WO2021143261A1 - 一种动画实现方法、装置、电子设备和存储介质 - Google Patents
一种动画实现方法、装置、电子设备和存储介质 Download PDFInfo
- Publication number
- WO2021143261A1 WO2021143261A1 PCT/CN2020/123677 CN2020123677W WO2021143261A1 WO 2021143261 A1 WO2021143261 A1 WO 2021143261A1 CN 2020123677 W CN2020123677 W CN 2020123677W WO 2021143261 A1 WO2021143261 A1 WO 2021143261A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- target
- virtual character
- training
- key frame
- posture
- Prior art date
Links
Images













Classifications
-
- A—HUMAN NECESSITIES
- A63—SPORTS; GAMES; AMUSEMENTS
- A63F—CARD, BOARD, OR ROULETTE GAMES; INDOOR GAMES USING SMALL MOVING PLAYING BODIES; VIDEO GAMES; GAMES NOT OTHERWISE PROVIDED FOR
- A63F13/00—Video games, i.e. games using an electronically generated display having two or more dimensions
- A63F13/55—Controlling game characters or game objects based on the game progress
- A63F13/56—Computing the motion of game characters with respect to other game characters, game objects or elements of the game scene, e.g. for simulating the behaviour of a group of virtual soldiers or for path finding
-
- A—HUMAN NECESSITIES
- A63—SPORTS; GAMES; AMUSEMENTS
- A63F—CARD, BOARD, OR ROULETTE GAMES; INDOOR GAMES USING SMALL MOVING PLAYING BODIES; VIDEO GAMES; GAMES NOT OTHERWISE PROVIDED FOR
- A63F13/00—Video games, i.e. games using an electronically generated display having two or more dimensions
- A63F13/60—Generating or modifying game content before or while executing the game program, e.g. authoring tools specially adapted for game development or game-integrated level editor
-
- A—HUMAN NECESSITIES
- A63—SPORTS; GAMES; AMUSEMENTS
- A63F—CARD, BOARD, OR ROULETTE GAMES; INDOOR GAMES USING SMALL MOVING PLAYING BODIES; VIDEO GAMES; GAMES NOT OTHERWISE PROVIDED FOR
- A63F13/00—Video games, i.e. games using an electronically generated display having two or more dimensions
- A63F13/60—Generating or modifying game content before or while executing the game program, e.g. authoring tools specially adapted for game development or game-integrated level editor
- A63F13/67—Generating or modifying game content before or while executing the game program, e.g. authoring tools specially adapted for game development or game-integrated level editor adaptively or by learning from player actions, e.g. skill level adjustment or by storing successful combat sequences for re-use
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T13/00—Animation
- G06T13/20—3D [Three Dimensional] animation
- G06T13/40—3D [Three Dimensional] animation of characters, e.g. humans, animals or virtual beings
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/20—Analysis of motion
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/70—Determining position or orientation of objects or cameras
- G06T7/73—Determining position or orientation of objects or cameras using feature-based methods
- G06T7/74—Determining position or orientation of objects or cameras using feature-based methods involving reference images or patches
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
- G06V10/7747—Organisation of the process, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
- G06V20/46—Extracting features or characteristics from the video content, e.g. video fingerprints, representative shots or key frames
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/10—Image acquisition modality
- G06T2207/10016—Video; Image sequence
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20081—Training; Learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
Definitions
- This application relates to the field of computer technology, and more to the field of image processing technology, and in particular to an animation realization method, device, electronic device and storage medium.
- animation production has played a wider role in all walks of life.
- animation production is usually involved.
- animation production is mainly used to manually draw key frames for animated characters.
- the method of making animated characters in games is mainly to manually draw key frames for animated characters in games.
- the method of manually drawing key frames requires frame-by-frame design, which is time-consuming and labor-intensive.
- an animation realization method device, electronic device, and storage medium are provided.
- an animation realization method which is executed by an electronic device, and includes:
- the first target animation segment includes a first key frame, and the first key frame includes initial pose data of the target virtual character;
- a second target animation clip is acquired, and the second target animation clip includes a first key frame and a second key frame.
- an animation realization device which is set in an electronic device, and the device includes:
- An animation processing unit for obtaining a first target animation segment of the target virtual character, the first target animation segment includes a first key frame, and the first key frame includes initial posture data of the target virtual character;
- the posture acquisition unit is used to input the initial posture data and the set target task into the trained control strategy network to obtain the target posture data of the target virtual character;
- the torque acquisition unit is used to obtain the torque of the first preset number of joints of the target virtual character according to the initial posture data and the target posture data of the target virtual character;
- the posture adjustment unit is used to adjust the target virtual character from the initial posture to the target posture by using the moments of the first preset number of joints to obtain the second key frame;
- the animation generating unit is used to obtain a second target animation segment, the second target animation segment including a first key frame and a second key frame.
- the embodiments of the present application also provide one or more computer-readable storage media.
- the computer-readable storage medium stores computer-readable instructions.
- the present application is implemented.
- an embodiment of the present application also provides an electronic device, including a memory and one or more processors.
- the memory stores computer-readable instructions that can run on the one or more processors.
- one or more processors are caused to implement the animation implementation methods described in the embodiments of the present application.
- FIG. 1 is a schematic diagram of a system architecture of an animation implementation method provided by an embodiment of the application
- FIG. 2 is a schematic diagram of an application scenario of an animation implementation method provided by an embodiment of the application
- FIG. 3 is a flowchart of an animation realization method provided by an embodiment of the application.
- FIG. 4 is a schematic diagram of joint positions of a human-shaped virtual character in an embodiment of the application.
- Figure 5 is a schematic diagram of completing a walking goal task provided by an embodiment of the application.
- FIG. 6 is a schematic diagram of a processing flow of a differential proportional controller provided by an embodiment of the application.
- FIG. 7 is a flowchart of a training process of a control strategy network provided by an embodiment of the application.
- FIG. 8 is a schematic diagram of a network structure of an actor network provided by an embodiment of the application.
- FIG. 9 is a schematic diagram of a network structure of another actor network provided by an embodiment of the application.
- FIG. 10 is a flowchart of a training process of a value evaluation network provided by an embodiment of this application.
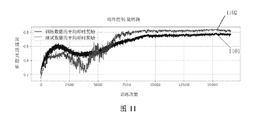
- FIG. 11 is a schematic diagram of a convergence curve of a training control strategy network provided by an embodiment of this application.
- FIG. 12 shows a display diagram of output effects of a trained control strategy network in an embodiment of the present application
- FIG. 13 is a schematic structural diagram of an animation realization device provided by an embodiment of the application.
- FIG. 14 is a schematic structural diagram of an electronic device provided by an embodiment of this application.
- first and second in the text are only used for descriptive purposes, and cannot be understood as expressing or implying relative importance or implicitly indicating the number of technical features indicated. Therefore, the features defined with “first” and “second” may explicitly or implicitly include one or more of these features. In the description of the embodiments of the present application, unless otherwise specified, “multiple” The meaning is two or more.
- Skeleton animation is a kind of model animation.
- the model has a skeleton structure composed of interconnected "skeletons”, which can generate animation for the model by changing the orientation and position of the bones.
- Virtual character The controllable object in the application, which promotes the application process through the behavior of the controllable object. If the application is a MOBA game or RTS game, the virtual object is a controllable game character in the game. If the application is a virtual reality application, virtual The object is a virtual reality character in a virtual reality application.
- Target task A task used to instruct the virtual character to complete a specified action, such as "forward”, “shooting”, “somersault”, “cyclone kick”, etc.
- Each virtual character can complete multiple types of target tasks, and different types of virtual characters can complete different types of target tasks.
- Different control instructions can be set in advance to instruct the virtual character to complete different target tasks. For example, the player can trigger the corresponding control instruction through the control button to set the current target task for the virtual character.
- Physical animation The animation played in the physics engine is called physical animation.
- the state of the animation at the current moment is determined by the state at the previous moment and the current force. Since the physical animation is a simulation of the real world, it can be more realistic Animation effect.
- Physics engine Refers to an engine that simulates the laws of physics through computer-readable instructions. It is mainly used in computational physics, video games, and computer animation. It can use variables such as mass, speed, friction and resistance to predict the behavior of virtual characters under different conditions. Action effect.
- Torque It can also be called torsional force.
- torque refers to the tendency of force to cause an object to rotate around a rotation axis or fulcrum; in the embodiments of the present application, torque refers to force that causes bones to rotate around a joint The trend.
- Reinforcement learning A field in machine learning that emphasizes how to act based on the environment in order to maximize the expected benefits. It is widely used in motion control problems.
- PPO Proximal Policy Optimization, near-end policy optimization algorithm
- off-policy off-policy
- critic value evaluation network
- Episode a concept in reinforcement learning.
- a continuous segment of the interaction between the virtual character and the environment in reinforcement learning is called Episode, which is a sample animation segment in this embodiment of the application.
- PD controller (proportional-derivative controller) is a common feedback loop component in industrial control applications.
- the proportional unit P controls the error between the current position and the target position
- the differential unit D controls the error between the current speed and the target speed.
- the controller realizes that the system stably reaches the target state by outputting the error-related value feedback to the system.
- the output result of the PD controller depends on the specific scenario. For example, for rotation problems, the PD controller outputs torque, and for translation problems, the PD controller outputs force.
- StablePD controller An improved algorithm of PD controller.
- the traditional PD algorithm is sensitive to the control parameters spring and damper. When the spring parameter is set too large, the stability problem of high proportional gain is prone to occur. StablePD also considers the position and acceleration of the next time period to achieve faster and more stable control. Experiments have shown that StablePD can use a longer control interval to achieve a more stable control effect than traditional PD.
- Retarget Retargeting technology, subdivided into role redirection and environment redirection.
- Character redirection refers to the process of copying animation data from one character to another. The two characters may have slightly different skeletons and different physical parameters.
- Environment redirection refers to the process of copying animation data from one environment to another, such as terrain differences.
- the embodiments of the present application provide an animation realization method, device, electronic device, and storage medium.
- the embodiments of the application involve artificial intelligence (AI) and machine learning (ML) technologies, and are designed based on computer vision (CV) technology and machine learning in artificial intelligence.
- AI artificial intelligence
- ML machine learning
- CV computer vision
- Artificial intelligence is a theory, method, technology and application system that uses digital computers or machines controlled by digital computers to simulate, extend and expand human intelligence, perceive the environment, acquire knowledge, and use knowledge to obtain the best results.
- artificial intelligence is a comprehensive technology of computer science, which attempts to understand the essence of intelligence and produce a new kind of intelligent machine that can react in a similar way to human intelligence.
- Artificial intelligence is to study the design principles and implementation methods of various intelligent machines, so that the machines have the functions of perception, reasoning and decision-making.
- Artificial intelligence technology mainly includes several major directions such as computer vision technology, speech processing technology, and machine learning/deep learning.
- artificial intelligence With the research and progress of artificial intelligence technology, artificial intelligence has been researched and applied in many fields, such as common smart home, image retrieval, video surveillance, smart speakers, smart marketing, unmanned driving, autonomous driving, drones, and robots It is believed that with the development of technology, artificial intelligence will be applied in more fields and exert more and more important value.
- Computer Vision is a science that studies how to make machines "see”. To put it further, it refers to the use of cameras and computers instead of human eyes to identify, track, and measure machine vision for targets, and further Do graphic processing to make computer processing an image more suitable for human eyes to observe or transmit to the instrument for inspection.
- Computer vision technology usually includes image processing, image recognition, image semantic understanding, image retrieval, OCR, video processing, video semantic understanding, video content/behavior recognition, three-dimensional object reconstruction, 3D technology, virtual reality, augmented reality, synchronous positioning and mapping Construction and other technologies also include common face recognition, fingerprint recognition and other biometric recognition technologies.
- Machine learning is a multi-field interdisciplinary subject, involving probability theory, statistics, approximation theory, convex analysis, algorithm complexity theory and other subjects. Specializing in the study of how computers simulate or realize human learning behaviors in order to acquire new knowledge or skills, and reorganize the existing knowledge structure to continuously improve its own performance.
- Machine learning is the core of artificial intelligence, the fundamental way to make computers intelligent, and its applications cover all fields of artificial intelligence.
- Machine learning and deep learning usually include artificial neural networks, belief networks, reinforcement learning, transfer learning, inductive learning and other technologies.
- a control strategy network based on deep reinforcement learning is used to learn a reference animation segment containing the posture sequence of a reference virtual character, and in the process of generating the target animation segment, the learned control strategy network is used for different virtual characters.
- the character generates animation clips.
- the animation implementation method provided in the embodiments of the present application can be applied to scenes such as 3D (3 Dimensions, three-dimensional) stereoscopic games, 3D animation movies, and VR (Virtual Reality, virtual reality).
- 3D stereo game a large number of virtual characters are generally included.
- the virtual characters here can also be called physical characters. In the physics engine, these virtual characters can have mass, be affected by gravity, and so on.
- the virtual character may be composed of bones.
- the bone refers to a movable skeleton constructed by joints, and is an active virtual body that drives the movement of the entire virtual character.
- the virtual character can be composed of bones and skin.
- the skin refers to a triangular mesh wrapped around the bone. Each vertex of the mesh is controlled by one or more bones. When skinned, the bones will not be rendered in the game screen.
- the virtual character can be controlled by the player, or it can be controlled automatically according to the progress of the game.
- virtual characters such as “warrior”, “magic”, “shooter”, “athlete” and so on.
- Different types of virtual characters have some of the same action types, such as running, walking, jumping, and squatting, and some different action types, such as attack and defense.
- different types of virtual characters can complete the same type of target task, and can also complete different types of target tasks.
- the animation realization method provided by the embodiment of the present application can generate animation clips according to the target task set for the virtual character.
- FIG. 1 An application scenario of the animation implementation method provided in the embodiment of the present application can be referred to as shown in FIG. 1, and the application scenario includes a terminal device 101 and a game server 102.
- the terminal device 101 and the game server 102 may communicate with each other through a communication network.
- the communication network can be a wired network or a wireless network.
- the terminal device 101 is an electronic device that can install various applications and can display the running interface of the installed application.
- the electronic device may be mobile or fixed. For example, mobile phones, tablet computers, various types of wearable devices, vehicle-mounted devices, or other electronic devices that can implement the above-mentioned functions.
- Each terminal device 101 is connected to a game server 102 through a communication network.
- the game server 102 may be a server of a game platform, a server or a server cluster composed of several servers or a cloud computing center, or a virtualization platform.
- FIG. 2 shows a schematic diagram of an application scenario of an animation implementation method provided by an embodiment of the present application.
- a client of an AR (Augmented Reality) game is installed in the terminal device 101.
- the video information of the real environment is collected, that is, the desktop of the desk 220.
- the physical engine in the terminal device combines the desktop situation of the desk 220 to generate an animation of the virtual character 210.
- the AR animation of the virtual character 210 on the desk 220 is displayed.
- the virtual character can interact with the user and the current scene.
- the client receives the user input through the control button to instruct the virtual character 210 to perform a certain target task (such as squatting), and obtains the current state information of the first key frame of the virtual character 210 and the target
- the task is sent to the game server 102.
- the game server 102 stores a trained control strategy network for different target tasks, and the control strategy network is trained based on a reference animation segment containing a reference posture sequence of a reference virtual character.
- the game server 102 inputs the state information of the virtual character 210 in the first key frame and the target task into the control strategy network, and the control strategy network outputs the target posture data of the second key frame, and sends the target posture data back to the client.
- the client terminal calculates the torque of each joint of the virtual character 210 according to the initial posture data and target posture data of the virtual character 210. Based on the physics engine, the client adjusts each joint of the virtual character 210 in the first key frame according to the torque of each joint, and obtains the target pose of the virtual character in the second key frame, and then generates the gap between the first key frame and the second key frame. Fixed frame and the second key frame.
- the client terminal sequentially displays the first key frame, the fixed frame between the first key frame and the second key frame, and the second key frame to obtain the animation segment of the virtual character performing the set target task.
- the foregoing process may be independently completed by a client installed in the terminal device 101.
- the client receives the operation of instructing the virtual character 210 to perform a certain target task input by the user through the control button, and obtains the current state information of the first key frame of the virtual character 210 and the target task.
- the terminal device 101 stores for different target tasks.
- There is a well-trained control strategy network and the control strategy network is trained based on the reference animation clips containing the reference pose sequence of the reference virtual character.
- the state information and the target task of the virtual character 210 in the first key frame are input into the control strategy network, and the control strategy network outputs the target posture data of the second key frame.
- the client terminal calculates the torque of each joint of the virtual character 210 according to the initial posture data and target posture data of the virtual character 210. Based on the physics engine, the client adjusts each joint of the virtual character 210 in the first key frame according to the torque of each joint, and obtains the target pose of the virtual character in the second key frame, and then generates the gap between the first key frame and the second key frame. Fixed frame and the second key frame. The client terminal sequentially displays the first key frame, the fixed frame between the first key frame and the second key frame, and the second key frame to obtain the animation segment of the virtual character performing the set target task.
- the animation implementation method provided in this application can be applied to the game server 102, and can also be applied to the client of a terminal device.
- the terminal device 101 implements the animation implementation method provided in this application, or the game server 102 and The cooperation of the client in the terminal device 101 is completed.
- Fig. 3 shows a flowchart of an animation realization method provided by an embodiment of the present application. As shown in Figure 3, the method includes the following steps:
- Step S301 Obtain a target animation segment T0, the target animation segment T0 includes a first key frame, and the first key frame includes initial posture data of the target virtual character.
- the target virtual character may be in the form of a character, an animal, a cartoon, or other forms, which is not limited in the embodiment of the present application.
- the target virtual character can be displayed in a three-dimensional form or in a two-dimensional form.
- the target virtual character has bones, and there are joints between adjacent bones. By changing the position and rotation angle of each joint, the posture of the target virtual character can be changed. After a series of postures of the target virtual character are connected, a series of postures can be formed. action.
- the skeletal animation is used for calculation and presentation, which can make the animation effect more abundant.
- the virtual object and the animation are separated, that is, only the skin weight of the virtual object for the bones is recorded, and the animation of the bones can be made separately.
- resource capacity is greatly saved.
- the target animation segment T0 may be a animation segment pre-saved in the physics engine of the terminal device, or an animation segment that has been generated in the game, or a animation segment input by the user.
- the target animation clip T0 contains the first key frame.
- a frame is the smallest unit of a single image in the animation, which is equivalent to each frame of the film on the film.
- the frame is represented as a frame or a mark on the time axis of the animation software.
- a key frame is equivalent to the original picture in a two-dimensional animation. It refers to the frame where the key action in the movement or change of the character or object is located. Since many frames of a video are actually not related to the action performed, the frame related to the action is used as the key frame.
- the animation between the key frame and the key frame is a fixed frame, where the number of frames that differ between two adjacent key frames is preset.
- a key frame can be set for every 20 frames, that is, an animation
- the 0th frame, 20th frame, 40th frame... of the clip are set as key frames, and the 1st to 19th frames, 21st to 39th frames... are fixed frames.
- Figure 4 is a schematic diagram of the joint positions of a human-shaped virtual character in an embodiment of the application. As shown in the figure, it is assumed that the human-shaped character has 15 joints, and the joint indicated by A15 is The root joint is the position of the pelvis of the humanoid character and is also the top parent node. The remaining 14 joints are the chest indicated by A1, the neck indicated by A2, the right leg indicated by A3, the left leg indicated by A4, the right knee indicated by A5, the left knee indicated by A6, and the left knee indicated by A7.
- left ankle of A8 left ankle indicated by A8, right forearm indicated by A9, left forearm indicated by A10, right elbow indicated by A11, left elbow indicated by A12, right wrist indicated by A13, and right wrist indicated by A14 Instructed left wrist.
- the elbow and knee joints are rotating joints, the wrist joints are fixed joints, and the other joints are ball joints. Therefore, the virtual character can be configured with a total of 43 degrees of freedom. It is understandable that the human-shaped virtual character may also include other numbers of joints, which is only an illustration here, and should not be construed as a limitation on this application.
- the position data and rotation data of all joints of the virtual character constitute the posture data of the virtual character.
- the joint position of a character can be represented by a three-dimensional vector, and the rotation of a character’s joint can be represented by a quaternion. Therefore, the posture of a character’s joint can be represented by a seven-dimensional vector.
- the aforementioned initial posture data of the target virtual character can be obtained by the terminal device based on the physics engine, that is, the target animation segment T0 is input into the physics engine, and the physics engine can directly output the initial posture data in the first key frame of the animation segment T0.
- Step S302 Input the initial posture data and the set target task into the trained control strategy network to obtain the target posture data of the target virtual character.
- each control button corresponds to a target task
- the user can set a target task for the virtual character through the control button, and the virtual character will perform an action corresponding to the target task.
- the target task set for the target virtual character is "jump".
- the target task may also be other tasks, such as making the target virtual character advance in a given direction, or allowing the target virtual character to use a whirlwind kick to kick to a designated position, which is not limited in this embodiment of the application.
- the target posture data may be obtained by the terminal device directly inputting at least the initial posture data and the set target task into the control strategy network. At this time, the terminal device stores the trained control strategy network.
- the target posture data can also be obtained by the terminal device through interaction with the server.
- the server stores a trained control strategy network, and the terminal device sends at least the initial posture data and the set target task to the server.
- the server inputs at least the initial posture data and the set target task into the control strategy network to obtain the target posture data, and then feeds back the calculated target posture data to the terminal device.
- Step S303 According to the initial posture data and the target posture data of the target virtual character, the torques of the N joints of the target virtual character are adjusted.
- N is a positive integer greater than or equal to 1.
- Torque refers to the tendency of force to cause bones to rotate around joints.
- the StablePD controller can be used to calculate the torque value, that is, the initial posture data and target posture data of the target virtual character are input into the StablePD controller to obtain the torque acting on each joint of the target virtual character, and the torque is fed back to The physics engine thus realizes the stable control of the target virtual character to the target posture.
- Step S304 Use the moments of the N joints to adjust the target virtual character from the initial posture to the target posture to obtain a second key frame.
- the physics engine can apply the torque of each joint to each joint of the target virtual character, adjust the posture of the target virtual character in the last frame of animation, and obtain the posture of the target virtual character in the next frame of animation.
- the torque is directly applied to each joint of the target virtual character, so that the posture of each joint can be adjusted accurately, so that the target virtual character presents the corresponding action posture, the animation effect is better, rich and natural, and the traditional animation technology is realized.
- the unreachable action effect makes the action posture of the target virtual character more realistic.
- Step S305 Obtain the target animation segment T1.
- the target animation segment T1 includes a first key frame and a second key frame.
- the second key frame is the next key frame of the first key frame.
- the posture data of the target virtual character in the second key frame can be used as the initial posture data, and at least the initial posture data in the second key frame and the target task are input into the strategy control network to obtain the target virtual character in the third key frame.
- the third key frame is the next key frame of the second key frame.
- Use the initial posture data in the second key frame and the target posture data of the target virtual character in the third key frame to adjust the torque of each joint of the target virtual character in the second key frame, and use the torque to transfer the target virtual character from the second key frame.
- the initial posture in the frame is adjusted to the target posture in the third key frame, and the fixed frame between the second key frame and the third key frame and the third key frame are obtained.
- subsequent animation frames can be generated in sequence.
- a coherent action can be formed, and a cartoon clip in which the target virtual character performs the target task through a series of actions is obtained.
- the target animation segment T0 and the target animation segment T1 may be separately expressed as “first target animation segment” and “second target animation segment”, respectively.
- the control strategy network is used to obtain the target posture data of the target virtual character in the second key frame, and the initial posture data and target posture data of the target virtual character are used to obtain the torque for adjusting the target virtual character, and the torque is used to adjust the target virtual character.
- the second key frame is obtained from the initial posture of the target virtual character, that is, the posture sequence of the target virtual character can be generated according to the first key frame and the target task, and then the animation clip of the target virtual character can be obtained, thereby shortening the working time of the staff and improving the work efficiency .
- the target virtual character uses torque to adjust the posture of the target virtual character
- the real physical attributes are given to the target virtual character, and the movement of the target virtual character is calculated based on this to obtain the posture of the target virtual character, which can be more realistic
- the target posture of the scene achieves more realistic action effects.
- the target posture data of the target virtual character is calculated and output based on the reinforcement learning model.
- a deep learning model is used to control the motion trajectory of a virtual character. Deep learning is mainly trained through a large number of labeled samples. Based on the powerful identification learning capabilities of the deep model, significantly superior results can often be obtained in scenarios with a large amount of labeled data.
- deep reinforcement learning allows virtual characters to explore in the environment to learn strategies. It does not require a large number of labeled samples, does not require data preprocessing, and is more efficient. It is more suitable for the embodiments of this application.
- Animated game scene Different from deep learning, deep reinforcement learning allows virtual characters to explore in the environment to learn strategies. It does not require a large number of labeled samples, does not require data preprocessing, and is more efficient. It is more suitable for the embodiments of this application. Animated game scene.
- the types of data input to the reinforcement learning model are different.
- the target pose data of the target virtual character in the second key frame is obtained in the following manner:
- the state information and the target task of the target virtual character in the first key frame are input into the control strategy network, and the target posture data of the target virtual character output by the control strategy network is obtained.
- control strategy network is obtained by training according to the reference animation clip, which contains the reference posture sequence of the reference virtual character to complete the target task.
- the reference virtual object refers to the virtual object that has been animated, and the action of the reference virtual object is called the reference action, and kinematics can be used to express the reference action.
- the target virtual object and the reference virtual object are two virtual objects with the same or similar skeletons.
- the skeleton is the same, which can be expressed as the size, shape, and connection relationship of all bones in the skeleton of the target virtual object and the reference virtual object; the skeletons are similar, including but not limited to at least one of the following: the target virtual object and The bones in the skeleton of the reference virtual object have similar sizes, similar shapes, and similar connection relationships between the bones.
- the reference virtual animation supports any animation clip of a single virtual character, which can be data obtained through a motion capture device or a simple video clip.
- the reference virtual character can complete multiple actions such as walking, running, rotating kick, backflip and so on.
- the state information of the target virtual character is used to characterize the physical state of the target virtual object, and may include current phase data, current initial posture data, current speed data, and historical posture sequence of the target virtual character.
- the current phase data is used to characterize the stage of the target virtual character in the first key frame.
- the current phase data has a value range of 0 to 1, and is used to define the phase of the target virtual character's current state in the action segment.
- the entire learned animation sequence has periodicity, and the actions at the same stage in different cycles are highly similar.
- the phase information is used to make the model output similar action information at the same phase to enhance The fitting ability of the model.
- phase data can also be identified by time.
- T the total length of time required to play these 30 frames of animation screens
- the playback time corresponding to the first frame of animation screens is recorded as the start time
- the previous frame of animation screen corresponds to
- the current initial posture data is used to characterize the current posture of the target virtual character, that is, the posture of the target virtual character in the first key frame.
- the posture data of the virtual character includes the position data and rotation data of all the joints of the virtual character.
- the joint position of the virtual character can be represented by a three-dimensional vector
- the joint rotation of the virtual character can be represented by a quaternion. Therefore, in one embodiment, the posture of a virtual character can be represented by a seven-dimensional vector.
- the three-dimensional vector in the posture data represents the space coordinates of the joint
- the unit quaternion in the rotation data represents the rotation in the three-dimensional space.
- the posture data can also be characterized in other forms, and the posture of the target virtual character can be determined more accurately by using multiple forms of data to represent the posture of the target virtual character.
- the quaternion is a kind of super complex number.
- a complex number is composed of a real number plus an imaginary unit i.
- Each quaternion is a linear combination of 1, i, j, and k.
- the quaternion can generally be expressed as: a+bi+cj+dk, where a, b, c, and d are real numbers.
- i rotation represents the rotation from the positive X axis to the positive Y axis in the plane where the X axis and the Y axis intersect
- j rotation represents the intersection of the Z axis and the X axis.
- k rotation represents the positive rotation of the Y axis to the positive direction of the Z axis in the plane where the Y axis and the Z axis intersect
- -i rotation represents the reverse rotation of i rotation
- - j rotation represents the reverse rotation of j rotation
- -k rotation represents the reverse rotation of k rotation.
- the current speed data is used to characterize the current speed state of the target virtual character, that is, the speed of the target virtual character in the first key frame.
- the current velocity data of the target virtual character includes the linear velocity and angular velocity of all joints of the virtual character. Because the linear velocity of each joint can be represented by a three-dimensional vector, which are the speed on the X axis, the speed on the Y axis, and the speed on the Z axis; and the angular velocity can also be represented by a three-dimensional vector, which is the speed on the X axis, The speed on the Y axis and the speed on the Z axis. Therefore, the speed of a character joint can be represented by a six-dimensional vector. If the target virtual character includes N joints, the velocity dimension of the target virtual character may be N ⁇ 6. Using the combination of linear velocity and angular velocity to represent the speed data of the target virtual character is beneficial to more accurately determine the speed of the target virtual character.
- the historical posture sequence is used to characterize the posture of the target virtual character in the historical time period.
- the posture information of the root joint of the target virtual character in the historical time period can be used as the historical posture sequence of the target virtual character.
- 10 frames of root joints are collected in a historical time window of 1s, because each root joint
- the posture of is represented by a seven-dimensional vector
- the historical posture sequence of the target virtual character is represented by a 70-dimensional vector.
- the historical posture sequence of the target virtual character can describe the current state of the target virtual character more comprehensively.
- the state information of the target virtual character in the embodiment of the present application may also include other forms of characterization data.
- the data in multiple dimensions and multiple forms is input into the reinforcement learning model to describe the current physical state of the target virtual character, so as to obtain more information. Accurate calculation results.
- the state information and the target task of the target virtual character in the first key frame are input into the control strategy network to obtain the target posture data of the target virtual character.
- the target task can be represented by a vector. For example, suppose that the target task is to make the target virtual character advance in a given direction, and the given direction can be represented by a two-dimensional vector on a horizontal plane.
- the state information of the target virtual character in the last frame of animation and the vector representing the target task can be spliced into the control strategy network, and the control strategy network will output the torque used to adjust the joints of the target virtual character.
- the state information and the target task of the target virtual character are input into the control strategy network to obtain the target posture data of the target virtual character.
- the Actor-Critic (AC) algorithm framework based on reinforcement learning is used for training.
- the AC algorithm framework includes an Actor network and a Critic network.
- the control strategy network in this embodiment of the application is the Actor network.
- the evaluation network is the Critic network.
- the control strategy network trains the current strategy and outputs posture data, while the value evaluation network is used to guide the learning of the control strategy network.
- it is necessary to train both the control strategy network and the value evaluation network and only the control strategy network can be used in actual application. The specific training process of the control strategy network and the value evaluation network will be introduced in detail below.
- the target pose data of the target virtual character in the second key frame is obtained in the following way:
- the state information of the target virtual character in the first key frame, the target task and the environment information of the scene environment in which the target virtual character is located are input into the control strategy network, and the target posture data of the target virtual character output by the control strategy network is obtained.
- control strategy network is obtained by training according to the reference animation clip, which contains the reference posture sequence of the reference virtual character to complete the target task.
- the environment information is used to characterize the virtual environment where the target virtual object is located.
- the virtual environment may be a physical environment simulated by a physics engine. In the simulated physical environment, the virtual object obeys dynamics laws, so that the motion of the virtual object is close to the real situation.
- the above-mentioned scene environment may be a scene displayed (or provided) when the physics engine is running in a terminal device, and the scene environment refers to a scene created for target virtual objects to perform activities (such as game competition).
- the scene environment may be a simulation environment of the real world, a semi-simulation and semi-fictional environment, or a purely fictitious environment.
- the scene environment may be a two-dimensional virtual environment, a 2.5-dimensional virtual environment, or a three-dimensional virtual environment, which is not limited in the embodiment of the present application.
- the environment information is the height map of the terrain around the current character.
- the target posture data of the target virtual character is output through the above-mentioned control strategy network.
- the target pose data is used to characterize the target pose that the target virtual character needs to achieve in the next time segment, and this target pose data is specifically used for the calculation of the torque value. Therefore, the target pose data here is the rotation data of all the joints of the target virtual character.
- the target pose data of a joint can be represented by a quaternion.
- the redirection of the character and the environment can be realized, that is, only a reference animation sequence of a reference virtual character based on a certain scene is generated, and the skeleton of the reference virtual character is the same as or similar to the skeleton of the reference virtual character.
- the scene-like animation of the target virtual character can directly use the reference animation sequence to generate the scene-like animation of the target virtual character through the model, which greatly reduces the working time and improves the work efficiency.
- the foregoing process of obtaining the target posture data of the target virtual character through the control strategy network can be implemented in a terminal device, or can be implemented in a server and the server sends the target posture data to the terminal device.
- the above steps use the moments of the N joints to adjust the target virtual character from the initial pose to the target pose to obtain the second key frame, including: Using the moments of the N joints, the target virtual character is adjusted from the initial posture to the target posture, and the fixed frame between the first key frame and the second key frame and the second key frame are obtained.
- the target animation segment T1 is composed of at least a first key frame, M fixed frames, and a second key frame.
- the terminal device after the terminal device obtains the target posture data, it can calculate and adjust the torque of each joint according to the initial posture data, and further obtain the second key frame, and the fixation between the first key frame and the second key frame.
- the fixed frame is an animation frame between two key frames.
- the fixed frame can be determined by the interpolation method, or the fixed frame can be obtained by adjusting the pose of the target virtual character for the moment.
- N and M in each embodiment of the present application may be separately expressed as “first preset number” and “second preset number”.
- adjusting the moments of the N joints of the target virtual character, as well as the fixed frame and the second key frame are obtained in the following manner:
- the torque of the N joints of the target virtual character in the first key frame is adjusted
- the moment is used to adjust the posture of the target virtual character in the M-th fixed frame to obtain a second key frame, which is the next frame of animation of the M-th fixed frame.
- torque is used to control the target virtual character to move.
- the information output by the control strategy network is the angular velocity
- the PD control algorithm is used to dynamically control the angular velocity information, and the effect is calculated based on the angular velocity information
- the physics engine controls the target virtual character to move according to the torque.
- a method based on position control is used. It has a better control effect on the target virtual character, so as to achieve a more natural action effect.
- FIG. 6 is a schematic diagram of a processing flow of the differential proportional controller in the embodiment of the application.
- the entire closed-loop control system is equivalent to hierarchical control, and the target virtual character is set in the first
- the state information St of the key frame is input to the control strategy network, and the control strategy network outputs the target posture data of the second key frame.
- the target attitude calculated using torque data of each joint rotation data using a PD controller dynamically controls the rotation data of the target posture of the virtual character to the first key frame of t A, t is calculated based on the posture A to obtain a first keyframe Moment, the moment is used in the physics engine to control the target virtual character, thereby obtaining the state information S t+1 of the second key frame, which will then be used as the input of the control strategy network to obtain the attitude At + of the second key frame 1.
- continuous control of the target role can be achieved.
- the torque of each joint can be calculated according to the following formula:
- ⁇ n represents the torque of the nth frame
- k p represents the proportional gain
- k d represents the differential gain
- q n represents the rotation data at the current moment, Represents the angular velocity at the current moment, q n and Can be obtained directly from the physics engine; Indicates the angular acceleration at the current moment, calculated by inverse dynamics; Is the rotation data at the next moment, that is, the output of the control strategy network; Indicates the angular velocity at the next moment, which is always set to 0 here.
- ⁇ t represents cycle time, that is, the length of time between the current moment and the next moment.
- the control strategy network outputs the rotation data of each joint, and then dynamically controls the target character to the corresponding position through PD control, which is more stable than the torque control posture, and the control strategy network outputs the rotation data of each joint.
- the distribution variance is small and the sampling samples are small, so the control strategy network converges quickly.
- one control strategy network can be trained for the same type of target task, and corresponding control strategy networks can be trained for different types of target tasks. For example, “shooting forward”, “shooting left” and “shooting right” all belong to shooting, but the shooting direction is different, so they belong to the same type of target task, and a control strategy network can be trained. But “shooting” and “running” belong to different types of target tasks, and the corresponding control strategy network can be trained separately.
- an AC algorithm framework based on reinforcement learning is used for training.
- the AC algorithm framework includes an Actor network and a Critic network.
- the control strategy network in this embodiment of the application is the Actor network, and the value evaluation network is the Critic network. .
- the control strategy network trains the current strategy and outputs posture data, while the value evaluation network is used to guide the learning of the control strategy network.
- both the control strategy network and the value evaluation network need to be trained.
- the network structure of the value assessment network and the control strategy network can be the same or different.
- the value evaluation network and the control strategy network use the same input structure and input data.
- the output of the value evaluation network and the control strategy network are different.
- the output of the control strategy network is target attitude data, and the output of the value evaluation network is one Dimensional data represents the value of the state at the current moment.
- the training process of the control strategy network can be as shown in Figure 7, including the following steps:
- Step S701 Input the current state information and the set training task of the training virtual object in the sample animation clip into the control strategy network, and obtain the posture data of the training virtual object at the next time output by the control strategy network.
- control strategy network in the embodiment of the present application is a control strategy network to be trained (including untrained and training).
- the current moment is the playback moment corresponding to the sample animation screen of the current key frame
- the next moment is the playback moment corresponding to the sample animation screen of the next key frame.
- the state information of the training virtual object includes current phase data, current initial posture data, current speed data, and historical posture sequence, which are the same as the state information of the target virtual character above, and will not be repeated here.
- the training virtual object is the object of the control strategy output by the control strategy network during the training process.
- the training virtual object and the reference virtual object are two virtual objects with the same or similar skeletons.
- the same skeleton can be expressed as the size, shape, and connection relationship between all bones in the skeleton of the training virtual object and the reference virtual object; the skeletons are similar, including but not limited to at least one of the following: training virtual object and The bones in the skeleton of the reference virtual object have similar sizes, similar shapes, and similar connection relationships between the bones.
- the training task is set corresponding to the target task in the use process.
- the training task may be to make the training virtual object advance in a given direction, or to make the training virtual object use a whirlwind kick to kick to a specified position.
- the control strategy network can be a network with targets, including an input layer, a hidden layer, and an output layer.
- the hidden layer may include a layer of neural network, or may include a multilayer neural network, which can be set according to actual conditions, which is not limited in the embodiment of the present application.
- the neural network layer in the hidden layer can be a fully connected layer.
- the hidden layer may include two fully connected layers, where the first fully connected layer may include 1024 neurons, and the second fully connected layer may include 512 neurons.
- the activation function between the neural network layers is the ReLU (Rectified Linear Unit, linear rectification function) function.
- the network structure of the actor network is shown in Figure 8.
- the state information of the training virtual object at the current moment and the set training task can be input into the control strategy network to obtain the next moment output of the control strategy network.
- a control strategy which is to train the posture of the virtual object at the next moment.
- the state information and the training task are both one-dimensional information, and the state information and the training task information are spliced together and input into the two fully connected hidden layers.
- the output of the model is a linear output. Assuming that the distribution of the character pose satisfies the Gaussian distribution, the model outputs the mean of the Gaussian distribution, and the variance of the Gaussian distribution is used as the hyperparameter of the network.
- the environment information of the scene environment where the training virtual object is located can be obtained, and the environment information of the scene environment may be a topographic map of the scene environment.
- the environment information of the scene environment, the current state information of the training object and the training task are input into the control strategy network to obtain the posture of the training virtual object at the next time output by the control strategy network.
- the state information and training tasks are both one-dimensional information.
- the topographic map is two-dimensional data.
- the topographic map uses a three-layer convolutional network to complete the plane information extraction.
- the output result is flattened into one dimension and then spliced with the state information and the training task. Input to two fully connected hidden layers.
- the output of the model is a linear output. Assuming that the distribution of the character pose satisfies the Gaussian distribution, the model outputs the mean of the Gaussian distribution, and the variance of the Gaussian distribution is used as the hyperparameter of the network.
- the control strategy network can also include a feature extraction network, which is composed of a multi-layer convolutional network and a fully connected layer, which is used to extract terrain features from the input environment information of the scene environment. Combine the extracted terrain features with the input state information of the training object and the training task to determine the posture data of the virtual object to be trained at the next moment.
- a feature extraction network which is composed of a multi-layer convolutional network and a fully connected layer, which is used to extract terrain features from the input environment information of the scene environment. Combine the extracted terrain features with the input state information of the training object and the training task to determine the posture data of the virtual object to be trained at the next moment.
- Step S702 Input the state information of the training virtual object at the current moment and the set training task into the value evaluation network to obtain the current state value output by the value evaluation network.
- the value evaluation network is obtained by training with reference to animation clips.
- the state value output by the value evaluation network is used to measure the output attitude of the control strategy network. That is, after the virtual object is trained to perform the current action, the state information changes to s, and the state value V(s) evaluates the current
- the quality of the state is an indirect measure of the quality of the action. It is understandable that the larger the state value V(s), the better the state.
- the learning standard of the state value V(s) output by the Critic network is calculated from a series of reward information feedback from the environment, that is, after the reward information at multiple moments is obtained, it can be estimated through temporal-difference learning.
- Time difference learning is a central idea in reinforcement learning. Similar to the Monte Carlo method, time difference learning can learn directly from experience without the need for complete knowledge of the environment. Similar to the dynamic programming method, time difference learning can improve on the existing estimation results without waiting for the end of the entire event.
- Step S703 Adjust the parameters of the control strategy network according to the state value and continue training the control strategy network after adjusting the parameters until the set training end condition is reached, and the trained control strategy network is obtained.
- the electronic device can adjust the parameters of the control strategy network according to the state value and the posture data of the training virtual object at the next moment output by the control strategy network and continue to train the control strategy network after adjusting the parameters until Until the set training end condition is reached, the trained control strategy network is obtained.
- the Actor network is trained according to the posture data output by the Actor network (that is, the control strategy network) and the state value output by the Critic network (that is, the value evaluation network). Therefore, the Actor network obtains the learning standard according to the Critic network, so it can calculate the error and gradient according to the loss function, and train the Actor network, and finally use the trained Actor network as the trained control strategy network.
- the network structure of the value evaluation network (critic network) and the control strategy network in the embodiment of the present application may be the same or different.
- the value evaluation network is used to evaluate the control strategy output by the control strategy network, and determine the reward value for the training virtual object to imitate the reference virtual character and complete the training task.
- the value evaluation network is also obtained through training.
- the training process of the value evaluation network is shown in Figure 10 and includes the following steps:
- Step S1001 Determine the instant reward value of the training virtual object at the current time according to the state information of the virtual character at the next time and the set training task in the training virtual object and the reference animation clip.
- the instant reward value at the current moment includes two parts: task target reward and imitation target reward.
- the imitation goal reward is used to motivate and train the posture of the virtual object to be consistent with the posture of the reference virtual character.
- the essence is to compare the similarity between the posture of the reference virtual character and the posture of the training object when they are in the same phase. The closer the two are, the imitating target The higher the reward; conversely, the lower the reward for imitating the target.
- the task target reward is determined according to the training virtual object's completion of the training task.
- the task target reward at the current moment is determined according to the state information of the training virtual object at the next moment and the set training task, which is used to evaluate the completion degree of the target task;
- the state information of the training virtual object at the next moment and the state information of the reference virtual character at the next moment determine the imitation target reward at the current moment, which is used to evaluate the similarity between the training virtual object and the reference virtual object, and then determine the action of the training virtual object Whether it is natural
- the instant reward value at the current moment is determined.
- the task target reward and the imitation target reward are weighted, and the weighted value is used as the instant reward value r t , as shown in the following formula:
- w I is the weight of the imitation target reward
- w G is the weight of the task goal reward
- w I and w G are related to the network parameters of the value assessment network.
- the imitation target can be rewarded It is subdivided into four aspects: posture similarity, speed similarity, end joint similarity, centroid posture similarity, the weighted value of the four parts is used as the final instant reward, specifically, imitating the target reward It can be expressed as:
- w p is the attitude similarity
- w v is the speed similarity
- w e is the similarity of the end joint
- w c is the similarity of centroid posture the weight of.
- the posture similarity Used to describe the posture similarity between the training object and the reference virtual character.
- the similarity between the position and rotation of each joint can be expressed as:
- the posture data of the j-th joint of the reference virtual character can be represented by a quaternion. Represents the posture data of the j-th joint of the training object at time t.
- Speed similarity It is used to describe the speed similarity between the training object and the reference virtual character, including the similarity between the angular velocity and linear velocity of each joint and the target posture, which can be expressed as:
- End joint similarity It is used to describe the similarity of the end joint posture of the training object and the reference virtual character, including the limb joints, which can be expressed as
- the task goal reward setting can also be different. For example, if the training task is to make the training object imitate the walking posture of the reference virtual character and complete the task of turning during walking, set a task goal reward for the walking direction to encourage the training object to move in the specified direction at a given speed . If the training task is to let the training subject use the whirlwind kick, kick to the designated position. For example, a random target sphere is designated around the training object, and the training object uses a whirlwind kick to hit the designated target sphere.
- the task vector of this training task consists of two parts, one is the position of the given target sphere It can be represented by a three-dimensional vector in space, and the other is a two-valued flag h, indicating whether the target was hit in the previous time period.
- the task target reward can be expressed as:
- Step S1002 according to the instant reward value and state value of the training virtual object at each moment in the sample animation clip, determine the expected reward value of the training virtual object.
- the expected reward value of the training virtual object specifically, the expected reward value of the training virtual object It can be calculated according to the following formula:
- the end of the sample animation clip is determined according to at least one of the following conditions:
- the length of the sample animation segment reaches the time threshold; the posture data of the training virtual object meets the fall threshold; the difference between the posture data of the training virtual object and the posture data of the reference virtual object is greater than the difference threshold; the speed data of the training virtual object is greater than the speed threshold.
- the sample animation segment is considered to be over.
- the virtual object is trained to fall, it is considered that the sample animation clip is over, where the fall is defined as the specified joint touches the ground.
- the difference between the sample animation clip and the reference animation clip is too large.
- the rotation angle difference of the root joint exceeds the angle threshold, which is generally set to 90 degrees.
- the speed data of the training virtual object is greater than the speed threshold.
- the end of the sample animation segment is determined, so as to ensure the similarity between the training virtual object and the reference virtual object and the real degree of the training virtual object, thereby improving the accuracy of training.
- Step S1003 Adjust the parameters of the value evaluation network according to the expected reward value and continue training the value evaluation network after adjusting the parameters until the set training end condition is reached, and the trained value evaluation network is obtained.
- the training end condition may be that the number of training times reaches the set number of times, the range of change of the expected reward value obtained from N consecutive trainings is within the set range, or the expected reward value reaches the set threshold.
- PPO Proximal Policy Optimization
- SAC Soft Actor-Critic, flexible actuation/evaluation
- DDPG Deep Deterministic Policy Gradient, deep deterministic policy gradient
- Figure 11 shows the training effect of the above method. Taking the recurring rotating kick as an example, the model converges after running for 15,000 iterations and about 24 hours.
- the abscissa represents the number of iterations of training, that is, the number of training, and the ordinate represents the reward value of the feedback.
- the curve 1001 is the average instant reward of each piece of training data (ie, Train_Avg_Return_0 in Figure 11), which can reach 0.78;
- the curve 1002 is the average instant reward of each piece of test data (ie, Test_Avg_Return_0 in FIG. 11), which can reach 0.82.
- Fig. 12 shows a display diagram of the output effect of the trained control strategy network in the embodiment of the application.
- the posture of the reference virtual character 1201 is basically the same as the posture of the target virtual character 1202, and the target The virtual character reproduces the reference virtual character in the reference animation clip very well.
- the control strategy network is used to obtain the target posture data of the target virtual character in the second key frame, and the initial posture data and target posture data of the target virtual character are used to obtain the torque for adjusting the target virtual character, and the torque is used to adjust the target virtual character.
- the initial posture of the target virtual character is obtained, and the fixed frame between the first key frame and the second key frame and the second key frame are obtained. That is, the posture sequence of the target virtual character can be generated according to the first key frame and the target task, and then the animation of the target virtual character Fragments, thereby shortening the working time of staff and improving work efficiency.
- the target virtual character uses torque to adjust the posture of the target virtual character
- the real physical attributes are given to the target virtual character, and the movement of the target virtual character is calculated based on this to obtain the posture of the target virtual character, which can be more realistic
- the target posture of the scene achieves more realistic action effects.
- a game client is installed in the terminal device, and the client interacts with the server to realize the whirlwind kick of the game character and hit the target sphere.
- the user inputs a whirlwind kick instruction through the control buttons, instructing the game character controlled by him to perform the action of kicking the target sphere.
- the game client obtains the status information of the target virtual character in the A0 key frame contained in the animation segment T0.
- the A0 key frame may be the current animation frame being displayed in the display interface.
- the A0 key frame is used as the last frame of animation, and the status information of the target virtual character in the A0 key frame and the target task of whirlwind kicking are sent to the server.
- the target task of the whirlwind kick can also be a task vector, which includes the position coordinates of the target sphere.
- the trained control strategy network is stored in the server.
- the server inputs the state information in the A0 key frame and the target task of the whirlwind kick into the trained control strategy network to obtain the target posture data of the target virtual character in the A1 key frame, and the A1 key frame is the next key frame of the A0 key frame.
- the server sends the target posture data of the target virtual character in the A1 key frame back to the game client.
- the game client obtains the initial posture data of the target virtual character in the A0 key frame and the target posture data of the target virtual character in the A1 key frame. According to the initial posture data and the target posture data, formula 1 is used to calculate the moments acting on the N joints of the target virtual character in the A0 key frame.
- the game client applies the obtained torque to the N joints of the target virtual character in the A0 key frame, adjusts the posture of the target virtual character, and obtains the B0 fixed frame.
- the fixed frame is the animation frame between the A0 key frame and the A1 key frame, where 20 fixed frames are set between the A0 key frame and the A1 key frame.
- the game client obtains the B0 posture data of the target virtual character in the B0 fixed frame. According to the B0 posture data and the target posture data, formula 1 is used to calculate the moments acting on the N joints of the target virtual character in the B0 fixed frame.
- the game client applies the obtained torque to the N joints of the target virtual character in the B0 fixed frame, adjusts the posture of the target virtual character, and obtains the B1 fixed frame. Repeat the above steps until the B19 posture data of the target virtual character in the B19 fixed frame is obtained. According to the B19 posture data and the target posture data, formula 1 is used to calculate the moments acting on the N joints of the target virtual character in the B19 fixed frame to obtain the A1 key frame.
- the game client continues to use the A1 key frame as the last frame of animation, sends the target virtual character's status information and target tasks in the A1 key frame to the server, and receives the target posture data of the A2 key frame sent by the server.
- the game client is based on the physics engine, and gets the fixed frame between the A1 key frame and the A2 key frame, and the A2 key frame.
- multiple animation frames can be generated to obtain the animation segment T1 in which the target virtual character completes the target task of whirlwind kicking.
- the animation segment T1 includes the aforementioned A0 key frame, B0 to B19 fixed frame, A1 key frame, B20 to B29 fixed frame, A2 key frame, and multiple animation frames generated subsequently.
- the control strategy network is trained based on the sample animation clips of the virtual character performing the whirlwind kicking task. Therefore, the control strategy network can determine the number of animation frames contained in the animation clip T1.
- FIG. 13 shows a structural block diagram of an animation realization apparatus provided by an embodiment of the present application.
- the animation realization device is set in an electronic device, and the device can be implemented as all or a part of the terminal device 101 in FIG. 1 through hardware or a combination of software and hardware.
- the device includes an animation processing unit 1301, a posture acquisition unit 1302, a moment acquisition unit 1303, a posture adjustment unit 1304, and an animation generation unit 1305.
- the animation processing unit 1301 obtains the target animation segment T0 of the target virtual character.
- the target animation segment T0 includes the first key frame, and the first key frame includes the initial posture data of the target virtual character.
- the posture acquisition unit 1302 is used to input the initial posture data and the set target task into the trained control strategy network to obtain the target posture data of the target virtual character.
- the torque acquisition unit 1303 is configured to obtain the torques of the N joints of the adjusted target virtual character according to the initial posture data and the target posture data of the target virtual character; N is a positive integer greater than or equal to 1.
- the posture adjustment unit 1304 is used to adjust the target virtual character from the initial posture to the target posture by using the moments of the N joints to obtain the second key frame.
- the animation generating unit 1305 is configured to obtain a target animation segment T1, and the target animation segment T1 includes a first key frame and a second key frame.
- the posture adjustment unit 1304 is used to adjust the target virtual character from the initial posture to the target posture by using the moments of the N joints to obtain the fixed frame between the first key frame and the second key frame and the second key frame;
- the target animation clip T1 is composed of at least a first key frame, M fixed frames, and a second key frame.
- the posture acquiring unit 1302 is specifically configured to:
- the state information and target tasks of the target virtual character in the first key frame are input into the control strategy network to obtain the target posture data of the target virtual character output by the control strategy network; the control strategy network is trained according to the reference animation clip, refer to the animation clip Contains the reference posture sequence of the reference virtual character to complete the target task.
- the posture acquiring unit 1302 is specifically configured to:
- control strategy network Input the state information of the target virtual character in the first key frame, the target task and the environment information of the scene environment in which the target virtual character is located into the control strategy network, and obtain the target posture data of the target virtual character output by the control strategy network; control strategy network It is obtained by training based on the reference animation clip, which contains the reference posture sequence of the reference virtual character to complete the target task.
- the state information includes the current phase data of the target virtual character, the current initial posture data, the current speed data, and the historical posture sequence; wherein the current phase data is used to characterize the target virtual character's position in the first key frame.
- the current initial posture data is used to characterize the current posture of the target virtual character
- the current speed data is used to characterize the current speed state of the target virtual character
- the historical posture sequence is used to characterize the posture of the target virtual character in a historical time period.
- the device further includes a network training unit 1306, configured to:
- the network training unit 1306 is used to:
- the network training unit 1306 is used to:
- the instant reward value at the current moment is determined.
- the imitation target reward includes at least one of the following: posture similarity, speed similarity, end joint similarity, and centroid posture similarity;
- Pose similarity is used to characterize the similarity of the posture data of the training virtual object and the reference virtual character; speed similarity is used to characterize the similarity of the speed data of the training virtual object and the reference virtual character; end joint similarity is used to characterize the training virtual object The similarity with the posture data of the end joints of the reference virtual character; the centroid posture similarity is used to characterize the similarity between the center of gravity position of the training virtual object and the reference virtual character.
- the network training unit 1306 is configured to determine the end of the sample animation clip according to at least one of the following:
- the length of the sample animation segment reaches the time threshold; the posture data of the training virtual object meets the fall threshold; the difference between the posture data of the training virtual object and the posture data of the reference virtual object is greater than the difference threshold; the speed data of the training virtual object is greater than the speed threshold.
- the network training unit 1306 is used to:
- the environment information, the state information of the training virtual object at the current moment, and the training task are input into the control strategy network, and the posture of the training virtual object at the next moment output by the control strategy network is obtained.
- an embodiment of the present application also provides an electronic device.
- the electronic device can be a terminal device, such as the terminal device 101 shown in FIG. 1, or an electronic device such as a smart phone, a tablet, a laptop or a computer.
- the electronic device includes at least a memory for storing data and a One or more processors for data processing.
- processors for one or more processors used for data processing, one or more processors, CPU, GPU (Graphics Processing Unit, graphics processing unit), DSP, or FPGA can be used to perform the processing.
- operation instructions are stored in the memory, and the operation instructions may be computer-executable code. The operation instructions are used to implement each step in the flow of the video screening method of the embodiment of the present application.
- FIG. 14 is a schematic structural diagram of an electronic device provided by an embodiment of the application; as shown in FIG. 14, the electronic device 140 in an embodiment of the application includes: one or more processors 141, a display 142, a memory 143, and an input device 146, a bus 145, and a communication device 144; the one or more processors 141, a memory 143, an input device 146, a display 142, and a communication device 144 are all connected by a bus 145, and the bus 145 is used for the one or more processors 141 , The memory 143, the display 142, the communication device 144 and the input device 146 to transfer data.
- the memory 143 may be used to store software programs and modules, such as program instructions/modules corresponding to the animation implementation method in the embodiment of the present application.
- the processor 141 executes the electronic device 140 by running the software programs and modules stored in the memory 143
- the memory 143 may mainly include a program storage area and a data storage area.
- the program storage area may store an operating system, an application program of at least one application, etc.; the storage data area may store data created based on the use of the electronic device 140 (such as animation clips). , Control Strategy Network), etc.
- the memory 143 may include a high-speed random access memory, and may also include a non-volatile memory, such as at least one magnetic disk storage device, a flash memory device, or other volatile solid-state storage devices.
- the processor 141 is the control center of the electronic device 140. It uses the bus 145 and various interfaces and lines to connect the various parts of the entire electronic device 140, runs or executes the software programs and/or modules stored in the memory 143, and calls the The data in the memory 143 executes various functions of the electronic device 140 and processes data.
- the processor 141 may include one or more processing units, such as a CPU, a GPU (Graphics Processing Unit, graphics processing unit), a digital processing unit, and so on.
- the processor 141 displays the generated animation clip to the user through the display 142.
- the processor 141 may also be connected to the network through the communication device 144. If the electronic device is a terminal device, the processor 141 may transmit data between the communication device 144 and the game server. If the electronic device is a game server, the processor 141 may transmit data between the communication device 144 and the terminal device.
- the input device 146 is mainly used to obtain user input operations.
- the input device 146 may also be different.
- the input device 146 may be an input device such as a mouse and a keyboard; when the electronic device is a portable device such as a smart phone or a tablet computer, the input device 146 may be a touch screen.
- An embodiment of the present application also provides a computer storage medium, in which computer-executable instructions are stored, and the computer-executable instructions are used to implement the animation implementation method of any embodiment of the present application.
- various aspects of the animation implementation method provided in this application can also be implemented in the form of a program product, which includes program code.
- the program product runs on a computer device
- the program code is used to make the computer
- the device executes the steps of the animation realization method according to various exemplary embodiments of the application described above in this specification.
- the computer device may execute the animation generation process in steps S301 to S306 as shown in FIG. 3.
- the program product can adopt any combination of one or more readable media.
- the readable medium may be a readable signal medium or a readable storage medium.
- the readable storage medium may be, for example, but not limited to, an electrical, magnetic, optical, electromagnetic, infrared, or semiconductor system, device, or device, or a combination of any of the above. More specific examples (non-exhaustive list) of readable storage media include: electrical connections with one or more wires, portable disks, hard disks, random access memory (RAM), read-only memory (ROM), erasable Type programmable read only memory (EPROM or flash memory), optical fiber, portable compact disk read only memory (CD-ROM), optical storage device, magnetic storage device, or any suitable combination of the above.
- the readable signal medium may include a data signal propagated in baseband or as a part of a carrier wave, and readable program code is carried therein. This propagated data signal can take many forms, including, but not limited to, electromagnetic signals, optical signals, or any suitable combination of the foregoing.
- the readable signal medium may also be any readable medium other than a readable storage medium, and the readable medium may send, propagate, or transmit a program for use by or in combination with the instruction execution system, apparatus, or device.
- the disclosed device and method may be implemented in other ways.
- the device embodiments described above are merely illustrative, for example, the division of units is only a logical function division, and there may be other divisions in actual implementation, such as: multiple units or components can be combined or integrated To another system, or some features can be ignored, or not implemented.
- the coupling, or direct coupling, or communication connection between the components shown or discussed may be indirect coupling or communication connection through some interfaces, devices or units, and may be in electrical, mechanical or other forms. of.
- the units described above as separate components may or may not be physically separate, and the components displayed as units may or may not be physical units, that is, they may be located in one place or distributed on multiple network units; Some or all of the units may be selected according to actual needs to achieve the objectives of the solutions of the embodiments.
- the functional units in the embodiments of the present application can be all integrated into one processing unit, or each unit can be individually used as a unit, or two or more units can be integrated into one unit;
- the unit can be implemented in the form of hardware, or in the form of hardware plus software functional units.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Multimedia (AREA)
- General Physics & Mathematics (AREA)
- Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Databases & Information Systems (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- Human Computer Interaction (AREA)
- Processing Or Creating Images (AREA)
Abstract
一种动画实现方法,包括:获得第一目标动画片段,第一目标动画片段中包括第一关键帧,第一关键帧中包括目标虚拟角色的初始姿态数据;将初始姿态数据以及设定的目标任务输入已训练的控制策略网络中得到目标虚拟角色的目标姿态数据;根据目标虚拟角色的初始姿态数据和目标姿态数据,调整目标虚拟角色的第一预设数量的关节的力矩;利用第一预设数量的关节的力矩,将目标虚拟角色由初始姿态调整至目标姿态,得到第二关键帧;获取第二目标动画片段,第二目标动画片段由至少第一关键帧以及第二关键帧组成。
Description
本申请要求于2020年01月19日提交中国专利局,申请号为2020100598453,申请名称为“一种动画实现方法、装置、电子设备和存储介质”的中国专利申请的优先权,其全部内容通过引用结合在本申请中。
本申请涉及计算机技术领域、更涉及图像处理技术领域,尤其涉及一种动画实现方法、装置、电子设备和存储介质。
随着科学技术的飞速发展,动画制作在各行各业中都起到较为广泛的作用。比如,对于游戏产业来说,不论是单机游戏、网游还是手游的开发,通常都会涉及到动画制作。
目前,动画制作主要是由人工绘制关键帧用于动画角色中,比如,游戏中动画人物的动作制作方法,主要是人工绘制关键帧用于游戏中的动画角色中。然而,人工绘制关键帧的方法需要逐帧设计,十分耗时耗力。
发明内容
根据本申请提供的各种实施例,提供了一种动画实现方法、装置、电子设备和存储介质。
根据本申请实施例的第一方面,提供了一种动画实现方法,由电子设备执行,包括:
获得第一目标动画片段,第一目标动画片段中包括第一关键帧,第一关键帧中包括目标虚拟角色的初始姿态数据;
将初始姿态数据以及设定的目标任务输入已训练的控制策略网络中得到目标虚拟角色的目标姿态数据;
根据目标虚拟角色的初始姿态数据和目标姿态数据,调整目标虚拟角色 的第一预设数量的关节的力矩;
利用第一预设数量的关节的力矩,将目标虚拟角色由初始姿态调整至目标姿态,得到第二关键帧;及
获取第二目标动画片段,第二目标动画片段包括第一关键帧以及第二关键帧。
第二方面,本申请实施例提供一种动画实现装置,设置于电子设备中,装置包括:
动画处理单元,用于获得目标虚拟角色的第一目标动画片段,第一目标动画片段中包括第一关键帧,第一关键帧中包括目标虚拟角色的初始姿态数据;
姿态获取单元,用于将初始姿态数据以及设定的目标任务输入已训练的控制策略网络中得到目标虚拟角色的目标姿态数据;
力矩获取单元,用于根据目标虚拟角色的初始姿态数据和目标姿态数据,得到调整目标虚拟角色的第一预设数量的关节的力矩;
姿态调整单元,用于利用第一预设数量的关节的力矩,将目标虚拟角色由初始姿态调整至目标姿态,得到第二关键帧;
动画生成单元,用于获取第二目标动画片段,第二目标动画片段包括第一关键帧以及第二关键帧。
第三方面,本申请实施例还提供一个或多个计算机可读存储介质,计算机可读存储介质内存储有计算机可读指令,计算机可读指令被一个或多个处理器执行时,实现本申请各实施例所述的动画实现方法。
第四方面,本申请实施例还提供一种电子设备,包括存储器和一个或多个处理器,存储器上存储有可在一个或多个处理器上运行的计算机可读指令,当计算机可读指令被一个或多个处理器执行时,使得一个或多个处理器实现本申请各实施例所述的动画实现方法。
本申请的一个或多个实施例的细节在下面的附图和描述中提出。基于本 申请的说明书、附图以及权利要求书,本申请的其它特征、目的和优点将变得更加明显。
为了更清楚地说明本申请实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例提供的一种动画实现方法的系统架构示意图;
图2为本申请实施例提供的一种动画实现方法的应用场景示意图;
图3为本申请实施例提供的一种动画实现方法的流程图;
图4为本申请实施例中一种人型虚拟角色的关节位置示意图;
图5为本申请实施例提供的完成一个走路目标任务的示意图;
图6为本申请实施例提供的微分比例控制器的一个处理流程示意图;
图7为本申请实施例提供的一种控制策略网络的训练过程的流程图;
图8为本申请实施例提供的一种actor网络的网络结构示意图;
图9为本申请实施例提供的另一种actor网络的网络结构示意图;
图10为本申请实施例提供的一种价值评估网络的训练过程的流程图;
图11为本申请实施例提供的一种训练控制策略网络的收敛曲线的示意图;
图12示出了本申请实施例中一种已训练的控制策略网络输出效果展示图;
图13为本申请实施例提供的一种动画实现装置的结构示意图;及
图14为本申请实施例提供的一种电子设备的结构示意图。
为了使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请作进一步地详细描述,显然,所描述的实施例仅仅是本申请一部分实施 例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本申请保护的范围。
下文中所用的词语“示例性”的意思为“用作例子、实施例或说明性”。作为“示例性”所说明的任何实施例不必解释为优于或好于其它实施例。
文中的术语“第一”、“第二”仅用于描述目的,而不能理解为明示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征,在本申请实施例的描述中,除非另有说明,“多个”的含义是两个或两个以上。
以下对本申请实施例中的部分用语进行解释说明,以便于本领域技术人员理解。
骨骼动画:骨骼动画是模型动画中的一种,模型具有互相连接的“骨骼”组成的骨架结构,通过改变骨骼的朝向和位置来为模型生成动画。
虚拟角色:应用中的可操控对象,通过可操控对象的行为来推动应用的进程,若应用为MOBA游戏或者RTS游戏,虚拟对象为游戏中的可控制游戏角色,若应用为虚拟现实应用,虚拟对象为虚拟现实应用中的虚拟现实角色。
目标任务:用于指示虚拟角色完成指定动作的任务,例如,“前进”、“射击”、“翻跟斗”、“旋风踢球”等。每个虚拟角色可以完成多种类型的目标任务,不同类型的虚拟角色可以完成不同类型的目标任务。可以预先设置不同的控制指令,指示虚拟角色完成不同的目标任务,例如,玩家可以通过控制按键触发对应的控制指令,为虚拟角色设定当前的目标任务。
物理动画:在物理引擎中播放的动画称为物理动画,动画当前时刻的状态由前一时刻的状态和当前的受力情况决定,由于物理动画是对真实世界的模拟,因此可以得到较为逼真的动画效果。
物理引擎:指通过计算机可读指令模拟物理规律的引擎,主要用在计算 物理学、电子游戏以及计算机动画中,可以使用质量、速度、摩擦力及阻力等变量,预测虚拟角色在不同情况下的动作效果。
力矩(torque):也可以称为扭转的力,在物理学中,力矩指作用力促使物体绕着转动轴或支点转动的趋向;在本申请实施例中,力矩指作用力促使骨骼绕关节转动的趋向。
强化学习:机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益,被广泛应用于运动控制问题。
PPO:(Proximal Policy Optimization,近端策略优化算法)强化学习中策略梯度算法群中的一种,属于off-policy(离策略)算法,具有actor(控制策略网络)和critic(价值评估网络)两个子网络,该方法的优势是可以应用于连续型动作,收敛性快且可以实现分布式训练,是目前强化学习领域的主流算法。
Episode:强化学习中的一个概念,强化学习中的虚拟角色与环境交互的一个连续片段称为Episode,本申请实施例中为样本动画片段。
PD控制器:(比例-微分控制器)是一个在工业控制应用中常见的反馈回路部件,比例单元P控制当前位置和目标位置的误差,微分单元D控制当前速度和目标速度的误差。控制器通过输出与误差相关的值反馈到系统来实现系统稳定达到目标状态。PD控制器输出的结果根据具体场景而定,如对于旋转问题,PD控制器输出力矩,对于平移问题,PD控制器输出力。
StablePD控制器:PD控制器的一种改进算法,传统的PD算法对控制参数spring和damper敏感,当spring参数设置过大时,容易出现高比例增益的稳定性问题。StablePD同时考虑了下一个时间周期的位置和加速度实现更快更稳定的控制,试验证明,StablePD可以使用更长的控制间隔来实现比传统PD更稳定的控制效果。
Retarget:重定向技术,细分为角色重定向和环境重定向。角色重定向是指将动画数据从一个角色拷贝到另一个角色的过程,两个角色间可能骨架略 有不同,可能物理参数不同。环境重定向指将动画数据从一个环境拷贝到另一个环境的过程,如地形差异。
下面结合附图及具体实施例对本申请作进一步详细的说明。
为了解决相关技术中的技术问题,本申请实施例提供了一种动画实现方法、装置、电子设备和存储介质。本申请实施例涉及人工智能(Artificial Intelligence,AI)和机器学习(Machine Learning,ML)技术,基于人工智能中的计算机视觉(Computer Vision,CV)技术和机器学习而设计。
人工智能是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。人工智能技术主要包括计算机视觉技术、语音处理技术、以及机器学习/深度学习等几大方向。
随着人工智能技术研究和进步,人工智能在多个领域展开研究和应用,例如常见的智能家居、图像检索、视频监控、智能音箱、智能营销、无人驾驶、自动驾驶、无人机、机器人、智能医疗等,相信随着技术的发展,人工智能将在更多的领域得到应用,并发挥越来越重要的价值。
计算机视觉技术(Computer Vision,CV)是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取信息的人工智能系统。计算机视觉技术通常包括图像处理、图像识别、图像语义理解、图像检索、OCR、视频处理、视频语义理解、视频内容/行为识别、三维物体重建、3D技术、虚拟现实、增强现实、同步定位与地图构建等技术,还包括常见的人脸识别、指 纹识别等生物特征识别技术。
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习等技术。本申请实施例采用了基于深度强化学习的控制策略网络对包含参考虚拟角色的姿态序列的参考动画片段进行学习,并在生成目标动画片段的过程中,利用学习得到的控制策略网络针对不同的虚拟角色生成动画片段。
本申请实施例提供的动画实现方法可以应用于3D(3 Dimensions,三维)立体游戏、3D动画电影以及VR(Virtual Reality,虚拟现实)等场景中。例如,在3D立体游戏中,一般包含大量的虚拟角色。这里的虚拟角色也可以称为物理角色,在物理引擎中,这些虚拟角色可以拥有质量,受到重力的作用等等。在一些实施例中,虚拟角色可以由骨骼构成,骨骼是指由关节搭建出的且可以活动的骨架,是活动的虚拟主体,驱动整个虚拟角色运动。在另一些实施例中,虚拟角色可以由骨骼和蒙皮构成,蒙皮是指包裹在骨骼周围的三角形网格,网格的每个顶点被一个或多个骨骼控制,当骨骼周围包裹有蒙皮时,骨骼不会在游戏画面中被渲染出来。
在游戏中,虚拟角色可以由玩家进行控制,也可以按照游戏进度自动实现角色的控制。虚拟角色的类型也多种多样,如“战士”、“法师”、“射手”、“运动员”等。不同类型的虚拟角色有一部分动作类型是相同的,比如,跑、走、跳以及蹲等,还有一部分动作类型是不同的,比如攻击方式和防御方式等。并且,不同类型的虚拟角色可以完成相同类型的目标任务,也可以完成不同类型的目标任务。本申请实施例提供的动画实现方法,可以根据针对虚拟角色设定目标任务,生成动画片段。
本申请实施例提供的动画实现方法的一种应用场景可以参见图1所示,该应用场景中包括终端设备101和游戏服务器102。终端设备101与游戏服务器102之间可以通过通信网络进行通信。该通信网络可以是有线网络或无线网络。
其中,终端设备101为可以安装各类应用程序,并且能够将已安装的应用程序的运行界面进行显示的电子设备,该电子设备可以是移动的,也可以是固定的。例如,手机、平板电脑、各类可穿戴设备、车载设备或其它能够实现上述功能的电子设备等。各终端设备101通过通信网络与游戏服务器102连接,游戏服务器102可以是游戏平台的服务器,可以是一台服务器或由若干台服务器组成的服务器集群或云计算中心,或者是一个虚拟化平台。
请参考图2,其示出了本申请一个实施例提供的动画实现方法的应用场景的示意图。终端设备101中安装有某AR(Augmented Reality,增强现实)游戏的客户端。如图2所示,在该AR游戏的游戏界面中,采集现实环境的视频信息,即办公桌220的桌面,终端设备中的物理引擎结合办公桌220的桌面情况,生成虚拟角色210的动画,从而显示虚拟角色210在办公桌220上的AR动画。
在该AR游戏中,虚拟角色可以跟用户、跟当前场景交互。在在一个实施例中,客户端接收到用户通过控制按键输入的指示虚拟角色210执行某一项目标任务(如蹲下)的操作,获取虚拟角色210当前第一关键帧的状态信息以及该目标任务并发送至游戏服务器102。游戏服务器102上针对不同的目标任务存储有已经训练好的控制策略网络,控制策略网络是根据包含参考虚拟角色的参考姿态序列的参考动画片段训练得到的。游戏服务器102将虚拟角色210在第一关键帧的状态信息以及目标任务输入控制策略网络,控制策略网络输出第二关键帧的目标姿态数据,并将目标姿态数据发送回客户端。客户端根据虚拟角色210的初始姿态数据和目标姿态数据,计算得到虚拟角色210的各个关节的力矩。客户端基于物理引擎,根据各个关节的力矩调整 第一关键帧中虚拟角色210的各个关节,得到第二关键帧中的虚拟角色的目标姿态,进而生成第一关键帧与第二关键帧之间的固定帧以及第二关键帧。客户端依次显示第一关键帧、第一关键帧与第二关键帧之间的固定帧、第二关键帧,获得虚拟角色执行设定的目标任务的动画片段。
在另一种实施例中,上述过程可以由终端设备101中安装的客户端独立完成。客户端接收到用户通过控制按键输入的指示虚拟角色210执行某一项目标任务的操作,获取虚拟角色210当前第一关键帧的状态信息以及该目标任务,终端设备101中针对不同的目标任务存储有已经训练好的控制策略网络,控制策略网络是根据包含参考虚拟角色的参考姿态序列的参考动画片段训练得到的。终端设备101中将虚拟角色210在第一关键帧的状态信息以及目标任务输入控制策略网络,控制策略网络输出第二关键帧的目标姿态数据。客户端根据虚拟角色210的初始姿态数据和目标姿态数据,计算得到虚拟角色210的各个关节的力矩。客户端基于物理引擎,根据各个关节的力矩调整第一关键帧中虚拟角色210的各个关节,得到第二关键帧中的虚拟角色的目标姿态,进而生成第一关键帧与第二关键帧之间的固定帧以及第二关键帧。客户端依次显示第一关键帧、第一关键帧与第二关键帧之间的固定帧、第二关键帧,获得虚拟角色执行设定的目标任务的动画片段。
需要说明的是,本申请提供的动画实现方法可以应用于游戏服务器102,也可以应用于终端设备的客户端中,由终端设备101实施本申请提供的动画实现方法,还可以由游戏服务器102与终端设备101中的客户端配合完成。
图3示出了本申请一个实施例提供的动画实现方法的流程图。如图3所示,该方法包括如下步骤:
步骤S301,获得目标动画片段T0,目标动画片段T0中包括第一关键帧,第一关键帧中包括目标虚拟角色的初始姿态数据。
其中,目标虚拟角色可以是人物形态,可以是动物、卡通或者其它形态,本申请实施例对此不作限定。目标虚拟角色可以通过三维形式展示,也可以 通过二维形式展示。目标虚拟角色具有骨骼,相邻的骨骼之间具有关节,通过改变每个关节的位置和旋转角度,可以改变目标虚拟角色的姿态,将目标虚拟角色的一系列姿态连贯后,即可形成连贯的动作。
本申请实施例中利用骨骼动画进行计算和呈现,可以让动画效果做得更丰富。并且,做到了虚拟对象和动画分离,即只需要记录虚拟对象对于骨骼的蒙皮权重,就可以单独的去制作骨骼的动画,在保证蒙皮信息和骨骼信息一致的情况下,还可以多个虚拟对象之间共享骨骼动画。此外,也大大的节省资源容量。
目标动画片段T0可以是终端设备的物理引擎中预先保存的动画片段,或者是游戏中已生成的动画片段,也可以是用户输入的动画片段。目标动画片段T0中包含第一关键帧。帧就是动画中最小单位的单幅影像画面,相当于电影胶片上的每一格镜头,在动画软件的时间轴上帧表现为一格或一个标记。关键帧相当于二维动画中的原画,指角色或者物体运动或变化中的关键动作所处的那一帧,由于一个视频很多帧其实与所做的动作无关,将与动作有关的帧作为关键帧。本申请实施例中,关键帧与关键帧之间的动画为固定帧,其中,相邻两关键帧之间相差的帧数为预先设置,例如,可以为每20帧设置一个关键帧,即动画片段的第0帧、第20帧、第40帧……设置为关键帧,则第1帧至第19帧、第21帧至第39帧……为固定帧。
为了便于介绍,请参阅图4,图4为本申请实施例中一种人型虚拟角色的关节位置示意图,如图所示,假设人型角色有15个关节,其中,A15所指示的关节为根(root)关节,在人型角色的盆骨位置,也是最顶层的父节点。其余的14个关节分别为A1所指示的胸膛、A2所指示的脖子、A3所指示的右腿、A4所指示的左腿、A5所指示的右膝、A6所指示的左膝、A7所指示的右踝、A8所指示的左踝、A9所指示的右大臂、A10所指示的左大臂、A11所指示的右肘、A12所指示的左肘、A13所指示的右手腕以及A14所指示的左手腕。其中肘关节和膝关节是转动关节,腕关节是固定关节,其他 关节均为球关节,因此,虚拟角色可以配置共43个自由度。可以理解的是,人型虚拟角色还可以包括其他数量的关节,此处仅为一个示意,不应理解为对本申请的限定。
在一个实施例中,虚拟角色所有关节的位置数据和旋转数据构成了该虚拟角色的姿态数据。角色的关节位置可以用三维向量表示,角色的关节旋转则可以使用四元数来表示,因此,一个角色关节的姿态可以用七维向量表示。
上述目标虚拟角色的初始姿态数据可以由终端设备基于物理引擎获得,即将目标动画片段T0输入物理引擎中,物理引擎可直接输出该动画片段T0中第一关键帧中的初始姿态数据。
步骤S302、将初始姿态数据以及设定的目标任务输入已训练的控制策略网络中得到目标虚拟角色的目标姿态数据。
在游戏过程中,用户可以通过控制按键控制虚拟角色执行不同的动作。在本申请实施例中,每个控制按键对应一项目标任务,用户可以通过控制按键为虚拟角色设定目标任务,虚拟角色将执行该目标任务对应的动作。例如,用户通过显示界面上的控制按键输入“跳跃”的控制指令,使目标虚拟角色从地面跳起,则针对目标虚拟角色设定的目标任务即为“跳跃”。目标任务还可以是其它任务,如使目标虚拟角色沿给定的方向前进,或者让目标虚拟角色使用旋风踢的动作,踢到指定的位置,本申请实施例对此不作限定。
在一个实施例中,目标姿态数据可以为终端设备直接将至少初始姿态数据以及设定的目标任务输入控制策略网络中得到,此时,终端设备中存储有已训练的控制策略网络。
在一个实施例中,目标姿态数据也可以为终端设备通过与服务器交互得到,此时,服务器中存储有已训练的控制策略网络,终端设备将至少初始姿态数据以及设定的目标任务向服务器发送,服务器将至少初始姿态数据以及设定的目标任务输入控制策略网络中得到目标姿态数据,再将计算得到的目标姿态数据反馈回终端设备。
步骤S303、根据目标虚拟角色的初始姿态数据和目标姿态数据,得到调整目标虚拟角色的N个关节的力矩。其中,N为大于或者等于1的正整数。
力矩指作用力促使骨骼绕关节转动的趋向。在一个实施例中,可以利用StablePD控制器计算力矩值,即将目标虚拟角色的初始姿态数据以及目标姿态数据输入StablePD控制器中,得到作用于目标虚拟角色的各个关节的力矩,并将力矩反馈到物理引擎中从而实现将目标虚拟角色稳定的控制至目标姿态。
步骤S304、利用N个关节的力矩,将目标虚拟角色由初始姿态调整至目标姿态,得到第二关键帧。
具体实施过程中,可以由物理引擎将各个关节的力矩作用于目标虚拟角色的各个关节,对上一帧动画画面中目标虚拟角色的姿态进行调整,得到下一帧动画画面中目标虚拟角色的姿态。通过物理引擎将力矩直接作用于目标虚拟角色的各个关节,从而可以对各个关节的姿态进行准确地调整,使得目标虚拟角色呈现出相应的动作姿态,动画效果更佳丰富自然,实现了传统动画技术达不到的动作效果,使目标虚拟角色的动作姿态更加逼真。
步骤S305、获取目标动画片段T1。
其中,目标动画片段T1包括第一关键帧以及第二关键帧。第二关键帧为第一关键帧的下一关键帧。
进一步的,可以将第二关键帧中目标虚拟角色的姿态数据作为初始姿态数据,至少将第二关键帧中的初始姿态数据以及目标任务输入策略控制网络得到第三关键帧中目标虚拟角色的目标姿态数据,第三关键帧为第二关键帧的下一关键帧。利用第二关键帧中的初始姿态数据和第三关键帧中目标虚拟角色的目标姿态数据得到调整第二关键帧中目标虚拟角色各个关节的力矩,并利用力矩,将目标虚拟角色由第二关键帧中的初始姿态调整至第三关键帧中的目标姿态,得到第二关键帧与第三关键帧之间的固定帧以及第三关键帧。以此类推,可以依次生成后续的动画帧。
将目标虚拟角色的一系列姿态连贯后,即可形成连贯的动作,得到目标 虚拟角色通过一系列动作执行目标任务的动画片段。
可以理解,在其他实施例中,也可以将目标动画片段T0和目标动画片段T1分别用“第一目标动画片段”和“第二目标动画片段”来做区分性表述。
本申请实施例利用控制策略网络得到第二关键帧中目标虚拟角色的目标姿态数据,并通过目标虚拟角色的初始姿态数据和目标姿态数据,得到调整目标虚拟角色的力矩,利用力矩调整目标虚拟角色的初始姿态,得到第二关键帧,即可以根据第一关键帧和目标任务生成目标虚拟角色的姿态序列,进而得到目标虚拟角色的动画片段,从而缩短了工作人员的工作时间,提升了工作效率。此外,由于目标虚拟角色是利用力矩调整目标虚拟角色的姿态,因此赋予了目标虚拟角色真实的物理属性,并基于此来计算目标虚拟角色的运动得到目标虚拟角色的姿态,因此可以得到更符合实际场景的目标姿态,实现更逼真的动作效果。
本申请实施例中,目标虚拟角色的目标姿态数据基于强化学习模型计算输出。相关技术中,有利用深度学习模型进行虚拟角色运动轨迹的控制。深度学习主要通过大量的有标记样本来进行训练,基于深度模型强大的标识学习的能力,在拥有大量有标记数据的场景下往往能够得到显著优越的效果。
然而,在很多场景下有标记的样本很难获得,代价很大。例如本申请实施例中的游戏为例,若利用深度学习技术,就必须用大量的人类玩家在游戏内的操作数据来训练模型。这就意味着这种方法只在那些已经上线且记录了用户的大量操作数据的游戏中有实现的可能性,适用范围有限。角色动画等场景也存在着相似的问题,本身就不存在足够的数据来进行训练。
与深度学习不同的是,深度强化学习是让虚拟角色在环境中进行探索来学习策略,不需要大量经过标记的样本,无需进行数据预处理,效率较高,更为适应本申请实施例中的动画游戏场景。
针对不同的目标任务和应用场景,向强化学习模型中输入的数据类型不同。
一种可能的实施例中,上述第二关键帧中目标虚拟角色的目标姿态数据通过以下方式获取:
获取目标虚拟角色在第一关键帧中的状态信息;
将目标虚拟角色在第一关键帧中的状态信息和目标任务输入控制策略网络,获得控制策略网络输出的目标虚拟角色的目标姿态数据。
其中,控制策略网络是根据参考动画片段训练得到的,参考动画片段包含参考虚拟角色完成目标任务的参考姿态序列。
参考虚拟对象是指已经制作好动画的虚拟对象,参考虚拟对象的动作称为参考动作,可以用运动学来表示参考动作。可选地,目标虚拟对象和参考虚拟对象是两个骨架相同或相近的虚拟对象。
骨架相同,可以表示为目标虚拟对象和参考虚拟对象的骨架中的所有骨骼的尺寸、形状,以及骨骼之间的连接关系完全相同;骨架相近,包括但不限于以下至少一种:目标虚拟对象和参考虚拟对象的骨架中的骨骼的尺寸相近、形状相近、骨骼之间的连接关系相近。
参考虚拟动画支持单个虚拟角色的任意动画片段,可以是通过动作捕捉设备获取的数据,也可以是简单的视频片段。参考虚拟动画中,参考虚拟角色可以完成走路,奔跑,旋转踢,后空翻等多个动作。
目标虚拟角色的状态信息用于表征目标虚拟对象的物理状态,可以包括目标虚拟角色的当前相位数据、当前的初始姿态数据、当前速度数据和历史姿态序列。
其中,当前相位数据用于表征目标虚拟角色在第一关键帧中所处的阶段。当前相位数据的取值范围为0至1,用于定义目标虚拟角色的当前状态在动作片段中所处的阶段。对于可循环动画而言,整个学习的动画序列存在周期性,而不同周期的同一阶段的动作具备高度相似性,本申请实施例中利用相位信息来使得模型在相同相位输出类似的动作信息,增强模型的拟合能力。
例如,完成一个走路目标任务需要如图5所示的6帧动画画面,第一关 键帧动画画面为图5中的第5帧动画画面,则相位数据为5/30=1/6。相位数据也可以通过时间进行标识。例如,完成某一个目标任务需要30帧动画画面,播放这30帧动画画面所需的总时间长度为T,将第一帧动画画面对应的播放时刻记为开始时刻,设上一帧动画画面对应的播放时刻t,则上一帧动画画面中目标虚拟角色的相位数据Ph可以表示为Ph=t/T。
当前的初始姿态数据用于表征目标虚拟角色当前的姿态,即目标虚拟角色在第一关键帧中的姿态。具体实施过程中,虚拟角色的姿态数据包括虚拟角色所有关节的位置数据和旋转数据。其中,虚拟角色的关节位置可以用三维向量表示,虚拟角色的关节旋转则可以使用四元数来表示,因此,在一个实施例中,一个虚拟角色的姿态可以用七维向量表示。可以理解的是,姿态数据中的三维向量表示关节的空间坐标,而旋转数据中的单位四元数表示三维空间里的旋转情况。当然,姿态数据还可以采用其他形式来表征,采用多种形式的数据表示目标虚拟角色的姿态,可以更准确地确定目标虚拟角色的姿态。
其中,四元数是一种超复数。复数是由实数加上虚数单位i组成,相似地,四元数都是由实数加上三个虚数单位i、j、k组成,并且,三个虚数之间具有如下关系:i
2=j
2=k
2=﹣1,i
0=j
0=k
0=1。每个四元数都是1、i、j和k的线性组合,四元数一般可表示为:a+bi+cj+dk,其中a、b、c、d是实数。i、j、k本身的几何意义可以理解为一种旋转,其中i旋转代表X轴与Y轴相交平面中自X轴正向向Y轴正向的旋转,j旋转代表Z轴与X轴相交平面中自Z轴正向向X轴正向的旋转,k旋转代表Y轴与Z轴相交平面中Y轴正向向Z轴正向的旋转,-i旋转表示i旋转的反向旋转,-j旋转表示j旋转的反向旋转,-k旋转表示k旋转的反向旋转。
当前速度数据用于表征目标虚拟角色当前的速度状态,即目标虚拟角色在第一关键帧中的速度。具体实施过程中,目标虚拟角色的当前速度数据包括虚拟角色所有关节的线速度和角速度。由于每个关节的线速度可以用三维 向量表示,分别为X轴上的速度、Y轴上的速度以及Z轴上的速度;且角速度也可以用三维向量表示,分别为X轴上的速度、Y轴上的速度以及Z轴上的速度。因此,一个角色关节的速度可以用六维向量表示。若目标虚拟角色包括N个关节,则目标虚拟角色的速度维数可以是N×6。采用线速度和角速度的组合来表示目标虚拟角色的速度数据,有利于更准确地确定目标虚拟角色的速度。
历史姿态序列用于表征目标虚拟角色在历史时间段内的姿态。具体实施过程中,可以将目标虚拟角色的根关节的历史时间段内的姿态信息作为目标虚拟角色的历史姿态序列,例如在1s的历史时间窗口内采10帧的根关节,由于每个根关节的姿态用七维向量表示,目标虚拟角色的历史姿态序列则使用70维的向量来表示。目标虚拟角色的历史姿态序列可以更全面地描述目标虚拟角色的当前状态。
本申请实施例中目标虚拟角色的状态信息还可以包括其他形式的表征数据,将多种维度多种形式的数据输入强化学习模型,用于描述目标虚拟角色的当前物理状态,从而能够得到更为准确的计算结果。
将目标虚拟角色在第一关键帧中的状态信息和目标任务输入控制策略网络,获得目标虚拟角色的目标姿态数据。目标任务输入控制策略网络时,目标任务可以使用向量表示。例如,假设目标任务是使目标虚拟角色沿给定的方向前进,给定的方向可以通过在水平平面上的一个二维向量表示。可以将目标虚拟角色在上一帧动画画面中的状态信息和表示目标任务的向量拼接在一起输入控制策略网络,控制策略网络将输出用于调目标虚拟角色的各个关节的力矩。
本申请实施例中将目标虚拟角色的状态信息和目标任务输入控制策略网络,获得目标虚拟角色的目标姿态数据。在一个实施例中,采用基于强化学习的玩家评判(Actor-Critic,AC)算法框架进行训练,AC算法框架包括Actor网络以及Critic网络,本申请实施例中的控制策略网络即为Actor网络,价 值评估网络即为Critic网络。其中,控制策略网络训练的是当前策略,输出姿态数据,而价值评估网络用于指导控制策略网络的学习。训练的时候需要对控制策略网络和价值评估网络均进行训练,实际应用的时候仅使用控制策略网络即可。控制策略网络和价值评估网络的具体训练过程将在下文中详细介绍。
在一个实施例中,还需要考虑目标虚拟角色所处的场景环境对目标虚拟角色的影响。即当实际场景中的环境与参考动画中的环境不一致时,需要结合目标虚拟角色所处的场景环境。则此时,第二关键帧中目标虚拟角色的目标姿态数据通过以下方式获取:
获取目标虚拟角色在第一关键帧中的状态信息和目标虚拟角色所处的场景环境的环境信息;
将目标虚拟角色在第一关键帧中的状态信息、目标任务和目标虚拟角色所处的场景环境的环境信息输入控制策略网络,获得控制策略网络输出的目标虚拟角色的目标姿态数据。
其中,控制策略网络是根据参考动画片段训练得到的,参考动画片段包含参考虚拟角色完成目标任务的参考姿态序列。
环境信息用于表征目标虚拟对象所处的虚拟环境。虚拟环境可以是由物理引擎模拟的物理环境,在模拟的物理环境中,虚拟对象遵守动力学规律,使得虚拟对象的运动接近现实情况。
其中,上述场景环境可以是物理引擎在终端设备中运行时显示(或提供)的场景,该场景环境是指营造出的供目标虚拟对象进行活动(如游戏竞技)的场景。该场景环境可以是对真实世界的仿真环境,也可以是半仿真半虚构的环境,还可以是纯虚构的环境。场景环境可以是二维虚拟环境,也可以是2.5维虚拟环境,或者是三维虚拟环境,本申请实施例对此不作限定。
例如,如果物理引擎中的环境与参考动画中的环境不同是地形不同时,则环境信息为当前角色周围地形的高度图。
本申请实施例中,通过上述控制策略网络,输出目标虚拟角色的目标姿态数据。目标姿态数据用于表征目标虚拟角色下一个时间片段需要达到的目标姿态,而这个目标姿态数据具体用于力矩值的计算,因此,这里的目标姿态数据为目标虚拟角色所有关节的旋转数据,因此,一个关节的目标姿态数据可以用四元数表示。
通过上述基于强化学习模型的方法,可以实现角色的重定向和环境的重定向,即只需生成一个参考虚拟角色基于某一场景的参考动画序列,则针对与该参考虚拟角色骨架相同或骨架相近的目标虚拟角色的类似场景动画,可以直接利用参考动画序列,通过模型生成目标虚拟角色类似场景的动画,大大缩短了工作时间,提升了工作效率。
上述通过控制策略网络获取目标虚拟角色的目标姿态数据的过程可以在终端设备中实现,也可以在服务器中实现并由服务器将目标姿态数据发送至终端设备。
进一步地,第一关键帧与第二关键帧之间包括M个固定帧,则上述步骤利用N个关节的力矩,将目标虚拟角色由初始姿态调整至目标姿态,得到第二关键帧,包括:利用N个关节的力矩,将目标虚拟角色由初始姿态调整至目标姿态,得到第一关键帧与第二关键帧之间的固定帧以及第二关键帧。
这种情况下,目标动画片段T1由至少第一关键帧、M个固定帧以及第二关键帧组成。
具体来说,终端设备获取目标姿态数据后,则可根据初始姿态数据,通过计算得到调整各个关节的力矩,并进一步得到第二关键帧,以及第一关键帧与第二关键帧之间的固定帧。其中,固定帧为两关键帧之间的动画帧,可以利用插值的方法确定固定帧,也可以为力矩调整目标虚拟角色的姿态而得到固定帧。
可以理解,在其他实施例中,可以将本申请各实施例中的“N”和“M”分别用“第一预设数量”和“第二预设数量”进行区分性表述。
在一个实施例中,调整目标虚拟角色的N个关节的力矩,以及固定帧、第二关键帧通过如下方式得到:
根据初始姿态数据和目标姿态数据,得到调整第一关键帧中目标虚拟角色的N个关节的力矩;
利用力矩调整目标虚拟角色的初始姿态,得到第一固定帧,第一固定帧是第一关键帧的下一帧动画;
针对除第一固定帧和第M固定帧之外的每一固定帧,获取上一固定帧中目标虚拟角色的姿态数据,利用上一帧中目标虚拟角色的姿态数据和目标姿态数据,得到调整固定帧中目标虚拟角色的N个关节的力矩;利用力矩调整固定帧中目标虚拟角色的姿态,得到下一固定帧;
获取第M固定帧中目标虚拟角色的姿态数据,利用第M固定帧中目标虚拟角色的姿态数据和目标姿态数据,得到调整第M固定帧中目标虚拟角色的N个关节的力矩;
利用力矩调整第M固定帧中目标虚拟角色的姿态,得到第二关键帧,第二关键帧是第M固定帧的下一帧动画。
具体实施过程中,采用了力矩来控制目标虚拟角色进行运动。这样可以实现较为真实的物理效果,且可以感知碰撞等相互作用。利用力矩对目标虚拟角色进行控制有多种方式,例如基于速度控制的方法,在该方法中,控制策略网络输出的信息为角速度,然后采用PD控制算法动态控制角速度信息,基于角速度信息计算出作用于目标虚拟角色各个关节的力矩,然后由物理引擎根据力矩控制目标虚拟角色进行运动。
本申请实施例中利用基于位置控制的方法。其对目标虚拟角色的控制效果较好,从而实现较为自然的动作效果。
为了便于理解,可以参考图6,图6为本申请实施例中微分比例控制器的一个处理流程示意图,如图6所示,整个闭环控制系统相当于分层控制,将目标虚拟角色在第一关键帧的状态信息St输入至控制策略网络,由该控制 策略网络输出第二关键帧的目标姿态数据。这里计算力矩利用的目标姿态数据为各个关节的旋转数据,利用PD控制器动态地将目标虚拟角色的旋转数据控制到第一关键帧的姿态A
t,基于第一关键帧的姿态A
t计算得到力矩,在物理引擎中采用力矩对目标虚拟角色进行控制,由此得到第二关键帧的状态信息S
t+1,于是将作为控制策略网络的输入,从而得到第二关键帧的姿态A
t+1,依次类推,可以实现对目标角色的连续控制。
具体地,可以根据以下公式计算每个关节的力矩:
其中,τ
n表示第n帧的力矩;k
p表示比例增益;k
d表示微分增益;q
n表示当前时刻的旋转数据,
 表示当前时刻的角速度,q
n和
表示当前时刻的角速度,q
n和
 可以直接从物理引擎中获得;
可以直接从物理引擎中获得;
 表示当前时刻的角加速度,通过逆动力学方式计算获得;
表示当前时刻的角加速度,通过逆动力学方式计算获得;
 为下一时刻的旋转数据,即控制策略网络的输出;
为下一时刻的旋转数据,即控制策略网络的输出;
 表示下一时刻的角速度,这里总是置为0。Δt表示周期时间,即当前时刻与下一时刻之间的时长。
表示下一时刻的角速度,这里总是置为0。Δt表示周期时间,即当前时刻与下一时刻之间的时长。
通过上述方式,控制策略网络输出各个关节的旋转数据,再通过PD控制动态的将目标角色控制到对应的位置,相比力矩控制姿态更稳定,且控制策略网络输出每个关节的旋转数据,其分布方差较小,且采样样本小,因此控制策略网络收敛速度快。
以下详细介绍本申请实施例所采用的控制策略网络和价值评估网络的训练过程。
在本申请实施例中,针对同一类型的目标任务,可以训练一个控制策略网络,针对不同类型的目标任务,可以分别训练相应的控制策略网络。例如,“向前射击”、“向左射击”和“向右射击”均属于射击,仅是射击的方向不同,因此属于同一类型的目标任务,可以训练一个控制策略网络。而“射击”和“跑步”属于不同类型的目标任务,可以分别训练相应的控制策略网络。
本申请在一个实施例中,采用基于强化学习的AC算法框架进行训练,AC算法框架包括Actor网络以及Critic网络,本申请实施例中的控制策略 网络即为Actor网络,价值评估网络即为Critic网络。其中,控制策略网络训练的是当前策略,输出姿态数据,而价值评估网络用于指导控制策略网络的学习。训练的时候需要对控制策略网络和价值评估网络均进行训练。其中,价值评估网络与控制策略网络的网络结构可以是一致的,也可以是不同的。本申请实施例中价值评估网络与控制策略网络采用相同的输入结构和输入数据,价值评估网络与控制策略网络的输出不同,控制策略网络的输出为目标姿态数据,而价值评估网络的输出为一维数据,表示的当前时刻的状态价值。
具体地,控制策略网络的训练过程可以如图7所示,包括如下步骤:
步骤S701、将样本动画片段中训练虚拟对象在当前时刻的状态信息和设定的训练任务输入控制策略网络,得到控制策略网络输出的下一时刻的训练虚拟对象的姿态数据。
其中,每一时刻对应一关键帧动画。可以理解,本申请实施例中的控制策略网络,为待训练的(包括未训练和训练中)的控制策略网络。
当前时刻为当前关键帧的样本动画画面对应的播放时刻,下一时刻为下一关键帧样本动画画面对应的播放时刻。训练虚拟对象的状态信息包括当前相位数据、当前的初始姿态数据、当前速度数据和历史姿态序列,与上文中目标虚拟角色的状态信息相同,这里不做赘述。
训练虚拟对象是在训练过程中控制策略网络输出的控制策略的作用对象。训练虚拟对象和参考虚拟对象是两个骨架相同或相近的虚拟对象。骨架相同,可以表示为训练虚拟对象和参考虚拟对象的骨架中的所有骨骼的尺寸、形状,以及骨骼之间的连接关系完全相同;骨架相近,包括但不限于以下至少一种:训练虚拟对象和参考虚拟对象的骨架中的骨骼的尺寸相近、形状相近、骨骼之间的连接关系相近。在训练控制策略网络之前,需要先获取包含参考虚拟角色的姿态序列的样本动画片段。
训练任务对应于使用过程中的目标任务进行设定。示例性地,训练任务可以是使训练虚拟对象沿给定的方向前进,或者是让训练虚拟对象使用旋风 踢的动作,踢到指定的位置。
控制策略网络(actor网络)可以是带目标的网络,包括输入层、隐藏层和输出层。其中,隐藏层中可以包括一层神经网络,也可以包括多层神经网络,可以根据实际情况进行设定,本申请实施例对此不作限定。隐藏层中的神经网络层可以是全连接层。例如,隐藏层中可以包括两层全连接层,其中,第一全连接层可以包括1024个神经元,第二全连接层可以包括512个神经元。当隐藏层包括两层或两层以上的神经网络层时,神经网络层之间的激活函数为ReLU(Rectified Linear Unit,线性整流函数)函数。
在一种实施例中,actor网络的网络结构如图8所示,可以将训练虚拟对象在当前时刻的状态信息和设定的训练任务输入控制策略网络,得到控制策略网络输出的下一时刻的控制策略,该控制策略为下一时刻训练虚拟对象的姿态。其中,状态信息和训练任务都是一维信息,将状态信息和训练任务信息做拼接,共同输入到两层的全连接隐藏层。模型的输出为线性输出,假设角色姿态的分布满足高斯分布,模型输出高斯分布的均值,而高斯分布的方差则作为网络的超参数。
在另一种实施例中,如图9所示,可以获取训练虚拟对象所处的场景环境的环境信息,场景环境的环境信息可以是场景环境的地形图。将场景环境的环境信息、训练对象在当前时刻的状态信息和训练任务输入控制策略网络,得到控制策略网络输出的下一时刻的训练虚拟对象的姿态。其中状态信息和训练任务都是一维信息,地形图是二维数据,地形图使用三层卷积网络完成平面信息提取,将输出结果展平成一维后与状态信息和训练任务做拼接,共同输入到两层的全连接隐藏层。模型的输出为线性输出,假设角色姿态的分布满足高斯分布,模型输出高斯分布的均值,而高斯分布的方差则作为网络的超参数。
例如,对于一些视觉任务,需要自适应地形环境,控制策略网络还可以包括特征提取网络,由多层卷积网络和全连接层组成,用于从输入的场景环 境的环境信息中提取地形特征,将提取的地形特征与输入的训练对象的状态信息和训练任务进行合并,确定下一时刻训练虚拟对象的姿态数据。
步骤S702、将训练虚拟对象在当前时刻的状态信息和设定的训练任务输入价值评估网络,得到价值评估网络输出的当前时刻的状态价值。
其中,价值评估网络是根据参考动画片段训练得到的。具体实施过程中,由价值评估网络输出的状态价值来衡量控制策略网络的输出姿态的好坏,即训练虚拟对象执行完当前的动作之后,状态信息变化为s,状态价值V(s)评估当前状态的好坏,间接衡量动作的好坏,可以理解的是,状态价值V(s)越大表示状态越好。Critic网络输出的状态价值V(s)的学习标准是由环境反馈的一系列奖励信息计算而来的,即得到多个时刻的奖励信息之后,可以通过时间差分学习(temporal-difference learning)估计出当前状态价值V(s)。
时间差分学习是强化学习中的一个中心思想,类似蒙特卡洛方法,时间差分学习能够直接从经验中学习而不需要对于环境的完整知识。类似动态规划方法,时间差分学习能够在现有的估计结果上进行提升而不需要等待整个事件结束。
步骤S703、根据状态价值调整控制策略网络的参数并对调整参数后的控制策略网络继续进行训练,直至达到设定的训练结束条件为止,得到已训练的控制策略网络。
在一个实施例中,电子设备可以根据状态价值、以及控制策略网络输出的下一时刻的训练虚拟对象的姿态数据,调整控制策略网络的参数并对调整参数后的控制策略网络继续进行训练,直至达到设定的训练结束条件为止,得到已训练的控制策略网络。
本申请实施例中,根据Actor网络(即控制策略网络)输出的姿态数据,以及Critic网络(即价值评估网络)输出的状态价值,对该Actor网络进行训练。从而Actor网络根据Critic网络得到学习标准,因此可以根据损失函数计算误差和梯度,并对Actor网络进行训练,最终将训练得到的Actor网 络作为已训练的控制策略网络。
本申请实施例中的价值评估网络(Critic网络)与控制策略网络的网络结构可以是一致的,也可以是不同的。价值评估网络用于对控制策略网络输出的控制策略进行评价,确定训练虚拟对象模仿参考虚拟角色及完成训练任务的奖励值。价值评估网络也是经过训练得到的。价值评估网络的训练过程如图10所示,包括如下步骤:
步骤S1001、根据训练虚拟对象和参考动画片段中参考虚拟角色在下一时刻的状态信息及设定的训练任务,确定训练虚拟对象当前时刻的即时奖励值。
其中,当前时刻的即时奖励值包括任务目标奖励和模仿目标奖励两部分。模仿目标奖励用于激励训练虚拟对象的姿态与参考虚拟角色的姿态保持一致,本质是在相同相位时,比较参考虚拟角色的姿态和训练对象的姿态的相似程度,两者越接近,则模仿目标奖励越高;反之,模仿目标奖励越低。任务目标奖励根据训练虚拟对象完成训练任务的情况确定。
根据上述描述,在一个实施例中,根据训练虚拟对象在下一时刻的状态信息及设定的训练任务,确定当前时刻的任务目标奖励,用于评价目标任务的完成程度;
根据训练虚拟对象在下一时刻的状态信息与参考虚拟角色在下一时刻的状态信息,确定当前时刻的模仿目标奖励,用于评价训练虚拟对象与参考虚拟对象的相似程度,进而判断训练虚拟对象的动作是否自然;
根据任务目标奖励和模仿目标奖励,确定当前时刻的即时奖励值。
具体的,将任务目标奖励和模仿目标奖励进行加权,加权后的值作为即时奖励值r
t,具体如下公式所示:
其中,
 表示时刻t对应的模仿目标奖励,w
I为模仿目标奖励的权重,
表示时刻t对应的模仿目标奖励,w
I为模仿目标奖励的权重,
 表示时刻t对应的任务目标奖励,w
G为任务目标奖励的权重。w
I和w
G与价值 评估网络的网络参数相关。
表示时刻t对应的任务目标奖励,w
G为任务目标奖励的权重。w
I和w
G与价值 评估网络的网络参数相关。
在一个实施例中,可以将模仿目标奖励
 细分为四个方面:姿态相似度、速度相似度、末端关节相似度、质心姿态相似度,四个部分加权后的值作为最后的即时奖励,具体的,模仿目标奖励
细分为四个方面:姿态相似度、速度相似度、末端关节相似度、质心姿态相似度,四个部分加权后的值作为最后的即时奖励,具体的,模仿目标奖励
 可以表示为:
可以表示为:
其中,w
p为姿态相似度
 的权重,w
v为速度相似度
的权重,w
v为速度相似度
 的权重,w
e为末端关节相似度
的权重,w
e为末端关节相似度
 的权重,w
c为质心姿态相似度
的权重,w
c为质心姿态相似度
 的权重。
的权重。
其中,姿态相似度
 用于描述训练对象与参考虚拟角色的姿态相似度,各个关节的位置和旋转度之间的相似度,可以表示为:
用于描述训练对象与参考虚拟角色的姿态相似度,各个关节的位置和旋转度之间的相似度,可以表示为:
速度相似度
 用于描述训练对象与参考虚拟角色的速度相似度,包括各个关节的角速度与线速度与目标姿态之间的相似度,可以表示为:
用于描述训练对象与参考虚拟角色的速度相似度,包括各个关节的角速度与线速度与目标姿态之间的相似度,可以表示为:
末端关节相似度
 用于描述训练对象与参考虚拟角色末端关节姿态的相似度,包括四肢关节,可以表示为:
用于描述训练对象与参考虚拟角色末端关节姿态的相似度,包括四肢关节,可以表示为:
质心姿态相似度
 用于描述训练对象与参考虚拟角色的重心位置的相似度,可以表示为:
用于描述训练对象与参考虚拟角色的重心位置的相似度,可以表示为:
当然,模仿目标奖励
 还可以包括其他相似度,例如根关节相似度等。一般来说,相似度个数越多,计算结果越准确,但计算量会越多。
还可以包括其他相似度,例如根关节相似度等。一般来说,相似度个数越多,计算结果越准确,但计算量会越多。
根据训练任务的类型不同,任务目标奖励的设置也可以不同。例如,如果训练任务是使训练对象模仿参考虚拟角色走路姿态,并在走路过程中完成转向的任务,设定一个针对走路方向的任务目标奖励,以鼓励训练对象朝指定方向以给定的速度前进。如果训练任务是让训练对象使用旋风踢的动作,踢到指定的位置。例如,在训练对象周围指定一个随机的目标球体,训练对象用旋风踢来踢到指定的目标球体。该训练任务的任务向量由两部分组成,一个是给定的目标球体的位置
 可以由空间中一个三维向量表示,另一个是一个二值的标志h,表明目标在前一个时间周期是否被击中。
可以由空间中一个三维向量表示,另一个是一个二值的标志h,表明目标在前一个时间周期是否被击中。
在踢中目标球体的训练任务中,任务目标奖励可以表示为:
其中,
 表示目标球体的位置,
表示目标球体的位置,
 表示时刻t训练虚拟对象的末端关节的位置。该训练任务的目标是,不仅能够保证旋风踢姿态的同时,还能够准确踢到指定的目标,完成任务。
表示时刻t训练虚拟对象的末端关节的位置。该训练任务的目标是,不仅能够保证旋风踢姿态的同时,还能够准确踢到指定的目标,完成任务。
步骤S1002、根据样本动画片段中每个时刻训练虚拟对象的即时奖励值和状态价值,确定训练虚拟对象的期望奖励值。
收集到一个样本动画片段后,使用GAE(map autoencoder,图自编码器) 算法实现训练虚拟对象的期望奖励值,具体的,训练虚拟对象的期望奖励值
 可以根据以下公式计算:
可以根据以下公式计算:
其中,

上述公式9中,
 为t时刻计算得出的收获值,λ为0到1的参数;R
t为时刻t的即时奖励值,γ为衰减因子,V(S
t)为t时刻价值评估网络输出的状态价值,n为样本动画片段中关键帧的数量。
为t时刻计算得出的收获值,λ为0到1的参数;R
t为时刻t的即时奖励值,γ为衰减因子,V(S
t)为t时刻价值评估网络输出的状态价值,n为样本动画片段中关键帧的数量。
进一步地,根据以下至少一项条件确定样本动画片段结束:
样本动画片段时长到达时长阈值;训练虚拟对象的姿态数据满足摔倒阈值;训练虚拟对象的姿态数据与参考虚拟对象的姿态数据之差大于差异阈值;训练虚拟对象的速度数据大于速度阈值。
具体来说,样本动画片段时长超过设定的时长阈值,则认为样本动画片段结束。或者,训练虚拟对象摔倒,则认为样本动画片段结束,其中,摔倒的定义为指定的关节接触到了地面。或者,样本动画片段与参考动画片段的差异过大,这里主要指根关节的旋转角度差异超过角度阈值,一般设置为90度。或者,训练虚拟对象的速度数据大于速度阈值。
根据上述方式确定样本动画片段结束,从而保证训练虚拟对象与参考虚拟对象的相似程度以及训练虚拟对象的真实程度,进而提高训练的准确性。
步骤S1003、根据期望奖励值调整价值评估网络的参数并对调整参数后的价值评估网络继续进行训练,直至达到设定的训练结束条件为止,得到已训练的价值评估网络。
其中,训练结束条件可以是训练次数达到设定次数、连续N次训练得到的期望奖励值的变化幅度在设定幅度之内或期望奖励值达到设定阈值。
示例性地,可以采用PPO(Proximal Policy Optimization,近端策略优化)算法、SAC(Soft Actor-Critic,柔性致动/评价)算法或DDPG(Deep Deterministic Policy Gradient,深度确定性策略梯度)算法等用于处理连续控制问题的深度强化学习算法对上述模型进行训练。
图11示出了上述方法的训练效果。以复现旋转踢动作为例,在运行15000次迭代,大概24h后,模型收敛。图11中横坐标表示训练的迭代次数,即训练次数,纵坐标表示反馈的奖励值,其中,曲线1001为训练数据的每一条数据的平均即时奖励(即,图11中的Train_Avg_Return_0),可达到0.78;曲线1002为测试数据的每一条数据的平均即时奖励(即,图11中的Test_Avg_Return_0),可达到0.82。
图12示出了本申请实施例中已训练的控制策略网络输出效果展示图,图12中在某一时刻的动画画面中,参考虚拟角色1201的姿态与目标虚拟角色1202的姿态基本一致,目标虚拟角色很好的复现了参考动画片段中的参考虚拟角色。
本申请实施例利用控制策略网络得到第二关键帧中目标虚拟角色的目标姿态数据,并通过目标虚拟角色的初始姿态数据和目标姿态数据,得到调整目标虚拟角色的力矩,利用力矩调整目标虚拟角色的初始姿态,得到第一关键帧与第二关键帧之间的固定帧以及第二关键帧,即可以根据第一关键帧和目标任务生成目标虚拟角色的姿态序列,进而得到目标虚拟角色的动画片段,从而缩短了工作人员的工作时间,提升了工作效率。此外,由于目标虚拟角色是利用力矩调整目标虚拟角色的姿态,因此赋予了目标虚拟角色真实的物理属性,并基于此来计算目标虚拟角色的运动得到目标虚拟角色的姿态,因此可以得到更符合实际场景的目标姿态,实现更逼真的动作效果。
以下通过具体实例说明本申请实施例提供的动画实现方法的实现过程。
终端设备中安装有游戏客户端,客户端与服务器进行交互实现游戏角色实现旋风踢的动作,并踢中目标球体。假设在游戏中用户通过控制按键输入旋风踢指令,指示由其控制的游戏角色执行向目标球体踢的动作。
游戏客户端基于已有的动画片段T0,获取动画片段T0包含的A0关键帧中的目标虚拟角色的状态信息,A0关键帧可以是显示界面中正在显示的当前动画帧。将A0关键帧作为上一帧动画,将目标虚拟角色在A0关键帧中的状态信息和旋风踢球的目标任务向服务器发送。其中,旋风踢球的目标任务也可以是一个任务向量,该向量中包括目标球体的位置坐标。
服务器中存储有已训练的控制策略网络。服务器将A0关键帧中的状态信息和旋风踢球的目标任务输入已训练的控制策略网络,得到A1关键帧中目标虚拟角色的目标姿态数据,A1关键帧为A0关键帧的下一关键帧。
服务器将A1关键帧中的目标虚拟角色的目标姿态数据发送回游戏客户端。
游戏客户端获取A0关键帧中目标虚拟角色的初始姿态数据,以及A1关键帧中目标虚拟角色的目标姿态数据。根据初始姿态数据和目标姿态数据,利用公式1计算作用于A0关键帧中目标虚拟角色的N个关节的力矩。
游戏客户端基于物理引擎将得到的力矩作用于A0关键帧中目标虚拟角色的N个关节,调整目标虚拟角色的姿态,得到B0固定帧。固定帧为A0关键帧与A1关键帧之间的动画帧,这里A0关键帧与A1关键帧之间设置有20个固定帧。
游戏客户端获取B0固定帧中目标虚拟角色的B0姿态数据。根据B0姿态数据和目标姿态数据,利用公式1计算作用于B0固定帧中目标虚拟角色的N个关节的力矩。
游戏客户端基于物理引擎将得到的力矩作用于B0固定帧中目标虚拟角色的N个关节,调整目标虚拟角色的姿态,得到B1固定帧。重复上述步骤,直至获取B19固定帧中目标虚拟角色的B19姿态数据。根据B19姿态数据和目标姿态数据,利用公式1计算作用于B19固定帧中目标虚拟角色的N个关节的力矩得到A1关键帧。
重复上述步骤,游戏客户端继续将A1关键帧作为上一帧动画,将目标虚 拟角色在A1关键帧中的状态信息和目标任务向服务器发送,并接收服务器发送的A2关键帧的目标姿态数据。游戏客户端基于物理引擎,得到A1关键帧与A2关键帧之间的固定帧,以及A2关键帧。
以此类推,可以生成多个动画帧,获得目标虚拟角色完成旋风踢球的目标任务的动画片段T1。动画片段T1中包括上述的A0关键帧、B0至B19固定帧、A1关键帧、B20至B29固定帧、A2关键帧以及后续生成的多个动画帧。在该实施例中,控制策略网络是基于参考虚拟角色执行旋风踢球任务的样本动画片段进行训练得到的,因此,控制策略网络可以确定动画片段T1中所包含的动画帧的数量。
下述为本申请装置实施例,对于装置实施例中未详尽描述的细节,可以参考上述一一对应的方法实施例。
请参考图13,其示出了本申请一个实施例提供的动画实现装置的结构方框图。该动画实现装置设置于电子设备中,该装置可以通过硬件或者软硬件的结合实现成为图1中终端设备101的全部或者一部分。该装置包括:动画处理单元1301、姿态获取单元1302、力矩获取单元1303、姿态调整单元1304、和动画生成单元1305。
其中,动画处理单元1301,获得目标虚拟角色的目标动画片段T0,目标动画片段T0中包括第一关键帧,第一关键帧中包括目标虚拟角色的初始姿态数据。
姿态获取单元1302,用于将初始姿态数据以及设定的目标任务输入已训练的控制策略网络中得到目标虚拟角色的目标姿态数据。
力矩获取单元1303,用于根据目标虚拟角色的初始姿态数据和目标姿态数据,得到调整目标虚拟角色的N个关节的力矩;N为大于或者等于1的正整数。
姿态调整单元1304,用于利用N个关节的力矩,将目标虚拟角色由初始姿态调整至目标姿态,得到第二关键帧。
动画生成单元1305,用于获取目标动画片段T1,目标动画片段T1包括第一关键帧以及第二关键帧。
在在一个实施例中,第一关键帧与第二关键帧之间包括M个固定帧;
姿态调整单元1304,用于利用N个关节的力矩,将目标虚拟角色由初始姿态调整至目标姿态,得到第一关键帧与第二关键帧之间的固定帧以及第二关键帧;目标动画片段T1由至少第一关键帧、M个固定帧以及第二关键帧组成。
在在一个实施例中,姿态获取单元1302,具体用于:
获取目标虚拟角色在第一关键帧中的状态信息;
将目标虚拟角色在第一关键帧中的状态信息和目标任务输入控制策略网络,获得控制策略网络输出的目标虚拟角色的目标姿态数据;控制策略网络是根据参考动画片段训练得到的,参考动画片段包含参考虚拟角色完成目标任务的参考姿态序列。
在在一个实施例中,姿态获取单元1302,具体用于:
获取目标虚拟角色在第一关键帧中的状态信息和目标虚拟角色所处的场景环境的环境信息;
将目标虚拟角色在第一关键帧中的状态信息、目标任务和目标虚拟角色所处的场景环境的环境信息输入控制策略网络,获得控制策略网络输出的目标虚拟角色的目标姿态数据;控制策略网络是根据参考动画片段训练得到的,参考动画片段包含参考虚拟角色完成目标任务的参考姿态序列。
在在一个实施例中,状态信息包括目标虚拟角色的当前相位数据、当前的初始姿态数据、当前速度数据和历史姿态序列;其中,当前相位数据用于表征目标虚拟角色在第一关键帧中所处的阶段,当前的初始姿态数据用于表征目标虚拟角色当前的姿态,当前速度数据用于表征目标虚拟角色当前的速度状态,历史姿态序列用于表征目标虚拟角色在历史时间段内的姿态。
在在一个实施例中,装置还包括网络训练单元1306,用于:
将样本动画片段中训练虚拟对象在当前时刻的状态信息和设定的训练任务输入控制策略网络,得到控制策略网络输出的下一时刻的训练虚拟对象的姿态数据;每一时刻对应一关键帧动画;
将训练虚拟对象在当前时刻的状态信息和设定的训练任务输入价值评估网络,得到价值评估网络输出的当前时刻的状态价值;价值评估网络是根据参考动画片段训练得到的;
根据状态价值调整控制策略网络的参数并对调整参数后的控制策略网络继续进行训练,直至达到设定的训练结束条件为止,得到已训练的控制策略网络。
在在一个实施例中,网络训练单元1306,用于:
根据训练虚拟对象和参考动画片段中参考虚拟角色在下一时刻的状态信息及设定的训练任务,确定训练虚拟对象当前时刻的即时奖励值;
根据样本动画片段中每个时刻训练虚拟对象的即时奖励值和状态价值,确定训练虚拟对象的期望奖励值;
根据期望奖励值调整价值评估网络的参数并对调整参数后的价值评估网络继续进行训练,直至达到设定的训练结束条件为止,得到已训练的价值评估网络。
在在一个实施例中,网络训练单元1306,用于:
根据训练虚拟对象在下一时刻的状态信息及设定的训练任务,确定当前时刻的任务目标奖励;
根据训练虚拟对象在下一时刻的状态信息与参考虚拟角色在下一时刻的状态信息,确定当前时刻的模仿目标奖励;
根据任务目标奖励和模仿目标奖励,确定当前时刻的即时奖励值。
在在一个实施例中,模仿目标奖励包括以下至少一项:姿态相似度、速度相似度、末端关节相似度、质心姿态相似度;
姿态相似度用于表征训练虚拟对象与参考虚拟角色的姿态数据的相似度; 速度相似度用于表征训练虚拟对象与参考虚拟角色的速度数据的相似度;末端关节相似度用于表征训练虚拟对象与参考虚拟角色的末端关节的姿态数据的相似度;质心姿态相似度用于表征训练虚拟对象与参考虚拟角色的重心位置的相似度。
在在一个实施例中,网络训练单元1306,用于根据以下至少一项确定样本动画片段结束:
样本动画片段时长到达时长阈值;训练虚拟对象的姿态数据满足摔倒阈值;训练虚拟对象的姿态数据与参考虚拟对象的姿态数据之差大于差异阈值;训练虚拟对象的速度数据大于速度阈值。
在在一个实施例中,网络训练单元1306,用于:
获取训练虚拟对象所处的场景环境的环境信息;
将环境信息、训练虚拟对象在当前时刻的状态信息和训练任务输入控制策略网络,得到控制策略网络输出的下一时刻的训练虚拟对象的姿态。
与上述方法实施例相对应地,本申请实施例还提供了一种电子设备。该电子设备可以是终端设备,如图1中所示的终端设备101,也可以是智能手机、平板电脑,手提电脑或计算机等电子设备,该电子设备至少包括用于存储数据的存储器和用于数据处理的一个或多个处理器。其中,对于用于数据处理的一个或多个处理器而言,在执行处理时,可以采用微一个或多个处理器、CPU、GPU(Graphics Processing Unit,图形处理单元)、DSP或FPGA实现。对于存储器来说,存储器中存储有操作指令,该操作指令可以为计算机可执行代码,通过该操作指令来实现上述本申请实施例的视频筛选方法的流程中的各个步骤。
图14为本申请实施例提供的一种电子设备的结构示意图;如图14所示,本申请实施例中该电子设备140包括:一个或多个处理器141、显示器142、 存储器143、输入设备146、总线145和通讯设备144;该一个或多个处理器141、存储器143、输入设备146、显示器142和通讯设备144均通过总线145连接,该总线145用于该一个或多个处理器141、存储器143、显示器142、通讯设备144和输入设备146之间传输数据。
其中,存储器143可用于存储软件程序以及模块,如本申请实施例中的动画实现方法对应的程序指令/模块,处理器141通过运行存储在存储器143中的软件程序以及模块,从而执行电子设备140的各种功能应用以及数据处理,如本申请实施例提供的动画实现方法。存储器143可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个应用的应用程序等;存储数据区可存储根据电子设备140的使用所创建的数据(比如动画片段、控制策略网络)等。此外,存储器143可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
处理器141是电子设备140的控制中心,利用总线145以及各种接口和线路连接整个电子设备140的各个部分,通过运行或执行存储在存储器143内的软件程序和/或模块,以及调用存储在存储器143内的数据,执行电子设备140的各种功能和处理数据。在一个实施例中,处理器141可包括一个或多个处理单元,如CPU、GPU(Graphics Processing Unit,图形处理单元)、数字处理单元等。
本申请实施例中,处理器141将生成的动画片段通过显示器142展示给用户。
处理器141还可以通过通讯设备144连接网络,如果电子设备是终端设备,则处理器141可以通过通讯设备144与游戏服务器之间传输数据。如果电子设备是游戏服务器,则处理器141可以通过通讯设备144与终端设备之间传输数据。
该输入设备146主要用于获得用户的输入操作,当该电子设备不同时,该输入设备146也可能不同。例如,当该电子设备为计算机时,该输入设备146可以为鼠标、键盘等输入设备;当该电子设备为智能手机、平板电脑等便携设备时,该输入设备146可以为触控屏。
本申请实施例还提供了一种计算机存储介质,该计算机存储介质中存储有计算机可执行指令,该计算机可执行指令用于实现本申请任一实施例的动画实现方法。
在一些可能的实施方式中,本申请提供的动画实现方法的各个方面还可以实现为一种程序产品的形式,其包括程序代码,当程序产品在计算机设备上运行时,程序代码用于使计算机设备执行本说明书上述描述的根据本申请各种示例性实施方式的动画实现方法的步骤,例如,计算机设备可以执行如图3所示的步骤S301至S306中的动画生成流程。
程序产品可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。
可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括——但不限于——电磁信号、光信号或上述的任意合适的组合。可读信号介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。
在本申请所提供的几个实施例中,应该理解到,所揭露的设备和方法, 可以通过其它的方式实现。以上所描述的设备实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,如:多个单元或组件可以结合,或可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的各组成部分相互之间的耦合、或直接耦合、或通信连接可以是通过一些接口,设备或单元的间接耦合或通信连接,可以是电性的、机械的或其它形式的。
上述作为分离部件说明的单元可以是、或也可以不是物理上分开的,作为单元显示的部件可以是、或也可以不是物理单元,即可以位于一个地方,也可以分布到多个网络单元上;可以根据实际的需要选择其中的部分或全部单元来实现本实施例方案的目的。
另外,在本申请各实施例中的各功能单元可以全部集成在一个处理单元中,也可以是各单元分别单独作为一个单元,也可以两个或两个以上单元集成在一个单元中;上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能单元的形式实现。
以上,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。
Claims (14)
- 一种动画实现方法,由电子设备执行,其特征在于,包括:获得第一目标动画片段,所述第一目标动画片段中包括第一关键帧,所述第一关键帧中包括目标虚拟角色的初始姿态数据;将所述初始姿态数据以及设定的目标任务输入已训练的控制策略网络中,得到目标虚拟角色的目标姿态数据;根据所述目标虚拟角色的初始姿态数据和目标姿态数据,调整所述目标虚拟角色的第一预设数量的关节的力矩;利用所述第一预设数量的关节的力矩,将所述目标虚拟角色由初始姿态调整至目标姿态,得到第二关键帧;获取第二目标动画片段,所述第二目标动画片段包括第一关键帧以及所述第二关键帧。
- 根据权利要求1所述的方法,其特征在于,所述第一关键帧与所述第二关键帧之间包括第二预设数量的固定帧;所述第二目标动画片段,包括第一关键帧、所述第二预设数量的固定帧以及所述第二关键帧;所述利用所述第一预设数量的关节的力矩,将所述目标虚拟角色由初始姿态调整至目标姿态,得到第二关键帧,包括:利用所述第一预设数量的关节的力矩,将所述目标虚拟角色由初始姿态调整至目标姿态,得到第二关键帧、以及所述第一关键帧与所述第二关键帧之间的固定帧。
- 根据权利要求1所述的方法,其特征在于,所述将所述初始姿态数据以及设定的目标任务输入已训练的控制策略网络中,得到目标虚拟角色的目标姿态数据,包括:获取所述目标虚拟角色在所述第一关键帧中的状态信息;所述状态信息中包括所述初始姿态数据;将所述目标虚拟角色在所述第一关键帧中的状态信息和所述目标任务输入控制策略网络,获得所述控制策略网络输出的所述目标虚拟角色的目标姿态数据;所述控制策略网络是根据参考动画片段训练得到的,所述参考动画片段包含参考虚拟角色完成所述目标任务的参考姿态序列。
- 根据权利要求1所述的方法,其特征在于,所述将所述初始姿态数据以及设定的目标任务输入已训练的控制策略网络中,得到目标虚拟角色的目标姿态数据,包括:获取所述目标虚拟角色在所述第一关键帧中的状态信息和所述目标虚拟角色所处的场景环境的环境信息;所述状态信息中包括所述初始姿态数据;将所述目标虚拟角色在所述第一关键帧中的状态信息、所述目标任务和所述目标虚拟角色所处的场景环境的环境信息输入控制策略网络,获得所述控制策略网络输出的所述目标虚拟角色的目标姿态数据。
- 根据权利要求3或4所述的方法,其特征在于,所述状态信息包括目标虚拟角色的当前相位数据、当前的所述初始姿态数据、当前速度数据和历史姿态序列;其中,所述当前相位数据用于表征所述目标虚拟角色在所述第一关键帧中所处的阶段,所述当前的所述初始姿态数据用于表征所述目标虚拟角色当前的姿态,所述当前速度数据用于表征所述目标虚拟角色当前的速度状态,所述历史姿态序列用于表征所述目标虚拟角色在历史时间段内的姿态。
- 根据权利要求3或4所述的方法,其特征在于,所述控制策略网络的训练步骤,包括:将样本动画片段中训练虚拟对象在当前时刻的状态信息和设定的训练任务输入待训练的控制策略网络,得到所述控制策略网络输出的下一时刻的所述训练虚拟对象的姿态数据;每一时刻对应一关键帧动画;将训练虚拟对象在当前时刻的状态信息和设定的训练任务输入价值评估网络,得到价值评估网络输出的当前时刻的状态价值;所述价值评估网络是 根据所述参考动画片段训练得到的;根据所述状态价值、以及所述下一时刻的所述训练虚拟对象的姿态数据,调整所述控制策略网络的参数并对调整参数后的控制策略网络继续进行训练,直至达到设定的训练结束条件为止,得到已训练的控制策略网络。
- 根据权利要求6所述的方法,其特征在于,所述价值评估网络的训练步骤,包括:根据所述训练虚拟对象和参考动画片段中参考虚拟角色在下一时刻的状态信息及设定的训练任务,确定所述训练虚拟对象当前时刻的即时奖励值;根据样本动画片段中每个时刻所述训练虚拟对象的即时奖励值和状态价值,确定所述训练虚拟对象的期望奖励值;根据所述期望奖励值调整所述价值评估网络的参数并对调整参数后的价值评估网络继续进行训练,直至达到设定的训练结束条件为止,得到已训练的价值评估网络。
- 根据权利要求7所述的方法,其特征在于,所述根据所述训练虚拟对象和参考动画片段中参考虚拟角色在下一时刻的状态信息及设定的训练任务,确定所述训练虚拟对象当前时刻的即时奖励值,包括:根据所述训练虚拟对象在下一时刻的状态信息及设定的训练任务,确定当前时刻的任务目标奖励;根据所述训练虚拟对象在下一时刻的状态信息与所述参考虚拟角色在下一时刻的状态信息,确定当前时刻的模仿目标奖励;根据所述任务目标奖励和所述模仿目标奖励,确定当前时刻的即时奖励值。
- 根据权利要求8所述的方法,其特征在于,所述模仿目标奖励包括以下至少一项:姿态相似度、速度相似度、末端关节相似度、以及质心姿态相似度;其中,所述姿态相似度用于表征所述训练虚拟对象与所述参考虚拟角色 的姿态数据的相似度;所述速度相似度用于表征所述训练虚拟对象与所述参考虚拟角色的速度数据的相似度;所述末端关节相似度用于表征所述训练虚拟对象与所述参考虚拟角色的末端关节的姿态数据的相似度;所述质心姿态相似度用于表征所述训练虚拟对象与所述参考虚拟角色的重心位置的相似度。
- 根据权利要求7所述的方法,其特征在于,根据以下至少一项确定所述样本动画片段结束:所述样本动画片段时长到达时长阈值;所述训练虚拟对象的姿态数据满足摔倒阈值;所述训练虚拟对象的姿态数据与所述参考虚拟对象的姿态数据之差大于差异阈值;所述训练虚拟对象的速度数据大于速度阈值。
- 根据权利要求7所述的方法,其特征在于,所述将样本动画片段中训练虚拟对象在当前时刻的状态信息和设定的训练任务输入待训练的控制策略网络,得到所述控制策略网络输出的下一时刻的所述训练虚拟对象的姿态数据,包括:获取所述训练虚拟对象所处的场景环境的环境信息;将所述环境信息、所述训练虚拟对象在当前时刻的状态信息和所述训练任务输入待训练的所述控制策略网络,得到控制策略网络输出的下一时刻的所述训练虚拟对象的姿态数据。
- 一种动画实现装置,设置于电子设备中,其特征在于,所述装置包括:动画处理单元,用于获得目标虚拟角色的第一目标动画片段,所述第一目标动画片段中包括第一关键帧,所述第一关键帧中包括目标虚拟角色的初始姿态数据;姿态获取单元,用于将所述初始姿态数据以及设定的目标任务输入已训练的控制策略网络中得到目标虚拟角色的目标姿态数据;力矩获取单元,用于根据所述目标虚拟角色的初始姿态数据和目标姿态数据,得到调整所述目标虚拟角色的第一预设数量的关节的力矩;姿态调整单元,用于利用所述第一预设数量的关节的力矩,将所述目标虚拟角色由初始姿态调整至目标姿态,得到第二关键帧;动画生成单元,用于获取第二目标动画片段,所述第二目标动画片段包括至少所述第一关键帧以及所述第二关键帧。
- 一个或多个计算机可读存储介质,所述计算机可读存储介质内存储有计算机可读指令,其特征在于:所述计算机可读指令被一个或多个处理器执行时,实现权利要求1~11任一项所述的方法。
- 一种电子设备,其特征在于,包括存储器和一个或多个处理器,所述存储器上存储有可在所述一个或多个处理器上运行的计算机可读指令,当所述计算机可读指令被所述一个或多个处理器执行时,使得所述一个或多个处理器实现权利要求1~11任一项所述的方法。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP20914239.7A EP4006843A4 (en) | 2020-01-19 | 2020-10-26 | ANIMATION IMPLEMENTATION METHOD AND DEVICE, ELECTRONIC DEVICE AND STORAGE MEDIA |
| US17/686,947 US11928765B2 (en) | 2020-01-19 | 2022-03-04 | Animation implementation method and apparatus, electronic device, and storage medium |
| US18/417,940 US20240153187A1 (en) | 2020-01-19 | 2024-01-19 | Virtual character posture adjustment |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202010059845.3A CN111260762B (zh) | 2020-01-19 | 2020-01-19 | 一种动画实现方法、装置、电子设备和存储介质 |
| CN202010059845.3 | 2020-01-19 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/686,947 Continuation US11928765B2 (en) | 2020-01-19 | 2022-03-04 | Animation implementation method and apparatus, electronic device, and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021143261A1 true WO2021143261A1 (zh) | 2021-07-22 |
Family
ID=70949306
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2020/123677 WO2021143261A1 (zh) | 2020-01-19 | 2020-10-26 | 一种动画实现方法、装置、电子设备和存储介质 |
Country Status (4)
| Country | Link |
|---|---|
| US (2) | US11928765B2 (zh) |
| EP (1) | EP4006843A4 (zh) |
| CN (1) | CN111260762B (zh) |
| WO (1) | WO2021143261A1 (zh) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114917586A (zh) * | 2022-06-01 | 2022-08-19 | 北京字跳网络技术有限公司 | 模型的训练方法、对象的控制方法、装置、介质及设备 |
| CN116957917A (zh) * | 2023-06-19 | 2023-10-27 | 广州极点三维信息科技有限公司 | 一种基于近端策略优化的图像美化方法及装置 |
| CN117666788A (zh) * | 2023-12-01 | 2024-03-08 | 世优(北京)科技有限公司 | 一种基于穿戴式交互设备的动作识别方法及系统 |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN111260762B (zh) | 2020-01-19 | 2023-03-28 | 腾讯科技(深圳)有限公司 | 一种动画实现方法、装置、电子设备和存储介质 |
| CN111696184B (zh) * | 2020-06-10 | 2023-08-29 | 上海米哈游天命科技有限公司 | 骨骼蒙皮融合确定方法、装置、设备和存储介质 |
| CN111773686A (zh) * | 2020-06-30 | 2020-10-16 | 完美世界(北京)软件科技发展有限公司 | 动画的生成方法和装置、存储介质、电子装置 |
| CN112258608B (zh) * | 2020-10-22 | 2021-08-06 | 北京中科深智科技有限公司 | 一种基于数据驱动的动画自动生成方法及系统 |
| CN112454390B (zh) * | 2020-11-27 | 2022-05-17 | 中国科学技术大学 | 基于深度强化学习的仿人机器人面部表情模仿方法 |
| CN112926629B (zh) * | 2021-01-29 | 2024-04-02 | 北京字节跳动网络技术有限公司 | 超参数确定方法、装置、深度强化学习框架、介质及设备 |
| CN115222854A (zh) * | 2021-04-15 | 2022-10-21 | 北京字跳网络技术有限公司 | 虚拟形象的碰撞处理方法、装置、电子设备和存储介质 |
| CN113599807A (zh) * | 2021-08-03 | 2021-11-05 | 上海米哈游璃月科技有限公司 | 一种显示方法、装置、存储介质及电子设备 |
| CN114998491B (zh) * | 2022-08-01 | 2022-11-18 | 阿里巴巴(中国)有限公司 | 数字人驱动方法、装置、设备及存储介质 |
| CN115713582B (zh) * | 2022-12-02 | 2023-10-27 | 北京百度网讯科技有限公司 | 虚拟形象生成方法、装置、电子设备和介质 |
| CN115861500B (zh) * | 2022-12-09 | 2023-08-18 | 上海哔哩哔哩科技有限公司 | 2d模型碰撞体生成方法及装置 |
| CN115797606B (zh) * | 2023-02-07 | 2023-04-21 | 合肥孪生宇宙科技有限公司 | 基于深度学习的3d虚拟数字人交互动作生成方法及系统 |
| CN116071473B (zh) * | 2023-03-03 | 2023-06-13 | 成都信息工程大学 | 一种动画运动关键帧的获取方法及系统 |
| CN116030168B (zh) * | 2023-03-29 | 2023-06-09 | 腾讯科技(深圳)有限公司 | 中间帧的生成方法、装置、设备及存储介质 |
| CN117078813B (zh) * | 2023-10-18 | 2023-12-15 | 北京华航唯实机器人科技股份有限公司 | 三维仿真场景中模型数据和动画数据的输出方法及装置 |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101883287A (zh) * | 2010-07-14 | 2010-11-10 | 清华大学深圳研究生院 | 一种多视点视频编码边信息融合的方法 |
| CN102855470A (zh) * | 2012-07-31 | 2013-01-02 | 中国科学院自动化研究所 | 基于深度图像的人体姿态估计方法 |
| CN106600668A (zh) * | 2016-12-12 | 2017-04-26 | 中国科学院自动化研究所 | 一种与虚拟角色进行互动的动画生成方法、装置及电子设备 |
| CN108022286A (zh) * | 2017-11-30 | 2018-05-11 | 腾讯科技(深圳)有限公司 | 画面渲染方法、装置及存储介质 |
| CN108182719A (zh) * | 2017-12-28 | 2018-06-19 | 北京聚力维度科技有限公司 | 人工智能自适应障碍地形的行进动画生成方法和装置 |
| CN109471712A (zh) * | 2018-11-21 | 2019-03-15 | 腾讯科技(深圳)有限公司 | 虚拟环境中的虚拟对象的调度方法、装置及设备 |
| CN110516389A (zh) * | 2019-08-29 | 2019-11-29 | 腾讯科技(深圳)有限公司 | 行为控制策略的学习方法、装置、设备及存储介质 |
| CN111260762A (zh) * | 2020-01-19 | 2020-06-09 | 腾讯科技(深圳)有限公司 | 一种动画实现方法、装置、电子设备和存储介质 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10535174B1 (en) * | 2017-09-14 | 2020-01-14 | Electronic Arts Inc. | Particle-based inverse kinematic rendering system |
| CN109345614B (zh) * | 2018-09-20 | 2023-04-07 | 山东师范大学 | 基于深度强化学习的ar增强现实大屏互动的动画仿真方法 |
| US11132606B2 (en) * | 2019-03-15 | 2021-09-28 | Sony Interactive Entertainment Inc. | Reinforcement learning to train a character using disparate target animation data |
| CN110310350B (zh) * | 2019-06-24 | 2021-06-11 | 清华大学 | 基于动画的动作预测生成方法和装置 |
-
2020
- 2020-01-19 CN CN202010059845.3A patent/CN111260762B/zh active Active
- 2020-10-26 EP EP20914239.7A patent/EP4006843A4/en active Pending
- 2020-10-26 WO PCT/CN2020/123677 patent/WO2021143261A1/zh unknown
-
2022
- 2022-03-04 US US17/686,947 patent/US11928765B2/en active Active
-
2024
- 2024-01-19 US US18/417,940 patent/US20240153187A1/en active Pending
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101883287A (zh) * | 2010-07-14 | 2010-11-10 | 清华大学深圳研究生院 | 一种多视点视频编码边信息融合的方法 |
| CN102855470A (zh) * | 2012-07-31 | 2013-01-02 | 中国科学院自动化研究所 | 基于深度图像的人体姿态估计方法 |
| CN106600668A (zh) * | 2016-12-12 | 2017-04-26 | 中国科学院自动化研究所 | 一种与虚拟角色进行互动的动画生成方法、装置及电子设备 |
| CN108022286A (zh) * | 2017-11-30 | 2018-05-11 | 腾讯科技(深圳)有限公司 | 画面渲染方法、装置及存储介质 |
| CN108182719A (zh) * | 2017-12-28 | 2018-06-19 | 北京聚力维度科技有限公司 | 人工智能自适应障碍地形的行进动画生成方法和装置 |
| CN109471712A (zh) * | 2018-11-21 | 2019-03-15 | 腾讯科技(深圳)有限公司 | 虚拟环境中的虚拟对象的调度方法、装置及设备 |
| CN110516389A (zh) * | 2019-08-29 | 2019-11-29 | 腾讯科技(深圳)有限公司 | 行为控制策略的学习方法、装置、设备及存储介质 |
| CN111260762A (zh) * | 2020-01-19 | 2020-06-09 | 腾讯科技(深圳)有限公司 | 一种动画实现方法、装置、电子设备和存储介质 |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP4006843A4 |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114917586A (zh) * | 2022-06-01 | 2022-08-19 | 北京字跳网络技术有限公司 | 模型的训练方法、对象的控制方法、装置、介质及设备 |
| CN116957917A (zh) * | 2023-06-19 | 2023-10-27 | 广州极点三维信息科技有限公司 | 一种基于近端策略优化的图像美化方法及装置 |
| CN116957917B (zh) * | 2023-06-19 | 2024-03-15 | 广州极点三维信息科技有限公司 | 一种基于近端策略优化的图像美化方法及装置 |
| CN117666788A (zh) * | 2023-12-01 | 2024-03-08 | 世优(北京)科技有限公司 | 一种基于穿戴式交互设备的动作识别方法及系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN111260762A (zh) | 2020-06-09 |
| CN111260762B (zh) | 2023-03-28 |
| EP4006843A4 (en) | 2023-03-29 |
| EP4006843A1 (en) | 2022-06-01 |
| US11928765B2 (en) | 2024-03-12 |
| US20240153187A1 (en) | 2024-05-09 |
| US20220198732A1 (en) | 2022-06-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2021143261A1 (zh) | 一种动画实现方法、装置、电子设备和存储介质 | |
| WO2021143289A1 (zh) | 动画处理方法、装置、计算机存储介质及电子设备 | |
| US11113860B2 (en) | Particle-based inverse kinematic rendering system | |
| CN111223170B (zh) | 动画生成方法、装置、电子设备和存储介质 | |
| CN111028317B (zh) | 虚拟对象的动画生成方法、装置、设备及存储介质 | |
| Ishigaki et al. | Performance-based control interface for character animation | |
| US11514638B2 (en) | 3D asset generation from 2D images | |
| US11217001B2 (en) | Systems and methods for supervised and unsupervised animation style transfer | |
| US10885691B1 (en) | Multiple character motion capture | |
| TW202244852A (zh) | 用於擷取臉部表情且產生網格資料之人工智慧 | |
| US20230267668A1 (en) | Joint twist generation for animation | |
| Lin et al. | Temporal IK: Data-Driven Pose Estimation for Virtual Reality | |
| Lan | Simulation of Animation Character High Precision Design Model Based on 3D Image | |
| US20240135618A1 (en) | Generating artificial agents for realistic motion simulation using broadcast videos | |
| TWI814318B (zh) | 用於使用模擬角色訓練模型以用於將遊戲角色之臉部表情製成動畫之方法以及用於使用三維(3d)影像擷取來產生遊戲角色之臉部表情之標籤值之方法 | |
| Li et al. | Real-time Physics-based Interaction in Augmented Reality | |
| KR102531789B1 (ko) | 클라우드 기반 메타버스 콘텐츠 협업 시스템 | |
| Rajendran | Understanding the Desired Approach for Animating Procedurally | |
| Liang et al. | A motion-based user interface for the control of virtual humans performing sports | |
| Ismail et al. | Editing Virtual Human Motion Techniques With Dynamic Motion Simulator And Controller | |
| Singh et al. | Development of Virtual Reality Training module for Maithari of Martial Art Kalari | |
| Macedo | Paralympic VR Game | |
| Pelechano et al. | A Framework for Rendering, Simulation and Animation of Crowds. | |
| CN116468827A (zh) | 数据处理方法及相关产品 | |
| Oore | DIGITAL MARIONETTE: augmenting kinematics with physics for multi-track desktop performance animation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20914239 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2020914239 Country of ref document: EP Effective date: 20220224 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |