WO2015129109A1 - Index management device - Google Patents
Index management device Download PDFInfo
- Publication number
- WO2015129109A1 WO2015129109A1 PCT/JP2014/080851 JP2014080851W WO2015129109A1 WO 2015129109 A1 WO2015129109 A1 WO 2015129109A1 JP 2014080851 W JP2014080851 W JP 2014080851W WO 2015129109 A1 WO2015129109 A1 WO 2015129109A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- node
- key
- hierarchy
- pointer
- group
- Prior art date
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/901—Indexing; Data structures therefor; Storage structures
- G06F16/9027—Trees
Definitions
- the present invention relates to an index management apparatus, and is particularly suitable for use in an index management apparatus that manages an index tree used for speeding up data retrieval.
- an index tree is widely known as a technique for speeding up data retrieval. For example, when searching for data corresponding to a specific key, it takes a lot of time to examine all the records in the database one by one from the top. Thus, in order to speed up the search for a specific key, an index tree is often assigned (see, for example, Patent Documents 1 and 2).
- a set of data to be recorded is called a record, and data used for searching is called a key.
- the other data is called value.
- To search for records by key it is desirable that the records be sorted in key order. However, it is a time consuming process to record and sort records in key order. Therefore, records are generally recorded in the order of arrival, and pointers to records corresponding to keys are generally sorted and recorded separately in a tree structure. This is the index tree. The reason why the sorted state is maintained in the tree structure is to reduce the processing time by limiting the addition and deletion of the key of the index tree accompanying the addition and deletion of records to a part.
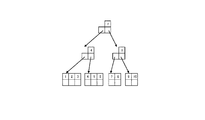
- FIG. 8 is a diagram for explaining the concept of the index tree.
- the index tree has a tree-like structure, and the lowermost node is called a leaf node and the other nodes are called internal nodes.
- the top node is called a root node, and a node that is neither a root nor a leaf is called a branch node.
- the branch node has one hierarchy, but it is also possible to have a plurality of hierarchies.
- Each node stores a set of a predetermined number of keys 101 and pointers 102, but the leftmost key is omitted for internal nodes.
- the pairs of keys and pointers that are entries of each node are arranged in ascending or descending order of key values.
- Each of these entries has a one-to-one correspondence with the node corresponding to the child of that node, the value of the leftmost key of the child node (the leftmost omitted key if the child node is an internal node), and the child Stores a pointer to the position of the node.
- the entry of the leaf node which is the final hierarchy of the node, stores the key value of each record and the position of the record.
- the root node stores a set of two keys “10” and “19” and three pointers.
- the first (leftmost) pointer is position information indicating the storage position of a child node having a key having a value of “1” or more and smaller than “10” as an entry.
- the second pointer is position information indicating a storage position of a child node having a key whose value is “10” or more and smaller than “19” as an entry.
- the third pointer is position information indicating the storage position of a child node having a key whose value is “19” or more as an entry.
- the leftmost branch node stores a set of two keys “4” and “7” and three pointers.
- the first pointer is position information indicating the storage position of a child node having a key having a value of “1” or more and smaller than “4” as an entry.
- the second pointer is position information indicating a storage position of a child node having a key having a value of “4” or more and smaller than “7” as an entry.
- the third pointer is position information indicating a storage position of a child node having a key whose value is “7” or more as an entry.
- the other branch nodes store pairs of two keys and three pointers.
- the leftmost leaf node stores a set of three keys “1”, “2” 3, “3” and three pointers.
- the first pointer is position information indicating the position of the record in which the data corresponding to the key “1” is stored.
- the second pointer is position information indicating the position of the record in which data corresponding to the key “2” is stored.
- the third pointer is position information indicating the position of the record in which the data corresponding to the key “3” is stored.
- other leaf nodes store pairs of three keys and three pointers.
- the second pointer in the root node, the leftmost pointer in the second branch node, and the fourth leaf By tracing the node, the data corresponding to the key “11” can be efficiently searched.
- the third leaf searched by sequentially tracing from the root node as the node to which the entry should be added.
- the node already has three entries and has no space.
- the third leaf node is divided at the position of the key “9” equal to or higher than the division key “8”.
- To generate a new leaf node move the entry before the split key “8” to the first split node, and move the entry after the split key “8” to the second split node. By moving, an empty entry to which a record with the key “8” can be added is generated.
- Non-Patent Document 1 which is one method of the index tree, as shown in FIG. 10
- the tree is grown to the upper layer side when dividing the node. In this way, the number of hierarchies in the index tree is the same for every leaf node, and the whole is balanced.
- the number of disk I / Os determines the performance of the index tree in the disk environment.
- the latency of the disk is about 10 ms
- the latency of the memory is about 100 ns
- the latency of the cache is about 1 ns. Therefore, to increase the search efficiency, it is necessary to reduce the number of disk I / Os as much as possible.
- the access ratio is higher in the upper hierarchy node, and the access ratio is lower in the lower hierarchy node (see, for example, Non-Patent Document 2). Therefore, if the highest level root node is stored in the cache, the branch node is stored in the memory, and the leaf node is stored in the disk, the number of disk I / Os can be reduced.
- the B-tree is a method optimized for disk access.
- the node size of the B-tree is typically equal to the size of a disk block (unit of data I / O on the disk, typically 4 Kbytes).
- the fanout (number of child nodes) is about 500 if the node size is set to 4 Kbytes. Therefore, in the case of a B-tree consisting of three layers as shown in FIG. 11, if there is a small amount of memory (about 2 Mbytes), data can be extracted from a large amount (about 1 Gbyte) of database with one disk I / O. Is possible.
- a cache line is a unit in which the CPU transfers data from the memory to the cache. In recent CPUs, a cache line is often composed of 64-byte data.
- a method called “CSB + tree” is known as an index tree optimized for the in-memory environment by reducing the number of lines (for example, see Non-Patent Document 3).
- the storage capacity is reduced by deleting the pointer from the entry of the node, and the number of lines can be reduced by increasing the number of keys that can be stored in one node.
- the CSB + tree also has an advantage that access to the cache line in which the pointer is recorded can be omitted.
- a plurality of nodes are grouped to generate a node group.
- the entry of the internal node does not have a pointer corresponding to each key individually, but has only a pointer indicating the head position of the node group in the lower hierarchy.
- the entry of each node in the group is stored in a continuous area of the memory, and the position of the corresponding key is specified based on the offset amount from the head position of the child node.
- the search from the root node shows that the key “13” is in the second node group in the leaf node.
- the search speed increases.
- the insertion process is slower than in the B-tree.
- FIG. 13A since there is a pointer corresponding to each key in the case of a B-tree, child nodes newly generated by node division can be freely arranged.
- the CSB + tree as shown in FIG. 13B, it is necessary to rearrange the child nodes so that the key values are in ascending order or descending order in the node group. There was a problem that would slow down.
- the present invention has been made to solve such a problem, and it is possible to speed up the data search process in an in-memory environment and to suppress the slowdown of the update process. Objective.
- a leaf node storing a set of a predetermined number of keys and a predetermined number of values is defined as the 0th hierarchy, and the nth hierarchy or lower (n is “1 ⁇ n ⁇ all hierarchies”).
- n is “1 ⁇ n ⁇ all hierarchies”.
- an index is obtained by a first type node storing a set of a predetermined number of keys and a predetermined number of pointers representing the positions of child nodes or a predetermined number of values.
- the search of the index tree and the second type node storing a predetermined number of keys and one group pointer indicating the head position of the node group in the lower layer are performed. I try to manage updates.
- a predetermined number of keys and a single group pointer representing the start position of a node group in a lower hierarchy are stored in the lower hierarchy of the first hierarchy and higher than the nth hierarchy.
- the search and update of the index tree is managed by a third type of node storing a reduction pointer having a size sufficient to represent the position of each node.
- search and update of the index tree are managed by the second type node.
- an upper layer node has a lower update rate instead of a higher access rate
- a lower layer node has a higher update rate instead of a lower access rate.
- search and update of the index tree are managed in the upper hierarchy by the second type node that can perform the search process at high speed.
- search and update of the index tree are managed by the first type node that can perform the key insertion processing at high speed.
- search and update of the index tree are managed by the second type node that can perform the search process at high speed.
- the offset amount in the node group is obtained based on the reduction pointer, each node can be freely arranged in the node group, and even in data update processing that requires node division or the like It can be done at high speed.
- the storage capacity required for the reduced pointer is small, the number of keys that can be stored in one node can be increased, and the number of hierarchies in the index tree can be reduced to speed up the search process.
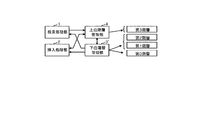
- FIG. 1 is a block diagram illustrating a functional configuration example of an index management apparatus according to the first embodiment.
- the index management device according to the first embodiment includes an index tree including a leaf node as the lowest hierarchy, a root node as the highest hierarchy, and one or more branch nodes between the leaf nodes and the root node.
- the search processing unit 1, the insertion processing unit 2, the lower layer management unit 3, and the upper layer management unit 4 are provided.
- the above functional blocks 1 to 4 can be configured by any of hardware, DSP (Digital Signal Processor), and software.
- DSP Digital Signal Processor
- each of the functional blocks 1 to 4 is actually configured with a computer CPU, RAM, ROM, and the like, and is stored in a recording medium such as RAM, ROM, hard disk, or semiconductor memory. Is realized by operating.
- the hierarchy having a leaf node storing a set of a predetermined number of keys and a predetermined number of values is defined as the 0th hierarchy, and the nth hierarchy or lower (n is “1 ⁇ n ⁇ total number of hierarchy ⁇ 1”) Arbitrary values that satisfy) are set as lower hierarchies, and hierarchies above the nth hierarchy are upper hierarchies.
- the index tree is composed of four layers from the 0th layer to the 3rd layer.
- One leaf node is composed of a set of a maximum of three keys and the same number of values as the keys.
- the search processing unit 1 searches for desired data (value) from a database (memory) in an in-memory environment using an index tree. Specifically, the search processing unit 1 supplies a search key to the upper layer management unit 4 and searches for a value corresponding to the search key by the processing of the upper layer management unit 4 and the lower layer management unit 3. Then, the retrieved value is received from the lower hierarchy management unit 3.
- the insertion processing unit 2 inserts desired data (a set of key and value) into the index tree. Specifically, the insertion processing unit 2 supplies the key and value to be inserted to the upper layer management unit 4, and should be inserted from the value of the insertion key by the processing of the upper layer management unit 4 and the lower layer management unit 3. A leaf node is determined, and a key / value pair is added to an appropriate position of the determined leaf node. Then, the notification of insertion completion is received from the lower hierarchy management unit 3 or the upper hierarchy management unit 4.
- the lower hierarchy management unit 3 uses the first type node storing a set of a predetermined number of keys and a predetermined number of pointers or a predetermined number of values indicating the positions of the child nodes. Manage tree exploration and updates.
- This first type of node is the same as the node used in the B-tree, for example.
- the upper layer management unit 4 uses the second type of node storing a predetermined number of keys and one group pointer representing the head position of the lower layer node group in the upper layer of the index tree to generate an index tree.
- Manage search and update of This second type of node is the same as the node used in the CSB + tree, for example.
- FIG. 2 is a diagram showing a specific example of an index tree searched and updated by the lower hierarchy management unit 3 and the upper hierarchy management unit 4.
- the first hierarchy which is a lower hierarchy managed by the lower hierarchy management unit 3
- the first hierarchy is a first type that stores a set of a maximum of two keys and one more pointer than the key. It consists of nodes. Each pointer represents the position of the left end of the leaf node in the 0th hierarchy one level below.
- the leaf node which is the other lower layer, is composed of a set of a maximum of three keys and the same number of values as the keys.
- the second and third hierarchies managed by the upper hierarchy management unit 4 have a maximum of two keys and one group pointer indicating the head position of the node group in the next lower hierarchy. It is composed of a second type of node that stores.
- One node group Gr 2-1 is set in the second layer below one of the third layers, and three node groups Gr 1-1 and Gr 1 ⁇ are set in the first layer below one of the second layers. 2 and Gr 1-3 are set.
- the search processing unit 1 passes the search key to the upper layer management unit 4. In the following description, it is assumed that the value of the search key is “15”.
- the upper layer management unit 4 identifies the highest third layer and the node that is the root node there. Then, the upper layer management unit 4 searches for the key having the maximum value below the search key from the keys stored in the root node. Further, the upper layer management unit 4 traces the position specified by calculating the offset amount from the head position of the node group indicated by the group pointer stored in the same node together with the searched key based on the node size. To the lower layer.
- the upper hierarchy management unit 4 transitions to the node at the head position of the node group Gr 2-1 in the second hierarchy one level lower in accordance with the group pointer stored in the same node together with the omitted key. .
- the upper layer management unit 4 performs the same processing as described above. That is, the upper layer management unit 4 searches for a key having the maximum value below the search key “15” among the keys stored in the node at the head position of the node group Gr 2-1 that has transitioned from the root node. To do. In this case, the searched key is “10”. As described above, when the second key from the left end in the node including the omitted key is searched, the offset amount is the node size ⁇ 1. In this case, the upper hierarchy management unit 4 determines the head position of the node group Gr 1-1 in the first lower hierarchy according to the group pointer and offset amount stored in the same node together with the searched key “10”. To the second node.
- the lower layer management unit 3 Since the first layer that has transitioned at this time is a lower layer, the lower layer management unit 3 performs processing.
- the lower hierarchy management unit 3 searches for the key having the maximum value below the search key from the keys stored in the identified node. Furthermore, the lower layer management unit 3 moves to the lower layer by following the position indicated by the pointer stored in the same node together with the searched key.
- the lower hierarchy management unit 3 makes a direct transition to the fifth leaf node from the left end in the lower 0th hierarchy according to the pointer stored as a pair with the searched key “13”. Since the search key “15” is in this node, the lower hierarchy management unit 3 acquires the value corresponding to the position of the search key and passes it to the search processing unit 1. Thereby, the search processing by the search processing unit 1 ends.
- the insertion processing unit 2 passes the combination of the insertion key and the value to the upper layer management unit 4.
- the value of the insertion key is “9”.
- the upper hierarchy management unit 4 and the lower hierarchy management unit 3 search for a leaf node into which the insertion key “9” is to be inserted, following the same procedure as the search process described above. Thereby, it changes to the 3rd leaf node from the left end.
- the lower hierarchy management unit 3 determines whether or not there is an empty space in the searched leaf node. If there is an empty space, the set of the insertion key “9” and value is inserted into the leaf node. In the example of FIG. 2, since there is one free space in the third leaf node from the left end, it is possible to insert a pair of the insertion key “9” and value into that node.
- the lower hierarchy management unit 3 divides the leaf node and inserts a pair of an insertion key and a pointer. For example, it is assumed that the value of the insertion key passed from the insertion processing unit 2 to the upper hierarchy management unit 4 is “17”. In this case, when the upper hierarchy management unit 4 and the lower hierarchy management unit 3 search for a leaf node into which the insertion key “17” is to be inserted, the transition is made to the sixth leaf node from the left end.
- this sixth node already has three key / value pairs stored and has no free space. Therefore, the lower hierarchy management unit 3 divides this sixth leaf node to secure an empty space, and inserts a set of the insertion key “17” and value.
- the lower layer management unit 3 first acquires a new empty node. Next, the lower hierarchy management unit 3 moves a set of a key that is equal to or higher than a predetermined split key among the three keys included in the sixth leaf node and a value corresponding thereto to a new node.
- the value of the split key is, for example, the median value of the three key values.
- the lower layer management unit 3 inserts the pair of the insertion key “17” and the value into the new node if the insertion key “17” is equal to or higher than the split key, and otherwise to the original node.
- the lower hierarchy management unit 3 sets the split key and the pointer to the new node to the node on the search path in the first hierarchy one level higher than the zeroth hierarchy in which the leaf node exists (second node from the left end). ) To add. At this time, if there is no space for adding a new key / pointer pair to the node, a new node is secured in the node group.
- the node at the third position in the node group is initialized, and the second entry is moved to this node.
- a set of the insertion key “17” and the value is inserted into the space created by the node division.
- the copy of the node did not occur because the second node was divided, but if the first node was divided, the second node was copied as the third node, and the second node Is initialized (empty) to divide the first node.
- the lower layer management unit 3 divides the node in the 0th layer and inserts the insertion key “17”, and accordingly, the node group Gr 1 ⁇ to which the node to which a key is newly added in the first layer belongs. Determine if 1 has space to add a node. If there is a space, the node after the position immediately after the node to be divided in the node group Gr 1-1 is copied to the right one position. Then, the node immediately after the node to be divided is initialized to secure a new empty node. This enables node division.
- the lower hierarchy management unit 3 acquires a new node group. Then, the lower hierarchy management unit 3 moves some of the nodes (for example, the rear half in the node group Gr 1-1 ) to a new node group. As a result, a space for adding a node is created in the node group Gr 1-1 . Therefore, a space for adding an entry can be created by node division.
- the lower hierarchy management unit 3 When a node is moved or a new node group is acquired in the first hierarchy, the lower hierarchy management unit 3 requests the upper hierarchy management unit 4 to perform the second hierarchy one level higher than the first hierarchy, Necessary keys are added to the nodes (leftmost node) in the node group on the search path. If there is no space for adding a new key in this node, the insertion space is secured by moving the node or acquiring the node group in the second hierarchy as in the first hierarchy. In this case, it is necessary to add a new key to the root node, but when there is no free space and the root node is divided, an unused and lowest-order node is made a new root node.
- FIG. 3 is a diagram illustrating a configuration example of the index tree after the combination of the insertion key “17” and the value is inserted into the index tree illustrated in FIG.
- node division is performed in the 0th hierarchy, and accordingly, entries are added also in the 1st hierarchy and the 2nd hierarchy. ing.
- the first hierarchy storing a set of a predetermined number of keys and a predetermined number of pointers or a predetermined number of values is stored in the lower hierarchy consisting of the 0th hierarchy and the first hierarchy.
- the search and update of the index tree is managed by the type of node (B-tree node).
- search and update of the index tree by the second type node (CSB + tree node) storing a predetermined number of keys and one group pointer.
- the index tree has the property that the higher the access ratio, the lower the access ratio, the lower the update ratio, and the lower hierarchy node, the lower the access ratio, the higher the update ratio.
- search and update of the index tree are managed in the upper layer by the second type node that can perform the search process at high speed.
- search and update of the index tree are managed by the first type node that can perform the key insertion processing at high speed.
- FIG. 4 is a block diagram illustrating a functional configuration example of the index management apparatus according to the second embodiment.
- the index management apparatus according to the second embodiment includes, as its functional configuration, a search processing unit 1, an insertion processing unit 2, a lower hierarchy management unit 3, an upper hierarchy management unit 4, and a middle hierarchy management unit. 5.
- a search processing unit 1 search processing unit 1
- insertion processing unit 2 insertion processing unit 2
- lower hierarchy management unit 3 lower hierarchy management unit 3
- an upper hierarchy management unit 4 and a middle hierarchy management unit. 5.
- those given the same reference numerals as those shown in FIG. 1 have the same functions, and therefore redundant description is omitted here.
- the hierarchy in which the leaf node exists is defined as the 0th hierarchy, and the 0th hierarchy and the 1st hierarchy immediately above the 0th hierarchy are defined as the lower hierarchy.
- a second hierarchy that is one level higher than the first hierarchy is a middle hierarchy, and a third hierarchy or higher is an upper hierarchy.
- the index tree is composed of four layers from the 0th layer to the 3rd layer. Among these, the 0th hierarchy and the 1st hierarchy are the lower hierarchy, the 2nd hierarchy is the middle hierarchy, and the 3rd hierarchy is the upper hierarchy.
- the middle level management unit 5 stores a predetermined number of keys and one group pointer representing the head position of the node group one level lower in the middle level of the index tree, and each of the nodes in the node group. Search and update of the index tree is managed by a third type node that stores a reduction pointer that is a pointer representing the position of the node and is smaller in size than the pointer stored in the first type node.
- FIG. 5 is a diagram illustrating a specific example of an index tree searched and updated by the lower hierarchy management unit 3, the upper hierarchy management unit 4, and the middle hierarchy management unit 5.
- FIG. 5 is substantially the same as the index tree shown in FIG. 2, but the second hierarchy node defined as the middle hierarchy is different from the index tree of FIG.
- the second hierarchy which is the middle hierarchy, has a maximum of two keys, one group pointer that represents the start position of the node group that is one level below, and the same number of reduced pointers as the keys.
- the size of the normal pointer in the first layer is 4 bytes
- the size of the reduced pointer is 2 bytes.
- the pointer must be 4 bytes or larger, but if the node is somewhere in the 64 Kbyte node group, it is 2 bytes. This is because the node can be specified by the above pointer.
- a pointer to the head of a node group is used, a child node can be specified even if the pointer is reduced.
- the search processing unit 1 passes the search key to the upper layer management unit 4. In the following description, it is assumed that the value of the search key is “15”.
- the processing of the upper layer management unit 4 in the third layer, which is the upper layer, is the same as in the first embodiment. Since the second hierarchy that has transitioned from the third hierarchy is the middle hierarchy, the middle hierarchy management unit 5 performs processing. That is, the middle level management unit 5 selects a key having the maximum value below the search key “15” among the keys stored in the node at the head position of the node group Gr 2-1 that has transitioned from the root node. Explore. In this case, the searched key is “10”.
- the middle level management unit 5 sets the offset amount from the head position of the node group indicated by the group pointer stored in the same node together with the key “10” searched as described above as the key “10”. The calculation is performed based on the reduction pointer stored as a set. Then, by tracing the position specified by the this group pointers and the offset amount, the transition from the head position of the node group Gr 1-1 in the first hierarchy down one on the second node.
- the lower layer management unit 3 performs the same processing as in the first embodiment.
- a transition is made directly to the fifth leaf node from the left end in the next lower 0th hierarchy, and the search key “15” is searched from within the leaf node.
- the value corresponding to the position is acquired and passed to the search processing unit 1. Thereby, the search processing by the search processing unit 1 ends.
- the search for the leaf node into which the insertion key is to be inserted is performed according to the same procedure as the search processing described above. Thereafter, the processing for inserting the combination of the insertion key and the value into the retrieved leaf node is the same as that in the first embodiment described above, and thus the description thereof is omitted here.
- the entry of each node in the node group is stored in a continuous area of the memory. It is not essential, and each node can be freely arranged in the node group as shown in FIG. Therefore, even data update processing that requires node division or the like can be performed at high speed.
- a reduction pointer is provided corresponding to each key, and the storage capacity required for the reduction pointer is reduced, so that a key that can be stored in one node is reduced. You can increase the number. Thereby, the number of hierarchies (lines) of the index tree can be reduced, and the search process can be speeded up.
- the index tree is divided into the upper hierarchy, the middle hierarchy, and the lower hierarchy and the reduced pointer is used in the middle hierarchy.
- the present invention is not limited to this.
- the index tree may be managed by dividing it into an upper hierarchy and a lower hierarchy, and a reduction pointer may be used in the lower hierarchy.
- an index management apparatus is configured by including a search processing unit 1, an insertion processing unit 2, a lower layer management unit 3 ', and an upper layer management unit 4.
- the lower hierarchy management unit 3 ′ sets a hierarchy having leaf nodes as the 0th hierarchy, and is lower than the 1st hierarchy and below the nth hierarchy (n is an arbitrary value satisfying “1 ⁇ n ⁇ total number of hierarchies ⁇ 1”).
- a predetermined number of keys and a single group pointer representing the head position of a node group in a lower hierarchy are stored, and a third type node storing a reduced pointer representing the position of each node in the node group Manage the search and update of the index tree.
- search and update of the index tree are managed by the first type node.
- the present invention is applied to an index tree including internal nodes in which the leftmost key is not omitted. Is also possible.
- the index management apparatus is used for updating data such as relational database indexes, map processing incorporated in many programs, file systems, key-value stores, OLAP (online analytical processing) systems, and the like. However, it can be widely used for a system that may perform a search against the system.
- each of the first and second embodiments described above is merely an example of a specific example for carrying out the present invention, and the technical scope of the present invention should not be interpreted in a limited manner. It will not be. That is, the present invention can be implemented in various forms without departing from the gist or the main features thereof.
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
The present invention manages the searching and refreshing of an index tree using a first type of node for storing a set of a prescribed number of keys and a prescribed number of pointers indicating the position of a child node or a prescribed number of values, for lower levels at or below an nth level (n is an arbitrary value satisfying "1≤n<number of all levels-1"), by using the quality of the access rate being higher and the refresh rate being lower in higher level nodes and the access rate being lower and the refresh rate being higher in lower level nodes. Meanwhile, the present invention makes it possible to quickly perform data search processing and refresh processing, by managing the searching and refreshing of the index tree using a second type of node for storing a prescribed number of keys and one group pointer indicating the head position of a lower level node group, for higher levels above the nth level.
Description
本発明は、インデックス管理装置に関し、特に、データの検索を高速化するために用いるインデックスツリーを管理するインデックス管理装置に用いて好適なものである。
The present invention relates to an index management apparatus, and is particularly suitable for use in an index management apparatus that manages an index tree used for speeding up data retrieval.
従来、データの検索を高速化する技術として、インデックスツリーと呼ばれる手法が広く知られている。例えば、特定のキーに対応するデータを検索する場合、データベース内の全てのレコードを先頭から1つずつ調べていくと膨大な時間がかかってしまう。そこで、特定のキーに対する検索を高速化するために、インデックスツリーを付与することが多い(例えば、特許文献1,2参照)。
Conventionally, a technique called an index tree is widely known as a technique for speeding up data retrieval. For example, when searching for data corresponding to a specific key, it takes a lot of time to examine all the records in the database one by one from the top. Thus, in order to speed up the search for a specific key, an index tree is often assigned (see, for example, Patent Documents 1 and 2).
記録するデータの組をレコードと呼び、その中で検索に用いられるデータを特にキーと呼ぶ。その他のデータはバリューと呼ぶ。レコードをキーで検索するには、キー順にレコードがソートされているのが望ましい。しかし、レコードをキー順にソートして記録するのは時間がかかる処理である。そこで、レコードは到着順に記録し、キーと対応するレコードへのポインタをツリー構造でソートして別途記録するのが一般的である。これがインデックスツリーである。ソートした状態をツリー構造で維持するのは、レコードの追加と削除に伴うインデックスツリーのキーの追加と削除を、一部に限定することで処理時間を短縮するためである。
* A set of data to be recorded is called a record, and data used for searching is called a key. The other data is called value. To search for records by key, it is desirable that the records be sorted in key order. However, it is a time consuming process to record and sort records in key order. Therefore, records are generally recorded in the order of arrival, and pointers to records corresponding to keys are generally sorted and recorded separately in a tree structure. This is the index tree. The reason why the sorted state is maintained in the tree structure is to reduce the processing time by limiting the addition and deletion of the key of the index tree accompanying the addition and deletion of records to a part.
図8は、インデックスツリーの概念を説明するための図である。インデックスツリーは、ツリー状の構造を持ち、最下層のノードをリーフノード、その他のノードを内部ノードと呼ぶ。また、一番上のノードをルートノードと呼び、ルートでもリーフでもないノードをブランチノードと呼ぶ。図8ではブランチノードが1階層となっているが、複数階層にすることも可能である。各ノードには所定数のキー101とポインタ102との組が格納されているが、内部ノードについては左端のキーが省略されている。
FIG. 8 is a diagram for explaining the concept of the index tree. The index tree has a tree-like structure, and the lowermost node is called a leaf node and the other nodes are called internal nodes. The top node is called a root node, and a node that is neither a root nor a leaf is called a branch node. In FIG. 8, the branch node has one hierarchy, but it is also possible to have a plurality of hierarchies. Each node stores a set of a predetermined number of keys 101 and pointers 102, but the leftmost key is omitted for internal nodes.
各ノードのエントリであるキーとポインタとの組は、キーの値の昇順もしくは降順で並んでいる。これらのエントリはそれぞれ、そのノードの子に相当するノードと1対1に対応し、子ノードの左端のキー(子ノードが内部ノードの場合は左端の省略されているキー)の値と、子ノードの位置を指すポインタとを格納する。ノードの最終階層であるリーフノードのエントリには、各レコードのキーの値とレコードの位置とを格納する。
The pairs of keys and pointers that are entries of each node are arranged in ascending or descending order of key values. Each of these entries has a one-to-one correspondence with the node corresponding to the child of that node, the value of the leftmost key of the child node (the leftmost omitted key if the child node is an internal node), and the child Stores a pointer to the position of the node. The entry of the leaf node, which is the final hierarchy of the node, stores the key value of each record and the position of the record.
図8の例において、ルートノードには2つのキー“10”、“19”と3つのポインタとの組が格納されている。3つのポインタのうち、1つ目(左端)のポインタは、値が“1”以上で“10”より小さいキーをエントリとして持つ子ノードの格納位置を表す位置情報である。2つ目のポインタは、値が“10”以上で“19”より小さいキーをエントリとして持つ子ノードの格納位置を表す位置情報である。3つ目のポインタは、値が“19”以上のキーをエントリとして持つ子ノードの格納位置を表す位置情報である。
In the example of FIG. 8, the root node stores a set of two keys “10” and “19” and three pointers. Among the three pointers, the first (leftmost) pointer is position information indicating the storage position of a child node having a key having a value of “1” or more and smaller than “10” as an entry. The second pointer is position information indicating a storage position of a child node having a key whose value is “10” or more and smaller than “19” as an entry. The third pointer is position information indicating the storage position of a child node having a key whose value is “19” or more as an entry.
また、左端のブランチノードには2つのキー“4”、“7”と3つのポインタとの組が格納されている。3つのポインタのうち、1つ目のポインタは、値が“1”以上で“4”より小さいキーをエントリとして持つ子ノードの格納位置を表す位置情報である。2つ目のポインタは、値が“4”以上で“7”より小さいキーをエントリとして持つ子ノードの格納位置を表す位置情報である。3つ目のポインタは、値が“7”以上のキーをエントリとして持つ子ノードの格納位置を表す位置情報である。他のブランチノードも同様に、2つのキーと3つのポインタとの組が格納されている。
The leftmost branch node stores a set of two keys “4” and “7” and three pointers. Of the three pointers, the first pointer is position information indicating the storage position of a child node having a key having a value of “1” or more and smaller than “4” as an entry. The second pointer is position information indicating a storage position of a child node having a key having a value of “4” or more and smaller than “7” as an entry. The third pointer is position information indicating a storage position of a child node having a key whose value is “7” or more as an entry. Similarly, the other branch nodes store pairs of two keys and three pointers.
さらに、左端のリーフノードには3つのキー“1”、“2” 、“3”と3つのポインタとの組が格納されている。3つのポインタのうち、1つ目のポインタは、キー“1”に対応するデータが格納されているレコードの位置を表す位置情報である。2つ目のポインタは、キー“2”に対応するデータが格納されているレコードの位置を表す位置情報である。3つ目のポインタは、キー“3”に対応するデータが格納されているレコードの位置を表す位置情報である。他のリーフノードも同様に、3つのキーと3つのポインタとの組が格納されている。
Furthermore, the leftmost leaf node stores a set of three keys “1”, “2” 3, “3” and three pointers. Of the three pointers, the first pointer is position information indicating the position of the record in which the data corresponding to the key “1” is stored. The second pointer is position information indicating the position of the record in which data corresponding to the key “2” is stored. The third pointer is position information indicating the position of the record in which the data corresponding to the key “3” is stored. Similarly, other leaf nodes store pairs of three keys and three pointers.
図8のように構成されたインデックスツリーを用いて、例えばキー“11”に対応するデータを検索する場合、ルートノードにおける2番目のポインタ、2番目のブランチノードにおける左端のポインタおよび4番目のリーフノードを辿って、キー“11”に対応するデータを効率的に検索することができる。
For example, when searching for data corresponding to the key “11” using the index tree configured as shown in FIG. 8, the second pointer in the root node, the leftmost pointer in the second branch node, and the fourth leaf By tracing the node, the data corresponding to the key “11” can be efficiently searched.
ところで、レコード内のあるフィールドに対してインデックスを作成した場合、レコードの追加や削除といった更新系の処理をしたときに、レコード自体だけでなくインデックスの内容も更新する必要がある。レコードを追加する場合は、先の検索の場合と同じようにルートノードから順に辿ってエントリを追加するリーフノードを探し出す。ノードに空きがあるなら、昇順または降順の順序を守ってエントリを追加するだけでインデックスの追加は終了する。
By the way, when an index is created for a field in a record, it is necessary to update not only the record itself but also the contents of the index when an update process such as addition or deletion of the record is performed. When adding a record, the leaf node to which the entry is added is searched in order from the root node in the same manner as in the previous search. If there is a vacancy in the node, the index addition is completed simply by adding entries in ascending or descending order.
一方、ノードに空きがないときは、新たにノードを追加して空きエントリを作る必要がある。例えば、図9(a)に示すようにインデックスツリーが構成されたフィールドにおいて、キー“8”のレコードを追加する場合、エントリを追加すべきノードとしてルートノードから順に辿って探索した3番目のリーフノードには、既に3つのエントリが格納されていて、空きがない。
On the other hand, if there is no available node, it is necessary to add a new node to create a free entry. For example, when adding the record of key “8” in the field in which the index tree is configured as shown in FIG. 9A, the third leaf searched by sequentially tracing from the root node as the node to which the entry should be added. The node already has three entries and has no space.
この場合は、図9(b)に示すように、現在の3番目のリーフノードにある3つのキーのうち、分割キー“8”以上のキー“9”の位置で3番目のリーフノードを分割して新たにリーフノードを生成し、分割キー“8”よりも前側のエントリを1つ目の分割ノードに移動し、分割キー“8”よりも後側のエントリを2つ目の分割ノードに移動することにより、キー“8”のレコードを追加可能な空きエントリを生成する。
In this case, as shown in FIG. 9B, among the three keys in the current third leaf node, the third leaf node is divided at the position of the key “9” equal to or higher than the division key “8”. To generate a new leaf node, move the entry before the split key “8” to the first split node, and move the entry after the split key “8” to the second split node. By moving, an empty entry to which a record with the key “8” can be added is generated.
ところが、図9(b)のようにツリーを下層側に成長させると、ルートノードからリーフノードまでの階層数が一部のみ変化し、全体としてバランスしない状態となる。このようにバランスが崩れたインデックスツリーでは、検索効率が低下してしまう。そこで、インデックスツリーの一方式である「Bツリー」(例えば、非特許文献1参照)では、図10に示すように、ノードを分割する際にツリーを上層側に成長させるようにしている。このようにすれば、インデックスツリーの階層数はどのリーフノードに対しても同じとなり、全体としてバランスする。
However, when the tree is grown on the lower layer side as shown in FIG. 9B, only a part of the number of layers from the root node to the leaf node is changed, and the whole state is not balanced. In such an unbalanced index tree, the search efficiency is lowered. Therefore, in the “B-tree” (see, for example, Non-Patent Document 1), which is one method of the index tree, as shown in FIG. 10, the tree is grown to the upper layer side when dividing the node. In this way, the number of hierarchies in the index tree is the same for every leaf node, and the whole is balanced.
データベースがハードディスクに格納される場合、ディスクI/Oの数が、ディスク環境でのインデックスツリーの性能を決定する。すなわち、ディスクのレイテンシは10ms程度、メモリのレイテンシは100ns程度、キャッシュのレイテンシは1ns程度であるから、検索効率を上げるには、ディスクI/Oの数をできるだけ少なくすることが必要となる。
When the database is stored on the hard disk, the number of disk I / Os determines the performance of the index tree in the disk environment. In other words, the latency of the disk is about 10 ms, the latency of the memory is about 100 ns, and the latency of the cache is about 1 ns. Therefore, to increase the search efficiency, it is necessary to reduce the number of disk I / Os as much as possible.
一方、インデックスツリーはその構造上、上位階層のノードほどアクセス比率が高くなり、下位階層のノードほどアクセス比率は低くなる(例えば、非特許文献2参照)。したがって、最上位のルートノードをキャッシュに格納し、ブランチノードをメモリに格納し、リーフノードをディスクに格納すれば、ディスクI/Oの数を減らすことが可能である。特にBツリーは、ディスクのアクセスに最適化された方式である。
On the other hand, due to the structure of the index tree, the access ratio is higher in the upper hierarchy node, and the access ratio is lower in the lower hierarchy node (see, for example, Non-Patent Document 2). Therefore, if the highest level root node is stored in the cache, the branch node is stored in the memory, and the leaf node is stored in the disk, the number of disk I / Os can be reduced. In particular, the B-tree is a method optimized for disk access.
すなわち、Bツリーのノードサイズは、典型的にはディスクブロック(ディスク上のデータのI/Oの単位で、通例では4Kバイト)の大きさに等しい。ノードに格納されるのが4バイトのキーと4バイトのポインタの場合、ノードサイズを4Kバイトにすれば、ファンアウト(子ノードの数)は約500となる。したがって、図11のように3階層から成るBツリーの場合、少量(2Mバイト程度)のメモリがあれば、多量(1Gバイト程度)のデータベースから、1回のディスクI/Oでデータを取り出すことが可能である。
That is, the node size of the B-tree is typically equal to the size of a disk block (unit of data I / O on the disk, typically 4 Kbytes). When a 4-byte key and a 4-byte pointer are stored in the node, the fanout (number of child nodes) is about 500 if the node size is set to 4 Kbytes. Therefore, in the case of a B-tree consisting of three layers as shown in FIG. 11, if there is a small amount of memory (about 2 Mbytes), data can be extracted from a large amount (about 1 Gbyte) of database with one disk I / O. Is possible.
これに対して、全てのデータがメモリに格納されたインメモリ環境では、ディスクI/Oがなくなるので、Bツリーの性能は、アクセスするキャッシュラインの数に強く依存する。キャッシュラインとは、CPUがメモリからキャッシュへとデータを移送する単位である。近年のCPUでは、64バイトのデータでキャッシュラインを構成することが多い。
On the other hand, in an in-memory environment in which all data is stored in memory, disk I / O is lost, and the performance of the B-tree strongly depends on the number of cache lines to be accessed. A cache line is a unit in which the CPU transfers data from the memory to the cache. In recent CPUs, a cache line is often composed of 64-byte data.
このライン数を削減してインメモリ環境に最適化したインデックスツリーとして、「CSB+ツリー」と呼ばれる方式が知られている(例えば、非特許文献3参照)。CSB+ツリーは、ノードのエントリからポインタを削除することによって記憶容量を削減し、そのぶん1つのノードに格納可能なキーの数を増やすことによってライン数を削減できるようにしたものである。また、CSB+ツリーには、ポインタを記録したキャッシュラインへのアクセスを省略できるという利点もある。
A method called “CSB + tree” is known as an index tree optimized for the in-memory environment by reducing the number of lines (for example, see Non-Patent Document 3). In the CSB + tree, the storage capacity is reduced by deleting the pointer from the entry of the node, and the number of lines can be reduced by increasing the number of keys that can be stored in one node. The CSB + tree also has an advantage that access to the cache line in which the pointer is recorded can be omitted.
図12に示すように、CSB+ツリーでは、複数のノードをまとめてノードグループを生成する。内部ノードのエントリは、各キーに個別に対応するポインタを持たず、下階層のノードグループの先頭位置を表すポインタのみを持つ。グループ内で各ノードのエントリはメモリの連続領域に格納されており、子ノードの先頭位置からのオフセット量に基づいて該当するキーの位置が特定される。
As shown in FIG. 12, in the CSB + tree, a plurality of nodes are grouped to generate a node group. The entry of the internal node does not have a pointer corresponding to each key individually, but has only a pointer indicating the head position of the node group in the lower hierarchy. The entry of each node in the group is stored in a continuous area of the memory, and the position of the corresponding key is specified based on the offset amount from the head position of the child node.
例えば、キー“13”に対応するデータを検索する場合、ルートノードからの探索によって、キー“13”はリーフノードにおける2番目のノードグループ内にあることが分かる。ここで、2番目のノードグループの先頭アドレスが“0xA000”であったとする。また、ノードサイズが12バイトであったとすると、キー“13”に対応するアドレスは“0xA00C”(=0xA000+0x000C×1)と計算される。
For example, when searching for data corresponding to the key “13”, the search from the root node shows that the key “13” is in the second node group in the leaf node. Here, it is assumed that the top address of the second node group is “0xA000”. If the node size is 12 bytes, the address corresponding to the key “13” is calculated as “0xA00C” (= 0xA000 + 0x000C × 1).
CSB+ツリーのようにポインタを削除すると、検索速度は速くなる。しかし、レコードの追加に伴ってインデックスに新たなキーを挿入する場合、その挿入処理はBツリーに比べて遅くなってしまう。図13(a)のように、Bツリーの場合は各キーに対応するポインタがあるので、ノード分割によって新たに生成した子ノードを自由に配置することができる。これに対して、CSB+ツリーの場合は、図13(b)に示すように、ノードグループ内でキーの値が昇順または降順となるように子ノードを並び替える必要があるため、そのぶん処理速度が遅くなってしまうという問題があった。
If the pointer is deleted like a CSB + tree, the search speed increases. However, when a new key is inserted into the index as a record is added, the insertion process is slower than in the B-tree. As shown in FIG. 13A, since there is a pointer corresponding to each key in the case of a B-tree, child nodes newly generated by node division can be freely arranged. On the other hand, in the case of the CSB + tree, as shown in FIG. 13B, it is necessary to rearrange the child nodes so that the key values are in ascending order or descending order in the node group. There was a problem that would slow down.
以上のように、インメモリ環境に最適化されたCSB+ツリーを採用してポインタ削減により検索処理を高速化しようとすると、インデックスにおけるキーの挿入処理が低速化してしまうため、レコードの更新が多いワークロードに対して、全体としての処理性能が高くならないという問題があった。
As described above, if the CSB + tree optimized for the in-memory environment is used to speed up the search process by reducing the pointer, the key insertion process in the index is slowed down. There is a problem that the overall processing performance does not increase with respect to the load.
本発明は、このような問題を解決するために成されたものであり、インメモリ環境においてデータの検索処理を高速化できるようにするとともに、更新処理の低速化を抑制できるようにすることを目的とする。
The present invention has been made to solve such a problem, and it is possible to speed up the data search process in an in-memory environment and to suppress the slowdown of the update process. Objective.
上記した課題を解決するために、本発明では、所定数のキーと所定数のバリューとの組を格納したリーフノードを第0階層として、第n階層以下(nは「1≦n<全階層数-1」を満たす任意の値)の下位階層において、所定数のキーと子ノードの位置を表す所定数のポインタまたは所定数のバリューとの組を格納した第1の種類のノードによって、インデックスツリーの探索および更新を管理する。一方、第n階層よりも上の上位階層においては、所定数のキーと下階層のノードグループの先頭位置を表す1つのグループポインタとを格納した第2の種類のノードによって、インデックスツリーの探索および更新を管理するようにしている。
In order to solve the above-described problem, in the present invention, a leaf node storing a set of a predetermined number of keys and a predetermined number of values is defined as the 0th hierarchy, and the nth hierarchy or lower (n is “1 ≦ n <all hierarchies”). In the lower hierarchy of (any value satisfying the number -1 "), an index is obtained by a first type node storing a set of a predetermined number of keys and a predetermined number of pointers representing the positions of child nodes or a predetermined number of values. Manage tree exploration and updates. On the other hand, in the upper layer above the nth layer, the search of the index tree and the second type node storing a predetermined number of keys and one group pointer indicating the head position of the node group in the lower layer are performed. I try to manage updates.
本発明の他の態様では、第1階層以上で第n階層以下の下位階層において、所定数のキーと下階層のノードグループの先頭位置を表す1つのグループポインタとを格納するとともに、ノードグループ内の各ノードの位置を表すのに十分なサイズの縮小ポインタを格納した第3の種類のノードによって、インデックスツリーの探索および更新を管理するようにしている。一方、第n階層よりも上の上位階層においては、第2の種類のノードによってインデックスツリーの探索および更新を管理するようにしている。
In another aspect of the present invention, a predetermined number of keys and a single group pointer representing the start position of a node group in a lower hierarchy are stored in the lower hierarchy of the first hierarchy and higher than the nth hierarchy. The search and update of the index tree is managed by a third type of node storing a reduction pointer having a size sufficient to represent the position of each node. On the other hand, in the upper hierarchy above the n-th hierarchy, search and update of the index tree are managed by the second type node.
上記のように構成した本発明によれば、一般的にインデックスツリーでは上位階層のノードほどアクセス比率が高い代わりに更新比率が低く、下位階層のノードほどアクセス比率が低い代わりに更新比率が高いという性質を利用して、上位階層においては、検索処理を高速に行うことが可能な第2の種類のノードによってインデックスツリーの探索および更新が管理される。逆に、下位階層においては、キーの挿入処理を高速に行うことが可能な第1の種類のノードによってインデックスツリーの探索および更新が管理される。これにより、インメモリ環境において、データの検索処理を高速化するとともに、更新処理の低速化を抑制することができる。
According to the present invention configured as described above, in an index tree, generally, an upper layer node has a lower update rate instead of a higher access rate, and a lower layer node has a higher update rate instead of a lower access rate. Using the property, search and update of the index tree are managed in the upper hierarchy by the second type node that can perform the search process at high speed. On the other hand, in the lower hierarchy, search and update of the index tree are managed by the first type node that can perform the key insertion processing at high speed. As a result, in the in-memory environment, it is possible to speed up the data search process and suppress the update process from being slowed down.
本発明の他の特徴によれば、上位階層においては、検索処理を高速に行うことが可能な第2の種類のノードによってインデックスツリーの探索および更新が管理される。一方、下位階層においては、ノードグループ内のオフセット量が縮小ポインタに基づいて求められるので、ノードグループ内で各ノードを自由に配置することができ、ノード分割等が必要となるデータの更新処理でも高速に行うことができる。また、縮小ポインタに必要な記憶容量は小さくて済むので、1つのノードに格納可能なキーの数を増やすことができ、インデックスツリーの階層数を減らして検索処理も高速化することができる。
According to another feature of the present invention, in the upper hierarchy, search and update of the index tree are managed by the second type node that can perform the search process at high speed. On the other hand, in the lower hierarchy, since the offset amount in the node group is obtained based on the reduction pointer, each node can be freely arranged in the node group, and even in data update processing that requires node division or the like It can be done at high speed. Further, since the storage capacity required for the reduced pointer is small, the number of keys that can be stored in one node can be increased, and the number of hierarchies in the index tree can be reduced to speed up the search process.
(第1の実施形態)
以下、本発明の第1の実施形態を図面に基づいて説明する。図1は、第1の実施形態によるインデックス管理装置の機能構成例を示すブロック図である。第1の実施形態によるインデックス管理装置は、最下位階層であるリーフノードと、最上位階層であるルートノードと、リーフノードとルートノードとの間にある1以上のブランチノードとからなるインデックスツリーを管理するものであって、その機能構成として、検索処理部1、挿入処理部2、下位階層管理部3および上位階層管理部4を備えて構成されている。 (First embodiment)
DESCRIPTION OF EXEMPLARY EMBODIMENTS Hereinafter, a first embodiment of the invention will be described with reference to the drawings. FIG. 1 is a block diagram illustrating a functional configuration example of an index management apparatus according to the first embodiment. The index management device according to the first embodiment includes an index tree including a leaf node as the lowest hierarchy, a root node as the highest hierarchy, and one or more branch nodes between the leaf nodes and the root node. As a functional configuration, thesearch processing unit 1, the insertion processing unit 2, the lower layer management unit 3, and the upper layer management unit 4 are provided.
以下、本発明の第1の実施形態を図面に基づいて説明する。図1は、第1の実施形態によるインデックス管理装置の機能構成例を示すブロック図である。第1の実施形態によるインデックス管理装置は、最下位階層であるリーフノードと、最上位階層であるルートノードと、リーフノードとルートノードとの間にある1以上のブランチノードとからなるインデックスツリーを管理するものであって、その機能構成として、検索処理部1、挿入処理部2、下位階層管理部3および上位階層管理部4を備えて構成されている。 (First embodiment)
DESCRIPTION OF EXEMPLARY EMBODIMENTS Hereinafter, a first embodiment of the invention will be described with reference to the drawings. FIG. 1 is a block diagram illustrating a functional configuration example of an index management apparatus according to the first embodiment. The index management device according to the first embodiment includes an index tree including a leaf node as the lowest hierarchy, a root node as the highest hierarchy, and one or more branch nodes between the leaf nodes and the root node. As a functional configuration, the
上記各機能ブロック1~4は、ハードウェア、DSP(Digital Signal Processor)、ソフトウェアの何れによっても構成することが可能である。例えばソフトウェアによって構成する場合、上記各機能ブロック1~4は、実際にはコンピュータのCPU、RAM、ROMなどを備えて構成され、RAMやROM、ハードディスクまたは半導体メモリ等の記録媒体に記憶されたプログラムが動作することによって実現される。
The above functional blocks 1 to 4 can be configured by any of hardware, DSP (Digital Signal Processor), and software. For example, when configured by software, each of the functional blocks 1 to 4 is actually configured with a computer CPU, RAM, ROM, and the like, and is stored in a recording medium such as RAM, ROM, hard disk, or semiconductor memory. Is realized by operating.
本実施形態では、所定数のキーと所定数のバリューとの組を格納したリーフノードがある階層を第0階層として、第n階層以下(nは「1≦n<全階層数-1」を満たす任意の値)を下位階層とし、第n階層よりも上の階層を上位階層とする。以下では、n=1の場合について説明する。つまり、第0階層およびその上の第1階層を下位階層とする。また、第1階層よりも上の第2階層以上を上位階層とする。図1の例では、インデックスツリーは第0階層から第3階層までの4階層で構成されている。このうち、第0階層および第1階層が下位階層、第2階層および第3階層が上位階層である。また、1つのリーフノードは、最大3個のキーと、当該キーと同数のバリューとの組により構成されている。
In the present embodiment, the hierarchy having a leaf node storing a set of a predetermined number of keys and a predetermined number of values is defined as the 0th hierarchy, and the nth hierarchy or lower (n is “1 ≦ n <total number of hierarchy−1”) Arbitrary values that satisfy) are set as lower hierarchies, and hierarchies above the nth hierarchy are upper hierarchies. Hereinafter, a case where n = 1 will be described. That is, the 0th hierarchy and the 1st hierarchy above it are set as a lower hierarchy. Further, the second and higher layers above the first layer are set as upper layers. In the example of FIG. 1, the index tree is composed of four layers from the 0th layer to the 3rd layer. Of these, the 0th and 1st hierarchies are lower hierarchies, and the 2nd and 3rd hierarchies are upper hierarchies. One leaf node is composed of a set of a maximum of three keys and the same number of values as the keys.
検索処理部1は、インデックスツリーを利用してインメモリ環境のデータベース(メモリ)から所望のデータ(バリュー)を検索するものである。具体的には、検索処理部1は、検索キーを上位階層管理部4に供給し、上位階層管理部4および下位階層管理部3の処理により、検索キーに対応するバリューを検索する。そして、その検索されたバリューを下位階層管理部3から受け取る。
The search processing unit 1 searches for desired data (value) from a database (memory) in an in-memory environment using an index tree. Specifically, the search processing unit 1 supplies a search key to the upper layer management unit 4 and searches for a value corresponding to the search key by the processing of the upper layer management unit 4 and the lower layer management unit 3. Then, the retrieved value is received from the lower hierarchy management unit 3.
挿入処理部2は、インデックスツリーに所望のデータ(キーとバリューとの組)を挿入するものである。具体的には、挿入処理部2は、挿入するキーとバリューとを上位階層管理部4に供給し、上位階層管理部4および下位階層管理部3の処理により、挿入キーの値から挿入すべきリーフノードを決定し、決定したリーフノードの適切な位置にキーとバリューとの組を追加する。そして、下位階層管理部3または上位階層管理部4から挿入完了の通知を受け取る。
The insertion processing unit 2 inserts desired data (a set of key and value) into the index tree. Specifically, the insertion processing unit 2 supplies the key and value to be inserted to the upper layer management unit 4, and should be inserted from the value of the insertion key by the processing of the upper layer management unit 4 and the lower layer management unit 3. A leaf node is determined, and a key / value pair is added to an appropriate position of the determined leaf node. Then, the notification of insertion completion is received from the lower hierarchy management unit 3 or the upper hierarchy management unit 4.
下位階層管理部3は、インデックスツリーの下位階層において、所定数のキーと、子ノードの位置を表す所定数のポインタまたは所定数のバリューとの組を格納した第1の種類のノードによって、インデックスツリーの探索および更新を管理する。この第1の種類のノードは、例えばBツリーで使用されるノードと同じである。
In the lower hierarchy of the index tree, the lower hierarchy management unit 3 uses the first type node storing a set of a predetermined number of keys and a predetermined number of pointers or a predetermined number of values indicating the positions of the child nodes. Manage tree exploration and updates. This first type of node is the same as the node used in the B-tree, for example.
また、上位階層管理部4は、インデックスツリーの上位階層において、所定数のキーと、下階層のノードグループの先頭位置を表す1つのグループポインタとを格納した第2の種類のノードによって、インデックスツリーの探索および更新を管理する。この第2の種類のノードは、例えばCSB+ツリーで使用されるノードと同じである。
Further, the upper layer management unit 4 uses the second type of node storing a predetermined number of keys and one group pointer representing the head position of the lower layer node group in the upper layer of the index tree to generate an index tree. Manage search and update of This second type of node is the same as the node used in the CSB + tree, for example.
図2は、下位階層管理部3および上位階層管理部4により探索および更新されるインデックスツリーの具体例を示す図である。図2に示すように、下位階層管理部3により管理される下位階層である第1階層は、最大2個のキーと、当該キーより1つ多いポインタとの組を格納した第1の種類のノードで構成されている。個々のポインタは、1つ下の第0階層にあるリーフノードの左端の位置を表している。もう1つの下位階層であるリーフノードは、最大3個のキーと、当該キーと同数のバリューとの組により構成されている。
FIG. 2 is a diagram showing a specific example of an index tree searched and updated by the lower hierarchy management unit 3 and the upper hierarchy management unit 4. As shown in FIG. 2, the first hierarchy, which is a lower hierarchy managed by the lower hierarchy management unit 3, is a first type that stores a set of a maximum of two keys and one more pointer than the key. It consists of nodes. Each pointer represents the position of the left end of the leaf node in the 0th hierarchy one level below. The leaf node, which is the other lower layer, is composed of a set of a maximum of three keys and the same number of values as the keys.
また、上位階層管理部4により管理される上位階層である第2階層および第3階層は、最大2個のキーと、1つ下の階層にあるノードグループの先頭位置を表す1つのグループポインタとを格納した第2の種類のノードで構成されている。第3階層の1つの下の第2階層には1つのノードグループGr2-1が設定され、第2階層の1つの下の第1階層には3つのノードグループGr1-1,Gr1-2,Gr1-3が設定されている。
The second and third hierarchies managed by the upper hierarchy management unit 4 have a maximum of two keys and one group pointer indicating the head position of the node group in the next lower hierarchy. It is composed of a second type of node that stores. One node group Gr 2-1 is set in the second layer below one of the third layers, and three node groups Gr 1-1 and Gr 1− are set in the first layer below one of the second layers. 2 and Gr 1-3 are set.
ここで、図2のように構成されたインデックスツリーを用いて、検索処理部1による検索処理を行う場合の動作を説明する。まず、検索処理部1は、検索キーを上位階層管理部4に渡す。なお、以下では、検索キーの値が“15”であるものとして説明する。
Here, the operation when the search processing by the search processing unit 1 is performed using the index tree configured as shown in FIG. 2 will be described. First, the search processing unit 1 passes the search key to the upper layer management unit 4. In the following description, it is assumed that the value of the search key is “15”.
上位階層管理部4は、最上位の第3階層と、そこでルートノードになっているノードとを特定する。そして、上位階層管理部4は、当該ルートノードに格納されているキーの中から、検索キー以下で最大の値を持つキーを探索する。さらに、上位階層管理部4は、探索したキーと共に同じノード内に格納されているグループポインタが示すノードグループの先頭位置からのオフセット量をノードサイズに基づいて計算することによって特定される位置を辿って下位層に遷移する。
The upper layer management unit 4 identifies the highest third layer and the node that is the root node there. Then, the upper layer management unit 4 searches for the key having the maximum value below the search key from the keys stored in the root node. Further, the upper layer management unit 4 traces the position specified by calculating the offset amount from the head position of the node group indicated by the group pointer stored in the same node together with the searched key based on the node size. To the lower layer.
図2の例の場合、ルートノードに格納されているキーのうち、検索キー“15”以下で最大の値を持つキーは存在しない(省略されている)。このように、省略された左端のキーが探索された場合、オフセット量はゼロである。この場合、上位階層管理部4は、省略されたキーと共に同じノード内に格納されているグループポインタに従って、1つ下の第2階層にあるノードグループGr2-1の先頭位置のノードに遷移する。
In the case of the example of FIG. 2, there is no key having the maximum value below the search key “15” among keys stored in the root node (omitted). Thus, when the omitted leftmost key is searched, the offset amount is zero. In this case, the upper hierarchy management unit 4 transitions to the node at the head position of the node group Gr 2-1 in the second hierarchy one level lower in accordance with the group pointer stored in the same node together with the omitted key. .
遷移した第2階層も上位階層であるから、上位階層管理部4によって上述と同様の処理を行う。すなわち、上位階層管理部4は、ルートノードから遷移してきたノードグループGr2-1の先頭位置のノードに格納されているキーのうち、検索キー“15”以下で最大の値を持つキーを探索する。この場合に探索されるキーは“10”である。このように、省略されたキーも含めてノード内の左端から2番目のキーが探索された場合、オフセット量はノードサイズ×1となる。この場合、上位階層管理部4は、探索したキー“10”と共に同じノード内に格納されているグループポインタとオフセット量に従って、1つ下の第1階層にあるノードグループGr1-1の先頭位置から2番目のノードに遷移する。
Since the transitioned second layer is also an upper layer, the upper layer management unit 4 performs the same processing as described above. That is, the upper layer management unit 4 searches for a key having the maximum value below the search key “15” among the keys stored in the node at the head position of the node group Gr 2-1 that has transitioned from the root node. To do. In this case, the searched key is “10”. As described above, when the second key from the left end in the node including the omitted key is searched, the offset amount is the node size × 1. In this case, the upper hierarchy management unit 4 determines the head position of the node group Gr 1-1 in the first lower hierarchy according to the group pointer and offset amount stored in the same node together with the searched key “10”. To the second node.
このとき遷移した第1階層は下位階層であるから、下位階層管理部3によって処理を行う。下位階層管理部3は、特定されたノードに格納されているキーの中から、検索キー以下で最大の値を持つキーを探索する。さらに、下位階層管理部3は、探索したキーと共に同じノード内に格納されているポインタが示す位置を辿って下位層に遷移する。
Since the first layer that has transitioned at this time is a lower layer, the lower layer management unit 3 performs processing. The lower hierarchy management unit 3 searches for the key having the maximum value below the search key from the keys stored in the identified node. Furthermore, the lower layer management unit 3 moves to the lower layer by following the position indicated by the pointer stored in the same node together with the searched key.
図2の例の場合、ノードグループGr1-1の先頭位置から2番目のノードに格納されているキーのうち、検索キー“15”以下で最大の値を持つキーは“13”である。この場合、下位階層管理部3は、探索したキー“13”との組として格納されているポインタに従って、1つ下の第0階層にある左端から5番目のリーフノードにダイレクトに遷移する。検索キー“15”はこのノード内にあるので、下位階層管理部3は当該検索キーの位置に対応するバリューを取得し、検索処理部1に渡す。これにより、検索処理部1による検索処理が終了する。
In the case of the example in FIG. 2, among the keys stored in the second node from the head position of the node group Gr 1-1 , the key having the maximum value below the search key “15” is “13”. In this case, the lower hierarchy management unit 3 makes a direct transition to the fifth leaf node from the left end in the lower 0th hierarchy according to the pointer stored as a pair with the searched key “13”. Since the search key “15” is in this node, the lower hierarchy management unit 3 acquires the value corresponding to the position of the search key and passes it to the search processing unit 1. Thereby, the search processing by the search processing unit 1 ends.
次に、図2のように構成されたインデックスツリーを用いて、挿入処理部2による挿入処理を行う場合の動作を説明する。まず、挿入処理部2は、挿入キーとバリューとの組を上位階層管理部4に渡す。なお、以下では、挿入キーの値が“9”であるものとして説明する。上位階層管理部4および下位階層管理部3は、上述した検索処理と同様の手順に従って、挿入キー“9”を挿入すべきリーフノードの探索を行う。これにより、左端から3番目のリーフノードに遷移する。
Next, the operation when the insertion processing by the insertion processing unit 2 is performed using the index tree configured as shown in FIG. First, the insertion processing unit 2 passes the combination of the insertion key and the value to the upper layer management unit 4. In the following description, it is assumed that the value of the insertion key is “9”. The upper hierarchy management unit 4 and the lower hierarchy management unit 3 search for a leaf node into which the insertion key “9” is to be inserted, following the same procedure as the search process described above. Thereby, it changes to the 3rd leaf node from the left end.
ここで、下位階層管理部3は、検索されたリーフノードに空きスペースがあるか否かを判定する。そして、空きスペースがある場合は、そのリーフノードに挿入キー“9”とバリューとの組を挿入する。図2の例では、左端から3番目のリーフノードに1つ空きスペースがあるので、そのノード内に挿入キー“9”とバリューとの組を挿入することが可能である。
Here, the lower hierarchy management unit 3 determines whether or not there is an empty space in the searched leaf node. If there is an empty space, the set of the insertion key “9” and value is inserted into the leaf node. In the example of FIG. 2, since there is one free space in the third leaf node from the left end, it is possible to insert a pair of the insertion key “9” and value into that node.
一方、検索されたリーフノードに空きスペースがない場合、下位階層管理部3は、そのリーフノードを分割して挿入キーとポインタとの組を挿入する。例えば、挿入処理部2から上位階層管理部4に渡された挿入キーの値が“17”であったとする。この場合、上位階層管理部4および下位階層管理部3が挿入キー“17”を挿入すべきリーフノードの探索を行うことにより、左端から6番目のリーフノードに遷移する。
On the other hand, when there is no empty space in the searched leaf node, the lower hierarchy management unit 3 divides the leaf node and inserts a pair of an insertion key and a pointer. For example, it is assumed that the value of the insertion key passed from the insertion processing unit 2 to the upper hierarchy management unit 4 is “17”. In this case, when the upper hierarchy management unit 4 and the lower hierarchy management unit 3 search for a leaf node into which the insertion key “17” is to be inserted, the transition is made to the sixth leaf node from the left end.
しかし、この6番目のノードには既に3つのキーとバリューの組が格納されていて、空きスペースがない。そこで、下位階層管理部3は、この6番目のリーフノードを分割して空きスペースを確保し、挿入キー“17”とバリューとの組を挿入する。
However, this sixth node already has three key / value pairs stored and has no free space. Therefore, the lower hierarchy management unit 3 divides this sixth leaf node to secure an empty space, and inserts a set of the insertion key “17” and value.
具体的には、下位階層管理部3は、まず、新たな空のノードを取得する。次に、下位階層管理部3は、6番目のリーフノードに含まれる3つのキーのうち、所定の分割キー以上のキーとそれに対応するバリューとの組を新たなノードに移す。ここで、分割キーの値は、例えば、3つのキーの値の中央値とする。その後、下位階層管理部3は、挿入キー“17”が分割キー以上の場合は新たなノードに、そうでなければ元のノードに挿入キー“17”とバリューとの組を挿入する。
Specifically, the lower layer management unit 3 first acquires a new empty node. Next, the lower hierarchy management unit 3 moves a set of a key that is equal to or higher than a predetermined split key among the three keys included in the sixth leaf node and a value corresponding thereto to a new node. Here, the value of the split key is, for example, the median value of the three key values. After that, the lower layer management unit 3 inserts the pair of the insertion key “17” and the value into the new node if the insertion key “17” is equal to or higher than the split key, and otherwise to the original node.
このようにノード分割を行った場合、新たに生成したリーフノードを指すポインタを、上位階層のノードのエントリに追加しなければならない。すなわち、下位階層管理部3は、分割キーと新ノードへのポインタを、リーフノードのある第0階層よりも1つ上の第1階層の、探索パス上にあるノード(左端から2番目のノード)に追加する。このとき、そのノードに新たなキーとポインタの組を追加するスペースがなければ、ノードグループ内で新たなノードを確保する。
When node division is performed in this way, a pointer pointing to the newly generated leaf node must be added to the entry of the upper layer node. That is, the lower hierarchy management unit 3 sets the split key and the pointer to the new node to the node on the search path in the first hierarchy one level higher than the zeroth hierarchy in which the leaf node exists (second node from the left end). ) To add. At this time, if there is no space for adding a new key / pointer pair to the node, a new node is secured in the node group.
図2の例では、左から2番目のノードに空きスペースがないので、ノードグループ内の3番目の位置のノードを初期化し、このノードに2番目のエントリを移す。このノード分割によってできたスペースに、挿入キー“17”とバリューとの組を挿入する。この例では、2番目のノードが分割されたためノードのコピーは発生しなかったが、仮に1番目のノードが分割されたとすると、2番目のノードを3番目のノードとしてコピーし、2番目のノードを初期化にする(空にする)ことによって、1番目のノードを分割する。
In the example of FIG. 2, since there is no empty space in the second node from the left, the node at the third position in the node group is initialized, and the second entry is moved to this node. A set of the insertion key “17” and the value is inserted into the space created by the node division. In this example, the copy of the node did not occur because the second node was divided, but if the first node was divided, the second node was copied as the third node, and the second node Is initialized (empty) to divide the first node.
上に述べたとおり、第1階層のようにノードグループが設定されている場合、空きスペースの確保は以下のようにして行う。下位階層管理部3は、まず、第0階層においてノード分割をして挿入キー“17”を挿入したことに伴い、新たに第1階層でキーを追加しようとするノードが属するノードグループGr1-1にノードを追加するスペースがあるか否かを判定する。スペースがあれば、当該ノードグループGr1-1内の分割されるノードの直後の位置以降のノードを1つ右の位置にコピーする。そして、分割するノードの直後のノードを初期化して、新たな空のノードを確保する。これによってノード分割が可能になる。
As described above, when a node group is set as in the first hierarchy, an empty space is secured as follows. First, the lower layer management unit 3 divides the node in the 0th layer and inserts the insertion key “17”, and accordingly, the node group Gr 1− to which the node to which a key is newly added in the first layer belongs. Determine if 1 has space to add a node. If there is a space, the node after the position immediately after the node to be divided in the node group Gr 1-1 is copied to the right one position. Then, the node immediately after the node to be divided is initialized to secure a new empty node. This enables node division.
一方、ノードグループGr1-1に空のノードがない場合、下位階層管理部3は新たなノードグループを取得する。そして、下位階層管理部3は、一部(例えば、ノードグループGr1-1内の後ろ半分)のノードを新たなノードグループに移動させる。これにより、ノードグループGr1-1内にノードを追加するスペースができるので、ノード分割によってエントリを追加するスペースを作成できる。
On the other hand, when there is no empty node in the node group Gr 1-1 , the lower hierarchy management unit 3 acquires a new node group. Then, the lower hierarchy management unit 3 moves some of the nodes (for example, the rear half in the node group Gr 1-1 ) to a new node group. As a result, a space for adding a node is created in the node group Gr 1-1 . Therefore, a space for adding an entry can be created by node division.
第1階層でノードの移動や新たなノードグループの取得などを行った場合、下位階層管理部3は上位階層管理部4に依頼して、第1階層よりも1つ上の第2階層の、探索パス上にあるノードグループ内のノード(左端のノード)に、必要なキーを追加する。このノードに新たなキーを追加するスペースがなければ、第2階層でも第1の階層と同様にノードの移動またはノードグループの取得などを行って挿入スペースを確保する。この場合、ルートノードに新たなキーを追加する必要があるが、空きスペースがなくてルートノードが分割される場合には、未使用かつ最下位の階層のノードを新たなルートノードにする。
When a node is moved or a new node group is acquired in the first hierarchy, the lower hierarchy management unit 3 requests the upper hierarchy management unit 4 to perform the second hierarchy one level higher than the first hierarchy, Necessary keys are added to the nodes (leftmost node) in the node group on the search path. If there is no space for adding a new key in this node, the insertion space is secured by moving the node or acquiring the node group in the second hierarchy as in the first hierarchy. In this case, it is necessary to add a new key to the root node, but when there is no free space and the root node is divided, an unused and lowest-order node is made a new root node.
図3は、図2に示したインデックスツリーに対して挿入キー“17”とバリューとの組を挿入した後のインデックスツリーの構成例を示す図である。図3に示す例では、挿入キー“17”とバリューとの組を挿入するために第0階層においてノード分割が行われ、それに伴って第1階層および第2階層においてもエントリの追加が行われている。
FIG. 3 is a diagram illustrating a configuration example of the index tree after the combination of the insertion key “17” and the value is inserted into the index tree illustrated in FIG. In the example shown in FIG. 3, in order to insert the set of the insertion key “17” and the value, node division is performed in the 0th hierarchy, and accordingly, entries are added also in the 1st hierarchy and the 2nd hierarchy. ing.
以上詳しく説明したように、第1の実施形態では、第0階層および第1階層から成る下位階層では、所定数のキーと所定数のポインタまたは所定数のバリューとの組を格納した第1の種類のノード(Bツリーのノード)によってインデックスツリーの探索および更新を管理する。一方、第1階層よりも上の第2階層以上の上位階層では、所定数のキーと1つのグループポインタとを格納した第2の種類のノード(CSB+ツリーのノード)によってインデックスツリーの探索および更新を管理するようにしている。
As described above in detail, in the first embodiment, the first hierarchy storing a set of a predetermined number of keys and a predetermined number of pointers or a predetermined number of values is stored in the lower hierarchy consisting of the 0th hierarchy and the first hierarchy. The search and update of the index tree is managed by the type of node (B-tree node). On the other hand, in the upper hierarchy higher than the second hierarchy above the first hierarchy, search and update of the index tree by the second type node (CSB + tree node) storing a predetermined number of keys and one group pointer. To manage.
インデックスツリーは、上位階層のノードほどアクセス比率が高い代わりに更新比率が低く、下位階層のノードほどアクセス比率が低い代わりに更新比率が高いという性質を持つ。第1の実施形態ではこの性質を利用して、上位階層においては、検索処理を高速に行うことが可能な第2の種類のノードによってインデックスツリーの探索および更新が管理される。逆に、下位階層においては、キーの挿入処理を高速に行うことが可能な第1の種類のノードによってインデックスツリーの探索および更新が管理される。これにより、インメモリ環境において、データの検索処理を高速化するとともに、更新処理の速度低下を抑制することができる。
The index tree has the property that the higher the access ratio, the lower the access ratio, the lower the update ratio, and the lower hierarchy node, the lower the access ratio, the higher the update ratio. In the first embodiment, by utilizing this property, search and update of the index tree are managed in the upper layer by the second type node that can perform the search process at high speed. On the other hand, in the lower hierarchy, search and update of the index tree are managed by the first type node that can perform the key insertion processing at high speed. As a result, in the in-memory environment, it is possible to speed up the data search process and suppress a decrease in the speed of the update process.
(第2の実施形態)
次に、本発明の第2の実施形態を図面に基づいて説明する。図4は、第2の実施形態によるインデックス管理装置の機能構成例を示すブロック図である。図4に示すように、第2の実施形態によるインデックス管理装置は、その機能構成として、検索処理部1、挿入処理部2、下位階層管理部3、上位階層管理部4および中位階層管理部5を備えて構成されている。なお、この図4において、図1に示した符号と同一の符号を付したものは同一の機能を有するものであるので、ここでは重複する説明を省略する。 (Second Embodiment)
Next, a second embodiment of the present invention will be described with reference to the drawings. FIG. 4 is a block diagram illustrating a functional configuration example of the index management apparatus according to the second embodiment. As shown in FIG. 4, the index management apparatus according to the second embodiment includes, as its functional configuration, asearch processing unit 1, an insertion processing unit 2, a lower hierarchy management unit 3, an upper hierarchy management unit 4, and a middle hierarchy management unit. 5. In FIG. 4, those given the same reference numerals as those shown in FIG. 1 have the same functions, and therefore redundant description is omitted here.
次に、本発明の第2の実施形態を図面に基づいて説明する。図4は、第2の実施形態によるインデックス管理装置の機能構成例を示すブロック図である。図4に示すように、第2の実施形態によるインデックス管理装置は、その機能構成として、検索処理部1、挿入処理部2、下位階層管理部3、上位階層管理部4および中位階層管理部5を備えて構成されている。なお、この図4において、図1に示した符号と同一の符号を付したものは同一の機能を有するものであるので、ここでは重複する説明を省略する。 (Second Embodiment)
Next, a second embodiment of the present invention will be described with reference to the drawings. FIG. 4 is a block diagram illustrating a functional configuration example of the index management apparatus according to the second embodiment. As shown in FIG. 4, the index management apparatus according to the second embodiment includes, as its functional configuration, a
本実施形態では、リーフノードがある階層を第0階層として、当該第0階層およびそれより1つ上の第1階層を下位階層とする。また、第1階層より1つ上の第2階層を中位階層とし、第3階層以上を上位階層とする。図4の例では、インデックスツリーは第0階層から第3階層までの4階層で構成されている。このうち、第0階層および第1階層が下位階層、第2階層が中位階層、第3階層が上位階層である。
In this embodiment, the hierarchy in which the leaf node exists is defined as the 0th hierarchy, and the 0th hierarchy and the 1st hierarchy immediately above the 0th hierarchy are defined as the lower hierarchy. In addition, a second hierarchy that is one level higher than the first hierarchy is a middle hierarchy, and a third hierarchy or higher is an upper hierarchy. In the example of FIG. 4, the index tree is composed of four layers from the 0th layer to the 3rd layer. Among these, the 0th hierarchy and the 1st hierarchy are the lower hierarchy, the 2nd hierarchy is the middle hierarchy, and the 3rd hierarchy is the upper hierarchy.
中位階層管理部5は、インデックスツリーの中位階層において、所定数のキーと1つ下の階層のノードグループの先頭位置を表す1つのグループポインタとを格納するとともに、当該ノードグループ内の各ノードの位置を表すポインタであって第1の種類のノードに格納されるポインタよりもサイズの小さい縮小ポインタを格納した第3の種類のノードによって、インデックスツリーの探索および更新を管理する。
The middle level management unit 5 stores a predetermined number of keys and one group pointer representing the head position of the node group one level lower in the middle level of the index tree, and each of the nodes in the node group. Search and update of the index tree is managed by a third type node that stores a reduction pointer that is a pointer representing the position of the node and is smaller in size than the pointer stored in the first type node.
図5は、下位階層管理部3、上位階層管理部4および中位階層管理部5により探索および更新されるインデックスツリーの具体例を示す図である。この図5は、図2に示したインデックスツリーと略同じであるが、中位階層として定義した第2階層のノードが図2のインデックスツリーと異なっている。
FIG. 5 is a diagram illustrating a specific example of an index tree searched and updated by the lower hierarchy management unit 3, the upper hierarchy management unit 4, and the middle hierarchy management unit 5. FIG. 5 is substantially the same as the index tree shown in FIG. 2, but the second hierarchy node defined as the middle hierarchy is different from the index tree of FIG.
図5に示すように、中位階層である第2階層は、最大2個のキーと、1つ下の階層にあるノードグループの先頭位置を表す1つのグループポインタと、キーと同数の縮小ポインタとを格納した第3の種類のノードで構成されている。例えば、第1階層における通常のポインタのサイズが4バイトであるの対し、縮小ポインタのサイズは2バイトである。これは例えば、ノードが4Gバイトのアドレス空間のどこかにある場合にはポインタの大きさは4バイト以上でなければならないが、ノードが64Kバイトのノードグループのどこかにある場合には2バイト以上のポインタでノードを特定できるからである。このように、ノードグループの先頭へのポインタを使えば、ポインタを縮小しても子ノードを特定できる。
As shown in FIG. 5, the second hierarchy, which is the middle hierarchy, has a maximum of two keys, one group pointer that represents the start position of the node group that is one level below, and the same number of reduced pointers as the keys. Are stored in a third type node. For example, the size of the normal pointer in the first layer is 4 bytes, whereas the size of the reduced pointer is 2 bytes. For example, if the node is somewhere in the 4 Gbyte address space, the pointer must be 4 bytes or larger, but if the node is somewhere in the 64 Kbyte node group, it is 2 bytes. This is because the node can be specified by the above pointer. Thus, if a pointer to the head of a node group is used, a child node can be specified even if the pointer is reduced.
ここで、図5のように構成されたインデックスツリーを用いて、検索処理部1による検索処理を行う場合の動作を説明する。まず、検索処理部1は、検索キーを上位階層管理部4に渡す。なお、以下では、検索キーの値が“15”であるものとして説明する。
Here, the operation when the search processing by the search processing unit 1 is performed using the index tree configured as shown in FIG. 5 will be described. First, the search processing unit 1 passes the search key to the upper layer management unit 4. In the following description, it is assumed that the value of the search key is “15”.
上位階層である第3階層における上位階層管理部4の処理は、第1の実施形態と同様である。第3階層から遷移した第2階層は中位階層であるから、中位階層管理部5によって処理を行う。すなわち、中位階層管理部5は、ルートノードから遷移してきたノードグループGr2-1の先頭位置のノードに格納されているキーのうち、検索キー“15”以下で最大の値を持つキーを探索する。この場合に探索されるキーは“10”である。
The processing of the upper layer management unit 4 in the third layer, which is the upper layer, is the same as in the first embodiment. Since the second hierarchy that has transitioned from the third hierarchy is the middle hierarchy, the middle hierarchy management unit 5 performs processing. That is, the middle level management unit 5 selects a key having the maximum value below the search key “15” among the keys stored in the node at the head position of the node group Gr 2-1 that has transitioned from the root node. Explore. In this case, the searched key is “10”.
さらに、中位階層管理部5は、以上のように探索したキー“10”と共に同じノード内に格納されているグループポインタが示すノードグループの先頭位置からのオフセット量を、当該キー“10” との組として格納されている縮小ポインタに基づいて計算する。そして、このグループポインタとオフセット量とによって特定される位置を辿ることにより、1つ下の第1階層にあるノードグループGr1-1の先頭位置から2番目のノードに遷移する。
Further, the middle level management unit 5 sets the offset amount from the head position of the node group indicated by the group pointer stored in the same node together with the key “10” searched as described above as the key “10”. The calculation is performed based on the reduction pointer stored as a set. Then, by tracing the position specified by the this group pointers and the offset amount, the transition from the head position of the node group Gr 1-1 in the first hierarchy down one on the second node.
このとき遷移した第1階層は下位階層であるから、下位階層管理部3によって第1の実施形態と同様の処理を行う。これにより、キー“13”との組として格納されているポインタに従って、1つ下の第0階層にある左端から5番目のリーフノードにダイレクトに遷移し、そのリーフノード内から検索キー“15”の位置に対応するバリューを取得し、検索処理部1に渡す。これにより、検索処理部1による検索処理が終了する。
Since the first layer that has transitioned at this time is a lower layer, the lower layer management unit 3 performs the same processing as in the first embodiment. As a result, in accordance with the pointer stored as a pair with the key “13”, a transition is made directly to the fifth leaf node from the left end in the next lower 0th hierarchy, and the search key “15” is searched from within the leaf node. The value corresponding to the position is acquired and passed to the search processing unit 1. Thereby, the search processing by the search processing unit 1 ends.
なお、挿入処理部2による挿入処理では、まず、挿入キーを挿入すべきリーフノードの検索を上述した検索処理と同様の手順に従って行う。その後、検索したリーフノードに挿入キーとバリューとの組を挿入する処理は、上述した第1の実施形態と同様なので、ここでは説明を省略する。
In the insertion processing by the insertion processing unit 2, first, the search for the leaf node into which the insertion key is to be inserted is performed according to the same procedure as the search processing described above. Thereafter, the processing for inserting the combination of the insertion key and the value into the retrieved leaf node is the same as that in the first embodiment described above, and thus the description thereof is omitted here.
以上詳しく説明したように、第2の実施形態では、ノードグループ内のオフセット量が縮小ポインタに基づいて求められるので、ノードグループ内で各ノードのエントリはメモリの連続領域に格納されていることは必須でなく、図6のようにノードグループ内で各ノードを自由に配置することができる。そのため、ノード分割等が必要となるデータの更新処理でも高速に行うことができる。
As described above in detail, in the second embodiment, since the offset amount in the node group is obtained based on the reduction pointer, the entry of each node in the node group is stored in a continuous area of the memory. It is not essential, and each node can be freely arranged in the node group as shown in FIG. Therefore, even data update processing that requires node division or the like can be performed at high speed.
そして、このようにデータの更新処理を高速にするために各キーに対応させて縮小ポインタを設けつつ、当該縮小ポインタに必要な記憶容量を削減することにより、1つのノードに格納可能なキーの数を増やすことができる。これにより、インデックスツリーの階層数(ライン数)を減らし、検索処理も高速化することができる。
Thus, in order to speed up the data update process, a reduction pointer is provided corresponding to each key, and the storage capacity required for the reduction pointer is reduced, so that a key that can be stored in one node is reduced. You can increase the number. Thereby, the number of hierarchies (lines) of the index tree can be reduced, and the search process can be speeded up.
なお、上記第2の実施形態では、インデックスツリーを上位階層、中位階層、下位階層に分けて管理し、中位階層において縮小ポインタを用いる例について説明したが、本発明はこれに限定されない。例えば、インデックスツリーを上位階層と下位階層に分けて管理し、下位階層において縮小ポインタを用いるようにしてもよい。
In the second embodiment, the example in which the index tree is divided into the upper hierarchy, the middle hierarchy, and the lower hierarchy and the reduced pointer is used in the middle hierarchy has been described. However, the present invention is not limited to this. For example, the index tree may be managed by dividing it into an upper hierarchy and a lower hierarchy, and a reduction pointer may be used in the lower hierarchy.
すなわち、図7に示すように、検索処理部1、挿入処理部2、下位階層管理部3’および上位階層管理部4を備えてインデックス管理装置を構成する。下位階層管理部3’は、リーフノードのある階層を第0階層として、第1階層以上で第n階層以下(nは「1≦n<全階層数-1」を満たす任意の値)の下位階層において、所定数のキーと下階層のノードグループの先頭位置を表す1つのグループポインタとを格納するとともに、ノードグループ内の各ノードの位置を表す縮小ポインタを格納した第3の種類のノードによってインデックスツリーの探索および更新を管理する。なお、第0階層については第1の種類のノードによってインデックスツリーの探索および更新を管理する。
That is, as shown in FIG. 7, an index management apparatus is configured by including a search processing unit 1, an insertion processing unit 2, a lower layer management unit 3 ', and an upper layer management unit 4. The lower hierarchy management unit 3 ′ sets a hierarchy having leaf nodes as the 0th hierarchy, and is lower than the 1st hierarchy and below the nth hierarchy (n is an arbitrary value satisfying “1 ≦ n <total number of hierarchies−1”). In a hierarchy, a predetermined number of keys and a single group pointer representing the head position of a node group in a lower hierarchy are stored, and a third type node storing a reduced pointer representing the position of each node in the node group Manage the search and update of the index tree. For the 0th hierarchy, search and update of the index tree are managed by the first type node.
また、上記実施形態では、内部ノードについては左端のキーが省略されている例について説明したが、左端のキーが省略されていない内部ノードにより構成されるインデックスツリーに対して本発明を適用することも可能である。
In the above embodiment, an example in which the leftmost key is omitted for the internal node has been described. However, the present invention is applied to an index tree including internal nodes in which the leftmost key is not omitted. Is also possible.
上記第1および第2の実施形態によるインデックス管理装置は、リレーショナルデータベースのインデックス、多くのプログラムに組み込まれるマップ処理、ファイルシステム、キーバリューストア、OLAP(online analytical processing)システムなど、更新されるデータに対して検索をかけることのあるシステムに対しては広く利用することが可能である。
The index management apparatus according to the first and second embodiments described above is used for updating data such as relational database indexes, map processing incorporated in many programs, file systems, key-value stores, OLAP (online analytical processing) systems, and the like. However, it can be widely used for a system that may perform a search against the system.
その他、上記第1および第2の実施形態は、何れも本発明を実施するにあたっての具体化の一例を示したものに過ぎず、これらによって本発明の技術的範囲が限定的に解釈されてはならないものである。すなわち、本発明はその要旨、またはその主要な特徴から逸脱することなく、様々な形で実施することができる。
In addition, each of the first and second embodiments described above is merely an example of a specific example for carrying out the present invention, and the technical scope of the present invention should not be interpreted in a limited manner. It will not be. That is, the present invention can be implemented in various forms without departing from the gist or the main features thereof.
1 検索処理部
2 挿入処理部
3,3’ 下位階層管理部
4 上位階層管理部
5 中位階層管理部 DESCRIPTION OFSYMBOLS 1 Search processing part 2 Insertion processing part 3, 3 'Lower hierarchy management part 4 Upper hierarchy management part 5 Middle hierarchy management part
2 挿入処理部
3,3’ 下位階層管理部
4 上位階層管理部
5 中位階層管理部 DESCRIPTION OF
Claims (8)
- 最下位階層であるリーフノードおよびその他の内部ノードからなるインデックスツリーを管理するインデックス管理装置であって、
所定数のキーと所定数のバリューとの組を格納した上記リーフノードのある階層を第0階層として、第n階層以下(nは「1≦n<全階層数-1」を満たす任意の値)の下位階層において、所定数のキーと子ノードの位置を表す所定数のポインタまたは所定数のバリューとの組を格納した第1の種類のノードによって、上記インデックスツリーの探索および更新を管理する下位階層管理部と、
上記第n階層よりも上の上位階層において、所定数のキーと下階層のノードグループの先頭位置を表す1つのグループポインタとを格納した第2の種類のノードによって、上記インデックスツリーの探索および更新を管理する上位階層管理部とを備えたことを特徴とするインデックス管理装置。 An index management device that manages an index tree composed of leaf nodes and other internal nodes that are the lowest layers,
The hierarchy with the leaf node storing a set of a predetermined number of keys and a predetermined number of values is defined as the 0th hierarchy, and any value satisfying the nth hierarchy or lower (n is “1 ≦ n <total number of hierarchies−1”) The index tree search and update are managed by a first type node storing a set of a predetermined number of keys and a predetermined number of pointers representing positions of child nodes or a predetermined number of values in a lower hierarchy of A lower hierarchy management unit,
Searching and updating the index tree by a second type node storing a predetermined number of keys and one group pointer representing the head position of a node group in the lower hierarchy in the upper hierarchy above the nth hierarchy An index management apparatus comprising an upper layer management unit for managing - 上記下位階層管理部は、上記第1の種類のノードに格納されているキーの中から検索キー以下で最大の値を持つキーを探索し、探索したキーと共に同じノード内に格納されているポインタが示す位置を辿るようになされ、
上記上位階層管理部は、上記第2の種類のノードに格納されているキーの中から上記検索キー以下で最大の値を持つキーを探索し、探索したキーと共に同じノード内に格納されているグループポインタが示すノードグループの先頭位置からのオフセット量をノードサイズに基づいて計算することによって特定される位置を辿るようになされていることを特徴とする請求項1に記載のインデックス管理装置。 The lower layer management unit searches for a key having a maximum value below the search key from keys stored in the first type node, and a pointer stored in the same node together with the searched key To follow the position indicated by
The upper layer management unit searches for a key having the maximum value below the search key from the keys stored in the second type node, and stores the key in the same node together with the searched key. 2. The index management apparatus according to claim 1, wherein the index management apparatus is configured to follow a position specified by calculating an offset amount from the head position of the node group indicated by the group pointer based on the node size. - 上記下位階層管理部は、上記第1の種類のノードに格納されているキーの中から挿入キー以下で最大の値を持つキーを探索し、探索したキーと共に同じノード内に格納されているポインタが示す位置を辿ることによって上記挿入キーを挿入すべきリーフノードの探索を行い、探索されたリーフノードに空きスペースがある場合はそのリーフノードに上記挿入キーとバリューとの組を挿入する一方、探索されたリーフノードに空きスペースがない場合はそのリーフノードを分割して上記挿入キーとバリューとの組を挿入するようになされ、
上記上位階層管理部は、上記第2の種類のノードに格納されているキーの中から上記挿入キー以下で最大の値を持つキーを探索し、探索したキーと共に同じノード内に格納されているグループポインタが示すノードグループの先頭位置からのオフセット量をノードサイズに基づいて計算することによって特定される位置を辿るようになされていることを特徴とする請求項1に記載のインデックス管理装置。 The lower layer management unit searches for a key having the maximum value below the insertion key from the keys stored in the first type node, and a pointer stored in the same node together with the searched key The leaf node to which the insertion key is to be inserted is searched by following the position indicated by, and when there is an empty space in the searched leaf node, the pair of the insertion key and value is inserted into the leaf node, If there is no empty space in the searched leaf node, the leaf node is divided and the combination of the above insertion key and value is inserted.
The upper layer management unit searches for a key having the maximum value below the insertion key from among the keys stored in the second type node, and is stored in the same node together with the searched key. 2. The index management apparatus according to claim 1, wherein the index management apparatus is configured to follow a position specified by calculating an offset amount from the head position of the node group indicated by the group pointer based on the node size. - 上記第1階層よりも1つ上の上記第2階層を中位階層、当該第2階層よりも上の第3階層以上を上位階層とし、
上記中位階層において、所定数のキーと下階層のノードグループの先頭位置を表す1つのグループポインタとを格納するとともに、上記ノードグループ内の各ノードの位置を表すポインタであって上記第1の種類のノードに格納されるポインタよりもサイズの小さい縮小ポインタを格納した第3の種類のノードによって、上記インデックスツリーの探索および更新を管理する中位階層管理部を更に備えたことを特徴とする請求項1に記載のインデックス管理装置。 The second hierarchy, which is one level above the first hierarchy, is the middle hierarchy, the third hierarchy above the second hierarchy is the upper hierarchy,
In the middle hierarchy, a predetermined number of keys and one group pointer representing the head position of the node group in the lower hierarchy are stored, and the pointer represents the position of each node in the node group, the first hierarchy A third-level node storing a reduced pointer having a size smaller than the pointer stored in the type node further includes a middle-level management unit that manages search and update of the index tree. The index management device according to claim 1. - 上記中位階層管理部は、上記第3の種類のノードに格納されているキーの中から上記検索キー以下で最大の値を持つキーを探索し、探索したキーと共に同じノード内に格納されているグループポインタが示すノードグループの先頭位置からのオフセット量を上記縮小ポインタに基づいて計算することによって特定される位置を辿るようになされていることを特徴とする請求項4に記載のインデックス管理装置。 The middle level manager searches for a key having the maximum value below the search key from the keys stored in the third type node, and stores the key in the same node together with the searched key. 5. The index management device according to claim 4, wherein the index management device is adapted to follow a position specified by calculating an offset amount from a head position of a node group indicated by a group pointer based on the reduced pointer. .
- 最下位階層であるリーフノードおよびその他の内部ノードからなるインデックスツリーを管理するインデックス管理装置であって、
所定数のキーと所定数のバリューとの組を格納した上記リーフノードのある階層を第0階層として、第1階層以上で第n階層以下(nは「1≦n<全階層数-1」を満たす任意の値)の下位階層において、所定数のキーと下階層のノードグループの先頭位置を表す1つのグループポインタとを格納するとともに、上記ノードグループ内の各ノードの位置を表すのに十分なサイズの縮小ポインタを格納した第3の種類のノードによって、上記インデックスツリーの探索および更新を管理する下位階層管理部と、
上記第n階層よりも上の上位階層において、所定数のキーと下階層のノードグループの先頭位置を表す1つのグループポインタとを格納した第2の種類のノードによって、上記インデックスツリーの探索および更新を管理する上位階層管理部とを備えたことを特徴とするインデックス管理装置。 An index management device that manages an index tree composed of leaf nodes and other internal nodes that are the lowest layers,
A hierarchy having the leaf node storing a set of a predetermined number of keys and a predetermined number of values is defined as the 0th hierarchy, and the 1st hierarchy to the nth hierarchy (n is “1 ≦ n <total number of hierarchy-1”) A predetermined number of keys and one group pointer representing the head position of a node group in the lower hierarchy, and sufficient to represent the position of each node in the node group A lower layer management unit that manages the search and update of the index tree by a third type of node that stores a reduced pointer of an appropriate size;
Searching and updating the index tree by a second type node storing a predetermined number of keys and one group pointer representing the head position of a node group in the lower hierarchy in the upper hierarchy above the nth hierarchy An index management apparatus comprising an upper layer management unit for managing - 上記下位階層管理部は、上記第3の種類のノードに格納されているキーの中から上記検索キー以下で最大の値を持つキーを探索し、探索したキーと共に同じノード内に格納されているグループポインタが示すノードグループの先頭位置からのオフセット量を上記縮小ポインタに基づいて計算することによって特定される位置を辿るようになされ、
上記上位階層管理部は、上記第2の種類のノードに格納されているキーの中から上記検索キー以下で最大の値を持つキーを探索し、探索したキーと共に同じノード内に格納されているグループポインタが示すノードグループの先頭位置からのオフセット量をノードサイズに基づいて計算することによって特定される位置を辿るようになされていることを特徴とする請求項6に記載のインデックス管理装置。 The lower layer management unit searches for a key having the maximum value below the search key from the keys stored in the third type node, and stores the key in the same node together with the searched key. It follows the position specified by calculating the offset amount from the head position of the node group indicated by the group pointer based on the reduced pointer,
The upper layer management unit searches for a key having the maximum value below the search key from the keys stored in the second type node, and stores the key in the same node together with the searched key. 7. The index management apparatus according to claim 6, wherein the index management apparatus is configured to follow a position specified by calculating an offset amount from the head position of the node group indicated by the group pointer based on the node size. - 上記下位階層管理部は、上記第3の種類のノードに格納されているキーの中から上記挿入キー以下で最大の値を持つキーを探索し、探索したキーと共に同じノード内に格納されているグループポインタが示すノードグループの先頭位置からのオフセット量を上記縮小ポインタに基づいて計算することによって特定される位置を辿ることによって上記挿入キーを挿入すべきリーフノードの探索を行い、探索されたリーフノードに空きスペースがある場合はそのリーフノードに上記挿入キーとバリューとの組を挿入する一方、探索されたリーフノードに空きスペースがない場合はそのリーフノードを分割して上記挿入キーとポインタとの組を挿入するようになされ、
上記上位階層管理部は、上記第2の種類のノードに格納されているキーの中から上記挿入キー以下で最大の値を持つキーを探索し、探索したキーと共に同じノード内に格納されているグループポインタが示すノードグループの先頭位置からのオフセット量をノードサイズに基づいて計算することによって特定される位置を辿るようになされていることを特徴とする請求項6に記載のインデックス管理装置。 The lower layer management unit searches for a key having the maximum value below the insertion key from the keys stored in the third type node, and stores the key in the same node together with the searched key. The leaf node to which the insertion key is to be inserted is searched by following the position specified by calculating the offset amount from the head position of the node group indicated by the group pointer based on the reduction pointer, and the searched leaf If there is an empty space in the node, the pair of the insertion key and value is inserted into the leaf node. On the other hand, if there is no empty space in the searched leaf node, the leaf node is divided and the insertion key and the pointer are inserted. Was made to insert a pair of
The upper layer management unit searches for a key having the maximum value below the insertion key from among the keys stored in the second type node, and is stored in the same node together with the searched key. 7. The index management apparatus according to claim 6, wherein the index management apparatus is configured to follow a position specified by calculating an offset amount from the head position of the node group indicated by the group pointer based on the node size.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2014036341A JP6006740B2 (en) | 2014-02-27 | 2014-02-27 | Index management device |
| JP2014-036341 | 2014-02-27 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2015129109A1 true WO2015129109A1 (en) | 2015-09-03 |
Family
ID=54008453
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2014/080851 WO2015129109A1 (en) | 2014-02-27 | 2014-11-21 | Index management device |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP6006740B2 (en) |
| WO (1) | WO2015129109A1 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109510707A (en) * | 2019-01-16 | 2019-03-22 | 北京交通大学 | Group key management method based on tree model |
| CN112783896A (en) * | 2021-01-12 | 2021-05-11 | 湖北宸威玺链信息技术有限公司 | Method for reducing memory usage rate for loading files |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2017179140A1 (en) * | 2016-04-13 | 2017-10-19 | 株式会社日立製作所 | Computer and database management method |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07191891A (en) * | 1993-10-20 | 1995-07-28 | Microsoft Corp | Computer method and storage structure for storage of, and access to, multidimensional data |
| JP2000324172A (en) * | 1999-05-11 | 2000-11-24 | Nec Corp | Method for storing prefix concerning address |
| JP2001202277A (en) * | 1999-12-08 | 2001-07-27 | Hewlett Packard Co <Hp> | Data processing system |
| WO2013035287A1 (en) * | 2011-09-08 | 2013-03-14 | 日本電気株式会社 | Database management device, database management method, and program |
-
2014
- 2014-02-27 JP JP2014036341A patent/JP6006740B2/en active Active
- 2014-11-21 WO PCT/JP2014/080851 patent/WO2015129109A1/en active Application Filing
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07191891A (en) * | 1993-10-20 | 1995-07-28 | Microsoft Corp | Computer method and storage structure for storage of, and access to, multidimensional data |
| JP2000324172A (en) * | 1999-05-11 | 2000-11-24 | Nec Corp | Method for storing prefix concerning address |
| JP2001202277A (en) * | 1999-12-08 | 2001-07-27 | Hewlett Packard Co <Hp> | Data processing system |
| WO2013035287A1 (en) * | 2011-09-08 | 2013-03-14 | 日本電気株式会社 | Database management device, database management method, and program |
Non-Patent Citations (1)
| Title |
|---|
| JUN RAO ET AL.: "Making B+-Trees Cache Conscious in Main Memory", SIGMOD '00 PROCEEDINGS OF THE 2000 ACM SIGMOD INTERNATIONAL CONFERENCE ON MANAGEMENT OF DATA, 15 May 2000 (2000-05-15), pages 475 - 486, XP003000891 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109510707A (en) * | 2019-01-16 | 2019-03-22 | 北京交通大学 | Group key management method based on tree model |
| CN112783896A (en) * | 2021-01-12 | 2021-05-11 | 湖北宸威玺链信息技术有限公司 | Method for reducing memory usage rate for loading files |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2015162042A (en) | 2015-09-07 |
| JP6006740B2 (en) | 2016-10-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11899641B2 (en) | Trie-based indices for databases | |
| US9672235B2 (en) | Method and system for dynamically partitioning very large database indices on write-once tables | |
| US10831736B2 (en) | Fast multi-tier indexing supporting dynamic update | |
| WO2018064962A1 (en) | Data storage method, electronic device and computer non-volatile storage medium | |
| US10114908B2 (en) | Hybrid table implementation by using buffer pool as permanent in-memory storage for memory-resident data | |
| CN105117415B (en) | A kind of SSD data-updating methods of optimization | |
| CN105117417A (en) | Read-optimized memory database Trie tree index method | |
| CN107526550B (en) | Two-stage merging method based on log structure merging tree | |
| KR20090048624A (en) | Dynamic fragment mapping | |
| CN103914483B (en) | File memory method, device and file reading, device | |
| CN106570113B (en) | Mass vector slice data cloud storage method and system | |
| JP5790755B2 (en) | Database management apparatus and database management method | |
| CN114281989A (en) | Data deduplication method and device based on text similarity, storage medium and server | |
| JP6006740B2 (en) | Index management device | |
| CN107273443B (en) | Mixed indexing method based on metadata of big data model | |
| CN110832473B (en) | Log structure management system and method | |
| EP3940572A1 (en) | Data generalization device, data generalization method, and program | |
| WO2012081165A1 (en) | Database management device and database management method | |
| JP2008065716A (en) | Device, method and program for data management | |
| JP2007048318A (en) | Relational database processing method and relational database processor | |
| KR100878142B1 (en) | Method of configuring a modified b-tree index for an efficient operation on flash memory | |
| US9824105B2 (en) | Adaptive probabilistic indexing with skip lists | |
| US20220365905A1 (en) | Metadata processing method and apparatus, and a computer-readable storage medium | |
| Pinkas et al. | A simple recursive tree oblivious ram | |
| Xu et al. | Efficiently Update Disk-Resident Interval Tree |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 14883789 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 14883789 Country of ref document: EP Kind code of ref document: A1 |