WO2021064767A1 - 制御装置、方法及びシステム - Google Patents
制御装置、方法及びシステム Download PDFInfo
- Publication number
- WO2021064767A1 WO2021064767A1 PCT/JP2019/038455 JP2019038455W WO2021064767A1 WO 2021064767 A1 WO2021064767 A1 WO 2021064767A1 JP 2019038455 W JP2019038455 W JP 2019038455W WO 2021064767 A1 WO2021064767 A1 WO 2021064767A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- learning
- network
- information
- congestion level
- learner
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images


















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/20—Ensemble learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/092—Reinforcement learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/285—Selection of pattern recognition techniques, e.g. of classifiers in a multi-classifier system
Definitions
- the present invention relates to control devices, methods and systems.
- Moving image data is distributed from a server on a network, the moving image data is played back on a terminal, and a robot or the like installed in a factory or the like is remotely controlled from the server.
- Patent Document 1 describes that a learning control system is provided with a technique capable of improving learning efficiency and optimizing the entire system even under incomplete information.
- Patent Document 2 describes that when a reward and a teacher signal are given from the environment, a learning device capable of improving learning efficiency is provided by effectively using both of them.
- machine learning In recent years, due to the usefulness of machine learning, the application of machine learning to various fields has been studied. For example, it is being considered to apply machine learning to games such as chess and control of robots and the like.
- maximization of the score in the game is set as a reward, and the performance of machine learning is evaluated.
- the realization of the target motion is set as a reward, and the performance of machine learning is evaluated.
- learning performance is discussed by the sum of immediate reward and episode-based reward.
- the state can be determined relatively easily.
- the squares on the board are set to the state, and in the control of the robot, the discretized positions (angles) of the arms and the like are set to the state.
- a main object of the present invention is to provide a control device, a method and a system that contribute to realizing efficient network control using machine learning.
- each is based on the learning information of a plurality of learning devices that learn actions for controlling a network and a mature first learning device among the plurality of learning devices. Further, a control device including a learning device management unit for setting learning information of a second learning device that is not mature among the plurality of learning devices is provided.
- each of the plurality of learners is based on the step of learning the behavior for controlling the network and the learning information of the mature first learner among the plurality of learners.
- a method including a step of setting learning information of a second learning device that is not mature among the plurality of learning devices is provided.
- the control device includes a terminal, a server that communicates with the terminal, and a control device that controls the terminal and a network including the server, and each of the control devices includes the network. Based on the learning information of the plurality of learners that learn the behavior for controlling the above and the first learner that is mature among the plurality of learners, the second of the plurality of learners that is not mature.
- a system is provided that includes a learning device management unit that sets learning information for the learning device.
- control devices, methods and systems that contribute to realizing efficient network control using machine learning are provided.
- other effects may be produced in place of or in combination with the effect.
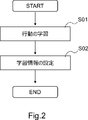
- the control device 100 includes a plurality of learners 101 and a learner management unit 102 (see FIG. 1). Each of the plurality of learners 101 learns an action for controlling the network (step S01 in FIG. 2).
- the learning device management unit 102 uses the learning information of the first learning device 101, which is mature among the plurality of learning devices 101, to obtain the learning information of the second learning device 101, which is not mature among the plurality of learning devices 101.
- Set step S02 in FIG. 2.
- the control device 100 learns the behavior of controlling the state of the network by using the plurality of learners 101.
- the learning progress in each learning device 101 is biased, and the number of immature learning devices 101 (learning devices 101 in which learning is not sufficiently advanced) increases. Therefore, the control device 100 sets the learning information of the mature learning device 101 in the learning information (for example, Q table, weight) of the immature learning device 101, and promotes the learning of the immature learning device 101.
- the mature learner 101 can be obtained at an early stage, and efficient network control using machine learning can be realized.
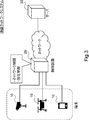
- FIG. 3 is a diagram showing an example of a schematic configuration of the communication network system according to the first embodiment.
- the communication network system includes a terminal 10, a control device 20, and a server 30.
- the terminal 10 is a device having a communication function.
- Examples of the terminal 10 include a WEB camera, a surveillance camera, a drone, a smartphone, a robot, and the like.
- the purpose is not to limit the terminal 10 to the above-mentioned WEB camera or the like.
- the terminal 10 can be any device having a communication function.
- the terminal 10 communicates with the server 30 via the control device 20.
- Various applications and services are provided by the terminal 10 and the server 30.
- the server 30 analyzes the image data from the WEB camera and manages the materials of the factory or the like.
- the terminal 10 is a drone
- a control command is transmitted from the server 30 to the drone, and the drone transports luggage and the like.
- the terminal 10 is a smartphone
- the video is distributed from the server 30 to the smartphone, and the user watches the video using the smartphone.
- the control device 20 is, for example, a communication device such as a proxy server or a gateway, and is a device that controls a network including a terminal 10 and a server 30.
- the control device 20 controls the network by changing the values of the TCP (Transmission Control Protocol) parameter group and the buffer control parameter group.
- TCP Transmission Control Protocol
- buffer control For example, as a control of TCP parameters, changing the flow window size is exemplified.
- buffer control include changing parameters related to the minimum guaranteed bandwidth, RED (Random Early Detection) loss rate, loss start queue length, and buffer length in queue management of a plurality of buffers.
- control parameters parameters that affect communication (traffic) between the terminal 10 and the server 30, such as the above TCP parameters and parameters related to buffer control, are referred to as "control parameters”.
- the control device 20 controls the network by changing the control parameters.
- the network control by the control device 20 may be performed at the time of packet transfer of the own device (control device 20), or may be performed by instructing the terminal 10 or the server 30 to change the control parameters.
- control device 20 controls the network by changing the flow window size of the TCP session formed with the terminal 10.
- the control device 20 may control the network by changing the size of a buffer for storing packets received from the server 30 or changing the cycle of reading packets from the buffer.
- the control device 20 uses "machine learning” to control the network. More specifically, the control device 20 controls the network based on the learning model obtained by reinforcement learning.
- control device 20 may control the network based on learning information (Q table) obtained as a result of reinforcement learning called Q-learning.
- the "agent” is trained so as to maximize the “value” in the given "environment”.
- the network including the terminal 10 and the server 30 is the "environment”
- the control device 20 is trained so as to optimize the state of the network.
- the state s indicates what kind of state the environment (network) is in.
- traffic for example, throughput, average packet arrival interval, etc.
- Action a indicates an action that the agent (control device 20) can take with respect to the environment (network). For example, in the case of a communication network system, changing the setting of the TCP parameter group, turning on / off the function, and the like are exemplified as the action a.
- the reward r indicates how much evaluation can be obtained as a result of the agent (control device 20) executing the action a in a certain state s.
- the control device 20 is defined as a positive reward if the throughput increases as a result of changing a part of the TCP parameter group, and a negative reward if the throughput decreases.
- Q-learning learning proceeds so as to maximize the value in the future, instead of maximizing the reward (immediate reward) obtained at the present time (Q-table is constructed).
- the learning of the agent in Q learning is performed so as to maximize the value (Q value, state action value) when the action a in a certain state s is adopted.
- the Q value (state action value) is expressed as Q (s, a).
- Q-learning it is premised that the action of the agent to transition to a high-value state by the action has the same value as the transition destination. Based on such a premise, the Q value at the present time t can be expressed by the Q value at the next time point t + 1 (see equation (1)).
- Es t + 1 is the expected value relating to the state S t + 1
- Ea t + 1 denotes the expected value behavioral a t + 1.
- ⁇ is the discount rate.
- the Q value is updated according to the result of adopting the action a in a certain state s. Specifically, the Q value is updated according to the following equation (2).
- ⁇ is a parameter called the learning rate and controls the update of the Q value.
- "max" in the equation (2) is a function that outputs the maximum value of the possible actions a in the state St + 1.
- a method for the agent (control device 20) to select the action a a method called ⁇ -greedy can be adopted.
- an action is randomly selected with a probability of ⁇ , and the most valuable action is selected with a probability of 1- ⁇ .
- a Q-table as shown in FIG. 4 is generated.
- the control device 20 may control the network based on a learning model obtained as a result of reinforcement learning using deep learning called DQN (Deep Q Network).
- DQN Deep Q Network
- the action value function is expressed by the Q table, but in DQN, the action value function is expressed by deep learning.
- the optimal action value function is calculated by an approximate function using a neural network.
- the optimal action value function is a function that outputs the value of performing a certain action a in a certain state s.
- the neural network includes an input layer, an intermediate layer (hidden layer), and an output layer.
- the input layer inputs the state s. There is a corresponding weight in the link of each node in the middle layer.
- the output layer outputs the value of action a.
- the nodes of the input layer correspond to the network states S1 to S3.
- the state of the network input to the input layer is weighted by the intermediate layer and output to the output layer.
- the nodes of the output layer correspond to the actions A1 to A3 that the control device 20 can take.
- Node of the output layer outputs value of action value function Q (s t, a t) corresponding to each of the actions A1 ⁇ A3.
- connection parameters weights between the nodes that output the above action value function are learned.
- the error function shown in the following equation (3) is set and learning is performed by backpropagation.
- the operation mode of the control device 20 includes two operation modes.
- the first operation mode is a learning mode for calculating a learning model.
- a Q table as shown in FIG. 4 is calculated.
- the control device 20 executes reinforcement learning by "DQN”
- the weight as shown in FIG. 6 is calculated.
- the second operation mode is a control mode in which the network is controlled using the learning model calculated in the learning mode. Specifically, the control device 20 in the control mode calculates the current network state s and selects the most valuable action a among the actions a that can be taken in the case of the state s. The control device 20 executes an operation (network control) corresponding to the selected action a.
- the control device 20 calculates a learning model for each network congestion state. For example, when the congestion state of the network is divided into three stages, three learning models corresponding to each congestion state are calculated. In the following description, the network congestion state will be referred to as "congestion level".
- the control device 20 calculates a learning model (learning information such as a Q table and weights) corresponding to each congestion level in the learning mode.
- the control device 20 selects a learning model corresponding to the current congestion level from a plurality of learning models (learning models for each congestion level) and controls the network.
- FIG. 7 is a diagram showing an example of a processing configuration (processing module) of the control device 20 according to the first embodiment.
- the control device 20 includes a packet transfer unit 201, a feature amount calculation unit 202, a congestion level calculation unit 203, a network control unit 204, a reinforcement learning execution unit 205, and a storage unit 206. Consists of including.
- the packet transfer unit 201 is a means for receiving a packet transmitted from the terminal 10 or the server 30 and transferring the received packet to the opposite device.
- the packet transfer unit 201 performs packet transfer according to the control parameters notified from the network control unit 204.
- the packet transfer unit 201 performs packet transfer with the notified flow window size.
- the packet transfer unit 201 delivers a copy of the received packet to the feature amount calculation unit 202.
- the feature amount calculation unit 202 is a means for calculating the feature amount that characterizes the communication traffic between the terminal 10 and the server 30.
- the feature amount calculation unit 202 extracts a traffic flow that is a target of network control from the acquired packet.
- the traffic flow that is the target of network control is a group consisting of packets having the same source IP (Internet Protocol) address, destination IP address, port number, and the like.
- the feature amount calculation unit 202 calculates the feature amount from the extracted traffic flow. For example, the feature amount calculation unit 202 calculates throughput, average packet arrival interval, packet loss rate, jitter, and the like as feature amounts. The feature amount calculation unit 202 stores the calculated feature amount in the storage unit 206 together with the calculation time. Since existing techniques can be used for calculation of throughput and the like and are obvious to those skilled in the art, detailed description thereof will be omitted.
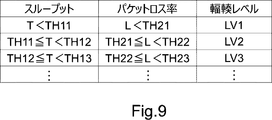
- the congestion level calculation unit 203 calculates the congestion level indicating the degree of network congestion based on the feature amount calculated by the feature amount calculation unit 202. For example, the congestion level calculation unit 203 may calculate the congestion level according to the range including the feature amount (for example, throughput). For example, the congestion level calculation unit 203 may calculate the congestion level based on the table information as shown in FIG.
- the congestion level is calculated as “2”.
- the congestion level calculation unit 203 may calculate the congestion level based on a plurality of features. For example, the congestion level calculation unit 203 may calculate the congestion level using the throughput and the packet loss rate. In this case, the congestion level calculation unit 203 calculates the congestion level based on the table information as shown in FIG. For example, in the example of FIG. 9, when the throughput T is included in the range of “TH11 ⁇ T ⁇ TH12” and the packet loss rate is included in the range of “TH21 ⁇ L ⁇ TH22”, the congestion level is “. 2 ”is calculated.
- the congestion level calculation unit 203 delivers the calculated congestion level to the network control unit 204 and the reinforcement learning execution unit 205.
- the network control unit 204 is a means for controlling the network based on the behavior obtained from the learning model generated by the reinforcement learning execution unit 205.
- the network control unit 204 determines the control parameters to be notified to the packet transfer unit 201 based on the learning model obtained as a result of reinforcement learning. At that time, the network control unit 204 selects one learning model from the plurality of learning models, and controls the network based on the behavior obtained from the selected learning model.
- the network control unit 204 is a module that mainly operates in the control mode.
- the network control unit 204 selects a learning model (Q table, weight) according to the congestion level notified from the congestion level calculation unit 203. Next, the network control unit 204 reads the latest (current time) feature amount from the storage unit 206.
- a learning model Q table, weight
- the network control unit 204 estimates (calculates) the state of the network to be controlled from the read feature amount. For example, the network control unit 204 refers to a table (see FIG. 10) in which the feature amount F and the network state are associated with each other, and calculates the network state corresponding to the current feature amount F.
- the network state can be regarded as the "traffic state". That is, in the disclosure of the present application, the "traffic state” and the “network state” can be interchanged with each other.
- FIG. 10 shows a case where the network state is calculated from the feature amount F regardless of the congestion level
- the feature amount and the network state may be associated with each congestion level.
- the network control unit 204 refers to the Q-table selected according to the congestion level, and the value Q of each action corresponding to the current network state. Get the highest behavior. For example, in the example of FIG. 4, the calculated traffic state is "state S1", and the value Q (S1, A3) of the values Q (S1, A1), Q (S1, A2), and Q (S1, A3). If A1) is the maximum, the action A1 is read out.
- the network control unit 204 applies the weight selected according to the congestion level to the neural network as shown in FIG.
- the network control unit 204 inputs the current network state into the neural network and acquires the most valuable action among the possible actions.
- the network control unit 204 determines the control parameters according to the acquired action, and sets (notifies) the packet transfer unit 201.
- a table (see FIG. 11) in which actions and control contents are associated is stored in the storage unit 206, and the network control unit 204 determines a control parameter to be set in the packet transfer unit 201 with reference to the table. ..
- the network control unit 204 sends the control parameter corresponding to the change content to the packet transfer unit 201. Notice.
- the reinforcement learning execution unit 205 is a means for learning actions (control parameters) for controlling the network.
- the reinforcement learning execution unit 205 executes the Q-learning and the reinforcement learning by DQN described above to generate a learning model.
- the reinforcement learning execution unit 205 is a module that mainly operates in the learning mode.
- the reinforcement learning execution unit 205 calculates the network state s at the current time t from the feature amount stored in the storage unit 206.
- the reinforcement learning execution unit 205 selects the action a from the possible actions a in the calculated state s by a method such as the above-mentioned ⁇ -greedy method.
- the reinforcement learning execution unit 205 notifies the packet transfer unit 201 of the control content (updated value of the control parameter) corresponding to the selected action.
- the reinforcement learning execution unit 205 determines the reward according to the change of the network according to the above behavior.
- the reinforcement learning execution unit 205 sets a positive value in the reward rt + 1 described in the equations (2) and (3) when the throughput increases as a result of taking the action a.
- the reinforcement learning execution unit 205 sets a negative value in the reward rt + 1 described in the equations (2) and (3) when the throughput decreases as a result of taking the action a.
- the reinforcement learning execution unit 205 generates a learning model for each congestion level.
- FIG. 12 is a diagram showing an example of the internal configuration of the reinforcement learning execution unit 205.
- the reinforcement learning execution unit 205 includes a learning device management unit 211 and a plurality of learning devices 212-1 to 212-N (N is a positive integer, the same applies hereinafter).
- the learning device management unit 211 is a means for managing the operation of the learning device 212.
- Each of the plurality of learners 212 learns actions for controlling the network.
- the learner 212 is prepared for each congestion level. In FIG. 12, the corresponding congestion levels are shown in parentheses.
- the learning device 212 calculates a learning model (Q table, weight applied to the neural network) for each congestion level and stores it in the storage unit 206.
- each learner 212 prepared for each congestion level are the same. That is, the number of elements (state s, number of actions a) of the Q table generated for each congestion level is the same. Also, the structure of the array that stores the weights generated for each congestion level is the same.
- the configuration of the array that manages the weight applied to the level 1 learner 212-1 and the configuration of the array that manages the weight applied to the level 2 learner 212-2 can be the same.
- the learner management unit 211 selects the learner 212 corresponding to the congestion level notified from the congestion level calculation unit 203.
- the learning device management unit 211 instructs the selected learning device 212 to start learning.
- the learning device 212 that receives the instruction executes the Q-learning and the reinforcement learning by DQN described above.
- the learning device 212 notifies the learning device management unit 211 of an index (hereinafter, referred to as a learning degree) indicating the progress of learning. For example, the learning device 212 notifies the learning device management unit 211 of the number of times the Q table is updated and the number of times the weight is updated as the learning degree.
- a learning degree an index
- the learning device management unit 211 determines whether the learning by each learning device 212 is sufficiently advanced (from a predetermined number of events that the learning device can make an appropriate judgment). It is determined whether the learning pattern is being learned) or whether the learning by each learning device 212 is insufficient.
- a situation in which the learning device 212 is sufficiently advanced and mature learning information (Q table, weight) is obtained is described as "the learning device is mature”. Further, a situation in which the learning device 212 is insufficiently learned and mature learning information is not obtained (a situation in which immature learning information is obtained) is described as "the learning device is immature”.
- the learner management unit 211 executes a threshold value process (for example, a process of determining whether the acquired value is equal to or less than the threshold value) for the learning degree acquired from the learner device 212, and as a result.
- the learning state of the learning device 212 (the learning device 212 is mature or immature) is determined according to the above. For example, the learning device management unit 211 determines that the learning device 212 is mature if the learning degree is equal to or higher than the threshold value, and determines that the learning device 212 is not mature if the learning degree is smaller than the threshold value.
- the learning device management unit 211 reflects the determination result of the learning state in the learning device management table (see FIG. 13) stored in the storage unit 206.
- the learner 212 Since the learner 212 is prepared for each congestion level, the progress of learning will differ depending on the network conditions. That is, the state of the network changes as a result of the action selected by the ⁇ -greedy method or the like, but the congestion level calculated that the change (state transition) of the network is biased also becomes biased. If the congestion level is biased, a situation may occur in which the specific learner 212 matures early, but the learning of the other learner 212 is hardly advanced.
- the learner management unit 211 said the immature learner. Promotes learning of 212.
- the learner management unit 211 duplicates the Q table and weight of the mature learner 212 to the Q table and weight of the immature learner 212. At that time, the learning device management unit 211 determines the learning device 212 that is the duplication source of the Q table and the weight based on the congestion level assigned to each learning device 212. For example, the learner management unit 211 duplicates the Q table and weights of the learner 212 having adjacent congestion levels to the Q table and weight of the immature learner 212.
- the congestion level 3 learner 212 if the congestion level 3 learner 212 is immature, the Q table and weights of the congestion level 2 learner 212 adjacent to the congestion level are duplicated as the weights of the learner 212. .. Similarly, if the congestion level 4 learner 212 is immature, the Q table of the mature learner 212 with adjacent congestion levels (next to the right in FIG. 14) and the Q of the learner 212 with a weight of congestion level 4 are adjacent. Duplicates as a table or weight.
- the congestion level calculation unit 203 calculates the congestion level indicating the congestion state of the network.
- a congestion level is assigned to each of the plurality of learners 212.
- the learning device management unit 211 is based on the learning information of the mature first learning device (for example, the learning device 212-2 of FIG. 14) among the plurality of learning devices 212, and the immature second learning device (for example). , The learning information of the learning device 212-3) of FIG. 14 is set. At that time, the learning device management unit 211 selects the first learning device for setting the learning information based on the congestion level assigned to the second learning device.
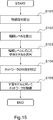
- control device 20 The operation of the control device 20 according to the first embodiment in the control mode is summarized in the flowchart shown in FIG.
- the control device 20 acquires the packet and calculates the feature amount (step S101).
- the control device 20 calculates the congestion level of the network based on the calculated feature amount (step S102).
- the control device 20 selects a learning model according to the congestion level (step S103).
- the control device 20 identifies the state of the network based on the calculated features (step S104).
- the control device 20 controls the network by the most valuable action according to the state of the network by using the learning model selected in step S103 (step S105).
- the network control unit 204 of the control device 20 confirms whether or not the selected learner 212 is immature by referring to the learner management table (see FIG. 13) stored in the storage unit 206. As a result of the confirmation, if the selected learner 212 is immature, the network control unit 204 does not need to use the learning model generated by the learner 212 and does not need to change the control parameters. Alternatively, the network control unit 204 may select the learner 212 adjacent to the congestion level of the selected learner 212 and determine the control parameter. However, in this case, since the action obtained from the learner 212 that does not match the congestion level is selected, the network control unit 204 may slow down the update of the control parameter corresponding to the action. Specifically, the network control unit 204 may multiply the acquired control parameter by a value smaller than 1, and suppress the influence on the network change due to the change of the control parameter.
- FIGS. 16 and 17 summarize the operations of the control device 20 according to the first embodiment in the learning mode.
- FIG. 16 is a flowchart showing an example of the basic operation of the control device 20 in the learning mode.
- the control device 20 acquires the packet and calculates the feature amount (step S201).
- the control device 20 calculates the congestion level of the network based on the calculated feature amount (step S202).
- the control device 20 selects the learning device 212 to be learned according to the congestion level (step S203).
- the control device 20 starts learning of the selected learner 212 (step S204). More specifically, the selected learner 212 sets the packet group (packet group including the packet observed in the past) observed while the condition (congestion level) for which the learner 212 is selected is satisfied. Learn using.
- FIG. 17 is a flowchart showing an example of an operation performed by the control device 20 at a periodic or predetermined timing in the learning mode.
- the control device 20 determines whether or not the immature learner 212 exists at a predetermined cycle, a predetermined timing, or the like (step S301). If the control device 20 has an immature learner 212 and the learner 212 adjacent to the congestion level is mature, the control device 20 makes the learning information (Q table, weight) by the mature learner 212 immature. It is duplicated in the learning information of the learning device 212 (step S302).
- the predetermined cycle is, for example, an hourly cycle or a daily cycle.
- the predetermined timing is, for example, a timing at which the learning device 212 to be learned is switched as the network state (congestion level) is switched.
- a plurality of learning devices are prepared.
- the reason is that the state of the network has various patterns such as stability and instability, so when learning with a single learner, a huge state space is required and the learning may not converge.
- the learning progress between the learning devices is biased, and the number of immature learning devices (learning devices in which learning is not sufficiently advanced) increases. Therefore, an efficient learning method for immature learning devices is required in consideration of the bias regarding learning between learning devices.
- the control device 20 realizes a shortening of the learning period by transferring the learning information of the mature learning device to the immature learning device. At that time, the control device 20 performs more accurate transfer learning by selecting the transfer source learner in consideration of the relationship between the network congestion levels. That is, it is assumed that the learning information (Q table, weight) finally output by the learning devices having adjacent congestion levels will be close to each other even if there are some differences. That is, the fact that the congestion levels are adjacent means that the target environment (network) of each learner is similar, and the learning information for optimal action is also similar (close). Shown.
- control device 20 sets the learning information generated by the mature learning device as the learning information of the immature learning device, so that the time from the start of learning until the learning device matures (distance between the learning information). Is shortened. As a result, efficient learning for an immature learner is realized.
- the structure of the Q table and the weight is common among the learning models.
- different congestion levels may result in different optimal learning model structures (Q-table and weight configurations).
- Each learner 212 calculates log information related to the generation of the learning model. Specifically, each learner 212 stores a set of network status (status) and action (action) used for learning as a log.
- the learner 212 generates a log as shown in FIG. 18 and stores it in the storage unit 206.
- the learner 212-1 which generates a congestion level 1 learning model, generates a log containing throughput and behavior.
- the learner 212-3 which generates a congestion level 3 learning model, generates a log containing throughput and behavior.
- the learning device management unit 211 When an immature learning model (Q table, weight) exists at a predetermined timing, the learning device management unit 211 causes the immature learning device 212 to perform learning by using the log of the mature learning device 212. .. More specifically, the learner management unit 211 processes the logs generated by the learners 212 (learners whose congestion levels are adjacent to each other) located on both sides of the immature learner 212, and generates a learning log. To do.
- the learning device management unit 211 extracts a log having a common behavior from the two logs generated by the learning devices 212 on both sides of the immature learning device 212. For example, in the example of FIG. 18, since the action A1 and the action A2 are common to the two logs, these logs are extracted.
- the learner management unit 211 calculates the median value (mean value) of the status of the same action from the extracted logs. In the example of FIG. 18, the average value of T11 Mbps and T32 Mbps of action A1 and the average value of T12 Mbps and T31 Mbps of action A2 are calculated, respectively.
- the learning device management unit 211 generates the above actions and their average values as a learning amount log. For example, from the log shown in FIG. 18, a learning log as shown in FIG. 19 is generated.
- the learning device management unit 211 passes the learning log generated as described above to the immature learning device 212 for learning.
- the immature learner 212-2 learns using the learning log for the learning log shown in FIG. 19, and generates learning information (Q table, weight) according to the congestion level 2.
- the mature first and third learners for example, the learners corresponding to levels 1 and 3 in the example of FIG. 18
- the learning information of the second learning device (learning device corresponding to level 2) is set.
- FIG. 20 is a diagram showing an example of the hardware configuration of the control device 20.
- the control device 20 can be configured by an information processing device (so-called computer), and includes the configuration illustrated in FIG. 20.
- the control device 20 includes a processor 311, a memory 312, an input / output interface 313, a communication interface 314, and the like.
- the components such as the processor 311 are connected by an internal bus or the like so that they can communicate with each other.
- control device 20 may include hardware (not shown), or may not include an input / output interface 313 if necessary.
- number of processors 311 and the like included in the control device 20 is not limited to the example of FIG. 20, and for example, a plurality of processors 311 may be included in the control device 20.
- the processor 311 is a programmable device such as a CPU (Central Processing Unit), an MPU (Micro Processing Unit), and a DSP (Digital Signal Processor). Alternatively, the processor 311 may be a device such as an FPGA (Field Programmable Gate Array) or an ASIC (Application Specific Integrated Circuit). The processor 311 executes various programs including an operating system (OS).
- OS operating system
- the memory 312 is a RAM (RandomAccessMemory), a ROM (ReadOnlyMemory), an HDD (HardDiskDrive), an SSD (SolidStateDrive), or the like.
- the memory 312 stores an OS program, an application program, and various data.
- the input / output interface 313 is an interface of a display device or an input device (not shown).
- the display device is, for example, a liquid crystal display or the like.
- the input device is, for example, a device that accepts user operations such as a keyboard and a mouse.
- the communication interface 314 is a circuit, module, or the like that communicates with another device.
- the communication interface 314 includes a NIC (Network Interface Card) and the like.
- the function of the control device 20 is realized by various processing modules.
- the processing module is realized, for example, by the processor 311 executing a program stored in the memory 312.
- the program can also be recorded on a computer-readable storage medium.
- the storage medium may be a non-transient such as a semiconductor memory, a hard disk, a magnetic recording medium, or an optical recording medium. That is, the present invention can also be embodied as a computer program product.
- the program can be downloaded via a network or updated using a storage medium in which the program is stored.
- the processing module may be realized by a semiconductor chip.
- terminal 10 and the server 30 can also be configured by an information processing device like the control device 20, and the basic hardware configuration thereof is not different from that of the control device 20, so the description thereof will be omitted.
- control device 20 may be separated into a device that controls the network and a device that generates a learning model.
- the storage unit 206 that stores the learning information (learning model) may be realized by an external database server or the like. That is, the disclosure of the present application may be implemented as a system including learning means, control means, storage means and the like.
- the learning information of the mature learning device 212 whose congestion level is adjacent is duplicated with the learning information of the immature learning device 212.
- the learning information to be replicated may be weighted according to the distance between the immature learning device 212 and the mature learning device 212 at the congestion level. For example, as shown in FIG. 21, the learning of the learning device 212-1 and the learning device 212-2 may be mature, and the learning devices 212-3 to 212-5 may be immature.
- the learning information generated by the plurality of mature learning devices 212 is the learning information of the immature learning device 212. May be set to.
- the learning device management unit 211 may change the degree of influence of the learning information generated by the mature learning device 212 according to the congestion level. For example, as shown in FIG. 22, consider a case where the learners 212-1 to 212-3 are mature and the learners 212-4 are immature. In this case, the learning device management unit 211 may generate learning information to be set in the immature learning device 212 by a weighted average that gives a larger weight as the congestion level is closer to the immature learning device 212.
- the learning information of the learning device 212-3 having the adjacent congestion level has a weight of "0.6", and the learning information of the learning device 212-2 having the congestion level separated by one is "0.3".
- a weight of "0.1" is given to the learning information of the learner 212-1, which is separated by two weights and congestion levels.
- the case where the mature learner 212 exists on one side (left side, the side where the congestion level is small) of the immature learner 212 has been described, but mature learning is performed on both sides of the immature learner 212. Even when the vessel 212 is present, learning information can be generated in the same manner as described above. Specifically, if the learning devices 212 on both sides of the immature learning device 212 are mature, the learning device management unit 211 gives 0.5 weights to each of the learning information by the learning devices 212 on both sides, and the weight is 0.5. Learning information may be generated from the total value.
- control device 20 may control a unit of 10 terminals or a group of a plurality of terminals 10 as a control target. That is, even if the same terminal 10 is used, different applications have different port numbers and the like, and are treated as different flows.
- the control device 20 may apply the same control (change of control parameters) to packets transmitted from the same terminal 10.
- the control device 20 may, for example, treat terminals 10 of the same type as one group and apply the same control to packets transmitted from terminals 10 belonging to the same group.
- the learner management unit (102, 211) The learning information of the second learning device (101, 212) is set based on the learning information of the mature first and third learning devices (101, 212) among the plurality of learning devices (101, 212).
- the control device (20, 100) according to Appendix 1.
- Appendix 3 A congestion level calculation unit for calculating the congestion level indicating the congestion state of the network is further provided.
- the control device (20, 100) according to Appendix 1 or 2, wherein the congestion level is assigned to each of the plurality of learners (101, 212).
- Appendix 4 The learner management unit (102, 211)
- the control device (20, 20) according to Appendix 3, which selects the first learning device (101, 212) for setting the learning information based on the congestion level assigned to the second learning device (101, 212). 100).
- Appendix 1 further includes a control unit (204) that selects one learning model from the learning models generated by each of the plurality of learning devices and controls the network based on the behavior obtained from the selected learning model.
- the control device (20, 100) according to any one of 4 to 4.
- [Appendix 6] Steps to learn actions to control the network in each of the plurality of learners (101, 212), and Based on the learning information of the mature first learning device (101, 212) among the plurality of learning devices (101, 212), the immature second of the plurality of learning devices (101, 212) Steps to set the learning information of the learning device (101, 212), How to include.
- the step of setting the learning information is The learning information of the second learning device (101, 212) is set based on the learning information of the mature first and third learning devices (101, 212) among the plurality of learning devices (101, 212).
- the step of setting the learning information is The method according to Appendix 8, wherein the first learning device (101, 212) for setting the learning information is selected based on the congestion level assigned to the second learning device (101, 212).
- Appendix 6 further includes a step of selecting one learning model from the learning models generated by each of the plurality of learning devices (101, 212) and controlling the network based on the behavior obtained from the selected learning model. 9. The method according to any one of 9.
- the learner management unit (102, 211) The learning information of the second learning device (101, 212) is set based on the learning information of the mature first and third learning devices (101, 212) among the plurality of learning devices (101, 212).
- a congestion level calculation unit for calculating the congestion level indicating the congestion state of the network is further provided.
- the system according to Appendix 11 or 12, wherein the congestion level is assigned to each of the plurality of learners (101, 212).
- the learner management unit (102, 211) The system according to Appendix 13, wherein the first learning device (101, 212) for setting the learning information is selected based on the congestion level assigned to the second learning device (101, 212).
- [Appendix 15] A control unit (204) that selects one learning model from the learning models generated by each of the plurality of learning devices (101, 212) and controls the network based on the behavior obtained from the selected learning model.
- [Appendix 16] On the computer (311) A process of learning actions for controlling a network in each of a plurality of learners (101, 212), and Based on the learning information of the mature first learning device (101, 212) among the plurality of learning devices (101, 212), the immature second of the plurality of learning devices (101, 212) The process of setting the learning information of the learning device (101, 212) and A program that executes.
- Terminal 20 100 Control device 30 Server 101, 212, 212-1 to 212-N Learner 102, 211 Learner management unit 201 Packet transfer device 202 Feature amount calculation unit 203 Congestion level calculation unit 204 Network control unit 205 Reinforcement learning Execution unit 206 Storage unit 311 Processor 312 Memory 313 Input / output interface 314 Communication interface
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Medical Informatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- Health & Medical Sciences (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US17/640,847 US20220343220A1 (en) | 2019-09-30 | 2019-09-30 | Control apparatus, method and system |
| PCT/JP2019/038455 WO2021064767A1 (ja) | 2019-09-30 | 2019-09-30 | 制御装置、方法及びシステム |
| JP2021550732A JP7251646B2 (ja) | 2019-09-30 | 2019-09-30 | 制御装置、方法及びシステム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/038455 WO2021064767A1 (ja) | 2019-09-30 | 2019-09-30 | 制御装置、方法及びシステム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021064767A1 true WO2021064767A1 (ja) | 2021-04-08 |
Family
ID=75337004
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/038455 Ceased WO2021064767A1 (ja) | 2019-09-30 | 2019-09-30 | 制御装置、方法及びシステム |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20220343220A1 (https=) |
| JP (1) | JP7251646B2 (https=) |
| WO (1) | WO2021064767A1 (https=) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023115444A (ja) * | 2022-02-08 | 2023-08-21 | コニカミノルタ株式会社 | 機械学習装置、および機械学習プログラム |
| WO2023214585A1 (ja) * | 2022-05-02 | 2023-11-09 | 三菱重工業株式会社 | 学習装置、学習方法及び学習プログラム |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4175370A3 (en) | 2021-10-28 | 2023-08-30 | Nokia Solutions and Networks Oy | Power saving in radio access network |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009027303A (ja) * | 2007-07-18 | 2009-02-05 | Univ Of Electro-Communications | 通信装置および通信方法 |
| JP2013106202A (ja) * | 2011-11-14 | 2013-05-30 | Fujitsu Ltd | パラメータ設定装置、コンピュータプログラム及びパラメータ設定方法 |
| JP2018106466A (ja) * | 2016-12-27 | 2018-07-05 | 株式会社日立製作所 | 制御装置及び制御方法 |
| JP2019041338A (ja) * | 2017-08-28 | 2019-03-14 | 日本電信電話株式会社 | 無線通信システム、無線通信方法および集中制御局 |
| US20190141113A1 (en) * | 2017-11-03 | 2019-05-09 | Salesforce.Com, Inc. | Simultaneous optimization of multiple tcp parameters to improve download outcomes for network-based mobile applications |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11537931B2 (en) * | 2017-11-29 | 2022-12-27 | Google Llc | On-device machine learning platform to enable sharing of machine-learned models between applications |
| JP7440420B2 (ja) * | 2018-05-07 | 2024-02-28 | グーグル エルエルシー | 包括的機械学習サービスを提供するアプリケーション開発プラットフォームおよびソフトウェア開発キット |
| WO2020013884A1 (en) * | 2018-07-13 | 2020-01-16 | Google Llc | Machine-learned prediction of network resources and margins |
-
2019
- 2019-09-30 JP JP2021550732A patent/JP7251646B2/ja active Active
- 2019-09-30 US US17/640,847 patent/US20220343220A1/en active Pending
- 2019-09-30 WO PCT/JP2019/038455 patent/WO2021064767A1/ja not_active Ceased
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009027303A (ja) * | 2007-07-18 | 2009-02-05 | Univ Of Electro-Communications | 通信装置および通信方法 |
| JP2013106202A (ja) * | 2011-11-14 | 2013-05-30 | Fujitsu Ltd | パラメータ設定装置、コンピュータプログラム及びパラメータ設定方法 |
| JP2018106466A (ja) * | 2016-12-27 | 2018-07-05 | 株式会社日立製作所 | 制御装置及び制御方法 |
| JP2019041338A (ja) * | 2017-08-28 | 2019-03-14 | 日本電信電話株式会社 | 無線通信システム、無線通信方法および集中制御局 |
| US20190141113A1 (en) * | 2017-11-03 | 2019-05-09 | Salesforce.Com, Inc. | Simultaneous optimization of multiple tcp parameters to improve download outcomes for network-based mobile applications |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023115444A (ja) * | 2022-02-08 | 2023-08-21 | コニカミノルタ株式会社 | 機械学習装置、および機械学習プログラム |
| JP7764776B2 (ja) | 2022-02-08 | 2025-11-06 | コニカミノルタ株式会社 | 機械学習装置、および機械学習プログラム |
| WO2023214585A1 (ja) * | 2022-05-02 | 2023-11-09 | 三菱重工業株式会社 | 学習装置、学習方法及び学習プログラム |
| JP2023165310A (ja) * | 2022-05-02 | 2023-11-15 | 三菱重工業株式会社 | 学習装置、学習方法及び学習プログラム |
| JP7814236B2 (ja) | 2022-05-02 | 2026-02-16 | 三菱重工業株式会社 | 学習装置、学習方法及び学習プログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| US20220343220A1 (en) | 2022-10-27 |
| JPWO2021064767A1 (https=) | 2021-04-08 |
| JP7251646B2 (ja) | 2023-04-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11876697B2 (en) | Extensible network traffic engineering platform for increasing network resiliency in cloud applications | |
| Chen et al. | Dynamic routing optimization in software-defined networking based on a metaheuristic algorithm | |
| CN108962238B (zh) | 基于结构化神经网络的对话方法、系统、设备及存储介质 | |
| CN111090631B (zh) | 分布式环境下的信息共享方法、装置和电子设备 | |
| CN112422443B (zh) | 一种拥塞算法的自适应控制方法、存储介质、设备及系统 | |
| CN114866489B (zh) | 拥塞控制方法和装置及拥塞控制模型的训练方法和装置 | |
| CN116685985A (zh) | 具有多样化反馈的联合学习系统与方法 | |
| JP7251646B2 (ja) | 制御装置、方法及びシステム | |
| JP7251647B2 (ja) | 制御装置、制御方法及びシステム | |
| CN112667400A (zh) | 边缘自治中心管控的边云资源调度方法、装置及系统 | |
| CN113966596A (zh) | 用于数据流量路由的方法和设备 | |
| Wei et al. | GRL-PS: Graph embedding-based DRL approach for adaptive path selection | |
| CN114090108A (zh) | 算力任务执行方法、装置、电子设备及存储介质 | |
| CN115225512B (zh) | 基于节点负载预测的多域服务链主动重构机制 | |
| JP7259978B2 (ja) | 制御装置、方法及びシステム | |
| Liu et al. | ScaleFlux: Efficient stateful scaling in NFV | |
| CN120639690A (zh) | 基于深度强化学习的无人机任务网络消息传输路由规划系统及方法 | |
| JP2021124832A (ja) | 推論装置、推論方法、及びプログラム | |
| Liu et al. | Optimizing lightweight neural networks for efficient mobile edge computing | |
| Gomez et al. | Federated intelligence for active queue management in inter-domain congestion | |
| US20250385809A1 (en) | Reinforcement learning for switch power optimization | |
| Xie et al. | Adaptive routing of task in computing force network by integrating graph convolutional network and deep Q-network | |
| WO2021064771A1 (ja) | システム、方法及び制御装置 | |
| Poncea et al. | Design and implementation of an Openflow SDN controller in NS-3 discrete-event network simulator | |
| CN118042018B (zh) | 一种基于stsgcn的智能多路径数据调度方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19947635 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021550732 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19947635 Country of ref document: EP Kind code of ref document: A1 |