WO2019113471A1 - Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork - Google Patents
Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork Download PDFInfo
- Publication number
- WO2019113471A1 WO2019113471A1 PCT/US2018/064516 US2018064516W WO2019113471A1 WO 2019113471 A1 WO2019113471 A1 WO 2019113471A1 US 2018064516 W US2018064516 W US 2018064516W WO 2019113471 A1 WO2019113471 A1 WO 2019113471A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- image
- pattern
- plural
- style
- artwork
- Prior art date
Links
Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/0021—Image watermarking
- G06T1/0028—Adaptive watermarking, e.g. Human Visual System [HVS]-based watermarking
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2201/00—General purpose image data processing
- G06T2201/005—Image watermarking
- G06T2201/0202—Image watermarking whereby the quality of watermarked images is measured; Measuring quality or performance of watermarking methods; Balancing between quality and robustness
Definitions
- the present technology concerns message signaling.
- the technology is particularly illustrated in the context of message signaling through artwork of grocery item packaging, to convey plural-bit messages - of the sort presently conveyed by UPC barcodes. However, the technology is not so-limited.
- Barcodes are in widespread use on retail items, but take up real estate that the manufacturers would prefer to use for other purposes. Some retail brands find that printing a barcode on a product detracts from its aesthetics.
- Watermarking is gaining adoption as an alternative to visible barcodes. Watermarking involves making subtle changes to packaging artwork to convey a multi-bit product identifier or other message. These changes are generally imperceptible to humans, but are detectable by a computer.
- Fig. 1 shows an illustrative digital watermark pattern, including a magnified view depicting its somewhat mottled appearance.
- the watermark pattern is scaled-down in amplitude so that, when overlaid with packaging artwork in a tiled fashion, it is an essentially transparent layer that is visually imperceptible amid the artwork details.
- Designing watermarked packaging involves establishing a tradeoff between this amplitude factor, and detectability. To assure reliable detection - even under the adverse imaging conditions that are sometimes encountered by supermarket scanners - the watermark should have as strong an amplitude as possible. However, the greater the amplitude, the more apparent the pattern of the watermark becomes on the package. A best balance is struck when the watermark amplitude is raised to just below the point where the watermark pattern becomes visible to human viewers of the packaging.
- Fig. 2 illustrates this graphically.
- a watermark When a watermark is added to artwork at low levels, human visibility of the watermark is nil. As strength of the watermark increases, there becomes a point at which humans can start perceiving the watermark pattern. Increases in watermark amplitude beyond this point result in progressively greater perception (e.g., from barely, to mild, to conspicuous, to blatant). Point “A” is the desired“sweet-spot” value, at which the amplitude of the watermark is maximum, while visibility of the watermark is still below the point of human perception.
- Dry offset offers only gross control of dot size and other print structures. For example, if a digital artwork file specifies that ink dots are to be laid down with a density of 15%, a dry offset press will typically deposit a much greater density of ink, e.g., with 30% density.
- a profile for a particular model of dry offset press may specify that artwork indicating a 15% density will actually be rendered with a 25% density (e.g., a 10% dot gain). But there is a great deal of variation between presses of the same model - depending on factors including age, maintenance, consumables, temperature, etc. So instead of depositing ink at a 25% density - as indicated by a printer’s profile, a particular press may instead deposit ink at a 20% density. Or a 40% density. Or anything in between.
- Packaging artwork that has been carefully designed to set the watermark amplitude to the point“A” sweet-spot of Fig. 2, may instead be printed with the watermark amplitude at point“B”, making the watermark plainly visible.
- the payload data may be encoded as overt elements of the artwork.
- a digital watermark in which the amplitude is set to a plainly human-visible level.
- a 1D or 2D black and white barcode that is used as a fill pattern, e.g., laid down by a paintbrush in Adobe Photoshop software.
- a digital watermark with its amplitude set to a plainly human-visible level, yields a pattern that does not fit well into the design of most packaging. Painted barcode fills similarly have limited practical utility.
- a neural network is applied to imagery including a machine readable code, to transform its appearance while maintaining its machine readability.
- One particular method includes training a neural network with a style image having various features.
- the trained network is then applied to an input pattern that encodes a plural-symbol payload.
- the network adapts features from the style image to express details of the input pattern, to thereby produce an output image in which features from the style image contribute to encoding of the plural-symbol payload.
- This output image can then be used as a graphical component in product packaging, such as a background, border, or pattern fill.
- the input pattern is a watermark pattern, while in others it is a host image that has been previously watermarked.
- Fig. 1 is an illustration of a digital watermark pattern.
- Fig. 2 is a graph showing how a digital watermark is human-imperceptible at low strengths, but becomes progressively more conspicuous at higher strengths.
- Fig. 3 is a diagram depicting an algorithm for generating a digital watermark tile.
- Fig. 4 details an illustrative neural network that can be used in embodiments of the present technology
- FIGs. 5 and 6 further detail use of the Fig. 4 neural network in an illustrative embodiment of the technology.
- Fig. 7 details an algorithm employed in one illustrative embodiment of the technology.
- Fig. 8 shows an obfuscated code signal produced by the present technology from the digital watermark pattern of Fig. 1 and a (depicted) bitonal geometrical pattern.
- Fig. 9 shows another obfuscated code signal produced by the present technology from the digital watermark pattern of Fig. 1 and a (depicted) bitonal geometrical pattern.
- Fig. 10 shows still another obfuscated code signal produced by the present technology from the digital watermark pattern of Fig. 1 and still another (depicted) bitonal geometrical pattern.
- Fig. 11 shows a line art counterpart to the image of Fig. 10, produced by the method of Fig. 12.
- Fig. 12 details an algorithm for further-processing an image produced with the present technology.
- Fig. 13 shows another pattern produced by methods of the present technology.
- Fig. 14A depicts a user interface of software that generates a watermark pattern with user-defined parameters, and enables an artist to specify a style to be applied to the pattern.
- Figs. 14B and 14C detail exemplary methods employed by the software of Fig. 14A.
- Figs. 14D, 14E, 14F and 14G are images on which the“Candy,”“Mosaic,”“Feathers,” and“La Muse” styles visible in Fig. 14 are based.
- Figs. 15A - 15ZZ depict continuous tone watermark patterns that have been processed in accordance with aspects of the present technology.
- Figs. 16A - 16C show how stylization of a watermark pattern serves to scale, translate, and rotate features of a style image to mimic, or echo, features of the watermark pattern.
- Figs. 17A - 17E illustrate how three patterns can be combined: a host image, a watermark pattern, and a style image.
- Figs. 18A - 18C illustrate the Lenna image styled with images of candy balls, denim, and grass, respectively.
- Figs. 19A - 19C illustrate that a sparse mark, rendered as a Delaunay triangulation, can be stylized with a pattern of leaves, resulting in an output image in which the leaves are morphed in scale, location and rotation to correspond to triangles of the Delaunay pattern.
- Fig. 20 depicts an inverted transform method according to one aspect of the technology.
- Figs. 21 A - 21E depicts application of an inverted transform method in connection with a Voronoi pattern.
- Fig. 22 depicts an inverted transform method according to one aspect of the technology.
- Figs. 23A and 23B show a Voronoi pattern based on a sparse pattern of dots, and the same pattern after application of the inverted transform method of Fig. 22.
- Figs. 24A and 24B are enlargements from Figs. 23 A and 23B.
- Figs. 25A and 25B illustrate how artistic signaling patterns according to the present technology can be used as background patterns on a boxed item of food.
- Figs. 26 and 27 are like Figs 25 A and 25B, but showing application of artistic signaling patterns to food items in cans and plastic tubs.
- Figs. 28A and 28B illustrate use of artistic signaling patterns, based on continuous tone watermarks, as graphic backgrounds on a grocery item.
- Figs. 29A - 29C illustrate use of artistic signaling patterns, based on sparse watermarks, as graphic backgrounds on a grocery item.
- Figs. 30A and 30B show polygon-based patterns based on continuous tone watermarks.
- Fig. 31 A shows an artistic signaling pattern generated from a sparse mark using various image transformations.
- Fig. 31B is an enlargement from Fig. 31 A.
- Figs. 32A, 32B, 33A, 33B, 34A, 34B, 35A, 35B, 36A, 36B, 37A, 37B, 38A and 38B are similar to Figs. 31A and 31B, but using different image transformations.
- Figs. 39A and 40A show artistic signaling patterns generated from a continuous tone watermark using various image transformations, and Figs. 39B and 40B are enlargements thereof.
- Fig. 41 shows an artistic signaling pattern produced from a sparse mark.
- Fig. 42A shows an excerpt from a watermarked poster
- Fig. 42B shows an enlargement from Fig. 42A.
- Figs. 43 and 44 show excerpts of tiles of signal-carrying patterns.
- Fig. 45 shows how glyphs hand-written on a tablet can employ a signal-carrying pattern.
- Fig. 46 shows how strokes on a tablet can have directional texture associated with the brush, and/or its direction of use, while also employing a signal-carrying pattern.
- Fig. 47 conceptually-illustrates how two overlapping brush strokes may effect a darkening of a common region, while maintaining two directional textures.
- Fig. 48 conceptually-illustrates how two overlapping brush strokes that apply a signal-carrying pattern may effect a darkening of a common region by changing mean value of the pattern.
- Fig. 49A shows that the mean value of patterning in a rendering of handwritten glyphs can depend on stylus-applied pressure.
- Fig. 49B is like Fig. 49A but with the patterning less-exaggerated in contrast.
- Fig. 49C is like Fig. 49B, but is presented at a more typical scale.
- Figs. 50A and 50B show how handwritten glyphs entered by a stylus can be patterned with different patterns, including a neural network-derived signal-carrying pattern.
- Fig. 51 shows the user interface of a prior art tablet drawing program.
- Fig. 52 shows correspondence between a signal-carrying pattern, and handwritten strokes of different pressures - causing the pattern to be rendered with different mean values.
- Fig. 53 shows a traveling salesman line pattern, derived from another optical code pattern, that conveys a plural-bit payload.
- Fig. 54 is like Fig. 53, but showing a brick wall line pattern.
- Fig. 55 is like Fig. 53, but showing a Voronoi pattern.
- Figs. 55A and 55B illustrate how line patterns that encode plural-bit data, such as the Voronoi pattern of Fig. 55, can be used as fill patterns in graphical art.
- Fig. 56 is like Fig. 53, but showing a Delaunay triangulation pattern.
- Figs. 57A and 57B are like Fig. 53, but showing different line patterns.
- Fig. 3 shows an illustrative direct sequence spread spectrum watermark generator.
- a plural- symbol message payload e.g., 40 binary bits, which may represent a product’s Global Trade
- GTIN Global System for Mobile Communications
- This coder transforms the symbols of the message payload into a much longer array of encoded message elements (e.g., binary or M-ary elements) using an error correction method.
- Suitable coding methods include block codes, BCF1, Reed Solomon, convolutional codes, turbo codes, etc.
- the coder output may comprise hundreds or thousands of binary bits, e.g., 4,096, which may be termed“raw bits.”
- These raw bits each modulate a pseudorandom noise (carrier) sequence of length 16, e.g., by XORing. Each raw bit thus yields a 16-bit modulated carrier sequence, for an enlarged payload sequence of 65,536 elements.
- This sequence is mapped to elements of a square block having 256 x 256 embedding locations. These locations correspond to pixel samples at a configurable spatial resolution, such as 100 or 300 dots per inch (DPI). (In a 300 DPI embodiment, a 256 x 256 block corresponds to an area of about 0.85 inches square.) Such blocks can be tiled edge-to-edge to for printing on the paper or plastic of a product package/label.
- DPI dots per inch
- mapping functions to map the enlarged payload sequence to embedding locations.
- the sequence is pseudo-randomly mapped to the embedding locations.
- they are mapped to bit cell patterns of differentially encoded bit cells as described in published patent application US20160217547.
- the block size may be increased to accommodate the differential encoding of each encoded bit in a pattern of differential encoded bit cells, where the bit cells correspond to embedding locations at a target resolution (e.g., 300 DPI).
- the enlarged payload sequence of 65,536 elements is a hi modal signal, e.g., with values of 0 and 1. It is mapped to a larger hi modal signal centered at 128, e.g., with values of 95 and 161.
- a synchronization signal is commonly included in a digital watermark, to help discern parameters of any affine transform to which the watermark may have been subjected prior to decoding (e.g., by image capture with a camera having an oblique view of the pattern), so that the payload can be correctly decoded.
- a particular synchronization signal (sometimes termed a calibration signal, or registration signal, or grid signal) comprises a set of dozens of magnitude peaks or sinusoids of pseudorandom phase, in the Fourier domain. This signal is transformed to the spatial domain in a 256 x 256 block size (e.g., by an inverse Fast Fourier transform), corresponding to the 256 x 256 embedding locations to which the enlarged payload sequence is mapped.
- a threshold value e.g. 40
- a negative threshold value e.g., -40.
- This spatial domain synchronization signal is summed with the block-mapped 256 x 256 payload sequence to yield a final watermark signal block.
- a block of size 128 x 128 is generated, e.g., with a coder output of 1024 bits, and a payload sequence that maps each of these bits 16 times to 16,384 embedding locations.
- the just-described watermark signal may be termed a“continuous tone” watermark signal. It is usually characterized by multi-valued data, i.e., not being just on/off (or 1/0, or black/white) - thus the “continuous” moniker.
- Each pixel of the host image (or of a region within the host image) is associated with one corresponding element of the watermark signal.
- a majority of the pixels in the image (or image region) are changed in value by combination with their corresponding watermark elements.
- the changes are typically both positive and negative, e.g., changing the local luminance of the imagery up in one location, while changing it down in another. And the changes may be different in degree - some pixels are changed a relatively smaller amount, while other pixels are changed a relatively larger amount.
- the amplitude of the watermark signal is low enough that its presence within the image escapes notice by casual viewers (i.e., it is steganographic).
- a“chrominance” watermark instead of a“luminance” watermark.
- An example is detailed, e.g., in US patent 9,245,308, the disclosure of which is incorporated herein by reference.
- “Sparse” or“binary” watermarks are different from continuous tone watermarks in several respects. They do not change a majority of pixel values in the host image (or image region). Rather, they have a print density (which may sometimes be set by the user) that results in marking between 5% and 45% of pixel locations in the image. Adjustments are all made in the same direction, e.g., reducing luminance. Sparse elements are typically bitonal, e.g., being either white or black. Although sparse watermarks may be formed on top of other imagery, they are usually presented in regions of artwork that are blank, or colored with a uniform tone. In such cases a sparse marking may contrast with its background, rendering the marking visible to casual viewers. As with continuous tone watermarks, sparse watermarks generally take the form of signal blocks that are tiled across an area of imagery. Exemplary sparse marking technology is detailed in the patent documents referenced at the beginning of this specification.
- a sparse pattern can be rendered in various forms. Most straight-forward is as a seemingly- random pattern of dots. But more artistic renderings are possible, including Voronoi, Delaunay, and stipple half-toning. Such techniques are detailed in above -cited application 62/682,731. (In a simple Voronoi pattern, a line segment is formed between a dot and each of its neighboring dots, for all the dots in the input pattern. Each line segment extends until it intersects with another such line segment. Each dot is thus surrounded by a polygon.)
- a first exemplary embodiment of the present technology processes a watermark signal block, such as described herein, with a neural network.
- the network can be of various designs. One, shown in Fig. 4, is based on the VGG network described in Simonyan et al, Very Deep Convolutional Networks for Large-Scale Image Recognition, arXiv preprint 1409.1556n6, April 10, 2015 (familiar to those skilled in that art, and attached to application 62/596,730), but lacking its three fully-connected layers, and its SoftMax classifier.
- the network of Fig. 4 is characterized by five stacks of convolutional layers, each based on 3x3 receptive fields. These 3x3 filters are convolved with their inputs at every pixel, i.e., with a stride of 1.
- the first stack includes two cascaded convolutional layers, of 64 channels each.
- the second stack again includes two cascaded convolutional layers, but of 128 channels each.
- the third stack includes four cascaded convolutional layers, of 256 channels each.
- the fourth and fifth stacks include four cascaded convolutional layers, of 512 channels each.
- Each layer includes a Rectified Linear Unit (ReLu) stage to zero any negative values in the convolutional outputs.
- Each stack additionally includes a concluding average pooling layer (rather than the max pooling layer taught by Simonyan), which is indicated in Fig.
- the input image is an RGB image of size 224 x 224 pixels.
- the VGG network was designed to identify images, e.g., to determine into which of several classes (dog, cat, car, etc.) an image belongs. And the network here is configured for this purpose - employing filter kernels that have been trained to classify an input image into one of the one thousand classes of the ImageNet collection. However, the network is here used for a different purpose. It is here used to discern“features” that help characterize a watermark image. And it is used again to discern features that characterize a geometrical pattern image. And it is used a third time to characterize features of a test image (which may be a frame of pseudo-random noise).
- This test image is then adjusted to drive its features to more closely correspond both to features of the watermark image and to features of the geometrical pattern image.
- the adjusted test image is then re-submitted to the network, and its features are re-determined. Adjustment of the test image continues in an iterative fashion until a final form is reached that incorporates geometrical attributes of the geometrical pattern image, while also being decodable by a digital watermark decoder.
- a watermark signal block (A) is input to the network.
- Each of the stacks of convolutional layers produces filter responses, determined by applying the convolutional parameters of their 3x3 filters on respective excerpts of input data. These filter responses are stored as reference features for the watermark signal block, and will later serve as features towards which features of the third image are to be steered.
- a similar operation is applied to the geometrical pattern image (B).
- the geometrical pattern image is applied to the network, and each of the stacks produces corresponding filter responses. In this case, however, these filter responses are processed to determine correlations between different filter channels of a layer.
- This correlation data which is further detailed below, serves as feature data indicating the style, or texture, of the geometrical pattern image. This correlation data is stored, and is later used as a target towards which similarly-derived correlation data from the test image is to be steered.
- a test image (C) is next applied to the network.
- the starting test image can be of various forms. Exemplary is a noise signal.
- Each of the stacks of convolutional layers produces filter responses.
- Correlations between such filter responses - between channels of layers - are also determined.
- the test image is then adjusted, so that its filter responses more closely approximate those of the watermark signal block, and so that its texture -indicating correlation data more closely approximates that of the geometrical pattern block.
- a layer l in the first stack of Fig. 5, with 64 (Ni) channels has 64 distinct feature maps, each of size Mi, where Mi is the number of elements in the feature map (width times height, or 222 2 ).
- a matrix W 1 , of dimensions 64 x 222 2 can thus be defined for each layer in the network, made up of the 64 filter responses for each of the 222 2 positions in the output from layer 1.
- W # defines the activation of the /th filter at position / in this layer.
- a test image x is applied to the network, a different matrix is similarly defined by its filter responses. Call this matrix X.
- a loss function can then be defined based on differences between these filter response matrices.
- a squared-loss error is commonly used, and may be computed, for a given layer l, as
- This derivative establishes the gradients used to adjust the test image using back-propagation gradient descent methods. By iteratively applying this procedure, the test image can be morphed until it generates the same filter responses, in a particular layer of the network, as the watermark image w.
- the geometrical pattern image can be denoted as g.
- a variant feature space is built, based on correlations between filter responses, using a Gram matrix.
- Gram matrix is composed of elements that are inner products of vectors in a Euclidean space.
- the vectors involved are the different filter responses resulting when the geometrical pattern is applied to the network.
- the filter responses for a given layer l of geometrical pattern image g are expressed as the matrix G- j , where i denotes one of the N filter channels (e.g., one of the 64 filter channels for the first layer), and j denotes the spatial position (from among 222 2 positions for the first layer).
- the correlation-indicating Gram matrix C for a particular layer in geometrical pattern image g is an Nx N matrix:
- the Gram matrix is the inner product between the vectorized filter responses i and j in layer l, when the geometrical pattern image g is applied to the network (i.e., the inner product between intermediate activations - a tensor operation that results in an N x N matrix for each layer of N channels).
- This procedure is again applied twice: once on the geometrical pattern image, and once on the test image. Two feature correlations result, as indicated by the two Gram matrices.
- the total loss function, across plural layers L, between the geometrical pattern image g and the test image x is then where ai are weighting factors for the contribution of each layer to the total loss.
- Lossw and LOSSG can be used to adjust the test image to more closely approximate the watermark block image, and the geometrical pattern image, respectively, the loss functions are desirably applied jointly, in a weighted fashion. That is:
- LOSS total aLoss w + LOSS G
- a and b are weighting factors for the watermark pattern and the geometrical pattern, respectively.
- the derivative of this combined loss function, with respect to the pixel values of the test image x, is then used to drive the back propagation adjustment process.
- An optimization routine, BFGS can optionally be applied. (C./, Zhu et al, Algorithm 778: L-BFGS-B: Fortran Subroutines for Large-Scale Bound-Constrained Optimization, ACM Trans on Mathematical Software, 23(4), pp. 550-560, 1997.)
- the loss factor LOSSG is based on filter responses from many of the 16 different convolution layers in the network - in some cases all of the layers.
- the loss factor Lossw is typically based on filter responses from a small number of layers - in some cases just one (e.g., the final layer in stack #4).
- the described procedure is applied to iteratively adjust the test image until it adopts patterning from the geometrical pattern image to a desired degree, e.g., to a degree sufficient to obfuscate the mottled patterning of the watermark block - while still maintaining the machine readability of the watermark block.
- Fig. 7 is a flow chart detailing aspects of the foregoing method.
- Fig. 8 shows an illustrative application of the method.
- a bitonal geometrical pattern of the same size as the earlier-defined watermark signal block was created to serve as the style image, comprising concentric black and white circles. Its Gram matrix was computed, for the 16 layers in the Fig. 4 network. After 20 iterations, the detailed procedure updated an input random image until it took the form shown on the right.
- Fig. 9 shows a similar example, this one based on a bitonal checkerboard pattern.
- Fig. 10 shows another example, this one based on a pattern of tiled concentric squares.
- the patterns of Figs. 8, 9 and 10 are robust to such printing errors. If more or less ink is applied due to press variability, the package appearance will change somewhat. But it will not cause a pattern that is meant to be concealed, to become visible. And the strength of the encoded signal is robust - far to the right on Fig. 2, and far stronger than the strengths (e.g.,“A” to“B”) with which watermarks intended for imperceptibility are applied. Supermarket scanners thus more reliably decode the product identifying information (e.g., GTINs) from such printing, even if only a fraction of the pattern is depicted in an image frame, or if contrast or glare issues would impair reading of an imperceptible watermark.
- product identifying information e.g., GTINs
- Figs. 8-10 can be further processed to form line art images.
- Fig. 11 shows an example.
- Such line art images are even more robust to press variations, and extend application of this technology to other forms of printing that are commonly based on line structures (e.g., intaglio).
- the Fig. 11 image is derived from the Fig. 10 (right side) image by first binarizing the image against a threshold value, e.g., of 128 (i.e., setting all pixels having a value above 128 to a value of 255, and setting all other pixels to a value of 0).
- a skeletonizing operation e.g., a medial axis filter
- The“skeleton” thereby produced is then dilated, by a dilation filter (e.g., replacing each pixel in the skeleton with a round pixelated dot, e.g., of diameter 2-20).
- a dilation filter e.g., replacing each pixel in the skeleton with a round pixelated dot, e.g., of diameter 2-20.
- Fig. 10 image is simply binarized. Such an image is shown in Fig. 13.
- a watermark signal strength metric can be derived as detailed, e.g., in US patent 9,690,967, and in US applications 16/129,487, filed September 12, 2018, 15/816,098, filed November 17, 2017, and 15/918,924, filed March 12, 2018, the disclosures of which are incorporated herein by reference.
- thresholds may be tested, and strength metrics for the watermark signal can be determined for each.
- the threshold that yields the strongest watermark signal strength may be selected Similarly, when using a neural network to morph a test image to take on attributes of a geometrical pattern, the geometrical pattern may come to dominate the morphed test image - depending on the weighting parameters a and b, and the number of iterations.
- periodically assessing the strength of the watermark signal can inform decisions such as suitable weights for a and b, and when to conclude the iterative process.
- a second exemplary embodiment is conceptually similar to the first exemplary embodiment, so the teachings detailed above and elsewhere are generally applicable. In the interest of conciseness, such common aspects are not repeated here.
- This second embodiment is hundreds or thousands of times faster than the first embodiment in applying a particular style to an image - requiring only a forward pass through the network.
- the network must first be pre-trained to apply this particular style, and the training process is relatively lengthy (e.g., four hours on a capable GPU machine).
- An advantage of this embodiment for our purposes is that, once trained, the network can quickly apply the style to any watermark (or watermarked) input image.
- This method is thus suitable for use in a tool for graphic artists, by which they can apply one of dozens or hundreds of styles (for which training has been performed in advance) to an input pattern, e.g., to generate a signal-carrying pattern for incorporation into their artwork.
- Fig. 14A is a screenshot of the user interface 140 of such a software tool.
- a palette of pre-trained neural styles is on the left, such as style 141 derived from Edvard Munch’s“The Scream.”
- Also included can be some algorithmic patterns 142, such as Voronoi, Delaunay and stipples, as referenced elsewhere.
- dialog features 143 by which the user can specify attributes of a watermark pattern. That is, in this particular example, a watermark pattern is not input, per se. Rather, parameters for a watermark pattern are specified through the user interface, and the watermark pattern is generated on the fly, as part of operation of the software.
- a sparse dot marking may be generated if an algorithmic pattern, such as Voronoi, is selected.
- a continuous tone watermark may be generated if one of the other styles is selected.
- the selected style is then applied to the specified watermark.
- the user enters parameters specifying the payload of the watermark signal (e.g., a 12 digit GTIN code), and the resolution of the desired watermark signal block in watermarks per inch (WPI).
- the user also specifies the physical scale of the watermark signal block (in inches), and the strength (“Durability”) with which the watermark signal is to be included in the finished, stylized, block.
- An analysis tool termed Ratatouille, can be selectively invoked to perform a signal strength analysis of the resulting stylized block, in accordance with teachings of the patent documents referenced earlier.
- a moment after the parameters are input (typically well less than ten seconds), a stylized, watermarked signal block is created, and stored in an output directory with a file name that indicates metadata about its creation, such as the date, time, style, and GTIN.
- a rendering 144 of the signal block is also presented in the UI, for user review.
- Figs. 14B and 14C further detail aspects of the software’s operation.
- the pre-training to generate the neural styles 141 of Fig. 14 proceeds according to the method of Johnson, referenced earlier. As noted, this method is familiar to artisans; its method is briefly reviewed in a separate section, below. His paper has been cited over a thousand times in subsequent work. His method has been implemented in various freely-accessible forms.
- One is an archive of software code written by author Justin Johnson, available at github ⁇ dot>com/jcjohnson/fast-neural-style. (The ⁇ dot> convention is used in lieu of a period, to assure there is no browser-executable code in this specification, per MPEP ⁇ 608.)
- Another is an archive of code written by Logan Engstrom, available at
- Appendices A, B and C to application 62/745,219 form part of this specification and present material from the public gitbub web site - including source code - for the method of Johnson, and for its implementation by Engstrom and Rosebrock, respectively.
- Such code can use previously compiled style models, e.g., in a binary Torch format (*.t7). Sample t7 models are freely available from an archived Justin Johnson page from a Stanford web server,
- style models can be newly-created.
- Figs. 14D, 14E, 14F and 14G show the original images that were used as style images in the method of Johnson, to define the“Candy,”“Mosaic,”“Feathers,” and“La Muse” styles - each of which is a selectable option for applying to a watermark pattern, in the user interface of Fig. 14A.
- Fig. 15A shows a result of the method, when a network using the method of Johnson is trained to apply a style derived from a photograph of rice grains, and this style is applied to a watermark pattern that encodes a particular plural-bit payload (in this case a continuous tone luminance watermark, like that shown in Fig. 1).
- Figs. 15B - 15ZZ show similar results, when the network is trained to apply other styles to such a watermarked pattern.
- Some of the styles are based on photographs of physical items, e.g., grains of rice, water droplets on grass, leaves of grass, pasta noodles, candy corn, woven basket reeds, denim fabric, etc. (natural imagery).
- Others of the styles are based on computer graphics (synthetic imagery), such as the geometric bitonal imagery used as inputs in Figs. 8-10.
- Fig. 15WW is generated by applying the Johnson method with the“Candy” style (e.g., as shown in Fig. 14) to a continuous tone watermark, converting to greyscale, increasing the contrast, and applying a blue spot color.
- Fig. 15XX is similarly generated, except that it is rendered in a duotone mode. That is, highlights and mid-tones of the image are identified and rendered in a first user-selected (light blue) color. The remaining, darker, tones are rendered in a second user-selected (darker blue) color.
- Fig. 15YY is similar to Fig. 15WW, but generated with the“Feather” style.
- Fig. 15ZZ is similar, but generated with the“Mosaic” style.
- style images can yield better or worse results depending on the atomic scale of elements depicted in the image.
- the watermark pattern, to which the style is applied is commonly comprised of units (watermark elements, or“waxels”) that have a particular scale, e.g., regions of 2x2 or 3x3 pixels.
- the stylized results most faithfully follow the style image, and the watermark is most reliably readable from the stylized result, if the style image has a structure with elements of a comparable scale. Comparable here means a majority of elements in the style image have a scale in the range of 0.5 to 25x that of elements in the watermark.
- individual rice grains in a style image desirably have a minimum dimension (width) of 1.5 pixels, and a maximum dimension (length) of 75 pixels.
- width width
- length length
- blades of grass, weaves of fabric or basketry, droplets of water, pieces of candy corn, etc. Best results are with items that are not just comparable, but close, in scale, e.g., in a range of 0.5x - 3x the waxel dimension.
- the style transfer network can morph the style pattern to assume spatial attributes of the watermark pattern, without either grossly departing from the style of the style image, nor distorting the scale of the watermark waxels so that their readability is impaired.
- Fig. 16A shows an excerpt of a watermark pattern.
- Fig. 16B shows a pattern resulting after a network trained with the Johnson method, using a raindrop style pattern, is applied to the Fig. 16A excerpt of a watermark pattern.
- Fig. 16C overlays Figs. 16A and 16B. Note how the network has adapted the orientation, translation, scale and contours of the raindrops to conform to the orientation, translation, scale and contours of features within the watermark pattern. The correlation is somewhat astonishing.
- continuous tone watermark signals are commonly spread across host artwork at a very low amplitude, changing pixel values in an image a small amount - perhaps up to 10 or 20 digital numbers in an 8-bit (0-255) image.
- the signal needn’t be spread across the image; it may be lumpy - limited to local regions, e.g., just 10-30% of the image (as in the water droplets style of Fig. 16B). But in those local regions its amplitude can be much greater, e.g., spanning 100-, 200- or more bits of dynamic range; in some cases the full 256 bits.
- the net signal energy may be comparable, but its concentration in limited areas can make the signaling more robust to distortion and signal loss.
- one aspect of the present technology concerns a method of generating artwork for labeling of a food package.
- Such method includes receiving imagery that encodes a plural-bit payload therein; neural network processing the imagery to reduce a difference measure between the processed imagery and a style image; and incorporating some or all of the neural network-processed imagery in artwork for labeling of a food package, where the plural-bit payload persists in the neural network- processed imagery.
- Such arrangement enables a compliant decoder module in a retail point of sale station to recover the plural-bit payload from an image of the food package.
- a first image (e.g., a host image, depicting a subject) is digitally-watermarked to encode a plural-bit payload therein, yielding a second image.
- This second image is neural network- processed to reduce a difference measure between the processed second image and a style image.
- the distance measure can be based on a difference between a Gram matrix for the processed second image and a Gram matrix for the style image.
- a further aspect of the technology involves a method that starts by receiving a pattern that encodes a plural-symbol payload. This pattern is then stylized, using a neural network (typically previously-trained), to produce a stylized output image.
- the style is based on a style image having various features, wherein the network adapts features from the style image to express details of the received pattern, to thereby produce an image in which features from the style image contribute to encoding of said plural-symbol payload.
- a method again starts with an input pattern that encodes a plural-symbol payload. This pattern is then stylized, using a neural network, to produce a stylized output image.
- the network is trained based on an image depicting a multitude of items of a first type (rain drops, rice grains, candy balls, leaves, blades of grass, stones, beans, pasta noodles, bricks, fabric threads, etc.).
- the network adapts scale, location, and rotation of the items as depicted in the stylized output image to echo, or mimic, features of the originally-input pattern, to thereby produce an image depicting plural of the items in a configuration that encodes said plural-symbol payload.
- a user interface enables a user to define a multi-symbol payload, and to select from among plural different styles.
- a sparse watermark pattern is generated. This pattern includes a web of lines defining plural polygons, with the arrangement of the polygons encoding the payload.
- a continuous tone watermark pattern is generated, and elements of the second style are adapted to mimic elements of the watermark pattern and encode the payload.
- Yet another method involves receiving a sparse pattern of points that encodes plural-symbol data, such as a Global Trade Item Number identifier.
- a transformed image is generated from this sparse pattern of points by a process that includes transforming the sparse pattern by applying a directional blur or wind filter in a first direction. Such filtering may also be applied to the sparse pattern in a second direction, and the results combined with the earlier results.
- the artwork has first and second regions, which may be adjoining.
- the first region includes a background pattern that has been stylized from a watermarked input image using a neural network.
- the second region may include a watermarked image that has not been stylized using a neural network, yet the watermark included in the second region is geometrically-aligned with a watermark signal included in the first region.
- a detector can jointly use signals from both regions in decoding the payload.
- Still another aspect of the technology involves receiving a watermarked image, and then stylizing the watermarked image, to produce a styled output. This styled output is then false-colored, and incorporated into artwork.
- a further aspect involves obtaining data defining a square watermark signal block, comprising N rows and N columns of elements.
- This signal block encodes an identifier, such as a Global Trade Item Number identifier. Plural of these row and columns are replicated along two adjoining edges of the square signal block, producing an enlarged signal block having M rows and M columns of elements.
- the enlarged block is then sent for processing to a style-transfer neural network.
- the enlarged signal block is received back after processing, and an N row by N column portion is excerpted from the received block. This excerpt is then used, in tiled fashion, within artwork to convey the identifier to camera-equipped devices (e.g., enabling a POS terminal to add an item to a shopper’s checkout tally).
- Yet another aspect is a method including: receiving a pattern of dots encoding a plural-symbol payload, and then padding the pattern of dots, by replicating portions of the pattern along at least two adjoining sides of the square, to yield a larger pattern of dots.
- a pattern of polygons is then generated from this larger pattern of dots.
- the polygon pattern can then be used as a fill or background pattern in commercial art, such as product packaging.
- Still another method includes obtaining a watermark signal that encodes an identifier and is represented by watermark signal elements (e.g., waxels) of a first size.
- This watermark signal is stylized in accordance with a style image, which depicts multiple items of a first type (e.g., grains of rice, droplets of water, pieces of candy), where the items depicted in the style image have a size that is between 0.5 and 25 times said first size.
- Yet another aspect of the technology concerns a method for producing a code for message signaling through an image.
- the method employs a neural network having an input, one or more outputs, and plural intermediate layers.
- Each layer comprises plural filters, where each filter is characterized by plural parameters that define a response of the filter to a given input.
- the method is characterized by iteratively adjusting an input test image, based on results produced by the filters of said neural network, until the test image adopts both (1) style features from one image, and (2) signal-encoding features from a second image.
- Yet a further aspect of the technology is a method for producing a code for message signaling through an image, using a deep neural network - which may have been trained to perform object recognition.
- the network has an input, one or more outputs, and plural intermediate layers, where each layer includes multiple filters, each characterized by plural parameters that define a response of the filter to a given input.
- the method includes receiving an image comprising a machine readable code that is readable by a digital watermark decoder, where the machine readable code includes a signal modulated to convey a plural-symbol payload. This machine readable code image is presented to the network, causing the filters in the network layers to produce machine readable code image filter responses.
- the method further includes receiving an artwork image; presenting the artwork image to the network; and determining correlations between filter responses in different of the layers, to thereby determine style information for the artwork image.
- the method further includes receiving an initial test image, and presenting same to the neural network, causing filters in plural of the layers to produce test image filter responses.
- Style information for the test image is then determined by establishing correlations between the test image filter responses of plural of the filter layers.
- a first loss function is determined based on differences between the test image filter responses and the machine readable code image filter responses, for filters in one or more of said layers.
- a second loss function is determined based on a difference between the style information for the first and test images. The test image is then adjusted based on the determined first and second loss information.
- test image is transformed into an image in which the modulated signal is obfuscated by the style of the artwork image, yet is still readable by the digital watermark decoder.
- Still another aspect of the technology concerns a method for producing an obfuscated code for message signaling through an image.
- This method includes: receiving a plural symbol payload; applying an error correction coding algorithm to the plural symbol payload to generate an enlarged bit sequence; and processing the enlarged bit sequence with pseudo-random data to yield a pseudo-random bit sequence.
- This bit sequence is mapped to locations in an image block.
- a counterpart image block depicts a spatial domain counterpart to plural signal peaks in a spatial frequency domain, and the two image blocks are combined to yield a code pattern from which the plural symbol payload can be recovered by a decoder.
- This code is applied to a multi-layer convolutional neural network. Filter responses for one or more layers in the network are stored as first reference data.
- a pattern (e.g., a bitonal geometric pattern) is then applied to the convolutional neural network.
- Data indicating correlations between filter responses between two or more of the layers, are stored as second reference data.
- a test image is then modified based on the first and second reference data, to yield an obfuscated code pattern, different from the code pattern and different from said geometrical pattern, from which the plural symbols can be recovered by the decoder.
- one use of these technologies is in producing artwork for use in packaging retail items, such as grocery items.
- a part of the artwork can be based on the stylized output image. This enables a camera-equipped point of sale apparatus to identify the package, by decoding the plural symbol payment (which may comprise a GTIN).
- Another aspect of the technology is a packaged food product having label artwork that is derived from a pattern substantially similar (in a copyright sense) to one of the patterns illustrated in Figs. 1, 8-11, 13, 14A, 15A-15ZZ, 19A, 19B, 21D, 21E, 29A-29C, 30A, 30B, 31A - 41, and 44.
- the pattern may be monochrome or colored (included false-colored).
- the earlier-discussed Gatys approach has three inputs: a style image, a content image, and a test image (which may be a noise frame).
- a network iteratively modifies the test image until it reaches a suitable compromise between the style image and the content image - by optimizing a loss function based on differences from those first two inputs.
- the Johnson approach uses a single-pass feed forward network, trained to establish parameters configuring it to apply a single style image. After training it has just one input - the content image.
- Johnson’s feed-forward image transformation network is a convolutional neural network configured by parameter weights W. It transforms input images x into output images y by the mapping:
- the weights W are established using information from a second, VGG-16 network, termed a loss network.
- This network is one that has been pretrained for image classification, e.g., on the ImageNet dataset. Such training configures it to produce features that represent semantic and perceptual information about applied imagery. These features are used to define a feature reconstruction loss and a style reconstruction loss that measure differences in content and style between images.
- the content target y c is actually the input image x
- Two perceptual scalar loss functions are used in this process, to measure high-level semantic and perceptual differences between images. Instead of encouraging the pixels of the output image y (i.e.,/ (x)) to exactly match the pixels of the target image y, the Johnson network encourages them to have similar feature representations as computed by the loss network.
- the first loss function indicates similarity to the originally-input image. This is termed the feature reconstruction loss.
- f](c) as the activation of the /th layer of the loss network f when processing an image x. If j is a convolution layer having C filters, then f](c) will be a feature map of shape Q x H j x W j .
- the feature reconstruction loss is the (squared, normalized) Euclidean distance between feature representations:
- the second loss function indicates style similarity to the style image. This is termed the style reconstruction loss.
- a Gram matrix is used. Again, let ⁇ j>j(x) be the activations at the /th layer of the loss network f for the input x, which is a feature map of shape C, x //, x Wj.
- the Gram matrix Gf(x) is the Cj x Cj matrix whose elements are given by:
- the style reconstruction loss is the squared Frobenius norm of the difference between the Gram matrices of the output and target images:
- Johnson computes the feature reconstruction loss using feature data output by layer relu2_2 of the VGG-16 loss network., and computes the style reconstruction loss from feature data output by layers relul_2, relu2_2, relu3_3 and relu4_3.
- weights W of the image transformation network To train weights W of the image transformation network, Johnson applies the 80,000 images of the Microsoft COCO dataset to the network.
- the images output by the image transformation network are examined by the loss network to compute feature reconstruction loss and style reconstruction loss data.
- the weights W of the image transformation network are adjusted, in a stochastic gradient descent method, to iteratively reduce a weighted combination of the two loss function fj and £2, using corresponding regularization parameters l;:
- the image transformation network is trained to cause the output images to adopt the style of the style image, while still maintaining the general image content and overall spatial structure of the input images.
- Fig. 17A is first host artwork, in a vector format.
- Fig. 17B is a watermark pattern that encodes a particular payload. These two images are combined (e.g., by weighted summing, multiplication, or otherwise) to yield the watermarked artwork of Fig. 17C.
- Fig. 17D shows a style image with which a network has been trained by the Johnson method.
- Fig. 17E shows the composite artwork of Fig. 17C, after stylization by the trained Johnson network. (As just-discussed in connection with Figs. 16A - 16C, the stylized elements (droplets) in Fig. 17E are adapted in size, position, and contours, to conform to features within the Fig. 17B watermark pattern.)
- One application of the just-described process is to generate logos of consumer brands, which are both watermarked (e.g., to convey a URL to a corporate web page) and stylized. Such stylized logos can be printed, e.g., on packaging artwork.
- the host artwork needn’t be bitonal (e.g., black and white), and it needn’t be in vector format. Instead, it can be continuously-toned, such as a greyscale or RGB image.
- Fig. 18 A shows a watermarked version of the Lenna image, after stylization using the network that produced Fig. 15PP (i.e., applying a candy ball style).
- Fig. 18B shows a watermarked version of Lenna stylized with the same network that produced Fig. 15VV (i.e., applying a denim fabric style).
- Fig. 18C shows a watermarked version of Lenna stylized with the same network that produced Fig. 15F (applying a grass style).
- the watermark signal can be embedded at an amplitude far greater than usual.
- continuous tone watermark signals are usually applied at amplitudes small enough to prevent the watermark patterning from being perceptible to casual viewers. But since the image texture is so-altered by stylization, patterning due to the watermark signal is masked - even if grossly visible prior to stylization (as in Fig. 17C).
- the detailed methods can be applied to any watermark pattern or watermarked imagery.
- Fig. 19A shows a sparse watermark rendered as a Delaunay triangle pattern.
- Fig. 19B shows this same watermark after stylization with a leaf pattern. Again, each of the leaf elements in Fig.
- FIG. 19B has been scaled, rotated, and positioned to correspond to one of the component triangles within the Delaunay pattern.
- Fig. 19C shows enlargements of the lower right corners of the two images (indicated by the dashed squares in Figs. 19A and 19B) overlaid together, by which the correspondence can be examined.
- a single pattern can be parlayed into a dozen or more different patterns using invertible transforms.
- Invertible transforms are those that can be reversed - enabling a transformed set of information to be restored back to its original state.
- invertible transforms include affine transforms such as rotation, scaling (both scaling uniformly in x- and y-, and non-uniformly), translation, reflection, and shearing.
- Invertible geometrical transforms also include non-affine transforms, such as perspective, cylindrical, spherical, hyperbolic and conformal distortion.
- color transforms color inversion, etc.
- FIG. 20 A general process employing this aspect of the technology is depicted by Fig. 20.
- a watermark pattern is generated, transformed, stylized, and inverse-transformed.
- a continuous tone watermark pattern is generated (Fig. 21 A), containing a desired payload.
- a sparse mark (Fig. 21B) is derived from the Fig. 21A pattern, e.g., by thresholding, or by one of the techniques detailed in the cited patent documents.
- the dots are enlarged in size for sake of visibility.
- the Fig. 21B pattern is then asymmetrically (differentially) scaled - expanding the horizontal expanse by a factor of two - producing the Fig. 21C pattern. That pattern is then converted into a corresponding Voronoi pattern, shown in Fig. 21D. That pattern is then inverse-transformed - compressing the horizontal expanse by a factor of two - producing the Fig. 21E pattern.
- the original watermark pattern is thus differentially-scaled, and then inverse-differentially- scaled. This restores the watermark pattern to its original state.
- the Voronoi cells are added in the middle of the process. They do not undergo two complementary operations. Rather, that Voronoi pattern is just horizontally compressed by a factor of two (i.e., scaled by a horizontal factor of 0.5). Its appearance thus changes.
- Fig. 23 A shows the Voronoi pattern corresponding to the original dot pattern of Fig. 22B.
- Fig. 23B is the Voronoi pattern produced by the just-detailed transform/inverted-transform method (i.e., it is an enlargement of Fig. 22E).
- Each is shown overlaid with the original patterns of dots.
- each dot is still surrounded by a polygon. But the shapes of the polygons are different, as is particularly evident from the enlarged excerpts of Figs. 24A and 24B (corresponding to the lower right hand corners of Figs. 23A and 23B, respectively).
- Figs. 25A and 25B show that visible patterning encoded with machine readable data, produced according to the methods herein, can be used as a background pattern, or texture, on a food container - such as a cereal or cake mix box. Such patterning can appear at any location on the container, and on any face(s) (not just the illustrated front face).
- Fig. 26 shows such a pattern on a can, such as a drink can, a soup can, or a can of vegetables.
- Fig. 27 shows such a pattern on a plastic tub, such as a yogurt or sour cream tub.
- Voronoi pattern While a Voronoi pattern is illustrated, it should be understood that patterns produced by any of the processes referenced herein, including all of the patterns illustrated herein, can be so-utilized, including in color, in false-color, in grey-scale, and in line art counterparts.
- Figs. 28A and 28B are enlarged excerpts from a yogurt container, depicting signal-conveying artwork produced by the above-detailed process (employing a trained network according to the Johnson method) employed as background patterns.
- the pattern of Fig, 28A was produced using a Johnson network to apply a bubble gum balls pattern to a watermark signal block, e.g., as shown in Fig. 15PP.
- the pattern of Fig. 28B was produced by the method of Johnson to apply a fanciful pattern to a watermark signal block, e.g., as shown in Fig. 15D. Both patterns have been altered in coloration - an additional processing step that does not impair decodability of the luminance -based watermark signal blocks on which both are based.
- the artwork on the yogurt containers depicted in Figs. 28A/28B also includes a depiction of a vanilla tree flower, branch and leaf.
- This artwork is defined by layers of patterned spot color inks (e.g., Pantone 121, 356, 476) and black.
- the flower petals are predominantly screened Pantone 121. That layer is watermarked with a luminance watermark.
- the payload conveyed by the watermark in the flower petals i.e., the GTIN for the yogurt product
- the watermark in the violet background patterning which is rendered with screened Pantone 2071).
- the watermark signal block portions encoded within the flower petals are geometrically registered with the watermark signal block portions encoded within the background patterning. (A few such blocks are shown by dashed lines in Fig. 28B ; many span both the background pattern and the foreground vanilla art.) Both the foreground pattern and background pattern watermarks contribute signal by which a detector extracts the watermark payload; the detector doesn’t distinguish between the signals contributed by the different layers since they seamlessly represent common watermark signal blocks.
- edge artifacts can be a problem.
- Watermark patterns themselves, are continuous at their edges. If tiled, watermark patterns continue seamlessly across the edges.
- Style patterns in contrast, are typically not continuous at their edges. Further, the convolution operations performed by style transfer networks can “run out of pixels” when convolving at image edges. This can lead to disruptions in the edge-continuity of the watermark.
- a 128 x 128 element watermark signal block may be padded, for example, to 150 x 150 elements.
- This enlarged image is processed by the style transfer network.
- the network outputs a processed 150 x 150 image.
- the center 128 x 128 elements are then excerpted. No edge artifacts then appear.
- applicant generates a 256 x 256 element input image by tiling four watermark signal blocks.
- the network outputs a 256 x 256 style -processed image. Again, an interior (e.g., central) 128 x 128 block is excerpted from this result. (All of the signal blocks shown in Figs. 15A - 15ZZ are seamlessly tileable.)
- Fig. 29A is an excerpt of product packaging showing a sparse dot pattern (a stipple pattern) as a graphical background (enlarged about 3X).
- Fig. 29B shows a Voronoi counterpart to the Fig. 29A pattern, again used as a graphical background.
- Fig. 29C shows a Delaunay counterpart to the Fig. 29A pattern.
- a background spot or process color may be rendered darker than normal, so that the addition of a light-colored pattern of dots or lines serves to lighten the area to achieve a desired appearance.
- an ink can be applied at a higher screen setting, or with a smaller proportion of a thinner, to yield a darker tone. Or a darker ink color can be selected.
- the addition of dark features darkens the light background color. This can be mitigated by starting with a lighter background color, so the addition of the darker features yields a composite appearance of a desired tone.
- the background ink layer may be screened-back, or the ink may be diluted. Or a lighter ink may be chosen. (Of course, if white is the background, as in Figs. 29A - 29C, then options to further lighten the background are limited.)
- Triangulation patterns can be used as the bases for many aesthetically pleasing patterns suitable for product packaging, etc.
- One class of such patterns is to take a Delaunay pattern, and fill the triangles with different greyscale values, or with differently-screened tones of a particular color. As long as the lines bounding the triangles are lighter, or darker, than most of the triangle interiors, the pattern will decode fine. (The convergences of lighter or darker boundary lines at the triangle vertices define points of localized luminance extrema by which the encoded signals are represented.)
- FIG. 30A Another pleasing triangle-based arrangement is shown in Fig. 30A.
- This pattern is two patterns overlaid, each conveying a payload signal, but at different spatial resolutions - permitting decoding from two different (overlapping) reading distance zones.
- the triangles are not bordered by lighter or darker lines.
- the vertices thus don’t serve as luminance extrema that represent the encoded signals.
- the vertices and edges correspond to a sparse mark obtained from local extrema in the gradients within the watermark signal block.
- the motive is that each triangle encircles local minima or maxima in the signal tile.
- the lightness or darkness within each triangle corresponds to the lightness or darkness of a corresponding area in the watermark signal block. So the greyscale values of the triangles actually carry the signal.
- the triangles needn’t be defined by gradients in the watermark signal.
- a random scattering of points can serve as vertices for a field of triangles and will work just as well, defining triangles whose interiors are made darker or lighter in correspondence with localized luminance within the desired watermark signal block.
- the triangles must be commensurately small to effective carry the signal - on the order of eight square waxels, or about 2000 triangles per 128 x 128 waxel block (the more the better). But such triangles are often smaller than desired for aesthetic purposes, e.g., when rendered by printing at 75 waxels per inch.
- both the large and small triangles encode the same payload, although this needn’t be in the case.
- the larger scale overlay needn't be signal-bearing. It can be a strictly ornamental pattern, within which the smaller scale triangles serve as an interesting, and signal- conveying, texture detail.
- polygons other than triangles can be employed.
- the smaller triangles would be sub-triangulations of the larger triangles, to further enhance aesthetics. More simply, the vertices of each larger triangles may be snapped to the nearest vertices of the small triangles.
- Fig. 30B shows a watermark signal block quantized into triangular areas, with the luminance of each area corresponding to the a luminance within the watermark.
- an item may be packaged for retail sale in packaging that includes an array of adjoining polygons of different areas, where the arrangement, shading, or coloring of the polygons encodes a plural-bit payload for reading by a point-of- sale scanner or by a consumer’s camera-equipped mobile device.
- the polygons may be triangles, but need not be.
- the polygons may be bordered by lines that join at vertices, where the vertices define luminance variations that encode the payload.
- the polygons may be filled with shadings of different chrominances or luminances, where the differently-shaded interiors define chrominance or luminance variations that encode the payload.
- Fig. 31 A shows a pattern derived using Photoshop software to manipulate a sparse watermark (generated using any of the methods taught in the earlier-cited patent documents), and Fig. 31B shows an enlarged excerpt.
- the sparse, dark dots are here all smeared in straight parallel lines. The dots thus have corresponding tails which diminish in darkness with distance from the original location. The dots themselves appear inverted, as white regions.
- a sparse dot watermark (black dots on white background) is created, with a desired payload, using the Digimarc Barcode plug-in software for Photoshop. Dot density is set to 20, and dot size is set to 4.
- the Photoshop Wind filter is applied, with the option From the Left selected. This Wind filter is applied three successive times. The resulting image is then inverted (Image/ Adjustments/Invert), and the mode is changed to Lighten. A new layer is then created and the above acts are repeated, but this time with the Wind option set to From the Right.
- a wind filter detects edges in an image, and extends new features from the detected edges.
- the features are commonly tails that diminish in width and intensity with distance from the edges.
- Figs. 32A and 32B The pattern of Figs. 32A and 32B is generated in Photoshop software by creating a sparse dot watermark as before, with a dot density of 20 and a dot size of 4.
- a negative sparse dot watermark i.e., white dots on a black background.
- dot density is set to 20 and dot size is set to 4.
- the mode of the top layer is then changed to Lighten.
- Figs. 34A and 34B show a pattern produced from a sparse field of white dots on a black background, which are then smeared in straight parallel lines. Here the dots have corresponding tails which diminish in brightness with distance from the original location.
- This pattern can be produced by generating a negative sparse dot watermark as just-detailed, with dot density of 20 and dot size of 4.
- a new layer is created with the same dot pattern.
- a Wind filter is then applied, with Direction set to From the Left. This filter is applied a second time on this layer. The mode of the top layer is then changed to Lighten.
- the pattern of Figs. 36A and 36B is produced by from a field of black dots on a white, with dot density of 20 and dot size of 4.
- the Mode of the top layer is then changed to Multiply.
- the pattern of Figs. 37A and 37B starts with a pattern of white dots on black, as before.
- the Wind filter is applied, set to From the Right. This filter is re-applied two more times.
- a new layer is then created with the same dot pattern, and the Wind filter is similarly applied three times, but this time set to From the Left.
- the mode of the top layer is then changed to Lighten.
- Figs. 38A and 38B look similar to Figs. 39A and 39B, except each clump of dots numbers between 0 and 9 dots, depending on the local amplitude of the watermark.
- This pattern is generated by generating a sparse mark of black dots on a white background, as described earlier.
- the mode is then changed to Bitmap, at 300 Pixels/Inch, and with a Halftone Screen.
- the halftone screen parameters are set to a Frequency of 50 Lines/Inch, an Angle of 90 Degrees, and a Shape of Line.
- Figs. 39A and 39B appear to show a continuous tone luminance watermark that is sampled at points along spaced-apart parallel lines. Around each sample point a clump of black dots (numbering from 0 to 4 dots) is formed, in accordance with the amplitude of the watermark at that point. A pattern of intermittent line-like structures, of varying thickness, is thereby formed.
- Such pattern is produced by starting with a greyscale document set to 4% black.
- the Photoshop software is then used to change the mode to Bitmap, with settings of 300 Pixels/Inch, Halftone Screen, a Frequency of 50 Lines/Inch, an Angle of 90 degrees, and Shape set to Line.
- Figs. 40A and 40B have the appearance of a continuous tone luminance watermark that is sampled at points in an orthogonal two-dimensional grid.
- a clump of black dots e.g., numbering from 0 to 7 dots is then formed around each sample point, in accordance with the amplitude of the watermark at that point.
- Such pattern is produced by starting with a greyscale document set to 4% black.
- the Photoshop software is then used to change the mode to Bitmap, with settings of 300 Pixels/Inch, Halftone Screen, a Frequency of 50 Lines/Inch, and an Angle of 45 degrees.
- the Shape is set to Line.
- Fig. 42A shows an excerpt from artwork for a conference poster.
- Fig. 42B is an enlargement from the lower right corner of Fig. 42A.
- the shadows of the letters include diagonal dark blue lines that are broken into segments. These segments, and their breaks, serve to modulate the local luminance and chrominance of the artwork - modulations that are used to encode the watermark payload. (It will also be seen that the fills of the letters are Voronoi patterns based on a sparse watermark.)
- the modulation of lines is implemented as follows: two images are created with slanted lines. All the lines are dashed, but lines in the first image have longer dashes than lines in the second image, so the average greyscale value of lines in the second image is lighter.
- a watermark signal block is thresholded to create a binary mask, so that watermark block signal values between 128 and 255 (in an 8- bit image representation) are white, while watermark signal values of 0 - 127 are black. Then we choose complete line segments from the second image within the white masked area, and we apply the black mask similarly to choose the segments from the first image.
- the lighter greyscale dashed lines are thus picked in regions where the watermark signal block is lighter, and the darker greyscale dashed lines are thus picked in regions where the watermark signal block is darker.
- the combination of the dashed lines from the two masked layers produces the embedded image.
- line continuity modulation can be effected by poking holes in an array of continuous lines at positions defined by dots in a negative sparse mark.
- Another aspect of the present technology concerns code signaling via manually-created art and other content.
- Styluses are in widespread use for manually-creating content, both by graphics professionals (e.g., producing art) and by office workers (e.g., taking handwritten notes). Styluses are commonly used with tablets. Tablets may be categorized in two varieties. One variety is tablets in which a stylus is applied to a touch-sensitive display screen of a computer (e.g., the Apple iPad device). The other variety is tablets in which a stylus is applied on a touch-sensitive pad that serves as a peripheral to a separate computer (e.g., the Wacom Intuos device). The latter device is sometimes termed a graphics tablet.
- tablets repeatedly sense the X- and Y- locations of the tip of the stylus, allowing the path of the stylus to be tracked.
- a marking - such as a pen or pencil stroke - can thereby be formed on a display screen, and corresponding artwork data can be stored in a memory.
- So-called“passive” systems (as typified by many Wacom devices) employ electromagnetic induction technology, where horizontal and vertical wires in the tablet operate as both transmitting and receiving coils. The tablet generates an
- an inductor-capacitor (LC) circuit in the stylus Inductor-capacitor (LC) circuit in the stylus.
- the wires in the tablet then change to a receiving mode and read the signal generated by the stylus.
- Modern arrangements also provide pressure sensitivity and one or more buttons, with the electronics for this information present in the stylus.
- changing the pressure on the stylus nib or pressing a button changed the properties of the LC circuit, affecting the signal generated by the stylus, while modern ones often encode into the signal as a digital data stream.
- electromagnetic signals the tablet is able to sense the stylus position without the stylus having to even touch the surface, and powering the stylus with this signal means that devices used with the tablet never need batteries.
- Active tablets differ in that the stylus contains self-powered electronics that generate and transmit a signal to the tablet. These styluses rely on an internal battery rather than the tablet for their power, resulting in a more complex stylus. However, eliminating the need to power the stylus from the tablet means that the tablet can listen for stylus signals constantly, as it does not have to alternate between transmit and receive modes. This can result in less jitter.
- capacitive sensing in which electric coupling between electrodes within the tablet varies in accordance with the presence of an object - other than air - adjacent the electrodes.
- capacitive sensing system There are two types of capacitive sensing system: mutual capacitance, where an object (finger, stylus) alters the mutual coupling between row and column electrodes (which are scanned sequentially); and self- or absolute capacitance, where the object (such as a finger) loads the sensor or increases the parasitic capacitance to ground.
- object finger, stylus
- self- or absolute capacitance where the object (such as a finger) loads the sensor or increases the parasitic capacitance to ground.
- Most smartphone touch screens are based on capacitive sensing.
- the Anoto pen is an example of such a stylus.
- the pressure with which the stylus is urged against the virtual writing surface can be sensed by various means, including sensors in the stylus itself (e.g., a piezo-electric strain gauge), and sensors in the tablet surface (e.g., sensing deflection by a change in capacitance). Examples are taught in U.S. patent documents 20090256817, 20120306766, 20130229350, 20140253522, and references cited therein.
- a computer device monitors movements of the stylus, and writes corresponding information to a memory.
- This information details the locations traversed by the status, and may also include information about the pressure applied by the stylus.
- the location information may be a listing of every ⁇ X,Y ⁇ point traversed by the stylus, or only certain points may be stored - with the computer filling-in the intervening locations by known vector graphics techniques.
- Each stroke may be stored as a distinct data object, permitting the creator to“un-do” different strokes, or to format different strokes differently.
- Each stroke is commonly associated with a tool, such as a virtual pen, pencil or brush.
- the term “brush” is used in this description to refer to all such tools.
- the tool defines characteristics by which the stroke is rendered for display, e.g., whether as a shape that is filled with a fully saturated color (e.g., as is commonly done with pen tools), or as a shape that is filled with a pattern that varies in luminance, and sometimes chrominance, across its extent (e.g., as is commonly done with pencil tools).
- the pressure data may be used to vary the width of the stroke, or to increase the darkness or saturation or opacity of the pattern laid down by the stroke.
- Different“layers” may be formed - one on top of the other - by instructions that the user issues through a graphical user interface. Alternatively, different layers may be formed automatically - each time the user begins a new stroke.
- the ink patterns in the different layers may be rendered in an opaque fashion - occluding patterns in any lower layer, or may be only partially opaque (transparent) - allowing a lower layer to partially show-through.
- opacity may be varied based on stylus pressure. Additionally, going over a stroke a second time with the same tool may serve to increase its opacity.
- Transparency is commonly implemented by a dedicated“alpha” channel in the image representation.
- the image representation may comprise red, green, blue and alpha channels.
- Figs. 43 and 44 are tiles of illustrative signal-bearing patterns. These are greatly magnified for purposes of reproduction; the actual patterns have a much finer scale. Also, the actual patterns are continuous - the right edge seamlessly continues the pattern on the left edge, and similarly with the top and bottom edges. As described earlier, Fig. 43 may be regarded as a continuous pattern - comprised of element values (e.g., pixels) that vary through a range of values. Fig. 44 may be regarded as a sparse pattern
- Fig. 43 also greatly exaggerates the contrast of the pattern for purposes of illustration.
- the depicted tile has a mean value (amplitude) of 128, on a 0-255 scale, and some pixels have values of near 0 and others have values near 255. More typically the variance, or standard deviation, from the mean is much smaller, such as 5 or 15 digital numbers.
- Such patterns commonly have an apparently uniform tonal value, with a mottling, or salt-and-pepper noise, effect that may be discerned only on close human inspection.
- a first method for human-authoring of signal-bearing content is to tile blocks of a desired signal carrying pattern, edge-to-edge, in a layer, to create a pattern coextensive with the size of the user’s canvas.
- a second layer e.g., of solid, opaque, white, is then applied on top of the first. This second layer is all that is visible to the user, and serves as the canvas layer on which the user works.
- the tool employed by the user to author signal-bearing content does not apply pattern (e.g., virtual ink, or pixels) to this second layer, but rather erases from it - revealing portions of the patterned first layer below.
- the erasing in this arrangement is implemented as changing the transparency of the second layer - allowing excerpts of the underlying first layer to become visible.
- the tool used can be a pen, pencil, brush, or the like.
- the tool may change the transparency of every pixel within its stroke boundary to 100% (or, put another way, may change the opacity of every pixel to 0%).
- the brush may change the transparency differently at different places within the area of the stroke, e.g., across the profile of the brush.
- Fig. 45 shows the former case - the brush changes the transparency of every pixel in its path from 0% to 100%, resulting in a pattern with sharp edges.
- Fig. 46 shows the latter case - different regions in the brush change the transparency differently - a little in some places, a lot in others. (In so-doing, the brush changes the mean value, and the variance, of the underlying pattern as rendered on the canvas.) Such a brush adds texture.
- the texture added by a brush commonly has an orientation that is dependent on the direction the brush is used - just as filaments of a physical brush leave fine lines of texture in their wake.
- the signal carrying pattern revealed by the brush has a texture, too. But the signal-carrying pattern texture always has a fixed orientation - both in rotation, scale and position. It does not matter in which direction the brush is applied; the spatial pose of the revealed pattern is constant.
- repeated brush strokes across a region successively increase the transparency of the top layer, revealing the underlying signal-carrying pattern to successively darker degrees.
- a first brush stroke may reveal the pattern by applying a 20% transparency to the covering second layer. Such a pattern has a light tone; a high mean value (and a small variance).
- a second brush over the same area stroke may increase the transparency to 40%, darkening the tone a bit, and increasing the variance. And then 60%, and 80%, until finally the covering layer is 100% transparent, revealing the underlying pattern with its original mean and variance. With each increase in transparency, the contrast of the rendered, revealed signal pattern is increased.
- Figs. 47 and 48 conceptually illustrates how a prior art brush applies marks to a canvas - with a texture whose orientation is dependent on the directions of the strokes (shown by arrows). Where strokes overlap, a darker marking is rendered - since more virtual ink is applied in the region of overlap.
- Fig. 48 is a counterpart illustration for this aspect embodiment of the present technology. The orientation of the pattern does not depend on the direction of the brush stroke. Where strokes cross, the underlying pattern is rendered more darkly, with greater contrast.
- the degree of transparency of a stroke can also be varied by changing the pressure applied to the stylus. At one pressure, a stroke may increase the transparency of the covering layer by 70% (e.g., from 0% to 70%). At a second, higher, pressure, a stroke may change the transparency of the covering layer by 100% (from 0% to 100%). Many intermediate values are also possible. Such arrangement is shown in Fig. 49A. The digit‘5’ is written at one pressure, and the digit‘7’ is written with a lighter pressure. The latter stroke is rendered with less transparency (pixels within the boundaries of the‘5’ stroke are rendered at 100% transparency, whereas the pixels within the‘7’ are rendered at a lesser transparency). The mean value of the pixels within the boundary of the‘5’ in Fig. 47 matches the mean value of the corresponding pixels in the underlying signal-carrying pattern. In contrast, the mean value of the pixels within the boundary of the‘7’ have a mean value higher than that of the corresponding pixels in the underlying pattern.
- Fig. 49B shows handwritten digits with contrast of a more typical value.
- Fig. 49C shows the handwritten digits with a more typical contrast and size.
- the system memory may store just a single tile’s worth of pattern data.
- Such a tile may have dimensions of 128 x 128 (e.g., pixels), while the canvas may have dimensions of 1280 x 1024.
- the system effects a modulo operation to provide pattern when the original tile“runs-out” of data (i.e., after coordinate ⁇ 10,128 ⁇ . That is, for the start of the stroke, the erasing operation reveals the signal pattern between coordinates ⁇ 10,100 ⁇ and ⁇ 10,128 ⁇ . Once it reaches value 128 (in either dimension), it performs a mod- 128 operation and continues. Thus, the pattern that is revealed at coordinates ⁇ 10,130 ⁇ is read from tile coordinates ⁇ 10,2 ⁇ , and so forth.
- a signaling brush i.e., one that reveals the signal-carrying pattern
- the system effects a modulo operation to provide pattern when the original tile“runs-out” of data (i.e., after coordinate ⁇ 10,128 ⁇ . That is, for the start of the stroke, the erasing operation reveals the signal pattern between coordinates ⁇ 10,100 ⁇ and ⁇ 10,128 ⁇ . Once it reaches value 128 (in either dimension), it performs a mod- 128 operation
- a brush applies digital ink to an artwork layer in a pattern conveying the plural-bit payload.
- the pattern is two-dimensional and stationary, with an anchor point (e.g., at the upper left corner of the canvas) to which the pattern is spatially related (i.e., establishing what part of the pattern is to be laid-down at what part of the canvas).
- a simple implementation can be achieved by using the capability to pattern-draw that is built into certain graphics tools, like Photoshop.
- a tile of signal-conveying pattern can be imported as an image, selected, and then defined as a Photoshop pattern (by Edit/Define Pattern).
- the user then paints with this pattern by selecting the Pattern Stamp tool, selecting the just-defined pattern from the pattern menu, and choosing a brush from the Brush Presets panel.
- the“Aligned” option the pattern is aligned from one paint stroke to the next.
- the pattern is centered on the stylus location each time a new stroke is begun.
- software may be written so that stylus pressure (or stroke over-writing) modulates the mean value of the payload-carrying pattern: darker pattern (i.e., lower mean values) is deposited with more pressure; lighter pattern (higher mean values) is deposited with less pressure.
- the signal-carrying strength of the pattern i.e., its variance
- the signal-carrying pattern typically includes both plural-bit payload information, and also a synchronization signal.
- the payload information may include data identifying the user, the date, the GPS-indicated time, a product GTIN, or other metadata specified by the user. This information may literally be encoded in the payload, or the payload may be a generally-unique ID that serves as a pointer into a local or remote database where corresponding metadata is stored.
- the payload is error-correction encoded, randomized, and expressed as +/-“chips” that serve to increase or decrease parameters (e.g., luminance or chrominance) of respective pixels in a reference signal tile.
- the synchronization signal can comprise an ensemble of multiple spatial domain sinusoids of different frequencies (and, optionally, of different phases and amplitudes), which can be specified succinctly by parameters in a frequency domain representation.
- a Fourier transform can then be applied to produce a corresponding spatial domain representation of any dimension.
- the resulting sinusoids are coextensive with the reference signal tile, and are added to it, further adjusting pixel values.
- the software enables the brushes to be configured to apply signal-carrying patterns having different means and variances, as best suits the user’s requirements.
- a pattern having a light tone such as a mean digital value of 200
- a pattern having a dark tone such as a mean value of 50
- the variance may be user selectable - indicating the degree of visible mottling desired by the content creator.
- the user may invoke software to present a user-interface by which such specific parameters of the brush can be specified.
- the software program responds by generating a reference signal tile (or a needed excerpt) having desired mean and variance values.
- reference data for the tile is to store reference data for the tile as an array of real-valued numbers, ranging from -1 to +1. (Such an array can be produced by summing a +/- chip, and a synchronization signal value, for each element in a tile, and then scaling the resultant array to yield the -1 to +1 data array.)
- This reference data can then be multiplied by a user-selected variance (e.g., 15, yielding values between -15 and +15), and then summed with a user-specified mean value (e.g., 200, yielding values between 185 and 215) to generate a reference tile with the desired variance and mean.
- a user-selected variance e.g., 15, yielding values between -15 and +15
- a user-specified mean value e.g. 200, yielding values between 185 and 215
- the variance or the mean, or both, may be modulated in accordance with the stylus pressure. If the pressure increases, the darkness can be increased by reducing the mean value. (E.g., a nominal pressure may correspond to a mean value of 128; greater pressures may cause this value to reduce - ultimately to 30; lesser pressures may cause this value to increase - ultimately to 220.)
- the spatial scale of the signaling pattern can also be varied, e.g., by specifying a reference signal tile that conveys its information at a specific spatial scale.
- a tile that is usually 128 x 128 pixels may instead be specified as 256 x 256 pixels, causing the spatial scale to double (which halves the spatial frequency of the signaling components). Again, the user can set such parameter to whatever value gives a desired visual effect.
- the reference data can be generated accordingly, e.g., by spreading the payload chips over a 256 x 256 data array, and summing with a spatial synchronization signal that has been transformed from its frequency domain representation to a spatial signal having a 256 x 256 scale.
- a smaller scale is used, so that the payload can be recovered from a smaller excerpt of pattern- based art.
- Some drawing applications associate a (virtual) physical texture with the canvas. This causes certain tools to behave differently: the virtual ink deposited depends not just on the tool configuration, but also on the surface microtopology where the ink is applied. At points where the surface microtopology has a local maximum, more ink is deposited (being analogous to more pressure being applied - by the surface more firmly engaging the tool at such locations). At valleys between such maxima, less ink is deposited.
- a texture descriptor associated with the canvas serves to similarly modulate the contrast with which the signal-carrying pattern is rendered on the canvas.
- the pattern is rendered more darkly at locations where the texture has higher local peaks. As the user applies more pressure to the stylus, more of the valleys between the peaks are filled-in with pattern (or are filled-in with darker pattern).
- Figs. 50A and 50B show stylus strokes with exemplary neural network-produced patterning. Patterns based on natural imagery (e.g., the rice grains and water droplets of Figs. 15A and 15B) and synthetic imagery (e.g., bitonal geometrical patterns of the sort used in Figs. 8-10) can both be used.
- natural imagery e.g., the rice grains and water droplets of Figs. 15A and 15B
- synthetic imagery e.g., bitonal geometrical patterns of the sort used in Figs. 8-10) can both be used.
- Fig. 51 shows a prior art user interface 510 of a tablet drawing app (Sketchbook by Autodesk, Inc.).
- the interface includes a tools menu 514, a properties panel 516, and a layers guide 518.
- the user can pick up a desired tool (e.g., brush, pencil, etc.) by tapping the stylus on a corresponding icon in the tools menu 514.
- the properties panel 516 can be opened to customize the parameters of the tool.
- the layers guide 518 enables the user to select different layers for editing.
- one or more tools are dedicated to the purpose of drawing with a signal-carrying pattern, as detailed above. These tools may be so denoted by including graphical indicia within the icon, such as the binary bits“101,” thereby clueing-in the user to their data encoding functionality.
- selections can be made from the properties panel 516 to define signal-customization parameters, such as the pattern to be used (e.g., the patterns of Figs. 1, 11, 15A, 44, etc.), color, mean value, variance, and scale - in addition to the parameters usually associated with prior art tools.
- no tools are dedicated to applying signal-carrying patterns. Instead, all tools have this capability. This capability can be invoked, for a particular tool, making a corresponding selection in that tool’s properties panel. Again, signal-customization options such as mean value, variance, and scale can be presented.
- all tools apply signal-carrying patterns.
- the properties panel for each tool include options by which such signal can be customized.
- certain embodiments according to these aspects of the technology concern a method of generating user-authored graphical content.
- Such method makes use of a hardware system including a processor and a memory, and includes: receiving authoring instructions from a user, where the instructions taking the form of plural strokes applied to a virtual canvas by a virtual tool; and responsive to said instructions, rendering a first signal-carrying pattern on the canvas in a first area included within a first stroke.
- Such arrangement is characterized in that (1) the content conveys a plural-bit digital payload encoded by said signal-carrying pattern; and (2) the signal-carrying pattern was earlier derived, using a neural network, from an image depicting a natural or synthetic pattern.
- Another method is similar, but is characterized in that (1) the graphical content conveys a plural- bit digital payload encoded by said signal-carrying pattern; (2) the first signal-carrying pattern is rendered with a first mean value or contrast, due a pressure with which the user applies the physical stylus to a substrate when making the first stroke; and (3) the second signal-carrying pattern is rendered with a second mean value or contrast due to a pressure with which the user applies the physical stylus to the substrate when making the second stroke, where the second value is different than the first.
- Another method is also similar, but involves - responsive to input from the user’s virtual tool - rendering a first signal-carrying pattern on the canvas in a first area included within a first stroke, and rendering a second signal-carrying pattern on the canvas in a second area included within a second stroke, where the rendered first and second patterns both correspond to a common reference pattern stored in the memory.
- Such arrangement is characterized in that (1) the graphical content conveys a plural-bit digital payload encoded by patterns defined by the plural strokes; and (2) elements of the first pattern, rendered within the first area, have a variance or mean amplitude that differs from a variance or mean amplitude, respectively, of spatially-corresponding elements of the reference pattern.
- FIG. 52 An example of this latter arrangement is illustrated by Fig. 52.
- Elements of the“7” on the right side of the figure e.g., within the small box, have a mean amplitude that is different than that of spatially-corresponding elements of the reference pattern (e.g., within the corresponding small box in the center of the figure).
- Graphical content produced by the described arrangements can be printed and scanned, or imaged by a camera-equipped device (like a smartphone) from on-screen or a print rendering, to produce an image from which the payload can be extracted, using techniques detailed in the cited art.
- the image format is irrelevant - data can be extracted from TIF, JPG, PDF, etc., data.
- This enables a great number of applications, including authoring artwork for product packaging that encodes a UPC code or that links to product information, communicating copyright, indicating irrefutable authorship, and authenticating content (e.g., by use of digital signature conveyed by the pattern). It also helps bridge the analog/digital divide, by enabling handwritten notes - on tablets and electronic whiteboards - to be electronically stored and searched, using metadata that is inseparably bound with the notes.
- plural-bit payloads can be encoded by sparse dot fields. Dot fields can be used in many artworks, but line -based patterns are often preferred.
- a first line pattern based on a dot field is a traveling salesman path that simply connects the dots. Such a pattern is shown in Fig. 53. Each corner point in this artwork is the location of a dot in the original sparse field.
- Various traveling salesman algorithms are known. A suitable one is the Lin- Kernighan heuristic, described in Helsgaun, An Effective Implementation of the Lin-Kernighan Traveling Salesman Heuristic. DATALOGISKE SKRIFTER (Writings on Computer Science), No. 81, 1998, Roskilde University, which can be found at http://www.akira.ruc.dk/ ⁇ keld/resettrcit/LKH/.
- This traveling salesman approach is effective in retaining the signaling properties of the sparse code because it traverses points, namely minima, of high priority components of a corresponding continuous tone watermark signal (i.e., an optical code signal). Further, due to the fact that the path of line segments does not cross (other than at the“cities’), it does not create line crossings that would otherwise represent spurious minima.
- FIG. 54 A second line pattern based on a dot field is shown in Fig. 54.
- This optical code signal is created by placing creating a uniform array of parallel lines across the dot field, and dropping vertical lines through each dot. This approach retains the signaling properties of the dot field because it places the dark vertical lines through coordinates at its luminance minima.
- first and second patterns place dark markings at coordinates in the signal tile corresponding to luminance minima (i.e., the dot locations).
- a complementary approach that retains a robust optical code signal is to place dark markings in valleys around luminance maxima of a watermark signal.
- a Voronoi pattern is an example. Such approaches may be inverted for dark artwork, in which the sparse signal carrying elements are luminance maxima (bright pixels) relative to a darker background.
- FIG. 55 A Voronoi pattern is shown in Fig. 55. Such a pattern is generated by creating a line segment between each pair of adjoining sparse points, orienting the segment to be equidistant from the pair of points, and continuing the segment until it intersects with another such line segment.
- Figs. 55A and 55B shows how such a pattern can be used as a fill element in artwork.
- a fourth line pattern, shown in Fig. 56, is the dual of the Voronoi pattern and is termed a Delaunay triangulation. Such a pattern forms triangles from proximate triads of sparse points, subject to the condition that no point is within the circumcircle of any triangle.
- Voronoi and Delaunay patterns are graph duals; e.g., connecting the centers of the circumcircles of the triangles in the Delaunay triangulation produces the Voronoi diagram.
- the Voronoi diagram may be implemented using the Voronoi function in MatLab from MathWorks, or via a Delaunay triangulation computed by the Qhull program.
- Qhull outputs the Voronoi vertices for each Voronoi region.
- Figs. 58A and 58B illustrate additional examples of line patterns generated from coordinates of maxima points in an optical code signal tile.
- Fig. 58 A is generated by programmatically forming squares around coordinates of maxima.
- Fig. 58B is generated by forming rectangles around coordinates of maxima.
- a watermark decoder (e.g., as taught in US Patent 6,590,996, and typified by the Digimarc app in the Apple App Store) can extract the encoded plural-bit payload from each of each of the patterns depicted in Figs. 53 - 57B.
- Dot patterns from which such line patterns are derived can be produced in various ways. Each typically starts with a continuous tone watermark pattern (sometimes termed a dense code, or a composite dense code - reflecting the presence of both payload and reference signals).
- a continuous tone watermark pattern sometimes termed a dense code, or a composite dense code - reflecting the presence of both payload and reference signals.
- One arrangement creates a sparse dot pattern by applying a thresholding operation to a dense code, to identify locations of extreme low values (i.e., dark) in the dense code. These locations are then marked in a sparse tile (aka block). The threshold level establishes the print density of the resulting sparse mark.
- Another arrangement identifies the darkest elements of a reference signal, and logically-ANDs these with dark elements of the payload signal, to thereby identify locations in a sparse signal tile at which marks should be formed.
- a threshold value can establish which reference signal elements are dark enough to be considered, and this value can be varied to achieve a desired dot density.
- Still another arrangement employs a reference signal generated at a relatively higher resolution, and a payload signal generated at a relatively lower resolution.
- the latter signal has just two values (i.e., it is bitonal); the former signal has more values (i.e., it is multi-level, such as binary greyscale or comprised of floating point values).
- the payload signal is interpolated to the higher resolution of the reference signal, and in the process is converted from bitonal form to multi-level.
- the two signals are combined at the higher resolution, and a thresholding operation is applied to the result to identify locations of extreme (e.g., dark) values. Again, these locations are marked in a sparse tile.
- the threshold level again establishes the print density of the resulting sparse mark.
- Yet another arrangement again employs a reference signal generated at a relatively higher resolution, and a bitonal payload signal generated at a relatively lower resolution.
- a mapping is established between the two signals, so that each element of the payload signal is associated with four or more spatially-corresponding elements of the reference signal.
- a mark is made at a corresponding location in the sparse tile.
- a further arrangement is based on a dense multi-level reference signal tile. Elements of this signal are sorted by value, to identify the darkest elements - each with a location. These darkest elements are paired. One element is selected from each pairing in accordance with bits of the payload. Locations in the sparse tile, corresponding to locations of the selected dark elements, are marked to form the sparse signal.
- Still another arrangement sorts samples in a tile of the reference signal by darkness, yielding a ranked list - each dark sample being associated with a location. Some locations are always-marked, to ensure the reference signal is strongly expressed. Others are marked, or not, based on values of message signal data assigned to such locations (e.g., by a scatter table).
- Arrangements that operate on composite codes can further include weighting the reference and payload signals in ratios different than 1:1, to achieve particular visibility or robustness goals.
- Each of these arrangements can further include the act of applying a spacing constraint to candidate marks within the sparse block, to prevent clumping of marks.
- the spacing constraint may take the form of a keep-out zone that is circular, elliptical, or of other (e.g., irregular) shape.
- the keep-out zone may have two, or more, or less, axes of symmetry (or none).
- Enforcement of the spacing constraint can employ an associated data structure having one element for each location in the sparse block. As dark marks are added to the sparse block, corresponding data is stored in the data structure identifying locations that - due to the spacing constraint - are no longer available for possible marking.
- the patterns produced by the present technology can be displayed on, and read from, digital displays - such as smartphones, digital watches, electronic signboards, tablets, etc.
- product surfaces may be textured with such patterns (e.g., by injection molding or laser ablation) to render them machine-readable.
- the watermarks referenced above include two components: a reference or synchronization signal (enabling geometric registration), and a payload signal (conveying plural symbols of information - such as a GTIN). It will be noted that each of the depicted signal carrying patterns can be detected by the Digimarc app for the iPhone or Android smartphones. (The Digimarc app practices methods detailed in the cited patent documents, e.g., US patent 6,590,996.)
- the VGG neural network of Fig. 4 is employed in an illustrative neural network-based style transfer embodiment, but other neural networks can also be used.
- Another suitable network is the “AlexNet” network, e.g., as implemented in Babenko, et al, Neural Codes for Image Retrieval, arXiv preprint arXiv: 1404.1777 (2014)).
- the watermark image, or the geometrical pattern image are instead used as starting points, and are then morphed by the detailed methods towards the other image.
- Caffe is one - an open source framework for deep learning algorithms, distributed by the Berkeley Vision and Learning Center. Another is Google’s TensorFlow.
- applicant uses a computer equipped with multiple Nvidia TitanX GPU cards. Each card includes 3,584 CUDA cores, and 12 GB of fast GDDR5X memory.
- the neural networks can be implemented in a variety of other hardware structures, such as a microprocessor, an ASIC (Application Specific Integrated Circuit) and an FPGA (Field
- Hybrids of such arrangements can also be employed, such as reconfigurable hardware, and ASIPs.
- Applicant means a particular structure, namely a multipurpose, clock-driven, integrated circuit that includes both integer and floating point arithmetic logic units (AFUs), control logic, a collection of registers, and scratchpad memory (aka cache memory), linked by fixed bus interconnects.
- the control logic fetches instruction codes from a memory (often external), and initiates a sequence of operations required for the AFUs to carry out the instruction code.
- the instruction codes are drawn from a limited vocabulary of instructions, which may be regarded as the microprocessor’s native instruction set.
- a particular implementation of one of the above -detailed algorithms on a microprocessor - such as the conversion of an iterated test image into a line art pattern - can begin by first defining the sequence of operations in a high level computer language, such as MatFab or C++ (sometimes termed source code), and then using a commercially available compiler (such as the Intel C++ compiler) to generate machine code (i.e., instructions in the native instruction set, sometimes termed object code) from the source code. (Both the source code and the machine code are regarded as software instructions herein.) The process is then executed by instructing the microprocessor to execute the compiled code.
- a high level computer language such as MatFab or C++ (sometimes termed source code)
- a commercially available compiler such as the Intel C++ compiler
- microprocessors are now amalgamations of several simpler microprocessors (termed “cores”). Such arrangements allow multiple operations to be executed in parallel. (Some elements - such as the bus structure and cache memory may be shared between the cores.)
- microprocessor structures include the Intel Xeon, Atom and Core-I series of devices. They are attractive choices in many applications because they are off-the-shelf components.
- GPUs Graphics Processing Units
- GPUs are similar to microprocessors in that they include AFUs, control logic, registers, cache, and fixed bus interconnects.
- the native instruction sets of GPUs are commonly optimized for image/video processing tasks, such as moving large blocks of data to and from memory, and performing identical operations simultaneously on multiple sets of data (e.g., pixels or pixel blocks).
- Other specialized tasks such as rotating and translating arrays of vertex data into different coordinate systems, and interpolation, are also generally supported.
- the leading vendors of GPU hardware include Nvidia, ATI/AMD, and Intel.
- Applicant intends references to microprocessors to also encompass GPUs. GPUs are attractive structural choices for execution of the detailed arrangements, due to the nature of the data being processed, and the opportunities for parallelism.
- microprocessors can be reprogrammed, by suitable software, to perform a variety of different algorithms, ASICs cannot. While a particular Intel microprocessor might be programmed today to serve as a deep neural network, and programmed tomorrow to prepare a user’s tax return, an ASIC structure does not have this flexibility. Rather, an ASIC is designed and fabricated to serve a dedicated task, or limited set of tasks. It is purpose-built.
- An ASIC structure comprises an array of circuitry that is custom-designed to perform a particular function.
- gate array sometimes termed semi -custom
- full-custom the hardware comprises a regular array of (typically) millions of digital logic gates (e.g., XOR and/or AND gates), fabricated in diffusion layers and spread across a silicon substrate.
- Metallization layers, defining a custom interconnect, are then applied - permanently linking certain of the gates in a fixed topology. (A consequence of this hardware structure is that many of the fabricated gates - commonly a majority - are typically left unused.)
- full-custom ASICs In full-custom ASICs, however, the arrangement of gates is custom-designed to serve the intended purpose (e.g., to perform a specified function). The custom design makes more efficient use of the available substrate space - allowing shorter signal paths and higher speed performance. Full-custom ASICs can also be fabricated to include analog components, and other circuits.
- a drawback is the significant time and expense required to design and fabricate circuitry that is tailor-made for one particular application.
- An ASIC -based implementation of one of the above arrangements again can begin by defining the sequence of algorithm operations in a source code, such as MatLab or C++.
- a source code such as MatLab or C++.
- the source code is compiled to a “hardware description language,” such as VHDL (an IEEE standard), using a compiler such as
- HDLCoder available from MathWorks.
- the VHDL output is then applied to a hardware synthesis program, such as Design Compiler by Synopsis, HDL Designer by Mentor Graphics, or Encounter RTL Compiler by Cadence Design Systems.
- the hardware synthesis program provides output data specifying a particular array of electronic logic gates that will realize the technology in hardware form, as a special- purpose machine dedicated to such purpose.
- This output data is then provided to a semiconductor fabrication contractor, which uses it to produce the customized silicon part. (Suitable contractors include TSMC, Global Foundries, and ON Semiconductors.)
- a third hardware structure that can be used to implement the above-detailed arrangements is an FPGA.
- An FPGA is a cousin to the semi-custom gate array discussed above.
- the interconnect is defined by a network of switches that can be electrically configured (and reconfigured) to be either on or off.
- the configuration data is stored in, and read from, a memory (which may be external).
- FPGAs also differ from semi-custom gate arrays in that they commonly do not consist wholly of simple gates. Instead, FPGAs can include some logic elements configured to perform complex combinational functions. Also, memory elements (e.g., flip-flops, but more typically complete blocks of RAM memory) can be included. Again, the reconfigurable interconnect that characterizes FPGAs enables such additional elements to be incorporated at desired locations within a larger circuit.
- FPGA structures include the Stratix FPGA from Altera (now Intel), and the Spartan FPGA from Xilinx.
- implementation of the above -detailed arrangements begins by specifying a set of operations in a high level language. And, as with the ASIC implementation, the high level language is next compiled into VHDL. But then the interconnect configuration instructions are generated from the VHDL by a software tool specific to the family of FPGA being used (e.g.,
- One structure employs a microprocessor that is integrated on a substrate as a component of an ASIC.
- SOC System on a Chip
- FPGA field-programmable gate array
- SORC System on a Programmable Chip
- ASIC application specific integrated circuit
- certain aspects of the ASIC operation can be reconfigured by parameters stored in one or more memories.
- the weights of convolution kernels can be defined by parameters stored in a re -writable memory.
- the same ASIC may be incorporated into two disparate devices, which employ different convolution kernels.
- One may be a device that employs a neural network to recognize grocery items.
- Another may be a device that morphs a watermark pattern so as to take on attributes of a desired geometrical pattern, as detailed above.
- ASIPS application-specific instruction set processors
- ASIPS can be thought of as microprocessors.
- the instruction set is tailored - in the design stage, prior to fabrication - to a particular intended use.
- an ASIP may be designed to include native instructions that serve operations associated with some or all of: convolution, pooling, ReLU, etc., etc.
- native instruction set would lack certain of the instructions available in more general purpose microprocessors.
- Processing hardware suitable for neural network are also widely available in“the cloud,” such as the Azure service by Microsoft Corp, and CloudAI by Google.
- Software and hardware configuration data/instructions are commonly stored as instructions in one or more data structures conveyed by tangible media, such as magnetic or optical discs, memory cards, ROM, etc., which may be accessed across a network.
Abstract
A neural network is applied to imagery including a machine readable code, to transform its appearance while maintaining its machine readability. One particular method includes training a neural network with a style image having various features. The trained network is then applied to an input pattern that encodes a plural-symbol payload. The network adapts features from the style image to express details of the input pattern, to thereby produce an output image in which features from the style image contribute to encoding of the plural-symbol payload. This output image can then be used as a graphical component in product packaging, such as a background, border, or pattern fill. In some embodiments, the input pattern is a watermark pattern, while in others it is a host image that has been previously watermarked. A great variety of other features and arrangements are also detailed.
Description
ARTWORK GENERATED TO CONVEY DIGITAL MESSAGES. AND METHODS/APPARATUSES FOR GENERATING SUCH ARTWORK
Related Application Data
This application is a continuation of application 16/212,125, filed December 6, 2018, which clai s priority to provisional applications 62/745,219, filed October 12, 2018, and 62/596,730, filed December 8, 2017. This application also claims priority to provisional application 62/682,731, filed June 8, 2018.
The subject matter of the present application is related to that of copending applications
15/072,884, filed March 17, 2016 (published as 20170024840), 16/002,989, filed June 7, 2018,
16/129,487, filed September 12, 2018, and 62/751,084, filed October 26, 2018.
The disclosures of the above applications are incorporated herein by reference.
A counterpart to the present application was earlier filed in the United States, as application 16/212,125. Color drawings were submitted with that application. Unlike the U.S., the PCT will not reproduce color drawings. For a fuller understanding, the public can obtain color counterparts to the present drawings from the cited application at the U.S. Patent Office.
Technical Field
The present technology concerns message signaling. The technology is particularly illustrated in the context of message signaling through artwork of grocery item packaging, to convey plural-bit messages - of the sort presently conveyed by UPC barcodes. However, the technology is not so-limited.
Background and Introduction
Barcodes are in widespread use on retail items, but take up real estate that the manufacturers would prefer to use for other purposes. Some retail brands find that printing a barcode on a product detracts from its aesthetics.
Steganographic digital watermarking is gaining adoption as an alternative to visible barcodes. Watermarking involves making subtle changes to packaging artwork to convey a multi-bit product identifier or other message. These changes are generally imperceptible to humans, but are detectable by a computer.
Fig. 1 shows an illustrative digital watermark pattern, including a magnified view depicting its somewhat mottled appearance. In actual use, the watermark pattern is scaled-down in amplitude so that, when overlaid with packaging artwork in a tiled fashion, it is an essentially transparent layer that is visually imperceptible amid the artwork details.
Designing watermarked packaging involves establishing a tradeoff between this amplitude factor, and detectability. To assure reliable detection - even under the adverse imaging conditions that are sometimes encountered by supermarket scanners - the watermark should have as strong an amplitude as possible. However, the greater the amplitude, the more apparent the pattern of the watermark becomes on the package. A best balance is struck when the watermark amplitude is raised to just below the point where the watermark pattern becomes visible to human viewers of the packaging.
Fig. 2 illustrates this graphically. When a watermark is added to artwork at low levels, human visibility of the watermark is nil. As strength of the watermark increases, there becomes a point at which humans can start perceiving the watermark pattern. Increases in watermark amplitude beyond this point result in progressively greater perception (e.g., from barely, to mild, to conspicuous, to blatant). Point “A” is the desired“sweet-spot” value, at which the amplitude of the watermark is maximum, while visibility of the watermark is still below the point of human perception.
Setting the watermark amplitude to this sweet-spot value, when creating packaging artwork (e.g., using Adobe Illustrator software), is one thing. Hitting this sweet-spot“on-press” is another.
All print technologies, being physical processes, have inherent uncertainty. Some print technologies have more uncertainty than others. Dry offset printing is one; it is notably inaccurate. (Dry offset is advantageous in other respects; for example, it works well with the tapered shapes of plastic tubs, such as for yogurt and sour cream.)
Dry offset offers only gross control of dot size and other print structures. For example, if a digital artwork file specifies that ink dots are to be laid down with a density of 15%, a dry offset press will typically deposit a much greater density of ink, e.g., with 30% density.
Printer profiles exist to characterize such behavior. A profile for a particular model of dry offset press may specify that artwork indicating a 15% density will actually be rendered with a 25% density (e.g., a 10% dot gain). But there is a great deal of variation between presses of the same model - depending on factors including age, maintenance, consumables, temperature, etc. So instead of depositing ink at a 25% density - as indicated by a printer’s profile, a particular press may instead deposit ink at a 20% density. Or a 40% density. Or anything in between.
This uncertainty poses a big obstacle for use of digital watermark technology. Packaging artwork that has been carefully designed to set the watermark amplitude to the point“A” sweet-spot of Fig. 2, may instead be printed with the watermark amplitude at point“B”, making the watermark plainly visible.
Our US patent publication 20110214044 teaches that, rather than attempt to hide a digital watermark signal in artwork, the payload data may be encoded as overt elements of the artwork. One example is a digital watermark in which the amplitude is set to a plainly human-visible level. Another
example is a 1D or 2D black and white barcode that is used as a fill pattern, e.g., laid down by a paintbrush in Adobe Photoshop software.
These techniques often do not prove satisfactory. As illustrated by Fig. 1 , a digital watermark, with its amplitude set to a plainly human-visible level, yields a pattern that does not fit well into the design of most packaging. Painted barcode fills similarly have limited practical utility.
In accordance with one aspect of the technology, a neural network is applied to imagery including a machine readable code, to transform its appearance while maintaining its machine readability. One particular method includes training a neural network with a style image having various features. The trained network is then applied to an input pattern that encodes a plural-symbol payload. The network adapts features from the style image to express details of the input pattern, to thereby produce an output image in which features from the style image contribute to encoding of the plural-symbol payload. This output image can then be used as a graphical component in product packaging, such as a background, border, or pattern fill. In some embodiments, the input pattern is a watermark pattern, while in others it is a host image that has been previously watermarked.
The foregoing and additional features and advantages of the present technology will be more readily apparent from the following detailed description, which proceeds with reference to the accompanying drawings.
Brief Description of the Drawings
In the U.S., the patent or application file contains at least one drawing executed in color. Copies of this patent or patent application publication with color drawing(s) will be provided by the Office upon request and payment of the necessary fee.
Fig. 1 is an illustration of a digital watermark pattern.
Fig. 2 is a graph showing how a digital watermark is human-imperceptible at low strengths, but becomes progressively more conspicuous at higher strengths.
Fig. 3 is a diagram depicting an algorithm for generating a digital watermark tile.
Fig. 4 details an illustrative neural network that can be used in embodiments of the present technology
Figs. 5 and 6 further detail use of the Fig. 4 neural network in an illustrative embodiment of the technology.
Fig. 7 details an algorithm employed in one illustrative embodiment of the technology.
Fig. 8 shows an obfuscated code signal produced by the present technology from the digital watermark pattern of Fig. 1 and a (depicted) bitonal geometrical pattern.
Fig. 9 shows another obfuscated code signal produced by the present technology from the digital watermark pattern of Fig. 1 and a (depicted) bitonal geometrical pattern.
Fig. 10 shows still another obfuscated code signal produced by the present technology from the digital watermark pattern of Fig. 1 and still another (depicted) bitonal geometrical pattern.
Fig. 11 shows a line art counterpart to the image of Fig. 10, produced by the method of Fig. 12.
Fig. 12 details an algorithm for further-processing an image produced with the present technology.
Fig. 13 shows another pattern produced by methods of the present technology.
Fig. 14A depicts a user interface of software that generates a watermark pattern with user-defined parameters, and enables an artist to specify a style to be applied to the pattern.
Figs. 14B and 14C detail exemplary methods employed by the software of Fig. 14A.
Figs. 14D, 14E, 14F and 14G are images on which the“Candy,”“Mosaic,”“Feathers,” and“La Muse” styles visible in Fig. 14 are based.
Figs. 15A - 15ZZ depict continuous tone watermark patterns that have been processed in accordance with aspects of the present technology.
Figs. 16A - 16C show how stylization of a watermark pattern serves to scale, translate, and rotate features of a style image to mimic, or echo, features of the watermark pattern.
Figs. 17A - 17E illustrate how three patterns can be combined: a host image, a watermark pattern, and a style image.
Figs. 18A - 18C illustrate the Lenna image styled with images of candy balls, denim, and grass, respectively.
Figs. 19A - 19C illustrate that a sparse mark, rendered as a Delaunay triangulation, can be stylized with a pattern of leaves, resulting in an output image in which the leaves are morphed in scale, location and rotation to correspond to triangles of the Delaunay pattern.
Fig. 20 depicts an inverted transform method according to one aspect of the technology.
Figs. 21 A - 21E depicts application of an inverted transform method in connection with a Voronoi pattern.
Fig. 22 depicts an inverted transform method according to one aspect of the technology.
Figs. 23A and 23B show a Voronoi pattern based on a sparse pattern of dots, and the same pattern after application of the inverted transform method of Fig. 22.
Figs. 24A and 24B are enlargements from Figs. 23 A and 23B.
Figs. 25A and 25B illustrate how artistic signaling patterns according to the present technology can be used as background patterns on a boxed item of food.
Figs. 26 and 27 are like Figs 25 A and 25B, but showing application of artistic signaling patterns to food items in cans and plastic tubs.
Figs. 28A and 28B illustrate use of artistic signaling patterns, based on continuous tone watermarks, as graphic backgrounds on a grocery item.
Figs. 29A - 29C illustrate use of artistic signaling patterns, based on sparse watermarks, as graphic backgrounds on a grocery item.
Figs. 30A and 30B show polygon-based patterns based on continuous tone watermarks.
Fig. 31 A shows an artistic signaling pattern generated from a sparse mark using various image transformations.
Fig. 31B is an enlargement from Fig. 31 A.
Figs. 32A, 32B, 33A, 33B, 34A, 34B, 35A, 35B, 36A, 36B, 37A, 37B, 38A and 38B are similar to Figs. 31A and 31B, but using different image transformations.
Figs. 39A and 40A show artistic signaling patterns generated from a continuous tone watermark using various image transformations, and Figs. 39B and 40B are enlargements thereof.
Fig. 41 shows an artistic signaling pattern produced from a sparse mark.
Fig. 42A shows an excerpt from a watermarked poster, and Fig. 42B shows an enlargement from Fig. 42A.
Figs. 43 and 44 show excerpts of tiles of signal-carrying patterns.
Fig. 45 shows how glyphs hand-written on a tablet can employ a signal-carrying pattern.
Fig. 46 shows how strokes on a tablet can have directional texture associated with the brush, and/or its direction of use, while also employing a signal-carrying pattern.
Fig. 47 conceptually-illustrates how two overlapping brush strokes may effect a darkening of a common region, while maintaining two directional textures.
Fig. 48 conceptually-illustrates how two overlapping brush strokes that apply a signal-carrying pattern may effect a darkening of a common region by changing mean value of the pattern.
Fig. 49A shows that the mean value of patterning in a rendering of handwritten glyphs can depend on stylus-applied pressure.
Fig. 49B is like Fig. 49A but with the patterning less-exaggerated in contrast.
Fig. 49C is like Fig. 49B, but is presented at a more typical scale.
Figs. 50A and 50B show how handwritten glyphs entered by a stylus can be patterned with different patterns, including a neural network-derived signal-carrying pattern.
Fig. 51 shows the user interface of a prior art tablet drawing program.
Fig. 52 shows correspondence between a signal-carrying pattern, and handwritten strokes of different pressures - causing the pattern to be rendered with different mean values.
Fig. 53 shows a traveling salesman line pattern, derived from another optical code pattern, that conveys a plural-bit payload.
Fig. 54 is like Fig. 53, but showing a brick wall line pattern.
Fig. 55 is like Fig. 53, but showing a Voronoi pattern.
Figs. 55A and 55B illustrate how line patterns that encode plural-bit data, such as the Voronoi pattern of Fig. 55, can be used as fill patterns in graphical art.
Fig. 56 is like Fig. 53, but showing a Delaunay triangulation pattern.
Figs. 57A and 57B are like Fig. 53, but showing different line patterns.
Detailed Description
Fig. 3 shows an illustrative direct sequence spread spectrum watermark generator. A plural- symbol message payload (e.g., 40 binary bits, which may represent a product’s Global Trade
Identification Number, or GTIN) is applied to an error correction coder. This coder transforms the symbols of the message payload into a much longer array of encoded message elements (e.g., binary or M-ary elements) using an error correction method. (Suitable coding methods include block codes, BCF1, Reed Solomon, convolutional codes, turbo codes, etc.) The coder output may comprise hundreds or thousands of binary bits, e.g., 4,096, which may be termed“raw bits.”
These raw bits each modulate a pseudorandom noise (carrier) sequence of length 16, e.g., by XORing. Each raw bit thus yields a 16-bit modulated carrier sequence, for an enlarged payload sequence of 65,536 elements. This sequence is mapped to elements of a square block having 256 x 256 embedding locations. These locations correspond to pixel samples at a configurable spatial resolution, such as 100 or 300 dots per inch (DPI). (In a 300 DPI embodiment, a 256 x 256 block corresponds to an area of about 0.85 inches square.) Such blocks can be tiled edge-to-edge to for printing on the paper or plastic of a product package/label.
There are several alternatives for mapping functions to map the enlarged payload sequence to embedding locations. In one, the sequence is pseudo-randomly mapped to the embedding locations. In another, they are mapped to bit cell patterns of differentially encoded bit cells as described in published patent application US20160217547. In the latter, the block size may be increased to accommodate the differential encoding of each encoded bit in a pattern of differential encoded bit cells, where the bit cells correspond to embedding locations at a target resolution (e.g., 300 DPI).
The enlarged payload sequence of 65,536 elements is a hi modal signal, e.g., with values of 0 and 1. It is mapped to a larger hi modal signal centered at 128, e.g., with values of 95 and 161.
A synchronization signal is commonly included in a digital watermark, to help discern parameters of any affine transform to which the watermark may have been subjected prior to decoding (e.g., by
image capture with a camera having an oblique view of the pattern), so that the payload can be correctly decoded. A particular synchronization signal (sometimes termed a calibration signal, or registration signal, or grid signal) comprises a set of dozens of magnitude peaks or sinusoids of pseudorandom phase, in the Fourier domain. This signal is transformed to the spatial domain in a 256 x 256 block size (e.g., by an inverse Fast Fourier transform), corresponding to the 256 x 256 embedding locations to which the enlarged payload sequence is mapped. (Spatial domain values larger than a threshold value, e.g., 40, are clipped to that threshold, and likewise with values smaller than a negative threshold value, e.g., -40.)
This spatial domain synchronization signal is summed with the block-mapped 256 x 256 payload sequence to yield a final watermark signal block.
In another embodiment, a block of size 128 x 128 is generated, e.g., with a coder output of 1024 bits, and a payload sequence that maps each of these bits 16 times to 16,384 embedding locations.
The just-described watermark signal may be termed a“continuous tone” watermark signal. It is usually characterized by multi-valued data, i.e., not being just on/off (or 1/0, or black/white) - thus the “continuous” moniker. Each pixel of the host image (or of a region within the host image) is associated with one corresponding element of the watermark signal. A majority of the pixels in the image (or image region) are changed in value by combination with their corresponding watermark elements. The changes are typically both positive and negative, e.g., changing the local luminance of the imagery up in one location, while changing it down in another. And the changes may be different in degree - some pixels are changed a relatively smaller amount, while other pixels are changed a relatively larger amount.
Typically the amplitude of the watermark signal is low enough that its presence within the image escapes notice by casual viewers (i.e., it is steganographic).
In a variant continuous tone watermark, the signal acts not to change the local luminance of artwork pixels, but rather their color. Such a watermark is termed a“chrominance” watermark (instead of a“luminance” watermark). An example is detailed, e.g., in US patent 9,245,308, the disclosure of which is incorporated herein by reference.
“Sparse” or“binary” watermarks are different from continuous tone watermarks in several respects. They do not change a majority of pixel values in the host image (or image region). Rather, they have a print density (which may sometimes be set by the user) that results in marking between 5% and 45% of pixel locations in the image. Adjustments are all made in the same direction, e.g., reducing luminance. Sparse elements are typically bitonal, e.g., being either white or black. Although sparse watermarks may be formed on top of other imagery, they are usually presented in regions of artwork that are blank, or colored with a uniform tone. In such cases a sparse marking may contrast with its background, rendering the marking visible to casual viewers. As with continuous tone watermarks, sparse watermarks generally take the form of signal blocks that are tiled across an area of imagery.
Exemplary sparse marking technology is detailed in the patent documents referenced at the beginning of this specification.
A sparse pattern can be rendered in various forms. Most straight-forward is as a seemingly- random pattern of dots. But more artistic renderings are possible, including Voronoi, Delaunay, and stipple half-toning. Such techniques are detailed in above -cited application 62/682,731. (In a simple Voronoi pattern, a line segment is formed between a dot and each of its neighboring dots, for all the dots in the input pattern. Each line segment extends until it intersects with another such line segment. Each dot is thus surrounded by a polygon.)
Unless otherwise indicated, the techniques described below can be applied to any type of watermarks - continuous tone luminance, continuous tone chrominance, sparse dot, Voronoi, Delaunay, stipple, etc., as well as to images incorporating such watermarks.
First Exemplary Embodiment
A first exemplary embodiment of the present technology processes a watermark signal block, such as described herein, with a neural network. The network can be of various designs. One, shown in Fig. 4, is based on the VGG network described in Simonyan et al, Very Deep Convolutional Networks for Large-Scale Image Recognition, arXiv preprint 1409.1556n6, April 10, 2015 (familiar to those skilled in that art, and attached to application 62/596,730), but lacking its three fully-connected layers, and its SoftMax classifier.
The network of Fig. 4 is characterized by five stacks of convolutional layers, each based on 3x3 receptive fields. These 3x3 filters are convolved with their inputs at every pixel, i.e., with a stride of 1. The first stack includes two cascaded convolutional layers, of 64 channels each. The second stack again includes two cascaded convolutional layers, but of 128 channels each. The third stack includes four cascaded convolutional layers, of 256 channels each. The fourth and fifth stacks include four cascaded convolutional layers, of 512 channels each. Each layer includes a Rectified Linear Unit (ReLu) stage to zero any negative values in the convolutional outputs. Each stack additionally includes a concluding average pooling layer (rather than the max pooling layer taught by Simonyan), which is indicated in Fig.
4 by the shaded layer at the right of each stack. The input image is an RGB image of size 224 x 224 pixels.
In its original conception, the VGG network was designed to identify images, e.g., to determine into which of several classes (dog, cat, car, etc.) an image belongs. And the network here is configured for this purpose - employing filter kernels that have been trained to classify an input image into one of the one thousand classes of the ImageNet collection. However, the network is here used for a different purpose. It is here used to discern“features” that help characterize a watermark image. And it is used
again to discern features that characterize a geometrical pattern image. And it is used a third time to characterize features of a test image (which may be a frame of pseudo-random noise). This test image is then adjusted to drive its features to more closely correspond both to features of the watermark image and to features of the geometrical pattern image. The adjusted test image is then re-submitted to the network, and its features are re-determined. Adjustment of the test image continues in an iterative fashion until a final form is reached that incorporates geometrical attributes of the geometrical pattern image, while also being decodable by a digital watermark decoder.
Figs. 5 and 6 help further explain this process. A watermark signal block (A) is input to the network. Each of the stacks of convolutional layers produces filter responses, determined by applying the convolutional parameters of their 3x3 filters on respective excerpts of input data. These filter responses are stored as reference features for the watermark signal block, and will later serve as features towards which features of the third image are to be steered.
A similar operation is applied to the geometrical pattern image (B). The geometrical pattern image is applied to the network, and each of the stacks produces corresponding filter responses. In this case, however, these filter responses are processed to determine correlations between different filter channels of a layer. This correlation data, which is further detailed below, serves as feature data indicating the style, or texture, of the geometrical pattern image. This correlation data is stored, and is later used as a target towards which similarly-derived correlation data from the test image is to be steered.
A test image (C) is next applied to the network. The starting test image can be of various forms. Exemplary is a noise signal. Each of the stacks of convolutional layers produces filter responses.
Correlations between such filter responses - between channels of layers - are also determined. The test image is then adjusted, so that its filter responses more closely approximate those of the watermark signal block, and so that its texture -indicating correlation data more closely approximates that of the geometrical pattern block.
Diving more deeply, consider the watermark image applied to the network to be denoted as w. This image can be characterized by the networks filters’ responses to this image. A layer l in the first stack of Fig. 5, with 64 (Ni) channels, has 64 distinct feature maps, each of size Mi, where Mi is the number of elements in the feature map (width times height, or 2222). A matrix W1, of dimensions 64 x 2222 can thus be defined for each layer in the network, made up of the 64 filter responses for each of the 2222 positions in the output from layer 1. W# defines the activation of the /th filter at position / in this layer.
If a test image x is applied to the network, a different matrix is similarly defined by its filter responses. Call this matrix X. A loss function can then be defined based on differences between these
filter response matrices. A squared-loss error is commonly used, and may be computed, for a given layer l, as

Taking the derivative of this function indicates the directions that the filter responses should change, and relative magnitudes of such changes:
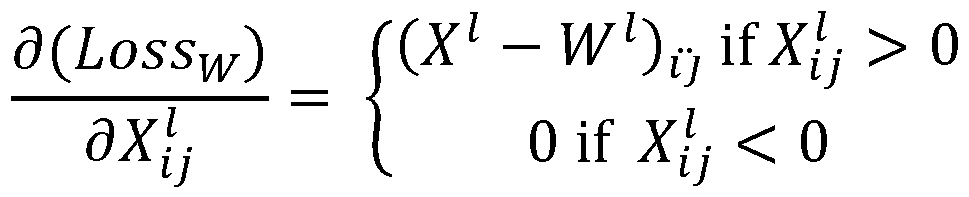
This derivative establishes the gradients used to adjust the test image using back-propagation gradient descent methods. By iteratively applying this procedure, the test image can be morphed until it generates the same filter responses, in a particular layer of the network, as the watermark image w.
The geometrical pattern image can be denoted as g. Rather than use filter responses, per se, as features of this image, a variant feature space is built, based on correlations between filter responses, using a Gram matrix.
As is familiar to artisans in such technology, and as detailed in a Wikipedia article entitled Gramain Matrix (attached to application 62/596,730), a Gram matrix is composed of elements that are inner products of vectors in a Euclidean space. In the present case the vectors involved are the different filter responses resulting when the geometrical pattern is applied to the network.
Consistent with the former notation used for the watermark pattern image w and the test image x, the filter responses for a given layer l of geometrical pattern image g are expressed as the matrix G-j , where i denotes one of the N filter channels (e.g., one of the 64 filter channels for the first layer), and j denotes the spatial position (from among 2222 positions for the first layer). The correlation-indicating Gram matrix C for a particular layer in geometrical pattern image g is an Nx N matrix:

That is, the Gram matrix is the inner product between the vectorized filter responses i and j in layer l, when the geometrical pattern image g is applied to the network (i.e., the inner product between intermediate activations - a tensor operation that results in an N x N matrix for each layer of N channels).
This procedure is again applied twice: once on the geometrical pattern image, and once on the test image. Two feature correlations result, as indicated by the two Gram matrices.
Gradient descent is then applied to the test image to minimize a mean-squared difference between elements of the two Gram matrices.
If Clj as defined above is the Gram matrix for the geometrical pattern image, and D\j is the corresponding Gram matrix for the test image, then the loss E associated with layer l for the two images is:

The total loss function, across plural layers L, between the geometrical pattern image g and the test image x is then
 where ai are weighting factors for the contribution of each layer to the total loss.
where ai are weighting factors for the contribution of each layer to the total loss.
The derivative of Ei with respect to the filter responses in that layer is expressed as:

Again, standard error back-propagation can be applied to determine the gradients of Ei, which can be used to iteratively adjust the test image, to bring its correlation features (Gram matrix) closer to that of the geometrical pattern image.
While the two loss functions defined above, Lossw and LOSSG, can be used to adjust the test image to more closely approximate the watermark block image, and the geometrical pattern image, respectively, the loss functions are desirably applied jointly, in a weighted fashion. That is:
LOSStotal= aLossw + LOSSG where a and b are weighting factors for the watermark pattern and the geometrical pattern, respectively.
The derivative of this combined loss function, with respect to the pixel values of the test image x, is then used to drive the back propagation adjustment process. An optimization routine, BFGS, can optionally be applied. (C./, Zhu et al, Algorithm 778: L-BFGS-B: Fortran Subroutines for Large-Scale Bound-Constrained Optimization, ACM Trans on Mathematical Software, 23(4), pp. 550-560, 1997.)
In a particular embodiment, the loss factor LOSSG is based on filter responses from many of the 16 different convolution layers in the network - in some cases all of the layers. In contrast, the loss factor Lossw is typically based on filter responses from a small number of layers - in some cases just one (e.g., the final layer in stack #4).
The foregoing discussion draws heavily from Gatys et al, Image Style Transfer Using
Convolutional Neural Networks, Proc. of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2414-2423, 2016, and its predecessor Gatys, et al, A Neural Algorithm of Artistic Style. arXiv preprint arXiv: 1508.06576, August 26, 2015 (both familiar to artisans in that field, and both attached to application 62/596,730), which provide additional details. Those papers, however, particularly concern transferring artistic styles between digitized paintings and photographs, and do not contemplate machine readable codes (nor geometrical patterns).
The Gatys work is reviewed and expanded in Johnson, et al, Perceptual Losses for Real-Time Style Transfer and Super-Resolution, European Conference on Computer Vision, October 8, 2016, pp. 694-711, and in Nikulin, et al, Exploring the Neural Algorithm of Artistic Style, arXiv preprint arXiv: 1602.07188, February 23, 2016 (both are again familiar to artisans in that field, and both are attached to application 62/596,730; the former method is sometimes termed“the method of Johnson” or “the Johnson method” herein).
The described procedure is applied to iteratively adjust the test image until it adopts patterning from the geometrical pattern image to a desired degree, e.g., to a degree sufficient to obfuscate the mottled patterning of the watermark block - while still maintaining the machine readability of the watermark block.
Fig. 7 is a flow chart detailing aspects of the foregoing method.
Fig. 8 shows an illustrative application of the method. A bitonal geometrical pattern of the same size as the earlier-defined watermark signal block was created to serve as the style image, comprising concentric black and white circles. Its Gram matrix was computed, for the 16 layers in the Fig. 4 network. After 20 iterations, the detailed procedure updated an input random image until it took the form shown on the right.
It will be recognized that this pattern shown on the right of Fig. 8 is more suitable for incorporating into packaging artwork than the pattern shown on the right of Fig. 1.
Fig. 9 shows a similar example, this one based on a bitonal checkerboard pattern.
Fig. 10 shows another example, this one based on a pattern of tiled concentric squares.
As noted in the Background discussion, some printing technologies have substantial variability. Dry offset was particularly mentioned. When printing a press run of product packaging, this variability can cause a digital watermark pattern, which is intended to be rendered with an ink coverage resulting in human imperceptibility, to pop into conspicuous visibility.
The patterns of Figs. 8, 9 and 10 are robust to such printing errors. If more or less ink is applied due to press variability, the package appearance will change somewhat. But it will not cause a pattern that is meant to be concealed, to become visible. And the strength of the encoded signal is robust - far to the right on Fig. 2, and far stronger than the strengths (e.g.,“A” to“B”) with which watermarks intended for imperceptibility are applied. Supermarket scanners thus more reliably decode the product identifying information (e.g., GTINs) from such printing, even if only a fraction of the pattern is depicted in an image frame, or if contrast or glare issues would impair reading of an imperceptible watermark.
The patterns on the right of Figs. 8-10 can be further processed to form line art images. Fig. 11 shows an example. Such line art images are even more robust to press variations, and extend application of this technology to other forms of printing that are commonly based on line structures (e.g., intaglio).
The Fig. 11 image is derived from the Fig. 10 (right side) image by first binarizing the image against a threshold value, e.g., of 128 (i.e., setting all pixels having a value above 128 to a value of 255, and setting all other pixels to a value of 0). A skeletonizing operation (e.g., a medial axis filter) is then applied to the binarized image. The“skeleton” thereby produced is then dilated, by a dilation filter (e.g., replacing each pixel in the skeleton with a round pixelated dot, e.g., of diameter 2-20). Such a procedure is illustrated by the flow chart of Fig. 12. (Additional information on such procedure is detailed in US application 16/129,487.)
In a variant embodiment (i.e., not strictly line art), the Fig. 10 image is simply binarized. Such an image is shown in Fig. 13.
Through this process, decodability of the encoded payload should persist. Accordingly, at the end of any image processing operation - and optionally at interim steps (e.g., between iterations) - the test image may be checked to confirm that the watermark is still decodable. A watermark signal strength metric can be derived as detailed, e.g., in US patent 9,690,967, and in US applications 16/129,487, filed September 12, 2018, 15/816,098, filed November 17, 2017, and 15/918,924, filed March 12, 2018, the disclosures of which are incorporated herein by reference.
In the cited binarization operations, different thresholds may be tested, and strength metrics for the watermark signal can be determined for each. In choosing between candidate thresholds that all yield suitable patterning for use in a particular package, the threshold that yields the strongest watermark signal strength may be selected
Similarly, when using a neural network to morph a test image to take on attributes of a geometrical pattern, the geometrical pattern may come to dominate the morphed test image - depending on the weighting parameters a and b, and the number of iterations. Here, too, periodically assessing the strength of the watermark signal can inform decisions such as suitable weights for a and b, and when to conclude the iterative process.
Second Exemplary Embodiment
A second exemplary embodiment is conceptually similar to the first exemplary embodiment, so the teachings detailed above and elsewhere are generally applicable. In the interest of conciseness, such common aspects are not repeated here.
This second embodiment is hundreds or thousands of times faster than the first embodiment in applying a particular style to an image - requiring only a forward pass through the network. However, the network must first be pre-trained to apply this particular style, and the training process is relatively lengthy (e.g., four hours on a capable GPU machine).
An advantage of this embodiment for our purposes is that, once trained, the network can quickly apply the style to any watermark (or watermarked) input image. This method is thus suitable for use in a tool for graphic artists, by which they can apply one of dozens or hundreds of styles (for which training has been performed in advance) to an input pattern, e.g., to generate a signal-carrying pattern for incorporation into their artwork.
Fig. 14A is a screenshot of the user interface 140 of such a software tool. A palette of pre-trained neural styles is on the left, such as style 141 derived from Edvard Munch’s“The Scream.” (Also included can be some algorithmic patterns 142, such as Voronoi, Delaunay and stipples, as referenced elsewhere.) The user clicks a button to select a desired style. In the upper right are dialog features 143 by which the user can specify attributes of a watermark pattern. That is, in this particular example, a watermark pattern is not input, per se. Rather, parameters for a watermark pattern are specified through the user interface, and the watermark pattern is generated on the fly, as part of operation of the software. (A sparse dot marking may be generated if an algorithmic pattern, such as Voronoi, is selected. A continuous tone watermark may be generated if one of the other styles is selected.) The selected style is then applied to the specified watermark.
In particular, the user enters parameters specifying the payload of the watermark signal (e.g., a 12 digit GTIN code), and the resolution of the desired watermark signal block in watermarks per inch (WPI). The user also specifies the physical scale of the watermark signal block (in inches), and the strength (“Durability”) with which the watermark signal is to be included in the finished, stylized, block. An analysis tool, termed Ratatouille, can be selectively invoked to perform a signal strength analysis of the
resulting stylized block, in accordance with teachings of the patent documents referenced earlier. A moment after the parameters are input (typically well less than ten seconds), a stylized, watermarked signal block is created, and stored in an output directory with a file name that indicates metadata about its creation, such as the date, time, style, and GTIN. A rendering 144 of the signal block is also presented in the UI, for user review.
Figs. 14B and 14C further detail aspects of the software’s operation.
The pre-training to generate the neural styles 141 of Fig. 14 proceeds according to the method of Johnson, referenced earlier. As noted, this method is familiar to artisans; its method is briefly reviewed in a separate section, below. His paper has been cited over a thousand times in subsequent work. His method has been implemented in various freely-accessible forms. One is an archive of software code written by author Justin Johnson, available at github<dot>com/jcjohnson/fast-neural-style. (The <dot> convention is used in lieu of a period, to assure there is no browser-executable code in this specification, per MPEP § 608.) Another is an archive of code written by Logan Engstrom, available at
github<dot>com/lengstrom/fast-style-transfer. Still another is code written by Adrian Rosebrock, using functionality of the open source library OpenCV (e.g., version 3.4.1), detailed at
www<dot>pyimagesearch<dot>com/2018/08/27/neural-style-transfer-with-opencv/. The Web Archive (web<dot>archive<dot>org) has backups of all these materials.
Appendices A, B and C to application 62/745,219 form part of this specification and present material from the public gitbub web site - including source code - for the method of Johnson, and for its implementation by Engstrom and Rosebrock, respectively. Such code can use previously compiled style models, e.g., in a binary Torch format (*.t7). Sample t7 models are freely available from an archived Justin Johnson page from a Stanford web server,
web<dot>archive<dot>org/web/20170917122404/http://cs. stanford.edu : 80/people/jcjohns/fast-neural- style/models/instance_norm/. Alternatively, style models can be newly-created.
Figs. 14D, 14E, 14F and 14G show the original images that were used as style images in the method of Johnson, to define the“Candy,”“Mosaic,”“Feathers,” and“La Muse” styles - each of which is a selectable option for applying to a watermark pattern, in the user interface of Fig. 14A.
Fig. 15A shows a result of the method, when a network using the method of Johnson is trained to apply a style derived from a photograph of rice grains, and this style is applied to a watermark pattern that encodes a particular plural-bit payload (in this case a continuous tone luminance watermark, like that shown in Fig. 1). Figs. 15B - 15ZZ show similar results, when the network is trained to apply other styles to such a watermarked pattern. Some of the styles are based on photographs of physical items, e.g., grains of rice, water droplets on grass, leaves of grass, pasta noodles, candy corn, woven basket reeds,
denim fabric, etc. (natural imagery). Others of the styles are based on computer graphics (synthetic imagery), such as the geometric bitonal imagery used as inputs in Figs. 8-10.
Fig. 15WW is generated by applying the Johnson method with the“Candy” style (e.g., as shown in Fig. 14) to a continuous tone watermark, converting to greyscale, increasing the contrast, and applying a blue spot color. Fig. 15XX is similarly generated, except that it is rendered in a duotone mode. That is, highlights and mid-tones of the image are identified and rendered in a first user-selected (light blue) color. The remaining, darker, tones are rendered in a second user-selected (darker blue) color.
Fig. 15YY is similar to Fig. 15WW, but generated with the“Feather” style. Fig. 15ZZ is similar, but generated with the“Mosaic” style.
It will be recognized that color features of the style images (Feather, Mosaic, etc.) are omitted from the images shown in Figs. 15WW - 15ZZ. The output from the neural network is often converted to greyscale and then false-colored - commonly in monochrome - for use in a particular packaging context. (It is often the case that structure is more important than color, when adapting features from a style image for use in consumer packaging. Color is commonly changed to suit the package colors. Compare, e.g., the colored gumballs of Fig. 15PP, and the falsely-colored gumball background of Fig. 28 A.)
Applicant has discovered that style images can yield better or worse results depending on the atomic scale of elements depicted in the image. The watermark pattern, to which the style is applied, is commonly comprised of units (watermark elements, or“waxels”) that have a particular scale, e.g., regions of 2x2 or 3x3 pixels. The stylized results most faithfully follow the style image, and the watermark is most reliably readable from the stylized result, if the style image has a structure with elements of a comparable scale. Comparable here means a majority of elements in the style image have a scale in the range of 0.5 to 25x that of elements in the watermark. Thus, for waxels that are 3x3 pixels, individual rice grains in a style image desirably have a minimum dimension (width) of 1.5 pixels, and a maximum dimension (length) of 75 pixels. Likewise for blades of grass, weaves of fabric or basketry, droplets of water, pieces of candy corn, etc. (Best results are with items that are not just comparable, but close, in scale, e.g., in a range of 0.5x - 3x the waxel dimension.)
By so doing, the style transfer network can morph the style pattern to assume spatial attributes of the watermark pattern, without either grossly departing from the style of the style image, nor distorting the scale of the watermark waxels so that their readability is impaired.
This is illustrated by Figs. 16A - 16C. Fig. 16A shows an excerpt of a watermark pattern. Fig. 16B shows a pattern resulting after a network trained with the Johnson method, using a raindrop style pattern, is applied to the Fig. 16A excerpt of a watermark pattern. Fig. 16C overlays Figs. 16A and 16B. Note how the network has adapted the orientation, translation, scale and contours of the raindrops to
conform to the orientation, translation, scale and contours of features within the watermark pattern. The correlation is somewhat astounding.
In the prior art, continuous tone watermark signals are commonly spread across host artwork at a very low amplitude, changing pixel values in an image a small amount - perhaps up to 10 or 20 digital numbers in an 8-bit (0-255) image. In some applications of style transfer-based watermarking, in contrast, the signal needn’t be spread across the image; it may be lumpy - limited to local regions, e.g., just 10-30% of the image (as in the water droplets style of Fig. 16B). But in those local regions its amplitude can be much greater, e.g., spanning 100-, 200- or more bits of dynamic range; in some cases the full 256 bits. The net signal energy may be comparable, but its concentration in limited areas can make the signaling more robust to distortion and signal loss.
Review
To review, one aspect of the present technology concerns a method of generating artwork for labeling of a food package. Such method includes receiving imagery that encodes a plural-bit payload therein; neural network processing the imagery to reduce a difference measure between the processed imagery and a style image; and incorporating some or all of the neural network-processed imagery in artwork for labeling of a food package, where the plural-bit payload persists in the neural network- processed imagery. Such arrangement enables a compliant decoder module in a retail point of sale station to recover the plural-bit payload from an image of the food package.
In a related method, a first image (e.g., a host image, depicting a subject) is digitally-watermarked to encode a plural-bit payload therein, yielding a second image. This second image is neural network- processed to reduce a difference measure between the processed second image and a style image.
In such arrangements, the distance measure can be based on a difference between a Gram matrix for the processed second image and a Gram matrix for the style image.
(It will be recognized that reducing a difference measure between the processed imagery and the style image can be replaced by increasing a similarity measure between the processed imagery and the style image.)
A further aspect of the technology involves a method that starts by receiving a pattern that encodes a plural-symbol payload. This pattern is then stylized, using a neural network (typically previously-trained), to produce a stylized output image. The style is based on a style image having various features, wherein the network adapts features from the style image to express details of the received pattern, to thereby produce an image in which features from the style image contribute to encoding of said plural-symbol payload.
In another aspect, a method again starts with an input pattern that encodes a plural-symbol payload. This pattern is then stylized, using a neural network, to produce a stylized output image. The network is trained based on an image depicting a multitude of items of a first type (rain drops, rice grains, candy balls, leaves, blades of grass, stones, beans, pasta noodles, bricks, fabric threads, etc.). The network adapts scale, location, and rotation of the items as depicted in the stylized output image to echo, or mimic, features of the originally-input pattern, to thereby produce an image depicting plural of the items in a configuration that encodes said plural-symbol payload.
Another aspect of the technology concerns a method in which a user interface enables a user to define a multi-symbol payload, and to select from among plural different styles. In response to user selection of a first style, a sparse watermark pattern is generated. This pattern includes a web of lines defining plural polygons, with the arrangement of the polygons encoding the payload. In response to user selection of a second style, a continuous tone watermark pattern is generated, and elements of the second style are adapted to mimic elements of the watermark pattern and encode the payload.
Yet another method involves receiving a sparse pattern of points that encodes plural-symbol data, such as a Global Trade Item Number identifier. A transformed image is generated from this sparse pattern of points by a process that includes transforming the sparse pattern by applying a directional blur or wind filter in a first direction. Such filtering may also be applied to the sparse pattern in a second direction, and the results combined with the earlier results.
Another aspect of the technology involves a food package on which artwork is printed, where the artwork encodes a plural bit payload (e.g., including a Global Trade Item Number identifier). The artwork has first and second regions, which may be adjoining. The first region includes a background pattern that has been stylized from a watermarked input image using a neural network.
In such arrangement, the second region may include a watermarked image that has not been stylized using a neural network, yet the watermark included in the second region is geometrically-aligned with a watermark signal included in the first region. By such variant arrangement, a detector can jointly use signals from both regions in decoding the payload.
Still another aspect of the technology involves receiving a watermarked image, and then stylizing the watermarked image, to produce a styled output. This styled output is then false-colored, and incorporated into artwork.
A further aspect involves obtaining data defining a square watermark signal block, comprising N rows and N columns of elements. This signal block encodes an identifier, such as a Global Trade Item Number identifier. Plural of these row and columns are replicated along two adjoining edges of the square signal block, producing an enlarged signal block having M rows and M columns of elements. The enlarged block is then sent for processing to a style-transfer neural network. The enlarged signal block is
received back after processing, and an N row by N column portion is excerpted from the received block. This excerpt is then used, in tiled fashion, within artwork to convey the identifier to camera-equipped devices (e.g., enabling a POS terminal to add an item to a shopper’s checkout tally).
Yet another aspect is a method including: receiving a pattern of dots encoding a plural-symbol payload, and then padding the pattern of dots, by replicating portions of the pattern along at least two adjoining sides of the square, to yield a larger pattern of dots. A pattern of polygons is then generated from this larger pattern of dots. The polygon pattern can then be used as a fill or background pattern in commercial art, such as product packaging.
Still another method includes obtaining a watermark signal that encodes an identifier and is represented by watermark signal elements (e.g., waxels) of a first size. This watermark signal is stylized in accordance with a style image, which depicts multiple items of a first type (e.g., grains of rice, droplets of water, pieces of candy), where the items depicted in the style image have a size that is between 0.5 and 25 times said first size.
Yet another aspect of the technology concerns a method for producing a code for message signaling through an image. The method employs a neural network having an input, one or more outputs, and plural intermediate layers. Each layer comprises plural filters, where each filter is characterized by plural parameters that define a response of the filter to a given input. The method is characterized by iteratively adjusting an input test image, based on results produced by the filters of said neural network, until the test image adopts both (1) style features from one image, and (2) signal-encoding features from a second image.
Yet a further aspect of the technology is a method for producing a code for message signaling through an image, using a deep neural network - which may have been trained to perform object recognition. The network has an input, one or more outputs, and plural intermediate layers, where each layer includes multiple filters, each characterized by plural parameters that define a response of the filter to a given input. The method includes receiving an image comprising a machine readable code that is readable by a digital watermark decoder, where the machine readable code includes a signal modulated to convey a plural-symbol payload. This machine readable code image is presented to the network, causing the filters in the network layers to produce machine readable code image filter responses. The method further includes receiving an artwork image; presenting the artwork image to the network; and determining correlations between filter responses in different of the layers, to thereby determine style information for the artwork image. The method further includes receiving an initial test image, and presenting same to the neural network, causing filters in plural of the layers to produce test image filter responses. Style information for the test image is then determined by establishing correlations between the test image filter responses of plural of the filter layers. A first loss function is determined based on
differences between the test image filter responses and the machine readable code image filter responses, for filters in one or more of said layers. A second loss function is determined based on a difference between the style information for the first and test images. The test image is then adjusted based on the determined first and second loss information. This procedure is repeated plural times, to incrementally adjust the test image to successively adopt more and more of the style of the artwork image. By such arrangement, the test image is transformed into an image in which the modulated signal is obfuscated by the style of the artwork image, yet is still readable by the digital watermark decoder.
Still another aspect of the technology concerns a method for producing an obfuscated code for message signaling through an image. This method includes: receiving a plural symbol payload; applying an error correction coding algorithm to the plural symbol payload to generate an enlarged bit sequence; and processing the enlarged bit sequence with pseudo-random data to yield a pseudo-random bit sequence. This bit sequence is mapped to locations in an image block. A counterpart image block depicts a spatial domain counterpart to plural signal peaks in a spatial frequency domain, and the two image blocks are combined to yield a code pattern from which the plural symbol payload can be recovered by a decoder. This code is applied to a multi-layer convolutional neural network. Filter responses for one or more layers in the network are stored as first reference data. A pattern (e.g., a bitonal geometric pattern) is then applied to the convolutional neural network. Data indicating correlations between filter responses between two or more of the layers, are stored as second reference data. A test image is then modified based on the first and second reference data, to yield an obfuscated code pattern, different from the code pattern and different from said geometrical pattern, from which the plural symbols can be recovered by the decoder.
As noted, one use of these technologies is in producing artwork for use in packaging retail items, such as grocery items. For example, a part of the artwork can be based on the stylized output image. This enables a camera-equipped point of sale apparatus to identify the package, by decoding the plural symbol payment (which may comprise a GTIN).
Another aspect of the technology is a packaged food product having label artwork that is derived from a pattern substantially similar (in a copyright sense) to one of the patterns illustrated in Figs. 1, 8-11, 13, 14A, 15A-15ZZ, 19A, 19B, 21D, 21E, 29A-29C, 30A, 30B, 31A - 41, and 44. The pattern may be monochrome or colored (included false-colored).
Review of the Johnson Method
The earlier-discussed Gatys approach has three inputs: a style image, a content image, and a test image (which may be a noise frame). A network iteratively modifies the test image until it reaches a suitable compromise between the style image and the content image - by optimizing a loss function based
on differences from those first two inputs. The Johnson approach, in contrast, uses a single-pass feed forward network, trained to establish parameters configuring it to apply a single style image. After training it has just one input - the content image.
Johnson’s feed-forward image transformation network is a convolutional neural network configured by parameter weights W. It transforms input images x into output images y by the mapping:
y = ί )
The weights W are established using information from a second, VGG-16 network, termed a loss network. This network is one that has been pretrained for image classification, e.g., on the ImageNet dataset. Such training configures it to produce features that represent semantic and perceptual information about applied imagery. These features are used to define a feature reconstruction loss and a style reconstruction loss that measure differences in content and style between images.
For each input image x there is a content target yc and a style target ys. For style transfer, the content target yc is actually the input image x, and the output image y should combine the content of x = \v with the style of ys. Two perceptual scalar loss functions are used in this process, to measure high-level semantic and perceptual differences between images. Instead of encouraging the pixels of the output image y (i.e.,/ (x)) to exactly match the pixels of the target image y, the Johnson network encourages them to have similar feature representations as computed by the loss network.
The first loss function indicates similarity to the originally-input image. This is termed the feature reconstruction loss. Consider f](c) as the activation of the /th layer of the loss network f when processing an image x. If j is a convolution layer having C filters, then f](c) will be a feature map of shape Q x Hj x Wj. The feature reconstruction loss is the (squared, normalized) Euclidean distance between feature representations:

An image y that minimizes this feature reconstruction loss for early layers in the VGG-16 image recognition network, tends to produce images that are visually indistinguishable from y. That’s not desired. Instead minimization of this feature reconstruction loss for one or more later layers in the network is employed. This produces images that preserve general shape and spatial structure, but permits variation in color, texture, and shape details. Thus, applying this feature reconstruction loss in training the image transformation network encourages the output image y to be perceptually similar (semantically similar) to the target image y, but does not drive the images to correspond exactly.
The second loss function indicates style similarity to the style image. This is termed the style reconstruction loss. As in Gatys, a Gram matrix is used.
Again, let <j>j(x) be the activations at the /th layer of the loss network f for the input x, which is a feature map of shape C, x //, x Wj. The Gram matrix Gf(x) is the Cj x Cj matrix whose elements are given by:

The style reconstruction loss is the squared Frobenius norm of the difference between the Gram matrices of the output and target images:

Minimizing this style reconstruction loss minimizes stylistic differences between the output and target images, but may mess with the spatial structure. Johnson found that generating the style reconstruction loss using information from later layers in the VGG-16 network helps preserve large-scale structure from the target image. Desirably, information from a set of layers /, rather than a single layer j is used. In such case the style reconstruction loss is the sum of losses for all such layers.
In a particular embodiment, Johnson computes the feature reconstruction loss using feature data output by layer relu2_2 of the VGG-16 loss network., and computes the style reconstruction loss from feature data output by layers relul_2, relu2_2, relu3_3 and relu4_3.
To train weights W of the image transformation network, Johnson applies the 80,000 images of the Microsoft COCO dataset to the network. The images output by the image transformation network are examined by the loss network to compute feature reconstruction loss and style reconstruction loss data. The weights W of the image transformation network are adjusted, in a stochastic gradient descent method, to iteratively reduce a weighted combination of the two loss function fj and £2, using corresponding regularization parameters l;:

(Johnson applied normalization - updating weights W of his image transformation network - in batch fashion. Ulyanov later demonstrated that superior results may be achieved by applying
normalization with a batch size of 1, i.e., with every training image. (See“Improved Texture Networks: Maximizing Quality and Diversity in Feed-Forward Stylization and Texture Synthesis,” Proc. of IEEE
Conf. on Computer Vision and Pattern Recognition, 2017, pp. 6924- 6932). For present purposes, the Ulyanov improvement is regarded as falling within the Johnson method.)
In the above -detailed manner, the image transformation network is trained to cause the output images to adopt the style of the style image, while still maintaining the general image content and overall spatial structure of the input images.
(Naturally, this is an abbreviated summary of the Johnson method. The reader is directed to the Johnson paper, and the many public implementations of his method on Github, for additional
information.)
Further Arrangements
Applicant has extended the above-detailed methods to combine elements from three images. This is illustrated by Figs. 17A-E.
Fig. 17A is first host artwork, in a vector format. Fig. 17B is a watermark pattern that encodes a particular payload. These two images are combined (e.g., by weighted summing, multiplication, or otherwise) to yield the watermarked artwork of Fig. 17C. Fig. 17D shows a style image with which a network has been trained by the Johnson method. Fig. 17E shows the composite artwork of Fig. 17C, after stylization by the trained Johnson network. (As just-discussed in connection with Figs. 16A - 16C, the stylized elements (droplets) in Fig. 17E are adapted in size, position, and contours, to conform to features within the Fig. 17B watermark pattern.)
One application of the just-described process is to generate logos of consumer brands, which are both watermarked (e.g., to convey a URL to a corporate web page) and stylized. Such stylized logos can be printed, e.g., on packaging artwork.
The host artwork needn’t be bitonal (e.g., black and white), and it needn’t be in vector format. Instead, it can be continuously-toned, such as a greyscale or RGB image. For example, Fig. 18 A shows a watermarked version of the Lenna image, after stylization using the network that produced Fig. 15PP (i.e., applying a candy ball style). Fig. 18B shows a watermarked version of Lenna stylized with the same network that produced Fig. 15VV (i.e., applying a denim fabric style). Fig. 18C shows a watermarked version of Lenna stylized with the same network that produced Fig. 15F (applying a grass style).
Since stylization typically imparts a dominating texture on the artwork, the watermark signal can be embedded at an amplitude far greater than usual. As noted, continuous tone watermark signals are usually applied at amplitudes small enough to prevent the watermark patterning from being perceptible to casual viewers. But since the image texture is so-altered by stylization, patterning due to the watermark signal is masked - even if grossly visible prior to stylization (as in Fig. 17C).
As noted, the detailed methods can be applied to any watermark pattern or watermarked imagery. Fig. 19A shows a sparse watermark rendered as a Delaunay triangle pattern. Fig. 19B shows this same watermark after stylization with a leaf pattern. Again, each of the leaf elements in Fig. 19B has been scaled, rotated, and positioned to correspond to one of the component triangles within the Delaunay pattern. Fig. 19C shows enlargements of the lower right corners of the two images (indicated by the dashed squares in Figs. 19A and 19B) overlaid together, by which the correspondence can be examined.
A single pattern can be parlayed into a dozen or more different patterns using invertible transforms. Invertible transforms are those that can be reversed - enabling a transformed set of information to be restored back to its original state.
In geometry, invertible transforms include affine transforms such as rotation, scaling (both scaling uniformly in x- and y-, and non-uniformly), translation, reflection, and shearing. Invertible geometrical transforms also include non-affine transforms, such as perspective, cylindrical, spherical, hyperbolic and conformal distortion. There are other invertible transforms as well, such as color transforms, color inversion, etc.
A general process employing this aspect of the technology is depicted by Fig. 20. A watermark pattern is generated, transformed, stylized, and inverse-transformed.
In a particular embodiment of the Fig. 20 process, a continuous tone watermark pattern is generated (Fig. 21 A), containing a desired payload. A sparse mark (Fig. 21B) is derived from the Fig. 21A pattern, e.g., by thresholding, or by one of the techniques detailed in the cited patent documents.
(The dots are enlarged in size for sake of visibility.) The Fig. 21B pattern is then asymmetrically (differentially) scaled - expanding the horizontal expanse by a factor of two - producing the Fig. 21C pattern. That pattern is then converted into a corresponding Voronoi pattern, shown in Fig. 21D. That pattern is then inverse-transformed - compressing the horizontal expanse by a factor of two - producing the Fig. 21E pattern.
The original watermark pattern is thus differentially-scaled, and then inverse-differentially- scaled. This restores the watermark pattern to its original state. But the Voronoi cells are added in the middle of the process. They do not undergo two complementary operations. Rather, that Voronoi pattern is just horizontally compressed by a factor of two (i.e., scaled by a horizontal factor of 0.5). Its appearance thus changes.
Fig. 23 A shows the Voronoi pattern corresponding to the original dot pattern of Fig. 22B. Fig. 23B is the Voronoi pattern produced by the just-detailed transform/inverted-transform method (i.e., it is an enlargement of Fig. 22E). Each is shown overlaid with the original patterns of dots. As can be seen, each dot is still surrounded by a polygon. But the shapes of the polygons are different, as is particularly
evident from the enlarged excerpts of Figs. 24A and 24B (corresponding to the lower right hand corners of Figs. 23A and 23B, respectively).
Figs. 25A and 25B show that visible patterning encoded with machine readable data, produced according to the methods herein, can be used as a background pattern, or texture, on a food container - such as a cereal or cake mix box. Such patterning can appear at any location on the container, and on any face(s) (not just the illustrated front face). Fig. 26 shows such a pattern on a can, such as a drink can, a soup can, or a can of vegetables. Fig. 27 shows such a pattern on a plastic tub, such as a yogurt or sour cream tub. While a Voronoi pattern is illustrated, it should be understood that patterns produced by any of the processes referenced herein, including all of the patterns illustrated herein, can be so-utilized, including in color, in false-color, in grey-scale, and in line art counterparts.
Figs. 28A and 28B are enlarged excerpts from a yogurt container, depicting signal-conveying artwork produced by the above-detailed process (employing a trained network according to the Johnson method) employed as background patterns. The pattern of Fig, 28A was produced using a Johnson network to apply a bubble gum balls pattern to a watermark signal block, e.g., as shown in Fig. 15PP.
The pattern of Fig. 28B was produced by the method of Johnson to apply a fanciful pattern to a watermark signal block, e.g., as shown in Fig. 15D. Both patterns have been altered in coloration - an additional processing step that does not impair decodability of the luminance -based watermark signal blocks on which both are based.
The artwork on the yogurt containers depicted in Figs. 28A/28B also includes a depiction of a vanilla tree flower, branch and leaf. This artwork is defined by layers of patterned spot color inks (e.g., Pantone 121, 356, 476) and black. For example, the flower petals are predominantly screened Pantone 121. That layer is watermarked with a luminance watermark. The payload conveyed by the watermark in the flower petals (i.e., the GTIN for the yogurt product) is the same payload as is conveyed by the watermark in the violet background patterning (which is rendered with screened Pantone 2071).
Moreover, although printed in different ink layers, the watermark signal block portions encoded within the flower petals are geometrically registered with the watermark signal block portions encoded within the background patterning. (A few such blocks are shown by dashed lines in Fig. 28B ; many span both the background pattern and the foreground vanilla art.) Both the foreground pattern and background pattern watermarks contribute signal by which a detector extracts the watermark payload; the detector doesn’t distinguish between the signals contributed by the different layers since they seamlessly represent common watermark signal blocks.
When processing a watermark or watermarked image with a style transfer networks, edge artifacts can be a problem. Watermark patterns, themselves, are continuous at their edges. If tiled, watermark patterns continue seamlessly across the edges. Style patterns, in contrast, are typically not
continuous at their edges. Further, the convolution operations performed by style transfer networks can “run out of pixels” when convolving at image edges. This can lead to disruptions in the edge-continuity of the watermark.
To address this problem, applicant pads the input watermark with rows and columns of additional watermark signal, as if from adjoining tiles, before applying to the style transfer network. A 128 x 128 element watermark signal block may be padded, for example, to 150 x 150 elements. This enlarged image is processed by the style transfer network. The network outputs a processed 150 x 150 image. The center 128 x 128 elements are then excerpted. No edge artifacts then appear.
In some instances, applicant generates a 256 x 256 element input image by tiling four watermark signal blocks. The network outputs a 256 x 256 style -processed image. Again, an interior (e.g., central) 128 x 128 block is excerpted from this result. (All of the signal blocks shown in Figs. 15A - 15ZZ are seamlessly tileable.)
Aspects of such method are illustrated in the flow charts of Fig. 14B and 14C. (The dashed rectangles show acts that are usually performed later - not necessarily by the software whose user interface is depicted in Fig. 14A.)
Fig. 29A is an excerpt of product packaging showing a sparse dot pattern (a stipple pattern) as a graphical background (enlarged about 3X). Fig. 29B shows a Voronoi counterpart to the Fig. 29A pattern, again used as a graphical background. Fig. 29C shows a Delaunay counterpart to the Fig. 29A pattern.
Comparing the right sides of Figs. 29 A - 29C, it will be seen that the introduction of more white features within the dark blue background serves to effectively lighten the blue background - at least as seen from a distance. In accordance with a further aspect of the present technology, a background spot or process color may be rendered darker than normal, so that the addition of a light-colored pattern of dots or lines serves to lighten the area to achieve a desired appearance. For example, an ink can be applied at a higher screen setting, or with a smaller proportion of a thinner, to yield a darker tone. Or a darker ink color can be selected.
Inversely on the left side. The addition of dark features darkens the light background color. This can be mitigated by starting with a lighter background color, so the addition of the darker features yields a composite appearance of a desired tone. The background ink layer may be screened-back, or the ink may be diluted. Or a lighter ink may be chosen. (Of course, if white is the background, as in Figs. 29A - 29C, then options to further lighten the background are limited.)
Triangulation patterns, based on sparse dot patterns, can be used as the bases for many aesthetically pleasing patterns suitable for product packaging, etc. One class of such patterns is to take a Delaunay pattern, and fill the triangles with different greyscale values, or with differently-screened tones
of a particular color. As long as the lines bounding the triangles are lighter, or darker, than most of the triangle interiors, the pattern will decode fine. (The convergences of lighter or darker boundary lines at the triangle vertices define points of localized luminance extrema by which the encoded signals are represented.)
Another pleasing triangle-based arrangement is shown in Fig. 30A. This pattern is two patterns overlaid, each conveying a payload signal, but at different spatial resolutions - permitting decoding from two different (overlapping) reading distance zones.
In the Fig. 30A arrangement, the triangles are not bordered by lighter or darker lines. The vertices thus don’t serve as luminance extrema that represent the encoded signals. Instead of carrying signal, the vertices and edges correspond to a sparse mark obtained from local extrema in the gradients within the watermark signal block. The motive is that each triangle encircles local minima or maxima in the signal tile. The lightness or darkness within each triangle corresponds to the lightness or darkness of a corresponding area in the watermark signal block. So the greyscale values of the triangles actually carry the signal. (In another arrangement, the triangles needn’t be defined by gradients in the watermark signal. A random scattering of points can serve as vertices for a field of triangles and will work just as well, defining triangles whose interiors are made darker or lighter in correspondence with localized luminance within the desired watermark signal block.)
Due to the typically-small physical size of the component watermark elements (waxels), the triangles must be commensurately small to effective carry the signal - on the order of eight square waxels, or about 2000 triangles per 128 x 128 waxel block (the more the better). But such triangles are often smaller than desired for aesthetic purposes, e.g., when rendered by printing at 75 waxels per inch.
So the same signal is added, with transparency, at a larger scale (e.g., 6x, or 12.5 waxels per inch). These larger triangles are more readily visible, but do not hinder the decoding of signal from the smaller triangles, because the larger triangles are effectively filtered-out by down-sampling and/or oct-axis filtering in the decoder.
In many embodiments, both the large and small triangles encode the same payload, although this needn’t be in the case. In other arrangements, the larger scale overlay needn't be signal-bearing. It can be a strictly ornamental pattern, within which the smaller scale triangles serve as an intriguing, and signal- conveying, texture detail. In still other arrangements, polygons other than triangles can be employed. In some arrangements, the smaller triangles would be sub-triangulations of the larger triangles, to further enhance aesthetics. More simply, the vertices of each larger triangles may be snapped to the nearest vertices of the small triangles.
Fig. 30B shows a watermark signal block quantized into triangular areas, with the luminance of each area corresponding to the a luminance within the watermark.
To review, in accordance with the just-noted aspect of the technology, an item may be packaged for retail sale in packaging that includes an array of adjoining polygons of different areas, where the arrangement, shading, or coloring of the polygons encodes a plural-bit payload for reading by a point-of- sale scanner or by a consumer’s camera-equipped mobile device. The polygons may be triangles, but need not be. The polygons may be bordered by lines that join at vertices, where the vertices define luminance variations that encode the payload. Alternatively, the polygons may be filled with shadings of different chrominances or luminances, where the differently-shaded interiors define chrominance or luminance variations that encode the payload.
Other patterns can be derived using image editing tools available in software packages such as Photoshop.
Fig. 31 A shows a pattern derived using Photoshop software to manipulate a sparse watermark (generated using any of the methods taught in the earlier-cited patent documents), and Fig. 31B shows an enlarged excerpt. The sparse, dark dots are here all smeared in straight parallel lines. The dots thus have corresponding tails which diminish in darkness with distance from the original location. The dots themselves appear inverted, as white regions.
This effect is generated by the following acts:
A sparse dot watermark (black dots on white background) is created, with a desired payload, using the Digimarc Barcode plug-in software for Photoshop. Dot density is set to 20, and dot size is set to 4. The Photoshop Wind filter is applied, with the option From the Left selected. This Wind filter is applied three successive times. The resulting image is then inverted (Image/ Adjustments/Invert), and the mode is changed to Lighten. A new layer is then created and the above acts are repeated, but this time with the Wind option set to From the Right.
As is familiar to artisans, a wind filter detects edges in an image, and extends new features from the detected edges. The features are commonly tails that diminish in width and intensity with distance from the edges.
(The noted plug-in practices watermarking techniques detailed in the cited prior art references, such as US patent 6,590,996. Other tools, such as the freeware Gimp, can be used instead of Photoshop.)
The pattern of Figs. 32A and 32B is generated in Photoshop software by creating a sparse dot watermark as before, with a dot density of 20 and a dot size of 4. The Motion Blur filter is then applied using settings of 0 Degrees and Distance = 32 pixels.
The pattern of Figs. 33A and 33B is generated by starting with a negative sparse dot watermark (i.e., white dots on a black background). Again, dot density is set to 20 and dot size is set to 4. A Motion Blur filter is applied with settings of 90 Degrees and Distance = 15 pixels. A new layer is then created
with the same dot pattern, and a Motion Blur filter is applied with settings of 0 degrees and Distance = 15 pixels. The mode of the top layer is then changed to Lighten.
Figs. 34A and 34B show a pattern produced from a sparse field of white dots on a black background, which are then smeared in straight parallel lines. Here the dots have corresponding tails which diminish in brightness with distance from the original location.
This pattern can be produced by generating a negative sparse dot watermark as just-detailed, with dot density of 20 and dot size of 4. A Motion Blur filter is applied, set to 0 Degrees, and Distance = 15 pixels. A new layer is created with the same dot pattern. A Wind filter is then applied, with Direction set to From the Left. This filter is applied a second time on this layer. The mode of the top layer is then changed to Lighten.
The pattern of Figs. 35A and 35B is produced by generating a negative sparse dot watermark as just-detailed, and applying a Motion Blur filter with settings of 90 degrees and Distance = 15 pixels.
The pattern of Figs. 36A and 36B is produced by from a field of black dots on a white, with dot density of 20 and dot size of 4. A Motion Blur filter is applied with settings of 90 Degrees and Distance = 15 pixels. A new layer is created with the same dot pattern, and the Motion Blur filter is applied to this new layer with settings of 0 Degrees and Distance = 15 pixels. The Mode of the top layer is then changed to Multiply.
The pattern of Figs. 37A and 37B starts with a pattern of white dots on black, as before. The Wind filter is applied, set to From the Right. This filter is re-applied two more times. A new layer is then created with the same dot pattern, and the Wind filter is similarly applied three times, but this time set to From the Left. The mode of the top layer is then changed to Lighten.
Figs. 38A and 38B look similar to Figs. 39A and 39B, except each clump of dots numbers between 0 and 9 dots, depending on the local amplitude of the watermark. This pattern is generated by generating a sparse mark of black dots on a white background, as described earlier. A Motion Blur filter is applied with settings of 90 Degrees, and Distance = 15 pixels. The mode is then changed to Bitmap, at 300 Pixels/Inch, and with a Halftone Screen. The halftone screen parameters are set to a Frequency of 50 Lines/Inch, an Angle of 90 Degrees, and a Shape of Line.
Figs. 39A and 39B appear to show a continuous tone luminance watermark that is sampled at points along spaced-apart parallel lines. Around each sample point a clump of black dots (numbering from 0 to 4 dots) is formed, in accordance with the amplitude of the watermark at that point. A pattern of intermittent line-like structures, of varying thickness, is thereby formed.
Such pattern is produced by starting with a greyscale document set to 4% black. The Digimarc plug-in software is then used to enhance this document with a continuous tone luminance mark at Strength = 10. The Photoshop software is then used to change the mode to Bitmap, with settings of 300
Pixels/Inch, Halftone Screen, a Frequency of 50 Lines/Inch, an Angle of 90 degrees, and Shape set to Line.
Figs. 40A and 40B have the appearance of a continuous tone luminance watermark that is sampled at points in an orthogonal two-dimensional grid. A clump of black dots (e.g., numbering from 0 to 7 dots) is then formed around each sample point, in accordance with the amplitude of the watermark at that point.
Such pattern is produced by starting with a greyscale document set to 4% black. The Digimarc plug-in software is then used to enhance this document with a continuous tone watermark at Strength = 10. The Photoshop software is then used to change the mode to Bitmap, with settings of 300 Pixels/Inch, Halftone Screen, a Frequency of 50 Lines/Inch, and an Angle of 45 degrees. The Shape is set to Line.
Of course the parameters given above can be modified more or less to yield results that are more or less different, as best suits a particular application. Similarly, the order of the detailed steps can be changed, and steps can be added or omitted. And naturally, the patterns can be colored, e.g., as shown in Fig. 41 in the corresponding US application, 16/212,125.
It will be recognized that a pattern like that shown in Fig. 41 has a visual appeal that a spattering of black dots, as in a plain sparse mark, does not. Such pattern, and others generated by the detailed techniques, thus give graphic designers greater options for encoding product identifiers on all surfaces of product packaging. And this new-found flexibility comes without the worry about press tolerances that was formerly a concern, since signal-carrying structures no longer need to be precisely rendered just below the threshold of human visibility.
Line Continuity Modulation
It should be recognized that there are other watermarking techniques besides the continuous tone and sparse arrangements detailed herein, and the detailed methods can be applied to artwork based on such other watermarking techniques. One example is line continuity modulation.
Fig. 42A shows an excerpt from artwork for a conference poster. Fig. 42B is an enlargement from the lower right corner of Fig. 42A. As can be seen, the shadows of the letters include diagonal dark blue lines that are broken into segments. These segments, and their breaks, serve to modulate the local luminance and chrominance of the artwork - modulations that are used to encode the watermark payload. (It will also be seen that the fills of the letters are Voronoi patterns based on a sparse watermark.)
The modulation of lines is implemented as follows: two images are created with slanted lines. All the lines are dashed, but lines in the first image have longer dashes than lines in the second image, so the average greyscale value of lines in the second image is lighter. A watermark signal block is thresholded to create a binary mask, so that watermark block signal values between 128 and 255 (in an 8-
bit image representation) are white, while watermark signal values of 0 - 127 are black. Then we choose complete line segments from the second image within the white masked area, and we apply the black mask similarly to choose the segments from the first image. The lighter greyscale dashed lines are thus picked in regions where the watermark signal block is lighter, and the darker greyscale dashed lines are thus picked in regions where the watermark signal block is darker. The combination of the dashed lines from the two masked layers produces the embedded image. A horizontal line density of at least 2/3 = 67% lines per waxel is found to be best to assure robust detection.
In a variant implementation, line continuity modulation can be effected by poking holes in an array of continuous lines at positions defined by dots in a negative sparse mark.
Styluses, Etc.
Another aspect of the present technology concerns code signaling via manually-created art and other content.
Styluses are in widespread use for manually-creating content, both by graphics professionals (e.g., producing art) and by office workers (e.g., taking handwritten notes). Styluses are commonly used with tablets. Tablets may be categorized in two varieties. One variety is tablets in which a stylus is applied to a touch-sensitive display screen of a computer (e.g., the Apple iPad device). The other variety is tablets in which a stylus is applied on a touch-sensitive pad that serves as a peripheral to a separate computer (e.g., the Wacom Intuos device). The latter device is sometimes termed a graphics tablet.
As is familiar to artisans, tablets repeatedly sense the X- and Y- locations of the tip of the stylus, allowing the path of the stylus to be tracked. A marking - such as a pen or pencil stroke - can thereby be formed on a display screen, and corresponding artwork data can be stored in a memory.
Various location-sensing technologies are used. So-called“passive” systems (as typified by many Wacom devices) employ electromagnetic induction technology, where horizontal and vertical wires in the tablet operate as both transmitting and receiving coils. The tablet generates an
electromagnetic signal, which is received by an inductor-capacitor (LC) circuit in the stylus. The wires in the tablet then change to a receiving mode and read the signal generated by the stylus. Modern arrangements also provide pressure sensitivity and one or more buttons, with the electronics for this information present in the stylus. On older tablets, changing the pressure on the stylus nib or pressing a button changed the properties of the LC circuit, affecting the signal generated by the stylus, while modern ones often encode into the signal as a digital data stream. By using electromagnetic signals, the tablet is able to sense the stylus position without the stylus having to even touch the surface, and powering the stylus with this signal means that devices used with the tablet never need batteries.
Active tablets differ in that the stylus contains self-powered electronics that generate and transmit a signal to the tablet. These styluses rely on an internal battery rather than the tablet for their power, resulting in a more complex stylus. However, eliminating the need to power the stylus from the tablet means that the tablet can listen for stylus signals constantly, as it does not have to alternate between transmit and receive modes. This can result in less jitter.
Many tablets now employ capacitive sensing, in which electric coupling between electrodes within the tablet varies in accordance with the presence of an object - other than air - adjacent the electrodes. There are two types of capacitive sensing system: mutual capacitance, where an object (finger, stylus) alters the mutual coupling between row and column electrodes (which are scanned sequentially); and self- or absolute capacitance, where the object (such as a finger) loads the sensor or increases the parasitic capacitance to ground. Most smartphone touch screens are based on capacitive sensing.
Then there are some styluses that don’t require a tablet - those that rely on optical sensing. These devices are equipped with small cameras that image features on a substrate, by which movement of the stylus can be tracked. Motion deduced from the camera data is sent to an associated computer device.
The Anoto pen is an example of such a stylus.
The pressure with which the stylus is urged against the virtual writing surface can be sensed by various means, including sensors in the stylus itself (e.g., a piezo-electric strain gauge), and sensors in the tablet surface (e.g., sensing deflection by a change in capacitance). Examples are taught in U.S. patent documents 20090256817, 20120306766, 20130229350, 20140253522, and references cited therein.
A variety of other stylus/tablet arrangements are known but are not belabored here; all can be used with the technology detailed herein.
In use, a computer device monitors movements of the stylus, and writes corresponding information to a memory. This information details the locations traversed by the status, and may also include information about the pressure applied by the stylus. The location information may be a listing of every {X,Y} point traversed by the stylus, or only certain points may be stored - with the computer filling-in the intervening locations by known vector graphics techniques. Each stroke may be stored as a distinct data object, permitting the creator to“un-do” different strokes, or to format different strokes differently.
Each stroke is commonly associated with a tool, such as a virtual pen, pencil or brush. (The term “brush” is used in this description to refer to all such tools.) The tool defines characteristics by which the stroke is rendered for display, e.g., whether as a shape that is filled with a fully saturated color (e.g., as is commonly done with pen tools), or as a shape that is filled with a pattern that varies in luminance, and sometimes chrominance, across its extent (e.g., as is commonly done with pencil tools). When pressure is
sensed, the pressure data may be used to vary the width of the stroke, or to increase the darkness or saturation or opacity of the pattern laid down by the stroke.
Users commonly think of their stylus strokes as applying digital“ink” to a virtual“canvas.” Different“layers” may be formed - one on top of the other - by instructions that the user issues through a graphical user interface. Alternatively, different layers may be formed automatically - each time the user begins a new stroke. The ink patterns in the different layers may be rendered in an opaque fashion - occluding patterns in any lower layer, or may be only partially opaque (transparent) - allowing a lower layer to partially show-through. (As noted, opacity may be varied based on stylus pressure. Additionally, going over a stroke a second time with the same tool may serve to increase its opacity.)
In practical implementation, all of the input information is written to a common memory, with different elements tagged with different attributes. The present description usually adopts the user’s view - speaking of canvas and layers, rather than the well-known memory constructs by which computer graphic data are stored. The mapping from“canvas” to“memory” is straightforward to the artisan.
Transparency is commonly implemented by a dedicated“alpha” channel in the image representation.
(For example, the image representation may comprise red, green, blue and alpha channels.)
Figs. 43 and 44 are tiles of illustrative signal-bearing patterns. These are greatly magnified for purposes of reproduction; the actual patterns have a much finer scale. Also, the actual patterns are continuous - the right edge seamlessly continues the pattern on the left edge, and similarly with the top and bottom edges. As described earlier, Fig. 43 may be regarded as a continuous pattern - comprised of element values (e.g., pixels) that vary through a range of values. Fig. 44 may be regarded as a sparse pattern
Fig. 43 also greatly exaggerates the contrast of the pattern for purposes of illustration. The depicted tile has a mean value (amplitude) of 128, on a 0-255 scale, and some pixels have values of near 0 and others have values near 255. More typically the variance, or standard deviation, from the mean is much smaller, such as 5 or 15 digital numbers. Such patterns commonly have an apparently uniform tonal value, with a mottling, or salt-and-pepper noise, effect that may be discerned only on close human inspection.
A first method for human-authoring of signal-bearing content is to tile blocks of a desired signal carrying pattern, edge-to-edge, in a layer, to create a pattern coextensive with the size of the user’s canvas. A second layer, e.g., of solid, opaque, white, is then applied on top of the first. This second layer is all that is visible to the user, and serves as the canvas layer on which the user works. The tool employed by the user to author signal-bearing content does not apply pattern (e.g., virtual ink, or pixels) to this second layer, but rather erases from it - revealing portions of the patterned first layer below.
Technically, the erasing in this arrangement is implemented as changing the transparency of the second layer - allowing excerpts of the underlying first layer to become visible. The tool used can be a pen, pencil, brush, or the like. The tool may change the transparency of every pixel within its stroke boundary to 100% (or, put another way, may change the opacity of every pixel to 0%). Alternatively, the brush may change the transparency differently at different places within the area of the stroke, e.g., across the profile of the brush.
Fig. 45 shows the former case - the brush changes the transparency of every pixel in its path from 0% to 100%, resulting in a pattern with sharp edges. Fig. 46 shows the latter case - different regions in the brush change the transparency differently - a little in some places, a lot in others. (In so-doing, the brush changes the mean value, and the variance, of the underlying pattern as rendered on the canvas.) Such a brush adds texture.
The texture added by a brush commonly has an orientation that is dependent on the direction the brush is used - just as filaments of a physical brush leave fine lines of texture in their wake. The signal carrying pattern revealed by the brush has a texture, too. But the signal-carrying pattern texture always has a fixed orientation - both in rotation, scale and position. It does not matter in which direction the brush is applied; the spatial pose of the revealed pattern is constant.
In some embodiments, repeated brush strokes across a region successively increase the transparency of the top layer, revealing the underlying signal-carrying pattern to successively darker degrees. A first brush stroke may reveal the pattern by applying a 20% transparency to the covering second layer. Such a pattern has a light tone; a high mean value (and a small variance). A second brush over the same area stroke may increase the transparency to 40%, darkening the tone a bit, and increasing the variance. And then 60%, and 80%, until finally the covering layer is 100% transparent, revealing the underlying pattern with its original mean and variance. With each increase in transparency, the contrast of the rendered, revealed signal pattern is increased.
This is schematically illustrated by Figs. 47 and 48. Fig. 47 conceptually illustrates how a prior art brush applies marks to a canvas - with a texture whose orientation is dependent on the directions of the strokes (shown by arrows). Where strokes overlap, a darker marking is rendered - since more virtual ink is applied in the region of overlap. Fig. 48 is a counterpart illustration for this aspect embodiment of the present technology. The orientation of the pattern does not depend on the direction of the brush stroke. Where strokes cross, the underlying pattern is rendered more darkly, with greater contrast.
The degree of transparency of a stroke can also be varied by changing the pressure applied to the stylus. At one pressure, a stroke may increase the transparency of the covering layer by 70% (e.g., from 0% to 70%). At a second, higher, pressure, a stroke may change the transparency of the covering layer by 100% (from 0% to 100%). Many intermediate values are also possible.
Such arrangement is shown in Fig. 49A. The digit‘5’ is written at one pressure, and the digit‘7’ is written with a lighter pressure. The latter stroke is rendered with less transparency (pixels within the boundaries of the‘5’ stroke are rendered at 100% transparency, whereas the pixels within the‘7’ are rendered at a lesser transparency). The mean value of the pixels within the boundary of the‘5’ in Fig. 47 matches the mean value of the corresponding pixels in the underlying signal-carrying pattern. In contrast, the mean value of the pixels within the boundary of the‘7’ have a mean value higher than that of the corresponding pixels in the underlying pattern.
(As noted, the contrast is greatly exaggerated in most of the images; Fig. 49B shows handwritten digits with contrast of a more typical value. Fig. 49C shows the handwritten digits with a more typical contrast and size.)
While the just-described arrangement employs an underlying, signal-conveying layer that is coextensive in size with the top layer, this is not necessary. Since the pattern is repeated in a tiled arrangement, the system memory may store just a single tile’s worth of pattern data. Such a tile may have dimensions of 128 x 128 (e.g., pixels), while the canvas may have dimensions of 1280 x 1024. If the user picks a signaling brush (i.e., one that reveals the signal-carrying pattern), and draws a brush stroke starting from canvas X-, Y- coordinates { 10,100}, and continuing to coordinates { 10,200} (and encompassing a surrounding region dependent on a profile of the brush), the system effects a modulo operation to provide pattern when the original tile“runs-out” of data (i.e., after coordinate { 10,128}. That is, for the start of the stroke, the erasing operation reveals the signal pattern between coordinates { 10,100} and { 10,128}. Once it reaches value 128 (in either dimension), it performs a mod- 128 operation and continues. Thus, the pattern that is revealed at coordinates { 10,130} is read from tile coordinates { 10,2}, and so forth.
While the foregoing description was based on erasing a blank layer to reveal a signal-carrying layer beneath, more typically a different approach is used. That is, a brush applies digital ink to an artwork layer in a pattern conveying the plural-bit payload. The pattern is two-dimensional and stationary, with an anchor point (e.g., at the upper left corner of the canvas) to which the pattern is spatially related (i.e., establishing what part of the pattern is to be laid-down at what part of the canvas).
A simple implementation can be achieved by using the capability to pattern-draw that is built into certain graphics tools, like Photoshop. In that software, a tile of signal-conveying pattern can be imported as an image, selected, and then defined as a Photoshop pattern (by Edit/Define Pattern). The user then paints with this pattern by selecting the Pattern Stamp tool, selecting the just-defined pattern from the pattern menu, and choosing a brush from the Brush Presets panel. By selecting the“Aligned” option, the pattern is aligned from one paint stroke to the next. (If Aligned is deselected, the pattern is centered on the stylus location each time a new stroke is begun.)
Instead of modulating transparency, software may be written so that stylus pressure (or stroke over-writing) modulates the mean value of the payload-carrying pattern: darker pattern (i.e., lower mean values) is deposited with more pressure; lighter pattern (higher mean values) is deposited with less pressure. The signal-carrying strength of the pattern (i.e., its variance) can be set as a menu parameter of the brush with which the pattern is applied.
The signal-carrying pattern typically includes both plural-bit payload information, and also a synchronization signal. The payload information may include data identifying the user, the date, the GPS-indicated time, a product GTIN, or other metadata specified by the user. This information may literally be encoded in the payload, or the payload may be a generally-unique ID that serves as a pointer into a local or remote database where corresponding metadata is stored. As is familiar from the prior art (including US patent 6,590,996), the payload is error-correction encoded, randomized, and expressed as +/-“chips” that serve to increase or decrease parameters (e.g., luminance or chrominance) of respective pixels in a reference signal tile. The synchronization signal can comprise an ensemble of multiple spatial domain sinusoids of different frequencies (and, optionally, of different phases and amplitudes), which can be specified succinctly by parameters in a frequency domain representation. A Fourier transform can then be applied to produce a corresponding spatial domain representation of any dimension. The resulting sinusoids are coextensive with the reference signal tile, and are added to it, further adjusting pixel values.
In some embodiments, the software enables the brushes to be configured to apply signal-carrying patterns having different means and variances, as best suits the user’s requirements. To introduce highlights into an artwork, a pattern having a light tone, such as a mean digital value of 200, can be employed. To introduce shadows, a pattern having a dark tone, such as a mean value of 50, can be employed. The variance, too, may be user selectable - indicating the degree of visible mottling desired by the content creator. As is familiar from graphics programs such as Photoshop, the user may invoke software to present a user-interface by which such specific parameters of the brush can be specified. The software program responds by generating a reference signal tile (or a needed excerpt) having desired mean and variance values.
One particular approach to enabling such variation in mean amplitude and variance is to store reference data for the tile as an array of real-valued numbers, ranging from -1 to +1. (Such an array can be produced by summing a +/- chip, and a synchronization signal value, for each element in a tile, and then scaling the resultant array to yield the -1 to +1 data array.) This reference data can then be multiplied by a user-selected variance (e.g., 15, yielding values between -15 and +15), and then summed with a user-specified mean value (e.g., 200, yielding values between 185 and 215) to generate a reference tile with the desired variance and mean.
The variance or the mean, or both, may be modulated in accordance with the stylus pressure. If the pressure increases, the darkness can be increased by reducing the mean value. (E.g., a nominal pressure may correspond to a mean value of 128; greater pressures may cause this value to reduce - ultimately to 30; lesser pressures may cause this value to increase - ultimately to 220.)
The spatial scale of the signaling pattern can also be varied, e.g., by specifying a reference signal tile that conveys its information at a specific spatial scale. For example, a tile that is usually 128 x 128 pixels may instead be specified as 256 x 256 pixels, causing the spatial scale to double (which halves the spatial frequency of the signaling components). Again, the user can set such parameter to whatever value gives a desired visual effect. (The reference data can be generated accordingly, e.g., by spreading the payload chips over a 256 x 256 data array, and summing with a spatial synchronization signal that has been transformed from its frequency domain representation to a spatial signal having a 256 x 256 scale.) Typically, a smaller scale is used, so that the payload can be recovered from a smaller excerpt of pattern- based art.
Some drawing applications associate a (virtual) physical texture with the canvas. This causes certain tools to behave differently: the virtual ink deposited depends not just on the tool configuration, but also on the surface microtopology where the ink is applied. At points where the surface microtopology has a local maximum, more ink is deposited (being analogous to more pressure being applied - by the surface more firmly engaging the tool at such locations). At valleys between such maxima, less ink is deposited.
So, too, with embodiments of the present technology. A texture descriptor associated with the canvas serves to similarly modulate the contrast with which the signal-carrying pattern is rendered on the canvas. The pattern is rendered more darkly at locations where the texture has higher local peaks. As the user applies more pressure to the stylus, more of the valleys between the peaks are filled-in with pattern (or are filled-in with darker pattern).
Although the depicted examples use a continuous-tone monochrome pattern consisting of just signal (e.g., the tile of Fig. 43), in many applications other signal-carrying patterns are used. Exemplary are the signal-carrying patterns produced using the neural network techniques described above. Figs. 50A and 50B show stylus strokes with exemplary neural network-produced patterning. Patterns based on natural imagery (e.g., the rice grains and water droplets of Figs. 15A and 15B) and synthetic imagery (e.g., bitonal geometrical patterns of the sort used in Figs. 8-10) can both be used.
Fig. 51 shows a prior art user interface 510 of a tablet drawing app (Sketchbook by Autodesk, Inc.). In addition to a drawing area 512, the interface includes a tools menu 514, a properties panel 516, and a layers guide 518. The user can pick up a desired tool (e.g., brush, pencil, etc.) by tapping the stylus
on a corresponding icon in the tools menu 514. The properties panel 516 can be opened to customize the parameters of the tool. The layers guide 518 enables the user to select different layers for editing.
In some embodiments of the present technology, one or more tools are dedicated to the purpose of drawing with a signal-carrying pattern, as detailed above. These tools may be so denoted by including graphical indicia within the icon, such as the binary bits“101,” thereby clueing-in the user to their data encoding functionality. When a user selects such a tool from the tools menu 514, selections can be made from the properties panel 516 to define signal-customization parameters, such as the pattern to be used (e.g., the patterns of Figs. 1, 11, 15A, 44, etc.), color, mean value, variance, and scale - in addition to the parameters usually associated with prior art tools.
In other embodiments, no tools are dedicated to applying signal-carrying patterns. Instead, all tools have this capability. This capability can be invoked, for a particular tool, making a corresponding selection in that tool’s properties panel. Again, signal-customization options such as mean value, variance, and scale can be presented.
In still other embodiments, all tools apply signal-carrying patterns. The properties panel for each tool include options by which such signal can be customized.
To review, certain embodiments according to these aspects of the technology concern a method of generating user-authored graphical content. Such method makes use of a hardware system including a processor and a memory, and includes: receiving authoring instructions from a user, where the instructions taking the form of plural strokes applied to a virtual canvas by a virtual tool; and responsive to said instructions, rendering a first signal-carrying pattern on the canvas in a first area included within a first stroke. Such arrangement is characterized in that (1) the content conveys a plural-bit digital payload encoded by said signal-carrying pattern; and (2) the signal-carrying pattern was earlier derived, using a neural network, from an image depicting a natural or synthetic pattern.
Another method is similar, but is characterized in that (1) the graphical content conveys a plural- bit digital payload encoded by said signal-carrying pattern; (2) the first signal-carrying pattern is rendered with a first mean value or contrast, due a pressure with which the user applies the physical stylus to a substrate when making the first stroke; and (3) the second signal-carrying pattern is rendered with a second mean value or contrast due to a pressure with which the user applies the physical stylus to the substrate when making the second stroke, where the second value is different than the first.
Another method is also similar, but involves - responsive to input from the user’s virtual tool - rendering a first signal-carrying pattern on the canvas in a first area included within a first stroke, and rendering a second signal-carrying pattern on the canvas in a second area included within a second stroke, where the rendered first and second patterns both correspond to a common reference pattern stored in the memory. Such arrangement is characterized in that (1) the graphical content conveys a plural-bit digital
payload encoded by patterns defined by the plural strokes; and (2) elements of the first pattern, rendered within the first area, have a variance or mean amplitude that differs from a variance or mean amplitude, respectively, of spatially-corresponding elements of the reference pattern.
An example of this latter arrangement is illustrated by Fig. 52. Elements of the“7” on the right side of the figure (e.g., within the small box), have a mean amplitude that is different than that of spatially-corresponding elements of the reference pattern (e.g., within the corresponding small box in the center of the figure).
Graphical content produced by the described arrangements can be printed and scanned, or imaged by a camera-equipped device (like a smartphone) from on-screen or a print rendering, to produce an image from which the payload can be extracted, using techniques detailed in the cited art. (The image format is irrelevant - data can be extracted from TIF, JPG, PDF, etc., data.) This enables a great number of applications, including authoring artwork for product packaging that encodes a UPC code or that links to product information, communicating copyright, indicating irrefutable authorship, and authenticating content (e.g., by use of digital signature conveyed by the pattern). It also helps bridge the analog/digital divide, by enabling handwritten notes - on tablets and electronic whiteboards - to be electronically stored and searched, using metadata that is inseparably bound with the notes.
More on Line Patterns Derived from Sparse Dot Fields
As reviewed herein, plural-bit payloads can be encoded by sparse dot fields. Dot fields can be used in many artworks, but line -based patterns are often preferred.
A first line pattern based on a dot field is a traveling salesman path that simply connects the dots. Such a pattern is shown in Fig. 53. Each corner point in this artwork is the location of a dot in the original sparse field. Various traveling salesman algorithms are known. A suitable one is the Lin- Kernighan heuristic, described in Helsgaun, An Effective Implementation of the Lin-Kernighan Traveling Salesman Heuristic. DATALOGISKE SKRIFTER (Writings on Computer Science), No. 81, 1998, Roskilde University, which can be found at http://www.akira.ruc.dk/~keld/resettrcit/LKH/.
This traveling salesman approach is effective in retaining the signaling properties of the sparse code because it traverses points, namely minima, of high priority components of a corresponding continuous tone watermark signal (i.e., an optical code signal). Further, due to the fact that the path of line segments does not cross (other than at the“cities’), it does not create line crossings that would otherwise represent spurious minima.
A second line pattern based on a dot field is shown in Fig. 54. This optical code signal is created by placing creating a uniform array of parallel lines across the dot field, and dropping vertical lines
through each dot. This approach retains the signaling properties of the dot field because it places the dark vertical lines through coordinates at its luminance minima.
These first and second patterns place dark markings at coordinates in the signal tile corresponding to luminance minima (i.e., the dot locations). A complementary approach that retains a robust optical code signal is to place dark markings in valleys around luminance maxima of a watermark signal. A Voronoi pattern is an example. Such approaches may be inverted for dark artwork, in which the sparse signal carrying elements are luminance maxima (bright pixels) relative to a darker background.
A Voronoi pattern is shown in Fig. 55. Such a pattern is generated by creating a line segment between each pair of adjoining sparse points, orienting the segment to be equidistant from the pair of points, and continuing the segment until it intersects with another such line segment. Figs. 55A and 55B shows how such a pattern can be used as a fill element in artwork.
A fourth line pattern, shown in Fig. 56, is the dual of the Voronoi pattern and is termed a Delaunay triangulation. Such a pattern forms triangles from proximate triads of sparse points, subject to the condition that no point is within the circumcircle of any triangle.
Voronoi and Delaunay patterns are graph duals; e.g., connecting the centers of the circumcircles of the triangles in the Delaunay triangulation produces the Voronoi diagram. The Voronoi diagram may be implemented using the Voronoi function in MatLab from MathWorks, or via a Delaunay triangulation computed by the Qhull program. Qhull outputs the Voronoi vertices for each Voronoi region.
(It will be recognized that the triangle pattern resulting from Delaunay triangulation of the present code -conveying sparse dot fields is non-linear and irregular, with triangles of different sizes, areas, vertex angles, and orientations. In contrast, another triangle-based optical code, the Microsoft Color Barcode, comprises linear arrays of identically-sized triangles, presented in parallel rows, with successive triangles oriented at 0 and 180 degrees.)
Figs. 58A and 58B illustrate additional examples of line patterns generated from coordinates of maxima points in an optical code signal tile. Fig. 58 A is generated by programmatically forming squares around coordinates of maxima. Similarly, Fig. 58B is generated by forming rectangles around coordinates of maxima.
A watermark decoder (e.g., as taught in US Patent 6,590,996, and typified by the Digimarc app in the Apple App Store) can extract the encoded plural-bit payload from each of each of the patterns depicted in Figs. 53 - 57B.
Dot patterns from which such line patterns are derived can be produced in various ways. Each typically starts with a continuous tone watermark pattern (sometimes termed a dense code, or a composite dense code - reflecting the presence of both payload and reference signals).
One arrangement creates a sparse dot pattern by applying a thresholding operation to a dense code, to identify locations of extreme low values (i.e., dark) in the dense code. These locations are then marked in a sparse tile (aka block). The threshold level establishes the print density of the resulting sparse mark.
Another arrangement identifies the darkest elements of a reference signal, and logically-ANDs these with dark elements of the payload signal, to thereby identify locations in a sparse signal tile at which marks should be formed. A threshold value can establish which reference signal elements are dark enough to be considered, and this value can be varied to achieve a desired dot density.
Still another arrangement employs a reference signal generated at a relatively higher resolution, and a payload signal generated at a relatively lower resolution. The latter signal has just two values (i.e., it is bitonal); the former signal has more values (i.e., it is multi-level, such as binary greyscale or comprised of floating point values). The payload signal is interpolated to the higher resolution of the reference signal, and in the process is converted from bitonal form to multi-level. The two signals are combined at the higher resolution, and a thresholding operation is applied to the result to identify locations of extreme (e.g., dark) values. Again, these locations are marked in a sparse tile. The threshold level again establishes the print density of the resulting sparse mark.
Yet another arrangement again employs a reference signal generated at a relatively higher resolution, and a bitonal payload signal generated at a relatively lower resolution. A mapping is established between the two signals, so that each element of the payload signal is associated with four or more spatially-corresponding elements of the reference signal. For each element of the payload signal that is dark, the location of the darkest of the four-or-more spatially corresponding elements in the reference signal is identified. A mark is made at a corresponding location in the sparse tile.
A further arrangement is based on a dense multi-level reference signal tile. Elements of this signal are sorted by value, to identify the darkest elements - each with a location. These darkest elements are paired. One element is selected from each pairing in accordance with bits of the payload. Locations in the sparse tile, corresponding to locations of the selected dark elements, are marked to form the sparse signal.
Still another arrangement sorts samples in a tile of the reference signal by darkness, yielding a ranked list - each dark sample being associated with a location. Some locations are always-marked, to ensure the reference signal is strongly expressed. Others are marked, or not, based on values of message signal data assigned to such locations (e.g., by a scatter table).
Arrangements that operate on composite codes can further include weighting the reference and payload signals in ratios different than 1:1, to achieve particular visibility or robustness goals.
Each of these arrangements can further include the act of applying a spacing constraint to candidate marks within the sparse block, to prevent clumping of marks. The spacing constraint may take the form of a keep-out zone that is circular, elliptical, or of other (e.g., irregular) shape. The keep-out zone may have two, or more, or less, axes of symmetry (or none). Enforcement of the spacing constraint can employ an associated data structure having one element for each location in the sparse block. As dark marks are added to the sparse block, corresponding data is stored in the data structure identifying locations that - due to the spacing constraint - are no longer available for possible marking.
Concluding Remarks
Having described and illustrated our technology with reference to exemplary embodiments, it should be recognized that our technology is not so limited.
For example, while described in the context of generating patterns for use in printing retail packaging, it should be recognized that the technology finds other applications as well, such as in printed security documents.
Moreover, printing is not required. The patterns produced by the present technology can be displayed on, and read from, digital displays - such as smartphones, digital watches, electronic signboards, tablets, etc.
Similarly, product surfaces may be textured with such patterns (e.g., by injection molding or laser ablation) to render them machine-readable.
All of the patterns disclosed herein can be inverted (black/white), colored, rotated and scaled - as best fits particular contexts.
While the specification refers to style transfer techniques employing the method of Johnson, it will be recognized that any other style transfer technique can be used - both currently-existing, and hereafter-developed.
It should be understood that the watermarks referenced above include two components: a reference or synchronization signal (enabling geometric registration), and a payload signal (conveying plural symbols of information - such as a GTIN). It will be noted that each of the depicted signal carrying patterns can be detected by the Digimarc app for the iPhone or Android smartphones. (The Digimarc app practices methods detailed in the cited patent documents, e.g., US patent 6,590,996.)
While the detailed embodiments involving continuous tone watermarks usually focused on luminance watermarks, it should be recognized that the same principles extend straightforwardly to chrominance watermarks.
Although described in the context of imagery, the same principles can likewise be applied to audio - taking a pseudo-random payload-conveying signal, and imparting to it a structured, patterned audio aesthetic that renders it more sonically pleasing.
The VGG neural network of Fig. 4 is employed in an illustrative neural network-based style transfer embodiment, but other neural networks can also be used. Another suitable network is the “AlexNet” network, e.g., as implemented in Babenko, et al, Neural Codes for Image Retrieval, arXiv preprint arXiv: 1404.1777 (2014)).
Naturally, the number and sizes of the layers and stacks can be varied as particular applications may indicate.
Additional code adapted by applicant for use in the detailed embodiments is publicly available at the github repository, at the web address
github<dot>com/USourcell/How_to_do_style_transfer_in_tensorflow/blob/master/Style_Transfer.ipynb. A printout of those materials is attached to U.S. application 62/596,730.
In the first embodiment, rather than start with a random image as the test image, the watermark image, or the geometrical pattern image, are instead used as starting points, and are then morphed by the detailed methods towards the other image.
While the detailed embodiments draw primarily from work by Gatys and Johnson regarding neural network-based style transfer, it will be recognized that there are other such neural network-based techniques - any of which can similarly be used as detailed above. Examples include Li et al, Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis, Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2479-2486; Chen, et al, Stylebank: An explicit representation for neural image style transfer, CVPR 2017, p. 4; Luan, et al, Deep Photo Style Transfer, CVPR 2017, pp. 6997-7005; and Huang, et al, Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization, 2017 Int’l Conference on Computer Vision, pp. 1510-1519. Others are detailed in U.S. patent documents 9,922,432, 20180158224, 20180082715, and 20180082407. Again, such techniques are familiar to artisans in the style transfer art.
Various examples of watermark encoding protocols and processing stages of these protocols are detailed in Applicant’s prior work, such as our US Patents Nos. 6,614,914, 5,862,260, and 6,674,876, and US patent publications 20100150434 and 20160275639 - all of which are incorporated herein by reference. More information on signaling protocols, and schemes for managing compatibility among protocols, is provided in US Patent No. 7,412,072, which is hereby incorporated by reference.
There are an increasing number of toolsets that have been designed specifically for working with neural networks. Caffe is one - an open source framework for deep learning algorithms, distributed by the Berkeley Vision and Learning Center. Another is Google’s TensorFlow.
In certain implementations, applicant uses a computer equipped with multiple Nvidia TitanX GPU cards. Each card includes 3,584 CUDA cores, and 12 GB of fast GDDR5X memory.
Alternatively, the neural networks can be implemented in a variety of other hardware structures, such as a microprocessor, an ASIC (Application Specific Integrated Circuit) and an FPGA (Field
Programmable Gate Array). Hybrids of such arrangements can also be employed, such as reconfigurable hardware, and ASIPs.
By microprocessor, Applicant means a particular structure, namely a multipurpose, clock-driven, integrated circuit that includes both integer and floating point arithmetic logic units (AFUs), control logic, a collection of registers, and scratchpad memory (aka cache memory), linked by fixed bus interconnects. The control logic fetches instruction codes from a memory (often external), and initiates a sequence of operations required for the AFUs to carry out the instruction code. The instruction codes are drawn from a limited vocabulary of instructions, which may be regarded as the microprocessor’s native instruction set.
A particular implementation of one of the above -detailed algorithms on a microprocessor - such as the conversion of an iterated test image into a line art pattern - can begin by first defining the sequence of operations in a high level computer language, such as MatFab or C++ (sometimes termed source code), and then using a commercially available compiler (such as the Intel C++ compiler) to generate machine code (i.e., instructions in the native instruction set, sometimes termed object code) from the source code. (Both the source code and the machine code are regarded as software instructions herein.) The process is then executed by instructing the microprocessor to execute the compiled code.
Many microprocessors are now amalgamations of several simpler microprocessors (termed “cores”). Such arrangements allow multiple operations to be executed in parallel. (Some elements - such as the bus structure and cache memory may be shared between the cores.)
Examples of microprocessor structures include the Intel Xeon, Atom and Core-I series of devices. They are attractive choices in many applications because they are off-the-shelf components.
Implementation need not wait for custom design/fabrication.
Closely related to microprocessors are GPUs (Graphics Processing Units). GPUs are similar to microprocessors in that they include AFUs, control logic, registers, cache, and fixed bus interconnects. However, the native instruction sets of GPUs are commonly optimized for image/video processing tasks, such as moving large blocks of data to and from memory, and performing identical operations simultaneously on multiple sets of data (e.g., pixels or pixel blocks). Other specialized tasks, such as rotating and translating arrays of vertex data into different coordinate systems, and interpolation, are also generally supported. The leading vendors of GPU hardware include Nvidia, ATI/AMD, and Intel. As used herein, Applicant intends references to microprocessors to also encompass GPUs.
GPUs are attractive structural choices for execution of the detailed arrangements, due to the nature of the data being processed, and the opportunities for parallelism.
While microprocessors can be reprogrammed, by suitable software, to perform a variety of different algorithms, ASICs cannot. While a particular Intel microprocessor might be programmed today to serve as a deep neural network, and programmed tomorrow to prepare a user’s tax return, an ASIC structure does not have this flexibility. Rather, an ASIC is designed and fabricated to serve a dedicated task, or limited set of tasks. It is purpose-built.
An ASIC structure comprises an array of circuitry that is custom-designed to perform a particular function. There are two general classes: gate array (sometimes termed semi -custom), and full-custom. In the former, the hardware comprises a regular array of (typically) millions of digital logic gates (e.g., XOR and/or AND gates), fabricated in diffusion layers and spread across a silicon substrate. Metallization layers, defining a custom interconnect, are then applied - permanently linking certain of the gates in a fixed topology. (A consequence of this hardware structure is that many of the fabricated gates - commonly a majority - are typically left unused.)
In full-custom ASICs, however, the arrangement of gates is custom-designed to serve the intended purpose (e.g., to perform a specified function). The custom design makes more efficient use of the available substrate space - allowing shorter signal paths and higher speed performance. Full-custom ASICs can also be fabricated to include analog components, and other circuits.
Generally speaking, ASIC-based implementations of the detailed arrangements offer higher performance, and consume less power, than implementations employing microprocessors. A drawback, however, is the significant time and expense required to design and fabricate circuitry that is tailor-made for one particular application.
An ASIC -based implementation of one of the above arrangements again can begin by defining the sequence of algorithm operations in a source code, such as MatLab or C++. However, instead of compiling to the native instruction set of a multipurpose microprocessor, the source code is compiled to a “hardware description language,” such as VHDL (an IEEE standard), using a compiler such as
HDLCoder (available from MathWorks). The VHDL output is then applied to a hardware synthesis program, such as Design Compiler by Synopsis, HDL Designer by Mentor Graphics, or Encounter RTL Compiler by Cadence Design Systems. The hardware synthesis program provides output data specifying a particular array of electronic logic gates that will realize the technology in hardware form, as a special- purpose machine dedicated to such purpose. This output data is then provided to a semiconductor fabrication contractor, which uses it to produce the customized silicon part. (Suitable contractors include TSMC, Global Foundries, and ON Semiconductors.)
A third hardware structure that can be used to implement the above-detailed arrangements is an FPGA. An FPGA is a cousin to the semi-custom gate array discussed above. Flowever, instead of using metallization layers to define a fixed interconnect between a generic array of gates, the interconnect is defined by a network of switches that can be electrically configured (and reconfigured) to be either on or off. The configuration data is stored in, and read from, a memory (which may be external). By such arrangement, the linking of the logic gates - and thus the functionality of the circuit - can be changed at will, by loading different configuration instructions from the memory, which reconfigure how these interconnect switches are set.
FPGAs also differ from semi-custom gate arrays in that they commonly do not consist wholly of simple gates. Instead, FPGAs can include some logic elements configured to perform complex combinational functions. Also, memory elements (e.g., flip-flops, but more typically complete blocks of RAM memory) can be included. Again, the reconfigurable interconnect that characterizes FPGAs enables such additional elements to be incorporated at desired locations within a larger circuit.
Examples of FPGA structures include the Stratix FPGA from Altera (now Intel), and the Spartan FPGA from Xilinx.
As with the other hardware structures, implementation of the above -detailed arrangements begins by specifying a set of operations in a high level language. And, as with the ASIC implementation, the high level language is next compiled into VHDL. But then the interconnect configuration instructions are generated from the VHDL by a software tool specific to the family of FPGA being used (e.g.,
Stratix/Spartan).
Hybrids of the foregoing structures can also be used to implement the detailed arrangements.
One structure employs a microprocessor that is integrated on a substrate as a component of an ASIC.
Such arrangement is termed a System on a Chip (SOC). Similarly, a microprocessor can be among the elements available for reconfigurable -interconnection with other elements in an FPGA. Such
arrangement may be termed a System on a Programmable Chip (SORC).
Another hybrid approach, termed reconfigurable hardware by the Applicant, employs one or more ASIC elements. However, certain aspects of the ASIC operation can be reconfigured by parameters stored in one or more memories. For example, the weights of convolution kernels can be defined by parameters stored in a re -writable memory. By such arrangement, the same ASIC may be incorporated into two disparate devices, which employ different convolution kernels. One may be a device that employs a neural network to recognize grocery items. Another may be a device that morphs a watermark pattern so as to take on attributes of a desired geometrical pattern, as detailed above. The chips are all identically produced in a single semiconductor fab, but are differentiated in their end-use by different kernel data stored in memory (which may be on-chip or off).
Yet another hybrid approach employs application-specific instruction set processors (ASIPS). ASIPS can be thought of as microprocessors. However, instead of having multi-purpose native instruction sets, the instruction set is tailored - in the design stage, prior to fabrication - to a particular intended use. Thus, an ASIP may be designed to include native instructions that serve operations associated with some or all of: convolution, pooling, ReLU, etc., etc. However, such native instruction set would lack certain of the instructions available in more general purpose microprocessors.
Reconfigurable hardware and ASIP arrangements are further detailed in US patent 9,819,950, the disclosure of which is incorporated herein by reference.
Processing hardware suitable for neural network are also widely available in“the cloud,” such as the Azure service by Microsoft Corp, and CloudAI by Google.
In addition to the toolsets developed especially for neural networks, familiar image processing libraries such as OpenCV can be employed to perform many of the methods detailed in this specification. Software instructions for implementing the detailed functionality can also be authored by the artisan in C, C++, MatLab, Visual Basic, Java, Python, Tel, Perl, Scheme, Ruby, etc., based on the descriptions provided herein.
Software and hardware configuration data/instructions are commonly stored as instructions in one or more data structures conveyed by tangible media, such as magnetic or optical discs, memory cards, ROM, etc., which may be accessed across a network.
Some of applicant’s other work involving neural networks is detailed in US patent applications 15/726,290, filed October 5, 2017, 15/059,690, filed March 3, 2016 (now patent 9,892,301), 15/149,477, filed May 9, 2016, 15/255,114, filed September 1, 2016 (now patent 10,042,038), and in published applications 20150030201, 20150055855 and 20160187199.
Additional information about the retail environments in which the encoded signals are utilized is provided in published US applications 20170249491, and in pending US application 15/851,298, filed December 21, 2017.
This specification has discussed various arrangements. It should be understood that the methods, elements and features detailed in connection with one arrangement can be combined with the methods, elements and features detailed in connection with other arrangements.
In addition to the prior art works identified above, other documents from which useful techniques can be drawn include:
• Goodfellow, et al, Generative adversarial nets, Advances in Neural Information Processing
Systems, 2014 (pp. 2672-2680);
• Ulyanov, et al, Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv: 1607.08022, July 27, 2016;
• Zhu, et al, Unpaired image-to-image translation using cycle-consistent adversarial networks. arXiv preprint arXiv: 1703.10593, March 30, 2017.
Moreover, it will be recognized that the detailed technology can be included with other technologies - current and upcoming - to advantageous effect. Implementation of such combinations should be straightforward to the artisan from the teachings provided in this disclosure.
While this disclosure has detailed particular ordering of acts and particular combinations of elements, it will be recognized that other contemplated methods may re-order acts (possibly omitting some and adding others), and other contemplated combinations may omit some elements and add others, etc.
Although disclosed as complete systems, sub-combinations of the detailed arrangements are also separately contemplated (e.g., omitting various of the features of a complete system).
While certain aspects of the technology have been described by reference to illustrative methods, it will be recognized that apparatuses configured to perform the acts of such methods are also contemplated as part of Applicant’s inventive work. Likewise, other aspects have been described by reference to illustrative apparatus, and the methodology performed by such apparatus is likewise within the scope of the present technology. Still further, tangible computer readable media containing instructions for configuring a processor or other programmable system to perform such methods is also expressly contemplated.
To provide a comprehensive disclosure, while complying with the U.S. Patent Act’s requirement of conciseness, Applicant incorporates-by-reference each of the documents referenced herein. (Such materials are incorporated in their entireties, even if cited above in connection with specific of their teachings.) These references disclose technologies and teachings that Applicant intends be incorporated into the arrangements detailed herein, and into which the technologies and teachings presently-detailed be incorporated.
Claims
1. A method of generating artwork for labeling of a food package, comprising the acts: receiving imagery that encodes a plural-bit payload therein;
neural network processing the imagery to reduce a difference measure between the processed imagery and a style image, yielding an output image; and
incorporating some or all of the output image in artwork for labeling of a food package;
wherein the plural-bit payload persists in the output image, enabling a compliant decoder module in a retail point of sale station to recover the plural-bit payload from an image of the food package.
2. The method of claim 1 in which the distance measure is based on a difference between a Gram matrix for the processed imagery and a Gram matrix for the style image.
3. The method of claim 1 in which the style image includes various features, wherein the neural network adapts features from the style image to express details of the received imagery, to thereby yield an output image in which features from the style image contribute to encoding of said plural-bit payload.
4. The method of claim 1 in which the style image depicts a multitude of items of a first type, wherein the neural network processing adapts scale, location, and rotation of said items as depicted in the output image to echo features of the received imagery, to thereby produce an output image depicting plural of said items in a configuration that encodes said plural-bit payload.
5. A method comprising the acts:
digitally-watermarking a first image to encode a plural-bit payload therein, yielding a second image; and
neural network processing the second image to reduce a difference measure between the processed second image and a style image.
6. The method of claim 5 in which the distance measure is based on a difference between a Gram matrix for the processed second image and a Gram matrix for the style image.
7. The method of claim 6 that includes incorporating some or all of the processed second image within label artwork for food product packaging.
8. The method of claim 5 in which the plural-bit payload is recoverable by a digital watermark decoder from the processed second image.
9. A method comprising the acts:
receiving a pattern that encodes a plural-symbol payload; and
applying a style to said pattern, using a previously-trained neural network, to produce a stylized output image, the style being based on a style image having various features, wherein the network adapts features from the style image to express details of the received pattern, to thereby produce an image in which features from the style image contribute to encoding of said plural-symbol payload.
10. The method of claim 9 in which said applying act comprises applying said pattern to a neural network that has been previously-trained with a style image using the method of Johnson.
11. A method comprising the acts:
receiving a pattern that encodes a plural-symbol payload; and
applying a style to said pattern, using a previously-trained neural network, to produce a stylized output image, the style being based on a style image depicting a multitude of items of a first type, wherein the network adapts scale, location, and rotation of said items as depicted in the stylized output image to echo features of the received pattern, to thereby produce an image depicting plural of said items in a configuration that encodes said plural-symbol payload.
12. The method of claim 11 in which the items are selected from the list: rice grains, droplets, stones, leaves, weaves of fabric or basketry, pasta, bricks, or candy.
13. The method of claim 11 that further includes printing artwork on a substrate to serve as a package for a food item, the artwork including a portion based on said image, wherein configuration of said items in said portion of the printed artwork permits identification of said package by a camera- equipped point of sale apparatus.
14. The method of claim 11 in which said pattern is a pattern of polygons.
15. A non-transitory computer readable medium containing software instructions for configuring a processor-based apparatus to perform acts including:
presenting a user interface that enables a user to define a multi-symbol payload, and to select from among plural different styles;
in response to user selection of a first style, generating a sparse watermark pattern, the pattern including a web of lines defining plural polygons, the arrangement of the polygons encoding the payload; and
in response to user selection of a second style, generating a continuous tone watermark pattern, and adapting elements of the second style to mimic elements of the watermark pattern and encode the payload.
16. A method comprising the acts:
receiving a sparse pattern of points that encodes plural-symbol data, including a Global Trade Item Number identifier;
generating a transformed image, said generating including transforming said sparse pattern of points by applying a directional blur or wind filter in a first direction; and
incorporating said transformed image in packaging artwork for a retail item;
wherein said identifier can be decoded from said packaging artwork by a camera-equipped point- of-sale apparatus.
17. The method of claim 16 that further includes applying the direction blur or wind filter to said sparse pattern of points in a second direction, and combining results of said filtering in the first and second directions in producing said transformed image.
18. A food package having artwork printed thereon, the artwork encoding a payload including a Global Trade Item Number identifier, the artwork having first and second regions, the first region including a background pattern that has been stylized from a watermarked input image using a neural network.
19. The package of claim 18 in which the second region includes a watermarked image that has not been stylized using a neural network, wherein the watermark included in the second region is geometrically-aligned with a watermark signal included in the first region, wherein a detector can jointly use signals from both regions in decoding the payload.
20. The food package of claim 18 in which the first region includes a background pattern that has been stylized from a watermarked input image using a neural network, and then false-colored.
21. A method comprising:
receiving a watermarked image;
step for stylizing the watermarked image, producing a styled output;
false-coloring the styled output; and
incorporating the false-colored styled output in artwork printed on packaging for a retail item; wherein the false-colored styled output in said artwork serves to convey a plural-symbol Global Trade Item Number identifier to a camera-equipped point-of-sale apparatus, enabling the apparatus to add the item to a shopper’ s checkout tally.
22. A method comprising the acts:
obtaining data defining a square watermark signal block, comprising N rows and N columns of elements, the watermark signal block encoding a Global Trade Item Number identifier;
replicating plural of said rows and columns along two adjoining edges of the square signal block, producing an enlarged signal block having M rows and M columns of elements;
sending the enlarged signal block to a style -transfer neural network;
receiving the enlarged signal block after processing by the style-transfer neural network;
excerpting an N row by N column portion from within the received signal block; and
using said excerpted portion, in tiled fashion, in artwork printed on food packaging, wherein the tiled portion in the food packaging serves to convey the Global Trade Item Number identifier to a camera- equipped point-of-sale apparatus, enabling the apparatus to add the item to a shopper’s checkout tally.
23. A packaged food product having label artwork that includes one of the patterns illustrated in the application figures as a background element, the pattern conveying a plural-symbol GTIN enabling the food product to be recognized by a camera-equipped point of sale apparatus.
24. The food product of claim 23 in which the pattern is colored.
25. A method comprising the acts:
receiving a pattern of dots encoding a plural-symbol payload;
padding the pattern of dots, by replicating portions of the pattern along at least two adjoining sides of the square, yielding a larger pattern of dots;
generating a pattern of polygons from the larger pattern of dots; and
printing artwork on a substrate to serve as a package for a food item, the artwork including a background based on said pattern of polygons, the background pattern encoding said payload, permitting identification of said package by a camera-equipped point of sale apparatus.
26. The method of claim 25 that further includes:
applying a style to the pattern of polygons using a previously-trained neural network, producing a stylized output image;
excerpting a central region of the stylized output image; and
composing said artwork employing portions of two or more of said excerpted regions, tiled together.
27. A method comprising the acts:
obtaining a watermark signal, the watermark signal encoding an identifier and being represented by watermark signal elements of a first size;
stylizing the watermark signal in accordance with a style image, the style image depicting a multitude of items of a first type; and
employing the stylized watermark signal in printing on an object;
wherein the stylized watermark signal enables the object to be identified by a camera-equipped apparatus; and
the items depicted in the style image have a size that is between 0.5 and 25 times said first size.
28. The method of claim 27 in which the watermark signal is a host image that has been encoded with a watermark payload.
29. The method of claim 27 in which the watermark signal is solitary, i.e., not encoded in a host image.
30. A method for producing a code for message signaling through an image, the method employing a deep neural network, the network having an input, one or more outputs, and plural intermediate layers, each layer comprising plural filters, each filter characterized by plural parameters that define a response of the filter to a given input, the method comprising the acts: iteratively adjusting an input test image, based on results produced by the filters of said neural network, until the test image adopts both (1) style features from one image, and (2) signal-encoding features from a second image.
31. A method for producing a code for message signaling through an image, the method employing a deep neural network trained to perform object recognition, the network having an input, one or more outputs, and plural intermediate layers, each layer comprising plural filters, each filter characterized by plural parameters that define a response of the filter to a given input, the method comprising the acts:
(a) receiving an image comprising a machine readable code that is readable by a digital watermark decoder, the machine readable code including a signal modulated to convey a plural-symbol payload;
(b) receiving an artwork image;
(c) presenting the machine readable code image to the network, causing the filters in said layers to produce machine readable code image filter responses;
(d) presenting the artwork image to the network, and determining correlations between filter responses in different of the layers, to thereby determine style information for the artwork image;
(e) receiving an initial test image;
(f) presenting the test image to the neural network, causing filters in plural of said layers to produce test image filter responses;
(g) determining style information for the test image by determining correlations between the test image filter responses of plural of said filter layers;
(h) determining a first loss function based on differences between said test image filter responses and said machine readable code image filter responses, for filters in one or more of said layers;
(i) determining a second loss function based on a difference between said style information for the first and test images;
(j) adjusting the test image based on the determined first and second loss information; and performing acts (f) through (j) one or more times, to incrementally adjust the test image to successively adopt more and more of the style of the artwork image;
wherein the test image is transformed into an image in which the modulated signal is obfuscated by the style of the artwork image, yet is still readable by said digital watermark decoder.
32. The method of claim 31 that further includes, after performing acts (f) through (j) said one or more times, further processing the test image, and incorporating the further-processed test image into artwork for packaging of a retail product.
33. The method of claim 32 in which the further processing includes performing a binarization process on the test image.
34. The method of claim 33 in which the further processing includes performing a skeletonization process on the binarized test image.
35. The method of claim 34 in which the further processing includes performing a dilation process on the binarized, skeletonized test image.
36. The method of claim 33 in which the further processing includes performing a dilation process on the binarized test image.
37. The method of claim 32 that includes printing a product package incorporating said further-processed test image.
38. The method of claim 37 that further includes scanning, with a retail point of sale scanner, the printed product package incorporating said further-processed test image.
39. The method of claim 31 in which the artwork image depicts a spatially repeating geometric pattern.
40. The method of claim 31 in which the artwork image depicts a symmetric geometric pattern.
41. The method of claim 31 in which the initial test image comprises the machine readable code image.
42. The method of claim 31 in which the initial test image comprises a random image.
43. The method of claim 31 in which said outputs comprise outputs of a last intermediate layer.
44. The method of claim 31 that further includes, after performing acts (f) through (j) one or more times, further-processing the test image.
45. The method of claim 44 in which the further processing includes binarizing the test image, determining a morphological skeleton of the binarized text image, and dilating the morphological skeleton.
46. A method for producing an obfuscated code for message signaling through an image, the method comprising the acts:
receiving a plural symbol payload;
applying an error correction coding algorithm to the plural symbol payload to generate an enlarged bit sequence;
processing the enlarged bit sequence with pseudo-random data to yield a pseudo-random bit sequence;
mapping the pseudo-random bit sequence to locations in an image block;
combining said image block with an image block depicting a spatial domain counterpart to plural signal peaks in a spatial frequency domain, to yield a code pattern from which the plural symbol payload can be recovered by a decoder;
applying the code to a multi-layer convolutional neural network, and storing filter responses of one or more layers as first reference data;
applying a geometrical pattern to said convolutional neural network, and storing data indicating correlations between filter responses between two or more of said layers as second reference data; and modifying a test image based on said first and second reference data, to yield an obfuscated code pattern, different from said code pattern and different from said geometrical pattern, from which the plural symbols can be recovered by said decoder.
47. A method of generating user-authored graphical content, using a system including a hardware processor and a memory, the method comprising the acts:
receiving authoring instructions from a user, said instructions taking the form of plural strokes applied to a virtual canvas by a virtual tool; and
responsive to said instructions, rendering a first signal-carrying pattern on the canvas in a first area included within a first stroke;
wherein the graphical content conveys a plural-bit digital payload encoded by said signal-carrying pattern; and
wherein said signal-carrying pattern was earlier derived, using a neural network, from an image depicting a natural or synthetic pattern.
48. A method of generating user-authored graphical content, using a system including a hardware processor and a memory, the method comprising the acts:
receiving authoring instructions from a user, said instructions taking the form of plural strokes applied to a virtual canvas by a virtual tool, manipulated using a physical stylus; and
responsive to said instructions, rendering a first signal-carrying pattern on the canvas in a first area defined by a first stroke, and rendering a second signal-carrying pattern on the canvas in a second area defined by a second stroke
wherein the graphical content conveys a plural-bit digital payload encoded by said signal-carrying pattern; and
wherein the first signal-carrying pattern is rendered with a first mean value or contrast due a pressure with which the user applies the physical stylus to a substrate when making the first stroke, and the second signal-carrying pattern is rendered with a second mean value or contrast due to a pressure with which the user applies the physical stylus to the substrate when making the second stroke, the second value being different than the first.
49. A method of generating user-authored graphical content, using a system including a hardware processor and a memory, the method comprising the acts:
receiving authoring instructions from a user, said instructions taking the form of plural strokes applied to a virtual canvas by a virtual tool;
responsive to said instructions, rendering a first signal-carrying pattern on the canvas in a first area included within a first stroke, and rendering a second signal-carrying pattern on the canvas in a second area included within a second stroke, the rendered first and second patterns both corresponding to a reference pattern stored in the memory;
wherein the graphical content conveys a plural-bit digital payload encoded by patterns defined by said plural strokes; and
wherein elements of the first pattern, rendered within the first area, have a variance or mean amplitude that differs from a variance or mean amplitude, respectively, of spatially-corresponding elements of the reference pattern.
50. The method of claim 49 that includes setting a transparency or contrast value for elements in the first area at a first value, and setting a corresponding transparency or contrast value for elements in the second area at a second value, where the first and second values are different.
51. The method of claim 50 that includes setting said first and second values based on pressures with which the user applies the first and second strokes, respectively, to the virtual canvas.
52. The method of claim 50 that includes setting said first and second values based on a different number of times that the user strokes said tool over the first and second areas on the virtual canvas.
53. The method of claim 49 in which the rendered first and second patterns have different chrominances.
54. The method of claim 49 wherein said reference pattern was earlier derived, using a neural network, from an image depicting a natural or synthetic pattern.
55. An item packaged for retail sale having artwork printed on the packaging, the artwork including an array of adjoining polygons of different areas, wherein the arrangement, shading, or coloring of the polygons encodes a plural-bit payload for reading by a point-of-sale scanner or by a consumer’s camera-equipped mobile device.
56. The item of claim 55 in which said polygons are triangles.
57. The item of claim 55 in which said polygons are bordered by lines that join together at vertices, wherein the vertices define luminance variations that encode the plural-bit payload.
58. The item of claim 55 in which said polygons have interiors that are filled with shading of different chrominances or luminances, wherein said differently-shaded interiors define chrominance or luminance variations that encode the plural-bit payload.
59. A method comprising the acts:
obtaining a line pattern defining an array of adjoining polygons of different areas, where the arrangement, shading, or coloring of the polygons encodes a plural-bit payload for reading by a point-of- sale scanner or by a consumer’s camera-equipped mobile device, said pattern having been earlier generated from a continuous-tone watermark pattern, or a sparse dot array, that encodes said payload; incorporating said line pattern into artwork to be printed on packaging of an item packaged for retail sale; and
printing said package artwork, including the line pattern.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP18836559.7A EP3721404A1 (en) | 2017-12-08 | 2018-12-07 | Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork |
Applications Claiming Priority (8)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762596730P | 2017-12-08 | 2017-12-08 | |
| US62/596,730 | 2017-12-08 | ||
| US201862682731P | 2018-06-08 | 2018-06-08 | |
| US62/682,731 | 2018-06-08 | ||
| US201862745219P | 2018-10-12 | 2018-10-12 | |
| US62/745,219 | 2018-10-12 | ||
| US16/212,125 | 2018-12-06 | ||
| US16/212,125 US20190213705A1 (en) | 2017-12-08 | 2018-12-06 | Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2019113471A1 true WO2019113471A1 (en) | 2019-06-13 |
Family
ID=65036890
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US2018/064516 WO2019113471A1 (en) | 2017-12-08 | 2018-12-07 | Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2019113471A1 (en) |
Cited By (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110570377A (en) * | 2019-09-11 | 2019-12-13 | 辽宁工程技术大学 | group normalization-based rapid image style migration method |
| CN111583380A (en) * | 2020-05-19 | 2020-08-25 | 北京数字绿土科技有限公司 | Rapid coloring method for segmenting point cloud connected region, terminal and storage medium |
| WO2020186234A1 (en) | 2019-03-13 | 2020-09-17 | Digimarc Corporation | Digital marking of items for recycling |
| CN113362411A (en) * | 2021-06-01 | 2021-09-07 | 智裳科技(上海)有限公司 | Method and system for quickly and automatically generating overprint patterns |
| US11276133B2 (en) | 2018-06-08 | 2022-03-15 | Digimarc Corporation | Generating signal bearing art using stipple, Voronoi and Delaunay methods and reading same |
| CN115983308A (en) * | 2023-03-20 | 2023-04-18 | 湖南半岛医疗科技有限公司 | Information code generation method and reading method for intelligent medical treatment |
| CN116309032A (en) * | 2023-05-24 | 2023-06-23 | 南昌航空大学 | Picture processing method, system and computer |
| US11704765B2 (en) | 2017-12-08 | 2023-07-18 | Digimarc Corporation | Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork |
Citations (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5862260A (en) | 1993-11-18 | 1999-01-19 | Digimarc Corporation | Methods for surveying dissemination of proprietary empirical data |
| US6590996B1 (en) | 2000-02-14 | 2003-07-08 | Digimarc Corporation | Color adaptive watermarking |
| US6614914B1 (en) | 1995-05-08 | 2003-09-02 | Digimarc Corporation | Watermark embedder and reader |
| US6674876B1 (en) | 2000-09-14 | 2004-01-06 | Digimarc Corporation | Watermarking in the time-frequency domain |
| US7412072B2 (en) | 1996-05-16 | 2008-08-12 | Digimarc Corporation | Variable message coding protocols for encoding auxiliary data in media signals |
| US20090129592A1 (en) * | 2005-12-05 | 2009-05-21 | Gerhard Frederick Swiegers | Method of forming a securitized image |
| US20090256817A1 (en) | 2008-02-28 | 2009-10-15 | New York University | Method and apparatus for providing input to a processor, and a sensor pad |
| US20100150434A1 (en) | 2008-12-17 | 2010-06-17 | Reed Alastair M | Out of Phase Digital Watermarking in Two Chrominance Directions |
| US20110214044A1 (en) | 2010-01-15 | 2011-09-01 | Davis Bruce L | Methods and Arrangements Relating to Signal Rich Art |
| US20120306766A1 (en) | 2011-06-01 | 2012-12-06 | Motorola Mobility, Inc. | Using pressure differences with a touch-sensitive display screen |
| US20130229350A1 (en) | 2012-03-02 | 2013-09-05 | Timothy C. Shaw | Pressure Sensitive Keys |
| US20140253522A1 (en) | 2013-03-11 | 2014-09-11 | Barnesandnoble.Com Llc | Stylus-based pressure-sensitive area for ui control of computing device |
| US20150030201A1 (en) | 2013-07-19 | 2015-01-29 | Digimarc Corporation | Feature-based watermark localization in digital capture systems |
| US20150055855A1 (en) | 2013-08-02 | 2015-02-26 | Digimarc Corporation | Learning systems and methods |
| US9245308B2 (en) | 2008-12-17 | 2016-01-26 | Digimarc Corporation | Encoding in two chrominance directions |
| US20160187199A1 (en) | 2014-08-26 | 2016-06-30 | Digimarc Corporation | Sensor-synchronized spectrally-structured-light imaging |
| US20160217547A1 (en) | 2015-01-22 | 2016-07-28 | Digimarc Corporation | Differential modulation for robust signaling and synchronization |
| US20160275639A1 (en) | 2015-03-20 | 2016-09-22 | Digimarc Corporation | Sparse modulation for robust signaling and synchronization |
| US20170024840A1 (en) | 2015-03-20 | 2017-01-26 | Digimarc Corporation | Sparse modulation for robust signaling and synchronization |
| US9690967B1 (en) | 2015-10-29 | 2017-06-27 | Digimarc Corporation | Detecting conflicts between multiple different encoded signals within imagery |
| US20170249491A1 (en) | 2011-08-30 | 2017-08-31 | Digimarc Corporation | Methods and arrangements for identifying objects |
| US9819950B2 (en) | 2015-07-02 | 2017-11-14 | Digimarc Corporation | Hardware-adaptable watermark systems |
| US9892301B1 (en) | 2015-03-05 | 2018-02-13 | Digimarc Corporation | Localization of machine-readable indicia in digital capture systems |
| US9922432B1 (en) | 2016-09-02 | 2018-03-20 | Artomatix Ltd. | Systems and methods for providing convolutional neural network based image synthesis using stable and controllable parametric models, a multiscale synthesis framework and novel network architectures |
| US20180082715A1 (en) | 2016-09-22 | 2018-03-22 | Apple Inc. | Artistic style transfer for videos |
| US20180082407A1 (en) | 2016-09-22 | 2018-03-22 | Apple Inc. | Style transfer-based image content correction |
| US20180158224A1 (en) | 2015-07-31 | 2018-06-07 | Eberhard Karls Universitaet Tuebingen | Method and device for image synthesis |
| US10042038B1 (en) | 2015-09-01 | 2018-08-07 | Digimarc Corporation | Mobile devices and methods employing acoustic vector sensors |
-
2018
- 2018-12-07 WO PCT/US2018/064516 patent/WO2019113471A1/en unknown
Patent Citations (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5862260A (en) | 1993-11-18 | 1999-01-19 | Digimarc Corporation | Methods for surveying dissemination of proprietary empirical data |
| US6614914B1 (en) | 1995-05-08 | 2003-09-02 | Digimarc Corporation | Watermark embedder and reader |
| US7412072B2 (en) | 1996-05-16 | 2008-08-12 | Digimarc Corporation | Variable message coding protocols for encoding auxiliary data in media signals |
| US6590996B1 (en) | 2000-02-14 | 2003-07-08 | Digimarc Corporation | Color adaptive watermarking |
| US6674876B1 (en) | 2000-09-14 | 2004-01-06 | Digimarc Corporation | Watermarking in the time-frequency domain |
| US20090129592A1 (en) * | 2005-12-05 | 2009-05-21 | Gerhard Frederick Swiegers | Method of forming a securitized image |
| US20090256817A1 (en) | 2008-02-28 | 2009-10-15 | New York University | Method and apparatus for providing input to a processor, and a sensor pad |
| US9245308B2 (en) | 2008-12-17 | 2016-01-26 | Digimarc Corporation | Encoding in two chrominance directions |
| US20100150434A1 (en) | 2008-12-17 | 2010-06-17 | Reed Alastair M | Out of Phase Digital Watermarking in Two Chrominance Directions |
| US20110214044A1 (en) | 2010-01-15 | 2011-09-01 | Davis Bruce L | Methods and Arrangements Relating to Signal Rich Art |
| US20120306766A1 (en) | 2011-06-01 | 2012-12-06 | Motorola Mobility, Inc. | Using pressure differences with a touch-sensitive display screen |
| US20170249491A1 (en) | 2011-08-30 | 2017-08-31 | Digimarc Corporation | Methods and arrangements for identifying objects |
| US20130229350A1 (en) | 2012-03-02 | 2013-09-05 | Timothy C. Shaw | Pressure Sensitive Keys |
| US20140253522A1 (en) | 2013-03-11 | 2014-09-11 | Barnesandnoble.Com Llc | Stylus-based pressure-sensitive area for ui control of computing device |
| US20150030201A1 (en) | 2013-07-19 | 2015-01-29 | Digimarc Corporation | Feature-based watermark localization in digital capture systems |
| US20150055855A1 (en) | 2013-08-02 | 2015-02-26 | Digimarc Corporation | Learning systems and methods |
| US20160187199A1 (en) | 2014-08-26 | 2016-06-30 | Digimarc Corporation | Sensor-synchronized spectrally-structured-light imaging |
| US20160217547A1 (en) | 2015-01-22 | 2016-07-28 | Digimarc Corporation | Differential modulation for robust signaling and synchronization |
| US9892301B1 (en) | 2015-03-05 | 2018-02-13 | Digimarc Corporation | Localization of machine-readable indicia in digital capture systems |
| US20170024840A1 (en) | 2015-03-20 | 2017-01-26 | Digimarc Corporation | Sparse modulation for robust signaling and synchronization |
| US20160275639A1 (en) | 2015-03-20 | 2016-09-22 | Digimarc Corporation | Sparse modulation for robust signaling and synchronization |
| US9819950B2 (en) | 2015-07-02 | 2017-11-14 | Digimarc Corporation | Hardware-adaptable watermark systems |
| US20180158224A1 (en) | 2015-07-31 | 2018-06-07 | Eberhard Karls Universitaet Tuebingen | Method and device for image synthesis |
| US10042038B1 (en) | 2015-09-01 | 2018-08-07 | Digimarc Corporation | Mobile devices and methods employing acoustic vector sensors |
| US9690967B1 (en) | 2015-10-29 | 2017-06-27 | Digimarc Corporation | Detecting conflicts between multiple different encoded signals within imagery |
| US9922432B1 (en) | 2016-09-02 | 2018-03-20 | Artomatix Ltd. | Systems and methods for providing convolutional neural network based image synthesis using stable and controllable parametric models, a multiscale synthesis framework and novel network architectures |
| US20180082715A1 (en) | 2016-09-22 | 2018-03-22 | Apple Inc. | Artistic style transfer for videos |
| US20180082407A1 (en) | 2016-09-22 | 2018-03-22 | Apple Inc. | Style transfer-based image content correction |
Non-Patent Citations (19)
| Title |
|---|
| "Improved Texture Networks: Maximizing Quality and Diversity in Feed-Forward Stylization and Texture Synthesis", PROC. OF IEEE CONF. ON COMPUTER VISION AND PATTERN RECOGNITION, 2017, pages 6924 - 6932 |
| BABENKO ET AL.: "Neural Codes for Image Retrieval", ARXIV PREPRINT ARXIV: 1404.1777, 2014 |
| CHAO KE ET AL: "Kernel target alignment for feature kernel selection in universal steganographic detection based on multiple kernel SVM", INSTRUMENTATION&MEASUREMENT, SENSOR NETWORK AND AUTOMATION (IMSNA), 2012 INTERNATIONAL SYMPOSIUM ON, IEEE, 25 August 2012 (2012-08-25), pages 222 - 227, XP032456671, ISBN: 978-1-4673-2465-6, DOI: 10.1109/MSNA.2012.6324554 * |
| CHEN ET AL., STYLEBANK: AN EXPLICIT REPRESENTATION FOR NEURAL IMAGE STYLE TRANSFER, CVPR, 2017, pages 4 |
| GATYS ET AL.: "A Neural Algorithm of Artistic Style", ARXIV PREPRINT ARXIV: 1508.06576, 26 August 2015 (2015-08-26) |
| GATYS ET AL.: "Image Style Transfer Using Convolutional Neural Networks", PROC. OF IEEE CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR, 2016, pages 2414 - 2423, XP055571216, DOI: doi:10.1109/CVPR.2016.265 |
| GOODFELLOW ET AL.: "Generative adversarial nets", ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS, 2014, pages 2672 - 2680, XP055572979, DOI: doi:https://dl.acm.org/citation.cfm?id=2969125 |
| HELSGAUN: "DATALOGISKE SKRIFTER (Writings on Computer Science", 1998, ROSKILDE UNIVERSITY, article "An Effective Implementation of the Lin-Kernighan Traveling Salesman Heuristic" |
| HUANG ET AL.: "Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization", INT'L CONFERENCE ON COMPUTER VISION, 2017, pages 1510 - 1519, XP033283010, DOI: doi:10.1109/ICCV.2017.167 |
| JAMIE HAYES ET AL: "Generating Steganographic Images via Adversarial Training", PROCEEDINGS OF THE 31ST ANNUAL CONFERENCE ON ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS (NIPS'30), 1 March 2017 (2017-03-01), pages 1951 - 1960, XP055573249, ISBN: 978-1-5108-6096-4, Retrieved from the Internet <URL:http://papers.nips.cc/paper/6791-generating-steganographic-images-via-adversarial-training.pdf> [retrieved on 20190322] * |
| JOHNSON ET AL.: "Perceptual Losses for Real-Time Style Transfer and Super-Resolution", EUROPEAN CONFERENCE ON COMPUTER VISION, 8 October 2016 (2016-10-08), pages 694 - 711, XP055431982, DOI: doi:10.1007/978-3-319-46475-6_43 |
| JUN-YAN ZHU ET AL: "Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks", 2017 IEEE INTERNATIONAL CONFERENCE ON COMPUTER VISION (ICCV), 30 March 2017 (2017-03-30), pages 2242 - 2251, XP055573065, ISBN: 978-1-5386-1032-9, DOI: 10.1109/ICCV.2017.244 * |
| LI ET AL.: "Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis", PROC. IEEE CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR, 2016, pages 2479 - 2486, XP033021428, DOI: doi:10.1109/CVPR.2016.272 |
| LUAN ET AL., DEEP PHOTO STYLE TRANSFER, CVPR, 2017, pages 6997 - 7005 |
| NIKULIN ET AL.: "Exploring the Neural Algorithm of Artistic Style", ARXIV PREPRINT ARXIV: 1602.07188, 23 February 2016 (2016-02-23) |
| SIMONYAN ET AL.: "Very Deep Convolutional Networks for Large-Scale Image Recognition", ARXIV PREPRINT 1409.1556V6, 10 April 2015 (2015-04-10) |
| ULYANOV ET AL.: "Instance normalization: The missing ingredient for fast stylization", ARXIV PREPRINT ARXIV: 1607.08022, 27 July 2016 (2016-07-27) |
| ZHU ET AL.: "Algorithm 778: L-BFGS-B: Fortran Subroutines for Large-Scale Bound-Constrained Optimization", ACM TRANS. ON MATHEMATICAL SOFTWARE, vol. 23, no. 4, 1997, pages 550 - 560 |
| ZHU ET AL.: "Unpaired image-to-image translation using cycle-consistent adversarial networks", ARXIV PREPRINT ARXIV: 1703.10593, 30 March 2017 (2017-03-30) |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11704765B2 (en) | 2017-12-08 | 2023-07-18 | Digimarc Corporation | Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork |
| US11276133B2 (en) | 2018-06-08 | 2022-03-15 | Digimarc Corporation | Generating signal bearing art using stipple, Voronoi and Delaunay methods and reading same |
| US11657470B2 (en) | 2018-06-08 | 2023-05-23 | Digimarc Corporation | Generating signal bearing art using Stipple, Voronoi and Delaunay methods and reading same |
| WO2020186234A1 (en) | 2019-03-13 | 2020-09-17 | Digimarc Corporation | Digital marking of items for recycling |
| EP4148684A1 (en) | 2019-03-13 | 2023-03-15 | Digimarc Corporation | Digital marking |
| CN110570377A (en) * | 2019-09-11 | 2019-12-13 | 辽宁工程技术大学 | group normalization-based rapid image style migration method |
| CN111583380A (en) * | 2020-05-19 | 2020-08-25 | 北京数字绿土科技有限公司 | Rapid coloring method for segmenting point cloud connected region, terminal and storage medium |
| CN113362411A (en) * | 2021-06-01 | 2021-09-07 | 智裳科技(上海)有限公司 | Method and system for quickly and automatically generating overprint patterns |
| CN113362411B (en) * | 2021-06-01 | 2024-04-12 | 智裳科技(上海)有限公司 | Method and system for quickly and automatically generating full-printed pattern |
| CN115983308A (en) * | 2023-03-20 | 2023-04-18 | 湖南半岛医疗科技有限公司 | Information code generation method and reading method for intelligent medical treatment |
| CN115983308B (en) * | 2023-03-20 | 2023-06-16 | 湖南半岛医疗科技有限公司 | Information code generation method and reading method for intelligent medical treatment |
| CN116309032A (en) * | 2023-05-24 | 2023-06-23 | 南昌航空大学 | Picture processing method, system and computer |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11704765B2 (en) | Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork | |
| WO2019113471A1 (en) | Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork | |
| US11238556B2 (en) | Embedding signals in a raster image processor | |
| US11657470B2 (en) | Generating signal bearing art using Stipple, Voronoi and Delaunay methods and reading same | |
| US11651469B2 (en) | Generating artistic designs encoded with robust, machine-readable data | |
| US11514285B2 (en) | Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork | |
| US10896307B2 (en) | Generating and reading optical codes with variable density to adapt for visual quality and reliability | |
| JP6741347B2 (en) | Sparse modulation for robust signaling and synchronization | |
| CN108352083B (en) | 2D image processing for stretching into 3D objects | |
| US11393200B2 (en) | Hybrid feature point/watermark-based augmented reality | |
| JP2021515442A (en) | Generating and reading optical cords with variable densities to suit visual quality and reliability | |
| CA3132866A1 (en) | Digital marking of items for recycling | |
| CN103038781A (en) | Hidden image signaling | |
| Peng et al. | Fabricating QR codes on 3D objects using self-shadows | |
| US11270103B2 (en) | Image processing methods and arrangements | |
| EP3721404A1 (en) | Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork | |
| US20220036496A1 (en) | Artwork generated to convey digital messages, and methods/apparatuses for generating such artwork | |
| US20220292625A1 (en) | Pre-press warping arrangements for watermarks and associated graphic artworks, with related quality control techniques | |
| CA3234423A1 (en) | Use of imperfect patterns to encode data on surfaces | |
| US20230306550A1 (en) | Method for embedding information in a decorative label | |
| Pena-Pena et al. | HedcutDrawings: Rendering Hedcut Style Portraits. | |
| Kamath et al. | Hiding in Plain Sight: Enabling the Vision of Signal Rich Art | |
| Sun et al. | A system scheme of 3D object reconstruction from single 2D graphics based on neural networks |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 18836559 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2018836559 Country of ref document: EP Effective date: 20200708 |