WO2012121011A1 - 集合拡張処理装置、集合拡張処理方法、プログラム、及び、非一時的な記録媒体 - Google Patents
集合拡張処理装置、集合拡張処理方法、プログラム、及び、非一時的な記録媒体 Download PDFInfo
- Publication number
- WO2012121011A1 WO2012121011A1 PCT/JP2012/054211 JP2012054211W WO2012121011A1 WO 2012121011 A1 WO2012121011 A1 WO 2012121011A1 JP 2012054211 W JP2012054211 W JP 2012054211W WO 2012121011 A1 WO2012121011 A1 WO 2012121011A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- segment
- character string
- score
- unit
- segment element
- Prior art date
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2457—Query processing with adaptation to user needs
- G06F16/24578—Query processing with adaptation to user needs using ranking
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2457—Query processing with adaptation to user needs
- G06F16/24575—Query processing with adaptation to user needs using context
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/3332—Query translation
- G06F16/3338—Query expansion
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/06—Buying, selling or leasing transactions
- G06Q30/0601—Electronic shopping [e-shopping]
Definitions
- the present invention relates to a collective expansion processing device, a collective expansion processing method, a program, and a non-transitory recording medium, and particularly relates to acquisition of words included in the semantically same category.
- Patent Literature 1 discloses an information transmission / reception system that displays product categories “home appliances”, “books”, “computers”, and the like on a product listing page. The user can easily narrow down the products by selecting the category of the product desired to be purchased from among these categories.
- Non-Patent Document 1 discloses an algorithm for extracting a semantic vocabulary category from a separated sentence (referred to as “g-Espresso algorithm”).
- Non-Patent Document 2 discloses an algorithm (referred to as “g-Monaka algorithm”) for extracting a semantic vocabulary category from non-separated text.
- the present invention solves the above-described problems, and is a set expansion processing device, a set expansion processing method, a program, and a non-temporary method suitable for selecting words that belong to semantically the same category. It is an object to provide a simple recording medium.
- a set expansion processing device provides: A reception unit that accepts a seed string, A search unit for searching for a document including the accepted seed character string and obtaining a snippet of the searched document; By segmenting the obtained snippet with a predetermined segment delimiter character string, a segment consisting of a character string that appears before and after the accepted seed character string and a character string in which the seed character string is arranged in the order of appearance is obtained.
- Segment acquisition department A segment element acquisition unit that obtains a segment element by dividing each of the obtained segments with a predetermined segment element delimiter character string, A segment score calculation unit that calculates the segment score of each of the obtained segments based on the variance or standard deviation of the lengths of the segment elements that appear in the segment; A segment element score of each segment element included in each of the obtained segments, a distance between a position where the accepted seed character string appears in the segment and a position where the segment element appears in the segment; and A segment element score calculator that calculates based on the segment score calculated for the segment, Based on the segment element score calculated for each of the obtained segment elements, one of the segment elements is selected as a candidate instance included in the extended set obtained by extending the set including the accepted seed character string. Selection part to It is characterized by providing.
- An n-gram connection graph including the extracted instance candidates is generated from a snippet obtained by searching using the instance candidates, and contexts before and after the accepted seed string in the connection graph are generated.
- a set including the seed character string from the instance candidate based on the similarity and calculating the similarity between the seed character string and the instance candidate based on the context before and after the instance candidate The method further includes an extraction unit that extracts instances to be included in the extended set obtained by extending.
- the segment score and the segment element score are determined by the segment elements included in the segment. It is a value that is not selected by the selection unit as the instance candidate.
- the segment element score of each segment element appearing in each of the obtained segments is the shortest distance between the position where the accepted seed character string appears in the segment and the position where the segment element appears in the segment. It is characterized by an exponential decay.
- the set expansion processing method is: A set expansion processing method executed by a set expansion processing apparatus including a reception unit, a search unit, a segment acquisition unit, a segment element acquisition unit, a segment score calculation unit, a segment element score calculation unit, and a selection unit There, A receiving step in which the receiving unit receives a seed character string; A search step in which the search unit searches for a document including the accepted seed character string to obtain a snippet of the searched document; The segment acquisition unit divides the obtained snippet with a predetermined segment delimiter character string, thereby arranging a character string that appears before and after the accepted seed character string and the seed character string in the order of appearance.
- a segment acquisition step for obtaining a segment consisting of a row A segment element acquisition step in which the segment element acquisition unit obtains a segment element by dividing each of the obtained segments by a predetermined segment element delimiter string; A segment score calculation step in which the segment score calculation unit calculates each segment score of the obtained segment based on a variance or standard deviation of each length of the segment elements appearing in the segment; The segment element score calculation unit calculates a segment element score of each segment element included in each of the obtained segments, a position where the accepted seed character string appears in the segment, and the segment element in the segment.
- a segment element score calculating step for calculating based on the distance to the appearing position and the segment score calculated for the segment; Based on the segment element score calculated for each of the obtained segment elements, the selection unit includes any one of the segment elements in an extended set obtained by extending the set including the accepted seed character string.
- a selection process to select as instance candidates, It is characterized by providing.
- the program according to the third aspect of the present invention is: Computer A reception unit that accepts a seed string, A search unit for searching for a document including the accepted seed character string and obtaining a snippet of the searched document; By segmenting the obtained snippet with a predetermined segment delimiter character string, a segment consisting of a character string that appears before and after the accepted seed character string and a character string in which the seed character string is arranged in the order of appearance is obtained.
- Segment acquisition department A segment element acquisition unit that obtains a segment element by dividing each of the obtained segments with a predetermined segment element delimiter character string, A segment score calculation unit that calculates the segment score of each of the obtained segments based on the variance or standard deviation of the lengths of the segment elements that appear in the segment; A segment element score of each segment element included in each of the obtained segments, a distance between a position where the accepted seed character string appears in the segment and a position where the segment element appears in the segment; and A segment element score calculator that calculates based on the segment score calculated for the segment, Based on the segment element score calculated for each of the obtained segment elements, one of the segment elements is selected as a candidate instance included in the extended set obtained by extending the set including the accepted seed character string. Selection part to It is made to function as.
- a non-transitory computer-readable recording medium is provided.
- Computer A reception unit that accepts a seed string
- a search unit for searching for a document including the accepted seed character string and obtaining a snippet of the searched document; By segmenting the obtained snippet with a predetermined segment delimiter character string, a segment consisting of a character string that appears before and after the accepted seed character string and a character string in which the seed character string is arranged in the order of appearance is obtained.
- Segment acquisition department A segment element acquisition unit that obtains a segment element by dividing each of the obtained segments with a predetermined segment element delimiter character string, A segment score calculation unit that calculates the segment score of each of the obtained segments based on the variance or standard deviation of the lengths of the segment elements that appear in the segment; A segment element score of each segment element included in each of the obtained segments, a distance between a position where the accepted seed character string appears in the segment and a position where the segment element appears in the segment; and A segment element score calculator that calculates based on the segment score calculated for the segment, Based on the segment element score calculated for each of the obtained segment elements, one of the segment elements is selected as a candidate instance included in the extended set obtained by extending the set including the accepted seed character string. Selection part to A program characterized by functioning as a program is recorded.
- the above program can be distributed and sold via a computer communication network independently of the computer on which the program is executed.
- the recording medium can be distributed and sold independently from the computer.
- FIG. 1 It is a figure which shows the relationship between the collective expansion processing apparatus which concerns on embodiment of this invention, and a shopping server. It is a figure which shows schematic structure of the typical information processing apparatus with which the collective expansion processing apparatus which concerns on embodiment of this invention is implement
- FIG. It is a figure for demonstrating the searched document. It is a figure for demonstrating a segment. It is a figure for demonstrating a segment element. It is a figure for demonstrating a segment score and a segment element score. It is a figure for demonstrating the candidate of the selected instance.
- FIG. 5 is a flowchart for explaining a set expansion process performed by each unit of the set expansion processing apparatus according to the first embodiment. It is a figure for demonstrating the general
- FIG. 10 is a flowchart for explaining a set expansion process performed by each unit of the set expansion processing apparatus according to the second embodiment.
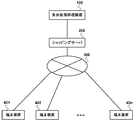
- the collective expansion processing apparatus 100 is connected to a shopping server 200 as shown in FIG.
- Shopping server 200 is connected to the Internet 300.
- a plurality of terminal devices 401, 402 to 40n operated by a user are connected to the Internet 300.
- the shopping server 200 presents product information registered in the shopping server 200 to the terminal devices 401 to 40n via the Internet 300, and accepts product orders from the terminal devices 401 to 40n.
- the products registered in the shopping server 200 are categorized based on the types of products and presented to the users of the terminal devices 401 to 40n.
- the collective expansion processing device 100 performs collective expansion processing on products handled by the shopping server 200 and presents product category candidates.
- set expansion refers to a task of obtaining a set of words belonging to the same category as the seed by giving a small number of correct answer sets as seeds.
- “Chinese wok” and “pressure cooker” of kitchen utensils are used as seeds
- “earthen pot”, “Yukihira pot”, “tagine pot”, and the like are semantically belonging to the same category.
- the collective expansion processing device 100 when “Chinese wok” and “pressure cooker” are given as seeds, “earthen pot”, “Yukihira pot” and “tagine pot” are terms belonging to the same category “wok”. ”Etc.
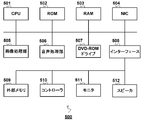
- the information processing apparatus 500 includes a CPU (Central Processing Unit) 501, a ROM (Read only Memory) 502, a RAM (Random Access Memory) 503, a NIC (Network Interface Card) 504, an image A processing unit 505, an audio processing unit 506, a DVD-ROM (Digital Versatile Disc ROM) drive 507, an interface 508, an external memory 509, a controller 510, a monitor 511, and a speaker 512 are provided.
- a CPU Central Processing Unit
- ROM Read only Memory
- RAM Random Access Memory
- NIC Network Interface Card
- the CPU 501 controls the overall operation of the information processing apparatus 500 and is connected to each component to exchange control signals and data.
- the ROM 502 stores an IPL (Initial Program Loader) that is executed immediately after the power is turned on, and when this is executed, a predetermined program is read into the RAM 503 and execution of the program by the CPU 501 is started.
- the ROM 502 stores an operating system program and various data necessary for operation control of the entire information processing apparatus 500.
- the RAM 503 is for temporarily storing data and programs, and holds programs and data read from the DVD-ROM and other data necessary for communication.
- the NIC 504 is used to connect the information processing apparatus 500 to a computer communication network such as the Internet 300, and conforms to the 10BASE-T / 100BASE-T standard used when configuring a LAN (Local Area Network).
- Analog modems for connecting to the Internet using telephone lines ISDN (Integrated Services Digital Network) modems, ADSL (Asymmetric Digital Subscriber Line) modems, cable modems for connecting to the Internet using cable television lines, etc. These are constituted by an interface (not shown) that mediates between these and the CPU 501.
- the image processing unit 505 processes the data read from the DVD-ROM or the like by an image arithmetic processor (not shown) provided in the CPU 501 or the image processing unit 505, and then processes the processed data in a frame memory provided in the image processing unit 505. (Not shown).
- the image information recorded in the frame memory is converted into a video signal at a predetermined synchronization timing and output to the monitor 511. Thereby, various page displays are possible.
- the audio processing unit 506 converts audio data read from a DVD-ROM or the like into an analog audio signal, and outputs the analog audio signal from a speaker 512 connected thereto. Further, under the control of the CPU 501, a sound to be generated during the progress of the processing performed by the information processing apparatus 500 is generated, and a sound corresponding to the sound is output from the speaker 512.
- the DVD-ROM loaded in the DVD-ROM drive 507 stores a program for realizing the collective expansion processing apparatus 100 according to the embodiment, for example. Under the control of the CPU 501, the DVD-ROM drive 507 performs a reading process on the DVD-ROM mounted on the DVD-ROM drive 507 to read out necessary programs and data, and these are temporarily stored in the RAM 503 or the like.
- the external memory 509, the controller 510, the monitor 511, and the speaker 512 are detachably connected to the interface 508.
- the external memory 509 stores data related to the user's personal information in a rewritable manner.
- the controller 510 accepts an operation input performed when various settings of the information processing apparatus 500 are performed.
- the user of the information processing apparatus 500 can record these data in the external memory 509 as appropriate by inputting instructions via the controller 510.
- the monitor 511 presents the data output by the image processing unit 505 to the user of the information processing apparatus 500.
- the speaker 512 presents the audio data output by the audio processing unit 506 to the user of the information processing apparatus 500.
- the information processing apparatus 500 uses a large-capacity external storage device such as a hard disk to perform the same function as the ROM 502, RAM 503, external memory 509, DVD-ROM mounted on the DVD-ROM drive 507, and the like. You may comprise.
- a large-capacity external storage device such as a hard disk to perform the same function as the ROM 502, RAM 503, external memory 509, DVD-ROM mounted on the DVD-ROM drive 507, and the like. You may comprise.
- the set expansion processing apparatus 100 selects instance candidates included in an extended set obtained by extending a set including a seed character string.
- the set expansion processing apparatus 100 includes a reception unit 101, a search unit 102, a segment acquisition unit 103, a segment element acquisition unit 104, a segment score calculation unit 105, and a segment An element score calculation unit 106 and a selection unit 107 are included.
- the collective expansion processing device 100 presents candidates for words (instances) appropriate as words belonging to the category of kitchen product pots.
- the accepting unit 101 accepts a seed character string.
- the seed character string is, for example, a correct word (such as “Chinese wok” or “pressure cooker”) included in a set of words belonging to the category “hot pot”.
- a correct word such as “Chinese wok” or “pressure cooker” included in a set of words belonging to the category “hot pot”.
- the user inputs, as a query, a concatenation of all seed character strings separated by spaces in the search field 601 of the search engine on the WEB page, and presses the search button 602.
- the reception unit 101 receives “Chinese wok” and “pressure cooker” input in the search field 601 as seed character strings.
- the type of search engine is arbitrary.
- the CPU 501 and the controller 510 cooperate to function as the receiving unit 101.
- the search unit 102 searches for a document including the accepted seed character string and obtains a snippet.
- the snippet is, for example, a text part including a query displayed as a search result when using a search engine of a WEB page.
- the search unit 102 inputs, as a query, a concatenation of all seed character strings separated by spaces to the search engine of the WEB page, and obtains a list of, for example, the top 300 snippets of search results.
- the search unit 102 searches the WEB page using a search engine using “Chinese wok pressure cooker” as a query, and the snippet 1 of FIG. 4 including the given seed strings “Chinese wok” and “pressure cooker”.
- search unit 102 is not limited to obtaining a document using an external device as described above, and may have a search function inside.
- the search unit 102 may obtain a snippet using a Web search API.
- the search unit 102 functions as the search unit 102 in cooperation with the CPU 501 and the NIC 504.
- the segment acquisition unit 103 obtains a segment composed of a character string in which a character string that appears before and after the seed character string and the seed character string are arranged in the order of appearance by dividing the obtained snippet with a predetermined segment delimiter character string. .
- the snippet is generally separated by a predetermined delimiter character string so that the user can see at a glance how the search word is used in the page including the search word.
- a predetermined segment delimiter character string is “...”.
- the segment acquisition unit 103 normalizes the obtained snippets 1, 2, 3 to 300 using Unicode NFKC, unifies them into lower case letters, and divides them into a plurality of character strings using the segment delimiter character string “. .
- the segment acquisition unit 103 excludes duplicate character strings from the divided character strings and obtains the remaining character strings as segments.
- the segment acquisition unit 103 excludes duplicate character strings from the divided character strings and obtains the remaining character strings as segments.
- the segment acquisition unit 103 excludes duplicate character strings from the divided character strings and obtains the remaining character strings as segments.
- FIG. 5 shows the segments 1-1 to 1-3 obtained from the snippet 1 by the segment acquisition unit 103.
- the segment delimiter character string is not limited to the character string “...”.
- the segment delimiter character string is set to “---”. Or the character string “##”.
- the method of obtaining a segment is not limited to the method of obtaining a segment using a segment delimiter character string.
- the segment is appropriately acquired according to the snippet presented by the search engine or Web search API used. For example, when one snippet is presented without being separated by a symbol such as “...”, The snippet is set as one segment.
- a portion corresponding to a segment in the snippet is presented in bullets or the like, a portion corresponding to one line of the bullet is defined as one segment.
- the CPU 501 functions as the segment acquisition unit 103.
- the segment element acquisition unit 104 obtains a segment element by dividing each obtained segment with a predetermined segment element delimiter character string.
- the predetermined segment element delimiter character string is a punctuation mark or a symbol (“,”, “,”, “.”, “!”, “[”, “]”, Etc.), and these segment element delimiter characters Segments are separated by columns to obtain segment elements.
- the segment element acquisition unit 104 delimits the segments 1-1, 1-2, and 1-3 in FIG.
- the CPU 501 functions as the segment element acquisition unit 104.
- the segment score calculation unit 105 calculates the segment score of each obtained segment based on the variance or standard deviation of the lengths of the segment elements that appear in the segment.
- the segment score and the segment element score described later are the segments included in the segment. It is assumed that the element has a value that is not selected by the selection unit 107 as an instance candidate.
- the length of the segment element is defined by the number of Unicode characters, but is not limited thereto. For example, the number of bytes in other character codes can be used as the length of the segment element.
- segments 1-1 and 1-3 include normal sentences, but segment 1-2 does not include normal sentences.
- the variation in the length of the segment elements included in the segments 1-1 and 1-3 is larger than the variation in the length of the segment elements included in the segment 1-2. That is, a segment including a normal sentence generally has a tendency that the lengths of the segment elements included in the segment are not aligned as compared with a segment not including a normal sentence.
- a segment including a normal sentence often does not include an instance belonging to the same semantic range as the seed character string, and thus is not suitable as a segment for obtaining a candidate instance. Therefore, in the following, a segment whose segment element standard deviation exceeds a predetermined threshold is excluded from the segment from which the candidate instance is obtained.
- the predetermined threshold is 5.00.
- the segment score calculation unit 105 uses the standard deviation value itself as the segment score when the standard deviation of the length of the segment element is less than 5.00, and the segment score when the standard deviation is 5.00 or more. Is 5.00.
- FIG. 7 shows the segment score calculated by the segment score calculation unit 105.
- the table of FIG. 7 includes “snippet 701a” obtained as a query of the seed character string, “segment 702a” included in the snippet 701a, “segment element 703a” included in the segment 702a, and “length” of the segment element 703a.
- 704a “ standard deviation 705a ”of length 704a,“ segment score 706a ”calculated based on the standard deviation 705a, and“ segment element score 707a ”calculated by the segment element score calculation unit 106 described later. And are described in association with each other.
- the standard deviation is calculated as “5.27”. Accordingly, the segment score calculation unit 105 sets the segment score of the segment 1-1 to “5.00”, the segment score of the segment 1-2 to “1.34”, the segment 1-3, as indicated by 706a in FIG. Is obtained as “5.00”.
- the CPU 501 functions as the segment score calculation unit 105.
- the segment element score calculation unit 106 sets the segment element score of each segment element included in each of the obtained segments, the position where the seed character string accepted in the segment appears, and the segment element appears in the segment. The calculation is performed based on the distance to the position and the segment score calculated for the segment.
- the segment element score is set to a value that prevents the segment element from being selected by the selection unit 107 as a candidate instance. For example, the segment element score calculation unit 106 sets the segment element score to “0” when the segment score is “5.00”. On the other hand, when the segment score is less than “5.00”, the segment element score calculation unit 106 sets the distance between the position where the seed character string accepted in the segment appears and the position where the segment element appears in the segment. Calculate the segment element score based on it. Segment and position p i: (number of seed string j), and a segment element in segment appears, as shown in FIG.
- the order of appearance in the segment where the position s j the seed string in the segment appears It is the appearance order in the segment when the elements are arranged, and the distance is the difference in the appearance order between the position s j and the position p i . That is, assuming that the seed character string is “Chinese wok” and “pressure cooker”, the position s 1 where the seed character string “pressure cooker” (P 4 ) appears in the segment 1-2 is the “4” th, and the seed character The position s 2 where the row “Chinese wok” (P 8 ) appears is the “8” th position.
- the position p 5 where the segment element “parent pot” (P 5 ) appears in the segment 1-2 is the “5th” position, and the seed string “Chinese pot” (P 8 ) and the segment element “parent pot” (P The distance to P 5 ) is 3.
- the score that decays exponentially according to the distance from the nearest seed character string is obtained, but various modifications are possible in the way of obtaining the score.
- the distance between each seed character string and the segment element is obtained, and a score that linearly attenuates according to the average value of the obtained distances may be used as the segment element score of each segment element.
- the search unit searches for similar words in the seed character string in addition to the seed character string.
- a snippet that includes similar words in the seed string such as “pressure pan” is obtained.
- the segment element score calculation unit 106 can similarly handle similar words of the seed character string as a seed character string by using a known kanji / kana character conversion program or the like.
- the segment element score S i can be calculated according to Equation 1.
- the CPU 501 functions as the segment element score calculation unit 106.
- the selection unit 107 selects one of the segment elements from the instance set included in the extended set obtained by extending the set including the accepted seed character string. Select as a candidate.
- the extended set is a set obtained after performing the set expansion process, and is a set of words included in the category that is semantically identical to the seed character string.
- the selection unit 107 excludes segment elements having a segment element score value less than “0.10” from the instance candidates, and selects the remaining segment elements as instance candidates. That is, since the segment element scores of the segment elements obtained from the segments 1-1 and 1-3 are all “0” (FIG. 7), the selection unit 107 selects the segment elements obtained from the segments 1-1 and 1-3 as candidates.
- the selection unit 107 selects “pasta machine”, “others”, and “further” having a segment element score of less than “0.10” among the segment elements obtained from the segment 1-2.
- the segment element with the price “is excluded”, and the remaining segment elements are selected as candidates for instances included in the category that is semantically identical to “Chinese wok” and “pressure cooker”.
- the method for selecting instance candidates has been described by taking one snippet as an example. However, in reality, segment elements are obtained from a large number of snippets to obtain segment element scores, and instance candidates are selected. . In this case, segment element scores may be obtained from different snippets for the same segment element.
- segment elements included in the category that is semantically the same as the seed character string are often included in a plurality of snippets, and therefore, a plurality of segment element scores are highly likely to be obtained. Accordingly, when a plurality of segment element scores are obtained, the sum, maximum value, etc. thereof are used as the segment element score value of the segment element. By processing in this way, a more appropriate instance candidate can be selected.
- the CPU 501 functions as the selection unit 107.
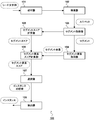
- the receiving unit 101 receives a seed character string (step S101). For example, as illustrated in FIG. 4, the reception unit 101 receives “Chinese wok” and “pressure cooker” input as queries in the search field 601 of the search engine on the WEB page as seed character strings.
- the search unit 102 searches for a document including the accepted seed character string and obtains a snippet (step S102). For example, the search unit 102 searches the seed character strings “Chinese wok” and “pressure cooker” as queries, and obtains the top 300 snippets 1, 2, 3 to 300 of the search results as shown in FIG.
- the number of snippets that the search unit 102 obtains is arbitrary, but more appropriate instance candidates can be selected by obtaining approximately 100 or more snippets.
- the segment acquisition unit 103 obtains a segment by dividing the snippet obtained by the search unit 102 with a segment delimiter character string (step S103). For example, the segment acquisition unit 103 delimits the snippets 1, 2, 3 to 300 with the segment delimiter character string “. For example, the segment acquisition unit 103 obtains segments 1-1 to 1-3 from the snippet 1 as shown in FIG.
- the segment element acquisition unit 104 obtains a segment element by dividing the segment with a predetermined segment element delimiter character string (step S104). For example, segments 1-1 to 1-3 are separated by segment element delimiter strings (“,”, “,”, “.”, “!”, “[”, “]”, Etc.), and the segments shown in FIG. Elements (segment element groups 1-1P, 1-2P, 1-3P) are obtained.
- the segment score calculation unit 105 calculates each segment score of the segment based on the standard deviation of the length of the segment element included in the segment (step S105). For example, when the standard deviation of the segment element length is less than 5.00, the segment score calculation unit 105 sets the standard deviation value itself as the segment score, and the standard deviation of the segment element length is 5.00 or more. In this case, the segment score is set to 5.00. That is, the segment score calculation unit 105 sets the segment score of the segment 1-1 with the standard deviation “5.89” to “5.00” and the segment score of the segment 1-2 with the standard deviation “1.34” to “ The segment score of segment 1-3 with 1.34 ”and standard deviation“ 5.27 ”is obtained as“ 5.00 ”.
- the segment element score calculation unit 106 determines the segment element score of the segment element, the distance between the position where the seed character string accepted in the segment appears and the position where the segment element appears in the segment, and the segment Is calculated based on the segment score calculated for (Step S106). For example, the segment element score calculation unit 106 sets the segment element score to “0” when the segment score is “5.00”, and sets the seed string in the segment when the segment score is less than “5.00”.
- a segment element score 707a (FIG. 7) is calculated based on the equation (Equation 1) using the distance between the appearing position and the position where the segment element appears.
- the selection unit 107 selects a candidate instance belonging to the category that is semantically identical to the seed character string, based on the obtained segment element score for the segment element (step S107). For example, as illustrated in FIG. 8, the selection unit 107 selects a segment element having a segment element score value of “0.10” or more as an instance candidate.
- parent and child pot” and “tagine pot” are terms included in the same category of “pan” as “Chinese pot” and “pressure cooker” in the seed character string, and are therefore semantically identical. Candidate words belonging to the category can be selected.
- the set expansion processing apparatus 100 excludes words that are not semantically irrelevant by filtering the instance candidates included in the extended set based on the context.
- the set expansion processing apparatus 100 includes a reception unit 101, a search unit 102, a segment acquisition unit 103, a segment element acquisition unit 104, a segment score calculation unit 105, a segment An element score calculation unit 106, a selection unit 107, and an extraction unit 108 are included.
- the reception unit 101, the search unit 102, the segment acquisition unit 103, the segment element acquisition unit 104, the segment score calculation unit 105, the segment element score calculation unit 106, and the selection unit 107 of the present embodiment have the same functions as in the first embodiment. Have Hereinafter, the extraction unit 108 having different functions will be described.
- the instance candidate is considered to be semantically similar to the seed character string as the context before and after the seed character string is similar to the context before and after the instance candidate. Therefore, the set expansion processing apparatus 100 according to the second embodiment obtains the similarity between the seed character string and the instance candidate based on the context before and after the seed character string and the context before and after the instance candidate, and sets the similarity to the similarity. Based on the instance candidates, the instance is extracted. This eliminates words that are semantically irrelevant.
- the set expansion apparatus 100 ranks candidate instances from the similarities calculated based on the g-Monaka algorithm, and extracts those having similarities equal to or higher than a predetermined value as instances. Note that the method for obtaining the similarity is not limited to the g-Monaka algorithm. For example, the g-Espresso algorithm may be used.
- the extraction unit 108 generates an n-gram connection graph including the extracted instance candidates from the snippet obtained by searching using the instance candidates. Then, the extraction unit 108 calculates the similarity between the seed character string and the instance based on the context before and after the accepted seed character string and the context before and after the candidate instance in the connection graph, Based on the similarity, an instance to be included in the extended set obtained by extending the set including the seed character string is extracted from the candidate instance.
- the similarity calculation method based on the g-Monaka algorithm will be described in detail below.
- the extraction unit 108 inputs each of the instance candidates selected by the selection unit 107 as a query to the search engine of the WEB page, and obtains a list of the top 300 snippets of the search results. Then, the extraction unit 108 normalizes the obtained snippet with Unicode NFKC, unifies it into lowercase letters, and removes duplication. Also, exclude those that are not suitable as snippets, such as extremely small percentages of Japanese and many symbols.
- connection matrix M (u, v) for all character n-grams included in the remaining set of snippets.
- the connection matrix M (u, v) is expressed by the equation (Equation 2).
- connection graph a directed weighted graph
- M a connection matrix
- n-gram u and the right context of n-gram v are similar can be considered in association with the concept of bibliographic coupling of the citation analysis technique.
- bibliographic combination means that documents x and y cite the same document. That is, bibliographic coupling can be considered in association with whether n-gram u and n-gram v are connected to the same n-gram.
- whether the left context of n-gram u and the left context of n-gram v are similar can be considered in association with the concept of co-citation of the citation analysis method.
- Co-citation means that documents x and y are cited by the same document. That is, it can be considered that n-gram u and n-gram v are connected from the same n-gram.
- Similarity matrices A R and A L indicating whether or not the right context and the left context of n-gram u and n-gram v are similar are obtained corresponding to the bibliographic combination matrix and the co-citation matrix, respectively.
- the right context similarity matrix A R and the left context similarity matrix A L can be expressed by the equation (Equation 3) using the connection matrix M.
- the extraction unit 108 obtains a right context similarity matrix A R and a left context similarity matrix A L for all n-grams.
- the extraction unit 108 obtains a similarity matrix A indicating the similarity between the n-gram u and the n-gram v by using a weighted generalized average for each element, as shown in Expression (Equation 4).
- the extraction unit 108 obtains a Laplacian kernel R ⁇ (A) from the equations 5 and 6 using the similarity matrix A.
- the (i, j) element of R ⁇ (A) corresponds to the similarity between n-gram i and n-gram j. Therefore, the extraction unit 108 calculates R ⁇ (A) v 0 using the seed vector v 0 (a vector in which the element corresponding to the seed character string is 1 and the others are 0). The value obtained is the similarity.
- the value of ⁇ is arbitrary, for example, 1.0-2.
- the extraction unit 108 extracts, for example, an instance whose calculated similarity exceeds a predetermined value. For example, as shown in FIG. 12, when the degree of similarity is obtained and the predetermined value is “0.10”, the extraction unit 108 selects “pressure cooker”, “Chinese cooker”, “parent / child cooker”, “tagine cooker”. , “Iga-yaki” is extracted as an instance.
- the CPU 501 functions as the extraction unit 108.
- the extraction unit 108 obtains a snippet by searching with a search engine using the instance candidate (step S208). For example, the extraction unit 108 inputs the instance candidates as a query to the search engine of the WEB page, and obtains a list of the top 300 snippets of the search results.
- the extraction unit 108 generates an n-gram connection graph including instance candidates from the obtained snippet (step S209).
- the extraction unit 108 excludes inappropriate ones from 300 snippets, and obtains a connection matrix M for n-grams of all characters included in the remaining set of snippets.
- the set V of all n-grams and node set generates a connection graph G M expressed M (Formula 2) as a connection matrix.
- the extraction unit 108 calculates the similarity between the seed character string and the instance candidate based on the context before and after the seed character string and the context before and after the instance candidate in the connection graph (step S210). For example, the extraction unit 108 obtains a right context similarity matrix A R and a left context similarity matrix A L based on the equation (Equation 3), and, for each element, as shown in the equation (Equation 4), A similarity matrix A is obtained by performing weighted generalized averaging on. Furthermore, the Laplacian kernel R ⁇ (A) using the similarity matrix A is obtained based on the equations (Equations 5 and 6), and the similarity of the instance candidate with respect to the seed character string is obtained by multiplying by the seed vector v 0. Ask.
- the extraction unit 108 extracts an instance based on the similarity (step S211). For example, the extraction unit 108 extracts an instance whose calculated similarity exceeds “0.10” as an instance as shown in FIG. Alternatively, the extraction unit 108 may extract a predetermined number from those having a high degree of similarity. For example, when there are nine instance candidates as shown in FIG. 12, if the predetermined number is four, the extraction unit 108 selects the top four “pressure cooker”, “Chinese cooker”, “parent-child” in similarity. Extract “pan” and “tagine pan” as instances.
- words that are not semantically irrelevant can be excluded, and more appropriate terms can be extracted by regarding them as being included in the same category.
- the collective expansion processing apparatus 100 has been described as being applied to the category generation of a shopping site product, but is not limited thereto. For example, it can be applied to acquisition of specific expressions, dictionary construction, and the like.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- General Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Computational Linguistics (AREA)
- Accounting & Taxation (AREA)
- Finance (AREA)
- Development Economics (AREA)
- Economics (AREA)
- Marketing (AREA)
- Strategic Management (AREA)
- General Business, Economics & Management (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Document Processing Apparatus (AREA)
Abstract
Description
シード文字列を受け付ける受付部、
前記受け付けられたシード文字列を含む文書を検索して、当該検索された文書のスニペットを得る検索部、
前記得られたスニペットを所定のセグメント区切文字列で区切ることにより、前記受け付けられたシード文字列の前後に出現する文字列と、当該シード文字列とを出現順に並べた文字列からなるセグメントを得るセグメント取得部、
前記得られたセグメントのそれぞれを、所定のセグメント要素区切文字列で区切ることにより、セグメント要素を得るセグメント要素取得部、
前記得られたセグメントのそれぞれのセグメントスコアを、当該セグメントに出現するセグメント要素のそれぞれの長さの分散もしくは標準偏差に基づいて計算するセグメントスコア計算部、
前記得られたセグメントのそれぞれに含まれるセグメント要素のそれぞれのセグメント要素スコアを、当該セグメントにおいて前記受け付けられたシード文字列が出現する位置と当該セグメントにおいて当該セグメント要素が出現する位置との距離、ならびに、当該セグメントについて計算されたセグメントスコアに基づいて計算するセグメント要素スコア計算部、
前記得られたセグメント要素のそれぞれについて計算されたセグメント要素スコアに基づいて、当該セグメント要素からいずれかを、前記受け付けられたシード文字列を含む集合を拡張した拡張集合に含まれるインスタンスの候補として選択する選択部、
を備えることを特徴とする。
前記インスタンスの候補を用いて検索することにより得られたスニペットから、前記抽出されたインスタンスの候補を含むnグラムの接続グラフを生成し、当該接続グラフにおける前記受け付けられたシード文字列の前後の文脈と当該インスタンスの候補の前後の文脈とに基づいて当該シード文字列と当該インスタンスの候補との類似度を計算し、当該類似度に基づいて、当該インスタンスの候補から、当該シード文字列を含む集合を拡張した拡張集合に含めるべきインスタンスを抽出する抽出部
をさらに備えることを特徴とする。
前記得られたセグメントのそれぞれについて、当該セグメントに出現するセグメント要素のそれぞれの長さの標準偏差が所定の閾値を超える場合、前記セグメントスコアならびに前記セグメント要素スコアは、当該セグメントに含まれるセグメント要素が前記インスタンスの候補として前記選択部により選択されることがないような値となる
ことを特徴とする。
前記得られたセグメントのそれぞれに出現するセグメント要素のそれぞれのセグメント要素スコアは、当該セグメントにおいて前記受け付けられたシード文字列が出現する位置と当該セグメントにおいて当該セグメント要素が出現する位置との最短距離に対して指数的に減衰する
ことを特徴とする。
受付部と、検索部と、セグメント取得部と、セグメント要素取得部と、セグメントスコア計算部と、セグメント要素スコア計算部と、選択部と、を備える集合拡張処理装置が実行する集合拡張処理方法であって、
前記受付部が、シード文字列を受け付ける受付工程、
前記検索部が、前記受け付けられたシード文字列を含む文書を検索して、当該検索された文書のスニペットを得る検索工程、
前記セグメント取得部が、前記得られたスニペットを所定のセグメント区切文字列で区切ることにより、前記受け付けられたシード文字列の前後に出現する文字列と、当該シード文字列とを出現順に並べた文字列からなるセグメントを得るセグメント取得工程、
前記セグメント要素取得部が、前記得られたセグメントのそれぞれを、所定のセグメント要素区切文字列で区切ることにより、セグメント要素を得るセグメント要素取得工程、
前記セグメントスコア計算部が、前記得られたセグメントのそれぞれのセグメントスコアを、当該セグメントに出現するセグメント要素のそれぞれの長さの分散もしくは標準偏差に基づいて計算するセグメントスコア計算工程、
前記セグメント要素スコア計算部が、前記得られたセグメントのそれぞれに含まれるセグメント要素のそれぞれのセグメント要素スコアを、当該セグメントにおいて前記受け付けられたシード文字列が出現する位置と当該セグメントにおいて当該セグメント要素が出現する位置との距離、ならびに、当該セグメントについて計算されたセグメントスコアに基づいて計算するセグメント要素スコア計算工程、
前記選択部が、前記得られたセグメント要素のそれぞれについて計算されたセグメント要素スコアに基づいて、当該セグメント要素からいずれかを、前記受け付けられたシード文字列を含む集合を拡張した拡張集合に含まれるインスタンスの候補として選択する選択工程、
を備えることを特徴とする。
コンピュータを、
シード文字列を受け付ける受付部、
前記受け付けられたシード文字列を含む文書を検索して、当該検索された文書のスニペットを得る検索部、
前記得られたスニペットを所定のセグメント区切文字列で区切ることにより、前記受け付けられたシード文字列の前後に出現する文字列と、当該シード文字列とを出現順に並べた文字列からなるセグメントを得るセグメント取得部、
前記得られたセグメントのそれぞれを、所定のセグメント要素区切文字列で区切ることにより、セグメント要素を得るセグメント要素取得部、
前記得られたセグメントのそれぞれのセグメントスコアを、当該セグメントに出現するセグメント要素のそれぞれの長さの分散もしくは標準偏差に基づいて計算するセグメントスコア計算部、
前記得られたセグメントのそれぞれに含まれるセグメント要素のそれぞれのセグメント要素スコアを、当該セグメントにおいて前記受け付けられたシード文字列が出現する位置と当該セグメントにおいて当該セグメント要素が出現する位置との距離、ならびに、当該セグメントについて計算されたセグメントスコアに基づいて計算するセグメント要素スコア計算部、
前記得られたセグメント要素のそれぞれについて計算されたセグメント要素スコアに基づいて、当該セグメント要素からいずれかを、前記受け付けられたシード文字列を含む集合を拡張した拡張集合に含まれるインスタンスの候補として選択する選択部、
として機能させることを特徴とする。
コンピュータを、
シード文字列を受け付ける受付部、
前記受け付けられたシード文字列を含む文書を検索して、当該検索された文書のスニペットを得る検索部、
前記得られたスニペットを所定のセグメント区切文字列で区切ることにより、前記受け付けられたシード文字列の前後に出現する文字列と、当該シード文字列とを出現順に並べた文字列からなるセグメントを得るセグメント取得部、
前記得られたセグメントのそれぞれを、所定のセグメント要素区切文字列で区切ることにより、セグメント要素を得るセグメント要素取得部、
前記得られたセグメントのそれぞれのセグメントスコアを、当該セグメントに出現するセグメント要素のそれぞれの長さの分散もしくは標準偏差に基づいて計算するセグメントスコア計算部、
前記得られたセグメントのそれぞれに含まれるセグメント要素のそれぞれのセグメント要素スコアを、当該セグメントにおいて前記受け付けられたシード文字列が出現する位置と当該セグメントにおいて当該セグメント要素が出現する位置との距離、ならびに、当該セグメントについて計算されたセグメントスコアに基づいて計算するセグメント要素スコア計算部、
前記得られたセグメント要素のそれぞれについて計算されたセグメント要素スコアに基づいて、当該セグメント要素からいずれかを、前記受け付けられたシード文字列を含む集合を拡張した拡張集合に含まれるインスタンスの候補として選択する選択部、
として機能させることを特徴とするプログラムを記録する。
情報処理装置500は、図2に示すように、CPU(Central Processing Unit)501と、ROM(Read only Memory)502と、RAM(Random Access Memory)503と、NIC(Network Interface Card)504と、画像処理部505と、音声処理部506と、DVD-ROM(Digital Versatile Disc ROM)ドライブ507と、インターフェース508と、外部メモリ509と、コントローラ510と、モニタ511と、スピーカ512と、を備える。
実施形態1の集合拡張処理装置100は、シード文字列を含む集合を拡張した拡張集合に含まれるインスタンスの候補を選択するものである。

次に、本実施形態の集合拡張処理装置100の各部が行う動作について図9のフローチャートを用いて説明する。集合拡張処理装置100に電源が入れられ、所定の操作が行われると、CPU 501は図9のフローチャートに示す集合拡張処理を開始する。
実施形態2の集合拡張処理装置100は、拡張集合に含まれるインスタンスの候補について、文脈に基づいてフィルタをかけることにより、意味的に無関係な語を排除するものである。

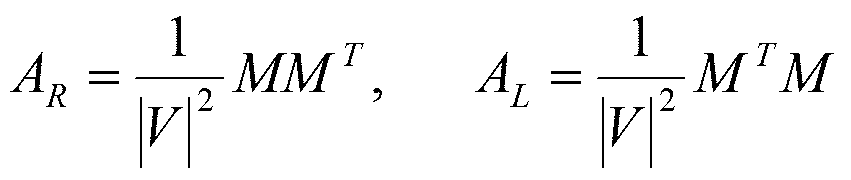
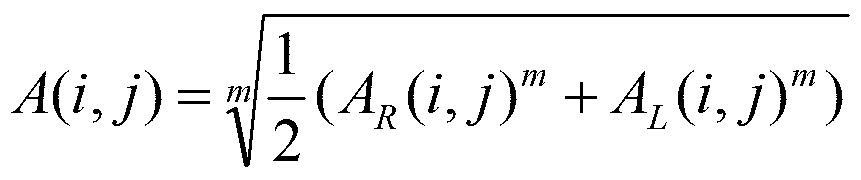
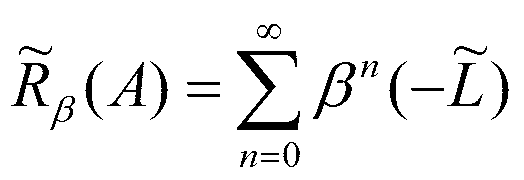

次に、本実施形態の集合拡張処理装置100の各部が行う動作について図13のフローチャートを用いて説明する。集合拡張処理装置100に電源が入れられ、所定の操作が行われると、CPU 501は図13のフローチャートに示す集合拡張処理を開始する。なお、図13のフローチャートにおいて、図9のフローチャートと同じステップ番号が付されているステップは、図9のフローチャートにおける処理と同様の処理を行う。したがって、これらの説明は省略する。
101 受付部
102 検索部
103 セグメント取得部
104 セグメント要素取得部
105 セグメントスコア計算部
106 セグメント要素スコア計算部
107 選択部
108 抽出部
200 ショッピングサーバ
300 インターネット
401、402~40n 端末装置
500 情報処理装置
501 CPU
502 ROM
503 RAM
504 NIC
505 画像処理部
506 音声処理部
507 DVD-ROMドライブ
508 インターフェース
509 外部メモリ
510 コントローラ
511 モニタ
512 スピーカ
601 検索欄
602 検索ボタン
Claims (7)
- シード文字列を受け付ける受付部、
前記受け付けられたシード文字列を含む文書を検索して、当該検索された文書のスニペットを得る検索部、
前記得られたスニペットを所定のセグメント区切文字列で区切ることにより、前記受け付けられたシード文字列の前後に出現する文字列と、当該シード文字列とを出現順に並べた文字列からなるセグメントを得るセグメント取得部、
前記得られたセグメントのそれぞれを、所定のセグメント要素区切文字列で区切ることにより、セグメント要素を得るセグメント要素取得部、
前記得られたセグメントのそれぞれのセグメントスコアを、当該セグメントに出現するセグメント要素のそれぞれの長さの分散もしくは標準偏差に基づいて計算するセグメントスコア計算部、
前記得られたセグメントのそれぞれに含まれるセグメント要素のそれぞれのセグメント要素スコアを、当該セグメントにおいて前記受け付けられたシード文字列が出現する位置と当該セグメントにおいて当該セグメント要素が出現する位置との距離、ならびに、当該セグメントについて計算されたセグメントスコアに基づいて計算するセグメント要素スコア計算部、
前記得られたセグメント要素のそれぞれについて計算されたセグメント要素スコアに基づいて、当該セグメント要素からいずれかを、前記受け付けられたシード文字列を含む集合を拡張した拡張集合に含まれるインスタンスの候補として選択する選択部、
を備えることを特徴とする集合拡張処理装置。 - 請求項1に記載の集合拡張処理装置であって、
前記インスタンスの候補を用いて検索することにより得られたスニペットから、前記抽出されたインスタンスの候補を含むnグラムの接続グラフを生成し、当該接続グラフにおける前記受け付けられたシード文字列の前後の文脈と当該インスタンスの候補の前後の文脈とに基づいて当該シード文字列と当該インスタンスの候補との類似度を計算し、当該類似度に基づいて、当該インスタンスの候補から、当該シード文字列を含む集合を拡張した拡張集合に含めるべきインスタンスを抽出する抽出部
をさらに備えることを特徴とする集合拡張処理装置。 - 請求項1又は2に記載の集合拡張処理装置であって、
前記得られたセグメントのそれぞれについて、当該セグメントに出現するセグメント要素のそれぞれの長さの標準偏差が所定の閾値を超える場合、前記セグメントスコアならびに前記セグメント要素スコアは、当該セグメントに含まれるセグメント要素が前記インスタンスの候補として前記選択部により選択されることがないような値となる
ことを特徴とする集合拡張処理装置。 - 請求項1に記載の集合拡張処理装置であって、
前記得られたセグメントのそれぞれに出現するセグメント要素のそれぞれのセグメント要素スコアは、当該セグメントにおいて前記受け付けられたシード文字列が出現する位置と当該セグメントにおいて当該セグメント要素が出現する位置との最短距離に対して指数的に減衰する
ことを特徴とする集合拡張処理装置。 - 受付部と、検索部と、セグメント取得部と、セグメント要素取得部と、セグメントスコア計算部と、セグメント要素スコア計算部と、選択部と、を備える集合拡張処理装置が実行する集合拡張処理方法であって、
前記受付部が、シード文字列を受け付ける受付工程、
前記検索部が、前記受け付けられたシード文字列を含む文書を検索して、当該検索された文書のスニペットを得る検索工程、
前記セグメント取得部が、前記得られたスニペットを所定のセグメント区切文字列で区切ることにより、前記受け付けられたシード文字列の前後に出現する文字列と、当該シード文字列とを出現順に並べた文字列からなるセグメントを得るセグメント取得工程、
前記セグメント要素取得部が、前記得られたセグメントのそれぞれを、所定のセグメント要素区切文字列で区切ることにより、セグメント要素を得るセグメント要素取得工程、
前記セグメントスコア計算部が、前記得られたセグメントのそれぞれのセグメントスコアを、当該セグメントに出現するセグメント要素のそれぞれの長さの分散もしくは標準偏差に基づいて計算するセグメントスコア計算工程、
前記セグメント要素スコア計算部が、前記得られたセグメントのそれぞれに含まれるセグメント要素のそれぞれのセグメント要素スコアを、当該セグメントにおいて前記受け付けられたシード文字列が出現する位置と当該セグメントにおいて当該セグメント要素が出現する位置との距離、ならびに、当該セグメントについて計算されたセグメントスコアに基づいて計算するセグメント要素スコア計算工程、
前記選択部が、前記得られたセグメント要素のそれぞれについて計算されたセグメント要素スコアに基づいて、当該セグメント要素からいずれかを、前記受け付けられたシード文字列を含む集合を拡張した拡張集合に含まれるインスタンスの候補として選択する選択工程、
を備えることを特徴とする集合拡張処理方法。 - コンピュータを、
シード文字列を受け付ける受付部、
前記受け付けられたシード文字列を含む文書を検索して、当該検索された文書のスニペットを得る検索部、
前記得られたスニペットを所定のセグメント区切文字列で区切ることにより、前記受け付けられたシード文字列の前後に出現する文字列と、当該シード文字列とを出現順に並べた文字列からなるセグメントを得るセグメント取得部、
前記得られたセグメントのそれぞれを、所定のセグメント要素区切文字列で区切ることにより、セグメント要素を得るセグメント要素取得部、
前記得られたセグメントのそれぞれのセグメントスコアを、当該セグメントに出現するセグメント要素のそれぞれの長さの分散もしくは標準偏差に基づいて計算するセグメントスコア計算部、
前記得られたセグメントのそれぞれに含まれるセグメント要素のそれぞれのセグメント要素スコアを、当該セグメントにおいて前記受け付けられたシード文字列が出現する位置と当該セグメントにおいて当該セグメント要素が出現する位置との距離、ならびに、当該セグメントについて計算されたセグメントスコアに基づいて計算するセグメント要素スコア計算部、
前記得られたセグメント要素のそれぞれについて計算されたセグメント要素スコアに基づいて、当該セグメント要素からいずれかを、前記受け付けられたシード文字列を含む集合を拡張した拡張集合に含まれるインスタンスの候補として選択する選択部、
として機能させることを特徴とするプログラム。 - コンピュータを、
シード文字列を受け付ける受付部、
前記受け付けられたシード文字列を含む文書を検索して、当該検索された文書のスニペットを得る検索部、
前記得られたスニペットを所定のセグメント区切文字列で区切ることにより、前記受け付けられたシード文字列の前後に出現する文字列と、当該シード文字列とを出現順に並べた文字列からなるセグメントを得るセグメント取得部、
前記得られたセグメントのそれぞれを、所定のセグメント要素区切文字列で区切ることにより、セグメント要素を得るセグメント要素取得部、
前記得られたセグメントのそれぞれのセグメントスコアを、当該セグメントに出現するセグメント要素のそれぞれの長さの分散もしくは標準偏差に基づいて計算するセグメントスコア計算部、
前記得られたセグメントのそれぞれに含まれるセグメント要素のそれぞれのセグメント要素スコアを、当該セグメントにおいて前記受け付けられたシード文字列が出現する位置と当該セグメントにおいて当該セグメント要素が出現する位置との距離、ならびに、当該セグメントについて計算されたセグメントスコアに基づいて計算するセグメント要素スコア計算部、
前記得られたセグメント要素のそれぞれについて計算されたセグメント要素スコアに基づいて、当該セグメント要素からいずれかを、前記受け付けられたシード文字列を含む集合を拡張した拡張集合に含まれるインスタンスの候補として選択する選択部、
として機能させることを特徴とするプログラムを記録した非一時的なコンピュータ読み取り可能な記録媒体。
Priority Applications (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| BR112012030691A BR112012030691A2 (pt) | 2011-03-04 | 2012-02-22 | dispositivo e método de processamento de expansão de conjunto, programa, e, meio de gravação |
| KR1020127032826A KR101243457B1 (ko) | 2011-03-04 | 2012-02-22 | 집합 확장 처리 장치, 집합 확장 처리 방법, 및 비일시적인 기록 매체 |
| CN201280001852.1A CN102971733B (zh) | 2011-03-04 | 2012-02-22 | 集合扩展处理装置及集合扩展处理方法 |
| CA2801298A CA2801298C (en) | 2011-03-04 | 2012-02-22 | Device and method for selecting instances in expanded set containing given seed string |
| EP12755096.0A EP2682880A4 (en) | 2011-03-04 | 2012-02-22 | ASSEMBLY EXTENSION DEVICE, ASSEMBLY EXTENSION METHOD, PROGRAM, AND NON-TRANSIENT STORAGE MEDIUM |
| US13/700,898 US9268821B2 (en) | 2011-03-04 | 2012-02-22 | Device and method for term set expansion based on semantic similarity |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011048124A JP5043209B2 (ja) | 2011-03-04 | 2011-03-04 | 集合拡張処理装置、集合拡張処理方法、プログラム、及び、記録媒体 |
| JP2011-048124 | 2011-03-04 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2012121011A1 true WO2012121011A1 (ja) | 2012-09-13 |
Family
ID=46797980
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2012/054211 WO2012121011A1 (ja) | 2011-03-04 | 2012-02-22 | 集合拡張処理装置、集合拡張処理方法、プログラム、及び、非一時的な記録媒体 |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US9268821B2 (ja) |
| EP (1) | EP2682880A4 (ja) |
| JP (1) | JP5043209B2 (ja) |
| KR (1) | KR101243457B1 (ja) |
| CN (1) | CN102971733B (ja) |
| BR (1) | BR112012030691A2 (ja) |
| CA (1) | CA2801298C (ja) |
| TW (1) | TWI385545B (ja) |
| WO (1) | WO2012121011A1 (ja) |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9519691B1 (en) * | 2013-07-30 | 2016-12-13 | Ca, Inc. | Methods of tracking technologies and related systems and computer program products |
| US9886950B2 (en) * | 2013-09-08 | 2018-02-06 | Intel Corporation | Automatic generation of domain models for virtual personal assistants |
| CN104216934B (zh) * | 2013-09-29 | 2018-02-13 | 北大方正集团有限公司 | 一种知识抽取方法及系统 |
| CN104516904B (zh) * | 2013-09-29 | 2018-04-03 | 北大方正集团有限公司 | 一种关键知识点推荐方法及其系统 |
| CN104216933A (zh) * | 2013-09-29 | 2014-12-17 | 北大方正集团有限公司 | 一种知识点隐性关系获取方法及其系统 |
| US10095747B1 (en) * | 2016-06-06 | 2018-10-09 | @Legal Discovery LLC | Similar document identification using artificial intelligence |
| US10679088B1 (en) * | 2017-02-10 | 2020-06-09 | Proofpoint, Inc. | Visual domain detection systems and methods |
| CN111047130B (zh) * | 2019-06-11 | 2021-03-02 | 北京嘀嘀无限科技发展有限公司 | 用于交通分析和管理的方法和系统 |
| JP7553314B2 (ja) | 2020-10-13 | 2024-09-18 | 株式会社リクルート | 推定装置、推定方法及びプログラム |
| US11734365B1 (en) | 2022-02-28 | 2023-08-22 | Unlimidata Limited | Knowledge-enriched item set expansion system and method |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04293161A (ja) * | 1991-03-20 | 1992-10-16 | Hitachi Ltd | 文書検索方法および装置 |
| JP2009048226A (ja) | 2007-08-13 | 2009-03-05 | Rakuten Inc | 情報送受信システム、情報管理装置、申込受付装置、情報送受信方法、情報管理処理プログラム、及び申込受付処理プログラム |
| JP2009110231A (ja) * | 2007-10-30 | 2009-05-21 | Nippon Telegr & Teleph Corp <Ntt> | 文章検索サーバコンピュータ,文章検索方法,文章検索プログラム,そのプログラムを記録した記録媒体 |
| JP2010055164A (ja) * | 2008-08-26 | 2010-03-11 | Nippon Telegr & Teleph Corp <Ntt> | 文章検索装置、文章検索方法、文章検索プログラムおよびその記録媒体 |
| JP2010123036A (ja) * | 2008-11-21 | 2010-06-03 | Nippon Telegr & Teleph Corp <Ntt> | 文書検索装置、文書検索方法、および文書検索プログラム |
| JP2010198269A (ja) * | 2009-02-25 | 2010-09-09 | Yahoo Japan Corp | 意味ドリフトの発生評価方法及び装置 |
Family Cites Families (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5757983A (en) | 1990-08-09 | 1998-05-26 | Hitachi, Ltd. | Document retrieval method and system |
| US6711585B1 (en) * | 1999-06-15 | 2004-03-23 | Kanisa Inc. | System and method for implementing a knowledge management system |
| US6636848B1 (en) * | 2000-05-31 | 2003-10-21 | International Business Machines Corporation | Information search using knowledge agents |
| US6941297B2 (en) * | 2002-07-31 | 2005-09-06 | International Business Machines Corporation | Automatic query refinement |
| US20080177994A1 (en) * | 2003-01-12 | 2008-07-24 | Yaron Mayer | System and method for improving the efficiency, comfort, and/or reliability in Operating Systems, such as for example Windows |
| US7350187B1 (en) | 2003-04-30 | 2008-03-25 | Google Inc. | System and methods for automatically creating lists |
| US20050060150A1 (en) * | 2003-09-15 | 2005-03-17 | Microsoft Corporation | Unsupervised training for overlapping ambiguity resolution in word segmentation |
| US7870039B1 (en) * | 2004-02-27 | 2011-01-11 | Yahoo! Inc. | Automatic product categorization |
| GB0413743D0 (en) * | 2004-06-19 | 2004-07-21 | Ibm | Method and system for approximate string matching |
| US7565348B1 (en) * | 2005-03-24 | 2009-07-21 | Palamida, Inc. | Determining a document similarity metric |
| TW200821913A (en) * | 2006-11-15 | 2008-05-16 | Univ Nat Chiao Tung | String matching system by using bloom filter to achieve sub-linear computation time and method thereof |
| US7930302B2 (en) * | 2006-11-22 | 2011-04-19 | Intuit Inc. | Method and system for analyzing user-generated content |
| CN101261623A (zh) * | 2007-03-07 | 2008-09-10 | 国际商业机器公司 | 基于搜索的无词边界标记语言的分词方法以及装置 |
| US7849081B1 (en) * | 2007-11-28 | 2010-12-07 | Adobe Systems Incorporated | Document analyzer and metadata generation and use |
| US8001139B2 (en) * | 2007-12-20 | 2011-08-16 | Yahoo! Inc. | Using a bipartite graph to model and derive image and text associations |
| TW201035783A (en) * | 2009-03-31 | 2010-10-01 | Inventec Corp | Chinese word segmentation syatem and method thereof |
| US9569285B2 (en) * | 2010-02-12 | 2017-02-14 | International Business Machines Corporation | Method and system for message handling |
| US8548800B2 (en) * | 2010-10-29 | 2013-10-01 | Verizon Patent And Licensing Inc. | Substitution, insertion, and deletion (SID) distance and voice impressions detector (VID) distance |
| US8972240B2 (en) * | 2011-05-19 | 2015-03-03 | Microsoft Corporation | User-modifiable word lattice display for editing documents and search queries |
-
2011
- 2011-03-04 JP JP2011048124A patent/JP5043209B2/ja active Active
-
2012
- 2012-02-22 WO PCT/JP2012/054211 patent/WO2012121011A1/ja active Application Filing
- 2012-02-22 BR BR112012030691A patent/BR112012030691A2/pt not_active Application Discontinuation
- 2012-02-22 CN CN201280001852.1A patent/CN102971733B/zh active Active
- 2012-02-22 EP EP12755096.0A patent/EP2682880A4/en not_active Withdrawn
- 2012-02-22 US US13/700,898 patent/US9268821B2/en active Active
- 2012-02-22 CA CA2801298A patent/CA2801298C/en active Active
- 2012-02-22 KR KR1020127032826A patent/KR101243457B1/ko active IP Right Grant
- 2012-02-29 TW TW101106600A patent/TWI385545B/zh active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04293161A (ja) * | 1991-03-20 | 1992-10-16 | Hitachi Ltd | 文書検索方法および装置 |
| JP2009048226A (ja) | 2007-08-13 | 2009-03-05 | Rakuten Inc | 情報送受信システム、情報管理装置、申込受付装置、情報送受信方法、情報管理処理プログラム、及び申込受付処理プログラム |
| JP2009110231A (ja) * | 2007-10-30 | 2009-05-21 | Nippon Telegr & Teleph Corp <Ntt> | 文章検索サーバコンピュータ,文章検索方法,文章検索プログラム,そのプログラムを記録した記録媒体 |
| JP2010055164A (ja) * | 2008-08-26 | 2010-03-11 | Nippon Telegr & Teleph Corp <Ntt> | 文章検索装置、文章検索方法、文章検索プログラムおよびその記録媒体 |
| JP2010123036A (ja) * | 2008-11-21 | 2010-06-03 | Nippon Telegr & Teleph Corp <Ntt> | 文書検索装置、文書検索方法、および文書検索プログラム |
| JP2010198269A (ja) * | 2009-02-25 | 2010-09-09 | Yahoo Japan Corp | 意味ドリフトの発生評価方法及び装置 |
Non-Patent Citations (4)
| Title |
|---|
| MAMORU KOMACHI; TAKU KUDO; MASAHI SHIMBO; YUJI MATSUMOTO: "Graph-based analysis of semantic drift in espresso-like bootstrapping algorithms", PROC. OF THE EMNLP 2008, 2008, pages 1011 - 1020, XP058324399 |
| MASATO HAGIWARA; YASUHIRO OGAWA; KATSUHIKO TOYAMA: "Extraction of semantic categories from sentences without spaces based on graph kernels", PROCEEDINGS AT THE 15TH ANNUAL CONVENTION OF THE ASSOCIATION FOR NATURAL LANGUAGE PROCESSING, 2009, pages 697 - 700 |
| See also references of EP2682880A4 |
| SHIN'YA MURATA ET AL.: "Ranking search results based on information needs in conjunction with click log analysis", DATABASE SOCIETY OF JAPAN RONBUNSHI, vol. 7, no. 4, 27 March 2009 (2009-03-27), pages 37 - 42, XP008171535 * |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20130016372A (ko) | 2013-02-14 |
| US9268821B2 (en) | 2016-02-23 |
| US20130144875A1 (en) | 2013-06-06 |
| KR101243457B1 (ko) | 2013-03-13 |
| TW201250505A (en) | 2012-12-16 |
| CN102971733A (zh) | 2013-03-13 |
| BR112012030691A2 (pt) | 2017-07-11 |
| EP2682880A1 (en) | 2014-01-08 |
| EP2682880A4 (en) | 2014-12-17 |
| TWI385545B (zh) | 2013-02-11 |
| JP2012185666A (ja) | 2012-09-27 |
| CN102971733B (zh) | 2014-05-14 |
| JP5043209B2 (ja) | 2012-10-10 |
| CA2801298A1 (en) | 2012-09-13 |
| CA2801298C (en) | 2014-11-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5043209B2 (ja) | 集合拡張処理装置、集合拡張処理方法、プログラム、及び、記録媒体 | |
| CN107203507B (zh) | 特征词汇提取方法及装置 | |
| JP2015156099A (ja) | 会議支援装置、会議支援装置の制御方法、及びプログラム | |
| CN108536676B (zh) | 数据处理方法、装置、电子设备及存储介质 | |
| US11386275B2 (en) | Menu generation system | |
| JP5338835B2 (ja) | 類義語リストの生成方法および生成装置、当該類義語リストを用いた検索方法および検索装置、ならびに、コンピュータプログラム | |
| JP6261639B2 (ja) | メニュー生成システム | |
| JP7351782B2 (ja) | 情報処理システム、情報処理装置、情報処理方法及びプログラム | |
| Amano et al. | Food category representatives: Extracting categories from meal names in food recordings and recipe data | |
| JP6305630B2 (ja) | 文書検索装置、方法及びプログラム | |
| JP2009237755A (ja) | 関連語検索方法及び装置、関連語検索プログラム、コンテンツ検索方法及び装置、並びにコンテンツ検索プログラム | |
| JP2012038064A (ja) | 会議キーワード抽出装置、会議キーワード抽出方法、及び会議キーワード抽出プログラム | |
| JP6545112B2 (ja) | コンピュータ、メニュー生成システム、メニュー提示方法 | |
| JP2004157649A (ja) | 階層化されたユーザプロファイル作成方法およびシステム並びに階層化されたユーザプロファイル作成プログラムおよびそれを記録した記録媒体 | |
| JP6056291B2 (ja) | 情報処理装置、データ表示装置及びプログラム | |
| JP2018018428A (ja) | 情報処理装置及びプログラム | |
| CN113892110A (zh) | 基于图像的菜肴识别装置和方法 | |
| JP5199968B2 (ja) | キーワードタイプ判定装置、キーワードタイプ判定方法およびキーワードタイプ判定プログラム | |
| JP6810362B2 (ja) | コンピュータ、メニュー提示方法、プログラム | |
| JP2009217367A (ja) | 関連語辞書作成方法及び装置、並びに関連語辞書作成プログラム | |
| JP2010256960A (ja) | 類似度判定システム、類似度判定方法および類似度判定用プログラム | |
| JP2018014151A (ja) | コンピュータ,変換システム,変換方法,プログラム | |
| CN112307155A (zh) | 针对互联网中文文本的关键词提取方法和提取系统 | |
| JP2005182408A (ja) | 用語検索支援システム、用語検索支援方法及び用語検索支援プログラム | |
| Xu et al. | Extracting Food Names from Food Reviews |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WWE | Wipo information: entry into national phase |
Ref document number: 201280001852.1 Country of ref document: CN |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 12755096 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2801298 Country of ref document: CA |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2012755096 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 20127032826 Country of ref document: KR Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 13700898 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112012030691 Country of ref document: BR |
|
| ENP | Entry into the national phase |
Ref document number: 112012030691 Country of ref document: BR Kind code of ref document: A2 Effective date: 20121130 |