WO2020004575A1 - 学習方法、混合率予測方法及び学習装置 - Google Patents
学習方法、混合率予測方法及び学習装置 Download PDFInfo
- Publication number
- WO2020004575A1 WO2020004575A1 PCT/JP2019/025676 JP2019025676W WO2020004575A1 WO 2020004575 A1 WO2020004575 A1 WO 2020004575A1 JP 2019025676 W JP2019025676 W JP 2019025676W WO 2020004575 A1 WO2020004575 A1 WO 2020004575A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- learning
- virtual
- data
- expression level
- cell
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
- G16B40/20—Supervised data analysis
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B25/00—ICT specially adapted for hybridisation; ICT specially adapted for gene or protein expression
- G16B25/10—Gene or protein expression profiling; Expression-ratio estimation or normalisation
Definitions
- the present disclosure relates to a learning method, a mixture ratio prediction method, and a learning device.
- the embodiments of the present invention have been made in view of the above points, and have as its object to accurately and quickly predict the mixing ratio of each cell type included in a cell group.
- the embodiment of the present invention is configured such that when cell group expression level data indicating the expression level of each gene of the cell group to be predicted is input, the mixing ratio of the cells included in the cell group is determined. Learning the machine learning model so as to output, wherein the learning step arbitrarily sets a virtual mixing ratio that is a virtual mixing ratio different from each other among a plurality of learning data, and performs gene expression in each type of cell. Based on the original data indicating the amount, a learning data set including data generated by obtaining a virtual expression amount that is a virtual gene expression amount corresponding to a virtual mixing ratio is used for each learning data.
- FIG. 4 is a diagram illustrating learning data used in the mixture ratio prediction device according to the embodiment of the present invention. It is a figure showing generation of learning data of a mixture rate prediction device in an embodiment of the invention. It is a figure showing an example of functional composition of a mixture rate prediction device in an embodiment of the invention.
- FIG. 2 is a diagram illustrating an example of a hardware configuration of a mixture ratio prediction device according to an embodiment of the present invention.
- 9 is a flowchart illustrating an example of a learning data set creation process. It is a flowchart which shows an example of a learning process. It is a flowchart which shows an example of a prediction process.
- FIG. 9 is a diagram showing a comparative example with a conventional method.
- the mixing ratio is a ratio of cell types contained in bulk cells.
- the bulk cell is a cell group in which a plurality of types of cells are mixed.
- the mixing ratio may be referred to as a content ratio or an existence ratio.
- a sample cell obtained by mixing a plurality of types of immune cells is used as a bulk cell.
- the bulk cells may include various cells other than immune cells (for example, cancer cells, muscle cells, nerve cells, and the like).
- the mixture ratio prediction device 10 for a predictor realized by, for example, a trained neural network, supplies data (hereinafter, “Bull cell gene expression amount” By inputting “bulk cell expression amount data”, data indicating the mixing ratio of each cell type included in the bulk cells (hereinafter, also referred to as “mixing ratio prediction data”) is output.
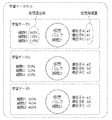
- the mixture ratio prediction device 10 learns a machine learning model using a learning data set including a plurality of learning data including a “virtual mixture ratio” and a “virtual expression amount”. As shown in FIG. 2, each learning data is virtual data generated for one virtual bulk. In the example shown in FIG. 2, the learning data set includes learning data 1 to 3, but the number of learning data included in the learning data set is not limited.
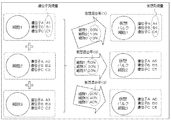
- FIG. 3 shows the concept of generation of learning data in the mixture ratio prediction device 10.
- the mixing ratio prediction device 10 generates virtual bulk cells, which are virtual bulk cells, using the gene expression levels of a plurality of cells in order to predict the mixing ratio of the cell types contained in the bulk cells.
- FIG. 3 generates “virtual bulk cell 1”, “virtual bulk cell 2”, and “virtual bulk cell 3” using “cell 1”, “cell 2”, and “cell 3”.
- the “virtual bulk cell” does not actually exist, but is a virtual one obtained by calculation to generate learning data used for the mixture ratio prediction described later.
- each cell is composed of “gene A”, “gene B” and “gene C”, respectively.
- the gene expression level of the gene A is “A1”
- the gene expression level of the gene B is “B1”
- the gene expression level of the gene C is “C1”.
- “cell 2” has a gene A gene expression level of “A2”, a gene B gene expression level of “B2”, and a gene C gene expression level of “C2”.
- the gene expression level of gene A is “A3”
- the gene expression level of gene B is “B3”
- the gene expression level of gene C is “C3”.
- cells 1 to 3 and genes A to C are simplified names for explanation. Further, the number and types of genes constituting actual cells are different.
- the mixing ratio prediction device 10 sets a virtual mixing ratio for each cell.
- the virtual mixing ratio (1) “cell 1: 80%, cell 2: 10%, cell 3: 10%”, (2) “cell 1: 50%, cell 2: 30%, (Cell 3: 20%), (3) "cell 1: 20%, cell 2: 40%, cell 3: 40%”.
- the mixing ratio predicting apparatus 10 mixes the “cell 1” at 80%, the “cell 2” at 10%, and the “cell 3” at 10% according to the virtual mixing ratio (1). 1 "is generated. Then, the mixing ratio prediction device 10 uses the ratios A1 to C1 of the genes A to C constituting the cells 1 to 3, respectively, to generate virtual gene expression of the genes A to C constituting the “virtual bulk cell 1”. The virtual expression amounts A4 to C4, which are the amounts, are obtained.
- the mixing ratio predicting apparatus 10 generates “virtual bulk cells 2” at the virtual mixing ratio (2), and obtains the virtual expression levels A5 to C5 of the genes A to C. Further, the mixing ratio prediction device 10 generates “virtual bulk cells 3” at the virtual mixing ratio (3), and obtains the virtual expression levels A6 to C6 of the genes A to C.
- the mixing ratio prediction device 10 even when information of a sufficient amount of bulk cells cannot be obtained as learning data, the virtual mixing ratio and the virtual expression amount can be used as learning data. It becomes possible to predict the mixing ratio of cells from the gene expression level of bulk cells. That is, the mixture ratio prediction apparatus 10 can realize prediction using learning data, which is virtual information obtained by generation processing, instead of data obtained by measurement or the like. In other words, the mixture ratio prediction device 10 uses a new method of learning with virtual data instead of the conventional learning process.
- the predictor is realized by a learned neural network.
- the predictor is not limited to a learned neural network, and may be realized by various machine learning models such as a decision tree and a support vector machine.
- FIG. 4 is a diagram illustrating an example of a functional configuration of the mixture ratio prediction device 10 according to the embodiment of the present invention.
- the mixture ratio prediction device 10 includes a data set creation unit 101, a learning unit 102, and a prediction unit 103. Further, in the storage device, the mixture ratio prediction device 10 stores, in the storage device, gene expression amount data 211, virtual mixture ratio data 212, virtual expression amount data (hereinafter also referred to as “virtual bulk cell expression amount data”) 213, learning data 214, and the like. Can be stored and used.
- the storage device illustrated in FIG. 4 is storage means such as the RAM 205, the ROM 206, and the auxiliary storage device 208, and each data can be stored in any one of the storage devices.
- the data set creation unit 101 executes a learning data set creation process. That is, the data set creating unit 101 creates the learning data set 215 with the gene expression amount data 211 for each cell type as an input.
- the data set creation unit 101 includes a mixture ratio creation unit 111, a bulk cell creation unit 112, and a learning data creation unit 113.
- the mixing ratio generating unit 111 generates virtual mixing ratio data 212 indicating a virtual mixing ratio for each cell type included in the bulk cells. At this time, the mixture ratio generation unit 111 generates a plurality of virtual mixture ratio data 212.
- the bulk cell creating unit 112 uses the gene expression amount data 211 for each cell type and the virtual mixture ratio data 212 for each virtual mixture ratio data 212 to generate a virtual bulk indicating the gene expression amount of a virtual bulk cell.
- the cell expression amount data 213 is created.
- the learning data creating unit 113 creates a set of the virtual bulk cell expression amount data 213 and the virtual mixing ratio data 212 as the learning data 214 for each virtual mixing ratio data 212. As a result, a learning data set 215 composed of a plurality of learning data 214 is created. In the example of FIG. 4, the learning data set 215 includes three pieces of learning data 214. However, as described above, the number of learning data 214 included in the learning data set 215 is not limited.
- the learning unit 102 performs a learning process. That is, the learning unit 102 updates the parameters of the neural network using the respective learning data 214 included in the learning data set 215. Thereby, the neural network is learned, and a predictor is realized.
- the prediction unit 103 is a predictor realized by a learned neural network, and performs a prediction process. That is, the prediction unit 103 receives, as input, bulk cell expression level data indicating the gene expression level of the bulk cell, and outputs mixing rate prediction data indicating a predicted value of the mixing rate for each cell type included in the bulk cell.
- one mixing ratio prediction device 10 includes three functional units of a data set creation unit 101, a learning unit 102, and a prediction unit 103. Each of these functional units may be distributed among a plurality of devices.
- the mixture ratio prediction device 10 may be configured by a data set creation device having the data set creation unit 101 and a prediction device having the learning unit 102 and the prediction unit 103.
- the prediction device may be configured by a device that performs only the learning process and a device that performs only the prediction process.
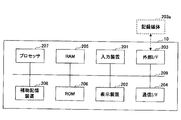
- FIG. 5 is a diagram illustrating an example of a hardware configuration of the mixture ratio prediction device 10 according to the embodiment of the present invention.
- the mixing ratio prediction device 10 includes an input device 201, a display device 202, an external I / F 203, a communication I / F 204, and a random access memory (RAM) 205. , A ROM (Read Only Memory) 206, a processor 207, and an auxiliary storage device 208. These pieces of hardware are mutually connected by a bus 209.
- the input device 201 is, for example, a keyboard, a mouse, a touch panel, or the like, and is used by a user to input various operations.
- the display device 202 is, for example, a display or the like, and displays various processing results of the mixture ratio prediction device 10. Note that the mixture ratio prediction device 10 may not include at least one of the input device 201 and the display device 202.
- the external I / F 203 is an interface with an external device.
- the external device includes a recording medium 203a and the like.
- the mixture ratio prediction device 10 can read and write the recording medium 203a and the like via the external I / F 203.
- the recording medium 203a may store one or more programs or the like that realize the respective functional units (that is, the data set creation unit 101, the learning unit 102, and the prediction unit 103) included in the mixture ratio prediction device 10.
- Examples of the recording medium 203a include a flexible disk, a CD (Compact Disc), a DVD (Digital Versatile Disk), an SD memory card (Secure Digital Memory card), and a USB (Universal Serial Bus) memory card.
- a flexible disk a CD (Compact Disc), a DVD (Digital Versatile Disk), an SD memory card (Secure Digital Memory card), and a USB (Universal Serial Bus) memory card.
- the communication I / F 204 is an interface for connecting the mixture ratio prediction device 10 to a communication network.
- One or more programs realizing each functional unit of the mixture ratio prediction device 10 may be obtained (downloaded) from a predetermined server device or the like via the communication I / F 204.
- the RAM 205 is a volatile semiconductor memory that temporarily stores programs and data.
- the ROM 206 is a non-volatile semiconductor memory that can retain programs and data even when the power is turned off.
- the ROM 206 stores, for example, settings related to an OS (Operating System), settings related to a communication network, and the like.
- OS Operating System
- the processor 207 is, for example, a CPU (Central Processing Unit), a GPU (Graphics Processing Unit), or the like, and is an arithmetic device that reads a program or data from the ROM 206 or the auxiliary storage device 208 onto the RAM 205 and executes processing.
- Each functional unit included in the mixture ratio prediction device 10 is realized by, for example, a process of causing the processor 207 to execute one or more programs stored in the auxiliary storage device 208.
- the mixture ratio prediction device 10 may include both a CPU and a GPU as the processor 207, or may include only one of the CPU and the GPU.
- the auxiliary storage device 208 is, for example, a hard disk drive (HDD) or a solid state drive (SSD), and is a nonvolatile storage device that stores programs and data.
- the auxiliary storage device 208 includes, for example, an OS, various application software, one or more programs for realizing each functional unit of the mixture ratio prediction device 10, and the like.
- the mixture ratio prediction device 10 according to the embodiment of the present invention can realize various processes described later by having the hardware configuration shown in FIG. In the example shown in FIG. 5, a case has been described where the mixture ratio prediction device 10 according to the embodiment of the present invention is realized by one device (computer), but the present invention is not limited to this.
- the mixture ratio prediction device 10 according to the embodiment of the present invention may be realized by a plurality of devices (computers).
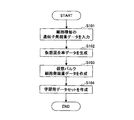
- FIG. 6 is a flowchart illustrating an example of the learning data set creation process.
- the data set creation unit 101 acquires gene expression amount data for each cell type (step S101).
- the LM22 data set can be used.
- the LM22 data set is a set of data obtained by measuring the expression levels of 547 types of genes in each of 22 types of immune cells fractionated into a uniform population. For details of the LM22 data set, see, for example, Non-Patent Document 1 described above.
- gene expression amount data for each cell type can also be obtained by single-cell RNA-Seq analysis.
- the mixture ratio generation unit 111 of the data set creation unit 101 generates a plurality of virtual mixture ratio data (Step S102).
- the number of generated virtual mixing ratio data is represented by P
- the p (1 ⁇ p ⁇ P) -th virtual mixing ratio data a p is an N-dimensional vector (that is, the total number of cell types is defined as the number of dimensions).
- the bulk cell creating unit 112 of the data set creating unit 101 converts the virtual bulk cell expression amount data using the gene expression amount data for each cell type and the virtual mixing ratio data for each virtual mixing ratio data. It is created (step S103).
- Virtual mixing ratio data b p for example, after multiplying each element a np (1 ⁇ n ⁇ N ) for a given noise a p (e.g., salt pepper noise and Lognormal noise, etc.), these noises It is created by normalizing so that the sum of the multiplied elements anp (1 ⁇ n ⁇ N) becomes 1.
- the learning data set D using the gene expression amount data (for example, the LM22 data set) for each cell type obtained as actual measurement.
- y p is the data showing the gene expression level of a virtual bulk cell
- learning of the neural network for realizing the predictor is performed using the learning data set D.
- a plurality of gene expression amount data of the same cell type may be input.
- the gene expression amount data x i and x i ′ of the cell type i may be input.
- gene expression level data x 1, ⁇ , x i, ⁇ , and x N, gene expression data x 1, ⁇ , x i ' , ⁇ , against the x N Steps S103 to S104 may be executed.
- the learning data sets D ⁇ (y p, a p)
- p 1, ⁇ , P ⁇ are created. Therefore, in this case, the learning of the neural network that realizes the predictor may be performed using the learning data sets D and D ′. The same applies when three or more gene expression data of the same cell type are input.
- FIG. 7 is a flowchart illustrating an example of the learning process.
- p 1, ⁇ , P ⁇ to enter (step S201).
- the learning unit 102, the training data (y p, a p) included in the learning data set D is used to calculate an error of a predetermined error function (step S202). That is, the learning unit 102, the virtual bulk cell expression amount data y p the prediction unit 103 (i.e., the neural network is not already learned) is input to the output data indicating the mixing ratio of each cell type included in the virtual bulk cell p a p ⁇ . Then, the learning unit 102 calculates an error between the output data a p ⁇ and the correct answer data a p using a predetermined error function.
- the error function for example, softmax cross entropy, mean squared error, or the like is used.
- the learning unit 102 updates the parameters of the neural network using the error calculated in step S202 (step S203). That is, the learning unit 102 updates the parameter so that the error is minimized, for example, using the error back propagation method or the like. Thereby, the neural network that realizes the predictor is learned.
- the mixture ratio prediction device 10 As described above, in the mixture ratio prediction device 10 according to the embodiment of the present invention, a learned neural network that realizes a predictor can be obtained.
- FIG. 8 is a flowchart illustrating an example of the prediction process.
- the prediction unit 103 inputs the bulk cell expression amount data y (Step S301).
- the bulk cell expression level data y can be obtained, for example, by measuring the gene expression level of the bulk cell by a known method (eg, analysis using a DNA microarray or RNA-Seq analysis).
- the prediction unit 103 predicts the mixing ratio of each cell type included in the bulk cell corresponding to the bulk cell expression amount data y by the predictor, and outputs the mixing ratio prediction data a indicating the predicted value. (Step S302). As a result, the mixture ratio prediction data a in which the mixture ratio of the N cell types is represented by an N-dimensional vector is obtained.
- the mixing ratio prediction data a can be obtained from the bulk cell expression amount data y.
- the mixing ratio prediction device 10 according to the embodiment of the present invention can directly predict the mixing ratio of each cell type included in the bulk cell from the gene expression amount of the bulk cell. it can.
- the mixing ratio prediction device 10 according to the embodiment of the present invention does not need to model the bulk cells for the prediction of the mixing ratio. Rate can be predicted quickly.
- FIG. 9 is a diagram showing a comparative example with the conventional method.
- the GSE20300 data set was used as the bulk cell expression amount data y.
- FIG. 9A is a diagram in which the relationship between the actually measured value and the predicted value of the mixing ratio when the CIBERSORT described in Non-Patent Document 1 is used as a conventional method is plotted as points.
- FIG. 9B is a diagram in which the relationship between the actually measured value and the predicted value of the mixing ratio when the method according to the embodiment of the present invention is used is plotted as a point.
- PMNs 19 cell types out of 22 cell types are collectively referred to as “PMNs”, and the “PMNs” and the cell type “PMNs” are used. Lymphocytes "and the cell type” monocytes "were plotted.
- the mixture ratio prediction device 10 in the embodiment of the present invention can predict the mixture ratio with higher accuracy than the conventional method such as CIBERSORT.
- the mixture ratio prediction device 10 uses the predictor realized by the learned neural network to calculate the cell expression level in the bulk cell from the data indicating the gene expression level in the bulk cell.
- the mixing ratio for each species can be predicted.
- the mixture ratio prediction device 10 according to the embodiment of the present invention uses data indicating the gene expression level for each cell type, and data indicating the virtual bulk cell gene expression level, Learning data, which is a set of data indicating the mixing ratio for each cell type included in the virtual bulk cells, is generated.
- the mixing ratio prediction device 10 in the embodiment of the present invention it is difficult to measure the gene expression amount in the bulk cell and the mixing ratio of each cell type included in the bulk cell by experiments or the like. Even in this case, the learning data set can be easily created.
- the mixture ratio prediction device 10 by using the predictor trained as described above, for example, even in a case where linearity cannot be assumed for the gene expression amount, the mixture ratio is high.
- the mixing ratio can be predicted with accuracy.
- the case where linearity can be assumed for the gene expression amount means that the gene expression amount of the bulk cell can be expressed by the sum of the product of the gene expression amount of each cell type and the mixing ratio of the cell type (further, , And the sum can be expressed as the sum of a term representing noise).
- the mixing ratio for each cell type contained in the bulk cell is predicted has been described, but the present invention is not limited to this.
- the mixing ratio for each component contained in an unknown chemical substance is It is also applicable to the case of prediction.
- the embodiment of the present invention is applicable to any task of estimating a mixing ratio for each unknown signal in a problem setting where a pure (or element) signal is obtained.
- the data set creation unit 101 is provided in the mixture ratio prediction device 10, but is not limited thereto. That is, the data set creation unit 101 and the learning unit 102 or the prediction unit 103 may be provided as different devices as a data set creation device, a learning device, and a prediction device, respectively.
- Reference Signs List 10 mixing ratio prediction device 101 data set creation unit 102 learning unit 103 prediction unit 111 mixing ratio generation unit 112 bulk cell creation unit 113 learning data creation unit
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Medical Informatics (AREA)
- General Health & Medical Sciences (AREA)
- Data Mining & Analysis (AREA)
- Theoretical Computer Science (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Biophysics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Evolutionary Biology (AREA)
- Biotechnology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Databases & Information Systems (AREA)
- Software Systems (AREA)
- Public Health (AREA)
- Evolutionary Computation (AREA)
- Epidemiology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioethics (AREA)
- Artificial Intelligence (AREA)
- Genetics & Genomics (AREA)
- Molecular Biology (AREA)
- Chemical & Material Sciences (AREA)
- Hematology (AREA)
- Urology & Nephrology (AREA)
- Biomedical Technology (AREA)
- Food Science & Technology (AREA)
- Medicinal Chemistry (AREA)
- Analytical Chemistry (AREA)
- Biochemistry (AREA)
- General Physics & Mathematics (AREA)
- Immunology (AREA)
- Pathology (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Investigating Or Analysing Biological Materials (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020527651A JP7421475B2 (ja) | 2018-06-29 | 2019-06-27 | 学習方法、混合率予測方法及び学習装置 |
| US17/134,802 US20210151128A1 (en) | 2018-06-29 | 2020-12-28 | Learning Method, Mixing Ratio Prediction Method, and Prediction Device |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018124385 | 2018-06-29 | ||
| JP2018-124385 | 2018-06-29 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/134,802 Continuation US20210151128A1 (en) | 2018-06-29 | 2020-12-28 | Learning Method, Mixing Ratio Prediction Method, and Prediction Device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020004575A1 true WO2020004575A1 (ja) | 2020-01-02 |
Family
ID=68984915
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2019/025676 Ceased WO2020004575A1 (ja) | 2018-06-29 | 2019-06-27 | 学習方法、混合率予測方法及び学習装置 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20210151128A1 (https=) |
| JP (1) | JP7421475B2 (https=) |
| WO (1) | WO2020004575A1 (https=) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115151918A (zh) * | 2020-02-18 | 2022-10-04 | 昭和电工材料株式会社 | 信息处理系统、信息处理方法及信息处理程序 |
| CN115831259A (zh) * | 2022-12-12 | 2023-03-21 | 华东理工大学 | 聚氰酸酯的性能预测方法及其应用 |
| JP2023518185A (ja) * | 2020-03-12 | 2023-04-28 | ボストンジーン コーポレイション | 発現データのデコンボリューションのためのシステム及び方法 |
| WO2023153413A1 (ja) * | 2022-02-08 | 2023-08-17 | テルモ株式会社 | 2種類以上の細胞を含む培養細胞における目的細胞の割合を予測するためのシステム、プログラム及び方法 |
| US12488239B2 (en) | 2019-11-12 | 2025-12-02 | Resonac Corporation | Input data generation system, input data generation method, and storage medium |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20240177803A1 (en) | 2022-11-17 | 2024-05-30 | Bostongene Corporation | Comprehensive immunoprofiling of peripheral blood |
| EP4695425A1 (en) | 2023-04-13 | 2026-02-18 | BostonGene Corporation | Pan-cancer tumor microenvironment classification based on immune escape mechanisms and immune infiltration |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017530693A (ja) * | 2014-08-08 | 2017-10-19 | ナノストリング テクノロジーズ,インコーポレイティド | 遺伝子発現データを使用した混成細胞集団のデコンボリューション方法 |
| WO2018012601A1 (ja) * | 2016-07-14 | 2018-01-18 | 大日本印刷株式会社 | 画像解析システム、培養管理システム、画像解析方法、培養管理方法、細胞群製造方法及びプログラム |
| US20180057859A1 (en) * | 2016-05-06 | 2018-03-01 | Craig E. Nelson | Method for identifying rare cell types by single cell assisted deconvolution of population gene expression data |
| JP2018512071A (ja) * | 2015-01-22 | 2018-05-10 | ザ ボード オブ トラスティーズ オブ ザ レランド スタンフォード ジュニア ユニバーシティー | 異なる細胞サブセットの比率の決定方法およびシステム |
-
2019
- 2019-06-27 JP JP2020527651A patent/JP7421475B2/ja active Active
- 2019-06-27 WO PCT/JP2019/025676 patent/WO2020004575A1/ja not_active Ceased
-
2020
- 2020-12-28 US US17/134,802 patent/US20210151128A1/en active Pending
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017530693A (ja) * | 2014-08-08 | 2017-10-19 | ナノストリング テクノロジーズ,インコーポレイティド | 遺伝子発現データを使用した混成細胞集団のデコンボリューション方法 |
| JP2018512071A (ja) * | 2015-01-22 | 2018-05-10 | ザ ボード オブ トラスティーズ オブ ザ レランド スタンフォード ジュニア ユニバーシティー | 異なる細胞サブセットの比率の決定方法およびシステム |
| US20180057859A1 (en) * | 2016-05-06 | 2018-03-01 | Craig E. Nelson | Method for identifying rare cell types by single cell assisted deconvolution of population gene expression data |
| WO2018012601A1 (ja) * | 2016-07-14 | 2018-01-18 | 大日本印刷株式会社 | 画像解析システム、培養管理システム、画像解析方法、培養管理方法、細胞群製造方法及びプログラム |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12488239B2 (en) | 2019-11-12 | 2025-12-02 | Resonac Corporation | Input data generation system, input data generation method, and storage medium |
| CN115151918A (zh) * | 2020-02-18 | 2022-10-04 | 昭和电工材料株式会社 | 信息处理系统、信息处理方法及信息处理程序 |
| JP2023518185A (ja) * | 2020-03-12 | 2023-04-28 | ボストンジーン コーポレイション | 発現データのデコンボリューションのためのシステム及び方法 |
| JP7541585B2 (ja) | 2020-03-12 | 2024-08-28 | ボストンジーン コーポレイション | 発現データのデコンボリューションのためのシステム及び方法 |
| JP2024174879A (ja) * | 2020-03-12 | 2024-12-17 | ボストンジーン コーポレイション | 発現データのデコンボリューションのためのシステム及び方法 |
| JP7818662B2 (ja) | 2020-03-12 | 2026-02-20 | ボストンジーン コーポレイション | 発現データのデコンボリューションのためのシステム及び方法 |
| WO2023153413A1 (ja) * | 2022-02-08 | 2023-08-17 | テルモ株式会社 | 2種類以上の細胞を含む培養細胞における目的細胞の割合を予測するためのシステム、プログラム及び方法 |
| CN115831259A (zh) * | 2022-12-12 | 2023-03-21 | 华东理工大学 | 聚氰酸酯的性能预测方法及其应用 |
| CN115831259B (zh) * | 2022-12-12 | 2023-09-05 | 华东理工大学 | 聚氰酸酯的性能预测方法及其应用 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2020004575A1 (ja) | 2021-08-12 |
| JP7421475B2 (ja) | 2024-01-24 |
| US20210151128A1 (en) | 2021-05-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7421475B2 (ja) | 学習方法、混合率予測方法及び学習装置 | |
| JP7545535B2 (ja) | 量子古典コンピューティングハードウェア用いた量子コンピューティング対応の第一原理分子シミュレーションのための方法とシステム | |
| Kim et al. | Gene regulatory network reconstruction: harnessing the power of single-cell multi-omic data | |
| Benidt et al. | SimSeq: a nonparametric approach to simulation of RNA-sequence datasets | |
| Varoquaux et al. | A statistical approach for inferring the 3D structure of the genome | |
| Fang et al. | Statistical methods for identifying differentially expressed genes in RNA-Seq experiments | |
| Lewis et al. | What evidence is there for the homology of protein-protein interactions? | |
| Köhler et al. | Flexible Bayesian additive joint models with an application to type 1 diabetes research | |
| Sheetlin et al. | Frameshift alignment: statistics and post-genomic applications | |
| Ding et al. | Bias correction for selecting the minimal-error classifier from many machine learning models | |
| LeGault et al. | Inference of alternative splicing from RNA-Seq data with probabilistic splice graphs | |
| Kuśmirek et al. | De novo assembly of bacterial genomes with repetitive DNA regions by dnaasm application | |
| Geuenich et al. | The impacts of active and self-supervised learning on efficient annotation of single-cell expression data | |
| Nute et al. | Scaling statistical multiple sequence alignment to large datasets | |
| Rijal et al. | A differentiable Gillespie algorithm for simulating chemical kinetics, parameter estimation, and designing synthetic biological circuits | |
| Low et al. | CORNAS: coverage-dependent RNA-Seq analysis of gene expression data without biological replicates | |
| Tapia et al. | A motion planning approach to studying molecular motions | |
| CN111209930A (zh) | 一种生成授信策略的方法、装置和电子设备 | |
| Park et al. | A random effect model for reconstruction of spatial chromatin structure | |
| Sjögren et al. | Weighted analysis of general microarray experiments | |
| Peng et al. | itreepack: Protein complex side-chain packing by dual decomposition | |
| JP7747250B1 (ja) | 乱数生成装置、設計支援装置、乱数生成方法及びプログラム | |
| Lai et al. | Assessing the merits: an opinion on the effectiveness of simulation techniques in tumor subclonal reconstruction | |
| Balikci et al. | BioMark: biomarker analysis tool | |
| Hua et al. | PGS: a dynamic and automated population-based genome structure software |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19827199 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2020527651 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 19827199 Country of ref document: EP Kind code of ref document: A1 |