WO2013154010A1 - 音声認識サーバ統合装置および音声認識サーバ統合方法 - Google Patents
音声認識サーバ統合装置および音声認識サーバ統合方法 Download PDFInfo
- Publication number
- WO2013154010A1 WO2013154010A1 PCT/JP2013/060238 JP2013060238W WO2013154010A1 WO 2013154010 A1 WO2013154010 A1 WO 2013154010A1 JP 2013060238 W JP2013060238 W JP 2013060238W WO 2013154010 A1 WO2013154010 A1 WO 2013154010A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- recognition
- recognition server
- server
- speech
- result
- Prior art date
Links
- 230000010354 integration Effects 0.000 title claims abstract description 137
- 238000000034 method Methods 0.000 title claims description 51
- 239000000284 extract Substances 0.000 claims 4
- 238000000605 extraction Methods 0.000 claims 1
- 230000006870 function Effects 0.000 abstract description 24
- 238000011156 evaluation Methods 0.000 abstract description 5
- 238000012545 processing Methods 0.000 description 28
- 238000004891 communication Methods 0.000 description 20
- 238000010586 diagram Methods 0.000 description 17
- 230000015572 biosynthetic process Effects 0.000 description 9
- 238000003786 synthesis reaction Methods 0.000 description 9
- 230000004044 response Effects 0.000 description 6
- 238000006243 chemical reaction Methods 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 238000002474 experimental method Methods 0.000 description 2
- 235000016496 Panda oleosa Nutrition 0.000 description 1
- 240000000220 Panda oleosa Species 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 238000003672 processing method Methods 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
Images














Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
- G10L15/30—Distributed recognition, e.g. in client-server systems, for mobile phones or network applications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
- G10L15/32—Multiple recognisers used in sequence or in parallel; Score combination systems therefor, e.g. voting systems
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
Definitions
- the present invention connects a terminal device for a user to operate using voice and a plurality of voice recognition servers that recognize voice data and return the result, and integrates the recognition results obtained by the plurality of voice recognition servers.
- the present invention relates to an apparatus and a method for providing a user with an optimal speech recognition result.
- a speech recognition server is operated as a general-purpose service
- the entity that provides services for terminals handled by users and the entity that operates the speech recognition server are often different.
- the development of the speech recognition server and the development of the speech recognition application are performed separately, and they may not be mutually optimized.
- a general-purpose speech recognition server may generally not exhibit sufficient performance for a specific phrase while exhibiting high performance.
- An object of the present invention is to optimally integrate the speech recognition result of the general-purpose speech recognition server and the speech recognition result of the dedicated speech recognition server, and finally provide a speech recognition function with few errors.
- a list of specific words included in the terminal device owned by the user is obtained in advance, and a dedicated speech recognition server is constructed based on the data of those words. Moreover, the performance of a general-purpose speech recognition server is evaluated in advance using those data. Based on the evaluation results, which of the recognition results obtained from the dedicated and general-purpose speech recognition servers is used and what weighting is applied to them, the optimal recognition result can be obtained. Keep it in the form of a database.
- the user actually uses the speech recognition function the input speech is recognized by a dedicated and general-purpose speech recognition server, and then the results obtained there are compared with the contents of the database described above to obtain the optimal speech. Get recognition result. Further, by using the response speed in addition to the correctness of the speech recognition as a reference for the prior evaluation, it is possible to obtain the correct speech recognition result as soon as possible.
- a device that relays between a terminal device for a user to operate using speech and a speech recognition server that recognizes speech data and returns the result
- An integrated method learning unit that learns and stores parameters for integrating recognition results based on a word registered by the user or a list of words frequently used by the user, and voice data that is intended for voice recognition by the user
- Receiving from the terminal device means for transmitting the received speech data to a general-purpose speech recognition server and a dedicated speech recognition server, and receiving a recognition result of the speech data by the general-purpose speech recognition server and the dedicated speech recognition server A recognition result obtained by the general-purpose speech recognition server and the dedicated speech recognition server, and the stored recognition result integration parameter.
- those comprising a recognition result integration unit that selects an optimal recognition result, and means for transmitting the selected recognition result to the terminal device.
- the speech recognition server integration device of the present invention further, means for receiving a word registered by the user or a list of words frequently used by the user from the terminal device, and speech synthesis for generating synthesized speech based on the received word Unit, means for transmitting the generated synthesized speech to the general-purpose speech recognition server and the dedicated speech recognition server, and means for receiving a recognition result of the synthesized speech by the general-purpose speech recognition server and the dedicated speech recognition server,
- the integration method learning unit may analyze the phrase that is the basis of the synthesized speech and the recognition result together to learn and store the recognition result integration parameter.
- the speech recognition server integration device of the present invention means for receiving a list of phrases registered by the user or frequently used phrases from the terminal device, and a list of phrases for recognition from the general-purpose speech recognition server And a phrase comparison / similarity estimation unit that compares the phrase list for recognition with the phrase list received from the terminal device and estimates similarity, and the integration method learning unit It may be stored as a parameter for recognition result integration.
- a step of learning and storing parameters for integration of recognition results based on a phrase registered by the user or a list of phrases frequently used by the user Transmitting speech data intended to be transmitted to a general-purpose speech recognition server and a dedicated speech recognition server, receiving a recognition result of the speech data by the general-purpose speech recognition server and the dedicated speech recognition server, and general-purpose speech And comparing the recognition result of the recognition server and the recognition result of the dedicated speech recognition server with the recognition result integration parameter and selecting the optimum speech recognition result.
- the recognition result of the general-purpose speech recognition server is regarded as important for general words and phrases, and the result of the dedicated speech recognition server is regarded as important for user-specific words and phrases in an optimum form for each input.
- the recognition results are integrated, and finally it is possible to provide the user with a voice recognition function with few errors. In addition to fewer errors, it is possible to realize a highly convenient system in terms of response speed.
- Example 3 of this invention It is a block diagram of the speech recognition server integration apparatus of Example 3 of this invention. It is a figure which shows the process of parameter estimation for result integration using the recognition term phrase list of Example 3 of this invention. It is a block diagram of the speech recognition server apparatus of Example 4 of this invention. It is a block diagram of the speech recognition server apparatus of Example 5 of this invention.
- FIG. 1 is a diagram illustrating a configuration example of a speech recognition server integration device based on Embodiment 1 of the present invention.
- the voice recognition function is provided using the user terminal 102, the relay server 104, the general-purpose voice recognition server group 106, and the dedicated voice recognition server 108.
- the general-purpose speech recognition server group 106 may be a single general-purpose speech recognition server.
- the user terminal 102 is a terminal device possessed by the individual user.
- the user terminal 102 holds a phrase list unique to the user such as an address book and a song name list. Yes.
- the phrase list unique to these users is referred to as a “user dictionary”.
- the user dictionary holds a list of words registered by the user or frequently used by the user.
- the general-purpose speech recognition server group 106 is one or more speech recognition servers that are not assumed to be used only by services realized by the present invention. In general, a large-scale word list is built in and recognition performance for various words is high, while some words included in the user dictionary may not be recognized correctly.
- the dedicated speech recognition server 108 is a speech recognition server specialized for services realized by the present invention, and is designed to recognize all or most of the words included in the user dictionary.
- the dedicated speech recognition server 108 is designed to output a result of “no recognition result” when a phrase not included in the user dictionary is input.
- the dedicated speech recognition server is not limited to being configured as a server, and may be a dedicated speech recognition device, or may be built in a user terminal or a relay server as in the second and fifth embodiments.
- the relay server 104 corresponds to the “voice recognition server integration device” of the present invention, and connects the user terminal 102 and the voice recognition servers 106 and 108 to integrate voice recognition results. Data exchange with the user terminal 102 is performed via the terminal device communication unit 110. Data exchange with the voice recognition servers 106 and 108 is performed via the recognition server communication unit 112.
- the relay server 104 includes a terminal device communication unit 110, a speech synthesis unit 114, an integration method learning unit 116, a signal processing unit 120, a recognition result integration unit 122, a recognition server communication unit 112, and the like.
- the operation of the relay server 104 will be described.
- data in the user dictionary 124 is transmitted via the terminal device communication unit 110.
- This data is sent directly to the recognition server communication unit 112 and further sent to the dedicated speech recognition server 108.
- the dedicated speech recognition server 108 performs tuning so as to correctly recognize the words included in the user dictionary data sent thereto.
- the user dictionary data received by the terminal device communication unit 110 is also sent to the speech synthesis unit 114.
- synthesized speech data is created based on user dictionary data sent as a character string.
- the synthesized speech data for one word may be one or a plurality of pieces having different sound quality.
- the generated synthesized speech data is sent to the general-purpose speech recognition server group 106 and the dedicated speech recognition server 108 via the recognition server communication unit 112.
- the recognition server communication unit 112 receives them and sends them to the integrated method learning unit 116.
- the integration method learning unit 116 analyzes the user dictionary data that is the basis of the synthesized speech and the recognition result, and learns parameters for integrating the recognition result.
- the obtained parameters are stored as result integration parameters 118. At this point, the pre-learning process of the system using the present invention ends.
- the input voice data acquired by the user terminal 102 is received by the terminal device communication unit 110.
- the received data is sent to the signal processing unit 120 and subjected to necessary processing.
- the necessary processing refers to, for example, removing noise from input speech including noise, but is not necessarily required, and no processing may be performed.
- Data output from the signal processing unit 120 is sent to the general-purpose speech recognition server group 106 and the dedicated speech recognition server 108 via the recognition server communication unit 112.
- the recognition results returned from these servers are sent to the recognition result integration unit 122 via the recognition server communication unit 112.
- the recognition result integration unit 122 compares a plurality of recognition results with the parameters included in the result integration parameter 118, and selects an optimal recognition result.
- the selected recognition result is sent to the user terminal 102 via the terminal device communication unit 110. Based on this result, the user terminal 102 provides services such as setting a destination of a navigation function, making a call, and playing a music piece.
- FIG. 2 is a diagram showing a processing procedure until a result integration parameter is created using user dictionary data in the configuration shown in FIG.
- user dictionary data is sent to a dedicated speech recognition server as it is.
- the speech recognition engine is tuned so that the sent phrase is the recognition target. Therefore, when data uttering a word that is not included in the user dictionary is sent, the dedicated speech recognition server returns an incorrect result or returns a result indicating that recognition is impossible.
- the user dictionary data is also sent to the speech synthesis unit, where synthesized speech data is created. Normally, one synthesized speech is created for one word, but if the speech synthesizer has a function that allows you to select the speaker, speech speed, voice pitch, etc., change them. Thus, if a plurality of synthesized speech data is created for the same word / phrase, it is possible to further improve the performance of the integrated method learning performed later.
- the synthesized speech data thus obtained is sent to each general-purpose speech recognition server and dedicated speech recognition server. Recognition results are returned from those servers. In addition, not only the recognition result but also a reliability score associated therewith may be attributed together. Based on these, the integration method learning unit learns the integration method, and the result is stored in a result integration parameter.
- FIG. 3 is a diagram showing an example of the simplest configuration of result integration parameters.
- the server holds only whether or not each word / phrase in the user dictionary is correctly recognized by ⁇ and ⁇ . That is, this figure shows that the words “Ichiro Suzuki” and “Jiro Yamada” were correctly recognized by the general-purpose speech recognition server but were not correctly recognized otherwise.
- FIG. 4 is an example when similar learning is performed using three general-purpose speech recognition servers.
- Fig. 5 shows the processing procedure when the recognition is actually performed using the results shown in Figs.
- Input voice data is first pre-processed by the signal processing unit.
- a typical process in the signal processing unit there is a noise suppression process as disclosed in Patent Document 1.
- the processing described below is repeated as many times as the number of audio data. Further, when it is considered that the processing in the signal processing unit is unnecessary, the input voice data is directly used as output data of the signal processing unit.
- the output data of the signal processing unit is sent to the general-purpose speech recognition server and the dedicated speech recognition server. All these results are sent to the recognition result integration unit.
- the recognition result integration unit first checks the recognition result of the dedicated speech recognition server. If the recognition result of the dedicated recognition server is “no recognition result”, the final recognition result is determined only from the recognition result of the general-purpose speech recognition server. That is, when there is only one general-purpose speech recognition server, the result is adopted as it is. If there are multiple units, a majority vote is taken between the recognition results. When taking a majority vote, if each recognition server gives a reliability score, a majority vote weighted by that value can be used. In addition, the performance of each recognition server can be estimated in advance and used as a weighting coefficient. For such integration of recognition results of a plurality of speech recognition servers for general words / phrases, a known technique as shown in Patent Document 2 can be used.
- a result integration parameter as shown in FIG. 3 or FIG. 4 is referred to.
- the recognition result of the dedicated speech recognition server is “Hitachi Taro”, when the corresponding line of the result integration parameter is viewed, this phrase should not be recognized by the general-purpose speech recognition server. Therefore, the result of the dedicated speech recognition server is adopted as it is.
- the recognition result of the dedicated speech recognition server is “Ichiro Suzuki”, it can be seen from the corresponding line of the result integration parameter that this phrase can also be recognized by the dedicated speech recognition server.
- the recognition result of the general-purpose speech recognition server is checked next. If the recognition result of the general-purpose speech recognition server is also “Ichiro Suzuki”, “Ichiro Suzuki” can be used as the final recognition result, but if not, the general-purpose performance generally seems to be high.
- the result of the voice recognition server is given priority, or the recognition result of the general-purpose voice recognition server and the dedicated voice recognition server having the higher reliability score is adopted as the final recognition result.
- the recognition result of the general-purpose speech recognition server is misrecognized by the dedicated speech recognition server, it can be rejected based on the recognition result of the general-purpose speech recognition server. Become. The same applies to the example of FIG.
- the result of the dedicated speech recognition server is used unconditionally. Since “Ichiro Suzuki” is a word that can be recognized by all three general-purpose speech recognition servers, the final recognition result is determined by a majority decision based on these recognition results, or a majority decision including a dedicated speech recognition server. To do. If the recognition result of the dedicated speech recognition server is “Jiro Yamada”, the only general-purpose speech recognition server that can correctly recognize this is the first, so this server and the dedicated speech recognition server The final recognition result is obtained by performing the same processing as in the example of FIG.
- FIG. 6 shows another example of the result integration parameters different from those in FIGS. 3 and 4.
- the probability that the word / phrase is correctly recognized is replaced with a numerical value of weight and held.
- the probability of correct recognition is, for example, that the word “Ichiro Suzuki” is recognized with synthesized speech made by changing various parameters for speech synthesis, and the number of recognition results is correct. It can be estimated depending on whether there was.
- the general-purpose speech recognition server is configured to return a plurality of recognition result candidates, the average rank of the correct words, the average reliability score, and the like can be used.
- a value obtained by converting these values into weight values by appropriate non-linear conversion is held in a result integration parameter.
- the recognition result of the dedicated speech recognition server is “Ichiro Suzuki”
- the result of the general-purpose server 1 is “Ichiro Sasaki”
- the results of the general-purpose servers 2 and 3 are “Ichiro Suzuki”
- the weight of “Ichiro Sasaki” Is 3.0
- the weight of “Ichiro Suzuki” is the sum of 1.4 and 1.2, which is 2.6, and the former is larger, so “Ichiro Sasaki” is the final recognition result.
- FIG. 7 shows another example of the result integration parameters different from those shown in FIGS.
- the recognition result obtained at that time is stored as a result integration parameter. Setting the weight of each server is the same as in the example of FIG.
- the recognition result of the second place or less may be stored together regardless of the number of experiments.
- the result integration parameter is referred to based on the recognition result of the dedicated speech recognition server, as in the previous examples.
- the recognition result of the general-purpose speech recognition server matches that stored in the result integration parameter.
- the recognition result of the dedicated speech recognition server is “Hitachi Taro”
- the result of the general-purpose server 1 is “Hitachi City”
- the result of the general-purpose server 2 is “20 years old”
- the result of the general-purpose server 3 is “Hitachi”.
- a majority decision is made on each recognition result, and finally “Hitachi Taro” is selected.
- FIG. 8 is a diagram illustrating an example of a speech recognition result integration method using detection of homonymous notation.
- the recognition result of the dedicated speech recognition server is “Ichiro Sato”
- it is compared with each recognition result of the general-purpose speech recognition server to check whether or not the same phonetic notation is included.
- each kanji reading is held as data, and the pronunciation notation is obtained by concatenating the kanji readings constituting the word.
- the rules for giving readings for partial spellings are retained, and phonetic notation is obtained by sequentially applying these rules.
- pronunciation notation can be obtained by a technique generally called Grapheme to Phoneme.
- pronunciation information is included in the user dictionary data such as kanji notation and kana notation, and in such a case, it is utilized.
- the recognition result notation is converted into a recognition result notation by the dedicated speech recognition server.
- the recognition result “Ichiro Sato” of the general-purpose speech recognition server 1 is the same sound as the recognition result of the dedicated speech recognition server, it is converted to “Ichiro Sato”.
- the result of the majority decision by the three general-purpose speech recognition servers is “Ichiro Sato”, which is adopted as the final result.
- FIG. 9 is a diagram showing an example of a specific implementation form of the user terminal, taking as an example the case of providing a navigation function or a hands-free call function in a car.
- all functions such as a microphone device 904, an application 906, and a communication module 908 are mounted in the car navigation device 902.
- the car navigation device 902 and the smartphone 910 are connected, the microphone device 904 uses the car navigation device 902, and the communication unit 908 uses the smartphone 910.
- the applications 912 and 914 are arranged in a distributed manner in the car navigation apparatus and in the smartphone, or arranged in only one of them according to the respective functions.
- all functions are implemented in the smartphone 910.
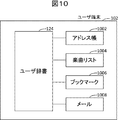
- FIG. 10 is a diagram showing an example of a method for creating the user dictionary 124 constituting the present invention.
- the addresses of people included therein are registered in the user dictionary.
- the music name and artist name included therein are registered in the user dictionary.
- the page title registered as the bookmark 1006 of the web browser can be registered in the user dictionary.
- a method of analyzing data such as mail 1008 and short messages stored in the user terminal and registering frequently occurring phrases in the user dictionary is also possible.
- FIG. 11 is a diagram showing an example of a special configuration specialized for the present invention by changing the configuration of a general speech synthesizer.
- the speech synthesizer 114 includes a synthesized speech creation unit 1102 and speech unit data 1106 to 1110.
- segment data is the name of data for use in a method for creating synthesized speech by directly joining data, but instead of directly joining, a method for synthesizing waveforms by statistical processing and signal processing is used. Even in this case, since a similar data set is used for processing units such as individual phonemes and syllables, the following method can be applied.
- a synthesized speech creating unit 1102 joins speech unit data, performs appropriate signal processing if necessary, and creates standard synthesized speech.
- each general-purpose speech recognition server group since it is important to know how each general-purpose speech recognition server group reacts to the voice of the specific user who is the owner of the user terminal, it is created by the speech synthesizer.
- the synthesized voice is also preferably similar to the voice of the user. Therefore, every time the user uses the voice recognition function or every time other voice function or voice call is used, the voice is stored as user voice data 1112, and this is used to make a voice conversion unit 1104.
- the standard synthesized speech is converted to user adaptive speech. By using the converted speech as an input to the general-purpose speech recognition server group, it is possible to perform performance prediction with higher accuracy, and it can be expected that the value of the result integration parameter will be more appropriate.
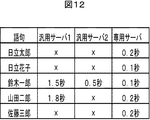
- FIG. 12 is a diagram showing an example of result integration parameters when the response speed is used as an evaluation criterion in addition to correct speech recognition.
- recognition using synthesized speech corresponding to each word / phrase included in the user dictionary data is executed, and the average time required for the processing is stored as a parameter.
- the recognition result of the dedicated speech recognition server is “Ichiro Suzuki”
- the recognition result of the general-purpose server 2 is expected to be obtained in 0.5 seconds. You have to wait 1.5 seconds to get it.
- this response time exceeds the upper limit assumed by the application, the result integration process is performed when the result of the general-purpose server 2 is obtained.
- the result integration process takes almost no time, the final recognition result can be obtained with a response time of about 0.5 seconds, and the convenience for the user can be improved.
- FIG. 13 is a diagram showing a configuration of an example in which a function equivalent to the example shown in FIG. 1 is realized using the dedicated speech recognition unit 108 incorporated in the user terminal.
- the user terminal 102 recognizes a word / phrase included in the user dictionary 124 using the dedicated voice recognition unit 108 existing inside without using the relay server 104.
- the method for performing the performance evaluation of the general-purpose speech recognition server group 106 in advance using the user dictionary data is the same as that shown in FIG.
- recognition by the general-purpose speech recognition server 106 is performed via the relay server 104, and at the same time, recognition is also performed by the dedicated speech recognition unit 108 in the user terminal.
- FIG. 14 is a diagram showing another configuration example of the speech recognition server integration device according to the present invention.
- the general-purpose speech recognition server group 106 As a function of the general-purpose speech recognition server group 106, a case is assumed in which a recognition term phrase list used therein is available.
- the user dictionary data sent from the user terminal 102 to the relay server 104 is sent to the phrase comparison / similarity estimation unit 126.
- This section compares the recognition phrase list obtained from the general-purpose speech recognition server group 106 with the user dictionary data, and determines whether each word included in the user dictionary 124 can be correctly recognized by each server.
- the determination result is sent to the integration method learning unit 116, and the result organized as a parameter is held in the result integration parameter 118.
- the user dictionary data is sent to the dedicated speech recognition server 108 as it is, and the dedicated speech recognition server is tuned as in the example shown in FIG.
- the general-purpose voice recognition server 106 and the dedicated voice data are sent via the signal processing unit 120 as in the example shown in FIG.
- the data is sent to the voice recognition server 108.
- the recognition results returned from these servers are sent to the recognition result integration unit 122, where an optimum recognition result is selected by comparison with the result integration parameter 118. After the selected recognition result is transmitted to the user terminal 102, it is the same as the example shown in FIG.
- FIG. 15 is a diagram showing a processing procedure until a result integration parameter is created using user dictionary data in the configuration shown in FIG.
- a recognition speech phrase list is simply acquired from each general-purpose speech recognition server without creating synthesized speech or trying to execute speech recognition using it. These lists are compared with the words / phrases included in the user dictionary data, and data indicating which word / phrase list of which general-purpose speech recognition server contains each word / phrase in the user dictionary data.
- the result integration parameters that summarize the obtained results are shown in FIG. It becomes the same as FIG. Therefore, how to use the actual recognition is the same as the example described above.
- the unigram value is set to be easy to recognize the word, or the double gram or trigram maximum value is set to be easy to recognize the word.
- a method is conceivable.
- FIG. 16 shows an example configuration in which a function equivalent to the example shown in FIG. 1 is realized by a device in which an input / output function with a user and a voice recognition server integration function are incorporated in a single device.
- the user dictionary data included in the user dictionary 124 stored inside the speech recognition server integration device 104 is transferred to the speech synthesis unit 114 and the recognition server communication unit 112 in the device.
- the voice spoken by the user is captured by the microphone device 128 and transferred to the signal processing unit 120.
- the processing method using these is the same as that described in the example of FIG. 1, and as a result, the recognition result integration unit 122 finalizes the recognition result.
- This recognition result is transferred to the display unit 132 in the apparatus and presented to the user.
- FIG. 17 is a diagram showing a configuration when the functions of the dedicated speech recognition server are incorporated into the speech recognition server integration device based on the example shown in FIG.
- the part in which the input voice is taken in from the microphone device 128 included in the voice recognition server integration apparatus 104 and the user dictionary data is transferred from the user dictionary 124 is the same as the example of FIG.
- the unit 108 is incorporated in the apparatus, and directly reads out the contents of the user dictionary and recognizes audio data sent from the microphone apparatus.
- the single recognition result obtained there is sent to the recognition result integration unit 122 and integrated with the recognition result obtained by the general-purpose speech recognition server group 106.
- the integrated recognition result is sent to the application 130 existing in the apparatus, where it is utilized according to the purpose of each application.
- the present invention can be used as a voice data relay device for providing a highly accurate voice recognition function by interposing between an in-vehicle terminal and a voice recognition server.
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Telephonic Communication Services (AREA)
- Two-Way Televisions, Distribution Of Moving Picture Or The Like (AREA)
- Machine Translation (AREA)
Abstract
汎用音声認識サーバの音声認識結果と専用音声認識サーバの音声認識結果とを最適な形で統合し、最終的に間違いの少ない音声認識機能を提供する。 ユーザ辞書データに含まれる語句を使って専用の音声認識サーバ108を構築するとともに、それらのデータを用い、汎用の音声認識サーバ106の性能を事前評価する。この評価結果をもとに、専用および汎用の音声認識サーバから得られた認識結果に対し、どれを採用し、それらに対してどのような重み付けを行えば最適な認識結果が得られるかを、結果統合用パラメータ118としてデータベースの形で保持しておく。認識実行時には、専用および汎用の音声認識サーバによる認識結果を、結果統合用パラメータ118と比較することにより、最適な認識結果を得る。
Description
本発明は、ユーザが音声を用いて操作を行うための端末装置と、音声データを認識してその結果を返す複数の音声認識サーバとを繋ぎ、複数の音声認識サーバにより得られる認識結果を統合して最適な音声認識結果をユーザに提供するための装置および方法に関する。
車載情報機器や携帯電話などの操作を、ユーザの声により行うための音声認識機能が、数多くの機器に搭載されている。さらに近年では、データ通信技術の発展により、音声データをサーバに送信し、サーバの潤沢な計算資源を用いてより高精度の音声認識を行う方式が普及しつつある。また、特許文献1に示されるように、こうした音声認識サーバをより有効に用いるため、個人用端末と音声認識サーバとの間に中継サーバを置き、その中で付加的な処理を行う方式も提案されている。
音声認識サーバが汎用のサービスとして運営される例が増えており、ユーザが扱う端末向けのサービスを提供する主体と、音声認識サーバを運営する主体とが異なる場合が多くなっている。また、運営主体が同一である場合においても、音声認識サーバの開発と音声認識アプリケーションの開発を別個に行い、それらが相互に最適化されていない場合もある。このような状況で、汎用の音声認識サーバが全般的には高い性能を示しながら、特定の語句に対しては必ずしも十分な性能を示さないということがある。
一方、特定のアプリケーションを使用する特定のユーザに着目した場合、そのユーザの知人の名前や好きな音楽の楽曲名など、一般的ではないが重要度の高い語句が存在する。こうした語句を認識するためには、専用の音声認識サーバを設けることが望ましいが、専用音声認識サーバの開発には十分なコストをかけられないことが多く、一般的な語句に対する性能では、汎用音声認識サーバに劣ることになる。このように、汎用音声認識サーバと専用音声認識サーバとでは、語句によって認識の得手不得手があり、音声認識性能が異なる。したがって、ユーザの発した語句によってこれらを使い分けることが求められるが、音声認識というのが「内容のわからない発話に対して内容を推定する」タスクである以上、事前に発話内容を知ってサーバの使い分けを行うことは原理的に不可能である。
本発明は、汎用音声認識サーバの音声認識結果と専用音声認識サーバの音声認識結果とを最適な形で統合し、最終的に間違いの少ない音声認識機能を提供することを目的とする。
本発明においては、ユーザが持つ端末装置に含まれる特定単語のリストをあらかじめ入手し、それらの単語のデータをもとに、専用の音声認識サーバを構築する。また、それらのデータを用い、汎用音声認識サーバの性能を事前評価する。その評価結果をもとに、専用および汎用の音声認識サーバから得られた認識結果の中で、どれを採用し、それらに対してどのような重み付けを行えば最適な認識結果が得られるかを、データベースの形で保持しておく。ユーザが実際に音声認識機能を用いる際には、専用および汎用の音声認識サーバにより入力音声を認識した後、そこで得られる結果を、先に述べたデータベースの内容と比較することにより、最適な音声認識結果を得る。また、事前評価の基準として、音声認識の正しさに加えて応答速度を用いることで、なるべく正しい音声認識結果を、なるべく早く得ることができるようにする。
本発明の音声認識サーバ統合装置の一例を挙げるならば、ユーザが音声を用いて操作を行うための端末装置と、音声データを認識してその結果を返す音声認識サーバとの間を中継する装置であって、ユーザが登録した語句もしくはユーザがよく使う語句のリストに基づいて認識結果統合用のパラメータを学習し保存する統合方式学習部と、ユーザが音声認識を意図して発した音声のデータを前記端末装置から受信する手段と、前記受信した音声データを汎用音声認識サーバおよび専用音声認識サーバに送信する手段と、前記音声データの前記汎用音声認識サーバおよび専用音声認識サーバによる認識結果を受信する手段と、前記汎用音声認識サーバおよび専用音声認識サーバによる認識結果を、前記保存された認識結果統合用のパラメータと比較し、最適な認識結果を選択する認識結果統合部と、前記選択された認識結果を前記端末装置に送信する手段とを備えるものである。
本発明の音声認識サーバ統合装置において、更に、前記端末装置からユーザが登録した語句もしくはユーザがよく使う語句のリストを受信する手段と、前記受信した語句をもとに合成音声を生成する音声合成部と、前記生成された合成音声を前記汎用音声認識サーバおよび専用音声認識サーバに送信する手段と、前記合成音声の前記汎用音声認識サーバおよび専用音声認識サーバによる認識結果を受信する手段を備え、前記統合方式学習部は、前記合成音声の基となった語句と前記認識結果とを合わせて解析し、認識結果統合用パラメータを学習し保存するものでよい。
また、本発明の音声認識サーバ統合装置において、更に、前記端末装置からユーザが登録した語句もしくはユーザがよく使う語句のリストを受信する手段と、前記汎用音声認識サーバから認識用の語句リストを受信する手段と、前記認識用の語句リストを前記端末装置から受信した語句リストと比較し、類似度を推定する語句比較・類似度推定部とを備え、前記統合方式学習部は、前記推定結果を認識結果統合用のパラメータとして保存するものでよい。
本発明の音声認識サーバ統合方法の一例を挙げるならば、ユーザが登録した語句もしくはユーザがよく使う語句のリストに基づいて認識結果統合用のパラメータを学習して保存するステップと、ユーザが音声認識を意図して発した音声のデータを汎用音声認識サーバおよび専用音声認識サーバに送信するステップと、前記音声データの前記汎用音声認識サーバおよび専用音声認識サーバによる認識結果を受信するステップと、汎用音声認識サーバの認識結果および専用音声認識サーバの認識結果と、前記認識結果統合用パラメータとを比較して、最適な音声認識結果を選択するステップと、から成るものである。
本発明により、一般的な語句に関しては汎用音声認識サーバの認識結果を重要視し、ユーザ固有の語句に関しては専用音声認識サーバの結果を重要視するなど、個々の入力に対して最適な形で認識結果の統合が行われ、最終的に間違いの少ない音声認識機能をユーザに提供することが可能となる。また、間違いが少ないだけでなく、応答速度の点でも利便性の高いシステムを実現することができる。
以下、図面を用いて本発明の実施例を説明する。なお、発明を実施するための形態を説明するための全図において、同一の機能を有する要素には同一の名称、符号を付して、その繰り返しの説明を省略する。
図1は、本発明の実施例1に基づく音声認識サーバ統合装置の構成例を示す図である。音声認識機能は、ユーザ端末102、中継サーバ104、汎用音声認識サーバ群106、専用音声認識サーバ108を用いて提供される。なお、汎用音声認識サーバ群106は、単一の汎用音声認識サーバでも構わない。
ユーザ端末102は、ユーザ個人が持つ端末装置で、入力音声データの取得および音声認識結果に基づくサービスの提供を行う他に、アドレス帳や楽曲名リストなどのユーザに固有の語句リストを保持している。以下では、これらのユーザに固有の語句リストのことを「ユーザ辞書」と呼ぶ。ユーザ辞書には、ユーザが登録した語句もしくはユーザがよく使う語句のリストが保持されている。
汎用音声認識サーバ群106は、本発明により実現されるサービスのみにより使用されることを想定していない、1台以上の音声認識サーバである。一般に、大規模な語句リストを内蔵し、様々な言葉に対する認識性能が高い一方、ユーザ辞書に含まれる一部の語句については、正しく認識できない可能性がある。
専用音声認識サーバ108は、本発明により実現されるサービスに特化した音声認識サーバであり、ユーザ辞書に含まれる語句のすべてもしくは大半を認識するように設計されている。専用音声認識サーバ108は、ユーザ辞書に含まれない語句が入力された場合には、「認識結果なし」という結果が出力されるよう設計されている。専用音声認識サーバは、サーバとして構成されるものにかぎらず、専用音声認識装置でも良いし、また、実施例2や実施例5のように、ユーザ端末や中継サーバに内蔵されるものでもよい。
中継サーバ104は、本発明の「音声認識サーバ統合装置」に該当するもので、ユーザ端末102と音声認識サーバ106,108とを繋ぎ、音声認識結果の統合などを行う。ユーザ端末102とのデータのやりとりは、端末装置通信部110を介して行う。また、音声認識サーバ106,108とのデータのやりとりは、認識サーバ通信部112を介して行う。中継サーバ104は、端末装置通信部110、音声合成部114、統合方式学習部116、信号処理部120、認識結果統合部122、認識サーバ通信部112などから構成されている。
中継サーバ104の動作を説明する。はじめに、ユーザがユーザ端末102を通信可能な状態にセットすると、ユーザ辞書124のデータが端末装置通信部110を経由して送信される。このデータは直接認識サーバ通信部112に送られ、さらに専用音声認識サーバ108に送られる。専用音声認識サーバ108では、送られてきたユーザ辞書データに基づき、そこに含まれる語句を正しく認識できるようチューニングを行う。一方、端末装置通信部110で受信されたユーザ辞書データは、音声合成部114にも送られる。ここでは、文字列として送られてきたユーザ辞書データをもとに、合成音声データが作られる。一つの語句に対する合成音声データは、一つでも良いし、音質の違う複数のものであっても良い。作成された合成音声データは、認識サーバ通信部112を介して、汎用音声認識サーバ群106および専用音声認識サーバ108に送られる。これらに対する認識結果が各サーバから返されると、認識サーバ通信部112がそれを受信し、統合方式学習部116に送る。統合方式学習部116では、合成音声のもととなったユーザ辞書データと認識結果とを合わせて解析し、認識結果統合のためのパラメータを学習する。得られたパラメータは、結果統合用パラメータ118として保存される。この時点で、本発明を用いたシステムの事前学習処理が終了する。
ユーザが実際に音声インタフェースを使う際には、ユーザ端末102で取得した入力音声データが、端末装置通信部110により受信される。受信されたデータは、信号処理部120に送られ、必要な処理が施される。ここで、必要な処理とは、例えば雑音を含む入力音声から雑音を取り除くこと等を指すが、必ずしも必須ではなく、何も処理をしなくても良い。信号処理部120から出力されたデータは、認識サーバ通信部112を経て、汎用音声認識サーバ群106および専用音声認識サーバ108に送られる。これらのサーバから返された認識結果は、認識サーバ通信部112を経て、認識結果統合部122に送られる。認識結果統合部122では、複数の認識結果と、結果統合用パラメータ118に含まれるパラメータとを比較して、最適な認識結果を選択する。選択された認識結果は、端末装置通信部110を経て、ユーザ端末102に送られる。ユーザ端末102では、この結果をもとに、ナビゲーション機能の目的地を設定する、電話をかける、楽曲を再生するなどのサービスを提供する。
図2は、図1に示した構成において、ユーザ辞書データを使って結果統合用パラメータを作成するまでの処理の手順を示す図である。まず、ユーザ辞書データは、そのまま専用音声認識サーバに送られる。専用音声認識サーバでは、送られてきた語句を認識対象とするよう、音声認識エンジンをチューニングする。従って、ユーザ辞書に含まれない語句を発声したデータが送られてきた場合、専用音声認識サーバは、間違った結果を返すか、もしくは認識不能という結果を返すことになる。一方、ユーザ辞書データは、音声合成部にも送られ、そこで合成音声データが作成される。通常、一つの語句に対しては一つの合成音声が作られるが、音声合成部が、話者や話速、声の高さなどを選択できるような機能を持っている場合は、それらを変化させて、同じ語句に対して複数の合成音声データを作成すれば、後段で行う統合方式学習の性能をより高めることができる。
こうして得られた合成音声データは、各汎用音声認識サーバおよび専用音声認識サーバに送られる。それらのサーバからは、認識結果が返される。また、認識結果だけではなく、それに付随する信頼度スコアが一緒に帰される場合もある。これらを元に、統合方式学習部で統合方式を学習し、その結果を結果統合用パラメータに保存する。
図3は、結果統合用パラメータの最も簡単な構成の例を示す図である。この例では、汎用音声認識サーバが1台だけ存在すると仮定し、そのサーバで、ユーザ辞書の各語句が正しく認識されたかどうかだけを○と×で保持している。即ち、「鈴木一郎」「山田二郎」という語句は汎用音声認識サーバで正しく認識されたが、それ以外は正しく認識されなかったということを、この図は表している。図4は、同様の学習を、3台の汎用音声認識サーバを用いて行った際の例である。
図3、図4に示したような結果を使って実際に認識を行う際の処理の手順を、図5に示す。入力音声データは、はじめに信号処理部で事前処理される。信号処理部での処理の代表的なものとして、特許文献1に示されるような雑音抑圧処理が挙げられる。信号処理部での処理の結果、一つの入力音声データに対して一つの音声データが得られるのが普通であるが、設定を変えて複数の音声データが得られる場合もある。そのような場合には、以下に述べる処理を、音声データの数だけ繰り返す。また、信号処理部での処理が不要と思われる場合には、入力音声データをそのまま信号処理部の出力データとする。
信号処理部の出力データは、汎用音声認識サーバおよび専用音声認識サーバに送られる。これらの結果がすべて認識結果統合部に送られる。認識結果統合部では、まず専用音声認識サーバの認識結果をチェックする。専用認識サーバの認識結果が、「認識結果なし」であった場合、汎用音声認識サーバの認識結果のみから最終的な認識結果を決定する。すなわち、汎用音声認識サーバが1台しかない場合は、その結果をそのまま採用する。複数台ある場合には、それらの認識結果のあいだで多数決を取る。多数決を取る際、各認識サーバが信頼度スコアを付与する場合であれば、その値で重み付けをした多数決とすることもできる。また、事前に各認識サーバの性能を推定して、重み付けの係数とすることもできる。このような、一般的な語句に対する複数の音声認識サーバの認識結果の統合については、特許文献2に示されるような公知の技術を用いることが可能である。
一方、専用音声認識サーバの認識結果として、ユーザ辞書データに含まれる語句が得られた場合、図3や図4に示したような結果統合用パラメータを参照する。例えば、図3の例で、専用音声認識サーバの認識結果が「日立太郎」であった場合、結果統合用パラメータの該当する行を見ると、この語句は汎用音声認識サーバでは認識できないはずだということがわかるので、専用音声認識サーバの結果をそのまま採用する。一方、専用音声認識サーバの認識結果が「鈴木一郎」であった場合、結果統合用パラメータの該当する行を見ると、この語句は専用音声認識サーバでも認識されうるということがわかる。そこで次に汎用音声認識サーバの認識結果をチェックする。汎用音声認識サーバの認識結果も「鈴木一郎」である場合にはそのまま「鈴木一郎」を最終的な認識結果とすれば良いが、そうでない場合には、一般的に性能が高いと思われる汎用音声認識サーバの結果を優先するか、もしくは汎用音声認識サーバと専用音声認識サーバの認識結果のうち、信頼度スコアの高い方を最終認識結果として採用する。これにより、「鈴木一郎」と似た発音の言葉が、専用音声認識サーバにより誤認識されてしまった場合であっても、汎用音声認識サーバの認識結果に基づきこれを棄却することができるようになる。図4の例でも同様であり、「日立太郎」については無条件で専用音声認識サーバの結果を採用する。「鈴木一郎」については3台の汎用音声認識サーバすべてが認識可能な語句であるので、これらの認識結果での多数決、もしくはこれらすべてに専用音声認識サーバも加えての多数決により最終認識結果を決定する。また、専用音声認識サーバの認識結果が「山田二郎」であった場合には、これを正しく認識できる可能性のある汎用音声認識サーバは1番のみであることから、このサーバと専用音声認識サーバとの間で、図3の例と同じ処理を行うことにより最終認識結果を得る。
図6は、図3や図4とは異なるもう一つの結果統合用パラメータの実現例である。ここでは、ある語句が各汎用音声認識サーバで認識可能な場合に、その語句が正しく認識される確率を重みの数値に置き換えて保持している。ここで、正しく認識される確率は、たとえば「鈴木一郎」という語句に対し、音声合成用パラメータを様々に変えて作った合成音声による認識を行い、それらに対する認識結果のうち何個が正しいものであったかにより推定することができる。また、汎用音声認識サーバが複数の認識結果候補を返す仕様になっている場合には、正解単語の平均順位や平均信頼度スコアなどを用いることもできる。これらの値を適当な非線形変換により重み値に変換したものを、結果統合用パラメータに保持する。この例では、専用音声認識サーバの認識結果が「鈴木一郎」、汎用サーバ1の結果が「佐々木一郎」、汎用サーバ2と3の結果が「鈴木一郎」だった場合、「佐々木一郎」の重みが3.0、「鈴木一郎」の重みが1.4と1.2の和で2.6となり、前者の方が大きいことから、「佐々木一郎」を最終認識結果とする。
図7は、図3,4,6とは異なるもう一つの結果統合用パラメータの実現例である。ここでは、ユーザ辞書データに含まれる語句を汎用音声認識サーバで認識して、正しく認識されなかった場合においても、そのときに得られた認識結果を結果統合用パラメータとして保存しておく。それぞれのサーバの重みを設定するのは図6の例と同様である。複数回の実験を行った際には、最も多かった結果のみか、もしくは複数の認識結果を保存しておいても良い。また、実験の回数にかかわらず、2位以下の認識結果も併せて保存しておいても良い。認識実行時には、これまでの例と同じように、専用音声認識サーバの認識結果に基づき結果統合用パラメータを参照する。その際、汎用音声認識サーバの認識結果が、結果統合用パラメータに保存されているものと一致するかどうかをチェックする。例えば、専用音声認識サーバの認識結果が「日立太郎」で、汎用サーバ1の結果が「日立市」、汎用サーバ2の結果が「二十歳」、汎用サーバ3の結果が「日立」だった場合、汎用サーバ1の結果は「日立太郎」に変換した上で、各認識結果での多数決を行い、最終的に「日立太郎」が選択される。
図8は、同音異表記の検出を利用した、音声認識結果統合方式の例を示す図である。図に示すように、専用音声認識サーバの認識結果が「左藤一郎」である場合、これを汎用音声認識サーバの各認識結果と比較し、同音異表記が含まれないかをチェックする。ここで、表記から発音を推定するには、日本語であれば、個々の漢字の読みをデータとして保持しておき、当該語句を構成する漢字の読みを連結することにより発音表記を得る。英語であれば、部分的な綴りに対する読み付与のルールを保持しておき、これらを順次適用することにより発音表記を得る。その他の言語の場合であっても、一般にGrapheme to Phonemeと呼ばれる技術によって、発音表記を得ることができることは良く知られている。また、ユーザ辞書データの中に、漢字表記とカナ表記のように、発音情報が含まれている場合もあり、そのような場合にはそれを活用する。上述のチェックにより、同音異表記が含まれている場合には、当該認識結果の表記を専用音声認識サーバによる認識結果の表記に変換して用いる。図の例では、汎用音声認識サーバ1の認識結果「佐藤一郎」が、専用音声認識サーバの認識結果と同音であることから、これを「左藤一郎」に変換する。その結果、3台の汎用音声認識サーバによる多数決の結果は「左藤一郎」となり、これが最終結果として採用される。
図9は、自動車内でのナビゲーション機能やハンズフリー通話機能などを提供する場合を例に、ユーザ端末の具体的な実現形態の例を示した図である。(a)では、マイク装置904、アプリケーション906、通信モジュール908などのすべての機能をカーナビゲーション装置902内に実装している。(b)では、カーナビゲーション装置902とスマートフォン910とを連結し、マイク装置904はカーナビゲーション装置902のものを、通信部908はスマートフォン910のものを用いている。アプリケーション912,914は、それぞれの機能に応じて、カーナビゲーション装置内とスマートフォン内に分散して配置するか、もしくはどちらか片方のみに配置する。(c)では、スマートフォン910内に、すべての機能を実装する。
図10は、本発明を構成するユーザ辞書124の作成方法の例を示した図である。例えば、ユーザ端末102内にアドレス帳1002が存在する場合には、そこに含まれる人名をユーザ辞書に登録する。同様に、音楽プレーヤーの楽曲リスト1004が存在する場合には、そこに含まれる楽曲名やアーティスト名をユーザ辞書に登録する。また、ウェブブラウザのブックマーク1006として登録されたページタイトルをユーザ辞書に登録することもできる。その他に、ユーザ端末内に蓄積されたメール1008やショートメッセージなどのデータを解析し、そこに頻出する語句をユーザ辞書に登録するという方式も可能である。これらのデータに関しては、ユーザ端末がはじめて本発明によるシステムに接続された際には、ユーザ端末に含まれる全ユーザ辞書データをシステムに送信するのに加えて、アドレス帳や楽曲リストなどへの新規エントリの追加時には、新規追加データのみをシステムに追加送信し、結果統合用パラメータの更新を促すという方式を採ることもできる。このとき、結果統合用パラメータだけでなく、専用音声認識部の照合用辞書も同時に更新する必要がある。
図11は、一般的な音声合成部の構成を変更し、本発明に特化した特殊な構成の一例を示す図である。一般に音声合成部114は、合成音声作成部1102と、音声素片データ1106~1110とから成る。ここで、素片データとは、データを直接つなぎあわせて合成音声を作る方式で用いるためのデータの名称であるが、直接つなぎあわせる代わりに、統計処理と信号処理により波形を合成する方式を用いる場合でも、個々の音素や音節などの処理単位に対し、類似のデータ集合を用いるため、以下に述べる方式を適用することは可能である。合成音声作成部1102では、音声素片データを繋ぎ合わせ、必要であれば適切な信号処理を行い、標準合成音声を作成する。しかし、本発明においては、ユーザ端末の所有者である特定ユーザの声に対して各汎用音声認識サーバ群がどのように反応するかを知ることが重要であるので、音声合成部で作成される合成音声も、ユーザの声に似たものであることが望ましい。そこで、ユーザが音声認識機能を使用するたびに、あるいはそれ以外の音声機能や音声通話を使用するたびに、その声をユーザ音声データ1112として蓄積しておき、これを活用して音声変換部1104により標準合成音声からユーザ適応音声への変換を行う。こうして変換した音声を汎用音声認識サーバ群への入力とすることにより、より精度の高い性能予測を行うことが可能となり、結果統合用パラメータの値もより適切なものになることが期待できる。
図12は、音声認識の正しさに加えて、応答速度を評価基準とする場合の結果統合用パラメータの例を示す図である。この例では、ユーザ辞書データに含まれる各語句に対応する合成音声を用いた認識を実行し、その処理にかかった平均時間をパラメータとして保持しておく。この例でいうと、専用音声認識サーバの認識結果が「鈴木一郎」であった場合、汎用サーバ2の認識結果は0.5秒で得られると期待されるが、汎用サーバ1の認識結果を得るには1.5秒も待たなければならない。この応答時間がアプリケーションで想定される上限値を上回る場合、汎用サーバ2の結果が得られた時点で結果統合処理を行う。これにより、結果統合処理にほとんど時間がかからないと仮定すると、約0.5秒の応答時間で最終認識結果を得ることができることになり、ユーザの利便性を向上させることができる。
図13は、ユーザ端末内に組み込まれた専用音声認識部108を用いて、図1に示した例と同等の機能を実現するような例の構成を示した図である。ここでは、ユーザ端末102が、中継サーバ104を介することなく、内部に存在する専用音声認識部108を用いてユーザ辞書124に含まれる語句の認識を行う。ユーザ辞書データを用いて、汎用音声認識サーバ群106の性能評価を事前に行う方法は、図1の場合に示したものと同様である。認識実行時には、中継サーバ104を介して汎用音声認識サーバ106による認識を実行すると同時に、ユーザ端末内の専用音声認識部108でも認識を実行する。このような、端末内の音声認識部と、通信装置を介して接続された音声認識部とを併用する方式は、特許文献3にも示されているが、特許文献3記載の発明が、通信経路が確立されているかどうかという点に着目して結果の取捨選択を行うのに対し、本発明では、事前に行った音声認識の結果に基づき求めた結果統合用パラメータを用いるという点が異なっている。
図14は、本発明に基づく音声認識サーバ統合装置のもう一つの構成例を示す図である。ここでは、汎用音声認識サーバ群106の機能として、そこで用いられている認識用語句リストが入手可能である場合を想定する。そのような条件のもとで、ユーザ端末102から中継サーバ104に送られたユーザ辞書データは、語句比較・類似度推定部126に送られる。当該部では、汎用音声認識サーバ群106から入手した認識用語句リストとユーザ辞書データとを比較し、ユーザ辞書124に含まれる各語句が、各々のサーバで正しく認識されうるかどうかを判定する。判定結果は統合方式学習部116に送られ、パラメータとして整理されたものが結果統合用パラメータ118に保持される。一方、ユーザ辞書データがそのまま専用音声認識サーバ108に送られ、専用音声認識サーバがチューニングされるのは、図1に示した例と同じである。
このような準備が済んだ状態で、ユーザ端末102から入力音声データが送られてくると、図1に示した例と同様に、信号処理部120を経由して、汎用音声認識サーバ106および専用音声認識サーバ108に当該データが送られる。それらのサーバから返された認識結果は、認識結果統合部122に送られ、そこで、結果統合用パラメータ118との比較により、最適な認識結果が選択される。選択された認識結果がユーザ端末102に送信されて後は、図1に示した例と同様である。
図15は、図14に示した構成において、ユーザ辞書データを使って結果統合用パラメータを作成するまでの処理の手順を示す図である。この例では、合成音声を作成することも、それを使って音声認識を実行してみることもなく、単に各汎用音声認識サーバから認識用語句リストを取得する。これらのリストと、ユーザ辞書データに含まれる語句とを比較し、ユーザ辞書データの各語句が、どの汎用音声認識サーバの語句リストに含まれているかをデータ化する。ここでは、認識用語句リストに含まれている(○)か、含まれていない(×)かのどちらかしか有り得ないことから、得られた結果をまとめた結果統合用パラメータは、図3ないし図4と同じものになる。従って、実際の認識を行う際の使い方も、前述した例と同じになる。また、各汎用音声認識サーバから、語句リストのみならず、それらの語句の認識されやすさを表す言語モデルを入手することが可能な際には、図6のような重み付きの結果統合用パラメータを作成することもできる。たとえば、代表的な言語モデルであるNグラム言語モデルを用いる場合、ユニグラムの値をその単語の認識されやすさとする、もしくは倍グラムやトライグラムの最大値をその単語の認識されやすさとするなどの方式が考えられる。
図16は、ユーザとの間の入出力機能と音声認識サーバ統合機能とを単一の装置の中に組み込んだ装置により、図1に示した例と同等の機能を実現するような例の構成を示した図である。ここでは、音声認識サーバ統合装置104の内部に蓄積されているユーザ辞書124に含まれるユーザ辞書データが、装置内の音声合成部114および認識サーバ通信部112に転送される。ユーザが話した声は、マイク装置128により取り込まれ、信号処理部120に転送される。これらを用いた処理の進め方は、図1の例において説明したものと同等であり、結果として認識結果統合部122にて認識結果が確定させられる。この認識結果は、装置内の表示部132に転送され、ユーザに提示される。
図17は、図16に示した例をもとに、さらに専用音声認識サーバが担っている機能を音声認識サーバ統合装置に組み込んだ場合の構成を示した図である。音声認識サーバ統合装置104に含まれるマイク装置128から入力音声が取り込まれ、ユーザ辞書124からユーザ辞書データが転送される部分は図16の例と同様であるが、それらに加えて、専用音声認識部108が装置内に組み込まれており、ユーザ辞書の内容を直接読み出した上で、マイク装置から送られてくる音声データを認識する。そこで得られた単体認識結果は、認識結果統合部122に送られ、汎用音声認識サーバ群106によって得られた認識結果と統合される。統合された認識結果は、装置内に存在するアプリケーション130に送られ、そこで各々のアプリケーションの目的に沿って活用される。
本発明は、車載端末と音声認識サーバとの間に介在して、高精度の音声認識機能を提供するための音声データ中継装置として利用可能である。
102 ユーザ端末
104 中継サーバ
106 汎用音声認識サーバ群
108 専用音声認識サーバ
110 端末装置通信部
112 認識サーバ通信部
114 音声合成部
116 統合方式学習部
118 結果統合用パラメータ
120 信号処理部
122 認識結果統合部
124 ユーザ辞書
126 語句比較・類似度推定部
128 マイク装置
130 アプリケーション
132 表示部
104 中継サーバ
106 汎用音声認識サーバ群
108 専用音声認識サーバ
110 端末装置通信部
112 認識サーバ通信部
114 音声合成部
116 統合方式学習部
118 結果統合用パラメータ
120 信号処理部
122 認識結果統合部
124 ユーザ辞書
126 語句比較・類似度推定部
128 マイク装置
130 アプリケーション
132 表示部
Claims (15)
- ユーザが音声を用いて操作を行うための端末装置と、音声データを認識してその結果を返す音声認識サーバとの間を中継する装置であって、
ユーザが登録した語句もしくはユーザがよく使う語句のリストに基づいて認識結果統合用のパラメータを学習し保存する統合方式学習部と、
ユーザが音声認識を意図して発した音声のデータを前記端末装置から受信する手段と、
前記受信した音声データを汎用音声認識サーバおよび専用音声認識サーバに送信する手段と、
前記音声データの前記汎用音声認識サーバおよび専用音声認識サーバによる認識結果を受信する手段と、
前記汎用音声認識サーバおよび専用音声認識サーバによる認識結果を、前記保存された認識結果統合用のパラメータと比較し、最適な認識結果を選択する認識結果統合部と、
前記選択された認識結果を前記端末装置に送信する手段と
を備える音声認識サーバ統合装置。 - 請求項1記載の音声認識サーバ統合装置において、更に、
前記端末装置からユーザが登録した語句もしくはユーザがよく使う語句のリストを受信する手段と、
前記受信した語句をもとに合成音声を生成する音声合成部と、
前記生成された合成音声を前記汎用音声認識サーバおよび専用音声認識サーバに送信する手段と、
前記合成音声の前記汎用音声認識サーバおよび専用音声認識サーバによる認識結果を受信する手段を備え、
前記統合方式学習部は、前記合成音声の基となった語句と前記認識結果とを合わせて解析し、認識結果統合用パラメータを学習し保存することを特徴とする音声認識サーバ統合装置。 - 請求項1記載の音声認識サーバ統合装置において、更に、
前記端末装置からユーザが登録した語句もしくはユーザがよく使う語句のリストを受信する手段と、
前記汎用音声認識サーバから認識用の語句リストを受信する手段と、
前記認識用の語句リストを前記端末装置から受信した語句リストと比較し、類似度を推定する語句比較・類似度推定部とを備え、
前記統合方式学習部は、前記推定結果を認識結果統合用のパラメータとして保存することを特徴とする音声認識サーバ統合装置。 - ユーザが音声を用いて操作を行うための装置であって、
ユーザが登録した語句もしくはユーザがよく使う語句のリストに基づいて認識結果統合用のパラメータを学習し保存する統合方式学習部と、
ユーザが音声認識を意図して発した音声のデータを汎用音声認識サーバおよび専用音声認識サーバに送信する手段と、
前記音声データの前記汎用音声認識サーバおよび専用音声認識サーバによる認識結果を受信する手段と、
前記汎用音声認識サーバおよび専用音声認識サーバの認識結果を、前記保存された認識結果統合用パラメータと比較し、最適な認識結果を選択する認識結果統合部と、
前記選択された認識結果を表示する表示部を備える音声認識サーバ統合装置。 - 請求項4記載の音声認識サーバ統合装置において、更に、
ユーザが登録した語句もしくはユーザがよく使う語句を記憶するユーザ辞書と、
前記ユーザ辞書に記憶した語句をもとに合成音声を生成する音声合成部と、
前記生成された合成音声を前記汎用音声認識サーバおよび専用音声認識サーバに送信する手段と、
前記合成音声の前記汎用音声認識サーバおよび専用音声認識サーバによる認識結果を受信する手段とを備え、
前記統合方式学習部は、前記合成音声の基となった語句と前記認識結果とを合わせて解析し、認識結果統合用パラメータを学習し保存することを特徴とする音声認識サーバ統合装置。 - 請求項4記載の音声認識サーバ統合装置において、更に、
ユーザが登録した語句もしくはユーザがよく使う語句のリストを記憶するユーザ辞書と、
前記汎用音声認識サーバから認識用の語句リストを受信する手段と、
前記認識用の語句リストを前記ユーザ辞書の語句リストと比較し、類似度を推定する語句比較・類似推定部とを備え、
前記統合方式学習部は、前記推定結果を認識結果統合用のパラメータとして保存することを特徴とする音声認識サーバ統合装置。 - 請求項1~6の何れか1つに記載の音声認識サーバ統合装置において、
前記専用音声認識サーバは、ユーザが登録した語句もしくはユーザがよく使う語句のリストをもとに認識対象語句リストを作成し、このリストに含まれる語句を高い精度で認識することが可能なことを特徴とする音声認識サーバ統合装置。 - 請求項1~6の何れか1つに記載の音声認識サーバ統合装置において、
前記専用音声認識サーバは、前記音声認識サーバ統合装置或いは端末装置内に音声専用認識部として組み込まれていることを特徴とする音声認識サーバ統合装置。 - 請求項2または請求項5に記載の音声認識サーバ統合装置において、
前記認識結果統合用パラメータは、ユーザが登録した語句もしくはユーザがよく使う語句に対する音声認識サーバの認識結果の正誤を蓄積するものであり、
前記認識結果統合部は、前記専用音声認識サーバによる認識結果をもとに、その単語に対する音声認識サーバの認識結果を前記認識結果統合用パラメータから取り出し、かつ、
前記取り出した結果が正であるような音声認識サーバによる音声認識結果のみを取り出し、前記取り出した認識結果に基づき最適な認識結果を選択することを特徴とする音声認識サーバ統合装置。 - 請求項2または請求項5に記載の音声認識サーバ統合装置において、
前記認識結果統合用パラメータは、ユーザが登録した語句もしくはユーザがよく使う語句に対する音声認識サーバの認識結果の正誤、および、個々の語句に対する前記音声認識サーバの認識結果の信頼度を表す値を蓄積するものであり、
前記認識結果統合部は、前記専用音声認識サーバによる認識結果をもとに、前記認識結果統合用パラメータからその単語に対する前記音声認識サーバの認識結果およびその信頼度を取り出し、かつ、前記取り出した認識結果が正であるような音声認識サーバによる音声認識結果および信頼度のみを取り出し、前記取り出した音声認識結果を前記信頼度の重み付けをして統合することを特徴とする音声認識サーバ統合装置。 - 請求項2または請求項5に記載の音声認識サーバ統合装置において、
前記認識結果統合用パラメータは、ユーザが登録した語句もしくはユーザがよく使う語句に対する音声認識サーバの認識にかかる時間を測定し測定値を蓄積するものであり、
前記認識結果統合部は、前記専用音声認識サーバによる認識結果をもとに、前記認識結果統合用パラメータからその単語に対する前記音声認識サーバの認識所要時間を取り出し、アプリケーションに依存して決まる認識所要時間の許容上限値を取得し、音声認識サーバのうち認識所要時間が前記許容上限値を下回るもののみの認識結果を取り出すことにより、前記取り出した認識結果をもとに最適な認識結果を選択することを特徴とする音声認識サーバ統合装置。 - 請求項2または請求項5に記載の音声認識サーバ統合装置において、
前記認識結果統合用パラメータは、ユーザが登録した語句もしくはユーザがよく使う語句に対する音声認識サーバの認識結果の正誤および1つもしくは複数の誤認識結果を蓄積するものであり、
前記認識結果統合部は、前記専用音声認識サーバによる認識結果をもとに、前記認識結果統合用パラメータからその単語に対する前記音声認識サーバの認識結果の正誤および誤認識結果を取り出し、前記取り出した認識結果が誤である場合には前記取り出した誤認識結果を実行時の認識結果と比較し、前記比較の結果が同一であると判定された場合のみ当該認識結果を有効とすることにより、前記有効とされた認識結果をもとに最適な認識結果を選択することを特徴とする音声認識サーバ統合装置。 - ユーザが登録した語句もしくはユーザがよく使う語句のリストに基づいて認識結果統合用のパラメータを学習して保存するステップと、
ユーザが音声認識を意図して発した音声のデータを汎用音声認識サーバおよび専用音声認識サーバに送信するステップと、
前記音声データの前記汎用音声認識サーバおよび専用音声認識サーバによる認識結果を受信するステップと、
汎用音声認識サーバの認識結果および専用音声認識サーバの認識結果と、前記認識結果統合用パラメータとを比較して、最適な音声認識結果を選択するステップと、
から成る音声認識サーバ統合方法。 - 請求項13記載の音声認識サーバ統合方法において、更に、
ユーザが登録した語句もしくはユーザがよく使う語句をもとに合成音声を生成するステップと、
前記生成された合成音声を前記汎用音声認識サーバおよび専用音声認識サーバに送信するステップと、
前記合成音声の前記汎用音声認識サーバおよび専用音声認識サーバによる認識結果を受信するステップとを備え、
認識結果統合用のパラメータを学習して保存するステップは、前記合成音声の基となった語句と前記認識結果とを合わせて解析し、認識結果統合用パラメータを学習し保存することを特徴とする音声認識サーバ統合方法。 - 請求項13記載の音声認識サーバ統合方法において、更に、
ユーザが登録した語句もしくはユーザがよく使う語句のリストを得るステップと、
前記汎用音声認識サーバから認識用の語句リストを受信するステップと、
前記認識用の語句リストを、前記ユーザが登録した語句もしくはユーザがよく使う語句のリストと比較し、類似度を推定するステップとを備え、
前記認識結果統合用のパラメータを学習して保存するステップは、前記推定結果を認識結果統合用のパラメータとして保存することを特徴とする音声認識サーバ統合方法。
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US14/391,200 US9524718B2 (en) | 2012-04-09 | 2013-04-03 | Speech recognition server integration device that is an intermediate module to relay between a terminal module and speech recognition server and speech recognition server integration method |
| CN201380018950.0A CN104221078B (zh) | 2012-04-09 | 2013-04-03 | 声音识别服务器综合装置以及声音识别服务器综合方法 |
| EP13775442.0A EP2838085B1 (en) | 2012-04-09 | 2013-04-03 | Voice recognition server integration device and voice recognition server integration method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2012088230A JP5957269B2 (ja) | 2012-04-09 | 2012-04-09 | 音声認識サーバ統合装置および音声認識サーバ統合方法 |
| JP2012-088230 | 2012-04-09 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2013154010A1 true WO2013154010A1 (ja) | 2013-10-17 |
Family
ID=49327578
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2013/060238 WO2013154010A1 (ja) | 2012-04-09 | 2013-04-03 | 音声認識サーバ統合装置および音声認識サーバ統合方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US9524718B2 (ja) |
| EP (1) | EP2838085B1 (ja) |
| JP (1) | JP5957269B2 (ja) |
| CN (1) | CN104221078B (ja) |
| WO (1) | WO2013154010A1 (ja) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3037982A3 (en) * | 2014-12-25 | 2016-07-20 | Clarion Co., Ltd. | Intention estimation equipment and intention estimation system |
| EP3193482B1 (en) * | 2014-10-08 | 2020-02-05 | Huawei Technologies Co., Ltd. | Message processing method and apparatus |
| CN110827794A (zh) * | 2019-12-06 | 2020-02-21 | 科大讯飞股份有限公司 | 语音识别中间结果的质量评测方法和装置 |
Families Citing this family (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102012202407B4 (de) * | 2012-02-16 | 2018-10-11 | Continental Automotive Gmbh | Verfahren zum Phonetisieren einer Datenliste und sprachgesteuerte Benutzerschnittstelle |
| JP5698864B2 (ja) * | 2012-03-07 | 2015-04-08 | パイオニア株式会社 | ナビゲーション装置、サーバ、ナビゲーション方法及びプログラム |
| DE102014200570A1 (de) * | 2014-01-15 | 2015-07-16 | Bayerische Motoren Werke Aktiengesellschaft | Verfahren und System zur Erzeugung eines Steuerungsbefehls |
| DE102014114845A1 (de) * | 2014-10-14 | 2016-04-14 | Deutsche Telekom Ag | Verfahren zur Interpretation von automatischer Spracherkennung |
| CN104683456B (zh) * | 2015-02-13 | 2017-06-23 | 腾讯科技(深圳)有限公司 | 业务处理方法、服务器及终端 |
| US20180047387A1 (en) * | 2015-03-05 | 2018-02-15 | Igal NIR | System and method for generating accurate speech transcription from natural speech audio signals |
| US10152298B1 (en) * | 2015-06-29 | 2018-12-11 | Amazon Technologies, Inc. | Confidence estimation based on frequency |
| US9734821B2 (en) | 2015-06-30 | 2017-08-15 | International Business Machines Corporation | Testing words in a pronunciation lexicon |
| KR20170032096A (ko) * | 2015-09-14 | 2017-03-22 | 삼성전자주식회사 | 전자장치, 전자장치의 구동방법, 음성인식장치, 음성인식장치의 구동 방법 및 컴퓨터 판독가능 기록매체 |
| US20180025731A1 (en) * | 2016-07-21 | 2018-01-25 | Andrew Lovitt | Cascading Specialized Recognition Engines Based on a Recognition Policy |
| CN106297797B (zh) * | 2016-07-26 | 2019-05-31 | 百度在线网络技术(北京)有限公司 | 语音识别结果纠错方法和装置 |
| US10748531B2 (en) * | 2017-04-13 | 2020-08-18 | Harman International Industries, Incorporated | Management layer for multiple intelligent personal assistant services |
| JP6934351B2 (ja) * | 2017-08-03 | 2021-09-15 | 株式会社大塚商会 | Aiサービス利用支援システム |
| US10013654B1 (en) | 2017-11-29 | 2018-07-03 | OJO Labs, Inc. | Cooperatively operating a network of supervised learning processors to concurrently distribute supervised learning processor training and provide predictive responses to input data |
| US10019491B1 (en) * | 2017-11-29 | 2018-07-10 | OJO Labs, Inc. | Machine learning of response selection to structured data input |
| CN108428446B (zh) * | 2018-03-06 | 2020-12-25 | 北京百度网讯科技有限公司 | 语音识别方法和装置 |
| JP6543755B1 (ja) * | 2018-04-13 | 2019-07-10 | 株式会社Tbsテレビ | 音声認識テキストデータ出力制御装置、音声認識テキストデータ出力制御方法、及びプログラム |
| TWI682386B (zh) * | 2018-05-09 | 2020-01-11 | 廣達電腦股份有限公司 | 整合式語音辨識系統及方法 |
| US11107475B2 (en) | 2019-05-09 | 2021-08-31 | Rovi Guides, Inc. | Word correction using automatic speech recognition (ASR) incremental response |
| JP7104247B2 (ja) * | 2019-07-09 | 2022-07-20 | グーグル エルエルシー | オンデバイスの音声認識モデルの訓練のためのテキストセグメントのオンデバイスの音声合成 |
| KR102321801B1 (ko) | 2019-08-20 | 2021-11-05 | 엘지전자 주식회사 | 지능적 음성 인식 방법, 음성 인식 장치 및 지능형 컴퓨팅 디바이스 |
| KR20210027991A (ko) * | 2019-09-03 | 2021-03-11 | 삼성전자주식회사 | 전자장치 및 그 제어방법 |
| JP7522060B2 (ja) | 2021-03-03 | 2024-07-24 | 株式会社Nttドコモ | 音声認識装置 |
| US20240005917A1 (en) * | 2021-03-16 | 2024-01-04 | Shenzhen Horizon Robotics Technology Co., Ltd. | Speech interaction method ,and apparatus, computer readable storage medium, and electronic device |
| WO2024185283A1 (ja) * | 2023-03-08 | 2024-09-12 | 日本電気株式会社 | 情報処理装置、情報処理方法、及び、記録媒体 |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002116796A (ja) | 2000-10-11 | 2002-04-19 | Canon Inc | 音声処理装置、音声処理方法及び記憶媒体 |
| JP2006243673A (ja) * | 2005-03-07 | 2006-09-14 | Canon Inc | データ検索装置および方法 |
| JP2008242067A (ja) | 2007-03-27 | 2008-10-09 | Advanced Telecommunication Research Institute International | 音声認識装置、音声認識システムおよび音声認識方法 |
| JP2010085536A (ja) * | 2008-09-30 | 2010-04-15 | Fyuutorekku:Kk | 音声認識システム、音声認識方法、音声認識クライアントおよびプログラム |
| JP2010224301A (ja) | 2009-03-24 | 2010-10-07 | Denso Corp | 音声認識システム |
| WO2011121978A1 (ja) * | 2010-03-29 | 2011-10-06 | 日本電気株式会社 | 音声認識システム、装置、方法、およびプログラム |
| JP2013007764A (ja) * | 2011-06-22 | 2013-01-10 | Clarion Co Ltd | 音声データ中継装置、端末装置、音声データ中継方法、および音声認識システム |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR0165244B1 (ko) * | 1992-08-31 | 1999-03-20 | 윤종용 | 비디오 프린터의 화상 메모리 시스템 |
| JP3968133B2 (ja) * | 1995-06-22 | 2007-08-29 | セイコーエプソン株式会社 | 音声認識対話処理方法および音声認識対話装置 |
| US6076054A (en) * | 1996-02-29 | 2000-06-13 | Nynex Science & Technology, Inc. | Methods and apparatus for generating and using out of vocabulary word models for speaker dependent speech recognition |
| JP2003108170A (ja) * | 2001-09-26 | 2003-04-11 | Seiko Epson Corp | 音声合成学習方法および音声合成学習装置 |
| US7231019B2 (en) | 2004-02-12 | 2007-06-12 | Microsoft Corporation | Automatic identification of telephone callers based on voice characteristics |
| CN1753083B (zh) * | 2004-09-24 | 2010-05-05 | 中国科学院声学研究所 | 语音标记方法、系统及基于语音标记的语音识别方法和系统 |
| JP2007033901A (ja) | 2005-07-27 | 2007-02-08 | Nec Corp | 音声認識システム、音声認識方法、および音声認識用プログラム |
| JP5233989B2 (ja) * | 2007-03-14 | 2013-07-10 | 日本電気株式会社 | 音声認識システム、音声認識方法、および音声認識処理プログラム |
| US7933777B2 (en) * | 2008-08-29 | 2011-04-26 | Multimodal Technologies, Inc. | Hybrid speech recognition |
| CN101923854B (zh) * | 2010-08-31 | 2012-03-28 | 中国科学院计算技术研究所 | 一种交互式语音识别系统和方法 |
-
2012
- 2012-04-09 JP JP2012088230A patent/JP5957269B2/ja active Active
-
2013
- 2013-04-03 WO PCT/JP2013/060238 patent/WO2013154010A1/ja active Application Filing
- 2013-04-03 CN CN201380018950.0A patent/CN104221078B/zh not_active Expired - Fee Related
- 2013-04-03 US US14/391,200 patent/US9524718B2/en active Active
- 2013-04-03 EP EP13775442.0A patent/EP2838085B1/en active Active
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2002116796A (ja) | 2000-10-11 | 2002-04-19 | Canon Inc | 音声処理装置、音声処理方法及び記憶媒体 |
| JP2006243673A (ja) * | 2005-03-07 | 2006-09-14 | Canon Inc | データ検索装置および方法 |
| JP2008242067A (ja) | 2007-03-27 | 2008-10-09 | Advanced Telecommunication Research Institute International | 音声認識装置、音声認識システムおよび音声認識方法 |
| JP2010085536A (ja) * | 2008-09-30 | 2010-04-15 | Fyuutorekku:Kk | 音声認識システム、音声認識方法、音声認識クライアントおよびプログラム |
| JP2010224301A (ja) | 2009-03-24 | 2010-10-07 | Denso Corp | 音声認識システム |
| WO2011121978A1 (ja) * | 2010-03-29 | 2011-10-06 | 日本電気株式会社 | 音声認識システム、装置、方法、およびプログラム |
| JP2013007764A (ja) * | 2011-06-22 | 2013-01-10 | Clarion Co Ltd | 音声データ中継装置、端末装置、音声データ中継方法、および音声認識システム |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3193482B1 (en) * | 2014-10-08 | 2020-02-05 | Huawei Technologies Co., Ltd. | Message processing method and apparatus |
| US10567507B2 (en) | 2014-10-08 | 2020-02-18 | Huawei Technologies Co., Ltd. | Message processing method and apparatus, and message processing system |
| EP3037982A3 (en) * | 2014-12-25 | 2016-07-20 | Clarion Co., Ltd. | Intention estimation equipment and intention estimation system |
| US9569427B2 (en) | 2014-12-25 | 2017-02-14 | Clarion Co., Ltd. | Intention estimation equipment and intention estimation system |
| CN110827794A (zh) * | 2019-12-06 | 2020-02-21 | 科大讯飞股份有限公司 | 语音识别中间结果的质量评测方法和装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2838085A1 (en) | 2015-02-18 |
| EP2838085A4 (en) | 2016-01-13 |
| CN104221078A (zh) | 2014-12-17 |
| JP5957269B2 (ja) | 2016-07-27 |
| CN104221078B (zh) | 2016-11-02 |
| US9524718B2 (en) | 2016-12-20 |
| US20150088506A1 (en) | 2015-03-26 |
| EP2838085B1 (en) | 2019-09-04 |
| JP2013218095A (ja) | 2013-10-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5957269B2 (ja) | 音声認識サーバ統合装置および音声認識サーバ統合方法 | |
| US6910012B2 (en) | Method and system for speech recognition using phonetically similar word alternatives | |
| JP5066483B2 (ja) | 言語理解装置 | |
| EP1936606B1 (en) | Multi-stage speech recognition | |
| JP6251958B2 (ja) | 発話解析装置、音声対話制御装置、方法、及びプログラム | |
| JP5200712B2 (ja) | 音声認識装置、音声認識方法及びコンピュータプログラム | |
| EP2048655B1 (en) | Context sensitive multi-stage speech recognition | |
| US20040039570A1 (en) | Method and system for multilingual voice recognition | |
| US20060122837A1 (en) | Voice interface system and speech recognition method | |
| WO2012073275A1 (ja) | 音声認識装置及びナビゲーション装置 | |
| JP5868544B2 (ja) | 音声認識装置および音声認識方法 | |
| JP2007213005A (ja) | 認識辞書システムおよびその更新方法 | |
| KR19980070329A (ko) | 사용자 정의 문구의 화자 독립 인식을 위한 방법 및 시스템 | |
| EP1734509A1 (en) | Method and system for speech recognition | |
| US7912707B2 (en) | Adapting a language model to accommodate inputs not found in a directory assistance listing | |
| JP2007047412A (ja) | 認識文法モデル作成装置、認識文法モデル作成方法、および、音声認識装置 | |
| JP5274191B2 (ja) | 音声認識装置 | |
| EP1743325A2 (en) | System and method for speech-to-text conversion using constrained dictation in a speak-and-spell mode | |
| US10866948B2 (en) | Address book management apparatus using speech recognition, vehicle, system and method thereof | |
| US20050187767A1 (en) | Dynamic N-best algorithm to reduce speech recognition errors | |
| WO2008150003A1 (ja) | キーワード抽出モデル学習システム、方法およびプログラム | |
| CN114360514A (zh) | 语音识别方法、装置、设备、介质及产品 | |
| JP3444108B2 (ja) | 音声認識装置 | |
| JP3911178B2 (ja) | 音声認識辞書作成装置および音声認識辞書作成方法、音声認識装置、携帯端末器、音声認識システム、音声認識辞書作成プログラム、並びに、プログラム記録媒体 | |
| KR20050101695A (ko) | 인식 결과를 이용한 통계적인 음성 인식 시스템 및 그 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 13775442 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 14391200 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2013775442 Country of ref document: EP |