WO2021059968A1 - 音声認識装置、音声認識方法、およびプログラム - Google Patents
音声認識装置、音声認識方法、およびプログラム Download PDFInfo
- Publication number
- WO2021059968A1 WO2021059968A1 PCT/JP2020/033974 JP2020033974W WO2021059968A1 WO 2021059968 A1 WO2021059968 A1 WO 2021059968A1 JP 2020033974 W JP2020033974 W JP 2020033974W WO 2021059968 A1 WO2021059968 A1 WO 2021059968A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- voice
- user
- language
- target
- recognition
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images










Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/22—Interactive procedures; Man-machine interfaces
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/02—Preprocessing operations, e.g. segment selection; Pattern representation or modelling, e.g. based on linear discriminant analysis [LDA] or principal components; Feature selection or extraction
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification techniques
- G10L17/04—Training, enrolment or model building
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/166—Editing, e.g. inserting or deleting
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/242—Dictionaries
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/221—Announcement of recognition results
Definitions
- the present invention relates to a voice recognition device, a voice recognition method, and a program.
- Patent Document 1 describes an example of a device for producing subtitles from voice.
- the voice recognition unit recognizes the target voice or the voice obtained by reciting the target voice and converts it into text
- the text division / combination unit divides the text after voice recognition to generate subtitle text. To do.
- voice information input from a microphone is converted into text information by using a voice / text conversion unit and transmitted to a mobile phone by using a text transmission unit, and further, a text reception unit It is described that the received text information is converted into voice information by using the text / voice conversion unit and output from the speaker.
- the present invention has been made in view of the above circumstances, and an object of the present invention is to provide a technique for improving speech recognition accuracy in transcribing speech.
- the first aspect relates to voice recognition recognition.
- the voice recognition device is A voice reproduction means for reproducing the target voice for voice recognition divided into predetermined sections for each predetermined section, and A voice recognition means for recognizing a spoken voice in which the user repeats the target voice for each target voice.
- a text information generating means that generates text information of the spoken voice based on the recognition result of the voice recognition means, and It has a storage means for storing the utterance voice and the recognition result corresponding to the utterance voice as learning data in association with the identification information for each user.
- the voice recognition means recognizes using a recognition engine learned from the learning data for each user.
- the second aspect relates to a speech recognition method performed by at least one computer.
- the voice recognition method according to the second aspect is The voice recognition device
- the target voice for voice recognition which is divided into predetermined sections, is reproduced for each predetermined section.
- the user recognizes the spoken voice that repeats the target voice.
- the text information of the utterance voice is generated.
- the identification information for each user is associated with the uttered voice and the recognition result corresponding to the uttered voice, and stored as learning data.
- recognizing the uttered voice it includes recognizing using a recognition engine learned from the learning data for each user.
- this invention may be a program that causes at least one computer to execute the method of the second aspect, or a recording medium that can be read by a computer that records such a program. You may.
- This recording medium includes non-temporary tangible media.
- This computer program includes computer program code that causes the computer to perform its speech recognition method on a speech recognition device when executed by the computer.
- the various components of the present invention do not necessarily have to be independent of each other, and a plurality of components are formed as one member, and one component is formed of a plurality of members. It may be that a certain component is a part of another component, a part of a certain component overlaps with a part of another component, and the like.
- the order of description does not limit the order in which the plurality of procedures are executed. Therefore, when implementing the method and computer program of the present invention, the order of the plurality of procedures can be changed within a range that does not hinder the contents.
- the method of the present invention and the plurality of procedures of the computer program are not limited to being executed at different timings. Therefore, another procedure may occur during the execution of a certain procedure, a part or all of the execution timing of the certain procedure and the execution timing of the other procedure may overlap, and the like.
- acquisition means that the own device retrieves data or information stored in another device or storage medium (active acquisition), and is output to the own device from the other device. Includes at least one of entering data or information (passive acquisition).
- active acquisition include making a request or inquiry to another device and receiving the reply, and accessing and reading another device or storage medium.
- passive acquisition may be receiving information to be delivered (or transmitted, push notification, etc.).
- acquisition may be to select and acquire the received data or information, or to select and receive the delivered data or information.
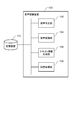
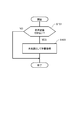
- FIG. 1 is a block diagram conceptually showing a configuration example of the voice recognition system 1 according to the embodiment of the present invention.
- the voice recognition system 1 of the present embodiment is a system for transcribing voice into text.
- the voice recognition system 1 includes a voice recognition device 100, a voice input unit such as a microphone 4, and a voice output unit such as a speaker 6.
- the speaker 6 is preferably, but is not limited to, headphones worn by the user U so that the output voice is not input to the microphone 4.
- the user U listens to the original voice of the voice recognition target (hereinafter, also referred to as the recognition target voice data 10) output from the speaker 6, and the spoken voice 20 repeated by the user U is input from the microphone 4.
- the voice recognition device 100 performs voice recognition processing to generate text information (hereinafter, also referred to as text data 30).
- the voice recognition device 100 has a voice recognition engine 200.
- the speech recognition engine 200 has various models, for example, a language model 210, an acoustic model 220, and a word dictionary 230.
- the voice recognition device 100 recognizes the utterance voice 20 in which the user U repeats the recognition target voice data 10 using the voice recognition engine 200, and outputs the text data 30 as the recognition result.
- each model used in the voice recognition engine 200 is provided for each speaker.
- the original voice data 10 to be recognized has variations in pronunciation, speed, volume, etc. depending on the person who spoke, has habits for each person, and has a recording environment (environment, recording equipment, type of recorded data, etc.). Due to various reasons, the sound quality may not meet the level applicable to speech recognition. Therefore, the recognition accuracy is lowered and erroneous recognition occurs. Therefore, the user U called an annotator recites the utterance content included in the heard recognition target voice data 10 by listening to the original recognition target voice data 10 output from the speaker 6.
- the voice recognition device 100 recognizes the utterance voice 20 repeated by the user U under certain conditions. It is preferable that the user U repeats (utters) the utterance speed, utterance, etc. so as to be a standard suitable for voice recognition.
- the voice recognition device 100 of the present embodiment learns the characteristics and habits of the spoken voice of the annotator. As a result, the recognition accuracy of the voice recognition device 100 is increased.
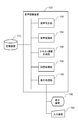
- FIG. 2 is a functional block diagram showing a logical configuration example of the voice recognition device 100 according to the embodiment of the present invention.
- the voice recognition device 100 includes a voice reproduction unit 102, a voice recognition unit 104, a text information generation unit 106, and a storage processing unit 108.
- the voice reproduction unit 102 reproduces the original target voice for voice recognition (hereinafter, also referred to as section voice 12 (see FIG. 5)) divided into predetermined sections toward the user U for each predetermined section.
- the voice recognition unit 104 recognizes the utterance voice 20 in which the user U repeats the section voice 12 for each section voice 12.
- the voice recognition unit 104 uses a model for each user U, for example, a language model 210 for each user U, an acoustic model 220, and a word dictionary 230.
- Each model for each user U is stored in, for example, a storage device 110.
- the text information generation unit 106 generates text information (text data 30) of the spoken voice 20 recognized by the voice recognition unit 104.
- the storage processing unit 108 stores the identification information for each user U (indicated as the user ID in the figure), the uttered voice 20 and the recognition result corresponding to the uttered voice 20 as learning data 240 (FIG. 6) in association with each other. Store in device 110.
- FIG. 3 is a block diagram illustrating a hardware configuration of a computer 1000 that realizes the voice recognition device 100 shown in FIG.
- the computer 1000 has a bus 1010, a processor 1020, a memory 1030, a storage device 1040, an input / output interface 1050, and a network interface 1060.
- the bus 1010 is a data transmission path for the processor 1020, the memory 1030, the storage device 1040, the input / output interface 1050, and the network interface 1060 to transmit and receive data to and from each other.
- the method of connecting the processors 1020 and the like to each other is not limited to the bus connection.
- the processor 1020 is a processor realized by a CPU (Central Processing Unit), a GPU (Graphics Processing Unit), or the like.
- the memory 1030 is a main storage device realized by a RAM (Random Access Memory) or the like.
- the storage device 1040 is an auxiliary storage device realized by an HDD (Hard Disk Drive), an SSD (Solid State Drive), a memory card, a ROM (Read Only Memory), or the like.
- the storage device 1040 stores a program module that realizes each function of the computer 1000. When the processor 1020 reads each of these program modules into the memory 1030 and executes them, each function corresponding to the program module is realized.
- the storage device 1040 also stores each model of the voice recognition engine 200.
- the program module may be recorded on a recording medium.
- the recording medium on which the program module is recorded includes a medium that can be used by the non-temporary tangible computer 1000, and the program code that can be read by the computer 1000 (processor 1020) may be embedded in the medium.
- the input / output interface 1050 is an interface for connecting the computer 1000 and various input / output devices.
- the network interface 1060 is an interface for connecting the computer 1000 to the communication network.
- This communication network is, for example, LAN (Local Area Network) or WAN (Wide Area Network).
- the method of connecting the network interface 1060 to the communication network may be a wireless connection or a wired connection.
- the computer 1000 is connected to necessary devices (for example, the microphone 4 and the speaker 6) via the input / output interface 1050 or the network interface 1060.
- the computer 1000 that realizes the voice recognition device 100 is, for example, a personal computer, a smartphone, a tablet terminal, or the like.
- the computer 1000 that realizes the voice recognition device 100 may be a dedicated terminal device.
- the voice recognition device 100 is realized by installing and starting an application program for realizing the voice recognition device 100 on the computer 1000.
- the computer 1000 is a web server, and the user activates a browser on a user terminal such as a personal computer, a smartphone, or a tablet terminal to provide the service of the voice recognition device 100 via a network such as the Internet. By accessing the page, the function of the voice recognition device 100 may be used.
- the computer 1000 may be a server device of a system such as SaaS (Software as a Service) that provides the service of the voice recognition device 100.
- SaaS Software as a Service
- the user may access the server device from a user terminal such as a personal computer, a smartphone, or a tablet terminal via a network such as the Internet, and the voice recognition device 100 may be realized by a program running on the server device.
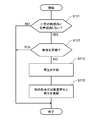
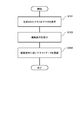
- FIG. 4 is a flowchart showing an example of the operation of the voice recognition device 100 of the present embodiment.
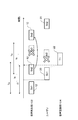
- FIG. 5 is a diagram for explaining the relationship of information in the voice recognition device 100 of the present embodiment.
- the voice reproduction unit 102 reproduces the original target voice for voice recognition divided into predetermined sections (step S101). Specifically, the voice reproduction unit 102 divides the recognition target voice data 10 into predetermined sections and outputs the recognition target voice data 10 via the speaker 6. Sa1, Sa2, and Sa3 in FIG. 5 are each section voice 12.
- the predetermined section is, for example, a section including at least one of a sentence, a phrase, and a word included in the voice to be recognized.
- Each section may contain multiple sentences, clauses, and words. The number of sentences, clauses and words contained in each section does not have to be constant.
- the voice reproduction unit 102 reproduces the section voice 12 by dividing the recognition target voice data 10 for each section including any one of a sentence, a phrase, and a word. During each section voice 12, there may be no sound, or a predetermined notification sound may be output.
- the voice recognition unit 104 recognizes the section voice 12 by using the voice recognition engine 200 including the language model 210, the acoustic model 220, and the word dictionary 230.
- the voice recognition device 100 stores each model (for example, language model 210, acoustic model 220, and word dictionary 230) used in the voice recognition engine 200 for each user U.
- Each model is generated by learning the voice of the corresponding user U and its recognition result. Therefore, each model reflects the voice characteristics and habits of the corresponding user U. The learning of the model will be described in the embodiment described later.
- Each model is associated with a user ID that identifies the user U.
- the voice recognition unit 104 acquires the user ID of the user U, and reads out and prepares the voice recognition engine 200 corresponding to the acquired user ID.
- the method of acquiring the user ID is exemplified below.
- biometric information such as a voiceprint may be used instead of the user ID.
- the identification information for example, individual identification information (UID: User Identifier), IMEI (International Mobile Equipment Identity), etc.
- UID User Identifier
- IMEI International Mobile Equipment Identity
- the identification information of the mobile terminal that has activated the voice recognition device 100 is acquired as the user ID.
- a list of pre-registered users is displayed and the user U is made to select. Acquire the user ID associated with the user in advance.
- the voice recognition unit 104 recognizes the utterance voice 20 repeated by the user U (step S103).
- the utterance voice 20 of the user U is input to the voice recognition unit 104 via the microphone 4.
- the user U listens to the section voice 12 reproduced by the voice reproduction unit 102 and repeats the voice. User U repeats every time he hears the section voice 12.
- Sb1, Sb2, and Sb3 in FIG. 5 are the utterance voices 20.
- the voice recognition unit 104 detects the division of each utterance voice 20 to be input by detecting the silent section ss between each utterance voice 20 repeated by the user U.
- the voice recognition unit 104 recognizes each of the detected utterance voices 20, and passes the recognition result 22 to the text information generation unit 106.
- T1, T2, and T3 in FIG. 5 are the recognition results 22.
- the text information generation unit 106 generates the text information (text data 30) of the utterance voice 20 (step S105).
- the text information generation unit 106 sequentially acquires the recognition result 22 of the utterance voice 20 corresponding to each section voice 12 from the voice recognition unit 104, and connects these to generate the text data 30 corresponding to the series of utterance voice 20.
- the recognition result 22 acquired from the voice recognition unit 104 may include information such as likelihood.
- the text information generation unit 106 creates a sentence by connecting the recognition results 22 corresponding to the utterance voice 20 of each section voice 12 by using the language model 210 and the word dictionary 230, and generates the text data 30.
- the text data 30 is a text format file in which the generated text is described.
- the storage processing unit 108 associates the utterance voice 20 and the recognition result 22 for each user U and stores them in the storage device 110 as learning data 240 (step S107).
- FIG. 6 is a diagram showing an example of the data structure of the learning data 240.
- the learning data 240 stores the identification information (user ID) of the user U, the utterance voice 20, and the recognition result 22 in association with each other.
- the voice recognition unit 104 can perform voice recognition using the voice recognition engine 200 that has learned the utterance characteristics of each user U, so that the recognition accuracy can be improved.
- the voice recognition device 100 of the present embodiment has a configuration in which the repeat of the user U performs processing according to the repeat state of the user U, such as when the repeat of the user U cannot catch up with the voice reproduction by the voice reproduction unit 102. Except for the points, it is the same as the above embodiment. Since the voice recognition device 100 of the present embodiment has the same configuration as the voice recognition device 100 of FIG. 2, it will be described with reference to FIG.
- ⁇ Function configuration example> When the voice recognition unit 104 does not recognize the spoken voice 20 repeated by the user within a certain period of time, the voice reproduction unit 102 interrupts the reproduction of the section voice 12, and then the section before the time when the reproduction is interrupted. The reproduction of the section voice 12 is restarted from.
- the voice reproduction unit 102 does not interrupt the reproduction of the section voice 12 when the utterance voice 20 repeated by the user U is not recognized in the section different from the section in which the section voice 12 divided in advance is reproduced.
- the section different from the section in which the pre-divided section voice 12 is reproduced is, for example, a non-reproduced section between each of the plurality of section voices 12 that are reproduced by dividing the recognition target voice data 10. ..
- the interval of the non-regeneration section is the time interval ts.
- the voice reproduction unit 102 sets the reproduction speed of the target voice (section voice 12) of a certain section according to the voice input speed when the spoken voice 20 repeated by the user U is input to the section before the section. And change.
- the playback speed control method is exemplified below, but is not limited to these.
- the voice reproduction unit 102 makes the reproduction speed slower than the predetermined speed if the input speed of the utterance voice 20 is slower than the predetermined speed, and determines the reproduction speed if the input speed of the utterance voice 20 is faster than the predetermined speed. Faster than the speed of.
- the voice reproduction unit 102 may reproduce the original voice (section voice 12) to be recognized at the same speed as the input speed of the utterance voice 20.
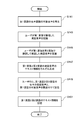
- FIG. 7 is a flowchart showing an example of the operation of the voice recognition device 100 of the present embodiment.
- FIG. 8 is a diagram for explaining the relationship of information in the voice recognition device 100 of the present embodiment.
- the flowchart of FIG. 7 operates, for example, every time the voice reproduction unit 102 outputs each section voice 12 of the recognition target voice data 10 in step S101 of FIG.
- the voice reproduction unit 102 determines whether or not the voice recognition unit 104 has recognized the spoken voice 20 repeated by the user within a certain time (step S111). This determination method is exemplified below. (1) Every time the voice recognition unit 104 recognizes the utterance voice 20 of the user U (when the utterance voice 20 is detected or when the recognition result 22 is generated), the voice recognition unit 104 notifies the voice reproduction unit 102 of the recognition. To do. The voice reproduction unit 102 measures the time interval of the notification from the voice recognition unit 104, and determines whether or not it is within a certain time Tx. (2) Each time the voice recognition unit 104 recognizes the utterance voice 20 of the user U, the voice recognition unit 104 notifies the voice reproduction unit 102 of the recognition.
- the voice reproduction unit 102 When the voice reproduction unit 102 acquires the notification within a certain time Tx from the time when the section voice 12 is reproduced (reproduction start or reproduction end), the voice reproduction unit 102 determines that it has been recognized and acquires the notification within a certain time Tx. If not, it is determined that it is not recognized. (3) When the voice recognition unit 104 cannot recognize the next utterance voice 20 within Tx for a certain period of time from the time when the utterance voice 20 repeated by the user U last time is recognized, the voice recognition unit 104 informs the voice reproduction unit 102 to that effect. Notice.
- the recognized time point is, for example, either a time point when the input of the utterance voice 20 is detected or a time point when the recognition result 22 of the utterance voice 20 is generated.
- the voice reproduction unit 102 inquires the voice recognition unit 104 whether or not the spoken voice 20 can be recognized after a certain period of time has elapsed from the time when the section voice 12 is reproduced (reproduction start or reproduction end). (5) Whether or not the voice recognition unit 102 has input the utterance voice 20 of the user U from the microphone 4 within a certain period of time Tx from the time when the section voice 12 is played back on the voice recognition unit 104 (playback start or playback end). Is detected. The voice reproduction unit 102 determines that the spoken voice 20 is recognized when it is input, and determines that it is not recognized when there is no input.
- the voice reproduction unit 102 interrupts the reproduction of the section voice 12 (step S113).
- the voice recognition unit 104 generates the recognition result 22 of T1 at a time t1 within a certain time Tx from the time when the voice reproduction unit 102 starts reproducing the section voice 12 of Sa1. Therefore, the voice reproduction unit 102 reproduces the section voice 12 of Sa2 in the next section.
- the audio reproduction unit 102 interrupts the reproduction of the section audio 12 of Sa3.
- the voice reproduction unit 102 resumes the reproduction of the section audio 12 from the time before the time when the reproduction is interrupted (step S115).
- the audio reproduction unit 102 interrupts the reproduction of the section audio 12 of Sa3, and then reproduces the previous section audio 12 of Sa2 again.
- the user U repeats the section voice 12 of the Sa2.
- the voice recognition unit 104 can recognize the spoken voice 20 of Sb2.
- FIG. 9 is a flowchart showing another operation example of the voice recognition device 100 of the present embodiment.
- the flowchart of FIG. 9 includes step S121 between steps S111 and S113 of the flowchart of FIG. 7.
- step S111 When the voice reproduction unit 102 does not recognize the spoken voice 20 repeated by the user U (YES in step S111), the voice reproduction unit 102 in a section (non-reproduction section) different from the section in which the pre-divided section voice 12 is reproduced (step). YES in S121), step S113 and step S115 are bypassed, and the reproduction of the section voice 12 is not interrupted.
- the voice reproduction unit 102 When the voice reproduction unit 102 does not recognize the spoken voice 20 repeated by the user U (YES in step S111), the voice reproduction unit 102 is not a section (non-reproduction section) different from the section in which the pre-divided section voice 12 is reproduced (YES in step S111). The process proceeds to step S121 (NO) and step S113, and the reproduction of the section voice 12 is interrupted.
- step S111 the voice reproduction unit 102 measures the time of the non-reproduction section between the reproduced section sounds 12, and adds the time interval ts of the non-reproduction section to the fixed time Tx. You may judge.
- FIG. 10 is a flowchart showing still another operation example of the voice recognition device 100 of the present embodiment.
- the flowchart of FIG. 10 operates at all times, on a regular basis, or when requested.
- the voice reproduction unit 102 measures the input speed of the utterance voice 20 input to the microphone 4.
- the input speed is, for example, at least one of the number of words, the number of characters, and the number of phonemes in a unit time.
- the voice reproduction unit 102 adjusts the reproduction speed according to the input speed of the utterance voice 20.
- the playback speed like the input speed, is at least one of the number of words, the number of characters, and the number of phonemes in a unit time. Then, the voice reproduction unit 102 adjusts the reproduction speed to be equal to or less than the input speed of the utterance voice 20, and reproduces the section voice 12.
- the voice reproduction unit 102 can control the reproduction of the section voice 12 according to the voice recognition state and the input speed of the utterance voice 20, so that the user can control the reproduction. Even if U's recitation cannot keep up, the work can be returned smoothly without stagnation. Further, according to the present embodiment, since the reproduction speed can be adjusted to the repeat speed of the user U, the reproduction of the section voice 12 is appropriately adjusted even when the utterance speed of the user U is fast or slow. it can. As a result, the user U can continue to work comfortably without catching up with the repeats or having time to spare.
- the voice recognition device 100 of the present embodiment is the same as any of the above-described embodiments except that it has a configuration for machine learning the recognition result of the utterance voice 20 of the user U.
- the voice recognition device 100 of the present embodiment will be described with reference to FIG.
- the storage processing unit 108 associates the utterance voice 20 repeated by the user U with the section voice 12 of the predetermined section and stores it as learning data 240. ..
- FIG. 11 is a diagram showing an example of the data structure of the learning data 240 of the present embodiment.
- the learning data 240 of FIG. 11 stores the section voice 12 in association with the learning data 240 of FIG.
- the learning data 240 generated in this way is used for machine learning of the voice recognition engine 200 for each user U.
- each model of the voice recognition engine 200 for each user U is used by using the learning data 240 for each user U generated in this way.
- a voice recognition engine 200 specialized for the user U can be constructed.
- the voice recognition device 100 of the present embodiment is the same as any of the above embodiments except that it has a configuration of translating the first language and the first language into a second language, reciting them, and transcribing the voice information into a text. ..
- the voice recognition unit 104 uses the spoken voice of the repeated first language and the first language as the second language (for example). , Japanese), and each of the spoken voices 20 uttered is recognized.
- the text information generation unit 106 generates text data 30 of the spoken voices 20 of the first language and the second language, respectively, based on the recognition result by the voice recognition unit 104.
- the storage processing unit 108 stores the spoken voice 20 of the first language and the second language repeated by the user U and the section voice 12 of the first language reproduced by the voice reproduction unit 102 in association with each other.
- the first language is English and the second language is Japanese.
- the first language may be a dialect (eg, Osaka Ben)
- the second language may be a standard language, or vice versa
- the first language may be a standard language
- the second language may be a dialect.
- the first language may be honorific
- the second language may be non-honorific, and vice versa.
- FIG. 12 is a flowchart showing an operation example of the voice recognition device 100 of the present embodiment.
- the voice reproduction unit 102 divides the target voice for voice recognition in the first language into a predetermined section (section voice 12) and reproduces the target voice (step S141).
- the voice recognition unit 104 recognizes the spoken voice 20 that the user U repeats in the first language (step S143).
- the voice recognition unit 104 recognizes the spoken voice 20 that the user U repeats in the second language (step S145).
- the text information generation unit 106 generates text data 30 based on the recognition result 22 of the utterance voice 20 recognized in steps S143 and S145 (step S147).
- the storage processing unit 108 associates the user ID, the uttered voice 20 of the first language, the uttered voice 20 of the second language, and the target voice of the first language reproduced by the voice reproduction unit 102 with the translation engine. It is stored in the storage device 110 as learning data 340 (step S149).
- FIG. 13 is a diagram showing an example of the data structure of the training data 340.
- the learning data 340 is stored by associating the section voice 12 reproduced by the voice reproduction unit 102 with the utterance voice 20 of the first language and the utterance voice 20 of the second language in the same section. To do. Further, as in the example of FIG. 13B, the learning data 340 may be stored in association with the recognition result of each language.
- the storage processing unit 108 stores the text data 30 of the first language generated in step S147 and the text data 30 of the second language in association with each other in the storage device 110 (step S151).
- the user U who has heard the first language recognizes the voice information repeated in the first language and the voice information spoken by translating the first language into the second language, and outputs the text information.
- the spoken voice 20 in which the first language is repeated, the spoken voice 20 in the second language, and the section voice 12 reproduced by the voice reproducing unit 102 can be stored in association with each other.
- this information can be used as the learning data 340 of the translation engine.
- the voice recognition device 100 of the present embodiment is the same as any of the above-described embodiments except that it has a configuration for registering an unknown word.
- FIG. 14 is a functional block diagram showing a functional configuration example of the voice recognition device 100 of the present embodiment.
- the voice recognition device 100 further includes a registration unit 120 in addition to the configuration of the voice recognition device 100 of the above embodiment.
- the registration unit 120 registers in the dictionary a word that cannot be recognized by the voice recognition unit 104 among the words spoken by the user U as an unknown word.
- FIG. 15 is a flowchart showing an operation example of the voice recognition device 100 of the present embodiment. This flowchart starts, for example, when the voice recognition unit 104 cannot recognize the utterance voice 20 of the user U in step S103 of FIG. 4 (YES in step S151). Then, the registration unit 120 registers the words that cannot be recognized by the voice recognition unit 104 among the words spoken by the user U in the dictionary as unknown words (step S153).
- the dictionary includes both models such as the language model 210, the acoustic model 220, and the word dictionary 230 for each user U of the present embodiment, and general-purpose models that are not specialized for the user.
- voice information can be registered in at least one of different units such as a word, n sets of word strings, and phoneme strings. Therefore, the voice information of the words that cannot be recognized by the voice recognition unit 104 may be decomposed into each unit and registered in the dictionary as unknown words.
- the word registered as an unknown word may be registered by the user U by the same editing function as in the embodiment described later. Alternatively, it may be learned by machine learning or the like.
- words that cannot be recognized by the voice recognition unit 104 can be registered in the dictionary as unknown words, so that the same effect as that of the above embodiment can be obtained, and the voice recognition engine 200 can be further developed. It is possible to go and improve the recognition accuracy.
- the voice recognition device 100 of the present embodiment is the same as any of the above-described embodiments except that it has a configuration for editing the recognition target voice data 10.
- FIG. 16 is a functional block diagram showing a functional configuration example of the voice recognition device 100 of the present embodiment.
- the voice recognition device 100 of the present embodiment further includes a display processing unit 130 in addition to the configuration of the voice recognition device 100 of the above embodiment.
- the display processing unit 130 causes the display device 132 to display the text data 30 generated by the text information generation unit 106.
- the text data 30 may be updated and displayed every time the recognition result 22 is added to the text data 30 by the text information generation unit 106, all the recognition target voice data 10 may be reproduced, or a predetermined range.
- the text data 30 in the range corresponding to the reproduced voice up to the time when the reproduction up to the end of the reproduction may be displayed after the end of the reproduction.
- the operation instruction of the user U may be received and displayed.
- the text information generation unit 106 accepts an editing operation of the text data 30 displayed on the display device 132, and updates the text data 30 according to the editing operation.
- the user U can perform an editing operation by using an input device 134 such as a keyboard, a mouse, a touch panel, and an operation switch.
- the storage processing unit 108 may update the recognition result of the learning data 240 corresponding to the updated text data 30.
- the display device 132 may be included in the voice recognition device 100 or may be an external device.
- the display device 132 is, for example, a liquid crystal display, a plasma display, a CRT (Cathode Ray Tube) display, an organic EL (ElectroLuminescence) display, or the like.
- FIG. 17 is a flowchart showing an operation example of the voice recognition device 100 of the present embodiment.
- the display processing unit 130 causes the display device 132 to display the text data 30 generated by the text information generation unit 106 (step S161). Then, the editing operation of the user U is accepted by the operation menu for accepting the editing operation (step S163).
- a word whose likelihood of the recognition result 22 by the voice recognition unit 104 is equal to or less than the reference value is highlighted so as to be distinguishable from other parts, and the user U is made to highlight it. You may ask for confirmation. User U can check if the highlighted word is correct and edit it if necessary.
- the text information generation unit 106 updates the text data 30 according to the editing operation received in step S163 (step S165).
- the user U can check the transcribed text data 30 and correct it as necessary, so that the accuracy of the transcribed text data 30 is improved.
- the voice reproduction unit 102 receives the section voice associated with the text of the received portion. 12 may be reproduced.
- the correctness of the text data 30 can be confirmed by reproducing the section voice 12 that is the source of the text data 30, and further, correction can be made by an editing operation.
- the voice recognition device 100 may further include a specific unit (not shown) that identifies one of the voice recognition engines 200 existing for each user, which corresponds to the user indicated by the user ID of the learning data.
- the voice recognition engine 200 corresponding to the user ID of the learning data is specified by the specific unit, and the learning data can be trained by the specified recognition engine 200.
- a voice reproduction means for reproducing the target voice for voice recognition divided into predetermined sections for each predetermined section, and A voice recognition means for recognizing a spoken voice in which the user repeats the target voice for each target voice.
- a text information generating means that generates text information of the spoken voice based on the recognition result of the voice recognition means, and A storage means for storing the identification information for each user, the uttered voice, and the recognition result corresponding to the uttered voice as learning data in association with each other.
- the voice recognition means is a voice recognition device that recognizes using a recognition engine learned from the learning data for each user.
- the voice reproduction means interrupts the reproduction of the target voice, and then a time point before the time when the reproduction is interrupted. Resume playback of the target audio from the section of 1.
- the voice recognition device described in. 3. 3.
- the voice reproduction means does not interrupt the reproduction of the target voice when the spoken voice repeated by the user is not recognized in a section different from the section in which the target voice is reproduced, which is divided in advance. 2.
- the voice recognition device described in. 4. The voice reproduction means changes the reproduction speed of the target voice in a certain section according to the voice input speed when the spoken voice repeated by the user is input to the section before the section. 1. 1. From 3.
- the voice recognition device according to any one of the above. 5.
- the storage means stores the target voice of the predetermined section in association with the spoken voice repeated by the user after the voice reproducing means reproduces the target voice of the predetermined section. 1. 1. From 4. The voice recognition device according to any one of the above. 6.
- the voice reproduction means after reproducing the voice recognition target voice of the first language, The voice recognition means voice-recognizes the uttered voice of the first language and the uttered voice uttered by translating the first language into a second language, respectively.
- the text information generating means generates the text information of the spoken voice of the first language and the second language, respectively, based on the recognition result by the voice recognition means.
- the storage means stores the spoken voice of the first language repeated by the user, the spoken voice of the second language, and the target voice of the first language reproduced by the voice reproducing means in association with each other. Let, 1. 1. From 5. The voice recognition device according to any one of the above. 7. Among the words spoken by the user, a registration means for registering a word that could not be recognized by the voice recognition means as an unknown word in the dictionary is further provided. 1. 1. From 6. The voice recognition device according to any one of the above. 8. A display means for displaying the text information is further provided. 1. 1. From 7. The voice recognition device according to any one of the above. 9. The text information generating means accepts an editing operation of the text information displayed on the display means, and updates the text information according to the editing operation. 8. The voice recognition device described in.
- the voice recognition device The target voice for voice recognition, which is divided into predetermined sections, is reproduced for each predetermined section. For each target voice, the user recognizes the spoken voice that repeats the target voice. Based on the recognition result of the utterance voice, the text information of the utterance voice is generated. The identification information for each user is associated with the uttered voice and the recognition result corresponding to the uttered voice, and stored as learning data. A voice recognition method for recognizing an uttered voice by using a recognition engine learned from the learning data for each user. 11.
- the voice recognition device If the user does not recognize the spoken voice repeated by the user within a certain period of time, the reproduction of the target voice is interrupted, and then the reproduction of the target voice is restarted from the section before the time when the reproduction is interrupted. , 10.
- the voice recognition device In a section different from the section in which the target voice is reproduced, which is divided in advance, the reproduction of the target voice is not interrupted when the spoken voice repeated by the user is not recognized. 11.
- the voice recognition method described in. 13 The voice recognition device The reproduction speed of the target voice in a certain section is changed according to the voice input speed when the spoken voice repeated by the user is input to the section before the section. 10. From 12.
- the voice recognition device After playing the target voice in the predetermined section, the spoken voice repeated by the user is associated with the target voice in the predetermined section and stored. 10. To 13. The voice recognition method described in any one of the above. 15. The voice recognition device After playing the voice recognition target voice of the first language The uttered voice of the first language that was repeated and the uttered voice that was uttered by translating the first language into a second language were voice-recognized. Based on the recognition result, the text information of the utterance voice of the first language and the second language is generated, respectively. The uttered voice of the first language recited by the user, the uttered voice of the second language, and the reproduced target voice of the first language are stored in association with each other. 10. From 14.
- the voice recognition method described in any one of the above. 16 The voice recognition device further Among the words spoken by the user, the unrecognized words are registered in the dictionary as unknown words. 10. To 15. The voice recognition method described in any one of the above. 17. The voice recognition device further Displaying the text information on the display unit, 10. From 16. The voice recognition method described in any one of the above. 18. The voice recognition device The editing operation of the text information displayed on the display unit is accepted, and the text information is updated according to the editing operation. 17. The voice recognition method described in.
- a procedure for reproducing the target voice for voice recognition divided into predetermined sections for each predetermined section A procedure for recognizing a spoken voice in which a user repeats the target voice for each target voice using a recognition engine learned from the learning data for each user.
- a procedure for generating text information of the utterance voice based on the recognition result of the utterance voice A program for executing a procedure of associating the utterance voice and the recognition result corresponding to the utterance voice with the identification information for each user and storing them as learning data.
- In order to make the computer further execute the procedure of registering the unrecognized words in the dictionary as unknown words among the words spoken by the user. 19. From 24.
- To make the computer further execute the procedure for displaying the text information on the display unit. 19. To 25.
- the program described in any one of. 27. A procedure for accepting an editing operation of the text information displayed on the display unit and updating the text information according to the editing operation, for causing the computer to execute the procedure. 26.
Landscapes
- Engineering & Computer Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Multimedia (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Computational Linguistics (AREA)
- Theoretical Computer Science (AREA)
- Artificial Intelligence (AREA)
- General Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Machine Translation (AREA)
- Electrically Operated Instructional Devices (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US17/760,847 US20220335951A1 (en) | 2019-09-27 | 2020-09-08 | Speech recognition device, speech recognition method, and program |
| JP2021548767A JP7416078B2 (ja) | 2019-09-27 | 2020-09-08 | 音声認識装置、音声認識方法、およびプログラム |
| US19/324,688 US20260011333A1 (en) | 2019-09-27 | 2025-09-10 | Speech recognition device, speech recognition method, and program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019176484 | 2019-09-27 | ||
| JP2019-176484 | 2019-09-27 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/760,847 A-371-Of-International US20220335951A1 (en) | 2019-09-27 | 2020-09-08 | Speech recognition device, speech recognition method, and program |
| US19/324,688 Continuation US20260011333A1 (en) | 2019-09-27 | 2025-09-10 | Speech recognition device, speech recognition method, and program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021059968A1 true WO2021059968A1 (ja) | 2021-04-01 |
Family
ID=75166092
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/033974 Ceased WO2021059968A1 (ja) | 2019-09-27 | 2020-09-08 | 音声認識装置、音声認識方法、およびプログラム |
Country Status (3)
| Country | Link |
|---|---|
| US (2) | US20220335951A1 (https=) |
| JP (1) | JP7416078B2 (https=) |
| WO (1) | WO2021059968A1 (https=) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7288530B1 (ja) | 2022-03-09 | 2023-06-07 | 陸 荒川 | システムおよびプログラム |
| WO2025191650A1 (ja) * | 2024-03-11 | 2025-09-18 | ファナック株式会社 | 音声コマンド作成装置、及びコンピュータが読み取り可能な記憶媒体 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003345379A (ja) * | 2002-03-20 | 2003-12-03 | Japan Science & Technology Corp | 音声映像変換装置及び方法、音声映像変換プログラム |
| JP2004170765A (ja) * | 2002-11-21 | 2004-06-17 | Sony Corp | 音声処理装置および方法、記録媒体並びにプログラム |
| JP2013182261A (ja) * | 2012-03-05 | 2013-09-12 | Nippon Hoso Kyokai <Nhk> | 適応化装置、音声認識装置、およびそのプログラム |
| JP2014240940A (ja) * | 2013-06-12 | 2014-12-25 | 株式会社東芝 | 書き起こし支援装置、方法、及びプログラム |
| JP2017161726A (ja) * | 2016-03-09 | 2017-09-14 | 株式会社アドバンスト・メディア | 情報処理装置、情報処理システム、サーバ、端末装置、情報処理方法及びプログラム |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010197669A (ja) * | 2009-02-25 | 2010-09-09 | Kyocera Corp | 携帯端末、編集誘導プログラムおよび編集装置 |
| JP6430137B2 (ja) * | 2014-03-25 | 2018-11-28 | 株式会社アドバンスト・メディア | 音声書起支援システム、サーバ、装置、方法及びプログラム |
| WO2017068826A1 (ja) * | 2015-10-23 | 2017-04-27 | ソニー株式会社 | 情報処理装置、情報処理方法、およびプログラム |
-
2020
- 2020-09-08 WO PCT/JP2020/033974 patent/WO2021059968A1/ja not_active Ceased
- 2020-09-08 JP JP2021548767A patent/JP7416078B2/ja active Active
- 2020-09-08 US US17/760,847 patent/US20220335951A1/en not_active Abandoned
-
2025
- 2025-09-10 US US19/324,688 patent/US20260011333A1/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003345379A (ja) * | 2002-03-20 | 2003-12-03 | Japan Science & Technology Corp | 音声映像変換装置及び方法、音声映像変換プログラム |
| JP2004170765A (ja) * | 2002-11-21 | 2004-06-17 | Sony Corp | 音声処理装置および方法、記録媒体並びにプログラム |
| JP2013182261A (ja) * | 2012-03-05 | 2013-09-12 | Nippon Hoso Kyokai <Nhk> | 適応化装置、音声認識装置、およびそのプログラム |
| JP2014240940A (ja) * | 2013-06-12 | 2014-12-25 | 株式会社東芝 | 書き起こし支援装置、方法、及びプログラム |
| JP2017161726A (ja) * | 2016-03-09 | 2017-09-14 | 株式会社アドバンスト・メディア | 情報処理装置、情報処理システム、サーバ、端末装置、情報処理方法及びプログラム |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7288530B1 (ja) | 2022-03-09 | 2023-06-07 | 陸 荒川 | システムおよびプログラム |
| JP2023131648A (ja) * | 2022-03-09 | 2023-09-22 | 陸 荒川 | システムおよびプログラム |
| WO2025191650A1 (ja) * | 2024-03-11 | 2025-09-18 | ファナック株式会社 | 音声コマンド作成装置、及びコンピュータが読み取り可能な記憶媒体 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2021059968A1 (https=) | 2021-04-01 |
| JP7416078B2 (ja) | 2024-01-17 |
| US20220335951A1 (en) | 2022-10-20 |
| US20260011333A1 (en) | 2026-01-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11978432B2 (en) | On-device speech synthesis of textual segments for training of on-device speech recognition model | |
| JP6740504B1 (ja) | 発話分類器 | |
| US12548549B2 (en) | On-device personalization of speech synthesis for training of speech recognition model(s) | |
| US11676572B2 (en) | Instantaneous learning in text-to-speech during dialog | |
| US20260011333A1 (en) | Speech recognition device, speech recognition method, and program | |
| JP2016062357A (ja) | 音声翻訳装置、方法およびプログラム | |
| JP2014240940A (ja) | 書き起こし支援装置、方法、及びプログラム | |
| US20250118298A1 (en) | System and method for optimizing a user interaction session within an interactive voice response system | |
| KR20240122776A (ko) | 뉴럴 음성 합성의 적응 및 학습 | |
| WO2024178262A1 (en) | Personalized aphasia communication assistant system | |
| JP2014134640A (ja) | 文字起こし装置およびプログラム | |
| JP7326931B2 (ja) | プログラム、情報処理装置、及び情報処理方法 | |
| US7092884B2 (en) | Method of nonvisual enrollment for speech recognition | |
| EP4261822A1 (en) | Setting up of speech processing engines | |
| KR102362815B1 (ko) | 음성 인식 선곡 서비스 제공 방법 및 음성 인식 선곡 장치 | |
| JP2020034832A (ja) | 辞書生成装置、音声認識システムおよび辞書生成方法 | |
| JPWO2018043139A1 (ja) | 情報処理装置および情報処理方法、並びにプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20869210 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021548767 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20869210 Country of ref document: EP Kind code of ref document: A1 |