WO2020141591A1 - 符号化装置、復号装置、符号化方法、及び復号方法 - Google Patents
符号化装置、復号装置、符号化方法、及び復号方法 Download PDFInfo
- Publication number
- WO2020141591A1 WO2020141591A1 PCT/JP2019/050438 JP2019050438W WO2020141591A1 WO 2020141591 A1 WO2020141591 A1 WO 2020141591A1 JP 2019050438 W JP2019050438 W JP 2019050438W WO 2020141591 A1 WO2020141591 A1 WO 2020141591A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- block
- unit
- interpolation filter
- prediction
- image
- Prior art date
Links
Images

































Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/523—Motion estimation or motion compensation with sub-pixel accuracy
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/117—Filters, e.g. for pre-processing or post-processing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/119—Adaptive subdivision aspects, e.g. subdivision of a picture into rectangular or non-rectangular coding blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/42—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by implementation details or hardware specially adapted for video compression or decompression, e.g. dedicated software implementation
- H04N19/423—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by implementation details or hardware specially adapted for video compression or decompression, e.g. dedicated software implementation characterised by memory arrangements
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/513—Processing of motion vectors
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/503—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving temporal prediction
- H04N19/51—Motion estimation or motion compensation
- H04N19/527—Global motion vector estimation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/59—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving spatial sub-sampling or interpolation, e.g. alteration of picture size or resolution
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/80—Details of filtering operations specially adapted for video compression, e.g. for pixel interpolation
Definitions
- the present disclosure relates to video coding, for example, a system, a component, and a method in moving image coding and decoding.
- Video coding technology is based on H.264. H.261 and MPEG-1 from H.264. H.264/AVC (Advanced Video Coding), MPEG-LA, H.264. H.265/HEVC (High Efficiency Video Coding), and H.264. It has progressed to 266/VVC (Versatile Video Codec). With this advance, there is a constant need to provide improvements and optimizations in video coding techniques to handle the ever-increasing amount of digital video data in various applications.
- Non-Patent Document 1 relates to an example of a conventional standard relating to the video coding technique described above.
- H. 265 (ISO/IEC 23008-2 HEVC)/HEVC (High Efficiency Video Coding)
- the present disclosure may contribute to one or more of, for example, improved coding efficiency, improved image quality, reduced throughput, reduced circuit size, improved processing speed, and proper selection of elements or operations.
- a configuration or method is provided. It should be noted that the present disclosure may include configurations or methods that may contribute to benefits other than the above.
- an encoding device is an encoding device that encodes an encoding target block included in an image, the circuit including a circuit and a memory connected to the circuit.
- a first prediction image in integer pixel units is generated, and an interpolation filter is used to detect the fractional pixel position between a plurality of integer pixels included in the first prediction image.
- an interpolation filter is used to detect the fractional pixel position between a plurality of integer pixels included in the first prediction image.
- a second predicted image is generated, the block to be coded is coded based on the second predicted image, and in the use of the interpolation filter, the first interpolation filter and the first interpolation filter are used.
- One interpolation filter and a second interpolation filter having a different number of taps are switched and used.
- Some implementations of the embodiments in this disclosure may improve coding efficiency, simplify the coding/decoding process, or speed up the coding/decoding process.
- An appropriate filter, block size, motion vector, reference picture, reference block, etc. may be efficiently selected to use appropriate components/operations for encoding and decoding.
- a configuration or method according to an aspect of the present disclosure includes, for example, improvement of coding efficiency, improvement of image quality, reduction of processing amount, reduction of circuit size, improvement of processing speed, and appropriate selection of elements or operations. Can contribute to more than one of them. Note that the configuration or method according to one aspect of the present disclosure may contribute to benefits other than the above.
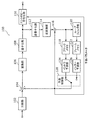
- FIG. 1 is a block diagram showing a functional configuration of an encoding device according to an embodiment.
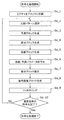
- FIG. 2 is a flowchart showing an example of the overall encoding process performed by the encoding device.
- FIG. 3 is a conceptual diagram showing an example of block division.
- FIG. 4A is a conceptual diagram showing an example of a slice configuration.
- FIG. 4B is a conceptual diagram showing an example of a tile configuration.
- FIG. 5A is a table showing conversion basis functions corresponding to various conversion types.
- FIG. 5B is a conceptual diagram showing an example of SVT (Spatially Varying Transform).
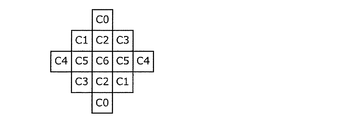
- FIG. 6A is a conceptual diagram showing an example of the shape of a filter used in an ALF (adaptive loop filter).
- FIG. 1 is a block diagram showing a functional configuration of an encoding device according to an embodiment.
- FIG. 2 is a flowchart showing an example of the overall encoding process performed by the encoding device.
- FIG. 3 is a conceptual diagram
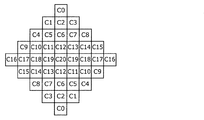
- FIG. 6B is a conceptual diagram showing another example of the shape of the filter used in ALF.
- FIG. 6C is a conceptual diagram showing another example of the shape of the filter used in ALF.
- FIG. 7 is a block diagram showing an example of a detailed configuration of a loop filter unit that functions as a DBF (deblocking filter).
- FIG. 8 is a conceptual diagram showing an example of a deblocking filter having a filter characteristic symmetrical with respect to a block boundary.
- FIG. 9 is a conceptual diagram for explaining a block boundary where the deblocking filter processing is performed.
- FIG. 10 is a conceptual diagram showing an example of the Bs value.
- FIG. 11 is a flowchart showing an example of processing performed by the prediction processing unit of the encoding device.
- FIG. 11 is a flowchart showing an example of processing performed by the prediction processing unit of the encoding device.
- FIG. 12 is a flowchart showing another example of the processing performed by the prediction processing unit of the encoding device.
- FIG. 13 is a flowchart showing another example of the processing performed by the prediction processing unit of the encoding device.
- FIG. 14 is a conceptual diagram showing an example of 67 intra prediction modes in intra prediction according to the embodiment.
- FIG. 15 is a flowchart showing an example of the basic processing flow of inter prediction.
- FIG. 16 is a flowchart showing an example of motion vector derivation.
- FIG. 17 is a flowchart showing another example of motion vector derivation.
- FIG. 18 is a flowchart showing another example of motion vector derivation.
- FIG. 19 is a flowchart showing an example of inter prediction in the normal inter mode.
- FIG. 20 is a flowchart showing an example of inter prediction in the merge mode.
- FIG. 21 is a conceptual diagram for explaining an example of motion vector derivation processing in the merge mode.
- FIG. 22 is a flowchart showing an example of FRUC (frame rate up conversion) processing.
- FIG. 23 is a conceptual diagram for explaining an example of pattern matching (bilateral matching) between two blocks along a motion trajectory.
- FIG. 24 is a conceptual diagram for explaining an example of pattern matching (template matching) between a template in the current picture and a block in the reference picture.
- FIG. 25A is a conceptual diagram for explaining an example of derivation of a motion vector in sub-block units based on motion vectors of a plurality of adjacent blocks.
- FIG. 25B is a conceptual diagram for explaining an example of derivation of a motion vector in a sub-block unit in an affine mode having three control points.
- FIG. 26A is a conceptual diagram for explaining the affine merge mode.
- FIG. 26B is a conceptual diagram for explaining the affine merge mode having two control points.
- FIG. 26C is a conceptual diagram for explaining an affine merge mode having three control points.
- FIG. 27 is a flowchart showing an example of processing in the affine merge mode.
- FIG. 28A is a conceptual diagram for explaining an affine inter mode having two control points.
- FIG. 28B is a conceptual diagram for explaining an affine inter mode having three control points.
- FIG. 29 is a flowchart showing an example of processing in the affine inter mode.
- FIG. 30A is a conceptual diagram for explaining an affine inter mode in which a current block has three control points and an adjacent block has two control points.
- FIG. 30B is a conceptual diagram for explaining an affine inter mode in which a current block has two control points and an adjacent block has three control points.
- FIG. 31A is a flowchart showing a merge mode including DMVR (decoder motion vector refinement).
- FIG. 31B is a conceptual diagram for explaining an example of DMVR processing.
- FIG. 32 is a flowchart showing an example of generation of a predicted image.
- FIG. 33 is a flowchart showing another example of generation of a predicted image.
- FIG. 34 is a flowchart showing another example of generation of a predicted image.
- FIG. 35 is a flowchart for explaining an example of a predicted image correction process by an OBMC (overlapped block motion compensation) process.
- FIG. 36 is a conceptual diagram for explaining an example of a predicted image correction process by the OBMC process.
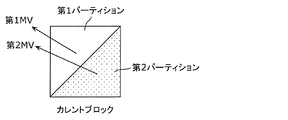
- FIG. 37 is a conceptual diagram for explaining generation of prediction images of two triangles.
- FIG. 38 is a conceptual diagram for explaining a model assuming a uniform linear motion.
- FIG. 39 is a conceptual diagram for explaining an example of a predictive image generation method using a brightness correction process by a LIC (local illumination compensation) process.
- FIG. 40 is a block diagram showing an implementation example of the encoding device.
- FIG. 41 is a block diagram showing a functional configuration of the decoding device according to the embodiment.
- FIG. 42 is a flowchart showing an example of the overall decoding process performed by the decoding device.
- FIG. 43 is a flowchart showing an example of processing performed by the prediction processing unit of the decoding device.
- FIG. 44 is a flowchart showing another example of the processing performed by the prediction processing unit of the decoding device.
- FIG. 45 is a flowchart showing an example of inter prediction in the normal inter mode in the decoding device.
- FIG. 46 is a block diagram illustrating an implementation example of the decoding device.
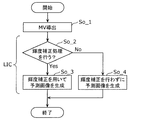
- FIG. 47 is a flowchart showing an example of the interpolation filter determination process in the embodiment.
- FIG. 48 is a diagram showing an example of the first interpolation filter in the embodiment.
- FIG. 49 is a diagram showing an example of the second interpolation filter in the embodiment.
- FIG. 50 is a diagram showing an example of blocks to which the interpolation filter determined in the embodiment is applied.
- FIG. 51 is a block diagram showing the overall configuration of a content supply system that realizes a content distribution service.
- FIG. 52 is a conceptual diagram showing an example of a coding structure at the time of scalable coding.
- FIG. 53 is a conceptual diagram showing an example of a coding structure at the time of scalable coding.
- FIG. 54 is a conceptual diagram showing an example of a web page display screen.
- FIG. 55 is a conceptual diagram showing an example of a web page display screen.
- FIG. 56 is a block diagram showing an example of a smartphone.
- FIG. 57 is a block diagram showing a configuration example of a smartphone.
- An encoding device is an encoding device that encodes an encoding target block included in an image, and includes a circuit and a memory connected to the circuit, and the circuit includes: In operation, based on the motion vector, a first prediction image in integer pixel units is generated, and an interpolation filter is used to calculate the value of the fractional pixel position between a plurality of integer pixels included in the first prediction image. By interpolating, a second predicted image is generated, the block to be coded is coded based on the second predicted image, and in the use of the interpolation filter, the first interpolation filter and the first interpolation filter are used. The filter and the second interpolation filter having a different tap number are switched and used.
- the interpolation filter used for motion compensation of the encoding target block is determined as the first interpolation filter, and if the size of the encoding target block is not larger than the threshold size, the encoding is performed.
- An interpolation filter used for motion compensation of the target block is determined as the second interpolation filter, the determined prediction filter is used to generate the second predicted image, and the second interpolation filter is configured to perform the first interpolation. It may have shorter taps than the filter.
- the second interpolation filter having a tap shorter than that when the size of the target block for encoding is larger than the threshold size is used for motion compensation.
- the motion compensation is performed in units of smaller blocks, the number of times of motion compensation increases, and the number of times of reading samples from the memory for motion compensation also increases.
- the number of taps of the interpolation filter decreases, the number of samples read from the memory for the interpolation process decreases. Therefore, by using an interpolation filter having shorter taps for smaller blocks, it is possible to reduce the number of read samples per read, and suppress an increase in memory bandwidth even if the number of read samples is increased. can do.
- the first interpolation filter may be an 8-tap filter.
- the second interpolation filter may be a 6-tap filter.
- a 6-tap filter can be used as the second interpolation filter, and it is possible to achieve a balance between the accuracy of interpolation and the reduction of memory bandwidth.
- the threshold size may be a 4 ⁇ 4 pixel size.
- the second interpolation filter can be applied to the block of 4x4 pixel size, and the memory bandwidth can be effectively reduced.
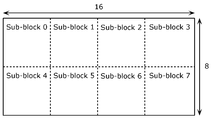
- the encoding target block may be an affine mode sub-block.
- the second interpolation filter can be applied to the affine mode sub-block. Therefore, the processing load of affine motion compensation, which has a relatively high processing load, can be reduced.
- a decoding device is a decoding device that decodes a block to be decoded included in an image, and includes a circuit and a memory connected to the circuit, and the circuit operates in operation.
- a first prediction image in units of integer pixels based on the vector and using an interpolation filter to interpolate the value of a decimal pixel position between a plurality of integer pixels included in the first prediction image.
- a second prediction image is generated, the decoding target block is decoded based on the second prediction image, and in the use of the interpolation filter, the first interpolation filter, the first interpolation filter and the number of taps are A different second interpolation filter is used by switching.
- the interpolation filter in switching the interpolation filter, it is determined whether the size of the decoding target block is larger than a threshold size, and the size of the decoding target block is the threshold size. If the size is larger than the threshold value, the interpolation filter used for motion compensation of the decoding target block is determined to be the first interpolation filter, and if the size of the decoding target block is not larger than the threshold size, the motion compensation of the decoding target block is performed.
- the interpolation filter to be used is determined as the second interpolation filter, the determined prediction filter is used to generate the second predicted image, and the second interpolation filter has a tap shorter than that of the first interpolation filter. May have.
- the second interpolation filter having a tap shorter than that when the size of the decoding target block is larger than the threshold size can be used for motion compensation. .. If the motion compensation is performed in units of smaller blocks, the number of times of motion compensation increases and the number of times of reading samples from the memory for motion compensation increases. On the other hand, if the number of taps of the interpolation filter decreases, the number of samples read from the memory for the interpolation process decreases. Therefore, by using an interpolation filter having shorter taps for smaller blocks, it is possible to reduce the number of read samples per read, and suppress an increase in memory bandwidth even if the number of read samples is increased. can do.
- the first interpolation filter may be an 8-tap filter.
- the second interpolation filter may be a 6-tap filter.
- a 6-tap filter can be used as the second interpolation filter, and it is possible to achieve a balance between the accuracy of interpolation and the reduction of memory bandwidth.
- the threshold size may be 4 ⁇ 4 pixel size.
- the second interpolation filter can be applied to the block of 4x4 pixel size, and the memory bandwidth can be effectively reduced.
- the decoding target block may be an affine mode sub-block.
- the second interpolation filter can be applied to the affine mode sub-block. Therefore, the processing load of affine motion compensation, which has a relatively high processing load, can be reduced.
- the following describes embodiments of the encoding device and the decoding device.
- the embodiments are examples of the encoding device and the decoding device to which the processing and/or the configuration described in each aspect of the present disclosure can be applied.
- the processing and/or the configuration can be implemented in an encoding device and a decoding device different from the embodiment.
- any of the following may be performed.
- a function or a process performed by a part of the plurality of components of the encoding device or the decoding device is added or replaced with a function or a process.
- Arbitrary changes such as deletion may be made.
- any function or process may be replaced or combined with any other function or process described in any of the aspects of the present disclosure.
- Some components of the plurality of components configuring the encoding device or the decoding device according to the embodiment may be combined with the components described in any of the aspects of the present disclosure. , May be combined with a component having a part of the function described in any of the aspects of the present disclosure, or a component that performs a part of the processing performed by the component described in each aspect of the present disclosure. May be combined with.
- a component including a part of the functions of the encoding device or the decoding device according to the embodiment, or a component that performs a part of the processing of the encoding device or the decoding device according to the embodiment is disclosed.
- any one of the plurality of processes included in the method is the same as or similar to the process described in any of the aspects of the present disclosure. It may be replaced or combined with any of the processes.
- a part of the plurality of processes included in the method performed by the encoding device or the decoding device according to the embodiment may be combined with the process described in any of the aspects of the present disclosure. ..
- the method of performing the process and/or the configuration described in each aspect of the present disclosure is not limited to the encoding device or the decoding device according to the embodiment.
- the processing and/or the configuration may be implemented in an apparatus used for a purpose different from the moving picture encoding or moving picture decoding disclosed in the embodiments.
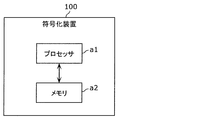
- FIG. 1 is a block diagram showing a functional configuration of an encoding device 100 according to the embodiment.
- the encoding device 100 is a moving image encoding device that encodes a moving image in block units.
- the encoding device 100 is a device that encodes an image in block units, and includes a division unit 102, a subtraction unit 104, a conversion unit 106, a quantization unit 108, and entropy encoding.
- Unit 110 inverse quantization unit 112, inverse transform unit 114, addition unit 116, block memory 118, loop filter unit 120, frame memory 122, intra prediction unit 124, inter prediction unit 126, And a prediction control unit 128.
- the encoding device 100 is realized by, for example, a general-purpose processor and a memory.
- the processor when the software program stored in the memory is executed by the processor, the processor causes the dividing unit 102, the subtracting unit 104, the converting unit 106, the quantizing unit 108, the entropy coding unit 110, and the dequantizing unit 112.
- the encoding device 100 includes a division unit 102, a subtraction unit 104, a conversion unit 106, a quantization unit 108, an entropy encoding unit 110, an inverse quantization unit 112, an inverse transformation unit 114, an addition unit 116, a loop filter unit 120.
- the intra prediction unit 124, the inter prediction unit 126, and the prediction control unit 128 may be realized as one or more dedicated electronic circuits.
- the following describes the overall processing flow of the encoding device 100, and then each component included in the encoding device 100.
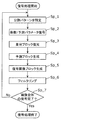
- FIG. 2 is a flowchart showing an example of the overall encoding process performed by the encoding device 100.
- the division unit 102 of the encoding device 100 divides each picture included in the input image, which is a moving image, into a plurality of fixed size blocks (for example, 128 ⁇ 128 pixels) (step Sa_1). Then, the division unit 102 selects a division pattern (also referred to as a block shape) for the fixed size block (step Sa_2). That is, the division unit 102 further divides the fixed-size block into a plurality of blocks that form the selected division pattern. Then, the encoding device 100 performs the processes of steps Sa_3 to Sa_9 on each of the plurality of blocks (that is, the encoding target block).
- a division pattern also referred to as a block shape
- the prediction processing unit including all or part of the intra prediction unit 124, the inter prediction unit 126, and the prediction control unit 128 generates a prediction signal (also referred to as a prediction block) of a block to be coded (also referred to as a current block). (Step Sa_3).
- the subtraction unit 104 generates a difference between the encoding target block and the prediction block as a prediction residual (also referred to as a difference block) (step Sa_4).
- the conversion unit 106 and the quantization unit 108 generate a plurality of quantized coefficients by performing conversion and quantization on the difference block (step Sa_5).
- a block including a plurality of quantized coefficients is also called a coefficient block.
- the entropy coding unit 110 generates a coded signal by performing coding (specifically, entropy coding) on the coefficient block and the prediction parameter related to generation of the prediction signal (step). Sa — 6).
- the encoded signal is also referred to as an encoded bitstream, a compressed bitstream, or a stream.
- the inverse quantization unit 112 and the inverse transformation unit 114 restore a plurality of prediction residuals (that is, difference blocks) by performing inverse quantization and inverse transformation on the coefficient block (step Sa_7).
- the adding unit 116 reconstructs the current block into a reconstructed image (also referred to as a reconstructed block or a decoded image block) by adding a prediction block to the restored difference block (step Sa_8). As a result, a reconstructed image is generated.
- a reconstructed image also referred to as a reconstructed block or a decoded image block
- the loop filter unit 120 filters the reconstructed image as necessary (step Sa_9).
- step Sa_10 determines whether or not the encoding of the entire picture is completed (step Sa_10), and when it is determined that the encoding is not completed (No in step Sa_10), repeatedly executes the processing from step Sa_2. To do.
- the encoding device 100 selects one division pattern for fixed-size blocks and encodes each block according to the division pattern, but according to each of the plurality of division patterns. Each block may be encoded.
- the encoding apparatus 100 evaluates the cost for each of the plurality of division patterns and, for example, the encoded signal obtained by the encoding according to the division pattern with the smallest cost is used as the output encoded signal. You may choose.
- steps Sa_1 to Sa_10 are performed sequentially by the encoding device 100.
- some of the plurality of processes may be performed in parallel, and the order of these processes may be changed.
- the dividing unit 102 divides each picture included in the input moving image into a plurality of blocks, and outputs each block to the subtracting unit 104.
- the dividing unit 102 first divides the picture into blocks of a fixed size (for example, 128 ⁇ 128). Other fixed block sizes may be employed. This fixed size block is sometimes referred to as a coding tree unit (CTU).
- CTU coding tree unit
- the dividing unit 102 divides each fixed-size block into a variable-size (for example, 64 ⁇ 64 or less) block based on, for example, recursive quadtree and/or binary tree block division. To do. That is, the dividing unit 102 selects a division pattern.
- This variable size block may be referred to as a coding unit (CU), prediction unit (PU) or transform unit (TU).
- CU coding unit
- PU prediction unit
- TU transform unit
- FIG. 3 is a conceptual diagram showing an example of block division in the embodiment.
- solid lines represent block boundaries by quadtree block division
- broken lines represent block boundaries by binary tree block division.
- the block 10 is a square block of 128 ⁇ 128 pixels (128 ⁇ 128 block).
- the 128 ⁇ 128 block 10 is first divided into four square 64 ⁇ 64 blocks (quadtree block division).
- the upper left 64x64 block is vertically divided into two rectangular 32x64 blocks, and the left 32x64 block is further vertically divided into two rectangular 16x64 blocks (binary tree block division). As a result, the upper left 64x64 block is divided into two 16x64 blocks 11 and 12 and a 32x64 block 13.
- the upper right 64x64 block is horizontally divided into two rectangular 64x32 blocks 14 and 15 (binary tree block division).
- the lower left 64x64 block is divided into four square 32x32 blocks (quadtree block division).
- the upper left block and the lower right block of the four 32 ⁇ 32 blocks are further divided.
- the upper left 32x32 block is vertically divided into two rectangular 16x32 blocks, and the right 16x32 block is further divided horizontally into two 16x16 blocks (binary tree block division).
- the lower right 32x32 block is horizontally divided into two 32x16 blocks (binary tree block division).
- the lower left 64x64 block is divided into a 16x32 block 16, two 16x16 blocks 17 and 18, two 32x32 blocks 19 and 20, and two 32x16 blocks 21 and 22.
- the lower right 64x64 block 23 is not divided.
- the block 10 is divided into 13 variable-sized blocks 11 to 23 based on the recursive quadtree and binary tree block division.
- Such division may be called QTBT (quad-tree plus binary tree) division.
- one block is divided into four or two blocks (quadtree or binary tree block division), but the division is not limited to these.
- one block may be divided into three blocks (ternary tree block division). Partitioning including such ternary tree block partitioning may be referred to as MBT (multi type tree) partitioning.
- MBT multi type tree
- Picture configuration slice/tile Pictures may be organized in slices or tiles to decode the pictures in parallel.
- the picture in slice units or tile units may be configured by the dividing unit 102.
- a slice is a basic coding unit that constitutes a picture.
- a picture is composed of, for example, one or more slices.
- a slice consists of one or more continuous CTUs (Coding Tree Units).
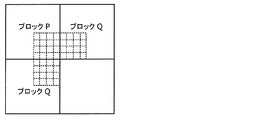
- FIG. 4A is a conceptual diagram showing an example of a slice configuration.
- the picture includes 11 ⁇ 8 CTUs and is divided into four slices (slices 1-4).
- Slice 1 consists of 16 CTUs
- slice 2 consists of 21 CTUs
- slice 3 consists of 29 CTUs
- slice 4 consists of 22 CTUs.
- each CTU in the picture belongs to one of the slices.
- the shape of the slice is a shape obtained by horizontally dividing the picture.
- the slice boundary does not have to be the edge of the screen, and may be any of the boundaries of the CTU in the screen.
- the processing order (coding order or decoding order) of the CTUs in the slice is, for example, the raster scan order.
- the slice includes header information and encoded data.
- the header information may describe the characteristics of the slice such as the CTU address at the beginning of the slice and the slice type.
- a tile is a unit of a rectangular area that constitutes a picture.
- a number called TileId may be assigned to each tile in raster scan order.
- FIG. 4B is a conceptual diagram showing an example of the tile configuration.
- the picture includes 11 ⁇ 8 CTUs and is divided into four rectangular area tiles (tiles 1-4).
- the processing order of the CTU is changed as compared with the case where the tile is not used. If tiles are not used, multiple CTUs within a picture are processed in raster scan order. If tiles are used, at least one CTU in each of the tiles is processed in raster scan order.
- the processing order of the plurality of CTUs included in tile 1 is from the left end of the first row of tile 1 to the right end of the first row of tile 1, and then to the left end of the second row of tile 1. To the right end of the second row of tile 1.
- one tile may include one or more slices, and one slice may include one or more tiles.
- the subtraction unit 104 subtracts the prediction signal (prediction sample input from the prediction control unit 128 described below) from the original signal (original sample) in units of blocks input from the division unit 102 and divided by the division unit 102. .. That is, the subtraction unit 104 calculates a prediction error (also referred to as a residual) of a block to be coded (hereinafter referred to as a current block). Then, the subtraction unit 104 outputs the calculated prediction error (residual error) to the conversion unit 106.
- a prediction error also referred to as a residual of a block to be coded
- the original signal is an input signal of the encoding device 100, and is a signal (for example, a luminance (luma) signal and two color difference (chroma) signals) representing an image of each picture forming a moving image.
- a signal representing an image may be referred to as a sample.
- the transformation unit 106 transforms the prediction error in the spatial domain into a transform coefficient in the frequency domain, and outputs the transform coefficient to the quantization unit 108. Specifically, the conversion unit 106 performs a predetermined discrete cosine transform (DCT) or discrete sine transform (DST) on the prediction error in the spatial domain, for example.
- DCT discrete cosine transform
- DST discrete sine transform
- the conversion unit 106 adaptively selects a conversion type from a plurality of conversion types, and converts the prediction error into a conversion coefficient by using a conversion basis function (transform basis function) corresponding to the selected conversion type. You may. Such a conversion is sometimes called an EMT (explicit multiple core transform) or an AMT (adaptive multiple transform).
- the plurality of conversion types include, for example, DCT-II, DCT-V, DCT-VIII, DST-I and DST-VII.
- FIG. 5A is a table showing conversion basis functions corresponding to conversion type examples.
- N indicates the number of input pixels.
- the selection of a conversion type from these plural conversion types may depend on, for example, the type of prediction (intra prediction and inter prediction), or may depend on the intra prediction mode.
- the information indicating whether or not such EMT or AMT is applied (for example, called an EMT flag or AMT flag) and the information indicating the selected conversion type are usually signalized at the CU level. It should be noted that the signalization of these pieces of information is not limited to the CU level and may be another level (eg, bit sequence level, picture level, slice level, tile level or CTU level).
- the conversion unit 106 may reconvert the conversion coefficient (conversion result). Such re-conversion is sometimes called AST (adaptive secondary transform) or NSST (non-separable secondary transform). For example, the transform unit 106 retransforms each subblock (for example, 4 ⁇ 4 subblock) included in the block of transform coefficients corresponding to the intra prediction error.
- the information indicating whether to apply the NSST and the information about the transformation matrix used for the NSST are usually signalized at the CU level. Note that the signalization of these pieces of information is not limited to the CU level, and may be another level (for example, a sequence level, a picture level, a slice level, a tile level, or a CTU level).
- the conversion unit 106 may be applied with separable conversion and non-separable conversion.
- the separable conversion is a method of performing the conversion a plurality of times by separating each direction by the number of input dimensions
- the non-separable conversion is a method of converting two or more dimensions when the input is multidimensional. This is a method of collectively considering it as one-dimensional and performing conversion collectively.
- Non-Separable conversion if the input is a 4 ⁇ 4 block, it is regarded as one array having 16 elements, and a 16 ⁇ 16 conversion matrix is applied to the array.
- An example is one that performs conversion processing in.
- a conversion in which a 4 ⁇ 4 input block is regarded as one array having 16 elements and then a Givens rotation is performed a plurality of times for the array (Hypercube conversion) Givens Transform) may be held.
- the conversion in the conversion unit 106 it is possible to switch the type of the base to be converted into the frequency domain according to the area in the CU.
- One example is SVT (Spatially Varying Transform).
- SVT spatialally Varying Transform
- the CU is divided into two in the horizontal or vertical direction, and only one of the regions is converted into the frequency domain.
- the type of conversion base can be set for each region, and for example, DST7 and DCT8 are used. In this example, only one of the two areas in the CU is converted and the other is not converted, but both areas may be converted.
- the division method is not limited to the bisector, but may be quadrant, or information such as the split is separately coded and signaled in the same manner as the CU split, so that it can be made more flexible.
- the SVT may also be referred to as SBT (Sub-block Transform).
- the quantization unit 108 quantizes the transform coefficient output from the transform unit 106. Specifically, the quantization unit 108 scans the transform coefficient of the current block in a predetermined scanning order, and quantizes the transform coefficient based on the quantization parameter (QP) corresponding to the scanned transform coefficient. Then, the quantization unit 108 outputs the quantized transform coefficient of the current block (hereinafter, referred to as a quantized coefficient) to the entropy coding unit 110 and the dequantization unit 112.
- the predetermined scanning order may be predetermined.
- the predetermined scan order is the order for quantization/inverse quantization of transform coefficients.
- the predetermined scanning order may be defined in ascending order of frequencies (from low frequency to high frequency) or in descending order (from high frequency to low frequency).
- Quantization parameter is a parameter that defines the quantization step (quantization width). For example, the quantization step increases as the value of the quantization parameter increases. That is, as the value of the quantization parameter increases, the quantization error increases.
- a quantization matrix may be used for quantization.
- quantization refers to digitizing a value sampled at a predetermined interval in association with a predetermined level, and is referred to in this technical field by using other expressions such as rounding, rounding, and scaling. Rounding, rounding, or scaling may be used.
- the predetermined interval and level may be predetermined.
- the quantization matrix As methods of using the quantization matrix, there are a method of using the quantization matrix set directly on the encoding device side and a method of using the default quantization matrix (default matrix).
- the quantization matrix can be set according to the characteristics of the image by directly setting the quantization matrix. However, in this case, there is a demerit that the code amount is increased by encoding the quantization matrix.
- the quantization matrix may be designated by, for example, SPS (sequence parameter set: Sequence Parameter Set) or PPS (picture parameter set: Picture Parameter Set).
- SPS sequence parameter set: Sequence Parameter Set
- PPS picture parameter set: Picture Parameter Set
- the SPS contains the parameters used for the sequence and the PPS contains the parameters used for the picture.
- the SPS and PPS may be simply called a parameter set.
- the entropy coding unit 110 generates a coded signal (coded bit stream) based on the quantized coefficient input from the quantization unit 108. Specifically, the entropy coding unit 110, for example, binarizes the quantized coefficient, arithmetically codes the binary signal, and outputs a compressed bitstream or sequence.
- the inverse quantization unit 112 inversely quantizes the quantized coefficient input from the quantization unit 108. Specifically, the dequantization unit 112 dequantizes the quantized coefficient of the current block in a predetermined scanning order. Then, the inverse quantization unit 112 outputs the inversely quantized transform coefficient of the current block to the inverse transform unit 114.
- the predetermined scanning order may be predetermined.
- the inverse transform unit 114 restores the prediction error (residual error) by inversely transforming the transform coefficient input from the inverse quantization unit 112. Specifically, the inverse transform unit 114 restores the prediction error of the current block by performing the inverse transform corresponding to the transform performed by the transform unit 106 on the transform coefficient. Then, the inverse transformation unit 114 outputs the restored prediction error to the addition unit 116.
- the restored prediction error does not match the prediction error calculated by the subtraction unit 104, because information is usually lost due to quantization. That is, the restored prediction error usually includes the quantization error.
- the adding unit 116 reconstructs the current block by adding the prediction error input from the inverse transform unit 114 and the prediction sample input from the prediction control unit 128. Then, the addition unit 116 outputs the reconstructed block to the block memory 118 and the loop filter unit 120.
- the reconstruction block may also be referred to as a local decoding block.
- the block memory 118 is a storage unit that stores, for example, a block referred to in intra prediction and is included in a current picture to be coded. Specifically, the block memory 118 stores the reconstructed block output from the addition unit 116.
- the frame memory 122 is, for example, a storage unit that stores a reference picture used for inter prediction, and may be called a frame buffer. Specifically, the frame memory 122 stores the reconstructed block filtered by the loop filter unit 120.
- the loop filter unit 120 applies a loop filter to the block reconstructed by the adding unit 116, and outputs the filtered reconstructed block to the frame memory 122.
- the loop filter is a filter (in-loop filter) used in the coding loop, and includes, for example, a deblocking filter (DF or DBF), a sample adaptive offset (SAO), an adaptive loop filter (ALF), and the like.
- a least-squares error filter for removing coding distortion is applied, and for example, for each 2 ⁇ 2 sub-block in the current block, a plurality of sub-blocks based on the direction and activity of a local gradient are used. One filter selected from the filters is applied.
- sub-blocks eg 2x2 sub-blocks
- D for example, 0 to 2 or 0 to 4
- the gradient activation value A for example, 0 to 4
- the gradient direction value D is derived, for example, by comparing gradients in a plurality of directions (for example, horizontal, vertical, and two diagonal directions).
- the gradient activation value A is derived, for example, by adding gradients in a plurality of directions and quantizing the addition result.
- the filter for the sub-block is determined from the multiple filters.
- FIG. 6A to 6C are diagrams showing a plurality of examples of the shapes of filters used in ALF.
- 6A shows a 5 ⁇ 5 diamond shaped filter
- FIG. 6B shows a 7 ⁇ 7 diamond shaped filter
- FIG. 6C shows a 9 ⁇ 9 diamond shaped filter.
- the information indicating the shape of the filter is usually signalized at the picture level.
- the signalization of the information indicating the shape of the filter does not have to be limited to the picture level and may be another level (for example, a sequence level, a slice level, a tile level, a CTU level or a CU level).
- ALF on/off may be determined at the picture level or the CU level, for example. For example, it may be determined whether to apply ALF at the CU level for luminance, or whether to apply ALF at the picture level for color difference.
- the information indicating ON/OFF of ALF is usually signaled at the picture level or CU level. Signaling of information indicating ON/OFF of ALF does not need to be limited to the picture level or the CU level, and may be at another level (for example, sequence level, slice level, tile level or CTU level). Good.
- the coefficient set of multiple selectable filters (eg up to 15 or 25 filters) is usually signaled at the picture level.
- the signalization of the coefficient set does not have to be limited to the picture level, and may be another level (eg, sequence level, slice level, tile level, CTU level, CU level or sub-block level).
- the loop filter unit 120 reduces the distortion generated at the block boundary by filtering the block boundary of the reconstructed image.
- FIG. 7 is a block diagram showing an example of a detailed configuration of the loop filter unit 120 that functions as a deblocking filter.
- the loop filter unit 120 includes a boundary determination unit 1201, a filter determination unit 1203, a filter processing unit 1205, a processing determination unit 1208, a filter characteristic determination unit 1207, and switches 1202, 1204 and 1206.
- the boundary determination unit 1201 determines whether or not the pixel to be deblocked/filtered (that is, the target pixel) exists near the block boundary. Then, the boundary determination unit 1201 outputs the determination result to the switch 1202 and the processing determination unit 1208.
- the switch 1202 outputs the image before the filter processing to the switch 1204 when the boundary determining unit 1201 determines that the target pixel exists near the block boundary. On the contrary, when the boundary determining unit 1201 determines that the target pixel does not exist near the block boundary, the switch 1202 outputs the image before the filter processing to the switch 1206.
- the filter determination unit 1203 determines whether to perform deblocking filter processing on the target pixel based on the pixel values of at least one peripheral pixel around the target pixel. Then, the filter determination unit 1203 outputs the determination result to the switch 1204 and the processing determination unit 1208.
- the switch 1204 When the filter determination unit 1203 determines that the target pixel is to be subjected to the deblocking filter process, the switch 1204 outputs the image before the filter process acquired via the switch 1202 to the filter processing unit 1205. On the contrary, the switch 1204 outputs the image before the filter processing acquired via the switch 1202 to the switch 1206 when the filter determination unit 1203 determines that the target pixel is not subjected to the deblocking filter processing.
- the filter processing unit 1205 When the image before filtering is acquired via the switches 1202 and 1204, the filter processing unit 1205 performs deblocking filter processing having the filter characteristic determined by the filter characteristic determining unit 1207 on the target pixel. Execute. Then, the filter processing unit 1205 outputs the pixel after the filter processing to the switch 1206.
- the switch 1206 selectively outputs pixels that have not been deblocked and filtered by the processing determination unit 1208 and pixels that have been deblocked and filtered by the filter processing unit 1205.
- the processing determination unit 1208 controls the switch 1206 based on the determination results of the boundary determination unit 1201 and the filter determination unit 1203. That is, the processing determination unit 1208 determines that the boundary determination unit 1201 determines that the target pixel exists near the block boundary, and that the filter determination unit 1203 determines that the target pixel is to undergo deblocking filter processing. , The pixel subjected to the deblocking filter processing is output from the switch 1206. Also, in cases other than the above case, the processing determination unit 1208 causes the switch 1206 to output the pixels that have not been subjected to deblocking filter processing. By repeatedly outputting such pixels, the image after the filter processing is output from the switch 1206.
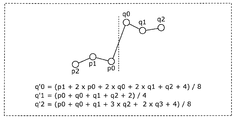
- FIG. 8 is a conceptual diagram showing an example of a deblocking filter having a symmetric filter characteristic with respect to a block boundary.
- one of two deblocking filters having different characteristics that is, a strong filter or a weak filter is selected using a pixel value and a quantization parameter.
- a strong filter as shown in FIG. 8
- the pixel values of the pixels q0 to q2 are calculated by the following formula, for example.
- the pixel values q′0 to q′2 are changed by performing
- p0 to p2 and q0 to q2 are the pixel values of the pixels p0 to p2 and the pixels q0 to q2, respectively.
- q3 is the pixel value of the pixel q3 adjacent to the pixel q2 on the opposite side of the block boundary.
- the coefficient by which the pixel value of each pixel used for deblocking filter processing is multiplied is the filter coefficient.
- clip processing may be performed so that the pixel value after calculation does not exceed the threshold value and is not set.
- the pixel value after the calculation according to the above formula is clipped to “the calculation target pixel value ⁇ 2 ⁇ threshold value” using the threshold value determined from the quantization parameter. Thereby, excessive smoothing can be prevented.
- FIG. 9 is a conceptual diagram for explaining a block boundary where deblocking filter processing is performed.
- FIG. 10 is a conceptual diagram showing an example of the Bs value.
- the block boundary on which the deblocking filter processing is performed is, for example, the boundary of PU (Prediction Unit) or TU (Transform Unit) of the 8 ⁇ 8 pixel block as shown in FIG.
- the deblocking filtering process can be performed in units of 4 rows or 4 columns.
- the deblocking filtering process for the color difference signal is performed when the Bs value is 2.
- the deblocking filtering process on the luminance signal is performed when the Bs value is 1 or more and a predetermined condition is satisfied.
- the predetermined condition may be predetermined. Note that the Bs value determination conditions are not limited to those shown in FIG. 10, and may be determined based on other parameters.
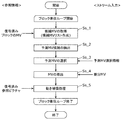
- FIG. 11 is a flowchart showing an example of processing performed by the prediction processing unit of the encoding device 100.
- the prediction processing unit includes all or some of the components of the intra prediction unit 124, the inter prediction unit 126, and the prediction control unit 128.
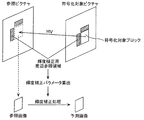
- the prediction processing unit generates a prediction image of the current block (step Sb_1).
- This prediction image is also called a prediction signal or a prediction block.
- the prediction signal includes, for example, an intra prediction signal or an inter prediction signal.
- the prediction processing unit generates a reconstructed image that has already been obtained by performing prediction block generation, difference block generation, coefficient block generation, difference block restoration, and decoded image block generation. The predicted image of the current block is generated by using this.
- the reconstructed image may be, for example, an image of a reference picture or an image of an encoded block in a current picture that is a picture including a current block.
- the coded block in the current picture is, for example, a block adjacent to the current block.
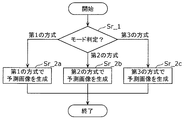
- FIG. 12 is a flowchart showing another example of the processing performed by the prediction processing unit of the encoding device 100.
- the prediction processing unit generates a predicted image by the first method (step Sc_1a), a predicted image by the second method (step Sc_1b), and a predicted image by the third method (step Sc_1c).
- the first method, the second method, and the third method are different methods for generating a predicted image, and are, for example, an inter prediction method, an intra prediction method, and a prediction method other than them. It may be. In these prediction methods, the reconstructed image described above may be used.
- the prediction processing unit selects any one of the plurality of prediction images generated in steps Sc_1a, Sc_1b, and Sc_1c (step Sc_2).
- the selection of the predicted image that is, the selection of the scheme or mode for obtaining the final predicted image may be performed based on the cost calculated for each generated predicted image. Alternatively, the selection of the predicted image may be performed based on the parameter used in the encoding process.
- the coding apparatus 100 may signal the information for specifying the selected predicted image, method, or mode into a coded signal (also referred to as a coded bitstream).
- the information may be, for example, a flag or the like.
- the decoding device can generate a predicted image according to the scheme or mode selected in the encoding device 100 based on the information.
- the prediction processing unit selects one of the prediction images after generating the prediction image by each method. However, the prediction processing unit selects a method or mode based on the parameters used in the above-described encoding process before generating those predicted images, and generates a predicted image according to the method or mode. Good.
- the first method and the second method are intra prediction and inter prediction, respectively, and the prediction processing unit determines the final predicted image for the current block from the predicted images generated according to these prediction methods. You may choose.
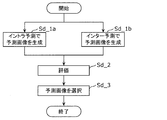
- FIG. 13 is a flowchart showing another example of the processing performed by the prediction processing unit of the encoding device 100.
- the prediction processing unit generates a predicted image by intra prediction (step Sd_1a) and a predicted image by inter prediction (step Sd_1b).
- the predicted image generated by intra prediction is also referred to as an intra predicted image
- the predicted image generated by inter prediction is also referred to as an inter predicted image.
- the prediction processing unit evaluates each of the intra prediction image and the inter prediction image (step Sd_2). Cost may be used for this evaluation. That is, the prediction processing unit calculates the cost C of each of the intra prediction image and the inter prediction image.
- D is the coding distortion of the predicted image, and is represented by, for example, the sum of absolute differences between the pixel value of the current block and the pixel value of the predicted image.
- R is the generated code amount of the predicted image, and specifically, the code amount necessary for coding the motion information or the like for generating the predicted image.
- ⁇ is, for example, an undetermined multiplier of Lagrange.
- the prediction processing unit selects the prediction image for which the smallest cost C is calculated from the intra prediction image and the inter prediction image as the final prediction image of the current block (step Sd_3). That is, the prediction method or mode for generating the predicted image of the current block is selected.
- the intra prediction unit 124 generates a prediction signal (intra prediction signal) by referring to a block in the current picture stored in the block memory 118 and performing intra prediction (also referred to as intra prediction) of the current block. Specifically, the intra prediction unit 124 generates an intra prediction signal by performing intra prediction with reference to a sample (for example, a luminance value and a color difference value) of a block adjacent to the current block, and predicts and controls the intra prediction signal. Output to the unit 128.
- the intra prediction unit 124 performs intra prediction using one of a plurality of prescribed intra prediction modes.
- the multiple intra prediction modes typically include one or more non-directional prediction modes and multiple directional prediction modes.
- the plurality of prescribed modes may be prescribed in advance.
- the one or more non-directional prediction modes are, for example, H.264. It includes Planar prediction mode and DC prediction mode defined by the H.265/HEVC standard.
- a plurality of directional prediction modes are, for example, H.264. It includes a prediction mode in 33 directions defined by the H.265/HEVC standard. In addition to the 33 directions, the plurality of directional prediction modes may further include 32 directional prediction modes (total of 65 directional prediction modes).
- FIG. 14 is a conceptual diagram showing all 67 intra prediction modes (2 non-directional prediction modes and 65 directional prediction modes) that can be used in intra prediction. The solid arrow indicates the H. It represents the 33 directions defined by the H.265/HEVC standard and the dashed arrows represent the added 32 directions (two non-directional prediction modes are not shown in FIG. 14).
- the luminance block may be referred to in the intra prediction of the color difference block. That is, the color difference component of the current block may be predicted based on the luminance component of the current block.
- Such intra prediction is sometimes called CCLM (cross-component linear model) prediction.
- the intra-prediction mode (for example, called CCLM mode) of the color difference block that refers to such a luminance block may be added as one of the intra-prediction modes of the color difference block.
- the intra prediction unit 124 may correct the pixel value after intra prediction based on the gradient of reference pixels in the horizontal/vertical directions. Intra prediction with such a correction is sometimes called PDPC (position dependent intra prediction combination). Information indicating whether or not PDPC is applied (for example, a PDPC flag) is usually signaled at the CU level. Note that the signaling of this information does not have to be limited to the CU level, but may be at other levels (eg, sequence level, picture level, slice level, tile level or CTU level).
- the inter prediction unit 126 refers to a reference picture stored in the frame memory 122 and is different from the current picture to perform inter prediction (also referred to as inter-picture prediction) of the current block, thereby predicting a prediction signal (inter prediction). Prediction signal). Inter prediction is performed in units of the current block or the current sub-block (for example, 4 ⁇ 4 block) in the current block. For example, the inter prediction unit 126 performs a motion estimation on a current block or a current subblock in a reference picture to find a reference block or a subblock that best matches the current block or the current subblock.
- the inter prediction unit 126 acquires motion information (for example, motion vector) that compensates for the motion or change from the reference block or sub-block to the current block or sub-block.
- the inter prediction unit 126 performs motion compensation (or motion prediction) based on the motion information, and generates an inter prediction signal of the current block or sub block.
- the inter prediction unit 126 outputs the generated inter prediction signal to the prediction control unit 128.
- the motion information used for motion compensation may be signaled as an inter prediction signal in various forms.
- the motion vector may be signalized.
- the difference between the motion vector and the motion vector predictor may be signalized.
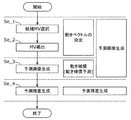
- FIG. 15 is a flowchart showing an example of the basic flow of inter prediction.
- the inter prediction unit 126 first generates a predicted image (steps Se_1 to Se_3). Next, the subtraction unit 104 generates a difference between the current block and the predicted image as a prediction residual (step Se_4).
- the inter prediction unit 126 determines the motion vector (MV) of the current block (steps Se_1 and Se_2) and performs the motion compensation (step Se_3) to generate the predicted image. To do. Further, the inter prediction unit 126 determines the MV by selecting a candidate motion vector (candidate MV) (step Se_1) and deriving the MV (step Se_2). The selection of the candidate MV is performed, for example, by selecting at least one candidate MV from the candidate MV list. In the derivation of MV, the inter prediction unit 126 determines at least one selected candidate MV as the MV of the current block by selecting at least one candidate MV from among at least one candidate MV. May be.
- the inter prediction unit 126 may determine the MV of the current block by searching the area of the reference picture indicated by the candidate MV for each of the selected at least one candidate MV. It should be noted that searching the area of the reference picture may be referred to as motion estimation.
- steps Se_1 to Se_3 are performed by the inter prediction unit 126, but the processes such as step Se_1 or step Se_2 may be performed by another component included in the encoding device 100. ..
- FIG. 16 is a flowchart showing an example of motion vector derivation.
- the inter prediction unit 126 derives the MV of the current block in a mode for encoding motion information (for example, MV).
- the motion information is coded as a prediction parameter and signalized. That is, the encoded motion information is included in the encoded signal (also referred to as an encoded bitstream).
- the inter prediction unit 126 derives the MV in a mode in which motion information is not encoded. In this case, the motion information is not included in the encoded signal.
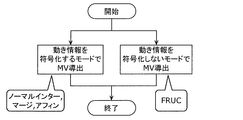
- the MV derivation mode may include a normal inter mode, a merge mode, a FRUC mode, and an affine mode, which will be described later.
- modes for encoding motion information include a normal inter mode, a merge mode, and an affine mode (specifically, an affine inter mode and an affine merge mode).
- the motion information may include not only the MV but also the motion vector predictor selection information described later. Further, as a mode in which motion information is not coded, there is a FRUC mode or the like.
- the inter prediction unit 126 selects a mode for deriving the MV of the current block from these plural modes, and derives the MV of the current block using the selected mode.
- FIG. 17 is a flowchart showing another example of motion vector derivation.
- the inter prediction unit 126 derives the MV of the current block in the mode of encoding the difference MV.
- the difference MV is coded as a prediction parameter and signalized. That is, the encoded difference MV is included in the encoded signal.
- This difference MV is the difference between the MV of the current block and its predicted MV.
- the inter prediction unit 126 derives the MV in a mode in which the difference MV is not encoded.
- the encoded difference MV is not included in the encoded signal.
- the MV derivation modes include a normal inter mode, a merge mode, a FRUC mode, and an affine mode, which will be described later.
- the mode for encoding the differential MV includes a normal inter mode and an affine mode (specifically, an affine inter mode).
- modes that do not encode the difference MV include a FRUC mode, a merge mode, and an affine mode (specifically, an affine merge mode).
- the inter prediction unit 126 selects a mode for deriving the MV of the current block from these plural modes, and derives the MV of the current block using the selected mode.
- FIG. 18 is a flowchart showing another example of motion vector derivation.
- the modes that do not encode the difference MV include a merge mode, a FRUC mode, and an affine mode (specifically, an affine merge mode).
- the merge mode is a mode for deriving the MV of the current block by selecting a motion vector from the surrounding encoded blocks
- the FRUC mode is This is a mode for deriving the MV of the current block by performing a search between coded areas.
- the affine mode is a mode in which the motion vector of each of the plurality of sub-blocks forming the current block is derived as the MV of the current block, assuming affine transformation.
- the inter prediction unit 126 when the inter prediction mode information indicates 0 (0 in Sf_1), the inter prediction unit 126 derives a motion vector in the merge mode (Sf_2). Moreover, when the inter prediction mode information indicates 1 (1 in Sf_1), the inter prediction unit 126 derives a motion vector in the FRUC mode (Sf_3). Further, when the inter prediction mode information indicates 2 (2 in Sf_1), the inter prediction unit 126 derives a motion vector in the affine mode (specifically, the affine merge mode) (Sf_4). Further, when the inter prediction mode information indicates 3 (3 in Sf_1), the inter prediction unit 126 derives a motion vector in a mode for encoding the difference MV (for example, normal inter mode) (Sf_5).
- the normal inter mode is an inter prediction mode in which the MV of the current block is derived from the area of the reference picture indicated by the candidate MV based on a block similar to the image of the current block. Further, in this normal inter mode, the difference MV is encoded.
- FIG. 19 is a flowchart showing an example of inter prediction in the normal inter mode.
- the inter prediction unit 126 first acquires a plurality of candidate MVs for the current block based on information such as the MVs of a plurality of coded blocks surrounding the current block temporally or spatially (step). Sg_1). That is, the inter prediction unit 126 creates a candidate MV list.
- the inter prediction unit 126 selects each of N (N is an integer of 2 or more) candidate MVs from the plurality of candidate MVs acquired in step Sg_1 as a motion vector predictor candidate (also referred to as a predicted MV candidate). As a result, extraction is performed according to a predetermined priority order (step Sg_2). Note that the priority may be predetermined for each of the N candidate MVs.
- the inter prediction unit 126 selects one motion vector predictor candidate from the N motion vector predictor candidates as a motion vector predictor (also referred to as a motion vector MV) of the current block (step Sg_3). At this time, the inter prediction unit 126 encodes the motion vector predictor selection information for identifying the selected motion vector predictor into a stream.
- the stream is the above-described coded signal or coded bit stream.
- the inter prediction unit 126 refers to the coded reference picture and derives the MV of the current block (step Sg_4). At this time, the inter prediction unit 126 further encodes the difference value between the derived MV and the motion vector predictor as a difference MV into a stream.
- the coded reference picture is a picture composed of a plurality of blocks reconstructed after coding.
- the inter prediction unit 126 generates a predicted image of the current block by performing motion compensation on the current block using the derived MV and the encoded reference picture (step Sg_5).
- the predicted image is the inter prediction signal described above.
- the information included in the encoded signal and indicating the inter prediction mode (normal inter mode in the above example) used to generate the predicted image is encoded as a prediction parameter, for example.
- the candidate MV list may be commonly used with lists used in other modes. Further, the process related to the candidate MV list may be applied to the process related to the list used in another mode.
- the processing related to this candidate MV list is, for example, extraction or selection of candidate MVs from the candidate MV list, rearrangement of candidate MVs, or deletion of candidate MVs.
- the merge mode is an inter prediction mode that derives the MV by selecting the candidate MV as the MV of the current block from the candidate MV list.
- FIG. 20 is a flowchart showing an example of inter prediction in merge mode.
- the inter prediction unit 126 first acquires a plurality of candidate MVs for the current block based on information such as the MVs of a plurality of coded blocks surrounding the current block temporally or spatially (step). Sh_1). That is, the inter prediction unit 126 creates a candidate MV list.
- the inter prediction unit 126 derives the MV of the current block by selecting one candidate MV from the plurality of candidate MVs acquired in step Sh_1 (step Sh_2). At this time, the inter prediction unit 126 encodes the MV selection information for identifying the selected candidate MV into a stream.
- the inter prediction unit 126 generates a predicted image of the current block by performing motion compensation on the current block using the derived MV and the encoded reference picture (step Sh_3).
- the information included in the encoded signal and indicating the inter prediction mode (merge mode in the above example) used for generating the predicted image is encoded as, for example, a prediction parameter.
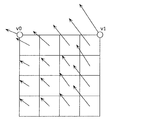
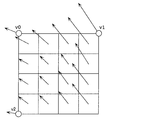
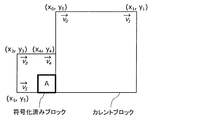
- FIG. 21 is a conceptual diagram for explaining an example of the motion vector derivation process of the current picture in the merge mode.
- Predictive MV candidates include spatially adjacent prediction MVs that are MVs of a plurality of encoded blocks that are spatially peripheral to the target block, and blocks around which the position of the target block in the encoded reference picture is projected.
- There are a temporally adjacent prediction MV which is an MV that the user has, a combined prediction MV which is an MV generated by combining the spatially adjacent prediction MV and the MV values of the temporally adjacent prediction MV, and a zero prediction MV which is a MV having a value of zero.
- variable length coding unit a signal indicating which prediction MV has been selected, merge_idx, is described in the stream and coded.
- the prediction MVs registered in the prediction MV list described in FIG. 21 are examples, and the number may be different from the number in the figure, or may be a configuration that does not include some types of the prediction MV in the figure.
- the configuration may be such that a prediction MV other than the type of prediction MV in the figure is added.
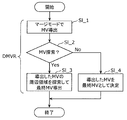
- the final MV may be determined by using the MV of the target block derived by the merge mode and performing a DMVR (decoder motion vector refinement) process described later.
- DMVR decoder motion vector refinement
- the candidate of the predicted MV is the above-mentioned candidate MV
- the predicted MV list is the above-mentioned candidate MV list.
- the candidate MV list may be referred to as a candidate list.
- the merge_idx is MV selection information.
- the motion information may be derived on the decoding device side without being signalized on the encoding device side. Note that, as described above, H.264.
- the merge mode defined by the H.265/HEVC standard may be used.
- the motion information may be derived by performing a motion search on the decoding device side. In the embodiment, on the decoding device side, motion search is performed without using the pixel value of the current block.
- the mode for performing motion search on the decoding device side is sometimes called a PMMVD (pattern matched motion vector derivation) mode or a FRUC (frame rate up-conversion) mode.
- PMMVD pattern matched motion vector derivation
- FRUC frame rate up-conversion
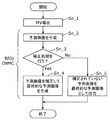
- a list of a plurality of candidates each having a prediction motion vector (MV) (that is, a candidate MV list, (It may be common to the merge list) is generated (step Si_1).
- the best candidate MV is selected from the plurality of candidate MVs registered in the candidate MV list (step Si_2). For example, the evaluation value of each candidate MV included in the candidate MV list is calculated, and one candidate MV is selected based on the evaluation value.
- the motion vector for the current block is derived based on the motion vector of the selected candidate (step Si_4).
- the motion vector of the selected candidate (best candidate MV) is directly derived as the motion vector for the current block.
- the motion vector for the current block may be derived by performing pattern matching in the peripheral area of the position in the reference picture corresponding to the motion vector of the selected candidate. That is, a pattern matching in a reference picture and a search using an evaluation value are performed on a region around the best candidate MV, and if there is an MV with a better evaluation value, the best candidate MV is set to the MV. It may be updated to be the final MV of the current block. It is also possible to adopt a configuration in which the process of updating to an MV having a better evaluation value is not performed.
- the inter prediction unit 126 performs motion compensation on the current block using the derived MV and the encoded reference picture to generate a predicted image of the current block (step Si_5).
- the same processing may be performed when processing is performed in sub-block units.
- the evaluation value may be calculated by various methods. For example, a reconstructed image of an area in a reference picture corresponding to a motion vector and a predetermined area (the area is an area of another reference picture or an area of an adjacent block of the current picture, for example, as shown below). May be used).
- the predetermined area may be predetermined.
- the difference between the pixel values of the two reconstructed images may be calculated and used as the evaluation value of the motion vector.
- the evaluation value may be calculated using other information in addition to the difference value.
- one candidate MV included in the candidate MV list (for example, merge list) is selected as a start point of the search by pattern matching.
- the first pattern matching or the second pattern matching may be used as the pattern matching.
- the first pattern matching and the second pattern matching may be referred to as bilateral matching and template matching, respectively.
- the predetermined area may be predetermined.
- FIG. 23 is a conceptual diagram for explaining an example of first pattern matching (bilateral matching) between two blocks in two reference pictures along a motion trajectory.
- first pattern matching in a pair of two blocks in two different reference pictures (Ref0, Ref1) which are two blocks along the motion trajectory of the current block (Cur block).
- Two motion vectors (MV0, MV1) are derived by searching for the best matching pair. Specifically, for the current block, the reconstructed image at the specified position in the first coded reference picture (Ref0) specified by the candidate MV and the symmetric MV obtained by scaling the candidate MV at the display time interval.
- the difference with the reconstructed image at the designated position in the second coded reference picture (Ref1) designated by is derived, and the evaluation value is calculated using the obtained difference value. It is possible to select, as the final MV, the candidate MV having the best evaluation value among the plurality of candidate MVs, which may bring good results.
- the motion vector (MV0, MV1) pointing to two reference blocks is the temporal distance between the current picture (CurPic) and the two reference pictures (Ref0, Ref1). It is proportional to (TD0, TD1).
- a mirror-symmetric bidirectional motion vector is used. Is derived.
- MV derivation>FRUC> template matching In the second pattern matching (template matching), pattern matching is performed between a template in the current picture (a block adjacent to the current block in the current picture (for example, an upper and/or left adjacent block)) and a block in the reference picture. Done. Therefore, in the second pattern matching, a block adjacent to the current block in the current picture is used as the predetermined area for calculating the above-described candidate evaluation value.
- FIG. 24 is a conceptual diagram for explaining an example of pattern matching (template matching) between a template in the current picture and a block in the reference picture.
- the current block is searched by searching the reference picture (Ref0) for the block that most matches the block adjacent to the current block (Cur block) in the current picture (CurPic).
- Motion vectors are derived.
- the reconstructed image of the left adjacent and/or upper adjacent encoded areas and the equivalent in the encoded reference picture (Ref0) specified by the candidate MV are equal.
- the difference from the reconstructed image at the position is derived, the evaluation value is calculated using the obtained difference value, and the candidate MV having the best evaluation value among the plurality of candidate MVs is selected as the best candidate MV. It is possible.
- a FRUC flag indicating whether or not the FRUC mode is applied may be signaled at the CU level. Further, when the FRUC mode is applied (for example, when the FRUC flag is true), information indicating an applicable pattern matching method (first pattern matching or second pattern matching) may be signaled at the CU level. .. Note that the signaling of these pieces of information is not limited to the CU level, and may be another level (eg, sequence level, picture level, slice level, tile level, CTU level or sub-block level). ..
- FIG. 25A is a conceptual diagram for explaining an example of derivation of a motion vector in sub-block units based on motion vectors of a plurality of adjacent blocks.
- the current block includes 16 4x4 subblocks.
- the motion vector v0 of the upper left corner control point of the current block is derived based on the motion vector of the adjacent block
- the motion vector v1 of the upper right corner control point of the current block is derived based on the motion vector of the adjacent sub block.
- two motion vectors v0 and v1 may be projected and the motion vector (vx, vy) of each sub-block in the current block may be derived by the following expression (1A).
- x and y indicate the horizontal position and vertical position of the sub-block, respectively, and w indicates a predetermined weighting coefficient.
- the predetermined weighting factor may be predetermined.
- Information indicating such an affine mode may be signaled at the CU level.
- the signalization of the information indicating the affine mode does not have to be limited to the CU level, but may be another level (eg, sequence level, picture level, slice level, tile level, CTU level or sub-block level). May be.
- an affine mode may include several modes in which the method of deriving the motion vector of the upper left and upper right corner control points is different.
- FIG. 25B is a conceptual diagram for explaining an example of derivation of a motion vector in a sub-block unit in an affine mode having three control points.
- the current block includes 16 4x4 sub-blocks.
- the motion vector v0 of the upper left corner control point of the current block is derived based on the motion vector of the adjacent block, and similarly, the motion vector v1 of the upper right corner control point of the current block and the adjacent vector are calculated based on the motion vector of the adjacent block.
- the motion vector v2 of the lower left corner control point of the current block is derived based on the motion vector of the block.
- the three motion vectors v0, v1 and v2 may be projected and the motion vector (vx, vy) of each sub-block in the current block may be derived by the following equation (1B).
- x and y respectively indicate the horizontal position and the vertical position of the center of the sub-block
- w indicates the width of the current block
- h indicates the height of the current block.
- Affine modes with different numbers of control points may be signaled by switching at the CU level.
- Information indicating the number of control points in the affine mode used at the CU level may be signaled at another level (eg, sequence level, picture level, slice level, tile level, CTU level or sub-block level). Good.
- the affine mode having such three control points may include some modes in which the method of deriving the motion vector of the upper left, upper right and lower left corner control points is different.
- FIGS. 26A, 26B, and 26C are conceptual diagrams for explaining the affine merge mode.
- the predicted motion vector of each control point of the current block is calculated based on the plurality of motion vectors corresponding to the block encoded in the affine mode. Specifically, these blocks are examined in the order of coded block A (left), block B (top), block C (top right), block D (bottom left) and block E (top left), and in affine mode. The first valid block encoded is identified. The predicted motion vector of the control point of the current block is calculated based on the plurality of motion vectors corresponding to the specified block.
- the upper left corner and the upper right corner of the encoded block including the block A are The motion vectors v3 and v4 projected at the position of are derived. Then, the predicted motion vector v0 of the control point at the upper left corner of the current block and the predicted motion vector v1 of the control point at the upper right corner of the current block are calculated from the derived motion vectors v3 and v4.
- the upper left corner and the upper right corner of the encoded block including the block A are And the motion vectors v3, v4, and v5 projected to the position of the lower left corner are derived. Then, from the derived motion vectors v3, v4, and v5, the predicted motion vector v0 of the control point at the upper left corner of the current block, the predicted motion vector v1 of the control point at the upper right corner, and the predicted motion vector of the control point at the lower left corner of the current block. v2 is calculated.
- this predictive motion vector deriving method may be used for deriving the predictive motion vector of each control point of the current block in step Sj_1 of FIG. 29 described later.
- FIG. 27 is a flowchart showing an example of the affine merge mode.
- the inter prediction unit 126 first derives the prediction MV of each control point of the current block (step Sk_1).
- the control points are the upper left corner and the upper right corner of the current block as shown in FIG. 25A, or the upper left corner, the upper right corner and the lower left corner of the current block as shown in FIG. 25B.
- the inter prediction unit 126 performs the sequence of the coded block A (left), block B (upper), block C (upper right), block D (lower left), and block E (upper left). Examine these blocks and identify the first valid block encoded in affine mode.
- the inter prediction unit 126 causes the motion vector v3 of the upper left corner and the upper right corner of the encoded block including the block A and From v4, the motion vector v0 of the control point at the upper left corner of the current block and the motion vector v1 of the control point at the upper right corner are calculated.
- the inter prediction unit 126 projects the motion vectors v3 and v4 of the upper left corner and the upper right corner of the coded block onto the current block, thereby predicting the predicted motion vector v0 of the control point at the upper left corner of the current block and the upper right corner of the current block.
- the predicted motion vector v1 of the corner control point is calculated.
- the inter prediction unit 126 moves the upper left corner, the upper right corner, and the lower left corner of the encoded block including the block A, as illustrated in FIG. 26C. From the vectors v3, v4 and v5, the motion vector v0 of the control point at the upper left corner of the current block, the motion vector v1 of the control point at the upper right corner, and the motion vector v2 of the control point at the lower left corner are calculated.
- the inter prediction unit 126 projects the motion vectors v3, v4, and v5 of the upper left corner, the upper right corner, and the lower left corner of the encoded block onto the current block to predict the predicted motion of the control point at the upper left corner of the current block.
- the vector v0, the predicted motion vector v1 of the control point at the upper right corner, and the motion vector v2 of the control point at the lower left corner are calculated.
- the inter prediction unit 126 performs motion compensation on each of the plurality of sub blocks included in the current block. That is, the inter prediction unit 126, for each of the plurality of sub-blocks, the two motion vector predictors v0 and v1 and the above formula (1A), or the three motion vector predictors v0, v1 and v2 and the above formula (1B). ) And are used to calculate the motion vector of the sub-block as an affine MV (step Sk_2). Then, the inter prediction unit 126 performs motion compensation on the sub block using the affine MV and the encoded reference picture (step Sk_3). As a result, motion compensation is performed on the current block, and a predicted image of the current block is generated.
- FIG. 28A is a conceptual diagram for explaining an affine inter mode having two control points.
- the motion vector selected from the motion vectors of the coded blocks A, B and C adjacent to the current block is the prediction of the control point at the upper left corner of the current block. It is used as the motion vector v0.
- the motion vector selected from the motion vectors of the coded blocks D and E adjacent to the current block is used as the predicted motion vector v1 of the control point at the upper right corner of the current block.
- FIG. 28B is a conceptual diagram for explaining an affine inter mode having three control points.
- the motion vector selected from the motion vectors of the coded blocks A, B and C adjacent to the current block is the prediction of the control point at the upper left corner of the current block. It is used as the motion vector v0.
- the motion vector selected from the motion vectors of the coded blocks D and E adjacent to the current block is used as the predicted motion vector v1 of the control point at the upper right corner of the current block.
- the motion vector selected from the motion vectors of the coded block F and the block G adjacent to the current block is used as the predicted motion vector v2 of the control point at the lower left corner of the current block.
- FIG. 29 is a flowchart showing an example of the affine inter mode.
- the inter prediction unit 126 derives the prediction MV (v0, v1) or (v0, v1, v2) of each of the two or three control points of the current block. (Step Sj_1).
- the control points are points at the upper left corner, upper right corner, or lower left corner of the current block, as shown in FIG. 25A or FIG. 25B.
- the inter prediction unit 126 predicts the control point of the current block by selecting the motion vector of one of the coded blocks in the vicinity of each control point of the current block shown in FIG. 28A or 28B.
- the motion vector (v0, v1) or (v0, v1, v2) is derived.
- the inter prediction unit 126 encodes the motion vector predictor selection information for identifying the selected two motion vectors into a stream.
- the inter prediction unit 126 determines which motion vector of a block is selected from the coded blocks adjacent to the current block as the motion vector predictor of the control point by using cost evaluation or the like, and which motion vector predictor is selected. A flag indicating whether it has been selected may be described in the bitstream.
- the inter prediction unit 126 performs motion search (steps Sj_3 and Sj_4) while updating the motion vector predictor selected or derived in step Sj_1 (step Sj_2). That is, the inter prediction unit 126 calculates the motion vector of each sub-block corresponding to the updated motion vector predictor as the affine MV using the above formula (1A) or formula (1B) (step Sj_3). Then, the inter prediction unit 126 performs motion compensation on each sub block using the affine MV and the encoded reference picture (step Sj_4). As a result, the inter prediction unit 126 determines, as a motion vector of the control point, a motion vector predictor that yields the smallest cost in the motion search loop (step Sj_5). At this time, the inter prediction unit 126 further encodes each difference value between the determined MV and the motion vector predictor as a difference MV in the stream.
- the inter prediction unit 126 generates a predicted image of the current block by performing motion compensation on the current block using the determined MV and the encoded reference picture (step Sj_6).
- FIG. 30A and FIG. 30B are conceptual diagrams for explaining a control point prediction vector deriving method in the case where the number of control points is different between the coded block and the current block.
- a current block has three control points of an upper left corner, an upper right corner and a lower left corner, and a block A adjacent to the left of the current block has two control points and is encoded in an affine mode. If so, the motion vectors v3 and v4 projected at the positions of the upper left corner and the upper right corner of the encoded block including the block A are derived. Then, the predicted motion vector v0 of the control point at the upper left corner of the current block and the predicted motion vector v1 of the control point at the upper right corner of the current block are calculated from the derived motion vectors v3 and v4. Further, the predicted motion vector v2 of the control point at the lower left corner is calculated from the derived motion vectors v0 and v1.
- the current block has two control points at the upper left corner and the upper right corner, and the block A adjacent to the left of the current block is encoded in the affine mode having three control points.
- the motion vectors v3, v4, and v5 projected at the positions of the upper left corner, the upper right corner, and the lower left corner of the encoded block including the block A are derived.
- the predicted motion vector v0 of the control point at the upper left corner of the current block and the predicted motion vector v1 of the control point at the upper right corner of the current block are calculated from the derived motion vectors v3, v4, and v5.
- This predictive motion vector deriving method may be used for deriving the predictive motion vector of each control point of the current block in step Sj_1 in FIG.
- FIG. 31A is a flowchart showing the relationship between the merge mode and DMVR.
- the inter prediction unit 126 derives the motion vector of the current block in the merge mode (step Sl_1). Next, the inter prediction unit 126 determines whether or not to search a motion vector, that is, a motion search (step Sl_2). Here, when the inter prediction unit 126 determines not to perform the motion search (No in step Sl_2), the inter prediction unit 126 determines the motion vector derived in step Sl_1 as the final motion vector for the current block (step Sl_4). That is, in this case, the motion vector of the current block is determined in the merge mode.
- step Sl_3 the final motion vector is derived (step Sl_3). That is, in this case, the motion vector of the current block is determined by DMVR.
- FIG. 31B is a conceptual diagram for explaining an example of DMVR processing for determining the MV.
- the optimal MVP set in the current block (for example, in merge mode) is set as the candidate MV.
- the candidate MV (L0) the reference pixel is specified from the first reference picture (L0) which is a coded picture in the L0 direction.
- the reference pixel is specified from the second reference picture (L1) which is a coded picture in the L1 direction.
- a template is generated by averaging these reference pixels.
- the peripheral areas of the candidate MVs of the first reference picture (L0) and the second reference picture (L1) are searched respectively, and the MV with the lowest cost is determined as the final MV.
- the cost value may be calculated using, for example, a difference value between each pixel value of the template and each pixel value of the search area, a candidate MV value, and the like.
- any processing may be used as long as it is a processing that can search the periphery of the candidate MV and derive the final MV.
- BIO/OBMC In motion compensation, there is a mode in which a predicted image is generated and the predicted image is corrected.
- the mode is, for example, BIO and OBMC described later.
- FIG. 32 is a flowchart showing an example of generation of a predicted image.
- the inter prediction unit 126 generates a predicted image (step Sm_1), and corrects the predicted image according to, for example, one of the above modes (step Sm_2).
- FIG. 33 is a flowchart showing another example of generation of a predicted image.
- the inter prediction unit 126 determines the motion vector of the current block (step Sn_1). Next, the inter prediction unit 126 generates a predicted image (step Sn_2) and determines whether or not to perform correction processing (step Sn_3). Here, when the inter prediction unit 126 determines to perform the correction process (Yes in step Sn_3), the inter prediction unit 126 corrects the predicted image to generate a final predicted image (step Sn_4). On the other hand, when the inter prediction unit 126 determines not to perform the correction process (No in step Sn_3), it outputs the predicted image as a final predicted image without correction (step Sn_5).
- the mode is, for example, LIC described later.
- FIG. 34 is a flowchart showing another example of generation of a predicted image.
- the inter prediction unit 126 derives the motion vector of the current block (step So_1). Next, the inter prediction unit 126 determines whether to perform the brightness correction process (step So_2). Here, when the inter prediction unit 126 determines to perform the brightness correction process (Yes in step So_2), the inter prediction unit 126 generates a predicted image while performing the brightness correction (step So_3). That is, the predicted image is generated by the LIC. On the other hand, when the inter prediction unit 126 determines not to perform the brightness correction process (No in step So_2), the inter prediction unit 126 generates a predicted image by normal motion compensation without performing the brightness correction (step So_4).
- the inter prediction signal may be generated using not only the motion information of the current block obtained by the motion search but also the motion information of the adjacent block. Specifically, the prediction signal based on the motion information obtained by the motion search (in the reference picture) and the prediction signal based on the motion information of the adjacent block (in the current picture) are weighted and added to obtain the current The inter prediction signal may be generated for each sub-block in the block.
- Such inter prediction (motion compensation) is sometimes called OBMC (overlapped block motion compensation).
- information indicating the size of the sub-block for the OBMC may be signaled at the sequence level. Further, information indicating whether to apply the OBMC mode (for example, called an OBMC flag) may be signaled at the CU level. Note that the level of signalization of these information does not need to be limited to the sequence level and the CU level, and may be another level (for example, a picture level, a slice level, a tile level, a CTU level or a sub-block level). Good.
- 35 and 36 are a flowchart and a conceptual diagram for explaining the outline of the predicted image correction process by the OBMC process.
- a predicted image (Pred) obtained by normal motion compensation is acquired using the motion vector (MV) assigned to the processing target (current) block.
- MV motion vector assigned to the processing target (current) block.
- an arrow “MV” indicates a reference picture and indicates what the current block of the current picture refers to in order to obtain a predicted image.
- the motion vector (MV_L) already derived for the coded left adjacent block is applied (reused) to the block to be coded to obtain the predicted image (Pred_L).
- the motion vector (MV_L) is indicated by the arrow “MV_L” pointing from the current block to the reference picture.
- the first prediction image is corrected by superimposing the two prediction images Pred and Pred_L. This has the effect of blending the boundaries between adjacent blocks.
- the motion vector (MV_U) already derived for the encoded upper adjacent block is applied (reused) to the encoding target block to obtain the prediction image (Pred_U).
- the motion vector (MV_U) is indicated by an arrow “MV_U” pointing from the current block to the reference picture.
- the predicted image Pred_U is superimposed on the predicted image (for example, Pred and Pred_L) subjected to the first correction to perform the second correction of the predicted image. This has the effect of blending the boundaries between adjacent blocks.
- the predicted image obtained by the second correction is the final predicted image of the current block in which the boundaries with adjacent blocks are mixed (smoothed).
- the above example is a two-pass correction method that uses left-adjacent and upper-adjacent blocks, but the correction method is a three-pass or more pass that also uses right-adjacent and/or lower-adjacent blocks.
- the correction method of may be used.
- the overlapping area may not be the pixel area of the entire block, but may be only a partial area near the block boundary.
- the predictive image correction process of the OBMC for obtaining one predictive image Pred by superimposing the additional predictive images Pred_L and Pred_U from one reference picture has been described.
- the same process may be applied to each of the plurality of reference pictures.
- by performing image correction of OBMC based on a plurality of reference pictures after obtaining a corrected predicted image from each reference picture, further superimposing the obtained plurality of corrected predicted images. To get the final predicted image.
- the unit of the target block may be a prediction block unit or a sub-block unit obtained by further dividing the prediction block.
- the encoding device may determine whether or not the target block belongs to a complex region of motion.
- the coding apparatus sets a value of 1 as obmc_flag and applies OBMC processing to code when it belongs to a complex area of motion, and codes as obmc_flag when it does not belong to a complex area of motion.
- the value 0 is set to encode the block without applying OBMC processing.
- the decoding device by decoding obmc_flag described in the stream (for example, a compression sequence), whether or not to apply the OBMC process is switched according to the value and decoding is performed.
- the inter prediction unit 126 generates one rectangular predicted image for the rectangular current block.
- the inter prediction unit 126 generates a plurality of predicted images having a shape different from the rectangle for the rectangular current block, and combines the plurality of predicted images to generate a final rectangular predicted image. You may.
- the shape different from the rectangle may be, for example, a triangle.
- FIG. 37 is a conceptual diagram for explaining the generation of two triangular predicted images.
- the inter prediction unit 126 generates a triangular predicted image by performing motion compensation on the first triangular partition in the current block using the first MV of the first partition. Similarly, the inter prediction unit 126 generates a triangular predicted image by performing motion compensation on the triangular second partition in the current block using the second MV of the second partition. Then, the inter prediction unit 126 combines these prediction images to generate a prediction image of the same rectangle as the current block.
- the first partition and the second partition are each triangular, but they may be trapezoidal or may have mutually different shapes.
- the current block is composed of two partitions, but it may be composed of three or more partitions.
- first partition and the second partition may overlap. That is, the first partition and the second partition may include the same pixel area.
- the predicted image of the current block may be generated using the predicted image of the first partition and the predicted image of the second partition.
- a prediction image is generated by inter prediction for both two partitions is shown, but a prediction image may be generated by intra prediction for at least one partition.
- BIO a mode for deriving a motion vector based on a model assuming constant velocity linear motion. This mode is sometimes called a BIO (bi-directional optical flow) mode.
- FIG. 38 is a conceptual diagram for explaining a model assuming constant velocity linear motion.
- (vx, vy) indicates a velocity vector
- ⁇ 0, ⁇ 1 indicate a temporal distance between the current picture (Cur Pic) and two reference pictures (Ref0, Ref1), respectively.
- (MVx0, MVy0) indicates a motion vector corresponding to the reference picture Ref0
- (MVx1, MVy1) indicates a motion vector corresponding to the reference picture Ref1.
- This optical flow equation is (i) the temporal derivative of the luminance value, (ii) the product of the horizontal velocity and the horizontal component of the spatial gradient of the reference image, and (iii) the vertical velocity and the spatial gradient of the reference image. The product of the vertical components of and the sum of are equal to zero.
- the motion vector in block units obtained from the merge list or the like may be corrected in pixel units.
- the motion vector may be derived on the decoding device side by a method different from the motion vector derivation based on a model that assumes constant velocity linear motion.
- the motion vector may be derived in sub-block units based on the motion vectors of a plurality of adjacent blocks.
- FIG. 39 is a conceptual diagram for explaining an example of a predicted image generation method using the brightness correction processing by the LIC processing.
- the MV is derived from the encoded reference picture, and the reference image corresponding to the current block is acquired.
- the current block information indicating how the luminance value has changed between the reference picture and the current picture is extracted.
- This extraction is performed using the luminance pixel values of the encoded left adjacent reference area (peripheral reference area) and the encoded upper adjacent reference area (peripheral reference area) in the current picture, and the reference picture specified by the derived MV. It is performed based on the luminance pixel value at the equivalent position. Then, the brightness correction parameter is calculated using the information indicating how the brightness value has changed.
- Prediction image for the current block is generated by performing the brightness correction process that applies the brightness correction parameter to the reference image in the reference picture specified by MV.
- the shape of the peripheral reference area in FIG. 39 is an example, and shapes other than this may be used.
- the processing of generating a predicted image from one reference picture has been described, but the same applies to the case of generating a predicted image from a plurality of reference pictures, and the reference image acquired from each reference picture is described above.
- the predicted image may be generated after the brightness correction processing is performed by the same method as described above.
- lic_flag is a signal indicating whether to apply LIC processing.
- the encoding device it is determined whether or not the current block belongs to the area in which the luminance change occurs, and if it belongs to the area in which the luminance change occurs, the value is set as lic_flag.
- a value 0 is set as lic_flag and encoding is performed without applying LIC processing.
- the decoding device by decoding the lic_flag described in the stream, whether or not to apply the LIC processing may be switched according to the value to perform the decoding.
- determining whether to apply the LIC processing for example, there is a method of determining whether to apply the LIC processing in the peripheral block.
- determining whether to apply the LIC processing in the peripheral block For example, when the current block is in the merge mode, it is determined whether or not the surrounding coded blocks selected at the time of deriving the MV in the merge mode process are coded by applying the LIC process. .. Encoding is performed by switching whether or not to apply the LIC processing according to the result. Even in the case of this example, the same processing is applied to the processing on the decoding device side.
- the inter prediction unit 126 derives a motion vector for obtaining a reference image corresponding to the target block to be encoded from a reference picture that is an encoded picture.
- the inter prediction unit 126 for the target block to be encoded, the luminance pixel values of the left adjacent and upper adjacent encoded peripheral reference areas and the luminance pixels at the same position in the reference picture specified by the motion vector. Using the value, information indicating how the luminance value has changed between the reference picture and the current picture to be encoded is extracted to calculate the luminance correction parameter. For example, the luminance pixel value of a pixel in the peripheral reference area in the current picture is set to p0, and the luminance pixel value of a pixel in the peripheral reference area in the reference picture at the same position as the pixel is set to p1.
- the inter prediction unit 126 performs a brightness correction process on the reference image in the reference picture specified by the motion vector using the brightness correction parameter, thereby generating a predicted image for the encoding target block.
- the brightness pixel value in the reference image is p2
- the brightness pixel value of the predicted image after the brightness correction process is p3.
- the shape of the peripheral reference area in FIG. 39 is an example, and shapes other than this may be used. Further, a part of the peripheral reference area shown in FIG. 39 may be used. For example, an area including a predetermined number of pixels thinned from each of the upper adjacent pixel and the left adjacent pixel may be used as the peripheral reference area.
- the peripheral reference area is not limited to the area adjacent to the encoding target block, and may be an area not adjacent to the encoding target block.
- the predetermined number of pixels may be predetermined.
- the peripheral reference area in the reference picture is an area specified by the motion vector of the encoding target picture from the peripheral reference area in the encoding target picture, but other peripheral motion vectors are used. It may be a designated area.
- the other motion vector may be a motion vector of the peripheral reference area in the current picture.
- LIC processing may be applied not only to luminance but also to color difference.
- a correction parameter may be derived individually for each of Y, Cb, and Cr, or a common correction parameter may be used for any of them.
- the correction parameter may be derived using the peripheral reference area of the current sub-block and the peripheral reference area of the reference sub-block in the reference picture specified by the MV of the current sub-block.
- the prediction control unit 128 selects either the intra prediction signal (the signal output from the intra prediction unit 124) or the inter prediction signal (the signal output from the inter prediction unit 126), and subtracts the selected signal as the prediction signal. It is output to the unit 104 and the addition unit 116.
- the prediction control unit 128 may output the prediction parameter input to the entropy coding unit 110.
- the entropy coding unit 110 may generate a coded bitstream (or sequence) based on the prediction parameter input from the prediction control unit 128 and the quantization coefficient input from the quantization unit 108.
- the prediction parameter may be used in the decoding device.
- the decoding device may receive and decode the encoded bitstream, and may perform the same processing as the prediction processing performed by the intra prediction unit 124, the inter prediction unit 126, and the prediction control unit 128.
- the prediction parameter is a selected prediction signal (for example, a motion vector, a prediction type, or a prediction mode used by the intra prediction unit 124 or the inter prediction unit 126), or an intra prediction unit 124, an inter prediction unit 126, and a prediction control unit. It may include any index, flag, or value based on or indicative of the prediction process performed at 128.
- FIG. 40 is a block diagram showing an implementation example of the encoding device 100.
- the encoding device 100 includes a processor a1 and a memory a2.
- the plurality of components of the encoding device 100 shown in FIG. 1 are implemented by the processor a1 and the memory a2 shown in FIG.
- the processor a1 is a circuit that performs information processing, and is a circuit that can access the memory a2.
- the processor a1 is a dedicated or general-purpose electronic circuit that encodes a moving image.
- the processor a1 may be a processor such as a CPU.
- the processor a1 may be an aggregate of a plurality of electronic circuits. Further, for example, the processor a1 may play the role of a plurality of components among the plurality of components of the encoding device 100 shown in FIG.
- the memory a2 is a dedicated or general-purpose memory that stores information for the processor a1 to encode a moving image.
- the memory a2 may be an electronic circuit and may be connected to the processor a1. Further, the memory a2 may be included in the processor a1. Further, the memory a2 may be an aggregate of a plurality of electronic circuits.
- the memory a2 may be a magnetic disk, an optical disk, or the like, and may be expressed as a storage, a recording medium, or the like.
- the memory a2 may be a non-volatile memory or a volatile memory.
- the memory a2 may store a moving image to be encoded, or may store a bit string corresponding to the encoded moving image. Further, the memory a2 may store a program for the processor a1 to encode a moving image.
- the memory a2 may play the role of a component for storing information among the plurality of components of the encoding device 100 shown in FIG.
- the memory a2 may serve as the block memory 118 and the frame memory 122 shown in FIG. More specifically, the memory a2 may store reconstructed blocks, reconstructed pictures, and the like.
- not all of the plurality of components shown in FIG. 1 and the like may be implemented, or all of the plurality of processes described above may not be performed.
- a part of the plurality of constituent elements illustrated in FIG. 1 and the like may be included in another device, and a part of the plurality of processes described above may be executed by another device.
- FIG. 41 is a block diagram showing a functional configuration of the decoding device 200 according to the embodiment.
- the decoding device 200 is a moving image decoding device that decodes a moving image in block units.
- the decoding device 200 includes an entropy decoding unit 202, an inverse quantization unit 204, an inverse transformation unit 206, an addition unit 208, a block memory 210, a loop filter unit 212, and a frame memory 214. And an intra prediction unit 216, an inter prediction unit 218, and a prediction control unit 220.
- the decryption device 200 is realized by, for example, a general-purpose processor and a memory.
- the processor entropy decoding unit 202, inverse quantization unit 204, inverse transformation unit 206, addition unit 208, loop filter unit 212, intra prediction unit. 216, the inter prediction unit 218, and the prediction control unit 220.
- the decoding device 200 is a dedicated one corresponding to the entropy decoding unit 202, the dequantization unit 204, the inverse transformation unit 206, the addition unit 208, the loop filter unit 212, the intra prediction unit 216, the inter prediction unit 218, and the prediction control unit 220. May be implemented as one or more electronic circuits of
- FIG. 42 is a flowchart showing an example of the overall decoding process performed by the decoding device 200.
- the entropy decoding unit 202 of the decoding device 200 specifies a division pattern of a fixed size block (for example, 128 ⁇ 128 pixels) (step Sp_1).
- This division pattern is a division pattern selected by the encoding device 100.
- the decoding device 200 performs the processes of steps Sp_2 to Sp_6 on each of the plurality of blocks that form the division pattern.
- the entropy decoding unit 202 decodes (specifically, entropy decoding) the encoded quantized coefficient and the prediction parameter of the decoding target block (also referred to as the current block) (step Sp_2).
- the inverse quantization unit 204 and the inverse transformation unit 206 restore a plurality of prediction residuals (that is, difference blocks) by performing inverse quantization and inverse transformation on the plurality of quantized coefficients (step Sp_3). ).
- the prediction processing unit including all or part of the intra prediction unit 216, the inter prediction unit 218, and the prediction control unit 220 generates a prediction signal (also referred to as a prediction block) of the current block (step Sp_4).
- the addition unit 208 reconstructs the current block into a reconstructed image (also referred to as a decoded image block) by adding the prediction block to the difference block (step Sp_5).
- the loop filter unit 212 filters the reconstructed image (step Sp_6).
- the decoding device 200 determines whether or not the decoding of the entire picture is completed (step Sp_7), and when it is determined that the decoding is not completed (No in step Sp_7), the processing from step Sp_1 is repeatedly executed.
- steps Sp_1 to Sp_7 are sequentially performed by the decoding device 200. Alternatively, some of the processes may be performed in parallel, and the order of the processes may be changed.
- the entropy decoding unit 202 entropy-decodes the encoded bitstream. Specifically, the entropy decoding unit 202, for example, arithmetically decodes a coded bitstream into a binary signal. Then, the entropy decoding unit 202 debinarizes the binary signal. The entropy decoding unit 202 outputs the quantized coefficient in block units to the inverse quantization unit 204. The entropy decoding unit 202 may output the prediction parameter included in the coded bitstream (see FIG. 1) to the intra prediction unit 216, the inter prediction unit 218, and the prediction control unit 220 according to the embodiment. The intra prediction unit 216, the inter prediction unit 218, and the prediction control unit 220 can execute the same prediction process as the processes performed by the intra prediction unit 124, the inter prediction unit 126, and the prediction control unit 128 on the encoding device side.
- the inverse quantization unit 204 inversely quantizes the quantized coefficient of the decoding target block (hereinafter referred to as the current block) that is the input from the entropy decoding unit 202. Specifically, the inverse quantization unit 204 inversely quantizes each quantized coefficient of the current block based on the quantized parameter corresponding to the quantized coefficient. Then, the inverse quantization unit 204 outputs the inversely quantized quantized coefficient (that is, the transform coefficient) of the current block to the inverse transform unit 206.
- the inverse transform unit 206 restores the prediction error by inversely transforming the transform coefficient that is the input from the inverse quantization unit 204.
- the inverse transform unit 206 determines the current block based on the information indicating the read transformation type.
- the conversion coefficient of is inversely transformed.
- the inverse transform unit 206 applies inverse retransform to the transform coefficient.
- the addition unit 208 reconstructs the current block by adding the prediction error that is the input from the inverse transform unit 206 and the prediction sample that is the input from the prediction control unit 220. Then, the addition unit 208 outputs the reconstructed block to the block memory 210 and the loop filter unit 212.
- the block memory 210 is a storage unit for storing a block that is referred to in intra prediction and that is included in a decoding target picture (hereinafter referred to as a current picture). Specifically, the block memory 210 stores the reconstructed block output from the addition unit 208.
- the loop filter unit 212 applies a loop filter to the blocks reconstructed by the adder 208, and outputs the reconstructed blocks that have been filtered to the frame memory 214, the display device, and the like.
- one of the plurality of filters is selected based on the direction and the activity of the local gradient, The selected filter is applied to the reconstruction block.
- the frame memory 214 is a storage unit for storing a reference picture used for inter prediction, and is sometimes called a frame buffer. Specifically, the frame memory 214 stores the reconstructed block filtered by the loop filter unit 212.
- FIG. 43 is a flowchart showing an example of processing performed by the prediction processing unit of the decoding device 200.
- the prediction processing unit includes all or some of the components of the intra prediction unit 216, the inter prediction unit 218, and the prediction control unit 220.
- the prediction processing unit generates a prediction image of the current block (step Sq_1).
- This prediction image is also called a prediction signal or a prediction block.
- the prediction signal includes, for example, an intra prediction signal or an inter prediction signal.
- the prediction processing unit generates a reconstructed image that has already been obtained by performing prediction block generation, difference block generation, coefficient block generation, difference block restoration, and decoded image block generation. The predicted image of the current block is generated by using this.
- the reconstructed image may be, for example, an image of a reference picture or an image of a decoded block in the current picture that is a picture including the current block.
- the decoded block in the current picture is, for example, a block adjacent to the current block.
- FIG. 44 is a flowchart showing another example of the processing performed by the prediction processing unit of the decoding device 200.
- the prediction processing unit determines the method or mode for generating the predicted image (step Sr_1). For example, this scheme or mode may be determined based on, for example, a prediction parameter or the like.
- the prediction processing unit determines the first method as the mode for generating the prediction image, the prediction processing unit generates the prediction image according to the first method (step Sr_2a). Further, when the prediction processing unit determines the second method as the mode for generating the predicted image, the prediction processing unit generates the predicted image according to the second method (step Sr_2b). Further, when the prediction processing unit determines the third method as the mode for generating the predicted image, the prediction processing unit generates the predicted image according to the third method (step Sr_2c).
- the first method, the second method, and the third method are different methods for generating a predicted image, and are, for example, an inter prediction method, an intra prediction method, and a prediction method other than them. It may be. In these prediction methods, the reconstructed image described above may be used.
- the intra prediction unit 216 refers to the block in the current picture stored in the block memory 210 based on the intra prediction mode read from the encoded bitstream to perform intra prediction, thereby performing prediction signals (intra prediction). Signal). Specifically, the intra prediction unit 216 generates an intra prediction signal by performing intra prediction with reference to a sample (for example, a luminance value and a color difference value) of a block adjacent to the current block, and predicts and controls the intra prediction signal. Output to the section 220.
- a sample for example, a luminance value and a color difference value
- the intra prediction unit 216 may predict the color difference component of the current block based on the luminance component of the current block. ..
- the intra prediction unit 216 corrects the pixel value after intra prediction based on the gradient of the reference pixels in the horizontal/vertical directions.
- the inter prediction unit 218 refers to the reference picture stored in the frame memory 214 to predict the current block.
- the prediction is performed in units of the current block or a sub block (for example, 4 ⁇ 4 block) in the current block.
- the inter prediction unit 218 performs motion compensation using motion information (for example, a motion vector) that has been deciphered from a coded bitstream (for example, a prediction parameter output from the entropy decoding unit 202), or the current block or
- the inter prediction signal of the sub block is generated, and the inter prediction signal is output to the prediction control unit 220.
- the inter prediction unit 218 uses not only the motion information of the current block obtained by the motion search but also the motion information of the adjacent block. , Generate inter prediction signals.
- the inter prediction unit 218 follows the pattern matching method (bilateral matching or template matching) read from the coded stream. Motion information is derived by performing a motion search. Then, the inter prediction unit 218 performs motion compensation (prediction) using the derived motion information.
- the inter prediction unit 218 derives a motion vector based on a model assuming a uniform linear motion when the BIO mode is applied.
- the inter prediction unit 218 determines the motion vector in subblock units based on the motion vectors of a plurality of adjacent blocks. Derive.
- the inter prediction unit 218 derives an MV based on the information deciphered from the coded stream and uses the MV. Motion compensation (prediction).
- FIG. 45 is a flowchart showing an example of inter prediction in the normal inter mode in the decoding device 200.
- the inter prediction unit 218 of the decoding device 200 performs motion compensation for each block.
- the inter prediction unit 218 acquires a plurality of candidate MVs for the current block based on information such as the MVs of a plurality of decoded blocks surrounding the current block temporally or spatially (step Ss_1). That is, the inter prediction unit 218 creates a candidate MV list.
- the inter prediction unit 218 determines each of N (N is an integer of 2 or more) candidate MVs among the plurality of candidate MVs acquired in step Ss_1 as a motion vector predictor candidate (also referred to as a predicted MV candidate). As a result, extraction is performed according to a predetermined priority order (step Ss_2). In addition, the priority may be predetermined for each of the N predicted MV candidates.
- the inter prediction unit 218 decodes the motion vector predictor selection information from the input stream (that is, the encoded bitstream), and uses the decoded motion vector predictor selection information, the N predicted MV candidates.
- One of the predicted MV candidates is selected as a predicted motion vector (also referred to as predicted MV) of the current block (step Ss_3).
- the inter prediction unit 218 decodes the difference MV from the input stream and adds the difference value that is the decoded difference MV and the selected motion vector predictor to calculate the MV of the current block. It is derived (step Ss_4).
- the inter prediction unit 218 generates a predicted image of the current block by performing motion compensation on the current block using the derived MV and the decoded reference picture (step Ss_5).
- the prediction control unit 220 selects either the intra prediction signal or the inter prediction signal, and outputs the selected signal to the adding unit 208 as a prediction signal.
- the configurations, functions, and processes of the prediction control unit 220, the intra prediction unit 216, and the inter prediction unit 218 on the decoding device side are the same as those of the prediction control unit 128, the intra prediction unit 124, and the inter prediction unit 126 on the encoding device side. May correspond to the configuration, function, and processing of.
- FIG. 46 is a block diagram showing an implementation example of the decoding device 200.
- the decoding device 200 includes a processor b1 and a memory b2.
- the plurality of components of the decoding device 200 shown in FIG. 41 are implemented by the processor b1 and the memory b2 shown in FIG.
- the processor b1 is a circuit that performs information processing, and is a circuit that can access the memory b2.
- the processor b1 is a dedicated or general-purpose electronic circuit that decodes an encoded moving image (that is, an encoded bit stream).
- the processor b1 may be a processor such as a CPU.
- the processor b1 may be an aggregate of a plurality of electronic circuits. Further, for example, the processor b1 may play a role of a plurality of constituent elements among the plurality of constituent elements of the decoding device 200 illustrated in FIG. 41 and the like.
- the memory b2 is a dedicated or general-purpose memory that stores information for the processor b1 to decode the encoded bitstream.
- the memory b2 may be an electronic circuit and may be connected to the processor b1.
- the memory b2 may be included in the processor b1. Further, the memory b2 may be an aggregate of a plurality of electronic circuits.
- the memory b2 may be a magnetic disk, an optical disk, or the like, or may be expressed as a storage, a recording medium, or the like.
- the memory b2 may be a non-volatile memory or a volatile memory.
- the memory b2 may store a moving image or an encoded bitstream. Further, the memory b2 may store a program for the processor b1 to decode the encoded bitstream.
- the memory b2 may play the role of a component for storing information among the plurality of components of the decoding device 200 shown in FIG. 41 and the like.
- the memory b2 may serve as the block memory 210 and the frame memory 214 shown in FIG. More specifically, the memory b2 may store reconstructed blocks, reconstructed pictures, and the like.
- the decoding device 200 not all of the plurality of components shown in FIG. 41 or the like may be implemented, or all of the plurality of processes described above may not be performed. Some of the plurality of components shown in FIG. 41 and the like may be included in another device, and some of the plurality of processes described above may be executed by another device.
- each term may be defined as follows.
- a picture is either an array of luma samples in monochrome format, or an array of luma samples in 4:2:0, 4:2:2 and 4:4:4 color format and two chroma samples. It is a corresponding array.
- the picture may be a frame or a field.
- a frame is a composition of a top field in which a plurality of sample rows 0, 2, 4,... Is generated and a bottom field in which a plurality of sample rows 1, 3, 5,.
- a slice is an independent slice segment and an integer number of coding trees contained in all subsequent dependent slice segments that precede the next independent slice segment (if any) in the same access unit. It is a unit.
- a tile is a rectangular area of a plurality of coding tree blocks in a specific tile row and specific tile row in a picture.
- a tile may be a rectangular area of a frame intended to be independently decoded and coded, although a loop filter across the edges of the tile may still be applied.
- a block is an MxN (N rows and M columns) array of multiple samples or an MxN array of multiple transform coefficients.
- a block may be a square or rectangular region of pixels that consists of multiple matrices of one luminance and two color differences.
- a CTU may be a coding tree block of a plurality of luma samples of a picture having a three sample array or two corresponding coding tree blocks of a plurality of chrominance samples. ..
- the CTU may be a multi-sample coding tree block of either a monochrome picture or a picture coded using three separate color planes and a syntax structure used to code the multiple samples. May be
- the super block may be a square block of 64 ⁇ 64 pixels that constitutes one or two mode information blocks, or may be recursively divided into four 32 ⁇ 32 blocks and further divided.
- FIG. 47 is a flowchart showing an example of the interpolation filter determination process in the embodiment.
- the prediction processing unit determines the motion vector (MV) of the current block and performs motion compensation based on the determined MV to generate the predicted image, as shown in FIG. 15, for example.
- motion compensation first, a first prediction image in integer pixel units is generated based on MV, and then an interpolation filter is used to calculate a decimal number between a plurality of integer pixels included in the first prediction image.
- a second predicted image is generated by interpolating the value (sample) at the pixel position.
- the interpolation filter determination process is included in the motion compensation process.
- the inter prediction unit 126/218 determines whether the size of the encoding/decoding target block is larger than the threshold size.
- An example of the threshold size is a 4x4 pixel size. In this case, if the size of the encoding/decoding target block is 4 ⁇ 4 pixel size, the inter prediction unit 126/218 determines that the size of the encoding/decoding target block is not larger than the threshold size. On the other hand, if the size of the encoding/decoding target block is larger than the 4 ⁇ 4 pixel size, the inter prediction unit 126/218 determines that the size of the encoding/decoding target block is larger than the threshold size.
- the inter prediction unit 126/218 uses the interpolation used for motion compensation of the encoding/decoding target block.
- the filter is determined to be the first interpolation filter.
- the first interpolation filter for example, an 8-tap interpolation filter as shown in FIG. 48 can be used.
- FIG. 48 is a diagram showing an example of the first interpolation filter in the embodiment. Specifically, as the first interpolation filter, 8-tap interpolation filter coefficients for each 1/16 motion vector accuracy (decimal sample position) are illustrated. For example, if the precision of the motion vector is "8/16", ⁇ -1, 4, -11, 40, 40, -11, 4, -1 ⁇ is used as the 8-tap interpolation filter coefficient.
- the inter prediction unit 126/218 uses it for motion compensation of the encoding/decoding target block.
- the interpolation filter is determined to be the second interpolation filter.
- the second interpolation filter has a shorter tap than the first interpolation filter. That is, the number of taps of the second interpolation filter is smaller than the number of taps of the first interpolation filter.
- a 6-tap interpolation filter as shown in FIG. 49 can be used.
- FIG. 49 is a diagram showing an example of the second interpolation filter in the embodiment. Specifically, as the second interpolation filter, a 6-tap interpolation filter coefficient for each of 1/16 motion vector accuracy (decimal sample position) is illustrated. For example, if the precision of the motion vector is “8/16”, ⁇ 3, -11, 40, 40, -11, 3 ⁇ is used as the 6-tap interpolation filter coefficient.
- step S1004 the encoding/decoding target block is encoded/decoded using the determined interpolation filter.
- the inter prediction unit 126/218 performs motion compensation on the coding/decoding target block using the determined interpolation filter to generate an inter prediction signal of the coding/decoding target block. ..
- the generated inter prediction signal is output to the prediction control unit 128/220 as described above.
- the first interpolation filter and the second interpolation filter having a different tap number from the first interpolation filter can be switched and used according to the size of the encoding/decoding target block. it can.
- the encoding/decoding target block may be any block for which motion compensation is performed, and is not particularly limited.
- an affine mode sub-block can be used as the encoding/decoding target block.
- a 4 ⁇ 4 pixel size can be used as the threshold size.
- FIG. 50 is a diagram showing an example of a block to which the interpolation filter determined in the embodiment is applied.
- the interpolation filter is applied to each of eight 4 ⁇ 4 pixel sub-blocks obtained by dividing a 16 ⁇ 8 pixel block into eight.
- the present disclosure introduces a size adaptive interpolation filter decision process into the inter prediction process. This process reduces the worst case memory bandwidth of the inter-prediction process and the worst case complexity in terms of the number of operations for affine motion compensation.
- the number of motion compensations will increase, and the number of samples read from memory for motion compensation will also increase.
- the number of taps of the interpolation filter decreases, the number of samples read from the memory for the interpolation process decreases. Therefore, by using an interpolation filter having a shorter tap for a smaller block, the number of read samples per time is reduced, so that an increase in memory bandwidth is suppressed even if the number of sample read times is increased. be able to.
- the second interpolation filter to the affine mode sub-block, it is possible to reduce the processing load of the affine motion compensation, which has a relatively high processing load.
- One or more aspects disclosed herein may be implemented in combination with at least a part of other aspects in the present disclosure.
- a part of the processes, a part of the configuration of the apparatus, a part of the syntax, and the like described in the flowcharts of one or more aspects disclosed herein may be implemented in combination with other aspects.
- each of the functional or functional blocks can be generally realized by an MPU (micro processing unit) and a memory. Further, the processing by each of the functional blocks may be realized as a program execution unit such as a processor that reads and executes software (program) recorded in a recording medium such as a ROM. The software may be distributed. The software may be recorded in various recording media such as a semiconductor memory. Note that each functional block can be realized by hardware (dedicated circuit). Various combinations of hardware and software can be employed.
- each embodiment may be realized by centralized processing using a single device (system), or may be realized by distributed processing using a plurality of devices.
- the processor that executes the above program may be a single processor or a plurality of processors. That is, centralized processing may be performed or distributed processing may be performed.
- an application example of the moving image coding method (image coding method) or the moving image decoding method (image decoding method) shown in each of the above-described embodiments, and various systems for implementing the application example explain.
- Such a system may be characterized by having an image encoding device using the image encoding method, an image decoding device using the image decoding method, or an image encoding/decoding device including both.
- Other configurations of such a system can be appropriately changed depending on the case.
- FIG. 51 is a diagram showing an overall configuration of an appropriate content supply system ex100 that realizes a content distribution service.
- the area for providing communication services is divided into desired sizes, and base stations ex106, ex107, ex108, ex109, and ex110, which are fixed wireless stations in the illustrated example, are installed in each cell.
- each device such as a computer ex111, a game machine ex112, a camera ex113, a home appliance ex114, and a smartphone ex115 is connected to the Internet ex101 via an Internet service provider ex102 or a communication network ex104 and base stations ex106 to ex110.
- the content supply system ex100 may be configured to be connected by combining any of the above devices.
- each device may be directly or indirectly connected to each other via a telephone network, a short-range wireless communication, or the like, without using the base stations ex106 to ex110.
- the streaming server ex103 may be connected to each device such as the computer ex111, the game machine ex112, the camera ex113, the home appliance ex114, and the smartphone ex115 via the internet ex101 and the like. Further, the streaming server ex103 may be connected to a terminal or the like in a hotspot in the airplane ex117 via the satellite ex116.
- the streaming server ex103 may be directly connected to the communication network ex104 without using the Internet ex101 or the Internet service provider ex102, or may be directly connected to the airplane ex117 without using the satellite ex116.
- the camera ex113 is a device such as a digital camera capable of shooting still images and moving images.
- the smartphone ex115 is a smartphone device, a mobile phone, a PHS (Personal Handy-phone System), or the like that supports a mobile communication system called 2G, 3G, 3.9G, 4G, and 5G in the future.
- a mobile communication system called 2G, 3G, 3.9G, 4G, and 5G in the future.
- the home appliance ex114 is a refrigerator, a device included in a household fuel cell cogeneration system, or the like.
- a terminal having a shooting function is connected to the streaming server ex103 via the base station ex106 and the like, which enables live distribution and the like.
- the terminals (computer ex111, game machine ex112, camera ex113, home appliances ex114, smartphone ex115, terminals in the airplane ex117, etc.) are used for the above still image or moving image content taken by the user using the terminal.
- the encoding process described in each embodiment may be performed, the video data obtained by encoding may be multiplexed with the audio data obtained by encoding the sound corresponding to the video, and the obtained data may be streamed. It may be transmitted to the server ex103. That is, each terminal functions as an image encoding device according to an aspect of the present disclosure.
- the streaming server ex103 streams the content data transmitted to the requested client.
- the client is a terminal or the like in the computer ex111, the game machine ex112, the camera ex113, the home appliance ex114, the smartphone ex115, or the airplane ex117 that can decode the encoded data.
- Each device that receives the distributed data may decrypt the received data and reproduce it. That is, each device may function as the image decoding device according to one aspect of the present disclosure.
- the streaming server ex103 may be a plurality of servers or a plurality of computers, and may decentralize data for processing, recording, or distributing.
- the streaming server ex103 may be realized by a CDN (Contents Delivery Network), and content distribution may be realized by a network connecting a large number of edge servers distributed around the world and the edge servers.
- CDN Contents Delivery Network
- content distribution may be realized by a network connecting a large number of edge servers distributed around the world and the edge servers.
- physically close edge servers can be dynamically assigned according to clients. Then, the content can be cached and delivered to the edge server to reduce the delay.
- the processing is distributed among multiple edge servers, the distribution subject is switched to another edge server, or a failure occurs. Since the delivery can be continued by bypassing the network part, fast and stable delivery can be realized.
- the coding processing of the captured data may be performed by each terminal, may be performed by the server side, or may be shared by the other.
- a processing loop is performed twice.
- the first loop the complexity of the image or the code amount in units of frames or scenes is detected.
- the second loop processing for maintaining the image quality and improving the coding efficiency is performed.
- the terminal performs the first encoding process
- the server side that receives the content performs the second encoding process, so that it is possible to improve the quality and efficiency of the content while reducing the processing load on each terminal. it can.
- the first encoded data made by a terminal can be received and reproduced by another terminal, which enables more flexible real-time distribution.
- the camera ex113 or the like extracts a feature amount (feature or characteristic amount) from an image, compresses data relating to the feature amount as metadata, and sends the metadata to the server.
- the server performs compression according to the meaning of the image (or the importance of the content), for example, determining the importance of the object from the feature amount and switching the quantization accuracy.
- the feature amount data is particularly effective for improving the precision and efficiency of motion vector prediction at the time of re-compression in the server.
- the terminal may perform simple encoding such as VLC (variable length encoding), and the server may perform encoding with a large processing load such as CABAC (context adaptive binary arithmetic encoding method).
- a stadium, a shopping mall, a factory, or the like there may be a plurality of video data in which almost the same scene is shot by a plurality of terminals.
- GOP Group of Picture
- Distributed processing is performed by assigning encoding processing to each unit. As a result, the delay can be reduced and more real-time performance can be realized.
- the server may manage and/or instruct so that the video data shot by each terminal can be referred to each other.
- the encoded data from each terminal may be received by the server, the reference relationship may be changed among a plurality of data, or the picture itself may be corrected or replaced and re-encoded. This makes it possible to generate streams with improved quality and efficiency of each piece of data.
- the server may transcode the video data to change the coding method and then distribute the video data.
- the server may convert the MPEG type encoding method to the VP type (for example, VP9), or the H.264 standard. H.264. It may be converted to 265 or the like.
- the encoding process can be performed by the terminal or one or more servers. Therefore, in the following, the description such as “server” or “terminal” is used as the entity that performs the process, but a part or all of the process performed by the server may be performed by the terminal, or the process performed by the terminal may be performed. Some or all may be done at the server. The same applies to the decoding process.
- the server not only encodes the two-dimensional moving image, but also automatically encodes the still image based on scene analysis of the moving image, or at the time specified by the user, and transmits the still image to the receiving terminal.
- the server can determine the three-dimensional shape of the scene based on not only the two-dimensional moving image but also the video shot of the same scene from different angles. Can be generated.
- the server may separately encode the three-dimensional data generated by the point cloud or the like, and based on the result of recognizing or tracking the person or the object using the three-dimensional data, a plurality of images to be transmitted to the receiving terminal may be transmitted. It may be generated by selecting or reconstructing it from a video image captured by the terminal.
- the user can arbitrarily select each video corresponding to each photographing terminal to enjoy the scene, and can select the video of the selected viewpoint from the three-dimensional data reconstructed using a plurality of images or videos. You can also enjoy the cut out content. Furthermore, along with the video, the sound is also picked up from a plurality of different angles, and the server multiplexes the sound from a specific angle or space with the corresponding video, and transmits the multiplexed video and sound. Good.
- the server may create viewpoint images for the right eye and the left eye, respectively, and perform encoding that allows reference between the viewpoint videos by Multi-View Coding (MVC) or the like. It may be encoded as another stream without referring to it. At the time of decoding another stream, it is preferable to reproduce them in synchronization with each other so that a virtual three-dimensional space is reproduced according to the user's viewpoint.
- MVC Multi-View Coding
- the server may superimpose the virtual object information in the virtual space on the camera information in the physical space based on the three-dimensional position or the movement of the user's viewpoint.
- the decoding device may acquire or hold the virtual object information and the three-dimensional data, generate a two-dimensional image according to the movement of the viewpoint of the user, and smoothly connect the data to create the superimposed data.
- the decoding device may transmit the movement of the user's viewpoint to the server in addition to the request for the virtual object information.
- the server may create the superimposition data in accordance with the movement of the viewpoint received from the three-dimensional data stored in the server, encode the superimposition data, and deliver it to the decoding device.
- the superimposition data typically has an ⁇ value indicating transparency other than RGB
- the server sets the ⁇ value of a portion other than an object created from three-dimensional data to 0 or the like, and May be encoded in a state in which is transmitted.
- the server may generate data in which RGB values having a predetermined value are set in the background like chroma keys and the portions other than the objects are set in the background color.
- the RGB value of the predetermined value may be predetermined.
- the decryption process of the distributed data may be performed by the client (for example, the terminal), the server side, or the processes may be shared by each other.
- a certain terminal may send a reception request to a server once, another terminal may receive the content corresponding to the request, perform a decoding process, and the decoded signal may be transmitted to a device having a display. It is possible to reproduce high-quality data by distributing the processing and selecting an appropriate content regardless of the performance of the terminal capable of communication.
- a partial area such as a tile into which a picture is divided may be decoded and displayed on the viewer's personal terminal. As a result, it is possible to confirm the field in which the user is in charge or a region to be confirmed in more detail, while sharing the entire image.
- the user may switch in real time while freely selecting a user's terminal, a decoding device such as a display arranged indoors or outdoors, or a display device.
- a decoding device such as a display arranged indoors or outdoors, or a display device.
- it is possible to perform decoding by switching the terminal to be decoded and the terminal to be displayed by using the position information of itself. This allows information to be mapped and displayed on a wall or part of the ground of an adjacent building in which the displayable device is embedded while the user is traveling to the destination.
- Access to the encoded data on the network is cached in a server that can be accessed from the receiving terminal in a short time or is copied to the edge server in the content delivery service. It is also possible to switch the bit rate of the received data based on easiness.
- the server may have a plurality of streams having the same content and different qualities as individual streams, but as shown in the figure, it is possible to realize a temporal/spatial scalable that is realized by performing coding by dividing into layers.
- a configuration may be used in which contents are switched by utilizing the characteristics of streams.
- the decoding side decides which layer to decode according to an internal factor such as performance and an external factor such as the state of the communication band, so that the decoding side determines low-resolution content and high-resolution content. You can freely switch and decrypt.
- the device can decode the same stream up to different layers.
- the burden on the side can be reduced.
- the picture is coded for each layer, and in addition to the configuration that realizes scalability in the enhancement layer above the base layer, the enhancement layer includes meta information based on image statistical information and the like. Good.
- the decoding side may generate high-quality content by super-resolution of the base layer picture based on the meta information. Super-resolution may improve signal-to-noise ratio while maintaining and/or increasing resolution.
- the meta information is information for specifying a linear or non-linear filter coefficient used for super-resolution processing, or information for specifying parameter values for filter processing, machine learning, or least-squares calculation used for super-resolution processing, etc. including.
- a configuration may be provided in which the picture is divided into tiles or the like according to the meaning of objects in the image.
- the decoding side decodes only a part of the area by selecting the tile to be decoded. Further, by storing the attributes of the object (person, car, ball, etc.) and the position in the video (coordinate position in the same image, etc.) as meta information, the decoding side can determine the position of the desired object based on the meta information.
- the meta information may be stored using a data storage structure different from the pixel data, such as an SEI (supplemental enhancement information) message in HEVC. This meta information indicates, for example, the position, size, or color of the main object.
- -Meta information may be stored in units composed of multiple pictures, such as streams, sequences, or random access units.
- the decoding side can acquire the time when a specific person appears in the video, and the like, and by combining the information on a picture-by-picture basis and the time information, the picture in which the object exists can be specified and the position of the object in the picture can be determined.
- FIG. 54 is a diagram showing an example of a web page display screen on the computer ex111 or the like.
- FIG. 55 is a diagram illustrating a display screen example of a web page on the smartphone ex115 or the like.
- the web page may include a plurality of link images that are links to the image content, and the appearance may be different depending on the browsing device.
- the display device When a plurality of link images are visible on the screen, the display device (until the user explicitly selects the link image, or until the link image approaches the center of the screen or the whole link image falls within the screen (
- the decoding device may display a still image or I picture included in each content as a link image, may display a video such as a gif animation with a plurality of still images or I pictures, and may display a base layer. Only the video may be received and the video may be decoded and displayed.
- the display device When the link image is selected by the user, the display device performs decoding while giving the base layer the highest priority, for example.
- the display device may decode up to the enhancement layer if there is information indicating that the content is scalable in the HTML forming the web page.
- the display device decodes only forward reference pictures (I picture, P picture, forward reference only B picture) before selection or when the communication band is very severe. By displaying and, the delay between the decoding time of the first picture and the display time (delay from the decoding start of the content to the display start) can be reduced.
- the display device may intentionally ignore the reference relationship of pictures, perform coarse decoding with all B pictures and P pictures as forward references, and perform normal decoding as the number of pictures received increases over time. ..
- the receiving terminal may add meta data in addition to image data belonging to one or more layers.
- Information such as weather or construction information may be received as information, and these may be associated and decrypted.
- the meta information may belong to the layer or may be simply multiplexed with the image data.
- a car, a drone, an airplane, or the like including the receiving terminal moves, so that the receiving terminal transmits the position information of the receiving terminal, thereby performing seamless reception and decoding while switching the base stations ex106 to ex110. realizable. Further, the receiving terminal can dynamically switch how much the meta information is received or how much the map information is updated according to the user's selection, the user's situation and/or the state of the communication band. Will be possible.
- the client can receive, decode, and reproduce the encoded information transmitted by the user in real time.
- the server may perform the editing process and then the encoding process. This can be realized by using the following configuration, for example.
- the server performs recognition processing such as shooting error, scene search, meaning analysis, and object detection from the original image data or encoded data in real time at the time of shooting or after storing. Then, the server manually or automatically corrects out-of-focus or camera shake based on the recognition result, or selects a less important scene such as a scene whose brightness is lower than other pictures or out of focus. Edit it by deleting it, emphasizing the edge of the object, changing the hue, and so on. The server encodes the edited data based on the editing result. It is also known that if the shooting time is too long, the audience rating will decrease, and the server will move not only in the less important scenes as described above so that the content falls within a specific time range depending on the shooting time. A scene or the like with a small number may be automatically clipped based on the image processing result. Alternatively, the server may generate and encode the digest based on the result of the semantic analysis of the scene.
- the server may intentionally change the face of a person in the peripheral portion of the screen, the inside of the house, or the like into an image that is out of focus and encode the image. Further, the server recognizes whether or not a face of a person different from the previously registered person is shown in the image to be encoded, and if it is shown, performs processing such as applying mosaic to the face part. May be.
- a user or a background area in which the user wants to process an image may be specified from the viewpoint of copyright.
- the server may perform processing such as replacing the designated area with another video or defocusing. If it is a person, the person in the moving image can be tracked to replace the image of the face portion of the person.
- the decoding device may first receive the base layer with the highest priority and perform decoding and reproduction, depending on the bandwidth.
- the decoding device may receive the enhancement layer during this period, and when the reproduction is performed twice or more, such as when the reproduction is looped, the decoding device may reproduce the high-quality image including the enhancement layer.
- the stream is thus encoded in a scalable manner, it is possible to provide an experience that the video is rough when it is not selected or at the stage of starting watching, but the stream gradually becomes smarter and the image becomes better.
- the same experience can be provided even if the coarse stream that is first played and the second stream that is coded by referring to the first moving image are configured as one stream. ..
- the LSI (large scale integration circuit) ex500 may be a single chip or may be composed of a plurality of chips.
- the moving picture coding or decoding software is installed in some recording medium (CD-ROM, flexible disk, hard disk, etc.) that can be read by the computer ex111 or the like, and the coding or decoding processing is performed using the software. Good.
- the smartphone ex115 has a camera, the moving image data acquired by the camera may be transmitted. The moving image data at this time may be data encoded by the LSI ex500 included in the smartphone ex115.
- the LSI ex500 may be configured to download and activate application software.
- the terminal first determines whether the terminal is compatible with the content encoding method or has the capability to execute a specific service.
- the terminal may download the codec or application software, and then acquire and reproduce the content.
- the content supply system ex100 via the internet ex101 but also a digital broadcasting system, at least the moving image coding device (image coding device) or the moving image decoding device (image decoding device) according to each of the above embodiments. Either can be incorporated. Since the multiplexed data in which the image and the sound are multiplexed is transmitted and received on the radio wave for broadcasting by using the satellite or the like, the difference is that the content supply system ex100 is suitable for the unicast configuration, which is suitable for the multicast. However, similar applications are possible for the encoding process and the decoding process.
- FIG. 56 is a diagram showing further details of the smartphone ex115 shown in FIG. Further, FIG. 57 is a diagram illustrating a configuration example of the smartphone ex115.
- the smartphone ex115 receives at the antenna ex450 for transmitting and receiving radio waves to and from the base station ex110, the camera unit ex465 capable of taking images and still images, the image captured by the camera unit ex465, and the antenna ex450.
- a display unit ex458 that displays data in which an image or the like is decoded is provided.
- the smartphone ex115 further includes an operation unit ex466 such as a touch panel, a voice output unit ex457 such as a speaker for outputting voice or sound, a voice input unit ex456 such as a microphone for inputting voice, and photographing.
- Memory unit ex467 that can store encoded video or still image, recorded audio, received image or still image, encoded data such as mail, or decoded data, and specify a user to start a network.
- a slot unit ex464 that is an interface unit with the SIM ex468 for authenticating access to various data is provided.
- An external memory may be used instead of the memory unit ex467.
- a main control unit ex460 capable of integrally controlling the display unit ex458 and the operation unit ex466, a power supply circuit unit ex461, an operation input control unit ex462, a video signal processing unit ex455, a camera interface unit ex463, a display control unit ex459, a modulation/ The demodulation unit ex452, the multiplexing/demultiplexing unit ex453, the audio signal processing unit ex454, the slot unit ex464, and the memory unit ex467 are connected via the synchronization bus ex470.
- the power supply circuit unit ex461 activates the smartphone ex115 and supplies power from the battery pack to each unit.
- the smartphone ex115 performs processing such as call and data communication under the control of the main control unit ex460 including a CPU, a ROM, a RAM, and the like.
- a voice signal processing unit ex454 converts a voice signal collected by the voice input unit ex456 into a digital voice signal
- a modulation/demodulation unit ex452 performs spread spectrum processing
- a transmission/reception unit ex451 performs digital-analog conversion processing. And frequency conversion processing is performed, and the resulting signal is transmitted via the antenna ex450.
- the received data is amplified, frequency conversion processing and analog-digital conversion processing are performed, spectrum modulation/demodulation unit ex452 performs spectrum despreading processing, and a voice signal processing unit ex454 converts the analog voice signal, which is then output by a voice output unit ex457.
- text, still image, or video data can be transmitted under the control of the main control unit ex460 via the operation input control unit ex462 based on the operation of the operation unit ex466 of the main body. Similar transmission/reception processing is performed.
- the video signal processing unit ex455 uses the video signal stored in the memory unit ex467 or the video signal input from the camera unit ex465 to perform each of the above-described embodiments.
- the moving picture coding method shown in the embodiment is used for compression coding, and the coded video data is sent to the multiplexing/demultiplexing unit ex453.
- the audio signal processing unit ex454 encodes the audio signal collected by the audio input unit ex456 while the video unit or the still image is being captured by the camera unit ex465, and sends the encoded audio data to the multiplexing/demultiplexing unit ex453.
- the multiplexing/demultiplexing unit ex453 multiplexes the coded video data and the coded audio data by a predetermined method, and the modulation/demodulation unit (modulation/demodulation circuit unit) ex452 and the transmission/reception unit ex451 perform modulation processing and conversion. It is processed and transmitted via the antenna ex450.
- the predetermined method may be predetermined.
- the multiplexing/demultiplexing unit ex453 performs the multiplexing.
- the multiplexed data is divided into a bit stream of video data and a bit stream of audio data, and the encoded video data is supplied to the video signal processing unit ex455 via the synchronization bus ex470.
- the encoded audio data is supplied to the audio signal processing unit ex454.
- the video signal processing unit ex455 decodes the video signal by the moving picture decoding method corresponding to the moving picture coding method shown in each of the above embodiments, and is linked from the display unit ex458 via the display control unit ex459.
- the video or still image included in the moving image file is displayed.
- the audio signal processing unit ex454 decodes the audio signal, and the audio output unit ex457 outputs the audio.
- audio playback may not be socially suitable depending on the user's situation. Therefore, as the initial value, it is preferable to reproduce only the video data without reproducing the audio signal, and the sound may be reproduced in synchronization only when the user performs an operation such as clicking on the video data. ..
- the smartphone ex115 has been described here as an example, in addition to the transmission/reception type terminal having both the encoder and the decoder as the terminal, the transmission terminal having only the encoder and the reception having only the decoder are provided. Another implementation format called a terminal is possible.
- the description has been made assuming that the multiplexed data in which the audio data is multiplexed with the video data is received or transmitted.
- character data related to video may be multiplexed in the multiplexed data.
- the video data itself may be received or transmitted instead of the multiplexed data.
- the main control unit ex460 including the CPU has been described as controlling the encoding or decoding process, but various terminals often include a GPU. Therefore, a configuration in which a large area is collectively processed by utilizing the performance of the GPU by a memory shared by the CPU and the GPU or a memory whose address is managed so as to be commonly used may be used. As a result, the coding time can be shortened, real-time performance can be secured, and low delay can be realized. In particular, it is efficient to collectively perform the motion search, deblock filter, SAO (Sample Adaptive Offset), and conversion/quantization processing in units of pictures or the like in the GPU instead of the CPU.
- SAO Sample Adaptive Offset
- the present disclosure can be used for, for example, a television receiver, a digital video recorder, a car navigation, a mobile phone, a digital camera, a digital video camera, a video conference system, an electronic mirror, or the like.
- Encoding device 102 Dividing unit 104 Subtracting unit 106 Transforming unit 108 Quantizing unit 110 Entropy encoding unit 112, 204 Inverse quantizing unit 114, 206 Inverse transforming unit 116, 208 Adder unit 118, 210 Block memory 120, 212 Loop filter Unit 122, 214 frame memory 124, 216 intra prediction unit 126, 218 inter prediction unit 128, 220 prediction control unit 200 decoding device 202 entropy decoding unit 1201 boundary determination unit 1202, 1204, 1206 switch 1203 filter determination unit 1205 filter processing unit 1207 Filter characteristic determination unit 1208 Processing determination unit a1, b1 Processor a2, b2 Memory
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
Description
まず、実施の形態に係る符号化装置を説明する。図1は、実施の形態に係る符号化装置100の機能構成を示すブロック図である。符号化装置100は、動画像をブロック単位で符号化する動画像符号化装置である。
図2は、符号化装置100による全体的な符号化処理の一例を示すフローチャートである。
分割部102は、入力動画像に含まれる各ピクチャを複数のブロックに分割し、各ブロックを減算部104に出力する。例えば、分割部102は、まず、ピクチャを固定サイズ(例えば128x128)のブロックに分割する。他の固定ブロックサイズが採用されてもよい。この固定サイズのブロックは、符号化ツリーユニット(CTU)と呼ばれることがある。そして、分割部102は、例えば再帰的な四分木(quadtree)及び/又は二分木(binary tree)ブロック分割に基づいて、固定サイズのブロックの各々を可変サイズ(例えば64x64以下)のブロックに分割する。すなわち、分割部102は、分割パターンを選択する。この可変サイズのブロックは、符号化ユニット(CU)、予測ユニット(PU)あるいは変換ユニット(TU)と呼ばれることがある。なお、種々の処理例では、CU、PU及びTUは区別される必要はなく、ピクチャ内の一部又はすべてのブロックがCU、PU、TUの処理単位となってもよい。
ピクチャを並列にデコードするために、ピクチャはスライス単位またはタイル単位で構成される場合がある。スライス単位またはタイル単位からなるピクチャは、分割部102によって構成されてもよい。
減算部104は、分割部102から入力され、分割部102によって分割されたブロック単位で、原信号(原サンプル)から予測信号(以下に示す予測制御部128から入力される予測サンプル)を減算する。つまり、減算部104は、符号化対象ブロック(以下、カレントブロックという)の予測誤差(残差ともいう)を算出する。そして、減算部104は、算出された予測誤差(残差)を変換部106に出力する。
変換部106は、空間領域の予測誤差を周波数領域の変換係数に変換し、変換係数を量子化部108に出力する。具体的には、変換部106は、例えば空間領域の予測誤差に対して所定の離散コサイン変換(DCT)又は離散サイン変換(DST)を行う。所定のDCT又はDSTは、予め定められていてもよい。
量子化部108は、変換部106から出力された変換係数を量子化する。具体的には、量子化部108は、カレントブロックの変換係数を所定の走査順序で走査し、走査された変換係数に対応する量子化パラメータ(QP)に基づいて当該変換係数を量子化する。そして、量子化部108は、カレントブロックの量子化された変換係数(以下、量子化係数という)をエントロピー符号化部110及び逆量子化部112に出力する。所定の走査順序は、予め定められていてもよい。
エントロピー符号化部110は、量子化部108から入力された量子化係数に基づいて符号化信号(符号化ビットストリーム)を生成する。具体的には、エントロピー符号化部110は、例えば、量子化係数を二値化し、二値信号を算術符号化し、圧縮されたビットストリームまたはシーケンスを出力する。
逆量子化部112は、量子化部108から入力された量子化係数を逆量子化する。具体的には、逆量子化部112は、カレントブロックの量子化係数を所定の走査順序で逆量子化する。そして、逆量子化部112は、カレントブロックの逆量子化された変換係数を逆変換部114に出力する。所定の走査順序は、予め定められていてもよい。
逆変換部114は、逆量子化部112から入力された変換係数を逆変換することにより予測誤差(残差)を復元する。具体的には、逆変換部114は、変換係数に対して、変換部106による変換に対応する逆変換を行うことにより、カレントブロックの予測誤差を復元する。そして、逆変換部114は、復元された予測誤差を加算部116に出力する。
加算部116は、逆変換部114から入力された予測誤差と予測制御部128から入力された予測サンプルとを加算することによりカレントブロックを再構成する。そして、加算部116は、再構成されたブロックをブロックメモリ118及びループフィルタ部120に出力する。再構成ブロックは、ローカル復号ブロックと呼ばれることもある。
ブロックメモリ118は、例えば、イントラ予測で参照されるブロックであって符号化対象ピクチャ(カレントピクチャという)内のブロックを格納するための記憶部である。具体的には、ブロックメモリ118は、加算部116から出力された再構成ブロックを格納する。
フレームメモリ122は、例えば、インター予測に用いられる参照ピクチャを格納するための記憶部であり、フレームバッファと呼ばれることもある。具体的には、フレームメモリ122は、ループフィルタ部120によってフィルタされた再構成ブロックを格納する。
ループフィルタ部120は、加算部116によって再構成されたブロックにループフィルタを施し、フィルタされた再構成ブロックをフレームメモリ122に出力する。ループフィルタとは、符号化ループ内で用いられるフィルタ(インループフィルタ)であり、例えば、デブロッキング・フィルタ(DFまたはDBF)、サンプルアダプティブオフセット(SAO)及びアダプティブループフィルタ(ALF)などを含む。
デブロッキング・フィルタでは、ループフィルタ部120は、再構成画像のブロック境界にフィルタ処理を行うことによって、そのブロック境界に生じる歪みを減少させる。
q’1=(p0+q0+q1+q2+2)/4
q’2=(p0+q0+q1+3×q2+2×q3+4)/8
図11は、符号化装置100の予測処理部で行われる処理の一例を示すフローチャートである。なお、予測処理部は、イントラ予測部124、インター予測部126、および予測制御部128の全てまたは一部の構成要素からなる。
イントラ予測部124は、ブロックメモリ118に格納されたカレントピクチャ内のブロックを参照してカレントブロックのイントラ予測(画面内予測ともいう)を行うことで、予測信号(イントラ予測信号)を生成する。具体的には、イントラ予測部124は、カレントブロックに隣接するブロックのサンプル(例えば輝度値、色差値)を参照してイントラ予測を行うことでイントラ予測信号を生成し、イントラ予測信号を予測制御部128に出力する。
インター予測部126は、フレームメモリ122に格納された参照ピクチャであってカレントピクチャとは異なる参照ピクチャを参照してカレントブロックのインター予測(画面間予測ともいう)を行うことで、予測信号(インター予測信号)を生成する。インター予測は、カレントブロック又はカレントブロック内のカレントサブブロック(例えば4x4ブロック)の単位で行われる。例えば、インター予測部126は、カレントブロック又はカレントサブブロックについて参照ピクチャ内で動き探索(motion estimation)を行い、そのカレントブロック又はカレントサブブロックに最も一致する参照ブロック又はサブブロックを見つける。そして、インター予測部126は、参照ブロック又はサブブロックからカレントブロック又はサブブロックへの動き又は変化を補償する動き情報(例えば動きベクトル)を取得する。インター予測部126は、その動き情報に基づいて、動き補償(または動き予測)を行い、カレントブロック又はサブブロックのインター予測信号を生成する。インター予測部126は、生成されたインター予測信号を予測制御部128に出力する。
図15は、インター予測の基本的な流れの一例を示すフローチャートである。
図16は、動きベクトル導出の一例を示すフローチャートである。
図18は、動きベクトル導出の他の例を示すフローチャートである。MV導出のモード、すなわちインター予測モードには、複数のモードがあり、大きく分けて、差分MVを符号化するモードと、差分動きベクトルを符号化しないモードとがある。差分MVを符号化しないモードには、マージモード、FRUCモード、およびアフィンモード(具体的には、アフィンマージモード)がある。これらのモードの詳細については、後述するが、簡単には、マージモードは、周辺の符号化済みブロックから動きベクトルを選択することによって、カレントブロックのMVを導出するモードであり、FRUCモードは、符号化済み領域間で探索を行うことによって、カレントブロックのMVを導出するモードである。また、アフィンモードは、アフィン変換を想定して、カレントブロックを構成する複数のサブブロックそれぞれの動きベクトルを、カレントブロックのMVとして導出するモードである。
ノーマルインターモードは、候補MVによって示される参照ピクチャの領域から、カレントブロックの画像に類似するブロックに基づいて、カレントブロックのMVを導出するインター予測モードである。また、このノーマルインターモードでは、差分MVが符号化される。
マージモードは、候補MVリストから候補MVをカレントブロックのMVとして選択することによって、そのMVを導出するインター予測モードである。
動き情報は符号化装置側から信号化されずに、復号装置側で導出されてもよい。なお、上述のように、H.265/HEVC規格で規定されたマージモードが用いられてもよい。また例えば、復号装置側で動き探索を行うことにより動き情報が導出されてもよい。実施の形態において、復号装置側では、カレントブロックの画素値を用いずに動き探索が行われる。
第1パターンマッチングでは、異なる2つの参照ピクチャ内の2つのブロックであってカレントブロックの動き軌道(motion trajectory)に沿う2つのブロックの間でパターンマッチングが行われる。したがって、第1パターンマッチングでは、上述した候補の評価値の算出のための所定の領域として、カレントブロックの動き軌道に沿う他の参照ピクチャ内の領域が用いられる。所定の領域は、予め定められていてもよい。
第2パターンマッチング(テンプレートマッチング)では、カレントピクチャ内のテンプレート(カレントピクチャ内でカレントブロックに隣接するブロック(例えば上及び/又は左隣接ブロック))と参照ピクチャ内のブロックとの間でパターンマッチングが行われる。したがって、第2パターンマッチングでは、上述した候補の評価値の算出のための所定の領域として、カレントピクチャ内のカレントブロックに隣接するブロックが用いられる。
次に、複数の隣接ブロックの動きベクトルに基づいてサブブロック単位で動きベクトルを導出するアフィンモードについて説明する。このモードは、アフィン動き補償予測(affine motion compensation prediction)モードと呼ばれることがある。
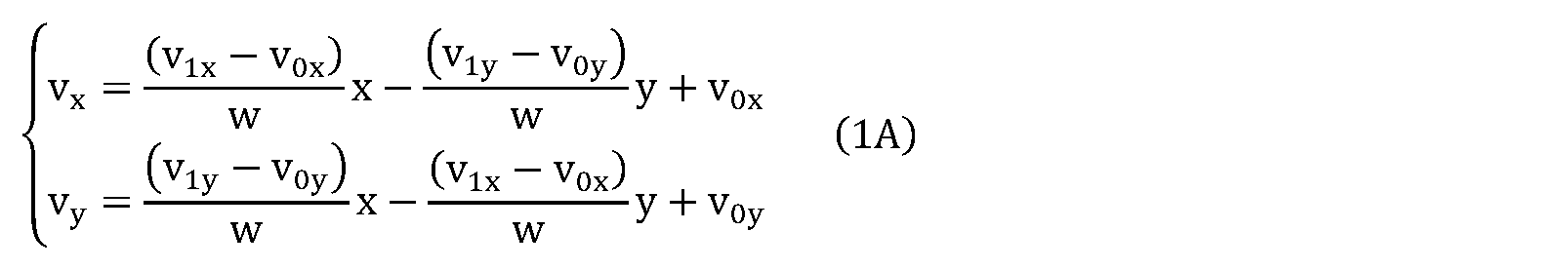
図25Bは、3つの制御ポイントを有するアフィンモードにおけるサブブロック単位の動きベクトルの導出の一例を説明するための概念図である。図25Bにおいて、カレントブロックは、16の4x4サブブロックを含む。ここでは、隣接ブロックの動きベクトルに基づいてカレントブロックの左上角制御ポイントの動きベクトルv0が導出され、同様に、隣接ブロックの動きベクトルに基づいてカレントブロックの右上角制御ポイントの動きベクトルv1、隣接ブロックの動きベクトルに基づいてカレントブロックの左下角制御ポイントの動きベクトルv2が導出される。そして、以下の式(1B)により、3つの動きベクトルv0、v1及びv2が投影されてもよく、カレントブロック内の各サブブロックの動きベクトル(vx,vy)が導出されてもよい。
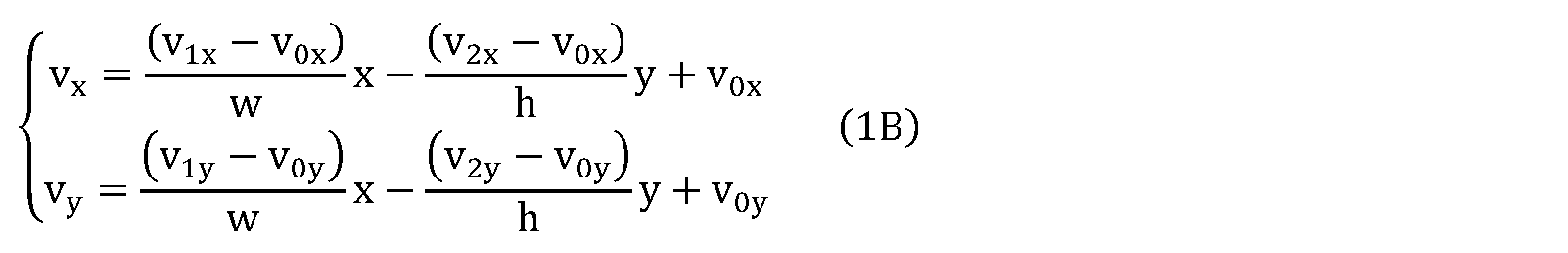
図26A、図26Bおよび図26Cは、アフィンマージモードを説明するための概念図である。
図28Aは、2つの制御ポイントを有するアフィンインターモードを説明するための概念図である。
異なる制御ポイント数(例えば、2つと3つ)のアフィンモードをCUレベルで切り替えて信号化する場合、符号化済みブロックとカレントブロックで制御ポイントの数が異なる場合がある。図30Aおよび図30Bは、符号化済みブロックとカレントブロックで制御ポイントの数が異なる場合の、制御ポイントの予測ベクトル導出方法を説明するための概念図である。
図31Aは、マージモードおよびDMVRの関係を示すフローチャートである。
動き補償では、予測画像を生成し、その予測画像を補正するモードがある。そのモードは、例えば、後述のBIOおよびOBMCである。
動き探索により得られたカレントブロックの動き情報だけでなく、隣接ブロックの動き情報も用いて、インター予測信号が生成されてもよい。具体的には、(参照ピクチャ内の)動き探索により得られた動き情報に基づく予測信号と、(カレントピクチャ内の)隣接ブロックの動き情報に基づく予測信号と、を重み付け加算することにより、カレントブロック内のサブブロック単位でインター予測信号が生成されてもよい。このようなインター予測(動き補償)は、OBMC(overlapped block motion compensation)と呼ばれることがある。
次に、動きベクトルを導出する方法について説明する。まず、等速直線運動を仮定したモデルに基づいて動きベクトルを導出するモードについて説明する。このモードは、BIO(bi-directional optical flow)モードと呼ばれることがある。
次に、LIC(local illumination compensation)処理を用いて予測画像(予測)を生成するモードの一例について説明する。
予測制御部128は、イントラ予測信号(イントラ予測部124から出力される信号)及びインター予測信号(インター予測部126から出力される信号)のいずれかを選択し、選択した信号を予測信号として減算部104及び加算部116に出力する。
図40は、符号化装置100の実装例を示すブロック図である。符号化装置100は、プロセッサa1及びメモリa2を備える。例えば、図1に示された符号化装置100の複数の構成要素は、図40に示されたプロセッサa1及びメモリa2によって実装される。
次に、例えば上記の符号化装置100から出力された符号化信号(符号化ビットストリーム)を復号可能な復号装置について説明する。図41は、実施の形態に係る復号装置200の機能構成を示すブロック図である。復号装置200は、動画像をブロック単位で復号する動画像復号装置である。
図42は、復号装置200による全体的な復号処理の一例を示すフローチャートである。
エントロピー復号部202は、符号化ビットストリームをエントロピー復号する。具体的には、エントロピー復号部202は、例えば、符号化ビットストリームから二値信号に算術復号する。そして、エントロピー復号部202は、二値信号を多値化(debinarize)する。エントロピー復号部202は、ブロック単位で量子化係数を逆量子化部204に出力する。エントロピー復号部202は、実施の形態におけるイントラ予測部216、インター予測部218および予測制御部220に、符号化ビットストリーム(図1参照)に含まれている予測パラメータを出力してもよい。イントラ予測部216、インター予測部218および予測制御部220は、符号化装置側におけるイントラ予測部124、インター予測部126および予測制御部128で行われる処理と同じ予測処理を実行することができる。
逆量子化部204は、エントロピー復号部202からの入力である復号対象ブロック(以下、カレントブロックという)の量子化係数を逆量子化する。具体的には、逆量子化部204は、カレントブロックの量子化係数の各々について、当該量子化係数に対応する量子化パラメータに基づいて当該量子化係数を逆量子化する。そして、逆量子化部204は、カレントブロックの逆量子化された量子化係数(つまり変換係数)を逆変換部206に出力する。
逆変換部206は、逆量子化部204からの入力である変換係数を逆変換することにより予測誤差を復元する。
加算部208は、逆変換部206からの入力である予測誤差と予測制御部220からの入力である予測サンプルとを加算することによりカレントブロックを再構成する。そして、加算部208は、再構成されたブロックをブロックメモリ210及びループフィルタ部212に出力する。
ブロックメモリ210は、イントラ予測で参照されるブロックであって復号対象ピクチャ(以下、カレントピクチャという)内のブロックを格納するための記憶部である。具体的には、ブロックメモリ210は、加算部208から出力された再構成ブロックを格納する。
ループフィルタ部212は、加算部208によって再構成されたブロックにループフィルタを施し、フィルタされた再構成ブロックをフレームメモリ214及び表示装置等に出力する。
フレームメモリ214は、インター予測に用いられる参照ピクチャを格納するための記憶部であり、フレームバッファと呼ばれることもある。具体的には、フレームメモリ214は、ループフィルタ部212によってフィルタされた再構成ブロックを格納する。
図43は、復号装置200の予測処理部で行われる処理の一例を示すフローチャートである。なお、予測処理部は、イントラ予測部216、インター予測部218、および予測制御部220の全てまたは一部の構成要素からなる。
イントラ予測部216は、符号化ビットストリームから読み解かれたイントラ予測モードに基づいて、ブロックメモリ210に格納されたカレントピクチャ内のブロックを参照してイントラ予測を行うことで、予測信号(イントラ予測信号)を生成する。具体的には、イントラ予測部216は、カレントブロックに隣接するブロックのサンプル(例えば輝度値、色差値)を参照してイントラ予測を行うことでイントラ予測信号を生成し、イントラ予測信号を予測制御部220に出力する。
インター予測部218は、フレームメモリ214に格納された参照ピクチャを参照して、カレントブロックを予測する。予測は、カレントブロック又はカレントブロック内のサブブロック(例えば4x4ブロック)の単位で行われる。例えば、インター予測部218は、符号化ビットストリーム(例えば、エントロピー復号部202から出力される予測パラメータ)から読み解かれた動き情報(例えば動きベクトル)を用いて動き補償を行うことでカレントブロック又はサブブロックのインター予測信号を生成し、インター予測信号を予測制御部220に出力する。
符号化ビットストリームから読み解かれた情報がノーマルインターモードを適用することを示す場合、インター予測部218は、符号化ストリームから読み解かれた情報に基づいて、MVを導出し、そのMVを用いて動き補償(予測)を行う。
予測制御部220は、イントラ予測信号及びインター予測信号のいずれかを選択し、選択した信号を予測信号として加算部208に出力する。全体的に、復号装置側の予測制御部220、イントラ予測部216およびインター予測部218の構成、機能、および処理は、符号化装置側の予測制御部128、イントラ予測部124およびインター予測部126の構成、機能、および処理と対応していてもよい。
図46は、復号装置200の実装例を示すブロック図である。復号装置200は、プロセッサb1及びメモリb2を備える。例えば、図41に示された復号装置200の複数の構成要素は、図46に示されたプロセッサb1及びメモリb2によって実装される。
各用語は一例として、以下のような定義であってもよい。
次に、実施の形態における補間フィルタ決定処理の具体例について図47~図50を参照しながら説明する。図47は、実施の形態における補間フィルタ決定処理の一例を示すフローチャートである。補足すると、予測処理部は、例えば図15に示すように、カレントブロックの動きベクトル(MV)を決定し、決定したMVに基づいて動き補償を行うことによって、その予測画像を生成する。動き補償は、まず、MVに基づいて、整数画素単位の第1の予測画像を生成し、次に、補間フィルタを用いて、前記第1の予測画像に含まれる複数の整数画素の間の小数画素位置の値(サンプル)を補間することで、第2の予測画像を生成する。言い換えると、補間フィルタ決定処理は、動き補償処理に含まれる。
本開示は、サイズに適応する補間フィルタ決定プロセスをインター予測処理に導入する。このプロセスは、インター予測プロセスのワーストケースにおけるメモリ帯域幅を削減し、アフィン動き補償のための処理数に関してワーストケースにおける複雑さを削減する。
以上の各実施の形態において、機能的又は作用的なブロックの各々は、通常、MPU(micro proccessing unit)及びメモリ等によって実現可能である。また、機能ブロックの各々による処理は、ROM等の記録媒体に記録されたソフトウェア(プログラム)を読み出して実行するプロセッサなどのプログラム実行部として実現されてもよい。当該ソフトウェアは、配布されてもよい。当該ソフトウェアは、半導体メモリなどの様々な記録媒体に記録されてもよい。なお、各機能ブロックをハードウェア(専用回路)によって実現することも可能である。ハードウェア及びソフトウェアの様々な組み合わせが採用され得る。
図51は、コンテンツ配信サービスを実現する適切なコンテンツ供給システムex100の全体構成を示す図である。通信サービスの提供エリアを所望の大きさに分割し、各セル内にそれぞれ、図示された例における固定無線局である基地局ex106、ex107、ex108、ex109、ex110が設置されている。
また、ストリーミングサーバex103は複数のサーバ又は複数のコンピュータであって、データを分散して処理したり記録したり配信するものであってもよい。例えば、ストリーミングサーバex103は、CDN(Contents Delivery Network)により実現され、世界中に分散された多数のエッジサーバとエッジサーバ間をつなぐネットワークによりコンテンツ配信が実現されていてもよい。CDNでは、クライアントに応じて物理的に近いエッジサーバが動的に割り当てられ得る。そして、当該エッジサーバにコンテンツがキャッシュ及び配信されることで遅延を減らすことができる。また、いくつかのタイプのエラーが発生した場合又はトラフィックの増加などにより通信状態が変わる場合に複数のエッジサーバで処理を分散したり、他のエッジサーバに配信主体を切り替えたり、障害が生じたネットワークの部分を迂回して配信を続けることができるので、高速かつ安定した配信が実現できる。
互いにほぼ同期した複数のカメラex113及び/又はスマートフォンex115などの端末により撮影された異なるシーン、又は、同一シーンを異なるアングルから撮影した画像或いは映像を統合して利用することが増えてきている。各端末で撮影した映像は、別途取得した端末間の相対的な位置関係、又は、映像に含まれる特徴点が一致する領域などに基づいて統合され得る。
コンテンツの切り替えに関して、図52に示す、上記各実施の形態で示した動画像符号化方法を応用して圧縮符号化されたスケーラブルなストリームを用いて説明する。サーバは、個別のストリームとして内容は同じで質の異なるストリームを複数有していても構わないが、図示するようにレイヤに分けて符号化を行うことで実現される時間的/空間的スケーラブルなストリームの特徴を活かして、コンテンツを切り替える構成であってもよい。つまり、復号側が性能という内的要因と通信帯域の状態などの外的要因とに応じてどのレイヤを復号するかを決定することで、復号側は、低解像度のコンテンツと高解像度のコンテンツとを自由に切り替えて復号できる。例えばユーザが移動中にスマートフォンex115で視聴していた映像の続きを、例えば帰宅後にインターネットTV等の機器で視聴したい場合には、当該機器は、同じストリームを異なるレイヤまで復号すればよいので、サーバ側の負担を軽減できる。
図54は、コンピュータex111等におけるwebページの表示画面例を示す図である。図55は、スマートフォンex115等におけるwebページの表示画面例を示す図である。図54及び図55に示すようにwebページが、画像コンテンツへのリンクであるリンク画像を複数含む場合があり、閲覧するデバイスによってその見え方は異なっていてもよい。画面上に複数のリンク画像が見える場合には、ユーザが明示的にリンク画像を選択するまで、又は画面の中央付近にリンク画像が近付く或いはリンク画像の全体が画面内に入るまで、表示装置(復号装置)は、リンク画像として各コンテンツが有する静止画又はIピクチャを表示してもよいし、複数の静止画又はIピクチャ等でgifアニメのような映像を表示してもよいし、ベースレイヤのみを受信し、映像を復号及び表示してもよい。
また、車の自動走行又は走行支援のため2次元又は3次元の地図情報などのような静止画又は映像データを送受信する場合、受信端末は、1以上のレイヤに属する画像データに加えて、メタ情報として天候又は工事の情報なども受信し、これらを対応付けて復号してもよい。なお、メタ情報は、レイヤに属してもよいし、単に画像データと多重化されてもよい。
また、コンテンツ供給システムex100では、映像配信業者による高画質で長時間のコンテンツのみならず、個人による低画質で短時間のコンテンツのユニキャスト、又はマルチキャスト配信が可能である。このような個人のコンテンツは今後も増加していくと考えられる。個人コンテンツをより優れたコンテンツにするために、サーバは、編集処理を行ってから符号化処理を行ってもよい。これは、例えば、以下のような構成を用いて実現できる。
また、これらの符号化又は復号処理は、一般的に各端末が有するLSIex500において処理される。LSI(large scale integration circuitry)ex500(図51参照)は、ワンチップであっても複数チップからなる構成であってもよい。なお、動画像符号化又は復号用のソフトウェアをコンピュータex111等で読み取り可能な何らかの記録メディア(CD-ROM、フレキシブルディスク、又はハードディスクなど)に組み込み、そのソフトウェアを用いて符号化又は復号処理を行ってもよい。さらに、スマートフォンex115がカメラ付きである場合には、そのカメラで取得した動画データを送信してもよい。このときの動画データはスマートフォンex115が有するLSIex500で符号化処理されたデータであってもよい。
図56は、図51に示されたスマートフォンex115のさらに詳細を示す図である。また、図57は、スマートフォンex115の構成例を示す図である。スマートフォンex115は、基地局ex110との間で電波を送受信するためのアンテナex450と、映像及び静止画を撮ることが可能なカメラ部ex465と、カメラ部ex465で撮像した映像、及びアンテナex450で受信した映像等が復号されたデータを表示する表示部ex458とを備える。スマートフォンex115は、さらに、タッチパネル等である操作部ex466と、音声又は音響を出力するためのスピーカ等である音声出力部ex457と、音声を入力するためのマイク等である音声入力部ex456と、撮影した映像或いは静止画、録音した音声、受信した映像或いは静止画、メール等の符号化されたデータ、又は、復号化されたデータを保存可能なメモリ部ex467と、ユーザを特定し、ネットワークをはじめ各種データへのアクセスの認証をするためのSIMex468とのインタフェース部であるスロット部ex464とを備える。なお、メモリ部ex467の代わりに外付けメモリが用いられてもよい。
102 分割部
104 減算部
106 変換部
108 量子化部
110 エントロピー符号化部
112、204 逆量子化部
114、206 逆変換部
116、208 加算部
118、210 ブロックメモリ
120、212 ループフィルタ部
122、214 フレームメモリ
124、216 イントラ予測部
126、218 インター予測部
128、220 予測制御部
200 復号装置
202 エントロピー復号部
1201 境界判定部
1202、1204、1206 スイッチ
1203 フィルタ判定部
1205 フィルタ処理部
1207 フィルタ特性決定部
1208 処理判定部
a1、b1 プロセッサ
a2、b2 メモリ
Claims (14)
- 画像に含まれる符号化対象ブロックを符号化する符号化装置であって、
回路と、
前記回路に接続されたメモリと、を備え、
前記回路は、動作において、
動きベクトルに基づいて、整数画素単位の第1の予測画像を生成し、
補間フィルタを用いて、前記第1の予測画像に含まれる複数の整数画素の間の小数画素位置の値を補間することで、第2の予測画像を生成し、
前記第2の予測画像に基づいて、前記符号化対象ブロックを符号化し、
前記補間フィルタの使用では、第1補間フィルタと、前記第1補間フィルタとタップ数が異なる第2補間フィルタとが切り替えて用いられる、
符号化装置。 - 前記補間フィルタの切り替えにおいて、
前記符号化対象ブロックのサイズが閾値サイズよりも大きいか否かを判定し、
前記符号化対象ブロックのサイズが前記閾値サイズよりも大きい場合、前記符号化対象ブロックの動き補償に用いる補間フィルタを前記第1補間フィルタと決定し、
前記符号化対象ブロックのサイズが前記閾値サイズよりも大きくない場合、前記符号化対象ブロックの動き補償に用いる補間フィルタを前記第2補間フィルタと決定し、
決定された前記補間フィルタを用いて、前記第2の予測画像を生成し、
前記第2補間フィルタは、前記第1補間フィルタよりも短いタップを有する、
請求項1に記載の符号化装置。 - 前記第1補間フィルタは、8タップフィルタである、
請求項2に記載の符号化装置。 - 前記第2補間フィルタは、6タップフィルタである、
請求項2又は3に記載の符号化装置。 - 前記閾値サイズは、4x4画素サイズである、
請求項2~4のいずれか1項に記載の符号化装置。 - 前記符号化対象ブロックは、アフィンモードのサブブロックである、
請求項1~5のいずれか1項に記載の符号化装置。 - 画像に含まれる復号対象ブロックを復号する復号装置であって、
回路と、
前記回路に接続されたメモリと、を備え、
前記回路は、動作において、
動きベクトルに基づいて、整数画素単位の第1の予測画像を生成し、
補間フィルタを用いて、前記第1の予測画像に含まれる複数の整数画素の間の小数画素位置の値を補間することで、第2の予測画像を生成し、
前記第2の予測画像に基づいて、前記復号対象ブロックを復号し、
前記補間フィルタの使用では、第1補間フィルタと、前記第1補間フィルタとタップ数が異なる第2補間フィルタとが切り替えて用いられる、
復号装置。 - 前記補間フィルタの切り替えにおいて、
前記復号対象ブロックのサイズが閾値サイズよりも大きいか否かを判定し、
前記復号対象ブロックのサイズが前記閾値サイズよりも大きい場合、前記復号対象ブロックの動き補償に用いる補間フィルタを前記第1補間フィルタと決定し、
前記復号対象ブロックのサイズが前記閾値サイズよりも大きくない場合、前記復号対象ブロックの動き補償に用いる補間フィルタを前記第2補間フィルタと決定し、
決定された前記補間フィルタを用いて、前記前記第2の予測画像を生成し、
前記第2補間フィルタは、前記第1補間フィルタよりも短いタップを有する、
請求項7に記載の復号装置。 - 前記第1補間フィルタは、8タップフィルタである、
請求項8に記載の復号装置。 - 前記第2補間フィルタは、6タップフィルタである、
請求項8又は9に記載の復号装置。 - 前記閾値サイズは、4x4画素サイズである、
請求項8~10のいずれか1項に記載の復号装置。 - 前記復号対象ブロックは、アフィンモードのサブブロックである、
請求項7~11のいずれか1項に記載の復号装置。 - 画像の符号化対象ブロックを符号化する符号化方法であって、
動きベクトルに基づいて、整数画素単位の第1の予測画像を生成し、
補間フィルタを用いて、前記第1の予測画像に含まれる複数の整数画素の間の小数画素位置の値を補間することで、第2の予測画像を生成し、
前記第2の予測画像に基づいて、前記符号化対象ブロックを符号化し、
前記補間フィルタの使用では、第1補間フィルタと、前記第1補間フィルタとタップ数が異なる第2補間フィルタとが切り替えて用いられる、
符号化方法。 - 画像の復号対象ブロックを復号する復号方法であって、
動きベクトルに基づいて、整数画素単位の第1の予測画像を生成し、
補間フィルタを用いて、前記第1の予測画像に含まれる複数の整数画素の間の小数画素位置の値を補間することで、第2の予測画像を生成し、
前記第2の予測画像に基づいて、前記復号対象ブロックを復号し、
前記補間フィルタの使用では、第1補間フィルタと、前記第1補間フィルタとタップ数が異なる第2補間フィルタとが切り替えて用いられる、
復号方法。
Priority Applications (11)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020217013990A KR20210107624A (ko) | 2018-12-31 | 2019-12-23 | 부호화 장치, 복호 장치, 부호화 방법, 및 복호 방법 |
| EP19907263.8A EP3907990A4 (en) | 2018-12-31 | 2019-12-23 | ENCODING DEVICE, DECODING DEVICE, ENCODING METHOD AND DECODING METHOD |
| JP2020563865A JPWO2020141591A1 (ja) | 2018-12-31 | 2019-12-23 | 符号化装置、復号装置、符号化方法、及び復号方法 |
| CA3119646A CA3119646A1 (en) | 2018-12-31 | 2019-12-23 | Encoder, decoder, encoding method, and decoding method |
| MX2021005170A MX2021005170A (es) | 2018-12-31 | 2019-12-23 | Dispositivo de codificacion, dispositivo de decodificacion, metodo de codificacion y metodo de decodificacion. |
| BR112021009596-9A BR112021009596A2 (pt) | 2018-12-31 | 2019-12-23 | codificador, decodificador, método de codificação, e método de decodificação |
| CN201980075837.3A CN113056909A (zh) | 2018-12-31 | 2019-12-23 | 编码装置、解码装置、编码方法和解码方法 |
| US17/321,834 US11394968B2 (en) | 2018-12-31 | 2021-05-17 | Encoder that encodes a current block based on a prediction image generated using an interpolation filter |
| US17/837,171 US11722662B2 (en) | 2018-12-31 | 2022-06-10 | Encoder that encodes a current block based on a prediction image generated using an interpolation filter |
| JP2023050266A JP2023068203A (ja) | 2018-12-31 | 2023-03-27 | 復号装置及び復号方法 |
| US18/142,166 US12081749B2 (en) | 2018-12-31 | 2023-05-02 | Encoder that encodes a current block based on a prediction image generated using an interpolation filter |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862786935P | 2018-12-31 | 2018-12-31 | |
| US62/786935 | 2018-12-31 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/321,834 Continuation US11394968B2 (en) | 2018-12-31 | 2021-05-17 | Encoder that encodes a current block based on a prediction image generated using an interpolation filter |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020141591A1 true WO2020141591A1 (ja) | 2020-07-09 |
Family
ID=71406838
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/050438 WO2020141591A1 (ja) | 2018-12-31 | 2019-12-23 | 符号化装置、復号装置、符号化方法、及び復号方法 |
Country Status (10)
| Country | Link |
|---|---|
| US (3) | US11394968B2 (ja) |
| EP (1) | EP3907990A4 (ja) |
| JP (2) | JPWO2020141591A1 (ja) |
| KR (1) | KR20210107624A (ja) |
| CN (1) | CN113056909A (ja) |
| BR (1) | BR112021009596A2 (ja) |
| CA (1) | CA3119646A1 (ja) |
| MX (1) | MX2021005170A (ja) |
| TW (2) | TWI835963B (ja) |
| WO (1) | WO2020141591A1 (ja) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7176094B2 (ja) * | 2019-03-11 | 2022-11-21 | パナソニック インテレクチュアル プロパティ コーポレーション オブ アメリカ | 符号化装置及び符号化方法 |
| WO2020255367A1 (ja) * | 2019-06-21 | 2020-12-24 | 日本電信電話株式会社 | 符号化装置、符号化方法及びプログラム |
| US11570479B2 (en) * | 2020-04-24 | 2023-01-31 | Samsung Electronics Co., Ltd. | Camera module, image processing device and image compression method |
| WO2023200381A1 (en) * | 2022-04-12 | 2023-10-19 | Telefonaktiebolaget Lm Ericsson (Publ) | Enhanced interpolation filtering |
| WO2024117693A1 (ko) * | 2022-11-29 | 2024-06-06 | 현대자동차주식회사 | 아핀 모델 기반의 예측에서 움직임 보상 필터를 적응적으로 이용하는 비디오 코딩을 위한 방법 및 장치 |
| WO2024119488A1 (zh) * | 2022-12-09 | 2024-06-13 | Oppo广东移动通信有限公司 | 视频编解码方法、解码器、编码器及计算机可读存储介质 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004007337A (ja) * | 2002-04-25 | 2004-01-08 | Sony Corp | 画像処理装置およびその方法 |
| JP2012134870A (ja) * | 2010-12-22 | 2012-07-12 | Nippon Telegr & Teleph Corp <Ntt> | 映像符号化方法、及び映像復号方法 |
| WO2019188464A1 (ja) * | 2018-03-30 | 2019-10-03 | ソニー株式会社 | 画像符号化装置、画像符号化方法、画像復号装置、および画像復号方法 |
Family Cites Families (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101369746B1 (ko) * | 2007-01-22 | 2014-03-07 | 삼성전자주식회사 | 적응적 보간 필터를 이용한 영상 부호화, 복호화 방법 및장치 |
| US9077971B2 (en) * | 2008-04-10 | 2015-07-07 | Qualcomm Incorporated | Interpolation-like filtering of integer-pixel positions in video coding |
| US8750378B2 (en) * | 2008-09-23 | 2014-06-10 | Qualcomm Incorporated | Offset calculation in switched interpolation filters |
| US20120230407A1 (en) * | 2011-03-11 | 2012-09-13 | General Instrument Corporation | Interpolation Filter Selection Using Prediction Index |
| WO2012125452A1 (en) * | 2011-03-16 | 2012-09-20 | General Instrument Corporation | Interpolation filter selection using prediction unit (pu) size |
| JP5711098B2 (ja) * | 2011-11-07 | 2015-04-30 | 日本電信電話株式会社 | 画像符号化方法,画像復号方法,画像符号化装置,画像復号装置およびそれらのプログラム |
| KR101641606B1 (ko) * | 2012-07-09 | 2016-07-21 | 니폰 덴신 덴와 가부시끼가이샤 | 화상 부호화 방법, 화상 복호 방법, 화상 부호화 장치, 화상 복호 장치, 화상 부호화 프로그램, 화상 복호 프로그램 및 기록매체 |
| US10986367B2 (en) | 2016-11-04 | 2021-04-20 | Lg Electronics Inc. | Inter prediction mode-based image processing method and apparatus therefor |
| US10609384B2 (en) * | 2017-09-21 | 2020-03-31 | Futurewei Technologies, Inc. | Restriction on sub-block size derivation for affine inter prediction |
| US10841610B2 (en) * | 2017-10-23 | 2020-11-17 | Avago Technologies International Sales Pte. Limited | Block size dependent interpolation filter selection and mapping |
| BR112020016432A2 (pt) * | 2018-02-14 | 2020-12-15 | Huawei Technologies Co., Ltd. | Método implementado em codificador e decodificador, dispositivo de codificação e de decodificação de vídeo, e meio legível por computador não transitório |
| TWI700922B (zh) * | 2018-04-02 | 2020-08-01 | 聯發科技股份有限公司 | 用於視訊編解碼系統中的子塊運動補償的視訊處理方法和裝置 |
| WO2020098644A1 (en) * | 2018-11-12 | 2020-05-22 | Beijing Bytedance Network Technology Co., Ltd. | Bandwidth control methods for inter prediction |
-
2019
- 2019-12-23 CA CA3119646A patent/CA3119646A1/en active Pending
- 2019-12-23 EP EP19907263.8A patent/EP3907990A4/en active Pending
- 2019-12-23 KR KR1020217013990A patent/KR20210107624A/ko unknown
- 2019-12-23 MX MX2021005170A patent/MX2021005170A/es unknown
- 2019-12-23 JP JP2020563865A patent/JPWO2020141591A1/ja active Pending
- 2019-12-23 WO PCT/JP2019/050438 patent/WO2020141591A1/ja unknown
- 2019-12-23 BR BR112021009596-9A patent/BR112021009596A2/pt unknown
- 2019-12-23 CN CN201980075837.3A patent/CN113056909A/zh active Pending
- 2019-12-24 TW TW108147401A patent/TWI835963B/zh active
- 2019-12-24 TW TW113106079A patent/TW202425641A/zh unknown
-
2021
- 2021-05-17 US US17/321,834 patent/US11394968B2/en active Active
-
2022
- 2022-06-10 US US17/837,171 patent/US11722662B2/en active Active
-
2023
- 2023-03-27 JP JP2023050266A patent/JP2023068203A/ja active Pending
- 2023-05-02 US US18/142,166 patent/US12081749B2/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004007337A (ja) * | 2002-04-25 | 2004-01-08 | Sony Corp | 画像処理装置およびその方法 |
| JP2012134870A (ja) * | 2010-12-22 | 2012-07-12 | Nippon Telegr & Teleph Corp <Ntt> | 映像符号化方法、及び映像復号方法 |
| WO2019188464A1 (ja) * | 2018-03-30 | 2019-10-03 | ソニー株式会社 | 画像符号化装置、画像符号化方法、画像復号装置、および画像復号方法 |
Non-Patent Citations (3)
| Title |
|---|
| ANONYMOUS: "Advanced video coding for generic audiovisual services", ITU-T STANDARD H.264, no. H.264 (04/17), 13 April 2017 (2017-04-13), pages 1 - 812, XP044201839 * |
| JINGYA LI , RU-LING LIAO , CHING SOON LIM : "CE2-related: Using shorter-tap filter for 4x4 sized partition", THE JOINT VIDEO EXPLORATION TEAM OF ISO/IEC JTC1/SC29/WG11 AND ITU-T SG.16 , no. JVET-M0310, 9 January 2019 (2019-01-09), Marrakech MA, pages 1 - 7, XP030201158 * |
| S N AKULA , ALSHIN A; ALSHINA (SAMSUNG) E; CHOI (SAMSUNG) K; CHOI N; CHOI W; JEONG S; KIM C; MIN J; PARK J H; PARK M; PARK M W; PI: "Description of SDR, HDR and 360° video coding technology proposal considering mobile application scenario by Samsung", 10. JVET MEETING; 20180410 - 20180420; SAN DIEGO; (THE JOINT VIDEO EXPLORATION TEAM OF ISO/IEC JTC1/SC29/WG11 AND ITU-T SG.16 ), 3 April 2018 (2018-04-03), pages 1 - 119, XP030151189 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3907990A1 (en) | 2021-11-10 |
| JP2023068203A (ja) | 2023-05-16 |
| TWI835963B (zh) | 2024-03-21 |
| EP3907990A4 (en) | 2022-03-23 |
| US11722662B2 (en) | 2023-08-08 |
| CA3119646A1 (en) | 2020-07-09 |
| US20220329793A1 (en) | 2022-10-13 |
| BR112021009596A2 (pt) | 2021-08-10 |
| US20230300327A1 (en) | 2023-09-21 |
| MX2021005170A (es) | 2021-07-15 |
| US20210274172A1 (en) | 2021-09-02 |
| TW202425641A (zh) | 2024-06-16 |
| JPWO2020141591A1 (ja) | 2021-10-21 |
| KR20210107624A (ko) | 2021-09-01 |
| TW202032984A (zh) | 2020-09-01 |
| US11394968B2 (en) | 2022-07-19 |
| US12081749B2 (en) | 2024-09-03 |
| CN113056909A (zh) | 2021-06-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2020166643A1 (ja) | 符号化装置、復号装置、符号化方法、および復号方法 | |
| JP7214846B2 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| JP7202394B2 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2020141591A1 (ja) | 符号化装置、復号装置、符号化方法、及び復号方法 | |
| WO2020116630A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| JP7189234B2 (ja) | 符号化装置及び復号装置 | |
| JP7194199B2 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2019240050A1 (ja) | 符号化装置、復号装置、符号化方法および復号方法 | |
| WO2020116402A1 (ja) | 符号化装置、復号装置、符号化方法、および復号方法 | |
| WO2020162536A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| JP2022168052A (ja) | 復号装置及び符号化装置 | |
| JP2023029589A (ja) | 符号化装置及び復号装置 | |
| WO2020162535A1 (ja) | 符号化装置、復号装置、符号化方法、および復号方法 | |
| WO2020162534A1 (ja) | 符号化装置、復号装置、符号化方法、および復号方法 | |
| WO2020116242A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2020050279A1 (ja) | 符号化装置、復号装置、符号化方法および復号方法 | |
| WO2020031902A1 (ja) | 符号化装置、復号装置、符号化方法および復号方法 | |
| JP2023001298A (ja) | 復号装置及び復号方法 | |
| JP7079377B2 (ja) | 符号化装置、復号装置、符号化方法、および復号方法 | |
| WO2021025080A1 (ja) | 符号化装置、復号装置、符号化方法、および復号方法 | |
| WO2020179715A1 (ja) | 符号化装置、復号装置、符号化方法及び復号方法 | |
| WO2020122232A1 (ja) | 符号化装置、復号装置、符号化方法、および復号方法 | |
| WO2020121879A1 (ja) | 符号化装置、復号装置、符号化方法、および復号方法 | |
| WO2020050281A1 (ja) | 符号化装置、復号装置、符号化方法、および復号方法 | |
| WO2020054781A1 (ja) | 符号化装置、復号装置、符号化方法および復号方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19907263 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 3119646 Country of ref document: CA |
|
| ENP | Entry into the national phase |
Ref document number: 2020563865 Country of ref document: JP Kind code of ref document: A |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112021009596 Country of ref document: BR |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2019907263 Country of ref document: EP Effective date: 20210802 |
|
| ENP | Entry into the national phase |
Ref document number: 112021009596 Country of ref document: BR Kind code of ref document: A2 Effective date: 20210518 |