WO2015166606A1 - Natural language processing system, natural language processing method, and natural language processing program - Google Patents
Natural language processing system, natural language processing method, and natural language processing program Download PDFInfo
- Publication number
- WO2015166606A1 WO2015166606A1 PCT/JP2014/082428 JP2014082428W WO2015166606A1 WO 2015166606 A1 WO2015166606 A1 WO 2015166606A1 JP 2014082428 W JP2014082428 W JP 2014082428W WO 2015166606 A1 WO2015166606 A1 WO 2015166606A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- score
- tag
- sentence
- feature
- natural language
- Prior art date
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/268—Morphological analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/226—Validation
Definitions
- One aspect of the present invention relates to a natural language processing system, a natural language processing method, and a natural language processing program.
- Patent Document 1 discloses that the input text data is decomposed into morphemes, the position information corresponding to the decomposed morphemes is obtained by referring to the morpheme dictionary, and the cost using the position information is obtained.
- a morpheme analyzer that determines a morpheme string from morpheme string candidates obtained by the decomposition by a function.
- Morphological analysis is executed using a division model including a score for each feature. Since the division model, which can be said to be knowledge for morphological analysis, is generally fixed in advance, naturally, when trying to analyze a sentence belonging to a new field that is not covered by the division model or a sentence having a new property, Obtaining the correct result is very difficult. On the other hand, if the division model is to be corrected by a method such as machine learning, there is a possibility that the time required for the correction will increase so as not to be predicted. Therefore, it is desired to automatically correct the division model for morphological analysis within a certain time.
- a natural language processing system divides a single sentence by executing morphological analysis on a sentence using a division model obtained by machine learning using one or more training data.
- An analysis unit that sets at least a tag indicating the part of speech of each word to be obtained, and the division model includes an output feature score indicating the correspondence between the divided element and the tag, and two consecutive features.
- the analysis unit including a transition feature score indicating a combination of two tags corresponding to one divided element, a tag indicated by an analysis result obtained by the analysis unit, and a correct tag of one sentence Compare the correct answer data, and set the score of the output feature and the transition feature related to the correct tag corresponding to the tag of the incorrect answer higher than the current value, and the score of the output feature related to the tag of the incorrect answer Score preliminary transition feature is made lower than the current value, and a correction unit for correcting the divided model used by morphological analysis of the next sentence by the analysis unit.
- a natural language processing method is a natural language processing method executed by a natural language processing system including a processor, and uses a division model obtained by machine learning using one or more training data.
- the analysis step includes an output feature score indicating a correspondence between a divided element and a tag, and a transition feature score indicating a combination of two tags corresponding to two consecutive divided elements.
- a natural language processing program divides a sentence by executing a morphological analysis on a sentence using a division model obtained by machine learning using one or more training data.
- An analysis unit that sets at least a tag indicating the part of speech of each word to be obtained, and the division model includes an output feature score indicating the correspondence between the divided element and the tag, and two consecutive features.
- the analysis unit including a transition feature score indicating a combination of two tags corresponding to one divided element, a tag indicated by an analysis result obtained by the analysis unit, and a correct tag of one sentence
- the score of the output feature and the transition feature related to the correct tag corresponding to the tag of the incorrect answer are set higher than the current value, and the score of the output feature related to the tag of the incorrect answer is set.
- the scores of the transition feature is made lower than the current value, causes a computer to function as a correction unit for correcting the divided model used by morphological analysis of the next sentence by the analysis unit.
- the analysis result is compared with the correct answer data, and the division model is corrected based on the difference between them.
- the analysis split model can be automatically modified within a certain time (in other words, within a predictable time range).
- the division model for morphological analysis can be automatically corrected within a certain time.
- the natural language processing system 10 is a computer system that performs morphological analysis.
- the morpheme analysis is a process of dividing a sentence into morpheme strings and determining the part of speech of each morpheme.
- a sentence is a unit of linguistic expression that represents one complete statement, and is expressed by a character string.
- a morpheme is the smallest language unit that has meaning.
- a morpheme sequence is a sequence of one or more morphemes obtained by dividing a sentence into one or more morphemes.
- Part of speech is the division of words by grammatical function or form.
- the natural language processing system 10 performs morphological analysis on individual sentences using the division model 20.
- One of the features of the natural language processing system 10 is that when the division model 20 is learned, the division model 20 is corrected each time a morphological analysis is performed on each sentence.
- the natural language processing system 10 including the confirmed division model 20 is provided to the user. The user can cause the natural language processing system 10 to execute morpheme analysis. At this time, the morpheme analysis is executed without correcting the division model 20.
- the “division model” in this specification is a standard (cue) when a sentence is divided into one or more morphemes, and is indicated by a score of each feature. This division model is obtained by machine learning using one or more training data.
- the training data is data indicating at least a sentence divided into words and a part of speech of each word obtained by dividing the sentence.
- a feature is a clue for obtaining a correct result in morphological analysis. In general, what is used as a feature (cue) is not limited.
- the feature score is a numerical value representing the likelihood of the feature.
- FIG. 1 briefly shows the concept of processing in the natural language processing system 10 according to the present embodiment.
- a gear M in FIG. 1 indicates execution of morphological analysis.
- the natural language processing system 10 divides the sentence s 1 into one or more morphemes by executing a morphological analysis using the division model w 1 .
- the natural language processing system 10 divides a sentence into one or more morphemes by dividing the sentence into individual characters and executing character unit processing.
- the divided element to be processed is a character.
- the natural language processing system 10 indicates the result of morphological analysis by setting a tag for each character (divided element).
- a “tag” in this specification is a label indicating an attribute or function of a character. Tags will be described in more detail later.
- the natural language processing system 10 When the morphological analysis is executed, the natural language processing system 10 accepts data (correct data) indicating the correct answer of the morphological analysis of the sentence s 1 , compares the analysis result with the correct data, and corrects the divided model w 1. in obtaining a new division model w 2. Specifically, the natural language processing system 10 evaluates that the entire analysis result is wrong when at least a part of tagging in the morphological analysis of the sentence s 1 is wrong. Then, the natural language processing system 10 evaluates the feature corresponding to each tag in the correct answer data as “correct (+1)”, sets the feature score higher than the current value, and corresponds to each tag in the analysis result.
- the natural language processing system 10 evaluates each tag in the correct answer data as “correct (+1)”, while evaluating a tag related to each character in the analysis result as “wrong ( ⁇ 1)” After canceling the two evaluation results, the score of the feature corresponding to the tag evaluated as “correct (+1)” is increased, and the score of the feature corresponding to the tag evaluated as “mistake ( ⁇ 1)” May be lowered.
- the natural language processing system 10 the tag t a in solution data, t b, t c, t d, the score of the feature by evaluating the identity corresponding to t e a "correct (+1)" was higher than the current value, the tag t a in the execution result, t g, t h, t d, "definitely (-1)" a feature that corresponds to t e and evaluate the current value of the score of the identity and Lower than.
- the score of the feature corresponding to the tags t a , t d , and t c is not changed from the result before the update, and the score of the feature corresponding to the correct tags t b and t c is increased, and the incorrect answer The score of the feature corresponding to the tags t g and t h is lowered.
- the natural language processing system 10 When executing the morphological analysis for the next sentence s 2 , the natural language processing system 10 uses the division model w 2 . Then, the natural language processing system 10 accepts a correct answer data of the morphological analysis of the statement s 2, compares the execution result and its correct data, to modify the same divided model w 2 in the case of modifying the division models w 1 obtain a new division model w 3 that.
- the natural language processing system 10 corrects the division model (w 1 ⁇ w 2 , w 2 ⁇ w 3 ,..., W each time one sentence (s 1 , s 2 ,..., St) is processed in this way. t ⁇ w t + 1 ), and use the modified division model in the morphological analysis of the next sentence.
- Such a method of updating the model every time one piece of training data is processed is also referred to as “online learning” or “online machine learning”.
- the natural language processing system 10 converts a Japanese sentence “hon wo katte”, which corresponds to an English sentence “I blog a book”, into five letters x 1 : “book”. (hon) ", x 2:” the (wo) ", x 3:” Offer (ka) ", x 4:” Tsu (t) ", x 5: divided into” te (te) ". And the natural language processing system 10 sets a tag to each character by performing morphological analysis.
- the tag is a combination of the appearance mode of the character in the word, the part of speech of the word, and the subclass of the part of speech of the word, and uses an alphabet such as “SN-nc”. Expressed.
- the appearance mode is whether a certain character becomes one word alone or in combination with another character, and when the character is a part of a word consisting of two or more characters, This is information indicating where in the word the character is located.
- the appearance mode is indicated by one of S, B, I, and E.
- the appearance mode “S” indicates that the character becomes a single word by itself.
- the appearance mode “B” indicates that the character is positioned at the beginning of a word composed of two or more characters.
- the appearance mode “I” indicates that the character is located in the middle of a word composed of three or more characters.
- the appearance mode “E” indicates that the character is located at the end of a word composed of two or more characters.
- the example of FIG. 2 indicates that the characters x 1 , x 2 , and x 5 are each a single word, and the characters x 3 and x 4 form one word.
- scheme for the appearance mode is not limited.
- the scheme “SBIEO” is used, but for example, the scheme “IOB2” that is well known to those skilled in the art may be used.
- Examples of parts of speech include nouns, verbs, particles, adjectives, adjective verbs, conjunctions, and the like.
- the noun is represented by “N”
- the particle is represented by “P”
- the verb is represented by “V”.
- FIG. 2 indicates that the character x 1 is a noun, the character x 2 is a particle, the word consisting of the characters x 3 and x 4 is a verb, and the character x 5 is a particle.
- the part-of-speech subclass indicates the subordinate concept of the corresponding part-of-speech.
- nouns can be further classified into general nouns and proper nouns, and particles can be further classified into case particles, conjunctive particles, auxiliary particles, and the like.
- the general noun is represented by “nc”
- the proper noun is represented by “np”
- the case particle is represented by “k”
- the connection particle is represented by “sj”
- the general verb is “c”. Is represented.
- FIG. 2 shows that the character x 1 is a general noun, the character x 2 is a case particle, the word consisting of the characters x 3 and x 4 is a general verb, and the character x 5 is a connection particle. ing.
- the score of the feature stored in the division model 20 is a score of an output feature and a score of a transition feature.
- the output feature is a clue indicating the correspondence between a tag and a character or character type.
- the output feature is a clue indicating what kind of character or character type is likely to correspond to what kind of tag.
- the output feature corresponds to the feature representation of the output matrix of the hidden Markov model.
- an output feature of a unigram (a character string made up of only one character) and an output feature of a bigram (a character string made up of two consecutive characters) are used.
- the character type is a character type in a certain language.
- Japanese character types include kanji, hiragana, katakana, alphabet (uppercase and lowercase), Arabic numerals, kanji numerals, and middle black (•).
- the character type is represented by alphabets. For example, “C” indicates kanji, “H” indicates hiragana, “K” indicates katakana, “L” indicates alphabets, and “A” indicates Arabic numerals.
- FIG. 2 indicates that the characters x 1 and x 3 are kanji characters and the characters x 2 , x 4 , and x 5 are hiragana characters.
- the unigram output feature related to the character is a clue indicating the correspondence between the tag t and the character x. Further, the output feature of the unigram regarding the character type is a clue indicating the correspondence between the tag t and the character type c.
- the likelihood score s of the correspondence between the tag t and the letter x is indicated by ⁇ t / x, s ⁇ .
- a likelihood score s of correspondence between the tag t and the character type c is denoted by ⁇ t / c, s ⁇ .
- the division model 20 includes scores regarding a plurality of tags for one character or character type.
- the division model 20 When data on all types of tags is prepared for one character or character type, the division model 20 also has a score for a combination of a tag and a character or character type that cannot actually occur in the grammar. Including. However, the score of a feature that is impossible in grammar is relatively low.
- data indicating features that do not exist in the grammar can be prepared. For example, it is impossible in Japanese grammar that a word represented by Arabic numerals is a particle, but data can also be prepared for a feature such as “SPK / A”.
- the bigram output feature related to the character is a clue indicating the correspondence between the tag t and the character string x i x i + 1 .
- the bigram output feature related to the character type is a clue indicating the correspondence between the tag t and the character type column c i c i + 1 .
- the likelihood score s of the tag t and the characters x i and x i + 1 is represented by ⁇ t / x i / x i + 1 , s ⁇ .
- the likelihood score s of the tag t and the character types c i and c i + 1 is denoted by ⁇ t / c i / c i + 1 , s ⁇ .
- the transition feature a cue indicating a combination (combination consisting of two tags corresponding to two consecutive characters) tags t i and tag t i + 1 of the next character x i + 1 character x i.
- This transition feature is a bigram feature.
- the transition feature corresponds to the feature representation of the transition matrix of the hidden Markov model.
- the likelihood score s of the combination of the tag t i and the tag t i + 1 is represented by ⁇ t i / t i + 1 , s ⁇ .
- the division model 20 also stores data on combinations of two tags that cannot actually occur in the grammar.
- transition feature scores are shown. ⁇ SN-nc / SP-k, 0.0512 ⁇ ⁇ E-N-nc / E-N-nc, 0.0000 ⁇ ⁇ SPK / BVc, 0.0425 ⁇ ⁇ BVc / IVc, 0.0387 ⁇
- the natural language processing system 10 includes one or more computers. When the natural language processing system 10 includes a plurality of computers, each functional element of the natural language processing system 10 described later is realized by distributed processing.
- the type of individual computer is not limited. For example, a stationary or portable personal computer (PC) may be used, a workstation may be used, or a portable terminal such as a high-functional portable telephone (smart phone), a portable telephone, or a personal digital assistant (PDA). May be used.
- the natural language processing system 10 may be constructed by combining various types of computers. When a plurality of computers are used, these computers are connected via a communication network such as the Internet or an intranet.
- FIG. 3 shows a general hardware configuration of each computer 100 in the natural language processing system 10.
- a computer 100 includes a CPU (processor) 101 that executes an operating system, application programs, and the like, a main storage unit 102 that includes a ROM and a RAM, an auxiliary storage unit 103 that includes a hard disk and a flash memory, and a network.
- the communication control unit 104 includes a card or a wireless communication module, an input device 105 such as a keyboard and a mouse, and an output device 106 such as a display and a printer.
- the hardware modules to be mounted differ depending on the type of the computer 100.
- a stationary PC and a workstation often include a keyboard, a mouse, and a monitor as an input device and an output device, but in a smartphone, a touch panel often functions as an input device and an output device.
- Each functional element of the natural language processing system 10 described later reads predetermined software on the CPU 101 or the main storage unit 102, and operates the communication control unit 104, the input device 105, the output device 106, and the like under the control of the CPU 101. This is realized by reading and writing data in the main storage unit 102 or the auxiliary storage unit 103. Data and a database necessary for processing are stored in the main storage unit 102 or the auxiliary storage unit 103.
- the division model 20 is stored in the storage device in advance.
- the specific mounting method of the division model 20 is not limited.
- the division model 20 may be prepared as a relational database or a text file.
- the installation location of the division model 20 is not limited.
- the division model 20 may exist in the natural language processing system 10 or in another computer system different from the natural language processing system 10. May be.
- the natural language processing system 10 accesses the division model 20 via a communication network.
- the division model 20 is a set of scores of various features.
- the score is updated little by little by the processing of the natural language processing system 10 described later. After a certain number of sentences have been processed, there is a difference between the individual feature scores as described above.
- the natural language processing system 10 includes an acquisition unit 11, an analysis unit 12, and a correction unit 13 as functional components.
- the natural language processing system 10 accesses the division model 20 as necessary.
- Each functional element will be described below. In the present embodiment, the description will be made on the assumption that the natural language processing system 10 processes a Japanese sentence.
- the language of the sentence processed by the natural language processing system 10 is not limited to Japanese, and sentences in other languages such as Chinese can be analyzed.
- the acquisition unit 11 is a functional element that acquires a sentence to be divided into morpheme strings.
- the acquisition method of the sentence by the acquisition part 11 is not limited.
- the acquisition unit 11 may collect sentences from any website on the Internet (so-called crawling).
- the acquisition unit 11 may read a sentence stored in advance in a database in the natural language processing system 10, or read a sentence stored in a database on a computer system other than the natural language processing system 10 via a communication network. It may be accessed and read by.
- the acquisition unit 11 may accept a sentence input by a user of the natural language processing system 10.
- the acquisition unit 11 acquires one sentence and outputs it to the analysis unit 12.
- the acquisition unit 11 acquires the next sentence and outputs it to the analysis unit 12.
- the analysis unit 12 is a functional element that performs morphological analysis on individual sentences.
- the analysis unit 12 executes the following process every time one sentence is input.
- the analysis unit 12 divides one sentence into individual characters and determines the character type of each character.
- the analysis unit 12 stores in advance a comparison table between characters and character types, or a regular expression for determining a character type, and determines a character type using the comparison table or regular expression.
- the analysis unit 12 determines a tag for each character using a Viterbi algorithm. For the i-th character, the analysis unit 12 determines which candidate tag among the plurality of candidate tags of the (i-1) -th character for each tag (candidate tag) that may be finally selected. It is determined whether or not the score (also referred to as “connection score”) is the highest.
- the connection score is a total value of various scores related to the calculation target tag (unigram output feature score, bigram output feature score, and transition feature score). For example, when the i-th tag is “SN-nc”, the analysis unit 12 has the highest connection score when the (i ⁇ 1) -th tag is “SPK”.
- the analysis unit 12 stores all the combinations (for example, (S ⁇ P ⁇ k, S ⁇ N ⁇ nc), (E ⁇ N ⁇ nc, S ⁇ V ⁇ c), etc.) having the highest connection score. .
- the analysis unit 12 executes such processing while proceeding character by character from the first character to the sentence end symbol.
- the combination of the tag of the last character and the end-of-sentence symbol having the highest connection score is determined as one (for example, the combination is (E- Vc, EOS)).
- the tag of the last character is determined (for example, the tag is determined to be “EVC”), and as a result, the tag of the second character from the end is also determined.
- the tags are fixed to the formulas in order from the end to the beginning of the sentence.
- FIG. 5 schematically shows such processing by the analysis unit 12.
- FIG. 5 shows an example of tagging a sentence consisting of four characters.
- the tags are simplified as “A1”, “B2”, etc., and the number of candidate tags for each character is three.
- a thick line in FIG. 5 indicates a combination of a tag determined to have the highest connection score obtained by processing a sentence from the front.
- the tag C1 has the highest connection score with the tag B1
- the tag C2 has the highest connection score with the tag B1
- the tag C3 has the highest connection score with the tag B2.
- FIG. 5 shows an example of tagging a sentence consisting of four characters.
- the tags are simplified as “A1”, “B2”, etc., and the number of candidate tags for each character is three.
- a thick line in FIG. 5 indicates a combination of a tag determined to have the highest connection score obtained by processing a sentence from the front.
- the tag C1 has the highest connection score with the tag B1
- the tag C2 has
- the analysis unit 12 determines that the tags of the first to fourth characters are A2, B1, C2, and D1, respectively.
- the analysis unit 12 outputs a sentence with each character tagged as an analysis result.
- the analysis unit 12 outputs the analysis result to at least the correction unit 13 because the analysis result is necessary for correcting the divided model 20.
- the analysis unit 12 may perform further output.
- the analysis unit 12 may display the analysis result on a monitor or print it on a printer, write the analysis result to a text file, or store the analysis result in a storage device such as a memory or a database. May be.
- the analysis unit 12 may transmit the analysis result to an arbitrary computer system other than the natural language processing system 10 via a communication network.
- the correction unit 13 is a functional element that corrects the divided model 20 based on the difference between the analysis result obtained from the analysis unit 12 and the correct answer of the morphological analysis of the sentence.
- “modification of the division model” is processing for changing the score of at least one feature in the division model. In some cases, even if an attempt is made to change a certain score, the value may not change as a result.
- the correction unit 13 executes the following processing every time one analysis result is input.
- the correction unit 13 acquires correct answer data corresponding to the input analysis result, that is, data indicating the correct answer of the morphological analysis of the sentence processed by the analysis unit 12.
- the correct answer data in the present embodiment is data indicating tags (combination of appearance mode, part of speech, and part of speech subclass) of each character forming a sentence. This correct answer data is created manually.
- the method for acquiring correct data by the correction unit 13 is not limited.
- the correction unit 13 may read correct data stored in advance in a database in the natural language processing system 10, or may read sentences stored in a database on a computer system other than the natural language processing system 10 in a communication network. You may access and read via.
- the correction unit 13 may accept correct answer data input by the user of the natural language processing system 10.
- the correction unit 13 compares the input analysis result with the correct data and identifies the difference between them.
- the correction unit 13 ends the process without correcting the division model 20, generates a completion notification, and outputs it to the acquisition unit 11.
- This completion notification is a signal indicating that the processing in the correction unit 13 has been completed and the morphological analysis for the next sentence can be executed.
- the fact that the analysis result completely matches the correct answer data does not require correction of the division model 20 at least at this point, so the natural language processing system 10 (more specifically, the analysis unit 12) has the current division model 20 Is used as is to parse the next sentence.
- each character is also expressed as x 1 to x 5 .
- x 1 ⁇ SN—nc ⁇ x 2 : ⁇ SPK ⁇ x 3 : ⁇ BVc ⁇ x 4 : ⁇ EVV ⁇ x 5 : ⁇ SP-sj ⁇
- the correction unit 13 determines that the analysis result and the correct data match completely, and notifies the acquisition unit 11 of the completion notification without correcting the analysis unit 12. Output.
- the correction unit 13 updates at least a part of the scores of the divided model 20. More specifically, the correcting unit 13 sets the feature score related to the correct tag corresponding to the incorrect tag to be higher than the current value, and sets the feature score related to the incorrect tag to be lower than the current value. To do.
- the analysis unit 12 obtains the following analysis result from a Japanese sentence “Buy Book”.
- x 1 ⁇ SN—nc ⁇ x 2 : ⁇ SPK ⁇ x 3 : ⁇ BVc ⁇ x 4 : ⁇ IVc ⁇ x 5 : ⁇ EVV ⁇
- the correction unit 13 evaluates the feature corresponding to each tag in the correct answer data as “correct (+1)” and sets the score of the feature higher than the current value. Then, the feature corresponding to each tag in the analysis result is evaluated as “error ( ⁇ 1)”, and the score of the feature is made lower than the current value. In consideration of the part that is offset as a result, it can be said that the correction unit 13 finally performs the following processing.
- the correction unit 13 calculates the scores for the output features “EV ⁇ c / t (t)” and “SP ⁇ sj / te (te)” corresponding to the correct tags of the characters x 4 and x 5 from the current value.
- the score for the output features “IVc / t (t)” and “EVc / t (te)” related to the incorrect tag is made smaller than the current value.
- the score of the output feature of the unigram related to the analyzed sentence is updated.
- the correcting unit 13 sets the scores for the output features “EVC / H” and “SP-sj / H” related to the correct tags of the characters x 4 and x 5 that are incorrect answers to the current values.
- the score for the output features “IVc / H” and “EVc / H” related to the incorrect answer tag is made smaller than the current value. Thereby, the score of the output feature of the unigram related to the analyzed sentence (score regarding the character type) is updated.
- the correcting unit 13 obtains a score for the output feature “EV ⁇ c / t (t) / te (te)” related to the correct tags of the characters x 4 and x 5 that were incorrect from the current value.
- the score for the output feature “IVV / t (t) / te (te)” related to the incorrect tag is made smaller than the current value. This updates the bigram output feature score (character score) associated with the analyzed sentence.
- the correcting unit 13 increases the score for the output feature “EVC / H / H” related to the correct tags of the characters x 4 and x 5 that are incorrect answers from the current value, and corrects the incorrect answer.
- the score for the output feature “IVc / H / H” related to the tag is made smaller than the current value. This updates the bigram output feature score (score for the character type) associated with the analyzed sentence.
- the correcting unit 13 uses the transition features “BVc / EVVc” and “EVc / SP-sj” associated with the correct tags of the characters x 4 and x 5 that were incorrect.
- the score for the transition features “BVc / IVVc” and “IVc / EVVc” related to the incorrect answer tag are set higher than the current value. Make it smaller than the current value. As a result, the score of the transition feature related to the analyzed sentence is updated.
- the correction unit 13 evaluates each tag in the correct answer data as “correct (+1)”, while evaluating the tag related to each character in the analysis result as “wrong ( ⁇ 1)”. , After offsetting the two evaluation results for each tag, increase the score of the feature corresponding to the tag evaluated as “correct (+1)”, and correspond to the tag evaluated as “wrong ( ⁇ 1)” The score of the feature to be performed may be lowered.
- the modification unit 13 may use SCW (Soft Confidence-Weighted Learning).
- SCW Soft Confidence-Weighted Learning
- This SCW is a method in which a parameter with a large variance is regarded as not yet confident (inaccurate) and the parameter is greatly updated, and a parameter with a small variance is regarded as accurate to some extent and the parameter is updated to a small value. is there.
- the correcting unit 13 determines the amount of change in the score based on the variance of the score having the value range.
- a Gaussian distribution is introduced into the division model 20 (vector w), and the correction unit 13 simultaneously updates the average and covariance matrix of each score in addition to updating each score.
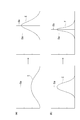
- the average initial value of each score is zero.
- FIG. 6A shows a mode in which a score with a large variance is changed greatly (that is, the amount of change in the score is large), and FIG. 6B shows a mode in which a score with a small variance is changed slightly (that is, the score is changed). The variation is small).
- FIGS. 6A and 6B show that the covariance matrix ⁇ is also updated when the score is updated from Sa to Sb.
- the accuracy of score calculation can be maintained without considering the correlation between a certain feature and other features, so in this embodiment, the off-diagonal of the covariance matrix is used. Calculate only diagonal elements without calculating elements. Thereby, the update speed of a score can be raised.
- the correcting unit 13 may update the feature score using a method other than SCW.
- methods other than SCW include Perceptron, Passive Aggressive (PA), Confidence Weighted (CW), and Adaptive Regularization of Weight Vectors (AROW).
- the correction unit 13 When the division model 20 is corrected by updating the feature score related to the analyzed sentence, the correction unit 13 generates a completion notification and outputs it to the acquisition unit 11. In this case, the natural language processing system 10 (more specifically, the analysis unit 12) analyzes the next sentence using the modified division model 20.
- the acquisition unit 11 acquires one sentence (step S11).
- the analysis unit 12 performs morphological analysis on the sentence using the division model 20 (step S12, analysis step).
- a tag such as “SN-nc” is given to each character of the sentence.
- the correcting unit 13 obtains a difference between the result of the morphological analysis by the analyzing unit 12 and the correct answer data of the morphological analysis (step S13).
- step S14 NO
- the correcting unit 13 ends the process without correcting the divided model 20.
- step S14 YES
- the correction unit 13 relates to the analyzed sentence.
- the division model 20 is corrected by updating the feature score (step S15, correction step). Specifically, the correcting unit 13 sets the feature score related to the correct tag corresponding to the incorrect tag to be higher than the current value, and sets the feature score related to the incorrect tag from the current value. Also lower.
- step S11 When the process in the correction unit 13 is completed, the process returns to step S11 (see step S16).
- the acquisition unit 11 acquires the next sentence (step S11), and the analysis unit 12 performs morphological analysis on the sentence (step S12).
- step S15 if the modification of the divided model 20 (step S15) has been executed in the processing of the previous sentence, the analysis unit 12 performs morphological analysis using the modified divided model 20.
- the correction unit 13 executes the processes after step S13. Such repetition continues as long as the sentence to be processed exists (see step S16).
- the first line in the algorithm means initialization of the division model 20 (variable w 1 ), and for example, the score of each feature is set to 0 by this processing.
- the For loop on the second line indicates that the processes on and after the third line are executed one sentence at a time.
- the third line means that the sentence xt is acquired and corresponds to step S11 described above.
- the fourth line shows a process of assigning a tag to each character by performing a morphological analysis based on the division model 20 (w t ) at that time, and corresponds to step S12 described above.
- y ⁇ t indicates the analysis result. Line 5, which means that to get the correct data y t of the morphological analysis of the sentence x t.
- Line 6 if there is a difference between the analysis result y ⁇ t and solution data y t means to update (modifying) the division model 20.
- the seventh line indicates that the correct answer data y t is learned as a positive example, and the eighth line indicates that the analysis result y ⁇ t including an error is learned as a negative example.
- the processing on the seventh and eighth lines corresponds to step S15 described above.
- the natural language processing program P1 includes a main module P10, an acquisition module P11, an analysis module P12, and a correction module P13.
- the main module P10 is a part that comprehensively controls morphological analysis and related processing.
- the functions realized by executing the acquisition module P11, the analysis module P12, and the correction module P13 are the same as the functions of the acquisition unit 11, the analysis unit 12, and the correction unit 13, respectively.
- the natural language processing program P1 may be provided after being fixedly recorded on a tangible recording medium such as a CD-ROM, DVD-ROM, or semiconductor memory.
- the natural language processing program P1 may be provided via a communication network as a data signal superimposed on a carrier wave.
- the natural language processing system performs a morphological analysis on one sentence using a division model obtained by machine learning using one or more training data.
- An analysis unit that sets at least a tag indicating the part of speech of each word to each divided element obtained by dividing the one sentence, and the division model has an output feature indicating a correspondence between the divided element and the tag.
- the analysis unit including a score and a score of a transition feature indicating a combination of two tags corresponding to two consecutive subdivided elements, a tag indicated by an analysis result obtained by the analysis unit, and one sentence Compared with the correct answer data indicating the correct answer tag, the score of the output feature and the transition feature related to the correct answer tag corresponding to the incorrect answer tag are set higher than the current value, and related to the incorrect answer tag. That the scores of the score and the transition feature output feature is made lower than the current value, and a correction unit for correcting the divided model used by morphological analysis of the next sentence by the analysis unit.
- a natural language processing method is a natural language processing method executed by a natural language processing system including a processor, and uses a division model obtained by machine learning using one or more training data.
- the analysis step includes an output feature score indicating a correspondence between a divided element and a tag, and a transition feature score indicating a combination of two tags corresponding to two consecutive divided elements.
- a natural language processing program divides a sentence by executing a morphological analysis on a sentence using a division model obtained by machine learning using one or more training data.
- An analysis unit that sets at least a tag indicating the part of speech of each word to be obtained, and the division model includes an output feature score indicating the correspondence between the divided element and the tag, and two consecutive features.
- the analysis unit including a transition feature score indicating a combination of two tags corresponding to one divided element, a tag indicated by an analysis result obtained by the analysis unit, and a correct tag of one sentence
- the score of the output feature and the transition feature related to the correct tag corresponding to the tag of the incorrect answer are set higher than the current value, and the score of the output feature related to the tag of the incorrect answer is set.
- the scores of the transition feature is made lower than the current value, causes a computer to function as a correction unit for correcting the divided model used by morphological analysis of the next sentence by the analysis unit.
- the analysis result is compared with the correct answer data, and the division model is corrected based on the difference between them.
- the analysis split model can be automatically modified within a certain time (in other words, within a predictable time range).
- the accuracy of the morphological analysis of the next sentence can be increased by increasing the feature score for the correct tag and decreasing the feature score for the tag that was incorrect.
- the divided element may be a character.
- morphological analysis can be executed without using a word dictionary that generally becomes large.
- the division model is corrected for each sentence using knowledge in units of characters rather than knowledge of words, it is assumed that the next sentence is different in field or nature from any sentence analyzed so far
- each of the output feature score and the transition feature score has a range of values
- a variance is set for each score
- the correction unit is based on the variance of each score.
- the amount of change in the score when the score is high or low may be determined.
- the division model 20 becomes very large in a language with many characters such as Japanese and Chinese.
- the storage capacity for will also be very large. Therefore, a technique called feature hashing may be introduced to digitize individual features using a hash function.
- the effect of digitizing characters and character strings representing a part of the features is high.
- the transition feature is hashed, it does not contribute much to the compression of the capacity of the division model 20, and the processing speed may be slow. Therefore, only the output features may be hashed without hashing the transition features. Note that only one type of hash function may be used, or different hash functions may be used for output features and transition features.
- the division model 20 stores data on the features in which individual characters are represented by numerical values. For example, a character “hon” is converted to a numerical value of 34, and a character “wo” is converted to a numerical value of 4788. By this numericalization, a set of bounded features can be formed. This feature hashing may assign the same numerical value to multiple characters or character strings, but it is very unlikely that the same numerical value will be assigned to characters or character strings that appear frequently. Collisions can be ignored.
- the division model may include an output feature quantified by a hash function.
- the analysis unit 12 may perform morphological analysis using a feature having a relatively high score without using a feature having a relatively low score (ignoring such a feature).
- techniques for ignoring features having relatively low scores include forward-backward splitting (Forward-Background Splitting (FOBOS)) and feature quantization (Feature Quantization).
- FOBOS Forward-Background Splitting
- Feature Quantization feature quantization
- FOBOS is a method of compressing the score to 0 by regularization (for example, L1 regularization).
- regularization for example, L1 regularization.
- the feature quantization is a technique for converting the score of a feature into an integer by multiplying the value after the decimal point by 10 n (n is a natural number of 1 or more). For example, when the score “0.1234456789” is multiplied by 1000 to make an integer, the score becomes “123”. By quantizing the score, the memory capacity required to store the score as text can be saved. In addition, this technique makes it possible to ignore features whose score is equal to or less than a predetermined value (for example, a feature whose score after integerization is 0 or a feature whose score is close to 0).
- the analysis unit 12 performs morpheme analysis without using the feature Fb.
- the regularization or quantization process is executed by, for example, the correction unit 13, another functional element in the natural language processing system 10, or a computer system different from the natural language processing system 10.
- the correction unit 13 performs regularization or quantization processing
- the correction unit 13 performs a morphological analysis on a set of sentences (for example, a certain number of sentences) in the natural language processing system 10 to determine what the division model 20 is.
- the regularization or quantization process is performed once.
- the analysis unit may execute the morphological analysis without using a feature whose score is equal to or lower than a predetermined value by regularization or quantization.
- features with relatively low scores for example, features whose score becomes 0 by regularization or quantization, or features whose score is close to 0
- the analysis unit 12 divides a sentence into individual characters and sets a tag for each character, but the divided element may be a word instead of a character. Accordingly, the analysis unit may perform morphological analysis using a division model and a word dictionary that indicate a score of a feature related to a word instead of a character.
- the natural language processing system according to the present invention can be applied to morphological analysis of an arbitrary language.
Abstract
Description
{S-N-nc/本(hon),0.0420}
{B-N-nc/本(hon),0.0310}
{S-P-k/本(hon),0.0003}
{B-V-c/本(hon),0.0031} The following is an example of an output feature score for the Japanese word “hon”. Although it is impossible in Japanese grammar that this character is a particle, as described above, data such as “SPK / hon” which does not exist in the grammar can be prepared.
{SN-nc / book, 0.0420}
{B-N-nc / hon, 0.0310}
{SPK / hon, 0.0003}
{BVc / hon, 0.0031}
{S-N-nc/C,0.0255}
{E-N-np/C,0.0488}
{S-P-k/C,0.0000}
{B-V-c/C,0.0299} In addition, an example of an output feature score regarding the character type “Kanji” is shown.
{SN-nc / C, 0.0255}
{EN-np / C, 0.0488}
{SPK / C, 0.0000}
{BVc / C, 0.0299}
{S-N-nc/本(hon)/を(wo),0.0420}
{B-N-nc/本(hon)/を(wo),0.0000}
{S-P-k/本(hon)/を(wo),0.0001}
{B-V-c/本(hon)/を(wo),0.0009} The following is an example of an output feature score for a bigram “hon wo”.
{SN-nc / book / hon (wo), 0.0420}
{B-N-nc / hon / (wo), 0.0000}
{SPK / hon / (wo), 0.0001}
{BVc / hon / (wo), 0.0009}
{S-N-nc/C/H,0.0455}
{E-N-np/C/H,0.0412}
{S-P-k/C/H,0.0000}
{B-V-c/C/H,0.0054} Moreover, the example of the score of the output feature regarding the bigram in which hiragana appears after the kanji is shown.
{SN-nc / C / H, 0.0455}
{EN-np / C / H, 0.0412}
{SPK / C / H, 0.0000}
{BVc / C / H, 0.0054}
{S-N-nc/S-P-k,0.0512}
{E-N-nc/E-N-nc,0.0000}
{S-P-k/B-V-c,0.0425}
{B-V-c/I-V-c,0.0387} Below, some examples of transition feature scores are shown.
{SN-nc / SP-k, 0.0512}
{E-N-nc / E-N-nc, 0.0000}
{SPK / BVc, 0.0425}
{BVc / IVc, 0.0387}
x1:{S-N-nc}
x2:{S-P-k}
x3:{B-V-c}
x4:{E-V-c}
x5:{S-P-sj} For example, the correct data for the above-described Japanese sentence “Hon Wo Katte” is as follows. For convenience, each character is also expressed as x 1 to x 5 .
x 1 : {SN—nc}
x 2 : {SPK}
x 3 : {BVc}
x 4 : {EVV}
x 5 : {SP-sj}
x1:{S-N-nc}
x2:{S-P-k}
x3:{B-V-c}
x4:{I-V-c}
x5:{E-V-c} For example, it is assumed that the
x 1 : {SN—nc}
x 2 : {SPK}
x 3 : {BVc}
x 4 : {IVc}
x 5 : {EVV}
Initialize w1
For t=1,2,…
Recieve instance xt
Predict structure y^t based on wt
Receive correct structure yt
If y^t≠yt, update
wt+1=update(wt,yt,+1)
wt+1=update(wt,y^t,-1) An example of an algorithm showing the operation of the natural
Initialize w 1
For t = 1, 2,...
Receive instance x t
Predict structure y ^ t based on w t
Receive correct structure y t
If y ^ t ≠ y t , update
w t + 1 = update (w t , y t , + 1)
w t + 1 = update (w t , y ^ t , −1)
DESCRIPTION OF
Claims (7)
- 1以上のトレーニングデータを用いた機械学習により得られる分割モデルを用いて、一つの文に対する形態素解析を実行することで、該一つの文を分割して得られる個々の被分割要素に、少なくとも単語の品詞を示すタグを設定する解析部であって、前記分割モデルが、被分割要素とタグとの対応を示す出力素性のスコアと、連続する二つの被分割要素に対応する二つのタグの組合せを示す遷移素性のスコアとを含む、該解析部と、
前記解析部により得られた解析結果で示されるタグと、前記一つの文の正解のタグを示す正解データとを比較し、不正解のタグに対応する正解のタグに関連する前記出力素性のスコアおよび前記遷移素性のスコアを現在値よりも高くし、該不正解のタグに関連する前記出力素性のスコアおよび前記遷移素性のスコアを現在値よりも低くすることで、前記解析部による次の文の形態素解析で用いられる前記分割モデルを修正する修正部と
を備える自然言語処理システム。 By using a division model obtained by machine learning using one or more training data and performing morphological analysis on one sentence, each divided element obtained by dividing the one sentence has at least a word An analysis unit for setting a tag indicating the part of speech of the combination, wherein the division model is a combination of a score of an output feature indicating a correspondence between a divided element and a tag and two tags corresponding to two consecutive divided elements Including the transition feature score indicating
The tag indicated by the analysis result obtained by the analysis unit is compared with correct data indicating the correct tag of the one sentence, and the score of the output feature related to the correct tag corresponding to the incorrect tag And the score of the transition feature is made higher than the current value, and the score of the output feature and the score of the transition feature related to the incorrect answer tag are made lower than the current value. A natural language processing system comprising: a correction unit that corrects the division model used in the morphological analysis. - 前記被分割要素が文字である、
請求項1に記載の自然言語処理システム。 The split element is a character;
The natural language processing system according to claim 1. - 前記分割モデルが、ハッシュ関数により数値化された前記出力素性を含む、
請求項1または2に記載の自然言語処理システム。 The division model includes the output feature quantified by a hash function;
The natural language processing system according to claim 1 or 2. - 前記出力素性のスコアおよび前記遷移素性のスコアのそれぞれが値の範囲を有し、各スコアについて分散が設定され、
前記修正部が、各スコアの分散に基づいて、該スコアを高くまたは低く際の該スコアの変化量を決定する、
請求項1~3のいずれか一項に記載の自然言語処理システム。 Each of the output feature score and the transition feature score has a range of values, and a variance is set for each score,
The correction unit determines the amount of change in the score when the score is increased or decreased based on the variance of each score.
The natural language processing system according to any one of claims 1 to 3. - 前記解析部が、正則化または量子化により前記スコアが所定値以下になった前記素性を用いることなく前記形態素解析を実行する、
請求項1~4のいずれか一項に記載の自然言語処理システム。 The analysis unit performs the morphological analysis without using the feature whose score is equal to or less than a predetermined value by regularization or quantization.
The natural language processing system according to any one of claims 1 to 4. - プロセッサを備える自然言語処理システムにより実行される自然言語処理方法であって、
1以上のトレーニングデータを用いた機械学習により得られる分割モデルを用いて、一つの文に対する形態素解析を実行することで、該一つの文を分割して得られる個々の被分割要素に、少なくとも単語の品詞を示すタグを設定する解析ステップであって、前記分割モデルが、被分割要素とタグとの対応を示す出力素性のスコアと、連続する二つの被分割要素に対応する二つのタグの組合せを示す遷移素性のスコアとを含む、該解析ステップと、
前記解析ステップにおいて得られた解析結果で示されるタグと、前記一つの文の正解のタグを示す正解データとを比較し、不正解のタグに対応する正解のタグに関連する前記出力素性のスコアおよび前記遷移素性のスコアを現在値よりも高くし、該不正解のタグに関連する前記出力素性のスコアおよび前記遷移素性のスコアを現在値よりも低くすることで、前記解析ステップにおける次の文の形態素解析で用いられる前記分割モデルを修正する修正ステップと
を含む自然言語処理方法。 A natural language processing method executed by a natural language processing system including a processor,
By using a division model obtained by machine learning using one or more training data and performing morphological analysis on one sentence, each divided element obtained by dividing the one sentence has at least a word An analysis step of setting a tag indicating the part of speech of the combination, wherein the division model is a combination of an output feature score indicating a correspondence between a divided element and a tag and two tags corresponding to two consecutive divided elements The analysis step comprising a transition feature score indicative of
The tag indicated by the analysis result obtained in the analysis step is compared with correct data indicating the correct tag of the one sentence, and the score of the output feature related to the correct tag corresponding to the incorrect tag And the score of the transition feature is made higher than the current value, and the score of the output feature and the score of the transition feature related to the incorrect answer tag are made lower than the current value, so that the next sentence in the analysis step A natural language processing method including a correction step of correcting the division model used in the morphological analysis. - 1以上のトレーニングデータを用いた機械学習により得られる分割モデルを用いて、一つの文に対する形態素解析を実行することで、該一つの文を分割して得られる個々の被分割要素に、少なくとも単語の品詞を示すタグを設定する解析部であって、前記分割モデルが、被分割要素とタグとの対応を示す出力素性のスコアと、連続する二つの被分割要素に対応する二つのタグの組合せを示す遷移素性のスコアとを含む、該解析部と、
前記解析部により得られた解析結果で示されるタグと、前記一つの文の正解のタグを示す正解データとを比較し、不正解のタグに対応する正解のタグに関連する前記出力素性のスコアおよび前記遷移素性のスコアを現在値よりも高くし、該不正解のタグに関連する前記出力素性のスコアおよび前記遷移素性のスコアを現在値よりも低くすることで、前記解析部による次の文の形態素解析で用いられる前記分割モデルを修正する修正部と
してコンピュータを機能させる自然言語処理プログラム。 By using a division model obtained by machine learning using one or more training data and performing morphological analysis on one sentence, each divided element obtained by dividing the one sentence has at least a word An analysis unit for setting a tag indicating the part of speech of the combination, wherein the division model is a combination of a score of an output feature indicating a correspondence between a divided element and a tag and two tags corresponding to two consecutive divided elements Including the transition feature score indicating
The tag indicated by the analysis result obtained by the analysis unit is compared with correct data indicating the correct tag of the one sentence, and the score of the output feature related to the correct tag corresponding to the incorrect tag And the score of the transition feature is made higher than the current value, and the score of the output feature and the score of the transition feature related to the incorrect answer tag are made lower than the current value. A natural language processing program for causing a computer to function as a correction unit for correcting the division model used in the morphological analysis.
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020167028427A KR101729461B1 (en) | 2014-04-29 | 2014-12-08 | Natural language processing system, natural language processing method, and natural language processing program |
| CN201480076197.5A CN106030568B (en) | 2014-04-29 | 2014-12-08 | Natural language processing system, natural language processing method and natural language processing program |
| JP2015512822A JP5809381B1 (en) | 2014-04-29 | 2014-12-08 | Natural language processing system, natural language processing method, and natural language processing program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201461985615P | 2014-04-29 | 2014-04-29 | |
| US61/985615 | 2014-04-29 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2015166606A1 true WO2015166606A1 (en) | 2015-11-05 |
Family
ID=54358353
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2014/082428 WO2015166606A1 (en) | 2014-04-29 | 2014-12-08 | Natural language processing system, natural language processing method, and natural language processing program |
Country Status (5)
| Country | Link |
|---|---|
| JP (1) | JP5809381B1 (en) |
| KR (1) | KR101729461B1 (en) |
| CN (1) | CN106030568B (en) |
| TW (1) | TWI567569B (en) |
| WO (1) | WO2015166606A1 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112101030A (en) * | 2020-08-24 | 2020-12-18 | 沈阳东软智能医疗科技研究院有限公司 | Method, device and equipment for establishing term mapping model and realizing standard word mapping |
| CN113204667A (en) * | 2021-04-13 | 2021-08-03 | 北京百度网讯科技有限公司 | Method and device for training audio labeling model and audio labeling |
| JP7352249B1 (en) | 2023-05-10 | 2023-09-28 | 株式会社Fronteo | Information processing device, information processing system, and information processing method |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108021559B (en) * | 2018-02-05 | 2022-05-03 | 威盛电子股份有限公司 | Natural language understanding system and semantic analysis method |
| CN110020434B (en) * | 2019-03-22 | 2021-02-12 | 北京语自成科技有限公司 | Natural language syntactic analysis method |
| KR102352481B1 (en) * | 2019-12-27 | 2022-01-18 | 동국대학교 산학협력단 | Sentence analysis device using morpheme analyzer built on machine learning and operating method thereof |
| CN116153516B (en) * | 2023-04-19 | 2023-07-07 | 山东中医药大学第二附属医院(山东省中西医结合医院) | Disease big data mining analysis system based on distributed computing |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH09114825A (en) * | 1995-10-19 | 1997-05-02 | Ricoh Co Ltd | Method and device for morpheme analysis |
| JP2003099426A (en) * | 2001-09-25 | 2003-04-04 | Canon Inc | Natural language processor, its control method and program |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN100530171C (en) * | 2005-01-31 | 2009-08-19 | 日电(中国)有限公司 | Dictionary learning method and devcie |
| CN100533431C (en) * | 2005-09-21 | 2009-08-26 | 富士通株式会社 | Natural language component identifying correcting apparatus and method based on morpheme marking |
| CN102681981A (en) * | 2011-03-11 | 2012-09-19 | 富士通株式会社 | Natural language lexical analysis method, device and analyzer training method |
| JP5795985B2 (en) | 2012-03-30 | 2015-10-14 | Kddi株式会社 | Morphological analyzer, morphological analysis method, and morphological analysis program |
-
2014
- 2014-12-08 CN CN201480076197.5A patent/CN106030568B/en active Active
- 2014-12-08 WO PCT/JP2014/082428 patent/WO2015166606A1/en active Application Filing
- 2014-12-08 KR KR1020167028427A patent/KR101729461B1/en active IP Right Grant
- 2014-12-08 JP JP2015512822A patent/JP5809381B1/en active Active
-
2015
- 2015-03-18 TW TW104108650A patent/TWI567569B/en active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH09114825A (en) * | 1995-10-19 | 1997-05-02 | Ricoh Co Ltd | Method and device for morpheme analysis |
| JP2003099426A (en) * | 2001-09-25 | 2003-04-04 | Canon Inc | Natural language processor, its control method and program |
Non-Patent Citations (1)
| Title |
|---|
| BIRD STEVEN ET AL., NATURAL LANGUAGE PROCESSING WITH PYTHON, 8 November 2010 (2010-11-08), pages 480 - 490, ISBN: 978-4-87311-470-5 * |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112101030A (en) * | 2020-08-24 | 2020-12-18 | 沈阳东软智能医疗科技研究院有限公司 | Method, device and equipment for establishing term mapping model and realizing standard word mapping |
| CN112101030B (en) * | 2020-08-24 | 2024-01-26 | 沈阳东软智能医疗科技研究院有限公司 | Method, device and equipment for establishing term mapping model and realizing standard word mapping |
| CN113204667A (en) * | 2021-04-13 | 2021-08-03 | 北京百度网讯科技有限公司 | Method and device for training audio labeling model and audio labeling |
| CN113204667B (en) * | 2021-04-13 | 2024-03-22 | 北京百度网讯科技有限公司 | Method and device for training audio annotation model and audio annotation |
| JP7352249B1 (en) | 2023-05-10 | 2023-09-28 | 株式会社Fronteo | Information processing device, information processing system, and information processing method |
Also Published As
| Publication number | Publication date |
|---|---|
| CN106030568A (en) | 2016-10-12 |
| KR20160124237A (en) | 2016-10-26 |
| TWI567569B (en) | 2017-01-21 |
| CN106030568B (en) | 2018-11-06 |
| JP5809381B1 (en) | 2015-11-10 |
| TW201544976A (en) | 2015-12-01 |
| KR101729461B1 (en) | 2017-04-21 |
| JPWO2015166606A1 (en) | 2017-04-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5809381B1 (en) | Natural language processing system, natural language processing method, and natural language processing program | |
| Abandah et al. | Automatic diacritization of Arabic text using recurrent neural networks | |
| JP5901001B1 (en) | Method and device for acoustic language model training | |
| Duan et al. | Online spelling correction for query completion | |
| US20120262461A1 (en) | System and Method for the Normalization of Text | |
| CN111444320A (en) | Text retrieval method and device, computer equipment and storage medium | |
| KR101544690B1 (en) | Word division device, word division method, and word division program | |
| CN109117474B (en) | Statement similarity calculation method and device and storage medium | |
| US11423237B2 (en) | Sequence transduction neural networks | |
| JP6817556B2 (en) | Similar sentence generation method, similar sentence generation program, similar sentence generator and similar sentence generation system | |
| US20220391647A1 (en) | Application-specific optical character recognition customization | |
| US20200279079A1 (en) | Predicting probability of occurrence of a string using sequence of vectors | |
| WO2019208507A1 (en) | Language characteristic extraction device, named entity extraction device, extraction method, and program | |
| KR20230061001A (en) | Apparatus and method for correcting text | |
| CN113255331B (en) | Text error correction method, device and storage medium | |
| JP2015169947A (en) | Model learning device, morphological analysis device and method | |
| Yang et al. | Spell Checking for Chinese. | |
| CN111090720B (en) | Hot word adding method and device | |
| JP5676517B2 (en) | Character string similarity calculation device, method, and program | |
| US20180033425A1 (en) | Evaluation device and evaluation method | |
| Kim et al. | Reliable automatic word spacing using a space insertion and correction model based on neural networks in Korean | |
| JP6303508B2 (en) | Document analysis apparatus, document analysis system, document analysis method, and program | |
| Yan et al. | A novel approach to improve the Mongolian language model using intermediate characters | |
| CN111667813B (en) | Method and device for processing file | |
| Meško et al. | Checking the writing of commas in Slovak |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| ENP | Entry into the national phase |
Ref document number: 2015512822 Country of ref document: JP Kind code of ref document: A |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 14890522 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 20167028427 Country of ref document: KR Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 14890522 Country of ref document: EP Kind code of ref document: A1 |