WO2013098561A1 - Method for characterising a polynucelotide by using a xpd helicase - Google Patents
Method for characterising a polynucelotide by using a xpd helicase Download PDFInfo
- Publication number
- WO2013098561A1 WO2013098561A1 PCT/GB2012/053273 GB2012053273W WO2013098561A1 WO 2013098561 A1 WO2013098561 A1 WO 2013098561A1 GB 2012053273 W GB2012053273 W GB 2012053273W WO 2013098561 A1 WO2013098561 A1 WO 2013098561A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- helicase
- pore
- target polynucleotide
- polynucleotide
- Prior art date
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
Definitions
- the invention relates to a new method of characterising a target polynucleotide.
- the method uses a pore and an XPD helicase.
- the helicase controls the movement of the target polynucleotide through the pore.
- Nanopores Transmembrane pores have great potential as direct, electrical biosensors for polymers and a variety of small molecules.
- recent focus has been given to nanopores as a potential DNA sequencing technology.
- Nanopore detection of the nucleotide gives a current change of known signature and duration.
- Strand Sequencing can involve the use of a nucleotide handling protein to control the movement of the polynucleotide through the pore.
- an XPD helicase can control the movement of a polynucleotide through a pore especially when a potential, such as a voltage, is applied.
- the helicase is capable of moving a target polynucleotide in a controlled and stepwise fashion against or with the field resulting from the applied voltage.
- the helicase is capable of functioning at a high salt concentration which is advantageous for characterising the
- polynucleotide and, in particular, for determining its sequence using Strand Sequencing. This is discussed in more detail below.
- the invention provides a method of characterising a target polynucleotide, comprising: (a) contacting the target polynucleotide with a transmembrane pore and a XPD helicase such that the target polynucleotide moves through the pore and the XPD helicase controls the movement of the target polynucleotide through the pore; and
- the invention also provides:
- a method of forming a sensor for characterising a target polynucleotide comprising forming a complex between a pore and an XPD helicase and thereby forming a sensor for characterising the target polynucleotide;
- kit for characterising a target polynucleotide comprising (a) a pore and (b) an XPD helicase;
- an analysis apparatus for characterising target polynucleotides in a sample comprising a plurality of pores and a plurality of an XPD helicase;
- a method of characterising a target polynucleotide comprising:
- an analysis apparatus for characterising target polynucleotides in a sample, characterised in that it comprises a XPD helicase
- kit for characterising a target polynucleotide comprising (a) an analysis apparatus for characterising target polynucleotides and (b) a XPD helicase.
- FIG. 1 A) Example schematic of use of a helicase to control DNA movement through a nanopore. The arrows shown on the trans side show the direction of motion of the DNA. The arrows on the cis side show direction of motion of the helicase relative to the DNA. From left to right) A ssDNA substrate (FiglB) with an annealed primer containing a cholesterol-tag is added to the cis side of the bilayer. The cholesterol tag binds to the bilayer, enriching the substrate at the bilayer surface. Helicase added to the cis compartment binds to the DNA. In the presence of divalent metal ions and NTP substrate, the helicase moves along the DNA.
- the DNA substrate Under an applied voltage, the DNA substrate is captured by the nanopore via the leader section on the DNA.
- the DNA is pulled through the pore under the force of the applied potential until a helicase, bound to the DNA, contacts the top of the pore, preventing further uncontrolled DNA translocation.
- the helicase movement along the DNA in a 5' to 3 ' direction facilitates the controlled translocation of the threaded DNA through the pore with the applied field.
- the helicase facilitates translocation of the DNA through the nanopore, feeding it into the trans compartment.
- the last section of DNA to pass through the nanopore is the 3' end.
- Helicase is able to move DNA through a nanopore in a controlled fashion, producing stepwise changes in current as the DNA moves through the nanopore.
- Example helicase-DNA events (140 mV, 400 mM NaCl, Hepes pH 8.0, 0.6nM 400 mer DNA, 100 nM XPD Mbu, 1 mM DTT, 1 mM ATP, 1 mM MgCl 2 ).
- Top Section of current vs. time acquisition of XPD 400mer DNA events through an MspA B2 nanopore. The open-pore current is ⁇ 95 pA. DNA is captured by the nanopore under the force of the applied potential (+140 mV).
- DNA with enzyme attached results in a long block (at ⁇ 25pA in this condition) that shows stepwise changes in current as the enzyme moves the DNA through the pore.
- the bottom traces shows an enlargement of one of the helicase controlled DNA movement events, showing DNA-enzyme capture, stepwise current changes as the DNA is pulled through the pore.
- FIG. 3 A further example of helicase controlled DNA movement event. Bottom) An enlargement of a section of the event showing the stepwise changes in current from the different sections of DNA as the strand moves through the nanopore.
- the helicase can control the movement of DNA in at least two modes of operation.
- the helicase moves along the DNA in the 5 '-3 ' direction, but the orientation of the DNA in the nanopore (dependent on which end of the DNA is captured) means that the enzyme can be used to either move the DNA out of the nanopore against the applied field, or move the DNA into the nanopore with the applied field.
- the enzyme can be used to either move the DNA out of the nanopore against the applied field, or move the DNA into the nanopore with the applied field.
- the enzyme moves the DNA into the nanopore in the direction of the field into the trans side of the bilayer.
- Fluorescence assay for testing enzyme activity A) A custom fluorescent substrate was used to assay the ability of the helicase to displace hybridised dsDNA. 1) The fluorescent substrate strand (50 nM final) has a 5' ssDNA overhang, and a 40 base section of hybridised dsDNA. The major upper strand has a carboxyfluorescein base at the 3 ' end, and the hybridised complement has a black-hole quencher (BHQ-1) base at the 5' end. When hybridised the fluorescence from the fluorescein is quenched by the local BHQ-1, and the substrate is essentially non- fluorescent. 1 ⁇ of a capture strand that is complementary to the shorter strand of the fluorescent substrate is included in the assay.
- concentrations of KC1 from 100 mM to 2 M.
- SEQ ID NO: 1 shows the codon optimised polynucleotide sequence encoding the MS-B 1 mutant MspA monomer. This mutant lacks the signal sequence and includes the following mutations: D90N, D91N, D93N, D118R, D134R and E139K.
- SEQ ID NO: 2 shows the amino acid sequence of the mature form of the MS-B 1 mutant of the MspA monomer. This mutant lacks the signal sequence and includes the following mutations: D90N, D91N, D93N, D118R, D134R and E139K.
- SEQ ID NO: 3 shows the polynucleotide sequence encoding one subunit of a-hemolysin- El l lN 147N ( -HL-NN; Stoddart et al, PNAS, 2009; 106(19): 7702-7707).
- SEQ ID NO: 4 shows the amino acid sequence of one subunit of a-HL-NN.
- SEQ ID Nos: 5 to 7 show the amino acid sequences of MspB, C and D.
- SEQ ID NOs: 8 and 9 show the amino acid sequences of XPD motifs V and VI.
- SEQ ID NOs: 10 to 62 show the amino acid sequences of the XPD helicases in Table 5.
- SEQ ID NOs: 63 to 68 show the sequences used in the Examples. Detailed description of the invention
- a pore includes two or more such pores
- reference to “a helicase” includes two or more such helicases
- reference to “a polynucleotide” includes two or more such polynucleotides, and the like.
- the invention provides a method of characterising a target polynucleotide.
- the method comprises contacting the target polynucleotide with a transmembrane pore and an XPD helicase such that the target polynucleotide moves through the pore and the XPD helicase controls the movement of the target polynucleotide through the pore.
- One or more characteristics of the target polynucleotide are then measured as the polynucleotide moves with respect to the pore using standard methods known in the art.
- One or more characteristics of the target are then measured as the polynucleotide moves with respect to the pore using standard methods known in the art.
- polynucleotide are preferably measured as the polynucleotide moves through the pore.
- Steps (a) and (b) are preferably carried out with a potential applied across the pore.
- the applied potential typically results in the formation of a complex between the pore and the helicase.
- the applied potential may be a voltage potential.
- the applied potential may be a chemical potential.
- An example of this is using a salt gradient across an amphiphilic layer. A salt gradient is disclosed in Holden et ah, J Am Chem Soc. 2007 Jul l l; 129(27):8650-5.
- the current passing through the pore as the polynucleotide moves with respect to the pore is used to determine the sequence of the target polynucleotide. This is Strand Sequencing.
- XPD helicases have a surprisingly high salt tolerance and so the method of the invention may be carried out at high salt concentrations.
- a charge carrier such as a salt
- a voltage offset is necessary to create a conductive solution for applying a voltage offset to capture and translocate the target polynucleotide and to measure the resulting sequence-dependent current changes as the polynucleotide moves with respect to the pore. Since the measurement signal is dependent on the concentration of the salt, it is advantageous to use high salt concentrations to increase the magnitude of the acquired signal.
- High salt concentrations provide a high signal to noise ratio and allow for currents indicative of the presence of a nucleotide to be identified against the background of normal current fluctuations.
- salt concentrations in excess of 100 mM are ideal, for example salt concentrations in excess of 400mM, 600mM or 800mM.
- the inventors have surprisingly shown that XPD helicases will function effectively at very high salt concentrations such as, for example, 1 M.
- the invention encompasses helicases which function effectively at salt concentrations in excess of 1M, for example 2M.
- XPD helicases when a voltage is applied, XPD helicases can surprisingly move the target polynucleotide in two directions, namely with or against the field resulting from the applied voltage.
- the method of the invention may be carried out in one of two preferred modes. Different signals are obtained depending on the direction the target polynucleotide moves with respect to the pore, ie in the direction of or against the field. This is discussed in more detail below.
- XPD helicases typically move the target polynucleotide through the pore one nucleotide at a time. XPD helicases can therefore function like a single-base ratchet. This is of course advantageous when sequencing a target polynucleotide because substantially all, if not all, of the nucleotides in the target polynucleotide may be identified using the pore.
- XPD helicases are capable of controlling the movement of single stranded polynucleotides and double stranded polynucleotides. This means that a variety of different target polynucleotides can be characterised in accordance with the invention.
- XPD helicases appear very resistant to the field resulting from applied voltages.
- the inventors have seen very little movement of the polynucleotide under an "unzipping" condition. Unzipping conditions will typically be in the absence of nucleotides, for example the absence of ATP.
- Unzipping conditions will typically be in the absence of nucleotides, for example the absence of ATP.
- the helicase When the helicase is operating in unzipping mode it acts like a brake preventing the target sequence from moving through the pore too quickly under the influence of the applied voltage. This is important because it means that there are no complications from unwanted "backwards" movements when moving polynucleotides against the field resulting from an applied voltage.
- the method of the invention is for characterising a target polynucleotide.
- polynucleotide such as a nucleic acid
- the polynucleotide or nucleic acid may comprise any combination of any nucleotides.
- the nucleotides can be naturally occurring or artificial.
- One or more nucleotides in the target polynucleotide can be oxidized or methylated.
- One or more nucleotides in the target polynucleotide may be damaged.
- One or more nucleotides in the target polynucleotide may be modified, for instance with a label or a tag.
- the target polynucleotide may comprise one or more spacers.
- a nucleotide typically contains a nucleobase, a sugar and at least one phosphate group.
- the nucleobase is typically heterocyclic.
- Nucleobases include, but are not limited to, purines and pyrimidines and more specifically adenine, guanine, thymine, uracil and cytosine.
- the sugar is typically a pentose sugar.
- Nucleotide sugars include, but are not limited to, ribose and deoxyribose.
- the nucleotide is typically a ribonucleotide or deoxyribonucleotide.
- the nucleotide typically contains a monophosphate, diphosphate or triphosphate. Phosphates may be attached on the 5' or 3' side of a nucleotide.
- Nucleotides include, but are not limited to, adenosine monophosphate (AMP), guanosine monophosphate (GMP), thymidine monophosphate (TMP), uridine monophosphate (UMP), cytidine monophosphate (CMP), cyclic adenosine monophosphate (cAMP), cyclic guanosine monophosphate (cGMP), deoxyadenosine monophosphate (dAMP), deoxyguanosine monophosphate (dGMP), deoxythymidine monophosphate (dTMP), deoxyuridine
- AMP adenosine monophosphate
- GFP guanosine monophosphate
- TMP uridine monophosphate
- CMP cytidine monophosphate
- cAMP cyclic adenosine monophosphate
- cGMP cyclic guanosine monophosphate
- dAMP deoxyadenosine monophosphate
- dGMP deoxythy
- dUMP deoxycytidine monophosphate
- dCMP deoxycytidine monophosphate
- the nucleotides are preferably selected from AMP, TMP, GMP, CMP, UMP, dAMP, dTMP, dGMP or dCMP.
- a nucleotide may be abasic (i.e. lack a nucleobase).
- the polynucleotide may be single stranded or double stranded. At least a portion of the polynucleotide is preferably double stranded.
- the polynucleotide can be a nucleic acid, such as deoxyribonucleic acid (DNA) or ribonucleic acid (RNA).
- the target polynucleotide can comprise one strand of RNA hybridized to one strand of DNA.
- the polynucleotide may be any synthetic nucleic acid known in the art, such as peptide nucleic acid (PNA), glycerol nucleic acid (GNA), threose nucleic acid (TNA), locked nucleic acid (LNA) or other synthetic polymers with nucleotide side chains.
- the whole or only part of the target polynucleotide may be characterised using this method.
- the target polynucleotide can be any length.
- the polynucleotide can be at least 10, at least 50, at least 100, at least 150, at least 200, at least 250, at least 300, at least 400 or at least 500 nucleotide pairs in length.
- the polynucleotide can be 1000 or more nucleotide pairs, 5000 or more nucleotide pairs in length or 100000 or more nucleotide pairs in length.
- the target polynucleotide is present in any suitable sample.
- the invention is typically carried out on a sample that is known to contain or suspected to contain the target polynucleotide. Alternatively, the invention may be carried out on a sample to confirm the identity of one or more target polynucleotides whose presence in the sample is known or expected.
- the sample may be a biological sample.
- the invention may be carried out in vitro on a sample obtained from or extracted from any organism or microorganism.
- the organism or microorganism is typically archaean, prokaryotic or eukaryotic and typically belongs to one the five kingdoms: plantae, animalia, fungi, monera and protista.
- the invention may be carried out in vitro on a sample obtained from or extracted from any virus.
- the sample is preferably a fluid sample.
- the sample typically comprises a body fluid of the patient.
- the sample may be urine, lymph, saliva, mucus or amniotic fluid but is preferably blood, plasma or serum.
- the sample is human in origin, but alternatively it may be from another mammal animal such as from commercially farmed animals such as horses, cattle, sheep or pigs or may alternatively be pets such as cats or dogs.
- a sample of plant origin is typically obtained from a commercial crop, such as a cereal, legume, fruit or vegetable, for example wheat, barley, oats, canola, maize, soya, rice, bananas, apples, tomatoes, potatoes, grapes, tobacco, beans, lentils, sugar cane, cocoa, cotton.
- the sample may be a non-biological sample.
- the non-biological sample is preferably a fluid sample.
- Examples of a non-biological sample include surgical fluids, water such as drinking water, sea water or river water, and reagents for laboratory tests.
- the sample is typically processed prior to being assayed, for example by centrifugation or by passage through a membrane that filters out unwanted molecules or cells, such as red blood cells.
- the sample may be measured immediately upon being taken.
- the sample may also be typically stored prior to assay, preferably below -70°C.
- a transmembrane pore is a structure that crosses the membrane to some degree. It permits ions, such as hydrated ions, driven by an applied potential to flow across or within the membrane.
- the transmembrane pore typically crosses the entire membrane so that ions may flow from one side of the membrane to the other side of the membrane. However, the transmembrane pore does not have to cross the membrane. It may be closed at one end. For instance, the pore may be a well in the membrane along which or into which ions may flow.
- the membrane is preferably an amphiphilic layer.
- An amphiphilic layer is a layer formed from amphiphilic molecules, such as phospholipids, which have both at least one hydrophilic portion and at least one lipophilic or hydrophobic portion.
- the amphiphilic layer may be a monolayer or a bilayer.
- the amphiphilic layer is typically a planar lipid bilayer or a supported bilayer.
- the amphiphilic layer is typically a lipid bilayer.
- Lipid bilayers are models of cell membranes and serve as excellent platforms for a range of experimental studies. For example, lipid bilayers can be used for in vitro investigation of membrane proteins by single-channel recording.
- lipid bilayers can be used as biosensors to detect the presence of a range of substances.
- the lipid bilayer may be any lipid bilayer. Suitable lipid bilayers include, but are not limited to, a planar lipid bilayer, a supported bilayer or a liposome.
- the lipid bilayer is preferably a planar lipid bilayer. Suitable lipid bilayers are disclosed in International
- Lipid bilayers are commonly formed by the method of Montal and Mueller (Proc. Natl. Acad. Sci. USA., 1972; 69: 3561-3566), in which a lipid monolayer is carried on aqueous solution/air interface past either side of an aperture which is perpendicular to that interface.
- Montal & Mueller The method of Montal & Mueller is popular because it is a cost-effective and relatively straightforward method of forming good quality lipid bilayers that are suitable for protein pore insertion.
- Other common methods of bilayer formation include tip-dipping, painting bilayers and patch-clamping of liposome bilayers.
- the lipid bilayer is formed as described in International
- the membrane is a solid state layer.
- a solid-state layer is not of biological origin.
- a solid state layer is not derived from or isolated from a biological environment such as an organism or cell, or a synthetically manufactured version of a biologically available structure.
- Solid state layers can be formed from both organic and inorganic materials including, but not limited to, microelectronic materials, insulating materials such as S1 3 N4, AI2O 3 , and SiO, organic and inorganic polymers such as polyamide, plastics such as Teflon® or elastomers such as two-component addition-cure silicone rubber, and glasses.
- the solid state layer may be formed from monatomic layers, such as graphene, or layers that are only a few atoms thick. Suitable graphene layers are disclosed in International Application No. PCT/US2008/010637 (published as WO 2009/035647).
- the method is typically carried out using (i) an artificial amphiphilic layer comprising a pore, (ii) an isolated, naturally-occurring lipid bilayer comprising a pore, or (iii) a cell having a pore inserted therein.
- the method is typically carried out using an artificial amphiphilic layer, such as an artificial lipid bilayer.
- the layer may comprise other transmembrane and/or intramembrane proteins as well as other molecules in addition to the pore. Suitable apparatus and conditions are discussed below.
- the method of the invention is typically carried out in vitro.
- the polynucleotide may be coupled to the membrane. This may be done using any known method. If the membrane is an amphiphilic layer, such as a lipid bilayer (as discussed in detail above), the polynucleotide is preferably coupled to the membrane via a polypeptide present in the membrane or a hydrophobic anchor present in the membrane.
- the hydrophobic anchor is preferably a lipid, fatty acid, sterol, carbon nanotube or amino acid.
- the polynucleotide may be coupled directly to the membrane.
- the polynucleotide is preferably coupled to the membrane via a linker.
- Preferred linkers include, but are not limited to, polymers, such as polynucleotides, polyethylene glycols (PEGs) and polypeptides. If a polynucleotide is coupled directly to the membrane, then some data will be lost as the characterising run cannot continue to the end of the polynucleotide due to the distance between the membrane and the helicase. If a linker is used, then the polynucleotide can be processed to completion. If a linker is used, the linker may be attached to the polynucleotide at any position. The linker is preferably attached to the polynucleotide at the tail polymer.
- the coupling may be stable or transient.
- the transient nature of the coupling is preferred. If a stable coupling molecule were attached directly to either the 5' or 3' end of a polynucleotide, then some data will be lost as the characterising run cannot continue to the end of the polynucleotide due to the distance between the bilayer and the helicase' s active site. If the coupling is transient, then when the coupled end randomly becomes free of the bilayer, then the polynucleotide can be processed to completion. Chemical groups that form stable or transient links with the membrane are discussed in more detail below.
- polynucleotide may be transiently coupled to an amphiphilic layer, such as a lipid bilayer using cholesterol or a fatty acyl chain.
- an amphiphilic layer such as a lipid bilayer using cholesterol or a fatty acyl chain.
- Any fatty acyl chain having a length of from 6 to 30 carbon atoms, such as hexadecanoic acid, may be used.
- the polynucleotide is coupled to an amphiphilic layer.
- Lipid Stable van Lengerich, B R. J. Rawle, et al. "Covalent attachment of lipid vesicles to a fluid-supported bilayer allows observation of DNA-mediated vesicle interactions.” Langmuir 26(11): 8666-72
- Polynucleotides may be functionalized using a modified phosphoramidite in the synthesis reaction, which is easily compatible for the addition of reactive groups, such as thiol, cholesterol, lipid and biotin groups.
- reactive groups such as thiol, cholesterol, lipid and biotin groups.
- These different attachment chemistries give a suite of attachment options for polynucleotides.
- Each different modification group tethers the polynucleotide in a slightly different way and coupling is not always permanent so giving different dwell times for the polynucleotide to the bilayer. The advantages of transient coupling are discussed above.
- Coupling of polynucleotides can also be achieved by a number of other means provided that a reactive group can be added to the polynucleotide.
- a reactive group can be added to the polynucleotide.
- a thiol group can be added to the 5' of ssDNA using polynucleotide kinase and ATPyS (Grant, G. P. and P. Z. Qin (2007).
- a facile method for attaching nitroxide spin labels at the 5' terminus of nucleic acids. Nucleic Acids Res 35(10): e77).
- the reactive group could be considered to be the addition of a short piece of DNA complementary to one already coupled to the bilayer, so that attachment can be achieved via hybridisation.
- Ligation of short pieces of ssDNA have been reported using T4 RNA ligase I (Troutt, A. B., M. G. McHeyzer- Williams, et al. (1992). "Ligation-anchored PCR: a simple amplification technique with single-sided specificity.” Proc Natl Acad Sci U S A 89(20): 9823- 5).
- either ssDNA or dsDNA could be ligated to native dsDNA and then the two strands separated by thermal or chemical denaturation.
- each single strand will have either a 5' or 3 ' modification if ssDNA was used for ligation or a modification at the 5' end, the 3 ' end or both if dsDNA was used for ligation.
- the polynucleotide is a synthetic strand, the coupling chemistry can be incorporated during the chemical synthesis of the polynucleotide. For instance, the
- polynucleotide can be synthesized using a primer a reactive group attached to it.
- a common technique for the amplification of sections of genomic DNA is using polymerase chain reaction (PCR).
- PCR polymerase chain reaction
- an antisense primer that has a reactive group, such as a cholesterol, thiol, biotin or lipid, each copy of the target DNA amplified will contain a reactive group for coupling.
- the transmembrane pore is preferably a transmembrane protein pore.
- a transmembrane protein pore is a protein structure that crosses the membrane to some degree. It permits ions driven by an applied potential to flow across or within the membrane.
- a transmembrane protein pore is typically a polypeptide or a collection of polypeptides that permits ions, such as analytes, to flow from one side of a membrane to the other side of the membrane.
- the transmembrane protein pore does not have to cross the membrane. It may be closed at one end. For instance, the transmembrane pore may form a well in the membrane along which or into which ions may flow.
- the transmembrane protein pore preferably permits analytes, such as nucleotides, to flow across or within the membrane, such as a lipid bilayer.
- the transmembrane protein pore allows a polynucleotide, such as DNA or RNA, to be moved through the pore.
- the transmembrane protein pore may be a monomer or an oligomer.
- the pore is preferably made up of several repeating subunits, such as 6, 7, 8 or 9 subunits.
- the pore is preferably a hexameric, heptameric, octameric or nonameric pore.
- the transmembrane protein pore typically comprises a barrel or channel through which the ions may flow.
- the subunits of the pore typically surround a central axis and contribute strands to a transmembrane ⁇ barrel or channel or a transmembrane oc-helix bundle or channel.
- the barrel or channel of the transmembrane protein pore typically comprises amino acids that facilitate interaction with analyte, such as nucleotides, polynucleotides or nucleic acids. These amino acids are preferably located near a constriction of the barrel or channel.
- the transmembrane protein pore typically comprises one or more positively charged amino acids, such as arginine, lysine or histidine, or aromatic amino acids, such as tyrosine or tryptophan. These amino acids typically facilitate the interaction between the pore and nucleotides, polynucleotides or nucleic acids.
- Transmembrane protein pores for use in accordance with the invention can be derived from ⁇ -barrel pores or a-helix bundle pores, ⁇ -barrel pores comprise a barrel or channel that is formed from ⁇ -strands.
- Suitable ⁇ -barrel pores include, but are not limited to, ⁇ -toxins, such as a-hemolysin, anthrax toxin and leukocidins, and outer membrane proteins/porins of bacteria, such as Mycobacterium smegmatis porin (Msp), for example MspA, outer membrane porin F (OmpF), outer membrane porin G (OmpG), outer membrane phospholipase A and Neisseria autotransporter lipoprotein (NalP).
- Msp Mycobacterium smegmatis porin
- OmpF outer membrane porin F
- OmpG outer membrane porin G
- a-helix bundle pores comprise a barrel or channel that is formed from cc-helices.
- Suitable a-helix bundle pores include, but are not limited to, inner membrane proteins and a outer membrane proteins, such as WZA and ClyA toxin.
- the transmembrane pore may be derived from Msp or from a-hemolysin (a-HL).
- the transmembrane protein pore is preferably derived from Msp, preferably from MspA. Such a pore will be oligomeric and typically comprises 7, 8, 9 or 10 monomers derived from Msp.
- the pore may be a homo-oligomeric pore derived from Msp comprising identical monomers. Alternatively, the pore may be a hetero-oligomeric pore derived from Msp comprising at least one monomer that differs from the others.
- the pore is derived from MspA or a homolog or paralog thereof.
- a monomer derived from Msp comprises the sequence shown in SEQ ID NO: 2 or a variant thereof.
- SEQ ID NO: 2 is the MS-(B 1)8 mutant of the MspA monomer. It includes the following mutations: D90N, D91N, D93N, Dl 18R, D134R and E139K.
- a variant of SEQ ID NO: 2 is a polypeptide that has an amino acid sequence which varies from that of SEQ ID NO: 2 and which retains its ability to form a pore. The ability of a variant to form a pore can be assayed using any method known in the art.
- the variant may be inserted into an amphihpilic layer along with other appropriate subunits and its ability to oligomerise to form a pore may be determined.
- Methods are known in the art for inserting subunits into membranes, such as amphiphilic layers.
- subunits may be suspended in a purified form in a solution containing a lipid bilayer such that it diffuses to the lipid bilayer and is inserted by binding to the lipid bilayer and assembling into a functional state.
- subunits may be directly inserted into the membrane using the "pick and place" method described in M.A. Holden, H. Bayley. J. Am. Chem. Soc. 2005, 127, 6502-6503 and International Application No. PCT/GB2006/001057 (published as WO 2006/100484).
- a variant will preferably be at least 50% homologous to that sequence based on amino acid identity. More preferably, the variant may be at least 55%, at least 60%, at least 65%>, at least 70%, at least 75%, at least 80%, at least 85%, at least 90% and more preferably at least 95%, 97% or 99% homologous based on amino acid identity to the amino acid sequence of SEQ ID NO: 2 over the entire sequence. There may be at least 80%, for example at least 85%, 90% or 95%, amino acid identity over a stretch of 100 or more, for example 125, 150, 175 or 200 or more, contiguous amino acids ("hard homology").
- Standard methods in the art may be used to determine homology.
- the UWGCG Package provides the BESTFIT program which can be used to calculate homology, for example used on its default settings (Devereux et al (1984) Nucleic Acids Research 12, p387- 395).
- the PILEUP and BLAST algorithms can be used to calculate homology or line up sequences (such as identifying equivalent residues or corresponding sequences (typically on their default settings)), for example as described in Altschul S. F. (1993) J Mol Evol 36:290-300; Altschul, S.F et al (1990) J Mol Biol 215:403-10.
- Software for performing BLAST analyses is publicly available through the National Center for Biotechnology Information
- SEQ ID NO: 2 is the MS-(B 1)8 mutant of the MspA monomer.
- the variant may comprise any of the mutations in the MspB, C or D monomers compared with MspA.
- the mature forms of MspB, C and D are shown in SEQ ID NOs: 5 to 7.
- the variant may comprise the following substitution present in MspB: A138P.
- the variant may comprise one or more of the following substitutions present in MspC: A96G, N102E and A138P.
- the variant may comprise one or more of the following mutations present in MspD: Deletion of Gl, L2V, E5Q, L8V, D13G, W21A, D22E, K47T, I49H, I68V, D91G, A96Q, N102D, S 103T, VI 041, S136K and G141A.
- the variant may comprise combinations of one or more of the mutations and substitutions from Msp B, C and D.
- the variant preferably comprises the mutation L88N.
- the variant of SEQ ID NO: 2 has the mutation L88N in addition to all the mutations of MS-B1 and is called MS-B2.
- the pore used in the invention is preferably MS- (B2)8.
- Amino acid substitutions may be made to the amino acid sequence of SEQ ID NO: 2 in addition to those discussed above, for example up to 1, 2, 3, 4, 5, 10, 20 or 30 substitutions.
- Conservative substitutions replace amino acids with other amino acids of similar chemical structure, similar chemical properties or similar side-chain volume.
- the amino acids introduced may have similar polarity, hydrophilicity, hydrophobicity, basicity, acidity, neutrality or charge to the amino acids they replace.
- the conservative substitution may introduce another amino acid that is aromatic or aliphatic in the place of a pre-existing aromatic or aliphatic amino acid.
- Conservative amino acid changes are well-known in the art and may be selected in accordance with the properties of the 20 main amino acids as defined in Table 2 below. Where amino acids have similar polarity, this can also be determined by reference to the hydropathy scale for amino acid side chains in Table 3.
- One or more amino acid residues of the amino acid sequence of SEQ ID NO: 2 may additionally be deleted from the polypeptides described above. Up to 1, 2, 3, 4, 5, 10, 20 or 30 residues may be deleted, or more.
- Variants may include fragments of SEQ ID NO: 2. Such fragments retain pore forming activity. Fragments may be at least 50, 100, 150 or 200 amino acids in length. Such fragments may be used to produce the pores. A fragment preferably comprises the pore forming domain of SEQ ID NO: 2. Fragments must include one of residues 88, 90, 91, 105, 1 18 and 134 of SEQ ID NO: 2. Typically, fragments include all of residues 88, 90, 91, 105, 1 18 and 134 of SEQ ID NO: 2. One or more amino acids may be alternatively or additionally added to the polypeptides described above. An extension may be provided at the amino terminal or carboxy terminal of the amino acid sequence of SEQ ID NO: 2 or polypeptide variant or fragment thereof.
- the extension may be quite short, for example from 1 to 10 amino acids in length. Alternatively, the extension may be longer, for example up to 50 or 100 amino acids.
- a carrier protein may be fused to an amino acid sequence according to the invention. Other fusion proteins are discussed in more detail below.
- a variant is a polypeptide that has an amino acid sequence which varies from that of SEQ ID NO: 2 and which retains its ability to form a pore.
- a variant typically contains the regions of SEQ ID NO: 2 that are responsible for pore formation. The pore forming ability of Msp, which contains a ⁇ -barrel, is provided by ⁇ -sheets in each subunit
- a variant of SEQ ID NO: 2 typically comprises the regions in SEQ ID NO: 2 that form ⁇ -sheets.
- One or more modifications can be made to the regions of SEQ ID NO: 2 that form ⁇ -sheets as long as the resulting variant retains its ability to form a pore.
- a variant of SEQ ID NO: 2 preferably includes one or more modifications, such as substitutions, additions or deletions, within its oc-helices and/or loop regions.
- the monomers derived from Msp may be modified to assist their identification or purification, for example by the addition of histidine residues (a hist tag), aspartic acid residues (an asp tag), a streptavidin tag or a flag tag, or by the addition of a signal sequence to promote their secretion from a cell where the polypeptide does not naturally contain such a sequence.
- An alternative to introducing a genetic tag is to chemically react a tag onto a native or engineered position on the pore. An example of this would be to react a gel-shift reagent to a cysteine engineered on the outside of the pore. This has been demonstrated as a method for separating hemolysin hetero-oligomers (Chem Biol. 1997 Jul; 4(7):497-505).
- the monomer derived from Msp may be labelled with a revealing label.
- the revealing label may be any suitable label which allows the pore to be detected. Suitable labels include, but are not limited to, fluorescent molecules, radioisotopes, e.g. 125 1, 5 S, enzymes, antibodies, antigens, polynucleotides and ligands such as biotin.
- the monomer derived from Msp may also be produced using D-amino acids.
- the monomer derived from Msp may comprise a mixture of L-amino acids and D- amino acids. This is conventional in the art for producing such proteins or peptides.
- the monomer derived from Msp contains one or more specific modifications to facilitate nucleotide discrimination.
- the monomer derived from Msp may also contain other non-specific modifications as long as they do not interfere with pore formation.
- a number of non-specific side chain modifications are known in the art and may be made to the side chains of the monomer derived from Msp. Such modifications include, for example, reductive alkylation of amino acids by reaction with an aldehyde followed by reduction with NaBFL, amidination with methylacetimidate or acylation with acetic anhydride.
- the monomer derived from Msp can be produced using standard methods known in the art.
- the monomer derived from Msp may be made synthetically or by recombinant means.
- the pore may be synthesized by in vitro translation and transcription (IVTT). Suitable methods for producing pores are discussed in International Application Nos. PCT/GB09/001690 (published as WO 2010/004273), PCT/GB09/001679 (published as WO 2010/004265) or PCT/GB 10/000133 (published as WO 2010/086603). Methods for inserting pores into membranes are discussed.
- the transmembrane protein pore is also preferably derived from a-hemolysin (a-HL).
- a-HL a-hemolysin
- the wild type a-HL pore is formed of seven identical monomers or subunits (i.e. it is heptameric).
- the sequence of one monomer or subunit of a-hemolysin-NN is shown in SEQ ID NO: 4.
- the transmembrane protein pore preferably comprises seven monomers each comprising the sequence shown in SEQ ID NO: 4 or a variant thereof.
- Residues 113 and 147 of SEQ ID NO: 4 form part of a constriction of the barrel or channel of a-HL.
- a pore comprising seven proteins or monomers each comprising the sequence shown in SEQ ID NO: 4 or a variant thereof are preferably used in the method of the invention.
- the seven proteins may be the same (homoheptamer) or different
- a variant of SEQ ID NO: 4 is a protein that has an amino acid sequence which varies from that of SEQ ID NO: 4 and which retains its pore forming ability.
- the ability of a variant to form a pore can be assayed using any method known in the art.
- the variant may be inserted into an amphiphilic layer, such as a lipid bilayer, along with other appropriate subunits and its ability to oligomerise to form a pore may be determined. Methods are known in the art for inserting subunits into amphiphilic layers, such as lipid bilayers. Suitable methods are discussed above.
- the variant may include modifications that facilitate covalent attachment to or interaction with the helicase.
- the variant preferably comprises one or more reactive cysteine residues that facilitate attachment to the helicase.
- the variant may include a cysteine at one or more of positions 8, 9, 17, 18, 19, 44, 45, 50, 51, 237, 239 and 287 and/or on the amino or carboxy terminus of SEQ ID NO: 4.
- Preferred variants comprise a substitution of the residue at position 8, 9, 17, 237, 239 and 287 of SEQ ID NO: 4 with cysteine (A8C, T9C, N17C, K237C, S239C or E287C).
- the variant is preferably any one of the variants described in International Application No. PCT/GB09/001690 (published as WO 2010/004273), PCT/GB 09/001679 (published as WO 2010/004265) or PCT/GB 10/000133 (published as WO 2010/086603).
- the variant may also include modifications that facilitate any interaction with nucleotides.
- the variant may be a naturally occurring variant which is expressed naturally by an organism, for instance by a Staphylococcus bacterium.
- the variant may be expressed in vitro or recombinantly by a bacterium such as Escherichia coli.
- Variants also include non-naturally occurring variants produced by recombinant technology. Over the entire length of the amino acid sequence of SEQ ID NO: 4, a variant will preferably be at least 50% homologous to that sequence based on amino acid identity.
- the variant polypeptide may be at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90% and more preferably at least 95%, 97% or 99% homologous based on amino acid identity to the amino acid sequence of SEQ ID NO: 4 over the entire sequence.
- homology can be determined as discussed above.
- Amino acid substitutions may be made to the amino acid sequence of SEQ ID NO: 4 in addition to those discussed above, for example up to 1, 2, 3, 4, 5, 10, 20 or 30 substitutions. Conservative substitutions may be made as discussed above.
- One or more amino acid residues of the amino acid sequence of SEQ ID NO: 4 may additionally be deleted from the polypeptides described above. Up to 1, 2, 3, 4, 5, 10, 20 or 30 residues may be deleted, or more.
- Variants may be fragments of SEQ ID NO: 4. Such fragments retain pore-forming activity. Fragments may be at least 50, 100, 200 or 250 amino acids in length. A fragment preferably comprises the pore-forming domain of SEQ ID NO: 4. Fragments typically include residues 119, 121, 135. 113 and 139 of SEQ ID NO: 4.
- One or more amino acids may be alternatively or additionally added to the polypeptides described above.
- An extension may be provided at the amino terminus or carboxy terminus of the amino acid sequence of SEQ ID NO: 4 or a variant or fragment thereof. The extension may be quite short, for example from 1 to 10 amino acids in length. Alternatively, the extension may be longer, for example up to 50 or 100 amino acids.
- a carrier protein may be fused to a pore or variant.
- a variant of SEQ ID NO: 4 is a subunit that has an amino acid sequence which varies from that of SEQ ID NO: 4 and which retains its ability to form a pore.
- a variant typically contains the regions of SEQ ID NO: 4 that are responsible for pore formation.
- a variant of SEQ ID NO: 4 typically comprises the regions in SEQ ID NO: 4 that form ⁇ -strands.
- the amino acids of SEQ ID NO: 4 that form ⁇ -strands are discussed above.
- One or more modifications can be made to the regions of SEQ ID NO: 4 that form ⁇ -strands as long as the resulting variant retains its ability to form a pore. Specific modifications that can be made to the ⁇ -strand regions of SEQ ID NO: 4 are discussed above.
- a variant of SEQ ID NO: 4 preferably includes one or more modifications, such as substitutions, additions or deletions, within its a-helices and/or loop regions. Amino acids that form a-helices and loops are discussed above.
- the variant may be modified to assist its identification or purification as discussed above.
- Pores derived from a-HL can be made as discussed above with reference to pores derived from Msp.
- the transmembrane protein pore is chemically modified.
- the pore can be chemically modified in any way and at any site.
- the transmembrane protein pore is preferably chemically modified by attachment of a molecule to one or more cysteines (cysteine linkage), attachment of a molecule to one or more lysines, attachment of a molecule to one or more non-natural amino acids, enzyme modification of an epitope or modification of a terminus. Suitable methods for carrying out such modifications are well-known in the art.
- transmembrane protein pore may be chemically modified by the attachment of any molecule.
- the pore may be chemically modified by attachment of a dye or a fluorophore.
- any number of the monomers in the pore may be chemically modified.
- One or more, such as 2, 3, 4, 5, 6, 7, 8, 9 or 10, of the monomers is preferably chemically modified as discussed above.
- cysteine residues may be enhanced by modification of the adjacent residues. For instance, the basic groups of flanking arginine, histidine or lysine residues will change the pKa of the cysteines thiol group to that of the more reactive S " group.
- the reactivity of cysteine residues may be protected by thiol protective groups such as dTNB. These may be reacted with one or more cysteine residues of the pore before a linker is attached.
- the molecule (with which the pore is chemically modified) may be attached directly to the pore or attached via a linker as disclosed in International Application Nos. PCT/GB09/001690 (published as WO 2010/004273), PCT/GB09/001679 (published as WO 2010/004265) or PCT/GB 10/000133 (published as WO 2010/086603).
- XPD helicases Any XPD helicase may be used in accordance with the invention.
- XPD helicases are also known as Rad3 helicases and the two terms can be used interchangeably.
- the XPD helicase typically comprises the amino acid motif X 1-X2-X3-G-X4-X5-X6-E-G (hereinafter called XPD motif V; SEQ ID NO: S).
- XPD motif V amino acid motif X 1-X2-X3-G-X4-X5-X6-E-G
- XPD motif V amino acid motif X 1-X2-X3-G-X4-X5-X6-E-G
- XI , X2, X5 and X6 are independently selected from G, P, A, V, L, I, M, C, F, Y, W, H, Q, N, S and T.
- XI , X2, X5 and X6 are preferably not charged.
- XI , X2, X5 and X6 are preferably not H.
- X5 is more preferably V, L, I, N or F.
- X6 is more preferably S or A.
- X3 and X4 may be any amino acid residue.
- X4 is preferably K. R or T.
- the XPD helicase typically comprises the amino acid motif Q-Xa-Xb-G-R-Xc-Xd-R-
- Xa, Xe and Xg may be any amino acid residue.
- Xb, Xc and Xd are independently selected from any amino acid except D, E, K and R.
- Xb, Xe and Xd are typically independently selected from G, P, A, V, L, I, M, C, F. Y, W, H, Q. N, S and T.
- Xb, Xc and Xd are preferably not charged.
- Xb, Xc and Xd are preferably not H.
- Xb is more preferably V, A, L, I or M.
- Xc is more preferably V.
- Xd is more preferably I, H, L, F, M or V.
- Xf may be D or E.
- Xg is X gi , X g 2, Xg3, X g 4, Xgs, Xg6 and X g7 .
- X g? . is preferably G, A, S or C.
- X g5 is preferably F, V, L, I, M, A, W or Y.
- X g6 is preferably L, F, Y, M, I or V.
- X g7 is preferably A, C, V, L, I, M or S.
- the XPD helicase preferably comprises XPD motifs V and VI.
- the most preferred XPD motifs V and VI are shown in Table 5 below.
- the XPD helicase preferably further comprises an iron sulphide (FeS) core between two Walker A and B motifs (motifs I and IS).
- An FeS core typically comprises an iron atom coordinated between the sulphide groups of cysteine residues.
- the FeS core is typically tetrahedral.
- the XPD helicase is preferably one of the helicases shown in Table 4 below or a variant thereof.
- AAU82137.1 conserved hypothetical protein luncultured archaeon
- ZP 02635303.1 putative ATP-dependent helicase rClostridium perfringens B str.
- the XPD helicase is more preferably one of the hehcases shown in Table 5 below or a variant thereof.
- the XPD helicase more preferably comprises the sequence of one of the helicases shown in Table 5, i.e. one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62, or a variant thereof.
- the XPD helicase most preferably comprises the sequence shown in SEQ ID NO: 10 or a variant thereof.
- a variant of a XPD helicase is an enzyme that has an amino acid sequence which varies from that of the wild-type helicase and which retains polynucleotide binding activity.
- 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 is an enzyme that has an amino acid sequence which varies from that of any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43,
- a variant of SEQ ID NO: 10 is an enzyme that has an amino acid sequence which varies from that of SEQ ID NO: 10 and which retains polynucleotide binding activity.
- the variant retains helicase activity. Methods for measuring helicase activity are known in the art. Helicase activity can also be measured as described in the Examples.
- the variant must work in at least one of the two modes discussed below. Preferably, the variant works in both modes.
- the variant may include modifications that facilitate handling of the polynucleotide encoding the helicase and/or facilitate its activity at high salt concentrations and/or room temperature. Variants typically differ from the wild-type helicase in regions outside of XPD motifs V and VI discussed above. However, variants may include modifications within one or both of these motifs.
- a variant will preferably be at least 10%, preferably 30% homologous to that sequence based on amino acid identity.
- the variant polypeptide may be at least 40%, at least 45%, at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%), at least 85%, at least 90% and more preferably at least 95%, 97% or 99% homologous based on amino acid identity to the amino acid sequence of any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62, such as SEQ ID NO: 10, over the entire sequence.
- the variant may differ from the wild-type sequence in any of the ways discussed above with reference to SEQ ID NOs: 2 and 4.
- variants may include fragments of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62.
- fragments retain polynucleotide binding activity.
- Fragments may be at least about 200, at least about 300, at least about 400, at least about 500, at least about 600 or at least about 700 amino acids in length. The length of the fragment will typically depend on the length of the wild-type sequence.
- fragments preferably comprise the XPD motif V and/or the XPD motif VI of the relevant wild-type sequence.
- Amino acid substitutions may be made to the amino acid sequence of SEQ ID NO: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 or 62, for example up to 1, 2, 3, 4, 5, 10, 20 or 30 substitutions.
- the substitutions are preferably conservative substitutions as discussed above.
- a variant, such as a fragment, of any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 preferably comprises the XPD motif V and/or the XPD motif VI of the relevant wild-type sequence.
- a variant, such as a fragment, of any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 more preferably comprises the XPD motif V and the XPD motif VI of the relevant wild-type sequence.
- a variant of SEQ ID NO: 10 preferably comprises XPD motif V of SEQ ID NO: 10 (YLWGTLSEG; SEQ ID NO: 11) and/or XPD motif VI of SEQ ID NO: 10 (QAMGRVVRSPTDYGARILLDGR; SEQ ID NO: 12).
- a variant of SEQ ID NO: 10 more preferably comprises both XPD motifs V and VI of SEQ ID NO: 10.
- the XPD motifs V and VI of each of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 are shown in Table 5.
- a variant of any one SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 may comprise XPD motifs V and/or VI from a different wild-type sequence.
- a variant of SEQ ID NO: 10 may comprise XPD motif V of SEQ ID NO: 13 (SLWGTLAEG; SEQ ID NO: 14) and/or XPD motif VI of SEQ ID NO: 13 (QAIGRVVRGPDDFGVRILADRR; SEQ ID NO: 15).
- a variant of any one SEQ ID NO s: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 may comprise any one of the preferred motifs shown in Table 5.
- Variants of any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 may also include modifications within XPD motif V and/or XPD motif VI of the relevant wild-type sequence. Suitable modifications to these motifs are discussed above when defining the two motifs.
- the helicase may be covalently attached to the pore.
- the helicase is preferably not covalently attached to the pore.
- the application of a voltage to the pore and helicase typically results in the formation of a sensor that is capable of sequencing target polynucleotides. This is discussed in more detail below.
- any of the proteins described herein i .e. the transmembrane protein pores or XPD helicases, may be modified to assist their identification or purification, for example by the addition of histidine residues (a his tag), aspartic acid residues (an asp tag), a streptavidin tag, a flag tag, a SUMO tag, a GST tag or a MBP tag, or by the addition of a signal sequence to promote their secretion from a cell where the polypeptide does not naturally contain such a sequence.
- An alternative to introducing a genetic tag is to chemically react a tag onto a native or engineered position on the pore or helicase.
- the pore and/or helicase may be labelled with a revealing label.
- the revealing label may be any suitable label which allows the pore to be detected. Suitable labels include, but are not limited to, fluorescent molecules, radioisotopes, e.g. 125 1, 35 S, enzymes, antibodies, antigens, polynucleotides and ligands such as biotin.
- Proteins may be made synthetically or by recombinant means.
- the pore and/or helicase may be synthesized by in vitro translation and transcription (IVTT).
- the amino acid sequence of the pore and/or helicase may be modified to include non-naturally occurring amino acids or to increase the stability of the protein.
- amino acids may be introduced during production.
- the pore and/or helicase may also be altered following either synthetic or recombinant production.
- the pore and/or helicase may also be produced using D-amino acids.
- the pore or helicase may comprise a mixture of L-amino acids and D-amino acids. This is conventional in the art for producing such proteins or peptides.
- the pore and/or helicase may also contain other non-specific modifications as long as they do not interfere with pore formation or helicase function.
- a number of non-specific side chain modifications are known in the art and may be made to the side chains of the protein(s). Such modifications include, for example, reductive alkylation of amino acids by reaction with an aldehyde followed by reduction with NaBH 4 , amidination with methylacetimidate or acylation with acetic anhydride.
- the pore and helicase can be produced using standard methods known in the art.
- Polynucleotide sequences encoding a pore or helicase may be derived and replicated using standard methods in the art. Polynucleotide sequences encoding a pore or helicase may be expressed in a bacterial host cell using standard techniques in the art. The pore and/or helicase may be produced in a cell by in situ expression of the polypeptide from a recombinant expression vector. The expression vector optionally carries an inducible promoter to control the expression of the polypeptide. These methods are described in described in Sambrook, J. and Russell, D. (2001). Molecular Cloning: A Laboratory Manual, 3rd Edition. Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY.
- the pore and/or helicase may be produced in large scale following purification by any protein liquid chromatography system from protein producing organisms or after recombinant expression.
- Typical protein liquid chromatography systems include FPLC, AKTA systems, the Bio-Cad system, the Bio-Rad BioLogic system and the Gilson HPLC system.
- the method of the invention involves measuring one or more characteristics of the target polynucleotide.
- the method may involve measuring two, three, four or five or more characteristics of the target polynucleotide.
- the one or more characteristics are preferably selected from (i) the length of the target polynucleotide, (ii) the identity of the target polynucleotide, (iii) the sequence of the target polynucleotide, (iv) the secondary structure of the target polynucleotide and (v) whether or not the target polynucleotide is modified. Any combination of (i) to (v) may be measured in accordance with the invention.
- the length of the polynucleotide may be measured using the number of interactions between the target polynucleotide and the pore.
- the identity of the polynucleotide may be measured in a number of ways.
- the identity of the polynucleotide may be measured in conjunction with measurement of the sequence of the target polynucleotide or without measurement of the sequence of the target polynucleotide.
- the former is straightforward; the polynucleotide is sequenced and thereby identified.
- the latter may be done in several ways. For instance, the presence of a particular motif in the polynucleotide may be measured (without measuring the remaining sequence of the polynucleotide).
- the measurement of a particular electrical and/or optical signal in the method may identify the target polynucleotide as coming from a particular source.
- the sequence of the polynucleotide can be determined as described previously. Suitable sequencing methods, particularly those using electrical measurements, are described in Stoddart D et al., Proc Natl Acad Sci, 12; 106(19):7702-7, Lieberman KR et al, J Am Chem Soc. 2010; 132(50): 17961-72, and International Application WO 2000/28312.
- the secondary structure may be measured in a variety of ways. For instance, if the method involves an electrical measurement, the secondary structure may be measured using a change in dwell time or a change in current flowing through the pore. This allows regions of single-stranded and double-stranded polynucleotide to be distinguished.
- the presence or absence of any modification may be measured.
- the method preferably comprises determining whether or not the target polynucleotide is modified by methylation, by oxidation, by damage, with one or more proteins or with one or more labels, tags or spacers. Specific modifications will result in specific interactions with the pore which can be measured using the methods described below. For instance, methylcyotsine may be
- a variety of different types of measurements may be made. This includes without limitation: electrical measurements and optical measurements. Possible electrical measurements include: current measurements, impedance measurements, tunnelling measurements (Ivanov AP et al., Nano Lett. 2011 Jan 12; 1 l(l):279-85), and FET measurements (International
- Optical measurements may be combined 10 with electrical measurements (Soni GV et al., Rev Sci Instrum. 2010 Jan;81(l):014301).
- the measurement may be a transmembrane current measurement such as measurement of ionic current flowing through the pore.
- the methods may be carried out using any apparatus that is suitable for investigating a membrane/pore system in which a pore is inserted into a membrane.
- the method may be carried out using any apparatus that is suitable for transmembrane pore sensing.
- the apparatus comprises a chamber comprising an aqueous solution and a barrier that separates the chamber into two sections.
- the barrier has an aperture in which the membrane containing the pore is formed.
- the methods may involve measuring the current passing through the pore as the polynucleotide moves with respect to the pore. Therefore the apparatus may also comprise an electrical circuit capable of applying a potential and measuring an electrical signal across the membrane and pore.
- the methods may be carried out using a patch clamp or a voltage clamp.
- the methods preferably involve the use of a voltage clamp.
- the methods of the invention may involve the measuring of a current passing through the pore as the polynucleotide moves with respect to the pore. Suitable conditions for measuring ionic currents through transmembrane protein pores are known in the art and disclosed in the Example. The method is typically carried out with a voltage applied across the membrane and pore. The voltage used is typically from +2 V to -2 V, typically -400 mV to +400mV.
- the voltage used is preferably in a range having a lower limit selected from -400 mV, -300 mV, -200 mV, -150 mV, -100 mV, -50 mV, -20mV and 0 mV and an upper limit independently selected from +10 mV, + 20 mV, +50 mV, +100 mV, +150 mV, +200 mV, +300 mV and +400 mV.
- the voltage used is more preferably in the range 100 mV to 240mV and most preferably in the range of 120 mV to 220 mV. It is possible to increase discrimination between different nucleotides by a pore by using an increased applied potential.
- the methods are typically carried out in the presence of any charge carriers, such as metal salts, for example alkali metal salt, halide salts, for example chloride salts, such as alkali metal chloride salt.
- Charge carriers may include ionic liquids or organic salts, for example tetramethyl ammonium chloride, trimethylphenyl ammonium chloride, phenyltrimethyl ammonium chloride, or l-ethyl-3 -methyl imidazolium chloride.
- the salt is present in the aqueous solution in the chamber Potassium chloride (KC1), sodium chloride (NaCl) or caesium chloride (CsCl) is typically used. KC1 is preferred.
- the salt concentration may be at saturation.
- the salt concentration may be 3M or lower and is typically from 0.1 to 2.5 M, from 0.3 to 1.9 M, from 0.5 to 1.8 M, from 0.7 to 1.7 M, from 0.9 to 1.6 M or from 1 M to 1.4 M.
- the salt concentration is preferably from 150 mM to 1 M.
- XPD helicases surprisingly work under high salt concentrations.
- the method is preferably carried out using a salt concentration of at least 0.3 M, such as at least 0.4 M, at least 0.5 M, at least 0.6 M, at least 0.8 M, at least 1.0 M, at least 1.5 M, at least 2.0 M, at least 2.5 M or at least 3.0 M.
- High salt concentrations provide a high signal to noise ratio and allow for currents indicative of the presence of a nucleotide to be identified against the background of normal current fluctuations.
- the methods are typically carried out in the presence of a buffer.
- the buffer is present in the aqueous solution in the chamber. Any buffer may be used in the method of the invention.
- the buffer is HEPES.
- Another suitable buffer is Tris-HCl buffer.
- the methods are typically carried out at a pH of from 4.0 to 12.0, from 4.5 to 10.0, from 5.0 to 9.0, from 5.5 to 8.8, from 6.0 to 8.7 or from 7.0 to 8.8 or 7.5 to 8.5.
- the pH used is preferably about 7.5.
- the methods may be carried out at from 0 °C to 100 °C, from 15 °C to 95 °C, from 16 °C to 90 °C, from 17 °C to 85 °C, from 18 °C to 80 °C, 19 °C to 70 °C, or from 20 °C to 60 °C.
- the methods are typically carried out at room temperature.
- the methods are optionally carried out at a temperature that supports enzyme function, such as about 37 °C.
- the method is typically carried out in the presence of free nucleotides or free nucleotide analogues and an enzyme cofactor that facilitate the action of the helicase.
- the free nucleotides may be one or more of any of the individual nucleotides discussed above.
- the free nucleotides include, but are not limited to, adenosine monophosphate (AMP), adenosine diphosphate (ADP), adenosine triphosphate (ATP), guanosine monophosphate (GMP), guanosine diphosphate (GDP), guanosine triphosphate (GTP), thymidine monophosphate (TMP), thymidine diphosphate (TDP), thymidine triphosphate (TTP), uridine monophosphate (UMP), uridine diphosphate (UDP), uridine triphosphate (UTP), cytidine monophosphate (CMP), cytidine diphosphate (CDP), cytidine triphosphate (CTP), cyclic adenosine monophosphate (cAMP), cyclic guanosine monophosphate (cGMP), deoxyadenosine monophosphate (dAMP), deoxyadenosine monophosphate (dAMP), deoxyadeno
- diphosphate deoxyadenosine triphosphate (dATP), deoxyguanosine monophosphate (dGMP), deoxyguanosine diphosphate (dGDP), deoxyguanosine triphosphate (dGTP), deoxythymidine monophosphate (dTMP), deoxythymidine diphosphate (dTDP), deoxythymidine triphosphate (dTTP), deoxyuridine monophosphate (dUMP), deoxyuridine diphosphate (dUDP), deoxyuridine triphosphate (dUTP), deoxycytidine monophosphate (dCMP), deoxycytidine diphosphate (dCDP) and deoxycytidine triphosphate (dCTP).
- the free nucleotides are preferably selected from AMP, TMP, GMP, CMP, UMP, dAMP, dTMP, dGMP or dCMP.
- the free nucleotides are preferably adenosine triphosphate (ATP).
- the enzyme cofactor is a factor that allows the helicase to function.
- the enzyme cofactor is preferably one or more divalent metal cations. Suitable divalent metal cations include, but are not limited to, Mg 2+ , Mn 2+ , Ca 2+ , Co iT and Fe .
- the enzyme cofactor is preferably Fe orMg .
- the enzyme cofactor is most preferably Fe 2+ and Mg 2+
- the target polynucleotide may be contacted with the XPD helicase and the pore in any order. In is preferred that, when the target polynucleotide is contacted with the XPD helicase and the pore, the target polynucleotide firstly forms a complex with the helicase. When the voltage is applied across the pore, the target polynucleotide/helicase complex then forms a complex with the pore and controls the movement of the polynucleotide through the pore.
- XPD helicases may work in two modes with respect to the pore.
- the method is preferably carried out using the XPD helicase such that it moves the target sequence through the pore with the field resulting from the applied voltage.
- the 5' end of the DNA is first captured in the pore, and the enzyme moves the DNA into the pore such that the target sequence is passed through the pore with the field until it finally translocates through to the trans side of the bilayer.
- the method is preferably carried out such that the enzyme moves the target sequence through the pore against the field resulting from the applied voltage. In this mode the 3' end of the DNA is first captured in the pore, and the enzyme moves the DNA through the pore such that the target sequence is pulled out of the pore against the applied field until finally ejected back to the cis side of the bilayer.
- the method of the invention most preferably involves a pore derived from MspA and a helicase comprising the sequence shown in SEQ ID NO: 8 or a variant thereof. Any of the embodiments discussed above with reference to MspA and SEQ ID NO: 8 may be used in combination.
- the invention also provides a method of forming a sensor for characterising a target polynucleotide.
- the method comprises forming a complex between a pore and a XPD helicase.
- the complex may be formed by contacting the pore and the helicase in the presence of the target polynucleotide and then applying a potential across the pore.
- the applied potential may be a chemical potential or a voltage potential as described above.
- the complex may be formed by covalently attaching the pore to the helicase. Methods for covalent attachment are known in the art and disclosed, for example, in International Application Nos.
- the complex is a sensor for characterising the target polynucleotide.
- the method preferably comprises forming a complex between a pore derived from Msp and a XPD helicase. Any of the embodiments discussed above with reference to the method of the invention equally apply to this method.
- kits for characterising a target polynucleotide comprise (a) a pore and (b) a XPD helicase. Any of the embodiments discussed above with reference to the method of the invention equally apply to the kits.
- the kit may further comprise the components of a membrane, such as the phospholipids needed to form an amphiphilic layer, such as a lipid bilayer.
- a membrane such as the phospholipids needed to form an amphiphilic layer, such as a lipid bilayer.
- kits of the invention may additionally comprise one or more other reagents or instruments which enable any of the embodiments mentioned above to be carried out.
- reagents or instruments include one or more of the following: suitable buffer(s) (aqueous solutions), means to obtain a sample from a subject (such as a vessel or an instrument comprising a needle), means to amplify and/or express polynucleotides, a membrane as defined above or voltage or patch clamp apparatus.
- Reagents may be present in the kit in a dry state such that a fluid sample resuspends the reagents.
- the kit may also, optionally, comprise instructions to enable the kit to be used in the method of the invention or details regarding which patients the method may be used for.
- the kit may, optionally, comprise nucleotides.
- the invention also provides an apparatus for characterising a target polynucleotide.
- the apparatus comprises a plurality of pores and a plurality of a XPD helicase.
- the apparatus preferably further comprises instructions for carrying out the method of the invention.
- the apparatus may be any conventional apparatus for polynucleotide analysis, such as an array or a chip. Any of the embodiments discussed above with reference to the methods of the invention are equally applicable to the apparatus of the invention.
- the apparatus is preferably set up to carry out the method of the invention.
- the apparatus preferably comprises:
- a sensor device that is capable of supporting the membrane and plurality of pores and being operable to perform polynucleotide characterising using the pores and helicases;
- At least one reservoir for holding material for performing the characterising
- a fluidics system configured to controllably supply material from the at least one reservoir to the sensor device; and a plurality of containers for receiving respective samples, the fluidics system being configured to supply the samples selectively from the containers to the sensor device.
- the apparatus may be any of those described in International Application No. No.
- PCT/GB08/004127 (published as WO 2009/077734), PCT/GB 10/000789 (published as WO 2010/122293), International Application No. PCT/GB 10/002206 (not yet published) or
- the target polynucleotide is characterised, such as partially or completely sequenced, using a XPD helicase, but without using a pore.
- the invention also provides a method of characterising a target polynucleotide which comprises contacting the target polynucleotide with a XPD helicase such that the XPD helicase controls the movement of the target polynucleotide.
- the target polynucleoide is preferably not contacted with a pore, such as a transmembrane pore.
- the method involves taking one or more measurements as the XPD helicase controls the movement of the polynucleotide and thereby characterising the target polynucleotide.
- the measurements are indicative of one or more characteristics of the target polynucleotide. Any such measurements may be taken in accordance with the invention. They include without limitation: electrical measurements and optical measurements. These are discussed in detail above. Any of the embodiments discussed above with reference to the pore-based method of the invention may be used in the method lacking a pore. For instance, any of the XPD helicases discussed above may be used.
- the invention also provides an analysis apparatus comprising a XPD helicase.
- the invention also provides a kit a for characterising a target polynucleotide comprising (a) an analysis apparatus for characterising target polynucleotides and (b) a XPD helicase.
- kit a for characterising a target polynucleotide comprising (a) an analysis apparatus for characterising target polynucleotides and (b) a XPD helicase.
- These apparatus and kits preferably do not comprise a pore, such as a transmembrane pore. Suitable apparatus are discussed above.
- Example 1 illustrates the invention.
- This example illustrates the use of a XPD helicase (XPD MBu) to control the movement of intact DNA strands through a nanopore.
- XPD MBu XPD helicase
- Primers were designed to amplify a -400 bp fragment of PhiX174.
- Each of the 5 '-ends of these primers included a 50 nucleotide non-complimentary region, either a homopolymeric stretch or repeating units of 10 nucleotide homopolymeric sections. These serve as identifiers for controlled translocation of the strand through a nanopore, as well as determining the directionality of translocation.
- the 5 '-end of the forward primer was "capped" to include four 2'-0-Methyl-Uracil (mU) nucleotides and the 5 '-end of the reverse primer was chemically phosphorylated.
- the DNA substrate design used in all the experiments described here is shown in Fig. IB.
- the DNA substrate consists of a 400base section of ssDNA from PhiX, with a 50T 5'-leader to aid capture by the nanopore (SEQ ID NO: 63).
- a primer SEQ ID NO: 64
- An additional primer SEQ ID NO: 65
- SEQ ID NO: 65 is used towards the 3' end of the strand to aid the capture of the strand by the 3' end.
- Buffered solution 400 mM NaCl, 10 mM Hepes pH 8.0, 1 mM ATP, 1 mM MgCl 2 , 1 mM DTT Nanopore: E.coli MS(B2)8 MspA ONLP3476 MS-(L88N/D90N/D91N/D93N/
- Enzyme XPD Mbu (ONLP3696, -6.2 ⁇ ) 16.1 ⁇ -> 100 nM final. Electrical measurements were acquired from single MspA nanopores inserted in 1,2- diphytanoyl-glycero-3-phosphocholine lipid (Avanti Polar Lipids) bilayers. Bilayers were formed across -100 ⁇ diameter apertures in 20 ⁇ thick PTFE films (in custom Delrin chambers) via the Montal-Mueller technique, separating two 1 mL buffered solutions. All experiments were carried out in the stated buffered solution. Single-channel currents were measured on Axopatch 200B amplifiers (Molecular Devices) equipped with 1440A digitizers.
- Ag/AgCl electrodes were connected to the buffered solutions so that the cis compartment (to which both nanopore and enzyme/DNA are added) is connected to the ground of the Axopatch headstage, and the trans compartment is connected to the active electrode of the headstage.
- Helicase ATPase activity was initiated as required by the addition of divalent metal (1 mM MgCl 2 ) and NTP (1 mM ATP) to the cis compartment. Experiments were carried out at a constant potential of +140 mV.
- the DNA strand is sequenced from a random starting point as the DNA is captured with a helicase at a random position along the strand.
- Nanopore strand sequencing experiments of this type generally require ionic salts.
- the ionic salts are necessary to create a conductive solution for applying a voltage offset to capture and translocate DNA, and to measure the resulting sequence dependent current changes as the DNA passes through the nanopore. Since the measurement signal is dependent in the concentration of the ions, it is advantageous to use high concentration ionic salts to increase the magnitude of the acquired signal. For nanopore sequencing salt concentrations in excess of 100 mM KC1 are ideal, and salt concentrations in excess of 400mM are preferred.
- helicases move along single- stranded polynucleotide substrates in uni-directional manner, moving a specific number of bases for each NTPase turned over.
- Fig. 1 illustrates the use of this movement to feed threaded DNA through the nanopore into the trans chamber in the same direction as the applied potential
- helicase movement could be exploited in other manners to feed DNA through the nanopore in a controlled fashion.
- Fig. 4 illustrates two basic 'forward' and 'reverse' modes of operation. In the forward mode, the DNA is fed into the pore by the helicase in the same direction as the DNA would move under the force of the applied field.
- This example illustrates the salt tolerance of a XPD helicase (XPD Mbu) using a fluorescence assay for testing enzyme activity.
- a custom fluorescent substrate was used to assay the ability of the helicase to displace hybridised dsDNA (Fig. 5A).
- the fluorescent substrate strand 50 nM final
- the fluorescent substrate strand has a 5' ssDNA overhang, and a 40 base section of hybridised dsDNA.
- the major upper strand has a carboxyfluorescein base at the 3 ' end
- the hybrised complement has a black-hole quencher (BHQ-1) base at the 5' end.
- BHQ-1 black-hole quencher
- Substrate DNA SEQ ID NO 66 with a carboxyfluorescein near the 3 ' end and SEQ ID NO 66
- Capture DNA SEQ ID NO: 68 with a carboxyfluorescein near the 3 ' end.
- the graph in Fig. 5B shows the initial rate of activity in buffer solutions (100 mM Hepes pH 8.0, 1 mM ATP, 10 mM MgCl 2 , 50 nM fluorescent substrate DNA, 1 ⁇ capture DNA) containing different concentrations of KC1 from 100 mM to 1 M.
- the helicase works at 1 M.
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- Biotechnology (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Analytical Chemistry (AREA)
- Physics & Mathematics (AREA)
- Immunology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
Abstract
The invention relates to a new method of characterising a target polynucleotide. The method uses a pore and an XPD helicase. The helicase controls the movement of the target polynucleotide through the pore.
Description
METHOD FOR CHARACTERISING A POLYNUCELOTIDE BY USING A XPD HELICASE
Field of the invention
The invention relates to a new method of characterising a target polynucleotide. The method uses a pore and an XPD helicase. The helicase controls the movement of the target polynucleotide through the pore.
Background of the invention
There is currently a need for rapid and cheap polynucleotide (e.g. DNA or RNA) sequencing and identification technologies across a wide range of applications. Existing technologies are slow and expensive mainly because they rely on amplification techniques to produce large volumes of polynucleotide and require a high quantity of specialist fluorescent chemicals for signal detection.
Transmembrane pores (nanopores) have great potential as direct, electrical biosensors for polymers and a variety of small molecules. In particular, recent focus has been given to nanopores as a potential DNA sequencing technology.
When a potential is applied across a nanopore, there is a change in the current flow when an analyte, such as a nucleotide, resides transiently in the barrel for a certain period of time. Nanopore detection of the nucleotide gives a current change of known signature and duration. In the "Strand Sequencing" method, a single polynucleotide strand is passed through the pore and the identity of the nucleotides are derived. Strand Sequencing can involve the use of a nucleotide handling protein to control the movement of the polynucleotide through the pore.
Summary of the invention
The inventors have demonstrated that an XPD helicase can control the movement of a polynucleotide through a pore especially when a potential, such as a voltage, is applied. The helicase is capable of moving a target polynucleotide in a controlled and stepwise fashion against or with the field resulting from the applied voltage. Surprisingly, the helicase is capable of functioning at a high salt concentration which is advantageous for characterising the
polynucleotide and, in particular, for determining its sequence using Strand Sequencing. This is discussed in more detail below.
Accordingly, the invention provides a method of characterising a target polynucleotide, comprising:
(a) contacting the target polynucleotide with a transmembrane pore and a XPD helicase such that the target polynucleotide moves through the pore and the XPD helicase controls the movement of the target polynucleotide through the pore; and
(b) taking one or more measurements as the polynucleotide moves with respect to the pore wherein the measurements are indicative of one or more characteristics of the target polynucleotide and thereby characterising the target polynucleotide.
The invention also provides:
a method of forming a sensor for characterising a target polynucleotide, comprising forming a complex between a pore and an XPD helicase and thereby forming a sensor for characterising the target polynucleotide;
use of an XPD helicase to control the movement of a target polynucleotide through a pore;
a kit for characterising a target polynucleotide comprising (a) a pore and (b) an XPD helicase; and
- an analysis apparatus for characterising target polynucleotides in a sample, comprising a plurality of pores and a plurality of an XPD helicase;
a method of characterising a target polynucleotide, comprising:
(a) contacting the target polynucleotide with a XPD helicase such that the XPD helicase controls the movement of the target polynucleotide; and
(b) taking one or more measurements as the XPD helicase controls the movement of the polynucleotide wherein the measurements are indicative of one or more characteristics of the target polynucleotide and thereby characterising the target polynucleotide;
use of a XPD helicase to control the movement of a target polynucleotide during characterisation of the polynucleotide;
- use of a XPD helicase to control the movement of a target polynucleotide during sequencing of part or all of the polynucleotide;
an analysis apparatus for characterising target polynucleotides in a sample, characterised in that it comprises a XPD helicase; and
a kit for characterising a target polynucleotide comprising (a) an analysis apparatus for characterising target polynucleotides and (b) a XPD helicase.
Description of the Figures
Fig. 1. A) Example schematic of use of a helicase to control DNA movement through a nanopore. The arrows shown on the trans side show the direction of motion of the DNA. The arrows on the cis side show direction of motion of the helicase relative to the DNA. From left to
right) A ssDNA substrate (FiglB) with an annealed primer containing a cholesterol-tag is added to the cis side of the bilayer. The cholesterol tag binds to the bilayer, enriching the substrate at the bilayer surface. Helicase added to the cis compartment binds to the DNA. In the presence of divalent metal ions and NTP substrate, the helicase moves along the DNA. Under an applied voltage, the DNA substrate is captured by the nanopore via the leader section on the DNA. The DNA is pulled through the pore under the force of the applied potential until a helicase, bound to the DNA, contacts the top of the pore, preventing further uncontrolled DNA translocation. The helicase movement along the DNA in a 5' to 3 ' direction facilitates the controlled translocation of the threaded DNA through the pore with the applied field. The helicase facilitates translocation of the DNA through the nanopore, feeding it into the trans compartment. The last section of DNA to pass through the nanopore is the 3' end. When the helicase has facilitated complete translocation of the DNA through the nanopore the helicase dissociates from the strand. B) One of the DNA substrate designs used in the Example.
Fig. 2. Helicase is able to move DNA through a nanopore in a controlled fashion, producing stepwise changes in current as the DNA moves through the nanopore. Example helicase-DNA events (140 mV, 400 mM NaCl, Hepes pH 8.0, 0.6nM 400 mer DNA, 100 nM XPD Mbu, 1 mM DTT, 1 mM ATP, 1 mM MgCl2). Top) Section of current vs. time acquisition of XPD 400mer DNA events through an MspA B2 nanopore. The open-pore current is ~95 pA. DNA is captured by the nanopore under the force of the applied potential (+140 mV). DNA with enzyme attached results in a long block (at ~25pA in this condition) that shows stepwise changes in current as the enzyme moves the DNA through the pore. Bottom) The bottom traces shows an enlargement of one of the helicase controlled DNA movement events, showing DNA-enzyme capture, stepwise current changes as the DNA is pulled through the pore.
Fig. 3. A further example of helicase controlled DNA movement event. Bottom) An enlargement of a section of the event showing the stepwise changes in current from the different sections of DNA as the strand moves through the nanopore.
Fig. 4. The helicase can control the movement of DNA in at least two modes of operation. The helicase moves along the DNA in the 5 '-3 ' direction, but the orientation of the DNA in the nanopore (dependent on which end of the DNA is captured) means that the enzyme can be used to either move the DNA out of the nanopore against the applied field, or move the DNA into the nanopore with the applied field. Left) When the 3 ' end of the DNA is captured the helicase works against the direction of the field applied by the voltage, pulling the threaded DNA out of the nanopore and into the cis chamber. Right) When the DNA is captured 5'-down in the nanopore, the enzyme moves the DNA into the nanopore in the direction of the field into the trans side of the bilayer.
Fig. 5. Fluorescence assay for testing enzyme activity. A) A custom fluorescent substrate was used to assay the ability of the helicase to displace hybridised dsDNA. 1) The fluorescent substrate strand (50 nM final) has a 5' ssDNA overhang, and a 40 base section of hybridised dsDNA. The major upper strand has a carboxyfluorescein base at the 3 ' end, and the hybridised complement has a black-hole quencher (BHQ-1) base at the 5' end. When hybridised the fluorescence from the fluorescein is quenched by the local BHQ-1, and the substrate is essentially non- fluorescent. 1 μΜ of a capture strand that is complementary to the shorter strand of the fluorescent substrate is included in the assay. 2) In the presence of ATP (1 mM) and MgC (10 mM), helicase (150 nM) added to the substrate binds to the 5' tail of the fluorescent substrate, moves along the major strand, and displaces the complementary strand as shown. 3) Once the complementary strand with BHQ-1 is fully displaced the fluorescein on the major strand fluoresces. 4) Excess of capture strand preferentially anneals to the complementary DNA to prevent re-annealing of initial substrate and loss of fluorescence. B) Graph of the initial rate of Mbu XPD helicase activity in buffer solutions (100 mM Hepes pH 8.0, 1 mM ATP, 10 mM MgC , 50 nM fluorescent substrate DNA, 1 μΜ capture DNA) containing different
concentrations of KC1 from 100 mM to 2 M.
Fig. 6. The structure of the spacer iSpl8 used in Example 1.
Description of the Sequence Listing
SEQ ID NO: 1 shows the codon optimised polynucleotide sequence encoding the MS-B 1 mutant MspA monomer. This mutant lacks the signal sequence and includes the following mutations: D90N, D91N, D93N, D118R, D134R and E139K.
SEQ ID NO: 2 shows the amino acid sequence of the mature form of the MS-B 1 mutant of the MspA monomer. This mutant lacks the signal sequence and includes the following mutations: D90N, D91N, D93N, D118R, D134R and E139K.
SEQ ID NO: 3 shows the polynucleotide sequence encoding one subunit of a-hemolysin- El l lN 147N ( -HL-NN; Stoddart et al, PNAS, 2009; 106(19): 7702-7707).
SEQ ID NO: 4 shows the amino acid sequence of one subunit of a-HL-NN.
SEQ ID NOs: 5 to 7 show the amino acid sequences of MspB, C and D.
SEQ ID NOs: 8 and 9 show the amino acid sequences of XPD motifs V and VI.
SEQ ID NOs: 10 to 62 show the amino acid sequences of the XPD helicases in Table 5. SEQ ID NOs: 63 to 68 show the sequences used in the Examples.
Detailed description of the invention
It is to be understood that different applications of the disclosed products and methods may be tailored to the specific needs in the art. It is also to be understood that the terminology used herein is for the purpose of describing particular embodiments of the invention only, and is not intended to be limiting.
In addition as used in this specification and the appended claims, the singular forms "a", "an", and "the" include plural referents unless the content clearly dictates otherwise. Thus, for example, reference to "a pore" includes two or more such pores, reference to "a helicase" includes two or more such helicases, reference to "a polynucleotide" includes two or more such polynucleotides, and the like.
All publications, patents and patent applications cited herein, whether supra or infra, are hereby incorporated by reference in their entirety.
Methods of the invention
The invention provides a method of characterising a target polynucleotide. The method comprises contacting the target polynucleotide with a transmembrane pore and an XPD helicase such that the target polynucleotide moves through the pore and the XPD helicase controls the movement of the target polynucleotide through the pore. One or more characteristics of the target polynucleotide are then measured as the polynucleotide moves with respect to the pore using standard methods known in the art. One or more characteristics of the target
polynucleotide are preferably measured as the polynucleotide moves through the pore. Steps (a) and (b) are preferably carried out with a potential applied across the pore. As discussed in more detail below, the applied potential typically results in the formation of a complex between the pore and the helicase. The applied potential may be a voltage potential. Alternatively, the applied potential may be a chemical potential. An example of this is using a salt gradient across an amphiphilic layer. A salt gradient is disclosed in Holden et ah, J Am Chem Soc. 2007 Jul l l; 129(27):8650-5.
In some instances, the current passing through the pore as the polynucleotide moves with respect to the pore is used to determine the sequence of the target polynucleotide. This is Strand Sequencing.
The method has several advantages. First, the inventors have surprisingly shown that XPD helicases have a surprisingly high salt tolerance and so the method of the invention may be carried out at high salt concentrations. In the context of Strand Sequencing, a charge carrier, such as a salt, is necessary to create a conductive solution for applying a voltage offset to capture and translocate the target polynucleotide and to measure the resulting sequence-dependent
current changes as the polynucleotide moves with respect to the pore. Since the measurement signal is dependent on the concentration of the salt, it is advantageous to use high salt concentrations to increase the magnitude of the acquired signal. High salt concentrations provide a high signal to noise ratio and allow for currents indicative of the presence of a nucleotide to be identified against the background of normal current fluctuations. For Strand Sequencing, salt concentrations in excess of 100 mM are ideal, for example salt concentrations in excess of 400mM, 600mM or 800mM. The inventors have surprisingly shown that XPD helicases will function effectively at very high salt concentrations such as, for example, 1 M. The invention encompasses helicases which function effectively at salt concentrations in excess of 1M, for example 2M.
Second, when a voltage is applied, XPD helicases can surprisingly move the target polynucleotide in two directions, namely with or against the field resulting from the applied voltage. Hence, the method of the invention may be carried out in one of two preferred modes. Different signals are obtained depending on the direction the target polynucleotide moves with respect to the pore, ie in the direction of or against the field. This is discussed in more detail below.
Third, XPD helicases typically move the target polynucleotide through the pore one nucleotide at a time. XPD helicases can therefore function like a single-base ratchet. This is of course advantageous when sequencing a target polynucleotide because substantially all, if not all, of the nucleotides in the target polynucleotide may be identified using the pore.
Fourth, XPD helicases are capable of controlling the movement of single stranded polynucleotides and double stranded polynucleotides. This means that a variety of different target polynucleotides can be characterised in accordance with the invention.
Fifth, XPD helicases appear very resistant to the field resulting from applied voltages. The inventors have seen very little movement of the polynucleotide under an "unzipping" condition. Unzipping conditions will typically be in the absence of nucleotides, for example the absence of ATP. When the helicase is operating in unzipping mode it acts like a brake preventing the target sequence from moving through the pore too quickly under the influence of the applied voltage. This is important because it means that there are no complications from unwanted "backwards" movements when moving polynucleotides against the field resulting from an applied voltage.
Sixth, XPD helicases are easy to produce and easy to handle. Their use therefore contributed to a straightforward and less expensive method of sequencing.
The method of the invention is for characterising a target polynucleotide. A
polynucleotide, such as a nucleic acid, is a macromolecule comprising two or more nucleotides.
The polynucleotide or nucleic acid may comprise any combination of any nucleotides. The nucleotides can be naturally occurring or artificial. One or more nucleotides in the target polynucleotide can be oxidized or methylated. One or more nucleotides in the target polynucleotide may be damaged. One or more nucleotides in the target polynucleotide may be modified, for instance with a label or a tag. The target polynucleotide may comprise one or more spacers.
A nucleotide typically contains a nucleobase, a sugar and at least one phosphate group. The nucleobase is typically heterocyclic. Nucleobases include, but are not limited to, purines and pyrimidines and more specifically adenine, guanine, thymine, uracil and cytosine. The sugar is typically a pentose sugar. Nucleotide sugars include, but are not limited to, ribose and deoxyribose. The nucleotide is typically a ribonucleotide or deoxyribonucleotide. The nucleotide typically contains a monophosphate, diphosphate or triphosphate. Phosphates may be attached on the 5' or 3' side of a nucleotide.
Nucleotides include, but are not limited to, adenosine monophosphate (AMP), guanosine monophosphate (GMP), thymidine monophosphate (TMP), uridine monophosphate (UMP), cytidine monophosphate (CMP), cyclic adenosine monophosphate (cAMP), cyclic guanosine monophosphate (cGMP), deoxyadenosine monophosphate (dAMP), deoxyguanosine monophosphate (dGMP), deoxythymidine monophosphate (dTMP), deoxyuridine
monophosphate (dUMP) and deoxycytidine monophosphate (dCMP). The nucleotides are preferably selected from AMP, TMP, GMP, CMP, UMP, dAMP, dTMP, dGMP or dCMP.
A nucleotide may be abasic (i.e. lack a nucleobase).
The polynucleotide may be single stranded or double stranded. At least a portion of the polynucleotide is preferably double stranded.
The polynucleotide can be a nucleic acid, such as deoxyribonucleic acid (DNA) or ribonucleic acid (RNA). The target polynucleotide can comprise one strand of RNA hybridized to one strand of DNA. The polynucleotide may be any synthetic nucleic acid known in the art, such as peptide nucleic acid (PNA), glycerol nucleic acid (GNA), threose nucleic acid (TNA), locked nucleic acid (LNA) or other synthetic polymers with nucleotide side chains.
The whole or only part of the target polynucleotide may be characterised using this method. The target polynucleotide can be any length. For example, the polynucleotide can be at least 10, at least 50, at least 100, at least 150, at least 200, at least 250, at least 300, at least 400 or at least 500 nucleotide pairs in length. The polynucleotide can be 1000 or more nucleotide pairs, 5000 or more nucleotide pairs in length or 100000 or more nucleotide pairs in length.
The target polynucleotide is present in any suitable sample. The invention is typically carried out on a sample that is known to contain or suspected to contain the target
polynucleotide. Alternatively, the invention may be carried out on a sample to confirm the identity of one or more target polynucleotides whose presence in the sample is known or expected.
The sample may be a biological sample. The invention may be carried out in vitro on a sample obtained from or extracted from any organism or microorganism. The organism or microorganism is typically archaean, prokaryotic or eukaryotic and typically belongs to one the five kingdoms: plantae, animalia, fungi, monera and protista. The invention may be carried out in vitro on a sample obtained from or extracted from any virus. The sample is preferably a fluid sample. The sample typically comprises a body fluid of the patient. The sample may be urine, lymph, saliva, mucus or amniotic fluid but is preferably blood, plasma or serum. Typically, the sample is human in origin, but alternatively it may be from another mammal animal such as from commercially farmed animals such as horses, cattle, sheep or pigs or may alternatively be pets such as cats or dogs. Alternatively a sample of plant origin is typically obtained from a commercial crop, such as a cereal, legume, fruit or vegetable, for example wheat, barley, oats, canola, maize, soya, rice, bananas, apples, tomatoes, potatoes, grapes, tobacco, beans, lentils, sugar cane, cocoa, cotton.
The sample may be a non-biological sample. The non-biological sample is preferably a fluid sample. Examples of a non-biological sample include surgical fluids, water such as drinking water, sea water or river water, and reagents for laboratory tests.
The sample is typically processed prior to being assayed, for example by centrifugation or by passage through a membrane that filters out unwanted molecules or cells, such as red blood cells. The sample may be measured immediately upon being taken. The sample may also be typically stored prior to assay, preferably below -70°C.
A transmembrane pore is a structure that crosses the membrane to some degree. It permits ions, such as hydrated ions, driven by an applied potential to flow across or within the membrane. The transmembrane pore typically crosses the entire membrane so that ions may flow from one side of the membrane to the other side of the membrane. However, the transmembrane pore does not have to cross the membrane. It may be closed at one end. For instance, the pore may be a well in the membrane along which or into which ions may flow.
Any membrane may be used in accordance with the invention. Suitable membranes are well-known in the art. The membrane is preferably an amphiphilic layer. An amphiphilic layer is a layer formed from amphiphilic molecules, such as phospholipids, which have both at least one hydrophilic portion and at least one lipophilic or hydrophobic portion. The amphiphilic layer may be a monolayer or a bilayer. The amphiphilic layer is typically a planar lipid bilayer or a supported bilayer.
The amphiphilic layer is typically a lipid bilayer. Lipid bilayers are models of cell membranes and serve as excellent platforms for a range of experimental studies. For example, lipid bilayers can be used for in vitro investigation of membrane proteins by single-channel recording. Alternatively, lipid bilayers can be used as biosensors to detect the presence of a range of substances. The lipid bilayer may be any lipid bilayer. Suitable lipid bilayers include, but are not limited to, a planar lipid bilayer, a supported bilayer or a liposome. The lipid bilayer is preferably a planar lipid bilayer. Suitable lipid bilayers are disclosed in International
Application No. PCT/GB08/000563 (published as WO 2008/102121), International Application No. PCT/GB08/004127 (published as WO 2009/077734) and International Application No. PCT/GB2006/001057 (published as WO 2006/100484).
Methods for forming lipid bilayers are known in the art. Suitable methods are disclosed in the Example. Lipid bilayers are commonly formed by the method of Montal and Mueller (Proc. Natl. Acad. Sci. USA., 1972; 69: 3561-3566), in which a lipid monolayer is carried on aqueous solution/air interface past either side of an aperture which is perpendicular to that interface.
The method of Montal & Mueller is popular because it is a cost-effective and relatively straightforward method of forming good quality lipid bilayers that are suitable for protein pore insertion. Other common methods of bilayer formation include tip-dipping, painting bilayers and patch-clamping of liposome bilayers.
In a preferred embodiment, the lipid bilayer is formed as described in International
Application No. PCT/GB08/004127 (published as WO 2009/077734).
In another preferred embodiment, the membrane is a solid state layer. A solid-state layer is not of biological origin. In other words, a solid state layer is not derived from or isolated from a biological environment such as an organism or cell, or a synthetically manufactured version of a biologically available structure. Solid state layers can be formed from both organic and inorganic materials including, but not limited to, microelectronic materials, insulating materials such as S13N4, AI2O3, and SiO, organic and inorganic polymers such as polyamide, plastics such as Teflon® or elastomers such as two-component addition-cure silicone rubber, and glasses. The solid state layer may be formed from monatomic layers, such as graphene, or layers that are only a few atoms thick. Suitable graphene layers are disclosed in International Application No. PCT/US2008/010637 (published as WO 2009/035647).
The method is typically carried out using (i) an artificial amphiphilic layer comprising a pore, (ii) an isolated, naturally-occurring lipid bilayer comprising a pore, or (iii) a cell having a pore inserted therein. The method is typically carried out using an artificial amphiphilic layer, such as an artificial lipid bilayer. The layer may comprise other transmembrane and/or
intramembrane proteins as well as other molecules in addition to the pore. Suitable apparatus and conditions are discussed below. The method of the invention is typically carried out in vitro.
The polynucleotide may be coupled to the membrane. This may be done using any known method. If the membrane is an amphiphilic layer, such as a lipid bilayer (as discussed in detail above), the polynucleotide is preferably coupled to the membrane via a polypeptide present in the membrane or a hydrophobic anchor present in the membrane. The hydrophobic anchor is preferably a lipid, fatty acid, sterol, carbon nanotube or amino acid.
The polynucleotide may be coupled directly to the membrane. The polynucleotide is preferably coupled to the membrane via a linker. Preferred linkers include, but are not limited to, polymers, such as polynucleotides, polyethylene glycols (PEGs) and polypeptides. If a polynucleotide is coupled directly to the membrane, then some data will be lost as the characterising run cannot continue to the end of the polynucleotide due to the distance between the membrane and the helicase. If a linker is used, then the polynucleotide can be processed to completion. If a linker is used, the linker may be attached to the polynucleotide at any position. The linker is preferably attached to the polynucleotide at the tail polymer.
The coupling may be stable or transient. For certain applications, the transient nature of the coupling is preferred. If a stable coupling molecule were attached directly to either the 5' or 3' end of a polynucleotide, then some data will be lost as the characterising run cannot continue to the end of the polynucleotide due to the distance between the bilayer and the helicase' s active site. If the coupling is transient, then when the coupled end randomly becomes free of the bilayer, then the polynucleotide can be processed to completion. Chemical groups that form stable or transient links with the membrane are discussed in more detail below. The
polynucleotide may be transiently coupled to an amphiphilic layer, such as a lipid bilayer using cholesterol or a fatty acyl chain. Any fatty acyl chain having a length of from 6 to 30 carbon atoms, such as hexadecanoic acid, may be used.
In preferred embodiments, the polynucleotide is coupled to an amphiphilic layer.
Coupling of polynucleotides to synthetic lipid bilayers has been carried out previously with various different tethering strategies. These are summarised in Table 1 below.
Table 1
Attachment group Type of coupling Reference
Thiol Stable Yoshina-Ishii, C. and S. G. Boxer (2003). "Arrays of mobile tethered vesicles on supported lipid bilayers." J Am Chem Soc 125(13): 3696-7.
Biotin Stable Nikolov, V., R. Lipowsky, et al. (2007). "Behavior of giant vesicles with anchored DNA molecules." Biophvs J 92(12): 4356-68
Cholestrol Transient Pfeiffer, I. and F. Hook (2004). "Bivalent cholesterol- based coupling of oligonucletides to lipid membrane assemblies." J Am Chem Soc 126(33): 10224-5
Lipid Stable van Lengerich, B , R. J. Rawle, et al. "Covalent attachment of lipid vesicles to a fluid-supported bilayer allows observation of DNA-mediated vesicle interactions." Langmuir 26(11): 8666-72
Polynucleotides may be functionalized using a modified phosphoramidite in the synthesis reaction, which is easily compatible for the addition of reactive groups, such as thiol, cholesterol, lipid and biotin groups. These different attachment chemistries give a suite of attachment options for polynucleotides. Each different modification group tethers the polynucleotide in a slightly different way and coupling is not always permanent so giving different dwell times for the polynucleotide to the bilayer. The advantages of transient coupling are discussed above.
Coupling of polynucleotides can also be achieved by a number of other means provided that a reactive group can be added to the polynucleotide. The addition of reactive groups to either end of DNA has been reported previously. A thiol group can be added to the 5' of ssDNA using polynucleotide kinase and ATPyS (Grant, G. P. and P. Z. Qin (2007). "A facile method for attaching nitroxide spin labels at the 5' terminus of nucleic acids. " Nucleic Acids Res 35(10): e77). A more diverse selection of chemical groups, such as biotin, thiols and fluorophores, can be added using terminal transferase to incorporate modified oligonucleotides to the 3 ' of ssDNA (Kumar, A., P. Tchen, et al. (1988) "Nonradioactive labeling of synthetic oligonucleotide probes with terminal deoxynucleotidyl transferase." Anal Biochem 169(2): 376-82).
Alternatively, the reactive group could be considered to be the addition of a short piece of DNA complementary to one already coupled to the bilayer, so that attachment can be achieved via hybridisation. Ligation of short pieces of ssDNA have been reported using T4 RNA ligase I (Troutt, A. B., M. G. McHeyzer- Williams, et al. (1992). "Ligation-anchored PCR: a simple amplification technique with single-sided specificity." Proc Natl Acad Sci U S A 89(20): 9823- 5). Alternatively either ssDNA or dsDNA could be ligated to native dsDNA and then the two strands separated by thermal or chemical denaturation. To native dsDNA, it is possible to add either a piece of ssDNA to one or both of the ends of the duplex, or dsDNA to one or both ends. Then, when the duplex is melted, each single strand will have either a 5' or 3 ' modification if ssDNA was used for ligation or a modification at the 5' end, the 3 ' end or both if dsDNA was used for ligation. If the polynucleotide is a synthetic strand, the coupling chemistry can be incorporated during the chemical synthesis of the polynucleotide. For instance, the
polynucleotide can be synthesized using a primer a reactive group attached to it.
A common technique for the amplification of sections of genomic DNA is using polymerase chain reaction (PCR). Here, using two synthetic oligonucleotide primers, a number of copies of the same section of DNA can be generated, where for each copy the 5' of each strand in the duplex will be a synthetic polynucleotide. By using an antisense primer that has a reactive group, such as a cholesterol, thiol, biotin or lipid, each copy of the target DNA amplified will contain a reactive group for coupling.
The transmembrane pore is preferably a transmembrane protein pore. A transmembrane protein pore is a protein structure that crosses the membrane to some degree. It permits ions driven by an applied potential to flow across or within the membrane. A transmembrane protein pore is typically a polypeptide or a collection of polypeptides that permits ions, such as analytes, to flow from one side of a membrane to the other side of the membrane. However, the transmembrane protein pore does not have to cross the membrane. It may be closed at one end. For instance, the transmembrane pore may form a well in the membrane along which or into which ions may flow. The transmembrane protein pore preferably permits analytes, such as nucleotides, to flow across or within the membrane, such as a lipid bilayer. The transmembrane protein pore allows a polynucleotide, such as DNA or RNA, to be moved through the pore.
The transmembrane protein pore may be a monomer or an oligomer. The pore is preferably made up of several repeating subunits, such as 6, 7, 8 or 9 subunits. The pore is preferably a hexameric, heptameric, octameric or nonameric pore.
The transmembrane protein pore typically comprises a barrel or channel through which the ions may flow. The subunits of the pore typically surround a central axis and contribute strands to a transmembrane β barrel or channel or a transmembrane oc-helix bundle or channel.
The barrel or channel of the transmembrane protein pore typically comprises amino acids that facilitate interaction with analyte, such as nucleotides, polynucleotides or nucleic acids. These amino acids are preferably located near a constriction of the barrel or channel. The transmembrane protein pore typically comprises one or more positively charged amino acids, such as arginine, lysine or histidine, or aromatic amino acids, such as tyrosine or tryptophan. These amino acids typically facilitate the interaction between the pore and nucleotides, polynucleotides or nucleic acids.
Transmembrane protein pores for use in accordance with the invention can be derived from β-barrel pores or a-helix bundle pores, β-barrel pores comprise a barrel or channel that is formed from β-strands. Suitable β-barrel pores include, but are not limited to, β-toxins, such as a-hemolysin, anthrax toxin and leukocidins, and outer membrane proteins/porins of bacteria, such as Mycobacterium smegmatis porin (Msp), for example MspA, outer membrane porin F
(OmpF), outer membrane porin G (OmpG), outer membrane phospholipase A and Neisseria autotransporter lipoprotein (NalP). a-helix bundle pores comprise a barrel or channel that is formed from cc-helices. Suitable a-helix bundle pores include, but are not limited to, inner membrane proteins and a outer membrane proteins, such as WZA and ClyA toxin. The transmembrane pore may be derived from Msp or from a-hemolysin (a-HL).
The transmembrane protein pore is preferably derived from Msp, preferably from MspA. Such a pore will be oligomeric and typically comprises 7, 8, 9 or 10 monomers derived from Msp. The pore may be a homo-oligomeric pore derived from Msp comprising identical monomers. Alternatively, the pore may be a hetero-oligomeric pore derived from Msp comprising at least one monomer that differs from the others. Preferably the pore is derived from MspA or a homolog or paralog thereof.
A monomer derived from Msp comprises the sequence shown in SEQ ID NO: 2 or a variant thereof. SEQ ID NO: 2 is the MS-(B 1)8 mutant of the MspA monomer. It includes the following mutations: D90N, D91N, D93N, Dl 18R, D134R and E139K. A variant of SEQ ID NO: 2 is a polypeptide that has an amino acid sequence which varies from that of SEQ ID NO: 2 and which retains its ability to form a pore. The ability of a variant to form a pore can be assayed using any method known in the art. For instance, the variant may be inserted into an amphihpilic layer along with other appropriate subunits and its ability to oligomerise to form a pore may be determined. Methods are known in the art for inserting subunits into membranes, such as amphiphilic layers. For example, subunits may be suspended in a purified form in a solution containing a lipid bilayer such that it diffuses to the lipid bilayer and is inserted by binding to the lipid bilayer and assembling into a functional state. Alternatively, subunits may be directly inserted into the membrane using the "pick and place" method described in M.A. Holden, H. Bayley. J. Am. Chem. Soc. 2005, 127, 6502-6503 and International Application No. PCT/GB2006/001057 (published as WO 2006/100484).
Over the entire length of the amino acid sequence of SEQ ID NO: 2, a variant will preferably be at least 50% homologous to that sequence based on amino acid identity. More preferably, the variant may be at least 55%, at least 60%, at least 65%>, at least 70%, at least 75%, at least 80%, at least 85%, at least 90% and more preferably at least 95%, 97% or 99% homologous based on amino acid identity to the amino acid sequence of SEQ ID NO: 2 over the entire sequence. There may be at least 80%, for example at least 85%, 90% or 95%, amino acid identity over a stretch of 100 or more, for example 125, 150, 175 or 200 or more, contiguous amino acids ("hard homology").
Standard methods in the art may be used to determine homology. For example the UWGCG Package provides the BESTFIT program which can be used to calculate homology, for
example used on its default settings (Devereux et al (1984) Nucleic Acids Research 12, p387- 395). The PILEUP and BLAST algorithms can be used to calculate homology or line up sequences (such as identifying equivalent residues or corresponding sequences (typically on their default settings)), for example as described in Altschul S. F. (1993) J Mol Evol 36:290-300; Altschul, S.F et al (1990) J Mol Biol 215:403-10. Software for performing BLAST analyses is publicly available through the National Center for Biotechnology Information
(http://www.ncbi.nlm.nih.gov/).
SEQ ID NO: 2 is the MS-(B 1)8 mutant of the MspA monomer. The variant may comprise any of the mutations in the MspB, C or D monomers compared with MspA. The mature forms of MspB, C and D are shown in SEQ ID NOs: 5 to 7. In particular, the variant may comprise the following substitution present in MspB: A138P. The variant may comprise one or more of the following substitutions present in MspC: A96G, N102E and A138P. The variant may comprise one or more of the following mutations present in MspD: Deletion of Gl, L2V, E5Q, L8V, D13G, W21A, D22E, K47T, I49H, I68V, D91G, A96Q, N102D, S 103T, VI 041, S136K and G141A. The variant may comprise combinations of one or more of the mutations and substitutions from Msp B, C and D. The variant preferably comprises the mutation L88N. The variant of SEQ ID NO: 2 has the mutation L88N in addition to all the mutations of MS-B1 and is called MS-B2. The pore used in the invention is preferably MS- (B2)8.
Amino acid substitutions may be made to the amino acid sequence of SEQ ID NO: 2 in addition to those discussed above, for example up to 1, 2, 3, 4, 5, 10, 20 or 30 substitutions. Conservative substitutions replace amino acids with other amino acids of similar chemical structure, similar chemical properties or similar side-chain volume. The amino acids introduced may have similar polarity, hydrophilicity, hydrophobicity, basicity, acidity, neutrality or charge to the amino acids they replace. Alternatively, the conservative substitution may introduce another amino acid that is aromatic or aliphatic in the place of a pre-existing aromatic or aliphatic amino acid. Conservative amino acid changes are well-known in the art and may be selected in accordance with the properties of the 20 main amino acids as defined in Table 2 below. Where amino acids have similar polarity, this can also be determined by reference to the hydropathy scale for amino acid side chains in Table 3.
Table 2 - Chemical properties of amino acids
Ala aliphatic, hydrophobic, neutral Met hydrophobic, neutral
Cys polar, hydrophobic, neutral Asn polar, hydrophilic, neutral
Asp polar, hydrophilic, charged (-) Pro hydrophobic, neutral
Glu polar, hydrophilic, charged (-) Gin polar, hydrophilic, neutral
Phe aromatic, hydrophobic, neutral Arg polar, hydrophilic, charged (+)
Gly aliphatic, neutral Ser polar, hydrophilic, neutral
His aromatic, polar, hydrophilic, Thr polar, hydrophilic, neutral
charged (+)
He aliphatic, hydrophobic, neutral Val aliphatic, hydrophobic, neutral
Lys polar, hydrophilic, charged(+) Trp aromatic, hydrophobic, neutral
Leu aliphatic, hydrophobic, neutral Tyr aromatic, polar, hydrophobic
Table 3- Hydropathy scale
Side Chain Hydropathy
He 4.5
Val 4.2
Leu 3.8
Phe 2.8
Cys 2.5
Met 1.9
Ala 1.8
Gly -0.4
Thr -0.7
Ser -0.8
Trp -0.9
Tyr -1.3
Pro -1.6
His -3.2
Glu -3.5
Gin -3.5
Asp -3.5
Asn -3.5
Lys -3.9
Are -4.5
One or more amino acid residues of the amino acid sequence of SEQ ID NO: 2 may additionally be deleted from the polypeptides described above. Up to 1, 2, 3, 4, 5, 10, 20 or 30 residues may be deleted, or more.
Variants may include fragments of SEQ ID NO: 2. Such fragments retain pore forming activity. Fragments may be at least 50, 100, 150 or 200 amino acids in length. Such fragments may be used to produce the pores. A fragment preferably comprises the pore forming domain of SEQ ID NO: 2. Fragments must include one of residues 88, 90, 91, 105, 1 18 and 134 of SEQ ID NO: 2. Typically, fragments include all of residues 88, 90, 91, 105, 1 18 and 134 of SEQ ID NO: 2.
One or more amino acids may be alternatively or additionally added to the polypeptides described above. An extension may be provided at the amino terminal or carboxy terminal of the amino acid sequence of SEQ ID NO: 2 or polypeptide variant or fragment thereof. The extension may be quite short, for example from 1 to 10 amino acids in length. Alternatively, the extension may be longer, for example up to 50 or 100 amino acids. A carrier protein may be fused to an amino acid sequence according to the invention. Other fusion proteins are discussed in more detail below.
As discussed above, a variant is a polypeptide that has an amino acid sequence which varies from that of SEQ ID NO: 2 and which retains its ability to form a pore. A variant typically contains the regions of SEQ ID NO: 2 that are responsible for pore formation. The pore forming ability of Msp, which contains a β-barrel, is provided by β-sheets in each subunit A variant of SEQ ID NO: 2 typically comprises the regions in SEQ ID NO: 2 that form β-sheets. One or more modifications can be made to the regions of SEQ ID NO: 2 that form β-sheets as long as the resulting variant retains its ability to form a pore. A variant of SEQ ID NO: 2 preferably includes one or more modifications, such as substitutions, additions or deletions, within its oc-helices and/or loop regions.
The monomers derived from Msp may be modified to assist their identification or purification, for example by the addition of histidine residues (a hist tag), aspartic acid residues (an asp tag), a streptavidin tag or a flag tag, or by the addition of a signal sequence to promote their secretion from a cell where the polypeptide does not naturally contain such a sequence. An alternative to introducing a genetic tag is to chemically react a tag onto a native or engineered position on the pore. An example of this would be to react a gel-shift reagent to a cysteine engineered on the outside of the pore. This has been demonstrated as a method for separating hemolysin hetero-oligomers (Chem Biol. 1997 Jul; 4(7):497-505).
The monomer derived from Msp may be labelled with a revealing label. The revealing label may be any suitable label which allows the pore to be detected. Suitable labels include, but are not limited to, fluorescent molecules, radioisotopes, e.g. 1251, 5 S, enzymes, antibodies, antigens, polynucleotides and ligands such as biotin.
The monomer derived from Msp may also be produced using D-amino acids. For instance, the monomer derived from Msp may comprise a mixture of L-amino acids and D- amino acids. This is conventional in the art for producing such proteins or peptides.
The monomer derived from Msp contains one or more specific modifications to facilitate nucleotide discrimination. The monomer derived from Msp may also contain other non-specific modifications as long as they do not interfere with pore formation. A number of non-specific
side chain modifications are known in the art and may be made to the side chains of the monomer derived from Msp. Such modifications include, for example, reductive alkylation of amino acids by reaction with an aldehyde followed by reduction with NaBFL, amidination with methylacetimidate or acylation with acetic anhydride.
The monomer derived from Msp can be produced using standard methods known in the art. The monomer derived from Msp may be made synthetically or by recombinant means. For example, the pore may be synthesized by in vitro translation and transcription (IVTT). Suitable methods for producing pores are discussed in International Application Nos. PCT/GB09/001690 (published as WO 2010/004273), PCT/GB09/001679 (published as WO 2010/004265) or PCT/GB 10/000133 (published as WO 2010/086603). Methods for inserting pores into membranes are discussed.
The transmembrane protein pore is also preferably derived from a-hemolysin (a-HL). The wild type a-HL pore is formed of seven identical monomers or subunits (i.e. it is heptameric). The sequence of one monomer or subunit of a-hemolysin-NN is shown in SEQ ID NO: 4. The transmembrane protein pore preferably comprises seven monomers each comprising the sequence shown in SEQ ID NO: 4 or a variant thereof. Amino acids 1, 7 to 21, 31 to 34, 45 to 51, 63 to 66, 72, 92 to 97, 104 to 111, 124 to 136, 149 to 153, 160 to 164, 173 to 206, 210 to 213, 217, 218, 223 to 228, 236 to 242, 262 to 265, 272 to 274, 287 to 290 and 294 of SEQ ID NO: 4 form loop regions. Residues 113 and 147 of SEQ ID NO: 4 form part of a constriction of the barrel or channel of a-HL.
In such embodiments, a pore comprising seven proteins or monomers each comprising the sequence shown in SEQ ID NO: 4 or a variant thereof are preferably used in the method of the invention. The seven proteins may be the same (homoheptamer) or different
(heteroheptamer).
A variant of SEQ ID NO: 4 is a protein that has an amino acid sequence which varies from that of SEQ ID NO: 4 and which retains its pore forming ability. The ability of a variant to form a pore can be assayed using any method known in the art. For instance, the variant may be inserted into an amphiphilic layer, such as a lipid bilayer, along with other appropriate subunits and its ability to oligomerise to form a pore may be determined. Methods are known in the art for inserting subunits into amphiphilic layers, such as lipid bilayers. Suitable methods are discussed above.
The variant may include modifications that facilitate covalent attachment to or interaction with the helicase. The variant preferably comprises one or more reactive cysteine residues that facilitate attachment to the helicase. For instance, the variant may include a cysteine at one or more of positions 8, 9, 17, 18, 19, 44, 45, 50, 51, 237, 239 and 287 and/or on the amino or
carboxy terminus of SEQ ID NO: 4. Preferred variants comprise a substitution of the residue at position 8, 9, 17, 237, 239 and 287 of SEQ ID NO: 4 with cysteine (A8C, T9C, N17C, K237C, S239C or E287C). The variant is preferably any one of the variants described in International Application No. PCT/GB09/001690 (published as WO 2010/004273), PCT/GB 09/001679 (published as WO 2010/004265) or PCT/GB 10/000133 (published as WO 2010/086603).
The variant may also include modifications that facilitate any interaction with nucleotides.
The variant may be a naturally occurring variant which is expressed naturally by an organism, for instance by a Staphylococcus bacterium. Alternatively, the variant may be expressed in vitro or recombinantly by a bacterium such as Escherichia coli. Variants also include non-naturally occurring variants produced by recombinant technology. Over the entire length of the amino acid sequence of SEQ ID NO: 4, a variant will preferably be at least 50% homologous to that sequence based on amino acid identity. More preferably, the variant polypeptide may be at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%, at least 85%, at least 90% and more preferably at least 95%, 97% or 99% homologous based on amino acid identity to the amino acid sequence of SEQ ID NO: 4 over the entire sequence. There may be at least 80%, for example at least 85%, 90% or 95%, amino acid identity over a stretch of 200 or more, for example 230, 250, 270 or 280 or more, contiguous amino acids ("hard homology"). Homology can be determined as discussed above.
Amino acid substitutions may be made to the amino acid sequence of SEQ ID NO: 4 in addition to those discussed above, for example up to 1, 2, 3, 4, 5, 10, 20 or 30 substitutions. Conservative substitutions may be made as discussed above.
One or more amino acid residues of the amino acid sequence of SEQ ID NO: 4 may additionally be deleted from the polypeptides described above. Up to 1, 2, 3, 4, 5, 10, 20 or 30 residues may be deleted, or more.
Variants may be fragments of SEQ ID NO: 4. Such fragments retain pore-forming activity. Fragments may be at least 50, 100, 200 or 250 amino acids in length. A fragment preferably comprises the pore-forming domain of SEQ ID NO: 4. Fragments typically include residues 119, 121, 135. 113 and 139 of SEQ ID NO: 4.
One or more amino acids may be alternatively or additionally added to the polypeptides described above. An extension may be provided at the amino terminus or carboxy terminus of the amino acid sequence of SEQ ID NO: 4 or a variant or fragment thereof. The extension may be quite short, for example from 1 to 10 amino acids in length. Alternatively, the extension may be longer, for example up to 50 or 100 amino acids. A carrier protein may be fused to a pore or variant.
As discussed above, a variant of SEQ ID NO: 4 is a subunit that has an amino acid sequence which varies from that of SEQ ID NO: 4 and which retains its ability to form a pore. A variant typically contains the regions of SEQ ID NO: 4 that are responsible for pore formation. The pore forming ability of a-HL, which contains a β-barrel, is provided by β-strands in each subunit. A variant of SEQ ID NO: 4 typically comprises the regions in SEQ ID NO: 4 that form β-strands. The amino acids of SEQ ID NO: 4 that form β-strands are discussed above. One or more modifications can be made to the regions of SEQ ID NO: 4 that form β-strands as long as the resulting variant retains its ability to form a pore. Specific modifications that can be made to the β-strand regions of SEQ ID NO: 4 are discussed above.
A variant of SEQ ID NO: 4 preferably includes one or more modifications, such as substitutions, additions or deletions, within its a-helices and/or loop regions. Amino acids that form a-helices and loops are discussed above.
The variant may be modified to assist its identification or purification as discussed above.
Pores derived from a-HL can be made as discussed above with reference to pores derived from Msp.
In some embodiments, the transmembrane protein pore is chemically modified. The pore can be chemically modified in any way and at any site. The transmembrane protein pore is preferably chemically modified by attachment of a molecule to one or more cysteines (cysteine linkage), attachment of a molecule to one or more lysines, attachment of a molecule to one or more non-natural amino acids, enzyme modification of an epitope or modification of a terminus. Suitable methods for carrying out such modifications are well-known in the art. The
transmembrane protein pore may be chemically modified by the attachment of any molecule. For instance, the pore may be chemically modified by attachment of a dye or a fluorophore.
Any number of the monomers in the pore may be chemically modified. One or more, such as 2, 3, 4, 5, 6, 7, 8, 9 or 10, of the monomers is preferably chemically modified as discussed above.
The reactivity of cysteine residues may be enhanced by modification of the adjacent residues. For instance, the basic groups of flanking arginine, histidine or lysine residues will change the pKa of the cysteines thiol group to that of the more reactive S" group. The reactivity of cysteine residues may be protected by thiol protective groups such as dTNB. These may be reacted with one or more cysteine residues of the pore before a linker is attached.
The molecule (with which the pore is chemically modified) may be attached directly to the pore or attached via a linker as disclosed in International Application Nos.
PCT/GB09/001690 (published as WO 2010/004273), PCT/GB09/001679 (published as WO 2010/004265) or PCT/GB 10/000133 (published as WO 2010/086603).
Any XPD helicase may be used in accordance with the invention. XPD helicases are also known as Rad3 helicases and the two terms can be used interchangeably.
The structures of XPD helicases are known in the art (Cell 2008 May 30;133(5):801 -12.
Staicture of the DNA repair helicase XPD. Liu H, Rudolf J, J ohnson KA, McMahon SA, Oke M, Carter L, McRobbie AM, Brown SE, Naismith JH, White MF). The XPD helicase typically comprises the amino acid motif X 1-X2-X3-G-X4-X5-X6-E-G (hereinafter called XPD motif V; SEQ ID NO: S). XL X2, X5 and X6 are independently selected from any amino acid except D, E, K and R. XI , X2, X5 and X6 are independently selected from G, P, A, V, L, I, M, C, F, Y, W, H, Q, N, S and T. XI , X2, X5 and X6 are preferably not charged. XI , X2, X5 and X6 are preferably not H. XI i s more preferably V, L. I, S or Y. X5 is more preferably V, L, I, N or F. X6 is more preferably S or A. X3 and X4 may be any amino acid residue. X4 is preferably K. R or T.
The XPD helicase typically comprises the amino acid motif Q-Xa-Xb-G-R-Xc-Xd-R-
(Xe)3-Xf-(Xg)?-D-Xh-R (hereinafter called XPD motif VI; SEQ ID NO: 9). Xa, Xe and Xg may be any amino acid residue. Xb, Xc and Xd are independently selected from any amino acid except D, E, K and R. Xb, Xe and Xd are typically independently selected from G, P, A, V, L, I, M, C, F. Y, W, H, Q. N, S and T. Xb, Xc and Xd are preferably not charged. Xb, Xc and Xd are preferably not H. Xb is more preferably V, A, L, I or M. Xc is more preferably V. A, L, I, M or C. Xd is more preferably I, H, L, F, M or V. Xf may be D or E. (Xg is Xgi, Xg2, Xg3, Xg4, Xgs, Xg6 and Xg7. Xg?. is preferably G, A, S or C. Xg5 is preferably F, V, L, I, M, A, W or Y. Xg6 is preferably L, F, Y, M, I or V. Xg7 is preferably A, C, V, L, I, M or S.
The XPD helicase preferably comprises XPD motifs V and VI. The most preferred XPD motifs V and VI are shown in Table 5 below.
The XPD helicase preferably further comprises an iron sulphide (FeS) core between two Walker A and B motifs (motifs I and IS). An FeS core typically comprises an iron atom coordinated between the sulphide groups of cysteine residues. The FeS core is typically tetrahedral.
The XPD helicase is preferably one of the helicases shown in Table 4 below or a variant thereof.
Table 4 - Preferred XPD helicases
1 YP 566221.1 Rad3-related DNA helicases TMethanococcoides burtonii DSM
2 YP 003727831.1 DEAD 2 domain-containing protein [Methanohalobium
3 YP 004617026.1 DEAD 2 domain-containing protein [Methanosal sum zhilinae
4 YP 003541314.1 DEAD/DEAH box helicase [Methanohalophilus mahii DSM
5 NP 63361 1.1 DNA repair helicase [Methanosarcina mazei Go 11
6 NP 615308.1 DNA helicase RepD [Methanosarcina acetivorans C2A1
7 YP 304917.1 DNA helicase RepD [Methanosarcina barkeri str. Fusarol
8 YP 686711.1 putative ATP-dependent DNA-repair helicase [uncultured
9 YP 003355887.1 DNA repair helicase TMethanocella paludicola SANAE1
10 ZP 08042768.1 DEAD 2 domain protein [Haladaptatus paucihalophilus
11 YP 003401909.1 DEAD 2 domain protein THaloterrigena turkmenica DSM 55111
12 YP 004035231.1 DNA helicase, rad3 [Halogeometricum borinquense DSM
13 YP 0035341 13.1 helicase THaloferax volcanii DS21 >gb|ADE05091.1 | helicase
14 YP 003176661.1 DEAD 2 domain protein THalomicrobium mukohataei DSM
15 YP 326312.1 DNA repair helicase-like protein TNatronomonas pharaonis
16 YP 004595879.1 DEAD 2 domain-containing protein [Halopiger xanaduensis
17 ZP 08967673.1 DEAD 2 domain protein TNatronobacterium gregoryi SP21
18 YP 003735388.1 DEAD 2 domain-containing protein [Halalkalicoccus jeotgali
19 YP 003479905.1 DEAD 2 domain-containing protein rNatrialba magadii ATCC
20 YP 003130325.1 DEAD 2 domain protein THalorhabdus utahensis DSM 129401
21 YP 002567268.1 DEAD 2 domain protein THalorubrum lacusprofundi ATCC
22 ZP 08561264.1 DEAD 2 domain protein j"Halorhabdus tiamatea SARL4B1
23 YP 004794633.1 helicase THaloarcula hispanica ATCC 339601 >gb|AEM55645.1 |
24 YP 137192.1 helicase THaloarcula marismortui ATCC 430491
25 ZP 08963818.1 helicase c2 [Natrinema pellirubrum DSM 156241
26 NP 281042.1 helicase THalobacterium sp. NRC-H >reflYP 001690174.11
27 YP 004808929.1 DEAD 2 domain-containing protein [halophilic archaeon
28 CCC41858.1 DNA repair helicase Rad3 rHaloquadratum walsbyi C231
29 YP 659380.1 DNA repair helicase-like protein rHaloquadratum walsbvi DSM
30 YP 686810.1 putative ATP-dependent helicase [uncultured methanogenic
31 ZP 09027753.1 Helicase-like, DEXD box c2 type [Hal obacterium sp. DL11
32 ZP 08042627.1 helicase [Haladaptatus paucihalophilus DX2531
33 YP 002565485.1 helicase c2 [Halorubrum lacusprofundi ATCC 492391
34 YP 003737184.1 helicase [Halalkalicoccus jeotgali B31 >gb|ADJ15392.1 helicase
35 YP 003480051.1 helicase c2 TNatrialba magadii ATCC 430991 >gb|ADD05489.1 |
36 YP 004808332.1 helicase c2 [halophilic archaeon DL311 >gb|AEN05959.1
37 ZP 08967636.1 helicase c2 [Natronobacterium gregoryi SP21 >gb|EHA70214.1 |
ZP 09028751 .1 type III restriction protein res subunit rHalobacterium sp. DL11
YP 326140.1 DNA repair helicase rNatronomonas pharaonis DSM 21601
YP 004595921.1 helicase c2 THalopiger xanaduensis SH-61 >gb|AEH36042.1 |
ZP 08963989. 1 helicase c2 rNatrinema pellirubrum DSM 156241
ZP 08560622, 1 helicase THalorhabdus tiamatea SARL4B1 >reflZP 08560903.11
YP 003405301 , 1 helicase c2 THaloterrigena turkmenica DSM 551 11
ZP 08558438.1 helicase c2 THalorhabdus tiamatea SARL4B1 >gb|EGM36622.1 |
YP 003131362.1 helicase c2 THalorhabdus utahensis DSM 129401
EHF09015.1 DEAD 2 domain protein TMethanolinea tarda NOBI-11
YP 001030540.1 queuine tRNA-ribosyltransferase TMethanocorpusculum
YP 135387.1 helicase THaloarcula marismortui ATCC 430491
YP 004795935.1 helicase THaloarcula hispanica ATCC 339601 >gb|AEM56947.1 |
YP 003178787, 1 helicase c2 THalomicrobium mukohataei DSM 122861
YP 0038951 10, 1 DEAD 2 domain-containing protein TMethanoplanus
ABQ75766.1 DNA repair helicase Rad3 luncultured haloarchaeonl
YP 003535402.1 helicase THaloferax volcanii DS21 >gb I ADE04644. i l helicase
YP 502434, 1 helicase c2 TMethanospirillum hungatei JF-11 >gb IABD40715. i l
CCC40051.1 DNA repair helicase Rad3 THaloquadratum walsbyi C231
YP 657741.1 DNA repair helicase Rad3 THaloquadratum walsbyi DSM
YP 004424267.1 DNA repair helicase rad3 iPyrococcus sp. NA21
P 578662.1 DNA repair helicase rad3, putative TPyrococcus furiosus DSM
BAB 59155, 1 DNA repair helicase TThermoplasma volcanium GSS 11
NP 110532.1 Rad3 -related DNA helicase iThermoplasma volcanium GSS 11
YP 004036893.1 DNA helicase, rad3 rHalogeometricum borinquense DSM
CB1 338285.1 putative helicase luncultured archaeonl
AAU82137.1 conserved hypothetical protein luncultured archaeon
YP 844078, 1 helicase c2 TMethanosaeta thermophila PT1 >gb|ABKl 5438.11
NP 127020, 1 DNA repair helicase rad3 iPyrococcus abyssi GE51
YP 001404278.1 DEAD 2 domain-containing protein TCandidatus
NP 280229.1 helicase rHalobacterium sp. NRC-11 >reflYP 001689339.11
YP 002994616, 1 ERCC2/XPD/Rad3 -related DNA repair helicase rThermococcus
NP 393536.1 Rad3-related DNA helicase IThermoplasma acidophilum DSM
YP 004071335.1 DNA repair Rad3-like helicase rThermococcus barophilus MP1
YP 002307425.1 ERCC2/XPD/Rad3 -related DNA repair helicase rThermococcus
YP 002466730.1 DEAD 2 domain protein rMethanosphaerula palustris El-9cl
ZP 04876197.1 DEAD 2 family rAciduliprofundum boonei T4691
YP 004623247.1 DNA repair helicase rad3 iPyrococcus yayanosii CH11
YP 002583205.1 DNA repair helicase Rad3 rThermococcus sp. AM41
YP 004763640.1 ERCC2/XPD/Rad3 -related DNA repair helicase rThermococcus
ZP 08857944, 1 hypothetical protein HMPREF9022 03601 rErysipelotrichaceae
ZP 04875144.1 DEAD 2 family rAciduliprofundum boonei T4691
ZP 07832784.1 DEAD2 domain protein rClostridium sp. HGF21
091 -IM 14.1 RecName: Full=ATP-dependent DNA helicase Ta0057
XP 001736798.1 regulator of telomere elongation helicase 1 rtell rEntamoeba
YP 004038234.1 DEAD 2 domain-containing protein rHalogeometricum
ΕΕΊ Γ89549.1 DEAD 2 domain protein rCandidatus Micrarchaeum
NP 142644.1 hypothetical protein PH0697 rPyrococcus horikoshii OT31
EGQ39936.1 Rad3-related DNA helicase TCandidatus Nanosalinarum sp.
NP 348298.1 Rad3 -related DNA helicase rClostridium acetobutylicum ATCC
ZP 05426745.1 helicase rEnterococcus faecalis T21 >gb|EET99653.1 | helicase
EH J12338.1 DEAD 2 protein rEnterococcus faecalis TX13411
ZP 07559866.1 DEAD 2 protein rEnterococcus faecalis TX08601
ZP 02638747.1 putative ATP-dependent helicase rClostridium perfringens CPE
EG043484.1 Rad3-related DNA helicase iCandidatus Nanosalina sp.
YP 695853.1 putative ATP-dependent helicase rClostridium perfringens P 651401.1 DNA repair helicase rEntamoeba histolytica HM-1 TMSS1
YP 004094073.1 helicase c2 rBacillus cellulosilyticus DSM 25221
ZP 02635303.1 putative ATP-dependent helicase rClostridium perfringens B str.
YP 002459406.1 DEAD/DEAH box helicase rDesulfitobacterium hafniense
97 ZP 02631448.1 putative ATP-dependent helicase ["Clostridium perfringens E str.
98 YP 183197.1 ERCC2/XPD/Rad3 -related DNA repair helicase IThermococcus
99 XP 003386532.1 PREDICTED: TFIIH basal transcription factor complex helicase
100 YP 698539.1 ATP-dependent helicase [Clostridium perfringens SM1011
101 ZP 06870390 ! ATP-dependent helicase TFusobacterium nucleatum subsp.
102 YP 003851460.1 DEAD 2 domain-containing protein rTherrnoanaerobacterium
103 YP 001046704.1 helicase c2 TMethanoculleus marisnigri JR11 >gb|ABN56722.11
104 ZP 01860521.1 probable helicase protein [Bacillus sp. SG-H >gb|EDL64380.1 |
105 YP 518026.1 hypothetical protein DSY1793 rDesulfitobacterium hafniense
106 NP 562113.1 helicase protein [Clostridium perfringens str. 131
107 ZP 02643466.1 putative ATP-dependent helicase [Clostridium perfringens
108 NP 603640.1 ATP-dependent helicase DinG [Fusobacterium nucleatum subsp.
109 XP 003488158.1 PREDICTED: Fanconi anemia group J protein-like TBombus
110 ZP 05562829.1 helicase TEnterococcus faecalis DS51 >refjZP 05572349.11
111 AEA93627.1 DNA-directed DNA polymerase III epsilon subunit
112 ZP 07571029. 1 DEAD 2 protein TEnterococcus faecalis TX04111
113 ZP 07550093 , 1 DEAD 2 protein TEnterococcus faecalis TX42481
114 ZP 07758962.1 DEAD 2 protein TEnterococcus faecalis TX04701
115 EFT88579.1 DEAD 2 protein TEnterococcus faecalis TX21411
116 ZP 05472340.1 helicase TAnaerococcus vaginalis ATCC 511701
117 ZP 06629187.1 putative helicase TEnterococcus faecalis R7121
118 EFT95025.1 Dead 2 protein TEnterococcus faecalis TX00121
119 ZP 03982997.1 DNA-directed DNA polymerase III epsilon subunit
120 ZP 05595984.1 DEAD 2 family protein TEnterococcus faecalis Tl 11
121 ZP 05566414.1 DEAD 2 TEnterococcus faecalis Merz961 >gb|EEU69371.11
122 ZP 05592774.1 helicase TEnterococcus faecalis AR01 DG1 >gb|EEU87568.1 |
123 EFU14918.1 DEAD 2 protein TEnterococcus faecalis TX 13421
124 ZP 05599911 , 1 helicase TEnterococcus faecalis X981 >gb|EEU94705.11 helicase
125 ZP 05569608.1 DEAD 2 TEnterococcus faecalis HIP1 17041 >gb|EEU72565.11
126 NP 814892.1 helicase TEnterococcus faecalis V5831 >gb|AAO80962.1 |
127 ZP 05423702.1 helicase TEnterococcus faecalis Til >gb|EET96610.11 helicase
128 ZP 04439070.1 DNA-directed DNA polymerase III epsilon subunit
129 ZP 05579939.1 DNA repair helicase iEnterococcus faecalis Fly 11
130 ZP 05558182.1 DEAD 2 protein TEnterococcus faecalis T81 >gb|EEU26309.1 |
131 ZP 04971104.1 ATP-dependent helicase TFusobacterium nucleatum subsp.
132 ZP 05577237.1 DNA repair helicase TEnterococcus faecalis El Soil
133 ZP 03948465.1 DNA-directed DNA polymerase III epsilon subunit
134 ZP 05502750, 1 helicase TEnterococcus faecalis T31 >gb|EEU23116.11 helicase
135 ZP 04434884.1 DNA-directed DNA polymerase III epsilon subunit
136 ZP 08170094.1 DEAD2 domain protein TAnaerococcus hydrogenalis ACS-025-
137 EGG57994.1 DEAD2 domain protein TEnterococcus faecalis TX 14671
138 EFT39574.1 DEAD 2 protein TEnterococcus faecalis TX21371
139 ZP 05580877.1 DEAD 2 domain-containing protein TEnterococcus faecalis D61
140 ZP 07761503.1 DEAD 2 protein iEnterococcus faecalis TX06351
141 ZP 05583934.1 helicase TEnterococcus faecalis CHI 881 >gb|EEU84905.1 |
142 ZP 07568518.1 DEAD 2 protein TEnterococcus faecalis TX01091
143 XP 001943653.1 PREDICTED: TFIIH basal transcription factor complex helicase
144 XP 003397282.1 PREDICTED: Fanconi anemia group J protein homolog
145 AAB62733.1 RepD TDictyostelium discoideuml
146 XP 647302.1 transcription factor IIH component TDictyostelium discoideum
147 ZP 04666640.1 DEAD 2 domain-containing protein TClostridiales bacterium
148 ZP 05475592.1 helicase TEnterococcus faecalis ATCC 42001 >gb|EEU17449.1 |
149 XP 0021 72261.1 DNA repair helicase RAD3 TSchizosaccharomyces iaponicus
150 YP 002959163.1 DNA repair helicase, ERCC2/XPD/rad3/TFIIH helicase beta
151 ZP 08958775.1 hypothetical protein HALl 05693 THalomonas sp. HAL 11
152 ZP 07555075.1 DEAD 2 protein TEnterococcus faecalis TX08551
153 ZP 06600298.1 ATP-dependent helicase TFusobacterium periodonticum ATCC
154 ZP 07106135.1 DEAD2 domain protein TEnterococcus faecalis TUSoD Efl 11
155 NP 593025.1 transcription factor TFIIH complex subunit Radl5
156 XP 001605333.2 PREDICTED: TFIIH basal transcription factor complex helicase
157 CAA45870.1 rhp3+ rSchizosaccharomyces pombel
158 CAA43022.1 radl 5 rSchizosaccharomyces pombel
159 EGG04750. 1 hvpothetical protein MELLADRAFT 108080 TMelampsora
160 EEH20175.1 TFIIH basal transcription factor complex helicase subunit
161 ZP 02430992.1 hypothetical protein CLOSCI 01208 [Clostridium scindens
162 ZP 08601936.1 hypothetical protein HMPREF0993 01313 TLachnospiraceae
163 XP 780825.2 PREDICTED: similar to TFIIH basal transcription factor
164 XP 003307004.1 hypothetical protein PTT 20325 rPyrenophora teres f. teres 0-11
165 ADD93161. 1 hypothetical protein luncultured archaeon MedDCM-OCT-S05-
166 EFW43568.1 nucleotide excision repair protein TCapsaspora owczarzaki
167 ZP 03759096.1 hypothetical protein CLOSTASPAR 03119 ("Clostridium
168 YP 003246012.1 DEAD 2 domain-containing protein iPaenibacillus sp.
169 AAA85822.1 ERCC2/XPD rxiphophorus maculatusl
170 XP 002796308.1 DNA repair helicase RAD3 [Paracoccidioides brasiliensis PbO 11
171 EFT92378.1 DEAD 2 protein TEnterococcus faecalis TX42441
172 EGF80866.1 hypothetical protein BATDEDRAFT 29908 rBatrachochytrium
173 ZP 078971 18.1 DEAD 2 domain protein TPaenibacillus vortex V4531
174 CB068748.1 probable RAD3-DNA helicase/ATPase rSporisorium reilianum
175 EGP86663.1 hypothetical protein MYCGRDRAFT 43883 rMycosphaerella
176 EGW30235.1 DNA helicase component of transcription factor b TSpathaspora
177 ZP 03166460.1 hypothetical protein RUMLAC 00106 TRuminococcus lactaris
178 YP 003152744.1 DEAD 2 domain-containing protein TAnaerococcus prevotii
179 ZP 06750962.1 ATP-dependent helicase, DinG family [Fusobacterium sp.
180 ZP 07670993.1 putative helicase TErysipelotrichaceae bacterium 3 1 531
181 ZP 04572193.1 ATP-dependent helicase DinG iFusobacterium sp. 4 1 131
182 ZP 06673551.1 DNA helicase TEnterococcus faecium E10391 >gb IEFF33221. i l
183 EFU18615.1 DEAD 2 protein TEnterococcus faecalis TX 13461
184 EGG20082.1 transcription factor IIH component TDictyostelium fasciculatuml
185 YP 002944692.1 DEAD 2 domain-containing protein iVariovorax paradoxus
186 EHA50547.1 DNA repair helicase radl 5 TMagnaporthe oryzae 70-151
187 EEQ84204.1 DNA repair helicase RAD3 rAjellomyces dermatitidis ER-31
188 CCE41018.1 hypothetical protein CPAR2 300070 TCandida parapsilosisl
189 ZP 05550498.1 ATP-dependent helicase [Fusobacterium sp. 3 1 36A21
190 XP 003292674.1 hypothetical protein DICPUDRAFT 50564 rDictyostelium
191 YP 003821569.1 helicase c2 [Clostridium saccharolyticum WM11
192 XP 002550658.1 DNA repair helicase RAD3 [Candida tropicalis MYA-34041
193 ZP 08689728.1 ATP-dependent helicase [Fusobacterium sp. 2 1 311
194 XP 002499882.1 predicted protein [Micromonas sp. RCC2991 >gb|AC061 140.11
195 ZP 06747464.1 ATP-dependent helicase, DinG family [Fusobacterium sp.
196 CBK74961 1 Rad3-related DNA helicases [Butyrivibrio fibrisolvens 16/41
197 ABZ07948.1 putative DEAD 2 [uncultured marine microorganism
198 EEH08589.1 DNA repair helicase RAD3 [Aiellomvces capsulatus G186AR1
199 YP 003959319.1 hypothetical protein ELI 1370 [Eubacterium limosum KIST6121
200 XP 001727494.1 DNA repair helicase radl 5 [Aspergillus oryzae RIB401
201 NP 001 13341 1.1 TFIIH basal transcription factor complex helicase subunit
202 EGM49944.1 DEAD2 domain protein [Lactobacillus salivarius GJ-241
203 ADJ786I9.1 Superfamily II DNA and RNA helicase [Lactobacillus salivarius
204 ZP 04009603.1 superfamily II DNA RNA helicase [Lactobacillus salivarius
205 XP 003456443.1 PREDICTED: TFIIH basal transcription factor complex helicase
206 ZP 05922403.1 helicase TEnterococcus faecium TC 61 >ref|ZP 06446725.11
207 ZP 00604560.1 DEAD 2 TEnterococcus faecium DOl >ref|ZP 05657789.11
208 AD Y 43014.1 TFIIH basal transcription factor complex helicase XPD subunit,
209 ZP 06680717.1 DNA helicase TEnterococcus faecium E10711 >gb IEFF19797. i l
210 XP 001210680.1 DNA repair helicase RAD3 [Aspergillus terreus NIH26241
211 ZP 05664394.1 DEAD 2 helicase fEnterococcus faecium 1,231,5011
212 ZP 07872333.1 helicase c2 domain-containing protein [Listeria ivanovii FSL F6-
213 XP 002375772. Ϊ TFIIH complex helicase Rad3, putative [Aspergillus flavus
214 XP 002995821.1 hvpothetical protein NCER 101 193 TNosema ceranae BRL011
215 EGE80033.1 DNA repair helicase RAD3 rAjellomyces dermatitidis ATCC
216 XP 001930685.1 TFIIH basal transcription factor complex helicase subunit
217 ZP 05678362.1 DEAD 2 helicase [Enterococcus faecium Com 151
218 ZP 08193463.1 helicase c2 [Clostridium papyrosolvens DSM 27821
219 XP 002432433.1 TFIIH basal transcription factor complex helicase subunit,
220 ZP 08278913.1 DEAD2 domain protein TPaenibacillus sp. HGF51
221 EFY8484L 1 DNA repair helicase RAD3 TMetarhizium acridum COMa 1021
222 EFY99240, 1 DNA repair helicase RAD3 [Metarhizium anisopliae ARSEF
223 XP 001638817.1 predicted protein TNematostella vectensisl >gb|ED046754.1 |
224 ZP 08401953.1 helicase c2 rRubrivivax benzoatilyticus JA21 >gb|EGJ10286.1 |
225 YP 004886930.1 hypothetical protein TEH 14390 I etragenococcus halophilus
226 XP 001 /49760.1 hypothetical protein HVIonosiga brevicollis MX11
227 YP 535245, 1 superfamily II DNA/RNA helicase [Lactobacillus salivarius
228 XP 002126055.1 PREDICTED: similar to ERCC2/XPD gene product TCiona
229 EGC43631.1 DNA repair helicase RAD3 rAjellomyces capsulatus H881
230 ZP 07207225.1 DEAD2 domain protein [Lactobacillus salivarius ACS-1 16-V-
231 EEH44570.1 DNA repair helicase RAD3 [Paracoccidioides brasiliensis Pb 181
232 ZP 03981356.1 DNA-directed DNA polymerase ΠΙ epsilon subunit
233 EFX74423.1 hypothetical protein DAPPUDRAFT 324413 [Daphnia pulexl
234 ZP 06696925.1 DNA helicase [Enterococcus faecium El 6791 >gb|EFF27693.1 |
235 YP 608233.1 hypothetical protein PSEEN2644 [Pseudomonas entomophila
236 ZP 08007354.1 hypothetical protein HMPREF 1013 03969 [Bacillus sp.
237 CBF88902.1 TP A: 5' to 3' DNA helicase (Eurofung) [Aspergillus nidulans
238 ZP 03952877.1 DNA-directed DNA polymerase III epsilon subunit
239 EGLI74151. 1 hypothetical protein FOXB 15338 [Fusarium oxy sporum
240 EER42275.1 DNA repair helicase RAD3 [Ajellomyces capsulatus H1431
241 ZP 06682941.1 DNA helicase [Enterococcus faecium E9801 >gb|EFF37253.1 |
242 XP 001799767.1 hypothetical protein SNOG 09475 [Phaeosphaeria nodorum
243 ZP 06623685.1 DEAD2 domain protein [Enterococcus faecium PC4.11
244 XP 002850254.1 DNA repair helicase RAD3 [Arthroderma otae CBS 1134801
245 ZP 03939707.1 DNA-directed DNA polymerase III epsilon subunit
246 ZP 03942652.1 DNA-directed DNA polymerase III epsilon subunit
247 ZP 05667230.1 DEAD 2 helicase [Enterococcus faecium 1, 141,7331
248 ZP 08142092.1 DEAD 2 domain-containing protein [Pseudomonas sp. TJI-511
249 EGL98319.1 DinG family ATP-dependent helicase [Lactobacillus salivarius
250 EGX45813. 1 hypothetical protein AOL s00117gl 8 [Arthrobotrys oligospora
251 YP 001374582. 1 bifunctional ATP-dependent DNA helicase/DNA polymerase III
252 XP 384471.1 hypothetical protein FG04295.1 [Gibberella zeae PH-H
253 XP 002610234.1 hypothetical protein BRAFLDRAFT 286830 [Branchio stoma
254 ZP 05103122.1 hypothetical protein MDMS009 258 [Methylophaga
255 XP 002177848.1 xeroderma pigmentosum group D complementing protein
256 YP 90 1517. 1 DEAD 2 domain-containing protein [Pelobacter propionicus
257 YP 004646156.1 Rtel-1 rPaenibacillus mucilaginosus KNP4141 >gb|AEI46286.1 |
258 EHE97994.1 hypothetical protein HMPREF9469 03327 [Clostridium
259 ZP 07913491.1 ATP-dependent helicase DinG [Fusobacterium gonidiaformans
260 XP 001264365.1 TFIIH complex helicase Rad3, putative [Neosartorya fischeri
261 CBK81746.1 Rad3 -related DNA helicases TCoprococcus catus GD/71
262 P 001 104820.1 FancJ-like protein [Bombyx moril >dbj |B AF94023.11 FancJ-like
263 EFN69563.1 TFIIH basal transcription factor complex helicase subunit
264 EGX89191.1 DNA repair helicase RAD3 [Cordyceps militaris CM011
265 YP 003463379.1 hypothetical protein lse 0136 [Listeria seeligeri serovar l/2b str.
266 ZP 04851424.1 DEAD 2 domain-containing protein [Paenibacillus sp. oral
267 ZP 06525127.1 ATP-dependent helicase DinG [Fusobacterium sp. Di ll
268 ZP 08598770.1 ATP-dependent helicase, DinG family [Fusobacterium sp.
269 YP 004155261.1 helicase c2 [Variovorax paradoxus EPS1 >gb|ADU37150.1 |
270 CBX95892.1 similar to TFIIH basal transcription factor complex helicase
271 EFQ33459.1 DNA repair helicase rGlomerella graminicola Ml .0011
272 ZP 07775478.1 DEAD 2 [Pseudomonas fluorescens WH61 >gb|EFQ63207.11
273 ZP 05814223.1 ATP-dependent helicase [Fusobacterium sp. 3 1 331
274 ADD93162.1 hypothetical protein luncultured archaeon MedDCM-OCT-S05-
275 YP 004383205. 1 hypothetical protein MCON 0548 TMethanosaeta concilii GP61
276 ZP 08687376.1 ATP-dependent helicase DinG TFusobacterium mortiferum
277 XP 752761.1 TFIIH complex helicase Rad3 [Aspergillus fumigatus Af2931
278 YP 004701945. 1 DEAD 2 domain-containing protein iPseudomonas putida S I 61
279 XP 505677.1 YALI0F20746p TYarrowia hpolytical >emb|CAG78486.1 |
280 YP 004399302. 1 DEAD 2 domain-containing protein [Lactobacillus buchneri
281 YP 003278262. 1 hypothetical protein CtC B 1 2220 TComamonas testosteroni
282 XP 003464723. 1 PREDICTED: TFIIH basal transcription factor complex helicase
283 XP 003048472. 1 predicted protein TNectria haematococca mpVI 77-13-41
284 XP 760298.1 hypothetical protein UM04151. 1 TUstilago mavdis 5211
285 YP 004840690. 1 hypothetical protein LSA 03010 [Lactobacillus sanfranciscensis
286 YP 002872713. 1 hypothetical protein PFLU3138 TPseudomonas fluorescens
287 YP 004853959. 1 putative ATP dependent helicase [Listeria ivanovii subsp.
288 XP 001324631. 1 helicase [Trichomonas vaginalis G31 >gb|EAY12408. I I
289 ZP 08581 874.1 hypothetical protein HMPREF0404 01 165 TFusobacterium sp.
290 EFS01 538, 1 helicase c2 domain-containing protein [Listeria seeligeri FSL
291 XP 001 189997. 1 PREDICTED: similar to TFIIH basal transcription factor
292 XP 360589.2 hypothetical protein MGG 03132 [Magnaporthe oryzae 70-151
293 EGR44274. 1 DNA excision repair helicase [Trichoderma reesei QM6al
294 XP 0021 15878. 1 hypothetical protein TRIADDRAFT 30066 [Trichoplax
295 YP 002140828. 1 DNA helicase, DEAD 2 domain-containing protein [Geobacter
296 CB 93524.1 DEAD 2 [Eubacterium rectale M104/11
297 CBK90099. 1 DEAD 2 [Eubacterium rectale DSM 176291
298 ZP 04574821.1 ATP-dependent helicase DinG [Fusobacterium sp. 7 11
299 XP 001500524.3 PREDICTED: LOW QUALITY PROTEIN: TFIIH basal
300 EFR92206.1 helicase c2 domain-containing protein [Listeria innocua FSL S4-
301 MP 967260.1 ATP dependent helicase [Bdellovibrio bacteriovorus HD1001
302 ZP 06645172.1 putative helicase [Erysipelotrichaceae bacterium 5 2 54FAA1
303 YP 002937404. 1 putative ATP-dependent DNA-repair helicase [Eubacterium
304 AE06183 1 .1 hypothetical protein MYCTH 104059 IMvceliophthora
305 XP 002723661. 1 PREDICTED: excision repair cross-complementing rodent
306 ZP 07928170.1 helicase c2 rFusobacterium ulcerans ATCC 491851
307 EFS04602. 1 helicase c2 domain-containing protein [Listeria seeligeri FSL
308 ZP 05792445.1 putative helicase [Butyrivibrio crossotus DSM 28761
309 XP 002829448. 1 PREDICTED: LOW QUALITY PROTEIN: TFIIH basal
310 ZP 02358461.1 DNA repair helicase [Burkholderia oklahomensis EO 1471
31 1 AAB58296.1 DNA helicase [Mus musculusl
312 XP 003245432. 1 PREDICTED: Fanconi anemia group J protein homolog isoform
313 XP 001943091.2 PREDICTED: Fanconi anemia group J protein homolog isoform
314 YP 004232710. 1 DEAD 2 domain-containing protein [Acidovorax avenae subsp.
315 EGY20402. 1 DNA repair helicase RAD3 [Verticillium dahliae VdLs.171
316 ZP 08812184.1 DEAD 2 family protein TDesulfosporosinus sp. OT1
317 B AJ21097. 1 excision repair cross-complementing rodent repair deficiency,
318 BAE26794.1 unnamed protein product [Mus musculusl
319 ZP 08130487.1 putative helicase [Clostridium sp. D51 >gb|EGB92074.11
320 XP 868818.1 hypothetical protein AN9436.2 [Aspergillus nidulans FGSC A41
321 XP 001656074. 1 DNA repair helicase rad3/xp-d [Aedes aegyptil
322 ZP 07045589.1 DeaD2 rComamonas testosteroni S441 >gb|EFI60820.11 DeaD2
323 NP 031975.2 TFIIH basal transcription factor complex helicase XPD subunit
324 YP 001353393. 1 Rad3-related DNA helicases rJanthinobacterium sp. Marseillel
325 NP 001 166280. 1 excision repair cross-complementing rodent repair deficiency,
326 AAH34517.1 Ercc2 protein [Mus musculusl
327 NP 001 23 320. 1 TFIIH basal transcription factor complex helicase XPD subunit
328 XP 002561536. 1 Pcl 6gl2370 rPenicillium chrysogenum Wisconsin 54-12551
329 AE071602.1 hypothetical protein THITE 2124189 [Thielavia terrestris
330 YP 968571.1 helicase c2 [Acidovorax citrulli AACOO-H >gb I ABM30797. 1
33 1 XP 001548663. 1 conserved hypothetical protein [Botryotinia fuckeliana B05.101
332 YP 004752764. 1 DinG family ATP-dependent helicase [Collimonas fungivorans
333 CCD469 ] 6.1 similar to DNA repair helicase RAD3 TBotryotinia fuckelianal
334 XP 001392821.1 DNA repair helicase radl 5 [Aspergillus niger CBS 513.881
335 ZP 02466136.1 putative ATP-dependent helicase TBurkholderia thailandensis
336 YP 004230200.1 helicase c2 [Burkholderia sp. CCGE10011 >gb|ADX57140.1 |
337 YP 002538024.1 DEAD/DEAH box helicase TGeobacter sp. FRC-321
338 EGJ23664.1 Helicase c2 domain protein [Listeria monocytogenes str. Scott
339 ZP 02365524.1 DNA repair helicase TBurkholderia oklahomensis C67861
340 ZP 08637589.1 hypothetical protein GME 12875 [Halomonas sp. TD011
341 YP 012782.1 hypothetical protein LMO£2365 0172 [Listeria monocytogenes
342 YP 003967478.1 helicase c2 rilyobacter polytropus DSM 29261
343 ZP 05230929.1 conserved hypothetical protein [Listeria monocytogenes FSL II-
344 XP 311900.4 AGAP002988-PA TAnopheles gambiae str. PEST1
345 YP 848334.1 helicase c2 domain-containing protein IXisteria welshimeri
346 EGG19835.1 DEAD/DEAH box helicase TDictyostelium fasciculatuml
347 EFD93152.1 DEAD 2 domain protein TCandidatus Parvarchaeum
348 EFD92202.1 DEAD 2 domain protein TCandidatus Parvarchaeum
349 XP 003007283.1 DNA repair helicase RAD3 rVerticillium albo-atrum VaMs.1021
350 ZP 078961 15.1 DNA-directed DNA polymerase III epsilon subunit
351 ZP 02078033.1 hypothetical protein EUBDOL 01841 TEubacterium dolichum
352 XP 003082439.1 DNA repair/transcription factor protein (ISS) TOstreococcus
353 ZP 06555278 ! conserved hypothetical protein [Listeria monocytogenes FSL 12-
354 YP 002756898.1 ATP dependent helicase [Listeria monocytogenes serotype 4b
355 ZP 00230627.1 conserved hypothetical protein [Listeria monocytogenes str. 4b
356 ZP 07707600.1 DEAD 2 domain protein [Bacillus sp. m3-131
357 ZP 02376616.1 helicase c2 TBurkholderia ubonensis Bu|
358 YP 003305885.1 helicase c2 TStreptobacillus moniliformis DSM 121 121
359 XP 0015391 10.1 DNA repair helicase RAD3 rAjellomyces capsulatus NAmll
360 NP 469540.1 hypothetical protein linO 195 [Listeria innocua Clip 112621
361 ZP 03777358.1 hypothetical protein CLOHYLEM 04410 [Clostridium
362 ZP 02501541 .1 hypothetical protein Bpsel 12 28444 [Burkholderia
363 EGD01053.1 helicase c2 [Burkholderia sp. TJI491
364 YP 001513884.1 DEAD 2 domain-containing protein [Alkaliphilus oremlandii
365 YP 004029082.1 DNA REPAIR HELICASE (RAD3/RAD15/XPD FAMILY)
366 EFR95270.1 helicase c2 domain-containing protein [Listeria innocua FSL Jl-
367 AAM45142.1 excision repair cross-complementing rodent repair deficiency,
368 BAB23443.1 unnamed protein product [Mus musculusl
369 ZP 02384949, 1 DNA repair helicase [Burkholderia thailandensis Bt41
370 AAI10524.1 Excision repair cross-complementing rodent repair deficiency,
371 NP 000391.1 TFILH basal transcription factor complex helicase XPD subunit
372 NP 001233519.1 TFILH basal transcription factor complex helicase subunit [Pan
373 ZP 02414937.1 Uvs006 [Burkholderia pseudomallei 141
374 CAA36463.1 ercc2 gene product [Homo sapiensl
375 YP 002908815.1 putative ATP-dependent helicase [Burkholderia glumae BGR11
376 ZP 03462972.1 hypothetical protein BACPEC 02058 [[Bacteroidesl
377 AEO05170.1 hypothetical protein LMRG 02402 [Listeria monocytogenes
378 ZP 00234550.1 conserved hypothetical protein [Listeria monocytogenes str. l/2a
379 NP 463690.1 hypothetical protein lmo0157 [Listeria monocytogenes EGD-el
380 YP 001321959.1 DEAD 2 domain-containing protein TAlkaliphilus
381 ZP 08090025.1 hypothetical protein HMPREF9474 01776 [Clostridium
382 CBL13167.1 DEAD 2 TRoseburia intestinalis XB6B41
383 ZP 02206869.1 hypothetical protein COPEUT 01661 [Coprococcus eutactus
384 XP 003510809.1 PREDICTED: Fanconi anemia group J protein homolog
385 EGS23598.1 hypothetical protein CTHT 0002930 [Chaetomium
386 XP 970844.1 PREDICTED: similar to Xeroderma pigmentosum D CG9433-
387 NP 001096787.1 TFILH basal transcription factor complex helicase XPD subunit
388 EFX06354.1 tfiih complex helicase [Grosmannia clavigera kwl4071
389 ZP 05591145.1 DNA repair helicase [Burkholderia thailandensis E2641
390 ABM06129.1 excision repair cross-complementing rodent repair deficiency,
391 YP 001075221.1 putative ATP-dependent helicase [Burkholderia pseudomallei
392 ZP 08274812.1 DinG family ATP-dependent helicase iOxalobacteraceae
393 YP 439745.1 DNA repair helicase [Burkholderia thailandensis E2641
394 ZP 02406424.1 hypothetical protein BpseD 29478 TBurkholderia pseudomallei
395 ZP 0189321 1.1 DEAD 2 TMarinobacter algicola DG8931 >gb|EDM48600.1 |
396 YP 337604.1 Uvs006 [Burkholderia pseudomallei 1710bl >gb|ABA53062.1 |
397 ZP 01739164.1 hypothetical protein MELB 17 23815 [Marinobacter sp. ELB 171
398 YP 110868.1 hypothetical protein BPSS0856 [Burkholderia pseudomallei
399 CBL41994.1 Rad3-related DNA helicases Tbutyrate-producing bacterium
400 ZP 02459185.1 hypothetical protein Bpseu9 28802 TBurkholderia pseudomallei
401 YP 00 1062257.1 putative ATP-dependent helicase TBurkholderia pseudomallei
402 ZP 02451021 .1 hypothetical protein Bpse9 29690 TBurkholderia pseudomallei
403 ZP 02493334.1 hypothetical protein BpseN 28103 TBurkholderia pseudomallei
404 NP 497182.2 hypothetical protein Y50D7A.2 TCaenorhabditis elegansl
405 XP 002640826.1 Hypothetical protein CBG15713 TCaenorhabditis briggsael
406 ZP 06114232. 1 putative helicase [Clostridium hathewayi DSM 134791
407 YP 002351431.1 helicase c2 domain protein [Listeria monocytogenes HCC231
408 YP 003898973.1 hypothetical protein HELO 3904 THalomonas elongata DSM
409 ZP 03450263.1 putative ATP-dependent helicase TBurkholderia pseudomallei
410 ZP 02474695.1 hypothetical protein BpseB 28268 [Burkholderia pseudomallei
411 BAF62336.1 DNA-repair protein complementing XP-D cells [Sus scrofal
412 ZP 04588908.1 DEAD 2 protein TPseudomonas syringae pv. oryzae str. 1 61
413 EGH68459.1 hypothetical protein PSYAC 26881 TPseudomonas syringae pv.
414 ZP 03569477.1 helicase c2 TBurkholderia multivorans CGD2M1
415 ZP 08477214.1 Rad3-related DNA helicase [Lactobacillus corvniformis subsp.
416 ZP 03543327.1 DEAD 2 domain protein TComamonas testosteroni KF-H
417 ZP 08976894. 1 DEAD 2 domain protein [Desulfitobacterium metallireducens
418 ZP 05232273.1 conserved hypothetical protein [Listeria monocytogenes FSL
419 ZP 04744708, 1 putative ATP-dependent helicase TRoseburia intestinalis Ll-821
420 YP 001584206.1 helicase c2 TBurkholderia multivorans ATCC 176161
421 EHF07121.1 hypothetical protein HMPREF 1020 01003 [Clostridium sp.
422 YP 001948666.1 putative ATP-dependent DNA helicase [Burkholderia
423 CAF32100.1 DNA repair helicase, putative [Aspergillus fumigatusl
424 EHB09904.1 TFIIH basal transcription factor complex helicase subunit,
425 ZP 09000595.1 helicase c2 [Paenibacillus lactis 1541 >gb|EHB65769.1 | helicase
426 ZP 02881609.1 DEAD 2 domain protein TBurkholderia graminis C4D1 Ml
427 XP 003341121.1 PREDICTED: LOW QUALITY PROTEIN: TFIIH basal
428 ZP 08574707.1 DNA helicase (putative) [Lactobacillus coryniformis subsp.
429 ZP 03583039.1 helicase c2 [Burkholderia multivorans CGD11 >gb|EEE03212.1 |
430 YP 002234127.1 hypothetical protein BCAM1516A [Burkholderia cenocepacia
431 NP 784122.1 DNA helicase (putative) [Lactobacillus plantarum WCFS 11
432 YP 372388.1 Rad3-related DNA helicases-like [Burkholderia sp. 3831
433 XP 002025881.1 GL10160 TDrosophila persimilisl >ref|XP 002138963.11
434 YP 003607521.1 helicase c2 [Burkholderia sp. CCGE10021 >gb IADG18010. i l
435 ZP 08981155.1 DEAD 2 domain protein [Desulfosporosinus meridiei DSM
436 XP 001910036.1 hypothetical protein [Podospora anserina S mat+1
437 CBY20154.1 unnamed protein product [Oikopleura dioical
438 YP 001557350 ! DEAD 2 domain-containing protein [Clostridium
439 EHB06437.1 Fanconi anemia group J protein [Heterocephalus glaberl
440 AAS21351 .1 helicase-like protein NHL-like protein [Oikopleura dioical
441 YP 001 1 17339.1 helicase c2 [Burkholderia vietnamiensis G41 >gb| AB057874. i l
442 ZP 06248030.1 DEAD 2 domain protein [Clostridium thermocellum JW201
443 ZP 03626657.1 DEAD 2 domain protein [bacterium Ellin5141
444 EGC82354.1 DEAD2 domain protein [Anaerococcus prevotii ACS-065-V-
445 YP 001669171.1 DEAD 2 domain-containing protein [Pseudomonas putida GB-
446 YP 001779577.1 helicase c2 [Burkholderia cenocepacia MCO-31
447 EGX97283. 1 superfamily II DNA/RNA helicase [Lactobacillus ruminis
448 YP 001036721.1 DEAD 2 [Clostridium thermocellum ATCC 274051
449 EDM05558.1 BRCA1 interacting protein C-terminal helicase 1 (predicted)
450 ZP 08564414, 1 superfamily II DNA/RNA helicase [Lactobacillus ruminis
451 YP 338478, 1 DNA repair helicase. truncation [Burkholderia mallei ATCC
452 ZP 05429973.1 DEAD 2 domain protein [Clostridium thermocellum DSM
453 ZP 02908774.1 helicase c2 [Burkholderia ambifaria MEX-51 >gb IEDT40109. i l
454 YP 003074789.1 hypothetical protein TERTU 3456 TTeredinibacter turnerae
455 CBL10637.1 DEAD 2 TRoseburia intestinalis M50/11
456 ZP 08080348, 1 superfamilv II DNA/RNA helicase [Lactobacillus ruminis
457 ZP 05714130, 1 helicase. putative TEnterococcus faecium DOl
458 YP 002505020.1 DEAD 2 domain-containing protein [Clostridium
459 XP 002762284.1 PREDICTED: TFIIH basal transcription factor complex
460 ZP 07869402.1 helicase c2 domain-containing protein [Listeria marthii FSL S4-
461 YP 004394741.1 hypothetical protein CbC4 0061 [Clostridium botulinum
462 YP 004681432.1 Rad3-like DNA helicase TCupriavidus necator N- 11
463 ZP 00442058.1 putative ATP-dependent helicase [Burkholderia mallei GB8
464 EHA18240.1 DNA repair helicase. subunit of TFIIH [Aspergillus niger
465 EGT47910.1 hypothetical protein CAEBREN 01520 [Caenorhabditis
466 ZP 03929588.1 DNA-directed DNA polymerase III epsilon subunit
467 YP 001889149.1 DEAD 2 domain-containing protein [Burkholderia
468 ZP 04156392, 1 DnaO family exonuclease DinG family helicase TBacillus
469 YP 003050 181 , i helicase c2 [Methylovorus glucosetrophus SIP3 -41
470 XP 002063431.1 GK21904 [Drosophila willistonil >gb|EDW74417.1 | GK21904
471 YP 235981.1 DEAD 2 [Pseudomonas syringae pv. svringae B728al
472 ZP 07004902.1 ATP-dependent helicase [Pseudomonas savastanoi pv.
473 ZP 02371055.1 DNA repair helicase [Burkholderia thailandensis TXDOH1
474 XP 002006040.1 GI2081 1 TDrosophila moiavensisl >gb|EDW09975.11 GI20811
475 ADI95426.1 DEAD-2 domain-containing protein [Pseudomonas putidal
476 NP 744983.1 DEAD 2 domain-containing protein [Pseudomonas putida
477 ADR60507.1 DEAD 2 domain protein [Pseudomonas putida BIRD- 11
478 ZP 06493673.1 DEAD 2 [Pseudomonas svringae pv. syringae FF51
479 YP 00131 1945.1 DEAD 2 domain-containing protein [Clostridium beiierinckii
480 ADP99485.1 Rad3-related DNA helicase [Marinobacter adhaerens HP151
481 YP 001268 166.1 DEAD 2 domain-containing protein [Pseudomonas putida F 11
482 YP 003923571.1 DNA helicase 0 [Lactobacillus plantarum subsp. plantarum ST-
483 XP 340870.3 PREDICTED: BRCA1 interacting protein C-terminal helicase 1
484 YP 004619190.1 ATP-dependent helicase-like protein TRamlibacter tataouinensis
485 ZP 04947353.1 Rad3-related DNA helicase [Burkholderia dolosa AU01581
486 YP 623840.1 helicase c2 TBurkholderia cenocepacia AU 10541
487 YP 877033.1 DNA repair helicase. truncation [Clostridium novvi NT1
488 ZP 02083792.1 hypothetical protein CLOBOL 01315 [Clostridium bolteae
489 ZP 03212705.1 Rad3-related DNA helicase [Lactobacillus rhamnosus HN0011
490 ZP 04941727.1 Rad3-related DNA helicase [Burkholderia cenocepacia PC1841
491 ZP 02889716, 1 helicase c2 [Burkholderia ambifaria IOP40- 101
492 YP 775689.1 helicase c2 [Burkholderia ambifaria AMMD1 >gblABI89355.1 l
493 ZP 04150622.1 DnaO family exonuclease/DinG family helicase [Bacillus
494 XP 001653621.1 regulator of telomere elongation helicase 1 rtell [Aedes aegyptil
495 YP 001230873.1 DEAD 2 domain-containing protein TGeobacter uraniireducens
496 YP 840785 , 1 Rad3-related DNA helicase TRalstonia eutropha HI 61
497 ZP 07324798.1 DEAD 2 domain protein TAcetivibrio cellulolvticus CD21
498 ZP 05132613.1 DEAD 2 domain-containing protein [Clostridium sp.
499 ZP 05347278.1 putative helicase [Bryantella formatexigens DSM 144691
500 ZP 08980710.1 Exonuclease RNase T and DNA polymerase III
The XPD helicase is more preferably one of the hehcases shown in Table 5 below or a variant thereof. The XPD helicase more preferably comprises the sequence of one of the helicases shown in Table 5, i.e. one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62, or a variant thereof.
Table 5 - More preferred XPD helicases and most preferred XPD motifs V and VI


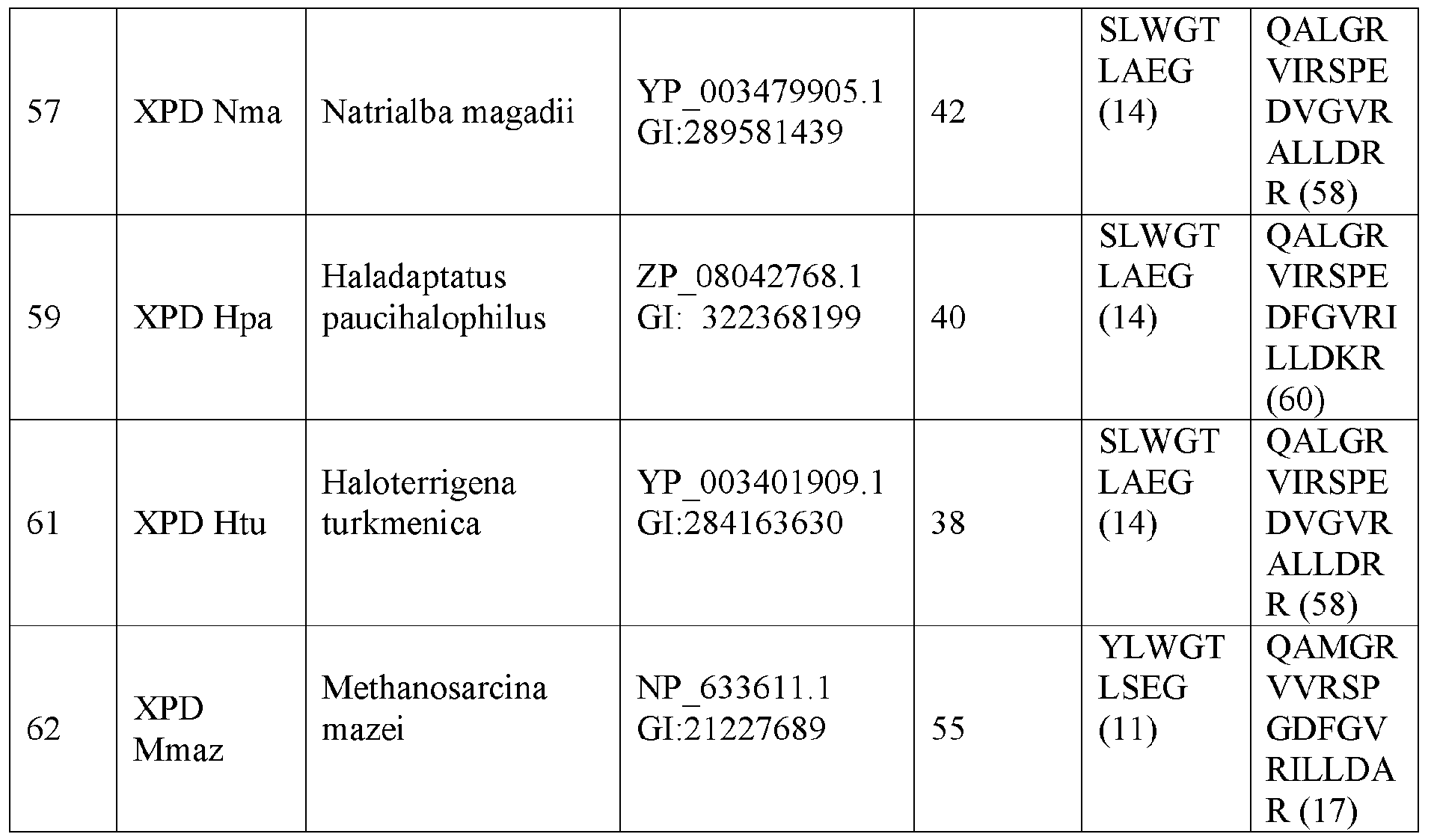
The XPD helicase most preferably comprises the sequence shown in SEQ ID NO: 10 or a variant thereof.
A variant of a XPD helicase is an enzyme that has an amino acid sequence which varies from that of the wild-type helicase and which retains polynucleotide binding activity. In particular, a variant of any one of SEQ ID Os: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41,
43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 is an enzyme that has an amino acid sequence which varies from that of any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43,
44, 46, 49, 52, 55, 57, 59, 61 and 62 and which retains polynucleotide binding activity. A variant of SEQ ID NO: 10 is an enzyme that has an amino acid sequence which varies from that of SEQ ID NO: 10 and which retains polynucleotide binding activity. The variant retains helicase activity. Methods for measuring helicase activity are known in the art. Helicase activity can also be measured as described in the Examples. The variant must work in at least one of the two modes discussed below. Preferably, the variant works in both modes. The variant may include modifications that facilitate handling of the polynucleotide encoding the helicase and/or facilitate its activity at high salt concentrations and/or room temperature. Variants typically differ from the wild-type helicase in regions outside of XPD motifs V and VI discussed above. However, variants may include modifications within one or both of these motifs.
Over the entire length of the amino acid sequence of any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62, such as SEQ ID NO: 10, a variant will preferably be at least 10%, preferably 30% homologous to that sequence
based on amino acid identity. More preferably, the variant polypeptide may be at least 40%, at least 45%, at least 50%, at least 55%, at least 60%, at least 65%, at least 70%, at least 75%, at least 80%), at least 85%, at least 90% and more preferably at least 95%, 97% or 99% homologous based on amino acid identity to the amino acid sequence of any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62, such as SEQ ID NO: 10, over the entire sequence. There may be at least 70%, for example at least 80%, at least 85%, at least 90% or at least 95%, amino acid identity over a stretch of 150 or more, for example 200, 300, 400, 500, 600, 700, 800, 900 or 1000 or more, contiguous amino acids ("hard homology"). Homology is determined as described above. The variant may differ from the wild-type sequence in any of the ways discussed above with reference to SEQ ID NOs: 2 and 4.
In particular, variants may include fragments of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62. Such fragments retain polynucleotide binding activity. Fragments may be at least about 200, at least about 300, at least about 400, at least about 500, at least about 600 or at least about 700 amino acids in length. The length of the fragment will typically depend on the length of the wild-type sequence. As discussed in more detail below, fragments preferably comprise the XPD motif V and/or the XPD motif VI of the relevant wild-type sequence.
Amino acid substitutions may be made to the amino acid sequence of SEQ ID NO: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 or 62, for example up to 1, 2, 3, 4, 5, 10, 20 or 30 substitutions. The substitutions are preferably conservative substitutions as discussed above.
A variant, such as a fragment, of any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 preferably comprises the XPD motif V and/or the XPD motif VI of the relevant wild-type sequence. A variant, such as a fragment, of any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 more preferably comprises the XPD motif V and the XPD motif VI of the relevant wild-type sequence. For instance, a variant of SEQ ID NO: 10 preferably comprises XPD motif V of SEQ ID NO: 10 (YLWGTLSEG; SEQ ID NO: 11) and/or XPD motif VI of SEQ ID NO: 10 (QAMGRVVRSPTDYGARILLDGR; SEQ ID NO: 12). A variant of SEQ ID NO: 10 more preferably comprises both XPD motifs V and VI of SEQ ID NO: 10. The XPD motifs V and VI of each of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 are shown in Table 5. However, a variant of any one SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 may comprise XPD motifs V and/or VI from a different wild-type sequence. For instance, a variant of SEQ ID NO: 10 may comprise XPD motif V of SEQ ID NO: 13 (SLWGTLAEG; SEQ
ID NO: 14) and/or XPD motif VI of SEQ ID NO: 13 (QAIGRVVRGPDDFGVRILADRR; SEQ ID NO: 15). A variant of any one SEQ ID NO s: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 may comprise any one of the preferred motifs shown in Table 5. Variants of any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 may also include modifications within XPD motif V and/or XPD motif VI of the relevant wild-type sequence. Suitable modifications to these motifs are discussed above when defining the two motifs.
The helicase may be covalently attached to the pore. The helicase is preferably not covalently attached to the pore. The application of a voltage to the pore and helicase typically results in the formation of a sensor that is capable of sequencing target polynucleotides. This is discussed in more detail below.
Any of the proteins described herein, i .e. the transmembrane protein pores or XPD helicases, may be modified to assist their identification or purification, for example by the addition of histidine residues (a his tag), aspartic acid residues (an asp tag), a streptavidin tag, a flag tag, a SUMO tag, a GST tag or a MBP tag, or by the addition of a signal sequence to promote their secretion from a cell where the polypeptide does not naturally contain such a sequence. An alternative to introducing a genetic tag is to chemically react a tag onto a native or engineered position on the pore or helicase. An example of this would be to react a gel-shift reagent to a cysteine engineered on the outside of the pore. This has been demonstrated as a method for separating hemolysin hetero-oligomers (Chem Biol. 1997 Jul;4(7):497-505).
The pore and/or helicase may be labelled with a revealing label. The revealing label may be any suitable label which allows the pore to be detected. Suitable labels include, but are not limited to, fluorescent molecules, radioisotopes, e.g. 1251, 35S, enzymes, antibodies, antigens, polynucleotides and ligands such as biotin.
Proteins may be made synthetically or by recombinant means. For example, the pore and/or helicase may be synthesized by in vitro translation and transcription (IVTT). The amino acid sequence of the pore and/or helicase may be modified to include non-naturally occurring amino acids or to increase the stability of the protein. When a protein is produced by synthetic means, such amino acids may be introduced during production. The pore and/or helicase may also be altered following either synthetic or recombinant production.
The pore and/or helicase may also be produced using D-amino acids. For instance, the pore or helicase may comprise a mixture of L-amino acids and D-amino acids. This is conventional in the art for producing such proteins or peptides.
The pore and/or helicase may also contain other non-specific modifications as long as they do not interfere with pore formation or helicase function. A number of non-specific side
chain modifications are known in the art and may be made to the side chains of the protein(s). Such modifications include, for example, reductive alkylation of amino acids by reaction with an aldehyde followed by reduction with NaBH4, amidination with methylacetimidate or acylation with acetic anhydride.
The pore and helicase can be produced using standard methods known in the art.
Polynucleotide sequences encoding a pore or helicase may be derived and replicated using standard methods in the art. Polynucleotide sequences encoding a pore or helicase may be expressed in a bacterial host cell using standard techniques in the art. The pore and/or helicase may be produced in a cell by in situ expression of the polypeptide from a recombinant expression vector. The expression vector optionally carries an inducible promoter to control the expression of the polypeptide. These methods are described in described in Sambrook, J. and Russell, D. (2001). Molecular Cloning: A Laboratory Manual, 3rd Edition. Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY.
The pore and/or helicase may be produced in large scale following purification by any protein liquid chromatography system from protein producing organisms or after recombinant expression. Typical protein liquid chromatography systems include FPLC, AKTA systems, the Bio-Cad system, the Bio-Rad BioLogic system and the Gilson HPLC system.
The method of the invention involves measuring one or more characteristics of the target polynucleotide. The method may involve measuring two, three, four or five or more characteristics of the target polynucleotide. The one or more characteristics are preferably selected from (i) the length of the target polynucleotide, (ii) the identity of the target polynucleotide, (iii) the sequence of the target polynucleotide, (iv) the secondary structure of the target polynucleotide and (v) whether or not the target polynucleotide is modified. Any combination of (i) to (v) may be measured in accordance with the invention.
For (i), the length of the polynucleotide may be measured using the number of interactions between the target polynucleotide and the pore.
For (ii), the identity of the polynucleotide may be measured in a number of ways. The identity of the polynucleotide may be measured in conjunction with measurement of the sequence of the target polynucleotide or without measurement of the sequence of the target polynucleotide. The former is straightforward; the polynucleotide is sequenced and thereby identified. The latter may be done in several ways. For instance, the presence of a particular motif in the polynucleotide may be measured (without measuring the remaining sequence of the polynucleotide). Alternatively, the measurement of a particular electrical and/or optical signal in the method may identify the target polynucleotide as coming from a particular source.
For (iii), the sequence of the polynucleotide can be determined as described previously. Suitable sequencing methods, particularly those using electrical measurements, are described in Stoddart D et al., Proc Natl Acad Sci, 12; 106(19):7702-7, Lieberman KR et al, J Am Chem Soc. 2010; 132(50): 17961-72, and International Application WO 2000/28312.
For (iv), the secondary structure may be measured in a variety of ways. For instance, if the method involves an electrical measurement, the secondary structure may be measured using a change in dwell time or a change in current flowing through the pore. This allows regions of single-stranded and double-stranded polynucleotide to be distinguished.
For (v), the presence or absence of any modification may be measured. The method preferably comprises determining whether or not the target polynucleotide is modified by methylation, by oxidation, by damage, with one or more proteins or with one or more labels, tags or spacers. Specific modifications will result in specific interactions with the pore which can be measured using the methods described below. For instance, methylcyotsine may be
distinguished from cytosine on the basis of the current flowing through the pore during its interation with each nucleotide.
A variety of different types of measurements may be made. This includes without limitation: electrical measurements and optical measurements. Possible electrical measurements include: current measurements, impedance measurements, tunnelling measurements (Ivanov AP et al., Nano Lett. 2011 Jan 12; 1 l(l):279-85), and FET measurements (International
Application WO 2005/124888). Optical measurements may be combined 10 with electrical measurements (Soni GV et al., Rev Sci Instrum. 2010 Jan;81(l):014301). The measurement may be a transmembrane current measurement such as measurement of ionic current flowing through the pore.
Electrical measurements may be made using standard single channel recording equipment as describe in Stoddart D et al., Proc Natl Acad Sci, 12; 106(19):7702-7, Lieberman KR et al, J Am Chem Soc. 2010; 132(50): 17961-72, and International Application
WO-2000/28312. Alternatively, electrical measurements may be made using a multi-channel system, for example as described in International Application WO-2009/077734 and
International Application WO-201 1/067559.
In a preferred embodiment, the method comprises:
(a) contacting the target polynucleotide with a transmembrane pore and a XPD helicase such that the target polynucleotide moves through the pore and the XPD helicase controls the movement of the target polynucleotide through the pore; and
(b) measuring the current passing through the pore as the polynucleotide moves with respect to the pore wherein the current is indicative of one or more characteristics of the target polynucleotide and thereby characterising the target polynucleotide.
The methods may be carried out using any apparatus that is suitable for investigating a membrane/pore system in which a pore is inserted into a membrane. The method may be carried out using any apparatus that is suitable for transmembrane pore sensing. For example, the apparatus comprises a chamber comprising an aqueous solution and a barrier that separates the chamber into two sections. The barrier has an aperture in which the membrane containing the pore is formed.
The methods may be carried out using the apparatus described in International
Application No. PCT/GB08/000562 (WO 2008/102120).
The methods may involve measuring the current passing through the pore as the polynucleotide moves with respect to the pore. Therefore the apparatus may also comprise an electrical circuit capable of applying a potential and measuring an electrical signal across the membrane and pore. The methods may be carried out using a patch clamp or a voltage clamp. The methods preferably involve the use of a voltage clamp.
The methods of the invention may involve the measuring of a current passing through the pore as the polynucleotide moves with respect to the pore. Suitable conditions for measuring ionic currents through transmembrane protein pores are known in the art and disclosed in the Example. The method is typically carried out with a voltage applied across the membrane and pore. The voltage used is typically from +2 V to -2 V, typically -400 mV to +400mV. The voltage used is preferably in a range having a lower limit selected from -400 mV, -300 mV, -200 mV, -150 mV, -100 mV, -50 mV, -20mV and 0 mV and an upper limit independently selected from +10 mV, + 20 mV, +50 mV, +100 mV, +150 mV, +200 mV, +300 mV and +400 mV. The voltage used is more preferably in the range 100 mV to 240mV and most preferably in the range of 120 mV to 220 mV. It is possible to increase discrimination between different nucleotides by a pore by using an increased applied potential.
The methods are typically carried out in the presence of any charge carriers, such as metal salts, for example alkali metal salt, halide salts, for example chloride salts, such as alkali metal chloride salt. Charge carriers may include ionic liquids or organic salts, for example tetramethyl ammonium chloride, trimethylphenyl ammonium chloride, phenyltrimethyl ammonium chloride, or l-ethyl-3 -methyl imidazolium chloride. In the exemplary apparatus discussed above, the salt is present in the aqueous solution in the chamber Potassium chloride (KC1), sodium chloride (NaCl) or caesium chloride (CsCl) is typically used. KC1 is preferred. The salt concentration may be at saturation. The salt concentration may be 3M or lower and is
typically from 0.1 to 2.5 M, from 0.3 to 1.9 M, from 0.5 to 1.8 M, from 0.7 to 1.7 M, from 0.9 to 1.6 M or from 1 M to 1.4 M. The salt concentration is preferably from 150 mM to 1 M. As discussed above, XPD helicases surprisingly work under high salt concentrations. The method is preferably carried out using a salt concentration of at least 0.3 M, such as at least 0.4 M, at least 0.5 M, at least 0.6 M, at least 0.8 M, at least 1.0 M, at least 1.5 M, at least 2.0 M, at least 2.5 M or at least 3.0 M. High salt concentrations provide a high signal to noise ratio and allow for currents indicative of the presence of a nucleotide to be identified against the background of normal current fluctuations.
The methods are typically carried out in the presence of a buffer. In the exemplary apparatus discussed above, the buffer is present in the aqueous solution in the chamber. Any buffer may be used in the method of the invention. Typically, the buffer is HEPES. Another suitable buffer is Tris-HCl buffer. The methods are typically carried out at a pH of from 4.0 to 12.0, from 4.5 to 10.0, from 5.0 to 9.0, from 5.5 to 8.8, from 6.0 to 8.7 or from 7.0 to 8.8 or 7.5 to 8.5. The pH used is preferably about 7.5.
The methods may be carried out at from 0 °C to 100 °C, from 15 °C to 95 °C, from 16 °C to 90 °C, from 17 °C to 85 °C, from 18 °C to 80 °C, 19 °C to 70 °C, or from 20 °C to 60 °C. The methods are typically carried out at room temperature. The methods are optionally carried out at a temperature that supports enzyme function, such as about 37 °C.
The method is typically carried out in the presence of free nucleotides or free nucleotide analogues and an enzyme cofactor that facilitate the action of the helicase. The free nucleotides may be one or more of any of the individual nucleotides discussed above. The free nucleotides include, but are not limited to, adenosine monophosphate (AMP), adenosine diphosphate (ADP), adenosine triphosphate (ATP), guanosine monophosphate (GMP), guanosine diphosphate (GDP), guanosine triphosphate (GTP), thymidine monophosphate (TMP), thymidine diphosphate (TDP), thymidine triphosphate (TTP), uridine monophosphate (UMP), uridine diphosphate (UDP), uridine triphosphate (UTP), cytidine monophosphate (CMP), cytidine diphosphate (CDP), cytidine triphosphate (CTP), cyclic adenosine monophosphate (cAMP), cyclic guanosine monophosphate (cGMP), deoxyadenosine monophosphate (dAMP), deoxyadenosine
diphosphate (dADP), deoxyadenosine triphosphate (dATP), deoxyguanosine monophosphate (dGMP), deoxyguanosine diphosphate (dGDP), deoxyguanosine triphosphate (dGTP), deoxythymidine monophosphate (dTMP), deoxythymidine diphosphate (dTDP), deoxythymidine triphosphate (dTTP), deoxyuridine monophosphate (dUMP), deoxyuridine diphosphate (dUDP), deoxyuridine triphosphate (dUTP), deoxycytidine monophosphate (dCMP), deoxycytidine diphosphate (dCDP) and deoxycytidine triphosphate (dCTP). The free nucleotides are preferably selected from AMP, TMP, GMP, CMP, UMP, dAMP, dTMP, dGMP or dCMP. The
free nucleotides are preferably adenosine triphosphate (ATP). The enzyme cofactor is a factor that allows the helicase to function. The enzyme cofactor is preferably one or more divalent metal cations. Suitable divalent metal cations include, but are not limited to, Mg2+, Mn2+, Ca2+, CoiT and Fe . The enzyme cofactor is preferably Fe orMg . The enzyme cofactor is most preferably Fe2+ and Mg2+
The target polynucleotide may be contacted with the XPD helicase and the pore in any order. In is preferred that, when the target polynucleotide is contacted with the XPD helicase and the pore, the target polynucleotide firstly forms a complex with the helicase. When the voltage is applied across the pore, the target polynucleotide/helicase complex then forms a complex with the pore and controls the movement of the polynucleotide through the pore.
As discussed above, XPD helicases may work in two modes with respect to the pore. First, the method is preferably carried out using the XPD helicase such that it moves the target sequence through the pore with the field resulting from the applied voltage. In this mode the 5' end of the DNA is first captured in the pore, and the enzyme moves the DNA into the pore such that the target sequence is passed through the pore with the field until it finally translocates through to the trans side of the bilayer. Alternatively, the method is preferably carried out such that the enzyme moves the target sequence through the pore against the field resulting from the applied voltage. In this mode the 3' end of the DNA is first captured in the pore, and the enzyme moves the DNA through the pore such that the target sequence is pulled out of the pore against the applied field until finally ejected back to the cis side of the bilayer.
The method of the invention most preferably involves a pore derived from MspA and a helicase comprising the sequence shown in SEQ ID NO: 8 or a variant thereof. Any of the embodiments discussed above with reference to MspA and SEQ ID NO: 8 may be used in combination.
Other methods
The invention also provides a method of forming a sensor for characterising a target polynucleotide. The method comprises forming a complex between a pore and a XPD helicase. The complex may be formed by contacting the pore and the helicase in the presence of the target polynucleotide and then applying a potential across the pore. The applied potential may be a chemical potential or a voltage potential as described above. Alternatively, the complex may be formed by covalently attaching the pore to the helicase. Methods for covalent attachment are known in the art and disclosed, for example, in International Application Nos.
PCT/GB09/001679 (published as WO 2010/004265) and PCT/GB 10/000133 (published as WO 2010/086603). The complex is a sensor for characterising the target polynucleotide. The
method preferably comprises forming a complex between a pore derived from Msp and a XPD helicase. Any of the embodiments discussed above with reference to the method of the invention equally apply to this method.
Kits
The present invention also provides kits for characterising a target polynucleotide. The kits comprise (a) a pore and (b) a XPD helicase. Any of the embodiments discussed above with reference to the method of the invention equally apply to the kits.
The kit may further comprise the components of a membrane, such as the phospholipids needed to form an amphiphilic layer, such as a lipid bilayer.
The kits of the invention may additionally comprise one or more other reagents or instruments which enable any of the embodiments mentioned above to be carried out. Such reagents or instruments include one or more of the following: suitable buffer(s) (aqueous solutions), means to obtain a sample from a subject (such as a vessel or an instrument comprising a needle), means to amplify and/or express polynucleotides, a membrane as defined above or voltage or patch clamp apparatus. Reagents may be present in the kit in a dry state such that a fluid sample resuspends the reagents. The kit may also, optionally, comprise instructions to enable the kit to be used in the method of the invention or details regarding which patients the method may be used for. The kit may, optionally, comprise nucleotides.
Apparatus
The invention also provides an apparatus for characterising a target polynucleotide. The apparatus comprises a plurality of pores and a plurality of a XPD helicase. The apparatus preferably further comprises instructions for carrying out the method of the invention. The apparatus may be any conventional apparatus for polynucleotide analysis, such as an array or a chip. Any of the embodiments discussed above with reference to the methods of the invention are equally applicable to the apparatus of the invention.
The apparatus is preferably set up to carry out the method of the invention.
The apparatus preferably comprises:
a sensor device that is capable of supporting the membrane and plurality of pores and being operable to perform polynucleotide characterising using the pores and helicases;
at least one reservoir for holding material for performing the characterising;
a fluidics system configured to controllably supply material from the at least one reservoir to the sensor device; and
a plurality of containers for receiving respective samples, the fluidics system being configured to supply the samples selectively from the containers to the sensor device. The apparatus may be any of those described in International Application No. No.
PCT/GB08/004127 (published as WO 2009/077734), PCT/GB 10/000789 (published as WO 2010/122293), International Application No. PCT/GB 10/002206 (not yet published) or
International Application No. PCT/US99/25679 (published as WO 00/28312).
Characterisation without a pore
In some embodiments, the target polynucleotide is characterised, such as partially or completely sequenced, using a XPD helicase, but without using a pore. In particular, the invention also provides a method of characterising a target polynucleotide which comprises contacting the target polynucleotide with a XPD helicase such that the XPD helicase controls the movement of the target polynucleotide. In this method, the target polynucleoide is preferably not contacted with a pore, such as a transmembrane pore. The method involves taking one or more measurements as the XPD helicase controls the movement of the polynucleotide and thereby characterising the target polynucleotide. The measurements are indicative of one or more characteristics of the target polynucleotide. Any such measurements may be taken in accordance with the invention. They include without limitation: electrical measurements and optical measurements. These are discussed in detail above. Any of the embodiments discussed above with reference to the pore-based method of the invention may be used in the method lacking a pore. For instance, any of the XPD helicases discussed above may be used.
The invention also provides an analysis apparatus comprising a XPD helicase. The invention also provides a kit a for characterising a target polynucleotide comprising (a) an analysis apparatus for characterising target polynucleotides and (b) a XPD helicase. These apparatus and kits preferably do not comprise a pore, such as a transmembrane pore. Suitable apparatus are discussed above.
The following Examples illustrate the invention. Example 1
This example illustrates the use of a XPD helicase (XPD MBu) to control the movement of intact DNA strands through a nanopore. The general method and substrate employed throughout this example is shown in Fig. 1 and described in the figure caption
Materials and Methods
Primers were designed to amplify a -400 bp fragment of PhiX174. Each of the 5 '-ends of these primers included a 50 nucleotide non-complimentary region, either a homopolymeric stretch or repeating units of 10 nucleotide homopolymeric sections. These serve as identifiers for controlled translocation of the strand through a nanopore, as well as determining the directionality of translocation. In addition, the 5 '-end of the forward primer was "capped" to include four 2'-0-Methyl-Uracil (mU) nucleotides and the 5 '-end of the reverse primer was chemically phosphorylated. These primer modifications then allow for the controlled digestion of predominantly only the antisense strand, using lambda exonuclease. The mU capping protects the sense strand from nuclease digestion whilst the P04 at the 5' of the antisense strand promotes it. Therefore after incubation with lambda exonuclease only the sense strand of the duplex remains intact, now as single stranded DNA (ssDNA). The generated ssDNA was then PAGE purified as previously described.
The DNA substrate design used in all the experiments described here is shown in Fig. IB. The DNA substrate consists of a 400base section of ssDNA from PhiX, with a 50T 5'-leader to aid capture by the nanopore (SEQ ID NO: 63). Annealed to this strand just after the 50T leader is a primer (SEQ ID NO: 64) containing a 3' cholesterol tag to enrich the DNA on the surface of the bilayer, and thus improve capture efficiency. An additional primer (SEQ ID NO: 65) is used towards the 3' end of the strand to aid the capture of the strand by the 3' end. Buffered solution: 400 mM NaCl, 10 mM Hepes pH 8.0, 1 mM ATP, 1 mM MgCl2, 1 mM DTT Nanopore: E.coli MS(B2)8 MspA ONLP3476 MS-(L88N/D90N/D91N/D93N/
D118R/D134R/E139K)8
Enzyme: XPD Mbu (ONLP3696, -6.2 μΜ) 16.1 μΐ -> 100 nM final. Electrical measurements were acquired from single MspA nanopores inserted in 1,2- diphytanoyl-glycero-3-phosphocholine lipid (Avanti Polar Lipids) bilayers. Bilayers were formed across -100 μιη diameter apertures in 20 μπι thick PTFE films (in custom Delrin chambers) via the Montal-Mueller technique, separating two 1 mL buffered solutions. All experiments were carried out in the stated buffered solution. Single-channel currents were measured on Axopatch 200B amplifiers (Molecular Devices) equipped with 1440A digitizers. Ag/AgCl electrodes were connected to the buffered solutions so that the cis compartment (to which both nanopore and enzyme/DNA are added) is connected to the ground of the Axopatch headstage, and the trans compartment is connected to the active electrode of the headstage.
After achieving a single pore in the bilayer, DNA polynucleotide and helicase were added to 100 μΕ of buffer and pre-incubated for 5mins (DNA = 6 nM, Enzyme = 1 μΜ). This pre-
incubation mix was added to 900 μΐ, of buffer in the cis compartment of the electrophysiology chamber to initiate capture of the helicase-DNA complexes in the MspA nanopore (to give final concentrations of DNA = 0.6 nM, Enzyme = 0.1 μΜ). Helicase ATPase activity was initiated as required by the addition of divalent metal (1 mM MgCl2) and NTP (1 mM ATP) to the cis compartment. Experiments were carried out at a constant potential of +140 mV.
Results and Discussion
The addition of Helicase-DNA substrate to MspA nanopores as shown in Fig. 1 produces characteristic current blocks as shown in Fig. 2 and 3. DNA which is not complexed with a helicase interacts transiently with the nanopore producing short-lived blocks in current (« 1 second). DNA with helicase bound and active (ie. moving along the DNA strand under ATPase action) produces long characteristic block levels with stepwise changes in current as shown in Fig. 2 and 3. Different DNA motifs in the nanopore give rise to unique current block levels.For a given substrate, we observe a characteristic pattern of current transitions that reflects the DNA sequence.
In the implementation shown in Fig. 1, the DNA strand is sequenced from a random starting point as the DNA is captured with a helicase at a random position along the strand.
Salt tolerance
Nanopore strand sequencing experiments of this type generally require ionic salts. The ionic salts are necessary to create a conductive solution for applying a voltage offset to capture and translocate DNA, and to measure the resulting sequence dependent current changes as the DNA passes through the nanopore. Since the measurement signal is dependent in the concentration of the ions, it is advantageous to use high concentration ionic salts to increase the magnitude of the acquired signal. For nanopore sequencing salt concentrations in excess of 100 mM KC1 are ideal, and salt concentrations in excess of 400mM are preferred.
However, many enzymes (including some helicases and DNA motor proteins) do not tolerate high salt conditions. Under high salt conditions the enzymes either unfold or lose structural integrity, or fail to function properly. The current literature for known and studied helicases shows that almost all helicases fail to function above salt concentrations of approximately 100 mM KCl/NaCl, and there are no reported helicases that show correct activity in conditions of 400 mM KC1 and above. While potentially halophilic variants of similar enzymes from halotolerant species exist, they are extremely difficult to express and purify in standard expression systems (e.g. E. coli).
We surprisingly show in this Example that XPD from Mbu displays salt tolerance up to very high levels of salt. We find that the enzyme retains functionality in salt concentrations of 400 mM KC1 through to 1 M KC1, either in fluorescence experiments or in nanopore
experiments.
Forward and reverse modes of operation
Most helicases move along single- stranded polynucleotide substrates in uni-directional manner, moving a specific number of bases for each NTPase turned over. Although Fig. 1 illustrates the use of this movement to feed threaded DNA through the nanopore into the trans chamber in the same direction as the applied potential, helicase movement could be exploited in other manners to feed DNA through the nanopore in a controlled fashion. Fig. 4 illustrates two basic 'forward' and 'reverse' modes of operation. In the forward mode, the DNA is fed into the pore by the helicase in the same direction as the DNA would move under the force of the applied field. The direction of movement of the DNA is shown by the trans arrows.For XPD Mbu, which is a 5'-3' helicase, this requires capturing the 5' end of the DNA in the nanopore until a helicase contacts the top of the nanopore, and the DNA is then fed into the nanopore under the control of the helicase with the field from the applied potential, moving from cis to trans. The reverse mode requires capturing the 3 ' end of the DNA, after which the helicase proceeds to pull the threaded DNA back out of the nanopore against the field from the applied potential, moving the DNA from cis to trans as indicated by the arrows. Fig. 4 shows these two modes of operation using XPD Mbu.
Example 2
This example illustrates the salt tolerance of a XPD helicase (XPD Mbu) using a fluorescence assay for testing enzyme activity.
A custom fluorescent substrate was used to assay the ability of the helicase to displace hybridised dsDNA (Fig. 5A). As shown in 1) of Fig. 5A, the fluorescent substrate strand (50 nM final) has a 5' ssDNA overhang, and a 40 base section of hybridised dsDNA. The major upper strand has a carboxyfluorescein base at the 3 ' end, and the hybrised complement has a black-hole quencher (BHQ-1) base at the 5' end. When hybrised the fluorescence from the fluorescein is quenched by the local BHQ-1, and the substrate is essentially non-fluorescent. 1 μΜ of a capture strand that is complementary to the shorter strand of the fluorescent substrate is included in the assay. As shown in 2), in the presence of ATP (1 mM) and MgCl2 (10 mM), helicase (150 nM) added to the substrate binds to the 5' tail of the fluorescent substrate, moves along the major strand, and displaces the complementary strand as shown. As shown in 3), once the
complementary strand with BHQ-1 is fully displaced the fluorescein on the major strand fluoresces. As shown in 4), an excess of capture strand preferentially anneals to the
complementary DNA to prevent re-annealing of initial substrate and loss of fluorescence. Substrate DNA: SEQ ID NO 66 with a carboxyfluorescein near the 3 ' end and SEQ ID
NO: 67 with a Black Hole Quencher- 1 at the 5' end.
Capture DNA: SEQ ID NO: 68 with a carboxyfluorescein near the 3 ' end.
The graph in Fig. 5B shows the initial rate of activity in buffer solutions (100 mM Hepes pH 8.0, 1 mM ATP, 10 mM MgCl2, 50 nM fluorescent substrate DNA, 1 μΜ capture DNA) containing different concentrations of KC1 from 100 mM to 1 M. The helicase works at 1 M.
Claims
1. A method of characterising a target polynucleotide, comprising:
(a) contacting the target polynucleotide with a transmembrane pore and a XPD helicase such that the target polynucleotide moves through the pore and the XPD helicase controls the movement of the target polynucleotide through the pore; and
(b) taking one or more measurements as the polynucleotide moves with respect to the pore wherein the measurements are indicative of one or more characteristics of the target polynucleotide and thereby characterising the target polynucleotide.
2. A method according to claim 1, wherein the one or more characteristics are selected from (i) the length of the target polynucleotide, (ii) the identity of the target polynucleotide, (iii) the sequence of the target polynucleotide, (iv) the secondary structure of of the target polynucleotide and (v) whether or not the target polynucleotide is modified.
3. A method according to claim 2, wherein the target polynucleotide is modified by methylation, by oxidation, by damage, with one or more proteins or with one or more labels, tags or spacers.
4. A method according to any one of claims 1 to 3, wherein the one or more characteristics of the target polynucleotide are measured by electrical measurement and/or optical measurement.
5. A method according to claim 4, wherein the electrical measurement is a current measurement, an impedance measurement, a tunnelling measurement or a field effect transistor (FET) measurement.
6. A method according to claim 1, wherein the method comprises:
(a) contacting the target polynucleotide with a transmembrane pore and a XPD helicase such that the target polynucleotide moves through the pore and the XPD helicase controls the movement of the target polynucleotide through the pore; and
(b) measuring the current passing through the pore as the polynucleotide moves with respect to the pore wherein the current is indicative of one or more characteristics of the target polynucleotide and thereby characterising the target polynucleotide.
7. A method according to any one of the preceding claims, wherein step (b) involves taking one or more measurements as the polynucleotide moves through the pore.
8. A method according to any one of the preceding claims, wherein the method further comprises the step of applying a voltage across the pore to form a complex between the pore and the helicase
9. A method according to any one of the preceding claims, wherein at least a portion of the polynucleotide is double stranded.
10. A method according to any one of the preceding claims, wherein the pore is a transmembrane protein pore or a solid state pore.
11. A method according to claim 10, wherein the transmembrane protein pore is selected from a hemolysin, leukocidin, Mycobacterium smegmatis porin A (MspA), outer membrane porin F (OmpF), outer membrane porin G (OmpG), outer membrane phospholipase A, Neisseria autotransporter lipoprotein (NalP) and WZA.
12. A method according to claim 1 1, wherein the transmembrane protein is (a) formed of eight identical subunits as shown in SEQ ID NO: 2 or (b) a variant thereof in which one or more of the seven subunits has at least 50% homology to SEQ ID NO: 2 based on amino acid identity over the entire sequence and retains pore activity.
13. A method according to claim 11, wherein the transmembrane protein is (a) a-hemolysin formed of seven identical subunits as shown in SEQ ID NO: 4 or (b) a variant thereof in which one or more of the seven subunits has at least 50% homology to SEQ ID NO: 4 based on amino acid identity over the entire sequence and retains pore activity.
14. A method according to any one of the preceding claims, wherein the XPD helicase comprises:
(a) the amino acid motif XI -X2-X3-G-X4-X5-X6-E-G (SEQ ID NO: 8), wherein XI, X2, X5 and X6 are independently selected from any amino acid except D. E. K and R and wherein X3 and X4 may be any amino acid residue; and/or (b) the amino acid motif Q-Xa-Xb-G-R-Xc-Xd-R-(Xe)3-Xf-(Xg)7-D-Xli-R (SEQ ID NO: 9), wherein Xa, Xe and Xg may be any amino acid residue and wherein Xb. Xc and Xd are independently selected from any amino acid except D, E, K and R.
15. A method according to claim 1.4, wherein XI , X2, X5 and X6 and/or Xb, Xc and Xd are independently selected from G, P, A, V, L, I, M, C, F, Y, W, H, Q, N, S and T.
16. A method according to claim 14 or 15, wherein the helica.se comprises the following motifs:
(a) YLWGTLSEG (SEQ I D NO: 11) and/or QAMGRWRSPTOYGARiLLDGR (SEQ
ID NO: 12);
(b) SLWGTLAEG (SEQ ID NO: 14) and/or QAIGRVVRGPDDFGVRllADRR. (SEQ ID
NO: 1 5);
(c) YLWGTLSEG (SEQ ID NO; 11) and/or QAMGRVVRSPGDFGVRILLDAR (SEQ ID NO: 17);
(d) YLWGTLSEG (SEQ ID NO: 1 1) and/or Q AMGKVVRSP SD YGARTLLDGR (SEQ ID NO: 19);
(e) SLWGTLAEG (SEQ ID NO: 14) and/or QALGRVVRSPTDFGVRVXVTJER (SEQ ID NO: 21 );
(f) VTGGVFAEG (SEQ ID NO: 23) and/or QAAGRVLRTPEDRGV1ALLGRR (SEQ
ID NO: 24);
(g) LGTGAFWEG (SEQ ID NO: 26) and/or QGVGRLiRDERDRGVLILCDNR (SEQ ID NO: 27);
(h) YIWGTLSEG (SEQ ID NO: 29) and/or QAMGRVVRSPTDYGAR!LIDGR. (SEQ ID
NO: 30);
(i) Yi .WG i LSkG (SEQ ID NO: 1 1) and/or QAMGRIVRSPDDYGVRILLDSR (SEQ ID NO: 32);
ij) SLWGTLAEG (SEQ ID NO: 14) and/or QAL-GR.VIRAPDDFGVRVf.ADKR (SEQ ID NO: 34);
(k) VSGGRLSEG (SEQ ID NO: 36) and/or QEiGRLIRSAEDTGACVILDKR (SEQ ID NO: 37);
(1) VMGGRNSEG (SEQ ID NO: 39) and/or QAAGR\¾RSEEEKGA\V\T,DYR (SEQ ID NO: 40),
(m) VMGGRNSEG (SEQ ID NO: 3 ) and/or QAAGRVTTRSEEEKGSIVILDYR (SEQ ID NO: 42); (n) SLWGTLAEG (SEQ ID NO: 14) and/or QAMGRVIRSPEDFGVRMLVD R (SEQ ID NO: 45);
(o) LATGRFAEG (SEQ ID NO: 47) and/or QMIGRLIRTENDYGVVVIQD R (SEQ ID NO: 48);
(p) IAEG LAEG (SEQ ID NO: 50) and/or QSIGRAIRGPTDNATIWLLDKR (SEQ ID NO: 51);
(q) VGKGKLAEG (SEQ ID NO: 53) and/or QAIGRAIRD TNDKCN LLDKR (SEQ ID NO: 54);
(r) VMGGRNSEG (SEQ ID NO: 39) and/or QAAGRVHRSAEEKGAIIILDYR (SEQ ID NO: 56);
(s) SLWGTLAEG (SEQ ID NO: 14) and/or QALGRVIRSPEDVGVRALLDRR (SEQ ID NO: 58);
it) SLWGTLAEG (SEQ ID NO: 14) and/or QALGRV1RSPEDFGVRILLDKR (SEQ ID NO: 60), or
(u) YLWGTLSEG (SEQ ID NO: 11 ) and/or QAMGRVVRSPGDFGVRILLDAR (SEQ ID NO: 17).
17. A method according to any one of the preceding claims, wherein the XPD helicase is one of the helicases shown in Table 4 or 5 or a variant thereof.
18. A method according to claim 17, wherein the XPD helicase comprises (a) the sequence shown in any one of SEQ ID NOs: 10, 13, 16, 18, 20, 22, 25, 28, 31, 33, 35, 38, 41, 43, 44, 46, 49, 52, 55, 57, 59, 61 and 62 or (b) a variant thereof having at least 30% homology to the relevant sequence based on amino acid identity over the entire sequence and retains helicase activity.
19. A method according to claim 18, wherein the XPD helicase comprises (a) the sequence shown in SEQ ID NO: 10 or (b) a variant thereof having at least 40% homology to the SEQ ID NO: 10 based on amino acid identity over the entire sequence and retains helicase activity.
20. A method according to any one of the preceding claims, wherein method is carried out using a salt concentration of at least 0.3 M and the salt is optionally KC1.
21. A method according to claim 20, wherein the salt concentration is at least 1.0 M.
22. A method of forming a sensor for characterising a target polynucleotide, comprising forming a complex between a pore and a XPD helicase and thereby forming a sensor for characterising the target polynucleotide.
23. A method according to claim 22, wherein the complex is formed by (a) contacting the pore and the helicase in the presence of the target polynucleotide and (a) applying a potential across the pore.
24. A method according to claim 23, wherein the potential is a voltage potential or a chemical potential.
25. A method according to claim 22, wherein the complex is formed by covalently attaching the pore to the helicase.
26. Use of a XPD helicase to control the movement of a target polynucleotide through a pore.
27. A kit for characterising a target polynucleotide comprising (a) a pore and (b) a XPD helicase.
28. A kit according to claim 27, wherein the kit further comprises a chip comprising an amphiphilic layer.
29. An analysis apparatus for characterising target polynucleotides in a sample, comprising a plurality of pores and a plurality of an XPD helicase.
30. An analysis apparatus according to claim 29, wherein the analysis apparatus comprises: a sensor device that is capable of supporting the plurality of pores and being operable to perform polynucleotide characterisation using the pores and helicases;
at least one reservoir for holding material for performing the characterisation;
a fluidics system configured to controllably supply material from the at least one reservoir to the sensor device; and
a plurality of containers for receiving respective samples, the fluidics system being configured to supply the samples selectively from the containers to the sensor device.
31. A method of characterising a target polynucleotide, comprising:
(a) contacting the target polynucleotide with a XPD helicase such that the XPD helicase controls the movement of the target polynucleotide; and
(b) taking one or more measurements as the XPD helicase controls the movement of the polynucleotide wherein the measurements are indicative of one or more characteristics of the target polynucleotide and thereby characterising the target polynucleotide.
32. A method according to claim 31, wherein:
(a) the one or more characteristics are as defined in claim 2;
(b) the target polynucleotide is as defined in claim 3 or 9;
(c) the one or more characteristics are measured as defined in claim 4 or 5;
(d) the XPD is as defined in any one of claims 14 to 19; or
(e) the method is carried out as defined in any claim 20 or 21.
33. Use of a XPD helicase to control the movement of a target polynucleotide during characterisation of the polynucleotide.
34. Use of a XPD helicase to control the movement of a target polynucleotide during sequencing of part or all of the polynucleotide.
35. An analysis apparatus for characterising target polynucleotides in a sample, characterised in that it comprises a XPD helicase.
36. A kit for characterising a target polynucleotide comprising (a) an analysis apparatus for characterising target polynucleotides and (b) a XPD helicase.
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201280068306.XA CN104136631B (en) | 2011-12-29 | 2012-12-28 | Method using XPD unwindase characterising polynucleotides |
| EP12816096.7A EP2798083B1 (en) | 2011-12-29 | 2012-12-28 | Method for characterising a polynucelotide by using a xpd helicase |
| US14/369,024 US9617591B2 (en) | 2011-12-29 | 2012-12-28 | Method for characterising a polynucleotide by using a XPD helicase |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201161581340P | 2011-12-29 | 2011-12-29 | |
| US61/581,340 | 2011-12-29 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2013098561A1 true WO2013098561A1 (en) | 2013-07-04 |
Family
ID=47561657
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/GB2012/053273 WO2013098561A1 (en) | 2011-12-29 | 2012-12-28 | Method for characterising a polynucelotide by using a xpd helicase |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US9617591B2 (en) |
| EP (1) | EP2798083B1 (en) |
| CN (1) | CN104136631B (en) |
| WO (1) | WO2013098561A1 (en) |
Cited By (93)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014135838A1 (en) | 2013-03-08 | 2014-09-12 | Oxford Nanopore Technologies Limited | Enzyme stalling method |
| WO2015056028A1 (en) | 2013-10-18 | 2015-04-23 | Oxford Nanopore Technologies Limited | Method of characterizing a target ribonucleic acid (rna) comprising forming a complementary polynucleotide which moves through a transmembrane pore |
| WO2015055981A2 (en) | 2013-10-18 | 2015-04-23 | Oxford Nanopore Technologies Limited | Modified enzymes |
| WO2015110813A1 (en) | 2014-01-22 | 2015-07-30 | Oxford Nanopore Technologies Limited | Method for attaching one or more polynucleotide binding proteins to a target polynucleotide |
| WO2015150787A1 (en) | 2014-04-04 | 2015-10-08 | Oxford Nanopore Technologies Limited | Method of target molecule characterisation using a molecular pore |
| WO2016055777A2 (en) | 2014-10-07 | 2016-04-14 | Oxford Nanopore Technologies Limited | Modified enzymes |
| WO2016055778A1 (en) | 2014-10-07 | 2016-04-14 | Oxford Nanopore Technologies Limited | Mutant pores |
| WO2016059375A1 (en) | 2014-10-17 | 2016-04-21 | Oxford Nanopore Technologies Limited | Methods for delivering an analyte to transmembrane pores |
| WO2016059363A1 (en) | 2014-10-14 | 2016-04-21 | Oxford Nanopore Technologies Limited | Method |
| CN105705656A (en) * | 2013-08-16 | 2016-06-22 | 牛津纳米孔技术公司 | Method |
| WO2016132123A1 (en) | 2015-02-19 | 2016-08-25 | Oxford Nanopore Technologies Limited | Hetero-pores |
| WO2016132124A1 (en) | 2015-02-19 | 2016-08-25 | Oxford Nanopore Technologies Limited | Method |
| US9551023B2 (en) | 2012-09-14 | 2017-01-24 | Oxford Nanopore Technologies Ltd. | Sample preparation method |
| US9617591B2 (en) | 2011-12-29 | 2017-04-11 | Oxford Nanopore Technologies Ltd. | Method for characterising a polynucleotide by using a XPD helicase |
| WO2017098322A1 (en) | 2015-12-08 | 2017-06-15 | Katholieke Universiteit Leuven Ku Leuven Research & Development | Modified nanopores, compositions comprising the same, and uses thereof |
| US9689033B2 (en) | 2013-11-26 | 2017-06-27 | Illumina, Inc. | Compositions and methods for polynucleotide sequencing |
| WO2017149316A1 (en) | 2016-03-02 | 2017-09-08 | Oxford Nanopore Technologies Limited | Mutant pore |
| US9758823B2 (en) | 2011-10-21 | 2017-09-12 | Oxford Nanopore Technologies Limited | Enzyme method |
| US9777049B2 (en) | 2012-04-10 | 2017-10-03 | Oxford Nanopore Technologies Ltd. | Mutant lysenin pores |
| WO2017174990A1 (en) | 2016-04-06 | 2017-10-12 | Oxford Nanopore Technologies Limited | Mutant pore |
| US9797009B2 (en) | 2012-07-19 | 2017-10-24 | Oxford Nanopore Technologies Limited | Enzyme construct |
| WO2017203269A1 (en) | 2016-05-25 | 2017-11-30 | Oxford Nanopore Technologies Limited | Method of nanopore sequencing of concatenaded nucleic acids |
| WO2018060740A1 (en) | 2016-09-29 | 2018-04-05 | Oxford Nanopore Technologies Limited | Method for nucleic acid detection by guiding through a nanopore |
| US9957560B2 (en) | 2011-07-25 | 2018-05-01 | Oxford Nanopore Technologies Ltd. | Hairpin loop method for double strand polynucleotide sequencing using transmembrane pores |
| WO2018100370A1 (en) | 2016-12-01 | 2018-06-07 | Oxford Nanopore Technologies Limited | Methods and systems for characterizing analytes using nanopores |
| US9995728B2 (en) | 2012-11-06 | 2018-06-12 | Oxford Nanopore Technologies Ltd. | Quadruplex method |
| US10006905B2 (en) | 2013-03-25 | 2018-06-26 | Katholieke Universiteit Leuven | Nanopore biosensors for detection of proteins and nucleic acids |
| WO2018146491A1 (en) | 2017-02-10 | 2018-08-16 | Oxford Nanopore Technologies Limited | Modified nanopores, compositions comprising the same, and uses thereof |
| WO2018203071A1 (en) | 2017-05-04 | 2018-11-08 | Oxford Nanopore Technologies Limited | Method of determining the presence or absence of a target analyte comprising using a reporter polynucleotide and a transmembrane pore |
| US10131943B2 (en) | 2012-12-19 | 2018-11-20 | Oxford Nanopore Technologies Ltd. | Analysis of a polynucleotide via a nanopore system |
| WO2018211241A1 (en) | 2017-05-04 | 2018-11-22 | Oxford Nanopore Technologies Limited | Transmembrane pore consisting of two csgg pores |
| US10167503B2 (en) | 2014-05-02 | 2019-01-01 | Oxford Nanopore Technologies Ltd. | Mutant pores |
| US10246741B2 (en) | 2011-05-27 | 2019-04-02 | Oxford Nanopore Technologies Ltd. | Coupling method |
| US10337060B2 (en) | 2014-04-04 | 2019-07-02 | Oxford Nanopore Technologies Ltd. | Method for characterising a double stranded nucleic acid using a nano-pore and anchor molecules at both ends of said nucleic acid |
| GB201907244D0 (en) | 2019-05-22 | 2019-07-03 | Oxford Nanopore Tech Ltd | Method |
| GB201907246D0 (en) | 2019-05-22 | 2019-07-03 | Oxford Nanopore Tech Ltd | Method |
| WO2019135091A1 (en) | 2018-01-05 | 2019-07-11 | Oxford Nanopore Technologies Limited | Method for selecting polynucleotides based on enzyme interaction duration |
| WO2019149626A1 (en) | 2018-02-02 | 2019-08-08 | Bayer Aktiengesellschaft | Control of resistent harmful organisms |
| US10385382B2 (en) | 2011-12-29 | 2019-08-20 | Oxford Nanopore Technologies Ltd. | Enzyme method |
| US10392658B2 (en) | 2014-01-22 | 2019-08-27 | Oxford Nanopore Technologies Ltd. | Method for controlling the movement of a polynucleotide through a transmembrane pore |
| US10400014B2 (en) | 2014-09-01 | 2019-09-03 | Oxford Nanopore Technologies Ltd. | Mutant CsgG pores |
| US10480026B2 (en) | 2014-10-17 | 2019-11-19 | Oxford Nanopore Technologies Ltd. | Method for nanopore RNA characterisation |
| WO2019224558A1 (en) | 2018-05-24 | 2019-11-28 | Oxford Nanopore Technologies Limited | Method for selecting polynucleotides based on the size in a globular form |
| WO2019224560A1 (en) | 2018-05-24 | 2019-11-28 | Oxford Nanopore Technologies Limited | Method |
| WO2019234432A1 (en) | 2018-06-06 | 2019-12-12 | Oxford Nanopore Technologies Limited | Method |
| WO2020005994A1 (en) * | 2018-06-26 | 2020-01-02 | Electronic Biosciences, Inc. | Controlled nanopore translocation utilizing extremophilic replication proteins |
| GB201917060D0 (en) | 2019-11-22 | 2020-01-08 | Oxford Nanopore Tech Ltd | Method |
| WO2020025909A1 (en) | 2018-07-30 | 2020-02-06 | Oxford University Innovation Limited | Assemblies |
| US10596523B2 (en) | 2015-05-20 | 2020-03-24 | Oxford Nanopore Inc. | Methods and apparatus for forming apertures in a solid state membrane using dielectric breakdown |
| GB202004944D0 (en) | 2020-04-03 | 2020-05-20 | King S College London | Method |
| US10669578B2 (en) | 2014-02-21 | 2020-06-02 | Oxford Nanopore Technologies Ltd. | Sample preparation method |
| US10689697B2 (en) | 2014-10-16 | 2020-06-23 | Oxford Nanopore Technologies Ltd. | Analysis of a polymer |
| WO2020128517A1 (en) | 2018-12-21 | 2020-06-25 | Oxford Nanopore Technologies Limited | Method of encoding data on a polynucleotide strand |
| US10739341B2 (en) | 2012-02-15 | 2020-08-11 | Oxford Nanopore Technologies Limited | Aptamer method |
| US10808231B2 (en) | 2012-07-19 | 2020-10-20 | Oxford Nanopore Technologies Limited | Modified helicases |
| US10962523B2 (en) | 2015-05-11 | 2021-03-30 | Oxford Nanopore Technologies Ltd. | Apparatus and methods for measuring an electrical current |
| WO2021111125A1 (en) | 2019-12-02 | 2021-06-10 | Oxford Nanopore Technologies Limited | Method of characterising a target polypeptide using a nanopore |
| WO2021111139A1 (en) | 2019-12-04 | 2021-06-10 | Oxford Nanopore Technologies Limited | Method |
| GB202107192D0 (en) | 2021-05-19 | 2021-06-30 | Oxford Nanopore Tech Ltd | Method |
| GB202107354D0 (en) | 2021-05-24 | 2021-07-07 | Oxford Nanopore Tech Ltd | Method |
| US11155860B2 (en) | 2012-07-19 | 2021-10-26 | Oxford Nanopore Technologies Ltd. | SSB method |
| US11169138B2 (en) | 2015-04-14 | 2021-11-09 | Katholieke Universiteit Leuven | Nanopores with internal protein adaptors |
| WO2021255475A1 (en) | 2020-06-18 | 2021-12-23 | Oxford Nanopore Technologies Limited | A method of selectively characterising a polynucleotide using a detector |
| WO2021255476A2 (en) | 2020-06-18 | 2021-12-23 | Oxford Nanopore Technologies Limited | Method |
| WO2021255477A1 (en) | 2020-06-18 | 2021-12-23 | Oxford Nanopore Technologies Limited | Method of repeatedly moving a double-stranded polynucleotide through a nanopore |
| WO2022020461A1 (en) | 2020-07-22 | 2022-01-27 | Oxford Nanopore Technologies Inc. | Solid state nanopore formation |
| WO2022074397A1 (en) | 2020-10-08 | 2022-04-14 | Oxford Nanopore Technologies Limited | Modification of a nanopore forming protein oligomer |
| US11352664B2 (en) | 2009-01-30 | 2022-06-07 | Oxford Nanopore Technologies Plc | Adaptors for nucleic acid constructs in transmembrane sequencing |
| EP4063521A1 (en) | 2016-05-25 | 2022-09-28 | Oxford Nanopore Technologies PLC | Method of nanopore sequencing |
| WO2022243692A1 (en) | 2021-05-19 | 2022-11-24 | Oxford Nanopore Technologies Plc | Methods for complement strand sequencing |
| US11572387B2 (en) | 2017-06-30 | 2023-02-07 | Vib Vzw | Protein pores |
| WO2023026056A1 (en) | 2021-08-26 | 2023-03-02 | Oxford Nanopore Technologies Plc | Nanopore |
| US11649480B2 (en) | 2016-05-25 | 2023-05-16 | Oxford Nanopore Technologies Plc | Method for modifying a template double stranded polynucleotide |
| WO2023118891A1 (en) | 2021-12-23 | 2023-06-29 | Oxford Nanopore Technologies Plc | Method of characterising polypeptides using a nanopore |
| WO2023118892A1 (en) | 2021-12-23 | 2023-06-29 | Oxford Nanopore Technologies Plc | Method |
| GB202307486D0 (en) | 2023-05-18 | 2023-07-05 | Oxford Nanopore Tech Plc | Method |
| WO2023123359A1 (en) * | 2021-12-31 | 2023-07-06 | 深圳华大生命科学研究院 | Helicase bch2x and use thereof |
| US11725205B2 (en) | 2018-05-14 | 2023-08-15 | Oxford Nanopore Technologies Plc | Methods and polynucleotides for amplifying a target polynucleotide |
| WO2023198911A2 (en) | 2022-04-14 | 2023-10-19 | Oxford Nanopore Technologies Plc | Novel modified protein pores and enzymes |
| WO2023222657A1 (en) | 2022-05-17 | 2023-11-23 | Oxford Nanopore Technologies Plc | Method and adaptors |
| WO2024033421A2 (en) | 2022-08-09 | 2024-02-15 | Oxford Nanopore Technologies Plc | Novel pore monomers and pores |
| WO2024033443A1 (en) | 2022-08-09 | 2024-02-15 | Oxford Nanopore Technologies Plc | Novel pore monomers and pores |
| WO2024033422A1 (en) | 2022-08-09 | 2024-02-15 | Oxford Nanopore Technologies Plc | Novel pore monomers and pores |
| US11921103B2 (en) | 2011-09-23 | 2024-03-05 | Oxford Nanopore Technologies Plc | Method of operating a measurement system to analyze a polymer |
| US11959906B2 (en) | 2012-02-16 | 2024-04-16 | Oxford Nanopore Technologies Plc | Analysis of measurements of a polymer |
| WO2024089270A2 (en) | 2022-10-28 | 2024-05-02 | Oxford Nanopore Technologies Plc | Pore monomers and pores |
| WO2024094986A1 (en) | 2022-10-31 | 2024-05-10 | Oxford Nanopore Technologies Plc | Method |
| WO2024100270A1 (en) | 2022-11-11 | 2024-05-16 | Oxford Nanopore Technologies Plc | Novel pore monomers and pores |
| WO2024099985A1 (en) | 2022-11-10 | 2024-05-16 | Bayer Aktiengesellschaft | Targeted crop protection product application based on genetic profiles |
| GB202407228D0 (en) | 2024-05-21 | 2024-07-03 | Oxford Nanopore Tech Plc | Method |
| US12042790B2 (en) | 2016-11-24 | 2024-07-23 | Oxford Nanopore Technologies Plc | Apparatus and methods for controlling insertion of a membrane channel into a membrane |
| WO2024200280A1 (en) | 2023-03-24 | 2024-10-03 | Oxford Nanopore Technologies Plc | Method and kits |
| WO2024213802A1 (en) | 2023-04-14 | 2024-10-17 | Oxford Nanopore Technologies Plc | Novel pore monomers and pores |
Families Citing this family (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AU2008217579A1 (en) | 2007-02-20 | 2008-08-28 | Oxford Nanopore Technologies Limited | Formation of lipid bilayers |
| GB0724736D0 (en) | 2007-12-19 | 2008-01-30 | Oxford Nanolabs Ltd | Formation of layers of amphiphilic molecules |
| GB201202519D0 (en) | 2012-02-13 | 2012-03-28 | Oxford Nanopore Tech Ltd | Apparatus for supporting an array of layers of amphiphilic molecules and method of forming an array of layers of amphiphilic molecules |
| GB201313121D0 (en) | 2013-07-23 | 2013-09-04 | Oxford Nanopore Tech Ltd | Array of volumes of polar medium |
| GB201418512D0 (en) | 2014-10-17 | 2014-12-03 | Oxford Nanopore Tech Ltd | Electrical device with detachable components |
| US10640822B2 (en) | 2016-02-29 | 2020-05-05 | Iridia, Inc. | Systems and methods for writing, reading, and controlling data stored in a polymer |
| US10859562B2 (en) | 2016-02-29 | 2020-12-08 | Iridia, Inc. | Methods, compositions, and devices for information storage |
| US10438662B2 (en) | 2016-02-29 | 2019-10-08 | Iridia, Inc. | Methods, compositions, and devices for information storage |
| GB201611770D0 (en) | 2016-07-06 | 2016-08-17 | Oxford Nanopore Tech | Microfluidic device |
| CN106317214B (en) * | 2016-09-05 | 2019-09-13 | 中国农业大学 | The heat-resisting GAP-associated protein GAP TaXPD of wheat and its encoding gene and application |
| JP7362112B2 (en) | 2017-06-29 | 2023-10-17 | プレジデント アンド フェローズ オブ ハーバード カレッジ | Deterministic step of polymer through nanopore |
| GB2568895B (en) | 2017-11-29 | 2021-10-27 | Oxford Nanopore Tech Ltd | Microfluidic device |
| CN112997080B (en) * | 2018-08-28 | 2024-10-01 | 南京大学 | Protein nanopores for analyte recognition |
| WO2020061997A1 (en) * | 2018-09-28 | 2020-04-02 | 北京齐碳科技有限公司 | Helicase and use thereof |
| CN113574381A (en) | 2019-03-12 | 2021-10-29 | 牛津纳米孔科技公司 | Nanopore sensing device, assembly, and method of operation |
| WO2021056598A1 (en) | 2019-09-29 | 2021-04-01 | 北京齐碳科技有限公司 | Mmup monomer variant and application thereof |
| CN113930406B (en) | 2021-12-17 | 2022-04-08 | 北京齐碳科技有限公司 | Pif1-like helicase and application thereof |
| CN114599666B (en) | 2020-06-19 | 2024-08-06 | 北京齐碳科技有限公司 | Pif1-like helicase and application thereof |
| US11837302B1 (en) | 2020-08-07 | 2023-12-05 | Iridia, Inc. | Systems and methods for writing and reading data stored in a polymer using nano-channels |
| WO2022126304A1 (en) * | 2020-12-14 | 2022-06-23 | 北京齐碳科技有限公司 | Modified helicase and application thereof |
| CN115777019A (en) | 2021-04-06 | 2023-03-10 | 成都齐碳科技有限公司 | Modified Prp43 helicases and uses thereof |
| WO2023215603A1 (en) | 2022-05-06 | 2023-11-09 | 10X Genomics, Inc. | Methods and compositions for in situ analysis of v(d)j sequences |
| WO2023225988A1 (en) * | 2022-05-27 | 2023-11-30 | 深圳华大生命科学研究院 | Method for maintaining nanopore sequencing speed |
| WO2024138632A1 (en) * | 2022-12-30 | 2024-07-04 | 深圳华大生命科学研究院 | Helicase, preparation method therefor and use thereof in sequencing |
Citations (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2000028312A1 (en) | 1998-11-06 | 2000-05-18 | The Regents Of The University Of California | A miniature support for thin films containing single channels or nanopores and methods for using same |
| WO2005124888A1 (en) | 2004-06-08 | 2005-12-29 | President And Fellows Of Harvard College | Suspended carbon nanotube field effect transistor |
| US20060063171A1 (en) * | 2004-03-23 | 2006-03-23 | Mark Akeson | Methods and apparatus for characterizing polynucleotides |
| WO2006100484A2 (en) | 2005-03-23 | 2006-09-28 | Isis Innovation Limited | Deliver of molecules to a li id bila |
| US7338807B2 (en) * | 1994-12-19 | 2008-03-04 | The United States Of America As Represented By The Department Of Health And Human Services | Screening assays for compounds that cause apoptosis |
| WO2008102121A1 (en) | 2007-02-20 | 2008-08-28 | Oxford Nanopore Technologies Limited | Formation of lipid bilayers |
| WO2009035647A1 (en) | 2007-09-12 | 2009-03-19 | President And Fellows Of Harvard College | High-resolution molecular graphene sensor comprising an aperture in the graphene layer |
| WO2009077734A2 (en) | 2007-12-19 | 2009-06-25 | Oxford Nanopore Technologies Limited | Formation of layers of amphiphilic molecules |
| WO2010004265A1 (en) | 2008-07-07 | 2010-01-14 | Oxford Nanopore Technologies Limited | Enzyme-pore constructs |
| WO2010004273A1 (en) | 2008-07-07 | 2010-01-14 | Oxford Nanopore Technologies Limited | Base-detecting pore |
| US20100092960A1 (en) * | 2008-07-25 | 2010-04-15 | Pacific Biosciences Of California, Inc. | Helicase-assisted sequencing with molecular beacons |
| WO2010086603A1 (en) | 2009-01-30 | 2010-08-05 | Oxford Nanopore Technologies Limited | Enzyme mutant |
| WO2010122293A1 (en) | 2009-04-20 | 2010-10-28 | Oxford Nanopore Technologies Limited | Lipid bilayer sensor array |
| WO2011067559A1 (en) | 2009-12-01 | 2011-06-09 | Oxford Nanopore Technologies Limited | Biochemical analysis instrument |
Family Cites Families (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2004092331A2 (en) | 2003-04-08 | 2004-10-28 | Li-Cor, Inc. | Composition and method for nucleic acid sequencing |
| JP4757804B2 (en) | 2004-10-27 | 2011-08-24 | 株式会社カネカ | Novel carbonyl reductase, its gene, and its use |
| GB0523282D0 (en) | 2005-11-15 | 2005-12-21 | Isis Innovation | Methods using pores |
| GB2453377A (en) | 2007-10-05 | 2009-04-08 | Isis Innovation | Transmembrane protein pores and molecular adapters therefore. |
| US8231969B2 (en) | 2008-03-26 | 2012-07-31 | University Of Utah Research Foundation | Asymmetrically functionalized nanoparticles |
| EP3686602A1 (en) | 2008-09-22 | 2020-07-29 | University of Washington | Msp nanopores and related methods |
| US9080211B2 (en) | 2008-10-24 | 2015-07-14 | Epicentre Technologies Corporation | Transposon end compositions and methods for modifying nucleic acids |
| GB0820927D0 (en) | 2008-11-14 | 2008-12-24 | Isis Innovation | Method |
| KR101797773B1 (en) | 2009-01-30 | 2017-11-15 | 옥스포드 나노포어 테크놀로지즈 리미티드 | Adaptors for nucleic acid constructs in transmembrane sequencing |
| BRPI1011384A2 (en) | 2009-02-23 | 2016-03-15 | Cytomx Therapeutics Inc | proproteins and their methods of use |
| GB0905140D0 (en) | 2009-03-25 | 2009-05-06 | Isis Innovation | Method |
| CN103392008B (en) | 2010-09-07 | 2017-10-20 | 加利福尼亚大学董事会 | Movement by continuation enzyme with the precision controlling DNA of a nucleotides in nano-pore |
| KR101939420B1 (en) | 2011-02-11 | 2019-01-16 | 옥스포드 나노포어 테크놀로지즈 리미티드 | Mutant pores |
| EP3848706B1 (en) | 2011-05-27 | 2023-07-19 | Oxford Nanopore Technologies PLC | Coupling method |
| CN103827320B (en) | 2011-07-25 | 2017-04-26 | 牛津纳米孔技术有限公司 | Hairpin loop method for sequencing double-stranded polynucleotides using transmembrane pores |
| US9758823B2 (en) | 2011-10-21 | 2017-09-12 | Oxford Nanopore Technologies Limited | Enzyme method |
| WO2013098561A1 (en) | 2011-12-29 | 2013-07-04 | Oxford Nanopore Technologies Limited | Method for characterising a polynucelotide by using a xpd helicase |
| WO2013098562A2 (en) | 2011-12-29 | 2013-07-04 | Oxford Nanopore Technologies Limited | Enzyme method |
| US10808231B2 (en) | 2012-07-19 | 2020-10-20 | Oxford Nanopore Technologies Limited | Modified helicases |
| US11155860B2 (en) | 2012-07-19 | 2021-10-26 | Oxford Nanopore Technologies Ltd. | SSB method |
| CA2879355C (en) | 2012-07-19 | 2021-09-21 | Oxford Nanopore Technologies Limited | Helicase construct and its use in characterising polynucleotides |
| JP6484604B2 (en) | 2013-03-14 | 2019-03-13 | アーケマ・インコーポレイテッド | Method for crosslinking a polymer composition in the presence of atmospheric oxygen |
| CN118256603A (en) | 2013-10-18 | 2024-06-28 | 牛津纳米孔科技公开有限公司 | Modified enzymes |
-
2012
- 2012-12-28 WO PCT/GB2012/053273 patent/WO2013098561A1/en active Application Filing
- 2012-12-28 EP EP12816096.7A patent/EP2798083B1/en active Active
- 2012-12-28 CN CN201280068306.XA patent/CN104136631B/en active Active
- 2012-12-28 US US14/369,024 patent/US9617591B2/en active Active
Patent Citations (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7338807B2 (en) * | 1994-12-19 | 2008-03-04 | The United States Of America As Represented By The Department Of Health And Human Services | Screening assays for compounds that cause apoptosis |
| WO2000028312A1 (en) | 1998-11-06 | 2000-05-18 | The Regents Of The University Of California | A miniature support for thin films containing single channels or nanopores and methods for using same |
| US20060063171A1 (en) * | 2004-03-23 | 2006-03-23 | Mark Akeson | Methods and apparatus for characterizing polynucleotides |
| WO2005124888A1 (en) | 2004-06-08 | 2005-12-29 | President And Fellows Of Harvard College | Suspended carbon nanotube field effect transistor |
| WO2006100484A2 (en) | 2005-03-23 | 2006-09-28 | Isis Innovation Limited | Deliver of molecules to a li id bila |
| WO2008102120A1 (en) | 2007-02-20 | 2008-08-28 | Oxford Nanopore Technologies Limited | Lipid bilayer sensor system |
| WO2008102121A1 (en) | 2007-02-20 | 2008-08-28 | Oxford Nanopore Technologies Limited | Formation of lipid bilayers |
| WO2009035647A1 (en) | 2007-09-12 | 2009-03-19 | President And Fellows Of Harvard College | High-resolution molecular graphene sensor comprising an aperture in the graphene layer |
| WO2009077734A2 (en) | 2007-12-19 | 2009-06-25 | Oxford Nanopore Technologies Limited | Formation of layers of amphiphilic molecules |
| WO2010004265A1 (en) | 2008-07-07 | 2010-01-14 | Oxford Nanopore Technologies Limited | Enzyme-pore constructs |
| WO2010004273A1 (en) | 2008-07-07 | 2010-01-14 | Oxford Nanopore Technologies Limited | Base-detecting pore |
| US20100092960A1 (en) * | 2008-07-25 | 2010-04-15 | Pacific Biosciences Of California, Inc. | Helicase-assisted sequencing with molecular beacons |
| WO2010086603A1 (en) | 2009-01-30 | 2010-08-05 | Oxford Nanopore Technologies Limited | Enzyme mutant |
| WO2010122293A1 (en) | 2009-04-20 | 2010-10-28 | Oxford Nanopore Technologies Limited | Lipid bilayer sensor array |
| WO2011067559A1 (en) | 2009-12-01 | 2011-06-09 | Oxford Nanopore Technologies Limited | Biochemical analysis instrument |
Non-Patent Citations (20)
| Title |
|---|
| ALTSCHUL S. F., J MOL EVOL, vol. 36, 1993, pages 290 - 300 |
| ALTSCHUL, S.F ET AL., J MOL BIOL, vol. 215, 1990, pages 403 - 10 |
| CELL., vol. 133, no. 5, 30 May 2008 (2008-05-30), pages 801 - 12 |
| CHEM BIOL., vol. 4, no. 7, July 1997 (1997-07-01), pages 497 - 505 |
| DEAMER DAVID: "Nanopore analysis of nucleic acids bound to exonucleases and polymerases.", ANNUAL REVIEW OF BIOPHYSICS 2010, vol. 39, 2010, pages 79 - 90, XP002693594, ISSN: 1936-1238 * |
| DEVEREUX ET AL., NUCLEIC ADDS RESEARCH, vol. 12, 1984, pages 387 - 395 |
| GRANT, G. P.; P. Z. QIN: "A facile method for attaching nitroxide spin labels at the 5' terminus of nucleic acids", NUCLEIC ACIDS RES, vol. 35, no. 10, 2007, pages E77 |
| HOLDEN ET AL., J AM CHEM SOC., vol. 129, no. 27, 11 July 2007 (2007-07-11), pages 8650 - 5 |
| HORNBLOWER B ET AL: "Single-molecule analysis of DNA-protein complexes using nanopores", NATURE METHODS, NATURE PUBLISHING GROUP, GB, vol. 4, no. 4, 1 January 2007 (2007-01-01), pages 315 - 317, XP009164677, ISSN: 1548-7091 * |
| IVANOV AP ET AL., NANO LETT., vol. 11, no. 1, 12 January 2011 (2011-01-12), pages 279 - 85 |
| KUMAR, A.; P. TCHEN ET AL.: "Nonradioactive labeling of synthetic oligonucleotide probes with terminal deoxynucleotidyl transferase", ANAL BIOCHEM, vol. 169, no. 2, 1988, pages 376 - 82 |
| LIEBERMAN KR ET AL., J AM CHEM SOC., vol. 132, no. 50, 2010, pages 17961 - 72 |
| M.A. HOLDEN; H. BAYLEY., J. AM. CHEM. SOC, vol. 127, 2005, pages 6502 - 6503 |
| MONTAL; MUELLER, PROC. NATL. ACAD. SCI. USA., vol. 69, 1972, pages 3561 - 3566 |
| SAMBROOK, J.; RUSSELL, D.: "Molecular Cloning: A Laboratory Manual, 3rd Edition.", 2001, COLD SPRING HARBOR LABORATORY PRESS |
| SEICO BENNER ET AL: "Sequence-specific detection of individual DNA polymerase complexes in real time using a nanopore", NATURE NANOTECHNOLOGY, vol. 2, no. 11, 1 November 2007 (2007-11-01), pages 718 - 724, XP055055941, ISSN: 1748-3387, DOI: 10.1038/nnano.2007.344 * |
| SONI GV ET AL., REV SCI INSTRUM., vol. 81, no. 1, January 2010 (2010-01-01), pages 014301 |
| STODDART D ET AL., PROC NATL ACAD SCI, vol. 106, no. 19, pages 7702 - 7 |
| STODDART ET AL., PNAS, vol. 106, no. 19, 2009, pages 7702 - 7707 |
| TROUTT, A. B.; M. G. MCHEYZER-WILLIAMS ET AL.: "Ligation-anchored PCR: a simple amplification technique with single-sided specificity", PROC NATL ACAD SCI USA, vol. 89, no. 20, 1992, pages 9823 - 5 |
Cited By (195)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11352664B2 (en) | 2009-01-30 | 2022-06-07 | Oxford Nanopore Technologies Plc | Adaptors for nucleic acid constructs in transmembrane sequencing |
| US11459606B2 (en) | 2009-01-30 | 2022-10-04 | Oxford Nanopore Technologies Plc | Adaptors for nucleic acid constructs in transmembrane sequencing |
| US11041194B2 (en) | 2011-05-27 | 2021-06-22 | Oxford Nanopore Technologies Ltd. | Coupling method |
| US11136623B2 (en) | 2011-05-27 | 2021-10-05 | Oxford Nanopore Technologies Limited | Coupling method |
| US11959135B2 (en) | 2011-05-27 | 2024-04-16 | Oxford Nanopore Technologies Plc | Coupling method |
| US11946102B2 (en) | 2011-05-27 | 2024-04-02 | Oxford Nanopore Technologies Plc | Coupling method |
| US10246741B2 (en) | 2011-05-27 | 2019-04-02 | Oxford Nanopore Technologies Ltd. | Coupling method |
| US10597713B2 (en) | 2011-07-25 | 2020-03-24 | Oxford Nanopore Technologies Ltd. | Hairpin loop method for double strand polynucleotide sequencing using transmembrane pores |
| US11168363B2 (en) | 2011-07-25 | 2021-11-09 | Oxford Nanopore Technologies Ltd. | Hairpin loop method for double strand polynucleotide sequencing using transmembrane pores |
| US11261487B2 (en) | 2011-07-25 | 2022-03-01 | Oxford Nanopore Technologies Plc | Hairpin loop method for double strand polynucleotide sequencing using transmembrane pores |
| US9957560B2 (en) | 2011-07-25 | 2018-05-01 | Oxford Nanopore Technologies Ltd. | Hairpin loop method for double strand polynucleotide sequencing using transmembrane pores |
| US10851409B2 (en) | 2011-07-25 | 2020-12-01 | Oxford Nanopore Technologies Ltd. | Hairpin loop method for double strand polynucleotide sequencing using transmembrane pores |
| US11921103B2 (en) | 2011-09-23 | 2024-03-05 | Oxford Nanopore Technologies Plc | Method of operating a measurement system to analyze a polymer |
| US9758823B2 (en) | 2011-10-21 | 2017-09-12 | Oxford Nanopore Technologies Limited | Enzyme method |
| US10724087B2 (en) | 2011-10-21 | 2020-07-28 | Oxford Nanopore Technologies Ltd. | Enzyme method |
| US11634763B2 (en) | 2011-10-21 | 2023-04-25 | Oxford Nanopore Technologies Plc | Enzyme method |
| US9617591B2 (en) | 2011-12-29 | 2017-04-11 | Oxford Nanopore Technologies Ltd. | Method for characterising a polynucleotide by using a XPD helicase |
| US10385382B2 (en) | 2011-12-29 | 2019-08-20 | Oxford Nanopore Technologies Ltd. | Enzyme method |
| US10739341B2 (en) | 2012-02-15 | 2020-08-11 | Oxford Nanopore Technologies Limited | Aptamer method |
| US11685922B2 (en) | 2012-02-15 | 2023-06-27 | Oxford Nanopore Technologies Plc | Aptamer method |
| US11959906B2 (en) | 2012-02-16 | 2024-04-16 | Oxford Nanopore Technologies Plc | Analysis of measurements of a polymer |
| US9777049B2 (en) | 2012-04-10 | 2017-10-03 | Oxford Nanopore Technologies Ltd. | Mutant lysenin pores |
| US10882889B2 (en) | 2012-04-10 | 2021-01-05 | Oxford Nanopore Technologies Ltd. | Mutant lysenin pores |
| US11845780B2 (en) | 2012-04-10 | 2023-12-19 | Oxford Nanopore Technologies Plc | Mutant lysenin pores |
| US10808231B2 (en) | 2012-07-19 | 2020-10-20 | Oxford Nanopore Technologies Limited | Modified helicases |
| US9797009B2 (en) | 2012-07-19 | 2017-10-24 | Oxford Nanopore Technologies Limited | Enzyme construct |
| US11525126B2 (en) | 2012-07-19 | 2022-12-13 | Oxford Nanopore Technologies Plc | Modified helicases |
| US11155860B2 (en) | 2012-07-19 | 2021-10-26 | Oxford Nanopore Technologies Ltd. | SSB method |
| US9551023B2 (en) | 2012-09-14 | 2017-01-24 | Oxford Nanopore Technologies Ltd. | Sample preparation method |
| US9995728B2 (en) | 2012-11-06 | 2018-06-12 | Oxford Nanopore Technologies Ltd. | Quadruplex method |
| US10131943B2 (en) | 2012-12-19 | 2018-11-20 | Oxford Nanopore Technologies Ltd. | Analysis of a polynucleotide via a nanopore system |
| US11085077B2 (en) | 2012-12-19 | 2021-08-10 | Oxford Nanopore Technologies Ltd. | Analysis of a polynucleotide via a nanopore system |
| US11560589B2 (en) | 2013-03-08 | 2023-01-24 | Oxford Nanopore Technologies Plc | Enzyme stalling method |
| US10221450B2 (en) | 2013-03-08 | 2019-03-05 | Oxford Nanopore Technologies Ltd. | Enzyme stalling method |
| WO2014135838A1 (en) | 2013-03-08 | 2014-09-12 | Oxford Nanopore Technologies Limited | Enzyme stalling method |
| US10006905B2 (en) | 2013-03-25 | 2018-06-26 | Katholieke Universiteit Leuven | Nanopore biosensors for detection of proteins and nucleic acids |
| US11761956B2 (en) | 2013-03-25 | 2023-09-19 | Katholieke Universiteit Leuven | Nanopore biosensors for detection of proteins and nucleic acids |
| US10514378B2 (en) | 2013-03-25 | 2019-12-24 | Katholieke Universiteit Leuven | Nanopore biosensors for detection of proteins and nucleic acids |
| US10802015B2 (en) | 2013-03-25 | 2020-10-13 | Katholieke Universiteit Leuven | Nanopore biosensors for detection of proteins and nucleic acids |
| US10976311B2 (en) | 2013-03-25 | 2021-04-13 | Katholieke Universiteit Leuven | Nanopore biosensors for detection of proteins and nucleic acids |
| CN105705656A (en) * | 2013-08-16 | 2016-06-22 | 牛津纳米孔技术公司 | Method |
| US11186857B2 (en) | 2013-08-16 | 2021-11-30 | Oxford Nanopore Technologies Plc | Polynucleotide modification methods |
| CN105705656B (en) * | 2013-08-16 | 2020-02-21 | 牛津纳米孔技术公司 | Method of producing a composite material |
| US10501767B2 (en) | 2013-08-16 | 2019-12-10 | Oxford Nanopore Technologies Ltd. | Polynucleotide modification methods |
| CN111235245A (en) * | 2013-08-16 | 2020-06-05 | 牛津纳米孔技术公司 | Method of producing a composite material |
| CN111235245B (en) * | 2013-08-16 | 2024-07-30 | 牛津纳米孔科技公开有限公司 | Method of |
| EP4006168A1 (en) | 2013-10-18 | 2022-06-01 | Oxford Nanopore Technologies PLC | Method of characterizing a target ribonucleic acid (rna) comprising forming a complementary polynucleotide which moves through a transmembrane pore |
| EP3575410A2 (en) | 2013-10-18 | 2019-12-04 | Oxford Nanopore Technologies Limited | Modified enzymes |
| CN117264925A (en) * | 2013-10-18 | 2023-12-22 | 牛津纳米孔科技公开有限公司 | Modified enzymes |
| EP3575410A3 (en) * | 2013-10-18 | 2020-03-04 | Oxford Nanopore Technologies Limited | Modified enzymes |
| US11111532B2 (en) | 2013-10-18 | 2021-09-07 | Oxford Nanopore Technologies Ltd. | Method of characterizing a target ribonucleic acid (RNA) comprising forming a complementary polynucleotide which moves through a transmembrane pore |
| WO2015056028A1 (en) | 2013-10-18 | 2015-04-23 | Oxford Nanopore Technologies Limited | Method of characterizing a target ribonucleic acid (rna) comprising forming a complementary polynucleotide which moves through a transmembrane pore |
| WO2015055981A3 (en) * | 2013-10-18 | 2015-06-11 | Oxford Nanopore Technologies Limited | Modified helicases |
| US10724018B2 (en) | 2013-10-18 | 2020-07-28 | Oxford Nanopore Technologies Ltd. | Modified helicases |
| WO2015055981A2 (en) | 2013-10-18 | 2015-04-23 | Oxford Nanopore Technologies Limited | Modified enzymes |
| US11525125B2 (en) | 2013-10-18 | 2022-12-13 | Oxford Nanopore Technologies Plc | Modified helicases |
| CN105899678A (en) * | 2013-10-18 | 2016-08-24 | 牛津纳米孔技术公司 | Modified enzymes |
| US11041196B2 (en) | 2013-11-26 | 2021-06-22 | Illumina, Inc. | Compositions and methods for polynucleotide sequencing |
| US9689033B2 (en) | 2013-11-26 | 2017-06-27 | Illumina, Inc. | Compositions and methods for polynucleotide sequencing |
| US10364462B2 (en) | 2013-11-26 | 2019-07-30 | Illumina, Inc. | Compositions and methods for polynucleotide sequencing |
| US11879155B2 (en) | 2013-11-26 | 2024-01-23 | Illumina, Inc. | Compositions and methods for polynucleotide sequencing |
| US10385389B2 (en) | 2014-01-22 | 2019-08-20 | Oxford Nanopore Technologies Ltd. | Method for attaching one or more polynucleotide binding proteins to a target polynucleotide |
| EP3097210B2 (en) † | 2014-01-22 | 2022-04-20 | Oxford Nanopore Technologies Limited | Method for attaching one or more polynucleotide binding proteins to a target polynucleotide |
| EP3097210B1 (en) | 2014-01-22 | 2018-11-14 | Oxford Nanopore Technologies Limited | Method for attaching one or more polynucleotide binding proteins to a target polynucleotide |
| US10392658B2 (en) | 2014-01-22 | 2019-08-27 | Oxford Nanopore Technologies Ltd. | Method for controlling the movement of a polynucleotide through a transmembrane pore |
| WO2015110813A1 (en) | 2014-01-22 | 2015-07-30 | Oxford Nanopore Technologies Limited | Method for attaching one or more polynucleotide binding proteins to a target polynucleotide |
| CN106103741A (en) * | 2014-01-22 | 2016-11-09 | 牛津纳米孔技术公司 | The method that one or more polynucleotide associated proteins are connected to target polynucleotide |
| US11725235B2 (en) | 2014-01-22 | 2023-08-15 | Oxford Nanopore Technologies Plc | Method for attaching one or more polynucleotide binding proteins to a target polynucleotide |
| US11542551B2 (en) | 2014-02-21 | 2023-01-03 | Oxford Nanopore Technologies Plc | Sample preparation method |
| US10669578B2 (en) | 2014-02-21 | 2020-06-02 | Oxford Nanopore Technologies Ltd. | Sample preparation method |
| US10337060B2 (en) | 2014-04-04 | 2019-07-02 | Oxford Nanopore Technologies Ltd. | Method for characterising a double stranded nucleic acid using a nano-pore and anchor molecules at both ends of said nucleic acid |
| US11236385B2 (en) | 2014-04-04 | 2022-02-01 | Oxford Nanopore Technologies Ltd. | Method for characterising a double stranded nucleic acid using a nano-pore and anchor molecules at both ends of said nucleic acid |
| WO2015150787A1 (en) | 2014-04-04 | 2015-10-08 | Oxford Nanopore Technologies Limited | Method of target molecule characterisation using a molecular pore |
| US11649490B2 (en) | 2014-04-04 | 2023-05-16 | Oxford Nanopore Technologies Plc | Method of target molecule characterisation using a molecular pore |
| US10774378B2 (en) | 2014-04-04 | 2020-09-15 | Oxford Nanopore Technologies Ltd. | Method of target molecule characterisation using a molecular pore |
| US10167503B2 (en) | 2014-05-02 | 2019-01-01 | Oxford Nanopore Technologies Ltd. | Mutant pores |
| US10443097B2 (en) | 2014-05-02 | 2019-10-15 | Oxford Nanopore Technologies Ltd. | Method of improving the movement of a target polynucleotide with respect to a transmembrane pore |
| US10844432B2 (en) | 2014-05-02 | 2020-11-24 | Oxford Nanopore Technologies, Ltd. | Method of improving the movement of a target polynucleotide with respect to a transmembrane pore |
| US11739377B2 (en) | 2014-05-02 | 2023-08-29 | Oxford Nanopore Technologies Plc | Method of improving the movement of a target polynucleotide with respect to a transmembrane pore |
| US11034734B2 (en) | 2014-09-01 | 2021-06-15 | Oxford Nanopore Technologies Ltd. | Mutant pores |
| EP4053150A1 (en) | 2014-09-01 | 2022-09-07 | Vib Vzw | Mutant csgg pores |
| US10400014B2 (en) | 2014-09-01 | 2019-09-03 | Oxford Nanopore Technologies Ltd. | Mutant CsgG pores |
| WO2016055778A1 (en) | 2014-10-07 | 2016-04-14 | Oxford Nanopore Technologies Limited | Mutant pores |
| US11965183B2 (en) | 2014-10-07 | 2024-04-23 | Oxford Nanopore Technologies Plc | Modified enzymes |
| WO2016055777A2 (en) | 2014-10-07 | 2016-04-14 | Oxford Nanopore Technologies Limited | Modified enzymes |
| US11180741B2 (en) | 2014-10-07 | 2021-11-23 | Oxford Nanopore Technologies Ltd. | Modified enzymes |
| EP4108679A1 (en) | 2014-10-07 | 2022-12-28 | Oxford Nanopore Technologies plc | Modified enzymes |
| US10266885B2 (en) | 2014-10-07 | 2019-04-23 | Oxford Nanopore Technologies Ltd. | Mutant pores |
| US11390904B2 (en) | 2014-10-14 | 2022-07-19 | Oxford Nanopore Technologies Plc | Nanopore-based method and double stranded nucleic acid construct therefor |
| WO2016059363A1 (en) | 2014-10-14 | 2016-04-21 | Oxford Nanopore Technologies Limited | Method |
| US10570440B2 (en) | 2014-10-14 | 2020-02-25 | Oxford Nanopore Technologies Ltd. | Method for modifying a template double stranded polynucleotide using a MuA transposase |
| US11401549B2 (en) | 2014-10-16 | 2022-08-02 | Oxford Nanopore Technologies Plc | Analysis of a polymer |
| US10689697B2 (en) | 2014-10-16 | 2020-06-23 | Oxford Nanopore Technologies Ltd. | Analysis of a polymer |
| US10760114B2 (en) | 2014-10-17 | 2020-09-01 | Oxford Nanopore Technologies Ltd. | Methods for delivering an analyte to transmembrane pores |
| WO2016059375A1 (en) | 2014-10-17 | 2016-04-21 | Oxford Nanopore Technologies Limited | Methods for delivering an analyte to transmembrane pores |
| US12129518B2 (en) | 2014-10-17 | 2024-10-29 | Oxford Nanopore Technologies Plc | Method for nanopore RNA characterization |
| US11021747B2 (en) | 2014-10-17 | 2021-06-01 | Oxford Nanopore Technologies Ltd. | Method for nanopore RNA characterisation |
| US11613771B2 (en) | 2014-10-17 | 2023-03-28 | Oxford Nanopore Technologies Plc | Methods for delivering an analyte to transmembrane pores |
| US10480026B2 (en) | 2014-10-17 | 2019-11-19 | Oxford Nanopore Technologies Ltd. | Method for nanopore RNA characterisation |
| US10472673B2 (en) | 2015-02-19 | 2019-11-12 | Oxford Nanopore Technologies Ltd. | Hetero-pores |
| US11307192B2 (en) | 2015-02-19 | 2022-04-19 | Oxford Nanopore Technologies Plc | Method for producing a hetero-oligomeric pore comprising two different monomers in a specific stiochiometric ratio |
| EP4019535A1 (en) | 2015-02-19 | 2022-06-29 | Oxford Nanopore Technologies plc | Hetero-pores |
| WO2016132124A1 (en) | 2015-02-19 | 2016-08-25 | Oxford Nanopore Technologies Limited | Method |
| WO2016132123A1 (en) | 2015-02-19 | 2016-08-25 | Oxford Nanopore Technologies Limited | Hetero-pores |
| US11169138B2 (en) | 2015-04-14 | 2021-11-09 | Katholieke Universiteit Leuven | Nanopores with internal protein adaptors |
| US10962523B2 (en) | 2015-05-11 | 2021-03-30 | Oxford Nanopore Technologies Ltd. | Apparatus and methods for measuring an electrical current |
| US11986775B2 (en) | 2015-05-20 | 2024-05-21 | Oxford Nanopore Technologies Plc | Methods and apparatus for forming apertures in a solid state membrane using dielectric breakdown |
| US10596523B2 (en) | 2015-05-20 | 2020-03-24 | Oxford Nanopore Inc. | Methods and apparatus for forming apertures in a solid state membrane using dielectric breakdown |
| EP3741452A1 (en) | 2015-05-20 | 2020-11-25 | Oxford Nanopore Inc. | Methods and apparatus for forming apertures in a solid state membrane using dielectric breakdown |
| US10976300B2 (en) | 2015-12-08 | 2021-04-13 | Katholieke Universiteit Leuven | Modified nanopores, compositions comprising the same, and uses thereof |
| WO2017098322A1 (en) | 2015-12-08 | 2017-06-15 | Katholieke Universiteit Leuven Ku Leuven Research & Development | Modified nanopores, compositions comprising the same, and uses thereof |
| WO2017149316A1 (en) | 2016-03-02 | 2017-09-08 | Oxford Nanopore Technologies Limited | Mutant pore |
| EP4015531A2 (en) | 2016-03-02 | 2022-06-22 | Oxford Nanopore Technologies PLC | Mutant pore |
| WO2017149317A1 (en) | 2016-03-02 | 2017-09-08 | Oxford Nanopore Technologies Limited | Mutant pore |
| US11685949B2 (en) | 2016-03-02 | 2023-06-27 | Oxford Nanopore Technologies Plc | Mutant pore |
| WO2017149318A1 (en) | 2016-03-02 | 2017-09-08 | Oxford Nanopore Technologies Limited | Mutant pores |
| US11597970B2 (en) | 2016-03-02 | 2023-03-07 | Oxford Nanopore Technologies Plc | Mutant pores |
| US12018326B2 (en) | 2016-03-02 | 2024-06-25 | Oxford Nanopore Technologies Plc | Mutant pore |
| US10975428B2 (en) | 2016-03-02 | 2021-04-13 | Oxford Nanopore Technologies Ltd. | Mutant pore |
| US11186868B2 (en) | 2016-03-02 | 2021-11-30 | Oxford Nanopore Technologies Plc | Mutant pore |
| US10995372B2 (en) | 2016-03-02 | 2021-05-04 | Oxford Nanopore Technologies Ltd. | Mutant pores |
| EP4019542A1 (en) | 2016-03-02 | 2022-06-29 | Oxford Nanopore Technologies plc | Mutant pores |
| EP4019543A1 (en) | 2016-03-02 | 2022-06-29 | Oxford Nanopore Technologies plc | Mutant pore |
| EP4122949A1 (en) | 2016-04-06 | 2023-01-25 | Oxford Nanopore Technologies plc | Mutant pore |
| WO2017174990A1 (en) | 2016-04-06 | 2017-10-12 | Oxford Nanopore Technologies Limited | Mutant pore |
| EP4397970A2 (en) | 2016-04-06 | 2024-07-10 | Oxford Nanopore Technologies PLC | Mutant pore |
| US11104709B2 (en) | 2016-04-06 | 2021-08-31 | Oxford Nanopore Technologies Ltd. | Mutant pore |
| US11939359B2 (en) | 2016-04-06 | 2024-03-26 | Oxford Nanopore Technologies Plc | Mutant pore |
| US11098355B2 (en) | 2016-05-25 | 2021-08-24 | Oxford Nanopore Technologies Ltd. | Method of nanopore sequencing of concatenated nucleic acids |
| EP4063521A1 (en) | 2016-05-25 | 2022-09-28 | Oxford Nanopore Technologies PLC | Method of nanopore sequencing |
| WO2017203269A1 (en) | 2016-05-25 | 2017-11-30 | Oxford Nanopore Technologies Limited | Method of nanopore sequencing of concatenaded nucleic acids |
| US11649480B2 (en) | 2016-05-25 | 2023-05-16 | Oxford Nanopore Technologies Plc | Method for modifying a template double stranded polynucleotide |
| US11085078B2 (en) | 2016-09-29 | 2021-08-10 | Oxford Nanopore Technologies Limited | Method for nucleic acid detection by guiding through a nanopore |
| WO2018060740A1 (en) | 2016-09-29 | 2018-04-05 | Oxford Nanopore Technologies Limited | Method for nucleic acid detection by guiding through a nanopore |
| US11739379B2 (en) | 2016-09-29 | 2023-08-29 | Oxford Nanopore Technologies Plc | Method for nucleic acid detection by guiding through a nanopore |
| US12042790B2 (en) | 2016-11-24 | 2024-07-23 | Oxford Nanopore Technologies Plc | Apparatus and methods for controlling insertion of a membrane channel into a membrane |
| US11466317B2 (en) | 2016-12-01 | 2022-10-11 | Oxford Nanopore Technologies Plc | Methods and systems for characterizing analytes using nanopores |
| EP4269617A2 (en) | 2016-12-01 | 2023-11-01 | Oxford Nanopore Technologies plc | Methods and systems for characterizing analytes using nanopores |
| WO2018100370A1 (en) | 2016-12-01 | 2018-06-07 | Oxford Nanopore Technologies Limited | Methods and systems for characterizing analytes using nanopores |
| WO2018146491A1 (en) | 2017-02-10 | 2018-08-16 | Oxford Nanopore Technologies Limited | Modified nanopores, compositions comprising the same, and uses thereof |
| US11840556B2 (en) | 2017-02-10 | 2023-12-12 | Oxford Nanopore Technologies Plc | Modified nanopores, compositions comprising the same, and uses thereof |
| US11789014B2 (en) | 2017-05-04 | 2023-10-17 | Oxford Nanopore Technologies Plc | Method of determining the presence or absence of a target analyte comprising using a reporter polynucleotide and a transmembrane pore |
| EP3892627A1 (en) | 2017-05-04 | 2021-10-13 | Oxford Nanopore Technologies Limited | Transmembrane pore consisting of two csgg pores |
| WO2018211241A1 (en) | 2017-05-04 | 2018-11-22 | Oxford Nanopore Technologies Limited | Transmembrane pore consisting of two csgg pores |
| US12024541B2 (en) | 2017-05-04 | 2024-07-02 | Oxford Nanopore Technologies Plc | Transmembrane pore consisting of two CsgG pores |
| WO2018203071A1 (en) | 2017-05-04 | 2018-11-08 | Oxford Nanopore Technologies Limited | Method of determining the presence or absence of a target analyte comprising using a reporter polynucleotide and a transmembrane pore |
| US11572387B2 (en) | 2017-06-30 | 2023-02-07 | Vib Vzw | Protein pores |
| US12084477B2 (en) | 2017-06-30 | 2024-09-10 | Vib Vzw | Protein pores |
| US11945840B2 (en) | 2017-06-30 | 2024-04-02 | Vib Vzw | Protein pores |
| WO2019135091A1 (en) | 2018-01-05 | 2019-07-11 | Oxford Nanopore Technologies Limited | Method for selecting polynucleotides based on enzyme interaction duration |
| WO2019149626A1 (en) | 2018-02-02 | 2019-08-08 | Bayer Aktiengesellschaft | Control of resistent harmful organisms |
| US11725205B2 (en) | 2018-05-14 | 2023-08-15 | Oxford Nanopore Technologies Plc | Methods and polynucleotides for amplifying a target polynucleotide |
| WO2019224560A1 (en) | 2018-05-24 | 2019-11-28 | Oxford Nanopore Technologies Limited | Method |
| WO2019224558A1 (en) | 2018-05-24 | 2019-11-28 | Oxford Nanopore Technologies Limited | Method for selecting polynucleotides based on the size in a globular form |
| US11920193B2 (en) | 2018-06-06 | 2024-03-05 | Oxford Nanopore Technologies Plc | Method of characterizing a polynucleotide |
| WO2019234432A1 (en) | 2018-06-06 | 2019-12-12 | Oxford Nanopore Technologies Limited | Method |
| WO2020005994A1 (en) * | 2018-06-26 | 2020-01-02 | Electronic Biosciences, Inc. | Controlled nanopore translocation utilizing extremophilic replication proteins |
| WO2020025909A1 (en) | 2018-07-30 | 2020-02-06 | Oxford University Innovation Limited | Assemblies |
| WO2020128517A1 (en) | 2018-12-21 | 2020-06-25 | Oxford Nanopore Technologies Limited | Method of encoding data on a polynucleotide strand |
| GB201907244D0 (en) | 2019-05-22 | 2019-07-03 | Oxford Nanopore Tech Ltd | Method |
| WO2020234612A1 (en) | 2019-05-22 | 2020-11-26 | Oxford Nanopore Technologies Limited | Method |
| GB201907246D0 (en) | 2019-05-22 | 2019-07-03 | Oxford Nanopore Tech Ltd | Method |
| WO2021099801A1 (en) | 2019-11-22 | 2021-05-27 | Oxford Nanopore Technologies Limited | Method for double strand sequencing |
| GB201917060D0 (en) | 2019-11-22 | 2020-01-08 | Oxford Nanopore Tech Ltd | Method |
| WO2021111125A1 (en) | 2019-12-02 | 2021-06-10 | Oxford Nanopore Technologies Limited | Method of characterising a target polypeptide using a nanopore |
| EP4270008A2 (en) | 2019-12-02 | 2023-11-01 | Oxford Nanopore Technologies PLC | Method of characterising a target polypeptide using a nanopore |
| WO2021111139A1 (en) | 2019-12-04 | 2021-06-10 | Oxford Nanopore Technologies Limited | Method |
| GB202004944D0 (en) | 2020-04-03 | 2020-05-20 | King S College London | Method |
| WO2021198695A1 (en) | 2020-04-03 | 2021-10-07 | King's College London | Method of detecting an analyte in a medium comprising a light scattering constituent |
| WO2021255475A1 (en) | 2020-06-18 | 2021-12-23 | Oxford Nanopore Technologies Limited | A method of selectively characterising a polynucleotide using a detector |
| WO2021255476A2 (en) | 2020-06-18 | 2021-12-23 | Oxford Nanopore Technologies Limited | Method |
| WO2021255477A1 (en) | 2020-06-18 | 2021-12-23 | Oxford Nanopore Technologies Limited | Method of repeatedly moving a double-stranded polynucleotide through a nanopore |
| WO2022020461A1 (en) | 2020-07-22 | 2022-01-27 | Oxford Nanopore Technologies Inc. | Solid state nanopore formation |
| WO2022074397A1 (en) | 2020-10-08 | 2022-04-14 | Oxford Nanopore Technologies Limited | Modification of a nanopore forming protein oligomer |
| WO2022243692A1 (en) | 2021-05-19 | 2022-11-24 | Oxford Nanopore Technologies Plc | Methods for complement strand sequencing |
| WO2022243691A1 (en) | 2021-05-19 | 2022-11-24 | Oxford Nanopore Technologies Plc | Multiplex methods of detecting molecules using nanopores |
| GB202107192D0 (en) | 2021-05-19 | 2021-06-30 | Oxford Nanopore Tech Ltd | Method |
| GB202107354D0 (en) | 2021-05-24 | 2021-07-07 | Oxford Nanopore Tech Ltd | Method |
| WO2023026056A1 (en) | 2021-08-26 | 2023-03-02 | Oxford Nanopore Technologies Plc | Nanopore |
| WO2023118891A1 (en) | 2021-12-23 | 2023-06-29 | Oxford Nanopore Technologies Plc | Method of characterising polypeptides using a nanopore |
| WO2023118892A1 (en) | 2021-12-23 | 2023-06-29 | Oxford Nanopore Technologies Plc | Method |
| WO2023123359A1 (en) * | 2021-12-31 | 2023-07-06 | 深圳华大生命科学研究院 | Helicase bch2x and use thereof |
| WO2023198911A2 (en) | 2022-04-14 | 2023-10-19 | Oxford Nanopore Technologies Plc | Novel modified protein pores and enzymes |
| WO2023222657A1 (en) | 2022-05-17 | 2023-11-23 | Oxford Nanopore Technologies Plc | Method and adaptors |
| WO2024033443A1 (en) | 2022-08-09 | 2024-02-15 | Oxford Nanopore Technologies Plc | Novel pore monomers and pores |
| WO2024033422A1 (en) | 2022-08-09 | 2024-02-15 | Oxford Nanopore Technologies Plc | Novel pore monomers and pores |
| WO2024033421A2 (en) | 2022-08-09 | 2024-02-15 | Oxford Nanopore Technologies Plc | Novel pore monomers and pores |
| WO2024089270A2 (en) | 2022-10-28 | 2024-05-02 | Oxford Nanopore Technologies Plc | Pore monomers and pores |
| WO2024094986A1 (en) | 2022-10-31 | 2024-05-10 | Oxford Nanopore Technologies Plc | Method |
| WO2024099985A1 (en) | 2022-11-10 | 2024-05-16 | Bayer Aktiengesellschaft | Targeted crop protection product application based on genetic profiles |
| WO2024100270A1 (en) | 2022-11-11 | 2024-05-16 | Oxford Nanopore Technologies Plc | Novel pore monomers and pores |
| WO2024200280A1 (en) | 2023-03-24 | 2024-10-03 | Oxford Nanopore Technologies Plc | Method and kits |
| WO2024213802A1 (en) | 2023-04-14 | 2024-10-17 | Oxford Nanopore Technologies Plc | Novel pore monomers and pores |
| GB202307486D0 (en) | 2023-05-18 | 2023-07-05 | Oxford Nanopore Tech Plc | Method |
| GB202407228D0 (en) | 2024-05-21 | 2024-07-03 | Oxford Nanopore Tech Plc | Method |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2798083B1 (en) | 2017-08-09 |
| US20150065354A1 (en) | 2015-03-05 |
| EP2798083A1 (en) | 2014-11-05 |
| US9617591B2 (en) | 2017-04-11 |
| CN104136631B (en) | 2017-03-01 |
| CN104136631A (en) | 2014-11-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP2798083B1 (en) | Method for characterising a polynucelotide by using a xpd helicase | |
| US11634763B2 (en) | Enzyme method | |
| US11560589B2 (en) | Enzyme stalling method | |
| KR102086182B1 (en) | Enzyme method | |
| AU2013220156B2 (en) | Aptamer method | |
| US9551023B2 (en) | Sample preparation method | |
| KR20140050067A (en) | Hairpin loop method for double strand polynucleotide sequencing using transmembrane pores |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 12816096 Country of ref document: EP Kind code of ref document: A1 |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 14369024 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REEP | Request for entry into the european phase |
Ref document number: 2012816096 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2012816096 Country of ref document: EP |