WO2020234984A1 - 学習装置、学習方法、コンピュータプログラム及び記録媒体 - Google Patents
学習装置、学習方法、コンピュータプログラム及び記録媒体 Download PDFInfo
- Publication number
- WO2020234984A1 WO2020234984A1 PCT/JP2019/020057 JP2019020057W WO2020234984A1 WO 2020234984 A1 WO2020234984 A1 WO 2020234984A1 JP 2019020057 W JP2019020057 W JP 2019020057W WO 2020234984 A1 WO2020234984 A1 WO 2020234984A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- gradient
- loss function
- loss
- machine learning
- update
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/217—Validation; Performance evaluation; Active pattern learning techniques
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0499—Feedforward networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/09—Supervised learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/094—Adversarial learning
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
Definitions
- the present invention relates to the technical fields of learning devices, learning methods, computer programs and recording media that update machine learning models.
- Machine learning models learned using deep learning have vulnerabilities related to hostile samples (Adversary Expert) generated to deceive machine learning models. ..
- hostile samples Advanced Expert
- the machine learning model may not be able to correctly classify (ie, misclassify) the hostile sample. For example, if the sample input to the machine learning model is an image, the class is "B" when it is input to the machine learning model even though the image is classified into the class "A" for humans. Images classified as are used as hostile samples.
- Non-Patent Document 1 describes an example of a method of constructing a robust machine learning model for a hostile sample. Specifically, Non-Patent Document 1 describes all of the plurality of machine learning models based on the first loss function of the plurality of machine learning models and the second loss function based on the gradient of the first loss function. Robust against hostile samples by updating multiple machine learning models (specifically, updating the parameters of multiple machine learning models) to narrow the space in which the hostile samples misclassify It describes how to build a machine learning model.
- Non-Patent Document 1 has a restriction that a specific function needs to be used as an activation function of a machine learning model. Specifically, in the method described in Non-Patent Document 1, there is a restriction that it is necessary to use the Leaky ReLu function as the activation function instead of the ReLu (Rectifier Liner Unit) function. This is because the method described in Non-Patent Document 1 utilizes a second loss function based on the gradient of the first loss function, so that the gradient becomes zero (that is, the differential coefficient becomes zero). This is because the ReLu function, which has a relatively wide range, has a small effect of the gradient of the first loss function on the update of the machine learning model (that is, the contribution of the second loss function to the update of the machine learning model). ..
- Non-Patent Document 1 has a technical problem that there is room for improvement from the viewpoint of reducing the processing load.
- An object of the present invention is to provide a learning device, a learning method, a computer program, and a recording medium capable of solving the above-mentioned technical problems.
- the first aspect of the learning device for solving the problem is a predicted loss for calculating a predicted loss function based on an error between the output of a plurality of machine learning models in which training data is input and the correct answer label corresponding to the training data.
- the gradient loss calculation means includes an update means, and (i) calculates the gradient loss function based on the gradient when the number of times the update process is performed is less than a predetermined number, and (ii) the update. When the number of times the processing is performed is greater than the predetermined number, the function indicating 0 is calculated as the gradient loss function.
- the second aspect of the learning device for solving the problem is a predicted loss that calculates a predicted loss function based on an error between the output of a plurality of machine learning models in which training data is input and the correct answer label corresponding to the training data.
- An update that updates the plurality of machine learning models based on a calculation means, a gradient loss calculation means for calculating a gradient loss function based on the gradient of the predicted loss function, and at least one of the predicted loss function and the gradient loss function.
- the update means includes an update means for performing the process, and (i) when the number of times the update process is performed is less than a predetermined number, the update means is based on both the predicted loss function and the gradient loss function. The process is performed, and (ii) when the number of times the update process is performed is greater than the predetermined number, the update process is performed based on the predicted loss function but not based on the gradient loss function.
- the first aspect of the learning method for solving the problem is to calculate a predicted loss function based on an error between the output of a plurality of machine learning models in which training data is input and the correct answer label corresponding to the training data.
- a calculation step a gradient loss calculation step for calculating a gradient loss function based on the gradient of the predicted loss function, and an update process for updating the plurality of machine learning models based on the predicted loss function and the gradient loss function.
- the gradient loss calculation step including the update step, (i) when the number of times the update process is performed is less than a predetermined number, the gradient loss function based on the gradient is calculated, and (ii) the update. When the number of times the processing is performed is greater than the predetermined number, a function indicating 0 is calculated as the gradient loss function.
- the second aspect of the learning method for solving the problem is a predicted loss for calculating a predicted loss function based on an error between the output of a plurality of machine learning models in which training data is input and the correct answer label corresponding to the training data.
- An update that updates the plurality of machine learning models based on a calculation step, a gradient loss calculation step for calculating a gradient loss function based on the gradient of the predicted loss function, and at least one of the predicted loss function and the gradient loss function.
- the update step including the update step of performing the process, (i) when the number of times the update process is performed is less than a predetermined number, the update is based on both the predicted loss function and the gradient loss function.
- the update process is performed based on the predicted loss function but not based on the gradient loss function.
- One aspect of the computer program for solving the problem is to cause the computer to execute the first or second aspect of the learning method described above.
- One aspect of the recording medium for solving the problem is a recording medium on which one aspect of the computer program described above is recorded.
- the machine learning model can be updated with a relatively low processing load.
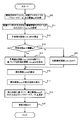
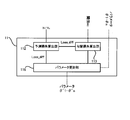
- FIG. 1 is a block diagram showing a hardware configuration of the learning device of the present embodiment.
- FIG. 2 is a block diagram showing a functional block realized in the CPU of the present embodiment.
- FIG. 3 is a flowchart showing an operation flow of the learning device of the present embodiment.
- FIG. 4 is a flowchart showing a flow of a modified example of the operation of the learning device of the present embodiment.
- FIG. 5 is a block diagram showing a modified example of the functional block realized in the CPU.
- n machine learning models f 1 , f 2 , ..., f n -1 and f n are trained using the training data set DS to train n (where n is an integer of 2 or more).
- learning device 1 from the machine learning model f 1 updates the f n of the learning apparatus, a learning method, an embodiment of a computer program and a recording medium will be described.
- FIG. 1 is a block diagram showing a hardware configuration of the learning device 1 of the present embodiment.
- FIG. 2 is a block diagram showing a functional block realized in the CPU 11 of the learning device 1.
- the learning device 1 includes a CPU (Central Processing Unit) 11, a RAM (Random Access Memory) 12, a ROM (Read Only Memory) 13, a storage device 14, an input device 15, and an output. It includes a device 16.
- the CPU 11, the RAM 12, the ROM 13, the storage device 14, the input device 15, and the output device 16 are connected via the data bus 17.
- the CPU 11 reads a computer program.
- the CPU 11 may read a computer program stored in at least one of the RAM 12, the ROM 13, and the storage device 14.
- the CPU 11 may read a computer program stored in a computer-readable recording medium using a recording medium reading device (not shown).
- the CPU 11 may acquire (that is, may read) a computer program from a device (not shown) arranged outside the learning device 1 via a network interface.
- the CPU 11 controls the RAM 12, the storage device 14, the input device 15, and the output device 16 by executing the read computer program.
- a logical functional block for updating the machine learning model f 1 to f n is realized in the CPU 11. That is, the CPU 11 can function as a controller for realizing a logical functional block for updating f n from the machine learning model f 1 .
- a prediction unit 111 and a specific “prediction loss calculation means” in the appendix to be described later are specified.
- the parameter update unit 116 which is a specific example of the "update means", is realized.
- the operations of the prediction unit 111, the prediction loss calculation unit 112, the gradient loss calculation unit 113, the loss function calculation unit 114, the differentiation unit 115, and the parameter update unit 116 will be described in detail later with reference to FIG. 3 and the like. Therefore, detailed description here will be omitted.
- the RAM 12 temporarily stores the computer program executed by the CPU 11.
- the RAM 12 temporarily stores data temporarily used by the CPU 11 when the CPU 11 is executing a computer program.
- the RAM 12 may be, for example, a D-RAM (Dynamic RAM).
- the ROM 13 stores a computer program executed by the CPU 11.
- the ROM 13 may also store fixed data.
- the ROM 13 may be, for example, a P-ROM (Programmable ROM).
- the storage device 14 stores the data stored in the learning device 1 for a long period of time.
- the storage device 14 may operate as a temporary storage device of the CPU 11.
- the storage device 14 may include, for example, at least one of a hard disk device, a magneto-optical disk device, an SSD (Solid State Drive), and a disk array device.
- the input device 15 is a device that receives an input instruction from the user of the learning device 1.
- the input device 15 may include, for example, at least one of a keyboard, a mouse and a touch panel.
- the output device 16 is a device that outputs information about the learning device 1 to the outside.
- the output device 16 may be a display device capable of displaying information about the learning device 1.
- FIG. 3 is a flowchart showing an operation flow of the learning device 1 of the present embodiment.
- the learning device 1 acquires information necessary for updating f n from the machine learning model f 1 (step S10). Specifically, the learning device 1 acquires f n from the machine learning model f 1 to be updated. Further, the learning device 1 acquires a training data set DS used for updating (that is, training) f n from the machine learning model f 1 .
- the learning apparatus 1 define the parameters theta 2, ⁇ ⁇ ⁇ , the behavior of the machine learning model f n-1 defining parameters theta 1 defines the behavior of the machine learning model f 1, the behavior of the machine learning model f 2 obtaining a parameter theta n that define the behavior of the parameter theta n-1 and machine learning model f n to. Further, the learning device 1 acquires the threshold value ec.
- Each of the machine learning models f 1 to f n is a machine learning model based on a neural network. However, each of the machine learning models f 1 to f n may be another type of machine learning model.
- the training data set DS is a data set including a plurality of unit data sets composed of training data (that is, training sample) X and correct label Y.
- the training data X is data input to each of the machine learning models f 1 to f n in order to update the machine learning models f 1 to f n .
- the correct answer label Y indicates the label (in other words, the classification) of the training data X. In other words, true label Y, if the training data X corresponding to the true label Y is inputted from the machine learning model f 1 to each of f n, label to each of the f n is originally output from the machine learning model f 1 Is shown.
- the parameter ⁇ k of the machine learning model f k includes the parameters of the neural network.
- the parameters of the neural network may include at least one of bias and weighting at each node constituting the neural network.
- the operation of updating f n from the machine learning model f 1 is assumed to be the operation of updating the parameters ⁇ 1 to ⁇ n . That is, it is assumed that the learning device 1 updates f n from the machine learning model f 1 by updating the parameters ⁇ 1 to ⁇ n .
- the threshold value ec is a threshold value used for comparing the number of times ⁇ n is updated from the parameter ⁇ 1 (hereinafter referred to as “update number et”). Since the parameters ⁇ 1 to ⁇ n are updated by performing the operation shown in FIG. 3, the update count et may mean the number of times the operation shown in FIG. 3 is performed. The result of comparison between the number of updates et and the threshold value ec will be described in detail later, but the gradient loss calculation unit 113 is used when calculating the gradient loss function Loss_grad.
- the prediction unit 111 inputs the training data X from the machine learning model f 1 to each of f n, machine learning model from f 1 f n is respectively output to the label (hereinafter referred to as "output label") y Acquire y n from 1 (step S11). That is, the prediction unit 111 has output label y 1 output by the machine learning model f 1 to which the training data X is input, output label y 2 output by the machine learning model f 2 to which the training data X is input, ...
- the output label y n-1 output by the machine learning model f n-1 to which the training data X is input and the output label y n to be output by the machine learning model f n to which the training data X is input are acquired.
- the output labels y 1 to y n acquired by the prediction unit 111 are output to the prediction loss calculation unit 112.
- the predicted loss calculation unit 112 calculates the predicted loss function Loss_diff based on the output labels y 1 to y n and the correct label Y (step S12). Specifically, the predicted loss calculation unit 112 calculates the predicted loss function Loss_diff k based on the error between the output label y k and the correct label Y. That is, the predicted loss calculation unit 112 has a predicted loss function Loss_diff 1 that represents the error between the output label y 1 and the correct label Y, a predicted loss function Loss_diff 2 that represents the error between the output label y 2 and the correct label Y, ...
- the predicted loss function Loss_diff n representing the error between the output label y n-1 and true label Y predicted loss function representing an error between Loss_diff n-1 and output label y n and true label Y.
- the error between the output label y and the correct label Y referred to here is, for example, a cross entropy error, but may be another type of error (for example, a square error). That is, the predicted loss function Loss_diff is a loss function capable of expressing the error between the output label y and the correct label Y as an cross entropy error, but it may be another kind of loss function.
- the softmax function is used as the activation function of the machine learning models f 1 to f n (particularly, the activation function of the output layer), but other types of activities are used.
- a conversion function (for example, at least one of a ReLu function and a Leaky ReLu function) may be used.
- the gradient loss calculation unit 113 determines whether or not the update count et is equal to or less than the threshold value ec (step S13).
- the threshold ec is typically a constant set to an integer greater than or equal to 1.
- the gradient loss calculation unit 113 may change the threshold value ec as necessary. That is, the gradient loss calculation unit 113 may change the threshold value ec acquired by the learning device 1 as necessary.
- step S13 when it is determined that the update count et is equal to or less than the threshold value ec (step S13: Yes), the gradient loss calculation unit 113 has the predicted loss function Loss_diff and the gradient loss function Ross_grad based on the gradient ⁇ . Is calculated (step S14).
- the gradient loss calculation unit 113 may calculate the gradient loss function Loss_grad based on the gradient ⁇ in the predicted loss function Loss_diff by a method different from the method described below.
- the gradient loss calculation unit 113 calculates the gradient ⁇ k of the predicted loss function Loss_diff k based on the following mathematical formula 1.
- the gradient loss calculation unit 113 based on Equation 1 below, the predicted loss function Loss_diff 1 gradient ⁇ 1, gradient ⁇ 2 predicted loss function Loss_diff 2, ⁇ , gradient of the predicted loss function Loss_diff n-1 Calculate the gradient ⁇ n of ⁇ n-1 and the predicted loss function Loss_diff n . Equation 1 below, as the slope ⁇ k of the predicted loss function Loss_diff k, which means the slope for the training data X of the predicted loss function Loss_diff k (i.e., gradient vectors) that is used.
- the gradient loss calculation unit 113 calculates the gradient loss function Loss_grad based on the similarity of the gradient ⁇ 1 to the gradient ⁇ n . Specifically, the gradient loss calculation unit 113 calculates the similarity of two gradients ⁇ from the gradient ⁇ 1 to the gradient ⁇ n for all combinations of the two gradients ⁇ . That is, the gradient loss calculation unit 113 includes (1) the similarity between the gradient ⁇ 1 and the gradient ⁇ 2 , the similarity between the gradient ⁇ 1 and the gradient ⁇ 3 , ..., the gradient ⁇ 1 and the gradient ⁇ n-1 .
- Similarity and similarity between gradient ⁇ 1 and gradient ⁇ n (2) similarity between gradient ⁇ 2 and gradient ⁇ 3 , similarity between gradient ⁇ 2 and gradient ⁇ 4 , ..., gradient ⁇ 2 And the similarity between the gradient ⁇ n-1 and the gradient ⁇ 2 and the gradient ⁇ n ..., (n-2)
- the similarity between the gradient ⁇ n-2 and the gradient ⁇ n-1 and the gradient ⁇ The similarity between n-2 and the gradient ⁇ n, and the similarity between (n-1) gradient ⁇ n-1 and the gradient ⁇ n are calculated.
- the gradient loss calculation unit 113 any index that can quantitatively indicate whether a gradient ⁇ i and slope ⁇ j are similar much, the degree of similarity between the gradient ⁇ i and slope ⁇ j May be used as.
- the gradient loss calculation unit 113 as shown in Equation 2 below, as the similarity between the gradient ⁇ i and slope ⁇ j, even with cosine similarity cos ij with the gradient ⁇ i and slope ⁇ j Good.
- the gradient loss calculation unit 113 calculates the sum of the calculated similarities as the gradient loss function Loss_grad.
- the gradient loss calculation unit 113 calculates the gradient loss function Loss_grad using the formula 3 below.
- the gradient loss calculation unit 113 may calculate a value corresponding to the calculated sum of similarity (for example, a value proportional to the sum of similarity) as the gradient loss function Loss_grad.
- step S13 determines whether the update count et is not equal to or less than the threshold ec (that is, the update count et is larger than the threshold ec) (step S13: No).
- the gradient loss calculation unit 113 Instead of calculating the gradient loss function Loss_grad based on the gradient ⁇ , calculates a function indicating 0 as the gradient loss function Loss_grad (step S15). That is, the gradient loss calculation unit 113 sets the function indicating 0 in the gradient loss function Loss_grad regardless of the gradient ⁇ (step S15).
- the gradient loss calculation unit 113 calculates the gradient loss function Loss_grad based on the gradient ⁇ .
- the gradient loss calculation unit 113 may calculate a function indicating 0 as the gradient loss function Loss_grad. That is, in step S13, the gradient loss calculation unit 113 may determine whether or not the number of updates et is smaller than the threshold value ec, instead of determining whether or not the number of updates et is equal to or less than the threshold value ec. Good.
- the loss function calculation unit 114 updates f n from the machine learning model f 1 based on the predicted loss function Loss_diff calculated in step S12 and the gradient loss function Loss_grad calculated in step S14 or S15 (that is,). , Update ⁇ n from the parameter ⁇ 1 ) to calculate the final loss function Loss to be referred to (step S16).
- the loss function calculation unit 114 may calculate the loss function Loss by any method as long as both the predicted loss function Loss_diff and the gradient loss function Loss_grad are reflected in the loss function Loss.
- the loss function calculation unit 114 may calculate the sum of the predicted loss function Loss_diff and the gradient loss function Loss_grad as the loss function Loss.
- the loss function calculation unit 114 may set (in other words, adjust or change) at least one of the weighting coefficients w_diff and w_grad.
- the larger the weighting coefficient w_diff the greater the importance (in other words, the degree of contribution) of the predicted loss function Loss_diff in the loss function Loss.
- the larger the weighting coefficient w_grad the greater the importance (in other words, the degree of contribution) of the gradient loss function Loss_grad in the loss function Loss.
- at least one of the weighting coefficients w_diff and w_grad may be a fixed value. In this case, at least one of the weighting coefficients w_diff and w_grad may be acquired by the learning device 1 as hyperparameters in step S10.
- the differential unit 115 calculates the differential coefficient of the loss function Loss calculated in step S16 (step S17). For example, the differential unit 115 calculates the differential coefficient of the loss function Loss with respect to the parameters ⁇ 1 to ⁇ n .
- the parameter updating unit 116 updates the parameters ⁇ 1 to ⁇ n so that the value of the loss function Loss becomes smaller based on the differential coefficient calculated in step S115 (step S18). For example, the parameter updating unit 116 may update the parameters ⁇ 1 to ⁇ n so that the value of the loss function Loss becomes small by using the gradient method based on the differential coefficient calculated in step S115. For example, the parameter updating unit 116 may update the parameters ⁇ 1 to ⁇ n so that the value of the loss function Loss becomes small by using the error back propagation method based on the differential coefficient calculated in step S115. As a result, the parameter update unit 116 describes the updated parameters ⁇ 1 to ⁇ n (in FIG. 2, the updated parameters ⁇ 1 to ⁇ n are referred to as “parameters ⁇ ′ 1 to ⁇ ′ n ”). Is output.
- the learning device 1 increments the update count et by 1 (step S19), and then ends the operation shown in FIG. After that, the learning device 1 repeats the operation shown in FIG. 3 until the update end condition of the parameters ⁇ 1 to ⁇ n (that is, the update end condition of the machine learning models f 1 to f n ) is satisfied.
- the update end condition may include a condition that the error between the output labels y 1 to y n of the machine learning models f 1 to f n and the correct label Y has become smaller than the permissible value.
- the update end condition may include a condition that the operation shown in FIG.
- the update end condition may include a condition that the update count et becomes a predetermined number or more.
- the value of the loss function Loss calculated based on both the predicted loss function Loss_diff and the gradient loss function Loss_grad becomes small.
- f n can be updated from the machine learning model f 1 .
- reducing the value of the loss function Loss is equivalent to reducing both the value of the predicted loss function Loss_diff and the value of the gradient loss function Loss_grad in a well-balanced manner.
- the value of the predicted loss function Loss_diff decreases, the error between y n and true label Y decreases from the machine learning model f 1 from the output label y 1 of f n.
- the parameter update unit 116 enhances the classification accuracy (in other words, identification accuracy) of each of the machine learning models f 1 to f n with respect to a normal sample (that is, a sample that is not a hostile sample).
- a normal sample that is, a sample that is not a hostile sample.
- the machine learning models f 1 to f n are updated so as to reduce the possibility that all of the machine learning models f 1 to f n misclassify the hostile sample.
- the learning device 1 can appropriately construct f n from the machine learning model f 1 which is robust to the hostile sample (and the classification accuracy of the normal sample is correspondingly high).
- the gradient loss function Loss_grad used for calculating the loss function Loss changes according to the number of updates et. Specifically, when the update count et is equal to or less than the threshold ec, the gradient loss function Loss_grad based on the gradient ⁇ is used to calculate the loss function Loss, and when the update count et is larger than the threshold ec.
- the gradient loss function Loss_grad which indicates 0, is used to calculate the loss function Loss. Therefore, when the number of updates et is larger than the threshold value ec, the predicted loss function Loss_diff is substantially used to calculate the loss function Loss (that is, update f n from the machine learning model f 1 ).
- the gradient loss function Loss_grad is no longer used. That is, when the number of updates et is larger than the threshold value ec, the gradient ⁇ is practically not used for calculating the loss function Loss (that is, updating f n from the machine learning model f 1 ). As a result, when the number of updates et is larger than the threshold value ec, the gradient loss function Loss_grad based on the gradient ⁇ does not have to be calculated. More specifically, when the number of updates et is larger than the threshold ec, the slope loss calculation unit 113 may not calculate the ⁇ n from the gradient ⁇ 1, and the similarity of ⁇ n from the gradient ⁇ 1 It is not necessary to calculate.
- the processing load of the learning device 1 is reduced by the amount that the calculation of the gradient ⁇ becomes unnecessary.
- the learning device 1 of this embodiment is different from the learning apparatus in a comparative example of calculating the gradient ⁇ regardless of the magnitude of the update count et, from the machine learning model f 1 at a relatively low processing load f n can be updated.
- the machine learning model is not used after that. Even if f 1 to f n is updated, the space in which the hostile samples that induce all the misclassifications of the machine learning models f 1 to f n exist is not excessively expanded. In other words, if the machine learning models f 1 to f n are updated more than a certain number of times using the gradient ⁇ , then the contribution of the gradient ⁇ to the update of the machine learning models f 1 to f n (that is, the degree of influence).
- the learning device 1 applies to the hostile sample substantially as in the case of updating f n from the machine learning model f 1 using the gradient ⁇ even when the number of updates et is larger than the threshold value ec.
- the robust machine learning model f 1 to f n can be appropriately constructed.
- the threshold value ec to be compared with the update count et may be set to an appropriate value based on the relationship between the update count et and the contribution of the gradient ⁇ to the update of the machine learning models f 1 to f n. ..
- the threshold ec, the machine from the learning model f 1 and circumstances contribution is relatively small gradient ⁇ for updating f n
- the contribution of the gradient ⁇ for updates from the machine learning model f 1 of f n relatively A large situation may be set to an appropriate value that can be distinguished from the number of updates et.
- the threshold ec is a situation there is no contribution even smaller problems gradient ⁇ for updates f n from the machine learning model f 1, is less gradient ⁇ contribution to update f n from the machine learning model f 1 In that case, a situation in which a problem may occur may be set to an appropriate value that can be distinguished from the number of updates et.
- the threshold value ec is a situation in which it is preferable to update f n from the machine learning model f 1 using the gradient ⁇ , and a situation in which f n can be updated from the machine learning model f 1 to f n without using the gradient ⁇ . , It may be set to an appropriate value that can be distinguished from the update count et.
- Non-Patent Document 1 the restriction of the activation function for preventing the contribution of the gradient loss function Loss_grad to the update of the machine learning model f 1 to f n is relaxed. Will be done. This is because, in the present embodiment, after the gradient ⁇ is used to update the machine learning model f 1 to f n more than a certain number of times, the gradient ⁇ is not used to update the machine learning model f 1 to f n. Because. That is, in the present embodiment, after the machine learning models f 1 to f n are updated more than a certain number of times using the gradient ⁇ , the contribution of the gradient ⁇ to the update of the machine learning models f 1 to f n becomes small.
- the Leaky ReLu function As the activation function, it is not always necessary to use the Leaky ReLu function as the activation function. That is, in the present embodiment, a function whose processing load required for updating the machine learning models f 1 to f n is lower than the Leaky ReLu function (for example, the ReLu function) can be used as the activation function. Therefore, the processing load required for updating the machine learning models f 1 to f n is lower than in the case where the Leaky ReLu function needs to be used as the activation function. In this respect as well, the learning device 1 of the present embodiment can update the machine learning model f 1 to f n with a relatively low processing load.
- calculating the gradient loss function Loss_grad showing 0 when the number of updates et is greater than the threshold ec is to calculate the gradient loss function Loss_grad when the number of updates et is greater than the threshold ec. It is substantially equivalent to calculating the loss function Loss without using it. That is, to calculate the gradient loss function Loss_grad showing 0 when the number of updates et is greater than the threshold ec is to calculate the machine learning model f 1 without using the gradient loss function Loss_grad when the number of updates et is greater than the threshold ec. It is substantially equivalent to updating f n from. Therefore, as shown in the flowchart of FIG.
- the loss function calculation unit 114 determines (i) the predicted loss function Loss_diff and the gradient when the update count et is equal to or less than the threshold ec when calculating the loss function Loss.
- the loss function Loss is calculated based on both the loss function Loss_grad (step S16a in FIG. 4), and (ii) when the update count et is not equal to or less than the threshold ec, the predicted loss function Loss_diff is not based on the gradient loss function Loss_grad.
- the loss function Loss may be calculated based on (step S16b in FIG. 4). Even in this case, since the restriction of the activation function is still relaxed, the learning device 1 can update the machine learning model f 1 to f n with a relatively low processing load.
- the gradient loss calculation unit 113 may calculate the gradient loss function Loss_grad based on the gradient ⁇ regardless of the update count et as shown in FIG. 4, or the update count etc. as shown in FIG.
- the calculation method of the gradient loss function Loss_grad may be changed according to the above.
- the learning device 1 includes a prediction unit 111, a loss function calculation unit 114, and a differentiation unit 115. However, the learning device 1 does not have to include at least one of the prediction unit 111, the loss function calculation unit 114, and the differentiation unit 115. For example, as shown in FIG. 5, the learning device 1 does not have to include all of the prediction unit 111, the loss function calculation unit 114, and the differentiation unit 115. When the learning device 1 does not include the prediction unit 111, the learning devices 1 may be input with output labels y 1 to y n output from the machine learning models f 1 to f n, respectively .
- the parameter update unit 116 does not calculate the loss function Loss, and the machine learning model f is based on the predicted loss function Loss_diff and the gradient loss function Loss_grad. You may update f n from 1 .
- the parameter update unit 116 calculates the loss function Loss, and then the machine learning model f 1 to f n based on the calculated loss function Loss. May be updated.
- the parameter update 116 does not calculate the derivative of the loss function Loss (or is not based on the derivative), and the machine learning models f 1 to f f. n may be updated.
- the parameter update unit 116 may update f n from the machine learning model f 1 after calculating the differential coefficient of the loss function Loss.
- the learning device 1 can update the machine learning models f 1 to f n based on the predicted loss function Loss_diff and the gradient loss function Loss_grad, what kind of machine learning models f 1 to f n can be used. You may update by the method.
- the learning device includes a prediction loss calculation means for calculating a prediction loss function based on an error between the output of a plurality of machine learning models into which training data is input and a correct answer label corresponding to the training data, and the prediction. It is provided with a gradient loss calculating means for calculating a gradient loss function based on the gradient of the loss function, and an updating means for performing an update process for updating the plurality of machine learning models based on the predicted loss function and the gradient loss function.
- the gradient loss calculating means (i) calculates the gradient loss function based on the gradient when the number of times the update process is performed is less than a predetermined number, and (ii) the number of times the update process is performed. Is a learning device characterized in that when is greater than the predetermined number, a function indicating 0 is calculated as the gradient loss function.
- the update means (i) is based on both the predicted loss function and the gradient loss function when the number of times the update process is performed is less than the predetermined number.
- the update process is performed and (ii) the number of times the update process is performed is greater than the predetermined number, the update process is performed based on the predicted loss function but not based on the gradient loss function.
- the learning device includes a prediction loss calculation means for calculating a prediction loss function based on an error between the output of a plurality of machine learning models into which training data is input and a correct answer label corresponding to the training data, and the prediction.
- a gradient loss calculating means for calculating a gradient loss function based on the gradient of the loss function, and an updating means for performing an update process for updating the plurality of machine learning models based on at least one of the predicted loss function and the gradient loss function.
- the predicted loss calculating means calculates a plurality of the predicted loss functions corresponding to the plurality of machine learning models, respectively, and the gradient loss calculating means is a plurality of the predicted loss functions.
- the learning device according to Appendix 5 is the learning device according to Appendix 4, wherein the gradient loss calculating means calculates the gradient loss function based on the cosine similarity of the gradients of the plurality of predicted loss functions.
- the update means performs the update process so that the differential coefficient of the predicted loss function and the final loss function based on the gradient loss function becomes small.
- Appendix 7 The learning method described in Appendix 7 includes a predicted loss calculation step of calculating a predicted loss function based on an error between the output of a plurality of machine learning models into which training data is input and a correct answer label corresponding to the training data, and the prediction. It includes a gradient loss calculation step of calculating a gradient loss function based on the gradient of the loss function, and an update process of updating the plurality of machine learning models based on the predicted loss function and the gradient loss function. In the gradient loss calculation step, (i) when the number of times the update process is performed is less than a predetermined number, the gradient loss function based on the gradient is calculated, and (ii) the number of times the update process is performed. Is more than the predetermined number, the learning method is characterized in that a function indicating 0 is calculated as the gradient loss function.
- Appendix 8 The learning method described in Appendix 8 includes a predicted loss calculation step of calculating a predicted loss function based on an error between the output of a plurality of machine learning models into which training data is input and a correct answer label corresponding to the training data, and the prediction.
- a gradient loss calculation step for calculating a gradient loss function based on the gradient of the loss function, and an update process for updating the plurality of machine learning models based on at least one of the predicted loss function and the gradient loss function.
- the update step (i) when the number of times the update process is performed is less than a predetermined number, the update process is performed based on both the predicted loss function and the gradient loss function. ii) When the number of times the update process is performed is greater than the predetermined number, the learning method is characterized in that the update process is performed based on the predicted loss function but not based on the gradient loss function. is there.
- Appendix 9 The computer program described in Appendix 9 is a computer program that causes a computer to execute the learning method described in Appendix 7 or 8.
- Appendix 10 The recording medium described in Appendix 10 is a recording medium on which the computer program described in Appendix 9 is recorded.
- the present invention can be appropriately modified within the scope of the claims and within the scope not contrary to the gist or idea of the invention which can be read from the entire specification, and learning devices, learning methods, computer programs and recording media accompanied by such changes are also made. It is included in the technical idea of the present invention.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Biology (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Multimedia (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Feedback Control In General (AREA)
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US17/610,497 US20220237416A1 (en) | 2019-05-21 | 2019-05-21 | Learning apparatus, learning method, computer program and recording medium |
| JP2021519927A JP7276436B2 (ja) | 2019-05-21 | 2019-05-21 | 学習装置、学習方法、コンピュータプログラム及び記録媒体 |
| PCT/JP2019/020057 WO2020234984A1 (ja) | 2019-05-21 | 2019-05-21 | 学習装置、学習方法、コンピュータプログラム及び記録媒体 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2019/020057 WO2020234984A1 (ja) | 2019-05-21 | 2019-05-21 | 学習装置、学習方法、コンピュータプログラム及び記録媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020234984A1 true WO2020234984A1 (ja) | 2020-11-26 |
Family
ID=73459090
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/020057 Ceased WO2020234984A1 (ja) | 2019-05-21 | 2019-05-21 | 学習装置、学習方法、コンピュータプログラム及び記録媒体 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20220237416A1 (https=) |
| JP (1) | JP7276436B2 (https=) |
| WO (1) | WO2020234984A1 (https=) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113360851A (zh) * | 2021-06-22 | 2021-09-07 | 北京邮电大学 | 一种基于Gap-loss函数的工业流水线生产状态检测方法 |
| CN113849648A (zh) * | 2021-09-28 | 2021-12-28 | 平安科技(深圳)有限公司 | 分类模型训练方法、装置、计算机设备和存储介质 |
| WO2022193432A1 (zh) * | 2021-03-17 | 2022-09-22 | 深圳前海微众银行股份有限公司 | 模型参数更新方法、装置、设备、存储介质及程序产品 |
| JP2023044336A (ja) * | 2021-09-17 | 2023-03-30 | 沖電気工業株式会社 | 学習装置、学習方法およびプログラム |
| WO2023245321A1 (zh) * | 2022-06-20 | 2023-12-28 | 北京小米移动软件有限公司 | 一种图像深度预测方法、装置、设备及存储介质 |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11593673B2 (en) * | 2019-10-07 | 2023-02-28 | Servicenow Canada Inc. | Systems and methods for identifying influential training data points |
| CN115410054B (zh) * | 2022-08-11 | 2026-01-06 | 清华大学 | 场景生成方法、模型测试方法及模型训练方法 |
| US12555366B2 (en) * | 2022-09-15 | 2026-02-17 | Waymo Llc | Semantic segmentation neural network for point clouds |
| CN116295344B (zh) * | 2023-03-08 | 2025-10-24 | 北京易航远智科技有限公司 | 实时建图方法、装置、电子设备及存储介质 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20170337481A1 (en) * | 2016-05-17 | 2017-11-23 | Xerox Corporation | Complex embeddings for simple link prediction |
| GB201615051D0 (en) * | 2016-09-05 | 2016-10-19 | Kheiron Medical Tech Ltd | Multi-modal medical image procesing |
| WO2019115865A1 (en) * | 2017-12-13 | 2019-06-20 | Nokia Technologies Oy | An apparatus, a method and a computer program for video coding and decoding |
-
2019
- 2019-05-21 WO PCT/JP2019/020057 patent/WO2020234984A1/ja not_active Ceased
- 2019-05-21 JP JP2021519927A patent/JP7276436B2/ja active Active
- 2019-05-21 US US17/610,497 patent/US20220237416A1/en not_active Abandoned
Non-Patent Citations (1)
| Title |
|---|
| KARIYAPPA, SANJAY ET AL.: "Improving Adversarial Robustness of Ensembles with Diversity Training", ARXIV, 28 January 2019 (2019-01-28), XP081009297, Retrieved from the Internet <URL:https://arxiv.org/pdf/1901.09981> [retrieved on 20190815] * |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022193432A1 (zh) * | 2021-03-17 | 2022-09-22 | 深圳前海微众银行股份有限公司 | 模型参数更新方法、装置、设备、存储介质及程序产品 |
| CN113360851A (zh) * | 2021-06-22 | 2021-09-07 | 北京邮电大学 | 一种基于Gap-loss函数的工业流水线生产状态检测方法 |
| CN113360851B (zh) * | 2021-06-22 | 2023-03-03 | 北京邮电大学 | 一种基于Gap-loss函数的工业流水线生产状态检测方法 |
| JP2023044336A (ja) * | 2021-09-17 | 2023-03-30 | 沖電気工業株式会社 | 学習装置、学習方法およびプログラム |
| JP7732299B2 (ja) | 2021-09-17 | 2025-09-02 | 沖電気工業株式会社 | 学習装置、学習方法およびプログラム |
| CN113849648A (zh) * | 2021-09-28 | 2021-12-28 | 平安科技(深圳)有限公司 | 分类模型训练方法、装置、计算机设备和存储介质 |
| CN113849648B (zh) * | 2021-09-28 | 2024-09-20 | 平安科技(深圳)有限公司 | 分类模型训练方法、装置、计算机设备和存储介质 |
| WO2023245321A1 (zh) * | 2022-06-20 | 2023-12-28 | 北京小米移动软件有限公司 | 一种图像深度预测方法、装置、设备及存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2020234984A1 (https=) | 2020-11-26 |
| US20220237416A1 (en) | 2022-07-28 |
| JP7276436B2 (ja) | 2023-05-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7276436B2 (ja) | 学習装置、学習方法、コンピュータプログラム及び記録媒体 | |
| US11100374B2 (en) | Apparatus and method with classification | |
| CN107122327B (zh) | 一种利用训练数据训练模型的方法和训练系统 | |
| JP2011248829A (ja) | 評価予測装置、評価予測方法、及びプログラム | |
| JP2012058972A (ja) | 評価予測装置、評価予測方法、及びプログラム | |
| US20190073587A1 (en) | Learning device, information processing device, learning method, and computer program product | |
| CN103365829A (zh) | 信息处理装置、信息处理方法和程序 | |
| CN110046707A (zh) | 一种神经网络模型的评估优化方法和系统 | |
| WO2014199920A1 (ja) | 予測関数作成装置、予測関数作成方法、及びコンピュータ読み取り可能な記録媒体 | |
| WO2019159915A1 (ja) | モデル学習装置、モデル学習方法、プログラム | |
| JP7036054B2 (ja) | 音響モデル学習装置、音響モデル学習方法、プログラム | |
| Shi et al. | Boosting conditional logit model | |
| Bokaeian et al. | Structural damage detection in plates using a deep neural network–couple sparse coding classification ensemble method | |
| US20220327394A1 (en) | Learning support apparatus, learning support methods, and computer-readable recording medium | |
| CN104281569B (zh) | 构建装置和方法、分类装置和方法以及电子设备 | |
| JP7548308B2 (ja) | 学習装置、学習方法およびプログラム | |
| EP4170549A1 (en) | Machine learning program, method for machine learning, and information processing apparatus | |
| JP7717649B2 (ja) | 学習装置、方法、プログラムおよび推論システム | |
| JP2023168813A5 (https=) | ||
| JP2022183763A (ja) | 学習装置、方法およびプログラム | |
| WO2019194128A1 (ja) | モデル学習装置、モデル学習方法、プログラム | |
| WO2013105404A1 (ja) | 信頼度計算装置、信頼度計算方法、及びコンピュータ読み取り可能な記録媒体 | |
| US20070223821A1 (en) | Pattern recognition method | |
| Dou et al. | Handling Imbalanced Classification Problems by Weighted Generalization Memorization Machine | |
| JP6705506B2 (ja) | 学習プログラム、情報処理装置および学習方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19929446 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2021519927 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19929446 Country of ref document: EP Kind code of ref document: A1 |