined, and l(x) is updated through the first-type hyperparameter combination, and g(x) is updated through the second-type hyperparameter combination.
- the overall performance of the first type of hyperparameter combination is better than that of the second type of hyperparameter combination.
- the number of evaluations of the first type of hyperparameter is higher than that of the second type of hyperparameter combination, or the first type of hyperparameter combination
- the average of the classification accuracy included in the multiple performance results of the hyperparameter combination is higher than the average of the classification accuracy included in the multiple performance results of the second type of hyperparameter combination, or the multiple performances of the first type of hyperparameter combination
- the average value of the loss value included in the result is lower than the average value of the loss value included in the multiple performance results of the second-type hyperparameter combination.
- the way to evaluate the superiority of the first-type hyperparameter combination over the second-type hyperparameter combination may be different, which can be specifically adjusted according to actual application scenarios.
- the embodiments of the present application are illustrative descriptions.
- KDE kernel density estimation
- TPE tree parameter estimation
- Gaussian process Gaussian process
- SMAC sequential model-based algorithm configuration
- the present application divides the multiple hyperparameter combinations into the first type of hyperparameter and the second type of hyperparameter according to the performance result, and the distribution range of the better performing hyperparameter can be determined according to the performance result of the first type of hyperparameter , So as to fit the first probability density function; according to the performance results of the second type of hyperparameters, determine the distribution range of the poorly performing hyperparameters, thereby fitting to obtain the second probability density function.
- the hyperparameter combination whose average classification accuracy value is higher than the preset value is classified into the second type of hyperparameter combination.
- the hyperparameter combinations whose average classification accuracy value is not higher than the preset value are classified into the second type of hyperparameter combinations.
- the performance result of a hyperparameter combination includes a loss value, generally the lower the loss value, the better the performance of the hyperparameter combination.
- the hyperparameter combination whose average loss value is lower than the preset value can be classified as the first The type of hyperparameter combination, which divides the hyperparameter combination whose average loss value is not lower than the preset value into the second type of hyperparameter combination.
- multiple hyperparameters can be combined and divided into two types according to a preset ratio.
- the ratio of 3:7 can be preset, and according to the multiple performance results of each hyperparameter combination, 3/10 of the better performance is divided into the first type of hyperparameter combination, and the poor performance 7/ 10 is divided into the second type of hyperparameter combination.
- the method of comparing the performance results of the hyperparameter combination may include: calculating the average value of the multiple performance results of each hyperparameter combination, sorting the average value of the multiple hyperparameter combinations, and then according to the sorting result, according to the preset The ratio uses the better-performing hyperparameter combination as the second hyperparameter combination, and the poorer-performing hyperparameter combination as the first hyperparameter combination.
- the performance result of the hyperparameter combination includes a loss value
- the lower the loss value the better the performance result of the hyperparameter combination
- the higher the loss value the better the performance of the hyperparameter combination.
- the worse the performance of the hyperparameter combination when the performance result of the hyperparameter combination includes classification accuracy, the higher the classification accuracy value, the better the performance of the hyperparameter combination, and the lower the classification accuracy value, the worse the performance of the hyperparameter combination.
- sampling can be performed according to the probability distribution fitted by the preset model.
- specific collection functions can include: Among them, x is the hyperparameter combination, After updating l(x) and g(x), collect the hyperparameter combinations again according to the probability distribution corresponding to l(x), and then determine the final collected multiple hyperparameter combinations based on l(x)/g(x) , That is, the collected multiple hyperparameter combinations satisfy the probability distributions corresponding to l(x) and g(x).
- Hyper-parameter combination which can accurately and efficiently determine a better-performing hyper-parameter combination.
- the optimal hyperparameter combination can be used as the hyperparameter combination of the neural network.
- the hyperparameter search space includes the hyperparameters of the convolutional neural network
- the hyperparameters included in the optimal hyperparameter combination are used as the hyperparameters of the convolutional neural network .
- the optimal hyperparameter combination includes parameters such as the number of convolutional layers, kernel size, expansion size, and ReLU position, the parameters included in the optimal hyperparameter combination are used as the number of convolutional layers and kernel size of the convolutional neural network , Expansion size, ReLU location, etc.
- the hyperparameter combination of the hyperparameter combination is re-evaluated, so as to avoid inaccurate performance results due to a small number of evaluations or errors in some performance results, and improve the accuracy of the performance results of the final hyperparameter combination. Further, the accurate performance results can be used to update the model, so that the model can converge quickly and improve convergence efficiency. And according to the model, the hyperparameter search space is further sampled, so that the hyperparameter combination with better performance can be determined accurately and efficiently.
- the foregoing describes the flow of the neural network optimization method provided by the present application.
- the following takes a specific application scenario as an example to give an exemplary introduction to the neural network optimization method provided by the present application.
- FIG. 5 is a schematic flowchart of another neural network optimization method provided by the present application.
- the hyperparameter search space can be randomly sampled, or the hyperparameter search space can be sampled according to the probability distribution determined by the preset model, to obtain K hyperparameter combinations, K is a positive integer, and the specific value of K can be based on actual conditions. Application scenarios are adjusted.
- the hyperparameter search space can include the number of convolutional layers, the number of convolution kernels, the expansion size, the position of the ReLU function in the neural network, the size of the anchor box, or the length and width of the anchor box.
- the value range of multiple hyper-parameter combinations such as the ratio of, if the hyper-parameter search space is currently being sampled for the first time, a batch of hyper-parameter combinations can be randomly collected from the hyper-parameter search space to obtain K hyper-parameter combinations, each The hyperparameter combination includes values such as the number of convolution layers, the number of convolution kernels, the expansion size, the position of the ReLU function in the neural network, the size of the anchor frame, or the ratio of the length and width of the anchor frame.
- step 501 reference may be made to the related description of step 401, which will not be repeated here.
- the resources included in the b-part resource may be different in different scenarios.
- the b-part computing resource may include b iterations, that is, the number of iterations is b; or, in Monte Carlo calculation, the b-part calculation
- the resource may include the number of samples used, for example, the number of samples is b; or, in a reinforcement learning scenario, the b pieces of computing resources may include the number of rounds of learning attempts.
- each hyperparameter combination can be evaluated b iterations to obtain b performance results for each hyperparameter combination.
- the convolutional neural network for image recognition as an example, the number of convolutional layers included in each hyperparameter combination, the number of convolution kernels, the expansion size, the position of the ReLU function in the convolutional neural network, and the anchor box
- the size or the ratio of the length and width of the anchor box is substituted into the convolutional neural network, and then the existing training data is used as the input of the convolutional neural network to obtain the output result of the convolutional neural network.
- the output of the network is compared with the actual value of the training data, and a performance result of the hyperparameter combination is obtained. If b iterations of evaluation are performed, b performance results are obtained.
- the picture shown in Figure 6 is used as the input of the convolutional neural network, and the number of convolutional layers, the number of convolution kernels, the expansion size, and the ReLU function included in the hyperparameter combination are used in the convolutional neural network.
- the position, the size of the anchor frame, or the ratio of the length and width of the anchor frame are substituted into the convolutional neural network, and the size of the anchor frame (that is, the black box shown in Figure 6) or the ratio of the length and width of the anchor frame are marked Figure out the animals to be identified or identified in the picture.
- pictures collected by vehicle sensors or cameras can be used as the input of the convolutional neural network, according to the anchor frame included in the hyperparameter combination (that is, as shown in Figure 7).
- the size of the black frame shown) or the ratio of the length to the width of the anchor frame, etc. mark the vehicle or other obstacles in the picture, so as to provide decision input information for the automatic driving control system of the vehicle and improve the safety of the vehicle.
- the second hyperparameter combination with the best performance is selected according to the multiple performance results of each hyperparameter combination.
- the parameters included in the performance result of the hyperparameter combination are different, and the way to measure whether the performance result is optimal may be different.
- the hyperparameter combination with the best performance result may be: the hyperparameter combination with the highest classification accuracy, or the highest average classification accuracy, or the hyperparameter combination with the lowest loss value, or the like.
- the optimal second hyperparameter combination After determining the optimal second hyperparameter combination, judge whether the K-1 hyperparameter combinations other than the second hyperparameter combination in the K hyperparameter combinations are better than the second hyperparameter combination under certain conditions Combination, if there is a combination that is better than the second hyperparameter combination under some conditions, you can re-evaluate the combination that is better than the second hyperparameter combination under some conditions, if there is no better than the second hyperparameter combination under some conditions
- the second hyperparameter combination can be re-evaluated. It can be understood that the hyperparameter combination that is superior to the second hyperparameter combination under some conditions mentioned in this step refers to the first hyperparameter combination that satisfies the first preset condition.
- the method of judging whether there is a combination of K-1 hyperparameter combinations that is better than the second hyperparameter combination under certain conditions may specifically include:
- n k ⁇ n k′ , and n k ⁇ c n , n k is the number of evaluations of the first hyperparameter combination, n k′ is the number of evaluations of the second hyperparameter combination, and c n is the preset number;
- the first hyperparameter combination satisfies one of the conditions, that is, the evaluation times of the first hyperparameter combination are too few, or the performance result is better than the partial performance result of the second hyperparameter combination, it can be understood as the first hyperparameter combination If the combination is better than the second hyperparameter combination under certain conditions, the first hyperparameter combination can be evaluated again.
- the criteria for selecting the hyperparameter combination to be re-evaluated is reduced, so that more hyperparameter combinations that are not optimal or have a few evaluation times can be evaluated again, so that the resulting multiple hyperparameters
- the overall performance result of the combination is more accurate.
- the combination of performance results can use 2b resources to perform an enhanced evaluation of the first hyperparameter combination whose performance results are better than the partial performance results of the second hyperparameter combination, and obtain multiple performance results of the first hyperparameter combination.
- the combination whose performance result is better than the second hyperparameter combination can be re-evaluated.
- the second hyperparameter combination can be re-evaluated to obtain the re-evaluated performance result, so that the second superparameter combination can be evaluated again.
- the performance result of parameter combination is more accurate.
- the 2b resources in step 505 or 506 can also be replaced with b computing resources, or more or less computing resources.
- b computing resources or more or less computing resources.
- step 503 After the re-evaluation, it is determined whether the computing resources are exhausted. If the computing resources are not exhausted, step 503 can be continued, that is, the optimal second hyperparameter combination is reselected.
- the computing resources include the aforementioned b resources and 2b resources.
- the computing resource may be a preset resource that can be used to evaluate the hyperparameter combination.
- the computing resource may include a preset number of iteration evaluation times, and step 507 is to determine whether the evaluation times of the K hyperparameter combinations reach the preset number. If the number of evaluations for K hyperparameter combinations has reached the preset number of times, the final performance result of the K hyperparameter combinations can be output; if the number of evaluations for K hyperparameter combinations does not reach the preset number of times, you can Continue to perform step 503, that is, continue to evaluate the hyperparameter combination until the number of evaluations reaches the preset number of times.
- the K hyperparameter combinations can be quickly evaluated through steps 501-507, the performance results of the K hyperparameter combinations are used to fit the Bayesian model, and the Bayesian model is repeated. Sampling, evaluation, the Bayesian model is modified by the evaluation data obtained by loop iteration, the probability distribution of the optimal hyperparameter combination can be fitted according to the Bayesian model, and the hyperparameter combination can be collected according to the probability distribution obtained by the final fitting.
- this application can also evaluate some hyper-parameter combinations that are not optimal or have fewer evaluation times among multiple hyper-parameter combinations, thereby improving The accuracy of the performance results of some hyperparameter combinations with suboptimal performance or less evaluation times can improve the accuracy of the overall performance of multiple hyperparameter combinations, so that the Bayesian model can converge quickly and can be accurately and efficiently determined Shows a better combination of hyperparameters.
- the final performance results of K hyperparameter combinations include the results of each hyperparameter combination evaluated in step 503 to step 507. Multiple performance results.
- steps 508-511 can refer to the relevant descriptions in the foregoing steps 403-406, which will not be repeated here.
- the hyperparameter combination that performs the best among multiple hyperparameter combinations, but also adds the evaluation of the hyperparameter combination that performs less than optimally or has a few evaluation times among multiple hyperparameter combinations.
- the number of times so that the performance results of potential hyperparameter combinations such as suboptimal performance or fewer evaluations are more accurate, to avoid problems such as inaccurate data caused by fewer evaluations or errors in partial evaluations, by increasing the number of evaluations
- the accuracy of the performance results of potential hyperparameter combinations is increased, and the accuracy of the overall performance results of multiple hyperparameter combinations is improved.
- the preset model can be quickly converged, and a better hyperparameter combination can be accurately and efficiently determined according to the preset model.
- the following uses the context information common object detection data set (common objects in context, COCO) data set as the input data of the neural network to compare the neural network optimization method provided by this application with the commonly used solutions, and compare the neural network provided by this application.
- the beneficial effects of the network optimization method are exemplified.
- the data set has 80 general object detection annotations, including about 11,000 training data sets and 5,000 test sets.
- the images included in the data set are mainly intercepted from complex daily scenes, and the target in the image is calibrated by precise segmentation.
- the images in the dataset include 91 types of targets, 328,000 images and 2.5 million labels.
- FIG. 8 which includes a comparison between the hyperparameters determined by the neural network optimization method provided by the present application and the hyperparameters determined by some commonly used methods, and the comparison of the output results after being substituted into the neural network.
- some commonly used methods include manual, random search, Bayesian optimization and hyperparameters (Bayesian optimization and hyperband, BOHB), etc.
- the manual method is to manually obtain the hyperparameter combination according to the empirical value
- the random search is to use the uniform distribution to collect the hyperparameter combination from the hyperparameter search space
- BOHB refers to the aforementioned related introduction
- the application shown in FIG. 8 is The neural network optimization method provided by this application determines the hyperparameter combination.
- x in APx or ARx is a numeric value
- it indicates the overlap ratio of the anchor frame and the target object.
- AP 50 indicates that the overlap ratio of the anchor frame and the target object to be detected in the image is 50%
- S, M, and L indicate the image
- the size of the object to be detected in the medium is divided into small (small, S), medium (M), and large (large, L).
- the specific classification criteria can be adjusted according to actual application scenarios.
- the neural network optimization method provided by this application can determine the hyperparameter combination with better performance results.
- the foregoing describes the flow of the neural network optimization method provided by this application in detail.
- the following describes the neural network optimization device provided by this application based on the foregoing neural network optimization method.
- the neural network optimization device is used to execute the foregoing corresponding to FIGS. 4-8 Steps of the method.
- the neural network optimization device includes:
- the sampling module 901 is configured to sample the hyperparameter search space to obtain multiple hyperparameter combinations.
- the hyperparameter search space includes the hyperparameters of the neural network, and the hyperparameters include parameters that are not obtained through training in the neural network;
- the evaluation module 902 is used to perform multiple iterative evaluations on multiple hyperparameter combinations to obtain multiple performance results of each hyperparameter combination in the multiple hyperparameter combinations, and the multiple performance results are substituted into each hyperparameter combination according to The result of the neural network output is determined, where, in any one of the multiple iterative evaluations, at least one performance result of each hyperparameter combination evaluated before the current evaluation is obtained, if multiple hyperparameter combinations exist.
- the first hyper-parameter combination that meets the first preset condition is re-evaluated to obtain the re-evaluated performance result of the first hyper-parameter combination, and the re-evaluated performance result is included in the first hyper-parameter combination Multiple performance results;
- the determining module 903 is configured to determine an optimal hyperparameter combination from multiple hyperparameter combinations according to multiple performance results of each hyperparameter combination;
- the update module 904 is configured to update the preset model through multiple performance results of each hyperparameter combination if the optimal hyperparameter combination does not meet the second preset condition.
- the preset model is used to fit the probability distribution, and the probability distribution is used for For re-sampling the hyperparameter search space;
- the selection module 905 is configured to use the optimal hyperparameter combination as the hyperparameter combination of the neural network if the optimal hyperparameter combination satisfies the second preset condition.
- the first preset condition includes: the number of evaluations of the first hyperparameter combination is not higher than the preset number, and the number of evaluations of the first hyperparameter combination is not higher than the evaluation of the second hyperparameter combination
- the second hyperparameter combination is the hyperparameter combination that performs the best among multiple hyperparameter combinations selected in any one iteration, or the hyperparameter combination that has the most evaluation times among multiple hyperparameter combinations; or, the first hyperparameter combination
- the evaluation times of the hyperparameter combination are higher than the preset times, and the evaluation times of the first hyperparameter combination are not higher than the evaluation times of the second hyperparameter combination, and some performance results of the second hyperparameter combination are worse than the first hyperparameter At least one performance result of the combination.
- the evaluation module 902 further includes: then determining whether there is a hyperparameter combination that satisfies the first preset condition among the multiple hyperparameter combinations, and if there is no hyperparameter combination that satisfies the first preset condition among the multiple hyperparameter combinations, Set the conditional first hyperparameter combination, then re-evaluate the second hyperparameter combination to obtain the re-evaluated performance result of the second hyperparameter combination, and the re-evaluated performance result of the second hyperparameter combination is included in the second hyperparameter Multiple performance results of the combination.
- the preset model includes a first probability density function and a second probability density function
- the update module 904 is specifically configured to: combine multiple hyperparameters according to at least one performance result of each hyperparameter combination It is divided into the first type of hyperparameter combination and the second type of hyperparameter combination.
- the multiple performance results of the first type of hyperparameter combination are better than the multiple performance results of the second type of hyperparameter combination.
- the first type of hyperparameter combination is updated through the first type of hyperparameter combination.
- a probability density function, and update the second probability density function through a combination of the second type of hyperparameters.
- the type of the first probability density function or the second probability density function may include: normal distribution, discrete distribution, truncated normal distribution, or lognormal distribution.
- the neural network is a convolutional neural network for recognizing pictures
- the types of hyperparameters in the hyperparameter search space include one or more of the following: the number of convolutional layers, the number of convolution kernels, The expansion size, the position of the ReLU function in the neural network, the size of the anchor frame or the ratio of the length and width of the anchor frame, the anchor frame is used to identify the object in the picture that needs to be recognized.
- the neural network is obtained by combining one or more building units, and the types of hyperparameters in the hyperparameter search space include one or more of the following: the number of network layers of a building unit, the building unit The number of neurons in each layer of the network or the operator of each neuron in the construction unit.
- the multiple performance results include classification accuracy or loss value
- the classification accuracy is used to indicate the accuracy of the neural network in recognizing the picture
- the loss value is the value of the loss function corresponding to the neural network
- the second preset condition Including: the classification accuracy of any one of the multiple performance results is greater than the first threshold, or the average value of the classification accuracy included in the multiple performance results is greater than the second threshold, or the loss value is not greater than the third threshold.
- the sampling module 901 is specifically configured to: randomly sample the hyperparameter search space to obtain multiple hyperparameter combinations; or, search for hyperparameters based on the probability distribution determined by the preset model before the update Space sampling is performed to obtain multiple hyperparameter combinations.
- FIG. 10 is a schematic structural diagram of another neural network optimization device provided by the present application, as described below.
- the neural network optimization device may include a processor 1001 and a memory 1002.
- the processor 1001 and the memory 1002 are interconnected by wires.
- the memory 1002 stores program instructions and data.
- the memory 1002 stores program instructions and data corresponding to the steps in FIG. 4 or FIG. 8 described above.
- the processor 1001 is configured to execute the method steps executed by the neural network optimization apparatus shown in any one of the embodiments in FIG. 4 or FIG. 8.
- the embodiment of the present application also provides a computer-readable storage medium.
- the computer-readable storage medium stores a program for generating the driving speed of the vehicle.
- the illustrated embodiment describes the steps in the method.
- the aforementioned neural network optimization device shown in FIG. 10 is a chip.
- the embodiment of the application also provides a neural network optimization device.
- the neural network optimization device may also be called a digital processing chip or a chip.
- the chip includes a processing unit and a communication interface.
- the processing unit obtains program instructions through the communication interface, and the program instructions are processed.
- Unit execution, and the processing unit is used to execute the method steps executed by the neural network optimization apparatus shown in any one of the embodiments in FIG. 4 or FIG. 8.
- the embodiment of the present application also provides a digital processing chip.
- the digital processing chip integrates circuits and one or more interfaces used to implement the above-mentioned processor 1001 or the functions of the processor 1001.
- the digital processing chip can complete the method steps of any one or more of the foregoing embodiments.
- no memory is integrated in the digital processing chip, it can be connected to an external memory through a communication interface.
- the digital processing chip implements the actions performed by the neural network optimization device in the foregoing embodiment according to the program code stored in the external memory.
- the embodiment of the present application also provides a product including a computer program, which when it is driven on a computer, causes the computer to execute the steps performed by the neural network optimization device in the method described in the embodiments shown in FIGS. 4 to 8.
- the neural network optimization device may be a chip.
- the chip includes a processing unit and a communication unit.
- the processing unit may be, for example, a processor, and the communication unit may be, for example, an input/output interface, a pin, or a circuit, etc. .
- the processing unit can execute the computer-executable instructions stored in the storage unit, so that the chip in the server executes the neural network optimization method described in the embodiments shown in FIG. 4 to FIG. 8.
- the storage unit is a storage unit in the chip, such as a register, a cache, etc.
- the storage unit may also be a storage unit located outside the chip in the wireless access device, such as Read-only memory (ROM) or other types of static storage devices that can store static information and instructions, random access memory (RAM), etc.
- ROM Read-only memory
- RAM random access memory
- the aforementioned processing unit or processor may be a central processing unit (CPU), a network processor (neural-network processing unit, NPU), a graphics processing unit (GPU), or a digital signal processing unit.
- CPU central processing unit
- NPU network processor
- GPU graphics processing unit
- DSP digital signal processor
- ASIC application specific integrated circuit
- FPGA field programmable gate array
- the general-purpose processor may be a microprocessor or any conventional processor.
- FIG. 11 is a schematic diagram of a structure of a chip provided in an embodiment of the application.
- the Host CPU assigns tasks.
- the core part of the NPU is the arithmetic circuit 1103.
- the arithmetic circuit 1103 is controlled by the controller 1104 to extract matrix data from the memory and perform multiplication operations.
- the arithmetic circuit 1103 includes multiple processing units (process engines, PE). In some implementations, the arithmetic circuit 1103 is a two-dimensional systolic array. The arithmetic circuit 1103 may also be a one-dimensional systolic array or other electronic circuit capable of performing mathematical operations such as multiplication and addition. In some implementations, the arithmetic circuit 1103 is a general-purpose matrix processor.
- the arithmetic circuit fetches the corresponding data of matrix B from the weight memory 1102 and caches it on each PE in the arithmetic circuit.
- the arithmetic circuit fetches matrix A data and matrix B from the input memory 1101 to perform matrix operations, and the partial result or final result of the obtained matrix is stored in an accumulator 1108.
- the unified memory 1106 is used to store input data and output data.
- the weight data directly passes through the storage unit access controller (direct memory access controller, DMAC) 1105, and the DMAC is transferred to the weight memory 1102.
- the input data is also transferred to the unified memory 1106 through the DMAC.
- DMAC direct memory access controller
- the bus interface unit (BIU) 1110 is used for the interaction between the AXI bus and the DMAC and the instruction fetch buffer (IFB) 1109.
- the bus interface unit 1110 (bus interface unit, BIU) is used for the instruction fetch memory 1109 to obtain instructions from the external memory, and is also used for the storage unit access controller 1105 to obtain the original data of the input matrix A or the weight matrix B from the external memory.
- the DMAC is mainly used to transfer the input data in the external memory DDR to the unified memory 1106 or to transfer the weight data to the weight memory 1102 or to transfer the input data to the input memory 1101.
- the vector calculation unit 1107 includes multiple arithmetic processing units, and if necessary, further processes the output of the arithmetic circuit, such as vector multiplication, vector addition, exponential operation, logarithmic operation, size comparison and so on. Mainly used for non-convolutional/fully connected layer network calculations in neural networks, such as batch normalization, pixel-level summation, and upsampling of feature planes.
- the vector calculation unit 1107 can store the processed output vector to the unified memory 1106.
- the vector calculation unit 1107 may apply a linear function and/or a non-linear function to the output of the arithmetic circuit 1103, such as linearly interpolating the feature plane extracted by the convolutional layer, and, for example, a vector of accumulated values, to generate the activation value.
- the vector calculation unit 1107 generates normalized values, pixel-level summed values, or both.
- the processed output vector can be used as an activation input to the arithmetic circuit 1103, for example for use in a subsequent layer in a neural network.
- the instruction fetch buffer 1109 connected to the controller 1104 is used to store instructions used by the controller 1104;
- the unified memory 1106, the input memory 1101, the weight memory 1102, and the fetch memory 1109 are all On-Chip memories.
- the external memory is private to the NPU hardware architecture.
- the calculation of each layer in the recurrent neural network can be performed by the arithmetic circuit 1103 or the vector calculation unit 1107.
- the processor mentioned in any one of the above can be a general-purpose central processing unit, a microprocessor, an ASIC, or one or more integrated circuits used to control the execution of the programs of the above-mentioned methods of FIGS. 4-8.
- the device embodiments described above are only illustrative, and the units described as separate components may or may not be physically separated, and the components displayed as units may or may not be physically separate.
- the physical unit can be located in one place or distributed across multiple network units. Some or all of the modules can be selected according to actual needs to achieve the objectives of the solutions of the embodiments.
- the connection relationship between the modules indicates that they have a communication connection, which can be specifically implemented as one or more communication buses or signal lines.
- this application can be implemented by means of software plus necessary general hardware.
- it can also be implemented by dedicated hardware including dedicated integrated circuits, dedicated CPUs, dedicated memory, Dedicated components and so on to achieve.
- all functions completed by computer programs can be easily implemented with corresponding hardware.
- the specific hardware structures used to achieve the same function can also be diverse, such as analog circuits, digital circuits or special-purpose circuits. Circuit etc.
- software program implementation is a better implementation in more cases.
- the technical solution of this application essentially or the part that contributes to the existing technology can be embodied in the form of a software product, and the computer software product is stored in a readable storage medium, such as a computer floppy disk.
- a readable storage medium such as a computer floppy disk.
- U disk mobile hard disk
- read-only memory read only memory, ROM
- random access memory random access memory
- magnetic disk or optical disk etc., including several instructions to make a computer device (which can be a personal A computer, a server, or a network device, etc.) execute the method described in each embodiment of the present application.
- the computer program product includes one or more computer instructions.
- the computer may be a general-purpose computer, a special-purpose computer, a computer network, or other programmable devices.
- the computer instructions may be stored in a computer-readable storage medium, or transmitted from one computer-readable storage medium to another computer-readable storage medium.
- the computer instructions may be transmitted from a website, computer, server, or data center. Transmission to another website, computer, server or data center via wired (such as coaxial cable, optical fiber, digital subscriber line (DSL)) or wireless (such as infrared, wireless, microwave, etc.).
- wired such as coaxial cable, optical fiber, digital subscriber line (DSL)
- wireless such as infrared, wireless, microwave, etc.
- the computer-readable storage medium may be any available medium that can be stored by a computer or a data storage device such as a server or a data center integrated with one or more available media.
- the usable medium may be a magnetic medium (for example, a floppy disk, a hard disk, and a magnetic tape), an optical medium (for example, a DVD), or a semiconductor medium (for example, a solid state disk (SSD)).
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Software Systems (AREA)
- General Physics & Mathematics (AREA)
- Computing Systems (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Mathematical Physics (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Multimedia (AREA)
- Probability & Statistics with Applications (AREA)
- Image Analysis (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Complex Calculations (AREA)
Abstract
本申请公开了人工智能领域的一种神经网络优化方法以及装置,用于高效、准确地确定出神经网络的超参数组合。该方法包括:对预设的超参数搜索空间进行采样得到多个超参数组合;对多个超参数组合进行多次迭代评估,以得到每个超参数组合的多个表现结果,其中,在任一次迭代评估中,获取每个超参数组合的至少一个表现结果,若存在满足第一预设条件的超参数组合,对该超参数组合进行再次评估得到其再次评估的表现结果;然后,确定出最优超参数组合;若最优超参数组合不满足第二预设条件,则通过每个超参数组合的多个表现结果更新用于下一次采样的预设模型;若最优超参数组合满足第二预设条件,则将最优超参数组合作为神经网络的超参数组合。
Description
本申请要求于2020年04月30日提交中国专利局、申请号为202010367582.2、申请名称为“一种神经网络优化方法以及装置”的中国专利申请的优先权,其全部内容通过引用结合在本申请中。
本申请涉及人工智能领域,尤其涉及一种神经网络优化方法以及装置。
在目前的神经网络中,将不通过训练得到的参数称为超参数,通常是通过大量实践经验来调整超参数,使得神经网络的模型表现更优秀(例如:图片分类准确率更高)。例如,深度神经网络由许多神经元组成,输入的数据通过输入端的神经元经由中间层神经元传输到输出端的神经元。在神经网络训练时,每个神经元的权重会根据损失函数的值来优化,从而减小更新后的模型输出的损失函数的值。因此,可以通过算法来优化参数得到模型。而超参数是用来调节整个网络训练过程的,例如神经网络的隐藏层的数量,核函数的大小、数量等等。超参数并不直接参与到训练的过程中,在训练过程中,超参数往往是不变的,但是超参数又对神经网络最终的表现至关重要,因此,选择一组合适的超参数尤为重要。
现有技术中,采用例如Successive Halving法来评估有价值的超参数组合,在选择合适的超参数组合的过程中,每次对多个超参数进行评估的过程中,都丢弃表现结果差的一半超参数组合,从而使得有效的超参数组合少,且因超参数组合的评估次数较少,导致超参数组合的评估结果可能因部分评估出现误差而不准确,进而导致使用了不准确的评估结果最终确定的最优超参数组合也并不准确。
发明内容
本申请公开了人工智能领域的一种神经网络优化方法以及装置,用于高效、准确地确定出神经网络的超参数组合。
第一方面,本申请提供一种神经网络优化方法,包括:对超参数搜索空间进行采样,得到多个超参数组合,超参数搜索空间包括神经网络的超参数,超参数包括神经网络中不通过训练得到的参数;对多个超参数组合进行多次迭代评估,以得到多个超参数组合中的每个超参数组合的多个表现结果,多个表现结果为根据代入每个超参数组合后的神经网络输出的结果确定,其中,在多次迭代评估中的任一次迭代评估中,获取当前次评估之前评估得到的每个超参数组合的至少一个表现结果,每个超参数组合的至少一个表现结果包括于每个超参数组合的多个表现结果中,若多个超参数组合存在满足第一预设条件的超参数组合,对满足第一预设条件的超参数组合进行再次评估,得到满足第一预设条件的超参数组合的再次评估的表现结果,再次评估的表现结果包括于满足第一预设条件的超参数组合的多个表现结果中;根据每个超参数组合的多个表现结果从多个超参数组合中确定出最优超参数组合;若最优超参数组合不满足第二预设条件,则通过每个超参数组合的多个表现 结果更新预设模型,预设模型用于拟合概率分布,概率分布用于对超参数搜索空间进行再次采样;若最优超参数组合满足第二预设条件,则将最优超参数组合作为神经网络的超参数组合。
因此,本申请实施方式中,在对多个超参数组合进行评估时,对满足第一预设条件的超参数组合即可进行再次评价,而并非仅关注多个超参数组合中表现最优的超参数的表现结果,可以得到表现不是最优的超参数组合的更多的表现结果,提高得到的多个超参数组合整体的表现结果的准确性。因此,根据整体更准确的多个超参数组合的表现结果更新的预设模型对应的概率分布也更可靠,从而根据该预设模型再次采样得到的超参数组合也更接近于最优组合,最终确定的最优超参数组合的表现也更优。并且,利用整体更准确的多个超参数组合的表现结果更新模型,可以使预设模型快速收敛,提高收敛效率,从而准确、高效地确定出表现更优的超参数组合。
在一种可能的实施方式中,上述的任意一次迭代还可以包括:根据每个超参数组合的至少一个表现结果从多个超参数组合中选取出第二超参数组合,第二超参数组合为多个超参数组合中表现最优的超参数组合,或者,第二超参数组合为多个超参数组合中评估次数最多的超参数组合,相应地,第一预设条件可以包括:第一超参数组合的评估次数不高于预设次数,且第一超参数组合的评估次数不高于第二超参数组合的评估次数;或者,第一超参数组合的评估次数高于预设次数,且第一超参数组合的评估次数不高于第二超参数组合的评估次数,且存在第二超参数组合的部分表现结果差于第一超参数组合的至少一个表现结果。可以理解为,在任意一次迭代评估中,在判断多个超参数组合中是否存在满足第一预设条件的第一超参数之前,还从多个超参数组合中选取第二超参数组合,并根据第二超参数的至少一个表现结果确定第一预设条件。
因此,本申请实施方式中,对于表现结果优于第二超参数组合的部分表现结果的超参数组合,也可以进行再次评估,或者,对于评估次数过低的超参数组合也可以进行再次评估,从而提高部分表现不是最优或者评估次数少的超参数组合的表现结果的数量,提高多个超参数整体的表现结果的准确性。
在一种可能的实施方式中,前述的多次迭代评估中的任一次评估,还可以包括:若多个超参数组合中不存在满足第一预设条件的第一超参数组合,则对第二超参数组合进行再次评估,得到第二超参数组合再次评估的表现结果,第二超参数组合的再次评估的表现结果包括于第二超参数组合的多个表现结果中。
本申请实施方式中,在对多个超参数组合进行迭代评估时,可以确定出多个超参数组合中表现最优或者被评估的次数最多的第二超参数组合,若存在满足第一预设条件的超参数组合,则对满足第一预设条件的超参数组合进行再次评估,若不存在满足第一预设条件的超参数组合,则对第二超参数组合进行评估。因此,本申请实施例不局限于关注多个超参数组合中表现最优的第二超参数组合,也对多个超参数组合中满足第一预设条件的其他超参数组合进行再次评估,从而使多个超参数组合的整体表现更准确,从而根据整体表现更准确的多个超参数的表现结果更新的预设模型也更可靠,再次采样得到的超参数组合也更倾向于最优组合。
在一种可能的实施方式中,从多个超参数组合中确定出第二超参数组合,可以包括:从多个超参数组合中确定出评估次数最多的超参数组合作为第二超参数组合;或者,若多个超参数组合中存在多个评估次数最多的超参数组合,则从多个评估次数最多的超参数组合中确定出表现结果最优的至少一个超参数组合作为第二超参数组合。
因此,本申请实施方式中,可以从多个超参数组合中选取评估次数最多的超参数组合或者表现最优的超参数组合作为最优的第二超参数组合,提供了多种选择方式。
在一种可能的实施方式中,本申请实施方式中,在每次迭代评估中,可以是对每个超参数组合进行评估,并获取当前次评估之前对每个超参数组合进行评估得到的一个或者多个表现结果,得到每个超参数组合的至少一个表现结果,也可以是直接获取本次迭代评估之前得到的所有评估结果,得到每个超参数组合的至少一个表现结果。因此,本申请提供了多种迭代评估方式,增加了超参数组合的表现结果的数据量,提高多个超参数组合的整体表现结果的准确性。
在一种可能的实施方式中,预设模型包括第一概率密度函数和第二概率密度函数,通过每个超参数组合的多个表现结果更新预设模型,可以包括:根据每个超参数组合的多个表现结果将多个超参数组合分为第一类超参数组合和第二类超参数组合,第一类超参数组合的表现优于第二类超参数组合的表现,第一类超参数组合的表现为根据第一类超参数组合的多个表现确定,第二类超参数组合的表现为根据第二类超参数的多个表现结果确定,通过第一类超参数组合更新第一概率密度函数,以及通过第二类超参数组合用于更新第二概率密度函数。
本申请实施方式中,本申请实施方式中,可以通过表现较优的第一类超参数组合更新第一概率密度函数,可以通过表现较差的第二类超参数组合更新第二概率密度函数。对超参数搜索空间进行再次采样的概率服从预设模型确定的概率分布,因此,通过表现优的超参数组合来更新第一概率密度函数,使第一概率密度函数对应的概率更精确,从而使再次采集到的超参数组合的表现结果也更好,提高模型的收敛速度,提高多个超参数组合的整体表现结果的准确性。
在一种可能的实施方式中,第一概率密度函数或第二概率密度函数的类型可以包括以下一种或多种:正态分布、离散分布、截断正态分布或者对数正态分布。本申请实施方式中,概率密度函数可以是多种模型,使得可以根据不同的场景选择概率密度函数。
在一种可能的实施方式中,神经网络为用于识别图片的卷积神经网络,超参数搜索空间中的超参数的种类包括以下一种或多种:卷积层数、卷积核数量、扩张大小、修正线性单元(rectified linear unit,ReLU)函数在神经网络中的位置、锚框的尺寸或者锚框的长和宽的比例,锚框用于标识图片中需要识别的对象。本申请实施方式中,可以确定卷积神经网络的最优超参数组合,从而可以得到精确度更高的卷积神经网络。
在一种可能的实施方式中,神经网络为通过一个或多个构建单元组合得到,超参数搜索空间中的超参数的种类包括以下一种或多种:一个构建单元的网络层数、构建单元中每层网络的神经元数量或者构建单元中每个神经元的操作算子。因此,通过本申请提供的神经网络优化方法,可以搜索到更优的构建单元,从而得到变现更优的神经网络。
在一种可能的实施方式中,多个表现结果包括分类精度或者损失值,分类精度用于表示神经网络识别图片的准确度,损失值为神经网络对应的损失函数的值;第二预设条件包括:多个表现结果中的任一个表现结果中的分类精度大于第一阈值,或者,多个表现结果包括的分类精度的平均值大于第二阈值,或者,损失值不大于第三阈值等。
因此,本申请实施方式中,可以通过分类精度或者损失值等衡量超参数的表现结果,通过分类精度或者损失值等表现确定出最优的超参数组合。
在一种可能的实施方式中,对超参数搜索空间进行采样,得到多个超参数组合,可以包括:对超参数搜索空间进行随机采样,得到多个超参数组合;或者,基于更新前的预设模型确定的概率分布对超参数搜索空间进行采样,得到多个超参数组合。
本申请实施方式中,可以对超参数搜索空间进行随机采样,如第一次对超参数搜索空间进行采样,也可以基于预设模型确定的概率分布对超参数搜索空间进行采样,提供了多种方式得到多个超参数组合。
第二方面,本申请提供的一种神经网络优化装置的结构示意图。该神经网络优化装置包括:
采样模块,用于对超参数搜索空间进行采样,得到多个超参数组合,超参数搜索空间包括神经网络的超参数,超参数包括神经网络中不通过训练得到的参数;
评估模块,用于对多个超参数组合进行多次迭代评估,以得到多个超参数组合中的每个超参数组合的多个表现结果,多个表现结果为根据代入每个超参数组合后的神经网络输出的结果确定,其中,在多次迭代评估中的任一次迭代评估中,获取当前次评估之前评估得到的每个超参数组合的至少一个表现结果,若多个超参数组合存在满足第一预设条件的第一超参数组合,对第一超参数组合进行再次评估,得到第一超参数组合的再次评估的表现结果,再次评估的表现结果包括于第一超参数组合的多个表现结果中;
确定模块,用于根据每个超参数组合的多个表现结果从多个超参数组合中确定出最优超参数组合;
更新模块,用于若最优超参数组合不满足第二预设条件,则通过每个超参数组合的多个表现结果更新预设模型,预设模型用于拟合概率分布,概率分布用于对超参数搜索空间进行再次采样;
选择模块,用于若最优超参数组合满足第二预设条件,则将最优超参数组合作为神经网络的超参数组合。
第二方面及第二方面任一种可能的实施方式产生的有益效果可参照第一方面及第一方面任一种可能实施方式的描述。
在一种可能的实施方式中,第一预设条件包括:第一超参数组合的评估次数不高于预设次数,且第一超参数组合的评估次数不高于第二超参数组合的评估次数,第二超参数组合为在任意一次迭代中选取出的多个超参数组合中表现最优的超参数组合,或者,多个超参数组合中评估次数最多的超参数组合,即在任意一次迭代中,判断是否存在满足第一预设条件的第一超参数组合之前,还选取第二超参数组合;或者,第一超参数组合的评估次数高于预设次数,且第一超参数组合的评估次数不高于第二超参数组合的评估次数,且存 在第二超参数组合的部分表现结果差于第一超参数组合的至少一个表现结果。
在一种可能的实施方式中,评估模块,还可以包括:若多个超参数组合中不存在满足第一预设条件的第一超参数组合,则对第二超参数组合进行再次评估,得到第二超参数组合再次评估的表现结果。
在一种可能的实施方式中,预设模型包括第一概率密度函数和第二概率密度函数,更新模块,具体用于:根据每个超参数组合的至少一个表现结果将多个超参数组合分为第一类超参数组合和第二类超参数组合,第一类超参数组合的表现优于第二类超参数组合的表现,第一类超参数组合的表现为根据第一类超参数组合的多个表现确定,第二类超参数组合的表现为根据第二类超参数的多个表现结果确定,通过第一类超参数组合更新第一概率密度函数,以及通过第二类超参数组合更新第二概率密度函数。
在一种可能的实施方式中,第一概率密度函数或第二概率密度函数的类型可以包括以下一种或多种:正态分布、离散分布、截断正态分布或者对数正态分布。
在一种可能的实施方式中,神经网络为用于识别图片的卷积神经网络,超参数搜索空间中的超参数的种类包括以下一种或多种:卷积层数、卷积核数量、扩张大小、ReLU函数在神经网络中的位置、锚框的尺寸或者锚框的长和宽的比例,锚框用于标识图片中需要识别的对象。
在一种可能的实施方式中,神经网络为通过一个或多个构建单元组合得到,超参数搜索空间中的超参数的种类包括以下一种或多种:一个构建单元的网络层数、构建单元中每层网络的神经元数量或者构建单元中每个神经元的操作算子。
在一种可能的实施方式中,多个表现结果包括分类精度或者损失值,分类精度为用于表示神经网络识别图片的准确度,损失值为神经网络对应的损失函数的值;第二预设条件包括:多个表现结果中的任一个表现结果中的分类精度大于第一阈值,或者,多个表现结果包括的分类精度的平均值大于第二阈值,或者,损失值不大于第三阈值。
在一种可能的实施方式中,采样模块,具体用于:对超参数搜索空间进行随机采样,得到多个超参数组合;或者,基于预设模型确定的概率分布对超参数搜索空间进行采样,得到多个超参数组合。
第三方面,本申请提供一种神经网络优化装置,包括:处理器和存储器,其中,处理器和存储器通过线路互联,处理器调用存储器中的程序代码用于执行上述第一方面任一项所示的神经网络优化方法中与处理相关的功能。可选地,该神经网络优化装置可以是芯片。
第四方面,本申请实施例提供了一种神经网络优化装置,该神经网络优化装置也可以称为数字处理芯片或者芯片,芯片包括处理单元和通信接口,处理单元通过通信接口获取程序指令,程序指令被处理单元执行,处理单元用于执行如上述第一方面或第一方面任一可选实施方式中与处理相关的功能。
第五方面,本申请实施例提供了一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行上述第一方面或第一方面任一可选实施方式中的方法。
第六方面,本申请实施例提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述第一方面或第一方面任一可选实施方式中的方法。
图1本申请应用的一种人工智能主体框架示意图;
图2为本申请实施例提供的一种卷积神经网络结构示意图;
图3为本申请实施例提供的另一种卷积神经网络结构示意图;
图4为本申请实施例提供的一种神经网络优化方法的流程示意图;
图5为本申请实施例提供的另一种神经网络优化方法的流程示意图;
图6为本申请实施例提供的一种应用场景示意图;
图7为本申请实施例提供的另一种应用场景示意图;
图8为本申请实施例提供的一种神经网络优化方法的准确率示意图;
图9为本申请实施例提供的一种神经网络优化装置的结构示意图;
图10为本申请实施例提供的一种神经网络优化装置的结构示意图;
图11为本申请实施例提供的一种芯片的结构示意图。
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本申请提供的神经网络优化方法可以应用于人工智能(artificial intelligence,AI)场景中。AI是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式作出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。人工智能领域的研究包括机器人,自然语言处理,计算机视觉,决策与推理,人机交互,推荐与搜索,AI基础理论等。
图1示出一种人工智能主体框架示意图,该主体框架描述了人工智能系统总体工作流程,适用于通用的人工智能领域需求。
下面从“智能信息链”(水平轴)和“IT价值链”(垂直轴)两个维度对上述人工智能主题框架进行阐述。
“智能信息链”反映从数据的获取到处理的一列过程。举例来说,可以是智能信息感知、智能信息表示与形成、智能推理、智能决策、智能执行与输出的一般过程。在这个过程中,数据经历了“数据—信息—知识—智慧”的凝练过程。
“IT价值链”从人智能的底层基础设施、信息(提供和处理技术实现)到系统的产业生态过程,反映人工智能为信息技术产业带来的价值。
(1)基础设施:
基础设施为人工智能系统提供计算能力支持,实现与外部世界的沟通,并通过基础平 台实现支撑。通过传感器与外部沟通;计算能力由智能芯片,如中央处理器(central processing unit,CPU)、网络处理器(neural-network processing unit,NPU)、图形处理器(英语:graphics processing unit,GPU)、专用集成电路(application specific integrated circuit,ASIC)或现场可编程逻辑门阵列(field programmable gate array,FPGA)等硬件加速芯片)提供;基础平台包括分布式计算框架及网络等相关的平台保障和支持,可以包括云存储和计算、互联互通网络等。举例来说,传感器和外部沟通获取数据,这些数据提供给基础平台提供的分布式计算系统中的智能芯片进行计算。
(2)数据
基础设施的上一层的数据用于表示人工智能领域的数据来源。数据涉及到图形、图像、语音、文本,还涉及到传统设备的物联网数据,包括已有系统的业务数据以及力、位移、液位、温度、湿度等感知数据。
(3)数据处理
数据处理通常包括数据训练,机器学习,深度学习,搜索,推理,决策等方式。
其中,机器学习和深度学习可以对数据进行符号化和形式化的智能信息建模、抽取、预处理、训练等。
推理是指在计算机或智能系统中,模拟人类的智能推理方式,依据推理控制策略,利用形式化的信息进行机器思维和求解问题的过程,典型的功能是搜索与匹配。
决策是指智能信息经过推理后进行决策的过程,通常提供分类、排序、预测等功能。
(4)通用能力
对数据经过上面提到的数据处理后,进一步基于数据处理的结果可以形成一些通用的能力,比如可以是算法或者一个通用系统,例如,翻译,文本的分析,计算机视觉的处理,语音识别,图像的识别等等。
(5)智能产品及行业应用
智能产品及行业应用指人工智能系统在各领域的产品和应用,是对人工智能整体解决方案的封装,将智能信息决策产品化、实现落地应用,其应用领域主要包括:智能制造、智能交通、智能家居、智能医疗、智能安防、自动驾驶,平安城市,智能终端等。
在上述的场景中,神经网络作为重要的节点,用于实现机器学习,深度学习,搜索,推理,决策等。本申请提及的神经网络可以包括多种类型,如深度神经网络(deep neural networks,DNN)、卷积神经网络(convolutional neural networks,CNN)、循环神经网络(recurrent neural networks,RNN)、残差网络或其他神经网络等。下面对一些神经网络进行示例性介绍。
神经网络可以是由神经单元组成的,神经单元可以是指以x
S和截距1为输入的运算单元,示例性地,该运算单元的输出可以为:

其中,s=1、2、……n,n为大于1的自然数,W
S为x
S的权重,b为神经单元的偏置。f为神经单元的激活函数(activation functions),用于将非线性特性引入神经网络中,来将神经单元中的输入信号转换为输出信号。该激活函数的输出信号可以作为下一层卷积层的输入。激活函数可以是sigmoid,修正线性单元(rectified linear unit,ReLU),tanh 等等函数。神经网络是将许多个上述单一的神经单元联结在一起形成的网络,即一个神经单元的输出可以是另一个神经单元的输入。每个神经单元的输入可以与前一层的局部接受域相连,来提取局部接受域的特征,局部接受域可以是由若干个神经单元组成的区域。
卷积神经网络(convolutional neural networks,CNN)是一种带有卷积结构的深度神经网络。卷积神经网络包含了一个由卷积层和子采样层构成的特征抽取器。该特征抽取器可以看作是滤波器,卷积过程可以看作是使用一个可训练的滤波器与一个输入的图像或者卷积特征平面(feature map)做卷积。卷积层是指卷积神经网络中对输入信号进行卷积处理的神经元层。在卷积神经网络的卷积层中,一个神经元可以只与部分邻层神经元连接。一个卷积层中,通常包含若干个特征平面,每个特征平面可以由一些矩形排列的神经单元组成。同一特征平面的神经单元共享权重,这里共享的权重就是卷积核。共享权重可以理解为提取图像信息的方式与位置无关。这其中隐含的原理是:图像的某一部分的统计信息与其他部分是一样的。即意味着在某一部分学习的图像信息也能用在另一部分上。所以对于图像上的所有位置,我们都能使用同样的学习得到的图像信息。在同一卷积层中,可以使用多个卷积核来提取不同的图像信息,一般地,卷积核数量越多,卷积操作反映的图像信息越丰富。
卷积核可以以随机大小的矩阵的形式初始化,在卷积神经网络的训练过程中卷积核可以通过学习得到合理的权重。另外,共享权重带来的直接好处是减少卷积神经网络各层之间的连接,同时又降低了过拟合的风险。
卷积神经网络可以采用误差反向传播(back propagation,BP)算法在训练过程中修正初始的超分辨率模型中参数的大小,使得超分辨率模型的重建误差损失越来越小。具体地,前向传递输入信号直至输出会产生误差损失,通过反向传播误差损失信息来更新初始的超分辨率模型中参数,从而使误差损失收敛。反向传播算法是以误差损失为主导的反向传播运动,旨在得到最优的超分辨率模型的参数,例如权重矩阵。
示例性地,下面以卷积神经网络(convolutional neural networks,CNN)为例。
CNN是一种带有卷积结构的深度神经网络,是一种深度学习(deep learning)架构,深度学习架构是指通过机器学习的算法,在不同的抽象层级上进行多个层次的学习。作为一种深度学习架构,CNN是一种前馈(feed-forward)人工神经网络,该前馈人工神经网络中的各个神经元对输入其中的图像中的重叠区域作出响应。
如图2所示,卷积神经网络(CNN)100可以包括输入层110,卷积层/池化层120,其中池化层为可选的,以及神经网络层130。
如图2所示卷积层/池化层120可以包括如示例121-126层,在一种实现中,121层为卷积层,122层为池化层,123层为卷积层,124层为池化层,125为卷积层,126为池化层;在另一种实现方式中,121、122为卷积层,123为池化层,124、125为卷积层,126为池化层。即卷积层的输出可以作为随后的池化层的输入,也可以作为另一个卷积层的输入以继续进行卷积操作。
以卷积层121为例,卷积层121可以包括很多个卷积算子,卷积算子也称为核,其在图像处理中的作用相当于一个从输入图像矩阵中提取特定信息的过滤器,卷积算子本质上 可以是一个权重矩阵,这个权重矩阵通常被预先定义。在对图像进行卷积操作的过程中,权重矩阵通常在输入图像上沿着水平方向一个像素接着一个像素(或两个像素接着两个像素……这取决于步长stride的取值)的进行处理,从而完成从图像中提取特定特征的工作。该权重矩阵的大小应该与图像的大小相关。需要注意的是,权重矩阵的纵深维度(depth dimension)和输入图像的纵深维度是相同的,在进行卷积运算的过程中,权重矩阵会延伸到输入图像的整个深度。因此,和一个单一的权重矩阵进行卷积会产生一个单一纵深维度的卷积化输出,但是大多数情况下不使用单一权重矩阵,而是应用维度相同的多个权重矩阵。每个权重矩阵的输出被堆叠起来形成卷积图像的纵深维度。不同的权重矩阵可以用来提取图像中不同的特征,例如一个权重矩阵用来提取图像边缘信息,另一个权重矩阵用来提取图像的特定颜色,又一个权重矩阵用来对图像中不需要的噪点进行模糊化等。该多个权重矩阵维度相同,经过该多个维度相同的权重矩阵提取后的特征图维度也相同,再将提取到的多个维度相同的特征图合并形成卷积运算的输出。
这些权重矩阵中的权重值在实际应用中需要经过大量的训练得到,通过训练得到的权重值形成的各个权重矩阵可以从输入图像中提取信息,从而帮助卷积神经网络100进行正确的预测。
当卷积神经网络100有多个卷积层的时候,初始的卷积层(例如121)往往提取较多的一般特征,该一般特征也可以称之为低级别的特征;随着卷积神经网络100深度的加深,越往后的卷积层(例如126)提取到的特征越来越复杂,比如高级别的语义之类的特征,语义越高的特征越适用于待解决的问题。
池化层:
由于常常需要减少训练参数的数量,因此卷积层之后常常需要周期性的引入池化层,即如图2中120所示例的121-126各层,可以是一层卷积层后面跟一层池化层,也可以是多层卷积层后面接一层或多层池化层。在图像处理过程中,池化层的唯一目的就是减少图像的空间大小。池化层可以包括平均池化算子和/或最大池化算子,以用于对输入图像进行采样得到较小尺寸的图像。平均池化算子可以在特定范围内对图像中的像素值进行计算产生平均值。最大池化算子可以在特定范围内取该范围内值最大的像素作为最大池化的结果。另外,就像卷积层中用权重矩阵的大小应该与图像大小相关一样,池化层中的运算符也应该与图像的大小相关。通过池化层处理后输出的图像尺寸可以小于输入池化层的图像的尺寸,池化层输出的图像中每个像素点表示输入池化层的图像的对应子区域的平均值或最大值。
神经网络层130:
在经过卷积层/池化层120的处理后,卷积神经网络100还不足以输出所需要的输出信息。因为如前所述,卷积层/池化层120只会提取特征,并减少输入图像带来的参数。然而为了生成最终的输出信息(所需要的类信息或别的相关信息),卷积神经网络100需要利用神经网络层130来生成一个或者一组所需要的类的数量的输出。因此,在神经网络层130中可以包括多层隐含层(如图2所示的131、132至13n)以及输出层140。在本申请中,该卷积神经网络为:以延迟预测模型的输出作为约束条件对超级单元进行搜索得到至少一 个第一构建单元,并对该至少一个第一构建单元进行堆叠得到。该卷积神经网络可以用于图像识别,图像分类,图像超分辨率重建等等。
在神经网络层130中的多层隐含层之后,也就是整个卷积神经网络100的最后层为输出层140,该输出层140具有类似分类交叉熵的损失函数,具体用于计算预测误差,一旦整个卷积神经网络100的前向传播(如图2由110至140的传播为前向传播)完成,反向传播(如图2由140至110的传播为反向传播)就会开始更新前面提到的各层的权重值以及偏差,以减少卷积神经网络100的损失及卷积神经网络100通过输出层输出的结果和理想结果之间的误差。
需要说明的是,如图2所示的卷积神经网络100仅作为一种卷积神经网络的示例,在具体的应用中,卷积神经网络还可以以其他网络模型的形式存在,例如,如图3所示的多个卷积层/池化层并行,将分别提取的特征均输入给全神经网络层130进行处理。
在神经网络中,部分参数需要通过训练来确定,而部分参数需要在训练之前来确定。下面对神经网络中所涉及到的一些参数进行说明。
超参数(hyper-parameter):是在开始学习过程之前设置值的参数,是不通过训练得到的参数。超参数用于调节神经网络的训练过程,例如卷积神经网络的隐藏层的数量,核函数的大小,数量等等。超参数并不直接参与到训练的过程,而只是配置变量。需要注意的是在训练过程中,超参数往往都是不变的。现在使用的各种神经网络,再经由数据,通过某种学习算法训练后,便得到了一个可以用来进行预测,估计的模型,如果这个模型表现的不好,有经验的工作者便会调整网络结构,算法中学习率或是每批处理的样本的个数等不通过训练得到的参数,一般称之为超参数。通常是通过大量的实践经验来调整超参数,使得神经网络的模型表现更为优秀,直到神经网络的输出满足需求。本申请所提及的一组超参数组合,即包括了神经网络的全部或者部分超参数的值。通常,神经网络由许多神经元组成,输入的数据通过这些神经元来传输到输出端。在神经网络训练时候,每个神经元的权重会随着损失函数的值来优化从而减小损失函数的值。这样便可以通过算法来优化参数得到模型。而超参数是用来调节整个网络训练过程的,如前述的卷积神经网络的隐藏层的数量,核函数的大小或数量等等。超参数并不直接参与到训练的过程中,而只作为配置变量。
优化器:用于优化机器学习算法的参数,比如网络权重。可以采用梯度下降、随机梯度下降或者动量梯度下降算法(adaptive moment estimation,Adam)等优化算法来进行参数优化。
学习率:是指在优化算法中每次迭代更新参数的幅度,也叫做步长。当步长过大会导致算法不收敛,模型的目标函数处于震荡的状态,而步长过小会导致模型的收敛速度过慢。
激活函数:指的是在每个神经元上添加的非线性函数,也就是神经网络具有非线性性质的关键,常用的激活函数可以包括有sigmoid,修正线性单元(rectified linear unit,ReLU),tanh等函数。
损失函数:也就是参数的优化过程中的目标函数。通常,损失函数的值越小,表示模型的是输出结果也就越准确,模型训练的过程即为最小化损失函数的过程。常用的损失函 数可以包括对数损失函数,平方损失函数,指数损失函数等。
通常,可以采用贝叶斯优化来从多组超参数中选择适用于神经网络的最优的超参数。例如,贝叶斯优化的流程可以包括:首先设定初始模型,然后选取该模型下最有可能符合预设条件的超参组合,检测该超参数组合是否满足预设条件,如果满足预设条件则过程终止,输出满足预设条件的超参数组合;如果不满足,则利用该组新数据修正模型后,继续下一轮迭代。常用的贝叶斯流程例如,从超参数搜索空间中采样多个超参数组合,对每个超参数组合进行评估,然后丢弃表现结果差的一半,对表现结果好的一半继续进行评估,然后再次丢弃表现结果差的一半,直到计算资源耗尽,从多个超参数组合中确定出表现最优的超参数组合。若该超参数组合不满足要求,则利用多个超参数组合的评估结果继续修正模型,并根据该模型再次从超参数搜索空间中采样多个超参数组合,并再次进行评估等,直到选择出表现结果满足要求的超参数组合。需要说明的是,本申请以下实施方式中,将此方式称为贝叶斯优化和超参数(Bayesian optimization and hyperband,BOHB),以下不再赘述。然而,在选择合适的超参数组合的过程中,每次对多个超参数组合进行评估的过程中,都丢弃表现结果差的一半超参数组合,从而使得有效的超参数组合的数量少,且丢弃的部分的表现结果可能不准确,导致根据该不准确的表现结果更新得到的模型的可靠性也越低,导致不能找到最优超参数组合。
因此,本申请提供一种神经网络优化方法,用于高效、准确地确定出神经网络的超参数组合。
参阅图4,本申请提供的一种神经网络优化方法的流程示意图,如下所述。
401、对超参数搜索空间进行采样,得到多个超参数组合。
超参数搜索空间中包括神经网络的超参数,可以从该超参数搜索空间中采集超参数,得到多个超参数组合。其中,一组超参数组合中可以包括一个或多个超参数的值。
具体地,超参数搜索空间中可以包括多种超参数,每种超参数的值可以是连续分布的值,也可以是离散分布的值。例如,超参数搜索空间中可以包括超参数A的取值范围为[0,10],超参数B的取值可以包括:1、5、8、9等。因此,在超参数搜索空间中采样时,可以从连续分布的值中任意取一个值,或者在离散分布的值中任意取一个值,得到一组超参数组合。
可选地,对超参数搜索空间进行采样的方式也可以有多种。
在一种可能的实施方式中,可以通过初始的概率分布或者随机采集超参数组合。例如,若当前为第一次对超参数搜索空间进行采样,则可以根据初始的概率分布来对超参数搜索空间进行采样,得到多个超参数组合。
在一种另可能的实施方式中,也可以通过以下步骤405中更新后的预设模型确定的概率分布,来对超参数搜索空间进行采样。例如,若对预设模型进行了更新,则可以根据预设模型确定的概率分布对超参数进行采样,从而得到多个超参数组合。
例如,在步骤401之前,即可获取预设模型,具体的采集函数可以包括:

 其中,x即为超参数组合,p(y|x)即为预设模型对应的概率分布,y为超参数组合的表现结果,α为预设的值。因此,可以根据该采集函数,对超参数搜索空间进行采集,得到符合预设模型对应的概率分布的多个超参数组合。
其中,x即为超参数组合,p(y|x)即为预设模型对应的概率分布,y为超参数组合的表现结果,α为预设的值。因此,可以根据该采集函数,对超参数搜索空间进行采集,得到符合预设模型对应的概率分布的多个超参数组合。
为便于理解,下面以一些具体的场景为例对本申请所涉及的超参数以及神经网络进行示例性说明。
在一种可能的场景中,若前述的神经网络是用于图片识别的卷积神经网络,该卷积神经网络可以参考前述图2和图3的相关描述。对应地,超参数搜索空间中包括的卷积神经网络的超参数可以包括以下一种或多种:卷积层数、卷积核数量、扩张大小、ReLU函数在神经网络中的位置、锚框的尺寸或者锚框的长和宽的比例等,其中,锚框用于标识图片中需要识别的对象。相应地,本申请提及的超参数组合可以包括前述的一种或者多种超参数。例如,在无人驾驶场景中,对道路物体检测功能需求很高,物体检测可以理解为在一张图片中,用一个或多个锚框去寻找物体所处的位置,通常可以提前定义多种锚框的类型,包括一张图中用多少锚框,每个锚框的长宽比等。
在一种可能的场景中,若前述的神经网络是通过结构搜索得到,即该神经网络由一个或多个构建单元组合或堆叠得到,则超参数搜索空间中包括的超参数可以包括:构建单元的网络层数、构建单元中每层网络的神经元数量或者构建单元中每个神经元上的操作算子等。相应地,本申请提及的超参数组合可以包括其中的一种或者多种超参数。例如,若需要搜索人脸识别神经网络的构建单元,则超参数搜索空间所包括的超参数可以包括人脸识别神经网络的构建单元的网络层数、构建单元中每层网络的神经元数量以及构建单元中每个神经元的操作算子等,该超参数组合用于构建人脸识别神经网络。
在一种可能的数据增广场景中,需要对已有的数据集所包括的数据进行变换操作,从而增加数据集所包括的数据量,得到增广后的数据集。在该场景下,需要确定对数据进行哪种变换,来达到数据增广的目的。超参数搜索空间中可以包括多种变换方式,该多种变换方式用于对数据进行变换,从而增加数据量。例如,在增广图片的场景中,该变换方式可以包括旋转、平移、或者对折等操作,增加图片的数量。
在一种可能的强化学习的场景中,需要确定出学习策略,该学习策略中所包括可调整变量即为神经网络的超参数,使神经网络可以根据该学习策略进行学习,从而调整神经网络的部分参数。例如,若神经网络中某个神经元的输入为x1和x2,x1的权重为w1,该神经元的输出为:w1*x1+w2*x2,则需要确定的学习策略为如何更新w1或w2,如确定调整步长、调整的计算方式等。
402、对多个超参数组合进行多次迭代评估,以得到每个超参数组合的多个表现结果。
在得到多个超参数组合之后,对该多个超参数组合进行多次迭代评估,得到每个超参数组合的多个表现结果。
其中,在任意一次迭代评估中,获取每个超参数组合的至少一个表现结果,若该多个超参数组合中存在满足第一预设条件的超参数组合,则对满足第一预设条件的超参数组合进行再次评估,得到该满足第一预设条件的超参数组合的再次评估的表现结果。该第一预设条件例如:评估次数最少或者表现结果优于一定表现结果等。因此,本申请实施方式中,对满足第一预设条件的超参数组合进行再次评估,而非仅关注表现最好的超参数组合,提高了多个超参数组合整体的表现结果的准确性,使得后续更新模型时,可以使模型快速收敛。
具体地,多次迭代评估中的任意一次迭代评估,可以包括:获取多个超参数中每个超参数组合的至少一个表现结果,根据每个超参数组合的至少一个表现结果从多个超参数组合中确定出第二超参数组合,该第二超参数组合为评估次数最多或者表现最好的超参数组合。然后可以根据该第二超参数组合的至少一个表现结果确定第一预设条件。然后判断该至少一个超参数组合中是否存在满足第一预设条件的超参数组合。若该多个超参数组合中存在满足第一预设条件的第一超参数组合,则对第一超参数组合进行再次评估,得到第一超参数组合的再次评估的表现结果,且第二超参数组合和第一超参数组合不相同。若多个超参数组合中不存在满足第一预设条件的第一超参数组合,则对第二超参数组合进行再次评估,得到第二超参数组合的再次评估的表现结果。
其中,获取每个超参数组合的至少一个表现结果的方式有多种,可以对该多个超参数组合进行评估,得到每个超参数组合的至少一个表现结果,或者,获取此次迭代评估之前,对所述每个超参数进行评估得到的至少一个表现结果。例如,在第一次评估时,对该多个超参数组合中的每个超参数组合进行评估,得到每个超参数组合的至少一个表现结果。在非第一次评估的任意第N次迭代评估时,获取前N-1次迭代评估得到的每个超参数的至少一个表现结果,然后基于该每个超参数组合的至少一个表现结果继续进行迭代评估,从而得到每个超参数组合的多个表现结果,N为大于1的正整数。
前述的第一预设条件和第二超参数组合的至少一个表现结果相关联,可以理解为第一预设条件为根据第二超参数组合的至少一个表现结果确定。具体地,根据第二超参数组合的至少一个表现结果确定的该第一预设条件可以包括以下其中一项:第一超参数组合的评估次数不高于预设次数,且第一超参数组合的评估次数不高于第二超参数组合的评估次数;或者,第一超参数组合的评估次数高于预设次数,但不高于第二超参数组合的评估次数,且第二超参数组合的至少一个表现结果中存在部分结果差于第一超参数组合的表现结果。可以理解为,当某一个超参数组合的评估次数较少时,得到的表现结果可能不准确,因此,可以对该超参数组合进行再次评估,得到再次评估的表现结果。或者,当某一个超参数组合的评估次数高于预设次数,但该超参数组合的评估结果优于第二超参数组合的部分表现结果,则可以对该超参数组合进行再次评估,通过再次评估得到的表现结果进一步确认该超参数组合的表现结果是否可以更优。因此,本申请实施方式可以通过对评估次数少或者部分表现结果好的超参数组合进行再次评估,若超参数组合的某一次的表现结果差,也可以再次进行评估,从而使该超参数组合的表现结果更准确。
例如,该第一预设条件具体可以表示为:
1、n
k<n
k′,且n
k<c
n,其中,n
k为第一超参数组合的评估次数,n
k′为第二超参数组合的评估次数,c
n为预设次数;
2、c
n<n
k<n
k′,且


其中,Y
(k)为第k个超参数组合的表现结果,Y
(k′)为第二超参数组合的表现结果。满足前述的其中一个条件,即可确定第一超参数组合满足第一预设条件。u为小于n
k的正整数,l为不大于u的正整数。
例如,若第一超参数组合具有10个表现结果,第二超参数组合具有50个表现结果,则可以遍历第二超参数组合的50个表现结果,确定该50个表现结果中是否存在10个表现结果差于第一超参数组合的10个表现结果。如评估结果中包括损失值,则可以比较第二超参数组合的10个损失值的平均值和第一超参数组合的10个损失值的平均值,判断第二超参数组合的50个损失值中,是否存在10个损失值的平均值大于第一超参数组合的10个损失值的平均值。若存在,则确定第一超参数组合满足第一预设条件;若不存在,则确定第一超参数组合不满足第一预设条件。
通常,若存在多个超参数组合的评估次数小于阈值,且不高于第二超参数组合的评估次数,即存在多个满足条件1的超参数组合,则将评估次数最少的超参数组合作为第一超参数组合,或者,将评估次数小于阈值,且不高于第二超参数组合的评估次数的每个超参数组合都作为第一超参数组合,即可以对该多个评估次数小于阈值,且不高于第二超参数组合的评估次数的超参数组合进行再次评估。若存在多个超参数组合满足条件2,则从该多个超参数组合选择表现较优的超参数组合作为第一超参数组合,或者,将该多个满足条件2的超参数组合中的每个超参数组合作为第一超参数组合,即可以对该多个满足条件2的超参数组合进行再次评估。
因此,可以通过该第一预设条件,从多个超参数组合中选出再次评估的超参数组合,从而使评估次数少,或者表现结果优于第二超参数组合的部分结果的超参数组合进行再次评估,从而提高该超参数组合的表现结果的准确性,进而提高多个超参数组合的整体的表现结果的准确性。
可以理解为,在确定出最优的第二超参数组合之后,放宽了选择再次评估的超参数组合的条件,使得更多表现不是最优或者评估次数少的超参数组合也可以进行再次评估,从而使最终得到的多个超参数组合的整体的表现结果更准确,进而提高后续更新模型的收敛速度。
此外,对超参数组合进行评估,得到超参数组合的表现结果的具体方式可以包括:将超参数组合所包括的超参数代入神经网络中,然后根据该神经网络的输出确定超参数组合的表现结果。该表现结果可以是神经网络输出的结果的分类精度、损失值、精确率(precision)、召回率(recall)或者时期(epoch)数量等。其中,分类精度表示神经网络识别图片的准确度;损失值为神经网络的损失函数的值;精确率用于表示神经网络输出的结果中,判定为真的样本,占实际为真的样本与实际为假的样本的和的比例,即表示的是预测为正的样本中有多少是正确的;召回率用于表示神经网络输出的结果中,判定为真的样本,占实际为真的样本的比例,即表示预测的样本中有多少正样本被预测正确;一个epoch表示在强化学习的场景中,将训练集中的全部样本训练一次。
403、根据每个超参数组合的多个表现结果从多个超参数组合中确定出最优超参数组合。
在得到每个超参数组合的多个表现结果之后,根据该每个超参数组合的多个表现结果,从多个超参数组合中确定出最优超参数组合。
具体地,可以将该多个超参数组合中,评估次数最多的超参数组合作为最优超参数组合。当评估次数最多的超参数组合有多个时,可以从多个评估次数最多的超参数组合中确 定出表现结果最优的超参数组合作为第二超参数组合。
其中,衡量表现结果是否最优的方式可以包括多种,具体可以包括表现结果所包括的参数进行确定,在不同的场景中,超参数组合的表现结果中所包括的参数不相同,衡量表现结果是否最优的方式可能不同。示例性地,表现结果最优的超参数组合可以是:分类精度最高、或者分类精度的平均值最高,或者损失值最低的超参数组合等。
404、判断最优超参数组合是否满足第二预设条件,若是,则执行步骤405,若否,则执行步骤406。
其中,在确定出最优超参数组合之后,判断该最优超参数组合是否满足第二预设条件。若该最优超参数组合满足第二预设条件,则将该最优超参数组合所包括的超参数作为神经网络的超参数,即执行步骤406。若该最优超参数组合不满足第二预设条件,则通过每个超参数组合的多个表现结果更新预设模型,即执行步骤405。
具体地,第二预设条件可以随着超参数组合的表现结果不同而变化,该第二预设条件在不同的场景中可能对应不同的条件,示例性地,下面以一些具体的场景为例进行示例性说明。当超参数组合的表现结果中包括分类精度时,第二预设条件可以包括:最优超参数组合的多个表现结果中的任一个表现结果中的分类精度大于第一阈值,或者,最优超参数组合的多个表现结果包括的分类精度的平均值大于第二阈值。当超参数组合的表现结果中包括神经网络的损失值时,则第二预设条件可以包括该损失值不大于第三阈值。当超参数组合的表现结果中包括精确率或者召回率时,该第二预设条件可以包括:任一个精确率大于第四阈值,或者,多个精确率的平均值大于第五阈值,或者,召回率大于第六阈值等。当超参数组合的表现结果中包括epoch数量等,则第二预设条件可以包括该epoch数量不大于第七阈值。
405、通过每个超参数组合的多个表现结果更新预设模型。
其中,若确定出的最优超参数组合不满足第二预设条件,则可以使用多个超参数组合中的每个超参数组合的多个表现结果来更新预设模型。该模型用于拟合概率分布,该概率分布用于对超参数进行采样。因此,在更新该预设模型之后,即可继续执行步骤401。
具体地,第一预设模型包括第一概率密度函数和第二概率密度函数。为便于理解,以下将第一概率密度函数表示为l(x),将第二概率密度函数表示为g(x)。通常,概率密度函数是连续函数,用于表示随机变量的输出值在某个确定的取值点附近的可能性。而随机变量的取值落在某个区域之内的概率则为概率密度函数在这个区域上的积分。当概率密度函数存在的时候,累积分布函数是概率密度函数的积分。
可选地,第一概率密度函数和第二概率密度函数的类型可以包括但不限于以下一种或多种:正态分布、离散分布、截断正态分布、对数正态分布、指数分布,伽玛分布(Gamma distribution),贝塔分布(Beta distribution)或者伯努利分布等等。概率密度函数的具体类型可以根据实际应用场景进行调整,本申请对此不作限定。
在得到多个超参数组合中每个超参数组合的多个表现结果之后,将该多个超参数组合分为两类,包括第一类超参数组合和第二类超参数组合,其中,第一类超参数组合的表现优于第二类超参数组合的表现,第一类超参数的表现为根据第一类超参数的多个表现结果 确定,第二类超参数组合的表现是根据第二类超参数组合的表现结果确定的,且通过第一类超参数组合更新l(x),通过第二类超参数组合更新g(x)。
可以理解为,第一类超参数组合的整体表现优于第二类超参数组合的整体表现,例如,第一类超参数的评估次数都高于第二类超参数组合,或者,第一类超参数组合的多个表现结果所包括的分类精度的平均值高于第二类超参数组合的多个表现结果所包括的分类精度的平均值,或者,第一类超参数组合的多个表现结果所包括的损失值的平均值低于第二类超参数组合的多个表现结果所包括的损失值的平均值等。在不同的场景中,评价第一类超参数组合优于第二类超参数组合的方式可能不同,具体可以根据实际应用场景进行调整,本申请实施例是示例性说明。
其中,通过表现结果更新概率密度函数的方式可以是通过核密度估计(kernel density estimation,KDE)、树参数估计(tree parzen estimator,TPE)、高斯过程(Gaussian process,GP)、基于序列模型的算法配置(sequential model-based algorithm configuration,SMAC)等方式更新概率密度参数。例如,以KDE为例,首先设定模型,如线性、可化线性或指数等模型,然后根据输入的每个超参数组合的多个表现结果,记录表现结果较优的超参数的分布范围,然后按照设定的模型以及该分布范围进行拟合,即可得到更新后的模型。更具体地,本申请按照表现结果将多个超参数组合分为了第一类超参数和第二类超参数,可以根据第一类超参数的表现结果,确定表现较优的超参数的分布范围,从而拟合得到第一概率密度函数;根据第二类超参数的表现结果,确定表现较差的超参数的分布范围,从而拟合得到第二概率密度函数。
此外,对多个超参数组合进行分类的方式有多种,下面示例性地对几种可行的分类方式进行介绍,具体可以根据实际应用场景进行调整,本申请对此不作限定。
方式一、与预设值比较后分类
确定每个超参数组合的表现结果的平均值,若该平均值优于预设值,则将对应的超参数组合分为第一类超参数组合,若该平均值不优于预设值,则将对应的超参数组合分为第二类超参数组合。其中,前述的平均值,也可以替换为多个表现结果中最优的值、分布最多的值等,具体可以根据实际应用场景进行调整,本申请仅以平均值为例进行示例性说明。
其中,确定平均值是否优于预设值,在不同的场景中有不同的确认方式。例如,若表现结果中包括分类精度,则通常精度越高,表示超参数组合的表现越好,因此,将平均分类精度值高于预设值的超参数组合分为第二类超参数组合,而将平均分类精度值不高于预设值的超参数组合分为第二类超参数组合。又例如,若超参数组合的表现结果中包括损失值,通常损失值越低,表示超参数组合的表现越好,因此,可以将平均损失值低于预设值的超参数组合分为第一类超参数组合,将平均损失值不低于预设值的超参数组合分为第二类超参数组合。
方式二、按比例分配
其中,可以将多个超参数组合,按照预设的比例分为两种。例如,可以预设设定3:7的比例,根据每个超参数组合的多个表现结果,将其中表现较优的3/10分为第一类超参数组合,将表现较差的7/10分为第二类超参数组合。其中,比较超参数组合的表现结果的方 式可以包括:计算每个超参数组合的多个表现结果的平均值,对多个超参数组合的平均值进行排序,然后根据排序结果,按照预设的比例将表现较优的超参数组合作为第二超参数组合,将表现较差的超参数组合作为第一超参数组合。
此外,除了基于每个超参数组合的多个表现结果的平均值进行排序,也可以基于每个超参数组合的多个表现结果中最优的表现结果的值进行排序,或者基于每个超参数组合的多个表现结果中分布最多的值进行排序,具体可以根据实际场景进行调整。
并且,与前述方式一类似地,当超参数组合的表现结果包括损失值时,则损失值越低,表示该超参数组合的表现结果越好,当损失值越高,则表示超参数组合的表现结果越差。或者,当超参数组合的表现结果包括分类精度时,分类精度值越高,则表示超参数组合的表现越好,分类精度值越低,则表示超参数组合的表现越差。
在通过每个超参数组合的多个表现结果更新预设模型之后,可以根据预设模型所拟合的概率分布进行采样。例如,具体的采集函数可以包括:

 其中,x即为超参数组合,
其中,x即为超参数组合,
 在更新了l(x)和g(x)之后,根据l(x)对应的概率分布再次采集超参数组合,然后基于l(x)/g(x)确定最终采集到的多个超参数组合,即采集到的多个超参数组合满足l(x)和g(x)所对应的概率分布。可以理解为,本申请实施方式中,需要最大化l(x)/g(x),从而增加采集到表现优的超参数组合的概率,使采集到的超参数组合更趋于表现最优的超参数组合,从而可以准确、高效地确定出表现更优的超参数组合。
在更新了l(x)和g(x)之后,根据l(x)对应的概率分布再次采集超参数组合,然后基于l(x)/g(x)确定最终采集到的多个超参数组合,即采集到的多个超参数组合满足l(x)和g(x)所对应的概率分布。可以理解为,本申请实施方式中,需要最大化l(x)/g(x),从而增加采集到表现优的超参数组合的概率,使采集到的超参数组合更趋于表现最优的超参数组合,从而可以准确、高效地确定出表现更优的超参数组合。
406、将最优超参数组合作为神经网络的超参数组合。
其中,在确定出最优的超参数组合,且该超参数组合满足第二预设条件之后,即可将该最优超参数组合作为神经网络的超参数组合。
例如,若超参数搜索空间中包括的是卷积神经网络的超参数,则在确定出最优超参数组合之后,将该最优超参数组合中包括的超参数作为卷积神经网络的超参数。如最优超参数组合中包括卷积层数、核大小、扩张大小、ReLU的位置等参数,则将最优超参数组合中所包括的参数作为卷积神经网络的卷积层数、核大小、扩张大小、ReLU的位置等。
因此,本申请实施方式中,在对多个超参数组合进行评估时,除了对多个超参数组合中表现最优的超参数组合进行评估之外,还可以对表现不是最优或者评估次数少的超参数组合进行再次评估,从而可以避免因评估次数少或者因部分表现结果出现误差等原因导致的表现结果不准确,提高最终得到的超参数组合的表现结果的准确性。进一步地,可以利用该准确的表现结果更新模型,使得模型可以快速收敛,提高收敛效率。且根据该模型进一步对超参数搜索空间进行采样,从而可以准确、高效地确定出表现更优的超参数组合。
前述对本申请提供的神经网络优化方法的流程进行了介绍,下面以一个具体的应用场景为例,对本申请提供的神经网络优化方法进行示例性介绍。
参阅图5,本申请提供的另一种神经网络优化方法的流程示意图。
501、对超参数搜索空间进行采样,得到K个超参数组合。
其中,可以对超参数搜索空间进行随机采样,也可以根据预设模型确定的概率分布对超参数搜索空间进行采样,得到K个超参数组合,K为正整数,K的具体取值可以根据实际应用场景进行调整。
例如,以卷积神经网络为例,超参数搜索空间中可以包括卷积层数、卷积核数量、扩张大小、ReLU函数在神经网络中的位置、锚框的尺寸或者锚框的长和宽的比例等多种超参数组合的取值范围,若当前为首次对超参数搜索空间进行采样,则可以从超参数搜索空间中随机采集一批超参数组合,得到K个超参数组合,每个超参数组合中都包括卷积层数、卷积核数量、扩张大小、ReLU函数在神经网络中的位置、锚框的尺寸或者锚框的长和宽的比例等的值。
具体地,步骤501可以参阅前述步骤401的相关描述,此处不再赘述。
502、用b份计算资源进行评估,得到每个超参数组合的至少一个表现结果。
其中,b分资源在不同的场景中所包括的资源可能不相同,例如,该b份计算资源可以包括b次迭代,即迭代次数为b;或者,在蒙特卡洛计算中,该b份计算资源可以包括所使用的样本个数,如样本的数量为b;或者,在强化学习的场景中,该b份计算资源可以包括学习尝试的轮数。
例如,可以对每个超参数组合进行b次迭代评估,得到每个超参数组合的b个表现结果。
以用于图片识别的卷积神经网络为例,可以将每个超参数组合所包括的卷积层数、卷积核数量、扩张大小、ReLU函数在卷积神经网络中的位置、锚框的尺寸或者所述锚框的长和宽的比例等值代入卷积神经网络中,然后通过已有的训练数据作为该卷积神经网络的输入,得到卷积神经网络的输出结果,对卷积神经网络的输出与训练数据实际的值进行对比,得到超参数组合的一个表现结果,若进行b次迭代评估,则得到b个表现结果。如图6所示,将图6所示的图片作为卷积神经网络的输入,将超参数组合中所包括的卷积层数、卷积核数量、扩张大小、ReLU函数在卷积神经网络中的位置、锚框的尺寸或者锚框的长和宽的比例等值代入卷积神经网络,通过锚框(即图6中所示的黑框)的尺寸或者锚框的长和宽的比例标记出图片中待识别或者识别出的动物。又例如,如图7所示,在无人驾驶场景中,可以将车辆传感器或者摄像机采集到的图片作为卷积神经网络的输入,根据超参数组合中所包括的锚框(即图7中所示的黑框)的尺寸或者锚框的长和宽的比例等,标记出图片中的车辆或者其他障碍物,从而为车辆自动驾驶控制系统提供决策输入信息,提高车辆行驶的安全性。
503、选出最优的第二超参数组合。
其中,在得到K个超参数组合中每个超参数组合的多个表现结果之后,根据每个超参数组合的多个表现结果筛选出表现最优的第二超参数组合。
在不同的场景中,超参数组合的表现结果中所包括的参数不相同,衡量表现结果是否最优的方式可能不同。示例性地,表现结果最优的超参数组合可以是:分类精度最高、或者分类精度的平均值最高,或者损失值最低的超参数组合等。
504、判断K-1个超参数组合中是否存在部分优于第二超参数组合的组合,若是,则执行步骤505,若否,则执行步骤506。
在确定出最优的第二超参数组合之后,判断K个超参数组合中除第二超参数组合之外的其余K-1个超参数组合是否存在部分条件下优于第二超参数组合的组合,若存在部分条 件下优于第二超参数组合的组合,则可以对该部分条件下优于第二超参数组合的组合进行再次评估,若不存在优于部分条件下第二超参数组合的组合,则可以对第二超参数组合进行再次评估。可以理解为,本步骤中所提及的部分条件下优于第二超参数组合的超参数组合,是指满足第一预设条件的第一超参数组合。
其中,判断K-1个超参数组合中是否存在部分条件下优于第二超参数组合的组合的方式,具体可以包括:
1、n
k<n
k′,且n
k<c
n,n
k为第一超参数组合的评估次数,n
k′为第二超参数组合的评估次数,c
n为预设次数;
2、c
n<n
k<n
k′,且
 且,
且,
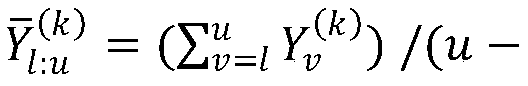
 该条件具体参阅前述步骤402中的相关描述,此处不再赘述。
该条件具体参阅前述步骤402中的相关描述,此处不再赘述。
若第一超参数组合满足其中之一的条件,即该第一超参数组合的评估次数过少,或者表现结果优于第二超参数组合的部分表现结果,则可以理解为该第一超参数组合在部分条件下优于第二超参数组合,即可对该第一超参数组合进行再次评估。
因此,本申请实施方式中,降低了选择再次评估的超参数组合的标准,使得更多表现不是最优或者评估次数少的超参数组合也可以进行再次评估,从而使最终得到的多个超参数组合的整体的表现结果更准确。
505、用2b份资源对优于第二超参数组合的超参数组合进行加强评估。
若确定存在优于第二超参数组合的组合,则表示K个超参数组合中存在评估次数不高于预设值,或者K个超参数组合中存在表现结果优于第二超参数组合的部分表现结果的组合,即可使用2b份资源对表现结果优于第二超参数组合的部分表现结果的第一超参数组合进行加强评估,得到第一超参数组合的多个表现结果。
因此,在本申请实施方式中,当存在优于第二超参数组合的组合时,可以对该表现结果优于第二超参数组合的组合进行再次评估。
506、用2b份资源对第二超参数组合进行加强评估。
若确定不存在表现结果优于第二超参数组合的部分表现结果的组合,则表示K个超参数组合的评估次数高于预设值,或者表现结果并未优于第二超参数组合,即可使用2b份资源对第二超参数组合进行加强评估,得到第二超参数组合的多个表现结果。
因此,本申请实施方式中,当确定不存在表现结果优于第二超参数组合的超参数组合之后,可以对第二超参数组合进行再次评估,得到再次评估的表现结果,从而使第二超参数组合的表现结果更准确。
此外,步骤505或506中的2b份资源也可以替换为b份计算资源,或者更多或更少的计算资源,此处仅仅以2b份资源进行加权评估为例进行示例性说明,具体可以根据实际应用场景进行调整,本申请对此不作限定。
507、判断计算资源是否耗尽,若是,则执行步骤508,若否,则执行步骤503。
在进行再次评估之后,判断计算资源是否耗尽,若计算资源并未耗尽,则可以继续执行步骤503,即重新选出最优的第二超参数组合。
该计算资源包括前述的b份资源和2b份资源。该计算资源可以是预先设定的可用于对 超参数组合进行评估的资源。例如,该计算资源可以包括预设次数的迭代评估次数,步骤507即判断对K个超参数组合的评估次数是否达到该预设次数。若对K个超参数组合的评估次数已达到该预设次数,则可以输出该K个超参数组合的最终表现结果;若对K个超参数组合的评估次数未达到该预设次数,则可以继续执行步骤503,即继续对超参数组合进行评估,直到评估次数达到预设次数。
因此,本申请实施方式中,可以通过步骤501-507,快速对K个超参数组合进行评估,利用该K个超参数组合的表现结果拟合贝叶斯模型,并根据贝叶斯模型重复进行采样、评估,利用循环迭代得到的评估数据修正贝叶斯模型,可以根据贝叶斯模型拟合最优超参数组合所服从的概率分布,并根据最终拟合得到的概率分布采集超参数组合。本申请除了对多个超参数组合中的最优超参数组合进行再次评估之外,还可以对多个超参数组合中部分表现不是最优或者评估次数较少的超参数组合进行评估,从而提高部分表现不是最优或者评估次数较少的超参数组合的表现结果的准确性,提高多个超参数组合的整体表现的准确性,从而使得贝叶斯模型可以快速收敛,可以准确、高效地确定出表现更优的超参数组合。
508、从K个超参数组合中确定出最优超参数组合。
其中,在确定计算资源耗尽之后,可以获取到K个超参数组合的最终表现结果,该K个超参数组合的最终表现结果包括前述步骤503至步骤507中评估得到的每个超参数组合的多个表现结果。
509、判断最优超参数组合是否满足第二预设条件。
510、通过每个超参数组合的多个表现结果更新预设模型。
511、将最优超参数组合作为神经网络的超参数组合。
具体地,步骤508--511可以参阅前述步骤403-406中的相关描述,此处不再赘述。
因此,本申请实施方式中,不局限于关注多个超参数组合中表现最好的超参数组合,也增加了多个超参数组合中表现不是最优或者评估次数较少的超参数组合的评估次数,从而使使表现不是最优或者评估次数较少等具有潜力的超参数组合的表现结果更准确,避免因评估次数少或者部分评估出现误差而导致的数据不准确等问题,通过增加评估次数增加了具有潜力的超参数组合的表现结果的准确性,提高多个超参数组合的整体的表现结果的准确性。从而可以使预设模型快速收敛,且根据该预设模型可以准确、高效地确定出表现更优的超参数组合。
示例性地,下面以上下文信息通用物体检测数据集(common objects in context,COCO)数据集作为神经网络的输入数据,对本申请提供的神经网络优化方法和常用的方案进行对比,对本申请提供的神经网络优化方法的有益效果进行示例性说明。该数据集拥有80个通用物体的检测标注,含有约1.1万训练数据集以及5千张测试集。该数据集中所包括的图像主要从复杂的日常场景中截取,图像中的目标通过精确的分割进行位置的标定。数据集中的图像包括91类目标,328000影像和2500000个标签。
参阅图8,其中包括了本申请提供的神经网络优化方法所确定的超参数,和常用的一些方式确定的超参数,代入神经网络后输出的结果的对比。其中,常用的一些方式包括人工、随机搜索和贝叶斯优化和超参数(Bayesian optimization and hyperband,BOHB)等。 其中,人工的方式即由人工根据经验值来取超参数组合;随机搜索即采用均匀分布从超参数搜索空间中采集超参数组合;BOHB参阅前述的相关介绍;图8中所示的本申请即由本申请提供的神经网络优化方法来确定超参数组合。
APx或者ARx中的x为数值时,表示锚框和目标物体的重合的比例,例如,AP
50表示图像中锚框和待检测的目标物体重合的比例为50%;S、M和L表示图像中待检测的物体的大小,分为小(small,S)、中(medium,M)和大(large,L),具体的分类标准可以根据实际应用场景进行调整。
可以理解为,在BOHB方案中,仅追求返回最优组合,而并不关注是否对贝叶斯模型的估计有所帮助。而本申请提供的神经网络优化方法中,除了关注多个超参数组合中表现最优的超参数组合,也对多个超参数组合中表现不是最优或者评估次数少的超参数组合进行再次评估,使对K个超参数组合的迭代过程中,得到的K个超参组合的总体表现达到渐近最优,即在评估次数趋于无穷大的时候,总体表现趋于最优表现。本申请实施例对于贝叶斯流程的整体给出保证,使能够更好的估计贝叶斯模型,已达到每次抽取的超参组合更接近最优组合的目的。
因此,由图8可知,本申请提供的神经网络优化方法,所确定的超参数组合,在应用到卷积神经网络中时,卷积神经网络识别图片所输出的AP和AR明显高于常用的一些方式。因此,本申请提供的神经网络优化方法,可以确定出表现结果更优的超参数组合。
前述对本申请提供的神经网络优化方法的流程进行了详细介绍,下面基于前述的神经网络优化方法,对本申请提供的神经网络优化装置进行阐述,该神经网络优化装置用于执行前述图4-8对应的方法的步骤。
参阅图9,本申请提供的一种神经网络优化装置的结构示意图。该神经网络优化装置包括:
采样模块901,用于对超参数搜索空间进行采样,得到多个超参数组合,超参数搜索空间包括神经网络的超参数,超参数包括神经网络中不通过训练得到的参数;
评估模块902,用于对多个超参数组合进行多次迭代评估,以得到多个超参数组合中的每个超参数组合的多个表现结果,多个表现结果为根据代入每个超参数组合后的神经网络输出的结果确定,其中,在多次迭代评估中的任一次迭代评估中,获取当前次评估之前评估得到的每个超参数组合的至少一个表现结果,若多个超参数组合存在满足第一预设条件的第一超参数组合,对第一超参数组合进行再次评估,得到第一超参数组合的再次评估的表现结果,该再次评估的表现结果包括于第一超参数组合的多个表现结果中;
确定模块903,用于根据每个超参数组合的多个表现结果从多个超参数组合中确定出最优超参数组合;
更新模块904,用于若最优超参数组合不满足第二预设条件,则通过每个超参数组合的多个表现结果更新预设模型,预设模型用于拟合概率分布,概率分布用于对超参数搜索空间进行再次采样;
选择模块905,用于若最优超参数组合满足第二预设条件,则将最优超参数组合作为神经网络的超参数组合。
在一种可能的实施方式中,第一预设条件包括:第一超参数组合的评估次数不高于预设次数,且第一超参数组合的评估次数不高于第二超参数组合的评估次数,第二超参数组合为在任意一次迭代中选取出的多个超参数组合中表现最优的超参数组合,或者,多个超参数组合中评估次数最多的超参数组合;或者,第一超参数组合的评估次数高于预设次数,且第一超参数组合的评估次数不高于第二超参数组合的评估次数,且存在第二超参数组合的部分表现结果差于第一超参数组合的至少一个表现结果。
在一种可能的实施方式中,评估模块902,还包括:然后判断多个超参数组合中是否存在满足第一预设条件的超参数组合,若多个超参数组合中不存在满足第一预设条件的第一超参数组合,则对第二超参数组合进行再次评估,得到第二超参数组合再次评估的表现结果,该第二超参数组合的再次评估的表现结果包括于第二超参数组合的多个表现结果中。
在一种可能的实施方式中,预设模型包括第一概率密度函数和第二概率密度函数,更新模块904,具体用于:根据每个超参数组合的至少一个表现结果将多个超参数组合分为第一类超参数组合和第二类超参数组合,第一类超参数组合的多个表现结果优于第二类超参数组合的多个表现结果,通过第一类超参数组合更新第一概率密度函数,以及通过第二类超参数组合更新第二概率密度函数。
在一种可能的实施方式中,第一概率密度函数或第二概率密度函数的类型可以包括:正态分布、离散分布、截断正态分布或者对数正态分布。
在一种可能的实施方式中,神经网络为用于识别图片的卷积神经网络,超参数搜索空间中的超参数的种类包括以下一种或多种:卷积层数、卷积核数量、扩张大小、ReLU函数在神经网络中的位置、锚框的尺寸或者锚框的长和宽的比例,锚框用于标识图片中需要识别的对象。
在一种可能的实施方式中,神经网络为通过一个或多个构建单元组合得到,超参数搜索空间中的超参数的种类包括以下一种或多种:一个构建单元的网络层数、构建单元中每层网络的神经元数量或者构建单元中每个神经元的操作算子。
在一种可能的实施方式中,多个表现结果包括分类精度或者损失值,分类精度用于表示神经网络识别图片的准确度,损失值为神经网络对应的损失函数的值;第二预设条件包括:多个表现结果中的任一个表现结果中的分类精度大于第一阈值,或者,多个表现结果包括的分类精度的平均值大于第二阈值,或者,损失值不大于第三阈值。
在一种可能的实施方式中,采样模块901,具体用于:对超参数搜索空间进行随机采样,得到多个超参数组合;或者,基于更新前的预设模型确定的概率分布对超参数搜索空间进行采样,得到多个超参数组合。
请参阅图10,本申请提供的另一种神经网络优化装置的结构示意图,如下所述。
该神经网络优化装置可以包括处理器1001和存储器1002。该处理器1001和存储器1002通过线路互联。其中,存储器1002中存储有程序指令和数据。
存储器1002中存储了前述图4或图8中的步骤对应的程序指令以及数据。
处理器1001用于执行前述图4或图8中任一实施例所示的神经网络优化装置执行的方法步骤。
本申请实施例中还提供一种计算机可读存储介质,该计算机可读存储介质中存储有用于生成车辆行驶速度的程序,当其在计算机上行驶时,使得计算机执行如前述图4至图8所示实施例描述的方法中的步骤。
可选地,前述的图10中所示的神经网络优化装置为芯片。
本申请实施例还提供了一种神经网络优化装置,该神经网络优化装置也可以称为数字处理芯片或者芯片,芯片包括处理单元和通信接口,处理单元通过通信接口获取程序指令,程序指令被处理单元执行,处理单元用于执行前述图4或图8中任一实施例所示的神经网络优化装置执行的方法步骤。
本申请实施例还提供一种数字处理芯片。该数字处理芯片中集成了用于实现上述处理器1001,或者处理器1001的功能的电路和一个或者多个接口。当该数字处理芯片中集成了存储器时,该数字处理芯片可以完成前述实施例中的任一个或多个实施例的方法步骤。当该数字处理芯片中未集成存储器时,可以通过通信接口与外置的存储器连接。该数字处理芯片根据外置的存储器中存储的程序代码来实现上述实施例中神经网络优化装置执行的动作。
本申请实施例中还提供一种包括计算机程序产品,当其在计算机上行驶时,使得计算机执行如前述图4至图8所示实施例描述的方法中神经网络优化装置所执行的步骤。
本申请实施例提供的神经网络优化装置可以为芯片,芯片包括:处理单元和通信单元,所述处理单元例如可以是处理器,所述通信单元例如可以是输入/输出接口、管脚或电路等。该处理单元可执行存储单元存储的计算机执行指令,以使服务器内的芯片执行上述图4至图8所示实施例描述的神经网络优化方法。可选地,所述存储单元为所述芯片内的存储单元,如寄存器、缓存等,所述存储单元还可以是所述无线接入设备端内的位于所述芯片外部的存储单元,如只读存储器(read-only memory,ROM)或可存储静态信息和指令的其他类型的静态存储设备,随机存取存储器(random access memory,RAM)等。
具体地,前述的处理单元或者处理器可以是中央处理器(central processing unit,CPU)、网络处理器(neural-network processing unit,NPU)、图形处理器(graphics processing unit,GPU)、数字信号处理器(digital signal processor,DSP)、专用集成电路(application specific integrated circuit,ASIC)或现场可编程逻辑门阵列(field programmable gate array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者也可以是任何常规的处理器等。
具体的,请参阅图11,图11为本申请实施例提供的芯片的一种结构示意图,所述芯片可以表现为神经网络处理器NPU 110,NPU 110作为协处理器挂载到主CPU(Host CPU)上,由Host CPU分配任务。NPU的核心部分为运算电路1103,通过控制器1104控制运算电路1103提取存储器中的矩阵数据并进行乘法运算。
在一些实现中,运算电路1103内部包括多个处理单元(process engine,PE)。在一些实现中,运算电路1103是二维脉动阵列。运算电路1103还可以是一维脉动阵列或者能够执行例如乘法和加法这样的数学运算的其它电子线路。在一些实现中,运算电路1103是 通用的矩阵处理器。
举例来说,假设有输入矩阵A,权重矩阵B,输出矩阵C。运算电路从权重存储器1102中取矩阵B相应的数据,并缓存在运算电路中每一个PE上。运算电路从输入存储器1101中取矩阵A数据与矩阵B进行矩阵运算,得到的矩阵的部分结果或最终结果,保存在累加器(accumulator)1108中。
统一存储器1106用于存放输入数据以及输出数据。权重数据直接通过存储单元访问控制器(direct memory access controller,DMAC)1105,DMAC被搬运到权重存储器1102中。输入数据也通过DMAC被搬运到统一存储器1106中。
总线接口单元(bus interface unit,BIU)1110,用于AXI总线与DMAC和取指存储器(Instruction Fetch Buffer,IFB)1109的交互。
总线接口单元1110(bus interface unit,BIU),用于取指存储器1109从外部存储器获取指令,还用于存储单元访问控制器1105从外部存储器获取输入矩阵A或者权重矩阵B的原数据。
DMAC主要用于将外部存储器DDR中的输入数据搬运到统一存储器1106或将权重数据搬运到权重存储器1102中或将输入数据数据搬运到输入存储器1101中。
向量计算单元1107包括多个运算处理单元,在需要的情况下,对运算电路的输出做进一步处理,如向量乘,向量加,指数运算,对数运算,大小比较等等。主要用于神经网络中非卷积/全连接层网络计算,如批归一化(batch normalization),像素级求和,对特征平面进行上采样等。
在一些实现中,向量计算单元1107能将经处理的输出的向量存储到统一存储器1106。例如,向量计算单元1107可以将线性函数和/或非线性函数应用到运算电路1103的输出,例如对卷积层提取的特征平面进行线性插值,再例如累加值的向量,用以生成激活值。在一些实现中,向量计算单元1107生成归一化的值、像素级求和的值,或二者均有。在一些实现中,处理过的输出的向量能够用作到运算电路1103的激活输入,例如用于在神经网络中的后续层中的使用。
控制器1104连接的取指存储器(instruction fetch buffer)1109,用于存储控制器1104使用的指令;
统一存储器1106,输入存储器1101,权重存储器1102以及取指存储器1109均为On-Chip存储器。外部存储器私有于该NPU硬件架构。
其中,循环神经网络中各层的运算可以由运算电路1103或向量计算单元1107执行。
其中,上述任一处提到的处理器,可以是一个通用中央处理器,微处理器,ASIC,或一个或多个用于控制上述图4-图8的方法的程序执行的集成电路。
另外需说明的是,以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。另外,本申请提供的装置实施例附图中,模块之间的连接关系表示它们之间具有通信连接,具体可以实现为一条 或多条通信总线或信号线。
通过以上的实施方式的描述,所属领域的技术人员可以清楚地了解到本申请可借助软件加必需的通用硬件的方式来实现,当然也可以通过专用硬件包括专用集成电路、专用CPU、专用存储器、专用元器件等来实现。一般情况下,凡由计算机程序完成的功能都可以很容易地用相应的硬件来实现,而且,用来实现同一功能的具体硬件结构也可以是多种多样的,例如模拟电路、数字电路或专用电路等。但是,对本申请而言更多情况下软件程序实现是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在可读取的存储介质中,如计算机的软盘、U盘、移动硬盘、只读存储器(read only memory,ROM)、随机存取存储器(random access memory,RAM)、磁碟或者光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例所述的方法。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。
所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本申请实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存储的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如固态硬盘(solid state disk,SSD))等。
本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的实施例能够以除了在这里图示或描述的内容以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
最后应说明的是:以上,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以权利要求的保护范围为准。
Claims (21)
- 一种神经网络优化方法,其特征在于,包括:对超参数搜索空间进行采样,得到多个超参数组合,所述超参数搜索空间包括神经网络的超参数,所述超参数代表所述神经网络中不通过训练得到的参数;对所述多个超参数组合进行多次迭代评估,以得到所述多个超参数组合中的每个超参数组合的多个表现结果,所述多个表现结果为根据代入所述每个超参数组合后的所述神经网络输出的结果确定,其中,所述多次迭代评估中的任意一次迭代评估中,获取当前次评估之前评估得到的所述每个超参数组合的至少一个表现结果,若所述多个超参数组合存在满足第一预设条件的第一超参数组合,则对所述第一超参数组合进行再次评估,得到所述第一超参数组合的再次评估的表现结果,所述再次评估的表现结果包括于所述第一超参数组合的多个表现结果中;根据所述每个超参数组合的所述多个表现结果从所述多个超参数组合中确定出最优超参数组合;若所述最优超参数组合不满足第二预设条件,则通过所述每个超参数组合的所述多个表现结果更新预设模型,所述预设模型用于拟合概率分布,所述概率分布用于对所述超参数搜索空间进行再次采样;若所述最优超参数组合满足所述第二预设条件,则将所述最优超参数组合作为所述神经网络的超参数组合。
- 根据权利要求1所述的方法,其特征在于,所述第一预设条件包括:所述第一超参数组合的评估次数不高于预设次数,且所述第一超参数组合的评估次数不高于第二超参数组合的评估次数,所述第二超参数组合为在所述任意一次迭代中选取出的所述多个超参数组合中表现最优的超参数组合,或者,所述多个超参数组合中评估次数最多的超参数组合;或者,所述第一超参数组合的评估次数高于预设次数,且所述第一超参数组合的评估次数不高于所述第二超参数组合的评估次数,且所述第二超参数组合的至少一个表现结果中存在部分表现结果差于所述第一超参数组合的至少一个表现结果。
- 根据权利要求1或2所述的方法,其特征在于,所述多次迭代评估中的任意一次迭代评估,还包括:若所述多个超参数组合中不存在满足所述第一预设条件的第一超参数组合,则对所述第二超参数组合进行再次评估,得到所述第二超参数组合的再次评估的表现结果,所述第二超参数的再次评估的表现结果包括于所述第二超参数组合的多个表现结果中。
- 根据权利要求1-3中任一项所述的方法,其特征在于,所述预设模型包括第一概率密度函数和第二概率密度函数,所述通过所述每个超参数组合的所述多个表现结果更新预设模型,包括:根据所述每个超参数组合的多个表现结果将所述多个超参数组合分为第一类超参数组合和第二类超参数组合,所述第一类超参数组合的表现优于所述第二类超参数组合的表现, 所述第一类超参数组合的表现为根据所述第一类超参数组合的多个表现确定,所述第二类超参数组合的表现为根据所述第二类超参数的多个表现结果确定;通过所述第一类超参数组合更新所述第一概率密度函数,以及通过所述第二类超参数组合更新所述第二概率密度函数。
- 根据权利要求4所述的方法,其特征在于,所述第一概率密度函数或所述第二概率密度函数的类型包括以下一种或多种:正态分布、离散分布、截断正态分布或者对数正态分布。
- 根据权利要求1-5中任一项所述的方法,其特征在于,所述神经网络包括用于识别图片的卷积神经网络,所述超参数搜索空间中的超参数的种类包括以下一种或多种:卷积层数、卷积核数量、扩张大小、修正线性单元ReLU函数在所述神经网络中的位置、锚框的尺寸或者所述锚框的长和宽的比例,所述锚框用于标识图片中需要识别的对象。
- 根据权利要求1-6中任一项所述的方法,其特征在于,所述神经网络为通过一个或多个构建单元组合得到,所述超参数搜索空间中的超参数的种类包括以下一种或多种:一个构建单元的网络层数、构建单元中每层网络的神经元数量或者构建单元中每个神经元的操作算子。
- 根据权利要求1-7中任一项所述的方法,其特征在于,所述多个表现结果包括分类精度或者损失值,所述分类精度用于表示所述神经网络识别图片的准确度,所述损失值为所述神经网络对应的损失函数的值;所述第二预设条件包括:多个表现结果中的任一个表现结果中的分类精度大于第一阈值,或者,所述多个表现结果包括的分类精度的平均值大于第二阈值,或者,损失值不大于第三阈值。
- 根据权利要求1-8中任一项所述的方法,其特征在于,所述对超参数搜索空间进行采样,得到多个超参数组合,包括:对所述超参数搜索空间进行随机采样,得到所述多个超参数组合;或者,基于预设模型确定的概率分布对所述超参数搜索空间进行采样,得到所述多个超参数组合。
- 一种神经网络优化装置,其特征在于,包括:采样模块,用于对超参数搜索空间进行采样,得到多个超参数组合,所述超参数搜索空间包括神经网络的超参数,所述超参数包括所述神经网络中不通过训练得到的参数;评估模块,用于对所述多个超参数组合进行多次迭代评估,以得到所述多个超参数组合中的每个超参数组合的多个表现结果,所述多个表现结果为根据代入所述每个超参数组合后的所述神经网络输出的结果确定,其中,在所述多次迭代评估中的任一次迭代评估中,获取当前次评估之前评估得到的所述每个超参数组合的至少一个表现结果,所述每个超参数组合的至少一个表现结果包括于所述每个超参数组合的多个表现结果中,若所述多个超参数组合存在满足第一预设条件的第一超参数组合,则对所述第一超参数组合进行再次评估,得到所述第一超参数组合的再次评估的表现结果,所述再次评估的表现结果包括于所述第一超参数组合的多个表现结果中;确定模块,用于根据所述每个超参数组合的所述多个表现结果从所述多个超参数组合中确定出最优超参数组合;更新模块,用于若所述最优超参数组合不满足第二预设条件,则通过所述每个超参数组合的所述多个表现结果更新预设模型,所述预设模型用于拟合概率分布,所述概率分布用于对所述超参数搜索空间进行再次采样;选择模块,用于若所述最优超参数组合满足所述第二预设条件,则将所述最优超参数组合作为所述神经网络的超参数组合。
- 根据权利要求10所述的装置,其特征在于,所述第一预设条件包括:所述第一超参数组合的评估次数不高于预设次数,且所述第一超参数组合的评估次数不高于所述第二超参数组合的评估次数,所述第二超参数组合为在所述任意一次迭代中选取出的所述多个超参数组合中表现最优的超参数组合,或者,所述多个超参数组合中评估次数最多的超参数组合;或者,所述第一超参数组合的评估次数高于预设次数,且所述第一超参数组合的评估次数不高于所述第二超参数组合的评估次数,且存在所述第二超参数组合的部分表现结果差于所述第一超参数组合的至少一个表现结果。
- 根据权利要求10或11所述的装置,其特征在于,所述评估模块还包括,若所述多个超参数组合中不存在满足所述第一预设条件的第一超参数组合,则对所述第二超参数组合进行再次评估,得到所述第二超参数组合再次评估的表现结果,所述第二超参数的再次评估的表现结果包括于所述第二超参数组合的多个表现结果中。
- 根据权利要求10-12中任一项所述的装置,其特征在于,所述预设模型包括第一概率密度函数和第二概率密度函数,所述更新模块,具体用于:根据所述每个超参数组合的至少一个表现结果将所述多个超参数组合分为第一类超参数组合和第二类超参数组合,所述第一类超参数组合的表现优于所述第二类超参数组合的表现,所述第一类超参数组合的表现为根据所述第一类超参数组合的多个表现确定,所述第二类超参数组合的表现为根据所述第二类超参数的多个表现结果确定,通过所述第一类超参数组合更新所述第一概率密度函数,以及通过所述第二类超参数组合更新所述第二概率密度函数。
- 根据权利要求13所述的装置,其特征在于,所述第一概率密度函数或所述第二概率密度函数的类型可以包括以下一种或多种:正态分布、离散分布、截断正态分布或者对数正态分布。
- 根据权利要求10-14中任一项所述的装置,其特征在于,所述神经网络为用于识别图片的卷积神经网络,所述超参数搜索空间中的超参数的种类包括以下一种或多种:卷积层数、卷积核数量、扩张大小、修正线性单元ReLU函数在所述神经网络中的位置、锚框的尺寸或者所述锚框的长和宽的比例,所述锚框用于标识图片中需要识别的对象。
- 根据权利要求10-15中任一项所述的装置,其特征在于,所述神经网络为通过一个 或多个构建单元组合得到,所述超参数搜索空间中的超参数的种类包括以下一种或多种:一个构建单元的网络层数、构建单元中每层网络的神经元数量或者构建单元中每个神经元的操作算子。
- 根据权利要求10-16中任一项所述的装置,其特征在于,所述多个表现结果包括分类精度或者损失值,所述分类精度用于表示所述神经网络识别图片的准确度,所述损失值为所述神经网络对应的损失函数的值;所述第二预设条件包括:多个表现结果中的任一个表现结果中的分类精度大于第一阈值,或者,所述多个表现结果包括的分类精度的平均值大于第二阈值,或者,损失值不大于第三阈值。
- 根据权利要求10-17中任一项所述的装置,其特征在于,所述采样模块,具体用于:对所述超参数搜索空间进行随机采样,得到所述多个超参数组合;或者,基于预设模型确定的概率分布对所述超参数搜索空间进行采样,得到所述多个超参数组合。
- 一种神经网络优化装置,其特征在于,包括处理器,所述处理器和存储器耦合,所述存储器存储有程序,当所述存储器存储的程序指令被所述处理器执行时实现权利要求1至9中任一项所述的方法。
- 一种计算机可读存储介质,包括程序,当其被处理单元所执行时,执行如权利要求1至9中任一项所述的方法。
- 一种神经网络优化装置,其特征在于,包括处理单元和通信接口,所述处理单元通过所述通信接口获取程序指令,当所述程序指令被所述处理单元执行时实现权利要求1至9中任一项所述的方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP21797025.0A EP4131077A4 (en) | 2020-04-30 | 2021-03-17 | METHOD AND DEVICE FOR NEURONAL NETWORK OPTIMIZATION |
| US17/975,436 US20230048405A1 (en) | 2020-04-30 | 2022-10-27 | Neural network optimization method and apparatus |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010367582.2A CN113592060A (zh) | 2020-04-30 | 2020-04-30 | 一种神经网络优化方法以及装置 |
| CN202010367582.2 | 2020-04-30 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/975,436 Continuation US20230048405A1 (en) | 2020-04-30 | 2022-10-27 | Neural network optimization method and apparatus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021218470A1 true WO2021218470A1 (zh) | 2021-11-04 |
Family
ID=78236997
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2021/081234 WO2021218470A1 (zh) | 2020-04-30 | 2021-03-17 | 一种神经网络优化方法以及装置 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20230048405A1 (zh) |
| EP (1) | EP4131077A4 (zh) |
| CN (1) | CN113592060A (zh) |
| WO (1) | WO2021218470A1 (zh) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114444727A (zh) * | 2021-12-31 | 2022-05-06 | 北京瑞莱智慧科技有限公司 | 核函数近似模型的训练方法、装置、电子模型及存储介质 |
| CN115034368A (zh) * | 2022-06-10 | 2022-09-09 | 小米汽车科技有限公司 | 车载模型训练方法、装置、电子设备、存储介质及芯片 |
| WO2023202484A1 (zh) * | 2022-04-19 | 2023-10-26 | 华为技术有限公司 | 神经网络模型的修复方法和相关设备 |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116578525A (zh) * | 2022-01-30 | 2023-08-11 | 华为技术有限公司 | 一种数据处理方法以及相关设备 |
| CN114492767B (zh) * | 2022-03-28 | 2022-07-19 | 深圳比特微电子科技有限公司 | 用于搜索神经网络的方法、装置及存储介质 |
| CN116992253A (zh) * | 2023-07-24 | 2023-11-03 | 中电金信软件有限公司 | 与目标业务关联的目标预测模型中超参数的取值确定方法 |
| CN118627152A (zh) * | 2024-08-13 | 2024-09-10 | 浙江大学 | 一种基于蒙特卡洛树搜索的高维微架构设计空间探索方法 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107783998A (zh) * | 2016-08-26 | 2018-03-09 | 华为技术有限公司 | 一种数据处理的方法以及装置 |
| CN109657805A (zh) * | 2018-12-07 | 2019-04-19 | 泰康保险集团股份有限公司 | 超参数确定方法、装置、电子设备及计算机可读介质 |
| CN110705641A (zh) * | 2019-09-30 | 2020-01-17 | 河北工业大学 | 基于贝叶斯优化和电子鼻的葡萄酒分类方法 |
| US20200057944A1 (en) * | 2018-08-20 | 2020-02-20 | Samsung Sds Co., Ltd. | Hyperparameter optimization method and apparatus |
| CN110889450A (zh) * | 2019-11-27 | 2020-03-17 | 腾讯科技(深圳)有限公司 | 超参数调优、模型构建方法和装置 |
| CN110956260A (zh) * | 2018-09-27 | 2020-04-03 | 瑞士电信公司 | 神经架构搜索的系统和方法 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11397887B2 (en) * | 2017-09-26 | 2022-07-26 | Amazon Technologies, Inc. | Dynamic tuning of training parameters for machine learning algorithms |
-
2020
- 2020-04-30 CN CN202010367582.2A patent/CN113592060A/zh active Pending
-
2021
- 2021-03-17 WO PCT/CN2021/081234 patent/WO2021218470A1/zh unknown
- 2021-03-17 EP EP21797025.0A patent/EP4131077A4/en active Pending
-
2022
- 2022-10-27 US US17/975,436 patent/US20230048405A1/en active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107783998A (zh) * | 2016-08-26 | 2018-03-09 | 华为技术有限公司 | 一种数据处理的方法以及装置 |
| US20200057944A1 (en) * | 2018-08-20 | 2020-02-20 | Samsung Sds Co., Ltd. | Hyperparameter optimization method and apparatus |
| CN110956260A (zh) * | 2018-09-27 | 2020-04-03 | 瑞士电信公司 | 神经架构搜索的系统和方法 |
| CN109657805A (zh) * | 2018-12-07 | 2019-04-19 | 泰康保险集团股份有限公司 | 超参数确定方法、装置、电子设备及计算机可读介质 |
| CN110705641A (zh) * | 2019-09-30 | 2020-01-17 | 河北工业大学 | 基于贝叶斯优化和电子鼻的葡萄酒分类方法 |
| CN110889450A (zh) * | 2019-11-27 | 2020-03-17 | 腾讯科技(深圳)有限公司 | 超参数调优、模型构建方法和装置 |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4131077A4 |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114444727A (zh) * | 2021-12-31 | 2022-05-06 | 北京瑞莱智慧科技有限公司 | 核函数近似模型的训练方法、装置、电子模型及存储介质 |
| CN114444727B (zh) * | 2021-12-31 | 2023-04-07 | 北京瑞莱智慧科技有限公司 | 活体检测的方法、装置、电子模型及存储介质 |
| WO2023202484A1 (zh) * | 2022-04-19 | 2023-10-26 | 华为技术有限公司 | 神经网络模型的修复方法和相关设备 |
| CN115034368A (zh) * | 2022-06-10 | 2022-09-09 | 小米汽车科技有限公司 | 车载模型训练方法、装置、电子设备、存储介质及芯片 |
| CN115034368B (zh) * | 2022-06-10 | 2023-09-29 | 小米汽车科技有限公司 | 车载模型训练方法、装置、电子设备、存储介质及芯片 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20230048405A1 (en) | 2023-02-16 |
| CN113592060A (zh) | 2021-11-02 |
| EP4131077A4 (en) | 2023-07-05 |
| EP4131077A1 (en) | 2023-02-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2021218470A1 (zh) | 一种神经网络优化方法以及装置 | |
| WO2022083536A1 (zh) | 一种神经网络构建方法以及装置 | |
| CN110175671B (zh) | 神经网络的构建方法、图像处理方法及装置 | |
| CN113705769B (zh) | 一种神经网络训练方法以及装置 | |
| WO2022042713A1 (zh) | 一种用于计算设备的深度学习训练方法和装置 | |
| US20220215227A1 (en) | Neural Architecture Search Method, Image Processing Method And Apparatus, And Storage Medium | |
| WO2021218517A1 (zh) | 获取神经网络模型的方法、图像处理方法及装置 | |
| WO2021244249A1 (zh) | 一种分类器的训练方法、数据处理方法、系统以及设备 | |
| CN110070107B (zh) | 物体识别方法及装置 | |
| WO2022052601A1 (zh) | 神经网络模型的训练方法、图像处理方法及装置 | |
| WO2022001805A1 (zh) | 一种神经网络蒸馏方法及装置 | |
| CN111291809B (zh) | 一种处理装置、方法及存储介质 | |
| WO2021164750A1 (zh) | 一种卷积层量化方法及其装置 | |
| CN112215332B (zh) | 神经网络结构的搜索方法、图像处理方法和装置 | |
| CN110222718B (zh) | 图像处理的方法及装置 | |
| WO2021129668A1 (zh) | 训练神经网络的方法和装置 | |
| CN113807399A (zh) | 一种神经网络训练方法、检测方法以及装置 | |
| WO2022007867A1 (zh) | 神经网络的构建方法和装置 | |
| CN112529146A (zh) | 神经网络模型训练的方法和装置 | |
| WO2022012668A1 (zh) | 一种训练集处理方法和装置 | |
| WO2021136058A1 (zh) | 一种处理视频的方法及装置 | |
| WO2022156475A1 (zh) | 神经网络模型的训练方法、数据处理方法及装置 | |
| CN113361549A (zh) | 一种模型更新方法以及相关装置 | |
| CN113536970A (zh) | 一种视频分类模型的训练方法及相关装置 | |
| US20220222934A1 (en) | Neural network construction method and apparatus, and image processing method and apparatus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 21797025 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021797025 Country of ref document: EP Effective date: 20221028 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |