WO2020001401A1 - 深度神经网络中的网络层运算方法及装置 - Google Patents
深度神经网络中的网络层运算方法及装置 Download PDFInfo
- Publication number
- WO2020001401A1 WO2020001401A1 PCT/CN2019/092553 CN2019092553W WO2020001401A1 WO 2020001401 A1 WO2020001401 A1 WO 2020001401A1 CN 2019092553 W CN2019092553 W CN 2019092553W WO 2020001401 A1 WO2020001401 A1 WO 2020001401A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- filter
- fixed
- point
- convolution
- layer
- Prior art date
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
Definitions
- the present application relates to the field of machine learning technology, and in particular, to a network layer operation method and device in a deep neural network.
- DNN Deep Neural Network
- CNN Convolutional Neural Network
- RNN Recurrent Neural Network
- LSTM Long Short Term Memory, Long Short-Term Memory Network
- DNNs generally use multiply / add operations on double-precision or single-precision floating-point data to implement the calculation of the basic unit of the network. Because the amount of data involved in the calculation is often large, the amount of calculations per operation when performing DNN calculations It is very large, which makes the computational efficiency of DNN low.
- the purpose of the embodiments of the present application is to provide a network layer operation method and device in a deep neural network to improve the operation efficiency of a DNN.
- the specific technical solutions are as follows:
- an embodiment of the present application provides a network layer operation method in a deep neural network.
- the method includes:
- the filter For each filter of the network layer, the filter is divided into a linear combination of a plurality of fixed-point convolution kernels, where a weight value in each fixed-point convolution kernel is a fixed-point quantization value with a specified bit width;
- the convolution operation is performed on the input data of the network layer and each fixed-point convolution kernel of the filter to obtain multiple convolution results, and according to multiple fixed points of the filter
- the linear combination of the convolution kernels weights and sums the convolution results to obtain the operation results of the filter
- the method further includes:
- splitting the filter into a linear combination of multiple fixed-point convolution kernels includes:
- the filter For each filter of the network layer, according to the preset number of quantized bits, the filter is split into a linear combination of multiple fixed-point convolution kernels, where the sum of the specified bit widths corresponding to each fixed-point convolution kernel Is equal to the preset number of quantization bits.
- the network layer includes a convolution layer, and the size of the weight tensor of the convolution layer is S ⁇ S ⁇ I ⁇ O;
- splitting the filter into a linear combination of multiple fixed-point convolution kernels includes:
- the filter For each filter of the convolution layer, the filter is split into a linear combination of multiple fixed-point convolution kernels according to a preset split formula, where the preset split formula is:
- the w i is the i-th filter of the convolution layer, the i ⁇ [1, O], and the p is the number of fixed-point convolution kernels obtained by splitting the filter w i , [alpha] j is the j-th point of the predetermined linear convolution kernel weighting coefficient, T j is the j-th point convolution kernel the size of j T S ⁇ S ⁇ I, B is the pre- Set the number of quantization bits, where b j is a specified bit width corresponding to the j-th fixed-point convolution kernel.
- the weighted summation of the convolution results to obtain the operation results of the filter includes:
- the convolution results of each fixed-point convolution kernel are weighted according to the preset linear weighting coefficients of the fixed-point convolution kernels of the filter, and the weighted convolution results are weighted. Add up to get the operation result of this filter.
- the network layer includes a fully connected layer, the size of the weight tensor of the fully connected layer is M ⁇ N, and each filter of the fully connected layer is a vector of size 1 ⁇ N;
- splitting the filter into a linear combination of multiple fixed-point convolution kernels includes:
- the vector For each vector with a size of 1 ⁇ N of the fully connected layer, the vector is split into a linear combination of multiple fixed-point convolution kernels according to a preset split formula, where the preset split formula is:
- the v x is the x-th vector of size 1 ⁇ N of the fully connected layer, the x ⁇ [1, M], and the q is a fixed-point convolution obtained by splitting the vector v x
- the number of kernels ⁇ y is a preset linear weighting coefficient of the y-th fixed-point convolution kernel, t y is the y-th fixed-point convolution kernel, the size of t y is 1 ⁇ N, and the B To preset the number of quantization bits, the b y is a specified bit width corresponding to the y-th fixed-point convolution kernel.
- the weighted summation of the convolution results to obtain the operation results of the filter includes:
- the convolution results of the fixed-point convolution kernels are weighted according to the preset linear weighting coefficients of the fixed-point convolution kernels of the vector, and each weighted Add the convolution results of to get the operation result of this vector.
- an embodiment of the present application provides a network layer computing device in a deep neural network, where the device includes:
- An obtaining module for obtaining a weight tensor of a network layer in a deep neural network, wherein the weight tensor includes a plurality of filters;
- a splitting module for each filter of the network layer, splitting the filter into a linear combination of a plurality of fixed-point convolution kernels, wherein a weight value in each fixed-point convolution kernel is Fixed-point quantization value
- An operation module is configured to perform convolution operations on each filter of the network layer and input data of the network layer and each fixed-point convolution kernel of the filter to obtain a plurality of convolution results, and according to the filtering, A linear combination of multiple fixed-point convolution kernels of the filter, weighting and summing each convolution result to obtain the operation result of the filter;
- the determining module is configured to determine that the operation results of the filters constitute output data of the network layer.
- the acquisition module is further configured to determine a preset number of quantized bits according to a preset application accuracy of the deep neural network
- the splitting module is specifically configured to:
- the filter For each filter of the network layer, according to the preset number of quantized bits, the filter is split into a linear combination of multiple fixed-point convolution kernels, where the sum of the specified bit widths corresponding to each fixed-point convolution kernel Is equal to the preset number of quantization bits.
- the network layer includes a convolution layer, and the size of the weight tensor of the convolution layer is S ⁇ S ⁇ I ⁇ O;
- the splitting module is specifically configured to:
- the filter For each filter of the convolution layer, the filter is split into a linear combination of multiple fixed-point convolution kernels according to a preset split formula, where the preset split formula is:
- the w i is the i-th filter of the convolution layer, the i ⁇ [1, O], and the p is the number of fixed-point convolution kernels obtained by splitting the filter w i , [alpha] j is the j-th point of the predetermined linear convolution kernel weighting coefficient, T j is the j-th point convolution kernel the size of j T S ⁇ S ⁇ I, B is the pre- Set the number of quantization bits, where b j is a specified bit width corresponding to the j-th fixed-point convolution kernel.
- the operation module is specifically configured to:
- the convolution results of each fixed-point convolution kernel are weighted according to the preset linear weighting coefficients of the fixed-point convolution kernels of the filter, and the weighted convolution results are weighted. Add up to get the operation result of this filter.
- the network layer includes a fully connected layer, the size of the weight tensor of the fully connected layer is M ⁇ N, and each filter of the fully connected layer is a vector of size 1 ⁇ N;
- the splitting module is specifically configured to:
- the vector For each vector with a size of 1 ⁇ N of the fully connected layer, the vector is split into a linear combination of multiple fixed-point convolution kernels according to a preset split formula, where the preset split formula is:
- the v x is the x-th vector of size 1 ⁇ N of the fully connected layer, the x ⁇ [1, M], and the q is a fixed-point convolution obtained by splitting the vector v x
- the number of kernels ⁇ y is a preset linear weighting coefficient of the y-th fixed-point convolution kernel, t y is the y-th fixed-point convolution kernel, the size of t y is 1 ⁇ N, and the B To preset the number of quantization bits, the b y is a specified bit width corresponding to the y-th fixed-point convolution kernel.
- the operation module is specifically configured to:
- the convolution results of the fixed-point convolution kernels are weighted according to the preset linear weighting coefficients of the fixed-point convolution kernels of the vector, and each weighted Add the convolution results of to get the operation result of this vector.
- an embodiment of the present application provides an electronic device including a processor and a machine-readable storage medium, where the machine-readable storage medium stores machine-executable instructions that can be executed by the processor, and the processing The machine is executed by the machine-executable instructions to execute the method provided by the first aspect of the embodiments of the present application.
- an embodiment of the present application provides a machine-readable storage medium that stores machine-executable instructions. When called and executed by a processor, the machine-executable instructions cause the processor to execute the embodiments of the present application.
- the method provided by the first aspect is a machine-readable storage medium that stores machine-executable instructions.
- an embodiment of the present application provides an application program for executing at runtime: the method provided in the first aspect of the embodiment of the present application.
- the filter is divided into multiple fixed-point convolutions for each filter in the weight tensor of the network layer.
- the linear combination of the kernels, the input data of the network layer and the fixed-point convolution kernels of the filter are respectively convolved to obtain multiple convolution results, and according to the linear combination of the multiple fixed-point convolution kernels of the filter , Weighting and summing each convolution result to obtain the operation result of the filter, and determining that the operation result of each filter constitutes the output data of the network layer.
- each fixed-point convolution kernel is a fixed-point quantization value with a specified bit width
- the filter that includes floating-point weights in the network layer weight tensor is split into multiple fixed-point inclusions.
- the linear combination of fixed-point convolution kernels with quantized weights reduces the amount of calculations for fixed-point quantized values compared to the calculation of floating-point data. Therefore, the amount of operations per DNN operation is reduced, thereby improving the efficiency of DNN operations.
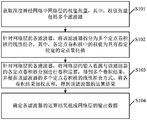
- FIG. 1 is a schematic flowchart of a network layer operation method in a deep neural network according to an embodiment of the present application
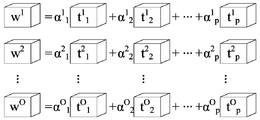
- FIG. 2 is a schematic diagram of splitting each filter of a convolution layer according to an embodiment of the present application
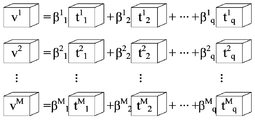
- FIG. 3 is a schematic diagram of splitting each vector with a fully connected layer size of 1 ⁇ N according to an embodiment of the present application
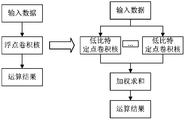
- FIG. 4 is a schematic diagram of a comparison between a corresponding network layer operation and a network layer operation according to an embodiment of the present application
- FIG. 5 is a schematic structural diagram of a network layer computing device in a deep neural network according to an embodiment of the present application
- FIG. 6 is a schematic structural diagram of an electronic device according to an embodiment of the present application.
- the embodiments of the present application provide a network layer operation method, device, electronic device, machine-readable storage medium, and application program in a deep neural network.
- the execution subject of the network layer operation method in the deep neural network provided by the embodiment of the present application may be an electronic device that executes an intelligent algorithm, and the electronic device may be an intelligent device with target detection and segmentation, behavior detection and recognition, or voice recognition.
- the execution body should include at least a processor equipped with a core processing chip.
- a manner of implementing a network layer operation method in a deep neural network provided by the embodiments of the present application may be at least one of software, hardware circuits, and logic circuits provided in an execution body.
- a network layer operation method in a deep neural network may include the following steps:
- the network layer in a deep neural network is used to perform network operations such as convolution and dot multiplication.
- the network layer may include a convolution layer and a fully connected layer.
- Each network layer includes a weight tensor for performing network operations.
- DNN is a relatively broad data processing method.
- DNN can be any of the data processing methods such as CNN, RNN, LSTM.
- the weight tensor includes: a specific weight in the Conv layer or a specific weight in the fully connected layer.
- the weight tensor of the k-th Conv layer be W
- its size is S ⁇ S ⁇ I ⁇ O
- w W (:,:,:, i) be the i-th filter of the Conv layer
- the size of the i-th filter is S ⁇ S ⁇ I, that is, the weight tensor of the Conv layer can be divided into O filters according to the number of output feature vectors; for the fully connected layer, the l-th filter
- the weight tensor of the fully connected layer is denoted by V and its size is M ⁇ N.
- the number of output feature vectors of the fully connected layer is M. Therefore, the size of the j-th filter of the fully connected layer is 1 ⁇ N. , The weight tensor of the fully connected layer can be divided into M filters according to the number of output feature vectors.
- the filter is divided into a linear combination of a plurality of fixed-point convolution kernels, where a weight value in each fixed-point convolution kernel is a fixed-point quantization value with a specified bit width.
- the weight of the weight tensor in the network layer is usually floating-point data.
- Floating-point data can be expressed as the product of a fixed-point quantization value and weight, or the weighted sum of multiple fixed-point quantization values and corresponding weights, where the weight can be It is obtained through multiple training processes, the weight represents the scaling coefficient, and the fixed-point quantized values are multiplied to obtain approximate floating-point data.
- the number of bits required for the model weight is different in different application scenarios.
- the weight needs to be expressed in 16-bit width;
- the weights need to be represented by 4 bits. In this case, the larger bit width will prevent the operation rate from being significantly reduced.
- the existence of multiple bit numbers on the same hardware platform will increase the complexity of circuit design and reduce circuit regularity.
- the splitting method unifies the weight tensor to a low-specific convolution kernel, which greatly reduces the amount of calculation and the regularity of the circuit design.
- a filter when a filter requires 8-bit width support, it can be split into a linear combination of four 2-bit fixed-point convolution kernels. Only 2-bit fixed-point data needs to be calculated each time. When the filter needs 4-bit bit width support, it can be split into two 2-bit fixed-point convolution kernels. The 2-bit fixed-point data needs to be calculated each time. This solution significantly reduces the calculation amount. The regularity of the circuit design is improved.
- the linear combination of weights indicates that the scale coefficients can be obtained through training.
- the method provided in the embodiment of the present application may further perform the following steps: determining a preset number of quantized bits according to a preset application precision of the deep neural network.
- S102 may be specifically: for each filter of the network layer, according to a preset number of quantization bits, the filter is divided into a linear combination of multiple fixed-point convolution kernels, where the specified bit width corresponding to each fixed-point convolution kernel The sum is equal to the preset number of quantization bits.
- the preset application accuracy of the deep neural network determines the number of preset quantization bits after quantization of each weight value in the weight tensor.
- the network layer may include a Conv layer, and the size of the weight tensor of the Conv layer may be S ⁇ S ⁇ I ⁇ O.
- S102 may specifically be: for each filter of the Conv layer, according to a preset splitting formula, the filter is split into a linear combination of multiple fixed-point convolution kernels.
- the preset splitting formula is shown in formula (1).
- w i is the i-th filter of the Conv layer, i ⁇ [1, O]] p is the number of fixed-point convolution kernels obtained by splitting the filter w i , and ⁇ j is the j-th fixed-point convolution.
- the kernel's preset linear weighting coefficient t j is the j-th fixed-point convolution kernel, t j is S ⁇ S ⁇ I, B is the preset number of quantization bits, and b j is the corresponding value of the j-th fixed-point convolution kernel. Specify the bit width.
- the filter w i of size S ⁇ S ⁇ I in this Conv layer is split into a linear combination of p lower-than-specific-point convolution kernels, and the j-th fixed-point convolution kernel is lowered.
- the bit width (ie, the specified bit width) of the bit number at a specific point is b j .
- the weight tensor of each Conv layer in the network model can be expressed as shown in Figure 2, that is, the model floating-point filter is split into multiple
- the linear combination of the low-ratio specific-point convolution kernels is actually a linear combination of the low-ratio specific-point weights in multiple low-ratio specific-point convolution kernels.
- the network layer may include a fully-connected layer
- the size of the weight tensor of the fully-connected layer may be M ⁇ N
- each filter of the fully-connected layer may be vectors of size 1 ⁇ N.
- S102 may specifically be: for each vector of the size of the fully connected layer of 1 ⁇ N, according to a preset splitting formula, the vector is split into a linear combination of multiple fixed-point convolution kernels.
- the preset splitting formula is shown in formula (2).
- v x is the x-th vector of size 1 ⁇ N in the fully connected layer
- q is the number of fixed-point convolution kernels obtained by splitting the vector v x
- ⁇ y is the first
- the preset linear weighting coefficients for y fixed-point convolution kernels t y is the y-th fixed-point convolution kernel
- the size of t y is 1 ⁇ N
- B is the preset number of quantized bits
- b y is the y-th fixed-point convolution
- each vector of size 1 ⁇ N in the fully connected layer can be understood as a filter of the fully connected layer, and each vector of size 1 ⁇ N in the fully connected layer is split.
- Is a linear combination of q low-ratio specific-point convolution kernels, and the bit-width (ie, specified bit width) of the low-bit specific-point convolution kernel of the y-th fixed-point convolution kernel is b y .
- the weight tensor of each fully connected layer in the network model can be expressed as shown in Figure 3, that is, the model floating point vector is split into multiple
- the linear combination of the low-ratio specific-point convolution kernels is actually a linear combination of the low-ratio specific-point weights in multiple low-ratio specific-point convolution kernels.
- an operation for the floating point weight Conv layer or the floating point weight fully connected layer can be split into multiple low ratio specific point weighted Conv layers or fully connected layers.
- the model structure shown in the left part of Fig. 4 can be divided into the model structure shown in the right part of Fig. 4 for operation, which greatly reduces the amount of model parameters and the amount of calculation.
- the computing granularity of the hardware platform is reduced, and the resource utilization of the hardware platform is improved.
- the convolution operation of the input data and each fixed-point convolution kernel is a process of performing dot multiplication and addition, which is not repeated here.
- the linear combination of multiple fixed-point convolution kernels of the filter can be used.
- the linear combination method is a weighted sum method, and the convolution results are also the same.
- the weighted sum of the modes can obtain the operation result of the filter.
- S103 may specifically be: for each filter of the Conv layer, according to a preset linear weighting coefficient of each fixed-point convolution kernel of the filter, the convolution of each fixed-point convolution kernel is performed. The product results are weighted, and the weighted convolution results are added to obtain the operation result of the filter.
- S103 may specifically be: for each vector of the size of the fully-connected layer of 1 ⁇ N, according to a preset linear weighting coefficient of each fixed-point convolution kernel of the vector, each fixed-point convolution kernel The weighted convolution result is weighted, and the weighted convolution results are added to obtain the operation result of the vector.
- the network layer is a Conv layer and a fully connected layer, and the process of filter splitting has been introduced.
- the filter is expressed as the product of a fixed-point convolution kernel and a preset linear weighting coefficient, The combined linear combination, therefore, when performing the convolution operation, the input data is convolved with each fixed-point convolution kernel, and the convolution results are weighted and summed according to a preset linear weighting coefficient to obtain the filter's Operation result.
- the filters of the network layer correspond to the number of output feature vectors of the network layer. Therefore, the output data of the network layer is actually a combination of the calculation results of the filters. For example, if a network layer includes 5 filters, the network The output data of the layer actually includes 5 feature vectors.
- the filter is divided into a linear combination of a plurality of fixed-point convolution kernels to divide the network layer.
- the input data and the fixed-point convolution kernels of the filter are respectively subjected to convolution operations to obtain multiple convolution results, and each convolution result is weighted according to a linear combination of multiple fixed-point convolution kernels of the filter.
- the operation results of the filter are obtained, and it is determined that the operation results of the filters constitute the output data of the network layer.
- each fixed-point convolution kernel is a fixed-point quantization value with a specified bit width
- the filter that includes floating-point weights in the network layer weight tensor is split into multiple fixed-point inclusions.
- the linear combination of fixed-point convolution kernels with quantized weights reduces the amount of calculations for fixed-point quantized values compared to the calculation of floating-point data. Therefore, the amount of operations per DNN operation is reduced, thereby improving the efficiency of DNN operations.
- an embodiment of the present application provides a network layer computing device in a deep neural network.
- the network layer computing device in the deep neural network may include:
- An obtaining module 510 is configured to obtain a weight tensor of a network layer in a deep neural network, where the weight tensor includes multiple filters;
- a splitting module 520 configured to split each filter of the network layer into a linear combination of multiple fixed-point convolution kernels, where a weight value in each fixed-point convolution kernel has a specified bit width Fixed-point quantization value;
- An operation module 530 is configured to perform convolution operations on each filter of the network layer and input data of the network layer and each fixed-point convolution kernel of the filter to obtain a plurality of convolution results, and according to the A linear combination of multiple fixed-point convolution kernels of the filter, weighting and summing the convolution results to obtain the operation results of the filter;
- the determining module 540 is configured to determine that the operation results of the filters constitute output data of the network layer.
- the obtaining module 510 may be further configured to determine a preset number of quantized bits according to a preset application accuracy of the deep neural network;
- the splitting module 520 may be specifically configured to:
- the filter For each filter of the network layer, according to the preset number of quantized bits, the filter is split into a linear combination of multiple fixed-point convolution kernels, where the sum of the specified bit widths corresponding to each fixed-point convolution kernel Is equal to the preset number of quantization bits.
- the network layer may include a convolution layer, and the size of the weight tensor of the convolution layer may be S ⁇ S ⁇ I ⁇ O;
- the splitting module 520 may be specifically configured to:
- the filter For each filter of the convolution layer, the filter is split into a linear combination of multiple fixed-point convolution kernels according to a preset split formula, where the preset split formula is:
- the w i is the i-th filter of the convolution layer, the i ⁇ [1, O], and the p is the number of fixed-point convolution kernels obtained by splitting the filter w i , [alpha] j is the j-th point of the predetermined linear convolution kernel weighting coefficient, T j is the j-th point convolution kernel the size of j T S ⁇ S ⁇ I, B is the pre- Set the number of quantization bits, where b j is a specified bit width corresponding to the j-th fixed-point convolution kernel.
- the operation module 530 may be specifically configured to:
- the convolution results of each fixed-point convolution kernel are weighted according to the preset linear weighting coefficients of the fixed-point convolution kernels of the filter, and the weighted convolution results are weighted. Add up to get the operation result of this filter.
- the network layer may include a fully-connected layer, and the size of the weight tensor of the fully-connected layer may be M ⁇ N, and each filter of the fully-connected layer may be each of a size of 1 ⁇ N. vector;
- the splitting module 520 may be specifically configured to:
- the vector For each vector with a size of 1 ⁇ N of the fully connected layer, the vector is split into a linear combination of multiple fixed-point convolution kernels according to a preset split formula, where the preset split formula is:
- the v x is the x-th vector of size 1 ⁇ N of the fully connected layer, the x ⁇ [1, M], and the q is a fixed-point convolution obtained by splitting the vector v x
- the number of kernels ⁇ y is a preset linear weighting coefficient of the y-th fixed-point convolution kernel, t y is the y-th fixed-point convolution kernel, the size of t y is 1 ⁇ N, and the B To preset the number of quantization bits, the b y is a specified bit width corresponding to the y-th fixed-point convolution kernel.
- the operation module 530 may be specifically configured to:
- the convolution results of the fixed-point convolution kernels are weighted according to the preset linear weighting coefficients of the fixed-point convolution kernels of the vector, and each weighted Add the convolution results of to get the operation result of this vector.
- the filter is divided into a linear combination of a plurality of fixed-point convolution kernels to divide the network layer.
- the input data and the fixed-point convolution kernels of the filter are respectively subjected to convolution operations to obtain multiple convolution results, and each convolution result is weighted according to a linear combination of multiple fixed-point convolution kernels of the filter.
- the operation results of the filter are obtained, and it is determined that the operation results of the filters constitute the output data of the network layer.
- each fixed-point convolution kernel is a fixed-point quantization value with a specified bit width
- the filter that includes floating-point weights in the network layer weight tensor is split into multiple fixed-point inclusions.
- the linear combination of fixed-point convolution kernels with quantized weights reduces the amount of calculations for fixed-point quantized values compared to the calculation of floating-point data. Therefore, the amount of operations per DNN operation is reduced, thereby improving the efficiency of DNN operations.
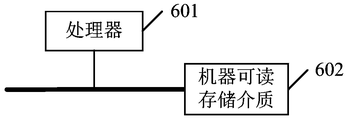
- an embodiment of the present application further provides an electronic device.
- the electronic device includes a processor 601 and a machine-readable storage medium 602.
- the processor 601 is configured to be executed by the machine-executable instructions stored on the machine-readable storage medium 602 to execute all steps of the network layer operation method in the deep neural network provided by the embodiment of the present application.
- the machine-readable storage medium 602 and the processor 601 may perform data transmission through a wired connection or a wireless connection, and the electronic device may communicate with other devices through a wired communication interface or a wireless communication interface.
- the above machine-readable storage medium may include RAM (Random Access Memory, Random Access Memory), and may also include NVM (Non-volatile Memory, non-volatile memory), such as at least one disk memory.
- NVM Non-volatile Memory, non-volatile memory
- the machine-readable storage medium may also be at least one storage device located far from the foregoing processor.
- the above processor may be a general-purpose processor, including a CPU (Central Processing Unit), a NP (Network Processor), etc .; it may also be a DSP (Digital Signal Processor, Digital Signal Processor), ASIC (Application Specific Integrated Circuit (ASIC), FPGA (Field-Programmable Gate Array), or other programmable logic devices, discrete gate or transistor logic devices, discrete hardware components.
- a CPU Central Processing Unit
- NP Network Processor
- DSP Digital Signal Processor
- ASIC Application Specific Integrated Circuit
- FPGA Field-Programmable Gate Array
- the processor of the electronic device can read the machine-executable instructions stored in the machine-readable storage medium and run the machine-executable instructions to realize: by obtaining the weight of the network layer in the deep neural network Tensor: For each filter in the weight tensor of the network layer, the filter is split into a linear combination of multiple fixed-point convolution kernels, and the input data of the network layer and the fixed-point convolution kernels of the filter are rolled separately. Multiplication operation to obtain multiple convolution results, and according to the linear combination of multiple fixed-point convolution kernels of the filter, the convolution results are weighted and summed to obtain the operation result of the filter and determine the operation of each filter The results make up the output data of the network layer.
- each fixed-point convolution kernel is a fixed-point quantization value with a specified bit width
- the filter that includes floating-point weights in the network layer weight tensor is split into multiple fixed-point inclusions.
- the linear combination of fixed-point convolution kernels with quantized weights reduces the amount of calculations for fixed-point quantized values compared to the calculation of floating-point data. Therefore, the amount of operations per DNN operation is reduced, thereby improving the efficiency of DNN operations.
- an embodiment of the present application provides a machine-readable storage medium for machine-executable instructions, the machine-executable instructions prompt a processor Perform all steps of the network layer operation method in the deep neural network provided by the embodiments of the present application.
- the machine-readable storage medium stores machine-executable instructions that execute the network layer operation method in the deep neural network provided by the embodiments of the present application at runtime, so it can be achieved by obtaining the network layer in the deep neural network.
- the filter is split into a linear combination of multiple fixed-point convolution kernels, and the input data of the network layer and each fixed-point convolution kernel of the filter Convolution operations are performed separately to obtain multiple convolution results, and each convolution result is weighted and summed according to the linear combination of multiple fixed-point convolution kernels of the filter to obtain the operation results of the filter and determine each filter
- the operation results of the processor constitute the output data of the network layer.
- each fixed-point convolution kernel is a fixed-point quantization value with a specified bit width
- the filter that includes floating-point weights in the network layer weight tensor is split into multiple fixed-point inclusions.
- the linear combination of fixed-point convolution kernels with quantized weights reduces the amount of calculations for fixed-point quantized values compared to the calculation of floating-point data. Therefore, the amount of operations per DNN operation is reduced, thereby improving the efficiency of DNN operations.
- an embodiment of the present application further provides an application program for executing at runtime: a network layer operation method in a deep neural network provided by the embodiment of the present application.
- the application program executes the network layer operation method in the deep neural network provided by the embodiment of the application when it is running, so that it can be achieved by obtaining the weight tensor of the network layer in the deep neural network and targeting the network layer.
- Each filter in the weight tensor is divided into a linear combination of multiple fixed-point convolution kernels, and the input data of the network layer and each fixed-point convolution kernel of the filter are convolved to obtain multiple convolutions.
- each convolution result is weighted and summed to obtain the operation result of the filter, and it is determined that the operation result of each filter constitutes the output data of the network layer.
- each fixed-point convolution kernel is a fixed-point quantization value with a specified bit width
- the filter that includes floating-point weights in the network layer weight tensor is split into multiple fixed-point inclusions.
- the linear combination of fixed-point convolution kernels with quantized weights reduces the amount of calculations for fixed-point quantized values compared to the calculation of floating-point data. Therefore, the amount of operations per DNN operation is reduced, thereby improving the efficiency of DNN operations.
Abstract
一种深度神经网络中的网络层运算方法及装置,该方法包括:获取深度神经网络中网络层的权值张量,其中,权值张量包括多个滤波器(S101),针对网络层的权值张量中各滤波器,将滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核中的权值为具有指定位宽的定点量化值(S102),将网络层的输入数据与滤波器的各定点卷积核分别进行卷积运算,得到多个卷积结果,并根据滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到滤波器的运算结果(S103),确定各滤波器的运算结果组成网络层的输出数据(S104)。通过本方法及装置,可以提高深度神经网络的运算效率。
Description
本申请要求于2018年6月27日提交中国专利局、申请号为201810679580.X发明名称为“深度神经网络中的网络层运算方法及装置”的中国专利申请的优先权,其全部内容通过引用结合在本申请中。
本申请涉及机器学习技术领域,特别涉及一种深度神经网络中的网络层运算方法及装置。
DNN(Deep Neural Network,深度神经网络)作为机器学习研究中的一个新兴领域,通过模仿人脑的机制来解析数据,是一种通过建立和模拟人脑进行分析学习的智能模型。目前,例如CNN(Convolutional Neural Network,卷积神经网络)、RNN(Recurrent Neural Network,循环神经网络)、LSTM(Long Short Term Memory,长短期记忆网络)等已在目标检测与分割、行为检测与识别、语音识别等方面得到了很好的应用。
传统的DNN一般采用双精度或单精度浮点数据的乘/加操作来实现网络基本单元的运算,由于参与运算的数据量往往较大,导致在进行DNN的运算时,每次运算的运算量很大,使得DNN的运算效率较低。
发明内容
本申请实施例的目的在于提供一种深度神经网络中的网络层运算方法及装置,以提高DNN的运算效率。具体技术方案如下:
第一方面,本申请实施例提供了一种深度神经网络中的网络层运算方法,所述方法包括:
获取深度神经网络中网络层的权值张量,其中,所述权值张量包括多个滤波器;
针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核中的权值为具有指定位宽的定点量化值;
针对所述网络层的各滤波器,将所述网络层的输入数据与该滤波器的各 定点卷积核分别进行卷积运算,得到多个卷积结果,并根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果;
确定各滤波器的运算结果组成所述网络层的输出数据。
可选的,在所述针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合之前,所述方法还包括:
根据所述深度神经网络的预设应用精度,确定预设量化比特数;
所述针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,包括:
针对所述网络层的各滤波器,根据所述预设量化比特数,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核对应的指定位宽之和等于所述预设量化比特数。
可选的,所述网络层包括卷积层,所述卷积层的权值张量的大小为S×S×I×O;
所述针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,包括:
针对所述卷积层的各滤波器,按照预设拆分公式,将该滤波器拆分为多个定点卷积核的线性组合,其中,所述预设拆分公式为:

所述w
i为所述卷积层的第i个滤波器,所述i∈[1,O],所述p为对所述滤波器w
i拆分后得到的定点卷积核的数量,所述α
j为第j个定点卷积核的预设线性加权系数,所述t
j为第j个定点卷积核,所述t
j的大小为S×S×I,所述B为预设量化比特数,所述b
j为第j个定点卷积核对应的指定位宽。
可选的,所述根据该滤波器的多个定点卷积核的线性组合方式,将各卷 积结果加权求和,得到该滤波器的运算结果,包括:
针对所述卷积层的各滤波器,按照该滤波器的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该滤波器的运算结果。
可选的,所述网络层包括全连接层,所述全连接层的权值张量的大小为M×N,所述全连接层的各滤波器为大小为1×N的各向量;
所述针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,包括:
针对所述全连接层的大小为1×N的各向量,按照预设拆分公式,将该向量拆分为多个定点卷积核的线性组合,其中,所述预设拆分公式为:

所述v
x为所述全连接层的第x个大小为1×N的向量,所述x∈[1,M],所述q为对所述向量v
x拆分后得到的定点卷积核的数量,所述β
y为第y个定点卷积核的预设线性加权系数,所述t
y为第y个定点卷积核,所述t
y的大小为1×N,所述B为预设量化比特数,所述b
y为第y个定点卷积核对应的指定位宽。
可选的,所述根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果,包括:
针对所述全连接层的大小为1×N的各向量,根据该向量的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该向量的运算结果。
第二方面,本申请实施例提供了一种深度神经网络中的网络层运算装置,所述装置包括:
获取模块,用于获取深度神经网络中网络层的权值张量,其中,所述权值张量包括多个滤波器;
拆分模块,用于针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核中的权值为具有指定位宽的定点量化值;
运算模块,用于针对所述网络层的各滤波器,将所述网络层的输入数据与该滤波器的各定点卷积核分别进行卷积运算,得到多个卷积结果,并根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果;
确定模块,用于确定各滤波器的运算结果组成所述网络层的输出数据。
可选的,所述获取模块,还用于根据所述深度神经网络的预设应用精度,确定预设量化比特数;
所述拆分模块,具体用于:
针对所述网络层的各滤波器,根据所述预设量化比特数,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核对应的指定位宽之和等于所述预设量化比特数。
可选的,所述网络层包括卷积层,所述卷积层的权值张量的大小为S×S×I×O;
所述拆分模块,具体用于:
针对所述卷积层的各滤波器,按照预设拆分公式,将该滤波器拆分为多个定点卷积核的线性组合,其中,所述预设拆分公式为:

所述w
i为所述卷积层的第i个滤波器,所述i∈[1,O],所述p为对所述滤波器w
i拆分后得到的定点卷积核的数量,所述α
j为第j个定点卷积核的预设线性加权系数,所述t
j为第j个定点卷积核,所述t
j的大小为S×S×I,所述B为预设量化比特数,所述b
j为第j个定点卷积核对应的指定位宽。
可选的,所述运算模块,具体用于:
针对所述卷积层的各滤波器,按照该滤波器的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该滤波器的运算结果。
可选的,所述网络层包括全连接层,所述全连接层的权值张量的大小为M×N,所述全连接层的各滤波器为大小为1×N的各向量;
所述拆分模块,具体用于:
针对所述全连接层的大小为1×N的各向量,按照预设拆分公式,将该向量拆分为多个定点卷积核的线性组合,其中,所述预设拆分公式为:

所述v
x为所述全连接层的第x个大小为1×N的向量,所述x∈[1,M],所述q为对所述向量v
x拆分后得到的定点卷积核的数量,所述β
y为第y个定点卷积核的预设线性加权系数,所述t
y为第y个定点卷积核,所述t
y的大小为1×N,所述B为预设量化比特数,所述b
y为第y个定点卷积核对应的指定位宽。
可选的,所述运算模块,具体用于:
针对所述全连接层的大小为1×N的各向量,根据该向量的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该向量的运算结果。
第三方面,本申请实施例提供了一种电子设备,包括处理器和机器可读存储介质,所述机器可读存储介质存储有能够被所述处理器执行的机器可执行指令,所述处理器被所述机器可执行指令促使执行本申请实施例第一方面所提供的方法。
第四方面,本申请实施例提供了一种机器可读存储介质,存储有机器可执行指令,在被处理器调用和执行时,所述机器可执行指令促使所述处理器 执行本申请实施例第一方面所提供的方法。
第五方面,本申请实施例提供了一种应用程序,用于在运行时执行:本申请实施例第一方面所提供的方法。
综上可见,本申请实施例提供的方案中,通过获取深度神经网络中网络层的权值张量,针对网络层的权值张量中各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,将网络层的输入数据与该滤波器的各定点卷积核分别进行卷积运算,得到多个卷积结果,并根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果,确定各滤波器的运算结果组成网络层的输出数据。由于各定点卷积核中的权值为具有指定位宽的定点量化值,通过对浮点数据进行定点量化,将网络层权值张量中包括浮点权值的滤波器拆分为多个包括定点量化权值的定点卷积核的线性组合,对定点量化值的运算量小于对浮点数据的运算量,因此,降低了DNN每次进行运算的运算量,从而提高了DNN的运算效率。
为了更清楚地说明本申请实施例和现有技术的技术方案,下面对实施例和现有技术中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例的深度神经网络中的网络层运算方法的流程示意图;
图2为本申请实施例的卷积层各滤波器的拆分示意图;
图3为本申请实施例的全连接层大小为1×N的各向量的拆分示意图;
图4为相应的网络层运算与本申请实施例的网络层运算的对比示意图;
图5为本申请实施例的深度神经网络中的网络层运算装置的结构示意图;
图6为本申请实施例的电子设备的结构示意图。
为使本申请的目的、技术方案、及优点更加清楚明白,以下参照附图并举实施例,对本申请进一步详细说明。显然,所描述的实施例仅仅是本申请 一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
为了提高DNN的运算效率,本申请实施例提供了一种深度神经网络中的网络层运算方法、装置、电子设备、机器可读存储介质及应用程序。
下面,首先对本申请实施例所提供的深度神经网络中的网络层运算方法进行介绍。
本申请实施例所提供的一种深度神经网络中的网络层运算方法的执行主体可以为执行智能算法的电子设备,电子设备可以为具有目标检测与分割、行为检测与识别或者语音识别的智能设备,例如远程计算机、远程服务器、智能相机、智能语音设备等等,执行主体中应该至少包括搭载有核心处理芯片的处理器。实现本申请实施例所提供的一种深度神经网络中的网络层运算方法的方式可以为设置于执行主体中的软件、硬件电路和逻辑电路中的至少一种方式。
如图1所示,本申请实施例所提供的一种深度神经网络中的网络层运算方法,可以包括如下步骤:
S101,获取深度神经网络中网络层的权值张量,其中,权值张量包括多个滤波器。
深度神经网络中的网络层用于进行卷积、点乘等网络运算,网络层可以包括卷积Conv层及全连接层,各网络层中均包含有进行网络运算的权值张量。DNN为一个较为宽泛的数据处理方法,DNN可以为CNN、RNN、LSTM等数据处理方法中的任意一种。
权值张量中包括:Conv层中的具体权值或者全连接层中的具体权值。将第k个Conv层的权值张量记为W,其大小为S×S×I×O,并且及w=W(:,:,:,i)为该Conv层的第i个滤波器,第i个滤波器的大小为S×S×I,即可以将Conv层的权值张量依据输出特征向量的个数划分为O个滤波器;对于全连接层来讲,将第l个全连接层的权值张量记为V,其大小为M×N,则全连接层的输出特征向量的个数为M,因此,全连接层的第j个滤波器的大小为1×N,可以将全连接层的 权值张量依据输出特征向量的个数划分为M个滤波器。
S102,针对网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核中的权值为具有指定位宽的定点量化值。
网络层中权值张量的权值通常情况下是浮点数据,浮点数据可以表示为一个定点量化值与权重的乘积,或者多个定点量化值与对应权重的加权和,其中权重可以是通过多次训练的过程得到,权重表示缩放系数,对定点量化值进行相乘可以得到近似的浮点数据。
在实际应用场景部署神经网络模型时,不同应用场景下对模型权值需要的比特数是不同的,对于某些较难的任务,如实现人脸识别功能,权值需要16比特位宽表示;对于某些较简单的任务,如实现目标检测功能,权值需要4比特位宽表示。在这种情况下,较大位宽会使得运算率无法得到明显的降低,同一硬件平台存在多种比特数的支持需求会增强电路设计的复杂度,降低电路规整性,因此,可以通过权值拆分的方法,将权值张量统一到低比特定点卷积核,大大降低了运算量及电路设计的规整性。例如,当某一滤波器需要8比特位宽支持时,可以将其拆分为4个2比特的定点卷积核的线性组合,每次只需要对2比特的定点数据进行运算;当某一滤波器需要4比特位宽支持时,可以将其拆分为2个2比特的定点卷积核的线性组合,每次只需要对2比特的定点数据进行运算,这种方案明显降低了运算量,提高了电路设计的规整性,这里线性组合的权重表示尺度系数可以通过训练得到。
可选的,在S102之前,本申请实施例所提供的方法还可以执行如下步骤:根据深度神经网络的预设应用精度,确定预设量化比特数。
则S102具体可以为:针对网络层的各滤波器,根据预设量化比特数,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核对应的指定位宽之和等于预设量化比特数。
如上所述,深度神经网络的预设应用精度决定了权值张量中各权值量化后的预设量化比特数,预设应用精度越大,预设量化比特数就越大。在进行各滤波器的拆分时,为了保证拆分结果的准确性,拆分得到的各定点卷积核对应的指定位宽之和等于预设量化比特数。
可选的,网络层可以包括Conv层,Conv层的权值张量的大小可以为S×S×I×O。
则S102具体可以为:针对Conv层的各滤波器,按照预设拆分公式,将该滤波器拆分为多个定点卷积核的线性组合。预设拆分公式如公式(1)所示。

其中,w
i为Conv层的第i个滤波器,i∈[1,O],p为对滤波器w
i拆分后得到的定点卷积核的数量,α
j为第j个定点卷积核的预设线性加权系数,t
j为第j个定点卷积核,t
j的大小为S×S×I,B为预设量化比特数,b
j为第j个定点卷积核对应的指定位宽。
针对网络中的Conv层,将该Conv层中大小为S×S×I的滤波器w
i拆分为p个低比特定点卷积核的线性组合,并记第j个定点卷积核的低比特定点比特数位宽(即指定位宽)为b
j。通过公式(1)将Conv层的权值张量中各滤波器拆分后,网络模型中每个Conv层的权值张量可以表示为如图2所示,即模型浮点滤波器拆分为多个低比特定点卷积核的线性组合,实质上也就是多个低比特定点卷积核中低比特定点权值的线性组合。
可选的,网络层可以包括全连接层,全连接层的权值张量的大小可以为M×N,全连接层的各滤波器为大小为1×N的各向量。
则S102具体可以为:针对全连接层的大小为1×N的各向量,按照预设拆分公式,将该向量拆分为多个定点卷积核的线性组合。预设拆分公式如公式(2)所示。

其中,v
x为全连接层的第x个大小为1×N的向量,x∈[1,M],q为对向量v
x拆分后得到的定点卷积核的数量,β
y为第y个定点卷积核的预设线性加权系数,t
y为第y个定点卷积核,t
y的大小为1×N,B为预设量化比特数,b
y为第y个定点卷积核对应的指定位宽。
针对网络中的全连接层,该全连接层中每个大小为1×N的向量可以理解为该全连接层的滤波器,将该全连接层中每个大小为1×N的向量拆分为q个低比特定点卷积核的线性组合,并记第y个定点卷积核的低比特定点比特数位宽(即指定位宽)为b
y。通过公式(2)将全连接层的权值张量中各向量拆分后,网络模型中每个全连接层的权值张量可以表示为如图3所示,即模型浮点向量拆分为多个低比特定点卷积核的线性组合,实质上也就是多个低比特定点卷积核中低比特定点权值的线性组合。
S103,针对网络层的各滤波器,将网络层的输入数据与该滤波器的各定点卷积核分别进行卷积运算,得到多个卷积结果,并根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果。
通过S102对网络层的权值张量定点化,可以将一个针对浮点权值Conv层或浮点权值全连接层的运算拆分为对多个低比特定点权值Conv层或全连接层的运算操作,如图4所示,在网络模型运算时,可以将图4左部分所示的模型结构拆分为图4右部分的模型结构进行运算,在大大减少模型参数量及运算量的同时,降低了硬件平台计算颗粒度,提升了硬件平台的资源利用率。
输入数据与各定点卷积核的卷积运算就是进行点乘、相加的过程,这里不再赘述。在得到每个定点卷积核的卷积结果后,可以根据该滤波器的多个定点卷积核的线性组合方式,例如线性组合方式为加权求和的方式,则将卷积结果也进行相同方式的加权求和,即可得到该滤波器的运算结果。
可选的,在网络层为Conv层时,S103具体可以为:针对Conv层的各滤波器,按照该滤波器的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该滤波器的运算结果。
在网络层为全连接层时,S103具体可以为:针对全连接层的大小为1×N的各向量,根据该向量的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该向量的运算结果。
在S102中已对网络层分别为Conv层和全连接层,进行滤波器拆分的过程进行介绍,在进行拆分的过程中,滤波器表示为定点卷积核与预设线性加权系数乘积、相加的线性组合,因此,在进行卷积运算时,输入数据分别与各定点卷积核进行卷积运算,并根据预设线性加权系数,对卷积结果进行加权求和,得到滤波器的运算结果。
S104,确定各滤波器的运算结果组成网络层的输出数据。
网络层的滤波器对应了网络层的输出特征向量的个数,因此,网络层的输出数据实际为各滤波器的运算结果的组合,例如,如果一个网络层包括5个滤波器,则该网络层的输出数据实际包括5个特征向量。
应用本实施例,通过获取深度神经网络中网络层的权值张量,针对网络层的权值张量中各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,将网络层的输入数据与该滤波器的各定点卷积核分别进行卷积运算,得到多个卷积结果,并根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果,确定各滤波器的运算结果组成网络层的输出数据。由于各定点卷积核中的权值为具有指定位宽的定点量化值,通过对浮点数据进行定点量化,将网络层权值张量中包括浮点权值的滤波器拆分为多个包括定点量化权值的定点卷积核的线性组合,对定点量化值的运算量小于对浮点数据的运算量,因此,降低了DNN每次进行运算的运算量,从而提高了DNN的运算效率。
相应于上述方法实施例,本申请实施例提供了一种深度神经网络中的网 络层运算装置,如图5所示,该深度神经网络中的网络层运算装置可以包括:
获取模块510,用于获取深度神经网络中网络层的权值张量,其中,所述权值张量包括多个滤波器;
拆分模块520,用于针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核中的权值为具有指定位宽的定点量化值;
运算模块530,用于针对所述网络层的各滤波器,将所述网络层的输入数据与该滤波器的各定点卷积核分别进行卷积运算,得到多个卷积结果,并根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果;
确定模块540,用于确定各滤波器的运算结果组成所述网络层的输出数据。
可选的,所述获取模块510,还可以用于根据所述深度神经网络的预设应用精度,确定预设量化比特数;
所述拆分模块520,具体可以用于:
针对所述网络层的各滤波器,根据所述预设量化比特数,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核对应的指定位宽之和等于所述预设量化比特数。
可选的,所述网络层可以包括卷积层,所述卷积层的权值张量的大小可以为S×S×I×O;
所述拆分模块520,具体可以用于:
针对所述卷积层的各滤波器,按照预设拆分公式,将该滤波器拆分为多个定点卷积核的线性组合,其中,所述预设拆分公式为:

所述w
i为所述卷积层的第i个滤波器,所述i∈[1,O],所述p为对所述滤波器w
i拆分后得到的定点卷积核的数量,所述α
j为第j个定点卷积核的预设线性加 权系数,所述t
j为第j个定点卷积核,所述t
j的大小为S×S×I,所述B为预设量化比特数,所述b
j为第j个定点卷积核对应的指定位宽。
可选的,所述运算模块530,具体可以用于:
针对所述卷积层的各滤波器,按照该滤波器的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该滤波器的运算结果。
可选的,所述网络层可以包括全连接层,所述全连接层的权值张量的大小可以为M×N,所述全连接层的各滤波器可以为大小为1×N的各向量;
所述拆分模块520,具体可以用于:
针对所述全连接层的大小为1×N的各向量,按照预设拆分公式,将该向量拆分为多个定点卷积核的线性组合,其中,所述预设拆分公式为:

所述v
x为所述全连接层的第x个大小为1×N的向量,所述x∈[1,M],所述q为对所述向量v
x拆分后得到的定点卷积核的数量,所述β
y为第y个定点卷积核的预设线性加权系数,所述t
y为第y个定点卷积核,所述t
y的大小为1×N,所述B为预设量化比特数,所述b
y为第y个定点卷积核对应的指定位宽。
可选的,所述运算模块530,具体可以用于:
针对所述全连接层的大小为1×N的各向量,根据该向量的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该向量的运算结果。
应用本实施例,通过获取深度神经网络中网络层的权值张量,针对网络层的权值张量中各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,将网络层的输入数据与该滤波器的各定点卷积核分别进行卷积运算,得到多 个卷积结果,并根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果,确定各滤波器的运算结果组成网络层的输出数据。由于各定点卷积核中的权值为具有指定位宽的定点量化值,通过对浮点数据进行定点量化,将网络层权值张量中包括浮点权值的滤波器拆分为多个包括定点量化权值的定点卷积核的线性组合,对定点量化值的运算量小于对浮点数据的运算量,因此,降低了DNN每次进行运算的运算量,从而提高了DNN的运算效率。
为了提高DNN的运算效率,本申请实施例还提供了一种电子设备,如图6所示,包括处理器601和机器可读存储介质602,其中,
机器可读存储介质602,用于存储能够被处理器601执行的机器可执行指令;
处理器601,用于被机器可读存储介质602上所存放的机器可执行指令促使执行本申请实施例提供的深度神经网络中的网络层运算方法的所有步骤。
机器可读存储介质602与处理器601之间可以通过有线连接或者无线连接的方式进行数据传输,并且电子设备可以通过有线通信接口或者无线通信接口与其他的设备进行通信。
上述机器可读存储介质可以包括RAM(Random Access Memory,随机存取存储器),也可以包括NVM(Non-volatile Memory,非易失性存储器),例如至少一个磁盘存储器。可选的,机器可读存储介质还可以是至少一个位于远离前述处理器的存储装置。
上述处理器可以是通用处理器,包括CPU(Central Processing Unit,中央处理器)、NP(Network Processor,网络处理器)等;还可以是DSP(Digital Signal Processor,数字信号处理器)、ASIC(Application Specific Integrated Circuit,专用集成电路)、FPGA(Field-Programmable Gate Array,现场可编程门阵列)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
本实施例中,该电子设备的处理器通过读取机器可读存储介质中存储的机器可执行指令,并通过运行该机器可执行指令,能够实现:通过获取深度 神经网络中网络层的权值张量,针对网络层的权值张量中各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,将网络层的输入数据与该滤波器的各定点卷积核分别进行卷积运算,得到多个卷积结果,并根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果,确定各滤波器的运算结果组成网络层的输出数据。由于各定点卷积核中的权值为具有指定位宽的定点量化值,通过对浮点数据进行定点量化,将网络层权值张量中包括浮点权值的滤波器拆分为多个包括定点量化权值的定点卷积核的线性组合,对定点量化值的运算量小于对浮点数据的运算量,因此,降低了DNN每次进行运算的运算量,从而提高了DNN的运算效率。
另外,相应于上述实施例所提供的深度神经网络中的网络层运算方法,本申请实施例提供了一种机器可读存储介质,用于机器可执行指令,所述机器可执行指令促使处理器执行本申请实施例提供的深度神经网络中的网络层运算方法的所有步骤。
本实施例中,机器可读存储介质存储有在运行时执行本申请实施例所提供的深度神经网络中的网络层运算方法的机器可执行指令,因此能够实现:通过获取深度神经网络中网络层的权值张量,针对网络层的权值张量中各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,将网络层的输入数据与该滤波器的各定点卷积核分别进行卷积运算,得到多个卷积结果,并根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果,确定各滤波器的运算结果组成网络层的输出数据。由于各定点卷积核中的权值为具有指定位宽的定点量化值,通过对浮点数据进行定点量化,将网络层权值张量中包括浮点权值的滤波器拆分为多个包括定点量化权值的定点卷积核的线性组合,对定点量化值的运算量小于对浮点数据的运算量,因此,降低了DNN每次进行运算的运算量,从而提高了DNN的运算效率。
另外,本申请实施例还提供了一种应用程序,用于在运行时执行:本申请实施例所提供的深度神经网络中的网络层运算方法。
本申请实施例中,应用程序在运行时执行本申请实施例所提供的深度神经网络中的网络层运算方法,因此能够实现:通过获取深度神经网络中网络 层的权值张量,针对网络层的权值张量中各滤波器,将滤波器拆分为多个定点卷积核的线性组合,将网络层的输入数据与滤波器的各定点卷积核分别进行卷积运算,得到多个卷积结果,并根据滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到滤波器的运算结果,确定各滤波器的运算结果组成网络层的输出数据。由于各定点卷积核中的权值为具有指定位宽的定点量化值,通过对浮点数据进行定点量化,将网络层权值张量中包括浮点权值的滤波器拆分为多个包括定点量化权值的定点卷积核的线性组合,对定点量化值的运算量小于对浮点数据的运算量,因此,降低了DNN每次进行运算的运算量,从而提高了DNN的运算效率。
对于电子设备、机器可读存储介质以及应用程序实施例而言,由于其所涉及的方法内容基本相似于前述的方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置、电子设备、机器可读存储介质以及应用程序实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上所述仅为本申请的较佳实施例而已,并不用以限制本申请,凡在本申请的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本申请保护的范围之内。
Claims (15)
- 一种深度神经网络中的网络层运算方法,其特征在于,所述方法包括:获取深度神经网络中网络层的权值张量,其中,所述权值张量包括多个滤波器;针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核中的权值为具有指定位宽的定点量化值;针对所述网络层的各滤波器,将所述网络层的输入数据与该滤波器的各定点卷积核分别进行卷积运算,得到多个卷积结果,并根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果;确定各滤波器的运算结果组成所述网络层的输出数据。
- 根据权利要求1所述的方法,其特征在于,在所述针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合之前,所述方法还包括:根据所述深度神经网络的预设应用精度,确定预设量化比特数;所述针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,包括:针对所述网络层的各滤波器,根据所述预设量化比特数,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核对应的指定位宽之和等于所述预设量化比特数。
- 根据权利要求1或2所述的方法,其特征在于,所述网络层包括卷积层,所述卷积层的权值张量的大小为S×S×I×O;所述针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,包括:针对所述卷积层的各滤波器,按照预设拆分公式,将该滤波器拆分为多个定点卷积核的线性组合,其中,所述预设拆分公式为:
 所述w i为所述卷积层的第i个滤波器,所述i∈[1,O],所述p为对所述滤波器w i拆分后得到的定点卷积核的数量,所述α j为第j个定点卷积核的预设线性加权系数,所述t j为第j个定点卷积核,所述t j的大小为S×S×I,所述B为预设量化比特数,所述b j为第j个定点卷积核对应的指定位宽。
所述w i为所述卷积层的第i个滤波器,所述i∈[1,O],所述p为对所述滤波器w i拆分后得到的定点卷积核的数量,所述α j为第j个定点卷积核的预设线性加权系数,所述t j为第j个定点卷积核,所述t j的大小为S×S×I,所述B为预设量化比特数,所述b j为第j个定点卷积核对应的指定位宽。 - 根据权利要求3所述的方法,其特征在于,所述根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果,包括:针对所述卷积层的各滤波器,按照该滤波器的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该滤波器的运算结果。
- 根据权利要求1或2所述的方法,其特征在于,所述网络层包括全连接层,所述全连接层的权值张量的大小为M×N,所述全连接层的各滤波器为大小为1×N的各向量;所述针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,包括:针对所述全连接层的大小为1×N的各向量,按照预设拆分公式,将该向量拆分为多个定点卷积核的线性组合,其中,所述预设拆分公式为:
 所述v x为所述全连接层的第x个大小为1×N的向量,所述x∈[1,M],所述q为对所述向量v x拆分后得到的定点卷积核的数量,所述β y为第y个定点卷积核的预设线性加权系数,所述t y为第y个定点卷积核,所述t y的大小为1×N,所述 B为预设量化比特数,所述b y为第y个定点卷积核对应的指定位宽。
所述v x为所述全连接层的第x个大小为1×N的向量,所述x∈[1,M],所述q为对所述向量v x拆分后得到的定点卷积核的数量,所述β y为第y个定点卷积核的预设线性加权系数,所述t y为第y个定点卷积核,所述t y的大小为1×N,所述 B为预设量化比特数,所述b y为第y个定点卷积核对应的指定位宽。 - 根据权利要求5所述的方法,其特征在于,所述根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果,包括:针对所述全连接层的大小为1×N的各向量,根据该向量的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该向量的运算结果。
- 一种深度神经网络中的网络层运算装置,其特征在于,所述装置包括:获取模块,用于获取深度神经网络中网络层的权值张量,其中,所述权值张量包括多个滤波器;拆分模块,用于针对所述网络层的各滤波器,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核中的权值为具有指定位宽的定点量化值;运算模块,用于针对所述网络层的各滤波器,将所述网络层的输入数据与该滤波器的各定点卷积核分别进行卷积运算,得到多个卷积结果,并根据该滤波器的多个定点卷积核的线性组合方式,将各卷积结果加权求和,得到该滤波器的运算结果;确定模块,用于确定各滤波器的运算结果组成所述网络层的输出数据。
- 根据权利要求7所述的装置,其特征在于,所述获取模块,还用于根据所述深度神经网络的预设应用精度,确定预设量化比特数;所述拆分模块,具体用于:针对所述网络层的各滤波器,根据所述预设量化比特数,将该滤波器拆分为多个定点卷积核的线性组合,其中,各定点卷积核对应的指定位宽之和等于所述预设量化比特数。
- 根据权利要求7或8所述的装置,其特征在于,所述网络层包括卷积层,所述卷积层的权值张量的大小为S×S×I×O;所述拆分模块,具体用于:针对所述卷积层的各滤波器,按照预设拆分公式,将该滤波器拆分为多个定点卷积核的线性组合,其中,所述预设拆分公式为:
 所述w i为所述卷积层的第i个滤波器,所述i∈[1,O],所述p为对所述滤波器w i拆分后得到的定点卷积核的数量,所述α j为第j个定点卷积核的预设线性加权系数,所述t j为第j个定点卷积核,所述t j的大小为S×S×I,所述B为预设量化比特数,所述b j为第j个定点卷积核对应的指定位宽。
所述w i为所述卷积层的第i个滤波器,所述i∈[1,O],所述p为对所述滤波器w i拆分后得到的定点卷积核的数量,所述α j为第j个定点卷积核的预设线性加权系数,所述t j为第j个定点卷积核,所述t j的大小为S×S×I,所述B为预设量化比特数,所述b j为第j个定点卷积核对应的指定位宽。 - 根据权利要求9所述的装置,其特征在于,所述运算模块,具体用于:针对所述卷积层的各滤波器,按照该滤波器的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该滤波器的运算结果。
- 根据权利要求7或8所述的装置,其特征在于,所述网络层包括全连接层,所述全连接层的权值张量的大小为M×N,所述全连接层的各滤波器为大小为1×N的各向量;所述拆分模块,具体用于:针对所述全连接层的大小为1×N的各向量,按照预设拆分公式,将该向量拆分为多个定点卷积核的线性组合,其中,所述预设拆分公式为:
 所述v x为所述全连接层的第x个大小为1×N的向量,所述x∈[1,M],所述q为对所述向量v x拆分后得到的定点卷积核的数量,所述β y为第y个定点卷积核的预设线性加权系数,所述t y为第y个定点卷积核,所述t y的大小为1×N,所述 B为预设量化比特数,所述b y为第y个定点卷积核对应的指定位宽。
所述v x为所述全连接层的第x个大小为1×N的向量,所述x∈[1,M],所述q为对所述向量v x拆分后得到的定点卷积核的数量,所述β y为第y个定点卷积核的预设线性加权系数,所述t y为第y个定点卷积核,所述t y的大小为1×N,所述 B为预设量化比特数,所述b y为第y个定点卷积核对应的指定位宽。 - 根据权利要求11所述的装置,其特征在于,所述运算模块,具体用于:针对所述全连接层的大小为1×N的各向量,根据该向量的各定点卷积核的预设线性加权系数,对各定点卷积核的卷积结果进行加权,并将各加权后的卷积结果相加,得到该向量的运算结果。
- 一种电子设备,其特征在于,包括处理器和机器可读存储介质,所述机器可读存储介质存储有能够被所述处理器执行的机器可执行指令,所述处理器被所述机器可执行指令促使执行权利要求1-6任一项所述的方法。
- 一种机器可读存储介质,其特征在于,存储有机器可执行指令,在被处理器调用和执行时,所述机器可执行指令促使所述处理器执行权利要求1-6任一项所述的方法。
- 一种应用程序,其特征在于,用于在运行时执行:权利要求1-6任一项所述的方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP19827144.7A EP3816866A4 (en) | 2018-06-27 | 2019-06-24 | METHOD AND DEVICE FOR OPERATING A NETWORK LAYER IN A DEEP NEURAL NETWORK |
| US17/254,002 US20210271973A1 (en) | 2018-06-27 | 2019-06-24 | Operation method and apparatus for network layer in deep neural network |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810679580.X | 2018-06-27 | ||
| CN201810679580.XA CN110647974A (zh) | 2018-06-27 | 2018-06-27 | 深度神经网络中的网络层运算方法及装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2020001401A1 true WO2020001401A1 (zh) | 2020-01-02 |
Family
ID=68984444
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2019/092553 WO2020001401A1 (zh) | 2018-06-27 | 2019-06-24 | 深度神经网络中的网络层运算方法及装置 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20210271973A1 (zh) |
| EP (1) | EP3816866A4 (zh) |
| CN (1) | CN110647974A (zh) |
| WO (1) | WO2020001401A1 (zh) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11449739B2 (en) * | 2019-08-22 | 2022-09-20 | Google Llc | General padding support for convolution on systolic arrays |
| US11443347B2 (en) * | 2019-08-30 | 2022-09-13 | Samsung Electronics Co., Ltd. | System and method for click-through rate prediction |
| CN111932437B (zh) * | 2020-10-10 | 2021-03-05 | 深圳云天励飞技术股份有限公司 | 图像处理方法、装置、电子设备及计算机可读存储介质 |
| CN114298280A (zh) * | 2021-12-29 | 2022-04-08 | 杭州海康威视数字技术股份有限公司 | 一种数据处理、网络训练方法、电子设备及存储介质 |
| CN114897147B (zh) * | 2022-05-18 | 2023-06-06 | 北京百度网讯科技有限公司 | 骨干网络的生成方法、装置、设备以及存储介质 |
| CN115758054B (zh) * | 2023-02-10 | 2023-04-14 | 上海登临科技有限公司 | 一种卷积计算方法、数据处理方法、芯片及电子设备 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106127297A (zh) * | 2016-06-02 | 2016-11-16 | 中国科学院自动化研究所 | 基于张量分解的深度卷积神经网络的加速与压缩方法 |
| CN106339753A (zh) * | 2016-08-17 | 2017-01-18 | 中国科学技术大学 | 一种有效提升卷积神经网络稳健性的方法 |
| US20170337471A1 (en) * | 2016-05-18 | 2017-11-23 | Nec Laboratories America, Inc. | Passive pruning of filters in a convolutional neural network |
| CN107392309A (zh) * | 2017-09-11 | 2017-11-24 | 东南大学—无锡集成电路技术研究所 | 一种基于fpga的通用定点数神经网络卷积加速器硬件结构 |
| CN107480770A (zh) * | 2017-07-27 | 2017-12-15 | 中国科学院自动化研究所 | 可调节量化位宽的神经网络量化与压缩的方法及装置 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10373050B2 (en) * | 2015-05-08 | 2019-08-06 | Qualcomm Incorporated | Fixed point neural network based on floating point neural network quantization |
| US20160328644A1 (en) * | 2015-05-08 | 2016-11-10 | Qualcomm Incorporated | Adaptive selection of artificial neural networks |
| EP3704638A1 (en) * | 2017-10-30 | 2020-09-09 | Fraunhofer Gesellschaft zur Förderung der Angewand | Neural network representation |
| WO2019114842A1 (zh) * | 2017-12-14 | 2019-06-20 | 北京中科寒武纪科技有限公司 | 一种集成电路芯片装置 |
| WO2019129070A1 (zh) * | 2017-12-27 | 2019-07-04 | 北京中科寒武纪科技有限公司 | 一种集成电路芯片装置 |
-
2018
- 2018-06-27 CN CN201810679580.XA patent/CN110647974A/zh active Pending
-
2019
- 2019-06-24 US US17/254,002 patent/US20210271973A1/en active Pending
- 2019-06-24 EP EP19827144.7A patent/EP3816866A4/en active Pending
- 2019-06-24 WO PCT/CN2019/092553 patent/WO2020001401A1/zh unknown
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20170337471A1 (en) * | 2016-05-18 | 2017-11-23 | Nec Laboratories America, Inc. | Passive pruning of filters in a convolutional neural network |
| CN106127297A (zh) * | 2016-06-02 | 2016-11-16 | 中国科学院自动化研究所 | 基于张量分解的深度卷积神经网络的加速与压缩方法 |
| CN106339753A (zh) * | 2016-08-17 | 2017-01-18 | 中国科学技术大学 | 一种有效提升卷积神经网络稳健性的方法 |
| CN107480770A (zh) * | 2017-07-27 | 2017-12-15 | 中国科学院自动化研究所 | 可调节量化位宽的神经网络量化与压缩的方法及装置 |
| CN107392309A (zh) * | 2017-09-11 | 2017-11-24 | 东南大学—无锡集成电路技术研究所 | 一种基于fpga的通用定点数神经网络卷积加速器硬件结构 |
Non-Patent Citations (1)
| Title |
|---|
| See also references of EP3816866A4 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3816866A4 (en) | 2022-05-11 |
| EP3816866A1 (en) | 2021-05-05 |
| CN110647974A (zh) | 2020-01-03 |
| US20210271973A1 (en) | 2021-09-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2020001401A1 (zh) | 深度神经网络中的网络层运算方法及装置 | |
| US20210004663A1 (en) | Neural network device and method of quantizing parameters of neural network | |
| US11373087B2 (en) | Method and apparatus for generating fixed-point type neural network | |
| CN108510067B (zh) | 基于工程化实现的卷积神经网络量化方法 | |
| CN108701250B (zh) | 数据定点化方法和装置 | |
| WO2019238029A1 (zh) | 卷积神经网络系统和卷积神经网络量化的方法 | |
| WO2020057000A1 (zh) | 网络量化方法、业务处理方法及相关产品 | |
| WO2022006919A1 (zh) | 基于激活定点拟合的卷积神经网络训练后量化方法及系统 | |
| CN106855952B (zh) | 基于神经网络的计算方法及装置 | |
| TWI744724B (zh) | 處理卷積神經網路的方法 | |
| WO2023011002A1 (zh) | 溢出感知的量化模型训练方法、装置、介质及终端设备 | |
| WO2019056946A1 (zh) | 一种基于深度神经网络的激活量量化方法及装置 | |
| CN106991999B (zh) | 语音识别方法及装置 | |
| US11704556B2 (en) | Optimization methods for quantization of neural network models | |
| CN114677548B (zh) | 基于阻变存储器的神经网络图像分类系统及方法 | |
| WO2022111002A1 (zh) | 用于训练神经网络的方法、设备和计算机可读存储介质 | |
| Choi et al. | Retrain-less weight quantization for multiplier-less convolutional neural networks | |
| CN111723901A (zh) | 神经网络模型的训练方法及装置 | |
| WO2021012148A1 (zh) | 基于深度神经网络的数据处理方法、装置及移动设备 | |
| CN111126557B (zh) | 神经网络量化、应用方法、装置和计算设备 | |
| CN110874627A (zh) | 数据处理方法、数据处理装置及计算机可读介质 | |
| CN114781618A (zh) | 一种神经网络量化处理方法、装置、设备及可读存储介质 | |
| CN114139678A (zh) | 卷积神经网络量化方法、装置、电子设备和存储介质 | |
| CN114492778A (zh) | 神经网络模型的运行方法、可读介质和电子设备 | |
| JP6757349B2 (ja) | 固定小数点を用いて認識処理を行う多層の畳み込みニューラルネットワーク回路を実現する演算処理装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 19827144 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2019827144 Country of ref document: EP Effective date: 20210127 |