WO2018011842A1 - 階層ネットワークを用いた演算処理システム - Google Patents
階層ネットワークを用いた演算処理システム Download PDFInfo
- Publication number
- WO2018011842A1 WO2018011842A1 PCT/JP2016/070376 JP2016070376W WO2018011842A1 WO 2018011842 A1 WO2018011842 A1 WO 2018011842A1 JP 2016070376 W JP2016070376 W JP 2016070376W WO 2018011842 A1 WO2018011842 A1 WO 2018011842A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- layer
- data
- intermediate data
- processing
- terminal
- Prior art date
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/11—Complex mathematical operations for solving equations, e.g. nonlinear equations, general mathematical optimization problems
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/088—Non-supervised learning, e.g. competitive learning
Definitions
- the present invention relates to an arithmetic processing system using a hierarchical network, and is particularly suitable for use in an arithmetic processing system that executes arithmetic operations using a neural network in which a plurality of processing layers are hierarchically connected.
- the final calculation result data in which the object included in the image is recognized is obtained by sequentially performing the intermediate layer processing and the total connection layer processing on the input image data. can get.
- the intermediate layer a plurality of processing layers are connected in a hierarchy. By repeating the feature amount extraction process in each processing layer, the feature amount included in the input image data is extracted in a high dimension, and the result is subjected to an intermediate calculation. Output as result data.
- a plurality of intermediate operation result data obtained from the intermediate layer are combined to output final operation result data.
- Patent Document 1 a circuit that realizes a fully coupled layer is configured using a circuit that realizes an intermediate layer, thereby reducing the overall circuit scale of an arithmetic processing device that realizes arithmetic processing using a neural network. It is described.
- Deep learning is based on a large amount of input data, and the computer repeats trial and error to create higher-order feature values and performs “unsupervised learning” that enables images to be classified based on them. . Deep learning has created the possibility of being able to recognize things that were previously unrecognizable by humans, and is attracting industry expectations.
- the deep learning learning process requires a large computation load, and it takes a very long processing time to derive an answer.
- a mobile terminal such as a smartphone or a tablet that does not have high arithmetic processing capability
- the processing takes an extremely long time.
- each frame image of a moving picture taken with a mobile terminal or many photographic images taken with a mobile terminal can be transmitted to a server, and the server can perform learning processing using these images as input data. .
- images taken by a user's mobile terminal are often related to the privacy of the user, and many users feel resistance to transmitting a large amount of the image to the server.
- the present invention has been made to solve such a problem, and an object thereof is to shorten the time required for the learning process while maintaining the confidentiality of information related to privacy. .
- the calculation by the neural network is executed separately for the first terminal and the second terminal having a higher calculation processing capability. That is, the first terminal executes processing up to a part of the first half of the plurality of intermediate layers, outputs the result as intermediate data to the second terminal, and the second terminal The intermediate data output from this terminal is used as an input, and the processing of some intermediate layers in the latter half of the plurality of intermediate layers is executed.
- the intermediate data output from the first terminal is not the original data itself held in the first terminal, the confidentiality of privacy-related information is ensured. can do.
- the processing time required for the calculation of the learning process can be shortened.
- the time concerning a learning process can be shortened, maintaining the secrecy of the information which concerns on privacy.
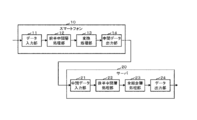
- FIG. 1 is a diagram showing an overall configuration example of an arithmetic processing system (hereinafter simply referred to as an arithmetic processing system) using a hierarchical network according to the first embodiment.
- the arithmetic processing system according to the first embodiment includes an arithmetic operation using a neural network in which an input layer, a plurality of intermediate layers for extracting feature amounts included in data input from a previous layer, and an output layer are connected in a hierarchical manner. Is to execute.
- the arithmetic processing system includes a smartphone 10 and a server 20.
- the smartphone 10 and the server 20 are configured to be connectable via a communication network 30 such as the Internet.
- the smartphone 10 is an example of a “first terminal” described in the claims.
- the server 20 is an example of a “second terminal” described in the claims, and has a higher processing capacity than the smartphone 10.
- FIG. 2 is a diagram illustrating an example of a neural network for operations performed by the smartphone 10 and the server 20.
- the data input to the input layer 101 is processed up to the processing of the middle layer 102 in the first half of the plurality of intermediate layers, The result is output to the server 20 as intermediate data.
- the intermediate data output from the intermediate layer 102 of the smartphone 10 is used as input to the input layer 201, and processing of some of the intermediate layers 202 and 203 in the latter half of the plurality of intermediate layers is executed. Is output to the output layer 204.
- the processing of the three intermediate layers 102, 202, and 203 is sequentially performed on the data input to the input layer 101, whereby each of the intermediate layers 102, In 202 and 203, the feature amount included in the data input from the previous layer is extracted in a high dimension, and the result is output to the output layer 204 as operation result data.
- the output data of the intermediate layer 102 in the smartphone 10 and the input data of the input layer 201 in the server 20 are the same.
- Each of the input layers 101 and 201, the intermediate layers 102, 202 and 203, and the output layer 204 includes a plurality of neurons (functions for setting data and executing predetermined processing on the data), and adjacent layers.
- a network however, the intermediate layer 102 and the input layer 201 are connected by the communication network 30.
- Each network between layers has a function of transmitting data to the next layer, and weights for data to be transmitted are set in each network.
- supervised learning in which input data and correct output data (correct answer) are given as a set in advance, only input data is given, and certain patterns and rules that are latent in the data are used as feature quantities. It is roughly divided into “Unsupervised learning” to be extracted.
- the arithmetic processing system according to the first embodiment can be applied to supervised learning and unsupervised learning.
- the present invention can also be applied to a prediction process after the learning process is completed.
- the prediction process is a process of inputting one data and outputting a correct answer using a learned neural network.
- the number of intermediate layers is three, only the process of the first intermediate layer 102 is executed by the smartphone 10, and the processes of the remaining two intermediate layers 202 and 203 are executed by the server 20.
- the total number of intermediate layers and the positions divided into the first and second half are not limited to this example.
- the computing capacity of the smartphone 10 is lower than that of the server 20, it is preferable to reduce the number of intermediate layers assigned to the smartphone 10 rather than the number of intermediate layers assigned to the server 20.
- the intermediate data output from the smartphone 10 to the server 20 may remain in the intermediate data to the extent that the features of the original data input to the input layer 101 can be recognized. There is. In this case, the user of the smartphone 10 may feel resistance to outputting a large amount of such intermediate data to the external server 20 for learning. Therefore, the number of intermediate layers allocated to the smartphone 10 is such that a high-dimensional feature amount is extracted to such an extent that the amount of calculation in the smartphone 10 does not increase too much and the features of the original input data are difficult to recognize. It is preferable to set it to a number.
- an encoding layer 103 may be added after the intermediate layer 102.
- the encoding layer 103 may convert the input data to a state in which the features of the input data cannot be recognized by performing an irreversible encoding process, and output the converted intermediate data to the server 20. .
- the intermediate data output from the intermediate layer 102 is data in which the characteristics of the input data are recognized to some extent. It is possible to reduce the number of intermediate layers allocated to.
- the data obtained by encoding the intermediate data can be said to be data having unique features corresponding to the features of the original data.
- the server 20 sequentially extracts the feature values for the encoded intermediate data, the operation result data finally obtained inherits features unique to the original data. Therefore, there is no problem even if the irreversible encoding process is performed in the middle of the calculation by the series of convolutional neural networks.
- FIG. 4 is a block diagram illustrating a functional configuration example of the arithmetic processing system according to the first embodiment.
- the arithmetic processing system shown in FIG. 4 shows an example in which arithmetic processing using a convolutional neural network is applied as an example of arithmetic processing using a hierarchical network.
- the arithmetic processing system shown in FIG. 4 includes an encoding layer 103 in the smartphone 10 as shown in FIG. 3, and the encoding layer 103 irreversibly encodes intermediate data generated by the intermediate layer 102. The example which performs is shown.
- an intermediate layer process and a fully connected layer process are sequentially performed on data input to the input layer.
- the intermediate layer a plurality of feature quantity extraction processing layers are hierarchically connected, and in each processing layer, convolution operation processing, activation processing, and pooling processing are performed on data input from the previous layer.
- the intermediate layer extracts the feature amount included in the input data in a high dimension by repeating the processing in each processing layer, and outputs the result to the all connected layers as intermediate operation result data.
- the fully connected layer a plurality of intermediate operation result data obtained from the intermediate layer are combined to output final operation result data.
- the smartphone 10 configuring the arithmetic processing system according to the first embodiment includes a data input unit 11, a first half intermediate layer processing unit 12, a conversion processing unit 13, and an intermediate data output unit 14 as functional configurations. It is configured with.
- the server 20 includes an intermediate data input unit 21, a latter half intermediate layer processing unit 22, a fully connected layer processing unit 23, and a data output unit 24 as functional configurations.
- Each functional block 11 to 14 of the smartphone 10 can be configured by any of hardware, DSP (Digital Signal Processor), and software.
- DSP Digital Signal Processor
- each of the functional blocks 11 to 14 actually includes a CPU, RAM, ROM, etc. of a computer, and is stored in a recording medium such as RAM, ROM, hard disk, or semiconductor memory. Is realized by operating.
- each functional block 21 to 24 of the server 20 can be configured by any of hardware, DSP, and software.
- each of the functional blocks 21 to 24 is actually configured by including a CPU, RAM, ROM, and the like of a computer, and is stored in a recording medium such as RAM, ROM, hard disk, or semiconductor memory. Is realized by operating.
- the data input unit 11 inputs data to be learned or predicted. When learning is performed, a large amount of data is input from the data input unit 11. On the other hand, when the prediction is performed after the learning process is completed, one or a plurality of data to be predicted is input from the data input unit 11.
- the processing of the data input unit 11 corresponds to inputting data to the input layer 101.
- the first-half intermediate layer processing unit 12 executes processing up to the first half of the plurality of intermediate layers, and outputs the result as intermediate data.
- the first half intermediate layer processing unit 12 corresponds to executing the processing up to the first intermediate layer 102 on the data input by the data input unit 11.
- the first half intermediate layer processing unit 12 performs a convolution operation process, an activation process, and a pooling process on the data input by the data input unit 11 as a process of the intermediate layer 102.
- a known method may be applied to any of the convolution operation processing, activation processing, and pooling processing.
- the data processed by the first half intermediate layer processing unit 12 is output as intermediate data from the pooling layer.
- the conversion processing unit 13 performs an irreversible conversion process on the intermediate data (pooling layer output data) obtained by the first half intermediate layer processing unit 12.
- the lossy conversion process is an irreversible encoding process that makes it impossible to completely restore the data before conversion.
- the irreversible conversion process by the conversion processing unit 13 corresponds to the encoding process in the encoding layer 103 shown in FIG.
- the irreversible conversion process performed by the conversion processing unit 13 may be an irreversible encoding process, and the contents thereof are not limited.
- the encoding layer 103 provided in the subsequent stage of the intermediate layer 102 is used as a fully connected layer of the convolutional neural network, and a plurality of intermediate data obtained from the first half intermediate layer processing unit 12 (a plurality of data obtained from each neuron of the intermediate layer 102). Data) can be combined and output.
- the intermediate data can be recognized to the extent that the characteristics of the original data input by the data input unit 11 can be recognized. Even if it remains, the feature can be converted into data that is difficult to recognize. Moreover, since it becomes impossible to restore
- the smartphone 10 when the smartphone 10 is configured to execute intermediate layer processing to the extent that the features of the original input data are difficult to recognize, it is not essential to provide the conversion processing unit 13. .
- the intermediate data output unit 14 outputs the intermediate data subjected to the irreversible conversion processing by the conversion processing unit 13 to the server 20.
- the intermediate data input unit 21 of the server 20 inputs the intermediate data output from the intermediate data output unit 14 of the smartphone 10.
- the intermediate data input by the intermediate data input unit 21 is data set in the input layer 201 of the server 20 as shown in FIG.
- the latter half intermediate layer processing unit 22 executes the processing of the latter half of the plurality of intermediate layers on the intermediate data input by the intermediate data input unit 21.
- the latter half intermediate layer processing unit 22 corresponds to executing the processes of the second intermediate layer 202 and the third intermediate layer 203 on the intermediate data input by the intermediate data input unit 21.
- the latter half middle layer processing unit 22 sequentially performs a convolution operation process, an activation process, and a pooling process in each layer as the processes of the middle layers 202 and 203.
- the all connected layer processing unit 23 combines and outputs a plurality of data (a plurality of data obtained from each neuron of the third intermediate layer 203) obtained by the latter half intermediate layer processing unit 22. Note that the processing layer corresponding to the processing of the all combined layer processing unit 23 is not shown in FIG. 3, but is connected to the subsequent stage of the intermediate layer 203.
- the data output unit 24 outputs the data processed by the all coupling layer processing unit 23 from the output layer 204 as final calculation result data.
- a series of arithmetic processing by a convolutional neural network composed of a plurality of layers is executed separately for the smartphone 10 and the server 20 having higher arithmetic processing capability. ing. That is, in the smartphone 10, the processes up to a part of the intermediate layer 102 in the first half of the plurality of intermediate layers 102, 202, and 203 are executed, and the result is output to the server 20 as intermediate data. Then, in the server 20, the intermediate data output from the smartphone 10 is used as an input, and the processing of some of the intermediate layers 202 and 203 in the latter half is executed.
- a part of the computation by the neural network is executed by the server 20 having a high computation processing capacity, so that the processing time required for the computation of the learning process can be shortened.
- the time concerning a learning process can be shortened, keeping the secrecy of the information concerning a user's privacy.
- the smartphone 10 and the server 20 perform a series of arithmetic processing using a convolutional neural network
- the present invention is not limited to this.
- the smartphone 10 may execute arithmetic processing using a convolutional neural network
- the server 20 may execute arithmetic processing (self-encoding processing) using an auto encoder.
- FIG. 5 is a diagram illustrating an example of a neural network when the server 20 performs self-encoding processing.
- feature amount extraction processing convolution operation processing, activation processing, pooling processing
- the first intermediate layer 102 for the data input to the input layer 101
- an encoding layer The irreversible conversion process by 103 is executed, and the result is output to the server 20 as intermediate data.
- the server 20 the intermediate data output from the encoding layer 103 of the smartphone 10 is input to the input layer 201, the self-encoding process is executed in the intermediate layer 302, and the result is output to the output layer 303.
- the same data as the data of the input layer 201 is given as a correct answer when performing the learning process. Then, when intermediate data is given to the input layer 201, a network connecting each neuron of the input layer 201 and each neuron of the intermediate layer 302 so that the same data is output from the output layer 303, or the intermediate layer 302 The weights for the networks connecting the neurons and the neurons of the output layer 303 are adjusted.
- FIG. 6 is a block diagram illustrating a functional configuration example of the arithmetic processing system according to the second embodiment.
- the server 20 includes a self-encoding processing unit 25 instead of the latter half intermediate layer processing unit 22 and the fully connected layer processing unit 23.
- the self-encoding processing unit 25 performs arithmetic processing (self-encoding processing) by the auto encoder in the intermediate layer 302 on the intermediate data of the input layer 201 input by the intermediate data input unit 21, and calculates the result.
- the result data is output to the output layer 303.
- the learning process and the prediction process can be executed with different values. In this way, for example, high-level deep learning is realized in a short time by performing supervised learning with a relatively small calculation load in the smartphone 10 and unsupervised learning in the server 20 with high calculation processing capability. It is also possible.
- the present invention is not limited to this.
- the smartphone 10 when a predetermined number of data is given to the input layer 101, the smartphone 10 has a predetermined number of times so that the time until the intermediate data is obtained in the last intermediate layer assigned to the smartphone 10 is within a predetermined time.
- An intermediate layer may be assigned and the remaining intermediate layer may be assigned to the server 20.
- the processing is performed within 1 second.
- the number of intermediate layers assigned to the smartphone 10 is one or two. In this way, when the predetermined number of data is transmitted for learning from the smartphone 10 to the server 20, at least the processing in the smartphone 10 can be completed within a desired time.
- the present invention is not limited to this. Any one of the first terminal and the second terminal may be used as long as the second terminal has a higher calculation processing capability than the first terminal.
- each of the first and second embodiments described above is merely an example of a specific example for carrying out the present invention, and the technical scope of the present invention should not be interpreted in a limited manner. It will not be. That is, the present invention can be implemented in various forms without departing from the gist or the main features thereof.
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Mathematical Physics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- General Health & Medical Sciences (AREA)
- Evolutionary Computation (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Computational Mathematics (AREA)
- Mathematical Analysis (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Operations Research (AREA)
- Algebra (AREA)
- Databases & Information Systems (AREA)
- Neurology (AREA)
- Image Analysis (AREA)
Abstract
スマートフォン10において、複数の中間層のうち前半の中間層102の処理までを実行し、その結果を中間データとしてサーバ20に出力し、サーバ20において、スマートフォン10から出力された中間データを入力として、複数の中間層のうち後半の中間層202,203の処理を実行することにより、スマートフォン10からサーバ20にオリジナルのデータが出力されることをなくして、オリジナルデータを保有するユーザのプライバシーに係る情報の秘匿性を確保するとともに、ニューラルネットワークによる演算の一部が演算処理能力の高いサーバ20で実行されるようにして、学習処理の演算に要する処理時間を短縮することができるようにする。
Description
本発明は、階層ネットワークを用いた演算処理システムに関し、特に、複数の処理層が階層的に接続されたニューラルネットワークによる演算を実行する演算処理システムに用いて好適なものである。
従来、複数の処理層が階層的に接続されたニューラルネットワークによる演算を実行する演算処理装置が知られている(例えば、特許文献1参照)。特に、画像認識を行う演算処理装置においては、いわゆる畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)が中核的な存在となっている。
畳み込みニューラルネットワークによれば、入力される画像データに対して中間層の処理および全結合層の処理が順次施されることにより、画像に含まれる対象物が認識された最終的な演算結果データが得られる。中間層では、複数の処理層が階層的に接続されており、各処理層において特徴量抽出処理を繰り返すことにより、入力画像データに含まれる特徴量を高次元で抽出し、その結果を中間演算結果データとして出力する。全結合層では、中間層から得られる複数の中間演算結果データを結合して最終的な演算結果データを出力する。
なお、特許文献1には、中間層を実現する回路を利用して全結合層を実現する回路を構成することにより、ニューラルネットワークによる演算処理を実現する演算処理装置の全体の回路規模を小さくすることが記載されている。
近年では、畳み込みニューラルネットワークによる演算を用いたディープラーニング(深層学習)の研究開発が盛んに行われている。ディープラーニングは、大量の入力データをもとに、コンピュータが自ら試行錯誤を繰り返して高次の特徴量を作り出し、それをもとに画像を分類可能にする「教師なし学習」を行うものである。ディープラーニングによって、これまで人間には認識できなかったものが認識できるようになる可能性が生まれており、産業界の期待を集めている。
しかしながら、ディープラーニングの学習処理には多大な演算負荷がかかり、答えを導き出すまでには非常に長い処理時間がかかる。特に、高い演算処理能力を持たないスマートフォンやタブレット等の携帯端末でディープラーニングを行おうとすると、処理に極めて長い時間がかかってしまうという問題があった。
そこで、この問題の解決方法の1つとして、ディープラーニングに必要な大量のデータを、比較的高い演算処理能力を有するサーバに携帯端末から送信し、サーバにおいて学習処理を実行することが考えられる。例えば、携帯端末で撮影した動画の各フレーム画像や、携帯端末で撮影した多数の写真画像などをサーバに送信し、サーバがこれらの画像を入力データとして学習処理を行うといった使い方が一例として考えられる。
しかしながら、ユーザの携帯端末で撮影される画像は、そのユーザのプライバシーに係るものであることが多く、これを大量にサーバに送信することに対して抵抗を感じるユーザは多い。
本発明は、このような問題を解決するために成されたものであり、プライバシーに係る情報の秘匿性を保ちつつ、学習処理にかかる時間を短くすることができるようにすることを目的とする。
上記した課題を解決するために、本発明では、第1の端末と、それよりも演算処理能力の高い第2の端末とに分けてニューラルネットワークによる演算を実行するようにしている。すなわち、第1の端末において、複数の中間層のうち前半の一部の中間層の処理までを実行し、その結果を中間データとして第2の端末に出力し、第2の端末において、第1の端末から出力された中間データを入力として、複数の中間層のうち後半の一部の中間層の処理を実行するようにしている。
上記のように構成した本発明によれば、第1の端末から出力される中間データは、第1の端末に保持されているオリジナルのデータそのものではないので、プライバシーに係る情報の秘匿性を確保することができる。また、ニューラルネットワークによる演算の一部が、演算処理能力の高い第2の端末で実行されるので、学習処理の演算に要する処理時間を短縮することができる。これにより、本発明によれば、プライバシーに係る情報の秘匿性を保ちつつ、学習処理にかかる時間を短くすることができる。
(第1の実施形態)
以下、本発明の第1の実施形態を図面に基づいて説明する。図1は、第1の実施形態による階層ネットワークを用いた演算処理システム(以下、単に演算処理システムという)の全体構成例を示す図である。第1の実施形態による演算処理システムは、入力層と、前階層から入力されるデータに含まれる特徴量を抽出する複数の中間層と、出力層とが階層的に接続されたニューラルネットワークによる演算を実行するものである。
以下、本発明の第1の実施形態を図面に基づいて説明する。図1は、第1の実施形態による階層ネットワークを用いた演算処理システム(以下、単に演算処理システムという)の全体構成例を示す図である。第1の実施形態による演算処理システムは、入力層と、前階層から入力されるデータに含まれる特徴量を抽出する複数の中間層と、出力層とが階層的に接続されたニューラルネットワークによる演算を実行するものである。
図1に示すように、第1の実施形態による演算処理システムは、スマートフォン10とサーバ20とを備えて構成されている。スマートフォン10とサーバ20との間は、例えばインターネット等の通信ネットワーク30により接続可能に構成されている。スマートフォン10は、特許請求の範囲に記載した「第1の端末」の一例である。サーバ20は、特許請求の範囲に記載した「第2の端末」の一例であり、スマートフォン10よりも高い演算処理能力を有している。
図2は、スマートフォン10およびサーバ20が行う演算のニューラルネットワークの一例を示す図である。図2に示すように、第1の実施形態では、スマートフォン10において、入力層101に入力されたデータに対し、複数の中間層のうち前半の一部の中間層102の処理までを実行し、その結果を中間データとしてサーバ20に出力する。また、サーバ20において、スマートフォン10の中間層102より出力される中間データを入力層201に対する入力として、複数の中間層のうち後半の一部の中間層202,203の処理を実行し、その結果を出力層204に出力する。
このように構成した第1の実施形態による演算処理システムでは、入力層101に入力されるデータに対して3つの中間層102,202,203の処理を順次実行することにより、各中間層102,202,203において、前階層から入力されるデータに含まれる特徴量を高次元で抽出し、その結果を演算結果データとして出力層204に出力する。ここで、スマートフォン10における中間層102の出力データと、サーバ20における入力層201の入力データとは同じものとなる。
入力層101,201、中間層102,202,203、出力層204の各層は複数のニューロン(データをセットし、そのデータに対して所定の処理を実行する機能)を含んでいて、隣接する層が備える各ニューロンどうしの間がネットワークにより接続されている(ただし、中間層102と入力層201との間は通信ネットワーク30により接続される)。層間の各ネットワークは、データを次の層に伝達する機能を有するものであり、それぞれのネットワークには、伝達するデータに対する重み付けが設定されている。
このようなニューラルネットワークを用いて学習を行う際は、学習対象とする多数のデータを入力層101に入力し、正しい答えが出力層204から出力されるように、各ネットワークの重み付けを思考錯誤的に変えながら調整する。ここで、出力層204から出力されるデータが正解とは異なるたびに重み付けの調整を繰り返すことにより、学習の精度を上げていくことが可能である。一般に、このような学習を演算処理能力の低いスマートフォン10で行うと、演算に非常に長い時間がかかる。これに対し、第1の実施形態では、演算処理能力が高いサーバ20と協働して学習を行うことにより、演算時間の短縮を図っている。
ところで、学習には、入力データと正しい出力データ(正解)とをあらかじめセットで与えて行う「教師あり学習」と、入力データのみを与え、そのデータに潜在する一定のパターンやルールを特徴量として抽出する「教師なし学習」とに大別される。第1の実施形態による演算処理システムは、教師あり学習にも教師なし学習にも適用することが可能である。また、学習処理が完了した後の予測処理にも適用することができることは言うまでもない。予測処理とは、1つのデータを入力し、学習済みのニューラルネットワークを用いて正解を出力する処理のことをいう。
なお、図2では、中間層の数を3つとし、そのうち最初の中間層102の処理のみをスマートフォン10で実行し、残り2つの中間層202,203の処理をサーバ20で実行する例について説明したが、中間層の総数および前後半に分ける位置はこの例に限定されない。ただし、スマートフォン10は演算処理能力がサーバ20に比べて低いので、サーバ20に割り当てる中間層の数よりもスマートフォン10に割り当てる中間層の数を少なくするのが好ましい。
一方、スマートフォン10に割り当てる中間層の数が少ないと、スマートフォン10からサーバ20に出力する中間データの中に、入力層101に入力されたオリジナルのデータの特徴が認識できる程度に残っている可能性がある。この場合、そのような中間データを外部のサーバ20に学習のための大量に出力することに対し、スマートフォン10のユーザが抵抗を感じるかもしれない。そこで、スマートフォン10に割り当てる中間層の数は、スマートフォン10での演算量が多くなり過ぎず、かつ、元の入力データの特徴が認識しにくくなる程度に高次元の特徴量が抽出されるような数に設定するのが好ましい。
あるいは、図3に示すように、中間層102の後段に符号化層103を追加するようにしてもよい。そして、この符号化層103において、不可逆的な符号化処理を行うことによって入力データの特徴が認識できない状態に変換した上で、その変換後の中間データをサーバ20に出力するようにしてもよい。このようにすれば、中間層102より出力される中間データが、入力データの特徴がある程度認識されるようなデータであっても問題はないので、演算量の軽減のみを考慮して、スマートフォン10に割り当てる中間層の数を少なくすることが可能である。
なお、入力層101にデータを入力して学習処理または予測処理を行う場合、元のデータを復元する必要性は全くない。また、入力データが有する特徴は中間データまで引き継がれているので、その中間データが符号化されたデータは、元データの特徴に対応する固有の特徴を有するデータと言える。さらに、その符号化された中間データを対象としてサーバ20において特徴量が順次抽出されていくので、最終的に得られる演算結果データは、元データに固有の特徴を引き継いだものとなっている。したがって、一連の畳み込みニューラルネットワークによる演算の途中で不可逆的な符号化処理を行っても問題はない。
図4は、第1の実施形態による演算処理システムの機能構成例を示すブロック図である。図4に示す演算処理システムは、階層ネットワークを用いた演算処理の一例として、畳み込みニューラルネットワークによる演算処理を適用した例を示している。また、図4に示す演算処理システムは、図3のようにスマートフォン10に符号化層103を設け、中間層102により生成される中間データに対して符号化層103にて不可逆的な符号化処理を行う例を示している。
畳み込みニューラルネットワークの場合、入力層に入力されるデータに対して中間層の処理および全結合層の処理を順次実行する。中間層では、複数の特徴量抽出処理層が階層的に接続されており、各処理層において、前階層から入力されるデータに対して畳み込み演算処理、活性化処理、プーリング処理を行う。中間層は、各処理層における処理を繰り返すことで入力データに含まれる特徴量を高次元で抽出し、その結果を中間演算結果データとして全結合層に出力する。全結合層では、中間層から得られる複数の中間演算結果データを結合して最終的な演算結果データを出力する。
図4に示すように、第1の実施形態による演算処理システムを構成するスマートフォン10は、その機能構成として、データ入力部11、前半中間層処理部12、変換処理部13および中間データ出力部14を備えて構成されている。また、サーバ20は、その機能構成として、中間データ入力部21、後半中間層処理部22、全結合層処理部23およびデータ出力部24を備えて構成されている。
スマートフォン10の各機能ブロック11~14は、ハードウェア、DSP(Digital Signal Processor)、ソフトウェアの何れによっても構成することが可能である。例えばソフトウェアによって構成する場合、上記各機能ブロック11~14は、実際にはコンピュータのCPU、RAM、ROMなどを備えて構成され、RAMやROM、ハードディスクまたは半導体メモリ等の記録媒体に記憶されたプログラムが動作することによって実現される。
また、サーバ20の各機能ブロック21~24も、ハードウェア、DSP、ソフトウェアの何れによっても構成することが可能である。例えばソフトウェアによって構成する場合、上記各機能ブロック21~24は、実際にはコンピュータのCPU、RAM、ROMなどを備えて構成され、RAMやROM、ハードディスクまたは半導体メモリ等の記録媒体に記憶されたプログラムが動作することによって実現される。
データ入力部11は、学習対象または予測対象のデータを入力する。学習を行う際には、多数のデータをデータ入力部11より入力する。一方、学習処理が終わった後で予測を行う際には、予測したい1つまたは複数のデータをデータ入力部11より入力する。このデータ入力部11の処理は、入力層101にデータを入力することに対応する。
前半中間層処理部12は、複数の中間層のうち前半の一部の中間層の処理までを実行し、その結果を中間データとして出力する。図3の例では、前半中間層処理部12は、データ入力部11により入力されたデータに対して、1番目の中間層102の処理までを実行することに対応する。具体的には、前半中間層処理部12は、中間層102の処理として、データ入力部11により入力されたデータに対して畳み込み演算処理、活性化処理、プーリング処理を行う。畳み込み演算処理、活性化処理、プーリング処理は何れも、公知の手法を適用してよい。前半中間層処理部12により処理されたデータは、中間データとしてプーリング層から出力される。
変換処理部13は、前半中間層処理部12により得られた中間データ(プーリング層の出力データ)に対して不可逆変換処理を行う。不可逆変換処理とは、変換前のデータを完全には復元することができなくする不可逆的な符号化処理のことである。この変換処理部13による不可逆変換処理は、図3に示す符号化層103における符号化処理に対応する。
ここで、変換処理部13が行う不可逆変換処理は、不可逆的な符号化処理であればよく、その内容は問わない。一例として、中間層102の後段に設けた符号化層103を畳み込みニューラルネットワークの全結合層とし、前半中間層処理部12から得られる複数の中間データ(中間層102の各ニューロンから得られる複数のデータ)を結合して出力する全結合処理とすることが可能である。
このように、前半中間層処理部12により得られた中間データに対して不可逆変換処理を施すことにより、データ入力部11により入力された大元のデータの特徴が認識できる程度に中間データの中に残っている場合であっても、その特徴を認識しにくいデータに変換することができる。また、不可逆変換処理を施した後は、変換前の中間データに復元することが不可能となるので、スマートフォン10のデータをサーバ20に提供するユーザのプライバシーを確実に守ることができる。
なお、上述したように、スマートフォン10において、大元の入力データの特徴が認識しにくくなる程度まで中間層の処理を実行するように構成する場合は、変換処理部13を設けることは必須ではない。
中間データ出力部14は、変換処理部13により不可逆変換処理された中間データをサーバ20に出力する。サーバ20の中間データ入力部21は、スマートフォン10の中間データ出力部14より出力された中間データを入力する。中間データ入力部21が入力する中間データは、図3に示すように、サーバ20の入力層201にセットされるデータである。
後半中間層処理部22は、中間データ入力部21により入力された中間データに対して、複数の中間層のうち後半の一部の中間層の処理を実行する。図3の例では、後半中間層処理部22は、中間データ入力部21により入力された中間データに対して、2番目の中間層202および3番目の中間層203の処理を実行することに対応する。具体的には、後半中間層処理部22は、中間層202,203の処理として、各層において畳み込み演算処理、活性化処理、プーリング処理を順次行う。
全結合層処理部23は、後半中間層処理部22により得られる複数のデータ(3番目の中間層203の各ニューロンから得られる複数のデータ)を結合して出力する。なお、この全結合層処理部23の処理に対応する処理層は図3には示されていないが、中間層203の後段に接続される。データ出力部24は、全結合層処理部23により処理されたデータを、最終的な演算結果データとして、出力層204から出力する。
以上詳しく説明したように、第1の実施形態では、複数階層から成る畳み込みニューラルネットワークによる一連の演算処理を、スマートフォン10と、それよりも演算処理能力の高いサーバ20とに分けて実行するようにしている。すなわち、スマートフォン10において、複数の中間層102,202,203のうち前半の一部の中間層102の処理までを実行し、その結果を中間データとしてサーバ20に出力する。そして、サーバ20において、スマートフォン10から出力された中間データを入力として、後半の一部の中間層202,203の処理を実行するようにしている。
このように構成した第1の実施形態によれば、スマートフォン10からサーバ20に出力される中間データは、スマートフォン10に保持されている元のデータそのものではないので、スマートフォン10のユーザのプライバシーに係る情報の秘匿性を確保することができる。また、中間データの中に元データの特徴が認識できる程度に残っている可能性を考慮して、中間データに対して不可逆的な符号化処理を行うことにより、ユーザのプライバシーをより強固に守ることができる。
また、第1の実施形態によれば、ニューラルネットワークによる演算の一部が、演算処理能力の高いサーバ20で実行されるので、学習処理の演算に要する処理時間を短縮することができる。これにより、第1の実施形態によれば、ユーザのプライバシーに係る情報の秘匿性を保ちつつ、学習処理にかかる時間を短くすることができる。
(第2の実施形態)
次に、本発明の第2の実施形態を図面に基づいて説明する。上記第1の実施形態では、スマートフォン10およびサーバ20において、畳み込みニューラルネットワークによる一連の演算処理を行う例について説明したが、本発明はこれに限定されない。例えば、以下に示す第2の実施形態のように、スマートフォン10において畳み込みニューラルネットワークによる演算処理を実行し、サーバ20においてオートエンコーダによる演算処理(自己符号化処理)を実行するようにしてもよい。
次に、本発明の第2の実施形態を図面に基づいて説明する。上記第1の実施形態では、スマートフォン10およびサーバ20において、畳み込みニューラルネットワークによる一連の演算処理を行う例について説明したが、本発明はこれに限定されない。例えば、以下に示す第2の実施形態のように、スマートフォン10において畳み込みニューラルネットワークによる演算処理を実行し、サーバ20においてオートエンコーダによる演算処理(自己符号化処理)を実行するようにしてもよい。
図5は、サーバ20において自己符号化処理を行う場合におけるニューラルネットワークの一例を示す図である。図5に示す例では、スマートフォン10において、入力層101に入力されたデータに対し、1番目の中間層102による特徴量抽出処理(畳み込み演算処理、活性化処理、プーリング処理)と、符号化層103による不可逆変換処理とを実行し、その結果を中間データとしてサーバ20に出力する。また、サーバ20において、スマートフォン10の符号化層103より出力された中間データを入力層201に対する入力として、中間層302において自己符号化処理を実行し、その結果を出力層303に出力する。
サーバ20において自己符号化処理を実行する場合、学習処理を行う際に、入力層201のデータと同じデータを正解として与える。そして、入力層201に中間データを与えたときに、それと同じデータが出力層303から出力されるように、入力層201の各ニューロンと中間層302の各ニューロンとを繋ぐネットワークや、中間層302の各ニューロンと出力層303の各ニューロンとを繋ぐネットワークに対する重み付けを調整する。
図6は、第2の実施形態による演算処理システムの機能構成例を示すブロック図である。なお、この図6において、図4に示した符号と同一の符号を付したものは同一の機能を有するものであるので、ここでは重複する説明を省略する。図6に示すように、サーバ20は、後半中間層処理部22および全結合層処理部23に代えて自己符号化処理部25を備えている。
自己符号化処理部25は、中間データ入力部21により入力された入力層201の中間データに対して、中間層302においてオートエンコーダによる演算処理(自己符号化処理)を実行し、その結果を演算結果データとして出力層303に出力する。
このように、第2の実施形態によれば、スマートフォン10において実行するニューラルネットワークによる演算処理の内容と、その演算結果である中間データを引き継いでサーバ20において実行するニューラルネットワークによる演算処理の内容とを異ならせて学習処理や予測処理を実行することができる。このようにすれば、例えば、スマートフォン10において演算負荷の比較的小さい教師あり学習を行い、演算処理能力の高いサーバ20において教師なし学習を行うことにより、短時間で高次のディープラーニングを実現することも可能となる。
なお、上記第1および第2の実施形態では、サーバ20に割り当てる中間層の数よりもスマートフォン10に割り当てる中間層の数を少なくする例について説明したが、本発明はこれに限定されない。例えば、所定数のデータを入力層101に与えたときに、スマートフォン10に割り当てた最終段の中間層に中間データが得られるまでの時間が所定時間以内となるように、スマートフォン10に所定数の中間層を割り当て、残りの中間層をサーバ20に割り当てるようにしてもよい。
例えば、スマートフォン10での中間層の処理を1秒以内に終わらせたい場合において、入力層101に所定数のサンプルデータを入力したときに、中間層が2階層までであれば1秒以内に処理が終わり、3階層にすると処理が1秒を超えることが分かったとする。この場合、スマートフォン10に割り当てる中間層の数は、1つまたは2つとする。このようにすれば、スマートフォン10からサーバ20に対して学習用に所定数のデータを送信する際に、少なくともスマートフォン10における処理が所望時間以内に終わるようにすることができる。
また、上記第1および第2の実施形態では、第1の端末の一例としてスマートフォン10を用い、第2の端末の一例としてサーバ20を用いる例について説明したが、本発明はこれに限定されない。第1の端末よりも第2の端末の方が演算処理能力が高い関係を有していれば、第1の端末および第2の端末としてどのようなものを用いてもよい。
その他、上記第1および第2の実施形態は、何れも本発明を実施するにあたっての具体化の一例を示したものに過ぎず、これらによって本発明の技術的範囲が限定的に解釈されてはならないものである。すなわち、本発明はその要旨、またはその主要な特徴から逸脱することなく、様々な形で実施することができる。
10 スマートフォン(第1の端末)
11 データ入力部
12 前半中間層処理部
13 変換処理部
14 中間データ出力部
20 サーバ(第2の端末)
21 中間データ入力部
22 後半中間層処理部
23 全結合層処理部
24 データ出力部
25 自己符号化処理部
101 スマートフォンの入力層
102 スマートフォンの中間層
103 スマートフォンの符号化層
201 サーバの入力層
202,302 サーバの中間層
203 サーバの中間層
204,303 サーバの出力層
11 データ入力部
12 前半中間層処理部
13 変換処理部
14 中間データ出力部
20 サーバ(第2の端末)
21 中間データ入力部
22 後半中間層処理部
23 全結合層処理部
24 データ出力部
25 自己符号化処理部
101 スマートフォンの入力層
102 スマートフォンの中間層
103 スマートフォンの符号化層
201 サーバの入力層
202,302 サーバの中間層
203 サーバの中間層
204,303 サーバの出力層
Claims (6)
- 入力層と、前階層から入力されるデータに含まれる特徴量を抽出する複数の中間層と、出力層とが階層的に接続されたニューラルネットワークによる演算を実行する演算処理システムであって、
第1の端末において、上記複数の中間層のうち前半の一部の中間層の処理までを実行し、その結果を中間データとして、上記第1の端末より演算処理能力が高い第2の端末に出力し、
上記第2の端末において、上記中間データを入力として、上記複数の中間層のうち後半の一部の中間層の処理を実行するようにしたことを特徴とする階層ネットワークを用いた演算処理システム。 - 上記第1の端末は、
上記複数の中間層のうち前半の一部の中間層の処理までを実行し、その結果を中間データとして出力する前半中間層処理部と、
上記前半中間層処理部により得られた上記中間データに対して不可逆変換処理を行う変換処理部と、
上記変換処理部により不可逆変換処理された中間データを上記第2の端末に出力する中間データ出力部とを備えたことを特徴とする請求項1に記載の階層ネットワークを用いた演算処理システム。 - 上記変換処理部が行う上記不可逆変換処理は、上記前半中間層処理部から得られる複数の中間データを結合して出力する全結合処理であることを特徴とする請求項2に記載の階層ネットワークを用いた演算処理システム。
- 上記第2の端末は、
上記中間データ出力部より出力された上記中間データを入力する中間データ入力部と、
上記中間データ入力部により入力された上記中間データに対して、上記複数の中間層のうち後半の一部の中間層の処理を実行する後半中間層処理部と、
上記後半中間層処理部により得られる複数のデータを結合して出力する全結合層処理部とを備えたことを特徴とする請求項2または3に記載の階層ネットワークを用いた演算処理システム。 - 上記第2の端末は、
上記中間データ出力部より出力された上記中間データを入力する中間データ入力部と、
上記中間データ入力部により入力された上記中間データに対して、オートエンコーダによる演算処理を実行する自己符号化処理部とを備えたことを特徴とする請求項2または3に記載の階層ネットワークを用いた演算処理システム。 - 上記第1の端末では、畳み込みニューラルネットワークによる演算処理を実行し、上記第2の端末では、上記オートエンコーダによる演算処理を実行することを特徴とする請求項1~3の何れか1項に記載の階層ネットワークを用いた演算処理システム。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US16/316,181 US20210334621A1 (en) | 2016-07-11 | 2016-07-11 | Arithmetic processing system using hierarchical network |
| EP16908746.7A EP3483791A4 (en) | 2016-07-11 | 2016-07-11 | CALCULATION SYSTEM USING A HIERARCHICAL NETWORK |
| JP2018527045A JPWO2018011842A1 (ja) | 2016-07-11 | 2016-07-11 | 階層ネットワークを用いた演算処理システム |
| PCT/JP2016/070376 WO2018011842A1 (ja) | 2016-07-11 | 2016-07-11 | 階層ネットワークを用いた演算処理システム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2016/070376 WO2018011842A1 (ja) | 2016-07-11 | 2016-07-11 | 階層ネットワークを用いた演算処理システム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2018011842A1 true WO2018011842A1 (ja) | 2018-01-18 |
Family
ID=60952961
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2016/070376 WO2018011842A1 (ja) | 2016-07-11 | 2016-07-11 | 階層ネットワークを用いた演算処理システム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US20210334621A1 (ja) |
| EP (1) | EP3483791A4 (ja) |
| JP (1) | JPWO2018011842A1 (ja) |
| WO (1) | WO2018011842A1 (ja) |
Cited By (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018045679A (ja) * | 2016-09-08 | 2018-03-22 | 公立大学法人会津大学 | 携帯端末を用いた察知エージェントシステム、察知エージェントシステムにおける機械学習方法、及びこれを実施するためのプログラム |
| JP2019053581A (ja) * | 2017-09-15 | 2019-04-04 | 沖電気工業株式会社 | 情報処理システム、情報処理装置、及びプログラム |
| JP2019139270A (ja) * | 2018-02-06 | 2019-08-22 | 公立大学法人会津大学 | 認証システム、認証方法及びコンピュータプログラム |
| JP2019153216A (ja) * | 2018-03-06 | 2019-09-12 | Kddi株式会社 | 学習装置、情報処理システム、学習方法、及びプログラム |
| EP3561733A1 (de) * | 2018-04-25 | 2019-10-30 | Deutsche Telekom AG | Kommunikationsgerät |
| CN112912901A (zh) * | 2018-10-18 | 2021-06-04 | 富士通株式会社 | 学习程序、学习方法以及学习装置 |
| JP2021531533A (ja) * | 2018-06-25 | 2021-11-18 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 信頼できる実行環境を使用するプライバシー強化深層学習クラウド・サービス |
| JP2022057428A (ja) * | 2020-09-30 | 2022-04-11 | Kddi株式会社 | Ai処理分散方法およびシステムならびにai処理ノード |
| DE112020006810T5 (de) | 2020-02-27 | 2022-12-15 | Hitachi, Ltd. | Betriebszustands-klassifikationssystem und betriebszustands-klassifikationsverfahren |
| JP2022552681A (ja) * | 2019-10-24 | 2022-12-19 | ディーピング ソース インコーポレイテッド. | 個人情報を保護するために原本データをコンシーリング処理して生成された変造データを認識するために使われる使用者ラーニングネットワークを学習する方法及びテストする方法、そしてこれを利用した学習装置及びテスト装置 |
| WO2024063096A1 (ja) * | 2022-09-20 | 2024-03-28 | モルゲンロット株式会社 | 情報処理システム、情報処理方法及びプログラム |
| JP7482011B2 (ja) | 2020-12-04 | 2024-05-13 | 株式会社東芝 | 情報処理システム |
| JP7490409B2 (ja) | 2020-03-25 | 2024-05-27 | 東芝テック株式会社 | 画像形成装置及び画像形成装置の制御方法 |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11528259B2 (en) | 2019-12-13 | 2022-12-13 | TripleBlind, Inc. | Systems and methods for providing a systemic error in artificial intelligence algorithms |
| US11431688B2 (en) * | 2019-12-13 | 2022-08-30 | TripleBlind, Inc. | Systems and methods for providing a modified loss function in federated-split learning |
| US10924460B2 (en) | 2019-12-13 | 2021-02-16 | TripleBlind, Inc. | Systems and methods for dividing filters in neural networks for private data computations |
| US11973743B2 (en) | 2019-12-13 | 2024-04-30 | TripleBlind, Inc. | Systems and methods for providing a systemic error in artificial intelligence algorithms |
| WO2022109215A1 (en) | 2020-11-20 | 2022-05-27 | TripleBlind, Inc. | Systems and methods for providing a blind de-identification of privacy data |
| US11625377B1 (en) | 2022-02-03 | 2023-04-11 | TripleBlind, Inc. | Systems and methods for enabling two parties to find an intersection between private data sets without learning anything other than the intersection of the datasets |
| US11539679B1 (en) | 2022-02-04 | 2022-12-27 | TripleBlind, Inc. | Systems and methods for providing a quantum-proof key exchange |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120254086A1 (en) * | 2011-03-31 | 2012-10-04 | Microsoft Corporation | Deep convex network with joint use of nonlinear random projection, restricted boltzmann machine and batch-based parallelizable optimization |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH06266692A (ja) * | 1993-03-12 | 1994-09-22 | Nippondenso Co Ltd | 神経回路網 |
| JPH07168799A (ja) * | 1993-09-22 | 1995-07-04 | Fuji Electric Co Ltd | ニューラルネットワークの学習装置 |
-
2016
- 2016-07-11 US US16/316,181 patent/US20210334621A1/en not_active Abandoned
- 2016-07-11 WO PCT/JP2016/070376 patent/WO2018011842A1/ja unknown
- 2016-07-11 EP EP16908746.7A patent/EP3483791A4/en not_active Withdrawn
- 2016-07-11 JP JP2018527045A patent/JPWO2018011842A1/ja active Pending
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120254086A1 (en) * | 2011-03-31 | 2012-10-04 | Microsoft Corporation | Deep convex network with joint use of nonlinear random projection, restricted boltzmann machine and batch-based parallelizable optimization |
Non-Patent Citations (3)
| Title |
|---|
| AYAE ICHINOSE ET AL.: "Deep Learning Framework Caffe no Bunsan Kankyo eno Tekiyo", DEIM FORUM2016, 29 February 2016 (2016-02-29), pages 1 - 5, XP055570412, Retrieved from the Internet <URL:http://db-event.jpn.org/deim2016/papers/134.pdf> [retrieved on 20160804] * |
| KENTA MURATA: "Dai 3 Sho Shinso Gakushu Nyumon Kaiso ga Fuete Okiru Mondai to sono Kaiketsu Hoho", WEB+DB PRESS, vol. 89, 25 November 2015 (2015-11-25), pages 62 - 65, XP009512844 * |
| See also references of EP3483791A4 * |
Cited By (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018045679A (ja) * | 2016-09-08 | 2018-03-22 | 公立大学法人会津大学 | 携帯端末を用いた察知エージェントシステム、察知エージェントシステムにおける機械学習方法、及びこれを実施するためのプログラム |
| JP2019053581A (ja) * | 2017-09-15 | 2019-04-04 | 沖電気工業株式会社 | 情報処理システム、情報処理装置、及びプログラム |
| JP2019139270A (ja) * | 2018-02-06 | 2019-08-22 | 公立大学法人会津大学 | 認証システム、認証方法及びコンピュータプログラム |
| JP2019153216A (ja) * | 2018-03-06 | 2019-09-12 | Kddi株式会社 | 学習装置、情報処理システム、学習方法、及びプログラム |
| EP3561733A1 (de) * | 2018-04-25 | 2019-10-30 | Deutsche Telekom AG | Kommunikationsgerät |
| JP7196195B2 (ja) | 2018-06-25 | 2022-12-26 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 信頼できる実行環境を使用するプライバシー強化深層学習クラウド・サービス |
| JP2021531533A (ja) * | 2018-06-25 | 2021-11-18 | インターナショナル・ビジネス・マシーンズ・コーポレーションInternational Business Machines Corporation | 信頼できる実行環境を使用するプライバシー強化深層学習クラウド・サービス |
| CN112912901A (zh) * | 2018-10-18 | 2021-06-04 | 富士通株式会社 | 学习程序、学习方法以及学习装置 |
| EP3869418A4 (en) * | 2018-10-18 | 2021-10-06 | Fujitsu Limited | LEARNING PROGRAM, LEARNING PROCESS, AND LEARNING DEVICE |
| JP7297226B2 (ja) | 2019-10-24 | 2023-06-26 | ディーピング ソース インコーポレイテッド. | 個人情報を保護するために原本データをコンシーリング処理して生成された変造データを認識するために使われる使用者ラーニングネットワークを学習する方法及びテストする方法、そしてこれを利用した学習装置及びテスト装置 |
| JP2022552681A (ja) * | 2019-10-24 | 2022-12-19 | ディーピング ソース インコーポレイテッド. | 個人情報を保護するために原本データをコンシーリング処理して生成された変造データを認識するために使われる使用者ラーニングネットワークを学習する方法及びテストする方法、そしてこれを利用した学習装置及びテスト装置 |
| DE112020006810T5 (de) | 2020-02-27 | 2022-12-15 | Hitachi, Ltd. | Betriebszustands-klassifikationssystem und betriebszustands-klassifikationsverfahren |
| JP7490409B2 (ja) | 2020-03-25 | 2024-05-27 | 東芝テック株式会社 | 画像形成装置及び画像形成装置の制御方法 |
| JP2022057428A (ja) * | 2020-09-30 | 2022-04-11 | Kddi株式会社 | Ai処理分散方法およびシステムならびにai処理ノード |
| JP7372221B2 (ja) | 2020-09-30 | 2023-10-31 | Kddi株式会社 | Ai処理分散方法およびシステム |
| JP7482011B2 (ja) | 2020-12-04 | 2024-05-13 | 株式会社東芝 | 情報処理システム |
| WO2024063096A1 (ja) * | 2022-09-20 | 2024-03-28 | モルゲンロット株式会社 | 情報処理システム、情報処理方法及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| US20210334621A1 (en) | 2021-10-28 |
| EP3483791A4 (en) | 2020-03-18 |
| EP3483791A1 (en) | 2019-05-15 |
| JPWO2018011842A1 (ja) | 2019-04-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2018011842A1 (ja) | 階層ネットワークを用いた演算処理システム | |
| CN111695415A (zh) | 图像识别模型的构建方法、识别方法及相关设备 | |
| KR102608467B1 (ko) | 뉴럴 네트워크의 경량화 방법, 이를 이용한 인식 방법, 및 그 장치 | |
| CN108776832B (zh) | 信息处理方法、装置、计算机设备和存储介质 | |
| JP7392112B2 (ja) | 帯域幅拡張のための特徴ディクショナリ | |
| JP2019087072A (ja) | 処理装置、推論装置、学習装置、処理システム、処理方法、及び処理プログラム | |
| WO2023179074A1 (zh) | 图像融合方法及装置、电子设备、存储介质、计算机程序、计算机程序产品 | |
| US20220114454A1 (en) | Electronic apparatus for decompressing a compressed artificial intelligence model and control method therefor | |
| CN114071141A (zh) | 一种图像处理方法及其设备 | |
| CN110175338B (zh) | 一种数据处理方法及装置 | |
| CN115293254A (zh) | 基于量子多层感知器的分类方法及相关设备 | |
| CN110363291B (zh) | 神经网络的运算方法、装置、计算机设备和存储介质 | |
| WO2022246986A1 (zh) | 数据处理方法、装置、设备及计算机可读存储介质 | |
| CN110728351A (zh) | 数据处理方法、相关设备及计算机存储介质 | |
| WO2021037174A1 (zh) | 一种神经网络模型训练方法及装置 | |
| WO2018135515A1 (ja) | 情報処理装置、ニューラルネットワークの設計方法及び記録媒体 | |
| CN111582284B (zh) | 用于图像识别的隐私保护方法、装置和电子设备 | |
| JP7171478B2 (ja) | 情報処理方法、及び情報処理システム | |
| US20230394306A1 (en) | Multi-Modal Machine Learning Models with Improved Computational Efficiency Via Adaptive Tokenization and Fusion | |
| CN112561050B (zh) | 一种神经网络模型训练方法及装置 | |
| US11574180B2 (en) | Methods for learning parameters of a convolutional neural network, and classifying an input datum | |
| US20220172416A1 (en) | System and method for performing facial image anonymization | |
| CN115545943A (zh) | 一种图谱的处理方法、装置及设备 | |
| KR102305981B1 (ko) | 신경망 압축 훈련 방법 및 압축된 신경망을 이용하는 방법 | |
| CN115631343A (zh) | 基于全脉冲网络的图像生成方法、装置、设备及存储介质 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 16908746 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2018527045 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2016908746 Country of ref document: EP Effective date: 20190211 |