WO2012086920A2 - 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템 및 그 오브젝트 저장 방법 및 컴퓨터에 의하여 독출가능한 저장 매체 - Google Patents
내용 기반 중복 방지 기능을 가지는 분산 저장 시스템 및 그 오브젝트 저장 방법 및 컴퓨터에 의하여 독출가능한 저장 매체 Download PDFInfo
- Publication number
- WO2012086920A2 WO2012086920A2 PCT/KR2011/008224 KR2011008224W WO2012086920A2 WO 2012086920 A2 WO2012086920 A2 WO 2012086920A2 KR 2011008224 W KR2011008224 W KR 2011008224W WO 2012086920 A2 WO2012086920 A2 WO 2012086920A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- data node
- target
- proxy server
- content
- client
- Prior art date
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/10—File systems; File servers
- G06F16/17—Details of further file system functions
- G06F16/174—Redundancy elimination performed by the file system
- G06F16/1748—De-duplication implemented within the file system, e.g. based on file segments
Definitions
- the present invention relates to a content-based object storage technology for efficiently performing deduplication or deduplication of an object in an object storage system.
- the present invention relates to a region-grouped data node.
- the present invention relates to a distributed storage system capable of storing objects reliably by storing them in a target data node selected based on location information of a client.
- Cloud computing is a concept of distributing and serving various information technology (IT) resources through the Internet network.
- IaaS infrastructure as a service
- PaaS Platform As A Service
- SaaS Software As A Service
- IaaS has a number of service categories, typically compute and storage services that provide compute resources in the form of virtual machines.
- the distributed storage system provides a cloud storage service, which uses a low specification hardware to create a common storage pool to satisfy elastic and flexible usage in a timely manner.
- simple and powerful object-based storage techniques are widely used to perform physical storage management directly on the storage device itself. Therefore, the performance of the storage device can be improved and the capacity of the storage device can be easily expanded. It also features the ability to safely share data independent of the platform.
- FIG. 1 is a diagram conceptually illustrating a distributed storage system according to the prior art.
- the object storage system shown in FIG. 1 stores metadata including an authentication server that handles the client's authentication, a proxy server (or master server) that handles the client's requirements, and a physical location of the objects. It includes a metadata database, a data node that is responsible for storing and managing physical objects, and a replica server that manages the replication of data.
- the client is initially authenticated through the authentication server. After the authentication is completed, the client requests the proxy server information of the data node managing the desired object.
- the proxy server refers to the metadata and sends the desired operation request to the corresponding data node, and the data node transmits the result of performing the operation to the client through the proxy server.
- the data node may provide a response directly to the client without going through the proxy server. In this case, the delay or data traffic can be reduced, but since all data nodes must have a client interface, the complexity of the data node can be increased.
- the object store replicates the data for its safety and high availability, and this copy is called a replica.
- Widely used distributed storage systems generally have two to three copies, but may have more copies depending on the importance of the object.
- Replicas of objects must be synchronized with each other, which is usually handled by separate replica servers.
- deduplication or deduplication technology is to store only one object when there is a request to store multiple objects with the same content.
- the latest popular movie file may be something that many people want to store in object storage.
- a request to upload an object of the same content occurs (even by another client)
- only the metadata that stores the location information for the object is kept separate. The object itself does not save again, improving economics.
- the duplication prevention technique checks whether the same logical name exists for all data nodes based on the logical name of the object. Therefore, the conventional physical location mapping method requires too much load because all existing objects need to be inspected to prevent duplication.
- An object of the present invention is to provide a content-based object storage technique for deduplication in the object storage system for cloud storage services.
- a distributed storage system for distributed storage in a plurality of data nodes the object transmitted over a network from a plurality of clients.
- a distributed storage system including: an authentication server for authenticating a client, a plurality of data nodes each storing at least one object, unique information of an object, and metadata including unique information of a data node in which the object is stored;
- an authentication server for authenticating a client
- a plurality of data nodes each storing at least one object, unique information of an object, and metadata including unique information of a data node in which the object is stored
- the unique information of the target data node in which the target object is to be stored by referring to the metadata.
- a proxy server that provides a list of clients to the client, the proxy server determines a content-specific index determined by the content of the target object when a store request is received from the client, and determines the determined content-specific index.
- Target Object Using Index Is determined to be duplicated with previously stored objects, and is configured to provide the client with a list of unique information of the target data node only for the non-duplicate target object, and the client uses the provided list of unique information of the target data node. Configured to store the target object.
- the proxy server is configured to determine the result of applying the predetermined hash function to the predetermined portion of the target object as the content specific index.
- the proxy server determines the content specific index using any one of MD5, SHA1, SHA256, SHA384, RMD128, RMD160, RMD256, RMD320, HAS160, and TIGER hash functions that use the first predetermined length of the target object as input. It is configured to.
- the metadata includes an object table comprising at least one of a user ID, a directory ID, an object ID, and a content specific index and an ID of a data node in which a copy of the object and a content specific index are stored. Contains the replica location table.
- data nodes are grouped by zone, and the proxy server is configured to determine a list of unique information of the target data node such that the same object is stored only in one of the data nodes belonging to the same zone group. do.
- the distributed storage system of the present invention selects a local group to which the target data node to store the target object based on the positional relationship between the data nodes and the client, and prioritizes the regional groups based on the distance between the selected regional group and the client. It further includes a location-aware server that determines the ranking, and the proxy server determines one target data node per regional group selected by the location aware server and uses the list of determined target data nodes to determine the metadata database.
- Is configured to send a list of target data nodes and a priority per region group to the client, the client storing the target object in a target data node belonging to the region group having the highest priority per region group. Sequentially according to more It is first caused to be further configured to copy operation is performed where the target object is replicated to the destination data node belonging to the group having a priority area.
- the proxy server gives priority to the data nodes included in the same area group by considering the available storage capacity and the object storage history of the data nodes included in the same area group, and selects the data node having the highest priority. It is further configured to determine as a target data node.
- the unique information of the object includes at least one of an ID, a size, a data type, and a creator of the object
- the unique information of the data node is one of an ID, an Internet Protocol (IP) address, and a physical location of the data node.
- IP Internet Protocol
- the metadata further includes at least one of usage of data nodes, a list of data nodes belonging to each regional group, a priority per region group for a target object, and a priority among data nodes belonging to the same regional group.
- the distributed storage method includes authenticating a client, receiving a request for storing an object of an authenticated client from which the proxy server wants to store a target object, and determining, by the proxy server, a content specific index determined by the content of the target object. Determining the content-specific index, determining whether the target object is duplicated with previously stored objects by using the determined content-specific index, and the proxy server determines unique information of the object only for the target object that is not duplicated.
- a target data node determining step of determining a target data node in which a target object is to be stored by referring to metadata including unique information of the data node in which the object is stored, by the proxy server, the unique information of the determined target data node. List of clients And providing the target object to the target data node included in the list. Further, the content specific index determination step includes the proxy server determining the result of applying the predetermined hash function to the predetermined portion of the target object as the content specific index.
- the content specific index determination step is performed by the proxy server by applying the initial predetermined length of the target object to any one of MD5, SHA1, SHA256, SHA384, RMD128, RMD160, RMD256, RMD320, HAS160, and TIGER hash functions. Determining an index.
- the metadata also includes an object table that includes at least one of a user ID, a directory ID, an object ID, and a content specific index and a replica location table that includes a content specific index and an ID of a data node where a copy of the object is stored. do.
- determining the target data node includes the proxy server determining a list of unique information of the target data node such that the same object is stored only in one of the data nodes belonging to the same zone group.
- the step of determining the target data node selects a regional group to which the location-aware server belongs to store the target object based on the location relationship of the data nodes and the client, and based on the distance between the selected regional group and the client. Determining a priority per regional group, and the proxy server determining one target data node per regional group selected by the location aware server.
- determining the target data node may include a step in which the proxy server gives priority to the data nodes included in the same regional group in consideration of the available storage capacity and the object storage history of the data nodes included in the same regional group, and the proxy. Determining, by the server, the data node having the highest priority as the target data node.
- the present invention can efficiently support the duplication and duplication prevention function required by the cloud storage service at the same time.
- FIG. 1 is a diagram conceptually illustrating a distributed storage system according to the prior art.
- FIG. 2 is a diagram conceptually illustrating an embodiment of a distributed storage system having a duplication prevention function according to an aspect of the present invention.
- FIG. 3 is a flowchart conceptually illustrating an object storage method of a distributed storage system having a duplication prevention function according to another aspect of the present invention.
- 5A and 5B are diagrams illustrating tables included in metadata used in the distributed storage system according to the present invention.
- FIG. 6 is a diagram conceptually showing another embodiment of a distributed storage system having a duplication prevention function according to an aspect of the present invention.
- FIG. 2 is a diagram conceptually illustrating an embodiment of a distributed storage system having a duplication prevention function according to an aspect of the present invention.
- the distributed storage system 200 shown in FIG. 2 includes a plurality of clients 210, 212, 216 and data nodes DN11-DN1n, DN21-DN2n, DNm1-DNmn connected to the network 290. .
- the distributed storage system 200 shown in FIG. 2 further includes an authentication server 220, a proxy server 250, and a metadata database 280.
- the authentication server 220 authenticates the client, and the data nodes DN11-DN1n, DN21-DN2n, and DNm1-DNmn each store at least one object.
- the metadata database 280 stores metadata including unique information of the object and unique information of the data node in which the object is stored.
- the authenticated client 210 transmits an object storage request of the client to the proxy server 250 in order to store the target object.
- the proxy server 250 does not store all target objects when there is an operation request, but whether the target object is already stored in one of the data nodes DN11-DN1n, DN21-DN2n, and DNm1-DNmn. Judge.
- the proxy server 250 In order to perform such a duplication prevention operation, the proxy server 250 first determines a content-specific index determined by the content of the target object, and the target object is pre-determined using the determined content-specific index. It is determined whether the stored objects are duplicated. If the target object is already stored in one of the data nodes, the proxy server 250 ignores the operation request. Therefore, it is possible to prevent the same object from being stored in many data nodes unnecessarily and wasting system resources. If the target object is different from the pre-stored objects, the proxy server 250 provides the client with a list of unique information of the target data node only for the non-duplicate target object. Then, the client 210 identifies the target data node by referring to the list of unique information of the provided target data node, and stores the target object in the corresponding target data node using the IP address of the target data node.
- the proxy server applies a hash function to a predetermined portion of the target object (eg, the first 65 megabytes of the target object) and determines the result as a content specific index for that target object.
- the content specific index may be all information used to easily find duplicate target objects.
- the hash function used by the proxy server 250 will be described later in detail with reference to FIG. 4. Since the proxy server 250 included in the distributed storage system 200 according to the present invention determines whether an object is the same by using a content-specific index, the proxy server 250 is the same object as the target object but has a different name given by another user. You can easily determine that the object is the same object as the target object.
- a 'target object' refers to an object that a client wants to store or an object that is of interest to be inquired from a data node.
- a "target data node” refers to a data node in which a target object is stored among a plurality of data nodes.
- 'priority' refers to a ranking determined by determining which regional group or data node is more suitable than another regional group or data node for storing a specific target object. The priority may include a priority of a specific regional group compared to other regional groups and a priority between data nodes belonging to the same regional group.
- the priority may be ranked directly by the client based on a preference for a particular region and data node with respect to a target object, or may be automatically determined by a proxy server or location aware server. This is described in detail later in the relevant part of the specification.
- the data nodes DN11-DN1n, DN21-DN2n, and DNm1-DNmn are included in any one of the first to m-th regional groups ZG1, ZG2, and ZGm.
- the zone groups ZG1, ZG2, ZG3 shown in FIG. 2 are defined by grouping locally adjacent data nodes, respectively, for effective distributed storage of replicas.
- data nodes belonging to the same local group are configured not to store the same object. That is, since a replica of one object is distributed and stored in data nodes belonging to another local group, two replicas are not commonly stored in two data nodes belonging to one local group.
- replicas of one object are mapped to data nodes belonging to different local groups in the metadata representing the physical location of the object. Therefore, even if a certain regional group suffers a physical damage such as a problem in the entire network, the replica is distributed to and stored in data nodes belonging to another regional group, thereby improving reliability.
- a regional group may be a data center or a server rack in a narrower area.
- data nodes belonging to the local group are registered in the metadata as belonging to the local group.
- the replicas of the object are then replicated to data nodes belonging to different local groups.
- all clients 210, 212, 216 and data nodes DN11-DN1n, DN21-DN2n, DNm1-DNmn communicate with each other via network 290. That is, there is a virtual channel between each client and each data.
- these virtual channels do not necessarily have the same conditions for every pair of client and data nodes.
- the communication environment of the virtual channel may vary depending on the physical distance between the client and the data node. The greater the physical distance between the client and the data node, the longer it takes to transmit and receive objects because objects are passed through more relay nodes or gateways.
- the communication environment of the virtual channel may also vary depending on the amount of network traffic and the performance of network resources constituting the virtual channel.
- the present invention selects the most optimal virtual channel between the client and the data node in consideration of the communication environment of the virtual channel.
- the distributed storage system according to the present invention may refer to a physical distance between a client and a local group. Therefore, the upload time of the object can be minimized by storing the object in a data node belonging to a local group located closest to the client including the stored object.
- the distributed storage system according to the present invention does not replicate to data nodes belonging to the same local group when replicating an object. Therefore, the target object to be stored is distributed and stored in several local groups.
- operation of data nodes in an adjacent area is often impossible. For example, suppose there are several data nodes in a data center, and this data center is set up as one regional group.
- the distributed storage system stores the target object only in one target data node of the data nodes of the corresponding data center, and the replica is stored in the target data node belonging to another local group. Therefore, even if all data nodes in the data center fail, the desired target object can be easily retrieved from the target data nodes belonging to different regional groups.
- the distributed storage system 200 is configured based on the contents of the object, not the metadata for mapping the actual physical location of the object based on the logical name of the object. Therefore, it is easy to determine whether the target object is already stored in order to perform the duplication prevention operation.
- FIG. 3 is a flowchart conceptually illustrating an object storage method of a distributed storage system having a duplication prevention function according to another aspect of the present invention.
- the authentication server authenticates the client included in the distributed storage system (S310). If authentication is successful, the proxy server receives an object storage request of an authenticated client that wants to store a target object (S320). If the request to save the object is not received, it waits until the operation request is received.
- the proxy server determines a content specific index by using the content of the target object (S330).
- the proxy server determines whether the target object is overlapped with previously stored objects by using the determined content specific index (S340).
- the proxy server If it is determined that the target object is a duplicate of the previously stored object, the proxy server ignores the storage request and waits for the next operation request. On the other hand, if it is determined that there is no duplicate object as a result of the determination of the overlap, the proxy server determines a target data node in which the non-duplicate target object is to be stored (S350). To determine the target data node, the proxy server may predetermine the weight value of each data node in consideration of the storage capacity of each data node for load balancing of the data nodes. Then, the proxy server first assigns the highest weight data node as a target data node with reference to the weight value. In this way, load balancing between data nodes is achieved.
- the proxy server When the target data node is determined, the proxy server provides the client with a list of the determined unique information of the target data node (S360), and the client stores the target object in the target data node included in the list (S370).
- the proxy server determines whether or not the object is duplicated only for objects having the same hash result value when uploading the object. Therefore, the duplication prevention operation can be performed efficiently. That is, according to the present invention, it is sufficient to determine whether the objects in the corresponding folder of the data node having the same result value are the same as the target object by looking at the result value obtained by applying the hash function to the target object when uploading the object. Because of the nature of the hash algorithm itself, if the contents are different, it is very rare that the result is duplicated. Therefore, finding the same object can be performed efficiently and duplication prevention becomes easy.
- a hash function is a function that compresses an input message of any length into a fixed length output.
- the hash function is used to verify the integrity of the data and to authenticate the message and must satisfy two properties: one-way and strong collision avoidance.
- it is computationally impossible to find any input message that satisfies a given condition.
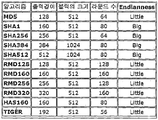
- the proxy server according to the present invention generates a content specific index using a hash function according to the hash algorithm shown in FIG. 4 lists the output length, block size, number of rounds and endianness of each algorithm.
- Endian is a method of arranging several consecutive objects in a one-dimensional space such as a computer memory.
- MD5 is a widely used hash algorithm, but there is an analysis that there is a problem in collision avoidance, so it is only used for compatibility with existing applications and is not commonly used.
- SHA1 is intended to be used by the DSA and is the default hash algorithm in many Internet applications.
- SHA256, SHA384, and SHA512 are hash algorithms having extended output lengths corresponding to 128, 192, and 256 bits, which are key lengths of the (Advanced Encryption Standard).
- RMD128 and RMD160 are hash algorithms designed to replace RIPEMD, MD4 and MD5 of the RIPE project.
- RMD128, which produces 128 bits of output, is also problematic in collision avoidance.
- the RMD160 is less efficient but more secure and is widely adopted by many Internet standards.
- RMD256 and RMD320 are extensions of RMD128 and RMD160, respectively.
- HAS160 is a hash function developed for the domestic standard signature algorithm KCDSA. Designed to take advantage of MD5 and SHA1. TIGER is optimized for 64-bit processors and is very fast on 64-bit processors.
- the proxy server according to the present invention uses the result obtained by applying various hash functions to the target object as the content specific index.
- 5A and 5B are diagrams illustrating tables included in metadata used in the distributed storage system according to the present invention.
- FIG. 5A illustrates an object table included in metadata
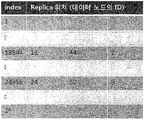
- FIG. 5B illustrates a replica location table.
- the object table includes items of a user ID, a directory ID, an object ID, and a content specific index of the object.
- the replica location table includes a location of a replica for each index as an item.
- the proxy server creates an object table as shown in FIG. 5A and stores the result value of applying the hash algorithm to the ID of each object and the contents of the object in an index column.
- Each object can be distinguished by user ID, directory ID, and object ID.
- MD5 can set an index column to 128 bits by generating a 128-bit fixed-length output by receiving an arbitrary length message.
- the input can be the first 64 megabytes in the object content. This is for easily explaining the present invention, and it is obvious that the present invention is not limited.
- the number of replicas is three, and the number of columns of the replica location table may be adjusted according to the actual number of replicas.
- the first column of the replica location table stores the indexes in order, and the columns after that are the IDs of the data nodes where the actual replica is located.
- the Ants object under the Movies directory of the user mjkim in the object table of FIG. 5A has an index value of 24356 when the MD5 hash algorithm is applied to the first 64 megabytes. If an index value of 24356 is found in the replica location table of FIG. 5B, it matches the IDs of the data nodes of 24, 52, and 9. That is, mjkim's Ants file exists at data nodes 24, 52, and 9.
- the data node makes it easy to search for an object by using an index value as a key when actually storing the object data. For example, you can create folders by index value. Objects with the same index will be stored in the same folder on the same data node. The duplication prevention operation can then be performed more quickly.
- FIG. 6 is a diagram conceptually showing another embodiment of a distributed storage system having a duplication prevention function according to an aspect of the present invention.
- FIG. 6 is a diagram conceptually showing another embodiment of a distributed storage system according to an aspect of the present invention.
- the distributed storage system 600 shown in FIG. 6 includes a plurality of clients 610, 612, 616 and data nodes DN11-DN1n, DN21-DN2n, DNm1-DNmn connected to the network 690. .
- the distributed storage system 600 shown in FIG. 6 further includes an authentication server 620, a proxy server 650, a location aware server 660, a replication server 670, and a metadata database 680.
- the proxy server 650 included in FIG. 6 may determine a result of applying a hash function to the target object as a content specific index when an object storage request is received, and the target object may use the determined content specific index. It may be determined whether it is the same as the stored target object.
- the target object is different from the pre-stored objects.
- the location aware server 660 included in the distributed storage system 600 shown in FIG. 6 is used to automatically select local groups or target data nodes.
- the proxy server 650 queries the location aware server 660 for the most advantageous local group.
- the location aware server 660 may determine the location of the client in various ways. In general, the location aware server 660 may determine the physical location of the client by the IP address of the client. The location aware server 660 selects as many regional groups as the number of basic replicas of the client according to the request of the proxy server 650, and transmits the selected regional group list to the proxy server 650. The location aware server 660 may be physically integrated into the proxy server 650 and implemented.
- the determining of the target data node belonging to each of the regional groups determined by the location aware server 660 may be performed by the proxy server 650 or the location aware server 660. If the location aware server 660 also determines the target data node, the location aware server 660 refers to the metadata database 680 to select the target data node that is closest to the client having the target object within the selected regional group. Can be. On the other hand, if the proxy server 650 selects the target data node, the proxy server 650 checks the state of the data nodes belonging to each regional group by using a load balancer 655, and among them, the optimal condition A data node having a can be selected as a target data node. Although load balancer 655 is shown to be included in proxy server 650, it should be understood that this is not a limitation of the present invention.
- the proxy server 650 manages the information of the data nodes in each regional group in metadata, and determines the weight value of each data node in advance in consideration of the storage capacity of each data node for load balancing of the data nodes. .
- load balancing between data nodes in a local group is maintained by selecting data nodes of request clients in consideration of object data stored in each data node and weight values of data nodes.
- the method according to the present invention can be embodied as computer readable codes on a computer readable recording medium.
- the computer-readable recording medium may include all kinds of recording devices in which data that can be read by a computer system is stored. Examples of computer-readable recording media include ROMs, RAMs, CD-ROMs, magnetic tapes, floppy disks, optical data storage devices, and the like, and may also be implemented in the form of carrier waves (for example, transmission over the Internet). Include.
- the computer readable recording medium can also store computer readable code that can be executed in a distributed fashion by a networked distributed computer system.
- the present invention can be applied to a technique for efficiently supporting deduplication in object storage that can provide a cloud storage service.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Storage Device Security (AREA)
Abstract
중복 방지 기능을 가지는 분산 저장 시스템 및 오브젝트 저장 방법이 개시된다. 분산 저장 시스템은 클라이언트를 인증하기 위한 인증 서버, 각각 적어도 하나의 오브젝트들을 저장하는 복수 개의 데이터 노드들, 오브젝트의 고유 정보 및 오브젝트가 저장된 데이터 노드의 고유 정보를 포함하는 메타데이터를 저장하는 메타데이터 데이터베이스, 및 대상 오브젝트를 저장하고자 하는 인증된 클라이언트의 오브젝트 저장 요청에 응답하여, 메타데이터를 참조하여 대상 오브젝트가 저장될 대상 데이터 노드의 고유 정보의 목록을 클라이언트에게 제공하는 프락시 서버를 포함한다. 프락시 서버는 클라이언트로부터 저장 요청이 수신되면, 대상 오브젝트의 내용에 의하여 결정되는 내용 특이적 인덱스를 결정하고, 결정된 내용 특이적 인덱스를 이용하여 대상 오브젝트가 기저장된 오브젝트들과 중복되는지 여부를 판단한다. 본 발명에 의하면 중복 방지 동작이 효율적으로 수행될 수 있다.
Description
본 발명은 오브젝트 스토리지 시스템에서 오브젝트의 중복 제거 또는 중복 방지(deduplication) 동작을 효율적으로 하기 위한 내용 기반(content_based) 오브젝트 저장 기술에 관한 것으로서, 특히, 중복 방지된 오브젝트들을 지역별로 그루핑된 데이터 노드들과 클라이언트의 위치 정보에 기반하여 선택된 대상 데이터 노드에 저장함으로써, 오브젝트를 신뢰성있게 저장할 수 있는 분산 저장 시스템에 관한 것이다.
클라우드 컴퓨팅은 인터넷 망을 통해 여러 가지 IT(Information Technology) 자원들을 분배하여 서비스하는 개념으로 가장 일반적인 서비스 분류로는 첫째, 하드웨어 인프라를 서비스로 제공하는 IaaS(Infrastructure As A Service), 둘째, 응용 개발 및 실행 플랫폼을 서비스로 제공하는 PaaS(Platform As A Service), 그리고 마지막으로 어플리케이션을 서비스로 제공하는 SaaS(Software As A Service)로 나눈다.
IaaS에는 많은 서비스 카테고리가 있는데, 대표적으로 연산 자원을 가상 머신 형태로 제공하는 연산 서비스와 저장 서비스가 있다. 이러한 분산 저장 시스템은 클라우드 스토리지 서비스를 제공하는데, 이를 이용하면 저사양의 하드웨어를 활용하여 공용의 저장소 풀(storage pool)을 만들어 탄력적이고 유연한 사용량을 적시에 만족하는 특징을 가진다. 이를 위해 널리 이용되는 단순하고 강력한 오브젝트 기반 스토리지 기법에서는 물리적인 저장 공간 관리 기능을 저장 장치 자체에서 직접 수행하게 한다. 그러므로, 저장 장치의 성능이 향상되고 손쉽게 저장 장치의 용량을 확장할 수 있다. 또한, 플랫폼과 독립적으로 데이터를 안전하게 공유할 수 있는 특징을 가진다.
도 1은 종래 기술에 의한 분산 저장 시스템을 개념적으로 나타내는 도면이다.
도 1에 도시되는 오브젝트 스토리지 시스템은 클라이언트의 인증을 처리하는 인증 서버, 클라이언트의 요구사항을 처리하는 프락시 서버(proxy server)(또는 마스터 서버), 오브젝트들의 물리적인 위치를 포함하는 메타데이터를 저장하는 메타데이터 데이터베이스, 실제 오브젝트 저장 및 관리를 담당하는 데이터 노드, 그리고 데이터의 복제 등을 관리하는 복제 서버(replicator server) 등을 포함한다. 클라이언트는 초기에 인증 서버를 통해 인증을 받으며, 인증이 완료된 후에는 프락시 서버에게 원하는 오브젝트를 관리하는 데이터 노드의 정보를 요청한다. 클라이언트의 요청에 대해 프락시 서버는 메타데이터를 참조하여 해당하는 데이터 노드에게 원하는 동작 요청을 전달하고, 데이터 노드는 동작을 수행한 결과를 프락시 서버를 통해 클라이언트에게 전달한다. 또는, 데이터 노드는 프락시 서버를 거치지 않고 직접 클라이언트에게 응답을 제공할 수도 있다. 이 경우 지연이나 데이터 트래픽이 감소하는 효과를 기대할 수 있으나 모든 데이터 노드가 클라이언트 인터페이스를 가져야 함으로 데이터 노드의 복잡도가 증가할 수 있다.
오브젝트 저장소는 데이터의 안전성과 높은 가용성을 위해 데이터를 복제(replication)하며 이런 복제본을 레플리카(replica)라고 한다. 널리 이용되는 분산 저장 시스템은 일반적으로 2개 내지 3개의 복제본을 가지지만, 오브젝트의 중요도에 따라 더 많은 복제본을 가지기도 한다. 오브젝트의 복제본은 서로 동기를 유지해야 하며 이는 보통 별도의 복제 서버(replicator server)에서 처리한다.
데이터 복제와 상반되는 개념으로 같은 내용의 여러 개의 오브젝트를 중복하여 저장하는 요청이 있을 때 하나의 오브젝트만 저장하는 것이 중복 제거 또는 중복 방지(deduplication) 기술이다. 예를 들어, 최신의 인기 영화 파일은 많은 사람들이 오브젝트 스토리지에 저장하고자 할 수 있다. 이런 경우 하나의 오브젝트만 유지하고(물론 복제본은 존재) 그 뒤에 같은 내용의 오브젝트를 업로드하는 요구가 발생할 때(다른 클라이언트에 의해서라도) 오브젝트에 대한 위치 정보를 저장한 메타데이터만 별도로 유지하고 같은 내용의 오브젝트 자체는 다시 저장하지 않음으로 해서 경제성을 향상시킨다.
그런데, 종래 기술에 의한 중복 방지 기법은 오브젝트의 논리적인 이름에 기반하여 모든 데이터 노드에 대하여 동일한 논리적인 이름이 존재하는지를 확인한다. 그러므로, 종래 기술에 의한 물리적 위치 매핑 방법에 따르면 중복 방지를 위해 기존의 모든 오브젝트를 다 검사해야 하기 때문에, 너무 많은 부하를 요구한다.
그러므로, 중복 방지 기법을 효율적으로 지원하기 위한 오브젝트의 효율적 분산 저장 방법이 절실히 요구된다. 또한, 이러한 중복 방지 기법 기법을 구현하는데 필요한 메타데이터의 구조를 제공하는 것이 절실히 요구된다.
본 발명의 목적은, 클라우드 스토리지 서비스를 위한 오브젝트 스토리지 시스템에서 중복 제거를 위한 내용 기반의 오브젝트 저장 기법을 제공하는 것이다.
또한, 본 발명의 목적은 오브젝트 중복 방지 동작을 효율적으로 수행할 수 있는 메타데이터의 구조를 제공하는 것이다.
상기와 같은 목적들을 달성하기 위한 본 발명의 일면은, 복수 개의 클라이언트들로부터 네트워크를 통해 전송되는 오브젝트를 복수 개의 데이터 노드들에 분산 저장하는 분산 저장 시스템(distribution storage system)에 관한 것이다. 본 발명의 일면에 의한 분산 저장 시스템은 클라이언트를 인증하기 위한 인증 서버, 각각 적어도 하나의 오브젝트들을 저장하는 복수 개의 데이터 노드들, 오브젝트의 고유 정보 및 오브젝트가 저장된 데이터 노드의 고유 정보를 포함하는 메타데이터를 저장하는 메타데이터 데이터베이스, 및 대상 오브젝트(target object)를 저장하고자 하는 인증된 클라이언트의 오브젝트 저장 요청에 응답하여, 메타데이터를 참조하여 대상 오브젝트가 저장될 대상 데이터 노드(target data node)의 고유 정보의 목록을 클라이언트에게 제공하는 프락시 서버를 포함하며, 프락시 서버는 클라이언트로부터 저장 요청이 수신되면, 대상 오브젝트의 내용에 의하여 결정되는 내용 특이적 인덱스(content-specific index)를 결정하고, 결정된 내용 특이적 인덱스를 이용하여 대상 오브젝트가 기저장된 오브젝트들과 중복되는지 여부를 판단하며, 중복되지 않은 대상 오브젝트에 대해서만 대상 데이터 노드의 고유 정보의 목록을 클라이언트에게 제공하도록 구성되고, 클라이언트는 제공된 대상 데이터 노드의 고유 정보의 목록을 이용하여 대상 오브젝트를 저장하도록 구성된다. 특히, 프락시 서버는 대상 오브젝트의 소정 부분에 소정 해쉬 함수를 적용한 결과를 내용 특이적 인덱스로서 결정하도록 구성된다. 더 나아가, 프락시 서버는 대상 오브젝트의 최초 소정 길이를 입력으로써 이용하는 MD5, SHA1, SHA256, SHA384, RMD128, RMD160, RMD256, RMD320, HAS160, 및 TIGER 해쉬 함수 중 어느 하나를 이용하여 내용 특이적 인덱스를 결정하도록 구성된다. 특히, 본 발명에 따르면, 메타데이터는 사용자 ID, 디렉토리 ID, 오브젝트 ID, 및 내용 특이적 인덱스 중 적어도 하나를 포함하는 오브젝트 테이블 및 내용 특이적 인덱스 및 오브젝트의 복제본이 저장된 데이터 노드의 ID를 포함하는 복제본 위치 테이블을 포함한다. 더 나아가, 데이터 노드들은 지역(zone)별로 그루핑되며, 프락시 서버는 동일한 오브젝트는 동일한 지역 그룹(zone group)에 속한 데이터 노드들 중 오직 하나에만 저장되도록 대상 데이터 노드의 고유 정보의 목록을 결정하도록 구성된다. 특히, 본 발명에 의한 분산 저장 시스템은 데이터 노드들 및 클라이언트의 위치 관계에 기반하여 대상 오브젝트를 저장할 대상 데이터 노드가 속하는 지역 그룹을 선택하고, 선택된 지역 그룹 및 클라이언트 간의 거리에 기반하여 지역 그룹별 우선 순위를 결정하는 위치 인식 서버(location-aware server)를 더 포함하고, 프락시 서버는 위치 인식 서버가 선택한 지역 그룹 당 하나의 대상 데이터 노드를 결정하고, 결정된 대상 데이터 노드들의 목록을 이용하여 메타데이터 데이터베이스를 갱신하며, 대상 데이터 노드들의 목록 및 지역 그룹별 우선 순위를 클라이언트에게 전송하도록 구성되고, 클라이언트는 가장 높은 지역 그룹별 우선 순위를 가지는 지역 그룹에 속하는 대상 데이터 노드에 대상 오브젝트를 저장함으로써, 우선 순위에 따라 순차적으로 더 낮은 우선 순위를 가지는 지역 그룹에 속하는 대상 데이터 노드들에 대상 오브젝트가 복제되는 복제 동작이 수행되도록 야기하도록 더욱 구성된다. 뿐만 아니라, 프락시 서버는 동일한 지역 그룹에 포함되는 데이터 노드들의 가용 저장 용량 및 오브젝트 저장 내역을 고려하여 동일한 지역 그룹에 포함되는 데이터 노드들에게 우선 순위를 부여하고, 가장 높은 우선 순위를 가지는 데이터 노드를 대상 데이터 노드로서 결정하도록 더욱 구성된다. 본 발명에 의하면, 오브젝트의 고유 정보는 오브젝트의 ID, 크기, 데이터 타입, 및 작성자 중 적어도 하나를 포함하고, 데이터 노드의 고유 정보는 데이터 노드의 ID, IP(Internet Protocol) 주소, 및 물리적 위치 중 적어도 하나를 포함한다. 특히, 메타데이터는 데이터 노드들의 사용량, 각 지역 그룹에 속한 데이터 노드들의 목록, 대상 오브젝트에 대한 지역 그룹별 우선 순위, 및 동일한 지역 그룹에 속한 데이터 노드들 간의 우선 순위 중 적어도 하나를 더 포함한다.
상기와 같은 목적들을 달성하기 위한 본 발명의 다른 면은 복수 개의 클라이언트들로부터 네트워크를 통해 전송되는 오브젝트를 복수 개의 데이터 노드들에 분산 저장하는 분산 저장 시스템에 오브젝트를 분산 저장하는 방법에 관한 것이다. 분산 저장 방법은, 클라이언트를 인증하는 단계, 프락시 서버가 대상 오브젝트를 저장하고자 하는 인증된 클라이언트의 오브젝트 저장 요청을 수신하는 단계, 프락시 서버가 대상 오브젝트의 내용에 의하여 결정되는 내용 특이적 인덱스를 결정하는 내용 특이적 인덱스 결정 단계, 결정된 내용 특이적 인덱스를 이용하여 프락시 서버가 대상 오브젝트가 기저장된 오브젝트들과 중복되는지 여부를 판단하는 단계, 및 프락시 서버가, 중복되지 않은 대상 오브젝트에 대해서만 오브젝트의 고유 정보 및 오브젝트가 저장된 데이터 노드의 고유 정보를 포함하는 메타데이터를 참조하여 대상 오브젝트가 저장될 대상 데이터 노드(target data node)를 결정하는 대상 데이터 노드 결정 단계, 프락시 서버가, 결정된 대상 데이터 노드의 고유 정보의 목록을 클라이언트에게 제공하는 단계, 및 클라이언트가 대상 오브젝트를 목록에 포함된 대상 데이터 노드에 저장하는 단계를 포함한다. 더 나아가, 내용 특이적 인덱스 결정 단계는 프락시 서버가 대상 오브젝트의 소정 부분에 소정 해쉬 함수를 적용한 결과를 내용 특이적 인덱스로서 결정하는 단계를 포함한다. 특히, 내용 특이적 인덱스 결정 단계는 프락시 서버가 대상 오브젝트의 최초 소정 길이를 MD5, SHA1, SHA256, SHA384, RMD128, RMD160, RMD256, RMD320, HAS160, 및 TIGER 해쉬 함수 중 어느 하나에 적용하여 내용 특이적 인덱스를 결정하는 단계를 포함한다. 또한, 메타데이터는 사용자 ID, 디렉토리 ID, 오브젝트 ID, 및 내용 특이적 인덱스 중 적어도 하나를 포함하는 오브젝트 테이블 및 내용 특이적 인덱스 및 오브젝트의 복제본이 저장된 데이터 노드의 ID를 포함하는 복제본 위치 테이블을 포함한다. 더 나아가, 대상 데이터 노드 결정 단계는 프락시 서버가, 동일한 오브젝트가 동일한 지역 그룹(zone group)에 속한 데이터 노드들 중 오직 하나에만 저장되도록 대상 데이터 노드의 고유 정보의 목록을 결정하는 단계를 포함한다. 바람직하게는, 대상 데이터 노드 결정 단계는 위치 인식 서버가 데이터 노드들 및 클라이언트의 위치 관계에 기반하여 대상 오브젝트를 저장할 대상 데이터 노드가 속하는 지역 그룹을 선택하고, 선택된 지역 그룹 및 클라이언트 간의 거리에 기반하여 지역 그룹별 우선 순위를 결정하는 단계, 및 프락시 서버가 위치 인식 서버가 선택한 지역 그룹 당 하나의 대상 데이터 노드를 결정하는 단계를 포함한다. 또는, 대상 데이터 노드 결정 단계는 프락시 서버가, 동일한 지역 그룹에 포함되는 데이터 노드들의 가용 저장 용량 및 오브젝트 저장 내역을 고려하여 동일한 지역 그룹에 포함되는 데이터 노드들에게 우선 순위를 부여하는 단계, 및 프락시 서버가, 가장 높은 우선 순위를 가지는 데이터 노드를 대상 데이터 노드로서 결정하는 단계를 포함한다.
본 발명에 의하여, 본 발명은 클라우드 스토리지 서비스에서 요구하는 복제와 중복 방지 기능을 동시에 효율적으로 지원할 수 있다.
또한, 본 발명에 의하면 중복 방지 동작을 수행할 때 오브젝트 내용의 일부를 입력으로 한 해수 함수의 결과값이 동일한 오브젝트에 대해서만 중복 체크를 함으로 인해 시간과 오버헤드를 현격하게 줄일 수 있다.
더 나아가, 본 발명에 의하면 데이터 노드들을 지역별로 그루핑하고, 복제본들이 상이한 지역에 분산되어 저장되도록 하기 때문에, 하나의 지역에 네트워크 문제가 발생했을 때에도 다른 지역에 저장된 복제본을 독출할 수 있어서 더욱 신뢰성 있는 서비스가 가능하게 된다.
도 1은 종래 기술에 의한 분산 저장 시스템을 개념적으로 나타내는 도면이다.
도 2는 본 발명의 일면에 의한 중복 방지 기능을 가지는 분산 저장 시스템의 일 실시예를 개념적으로 나타내는 도면이다.
도 3은 본 발명의 다른 면에 의한 중복 방지 기능을 가지는 분산 저장 시스템의 오브젝트 저장 방법을 개념적으로 나타내는 흐름도이다.
도 4는 본 발명에 적용될 수 있는 해시 함수의 특징을 설명하기 위한 표이다.
도 5a 및 도 5b는 본 발명에 의한 분산 저장 시스템에서 이용하는 메타데이터에 포함되는 테이블들을 예시하는 도면이다.
도 6은 본 발명의 일면에 의한 중복 방지 기능을 가지는 분산 저장 시스템의 다른 실시예를 개념적으로 나타내는 도면이다.
본 발명과 본 발명의 동작상의 이점 및 본 발명의 실시에 의하여 달성되는 목적을 충분히 이해하기 위해서는 본 발명의 바람직한 실시예를 예시하는 첨부 도면 및 첨부 도면에 기재된 내용을 참조하여야만 한다.
이하, 첨부한 도면을 참조하여 본 발명의 바람직한 실시예를 설명함으로서, 본 발명을 상세히 설명한다. 그러나, 본 발명은 여러 가지 상이한 형태로 구현될 수 있으며, 설명하는 실시예에 한정되는 것이 아니다. 그리고, 본 발명을 명확하게 설명하기 위하여 설명과 관계없는 부분은 생략되며, 도면의 동일한 참조부호는 동일한 부재임을 나타낸다.
명세서 전체에서, 어떤 부분이 어떤 구성요소를 "포함"한다고 할 때, 이는 특별히 반대되는 기재가 없는 한 다른 구성요소를 제외하는 것이 아니라, 다른 구성요소를 더 포함할 수 있는 것을 의미한다. 또한, 명세서에 기재된 "...부", "...기", "모듈", "블록" 등의 용어는 적어도 하나의 기능이나 동작을 처리하는 단위를 의미하며, 이는 하드웨어나 소프트웨어 또는 하드웨어 및 소프트웨어의 결합으로 구현될 수 있다.
도 2는 본 발명의 일면에 의한 중복 방지 기능을 가지는 분산 저장 시스템의 일 실시예를 개념적으로 나타내는 도면이다.
도 2에 도시된 분산 저장 시스템(200)은 네트워크(290)에 연결되는 복수 개의 클라이언트들(210, 212, 216) 및 데이터 노드들(DN11-DN1n, DN21-DN2n, DNm1-DNmn)을 포함한다. 또한, 도 2에 도시된 분산 저장 시스템(200)은 인증 서버(220), 프락시 서버(250) 및 메타데이터 데이터베이스(280)를 더 포함한다.
인증 서버(220)는 클라이언트를 인증하고, 데이터 노드들(DN11-DN1n, DN21-DN2n, DNm1-DNmn)은 각각 적어도 하나의 오브젝트들을 저장한다. 또한, 메타데이터 데이터베이스(280)는 오브젝트의 고유 정보 및 오브젝트가 저장된 데이터 노드의 고유 정보를 포함하는 메타데이터를 저장한다.
클라이언트들(210, 212, 216) 중 제1 클라이언트(210)가 오브젝트를 데이터 노드들(DN11-DN1n, DN21-DN2n, DNm1-DNmn) 중 하나에 저장하려고 시도하는 경우에 대해서 설명한다. 우선, 인증된 클라이언트(210)는 대상 오브젝트(target object)를 저장하기 위하여 프락시 서버(250)에 클라이언트의 오브젝트 저장 요청을 송신한다. 본 발명에 의한 프락시 서버(250)는 동작 요청이 있을 때 모든 대상 오브젝트를 저장하는 것이 아니라, 대상 오브젝트가 이미 데이터 노드들(DN11-DN1n, DN21-DN2n, DNm1-DNmn) 중 하나에 기저장되었는지를 판단한다. 이러한 중복 방지 동작을 수행하기 위하여, 프락시 서버(250)는 우선 대상 오브젝트의 내용에 의하여 결정되는 내용 특이적 인덱스(content-specific index)를 결정하고, 결정된 내용 특이적 인덱스를 이용하여 대상 오브젝트가 기저장된 오브젝트들과 중복되는지 여부를 판단한다. 만일, 대상 오브젝트가 이미 데이터 노드 중 하나에 기저장되어 있다면, 프락시 서버(250)는 동작 요청을 무시한다. 따라서, 동일한 오브젝트가 불필요하게 많은 데이터 노드에 저장되어 시스템 자원을 낭비하는 것을 방지할 수 있다. 만일, 대상 오브젝트가 기저장된 오브젝트들과 상이하다면, 프락시 서버(250)는 이와 같은 중복되지 않은 대상 오브젝트에 대해서만 대상 데이터 노드의 고유 정보의 목록을 클라이언트에게 제공한다. 그러면, 클라이언트(210)는 제공된 대상 데이터 노드의 고유 정보의 목록을 참조하여 대상 데이터 노드를 식별한 후, 대상 데이터 노드의 IP 주소 등을 이용하여 대상 오브젝트를 해당 대상 데이터 노드에 저장한다.
특히, 프락시 서버는 대상 오브젝트의 소정 부분(예를 들어 대상 오브젝트의 최초 65 메가바이트)에 해쉬 함수를 적용하고, 그 결과를 해당 대상 오브젝트에 대한 내용 특이적 인덱스로서 결정한다. 본 명세서에서 내용 특이적 인덱스는 중복되는 대상 오브젝트들을 쉽게 찾아내기 위하여 이용되는 모든 정보일 수 있다. 프락시 서버(250)가 이용하는 해쉬 함수에 대해서는 도 4를 이용하여 상세히 후술된다. 본 발명에 의한 분산 저장 시스템(200)에 포함되는 프락시 서버(250)는 내용 특이적 인덱스를 이용하여 오브젝트의 동일 여부를 판단하기 때문에, 대상 오브젝트와 동일한 오브젝트이지만 다른 사용자에 의하여 다른 명칭이 부여된 오브젝트도 대상 오브젝트와 같은 오브젝트라고 쉽게 판단할 수 있다.
본 명세서에서 '대상 오브젝트(target object)'란 클라이언트가 저장하고자 하는 오브젝트나 데이터 노드로부터 조회하고자 하는 관심 대상인 오브젝트를 의미한다. 또한, '대상 데이터 노드(target data node)'란 여러 개의 데이터 노드 중에서 대상 오브젝트가 저장된 데이터 노드를 의미한다. 그리고, 본 명세서에서 '우선 순위'란 특정 대상 오브젝트를 저장하기에 어떤 지역 그룹 또는 데이터 노드가 다른 지역 그룹 또는 데이터 노드에 비하여 더 적합한지 판단하여 매긴 순위를 나타낸다. 우선 순위에는 특정 지역 그룹이 다른 지역 그룹에 비하여 가지는 우선 순위 및 동일한 지역 그룹 내에 속한 데이터 노드들 간의 우선 순위가 포함될 수 있다. 또한, 우선 순위는 클라이언트가 직접 어느 대상 오브젝트에 관련한 특정 지역 및 데이터 노드에 대한 선호도에 기반하여 매길 수도 있고, 또는 프락시 서버 또는 위치 인식 서버에 의하여 자동으로 결정될 수도 있다. 이에 대해서는 명세서의 해당 부분에서 상세히 후술된다.
또한, 다시 도 2를 참조하면, 데이터 노드들(DN11-DN1n, DN21-DN2n, DNm1-DNmn)은 제1 내지 제m 지역 그룹(ZG1, ZG2, ZGm) 중 어느 하나에 포함된다는 것을 알 수 있다. 도 2에 도시되는 지역 그룹(ZG1, ZG2, ZG3)들은 효과적인 복제본의 분산 저장을 위하여, 각각 지역적으로 인접한 데이터 노드들을 그루핑함으로써 정의된다. 또한, 동일한 지역 그룹에 속하는 데이터 노드들은 동일한 오브젝트를 저장하지 않도록 구성된다. 즉, 하나의 오브젝트의 복제본은 다른 지역 그룹에 속하는 데이터 노드들에 분산되어 저장되기 때문에 두 개의 복제본이 어느 하나의 지역 그룹에 속한 두 개의 데이터 노드에 공통적으로 저장되지 않는다. 이를 메타데이터의 관점에서 보면, 오브젝트의 물리적인 위치를 나타내는 메타데이터에서 하나의 오브젝트의 복제본들은 다른 지역 그룹에 속한 데이터 노드들에 매핑된다. 그러므로, 어느 특정한 지역 그룹이 전체 네트워크 상에 문제가 생기는 등의 물리적인 피해를 입은 경우라도 복제본이 다른 지역 그룹에 속한 데이터 노드에 분산되어 저장되어 있으므로 신뢰성을 높일 수 있다.
본 발명에서, 지역 그룹은 하나의 데이터 센터가 될 수도 있고 좀 더 좁은 지역으로는 하나의 서버 랙이 될 수도 있다. 지역 그룹이 설정되면, 해당 지역 그룹 내에 속한 데이터 노드들을 그 지역 그룹에 속하는 것으로 메타데이터에 등록된다. 그러면, 오브젝트의 복제본들은 다른 지역 그룹에 속한 데이터 노드에 복제된다.
데이터 노드를 지역 그룹으로 그루핑함으로써 얻어지는 장점은 다음과 같다.
1) 본 발명에서, 모든 클라이언트들(210, 212, 216) 및 데이터 노드들(DN11-DN1n, DN21-DN2n, DNm1-DNmn)들은 네트워크(290)를 통하여 서로 통신한다. 즉, 클라이언트 각각 및 데이터 각각 간에는 가상 채널(virtual channel)이 존재한다. 그러나, 이러한 가상 채널은 클라이언트 및 데이터 노드의 모든 쌍에 대해 반드시 동일한 조건을 가지는 것은 아니다. 예를 들어, 가상 채널의 통신 환경은 클라이언트 및 데이터 노드 간의 물리적 거리에 따라 달라질 수 있다. 클라이언트 및 데이터 노드 간의 물리적 거리가 멀수록 오브젝트는 더 많은 릴레이 노드 또는 게이트웨이를 통하여 전달되기 때문에 송수신 시간이 오래 걸린다. 또한, 가상 채널의 통신 환경은 네트워크 트래픽의 양 및 가상 채널을 구성하는 네트워크 자원의 성능에 따라서도 달라질 수 있다. 가상 채널을 통해 전달되는 트래픽의 양이 많을수록 가상 채널 상에서 전송 충돌(transmission collision)이 발생될 가능성이 높아지며, 네트워크 자원의 성능이 높을수록 가상 채널의 송수신 속도는 빨라진다. 그러므로, 본 발명에서는 이와 같은 가상 채널의 통신 환경을 고려하여 클라이언트 및 데이터 노드 간에 가장 최적의 가상 채널을 선택한다. 최적의 가상 채널을 선택하기 위하여 본 발명에 의한 분산 저장 시스템에서는 클라이언트 및 지역 그룹 간의 물리적 거리를 참조할 수 있다. 따라서, 저장한 오브젝트를 포함하는 클라이언트로부터 가장 가까운 거리에 위치한 지역 그룹에 속한 데이터 노드에 오브젝트를 저장함으로써 오브젝트의 업로드 시간을 최소화할 수 있다.
2) 또한, 본 발명에 의한 분산 저장 시스템은 오브젝트를 복제할 때 동일한 지역 그룹에 속하는 데이터 노드로 복제되지 않도록 한다. 따라서, 저장할 대상 오브젝트는 여러 개의 지역 그룹에 분산 저장된다. 일반적으로, 네트워크 장애가 발생하면 인접 지역의 데이터 노드들의 동작도 불가능한 경우가 많다. 예를 들어, 어느 데이터 센터에 여러 개의 데이터 노드들이 존재하고, 이 데이터 센터가 하나의 지역 그룹으로 설정된다고 가정한다. 이러한 가정은 본 발명을 용이하게 설명하기 위한 것으로 본 발명을 한정하는 것이 아님은 명백하다. 갑작스런 정전 등의 사고로 해당 데이터 센터가 동작 불능의 상태에 빠지는 경우가 발생할 수 있다. 이 경우, 본 발명에 의한 분산 저장 시스템은 대상 오브젝트를 해당 데이터 센터의 데이터 노드들 중 오직 하나의 대상 데이터 노드에만 저장하고, 그 복제본은 다른 지역 그룹에 속하는 대상 데이터 노드에 저장한다. 그러므로, 데이터 센터의 모든 데이터 노드들이 장애를 일으키더라도, 다른 지역 그룹에 속하는 대상 데이터 노드로부터 원하는 대상 오브젝트를 용이하게 조회할 수 있다.
이상과 같이, 본 발명에 의한 분산 저장 시스템(200)은 오브젝트의 실제 물리적 위치를 매핑하는 메타데이터가 오브젝트의 논리적 이름에 기반한 것이 아니라 오브젝트의 내용에 기반하여 구성된다. 그러므로, 중복 방지 동작을 수행하기 위하여 대상 오브젝트가 이미 저장된 것인지에 대한 판단이 용이하게 이루어진다.
도 3은 본 발명의 다른 면에 의한 중복 방지 기능을 가지는 분산 저장 시스템의 오브젝트 저장 방법을 개념적으로 나타내는 흐름도이다.
우선, 분산 저장 시스템에 포함되는 클라이언트를 인증 서버가 인증한다(S310). 인증이 성공하면, 프락시 서버가 대상 오브젝트(target object)를 저장하고자 하는 인증된 클라이언트의 오브젝트 저장 요청을 수신한다(S320). 만일 오브젝트 저장 요청이 수신되지 않으면 동작 요청이 수신될 때까지 대기한다.
프락시 서버가 동작 요청을 수신하면, 프락시 서버는 대상 오브젝트의 내용을 이용하여 내용 특이적 인덱스를 결정한다(S330). 내용 특이적 인덱스가 결정되면, 프락시 서버는 결정된 내용 특이적 인덱스를 이용하여 대상 오브젝트가 기저장된 오브젝트들과 중복되는지 여부를 판단한다(S340).
대상 오브젝트가 기저장된 오브젝트와 중복된다고 판단되면, 프락시 서버는 해당 저장 요청을 무시하고, 다음 동작 요청이 있을 때까지 대기한다. 반면에, 중복 여부 판단결과 중복되는 오브젝트가 없는 것으로 확인되면, 프락시 서버는 중복되지 않은 대상 오브젝트가 저장될 대상 데이터 노드(target data node)를 결정한다(S350). 대상 데이터 노드를 결정하기 위하여, 프락시 서버는 데이터 노드들의 로드 밸런싱을 위해 각 데이터 노드의 스토리지 용량을 고려하여 각 데이터 노드의 가중치 값을 사전에 결정할 수 있다. 그러면, 프락시 서버는 가중치 값을 참조하여 가장 가중치가 높은 데이터 노드를 먼저 대상 데이터 노드로서 할당한다. 이를 통하여, 데이터 노드들 간의 로드 밸런싱이 달성된다.
대상 데이터 노드가 결정되면, 프락시 서버는 결정된 대상 데이터 노드의 고유 정보의 목록을 클라이언트에게 제공하고(S360), 클라이언트는 대상 오브젝트를 목록에 포함된 대상 데이터 노드에 저장한다(S370).
전술한 바와 같이, 본 발명에 의한 프락시 서버는 오브젝트를 업로드할 때 해쉬 결과값이 같은 오브젝트들만을 대상으로 중복 여부를 판단한다. 그러므로, 중복 방지 동작을 효율적으로 수행할 수 있다. 즉, 본 발명에 의하면 오브젝트를 업로드할 때 해쉬 함수를 대상 오브젝트에 적용해 얻어지는 결과값을 보고 결과값이 같은 데이터 노드의 해당 폴더내의 오브젝트들이 대상 오브젝트와 동일한지 여부를 판단하면 족하다. 해쉬 알고리즘 자체의 특성상 내용이 다르면 거의 결과값이 중복되는 경우는 아주 희박하기 때문에 그 만큼 같은 오브젝트를 찾는 일은 효율적으로 수행되게 되고 더불어 중복 방지는 쉬워지게 된다.
도 4는 본 발명에 적용될 수 있는 해쉬 함수의 특징을 설명하기 위한 표이다.
해쉬 함수(hash function)는 임의의 길이의 입력 메세지를 고정된 길이의 출력값으로 압축시키는 함수이다. 해쉬 함수는 데이터의 무결성 검증 및 메세지의 인증에 사용되며, 일방향성 및 강한 충돌 회피성이라는 두 가지 성질을 만족해야 한다. 해쉬 함수를 사용할 경우, 주어진 조건을 만족하는 임의의 입력 메세지를 찾는 것이 계산적으로 불가능해진다.
본 발명에 의한 프락시 서버는 도 4에 도시된 해쉬 알고리즘에 따르는 해쉬 함수를 이용하여 내용 특이적 인덱스를 생성한다. 도 4에는 각 알고리즘의 출력 길이, 블록 크기, 라운드 수 및 엔디언(Endianness)이 나열된다. 엔디언은 컴퓨터의 메모리와 같은 1차원의 공간에 여러 개의 연속된 대상을 배열하는 방법을 뜻한다.
도 4에는, MD5, SHA1, SHA256, SHA384, RMD128, RMD160, RMD256, RMD320, HAS160, 및 TIGER 해쉬 함수 등이 소개되지만, 이는 열거적인 의미로 해석되어야 하고, 본 발명을 한정하는 것이 아니다.
MD5는 널리 사용된 해쉬 알고리즘이지만, 충돌 회피성에서 문제점이 있다는 분석이 있으므로 기존의 응용과의 호환으로만 사용하고 흔히 사용되는 않는다. SHA1은 DSA에서 사용하도록 되어 있으며 많은 인터넷 응용에서 디폴트 해쉬 알고리즘으로 사용된다.
또한, SHA256, SHA384, SHA512는 (Advanced Encryption Standard)의 키 길이인 128, 192, 256 비트에 대응하도록 출력 길이를 늘인 해쉬 알고리즘이다. RMD128, RMD160은 RIPE 프로젝트의 RIPEMD나 MD4, MD5를 대신하기 위하여 디자인된 해쉬 알고리즘이다. 128 비트의 출력을 내는 RMD128은 역시 충돌 회피성에서 문제점이 있다. 이에 비하여, RMD160은 효율성은 떨어지지만 안전성을 높인 것으로 많은 인터넷 표준들에서 널리 채택되고 있다. RMD256과 RMD320은 각각 RMD128과 RMD160을 확장한 것이다.
그리고, HAS160은 국내 표준 서명 알고리즘 KCDSA를 위하여 개발된 해쉬 함수이다. MD5와 SHA1의 장점을 취하여 디자인 되었다. TIGER는 64 비트 프로세서에 최적화되어서 64 비트 프로세서에서는 매우 빠르다.
이와 같이, 본 발명에 의한 프락시 서버는 대상 오브젝트에 다양한 해쉬 함수를 적용하여 얻은 결과를 내용 특이적 인덱스로서 이용한다.
도 5a 및 도 5b는 본 발명에 의한 분산 저장 시스템에서 이용하는 메타데이터에 포함되는 테이블들을 예시하는 도면이다.
도 5a는 메타데이터에 포함되는 오브젝트 테이블을 예시하며, 도 5b는 복제본 위치 테이블을 예시한다. 오브젝트 테이블은 오브젝트의 사용자 ID(User ID), 디렉토리 ID(Directory ID), 오브젝트 ID(Object ID), 및 내용 특이적 인덱스(index)를 항목으로 포함한다. 그리고, 복제본 위치 테이블은 인덱스별 복제본의 위치를 항목으로 포함한다.
프락시 서버는 도 5a와 같은 오브젝트 테이블을 만들어 각 오브젝트의 ID와 오브젝트의 일부 내용으로 해쉬 알고리즘을 적용한 결과값을 인덱스 컬럼에 저장한다. 각 오브젝트는 사용자 ID, 디렉토리 ID 그리고 오브젝트 ID로 구분 가능하다. 해쉬 알고리즘으로 예를 들어 MD5를 쓴다면 MD5는 임의의 길이의 메시지를 입력 받아 128 비트짜리 고정 길이의 출력 값을 생성함으로 인덱스 컬럼을 128 비트로 설정할 수 있다. 입력값으로는 오브젝트 내용에서 처음 64메가 바이트로 할 수 있다. 이것은 본 발명을 용이하게 설명하기 위한 것으로서, 본 발명을 한정하는 것이 아님은 명백하다.
도 5b는 복제본의 개수가 3개인 경우를 가정한 경우이고 실제 복제본의 개수에 따라 복제본 위치 테이블의 컬럼 수를 조정하면 된다. 복제본 위치 테이블의 첫째 컬럼에서는 인덱스를 순서대로 저장하고 그 뒤의 컬럼들은 실제 복제본이 위치하는 데이터 노드의 ID 들이다. 예를 들어 도 5a의 오브젝트 테이블에서 mjkim 사용자의 Movies 디렉토리 밑의 Ants 오브젝트는 처음 64메가 바이트로 MD5 해쉬 알고리즘을 적용시 그 결과값이 24356이 나와서 그 값으로 인덱스 값을 가진다. 24356의 인덱스 값을 도 5b의 복제본 위치 테이블에서 찾으면 24, 52, 9의 데이터 노드의 ID와 매치가 된다. 즉, mjkim의 Ants 파일은 데이터 노드 24, 52 그리고 9에 존재하게 된다. 데이터 노드에서는 실제로 오브젝트 데이터를 저장할 때 인덱스 값을 키로 하여 쉽게 오브젝트 탐색이 가능하도록 한다. 예를 들어 인덱스 값 별로 폴더를 만들 수 있다. 같은 인덱스를 가지는 오브젝트들은 같은 데이터 노드의 같은 폴더에 저장되게 되는 것이다. 그러면 중복 방지 동작이 더욱 빠르게 수행될 수 있다.
도 6은 본 발명의 일면에 의한 중복 방지 기능을 가지는 분산 저장 시스템의 다른 실시예를 개념적으로 나타내는 도면이다.
도 6은 본 발명의 일면에 의한 분산 저장 시스템의 다른 실시예를 개념적으로 나타내는 도면이다.
도 6에 도시된 분산 저장 시스템(600)은 네트워크(690)에 연결되는 복수 개의 클라이언트들(610, 612, 616) 및 데이터 노드들(DN11-DN1n, DN21-DN2n, DNm1-DNmn)을 포함한다. 또한, 도 6에 도시된 분산 저장 시스템(600)은 인증 서버(620), 프락시 서버(650), 위치 인식 서버(660), 복제 서버(670) 및 메타데이터 데이터베이스(680)를 더 포함한다.
도 6에 도시된 클라이언트들(610, 612, 616), 인증 서버(620) 및 메타데이터 데이터베이스(680)의 구성 및 동작은 도 2에 도시되는 대응 구성 요소들의 그것과 유사하다. 그러므로, 명세서의 간략화를 위하여 반복적인 설명이 생략된다. 예를 들어, 도 6에 포함되는 프락시 서버(650)는 오브젝트 저장 요청이 있을 경우 대상 오브젝트에 해쉬 함수를 적용한 결과를 내용 특이적 인덱스로서 결정하고, 결정된 내용 특이적 인덱스를 이용하여 대상 오브젝트가 기저장된 대상 오브젝트와 동일한지 여부를 판단할 수 있다. 이하, 대상 오브젝트가 기저장된 오브젝트들과는 상이한 것일 경우에 대해서 설명한다.
도 6에 도시된 분산 저장 시스템(600)에 포함되는 위치 인식 서버(660)는 지역 그룹 또는 대상 데이터 노드를 자동으로 선택하기 위하여 이용된다. 인증된 클라이언트가 대상 오브젝트를 저장할 대상 데이터 노드에 대해서 프락시 서버(650)에 질의하면, 프락시 서버(650)는 가장 유리한 지역 그룹에 대해서 위치 인식 서버(660)에 문의한다.
위치 인식 서버(660)는 여러 가지 방법으로 클라이언트의 위치를 파악할 수 있는데, 일반적으로는 클라이언트의 IP 주소로 클라이언트의 물리적 위치를 파악할 수 있다. 위치 인식 서버(660)는 프락시 서버(650)의 요청에 따라 클라이언트의 기본 복제본 개수만큼의 지역 그룹을 선정한 후 선정된 지역 그룹 리스트를 프락시 서버(650)에게 전송한다. 위치 인식 서버(660)는 물리적으로 프락시 서버(650) 내에 통합되어 구현될 수 있다.
위치 인식 서버(660)에 의하여 결정된 지역 그룹 각각에 속하는 대상 데이터 노드를 결정하는 동작은 프락시 서버(650) 또는 위치 인식 서버(660)에 의하여 수행될 수 있다. 위치 인식 서버(660)가 대상 데이터 노드까지 결정하는 경우, 위치 인식 서버(660)는 메타데이터 데이터베이스(680)를 참조하여 선택된 지역 그룹 내에서 대상 오브젝트를 가지고 있는 클라이언트와 가장 근접한 대상 데이터 노드를 선택할 수 있다. 반면에, 프락시 서버(650)가 대상 데이터 노드를 선택한다면, 프락시 서버(650)는 로드 밸런서(load balancer, 655)를 이용하여 각 지역 그룹에 속하는 데이터 노드들의 상태를 점검하고, 이 중에서 최적 조건을 가지는 데이터 노드를 대상 데이터 노드로서 선택할 수 있다. 로드 밸런서(655)는 프락시 서버(650)에 포함되는 것으로 도시되었으나, 이는 본 발명을 한정하는 것이 아님이 이해되어야 한다.
또한, 프락시 서버(650)는 각 지역 그룹 내 데이터 노드들의 정보를 메타데이터에 관리하고, 데이터 노드들의 로드 밸런싱을 위해 각 데이터 노드의 스토리지 용량을 고려하여 각 데이터 노드의 가중치 값을 사전에 결정한다. 현재까지 각 데이터 노드의 오브젝트 저장 내역과 데이터 노드의 가중치 값을 고려해 요청 클라이언트의 데이터 노드를 선정함으로써 지역 그룹 내 데이터 노드간 로드 밸런싱을 유지한다.
본 발명은 도면에 도시된 실시예를 참고로 설명되었으나 이는 예시적인 것에 불과하며, 본 기술 분야의 통상의 지식을 가진 자라면 이로부터 다양한 변형 및 균등한 타 실시예가 가능하다는 점을 이해할 것이다.
또한, 본 발명에 따르는 방법은 컴퓨터로 읽을 수 있는 기록 매체에 컴퓨터가 읽을 수 있는 코드로서 구현하는 것이 가능하다. 컴퓨터가 읽을 수 있는 기록 매체는 컴퓨터 시스템에 의하여 읽혀질 수 있는 데이터가 저장되는 모든 종류의 기록 장치를 포함할 수 있다. 컴퓨터가 읽을 수 있는 기록 매체의 예로는 ROM, RAM, CD-ROM, 자기 테이프, 플로피 디스크, 광 데이터 저장 장치 등이 있으며, 또한 캐리어 웨이브(예를 들어 인터넷을 통한 전송)의 형태로 구현되는 것도 포함한다. 또한 컴퓨터가 읽을 수 있는 기록 매체는 네트워크로 연결된 분산 컴퓨터 시스템에 의하여 분산 방식으로 실행될 수 있는 컴퓨터가 읽을 수 있는 코드를 저장할 수 있다.
따라서, 본 발명의 진정한 기술적 보호 범위는 첨부된 등록청구범위의 기술적 사상에 의해 정해져야 할 것이다.
본 발명은 클라우드 스토리지 서비스를 제공할 수 있는 오브젝트 스토리지에서 중복 제거(deduplication)를 효율적으로 지원하기 위한 기술에 적용될 수 있다.
Claims (17)
- 복수 개의 클라이언트들로부터 네트워크를 통해 전송되는 오브젝트를 복수 개의 데이터 노드들에 분산 저장하는 분산 저장 시스템(distribution storage system)에 있어서,상기 클라이언트를 인증하기 위한 인증 서버;각각 적어도 하나의 오브젝트들을 저장하는 복수 개의 데이터 노드들;상기 오브젝트의 고유 정보 및 상기 오브젝트가 저장된 데이터 노드의 고유 정보를 포함하는 메타데이터를 저장하는 메타데이터 데이터베이스; 및대상 오브젝트(target object)를 저장하고자 하는 인증된 클라이언트의 오브젝트 저장 요청에 응답하여, 상기 메타데이터를 참조하여 상기 대상 오브젝트가 저장될 대상 데이터 노드(target data node)의 고유 정보의 목록을 상기 클라이언트에게 제공하는 프락시 서버를 포함하며, 상기 프락시 서버는,상기 클라이언트로부터 상기 저장 요청이 수신되면, 상기 대상 오브젝트의 내용에 의하여 결정되는 내용 특이적 인덱스(content-specific index)를 결정하고, 결정된 내용 특이적 인덱스를 이용하여 상기 대상 오브젝트가 기저장된 오브젝트들과 중복되는지 여부를 판단하며, 중복되지 않은 대상 오브젝트에 대해서만 상기 대상 데이터 노드의 고유 정보의 목록을 상기 클라이언트에게 제공하도록 구성되고, 상기 클라이언트는,제공된 상기 대상 데이터 노드의 고유 정보의 목록을 이용하여 상기 대상 오브젝트를 저장하도록 구성되는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템.
- 제1항에 있어서, 상기 프락시 서버는,상기 대상 오브젝트의 소정 부분에 소정 해시 함수를 적용한 결과를 상기 내용 특이적 인덱스로서 결정하도록 구성되는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템.
- 제2항에 있어서, 상기 프락시 서버는,상기 대상 오브젝트의 최초 소정 길이를 입력으로써 이용하는 MD5, SHA1, SHA256, SHA384, RMD128, RMD160, RMD256, RMD320, HAS160, 및 TIGER 해시 함수 중 어느 하나를 이용하여 상기 내용 특이적 인덱스를 결정하도록 구성되는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템.
- 제3항에 있어서, 상기 메타데이터는,사용자 ID, 디렉토리 ID, 오브젝트 ID, 및 상기 내용 특이적 인덱스 중 적어도 하나를 포함하는 오브젝트 테이블 및상기 내용 특이적 인덱스 및 상기 오브젝트의 복제본이 저장된 데이터 노드의 ID를 포함하는 복제본 위치 테이블을 포함하는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템.
- 제1항에 있어서,상기 데이터 노드들은 지역(zone)별로 그루핑되며,상기 프락시 서버는, 동일한 오브젝트는 동일한 지역 그룹(zone group)에 속한 데이터 노드들 중 오직 하나에만 저장되도록 상기 대상 데이터 노드의 고유 정보의 목록을 결정하도록 구성되는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템.
- 제5항에 있어서,상기 분산 저장 시스템은, 상기 데이터 노드들 및 상기 클라이언트의 위치 관계에 기반하여 상기 대상 오브젝트를 저장할 대상 데이터 노드가 속하는 지역 그룹을 선택하고, 선택된 지역 그룹 및 상기 클라이언트 간의 거리에 기반하여 상기 지역 그룹별 우선 순위를 결정하는 위치 인식 서버(location-aware server)를 더 포함하고,상기 프락시 서버는,상기 위치 인식 서버가 선택한 지역 그룹 당 하나의 대상 데이터 노드를 결정하고,결정된 대상 데이터 노드들의 목록을 이용하여 상기 메타데이터 데이터베이스를 갱신하며,상기 대상 데이터 노드들의 목록 및 상기 지역 그룹별 우선 순위를 상기 클라이언트에게 전송하도록 구성되고,상기 클라이언트는, 가장 높은 지역 그룹별 우선 순위를 가지는 지역 그룹에 속하는 대상 데이터 노드에 상기 대상 오브젝트를 저장함으로써, 상기 우선 순위에 따라 순차적으로 더 낮은 우선 순위를 가지는 지역 그룹에 속하는 대상 데이터 노드들에 상기 대상 오브젝트가 복제되는 복제 동작이 수행되도록 야기하도록 더욱 구성되는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템.
- 제6항에 있어서, 상기 프락시 서버는,동일한 지역 그룹에 포함되는 데이터 노드들의 가용 저장 용량 및 오브젝트 저장 내역을 고려하여 동일한 지역 그룹에 포함되는 데이터 노드들에게 우선 순위를 부여하고,가장 높은 우선 순위를 가지는 데이터 노드를 상기 대상 데이터 노드로서 결정하도록 더욱 구성되는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템.
- 제1항에 있어서,상기 오브젝트의 고유 정보는 상기 오브젝트의 ID, 크기, 데이터 타입, 및 작성자 중 적어도 하나를 포함하고,상기 데이터 노드의 고유 정보는 상기 데이터 노드의 ID, IP(Internet Protocol) 주소, 및 물리적 위치 중 적어도 하나를 포함하는 것을 특징으로 하는 중복 방지 기능을 가지는 분산 저장 시스템.
- 제5항에 있어서,상기 메타데이터는, 상기 데이터 노드들의 사용량, 각 지역 그룹에 속한 데이터 노드들의 목록, 대상 오브젝트에 대한 지역 그룹별 우선 순위, 및 동일한 지역 그룹에 속한 데이터 노드들 간의 우선 순위 중 적어도 하나를 더 포함하는 것을 특징으로 하는 중복 방지 기능을 가지는 분산 저장 시스템.
- 복수 개의 클라이언트들로부터 네트워크를 통해 전송되는 오브젝트를 복수 개의 데이터 노드들에 분산 저장하는 분산 저장 시스템(distribution storage system)에 오브젝트를 분산 저장하는 방법에 있어서,상기 클라이언트를 인증하는 단계;프락시 서버가 대상 오브젝트(target object)를 저장하고자 하는 인증된 클라이언트의 오브젝트 저장 요청을 수신하는 단계;상기 프락시 서버가 상기 대상 오브젝트의 내용에 의하여 결정되는 내용 특이적 인덱스를 결정하는 내용 특이적 인덱스 결정 단계;결정된 내용 특이적 인덱스를 이용하여 상기 프락시 서버가 상기 대상 오브젝트가 기저장된 오브젝트들과 중복되는지 여부를 판단하는 단계; 및상기 프락시 서버가, 중복되지 않은 대상 오브젝트에 대해서만 상기 오브젝트의 고유 정보 및 상기 오브젝트가 저장된 데이터 노드의 고유 정보를 포함하는 메타데이터를 참조하여 상기 대상 오브젝트가 저장될 대상 데이터 노드(target data node)를 결정하는 대상 데이터 노드 결정 단계;상기 프락시 서버가, 결정된 대상 데이터 노드의 고유 정보의 목록을 상기 클라이언트에게 제공하는 단계; 및상기 클라이언트가 상기 대상 오브젝트를 상기 목록에 포함된 대상 데이터 노드에 저장하는 단계를 포함하는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템에서 오브젝트를 저장하기 위한 방법.
- 제10항에 있어서, 상기 내용 특이적 인덱스 결정 단계는,상기 프락시 서버가 상기 대상 오브젝트의 소정 부분에 소정 해시 함수를 적용한 결과를 상기 내용 특이적 인덱스로서 결정하는 단계를 포함하는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템에서 오브젝트를 저장하기 위한 방법.
- 제11항에 있어서, 내용 특이적 인덱스 결정 단계는,상기 프락시 서버가 상기 대상 오브젝트의 최초 소정 길이를 MD5, SHA1, SHA256, SHA384, RMD128, RMD160, RMD256, RMD320, HAS160, 및 TIGER 해시 함수 중 어느 하나에 적용하여 상기 내용 특이적 인덱스를 결정하는 단계를 포함하는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템에서 오브젝트를 저장하기 위한 방법.
- 제12항에 있어서, 상기 메타데이터는,사용자 ID, 디렉토리 ID, 오브젝트 ID, 및 상기 내용 특이적 인덱스 중 적어도 하나를 포함하는 오브젝트 테이블 및상기 내용 특이적 인덱스 및 상기 오브젝트의 복제본이 저장된 데이터 노드의 ID를 포함하는 복제본 위치 테이블을 포함하는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템에서 오브젝트를 저장하기 위한 방법.
- 제10항에 있어서, 상기 대상 데이터 노드 결정 단계는,상기 프락시 서버가, 동일한 오브젝트가 동일한 지역 그룹(zone group)에 속한 데이터 노드들 중 오직 하나에만 저장되도록 상기 대상 데이터 노드의 고유 정보의 목록을 결정하는 단계를 포함하는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템에서 오브젝트를 저장하기 위한 방법.
- 제14항에 있어서, 상기 대상 데이터 노드 결정 단계는,위치 인식 서버가 상기 데이터 노드들 및 상기 클라이언트의 위치 관계에 기반하여 상기 대상 오브젝트를 저장할 대상 데이터 노드가 속하는 지역 그룹을 선택하고, 선택된 지역 그룹 및 상기 클라이언트 간의 거리에 기반하여 상기 지역 그룹별 우선 순위를 결정하는 단계; 및상기 프락시 서버가 상기 위치 인식 서버가 선택한 지역 그룹 당 하나의 대상 데이터 노드를 결정하는 단계를 포함하는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템에서 오브젝트를 저장하기 위한 방법.
- 제15항에 있어서, 상기 대상 데이터 노드 결정 단계는,상기 프락시 서버가, 동일한 지역 그룹에 포함되는 데이터 노드들의 가용 저장 용량 및 오브젝트 저장 내역을 고려하여 동일한 지역 그룹에 포함되는 데이터 노드들에게 우선 순위를 부여하는 단계; 및상기 프락시 서버가, 가장 높은 우선 순위를 가지는 데이터 노드를 상기 대상 데이터 노드로서 결정하는 단계를 포함하는 것을 특징으로 하는 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템에서 오브젝트를 저장하기 위한 방법.
- 제10항 내지 제16항 중 어느 한 항에 따르는 방법을 구현하기 위하여 컴퓨터에 의하여 실행될 수 있는 컴퓨터 프로그램 명령어들을 저장하는 컴퓨터에 의하여 독출가능한 저장 매체.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR10-2010-0134842 | 2010-12-24 | ||
| KR1020100134842A KR20120072909A (ko) | 2010-12-24 | 2010-12-24 | 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템 및 그 오브젝트 저장 방법 및 컴퓨터에 의하여 독출가능한 저장 매체 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2012086920A2 true WO2012086920A2 (ko) | 2012-06-28 |
| WO2012086920A3 WO2012086920A3 (ko) | 2012-09-07 |
Family
ID=46314561
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/KR2011/008224 WO2012086920A2 (ko) | 2010-12-24 | 2011-10-31 | 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템 및 그 오브젝트 저장 방법 및 컴퓨터에 의하여 독출가능한 저장 매체 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20120166403A1 (ko) |
| KR (1) | KR20120072909A (ko) |
| WO (1) | WO2012086920A2 (ko) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105119741A (zh) * | 2015-07-21 | 2015-12-02 | 重庆邮电大学 | 一种云网络可靠性度量方法 |
| CN110045987A (zh) * | 2012-09-28 | 2019-07-23 | 英特尔公司 | 用于sha256算法的消息调度的指令处理器 |
| CN112492008A (zh) * | 2020-11-19 | 2021-03-12 | 深圳壹账通智能科技有限公司 | 节点位置确定方法、装置、计算机设备和存储介质 |
| US10999060B2 (en) | 2018-10-26 | 2021-05-04 | Advanced New Technologies Co., Ltd. | Data processing method and apparatus |
Families Citing this family (71)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8484162B2 (en) | 2008-06-24 | 2013-07-09 | Commvault Systems, Inc. | De-duplication systems and methods for application-specific data |
| US8930306B1 (en) | 2009-07-08 | 2015-01-06 | Commvault Systems, Inc. | Synchronized data deduplication |
| US8572340B2 (en) | 2010-09-30 | 2013-10-29 | Commvault Systems, Inc. | Systems and methods for retaining and using data block signatures in data protection operations |
| US8364652B2 (en) | 2010-09-30 | 2013-01-29 | Commvault Systems, Inc. | Content aligned block-based deduplication |
| US9116850B2 (en) | 2010-12-14 | 2015-08-25 | Commvault Systems, Inc. | Client-side repository in a networked deduplicated storage system |
| US9020900B2 (en) | 2010-12-14 | 2015-04-28 | Commvault Systems, Inc. | Distributed deduplicated storage system |
| US9262486B2 (en) * | 2011-12-08 | 2016-02-16 | Here Global B.V. | Fuzzy full text search |
| US8996501B2 (en) | 2011-12-08 | 2015-03-31 | Here Global B.V. | Optimally ranked nearest neighbor fuzzy full text search |
| CN102546782B (zh) * | 2011-12-28 | 2015-04-29 | 北京奇虎科技有限公司 | 一种分布式系统及其数据操作方法 |
| US9100245B1 (en) * | 2012-02-08 | 2015-08-04 | Amazon Technologies, Inc. | Identifying protected media files |
| US20130232124A1 (en) * | 2012-03-05 | 2013-09-05 | Blaine D. Gaither | Deduplicating a file system |
| US8812456B2 (en) * | 2012-03-30 | 2014-08-19 | Netapp Inc. | Systems, methods, and computer program products for scheduling processing to achieve space savings |
| US8903764B2 (en) | 2012-04-25 | 2014-12-02 | International Business Machines Corporation | Enhanced reliability in deduplication technology over storage clouds |
| US9218376B2 (en) | 2012-06-13 | 2015-12-22 | Commvault Systems, Inc. | Intelligent data sourcing in a networked storage system |
| US8918372B1 (en) | 2012-09-19 | 2014-12-23 | Emc Corporation | Content-aware distributed deduplicating storage system based on consistent hashing |
| US9268784B1 (en) * | 2012-09-19 | 2016-02-23 | Emc Corporation | Content-aware distributed deduplicating storage system based on locality-sensitive hashing |
| US9135274B2 (en) * | 2012-11-21 | 2015-09-15 | General Electric Company | Medical imaging workflow manager with prioritized DICOM data retrieval |
| US9319474B2 (en) * | 2012-12-21 | 2016-04-19 | Qualcomm Incorporated | Method and apparatus for content delivery over a broadcast network |
| US9665591B2 (en) * | 2013-01-11 | 2017-05-30 | Commvault Systems, Inc. | High availability distributed deduplicated storage system |
| US20140214775A1 (en) * | 2013-01-29 | 2014-07-31 | Futurewei Technologies, Inc. | Scalable data deduplication |
| EP4224324A3 (en) * | 2013-02-27 | 2023-09-27 | Hitachi Vantara LLC | Rain-based archival system with self-describing objects |
| WO2014185918A1 (en) * | 2013-05-16 | 2014-11-20 | Hewlett-Packard Development Company, L.P. | Selecting a store for deduplicated data |
| EP2997496B1 (en) | 2013-05-16 | 2022-01-19 | Hewlett Packard Enterprise Development LP | Selecting a store for deduplicated data |
| US9270467B1 (en) * | 2013-05-16 | 2016-02-23 | Symantec Corporation | Systems and methods for trust propagation of signed files across devices |
| KR101451956B1 (ko) | 2013-06-07 | 2014-10-16 | 에스케이플래닛 주식회사 | 클라우드 서비스 시스템, 클라우드 서비스 장치 및 이를 이용한 방법 |
| CN103312815A (zh) * | 2013-06-28 | 2013-09-18 | 安科智慧城市技术(中国)有限公司 | 一种云存储系统及其数据存取方法 |
| US9178860B2 (en) * | 2013-08-22 | 2015-11-03 | Maginatics, Inc. | Out-of-path, content-addressed writes with untrusted clients |
| CN104469100A (zh) * | 2013-09-24 | 2015-03-25 | 张生福 | 一种分散式云端录像平台 |
| US9384206B1 (en) * | 2013-12-26 | 2016-07-05 | Emc Corporation | Managing data deduplication in storage systems |
| US9633056B2 (en) | 2014-03-17 | 2017-04-25 | Commvault Systems, Inc. | Maintaining a deduplication database |
| US10380072B2 (en) | 2014-03-17 | 2019-08-13 | Commvault Systems, Inc. | Managing deletions from a deduplication database |
| CN103942281B (zh) * | 2014-04-02 | 2017-07-25 | 北京中交兴路车联网科技有限公司 | 一种对持久化存储的对象进行操作的方法及装置 |
| WO2015167447A1 (en) * | 2014-04-29 | 2015-11-05 | Hitachi, Ltd. | Deploying applications in cloud environments |
| US11249858B2 (en) | 2014-08-06 | 2022-02-15 | Commvault Systems, Inc. | Point-in-time backups of a production application made accessible over fibre channel and/or ISCSI as data sources to a remote application by representing the backups as pseudo-disks operating apart from the production application and its host |
| US9852026B2 (en) | 2014-08-06 | 2017-12-26 | Commvault Systems, Inc. | Efficient application recovery in an information management system based on a pseudo-storage-device driver |
| US9575673B2 (en) | 2014-10-29 | 2017-02-21 | Commvault Systems, Inc. | Accessing a file system using tiered deduplication |
| US10339106B2 (en) | 2015-04-09 | 2019-07-02 | Commvault Systems, Inc. | Highly reusable deduplication database after disaster recovery |
| US9817599B2 (en) | 2015-05-11 | 2017-11-14 | Hewlett Packard Enterprise Development Lp | Storing indicators of unreferenced memory addresses in volatile memory |
| US9892005B2 (en) * | 2015-05-21 | 2018-02-13 | Zerto Ltd. | System and method for object-based continuous data protection |
| US20160350391A1 (en) | 2015-05-26 | 2016-12-01 | Commvault Systems, Inc. | Replication using deduplicated secondary copy data |
| US9766825B2 (en) | 2015-07-22 | 2017-09-19 | Commvault Systems, Inc. | Browse and restore for block-level backups |
| US20170192868A1 (en) | 2015-12-30 | 2017-07-06 | Commvault Systems, Inc. | User interface for identifying a location of a failed secondary storage device |
| WO2017142519A1 (en) * | 2016-02-17 | 2017-08-24 | Hitachi Data Systems Corporation | Content classes for object storage indexing systems |
| US10296368B2 (en) | 2016-03-09 | 2019-05-21 | Commvault Systems, Inc. | Hypervisor-independent block-level live browse for access to backed up virtual machine (VM) data and hypervisor-free file-level recovery (block-level pseudo-mount) |
| US9959058B1 (en) * | 2016-03-31 | 2018-05-01 | EMC IP Holding Company LLC | Utilizing flash optimized layouts which minimize wear of internal flash memory of solid state drives |
| US11113247B1 (en) * | 2016-05-10 | 2021-09-07 | Veritas Technologies Llc | Routing I/O requests to improve read/write concurrency |
| US10365974B2 (en) | 2016-09-16 | 2019-07-30 | Hewlett Packard Enterprise Development Lp | Acquisition of object names for portion index objects |
| US20180095985A1 (en) * | 2016-09-30 | 2018-04-05 | Cubistolabs, Inc. | Physical Location Scrambler for Hashed Data De-Duplicating Content-Addressable Redundant Data Storage Clusters |
| US11644992B2 (en) * | 2016-11-23 | 2023-05-09 | Samsung Electronics Co., Ltd. | Storage system performing data deduplication, method of operating storage system, and method of operating data processing system |
| CN106599178B (zh) * | 2016-12-12 | 2019-08-30 | 国云科技股份有限公司 | 一种可实现快速寻找并支持分布存储的大数据处理方法 |
| US10740193B2 (en) | 2017-02-27 | 2020-08-11 | Commvault Systems, Inc. | Hypervisor-independent reference copies of virtual machine payload data based on block-level pseudo-mount |
| US10359966B2 (en) * | 2017-05-11 | 2019-07-23 | Vmware, Inc. | Capacity based load balancing in distributed storage systems with deduplication and compression functionalities |
| US10664352B2 (en) | 2017-06-14 | 2020-05-26 | Commvault Systems, Inc. | Live browsing of backed up data residing on cloned disks |
| US11182256B2 (en) | 2017-10-20 | 2021-11-23 | Hewlett Packard Enterprise Development Lp | Backup item metadata including range information |
| US10592478B1 (en) * | 2017-10-23 | 2020-03-17 | EMC IP Holding Company LLC | System and method for reverse replication |
| CN108566277B (zh) * | 2017-12-22 | 2020-04-21 | 西安电子科技大学 | 云存储中基于数据存储位置的删除数据副本方法 |
| US10623889B2 (en) | 2018-08-24 | 2020-04-14 | SafeGraph, Inc. | Hyper-locating places-of-interest in buildings |
| US11010258B2 (en) | 2018-11-27 | 2021-05-18 | Commvault Systems, Inc. | Generating backup copies through interoperability between components of a data storage management system and appliances for data storage and deduplication |
| US10877947B2 (en) | 2018-12-11 | 2020-12-29 | SafeGraph, Inc. | Deduplication of metadata for places |
| US11698727B2 (en) | 2018-12-14 | 2023-07-11 | Commvault Systems, Inc. | Performing secondary copy operations based on deduplication performance |
| US11392551B2 (en) * | 2019-02-04 | 2022-07-19 | EMC IP Holding Company LLC | Storage system utilizing content-based and address-based mappings for deduplicatable and non-deduplicatable types of data |
| US11940956B2 (en) | 2019-04-02 | 2024-03-26 | Hewlett Packard Enterprise Development Lp | Container index persistent item tags |
| US20200327017A1 (en) | 2019-04-10 | 2020-10-15 | Commvault Systems, Inc. | Restore using deduplicated secondary copy data |
| US11463264B2 (en) | 2019-05-08 | 2022-10-04 | Commvault Systems, Inc. | Use of data block signatures for monitoring in an information management system |
| US11442896B2 (en) | 2019-12-04 | 2022-09-13 | Commvault Systems, Inc. | Systems and methods for optimizing restoration of deduplicated data stored in cloud-based storage resources |
| CN111131441A (zh) * | 2019-12-21 | 2020-05-08 | 西安天互通信有限公司 | 一种实时文件共享系统及方法 |
| US11687424B2 (en) | 2020-05-28 | 2023-06-27 | Commvault Systems, Inc. | Automated media agent state management |
| US11936624B2 (en) * | 2020-07-23 | 2024-03-19 | Dell Products L.P. | Method and system for optimizing access to data nodes of a data cluster using a data access gateway and bidding counters |
| CN114138756B (zh) * | 2020-09-03 | 2023-03-24 | 金篆信科有限责任公司 | 数据去重方法、节点及计算机可读存储介质 |
| US11899696B2 (en) | 2020-10-06 | 2024-02-13 | SafeGraph, Inc. | Systems and methods for generating multi-part place identifiers |
| US11762914B2 (en) | 2020-10-06 | 2023-09-19 | SafeGraph, Inc. | Systems and methods for matching multi-part place identifiers |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20050033615A (ko) * | 2002-07-25 | 2005-04-12 | 산요덴키가부시키가이샤 | 기밀 데이터의 입출력 처리에 관한 이력 정보를 중복하지않고 복수 저장할 수 있는 데이터 기억 장치 |
| KR20070108133A (ko) * | 2004-09-10 | 2007-11-08 | 코닌클리케 필립스 일렉트로닉스 엔.브이. | 가상 타이틀들을 사용할 때 공유된 콘텐트의 중복 복제를피하기 위한 시스템 및 방법 |
| KR20090062747A (ko) * | 2007-12-13 | 2009-06-17 | 한국전자통신연구원 | 파일 저장 시스템 및 파일 저장 시스템에서의 중복 파일관리 방법 |
| KR100985169B1 (ko) * | 2009-11-23 | 2010-10-05 | (주)피스페이스 | 분산 저장 시스템에서 파일의 중복을 제거하는 장치 및 방법 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8332375B2 (en) * | 2007-08-29 | 2012-12-11 | Nirvanix, Inc. | Method and system for moving requested files from one storage location to another |
| US8935366B2 (en) * | 2009-04-24 | 2015-01-13 | Microsoft Corporation | Hybrid distributed and cloud backup architecture |
| US8204867B2 (en) * | 2009-07-29 | 2012-06-19 | International Business Machines Corporation | Apparatus, system, and method for enhanced block-level deduplication |
| US8633838B2 (en) * | 2010-01-15 | 2014-01-21 | Neverfail Group Limited | Method and apparatus for compression and network transport of data in support of continuous availability of applications |
| US9130912B2 (en) * | 2010-03-05 | 2015-09-08 | International Business Machines Corporation | System and method for assisting virtual machine instantiation and migration |
-
2010
- 2010-12-24 KR KR1020100134842A patent/KR20120072909A/ko not_active Application Discontinuation
-
2011
- 2011-10-31 WO PCT/KR2011/008224 patent/WO2012086920A2/ko active Application Filing
- 2011-12-23 US US13/336,114 patent/US20120166403A1/en not_active Abandoned
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20050033615A (ko) * | 2002-07-25 | 2005-04-12 | 산요덴키가부시키가이샤 | 기밀 데이터의 입출력 처리에 관한 이력 정보를 중복하지않고 복수 저장할 수 있는 데이터 기억 장치 |
| KR20070108133A (ko) * | 2004-09-10 | 2007-11-08 | 코닌클리케 필립스 일렉트로닉스 엔.브이. | 가상 타이틀들을 사용할 때 공유된 콘텐트의 중복 복제를피하기 위한 시스템 및 방법 |
| KR20090062747A (ko) * | 2007-12-13 | 2009-06-17 | 한국전자통신연구원 | 파일 저장 시스템 및 파일 저장 시스템에서의 중복 파일관리 방법 |
| KR100985169B1 (ko) * | 2009-11-23 | 2010-10-05 | (주)피스페이스 | 분산 저장 시스템에서 파일의 중복을 제거하는 장치 및 방법 |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110045987A (zh) * | 2012-09-28 | 2019-07-23 | 英特尔公司 | 用于sha256算法的消息调度的指令处理器 |
| CN110045987B (zh) * | 2012-09-28 | 2023-05-12 | 太浩研究有限公司 | 用于sha256算法的消息调度的指令处理器 |
| CN105119741A (zh) * | 2015-07-21 | 2015-12-02 | 重庆邮电大学 | 一种云网络可靠性度量方法 |
| US10999060B2 (en) | 2018-10-26 | 2021-05-04 | Advanced New Technologies Co., Ltd. | Data processing method and apparatus |
| US11626972B2 (en) | 2018-10-26 | 2023-04-11 | Advanced New Technologies Co., Ltd. | Data processing method and apparatus |
| CN112492008A (zh) * | 2020-11-19 | 2021-03-12 | 深圳壹账通智能科技有限公司 | 节点位置确定方法、装置、计算机设备和存储介质 |
| CN112492008B (zh) * | 2020-11-19 | 2022-05-20 | 深圳壹账通智能科技有限公司 | 节点位置确定方法、装置、计算机设备和存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2012086920A3 (ko) | 2012-09-07 |
| KR20120072909A (ko) | 2012-07-04 |
| US20120166403A1 (en) | 2012-06-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2012086920A2 (ko) | 내용 기반 중복 방지 기능을 가지는 분산 저장 시스템 및 그 오브젝트 저장 방법 및 컴퓨터에 의하여 독출가능한 저장 매체 | |
| WO2012086919A2 (ko) | 복수 개의 프락시 서버를 포함하는 분산 저장 시스템 및 그 오브젝트 관리 방법 및 컴퓨터에 의하여 독출가능한 저장 매체 | |
| WO2012086918A2 (ko) | 오브젝트를 복수 개의 데이터 노드들의 위치에 기반하여 분산 저장하는 분산 저장 시스템 및 그 위치 기반 분산 저장 방법 및 컴퓨터에 의하여 독출 가능한 저장 매체 | |
| CN106250270B (zh) | 一种云计算平台下的数据备份方法 | |
| CN106156359B (zh) | 一种云计算平台下的数据同步更新方法 | |
| US9231988B2 (en) | Intercluster repository synchronizer and method of synchronizing objects using a synchronization indicator and shared metadata | |
| CN1531303B (zh) | 协议无关的客户端高速缓存系统和方法 | |
| US10296254B2 (en) | Method and device for synchronization in the cloud storage system | |
| EP2557514A1 (en) | Cloud Storage System with Distributed Metadata | |
| WO2014094468A1 (zh) | 实现浏览器数据同步的系统、方法及浏览器客户端 | |
| WO2016122526A1 (en) | Regenerated container file storing | |
| KR20120018178A (ko) | 객체 저장부들의 네트워크상의 스웜-기반의 동기화 | |
| CN109309730A (zh) | 一种可信的文件传输方法和系统 | |
| WO2005114411A1 (en) | Balancing load requests and failovers using a uddi proxy | |
| CN110633168A (zh) | 一种分布式存储系统的数据备份方法和系统 | |
| CN111158949A (zh) | 容灾架构的配置方法、切换方法及装置、设备和存储介质 | |
| CN111225003B (zh) | 一种nfs节点配置方法和装置 | |
| CN104636437A (zh) | 一种事件通知方法、监听器的处理方法及装置 | |
| CN104125294A (zh) | 一种大数据安全管理方法和系统 | |
| WO2013176431A1 (ko) | 단말을 서버에 할당하고 단말로의 효율적인 메시징을 위한 시스템 및 방법 | |
| JP2010277467A (ja) | 分散データ管理システム、データ管理装置、データ管理方法、およびプログラム | |
| EP2078385B1 (en) | Method and apparatus for preventing duplicate saving of resource between universal plug and play devices providing content directory service | |
| US20130246557A1 (en) | System, method, and computer program product for conditionally preventing the transfer of data based on a location thereof | |
| CN112799849B (zh) | 一种数据处理方法、装置、设备及存储介质 | |
| KR20130074227A (ko) | 분산 데이터 관리 시스템 및 그 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 11852183 Country of ref document: EP Kind code of ref document: A2 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 11852183 Country of ref document: EP Kind code of ref document: A2 |