WO2021006117A1 - Dispositif de traitement de synthèse vocale, procédé de traitement de synthèse vocale et programme - Google Patents
Dispositif de traitement de synthèse vocale, procédé de traitement de synthèse vocale et programme Download PDFInfo
- Publication number
- WO2021006117A1 WO2021006117A1 PCT/JP2020/025682 JP2020025682W WO2021006117A1 WO 2021006117 A1 WO2021006117 A1 WO 2021006117A1 JP 2020025682 W JP2020025682 W JP 2020025682W WO 2021006117 A1 WO2021006117 A1 WO 2021006117A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data
- unit
- processing
- context label
- acquired
- Prior art date
Links
- 238000012545 processing Methods 0.000 title claims abstract description 734
- 230000015572 biosynthetic process Effects 0.000 title claims abstract description 227
- 238000003786 synthesis reaction Methods 0.000 title claims abstract description 227
- 238000003672 processing method Methods 0.000 title claims description 11
- 238000000034 method Methods 0.000 claims abstract description 236
- 230000008569 process Effects 0.000 claims abstract description 209
- 238000004458 analytical method Methods 0.000 claims abstract description 92
- 238000003062 neural network model Methods 0.000 claims abstract description 31
- 238000013528 artificial neural network Methods 0.000 claims description 104
- 239000002131 composite material Substances 0.000 claims description 36
- 238000004364 calculation method Methods 0.000 claims description 34
- 238000006243 chemical reaction Methods 0.000 claims description 25
- 239000000203 mixture Substances 0.000 claims description 3
- 238000005457 optimization Methods 0.000 abstract description 32
- 230000000875 corresponding effect Effects 0.000 description 92
- 230000006870 function Effects 0.000 description 46
- 230000002441 reversible effect Effects 0.000 description 30
- PXFBZOLANLWPMH-UHFFFAOYSA-N 16-Epiaffinine Natural products C1C(C2=CC=CC=C2N2)=C2C(=O)CC2C(=CC)CN(C)C1C2CO PXFBZOLANLWPMH-UHFFFAOYSA-N 0.000 description 29
- 230000004048 modification Effects 0.000 description 27
- 238000012986 modification Methods 0.000 description 27
- 230000009466 transformation Effects 0.000 description 26
- 230000007246 mechanism Effects 0.000 description 22
- 238000010586 diagram Methods 0.000 description 16
- 230000004913 activation Effects 0.000 description 14
- 238000010606 normalization Methods 0.000 description 13
- 230000008878 coupling Effects 0.000 description 12
- 238000010168 coupling process Methods 0.000 description 12
- 238000005859 coupling reaction Methods 0.000 description 12
- 230000005236 sound signal Effects 0.000 description 8
- 239000011159 matrix material Substances 0.000 description 7
- 238000004611 spectroscopical analysis Methods 0.000 description 6
- 210000000225 synapse Anatomy 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 4
- 230000001537 neural effect Effects 0.000 description 4
- 238000003860 storage Methods 0.000 description 4
- 230000002194 synthesizing effect Effects 0.000 description 4
- 238000009826 distribution Methods 0.000 description 3
- 230000015654 memory Effects 0.000 description 3
- 230000000306 recurrent effect Effects 0.000 description 3
- 238000012549 training Methods 0.000 description 3
- 238000011282 treatment Methods 0.000 description 3
- 238000004891 communication Methods 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 239000004065 semiconductor Substances 0.000 description 2
- 230000002457 bidirectional effect Effects 0.000 description 1
- 210000004027 cell Anatomy 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 230000006866 deterioration Effects 0.000 description 1
- 230000010365 information processing Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 230000006403 short-term memory Effects 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
Images













Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
- G10L13/10—Prosody rules derived from text; Stress or intonation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/27—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique
- G10L25/30—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique using neural networks
Definitions
- the present invention relates to a speech synthesis processing technique.
- it relates to a text-to-speech (TTS) technique for converting text into speech.
- TTS text-to-speech
- TTS text speech synthesis
- high quality speech synthesis has become possible in recent years with the introduction of neural networks.
- the text-speech synthesis technology when synthesizing English-speech, the text-speech synthesis technology using the sequence-to-sequence method that learns and optimizes the phonetic continuation length and the acoustic model at the same time is used.
- the mel spectrogram is estimated from the text, and the voice waveform is acquired from the estimated mel spectrogram by the neural vocabulary.
- Non-Patent Document 1 a system using the above-mentioned text-to-speech synthesis technology, when the processing target language is English, it is possible to synthesize speech with the same quality as human speech (for example, Non-Patent Document 1). reference).
- Japanese is a language that uses kanji
- the number of kanji is enormous, and there are many variations in reading kanji, so Japanese text can be used as a model for text-to-sequence synthesis using the sequence-to-sequence method.
- the present invention considers the text speech using the sequence-to-sequence method even when a language other than English such as Japanese is used as the processing target language (the processing target language can be any language).
- the purpose is to realize a speech synthesis processing device, a speech synthesis processing method, and a program that learn and optimize by a model of a neural network for synthesis and realize high-quality speech synthesis processing.
- the first invention for solving the above problems is a speech synthesis processing device that executes speech synthesis processing using an encoder / decoder-type neural network with an arbitrary language as a processing target language, and includes a text analysis unit and a text analysis unit. , A full context label vector processing unit, an encoder unit, and a decoder unit.
- the text analysis unit executes text analysis processing on the text data of the language to be processed and acquires the context label data.
- the full context label vector processing unit acquires a context label for a single sound element that is a processing target in the process of acquiring the context label data from the context label data acquired by the text analysis unit, thereby performing a neural network. Get optimized full context label data suitable for the learning process of.
- the encoder unit acquires hidden state data by executing neural network encoding processing based on the optimized full context label data.
- the decoder unit acquires the acoustic feature data corresponding to the optimized full context label data by executing the decoding process of the neural network based on the hidden state data.
- the vocoder acquires audio waveform data from the acoustic features acquired by the decoder unit.
- this speech synthesis processing device processing (learning processing, prediction processing) by the neural network is executed using the optimized full context label data suitable for processing by the model of the neural network, so that the speech synthesis processing is highly accurate. Can be executed. That is, unlike the prior art, this speech synthesis processing device acquires and acquires context label data that does not include data on the phonemes that precede or follow the phoneme to be processed as optimized full context label data. The optimized full context label data is used to process the model of the neural network. In a neural network (particularly, a sequence-to-sequence type neural network), processing using time-series data is executed, so the processing target that had to be included in the context label data used in the conventional speech synthesis processing.
- the data that precedes or follows the phoneme of is redundant in the processing of the model of the neural network, which causes a decrease in processing efficiency. Since the speech synthesis processing device 100 uses the optimized full context label data (context label data composed of data about a single phoneme), the processing of the neural network model can be executed very effectively. As a result, this speech synthesis processing device can execute high-precision speech synthesis processing.
- this speech synthesis processing device performs text analysis processing according to the language to be processed, and from the full context label data acquired by the text analysis processing, a neural network (for example, a neural using a sequence-to-sequence method).
- a neural network for example, a neural using a sequence-to-sequence method.
- the processing target language can be any language
- a text using the sequence-to-sequence method By using a model of a neural network for speech synthesis, it is possible to perform learning and optimization and realize high-quality speech synthesis processing.
- single phoneme refers to the phoneme to be processed when the context label data is acquired in the text analysis process.
- optimization is a concept that includes keeping a predetermined error range within an allowable range.
- the second invention is the first invention, and the acoustic features are mel spectrogram data.
- this voice synthesis processing device can execute voice synthesis processing using the mel spectrogram data corresponding to the input text.
- the third invention is the first or second invention, and the vocoder acquires voice waveform data from the acoustic features by executing processing using the model of the neural network.
- this speech synthesis processing device can execute speech synthesis processing using a vocoder capable of neural network processing.
- the fourth invention is the third invention, in which the vocoder acquires voice waveform data from acoustic features by executing processing using a model of a neural network configured by a reversible conversion network.
- the vocoder performs processing using a model of a neural network configured by a reversible conversion network, so that the vocoder configuration can be simplified.
- the processing in the vocoder can be speeded up, and the voice synthesis processing can be executed in real time.
- the fifth invention is any one of the first to fourth inventions, further including a phoneme continuation length estimation unit that estimates the phoneme continuation length from the context label data of the phoneme unit.
- the full-context label vector processing unit continues the phoneme optimization full-context label data corresponding to the estimated phoneme continuation length during the period corresponding to the estimated phoneme continuation length, which is the phoneme continuation length estimated by the phoneme continuation length estimation unit. And output to the encoder section.
- the speech synthesis processing apparatus the input data to the encoder unit (optimized full context label data), on the basis of the phoneme duration of each phoneme obtained (estimated) by the phoneme duration estimation unit, stretching treatment (phoneme ph k )
- stretching treatment phoneme ph k
- the phoneme continuation length is estimated by using a model such as a hidden Markov model, which can stably and appropriately estimate the phoneme continuation length (phoneme continuation length estimation unit). (Processing by), and (2) the acoustic features are acquired by processing with a neural network model using the sequence-to-sequence method.
- a model such as a hidden Markov model, which can stably and appropriately estimate the phoneme continuation length (phoneme continuation length estimation unit).
- the acoustic features are acquired by processing with a neural network model using the sequence-to-sequence method.
- this speech synthesis processing device appropriately prevents problems such as failure of attention mechanism prediction, synthetic utterance stopping in the middle, and repeating the same phrase many times. At the same time, it is possible to execute highly accurate speech synthesis processing.
- the sixth invention is a speech synthesis processing method in which an arbitrary language is used as a processing target language and speech synthesis processing is executed using an encoder / decoder neural network, and is a text analysis step and a full context label vector processing step. , An encoding processing step, a decoding processing step, and a vocoder processing step.
- the text analysis process is executed on the text data of the language to be processed, and the context label data is acquired.
- the full context label vector processing step is a neural network by acquiring the context label for a single phone that is the sound element processed in the process of acquiring the context label data from the context label data acquired by the text analysis step. Get optimized full context label data suitable for the learning process of.
- the encoding process step acquires hidden state data by executing the neural network encoding process based on the optimized full context label data.
- the decoding process step acquires the acoustic feature data corresponding to the optimized full context label data by executing the decoding process of the neural network based on the hidden state data.
- the vocoder processing step acquires voice waveform data from the acoustic features acquired by the decoding processing step.
- the seventh invention is a program for causing a computer to execute the voice synthesis processing method of the sixth invention.
- the eighth invention is a speech synthesis processing apparatus that executes speech synthesis processing using an encoder / decoder type neural network with an arbitrary language as a processing target language, and is a text analysis unit and a full context label vector processing unit. It also includes an encoder unit, a phoneme continuation length estimation unit, a forced attention unit, an internal division processing unit, a context calculation unit, a decoder unit, and a vocoder.
- the text analysis unit executes text analysis processing on the text data of the language to be processed and acquires the context label data.
- the full context label vector processing unit acquires a context label for a single sound element that is a processing target in the process of acquiring the context label data from the context label data acquired by the text analysis unit, thereby performing a neural network. Get optimized full context label data suitable for the learning process of.
- the encoder unit acquires hidden state data by executing neural network encoding processing based on the optimized full context label data.
- the phoneme continuation length estimation unit estimates the phoneme continuation length from the context label data of each phoneme.
- the forced attention unit acquires the first weighting coefficient data based on the phoneme continuation length estimated by the phoneme continuation length estimation unit.
- the attention unit acquires the second weighting coefficient data based on the hidden state data acquired by the encoder unit.
- the internal division processing unit acquires the combined weighting coefficient data by performing internal division processing on the first weighting coefficient data and the second weighting coefficient data.
- the context calculation unit acquires the context state data by executing the weighting composition process on the hidden state data acquired by the encoder unit based on the composition weighting coefficient data.
- the decoder unit acquires the acoustic feature data corresponding to the optimized full context label data by executing the decoding process of the neural network based on the context state data.
- the vocoder acquires audio waveform data from the acoustic features acquired by the decoder unit.
- the phoneme continuation length is acquired by estimation processing (processing by the phoneme continuation length estimation unit) using a model such as a hidden Markov model, which can stably and appropriately estimate the phoneme continuation length.
- the prediction accuracy of the phoneme continuation length is guaranteed by processing using the phoneme continuation length. That is, in this speech synthesis processing device, the phoneme continuation length acquired by the estimation process (processing by the phoneme continuation length estimation unit) using a model such as the hidden Markov model, which can stably and appropriately estimate the phoneme continuation length.
- the prediction process is executed using the context state data generated by the weighting coefficient data obtained by appropriately synthesizing the weighting coefficient data acquired by the forced attention unit and the weighting coefficient data acquired by the attention unit using.
- this speech synthesis processing device even if the prediction of the attention mechanism fails (when appropriate weighting coefficient data cannot be acquired by the attention unit), the weighting by the weighting coefficient data acquired by the forced attention unit is weighted. Since the coefficient data can be acquired, it is possible to prevent the failure of the attention mechanism prediction from affecting the speech synthesis process.
- the acoustic features can be acquired by processing with a neural network model using the sequence-to-sequence method, so that highly accurate prediction processing of the acoustic features can be realized.
- this speech synthesis processing device appropriately prevents problems such as failure of attention mechanism prediction, synthetic utterance stopping in the middle, and repeating the same phrase many times. At the same time, it is possible to execute highly accurate speech synthesis processing.
- the internal division ratio when the internal division processing is executed may be a fixed value or a dynamically changing (updated) value.
- the processing target language can be any language
- a neural for text-to-speech synthesis using the sequence-to-sequence method is used as the processing target language (the processing target language can be any language)
- the network model it is possible to realize a speech synthesis processing device, a speech synthesis processing method, and a program that perform learning / optimization and realize high-quality speech synthesis processing.
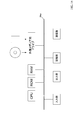
- the schematic block diagram of the speech synthesis processing apparatus 100 which concerns on 1st Embodiment.
- TTS processing (processing target language: Japanese) is executed by the speech synthesis processing device of the first modification of the first embodiment, and the mel spectrogram (prediction data) of the acquired speech waveform data and the actual speech waveform data of the input text.
- Schematic configuration diagram of the speech synthesis processing device 200 according to the second embodiment The figure for demonstrating the process of generating the data Dx2 to be input to the encoder part 3 based on the estimated phoneme continuation length.
- the schematic block diagram of the speech synthesis processing apparatus 300 which concerns on 3rd Embodiment.
- the block diagram which shows the hardware structure of the computer which realizes the speech synthesis processing apparatus which concerns on this invention.
- FIG. 1 is a schematic configuration diagram of the speech synthesis processing device 100 according to the first embodiment.
- the speech synthesis processing device 100 includes a text analysis unit 1, a full context label vector processing unit 2, an encoder unit 3, an attention unit 4, a decoder unit 5, and a vocoder 6.
- the text analysis unit 1 inputs the text data Din of the language to be processed, executes the text analysis process on the input text data Din, and performs a text analysis process on the input text data Din, which is a context label which is a phonetic label including a context composed of various language information. Get the series. Note that in languages such as Japanese, where the same character (for example, Kanji) has a different voice waveform when pronounced, depending on the accent and pitch, the phonemes before and after the phoneme (phoneme to be processed) Language information should also be included in the context label. As described above, the text analysis unit 1 includes the context label (preceding phoneme required by the processing target language and / or the data of the succeeding phoneme) for specifying the speech waveform when the text is pronounced. The full context label data Dx1 is output to the full context label vector processing unit 2.
- the full context label vector processing unit 2 inputs the data Dx1 (full context label data) output from the text analysis unit 1.
- the full context label vector processing unit 2 performs full context label vector processing for acquiring full context label data suitable for training processing of a sequence-to-sequence neural network model from the input full context label data Dx1. To execute. Then, the full context label vector processing unit 2 outputs the data acquired by the full context label vector processing as data Dx2 (optimized full context label data Dx2) to the encoder side prenet processing unit 31 of the encoder unit 3.
- the encoder unit 3 includes an encoder-side prenet processing unit 31 and an encoder-side LSTM layer 32 (LSTM: Long short-term memory).
- LSTM Long short-term memory
- the encoder-side prenet processing unit 31 inputs the data Dx2 output from the full context label vector processing unit 2.
- the encoder-side prenet processing unit 31 performs convolution processing (processing by a convolution filter), data normalization processing, and processing by an activation function (for example, ReLU: Selected Liner Unit) for the input data Dx2. ) Is executed to acquire data that can be input to the LSTM layer 32 on the encoder side. Then, the encoder-side prenet processing unit 31 outputs the data acquired by the above processing (pre-net processing) to the encoder-side LSTM layer 32 as data Dx3.
- the LSTM layer 32 on the encoder side is a layer corresponding to the hidden layer (LSTM layer) of the recurrent neural network, and the data Dx3 (this is the data Dx3 (t)) output from the prenet processing unit 31 on the encoder side at the current time t. ) And the data Dx4 (this is referred to as data Dx4 (t-1)) output from the encoder-side LSTM layer 32 in the previous time step.
- the LSTM layer 32 on the encoder side executes processing by the LSTM layer on the input data Dx3 (t) and data Dx4 (t-1), and uses the processed data as data Dx4 (data Dx4 (t)). Output to the attention unit 4.
- the attention unit 4 inputs the data Dx4 output from the encoder unit 3 and the data ho (output side hidden state data ho) output from the decoder side LSTM layer 52 of the decoder unit 5.
- the attention unit 4 outputs the acquired context state data c (t) to the decoder side LSTM layer 52.
- the decoder unit 5 includes a decoder-side pre-net processing unit 51, a decoder-side LSTM layer 52, a linear prediction unit 53, a post-net processing unit 54, and an adder 55.
- the decoder-side prenet processing unit 51 inputs the data Dy4 (this is called Dy4 (t-1)) one hour before the step, which is output from the linear prediction unit 53.
- the decoder-side prenet processing unit 51 has, for example, a plurality of layers (for example, two layers) of fully connected layers, and data normalization processing (for example, data (vector data) output from the linear prediction unit 53).
- data normalization processing for example, data (vector data) output from the linear prediction unit 53.
- processing by the activation function for example, processing by the ReLU function (ReLU: Rectifier Liner Unit)
- ReLU Rectifier Liner Unit
- processing by the activation function for example, processing by the ReLU function (ReLU: Rectifier Liner Unit)
- the decoder-side prenet processing unit 51 outputs the data acquired by the above processing (pre-net processing) to the decoder-side LSTM layer 52 as data Dy2.
- the decoder-side LSTM layer 52 is a layer corresponding to the hidden layer (LSTM layer) of the recurrent neural network.
- the decoder-side LSTM layer 52 includes data Dy2 (this is referred to as data Dy2 (t)) output from the decoder-side prenet processing unit 51 at the current time t, and the decoder-side LSTM in the previous time step.
- the data Dy3 output from the layer 52 (this is referred to as data Dy3 (t-1)) and the context state data c (t) at time t output from the attention unit 4 are input.
- the decoder-side LSTM layer 52 executes processing by the LSTM layer using the input data Dy2 (t), data Dy3 (t-1), and context state data c (t), and obtains the processed data. It is output to the linear prediction unit 53 as data Dy3 (data Dy3 (t)). Further, the decoder side LSTM layer 52 outputs the data Dy3 (t), that is, the output side hidden state data ho (t) at the time t to the attention unit 4.
- the linear prediction unit 53 inputs the data Dy3 output from the decoder side LSTM layer 52.
- the linear prediction unit 53 stores and holds data Dy3 (plurality of data Dy3) output from the decoder-side LSTM layer 52 within a predetermined period (for example, a period corresponding to one frame period for acquiring a mel spectrogram). Then, by performing a linear transformation using the plurality of data Dy3, the prediction data Dy4 of the mel spectrogram in a predetermined period is acquired. Then, the linear prediction unit 53 outputs the acquired data Dy4 to the postnet processing unit 54, the adder 55, and the decoder side prenet processing unit 51.
- a predetermined period for example, a period corresponding to one frame period for acquiring a mel spectrogram
- the post-net processing unit 54 has, for example, a convolution layer having a plurality of layers (for example, five layers), and includes convolution processing (processing by a convolution filter), data normalization processing, and processing by an activation function (processing by an activation function).
- convolution processing processing by a convolution filter
- data normalization processing processing by an activation function
- an activation function processing by an activation function
- the ReLU function Rectifier Liner Unit
- the tanh function processing is executed, the residual data (residual) of the prediction data (prediction mel spectrometer) is acquired, and the acquired residual data is used as data Dy5.
- the ReLU function ReLU: Rectifier Liner Unit
- the adder 55 inputs the prediction data Dy4 (prediction mel spectrometry data) output from the linear prediction unit 53 and the residual data Dy5 (residual data of the prediction mel spectrometry) output from the postnet processing unit 54. To do.
- the adder 55 executes addition processing on the prediction data Dy4 (data of the prediction mel spectrogram) and the residual data Dy5 (residual data of the prediction mel spectrogram), and the data after the addition processing (data of the prediction mel spectrogram). Data) is output to the vocoder 6 as data Dy6.
- the vocoder 6 inputs the data of the acoustic feature amount, and outputs the audio signal waveform corresponding to the acoustic feature amount from the input acoustic feature amount data.
- the vocoder 6 employs a vocoder using a model based on a neural network.
- the vocoder 6 uses the input acoustic features as mel spectrogram data and outputs the audio signal waveform corresponding to the mel spectrogram.
- the bocoder 6 trains a neural network model as a mel spectrogram and a voice signal waveform (teacher data) realized by the mel spectrogram, and acquires the optimization parameters of the parameters of the neural network.
- the vocoder 6 performs the process of optimizing the model of the neural network. Then, the vocoder 6 performs processing using the optimized neural network model at the time of prediction, and from the input mel spectrogram data (for example, the data Dy6 output from the decoder unit 5), the said The audio signal waveform corresponding to the mel spectrogram is predicted, and the data of the predicted audio signal waveform is output as data Dout.
- the input mel spectrogram data for example, the data Dy6 output from the decoder unit 5
- the operation of the speech synthesis processing device 100 will be described separately for (1) learning processing (processing at the time of learning) and (2) prediction processing (processing at the time of prediction).
- the text analysis unit 1 executes a text analysis process on the input text data Din, and acquires a series of context labels which are phonetic labels including contexts composed of various language information.
- Japanese is a language in which the voice waveform when pronounced is different even if the same character (for example, Kanji) is pronounced depending on the accent and pitch, so the language for the phonemes before and after the phoneme (phoneme to be processed). Information should also be included in the context label.
- the text analysis unit 1 executes text analysis processing for Japanese on the text data Din, and obtains parameters for specifying the voice waveform when the text is pronounced. If necessary, (1) data of only the phoneme, (2) data of the preceding phoneme, and / or the succeeding phoneme are acquired, and the acquired data are collectively acquired as full context label data.
- FIG. 2 is a diagram showing information (parameters) (example) included in the full context label data acquired by the text analysis process when the processing target language is Japanese.
- each parameter of the full context label data is data for specifying the content shown in the “outline” of FIG. 2, and is the data for the number of dimensions and the number of phonemes shown in the table of FIG. Is.
- the text analysis unit 1 collects the data of all the parameters in the table of FIG. 2 and acquires them as full context label data (vector data).
- the full context label data is 478-dimensional vector data.
- the full context label data Dx1 acquired as described above is output from the text analysis unit 1 to the full context label vector processing unit 2.
- the full context label vector processing unit 2 performs full context label vector processing for acquiring full context label data suitable for training processing of a sequence-to-sequence neural network model from the input full context label data Dx1. To execute. Specifically, the full context label vector processing unit 2 acquires the optimized full context label data Dx2 by deleting the parameter (data) for the preceding phoneme and the parameter (data) for the succeeding phoneme. For example, when the full context label data Dx1 is data including the parameters shown in FIG. 2, the optimized full context label is deleted by deleting the parameter (data) for the preceding phoneme and the parameter (data) for the succeeding phoneme. Acquire data Dx2.
- FIG. 3 is a diagram showing information (parameters) (example) included in the optimized full context label data acquired as described above.
- the optimized full context label data is 130-dimensional vector data, and it can be seen that the number of dimensions is significantly reduced as compared with the full context label data Dx1 which is 478-dimensional vector data.
- the model of the neural network used in the speech synthesis processing device 100 is a model of a sequence-to-sequence type neural network (recurrent neural network), and has an encoder-side LSTM layer 32 and a decoder-side LSTM layer 52. Therefore, the input data string can be learned and predicted in consideration of the time series relationship, so that the data of the preceding and succeeding neural networks required in the prior art becomes redundant and learned. It causes deterioration of processing efficiency and prediction processing accuracy. Therefore, in the speech synthesis processing device 100, as described above, the optimized full context label data Dx2 acquired by leaving only the parameters (data) for the phoneme is acquired, and the acquired optimized full context label data Dx2 is used. By performing the learning process and the prediction process, the process can be executed at high speed and with high accuracy.
- recurrent neural network recurrent neural network
- the data Dx2 (optimized full context label data Dx2) acquired as described above is output from the full context label vector processing unit 2 to the encoder side prenet processing unit 31 of the encoder unit 3.
- the encoder-side prenet processing unit 31 performs convolution processing (processing by the convolution filter), data normalization processing, and processing by the activation function (for example, processing by the convolution filter) for the data Dx2 input from the full context label vector processing unit 2.
- the ReLU function (process by ReLU: Rectifier Liner Unit) is executed, and the data that can be input to the LSTM layer 32 on the encoder side is acquired. Then, the encoder-side prenet processing unit 31 outputs the data acquired by the above processing (pre-net processing) to the encoder-side LSTM layer 32 as data Dx3.
- the encoder-side LSTM layer 32 includes data Dx3 (t) output from the encoder-side prenet processing unit 31 at the current time t and data Dx4 (data Dx4) output from the encoder-side LSTM layer 32 in the previous time step. Enter t-1). Then, the encoder side LSTM layer 32 executes the processing by the LSTM layer on the input data Dx3 (t) and data Dx4 (t-1), and the processed data is data Dx4 (data Dx4 (t)). ) Is output to the attention unit 4.
- the attention unit 4 inputs the data Dx4 output from the encoder unit 3 and the data ho (output side hidden state data ho) output from the decoder side LSTM layer 52 of the decoder unit 5.
- the attention unit 4 stores and holds the data Dy3 output from the decoder side LSTM layer 52 of the decoder unit 5, that is, the output side hidden state data ho for a predetermined time step.
- the attention unit 4 outputs the acquired context state data c (t) to the decoder side LSTM layer 52.
- the decoder-side prenet processing unit 51 inputs the data Dy4 (t-1) one hour before the step, which is output from the linear prediction unit 53.
- the decoder-side prenet processing unit 51 has, for example, a plurality of layers (for example, two layers) fully connected layers, and data normalization processing (for example, data (vector data) output from the linear prediction unit 53).
- data normalization processing for example, data (vector data) output from the linear prediction unit 53.
- processing by the activation function for example, processing by the ReLU function (ReLU: Rectifier Unit)
- ReLU Rectifier Unit
- processing by the activation function for example, processing by the ReLU function (ReLU: Rectifier Unit)
- data that can be input to the decoder side LSTM layer 52 is acquired.
- the decoder-side prenet processing unit 51 outputs the data acquired by the above processing (pre-net processing) to the decoder-side LSTM layer 52 as data Dy2.
- the decoder-side LSTM layer 52 includes data Dy2 (t) output from the decoder-side prenet processing unit 51 at the current time t and data Dy3 (data dy3) output from the decoder-side LSTM layer 52 in the previous time step.
- the t-1) and the context state data c (t) at time t output from the attention unit 4 are input.
- the decoder-side LSTM layer 52 executes processing by the LSTM layer using the input data Dy2 (t), data Dy3 (t-1), and context state data c (t), and obtains the processed data. It is output to the linear prediction unit 53 as data Dy3 (t). Further, the decoder side LSTM layer 52 outputs the data Dy3 (t), that is, the output side hidden state data ho (t) at the time t to the attention unit 4.
- the linear prediction unit 53 inputs the data Dy3 output from the decoder side LSTM layer 52.
- the linear prediction unit 53 stores and holds data Dy3 (plurality of data Dy3) output from the decoder-side LSTM layer 52 within a predetermined period (for example, a period corresponding to one frame period for acquiring a mel spectrogram). Then, by performing a linear transformation using the plurality of data Dy3, the prediction data Dy4 of the mel spectrogram in a predetermined period is acquired. Then, the linear prediction unit 53 outputs the acquired data Dy4 to the postnet processing unit 54, the adder 55, and the decoder side prenet processing unit 51.
- a predetermined period for example, a period corresponding to one frame period for acquiring a mel spectrogram
- the post-net processing unit 54 may, for example, perform convolution processing (processing by a convolution filter), data normalization processing, processing by an activation function (for example, processing by a ReLU function (ReLU: Directified Liner Unit), or processing by a tanh function). ) Is executed, the residual data (residual) of the predicted data (predicted mel spectrogram) is acquired, and the acquired residual data is output to the adder 55 as data Dy5.
- convolution processing processing by a convolution filter
- data normalization processing processing by an activation function (for example, processing by a ReLU function (ReLU: Directified Liner Unit), or processing by a tanh function).
- the adder 55 inputs the prediction data Dy4 (prediction mel spectrometry data) output from the linear prediction unit 53 and the residual data Dy5 (residual data of the prediction mel spectrometry) output from the postnet processing unit 54. To do.
- the adder 55 executes an addition process on the predicted data Dy4 (data of the predicted mel spectrogram) and the residual data Dy5 (residual data of the predicted mel spectrogram), and the data after the addition process (the data of the predicted mel spectrometer). Data) is output as data Dy6.
- the speech synthesis processing device 100 the data Dy6 (predicted mel spectrogram data) acquired as described above and the teacher data (correct mel spectrogram) of the mel spectrogram (acoustic feature amount) corresponding to the text data Din.
- the parameters of the model of the neural network of the encoder unit 3 and the decoder unit 5 are updated so that the difference between the two (comparison result) (for example, the difference expressed by the norm of the difference vector and the Euclidean distance) becomes small.
- this parameter update process is repeatedly executed, and the data Dy6 (predicted mel spectrogram data) and the mel spectrogram (acoustic feature amount) teacher data (correct mel spectrogram) corresponding to the text data Din are obtained.
- the difference between the two becomes sufficiently small (within a predetermined error range)
- the parameters of the neural network model are acquired as the optimization parameters.
- the coupling coefficient (weighting coefficient) between synapses included in each layer of the neural network model of the encoder unit 3 and the decoder unit 5 is set based on the optimization parameters acquired as described above.
- the model of the neural network of the encoder unit 3 and the decoder unit 5 can be used as an optimized model (trained model).
- the speech synthesis processing device 100 it is possible to construct a trained model (optimized model) of a neural network in which the input is text data and the output is mel spectrogram.
- the input acoustic feature amount is used as mel spectrogram data
- the output is used as the audio signal waveform corresponding to the mel spectrogram to execute the learning process. .. That is, in the vocoder 6, the mel spectrogram data is input, the voice synthesis process is executed by the process using the model by the neural network, and the voice waveform data is output.
- the audio waveform data output from the vocoder 6 is compared with the audio waveform data (correct audio waveform data) corresponding to the mel specogram input to the vocoder, and the difference between the two (comparison result) (for example, the norm of the difference vector).
- the parameter of the model of the vocoder 6's neural network is updated so that the difference expressed by the Euclidean distance) becomes small.
- this parameter update process is repeatedly executed, and the difference between the input data of the vocoder (mel specogram data) and the voice waveform data (correct voice waveform data) corresponding to the mel specogram input to the vocoder 6 is found.
- Obtain the parameters of the model of the neural network as optimization parameters that are sufficiently small (within a predetermined error range).
- the neural network of the vocoder 6 is set by setting the coupling coefficient (weighting coefficient) between synapses included in each layer of the model of the neural network of the vocoder 6 based on the optimization parameters acquired as described above. It can be an optimized model (trained model) of the model of.
- the vocoder 6 it is possible to construct a trained model (optimized model) of a neural network in which the input is text data and the output is mel spectrogram.
- the learning process may be executed in cooperation with (1) the learning process of the encoder unit 3 and the decoder unit 5 and (2) the learning process of the vocoder 6, as described above. In addition, the learning process may be executed individually.
- the speech synthesis processing device 100 executes the learning process in cooperation with (1) the learning process of the encoder unit 3 and the decoder unit 5 and (2) the learning process of the vocoder 6, the input is set as text data and the text is concerned.
- the learning process may be executed by acquiring.
- the trained model acquired by the above learning process that is, the optimization model (optimization parameters) of the neural network of the encoder unit 3 and the decoder unit 5 is set.
- the model) and the optimization model (model in which the optimization parameters are set) of the neural network of the vocoder 6 are constructed. Then, in the speech synthesis processing device 100, the prediction processing is executed using the trained model.
- the text analysis unit 1 executes a text analysis process for Japanese on the input text data Din, and acquires full context label data Dx1 as 478-dimensional vector data including the parameters shown in FIG. 2, for example. To do.
- the acquired full context label data Dx1 is output from the text analysis unit 1 to the full context label vector processing unit 2.
- the full context label vector processing unit 2 executes the full context label vector processing on the input full context label data Dx1 and acquires the optimized full context label Dx2.
- the optimized full context label Dx2 acquired here is the optimized full context label data Dx2 set when the training process of the sequence-to-sequence neural network model of the encoder unit 3 and the decoder unit 5 is performed. It is data having the same number of dimensions as and having the same parameters (information).
- the data Dx2 (optimized full context label data Dx2) acquired as described above is output from the full context label vector processing unit 2 to the encoder-side prenet processing unit 31 of the encoder unit 3.
- the encoder-side prenet processing unit 31 performs convolution processing (processing by the convolution filter), data normalization processing, and processing by the activation function (for example, processing by the convolution filter) for the data Dx2 input from the full context label vector processing unit 2.
- the ReLU function (process by ReLU: Rectifier Liner Unit) is executed, and the data that can be input to the LSTM layer 32 on the encoder side is acquired. Then, the encoder-side prenet processing unit 31 outputs the data acquired by the above processing (pre-net processing) to the encoder-side LSTM layer 32 as data Dx3.
- the encoder-side LSTM layer 32 includes data Dx3 (t) output from the encoder-side prenet processing unit 31 at the current time t and data Dx4 (data Dx4) output from the encoder-side LSTM layer 32 in the previous time step. Enter t-1). Then, the encoder side LSTM layer 32 executes processing (neural network processing) by the LSTM layer on the input data Dx3 (t) and data Dx4 (t-1), and the processed data is data Dx4 (data Dx4 (t-1). It is output to the attention unit 4 as data Dx4 (t)).
- the attention unit 4 inputs the data Dx4 output from the encoder unit 3 and the data ho (output side hidden state data ho) output from the decoder side LSTM layer 52 of the decoder unit 5.
- the attention unit 4 stores and holds the data Dy3 output from the decoder side LSTM layer 52 of the decoder unit 5, that is, the output side hidden state data ho for a predetermined time step.
- the attention unit 4 outputs the acquired context state data c (t) to the decoder side LSTM layer 52.
- the decoder-side prenet processing unit 51 inputs the data Dy4 (t-1) one hour before the step, which is output from the linear prediction unit 53.
- the decoder-side prenet processing unit 51 has, for example, a plurality of layers (for example, two layers) fully connected layers, and data normalization processing (for example, data (vector data) output from the linear prediction unit 53).
- data normalization processing for example, data (vector data) output from the linear prediction unit 53.
- processing by the activation function for example, processing by the ReLU function (ReLU: Rectifier Unit)
- ReLU Rectifier Unit
- processing by the activation function for example, processing by the ReLU function (ReLU: Rectifier Unit)
- data that can be input to the decoder side LSTM layer 52 is acquired.
- the decoder-side prenet processing unit 51 outputs the data acquired by the above processing (pre-net processing) to the decoder-side LSTM layer 52 as data Dy2.
- the decoder-side LSTM layer 52 includes data Dy2 (t) output from the decoder-side prenet processing unit 51 at the current time t and data Dy3 (data dy3) output from the decoder-side LSTM layer 52 in the previous time step.
- the t-1) and the context state data c (t) at time t output from the attention unit 4 are input.
- the decoder-side LSTM layer 52 executes processing by the LSTM layer using the input data Dy2 (t), data Dy3 (t-1), and context state data c (t), and obtains the processed data. It is output to the linear prediction unit 53 as data Dy3 (t). Further, the decoder side LSTM layer 52 outputs the data Dy3 (t), that is, the output side hidden state data ho (t) at time t to the attention unit 4.
- the linear prediction unit 53 inputs the data Dy3 output from the decoder side LSTM layer 52.
- the linear prediction unit 53 stores and holds data Dy3 (plurality of data Dy3) output from the decoder-side LSTM layer 52 within a predetermined period (for example, a period corresponding to one frame period for acquiring a mel spectrogram). Then, by performing a linear transformation using the plurality of data Dy3, the prediction data Dy4 of the mel spectrogram in a predetermined period is acquired. Then, the linear prediction unit 53 outputs the acquired data Dy4 to the postnet processing unit 54, the adder 55, and the decoder side prenet processing unit 51.
- a predetermined period for example, a period corresponding to one frame period for acquiring a mel spectrogram
- the post-net processing unit 54 may, for example, perform convolution processing (processing by a convolution filter), data normalization processing, processing by an activation function (for example, processing by a ReLU function (ReLU: Directified Liner Unit), or processing by a tanh function). ) Is executed, the residual data (residual) of the predicted data (predicted mel spectrogram) is acquired, and the acquired residual data is output to the adder 55 as data Dy5.
- convolution processing processing by a convolution filter
- data normalization processing processing by an activation function (for example, processing by a ReLU function (ReLU: Directified Liner Unit), or processing by a tanh function).
- the adder 55 inputs the prediction data Dy4 (prediction mel spectrometry data) output from the linear prediction unit 53 and the residual data Dy5 (residual data of the prediction mel spectrometry) output from the postnet processing unit 54. To do.
- the adder 55 executes addition processing on the prediction data Dy4 (data of the prediction mel spectrogram) and the residual data Dy5 (residual data of the prediction mel spectrogram), and the data after the addition processing (data of the prediction mel spectrogram). Data) is output to the vocabulary 6 as data Dy6.
- the vocoder 6 inputs data Dy6 (data of predicted mel spectrogram (data of acoustic feature amount)) output from the adder 55 of the decoder unit 5, and uses a trained model for the input data Dy6. Speech synthesis processing by neural network processing is executed, and voice signal waveform data corresponding to data Dy6 (predicted mel spectrogram) is acquired. Then, the vocoder 6 outputs the acquired voice signal waveform data as data Dout.
- the voice synthesis processing device 100 can acquire the voice waveform data Dout corresponding to the input text data Din.
- the speech synthesis processing apparatus 100 the text of the processing target language (Japanese in the above) is input, and the full context label data is acquired by the text analysis processing according to the processing target language, and the acquired full is obtained.
- the optimized full context label data which is the data suitable for executing the process (learning process and / or the prediction process) in the model of the neural network using the sequence-to-sequence method, is acquired.
- the input is the optimized full context label data
- the output is the mel spectrogram (an example of the acoustic feature amount)
- the encoder unit 3, the attention unit 4, and the decoder unit 5 use the neural network.
- the voice synthesis processing device 100 can acquire voice waveform data corresponding to the input text.
- the processing by the neural network is executed using the optimized full context label data suitable for processing by the model of the neural network using the sequence-to-sequence method, so that the processing is high.
- Accurate speech synthesis processing can be executed.
- the speech synthesis processing device 100 performs text analysis processing according to the language to be processed, and processes the full context label data acquired in the text analysis processing with a model of a neural network using a sequence-to-sequence method.
- the speech synthesis processing device 100 even when a language other than English such as Japanese is used as the processing target language (the processing target language can be any language), the text speech synthesis using the sequence-to-sequence method is used.
- the model of the neural network for learning and optimizing, it is possible to realize high-quality speech synthesis processing.
- the vocoder 6 performs processing using a model of a neural network capable of reversible conversion, for example, as disclosed in the following prior art document. This point is different from the first embodiment, and other than that, the voice synthesis processing device of this modification is the same as the voice synthesis processing device 100 of the first embodiment.
- Prior Art Document A R. Prenger, R. Valle, and B. Catanzaro, “WaveGlow: A flowbased generative network for speech synthesis,” in Proc. ICASSP, May 2019.
- FIG. 4 is a diagram showing a schematic configuration of a vocoder 6 of the voice synthesis processing device of the first modification of the first embodiment, and is a diagram clearly showing the flow of data in the learning process.
- FIG. 5 is a diagram showing a schematic configuration of a vocoder 6 of the voice synthesis processing device of the first modification of the first embodiment, and is a diagram clearly showing the flow of data in the prediction processing.
- the vocoder 6 of this modification includes a vector processing unit 61, an upsampling processing unit 62, and m (m: natural number) reversible processing units 63a to 63x.
- the vocoder 6 of this modification has a mel spectrogram (this is referred to as data h) and audio signal waveform data (correct answer data) corresponding to the mel spectrogram (this is referred to as data x) as acoustic features. Is input, and Gaussian white noise (this is referred to as data z) is output.
- the vector processing unit 61 inputs the voice signal waveform data x during the learning process, performs convolution processing on the input data x, for example, and performs a lossless processing unit 63a (first data input during the learning process). It is converted into vector data Dx1 having a number of dimensions that can be input to the lossless processing unit). Then, the vector processing unit 61 outputs the converted vector data Dx 1 to the reversible processing unit 63a.
- the upsampling processing unit 62 inputs the mel spectrogram data h as the acoustic feature amount, executes the upsampling process on the input mel spectrogram data h, and performs the processed data (upsampled mel spectrogram). Data) is output as data h1 to each WN conversion unit 632 of the reversible processing units 63a to 63x.
- the reversible processing unit 63a includes a reversible 1 ⁇ 1 convolution layer and an affine coupling layer.
- the weighting coefficient matrix Wk is set to be an orthogonal matrix, and therefore the inverse transformation is possible.
- the data DxA 1 acquired in this way is output from the reversible 1 ⁇ 1 convolution layer to the affine coupling layer.
- x is data having the number of bits of n1 ⁇ 2 (n1: natural number)
- x a is the data for the upper n1 bits of x
- x b is the data for the lower n1 bits of x. ..
- the data x a is output to the MN conversion unit 632 and the data synthesis unit 634. Further, the data x b is output to the affine transformation unit 633.
- the MN conversion unit 632 inputs the data x a output from the data division unit 631 and the upsampled mel spectrogram data h1 output from the upsampling processing unit 62. Then, the MN conversion unit 632 executes MN conversion (for example, conversion by WaveNet), which is an arbitrary conversion, on the data x a and the data h1, and uses the data s j , t j as parameters for the affine transformation. (S j : Matrix for affine transformation, t j : Offset for affine transformation) is acquired. The acquired data s j and t j as parameters of the affine transformation are output from the WN conversion unit 632 to the affine transformation unit 633.
- MN conversion for example, conversion by WaveNet
- the process corresponding to is executed and the data Dx 2 is acquired.
- the data synthesis processing in the data synthesis section 634 for example, x a, ', respectively, when the data of n1 bits, the upper n1 bits x a, and the lower n1 bits x b' x b becomes This is a process for acquiring n1 ⁇ 2 bit data.
- the data Dx 2 acquired in this way is output from the reversible processing unit 63a to the reversible processing unit 63b (second reversible processing unit).
- the same processing as in the reversible processing unit 63a is executed. That is, in the vocoder 6 of the present modification, as shown in FIG. 4, the processing of the reversible processing unit 63a is repeatedly executed m times. Then, the data z from the reversible processing unit 63x in the final stage is output.
- the vocoder 6 of this modification is provided with m reversible processing units.
- the parameters of the model of the neural network of the vocoder 6 of this modification are set so as to be variables. Note that ⁇ is, for example, data that correlates with the information amount I of the mel spectrogram data as the input acoustic feature amount.
- the likelihood ( ⁇ : neural network parameter) p ⁇ (x) when x is input can be defined by the following mathematical formula, and the likelihood p ⁇ (x). ) Is acquired, and the learning process is executed.
- p ⁇ (x): Likelihood when x is input ( ⁇ : Neural network parameter) s j (x, h): Output coefficient vector of the j-th affine coupling layer when x, h is input
- W k Coefficient matrix of the k-th reversible 1 ⁇ 1 convolution layer (matrix of weighting coefficients)
- z (x) Output value (output vector) when x is input.
- h Acoustic features (here, mel spectrogram)
- the optimization parameter ⁇ opt of the model of the neural network of the vocoder 6 of this modification is acquired by executing the process corresponding to the following mathematical formula.
- the parameters of the neural network model are set by the optimization parameter ⁇ opt acquired by the above learning process (the affin coupling layer of each reversible processing unit 63b to 63x, reversible 1 ⁇ 1 convolution). Layer parameters are set) and the trained model is built.
- the bocoder 6 of this modification uses the mel spectrogram (this is referred to as data h) as the acoustic feature amount and the data correlated with the information amount I of the mel spectrogram as the standard deviation ⁇ , and sets the mean value as “ The Gaussian white noise z set to "0" is input.
- the reverse processing is executed at the time of the prediction processing as at the time of the learning processing.
- the mel spectrogram data (for example, the data Dy6 output from the decoder unit 5) is input to the upsampling processing unit 62.
- the upsampling processing unit 62 inputs the mel spectrogram data h as the acoustic feature amount, executes the upsampling process on the input mel spectrogram data h, and performs the processed data (upsampled mel spectrogram). Data) is output as data h1 to each WN conversion unit 632 of the reversible processing units 63a to 63x.
- Gauss white noise z (referred to as data z) is input to the reversible processing unit 63x.
- the processing of the affine coupling layer and the processing of the reversible 1 ⁇ 1 convolution layer are executed for the input data z. As shown in FIG. 5, this process is repeatedly executed m times. Since each process is the same, the process in the reversible processing unit 63a will be described.
- the data synthesis unit 634 outputs the acquired data x a to the MN conversion unit 632 and the data dividing unit 631, and outputs the data x b 'in the affine transformation unit 633.
- the MN conversion unit 632 inputs the data x a output from the data synthesis unit 634 and the upsampled mel spectrogram data h1 output from the upsampling processing unit 62. Then, the MN conversion unit 632 executes MN conversion (for example, conversion by WaveNet), which is an arbitrary conversion, on the data x a and the data h1, and uses the data s j , t j as parameters for the affine transformation. (S j : Matrix for affine transformation, t j : Offset for affine transformation) is acquired. The acquired data s j and t j as parameters of the affine transformation are output from the WN conversion unit 632 to the affine transformation unit 633.
- MN conversion for example, conversion by WaveNet
- Data Dx '1 obtained by being processed by the lossless processor 63x ⁇ 63a as described above is input to the vector processing unit 61.
- the vector processing unit 61 acquires and outputs the predicted audio signal waveform data x from the data Dx ' 1 by executing the process opposite to that at the time of the learning process.
- the vocoder 6 of this modified example can acquire the predicted audio signal waveform data x from the input z (Gaussian white noise z) and the mel spectrogram data h.
- the vocoder 6 of this modified example adopts a configuration that can reversibly convert the neural network. Therefore, in the vocoder 6 of this modification, (1) the likelihood of the audio waveform data output when Gaussian white noise is input, and (2) the Gaussian output when the audio waveform data is input. Equivalent to the likelihood of white noise and easy to perform learning processing (easy to calculate) The latter (probability of Gaussian white noise output when voice waveform data is input) is used for learning processing. Therefore, the learning process can be performed efficiently.
- the prediction process is subjected to the process opposite to that at the time of the learning process (inverse conversion) by the trained model acquired by the above learning process. ) Can be realized.
- a configuration capable of directly predicting (acquiring) voice waveform data from mel spectrogram data as an acoustic feature can be realized with a simple configuration. Since the vocoder 6 of this modification has such a simple configuration, it is possible to perform prediction processing at high speed while maintaining processing accuracy, and it is possible to execute voice synthesis processing in real time. become.
- FIG. 6 shows a mel spectrogram (prediction data) of the voice waveform data acquired by executing TTS processing (processing target language: Japanese) by the voice synthesis processing device of this modified example, and a mel of the actual voice waveform data of the input text. It is a figure which shows the spectrogram (original data).
- the voice synthesis processing device of this modified example can predict (acquire) very accurate voice waveform data in the TTS processing.
- the speech synthesis processing device 100 using the encoder / decoder method has been described.
- the speech synthesis processing device 100 of the first embodiment includes an attention mechanism (attention unit 4), and can realize a neural speech synthesis process that simultaneously optimizes the phoneme continuation length and the acoustic model by using the attention mechanism. it can.
- the speech synthesis processing device 100 of the first embodiment can realize high-quality text speech synthesis in the natural speech class.
- the attention mechanism prediction may fail at the time of inference (during prediction processing), and this causes the synthetic utterance to stop in the middle. There is a problem that it is repeated many times.
- FIG. 7 is a schematic configuration diagram of the speech synthesis processing device 200 according to the second embodiment.
- the voice synthesis processing device 200 according to the second embodiment has a configuration in which the attention unit 4 is deleted and the phoneme continuation length estimation unit 7 is added in the voice synthesis processing device 100 of the first embodiment. Then, in the speech synthesis processing device 200 according to the second embodiment, in the speech synthesis processing device 100 of the first embodiment, the text analysis unit 1 is replaced with the text analysis unit 1A, and the full context label vector processing unit 2 is replaced with the full context. It has a configuration in which the label vector processing unit 2A is replaced and the decoder unit 5 is replaced with the decoder unit 5A.
- the text analysis unit 1A has the same function as the text analysis unit 1 of the first embodiment, and further has a function of acquiring the context label of the phoneme.
- the text analysis unit 1A acquires a phoneme context label from the text data Din of the language to be processed, and outputs the acquired phoneme context label data as data Dx01 to the phoneme continuation length estimation unit 7.
- the phoneme continuation length estimation unit 7 inputs the data Dx01 (phoneme context label data) output from the text analysis unit 1A.
- the phoneme continuation length estimation unit 7 executes a phoneme continuation length estimation process that estimates (acquires) the phoneme continuation length of the phoneme corresponding to the data Dx01 from the data Dx01 (phoneme context label data).
- the phoneme continuation length estimation unit 7 estimates (predicts) the phoneme continuation length of the phoneme from the context label of the phoneme using, for example, a hidden Markov model (HMM: Hidden Markov Model), a neural network model, or the like.
- Phoneme continuation length estimation processing is executed by the model (processing system).
- the phoneme continuation length estimation unit 7 outputs the phoneme continuation length data acquired (estimated) by the phoneme continuation length estimation process as data Dx02 to the full context label vector processing unit 2A.
- the full context label vector processing unit 2A has the same function as the full context label vector processing unit 2 of the first embodiment, and further, a period corresponding to the phoneme continuation length estimated by the phoneme continuation length estimation unit 7. In the above, it has a function of continuously outputting the optimized full context label data for the phoneme corresponding to the phoneme continuation length to the encoder unit 3.
- the full context label vector processing unit 2A includes data Dx1 (full context label data) output from the text analysis unit 1 and data Dx02 (phoneme continuation length data) output from the phoneme continuation length estimation unit 7. Enter.
- the full context label vector processing unit 2A inputs the data Dx1 (full context label data) output from the text analysis unit 1A.
- the full context label vector processing unit 2A performs full context label vector processing for acquiring full context label data suitable for learning processing of a sequence-to-sequence neural network model from the input full context label data Dx1.
- the full context label vector processing unit 2A outputs the data acquired by the full context label vector processing as data Dx2 (optimized full context label data Dx2) to the encoder side plenet processing unit 31 of the encoder unit 3.
- the full context label vector processing unit 2A outputs the optimized full context label data for the phoneme corresponding to the phoneme continuation length in the period corresponding to the phoneme continuation length estimated by the phoneme continuation length estimation unit 7. Continue to output to 3.
- the decoder unit 5A has a configuration in which the decoder unit LSTM layer 52 is replaced with the decoder side LSTM layer 52A in the decoder unit 5 of the first embodiment. Other than that, the decoder unit 5A is the same as the decoder unit 5 of the first embodiment.
- the decoder-side LSTM layer 52A has the same function as the decoder-side LSTM layer 52.
- the decoder-side LSTM layer 52A has data Dy2 (this is referred to as data Dy2 (t)) output from the decoder-side prenet processing unit 51 at the current time t, and the decoder-side LSTM in the previous time step.
- the data Dy3 output from the layer 52A (this is referred to as the data Dy3 (t-1)) and the input side hidden state data hi (t) at the time t output from the encoder unit 3 are input.
- the decoder-side LSTM layer 52A executes processing by the LSTM layer using the input data Dy2 (t), data Dy3 (t-1), and input-side hidden state data hi (t), and after the processing, The data is output to the linear prediction unit 53 as data Dy3 (data Dy3 (t)).
- FIG. 8 is a diagram for explaining a process of generating data Dx2 to be input to the encoder unit 3 based on the estimated phoneme continuation length.
- the operation of the speech synthesis processing device 200 will be described separately for (1) learning processing (processing at the time of learning) and (2) prediction processing (processing at the time of prediction).
- the text analysis unit 1A executes a text analysis process on the input text data Din, and acquires a series of context labels which are phonetic labels including contexts composed of various language information. To do.
- the text analysis unit 1A outputs the acquired full context label data as data Dx1 to the full context label vector processing unit 2 as in the first embodiment.
- the text analysis unit 1A acquires a phoneme context label from the text data Din of the language to be processed, and outputs the acquired phoneme context label data as data Dx01 to the phoneme continuation length estimation unit 7.
- the phoneme continuation length estimation unit 7 performs a phoneme continuation length estimation process that estimates (acquires) the phoneme continuation length of the phoneme corresponding to the data Dx01 from the data Dx01 (phoneme context label data) output from the text analysis unit 1A. Execute. Specifically, the phoneme continuation length estimation unit 7 estimates (predicts) the phoneme continuation length of the phoneme from the context label of the phoneme using, for example, a hidden Markov model (HMM: Hidden Markov Model), a neural network model, or the like. Phoneme continuation length estimation processing is executed by the model (processing system).
- HMM Hidden Markov Model
- the phoneme continuation length estimation unit 7 outputs the phoneme continuation length data acquired (estimated) by the phoneme continuation length estimation process as data Dx02 to the full context label vector processing unit 2A.
- the full context label vector processing unit 2A selects full context label data suitable for learning processing of a sequence-to-sequence neural network model from the data Dx1 (full context label data) output from the text analysis unit 1A.
- the full context label vector processing for acquisition (full context label vector processing similar to the first embodiment) is executed.
- the full context label vector processing unit 2A outputs the data acquired by the full context label vector processing as data Dx2 (optimized full context label data Dx2) to the encoder side plenet processing unit 31 of the encoder unit 3.
- the full context label vector processing unit 2A outputs the optimized full context label data for the phoneme corresponding to the phoneme continuation length in the period corresponding to the phoneme continuation length estimated by the phoneme continuation length estimation unit 7. Continue to output to 3.
- the data Dx2 (optimized full context label data Dx2) acquired by the full context label vector processing unit 2A is output from the full context label vector processing unit 2 to the encoder side plenet processing unit 31 of the encoder unit 3.
- the encoder-side prenet processing unit 31 performs convolution processing (processing by the convolution filter), data normalization processing, and processing by the activation function (for example, processing by the convolution filter) for the data Dx2 input from the full context label vector processing unit 2.
- the ReLU function (process by ReLU: Rectifier Liner Unit) is executed, and the data that can be input to the LSTM layer 32 on the encoder side is acquired. Then, the encoder-side prenet processing unit 31 outputs the data acquired by the above processing (pre-net processing) to the encoder-side LSTM layer 32 as data Dx3.
- the decoder-side prenet processing unit 51 inputs the data Dy4 (t-1) one hour before the step, which is output from the linear prediction unit 53.
- the decoder-side prenet processing unit 51 has, for example, a plurality of layers (for example, two layers) of fully connected layers, and data normalization processing (for example, data (vector data) output from the linear prediction unit 53).
- data normalization processing for example, data (vector data) output from the linear prediction unit 53.
- processing by the activation function for example, processing by the ReLU function (ReLU: Rectifier Liner Unit)
- ReLU Rectifier Liner Unit
- processing by the activation function for example, processing by the ReLU function (ReLU: Rectifier Liner Unit)
- the decoder-side prenet processing unit 51 outputs the data acquired by the above processing (pre-net processing) to the decoder-side LSTM layer 52 as data Dy2.
- the decoder-side LSTM layer 52A includes data Dy2 (t) output from the decoder-side prenet processing unit 51 at the current time t and data Dy3 (data Dy3) output from the decoder-side LSTM layer 52 in the previous time step.
- the decoder side LSTM layer 52A executes the processing by the LSTM layer using the input data Dy2 (t), the data Dy3 (t-1), and the input side hidden state data hi (t), and after the processing
- the data is output to the linear prediction unit 53 as data Dy3 (t).
- the linear prediction unit 53, the postnet processing unit 54, and the adder 55 the same processing as in the first embodiment is executed.
- the speech synthesis processing device 200 the data Dy6 (predicted mel spectrogram data) acquired as described above, and the teacher data (correct mel spectrogram) of the mel spectrogram (acoustic feature amount) corresponding to the text data Din.
- the parameters of the model of the neural network of the encoder unit 3 and the decoder unit 5A are updated so that the difference between the two (comparison result) (for example, the difference expressed by the norm of the difference vector and the Euclidean distance) becomes small.
- this parameter update process is repeatedly executed, and the data Dy6 (predicted mel spectrogram data) and the mel spectrogram (acoustic feature amount) teacher data (correct mel spectrogram) corresponding to the text data Din are obtained.
- the difference between the two becomes sufficiently small (within a predetermined error range)
- the parameters of the neural network model are acquired as the optimization parameters.
- the coupling coefficient (weighting coefficient) between synapses included in each layer of the neural network model of the encoder unit 3 and the decoder unit 5A is set based on the optimization parameters acquired as described above. Therefore, the model of the neural network of the encoder unit 3 and the decoder unit 5A can be used as an optimized model (trained model).
- a trained model (optimized model) of a neural network having an input as text data and an output as a mel spectrogram can be constructed.
- the trained model (optimized model) of the neural network acquired by the learning process in the speech synthesis processing device 100 of the first embodiment may be used. That is, in the voice synthesis processing device 200, the voice synthesis processing device uses the optimum parameters of the encoder unit 3 and the decoder unit 5 of the trained model of the neural network acquired by the learning process in the voice synthesis processing device 100 of the first embodiment. By setting the parameters of the encoder unit 3 and the decoder unit 5A of the 200, the trained model may be constructed in the speech synthesis processing device 200.
- the learning process is the same as that of the first embodiment.
- a trained model (optimized model) of a neural network having an input as text data and an output as a mel spectrogram can be constructed as in the first embodiment.
- the learning process may be executed in cooperation with (1) the learning process of the encoder unit 3 and the decoder unit 5A and (2) the learning process of the vocoder 6, as described above. In addition, the learning process may be executed individually.
- the speech synthesis processing device 200 executes the learning process in cooperation with (1) the learning process of the encoder unit 3 and the decoder unit 5A and (2) the learning process of the vocoder 6, the input is set as text data and the text is concerned.
- the learning process may be executed by acquiring.
- the speech synthesis processing device 200 sets the trained model acquired by the above learning process, that is, the optimization model (optimization parameters) of the neural network of the encoder unit 3 and the decoder unit 5A.
- the model) and the optimization model (model in which the optimization parameters are set) of the neural network of the vocoder 6 are constructed. Then, in the speech synthesis processing device 200, the prediction processing is executed using the trained model.
- the text analysis unit 1A executes a text analysis process for Japanese on the input text data Din, and acquires full context label data Dx1 as 478-dimensional vector data including the parameters shown in FIG. 2, for example. To do.
- the acquired full context label data Dx1 is output from the text analysis unit 1A to the full context label vector processing unit 2A.
- the text analysis unit 1A acquires a phoneme context label from the text data Din of the language to be processed, and outputs the acquired phoneme context label data as data Dx01 to the phoneme continuation length estimation unit 7.
- the phoneme continuation length estimation unit 7 performs a phoneme continuation length estimation process that estimates (acquires) the phoneme continuation length of the phoneme corresponding to the data Dx01 from the data Dx01 (phoneme context label data) output from the text analysis unit 1A. Execute. Specifically, the phoneme continuation length estimation unit 7 estimates (predicts) the phoneme continuation length of the phoneme from the context label of the phoneme using, for example, a hidden Markov model (HMM: Hidden Markov Model), a neural network model, or the like. Phoneme continuation length estimation processing is executed by the model (processing system).
- HMM Hidden Markov Model
- the phoneme continuation length estimation unit 7 uses the context label of the phoneme ph k (k: integer) to make a phoneme. by executing the duration estimation process to obtain the estimated phoneme duration dur of the phoneme ph k (ph k). For example, for each of the above phonemes (phoneme ph k ), the phoneme continuation length dur (ph k ) acquired (estimated) by the phoneme continuation length estimation unit 7 has the time length (continuation length) shown in FIG. It shall be.
- the phoneme continuation length estimation unit 7 uses the phoneme continuation length data (dur (ph k ) in the case of FIG. 8) acquired (estimated) by the phoneme continuation length estimation process as data Dx02, and the full context label vector processing unit 2A. Output to.
- the full context label vector processing unit 2A executes the full context label vector processing on the input full context label data Dx1 and acquires the optimized full context label Dx2.
- the optimized full context label Dx2 acquired here is the optimized full context label data Dx2 set when the learning process of the sequence-to-sequence neural network model of the encoder unit 3 and the decoder unit 5A is performed. It is data having the same number of dimensions as and having the same parameters (information).
- the data Dx2 (optimized full context label data Dx2) acquired as described above is output from the full context label vector processing unit 2 to the encoder side prenet processing unit 31 of the encoder unit 3.
- the full context label vector processing unit 2A outputs the optimized full context label data for the phoneme corresponding to the phoneme continuation length in the period corresponding to the phoneme continuation length estimated by the phoneme continuation length estimation unit 7.
- the full context label vector processing unit 2A may perform the optimized full context label data for the phoneme ph k.
- the phoneme ph k for optimization full context label data Dx2 (ph k) is a period corresponding to the estimated phoneme duration dur (ph k), is output to the repetition encoder 3. That is, in the full context label vector processing unit 2A, the time extension processing of the data (optimized full context label data Dx2 (ph k )) to be input to the encoder unit 3 based on the estimated phoneme continuation length dur (ph k ). Is executed.
- the encoder-side prenet processing unit 31 performs convolution processing (processing by a convolution filter), data normalization processing, and processing by an activation function (for example, processing by a convolution filter) for the data Dx2 input from the full context label vector processing unit 2A.
- the ReLU function (process by ReLU: Rectifier Liner Unit) is executed, and the data that can be input to the LSTM layer 32 on the encoder side is acquired. Then, the encoder-side prenet processing unit 31 outputs the data acquired by the above processing (pre-net processing) to the encoder-side LSTM layer 32 as data Dx3.
- the decoder side LSTM layer 52A executes the processing by the LSTM layer using the input data Dy2 (t), the data Dy3 (t-1), and the input side hidden state data hi (t), and after the processing
- the data is output to the linear prediction unit 53 as data Dy3 (t).
- the linear prediction unit 53, the postnet processing unit 54, and the adder 55 the same processing as in the first embodiment is executed.
- the vocoder 6 used the data Dy6 (data of the predicted mel spectrogram (data of the acoustic feature amount)) output from the adder 55 of the decoder unit 5A as an input, and used a trained model for the input data Dy6.
- the speech synthesis process by the neural network process is executed, and the speech signal waveform data corresponding to the data Dy6 (predicted mel spectrogram) is acquired. Then, the vocoder 6 outputs the acquired voice signal waveform data as data Dout.
- the voice synthesis processing device 200 can acquire the voice waveform data Dout corresponding to the input text data Din.
- the speech synthesis processing device 200 the text of the processing target language (Japanese in the above) is input, and the full context label data is acquired by the text analysis processing according to the processing target language, and the acquired full is obtained.
- the optimized full context label data which is the data suitable for executing the process (learning process and / or the prediction process) in the model of the neural network using the sequence-to-sequence method, is acquired.
- the input is the optimized full context label data
- the output is the mel spectrogram (an example of the acoustic feature amount)
- the encoder unit 3 and the decoder unit 5A use the neural network model.
- the voice signal waveform data corresponding to the mel spectrogram is acquired from the mel spectrogram (an example of the acoustic feature amount) acquired by the vocoder 6, and the acquired data is output. , Acquires voice waveform data (data Dout). As a result, the voice synthesis processing device 200 can acquire voice waveform data corresponding to the input text.
- phoneme ph phoneme duration dur period corresponding to ph k
- the optimization full context label data of the phoneme ph k the process of inputting the repetition encoder 3
- the prediction process is performed using the phoneme continuation length obtained by executing the estimation process using a model such as the hidden Markov model, which can stably and appropriately estimate the phoneme continuation length. Since it is executed, problems such as failure of attention mechanism prediction, synthetic speech stopping in the middle, and repeating the same phrase many times do not occur.
- the phoneme continuation length is estimated by using a model such as a hidden Markov model, which can stably and appropriately estimate the phoneme continuation length (phoneme continuation length estimation unit). (Processing according to 7), and (2) the acoustic features are acquired by processing with a neural network model using the sequence-to-sequence method.
- the speech synthesis processing device 200 appropriately prevents problems such as failure of attention mechanism prediction, synthetic utterance stopping in the middle, and repeating the same phrase many times. At the same time, it is possible to execute highly accurate speech synthesis processing.
- FIG. 9 is a schematic configuration diagram of the speech synthesis processing device 300 according to the third embodiment.
- the speech synthesis processing device 300 replaces the text analysis unit 1 with the text analysis unit 1A, the attention unit 4 with the attention unit 4A, and the decoder in the speech synthesis processing device 100 of the first embodiment. It has a configuration in which unit 5 is replaced with a decoder unit 5B.
- the speech synthesis processing device 300 has a configuration in which the phoneme continuation length estimation unit 7, the forced attention unit 8, the internal division processing unit 9, and the context calculation unit 10 are added to the speech synthesis processing device 100. There is.
- the text analysis unit 1A and the phoneme continuation length estimation unit 7 have the same configuration and functions as the text analysis unit 1A of the second embodiment.
- the phoneme continuation length estimation unit 7 outputs the phoneme continuation length data acquired (estimated) by the phoneme continuation length estimation process to the forced attention unit 8 as data Dx02.
- the attention unit 4A inputs the data Dx4 output from the encoder unit 3 and the data ho (output side hidden state data ho) output from the decoder side LSTM layer 52B of the decoder unit 5B.
- the attention unit 4A stores and holds the data Dx4 output from the encoder unit 3, that is, the input side hidden state data hi for a predetermined time step.
- the attention unit 4A stores and holds the data Dy3 output from the decoder side LSTM layer 52B of the decoder unit 5B, that is, the output side hidden state data ho for a predetermined time step.
- the weighting coefficient data w att (t) at the current time t is executed by executing the process corresponding to the function for acquiring the weighting coefficient data . .. .. Get S.
- the attention unit 4A receives the acquired weighting coefficient data watt (t) 1. .. .. S is output to the internal division processing unit 9. It should be noted that the set data hi 1. .. .. The set data of the weighting coefficient data for each element data of S is weighted coefficient data w att (t) 1. .. .. Notated as S.
- the forced attention unit 8 inputs the data Dx02 of the estimated phoneme continuation length output from the phoneme continuation length estimation unit 7.
- the forced attention unit 8 corresponds to the estimated phoneme continuation length (phoneme continuation length data Dx02) of the phoneme when the data processed by the encoder unit 3 for the phoneme corresponding to the phoneme continuation length data Dx02 is output.
- the weighting coefficient data w f (t) in which the weighting coefficient is forcibly set to a predetermined value (for example, “1”) during the period is generated. It should be noted that the set data of the input side hidden state data hi 1. .. ..
- the weighting coefficient data w f (t) obtained by expanding the data to S pieces (replicating and expanding the same data) around the time t is used as the weighting coefficient data w. f (t) 1. .. .. Notated as S.
- the forced attention unit 8 has the weighting coefficient data w f (t) 1. .. .. S is output to the internal division processing unit 9.
- the internal division processing unit 9 has weighting coefficient data watt (t) output from the attention unit 4A . .. .. S and the weighting coefficient data w f (t) output from the forced attention unit 8 . .. .. Enter S. Then, the internal division processing unit 9 performs weighting coefficient data watt (t) 1. .. .. S and weighting coefficient data w f (t) 1. .. ...
- the composite weighting coefficient data w (t) is acquired.
- the j-th composite weighting coefficient data w (t) j is acquired.
- the internal division processing unit 9 uses the acquired composite weighting coefficient data w (t) 1. .. .. Output S to the context calculation unit 10.
- the decoder unit 5B has a configuration in which the decoder unit 5B of the first embodiment replaces the decoder side LSTM layer 52 with the decoder side LSTM layer 52B. Other than that, the decoder unit 5B is the same as the decoder unit 5 of the first embodiment.
- the decoder-side LSTM layer 52B has the same function as the decoder-side LSTM layer 52.
- the decoder side LSTM layer 52B has data Dy2 (this is referred to as data Dy2 (t)) output from the decoder side prenet processing unit 51 at the current time t, and the decoder side LSTM in the previous time step.
- the data Dy3 output from the layer 52B (this is referred to as data Dy3 (t-1)) and the context state data c (t) at time t output from the context calculation unit 10 are input.
- the decoder-side LSTM layer 52B executes processing by the LSTM layer using the input data Dy2 (t), data Dy3 (t-1), and context state data c (t), and obtains the processed data. It is output to the linear prediction unit 53 as data Dy3 (data Dy3 (t)). Further, the decoder side LSTM layer 52B outputs the data Dy3 (t), that is, the output side hidden state data ho (t) at the time t to the attention unit 4A.
- 10 to 12 show the composite weighting coefficient data w (t) acquired from the weighting coefficient data w att (t) acquired by the attention unit 4A and the weighting coefficient data w f (t) acquired by the forced attention unit 8. It is a figure for demonstrating the process of acquiring the context state data c (t) using t).
- the text analysis unit 1A executes a text analysis process on the input text data Din, and acquires a series of context labels which are phonetic labels including contexts composed of various language information. To do.
- the text analysis unit 1A outputs the acquired full context label data as data Dx1 to the full context label vector processing unit 2 as in the first embodiment.
- the text analysis unit 1A acquires a phoneme context label from the text data Din of the language to be processed, and outputs the acquired phoneme context label data as data Dx01 to the phoneme continuation length estimation unit 7.
- the phoneme continuation length estimation unit 7 performs a phoneme continuation length estimation process that estimates (acquires) the phoneme continuation length of the phoneme corresponding to the data Dx01 from the data Dx01 (phoneme context label data) output from the text analysis unit 1A. Execute. Specifically, the phoneme continuation length estimation unit 7 estimates (predicts) the phoneme continuation length of the phoneme from the context label of the phoneme using, for example, a hidden Markov model (HMM: Hidden Markov Model), a neural network model, or the like. Phoneme continuation length estimation processing is executed by the model (processing system).
- HMM Hidden Markov Model
- the phoneme continuation length estimation unit 7 outputs the phoneme continuation length data acquired (estimated) by the phoneme continuation length estimation process to the forced attention unit 8 as data Dx02.
- the full context label vector processing unit 2A selects full context label data suitable for learning processing of a sequence-to-sequence neural network model from the data Dx1 (full context label data) output from the text analysis unit 1A.
- the full context label vector processing for acquisition (full context label vector processing similar to the first embodiment) is executed.
- the full context label vector processing unit 2A outputs the data acquired by the full context label vector processing as data Dx2 (optimized full context label data Dx2) to the encoder side plenet processing unit 31 of the encoder unit 3.
- the data Dx2 (optimized full context label data Dx2) acquired by the full context label vector processing unit 2A is output from the full context label vector processing unit 2 to the encoder side plenet processing unit 31 of the encoder unit 3.
- the encoder-side prenet processing unit 31 performs convolution processing (processing by the convolution filter), data normalization processing, and processing by the activation function (for example, processing by the convolution filter) for the data Dx2 input from the full context label vector processing unit 2.
- the ReLU function (process by ReLU: Rectifier Liner Unit) is executed, and the data that can be input to the LSTM layer 32 on the encoder side is acquired. Then, the encoder-side prenet processing unit 31 outputs the data acquired by the above processing (pre-net processing) to the encoder-side LSTM layer 32 as data Dx3.
- the attention unit 4A inputs the data Dx4 output from the encoder unit 3 and the data ho (output side hidden state data ho) output from the decoder side LSTM layer 52B of the decoder unit 5B.
- the attention unit 4A stores and holds the data Dx4 output from the encoder unit 3, that is, the input side hidden state data hi for a predetermined time step.
- the attention unit 4A stores and holds the data Dy3 output from the decoder side LSTM layer 52B of the decoder unit 5B, that is, the output side hidden state data ho for a predetermined time step.
- the weighting coefficient data w att (t) at the current time t is executed by executing the process corresponding to the function for acquiring the weighting coefficient data . .. .. Get S.
- the forced attention unit 8 corresponds to the estimated phoneme continuation length (phoneme continuation length data Dx02) of the phoneme when the data processed by the encoder unit 3 for the phoneme corresponding to the phoneme continuation length data Dx02 is output.
- the weighting coefficient data w f (t) in which the weighting coefficient is forcibly set to a predetermined value (for example, “1”) during the period is generated.
- the forced attention unit 8 is a set data hi 1. Of the input side hidden state data . .. ..
- the data is expanded to S pieces (the same data is duplicated and expanded) around time t.
- Coefficient data w f (t) 1. .. .. Generate S.
- the forced attention unit 8 has the weighting coefficient data w f (t) 1. .. .. S is output to the internal division processing unit 9.
- the internal division processing unit 9 has weighting coefficient data watt (t) output from the attention unit 4A . .. .. S and the weighting coefficient data w f (t) output from the forced attention unit 8 . .. .. Enter S. Then, the internal division processing unit 9 performs weighting coefficient data watt (t) 1. .. .. S and weighting coefficient data w f (t) 1. .. ...
- the internal division processing unit 9 uses the acquired composite weighting coefficient data w (t) 1. .. .. Output S to the context calculation unit 10.
- the internal division ratio ⁇ may be fixed to “0” during the learning process. In this case (when the internal division ratio ⁇ is fixed to “0”), the speech synthesis processing device 300 executes the learning process with the same configuration as that of the first embodiment. Further, at the time of learning processing, the internal division ratio ⁇ may be fixed to a predetermined value (for example, 0.5), and the learning processing may be executed in the speech synthesis processing apparatus 300.
- a predetermined value for example, 0.5
- the phoneme continuation length estimation unit 7 uses the context label of the phoneme ph k (k: integer) to make a phoneme. by executing the duration estimation process to obtain the estimated phoneme duration dur of the phoneme ph k (ph k). For example, for each of the above phonemes (phoneme ph k ), the phoneme continuation length dur (ph k ) acquired (estimated) by the phoneme continuation length estimation unit 7 has the time length (continuation length) shown in FIG. It shall be.
- the forced attention unit 8 corresponds to the estimated phoneme continuation length (phoneme continuation length data Dx02) of the phoneme when the data processed by the encoder unit 3 for the phoneme corresponding to the phoneme continuation length data Dx02 is output.
- the weighting coefficient data w f (t) in which the weighting coefficient is forcibly set to a predetermined value (for example, “1”) during the period is generated.
- the forced attention unit 8 sets a weighting coefficient for a period corresponding to the phoneme continuation length dur (ph k ) of the phoneme ph k.
- the weighting coefficient data w f (t) forcibly set to a predetermined value (for example, “1”) is continuously output to the internal division processing unit 9 (in FIG. 10, it is expressed as w f (t) [ph k ]). Corresponds to the part).
- the weighting coefficient data watt (t) acquired by the attention unit 4A is shown in association with the phoneme to be processed. Specifically, in FIG. 10, the period during which the weighting coefficient data w att (t) acquired by the attention unit 4A corresponding to the phoneme ph k is output is shown as “w att (t) [ph k ]”. ing. For convenience of explanation, FIG. 10 shows a case where the phoneme continuation length is correctly predicted by the attention unit 4A.
- the composite weighting coefficient data w (t) corresponding to the phoneme ph k is shown as “w (t) [ph k ]”.
- FIG. 11 is a diagram for explaining the processing at the time t2 (time step t2), and shows a part of the period when the phoneme to be processed is “ou” in FIG. 10 enlarged in the time axis direction. It is a figure.
- the forced attention unit 8 has the weighting coefficient data w f (t2) generated as described above . .. .. S is output to the internal division processing unit 9.
- the weighting coefficient data w att (t2) at time t2 is executed by executing the process corresponding to the function for acquiring the weighting coefficient data . .. .. Get S. Weighting coefficient data at time t2 w att (t) 1. .. .. It is assumed that S is the data (example) shown in FIG.
- the attention unit 4A has the weighting coefficient data watt (t2) acquired as described above . .. .. S is output to the internal division processing unit 9.
- the context calculation unit 10 outputs the acquired context state data c (t2) to the decoder side LSTM layer 52B of the decoder unit 5B.
- FIG. 12 is a diagram for explaining the processing at the time t3 (time step t3), and shows a part of the period of silence in FIG. 10 (the period shown by “silent” in FIG. 10). It is the figure enlarged in the time axis direction.
- the forced attention unit 8 has the weighting coefficient data w f (t3) generated as described above . .. .. S is output to the internal division processing unit 9.
- the weighting coefficient data w att (t3) at time t3 is executed by executing the process corresponding to the function for acquiring the weighting coefficient data . .. .. Get S. Weighting coefficient data at time t3 w att (t) 1. .. .. It is assumed that S is the data (example) shown in FIG.
- the attention unit 4A has the weighting coefficient data watt (t3) acquired as described above . .. .. S is output to the internal division processing unit 9.
- ⁇ 0.5, so w att (t3) 1. .. .. S and w f (t3) 1. .. ..
- the average value with S is the composite weighting coefficient data w (t) 1. .. .. It becomes S.
- w (t) 1. .. .. S is w (t) 1. .. ..
- the internal division processing unit 9 obtains the combined weighting coefficient data w (t2) 1. .. .. Output S to the context calculation unit 10.
- the context calculation unit 10 outputs the acquired context state data c (t3) to the decoder side LSTM layer 52B of the decoder unit 5B.
- the weighting coefficient data acquired by the attention unit 4A and the forced attention unit 8 are all 0, so the context state data c (t3) is also “0”. That is, as described above, the context state data c (t3) that appropriately indicates that the state is silent is acquired.
- the context state data c (t) acquired as described above is output to the decoder side LSTM layer 52B of the decoder unit 5B.
- the processing by the decoder-side prenet processing unit 51 is the same as that of the first embodiment.
- the decoder-side LSTM layer 52B includes data Dy2 (t) output from the decoder-side prenet processing unit 51 at the current time t and data Dy3 (data Dy3) output from the decoder-side LSTM layer 52 in the previous time step.
- the t-1) and the context state data c (t) at time t output from the context calculation unit 10 are input.
- the decoder-side LSTM layer 52A executes processing by the LSTM layer using the input data Dy2 (t), data Dy3 (t-1), and context state data c (t), and obtains the processed data. It is output to the linear prediction unit 53 as data Dy3 (t). In the linear prediction unit 53, the postnet processing unit 54, and the adder 55, the same processing as in the first embodiment is executed.
- the speech synthesis processing device 200 the data Dy6 (predicted mel spectrogram data) acquired as described above, and the teacher data (correct mel spectrogram) of the mel spectrogram (acoustic feature amount) corresponding to the text data Din.
- the parameters of the model of the neural network of the encoder unit 3 and the decoder unit 5B are updated so that the difference between the two (comparison result) (for example, the difference expressed by the norm of the difference vector and the Euclidean distance) becomes small.
- this parameter update process is repeatedly executed, and the data Dy6 (predicted mel spectrogram data) and the mel spectrogram (acoustic feature amount) teacher data (correct mel spectrogram) corresponding to the text data Din are obtained.
- the difference between the two becomes sufficiently small (within a predetermined error range)
- the parameters of the neural network model are acquired as the optimization parameters.
- the coupling coefficient (weighting coefficient) between synapses included in each layer of the neural network model of the encoder unit 3 and the decoder unit 5B is set based on the optimization parameters acquired as described above. Therefore, the model of the neural network of the encoder unit 3 and the decoder unit 5A can be used as an optimized model (trained model).
- the speech synthesis processing device 300 it is possible to construct a trained model (optimized model) of a neural network in which the input is text data and the output is mel spectrogram.
- the trained model (optimized model) of the neural network acquired by the learning process in the speech synthesis processing device 100 of the first embodiment may be used. That is, in the voice synthesis processing device 200, the voice synthesis processing device uses the optimum parameters of the encoder unit 3 and the decoder unit 5 of the trained model of the neural network acquired by the learning process in the voice synthesis processing device 100 of the first embodiment. By setting the parameters of the encoder unit 3 and the decoder unit 5B of the 200, the trained model may be constructed in the speech synthesis processing device 300.
- the learning process is the same as that of the first embodiment.
- a trained model (optimized model) of a neural network having an input as text data and an output as a mel spectrogram can be constructed as in the first embodiment.
- the learning process may be executed in cooperation with (1) the learning process of the encoder unit 3 and the decoder unit 5B and (2) the learning process of the vocoder 6, as described above. In addition, the learning process may be executed individually.
- the speech synthesis processing device 300 executes the learning process in cooperation with (1) the learning process of the encoder unit 3 and the decoder unit 5B and (2) the learning process of the vocoder 6, the input is set as text data and the text is concerned.
- the learning process may be executed by acquiring.
- the speech synthesis processing device 300 sets the trained model acquired by the above learning process, that is, the optimization model (optimization parameters) of the neural network of the encoder unit 3 and the decoder unit 5B.
- the model) and the optimization model (model in which the optimization parameters are set) of the neural network of the vocoder 6 are constructed. Then, in the speech synthesis processing device 300, the prediction processing is executed using the trained model.
- the text analysis unit 1A executes a text analysis process for Japanese on the input text data Din, and acquires full context label data Dx1 as 478-dimensional vector data including the parameters shown in FIG. 2, for example. To do.
- the acquired full context label data Dx1 is output from the text analysis unit 1A to the full context label vector processing unit 2.
- the text analysis unit 1A acquires a phoneme context label from the text data Din of the language to be processed, and outputs the acquired phoneme context label data as data Dx01 to the phoneme continuation length estimation unit 7.
- the phoneme continuation length estimation unit 7 performs a phoneme continuation length estimation process that estimates (acquires) the phoneme continuation length of the phoneme corresponding to the data Dx01 from the data Dx01 (phoneme context label data) output from the text analysis unit 1A. Execute. Specifically, the phoneme continuation length estimation unit 7 estimates (predicts) the phoneme continuation length of the phoneme from the context label of the phoneme using, for example, a hidden Markov model (HMM: Hidden Markov Model), a neural network model, or the like. Phoneme continuation length estimation processing is executed by the model (processing system).
- HMM Hidden Markov Model
- the phoneme continuation length estimation unit 7 uses the context label of the phoneme ph k (k: integer) to make a phoneme. by executing the duration estimation process to obtain the estimated phoneme duration dur of the phoneme ph k (ph k). For example, for each of the above phonemes (phoneme ph k ), the phoneme continuation length dur (ph k ) acquired (estimated) by the phoneme continuation length estimation unit 7 has the time length (continuation length) shown in FIG. It shall be.
- the phoneme continuation length estimation unit 7 outputs the phoneme continuation length data (dur (ph k ) in the case of FIG. 8) acquired (estimated) by the phoneme continuation length estimation process as data Dx02 to the forced attention unit 8. ..
- the forced attention unit 8 corresponds to the estimated phoneme continuation length (phoneme continuation length data Dx02) of the phoneme when the data processed by the encoder unit 3 for the phoneme corresponding to the phoneme continuation length data Dx02 is output.
- Weighting coefficient data w f (t) is generated in which the weighting coefficient is forcibly set to a predetermined value (for example, “1”) during the period.
- the forced attention unit 8 is a set data hi 1. Of the input side hidden state data . .. ..
- the data is expanded to S pieces (the same data is duplicated and expanded) around time t.
- Coefficient data w f (t) 1. .. .. Generate S.
- the forced attention unit 8 has the weighting coefficient data w f (t) 1. .. .. S is output to the internal division processing unit 9.
- the attention unit 4A inputs the data Dx4 output from the encoder unit 3 and the data ho (output side hidden state data ho) output from the decoder side LSTM layer 52B of the decoder unit 5B.
- the attention unit 4A stores and holds the data Dx4 output from the encoder unit 3, that is, the input side hidden state data hi for a predetermined time step.
- the attention unit 4A stores and holds the data Dy3 output from the decoder side LSTM layer 52B of the decoder unit 5B, that is, the output side hidden state data ho for a predetermined time step.
- the weighting coefficient data w att (t) at the current time t is executed by executing the process corresponding to the function for acquiring the weighting coefficient data . .. .. Get S.
- the internal division processing unit 9 has weighting coefficient data watt (t) output from the attention unit 4A . .. .. S and the weighting coefficient data w f (t) output from the forced attention unit 8 . .. .. Enter S. Then, the internal division processing unit 9 performs weighting coefficient data watt (t) 1. .. .. S and weighting coefficient data w f (t) 1. .. ...
- the internal division processing unit 9 uses the acquired composite weighting coefficient data w (t) 1. .. .. Output S to the context calculation unit 10.
- the decoder-side LSTM layer 52B executes processing by the LSTM layer using the input data Dy2 (t), data Dy3 (t-1), and context state data c (t), and obtains the processed data. It is output to the linear prediction unit 53 as data Dy3 (t).
- the vocoder 6 inputs data Dy6 (data of predicted mel spectrogram (data of acoustic feature amount)) output from the adder 55 of the decoder unit 5B, and uses a trained model for the input data Dy6.
- the speech synthesis process by the neural network process is executed, and the speech signal waveform data corresponding to the data Dy6 (predicted mel spectrogram) is acquired. Then, the vocoder 6 outputs the acquired voice signal waveform data as data Dout.
- the voice synthesis processing device 300 can acquire the voice waveform data Dout corresponding to the input text data Din.
- the weighting coefficient data watt (t) acquired by the attention unit 4A and the forced attention unit 8 are used even during the prediction processing, as described with reference to FIGS. 10 to 12.
- the context state data c (t) is generated by using the weighting coefficient data obtained by synthesizing the acquired weighting coefficient data w f (t) by the internal division processing. Then, in the speech synthesis processing device 300, the processing by the decoder unit 5B and the vocoder 6 is executed using the context state data c (t) generated as described above, so that the attention mechanism prediction fails. It is possible to appropriately prevent problems such as the cause, the synthetic speech stopping in the middle, and the same phrase being repeated many times.
- the weighting coefficient data acquired by the attention unit 4 is “0”. Even if it is (or less than or equal to a predetermined value) (or if the values of all element data of weight (t) 1 ... S are "0" (or less than or equal to a predetermined value)), speech synthesis In the processing device 300, the weight of the weighting coefficient data w f (t) acquired by the forced attention unit 8 can be used to prevent the failure of the attention mechanism prediction from affecting the speech synthesis processing. ) 1. .. .. S can be obtained (in the case of FIG. 13. The value of each element data of the composite weighting coefficient data w (t) 1 ... S is "0.5").
- the phoneme continuation length is estimated by using a model such as a hidden Markov model, which can stably and appropriately estimate the phoneme continuation length (phoneme continuation length estimation unit 7).
- the prediction accuracy of the phoneme continuation length is guaranteed by processing using the phoneme continuation length obtained by (processing by). That is, in the speech synthesis processing device 300, the phoneme continuation acquired by the estimation process (processing by the phoneme continuation length estimation unit 7) using a model such as the hidden Markov model, which can stably and appropriately estimate the phoneme continuation length.
- the acoustic features can be acquired by processing with a neural network model using the sequence-to-sequence method, so that highly accurate prediction processing of the acoustic features can be realized.
- the speech synthesis processing device 300 appropriately prevents problems such as failure of attention mechanism prediction, synthetic utterance stopping in the middle, and repeating the same phrase many times. At the same time, it is possible to execute highly accurate speech synthesis processing.
- the internal division ratio ⁇ is set to a fixed value (for example, 0.5) has been described, but the present invention is not limited to this, and the internal division ratio ⁇ is dynamically updated. It may be.
- the weighting coefficient data watt (t) input from the attention unit 4A 1. .. .. Weighting coefficient data w f (t) 1. S is continuously smaller than a predetermined value or substantially 0 for a predetermined period, and is input from the forced attention unit 8 . .. ..
- the encoder unit 3 and the decoder unit 5 are not limited to the above configuration, and may have other configurations.
- the encoder unit 3 and the decoder unit 5 may be configured by adopting the encoder and decoder configurations based on the transformer model architecture disclosed in Document A below.
- the attention mechanism installed between the encoder and the decoder according to the transformer model architecture is the mechanism described in this embodiment, that is, the attention unit 4, the forced attention unit 8, the internal division processing unit 9, and the context calculation unit 10.
- the weighting coefficient data acquired by the attention mechanism and the weighting coefficient data acquired by the forced attention unit 8 are combined by internal division processing, and the combined weighting coefficient data is used to replace the weighting coefficient data with a mechanism for acquiring context state data. do it.
- Reference A A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, AN. Gomez, L. Kaiser, I. Polosukhin, “Attention is all you need” 31 st Conference on Nural information Processing System (NIPS 2017), Long Beach, CA, USA.
- the encoder-side LSTM layer 32 and the decoder-side LSTM layer 52 may each include a plurality of LSTM layers. Further, the encoder-side LSTM layer 32 and the decoder-side LSTM layer 52 may each be composed of bidirectional LSTM layers (forward propagation and reverse propagation LSTM layers).
- the voice synthesis processing apparatus includes a text analysis unit 1 and a full context label vector processing unit 2, and is full from the full context label data acquired by the text analysis unit 1.
- a text analysis unit may be provided and the full context label vector processing unit may be omitted.
- each block may be individually integrated into one chip by a semiconductor device such as an LSI, or one chip so as to include a part or all of the blocks. It may be converted.
- LSI Although it is referred to as LSI here, it may be referred to as IC, system LSI, super LSI, or ultra LSI depending on the degree of integration.
- the method of making an integrated circuit is not limited to LSI, and may be realized by a dedicated circuit or a general-purpose processor.
- An FPGA Field Programmable Gate Array
- a reconfigurable processor that can reconfigure the connection and settings of the circuit cells inside the LSI may be used.
- a part or all of the processing of each functional block of each of the above embodiments may be realized by a program. Then, a part or all of the processing of each functional block of each of the above embodiments is performed by the central processing unit (CPU) in the computer. Further, the program for performing each process is stored in a storage device such as a hard disk or a ROM, and is read and executed in the ROM or the RAM.
- a storage device such as a hard disk or a ROM
- each process of the above embodiment may be realized by hardware, or may be realized by software (including the case where it is realized together with an OS (operating system), middleware, or a predetermined library). Further, it may be realized by mixed processing of software and hardware.
- OS operating system
- middleware middleware
- predetermined library a predetermined library
- each functional unit of the above embodiment when each functional unit of the above embodiment is realized by software, the hardware configuration shown in FIG. 14 (for example, CPU, GPU, ROM, RAM, input unit, output unit, communication unit, storage unit (for example, HDD, SSD)
- Each functional unit may be realized by software processing by using a storage unit (a storage unit realized by the above), a hardware configuration in which an external media drive or the like is connected by a bus Bus).
- each functional unit of the above embodiment is realized by software
- the software may be realized by using a single computer having the hardware configuration shown in FIG. 14, or a plurality of computers. It may be realized by using and distributed processing.
- execution order of the processing methods in the above embodiment is not necessarily limited to the description of the above embodiment, and the execution order can be changed without departing from the gist of the invention.
- a computer program that causes a computer to execute the above-mentioned method, and a computer-readable recording medium that records the program are included in the scope of the present invention.
- Examples of computer-readable recording media include flexible disks, hard disks, CD-ROMs, MOs, DVDs, DVD-ROMs, DVD-RAMs, large-capacity DVDs, next-generation DVDs, and semiconductor memories.
- the computer program is not limited to the one recorded on the recording medium, and may be transmitted via a telecommunication line, a wireless or wired communication line, a network typified by the Internet, or the like.
- Speech synthesis processing device 100, 200, 300 Speech synthesis processing device 1 Text analysis unit 2, 2A Full context label vector processing unit 3 Encoder unit 4, 4A Attention unit 5 Decoder unit 6 Vocoder 7 Phoneme continuation length estimation unit 8 Forced attention unit 9 Internal division processing unit 10 Context calculation unit
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Signal Processing (AREA)
- Machine Translation (AREA)
Abstract
L'invention concerne un dispositif de traitement de synthèse vocale réalisant un apprentissage et une optimisation et permettant un processus de synthèse vocale de haute qualité au moyen d'un modèle de réseau neuronal qui peut transformer une langue cible de traitement en une langue définie arbitrairement et qui concerne une synthèse texte-parole en utilisant le procédé de séquence à séquence. Dans un dispositif de traitement de synthèse vocale (100), un processus d'analyse de texte est réalisé conformément à une langue cible de traitement, des données d'étiquette à contexte complet optimisées qui sont appropriées pour un traitement avec un modèle de réseau neuronal sont acquises à partir de données d'étiquette à contexte complet acquises dans le processus d'analyse de texte, et les données d'étiquette à contexte complet optimisées acquises sont utilisées pour effectuer un processus, ce par quoi un processus de synthèse vocale hautement précis pour une langue cible de traitement arbitrairement défini peut être réalisé.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019-125726 | 2019-07-05 | ||
| JP2019125726 | 2019-07-05 | ||
| JP2019-200440 | 2019-11-05 | ||
| JP2019200440A JP7432199B2 (ja) | 2019-07-05 | 2019-11-05 | 音声合成処理装置、音声合成処理方法、および、プログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021006117A1 true WO2021006117A1 (fr) | 2021-01-14 |
Family
ID=74114026
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/025682 WO2021006117A1 (fr) | 2019-07-05 | 2020-06-30 | Dispositif de traitement de synthèse vocale, procédé de traitement de synthèse vocale et programme |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2021006117A1 (fr) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022133447A (ja) * | 2021-09-27 | 2022-09-13 | ベイジン バイドゥ ネットコム サイエンス テクノロジー カンパニー リミテッド | 音声処理方法、装置、電子機器及び記憶媒体 |
| JP2023027747A (ja) * | 2021-08-17 | 2023-03-02 | ベイジン バイドゥ ネットコム サイエンス テクノロジー カンパニー リミテッド | 音声処理方法、装置、機器、及びコンピュータ記憶媒体 |
| US11996084B2 (en) | 2021-08-17 | 2024-05-28 | Beijing Baidu Netcom Science Technology Co., Ltd. | Speech synthesis method and apparatus, device and computer storage medium |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018183650A2 (fr) * | 2017-03-29 | 2018-10-04 | Google Llc | Conversion de texte en parole de bout en bout |
-
2020
- 2020-06-30 WO PCT/JP2020/025682 patent/WO2021006117A1/fr active Application Filing
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018183650A2 (fr) * | 2017-03-29 | 2018-10-04 | Google Llc | Conversion de texte en parole de bout en bout |
Non-Patent Citations (5)
| Title |
|---|
| FUJIMOTO, TAKAHITO ET AL.: "Effect of input language feature values on Japanese End-to-End speech synthesis", LECTURE PROCEEDINGS OF 2019 SPRING RESEARCH CONFERENCE OF THE ACOUSTICAL SOCIETY OF JAPAN CD-ROM, 19 February 2019 (2019-02-19), pages 1061 - 1062 * |
| KURIHARA, KIYOSHI ET AL.: "Evaluation of Japanese end-to-end speech synthesis method inputting kana and prosodic symbols", IEICE TECHNICAL REPORT, vol. 118, no. 354, 3 December 2018 (2018-12-03), pages 89 - 94 * |
| PRENGER, RYAN ET AL.: "WAVEGLOW: A FLOW-BASED GENERATIVE NETWORK FOR SPEECH SYNTHESIS", PROC. ICASSP, vol. 19, 20 May 2019 (2019-05-20), pages 3617 - 3621, XP033565695, DOI: 10.1109/ICASSP.2019.8683143 * |
| SHEN, JONATHAN ET AL.: "NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS", PROC. ICASSP, vol. 18, 20 April 2018 (2018-04-20), pages 4779 - 4783, XP033403934, DOI: 10.1109/ICASSP.2018.8461368 * |
| YASUDA, YUSUKE ET AL.: "Towards end-to-end Japanese speech synthesis - An initial consideration of Japanese Tacotron", LECTURE PROCEEDINGS OF 2018 AUTUMN RESEARCH CONFERENCE OF THE ACOUSTICAL SOCIETV OF JAPAN, 29 August 2018 (2018-08-29), pages 1167 - 1168 * |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2023027747A (ja) * | 2021-08-17 | 2023-03-02 | ベイジン バイドゥ ネットコム サイエンス テクノロジー カンパニー リミテッド | 音声処理方法、装置、機器、及びコンピュータ記憶媒体 |
| JP7318161B2 (ja) | 2021-08-17 | 2023-08-01 | ベイジン バイドゥ ネットコム サイエンス テクノロジー カンパニー リミテッド | 音声処理方法、装置、機器、及びコンピュータ記憶媒体 |
| US11996084B2 (en) | 2021-08-17 | 2024-05-28 | Beijing Baidu Netcom Science Technology Co., Ltd. | Speech synthesis method and apparatus, device and computer storage medium |
| JP2022133447A (ja) * | 2021-09-27 | 2022-09-13 | ベイジン バイドゥ ネットコム サイエンス テクノロジー カンパニー リミテッド | 音声処理方法、装置、電子機器及び記憶媒体 |
| JP7412483B2 (ja) | 2021-09-27 | 2024-01-12 | ベイジン バイドゥ ネットコム サイエンス テクノロジー カンパニー リミテッド | 音声処理方法、装置、電子機器及び記憶媒体 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11605368B2 (en) | Speech recognition using unspoken text and speech synthesis | |
| CN111954903B (zh) | 多说话者神经文本到语音合成 | |
| US11587569B2 (en) | Generating and using text-to-speech data for speech recognition models | |
| Blaauw et al. | A neural parametric singing synthesizer | |
| JP7432199B2 (ja) | 音声合成処理装置、音声合成処理方法、および、プログラム | |
| WO2021006117A1 (fr) | Dispositif de traitement de synthèse vocale, procédé de traitement de synthèse vocale et programme | |
| CN111837178A (zh) | 语音处理系统和处理语音信号的方法 | |
| JP2023535230A (ja) | 2レベル音声韻律転写 | |
| Zhu et al. | Phone-to-audio alignment without text: A semi-supervised approach | |
| Ding et al. | Accentron: Foreign accent conversion to arbitrary non-native speakers using zero-shot learning | |
| CN116783647A (zh) | 生成多样且自然的文本到语音样本 | |
| JP7393585B2 (ja) | テキスト読み上げのためのWaveNetの自己トレーニング | |
| Wu et al. | Denoising Recurrent Neural Network for Deep Bidirectional LSTM Based Voice Conversion. | |
| JP5574344B2 (ja) | 1モデル音声認識合成に基づく音声合成装置、音声合成方法および音声合成プログラム | |
| WO2023023434A1 (fr) | Amélioration de la reconnaissance de la parole à l'aide d'une adaptation de modèle basée sur la synthèse de la parole | |
| CN115376484A (zh) | 基于多帧预测的轻量级端到端语音合成系统构建方法 | |
| WO2020166359A1 (fr) | Dispositif d'estimation, procédé d'estimation, et programme | |
| Heymans et al. | Efficient acoustic feature transformation in mismatched environments using a Guided-GAN | |
| Ngoc et al. | Adapt-Tts: High-Quality Zero-Shot Multi-Speaker Text-to-Speech Adaptive-Based for Vietnamese | |
| US20230076239A1 (en) | Method and device for synthesizing multi-speaker speech using artificial neural network | |
| EP4068279B1 (fr) | Procédé et système permettant d'effectuer une adaptation de domaine d'un modèle de reconnaissance vocale automatique de bout en bout | |
| Liu et al. | Pre-training Techniques for Improving Text-to-Speech Synthesis by Automatic Speech Recognition Based Data Enhancement | |
| Liu et al. | Check for updates Pre-training Techniques for Improving Text-to-Speech Synthesis by Automatic Speech Recognition Based Data Enhancement | |
| CN117678013A (zh) | 使用合成的训练数据的两级文本到语音系统 | |
| Abbas et al. | Multi-scale spectrogram modelling for neural text-to-speech |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20837364 Country of ref document: EP Kind code of ref document: A1 |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 20837364 Country of ref document: EP Kind code of ref document: A1 |