WO2019031268A1 - 情報処理装置、及び情報処理方法 - Google Patents
情報処理装置、及び情報処理方法 Download PDFInfo
- Publication number
- WO2019031268A1 WO2019031268A1 PCT/JP2018/028201 JP2018028201W WO2019031268A1 WO 2019031268 A1 WO2019031268 A1 WO 2019031268A1 JP 2018028201 W JP2018028201 W JP 2018028201W WO 2019031268 A1 WO2019031268 A1 WO 2019031268A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- speech
- information
- history
- utterances
- information processing
- Prior art date
Links
Images























Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/10—Speech classification or search using distance or distortion measures between unknown speech and reference templates
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
- G10L25/87—Detection of discrete points within a voice signal
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
- G06F40/35—Discourse or dialogue representation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/1815—Semantic context, e.g. disambiguation of the recognition hypotheses based on word meaning
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/183—Speech classification or search using natural language modelling using context dependencies, e.g. language models
- G10L15/19—Grammatical context, e.g. disambiguation of the recognition hypotheses based on word sequence rules
- G10L15/197—Probabilistic grammars, e.g. word n-grams
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
- G10L15/30—Distributed recognition, e.g. in client-server systems, for mobile phones or network applications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/18—Speech classification or search using natural language modelling
- G10L15/1822—Parsing for meaning understanding
Definitions
- the present technology relates to an information processing apparatus and an information processing method, and more particularly to an information processing apparatus and an information processing method capable of providing more convenient voice interaction.
- the signal processing unit cuts out a section in which a user's speech is recorded from a voice signal which is always input to the microphone. Then, the speech recognition unit transcribes the user's uttered content as a character string using the cut out voice signal, and the language understanding unit analyzes the user's instruction content using only the written character string.
- the signal processing unit cuts out the audio signal before the user's intention, and shifts to the subsequent processing. Even if the user instructs to add it later, only the contents are analyzed, and the device does not behave as intended by the user.
- the speech dialogue system behaves as the user intended, and a technique for providing more convenient speech interaction is required. There is.
- the present technology has been made in view of such a situation, and is intended to be able to provide more convenient voice interaction.
- the information processing apparatus is an information processing apparatus including a processing unit that connects the preceding and subsequent utterances according to the matching degree in the semantic unit of the preceding and succeeding utterances included in the user's utterance. is there.
- the information processing device in the information processing method of an information processing device, is adapted to the degree of matching in meaning units of utterances before and after being included in the user's utterances. It is an information processing method which connects the utterance before and behind.
- the preceding and succeeding utterances are connected according to the matching degree in the semantic unit of the preceding and succeeding utterances included in the user's utterance.
- the information processing apparatus includes: a processing unit that extracts, from the history of the user's past utterances, a history of past utterances compatible with the speech language understanding process for utterances including intervals; It is an information processor provided with the transmitting part which transmits the history of the extracted said past utterance with the voice signal according to the present utterance to the information processor which performs the said speech language understanding processing.
- An information processing method is that, in the information processing method of the information processing device, the information processing device is adapted to the speech language understanding processing for the utterance including the interval from the history of the user's past utterances.
- An information processing method for extracting a history of past utterances and transmitting the extracted history of the past utterances together with a voice signal corresponding to the current utterance of the user to an information processing apparatus that performs the speech language understanding process is there.
- the information processing apparatus and the information processing method from the history of the user's past utterances, the history of the past utterances compatible with the speech language understanding processing for the utterance including the interval is extracted
- the extracted history of the past utterance is transmitted to the information processing apparatus which performs the speech language understanding process together with the speech signal corresponding to the current utterance of the user.
- the information processing apparatus may be an independent apparatus or an internal block constituting one apparatus.
- VAD audio section detection
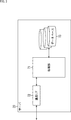
- FIG. 1 is a block diagram showing a configuration example of a voice dialogue system to which the present technology is applied.
- the voice dialogue system 1 is installed on the local side such as a user's home and is a voice processing apparatus 10 functioning as a user interface for voice dialogue service, and a cloud side installed in a data center etc. And a server 20 for performing the processing.
- the voice processing device 10 and the server 20 are mutually connected via the Internet 30.
- the voice processing device 10 is, for example, a speaker that can be connected to a network such as a home LAN (Local Area Network), and is also called a so-called smart speaker.
- This type of speaker can perform, for example, voice operation to devices such as lighting fixtures and air conditioners in addition to reproduction of music.
- the voice processing apparatus 10 is not limited to the speaker, and may be configured as, for example, a mobile device such as a smart phone or a mobile phone, a tablet computer, or the like.
- the voice processing apparatus 10 can provide (a user interface of) a voice interactive service to the user by cooperating with the server 20 via the Internet 30.
- the voice processing device 10 picks up the voice (user's speech) emitted from the user, and transmits the voice signal to the server 20 via the Internet 30. Also, the voice processing device 10 receives the processing data transmitted from the server 20 via the Internet, and outputs a voice corresponding to the processing data.
- the server 20 is a server that provides a cloud-based voice interaction service.
- the server 20 performs voice recognition processing for converting a voice signal transmitted from the voice processing device 10 via the Internet 30 into text data. Further, the server 20 performs processing such as speech language understanding processing on the speech recognition result (text data), and transmits processing data obtained as a result of the processing to the speech processing apparatus 10 via the Internet 30.
- FIG. 2 is a block diagram showing a configuration example of the speech processing device 10 of FIG.
- the audio processing device 10 is configured to include a processing unit 51, a microphone 52, a speaker 53, a sensor 54, and a communication I / F 55.
- the processing unit 51 includes, for example, a central processing unit (CPU), a microprocessor, and the like.
- the processing unit 51 operates as a central processing unit in the voice processing apparatus 10, such as various arithmetic processing and operation control of each unit.
- the microphone 52 is a device (sound collector) that converts external sound into an electrical signal.
- the microphone 52 supplies an audio signal obtained by the conversion to the processing unit 51.
- the speaker 53 is a device that converts an electrical signal into physical vibration to produce sound.
- the speaker 53 outputs a sound corresponding to the audio signal supplied from the processing unit 51.
- the sensor 54 is composed of various sensors.
- the sensor 54 performs sensing, and supplies sensor information (sensor data) according to the sensing result to the processing unit 51.
- an image sensor for imaging a subject a magnetic sensor for detecting the magnitude and direction of a magnetic field (magnetic field), an acceleration sensor for detecting acceleration, a gyro sensor for detecting angle (posture), angular velocity, and angular acceleration
- sensors can be included, such as proximity sensors that detect proximity, or biometric sensors that detect biometric information such as fingerprints, irises, and pulse.
- the sensor 54 can include a sensor for measuring the surrounding environment such as a temperature sensor for detecting temperature, a humidity sensor for detecting humidity, and an ambient light sensor for detecting the brightness of the surroundings.
- the sensor data may include various information such as position information (position data) calculated from a GPS (Global Positioning System) signal or the like, or time information measured by a clock means.
- the communication I / F 55 includes, for example, a communication interface circuit.
- the communication I / F 55 accesses the server 20 connected to the Internet 30 under the control of the processing unit 51 to exchange various data.
- the processing unit 51 has a part of functions provided by the voice dialogue system 1 (FIG. 1).
- the processing unit 51 performs predetermined signal processing on the audio signal supplied from the microphone 52, and supplies the audio signal obtained as a result to the communication I / F 55. Thereby, the voice signal of the user's speech is transmitted to the server 20 via the Internet 30.
- the processing unit 51 can supply sensor data to the communication I / F 55 and transmit the sensor data to the server 20 via the Internet 30.
- the processing unit 51 processes an audio signal supplied from the communication I / F 55, and supplies an audio signal obtained as a result to the speaker 53.
- the speaker 53 outputs a response voice according to the system response (voice signal of the system response).
- the voice processing apparatus 10 includes a display unit for displaying various types of information (for example, characters, images, etc.), an input unit for receiving an operation from the user, or various types of data.
- a storage unit or the like for example, voice data, text data, etc. may be further provided.
- the display unit includes, for example, a liquid crystal display or an organic EL display.
- the input unit includes, for example, a button, a keyboard, and the like.
- the input unit may be configured as a touch panel in which a touch sensor and a display unit are integrated, and an operation signal may be obtained according to an operation by a user's finger or a touch pen (stylus pen).
- the storage unit is configured of, for example, a flash memory which is a type of non-volatile memory, a dynamic random access memory (DRAM) which is a type of volatile memory, or the like.
- DRAM dynamic random access memory
- FIG. 3 is a block diagram showing a configuration example of the server 20 of FIG.
- the server 20 includes a processing unit 71, a communication I / F 72, and a database 73.
- the processing unit 71 includes, for example, a CPU, a microprocessor, and the like.
- the processing unit 71 operates as a central processing unit in the server 20, such as various arithmetic processing and operation control of each unit.
- the communication I / F 72 includes, for example, a communication interface circuit.
- the communication I / F 72 exchanges various data with the voice processing apparatus 10 connected via the Internet 30 according to the control from the processing unit 71.
- the database 73 is configured as, for example, a large capacity recording device such as a hard disk (HDD: Hard Disk Drive), a semiconductor memory, or an optical disk.
- the database 73 includes a speech recognition database for performing speech recognition processing, a speech language understanding database for performing speech language understanding processing, and the like.
- the speech recognition database and the speech language understanding database are an example of a database, and include a database (for example, a knowledge database, a speech database, a dialogue history database, etc.) required to realize the speech interaction service. Can.
- the processing unit 71 has a part of functions provided by the voice dialogue system 1 (FIG. 1).
- the processing unit 71 refers to the speech recognition database included in the database 73 and converts the speech signal of the user's speech transmitted from the speech processing apparatus 10 via the Internet 30 into text data. It performs processing such as speech recognition processing and speech language understanding processing. As a result, a system response to the user is generated and transmitted to the voice processing device 10 via the Internet 30 as processing data.
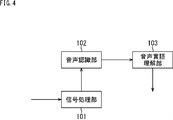
- FIG. 4 is a block diagram showing an example of a functional configuration of a voice dialogue system to which the present technology is applied.
- the speech dialog system 1 includes a signal processing unit 101, a speech recognition unit 102, and a speech language understanding unit 103.
- the signal processing unit 101 receives an audio signal obtained by converting the sound collected by the microphone 52.
- the signal processing unit 101 performs predetermined signal processing on the input voice signal, and supplies the voice signal obtained as a result to the voice recognition unit 102.
- the signal processing performed by the signal processing unit 101 for example, processing of cutting out a section where a user utters, and processing of removing noise to an audio signal are performed.
- the speech recognition unit 102 performs speech recognition processing for converting a speech signal supplied from the signal processing unit 101 into text data by referring to a speech-to-text conversion database or the like.
- the speech recognition unit 102 supplies the speech recognition result (text data of the speech) obtained as a result of the speech recognition process to the speech language understanding unit 103.
- the speech language understanding unit 103 performs predetermined speech language understanding processing on the speech recognition result supplied from the speech recognition unit 102, and the analysis result of the speech input content obtained as a result is processed in the processing unit (not shown) in the latter stage.
- the speech language understanding process performed by the speech language understanding unit 103 for example, a process of converting a speech recognition result (text data of a speech) which is a natural language into a representation that can be understood by a machine is performed.
- the signal processing unit 101 is assumed to be incorporated in the processing unit 51 (FIG. 2) of the local-side speech processing apparatus 10, and the speech recognition unit 102 and the speech language understanding unit 103 have a large capacity memory and storage. As it is necessary, it is assumed to be incorporated in the processing unit 71 (FIG. 3) of the server 20 on the cloud side.
- processing such as dialogue control processing Can be performed to generate a system response to the user.
- voice processing device 10 Although the case where one voice processing device 10 is provided is illustrated in the voice dialogue system 1 of FIG. 1 for convenience of explanation, for example, a plurality of voice processing devices 10 may be provided for each user. Can.
- a plurality of servers 20 can be provided for each function (module). More specifically, for example, a server 20 having a speech recognition module corresponding to the speech recognition unit 102, a server 20 having a speech language understanding module corresponding to the speech language understanding unit 103, etc. are provided as individual servers 20. Can.
- signal processing by the signal processing unit 101 voice recognition processing by the voice recognition unit 102, and speech language understanding processing by the speech language understanding unit 103 are performed in that order.
- voice recognition processing by the voice recognition unit 102 voice recognition processing by the voice recognition unit 102
- speech language understanding processing by the speech language understanding unit 103 speech language understanding processing by the speech language understanding unit 103
- main targets of the present technology are speech recognition processing and speech language understanding processing
- the contents of signal processing by the signal processing unit 101 will also be described in order to make the contents of the present technology easy to understand.
- the signal processing unit 101 mainly performs two processes.
- the first process is a process of cutting out only a time interval in which the user utters from an audio signal constantly input to the microphone 52. This process is called voice activity detection (VAD).
- VAD voice activity detection
- the second process is a process of suppressing noise and emphasizing the user's voice so that speech recognition can be correctly performed even in a noisy environment. This process is called speech enhancement.
- VAD voice activity detection
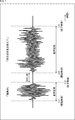
- FIG. 5 is a diagram showing an example of voice activity detection (VAD) in the waveform of the voice signal.
- VAD voice activity detection
- FIG. 5 shows the waveform of the speech signal of the user's speech when the amplitude is in the vertical direction and the time is in the horizontal direction.
- the signal processing unit 101 cuts out a section from the start time t1 to the end time t2 from the waveform of the sound signal as a section in which sound is continuously input in time. That is, in the waveform of the voice signal shown in FIG. 5, the process of cutting out the section from the start time t1 to the end time t2 is the voice section detection (VAD).
- VAD voice section detection
- the voice input After detecting the voice input, it cuts out until the voice input is interrupted.
- it is determined that the input is interrupted for about 500 milliseconds it is determined that the voice input is finished, and the signal is cut out.
- a value of 500 milliseconds is cut off here because a squeaking sound like a "cut” "tsu” sounds silent for a very short time (about 200 to 300 milliseconds) in an audio signal.
- the voice extracted by the signal processing unit 101 is written up in the text (voice recognition result) of the content actually uttered by the user by the voice recognition unit 102.
- this speech recognition result text data of speech
- the speech language understanding unit 103 finally converts this into a representation that can be understood by a machine.
- the speech language understanding unit 103 estimates "user's intention” from natural language, and analyzes its parameters (here, "date and time” and "place”).
- the input (IN1) and output (OUT1) of the API (hereinafter also referred to as speech recognition / speech language understanding program API) of the program having the functions of speech recognition and speech language understanding are as follows, for example.
- the waveform of the audio signal in the section from the start time t1 to the end time t2 extracted by the audio interval detection (VAD) illustrated in FIG. 5 corresponds to the extracted audio signal.
- the time when the extraction is started corresponds to the start time t1 of FIG. 5, and the time when the extraction is completed corresponds to the end time t2 of FIG.
- the time when the extraction is completed is the current time.
- FIG. 6 shows an output example (OUT1) of the speech recognition / speech language understanding program API that performs processing on the input (IN1).
- JSON JavaScript (registered trademark) Object Notation
- JSON JavaScript (registered trademark) Object Notation
- An object in JSON format consists of key-value pairs paired with colons (:), and these pairs are separated by commas (,) and listed zero or more, and the whole is enclosed by braces ( ⁇ ) It is expressed by
- objects and values are separated by commas (,) and enumerated zero or more, and enclosed by square brackets ([]) to express an ordered list of objects or values.
- “Input” means the speech recognition result of the input speech signal.
- speech recognition processing is performed on the cut-out speech signal, and a speech recognition result (text data of speech) of "Teach me the weather of tomorrow in Fukushima” is obtained.
- SemanticFrameList means a list of Semantic Frames, where "intent” and “slotSet” are included as the objects.
- “Intent” means the user's intention.
- the user intention “CheckWeather” which is “weather confirmation” is set.
- the key to one key is the interpretation of the word "Fukushima.” It is not possible to determine whether the proper noun "Fukushima" is a person's name, a place name, or a shop name such as a restaurant by itself. It is possible to judge that there is a high possibility of being a place name, with the context of checking the weather. On the other hand, for example, "Fukushima” when uttering "send mail to Fukushima" is likely to be a personal name.
- FIG. 7 is a diagram showing an example of the waveform of an audio signal in the case where speech is made with an "intermediate” space.
- FIG. 7 shows the waveform of the speech signal of the utterance "Teach me the weather of Fukushima, tomorrow," there are “ma” after “Fukuno” and 500 The input has been interrupted for about a millisecond.
- the section from the start time t11 to the end time t12 corresponding to the utterance "of Fukushima” and the start time t13 to the end time t14 corresponding to the utterance "Teach the weather of tomorrow" Sections are cut out as separate speech sections.
- the input (IN2) and the output (OUT2) of the speech recognition / speech language understanding program API are, for example, as follows.
- the waveform of the audio signal of the section corresponding to “Fukuno's” extracted by the audio interval detection (VAD) shown in FIG. 7 corresponds to the extracted audio signal, and the first input (IN2-1 ).
- the time at which the cutting is started corresponds to the start time t11 in FIG. 7, and the time at which the cutting is completed corresponds to the end time t12 in FIG.
- the waveform of the audio signal of the section corresponding to "Teach me tomorrow's weather" cut out by the voice section detection (VAD) shown in FIG. 7 corresponds to the cut-out sound signal, and the second input It will be (IN2-2).
- the time at which the cutting is started corresponds to the start time t13 in FIG. 7, and the time at which the cutting is completed corresponds to the end time t14 in FIG.
- FIG. 8 shows an output example (OUT2) of the speech recognition / speech language understanding program API that performs processing on the input (IN2).
- the speech recognition result obtained from the speech signal of the section corresponding to "Teach me tomorrow's weather” which is the second input (IN2-2) is shown. ing.
- “Check Weather” which is “weather confirmation” is set as the user's intention ("intent)
- “DateTime” is set as the parameter ("slotSet”). That is, when only “tell me the weather of tomorrow" is analyzed, the user's intended place ("Place") "Fukushima” is not analyzed.
- the voice processing device 10 such as a smart speaker is a device shared by a family
- the user utters “I want to confirm my next week's schedule” to the device
- the input (IN3) and output (OUT3) of the speech recognition / speech language understanding program API are as follows.
- the waveform of the audio signal of the section corresponding to "I want to confirm my next week's schedule" cut out by the voice section detection (VAD) is the cut out audio signal.
- the time at the beginning of the section cut out is the time at which the cut was started, and the last time of the section cut out is the time at which the cut was completed.
- FIG. 9 shows an output example (OUT3) of the speech recognition / speech language understanding program API that performs processing on the input (IN3).
- FIG. 9 the speech recognition result (text data of the speech) obtained from the speech signal of the section corresponding to "I want to confirm my next week's schedule” is shown.
- "ViewSchedule” which is “schedule display” is set as the user's intention ("intent)
- “DateTime” and “Owner” are set as its parameters ("slotSet”).
- “2017-04-02-2017-04-08” as “DateTime” and "I” as “Owner” are set.
- the user's speech contains, for example, a directive such as "I” or “this city” or a relative expression, it may not be possible to solve the content pointed to by language information alone. It will not be possible to read the user's intention correctly.
- the present technology provides an analysis method that can correctly understand the user's instruction content even when there is a "interval" in the user's utterance by using the history of the user's utterance content.
- the user's speech includes a directive or relative expression such as "I” or "this city”
- the content pointed to by the user may not be resolved by the language information alone.
- it is possible to analyze the contents by using information such as an analysis result of a camera image or position information by a GPS (Global Positioning System).
- speech history information is added to the input of the speech recognition / speech language understanding program API of the present technology as follows.
- the waveform of the audio signal of the section corresponding to "Teach me the weather" cut out by the voice section detection (VAD) is the cut out audio signal.
- the time at the beginning of the section cut out is the time at which the cut was started, and the last time of the section cut out is the time at which the cut was completed.
- the history information of the utterance includes the character string of the speech recognition result and the start time of clipping of the corresponding audio signal as the history of the past utterance, and the content is as shown in FIG. 10, for example.
- FIG. 10 is a diagram showing an example of speech history information.
- InputHistory means the history of speech, and here, as its objects, "input”, “beginTime” and “endTime” are included.
- a character string of speech recognition result is set as a speech history.
- the speech recognition result (text data of speech) which is "Fukushima's” uttered before “Teach the weather” is set as a history, with "between” being interposed.
- BeginTime and “endTime” are time information on the start and end of the speech, and are data representations in a format commonly used in a computer called UNIX (registered trademark) epoch milliseconds.
- the start time of the voice of "Fukushima's” the time information of "1490924835476" is set as the time information of "1490924836612" as the end time of the voice.
- FIG. 11 is a diagram showing an output example (OUT4) of a speech recognition / speech language understanding program API that performs processing on an input (IN4) including history information (HI4) of speech.
- “CurrentInput” means the speech recognition result of the input speech signal.
- speech recognition processing is performed on the cut-out speech signal, and a speech recognition result (text data of speech) of "Teach me the weather” is obtained.
- ConsideredInputs is the input used to estimate “intent” or “slotSet”.
- “Fukushima's” and “Teach me the weather” were used when estimating "Intent” which is “CheckWeather” and “Place” which is “Fukushima”. That is, not only the latest speech recognition result that is “tell the weather” but also the history information (HI4) of the utterance that is "Fukushima's” is used to estimate “intent” and "slotSet”.
- the waveform of the audio signal of the section corresponding to "Weekend" cut out by the voice section detection (VAD) is the cut out audio signal.
- the time at the beginning of the section cut out is the time at which the cut was started, and the last time of the section cut out is the time at which the cut was completed.
- the history information of the utterance has, for example, the content as shown in FIG.
- FIG. 12 is a diagram illustrating an example of speech history information.
- FIG. 13 shows an output example (OUT5) of the speech recognition / speech language understanding program API that performs processing on the input (IN5) including the history information (HI5) of the speech.
- the example at the time of connecting the history of the latest utterance is shown, it is not necessary to necessarily connect the history.
- the input (IN6) and the output (OUT6) of the speech recognition / speech language understanding program API are as follows, for example.
- the waveform of the audio signal of the section corresponding to "Teach me the weather" cut out by the voice section detection (VAD) is the cut out audio signal.
- the time at the beginning of the section cut out is the time at which the cut was started, and the last time of the section cut out is the time at which the cut was completed.
- the history information of the utterance has, for example, the content as shown in FIG.
- FIG. 14 shows an example of speech history information.
- FIG. 15 shows an output example (OUT6) of the speech recognition / speech language understanding program API for processing the input (IN6) including the history information (HI6) of the speech.
- the instruction content intended by the user is estimated even if the user utters while leaving “a gap”.
- the contents of specific speech language understanding processing will be described below.
- the speech language understanding unit 103 has three information sources of a semantic frame template (Semantic Frame Template), a word dictionary (including a proper noun database), and a language model.
- a semantic frame template Semantic Frame Template
- a word dictionary including a proper noun database
- a language model e.g., a language model of a semantic frame template
- the semantic frame template is also described as “IS (Information Source) 1”
- the word dictionary as “IS 2”
- IS 3 the language model
- the semantic frame template (IS1) is a template of a combination of "intent” and “slotSet”. It has a list of "intents”, for example, a list like ["CheckWeather”, “ViewSchedule”, “SendMail”, ...].
- slotSet is defined for each "intent”. For example, it has a correspondence such as “CheckWeather”: ["DateTime", “Place”]. This means that the supported parameters for "” weather confirmation "are” time “and” place ".
- the word dictionary (IS2) is a list in which so-called words are held together with their "part of speech” and “attribute score list”. "Part-of-speech” is a type such as "verb", “noun”, and “article”.
- the “attribute score list” is a list in which the word represents, with respect to each "attribute”, whether or not those words are represented by a value of 0-1.
- the “attribute score list” is an expression relating to “date and time” if it is the word “tomorrow”, for example, so the score for "date and time” is 1, and the score for the other "attributes” is close to zero.
- Proper nouns are also registered in this word dictionary (IS2).
- the "attribute score list" of each proper noun is given based on the proper noun database held internally.
- the proper noun database is a database that manages proper nouns of various categories (attributes), such as place names, facility names, music names, movie titles, and celebrity names. However, here, it is assumed that the music titles and movie titles are always updated to the latest information.
- the degree of prominence is set to 0 to 1 for each proper noun. For example, with respect to the word "Tokyo”, the prominence of "Tokyo" as the place name is assigned 1, the prominence of "Tokyo” as the music title is 0.6, and so on.
- the prominence degree may not be normalized among the categories.
- the proper nouns are generated in the word dictionary (IS2) according to the prominence degree held in the proper noun database, and the "attribute score list" is generated. For example, if the proper noun "Fukushima” is registered in the proper noun database as "place name”, "person's name”, or "restaurant name”, its prominence is given as an attribute score Ru.
- the attribute score is 0 for an attribute that has not been registered in the proper noun database.
- the language model is information on the user's utterance phrase about each "intent”. For example, "" CheckWeather "has the words” tell me the weather for ⁇ DateTime> 's ⁇ Place> "," tell me the weather for ⁇ Place>' s ⁇ DateTime> ", and so on. ", Information is held.
- ⁇ Place> and ⁇ DateTime> are parameters that express the user's intention, and match the parameters in the above-mentioned semantic frame template (IS1).
- the language model (IS3) holds the wording of ⁇ Place>, ⁇ DateTime>, and information of expression.
- ⁇ Place> has a wording of“ (place name) ”,“ (place name),... ”Or“ ⁇ DateTime> indicates “(date and time)”, “(several word) month (several word It is held as "the day”, "(numeral) day", and so on ".
- “(place name)” is an attribute of a word, which matches the “attribute” managed by the word dictionary (IS2) described above.
- the information may be stored in a format such as a statistical model learned from a large corpus.
- a method of generating a model such as a finite state machine (FSM) or a finite state transducer (FST) from a template may be applied.
- FSM finite state machine
- FST finite state transducer
- the speech language understanding unit 103 uses the three information sources of the semantic frame template (IS1), the word dictionary (IS2), and the language model (IS3) described above to input an input speech recognition result (text data of an utterance). ) Analyze the meaning of the user's voice instruction.
- IS1 semantic frame template
- IS2 word dictionary
- IS3 language model
- the general speech language understanding process comprises three steps of steps S11 to S13 shown in the flowchart of FIG.
- step S11 when there is a statistical model in which the language model (IS3) is learned from a large amount of corpus, the speech language understanding unit 103 determines the fitness as the likelihood of the input character string calculated by that statistical model.
- FSM finite automaton
- FST finite state transducer
- the speech language understanding unit 103 compares the calculated score with a threshold, and when the score is larger than the threshold, performs the determination of “adapted”.
- the word “Tomorrow” is given the attribute “date and time” in the word dictionary (IS2), and in the language model (IS3), “ ⁇ DateTime> is Since it holds information that there is a wording “(date and time)”, it is determined that “Tomorrow” is appropriate for ⁇ DateTime>.
- “around Tokyo” holds information that “Tokyo” is “place name” and “ ⁇ Place> has the phrase“ around (name of place) ””. , It is determined that it is suitable for ⁇ Place>.
- the entire input string matches the "CheckWeather" template "tell me the weather for ⁇ DateTime> 's ⁇ Place>", so it is determined that it is suitable for "CheckWeather”.
- step S12 the speech language understanding unit 103 performs the processing in step S11 so that the input character string corresponds to "CheckWeather", "Tomorrow” is for ⁇ DateTime>, "around Tokyo” is for ⁇ Place> Since it was determined that they are suitable, they are applied to the semantic frame template (IS1). Specifically, it applies to the format output from the speech language understanding unit 103.
- CheckWeather which is a weather check
- intent the user's intention
- DateTime and “Place” are set as its parameters (“slotSet”). It is set.
- Tomorrow as “DateTime” and “around Tokyo” as “Place” are respectively set.
- step S13 the speech language understanding unit 103 interprets and converts parameters as necessary.
- the expression "around Tokyo” deletes the portion “periphery” when it can be determined that the information "periphery” is often unnecessary in weather confirmation. That is, even when the user says “Tokyo” or “around Tokyo”, they are aligned with the expression "Tokyo” so that the application can perform the same processing.
- the output result of the speech language understanding unit 103 is, for example, as shown in FIG.
- steps S11 to S13 in FIG. 16 described above are a flow of general speech language understanding processing.
- speech language understanding processing of the present technology although history information of the utterance is used, it is necessary to determine whether or not the history of the past utterance is considered.
- a second input obtained by combining only the first input hypothesis using only the current input and one of the history of speech Analysis processing is performed with three input hypotheses of a hypothesis and a third input hypothesis in which two speech histories are combined.
- First score Ratio of parameters given to "intent" of each input hypothesis (2)
- Second score Score based on language model (IS3) for each input hypothesis )
- Third score Time difference between the history of the oldest past utterance and the history of the next oldest utterance in each input hypothesis (4)
- Fourth score combination of each input hypothesis number
- the second score for example, as a language model (IS3), "If in” CheckWeather “, information” Tell ⁇ Place> 's ⁇ DateTime> "is held,” tomorrow " When "Teach the weather in Tokyo” is uttered, the score will be deducted because "to" is missing.
- IS3 language model
- the difference is the difference between the current time and the history time. Also, for example, in the case where two speech histories are combined, the difference is the time between the time of the immediately preceding history and the time of the immediately preceding history.
- the score can be "0".
- the speech language understanding unit 103 it can be determined that the first score and the second score are better as the value is larger, and the third score and the fourth score are better as the value is smaller. That is, as the determination here, the utterances before and after “a while” are not combined (connected) blindly.
- the speech language understanding unit 103 for comparison and final selection, for example, using a method of performing rule processing like a decision tree while comparing numerical values of these scores, or It is possible to design a function that calculates the final score from the four score values and use a method of using it.
- first to fourth scores are examples of various scores, and some of the first to fourth scores may be used, and further others may be used.
- the score of may be used.
- the processing of calculating the score may be performed after removing a wording (a so-called filler) such as “E-T”.
- step S21 based on the speech recognition result from the speech recognition unit 102, the speech language understanding unit 103 generates an input hypothesis from the current input and the history information of the speech.
- step S22 the speech language understanding unit 103 calculates the matching degree for each input hypothesis generated in the process of step S21.
- the first score to the fourth score are calculated for the first input hypothesis “Teach the weather” and the second input hypothesis “Teach the weather tomorrow”. Ru.
- the degree of fitness including at least one of the degree of relatedness of speech before and after “between” and grammatical connection can be obtained.
- step S23 the speech language understanding unit 103 outputs from the semantic frame template (IS1) for each input hypothesis (for example, the first input hypothesis and the second input hypothesis) generated in the process of step S21. Generate a candidate.
- IS1 semantic frame template
- step S24 the speech language understanding unit 103 interprets and converts parameters as necessary.
- “Today” is March 31, 2017, “Tomorrow” is April 1, 2017, so the date and time specified by the user is April 1, 2017. It is expressed in a predetermined format.
- step S25 the speech language understanding unit 103 compares the input hypotheses and selects the most appropriate one.
- the first input hypothesis “Teach the weather” and the second input hypothesis “Teach the weather tomorrow” are compared, and there is more information, “Teach the weather tomorrow”
- a second input hypothesis that is That is, even if the user utters "after” after “tomorrow” as in “tomorrow's ,, tell me the weather", in the second input hypothesis, "in between It can be said that the user's intention is correctly read without interpreting the utterances before and after ".”
- FIG. 22 shows an example of the waveform of an audio signal in the case of uttering “I'm hungry, today,, teach the weather”.
- the speech language understanding unit 103 calculates the degree of matching for the first to third input hypotheses and further generates output candidates from the semantic frame template (IS1) (S22 in FIG. 21). , S23).
- the degree of matching is calculated by obtaining the above-described first to fourth scores.
- FIG. 23 shows an example of the score for each input hypothesis.
- 1.0 is obtained as a score based on the language model (IS3), since there is no element to be deducted. Furthermore, in the first input hypothesis, only the current input of "Teach the weather” is used, so 0 is obtained as the third score and the fourth score, respectively.
- a second score of the second input hypothesis 1.0 is obtained as a score based on the language model (IS3), since there is no element to be particularly deducted. Furthermore, in the second input hypothesis, not only the current input of "tell the weather” but also the speech history of "today” are used, so the third score is the current time and the history of the history. 0.6 seconds (600 milliseconds) indicating the difference from the time is obtained. Also, in the second input hypothesis, one history of utterances is combined with the current input, so 1 is obtained as the fourth score.
- a score of 0.4 is obtained as a score based on the language model (IS3). Furthermore, in the third input hypothesis, not only the current input of "tell the weather” but also the history of utterances of "today's” and “annoysed”, so as a third score, 0.7 seconds (700 milliseconds) is obtained, which indicates the difference between the time of the previous history and the time of the second history. Also, in the third input hypothesis, two histories of speech are connected to the current input, so 2 is obtained as the fourth score.
- the speech language understanding unit 103 for example, if “Today” is March 31, 2017, “Tomorrow” is April 1, 2017, so as the date and time designated by the user, "Tomorrow” is converted to "April 1, 2017” (S24 in FIG. 21). Then, the speech language understanding unit 103 compares the input hypotheses with each other according to the degree of matching thus obtained, and the most suitable one is selected (S25 in FIG. 21).
- the decision tree is compared while comparing the numerical values of these scores respectively.
- an input hypothesis to be finally output is selected. For example, in the example of FIG. 23, the second input hypothesis “Teach today's weather” is selected as the most appropriate one, and an output according to the second input hypothesis is made.
- the time interval of preceding and succeeding speech is compared with the threshold, and when the time interval is larger than the threshold, the time interval is not recognized as “intermediate”, and the input hypothesis is generated. It does not use in the input hypothesis without using the speech history of.
- the speech language understanding process using the history information of the speech makes it possible to capture the user's intention from the speech of the user (speech including "between"), which is more convenient. We explained that we can provide high quality voice interaction.
- image data obtained by the sensor 54 (FIG. 2) provided in the voice processing apparatus 10 is analyzed to recognize who the speaker is, and the recognition result By receiving, you will be able to identify the specific person that "I" points to.
- the waveform of the audio signal of the section corresponding to “I want to confirm the schedule for the next week” cut out by the voice section detection (VAD) is the cut out audio signal.
- the time at the beginning of the section cut out is the time at which the cut was started, and the last time of the section cut out is the time at which the cut was completed.
- the other sensor information includes information related to the speaker obtained from the image data, but the content is as shown in FIG. 24, for example.
- the history information of the utterance includes the character string of the speech recognition result and the start time of clipping of the corresponding audio signal as the history of the past utterance, and the content is, for example, as shown in FIG.
- FIG. 24 is a diagram showing an example of other sensor information.
- Image means sensor information obtained from image data, and “speaker” is included as the object.
- FIG. 25 is a diagram showing an example of utterance history information.
- FIG. 26 is a view showing an output example (OUT10) of the speech recognition / speech language understanding program API which performs processing corresponding to the other sensor information (SI10) and the input (IN10) including the history information of the utterance (HI10).
- steps S101 to S107 is executed by the voice processing apparatus 10 on the local side
- steps S201 to S204 is executed by the server 20 on the cloud side.
- step S101 the signal processing unit 101 of the processing unit 51 performs voice detection processing on a voice signal obtained by converting the sound collected by the microphone 52 and input thereto.
- step S102 the processing unit 51 performs filtering processing of speech history information.
- the speech history is extracted based on extraction information including, for example, a time interval or filler, information on a speaker (speaker information), and information on a user's line of sight (line of sight information).
- the history of utterances matching the history of utterances used in the speech language understanding process executed by the server 20 on the cloud side is selected.
- the term "filler” refers to a word, and includes, for example, words such as "E-o-t” and "Ano ⁇ ".
- step S103 the processing unit 51 determines a history of transmission target utterances (transmission history) based on the transmission policy.
- transmission history determination process for example, according to a predetermined transmission policy such as the maximum number of transmissions (for example, 10 histories at the maximum) related to the history of utterances, the maximum transmission data size (for example, 2 MB at the maximum), Among the speech histories extracted in the filtering process of step S102, the speech history to be actually transmitted is determined.
- step S104 under the control of the processing unit 51, the communication I / F 55, together with the audio signal obtained in the process of step S101, the history information of the utterance determined in the process of step S103 is transmitted to the server via the Internet 30. Send to 20.
- sensor data obtained from the sensor 54 (FIG. 2) may be transmitted.
- step S201 the communication I / F 72 receives the history information of speech and the speech signal transmitted from the speech processing apparatus 10 via the Internet 30 according to the control from the processing unit 71.
- step S202 the speech recognition unit 102 of the processing unit 71 performs speech recognition processing on the speech signal received in the process of step S201.
- step S203 the speech language understanding unit 103 of the processing unit 71 performs speech language understanding processing based on the speech history information received in the processing of step S201 and the speech recognition result obtained in the processing of step S202.
- the speech language understanding process for example, a process including the speech language understanding process of the present technology shown in FIG. 21 is performed. Further, here, other sensor information based on sensor data obtained from the sensor 54 (FIG. 2) may be used.
- step S204 the communication I / F 72 transmits the recognition / analysis result obtained in the process of step S203 to the voice processing apparatus 10 via the Internet 30 according to the control from the processing unit 71.
- step S105 the communication I / F 55 receives the recognition / analysis result transmitted from the server 20 via the Internet 30 according to the control from the processing unit 51.
- step S106 the processing unit 51 stores the recognition / analysis result received in the process of step S105, for example, in a memory.
- step S107 the speaker 53 outputs a voice according to (the voice signal of) the recognition / analysis result received in the process of step S105, under the control of the processing unit 51.
- the voice processing apparatus 10 not only the voice output from the speaker 53, but also text information or image information corresponding to the recognition / analysis result may be displayed on the display unit, for example.
- the server 20 on the cloud side performs speech language understanding processing using history information of speech corresponding to the first embodiment or the second embodiment described above, the user's It becomes possible to understand the user's intention from the utterance (the utterance including “in between”), and more convenient voice interaction can be provided.
- the data amount can be reduced. it can.
- the speech processing apparatus 10 is a mobile device, even when a sufficient band can not be secured by the mobile communication, history information of speech can be transmitted reliably.
- FIG. 27 shows the case where the speech processing device 10 on the local side manages the history information of the speech
- the history information of the speech is managed for each user by the server 20 on the cloud side. You may
- the input (IN) of the speech recognition / speech language understanding program API the case where the time when the extraction is started and the time when the extraction is completed is input together with the extracted speech signal Among the cut-out times at the end, for example, only one of the cut-out times may be input.
- the signal processing unit 101 (FIG. 4) is incorporated in the processing unit 51 (FIG. 2) of the speech processing apparatus 10 on the local side, and the speech recognition unit 102 (FIG. 4) and the speech language understanding unit 103 (FIG. 4). 4) has been described as being incorporated in the processing unit 71 (FIG. 3) of the server 20 on the cloud side, but the signal processing unit 101 to the speech language understanding unit 103 in FIG. It may be built into either device.
- all of the signal processing unit 101 to the speech language understanding unit 103 in FIG. 4 may be incorporated in the speech processing device 10 and the processing may be completed locally.
- various databases may be held by the server 20 on the Internet 30.
- all of the signal processing unit 101 to the speech language understanding unit 103 in FIG. 4 are incorporated in the server 20 side, and raw data of voice collected by the voice processing apparatus 10 is transmitted to the server 20 via the Internet 30. It may be sent to the
- JSON JavaScript (registered trademark) Object Notation
- XML Extensible Markup Language
- Other formats may be used.
- the format of the output (OUT) is not limited to the text format, and may be a binary format.
- FIG. 28 is a block diagram showing an example of a hardware configuration of a computer that executes the series of processes described above according to a program.
- a central processing unit (CPU) 1001, a read only memory (ROM) 1002, and a random access memory (RAM) 1003 are mutually connected by a bus 1004.
- An input / output interface 1005 is further connected to the bus 1004.
- An input unit 1006, an output unit 1007, a recording unit 1008, a communication unit 1009, and a drive 1010 are connected to the input / output interface 1005.
- the input unit 1006 includes a keyboard, a mouse, a microphone and the like.
- the output unit 1007 includes a display, a speaker, and the like.
- the recording unit 1008 includes a hard disk, a non-volatile memory, and the like.
- the communication unit 1009 includes a network interface or the like.
- the drive 1010 drives a removable recording medium 1011 such as a magnetic disk, an optical disk, a magneto-optical disk, or a semiconductor memory.
- the CPU 1001 loads the program stored in the ROM 1002 or the recording unit 1008 into the RAM 1003 via the input / output interface 1005 and the bus 1004, and executes the program. A series of processing is performed.
- the program executed by the computer 1000 can be provided by being recorded on, for example, a removable recording medium 1011 as a package medium or the like. Also, the program can be provided via a wired or wireless transmission medium such as a local area network, the Internet, or digital satellite broadcasting.
- the program can be installed in the recording unit 1008 via the input / output interface 1005 by attaching the removable recording medium 1011 to the drive 1010. Also, the program can be received by the communication unit 1009 via a wired or wireless transmission medium and installed in the recording unit 1008. In addition, the program can be installed in advance in the ROM 1002 or the recording unit 1008.
- the processing performed by the computer according to the program does not necessarily have to be performed chronologically in the order described as the flowchart. That is, the processing performed by the computer according to the program includes processing executed in parallel or separately (for example, parallel processing or processing by an object). Further, the program may be processed by one computer (processor) or may be distributed and processed by a plurality of computers.
- the embodiments of the present technology are not limited to the above-described embodiments, and various modifications can be made without departing from the scope of the present technology.
- the present technology can have a cloud computing configuration in which one function is shared and processed by a plurality of devices via a network.
- each step of the speech language understanding process shown in FIG. 21 and the speech interaction process shown in FIG. 27 can be executed by one device in addition to a plurality of devices. Furthermore, in the case where a plurality of processes are included in one step, the plurality of processes included in one step can be executed by being shared by a plurality of devices in addition to being executed by one device.
- the present technology can be configured as follows.
- An information processing apparatus comprising: a processing unit that connects the preceding and succeeding utterances according to the matching degree in the semantic unit of the preceding and following utterances included in the user's utterance.
- the processing unit is Based on the current utterance and the history of the past utterance, the matching degree in the meaning unit of the preceding and subsequent utterances is calculated, It is determined based on the calculated degree of matching whether or not to connect the preceding and subsequent utterances, The information processing apparatus according to (1), wherein the utterances before and after are connected when it is determined that the utterances before and after are connected.
- the processing unit uses the sensor information obtained from the sensor together with the current utterance and the history of the past utterance to calculate the matching degree in the semantic unit of the preceding and following utterances. Processing unit.
- the processing unit is Calculating a score for each input hypothesis obtained by temporarily connecting the preceding and succeeding utterances, Based on the calculated score for each input hypothesis, the fitness of the preceding and subsequent utterances for each input hypothesis is calculated;
- the information processing apparatus according to (2) or (3) wherein one input hypothesis is selected from a plurality of input hypotheses based on the calculated degree of fitness for each input hypothesis.
- the score is, for each input hypothesis, A first score obtained from the rate of use of parameters of the function according to the user's intention; A second score obtained from a language model relating to the information of the user's utterance phrase, A third score obtained from a temporal interval between the current utterance and the history of the past utterances or a temporal interval between the histories of the past utterances;
- the information processing apparatus according to (4) or (5), including at least one score of the fourth score obtained from the number of combinations of the current utterance and the history of the past utterance.
- the information processing apparatus includes at least one of a degree of association of the preceding and succeeding utterances and a grammatical connection.
- the processing unit determines whether or not the preceding and succeeding utterances are connected based on the interval between the processing units.
- the information processing apparatus uses only the history of valid utterances among the history of the past utterances.
- the information processing apparatus includes the content of the utterance of the user and information of a time when the user uttered.
- the information processing apparatus according to (3), wherein the sensor information includes image data obtained by imaging a subject, or position information indicating a position of the user. (12)
- the information processing apparatus An information processing method for connecting the preceding and subsequent utterances according to the matching degree in the semantic unit of the preceding and following utterances included in the user's utterance.
- a processing unit that extracts, from the history of the user's past utterances, a history of past utterances suitable for the speech language understanding processing for the utterance including the interval;
- An information processing apparatus comprising: a transmitter configured to transmit, to an information processing apparatus that performs the speech language understanding process, a history of the extracted past utterances together with an audio signal corresponding to a current utterance of the user.
- the processing unit extracts the history of the past utterance based on extracted information including time intervals, information on wording, information on speakers, or information on eye gaze of the user.
- Information processor as described.
- the information processing apparatus according to (13) or (14), wherein the transmission unit transmits the history of the past utterance based on the transmission maximum number regarding the history of the past utterance or the transmission maximum data size.
- the information processing apparatus From the history of the user's past utterances, extract the history of past utterances suitable for speech language understanding processing for utterances including intervals, An information processing method for transmitting a history of the extracted past utterances together with an audio signal corresponding to the current utterance of the user to an information processing apparatus that performs the speech language understanding process.
- 1 voice dialogue system 10 voice processing unit, 20 server, 30 Internet, 51 processing unit, 52 microphone, 53 speaker, 54 sensor, 55 communication I / F, 71 processing unit, 72 communication I / F, 73 database, 101 signal Processing unit, 102 speech recognition unit, 103 speech language understanding unit, 1000 computer, 1001 CPU
Abstract
本技術は、より利便性の高い音声インタラクションを提供することができるようにする情報処理装置、及び情報処理方法に関する。 ユーザの発話に含まれる間の前後の発話の意味単位での適合度に応じて、前後の発話を接続する処理部を備える情報処理装置が提供されることで、より利便性の高い音声インタラクションを提供することができる。本技術は、例えば、音声対話システムに適用することができる。
Description
本技術は、情報処理装置、及び情報処理方法に関し、特に、より利便性の高い音声インタラクションを提供することができるようにした情報処理装置、及び情報処理方法に関する。
近年、ユーザの発話に応じた応答を行う音声対話システムが、様々な分野で利用されはじめている。
例えば、音声対話システムを利用することで、ユーザが、「ここどこですか?」と質問したとき、「セントラルパークにいます。」という回答が返ってくる(例えば、特許文献1参照)。
ところで、音声による指示を受け付ける機器において、ユーザの発話に「間(ま)」があった場合、従来の音声言語理解プログラムでは、ユーザの指示を正しく理解することができない。
すなわち、音声対話システムにおいて、音声ユーザインターフェースを持つ機器では、まず、信号処理部が、常にマイクロフォンに入力される音声信号から、ユーザの発話が録音された区間を切り出す。そして、音声認識部が、その切り出された音声信号を使って、ユーザの発話内容を文字列として書き起こし、言語理解部が、その書き起こされた文字列のみを使ってユーザの指示内容を解析するためである。
「間」が空いてしまうと、ユーザが意図したことを言い切る前に、信号処理部が音声信号を切り出し、その後段の処理に移ってしまう。その後に付け足すようにユーザが指示をしたとしても、またその内容のみを解析してしまうため、機器は、ユーザの意図していた通りの挙動をしないことになる。
そのため、ユーザの発話に「間」が空いた場合でも、音声対話システムによって、ユーザの意図していた通りの挙動が行われ、より利便性の高い音声インタラクションを提供するための技術が求められている。
本技術はこのような状況に鑑みてなされたものであり、より利便性の高い音声インタラクションを提供することができるようにするものである。
本技術の第1の側面の情報処理装置は、ユーザの発話に含まれる間の前後の発話の意味単位での適合度に応じて、前記前後の発話を接続する処理部を備える情報処理装置である。
本技術の第1の側面の情報処理方法は、情報処理装置の情報処理方法において、前記情報処理装置が、ユーザの発話に含まれる間の前後の発話の意味単位での適合度に応じて、前記前後の発話を接続する情報処理方法である。
本技術の第1の側面の情報処理装置、及び情報処理方法においては、ユーザの発話に含まれる間の前後の発話の意味単位での適合度に応じて、前記前後の発話が接続される。
本技術の第2の側面の情報処理装置は、ユーザの過去の発話の履歴から、間を含んだ発話に対する音声言語理解処理に適合する過去の発話の履歴を抽出する処理部と、前記ユーザの現在の発話に応じた音声信号とともに、抽出された前記過去の発話の履歴を、前記音声言語理解処理を行う情報処理装置に送信する送信部とを備える情報処理装置である。
本技術の第2の側面の情報処理方法は、情報処理装置の情報処理方法において、前記情報処理装置が、ユーザの過去の発話の履歴から、間を含んだ発話に対する音声言語理解処理に適合する過去の発話の履歴を抽出し、前記ユーザの現在の発話に応じた音声信号とともに、抽出された前記過去の発話の履歴を、前記音声言語理解処理を行う情報処理装置に送信する情報処理方法である。
本技術の第2の側面の情報処理装置、及び情報処理方法においては、ユーザの過去の発話の履歴から、間を含んだ発話に対する音声言語理解処理に適合する過去の発話の履歴が抽出され、前記ユーザの現在の発話に応じた音声信号とともに、抽出された前記過去の発話の履歴が、前記音声言語理解処理を行う情報処理装置に送信される。
本技術の第1の側面及び第2の側面の情報処理装置は、独立した装置であってもよいし、1つの装置を構成している内部ブロックであってもよい。
本技術の第1の側面及び第2の側面によれば、より利便性の高い音声インタラクションを提供することができる。
なお、ここに記載された効果は必ずしも限定されるものではなく、本開示中に記載されたいずれかの効果であってもよい。
以下、図面を参照しながら本技術の実施の形態について説明する。なお、説明は以下の順序で行うものとする。
1.システム構成
2.前提となる技術
3.本技術の実施の形態
(1)第1の実施の形態:発話の履歴情報を利用した音声言語理解処理
(2)第2の実施の形態:センサ情報を利用した音声言語理解処理
4.変形例
5.コンピュータの構成
2.前提となる技術
3.本技術の実施の形態
(1)第1の実施の形態:発話の履歴情報を利用した音声言語理解処理
(2)第2の実施の形態:センサ情報を利用した音声言語理解処理
4.変形例
5.コンピュータの構成
<1.システム構成>
(音声対話システムの構成)
図1は、本技術を適用した音声対話システムの構成例を示すブロック図である。
図1は、本技術を適用した音声対話システムの構成例を示すブロック図である。
音声対話システム1は、ユーザ宅等のローカル側に設置され、音声対話サービスのユーザインターフェースとして機能する音声処理装置10と、データセンタ等のクラウド側に設置され、音声対話機能を実現するための処理を行うサーバ20とから構成されるようにすることができる。
音声対話システム1において、音声処理装置10とサーバ20とは、インターネット30を介して相互に接続されている。
音声処理装置10は、例えば、家庭内LAN(Local Area Network)等のネットワークに接続可能なスピーカであって、いわゆるスマートスピーカなどとも称される。この種のスピーカは、音楽の再生のほか、例えば、照明器具や空調設備などの機器に対する音声操作などを行うことができる。
なお、音声処理装置10は、スピーカに限らず、例えば、スマートフォンや携帯電話機等のモバイル機器や、タブレット型のコンピュータなどとして構成されるようにしてもよい。
音声処理装置10は、インターネット30を介してサーバ20と連携することで、ユーザに対し、音声対話サービス(のユーザインターフェース)を提供することができる。
すなわち、音声処理装置10は、ユーザから発せられた音声(ユーザ発話)を収音し、その音声信号を、インターネット30を介して、サーバ20に送信する。また、音声処理装置10は、インターネットを介してサーバ20から送信されてくる処理データを受信し、その処理データに応じた音声を出力する。
サーバ20は、クラウドベースの音声対話サービスを提供するサーバである。
サーバ20は、インターネット30を介して音声処理装置10から送信されてくる音声信号を、テキストデータに変換するための音声認識処理を行う。また、サーバ20は、音声認識結果(テキストデータ)に対し、音声言語理解処理などの処理を行い、その処理の結果得られる処理データを、インターネット30を介して音声処理装置10に送信する。
(音声処理装置の構成)
図2は、図1の音声処理装置10の構成例を示すブロック図である。
図2は、図1の音声処理装置10の構成例を示すブロック図である。
図2において、音声処理装置10は、処理部51、マイクロフォン52、スピーカ53、センサ54、及び通信I/F55を含んで構成される。
処理部51は、例えば、CPU(Central Processing Unit)やマイクロプロセッサ等から構成される。処理部51は、各種の演算処理や、各部の動作制御など、音声処理装置10における中心的な処理装置として動作する。
マイクロフォン52は、外部からの音を、電気信号に変換する機器(収音器)である。マイクロフォン52は、変換で得られる音声信号を、処理部51に供給する。
スピーカ53は、電気信号を物理振動に変えて音を出す機器である。スピーカ53は、処理部51から供給される音声信号に応じた音を出力する。
センサ54は、各種のセンサから構成される。センサ54は、センシングを行い、センシング結果に応じたセンサ情報(センサデータ)を、処理部51に供給する。
例えば、センサ54としては、被写体を撮像するイメージセンサ、磁場(磁界)の大きさや方向を検出する磁気センサ、加速度を検出する加速度センサ、角度(姿勢)や角速度、角加速度を検出するジャイロセンサ、近接するものを検出する近接センサ、あるいは、指紋や虹彩、脈拍などの生体情報を検出する生体センサなど、各種のセンサを含めることができる。
また、センサ54には、温度を検出する温度センサや、湿度を検出する湿度センサ、周囲の明るさを検出する環境光センサなどの周囲の環境を測定するためのセンサを含めることができる。なお、センサデータには、GPS(Global Positioning System)信号などから算出される位置情報(位置データ)や、計時手段により計時された時刻情報などの様々な情報を含めるようにしてもよい。
通信I/F55は、例えば、通信インターフェース回路等から構成される。通信I/F55は、処理部51からの制御に従い、インターネット30に接続されたサーバ20にアクセスして、各種のデータをやりとりする。
ここで、例えば、処理部51は、音声対話システム1(図1)により提供される機能のうち、一部の機能を有している。
すなわち、処理部51は、マイクロフォン52から供給される音声信号に対する所定の信号処理を行い、その結果得られる音声信号を、通信I/F55に供給する。これにより、ユーザの発話の音声信号が、インターネット30を介してサーバ20に送信される。また、処理部51は、センサデータを、通信I/F55に供給して、インターネット30を介してサーバ20に送信することができる。
また、処理部51は、通信I/F55から供給される音声信号を処理し、その結果得られる音声信号を、スピーカ53に供給する。これにより、スピーカ53からは、システム応答(の音声信号)に応じた応答音声が出力される。
なお、図2には図示していないが、音声処理装置10には、各種の情報(例えば文字や画像等)を表示するための表示部、ユーザからの操作を受け付ける入力部、又は各種のデータ(例えば音声データやテキストデータ等)を記憶する記憶部などをさらに設けるようにしてもよい。
ここで、表示部は、例えば、液晶ディスプレイや有機ELディスプレイ等から構成される。入力部は、例えば、ボタンやキーボード等から構成される。また、入力部は、タッチセンサと表示部とが一体化されたタッチパネルとして構成され、ユーザの指やタッチペン(スタイラスペン)による操作に応じた操作信号が得られるようにしてもよい。記憶部は、例えば、不揮発性メモリの一種であるフラッシュメモリ(Flash Memory)や、揮発性メモリの一種であるDRAM(Dynamic Random Access Memory)などから構成される。
(サーバの構成)
図3は、図1のサーバ20の構成例を示すブロック図である。
図3は、図1のサーバ20の構成例を示すブロック図である。
図3において、サーバ20は、処理部71、通信I/F72、及びデータベース73を含んで構成される。
処理部71は、例えば、CPUやマイクロプロセッサ等から構成される。処理部71は、各種の演算処理や、各部の動作制御など、サーバ20における中心的な処理装置として動作する。
通信I/F72は、例えば、通信インターフェース回路等から構成される。通信I/F72は、処理部71からの制御に従い、インターネット30を介して接続される音声処理装置10との間で、各種のデータをやりとりする。
データベース73は、例えば、ハードディスク(HDD:Hard Disk Drive)や半導体メモリ、光ディスク等の大容量の記録装置として構成される。
例えば、データベース73には、音声認識処理を行うための音声認識用データベースや、音声言語理解処理を行うための音声言語理解用データベースなどが含まれる。なお、音声認識用データベースや音声言語理解用データベースは、データベースの一例であって、音声対話サービスを実現するために必要となるデータベース(例えば、知識データベースや発話データベース、対話履歴データベース等)を含めることができる。
ここで、例えば、処理部71は、音声対話システム1(図1)により提供される機能のうち、一部の機能を有している。
すなわち、処理部71は、データベース73に含まれる音声認識用データベースを参照して、インターネット30を介して音声処理装置10から送信されてくるユーザの発話の音声信号を、テキストデータに変換するための音声認識処理や、音声言語理解処理などの処理を行う。これにより、ユーザに対するシステム応答が生成され、処理データとして、インターネット30を介して、音声処理装置10に送信される。
(音声対話システムの機能的構成例)
図4は、本技術を適用した音声対話システムの機能的構成例を示すブロック図である。
図4は、本技術を適用した音声対話システムの機能的構成例を示すブロック図である。
図4に示すように、音声対話システム1は、信号処理部101、音声認識部102、及び音声言語理解部103を含んで構成される。
信号処理部101には、マイクロフォン52により収音された音を変換して得られる音声信号が入力される。信号処理部101は、入力された音声信号に対し、所定の信号処理を行い、その結果得られる音声信号を、音声認識部102に供給する。
信号処理部101により行われる信号処理としては、例えば、ユーザの発話した区間を切り出す処理や、音声信号に対する雑音を除去する処理が行われる。
音声認識部102は、音声テキスト変換用データベースなどを参照することで、信号処理部101から供給される音声信号を、テキストデータに変換する音声認識処理を行う。音声認識部102は、音声認識処理の結果得られる音声認識結果(発話のテキストデータ)を、音声言語理解部103に供給する。
音声言語理解部103は、音声認識部102から供給される音声認識結果に対し、所定の音声言語理解処理を行い、その結果得られる音声入力内容の解析結果を、後段の処理部(不図示)に供給する。
音声言語理解部103により行われる音声言語理解処理としては、例えば、自然言語である音声認識結果(発話のテキストデータ)を、機械が理解できる表現に変換する処理が行われる。
なお、信号処理部101は、ローカル側の音声処理装置10の処理部51(図2)に組み込まれることが想定され、音声認識部102及び音声言語理解部103は、大容量のメモリやストレージを必要とするため、クラウド側のサーバ20の処理部71(図3)に組み込まれることが想定される。
また、図示はしていないが、音声言語理解部103の後段に設けられた処理部(不図示)では、音声言語理解部103からの解析結果に基づいた処理として、例えば対話制御処理などの処理が行われ、ユーザに対するシステム応答を生成することができる。
なお、説明の都合上、図1の音声対話システム1においては、1台の音声処理装置10が設けられる場合を図示しているが、例えば、ユーザごとに、複数の音声処理装置10を設けることができる。
また、図1の音声対話システム1では、1台のサーバ20が設けられる場合を図示しているが、例えば、機能(モジュール)ごとに、複数のサーバ20を設けることができる。より具体的には、例えば、音声認識部102に対応した音声認識モジュールを有するサーバ20や、音声言語理解部103に対応した音声言語理解モジュールを有するサーバ20などを、個別のサーバ20として設けることができる。
<2.前提となる技術>
通常、音声インターフェースを持つ機器では、信号処理部101による信号処理と、音声認識部102による音声認識処理と、音声言語理解部103による音声言語理解処理とがその順に行われる。なお、本技術の主なターゲットは、音声認識処理と音声言語理解処理となるが、本技術の内容が分かりやすくなるようにするために、信号処理部101による信号処理の内容についても説明する。
信号処理部101では、主に2つの処理が行われる。1つ目の処理は、マイクロフォン52に常時入力される音声信号からユーザが発話した時間区間のみを切り出すという処理である。この処理は、音声区間検出(VAD:Voice Activity Detection)と呼ばれる。2つ目の処理は、雑音の大きな環境であっても、正しく音声認識ができるように雑音を抑圧し、ユーザの音声を強調する処理である。この処理は、音声強調(Speech Enhancement)と呼ばれる。
ここで注意すべき点は、音声区間検出(VAD)は、入力信号の物理特性のみによって判定(判断)されることである。つまり、入力音声の振幅や周波数特性に基づき、入力音声の主たる成分が、音声であるか否かを逐次判定し、音声が時間的に連続して入力されている区間を切り出す処理となる。
図5は、音声信号の波形における音声区間検出(VAD)の例を示す図である。図5には、縦方向を振幅とし、横方向を時間としたときのユーザの発話の音声信号の波形を表している。
信号処理部101では、音声信号の波形から、音声が時間的に連続して入力されている区間として、開始時刻t1から終了時刻t2までの区間を切り出すことになる。すなわち、図5に示した音声信号の波形において、開始時刻t1乃至終了時刻t2の区間を切り出す処理が、音声区間検出(VAD)となる。
ここでは、音声の入力を検出してから、音声の入力が途絶えるまでを切り出す。多くの音声区間検出では、500ミリ秒程度入力が途絶えたと判定した場合に、音声入力が終了したと判定して信号を切り出す。例えば500ミリ秒という数値は、「切って」の「っ」のような促音(つまる音)は、音声信号ではごく短い間(200~300ミリ秒程度)無音となってしまうため、ここで切れてしまわないようにするためである。
さて、信号処理部101で切り出された音声は、音声認識部102にてユーザが実際に発話した内容のテキスト(音声認識結果)に書き起こされる。この音声認識結果(発話のテキストデータ)は、自然言語であるが、最終的に音声言語理解部103が、これを機械が理解できる表現に変換する。
例えば、ユーザが、「福島の明日の天気を教えて」と発話した場合、"ユーザの意図"は、「天気確認(Check Weather)」であり、今日が、2017年3月31日だったとした場合、天気を調べたい"日時"は、「2017年4月1日」で、"場所"は、「福島」であるということを解釈する。音声言語理解部103は、自然言語から"ユーザの意図"を推定し、そのパラメータ(ここでは、「日時」と「場所」)を解析する処理を行う。
この音声認識と音声言語理解の機能を有するプログラムのAPI(以下、音声認識・音声言語理解プログラムAPIともいう)の入力(IN1)と出力(OUT1)は、例えば、次のようになる。
<入力(IN1)>
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
例えば、図5に示した音声区間検出(VAD)により切り出された開始時刻t1乃至終了時刻t2の区間の音声信号の波形が、切り出された音声信号に相当する。また、切り出しを開始した時刻は、図5の開始時刻t1に相当し、切り出しが完了した時刻は、図5の終了時刻t2に相当している。なお、切り出しが完了した時刻は、現在の時刻であるとも言える。
<出力(OUT1)>
・音声認識結果
・意味フレームのリスト
ユーザ意図(intent)
パラメータ(SlotSet)
・音声認識結果
・意味フレームのリスト
ユーザ意図(intent)
パラメータ(SlotSet)
ここで、図6には、入力(IN1)に対する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT1)を示している。
なお、図6に示した出力例は、テキストフォーマットの一種であるJSON(JavaScript(登録商標) Object Notation)により記述している。JSON形式のオブジェクトは、キーと値のペアをコロン(:)で対にして、これらの対を、コンマ(,)で区切ってゼロ個以上列挙し、全体を波括弧({})でくくることで表現される。また、オブジェクトや値をコンマ(,)で区切ってゼロ個以上列挙し、角括弧([])でくくることで、オブジェクトや値の順序付きリストが表現される。
"input"は、入力した音声信号の音声認識結果を意味する。ここでは、切り出された音声信号に対する音声認識処理が行われ、"福島の明日の天気を教えて"である音声認識結果(発話のテキストデータ)が得られている。
"SemanticFrameList"は、意味フレーム(Semantic Frame)のリストを意味し、ここでは、そのオブジェクトとして、"intent"と"slotSet"が含まれる。
"intent"は、ユーザの意図を意味する。ここでは、「天気確認」である"CheckWeather"というユーザ意図が設定されている。
"slotSet"には、パラメータが格納される。"CheckWeather"の場合には、"slotSet"として、日時の"DateTime"と、場所の"Place"が設定される。ここでは、"DateTime"として"2017-04-01","Place"として"福島"が設定されている。
なお、パラメータであるところの"slotSet"の内容は、"intent"によって変わるものである。例えば、「音楽再生」である"PlayMusic"というユーザ意図の場合には、楽曲名の"Track"というパラメータを取り得るが、"CheckWeather"で楽曲名の"Track"というパラメータを取り得ることはない。
ここで、一つの鍵を握るのが、「福島」という単語の解釈である。「福島」という固有名詞は、それ単体では人名であるのか、地名であるのか、あるいは飲食店等の店名であるのかを判定することはできない。天気の確認を行おうとしているという文脈を持って、地名である可能性が高いと判定できる。一方で、例えば、「福島にメールを送って」と発話した場合の「福島」は、人名である可能性が高くなる。
さて、このような前提となる技術においては、現在の入力のみを考慮するので、例えば、ユーザが、「福島の、、、明日の天気を教えて」というように、「福島の」の後に、「間(ま)」を空けて発話をした場合には、「福島の」と「明日の天気を教えて」という発話を別々に解釈してしまう。
なお、本明細書において、ユーザの発話に含まれる「、、、」の表記は、発話中の「間(ま)」を表しているものとする。
図7は、「間」を空けて発話した場合の音声信号の波形の例を示す図である。図7には、「福島の、、、明日の天気を教えて」である発話の音声信号の波形を表しているが、「福島の」の後に、「間(ま)」があって、500ミリ秒程度入力が途絶えている。
そのため、信号処理部101では、「福島の」の発話に対応した開始時刻t11から終了時刻t12までの区間と、「明日の天気を教えて」の発話に対応した開始時刻t13から終了時刻t14までの区間が、別々の音声区間として切り出されている。
このとき、音声認識・音声言語理解プログラムAPIの入力(IN2)と出力(OUT2)は、例えば、次のようになる。
<入力(IN2)>
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
例えば、図7に示した音声区間検出(VAD)により切り出された「福島の」に対応する区間の音声信号の波形が、切り出された音声信号に相当し、1つ目の入力(IN2-1)とされる。この1つ目の入力では、切り出しを開始した時刻は、図7の開始時刻t11に相当し、切り出しが完了した時刻は、図7の終了時刻t12に相当している。
また、図7に示した音声区間検出(VAD)により切り出された「明日の天気を教えて」に対応する区間の音声信号の波形が、切り出された音声信号に相当し、2つ目の入力(IN2-2)とされる。この2つ目の入力では、切り出しを開始した時刻は、図7の開始時刻t13に相当し、切り出しが完了した時刻は、図7の終了時刻t14に相当している。
<出力(OUT2)>
ここで、図8には、入力(IN2)に対する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT2)を示している。
ここで、図8には、入力(IN2)に対する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT2)を示している。
図8においては、1つ目の出力(OUT2-1)として、1つ目の入力(IN2-1)である"福島の"に対応する区間の音声信号から得られる音声認識結果(発話のテキストデータ)が示されている。この1つ目の出力では、「福島の」のみでは、ユーザの意図がわからないため、"intent"は、"unknown"となる。
また、2つ目の出力(OUT2-2)として、2つ目の入力(IN2-2)である"明日の天気を教えて"に対応する区間の音声信号から得られる音声認識結果が示されている。この2つ目の出力では、ユーザの意図("intent")として、「天気確認」である"CheckWeather"が設定され、そのパラメータ("slotSet")として、"DateTime"が設定されている。すなわち、「明日の天気を教えて」だけを解析した場合、「福島」というユーザの意図した場所("Place")が解析されていない。
このように、ユーザの発話に「間」が空いてしまうと、「福島の」と「明日の天気を教えて」という発話が別々に解釈され、ユーザの意図を正しく読み取ることができなくなる。
また、例えば、スマートスピーカなどの音声処理装置10が、家族で共用するような機器である場合に、当該機器に対して、ユーザが、「私の来週の予定を確認したい」と発話した場合、音声認識・音声言語理解プログラムAPIの入力(IN3)と出力(OUT3)は、次のようになる。
<入力(IN3)>
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
例えば、音声区間検出(VAD)によって切り出された「私の来週の予定を確認したい」に対応する区間の音声信号の波形が、切り出された音声信号となる。また、切り出された区間の先頭の時刻が、切り出しを開始した時刻となり、切り出された区間の最後の時刻が、切り出しが完了した時刻となる。
<出力(OUT3)>
ここで、図9には、入力(IN3)に対する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT3)を示している。
ここで、図9には、入力(IN3)に対する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT3)を示している。
図9においては、"私の来週の予定を確認したい"に対応する区間の音声信号から得られる音声認識結果(発話のテキストデータ)が示されている。この出力では、ユーザの意図("intent")として、「予定表表示」である"ViewSchedule"が設定され、そのパラメータ("slotSet")として、"DateTime"と"Owner"が設定されている。ここでは、"DateTime"として"2017-04-02/2017-04-08","Owner"として"私"が設定されている。
"Owner"は、予定表の所有者を意味する。この例では、「私」というのが、予定表の所有者となる。これを受け取ったアプリケーションは、「私」という言葉を解釈しなければならない。ここでは、「私」というのが、一人称である知識を用い、スケジュール帳に登録されているユーザの中の誰であるのかを解決しなければならない。
このように、ユーザの発話に、例えば、「私」や「この街」といった指示語や相対的な表現が含まれていた場合、それが指す内容について、言語情報だけでは解決できないことがあり、ユーザの意図を正しく読み取ることができなくなる。
そこで、本技術では、ユーザの発話内容の履歴を用いることで、ユーザの発話に「間」があった場合においても、ユーザの指示内容を正しく理解できる解析方法を提供する。また、例えば、「私」や「この街」といった指示語や相対的な表現が、ユーザの発話に含まれていた場合、それが指す内容については、言語情報だけでは解決できないことがある。その場合には、カメラ画像の解析結果や、GPS(Global Positioning System)による位置情報などの情報を用いることで、その内容を解析できるようにする。
以下、本技術の内容を、本技術の実施の形態によって説明する。
<3.本技術の実施の形態>
(1)第1の実施の形態
本技術では、直近の発話の履歴を用いることで、ユーザの発話に「間」が入っても、意味のつながりや切れ目を判定(判断)し、ユーザの意図を正しく汲み取ることができるようにする。このとき、本技術の音声認識・音声言語理解プログラムAPIの入力には、次のように、発話の履歴情報が追加されることになる。
<入力>
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・発話の履歴情報(音声認識結果の文字列、対応する音声信号の切り出しの開始時刻)
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・発話の履歴情報(音声認識結果の文字列、対応する音声信号の切り出しの開始時刻)
ここでは、例えば、ユーザが、「福島の、、、天気を教えて、、、週末の」と、「間」を空けながら発話した場合の入出力の例を以下に示す。まず、「福島の」と発話した後に、「天気を教えて」と発話したとき、音声認識・音声言語理解プログラムAPIの入力(IN4)と出力(OUT4)は、例えば、次のようになる。
<入力(IN4)>
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・発話の履歴情報
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・発話の履歴情報
例えば、音声区間検出(VAD)によって切り出された「天気を教えて」に対応する区間の音声信号の波形が、切り出された音声信号となる。また、切り出された区間の先頭の時刻が、切り出しを開始した時刻となり、切り出された区間の最後の時刻が、切り出しが完了した時刻となる。
また、発話の履歴情報には、過去の発話の履歴として、音声認識結果の文字列、対応する音声信号の切り出しの開始時刻が含まれるが、例えば、図10に示すような内容となる。
<発話の履歴情報(HI4)>
図10は、発話の履歴情報の例を示す図である。
図10は、発話の履歴情報の例を示す図である。
"inputHistory"は、発話の履歴を意味し、ここでは、そのオブジェクトとして、"input"と"beginTime"及び"endTime"が含まれる。
"input"は、発話の履歴として、音声認識結果の文字列が設定される。ここでは、「間」を挟んで、「天気を教えて」の前に発話された"福島の"である音声認識結果(発話のテキストデータ)が、履歴として設定されている。
"beginTime"及び"endTime"は、発話の開始及び終了に関する時刻情報であって、UNIX(登録商標) epoch milliseconds と呼ばれる計算機で共通して使われている形式のデータ表現となっている。ここでは、"福島の"である音声の開始時刻として、"1490924835476"である時刻情報が、音声の終了時刻として、"1490924836612"である時刻情報が設定されている。
<出力(OUT4)>
図11は、発話の履歴情報(HI4)を含む入力(IN4)に対する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT4)を示す図である。
図11は、発話の履歴情報(HI4)を含む入力(IN4)に対する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT4)を示す図である。
"currentInput"は、入力した音声信号の音声認識結果を意味する。ここでは、切り出された音声信号に対する音声認識処理が行われ、"天気を教えて"である音声認識結果(発話のテキストデータ)が得られている。
"SemanticFrameList"のオブジェクトとして、"intent","slotSet",及び"consideredInputs"が含まれる。ここでは、ユーザの意図("intent")として、「天気確認」である"CheckWeather"が設定され、そのパラメータ("slotSet")として、"福島"である"Place"が設定されている。
"consideredInputs"は、"intent"や"slotSet"を推定するのに用いた入力とされる。ここでは、"CheckWeather"である"intent"や、"福島"である"Place"を推定する際に、"福島の"と"天気を教えて"が用いられたことを表している。すなわち、"天気を教えて"である直近の音声認識結果だけでなく、"福島の"である発話の履歴情報(HI4)が用いられて、"intent"と"slotSet"が推定されている。
次に、「天気を教えて」と発話した後に、さらに「間」をおいて「週末の」という発話があったとき、音声認識・音声言語理解プログラムAPIの入力(IN5)と出力(OUT5)は、例えば、次のようになる。
<入力(IN5)>
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・発話の履歴情報
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・発話の履歴情報
例えば、音声区間検出(VAD)によって切り出された「週末の」に対応する区間の音声信号の波形が、切り出された音声信号となる。また、切り出された区間の先頭の時刻が、切り出しを開始した時刻となり、切り出された区間の最後の時刻が、切り出しが完了した時刻となる。
また、このとき、発話の履歴情報は、例えば、図12に示すような内容となる。
<発話の履歴情報(HI5)>
図12は、発話の履歴情報の例を示す図である。
図12は、発話の履歴情報の例を示す図である。
図12においては、1つ目の発話の履歴として、「間」を挟んで、「週末の」の前に発話された"天気を教えて"である音声認識結果が設定されている。この1つ目の発話の履歴には、発話開始の時刻情報として、"1490924837154"が、発話終了の時刻情報として、"1490924839284"が設定されている。
また、2つ目の発話の履歴として、「間」を挟んで、「天気を教えて」の前に発話された"福島の"である音声認識結果が設定されている。この2つ目の発話の履歴には、発話開始の時刻情報として、"1490924835476"が、発話終了の時刻情報として、"1490924836612"が設定されている。
<出力(OUT5)>
図13は、発話の履歴情報(HI5)を含む入力(IN5)に対する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT5)を示している。
図13は、発話の履歴情報(HI5)を含む入力(IN5)に対する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT5)を示している。
図13においては、"currentInput"として、"週末の"である音声認識結果が得られている。
ユーザの意図("intent")として、「天気確認」である"CheckWeather"が設定され、そのパラメータ("slotSet")として、"DateTime"と"Place"が設定されている。また、"DateTime"として"2017-04-01/2017-04-02","Place"として"福島"が設定されている。
ここでは、"consideredInputs"によって、"CheckWeather"である"intent"や、"2017-04-01/2017-04-02"である"DateTime","福島"である"Place"を推定する際に、"福島の","天気を教えて",及び"週末の"が用いられたことを表している。すなわち、"週末の"である直近の音声認識結果だけでなく、"福島の"及び"天気を教えて"である発話の履歴情報(HI5)が用いられて、"intent"と"slotSet"が推定されている。
なお、上述の例では、直近の発話の履歴をつなげた場合の例を示しているが、必ずしも履歴をつなげる必要はない。例えば、「えーっと、、、天気を教えて」とユーザが発話したとき、音声認識・音声言語理解プログラムAPIの入力(IN6)と出力(OUT6)は、例えば、次のようになる。
<入力(IN6)>
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・発話の履歴情報
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・発話の履歴情報
例えば、音声区間検出(VAD)によって切り出された「天気を教えて」に対応する区間の音声信号の波形が、切り出された音声信号となる。また、切り出された区間の先頭の時刻が、切り出しを開始した時刻となり、切り出された区間の最後の時刻が、切り出しが完了した時刻となる。
また、このとき、発話の履歴情報は、例えば、図14に示すような内容となる。
<発話の履歴情報(HI6)>
図14は、発話の履歴情報の例を示している。
図14は、発話の履歴情報の例を示している。
図14においては、発話の履歴として、「間」を挟んで、「天気を教えて」の前に発話された"えーっと"が設定されている。この発話の履歴には、発話開始の時刻情報として、"1490924835476"が、発話終了の時刻情報として、"1490924836612"が設定されている。
<出力(OUT6)>
図15は、発話の履歴情報(HI6)を含む入力(IN6)に対する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT6)を示している。
図15は、発話の履歴情報(HI6)を含む入力(IN6)に対する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT6)を示している。
図15においては、"currentInput"として、"天気を教えて"である音声認識結果が得られている。
ユーザの意図("intent")として、「天気確認」である"CheckWeather"が設定されるが、そのパラメータは、なしとされる。
ここでは、"consideredInputs"によって、"CheckWeather"である"intent"を推測する際に、"天気を教えて"のみが用いられたことを表している。すなわち、直近の履歴として、「えーっと」を含む発話の履歴情報(HI6)が与えられたが、ユーザが機器に対して指示している内容とは直接関係がないため、"consideredInputs"には含まれていない。
このように、本技術では、直近の発話内容の履歴とその時刻情報を用いることで、ユーザが「間」を空けながら発話しても、ユーザの意図するところの指示内容を推定している。以下、具体的な音声言語理解処理の内容について説明する。
音声言語理解部103は、セマンティックフレームテンプレート(Semantic Frame Template)、単語辞書(固有名詞データベースを含む)、及び言語モデルの3つの情報源を持っている。以下、セマンティックフレームテンプレートを「IS(Information Source)1」,単語辞書を「IS2」,言語モデルを「IS3」とも表記する。
セマンティックフレームテンプレート(IS1)は、"intent"と"slotSet"との組み合わせのテンプレートである。"intent"のリストを持っており、例えば、["CheckWeather", "ViewSchedule", "SendMail",...]のようなリストになる。
さらに、それぞれの"intent"に対して、"slotSet"が定義されている。例えば、"CheckWeather":["DateTime", "Place"]というような対応用を持っている。これは、「"天気確認"に対してサポートしているパラメータは、「日時」と「場所」である」ということを意味する。
単語辞書(IS2)は、いわゆる単語が、その"品詞"と"属性スコアリスト"とともに保持されているリストである。"品詞"は、「動詞」、「名詞」、「助詞」などの種別である。"属性スコアリスト"は、その単語が、各"属性"について、それらしいかどうかを0~1の値で表現したリストである。
"属性"は、「日時」、「地名」、「楽曲名」などいくつかの種類があり、音声ユーザインターフェースのアプリケーションに着目して設計される。"属性スコアリスト"は、例えば、「明日」という単語であれば、「日時」に関する表現なので、"日時"に対するスコアは1,それ以外の"属性"に対するスコアは0に近い値となる。
この単語辞書(IS2)には、固有名詞も登録されている。各固有名詞の"属性スコアリスト"は、内部に抱えている固有名詞データベースをもとに付与される。固有名詞データベースは、地名、施設名、楽曲名、映画タイトル、有名人名など、様々なカテゴリ(属性)の固有名詞を管理しているデータベースである。ただし、ここでは、楽曲名や映画タイトル等については、常に最新情報にアップデートされているものとする。
また、それぞれの固有名詞には、著名度が0~1で設定されている。例えば、「東京」という単語について、地名の「東京」の著名度は1,楽曲名の「東京」の著名度は0.6,などのように付与されている。なお、著名度は、カテゴリ間で正規化されていなくてもよい。
さて、単語辞書(IS2)に視点を戻すと、固有名詞は、単語辞書(IS2)内では固有名詞データベースに保持されている著名度に従って、"属性スコアリスト"が生成される。例えば、「福島」という固有名詞は、「地名」としても、「人名」としても、「飲食店名」としても、固有名詞データベースに登録されているとした場合、その著名度が属性スコアとして付与される。なお、固有名詞データベースに登録されていなかった属性については、属性スコアが0となる。
言語モデル(IS3)は、各"intent"についてのユーザの発話の言い回しの情報である。例えば、「"CheckWeather"では、「<DateTime> の <Place> の天気を教えて」、「<Place> の <DateTime> の天気を教えて」、・・・の言い回しがある。」、という情報が保持されている。<Place>,<DateTime>は、ユーザの意図を表現するパラメータであり、上述のセマンティックフレームテンプレート(IS1)内のパラメータと一致している。
さらに、言語モデル(IS3)には、<Place>,<DateTime>の言い回し、表現の情報も保持されている。例えば、「<Place>は、「(地名)」、「(地名)周辺」、・・・の言い回しがある」や、「<DateTime>は、「(日時)」、「(数詞)月(数詞)日」、「(数詞)日」、・・・の言い回しがある」のように保持されている。ここで、「(地名)」は、単語の属性であり、上述の単語辞書(IS2)で管理されている"属性"と一致している。
なお、これらの情報の保持の仕方は、上述したテンプレートとして持つ以外に、大量のコーパスから学習された統計モデルのような形式でもよい。また、テンプレートから有限オートマトン(FSM:Finite State Machine)や有限状態トランスデューサ(FST:Finite State Transducer)などのモデルを生成する方法を適用してもよい。
さて、音声言語理解部103は、上述したセマンティックフレームテンプレート(IS1)、単語辞書(IS2)、及び言語モデル(IS3)の3つの情報源を用いて、入力された音声認識結果(発話のテキストデータ)から、ユーザの音声による指示の意味を解析する。
ここでは、比較のため、まず、発話の履歴情報を用いない、一般的な音声言語理解処理の流れについて説明する。一般的な音声言語理解処理は、図16のフローチャートに示したステップS11乃至S13の3ステップからなる。
(1)単語辞書(IS2)と言語モデル(IS3)の情報を用い、各"intent"について入力文字列の適合度を算出する(S11)。
(2)セマンティックフレームテンプレート(IS1)に当てはめる(S12)。
(3)必要に応じてパラメータの解釈・変換を行う(S13)。
(2)セマンティックフレームテンプレート(IS1)に当てはめる(S12)。
(3)必要に応じてパラメータの解釈・変換を行う(S13)。
ここでは、「明日の東京周辺の天気を教えて」という音声認識結果の入力があった場合を想定して、以下の音声言語理解処理の処理例を説明する。
まず、ステップS11において、音声言語理解部103は、言語モデル(IS3)が大量のコーパスから学習された統計モデルがある場合には、適合度は、その統計モデルが算出する入力文字列の尤度を用いる。
ここでは、有限オートマトン(FSM)を用いる場合には、入力文字列を受理できるか否かで0か1かの値をとる。また、有限状態トランスデューサ(FST)を用いる場合には、入力文字列とテンプレートとを比較した際の文字の挿入、削除、又は置換などの差異や、単語辞書(IS2)の属性スコアを考慮したスコアを算出することができる。
いずれの方法をとったとしても、音声言語理解部103は、算出されたスコアを閾値と比較し、スコアが閾値よりも大きい場合には、「適合した」という判定を行う。
ここでは、スコアを算出する過程で、「明日」という語句は、単語辞書(IS2)で"日時"という属性が付与されており、また、言語モデル(IS3)内に、「<DateTime>は、「(日時)」という言い回しがある」という情報を保持しているため、「明日」が、<DateTime>に相応しいことが判定される。同様に、「東京周辺」は、「東京」が"地名"であり、「<Place>は、「(地名)周辺」という言い回しがある」という情報を保持しているため、「東京周辺」が、<Place>に相応しいことが判定される。
そして、入力文字列全体としては、「<DateTime> の <Place> の天気を教えて」という"CheckWeather"のテンプレートとマッチすることから、"CheckWeather"に相応しいことが判定される。
次に、ステップS12において、音声言語理解部103は、ステップS11の処理で、入力文字列が、"CheckWeather"に相応しく、「明日」が、<DateTime>に、「東京周辺」が、<Place>に相応しいということが判定できたことから、それらを、セマンティックフレームテンプレート(IS1)に当てはめる。具体的には、音声言語理解部103から出力されるフォーマットに当てはめる。
ここでは、図17に示すように、ユーザの意図("intent")として、天気確認である「"CheckWeather"」が設定され、そのパラメータ("slotSet")として、"DateTime"と"Place"が設定されている。また、"DateTime"として"明日","Place"として"東京周辺"がそれぞれ設定されている。
最後に、ステップS13において、音声言語理解部103は、必要に応じてパラメータの解釈や変換を行う。
例えば、「明日」という表現のままでは、アプリケーションによっては処理を実行することができないので、具体的な年月日に変換する。その日が、2017年3月31日であるならば、「明日」は、2017年4月1日であるので、あらかじめ決められたフォーマットで、ユーザの指定した日時が、2017年4月1日であることを表現する。
また、「東京周辺」という表現は、天気確認においては、「周辺」という情報が不要であることが多いと判定できる場合には、「周辺」という部分を削除する。すなわち、ユーザが「東京」と言った場合でも、「東京周辺」と言った場合でも、アプリケーションが同様の処理を行うことができるように、「東京」という表現に揃えたりする。その結果として、音声言語理解部103の出力結果は、例えば、図18に示すようになる。
すなわち、図18においては、図17と比べて、「天気確認」である"CheckWeather"のパラメータである"DateTime"が、"明日"から、"2017-04-01"に変更され、"Place"が、"東京周辺"から"東京"に変更されている。
上述した図16のステップS11乃至S13の処理が、一般的な音声言語理解処理の流れとなる。さて、本技術の音声言語理解処理では、発話の履歴情報を用いるが、過去の発話の履歴を考慮するか否かの判定が必要となる。
例えば、ユーザが、「明日の、、、天気を教えて」のように、「明日の」の後に、「間」を空けて発話した場合を想定する。この場合、現在の入力である「天気を教えて」と、1つ前の履歴と接続した「明日の天気を教えて」とで、それぞれ解析処理を行う。ここでは、「天気を教えて」と「明日の天気を教えて」が入力仮説とされる。
なお、このとき、例えば、発話の履歴情報が2つ与えられた場合は、現在の入力のみを用いた第1の入力仮説と、発話の履歴を1つのみ結合して得られる第2の入力仮説と、発話の履歴を2つとも結合した第3の入力仮説の3つの入力仮説での解析処理が行われる。
そして、「天気を教えて」という第1の入力仮説を処理した場合の解析結果は、図19に示すようになる。一方で、「明日の天気を教えて」という第2の入力仮説を処理した場合の解析結果は、図20に示すようになる。
最終的にどちらの仮説を出力するかは、「どちらの情報が多いか」という基準(入力仮説ごとに得られる情報量)をベースに判定する。"CheckWeather"のパラメータは、<DateTime>と<Place>の2つあるが、「天気を教えて」である第1の入力仮説の場合には、2つともパラメータがない(0/2)に対し、「明日の天気を教えて」である第2の入力仮説の場合には、1つのパラメータが与えられている(1/2)。
このことを以て、「明日の」という直近の発話の履歴は、ユーザの「天気の確認を行いたい」という意図に関連しているという判定を行う。すなわち、上述の例であれば、"0/2"と"1/2"という与えられたパラメータの割合から判定することができる。
ただし、発話の履歴を結合しても、情報が増えない場合や、文として不自然な場合なども想定される。例えば、「えーっと、、、東京の天気を教えて」という入力に対しては、「えーっと」を結合しても、結合しなくても情報は増えない。この場合には、例えば、「東京の天気を教えて」という短い方の入力仮説を選択することとする。
そのため、ここでは、例えば、下記の4つのスコアを考慮し、入力仮説同士を比較して、最終的な選択が行われるものとする。
(1)第1のスコア:それぞれの入力仮説の"intent"に対して与えられたパラメータの割合
(2)第2のスコア:それぞれの入力仮説に対し、言語モデル(IS3)に基づくスコア
(3)第3のスコア:それぞれの入力仮説における、最も古い過去の発話の履歴と、次に古い過去の発話の履歴との間の時刻の差
(4)第4のスコア:それぞれの入力仮説の結合数
(2)第2のスコア:それぞれの入力仮説に対し、言語モデル(IS3)に基づくスコア
(3)第3のスコア:それぞれの入力仮説における、最も古い過去の発話の履歴と、次に古い過去の発話の履歴との間の時刻の差
(4)第4のスコア:それぞれの入力仮説の結合数
なお、第2のスコアとしては、例えば、言語モデル(IS3)として、「"CheckWeather"では、「<DateTime> の <Place> の天気を教えて」という情報が保持されている場合に、「明日の東京の天気教えて」が発話されたとき、「を」が抜けているので、スコアが減点されることになる。
また、第3のスコアとしては、例えば、発話の履歴を1つ結合している場合は、現在の時刻と履歴の時刻との差となる。また、例えば、発話の履歴を2つ結合している場合は、1つ前の履歴の時刻と2つ前の履歴の時刻との差となる。ここでは、現在の入力のみを用いている場合には、スコアを、"0"とすることができる。
また、第4のスコアとしては、例えば、現在の入力のみを用いている場合には、"0"とされ、発話の履歴を1つだけ結合した場合には、"1"とされる。
ただし、音声言語理解部103では、例えば、第1のスコアと第2のスコアは値が大きいほどよく、第3のスコアと第4のスコアは値が小さいほどよい、として判定することができる。すなわち、ここでの判定としては、「間」の前後の発話が、むやみやたらに結合(接続)されないようにしている。
そして、音声言語理解部103では、比較と最終選択の際には、例えば、これらのスコアの数値をそれぞれ比較しながら、決定木(Decision Tree)のようにルール処理を行う方法を用いたり、あるいは4つのスコアの数値から最終的なスコアを算出する関数を設計してそれを利用する方法を用いたりすることができる。
なお、上述した第1のスコア乃至第4のスコアは、様々なスコアの一例であって、第1のスコア乃至第4のスコアの一部のスコアが用いられるようにしてもよいし、さらに他のスコアが用いられるようにしてもよい。また、スコアを算出する際には、例えば「えーっと」等のような言葉の言い淀み(いわゆるフィラー)を取り除いてから、スコアの算出処理が行われるようにしてもよい。
(音声言語理解処理の流れ)
次に、図21のフローチャートを参照して、発話の履歴情報を用いる、本技術の音声言語理解処理の流れを説明する。
次に、図21のフローチャートを参照して、発話の履歴情報を用いる、本技術の音声言語理解処理の流れを説明する。
ステップS21において、音声言語理解部103は、音声認識部102からの音声認識結果に基づいて、現在の入力と、発話の履歴情報から、入力仮説を生成する。
ここでは、例えば、ユーザが、「明日の、、、天気を教えて」のように、「明日の」の後に、「間」を空けて発話した場合、「天気を教えて」である第1の入力仮説と、「明日の天気を教えて」である第2の入力仮説が生成される。
ステップS22において、音声言語理解部103は、ステップS21の処理で生成されたそれぞれの入力仮説に対して適合度を算出する。
ここでは、例えば、「天気を教えて」である第1の入力仮説と、「明日の天気を教えて」である第2の入力仮説に対し、第1のスコア乃至第4のスコアが算出される。これらのスコアを算出することで、例えば、「間」の前後の発話の関連度及び文法的なつながりの少なくとも一方を含む適合度が得られる。
ステップS23において、音声言語理解部103は、ステップS21の処理で生成されたそれぞれの入力仮説(例えば、第1の入力仮説と第2の入力仮説)に対して、セマンティックフレームテンプレート(IS1)から出力候補を生成する。
ステップS24において、音声言語理解部103は、必要に応じてパラメータの解釈と変換を行う。ここでは、例えば、「その日」が、2017年3月31日であるならば、「明日」は、2017年4月1日であるので、ユーザの指定した日時が、2017年4月1日であることが、所定のフォーマットで表現される。
ステップS25において、音声言語理解部103は、入力仮説同士を比較し、最もふさわしいものを選択する。
ここでは、例えば、「天気を教えて」である第1の入力仮説と、「明日の天気を教えて」である第2の入力仮説が比較され、より情報が多い、「明日の天気を教えて」である第2の入力仮説を選択することができる。すなわち、ユーザが、「明日の、、、天気を教えて」のように、「明日の」の後に、「間」を空けて発話した場合であっても、第2の入力仮説では、「間」の前後の発話を別々に解釈せずに、ユーザの意図を正しく読み取っていると言える。
以上、本技術の音声言語理解処理の流れを説明した。
(入力仮説選択の他の例)
次に、図22及び図23を参照して、入力仮説の選択の他の例を説明する。ここでは、例えば、ユーザが、「お腹空いた、、、今日の、、、天気を教えて」のように、「お腹空いた」の後と、「今日の」の後に、「間」を空けて発話した場合を想定する。
次に、図22及び図23を参照して、入力仮説の選択の他の例を説明する。ここでは、例えば、ユーザが、「お腹空いた、、、今日の、、、天気を教えて」のように、「お腹空いた」の後と、「今日の」の後に、「間」を空けて発話した場合を想定する。
すなわち、上述した例では、「間」が1つで、1つ前の発話の履歴を利用した場合を説明したが、ここでは、入力仮説選択の他の例として、「間」が2つで、1つ前の発話の履歴と2つ前の発話の履歴を利用する場合について説明する。
図22には、「お腹空いた、、、今日の、、、天気を教えて」と発話した場合の音声信号の波形の例を示している。
図22に示した音声信号の波形では、「お腹空いた」の後に、「間」があって、700ミリ秒程度入力が途絶えている。そのため、信号処理部101では、「お腹空いた」の発話に対応した開始時刻t21から終了時刻t22までの区間と、「今日の」の発話に対応した開始時刻t23から終了時刻t24までの区間が、別々の音声区間として切り出されている。
また、「今日の」の後に、「間」があって、600ミリ秒程度入力が途絶えている。そのため、信号処理部101では、「今日の」の発話に対応した開始時刻t23から終了時刻t24までの区間と、「天気を教えて」の発話に対応した開始時刻t25から終了時刻t26までの区間が、別々の音声区間として切り出されている。
このとき、現在の入力が、「天気を教えて」であり、過去の発話の履歴が、「お腹空いた」と「今日の」であるので、音声言語理解部103では、例えば、第1の入力仮説として「天気を教えて」、第2の入力仮説として、「今日の天気を教えて」、第3の入力仮説として「お腹空いた今日の天気を教えて」がそれぞれ生成される(図21のS21)。
次に、音声言語理解部103では、第1の入力仮説乃至第3の入力仮説に対して、適合度が算出され、さらにセマンティックフレームテンプレート(IS1)から出力候補が生成される(図21のS22,S23)。
ここでは、例えば、上述した第1のスコア乃至第4のスコアを求めることで、適合度が算出される。図23には、入力仮説ごとのスコアの例を示している。
図23において、「天気を教えて」である第1の入力仮説は、ユーザの意図として、「天気確認」である"CheckWeather"が設定されるが、そのパラメータは、「なし」とされる。このとき、"CheckWeather"のパラメータである"DateTime"と"Place"が、2つとも情報がないので、第1のスコアとして、0/2が得られる。
また、第1の入力仮説の第2のスコアとしては、言語モデル(IS3)に基づくスコアとして、特に減点される要素はないので、1.0が得られる。さらに第1の入力仮説では、「天気を教えて」である現在の入力のみを用いているため、第3のスコアと第4のスコアとして、0がそれぞれ得られる。
次に、「今日の天気を教えて」である第2の入力仮説は、「天気確認」である"CheckWeather"が設定され、そのパラメータとして、"今日"である日時が設定されている。このとき、"CheckWeather"のパラメータである"DateTime"と"Place"のうち、"DateTime"である1つの情報が与えられているため、第1のスコアとして、1/2が得られる。
また、第2の入力仮説の第2のスコアとしては、言語モデル(IS3)に基づくスコアとして、特に減点される要素はないので、1.0が得られる。さらに第2の入力仮説では、「天気を教えて」である現在の入力だけでなく、「今日の」である発話の履歴を用いているため、第3のスコアとして、現在の時刻と履歴の時刻との差を示す0.6秒(600ミリ秒)が得られる。また、第2の入力仮説では、現在の入力に対し、発話の履歴を1つ結合しているため、第4のスコアとして、1が得られる。
次に、「お腹空いた今日の天気を教えて」である第3の入力仮説は、「天気確認」である"CheckWeather"が設定され、そのパラメータとして、"今日"である日時が設定されている。このとき、"CheckWeather"のパラメータである"DateTime"と"Place"のうち、"DateTime"である1つの情報が与えられているため、第1のスコアとして、1/2が得られる。
また、第3の入力仮説の第2のスコアとしては、言語モデル(IS3)に基づくスコアとして、減点がなされて0.4が得られる。さらに第3の入力仮説では、「天気を教えて」である現在の入力だけでなく、「今日の」と「お腹空いた」である発話の履歴を用いているため、第3のスコアとして、1つ前の履歴の時刻と、2つ前の履歴の時刻との差を示す0.7秒(700ミリ秒)が得られる。また、第3の入力仮説では、現在の入力に対し、発話の履歴を2つ結合しているため、第4のスコアとして、2が得られる。
このとき、音声言語理解部103では、例えば、「その日」が、2017年3月31日であるならば、「明日」は、2017年4月1日であるので、ユーザの指定した日時として、「明日」が、「2017年4月1日」に変換される(図21のS24)。そして、音声言語理解部103では、このようにして得られる適合度に応じて、入力仮説同士を比較し、最もふさわしいものが選択される(図21のS25)。
ここでは、第1のスコアと第2のスコアは値が大きいほどよく、第3のスコアと第4のスコアは値が小さいほどよいので、これらのスコアの数値をそれぞれ比較しながら、決定木のようなルール処理や、所定の関数などを用いることで、最終的に出力する入力仮説を選択する。例えば、図23の例では、「今日の天気を教えて」である第2の入力仮説が最もふさわしいものとして選択され、第2の入力仮説に応じた出力がなされる。
なお、図22及び図23に示した入力仮説の選択の他の例では、「お腹空いた」の後に、700ミリ秒程度「間」があって、「今日の」と発話され、さらに、「今日の」の後に、600ミリ秒程度の「間」があって、「天気を教えて」と発話されている。このような、600ミリ秒や700ミリ秒程度の時間間隔であれば、「間」として認識すべきであるが、例えば、数十秒や数分などの時間間隔となると、「間」として認識すべきでないときもある。
そこで、ここでは、例えば、前後の発話の時間間隔を閾値と比較し、時間間隔が閾値よりも大きい場合には、当該時間間隔を「間」として認識せずに、入力仮説の生成時に、対象の発話の履歴を用いずに、入力仮説に含まれないようにすればよい。
以上、第1の実施の形態として、発話の履歴情報を用いた音声言語理解処理によって、ユーザの発話(「間」を含む発話)から、ユーザの意図を汲み取ることが可能となって、より利便性の高い音声インタラクションを提供することができることを説明した。
(2)第2の実施の形態
次に、他モーダル情報を用いて、解析する処理について説明する。例えば、家族で共用するような機器において、例えば、「私の、、、来週の予定を確認したい」という発話があった場合を想定する。この場合に、アプリケーションは、「私」という単語が一人称であるという言語知識と、話している人が誰であるかの情報がなければ、家族の誰の予定表を提示すればよいのかを判定することができない。
第2の実施の形態では、音声処理装置10に設けられたセンサ54(図2)により得られる画像データを解析して、話者が誰であるのかが認識されるようにして、その認識結果を受け取ることで、「私」が指す具体的な人物を特定することができるようにする。
ここでは、上述したように、「私の」と発話した後に、「間」を空けて、「来週の予定を確認したい」と発話したとき、音声認識・音声言語理解プログラムAPIの入力(IN10)と出力(OUT10)は、例えば、次のようになる。
<入力(IN10)>
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・発話の履歴情報(音声認識結果の文字列、対応する音声信号の切り出し開始時刻)
・他センサ情報
・切り出された音声信号
・切り出しを開始した時刻、切り出しが完了した時刻
・発話の履歴情報(音声認識結果の文字列、対応する音声信号の切り出し開始時刻)
・他センサ情報
例えば、音声区間検出(VAD)によって切り出された「来週の予定を確認したい」に対応する区間の音声信号の波形が、切り出された音声信号となる。また、切り出された区間の先頭の時刻が、切り出しを開始した時刻となり、切り出された区間の最後の時刻が、切り出しが完了した時刻となる。
また、他センサ情報には、画像データから得られる話者に関する情報が含まれるが、例えば、図24に示すような内容となる。さらに、発話の履歴情報には、過去の発話の履歴として、音声認識結果の文字列、対応する音声信号の切り出しの開始時刻が含まれるが、例えば、図25に示すような内容となる。
<他センサ情報(SI10)>
図24は、他センサ情報の例を示す図である。
図24は、他センサ情報の例を示す図である。
"image"は、画像データから得られるセンサ情報を意味し、そのオブジェクトとして、"speaker"が含まれる。
"speaker"は、画像データの解析結果から得られる話者を示す文字列が設定される。ここでは、センサ54(図2)により得られる画像データから、「話し手は、"アサミ"である」という情報が得られ、「私の、、、来週の予定を確認したい」と発話した"アサミ"が、話者として設定されている。
<発話の履歴情報(HI10)>
図25は、発話の履歴情報の例を示す図である。
図25は、発話の履歴情報の例を示す図である。
図25においては、発話の履歴として、「間」を挟んで、「来週の予定を確認したい」の前に発話された"私の"が設定されている。この発話の履歴には、発話開始の時刻情報として、"1490924841275"が、発話終了の時刻情報として、"1490924842978"が設定されている。
<出力(OUT10)>
図26は、他センサ情報(SI10)と発話の履歴情報(HI10)を含む入力(IN10)に対応する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT10)を示す図である。
図26は、他センサ情報(SI10)と発話の履歴情報(HI10)を含む入力(IN10)に対応する処理を行う音声認識・音声言語理解プログラムAPIの出力例(OUT10)を示す図である。
図26においては、"currentInput"として、"来週の予定を確認したい"である音声認識結果が得られている。
ユーザの意図("intent")として、「予定表表示」である"ViewSchedule"が設定され、そのパラメータ("slotSet")として、"DateTime"と"Owner"が設定されている。また、"DateTime"として"2017-04-02/2017-04-08","Owner"として"アサミ"が設定されている。
ここでは、"consideredInputs"によって、"ViewSchedule"である"intent"や、"2017-04-02/2017-04-08"である"DateTime","アサミ"である"Owner"を推定する際に、"私の",及び"来週の予定を確認したい"が用いられたことを表している。すなわち、"来週の予定を確認したい"である直近の音声認識結果だけでなく、"私の"である発話の履歴情報(HI10)とともに、"アサミ"である話者を含む他センサ情報(SI10)が用いられて、"intent"と"slotSet"が推定されている。
すなわち、ここでは、他センサ情報(SI10)を用いることで、「私」を、「アサミ」に置き換えることができる。なお、この置き換える処理は、図21のステップS24の処理でのパラメータの解釈・変換処理に相当し、「私」というパラメータを、「アサミ」に変換することで、「私」が、「アサミ」であることを特定している。
なお、ここでは、他センサ情報として、イメージセンサとしてのセンサ54(図2)から得られる画像データの解析結果を用いた場合を説明したが、磁気センサや加速度センサ等の他のセンサから得られるセンサデータの解析結果を用いるようにしてもよい。さらに、GPS(Global Positioning System)信号から算出される緯度経度情報が得られる場合には、例えば、ユーザの発話に含まれる「この街」という語句を、「東京」や「横浜」など、具体的な都市名に変換することができる。
以上、第2の実施の形態として、発話の履歴情報とともに、他センサ情報を用いた音声言語理解処理によって、ユーザの発話(「間」を含む発話)から、ユーザの意図を汲み取ることが可能になることを説明した。
(音声対話処理)
最後に、図27のフローチャートを参照して、音声処理装置10とサーバ20によって実行される、音声対話処理の流れを説明する。
最後に、図27のフローチャートを参照して、音声処理装置10とサーバ20によって実行される、音声対話処理の流れを説明する。
なお、図27において、ステップS101乃至S107の処理は、ローカル側の音声処理装置10により実行され、ステップS201乃至S204の処理は、クラウド側のサーバ20により実行される。
ステップS101において、処理部51の信号処理部101は、そこに入力される、マイクロフォン52により収音された音を変換して得られる音声信号に対し、音声の検出処理を行う。
ステップS102において、処理部51は、発話の履歴情報のフィルタリング処理を行う。このフィルタリング処理では、例えば、「間」の時間間隔やフィラー、話者に関する情報(話者情報)、ユーザの視線に関する情報(視線情報)を含む抽出情報に基づき、発話の履歴が抽出される。
すなわち、ここでは、クラウド側のサーバ20にて実行される音声言語理解処理で用いられる発話の履歴に適合する発話の履歴が取捨選択されることになる。なお、フィラーとは、言葉の言い淀みであって、例えば、「えーっと」や「あの~」のような言葉を含む。
ステップS103において、処理部51は、送信ポリシに基づき、送信対象の発話の履歴(送信履歴)を決定する。この送信履歴の決定処理では、例えば、発話の履歴に関する送信最大個数(例えば最大で10個の履歴等)や、送信最大データサイズ(例えば最大で2MB等)などのあらかじめ定められた送信ポリシに従い、ステップS102のフィルタリング処理で抽出された発話の履歴の中から、実際に送信する発話の履歴が決定される。
ステップS104において、通信I/F55は、処理部51からの制御に従い、ステップS101の処理で得られる音声信号とともに、ステップS103の処理で決定された発話の履歴情報を、インターネット30を介して、サーバ20に送信する。なお、ここでは、センサ54(図2)から得られるセンサデータが送信されるようにしてもよい。
ステップS201において、通信I/F72は、処理部71からの制御に従い、インターネット30を介して、音声処理装置10から送信されてくる、発話の履歴情報と音声信号を受信する。
ステップS202において、処理部71の音声認識部102は、ステップS201の処理で受信された音声信号に対し、音声認識処理を行う。
ステップS203において、処理部71の音声言語理解部103は、ステップS201の処理で受信された発話の履歴情報、及びステップS202の処理で得られる音声認識結果に基づいて、音声言語理解処理を行う。
なお、この音声言語理解処理としては、例えば、図21に示した本技術の音声言語理解処理を含む処理が行われる。また、ここでは、センサ54(図2)から得られるセンサデータに基づいた他センサ情報が用いられるようにしてもよい。
ステップS204において、通信I/F72は、処理部71からの制御に従い、ステップS203の処理で得られる認識・解析結果を、インターネット30を介して、音声処理装置10に送信する。
ステップS105において、通信I/F55は、処理部51からの制御に従い、インターネット30を介して、サーバ20から送信されてくる認識・解析結果を受信する。
ステップS106において、処理部51は、ステップS105の処理で受信した認識・解析結果を、例えばメモリに記録するなどして、保持する。
ステップS107において、スピーカ53は、処理部51からの制御に従い、ステップS105の処理で受信した認識・解析結果(の音声信号)に応じた音声を出力する。なお、音声処理装置10では、スピーカ53から音声を出力するに限らず、例えば、認識・解析結果に応じたテキスト情報や画像情報等を、表示部に表示するようにしてもよい。
以上、音声対話処理の流れを説明した。
この音声対話処理では、クラウド側のサーバ20で、上述した第1の実施の形態又は第2の実施の形態に対応した、発話の履歴情報を用いた音声言語理解処理が行われるため、ユーザの発話(「間」を含む発話)から、ユーザの意図を汲み取ることが可能となって、より利便性の高い音声インタラクションを提供することができる。
また、この音声対話処理では、ローカル側の音声処理装置10で、クラウド側のサーバ20に送信する発話の履歴情報が取捨選択され、送信ポリシに従い送信されるため、そのデータ量を削減することができる。例えば、音声処理装置10が、モバイル機器である場合に、そのモバイル通信で十分な帯域が確保できない場合でも、確実に発話の履歴情報を送信することができる。
なお、図27の説明では、ローカル側の音声処理装置10で、発話の履歴情報が管理されている場合を示したが、発話の履歴情報は、クラウド側のサーバ20によって、ユーザごとに管理されるようにしてもよい。
<4.変形例>
上述した説明では、音声認識・音声言語理解プログラムAPIの入力(IN)として、切り出された音声信号とともに、切り出しを開始した時刻と切り出しが完了した時刻が入力される場合を示したが、開始と終了の切り出し時刻のうち、例えば、切り出しが完了した時刻のみなど、いずれか一方の切り出し時刻が入力されるようにしてもよい。
また、上述した説明では、第2の実施の形態で、音声認識・音声言語理解プログラムAPIの入力(IN)として、音声信号及び切り出し時刻とともに、発話の履歴情報と他センサ情報が入力される場合を示したが、発話の履歴情報を用いずに、他センサ情報のみが、音声信号及び切り出し時刻とともに入力されるようにしてもよい。また、ここでは、時刻の差を表すディレイ情報を用いるようにしてもよい。
上述した説明では、信号処理部101(図4)は、ローカル側の音声処理装置10の処理部51(図2)に組み込まれ、音声認識部102(図4)及び音声言語理解部103(図4)は、クラウド側のサーバ20の処理部71(図3)に組み込まれるとして説明したが、図4の信号処理部101乃至音声言語理解部103のそれぞれは、音声処理装置10とサーバ20のうち、どちらの機器に組み込まれてもよい。
例えば、図4の信号処理部101乃至音声言語理解部103のすべてが、音声処理装置10側に組み込まれ、ローカル側で処理が完結するようにしてもよい。ただし、このような構成を採用した場合でも、各種のデータベースは、インターネット30上のサーバ20が保持するようにしてもよい。また、例えば、図4の信号処理部101乃至音声言語理解部103のすべてが、サーバ20側に組み込まれ、音声処理装置10により収音された音声の生データが、インターネット30を介してサーバ20に送信されるようにしてもよい。
なお、上述した説明では、音声認識・音声言語理解プログラムAPIの出力(OUT)のフォーマットとして、JSON(JavaScript(登録商標) Object Notation)を一例に説明したが、例えば、XML(Extensible Markup Language)などの他のフォーマットを用いるようにしてもよい。また、出力(OUT)のフォーマットは、テキスト形式に限らず、バイナリ形式であってもよい。
<5.コンピュータの構成>
上述した一連の処理(例えば、図21に示した音声言語理解処理など)は、ハードウェアにより実行することもできるし、ソフトウェアにより実行することもできる。一連の処理をソフトウェアにより実行する場合には、そのソフトウェアを構成するプログラムが、各装置のコンピュータにインストールされる。図28は、上述した一連の処理をプログラムにより実行するコンピュータのハードウェアの構成例を示すブロック図である。
コンピュータ1000において、CPU(Central Processing Unit)1001、ROM(Read Only Memory)1002、RAM(Random Access Memory)1003は、バス1004により相互に接続されている。バス1004には、さらに、入出力インターフェース1005が接続されている。入出力インターフェース1005には、入力部1006、出力部1007、記録部1008、通信部1009、及び、ドライブ1010が接続されている。
入力部1006は、キーボード、マウス、マイクロフォンなどよりなる。出力部1007は、ディスプレイ、スピーカなどよりなる。記録部1008は、ハードディスクや不揮発性のメモリなどよりなる。通信部1009は、ネットワークインターフェースなどよりなる。ドライブ1010は、磁気ディスク、光ディスク、光磁気ディスク、又は半導体メモリなどのリムーバブル記録媒体1011を駆動する。
以上のように構成されるコンピュータ1000では、CPU1001が、ROM1002や記録部1008に記録されているプログラムを、入出力インターフェース1005及びバス1004を介して、RAM1003にロードして実行することにより、上述した一連の処理が行われる。
コンピュータ1000(CPU1001)が実行するプログラムは、例えば、パッケージメディア等としてのリムーバブル記録媒体1011に記録して提供することができる。また、プログラムは、ローカルエリアネットワーク、インターネット、デジタル衛星放送といった、有線又は無線の伝送媒体を介して提供することができる。
コンピュータ1000では、プログラムは、リムーバブル記録媒体1011をドライブ1010に装着することにより、入出力インターフェース1005を介して、記録部1008にインストールすることができる。また、プログラムは、有線又は無線の伝送媒体を介して、通信部1009で受信し、記録部1008にインストールすることができる。その他、プログラムは、ROM1002や記録部1008に、あらかじめインストールしておくことができる。
ここで、本明細書において、コンピュータがプログラムに従って行う処理は、必ずしもフローチャートとして記載された順序に沿って時系列に行われる必要はない。すなわち、コンピュータがプログラムに従って行う処理は、並列的あるいは個別に実行される処理(例えば、並列処理あるいはオブジェクトによる処理)も含む。また、プログラムは、1のコンピュータ(プロセッサ)により処理されるものであってもよいし、複数のコンピュータによって分散処理されるものであってもよい。
なお、本技術の実施の形態は、上述した実施の形態に限定されるものではなく、本技術の要旨を逸脱しない範囲において種々の変更が可能である。例えば、本技術は、1つの機能を、ネットワークを介して複数の装置で分担、共同して処理するクラウドコンピューティングの構成をとることができる。
また、図21に示した音声言語理解処理や、図27の音声対話処理の各ステップは、1つの装置で実行する他、複数の装置で分担して実行することができる。さらに、1つのステップに複数の処理が含まれる場合には、その1つのステップに含まれる複数の処理は、1つの装置で実行する他、複数の装置で分担して実行することができる。
なお、本技術は、以下のような構成をとることができる。
(1)
ユーザの発話に含まれる間の前後の発話の意味単位での適合度に応じて、前記前後の発話を接続する処理部を備える
情報処理装置。
(2)
前記処理部は、
現在の発話と、過去の発話の履歴に基づいて、前記前後の発話の意味単位での適合度を算出し、
算出された前記適合度に基づいて、前記前後の発話を接続するか否かを判定し、
前記前後の発話を接続すると判定された場合に、前記前後の発話を接続する
前記(1)に記載の情報処理装置。
(3)
前記処理部は、前記現在の発話と、前記過去の発話の履歴とともに、センサから得られるセンサ情報を用い、前記前後の発話の意味単位での適合度を算出する
前記(2)に記載の情報処理装置。
(4)
前記処理部は、
前記前後の発話を仮に接続して得られる入力仮説ごとのスコアを算出し、
算出された前記入力仮説ごとのスコアに基づいて、前記入力仮説ごとの前記前後の発話の適合度を算出し、
算出された前記入力仮説ごとの適合度に基づいて、複数の入力仮説の中から、1つの入力仮説を選択する
前記(2)又は(3)に記載の情報処理装置。
(5)
前記処理部は、前記入力仮説ごとに得られる情報量に応じて、前記スコアを算出する
前記(4)に記載の情報処理装置。
(6)
前記スコアは、前記入力仮説ごとに、
前記ユーザの意図に応じた関数のパラメータの使用の割合から得られる第1のスコア、
前記ユーザの発話の言い回しの情報に関する言語モデルから得られる第2のスコア、
前記現在の発話と前記過去の発話の履歴との時間的な間隔、又は前記過去の発話の履歴同士の時間的な間隔から得られる第3のスコア、
及び前記現在の発話と前記過去の発話の履歴との結合数から得られる第4のスコア
のうち、少なくとも1以上のスコアを含む
前記(4)又は(5)に記載の情報処理装置。
(7)
前記適合度は、前記前後の発話の関連度及び文法的なつながりの少なくとも一方を含む
前記(1)乃至(6)のいずれかに記載の情報処理装置。
(8)
前記処理部は、前記間の間隔に基づいて、前記前後の発話を接続するかどうかを判定する
前記(2)乃至(7)のいずれかに記載の情報処理装置。
(9)
前記処理部は、前記過去の発話の履歴のうち、有効な発話の履歴のみを用いる
前記(2)に記載の情報処理装置。
(10)
前記過去の発話の履歴は、前記ユーザの発話の内容と発話された時刻の情報を含む
前記(9)に記載の情報処理装置。
(11)
前記センサ情報は、被写体を撮像して得られる画像データ、又は前記ユーザの位置を示す位置情報を含む
前記(3)に記載の情報処理装置。
(12)
情報処理装置の情報処理方法において、
前記情報処理装置が、
ユーザの発話に含まれる間の前後の発話の意味単位での適合度に応じて、前記前後の発話を接続する
情報処理方法。
(13)
ユーザの過去の発話の履歴から、間を含んだ発話に対する音声言語理解処理に適合する過去の発話の履歴を抽出する処理部と、
前記ユーザの現在の発話に応じた音声信号とともに、抽出された前記過去の発話の履歴を、前記音声言語理解処理を行う情報処理装置に送信する送信部と
を備える情報処理装置。
(14)
前記処理部は、間の時間間隔、言葉の言い淀みに関する情報、話者に関する情報、又は前記ユーザの視線情報を含む抽出情報に基づいて、前記過去の発話の履歴を抽出する
前記(13)に記載の情報処理装置。
(15)
前記送信部は、前記過去の発話の履歴に関する送信最大個数、又は送信最大データサイズに基づいて、前記過去の発話の履歴を送信する
前記(13)又は(14)に記載の情報処理装置。
(16)
情報処理装置の情報処理方法において、
前記情報処理装置が、
ユーザの過去の発話の履歴から、間を含んだ発話に対する音声言語理解処理に適合する過去の発話の履歴を抽出し、
前記ユーザの現在の発話に応じた音声信号とともに、抽出された前記過去の発話の履歴を、前記音声言語理解処理を行う情報処理装置に送信する
情報処理方法。
ユーザの発話に含まれる間の前後の発話の意味単位での適合度に応じて、前記前後の発話を接続する処理部を備える
情報処理装置。
(2)
前記処理部は、
現在の発話と、過去の発話の履歴に基づいて、前記前後の発話の意味単位での適合度を算出し、
算出された前記適合度に基づいて、前記前後の発話を接続するか否かを判定し、
前記前後の発話を接続すると判定された場合に、前記前後の発話を接続する
前記(1)に記載の情報処理装置。
(3)
前記処理部は、前記現在の発話と、前記過去の発話の履歴とともに、センサから得られるセンサ情報を用い、前記前後の発話の意味単位での適合度を算出する
前記(2)に記載の情報処理装置。
(4)
前記処理部は、
前記前後の発話を仮に接続して得られる入力仮説ごとのスコアを算出し、
算出された前記入力仮説ごとのスコアに基づいて、前記入力仮説ごとの前記前後の発話の適合度を算出し、
算出された前記入力仮説ごとの適合度に基づいて、複数の入力仮説の中から、1つの入力仮説を選択する
前記(2)又は(3)に記載の情報処理装置。
(5)
前記処理部は、前記入力仮説ごとに得られる情報量に応じて、前記スコアを算出する
前記(4)に記載の情報処理装置。
(6)
前記スコアは、前記入力仮説ごとに、
前記ユーザの意図に応じた関数のパラメータの使用の割合から得られる第1のスコア、
前記ユーザの発話の言い回しの情報に関する言語モデルから得られる第2のスコア、
前記現在の発話と前記過去の発話の履歴との時間的な間隔、又は前記過去の発話の履歴同士の時間的な間隔から得られる第3のスコア、
及び前記現在の発話と前記過去の発話の履歴との結合数から得られる第4のスコア
のうち、少なくとも1以上のスコアを含む
前記(4)又は(5)に記載の情報処理装置。
(7)
前記適合度は、前記前後の発話の関連度及び文法的なつながりの少なくとも一方を含む
前記(1)乃至(6)のいずれかに記載の情報処理装置。
(8)
前記処理部は、前記間の間隔に基づいて、前記前後の発話を接続するかどうかを判定する
前記(2)乃至(7)のいずれかに記載の情報処理装置。
(9)
前記処理部は、前記過去の発話の履歴のうち、有効な発話の履歴のみを用いる
前記(2)に記載の情報処理装置。
(10)
前記過去の発話の履歴は、前記ユーザの発話の内容と発話された時刻の情報を含む
前記(9)に記載の情報処理装置。
(11)
前記センサ情報は、被写体を撮像して得られる画像データ、又は前記ユーザの位置を示す位置情報を含む
前記(3)に記載の情報処理装置。
(12)
情報処理装置の情報処理方法において、
前記情報処理装置が、
ユーザの発話に含まれる間の前後の発話の意味単位での適合度に応じて、前記前後の発話を接続する
情報処理方法。
(13)
ユーザの過去の発話の履歴から、間を含んだ発話に対する音声言語理解処理に適合する過去の発話の履歴を抽出する処理部と、
前記ユーザの現在の発話に応じた音声信号とともに、抽出された前記過去の発話の履歴を、前記音声言語理解処理を行う情報処理装置に送信する送信部と
を備える情報処理装置。
(14)
前記処理部は、間の時間間隔、言葉の言い淀みに関する情報、話者に関する情報、又は前記ユーザの視線情報を含む抽出情報に基づいて、前記過去の発話の履歴を抽出する
前記(13)に記載の情報処理装置。
(15)
前記送信部は、前記過去の発話の履歴に関する送信最大個数、又は送信最大データサイズに基づいて、前記過去の発話の履歴を送信する
前記(13)又は(14)に記載の情報処理装置。
(16)
情報処理装置の情報処理方法において、
前記情報処理装置が、
ユーザの過去の発話の履歴から、間を含んだ発話に対する音声言語理解処理に適合する過去の発話の履歴を抽出し、
前記ユーザの現在の発話に応じた音声信号とともに、抽出された前記過去の発話の履歴を、前記音声言語理解処理を行う情報処理装置に送信する
情報処理方法。
1 音声対話システム, 10 音声処理装置, 20 サーバ, 30 インターネット, 51 処理部, 52 マイクロフォン, 53 スピーカ, 54 センサ, 55 通信I/F, 71 処理部, 72 通信I/F, 73 データベース, 101 信号処理部, 102 音声認識部, 103 音声言語理解部, 1000 コンピュータ, 1001 CPU
Claims (16)
- ユーザの発話に含まれる間の前後の発話の意味単位での適合度に応じて、前記前後の発話を接続する処理部を備える
情報処理装置。 - 前記処理部は、
現在の発話と、過去の発話の履歴に基づいて、前記前後の発話の意味単位での適合度を算出し、
算出された前記適合度に基づいて、前記前後の発話を接続するか否かを判定し、
前記前後の発話を接続すると判定された場合に、前記前後の発話を接続する
請求項1に記載の情報処理装置。 - 前記処理部は、前記現在の発話と、前記過去の発話の履歴とともに、センサから得られるセンサ情報を用い、前記前後の発話の意味単位での適合度を算出する
請求項2に記載の情報処理装置。 - 前記処理部は、
前記前後の発話を仮に接続して得られる入力仮説ごとのスコアを算出し、
算出された前記入力仮説ごとのスコアに基づいて、前記入力仮説ごとの前記前後の発話の適合度を算出し、
算出された前記入力仮説ごとの適合度に基づいて、複数の入力仮説の中から、1つの入力仮説を選択する
請求項2に記載の情報処理装置。 - 前記処理部は、前記入力仮説ごとに得られる情報量に応じて、前記スコアを算出する
請求項4に記載の情報処理装置。 - 前記スコアは、前記入力仮説ごとに、
前記ユーザの意図に応じた関数のパラメータの使用の割合から得られる第1のスコア、
前記ユーザの発話の言い回しの情報に関する言語モデルから得られる第2のスコア、
前記現在の発話と前記過去の発話の履歴との時間的な間隔、又は前記過去の発話の履歴同士の時間的な間隔から得られる第3のスコア、
及び前記現在の発話と前記過去の発話の履歴との結合数から得られる第4のスコア
のうち、少なくとも1以上のスコアを含む
請求項5に記載の情報処理装置。 - 前記適合度は、前記前後の発話の関連度及び文法的なつながりの少なくとも一方を含む
請求項1に記載の情報処理装置。 - 前記処理部は、前記間の間隔に基づいて、前記前後の発話を接続するかどうかを判定する
請求項2に記載の情報処理装置。 - 前記処理部は、前記過去の発話の履歴のうち、有効な発話の履歴のみを用いる
請求項2に記載の情報処理装置。 - 前記過去の発話の履歴は、前記ユーザの発話の内容と発話された時刻の情報を含む
請求項9に記載の情報処理装置。 - 前記センサ情報は、被写体を撮像して得られる画像データ、又は前記ユーザの位置を示す位置情報を含む
請求項3に記載の情報処理装置。 - 情報処理装置の情報処理方法において、
前記情報処理装置が、
ユーザの発話に含まれる間の前後の発話の意味単位での適合度に応じて、前記前後の発話を接続する
情報処理方法。 - ユーザの過去の発話の履歴から、間を含んだ発話に対する音声言語理解処理に適合する過去の発話の履歴を抽出する処理部と、
前記ユーザの現在の発話に応じた音声信号とともに、抽出された前記過去の発話の履歴を、前記音声言語理解処理を行う情報処理装置に送信する送信部と
を備える情報処理装置。 - 前記処理部は、間の時間間隔、言葉の言い淀みに関する情報、話者に関する情報、又は前記ユーザの視線情報を含む抽出情報に基づいて、前記過去の発話の履歴を抽出する
請求項13に記載の情報処理装置。 - 前記送信部は、前記過去の発話の履歴に関する送信最大個数、又は送信最大データサイズに基づいて、前記過去の発話の履歴を送信する
請求項14に記載の情報処理装置。 - 情報処理装置の情報処理方法において、
前記情報処理装置が、
ユーザの過去の発話の履歴から、間を含んだ発話に対する音声言語理解処理に適合する過去の発話の履歴を抽出し、
前記ユーザの現在の発話に応じた音声信号とともに、抽出された前記過去の発話の履歴を、前記音声言語理解処理を行う情報処理装置に送信する
情報処理方法。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019535101A JP7230806B2 (ja) | 2017-08-09 | 2018-07-27 | 情報処理装置、及び情報処理方法 |
| CN201880049934.0A CN110998719A (zh) | 2017-08-09 | 2018-07-27 | 信息处理设备和信息处理方法 |
| EP18843678.6A EP3667660A4 (en) | 2017-08-09 | 2018-07-27 | INFORMATION PROCESSING DEVICE AND INFORMATION PROCESSING PROCESS |
| US16/635,571 US20200219487A1 (en) | 2017-08-09 | 2018-07-27 | Information processing apparatus and information processing method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017153883 | 2017-08-09 | ||
| JP2017-153883 | 2017-08-09 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2019031268A1 true WO2019031268A1 (ja) | 2019-02-14 |
Family
ID=65272301
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2018/028201 WO2019031268A1 (ja) | 2017-08-09 | 2018-07-27 | 情報処理装置、及び情報処理方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20200219487A1 (ja) |
| EP (1) | EP3667660A4 (ja) |
| JP (1) | JP7230806B2 (ja) |
| CN (1) | CN110998719A (ja) |
| WO (1) | WO2019031268A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2021140134A (ja) * | 2020-03-04 | 2021-09-16 | ベイジン バイドゥ ネットコム サイエンス アンド テクノロジー カンパニー リミテッド | 音声を認識するための方法、装置、電子機器、コンピュータ可読記憶媒体及びコンピュータプログラム |
| JP2022501623A (ja) * | 2019-08-16 | 2022-01-06 | ペキン シャオミ モバイル ソフトウェア カンパニー, リミテッドBeijing Xiaomi Mobile Software Co., Ltd. | オーディオ処理方法、装置及び記憶媒体 |
| JP2022528582A (ja) * | 2019-06-13 | 2022-06-14 | エーアイ スピーチ カンパニー リミテッド | ヒューマンマシン対話方法及び電子デバイス |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11043214B1 (en) * | 2018-11-29 | 2021-06-22 | Amazon Technologies, Inc. | Speech recognition using dialog history |
| US11164562B2 (en) * | 2019-01-10 | 2021-11-02 | International Business Machines Corporation | Entity-level clarification in conversation services |
| KR20210044985A (ko) * | 2019-10-16 | 2021-04-26 | 엘지전자 주식회사 | 음성 처리 방법 및 음성 처리 장치 |
| CN113126765A (zh) * | 2021-04-22 | 2021-07-16 | 北京云迹科技有限公司 | 一种多模态输入交互方法、装置、机器人和存储介质 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS61285570A (ja) * | 1985-06-12 | 1986-12-16 | Hitachi Ltd | 音声入力装置 |
| WO2012023450A1 (ja) * | 2010-08-19 | 2012-02-23 | 日本電気株式会社 | テキスト処理システム、テキスト処理方法およびテキスト処理プログラム |
| JP2015060127A (ja) * | 2013-09-19 | 2015-03-30 | 株式会社東芝 | 音声同時処理装置、方法およびプログラム |
| JP2016004270A (ja) | 2014-05-30 | 2016-01-12 | アップル インコーポレイテッド | 手動始点/終点指定及びトリガフレーズの必要性の低減 |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5838871B2 (ja) * | 2012-03-14 | 2016-01-06 | 富士通株式会社 | データ解析装置、データ分割装置、データ解析方法、データ分割方法、データ解析プログラム、及びデータ分割プログラム |
| US9666192B2 (en) * | 2015-05-26 | 2017-05-30 | Nuance Communications, Inc. | Methods and apparatus for reducing latency in speech recognition applications |
| US10121471B2 (en) * | 2015-06-29 | 2018-11-06 | Amazon Technologies, Inc. | Language model speech endpointing |
-
2018
- 2018-07-27 US US16/635,571 patent/US20200219487A1/en not_active Abandoned
- 2018-07-27 JP JP2019535101A patent/JP7230806B2/ja active Active
- 2018-07-27 EP EP18843678.6A patent/EP3667660A4/en not_active Withdrawn
- 2018-07-27 CN CN201880049934.0A patent/CN110998719A/zh not_active Withdrawn
- 2018-07-27 WO PCT/JP2018/028201 patent/WO2019031268A1/ja unknown
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS61285570A (ja) * | 1985-06-12 | 1986-12-16 | Hitachi Ltd | 音声入力装置 |
| WO2012023450A1 (ja) * | 2010-08-19 | 2012-02-23 | 日本電気株式会社 | テキスト処理システム、テキスト処理方法およびテキスト処理プログラム |
| JP2015060127A (ja) * | 2013-09-19 | 2015-03-30 | 株式会社東芝 | 音声同時処理装置、方法およびプログラム |
| JP2016004270A (ja) | 2014-05-30 | 2016-01-12 | アップル インコーポレイテッド | 手動始点/終点指定及びトリガフレーズの必要性の低減 |
Non-Patent Citations (4)
| Title |
|---|
| HATA, SHOGO: "Sentence boundary detection focused on confidence measure of automatic speech recognition", RESEARCH REPORT OF INFORMATION PROCESSING SOCIETY OF JAPAN, vol. 2009 -SL, no. 20, 22 December 2009 (2009-12-22), pages 1 - 6, XP009507777 * |
| KAWAHARA, TATSUYA: "Intelligent Transcription using Spontaneous Speech Processing", RESEARCH REPORT OF INFORMATION PROCESSING SOCIETY OF JAPAN, vol. 2006, no. 136, 22 December 2006 (2006-12-22), pages 209 - 214, XP055576529 * |
| NAKAZAWA, SATOSHI: "Approval of sentence from video voice text recognition", PROCEEDINGS OF THE 8TH ANNUAL CONFERENCE OF THE ASSOCIATION FOR NATURAL LANGUAGE PROCESSING, 18 March 2002 (2002-03-18), pages 575 - 578, XP009518643, ISSN: 2188-4420 * |
| See also references of EP3667660A4 |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022528582A (ja) * | 2019-06-13 | 2022-06-14 | エーアイ スピーチ カンパニー リミテッド | ヒューマンマシン対話方法及び電子デバイス |
| JP7108799B2 (ja) | 2019-06-13 | 2022-07-28 | エーアイ スピーチ カンパニー リミテッド | ヒューマンマシン対話方法及び電子デバイス |
| JP2022501623A (ja) * | 2019-08-16 | 2022-01-06 | ペキン シャオミ モバイル ソフトウェア カンパニー, リミテッドBeijing Xiaomi Mobile Software Co., Ltd. | オーディオ処理方法、装置及び記憶媒体 |
| US11264027B2 (en) | 2019-08-16 | 2022-03-01 | Beijing Xiaomi Mobile Software Co., Ltd. | Method and apparatus for determining target audio data during application waking-up |
| JP7166294B2 (ja) | 2019-08-16 | 2022-11-07 | ペキン シャオミ モバイル ソフトウェア カンパニー, リミテッド | オーディオ処理方法、装置及び記憶媒体 |
| JP2021140134A (ja) * | 2020-03-04 | 2021-09-16 | ベイジン バイドゥ ネットコム サイエンス アンド テクノロジー カンパニー リミテッド | 音声を認識するための方法、装置、電子機器、コンピュータ可読記憶媒体及びコンピュータプログラム |
| JP7365985B2 (ja) | 2020-03-04 | 2023-10-20 | 阿波▲羅▼智▲聯▼(北京)科技有限公司 | 音声を認識するための方法、装置、電子機器、コンピュータ可読記憶媒体及びコンピュータプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3667660A4 (en) | 2020-12-23 |
| CN110998719A (zh) | 2020-04-10 |
| US20200219487A1 (en) | 2020-07-09 |
| JP7230806B2 (ja) | 2023-03-01 |
| EP3667660A1 (en) | 2020-06-17 |
| JPWO2019031268A1 (ja) | 2020-09-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20210249013A1 (en) | Method and Apparatus to Provide Comprehensive Smart Assistant Services | |
| JP7230806B2 (ja) | 情報処理装置、及び情報処理方法 | |
| US11423885B2 (en) | Utilizing pre-event and post-event input streams to engage an automated assistant | |
| US20220005458A1 (en) | On-device speech synthesis of textual segments for training of on-device speech recognition model | |
| US11687526B1 (en) | Identifying user content | |
| CN113614825A (zh) | 用于自动语音识别的字词网格扩增 | |
| US11151996B2 (en) | Vocal recognition using generally available speech-to-text systems and user-defined vocal training | |
| US11532301B1 (en) | Natural language processing | |
| US11568878B2 (en) | Voice shortcut detection with speaker verification | |
| KR20210013193A (ko) | 로컬 텍스트-응답 맵을 활용하여 사용자의 음성 발화에 대한 응답 렌더링 | |
| US10417345B1 (en) | Providing customer service agents with customer-personalized result of spoken language intent | |
| KR20220128397A (ko) | 자동 음성 인식을 위한 영숫자 시퀀스 바이어싱 | |
| US20240055003A1 (en) | Automated assistant interaction prediction using fusion of visual and audio input | |
| US11626107B1 (en) | Natural language processing | |
| WO2018043137A1 (ja) | 情報処理装置及び情報処理方法 | |
| CN110809796B (zh) | 具有解耦唤醒短语的语音识别系统和方法 | |
| JP2015099290A (ja) | 発話内重要語抽出装置とその装置を用いた発話内重要語抽出システムと、それらの方法とプログラム | |
| US20210064640A1 (en) | Information processing apparatus and information processing method | |
| US11935539B1 (en) | Integrating voice controls into applications | |
| US11935533B1 (en) | Content-related actions based on context | |
| US11756533B2 (en) | Hot-word free pre-emption of automated assistant response presentation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 18843678 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2019535101 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2018843678 Country of ref document: EP Effective date: 20200309 |