WO2020202731A1 - 情報処理システム及び情報処理方法 - Google Patents
情報処理システム及び情報処理方法 Download PDFInfo
- Publication number
- WO2020202731A1 WO2020202731A1 PCT/JP2020/002472 JP2020002472W WO2020202731A1 WO 2020202731 A1 WO2020202731 A1 WO 2020202731A1 JP 2020002472 W JP2020002472 W JP 2020002472W WO 2020202731 A1 WO2020202731 A1 WO 2020202731A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- information
- information processing
- learning
- user
- algorithm
- Prior art date
Links
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
- G06N5/022—Knowledge engineering; Knowledge acquisition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/04—Inference or reasoning models
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/044—Recurrent networks, e.g. Hopfield networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
Abstract
学習データの蓄積に基づき変化するアルゴリズムに対して、前記蓄積された学習データにおける特定の前記学習データに由来する影響度を調整し、調整後に得られる新たな学習データに基づき、再学習をさせる、情報処理システムが提供される。
Description
本開示は、情報処理システム及び情報処理方法に関する。
従来、ユーザからの音声等による入力に対して、自動で音声などの応答するAIエージェントシステムが提案されている。例えば、特許文献1には、ユーザからの発話文データに対して、AIエージェントが発話により応答する技術が記載されている。
一方、上記のAIエージェント等による応答は、学習データの蓄積に基づくアルゴリズムに基づき出力される場合がある。今後、このような学習データの蓄積に基づくアルゴリズムに関する技術が、ユーザの身近に存在するようになるほど、ユーザは、蓄積された学習データを都合よく修正したいときが生じるものと推測される。例えば、ある期間に蓄積された学習データにより生成されたアルゴリズムが、ユーザにとって不都合であるとする。しかしながら、その期間に蓄積された学習データには、ユーザにとって不都合ではない学習データも含まれている場合がある。このため、その期間に蓄積された学習データを消去してしまうと、ユーザにとって不都合ではない学習データも消去されてしまい、ユーザが意図するアルゴリズムの状態を生成させることができなくなると考えられる。
そこで、今後、蓄積された学習データを修正し、アルゴリズムに対して再学習する技術が求められるようになると推測される。しかしながら、特許文献1に記載の技術を含め、アルゴリズムの生成に用いられた学習データそのものを修正する技術は、未だ提案されていない。
そこで、本開示では、上記事情に鑑み、既に生成済みの学習データの蓄積に基づくアルゴリズムについて、アルゴリズムの生成に用いられた学習データを事後的に修正して、所望のアルゴリズムの状態を実現させることが可能な、情報処理システム及び情報処理方法を提案する。
また、本開示によれば、学習データの蓄積に基づき変化するアルゴリズムに対して、前記蓄積された学習データにおける特定の前記学習データに由来する影響度を調整し、調整後に得られる新たな学習データに基づき、再学習をさせる、情報処理システムが提供される。
また、本開示の別の観点によれば、プロセッサが、学習データの蓄積に基づき変化するアルゴリズムに対して、前記蓄積された学習データにおける特定の前記学習データに由来する影響度を調整し、調整後に得られる新たな学習データに基づき、再学習をさせる、情報処理方法が提供される。
以下に添付図面を参照しながら、本開示の好適な実施の形態について詳細に説明する。なお、本明細書及び図面において、実質的に同一の機能構成を有する構成要素については、同一の符号を付することにより重複説明を省略する。
なお、説明は以下の順序で行うものとする。
1.第1の実施形態
1.1.情報処理システム
1.2.ユーザ端末
1.3.情報処理システムとユーザ端末との間における情報の送受信
1.4.アルゴリズムの再学習方法
2.第2の実施形態
2.1.情報処理装置の構成
2.2.処理例
3.応用例
4.変形例
5.ハードウェア構成例
6.補足
1.第1の実施形態
1.1.情報処理システム
1.2.ユーザ端末
1.3.情報処理システムとユーザ端末との間における情報の送受信
1.4.アルゴリズムの再学習方法
2.第2の実施形態
2.1.情報処理装置の構成
2.2.処理例
3.応用例
4.変形例
5.ハードウェア構成例
6.補足
<1.第1の実施形態>
<<1.1.情報処理システム>>
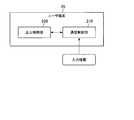
まず、図1を参照して、第1の実施形態に係る情報処理システム1について説明する。図1に示すように、第1の実施形態に係る情報処理システム1は、情報処理装置10で構成されている。以下、第1の実施形態では、情報処理システム1と情報処理装置10とが、同一であるものとする。情報処理装置10は、ネットワーク30を介して、ユーザ端末20に接続されている。
<<1.1.情報処理システム>>
まず、図1を参照して、第1の実施形態に係る情報処理システム1について説明する。図1に示すように、第1の実施形態に係る情報処理システム1は、情報処理装置10で構成されている。以下、第1の実施形態では、情報処理システム1と情報処理装置10とが、同一であるものとする。情報処理装置10は、ネットワーク30を介して、ユーザ端末20に接続されている。
情報処理装置10は、ユーザからの入力情報に応じて、学習データの蓄積に基づき生成されたアルゴリズムを用いて、出力情報を生成する機能を有する。また、情報処理装置10は、必要に応じて、上記アルゴリズムに対して再学習させる。
ユーザ端末20は、ユーザからの入力情報を、ネットワーク30を介して情報処理装置10に送信し、情報処理装置10からの応答に応じて、ユーザに各種の出力(例えば、画像又は音声の出力)を実施する機能を有する。本実施形態では、ユーザ端末20は、AIエージェントによる出力を実現する。ここで、AIエージェントとは、アルゴリズムに基づき出力される音声又は画像のモチーフとなるキャラクタである。当該キャラクタは、架空のキャラクタであってもよいし、実字するキャラクタであってもよい。
なお、ネットワーク30は、電話回線網、インターネット、衛星通信網などの公衆回線網や、LAN(Local Aera Network)、WAN(Wide Area Network)などを含んでもよい。また、ネットワーク30は、IP-VPN(Internet Protocol-Virtual Private Network)などの専用回線網を含んでもよい。
上記アルゴリズムは、情報処理装置10に蓄積される学習データに基づく。つまり、上記アルゴリズムは、学習データに基づく学習結果である。本実施形態に係る情報処理装置10は、上記アルゴリズムの学習履歴を記憶している。
ここで、図2を参照して、第1の実施形態に係る情報処理装置10が記憶している学習履歴データ40の一例について説明する。図2は、第1の実施形態に係る情報処理装置10が記憶している学習履歴データ40の概略構成の一例である。図2に示す学習履歴データ40は、アルゴリズムの学習内容を時系列で並べて構成されたデータである。図2には、学習NoがA番~C番までの3回分の学習についての学習内容が、時系列で並べられている。
例えば、NoAの学習では、時刻Aにおいて、学習内容Aの内容が学習されている。また、NoBの学習では、時刻Bにおいて、学習内容Bの内容が学習されている。さらに、NoCの学習では、時刻Cにおいて、学習内容Cの内容が学習されている。なお、それぞれの時刻では、それぞれの学習に対応する学習データに基づき、アルゴリズムの学習が実施されている。本実施形態では、このように、蓄積された学習データに基づき、アルゴリズムの学習が実施されている。
なお、図2に示す学習履歴データ40は、学習データと学習内容とを時系列で並べた構成を有するが、学習履歴データの構成は、これに限定されるものではない。また、図2には、学習NoA~Cの3回分の学習履歴が示されているが、学習履歴データは、2回分以下の学習履歴を有してもよいし、4回分以上の学習履歴を有してもよい。また、一度の学習において、複数の学習データが用いられてもよいし、複数の学習が実施されてもよい。
また、学習データは、特に限定されないが、例えば、アルゴリズムの使用環境下で蓄積されるデータに基づいてもよい。これにより、学習データの蓄積に基づくアルゴリズムは、ユーザによるアルゴリズムの使用環境に応じたアルゴリズムとなり得る。このため、情報処理システム1は、ユーザが所望するアルゴリズムの状態をより適切に実現することが可能になる。
また、学習データは、アルゴリズムに対するユーザの入力情報に基づく、アルゴリズムからの出力情報に関するデータを含んでもよい。これにより、アルゴリズムは、日頃のユーザからの入力情報及び当該入力情報に基づく出力情報に応じて学習される。上記入力情報及び出力情報には、ユーザに固有の情報が含まれ得る。このため、情報処理システム1は、上記学習データに基づき、ユーザが所望するアルゴリズムの状態をより適切に実現することが可能になる。
次いで、図3を参照して、第1の実施形態に係る情報処理装置10の構成について説明する。図3は、第1の実施形態に係る情報処理装置10の構成を示す機能ブロック図である。
情報処理装置10は、学習データの蓄積に基づき変化するアルゴリズムに対して、蓄積された学習データにおける特定の学習データに由来する影響度を調整し、調整後に得られる新たな学習データに基づき、再学習をさせる機能を有する。情報処理装置10が有する機能は、情報処理装置10が備える記憶部110、処理部120、解析部130、生成部140、出力制御部150、及び通信制御部160が協働することにより実現される。以下、情報処理装置10が備える各機能部について説明する。
記憶部110は、各種の情報を記憶する機能を有する。記憶部110に記憶された各種の情報は、必要に応じて、処理部120、解析部130、生成部140、又は通信制御部160により参照される。
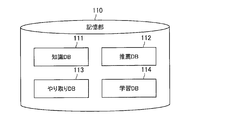
ここで、図4を参照して、本実施形態に係る記憶部110について、より詳細に説明する。図4は、第1の実施形態に係る記憶部110の構成の一例を示す機能ブロック図である。図4に示すように、記憶部110は、知識DB111、推薦DB112、やり取りDB113、及び学習DB114を有している。
知識DB111には、例えば解析部130がユーザからの入力情報を解析するために用いられる、各種の情報が記録されている。例えば、知識DB111には、各種の言葉の意味内容に関する情報が記録されている。例えば、知識DB111には、各種の言葉の辞書的な意味内容が記録されている。さらに、知識DB111には、ユーザに特有の言葉の意味内容が記録されている。例えば、「グンマ」という言葉は、一般的には、群馬県を意味する。しかし、ユーザによっては、「グンマ」という言葉が人の名前(例えば、「岩佐」という人の名前)を意味する場合がある。この場合、知識DB111は、「グンマ」という言葉は、「岩佐」という人の名前を指す場合があることを記憶する。あるいは、知識DB111では、各種の言葉の意味が確率的に規定されていてもよい。例えば、知識DB111には、「グンマ」という言葉が70%の確率で「岩佐」という人名を意味することが記録されていてもよい。
また、知識DB111には、ユーザに関するデータであるユーザデータを記憶してもよい。なお、ユーザデータは、アルゴリズムを学習させるための学習データに含まれてもよい。これにより、ユーザは、学習データに含まれるユーザ自身に関する情報を修正することが可能になる。この結果、情報処理装置10は、より適切にアルゴリズムを再学習させることが可能になり、ユーザが所望するアルゴリズムの状態をより適切に実現することが可能になる。
また、知識DB111には、天気又はニュースに関する情報が記録されてもよい。また、知識DB111には、例えばユーザにより入力されたメモ又はリマインダ等の情報が記録されてもよい。さらに、知識DB111には、Web抽出又は商品抽出をするための情報が記録されてもよい。
推薦DB112には、後述する推薦情報生成部142が出力情報を生成するために用いられる各種のデータが記録されている。例えば、推薦DB112には、ユーザの嗜好に関するデータが記録されていてもよい。例えば、ユーザは、「グンマ」という人物の曲を日頃聞いており、当該事実に関する情報が記憶部110に入力されているとする。この場合、推薦DB112には、「グンマ」の曲のプレイリストが記録されてもよい。また、推薦DB112には、例えば、曲Aの推薦スコアを0.2、曲Bの推薦スコアを0.8といったように、各種の曲について推薦スコアを付与したスコアリストが記録されてもよい。また、推薦DB112には、ユーザに推薦する音楽又は購買等に関する情報が記録されていてもよい。
上記の推薦DB112に記録されている情報は、生成部140に伝達され、生成部140が出力情報を生成するために用いられる。
やり取りDB113は、ユーザからの入力情報と、当該入力情報に対するアルゴリズムに基づく出力情報に関するデータを蓄積している。例えば、ある日、ユーザが「グンマ」の曲を流すことを要求する入力情報を、情報処理システム1に入力したとする。この結果、情報処理システム1は、アルゴリズムに基づき、「グンマ」の曲を流すための出力情報を生成し、例えばユーザ端末20に出力したとする。このとき、やり取りDB113には、当該入力情報と当該出力情報の内容と、これらの情報が入出力された時刻などが記録される。
本実施形態では、このようにやり取りDB113に記録された情報(例えば、入力情報及び出力情報に関連する情報)は、後述する学習DB114に記録された学習データを抽出するためのラベル情報として用いられる。第1の実施形態では、やり取りDB113に記録された情報は、知識DB111又は推薦DB112に記録された情報を更新するためにも用いられる。
本実施形態に係る情報処理装置10は、入力情報を取得すると、知識DB111と推薦DB112に記録された情報に基づき、出力情報を生成する。従って、情報処理装置10が実行する、出力情報を生成するためのアルゴリズムでは、知識DB111と推薦DB112に記録された情報が用いられる。このため、やり取りDB113に記録された学習データの蓄積に基づき、知識DB111又は推薦DB112に記録された情報が更新されると、上記アルゴリズムが変化する。
なお、入力情報と出力情報とが入出力される度に、知識DB111又は推薦DB112に記録された情報が更新されてもよい。この場合、入力情報と出力情報とが入出力される度に情報処理装置10が出力情報を生成するアルゴリズムが変化する。
学習DB114は、学習データが記録されている。当該学習データの記録は、ユーザによる指示に基づき行われてもよいし、又は情報処理システム1によりバックグラウンドで自動的に行われてもよい。学習データは、例えば、ユーザからの指示の内容、ユーザの状況、ユーザの周りの環境などの出力に必要な各種の情報を含んでもよい。また、学習データは、結果(例えば、後述する解析部130による解析結果、又は推薦情報生成部145による推薦結果)がどの程度適切であったのかを推定するための指標を含んでもよい。当該指標としては、例えば、解析又は推薦に対するユーザからのFB(フィードバック)等であってもよい。情報処理装置10が出力情報を生成するためのアルゴリズムの学習履歴が記録されている。学習DB114には、例えば、図2に示したように、学習内容を時系列で並べたフォーマットの学習履歴が記録されていてもよい。なお、学習DB114に記録されている情報には、学習データそのものは記録されていなくてもよい。この場合、学習DB114には、学習履歴と、その学習履歴に対応する学習データとを対応付ける情報が記録されていてもよい。
(処理部)
処理部120は、記憶部110に記憶された情報に対して、各種の処理を実施する機能を有する。処理部120は、蓄積された学習データにおける特定の学習データに由来する影響度を調整する機能を有する。また、処理部120は、調整後に得られる新たな学習データに基づき、アルゴリズムに対して再学習させる機能を有する。処理部120による処理の結果は、必要に応じて、解析部130又は記憶部110の少なくともいずれかに伝達される。なお、影響度の調整及びアルゴリズムに対する学習については、図5を参照して後述する。
処理部120は、記憶部110に記憶された情報に対して、各種の処理を実施する機能を有する。処理部120は、蓄積された学習データにおける特定の学習データに由来する影響度を調整する機能を有する。また、処理部120は、調整後に得られる新たな学習データに基づき、アルゴリズムに対して再学習させる機能を有する。処理部120による処理の結果は、必要に応じて、解析部130又は記憶部110の少なくともいずれかに伝達される。なお、影響度の調整及びアルゴリズムに対する学習については、図5を参照して後述する。
本実施形態では、影響度が処理部120により調整された上で、アルゴリズムの再学習が実施される。なお、当該影響度は、例えば、アルゴリズムに基づく出力情報に与える影響の度合いであってもよい。このため、当該影響度が調整されることにより、当該出力情報が修正される。従って、情報処理装置10は、当該影響度が調整することにより、ユーザにとってより適切な出力情報を生成することができる。
また、上記特定の学習データは、ユーザにより指定されてもよい。特定の学習データがユーザにより指定されることで、ユーザが所望する学習データに由来する影響度が調整される。この結果、情報処理装置10は、ユーザが所望するアルゴリズムの状態をより適切に実現することができる。
また、上記特定の学習データは、ユーザに関するデータであるユーザデータを含んでもよい。ユーザデータに由来する影響度が調整されることにより、ユーザが所望するアルゴリズムの状態がより適切に実現される。この結果、情報処理装置10は、よりユーザに関するデータに沿った出力情報を生成することが可能になる。
また、上記ユーザデータは、ユーザの位置に関する位置情報を含んでもよい。これにより、情報処理装置10は、よりユーザの位置に沿った内容の出力情報を生成することができるようになる。また、上記ユーザデータは、ユーザの嗜好に関する情報を含んでもよい。これにより、情報処理装置10は、よりユーザの嗜好に沿った内容の出力情報を生成することができるようになる。
また、処理部120は、ユーザデータの変化に応じて、アルゴリズムに対して再学習を行ってもよい。これにより、ユーザデータに変化があった場合には、情報処理装置10は、当該変化に応じたアルゴリズムの状態を実現し、より適切な出力情報を生成することが可能になる。
図5を参照して、処理部120についてより詳細に説明する。図5は、第1の実施形態に係る処理部120の構成を示す機能ブロック図である。図5に示すように、処理部120は、学習データを取得し、当該学習データを修正等することにより、修正後の学習データを出力することができる。また、図5に示すように、処理部120は、更新部121、抽出部122、判定部123、及び修正部124を備える。これらの機能部が生成する情報は、これらの機能部の間で適宜伝達されてもよい。
更新部121は、記憶部110の知識DB111又は推薦DB112の少なくともいずれかに記録された各種の情報を更新する機能を有する。例えば、更新部121は、ユーザからの入力情報に応じて、各種の情報を更新する。また、更新部121は、学習DB114に記録された学習データの変化に応じて、各種の情報を更新する。例えば、更新部121は、学習DB114に記録された学習データが削除又は修正等された際に、推薦DB112に記録された推薦スコアなどを更新してもよい。
本実施形態に係る情報処理装置10は、「入力情報を取得し、知識DB111又は推薦DB112に記録された各種の情報に基づき、出力情報を生成する」というアルゴリズムを実行する。本実施形態では、知識DB111又は推薦DB112に記録された各種の情報を更新することが、アルゴリズムの再学習に相当する。
抽出部122は、記憶部110に記録された各種の情報を抽出する機能を有する。より具体的には、抽出部122は、入力情報に関するデータが記録されたデータベースに基づいて、アルゴリズムの学習履歴の中から、所定の条件に合致する特定の学習履歴を抽出する。所定の条件に合致する特定の学習履歴は、例えば、ユーザが削除したい学習履歴であってもよい。所定の条件に合致する特定の学習履歴は、アルゴリズムの再学習に用いられる。例えば、特定の学習履歴が削除されると、当該学習履歴がなかったものとして、アルゴリズムの再学習が行われる。
また、学習履歴に対して学習データが対応付けられていてもよい。本実施形態に係る情報処理装置10は、当該学習データに由来する影響度を調整してもよい。当該影響度が調整されることにより、アルゴリズムの再学習が実施される。これにより、情報処理装置10は、ユーザにとってより適切な出力情報を生成することができる。
第1の実施形態に係る抽出部122は、入力情報に関するデータが記録されたやり取りDB113に基づいて、学習DB114の中から、所定の条件に合致する特定の学習履歴を抽出する。第1の実施形態では、上記所定の条件に合致する特定の学習履歴は、例えば、ユーザが指定するキーワードが含まれる学習データに基づくアルゴリズムの学習に関する履歴であってもよい。従って、第1の実施形態に係る抽出部122は、ユーザが指定するキーワードが含まれる学習データに基づく学習履歴を抽出する。
例えば、抽出部122は、ユーザから「グンマ」というキーワードの抽出を要求する入力情報を取得する。このとき、抽出部122は、記憶部110の知識DB111、推薦DB112、又はやり取りDB113のうちの少なくともいずれかから、「グンマ」というキーワードを含む情報を抽出してもよい。さらに、本実施形態に係る抽出部122は、上記キーワードを含む学習データに基づき学習されたことを表す学習履歴を、学習DB114から抽出してもよい。
判定部123は、各種の判定を実施する機能を有する。例えば、判定部123は、やり取りDB113に記録された出力情報と、生成部140により生成される出力情報との変化の大きさを判定してもよい。判定部123により判定された結果は、修正部124に伝達される。なお、後述するように、修正部124は、当該判定結果に基づき、学習データを削除又は修正等する。
修正部124は、学習データに由来する影響度を調整する機能を有する。より具体的には、第1の実施形態に係る修正部124は、学習DB114に記録された学習データを削除又は修正することにより、当該学習データに由来する影響度を調整する機能を有する。修正部124は、例えば、学習DB114に記録された、出力された出力情報を表す情報を削除又は修正してもよい。
上述のように、やり取りDB113に記録されたやり取り情報等は、アルゴリズムに影響を与えている。修正部124は、学習DB114に記録された学習データを削除又は修正することにより、学習データに由来する影響度を調整することができる。より具体的には、修正部124は、学習データを削除することにより、当該学習データに由来するアルゴリズムへの影響度をなくすことができる。また、修正部124は、学習データを修正することにより、当該学習データに由来するアルゴリズムへの影響度を増減させることができる。このように、修正部124は、学習DB114に記録された学習データを削除又は修正することにより、学習データに由来する影響度を調整することができる。
また、知識DB111又は推薦DB112に記録された情報は、学習DB114に記録された学習データに基づく情報である。このため、修正部124により、学習DB114に記録された学習データ(例えば、入力情報及び出力情報に関連する情報)が削除又は修正されることにより、知識DB111又は推薦DB112に記録された情報は再学習される。このようにして、本実施形態に係る情報処理装置10は、学習データに由来する影響度が調整し、アルゴリズムに対して再学習させる。
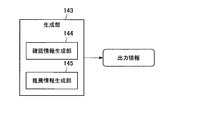
(生成部)
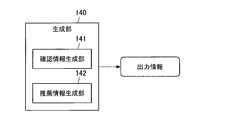
生成部140は、記憶部110に記憶された情報に基づき、各種の出力情報を生成する機能を有する。生成された出力情報は、出力制御部150に伝達される。生成部140の機能について、図6を参照してより詳細に説明する。図6は、第1の実施形態に係る生成部140の構成を示す機能ブロック図である。図6に示すように、生成部140は、確認情報生成部141及び推薦情報生成部142を備える。
生成部140は、記憶部110に記憶された情報に基づき、各種の出力情報を生成する機能を有する。生成された出力情報は、出力制御部150に伝達される。生成部140の機能について、図6を参照してより詳細に説明する。図6は、第1の実施形態に係る生成部140の構成を示す機能ブロック図である。図6に示すように、生成部140は、確認情報生成部141及び推薦情報生成部142を備える。
確認情報生成部141は、ユーザに各所の確認を実施するための出力情報を生成する機能を有する。例えば、修正部124により、学習DB114に記録された学習データが削除される場合に、確認情報生成部141は、当該学習データが削除されてもよいかユーザに確認するための出力情報を生成してもよい。
推薦情報生成部142は、ユーザに各種の推薦を実施するための出力情報を生成する。例えば、推薦情報生成部142は、ユーザが所望する音楽を再生するための出力情報を生成してもよい。このとき、推薦情報生成部142は、推薦DB112に記録された推薦スコア等に基づき、ユーザに推薦する内容を決定し、出力情報を生成してもよい。
(出力制御部)
出力制御部150は、出力情報の出力を制御する機能を有する。例えば、出力制御部150は、生成部140から取得した出力情報を、他の端末に出力させるための情報に変換してもよい。例えば、出力制御部150は、出力情報がテキスト情報で構成されている場合には、当該テキスト情報の内容を音声として出力するための音声情報に変換してもよい。出力制御部150は、取得又は生成した各種の情報を通信制御部160に伝達する。なお、出力制御部150は、生成部140から伝達された出力情報をそのまま通信制御部160に伝達してもよい。
出力制御部150は、出力情報の出力を制御する機能を有する。例えば、出力制御部150は、生成部140から取得した出力情報を、他の端末に出力させるための情報に変換してもよい。例えば、出力制御部150は、出力情報がテキスト情報で構成されている場合には、当該テキスト情報の内容を音声として出力するための音声情報に変換してもよい。出力制御部150は、取得又は生成した各種の情報を通信制御部160に伝達する。なお、出力制御部150は、生成部140から伝達された出力情報をそのまま通信制御部160に伝達してもよい。
(通信制御部)
通信制御部160は、情報処理装置10と各種の装置との間の各種の情報の送受信を制御する機能を有する。例えば、通信制御部160は、出力制御部150から伝達された情報を、ネットワーク30を介して、情報処理装置10からユーザ端末20への送信を制御する。また、通信制御部160は、情報処理装置10による外部の装置(例えばユーザ端末20)からの各種の情報の受信を制御する。受信された各種の情報は、通信制御部160を介して、記憶部110、処理部120、又は解析部130に伝達される。
通信制御部160は、情報処理装置10と各種の装置との間の各種の情報の送受信を制御する機能を有する。例えば、通信制御部160は、出力制御部150から伝達された情報を、ネットワーク30を介して、情報処理装置10からユーザ端末20への送信を制御する。また、通信制御部160は、情報処理装置10による外部の装置(例えばユーザ端末20)からの各種の情報の受信を制御する。受信された各種の情報は、通信制御部160を介して、記憶部110、処理部120、又は解析部130に伝達される。
<<1.2.ユーザ端末>>
次いで、図7を参照して、第1の実施形態に係るユーザ端末20の構成について説明する。図7は、第1の実施形態に係るユーザ端末20の構成を示す機能ブロック図である。図7に示すように、ユーザ端末20は、通信制御部210及び出力制御部220を備える。
次いで、図7を参照して、第1の実施形態に係るユーザ端末20の構成について説明する。図7は、第1の実施形態に係るユーザ端末20の構成を示す機能ブロック図である。図7に示すように、ユーザ端末20は、通信制御部210及び出力制御部220を備える。
(通信制御部)
通信制御部210は、ユーザ端末20と各種の装置(例えば、情報処理装置10)との間の各種の情報の送受信を制御する機能を有する。通信制御部160は、入力情報を取得し、情報処理装置10への当該入力情報の送信を制御する。なお、当該入力情報は、ユーザによる操作に基づいてユーザ端末20に入力されてもよいし、各種の装置から自動的に入力されてもよい。また、通信制御部210は、情報処理装置10から送信された出力情報に関連する情報の受信を制御する。受信された出力情報に関連する情報は、出力制御部220に伝達される。
通信制御部210は、ユーザ端末20と各種の装置(例えば、情報処理装置10)との間の各種の情報の送受信を制御する機能を有する。通信制御部160は、入力情報を取得し、情報処理装置10への当該入力情報の送信を制御する。なお、当該入力情報は、ユーザによる操作に基づいてユーザ端末20に入力されてもよいし、各種の装置から自動的に入力されてもよい。また、通信制御部210は、情報処理装置10から送信された出力情報に関連する情報の受信を制御する。受信された出力情報に関連する情報は、出力制御部220に伝達される。
(出力制御部)
出力制御部220は、ユーザ端末20による各種の出力を制御する。例えば、出力制御部220は、情報処理装置10から送信された出力情報に関連する情報を、ユーザ端末20が備える出力装置に伝達することにより、当該出力装置に各種の出力を実施させる。例えば、出力制御部220は、音楽を流すように、出力装置を制御してもよい。
出力制御部220は、ユーザ端末20による各種の出力を制御する。例えば、出力制御部220は、情報処理装置10から送信された出力情報に関連する情報を、ユーザ端末20が備える出力装置に伝達することにより、当該出力装置に各種の出力を実施させる。例えば、出力制御部220は、音楽を流すように、出力装置を制御してもよい。
<<1.3.情報処理システムとユーザ端末との間における情報の送受信>>
次いで、図8~10を参照して、第1の実施形態に係る情報処理装置10とユーザ端末20との間における情報の送受信について説明する。図8~10は、第1の実施形態に係る情報処理装置10とユーザ端末20とにおける情報の送受信の一例を示すフローチャート図である。まず、図8を参照して、第1の実施形態に係る情報処理装置10とユーザ端末20とにおける情報(入力情報及び出力情報)の送受信(以下、「情報処理装置10とユーザ端末20とにおけるやり取り」とも称する。)の一例について説明する。
次いで、図8~10を参照して、第1の実施形態に係る情報処理装置10とユーザ端末20との間における情報の送受信について説明する。図8~10は、第1の実施形態に係る情報処理装置10とユーザ端末20とにおける情報の送受信の一例を示すフローチャート図である。まず、図8を参照して、第1の実施形態に係る情報処理装置10とユーザ端末20とにおける情報(入力情報及び出力情報)の送受信(以下、「情報処理装置10とユーザ端末20とにおけるやり取り」とも称する。)の一例について説明する。
図8に示す例では、情報処理装置10は、ユーザ端末20から送信される入力情報に応じて、出力情報を生成する。ユーザ端末20は、生成された出力情報を受信し、当該出力情報に応じて、ユーザに各種の情報を出力する。以下、図8に沿ってより詳細に情報処理装置10とユーザ端末20とにおける情報の送受信について説明する。
まず、ユーザ端末20は、入力情報を取得する(ステップS102)。より具体的には、ユーザ端末20が備える通信制御部210が、ユーザからの入力情報を取得する。例えば、通信制御部210は、「グンマの好きな曲はXXである」という音声情報を入力情報として取得する。次いで、ユーザ端末20が入力情報を情報処理装置10に送信する(ステップS104)。
次いで、情報処理装置10は、入力情報を受信する(ステップS106)。受信された入力情報は、通信制御部160を介して解析部130に伝達される。
次いで、解析部130が、入力情報を解析する(ステップS108)。より具体的には、解析部130は、知識DB111に記憶された各種の情報等に基づいて、入力情報の意味内容を解析する。例えば、知識DB111には、「グンマ」という言葉は、「群馬県」という意味しか持たないことが記録されているものとする。この場合、解析部130は、入力情報の意味内容を理解できず、入力情報「グンマの好きな曲はXXである」が矛盾しているという解析結果を記憶部110に出力する。このとき、記憶部110は、やり取りDB113に、解析部130が解析した結果を記録する。より具体的には、記憶部110は、「グンマの好きな曲はXXである」という入力情報と、入力情報が送信された時刻とを対応付けて、やり取りDB113に記憶する。
次いで、生成部140が、出力情報を生成する(ステップS110)。より具体的には、生成部140は、解析部130が解析した結果と、記憶部110に記憶された情報とに基づいて、出力情報を出力する。例えば、生成部140は、「グンマって何?」という音声情報を出力情報として生成し、出力情報を出力制御部150に伝達する。このとき、記憶部110は、「グンマって何?」という出力情報を、ステップS108において記録された情報と対応付けて学習DB114に記録する。このとき、記憶部110は、やり取りがあったことをやり取りDB113に記録する。より具体的には、記憶部110は、やり取りがあった時刻及びやり取りの内容をやり取りDB113に記録する。
次いで、情報処理装置10は、出力情報をユーザ端末20に送信する(ステップS112)。
次いで、ユーザ端末20は、出力情報を出力する(ステップS114)。より具体的には、通信制御部210がユーザ端末20に送信された出力情報を取得し、出力情報を出力制御部220に伝達する。出力制御部220は、出力情報に基づき、ユーザ端末20が備える出力装置に出力情報を出力させる。ここでは、出力装置は、「グンマって何?」という音声情報を出力情報として出力する。
以上、情報処理装置10とユーザ端末20とにおける情報の送受信の一例について説明した。上記のように、入力情報及び出力情報は学習DB114に記録され、学習データとして用いられる。
次いで、図9を参照して、第1の実施形態に係る情報処理装置10とユーザ端末20とのやり取りに係る第2の例について説明する。図9に示すやり取りは、情報処理装置10が入力情報に基づき、知識DB111及び推薦DB112に記録された情報を更新する点で、図8に示したやり取りの例と異なる。
まず、ユーザ端末20は、入力情報を取得する(ステップS202)。より具体的には、通信制御部210は、ユーザからの入力情報を取得する。例えば、通信制御部210は、「グンマは、私の友達の岩佐君のあだ名です。」という音声情報を入力情報として取得する。
次いで、ステップS204及びS206の処理が実施されるが、ステップS204及びS206における処理は、ステップS104及びS106における処理と実質的に同一であるため、ここでは説明を省略する。
ステップS206の処理が終了すると、情報処理装置10は、入力情報を解析する(ステップS208)。より具体的には、解析部130が、知識DB111に記録された情報に基づき、入力情報の意味内容を解析する。解析部130は、解析した結果を処理部120に伝達する。
次いで、更新部121は、知識DB111に記録された情報を更新する(ステップS210)。より具体的には、更新部121は、知識DB111に、「グンマ」がユーザの友達であることを記録する。また、ここでは、「グンマの好きな曲はXXである」という情報が、知識DB111に記録されているものとする。このとき、更新部121は、ステップS208における解析結果に基づき、「グンマ」がXXという曲が好きであることを知識DB111に記録する。また、更新部121は、グンマが好きな曲のプレイリストを推薦DB112に作成する。さらに、更新部121は、グンマが好きな曲XXを当該プレイリストに追加する。
以上、図9を参照して、情報処理装置10とユーザ端末20とのやり取りの一例について説明した。図9に示した例では、情報処理装置10は、ユーザ端末20からの入力情報に応じて、記憶部110に記憶された情報を更新した。これにより、情報処理装置10は、よりユーザの所望に沿った出力情報を生成することが可能になる。例えば、情報処理装置10は、「グンマの好きな曲を流してください。」という入力情報が入力された場合には、グンマの好きな曲であるXXをユーザ端末20に出力させるための出力情報を生成することが可能になる。
次いで、図10を参照して、本実施形態に係る情報処理装置10とユーザ端末20とのやり取りに係る第3の例について説明する。第3の例では、第2の例に係る処理に加えて、情報処理装置10が出力情報をユーザ端末20に送信し、ユーザ端末20が出力情報を出力する処理が追加されている。以下、図10に沿って、第3の例について説明する。
まず、ユーザ端末20は、入力情報を取得する(ステップS302)。より具体的には、通信制御部210は、ユーザからの入力情報を取得する。例えば、通信制御部210は、「グンマの曲を流して。」という音声情報を入力情報として取得する。
次いで、ステップS304~S308の処理が実施されるが、ステップS304~S306の処理は、ステップS204~S208の処理と実質的に同一であるため、ここでは説明を省略する。
ステップS308の処理が終了すると、情報処理装置10は、出力情報を生成する(ステップS310)。より具体的には、推薦情報生成部142が、解析部130による解析結果と、推薦DB112に記録された情報とに基づき、出力情報を生成する。例えば、推薦情報生成部142は、推薦DB112に記憶されたグンマが好きなプレイリストに含まれる曲を再生させるための出力情報を生成する。再生される曲は、推薦スコアの最も高い曲であってもよいし、推薦スコアが例えば上位5%からランダムで選択される曲であってもよい。推薦情報生成部142は、出力情報を出力制御部150に伝達する。
次いで、情報処理装置10は、出力情報をユーザ端末20に送信する(ステップS312)。
次いで、情報処理装置10は、記憶部110に記憶された情報を更新する(ステップS314)。例えば、更新部121は、推薦情報生成部142に選択された曲の推薦スコアを上げる。また、更新部121は、入力された入力情報と出力された出力情報とを、学習DB114に記録する。また、やり取りDB113にはやり取りがあった時刻及びやり取りの内容などが記録される。
次いで、ユーザ端末20は、出力情報を出力する(ステップS316)。より具体的には、通信制御部210は、ユーザ端末20に送信された出力情報を取得し、取得した出力情報を出力制御部220に伝達する。出力制御部220は、出力装置に出力情報を出力させる。これにより、出力装置は、例えば、グンマが好きなプレイリストに含まれる曲を再生する。
以上、図10を参照して、本実施形態に係る情報処理装置10とユーザ端末20とのやり取りの第3の例について説明した。第3の例によれば、情報処理装置10は、ユーザ端末20からの入力情報に応じて、出力情報を生成し、生成した出力情報をユーザ端末20送信する。また、情報処理装置10は、入力情報と出力情報とに応じて、記憶部110に記憶された情報を更新する。
上記の図8~10を用いた説明では、「グンマ」という名詞を含む入力情報に基づき、「グンマ」に関する出力情報が生成された。これに限らず、「グンマ」という名詞を含まない入力情報に基づき、「グンマ」に関する出力情報が生成されてもよい。つまり、ユーザは、「グンマ」という言葉を発しないで、暗示的に「グンマ」に関する出力情報を生成する指示を情報処理装置10にすることもできる。
例えば、ステップS302において、ユーザは、「昨日聞いた曲と似たテイストの曲を流して。」という音声情報を入力情報として入力したとする。当該音声情報には、「グンマ」という言葉が含まれていないが、「昨日聞いた曲」とは、「グンマの曲」を意味するものとする。すると、ステップS308において、解析部130は、知識DB111に記録された情報に基づき、ユーザの入力情報に含まれる「昨日聞いた曲」が「グンマの曲」を意味するものと解析することができる。この結果、ステップS310において、推薦情報生成部142は、「グンマの曲」に似たテイストの曲をユーザ端末20に再生させるための出力情報を生成する。これに応じて、ステップS314において、更新部121は、推薦DB112に記憶された「グンマの曲」に似たテイストの曲の推薦スコアを上げる。さらに、ユーザ端末20は、ステップS316において、「グンマの曲」に似たテイストの曲を再生する。
ここでは、ステップS302において、ユーザが「昨日聞いた曲と似たテイストの曲を流して。」という音声情報を入力する例について説明したが、「昨日聞いた曲と全く違う曲を流して。」という音声情報がユーザ端末20に入力されてもよい。この場合、推薦情報生成部142は、「グンマの曲」と全く違うテイストの曲をユーザ端末20に再生させるための出力情報を生成する。これにより、ユーザ端末20は、「グンマの曲」と全く違うテイストの曲を再生することができる。さらに、更新部121は、推薦DB112に記録された「グンマの曲」と全く違うテイストの曲の推薦スコアを上げてもよい。
このように、本実施形態に係る情報処理装置10とユーザ端末20とによれば、ユーザは、直接的に「グンマ」という名詞を発話しなくとも、「グンマ」に関する出力情報をユーザ端末20に出力させることができる。さらに、更新部121は、記憶部110に記憶された「グンマ」に関する各種の情報を更新することもできる。
以上、本実施形態に係る情報処理装置10とユーザ端末20とのやり取りについて説明した。次いで、図11を参照して、上記のやり取りに基づき構築されたやり取りDB113、知識DB111の更新履歴、及び推薦DB112の更新履歴について説明する。図11は、第1の実施形態に係るやり取りDB113に記録された情報、知識DB111の更新履歴、及び推薦DB112の更新履歴の一例を示す図である。
図11には、やり取りDB113、知識DB111の更新履歴、及び推薦DB112の更新履歴について、それぞれ5つ(NoA~E)の情報が示されている。例えば、やり取りDB113のNo.Aには、時刻情報として「2018/11/22 PM8:00」、やり取り情報として、ユーザが家で「グンマの好きな曲には曲Eがある。」という入力情報を入力したことが記録されている。解析部130は、当該入力情報における「グンマ」という言葉が「岩佐」という人の名前を意味すると解析する。すると、更新部121は、「グンマ」という言葉が「岩佐」を意味する確率を上げる。より具体的には、更新部121は、知識DB111に記録された「グンマ」という言葉が「岩佐」を意味する確率を、80%から81%に上げる。これにより、解析部130は、「グンマ」という言葉を、81%の確率で「岩佐」という人名(あだ名)を意味すると解析するようになる。一方、更新部121は、知識DB111に記憶された「グンマ」という言葉が「群馬」という県名を意味する確率を、20%から19%に下げる。これにより、解析部130は、19%の確率で「グンマ」という言葉を「群馬」という県名を意味すると解析するようになる。また、更新部121は、推薦DB112に、「グンマ」の好きなプレイリストに曲Eを追加して記録する。
以下、No.Aと同様にして、No.B~Eに係るやり取り情報に応じて、知識DB111及び推薦DB112の記録が更新されている。具体的には、やり取りDB113のNo.Bには、時刻情報として「2018/11/28 PM8:01」、やり取り情報として、家で「グンマの好きな曲を流して。」というユーザからの入力情報があったことが記録されている。これに応じて、知識DB111において、「グンマ」が「群馬」を意味する確率が19%から18%に、「グンマ」が「岩佐」を意味する確率が81%から82%に更新されている。
また、やり取りDB113のNo.Cには、時刻情報として「2018/11/28 PM8:02」、やり取り情報として、ユーザが家でグンマの好きなプレイリストから曲AとBとEとを流したことが記録されている。これに応じて、知識DB111において、「グンマ」が「群馬」を意味する確率が18%から17%に、「グンマ」が「岩佐」を意味する確率が82%から83%に更新されている。
また、やり取りDB113のNo.Dには、時刻情報として「2018/11/28 PM8:15」、やり取り情報として、家でユーザが「いいね」という入力情報を入力したことが記録されている。当該「いいね」という入力情報は、No.Cにおける曲AとBとEとが流れたことに対する応答であると推測される。このため、推薦DB112において、曲Aの推薦スコアが0.2から0.3に、曲Bの推薦スコアが0.6から0.7に、曲Eの推薦スコアが0.0から0.5に更新されている。
さらに、やり取りDB113のNo.Eには、時刻情報として「2018/11/28 PM8:20」、やり取り情報として、ユーザが家で「私の好きな漫画のキャラクタはグンマ」という入力情報を入力したことが記録されている。これに応じて、知識DB111において、「グンマ」が「群馬」を意味する確率が17%から7%に、「グンマ」が「岩佐」を意味する確率が82%から73%に更新されている。さらに、知識DB111には、「グンマ」が漫画のキャラクタである可能性があることが追加され、「グンマ」が漫画のキャラクタを意味する確率が0%から20%に更新されている。
以上のように、本実施形態に係る情報処理装置10とユーザ端末20の間におけるやり取りにより、情報処理装置10が記憶している各種の情報が更新される。より具体的には、やり取りDB113に記憶された情報を学習データとし、当該学習データの蓄積に伴い、知識DB111及び推薦DB112に記憶された情報が更新される。生成部140は、知識DB111及び推薦DB112に記憶された情報に基づき、出力情報を生成する。このため、学習データの蓄積に伴い、情報処理装置10が出力情報を出力するためのアルゴリズムが変化する。
以下では、このように学習データの蓄積に基づき変化するアルゴリズムに対して再学習させる方法について説明する。より具体的には、情報処理装置10は、学習データに由来する影響度を調整することにより、アルゴリズムに対して再学習させる。上述のように、学習データである、学習DB114に記録された情報は、知識DB111又は推薦DB112に記録された情報に影響を与える。本実施形態に係る情報処理装置10は、やり取りDB113に記録された情報を修正等することにより、知識DB111又は推薦DB112に記録された情報への影響度を調整する。これにより、アルゴリズムの再学習が行われる。
やり取りDB113には、前述のように、ユーザによる入力情報に関する情報、出力情報に関する情報、又は記憶部110の状態変化の関する情報等が含まれる。本実施形態に係る情報処理装置10は、これらの情報のうちの少なくともいずれかを記憶していれば、アルゴリズムに対して再学習させることが可能である。ここで、ユーザによる入力情報に関する情報は、「誰が/いつ/どこで/何を言ったか」などを表す情報であってもよい。また、出力情報に関する情報は、情報処理装置10が「いつ/どこで/何を言ったか又は推薦したか」などを表す情報であってもよい。また、記憶部110の状態変化に関する情報には、知識DB111の更新履歴又は推薦DB112の更新履歴等の情報が含まれる。
<<1.4.アルゴリズムの再学習方法>>
<<<1.4.1.第1のアルゴリズムの再学習方法>>>
次いで、情報処理装置10がアルゴリズムに対して再学習させる第1の方法について説明する。
<<<1.4.1.第1のアルゴリズムの再学習方法>>>
次いで、情報処理装置10がアルゴリズムに対して再学習させる第1の方法について説明する。
第1のアルゴリズムの再学習方法では、情報処理装置10は、やり取りDB113からキーワードを抽出し、抽出結果に基づいて、知識DB111、推薦DB112、及びやり取りDB113に含まれる情報を削除する。
より具体的には、抽出部122は、抽出するためのキーワードを取得し、やり取りDB113からキーワードを抽出する。なお、当該キーワードは、例えば、ユーザの操作によりユーザ端末20に入力され、情報処理装置10に送信され、抽出部122に伝達されてもよい。ここでは、キーワードとして「グンマ」という言葉が、抽出部122に伝達されているものとする。抽出部122は、やり取りDB113から「グンマ」が含まれる情報を検索し、学習DB114から学習データを抽出する。
次いで、修正部124は、学習DB114に記録された「グンマ」を含む学習データを削除する。修正部124、例えば、学習DB114に記録された、「グンマが好きな曲はXXです。」、「グンマは、私の友達の岩佐君のあだ名です。」、及び「グンマの曲を流して。」という「グンマ」を含む学習データを削除する。また、修正部124は、知識DB111に記録されている、「グンマ」が「岩佐」を意味することを表す情報を削除する。さらに、修正部124は、推薦DB112に記憶されている、「グンマ」が好きなプレイリストを削除し、「グンマ」が好きな曲の推薦スコアを元に戻す。
この結果、入力情報として、情報処理装置10に「グンマの曲を流して。」という入力情報が入力されると、情報処理装置10は、当該入力情報の内容が矛盾した内容である解析するようになる。例えば、情報処理装置10が備える確認情報生成部141は、「グンマってなに?」という出力情報を生成してもよい。一方、推薦情報生成部142は、「グンマが好きなプレイリストはありません。」という出力情報を生成してもよい。
このように、「グンマ」に関する情報が記憶部110から削除されることにより、「グンマ」という言葉が含まれる学習データに基づくアルゴリズムへの影響を削除することができる。しかし、これだけでは、不都合が生じる場合がある。
例えば、「グンマ」という言葉が含まれない情報は、上記の「グンマ」というキーワードを用いた抽出では見つけることができない。例えば、入力情報として、「昨日聞いた曲と似たテイストの曲を流して。」という入力情報が、情報処理装置10に入力されていたとする。昨日聞いた曲がグンマの曲である場合、グンマの曲に似たテイストの推薦スコアが更新されている。この場合、「グンマ」という言葉を含んでいない上記の入力情報が、推薦DB112の情報に直接的に影響している。
さらに、「昨日聞いた曲と全く違う曲を流して。」という入力情報が情報処理装置10に入力されたとする。昨日聞いた曲がグンマの曲である場合、推薦DB112では、グンマの曲と全く違いテイストの曲の推薦スコアが更新されている。つまり、「グンマ」という言葉を含んでいない入力情報が、間接的に推薦DB112の情報に影響している。
このように、「グンマ」という情報を含んでいない入力情報に基づく影響についても、ユーザが記憶部110から削除したい場合があると考えられる。そこで、これらの影響を削除する方法として、各種のデータに関連する情報を予め例えば記憶部110に記憶させておく方法が考えられる。例えば、「昨日聞いた曲と似たテイストの曲を流して。」及び「昨日聞いた曲と全く違う曲を流して。」という入力情報が、「グンマの曲を流して。」という情報と関連する情報として、やり取りDB113に記憶させておく方法が考えられる。これにより、「グンマ」というキーワードでやり取りDB113を検索した場合に、上記の「昨日聞いた曲と似たテイストの曲を流して。」及び「昨日聞いた曲と全く違う曲を流して。」という情報がやり取りDB113から検索される。検索された情報に基づき、学習DB114から学習データが削除され、さらに、これらの2つの情報に関わる知識DB111及び推薦DB112の情報も削除される。
しかしながら、上記の方法では、やり取りDB113に記憶された各種の情報同士の関連を表す情報を、例えばやり取りDB113に記憶させておく必要がある。このため、やり取りDB113に記録される情報が膨大となってしまう。
<<<1.4.2.第2のアルゴリズムの再学習方法>>>
そこで、第2のアルゴリズムの再学習方法では、ある情報を削除した場合に、出力情報に不整合が発生する場合に、当該削除された情報を関連する情報として判定される。より具体的には、ある情報が削除された場合に、削除前の出力情報と、削除後の出力情報とが異なる場合には、当該削除された情報をキーワードに関連する情報として判定する。第2のアルゴリズムの再学習方法によれば、やり取りDB113に記憶された各種の情報同士の関連を表す情報を記録する必要がなくなる。
そこで、第2のアルゴリズムの再学習方法では、ある情報を削除した場合に、出力情報に不整合が発生する場合に、当該削除された情報を関連する情報として判定される。より具体的には、ある情報が削除された場合に、削除前の出力情報と、削除後の出力情報とが異なる場合には、当該削除された情報をキーワードに関連する情報として判定する。第2のアルゴリズムの再学習方法によれば、やり取りDB113に記憶された各種の情報同士の関連を表す情報を記録する必要がなくなる。
図12を参照して、第2のアルゴリズムの再学習方法について説明する。より具体的には、キーワードを含むやり取りに関する情報が削除されたときにおける、アルゴリズムに基づき出力される出力情報の変化に基づき、当該やり取り関する情報がキーワードと関連するか否かを判定する方法について説明する。
図12は、やり取りに関する情報の削除前後において生成される出力情報と、その前後の出力情報の変化に基づく処理内容とを示す図である。図12には、3つの例が示されている。以下、図12に示す3つの例について説明する。左側から順に、ユーザが昨日聞いた曲、出力(削除前と削除後)、出力の変化、及び処理内容が示されている。
出力(削除前)は、ユーザからの「昨日聞いた曲と似たテイストの曲を流して。」という入力情報に対する出力情報の内容である。また、以下の3つの例では、抽出部122は、「グンマ」というキーワードを含む情報を記憶部110から抽出し、修正部124が、抽出された情報を削除している。当該削除が行われた後における、上記入力情報に対する出力情報の内容を出力(削除後)として示されている。
1つ目の例では、やり取り情報として、昨日、ユーザが「グンマの曲」だけ聞いたことが記録されている。このため、入力情報に対する出力情報は、「グンマの曲」のみを流すための情報となる。一方、「グンマ」を含む情報が削除されると、「グンマの曲」を流したという履歴が消えたことにより、アルゴリズムがユーザの意図を理解することができなくなるため、出力情報は、「昨日曲流したっけ?」という情報に変化する。このように、キーワード「グンマ」を含む情報が削除されることにより、出力情報が変化した場合には、判定部123は、入力情報がキーワード「グンマ」と関連するデータ(関連データ)として判定する。このように、本実施形態に係る情報処理装置10は、キーワードを含む情報を削除し、削除前後の出力情報の変化に応じて、入力情報とキーワードとの関連性を判定することができる。このため、情報処理装置10は、入力情報の各々について、どのようなキーワードと関連しているのかを記憶する必要がなくなる。
次いで、2つ目の例では、昨日、ユーザがグンマの曲とグンマ以外の曲を昨日聞いている。つまり、出力(削除前)は、「グンマの曲」と「グンマ以外の曲」とを流す出力である。一方、「グンマ」を含む各種の情報が削除さえた後の出力(削除後)は、「グンマ以外の曲」のみを流す出力となっている。この場合にも、出力(削除前)と出力(削除後)とに変化が生じている。このため、判定部123は、入力情報がキーワード「グンマ」の関連データとして判定する。
次いで、3つ目の例では、昨日、ユーザが「グンマ以外の曲」だけ聞いている。このため、出力(削除前)は、「グンマ以外の曲」のみを流す出力となっている。一方、出力(削除前)の出力は、キーワードと関連の無い出力である。このため、出力(削除後)には、出力(削除前)からの変化がない。このとき、判定部123は、入力情報がキーワードと関連のないデータであると判定する。
このように、キーワードと入力情報との関連性を判定することで、当該キーワードに基づき、キーワードに関連する入力情報も削除することが可能になる。つまり、「グンマの曲を流して。」という入力情報に限らず、「昨日聞いた(グンマの)曲と似たテイストの曲を流して。」又は「昨日聞いた(グンマの)曲と全く違う曲を流して。」という、「グンマ」というキーワードに関連する入力情報も削除することができるようになる。入力情報が削除されると、削除された入力情報に基づくやり取りが実施されなかったことになり、知識DB111及び推薦DB112に記録された各種の情報が、更新される。このように、第2のアルゴリズムの再学習方法によれば、キーワードに関連する学習データであるやり取りに関する情報を削除することにより、アルゴリズムに対して再学習させることができる。
また、第2のアルゴリズムの再学習方法によれば、出力情報の変化に基づき、キーワードと入力情報との関連性が判定される。このため、情報処理装置10は、各種のキーワードと入力情報との関連性を記憶する必要がなくなり、より少ない情報に基づき、やり取りに関する情報を修正することが可能になる。この結果、情報処理装置10は、より少ない情報に基づき、アルゴリズムに対して再学習させることができる。
<<<1.4.3.第3のアルゴリズムの再学習方法>>>
上記の第2のアルゴリズムの再学習方法では、キーワードに関連する入力情報に関する情報がやり取りDB113から削除される。このため、入力情報の中に含まれる、キーワードと直接的に関連の無いデータ(例えば、ユーザの趣味嗜好に関連するデータ)まで削除される場合がある。
上記の第2のアルゴリズムの再学習方法では、キーワードに関連する入力情報に関する情報がやり取りDB113から削除される。このため、入力情報の中に含まれる、キーワードと直接的に関連の無いデータ(例えば、ユーザの趣味嗜好に関連するデータ)まで削除される場合がある。
そこで、出力情報への影響度が小さい入力情報については、削除せずに修正することが考えられる。これにより、キーワードに関連する入力情報からの出力情報への影響が完全に削除されないようにすることができる。この結果、キーワードに関連の無いデータ(例えば、ユーザの趣味嗜好に関連するデータ)等が削除される可能性が減る。
図13を参照して、学習DB114に記録された出力に関連する情報が修正されることを説明する。図13には、学習DB114に記録された出力が修正される例が、4つ示されている。以下、出力が修正される4つの例について説明する。なお、いずれの例についても、「グンマの曲を流して。」という入力情報に対する出力が修正されるものとする。具体的には、抽出部122は、「グンマ」というキーワードをやり取りDBから検索し、当該検索結果に基づき学習DB114から学習データを抽出する。修正部124は、抽出結果に応じて、以下で説明するように、出力を修正する。
1つ目の例では、ユーザは、昨日「グンマの曲」だけ聞いている。つまり、具体的には、グンマの曲が10曲再生されている。ユーザは、「グンマ」に関する情報を削除しようとしているため、当該出力に対して「だめ」というFB(フィードバック)があるものとする。この場合、修正部124は、「グンマ」に関連する情報を記憶部110から削除する。すると、解析部130は、「グンマの曲を流して。」という入力情報の意味内容が理解できなくなる。これに応じて、生成部140は、「昨日曲流したっけ?」という出力情報を生成する。このように1つ目の例では、出力の変化が大きいため、判定部123は、出力の変化が大きいと判定する。この判定結果を受けて、修正部124は、1つ目の例に対応するやり取り情報をやり取りDBから削除する。すなわち、修正部124は、当該やり取り情報に紐づけられた学習DB114に記録された学習データを削除する。さらに、修正部124は、ユーザのFBも学習DB114から削除する。
次いで、2つ目及び3つ目の例では、ユーザは、昨日「グンマの曲」と「グンマ以外の曲」を聞いている。ただし、2つ目の例及び3つ目の例では、ユーザが聞いた「グンマの曲」の数と「グンマ以外の曲」の数とが異なる。具体的には、2つ目の例では、ユーザ端末20は、「グンマの曲」を9曲、「グンマ以外の曲」を1曲流している。一方、3つ目の例では、ユーザ端末20は、「グンマの曲」を1曲、「グンマ以外の曲」を9曲流している。
2つ目の例では、キーワード「グンマ」に関連する学習データの削除の前後で、出力情報が「グンマの曲」を9曲及び「グンマ以外の曲」を1曲流す情報から、「グンマの曲」を1曲流す情報に変化している。この場合、2つ目の例におけるやり取り情報が削除される。これに伴い、ユーザの「だめ」というFBも削除されている。
一方、3つ目の例では、キーワード「グンマ」に関連する学習データの削除の前後で、出力情報が「グンマの曲」を1曲及び「グンマ以外の曲」を9曲流す情報から、「グンマ以外の曲」を9曲に変化している。この場合、出力情報の変化が小さいため、「グンマ以外の曲」を9曲流すという出力結果が削除される。これに伴い、ユーザの「いいね」というFBも維持されている。なお、この場合には、出力情報が上記キーワード「グンマ」に関連する学習データが削除された後における出力情報が出力されたものとして、ユーザからのFBが記録される。
このように、本実施形態に係る情報処理装置10によれば、出力の変化の大きさに応じて、出力の内容が修正される。つまり、情報処理装置10は、出力情報の記録を削除するだけでなく、出力情報を修正することにより、出力情報に由来するアルゴリズムへの影響度を調整することができる。これにより、情報処理装置10は、ユーザ所望するアルゴリズムの状態を実現することができる。
また、4つ目の例では、ユーザは、昨日、「グンマの曲」だけ聞いている。この場合、キーワードに関連する学習データが削除される前後で、出力情報が「グンマ以外の曲」を10曲流す情報から変わっていない。従って、出力の変化はない。このため、ユーザFBも「いいね」のままであり、出力情報に関する更新は行われない。
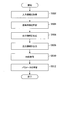
以上、図13を参照して、本実施形態に係る情報処理システム1による出力の修正例の概略について説明した。次に、図14を参照して、本実施形態に係る情報処理装置10によるやり取りDB113の更新処理について、より詳細に説明する。図14は、本開示の一実施形態に係る情報処理装置10によるやり取りDB113の更新処理を示すフローチャート図である。以下、図14に沿って、更新処理について説明する。
まず、情報処理装置10は、入力情報を取得する(ステップS402)。より具体的には、情報処理装置10は、例えばユーザからユーザ端末20に入力されたキーワードと当該キーワードに関する学習データの削除を要求する情報(以下、単に「要求情報」とも称する。)を入力情報として、ネットワーク30を介して受信する。ここで、上記キーワードは、例えば「グンマ」という言葉であるとする。情報処理装置10は、上記キーワードと要求情報とを入力情報として受信し、通信制御部160を介して、受信した入力情報を処理部120が備える抽出部122に伝達する。
次いで、抽出部122は、伝達された入力情報に基づき、関連情報を抽出する(ステップS404)。具体的には、抽出部122は、キーワードの「グンマ」という言葉に関連する情報を抽出する。より具体的には、抽出部122は、キーワードの「グンマ」という言葉に関連する、知識DB111、推薦DB112、又はやり取りDB113に記憶された情報を抽出する。なお、抽出部122は、やり取りDB113に記録された出力情報については抽出しない。
次いで、生成部140は、出力情報を生成する(ステップS406)。このとき、生成部140は、ステップS404において抽出された関連情報(なお、ステップS406において用いられる入力情報は除く。)が削除されたものとして、出力情報を生成する。つまり、生成部140は、キーワード「グンマ」に関連するやり取り等がなかったものとして、出力情報を生成する。このとき、生成部140が生成する出力情報は、やり取りDB113に記録されている出力情報と異なる場合がある。
次いで、判定部123は、出力情報の変化の大きさを判定する(ステップS408)。より具体的には、判定部123は、ステップS406において生成された出力情報と、学習DB114に記録された、当該出力情報を生成するために用いられた入力情報に対応する出力情報と、の差分の大きさを出力情報の変化の大きさとして判定する。
次いで、修正部124は、ステップS408における判定部123による判定結果に応じて、学習DB114に記録された出力情報を修正する(ステップS410)。例えば、ステップS408において、出力情報の変化が大きいと判定された場合には、修正部124は、学習DB114に記録された、ステップS408において判定の対象となった出力情報及びこれに対応する入力情報を削除する。このように、出力情報が削除された場合には、当該出力情報からのアルゴリズムへの影響がなくなる。
また、ステップS408において、出力情報の変化がないと判定された場合には、修正部124は、やり取りDB113に記録された、ステップS408において判定の対象となった出力情報を維持する。さらに、ステップS408において、出力情報の変化があり、当該変化が大きくないと判定された場合には、修正部124は、やり取りDB113に記録された、ステップS408において判定の対象となった出力情報を修正する。
次いで、抽出部122は、やり取りDB113に基づき、判定されていない出力情報が有ると判定した場合(ステップS412:Yes)、ステップS402に戻る。一方、やり取りDB113に基づき、判定されていない出力情報がないと判定した場合(ステップS412:No)、図14に示す更新処理は終了する。
以上のようにして、本実施形態に係る情報処理装置10は、やり取りDB113に記録されたやり取り情報を修正する。すなわち、学習DB114に記録された学習データが修正される。これにより、学習DB114に記録された入力情報又は出力情報等の学習データに由来する影響度が調整され、アルゴリズムの再学習が実施される。これにより、情報処理装置10は、ユーザが所望するアルゴリズムの状態をより適切に実現することができる。
<2.第2の実施形態>
第1の実施形態では、ルールベースの手法(つまり、知識DB111に推薦DB112記録されたスコア等を用いる手法)に基づくアルゴリズムを用いる例について説明した。しかし、本開示の技術は、例えばディープラーニングに代表される各種の機械学習技術のように、具体的な処理内容がブラックボックスとなっている技術にも適用できる。第2の実施形態では、上記ディープラーニングのような機械学習技術に本開示の技術が適用される例について説明する。なお、以下の説明において、第1の実施形態と重複する内容については、説明を省略する。
第1の実施形態では、ルールベースの手法(つまり、知識DB111に推薦DB112記録されたスコア等を用いる手法)に基づくアルゴリズムを用いる例について説明した。しかし、本開示の技術は、例えばディープラーニングに代表される各種の機械学習技術のように、具体的な処理内容がブラックボックスとなっている技術にも適用できる。第2の実施形態では、上記ディープラーニングのような機械学習技術に本開示の技術が適用される例について説明する。なお、以下の説明において、第1の実施形態と重複する内容については、説明を省略する。
<<2.1.情報処理装置の構成>>
図15を参照して第2の実施形態に係る情報処理装置11の構成について説明する。図15は、第2の実施形態に係る情報処理装置11の構成を示す機能ブロック図である。図15に示すように、情報処理装置11は、記憶部118、処理部128、解析部130、生成部143、出力制御部150、及び通信制御部160を備える。以下、第1の実施形態に係る情報処理装置11が備える機能部と異なる、記憶部118、処理部128、生成部143について説明する。
図15を参照して第2の実施形態に係る情報処理装置11の構成について説明する。図15は、第2の実施形態に係る情報処理装置11の構成を示す機能ブロック図である。図15に示すように、情報処理装置11は、記憶部118、処理部128、解析部130、生成部143、出力制御部150、及び通信制御部160を備える。以下、第1の実施形態に係る情報処理装置11が備える機能部と異なる、記憶部118、処理部128、生成部143について説明する。
まず、図16を参照して、第2の実施形態に係る記憶部118について説明する。図16は、第2の実施形態に係る記憶部118の構成を示す機能ブロック図である。第2の実施形態に係る記憶部118は、知識DB116、推薦DB117、やり取りDB113、及び学習DB114を備える。
また、第2の実施形態に係る知識DB116には、第1の実施形態に係る知識DB111のような言葉の意味内容を確率的に表すデータは記録されていない。さらに、第2の実施形態に係る推薦DB117には、第1の実施形態に係る推薦DB112に記録されている推薦スコアが記録されていない。第2の実施形態では、言葉の意味内容の解析又はユーザへの推薦などは、後述する解析部131及び生成部143が有するブラックボックスパラメータ(以下、単に「パラメータ」とも称する。)に基づき実施される。このため、第2に実施形態では、第2の実施形態に係る知識DB116及び推薦DB117と、第1の実施形態に係る知識DB111及び推薦DB112と、で記録されている情報が異なる。より具体的には、解析部131又は推薦情報生成部145は、複数の入力からなる入力層と、複数の出力からなる出力層とが、多層からなる中間層により接続されたネットワークに、入力値を入力して、解析結果又は推薦情報などに関する出力値を出力する。以下では、当該ネットワークにおけるノードの重みを規定するパラメータを「ブラックボックスパラメータ」と称する。
学習DB114には、学習データが記録されるイベントにおいて、入力値及び出力値が記録される。入力値は、例えば、ユーザの指示、ユーザ状況、環境情報などの出力値を得るために必要な各種の情報である。出力値は、例えば、解析結果などがどの程度適切だったかを推定するための指標(例えば、ユーザの反応等の情報)であり得る。学習データの記録は、ユーザによる指示に基づき、又は情報処理装置11がバックグラウンドで自動的に実施され得る。本実施形態では、やり取りDB113には、イベントの各々のインデックスがデータとして記録されている。さらに、やり取りDB113には、イベントで記録されたアルゴリズムの再学習に必要な学習データを抽出するためのラベル情報(例えば、イベントの発生時刻、入力情報又は出力情報の内容を示す情報など)が記録されている。このため、やり取りDB113に基づき、学習DB114から学習データを抽出することができる。
図17を参照して、第2の実施形態に係る記憶部118に記憶された情報について、第1の実施形態に係る記憶部110に記憶された情報との違いを中心に説明する。図17は、第2の実施形態に係るやり取りDB113に記録された情報、知識DB116の更新履歴、及び推薦DB117の更新履歴の一例を示す図である。図17に示すように、知識DB116及び推薦DB117には、意味内容の確率に関する情報及び推薦スコア等の情報が記録されていない。このため、図17に示すように、図11に示したような意味内容の更新履歴又は推薦スコアの更新履歴等は、第2の実施形態に係る記憶部118には記憶されていない。なお、第2の実施形態に係るやり取りDB113には、第1の実施形態に係るやり取りDB113と同様に、やり取りに関する情報が記録されている。
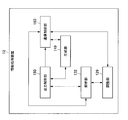
次いで、図18を参照して、第2の実施形態に係る処理部128について説明する。図18は、第2の実施形態に係る処理部128の構成を示す機能ブロック図である。第2の実施形態に係る処理部128は、第1の実施形態に係る処理部120が備える機能部に加えて、学習部125を備える。
学習部125は、解析部131又は生成部143が有する各種のパラメータの学習(例えば、強化学習)を実施する機能を有する。より具体的には、学習部125は、やり取りDB113に記録されたやり取り情報に基づき、例えば強化学習などの技術に基づき、パラメータの学習を実施する。これにより、パラメータが更新される。ここで、パラメータの学習とは、ブラックボックスパラメータを、入力値及び出力値(すなわち、学習データ)の蓄積に応じて最適化することをいう。なお、学習部125は、やり取りDB113に記録されたやり取りに関する情報が追加、削除又は修正される際に、学習部125は、パラメータの学習を実施してもよい。
第2の実施形態に係る情報処理装置11は、入力情報を取得すると、解析部131又は生成部143が有する各種のパラメータに基づき、出力情報を生成する。このため、学習部125が、パラメータを更新することは、情報処理装置11が出力情報を生成するためのアルゴリズムに対して再学習させることに相当する。
次いで、解析部131について説明する。第2の実施形態では、入力情報と出力情報とがどの対応関係をとるとポジティブなFBが得られるかが、ブラックボックスパラメータ(意味解析パラメータ)として学習される。第2の実施形態に係る解析部131は、第1の実施形態に係る解析部130と異なり、入力情報と意味内容との対応関係を確率という形ではなく、当該意味解析パラメータを用いて前後の文脈/状況から最適な対応を求める。より具体的には、ユーザからの音声情報が入力された場合には、解析部131は、例えば当該音声情報を入力値として、意味解析パラメータに基づき、音声情報の意味解析結果を出力する。また、解析部131は、音声に加えて、各種情報(ユーザの状況、特性情報、環境情報、ユーザの指示の内容など)を入力値として、音声情報の意味解析結果を出力してもよい。ここで、ユーザの特性情報は、例えば、年齢、性別又は住所などのユーザの特性に関する情報であってもよい。また、環境情報は、時間、場所又は一緒に居る人などに関する情報などのユーザが存在する空間に関する情報であってもよい。例えば、解析部131は、直前まで交友関係の話をしていると、「グンマ」を「岩佐」という人を意味すると解析してもよい。また、ユーザが群馬県に旅行に来ている場合には、「グンマ」を「群馬」という県名を意味すると解析してもよい。このように、直前まで話していた内容が意味解析パラメータに反映されてもよい。また、ロケーションの内容が意味解析パラメータに反映されてもよい。本実施形態では、解析部131が出力した意味解析結果は、後述する推薦情報生成部145が推薦情報を生成するための入力値として用いられる。なお、解析部130は、アルゴリズムの再学習時においても意味解析を行うが、その際の処理の詳細については後述する。
次いで、図19を参照して、生成部143について説明する。図19は、第2の実施形態に係る生成部143の構成を示す機能ブロック図である。図19に示す生成部143は、第1の実施形態に係る生成部140と同様に、確認情報生成部144及び推薦情報生成部145を備える。第1の実施形態に係る推薦情報生成部142は、上述のように、例えば曲の推薦スコア等に基づき、曲を推薦するための出力情報を生成した。一方、第2の実施形態では、どの曲を推薦する推薦情報を生成すると、ポジティブなFBが得られるかがブラックボックスパラメータ(推薦パラメータ)として学習されている。推薦情報生成部145は、当該推薦パラメータに基づき、例えば、前後の文脈又は状況等に基づき、最適な出力情報を生成し、ユーザに例えば音楽などを推薦する。より具体的には、推薦情報生成部145は、解析部130による解析結果、各種情報(ユーザの状況、特性情報、環境情報、ユーザの指示の内容など)及び推薦パラメータに基づき、推薦情報を出力として生成する。
本実施形態では、このように、意味解析又は推薦情報の生成には、音声情報及び上述した各種情報(ユーザの状況、特性情報、環境情報、ユーザの指示の内容など)などが用いられる。このため、多数の条件を考慮した処理を実施することが可能な機械学習技術は、本実施形態のように多様な条件に基づき推薦などの処理を行うことが必要な処理に適している。
例えば、ユーザの直前までの会話に登場した曲と類似する曲が流れるとユーザにとって好ましい場合がある。このとき、例えば上記推薦パラメータには、直前までのユーザの会話に登場した曲についての内容が反映され推薦情報生成部145は、当該推薦パラメータに基づき、ユーザが直前まで話していた曲に類似した曲を流すための出力情報を生成することができる。
また、以前にユーザに対してある曲が流された場合に、当該曲が流されてから例えば1週間以上経過してから、当該曲が再度流されることがユーザにとって好ましい場合がある。このとき、例えば推薦パラメータには、以前推薦された曲に関する情報が反映され推薦情報生成部145は、以前推薦された当該楽曲が流されてから1週間以上経過した場合に当該曲を推薦するとする出力情報を生成することができる。
<<2.2.処理例>>
まず、図20を参照して、情報処理装置11が、ブラックボックスパラメータ(意味解析パラメータ及び推薦パラメータ)を更新する処理であるパラメータ更新処理について説明する。図20は、第2の実施形態に係るパラメータ更新処理の一例を示すフローチャート図である。以下、図20に沿って、パラメータ更新処理について説明する。
まず、図20を参照して、情報処理装置11が、ブラックボックスパラメータ(意味解析パラメータ及び推薦パラメータ)を更新する処理であるパラメータ更新処理について説明する。図20は、第2の実施形態に係るパラメータ更新処理の一例を示すフローチャート図である。以下、図20に沿って、パラメータ更新処理について説明する。
まず、情報処理装置11は、入力情報を取得する(ステップS502)。情報処理装置11は、例えば、ユーザ端末20に入力情報を、ネットワーク30を介して、受信する。受信された入力情報は、通信制御部160を介して、解析部131に伝達される。
次いで、解析部131は、入力情報の意味内容を解析する(ステップS504)。より具体的には、解析部131は、記憶部118に記憶された意味解析パラメータに基づき、入力情報の意味内容を解析する。解析結果は、生成部143に伝達される。
次いで、生成部143は、出力情報を生成する(ステップS506)。より具体的には、推薦情報生成部145は、解析結果と、記憶部118に記憶された推薦パラメータとに基づき、ユーザに各種の推薦をするための出力情報を生成する。出力情報は、出力制御部150に伝達される。
次いで、出力制御部150は、出力情報を出力させる(ステップS508)。より具体的には、出力制御部150は、出力情報を通信制御部160に伝達する。出力情報は、例えばネットワーク30に接続されたユーザ端末20に送信される。これにより、ユーザ端末20は、出力情報を出力する。例えば、ユーザ端末20は、ユーザにある曲を推薦する音声を出力する。
次いで、情報処理装置11は、FBを取得する(ステップS510)。例えば、情報処理装置11は、ユーザからの出力結果に対する応答をFBとして取得する。取得されたFBは、処理部128に伝達される。
次いで、処理部128は、意味解析パラメータと推薦パラメータとを学習する(ステッS512)。具体的には、学習部125は、ユーザからのFBに基づき、記憶部118に記憶された意味解析パラメータと推薦パラメータとを学習する。これにより、意味解析パラメータと推薦パラメータとが更新される。これらのパラメータが更新されると、パラメータ更新処理が終了する。
以上、図19を参照して、パラメータ更新処理について説明した。このように、情報処理装置11が出力情報を生成するための各種のパラメータが、例えばユーザ等によるFBに基づき更新されることで、情報処理装置11は、よりユーザの所望する出力情報を生成することが可能になる。
次いで、図21を参照して、第2の実施形態に係る情報処理装置11が、アルゴリズムに対して再学習させる処理の概要について説明する。図21は、第2の実施形態に係る情報処理装置11が、アルゴリズムに対して再学習させる処理の概要を示す図である。
図21において、上側には、横軸を時間軸とした、ユーザと情報処理装置11とのやり取りの履歴が示されている。より具体的には、ユーザからの入力情報が情報処理装置11に入力され、当該入力情報に対する出力情報が出力された時刻(t1~t18)が時系列で時間軸上に並べられている。入力情報と出力情報との入出力があった時刻に、斜線が付された三角形のマーカが示されている。情報処理装置11は、これらのやり取りに基づき、アルゴリズムに対して学習させている。
次いで、第2の実施形態に係る情報処理装置11がアルゴリズムに対して再学習させる処理について説明する。第2の実施形態においても、第1の実施形態と同様に、やり取りDBに記録されたやり取りの記録が削除又は修正される。例えば、斜線又はグリッドの付されていない三角形のマークに対応する、時刻t6~t9におけるやり取りに関する情報は、やり取りDB113から削除されている。さらに、グリッドの付された三角形のマークに対応する、時刻t11、12、15におけるやり取りに関する情報は修正されている。例えば、これらの時刻に生成された出力情報が修正されている。また、斜線の付された三角形のマークに対応する時刻におけるやり取りは、そのまま残っている。
処理部120は、削除すべきやり取りをやり取りDB113に基づき検索し、当該やり取りを削除する。より具体的には、抽出部122は、例えばユーザからの入力に基づき、やり取りDB113に記録されたやり取り(ラベル情報)を検索する。例えば、抽出部122は、例えば上述した「グンマ」などのキーワードに基づき、やり取りDB113からラベル情報を検索し、当該ラベル情報に基づき学習データを抽出し得る。修正部124は、検索された学習データを学習DB114から削除する。また、修正部124は、検索されたラベル情報などをやり取りDB113から削除してもよい。
また、抽出部122は、削除すべきやり取りに関する情報から派生的な影響を受けている学習データを学習DB114から抽出してもよい。例えば、「グンマ」というキーワードに基づき学習データが削除される場合に、抽出部122は、当該削除の前後で出力情報が変化するイベントに対応する学習データを抽出してもよい。修正部124は、当該イベントに関わる学習データを削除してもよい。
このようにして削除されたイベントは、図21に示す時刻t6~t9におけるやり取りに対応する。
修正部124は、学習データを削除せず、修正してもよい。例えば、図13を参照して説明したように、修正部124は、キーワードに基づく学習データの削除による出力情報の変化の大きさに基づき学習データを修正してもよい。修正された学習データに対応するやり取りは、図21に示した時刻t11、12、15におけるやり取りに対応している。
上述したように、第2の実施形態では、やり取りに基づき、パラメータが学習される。従って、上記のようにやり取りの少なくとも一部が修正又は削除されることにより、パラメータを再学習することが可能になる。すなわち、やり取りの少なくとも一部を修正又は削除することにより、アルゴリズムに対して再学習させることが可能になる。この結果、特定の影響を排除したアルゴリズムを作成することができる。
次いで、図22を参照して、第2の実施形態に係る情報処理装置11が、パラメータを再学習させる処理について説明する。図22は、第2の実施形態に係るパラメータ再学習処理を示すフローチャート図である。以下、図22に沿って、第2の実施形態に係るパラメータ再学習処理について説明する。ここでは、図21に示したように、やり取りDB113に記録されている、各やり取りに関する情報が維持、修正又は削除されているものとする。
まず、判定部123は、更新(削除又は修正)の対象となるやり取りが実施された時刻tの値を1に設定する(ステップS602)。つまり、判定部123は、更新の対象となるやり取りを、最も古いやり取りに設定する。
次いで、判定部123は、やり取りDB113を参照し、設定された時刻に対応するやり取り情報を確認する(ステップS604)。やり取りDB113に設定された時刻に対応するやり取り情報が存在する場合(ステップS606:Yes)、ステップS608に進む。一方、設定された時刻に対応するやり取り情報が削除されている場合、(ステップS606:No)、ステップS610に進む。
やり取りDB113において、設定された時刻に対応するやり取り情報が存在する場合(ステップS606:Yes)、ステップS608において、学習部125は、パラメータの学習を実施する(ステップS610)。より具体的には、学習部125は、時刻tまでのやり取りに関連する情報に基づき、解析部131又は生成部143のうちの少なくともいずれかが有するパラメータの更新を実施する。
具体的には、学習部125は、意味解析パラメータ及び推薦パラメータを更新する。より具体的には、学習部125は、解析部130に、設定されている時刻tにおける、ユーザからの入力情報、各種情報、解析結果に対するFB情報を用いて、時刻t-1までの再学習に基づく意味解析パラメータを最適化することで、新たな意味解析パラメータを生成させる。ここで、FB情報は、ユーザからの直接的なFB(例えば、「良い」、「悪い」というFB)であってもよいし、暗黙的なFBであってもよい。また、FB情報は、ユーザの表情又は生体情報の変化であってもよい。これにより、意味解析パラメータが更新される。
また、学習部125は、推薦情報生成部145に、設定されている時刻tにおける入力情報、各種情報、出力された推薦情報及び当該推薦に対するFB情報を用いて、時刻t-1までの再学習に基づく推薦パラメータを最適化することで、新たな推薦パラメータを生成させる。これにより、推薦パラメータが更新される。
次いで、判定部123は、設定された時刻tに1を加算し、新たな時刻t+1を設定する(ステップS610)。次いで、判定部123は、新たに設定された時刻t+1が最大値を超えたか否かを判定する(ステップS612)。ここで、時刻t+1の最大値とは、例えば、やり取りDBに記録されたやり取りの数であってもよい。時刻t+1が最大値を超えたと判定されると(ステップS612:Yes)、図21に示すパラメータ再学習処理は終了する。一方、時刻t+1が最大値を超えていないと判定されると(ステップS612:No)、ステップS604に戻る。
以上、図22を参照して、パラメータ再学習処理について説明した。このように、過去のやり取り情報に基づき、順次パラメータが再学習される。これにより、情報処理装置11が出力情報を生成するためのアルゴリズムは再学習される。このようにして、第2の実施形態に係る情報処理装置11は、所望のアルゴリズムの状態を実現することが可能になる。
<3.応用例>
以下、本実施形態に係る情報処理システム1の応用例について説明する。
以下、本実施形態に係る情報処理システム1の応用例について説明する。
[ニュース読み上げ機能への応用例]
情報処理システム1が、アルゴリズムに基づき、ニュースなどに関する音声情報をユーザ端末20等が出力するための出力情報を生成する場合における、アルゴリズムの再学習について説明する。
情報処理システム1が、アルゴリズムに基づき、ニュースなどに関する音声情報をユーザ端末20等が出力するための出力情報を生成する場合における、アルゴリズムの再学習について説明する。
1つ目の例として、ユーザが引っ越して、ユーザの住所が変わり(つまり、位置情報が変わり)、ユーザの生活環境の地域性が変わる例について説明する。この場合、情報処理システム1がアルゴリズムに対して再学習を行わせるトリガは、特に限定されないが、情報処理システム1は、例えば、ユーザの明示(住所が変わったことの入力等)、又はGPS(Global Positioning System)情報に基づく属性情報(例えば、ユーザの定常的な位置情報)の変化の検出等に基づき、アルゴリズムに対して再学習を行わせてもよい。この場合、再学習の結果、情報処理システム1は、ユーザの行動特性に基づく推薦の傾向は維持したまま、当該地域に関する内容や、通勤又は通学経路に関する内容など、変更された住所を起点とした具体的推薦内容を最適化することができる。
2つ目の例として、ユーザが、母国を離れて留学に行った場合について説明する。この場合、情報処理システム1は、例えば、ユーザの住所の変更や、生活スタイルが「仕事」から「学生」に変更されたことに基づき、留学先に応じたニュースに関する出力情報を生成することができるように、アルゴリズムに対して再学習させることができる。
[ロボティクスへの応用例]
本開示の一実施形態に係る情報処理システム1が各種のロボティクスに適用される例について説明する。例えば、本開示の一実施形態に係る情報処理システム1は、「AIBO」(登録商標)などのエンターテインメントロボットに適用され得る。例えば、ユーザの引っ越しに伴い、情報処理システム1は、場所に関連する情報に基づき、アルゴリズムに対して再学習させることができる。
本開示の一実施形態に係る情報処理システム1が各種のロボティクスに適用される例について説明する。例えば、本開示の一実施形態に係る情報処理システム1は、「AIBO」(登録商標)などのエンターテインメントロボットに適用され得る。例えば、ユーザの引っ越しに伴い、情報処理システム1は、場所に関連する情報に基づき、アルゴリズムに対して再学習させることができる。
例えば、当該愛玩ロボットが「場所に関する癖」を学習の結果獲得しており、具体的には、当該愛玩ロボットが引っ越し前の家の間取りにおける階段の下をお気に入りの場所であるように振舞っていたとする。その後、ユーザが引っ越した新しい住居には階段がない場合において、当該愛玩ロボットがお気に入りの場所を探し続ける振舞いを行うことが考えられる。このとき、情報処理システム1は、アルゴリズムに対して再学習を行い、古い間取り(場所に関連する情報)に関連する学習データを後発的に削除することができる。これにより、当該愛玩ロボットは、それまでの成長の結果獲得した性格またはユーザに対する応答を維持しつつ、場所に関連する振る舞いのみを忘れることができる。このとき、情報処理システム1は、引っ越し元の場所に紐づく学習データを段階的に削除することで、上記愛玩ロボットに自然と新たな場所になじむ振る舞いを演出させることができる。
次いで、空港又はショッピングモール等の案内ロボットに本開示の情報処理システム1が適用される例について説明する。ここで、案内ロボットとは、客とのやり取りを通して、案内ロボットが配置された場所の案内が最適化されていくロボットである。ここで、情報処理システム1は、例えばフロア内のテナントの変更があった場合には、当該テナントに関連する情報(例えば当該テナントが取り扱っていた商品や、当該テナントを探している客との過去のやり取り、又は当該テナントを経路に含めた案内などに関連する情報)のみを各種データベースから削除し、アルゴリズムに対して再学習させてもよい。これにより、上記案内ロボットは、当該施設への慣れが維持されたまま、変化した環境に適した案内ができるようになる。例えば、テナントの変更後において、上記案内ロボットが変更前のテナントが扱っていた商品を求める客の要望を受けたとしても、存在しなくなった変更前のテナントを考慮した案内を行わなくなる。
次いで、本開示の情報処理システム1が産業用ロボットに適用される例について説明する。この場合、情報処理システム1は、当該産業用ロボットが扱う、ラインに流れる対象部品の仕様の変更があった場合に、当該仕様に関係する過去の履歴を削除することで、産業用ロボットが新たな仕様の部品がラインに流れたとしても、迅速に対応するように、アルゴリズムに対して再学習させることができる。
[その他産業への応用例]
次いで、本開示の情報処理システム1のその他産業への応用例について説明する。本開示の情報処理システム1は、自動運転又は運転ナビなどの技術にも適用され得る。
次いで、本開示の情報処理システム1のその他産業への応用例について説明する。本開示の情報処理システム1は、自動運転又は運転ナビなどの技術にも適用され得る。
例えば、情報処理システム1が、ユーザに運転ナビを提供する場合について説明する。この場合、情報処理システム1は、ユーザの別の地域への引っ越しや、工事等よる地図情報の変更に伴い、アルゴリズムに対して再学習させることができる。これにより、情報処理システム1は、ユーザの運転嗜好や生活スタイルなどに対応した運転ナビの傾向を維持したまま、新たな地域や、変更後の地図情報に最適化された経路推薦などを行うことができる。
また、情報処理システム1は、車両オーナーの変更に伴い、アルゴリズムに対して再学習させてもよい。これにより、再学習が実施されるまでの走行履歴や車両制御履歴に基づく、走行支援制御、車両制御に関する学習結果を残しつつ、車両は、変更前のオーナーの癖や好みを排除して、新たなオーナーの好みに適応した走行支援又は自律走行制御等を行うことができるようになる。このような再学習は、例えば同一地域で共用されるシェアカーについて、その登録ユーザが変わった場合などにも好適である。ここで当該アルゴリズムは、当該車両が搭載していてもよく、あるいは当該車両が参照するネットワーク上に配置されていてもよい。
次いで、本開示の情報処理システム1が投資アドバイザAIに適用される例について説明する。なお、投資アドバイザAIとは、ユーザに投資に関するアドバイスを実施するAI技術である。本開示の情報処理システム1によれば、学習履歴が蓄積されていく中で、動的に過去の学習データを削除し、アルゴリズムに対して再学習させることができる。アルゴリズムの再学習のトリガとしては、例えば、ユーザのポートフォリオ変更、ユーザの投資ポリシー変更、又は対象銘柄に関連する不正事件の発覚(他、アルゴリズムに対して再学習させるべき事実の後発的な発覚)等が挙げられる。
[他の応用例]
本開示の情報処理システム1によれば、各種の推薦(例えば、上述した音楽に関する推薦等)に関する出力情報が生成されないように、アルゴリズムに対して再学習させることができる。より具体的には、ユーザが嫌いになった友人を思い出したくないため、当該友人が推薦した音楽の影響をアルゴリズムから削除したい場合がある。この場合、情報処理システム1は、当該友人が推薦した音楽に関する学習データに由来する影響度を調整(例えば、削除)することにより、アルゴリズムに対して再学習させることができる。この結果、情報処理システム1は、再学習されたアルゴリズムに基づき、ユーザの友人が推薦した音楽に関する情報を出力情報として出力しなくなる。また、同様にして、ユーザが、嫌いになったスポーツを思い出したくないため、当該スポーツの購買の推薦によるアルゴリズムへの影響を削除したい場合がある。この場合も、情報処理システム1は、上記の音楽の影響を削除する場合と同様に、アルゴリズムに対して再学習させることができる。
本開示の情報処理システム1によれば、各種の推薦(例えば、上述した音楽に関する推薦等)に関する出力情報が生成されないように、アルゴリズムに対して再学習させることができる。より具体的には、ユーザが嫌いになった友人を思い出したくないため、当該友人が推薦した音楽の影響をアルゴリズムから削除したい場合がある。この場合、情報処理システム1は、当該友人が推薦した音楽に関する学習データに由来する影響度を調整(例えば、削除)することにより、アルゴリズムに対して再学習させることができる。この結果、情報処理システム1は、再学習されたアルゴリズムに基づき、ユーザの友人が推薦した音楽に関する情報を出力情報として出力しなくなる。また、同様にして、ユーザが、嫌いになったスポーツを思い出したくないため、当該スポーツの購買の推薦によるアルゴリズムへの影響を削除したい場合がある。この場合も、情報処理システム1は、上記の音楽の影響を削除する場合と同様に、アルゴリズムに対して再学習させることができる。
情報処理システム1は、やり取りDB等に記録された各種の情報を削除することができる。より具体的には、情報処理システム1は、記録されたメモ、リマインダ、情報処理システム1とユーザ端末20とのやり取り(例えば、日常会話)などに関する情報を削除することができる。例えば、情報処理システム1は、ユーザが嫌いになった友人を思い出したくない場合には、当該友人に関する情報を削除することができる。また、情報処理システム1は、ユーザの過去の彼女の記録が今の彼女に見られたときに困る場合には、当該過去の彼女に関する情報を削除することができる。また、ユーザが中学の頃の情報を思い出したくない場合には、情報処理システム1は、中学の頃の記録を削除することができる。さらに、ユーザが職場の近くの情報を思い出したくない場合には、情報処理システム1は、職場の近くの記録を削除することができる。このように、ユーザにとって都合の悪い情報を削除することにより、情報処理システム1は、よりユーザにとって適切な出力情報を生成することが可能になる。
<4.変形例>
以下、本開示の情報処理システムの変形例について説明する。
以下、本開示の情報処理システムの変形例について説明する。
[Webクローリングにより自動で情報を入手する例]
上記実施形態では、ユーザからの入力情報と、当該入力情報に対する出力情報と、を用いて、例えば、知識DB111、推薦DB112、又はやり取りDB113等の情報が更新された。つまり、ユーザからの入力情報と、情報処理装置10からの出力情報とに基づき、情報処理装置10は、アルゴリズムの学習、及び再学習を実施する。これに限らず、本実施形態に係る情報処理装置10は、例えばWebクローリングにより、世の中で流行っている情報を入手して、入手した情報に基づき、アルゴリズムの学習を実施してもよい。つまり、世の中の流行に関するデータが学習データとして用いられてもよい。これにより、情報処理装置10は、より世の中の流行に沿った出力情報を生成できるアルゴリズムの状態を実現することが可能になる。
上記実施形態では、ユーザからの入力情報と、当該入力情報に対する出力情報と、を用いて、例えば、知識DB111、推薦DB112、又はやり取りDB113等の情報が更新された。つまり、ユーザからの入力情報と、情報処理装置10からの出力情報とに基づき、情報処理装置10は、アルゴリズムの学習、及び再学習を実施する。これに限らず、本実施形態に係る情報処理装置10は、例えばWebクローリングにより、世の中で流行っている情報を入手して、入手した情報に基づき、アルゴリズムの学習を実施してもよい。つまり、世の中の流行に関するデータが学習データとして用いられてもよい。これにより、情報処理装置10は、より世の中の流行に沿った出力情報を生成できるアルゴリズムの状態を実現することが可能になる。
このとき、ユーザに対する推薦等のための学習の根拠となる入出力情報の特定にあたり、後述のように、ユーザの入力により当該根拠が間接的に指定されてもよい。また、後述の通り、再学習は、上記WebクローリングやユーザのWeb上での行動に基づき、自動的に実施されてもよい。
例えば、情報処理装置10は、ユーザに似た類型の属性一般化された情報(例えば、「40代独身女性」といった情報)に基づき、アルゴリズムの学習を実施してもよい。この場合、ユーザ自身の具体的行動等ではなく、当該一般化された属性情報のユーザの行動等に基づき、当該ユーザへの推薦等が行われる。この場合に、ユーザの属性情報に変化があった場合(例えば「40代独身の女性」から「50代既婚の女性」への変化)、情報処理装置10は、当該変更に応じて、アルゴリズムの再学習を実施することができる。
また、情報処理装置10は、ユーザ等によるSNS(Social Network Service)のフォロー(タイムライン等の参照)の結果を用いて、アルゴリズムを学習させてもよい。例えば、ユーザがAさんをフォローしているという状況によれば、ユーザがAさんに関心や共感を抱いていることが推定される。このため、情報処理装置10は、ユーザがAさんをフォローしている、という情報に基づき、Aさんの行動情報や嗜好情報に基づき、例えば推薦に用いられるアルゴリズムを学習させてもよい。
あるいは、情報処理システム1は、影響力をもつSNS上の特定発信者やブロガー、又は有名人に対するユーザの指定に基づいて、当該発信者等が編集する情報に応じたアルゴリズムの学習をさせることができる。例えば、情報処理システム1は、有名人がお勧めしている食べ物や場所などの情報に基づき、アルゴリズムを学習させることにより、ユーザに対しても当該食べ物や場所についての推薦がなされるようになる。
上記のようにして情報処理システム1は、Webクローリング等に基づき取得された情報を用いて、アルゴリズムを学習させることができる。このとき、情報処理システム1は、ユーザの他の発信者に対するフォロー状況や、キュレーターに対する指定が変化した場合に、本開示に係る技術が利用されてもよい。例えば、ユーザがAさんに対するフォローを解除した場合、ユーザがAさんの関心や共感を失ったと推定することができる。このため、Aさんに関する過去の学習結果について後発的にアルゴリズムの再学習を行うことで、ユーザに対する推薦傾向を大きく変化させないまま、Aさんの影響を受けた内容のみを排除することができる。あるいは、例えばキュレーターが罪を犯した場合(例えば、人気アイドル等)には、アルゴリズムを修正するための情報が情報処理システム1に送信されてもよい。例えば、情報処理システム1は、当該キュレーターを連想させる出力情報が生成されないように、アルゴリズムを再学習させてもよい。
上述のアルゴリズムの再学習において、やり取りDB等に記憶された情報が修正されるが、修正前後の情報がやり取りDB等に記憶されていてもよい。これにより、情報処理システム1は、修正前の情報を後発的に使用することが可能である。また、情報処理システム1は、修正又は削除された情報の一部を記憶していてもよい。
[ユーザの属性変更をトリガとしたアルゴリズムの再学習]
本開示の一実施形態に係る情報処理システム1は、ユーザの状況(行動又は嗜好状況等)の変化を検出し、当該検出の結果に応じて、記憶した履歴を削除してもよい。なお、このとき、情報処理システム1は、履歴を削除することをユーザに問い合わせてもよいし、ユーザに問い合わせずに消してしまってもよい。
本開示の一実施形態に係る情報処理システム1は、ユーザの状況(行動又は嗜好状況等)の変化を検出し、当該検出の結果に応じて、記憶した履歴を削除してもよい。なお、このとき、情報処理システム1は、履歴を削除することをユーザに問い合わせてもよいし、ユーザに問い合わせずに消してしまってもよい。
情報処理装置10は、ユーザに履歴に削除について問い合わせずに履歴を消した場合には、ユーザからの問い合わせがあった際に、削除した履歴を元に戻してもよい。このとき情報処理装置10は、履歴の回復を前提として、削除対象となった履歴を一定期間保存しておくことができる。また、情報処理システム1は、徐々に履歴の削除を繰り返し、アルゴリズムの再学習を繰り返すような、段階的な削除を行ってもよい。このとき情報処理システム1は、古い情報から順に情報を削除してもよいし、新しい情報から順に削除してもよい。
また、情報処理システム1は、段階的な履歴の削除にあたり、情報の新しさに関わらず、全体的に情報の密度を変えてもよい。つまり、情報処理システム1は、情報の新しさに関わらず、削除対象となる履歴において、各種の情報を間引くように段階的に削除を行ってもよい。また、情報処理システム1は、情報を段階的に削除すべき度合いをユーザに推薦してもよい。
[ユーザに無断での履歴削除する例]
情報処理システム1は、検出されたユーザ状況の変化などに応じて、ユーザに無断(つまり、ユーザに確認を実施しない)で、バックグラウンドで各種の情報(例えば、学習履歴又は過去のやり取り関する情報)を削除してもよい。
情報処理システム1は、検出されたユーザ状況の変化などに応じて、ユーザに無断(つまり、ユーザに確認を実施しない)で、バックグラウンドで各種の情報(例えば、学習履歴又は過去のやり取り関する情報)を削除してもよい。
情報処理システム1は、各種の情報の削除を所定のトリガに応じて、実施する場合がある。この場合、情報処理システム1は、削除のトリガとなるイベントが正しいかどうかのユーザに対する確認のみを、さりげなく行ってもよい。
[本番環境における使用環境データの削除]
上記実施形態では、情報処理システム1を構成する製品が出荷された後において学習が行われ、かつ、その学習結果について再学習が行われる処理について説明した。しかし、出荷前段階においても、出荷後を想定したシミュレーションデータを用いて、アルゴリズムの学習を行うことができる。例えば、使用することが想定されるユーザのペルソナ(表面的な性格)を用いた、アルゴリズムの学習が挙げられる。また、ロボットの使用環境を想定した、アルゴリズムの学習が挙げられる。このようにアルゴリズムの学習が行われた後、情報処理システム1は、出荷後の実環境の学習データの蓄積に応じて、出荷前に蓄積された学習データの少なくとも一部を削除することができる。
上記実施形態では、情報処理システム1を構成する製品が出荷された後において学習が行われ、かつ、その学習結果について再学習が行われる処理について説明した。しかし、出荷前段階においても、出荷後を想定したシミュレーションデータを用いて、アルゴリズムの学習を行うことができる。例えば、使用することが想定されるユーザのペルソナ(表面的な性格)を用いた、アルゴリズムの学習が挙げられる。また、ロボットの使用環境を想定した、アルゴリズムの学習が挙げられる。このようにアルゴリズムの学習が行われた後、情報処理システム1は、出荷後の実環境の学習データの蓄積に応じて、出荷前に蓄積された学習データの少なくとも一部を削除することができる。
[倫理観点の課題解決のための後発学習]
ここでは、アルゴリズムに基づき出力される出力情報が、倫理観点から好ましくないと判断される場合に、情報処理システム1がアルゴリズムを後発的に再学習させる例について説明する。例えば、情報処理システム1は、倫理観点から、過去のやり取りに関する情報を抽出することができる。例えば、情報処理システム1は、過去のやり取りに関する情報のうち、公平性を欠く可能性のあるやり取りに関する情報を抽出する。具体的には、情報処理システム1は、人種や性別、宗教や文化的慣習、地域的慣習などを対象として、差別的な、又はコンプライアンスの観点から問題が生じうるキーワードに基づき、フラグを立ててもよい。これにより、情報処理システム1は、フラグを立てられた情報が実際に倫理的観点から問題が生じうるかの判断や、当該やり取りに関する情報の削除などの処理を実施できる。
ここでは、アルゴリズムに基づき出力される出力情報が、倫理観点から好ましくないと判断される場合に、情報処理システム1がアルゴリズムを後発的に再学習させる例について説明する。例えば、情報処理システム1は、倫理観点から、過去のやり取りに関する情報を抽出することができる。例えば、情報処理システム1は、過去のやり取りに関する情報のうち、公平性を欠く可能性のあるやり取りに関する情報を抽出する。具体的には、情報処理システム1は、人種や性別、宗教や文化的慣習、地域的慣習などを対象として、差別的な、又はコンプライアンスの観点から問題が生じうるキーワードに基づき、フラグを立ててもよい。これにより、情報処理システム1は、フラグを立てられた情報が実際に倫理的観点から問題が生じうるかの判断や、当該やり取りに関する情報の削除などの処理を実施できる。
次いで、情報処理システム1は、上記倫理観点の判断結果に基づき、アルゴリズムの再学習を行う。倫理観点に基づくアルゴリズムの再学習の例を2つ紹介する。1つ目の例は、社会において、倫理観点での問題や事件が起きた場合におけるアルゴリズムの再学習についての例である。例えば、社会的に影響力を持つ人物の発言などにより、ある用語の用法や、特定の事象が差別的ニュアンスを含むものであるとの認識が社会において構成された場合に、当該用法や事象を踏まえず、アルゴリズムが情報提示を続けることは好ましくない。そこで、情報処理システム1には、当該事件後の価値観に合致するよう、アルゴリズムの再学習を行わせることができる。ここでアルゴリズムの再学習は、ユーザが使用する端末システムに対する修正プログラムの配信の形で行われてもよい。ここでアルゴリズムの再学習にあたっては、上記やり取りDBに基づく情報の仕分けが実施されたうえで、アルゴリズムの再学習が実施される。これによりアルゴリズムは、推薦や情報提示などにおける動作の傾向を維持しつつ、差別的であると社会に認識されるに至った動作を行うことを回避できる。このとき、ユーザは、アルゴリズムの再学習を拒否できてもよい。ユーザがアルゴリズムの再学習を拒否した場合には、情報処理システム1は、例えばユーザ端末20に対して、その後のAIエージェントの振る舞いの責任はユーザが追う旨のメッセージを提示させてもよい。
2つ目の例では、AIエージェントが出荷後に国境や地域をまたいで運用される場合にアルゴリズムの再学習が行われる。例えば、ユーザが保有する情報処理システムとともに日本から外国へ移住する場合、又は業務用機器が文化圏をまたぐ拠点間で移動される場合などが想定される。このとき、情報処理システム1は、移住又は移動後の地域の文化及び慣習に合致したやり取りに適合するよう、アルゴリズムを再学習させることができる。アルゴリズムの再学習は、ユーザによる操作に基づき実施されてもよい。地域や対象業界に応じて、当該地域や対象業界で採用する標準に準拠するよう設定するオプションが用意されていてもよい。つまり、情報処理システム1は、再学習後のアルゴリズムに基づき出力される出力情報が、当該地域や対象業界で採用する標準に準拠するように、アルゴリズムを再学習させてもよい。これにより、アルゴリズムはそれまでの動作の傾向を維持したまま、移動前の地域における、新たな地域の文化及び慣習には合致しない振る舞いの表出を防ぐことができる。
このように、情報処理システム1に基づき出力される出力情報が、倫理的に好ましくない出力(例えば、発話等)をした場合には、情報処理システム1は、倫理観点等に基づきアルゴリズムをより容易に再学習させることができる。また、倫理観点に基づきアルゴリズムが再学習されることにより、ユーザの地域又は文化圏をまたいだ利用や、業務用機器等の地域間展開が容易になる。
[所定期間が経過した際におけるアルゴリズムの再学習]
また、情報処理システム1は、所定の時期から経過した期間に応じて、アルゴリズムに対して再学習させてもよい。例えば、学習データに著作権などの権利に関わる処理が必要なデータが含まれる場合がある。より具体的には、例えば学習データに含まれるデータの著作権等の許諾期限が切れた場合には、情報処理システム1は、当該データに関する学習履歴を削除することで、学習結果(つまり、学習に基づき生成されたアルゴリズム)への影響をも取り除くことができる。このような処理は、著作権などの権利者がこのような処理を臨んだ場合に実施されてもよい。
また、情報処理システム1は、所定の時期から経過した期間に応じて、アルゴリズムに対して再学習させてもよい。例えば、学習データに著作権などの権利に関わる処理が必要なデータが含まれる場合がある。より具体的には、例えば学習データに含まれるデータの著作権等の許諾期限が切れた場合には、情報処理システム1は、当該データに関する学習履歴を削除することで、学習結果(つまり、学習に基づき生成されたアルゴリズム)への影響をも取り除くことができる。このような処理は、著作権などの権利者がこのような処理を臨んだ場合に実施されてもよい。
また、情報処理システム1は、アルゴリズムのトライアル期間(試用期間)が終了後にやり取りDB等の情報を削除することにより、アルゴリズムに対して再学習させてもよい。より具体的には、情報処理システム1は、AIキャラクター等について、無料トライアル期間終了後は、当該トライアル期間中のやり取りなどに関するデータを削除し、アルゴリズムに対して再学習させてもよい。
このように、情報処理システム1は、所定の時期から経過した期間に応じて、アルゴリズムに対して再学習させることにより、例えば、アルゴリズムを提供する提供者が所望のタイミングでアルゴリズムを再学習させることができる。
[ユーザへの警告]
情報処理システム1は、やり取りDB等の情報を削除する際に、当該削除によるアルゴリズムへの影響が大きい場合には、ユーザーに警告してもよい。例えば、複数人で構成されたグループにおける特定の1人に関する情報を削除しようとするときに、アルゴリズムへの影響が大きい場合がある。極端な場合には、当該1人の情報を削除することにより、グループのアルゴリズムへの影響が削除されてしまう場合が考えられる。
情報処理システム1は、やり取りDB等の情報を削除する際に、当該削除によるアルゴリズムへの影響が大きい場合には、ユーザーに警告してもよい。例えば、複数人で構成されたグループにおける特定の1人に関する情報を削除しようとするときに、アルゴリズムへの影響が大きい場合がある。極端な場合には、当該1人の情報を削除することにより、グループのアルゴリズムへの影響が削除されてしまう場合が考えられる。
また、情報処理システム1は、当該1人の情報を削除するときに、消えてはいけないデータがある可能性がある場合には、その旨をユーザーに警告してもよい。これは、グループ内の1人に関する情報を削除しようとしたときに、現在の趣味趣向からみて、消えてはいけないやり取りが消えてしまう場合があるからである。
また、情報処理システム1は、例えば、ユーザから「グンマの履歴を消してほしい。」という要求があった場合に、要求の意味の解釈を確認してもよい。これは、削除の候補となる単語が多義的である場合に、別の意義であると誤認することに伴う、ユーザの意図しない再学習を防止するためである。例えば、ユーザには、「グンマとは、あなたの友人のXXXのことですね?」という意味の解釈を確認する情報が出力されてもよい。これにより、地名としてのグンマに関する情報の削除ではないことを確認することができる。また、ユーザには、「(グンマの履歴を)消すとYYYのようになりますがいいですか?」という確認または、再学習を行った場合の影響の事前の可視化が実施されてもよい。なお、当該確認は、音声で実施されてもよいし、画面表示で実施されてもよい。また、ユーザの周辺に存在するディスプレイに表示されてもよい。これにより、ユーザは、確認の結果に応じて、履歴の削除をするか否か等を選択することができるようになる。
[他の情報処理システムとの連携]
本実施形態に係る情報処理システム1は、他の情報処理システム(例えば、AI技術が用いられたシステム)等に記憶された情報を削除してもよい。この場合、情報処理システム1は、他の情報処理システムに、削除すべきやり取りに関するデータを教える。当該他の情報処理システムは、本実施形態に係る情報処理システム1における処理と同様にして、やり取りDB等から情報を削除又は当該削除に基づく出力情報の不整合の修正等を実施し得る。
本実施形態に係る情報処理システム1は、他の情報処理システム(例えば、AI技術が用いられたシステム)等に記憶された情報を削除してもよい。この場合、情報処理システム1は、他の情報処理システムに、削除すべきやり取りに関するデータを教える。当該他の情報処理システムは、本実施形態に係る情報処理システム1における処理と同様にして、やり取りDB等から情報を削除又は当該削除に基づく出力情報の不整合の修正等を実施し得る。
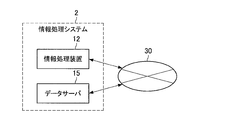
[複数の装置で構成された情報処理システム]
上記第1及び第2の実施形態では、情報処理装置10又は11により、情報処理システムが構成される。これに限らず、情報処理システムは、複数の装置で構成されてもよい。図23は、複数の装置で構成される情報処理システム2の一例を示す図である。図23に示すように、情報処理システム2は、情報処理装置12とデータサーバ15とで構成されている。また、情報処理装置12とデータサーバ15とは、ネットワーク30を介して接続されている。
上記第1及び第2の実施形態では、情報処理装置10又は11により、情報処理システムが構成される。これに限らず、情報処理システムは、複数の装置で構成されてもよい。図23は、複数の装置で構成される情報処理システム2の一例を示す図である。図23に示すように、情報処理システム2は、情報処理装置12とデータサーバ15とで構成されている。また、情報処理装置12とデータサーバ15とは、ネットワーク30を介して接続されている。
図24を参照して、情報処理装置12の構成について説明する。図24は、情報処理装置12の構成を示す機能ブロック図である。第1及び第2の実施形態に係る情報処理装置10及び11と異なり、図24に示す情報処理装置12は、知識DB、推薦DB、やり取りDB、又は学習DBなどに相当するデータベースを備えていない。これらのデータベースは、データサーバ15に記録されている。この場合、情報処理装置12は、ネットワークに接続されたデータサーバから必要に応じて情報を取得し、アルゴリズムに対する再学習などを実施することができる。なお、図24には、図示しないが、情報処理装置12は、各種の処理に必要な情報を記憶する記憶部を有しているものとする。
<5.ハードウェア構成>
続いて、図25を参照しながら、本開示の一実施形態に係る情報処理システム1を構成する情報処理装置10、11、12又はユーザ端末20のハードウェア構成の一例について、詳細に説明する。図25は、本開示の一実施形態に係るユーザ端末20又は情報処理システム1を構成する情報処理装置10、11、12のハードウェア構成の一構成例を示す機能ブロック図である。
続いて、図25を参照しながら、本開示の一実施形態に係る情報処理システム1を構成する情報処理装置10、11、12又はユーザ端末20のハードウェア構成の一例について、詳細に説明する。図25は、本開示の一実施形態に係るユーザ端末20又は情報処理システム1を構成する情報処理装置10、11、12のハードウェア構成の一構成例を示す機能ブロック図である。
本実施形態に係る情報処理システム1を構成する情報処理装置10は、主に、CPU601と、ROM602と、RAM603と、を備える。また、情報処理装置10は、更に、ホストバス604と、ブリッジ605と、外部バス606と、インタフェース607と、入力装置608と、出力装置609と、ストレージ装置610と、ドライブ612と、接続ポート614と、通信装置616とを備える。
CPU601は、演算処理装置及び制御装置として機能し、ROM602、RAM603、ストレージ装置610又はリムーバブル記録媒体613に記録された各種プログラムに従って、情報処理装置10内の動作全般又はその一部を制御する。ROM602は、CPU601が使用するプログラムや演算パラメータ等を記憶する。RAM603は、CPU601が使用するプログラムや、プログラムの実行において適宜変化するパラメータ等を一次記憶する。これらはCPUバス等の内部バスにより構成されるホストバス604により相互に接続されている。例えば、図3に示す処理部120、解析部130、生成部140、出力制御部150、及び通信制御部160は、CPU601により構成され得る。
ホストバス604は、ブリッジ605を介して、PCI(Peripheral Component Interconnect/Interface)バスなどの外部バス606に接続されている。また、外部バス606には、インタフェース607を介して、入力装置608、出力装置609、ストレージ装置610、ドライブ612、接続ポート614及び通信装置616が接続される。
入力装置608は、例えば、マウス、キーボード、タッチパネル、ボタン、スイッチ、レバー及びペダル等、ユーザが操作する操作手段である。また、入力装置608は、例えば、赤外線やその他の電波を利用したリモートコントロール手段(いわゆる、リモコン)であってもよいし、情報処理装置10の操作に対応した携帯電話やPDA等の外部接続機器615であってもよい。さらに、入力装置608は、例えば、上記の操作手段を用いてユーザにより入力された情報に基づいて入力信号を生成し、CPU601に出力する入力制御回路などから構成されている。情報処理装置10、11、12又はユーザ端末20のユーザは、この入力装置608を操作することにより、情報処理装置10、11、12に又はユーザ端末20対して各種のデータを入力したり処理動作を指示したりすることができる。
出力装置609は、取得した情報をユーザに対して視覚的又は聴覚的に通知することが可能な装置で構成される。このような装置として、CRTディスプレイ装置、液晶ディスプレイ装置、プラズマディスプレイ装置、ELディスプレイ装置及びランプ等の表示装置や、スピーカ及びヘッドホン等の音声出力装置や、プリンタ装置等がある。出力装置609は、例えば、情報処理装置10、11、12又はユーザ端末20が行った各種処理により得られた結果を出力する。具体的には、表示装置は、情報処理装置10、11、12又はユーザ端末20が行った各種処理により得られた結果を、テキスト又はイメージで表示する。他方、音声出力装置は、再生された音声データや音響データ等からなるオーディオ信号をアナログ信号に変換して出力する。
ストレージ装置610は、情報処理装置10の記憶部の一例として構成されたデータ格納用の装置である。ストレージ装置610は、例えば、HDD(Hard Disk Drive)等の磁気記憶部デバイス、半導体記憶デバイス、光記憶デバイス又は光磁気記憶デバイス等により構成される。このストレージ装置610は、CPU601が実行するプログラムや各種データ等を格納する。例えば、図3に示す記憶部110は、ストレージ装置610により構成され得る。
ドライブ612は、記録媒体用リーダライタであり、情報処理装置10に内蔵、あるいは外付けされる。ドライブ612は、装着されている磁気ディスク、光ディスク、光磁気ディスク又は半導体メモリ等のリムーバブル記録媒体613に記録されている情報を読み出して、RAM603に出力する。また、ドライブ612は、装着されている磁気ディスク、光ディスク、光磁気ディスク又は半導体メモリ等のリムーバブル記録媒体613に記録を書き込むことも可能である。リムーバブル記録媒体613は、例えば、DVDメディア、HD-DVDメディア又はBlu-ray(登録商標)メディア等である。また、リムーバブル記録媒体613は、コンパクトフラッシュ(登録商標)(CF:CompactFlash)、フラッシュメモリ又はSDメモリカード(Secure Digital memory card)等であってもよい。また、リムーバブル記録媒体613は、例えば、非接触型ICチップを搭載したICカード(Integrated Circuit card)又は電子機器等であってもよい。
接続ポート614は、情報処理装置10、11、12又はユーザ端末20に直接接続するためのポートである。接続ポート614の一例として、USB(Universal Serial Bus)ポート、IEEE1394ポート、SCSI(Small Computer System Interface)ポート等がある。接続ポート614の別の例として、RS-232Cポート、光オーディオ端子、HDMI(登録商標)(High-Definition Multimedia Interface)ポート等がある。この接続ポート614に外部接続機器615を接続することで、情報処理装置10は、外部接続機器615から直接各種のデータを取得したり、外部接続機器615に各種のデータを提供したりする。
通信装置616は、例えば、通信網(ネットワーク)917に接続するための通信デバイス等で構成された通信インタフェースである。通信装置616は、例えば、有線若しくは無線LAN(Local Area Network)、Bluetooth(登録商標)又はWUSB(Wireless USB)用の通信カード等である。また、通信装置616は、光通信用のルータ、ADSL(Asymmetric Digital Subscriber Line)用のルータ又は各種通信用のモデム等であってもよい。この通信装置616は、例えば、インターネットや他の通信機器との間で、例えばTCP/IP等の所定のプロトコルに則して信号等を送受信することができる。また、通信装置616に接続される通信網617は、有線又は無線によって接続されたネットワーク等により構成され、例えば、インターネット、家庭内LAN、赤外線通信、ラジオ波通信又は衛星通信等であってもよい。
以上、本開示の実施形態に係るユーザ端末20又は情報処理システム1を構成する情報処理装置10、11、12の機能を実現可能なハードウェア構成の一例を示した。上記の各構成要素は、汎用的な部材を用いて構成されていてもよいし、各構成要素の機能に特化したハードウェアにより構成されていてもよい。従って、本実施形態を実施する時々の技術レベルに応じて、適宜、利用するハードウェア構成を変更することが可能である。なお、図15では図示しないが、ユーザ端末20又は情報処理システム1を構成する情報処理装置10、11、12に対応する各種の構成を当然備える。
なお、上述のような本実施形態に係る情報処理システム1を構成する情報処理装置10、11、12の各機能を実現するためのコンピュータプログラムを作製し、パーソナルコンピュータ等に実装することが可能である。また、このようなコンピュータプログラムが格納された、コンピュータで読み取り可能な記録媒体も提供することができる。記録媒体は、例えば、磁気ディスク、光ディスク、光磁気ディスク、フラッシュメモリなどである。また、上記のコンピュータプログラムは、記録媒体を用いずに、例えばネットワークを介して配信してもよい。また、当該コンピュータプログラムを実行させるコンピュータの数は特に限定されない。例えば、当該コンピュータプログラムを、複数のコンピュータ(例えば、複数のサーバ等)が互いに連携して実行してもよい。
<6.補足>
以上、添付図面を参照しながら本開示の好適な実施形態について詳細に説明したが、本開示の技術的範囲はかかる例に限定されない。本開示の技術分野における通常の知識を有する者であれば、請求の範囲に記載された技術的思想の範疇内において、各種の変更例または修正例に想到し得ることは明らかであり、これらについても、当然に本開示の技術的範囲に属するものと了解される。
以上、添付図面を参照しながら本開示の好適な実施形態について詳細に説明したが、本開示の技術的範囲はかかる例に限定されない。本開示の技術分野における通常の知識を有する者であれば、請求の範囲に記載された技術的思想の範疇内において、各種の変更例または修正例に想到し得ることは明らかであり、これらについても、当然に本開示の技術的範囲に属するものと了解される。
例えば、上記実施形態では、情報処理システム1は、知識DB111と推薦DB112の両方から各種の情報を削除したが、本技術はかかる例に限定されない。例えば、情報処理システム1は、知識DB111又は推薦DB112のいずれか一方から各種の情報を削除してもよい。
また、影響を削除又は軽減したい情報の指定方法は、時間単位(秒、分、時間、日、月、又は年単位)であってもよい。また、指定方法は、場所(地名、又は地図領域)であってもよい。指定の対象が地図領域である場合には、ユーザは、例えばユーザ端末20に表示された地図をなぞる等の方法により、上記地図領域を指定してもよい。また、指定の対象は、個人であってもよいし、グループであってもよい。
また、情報処理システム1は、どのやり取りが削除又は修正されるのかを一覧で表示するための出力情報を生成してもよい。ユーザは、当該出力情報に基づく出力により、どのやり取りが削除又は修正されるのかを認識することができる。
また、情報処理システム1は、やり取りが削除又は修正されるレベルをユーザに選択させるための出力情報を生成してもよい。例えばユーザ端末20には、当該出力情報に基づき、各レベルで削除又は修正されるやり取りの代表等に関する情報が画像表示される。また、ユーザは、当該画像表示に基づき、やり取りに関する情報を削除又は修正するか否かを選択できる。
また、情報処理システム1は、やり取りが削除又は修正されることにより再学習されたアルゴリズムを、ユーザに試用させてもよい。このとき、情報処理システム1は、やり取りが削除又は修正される前のやり取りDBを保持しており、必要に応じて、やり取りが削除又は修正される前のアルゴリズムに戻すこともできる。
また、情報処理システム1は、やり取りの詳細を修正してもよい。当該修正は、ユーザによる操作、又は、情報処理システム1が自動で実施されてもよい。
また、上記実施形態では、アルゴリズムに対して再学習させるために、学習データが削除又は修正される。これに限らず、アルゴリズムに対して再学習させるために、必要に応じて、新たな学習データが追加されてもよい。
また、第2の実施形態には、例えば、RNN(Recurrent Neural Network:再帰型ニューラルネットワーク)、CNN(Convolutional Neural Network:畳み込みニューラルネットワーク)等のニューラルネットワークを用いた各種の機械学習技術が用いられてもよい。
また、例えば、上記知識DB111等のデータベースが搭載された製品があるとする。当該製品の出荷段階で上記データベースに記録された情報は、削除されないように保護されていてもよい。例えば、上記データベースは、アンインストールできないアプリ(例えば、携帯端末等で使用されるソフトウェア)に用いられてもよい。また、知識DB111に記録された情報のうちの特定の情報が、ユーザの指定により、削除されないように、保護されていてもよい。さらに、情報処理システム1は、やり取りなどの流れに応じて、保護すべきやり取りDB113に記録されたやり取り情報を設定してもよい。
また、上記の実施形態のフローチャートに示されたステップは、記載された順序に沿って時系列的に行われる処理はもちろん、必ずしも時系列的に処理されなくとも、並列的にまたは個別的に実行される処理をも含む。また時系列的に処理されるステップでも、場合によっては適宜順序を変更することが可能であることは言うまでもない。
また、本明細書に記載された効果は、あくまで説明的または例示的なものであって限定的ではない。つまり、本開示に係る技術は、上記の効果とともに、または上記の効果に代えて、本明細書の記載から当業者には明らかな他の効果を奏しうる。
なお、以下のような構成も本開示の技術的範囲に属する。
(1)
学習データの蓄積に基づき変化するアルゴリズムに対して、前記蓄積された学習データにおける特定の前記学習データに由来する影響度を調整し、調整後に得られる新たな学習データに基づき、再学習をさせる、
情報処理システム。
(2)
前記学習データは、前記アルゴリズムの使用環境下で蓄積されるデータに基づく、
前記(1)に記載の情報処理システム。
(3)
前記学習データは、前記アルゴリズムに対するユーザの入力情報に基づく、前記アルゴリズムからの出力情報に関するデータを含む、
前記(2)に記載の情報処理システム。
(4)
前記入力情報に関するデータを記録したデータベースに基づいて、前記アルゴリズムの学習履歴の中から、所定の条件に合致する特定の学習履歴を抽出する、
前記(3)に記載の情報処理システム。
(5)
前記特定の学習履歴に対応する前記学習データに由来する前記影響度を調整する、
前記(4)に記載の情報処理システム。
(6)
前記特定の学習データを削除又は修正することにより、前記影響度を調整する、
前記(1)~(5)のいずれか1項に記載の情報処理システム。
(7)
前記影響度は、前記アルゴリズムに基づく出力情報に与える影響の度合いである、
前記(1)~(6)のいずれか1項に記載の情報処理システム。
(8)
前記特定の学習データを変更する際に生じる、前記変更の前に得られる出力からの前記出力の変化に応じて、前記影響度を調整する、
前記(7)に記載の情報処理システム。
(9)
前記特定の学習データは、ユーザにより指定される、
前記(1)~(8)のいずれか1項に記載の情報処理システム。
(10)
前記特定の学習データは、ユーザに関するデータであるユーザデータを含む、
前記(1)~(9)のいずれか1項に記載の情報処理システム。
(11)
前記ユーザデータは、前記ユーザの位置に関する位置情報を含む、
前記(10)に記載の情報処理システム。
(12)
前記ユーザデータは、前記ユーザの嗜好に関する嗜好情報を含む、
前記(10)又は(11)に記載の情報処理システム。
(13)
前記ユーザデータの変化に応じて、前記アルゴリズムに対して再学習を行う、
前記(10)~(12)のいずれか1項に記載の情報処理システム。
(14)
前記特定の学習データは、流行に関連するデータを含む、
前記(1)~(13)のいずれか1項に記載の情報処理システム。
(15)
前記学習データは、倫理に関連するデータを含む、
前記(1)~(14)のいずれか1項に記載の情報処理システム。
(16)
所定の時期から経過した期間に応じて、前記アルゴリズムに対して再学習させる、
前記(1)~(15)のいずれか1項に記載の情報処理システム。
(17)
ユーザに前記再学習の内容に関する情報を出力する、
前記(1)~(16)のいずれか1項に記載の情報処理システム。
(18)
プロセッサが、
学習データの蓄積に基づき変化するアルゴリズムに対して、前記蓄積された学習データにおける特定の前記学習データに由来する影響度を調整し、調整後に得られる新たな学習データに基づき、再学習をさせる、
情報処理方法。
(1)
学習データの蓄積に基づき変化するアルゴリズムに対して、前記蓄積された学習データにおける特定の前記学習データに由来する影響度を調整し、調整後に得られる新たな学習データに基づき、再学習をさせる、
情報処理システム。
(2)
前記学習データは、前記アルゴリズムの使用環境下で蓄積されるデータに基づく、
前記(1)に記載の情報処理システム。
(3)
前記学習データは、前記アルゴリズムに対するユーザの入力情報に基づく、前記アルゴリズムからの出力情報に関するデータを含む、
前記(2)に記載の情報処理システム。
(4)
前記入力情報に関するデータを記録したデータベースに基づいて、前記アルゴリズムの学習履歴の中から、所定の条件に合致する特定の学習履歴を抽出する、
前記(3)に記載の情報処理システム。
(5)
前記特定の学習履歴に対応する前記学習データに由来する前記影響度を調整する、
前記(4)に記載の情報処理システム。
(6)
前記特定の学習データを削除又は修正することにより、前記影響度を調整する、
前記(1)~(5)のいずれか1項に記載の情報処理システム。
(7)
前記影響度は、前記アルゴリズムに基づく出力情報に与える影響の度合いである、
前記(1)~(6)のいずれか1項に記載の情報処理システム。
(8)
前記特定の学習データを変更する際に生じる、前記変更の前に得られる出力からの前記出力の変化に応じて、前記影響度を調整する、
前記(7)に記載の情報処理システム。
(9)
前記特定の学習データは、ユーザにより指定される、
前記(1)~(8)のいずれか1項に記載の情報処理システム。
(10)
前記特定の学習データは、ユーザに関するデータであるユーザデータを含む、
前記(1)~(9)のいずれか1項に記載の情報処理システム。
(11)
前記ユーザデータは、前記ユーザの位置に関する位置情報を含む、
前記(10)に記載の情報処理システム。
(12)
前記ユーザデータは、前記ユーザの嗜好に関する嗜好情報を含む、
前記(10)又は(11)に記載の情報処理システム。
(13)
前記ユーザデータの変化に応じて、前記アルゴリズムに対して再学習を行う、
前記(10)~(12)のいずれか1項に記載の情報処理システム。
(14)
前記特定の学習データは、流行に関連するデータを含む、
前記(1)~(13)のいずれか1項に記載の情報処理システム。
(15)
前記学習データは、倫理に関連するデータを含む、
前記(1)~(14)のいずれか1項に記載の情報処理システム。
(16)
所定の時期から経過した期間に応じて、前記アルゴリズムに対して再学習させる、
前記(1)~(15)のいずれか1項に記載の情報処理システム。
(17)
ユーザに前記再学習の内容に関する情報を出力する、
前記(1)~(16)のいずれか1項に記載の情報処理システム。
(18)
プロセッサが、
学習データの蓄積に基づき変化するアルゴリズムに対して、前記蓄積された学習データにおける特定の前記学習データに由来する影響度を調整し、調整後に得られる新たな学習データに基づき、再学習をさせる、
情報処理方法。
1、2 情報処理システム
10、11、12 情報処理装置
110 記憶部
111、116 知識DB
112、117 推薦DB
113 やり取りDB
114 学習DB
120、128 処理部
121 更新部
122 抽出部
123 判定部
124 修正部
125 学習部
130、131、132 解析部
140、143、149 生成部
141、144 確認情報生成部
142、145 推薦情報生成部
150 出力制御部
160 通信制御部
15 データサーバ
20 ユーザ端末
210 通信制御部
220 出力制御部
30 ネットワーク
10、11、12 情報処理装置
110 記憶部
111、116 知識DB
112、117 推薦DB
113 やり取りDB
114 学習DB
120、128 処理部
121 更新部
122 抽出部
123 判定部
124 修正部
125 学習部
130、131、132 解析部
140、143、149 生成部
141、144 確認情報生成部
142、145 推薦情報生成部
150 出力制御部
160 通信制御部
15 データサーバ
20 ユーザ端末
210 通信制御部
220 出力制御部
30 ネットワーク
Claims (18)
- 学習データの蓄積に基づき変化するアルゴリズムに対して、前記蓄積された学習データにおける特定の前記学習データに由来する影響度を調整し、調整後に得られる新たな学習データに基づき、再学習をさせる、
情報処理システム。 - 前記学習データは、前記アルゴリズムの使用環境下で蓄積されるデータに基づく、
請求項1に記載の情報処理システム。 - 前記学習データは、前記アルゴリズムに対するユーザの入力情報に基づく、前記アルゴリズムからの出力情報に関するデータを含む、
請求項2に記載の情報処理システム。 - 前記入力情報に関するデータを記録したデータベースに基づいて、前記アルゴリズムの学習履歴の中から、所定の条件に合致する特定の学習履歴を抽出する、
請求項3に記載の情報処理システム。 - 前記特定の学習履歴に対応する前記学習データに由来する前記影響度を調整する、
請求項4に記載の情報処理システム。 - 前記特定の学習データを削除又は修正することにより、前記影響度を調整する、
請求項1に記載の情報処理システム。 - 前記影響度は、前記アルゴリズムに基づく出力情報に与える影響の度合いである、
請求項1に記載の情報処理システム。 - 前記特定の学習データを変更する際に生じる、前記変更の前に得られる出力からの前記出力の変化に応じて、前記影響度を調整する、
請求項7に記載の情報処理システム。 - 前記特定の学習データは、ユーザにより指定される、
請求項1に記載の情報処理システム。 - 前記特定の学習データは、ユーザに関するデータであるユーザデータを含む、
請求項1に記載の情報処理システム。 - 前記ユーザデータは、前記ユーザの位置に関する位置情報を含む、
請求項10に記載の情報処理システム。 - 前記ユーザデータは、前記ユーザの嗜好に関する嗜好情報を含む、
請求項10に記載の情報処理システム。 - 前記ユーザデータの変化に応じて、前記アルゴリズムに対して再学習を行う、
請求項10に記載の情報処理システム。 - 前記特定の学習データは、流行に関連するデータを含む、
請求項1に記載の情報処理システム。 - 前記学習データは、倫理に関連するデータを含む、
請求項1に記載の情報処理システム。 - 所定の時期から経過した期間に応じて、前記アルゴリズムに対して再学習させる、
請求項1に記載の情報処理システム。 - ユーザに前記再学習の内容に関する情報を出力する、
請求項1に記載の情報処理システム。 - プロセッサが、
学習データの蓄積に基づき変化するアルゴリズムに対して、前記蓄積された学習データにおける特定の前記学習データに由来する影響度を調整し、調整後に得られる新たな学習データに基づき、再学習をさせる、
情報処理方法。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US17/442,770 US20220172047A1 (en) | 2019-04-04 | 2020-01-24 | Information processing system and information processing method |
| CN202080024844.3A CN113632113A (zh) | 2019-04-04 | 2020-01-24 | 信息处理系统和信息处理方法 |
| EP20784398.8A EP3951665A4 (en) | 2019-04-04 | 2020-01-24 | Information processing system and information processing method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019-071736 | 2019-04-04 | ||
| JP2019071736 | 2019-04-04 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020202731A1 true WO2020202731A1 (ja) | 2020-10-08 |
Family
ID=72668089
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/002472 WO2020202731A1 (ja) | 2019-04-04 | 2020-01-24 | 情報処理システム及び情報処理方法 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20220172047A1 (ja) |
| EP (1) | EP3951665A4 (ja) |
| CN (1) | CN113632113A (ja) |
| WO (1) | WO2020202731A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023238544A1 (ja) * | 2022-06-09 | 2023-12-14 | コニカミノルタ株式会社 | モデル管理装置、モデル管理システム及びモデル管理方法 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06266405A (ja) * | 1993-03-11 | 1994-09-22 | Toshiba Corp | ワンループコントローラ |
| JP2007200044A (ja) * | 2006-01-26 | 2007-08-09 | Matsushita Electric Works Ltd | 異常検出方法及び異常検出装置 |
| JP2013117861A (ja) * | 2011-12-02 | 2013-06-13 | Canon Inc | 学習装置、学習方法およびプログラム |
| JP2017142781A (ja) * | 2016-02-12 | 2017-08-17 | 富士通株式会社 | 確率的価格及び急変予測 |
| JP2017528852A (ja) * | 2014-07-10 | 2017-09-28 | ボルタ インダストリーズ, エルエルシー | 電気自動車のための充電ステーションに標的広告を提供するためのシステムおよび方法 |
| WO2017191696A1 (ja) | 2016-05-06 | 2017-11-09 | ソニー株式会社 | 情報処理システム、および情報処理方法 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101927706B1 (ko) * | 2016-08-03 | 2018-12-11 | 주식회사 버즈뮤직코리아 | 상황별 음악 추천 방법 및 이를 이용하는 장치 |
-
2020
- 2020-01-24 WO PCT/JP2020/002472 patent/WO2020202731A1/ja unknown
- 2020-01-24 US US17/442,770 patent/US20220172047A1/en active Pending
- 2020-01-24 CN CN202080024844.3A patent/CN113632113A/zh active Pending
- 2020-01-24 EP EP20784398.8A patent/EP3951665A4/en active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06266405A (ja) * | 1993-03-11 | 1994-09-22 | Toshiba Corp | ワンループコントローラ |
| JP2007200044A (ja) * | 2006-01-26 | 2007-08-09 | Matsushita Electric Works Ltd | 異常検出方法及び異常検出装置 |
| JP2013117861A (ja) * | 2011-12-02 | 2013-06-13 | Canon Inc | 学習装置、学習方法およびプログラム |
| JP2017528852A (ja) * | 2014-07-10 | 2017-09-28 | ボルタ インダストリーズ, エルエルシー | 電気自動車のための充電ステーションに標的広告を提供するためのシステムおよび方法 |
| JP2017142781A (ja) * | 2016-02-12 | 2017-08-17 | 富士通株式会社 | 確率的価格及び急変予測 |
| WO2017191696A1 (ja) | 2016-05-06 | 2017-11-09 | ソニー株式会社 | 情報処理システム、および情報処理方法 |
Non-Patent Citations (2)
| Title |
|---|
| See also references of EP3951665A4 |
| TAISHI IKEMATSU, TOSHIHIRO NAKAE, FUJIE NAGAMORI, MARIKO INOMAE, NAOYA MIYASHITA, HIDEAKI KIMATA: "An efficient user interface to simplify training process of deep learning for image recognition", IEICE TECHNICAL REPORT, vol. 115, no. 414 (2016-CVIM-200), 14 January 2016 (2016-01-14), JP, pages 89 - 94, XP009530350, ISSN: 0913-5685 * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023238544A1 (ja) * | 2022-06-09 | 2023-12-14 | コニカミノルタ株式会社 | モデル管理装置、モデル管理システム及びモデル管理方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20220172047A1 (en) | 2022-06-02 |
| EP3951665A1 (en) | 2022-02-09 |
| CN113632113A (zh) | 2021-11-09 |
| EP3951665A4 (en) | 2022-06-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20230328051A1 (en) | Methods, systems, and media for presenting information related to an event based on metadata | |
| US11810576B2 (en) | Personalization of experiences with digital assistants in communal settings through voice and query processing | |
| US20190197073A1 (en) | Methods, systems, and media for personalizing computerized services based on mood and/or behavior information from multiple data sources | |
| JP6305389B2 (ja) | 人工知能によるヒューマン・マシン間の知能チャットの方法および装置 | |
| US10909124B2 (en) | Predicting intent of a search for a particular context | |
| US8612866B2 (en) | Information processing apparatus, information processing method, and information processing program | |
| JP5336105B2 (ja) | メッセージから活動関連のコンテキスト情報を推測するための方法 | |
| CN101297355B (zh) | 响应自然语言语音口头表达的系统和方法 | |
| JP6704937B2 (ja) | パケット化されたオーディオ信号の変調 | |
| US11194796B2 (en) | Intuitive voice search | |
| US20190180747A1 (en) | Voice recognition apparatus and operation method thereof | |
| US10872116B1 (en) | Systems, devices, and methods for contextualizing media | |
| US20220391464A1 (en) | Query entity-experience classification | |
| US20100250366A1 (en) | Merge real-world and virtual markers | |
| US20210365511A1 (en) | Generation and delivery of content curated for a client | |
| KR102409719B1 (ko) | 공동구매 관리 시스템 및 방법 | |
| JP2023036574A (ja) | 対話推薦方法、モデルの訓練方法、装置、電子機器、記憶媒体ならびにコンピュータプログラム | |
| US11392589B2 (en) | Multi-vertical entity-based search system | |
| CN104346431A (zh) | 信息处理装置、信息处理方法和程序 | |
| WO2020202731A1 (ja) | 情報処理システム及び情報処理方法 | |
| US11769013B2 (en) | Machine learning based tenant-specific chatbots for performing actions in a multi-tenant system | |
| JP2020035409A (ja) | 特性推定装置、特性推定方法、及び特性推定プログラム等 | |
| US20230069133A1 (en) | Systems and methods for modeling user interactions | |
| WO2021075288A1 (ja) | 情報処理装置、情報処理方法 | |
| JP6898064B2 (ja) | 対話決定システム、対話決定方法、対話決定プログラム、及び端末装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20784398 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020784398 Country of ref document: EP Effective date: 20211104 |
|
| NENP | Non-entry into the national phase |
Ref country code: JP |