MODIFIED VALENCENE SYNTHASE POLYPEPTIDES, ENCODING NUCLEIC ACID MOLECULES AND USES THEREOF RELATED APPLICATIONS
Benefit of priority is claimed to U.S. Provisional Application Serial No. 61/455,990, entitled "MODIFIED VALENCENE SYNTHASE POLYPEPTIDES AND USES
THEREOF," filed on October 29, 2010 to Park E., Burlingame, R.P., Amick, J.D. and Julien, B., and to U.S. Provisional Application Serial No. 61/573,745, entitled "MODIFIED
VALENCENE SYNTHASE POLYPEPTIDES, ENCODING NUCLEIC ACID
MOLECULES AND USES THEREOF," filed September 9, 2011 to Park E., Burlingame R.P., Amick J.D., and Julien, B.
This application is related to U.S. Application Serial No. 13/317,839, filed the same day herewith, entitled "MODIFIED VALENCENE SYNTHASE POLYPEPTIDES, ENCODING NUCLEIC ACID MOLECULES AND USES THEREOF," which claims priority to U.S. Provisional Application Serial Nos. 61/455,990 and 61/573,745.
Where permitted, the subject matter of each of the above-referenced applications is incorporated by reference in its entirety.
Incorporation by reference of sequence listing provided electronically
An electronic version of the Sequence Listing is filed herewith, the contents of which are incorporated by reference in their entirety. The electronic file is 3.21 megabytes in size, and titled 203PCseq.001.txt.
FIELD OF INVENTION
Provided are modified valencene synthase polypeptides, nucleic acid molecules encoding the modified valencene synthases, and methods of using the modified valencene synthase polypeptides. Also provided are methods for producing modified terpene synthases. BACKGROUND
Valencene and nootkatone are sesquiterpenes naturally found in citrus oils, such as orange and grapefruit, and other plant matter. Valencene is derived from cyclization of the acyclic pyrophosphate terpene precursor, farnesyl diphosphate (FPP), and oxidation of valencene results in the formation of nootkatone. Although both valencene and nootkatone are used as a flavorant and fragrance, nootkatone in particular is widely used in the perfume and flavor industry. Thus, among the objects herein is the provision of modified valencene synthase polypeptides and methods of using the modified valencene synthase polypeptides for the production of valencene and nootkatone.
SUMMARY
Provided herein are nucleic acid molecules encoding modified valencene synthase polypeptides, and the modified valencene synthases encoded therein. Also provided herein are methods of making modified valencene synthase polypeptides. Also provided herein are methods for producing valencene, and methods for producing nootkatone from valencene. Also provided herein are methods for making modified terpene synthases, and the modified terpene synthases.
Provided herein are nucleic acid molecules encoding modified valencene synthase polypeptides. In some examples, the nucleic acid molecules provided herein encode a modified valencene synthase polypeptide containing a sequence of amino acids that has less than 100% identity to the modified valencene synthase polypeptide set forth in SEQ ID NO:3. In other examples, the nucleic acid molecules provided herein encode a modified valencene synthase polypeptide containing a sequence of amino acids that has 100% identity to the modified valencene synthase polypeptide set forth in SEQ ID NO:3. In some aspects, the modified valencene synthase polypeptides encoded by the nucleic acid molecules have less than 95% identity to the valencene synthase polypeptide set forth in SEQ ID NO:2. In other aspects, the modified valencene synthase polypeptides encoded by the nucleic acid molecules have greater than 62% sequence identity to the valencene synthase set forth in SEQ ID NO:2.
Also provided herein are nucleic acid molecules encoding modified valencene synthase polypeptides that contain amino acid modifications in a valencene synthase polypeptide that has a sequence of amino acids that has less than 100% sequence identity to the modified valencene synthase polypeptide set forth in SEQ ID NO:3. In some examples, the modified valencene synthase polypeptides contain a sequence of amino acids that has less than 95%) identity to the valencene synthase polypeptide set forth in SEQ ID NO:2. In other examples, the modified valencene synthase polypeptides contain a sequence of amino acids that has greater than 62% sequence identity to the valencene synthase set forth in SEQ ID NO:2. In some aspects, the modified valencene polypeptide encoded by the nucleic acid molecule contains a sequence of amino acids that has at least 82% sequence identity to the valencene synthase set forth in SEQ ID NO:2.
Provided herein are nucleic acid molecules encoding modified valencene synthase polypeptides that contain or contain at least 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136 or 137 amino acid modifications compared to the valencene synthase
not containing the modifications or the valencene synthase polypeptide set forth in SEQ ID NO:2.
Provided herein are nucleic acid molecules encoding modified valencene synthase polypeptides that contain a sequence of amino acids that have sequence identity to the valencene synthase set forth in SEQ ID NO:2 that is selected from among less than 95% and more than 75%; less than 94% and more than 75%; less than 93% and more than 75%; less than 92% and more than 75%; less than 95% and more than 80%; less than 94% and more than 80%; less than 93% and more than 80%; less than 92% and more than 80%; less than 95%) and more than 85%; less than 94% and more than 85%; less than 93% and more than 85%; and less than 92% and more than 85%. In some examples, the modified valencene synthase polypeptide encoded by the nucleic acid molecule provided herein has a sequence of amino acids that has less than or has about less than 94%, 93%, 92%, 91%, 90%, 89%, 88%, 87%, 86%, 85%, 84%, 83%, 82%, 81%, 80%, 79%, 78%, 77%, 76% or 75% identity to the valencene synthase set forth in SEQ ID NO:2. In other examples, the modified valencene synthase polypeptide has a sequence of amino acids that has at least 80% identity to the modified valencene synthase polypeptide set forth in SEQ ID NO:3. In yet other examples, the modified valencene synthase polypeptide has a sequence of amino acids that has at least or at least about 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% identity to the modified valencene synthase polypeptide set forth in SEQ ID NO:3.
Also provided herein are nucleic acid molecules encoding a modified valencene synthase polypeptide containing amino acid modifications compared to the valencene synthase set forth in SEQ ID NO:2; whereby the modified valencene synthase polypeptide comprises a sequence of amino acids that has less than 100%) identity and more than 62% identity to the valencene synthase polypeptide set forth in SEQ ID NO:2 and the modified valencene synthase polypeptide does not contain a sequence of amino acids set forth in any of SEQ ID NOS: 289-291, 346, 347, 752, 882, 883 or 886. In some aspects, the modified valencene synthase polypeptide does not contain a sequence of amino acids set forth in any of SEQ ID NOS: 6-8, 14-16 and 348. In other aspects, the modified valencene synthase polypeptide does not contain a sequence of amino acids set forth in SEQ ID NO: 3. In yet other aspects, the modified valencene synthase polypeptide does not contain a sequence of amino acids set forth in SEQ ID NO:5.
In some examples, the nucleic acid molecules provided herein encode a modified valencene synthase polypeptide that catalyzes the formation of valencene from an acyclic pyrophosphate terpene precursor. For example, the modified valencene synthase polypeptide
- -
catalyzes the formation of valencene from the acyclic pyrophosphate terpene precursor famesyl diphosphate (FPP).
Also provided herein are nucleic acid molecules encoding a modified valencene synthase polypeptide that produces valencene from FPP in a host cell in an amount that is greater than the amount of valencene produced from FPP by the valencene synthase set forth in SEQ ID NO:2 in the same host cell and under the same conditions, whereby the host cell is a cell that produces FPP. In some aspects, the host cell is a yeast cell. The amount of valencene produced by the modified valencene synthase polypeptide can be assessed by separately culturing yeast cells expressing the modified valencene synthase polypeptide and the valencene synthase set forth in SEQ ID NO:2 under the same conditions and in the same strain of yeast and comparing the amount of valencene produced. In some examples, the amount of valencene produced from FPP by the modified valencene synthase is at least 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 1 10%, 120%, 130%, 140%, 150%, 160%, 170%, 180%, 190%, 200%, 250%, 300%, 350%, 400%, 500% or more greater than the amount of valencene produced from FPP by the valencene synthase set forth in SEQ ID NO:2. In other examples, the amount of valencene produced from FPP by the modified valencene synthase is 10% to 500%, 10% to 250%, 50% to 250%, 100% to 500% or is 100% to 250% greater than the amount of valencene produced from FPP by the valencene synthase set forth in SEQ ID NO:2 . Exemplary modified valencene synthase polypeptides provided herein, for example as described below and in the Examples, produce increased valencene.
In some aspects, the modified valencene synthase polypeptide encoded by the nucleic acid molecule provided herein produces at least or about 0.1 g/L, 0.2 g L, 0.3 g L, 0.4 g L, 0.5 g/L, 0.6 g/L, 0.7 g/L, 0.8 g/L, 0.9 g/L 1.0 g/L, 1.1 g/L, 1.2 g/L, 1.3 g/L, 1.4 g/L, 1.5 g/L, 2.0 g/L, 2.5 g/L, 3.0 g/L, 3.5 g/L, 4.0 g/L, 4.5 g/L, 5.0 g/L or more valencene in the yeast cell culture medium. In other aspects, modified valencene synthase polypeptide encoded by the nucleic acid molecule provided herein produces 0.1 g/L to 5.0 g/L, 0.1 g/L to 3.0 g/L, 0.5 g/L to 5.0 g/L, 1.0 g/L to 5.0 g/L or 1.0 to 3.0 g/L valencene in the yeast cell culture medium. In such examples, the valencene is produced by large scale fermentation methods. It is understood that microculture or shake flask (e.g. 50 mL) or other smaller scale methods of production, while producing increased valencene, generally produce amounts of valencene of between or about between 10 mg/L to 1000 mg/L, such as 50-60 mg/L or 600-800 mg/L.
Provided herein are nucleic acid molecules encoding a modified valencene synthase polypeptide that contains at least one amino acid modification in a valencene synthase polypeptide at a position corresponding to positions selected from among 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41 , 50, 53, 54, 55, 56, 57, 58, 60, 62, 69, 77, 78, 82, 84, 85, 86, 87,
RECTIFIED SHEET (RULE 91)
ISA EP
88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 111, 113, 114, 116, 117, 118, 120, 121, 122, 124, 125, 127, 129, 130, 132, 135, 136, 138, 139, 141, 142, 144, 146, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 162, 163, 165, 166, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 186, 187, 188, 189, 190, 191, 193, 194, 195, 196, 197, 198, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 227, 228, 229, 238, 252, 257, 263, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300, 301, 302, 303, 305, 306, 307, 310, 311, 312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 329, 331, 332, 333, 334, 335, 336, 337, 338, 339, 340, 341, 342, 343, 344, 345, 346, 347, 348, 349, 350, 351, 352, 353, 354, 355, 356, 357, 358, 359, 360, 361, 362, 363, 364, 365, 366, 367, 368, 369, 370, 371, 372, 373, 375, 377, 378, 380, 381, 382, 386, 387, 388, 389, 390, 391, 392, 393, 394, 395, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 409, 410, 411, 412, 413, 414, 415, 422, 423, 424, 428, 429, 434, 435, 436, 438, 439, 440, 441, 442, 443, 444, 445, 446, 447, 448, 449, 451, 452, 454, 457, 465, 468, 473, 474, 484, 492, 495, 496, 499, 500, 501, 506, 522, 523, 524, 525, 526, 527, 528, 529, 530, 531, 532, 533, 534, 536 and 539 by CVS numbering with reference to amino acid positions set forth in SEQ ID NO:2.
In a specific embodiment, the nucleic acid molecule provided herein encodes a modified valencene synthase polypeptide with at least one modification that is an amino acid replacement selected from among amino acid replacements corresponding to MIT, S2R, S2K, S2E, S2Q, S2P, S2T, S2L, S2H, S2A, S2V, S3D, S3R, S3G, S3I, S3E, S3V, S3A, S3T, S3L, S3M, S3N, G4K, G4V, G4N, G4I, G4R, G4S, G4P, G4A, G4E, G4F, G4C, G4T, G4L, G4Q, E5A, E5G, E5S, E5T, E5D, E5H, E5I, E5P, E5L, E5N, E5V, T6R, T6V, T6D, T6L, T6A, T6E, T6K, T6S, T6G, T6C, T6M, T6Y, F7C, F7A, F7Q, F7K, F7S, F7G, F7T, F7L, F7R, F7P, F7N, T10V, A11T, D12N, S16N, LI 71, R19K, R19P, R19G, N20D, H21Q, L23S, L23I, K24A, K24Q, K24Y, K24T, G25Y, A26T, S27P, D28G, D28E, F29D, D33T, H34R, T35A, A36C, T37K, Q38V, Q38A, Q38N, Q38E, R40Q, H41I, R50G, T53L, T53R, D54A, D54P, D54C, A55T, A55P, A55R, A55V, A55Q, E56G, E56P, E56F, E56A, E56T, E56Q, D57R, D57P, D57S, D57Q, D57A, K58Q, K58R, K58P, K58E, K58A, V60I, V60G, K62R, V69I, F78L, I82V, A85M, I86L, Q87D, K88Q, K88A, K88H, L89I, C90Y, P91N, I92Y, I92N, I92S, Y93H, Y93F, Y93F, I94E, I94H, D95A, S96H, S96C, N97D, N97E, R98K, R98Y, R98D, A99N, A99M, H102Y, L106A, L106S, L106K, L106F, LU I S, Q113R, I166Y, K117T, V122I, E124N, K125A, K125Q, K127T, D129E, E130R, R132G, , S135E, S136A, N139S, Q142R, S146G, Y152H, M153N, M153G, H159Q, H159K, H159R, E163D, K173E, K173Q, K173A, Q178A, D179P, V181L, T182K, P183S, K184R, K184P, Q188R, I189A, I189V, I189P, T200Q, P202S, F209I, F209H, F209E, F209L, F209T, M210T, M212R,
M212D, M212N, M212S, M212A, M212Y, M212K, M212F, M212H, M212Q, M212I, M212S, M212V, I213Y, I213M, 1213 A, I213R, I213S, I213L, I213F, I213S, I213P, I213Q, I213N, I213K, 1213V, I213Y, N214D, N214E, N214S, N214L, N214Y, N214V, N214P, N214H, N214C, N214A, N214T, N214R, N214Y, N214Q, S215H, S215G, S215K, S215R, S215P, S215A, S215N, S215T, S215L, S215V, S215Q, S215D, T216Q, T216Y, T216E, T216P, T216R, T216C, T216V, T216K, T216D, T216A, T216S, T216K, S217R, S217K, S217F, S217I, S217T, S217G, S217Y, S217N, S217H, S217E, S217F, S217C, S217E, S217D, D218I, D218G, D218V, D218C, D218P, D218M, D218R, D218L, D218S, D218A, D218Y, D218K, D218E, H219D, H219A, H219L, H219C, H219W, H219R, H219S, H219F, H219E, H219G, H219Q, H219A, L220V, L220S, L220T, L220P, L220M, L220A, L220H, L220E, L220G, L220D, L220F, Y221C, Y221V, Y221Q, Y221F, Y221 S, Y221N,Y221T, Y221P, Y221L, Y221K, Y221W, Y221E, Y221V, Y221H, N227S, E238D, K252A, K252Q, T257A, D274M, D274N, D274S, D274F, D274G, D274H, D274E, F279S, F279I, F279P, F279D, F279L, F279N, F279M, F279H, F279C, F279A, F279G, F279W, E280L, P281 S, P281H, P281K, P281A, P281W, P281L, P281Y, Q282L, Q282S, Q282A, Q282I, Q282R,
Q282Y, Q282G, Q282W, Q282P, Q282E, Y283F, Y283N, A284T, A284G, A284P, A284V, A284R, A284D, A284E, A284S, A284H, A284K, A284I, A284W, A284M, Q292K, I299Y, Y307H, L310H, E311P, E311T, L313C, S314A, S314T, L315M, F316L, T317S, E318K, A319T, V320D, V320G, V320S, Q321A, W323R, N324S, I325T, E326K, E333D, K336R, L337I, L343V, A345V, A345T, N347L, N347S, E348A, E348S, E350K, G357R, H360L, H360A, C361R, V362A, E367G, N369I, Q370D, Q370H, Q370G, K371G, A375D, S377Y, Y387C, I397V, L399S, T405R, T409G, N410S, F424L, N429S, N429G, A436S, V439L, Q448L, C465S, K468Q, S473Y, K474T, E484D, I492V, E495G, K499E, P500L, T501P, P506S, D536E and A539V by CVS numbering with reference to positions set forth in SEQ ID NO:2.
In one embodiment, the nucleic acid molecule provided herein encodes a modified valencene synthase polypeptide with at least one modification that is an amino acid replacement and at least one amino acid replacement is at a position corresponding to positions selected from among 1, 2, 3, 4, 5, 6, 7, 11, 19, 20, 23, 24, 28, 38, 50, 53, 54, 55, 56, 57, 58, 60, 62, 69, 78, 82, 88, 93, 97, 98, 102, 106, 111, 113, 125, 132, 152, 153, 159, 163, 173, 184, 188, 189, 200, 202, 209, 210, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 227, 238, 252, 257, 274, 279, 280, 281, 282, 283, 284, 292, 297, 299, 307, 310, 311, 313, 314, 315, 316, 317, 318, 319, 320, 321, 323, 324, 325, 326, 333, 336, 337, 343, 345, 347, 348, 350, 357, 360, 361, 362, 367, 369, 370, 371, 375, 377, 387, 397, 399, 405, 409, 410, 424, 429, 436, 439, 448, 465, 468, 473, 474, 484, 492, 495, 499, 500, 501, 506, 536 and 539 by CVS numbering with reference to positions set forth in SEQ ID NO:2. For example, at least one
amino acid replacement in the modified valencene synthase polypeptide can be selected from among amino acid replacements corresponding to MIT, S2R, S2K, S2E, S2Q, S2P, S2T, S2L, S2H, S2A, S2V, S3D, S3R, S3G, S3I, S3E, S3V, S3A, S3T, S3L, S3M, S3N, G4K, G4V, G4N, G4I, G4R, G4S, G4P, G4A, G4E, G4F, G4C, G4T, G4L, E5A, E5G, E5S, E5T, E5D, E5H, E5I, E5P, E5L, E5N, T6R, T6V, T6D, T6L, T6A, T6E, T6K, T6S, T6G, T6C, T6M, T6Y, F7C, F7A, F7Q, F7K, F7S, F7G, F7T, F7L, F7R, F7P, Al IT, R19K, R19P, N20D, L23S, K24A, K24Q, K24Y, D28G, Q38V, Q38A, Q38N, R50G, T53L, T53R, D54A, D54P, D54C, A55T, A55P, A55R, A55V, A55Q, E56G, E56P, E56F, E56A, E56T, E56Q, D57R, D57P, D57S, D57Q, D57A, K58Q, K58R, K58P, K58E, K58A, V60I, V60G, K62R, V69I, F78L, I82V, K88Q, K88A, Y93H, N97D, R98K, H102Y, L106A, L106S, L106K,
L106F, LI U S, Q113R, K125A, K125Q, R132G, Y152H, M153N, M153G, H159Q, H159K, H159R, E163D, K173E, K173Q, K173A, K184R, Q188R, I189A, I189V, I189P, T200Q, P202S, F209I, F209H, F209E, F209L, F209T, M210T, M212R, M212D, M212N, M212S, M212A, M212Y, M212K, M212F, M212H, M212Q, I213Y, I213M, I213A, I213R, I213S, I213L, I213F, I213S, I213P, I213Q, I213N, I213K, I213V, N214D, N214E, N214S, N214L, N214Y, N214V, N214P, N214H, N214C, N214A, N214T, N214R, S215H, S215G, S215K, S215R, S215P, S215A, S215N, S215T, S215L, S215V, S215Q, T216Q, T216Y, T216E, T216P, T216R, T216C, T216V, T216K, T216D, T216A, T216S, S217R, S217K, S217F, S217I, S217T, S217G, S217Y, S217N, S217H, S217E, S217F, S217C, D218I, D218G, D218V, D218C, D218P, D218M, D218R, D218L, D218S, D218A, D218Y, D218K, H219D, H219A, H219L, H219C, H219W, H219R, H219S, H219F, H219E, L220V, L220S, L220T, L220P, L220M, L220A, L220H, L220E, L220G, L220D, Y221C, Y221V, Y221Q, Y221F, Y221 S, Y221N,Y221T, Y221P, Y221L, Y221K, Y221W, Y221E, Y221V, N227S, E238D, K252A, K252Q, T257A, D274M, D274N, D274S, D274F, D274G, D274H, D274E, F279S, F279I, F279P, F279D, F279L, F279N, F279M, F279H, F279C, F279A, F279G, F279W, E280L, P281 S, P281H, P281K, P281A, P281W, P281L, P281Y, Q282L, Q282S, Q282A, Q282I, Q282R, Q282Y, Q282G, Q282W, Q282P, Q282E, Y283F, Y283N, A284T, A284G, A284P, A284V, A284R, A284D, A284E, A284S, A284H, A284K, A284I, A284W, A284M, Q292K, I299Y, Y307H, L31 OH, E311 P, E311 T, L313C, S314A, S314T, L315M, F316L, T317S, E318K, A319T, V320D, V320G, V320S, Q321A, W323R, N324S, I325T, E326K, E333D, K336R, L337I, L343V, A345V, A345T, N347L, N347S, E348A, E348S, E350K, G357R, H360L, H360A, C361R, V362A, E367G, N369I, Q370D, Q370H, Q370G, K371G, A375D, S377Y, Y387C, I397V, L399S, T405R, T409G, N410S, F424L, N429S, N429G, A436S, V439L, Q448L, C465S, K468Q, S473Y, K474T, E484D, I492V, E495G, K499E, P500L, T501P, P506S, D536E and A539V by CVS numbering with reference to positions set forth in SEQ ID NO:2.
In another embodiment, the modified valencene synthase encoded by the nucleic acid molecule provided herein contains amino acid replacements at positions corresponding to positions selected from among 60, 97, 209, 212, 214, 221, 238, 292, 333, 345, 369, 405, 429, 473 and/or 536, with numbering relative to the valencene synthase polypeptide set forth in SEQ ID NO:2. For example, the encoded modified valencene synthase polypeptide contains amino acid replacements selected from among V60I, V60G, N97D, F209I, F209H, F209E, F209L, F209T, M212R, M212D, M212N, M212S, M212A, M212Y, M212K, M212F, M212H, M212Q, N214D, N214E, N214S, N214L, N214Y, N214V, N214P, N214H, N214C, N214A, N214T, N214R, Y221C, Y221V, Y221Q, Y221F, Y221 S, Y221N, Y221T, Y221P, Y221L, Y221K, Y221W, Y221E, Y221V, E238D, Q292K, E333D, A345V, A345T, N369I, T405R, N429S, N429G, S473Y, and/or D536E by CVS numbering with reference to positions set forth in SEQ ID NO:2.
Among the nucleic acid molecules provided herein are those that encode modified valencene synthase polypeptides that contain amino acid replacements selected from among replacements corresponding to N214D/S473Y; T405R; A345V/D536E; Y221C; E238D; F209I; N97D; E333D/N369I; N214D/T405R; N214D/A345V/T405R/D536E;
V60I/N214D/A345T/T405R; N214D/T405R/N429S; N214D/Q292K/T405R;
V60G/N214D/T405R; V60I/N214D/A345T/T405R/N429S ;
V60I/M212R/N214D/Y221V/A345T/T405R/N429G, by CVS numbering with numbering relative to positions set forth in SEQ ID NO:2.
In some examples, the nucleic acid molecule provided herein encodes a modified valencene synthase having amino acid replacements at positions corresponding to positions 60, 209, 238 and 292 by CVS numbering with numbering relative to positions in the valencene synthase polypeptide set forth in SEQ ID NO:2. For example, the encoded modified valencene synthase polypeptide contains a replacement at position V60 that is V60I or V60G; a replacement at position F209 that is F209I, F209H, F209E, F209L or F209T; a replacement at position E238 that is E238D; and a replacement at position Q292, that is Q292K, each by CVS numbering with numbering relative to positions set forth in SEQ ID NO:2.
In some examples, the nucleic acid molecule provided herein encodes a modified valencene synthase having amino acid replacements at positions corresponding to positions 60, 125, 173, 209, 238, 252 and 292 with numbering relative to the valencene synthase polypeptide set forth in SEQ ID NO:2. For example, the encoded modified valencene synthase polypeptide contains a replacement at position V60 that is V60I or V60G; a replacement at position K125 that is K125A or K125Q; a replacement at position K173 that is K173E, K173Q or K173A; a replacement at position F209 that is F209I, F209H, F209E,
F209L or F209T; a replacement at position E238 that is E238D; a replacement at position K252 that is K252Q; and a replacement at position Q292, that is Q292K, each by CVS numbering with numbering relative to positions set forth in SEQ ID NO:2.
Among the nucleic acid molecules provided herein are those that encode modified valencene synthase polypeptides that contain amino acid replacements selected from among replacements corresponding to:
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/
Kl 73 A/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/
Q321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y /T405R/ N429G/ A436S/T501P/D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/V320S/Q321 A/E326K/E333D/A345 T/N369I/ S377Y/T405R/N429G/A436S/ T501P/D536E;
K24A/Q38A/R50G/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F 209I/M212R/N214D/ H219D/Y221 V/E238D/K252A/Q292K/V320G/Q321 A/
E333D/A345T/N369I/S377Y/T405R/N429G/A436S/ T501P/D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/Q292K/L315M/Q321A/E333D/A345T/N369 I/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/V320G/Q321 A/E333D/A345T/N369 I/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E333D/A345T/G357R/N3691 /S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E333D/A345T/N369I/E367G /S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E333D/A345T/N369I/Q370 D/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/Q292K/I299Y/Q321A/E333D/A345T/N369I/ S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58AA^60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E333D/A345T/H360L/N3691 /S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/Q292K/T317S/Q321A/E333D/A345T/N369I /S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/V320D/Q321 A/E333D/A345T/N369 I/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38V/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/Q292K/Q321A/E333D/A345T/N369I/S377Y /T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/Q292K/Q321A/E333D/A345T/N369I/S377Y /T405R/T409G/N429G/A436S/E495G/ T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/P281 S/Q292K/Q321 A/E333D/L337I/A345T/ N369I/S377Y/T405R/N429G/A436S/ T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/Q292K/Q321A/E333D/A345T/N369I/A375 D/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E333D/K336R/A345T/N3691 /S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/E311 P/Q321 A/E333D/A345T/N3691 /S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E333D/A345T/N369I/Q370 H/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E333D/L343 V/A345T/H360 A/N369I/S377Y/T405R/N429G/A436S/ T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/Q282S/Q292K/Q321A/E333D/A345T/N369I /S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58AA^60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E333D/A345T/N369I/K371 G/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/Q292K/Q321A/E333D/A345T/N347L/N369I /S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/E311 T/Q321 A/E333D/A345T/N3691 /S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q282L/Q292K/Q321 A/E333D/A345T/N3691 /S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/S314T/Q321 A/E333D/A345T/N3691 /S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E333D/A345T/N369I/Q370 G/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/Q292K/L310H/Q321A/E333D/A345T/V362 A/N369I/S377Y/T405R/N429G/A436S/ T501P/D536E;
K24A/Q38A/K58A/V60I/F78L/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F2 09I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/L313C/Q321 A/E333D/A345T/N 369I/S377Y/T405R/N429G/A436S/ T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/I299Y/L310H/E311 P/Q321 A/ E333D/A345T/N369I/S377Y/T405R/ N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q282L/Q292K/L310H/Q321 A/E333D /A345T/N369I/S377Y/T405R/N429G/ A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q282L/Q292K/I299Y/E311 P/Q321 A/ E333D/A345T/N369I/S377Y/T405R/ N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L313 C/S314T/L315M/T317S/ Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/Q321 A/E333D/K336R/A345 T/N347L/G357R/N369I/S377Y/T405R/ N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/L310H/E311 T/L313 C/S314T/L315M /T317S/V320G/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252Q/P281 S/Q292K/T317S/Q321A/E333D/K336R /L337I/A345T/N347L/G357R/N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/T317S/Q321 A/E333D/K336R/L3371/ A345T/G357R/N369I/S377Y/T405R/ N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252Q/P281 S/Q292K/T317S/Q321A/E333D/K336R /A345T/N347L/G357R/N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/T317S/Q321 A/E333D/A345T /G357R/N369I/S377Y/T405R/N429G/ A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L310H/E311 T/L313 C/T317S/ V320G/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L313 C/S314T/L315M/T317S/ Q321A/E333D/K336R/A345T/N347LG357R/N369I/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/Q370 D/A375D/S377Y/T405R/T409G/N429G/ A436S/E495G/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L313 C/S314T/L315M/T317S/ Q321A/E333D/K336R/L337I/A345T/N347L/G357R/N369I/S377Y/T405R/N429G/A436S/ T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L313 C/S314T/L315M/T317S/ Q321A/E333D/K336R/L337I/A345T/G357R/N369I/S377Y/T405R/N429G/A436S/T501P/ D536E;
S2R/S3D/G4K/E5G/F7C/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125 Q/Kl 73 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E33 3D/A345T/N369I/S377Y/T405R/ N429G/A436S/T501P/D536E;
S2E/S3G/G4N/E5S/T6V/F7Q/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K 125Q/K173 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/ E333D/A345T/N369I/S377Y/T405R/ F424L/N429G/A436S/T501P/D536E;
S2K/S3R/G4V/E5G/T6R/F7A/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/ Kl 25Q/K173 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A345T/N369I/S377Y/T405R/ N429G/A436S/T501P/D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/D274M/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/D274N/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/D274S/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/D274F/Q292K/Q321A/E333D/A345T/N369I /S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/D274G/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/D274H/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/D274E/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/F279S/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/F279I/Q292K/Q321A/E333D/A345T/N369I/ S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58AA^60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/F279P/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/F279D/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/F279L/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/F279N/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A281 W/Q292K/Q321 A/E333D/A345T/ E350K/N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/F279M/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/F279H/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/F279C/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/P281 W/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/F279A/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/F279G/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/F279W/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58AA^60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/P281 H/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/P281 K/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/P281 A/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/P281 S/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/P281W/Y283F/Q292K/Q321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/P281 A/Q282P/Q292K/Q321 A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/F316L/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/E280L/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/P281 L/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/P281 Y/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/P281 L/Q282P/Q292K/Q321 A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/Q282S/Q292K/Q321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58AA^60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q282A/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q282I/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q282R/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q282Y/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q282L/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q282G/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/Q282G/Q292K/Q321A/N324S/E333D/ A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q282A/Q292K/Q321 A/E333D/A345T/ N347S/N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q282W/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q282P/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Q282E/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/A284T/Q292K/Y307H/Q321A/E333D/ A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58AA^60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284G/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284P/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284G/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284V/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284G/Q292K/D301X/Q321 A/E333D/A345 T/R358X/N369I/S377Y/V378X/T405R/ N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284R/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284D/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284E/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/Y283N/A284S/Q292K/Q321 A/E333D/ A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284H/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284K/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252A/A284I/Q292K/Q321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58AA^60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284W/Q292K/Q321 A/E333D/L342X/ A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284T/Q292K/Q321 A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252A/A284M/Q292K/Q321 A/W323R/E333D/ A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q282S/Q292K/E311 P/Q321 A/E333D / A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q282S/Q292K/L310H/E318K/Q321 A /E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q282S/Q292K/L310H/Q321 A/E333D /A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/E311P/Q321A/E333D/A345T/N369I /S377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/T317S/V320G/Q321 A/E333D/A345 T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/H360L/N369I /Q370H/ A375D/S377Y/T405R/T409G/N429G/A436S/E495G/T501P/ D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/Q370 H/ A375D/S377Y/T405R/T409G/N429G/A436S/E495G/T501P/ D536E;
S2P/S3R/G4R/E5D/T6R/F7A/K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K 125Q/K173 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/ E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
S3L/G4S/E5H/T6D/F7S/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q /K173Q/K184R/F209I/M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333 D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
S2T/S3R/E5I/T6L/F7K/K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/ Kl 73 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D /A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
S2L/S3D/G4S/E5I/T6A/F7G/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K 125Q/K173 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/ E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
S2H/S3E/G4P/E5S/T6E/F7T/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K 125Q/K173 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/ E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
S2L/S3G/G4V/E5S/T6E/F7Q/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K 125Q/K173 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/ E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
S2R/S3V/G4A/E5P/T6K/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125 Q/Kl 73 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E33 3D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
S2R/S3A/G4E/E5L/T6S/F7L/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K 125Q/K173 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/ E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
S2Q/G4I/E5T/T6D/F7K/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q /Kl 73 Q/Kl 84R/F209I/M212R N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333 D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
S2R/S3V/G4I/E5D/T6G/F7G/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K 125Q/K173 Q/Kl 84R/F209I/M212R N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/ E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/L106A/K125Q/K173Q/K184R/ F209I/M212R N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A345T/N369I/ S377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/L106S/K125Q/K173Q/K184R/F 209I/M212R N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S 377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/L106K/K125Q/K173Q/K184R/ F209I/M212R N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A345T/N369I/ S377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/T53L/D54A/A55P/E56P/D57P/K58R/V60I/K88Q/Y93H/N97D/R98K/ Kl 25Q/K173 Q/Kl 84R/F209I/M212R N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/M153N/K173Q/K184R/ F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A345T/N369I/ S377Y/ T405R/N429G/A436S/K474T/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/I213S/N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/ S377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219A/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y /T405R/ N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/Q188R/I 189V/P202S/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A 345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/M153N/K173Q/K184R/ F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A345T/N369I/ S377Y/ T405R/N429G/A436S/ K474T/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/H159R/K173Q/K184R/ F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A345T/N369I/ S377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/H159K/K173Q/K184R/ F209I/M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/ S377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/I189P/F 209I/M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S 377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/T53L/D54P/A55R/E56F/D57S/K58QA^60I/K88Q/Y93H/N97D/R98K/ Kl 25Q/K173 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252QQ292K/Q321 A /E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24Q/Q38N/D54A/A55V/E56A/D57Q/K58P/V60I/K88Q/Y93H/N97D/R98K/L106 F/Kl 25Q/K173 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q32 1A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24Q/Q38N/T53R/D54A/A55Q/E56T/D57A/K58R V60I/K88Q/Y93H/N97D/R98K /Kl 25Q/K173 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24Q/Q38N/T53R/D54C/A55V/E56Q/D57P/K58E/V60I/K88Q/Y93H/N97D/R98K/ Kl 25Q/K173 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/R132G/K173Q/K184R/ F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A345T/N369I/ S377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/H159Q/K173Q/K184R/ F209I/M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/ S377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/M153G/K173Q/K184R/ F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E333D/A345T/N369I/ S377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y /I397V/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/I189A/F 209I/M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S 377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/L310H/E311 P/Q321 A/E333D/A345 T/N369I/ S377Y/T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212N/I213 Y/N214L/S215R/T216R/S217I/D218P/H219A/L220D/Y221 S/E238D/K252Q/P 281 S/Q292K/L313C/S314T/L315M/T317S/Q321 A/E333D/K336R/L337I/A345T/G357R/N3 69I/S377Y/T405R/N429G/A436S/ T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/Q113R/K125Q/K173Q/K184R/ F209I/M212D/I213 Y/N214E/S215H/T216Q/D218I/H219L/L220V/Y221 Q/E238D/K252Q/P 281 S/Q292K/L313C/S314T/L315M/T317S/Q321 A/E333D/K336R/L337I/A345T/G357R/N3 69I/S377Y/T405R/N429G/A436S/ T501P/ D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212S/I213L/N214E/S215P/T216P/S217F/D218M/L220P/Y221 C/E238D/K252Q/Q292K/L 313C/S314T/L315M/T317S/Q321A/E333D/K336R/L337I/A345T/G357R/N369I/S377Y/T40 5R/N429G/A436S/T501P/ D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212A/N214Y/S215A/T216R/S217T/D218G/H219R/L220M/Y221N/E238D/K252Q/Q292 K/L313C/S314T/L315M/T317S/Q321A/E333D/K336R/L337I/A345T/G357R/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212N/I213M/N214S/T216Y/S217R/D218G/H219C/L220S/Y221 V/E238D/K252Q/P281 S/
-
Q292K/L313C/S314T/L315M T317S/A319T/Q321 A/E333D K336R/L337I/A345T N369I/S 377Y/T405R/N429G/A436S/T501P/ D536E;
K24Q/Q38N 58Q V60I/ 88Q Y93H/N97D/R98K/ 125Q 173Q/K184R/F209I/ M212D/I213A/S215G/T216E/S217K/D218V H219L/L220S Y221 F/E238D/ 252Q/P281 S/Q 292K/L313C/S314T L315M/T317S/Q321 A/E333D/ 336R/L337I/A345T/G357R/N369I/S37 7Y/T405R/N429G/A436S/ T501P/D536E;
K24Q/Q38N/ 58Q V60I/ 88QA^93H/N97D/R98K/ 125Q 173Q/ 184R/F209I M212S/I213R/N214S/S215Κ Γ216P/S217F/D218C/H219 W/L220T/Y221 S/E238D/K252Q/Q 292K/Q321A/E333D/A345T/N369I S377Y T405R/N429G/A436S/ T501 P D536E; and
K24Q/Q38N K58Q V60I/K88Q Y93H/N97D/R98 / 125Q/ 173Q 184R/F209H/
M212R/N214D H219D Y221 V/E238D K252Q/P281 S/Q292 /L313C/S314T L315Μ Γ317S/ Q321A^333D/K336RyL337I/A345T/G357R/N369yS377Y/T405R/N429G/A436Sy 501P D 536E, each with numbering relative to positions set forth in SEQ ID NO:2.
Provided herein are nucleic acid molecules having a sequence of nucleic acids set forth in any of SEQ ID NOS: 128-202, 204-288, 693-701, 704-712, 716-722, 754-775 and 800. Also provided herein are nucleic acid molecules having a sequence of nucleic acids having at least 95% sequence identity to a sequence of nucleic acids set forth in any of SEQ ID NOS: 128-202, 204-288, 693-701 , 704-712, 716-722, 754-775 and 800. Also provided herein are nucleic acid molecules having a sequence of nucleic acids that are degenerate to a sequence of nucleic acids set forth in any of SEQ ID NOS: 128-202, 204-288, 693-701, 704- 712, 716-722, 754-775 and 800. For example, the nucleic acid molecules have a sequence of nucleic acids set forth in any of SEQ ID NOS: 128-202, 204-288, 693-701, 704-712, 716-722, 754-775 and 800.
Provided herein are nucleic acid molecules encoding a modified valencene synthase having a sequence of amino acids set forth in any of SEQ ID NO: 3-66, 68-127, 723-731 , 734-742, 746-751, 810-832 and 857. Also provided herein are nucleic acid molecules encoding a modified valencene synthase having a sequence of amino acids that has at least 95% sequence identity to the sequence of amino acids set forth in any of SEQ ID NO: 3-66, 68-127, 723-731, 734-742, 746-751, 810-832 and 857. For example, the nucleic acid molecule encodes a modified valencene synthase that has a sequence of amino acids set forth in any of SEQ ID NO: 3-66, 68-127, 723-731, 734-742, 746-751, 810-832 and 857.
Also provided herein are nucleic acid molecules encoding modified valencene polypeptides that contain one or more heterologous domains or portions thereof from one or more terpene synthases, wherein the domain is an unstructured loop 1 ; alpha helix 1 ;
unstructured loop 2; alpha helix 2; unstructured loop 3; alpha helix 3; unstructured loop 4; alpha helix 4; unstructured loop 5; alpha helix 5; unstructured loop 6; alpha helix 6;
RECTIFIED SHEET (RULE 91)
ISA/EP
unstructured loop 7; alpha helix 7; unstructured loop 8; alpha helix 8; unstructured loop 9; alpha helix A; A-C loop; alpha helix C; unstructured loop 11 ; alpha helix D; unstructured loop 12; alpha helix Dl ; unstructured loop 13; alpha helix D2; unstructured loop 14; alpha helix E; unstructured loop 15; alpha helix F; unstructured loop 16; alpha helix Gl ;
unstructured loop 17; alpha helix G2; unstructured loop 18; alpha helix HI ; unstructured loop 19; alpha helix H2; unstructured loop 20; alpha helix H3; unstructured loop 21 ; alpha helix a- 1 ; unstructured loop 22; alpha helix I; unstructured loop 23; alpha helix J; J-K loop; alpha helix K; and/or unstructured loop 25.
Also provided herein are nucleic acid molecules encoding a modified valencene polypeptide that contains one or more heterologous domains or portions thereof from one or more terpene synthases. For example, the one or more heterologous domain can be selected from among unstructured loop 1 ; alpha helix 1 ; unstructured loop 2; alpha helix 2;
unstructured loop 3; alpha helix 3; unstructured loop 4; alpha helix 4; unstructured loop 5; alpha helix 5; unstructured loop 6; alpha helix 6; unstructured loop 7; alpha helix 7;
unstructured loop 8; alpha helix 8; unstructured loop 9; alpha helix A; A-C loop; alpha helix C; unstructured loop 11 ; alpha helix D; unstructured loop 12; alpha helix Dl ; unstructured loop 13; alpha helix D2; unstructured loop 14; alpha helix E; unstructured loop 15; alpha helix F; unstructured loop 16; alpha helix Gl; unstructured loop 17; alpha helix G2;
unstructured loop 18; alpha helix HI ; unstructured loop 19; alpha helix H2; unstructured loop 20; alpha helix H3; unstructured loop 21 ; alpha helix a-1 ; unstructured loop 22; alpha helix I; unstructured loop 23; alpha helix J; J-K loop; alpha helix K; and/or unstructured loop 25. In some examples, the heterologous domain or a contiguous portion thereof replaces all or a contiguous portion of the corresponding native domain of the valencene synthase not containing the heterologous domain. In other examples, the encoded modified valencene synthase contains all of a heterologous domain of a different terpene synthase. Also provided herein are nucleic acid molecules encoding a modified valencene polypeptide that contains at least 50%, 60%, 70%>, 80%>, 90%>, or 95%> of contiguous amino acids of a heterologous domain from one or more terpene synthases.
In one embodiment, the modified valencene synthase polypeptide encoded by the nucleic acid molecule contains a heterologous domain that is all or a contiguous portion of the unstructured loop 2 domain. For example, the encoded modified valencene synthase polypeptide contains a heterologous unstructured loop 2 domain or contiguous portion thereof, whereby the native unstructured loop 2 domain corresponding to amino acids residues 53-58 of the valencene synthase polypeptide set forth in SEQ ID NO:2 is replaced with all or a portion of the corresponding region from a different terpene synthase. In another embodiment, the modified valencene synthase polypeptide encoded by the nucleic acid
- -
molecule contains a heterologous domain that is all or a contiguous portion of the alpha helix 3 domain. For example, the encoded modified valencene synthase polypeptide contains a heterologous alpha helix 3 domain or contiguous portion thereof, whereby the native alpha helix 3 domain corresponding to amino acids residues 79-93 of the valencene synthase polypeptide set forth in SEQ ID NO:2 is replaced with all or a portion of the corresponding region from a different terpene synthase. In a further embodiment, the modified valencene synthase polypeptide encoded by the nucleic acid molecule contains a heterologous domain that is all of a contiguous portion of the unstructured loop 5 domain. For example, the encoded modified valencene synthase polypeptide contains an unstructured loop 5 domain or contiguous portion thereof, whereby the native unstructured loop 5 domain corresponding to amino acid residues 1 15-141 of the valencene synthase polypeptide set forth in SEQ ID NO:2 is replaced with all or a portion of the corresponding region from a different terpene synthase.
In yet another embodiment, the modified valencene synthase polypeptide encoded by the nucleic acid molecule contains a heterologous domain that is all or a contiguous portion of the unstructured loop 6 domain. For example, the encoded modified valencene synthase polypeptide contains a heterologous unstructured loop 6 domain or contiguous portion thereof, whereby the native unstructured loop 6 domain corresponding to amino acids residues 153-162 of the valencene synthase polypeptide set forth in SEQ ID NO:2 is replaced with all or a portion of the corresponding region from a different terpene synthase. In one embodiment, the modified valencene synthase polypeptide encoded by the nucleic acid molecule contains a heterologous domain that is all or a contiguous portion of the
unstructured loop 7 domain. For example, the encoded modified valencene synthase polypeptide contains a heterologous unstructured loop 7 domain or contiguous portion thereof, whereby the native unstructured loop 7 domain corresponding to amino acids residues 174-184 of the valencene synthase polypeptide set forth in SEQ ED NO:2 is replaced with all or a portion of the corresponding region from a different terpene synthase.
In another embodiment, the modified valencene synthase polypeptide encoded by the nucleic acid molecule contains a heterologous domain that is all or a contiguous portion of the unstructured loop 9 domain. For example, the encoded modified valencene synthase polypeptide contains a heterologous unstructured loop 9 domain or contiguous portion thereof, whereby the native unstructured loop 9 domain corresponding to amino acids residues 213-222 of the valencene synthase polypeptide set forth in SEQ ID NO:2 is replaced with all or a portion of the corresponding region from a different terpene synthase. In another embodiment, the modified valencene synthase polypeptide encoded by the nucleic acid molecule contains a heterologous domain that is all or a contiguous portion of the alpha helix Dl domain. For example, the encoded modified valencene synthase polypeptide contains a
RECTIFIED SHEET (RULE 91)
ISA/EP
heterologous alpha helix Dl domain or contiguous portion thereof, whereby the native alpha helix Dl domain corresponding to amino acids residues 310-322 of the valencene synthase polypeptide set forth in SEQ ID NO:2 is replaced with all or a portion of the corresponding region from a different terpene synthase.
In yet another embodiment, the modified valencene synthase polypeptide encoded by the nucleic acid molecule contains a heterologous domain that is all or a contiguous portion of the J-K loop domain. For example, the encoded modified valencene synthase polypeptide contains a heterologous J-K loop domain or contiguous portion thereof, whereby the native J- K loop domain corresponding to amino acids residues 522-534 of the valencene synthase polypeptide set forth in SEQ ID NO:2 is replaced with all or a portion of the corresponding region from a different terpene synthase. In another embodiment, the modified valencene synthase polypeptide encoded by the nucleic acid molecule contains a heterologous domain that is all or a contiguous portion of the unstructured loop 1 domain. For example, the encoded modified valencene synthase polypeptide contains a heterologous unstructured loop 1 domain or contiguous portion thereof, whereby the native unstructured loop 1 domain corresponding to amino acid residues 1 -29 of the valencene synthase polypeptide set forth in SEQ ID NO:2 is replaced with all or a portion of the corresponding region from a different terpene synthase.
In yet another embodiment, the modified valencene synthase polypeptide encoded by the nucleic acid molecule contains a heterologous domain that is all or a contiguous portion of the alpha helix 1 domain. For example, the encoded modified valencene synthase polypeptide contains a heterologous alpha helix 1 domain or contiguous portion thereof, whereby the native alpha helix 1 domain corresponding to amino acid residues 30-39 and 44-52 of SEQ ID NO:2 is replaced with all or a contiguous portion of the corresponding region from a different terpene synthase. In a further embodiment, the modified valencene synthase polypeptide encoded by the nucleic acid molecule contains a heterologous domain that is all or a contiguous portion of the unstructured loop 4 domain. For example, the encoded modified valencene synthase polypeptide contains a heterologous unstructured loop 4 domain or contiguous portion thereof, whereby the native unstructured loop 4 domain corresponding to amino acid residues 94-100 of SEQ ID NO:2 is replaced with all or a contiguous portion of the corresponding region from a different terpene synthase.
Provided herein are nucleic acid molecules encoding a modified valencene polypeptide that contains one or more heterologous domains or portions thereof from one or more terpene synthases wherein the different terpene synthase is a terpene synthase set forth in Table 5B. In one example, the different terpene synthase is selected from among Vitis
vinifera valencene synthase, tobacco epi-aristolochene synthase (TEAS) and Hyoscyamus muticus premnaspirodiene synthase (HPS).
In one embodiment, the encoded modified valencene synthase polypeptide has a heterologous unstructured loop 2 domain or a contiguous portion thereof, whereby amino acids residues corresponding to positions 53-58 of the valencene synthase polypeptide set forth in SEQ ID NO:2 are replaced with amino acids residues 58-63 of the TEAS polypeptide set forth in SEQ ID NO:295 or 941. In another enbodiement, the encoded modified valencene synthase polypeptide comprises a heterologous alpha helix 3 domain or a contiguous portion thereof and a heterologous unstructured loop 4 domain or contiguous portion thereof, whereby amino acids residues corresponding to positions 85-89 of the valencene synthase polypeptide set forth in SEQ ID NO:2 are replaced with amino acid residues 93-97 of the HPS polypeptide set forth in SEQ ID NO:942. In yet another embodiment, the encoded modified valencene synthase polypeptide contains a heterologous alpha helix 3 domain or a contiguous portion thereof and a heterologous unstructured loop 4 domain or a contiguous portion thereof, whereby amino acids residues corresponding to positions 85-99 of the valencene synthase polypeptide set forth in SEQ ID NO:2 are replaced with amino acid residues 96-112 of the Vitis vinifera valencene synthase set forth in SEQ ID NO:346. In a further embodiment, the encoded modified valencene synthase polypeptide contains a heterologous unstructured loop 5 domain or a contiguous portion thereof, whereby amino acid residues at positions corresponding to positions 115-146 of the valencene synthase polypeptide are replaced with amino acid residues 128-129 of the Vitis vinifera valencene synthase set forth in SEQ ID NO:346.
In a further embodiment, the encoded modified valencene synthase polypeptide comprises a heterologous unstructured loop 7 domain or a contiguous portion thereof, whereby amino acids residues at positions corresponding to positions 174-184 of the valencene synthase polypeptide set forth in SEQ ID NO:2 are replaced with amino acid residues 185-193 of the HPS polypeptide set forth in SEQ ID NO:942. In another embodiment, the encoded modified valencene synthase polypeptide comprises a heterologous loop 9 domain or a contiguous portion thereof, whereby amino acids residues at positions corresponding to positions 212-221 of the valencene synthase polypeptide set forth in SEQ ID NO:2 are replaced with amino acid residues 221-228 of the HPS polypeptide set forth in SEQ ID NO:942. In yet another embodiment, the encoded modified valencene synthase polypeptide comprises a heterologous loop 9 domain or a contiguous portion thereof, whereby amino acid residues at positions corresponding to positions 212-221 of the valencene synthase polypeptide set forth in SEQ ID NO:2 are replaced with amino acid residues 213-221 of the TEAS polypeptide set forth in SEQ ID NO:295.
- -
In one embodiment, the encoded modified valencene synthase polypeptide comprises a heterologous unstructured loop 9 domain or a contiguous portion thereof, whereby amino acid residues at positions corresponding to positions 212-221 of the valencene synthase polypeptide set forth in SEQ ID NO:2 are replaced with amino acid residues 223-230 of the Vitis vinifera valencene synthase set forth in SEQ ID NO:346. In other embodiments, the encoded modified valencene synthase polypeptide comprises a heterologous unstructured loop 1 domain or a contiguous portion thereof and a heterologous alpha helix 1 domain or a contiguous portion thereof, whereby amino acid residues at positions corresponding to position 3-41 of the valencene synthase polypeptide set forth in SEQ ID NO:2 are replaced with amino acid residues 3-51 of the Vitis vinifera valencene synthase set forth in SEQ ID NO:346. In yet another embodiment, the encoded modified valencene synthase polypeptide comprises a heterologous unstructured loop 6 domain or a contiguous portion thereof, whereby amino acids residues at positions corresponding to positions 152-163 of the valencene synthase polypeptide set forth in SEQ ID NO:2 are replaced with amino acid residues 163- 174 of the HPS polypeptide set forth in SEQ ID NO:942.
In one embodiment, the encoded modified valencene synthase polypeptide comprises a heterologous alpha helix Dl domain or contiguous portion thereof, whereby amino acids residues at positions corresponding to positions 310-322 of the valencene synthase polypeptide set forth in SEQ ID NO:2 are replaced with amino acid residues 317-329 of the HPS polypeptide set forth in SEQ ID NO:942. In another embodiment, the encoded modified valencene synthase polypeptide comprises a heterologous J-K loop domain or a contiguous portion thereof, whereby amino acids residues at positions corresponding to positions 522- 534 of the valencene synthase polypeptide set forth in SEQ ID NO:2 are replaced with amino acid residues 527-541 of the HPS polypeptide set forth in SEQ ID NO:942.
Among the nucleic acid molecules provided herein are those that encode modified valencene synthase polypeptides that contains replacements selected from among
modifications corresponding to:
K24Q/Q38N/ T53L D54A A55T/ E56G/ D57R / V60I/K88Q/Y93H/ N97D/ R98 / 125Q 173Q/K 184R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/
Q292 /Q321A/E333D/A345T/N369I/S377Y T405R/N429G/A436S/T501P/ D536E;
24Q/Q38N T53L/D54A/A55T/E56G D57R/V60I 88Q/Y93H/N97D R98 / 125 Q K 173Q/K 184R/F2091/M212R/N214D/H219D Y221 V/E238D/K252Q/P281 S/Q292K/L313 C/S314T L315M/T317S/Q321A/E333D/K336R/L337I/A345T N347IJG357R/N369I/S377Y/ T405R/N429G/A436S/T501 P/D536E;
i 4Q/Q38Nm3UD54A/A55T/E56G D57IW60I K88Q Y93H/N97D/R98K/K125 Q/K 173Q/K 184R/F209I/M212R/N214D/H219D/Y221 V E238D/K252Q/P281 S/Q292K/L313
RECTIFIED SHEET (RULE 91)
ISA/EP
C/S314T/L315M/T317S/Q321A/E333D/K336R/L337I/A345T/G357R/N369I/S377Y/T405R/
N429G/A436S/T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/
L175→— /V176→— /Q178→A176/D179→P177/V181→L179/
T182→K180/P183→S181/K184→P182/F209→I207/M212→R210/N214→D212/H219→D2
17/Y221→V219/E238→D236/K252→Q250/P281→S279/Q292→K290/L313→C311/S314
→T312/L315→M313/T317→S315/Q321→A319/E333→D331/K336→R334/L337→I335/A
345→T343/G357→R355/N369→I367/S377→Y375/T405→R403/N429→G427/A436→S43
4/T501→P499/D536→E534;
S2R/S3D/G4K/E5G/F7C/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125
Q/Kl 73Q/L175→— /VI 76→— /Q 178→A176/D 179→P177/
V181→L179/T182→K180/P183→S181/K184→P182/F209→I207/M212→R210/N214→D 212/H219→D217/Y221→V219/E238→D236/K252→Q250/P281→S279/Q292→K290/L31 3→C311/S314→T312/L315→M313/T317→S315/Q321→A319/E333→D331/K336→R334/ L337→I335/A345→T343/G357→R355/N369→I367/S377→Y375/T405→R403/N429→G4 27/A436→S434/E484→D482/T501→P499/D536→E534;
K24Q/Q38N/T53L/D54A/A55T/E56G/D57R/V60I/A85M/I86L/Q87D/K88H/L89I/C 90 Y/-— >R91/-— >A92/ >D93/I92→Y95/Y93→F96/I94→E97/
D95→A98/S96→H99/N97→E100/R98→Y101/A99→N102/L111→S114/K125→Q128/K17 3→Q 176/L175→— /VI 76→— /Q 178→A179/D 179→P 180/
V181→L182/T182→K183/P183→S184/K184→P185/F209→I210/M212→R213/N214→D2 15/H219→D220/Y221→V222/E238→D239/K252→Q253/P281→S282/Q292→K293/L313 →C314/S314→T315/L315→M316/T317→S318/Q321→A322/E333→D334/K336→R337/L 337→I338/A345→T346/G357→R358/N369→I370/S377→Y378/T405→R406/N429→G43 0/A436→S437/E484→D485/T501→P502/D536→E537;
R19K/K24Q/Q38N/T53L/D54A/A55T/E56G/D57R V60I/A85M/I86L/Q87D/K88H/ L89I/C90Y/-— >R91/-— >A92/-— >D93/I92→Y95/Y93→F96/
I94→E97/D95→A98/S96→H99/N97→E100/R98→Y101/A99→N102/K125→Q128/K173
→Q 176/L175→— /VI 76→— /Q 178→A179/D 179→P180/
V181→L182/T182→K183/P183→S184/K184→P185/F209→I210/M212→R213/N214→D2
15/H219→D220/Y221→V222/E238→D239/K252→Q253/P281→S282/Q292→K293/L313
→C314/S314→T315/L315→M316/T317→S318/Q321→A322/E333→D334/K336→R337/L
337→I338/A345→T346/G357→R358/N369→I370/S377→Y378/T405→R406/N429→G43
0/A436→S437/E484→D485/T501→P502/D536→E537;
K24Q/Q38N/T53L/D54A/A55T/E56G/D57R/V60I/A85M/I86L/Q87D/K88H/L89I/C
90 Y/-— >R91/-— >A92/—
→D93/I92→Y95/Y93→F96/I94→E97/D95→A98/S96→H99/N97→E100/R98→Y101/A99 →N102/K125→Q128/K173→Q176/L175→— /V176→—
/Q178→A179/D179→P180/V181→L182/T182→K183/P183→S184/K184→P185/F209→I2 10/M212→R213/N214→D215/H219→D220/Y221→V222/E238→D239/K252→Q253/P281 →S282/Q292→K293/L313→C314/S314→T315/L315→M316/T317→S318/Q321→A322/E 333→D334/K336→R337/L337→I338/A345→T346/G357→R358/N369→I370/S377→Y37 8/T405→R406/N429→G430/A436→S437/E484→D485/T501→P502/D536→E537;
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M2121/1213 Y/N214E/S215→— /T216→—
/S217→E215/D218→E216/H219→G217/L220→F218/Y221→K219/E238→D236/K252→ Q250/P281→S279/Q292→K290/L313→C311/S314→T312/L315→M313/T317→S315/Q32 1→A319/E333→D331/K336→R334/L337→I335/A345→T343/G357→R355/N369→I367/S 377→Y375/T405→R403/N429→G427/A436→S434/T501→P499/D536→E534;
R19K/K24Q/Q38N/T53L/D54A/A55T/E56G/D57R V60I/A85M/I86L/Q87D/ K88H/L89I/C90Y/-— >R91/-— >A92/-— >D93/I92→Y95/Y93→F96/
I94→E97/D95→A98/S96→H99/N97→E100/R98→Y101/A99→N102/K125→Q128/K173 →Q 176/L175→— /VI 76→— /Q 178→A179/D 179→P180/V181→L182/
T 182→K183/P183→S 184/K184→P185/F209→I210/M212→S213/N214→Y215/S215→D2 16/T216→K217/S21 Ί-Ι D218E/ H219Q/ L220S/ Y22 IK/ E238D/
K252Q/P281 S/Q292K/L313C/S314T/L315M/T317S/Q321A/E333D/K336R/L337I/A345T/G 357R/N369I/S377Y/T405R/N429G/A436S/E484D/T501P/D536ER19K/K24Q/Q38N/T53L/ D54A/A55T/E56G/D57R/V60I/A85M/I86L/Q87D/K88H/L89I/C90Y/-— >R91/-— >A92/— →D93/I92→Y95/Y93→F96/I94→E97/D95→A98/
S96→H99/N97→E100/R98→Y101/A99→N102/K125→Q128/K173→Q176/L175→— /V176→— / Q178→A179/ D179→P180/ V181→L182/
T 182→K183/P183→S 184/K184→P185/F209→I210/M212→S213/N214→Y215/S215→D2 16/T216→K217/S21 Ί-Ι D218E/ H219Q/
L220S/Y221K/E238D/K252Q/P281 S/Q292K/L313C/S314T/L315M/T317S/Q321 A/I325T/E 333D/K336R/L337I/A345T/G357R/N369I/S377Y/T405R/N429G/A436S/E484D/T501P/D53 6E;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/— >R91/— >A92/— >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ LI 75→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→V213/ 1213→Y214/ N214→~/ S215→~/ T216→Q215/ S217→D216/ D218→E217/ H219→A218/ L220→F2191 Y221→H220/
E238→D237/ K252→Q251/ P281→S280/ Q292→K291/ L313→C312/ S314→T313/ L315→M314/ T317→S316/ Q321→A320/ E333→D332/ K336→R335/ L337→I336/ A345→T344/ G357→R356/ N369→I368/ S377→Y376/ T405→R404/ N429→G428/ A436→S435/ E484→D483/ T501→P500/ D536→E535/
R19K/K24Q/Q38N/T53L/D54A/A55T/E56G/D57R V60I/A85M/I86L/Q87D/K88H/ L89I/C90Y/-— >R91/-— >A92/-— >D93/ I92→Y95/Y93→F96/
I94→E97/D95→A98/S96→H99/N97→E100/R98→Y101/A99→N102/K125→Q128/K173 →Q 176/L175→— /VI 76→— / Q 178→A179/ D 179→P180/
V181→L182/T182→K183/P183→S184/K184→P185/F209→I210/M212→Y213/I213→S21 4/N214→P215/S215→N216/T216→V217/S217→I218/H219→L220/L220→A221 /Y221→P 222/E238→D239/K252→Q253/Q292→K293/Q321→A322/E333→D334/A345→T346/N36 9→I370/S377→Y378/T405→R406/N429→G430/A436→S437/T501→P502/D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→K213/ 1213→P214/ N214→V215/ S215→T216/ T216→R217/ D218→L219/ H219→S220/ L220→A221/ Y221→L222/ E238→D239/ K252→Q253/ Q292→K293/ V320→A321/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ LI 75→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P 183→S 184/ Kl 84→P185/ F209→I210/ 1213→Q214/ N214→H215/ S215→L216/ T216→C2111 S217→F218/ D218→S219/ H219→R220/ L220→H221 / Y221→K222/ E238→D239/ K252→Q253/ Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→F213/ I213→N214/ N214→C215/ S215→V216/ T216→K217/ S217→Y218/ D218→A219/ H219→F220/ L220→T221/
Y221→Q222/ E238→D239/ K252→Q253/ Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→Y213/ 1213→R214/ N214→L215/ S215→N216/ T216→D217/ S217→N218/ D218→Y219/ H219→A220/ L220→E221/ Y221→W222/ E238→D239/ K252→Q253/ Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/ D536→E537;
K24Q/ D28G/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ K62R/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→S213/ I213→K214/ N214→A215/ S215→Q216/ T216→A217/ S217→H218/ D218→S219/ H219→L220/ L220→V221/ Y221→S222/ E238→D239/ K252→Q253/ Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/ D536→E537;
K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ K62R/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ LI 75→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→S213/ I213→L214/ N214→V215/ S215→R216/ T216→S217/ S217→E218/ D218→K219/ H219→D220/ L220→P221/ Y221→N222/ E238→D239/ K252→Q253/ Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→H213/ 1213→R214/ N214→T215/ S215→P216/ T216→A217/ S217→F218/ D218→C219/ H219→R220/ L220→G221/
Y221→E222/ E238→D239/ K252→Q253/ Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→Q213/ 1213→V214/ N214→R215/ S215→K216/ T216→R217/ S217→C218/ D218→V219/ H219→E220/ L220→A221 / Y221→V222/ E238→D239/ K252→Q253/ Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→V213/ 1213→Y214/ N214→— / S215→— / T216→Q215/ S217→D216/ D218→E217/ H219→A218/ L220→F2191 Y221→H220/ E238→D237/ K252→Q251/ P281→S280/ Q292→K291/ L313→C312/ S314→T313/ L315→M314/ T317→S316/ Q321→A320/ E333→D332/ K336→R335/ L337→I336/ A345→T344/ G357→R356/ N369→I368/ S377→Y376/ T405→R404/ N429→G428/ A436→S435/ Q448→L447/ E484→D483/ T501→P500/ D536→E535;
S2Q/ S3T/ G4F/ E5N/ T6C/ F7A/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2A/ S3G/ G4R/ E5G/ T6A/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/
M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2V/ S3L/ G4K7 E5S/ T6K7 F7R/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/
D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2K7 S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2P/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2C/ S3M/ G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ F209→I210/
M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217-/ D218E/ H219Q/ L220S/
Y221K/ E238D/ K252Q/ P281S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2Q/ S3N/ G4L/ E5G/ T6Y/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2L/ S3N/ G4S/ E5I/ T6D/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2P/ S3D/ G4R/ E5T/ T6G/ F7P/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/
S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P 183→S 184/ Kl 84→P185/ F209→E210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ T501→P502/ D536→E537;
K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ LI 11→S114/ K125→Q128/
K173→Q176/ L175→— / V176→— / Q178→A179/ D179→P180/ V181→L182/
T182→K183/ P183→S184/ K184→P185/ F209→E210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P 183→S 184/ Kl 84→P185/ F209→L210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→T210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/
S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→A213/ 1213→F214/ N214→L215/ S215→A216/ T216→C217/ S217→G218/ D218→R219/ H219→R220/ L220→P221 / Y221→T222/ E238→D239/ K252→Q253/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/ D536→E537;
S2A/ S3T/ G4S/ E5H/ T6S/ F7Q/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ I325T/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S3T/ G4Q/ E5V/ -— >S6/ -— >A7/ -— >S8/ -— >S9/ -— >L10/ -— >A11/ -— >Q12/ - — >I13/ -— >P14/ -— >Q15/ -— >P16/ T6→K17/ F7→N18/ T10→V21/ D12→N23/ S16→N27/ L17→I28/ R19→G30/ N20→D31/ H21→Q32/ L23→I34/ K24→T35/
G25→Y36/ A26→T37/ S27→P38/ D28→E39/ F29→D40/ T31→— / D33→T43/
H34→R44/ T35→A45/ A36→C46/ T37→K47/ Q38→E48/ R40→Q50/ H41→I51/
T53→L63/ D54→A64/ A55→T65/ E56→G66/ D57→R67/ V60→I70/ A85→M95/
I86→L96/ Q87→D97/ K88→H98/ L89→I99/ C90→Y100/ -— >R101/ -— >A102/— →D103/ I92→Y105/ Y93→F106/ I94→E107/ D95→A108/ S96→H109/ N97→E110/ R98→Y111/ A99→N112/ K125→Q138/ K173→Q186/ L175→— / V176→— /
Q 178→A189/ D 179→P 190/ VI 81→L192/ Tl 82→K193/ P 183→S 194/ Kl 84→P195/ F209→I220/ M212→R223/ N214→D225/ H219→D230/ Y221→V232/ E238→D249/ K252→Q263/ P281→S292/ Q292→K303/ L313→C324/ S314→T325/ L315→M326/ T317→S328/ Q321→A332/ E333→D344/ K336→R347/ L337→I348/ A345→T356/
G357→R368/ N369→I380/ S377→Y388/ T405→R416/ N429→G440/ A436→S447/ E484→D495/ T501→P512/ D536→E547;
K24Q/ Q38N/ K58Q/ V60I/ I86L/ K88H/ L89I/ P91N/ I92N/ Y93F/ I94H/ S96C/ R98D/ A99M/ -— >G101/ -— >D102/ K125→Q127/ K173→Q175/ K184→R186/
F209→I211 / M212→R214/ N214→D216/ H219→D221 / Y221→V223/ E238→D240/ K252→Q254/ P281→S283/ Q292→K294/ L313→C315/ S314→T316/ L315→M31 II T317→S319/ Q321→A323/ E333→D335/ K336→R338/ L337→I339/ A345→T347/ G357→R359/ N369→I371/ S377→Y379/ T405→R407/ N429→G431/ A436→S438/ T501→P503/ D536→E538;
K24Q/ Q38N/ K58Q/ V60I/ I86L/ K88H/ L89I/ P91N/ I92S/ Y93F/ I94H/ S96C/
R98D/ A99M/ -— >G101/ -— >D102/ K125→Q127/ K173→Q175/ K184→R186/
F209→I211 / M212→R214/ N214→D216/ H219→D221 / Y221→V223/ E238→D240/ K252→Q254/ P281→S283/ Q292→K294/ L313→C315/ S314→T316/ L315→M31 II T317→S319/ Q321→A323/ E333→D335/ K336→R338/ L337→I339/ A345→T347/ G357→R359/ N369→I371/ S377→Y379/ Y387→C389/ T405→R407/ N429→G431/ A436→S438/ T501→P503/ D536→E538;
S3T/ G4Q/ E5V/ -— >S6/ -— >A7/ -— >S8/ -— >S9/ -— >L10/ -— >A11/ -— >Q12/ - — >I13/ -— >P14/ -— >Q15/ -— >P16/ T6→K17/ F7→N18/ T10→V21/ D12→N23/ S16→N27/ L17→I28/ R19→G30/ N20→D31/ H21→Q32/ L23→I34/ K24→T35/
G25→Y36/ A26→T37/ S27→P38/ D28→E39/ F29→D40/ T31→— / D33→T43/
H34→R44/ T35→A45/ A36→C46/ T37→K47/ Q38→E48/ R40→Q50/ H41→I51/
T53→L63/ D54→A64/ A55→T65/ E56→G66/ D57→R67/ V60→I70/ A85→M95/
I86→L96/ Q87→D97/ K88→H98/ L89→I99/ C90→Y100/ -— >R101/ -— >A102/— →D103/ I92→Y105/ Y93→F106/ I94→E107/ D95→A108/ S96→H109/ N97→E110/ R98→Y111/ A99→N112/ K125→Q138/ K173→Q186/ L175→— / V176→— /
Q 178→A189/ D 179→P 190/ VI 81→L192/ Tl 82→K193/ P 183→S 194/ Kl 84→P195/ F209→I220/ M212→V223/ 1213→Y224/ N214→— / S215→— / T216→Q225/
S217→D226/ D218→E227/ H219→A228/ L220→F229/ Y221→H230/ E238→D247/ K252→Q261/ P281→S290/ Q292→K301/ L313→C322/ S314→T323/ L315→M324/ T317→S326/ Q321→A330/ E333→D342/ K336→R345/ L337→I346/ A345→T354/ G357→R366/ N369→I378/ S377→Y386/ T405→R414/ N429→G438/ A436→S445/ E484→D493/ T501→P510/ D536→E545;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→R213/ N214→V215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ T501→P502/ P506→S507/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ T257→A258/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N410→S411/ N429→G430/ A436→S437/ E484→D485/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V69L/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ T501→P502/ D536→E537;
R19K/ K24P/ Q38Y/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/
K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→V213/ 1213→Y214/ N214-/ S215→— / T216→Q215/ S217→D216/ D218→E217/ H219→A218/ L220→F2191 Y221→H220/ E238→D237/ K252→Q251/ P281→S280/ Q292→K291/ L313→C312/ S314→T313/ L315→M314/ T317→S316/ Q321→A320/ E333→D332/ K336→R335/ L337→I336/ A345→T344/ G357→R356/ N369→I368/ S377→Y376/ T405→R404/ N429→G428/ A436→S435/ E484→D483/ T501→P500/ D536→E535;
S2K7 S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/
D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2K7 S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314A/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ E348A/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2C/ S3M/ G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2C/ S3M7 G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/
K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→V213/ 1213→Y214/ N214→— / S215→~ 214/ T216→Q215/ S217→D216/ D218→E217/ H219→A218/ L220→F2191 Y221→H220/ E238→D237/ K252→Q251/ P281→S280/ Q292→K291/ L313→C312/ S314→T313/ L315→M314/ T317→S316/ Q321→A320/ E333→D332/ K336→R335/ L337→I336/ A345→T344/ G357→R356/ N369→I368/ S377→Y376/ T405→R404/ N429→G428/ A436→S435/ V439→L438/ E484→D483/ T501→P500/ D536→E535;
S2A/ S3G/ G4E/ E5A/ F7G/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ K499→E500/ T501→P502/ D536→E537;
S2C/ S3M/ G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2K7 S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E:
S2K7 S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/
K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ II 16→Y119/ Kl 17→T120/ V122→I125/ E124→N127/ K127→T130/ D129→E132/ E130→R133/ S135→E138/ S136→A139/ N139→S142/ Q142→R145/ S146→G149/ K173→Q176/ L175→— / V176→- -/ Q178→A179/ D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ T501→P502/ D536→E537;
S2K7 S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
Al IT/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M7 I86L/
Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/
L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ T501→P502/ D536→E537;
MIT/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ Y152→H155/ K173→Q176/ L175→— / V176→— / Q178→A179/ D179→P180/ V181→L182/
T182→K183/ P183→S184/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ C361→R362/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ K468→Q469/ E484→D485/ T501→P502/ D536→E537;
S2C/ S3M7 G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2C/ S3M7 G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2K7 S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ T200→Q201/
F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/
H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ Q448→L449/ E484→D485/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ E163→D166/ K173→Q176/ L175→— / V176→— / Q178→A179/ D179→P180/ V181→L182/
T182→K183/ P183→S184/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ Q448→L449/ E484→D485/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M210→T211 / M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ P500→L501/ T501→P502/ D536→E537;
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / VI 76→— / Q 178→A179/ D 179→P 180/ VI 81→L182/ Tl 82→K183/
P183→S184/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ E484→D485/ T501→P502/ D536→E537;
R19K/ N20D/ L23S/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→E176/ L175→— / V176→— / Q178→A179/ D179→P180/ V181→L182/
T182→K183/ P183→S184/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/ A436→S437/ C465→S466/ E484→D485/ T501→P502/ D536→E537/ A539→V540;
S2C/ S3M7 G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ E348A/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E;
S2C/ S3M/ G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/
D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
Dl 79→P180/ VI 81→L182/ Tl 82→K183/ PI 83→S 184/ Kl 84→P185/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/ S217→— / D218E/ H219Q/
L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/ E348S/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E/;
K24Q/ Q38N/ K58Q/ V60I/ K88Q/ P91N/ I92S/ Y93F/ I94H/ S96C/ R98D/ A99M/ - — >G101/ -— >D102/ K125→Q127/ K173→Q175/ K184→R186/ F209→I211/
M212→R214/ N214→D216/ H219→D221/ Y221→V223/ E238→D240/ K252→Q254/
Q292→K294/ Q321→A323/ E333→D335/ A345→T347/ N369→I371/ S377→Y379/ T405→R407/ N429→G431/ A436→S438/ T501→P503/ D536→E538;
K24Q/ Q38N/ K58Q/ V60I/ I82V/ K88Q/ P91N/ I92S/ Y93F/ I94H/ S96C/ R98D/ A99M/ -— >G101/ -— >D102/ K125→Q127/ K173→Q175/ K184→R186/ F209→I211/ M212→R214/ N214→D216/ H219→D221/ Y221→V223/ E238→D240/ K252→Q254/ Q292→K294/ Q321→A323/ E333→D335/ A345→T347/ N369→I371/ S377→Y379/ L399→S401/ T405→R407/ N429→G431/ A436→S438/ T501→P503/ D536→E538;
S3T/ G4Q/ E5V/ -— >S6/ -— >A7/ -— >S8/ -— >S9/ -— >L10/ -— >A11/ -— >Q12/ - — >I13/ -— >P14/ -— >Q15/ -— >P16/ T6→K17/ F7→N18/ T10→V21/ D12→N23/ S16→N27/ L17→I28/ R19→G30/ N20→D31/ H21→Q32/ L23→I34/ K24→T35/
G25→Y36/ A26→T37/ S27→P38/ D28→E39/ F29→D40/ T31→— / D33→T43/
H34→R44/ T35→A45/ A36→C46/ T37→K47/ Q38→E48/ R40→Q50/ H41→I51/
V48→I58/ T53→L63/ D54→A64/ A55→T65/ E56→G66/ D57→R67/ V60→I70/ I86→L96/ K88→H98/ L89→I99/ P91→N101/ I92→S102/ Y93→F103/ I94→H104/ S96→C106/ R98→D108/ A99→M109/ -— >G111/ -— >D112/ H102→Y114/ II 16→Y128/ Kl 17→T129/ V122→I134/ E124→N136/ K127→T139/ D129→E141/ E130→R142/ S135→E147/ S136→A148/ N139→S151/ Q142→R154/ S146→G158/ K173→Q185/ L175→— / V176→- -/ Q178→A188/ D179→P189/ V181→L191/ T182→K192/ P183→S193/ K184→P194/ F209→I219/ M212→V222/ 1213→Y223/ N214→— / S215→— / T216→Q224/
S217→D225/ D218→E226/ H219→A227/ L220→F228/ Y221→H229/ E238→D246/ K252→Q260/ P281→S289/ Q292→K300/ L313→C321/ S314→T322/ L315→M323/ T317→S325/ Q321→A329/ E333→D341/ K336→R344/ L337→I345/ A345→T353/ G357→R365/ N369→I377/ S377→Y385/ T405→R413/ N429→G437/ A436→S444/ E484→D492/ T501→P509/ D536→E544;
S3T/ G4Q/ E5V/ -— >S6/ -— >A7/ -— >S8/ -— >S9/ -— >L10/ -— >A11/ -— >Q12/ -
— >I13/ -— >P14/ -— >Q15/ -— >P16/ T6→K17/ F7→N18/ T10→V21/ D12→N23/ S16→N27/ L17→I28/ R19→G30/ N20→D31/ H21→Q32/ L23→I34/ K24→T35/
G25→Y36/ A26→T37/ S27→P38/ D28→E39/ F29→D40/ T31→— / D33→T43/
H34→R44/ T35→A45/ A36→C46/ T37→K47/ Q38→E48/ R40→Q50/ H41→I51/
T53→L63/ D54→A64/ A55→T65/ E56→G66/ D57→R67/ V60→I70/ I86→L96/
K88→H98/ L89→I99/ P91→N101/ I92→S102/ Y93→F103/ I94→H104/ S96→C106/ R98→D108/ A99→M109/ -— >G111/ -— >D112/ K125→Q137/ K173→Q185/ L175→— / V176→— / Q178→A188/ D179→P189/ V181→L191/ T182→K192/ P183→S193/
K184→P194/ F209→I219/ M212→V222/ I213→Y223/ N214→— / S215→— /
T216→Q224/ S217→D225/ D218→E226/ H219→A227/ L220→F228/ Y221→H229/ E238→D246/ K252→Q260/ P281→S289/ Q292→K300/ L313→C321/ S314→T322/
L315→M323/ T317→S325/ Q321→A329/ E333→D341/ K336→R344/ L337→I345/ A345→T353/ G357→R365/ N369→I377/ S377→Y385/ T405→R413/ N429→G437/ A436→S444/ E484→D492/ T501→P509/ D536→E544; and
S3T/ G4Q/ E5V/ -— >S6/ -— >A7/ -— >S8/ -— >S9/ -— >L10/ -— >A11/ -— >Q12/ - — >U3/ -— >P14/ -— >Q15/ -— >P16/ T6→K17/ F7→N18/ T10→V21/ D12→N23/ S16→N27/ L17→I28/ R19→G30/ N20→D31/ H21→Q32/ L23→I34/ K24→T35/
G25→Y36/ A26→T37/ S27→P38/ D28→E39/ F29→D40/ T31→— / D33→T43/
H34→R44/ T35→A45/ A36→C46/ T37→K47/ Q38→E48/ R40→Q50/ H41→I51/
T53→L63/ D54→A64/ A55→T65/ E56→G66/ D57→R67/ V60→I70/ A85→M95/
I86→L96/ Q87→D97/ K88→H98/ L89→I99/ C90→Y100/ -— >R101/ -— >A102/— →D103/ I92→Y105/ Y93→F106/ I94→E107/ D95→A108/ S96→H109/ N97→E110/ R98→Y111/ A99→N112/ K125→Q138/ K173→Q186/ L175→— / V176→— /
Q 178→A189/ D 179→P 190/ VI 81→L192/ Tl 82→K193/ P 183→S 194/ Kl 84→P195/ F209→I220/ M212→V223/ 1213→Y224/ N214→— / S215→— / T216→Q225/
S217→D226/ D218→E227/ H219→A228/ L220→F229/ Y221→H230/ E238→D247/ K252→Q261/ P281→S290/ Q292→K301/ L313→C322/ S314→T323/ L315→M324/ T317→S326/ Q321→A330/ E333→D342/ K336→R345/ L337→I346/ A345→T354/ G357→R366/ N369→I378/ S377→Y386/ T405→R414/ N429→G438/ A436→S445/ E484→D493/ T501→P510/ D536→E545.
Provided herein are nucleic acid molecules having a sequence of nucleic acids set forth in any of SEQ ID NO: 203, 352-353, 702, 703, 713-715, 776-799, 801-809, 891-894, 896, 945, 947, 949, 951, 953, 955, 957, 959, 961, 963, 965, 967, 969, 971, 973, 975, 977, 979, 981, 983, 985, 987, 989, 991, 993, 995, 997 and 999. Also provided herein are nucleic acid molecules having a sequence of nucleic acids that has at least 95% sequence identity to any of SEQ ID NO: 203, 352-353, 702, 703, 713-715, 776-799, 801-809, 891-894, 896, 945, 947,
949, 951, 953, 955, 957, 959, 961, 963, 965, 967, 969, 971, 973, 975, 977, 979, 981, 983, 985, 987, 989, 991, 993, 995, 997 and 999. Also provided herein are nucleic acid molecules having a sequence of nucleic acids that degenerate to any of SEQ ID NO: 203, 352-353, 702, 703, 713-715, 776-799, 801-809, 891-894, 896, 945, 947, 949, 951, 953, 955, 957, 959, 961, 963, 965, 967, 969, 971, 973, 975, 977, 979, 981, 983, 985, 987, 989, 991, 993, 995, 997 and 999. For example, provided herein are nucleic acid molecules having a sequence of nucleic acids set forth in any of SEQ ID NO: 203, 352-353, 702, 703, 713-715, 776-799, 801-809, 891-894, 896, 945, 947, 949, 951, 953, 955, 957, 959, 961, 963, 965, 967, 969, 971, 973, 975, 977, 979, 981, 983, 985, 987, 989, 991, 993, 995, 997 and 999.
Provided herein are nucleic acid molecules that encode a modified valencene synthase having a sequence of amino acids set forth in any of SEQ ID NOS: 67, 350,
351,732-733, 743-745, 833-856, 858-866, 887-890 and 895. Also provided herein are nucleic acid molecules that encode a modified valencene synthase having a sequence of amino acids that has at least 95% sequence identity to a sequence of amino acids set forth in any of SEQ ID NOS: 67, 350, 351,732-733, 743-745, 833-856, 858-866, 887-890 and 895. For example, provided herein are nucleic acid molecules that encode a modified valencene synthase having a sequence of amino acids set forth in any of SEQ ID NOS: 67, 350, 351,732-733, 743-745, 833-856, 858-866, 887-890 and 895.
In one example, the nucleic acid molecules provided herein can encode a modified valencene synthase having amino acid replacements corresponding to amino acid
replacements selected from among K24A/Q38A/K58A/V60I/K88A/Y93H/
N97D/R98K/K125 A/Kl 73 A/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q 292K/V320S/Q321A/E326K/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D5 36E; and K24A/Q38A/R50G/K58A/V60I/K88A/Y93H/N97D/R98K/
Kl 25 A/Kl 73 A/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/V320 G/ Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536E; and one or more further amino acid replacements.
Provided herein are nucleic acid molecules encoding a modified valencene synthase polypeptide wherein the unmodified valencene synthase polypeptide has the sequence of amino acids set forth in any of SEQ ID NOS: 2-4, 289-291, 346, 347, 752, 882 and 883.
Provided herein are nucleic acid molecules encoding a modified Citrus valencene synthase, wherein the modified valencene synthase contains amino acid differences compared to a citrus-derived valencene synthase. In some examples, the nucleic acid encodes a modified grapefruit or orange valencene synthase, wherein the modified valencene synthase contains amino acid differences compared to a grapefruit-derived or orange-derived valencene synthase. In one aspect, the citrus-derived valencene synthase has a sequence of amino acids set forth in any of SEQ ID NOS:2, 289-291, 752 and 886. In some embodiments, the encoded modified valencene synthase polypeptide is a fusion protein or chimeric protein.
In some embodiments, the nucleic acid molecules provided herein encode a modified valencene synthase polypeptide that exhibits increased catalytic activity compared to the valencene synthase set forth in SEQ ID NO:2. In other embodiments, the encoded modified valencene synthase polypeptide exhibits altered substrate specificity compared to the valencene synthase set forth in SEQ ID NO:2. In further embodiments, the encoded modified valencene synthase polypeptide exhibits altered product distribution compared to the valencene synthase set forth in SEQ ID NO:2.
For example, as described above, cells expressing modified valencene synthase polypeptides provided herein produce increased valencene compared to cells expressing
wildtype valencene synthase set forth in SEQ ID NO:2. In some examples, modified valencene synthase polypeptides provided herein also produce a decreased percentage of terpene products (e.g terpene byproduct or products derived therefrom) other than valencene compared to the percentage of the same terpene products (e.g. terpene byproduct or products derived therefrom) produced in the same host cell from a valencene synthase set forth in SEQ ID NO:2, whereby the terpene products are produced by the synthase in a host cell that produces FPP. For example, the terpene products other than valencene that can be produced include, but are not limited to, β-selinene, x-selinene, eremophilone, 7-epz-a-selinene, germacrene A or β-elemene. For example, germacrene A is detected as its spontaneous degradation product β-elemene, which is a product derived from the germacrene A byproduct that undergoes a heat induced rearrangement to form β-elemene. In particular examples, the terpene product is β-elemene. For example, modified valencene synthase polypeptides provided herein produce 95%, 80%, 70%, 60%, 50%, 40%, 30%, 20%, 10% or less levels of β-elemene than is produced by wildtype valencene synthase set forth in SEQ ID NO:2. The percentage of terpene product other than valencene as a percentage of total terpene product produced by the provided modified valencene synthase polypeptide is decreased by 0.01% to 90%, such as 1% to 80%, 5% to 80%, 10% to 60% or 0.01% to 20%. For example, the percentage of a terpene product other than valencene as a percentage of total terpene is decreased by at least or at least about 0.5%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90% or more. Exemplary of such nucleic acid molecules are nucleic acid molecules that encode a modified valencene polypeptide that contains amino acid replacement(s) at positions corresponding to positions 281, 313, 314, 315, 317, 336, 337, 347, or 357 with CVS numbering relative to the valencene synthase polypeptide set forth in SEQ ID NO:2. For example, the amino acid replacement is P281 S, P281H, P281K, P281A, P281W, P281L, P281Y, L313C, S314T, L315M, T317S, K336R, L337I, N347L, and/or G357R. In some examples, the nucleic acid molecule encodes a modified valencene synthase polypeptide that contains replacements at positions 281, 313, 314, 315, 317, 336, 337, and 357 with numbering relative to the valencene synthase polypeptide set forth in SEQ ID NO:2. In further examples, the nucleic acid molecule also can contain an amino acid replacement at position 347. For example, the encoded modified valencene synthase polypeptide contains replacements P281 S, L313C, S314T, L315M, T317S, K336R, L337I and G357R. In another example, the encoded modified valencene synthase polypeptide contains replacements P281 S, L313C, S314T, L315M, T317S, K336R, L337I, N347L and G357R. The encoded modified valencene synthase polypeptide also can contain other amino acid replacements so long as production of a terpene product, such as β- elemene, is decreased.
- -
Also provided herein are modified valencene synthase polypeptides encoded by any of the nucleic acid molecules provided herein.
Also provided are vectors containing the nucleic acid molecules provided herein. Vectors include prokaryotic, viral and eukaryotic vectors, such as for example, yeast vectors, including yeast expression vectors. Cells, including prokaryotic, such as bacterial cells, and eukaryotic, such as yeast, insect, plant or mammalian cells, containing the vectors are provided. In one example, the cell is a yeast cell, for example, a Saccharomyces genus cell or a Pichia genus cell. In an exemplary embodiment, the yeast cell is a Saccharomyces cerevisiae cell. In another example, the cell is a bacterial cell, for example, an Escherichia coli cell. The cells provided herein produce FPP. In a particular embodiment, the cells are modified to produce more FPP than a cell that has not been modified. For example, the cell contains a modification in the gene encoding squalene synthase, whereby the amount the squalene synthase expressed in the cell or the activity the squalene synthase expressed in the cell is reduced compared to an unmodified cell. Also provided herein are cells that express a modified valencene synthase polypeptide. Also provided herein are modified valencene synthases produced by a cell provided herein.
Also provided herein are transgenic plants containing a vector provided herein. In some examples, the transgenic plant is a Citrus plant. In other examples, the transgenic plant is a tobacco.
Provided herein are methods for producing a modified valencene synthase polypeptide wherein a nucleic acid molecule or vector provided herein is introduced into a cell and the cell is cultured under conditions suitable for the expression of the modified valencene synthase polypeptide encoded by the nucleic acid or vector. Also provided herein are methods for producing a modified valencene synthase polypeptide wherein a nucleic acid molecule or vector provided herein is introduced into a cell and the cell is cultured under conditions suitable for the expression of the modified valencene synthase polypeptide encoded by the nucleic acid or vector wherein the modified valencene synthase polypeptide is modified. In some examples, the modified valencene synthase polypeptide is isolated.
Provided herein is a method of producing valencene wherein an acyclic
pyrophosphate terpene precursor is contacted with any modified valencene synthase polypeptide provided herein or any modified valencene synthase polypeptide encoded by any nucleic acid molecule provided herein, under conditions suitable for the formation of valencene from the acyclic pyrophosphate terpene precursor. Also provided herein is a method of producing valencene wherein an acyclic pyrophosphate terpene precursor is contacted with any modified valencene synthase polypeptide provided herein or any modified valencene synthase polypeptide encoded by any nucleic acid molecule provided herein, under conditions suitable for the formation of
RECTIFIED SHEET (RULE 91)
ISA/EP
- -
valencene from the acyclic pyrophosphate terpene precursor whereby the valencene is isolated. In one embodiment, the step of contacting the acyclic pyrophosphate terpene precursor with the modified valencene synthase polypeptide is effected in vitro or in vivo. The acyclic pyrophosphate terpene precursor used in the method provided herein can be selected from among farnesyl diphosphate (FPP), geranyl diphosphate (GPP) and geranyl- geranyl diphosphate (GGPP). In a particular embodiment, the acyclic pyrophosphate terpene precursor is FPP.
Provided herein is a method of producing valencene by culturing a cell transformed with the nucleic acid molecule or vector provided herein, wherein the cell produces an acyclic pyrophosphate terpene precursor, the modified valencene synthase polypeptide encoded by the nucleic acid molecule or vector is expressed, and the modified valencene synthase polypeptide catalyzes the formation of valencene from the acyclic pyrophosphate terpene precursor. The acyclic pyrophosphate terpene precursor used in the method provided herein can be selected from among farnesyl diphosphate (FPP), geranyl diphosphate (GPP) and geranyl-geranyl diphosphate (GGPP). In a particular embodiment, the acyclic pyrophosphate terpene precursor can be FPP. In the method provided herein, the cell can be selected from among a bacteria, yeast, insect, plant or mammalian cell. In a particular embodiment, the cell is a yeast cell that is a Saccharomyces cerevisiae cell. The cells provided herein produce FPP. In a particular embodiment, the cells are modified to produce more FPP than a cell that has not been modified. For example, the cell contains a modification in the gene encoding squalene synthase, whereby the amount of squalene synthase expressed in the cell or the activity of squalene synthase expressed in the cell is reduced compared to an unmodified cell.
In one embodiment of the method of producing valencene by culturing a cell transformed with the nucleic acid molecule or vector provided herein, the amount of valencene produced is greater than the amount of valencene produced under the same conditions when the same host cell type is transformed with nucleic acid encoding the valencene synthase set forth in SEQ ID NO:2. For example, the amount of valencene produced is at least or about 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 1 10%, 120%, 130%, 140%, 150%, 160%, 170%, 180%, 190%, 200%, 250%, 300%, 350%, 400%, 500% or more greater than the amount of valencene produced under the same conditions by the valencene synthase set forth in SEQ ID NO:2. In another example, the amount of valencene produced is 10% to 500%, 10% to 250%, 50% to 250%, 100% to 500% or is 100% to 250% greater than the amount of valencene produced from FPP by the valencene synthase set forth in SEQ D NO:2. In another embodiment, the amount of valencene produced in the cell culture supernatant is at least or about 0.1 g L, 0.2 g/L, 0.3 g L,
RECTIFIED SHEET (REUL 91)
ISA/EP
- -
0.4 g L, 0.5 g/L, 0.6 g L, 0.7 g/L, 0.8 g L, 0.9 g L 1.0 g L, 1.1 g L, 1.2 g/L, 1.3 g L, 1.4 g L, 1.5 g L, 2.0 g L, 2.5 g L, 3.0 g L, 3.5 g/L, 4.0 g/L, 4.5 g/L or 5.0 g/L; or is 0.1 g/L to 5.0 g/L, 0.1 g/L to 3.0 g/L, 0.5 g/L to 5.0 g/L, 1.0 g L to 5.0 g/L or 1.0 to 3.0 g L in the yeast cell culture medium.
In a particular embodiment of the method provided herein, valencene is isolated. In another embodiment, valencene is oxidized to produce nootkatone. The oxidation can be performed biosynthetically or chemically. In another embodiment, the nootkatone is isolated.
Provided herein is a method for producing a modified terpene synthase comprising a heterologous domain wherein all or a contiguous portion of a domain of a first terpene synthase is replaced with all or a contiguous portion of the corresponding domain in a second terpene synthase, the amino acid sequence of the domain or contiguous portion of the domain of the first terpene synthase and second terpene synthases differ by at least one amino acid residue, and the domain is selected from among unstructured loop 1 ; alpha helix 1 ;
unstructured loop 2; alpha helix 2; unstructured loop 3; alpha helix 3; unstructured loop 4; alpha helix 4; unstructured loop 5; alpha helix 5; unstructured loop 6; alpha helix 6;
unstructured loop 7; alpha helix 7; unstructured loop 8; alpha helix 8; unstructured loop 9; alpha helix A; A-C loop; alpha helix C; unstructured loop 1 1; alpha helix D; unstructured loop 12; alpha helix Dl; unstructured loop 13; alpha helix D2; unstructured loop 14; alpha helix E; unstructured loop 15; alpha helix F; unstructured loop 16; alpha helix Gl ;
unstructured loop 17; alpha helix G2; unstructured loop 18; alpha helix HI ; unstructured loop 19; alpha helix H2; unstructured loop 20; alpha helix H3; unstructured loop 21; alpha helix a- 1 ; unstructured loop 22; alpha helix I; unstructured loop 23; alpha helix J; J- loop; alpha helix ; and/or unstructured loop 25, and the contiguous portion contains at least three amino acid residues, whereby a property of the modified terpene synthase is altered compared to the first terpene synthase. For example, the property of the modified terpene synthase is improved compared to the first terpene synthase.
In one embodiement of the method, at least 3, 4, 5, 6, 7, 8, 9, 10, 15, 20 or more amino acid residues from the domain of the first terpene synthase are replaced with at least 3, 4, 5, 6, 7, 8, 9, 10, 15, 20 or more amino acid residues from the corresponding domain of the second terpene synthase. In one aspect, all of the amino acid residues from the domain of the first terpene synthase are replaced with all of the amino acid residues from the corresponding domain of the second terpene synthase.
In one embodiment of the method provided herein, unstructured loop 1 contains amino acid residues corresponding to amino acids 1-29 of SEQ ID NO:2; alpha helix 1 contains amino acid residues corresponding to amino acids 30-39 and 44-52 of SEQ ID NO:2; unstructured loop 2 contains amino acid residues corresponding to amino acids 53-58 of SEQ
RECTIFIED SHEET (RULE 91)
ISA/EP
ID NO:2; alpha helix 2 contains amino acid residues corresponding to amino acids 59-71 of SEQ ID NO:2; unstructured loop 3 contains amino acid residues corresponding to amino acids 72-78 of SEQ ID NO:2; alpha helix 3 contains amino acid residues corresponding to amino acids 79-93 of SEQ ID NO:2; unstructured loop 4 contains amino acid residues corresponding to amino acids 94-100 of SEQ ID NO:2; alpha helix 4 contains amino acid residues corresponding to amino acids 101-114 of SEQ ID NO:2; unstructured loop 5 contains amino acid residues corresponding to amino acids 115-141 of SEQ ID NO:2; alpha helix 5 contains amino acid residues corresponding to amino acids 142-152 of SEQ ID NO:2; unstructured loop 6 contains amino acid residues corresponding to amino acids 153-162 of SEQ ID NO:2; alpha helix 6 contains amino acid residues corresponding to amino acids 163- 173 of SEQ ID NO:2; unstructured loop 7 contains amino acid residues corresponding to amino acids 174-184 of SEQ ID NO:2; alpha helix 7 contains amino acid residues corresponding to amino acids 185-194 of SEQ ID NO:2; unstructured loop 8 contains amino acid residues corresponding to amino acids 195-201 of SEQ ID NO:2; alpha helix 8 contains amino acid residues corresponding to amino acids 202-212 of SEQ ID NO:2; unstructured loop 9 contains amino acid residues corresponding to amino acids 213-222 of SEQ ID NO:2; alpha helix A contains amino acid residues corresponding to amino acids 223-253 of SEQ ID NO:2; A-C loop contains amino acid residues corresponding to amino acids 254-266 of SEQ ID NO:2; alpha helix C contains amino acid residues corresponding to amino acids 267-276 of SEQ ID NO:2; unstructured loop 11 contains amino acid residues corresponding to amino acids 277-283 of SEQ ID NO:2; alpha helix D contains amino acid residues corresponding to amino acids 284-305 of SEQ ID NO:2; unstructured loop 12 contains amino acid residues corresponding to amino acids 306-309 of SEQ ID NO:2; alpha helix Dl contains amino acid residues corresponding to amino acids 310-322 of SEQ ID NO:2; unstructured loop 13 contains amino acid residues corresponding to amino acids 323-328 of SEQ ID NO:2; alpha helix D2 contains amino acid residues corresponding to amino acids 329 of SEQ ID NO:2; unstructured loop 14 contains amino acid residues corresponding to amino acids 330-332 of SEQ ID NO:2; alpha helix E contains amino acid residues corresponding to amino acids 333- 351 of SEQ ID NO:2; unstructured loop 15 contains amino acid residues corresponding to amino acids 352-362 of SEQ ID NO:2; alpha helix F contains amino acid residues corresponding to amino acids 363-385 of SEQ ID NO:2; unstructured loop 16 contains amino acid residues corresponding to amino acids 386-390 of SEQ ID NO:2; alpha helix Gl contains amino acid residues corresponding to amino acids 391-395 of SEQ ID NO:2;
unstructured loop 17 contains amino acid residues corresponding to amino acids 396-404 of SEQ ID NO:2; alpha helix G2 contains amino acid residues corresponding to amino acids
405-413 of SEQ ID NO:2; unstructured loop 18 contains amino acid residues corresponding
to amino acids 414-421 of SEQ ID NO:2; alpha helix HI contains amino acid residues corresponding to amino acids 422-428 of SEQ ID NO:2; unstructured loop 19 contains amino acid residues corresponding to amino acids 429-431 of SEQ ID NO:2; alpha helix H2 contains amino acid residues corresponding to amino acids 432-447 of SEQ ID NO:2;
unstructured loop 20 contains amino acid residues corresponding to amino acids 448-450 of SEQ ID NO:2; alpha helix H3 contains amino acid residues corresponding to amino acids 451-455 of SEQ ID NO:2; unstructured loop 21 contains amino acid residues corresponding to amino acids 456-461 of SEQ ID NO:2; alpha helix a-1 contains amino acid residues corresponding to amino acids 462-470 of SEQ ID NO:2; unstructured loop 22 contains amino acid residues corresponding to amino acids 471-473 of SEQ ID NO:2; alpha helix I contains amino acid residues corresponding to amino acids 474-495 of SEQ ID NO:2; unstructured loop 23 contains amino acid residues corresponding to amino acids 496-508 of SEQ ID NO:2; alpha helix J contains amino acid residues corresponding to amino acids 509-521 of SEQ ID NO:2; J-K loop contains amino acid residues corresponding to amino acids 522-534 of SEQ ID NO:2; alpha helix K contains amino acid residues corresponding to amino acids 535-541 of SEQ ID NO:2; and unstructured loop 25 contains amino acid residues corresponding to amino acids 542-548 of SEQ ID NO:2.
In one embodiment of the provided method, all or a contiguous portion of two or more domains of a first terpene synthase are replaced with all or a contiguous portion of the corresponding domains of a second terpene synthase. In the method provided herein, one or more additional residues adjacent to the domain in the first terpene synthase are replaced. For example, at least or about 1, 2, 3, 4, 5 or more additional residues adjacent to the domain in the first terpene synthase are replaced.
In one embodiment of the method provided herein, amino acids corresponding to amino acids 53-58 of SEQ ID NO:2 in a first terpene synthase are replaced with the corresponding region from a second terpene synthase. In another embodiment, amino acids corresponding to amino acids 85-99 of SEQ ID NO:2 in a first terpene synthase are replaced with the corresponding region from a second terpene synthase. In another embodiment, amino acids corresponding to amino acids 115-146 of SEQ ID NO:2 in a first terpene synthase are replaced with the corresponding region from a second terpene synthase. In yet another embodiment, amino acids corresponding to amino acids 153-162 or 152-163 of SEQ ID NO:2 in a first terpene synthase are replaced with the corresponding region from a second terpene synthase. In a further embodiment, amino acids corresponding to amino acids 174- 184 of SEQ ID NO:2 in a first terpene synthase are replaced with the corresponding region from a second terpene synthase. In another embodiment, amino acids corresponding to amino acids 212-222 or 212-221 or 213-222 of SEQ ID NO:2 in a first terpene synthase are replaced
with the corresponding region from a second terpene synthase. In one embodiment, amino acids corresponding to amino acids 310-322 of SEQ ID NO:2 in a first terpene synthase are replaced with the corresponding region from a second terpene synthase. In another embodiment, amino acids corresponding to amino acids 522-534 of SEQ ID NO:2 in a first terpene synthase are replaced with the corresponding region from a second terpene synthase. In yet another embodiment, amino acids corresponding to amino acids 53-58 of SEQ ID NO:2 in a first terpene synthase are replaced with amino acids 58-63 of the TEAS polypeptide set forth in SEQ ID NO:295 or 941.
In one embodiment of the method, amino acids corresponding to amino acids 85-89 of SEQ ID NO:2 in a first terpene synthase are replaced with amino acids 93-97 of the HPS polypeptide set forth in SEQ ID NO:942. In another embodiment, amino acids corresponding to amino acids 85-99 of SEQ ID NO:2 in a first terpene synthase are replaced with amino acids 96-113 of the Vitis vinifera valencene synthase set forth in SEQ ID NO:346. In another embodiment, amino acids corresponding to amino acids 115-146 of SEQ ID NO:2 in a first terpene synthase are replaced with amino acids 128-159 of the Vitis vinifera valencene synthase set forth in SEQ ID NO:346. In yet another embodiment, amino acids corresponding to amino acids 152-163 of SEQ ID NO:2 in a first terpene synthase are replaced with amino acids 163-174 of the HPS polypeptide set forth in SEQ ID NO:942. In another embodiment, amino acids corresponding to amino acids 174-184 of SEQ ID NO:2 in a first terpene synthase are replaced with amino acids 185-193 of the HPS polypeptide set forth in SEQ ID NO:942. In yet another embodiment, wherein amino acids corresponding to amino acids 212- 222 or 212-221 of SEQ ID NO:2 in a first terpene synthase are replaced with amino acids 221-228 or 221-229 of the HPS polypeptide set forth in SEQ ID NO:942.
In one embodiment of the method, amino acids corresponding to amino acids 310- 322 of SEQ ID NO:2 in a first terpene synthase are replaced with amino acids 317-329 of the HPS polypeptide set forth in SEQ ID NO:942. In another embodiment, amino acids corresponding to amino acids 522-534 of SEQ ID NO:2 in a first terpene synthase are replaced with amino acids 527-541 of the HPS polypeptide set forth in SEQ ID NO:942. In yet another embodiment of the method, amino acids corresponding to amino acids 212-221 or 212-222 of the valencene synthase polypeptide set forth in SEQ ID NO:2 in a first terpene synthase are replaced with amino acids 213-221 of the TEAS polypeptide set forth in SEQ ID NO:295. In one embodiment of the method, amino acids 212-221 or 212-222 of the valencene synthase polypeptide set forth in SEQ ID NO:2 in a first terpene synthase are replaced with amino acids 223-230 of the Vitis vinifera valencene synthase set forth in SEQ ID NO:346. In another embodiment of the method, amino acids corresponding to amino acids 3-41 of the valencene synthase polypeptide set forth in SEQ ID NO:2 in a first terpene
- -
synthase are replaced with amino acids 3-51 of the Vitis vinifera valencene synthase set forth in SEQ ID NO:346.
In one embodiment of the method provided herein, the first terpene is a sesquiterpene. In another embodiment, the second terpene is a sesquiterpene. For example, the sesquiterpene can be selected from among a valencene synthase, a santalane synthase, TEAS and HPS. In one example, the santalene synthase has a sequence of amino acids selected from among SEQ ID NOS:481-485. In another embodiment of the method provided herein, a plurality of domains in a terpene synthase are replaced with the corresponding domains from two or more other terpenes.
In the method provided herein, a property of the modified terpene synthase can be improved compared to the first terpene synthase. For example, the property of the modified terpene synthase that is improved compared to the first terpene synthase is selected from among total terpene yield; specific terpene yield; catalytic activity, product distribution; and substrate specificity.
Also provided herein are modified terpene synthases produced by any of the methods provided herein.
BRIEF DESCRIPTION OF THE FIGURES
Figure 1: Figure 1 is an alignment of various citrus valencene synthases (CVS), including species variants and modified valencene synthases, including citrus valencene synthases from Citrus sinensis (SEQ ID NO:2; 289; 886) and Citrus x paradise (SEQ ID NO:290; 291 ; 752). Also included are modified valencene synthases provided herein containing amino acid replacements (V18 set forth as SEQ ID NO:3; and V19 set forth as SEQ ID NO:4). A "*" means that the residues or nucleotides in that column are identical in all sequences in the alignment, a ":" means that conserved substitutions have been observed, and a "." means that semi-conserved substitutions are observed. As described herein and in Figure 4, residues corresponding to positions in SEQ ID NO:2 can be identified based on CVS numbering as residues that occur at aligned loci between and among related or variant synthases.
Figure 2: Figure 2 is an alignment that identifies corresponding regions between and among exemplary synthases (e.g. valencene synthase from Vitis vinifera set forth in SEQ ID NO:346; 5-epi-aristolochene synthase (TEAS) from Nicotiana tabacum set forth in SEQ ID NO:941 ; and premnaspirodiene synthase (HPS) from Hyoscyamus muticus set forth in SEQ ID
NO:942) with respect to citrus valencene synthase set forth in SEQ ID NO:2. The alignment indicates structural domains, including unstructured loop 1 (UL 1 ; corresponding to amino acids 1-29 of SEQ ED NO:2); alpha helix 1 (AH 1 ; corresponding to amino acids 30-39 and 44-52 of SEQ ID NO:2); unstructured loop 2 (UL 2; corresponding to amino acids 53-58 of SEQ ID NO:2); alpha helix 2 (AH 2; corresponding to amino acids 59-71 of SEQ ID NO:2);
RECTIFIED SHEET (RULE 91)
ISA/EP
unstructured loop 3 (UL 3; corresponding to amino acids 72-78 of SEQ ID NO:2); alpha helix 3 (AH 3; corresponding to amino acids 79-93 of SEQ ID NO:2); unstructured loop 4 (UL 4; corresponding to amino acids 94-100 of SEQ ID NO:2); alpha helix 4 (AH 4; corresponding to amino acids 101-114 of SEQ ID NO:2); unstructured loop 5 (UL 5; corresponding to amino acids 115-141 of SEQ ID NO:2); alpha helix 5 (AH 5; corresponding to amino acids 142-152 of SEQ ID NO:2); unstructured loop 6 (UL 6; corresponding to amino acids 153-162 of SEQ ID NO:2); alpha helix 6 (AH 6; corresponding to amino acids 163-173 of SEQ ID NO:2); unstructured loop 7 (UL 7; corresponding to amino acids 174-184 of SEQ ID NO:2); alpha helix 7 (AH 7; corresponding to amino acids 185-194 of SEQ ID NO:2); unstructured loop 8 (UL 8; corresponding to amino acids 195-201 of SEQ ID NO:2); alpha helix 8 (AH 8;
corresponding to amino acids 202-212 of SEQ ID NO:2); unstructured loop 9 (UL 9;
corresponding to amino acids 213-222 of SEQ ID NO:2); alpha helix A (AH A;
corresponding to amino acids 223-253 of SEQ ID NO:2); A-C loop (corresponding to amino acids 254-266 of SEQ ID NO:2); alpha helix C (AH C; corresponding to amino acids 267-276 of SEQ ID NO:2); unstructured loop 11 (UL 11 ; corresponding to amino acids 277-283 of SEQ ID NO:2); alpha helix D (AH D; corresponding to amino acids 284-305 of SEQ ID NO:2); unstructured loop 12 (UL 12; corresponding to amino acids 306-309 of SEQ ID NO:2); alpha helix Dl (AH Dl ; corresponding to amino acids 310-322 of SEQ ID NO:2); unstructured loop 13 (UL 13; corresponding to amino acids 323-328 of SEQ ID NO:2); alpha helix D2 (AH D2; corresponding to amino acids 329 of SEQ ID NO:2); unstructured loop 14 (UL 14; corresponding to amino acids 330-332 of SEQ ID NO:2); alpha helix E (AH E; corresponding to amino acids 333-351 of SEQ ID NO:2); unstructured loop 15 (UL 15; corresponding to amino acids 352-362 of SEQ ID NO:2); alpha helix F (AH F; corresponding to amino acids 363-385 of SEQ ID NO:2); unstructured loop 16 (UL 16; corresponding to amino acids 386-390 of SEQ ID NO:2); alpha helix Gl (AH Gl ; corresponding to amino acids 391-395 of SEQ ID NO:2); unstructured loop 17 (UL 17; corresponding to amino acids 396-404 of SEQ ID NO:2); alpha helix G2 (AH G2; corresponding to amino acids 405-413 of SEQ ID NO:2); unstructured loop 18 (UL 18; corresponding to amino acids 414-421 of SEQ ID NO:2); alpha helix HI (AH HI ; corresponding to amino acids 422-428 of SEQ ID NO:2); unstructured loop 19 (UL 19; corresponding to amino acids 429-431 of SEQ ID NO:2); alpha helix H2 (AH H2; corresponding to amino acids 432-447 of SEQ ID NO:2); unstructured loop 20 (UL 20; corresponding to amino acids 448-450 of SEQ ID NO:2); alpha helix H3 (AH H3; corresponding to amino acids 451-455 of SEQ ID NO:2); unstructured loop 21 (UL 21 ; corresponding to amino acids 456-461 of SEQ ID NO:2); alpha helix a-1 (AH a-1 ;
corresponding to amino acids 462-470 of SEQ ID NO:2); unstructured loop 22 (UL 22; corresponding to amino acids 471-473 of SEQ ID NO:2); alpha helix I (AH I; corresponding
to amino acids 474-495 of SEQ ID NO:2); unstructured loop 23 (UL 23; corresponding to amino acids 496-508 of SEQ ID NO:2); alpha helix J (AH J; corresponding to amino acids 509-521 of SEQ ID NO:2); J-K loop (corresponding to amino acids 522-534 of SEQ ID NO:2); alpha helix K (AH K; corresponding to amino acids 535-541 of SEQ ID NO:2); and unstructured loop 25 (UL 25; corresponding to amino acids 542-548 of SEQ ID NO:2). The grey box indicates amino acid residues that are not part of any secondary structure domain. A "*" means that the residues or nucleotides in that column are identical in all sequences in the alignment, a ":" means that conserved substitutions have been observed, and a "." means that semi-conserved substitutions are observed. As described herein, residues corresponding to structural regions in SEQ ID NO:2 can be identified in other synthases as residues that occur at aligned loci between and among synthases. For example, the unstructured loop 2 of valencene synthase (amino acids 53-58 of SEQ ID NO:2) corresponds to amino acids 58-63 of the tobacco epi-aristolochene synthase (TEAS) polypeptide set forth in SEQ ID NO:941. Figure 3: Figure 3 is the reaction scheme for the production of valencene and nootkatone. Valencene synthases are class 1 plant terpene cyclases or synthases that convert farnesyl diphosphate (FPP) into the sesquiterpene valencene. Valencene can then be converted to nootkatone by oxidation.
Figure 4: Figure 4 sets forth alignments indicating CVS numbering of various terpene synthases. Figure 4A. An alignment of 5-epi-aristolochene synthase (TEAS) from Nicotiana tabacum set forth in SEQ ID NOS:295 and 941 ; and citrus valencene synthase set forth in SEQ ID NO:2. Figure 4B. An alignment of premnaspirodiene synthase (HPS) from
Hyoscyamus muticus set forth in SEQ ID NOS:296 and 942; and citrus valencene synthase set forth in SEQ ID NO:2. Figure 4C. An alignment of valencene synthase from Vitis vinifera set forth in SEQ ID NOS:346 and 347; and citrus valencene synthase set forth in SEQ ID NO:2. Figure 4D. An alignment of V277 set forth in SEQ ID NO:887; and citrus valencene synthase set forth in SEQ ID NO:2. A "*" means that the residues or nucleotides in that column are identical in all sequences in the alignment, a ":" means that conserved substitutions have been observed, and a "." means that semi -conserved substitutions are observed.
DETAILED DESCRIPTION
A. Definitions
B. Valencene Synthase
1. Structure
2. Function
3. Citrus valencene synthase
C. Modified Valencene Synthase Polypeptides And Encoding Nucleic Acid Molecules
1. Modified valencene synthase polypeptides - Exemplary Amino Acid
Replacements
2. Domain Swaps
3. Product Distribution Mutants
D. Methods for producing modified terpene synthases and encoding nucleic acid molecules
E. Production of modified valencene synthase polypeptides and encoding nucleic acid molecules
1. Isolation of nucleic acid encoding terpene synthases
2. Generation of mutant or modified nucleic acid
3. Vectors and Cells
4. Expression systems
a. Prokaryotic cells
b. Yeast cells
c. Plants and plant cells
d. Insects and insect cells
e. Mammalian cells
5. Purification
6. Fusion Proteins
F. Methods of Using and Assessing Valencene Synthase
1. Production of valencene
a. Exemplary cells for valencene production
b. Culture of cells for valencene production c. Isolation and assessment of valencene
2. Production of Nootkatone
G. Examples
A. DEFINITIONS
Unless defined otherwise, all technical and scientific terms used herein have the same meaning as is commonly understood by one of skill in the art to which the invention(s) belong. All patents, patent applications, published applications and publications, GENBANK sequences, websites and other published materials referred to throughout the entire disclosure herein, unless noted otherwise, are incorporated by reference in their entirety. In the event that there is a plurality of definitions for terms herein, those in this section prevail. Where reference is made to a URL or other such identifier or address, it is understood that such identifiers can change and particular information on the internet can come and go, but equivalent information is known and can be readily accessed, such as by searching the internet and/or appropriate databases. Reference thereto evidences the availability and public dissemination of such information.
As used herein, an acyclic pyrophosphate terpene precursor is any acyclic pyrophosphate compound that is a precursor to the production of at least one terpene, including, but not limited, farnesyl-pyrophosphate (FPP), to geranyl-pyrophosphate (GPP), and geranylgeranyl-pyrophosphate (GGPP). Acyclic pyrophosphate terpene precursor are thus substrates for terpene synthases.
As used herein, a terpene is an unsaturated hydrocarbon based on the isoprene unit (C5H8), and having a general formula C5xH8x, such as Ci0H16. Reference to a terpene includes acyclic, monocyclic and polycyclic terpenes. Terpenes include, but are not limited to, monoterpenes, which contain 10 carbon atoms; sesquiterpenes, which contain 15 carbon
atoms; diterpenes, which contain 20 carbon atoms, and triterpenes, which contain 30 carbon atoms. Reference to a terpene also includes stereoisomers of the terpene.
As used herein, a terpene synthase is a polypeptide capable of catalyzing the formation of one or more terpenes from an acyclic pyrophosphate terpene precursor, for example, FPP, GPP or GGPP.
herein, valencene is a sesquiterpene having the following structure:
Reference to valencene includes reference to any isomer thereof, including, but not limited to (+)-valencene.
As used herein, a "valencene synthase" or "valencene synthase polypeptide" is a polypeptide capable of catalyzing the formation of valencene from an acyclic pyrophosphate terpene precursor, typically farnesyl diphosphate (FPP). Typically a valencene synthase has greater than or greater than about or 63%, 65%, 70%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%), 99%) sequence identity with the valence synthase set forth in SEQ ID NO:2. Valencene can be the only product or one of a mixture of products formed from the reaction of an acyclic pyrophosphate terpene precursor with a valencene synthase. The amount of valencene produced from the reaction of a valencene synthase with an acyclic pyrophosphate terpene precursor typically is at least or at least about 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%), 80%), 90%) or more of the total amount of terpene produced in the reaction. In some instances, valencene is the predominant terpene produced (i.e. present in greater amounts than any other single terpene produced from the reaction of an acyclic pyrophosphate terpene precursor with a valencene synthase).
Reference to a valencene synthase includes any valencene synthase polypeptide including, but not limited to, a recombinantly produced polypeptide, a synthetically produced polypeptide and a valencene synthase polypeptide extracted or isolated from cells and plant matter including, but not limited to, citrus peel. Exemplary valencene synthase polypeptides include those isolated from citrus fruit, grapevine flowers (e.g. Vitis vinifera L. cv.
Gewurztraminer and Vitis vinifera L. cv. Cabernet Sauvignon (see, Lucker et ah, (2004) Phytochemistry 65(19):2649-59 and Martin et al, (2009) Proc. Natl. Acad. Sci, USA
106:7245-7250) SEQ ID NOS:346 and 347) and perilla (green shiso). Exemplary of valencene synthases are Citrus valencene synthase (CVS), including but not limited to, valencene synthase from Citrus sinensis (Sweet orange) (SEQ ID NOS:2, 289 and 752) and Citrus x paradisi (Grapefruit) (SEQ ID NOS:2, 290 and 291). Other exemplary valencene
synthase polypeptides include valencene synthase isolated from grapevine flowers, including Vitis vinifera L. cv. Gewurztraminer and Vitis vinifera L. cv. Cabernet Sauvignon (SEQ ID NOS:346 and 347) and valencene synthase isolated from Chamaecyparis nootkatensis pendula (SEQ ID NOS: 882 and 883).Reference to valencene synthase includes valencene synthase from any genus or species, and included allelic or species variants, variants encoded by splice variants, and other variants thereof, including polypeptides that have at least or at least about 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%), 99%) or more sequence identity to the valencene synthase set forth in SEQ ID NO:2. Valencene synthase also includes fragments thereof that retain valencene synthase activity.
As used herein, "valencene synthase activity" (also referred to herein as catalytic activity) refers to the ability to catalyze the formation of valencene from an acyclic pyrophosphate terpene precursor, such as farnesyl diphosphate (FPP). Methods to assess valencene formation from the reaction of a synthase with an acyclic pyrophosphate terpene precursor, such as FPP, are well known in the art and described herein. For example, the synthase can be expressed in a host cell, such as a yeast cell, that also produces FPP. The production of valencene can then be assessed and quantified using, for example, gas chromatography-mass spectrometry (GC-MS) (see Examples below). A synthase is considered to exhibit valencene synthase activity or the ability to catalyze the formation of valencene from an acyclic pyrophosphate terpene precursor such as FPP if the amount of valencene produced from the reaction is at least or at least about 1%, 5%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90% or more of the total amount of terpene produced in the reaction.
As used herein, "increased catalytic activity" with reference to the activity of a valencene synthase means that the ability to catalyze the formation of valencene from an acyclic pyrophosphate terpene precursor, such as farnesyl diphosphate (FPP), is increased thereby resulting in increased formation of valencene. For purposes herein, a valencene synthase exhibits increased catalytic activity if the amount of valencene produced from FPP by the modified valencene synthase is 10% to 500%, 10% to 250%, 50% to 250%, 100% to 500%) or is 100%) to 250%) greater than the amount of valencene produced from FPP by the valencene synthase set forth in SEQ ID NO:2, such as 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 110%, 120%, 130%, 140%, 150%, 160%, 170%, 180%, 190%, 200%, 250%, 300%, 350%, 400%, 500% or more greater than the amount of valencene produced from FPP by the valencene synthase set forth in SEQ ID NO:2. For example, a valencene synthase exhibits increased catalytic activity if the amount of valencene produced from FPP by the modified valencene synthase is at least or about at least 110%, 115%, 120%), 125%, 130%, 135%, 140%, 145%, 150%, 160%, 170%, 180%, 200%, 250%, 300%, 350%,
400%, 500%, 1500%, 2000%, 3000%, 4000%, 5000% of the amount of valencene produced from FPP by wild-type valencene synthase set forth in SEQ ID NO:2 under the same conditions.
As used herein, "wild-type" or "native" with reference to valencene synthase refers to a valencene synthase polypeptide encoded by a native or naturally occurring valencene synthase gene, including allelic variants, that is present in an organism, including a plant, in nature. Reference to wild-type valencene synthase without reference to a species is intended to encompass any species of a wild-type valencene synthase. The amino acid sequence of exemplary valencene synthases are set forth in SEQ ID NOS: 2, (isolated from Citrus sinensis cv. Valencia, Citrus sinensis cv. Cara Cara and Citrus x paradisi), SEQ ID NO:289 (isolated from Citrus sinensis cv. Valencia); and SEQ ID NO:290 (isolated from Citrus paradisi) and SEQ ID NO:291 (isolated from Citrus x paradisi).
As used herein, species variants refer to variants in polypeptides among different species, including different citrus species, such Citrus sinensis and Citrus x paradisi.
As used herein, allelic variants refer to variations in encoded proteins among members of the same species.
As used herein, a splice variant refers to a variant produced by differential processing of a primary transcript of genomic DNA that results in more than one type of mRNA.
As used herein, "modified valencene synthase polypeptide" refers to a valencene synthase polypeptide that has one or more amino acid differences compared to an unmodified or wild-type valencene synthase polypeptide. The one or more amino acid differences can be amino acid mutations such as one or more amino acid replacements (substitutions), insertions or deletions, or can be insertions or deletions of entire domains, and any combinations thereof. Typically, a modified valencene synthase polypeptide has one or more modifications in primary sequence compared to an unmodified or wild-type valencene synthase polypeptide. For example, a modified valencene synthase polypeptide provided herein can have at least 1 , 5, 10, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 90, 95, 100, 105, 110, 115, 120, 125, 130, 135 or more amino acid differences compared to an unmodified valencene synthase polypeptide. Any modification is contemplated as long as the resulting polypeptide exhibits at least one valencene synthase activity associated with a wild- type valencene synthase polypeptide, such as, for example, catalytic activity, the ability to bind FPP, and/or the ability to catalyze the formation of valencene from FPP.
As used herein, reference to a modified valencene synthase polypeptide producing valencene from FPP in an amount that is greater than the amount of valencene produced from
- -
FPP by a reference valencene synthase, such as a wild-type valencene synthase, indicates that the modified valencene synthase produces at least or about 10% more valencene from FPP than the reference valencene synthase produces. For example, such a modified valencene synthase polypeptide can produce at least or at least about 10%, 1 1%, 12%, 13%, 14%, 15%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 1 10%, 120%, 130%, 140%, 150%, 160%, 170%, 180%, 190%, 200%, 250%, 300%, 350%, 400%, 500%, 600%, 700%, 800%, 900%, 1000%, 2000%, 5000% or more valencene from FPP compared to the amount of valencene produced from FPP by a reference valencene synthase. The amount of valencene produced from FPP by a valencene synthase can be assessed by any method known in the art. When comparing the amount of valencene produced from FPP by two valencene synthases, such as a modified valencene synthase and a reference valencene synthase, such as a wild- type valencene synthase, it is understood that the assay is performed under the same conditions for each synthase. In one example, the amount of valencene produced from FPP by two valencene synthases, such as a modified valencene synthase and a reference valencene synthase, is assessed by expressing the modified valencene synthase and the reference valencene synthase separately in a yeast cell of the same strain (wherein expression is from the same expression vector) that also produces FPP, and culturing the cells under the same conditions such that valencene is produced. The amount of valencene produced in the cell culture expressing the modified valencene synthase is compared to the amount of valencene produced in the cell culture expressing the reference valencene synthase, using methods of quantification well known in the art, such as GC-MS.
As used herein, "CVS numbering" refers to the amino acid numbering of a valencene synthase set forth in SEQ ID NO:2. Amino acid residues in a synthase other than that set forth in SEQ ID NO:2 can be identified by CVS numbering by alignment of the other terpene synthase with valencene synthase set forth in SEQ ID NO:2. In such an instance, the amino acids of the terpene synthase that align or correspond (i.e. corresponding residues) to amino acids of valencene synthase set forth in SEQ ID NO:2 are identified by the numbering of the valencene synthase amino acids set forth in SEQ ED NO:2. Figure 1 depicts CVS numbering for valencene synthase polypeptides. Figure 4 depicts CVS numbering for exemplary other terpene synthases. For example, in Figure 1 , the figure depicts that by CVS numbering based on SEQ ED NO:2, amino acid residue 24 is a (Lys) in valencene synthase polypeptides set forth in SEQ ID NOS: 290, 291 , 752, 289 and 886, is an A (Ala) in the valencene synthase set forth in SEQ ED NO:3 and is a Q in the valencene synthase polypeptide set forth in SEQ ID NO:4. With reference to Figure 4, the figure depicts that by CVS numbering based on SEQ ED NO:2, amino acid residue 24 is an S in TEAS set forth in SEQ ID NO:295 or 941, is an S in HPS set forth in SEQ ED NO:942, is a T in valencene synthase from Vitis st forth in
RECTIFIED SHEET (RULE 91)
ISA/EP
SEQ ID NO:346 or 347, and is a T in V277 variant valencene synthase set forth in SEQ ID NO:887.
As used herein, corresponding residues refers to residues that occur at aligned loci. Related or variant polypeptides are aligned by any method known to those of skill in the art. Such methods typically maximize matches, and include methods such as using manual alignments and by using the numerous alignment programs available (for example, BLASTP) and others known to those of skill in the art. By aligning the sequences of polypeptides, one skilled in the art can identify corresponding residues, using conserved and identical amino acid residues as guides. Corresponding positions also can be based on structural alignments, for example by using computer simulated alignments of protein structure. For example, amino acid residues R264, W273, T403, Y404, C441 and D445 of the valencene synthase set forth in SEQ ID NO:2 correspond to amino acid residues R264, W273, T403, Y404, C440 and D444 of the tobacco epi-aristolochene synthase set forth in SEQ ID NO:295. In another example, the tyrosine in amino acid position 221 (Y221) of SEQ ID NO:2 corresponds to the cysteine in amino acid position 221 (C221) of SEQ ID NO:289. In other instances, corresponding regions can be identified. For example, the unstructured loop 2 of valencene synthase (amino acids 53-58 of SEQ ID NO:2) corresponds to amino acids 58-63 of the tobacco epi-aristolochene synthase (TEAS) polypeptide set forth in SEQ ID NO:295 (see Figure 2).
For purposes herein, reference to modifications as "corresponding to positions... with
CVS numbering based on SEQ ID NO:2" or similar phrases means the identified amino acid residue that is modified is the amino acid residue as set forth by amino acid number in SEQ ID NO:2 and amino acid residues that align with such residue in another synthase. Thus, reference to a modification, such as an amino acid replacement, that corresponds to, for example, Y221V in SEQ ID NO:2, includes amino acid replacement of the tyrosine at position 221 of SEQ ID NO:2 with a valine; and also includes replacement of the endogenous amino acid residue at the position corresponding to (or aligning with) position 221 of SEQ ID NO:2 in any other similar or related polypeptide, with a tyrosine. For example, also included would be replacement of the cysteine at position 221 of SEQ ID NO:289 with a tyrosine (C221V).
As used herein, domain or region (typically a sequence of three or more, generally 5 or 7 or more amino acids) refers to a portion of a molecule, such as a protein or the encoding nucleic acids, that is structurally and/or functionally distinct from other portions of the molecule and is identifiable. A protein can have one, or more than one, distinct domains. For example, a domain can be identified, defined or distinguished by homology of the sequence therein to related family members, such as other terpene synthases. A domain can be a linear
sequence of amino acids or a non-linear sequence of amino acids. Many polypeptides contain a plurality of domains. Such domains are known, and can be identified by, those of skill in the art. For exemplification herein, definitions are provided, but it is understood that it is well within the skill in the art to recognize particular domains by name. If needed appropriate software can be employed to identify domains. For example, as discussed above, corresponding domains in different terpene synthases can be identified by sequence alignments, such as using tools and algorithms well known in the art (for example, BLASTP).
As used herein, a functional domain refers to those portions of a polypeptide that is recognized by virtue of a functional activity, such as catalytic activity. A functional domain can be distinguished by its function, such as by catalytic activity, or an ability to interact with a biomolecule, such as substrate binding or metal binding. In some examples, a domain independently can exhibit a biological function or property such that the domain
independently or fused to another molecule can perform an activity, such as, for example catalytic activity or substrate binding.
As used herein, a structural domain refers to those portions of a polypeptide chain that can form an independently folded structure within a protein made up of one or more structural motifs.
As used herein, "heterologous" with respect to an amino acid or nucleic acid sequence refers to portions of a sequence that is not present in the native polypeptide or encoded by the native polynucleotide. For example, a portion of amino acids of a polypeptide, such as a domain or region or portion thereof, for a valencene synthase is heterologous thereto if such amino acids is not present in a native or wild-type valencene synthase (e.g. as set forth in SEQ ID NO:2), or encoded by the polynucleotide encoding therefor. Polypeptides containing such heterologous amino acids or polynucleotides encoding therefor are referred to as "chimeric polypeptides" or "chimeric polynucleotides," respectively.
As used herein, the phrase "a property of the modified terpene synthase is improved compared to the first terpene synthase" refers to a desirable change in a property of a modified terpene synthase compared to a terpene synthase that does not contain the modification(s). Typically, the property or properties are improved such that the amount of a desired terpene produced from the reaction of a substrate with the modified terpene synthase is increased compared to the amount of the desired terpene produced from the reaction of a substrate with a terpene synthase that is no so modified. Exemplary properties that can be improved in a modified terpene synthase include, for example, terpene production, catalytic activity, product distribution; substrate specificity; regioselectivity and stereoselectivity. One or more of the properties can be assessed using methods well known in the art to determine
whether the property had been improved (i.e. has been altered to be more desirable for the production of a desired terpene or terpenes).
As used herein, terpene productions (also referred to as terpene yield) refers to the amount (in weight or weight/volume) of terpene produced from the reaction of an acyclic pyrophosphate terpene precursor with a terpene synthase. Reference to total terpene production refers to the total amount of all terpenes produced from the reaction, while reference to specific terpene production refers to the amount of a specific terpene (e.g.
valencene), produced from the reaction.
As used herein, an improved terpene production refers to an increase in the total amount of terpene (i.e. improved total terpene production) or an increase in the specific amount of terpene (i.e. improved specific terpene production) produced from the reaction of an acyclic pyrophosphate terpene precursor with a modified terpene synthase compared to the amount produced from the reaction of the same acyclic pyrophosphate terpene precursor with a terpene synthase that is not so modified. The amount of terpene (total or specific) produced from the reaction of an acyclic pyrophosphate terpene precursor with a modified terpene synthase can be increased by at least or at least about 5%, 10%, 15%, 20%, 30%, 40%, 50%, 60%), 70%), 80%), 90%), 100%) or more compared to the amount of terpene produced from the reaction of the same acyclic pyrophosphate terpene precursor under the same conditions with a terpene synthase that is not so modified.
As used herein, substrate specificity refers to the preference of a valencene synthase for one target substrate over another, such as one acyclic pyrophosphate terpene precursor (e.g. farnesyl-pyrophosphate (FPP), geranyl-pyrophosphate (GPP), or geranylgeranyl- pyrophosphate (GGPP)) over another. Substrate specificity can be assessed using methods well known in the art, such as those that calculate kcat/Km. For example, the substrate specificity can be assessed by comparing the relative Kcat/Km , which is a measure of catalytic efficiency, of the enzyme against various substrates (e.g. GPP, FPP, GGPP).
As used herein, altered specificity refers to a change in substrate specificity of a modified terpene synthase polypeptide (such as a modified valencene synthase polypeptide) compared to a terpene synthase that is not so modified (such as, for example, a wild-type valencene synthase). The specificity (e.g. kcJKm) of a modified terpene synthase polypeptide for a substrate, such as FPP, GPP or GGPP, can be altered by at least or at least about 10%>, 15%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% or more compared to the specificity of a starting valencene synthase for the same substrate.
As used herein, improved substrate specificity refers to a change or alteration in the substrate specificity to a more desired specificity. For example, an improved substrate specificity can include an increase in substrate specificity of a modified terpene synthase
polypeptide for a desired substrate, such as FPP, GPP or GGPP. The specificity (e.g. kcat/Km) of a modified terpene synthase polypeptide for a substrate, such as FPP, GPP or GGPP, can be increased by at least or at least about 10%, 15%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%), 100%) or more compared to the specificity of a terpene synthase that is not so modified. .
As used herein, "product distribution" refers to the relative amounts of different terpenes produced from the reaction between an acyclic pyrophosphate terpene precursor, such as FPP, and a terpene synthase, including the modified valencene synthase polypeptides provided herein. The amount of a produced terpene can be depicted as a percentage of the total products produced by the terpene synthase. For example, the product distribution resulting from reaction of FPP with a valencene synthase can be 90%> (weight/volume) valencene and 10% (weight/volume) germacrene A. Methods for assessing the type and amount of a terpene in a solution are well known in the art and described herein, and include, for example, gas chromatography-mass spectrometry (GC-MS) (see Examples below).
As used herein, an altered product distribution refers to a change in the relative amount of individual terpenes produced from the reaction between an acyclic pyrophosphate terpene precursor, such as FPP, and a terpene synthase, such as valencene synthase.
Typically, the change is assessed by determining the relative amount of individual terpenes produced from the acyclic pyrophosphate terpene precursor using a first synthase (e.g. wild- type synthase) and then comparing it to the relative amount of individual terpenes produced using a second synthase (e.g. a modified synthase). An altered product distribution is considered to occur if the relative amount of any one or more terpenes is increased or decreased by at least or by at least about 0.5%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 50%, 60%, 70%, 80 or more.
As used herein, an improved product distribution refers to a change in the product distribution to one that is more desirable, i.e. contains more desirable relative amounts of terpenes. For example, an improved product distribution can contain an increased amount of a desired terpene and a decreased amount of a terpene that is not so desired. The amount of desired terpene in an improved production distribution can be increased by at least or by at least about 0.5%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 35%, 40%), 50%), 60%), 70%), 80% or more. The amount of a terpene that is not desired in an improved production distribution can be decreased by at least or by at least about 0.5%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 50%, 60%, 70%, 80%) or more.
As used herein, nucleic acids or nucleic acid molecules include DNA, RNA and analogs thereof, including peptide nucleic acids (PNA) and mixtures thereof. Nucleic acids can be single or double-stranded. When referring to probes or primers, which are optionally
labeled, such as with a detectable label, such as a fluorescent or radiolabel, single-stranded molecules are contemplated. Such molecules are typically of a length such that their target is statistically unique or of low copy number (typically less than 5, generally less than 3) for probing or priming a library. Generally a probe or primer contains at least 14, 16 or 30 contiguous nucleotides of sequence complementary to or identical to a gene of interest. Probes and primers can be 10, 20, 30, 50, 100 or more nucleic acids long.
As used herein, the term polynucleotide means a single- or double-stranded polymer of deoxyribonucleotides or ribonucleotide bases read from the 5' to the 3' end.
Polynucleotides include RNA and DNA, and can be isolated from natural sources, synthesized in vitro, or prepared from a combination of natural and synthetic molecules. The length of a polynucleotide molecule is given herein in terms of nucleotides (abbreviated "nt") or base pairs (abbreviated "bp"). The term nucleotides is used for single- and double-stranded molecules where the context permits. When the term is applied to double-stranded molecules it is used to denote overall length and will be understood to be equivalent to the term base pairs. It will be recognized by those skilled in the art that the two strands of a double- stranded polynucleotide can differ slightly in length and that the ends thereof can be staggered; thus all nucleotides within a double-stranded polynucleotide molecule can not be paired. Such unpaired ends will, in general, not exceed 20 nucleotides in length.
As used herein, heterologous nucleic acid is nucleic acid that is not normally produced in vivo by the cell in which it is expressed or that is produced by the cell but is at a different locus or expressed differently or that mediates or encodes mediators that alter expression of endogenous nucleic acid, such as DNA, by affecting transcription, translation, or other regulatable biochemical processes. Heterologous nucleic acid is generally not endogenous to the cell into which it is introduced, but has been obtained from another cell or prepared synthetically. Heterologous nucleic acid can be endogenous, but is nucleic acid that is expressed from a different locus or altered in its expression. Generally, although not necessarily, such nucleic acid encodes RNA and proteins that are not normally produced by the cell or in the same way in the cell in which it is expressed. Heterologous nucleic acid, such as DNA, also can be referred to as foreign nucleic acid, such as DNA. Thus, heterologous nucleic acid or foreign nucleic acid includes a nucleic acid molecule not present in the exact orientation or position as the counterpart nucleic acid molecule, such as DNA, is found in a genome. It also can refer to a nucleic acid molecule from another organism or species {i.e., exogenous).
Any nucleic acid, such as DNA, that one of skill in the art would recognize or consider as heterologous or foreign to the cell in which the nucleic acid is expressed is herein encompassed by heterologous nucleic acid; heterologous nucleic acid includes exogenously
- -
added nucleic acid that also is expressed endogenously. Examples of heterologous nucleic acid include, but are not limited to, nucleic acid that encodes traceable marker proteins, such as a protein that confers drug resistance, nucleic acid that encodes therapeutically effective substances, such as anti-cancer agents, enzymes and hormones, and nucleic acid, such as DNA, that encodes other types of proteins, such as antibodies. Antibodies that are encoded by heterologous nucleic acid can be secreted or expressed on the surface of the cell in which the heterologous nucleic acid has been introduced.
As used herein, a peptide refers to a polypeptide that is from 2 to 40 amino acids in length.
As used herein, the amino acids that occur in the various sequences of amino acids provided herein are identified according to their known, three-letter or one-letter abbreviations (Table 1). The nucleotides which occur in the various nucleic acid fragments are designated with the standard single-letter designations used routinely in the art.
As used herein, an "amino acid" is an organic compound containing an amino group and a carboxylic acid group. A polypeptide contains two or more amino acids. For purposes herein, amino acids include the twenty naturally-occurring amino acids, non-natural amino acids and amino acid analogs (i.e., amino acids wherein the a-carbon has a side chain).
In keeping with standard polypeptide nomenclature described in J. Biol. Chem., 243: 3557-3559 (1968), and adopted 37 C.F.R. §§ 1.821-1.822, abbreviations for the amino acid residues are shown in Table 1 :
Table 1 - Table of Correspondence
RECTIFIED SHEET (RULE 91)
It should be noted that all amino acid residue sequences represented herein by formulae have a left to right orientation in the conventional direction of amino-terminus to carboxyl-terminus. In addition, the phrase "amino acid residue" is broadly defined to include the amino acids listed in the Table of Correspondence (Table 1) and modified and unusual amino acids, such as those referred to in 37 C.F.R. §§ 1.821-1.822, and incorporated herein by reference. Furthermore, it should be noted that a dash at the beginning or end of an amino acid residue sequence indicates a peptide bond to a further sequence of one or more amino acid residues, to an amino-terminal group such as NH2 or to a carboxyl-terminal group such as COOH.
As used herein, "naturally occurring amino acids" refer to the 20 L-amino acids that occur in polypeptides.
As used herein, "non-natural amino acid" refers to an organic compound containing an amino group and a carboxylic acid group that is not one of the naturally-occurring amino acids listed in Table 1. Non-naturally occurring amino acids thus include, for example, amino acids or analogs of amino acids other than the 20 naturally-occurring amino acids and include, but are not limited to, the D-isostereomers of amino acids. Exemplary non-natural amino acids are known to those of skill in the art and can be included in a modified valencene synthase polypeptides provided herein.
As used herein, modification is in reference to modification of a sequence of amino acids of a polypeptide or a sequence of nucleotides in a nucleic acid molecule and includes deletions, insertions, and replacements of amino acids and nucleotides, respectively. For purposes herein, amino acid replacements (or substitutions), deletions and/or insertions, can be made in any of the valencene synthases provided herein. Modifications can be made by making conservative amino acid replacements and also non-conservative amino acid substitutions. For example, amino acid replacements that desirably or advantageously alter properties of the valencene synthase can be made. For example, amino acid replacements can be made to the valencene synthase such that the resulting modified valencene synthase can produce more valencene from FPP compared to an unmodified valencene synthase.
Amino acid replacements or substitutions contemplated include conservative substitutions, including, but not limited to, those set forth in Table 2. Suitable conservative substitutions of amino acids are known to those of skill in the art and can be made generally without altering the conformation or activity of the polypeptide. Those of skill in this art recognize that, in general, single amino acid substitutions in non-essential regions of a polypeptide do not substantially alter biological activity (see, e.g., Watson et al. Molecular Biology of the Gene, 4th Edition, 1987, The Benjamin/Cummings Pub. co., p.224).
Conservative amino acid substitutions are made, for example, in accordance with those set forth in Table 2 as follows:
TABLE 2
Other conservative substitutions also are permissible and can be determined empirically or in accord with known conservative substitutions. The effects of such substitutions can be calculated using substitution score matrices such PAM120, PAM-200, and PAM-250 as discussed in Altschul (J. Mol. Biol. 219:55565 (1991)).
As used herein, "primary sequence" refers to the sequence of amino acid residues in a polypeptide.
As used herein, "similarity" between two proteins or nucleic acids refers to the relatedness between the sequence of amino acids of the proteins or the nucleotide sequences of the nucleic acids. Similarity can be based on the degree of identity and/or homology of sequences of residues and the residues contained therein. Methods for assessing the degree of similarity between proteins or nucleic acids are known to those of skill in the art. For
example, in one method of assessing sequence similarity, two amino acid or nucleotide sequences are aligned in a manner that yields a maximal level of identity between the sequences. "Identity" refers to the extent to which the amino acid or nucleotide sequences are invariant. Alignment of amino acid sequences, and to some extent nucleotide sequences, also can take into account conservative differences and/or frequent substitutions in amino acids (or nucleotides). Conservative differences are those that preserve the physico-chemical properties of the residues involved. Alignments can be global (alignment of the compared sequences over the entire length of the sequences and including all residues) or local (the alignment of a portion of the sequences that includes only the most similar region or regions).
As used herein, the terms "homology" and "identity"" are used are used to describe relatedness between and among polypeptides (or encoding nucleic acid molecules). Identity refers to identical sequences; homology can include conservative amino acid changes. In general to identify corresponding positions the sequences of amino acids are aligned so that the highest order match is obtained (see, e.g. : Computational Molecular Biology. Lesk, A.M., ed., Oxford University Press, New York, 1988; Biocomputing: Informatics and Genome Projects, Smith, D.W., ed., Academic Press, New York, 1993; Computer Analysis of Sequence Data, Part I, Griffin, A.M., and Griffin, H.G., eds., Humana Press, New Jersey, 1994; Sequence Analysis in Molecular Biology, von Heinje, G., Academic Press, 1987; and Sequence Analysis Primer, Gribskov, M. and Devereux, J., eds., M Stockton Press, New York, 1991 ; Carillo et al. (1988) SIAM J Applied Math 48: 1073).
As use herein, "sequence identity" refers to the number of identical amino acids (or nucleotide bases) in a comparison between a test and a reference polypeptide or
polynucleotide. Homologous polypeptides refer to two or more peptides that have a predetermined number of identical or conservative amino acid residues. Homology also includes substitutions that do not change the encoded amino acid {i.e. "silent substitutions"). Sequence identity can be determined by standard alignment algorithm programs used with default gap penalties established by each supplier. Homologous nucleic acid molecules refer to two or more nucleotides that have a pre-determined number of identical or homologous nucleotides. Substantially homologous nucleic acid molecules hybridize typically at moderate stringency or at high stringency all along the length of the nucleic acid or along at least about 70%, 80%> or 90%) of the full-length nucleic acid molecule of interest. Also contemplated are nucleic acid molecules that contain degenerate codons in place of codons in the hybridizing nucleic acid molecule. (For determination of homology of proteins, conservative amino acids can be aligned as well as identical amino acids; in this case, percentage of identity and percentage homology varies). Whether any two nucleic acid molecules have nucleotide sequences (or any two polypeptides have amino acid sequences) that are at least 80%>, 85%>, 90%>, 95%>,
96%, 97%, 98%) or 99% "identical" can be determined using known computer algorithms such as the "FAST A" program, using for example, the default parameters as in Pearson et al. Proc. Natl. Acad. Sci. USA 85: 2444 (1988) (other programs include the GCG program package (Devereux, J., et al., Nucleic Acids Research 12(1): 387 (1984)), BLASTP, BLASTN, FASTA (Atschul, S.F., et al., J. Molec. Biol. 215:403 (1990); Guide to Huge Computers. Martin J. Bishop, ed., Academic Press, San Diego (1994), and Carillo et al. SIAM J Applied Math 48: 1073 (1988)). For example, the BLAST function of the National Center for Biotechnology Information database can be used to determine identity. Other commercially or publicly available programs include DNAStar "MegAlign" program (Madison, WI) and the University of Wisconsin Genetics Computer Group (UWG) "Gap" program (Madison WI)). Percent homology or identity of proteins and/or nucleic acid molecules can be determined, for example, by comparing sequence information using a GAP computer program {e.g. ,
Needleman et al. J. Mol. Biol. 48: 443 (1970), as revised by Smith and Waterman (Adv. Appl. Math. 2: 482 (1981)). Briefly, a GAP program defines similarity as the number of aligned symbols {i.e., nucleotides or amino acids) which are similar, divided by the total number of symbols in the shorter of the two sequences. Default parameters for the GAP program can include: (1) a unary comparison matrix (containing a value of 1 for identities and 0 for non identities) and the weighted comparison matrix of Gribskov et al. Nucl. Acids Res. 14: 6745 (1986), as described by Schwartz and Dayhoff, eds., Atlas of Protein Sequence and Structure, National Biomedical Research Foundation, pp. 353-358 (1979); (2) a penalty of 3.0 for each gap and an additional 0.10 penalty for each symbol in each gap; and (3) no penalty for end gaps. Clustal analysis also can be used to align either nucleotide or protein sequences and to score their level of identity and similarity (available at ebi.ac.uk/Tools/msa/clusalw2/ or ebi.ac.uk/ebisearch/search.ebi?db=medline&t=clustal*).
Therefore, as used herein, the term "identity" represents a comparison between a test and a reference polypeptide or polynucleotide. In one non-limiting example, "at least 90%> identical to" refers to percent identities from 90 to 100%> relative to the reference
polypeptides. Identity at a level of 90%> or more is indicative of the fact that, assuming for exemplification purposes a test and reference polypeptide length of 100 amino acids are compared, no more than 10%> {i.e., 10 out of 100) of amino acids in the test polypeptide differs from that of the reference polypeptides. Similar comparisons can be made between a test and reference polynucleotides. Such differences can be represented as point mutations randomly distributed over the entire length of an amino acid sequence or they can be clustered in one or more locations of varying length up to the maximum allowable, e.g., 10/100 amino acid difference (approximately 90%> identity). Differences are defined as nucleic acid or amino acid substitutions, insertions or deletions. At the level of homologies or identities
above about 85-90%, the result should be independent of the program and gap parameters set; such high levels of identity can be assessed readily, often without relying on software.
As used herein, it also is understood that the terms "substantially identical" or "similar" varies with the context as understood by those skilled in the relevant art, but that those of skill can assess such.
As used herein, an aligned sequence refers to the use of homology (similarity and/or identity) to align corresponding positions in a sequence of nucleotides or amino acids.
Typically, two or more sequences that are related by 50%> or more identity are aligned. An aligned set of sequences refers to 2 or more sequences that are aligned at corresponding positions and can include aligning sequences derived from RNAs, such as ESTs and other cDNAs, aligned with genomic DNA sequence.
As used herein, isolated or purified polypeptide or protein or biologically-active portion thereof is substantially free of cellular material or other contaminating proteins from the cell of tissue from which the protein is derived, or substantially free from chemical precursors or other chemicals when chemically synthesized. Preparations can be determined to be substantially free if they appear free of readily detectable impurities as determined by standard methods of analysis, such as thin layer chromatography (TLC), gel electrophoresis and high performance liquid chromatography (HPLC), used by those of skill in the art to assess such purity, or sufficiently pure such that further purification would not detectably alter the physical and chemical properties, such as proteolytic and biological activities, of the substance. Methods for purification of the compounds to produce substantially chemically pure compounds are known to those of skill in the art. A substantially chemically pure compound, however, can be a mixture of stereoisomers. In such instances, further purification might increase the specific activity of the compound.
The term substantially free of cellular material includes preparations of valencene synthase or terpene products in which the valencene synthase or terpene is separated from cellular components of the cells from which it is isolated or produced. In one embodiment, the term substantially free of cellular material includes preparations of valencene synthase or terpene products having less that about 30%, 20%, 10%, 5% or less (by dry weight) of non- valencene synthase or terpene proteins or products, including cell culture medium.
As used herein, production by recombinant methods by using recombinant DNA methods refers to the use of the well known methods of molecular biology for expressing proteins encoded by cloned DNA.
As used herein, vector (or plasmid) refers to discrete DNA elements that are used to introduce heterologous nucleic acid into cells for either expression or replication thereof. The vectors typically remain episomal, but can be designed to effect integration of a gene or
portion thereof into a chromosome of the genome. Also contemplated are vectors that are artificial chromosomes, such as bacterial artificial chromosomes, yeast artificial chromosomes and mammalian artificial chromosomes. Selection and use of such vehicles are well known to those of skill in the art.
As used herein, expression refers to the process by which nucleic acid is transcribed into mRNA and translated into peptides, polypeptides, or proteins. If the nucleic acid is derived from genomic DNA, expression can, if an appropriate eukaryotic host cell or organism is selected, include processing, such as splicing of the mRNA.
As used herein, an expression vector includes vectors capable of expressing DNA that is operative ly linked with regulatory sequences, such as promoter regions, that are capable of effecting expression of such DNA fragments. Such additional segments can include promoter and terminator sequences, and optionally can include one or more origins of replication, one or more selectable markers, an enhancer, a polyadenylation signal, and the like. Expression vectors are generally derived from plasmid or viral DNA, or can contain elements of both. Thus, an expression vector refers to a recombinant DNA or RNA construct, such as a plasmid, a phage, recombinant virus or other vector that, upon introduction into an appropriate host cell, results in expression of the cloned DNA. Appropriate expression vectors are well known to those of skill in the art and include those that are replicable in eukaryotic cells and/or prokaryotic cells and those that remain episomal or those which integrate into the host cell genome.
As used herein, vector also includes "virus vectors" or "viral vectors." Viral vectors are engineered viruses that are operatively linked to exogenous genes to transfer (as vehicles or shuttles) the exogenous genes into cells.
As used herein, an adenovirus refers to any of a group of DNA-containing viruses that cause conjunctivitis and upper respiratory tract infections in humans.
As used herein, naked DNA refers to histone-free DNA that can be used for vaccines and gene therapy. Naked DNA is the genetic material that is passed from cell to cell during a gene transfer process called transformation or transfection. In transformation or transfection, purified or naked DNA that is taken up by the recipient cell will give the recipient cell a new characteristic or phenotype.
As used herein, operably or operatively linked when referring to DNA segments means that the segments are arranged so that they function in concert for their intended purposes, e.g., transcription initiates in the promoter and proceeds through the coding segment to the terminator.
As used herein, a "chimeric protein" or "fusion protein" refers to a polypeptide operatively-linked to a different polypeptide. A chimeric or fusion protein provided herein
can include one or more valencene synthase polypeptides, or a portion thereof, and one or more other polypeptides for any one or more of a transcriptional/ translational control signals, signal sequences, a tag for localization, a tag for purification, part of a domain of an immunoglobulin G, and/or a targeting agent. A chimeric valencene synthase polypeptide also includes those having their endogenous domains or regions of the polypeptide exchanged with another polypeptide. These chimeric or fusion proteins include those produced by recombinant means as fusion proteins, those produced by chemical means, such as by chemical coupling, through, for example, coupling to sulfhydryl groups, and those produced by any other method whereby at least one polypeptide (i.e. valencene synthase), or a portion thereof, is linked, directly or indirectly via linker(s) to another polypeptide.
As used herein, recitation that a polypeptide "consists essentially" of a recited sequence of amino acids means that only the recited portion, or a fragment thereof, of the full- length polypeptide is present. The polypeptide can optionally, and generally will, include additional amino acids from another source or can be inserted into another polypeptide
As used herein, the singular forms "a," "an" and "the" include plural referents unless the context clearly dictates otherwise. Thus, for example, reference to polypeptide, comprising "an amino acid replacement"" includes polypeptides with one or a plurality of amino acid replacements.
As used herein, ranges and amounts can be expressed as "about" a particular value or range. About also includes the exact amount. Hence "about 5 %" means "about 5 %" and also "5 %."
As used herein, "optional" or "optionally" means that the subsequently described event or circumstance does or does not occur, and that the description includes instances where said event or circumstance occurs and instances where it does not. For example, an optionally step of isolating valencene means that the valencene is isolated or is not isolated.
As used herein, the abbreviations for any protective groups, amino acids and other compounds, are, unless indicated otherwise, in accord with their common usage, recognized abbreviations, or the IUPAC-IUB Commission on Biochemical Nomenclature (see, (1972) Biochem. 11 : 1726).
B. VALENCENE SYNTHASE
Valencene synthases are class 1 plant terpene cyclases, or terpene synthases, isoprenoid synthases or terpenoid cyclases, which convert farnesyl diphosphate into the sesquiterpene valencene. Valencene can then be converted to nootkatone by oxidation. Both valencene and nootkatone are natural constituents of citrus oils, such as orange and grapefruit, and are widely used ingredients in perfumery and the flavor industry.
- -
Valencene has been identified in citrus fruit, grapevine flowers, celery (Apium graveolens), mango (Mangifera indicd), olives (Olea europea) and coral. To date, valencene synthases have been isolated from citrus fruit, grapevine flowers and perilla (green shiso). Citrus valencene synthase (CVS) has been identified in the flavedo (outer peel) of Citrus sinensis (Sweet orange) (SEQ ID NOS:2, 289, 290) and Citrus x paradisi (Grapefruit) (SEQ ID NOS:291 and 752) (see, Chappell (2004) Trends Plant Sci., 9:266; Sharon-Asa et al, (2003) The Plant Journal 36:664-674; AF41 1 120 and U.S. Patent Nos. 7,273,735; 7,442,785; 7,790,426; and International PCT Appl. No. WO2005021705 and WO2003025193). A variant valencene synthase has been described containing amino acid replacements
A5171/1518 V (Eyal, E. Masters Thesis, Department of Plant Sciences, Weizmann Institute of Science, Rehovot, Israel; January, 2001; set forth in SEQ ID NO:886). Valencene synthases have also been identified and isolated from grapevine flowers, including Vitis vinifera L. cv. Gewiirztraminer and Vitis vinifera L. cv. Cabernet Sauvignon (see, Lucker et al., (2004) Phytochemistry 65(19):2649-59 and Martin et al., (2009) Proc. Natl. Acad. Sci, USA
106:7245-7250) (SEQ ID NOS:346 and 347). Valencene synthases also have been isolated from Chamaecyparis nootkatensis pendula (see e.g. International PCT Appl. No.
WO201 1074954; SEQ ID NOS: 882 and 883, and encoding nucleic acids set forth in SEQ ID NOS: 884 and 885, respectively),
a. Structure
Class 1 plant terpene cyclases include a diverse group of monomeric terpene synthases that share a common alpha helical architecture termed the class 1 terpenoid cyclase fold (see, e.g., Christianson, D.W., (2008) Curr Opin Chem Biol 12(2): 141-150 and
Bohlmann et al., (1998) Proc. Natl. Acad. Sci. USA 95:4126-4133). Although relatively little overall sequence similarity exists, class 1 plant terpene cyclases have homologous structures and some highly conserved motifs and/or residues. In its catalytic site, each terpene cyclase provides a template that binds the flexible isoprenoid substrate with an orientation and conformation such that upon cyclization, a specific intramolecular carbon-carbon bond is formed. Thus, the structure of each enzyme's catalytic site dictates the resulting cyclic monoterpenes, diterpenes and sesquiterpenes.
X-ray crystal structures of tobacco 5-epi-aristolochene synthase and pentalenene synthase revealed that class 1 plant terpene cyclases consist entirely of alpha helices interconnected by short connecting loops and turns (see, e.g., Starks et al, (1997), Science 277: 1815-1820 and Lesburg et al, (1997), Science 277: 1820-1824; see also Figure 2). These enzymes contain two distinct structural domains, an N-terminal domain, whose structure resembles catalytic cores of glycosyl hydrolysases but whose function remains largely unknown, and a C-terminal catalytic domain. The catalytic domain contains two conserved
RECTIFIED SHEET (RULE 91)
ISA/EP
metal binding motifs, i.e., aspartate -rich regions, which are responsible for enzyme catalytic activity. The catalytic site contains a large central cavity formed by mostly antiparallel alpha helices with the two aspartate -rich regions located on opposite walls. The aspartate-rich regions mediate binding of substrate diphosphates via bridging Mg2+ ions. Subsequent binding of the substrate induces conformational changes such that the N-terminal region forms a cap over the catalytic core that closes the active site to solvent, thereby stabilizing the reactive carbocation intermediates.
Conserved alpha helices C, D, F, G and H make up the catalytic or active site of class 1 plant terpene synthases. The active site is a hydrophobic pocket lined by aromatic residues to accommodate the olefin chain of the substrate. The aromatic residues stabilize carbocation intermediates through π-cation interactions. Aspartate-rich region 1 is located on Helix D and is characterized by conserved sequence DDxxD, which also functions to bind Mg2+ (see, e.g., Starks et al. , (1997), Science 277: 1815-1820). A second conserved metal-binding region is located on Helix H and is characterized by the conserved sequence [N/D]xxx[S/T]xxxE, also referred to as the "NSE/DTE motif." These two conserved metal binding motifs coordinate the binding of three Mg2+ ions to the isoprenoid disphosphate.
b. Function
Valencene synthase catalyzes the formation of valencene from the ubiquitous pyrophosphate intermediate farnesyl diphosphate (FPP), which is produced as part of the mevalonate-dependent isoprenoid biosynthetic pathway in fungi and animals and the non- mevalonate-dependent isoprenoid biosynthetic pathway in bacteria and higher plants.
Valencene (1,2,3,5, 6,7,8, 8a-octahydro-7-isopropenyl-l,8a-dimethyl-naphthalene) is then converted by oxidation to nootkatone (4,4a,5,6,7,8-hexahydro-6-isopropenyl-4,4-a-dimethyl- 2(3H)-naphthalenone). Figure 3 depicts the biochemical pathway.
Class 1 plant terpene cyclases such as valencene synthase are metal dependent cyclases that convert linear all-trans isoprenoid diphosphates, such as geranyl diphosphate, farnesyl diphosphate and geranyl-geranyl diphosphate, into cyclic monoterpenes, diterpenes and sesquiterpenes. Cyclization reactions proceed via electrophilic alkylation in which new carbon-carbon single bonds are formed through reaction of a highly reactive electron- deficient allylic carbocation and an electron-rich carbon-carbon double bond.
Terpene synthases contain divalent metal ions, typically Mg2+ ions or sometimes Mn2+, at the active center of the enzyme that are required for enzyme catalysis. More specifically, they are required for pyrophosphate departure. Generally, the enzymes contain two conserved metal binding motifs that line the catalytic site, including the aspartate-rich DDxxD motif that coordinates binding of two Mg2+ ions and the NSE/DTE motif that coordinates a third Mg2+ ion (see, Starks et al., (1997), Science 277:1815-1820 and Lesburg et
ah, (1997), Science 277: 1820-1824). The aspartate -rich regions of the catalytic active site mediate binding of prenyl diphosphates via bridging Mg ions. Binding of (Mg2+)3-PP; induces conformational changes such that the N-terminal region forms a cap over the catalytic core and therefore stabilizes the active site in a closed conformation that is free from bulk solvent. Loss of pyrophosphate (PP;) from the enzyme -bound substrate results in a highly reactive allylic carbocation that electrophilically attacks an intramolecular double bond further down the terpene chain to effect ring closure. The PP; anion accepts hydrogen bonds from conserved basic residues when bound in the closed synthase conformation and a hydrophobic pocket lined by aromatic residues cradles the prenyl side chain and likely templates the cyclization reaction by enforcing particular substrate conformations and stabilizing carbocations through π-stacking interactions (Noel et al, (2010) ACS Chemical Biology 5(4):377-392).
c. Citrus valencene synthase
Citrus valencene synthase is a sesquiterpene synthase found in citrus fruit, such as oranges and grapefruit, which converts all-trans farnesyl diphosphate (FPP) into the sesquiterpene valencene. Several citrus valencene synthases have been identified and isolated to date. The amino acid sequences of the citrus valencene synthases are not necessarily species-specific, as synthases isolated from a particular species {e.g. Citrus sinensis) can have the same or different sequence to that of another synthase isolated from the same species, and can have the same or different sequence as a synthase isolated from a different species {e.g. Citrus paradisi).
Citrus valencene synthases isolated and sequenced to date include the valencene synthase isolated from Citrus sinensis cv. Valencia (Valencia orange) as described herein (see Example 1), which is a 548 amino acid polypeptide having an amino acid sequence set forth in SEQ ID NO:2 (encoded by the cDNA sequence set forth in SEQ ID NO: 1). This synthase shares 100% nucleotide sequence identity with a valencene synthase isolated from Citrus paradisi (grapefruit: see U.S. Pat. No. 7,273,735) and with a valencene synthase isolated from the navel orange {Citrus sinensis cv. Cara Cara; Genbank Accession Nos. ACX70155). The nucleotide sequence that describes all three of these terpene synthases is set forth in SEQ ID NO: l (also Genbank Accession No. GQ988384). The corresponding polypeptide amino acid sequence is set forth in SEQ ID NO:2 A second valence synthase from Citrus paradisi also is described in U.S. Pat. No. 7,273,735 that contains 4 amino acid substitutions compared to the valencene synthase set forth in SEQ ID NO:2; I92N, D95H, R98S and A99P (SEQ ID NO:752, encoded by the cDNA set forth in SEQ ID NO:753). Another valencene synthase isolated from the flavedo (outer peel) of Citrus sinensis cv. Valencia has 2 amino acid substitutions compared to the valencene synthase set forth in SEQ ID NO:2; V123G and
Y221C (SEQ ID NO:289, encoded by the cDNA set forth in SEQ ID NO:292; Genbank Accession Nos. AAQ04608 and AF441124; see, Sharon- Asa et al, (2003) The Plant Journal 36:664-674). A further valencene synthase isolated from Citrus x paradisi has 2 different amino acid substitutions compared to the valencene synthase set forth in SEQ ID NO:2; Q87L and L239P (SEQ ID NO:290, encoded by the cDNA set forth in SEQ ID NO:293; see, U.S. Pat. No. 7,442,785); and another valencene synthase isolated from Citrus x paradisi a further (for a total of 3) amino acid substitutions compared to the valencene synthase set forth in SEQ ID NO:2; Q87L, L239P and N493D (SEQ ID NO:291, encoded by the cDNA set forth in SEQ ID NO:294; see, Genbank Accession Nos. AAM00426 and AF411120).
As described above, citrus valencene synthase contains an N-terminal domain (aa 1-
266 of SEQ ID NO:2) and a C-terminal catalytic domain (aa 267-548 of SEQ ID NO:2). Although valencene synthase does not necessarily share a high percentage of homology to other terpene synthases, the catalytic domain does share a common 3 -dimensional structure (described in, for example, U.S. Patent Nos. 6,465,772, 6,495,354 and 6,559,297) with other terpene synthases. When aligned and compared with the structure of tobacco 5-epi- aristolochene synthase (TEAS; described in Starks et al. (1999) Science 277: 1815-1820), it is apparent that Citrus valencene synthase contains the following structural domains:
unstructured loop 1 (corresponding to amino acids 1-29 of SEQ ID NO:2); alpha helix 1 (corresponding to amino acids 30-39 and 44-52 of SEQ ID NO:2); unstructured loop 2 (corresponding to amino acids 53-58 of SEQ ID NO:2); alpha helix 2 (corresponding to amino acids 59-71 of SEQ ID NO:2); unstructured loop 3 (corresponding to amino acids 72- 78 of SEQ ID NO:2); alpha helix 3 (corresponding to amino acids 79-93 of SEQ ID NO:2); unstructured loop 4 (corresponding to amino acids 94-100 of SEQ ID NO:2); alpha helix 4 (corresponding to amino acids 101-114 of SEQ ID NO:2); unstructured loop 5 (corresponding to amino acids 115-141 of SEQ ID NO:2); alpha helix 5 (corresponding to amino acids 142- 152 of SEQ ID NO:2); unstructured loop 6 (corresponding to amino acids 153-162 of SEQ ID NO:2); alpha helix 6 (corresponding to amino acids 163-173 of SEQ ID NO:2); unstructured loop 7 (corresponding to amino acids 174-184 of SEQ ID NO:2); alpha helix 7
(corresponding to amino acids 185-194 of SEQ ID NO:2); unstructured loop 8 (corresponding to amino acids 195-201 of SEQ ID NO:2); alpha helix 8 (corresponding to amino acids 202- 212 of SEQ ID NO:2); unstructured loop 9 (corresponding to amino acids 213-222 of SEQ ID NO:2); alpha helix A (corresponding to amino acids 223-253 of SEQ ID NO:2); A-C loop (corresponding to amino acids 254-266 of SEQ ID NO:2); alpha helix C (corresponding to amino acids 267-276 of SEQ ID NO:2); unstructured loop 11 (corresponding to amino acids 277-283 of SEQ ID NO:2); alpha helix D (corresponding to amino acids 284-305 of SEQ ID NO:2); unstructured loop 12 (corresponding to amino acids 306-309 of SEQ ID NO:2); alpha
helix Dl (corresponding to amino acids 310-322 of SEQ ID NO:2); unstructured loop 13 (corresponding to amino acids 323-328 of SEQ ID NO:2); alpha helix D2 (corresponding to amino acids 329 of SEQ ID NO:2); unstructured loop 14 (corresponding to amino acids 330- 332 of SEQ ID NO:2); alpha helix E (corresponding to amino acids 333-351 of SEQ ID NO:2); unstructured loop 15 (corresponding to amino acids 352-362 of SEQ ID NO:2); alpha helix F (corresponding to amino acids 363-385 of SEQ ID NO:2); unstructured loop 16 (corresponding to amino acids 386-390 of SEQ ID NO:2); alpha helix Gl (corresponding to amino acids 391-395 of SEQ ID NO:2); unstructured loop 17 (corresponding to amino acids 396-404 of SEQ ID NO:2); alpha helix G2 (corresponding to amino acids 405-413 of SEQ ID NO:2); unstructured loop 18 (corresponding to amino acids 414-421 of SEQ ID NO:2); alpha helix HI (corresponding to amino acids 422-428 of SEQ ID NO:2); unstructured loop 19 (corresponding to amino acids 429-431 of SEQ ID NO:2); alpha helix H2 (corresponding to amino acids 432-447 of SEQ ID NO:2); unstructured loop 20 (corresponding to amino acids 448-450 of SEQ ID NO:2); alpha helix H3 (corresponding to amino acids 451-455 of SEQ ID NO:2); unstructured loop 21 (corresponding to amino acids 456-461 of SEQ ID NO:2); alpha helix a-1 (corresponding to amino acids 462-470 of SEQ ID NO:2); unstructured loop 22 (corresponding to amino acids 471-473 of SEQ ID NO:2); alpha helix I (corresponding to amino acids 474-495 of SEQ ID NO:2); unstructured loop 23 (corresponding to amino acids 496-508 of SEQ ID NO:2); alpha helix J (corresponding to amino acids 509-521 of SEQ ID NO:2); J-K loop (corresponding to amino acids 522-534 of SEQ ID NO:2); alpha helix K (corresponding to amino acids 535-541 of SEQ ID NO:2); and unstructured loop 25
(corresponding to amino acids 542-548 of SEQ ID NO:2). The structural domains are depicted in Figure 2.
Within the C-terminal catalytic domain is the conserved metal binding site that contains aspartate-rich regions 1 and 2. Aspartate-rich region 1, containing the conserved DDxxD motif, corresponds to amino acids D301, D302, T303, Y304 and D305 of SEQ ID NO:2. Asp301 and Asp305 bind the diphosphate moieties of FPP through coordination with Mg2+. Aspartate-rich region 2, containing the NSE/DTE motif, corresponds to amino acids D445, D446, M447, Q448, G449, H450, E451, F452 and E453 of SEQ ID NO:2. This region binds an additional Mg2+ ion through amino acids Asp445, Gly449 and Glu453.
As noted above, the active site substrate binding pocket of valencene synthase is hydrophobic and contains aromatic residues. Amino acid residues D301, D305, D445, G449 and E453 from the aspartate-rich regions and amino acid residues R264, W273, N294, 1296, L297, S298, Y376, C402, C441, R442, L443, D446, Y522, D526 and Y528 of SEQ ID NO:2 form the substrate binding pocket of valencene synthase. These residues cradle the farnesyl side chain enforcing the substrate into a conformation that results in the production of
valencene. Upon (Mg PP; binding, valencene synthase undergoes a structural change from an open to closed active site whereby the N-terminal region forms a cap, or lid, over the active site. The active site lid residues correspond to N-terminal domain amino acid residues R8, P9, T10, Al l, D12, F13, H14 and P15 of SEQ ID NO:2 and C-terminal domain amino acid residues F452, E453, K455, R456, G457, A460, S461, A462, 1463, D525, D526, G527 and Y528 of SEQ ID NO:2.
Additional residues that reside near the valencene synthase active site and are conserved within eremophilone-type sesquiterpenes include amino acid residues L270, Y376, S401, C402, A403, Y404, V407, C441, 1518, 1521 and T529 of SEQ ID NO:2 (see, Greenhagen et al, (2006) Proc. Natl. Acad. Sci. USA 103:9826-9831 and U.S. Patent No. 7,442,785). These residues aid in the positioning of the reaction intermediates such that valencene is the dominantly formed product. Other products that can be produced by valencene synthase from FPP include, but are not limited to, germacrene A, beta-elemene (beta-elemene is formed by spontaneous decomposition of germacrene A), β-selinene, x- selinene and 7-epz-a-selinene. Amino acid residues A517 and 1518 of SEQ ID NO:2 were identified as playing a role in the late stage of the reaction after the CI -CIO cyclization, since mutation of them to A5171/1518V resulted in a β-elemene reaction product that may have derived from germacrene due to interruption of the normal reaction (see e.g. Eran Eyal (2001) Computer Modelling of the Enzymatic Reaction Catalysed by 5-epi-aristolochene cyclase. Doctoral Dissertation. Retrieved from Library Catalog Wiezmann Institute of Science.
(System No. 000083214).
C. MODIFIED VALENCENE SYNTHASE POLYPEPTIDES AND ENCODING NUCLEIC ACID MOLECULES
Provided herein are modified valencene synthase polypeptides. Also provided herein are nucleic acid molecules that encode any of the modified valencene synthase polypeptides provided herein. The modified valencene synthase polypeptides provided herein catalyze the formation of valencene and/or other terpenes from any suitable acyclic pyrophosphate terpene precursor, including, but not limited to, FPP, GPP and GGPP. Typically, the modified valencene synthase polypeptides catalyze the formation of valencene from FPP. The modifications can be made in any region or domain of a valencene synthase provided the resulting modified valencene synthase polypeptide at least retains valencene synthase activity
(i.e. the ability to catalyze the formation of valencene from an acyclic pyrophosphate terpene precursor, typically FPP).
The modifications can be a single amino acid modification, such as single amino acid replacements (substitutions), insertions or deletions, or multiple amino acid modifications, such as multiple amino acid replacements, insertions or deletions. In some examples, entire or
- -
partial domains or regions, such as any domain or region described herein below, are exchanged with corresponding domains or regions or portions thereof from another terpene synthase. Exemplary of modification are amino acid replacements, including single or multiple amino acid replacements. For example, modified valencene synthase polypeptides provided herein can contain at least or 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71 , 72, 73, 74, 75, 76, 77, 78, 79, 80, 81 , 82, 83, 84, 85, 90, 95, 100, 105, 1 10, 1 15, 120 or more modified positions compared to the valencene synthase polypeptide not containing the modification.
The modifications described herein can be in any valencene synthase polypeptide. Typically, modifications are made in a citrus valencene synthase (CVS) derived from citrus. For example, the modification described herein can be in a valencene synthase as set forth in any of SEQ ID NOS:2, 289-291, 346, 347, 752, 882 or 883 or any variant thereof, including any described in the art that have at least 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% sequence identity to the valencene synthase polypeptide set forth in any of SEQ ID NOS:2, 289-291, 346, 347, 752, 882 or 883. Exemplary of a variant valence synthase is set forth in SEQ ID NO:886. In particular, provided herein are modified citrus- derived valencene synthase polypeptides that contains one or more modifications compared to a valencene synthase polypeptide set forth in any of SEQ ID NOS: 2, 289-291, 752 or 886. Also, it is understood that any of the variants set forth in SEQ ID NOS: 3-127, 350, 351 , 723- 731, 732-745, 746-751, 810-866, 887-890, 895, 944, 946, 948, 950, 952,954, 956, 958, 960, 962, 964, 966, 968, 970, 972, 974, 976, 978, 980, 982, 984, 986, 988, 990, 992, 994, 996 and 998 can be further modified, such as by inclusion of any of the modifications described herein.
In particular, the modified valencene synthase polypeptides provided herein contain amino acid replacements or substitutions, additions or deletions, truncations or combinations thereof with reference to the valencene synthase polypeptide set forth in SEQ ID NO:2.
Generally, reference to positions and amino acids for modification, including amino acid replacement, herein are by CVS numbering with reference to the valencene synthase set forth in SEQ ED NO:2. It is within the level of one of skill in the art to make such modifications in valencene synthase polypeptides, such as any set forth in SEQ ID NOS: 2, 289-291 , 346, 347, 752, 882 or 883 or any variant thereof. For example, Figure 1 and Figure 4 depicts CVS numbering and corresponding positions between and among exemplary valencene synthase polypeptides. Based on this description, it is within the level of one of skill in the art to generate a valencene synthase containing any one or more of the described mutation, and test each for valencene synthase activity as described herein.
RECTIFIED SHEET (RULE 91)
ISA/EP
- -
Also, in some examples, provided herein are modified active fragments of valencene synthase polypeptides that contain any of the modifications provided herein. Such fragments retain one or more properties of a wild-type valencene synthase. Typically, the modified active fragments exhibit valencene synthase activity (i.e. catalyze the formation of valencene from an acyclic pyrophosphate terpene precursor, such as FPP).
Modifications in a valencene synthase polypeptide also can be made to a valencene synthase polypeptide that also contains other modifications, including modifications of the primary sequence and modifications not in the primary sequence of the polypeptide. For example, modifications described herein can be in a valencene synthase polypeptide that is a fusion polypeptide or chimeric polypeptide, including hybrids of different valencene synthase polypeptides or different terpene synthase polypeptides (e.g. contain one or more domains or regions from another terpene synthase) and also synthetic valencene synthase polypeptides prepared recombinantly or synthesized or constructed by other methods known in the art based upon the sequence of known polypeptides.
The valencene synthase polypeptides provided herein generally exhibit at least 62% amino acid sequence identity to the valencene synthase polypeptide set forth in SEQ ID NO:2. For example, the valencene synthase polypeptides provided herein generally exhibt at least or at least about 65%, 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 95%, 95%, 96%, 97%, 98% or 99% amino acid sequence identity to the valencene synthase polypeptide set forth in SEQ ID NO:2. In particular examples, the valencene synthase polypeptide also exhibits less than 95% sequence identity to the valencene synthase polypeptide set forth in SEQ ID NO:2. Thus, for example, valencene synthase polypeptides provided herein exhibt at least or more than 62% sequence identity to the valencene synthase polypeptide set forth in SEQ ID NO:2 and less than or less than about 94.7%, 94.6%, 94%, 93%, 92%, 91%, 90%, 89%, 88%, 87%, 86%, 84%, 83%, 82%, 81% 79%, 78%, 77%, 76%, 74%, 73%, 72% or 71% sequence identity with the wild-type valencene synthase polypeptide set forth in SEQ ID NO:2. Generally, the modified valencene synthase polypeptides provided herein exhibit between or about between 75% to 95%, between or about between 75% and 94%, between or about between 74% and 93%, between or about between 75% and 92%, between or about between 80% and 95%, between or about between 80% and 94%, between or about between 80% and 93%, between or about between 80% and 92%, between or about between 85% and 95%, between or about between 85% and 94%, between or about between 85% and 93% or between or about between 85% and 92%, each inclusive, sequence identity to the sequence of amino acids set forth in SEQ ID NO:2.
In some examples, the modified valencene synthase polypeptides have less than
100% or have 100% identity to the modified valencene synthase polypeptide set forth in SEQ
RECTIFIED SHEET (RULE 91)
ISA EP
ID NO:3. In other examples, the modified valencene synthase polypeptides have less than 100% or have 100%> identity to the modified valencene synthase polypeptide set forth in SEQ ID NO:4. In additional examples, the modified valencene synthase polypeptides have less than 100%) or have 100%) identity to the modified valencene synthase polypeptide set forth in SEQ ID NO:5. For example, provided herein are modified valencene synthase polypeptides that have a sequence of amino acids that is at least 80%> identity to the modified valencene synthase polypeptide set forth in SEQ ID NO:3 or SEQ ID NO:4, such as, for example, at least or at least about 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, or 99% identity to the modified valencene synthase polypeptide set forth in SEQ ID NO:3 or SEQ ID NO:4.
Percent identity can be determined by one skilled in the art using standard alignment programs. For example, as can be determined by one of skill in the art using standard alignment programs, a modified valencene synthase polypeptide containing 37 amino acid replacements (such as
K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/
F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L313 C/S314T/L315M/ T317S/Q321A/E333D/K336R/L337I/A345T/G357R/N369I/S377Y/T405R/
N429G/A436S/T501P/D536E , e.g. the modified valencene synthase polypeptide named V75 set forth in SEQ ID NO:5 as described below) exhibits about 93.2 %> homology to the valencene synthase set forth in SEQ ID NO:2. In other examples, a modified valencene synthase polypeptide provided herein contains at least 80, 81, 82, 83 or 84 modifications, including replacements, insertions and/or deletions, so that the resulting polypeptide is less than or is or is about 85%> identical to the wild-type valencene synthase polypeptide set forth in SEQ ID NO:2. In another example, a modified valencene polypeptide provided herein contains at least 107, 108, 109, 110, or 111 modifications (e.g. replacements, insertions and/or deletions) so that the resulting polypeptide is less than or or is or is about 80%> identical to the wild-type valencene synthase polypeptides set forth in SEQ ID NO:2.
The modifications can be in the N-terminal domain (corresponding to amino acids 1 - 266 of SEQ ID NO:2) and/or one or more modifications in the C-terminal catalytic domain (corresponding to amino acids 267-548 of SEQ ID NO:2). In some examples, the modifications are amino acid replacements. In further examples, the modified valencene synthase polypeptides provided herein contain one or more modifications in a structural domain such as the unstructured loop 1 (corresponding to amino acids 1-29 of SEQ ID NO:2); alpha helix 1 (corresponding to amino acids 30-39 and 44-52 of SEQ ID NO:2); unstructured loop 2 (corresponding to amino acids 53-58 of SEQ ID NO:2); alpha helix 2 (corresponding to amino acids 59-71 of SEQ ID NO:2); unstructured loop 3 (corresponding to amino acids
72-78 of SEQ ID NO:2); alpha helix 3 (corresponding to amino acids 79-93 of SEQ ID NO:2); unstructured loop 4 (corresponding to amino acids 94-100 of SEQ ID NO:2); alpha helix 4 (corresponding to amino acids 101-114 of SEQ ID NO:2); unstructured loop 5 (corresponding to amino acids 115-141 of SEQ ID NO:2); alpha helix 5 (corresponding to amino acids 142-152 of SEQ ID NO:2); unstructured loop 6 (corresponding to amino acids 153-162 of SEQ ID NO:2); alpha helix 6 (corresponding to amino acids 163-173 of SEQ ID NO:2); unstructured loop 7 (corresponding to amino acids 174-184 of SEQ ID NO:2); alpha helix 7 (corresponding to amino acids 185-194 of SEQ ID NO:2); unstructured loop 8 (corresponding to amino acids 195-201 of SEQ ID NO:2); alpha helix 8 (corresponding to amino acids 202-212 of SEQ ID NO:2); unstructured loop 9 (corresponding to amino acids 213-222 of SEQ ID NO:2); alpha helix A (corresponding to amino acids 223-253 of SEQ ID NO:2); A-C loop (corresponding to amino acids 254-266 of SEQ ID NO:2); alpha helix C (corresponding to amino acids 267-276 of SEQ ID NO:2); unstructured loop 11
(corresponding to amino acids 277-283 of SEQ ID NO:2); alpha helix D (corresponding to amino acids 284-305 of SEQ ID NO:2); unstructured loop 12 (corresponding to amino acids 306-309 of SEQ ID NO:2); alpha helix Dl (corresponding to amino acids 310-322 of SEQ ID NO:2); unstructured loop 13 (corresponding to amino acids 323-328 of SEQ ID NO:2); alpha helix D2 (corresponding to amino acids 329 of SEQ ID NO:2); unstructured loop 14 (corresponding to amino acids 330-332 of SEQ ID NO:2); alpha helix E (corresponding to amino acids 333-351 of SEQ ID NO:2); unstructured loop 15 (corresponding to amino acids 352-362 of SEQ ID NO:2); alpha helix F (corresponding to amino acids 363-385 of SEQ ID NO:2); unstructured loop 16 (corresponding to amino acids 386-390 of SEQ ID NO:2); alpha helix Gl (corresponding to amino acids 391-395 of SEQ ID NO:2); unstructured loop 17 (corresponding to amino acids 396-404 of SEQ ID NO:2); alpha helix G2 (corresponding to amino acids 405-413 of SEQ ID NO:2); unstructured loop 18 (corresponding to amino acids 414-421 of SEQ ID NO:2); alpha helix HI (corresponding to amino acids 422-428 of SEQ ID NO:2); unstructured loop 19 (corresponding to amino acids 429-431 of SEQ ID NO:2); alpha helix H2 (corresponding to amino acids 432-447 of SEQ ID NO:2); unstructured loop 20 (corresponding to amino acids 448-450 of SEQ ID NO:2); alpha helix H3 (corresponding to amino acids 451-455 of SEQ ID NO:2); unstructured loop 21 (corresponding to amino acids 456-461 of SEQ ID NO:2); alpha helix a-1 (corresponding to amino acids 462-470 of SEQ ID NO:2); unstructured loop 22 (corresponding to amino acids 471-473 of SEQ ID NO:2); alpha helix I (corresponding to amino acids 474-495 of SEQ ID NO:2); unstructured loop 23 (corresponding to amino acids 496-508 of SEQ ID NO:2); alpha helix J (corresponding to amino acids 509-521 of SEQ ID NO:2); J-K loop (corresponding to amino acids 522-534 of SEQ ID NO:2); alpha helix K (corresponding to amino acids 535-541 of SEQ ID NO:2);
and/or unstructured loop 25 (corresponding to amino acids 542-548 of SEQ ID NO:2). As described elsewhere herein, the modifications in a domain or structural domain can be by replacement of corresponding heterologous residues from another terpene synthase.
To retain valencene synthase activity, modifications typically are not made at those positions that are less tolerant to change. Such positions can be within domains or regions that are required for catalysis of valencene from FPP and/or substrate binding. In some instances, the positions are in regions that are highly conserved, such as the metal-binding aspartate-rich motifs (DDxxD). For example, as demonstrated in Example 3.C, positions corresponding to positions 301, 302, 303, 305 and 306 of SEQ ID NO:2, which are part of or adjacent to the first metal-binding aspartate-rich motif, and positions corresponding to positions 445, 446, and 449, which are part of a second aspartate-rich region, are generally less tolerant to modification and typically result in a polypeptide with decreased valencene synthase activity. Similarly, positions corresponding to 267, 269, 270, 271, 273, 295, 298, 441 and 442 of SEQ ID NO:2, which likely are involved in forming the substrate binding pocket, also are generally less tolerant to modification and typically result in a polypeptide with decreased valencene synthase activity. Other positions that are shown in Example 3.C to be less tolerant to change include, but are not limited to, positions corresponding to positions 8, 9, 178, 203, 277, 287, 312, 394, 398, 401, 402, 403, 404, 407, 408, 454 and 457 of SEQ ID NO:2.
Hence, provided herein are modified valencene synthase polypeptides, in particular modified valencene synthase polypeptides that exhibit increased valencene yield, that do not contain modification(s) (e.g. amino acid replacement or substitution) at any of amino acid residues 8, 9, 178, 203, 267, 269, 270, 271, 273, 277, 287, 295, 298, 301, 302, 303, 305, 306, 312, 394, 398, 401, 402, 403, 404, 407, 408, 441, 442, 445, 446, 449, 454 and 457 of SEQ ID NO:2. In some examples, other positions that are likely less tolerant to change can include, for example, positions 20, 264, 266, 376, 436, 448, 512, 515, 516, 519, 520, 527, 528 and 529 (U.S. Pat. Pub. No. US20100216186). In some examples, a modified valencene synthase provided herein with increased valencene yield typically does not contain modifications at any of positions corresponding to positions 20, 178, 203, 264, 266, 267, 269, 270, 271, 273, 277, 287, 295, 298, 301, 302, 303, 305, 306, 312, 376, 394, 398, 401, 402, 403, 404, 407, 408, 436, 441, 442, 445, 446, 448, 449, 454, 457, 512, 515, 516, 519, 520, 527, 528 and 529 of SEQ ID NO:2. It is understood that this is a guide only, and while modifications at these positions generally result in a valencene synthase with reduced activity compared to wild-type valencene synthase, such modifications can be included in any of the modified valencene synthases provided herein. For example, one of skill in the art understands conservative amino acid substitutions, such as those provided in Table 2, can be used to reduce the
likelihood of a modification resulting in a reduction in activity, such as a reduction in the amount of valencene produced from FPP compared to wild-type valencene synthase. Also, in some examples, modification can be made at any one of these positions when the
modification is due to a domain swap with amino acid set forth in a corresponding domain of another synthase polypeptide.
Hence, exemplary positions that can be modified, for example by amino acid replacement or substitution, include, but are not limited to, positions corresponding to positions 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 50, 53, 54, 55, 56, 57, 58, 60, 62, 69, 77, 78, 82, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 111, 113, 114, 116, 117, 118, 120, 121, 122, 124, 125, 127, 129, 130, 132, 135, 136, 138, 139, 141, 142, 144, 146, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 162, 163, 165, 166, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 186, 187, 188, 189, 190, 191, 193, 194, 195, 196, 197, 198, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 227, 228, 229, 238, 252, 257, 263, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300, 301, 302, 303, 305, 306, 307, 310, 311, 312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 329, 331, 332, 333, 334, 335, 336, 337, 338, 339, 340, 341, 342, 343, 344, 345, 346, 347, 348, 349, 350, 351, 352, 353, 354, 355, 356, 357, 358, 359, 360, 361, 362, 363, 364, 365, 366, 367, 368, 369, 370, 371, 372, 373, 375, 377, 378, 380, 381, 382, 386, 387, 388, 389, 390, 391, 392, 393, 394, 395, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 409, 410, 411, 412, 413, 414, 415, 422, 423, 424, 428, 429, 434, 435, 436, 438, 439, 440, 441, 442, 443, 444, 445, 446, 447, 448, 449, 451, 452, 454, 457, 465, 468, 473, 474, 484, 492, 495, 496, 499, 500, 501, 506, 522, 523, 524, 525, 526, 527, 528, 529, 530, 531, 532, 533, 534, 536 and/or 539 by CVS numbering with reference to amino acid positions set forth in SEQ ID NO:2.
These positions for modification are exemplary only. It is understood that many other positions in the valencene synthase polypeptide can be modified without adversely affecting the ability of the polypeptide to produce valencene from FPP. For example, other positions in the unstructured loops (including any of unstructured loops 1 through 25) could be modified without adversely affecting valencene production.
The modification can be an amino acid replacement, insertion or deletion. Typically, the modification is an amino acid replacement, which can be a conservative substitution, such as set forth in Table 2, or a non-conservative substitution. One of skill in the art understands that, in general, conservative amino acid substitutions reduce the likelihood of the
modification adversely affecting activity, such as a reduction in the amount of valencene produced from FPP compared to wild-type valencene synthase. Conversely, non-conservative substitutions are generally more likely to affect activity, thereby resulting in an increase or decrease in the amount of valencene produced from FPP compared to wild-type valencene synthase. Modifications that result in increased production of valencene from FPP can be identified using the assays described herein and well known in the art, thus allowing for identification of modified valencene synthase polypeptides with improved ability to produce valencene from FPP.
Exemplary amino acid substitutions (or replacements) that can be included in the modified valencene synthase polypeptides provided include, but are not limited to, amino acid replacement corresponding to MIT, S2R, S2K, S2E, S2Q, S2P, S2T, S2L, S2H, S2A, S2V, S2N, S2C, S2G, S3D, S3R, S3G, S3I, S3E, S3V, S3A, S3T, S3L, S3M, S3P, S3N, G4K, G4V, G4N, G4I, G4R, G4S, G4P, G4A, G4E, G4F, G4C, G4T, G4L, G4Q, E5A, E5G, E5S, E5T, E5D, E5H, E5I, E5P, E5L, E5N, E5V, E5R, T6R, T6V, T6D, T6L, T6A, T6E, T6K, T6S, T6G, T6C, T6M, T6Y, T6I, F7C, F7A, F7Q, F7K, F7S, F7G, F7T, F7L, F7R, F7P, F7N, F7D, F7E, F7V, T10V, A11T, D12N, S16N, LI 71, R19K, R19P, R19G, N20D, H21Q, L23LL23S, K24A, K24Q, K24Y, K24T, G25Y, A26T, S27P, D28G, D28E, F29D, D33T, H34R, T35A, A36C, T37K, Q38V, Q38A, Q38N, Q38E, R40Q, H41I, R50G, T53L, T53R, D54A, D54P, D54C, A55T, A55P, A55R, A55V, A55Q, E56G, E56P, E56F, E56A, E56T, E56Q, D57R, D57P, D57S, D57Q, D57A, K58Q, K58R, K58P, K58E, K58A, V60I, V60G, K62R, V69I, F78L, I82V, A85M, I86L, Q87D, K88Q, K88A, K88H, L89I, C90Y, P91N, I92Y, I92N, I92S, Y93H, Y93F, Y93F, I94E, I94H, D95A, S96H, S96C, N97D, N97E, R98K, R98Y, R98D, A99N, A99M, H102Y, L106A, L106S, L106K, L106F, Ll l l S, Q113R, I116Y, K117T, V122I, E124N, K125A, K125Q, K127T, D129E, E130R, R132G, S135E, S136A, N139S, Q142R, S146G, Y152H, M153N, M153G, H159Q, H159K, H159R, E163D, K173E, K173Q, K173A, Q178A, D179P, V181L, T182K, P183S, K184R, K184P, Q188R, I189A, I189V, I189P, T200Q, P202S, F209I, F209H, F209E, F209L, F209T, M210T, M212R, M212D, M212N, M212S, M212A, M212Y, M212K, M212F, M212H, M212Q, M212I, M212S, M212V, I213Y, I213M, I213A, I213R, I213S, I213L, I213F, I213S, I213P, I213Q, I213N, I213K, I213V, I213Y, N214D, N214E, N214S, N214L, N214Y, N214V,
N214P, N214H, N214C, N214A, N214T, N214R, N214Y, N214Q, S215H, S215G, S215K, S215R, S215P, S215A, S215N, S215T, S215L, S215V, S215Q, S215D, T216Q, T216Y, T216E, T216P, T216R, T216C, T216V, T216K, T216D, T216A, T216S, T216K, S217R, S217K, S217F, S217I, S217T, S217G, S217Y, S217N, S217H, S217E, S217F, S217C, S217E, S217D, D218I, D218G, D218V, D218C, D218P, D218M, D218R, D218L, D218S, D218A, D218Y, D218K, D218E, H219D, H219A, H219L, H219C, H219W, H219R, H219S,
H219F, H219E, H219G, H219Q, H219A, L220V, L220S, L220T, L220P, L220M, L220A, L220H, L220E, L220G, L220D, L220F, Y221C, Y221V, Y221Q, Y221F, Y221 S,
Y221N,Y221T, Y221P, Y221L, Y221K, Y221W, Y221E, Y221V, Y221H, N227S, E238D, K252A, K252Q, T257A, D274M, D274N, D274S, D274F, D274G, D274H, D274E, F279S, F279I, F279P, F279D, F279L, F279N, F279M, F279H, F279C, F279A, F279G, F279W, E280L, P281 S, P281H, P281K, P281A, P281W, P281L, P281Y, Q282L, Q282S, Q282A, Q282I, Q282R, Q282Y, Q282G, Q282W, Q282P, Q282E, Y283F, Y283N, A284T, A284G, A284P, A284V, A284R, A284D, A284E, A284S, A284H, A284K, A284I, A284W, A284M, Q292K, I299Y, Y307H, L31 OH, E311 P, E311 T, L313C, S314A, S314T, L315M, F316L, T317S, E318K, A319T, V320D, V320G, V320S, Q321A, W323R, N324S, I325T, E326K, E333D, K336R, L337I, L343V, A345V, A345T, N347L, N347S, E348A, E348S, E350K, G357R, H360L, H360A, C361R, V362A, E367G, N369I, Q370D, Q370H, Q370G, K371G, A375D, S377Y, Y387C, I397V, L399S, T405R, T409G, N410S, F424L, N429S, N429G, A436S, V439L, Q448L, C465S, K468Q, S473Y, K474T, E484D, I492V, E495G, K499E, P500L, T501P, P506S, D536E, or A539V by CVS numbering with reference to positions set forth in SEQ ID NO:2.
The modified valencene synthase polypeptides can contain any one or more of the recited amino acid substitutions, in any combination, with or without additional
modifications. Generally, multiple modifications provided herein can be combined by one of skill in the art so long as the modified polypeptide retains the ability to catalyze the formation of valencene and/or other terpenes from any suitable acyclic pyrophosphate terpene precursor, including, but not limited to, FPP, GPP and GGPP. Typically, the resulting modified valencene synthase polypeptide exhibits similar or increased valencene production from FPP compared to wild-type valencene synthase. In some instances, the resulting modified valencene synthase polypeptide exhibits decreased valencene production from FPP compared to wild-type valencene synthase.
Also provided herein are nucleic acid molecules that encode any of the modified valencene synthase polypeptides provided herein. In particular examples, the nucleic acid sequence can be codon optimized, for example, to increase expression levels of the encoded sequence. The particular codon usage is dependent on the host organism in which the modified polypeptide is expressed. One of skill in the art is familiar with optimal codons for expression in bacteria or yeast, including for example E. coli or Saccharomyces cerevisiae. For example, codon usage information is available from the Codon Usage Database available at kazusa.or.jp. codon (see Richmond (2000) Genome Biology, 1 :241 for a description of the database). See also, Forsburg (2004) Yeast, 10: 1045-1047; Brown et al. (1991) Nucleic Acids Research, 19:4298; Sharp et al. (1988) Nucleic Acids Res., 12:8207-8211 ; Sharp et al. (1991)
Yeast, 657-78. In examples herein, nucleic acid sequences provided herein are codon optimized based on codon usage in Saccharomyces cerevisiae.
The modified polypeptides and encoding nucleic acid molecules provided herein can be produced by standard recombinant DNA techniques known to one of skill in the art. Any method known in the art to effect mutation of any one or more amino acids in a target protein can be employed. Methods include standard site-directed or random mutagenesis of encoding nucleic acid molecules, or solid phase polypeptide synthesis methods. For example, as described herein, nucleic acid molecules encoding a valencene synthase polypeptide can be subjected to mutagenesis, such as random mutagenesis of the encoding nucleic acid, by error- prone PCR, site-directed mutagenesis, overlap PCR, gene shuffling, or other recombinant methods. The nucleic acid encoding the polypeptides can then be introduced into a host cell to be expressed heterologously. Hence, also provided herein are nucleic acid molecules encoding any of the modified polypeptides provided herein. In some examples, the modified valencene synthase polypeptides are produced synthetically, such as using solid phase or solutions phase peptide synthesis.
The encoded modified valencene synthase polypeptides provided herein exhibit valencene synthase activity. The encoded modified valencene synthase polypeptides can produce about the same amount or increased amount or more valencene from FPP compared to wild-type valencene synthase polypeptide set forth in SEQ ID NO:2 when tested in an appropriate assay (under the same conditions), such as any described below. For example, modified valencene polypeptides provided herein generally produce at least 40% of the amount of valencene from FPP compared to the amount of valencene produced from FPP by the wild-type valencene synthase produced in SEQ ID NO:2, such as at least 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 100%, 105%, 110%, 115%, or 120% of the amount.
Typically, the modified polypeptides provided herein exhibit increased production of valencene from FPP compared to the production by wild-type valencene synthase set forth in SEQ ID NO:2. For example, the modified valencene synthase polypeptides provided herein produce more or greater or increased valencene from FPP compared to wild-type valencene synthase polypeptide set forth in SEQ ID NO:2 when tested in an appropriate assay (under the same conditions). In some examples, the modified valencene synthase polypeptides provided herein can produce more than the amount, such as 110%) to 5000%), for example, 150%) to 2000%, such as 150% to 1000%, 500% to 2000%, or 200% to 500% of the amount of valencene from FPP compared to the amount of valencene produced from FPP by the wild- type valencene synthase produced in SEQ ID NO:2. For example, modified valencene polypeptides provided herein produce valencene from FPP in an amount that is increased at
least or at least about 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 110%, 120%, 130%, 140%, 150%, 160%, 170%, 180%, 190%, 200%, 250%, 300%, 350%, 400%, 500%) or more than the amount of valencene produced from FPP by the valencene synthase set forth in SEQ ID NO:2. It is understood that a 10%> increase in valencene production or greater valencene production, for example, means that the level of valencene produced by a modified polypeptide is 110%> or about 110%> of the level of valencene produced by the wildtype valencene synthase set forth in SEQ ID NO:2. As a fold-increase in valencene produced, the modified valencene polypeptides provided herein produce at least 1.1 -fold the amount of valencene produced from FPP by the valencene synthase set forth in SEQ ID NO:2, generally at least 1.5-fold or at least 2-fold. For example, the modified valencene polypeptides provided herein produce at least or about at least or 1.1 -fold, 1.2-fold, 1.3-fold, 1.4-fold, 1.5-fold, 1.6-fold. 1.7-fold, 1.8-fold, 1.9-fold., 2-fold, 2.5-fold, 3-fold, 4-fold, 5-fold, 6-fold, 7-fold, 8-fold, 9-fold, 10-fold, 15-fold, 20-fold, 25-fold, 30-fold, 40-fold, 50-fold, 60- fold, 70-fold, 80-fold, 90-fold, 100-fold or more the amount of valencene produced from FPP by the valencene synthase set forth in SEQ ID NO:2.
Based on the description herein, it is within the level of one of skill in the art to identify a modified valencene synthase that produces more valencene than is produced from wildtype valencene synthase. For example, as described herein, modified valencene synthase polypeptides can be selected for that result in increased production of valencene from FPP compared to the production by wild-type valencene synthase. This is exemplified in the Examples herein. For example, Example 3 describes the generation of mutant valencene synthase nucleic acid molecules encoding modified valencene synthase polypeptides and selection of transformants that produced elevated levels of valencene compared to those containing the wild-type gene. The DNA from selected transformants was sequenced to determine the amino acid change(s) in the encoded variant valencene synthase that conferred the increased property. It is within the level of one of skill in the art to generate and screen for mutants to select for those with altered properties as described herein. Section F describes assays to assess various properties and activities including, for example, production of valencene or nootkatone.
In some examples, the modified valencene synthase polypeptides provided herein exhibit altered substrate specificity and/or product selectivity, and/or altered product distribution (i.e. altered relative amounts and/or types of terpenes) compared to wild-type valencene synthase. In other examples, the modified valencene synthase polypeptides provided herein exhibit altered substrate specificity and/or product selectivity and/or altered product distribution (i.e. altered relative amounts and/or types of terpenes) compared to variant valencene synthase polypeptides set forth in SEQ ID NO:3 (VI 8) or SEQ ID NO:4
(VI 9). The product distribution of terpenes produced by wild-type valencene synthase includes valencene, as well as a number of other terpene products (e.g terpene byproduct or products derived therefrom) including, for example, β-selinene, x-selinene, eremophilone, 7- epz'-a-selinene, germacrene A and β-elemene. As described in Example 8 herein, the proportion of terpene product distribution as a percentage of total terpenes produced by wildtype valencene synthase is similar to variant valencene synthase polypeptides set forth in SEQ ID NO:3 or SEQ ID NO:4.
Modified valencene synthase polypeptides provided herein include those that exhibit an altered product distribution such that a greater percentage of valencene is produced as a total percentage of terpene product, and a decreased percentage of another terpene product or products (e.g. terpene byproduct or byproducts or products derived therefrom) is produced. For example, provided herein are modified valencene synthase polypeptides that produce a greater percentage of valencene as a percentage of the total amount of terpenes produced than is produced by wild-type valencene synthase set forth in SEQ ID NO:2. The amount of valencene produced as a percentage of total terpenes is increased 0.01% to 90%>, for example, 1% to 10%, such as greater than or about 0.5%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9% , 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80% or 90%. In some examples, the modified valencene synthase polypeptides provided herein produce less terpene products other than valenceneas a percentage of total terpenes than does wildtype valencene synthase set forth in SEQ ID NO:2 or the variant valencene synthase polypeptides set forth in SEQ ID NO:3 or 4. The percentage of product other than valencene can be decreased by greater than or about or 0.01% to 90%, 1% to 80%, 5% to 80%, 10% to 60% or 0.01% to 20%, such as greater than or about 0.5%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 20%, 30%, 40%, 50%, 60%, 70%), 80%) , 90%) or more. For example, modified valencene synthase polypeptides provided herein produce decreased percentage of β-elemene as a percentage of total terpenes produced than does a valencene synthase polypeptide set forth in SEQ ID NO:2, 3 or 4. The percentage of β-elemene as a percentage of total terpenes produced can be decreased by greater than or about or 0.01% to 50%, (i.e. reduction in the amount of β-elemene of 0.01% to 50%), 0.01% to 20%), for example, 1% to 10%>, such as decreased by greater than or about 0.5%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%,10%, 20%, 30%, 40% or 50%. Based on the description herein and in Example 8, it is within the level of one of skill in the art to identify such modified valencene synthases. Exemplary of such modified valencene synthase polypeptides that exhibit altered product distribution, such as decreased formation of β-elemene, are set forth in Section C.3 below.
The modified valencene polypeptides provided herein also can exhibit other activities and/or properties. The modified valencene synthase polypeptides can exhibit, for example,
increased catalytic activity, increased substrate (e.g. FPP) binding, increased stability and/or increased expression in a host cell. Such altered activities and properties can result in increased valencene production from FPP. In other examples, the modified valencene synthase polypeptides can catalyze the formation of terpenes other than valencene from any suitable substrate, such as, for example, FPP, GPP, GGPP. For example, the modified valencene synthases can produce one or more monoterpenes or diterpenes, or one or more sesquiterpenes other than valencene. Typically, the modified valencene synthase polypeptides produce more valencene than any other terpene.
In the subsections below, exemplary modified valencene synthase polypeptide, and encoding nucleic acid molecules, provided herein are described.
1. Modified valencene synthase polypeptides - Exemplary Amino Acid Replacements
Provided herein are modified valencene synthase polypeptides that contain one or more amino acid replacements in a valencene synthase polypeptide and that exhibit valencene synthase activity.The modified valencene synthase polypeptides can exhibit 50% to 5000%, such as 50% to 120%, 100% to 500% or 110% to 250% of the valencene production from FPP compared to the valencene synthase polypeptide not containing the amino acid replacement and/or compared to wild-type valencene synthase polypeptide set forth in SEQ ID NO:2.
Typically, the modified valencene polypeptides provided herein exhibit increased valencene production from FPP compared to the valencene synthase polypeptide not containing the amino acid replacement, such as compared to wild-type valencene synthase set forth in SEQ ID NO:2. For example, the modified valencene synthase polypeptides can produce valencene from FPP in an amount that is at least or about at least 101%), 102%, 103%, 104%, 105%, 106%, 107%, 108%, 109%, 110%, 115%, 120%, 125%, 130%, 135%, 140%, 145%, 150%, 160%, 170%, 180%, 200%, 250%, 300%, 350%, 400%, 500%, 1500%, 2000%, 3000%, 4000%, 5000% of the the amount of valencene produced from FPP by wild- type valencene synthase set forth in SEQ ID NO:2 under the same conditions. For example, the valencene production is increased at least or about at least 1.2-fold, 1.5-fold, 2-fold, 3- fold, 4-fold, 5-fold, 6-fold, 7-fold, 8-fold, 9-fold, 10-fold, 11-fold, 12-fold, 13-fold, 14-fold, 15-fold, 16-fold, 17-fold, 18-fold, 19-fold, 20-fold, 25-fold, 30-fold, 40-fold, 50-fold, 60-fold, 70-fold, 80-fold, 90-fold, 100-fold, 200-fold, 300-fold, 400-fold or more.
In particular examples, the modified valencene synthase polypeptides contain an amino acid replacement at one or more amino acid positions identified as being associated with increased valencene production. Such positions can be identified using mutagenesis and selection or screening methods to identify those positions that result in increased valencene
production. For example, as described herein in Example 3, valencene synthase mutants and encoding nucleic acids were generated by error prone PCR and were screened to identify those that resulted in elevated levels of valencene compared to valencene produced by valencene synthase set forth in SEQ ID NO:2. Variants VI 8 and VI 9, generated as containing combination of such mutations, exhibit at least 10-fold greater production of valencene compared to wildtype (see Example 3B). Further exemplary mutants are described in the Examples that exhibit increased valencene production as compared to VI 8 and VI 9 and/or the wild-type valencene synthase polypeptide set forth in SEQ ID NO:2.
The modified valencene synthase polypeptides can contain at least or 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,49, 50, 51, 53, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 59,70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 82, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, or more amino acid replacements.
Additional modifications, such as insertions or deletions, also can be included. The modified polypeptides generally contain at least 29 amino acid replacements. The amino acid replacement can be in a valencene synthase as set forth in any of SEQ ID NOS:2, 289-291, 346, 347, 752, 882 or 883 or any variant thereof. For example, the replacements can be in any citrus valencene synthase polypeptide, for example, any set forth in any of SEQ ID NOS: 2, 289-291, 752 or 886, or a variant thereof. As described above, in examples herein, the modified valencene synthase polypeptides exhibit less than 95% sequence identity to the valencene synthase set forth in SEQ ID NO:2, such as between or about between 62% to 94.9% sequence identity, and can contain at least 75%> sequence identity and less than 80%>, 81%, 82%, 83%, 85%, 85%, 86%, 87%, 88%, 89%, 90% , 91%, 92%, 93% or 94% sequence identity to the valencene synthase polypeptide set forth in SEQ ID NO:2. For example, modified valencene synthase polypeptides provided herein exhibit at least or about or 82%> and less than 95%> sequence identity to the valencene synthase set forth in SEQ ID NO:2.
For example, the modified valencene synthase polypeptides provided herein contain an amino acid replacement (substitution) at one or more amino acid positions corresponding to positions 1, 2, 3, 4, 5, 6, 7, 11, 19, 20, 23, 24, 28, 38, 50, 53, 54, 55, 56, 57, 58, 60, 62, 69, 78, 82, 88, 93, 97, 98, 102, 106, 111, 113, 125, 132, 152, 153, 159, 163, 173, 184, 188, 189, 200, 202, 209, 210, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 227, 238, 252, 257, 274, 279, 280, 281, 282, 283, 284, 292, 297, 299, 307, 310, 311, 313, 314, 315, 316, 317, 318, 319, 320, 321, 323, 324, 325, 326, 333, 336, 337, 343, 345, 347, 348, 350, 357, 360, 361, 362, 367, 369, 370, 371, 375, 377, 387, 397, 399, 405, 409, 410, 424, 429, 436, 439, 448, 465, 468,
473, 474, 484, 492, 495, 499, 500, 501, 506, 536 or 539 of the valencene synthase set forth in SEQ ID NO:2.
For example, the modified valencene polypeptides provided herein contain an amino acid replacement (substitution) at one or more amino acid positions corresponding to positions Ml, S2, S3, G4, E5, T6, F7, Al 1, R19, N20, L23, K24, D28, Q38, R50, T53, D54, A55, E56, D57, K58, V60, K62, V69, F78, 182, K88, Y93, N97, R98, HI 02, LI 06, LI 11, Q113, K125, R132, Y152, M153, H159, E163, K173, K184, Q188, 1189, T200, P202, F209, M210, M212, 1213, N214, S215, T216, S217, D218, H219, L220, Y221, N227, E238, K252, T257, D274, F279, E280, P281, Q282, Y283, A284, Q292, N297, 1299, Y307, L310, E311, L313, S314, L315, F316, T317, E318, A319, V320, Q321, W323, N324, 1325, E326, E333, K336, L337, L343, A345, N347, E348, E350, G357, H360, C361, V362, E367, N369, Q370, K371, A375, S377, Y387, 1397, L399, T405, T409, N410, F424, N429, V439, A436, Q448, C465, K468, S473, K474, E484, 1492, E495, K499, P500, T501, P506, D536 or A539 by CVS numbering with reference to the valencene synthase set forth in SEQ ID NO:2. It is understood that any amino acid replacements described herein can be made to the native or endogenous residue in the corresponding position in other valencene synthase polypeptides, including for example, a valencene synthase polypeptide set forth in any of SEQ ID NOS: 2, 289-291, 752 or 886, or a variant thereof. The corresponding position and amino acid replacement can be determined by alignment with SEQ ID NO:2 as depicted in Figure 1. Any amino acid residue can be used to replace the native or endogenous residue at the position. Typically, the amino acid residue is one that does not reduce or eliminate enzymatic activity. In some instances, the amino acid substitution is a conservative substitution, such as a substitution set forth in Table 2. In other instances, the amino acid substitution is not a conservative substitution. For example, the amino acid can be replaced by a arginine (R), lysine (K), glutamine (Q), glutamic acid (E), proline (P), threonine (T), leucine (L), histidine (H), aspartic acid (D), glycine (G), isoleucine (I), valine (V), alanine (A), asparagine (N), serine (S), cysteine (C), phenylalanine (F), methionine (M), tyrosine (Y), or tryptophan (W).
Exemplary amino acid substitutions (or replacements) that can be included in the modified valencene synthase polypeptides provided include, but are not limited to, MIT, S2R, S2K, S2E, S2Q, S2P, S2T, S2L, S2H, S2A, S2V, S3D, S3R, S3G, S3I, S3E, S3V, S3A, S3T, S3L, S3M, S3N, G4K, G4V, G4N, G4I, G4R, G4S, G4P, G4A, G4E, G4F, G4C, G4T, G4L, E5A, E5G, E5S, E5T, E5D, E5H, E5I, E5P, E5L, E5N, T6R, T6V, T6D, T6L, T6A, T6E, T6K, T6S, T6G, T6C, T6M, T6Y, F7C, F7A, F7Q, F7K, F7S, F7G, F7T, F7L, F7R, F7P, A11T, R19K, R19P, N20D, L23S, K24A, K24Q, K24Y, D28G, Q38V, Q38A, Q38N, R50G, T53L, T53R, D54A, D54P, D54C, A55T, A55P, A55R, A55V, A55Q, E56G, E56P, E56F, E56A, E56T, E56Q, D57R, D57P, D57S, D57Q, D57A, K58Q, K58R, K58P, K58E,
K58A, V60I, V60G, K62R, V69I, F78L, I82V, K88Q, K88A, Y93H, N97D, R98K, H102Y, L106A, L106S, L106K, L106F, LU I S, Q113R, K125A, K125Q, R132G,Y152H, M153N, M153G, H159Q, H159K, H159R, E163D, K173E, K173Q, K173A, K184R, Q188R, I189A, II 89V, I189P, T200Q, P202S, F209I, F209H, F209E, F209L, F209T, M210T, M212R, M212D, M212N, M212S, M212A, M212Y, M212K, M212F, M212H, M212Q, 1213 Y, I213M, 1213 A, I213R, I213S, I213L, I213F, I213S, I213P, I213Q, I213N, I213K, I213V, N214D, N214E, N214S, N214L, N214Y, N214V, N214P, N214H, N214C, N214A, N214T, N214R, S215H, S215G, S215K, S215R, S215P, S215A, S215N, S215T, S215L, S215V, S215Q, T216Q, T216Y, T216E, T216P, T216R, T216C, T216V, T216K, T216D, T216A, T216S, S217R, S217K, S217F, S217I, S217T, S217G, S217Y, S217N, S217H, S217E,
S217F, S217C, D218I, D218G, D218V, D218C, D218P, D218M, D218R, D218L, D218S, D218A, D218Y, D218K, H219D, H219A, H219L, H219C, H219W, H219R, H219S, H219F, H219E, L220V, L220S, L220T, L220P, L220M, L220A, L220H, L220E, L220G, L220D, Y221C, Y221V, Y221Q, Y221F, Y221 S, Y221N,Y221T, Y221P, Y221L, Y221K, Y221W, Y221E, Y221V, N227S, E238D, K252A, K252Q, T257A, D274M, D274N, D274S, D274F, D274G, D274H, D274E, F279S, F279I, F279P, F279D, F279L, F279N, F279M, F279H, F279C, F279A, F279G, F279W, E280L, P281 S, P281H, P281K, P281A, P281W, P281L, P281Y, Q282L, Q282S, Q282A, Q282I, Q282R, Q282Y, Q282G, Q282W, Q282P, Q282E, Y283F, Y283N, A284T, A284G, A284P, A284V, A284R, A284D, A284E, A284S, A284H, A284K, A284I, A284W, A284M, Q292K, I299Y, Y307H, L310H, E311P, E311T, L313C, S314A, S314T, L315M, F316L, T317S, E318K, A319T, V320D, V320G, V320S, Q321A, W323R, N324S, I325T, E326K, E333D, K336R, L337I, L343V, A345V, A345T, N347L, N347S, E348A, E348S, E350K, G357R, H360L, H360A, C361R, V362A, E367G, N369I, Q370D, Q370H, Q370G, K371G, A375D, S377Y, Y387C, I397V, L399S, T405R, T409G, N410S, F424L, N429S, N429G, A436S, V439L, Q448L, C465S, K468Q, S473Y, K474T,
E484D, I492V, E495G, K499E, P500L, T501P, P506S D536E or A539V by CVS numbering with reference to positions set forth in SEQ ID NO:2.
The modified valencene synthase polypeptides can contain any one or more of the recited amino acid substitutions, in any combination, with or without additional
modifications.
In some examples, the modified valencene synthase polypeptide provided herein contains an amino acid replacement at one or more amino acid positions corresponding to positions 60, 97, 209, 212, 214, 221, 238, 292, 333, 345, 369, 405, 429, 473 and/or 536 with reference to positions set forth in SEQ ID NO:2. For example, amino acid substitutions (or replacements) that can be included in the modified valencene synthase polypeptides provided include, but are not limited to, V60I, V60G, N97D, F209I, F209H, F209E, F209L, F209T,
M212R, M212D, M212N, M212S, M212A, M212Y, M212K, M212F, M212H, M212Q, N214D, N214E, N214S, N214L, N214Y, N214V, N214P, N214H, N214C, N214A, N214T, N214R, Y221C, Y221V, Y221Q, Y221F, Y221 S, Y221N, Y221T, Y221P, Y221L, Y221K, Y221W, Y221E, Y221V, E238D, Q292K, N97D, E333D, A345V, A345T, N369I, T405R, N429S, N429G, S473Y, and/or D536E by CVS numbering with reference to positions set forth in SEQ ID NO:2.
Other amino acid replacements also can be included in the modified valencene synthase polypeptides provided herein. For example, the modified valencene synthase polypeptides contains an amino acid replacement at one or more amino acid positions corresponding to positions 24, 38, 58, 60, 88, 93, 97, 98, 125, 173, 184, 209, 212, 214, 219, 221, 238, 252, 292, 321, 333, 345, 369, 377, 405, 429, 436, 501 and/or 536 with reference to positions set forth in SEQ ID NO:2. As described herein in Example 3, such amino acid positions are identified experimentally or by modeling as being residues targeted for mutagenesis. For example, the residues are located as surface residues and/or are identified as being either tolerated (e.g. having neutral effects on enzyme activity) or resulting in improved valencene production. For example, amino acid substitutions (or replacements) that can be included in the modified valencene synthase polypeptides provided include, but are not limited to, K24A, K24Q, D28G, Q38V, Q38A, Q38N, K58Q, K58R, K58P, K58E, K58A, V60I, V60G, K88Q, K88A, Y93H, N97D, R98K, K125A, K125Q, K173E, K173Q, K173A, Kl 84R, F209I, F209H, F209E, F209L, F209T, M212R, M212D, M212N, M212S, M212A, N214D, N214E, N214S, N214L, N214Y, N214V, M212Y, M212K, M212F, M212H, M212Q, H219D, H219A, H219L, H219C, H219W, H219R, H219S, H219F, H219E, Y221C, Y221V, Y221Q, Y221F, Y221S, Y221N, Y221T, Y221P, Y221L, Y221K, Y221W, Y221E, Y221V, N227S, E238D, K252Q, Q292K, Q321A, E333D, A345V, A345T, N369I, S377Y, T405R, N429S, N429G, A436S, T501P, and/or D536E by CVS numbering with reference to positions set forth in SEQ ID NO:2.
In some examples herein, modified valencene synthase polypeptides contain amino acid replacements at positions 60, 209, 238 and 292. For example, amino acid substitutions (or replacements) that can be included in the modified valencene synthase polypeptides provided include, but are not limited to, a replacement at position V60, for example amino acid replacement V60I or V60G; a replacement at position F209, for example amino acid replacement F209I, F209H, F209E, F209L, F209T; a replacement at position E238, for example amino acid replacement E238D; and a replacement at position Q292, for example amino acid replacement Q292K, each by CVS numbering with reference to positions set forth in SEQ ID NO:2. In other examples herein, modified valencene synthase polypeptides contain amino acid replacements at positions 60, 125, 173, 209, 238, 252 and 292. For
example, amino acid substitutions (or replacements) that can be included in the modified valencene synthase polypeptides provided include, but are not limited to, a replacement at position V60, for example amino acid replacement V60I or V60G; a replacement at position K125, for example amino acid replacement K125A or K125Q; a replacement at position K173, for example amino acid replacement K173E, K173Q or K173A; a replacement at position F209, for example amino acid replacement F209I, F209H, F209E, F209L, F209T; a replacement at position E238, for example amino acid replacement E238D; a replacement at position K252, for example amino acid replacement K252Q; and a replacement at position Q292, for example amino acid replacement Q292K, each with reference to positions set forth in SEQ ID NO:2.
Table 3 provides non-limiting examples of exemplary amino acid replacements at the identified positions, corresponding to amino acid positions of a valencene synthase polypeptide as set forth in SEQ ID NO:2. Included amongst these are exemplary single and combination mutations. In reference to such mutations, the first amino acid (one-letter abbreviation) corresponds to the amino acid that is replaced, the number corresponds to the position in the valencene synthase polypeptide sequence with reference to SEQ ID NO: 2, and the second amino acid (one-letter abbreviation) corresponds to the amino acid selected that replaces the first amino acid at that position. These mutations can be incorporated into any valencene synthase, including, for example, the wild-type valencene synthases set forth in SEQ ID NOS: 2, 289-291, 752 or 886, or a variant thereof. In some example, the modifications are incorporated into the valencene synthase set forth in SEQ ID NO:2. This results in the exemplary valencene synthase mutants provided in the Table, and encoding nucleic acid molecules. Also provided is the sequence identifier (SEQ ID NO) that sets forth exemplary amino acid sequences and encoding nucleic acid sequences of the modified valencene synthase polypeptides.
Table 3.
SE(
Mut
Mutation(s) N O No.
aa nt
VI N214D/S473Y 6 131
V2 T405R 7 132
V3 A345V/D536E 8 133
V4 Y221C 9 134
V5 E238D 10 135
V6 F209I 11 136
V7 N97D 12 137
V8 E333D/N369I 13 138
V9 N214D/T405R 14 139
V10 N214D/A345V/T405R/D536E 15 140
V12 V60I/N214D/A345T/T405R 16 141
V13 N214D/T405R/N429S 17 142
V14 N214D/Q292K/T405R 18 143
V15 V60G/N214D/T405R 19 144
V16 V60I/N214D/A345T/T405R/N429G 20 145
V17 V60I/M212R/N214D/Y221 V/A345T/T405R/N429G 21 146
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V18 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 128 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/K184
V19 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E 4 129 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/V320S/Q
V20 22 147 321A/E326K/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/
D536E
K24A/Q38A/R50G/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173
A/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/V
V21 23 148 320G/Q321A/ E333D/A345T/N369I/S377Y/T405R/N429G/A436S/
T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/L315M/
V22 24
Q321 A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501 P/ 149 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/L315M/
V23 24
Q321 A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501 P/ 168 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/V320G/Q
V24 25 150 321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/
D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V25 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 151 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V26 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 152 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V27 333D/A345T/ G357R/N369I/S377Y/T405R/N429G/A436S/T501P/ 26 153 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V28 27 154 333D/A345T/ N369I/E367G/S377Y/T405R/N429G/A436S/T501P/
D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V29 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 155 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V30 333D/A345T/ G357R/N369I/S377Y/T405R/N429G/A436S/T501P/ 26 156 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V31 333D/A345T/ N369I/Q370D/S377Y/T405R/N429G/A436S/T501P/ 28 157 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/ 98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/I299Y/Q
V32
321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ 29 158 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/V320G/Q
V33 321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ 25 159 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V34 30 160 333D/A345T/ H360L/N369I/S377Y/T405R/N429G/A436S/T501P/
D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/T317S/Q
V35 321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ 31 161 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/V320D/Q
V36 32 162 321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/
D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V37 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 163 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V38 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 164 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/V320D/Q
V39 32
321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ 167 D536E
K24A/Q38V/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V40 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 33 165 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V41 34 166 333D/A345T/ N369I/S377Y/T405R/T409G/N429G/A436S/E495G/
T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 S/Q292K/Q
V42 35 169 321A/E333D/ L337I/A345T/N369I/S377Y/T405R/N429G/A436S/
T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V43 333D/A345T/ N369I/A375D/S377Y/T405R/N429G/A436S/T501P/ 36 170 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V44
333D/K336R/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ 37 171 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221V/E238D/K252A/Q292K/E311P/Q
V45 72 321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ 38 1 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V46 39 173 333D/A345T/ N369I/Q370H/S377Y/T405R/N429G/A436S/T501P/
D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/T317S/Q
V47 321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ 31 174 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V48 40 175 333D/L343V/ A345T/H360A/N369I/S377Y/T405R/N429G/A436S/
T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282S/Q292K/Q
V49 41 176 321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/
D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V50 42
333D/A345T/ N369I/K371G/S377Y/T405R/N429G/A436S/T501P/ 177 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V51 333D/A345T/ N347L/N369I/S377Y/T405R/N429G/A436S/T501P/ 43 178 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221V/E238D/K252A/Q292K/E311T/Q
V52 44 179 321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/
D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282L/Q292K/Q
V53 45 180 321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/
D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/S314T/Q
V54
321A/E333D/ A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ 46 181 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E
V55 2 333D/A345T/ N369I/Q370G/S377Y/T405R/N429G/A436S/T501P/ 47 18 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/L31 OH/Q
V56 48 183 321A/E333D/ A345T/V362A/N369I/S377Y/T405R/N429G/A436S/
T501P/D536E
K24A/Q38A/K58A/V60I/F78L/K88A/Y93H/N97D/R98K/K125A/K173A
/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/L3
V57 49 184 13C/Q321A/ E333D/A345T/N369I/S377Y/T405R/N429G/A436S/
T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
V58
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/I2
and 99Y/L310H/ E311P/Q321A/E333D/A345T/N369I/S377Y/T405R/ 50 185 V59 N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q282L/Q
V60 292K/L31 OH/ Q321 A/E333D/A345T/N369I/S377Y/T405R/N429G/ 51 186 A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q282L/Q
V61 52 187 292K/I299Y/ E311 P/Q321 A/E333D/A345T/N369I/S377Y/T405R/
N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L
V62 53 188 313C/S314T/ L315M/T317S/Q321A/E333D/A345T/N369I/S377Y/
T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/Q
V63 54
321A/E333D/ K336R/A345T/N347L/G357R/N369I/S377Y/T405R/ 189 N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/L31 OH/E
V64 55 190 311T/L313C/ S314T/L315M/T317S/V320G/Q321 A/E333D/A345T/
N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/L31 OH/E
V65 311T/L313C/ S314T/L315M/T317S/V320G/Q321 A/E333D/A345T/ 55 191 N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/T
V66 56 192 317S/Q321A/ E333D/K336R/L337I/A345T/N347L/G357R/N369I/
S377Y/T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/T317S/Q
V67 57 193 321A/E333D/ K336R/L337I/A345T/G357R/N369I/S377Y/T405R/
N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/T
V68 58 194 317S/Q321A/ E333D/K336R/A345T/N347L/G357R/N369I/S377Y/
T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/T
V69 59 195 317S/Q321A/ E333D/A345T/G357R/N369I/S377Y/T405R/N429G/
A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L
V70 310H/E311T/L313C/T317S/V320G/Q321 A/E333D/A345T/N369I/S377Y/ 60 196 T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
V71 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L
61 197 313C/S314T/ L315M/T317S/Q321A/E333D/K336R/A345T/N347L
G357R/N369I/S377Y/T405R/N429G/A436S/T501 P/ D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E
V72 62 198 333D/A345T/ N369I/Q370D/A375D/S377Y/T405R/T409G/N429G/
A436S/E495G/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
V73
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L
and 313C/S314T/ L315M/T317S/Q321A/E333D/K336R/L337I/A345T/ 63 199 V74 N347L/G357R/N369I/S377Y/T405R/N429G/A436S/ T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
V75
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L
and 313C/S314T/ L315M/T317S/Q321A/E333D/K336R/L337I/A345T/ 5 130 V76 G357R/N369I/S377Y/T405R/N429G/A436S/T501 P/ D536E
S2R/S3D/G4K/E5G/F7C/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R
98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221 V/E238D
V77 64 200 /K252Q/ Q292K/Q321 A/E333D/A345T/N369I/S377Y/T405R/
N429G/A436S/T501P/D536E
S2E/S3G/G4N/E5S/T6V/F7Q/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97
D/ 98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221V/E2
V78 38D/K252Q/ Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/ 65 201 F424L/N429G/A436S/T501P/D536E
S2K7S3R/G4V/E5G/T6R/F7A/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N9
7D/R98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221 V/E
V79 2 238D/K252Q/ Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/ 66 20 N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V80
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/D274M/Q292K/
or 68 204 Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536
V81 E
V82 K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
or R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/D274N/Q292K/Q 69 205 V83 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V85 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/D274S/Q292K/Q 70 206 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V86 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/D274F/Q292K/Q 71 207 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
V87 K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
or R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/D274G/Q292K/Q 72 208 V88 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V89 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/D274G/Q292K/Q 72 211 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V90 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/D274G/Q292K/Q 72 212 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V91 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/D274H/Q292K/Q 73 209 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V93 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/D274E/Q292K/Q 74 210 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V94 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279S/Q292K/Q 75 213 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V95 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279S/Q292K/Q 75 223 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V96 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279S/Q292K/Q 75 232 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V97 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279I/Q292K/Q3 76 214 21A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V99/
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279P/Q292K/Q 77 215 V100 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V101 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279D/Q292K/Q 78 216 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
VI 02 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279L/Q292K/Q 79 217 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
V103 K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
or R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279L/Q292K/Q 79 226 VI 04 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V105 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279N/Q292K/Q 80 218 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V106 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279N/Q292K/Q 80 227 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A281 W/Q292K/
V107 Q321A/E333D/A345T/E350K/N369I/S377Y/T405R/N429G/A436S/T501 81 219 P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V108 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279M/Q292K/Q 82 220 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V109 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279H/Q292K/Q 83 221 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
V110 K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
or R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279C/Q292K/Q 84 222 VI 11 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 W/Q292K/
V112 85 224 Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536
E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V113 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279A/Q292K/Q 86 225 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V114 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279G/Q292K/Q 87 228 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V115 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279G/Q292K/Q 87 230 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V116 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 231 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/F279 W/Q292K/
V117 88 233 Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536
E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V118 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 H/Q292K/Q 89 234 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V119 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 K/Q292K/Q 90 235 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V120 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 K/Q292K/Q 90 245 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V121 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 A/Q292K/Q 91 236 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
V122 K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
or R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 A/Q292K/Q 91 242 V123 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/ 98K/K125A/K173A/K184
V124 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 S/Q292K/Q 92 237 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V125 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 S/Q292K/Q 92 250 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221V/E238D/K252A/P281W/Y283F/Q
V126 93 238 292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/
D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 A/Q282P/Q
V127 94 239 292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/
D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V128 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/F316L/Q 95 240 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V129 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/E280L/Q292K/Q 96 241 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V131 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 L/Q292K/Q 97 243 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V132 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 L/Q292K/Q 97 246 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V133 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 247 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V134 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 248 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V135 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/P281 Y/Q292K/Q 98 244 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221V/E238D/K252A/P281L/Q282P/Q
V137 292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ 99 249 D536E
V138 K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
or R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282S/Q292K/Q 100 251 V139 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V140 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282S/Q292K/Q 100 258 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V141 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282A/Q292K/Q 101 252 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V142 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282A/Q292K/Q 101 256 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V143 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282I/Q292K/Q 102 253 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V144 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282R/Q292K/Q 103 254 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/ 98K/K125A/K173A/K184
V145 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282R/Q292K/Q 103 260 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V146 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282Y/Q292K/Q 104 255 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V147 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282L/Q292K/Q 105 257 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V148 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282L/Q292K/Q 105 259 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V149 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282G/Q292K/Q 106 261 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282G/Q292K/Q
V150 262 321A/N324S/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ 107 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282A/Q292K/Q
V151 321A/E333D/A345T/N347S/N369I/S377Y/T405R/N429G/A436S/T501P/ 108 263 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282 W/Q292K/
V152 109 264 Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/D536
E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V153 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282P/Q292K/Q 110 265 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V154 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282P/Q292K/Q 110 266 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V155 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282E/Q292K/Q 111 267 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284T/Q292K/Y
V156 112
307H/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/ 268 D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V157 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284G/Q292K/Q 113 269 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
V158 K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
or R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284P/Q292K/Q 114 270 V159 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V160 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284G/Q292K/Q 115 272 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V161 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284V/Q292K/Q 116 273 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284G/Q292K/D
VI 62
301X/Q321A/ E333D/A345T/R358X/N369I/S377Y/V378X/T405R/ 117 275 N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/ 98K/K125A/K173A/K184
V163 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284R/Q292K/Q 118 276 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
VI 64 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284R/Q292K/Q 118 280 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
V165 K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
or R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284D/Q292K/Q 119 277 V166 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V167 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284E/Q292K/Q 120 278 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Y283N/A284S/Q
V168 121 279 292K/Q321A/E333D/ Α345Ί7
N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V169 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284H/Q292K/Q 122 281 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V170 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284K/Q292K/Q 123 282 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V171 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284I/Q292K/Q 124 283 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284 W/Q292K/
VI 72 84 Q321A/E333D/L342X/A345T/N369I/S377Y/T405R/N429G/A436S/T501 125 2 P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V173 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284T/Q292K/Q 126 285 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/A284M/Q292K/
VI 74 127 287 Q321A/W323R/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T50
1P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V175 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 286 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V176 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 288 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V177 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q292K/Q321 A/E 3 271 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24A/Q38A/K58A/V60I/K88A/Y93H/N97D/R98K/K125A/K173A/K184
V178 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252A/Q282R/Q292K/Q 103 274 321A/E333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q282S/Q2
V179 810 754 92K/E311P/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/
T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q282S/Q2
V180 811 755 92K/L310H/E318K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/
A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q282S/Q2
V181 812 756 92K/L310H/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/
T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/K184
VI 82 R/F209I/M212R/N214D/H219D/Y221V/E238D/K252Q/Q292K/E311P/Q 723 693 321A/E333D/A345T/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/T317S/V
V183 724 694 320G/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/
D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E
VI 84 813 757 333D/A345T/H360L/N369I/Q370H/A375D/S377Y/T405R/T409G/N429
G/A436S/E495G/T501P/ D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/K184
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E
V185 830 717 333D/A345T/N369I/Q370H/A375D/S377Y/T405R/T409G/N429G/A436S
/E495G/T501P/ D536E
S2P/S3R/G4R/E5D/T6R/F7A/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97
D/R98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221V/E2
V186 814 758 38D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/
A436S/T501P/D536E
S3L/G4S/E5H/T6D/F7S/K24Q/Q38N/K58Q/V60I/K88Q/
Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/M212R/
V187 815 759 N214D/H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/
N369I/S377Y/T405R/N429G/A436S/T501P/D536E
S2T/S3R/E5I/T6L/F7K/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98
K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221V/E238D/K
V188 816 760 252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S
/T501P/D536E
S2L/S3D/G4S/E5I/T6A/F7G/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97
D/R98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221V/E2
V189 817 761 38D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/
A436S/T501P/D536E
S2H/S3E/G4P/E5S/T6E/F7T/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97
D/R98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221V/E2
V190 818 762 38D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/
A436S/T501P/D536E
S2L/S3G/G4V/E5S/T6E/F7Q/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97
D/R98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221V/E2
V191 819 763 38D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/
A436S/T501P/D536E
S2R/S3V/G4A/E5P/T6K/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R
98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221 V/E238D
VI 92 764 /K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A43 820 6S/T501P/D536E
S2R/S3A/G4E/E5L/T6S/F7L/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97
D/R98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221V/E2
V193 821 765 38D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/
A436S/T501P/D536E
S2Q/G4I/E5T/T6D/F7K/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R9
8K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221 V/E238D/
VI 94 725 695 K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A43
6S/T501P/D536E
S2R/S3V/G4I/E5D/T6G/F7G/K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97
D/ 98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221V/E2
V195 822 766 38D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/
A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/L 106A/K125Q/K173
V196 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q 726 696 321A/E333D/A345T/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/L106S/K125Q/K173
V197 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q 727 697 321A/E333D/A345T/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/L 106K/K125Q/K173
V198 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q 728 698 321A/E333D/A345T/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/T53L/D54A/A55P/E56P/D57P/K58R/V60I/K88Q/Y93H/N9
7D/R98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221 V/E
V199 823 767 238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429
G/A436S/T501P/ D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/M153N/K17
3Q/K184R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/
V200 Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/K474T/T501 729 699 P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
V201 R/F209I/M212R/I213 S/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q3 824 768 21A/E333D/A345T/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
V202 R/F209I/M212R/N214D/H219A/Y221 V/E238D/K252Q/Q292K/Q321 A/E 730 700 333D/A345T/N369I/S377Y/T405R/ N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/Q 188R/1189V/P202S/F209I/M212R/N214D/H219D/Y221 V/E238D/K2
V203 825 769 52Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/
T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/M153N/K17
3Q/K184R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/
V204
Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/K474T/T501 826 770 P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/H159R/K173
V205 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q 827 771 321A/E333D/A345T/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/H159K/K173
V206 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q 828 772 321A/E333D/A345T/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
V207 R/1189P/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q3 829 773 21A/E333D/A345T/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/T53L/D54P/A55R/E56F/D57S/K58Q/V60I/K88Q/Y93H/N9
7D/R98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221 V/E
V208 731 701 238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N429
G/A436S/T501P/ D536E
K24Q/Q38N/D54A/A55V/E56A/D57Q/K58P/V60I/K88Q/Y93H/N97D/R
98K/L106F/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221V
V209 734 704 /E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N42
9G/A436S/T501P/ D536E
K24Q/Q38N/T53R/D54A/A55Q/E56T/D57A/K58R/V60I/K88Q/Y93H/N
97D/R98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221 V/
V210 E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N42 735 705 9G/A436S/T501P/ D536E
K24Q/Q38N/T53PJD54C/A55V/E56Q/D57P/K58E/V60I/K88Q/Y93H/N
97D/ 98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221 V/
V211
E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S377Y/T405R/N42 736 706 9G/A436S/T501P/ D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/R132G/K173
V212 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q 737 707 321A/E333D/A345T/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/H159Q/K173
V213 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q 738 708 321A/E333D/A345T/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/M153G/K17
3Q/K184R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/
V214 739 709 Q321A/E333D/A345T/N369I/S377Y/
T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
V215 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E 740 710 333D/A345T/N369I/S377Y/I397V/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
4 or
V216 R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q321 A/E 711 333D/A345T/ N369I/S377Y/T405R/N429G/A436S/T501P/D536E 741
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
V217 R/1189 A/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/Q 742 712 321A/E333D/A345T/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
V218
R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/Q292K/L31 OH/E
and 746 716 311P/Q321A/E333D/A345T/N369I/S377Y/T405R/N429G/A436S/T501P/
V219 D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212N/I213 Y/N214L/S215R/T216R/S217I/D218P/H219 A/L220
V220
D/Y221 S/E238D/K252Q/P281 S/Q292K/L313C/S314T/L315M/T317S/Q3 747 718 21 A/E333D/K336R/L337I/A345T/G357R/N369I/S377Y/T405R/N429G/
A436S/ T501P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/Q113R/K125Q/K173
Q/Kl 84R/F209I/M212D/I213 Y/N214E/S215H/T216Q/D218I/H219L/L22
V221 0V/Y221 Q/E238D/K252Q/P281 S/Q292K/L313C/S314T/L315M/T317S/Q 748 719 321A/E333D/K336R/L337I/A345T/G357R/N369I/S377Y/T405R/N429G/
A436S/ T501P/ D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212 S/I213 L/N214E/S215P/T216P/S217F/D218M/L220P/Y221
V222 C/E238D/K252Q/Q292K/L313C/S314T/L315M/T317S/Q321A/E333D/K 831 774 336R/L337I/ A345T/G357R/N369I/S377Y/T405R/N429G/A436S/T501P/
D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212A/N214Y/S215A/T216R/S217T/D218G/H219R/L220M/Y
V223 221N/E238D/K252Q/Q292K/L313C/S314T/L315M/T317S/Q321A/E333 832 775 D/K336R/L337I/A345T/G357R/N369I/S377Y/T405R/N429G/A436S/T50
1P/D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212N/I213 M/N214S/T216 Y/S217R/D218G/H219C/L220 S/Y2
V224 21 V/E238D/K252Q/P281 S/Q292K/L313C/S314T/L315M/T317S/A319Ί7 749 720 Q321A/E333D/K336R/L337I/A345T/N369I/S377Y/T405R/N429G/A436
S/T501P/ D536E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184
R/F209I/M212D/I213 A/S215G/T216E/S217K/D218 V/H219L/L220 S/Y22
V225 1F/E238D/K252Q/P281 S/Q292K/L313C/S314T/L315M/T317S/Q321A/E 750 721 333D/K336R/L337I/A345T/G357R/N369I/S377Y/T405R/N429G/A436S/
T501P/D536E
- -
2. Domain Swaps
Provided herein are modified terpene synthase polypeptides, in particular modified valencene synthase polypeptides, that are chimeric polypeptides containing a swap (deletion and insertion) by deletion of amino acid residues of one of more domains or regions therein or portions thereof and insertion of a heterologous sequence of amino acids. In some examples, the heterologous sequence is a randomized sequence of amino acids. In other examples, the heterologous sequence is a contiguous sequence of amino acids for the corresponding domain or region or portion thereof from another terepene synthase polypeptide. The heterologous sequence that is replaced or inserted generally includes at least 3, 4, 5, 6, 7, 8, 9, 10, 1 1, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35, 36, 37, 38, 39, 40, or more amino acids. In examples where the heterologous sequence is from a corresponding domain or a portion thereof of another terpene synthase, the heterologous sequence generally includes at least 50%, 60%, 70%, 80%, 90%, 95% or more contiguous amino acids of the corresponding domain or region or portion. In such an example, adjacent residues to the heterologous corresponding domain or region or portion thereof also can be included in a modified valencene polypeptide provided herein.
In one example of swap mutants provided herein, at least one domain or region or portion thereof of a valencene synthase polypeptide is replaced with a contiguous sequence of amino acids for the corresponding domain or region or portions thereof from another terpene synthase polypeptide. In some examples, 2, 3, 4, 5, 6, 7, 8, 9, 10 or more domains or regions or portions thereof are replaced with a contiguous sequence of amino acids for the corresponding domain or region or portions thereof from another terepene synthase polypeptide.
Any domain or region or portion thereof of a valencene synthase polypeptide can be replaced with a heterologous sequence of amino acids, such as heterologous sequence from the corresponding domain or region from another terpene. A domain or region can be a structural domain or a functional domain. One of skill in the art is familiar with domains or regions in terepene synthases. Functional domains include, for example, the catalytic domain or a portion thereof. Functional domains also can include functional domains identified as being associated with substrate specificity and product distributions, such as for example, the
RECTIFIED SHEET (RULE 91)
ISA/EP
Aristolochene specific domain, the ratio determinant domain, the Vestispiradiene specific domain, the substrate binding domain or the Hyoscyamus specific domain or other similar domains in other synthases (see e.g. U.S Patent No. 5,824,774). A structural domain can include all or a portion of unstructured loop 1 ; alpha helix 1 ; unstructured loop 2; alpha helix 2; unstructured loop 3; alpha helix 3; unstructured loop 4; alpha helix 4; unstructured loop 5; alpha helix 5; unstructured loop 6; alpha helix 6; unstructured loop 7; alpha helix 7;
unstructured loop 8; alpha helix 8; unstructured loop 9; alpha helix A; A-C loop; alpha helix C; unstructured loop 11 ; alpha helix D; unstructured loop 12; alpha helix Dl ; unstructured loop; alpha helix D2; unstructured loop 14; alpha helix E; unstructured loop 15; alpha helix F; unstructured loop 16; alpha helix Gl ; unstructured loop 17; alpha helix G2; unstructured loop 18; alpha helix HI ; unstructured loop 19; alpha helix H2; unstructured loop 20; alpha helix H3; unstructured loop 21 ; alpha helix a-1 ; unstructured loop 22; alpha helix I; unstructured loop 23; alpha helix J; J-K loop; alpha helix K and/or unstructured loop 25 (see e.g. Figure 2).
One of skill in the art is familiar with various terpene synthases and can identify corresponding domains or regions or portions of amino acids thereof. Table 5B below sets forth the sequence of exemplary terpene synthases. In particular examples herein, modified valencene synthase polypeptide domain swap mutants provided herein contain heterologous sequence from a corresponding domain or region or portion thereof of a terpene synthase polypeptide that is a Vitis vinifera valencene synthase (SEQ ID NOS:346 and 347), tobacco 5- epi-aristolochene synthase (TEAS; SEQ ID NO:295 or 941) or Hyoscyamus muticus premnaspirodiene synthase (HPS; SEQ ID NO:296 or 942).
Typically, the resulting modified valencene synthase exhibits valencene synthase activity and the ability to produce valencene from FPP. For example, the modified valencene synthase polypeptides exhibit 50% to 5000%, such as 50% to 120%, 100% to 500% or 110% to 250%) of the valencene production from FPP compared to the valencene synthase polypeptide not containing the modification (e.g. the amino acid replacement or swap of amino acid residues of a domain or region) and/or compared to wild-type valencene synthase polypeptide set forth in SEQ ID NO:2. Typically, as demonstrated in the Examples herein, the modified valencene polypeptides exhibit increased valencene production from FPP compared to the valencene synthase polypeptide not containing the modification, such as compared to wild-type valencene synthase set forth in SEQ ID NO:2. For example, the modified valencene synthase polypeptides can produce valencene from FPP in an amount that is at least or about 101%, 102%, 103%, 104%, 105%, 106%, 107%, 108%, 109%, 110%, 115%, 120%, 125%, 130%, 135%, 140%, 145%, 150%, 160%, 170%, 180%, 200%, 250%, 300%, 350%, 400%, 500%, 1500%, 2000%, 3000%, 4000%, 5000% of the amount of valencene produced from FPP by wild-type valencene synthase not containing the
modification under the same conditions. For example, the valence production is increased at least 1.2-fold, 1.5-fold, 2-fold, 3-fold, 4-fold, 5-fold, 6-fold, 7-fold, 8-fold, 9-fold, 10-fold, 11-fold, 12-fold, 13-fold, 14-fold, 15-fold, 16-fold, 17-fold, 18-fold, 19-fold, 20-fold or more.
In particular examples herein, modified valencene synthase polypeptides provided herein are swap mutants whereby all or a portion of one or more structural domains is replaced with a corresponding structural domain of another terpene polypeptide. Table 4A below identifies structural domains with numbering based on TEAS numbering or CVS numbering, which are common numbering schemes for all terpene synthases based on alignment of the synthase with TEAS or CVS, respectively (see e.g. Figure 4). Hence, the corresponding domain can be identified in other terpene synthases. Figure 2 herein further depicts the structural domains and regions in exemplary terpene synthases, and the corresponding amino acid residues of each.
Table 4B sets forth exemplary structural domain or domains or portions thereof that are replaced in a modified valencene synthase polypeptide provided herein, and also identifies exemplary corresponding replacement residues from other terpene synthases. Any of the
below domains or regions or portions thereof in a valencene synthase can be replaced with the corresponding region from another terpene synthase , including, but not limited to Vitis vinifera valencene synthase (SEQ ID NOS:346 and 347), TEAS (SEQ ID NO:295 and 941) or HPS (SEQ ID NO:296 and 942).
For example, in modified valencene polypeptides provided herein one or more of a portion of unstructured loop 1 and alpha helix 1 of valencene synthase (corresponding to amino acids 3-41 of SEQ ID NO:2) can be replaced with the corresponding region from Vitis vinifera (corresponding to amino acids 3-51 of SEQ ID NO:346); unstructured loop 2 of valencene synthase (corresponding to amino acids 53-58 of SEQ ID NO:2) can be replaced with the corresponding region from TEAS (corresponding to amino acids 58-63 of SEQ ID NO:295 or 941); a portion of alpha helix 3 (corresponding to amino acids 85-89 of SEQ ID NO:2) is replaced with amino acid residues 93-97 of HPS (SEQ ID NO:942); a portion of alpha helix 3 and unstructured loop 4 (corresponding to amino acids 85-99 of SEQ ID NO:2) is replaced with amino acid residues 93-110 of HPS (SEQ ID NO: 942); unstructured loop 5 and adjacent residues of valencene synthase (corresponding to amino acids 115-146 of SEQ ID NO:2) is replaced with the corresponding region from Vitis vinifera (corresponding to amino acids 128-159 of SEQ ID NO:346); unstructured loop 6 and adjacent residues
(corresponding to amino acids 152-163 of SEQ ID NO:2) is replaced with the corresponding region from HPS (corresponding to amino acids 163-174 of SEQ ID NO: 942); unstructured loop 7 (corresponding to amino acids 174-184 of SEQ ID NO:2) is replaced with the
corresponding region from HPS (corresponding to amino acids 185-193 of SEQ ID NO: 942); unstructured loop 9 and an adjacent residue (corresponding to amino acids 212-221 of SEQ ID NO:2) is replaced with the corresponding region from HPS (corresponding to amino acids 221-228 of SEQ ID NO: 942); alpha helix Dl (corresponding to amino acids 310-322 of SEQ ID NO:2) is replaced with the corresponding region from HPS (corresponding to amino acids 317-329 of SEQ ID NO: 942); and/or the J-K loop (corresponding to amino acids 522-534 of SEQ ID NO:2) is replaced with the corresponding region from HPS (corresponding to amino acids 527-541 of SEQ ID NO: 942). The resulting modifications can be amino acid insertions, deletions or amino acid replacements. For example, exemplary amino acid replacements include, but are not limited to, S3T, G4Q, E5V, T6K, F7N, T 10V, D 12N, S16N, LI 71, R19G, N20D, H21Q, L23I, K24T, G25Y, A26T, S27P, D28E, F29D, D33T, H34R, T35A, A36C, T37K, Q38E, R40Q, H41I, T53L, D54A, A55T, E56G, D57R, A85M, I86L, Q87D, K88H, L89I, C90Y, P91N, I92Y, I92N, I92S, Y93F, Y93F, I94E, I94H, D95A, S96H, S96C, N97E, R98Y, R98D, A99N, A99M, II 16Y, Kl 17T, V122I, E124N, K127T, D129E, E130R, S135E, S136A, N139S, Q142R, S146G, Q178A, D179P, V181L, T182K, P183S, K184P, M212I, M212S, M212V, , I213Y, N214Y, N214Q, S215D, T216K, S217E, S217D, D218E, H219G, H219Q, H219A, L220F, Y221 K or Y221 H by CVS numbering with reference to positions set forth in SEQ ID NO:2.
Exemplary swap modifications, i.e. deletion of a domain or region in a valencene synthase and insertion of heterologous amino acid of the corresponding domain or region from another terpene synthase, are set forth in Table 4C. The replaced (deleted) amino acids corresponding to residues in valencene synthase set forth in SEQ ID NO:2 are indicated, as well as the inserted amino acids from the corresponding domain or region of the other terpene synthase. It is understood that while this Table references amino acid positions of a valencene synthase by CVS numbering set forth in SEQ ID NO:2, similar swaps can be made in other valencene synthases, and in particular in other citrus-derived valencene synthases, by identification of corresponding amino acid residues and regions {see e.g. Figure 1 and Figure 2). Thus, such modifications can be made in a wild-type valencene synthase, such as any set forth in SEQ ID NOS: 2, 289-291, 346, 347, 752, 882 or 883 or any variant thereof. For example, swaps can be made in any valencene synthase polypeptide set forth in Table 3 above. For example, the domain substitutions described above can be made to any of the modified valencene synthase polypeptides set forth in SEQ ID NOS:3-66, 68-127, 348, 723- 731, 734-742, 746-751, 810-832 or 857. In one example, the domain substitutions described above are made to the modified synthase set forth in SEQ ID NO:4.
TABLE 4C: SWAP MODIFICATIONS
Modification Replaced Amino SEQ Inserted Amino Acids SEQ
Acids ID ID
NO NO
SGETFRPTADFHPSLW TQVSASSLAQIPQPKNRP
CVS3-41swapVITIS3-51 RNHFLKGASDFKTVDH 867 VANFHPNIWGDQFITYTP 872
TATQERH EDKVTRACKEEQI
CVS53-58swapTEAS58-63 TDAEDK 868 LATGRK 873
CVS85-99swapHPS 93-110 AIQKLCPIYIDSNRA 869 MLDHIYRADPYFEAHEYN 874
CVS85-99swapVITIS96-l 12 AIQKLCPIYIDSNRA 869 ALQHICNSFHDCNDMDG 875
CVS115-146swapVITIS128- GIKISCDVFEKFKDDE GYTISCDIFNKFTDERGR
1000 1001 159 GRFKSSLINDVQGMLS FKEALI SDVRGMLG
CVS174-184swap
SLVAQDHVTPK 870 SAAPHLKSP 877 HPS185-193
CVS212-221 swap
MINSTSDHLY 871 IYEEEEFK 878 HPS221-228
CVS212-221 swap
MINSTSDHLY 871 IYEEEGFK 879 HPS221-228 with E226G
CVS212-221 swap
MINSTSDHLY 871 SIYDKEQSK 880 TEAS213-221
CVS212-221 swap
MINSTSDHLY 871 VYQDEAFH 881 VITIS223-230
Any methods known in the art for generating chimeric polypeptides can be used to replace all or a contiguous portion of a domain or a first terpene synthase with all or a contiguous portion of the corresponding domain of a second synthase. For example, corresponding domains or regions of any two terpene synthases can be exchanged using any suitable recombinant method known in the art, or by in vitro synthesis. Exemplary of recombinant methods is a two stage overlapping PCR method, such as described in Example 3.D. In such methods, primers that introduce mutations at a plurality of codon positions in the nucleic acids encoding the targeted domain or portion thereof in the first terpene synthase can be employed, wherein the mutations together form the heterologous region {i.e. the corresponding region from the second terpene synthase). Alternatively, for example, randomized amino acids can be used to replace specific domains or regions. It is understood that primer errors, PCR errors and/or other errors in the cloning or recombinant methods can result in errors such that the resulting swapped or replaced region or domain does not exhibit an amino acid sequence that is identical to the corresponding region from the second terpene synthase.
In an exemplary PCR-based method, the first stage PCR uses (i) a downstream primer that anneals downstream of the region that is being replaced {e.g. primer 7-10.4, described in Example 5; SEQ ID NO:339), with a mutagenic primer that includes approximately fifteen nucleotides (or an effective number to effect annealing, such as 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 20, 25 nucleotides or more) of homologous sequence on each side of the domain or region to be exchanged or randomized flanking the region to be imported into the target gene, and (ii) an upstream primer that anneals upstream of the region that is being replaced {e.g. primer 7-10.3, described in Example 5; SEQ ID NO:338) together with an
opposite strand mutagenic primer that also includes approximately fifteen nucleotides (or an effective number to effect annealing, such as 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 20, 25 nucleotides or more) of homologous sequence on each side of the domain or region to be exchanged or randomized flanking the region to be imported into the target gene. If a replacement in which a domain or region of a first terpene synthase gene is replaced with the corresponding domain or region from a second terpene synthase is being performed, nucleotides in the mutagenic primers between the flanking regions from the first terpene synthase contain codons for the corresponding region of the second terpene synthase. In instances where the amino acids in a domain or region are to be randomized, nucleotides of the mutagenic primers between the flanking regions from the first terpene synthase contains random nucleotides. An overlapping PCR is then performed to join the two fragments, using the upstream and downstream oligo (e.g. primers 7-10.3 and 7-10.4). The resulting PCR product can then be cloned into any suitable vector for expression of the modified terpene synthase.
Further, any of the modified valencene synthase polypeptides containing swap mutations herein can contain one or more further amino acid replacements. Exemplary amino acid substitutions (or replacements) that can be included in the modified valencene synthase polypeptides provided include, but are not limited to, MIT, S2R, S2K, S2E, S2Q, S2P, S2T, S2L, S2H, S2A, S2V, S3D, S3R, S3G, S3I, S3E, S3V, S3A, S3T, S3L, S3M, S3N, G4K, G4V, G4N, G4I, G4R, G4S, G4P, G4A, G4E, G4F, G4C, G4T, G4L, E5A, E5G, E5S, E5T, E5D, E5H, E5I, E5P, E5L, E5N, T6R, T6V, T6D, T6L, T6A, T6E, T6K, T6S, T6G, T6C, T6M, T6Y, F7C, F7A, F7Q, F7K, F7S, F7G, F7T, F7L, F7R, F7P, Al IT, R19K, R19P, N20D, L23S, K24A, K24Q, K24Y, D28G, Q38V, Q38A, Q38N, R50G, T53L, T53R, D54A, D54P, D54C, A55T, A55P, A55R, A55V, A55Q, E56G, E56P, E56F, E56A, E56T, E56Q, D57R, D57P, D57S, D57Q, D57A, K58Q, K58R, K58P, K58E, K58A, V60I, V60G, K62R, V69I, F78L, I82V, K88Q, K88A, Y93H, N97D, R98K, H102Y, L106A, L106S, L106K, L106F, LI U S, Q113R, K125A, K125Q, R132G, Y152H, M153N, M153G, H159Q, H159K, H159R, E163D, K173E, K173Q, K173A, K184R, Q188R, I189A, I189V, I189P, T200Q, P202S, F209I, F209H, F209E, F209L, F209T, M210T, M212R, M212D, M212N, M212S, M212A, M212Y, M212K, M212F, M212H, M212Q, I213Y, I213M, I213A, I213R, I213S, I213L, I213F, I213S, I213P, I213Q, I213N, I213K, I213V, N214D, N214E, N214S, N214L, N214Y, N214V, N214P, N214H, N214C, N214A, N214T, N214R, S215H, S215G, S215K, S215R, S215P, S215A, S215N, S215T, S215L, S215V, S215Q, T216Q, T216Y, T216E, T216P, T216R, T216C, T216V, T216K, T216D, T216A, T216S, S217R, S217K, S217F, S217I, S217T, S217G, S217Y, S217N, S217H, S217E, S217F, S217C, D218I, D218G,
D218V, D218C, D218P, D218M, D218R, D218L, D218S, D218A, D218Y, D218K, H219D,
H219A, H219L, H219C, H219W, H219R, H219S, H219F, H219E, L220V, L220S, L220T, L220P, L220M, L220A, L220H, L220E, L220G, L220D, Y221C, Y221V, Y221Q, Y221F, Y221 S, Y221N,Y221T, Y221P, Y221L, Y221K, Y221W, Y221E, Y221V, N227S, E238D, K252A, K252Q, T257A, D274M, D274N, D274S, D274F, D274G, D274H, D274E, F279S, F279I, F279P, F279D, F279L, F279N, F279M, F279H, F279C, F279A, F279G, F279W, E280L, P281 S, P281H, P281K, P281A, P281W, P281L, P281Y, Q282L, Q282S, Q282A, Q282I, Q282R, Q282Y, Q282G, Q282W, Q282P, Q282E, Y283F, Y283N, A284T, A284G, A284P, A284V, A284R, A284D, A284E, A284S, A284H, A284K, A284I, A284W, A284M, Q292K, I299Y, Y307H, L31 OH, E311 P, E311 T, L313C, S314A, S314T, L315M, F316L, T317S, E318K, A319T, V320D, V320G, V320S, Q321A, W323R, N324S, I325T, E326K, E333D, K336R, L337I, L343V, A345V, A345T, N347L, N347S, E348A, E348S, E350K, G357R, H360L, H360A, C361R, V362A, E367G, N369I, Q370D, Q370H, Q370G, K371G, A375D, S377Y, Y387C, I397V, L399S, T405R, T409G, N410S, F424L, N429S, N429G, A436S, V439L, Q448L, C465S, K468Q, S473Y, K474T, E484D, I492V, E495G, K499E, P500L, T501P, P506S, D536E, or A539V by CVS numbering with reference to positions set forth in SEQ ID NO:2.
The modified valencene synthase polypeptides can contain any one or more of the recited amino acid substitutions, in any combination, in addition to a swap modification as described herein above.
Table 5A below sets forth exemplary modified valencene synthase polypeptides containing one or more swap modifications. The first amino acid (one-letter abbreviation) corresponds to the amino acid that is replaced with CVS numbering corresponding to the position in the valencene synthase polypeptide sequence with reference to SEQ ID NO: 2, and the second amino acid (one-letter abbreviation) corresponds to the amino acid selected that replaces the first amino acid at that position. It is understood that due to the swaps and insertion of new domains or regions, a modified valencene synthase can have greater or fewer amino acids compared to an unmodified valencene synthase not containing the swap. Thus, the amino acid numbering for the replacements can be altered. For purposes herein, reference to amino acid replacements is with reference to CVS numbering (see e.g. Figure 4). Thus, for example, in the mutant designated V239 the amino acid replacement designated F209→I210 in Table 5 A has a mutation F210I with respect to the valencene synthase polypeptide set forth in SEQ ID NO: 743 or F209I by CVS numbering. Also provided is the sequence identifier (SEQ ID NO) that sets forth exemplary amino acid sequences and encoding nucleic acid sequences of the modified valencene synthase polypeptides.
Table 5A. CVS variants swaps
Mut. Mutation(s) SEQ ID
No. NO aa nt
K24Q/Q38N/ T53L/ D54A/ A55T/ E56G/ D57 / V60I/K88Q/Y93H/
N97D/ R98K/ K125Q/K173Q/K184R/F209I/M212R/N214D/
V228 67 203 H219D/Y221V/E238D/K252Q/Q292K/Q321A/E333D/A345T/N369I/S37
7Y/T405R/N429G/A436S/T501P/ D536E
K24Q/Q38N/T53L/D54A/A55T/E56G/D57RA^60I/K88Q/Y93H/N97D/R
98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221 V/E238D
V229 /K252Q/P281 S/Q292K/L313C/S314T/L315M/T317S/Q321 A/E333D/K33 350 352 6R/L337I/A345T/N347L/G357R/N369I/S377Y/T405R/N429G/A436S/T5
01P/D536E
K24Q/Q38N/T53L/D54A/A55T/E56G/D57RA^60I/K88Q/Y93H/N97D/R
98K/K125Q/K173Q/K184R/F209I/M212R/N214D/H219D/Y221 V/E238D
V230
/K252Q/P281 S/Q292K/L313C/S314T/L315M/T317S/Q321 A/E333D/K33 351 353 V231 6R/L337I/A345T/G357R/N369I/S377Y/T405R/N429G/A436S/T501P/D5
36E
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/
V232 L175→— /V176→—
/Q178→A176/D179→P177/V181→L179/T182→K180/P183→S181/K18
V233
4→P 182/F209→I207/M212→R210/N214→D212/H219→D217/Y221→
V234 732 702 V219/E238→D236/K252→Q250/P281→S279/Q292→K290/L313→C31
V235 1/S314→T312/L315→M313/T317→S315/Q321→A319/E333→D331/K3
V236 36→R334/L337→I335/A345→T343/G357→R355/N369→I367/S377→Y
375/T405→R403/N429→G427/A436→S434/T501→P499/D536→E534
S2R/S3D/G4K/E5G/F7C/K24Q/Q38N/K58QA^60I/K88Q/Y93H/N97D/R
98K/K125Q/K173Q/L175→— /V176→—
/Q178→A176/D179→P177/V181→L179/T182→K180/P183→S181/K18
V237 4→P 182/F209→I207/M212→R210/N214→D212/H219→D217/Y221→
and V219/E238→D236/K252→Q250/P281→S279/Q292→K290/L313→C31 733 703 V238 1/S314→T312/L315→M313/T317→S315/Q321→A319/E333→D331/K3
36→R334/L337→I335/A345→T343/G357→R355/N369→I367/S377→Y
375/T405→R403/N429→G427/A436→S434/E484→D482/T501→P499/
D536→E534
K24Q/Q38N/T53L/D54A/A55T/E56G/D57R/V60I/A85M/I86L/Q87D/K8
8H/L89I/C90Y/ >R91/-— >A92/—
→D93/I92→Y95/Y93→F96/I94→E97/D95→A98/S96→H99/N97→E10
0/R98→Y101/A99→N102/Ll l l→S114/K125→Q128/K173→Q176/L17
5→— /V176→—
/Q178→A179/D179→P180/V181→L182/T182→K183/P183→S184/K18
V239 4→P 185/F209→I210/M212→R213/N214→D215/H219→D220/Y221→ 743 713
V222/E238→D239/K252→Q253/P281→S282/Q292→K293/L313→C31
4/S314→T315/L315→M316/T317→S318/Q321→A322/E333→D334/K3
36→R337/L337→I338/A345→T346/G357→R358/N369→I370/S377→Y
378/T405→R406/N429→G430/A436→S437/E484→D485/T501→P502/
D536→E537
R19K/K24Q/Q38N/T53L/D54A/A55T/E56G/D57R/V60I/A85M/I86L/Q8
7D/K88H/L89I/C90Y/-— >R91/-— >A92/—
→D93/I92→Y95/Y93→F96/I94→E97/D95→A98/S96→H99/N97→E10
0/R98→Y101/A99→N102/K125→Q128/K173→Q176/L175→—
/V176→—
/Q178→A179/D179→P180/V181→L182/T182→K183/P183→S184/K18
V240 744 714
4→P 185/F209→I210/M212→R213/N214→D215/H219→D220/Y221→
V222/E238→D239/K252→Q253/P281→S282/Q292→K293/L313→C31
4/S314→T315/L315→M316/T317→S318/Q321→A322/E333→D334/K3
36→R337/L337→I338/A345→T346/G357→R358/N369→I370/S377→Y
378/T405→R406/N429→G430/A436→S437/E484→D485/T501→P502/
D536→E537
V241 K24Q/Q38N/T53L/D54A/A55T/E56G/D57R/V60I/A85M/I86L/Q87D/K8 745 715
8H/L89I/C90Y/ >R91/-— >A92/—
→D93/I92→Y95/Y93→F96/I94→E97/D95→A98/S96→H99/N97→E10
0/R98→Y101/A99→N102/K125→Q128/K173→Q176/L175→—
/V176→—
/Q178→A179/D179→P180/V181→L182/T182→K183/P183→S184/K18
4→P 185/F209→I210/M212→R213/N214→D215/H219→D220/Y221→
V222/E238→D239/K252→Q253/P281→S282/Q292→K293/L313→C31
4/S314→T315/L315→M316/T317→S318/Q321→A322/E333→D334/K3
36→R337/L337→I338/A345→T346/G357→R358/N369→I370/S377→Y
378/T405→R406/N429→G430/A436→S437/E484→D485/T501→P502/
D536→E537
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K7K125Q/K173Q/K184
R/F209I/M2121/1213 Y/N214E/S215→— /T216→—
/S217→E215/D218→E216/H219→G217/L220→F218/Y221→K219/E23
V242 8→D236/K252→Q250/P281→S279/Q292→K290/L313→C311/S314→T 833 776
312/L315→M313/T317→S315/Q321→A319/E333→D331/K336→R334/
L337→I335/A345→T343/G357→R355/N369→I367/S377→Y375/T405
→R403/N429→G427/A436→S434/T501→P499/D536→E534
R19K/K24Q/Q38N/T53L/D54A/A55T/E56G/D57R/V60I/A85M/
I86L/Q87D/K88H/L89I/C90Y/ >R91/-— >A92/ >D93/
I92→Y95/Y93→F96/I94→E97/D95→A98/S96→H99/N97→E100/R98
→Y101/A99→N102/K125→Q128/K173→Q176/
L175→— /V176→— /Q178→A179/D179→P180/
V243 V181→L182/T182→K183/P183→S184/K184→P185/F209→I210/ 834 777
M212→S213/N214→Y215/S215→D216/T216→K217/S217-/ D218E/
H219Q/ L220S/ Y221K/ E238D/ K252Q/P281 S/Q292K/
L313C/S314T/L315M/T317S/Q321A/E333D/K336R/L337I/
A345T/G357R/N369I/S377Y/T405R/N429G/A436S/E484D/T501P/D536
E
R19K/K24Q/Q38N/T53L/D54A/A55T/E56G/D57R/V60I/A85M/I86L/Q8
7D/K88H/L89I/C90Y/-— >R91/-— >A92/—
→D93/I92→Y95/Y93→F96/I94→E97/D95→A98/S96→H99/N97→E10
0/R98→Y101/A99→N102/K125→Q128/K173→Q176/L175→—
/V176→— / Q178→A179/ D179→P180/ V181→L182/
V244
T182→K183/P183→S184/K184→P185/F209→I210/M212→S213/N214 835 778 →Y215/S215→D216/T216→K217/S217-/ D218E/ H219Q/
L220S/Y221K/E238D/K252Q/P281 S/Q292K/L313C/S314T/L315M/T317
S/Q321A/I325T/E333D/K336R/L337I/A345T/G357R/N369I/S377Y/T405
R/N429G/A436S/E484D/T501 P/D536E
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/— >R91/— >A92/— >D93/ I92→Y95/
Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/
A99→N102/ K125→Q128/ K173→Q176/ L175→— / V176→— /
Q178→A179/ D179→P180/ V181→L182/ T182→K183/ P183→S184/
K184→P185/ F209→I210/ M212→V213/ I213→Y214/ N214→-/
V245 836 779 S215→-/ T216→Q215/ S217→D216/ D218→E217/ H219→A218/
L220→F219/ Y221→H220/ E238→D237/ K252→Q251/ P281→S280/
Q292→K291/ L313→C312/ S314→T313/ L315→M314/ T317→S316/
Q321→A320/ E333→D332/ K336→R335/ L337→I336/ A345→T344/
G357→R356/ N369→I368/ S377→Y376/ T405→R404/ N429→G428/
A436→S435/ E484→D483/ T501→P500/ D536→E535
R19K/K24Q/Q38N/T53L/D54A/A55T/E56G/D57R/V60I/A85M/I86L/Q8
7D/K88H/L89I/C90Y/-— >R91/-— >A92/-— >D93/
I92→Y95/Y93→F96/I94→E97/D95→A98/S96→H99/N97→E100/R98
→Y101/A99→N102/K125→Q128/K173→Q176/L175→— /V176→— /
Q178→A179/ D179→P180/ V181→L182/
V246 837 780
T182→K183/P183→S184/K184→P185/F209→I210/M212→Y213/I213
→S214/N214→P215/S215→N216/T216→V217/S217→I218/H219→L22
0/L220→A221/Y221→P222/E238→D239/K252→Q253/Q292→K293/Q
321→A322/E333→D334/A345→T346/N369→I370/S377→Y378/T405
→R406/N429→G430/A436→S437/T501→P502/D536→E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V247 V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/ 838 781 P 183→S 184/ Kl 84→P 185/ F209→I210/ M212→K213/ 1213→P214/
N214→ V215/ S215→T216/ T216→R217/ D218→L219/ H219→ S220/
L220→A221/ Y221→L222/ E238→D239/ K252→Q253/ Q292→K293/
V320→A321/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/
S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/
D536→E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >Ό93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
V248 839 782 P 183→S 184/ Kl 84→P 185/ F209→I210/ 1213→Q214/ N214→H215/
S215→L216/ T216→C217/ S217→F218/ D218→S219/ H219→R220/
L220→H221/ Y221→K222/ E238→D239/ K252→Q253/ Q292→K293/
Q321→A322/ E333→D334/ A345→T346/ N369→I370/ S377→Y378/
T405→R406/ N429→G430/ A436→S437/ T501→P502/ D536→E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >Ό93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
V249 P 183→S 184/ Kl 84→P 185/ F209→I210/ M212→F213/ 1213→N214/ 840 783 N214→C215/ S215→V216/ T216→K217/ S217→Y218/ D218→A219/
H219→F220/ L220→T221/ Y221→Q222/ E238→D239/ K252→Q253/
Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/
S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/
D536→E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
V250 P 183→S 184/ Kl 84→P 185/ F209→I210/ M212→Y213/ 1213→R214/ 841 784 N214→L215/ S215→N216/ T216→D217/ S217→N218/ D218→Y2191
H219→A220/ L220→E221/ Y221→W222/ E238→D239/ K252→Q253/
Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/
S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/
D536→E537
K24Q/ D28G/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ K62R/
A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
V251 P183→S184/ K184→P185/ F209→I210/ M212→S213/ I213→K214/ 842 785 N214→A215/ S215→Q216/ T216→A217/ S217→H218/ D218→S219/
H219→L220/ L220→V221/ Y221→S222/ E238→D239/ K252→Q253/
Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/
S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/
D536→E537
K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ K62R/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
V252 P183→S184/ K184→P185/ F209→I210/ M212→S213/ I213→L214/ 843 786 N214→V215/ S215→R216/ T216→S217/ S217→E218/ D218→K219/
H219→D220/ L220→P221/ Y221→N222/ E238→D239/ K252→Q253/
Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/
S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/
D536→E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
V253 I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/ 844 787
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
P 183→S 184/ Kl 84→P 185/ F209→I210/ M212→H213/ 1213→R214/
N214→T215/ S215→P216/ T216→A217/ S217→F218/ D218→C2191
H219→R220/ L220→G221/ Y221→E222/ E238→D239/ K252→Q253/
Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/
S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/
D536→E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
V254 P 183→S 184/ Kl 84→P 185/ F209→I210/ M212→Q213/ 1213→V214/ 845 788 N214→R215/ S215→K216/ T216→R217/ S217→C218/ D218→V219/
H219→E220/ L220→A221/ Y221→V222/ E238→D239/ K252→Q253/
Q292→K293/ Q321→A322/ E333→D334/ A345→T346/ N369→I370/
S377→Y378/ T405→R406/ N429→G430/ A436→S437/ T501→P502/
D536→E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
P 183→S 184/ Kl 84→P 185/ F209→I210/ M212→V213/ 1213→Y214/
V255 N214→— / S215→— / T216→Q215/ S217→D216/ D218→E217/ 846 789 H219→A218/ L220→F2191 Y221→H220/ E238→D237/ K252→Q251/
P281→S280/ Q292→K291/ L313→C312/ S314→T313/ L315→M314/
T317→S316/ Q321→A320/ E333→D332/ K336→R335/ L337→I336/
A345→T344/ G357→R356/ N369→I368/ S377→Y376/ T405→R404/
N429→G428/ A436→S435/ Q448→L447/ E484→D483/ T501→P500/
D536→E535/ /
S2Q/ S3T/ G4F/ E5N/ T6C/ F7A/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
V256 D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 847 790 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/
L313C/ S314Ί7 L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/
G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E
S2A/ S3G/ G4R/ E5G/ T6A/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
V257 D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 848 791 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/
L313C/ S314Ί7 L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/
G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E
S2V/ S3L/ G4K/ E5S/ T6K/ F7R/ R19K/ K24Q/ Q38N/ T53L/ D54A/
Α55Ί7 E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >D93/ I92→Y95/ Y93→F96/ I94→E97/
V258 849 792
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/
F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K2111
S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/
L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/
G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E
S2K/ S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
V259
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
and 850 793 D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/
V260 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/
L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/
G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E
S2P/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/
A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V261
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
and 851 794 P183→S184/ K184→P185/ F209→I210/ M212→S213/ N214→Y215/
V262 S215→D216/ T216→K217/ S217-/ D218E/ H219Q/ L220S/ Y221 Y
E238D/ K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/
E333D/ K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/
A436S/ E484D/ T501P/ D536E
S2C/ S3M/ G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
V263 852
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 795 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/
L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/
G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E
S2Q/ S3N/ G4L/ E5G/ T6Y/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
V264
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 853 796 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/
L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/
G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E
S2L/ S3N/ G4S/ E5I/ T6D/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
V265 854
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 797 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/
L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/
G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E
S2P/ S3D/ G4R/ E5T/ T6G/ F7P/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
V266 →R91/ >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/ 855 798
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/
F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/
L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/ A345T/
G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/ D536E
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >Ό93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176 >— / Q 178→A179/ D 179→P 180/ V 181→L 182/ T 182→K183/
V267 P183- SI 84/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ 856 799 H219 D220/ Y221 ÷V222/ E238- →D239/ K252- →Q253/ P281- →S282/
Q292 K293/ L313 >C314/ S314- *T315/ L315-►M316/ T317- S318/
Q321 A322/ E333 >D334/ K336-→R337/ L337-→I338/ A345-►T346/
G357 R358/ N369 ÷I370/ S377- Y378/ T405→ R406/ N429-•G430/
A436 S437/ E484 >D485/ T501- >P502/ D536-►E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >Ό93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176 >— / Q 178→A179/ D 179→P 180/ V 181→L 182/ T 182→K183/
V268 P183- S 184/ Kl 84→P 185/ F209→E210/ M212→R213/ N214→D215/ 858 801 H219 D220/ Y221 ÷V222/ E238- →D239/ K252- →Q253/ P281- →S282/
Q292 K293/ L313 >C314/ S314- *T315/ L315-►M316/ T317- S318/
Q321 A322/ E333 >D334/ K336-→R337/ L337-→I338/ A345-►T346/
G357 R358/ N369 ÷I370/ S377- Y378/ T405→ R406/ N429-•G430/
A436 S437/ E484 >D485/ T501- >P502/ D536-►E537
K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/ I86L/
Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/ I92→Y95/
Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/ R98→Y101/
A99- ÷ 102/ LI 11→S114/ K125→Q128/ K173→Q176/ L175→— /
V176-→·— / Q 178→A179/ D 179→P 180/ V 181→L 182/ T 182→K183/
V269 P183- >S184/ K184→P185/ F209→E210/ M212→R213/ N214→D215/ 859 802
H219- D220/ Y221 V222/ E238- →D239/ K252- >Q253/ P281- →S282/
Q292- K293/ L313 >C314/ S314- >T315/ L315- M316/ T317- S318/
Q321- A322/ E333 >D334/ K336-→R337/ L337-→I338/ A345-►T346/
G357- R358/ N369 ÷I370/ S377- >Y378/ T405- >R406/ N429-•G430/
A436- S437/ E484 >D485/ T501-→P502/ D536-→E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >Ό93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176 >— / Q 178→A179/ D 179→P 180/ V 181→L 182/ T 182→K183/
V270 P183- S 184/ Kl 84→P 185/ F209→L210/ M212→R213/ N214→D215/ 860 803 H219 D220/ Y221 V222/ E238- →D239/ K252- →Q253/ P281- →S282/
Q292 K293/ L313 >C314/ S314- *T315/ L315-►M316/ T317- S318/
Q321 A322/ E333 >D334/ K336-→R337/ L337-→I338/ A345-►T346/
G357 R358/ N369 ÷I370/ S377- Y378/ T405→ R406/ N429-•G430/
A436 S437/ E484 >D485/ T501- >P502/ D536-►E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176 >— / Q 178→A179/ D 179→P 180/ V 181→L 182/ T 182→K183/
V271 4 P183- S 184/ Kl 84→P 185/ F209→T210/ M212→R213/ N214→D215/ 861 80 H219 >D220/ Y221- V222/ E238 →D239/ K252 Q253/ P281 →S282/
Q292 >K293/ L313- C314/ S314 T315/ L315- M316/ T317 *S318/
Q321 >A322/ E333- D334/ K336→R337/ L337- 1338/ A345 >T346/
G357 >R358/ N369- 1370/ S377 Y378/ T405- R406/ N429 G430/
A436→S437/ E484→D485/ T501→P502/ D536→E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176 >— / Q 178→A179/ D 179→P 180/ V 181→L 182/ T 182→K183/
P183- S 184/ Kl 84→P 185/ F209→I210/ M212→A213/ 1213→F214/
V272 862 805 N214 L215/ S215 A.216/ T216- >C217/ S217- ►G218/ D218- →R219/
H219 R220/ L220 ►P221/ Y221- »T222/ E238- >D239/ K252-→Q253/
Q292 K293/ L313 >C314/ S314- *T315/ L315- >M316/ T317-→S318/
Q321 A322/ E333 >D334/ K336-→R337/ L337-→I338/ A345- VT346/
G357 R358/ N369 ÷I370/ S377- Y378/ T405-•R406/ N429- >G430/
A436 S437/ T501 >P502/ D536- >E537
S2A/ S3T/ G4S/ E5H/ T6S/ F7Q/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -
→R91/ >A92/ >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
V273 I D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ | 863 | 806 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217-/ D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/ Q292K/
L313C/ S314T/ L315M/ T317S/ Q321A/ I325T/ E333D/ K336R/ L337I/
A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/
D536E
S3T/ G4Q/ E5V/ -— >S6/ -— >A7/ -— >S8/ -— >S9/ -— >L10/ -— >Al 1/
>Q12/ >I13/ -— >P14/ >Q15/ >P16/ T6→K17/ F7→N18/
T10→V21/ D12→N23/ S16→N27/ L17→I28/ R19→G30/ N20→D31/
H21→Q32/ L23→I34/ K24→T35/ G25→Y36/ A26→T37/ S27→P38/
D28→E39/ F29→D40/ T31→— / D33→T43/ H34→R44/ T35→A45/
A36→C46/ T37→K47/ Q38→E48/ R40→Q50/ H41→I51/ T53→L63/
D54→A64/ A55→T65/ E56→G66/ D57→R67/ V60→I70/ A85→M95/
I86→L96/ Q87→D97/ K88→H98/ L89→I99/ C90→Y100/ >R101/—
→A102/ -— >D103/ I92→Y105/ Y93→F106/ I94→E107/ D95→A108/
V274 864 807 S96→H109/ N97→E110/ R98→Y111/ A99→N112/ K125→Q138/
K173→Q186/ L175→— / V176→— / Q178→A189/ D179→P190/
V181- ^L192/ T182- K193/ P183→S194/ K184→P195/ F209→I220/
M212→R223/ N214- ^D225/ H219 →D230/ Y221 →V232/ E238→D249/
K252- ^Q263/ P281- S292/ Q292-→K303/ L313- >C324/ S314→T325/
L315- >M326/ T317- →S328/ Q321-→A332/ E333- D344/ K336→R347/
L337- >I348/ A345- T356/ G357- >R368/ N369→ 1380/ S377→Y388/
T405- R416/ N429- ^G440/ A436-→S447/ E484- >Β495/ Τ501→Ρ512/
D536-■ E547
K24Q/ Q38N/ K58Q/ V60I/ I86L/ K88H/ L89I/ P91N/ I92N/ Y93F/ I94H/
S96C/ R98D/ A99M/■ ^GIOI/ - -→D102/ K125→Q127/ K173→Q175/
K184→R186/ F209→I211/ M212-■^R214/ N214→D216/ H219→D221/
Y221→V223/ E238→D240/ K252→Q254/ P281→S283/ Q292→K294/
V275 865
L313→C315/ S314→T316/ L315- M317/ T317→S3191 Q321→A323/
E333→D335/ K336→R338/ L337-→I339/ A345→T347/ G357→R359/
N369→I371/ S377→Y379/ T405-►R407/ N429→G431/ A436→S438/
T501→P503/ D536→E538
K24Q/ Q38N/ K58Q/ V60I/ I86L/ K88H/ L89I/ P91N/ I92S/ Y93F/ I94H/
S96C/ R98D/ A99M/ >G101/ -— >D102/ K125→Q127/ K173→Q175/
K184→R186/ F209→I211/ M212→R214/ N214→D216/ H219→D221/
Y221→V223/ E238→D240/ K252→Q254/ P281→S283/ Q292→K294/
V276 L313→C315/ S314→T316/ L315→M317/ T317→S3191 Q321→A323/ 866 809 E333→D335/ K336→R338/ L337→I339/ A345→T347/ G357→R359/
N369→I371/ S377→Y379/ Y387→C389/ T405→R407/ N429→G431/
A436→S438/ T501→P503/ D536→E538
S3T/ G4Q/ E5V/ -— >S6/ -— >A7/ -— >S8/ -— >S9/ -— >L10/ -— >A11/
>Q12/ >I13/ -— >P14/ >Q15/ >P16/ T6→K17/ F7→N18/
T10→V21/ D12→N23/ S16→N27/ L17→I28/ R19→G30/ N20→D31/
H21→Q32/ L23→I34/ K24→T35/ G25→Y36/ A26→T37/ S27→P38/
D28→E39/ F29→D40/ T31→— / D33→T43/ H34→R44/ T35→A45/
A36→C46/ T37→K47/ Q38→E48/ R40→Q50/ H41→I51/ T53→L63/
D54→A64/ A55→T65/ E56→G66/ D57→R67/ V60→I70/ A85→M95/
I86→L96/ Q87→D97/ K88→H98/ L89→I99/ C90→Y100/ >R101/—
→A102/ -— >D103/ I92→Y105/ Y93→F106/ I94→E107/ D95→A108/
V277 S96→H109/ N97→E110/ R98→Y111/ A99→N112/ K125→Q138/ 887 891 K173→Q186/ L175→— / V176→— / Q178→A189/ D179→P190/
V181- ^L192/ T182- >K193/ P183- SI 94/ K184→P195/ F209→I220/
M212→V223/ I213- >Y224/ N214- →·— / S215→- -/ T216→Q225/
S217- >D226/ D218- *E227/ H219- ^A228/ L220- ^F229/ Y221→H230/
E238- D247/ K252- ^Q261/ P281- ^S290/ Q292- *K301/ L313→C322/
S314-►T323/ L315- >M324/ T317- *S326/ Q321- >A330/ E333→D342/
K336-■>R345/ L337- *I346/ A345-•T354/ G357- >R366/ N369→I378/
S377- >Y386/ T405-►R414/ N429- *G438/ A436-→S445/ E484→D493/
T501- >P510/ D536- >E545
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176 >— / Q 178→A179/ D 179→P 180/ V 181→L 182/ T 182→K183/
V278 P183- S 184/ Kl 84→P 185/ F209→I210/ M212→R213/ N214→V215/ 892 H219 D220/ Y221 ÷V222/ E238- →D239/ K252- →Q253/ P281- →S282/
Q292 K293/ L313 >C314/ S314-→T315/ L315-►M316/ T317- →S318/
Q321 A322/ E333 >D334/ K336-→R337/ L337-→I338/ A345- >T346/
G357 R358/ N369 ÷I370/ S377- >Y378/ T405→ R406/ N429- ►G430/
A436 S437/ E484 >D485/ T501- -*P502/ P506→ S507/ D536- •E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176 >— / Q 178→A179/ D 179→P 180/ V 181→L 182/ T 182→K183/
P183- SI 84/ K184→P185/ F209→I210/ M212→R213/ N214→D215/
V279
H219 -*D220/ Y221- →V222/ E238- →D239/ K252- →Q253/ T257- →A258/ 893 P281- >S282/ Q292- >K293/ L313- >C314/ S314-•T315/ L315→ M316/
T317- *S318/ Q321-►A322/ E333-►D334/ K336- ÷R337/ L337- »I338/
A345 VT346/ G357- ÷R358/ N369- ^1370/ S377→ Y378/ T405- R406/
N410 -*S411/ N429- >G430/ A436- ^S437/ E484- >D485/ T501- ÷P502/
D536 -*E537
R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V69L/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176 >— / Q 178→A179/ D 179→P 180/ V 181→L 182/ T 182→K183/
V280 P183- SI 84/ K184→P185/ F209→I210/ M212→R213/ N214→D215/ 890 894 H219 D220/ Y221 V222/ E238- →D239/ K252- →Q253/ P281- →S282/
Q292 K293/ L313 >C314/ S314-→T315/ L315-►M316/ T317- S318/
Q321 A322/ E333 >D334/ K336-→R337/ L337-→I338/ A345-►T346/
G357 R358/ N369 ÷I370/ S377- >Y378/ T405→ R406/ N429-•G430/
A436 S437/ E484 >D485/ T501- -*P502/ D536-►E537
R19K/ K24P/ Q38Y/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
V281 895 896 R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
P 183→S 184/ Kl 84→P 185/ F209→I210/ M212→V213/ 1213→Y214/
N214→— / S215→— / T216→Q215/ S217→D216/ D218→E2111
H219→A218/ L220→F2191 Y221→H220/ E238→D237/ K252→Q251/
P281→S280/ Q292→K291/ L313→C312/ S314→T313/ L315→M314/
T317→S316/ Q321→A320/ E333→D332/ K336→ 335/ L337→I336/
A345→T344/ G357→R356/ N369→I368/ S377→Y376/ T405→R404/
N429→G428/ A436→S435/ E484→D483/ T501→P500/ D536→E535
V287 S2K/ S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 944 945 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/
Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/
D536E
V288 S2K/ S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 946 947 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/
Q292K/ L313C/ S314A/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ E348A/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/
T501P/ D536E
V289 S2C/ S3M/ G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 948 949 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/
Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/
D536E
V290 S2C/ S3M/ G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 950 951 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/
Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/
D536E
V292 R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >Ό93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/ 952 953 P 183→S 184/ Kl 84→P 185/ F209→I210/ M212→V213/ 1213→Y214/
N214→— / S215→-214/ T216→Q215/ S217→D216/ D218→E217/
H219→A218/ L220→F2191 Y221→H220/ E238→D237/ K252→Q251/
P281→S280/ Q292→K291/ L313→C312/ S314→T313/ L315→M314/
T317→S316/ Q321→A320/ E333→D332/ K336→ 335/ L337→I336/
A345→T344/ G357→R356/ N369→I368/ S377→Y376/ T405→R404/
N429→G428/ A436→S435/ V439→L438/ E484→D483/ T501→P500/
D536→E535
V293 S2A/ S3G/ G4E/ E5A/ F7G/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/
E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ >R91/ -
— >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/
S96→H99/ N97→E 100/ R98→Y 101/ A99→N 102/ Kl 25→Q 128/
K173→Q176/ L175→— / V176→— / Q178→A179/ D179→P180/
V181→L182/ T182→K183/ P183→S184/ K184→P185/ F209→I210/
954 955 M212→R213/ N214→D215/ H219→D220/ Y221→V222/ E238→D239/
K252→Q253/ P281→S282/ Q292→K293/ L313→C314/ S314→T315/
L315→M316/ T317→S318/ Q321→A322/ E333→D334/ K336→R337/
L337→I338/ A345→T346/ G357→R358/ N369→I370/ S377→Y378/
T405→R406/ N429→G430/ A436→S437/ E484→D485/ K499→E500/
T501→P502/ D536→E537
V294 S2C/ S3M/ G4T/ E5G/ T6E/ F7S/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 956 957 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/
Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/
D536E
V295 S2K/ S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 958 959 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/
Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/
D536E
V296 S2K/ S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 960 961 F209→I210/ M212→S2131 N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281 S/
Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/
D536E
V297 R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ 1116→Y119/ Kl 17→T120/ V122→I125/
E124→N127/ K127→T130/ D129→E132/ E130→R133/ S135→E138/
962 963 S136→A139/ N139→S142/ Q142→R145/ S146→G149/ K173→Q176/
L175→— / V176→— / Q178→A179/ D179→P180/ V181→L182/
T182→K183/ P183→S184/ K184→P185/ F209→I210/ M212→R213/
N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/
P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/
T317→S318/ Q321- *A322/ E333- >D334/ K336-→R337/ L337→I338/
A345→T346/ G357-→R358/N369- ÷I370/ S377- >Y378/ T405→R406/
N429→G430/A436-→S437/ E484- >D485/T501-→P502/ D536→E537
V298 I S2K/S3E/G4C/E5T/T6M/F7L/R19K/K24Q/Q38N/T53L/D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/N97→E100/R98→Y101/A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/V181→L182/T182→K183/P183→S184/K184→P185/ | 964 | 965 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/
Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/
D536E
V299 I A11T/R19K/K24Q/Q38N/T53L/D54A/A55T/E56G/D57R/V60I/
A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >Ό93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
P183→S184/K184→P185/F209→I210/M212→R213/N214→D215/ | 966 | 967 H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/
Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/
Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/
G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/
A436→S437/ E484→D485/ T501→P502/ D536→E537
V300 MIT/ R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/
A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/ -— >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ Y152→H155/ K173→Q176/
L175- — / V 176→— / Q 178→A179/ D 179→P 180/ V 181→L 182/
T182- K183/P183 *S184/K184- >P185/ F209→ 1210/ M212→R213/
968 969 N214 D215/ H219→D220/ Y221-→V222/ E238-→D239/ K252→Q253/
P281- S282/ Q292 >K293/L313- >C314/ S314- >T315/ L315→M316/
T317- S318/ Q321 *A322/ E333-►D334/ K336-■^R337/ L337→I338/
A345 T346/ G357→R358/C361- ^R362/N369-→I370/ S377→Y378/
T405- R406/N429 -*G430/A436- ^S437/K468-→Q469/ E484→D485/
T501- P502/ D536 *E537
V301 I S2C/S3M/G4T/E5G/T6E/F7S/R19K/K24Q/Q38N/T53L/D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/N97→E100/R98→Y101/A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/V181→L182/T182→K183/P183→S184/K184→P185/ | 970 | 971 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/
Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/
D536E
V302 I S2C/S3M/G4T/E5G/T6E/F7S/R19K/K24Q/Q38N/T53L/D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/N97→E100/R98→Y101/A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/V181→L182/T182→K183/P183→S184/K184→P185/ | 972 | 973 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/
Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/ T501P/
D536E
V303 S2K/ S3E/ G4C/ E5T/ T6M/ F7L/ R19K/ K24Q/ Q38N/ T53L/ D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/ N97→E100/ R98→Y101/ A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/ V181→L182/ T182→K183/ P183→S184/ K184→P185/ 974 975 T200→Q201/ F209→I210/ M212→S213/ N214→Y215/ S215→D216/
T216→K217/ S217→— / D218E/ H219Q/ L220S/ Y22 IK/ E238D/
K252Q/ P281 S/ Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/
K336R/ L337I/ A345T/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/
E484D/ T501P/ D536E
V304 R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >Ό93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
P 183→S 184/ Kl 84→P 185/ F209→I210/ M212→R213/ N214→D215/ 976 977 H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/
Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/
Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/
G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/
A436→S437/ Q448→L449/ E484→D485/ T501→P502/ D536→E537
V305 R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >D93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ E163→D166/ K173→Q176/
L175→— / V176→— / Q178→A179/ D179→P180/ V181→L182/
T182→K183/ P183→S184/ K184→P185/ F209→I210/ M212→R213/
978 979 N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/
P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/
T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/
A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/
N429→G430/ A436→S437/ Q448→L449/ E484→D485/ T501→P502/
D536→E537
V306 R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >Ό93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
P183→S184/ K184→P185/ F209→I210/ M210→T211/ M212→R213/
980 981 N214→D215/ H219→D220/ Y221→V222/ E238→D239/ K252→Q253/
P281→S282/ Q292→K293/ L313→C314/ S314→T315/ L315→M316/
T317→S318/ Q321→A322/ E333→D334/ K336→R337/ L337→I338/
A345→T346/ G357→R358/ N369→I370/ S377→Y378/ T405→R406/
N429→G430/ A436→S437/ E484→D485/ P500→L501/ T501→P502/
D536→E537
V307 R19K/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/ V60I/ A85M/
I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ >A92/ >Ό93/
I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/ N97→E100/
R98→Y101/ A99→N102/ K125→Q128/ K173→Q176/ L175→— /
V176→— / Q178→A179/ D179→P180/ V181→L182/ T182→K183/
P 183→S 184/ Kl 84→P 185/ F209→I210/ M212→R2131 N214→D215/ 982 983 H219→D220/ Y221→V222/ E238→D239/ K252→Q253/ P281→S282/
Q292→K293/ L313→C314/ S314→T315/ L315→M316/ T317→S318/
Q321→A322/ E333→D334/ K336→R337/ L337→I338/ A345→T346/
G357→R358/ N369→I370/ S377→Y378/ T405→R406/ N429→G430/
A436→S437/ E484→D485/ T501→P502/ D536→E537
V308 R19K/ N20D/ L23S/ K24Q/ Q38N/ T53L/ D54A/ A55T/ E56G/ D57R/
984 985 V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -— >R91/ -— >A92/—
→D93/ I92→Y95/ Y93→F96/ I94→E97/ D95→A98/ S96→H99/
N97→E100/ R98→Y101/ A99→N102/ K125→Q128/ K173→E176/
L175→— /V176→— /Q178→A179/D179→P180/V181→L182/
T182→K183/ P183→S184/ K184→P185/ F209→ 1210/ M212→R213/
N214→D215/ H219→D220/ Y221→V222/ E238-→D239/ K252→Q253/
P281→S282/ Q292→K293/ L313→C314/ S314-•T315/ L315→M316/
T317→S318/ Q321→A322/ E333→D334/ K336-■*R337/ L337- >I338/
A345→T346/ G357→R358/N369→I370/ S377- Y378/ T405- R406/
N429→G430/ A436→S437/ C465→S466/ E484- >D485/T501- >P502/
D536→E537/ A539→V540
V309 I S2C/S3M/G4T/E5G/T6E/F7S/R19K/K24Q/Q38N/T53L/D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/ -
→R91/ >A92/ >Ό93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/N97→E100/R98→Y101/A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/V181→L182/T182→K183/P183→S184/K184→P185/ | 986 | 987 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/
Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ E348A/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/
T501P/D536E
V310 I S2C/S3M/G4T/E5G/T6E/F7S/R19K/K24Q/Q38N/T53L/D54A/
A55T/ E56G/ D57R/ V60I/ A85M/ I86L/ Q87D/ K88H/ L89I/ C90Y/—
→R91/ >A92/ >D93/ I92→Y95/ Y93→F96/ I94→E97/
D95→A98/ S96→H99/N97→E100/R98→Y101/A99→N102/
K125→Q128/ K173→Q176/ L175→— / V176→— / Q178→A179/
D179→P180/V181→L182/T182→K183/P183→S184/K184→P185/ 989 F209→I210/ M212→S213/ N214→Y215/ S215→D216/ T216→K217/
S217→— / D218E/ H219Q/ L220S/ Y221K/ E238D/ K252Q/ P281S/
Q292K/ L313C/ S314T/ L315M/ T317S/ Q321A/ E333D/ K336R/ L337I/
A345T/ E348S/ G357R/ N369I/ S377Y/ T405R/ N429G/ A436S/ E484D/
T501P/D536E/
V311 I K24Q/Q38N/K58Q/V60I/K88Q/P91N/I92S/Y93F/I94H/S96C/
R98D/ A99M/ >G101/ -— >D102/ K125→Q127/ K173→Q175/
K184→R186/ F209→I211/ M212→R214/N214→D216/ H219→D221/
990 991 Y221→V223/ E238→D240/ K252→Q254/ Q292→K294/ Q321→A323/
E333→D335/A345→T347/N369→I371/S377→Y379/ T405→R407/
N429→G431/ A436→S438/ T501→P503/ D536→E538
V312 I K24Q/Q38N/K58Q/V60I/I82V/K88Q/P91N/I92S/Y93F/I94H/
S96C/ R98D/ A99M/ >G101/ -— >D102/ K125→Q127/ K173→Q175/
K184→R186/ F209→I211/ M212→R214/N214→D216/ H219→D221/
992 Y221→V223/ E238→D240/ K252→Q254/ Q292→K294/ Q321→A323/ 993 E333→D335/A345→T347/N369→I371/S377→Y379/ L399→S401/
T405→R407/N429→G431/A436→S438/T501→P503/D536→E538
V313 I S3T/ G4Q/ E5V/ -— >S6/■ ■A7/ -— >S8/ -— >S9/ -— >L10/ -— >A11/
■Q12/ >I13/ -— >P14/ — >Q15/ >P16/T6→K17/F7→N18/
T10→V21/ D12→N23/ S16→N27/ L17→I28/ R19→G30/N20→D31/
H21→Q32/ L23→I34/ K24→T35/ G25→Y36/ A26→T37/ S27→P38/
D28→E39/ F29→D40/ T31→— / D33→T43/ H34→R44/ T35→A45/
A36→C46/ T37→K47/ Q38→E48/ R40→Q50/ H41→I51/ V48→I58/
T53→L63/ D54→A64/ A55→T65/ E56→G66/ D57→R67/ V60→I70/
I86→L96/ K88→H98/ L89→I99/ P91→N101/ I92→S102/ Y93→F103/ 994 995 I94→H104/ S96→C106/ R98→D108/ A99→M109/ -— >G111/—
→D112/ H102→Y114/ II 16→Y128/ Kl 17→T129/ V122→I134/
E124- ^N136/K127- →T139/D129- ^E141/E130- -*R142/S135→E147/
S136- >A148/N139-→S151/Q142- R154/S146- ^G158/K173→Q185/
L175- ÷— /V176→- -/Q178→A1 ?/D179→P189/V181→L191/
T182- ^K192/P183- ^S193/K184-►PI 94/ F209-■1219/ M212→V222/
1213—■Y223/N214- >— /S215→- / T216→Q224/ S217→D225/
D218- ^E226/ H219-→A227/ L220- -*F228/ Y221- ÷H229/ E238→D246/
K252- ^Q260/ P281- -*S289/ Q292- *K300/ L313- >C321/ S314→T322/
L315- >M323/ T317-→S325/ Q321-→A329/ E333- ^D341/ K336→R344/
L337- >I345/ A345-■T353/ G357- R365/ N369-•1377/ S377→Y385/
T405- >R413/ N429- -*G437/ A436-→S444/ E484- >D492/ T501→P509/
D536-■>E544
V314 I S3T/ G4Q/ E5V/ -— >S6/ -— •A7/ -— >S8/ -— >S9/ -— >L10/ -— >Al II
>Q12/ >I13/ -— >P14/ — >Q15/ >P16/ T6→K17/ F7→N18/
T10→V21/ D12→N23/ S16- N27/ L17→I28/ R19→G30/ N20 →D31/
H21→Q32/ L23→I34/ K24- T35/ G25→Y36/ A26→T37/ S27→P38/
D28→E39/ F29→D40/ T31- — / D33→T43/ H34→R44/ T35 A45/
A36→C46/ T37→K47/ Q38- E48/ R40→Q50/ H41→I51/ T53→L63/
D54→A64/ A55→T65/ E56- G66/ D57→R67/ V60→I70/ 186 ^L96/
K88→H98/ L89→I99/ P91- ►N101/ I92- >S102/ Y93- >F 103/ 194 HI 04/
S96→C106/ R98 D108/ A99→M109/ -— >Gl l l/ ~→D112/
996 997 K125→Q137/ K173 →Q185/ L175- →— / V176→- -/ Q178→A188/
D179→P189/ V181-→L191/ T182- -*K192/ P183- >S193/ K184→P194/
F209→I219/ M212- >V222/ 1213- Y223/ N214- ·— / S215→— /
T216→Q224/ S217- -*D225/ D218-→E226/ H219-→A227/ L220→F228/
Y221→H229/ E238-→D246/ K252-→Q260/ P281-→S289/ Q292→K300/
L313→C321/ S314- ÷T322/ L315- >M323/ T317- *S325/ Q321→A329/
E333→D341/ K336-→R344/ L337-→I345/ A345-►T353/ G357→R365/
N369→I377/ S377- >Y385/ T405- >R413/ N429- >G437/ A436→S444/
E484→D492/ T501-→P509/ D536- -*E544
V315 I S3T/ G4Q/ E5V/ -— >S6/ -— >A1I -— >S8/ -— >S9/ -— >L10/ - — >A11/
■Q12/ >I13/ -— >P14/ >Q15/ >P16/ T6→K17/ F7→N18/
T10→V21/ D12→N23/ S16→N27/ L17→I28/ R19→G30/ N20-→D31/
H21→Q32/ L23→I34/ K24→T35/ G25→Y36/ A26→T37/ S27-→P38/
D28→E39/ F29→D40/ T31→— / D33→T43/ H34→R44/ T35- A45/
A36→C46/ T37→K47/ Q38→E48/ R40→Q50/ H41→I51/ T53-→L63/
D54→A64/ A55→T65/ E56→G66/ D57→R67/ V60→I70/ A85→M95/
I86→L96/ Q87→D97/ K88→H98/ L89→I99/ C90→Y100/ -—►R101/—
→A102/ -— >D103/ I92→Y105/ Y93→F106/ I94→E107/ D95-■»A108/
S96→H109/ N97→E110/ R98→Y111/ A99→N112/ K125→Q138/ 998 999 K173→Q186/ L175→— / V176→— / Q178→A189/ D179→P190/
V181- ^L192/ T182- >K193/ P183- SI 94/ K184→P195/ F209→I220/
M212→V223/ I213- >Y224/ N214- →·— / S215→- -/ T216→Q225/
S217- >D226/ D218- *E227/ H219- ^A228/ L220- ^F229/ Y221→H230/
E238- D247/ K252- ^Q261/ P281- ^S290/ Q292- *K301/ L313→C322/
S314-►T323/ L315- >M324/ T317- *S326/ Q321- >A330/ E333→D342/
K336-■>R345/ L337- *I346/ A345-•T354/ G357- >R366/ N369→I378/
S377- >Y386/ T405-►R414/ N429- *G438/ A436-→S445/ E484→D493/
T501- P510/ D536- >E545
3. Product Distribution Mutants
Alternatively or in addition to effecting increased valencene production as described above, modified valencene polypeptides provided herein can exhibit other altered properties. For example, provided herein are modified valencene synthase polypeptides that exhibit altered substrate specificity and/or product selectivity, and/or altered product distribution (i.e. altered relative amounts and or types of terpenes) compared to wild-type valencene synthase set forth in SEQ ID NO:2. In other examples, provided herein are modified valencene synthase polypeptides that exhibit altered substrate specificity and/or product selectivity and/or altered product distribution (i.e. altered relative amounts and or types of terpenes)
compared to variant valencene synthase polypeptides set forth in SEQ ID NO:3 (VI 8) or SEQ ID NO:4 (VI 9). Such modified valencene synthase polypeptides can be used in methods to improve the production and/or generation of valencene, for example, by increasing the product distribution of valencene compared to other terpene products. This can result in methods that result in increased or improved purity of a valencene composition, increased or improved recovery of valencene from reaction medium and/or ease of methods to isolate valencene. Also, this can result in methods that also result in increased recovery of nootkatone by oxidation of the valencene.
For example, provided herein are modified valencene synthase polypeptides that produce decreased β-elemene as a percentage of total terpenes compared to β-elemene produced as a percentage of total terpenes by a valencene synthase polypeptide set forth in SEQ ID NO:2, 3 or 4. β-elemene is a degradation product of germacrene A, and is the measure of germacrene A produced. Hence, also provided herein are modified valencene synthase polypeptides that produce decreased germacrene A as a percentage of total terpenes compared to germacrene A produced as a percentage of total terpenes by a valencene synthase polypeptide set forth in SEQ ID NO:2, 3 or 4. For example, modified valencene synthase polypeptides provided herein produce 95%, 80%, 70%, 60%, 50%, 40%, 30%, 20%, 10% or less levels of β-elemene, and hence germacrene A, than is produced by wildtype valencene synthase set forth in SEQ ID NO:2. The percentage of β-elemene, and hence germacrene A, as a percentage of total terpene product produced can be decreased by greater than or about or 0.01% to 90%, such as 1% to 80%, 5% to 80%, 10% to 60% or 0.01% to 20%. For example, the percentage of terpene β-elemene product, and hence germacrene A, as a percentage of total terpene is decreased by at least or at least about 0.5%, 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90% or more. Modified valencene synthases provided herein result in increased or improved production of valencene as a percentage of total terpenes produced in a reaction compared to wildtype valencene synthase set forth in SEQ ID NO:2. The percentage of valencene produced or recovered by weight is greater than 68%, for example, greater than or at least 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80% or more.
Exemplary of such modified valencene polypeptides are polypeptides containing an amino acid modification at a position corresponding to residue 281, 313, 314, 315, 317, 336, 337 and/or 357 by CVS numbering with reference to positions set forth in SEQ ID NO:2. For example, amino acid replacements can be a replacement at any of the above positions that is P281 S, P281H, P281K, P281A, P281W, P281L, P281Y, L313C, S314T, L315M, T317S, K336R, L337I, N347L and/or G357R. Exemplary amino acid substitution(s) or
replacement(s) correspond to P281 S, L313C, S314T, L315M, T317S, K336R, L337I, N347L
and/or G357R by CVS numbering with reference to positions set forth in SEQ ID NO:2. For example, a modified valencene synthase polypeptide provided herein that exhibits reduced or decreased β-elemene formation contains amino acid substitutions (replacements)
corresponding to P281 S, L313C, S314T, L315M, T317S, K336R, L337I and G357R by CVS numbering with reference to positions set forth in SEQ ID NO:2. In some examples, a modified valencene synthase polypeptide provided herein that exhibits reduced or decreased β-elemene formation contains amino acid substitutions (replacements) corresponding to P281 S, L313C, S314T, L315M, T317S, K336R, L337I, N347L and G357R by CVS numbering with reference to positions set forth in SEQ ID NO:2. It is understood that further or additional amino acid modifications can be included so long as the modified valencene synthase polypeptide exhibits altered product distribution.
For example, exemplary valencene synthase polypeptides that exhibit altered product distributions and decreased β-elemene formation include those set forth below. Hence, the exemplary valencene synthase polypeptides also produce less germacrene A. For example:
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L313 C/S314T/
L315M/T317S/Q321A/E333D/K336R/A345T/N347L
G357R/N369I/S377Y/T405R/N429G/A436S/T501P/ D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L313 C/S314T/
L315M/T317S/Q321A/E333D/K336R/L337I/A345T/
N347L/G357R/N369I/S377Y/T405R/N429G/A436S/ T501P/D536E;
K24Q/Q38N/K58Q/V60I/K88Q/Y93H/N97D/R98K/K125Q/K173Q/K184R/F209I/ M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L313 C/S314T/
L315M/T317S/Q321A/E333D/K336R/L337I/A345T/
G357R/N369I/S377Y/T405R/N429G/A436S/T501P/ D536E
K24Q/Q38N/T53L/D54A/A55T/E56G/D57R/V60I/K88Q/Y93H/N97D/R98K/K125 Q/Kl 73 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L313 C/S314T/L315M/T317S/Q321A/E333D/K336R/L337I/A345T/N347L/G357R/N369I/S377Y/ T405R/N429G/A436S/T501P/D536E;
K24Q/Q38N/T53L/D54A/A55T/E56G/D57R/V60I/K88Q/Y93H/N97D/R98K/K125 Q/Kl 73 Q/Kl 84R/F209I/M212R/N214D/H219D/Y221 V/E238D/K252Q/P281 S/Q292K/L313 C/S314T/L315M/T317S/Q321A/E333D/K336R/L337I/A345T/G357R/N369I/S377Y/T405R/ N429G/A436S/T501P/D536E;
R19K/K24Q/Q38N/T53L/D54A/A55T/E56G/D57R V60I/A85M/I86L/Q87D/K88H/ L89I/C90Y/-— >R91/-— >A92/—
→D93/I92→Y95/Y93→F96/I94→E97/D95→A98/S96→H99/N97→E100/R98→Y101/A99 →N102/K125→Q128/K173→Q176/L175→— /V176→—
/Q178→A179/D179→P180/V181→L182/T182→K183/P183→S184/K184→P185/F209→I2 10/M212→R213/N214→D215/H219→D220/Y221→V222/E238→D239/K252→Q253/P281 →S282/Q292→K293/L313→C314/S314→T315/L315→M316/T317→S318/Q321→A322/E 333→D334/K336→R337/L337→I338/A345→T346/G357→R358/N369→I370/S377→Y37 8/T405→R406/N429→G430/A436→S437/E484→D485/T501→P502/D536→E537; and/or
S3T/ G4Q/ E5V/ -— >S6/ -— >A7/ -— >S8/ -— >S9/ -— >L10/ -— >A11/ -— >Q12/ - — >I13/ -— >P14/ -— >Q15/ -— >P16/ T6→K17/ F7→N18/ T10→V21/ D12→N23/ S16→N27/ L17→I28/ R19→G30/ N20→D31/ H21→Q32/ L23→I34/ K24→T35/
G25→Y36/ A26→T37/ S27→P38/ D28→E39/ F29→D40/ T31→— / D33→T43/
H34→R44/ T35→A45/ A36→C46/ T37→K47/ Q38→E48/ R40→Q50/ H41→I51/
T53→L63/ D54→A64/ A55→T65/ E56→G66/ D57→R67/ V60→I70/ A85→M95/
I86→L96/ Q87→D97/ K88→H98/ L89→I99/ C90→Y100/ -— >R101/ -— >A102/— →D103/ I92→Y105/ Y93→F106/ I94→E107/ D95→A108/ S96→H109/ N97→E110/ R98→Y111/ A99→N112/ K125→Q138/ K173→Q186/ L175→— / V176→— /
Q 178→A189/ D 179→P 190/ VI 81→L192/ Tl 82→K193/ P 183→S 194/ Kl 84→P195/ F209→I220/ M212→V223/ 1213→Y224/ N214→— / S215→— / T216→Q225/
S217→D226/ D218→E227/ H219→A228/ L220→F229/ Y221→H230/ E238→D247/ K252→Q261/ P281→S290/ Q292→K301/ L313→C322/ S314→T323/ L315→M324/ T317→S326/ Q321→A330/ E333→D342/ K336→R345/ L337→I346/ A345→T354/ G357→R366/ N369→I378/ S377→Y386/ T405→R414/ N429→G438/ A436→S445/ E484→D493/ T501→P510/ D536→E545.
Exemplary of such polypeptides include any set forth in SEQ ID NO:5, 61, 63, 350, 351, 744 or 887 or encoded by a sequence of nucleic acids set forth in any of SEQ ID NOS: 130, 197, 198, 352, 353, 714 or 891, or degenerate codons thereof.
D. Methods for producing modified terpene synthases and encoding nucleic acid molecules
Provided are methods for producing modified terpene synthase polypeptides. The methods can be used to generate terpene synthases with desired properties, including, but not limited to, increased terpene production upon reaction with an acyclic pyrophosphate terpene precursor, such as FPP, GPP or GGPP; altered product distribution; altered substrate specificity; and/or altered regioselectivity and/or stereoselectivity. Modified terpene synthases can be produced using any method known in the art and, optionally, screened for the desired properties. In particular examples, modified terpene synthases with desired properties are generated by mutation in accord with the methods exemplified herein. Thus,
provided herein are modified terpene synthases and nucleic acid molecules encoding the modified terpene synthases that are produced using the methods described herein.
Exemplary of the methods provided herein are those in which modified terpene synthases are produced by replacing one or more endogenous domains or regions of a first terpene synthase with the corresponding domain(s) or regions(s) from a second terpene synthase (i.e. heterologous domains or regions). In further examples, two or more
endogenous domains or regions of a first terpene synthase are replaced with the
corresponding heterologous domain(s) or regions(s) from two or more other terpene
synthases, such as a second, third, fourth, fifth, sixth, seventh, eighth, ninth, or tenth terpene synthase. Thus, the resulting modified terpene synthase can include heterologous domains or regions from 1, 2, 3, 4, 5, 6, 7, 8, 9 or more different terpene synthases. In further examples, the methods also or instead include replacing one or more domains or regions of a first terpene synthase with randomized amino acid residues.
Any terpene synthase can be used in the methods provided herein. The first terpene synthase (i.e. the terpene synthase to be modified) can be of the same or different class as the second (or third, fourth, fifth etc.) terpene synthase (i.e. the terpene synthase(s) from which the heterologous domain(s) or region(s) is derived). For example, included among the methods provided herein are those in which the terpene synthase to be modified is a
monoterpene, diterpene or sesquiterpene synthase, and the terpene synthase(s) from which the one or more the heterologous domains or regions are derived is a monoterpene, diterpene or sesquiterpene synthase. In some examples, all of the terpene synthases used in the methods provided herein are sesquiterpene synthases. Exemplary sesquiterpene synthases include, but are not limited to, valencene synthase, TEAS, HPS, and santalene synthase. Exemplary terpene synthases that can be used in the methods herein, including exemplary amino acid and nucleic acid sequences thereof, include but are not limited to, any set forth in Table 5B.
Table 5B.
Genbank Acc. SEQ ID NO
Synthase
No. aa nt
Abies grandis abietadiene cyclase AAB05407 355 521
Abies grandis E-a-bisabolene synthase AAK83562 359 522
Abies grandis pinene synthase 024475 356 523
Abies grandis γ-humulene synthase AAC05728 358 524
Abies grandis δ-selinene synthase AAC05727 357 525
Actinidia deliciosa germacrene-D synthase AAX16121.1 354 526
Antirrhinum majus (3S)-(E)-nerolidol synthase ABR24417 418 527
Arabidopsis thaliana (-)-E- -caryophylene synthase AA085539 419 528
Arabidopsis thaliana (E)- -ocimene synthase/ myrcene NP_567511 375 529 synthase
Arabidopsis thaliana (Z)-y-bisabolene synthase NP_193064 420 530
Arabidopsis thaliana (Z)-y-bisabolene synthase NP_193066 421 531
Arabidopsis thaliana GA1 ent-copalyl diphosphate NPJ92187 369 532 synthase/magnesium ion binding
Arabidopsis thaliana myrcene/ocimene synthase AAG09310 360 533
Arabidopsis thaliana similar to Nicotiana 5-epi-aristolochene AAB61105 362 534 synthase
Arabidopsis thaliana strong similarity to Nicotiana 5-epi- AAC64880 361 535 aristolochene synthase and Gossypium hirsutum δ cadinene
synthase
Arabidopsis thaliana terpene cyclase TCI CAA72070 363 536
Arabidopsis thaliana terpene synthase/cyclase family protein NP 174635 364 537
Arabidopsis thaliana terpene synthase/cyclase family protein NP 175312 365 538
Arabidopsis thaliana terpene synthase/cyclase family protein NP 188067 366 539
Arabidopsis thaliana terpene synthase/cyclase family protein NP 189746 367 540
Arabidopsis thaliana terpene synthase/cyclase family protein NP 193754 368 541
Arabidopsis thaliana terpene synthase/cyclase family protein NP 199276 370 542
Aribidopsis thaliana beta-caryophyllene/alpha-humulene AA085539 374 543 synthase
Aribidopsis thaliana terpene synthase AA085535 371 544
Aribidopsis thaliana terpene synthase AA085536 372 545
Aribidopsis thaliana terpene synthase AA085537 373 546
Artemisia annua (-)-beta-pinene synthase AAK58723 379 547
Artemisia annua (3R)-linalool synthase AAF13357 382 548
Artemisia annua (E)-beta-farnesene synthase AAX39387 422 549
Artemisia annua 8-epi-cedrol synthase AAF80333 423 550
Artemisia annua 8-epi-cedrol synthase CAC08805 424 551
Artemisia annua amorpha-4, 11 -diene synthase AAK15696 381 552
Artemisia annua (E)-beta-caryophyllene synthase AAL79181 425 553
Artemisia annua germacrene A synthase ABE03980 383 554
Artemisia annua putative sesquiterpene cyclase CAB56499 376 555
Artemisia annua putative sesquiterpene cyclase CAC 12731 377 556
Artemisia annua putative sesquiterpene cyclase CAC 12732 378 557
Artemisia annua sesquiterpene cyclase AAG24640 380 558
Aspergillus terreus aristolochene synthase AAF13263 426 559
Capsicum annuum 5-epi-aristolochene synthase CAA06614.1 385 560
Capsicum annuum 5-epi-aristolochene synthase AAC61260.1 384 561
Cichorium intybus germacrene A synthase long form AAM21658 387 562
Cichorium intybus germacrene A synthase short form AAM21659 386 563
Cinnamomum tenuipile geraniol synthase CAD29734 388 564
Cistus creticus subsp. Creticus germacrene B synthase ACF94469.1 389 565
Citrus junos (Ε)-β -farnesene synthase AAK54279 390 566
Citrus junos terpene synthase AAG01339 391 567
Citrus limon (+)-limonene synthase 1 AAM53944 393 568
Citrus limon γ-terpinene synthase AAM53943 392 569
Citrus sinensis terpene synthase 1 ACX70155.1 394 570
Citrus x paradisi putative terpene synthase AAM00426.1 395 571
Crepidiastrum sonochifolium germacrene A synthase ABB00361 396 572
Croton sublyratus copalyl diphosphate synthase BAA95612 397 573
Cucumis melo δ-cadinene synthase ABX83200 400 574
Cucumis melo a-farnesene synthase ABX83201 427 575
Cucumis sativus (E,E)-a-caryophyllene synthase AAU05952 428 576
Cucumis sativus (E)-a-farnesene synthase AAU05951 429 577
Cucurbita maxima copalyl diphosphate synthase 2 AAD04293 399 578
Cucurbita maxima ent-kaurene synthase B AAB39482 398 579
Elaeis oleifera sesquiterpene synthase AAC31570 401 580
Giberella fujikuroi (-)-copalyl diphosphate/(-)-ent-kaurene Q9UVY5 430 581 synthase
Ginkgo biloba levopimaradiene synthase AAL09965 402 582
Gossypium arboreum (+)-8-cadinene synthase CAA77191.1 403 583
Gossypium arboreum (+)-8-cadinene synthase AAB41259.1 405 584
Gossypium arboreum (+)-8-cadinene synthase isozyme C2 CAA76223.1 404 585
Gossypium arboreum (+)-8-cadinene synthase isozyme XCl Q39761 406 586
Gossypium arboreum (+)-8-cadinene synthase isozyme XCl 4 AAA93065.1 407 587
Gossypium arboreum (+)-a-cadinene synthase AAA93064 431 588
Gossypium hirsutum (+)-8-cadinene synthase AAC12784.1 408 589
Gossypium hirsutum (+)-8-cadinene synthase AAX44033.1 409 590
Gossypium hirsutum (+)-8-cadinene synthase AAF74977.1 410 591
Gossypium hirsutum (+)-8-cadinene synthase AAX44034.1 411 592
Helianthus annuus germacrene A synthase 1 ACA14463 412 593
Helianthus annuus germacrene A synthase 2 ABY49939 413 594
Helianthus annuus germacrene A synthase 3 ACZ50512 414 595
Helianthus annuus γ-cadinene synthase AAY41422 415 596
Hyoscyamus muticus premnaspirodiene synthase AAA86337.1 296 597
Hyoscyamus muticus premnaspirodiene synthase AAA86340.1 942 943
Hyoscyamus muticus vetispiradiene synthase AAA86339.1 416 598
Ixeris dentate germacrene A synthase AAL92481 432 599
Kitasatospora griseola diterpene cyclase-2 BAB39207 417 600
Lactuca sativa copalyldiphosphate synthase No. 1 BAB 12440 433 601
Lactuca sativa germacrene A synthase LTC1 AAM 11626 433 602
Lactuca sativa germacrene A synthase LTC2 AAM 11627 434 603
Lavandula angusivolia (E)-a-bergamotene synthase ABB73046 435 604
Lycopersicon esculentum germacrene C synthase AAC39432 436 605
Lycopersicon esculentum δ-elemene synthase AAG41889 437 606
Lycopersicon esculentum δ-elemene synthase AAG41890 438 607
Lycopersicon hirsutum germacrene B synthase AAG41891 439 608
Lycopersicon hirsutum germacrene D synthase AAG41892 440 609
Magnolia grandiflora β-cubebene synthase ACC66281 441 610
Malus x domestica (E,E)-a-farnesene synthase AA022848 442 611
Medicago truncatula (-)-cubebol synthase ABB01625 443 612
Medicago truncatula (E)- -caryophyllene synthase AAV36464 444 613
Medicago truncatula 3S-(E)-nerolidol synthase AAV36466 445 614
Mentha x pipereta (Z)-muurola-3,5-diene synthase CAH10288 446 615
Mentha x piperita (E)- -farnesene synthase AAB95209 447 616
Mikania micrantha β-caryophyllene synthase ACN67535 448 617
Nicotiana attenuata 5-epi-aristolochene synthase AA085555.1 449 618
Nicotiana tabacum 5-epi-aristolochene synthase L04680
295 619
AAA19216.1
Nicotiana tabacum 5-epi-aristolochene synthase GL2624425 941 619
Ocimum basilicum germacrene D synthase AAV63786 451 620
Ocimum basilicum a-zingiberene synthase AAV63788 452 621
Ocimum basilicum β-selinene synthase AAV63785 453 622
Ocimum basilicum δ-cadinene synthase Q5SBP5 454 623
Oryza sativa (E)-P-caryophyllene synthase ACF05331 455 624
Oryza sativa (E)- -caryophyllene synthase ABJ16553 456 625
Oryza sativa (E,E)-farnesol synthase ABJ16554 457 626
Oryza sativa a-zingiberene synthase ACF05529 458 627
Perilla frutescens var. frutescens sesquiterpene synthase AAX16076.1 459 628
Perilla frutescens var. frutescens valencene synthase AAX16077.1 460 629
Picea abies (E)-a-bisabolene synthase AAS47689 461 630
Picea abies (E,E)-a-farnesene synthase AAS47697 462 631
Picea abies longifolene synthase AAS47695 463 632
Pinus taeda (E,E)-a-farnesene synthase AA061226 464 633
Pisum sativum ent-kaurene synthase A AAB58822 465 634
Pogostemon cablin (-)-germacrene D synthase AAS86322 466 635
Pogostemon cablin (-)-germacrene A synthase AAS86320.1 467 636
Pogostemon cablin (+)- germacrene A synthase AAS86321.1 468 637
Pogostemon cablin patchoulol synthase AAS86323 469 638
Pogostemon cablin γ-curcumene synthase AAS86319 470 639
Populus balsamifera ssp. trichocarpa x Populus deltoides (-)- AAR99061.1 471 640 germacrene D synthase
Pseudotsuga menziesii (E)- -farnesene synthase AAX07265 472 641
Pseudotsuga menziesii (E)-y-bisabolene synthase AAX07266 473 642
Ricinus communis (+)-8-cadinene synthase isozyme A EEF38721.1 474 643
Ricinus communis (+)-8-cadinene synthase isozyme A EEF38510.1 475 644
Ricinus communis Casbene synthase EEF48772.1 476 645
Ricinus communis casbene synthase, chloroplastic P59287 477 646
Salvea sclarea labdenediol diphosphate synthase 478 647
WO2009101126
Salvea sclarea labdenediol diphosphate synthase 479 648
WO2009101126
Salvea sclarea sclareol synthase WO2009101126 480 649
Santalum album santalene synthase WO2009109597 481 650
Santalum album santalene synthase WO20100067309 482 651
Santalum album santalene synthase WO20100067309 483 652
Santalum album santalene synthase WO20100067309 484 653
Santalum album santalene synthase WO20100067309 485 654
Santalum album sesquiterpene synthase ACF24768.1 486 655
Santalum austrocaledonicum sesquiterpene synthase ADO87005.1 487 656
Santalum spicatum sesquiterpene synthase ADO87006.1 488 657
Scoparia dulcis copalyl diphosphate BAD03594 489 658
Solanum habrochaites sesquiterpene synthase 1 AAG41891.1 490 659
Solanum habrochaites sesquiterpene synthase 2 AAG41892 491 660
Solanum lycopersicum caryophyllene/alpha-humulene
D5KXD2 492 661 synthase
Solanum lycopersicum copalyl diphosphate synthase BAA84918 493 662
Solanum lycopersicum germacrene C synthase AAC39432 494 663
Solanum lycopersicum vetispiradiene synthase AAG09949.1 495 664
Solanum tuberosum putative vetispiradiene synthase 4 AAD02269 496 665
Solanum tuberosum vetispiradiene synthase BAA82092.1 497 666
Solidago canadensis germacrene A synthase CAC36896 498 667
Solidago canadensis germacrene D synthase CAE47440 499 668
Stevia rebaudiana (-)-copalyl diphosphate synthase AAB87091 500 669
Stevia rebaudiana (-)-ent-kaurene synthase AAD34295 501 670
Stevia rebaudiana kaurene synthase AAD34294 502 671
Taxus wallilchiana var. chinensis Taxadiene synthase Q9FT37 503 672
Vitis vinifera (-)-germacrene D synthase AAS66357.1 504 673
Vitis vinifera (+)-valencene synthase AC036239.1 505 674
Vitis vinifera (+)-valencene synthase AAS66358 346 675
Zea diploperennis (E)-P-caryophyllene synthase ABY79209 347 676
Zea luxurians (E)-P-caryophyllene synthase ABY79211 506 677
Zea m. huehuetenangensis (E)-P-caryophyllene synthase ABY79210 507 678
Zea mays (-)- -macrocarpene synthase AAS88576 508 679
Zea mays (-)-P-macrocarpene synthase AAT70085 509 680
Zea mays (-)-P-macrocarpene synthase ACF58240 510 681
Zea mays (E)-P-caryophyllene synthase ABY79206 511 682
Zea mays (E,E)-farnesol synthase AA018435 512 683
Zea mays sesquithujene synthase AAS88574 513 684
Zea mays S-P-bisabolene synthase AAS88571 514 685
Zea mays mexicana (E)-P-caryophyllene synthase ABY79212 515 686
Zea mays parviglumis (E)- -caryophyllene synthase ABY79213 516 687
Zea perennis (E)-P-caryophyllene synthase ABY79214 517 688
Zingiber officinale germacrene D synthase AAX409665 518 689
Zingiber zerumbet a-humulene synthase BAG12020 519 690
Zingiber zerumbet β-eudesmol synthase BAG12021 520 691
In the methods provided herein, all or a contiguous portion of an endogenous domain of a first terpene synthase can be replaced with all or a contiguous portion of the
corresponding heterologous domain from a second terpene synthase. For example, 3, 4, 5, 6, 7, 8, 9, 10 or more contiguous amino acids from a domain or region in a first synthase can be replaced with 3, 4, 5, 6, 7, 8, 9, 10 or more contiguous amino acids from the corresponding region from a second terpene synthase. In some examples, one or more amino acid residues adjacent to the endogenous domain of the first terpene synthase also are replaced, and/or one or more amino acid residues adjacent to the heterologous domain also are used in the
replacement. Further, the methods provided herein also include methods in which all or a contiguous portion of a first domain and all or a contiguous portion of a second adjacent domain are replaced with the corresponding domains (or portions thereof) from another terpene synthase.
Domains or regions that can be replaced include functional domains or structural domains. Exemplary domains or regions that can be replaced in a terpene synthase using the methods described herein include, but are not limited to, structural domains or regions corresponding to unstructured loop 1 (corresponding to amino acids 1-29 of SEQ ID NO:2); alpha helix 1 (corresponding to amino acids 30-39 and 44-52 of SEQ ID NO:2); unstructured loop 2 (corresponding to amino acids 53-58 of SEQ ID NO:2); alpha helix 2 (corresponding to amino acids 59-71 of SEQ ID NO:2); unstructured loop 3 (corresponding to amino acids 72-78 of SEQ ID NO:2); alpha helix 3 (corresponding to amino acids 79-93 of SEQ ID
NO:2); unstructured loop 4 (corresponding to amino acids 94-100 of SEQ ID NO:2); alpha helix 4 (corresponding to amino acids 101-114 of SEQ ID NO:2); unstructured loop 5 (corresponding to amino acids 115-141 of SEQ ID NO:2); alpha helix 5 (corresponding to amino acids 142-152 of SEQ ID NO:2); unstructured loop 6 (corresponding to amino acids 153-162 of SEQ ID NO:2); alpha helix 6 (corresponding to amino acids 163-173 of SEQ ID NO:2); unstructured loop 7 (corresponding to amino acids 174-184 of SEQ ID NO:2); alpha helix 7 (corresponding to amino acids 185-194 of SEQ ID NO:2); unstructured loop 8 (corresponding to amino acids 195-201 of SEQ ID NO:2); alpha helix 8 (corresponding to amino acids 202-212 of SEQ ID NO:2); unstructured loop 9 (corresponding to amino acids 213-222 of SEQ ID NO:2); alpha helix A (corresponding to amino acids 223-253 of SEQ ID NO:2); A-C loop (corresponding to amino acids 254-266 of SEQ ID NO:2); alpha helix C (corresponding to amino acids 267-276 of SEQ ID NO:2); unstructured loop 11
(corresponding to amino acids 277-283 of SEQ ID NO:2); alpha helix D (corresponding to amino acids 284-305 of SEQ ID NO:2); unstructured loop 12 (corresponding to amino acids 306-309 of SEQ ID NO:2); alpha helix Dl (corresponding to amino acids 310-322 of SEQ ID NO:2); unstructured loop 13 (corresponding to amino acids 323-328 of SEQ ID NO:2); alpha helix D2 (corresponding to amino acids 329 of SEQ ID NO:2); unstructured loop 14 (corresponding to amino acids 330-332 of SEQ ID NO:2); alpha helix E (corresponding to amino acids 333-351 of SEQ ID NO:2); unstructured loop 15 (corresponding to amino acids 352-362 of SEQ ID NO:2); alpha helix F (corresponding to amino acids 363-385 of SEQ ID NO:2); unstructured loop 16 (corresponding to amino acids 386-390 of SEQ ID NO:2); alpha helix Gl (corresponding to amino acids 391-395 of SEQ ID NO:2); unstructured loop 17 (corresponding to amino acids 396-404 of SEQ ID NO:2); alpha helix G2 (corresponding to amino acids 405-413 of SEQ ID NO:2); unstructured loop 18 (corresponding to amino acids 414-421 of SEQ ID NO:2); alpha helix HI (corresponding to amino acids 422-428 of SEQ ID NO:2); unstructured loop 19 (corresponding to amino acids 429-431 of SEQ ID NO:2); alpha helix H2 (corresponding to amino acids 432-447 of SEQ ID NO:2); unstructured loop 20 (corresponding to amino acids 448-450 of SEQ ID NO:2); alpha helix H3 (corresponding to amino acids 451-455 of SEQ ID NO:2); unstructured loop 21 (corresponding to amino acids 456-461 of SEQ ID NO:2); alpha helix a-1 (corresponding to amino acids 462-470 of SEQ ID NO:2); unstructured loop 22 (corresponding to amino acids 471-473 of SEQ ID NO:2); alpha helix I (corresponding to amino acids 474-495 of SEQ ID NO:2); unstructured loop 23 (corresponding to amino acids 496-508 of SEQ ID NO:2); alpha helix J (corresponding to amino acids 509-521 of SEQ ID NO:2); J-K loop (corresponding to amino acids 522-534 of SEQ ID NO:2); alpha helix K (corresponding to amino acids 535-541 of SEQ ID NO:2); and unstructured loop 25 (corresponding to amino acids 542-548 of SEQ ID NO:2). Any one or
more of these domains or regions, or a portion thereof, can be replaced with a corresponding domain from another terpene synthase using the methods provided herein. These domains are regions can be identified in any terpene synthase using methods well known in the art, such as, for example, by alignment using methods known to those of skill in the art (see, e.g, Figure 2). Such methods typically maximize matches, and include methods such as using manual alignments and by using the numerous alignment programs available (for example, BLASTP) and others known to those of skill in the art. By aligning the sequences of the valencene synthase set forth in SEQ ID NO:2, and any other terpene synthase, any of the domains or regions recited above can be identified in any terpene synthase.
In some examples of the methods provided herein, a region corresponding to a portion of unstructured loop 1 and alpha helix 1 of valencene synthase (corresponding to amino acids 3-41 of SEQ ID NO:2) in a first terpene synthase is replaced with the corresponding region from a second terpene synthase; the region corresponding to unstructured loop 2 (corresponding to amino acids 53-58 of SEQ ID NO:2) in a first terpene synthase is replaced with the corresponding region from a second terpene synthase; the region corresponding to a portion of alpha helix 3 (corresponding to amino acids 85-89 of SEQ ID NO:2) in a first terpene synthase is replaced with the corresponding region in a second terpene synthase; the region corresponding to a portion of alpha helix 3 and unstructured loop 4 (corresponding to amino acids 85-99 of SEQ ID NO:2) in a first terpene synthase is replaced with the corresponding region from a second terpene synthase; the region corresponding to unstructured loop 6 and adjacent residues (corresponding to amino acids 152-163 of SEQ ID NO:2) in a first terpene synthase is replaced with the corresponding region from a second terpene synthase; the region corresponding to unstructured loop 7 (corresponding to amino acids 174-184 of SEQ ID NO:2) in a first terpene synthase is replaced with the corresponding region from a second terpene synthase; the region corresponding to unstructured loop 9 and an adjacent residue (corresponding to amino acids 212-221 of SEQ ID NO:2) in a first terpene synthase is replaced with the corresponding region from a second terpene synthase; the region corresponding to alpha helix Dl
(corresponding to amino acids 310-322 of SEQ ID NO:2) in a first terpene synthase is replaced with the corresponding region from a second terpene synthase; and/or the region corresponding to the J-K loop (corresponding to amino acids 522-534 of SEQ ID NO:2) in a first terpene synthase is replaced with the corresponding region a second terpene synthase.
For example, provided herein are methods in which a portion of unstructured loop 1 and alpha helix 1 of valencene synthase (corresponding to amino acids 3-41 of SEQ ID NO:2) is replaced with amino acids 3-51 of the Vitis vinifera set forth in SEQ ID NO:346; the region corresponding to unstructured loop 2 (corresponding to amino acids 53-58 of SEQ ID NO:2)
of a first terpene synthase is replaced with amino acids 58-63 of the TEAS polypeptide set forth in SEQ ID NO:295 or 941 ; the region corresponding to a portion of alpha helix 3 (corresponding to amino acids 85-89 of SEQ ID NO:2) is replaced with amino acid residues 93-97 of the HPS set forth in SEQ ID NO:942); the region corresponding to a portion of alpha helix 3 and unstructured loop 4 (corresponding to amino acids 85-99 of SEQ ID NO:2) of a first terpene synthase is replaced with amino acid residues 93-110 of the HPS set forth in SEQ ID NO:942; the region corresponding to unstructured loop 6 and adjacent residues
(corresponding to amino acids 152-163 of SEQ ID NO:2) of a first terpene synthase is replaced with the amino acids 163-174 of the HPS set forth in SEQ ID NO:942; the region corresponding to unstructured loop 7 (corresponding to amino acids 174-184 of SEQ ID NO:2) of a first terpene synthase is replaced with the amino acids 185-193 of the HPS set forth in SEQ ID NO:942; the region corresponding to unstructured loop 9 and an adjacent residue (corresponding to amino acids 212-221 of SEQ ID NO:2) of a first terpene synthase is replaced with amino acids 221-228 of the HPS set forth in SEQ ID NO:942; the region corresponding to alpha helix Dl (corresponding to amino acids 310-322 of SEQ ID NO:2) of a first terpene synthase is replaced with amino acids 317-329 of the HPS set forth in SEQ ID NO:942); and/or the J-K loop (corresponding to amino acids 522-534 of SEQ ID NO:2) of a first terpene synthase is replaced with amino acids 527-541 of the HPS set forth in SEQ ID NO:942).
In the methods provided herein, all or a contiguous portion of an endogenous domain of a first terpene synthase can be replaced with all or a contiguous portion of the
corresponding heterologous domain from a second terpene synthase using an suitable recombinant method known in the art as discussed above in Section C.2.
E. Production of modified valencene synthase polypeptides and encoding nucleic acid molecules
Terpene synthase polypeptides and active fragments thereof, including valencene synthase polypeptides and active fragments thereof, can be obtained by methods well known in the art for recombinant protein generation and expression. Such polypeptides can be used to produce valencene from any suitable acyclic pyrophosphate terpene precursor, such as FPP, GPP or GGPP, in the host cell from which the synthase is expressed, or in vitro following purification of the synthase. Any method known to those of skill in the art for identification of nucleic acids that encode desired genes can be used to obtain the nucleic acid encoding a terpene synthase, such as a valencene synthase. For example, nucleic acid encoding unmodified or wild type valencene synthase polypeptides can be obtained using well known methods from a plant source, such as citrus {e.g. orange or grapefruit). Modified valencene polypeptides can then be engineered using any method known in the art for introducing
mutations into unmodified or wild type valencene synthases, including any method described herein, such as random mutagenesis of the encoding nucleic acid by error- prone PCR, site- directed mutagenesis, overlap PCR, or other recombinant methods. The nucleic acid encoding the polypeptides can then be introduced into a host cell to be expressed
heterologously.
In some examples, the terpene synthases provided herein, including modified valencene synthase polypeptides, are produced synthetically, such as using solid phase or solutions phase peptide synthesis.
1. Isolation of nucleic acid encoding terpene synthases
Nucleic acid encoding terpene synthases, such as valencene synthase, can be cloned or isolated using any available methods known in the art for cloning and isolating nucleic acid molecules. Such methods include PCR amplification of nucleic acids and screening of libraries, including nucleic acid hybridization screening. In some examples, methods for amplification of nucleic acids can be used to isolate nucleic acid molecules encoding a valencene synthase polypeptide, including for example, polymerase chain reaction (PCR) methods. A nucleic acid containing material can be used as a starting material from which a valencene synthase-encoding nucleic acid molecule can be isolated. For example, DNA and mRNA preparations from citrus fruit, including, but not limited to, orange {Citrus sinensis) and grapefruit {Citrus paradisi) can be used to obtain valencene synthase genes. Nucleic acid libraries also can be used as a source of starting material. Primers can be designed to amplify a terpene synthase-encoding molecule, such as a valencene synthase-encoding molecule. For example, primers can be designed based on known nucleic acid sequences encoding a terpene synthase, such as valencene synthase, such as those set forth in SEQ ID NOS: l and 292-294, or from back-translation of a valencene synthase amino acid sequence. Nucleic acid molecules generated by amplification can be sequenced and confirmed to encode a valencene synthase polypeptide.
Additional nucleotide sequences can be joined to a valencene synthase-encoding nucleic acid molecule, including linker sequences containing restriction endonuclease sites for the purpose of cloning the synthetic gene into a vector, for example, a protein expression vector or a vector designed for the amplification of the core protein coding DNA sequences. Furthermore, additional nucleotide sequences specifying functional DNA elements can be operatively linked to a valencene synthase-encoding nucleic acid molecule. Still further, nucleic acid encoding other moieties or domains also can be included so that the resulting synthase is a fusion protein. For example, nucleic acids encoding other enzymes, such as FPP synthase, or tags, such as His tags.
2. Generation of muant or modified nucleic acid
- -
Nucleic acid encoding a modified terpene synthase, such as a modified valencene synthase, can be prepared or generated using any method known in the art to effect mutation. Methods for modification include standard rational and/or random mutagenesis of encoding nucleic acid molecules (using e.g., error prone PCR, random site-directed saturation mutagenesis, or rational site-directed mutagenesis, such as, for example, mutagenesis kits (e.g. QuikChange available from Stratagene)). In addition, routine recombinant DNA techniques can be utilized to generate nucleic acids encoding polypeptides that contain heterologous amino acid. For example, nucleic acid encoding chimeric polypeptides or polypeptides containing heterologous amino acid sequence, can be generated using a two-step PCR method, such as described above and in Example 5, and or using restriction enzymes and cloning methodologies for routine subcloning of the desired chimeric polypeptide components.
Once generated, the nucleic acid molecules can be expressed in cells to generate modified terpene synthase polypeptides using any method known in the art. The modified terpene synthase polypeptides, such as modified valencene synthase polypeptides, can then be assessed by screening for a desired property or activity, for example, for the ability to produce a terpene from a substrate . In particular examples, modified terpene synthases with desired properties are generated by mutation and screened for a property in accord with the examples exemplified herein. Typically, in instances where a modified valencene synthase is generated, the modified valencene synthase polypeptides produce valencene from FPP.
Thus, provided herein are nucleic acids encoding any of the modified terpene synthases described herein, including any of the modified valencene synthase polypeptides described above and herein. Any of the nucleic acid molecules provided herein can be isolated or purified using methods well known in the art, or can be contained in a vector or cell. Exemplary of nucleic acid molecules provided herein are any set forth in Table 3 or 5A, or degenerates thereof. For example, exemplary of nucleic acid molecules provided herein are any that encode a modified valencene synthase polypeptide provided herein, such as any encoding a polypeptide set forth in any of SEQ ID NOS: 3-127, 350, 351 , 723-731 , 732-745, 746-751, 810-866, 887-890 and 895, or degenerates thereof. In one embodiment, nucleic acid molecules provided herein have at least 50, 60, 65, 70, 75, 80, 85, 90, 91, 92, 93, 94, 95, or 99% sequence identity or hybridize under conditions of medium or high stringency along at least 70% of the full-length of any nucleic acid encoding a modified valencene synthase polypeptide provided herein. For example, the nucleic acid molecules provided herein have at least or at least about at least 50, 60, 65, 70, 75, 80, 85, 90, 91, 92, 93, 94, 95, or 99% sequence identity to the nucleic acid sequence set forth in SEQ ID NO: 1. In another embodiment, a nucleic acid molecule can include those with degenerate codon sequences
RECTIFIED SHEET (RULE 91)
ISA/EP
encoding any of the valencene synthase polypeptides provided herein. Table 3 and 5A set forth exemplary nucleic acid sequences of exemplary modified valencene synthase polypeptides provided herein.
3. Vectors and Cells
For recombinant expression of one or more of the modified terpene synthase polypeptides provided herein, including modified valencene synthase polypeptides, the nucleic acid containing all or a portion of the nucleotide sequence encoding the synthase can be inserted into an appropriate expression vector, i.e., a vector that contains the necessary elements for the transcription and translation of the inserted protein coding sequence.
Depending upon the expression system used, the necessary transcriptional and translational signals also can be supplied by the native promoter for a valencene synthase gene, and/or their flanking regions. Thus, also provided herein are vectors that contain nucleic acid encoding the modified valencene synthase polypeptides. Cells, including prokaryotic and eukaryotic cells, containing the vectors also are provided. Such cells include bacterial cells, yeast cells, fungal cells, Archea, plant cells, insect cells and animal cells. In particular examples, the cells are yeast, such as Saccharomyces cerevisiae, that express an acyclic pyrophosphate terpene precursor, such as FPP. The cells are used to produce a terpene synthase, such as a valencene synthase polypeptide or modified valencene synthase polypeptide, by growing the above- described cells under conditions whereby the encoded valencene synthase is expressed by the cell. In some instances, the expressed synthase is purified. In other instances, the expressed synthase, such as valencene synthase, converts FPP to one or more terpenes (e.g. valencene) in the host cell.
Any method known to those of skill in the art for the insertion of DNA fragments into a vector can be used to construct expression vectors containing a chimeric gene containing appropriate transcriptional/translational control signals and protein coding sequences. These methods can include in vitro recombinant DNA and synthetic techniques and in vivo recombinants (genetic recombination). Expression of nucleic acid sequences encoding a valencene synthase polypeptide or modified valencene synthase polypeptide, or domains, derivatives, fragments or homologs thereof, can be regulated by a second nucleic acid sequence so that the genes or fragments thereof are expressed in a host transformed with the recombinant DNA molecule(s). For example, expression of the proteins can be controlled by any promoter/enhancer known in the art. In a specific embodiment, the promoter is not native to the genes for a valencene synthase protein. Promoters that can be used include but are not limited to prokaryotic, yeast, mammalian and plant promoters. The type of promoter depends upon the expression system used, described in more detail below.
In a specific embodiment, a vector is used that contains a promoter operably linked to nucleic acids encoding a valencene synthase polypeptide or modified valencene synthase polypeptide, or a domain, fragment, derivative or homolog, thereof, one or more origins of replication, and optionally, one or more selectable markers (e.g. , an antibiotic resistance gene). Vectors and systems for expression of valencene synthase polypeptides are described.
4. Expression systems
Terpene synthase polypeptides, including valencene synthase polypeptides (modified and unmodified) can be produced by any methods known in the art for protein production including in vitro and in vivo methods such as, for example, the introduction of nucleic acid molecules encoding the terpene synthase (e.g. valencene synthase) into a host cell or host plant for in vivo production or expression from nucleic acid molecules encoding the terpene synthase(e.g. valencene synthase) in vitro. Terpene synthases such as valencene synthase and modified valencene synthase polypeptides can be expressed in any organism suitable to produce the required amounts and forms of a synthase polypeptide. Expression hosts include prokaryotic and eukaryotic organisms such as E. coli, yeast, plants, insect cells, mammalian cells, including human cell lines and transgenic animals. Expression hosts can differ in their protein production levels as well as the types of post-translational modifications that are present on the expressed proteins. The choice of expression host can be made based on these and other factors, such as regulatory and safety considerations, production costs and the need and methods for purification.
Expression in eukaryotic hosts can include expression in yeasts such as those from the Saccharomyces genus (e.g. Saccharomyces cerevisiae) and Pichia genus (e.g. Pichia pastoria), insect cells such as Drosophila cells and lepidopteran cells, plants and plant cells such as citrus, tobacco, corn, rice, algae, and lemna. Eukaryotic cells for expression also include mammalian cells lines such as Chinese hamster ovary (CHO) cells or baby hamster kidney (BHK) cells. Eukaryotic expression hosts also include production in transgenic animals, for example, including production in serum, milk and eggs.
Many expression vectors are available and known to those of skill in the art for the expression of a terpene synthase, such as valencene synthase. The choice of expression vector is influenced by the choice of host expression system. Such selection is well within the level of skill of the skilled artisan. In general, expression vectors can include transcriptional promoters and optionally enhancers, translational signals, and transcriptional and translational termination signals. Expression vectors that are used for stable transformation typically have a selectable marker which allows selection and maintenance of the transformed cells. In some cases, an origin of replication can be used to amplify the copy number of the vectors in the cells.
Terpene synthases, including valencene synthase and modified valencene synthase polypeptides, also can be utilized or expressed as protein fusions. For example, a fusion can be generated to add additional functionality to a polypeptide. Examples of fusion proteins include, but are not limited to, fusions of a signal sequence, a tag such as for localization, e.g. a his6 tag or a myc tag, or a tag for purification, for example, a GST fusion, and a sequence for directing protein secretion and/or membrane association. In other examples, sesquiterpene synthases such as valencene synthase or modified valencene synthase polypeptides can be fused to FPP synthase, as described in Brodelius et al. (Eur. J. Biochem. (2002) 269: 3570- 3579).
Methods of production of terpene synthase polypeptides, including valencene synthase polypeptides, can include coexpression of an acyclic pyrophosphate terpene precursor, such as FPP, in the host cell. In some instances, the host cell naturally expresses FPP. Such a cell can be modified to express greater quantities of FPP (see e.g. US6531303). In other instances, a host cell that does not naturally produce FPP is modified genetically to produce FPP.
a. Prokaryotic cells
Prokaryotes, especially E. coli, provide a system for producing large amounts of the modified valencene synthase polypeptides provided herein. Transformation of E. coli is a simple and rapid technique well known to those of skill in the art. Exemplary expression vectors for transformation of E. coli cells, include, for example, the pGEM expression vectors, the pQE expression vectors, and the pET expression vectors (see, U.S. patent 4,952,496; available from NOVAGEN, Madison, WI; see, also literature published by Novagen describing the system). Such plasmids include pET 11a, which contains the T71ac promoter, T7 terminator, the inducible E. coli lac operator, and the lac repressor gene; pET 12a-c, which contains the T7 promoter, T7 terminator, and the E. coli ompT secretion signal; and pET 15b and pET19b (NOVAGEN, Madison, WI), which contain a His-Tag™ leader sequence for use in purification with a His column and a thrombin cleavage site that permits cleavage following purification over the column, the T7-lac promoter region and the T7 terminator.
Expression vectors for E. coli can contain inducible promoters that are useful for inducing high levels of protein expression and for expressing proteins that exhibit some toxicity to the host cells. Exemplary prokaryotic promoters include, for example, the β- lactamase promoter (Jay et al, (1981) Proc. Natl. Acad. Sci. USA 75:5543) and the tac promoter (DeBoer et al, Proc. Natl. Acad. Sci. USA 80:21-25 (1983)); see also "Useful Proteins from Recombinant Bacteria": in Scientific American 242:19-94 (1980)). Examples
of inducible promoters include the lac promoter, the trp promoter, the hybrid tac promoter, the T7 and SP6 RNA promoters and the temperature regulated XPL promoter.
Terpene synthases, including valencene synthase can be expressed in the cytoplasmic environment of E. coli. The cytoplasm is a reducing environment and for some molecules, this can result in the formation of insoluble inclusion bodies. Reducing agents such as dithiothreitol and β-mercaptoethanol and denaturants {e.g. , such as guanidine-HCl and urea) can be used to resolubilize the proteins. An alternative approach is the expression of valencene synthase in the periplasmic space of bacteria which provides an oxidizing environment and chaperonin-like and disulfide isomerases leading to the production of soluble protein. Typically, a leader sequence is fused to the protein to be expressed which directs the protein to the periplasm. The leader is then removed by signal peptidases inside the periplasm. Examples of periplasmic -targeting leader sequences include the pelB leader from the pectate lyase gene and the leader derived from the alkaline phosphatase gene. In some cases, periplasmic expression allows leakage of the expressed protein into the culture medium. The secretion of proteins allows quick and simple purification from the culture supernatant. Proteins that are not secreted can be obtained from the periplasm by osmotic lysis. Similar to cytoplasmic expression, in some cases proteins can become insoluble and denaturants and reducing agents can be used to facilitate solubilization and refolding.
Temperature of induction and growth also can influence expression levels and solubility. Typically, temperatures between 25 °C and 37 °C are used. Mutations also can be used to increase solubility of expressed proteins. Typically, bacteria produce aglycosylated proteins,
b. Yeast cells
Yeasts such as those from the Saccharomyces genus {e.g. Saccharomyces cerevisiae) Schizosaccharomyces pombe, Yarrowia lipolytica, Kluyveromyces lactis, and Pichia pastoris can be used to express the terpene synthases, such as the valencene synthase polypeptides, including the modified valencene synthase polypeptides, provided herein. Yeast can be transformed with episomal replicating vectors or by stable chromosomal integration by homologous recombination. In some examples, inducible promoters are used to regulate gene expression. Exemplary promoter sequences for expression of valencene synthase
polypeptides in yeast include, among others, promoters for metallothionine, 3- phosphoglycerate kinase (Hitzeman et al., J. Biol. Chem. 255:2073, 1980), or other glycolytic enzymes (Hess et al., J. Adv. Enzyme Reg. 7: 149, 1968; and Holland et al., Biochem. 17:4900, 1978), such as enolase, glyceraldehyde phosphate dehydrogenase, hexokinase, pyruvate decarboxylase, phosphofructokinase, glucose phosphate isomerase, 3-phosphoglycerate mutase, pyruvate kinase, triosephosphate isomerase, phosphoglucose isomerase, and glucokinase.
Other suitable vectors and promoters for use in yeast expression are further described in Hitzeman, EPA-73,657 or in Fleer et al, Gene, 107:285-195 (1991); and van den Berg et al., Bio/Technology, 8: 135-139 (1990). Another alternative includes, but is not limited to, the glucose-repressible ADH2 promoter described by Russell et al. (J. Biol. Chem. 258:2674, 1982) and Beier et al. (Nature 300:724, 1982), or a modified ADH1 promoter. Shuttle vectors replicable in both yeast and E. coli can be constructed by, for example, inserting DNA sequences from pBR322 for selection and replication in E. coli (Ampr gene and origin of replication) into the above-described yeast vectors. Exemplary of yeast shuttle vectors is YEp-CVS-ura, described in Example 1 , below.
Yeast expression vectors can include a selectable marker such as LEU2, TRP1, HIS3, and URA3 for selection and maintenance of the transformed DNA. Proteins expressed in yeast are often soluble and co-expression with chaperonins, such as Bip and protein disulfide isomerase, can improve expression levels and solubility. Additionally, proteins expressed in yeast can be directed for secretion using secretion signal peptide fusions such as the yeast mating type alpha-factor secretion signal from Saccharomyces cerevisiae and fusions with yeast cell surface proteins such as the Aga2p mating adhesion receptor or the Arxula adeninivorans glucoamylase. A protease cleavage site (e.g., the Kex-2 protease) can be engineered to remove the fused sequences from the polypeptides as they exit the secretion pathway.
Yeast naturally express the required proteins, including FPP synthase (which can produce FPP) for the mevalonate-dependent isoprenoid biosynthetic pathway. Thus, expression of the modified terpene synthases, including modified valencene synthase polypeptides provided herein, in yeast cells can result in the production of terpenes, such as valencene, from FPP. Exemplary yeast cells for the expression of terpene synthases, including modified valencene synthase polypeptides, include yeast modified to express increased levels of FPP. For example, yeast cells can be modified to produce less squalene synthase or less active squalene synthase (e.g. erg9 mutants; see e.g. U.S. Patent Nos.
6,531,303 and 6,689,593). This results in accumulation of FPP in the host cell at higher levels compared to wild-type yeast cells, which in turn can result in increased yields of terpenes (e.g. valencene). Exemplary modified yeast cells include, but are not limited to, modified Saccharomyces cerevisiae strains CALI5-1 (ura3, leu2, his3, trpl, Δ erg9::HIS3, HMG2cat/TRPl::rDNA, dppl, sue), ALX7-95 (ura3, his3, trpl, Aerg9::HIS3,
HMG2cat/TRPl::rDNA, dppl sue), ALX11-30 (ura3, trpl, erg9def25,
HMG2cat/TRPl::rDNA, dppl, sue) and those described in U.S. Patent Nos. 6,531,303, 6,689,593, and published U.S. Patent Appl. No. US20040249219,
c. Plants and plant cells
Transgenic plant cells and plants can be used for the expression of terpene synthases, including modified valencene synthase polypeptides. Expression constructs are typically transferred to plants using direct DNA transfer such as microprojectile bombardment and PEG-mediated transfer into protoplasts, and with agrobacterium-mediated transformation. Expression vectors can include promoter and enhancer sequences, transcriptional termination elements, and translational control elements. Expression vectors and transformation techniques are usually divided between dicot hosts, such as Arabidopsis and tobacco, and monocot hosts, such as corn and rice. Examples of plant promoters used for expression include the cauliflower mosaic virus promoter, the nopaline synthase promoter, the ribose bisphosphate carboxylase promoter and the ubiquitin and UBQ3 promoters. Selectable markers such as hygromycin, phosphomannose isomerase and neomycin phosphotransferase are often used to facilitate selection and maintenance of transformed cells. Transformed plant cells can be maintained in culture as cells, aggregates (callus tissue) or regenerated into whole plants. Transgenic plant cells also can include algae engineered to produce proteins (see, for example, Mayfield et al. (2003) PNAS 100:438-442). Transformed plants include, foe example, plant is selected from the genera Nicotiana, Solarium, Sorghum, Arabidopsis, Medicago (alfalfa), Gossypium (cotton), Brassica (rape). In some examples, the plant belongs to the species of Nicotiana tabacum, and is transformed with vectors that overexpress the valencene synthase and farnesyl diphosphate synthase, such as described in U.S. Pat. Pub. No. 20090123984.
d. Insects and insect cells
Insects and insect cells, particularly using a baculovirus expression system, can be used for expressing terpene synthase, including modified valencene synthase polypeptides (see, for example, Muneta et al. (2003) J. Vet. Med. Sci. 65(2) :219-23). Insect cells and insect larvae, including expression in the haemolymph, express high levels of protein and are capable of most of the post-translational modifications used by higher eukaryotes.
Baculoviruses have a restrictive host range which improves the safety and reduces regulatory concerns of eukaryotic expression. Typically, expression vectors use a promoter such as the polyhedrin promoter of baculovirus for high level expression. Commonly used baculovirus systems include baculoviruses such as Autographa californica nuclear polyhedrosis virus (AcNPV), and the Bombyx mori nuclear polyhedrosis virus (BmNPV) and an insect cell line such as Sf9 derived from Spodoptera frugiperda, Pseudaletia unipuncta (A7S) and Danaus plexippus (DpNl). For high level expression, the nucleotide sequence of the molecule to be expressed is fused immediately downstream of the polyhedrin initiation codon of the virus. Mammalian secretion signals are accurately processed in insect cells and can be used to
secrete the expressed protein into the culture medium. In addition, the cell lines Pseudaletia unipuncta (A7S) and Danaus plexippus (DpNl) produce proteins with glycosylation patterns similar to mammalian cell systems.
An alternative expression system in insect cells is the use of stably transformed cells. Cell lines such as the Schnieder 2 (S2) and Kc cells {Drosophila melanogaster) and C7 cells {Aedes albopictus) can be used for expression. The Drosophila metallothionein promoter can be used to induce high levels of expression in the presence of heavy metal induction with cadmium or copper. Expression vectors are typically maintained by the use of selectable markers such as neomycin and hygromycin.
e. Mammalian expression
Mammalian expression systems can be used to express terpene synthase, including modified valencene synthase polypeptides. Expression constructs can be transferred to mammalian cells by viral infection such as adenovirus or by direct DNA transfer such as liposomes, calcium phosphate, DEAE-dextran and by physical means such as electroporation and microinjection. Expression vectors for mammalian cells typically include an mRNA cap site, a TATA box, a translational initiation sequence (Kozak consensus sequence) and polyadenylation elements. Such vectors often include transcriptional promoter-enhancers for high level expression, for example the SV40 promoter-enhancer, the human cytomegalovirus (CMV) promoter, and the long terminal repeat of Rous sarcoma virus (RSV). These promoter-enhancers are active in many cell types. Tissue and cell-type promoters and enhancer regions also can be used for expression. Exemplary promoter/enhancer regions include, but are not limited to, those from genes such as elastase I, insulin, immunoglobulin, mouse mammary tumor virus, albumin, alpha- fetoprotein, alpha 1 -antitrypsin, beta-globin, myelin basic protein, myosin light chain-2, and gonadotropic releasing hormone gene control. Selectable markers can be used to select for and maintain cells with the expression construct. Examples of selectable marker genes include, but are not limited to, hygromycin B phosphotransferase, adenosine deaminase, xanthine-guanine phosphoribosyl transferase, aminoglycoside phosphotransferase, dihydrofolate reductase and thymidine kinase. Fusion with cell surface signaling molecules such as TCR-ζ and FcERI-y can direct expression of the proteins in an active state on the cell surface.
Many cell lines are available for mammalian expression including mouse, rat human, monkey, and chicken and hamster cells. Exemplary cell lines include, but are not limited to, BHK {i.e. BHK-21 cells), 293-F, CHO, CHO Express (CHOX; Excellgene), Balb/3T3, HeLa, MT2, mouse NS0 (non-secreting) and other myeloma cell lines, hybridoma and
heterohybridoma cell lines, lymphocytes, fibroblasts, Sp2/0, COS, NIH3T3, HEK293, 293S, 293T, 2B8, and HKB cells. Cell lines also are available adapted to serum-free media which
facilitates purification of secreted proteins from the cell culture media. One such example is the serum free EBNA-1 cell line (Pham et al, (2003) Biotechnol. Bioeng. 84:332-42).
5. Purification
Methods for purification of terpene synthases, such as valencene synthase, including modified valencene synthase polypeptides, from host cells depend on the chosen host cells and expression systems. For secreted molecules, proteins are generally purified from the culture media after removing the cells. For intracellular expression, cells can be lysed and the proteins purified from the extract. When transgenic organisms such as transgenic plants and animals are used for expression, tissues or organs can be used as starting material to make a lysed cell extract. Additionally, transgenic animal production can include the production of polypeptides in milk or eggs, which can be collected, and if necessary the proteins can be extracted and further purified using standard methods in the art.
Terpene synthases, including valencene synthase, can be purified using standard protein purification techniques known in the art including but not limited to, SDS-PAGE, size fraction and size exclusion chromatography, ammonium sulfate precipitation, chelate chromatography and ionic exchange chromatography. Expression constructs also can be engineered to add an affinity tag such as a myc epitope, GST fusion or His6 and affinity purified with myc antibody, glutathione resin, and Ni-resin, respectively, to a protein. Purity can be assessed by any method known in the art including gel electrophoresis and staining and spectrophotometric techniques.
6. Fusion Proteins
Fusion proteins containing a modified terpene synthase, including modified valencene synthase polypeptides, and one or more other polypeptides also are provided. Linkage of a terpene synthase polypeptide with another polypeptide can be effected directly or indirectly via a linker. In one example, linkage can be by chemical linkage, such as via
heterobifunctional agents or thiol linkages or other such linkages. Fusion also can be effected by recombinant means. Fusion of a terpene synthase, such as a valencene synthase polypeptide, to another polypeptide can be to the N- or C- terminus of the valencene synthase polypeptide.
A fusion protein can be produced by standard recombinant techniques. For example,
DNA fragments coding for the different polypeptide sequences can be ligated together in- frame in accordance with conventional techniques, e.g. , by employing blunt-ended or stagger- ended termini for ligation, restriction enzyme digestion to provide for appropriate termini, filling-in of cohesive ends as appropriate, alkaline phosphatase treatment to avoid undesirable joining, and enzymatic ligation. In another embodiment, the fusion gene can be synthesized by conventional techniques including automated DNA synthesizers. Alternatively, PCR
amplification of gene fragments can be carried out using anchor primers that give rise to complementary overhangs between two consecutive gene fragments that can subsequently be annealed and reamplified to generate a chimeric gene sequence (see, e.g., Ausubel et al. (eds.) Current Protocols in Molecular Biology, John Wiley & Sons, 1992). Moreover, many expression vectors are commercially available that already encode a fusion moiety (e.g., a GST polypeptide). A valencene synthase polypeptide-encoding nucleic acid can be cloned into such an expression vector such that the fusion moiety is linked in- frame to the valencene synthase protein.
F. METHODS OF USING AND ASSESSING TERPENE SYNTHASES
The modified terpene synthases provided herein can be used to, and assessed for their ability to, produce terpenes, including monoterpenes, diterpenes and sesquiterpenes, from any suitable acyclic pyrophosphate terpene precursor, including, but not limited to, farnesyl diphosphate (FPP), geranyl diphosphate (GPP) or geranyl-geranyl diphosphate (GGPP). Typically, the modified valencene synthase polypeptides provided herein catalyze the formation of valencene from FPP. Any method known to one of skill in the art can be used to produce terpenes, including valencene, with the modified terpene synthases, such as the modified valencene synthases, provided herein. The ability of the modified synthases provided herein to catalyze the formation of valencene or other terpenes from FPP or other substrates can be assessed using these methods. In some examples, the amount of terpene, such as valencene, produced from FPP or another substrate using the modified synthases is compared to the amount of terpene, such as valencene, produced from the same substrate using wild-type or unmodified synthase.
Other activities and properties of the modified terpene synthases, such as the modified valencene synthase polypeptides, also can be assessed using methods and assays well known in the art. In addition to assessing the activity of the modified synthases and their ability to catalyze the formation of terpenes, the kinetics of the reaction, modified regiochemistry or stereochemistry, altered substrate utilization and/or altered product distribution (i.e. altered amount of the different terpenes produced from FPP or another substrate) compared to the wild-type or unmodified terpene synthase can be assessed using methods well known in the art. For example, the type and amount of various terpenes produced from FPP, GPP or GGPP by the modified terpene synthase polypeptides can be assessed by gas chromatography methods (e.g. GC-MS), such as those described below and in Example 5. In some examples, terpenes that can be produced by the modified valencene synthase polypeptides from FPP include, but are not limited to, valencene, germacrene A, β- elemene, β-selinene, x-selinene and 7-epz-a-selinene.
Provided below are methods for the production of valencene and nootkatone from FPP using the modified valencene synthases provided herein. Such methods can be adapted by one of skill in the art to produce and assess other terpenes from FPP, GPP and/or GGPP by other modified terpene synthases provided herein.
1. Production of valencene
The modified valencene synthase polypeptides can be used to catalyze the formation of valencene from an acyclic pyrophosphate terpene precursor, such as FPP. In some examples, the modified valencene synthases provided herein are expressed in cells that produce or overproduce FPP, such that valencene is produced by the pathway described above. In other examples, the modified valencene synthases provided herein are expressed and purified from any suitable host cell, such as described in Section D. The purified synthases are then combined in vitro with a FPP to produce valencene.
In some examples, the modified valencene synthase provided herein is overexpressed and purified as described in Section D above. The modified valencene synthase is then incubated with the substrate farnesyl diphosphate and valencene is produced. The pH of the solution containing FPP and valencene synthase can impact the amount of valencene produced (see e.g. U.S. Pat. Pub. No. 20100216186). An organic solvent is added to partition the valencene into the organic phase for analysis. Production of valencene and quantification of the amount of product are then determined using any method provided herein, such as gas chromatography {e.g. GC-MS) using an internal standard. Alternatively, the modified valencene synthase is expressed in host cells that also produce FPP, resulting in production of valencene. The valencene can then be extracted from the cell culture medium with an organic solvent and subsequently isolated and purified by any known method, such as column chromatography or HPLC, and the amount and purity of the recovered valencene are assessed. In some examples, the valencene is converted by oxidation to nootkatone either before or after purification.
a. Exemplary cells for valencene production
Valencene can be produced by expressing a modified valencene synthase polypeptide provided herein in a cell line that produces FPP as part of the mevalonate-dependent isoprenoid biosynthetic pathway {e.g. fungi, including yeast cells and animal cells) or the mevalonate -independent isoprenoid biosynthetic pathway {e.g. bacteria and higher plants). In particular examples, valencene is produced by expressing a modified valencene synthase polypeptide provided herein in a cell line that has been modified to overproduce FPP.
Exemplary of such cells are modified yeast cells. For example, yeast cells that have been modified to produce less squalene synthase or less active squalene synthase {e.g. erg9 mutants; see e.g. U.S. Patent Nos. 6,531,303 and 6,689,593) are useful in the methods
provided herein to produce valencene. Reduced squalene synthase activity results in accumulation of FPP in the host cell at higher levels compared to wild-type yeast cells, which in turn can result in increased yields of valencene production. Exemplary modified yeast cells include, but are not limited to, modified Saccharomyces cerevisiae strains CALI5-1 (ura3, leu2, his3, trpl, Aerg9::HIS3, HMG2cat/TRPl::rDNA, dppl), ALX7-95 (ura3, his3, trpl, Aerg9::HIS3, HMG2cat/TRPl::rDNA, dppl, sue), ALX11-30 (ura3, trpl, erg9def25, HMG2cat/TRPl::rDNA, dppl, sue) and those described in U.S. Patent Nos. 6,531,303 and 6,689,593 and published U.S. Patent Appl. No. US20040249219.
Saccharomyces cerevisiae strain CALI5-1 is a derivative of SW23B#74 (described in U.S. Patent Nos. 6,531,303 and 6,689,593, and Takahashi et al. (2007) (Biotechnol Bioeng. 97(1): 170-181), which itself is derived from wild-type strain ATCC 28383 (MATa).
CALI5-1 was generated to have a decreased activity of the Dppl phosphatase (see e.g. U.S. Published Appl. No. US20040249219). Saccharomyces cerevisiae strain CALI5-1 contains, among other mutations, an erg9 mutation (the Aerg9::HIS3 allele) as well as a mutation supporting aerobic sterol uptake enhancement {sue). It also contains approximately 8 copies of the truncated HMG2 gene. The truncated form of HMG2 is driven by the GPD promoter and is therefore no longer under tight regulation, allowing for an increase in carbon flow to FPP. It also contains a deletion in the gene encoding diacylglycerol pyrophosphate (DGPP) phosphatase enzyme {dppl), which limits dephosphorylation of FPP.
ALX7-95 and ALX11-30.1 are derivatives of CALI5-1. ALX7-95 was derived from
CALI5-1 by correcting the Aleu2 deficiency of CALI5-1 with a functional leu gene so that leucine is not required to be supplemented to the media (see e.g. US2010/0151519). ALX11- 30 was constructed from CAL5-1 in several steps, described in Example 2, below,
b. Culture of cells for valencene production
In exemplary methods, a modified valencene synthase provided herein is expressed in a host cell line that has been modified to overexpress farnesyl diphosphate whereby upon expression of the modified valencene synthase, farnesyl diphosphate is converted to valencene. The host cell is cultured using any suitable method well known in the art. In some examples, such as for high throughput screening of cell expressing various modified valencene synthases, the cells expressing the modified valencene synthase are cultured in individual wells of a 96-well plate (see e.g. Example 3C, below). In other examples where the host cell is yeast, the cell expressing the modified valencene synthase polypeptides and FPP is cultured using fermentation methods such as those described in the Examples below.
A variety of fermentation methodologies can be utilized for the production of valencene from yeast cells expressing the modified valencene synthase polypeptides provided herein. For example, large scale production can be effected by either batch or continuous
fermentation. A classical batch fermentation is a closed system where the composition of the medium is set at the beginning of the fermentation and not subject to artificial alterations during the fermentation. Thus, at the beginning of the fermentation the medium is inoculated with the desired microorganism or microorganisms and fermentation is permitted to occur without further addition of nutrients. Typically, the concentration of the carbon source in a batch fermentation is limited, and factors such as pH and oxygen concentration are controlled. In batch systems the metabolite and biomass compositions of the system change constantly up to the time the fermentation is stopped. Within batch cultures cells typically modulate through a static lag phase to a high growth log phase and finally to a stationary phase where growth rate is diminished or halted. If untreated, cells in the stationary phase will eventually die.
A variation on the standard batch system is the Fed-Batch system, which is similar to a typical batch system with the exception that nutrients are added as the fermentation progresses. Fed-Batch systems are useful when catabolite repression tends to inhibit the metabolism of the cells and where it is desirable to have limited amounts of substrate in the medium. Also, the ability to feed nutrients will often result in higher cell densities in Fed- Batch fermentation processes compared to Batch fermentation processes. Factors such as pH, dissolved oxygen, nutrient concentrations, and the partial pressure of waste gases such as CO are generally measured and controlled in Fed-Batch fermentations.
Production of the valencene also can be accomplished with continuous fermentation.
Continuous fermentation is an open system where a defined fermentation medium is added continuously to a bioreactor and an equal amount of conditioned medium is removed simultaneously for processing. This system generally maintains the cultures at a constant high density where cells are primarily in their log phase of growth. Continuous fermentation allows for modulation of any number of factors that affect cell growth or end product concentration. For example, one method will maintain a limiting nutrient such as the carbon source or nitrogen level at a fixed rate and allow all other parameters to moderate. In other systems a number of factors affecting growth can be altered continuously while the cell concentration, measured by the medium turbidity, is kept constant. Continuous systems aim to maintain steady state growth conditions and thus the cell loss due to the medium removal must be balanced against the cell growth rate in the fermentation. Methods of modulating nutrients and growth factors for continuous fermentation processes as well as techniques for maximizing the rate of product formation are well known in the art.
Following cell culture, the cell culture medium can then be harvested to obtain the produced valencene.
In one exemplary method, the host cells expressing the modified valencene synthase polypeptides (e.g. Saccharomyces cerevisiae strain CALI5-1, ALX7-95 or ALX11-30) are grown in 3L fermentation tank at 28 °C, pH 4.5 for approximately 132 hours, maintaining glucose at between 0 and 1 g/L (see Example 2). Following fermentation, sodium sulfate is added to a final concentration of 10-15. Soybean oil also is added and agitated, and the oil containing the valencene (and other terpenes) is recovered by centrifugation.
c. Isolation and assessment of valencene
The valencene produced using the methods above with the modified valencene synthase polypeptides provided herein can be isolated and assessed by any method known in the art. In one example, the cell culture medium is extracted with an organic solvent to partition valencene and any other terpene produced, into the organic layer. Valencene production can be assessed and/or the valencene isolated from other products using any method known in the art, such as, for example, gas chromatography. For example, the organic layer can be analyzed by gas chromatography using cedrene and hexadecane as internal standards. This method is exemplified in Example 2 below.
The quantity of valencene produced can be determined by any known standard chromatographic technique useful for separating and analyzing organic compounds. For example, valencene production can be assayed by any known chromatographic technique useful for the detection and quantification of hydrocarbons, such as valencene and other terpenes, including, but not limited to, gas chromatography mass spectrometry (GC-MS), gas chromatography using a flame ionization detector (GC-FID), capillary GC-MS, high performance liquid chromatography (HPLC) and column chromatography. Typically, these techniques are carried out in the presence of known internal standards, for example, cedrene or hexadecane, which are used to quantify the amount of the terpene produced. For example, terpenes, including sesquiterpenes, such as valencene, can be identified by comparison of retention times and mass spectra to those of authentic standards in gas chromatography with mass spectrometry detection. Typical standards include, but are not limited to, cedrene and hexadecane. In other examples, quantification can be achieved by gas chromatography with flame ionization detection based upon calibration curves with known amounts of authentic standards and normalization to the peak area of an internal standard. These chromatographic techniques allow for the identification of any terpene present in the organic layer, including, for example, other terpenes produced by the modified valencene synthase, including, for example, germacrene A, β-selinene, x-selinene and 7-epz-a-selinene (see e.g. Example 8).
In particular examples, the amount of valencene produced by the modified valencene synthase polypeptides provided herein from FPP is at least or about 110%, 120%, 130%,
140%, 150%, 160%, 170%, 180%, 190%, 200%, 250%, 300%, 350%, 400%, 500%, 600%,
700%, 800%, 900%, 1000% or more of the valencene produced from FPP by the wild-type valencene synthase polypeptide set forth in SEQ ID NO:2. Typically, the amount of valencene produced using the methods described above and exemplified in the Examples below is at least or is about 0.1 g/L, 0.2 g/L, 0.3 g/L, 0.4 g/L, 0.5 g/L, 0.6 g/L, 0.7 g/L, 0.8 g/L, 0.9 g/L 1.0 g/L, 1.1 g/L, 1.2 g/L, 1.3 g/L, 1.4 g/L, 1.5 g/L, 2.0 g/L, 2.5 g/L, 3.0 g/L, 3.5 g/L, 4.0 g/L, 4.5 g/L or 5.0 g/L or more.
In some examples, kinetics of valencene production can be determined by synthase assays in which radioactive isoprenoid substrates, such as 3H FPP or 14C FPP, are utilized with varying concentrations of synthase. The products are extracted into an organic layer and radioactivity is measured using a liquid scintillation counter. Kinetic constants are determined from direct fits of the Michaelis-Menton equation to the data.
2. Production of Nootkatone
The modified valencene synthases provided herein produce valencene, which can then be oxidized to nootkatone. Nootkatone, which is the dominant grapefruit aroma, is an oxidized product of valencene. Valencene can undergo regioselective hydroxylation to form 2-hydroxy valencene, which is further oxidized to form nootkatone. Oxidation of valencene can be carried out through chemical or biosynthetic means (see e.g. U.S. Patent No.
5,847,226, Eur. Pat. No. EPl 083233; Girhard et al, (2009) Microb. Cell Fact. 8:36; Fraatz et al, (2009) Appl Microbiol Biotechnol. 83(1):35-41 ; Furusawa et al. (2005) Chem Pharm. Bull. 53: 1513-1514; Salvador et al, (2002) Green Chemistry, 4, 352-356). Biochemical oxidation can be effected by a laccase, hydroxylase, or other oxidative enzyme. In some examples, valencene is converted to nootkatone using chromium trioxide or a silica phosphonate -immobilized chromium (III) catalyst {see e.g. Example 7). Nootkatone formation can be confirmed and/or quantified by any of the chromatographic techniques described herein.
G. EXAMPLES
The following examples are included for illustrative purposes only and are not intended to limit the scope of the invention.
Example 1
Cloning of wild-type valencene synthase
The valencene synthase gene (CVS) from Citrus sinensis cv. Valencia (Valencia orange) was cloned from RNA isolated from the juice vesicles of freshly harvested Valencia orange using the procedure previously described in Example 1 of U.S. Patent No. 7,442,785.
First, Yep-GW-URA (Takahashi et al, (2007) Biotechnol Bioeng. 97(1): 170-181) was generated by inserting a gateway cloning cassette (RfB) with the form attRl -CmR-<x<iB gene-flftR2 (Hartley et al., (2000) Genome Res. 10: 1788-1795) into the Smal restriction site of
YEp352-URA (SEQ ID NO:692, Bio-Technical Resources), which contains an URA3 selectable marker, an ADH1 promoter and an ADH1 terminator flanking, two BamHI sites (one 5' to the ADH1 promoter and the other 3' to the ADH terminator), a 2-micron ori, an ampicillin resistance gene and a colEl origin of replication. The resuling vector was designated YEp-CVS-URA.
The CVS gene (set forth in SEQ ID NO: l, and encoding amino acid sequence is set forth in SEQ ID NO:2) was then amplified from RNA isolated from the juice vesicles of freshly harvested Valencia orange to contain restriction sites for subcloning into the yeast shuttle expression vector Yep-GW-URA. Following digestion of Yep-GW-URA with EcoRI and Xbal, the amplified product was cloned into the yeast shuttle expression vector YEp-GW- URA.
The YEp-CVS-ura vector was maintained in S. cerevisiae by selecting on SD minimal medium lacking uracil at 28 °C. The vector also was maintained in Escherichia coli by selecting for resistance to ampicillin on LB medium containing 100 μg/mL ampicillin.
Example 2
Production of valencene
To screen for production of valencene, the Saccharomyces cerevisiae yeast cell strains CALI5-1 (ura3, leu2, his3, trpl, Aerg9::HIS3, HMG2cat/TRPl::rDNA, dppl, sue), ALX7-95 (ura3, his3, trpl, Aerg9::HIS3, HMG2cat/TRPl::rDNA, dppl, sue) or ALX11-30 (ura3, trpl, erg9de/25, HMG2cat/TRPl::rDNA, dppl, sue) were used.
The CALI5-1 strain (see U.S. published Appl. No. US20040249219; U.S. Patent No. 6,531,303 and 6,689,593) has & Aleu2 deletion, which required the introduction of leucine into its media. ALX7-95 was derived from CALI5-1 by correcting the Aleu2 deficiency of CALI5-1 with a functional LEU2 gene (see U.S. published Appl. No.
US2010/0151519).
ALX11-30 was constructed from CALI5-1 in several steps from ALX7-175.1 as described in US2010/0151519. Briefly, ALX7-95 HPS was obtained by transforming a plasmid containing the Hyoscyamus muticus premnaspirodiene synthase (HPS) into ALX7-95 strain. The YEp-HPS plasmid was obtained by cloning the gene for HPS into Yep-GW-URA to give YEp-HPS-ura (YEp-HPS). Then, an error prone PCR reaction of the ERG9 gene was performed, and the resulting DNA was transformed into ALX7-95 harboring YEpHPS.
Transformants were plated on YP medium lacking ergosterol and screened for
premnaspirodiene production. Those that produced high levels of premnaspirodiene were saved. One strain, ALX7-168.25 [ura3, trpl, his3, erg9def25, HMG2cat/TRPl::rDNA, dppl, sue, YEpHPS] was transformed with a PCR fragment of the complete HIS3 gene to create a functional HIS3 gene. Transformants were isolated that were able to grow in the absence of
histidine in the medium. From this transformation, ALX7- 175.1 was isolated [ura3, trpl, erg9def25, HMG2cat/TRPl::rDNA, dppl, sue YEpHPS] . Finally, the plasmid YEpHPS was removed by growing ALX7- 175.1 several generations in YPD (10 g/L yeast extract, 20 g/L peptone, 20 g/L glucose) and plating cells on YPD plates. Colonies were identified that were unable to grow on SD medium without uracil (0.67 Bacto yeast nitrogen base without amino acids, 2% glucose, 0.14% yeast synthetic drop-out medium without uracil). This strain was designated ALXl 1-30.
For screening for production of valencene by valencene synthase or mutants, the YEp-CVS-ura plasmid, containing the CVS gene or modified versions of the CVS gene, was transformed into the above yeast strains using the lithium acetate yeast transformation kit (Sigma- Aldrich). The ALX7-95 and ALXl 1-30 strains generally produced more valencene than the CALI5-1 strain. CALI5-1 was used for initial screening in vials (as described in Example 3) and production in fermenters. Subsequently, ALX7-95 or ALXl 1-30 were used for screening in vials and fermenters. Typically, ALX7-95 was used for screening in vials and ALXl 1-30 was used for fermenters.
Transformants were selected on SDE-ura medium (0.67 % Bacto yeast nitrogen base without amino acids, 2 % glucose, 0.14 % yeast synthetic drop-out medium supplement without uracil, and 40 mg/L ergosterol as needed). Colonies were picked and screened for valencene production using the microculture assay described below.
Production of valencene was performed in a 3-L fermentation tank (New Brunswick
Bioflow 110). One liter of fermentation medium was prepared and autoclaved in the fermentation tank (20 g (NH4)2S04, 20 g KH2P04, 1 g NaCl, MgS04'7H20, 4 g Solulys corn steep solids (Roquette)). The following components were then added: 20 ml mineral solution (0.028 % FeS04 «7H20, 0.029 % ZnS04 «7H20, 0.008 % CuS04 «5H20, 0.024 %
Na2Mo04 «2H20, 0.024 % CoCl2 «6H20, 0.017 % MnS04 «H20, 1 mL HC1); 10 mL 50 % glucose; 30 mL vitamin solution (0.001 % biotin; 0.012 % calcium pantothenate, 0.06 % inositol, 0.012 % pyridoxine-HCl, 0.012 % thiamine-HCl); 10 mL 10 % CaCl2, and 20 mL autoclaved soybean oil (purchased from local groceries). For sterol-requiring strains, including CALI5-1 and ALX7-95, 50 mg/L cholesterol or 40 mg/L ergosterol was included in the medium.
The seed culture for inoculating the fermentation medium was prepared by inoculating 50 mL of SDE-ura-trp medium (see Example 3.C.2.) with CALI5-1, ALX7-95 or ALXl 1-30 containing the YEp-CVS-ura plasmid. This culture was grown at 28 °C until early stationary phase (24-48 hr). One mL of this culture was inoculated into 500 mL of SDE-ura- trp medium and grown for 24 hr at 28 °C. A 50-mL aliquot (5 % inoculum) was used to inoculate the medium in the fermentation tank.
The fermentor was maintained at 28 °C. The air flow was 1 wm and the d02 was maintained above 30 % by adjusting the agitation. The pH was maintained at 4.5 using phosphoric acid and NaOH or NH4OH.
When the glucose concentration fell below 1 g/L, a feeding regimen was initiated such that the glucose in the fermentor was kept between 0 and 1 g/L. The glucose feed consisted of 60 % glucose (w/v).
At the end of the fermentation, generally about 132 hours after inoculation, sodium sulfate was added to 10-15 % final concentration as was an additional 50 mL soybean oil, and the contents of the fermentor were agitated for one hour. After allowing the fermentation vessel contents to settle, the oil was recovered by centrifugation and the valencene content in the oil was determined.
To assay valencene, 3 mL of suspension was placed in a vial to which 3 mL of acetone containing 20 mg/L cedrene was added. After vortexing, the mixture was extracted with 6 mL hexane containing 10 mg/L hexadecane followed by additional vortexing. The organic phase was transferred to a second vial for analysis by gas chromatography using cedrene and hexadecane as internal standards for extraction efficiency and injection, respectively. The CALI5-1, ALX7-95 or ALX11-30 S. cerevisiae containing Yep-CVS-ura, and expressing valencene synthase, was found to produce valencene.
Example 3
Generation of valencene synthase mutants
Valencene synthase mutants were generated by error-prone PCR (epPCR) of the valencene synthase gene. The mutants were then screened for their ability to produce valencene using a high throughput screening assay.
A. Generation of valencene synthase mutants by epPCR
For error-prone PCR of the CVS gene, either the whole YEp-CVS-ura plasmid or a 3 kb BamHI DNA fragment containing the CVS gene, excised from plasmid and gel-purified, was used. DNA equivalent to between 270 to 360 ng of the CVS gene was used as template for error-prone PCR using the GeneMorph II random mutagenesis kit (Stratagene). PCR conditions were 30 cycles of 96 °C for 1 min, 55 °C annealing for 1 min, 72 °C extension for 2 min using the forward primer CVSpcrF 1 (5 ' -CATTCACGCACACTACTCTCT-3 ' , SEQ ID NO:344) and the reverse primer CVSpcrRl (5 ' -GCCGACAACCTTGATTGGAG-3 ' , SEQ ID NO:345). Digestion of the PCR reaction product using Eco RI and Xbal provided a library of mutagenized CVS genes, which were used to replace the wild type CVS gene of YEp-CVS- ura using the same restriction endonucleases. A plasmid library was prepared by passaging the DNA through E. coli. This DNA library was then used to transform yeast strains CALI5- 1 or ALX7-95. Yeast transformants were screened as described in Example 2. Those
transformants that produced elevated levels of valencene (>110 %), as compared to transformants containing the wild type gene (110 % of wildtype levels, i.e., a 10 % increase versus wildtype), were retested in vial, shake flask, and fermentation cultures to confirm a higher level production of valencene. Plasmid DNA was isolated from strains confirmed to produce higher levels of valencene and was sequenced to determine amino acid changes in variant valencene synthase enzymes.
Table 6 sets forth the valencene synthase mutants that were produced using error prone PCR. The table includes the nucleotide mutations and the resulting amino acid mutations (if any), and the percentage increase in production of valencene compared to wild- type valencene synthase (assessed using transformants cultured in a shaker flask). When cultured in a shaker flask, clone V8 produced 287 % more valencene than wildtype CVS.
Additional valencene synthase mutants, set forth in Table 7, were then produced using a variety of methods. In the first method, the amino acid mutations in mutants VI and V2 were combined using standard recombinant DNA and PCR methods to produce a variant designated V9. Similarly, the variant VI 0 was generated by recombination of mutations in VI, V2, and V3. Neither V9 nor V10 contained the S473Y mutation found in VI, as this mutation was eliminated during the restriction digest used to combine VI with V2 or V3. The plasmid DNA from variant V9 was then subjected to error prone PCR using the methods
described above to produce the variants V12, V13, V14 and V15. The plasmid DNA from variant V12 was then subjected to saturation mutagenesis at position 429 to produce the variant VI 6, and the plasmid DNA from variant VI 6 was subsequently subjected to saturation mutagenesis at position 221 to produce the variant VI 7. Table 7 sets forth the valencene synthase mutants with combined mutations, and includes the nucleotide mutations and the resulting amino acid mutations (if any), and the percentage increase in production of valencene compared to wild-type valencene synthase, or compared to the VI variant for V9 and V10 (as assessed using transformants cultured in a shaker flask), or compared to V12 for variant VI 6, or compared to VI 6 for variant VI 7. When cultured in a shaker flask, clone VI 0 produced 88 % more valencene than clone VI .
Table 7. Valencene Synthase Variants
SEO ID NO: Valencene %
Nucleotide Amino acid increase vs. parent iviutant
changes changes in shake flask nt aa culture
V9 G147A silent 139 14 51
G558T silent (vs. VI)
A640G N214D
C1214G T405R
V10 G147A silent 140 15 88
G558T silent (vs. VI)
A640G N214D
A966G silent
C1034T A345V
C1214G T405R
C1218T silent
G1587C silent
T1608G D536E
T1617A silent
V12 G147A silent 141 16 67
G178A V60I (vs. V9)
G558T silent
T588C silent
A640G N214D
G1033A A345T
C1214G T405R
V13 G147A silent 142 17 21
G558T silent (vs. V9)
A640G N214D
C1214G T405R
A1286G N429S
V14 G147A silent 143 18 48
G558T silent (vs. V9)
A640G N214D
G726A silent
C874A Q292K
C1214G T405R
V15 G126A Silent 144 19 17
G147A silent (vs. V9)
T179G V60G
C507T silent
G558T silent
A640G N214D
C1214G T405R
V16 G147A silent 145 20 30
G178A V60I (vs. VI 2)
G558T silent
T588C silent
A640G N214D
T808C Silent
G1033A A345T
C1214G T405R
A1285G N429G
A1286G "
V17 G147A silent 146 21 21
G178A V60I (vs. VI 6)
G558T silent
T588C silent
T635G M212R
A640G N214D
T661G Y221V
A662T "
T808C silent
G1033A A345T
C1214G T405R
A1285G N429G
A1286G "
Table 8 below sets forth the fermentation titer in g/L for wildtype CVS and several
CVS variants identified above for fermentation in 3 L fermentors. For each experiment, the variants were expressed in CALI5-1 and fermentation conditions were identical.
Accordingly, the differences observed in valencene fermentation yields within an individual experiment can be attributed to differences in the valencene synthase genes being expressed. As is shown in Table 8, all CVS variants produced an increased amount of valencene as compared to wildtype CVS.
Table i. Comparison of valencene production
Expt CVS Amino Acid Changes Fermentation Variant Titer, g/L
1 wt 0.079 VI N214D, S473Y 0.097 V2 T405R 0.068 V9 N214D, T405R 0.200
2 wt 0.142 VI N214D, S473Y 0.384 V9 N214D, T405R 0.518
3 wt 0.212 VI N214D, S473Y 0.416 V9 N214D, T405R 0.517
4 wt 0.187 V9 N214D, T405R 0.779 V10 N214D, A345V, T405R, D536E 0.644 V12 V60I, N214D, A345T, T405R 0.858
5 V9 N214D, T405R 0.741 V12 V60I, N214D, A345T, T405R 0.904
6 V12 V60I, N214D, A345T, T405R 0.981
I I V17 I V60I, M212 , N214D, Y221V, A345T, T405R, N429G | 1.59
The increased valencene production by yeast transformants containing the mutant valencene synthase genes indicated that mutations at amino acid positions 60, 97, 209, 212, 214, 221, 238, 292, 333, 345, 369, 405, 429, 473 and 536, alone or in combination, are either tolerated or result in improved valencene production. Some of these positions were identified multiple times in independent variants. For example, the valine at position 60 of the wild type enzyme has been substituted with isoleucine in variant V12 or glycine in variant V15; the alanine at position 345 has been substituted with either threonine in variant V12 or valine in variant V3; and tyrosine at position 221 has been substituted with either cysteine in variant V4 or valine in variant VI 7. Positions 60, 97, 209, 212, 214, 221, and 238 are situated in the non-catalytic domain of the enzyme with homology to glycosyl hydrolases.
B. Generation of valencene synthase mutants with combinations of mutations
Amino acid alterations identified in Example 3. A, above, and in similar error prone PCR experiments as described above, were combined in a single enzyme. Also included were mutations at positions 24, 38, 58, 88, 125, 173 and 252 of the valencene synthase set forth in SEQ ID NO:2, which, according to a model of the three dimensional structure of valencene synthase, are on the surface of the protein. Two variant enzymes were synthesized, each with 29 amino acid changes. Variants CVS VI 8 (SEQ ID NO:3) and CVS VI 9 (SEQ ID NO:4) each contained 22 mutations that were previously identified by error-prone PCR as having beneficial or neutral effects on enzyme activity, and also seven mutations in surface residues. VI 8 contained mutations of each of the surface residues to alanine, and VI 9 contained mutation of each of the surface residues to glutamine or asparagine. Table 9 sets forth the amino acid residues at the targeted positions. Table 10 sets forth the amino acid and nucleotide changes in CVS VI 9 as compared to wildtype CVS. Table 11 sets forth the silent nucleotide changes in codon-optimized CVS VI 9 (SEQ ID NO: 129) as compared to wildtype CVS (SEQ ID NO: 1).
Codon-optimized CVS V18 (SEQ ID NO:128) and CVS V19 (SEQ ID NO:129) genes were cloned into the YEp-CVS-ura plasmid and transformed into ALX11-30 S.
cerevisiae. Valencene production by each of the transformants was assessed following fermentation, as described in Example 2 above. Each of the transformants produced valencene at levels comparable to the variant V12. While valencene production by variant VI 2 was conducted in CALI5-1 cells, the production in ALX7-95 cells is expected to be similar as the only difference in the two strains is in the presence of a leu marker. Each of the transformants also produced valencene with approximately 10-fold greater titer than ALX7- 95 S. cerevisiae expressing the wildtype valencene synthase. Typically, production of valencene by mutants is 10 to 20 times the production level of wildtype CVS.
Table 10. CVS V19 amino acid mutations and corresponding nucleotide changes versus wildtype CVS
Nucleotide Changes vs
Mutant Amino Acid Mutations
wildtype CVS
K24Q AAA→CAA
Q38N CAA→AAT
K58Q AAG→CAA
V60I GTT→ATT
K88Q AAA→CAA
Y93H TAT→CAT
N97D AAT→GAT
R98K AGA→AAA
K125Q AAG→CAA
K173Q AAG→CAA
V19
K184R AAG→AGA
F209I TTT→ATT
M212R ATG→AGA
N214D AAT→GAT
H219D CAT→GAT
Y221V TAC→GTT
E238D GAG→GAT
K252Q AAA→CAA
Q292K CAA→AAA
Q321A CAA→GCT
E333D GAA→GAT
A345T GCT→ACA
N369I AAT→ATT
S377Y TCT→TAC
T405R ACA→AGA
N429G AAT→GGT
A436S GCA→TCT
T501P ACC→CCA
D536E GAT→GAA
Table 11. Synonymous Nucleotide changes in codon optimized CVS V19
Nucleotide Changes vs
Mutant Mutations
wildtype CVS
S2S TCG→TCA
G4G GGA→GGT
T6T ACA→ACT
R8R CGT→AGA
P9P CCT→CCA
AHA GCA→GCT
F13F TTC→TTT
P15P CCT→CCA
S16S AGT→TCT
L17L TTA→TTG
N20N AAC→AAT
F22F TTC→TTT
L23L CTC→TTG
A26A GCT→GCA
S27S TCT→TCA
F29F TTC→TTT
T31T ACA→ACT
T35T ACT→ AC A
A36A GCA→GCT
T37T ACT→ AC A
R40R CGA→AGA
H41H CAC→CAT
V19 E42E GAG→GAA
A43A GCA→GCT
L44L CTG→TTG
K45K AAA→AAG
E47E GAG→GAA
V48V GTA→GTT
R49R AGG→AGA
1521 ATA→ ATT
T53T ACA→ACT
A55A GCT→GCA
P59P CCT→CCA
Q61Q CAG→CAA
K62K AAG→AAA
L63L TTA→TTG
R64R CGC→AGA
V69V GTA→GTT
R71R CGC→AGA
L72L CTG→TTG
G73G GGG→GGT
V74V GTG→GTT
Y76Y TAT→TAC
H77H CAC→CAT
E79E GAG→GAA
1821 A85A
1861
L89L
1921 D95D
S96S L101L H102H T103T S105S L106L F108F R109R L111L R112R QH3Q G115G
11161
S119S
VI 22V
F123F
E124E
F126F
K127K
E130E
K134K
S135S
S136S
II 381 N139N G143G L145L S146S Y148Y E149E A150A A151A Y152Y A154A R156R G157G
11601 L161L A164A A166A F167F T169T H171H L172L V176V A177A Q178Q VI 81 V T182T P183P L185L A186A Q188Q
11891 N190N L193L Y194Y R195R P196P L197L R198R T200T L201L L204L E205E A206A R207R Y208Y S211S 12131 S215S T216T S217S L220L N222N K223K L225L L226L F228F A229A L231L F233F N234N 12351 L237L L239L H240H K241K E242E L244L N245N L247L T248T K249K L254L D255D F256F T258T L260L P261P A263A D265D L267L V268V E269E L270L Y271 Y L275L G276G T277T Y278Y F279F
E280E P281P Y283Y A284A G286G K288K I289I T291T L293L N294N I296I L297L I299I I300I T303T Y304Y A306A Y307Y T309T L310L L313L S314S L315L F316F T317T A319 A R322R N324N E326E A327A V328V D329D L331L Y334Y K336K L337L I338I R340R T341T L342L L343L F346F N347N I349I E350E E351E A354A K355K G357G S359S H360H C361C R363R Y364Y A365A E367E E368E K371K V372V
G374G A375A Y376Y A380A K381K F383F S384S Y387Y V388V P389P T390T E392E E393E Y394Y P396P A398A L399L T400T S401S C402C F406F V407V I408I T409T S411S F412F L413L G414G F418F A419A T420T K421K E422E V423V F424F 1427 I S428S N430N P431P K432K V434V A437A S438S I440I C441C L443L D445D D446D G449G H450H E451E E453E Q454Q K455K G457G H458H A460A S461S A462A
C465C
Y466Y
T467T
K468K
Q469Q
V472V
S473S
A477A
14781
K479K
F481F
E482E
E484E
A486A
N487N
A488A
K490K
I492I
N493N
E494E
E495E
L496L
K499K
V502V
A504A
R505R
L507L
L508L
G509G
T510T
L512L
L514L
R516R
A517A
15181
15211
Y522Y
E524E
D525D
G527G
Y528Y
T529T
Y532Y
L533L
K535K
I538I
A539A
V541 V
L542L
G543G
D544D
H545H
C. Saturation mutagenesis of CVS V18 and V19
The CVS VI 8 gene was subjected to saturation mutagenesis of various residues of the N-terminal domain and a portion of the C-terminal catalytic domain (amino acids 267-462) to identify amino acids that were amenable to alteration, providing either positive or neutral
- -
effects on activity, as measured by productivity of valencene. Following mutagenesis, plasmid DNA containing the mutant genes was transformed into Saccharomyces cerevisiae strain ALX7-95. Transformant colonies were then screened for valencene production. Plasmid DNA from transformants that exhibited valencene production of greater than 1 10 % than the valencene production from transformants containing the CVS VI 8 gene were then sequenced.
1. Mutagenesis
Overlapping PCR was used to generate mutations at various positions of the gene. For each position to be mutated, a pair of complementary mutagenic primers was synthesized, each containing 15 base pairs of homology on each side of the amino acid position to be mutated and random nucleotides at the codon targeted for mutagenesis.
Mutagenic primers for the desired codon change were used in PCR reactions with either the upstream primer 1 1-157.7 (5 '-AAGGTACCATTTAAAAAAATGTC-3 ' ; SEQ ID NO.-297) or the downstream primer 1 1 -157.8 (5 '-TTTCTCTAG ATTAAAATGGAACA-3 ' ; SEQ ID NO:298) to generate two PCR products, each containing random nucleotides at the desired codon. The two PCR fragments were joined using an overlapping PCR reaction, in which the two fragments were mixed in equal molar ratios and subjected to 5 cycles of PCR amplification without primers. PCR conditions were one cycle at 96 °C for 2 minutes and then 5 cycles of 94 °C for 30 seconds, 38 °C for 30 seconds, and 72 °C for 2 minutes. Twenty to thirty additional cycles were then performed under the same PCR conditions in the presence of primers 1 1-157.7 and 1 1-157.8.
The PCR reactions were ethanol precipitated by mixing 0.1 volumes 3 M sodium acetate pH 4.8 and two volumes 100 % ethanol and spinning in a micro fuge for 15 minutes. The resulting DNA pellet was washed with 70 % ethanol. The DNA was dissolved in 16 μΐ, milli Q purified water before being combined with 1 ih Kpn\, 1 iLXba\ and 2 iL lOx digestion buffer. The digestion reaction was then incubated at 37 °C. After completion, the restriction digest was run on a 1 % agarose gel and the 1.6 kb fragment was excised from the gel. The DNA was then eluted using a Freeze n Squeeze elution column (Bio-Rad). The DNA fragment was ligated into the Kpn\ and Xbal sites of YEp-CVS-ura, and the resulting plasmid was electroporated into DH10B E. coli cells (Invitrogen). A tenth of the volume of transformation culture was plated on LB ampicillin plates (100 μg mL), and the remaining cells were inoculated into liquid LB ampicillin (100 μg/mL) for preparation of plasmid DNA. The plates and cultures were grown overnight at 37 °C. For those transformations that had greater than 200 colonies on the LB ampicillin plate, 3 ml of the LB culture was centrifuged for extraction of plasmid DNA. Each resulting plasmid DNA preparation contained a pool of mutant genes, with each pool having random mutations in nucleotides at the same, single codon.
RECTIFIED SHEET (RULE 91)
ISA/EP
The plasmid DNA from each pool was transformed into Saccharomyces cerevisiae strain ALX7-95 using a lithium acetate yeast transformation kit from Sigma-Aldrich.
Transformants were selected on SDE agar medium (0.67 % Bacto yeast nitrogen base without amino acids, 2 % glucose, 0.14 % yeast synthetic drop-out medium without uracil, leucine, histidine, tryptophan, 40 mg/L ergosterol) after three days growth at 28-30 °C.
2. Screening
To screen transformants for valencene production, a high-throughput screening procedure using microvial cultures was employed. Transformant yeast colonies were inoculated into individual wells of 96-well microtiter plates filled with 200 μΐ^ of SDE. The plate was grown for two to three days at 28 °C. After growth to saturation, 10 μΐ^ from each well was used to inoculate 2 mL glass vials containing 250 μΐ^ of medium suitable for growth and valencene production. The vials were sealed with serum-stoppered caps and then incubated with shaking for two to three days at 28 °C. The products were extracted first by introducing 250 μΐ^ of acetone through the serum stopper and vortexing, followed by addition of 500 μL· of n-hexane and vortexing. After phase separation, the vials were placed on the sample tray of a gas chromatography autosampler, which removed one microliter of the organic phase for analysis of sesquiterpenes. The acetone and hexane used for extraction were each spiked with internal standards to aid in quantitation of the samples. The extracted samples were analyzed by gas chromatography and the amount of valencene was calculated from the peak area.
Those mutants that produced >110 % valencene relative to CVS VI 8 were also screened in shake flasks. A 10 mL seed culture in SDE medium was grown for 24 hr, and 2.5 mL was used to inoculate 50 mL fermentation medium (2 % ammonium sulfate, 2 % potassium phosphate, 0.1 % NaCl, 0.6 % MgS04-7H20, 0.4 % yeast extract, 1 mL mineral solution [FeS04-7H20 0.028 %, ZnS04-7H20 0.029 %, CuS04-5H20 0.008 %,
Na2Mo04-2H20 0.024 %, CoCl2-6H20 0.024 %, MnS04-H20 0.017 %, HC1 1 mL], 0.5 ml 50 % glucose, 1.5 ml vitamin solution [biotin 0.001%, Ca-pantothenate 0.012 %>, inositol 0.06 %, pyridoxine-HCl 0.012 %, thiamine-HCl 0.012 %], 0.5 ml 10 % CaCl2) in a 250 unbaffled flask. The cultures were grown at 28 °C. After 16 hr of incubation, the cultures were fed 3.6 ml 50 % glucose and 0.667 ml 12.5 % yeast extract. Feeding occurred every 24 after the initial feed. The pH of the cultures was adjusted to 4.5 every 24 hrs with the addition of 30 % NaOH. After approximately 88 hours of incubation, 0.1 ml of IGEPAL CA-630 was added and the culture was incubated with shaking to fully emulsify the vegetable oil. After 30 minutes, a 2 mL culture sample was taken. The sample was extracted with 2 mL
acetone/cedrene solution and then extracted with 4 mL hexane/hexadecane solution. An aliquot was analyzed by GC and the amount of valencene was determined.
- -
3. Results
a. Initial screen for tolerance for mutation
Table 12 below provides a summary of amino acid positions and their general tolerance for mutation, as determined by their valencene production. Table 12 sets forth the position of the mutated amino acid, the secondary structure present for each amino acid and the percentage of samples that produced <30 % valencene and >90 % valencene, as compared to the percentage of valencene produced by parent CVS VI 8. Amino acid positions where ≥50 % of the samples produced <30 % or >90 % valencene, as compared to the parent CVS V 18, are highlighted. For example, at amino acid position 271 , 72 of 96 samples tested (75 %) produced <30 % valencene and 3 of 96 samples tested (3.13 %) produced >90 % valencene, as compared to the production of valencene by parent CVS V 18. This position was therefore considered invariant or nearly invariant. In contrast, at amino acid position 282, 91.56 % of samples (88 samples) produced >90 % valencene, as compared to parent CVS VI 8, with only 4.17 % producing <30 % valencene. This position was considered moderately tolerant to change. Thus, as shown in Table 12 below, amino acid positions 267, 269, 270, 271 , 273, 295, 298, 301, 302, 303, 305, 306, 312, 403, 404, 407, 442, 445 and 446 have a large proportion of variants with low activity, and these positions were considered to be relatively invariant. In contrast, amino acid positions 92, 166, 171, 184, 202, 218, 281, 282, 293, 320, 333, 337, 344, 347, 352, 353, 355, 357, 360, 361, 362, 363, 364, 366, 367, 386, 415 and 428 have a large proportion of variants with high activity, and these positions were considered to be particulary tolerant to change.
RECTIFIED SHEET (RULE 91)
ISA/EP
b. Further analysis of invariant and tolerant amino acids
In order to determine the overall effectiveness of the randomization, 19 independent bacterial clones mutated at amino acid 270 were randomly selected and sequenced to identify the mutations. Of these 19 independent bacterial isolates, none retained the original codon. Two isolates encoded wildtype amino acid leucine by a changed codon (silent mutation), and one isolate had a stop codon at amino acid 270. The remaining clones encoded various other amino acids.
Individual mutant isolates at amino acid residue 270, an amino acid that was determined to be invariant or nearly invariant, were further analyzed. As shown in the Table above, only 11.46 % of isolates at amino acid 270 produced more than 30 % valencene, as compared to parent CVS VI 8 levels. Two of these samples were the two CVS VI 8 controls. Thus, only 10 of 94 mutant samples (10.63 %) produced a significant level of valencene. These isolates, plus one non-valencene producing isolate, were subjected to DNA sequencing of their mutant plasmids. Nine (9) of the valencene producing isolates encoded leucine, although the original codon had been mutated from TTG to CTC, CTA, CTT or TTA. The only other valencene producing isolate encoded wildtype Leu270, but had a mutation at amino acid 269, due to an apparent error within the DNA primer sequence or introduced during PCR amplification. The valencene non-producing isolate that was sequenced contained the mutation L270E.
Individual mutant isolates from five amino acid positions that were identified as moderately tolerant to change in the saturation mutagenesis screen were analyzed further. The top valencene producing mutant isolates identified for amino acid positions 274, 279, 281, 282 and 284 were regrown in microvial cultures and their valencene production was determined as described in Example 3.C.2 above. Additionally, up to 24 independent clones were sequenced to determine the exact amino acid mutations.
Table 13 sets forth the identified mutants. Each of these mutations are present in addition to the 29 mutations present in CVS VI 8 (described in Example 3.B, above). The amount of valencene produced in the initial microculture and valencene production levels (from an average of 3 or more microvial cultures) relative to the levels produced by CVS VI 8 also are included in the table. In some instances, the wildtype amino acid codon was maintained. In other instances, the nucleic acid mutation was silent such that the amino acid sequence of resulting valencene synthase was the same as that of CVS VI 8. Silent mutations are indicated in italic font. In other instances, mutations were observed in addition to the targeted mutation, likely due to errors introduced during the PCR amplification.
In the initial screen, 67.71 % of the 94 mutants screened at amino acid residue 274 produced >90 % valencene, as compared to the production of valencene by parent CVS VI 8.
The high number of mutants that were identified were likely the result of a lower than normal amount of valencene produced from cells transformed with the parent CVS VI 8 mutant. Repeat screening was performed where the amount of valencene produced from cells transformed with CVS VI 8 was more typical, and fewer mutants were identified. In the repeat testing, sequencing of 14 independent mutant isolates identified revealed that the only isolates that had >90 % valencene production compared to the parent CVS VI 8 were those containing wildtype residue D274 (see, for example, mutants V84 and V92). Overall, seven different mutations were identified, with 8 of the 14 mutant isolates containing the mutations D274M, D274N or D274G.
In the initial screen, 54.17 % of the 94 mutants screened at amino acid residue 279 produced >90 % valencene, as compared to the production of valencene by parent CVS VI 8. Repeat testing and sequencing of 24 independent mutant isolates revealed that 19 of 23 repeat cultures encoding for 11 different amino acids produced >90 % valencene compared to parent CVS VI 8.
In the initial screen, 88.54 % of the 94 mutants screened at amino acid residue 281 produced >90% valencene, as compared to the production of valencene by parent CVS VI 8 and were considered moderately tolerant to change. Repeat testing of 20 independent mutant isolates revealed that all mutant isolates produced >90 % valencene compared to parent CVS V18. Eleven (11) of the 20 mutant isolates contained the mutations P281A, P281L, P281 S or P281K.
In the initial screen, 91.67 % of the 94 mutants screened at amino acid residue 282 produced >90 % valencene, as compared to the production of valencene by parent CVS VI 8. Sequencing of 18 independent mutant isolates revealed that 11 of the 18 mutant isolates contained the amino acid mutations Q282S, Q282A, Q282R, Q282P or Q282L.
In the initial screen, 40.63 % of the 94 mutants screened at amino acid residue 284 produced >90 % valencene, as compared to the production of valencene by parent CVS VI 8. Repeat testing and sequencing of 23 independent mutant isolates revealed that 14 or 23 repeat cultures, encoding for 11 different amino acids, produced >90 % valencene compared to parent CVS VI 8. Three isolates encoded for wildtype amino acid A284.
c. Increased valencene producing isolates
Plasmid DNA was extracted from the transformants identified in the experiments above as producing greater than 110 % of valencene relative to transformants containing the CVS V18 gene {i.e., a 10 % increase versus CVS V18), and the nucleic acid sequences of the CVS genes were determined. Table 14 below shows results of isolated mutants meeting this criterion. Table 14 sets forth the the amino acid and nucleotide changes found by sequencing. Each of these mutations is present in addition to the 29 mutations present in CVS VI 8 (described in Example 3.B, above). The valencene production levels (measured from the cultures in shake flasks) relative to the levels produced by CVS VI 8 also are included in the table. In some instances, the nucleic acid mutation was silent such that the amino acid sequence of resulting valencene synthase was the same as that of CVS VI 8. Silent mutations are indicated in italic font. In other instances, mutations were observed in addition to the targeted mutation, likely due to errors introduced during the PCR amplification. Clone V40
contains the amino acid mutation A38V. Parental gene CVS VI 8 contains the mutation Q38A. Thus, the mutation in Clone V40 corresponds to Q38V for wildtype CVS.
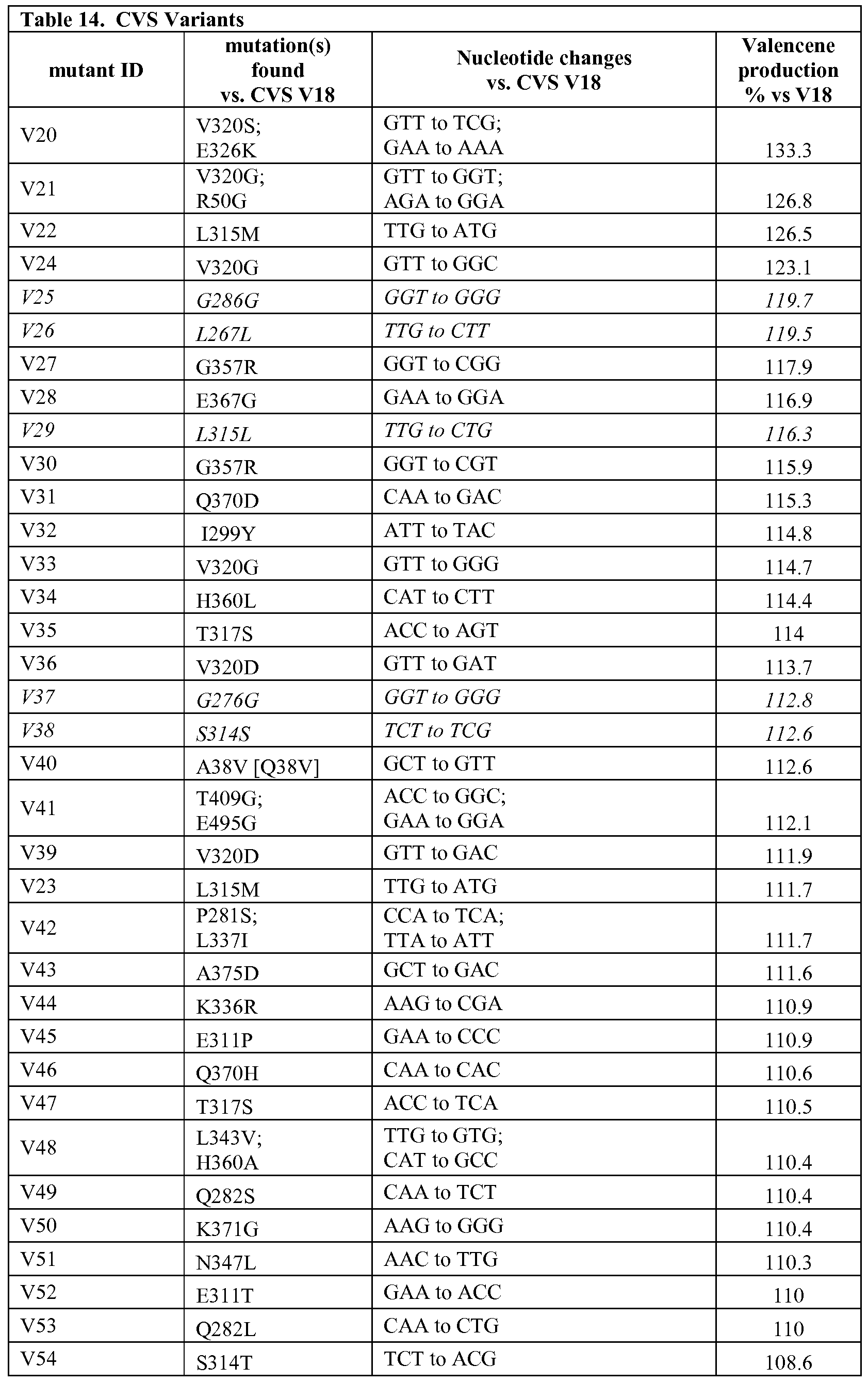
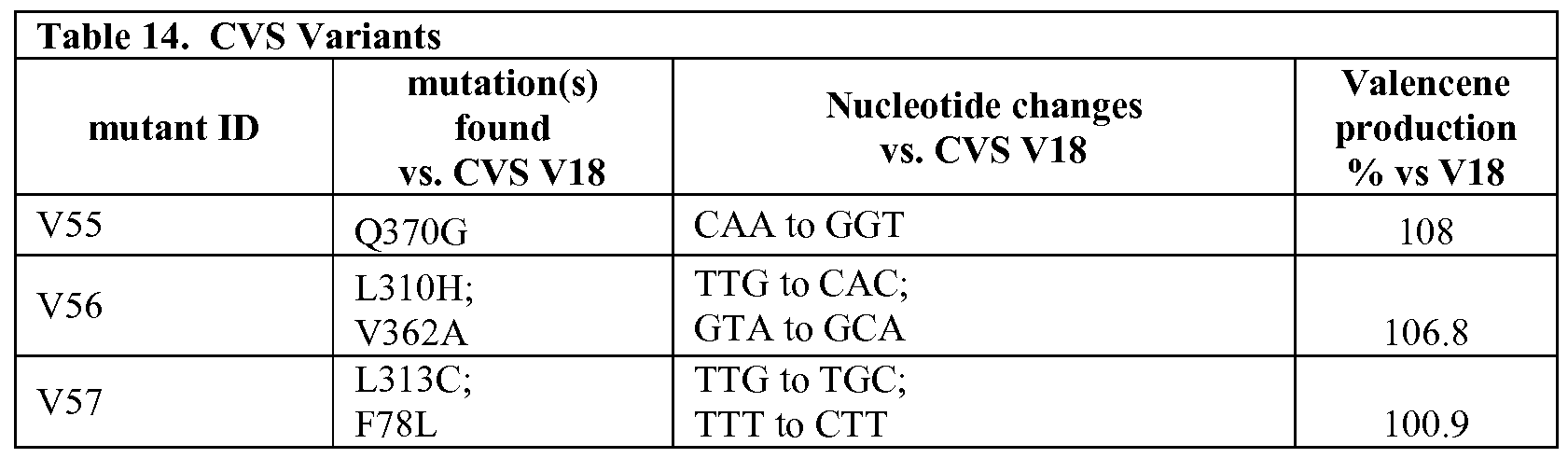
Example 4
Combination mutants
In this example, CVS variants were generated containing a combination of mutations identified in Example 3. In addition, a variety of additional mutants were generated.
A. Combining beneficial mutations identified by saturation mutagenesis
Beneficial mutations, identified as described in Example 3 above, were combined using overlapping PCR methods (see, Xiong et al., (2004) Nucleic Acids Research
32(12):e98) with CVS V19 as a template. Table 15 sets forth a series of 38 oligos that were generated containing mutations at the positions identified in Table 14 above. The oligos listed in Table 15 cover the region of the VI 9 gene beginning from the unique internal Ndel restriction site to the unique Bglll restriction site. Each of the oligos belongs to one of eight overlapping sequence groups. The sequence groups are set forth in Table 16 below. Each oligo within a single sequence group provides either the wild type codon or mutant codon(s) of the indicated amino acids. Sequence overlaps between groups were designed to give melting temperatures of 40 to 50 °C.
To obtain a complete, mutagenized DNA fragment of the Ndel and Bglll region, one or more oligos from each of the eight sequence groups was combined in various PCR reactions. In each PCR reaction, the oligo(s) from groups one and eight were used at a total concentration of 30 pmol per 50 μΕ reaction. The oligos from groups 2 through 7 were used at a total concentration of 1.5 pmol per 50 μΕ reaction, per oligo group. The initial denaturation cycle was 2 minutes at 95 °C. A "touchdown PCR" thermocycling protocol was used, wherein the initial annealing temperature of 46 °C was decreased by two degrees after each two cycles until a final annealing temperature of 38 °C was attained. A total of 30 PCR cycles were completed, including 22 cycles with an annealing temperature of 38 °C. Each cycle consisted of a 30 second denaturation step, a 30 second annealing step, and a 2 minute extension step. The PCR protocol concluded with a 7 minute extension step. Completed PCR reaction products were gel purified from 1.2 % agarose gels using either a Qia-quick gel extraction column (Qiagen) or a Freeze and Squeeze column (Bio-Rad). Cleaned PCR products were digested with restriction enzymes Ndel and Bglll, and were ligated into the
Ndel and Bglll sites of YEp-CVS-UVA. Ligations were electroporated into E. coli DH10B cells as described in Example 3.C.2 above.
Table 15. Oligos for overlapping PCR
SEQ
Oligo Sequence ID
NO
21-73-1 AAATTGCCATATGCTAGAGATAGATTGGTTGAATTGTACTTTTGGGATTTG 299
21-73-2 AAATTGCCATATGCTAGAGATAGACTTGTTGAATTGTACTTTTGGGATTTG 300
GATTTTTCTACCAAAAGCGTATTGTGRTTCAAAATAAGTMCCCAAATCCCA
21-73-3 301
AAAG AC
GATTTTTCTACCAAAAGCGTAAGATGRTTCAAAATAAGTMCCCAAATCCCA
21-73-4 302
AAAGTAC
GATTTTTCTACCAAAAGCGTACAGTGRTTCAAAATAAGTMCCCAAATCCCA
21-73-5 303
AAAGTAC
CTTTTGGTAGAAAAATCATGACTAAATTGAACTACATTTTGTCCATTATTG
21-73-6 304
ATGATACCTACGATG
CTTTTGGTAGAAAAATCATGACTAAATTGAACTACATTTTGTCCTACATTG
21-73-7 305
ATGATACCTACGATG
21-73-8 GAACAAAGACAATTCTTCCAAAGTACCGTAAGCATCGTAGGTATCATC 306
21-73-9 GGTGAACAAAGACAATTCTTCGTGAGTACCGTAAGCATCGTAGGTATCATC 307
21-73-10 GGTGAACAAAGACAATTCGGKCAAAGTACCGTAAGCATCGTAGGTATCATC 308
21-73-11 GGTGAACAAAGACAATTCGGKGTGAGTACCGTAAGCATCGTAGGTATCATC 309
21-73-12 TTCTTCCAAAGTACCGTAAGCATCGTAGGTATCATC 310
21-73-13 CAATTCTTCCAAAGTACCGTAAGCATCGTAGGTATCATC 311
RTCAGCTTCACTGAACAKCGWGCATTCGGKGTGAGTACCGTAAGCATCGTA
21-73-14 312
GGTATCATC
VCCAGCTTCACTGAACAKCGWGCATTCGGKGTGAGTACCGTAAGCATCGTA
21-73-15 313
GGTATCATC
21-73-16 GAATTGTCTTTGTTCACCGAAGCTGTTGCTCGTTGGAACATTGAAGC 314
GGTACTTTGGAAGAATTGWCGMTGTTCACCGAAGCTGTTGCTCGTTGGAAC
21-73-17 315
ATTGAAGC
CTTACGGTACTTTGGAAGAATGCWCGMTGTTCACCGAAGCTGTTGCTCGTT
21-73-18 316
GGAACATTGAAGC
CTTACGGTACTTTGGAAGAATGCWCGMTGTTCTCAGAAGCTGTTGCTCGTT
21-73-19 317
GGAACATTGAAGC
CTTACGGTACTTTGGAAGAATGCWCGMTGTTCAGTGAAGCTGTTGCTCGTT
21-73-20 318
GGAACATTGAAGC
21-73-21 GAAGAATTGTCTTTGTTCTCAGAAGCTGAYGCTCGTTGGAACATTGAAGC 319
21-73-22 GAAGAATTGTCTTTGTTCTCAGAAGCTGGBGCTCGTTGGAACATTGAAGC 320
21-73-23 GAAGAATTGTCTTTGTTCAGTGAAGCTGAYGCTCGTTGGAACATTGAAGC 321
21-73-24 GAAGAATTGTCTTTGTTCAGTGAAGCTGGBGCTCGTTGGAACATTGAAGC 322
21-73-25 GAAGAATTGTCTTTGTTCAGTGAAGCTGTTGCTCGTTGGAACATTGAAGC 323
21-73-26 GAAGAATTGTCTTTGTTCTCAGAAGCTGTTGCTCGTTGGAACATTGAAGC 324
21-73-27 GAAGAATTGTCTTTGTTCACCGAAGCTGAYGCTCGTTGGAACATTGAAGC 325
21-73-28 GAAGAATTGTCTTTGTTCACCGAAGCTGGBGCTCGTTGGAACATTGAAGC 326
CACMCCGAATGCWCGMTGTTCAGTGAAGCTGGBGCTCGTTGGAACATTGAA
21-73-29 327
GC
CACMCCGAATGCWCGMTGTTCAGTGAAGCTGAYGCTCGTTGGAACATTGAA
21-73-30 328
GC
TCTGTAGATTAACTTCATATAATCTGGCAACATGTCAACAGCTTCAATGTT
21-73-31 329
CCAACGAGC
TCTGTAGATWAWTCGCATATAATCTGGCAACATGTCAACAGCTTCAATGTT
21-73-32 330
CCAACGAGC
ATATGAAGTTAATCTACAGAACTTTGTTGGATACATTCAACGAAATAGAAG
21-73-33 331
AGGATATGG
ATATGAAGWTWATCTACAGAACTTTGTTGGATACATTCTTGGAAATAGAAG
21-73-34 332
AGGATATGG
ATATGCGAWTWATCTACAGAACTTTGTTGGATACATTCAACGAAATAGAAG
21-73-35 333
AGGATATGG
ATATGCGAWTWATCTACAGAACTTTGTTGGATACATTCTTGGAAATAGAAG
21-73-36 334
AGGATATGG
21-73-37 ACAATGAGATCTMCGTTGTTTAGCCATATCCTCTTCTATTTC 335
21-73-38 ACAATGAGATCTACCTTGTTTAGCCATATCCTCTTCTATTTC 336
M is A or C; W is A or T; K is G or T; is G or A; B is G or C or T; and Y is T or C.
Mutants were screened using the microvial method described in Example 3.C.2 above, and mutants with >110 % valencene productivity of VI 9 were further screened in shake flask cultures. Various mutations were additionally screened using the ALX11-30
(ura3, trpl, erg9def25, HMG2cat/TRP 1 : :rDNA, dppl, sue) strain of Saccharomyces
cerevisiae using the microvial method described in Example 3.C.2, above.
Table 17 below sets forth the identified mutants, including the nucleic acid and amino acid mutations, and the valencene production in shake flask cultures relative to the valencene production of transformants containing the CVS VI 9 gene. The mutations indicated in the table are in addition to the 29 mutations present in CVS V19, described in Example 3.B, above. In some instances, the nucleic acid mutation was silent such that the amino acid sequence of resulting valencene synthase was the same as that of CVS VI 9. Silent mutations are indicated in italic font. For example, in ALX7-95 cells, variant V58 produces 99.91 % valencene as compared to the valencene production of CVS VI 9. Sequencing resulted in only partial sequence data for V180 and V181
Table 17. CVS Variants (mutations in addition to those in CVS V19)
Amino Amino
Valencene
Nucleotide acid Nucleotide acid SEQ ID NO
production %
Mutant changes vs. changes changes vs. changes nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
CCT→ TCA P281 S CCA→ TCA P281 S
ATC→ TAC I299Y ATT→ TAC I299Y 99.91
V58 185 50
CTT→ CAC L310H TTG→ CAC L310H (Alx7-95) GAA→ CCC E311P GAA→ CCC E311P
CCT→ TCA P281 S GGT→ GGG G276G 108.53
V60 186 51
CAA→ CTG Q282L CCA→ TCA P281 S (Alx7-95)
CTT→ CAC L310H CAA→ CTG Q282L
TTG→ CAC L310H
CCT→ TCA P281 S CCA→ TCA P281 S
ATC→ TAC I299Y ATT→ TAC I299Y 96.17
V59 185 50
CTT→ CAC L310H TTG→ CAC L310H (Alx7-95) GAA→ CCC E311P GAA→ CCC E311P
GGT→ GGG G276G
CCT→ TCA P281 S
CCA→ TCA P281 S
CAA→ CTG Q282L 89.18
V61 CAA→ CTG Q282L 187 52
ATC→ TAC I299Y (Alx7-95)
ATT→ TAC I299Y
GAA→ CCC E311P
GAA→ CCC E311P
GGT→ GGG G276G
CCT→ TCA P281 S
CCA→ TCA P281 S
CTC→ TGC L313C
TTG→ TGC L313C 79.12
V62 AGC→ ACG S314T 188 53
TCT→ ACG S314T (Alx7-95) CTC→ATG L315M
TTG→ATG L315M
ACT→ AGT T317S
ACC→ AGT T317S
CCT→ TCA P281 S CCA→ TCA P281 S
AGC→ TCG S314S TCT→ TCG S314S 109.63 CTC→ CTG L315L TTG→ CTG L315L (Alx7-95)
V63 189 54
AAA→ CGA K336 AAG→ CGA K336R 77 and 97 AAT→ TTG N347L AAC→ TTG N347L (Alxl l-30) GGA→ CGT G357R GGT→ CGT G357R
GGT→ GGG G276G
CTT→ CAC L310H
TTG→ CAC L310H
GAA→ ACC E311T
GAA→ ACC E311T
CTC→ TGC L313C
TTG→ TGC L313C 75.46
V64 AGC→ ACG S314T 190 55
TCT→ ACG S314T (Alx7-95) CTC→ATG L315M
TTG→ATG L315M
ACT→ AGT T317S
ACC→ AGT T317S
GTT→ GGC V320G
GTT→ GGC V320G
GGT→ GGG G276G
CCT→ TCA P281 S
CCA→ TCA P281 S
ACT→ AGT T317S
ACC→ AGT T317S
AAA→ CGA K336R 86.56
V66 AAG→ CGA K336R 192 56
TTG→ ATT L337I (Alx7-95)
TTA→ ATT L337I
AAT→ TTG N347L
AAC→ TTG N347L
GGA→ CGG G357R
GGT→ CGG G357R
ACT→ AGT T317S ACC→ AGT T317S
AAA→ CGA K336R AAG→ CGA K336R 101.46
V67 193 57
TTG→ ATT L337I TTA→ ATT L337I (Alx7-95) GGA→ CGG G357R GGT→ CGG G357R
GGT→ GGG G276G
CCT→ TCA P281 S
CCA→ TCA P281 S
ACT→ AGT T317S
ACC→ AGT T317S 99.32
V68 AAA→ CGA K336R 194 58
AAG→ CGA K336R (Alx7-95) AAT→ TTG N347L
AAC→ TTG N347L
GGA→ CGG G357R
GGT→ CGG G357R
GGT→ GGG G276G
CCT→ TCA P281 S
CCA→ TCA P281 S 98.89
V69 ACT→ AGT T317S 195 59
ACC→ AGT T317S (Alx7-95) GGA→ CGG G357R
GGT→ CGG G357R
CTT→ CAC L310H GGT→ GGG G276G
GAA→ ACC E311T TTG→ CAC L310H
CTC→ TGC L313C GAA→ ACC E311T 96.91
V65 191 55
AGC→ ACG S314T TTG→ TGC L313C (Alx7-95) CTC→ATG L315M TCT→ ACG S314T
ACT→ AGT T317S TTG→ATG L315M
GTT→ GGG V320G ACC→ AGT T317S
GTT→ GGG V320G
GGT→ GGG G276G
CCT→ TCA P281 S
CCA→ TCA P281 S
CTT→ CAC L310H
TTG→ CAC L310H
GAA→ ACC E311T
GAA→ ACC E311T
CTC→ TGC L313C 85.16
V70 TTG→ TGC L313C 196 60
AGC→ TCG S314S (Alx7-95)
TCT→ TCG S314S
CTC→CTG L315L
TTG→CTG L315L
ACC→ AGT T317S
ACC→ AGT T317S
GTT→ GGC V320G
GTT→ GGC V320G
none none GGT→ GGG G276G
CCT→TCA P281 S CCA→TCA P281 S
V179 754 810 82
CAA→TCT Q282S CAA→TCT Q282S
GAA→CCT E311P GAA→CCT E311P
none none GGT→ GGG G276G
CCT→TCA P281 S CCA→TCA P281 S
V180 CAA→TCT Q282S CAA→TCT Q282S 755 811 79
CTT→CAC L310H TTG→CAC L310H
GAA→AAA E318K GAA→AAA E318K
none none GGT→ GGG G276G
CCT→TCA P281 S CCA→TCA P281 S
V181 756 812 98
CAA→TCT Q282S CAA→TCT Q282S
CTT→CAC L310H TTG→CAC L310H
none none TTG→TTA L293L
V182 693 723 98.9
GAA→CCC E311P GAA→CCC E311P
ACT→AGT T317S ACC→AGT T317S
V183 694 724 93
GTT→GGG V320G GTT→GGG V320G
18 and CTT→CAC L310H TTG→CAC L310H
716 746 ND V219 GAA→CCC E311P GAA→CCC E311P
B. Generation of additional valencene synthase mutants
Additional valencene synthase mutants, set forth in Table 19, were then produced using standard recombinant DNA and PCR methods. The mutations indicated in the table are in addition to the 29 mutations present in CVS VI 9, described in Example 3.B, above. The amino acid mutations identified in mutants V46, V43 and V41 (see Table 14 above) were combined using standard recombinant DNA and PCR methods to produce variants designated V184 and V185. To generate V184 and V185, primers 21-73.39 and 7-10.4 (see Table 18 below) were used in a single PCR reaction with plasmid DNA from mutant V41 as template.
Variants V73 and V74 were generated by recombination of mutations in V62 and V66. Variants V75 and V76 were generated by recombinations of mutations in V62 and V67. Variants V73, V74, V75 and V76 were all generated using the overlapping PCR technique as described in Example 3C, with the following exceptions. In the first stage, primers 7-10.3 and 21-71.42 were used in one reaction to amplify a portion of V62 and primers 21-71.41 and 7-10.4 were used in a section PCR to amplify a portion of either V66 or V67. Primers 7-10.3 and 7-10.4 then were used to generate a full-length gene from the two first stage products .
Table 18. Oli os for PCR
SEQ ID
Oligo Sequence
NO
CTCGGTACCATTTAAAAAAATGNNNNNNNNNNNNNNNNNNAGACCAAC mutCVS2-7 337
TGCTGATTTTC
7-10.3 CCAAGCTGAATTCGAGCTCG 338
7-10.4 ACTTGACCAAACCTCTGGCG 339
AGGTAGATCTCWTTGTGTAAGATACGCTAAAGAAGAAATTCAMAAGGT
21-73.39 897
TATTGGTG
21-71.41 GCTCGTTGGAACATTGAAGCTGTTGACATG 898
21-71.42 CATGTCAACAGCTTCAATGTTCCAACGAGC 899
21-108.1 GTTAGAAGAATGATTNNNNNNNNNNNNNNNNNNCCAATTCAAAAATTG 900
21-108.2 CAATTTTTGAATTGGNNNNNNNNNNNNNNNNNNAATCATTCTTCTAAC 901
GAAGCAAGATACATTATGTCANNNNNNNNNNNNNNNNNNNNNNNNNNN
21-140.1 902
NNNAACAAGACTTTG AAAT CG
CGAAATTTAACAAAGTCTTGTTNNNNNNNNNNNNNNNNNNNNNNNNNN
21-140.2 903
NNNNTGACATAATGTATCTTGCTTC
GAAAATCAGCAGTTGGTCTNNNNNNNNNNNNNNNNNNCATTTTTTTAA
revAA2-7rnd 904
ATGGTACCGAG
21-145.13 CGCCCCGTCGCCGACTTCTCCCCATCTTTGTGGAAAAATC 905
21-145.14 GATTTTTCCACAAAGATGGGGAGAAGTCGGCGACGGGGCG 906
21-145.15 CGTCCTGTGGCAAACTTTCACCCATCTTTGTGGAAAAATC 907
21-145.16 GATTTTTCCACAAAGATGGGTGAAAGTTTGCCACAGGACG 908
21-145.17 CGCCCTGTTGCAGATTTTTCTCCATCTTTGTGGAAAAATC 909
21-145.18 GATTTTTCCACAAAGATGGAGAAAAATCTGCAACAGGGCG 910
21-145.25 GAAAAGTATGCTCAAGAGATTGAAGCTTTGAAGGAAGAAG 911
21-145.26 CTTCTTCCTTCAAAGCTTCAATCTCTTGAGCATACTTTTC 912
21-145.27 GCCTGCAAAGAGGAGCAGATTGAAGCTTTGAAGGAAGAAG 913
21-145.28 CTTCTTCCTTCAAAGCTTCAATCTGCTCCTCTTTGCAGGC 914
21-145.29 CATTTCAGATTGTTGAGACAACAAGGGTACACTATTTCATGTG 915
21-145.30 CACATGAAATAGTGTACCCTTGTTGTCTCAACAATCTGAAATG 916
21-145.31 CATTTCAGATTGTTGAGACAACACGGTTTCAACATCTCTC 917
21-145.32 GAGAGATGTTGAAACCGTGTTGTCTCAACAATCTGAAATG 918
21-145.33 CATTTCAGATTGTTGAGACAACATGGTTACAACGTCTCTCC 919
21-145.34 GGAGAGACGTTGTAACCATGTTGTCTCAACAATCTGAAATG 920
21-145.35 GACATCAGGGGCCTACTGAACTTGTATGAAGCTGCTTATATG 921
21-145.36 CATATAAGCAGCTTCATACAAGTTCAGTAGGCCCCTGATGTC 922
21-145.37 GATGTCTTAGGATTATTAAACTTGTATGAAGCTGCTTATATG 923
21-145.38 CATATAAGCAGCTTCATACAAGTTTAATAATCCTAAGACATC 924
21-145.39 GATGTAAGAGGCATGCTAGGCTTGTATGAAGCTGCTTATATG 925
21-145.40 CATATAAGCAGCTTCATACAAGCCTAGCATGCCTCTTACATC 926
Mutants were screened in either ALX7-95 or ALX11-30 using the microvial method described in Example 3.C.2, above, and mutants with >110 % valencene productivity of V19 (i.e., 10 % greater valencene produced than wildtype) were further screened in shake flask cultures. Table 19 below sets forth the identified mutants, including the nucleic acid and amino acid mutations, and the valencene production in shake flask cultures relative to the valencene production of transformants containing the CVS VI 9 gene. The mutations indicated in the table are in addition to the 29 mutations present in CVS VI 9, described in Example 3.B, above. In some instances, the nucleic acid mutation was silent such that the amino acid sequence of resulting valencene synthase was the same as that of CVS VI 9. Silent mutations are indicated in italic font. The V75 variant was found to have an
improvement in product distribution, resulting in a roughly 50% reduction in the production of side-product germacrene A, measured as β-elemene.
ND: Not determined
C. Generation of additional valencene synthase mutants
Further additional valencene synthase mutants were produced using a variety of methods. The mutants were generated as described below in subsections a-e.
All of the generated mutants were screened in ALX7-95 using the microvial method described in Example 3.C.2, above, and mutants with >110 % valencene productivity of CVS VI 9 (i.e., 10 % increase in valencene versus CVS VI 9) were further screened in shake flask cultures. In some examples, mutants that had at least 90% of VI 9 titer, or mutants that had other desirable characteristics, such as an increase in enzyme specificity, were screened in shake flask cultures. The identified mutants were sequenced. Tables 20-24 below sets forth the identified mutants, including the nucleic acid and amino acid mutations, and the percent (%) valencene production in initial microcultures and shake flask cultures relative to the valencene production of transformants containing the CVS VI 9 gene.
Where indicated, the mutations indicated in the tables are in addition to the 29 mutations present in CVS VI 9, described in Example 3.B, above. In some instances, the nucleic acid mutation was silent such that the amino acid sequence of resulting valencene synthase was the same as that of CVS VI 9. In addition, the nucleic acid encoding the mutant CVS V19 (SEQ ID NO: 129) is codon optimized for yeast. Thus, some of the silent mutations resulted in a codon that was the same as that for wildtype CVS. For example, in mutant
VI 82, leucine 293 is encoded by the wildtype CVS codon TTA, whereas the parent CVS VI 9 codon was TTG. All silent mutations are indicated in italic font. Several mutants contain the mutation Q58K. Parental gene CVS VI 9 contains the mutation K58Q. Thus, compared to wildtype CVS, this mutation is silent, albeit with a change in the nucleic acid codon (AAG in wildtype CVS, AAA in the mutant CVS).
a. V186, V77, V187, V78, V188, V189, V190, V79, V191, V192, V193, V194 and V195
CVS variants V186, V77, V187, V78, V188, V189, V190, V79, V191, V192, V193, VI 94 and VI 95 were generated by a single PCR reaction from the CVS VI 9 gene using forward oligo mutCVS2-7 (SEQ ID NO:337) and reverse oligo 7-10.4 (SEQ ID NO:339).
PCR cleanup, restriction digestion, ligations, transformations, and testing were performed as described in Section A above. The mutations were in addition to the 29 mutations present in CVS V19 (SEQ ID NO:4), described in Example 3.B, above. The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 are set forth in Table 20 below.
Table 20. CVS Variants (mutations in addition to those in CVS VI 9)
Amino Amino
Nucleotide acid Nucleotide acid SEQ ID NO Valencene production %
Mutant changes vs. changes changes vs. changes nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
TCG→CCG S2P TCA→CCG S2P
TCT→CGT S3R TCT→CGT S3R
V186 758 814 ND
GGA→CGG G4R GGT→CGG G4R
GAA→GAT E5D GAA→GAT E5D
ACA- >AGG T6R ACT- >AGG T6R
TTT-►GCG F7A TTT- >GCG F7A
TCG- ►CGG S2R TCA- ►CGG S2R
TCT-►GAC S3D TCT-►GAC S3D
105 (Alx7-95) GGA- >AAG G4K GGT-►AAG G4K
V77 200 64 96.28 (Alxl l- GAA- *GGT E5G GAA- *GGT E5G
30) ACA- >ACG T6T ACT- >ACG T6T
TTT-►TGT F7C TTT-►TGT F7C
TCT- >TTA S3L TCT- >TTA S3L
GGA- >TCA G4S GGT-►TCA G4S
V187 GAA- >CAT E5H GAA- >CAT E5H 759 815 ND
ACA-►GAC T6D ACT-►GAC T6D
TTT-►AGT F7S TTT-►AGT F7S
TCG- >GAG S2E TCA- ►GAG S2E
TCT-►GGA S3G TCT-►GGA S3G
99.75 (Alx7- GGA- *AAT G4N GGT- >AAT G4N
95)
V78 GAA- *AGT E5S GAA- AGT E5S 201 65
107.9 (Alxl l- ACA- *GTC T6V ACT- >GTC T6V
30) TTT-►CAA F7Q TTT-►CAA F7Q
TTT - ^CTC F424L TTC - ^CTC F424L
TCG- ►ACG S2T TCA- ►ACG S2T
TCT-►CGA S3R TCT-►CGA S3R
Vli GAA- ÷ATC E5I GAA- ÷ATC E5I 760 816 ND
ACA- ÷CTC T6L ACT- >CTC T6L
TTT—►AAA F7K TTT—■AAA F7K
TCG- *TTA S2L TCA- TTA S2L
TCT- >GAT S3D TCT-►GAT S3D
GGA- *AGT G4S GGT- >AGT G4S
V189 761 817 ND
GAA- ÷ATC E5I GAA- ÷ATC E5I
ACA- >GCA T6A ACT-►GCA T6A
TTT—►GGG F7G TTT— GGG F7G
TCG- ►CAT S2H TCA- ►CAT S2H
TCT— >GAG S3E TCT—■GAG S3E
GGA- >CCC G4P GGT-►CCC G4P
V190 762 818 ND
GAA- VTCT E5S GAA- ÷TCT E5S
ACA- >GAG T6E ACT-►GAG T6E
TTT-►ACT F7T TTT-►ACT F7T
TCG- >AAG S2K TCA- ►AAG S2K
TCT-►CGC S3R TCT-►CGC S3R
GGA- *GTA G4V GGT- >GTA G4V
V79 202 66 103 (Alx7-95) GAA- >GGG E5G GAA-►GGG E5G
ACA-►AGG T6R ACT-►AGG T6R
TTT-►GCG F7A TTT-►GCG F7A
TCG- ►CTA S2L TCA- ►CTA S2L
TCT—►GGC S3G TCT—•GGC S3G
GGA- ÷GTT G4V GGT- GTT G4V
V191 763 819 ND
GAA- VTCT E5S GAA- ÷TCT E5S
ACA- >GAA T6E ACT-►GAA T6E
TTT—■CAA F7Q TTT—■CAA F7Q
TCG- ►CGG S2R TCA- ►CGG S2R
TCT-■GTG S3V TCT-►GTG S3V
V192 GGA-►GCG G4A GGT-►GCG G4A 764 820 ND
GAA- >CCT E5P GAA- *CCT E5P
ACA-►AAA T6K ACT-►AAA T6K
TCG- ►AGA S2R TCA- ►AGA S2R
TCT-►GCT S3A TCT-►GCT S3A
V193 765 821 ND
GGA-►GAA G4E GGT-►GAA G4E
GAA- >CTG E5L GAA- >CTG E5L
ACA→AGC T6S ACT→AGC T6S
TTT→CTT F7L TTT→CTT F7L
TCG→CAG S2Q TCA→CAG S2Q
TCT→AGC S3S TCT→AGC S3S
GGA→ATT G4I GGT→ATT G4I
V194 695 725 95.91
GAA→ACG E5T GAA→ACG E5T
ACA→GAC T6D ACT→GAC T6D
TTT→AAG F7K TTT→AAG F7K
TCG→AGG S2 TCA→AGG S2R
TCT→GTG S3V TCT→GTG S3V
GGA→ATT G4I GGT→ATT G4I
V195 766 822 ND
GAA→GAT E5D GAA→GAT E5D
ACA→GGC T6G ACT→GGC T6G
TTT→GGG F7G TTT→GGG F7G
b. V196, V197, V198, V200, V201, V202, V203, V204, V205, V206, V207, V212, V213, V214, V215, V216 and V217
CVS variants V196, V197, V198, V200, V201, V202, V203, V204, V205, V206, V207, V212, V213, V214, V215, V216 and V217 contain mutations at various amino acids, including L106, R132, M153, H159, Q188, 1189, P202, 1213, H219, 1397 and K474. These mutants were generated by saturation mutagenesis of single amino acid positions of the amino terminal non-catalytic domain of the CVS VI 9 gene as described in Example 3C.1, with the exception that outer primers 7-10.3 and 7-10.4 (see Table 18), were used in place of primers 11-157.7 and 11-157.8, respectively. PCR cleanup, restriction digestion, ligations,
transformations, and testing were performed as described in Section A above. The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 are set forth in Table 21 below. The mutations were in addition to the 29 mutations present in CVS V19 (SEQ ID NO:4), described in
Example 3.B, above, with the exception of variant V202. As indicated in Table 21 below, wildtype CVS contains a histidine at residue 219 and CVS VI 9 contains an aspartic acid at residue 219, whereas V202 contains an alanine at residue 219.
Table 2] . CVS Variants (mutations in addition 1 o those in CVS V19)
Amino Amino
Nucleotide acid Nucleotide acid SEQ ID NO Valencene production %
Mutant changes vs. changes changes vs. changes nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
CTT→ GCC L106A TTG→ GCC L106A
V196 696 726 110.59
AGT→ TCC S146S TCT→ TCC S146S
V197 CTT→ TCG L106S TTG→ TCG L106S 697 727 109.57
V198 CTT→ AAG L106K TTG→ AAG L106K 698 728 116.26
ATG→AAT M153N ATG→AAT M153N
V200 none none TTA→TTG L337L 699 729 128.6
AAG→ACG K474T AAG→ACG K474T
V201 ATC→TCG I213S ATT→TCG I213S 768 824 ND
V202 CAT→GCC H219A GAT→GCC D219A 700 730 96.7
CAG→CGA Q188R CAA→CGA Q188R
V203 ATA→GTT 1189V ATT→GTT 1189V 769 825 115.36
CCA→TCA P202S CCA→TCA P202S
GGA→GGC G374G GGT→GGC G374G
GAA→GAG E475E GAA→GAG E475E
ATG→AAT M153N ATG→AAT M153N
V204 770 826 112.74
AAG→ACG K474T AAG→ACG K474T
V205 CAT→CGC H159 CAT→CGC H159R 771 827 120.57
V206 CAT→ AAA H159K CAT→ AAA H159K 772 828 116.01
V207 ATA→CCC I189P ATT→CCC I189P 773 829 115.81
V212 AGA→GGA R132G AGA→GGA R132G 707 737 101.86
CAT→CAA H159Q CAT→CAA H159Q
GAA→GAG E318E GAA→GAG E318E
V213 708 738 125.17 none none GAA→GAG E326E
ATT→ATC I391I ATT→ATC 13911
V214 ATG→GGG M153G ATG→GGG M153G 709 739 121.35
ATT→GTT I397V ATT→GTT I397V 125.90
V215 710 740
none none CAT→CAC H77H
ATT→ATC 11891 ATT→ATC 11891
V216 711 741 123.20
AGA→AGG R203R AGA→AGG R203R
ATA→GCG I189A ATT→GCG I189A
V217 712 742 120.30
AGA→AGG R203R AGA→AGG R203R
c. V199, V208, V209, V210 and V211
CVS variants VI 99, V208, V209, V210 and V211 contain mutations at amino acids 53 through 58, and were generated by a single PCR reaction from the CVS VI 9 gene using forward oligo 21-108-1 (SEQ ID NO:340) and reverse oligo 21-108-2 (SEQ ID NO:341) (see Table 18). The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 are set forth in Table 22 below. V209 additionally contains a mutation at LI 06, introduced during PCR amplification.
Table 22. CVS Variants
Amino Amino
Nucleotide acid Nucleotide acid SEQ I D NO Valencene production %
Mutant changes vs. changes changes vs. changes
nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
AAA- ^CAA K24Q
CAA- ■ AAT Q38N
ACA - ^ CTA T53L
GAT - ^ GCC D54A
GCT - ÷ CCA A55P
GAA - ^ CCG E56P
GAT- > CCC D57P
AAG - ^ CGC K58R
ACT→ CTA T53L
GTT- ■ ATT V60I
GAT→ GCC D54A
AAA- ^CAA K88Q
GCA→ CCA A55P
V199 TAT- ÷CAT Y93H 767 823 105.81
GAA→ CCG E56P
AAT- ^GAT N97D
GAT→ CCC D57P
AGA- ■ AAA R98K
CAA→ CGC Q58R
AAG- ^CAA K125Q
AAG- ^CAA K173Q
AAG- ^AGA K184R
TTT- ^ATT F209I
ATG- >AGA M212R
AAT- ^GAT N214D
CAT- ^GAT H219D
TAC- ->GTT Y221V
GAG- >GAT E238D
AAA- >CAA K252Q
CAA- >AAA Q292K
CAA- >GCT Q321A
GAA-►GAT E333D
GCT-►ACA A345T
AAT-►ATT N369I
TCT-►TAC S377Y
ACA-►AGA T405R
AAT-►GGT N429G
GCA- >TCT A436S
ACC-►CCA T501P
GAT- >GAA D536E
AAA- →CAA K24Q
CAA- →AAT Q38N
ACA →CTC T53L
GAT →CCT D54P
GCT →CGC A55R
GAA →TTC E56F
GAT- →TCG D57S
AAG - →CAA K58Q
GTT- →ATT V60I
AAA- →CAA K88Q
TAT- →CAT Y93H
AAT- →GAT N97D
AGA- -►AAA R98K
AAG- →CAA 125Q
AAG- →CAA K173Q
AAG- ->AGA K184R ACT→CTC T53L
TTT- ->ATT F209I GAT→CCT D54P
V208 701 731 109.2
ATG- ^AGA M212R GCA→CGC A55R
AAT- ->GAT N214D GAA→TTC E56F
CAT- ->GAT H219D GAT→TCG D57S
TAC- ->GTT Y221V
GAG- →GAT E238D
AAA- →CAA K252Q
CAA- ■ AAA Q292K
CAA- →GCT Q321A
GAA- →GAT E333D
GCT- ÷ACA A345T
AAT- →ATT N369I
TCT- ÷TAC S377Y
ACA- ÷AGA T405R
AAT- ->GGT N429G
GCA- →TCT A436S
ACC- ^CCA T501P
GAT- ÷GAA D536E
AAA- >CAA K24Q
CAA- >AAT Q38N
ACA- >ACG T53T
ACT→ACG T53T
GAT- >GCC D54A
GAT→GCC D54A
GCT- >GTT A55V
GCA→GTT A55V
GAA- *GCC E56A
V209 GAA→GCC E56A 704 734 104.53
GAT- >CAG D57Q
GAT→CAG D57Q
AAG- *CCC K58P
CAA→CCC Q58P
GTT- >ATT V60I
TTG→TTC L106F
AAA- >CAA K88Q
TAT-►CAT Y93H
AAT- >GAT N97D
AGA- >AAA R98K
CTT- TTC L106F
AAG- >CAA K125Q
AAG- >CAA K173Q
AAG- ►AGA K184R
TTT- >ATT F209I
ATG- ►AGA M212R
AAT- ►GAT N214D
CAT- ►GAT H219D
TAC- >GTT Y221V
GAG- >GAT E238D
AAA- ►CAA K252Q
CAA- ►AAA Q292K
CAA- >GCT Q321A
GAA- GAT E333D
GCT- ►ACA A345T
AAT- >ATT N369I
TCT- ►TAC S377Y
ACA- ►AGA T405R
AAT- >GGT N429G
GCA- >TCT A436S
ACC- ►CCA T501P
GAT- •GAA D536E
AAA ÷CAA K24Q
CAA >AAT Q38N
CTG ÷TTA L44L
ACA ►CGA T53R
GAT ►GCA D54A
GCT ►CAA A55Q
GAA ÷ACC E56T
GAT ►GCC D57A
AAG >CGG K58R
GTT ►ATT V60I
AAA CAA K88Q
TAT ►CAT Y93H
AAT ►GAT N97D
AGA ►AAA R98K TTG- >TTA L44L
AAG ►CAA K125Q ACT- ►CGA T53R
AAG ►CAA K173Q GAT- ►GCA D54A
AAG ►AGA K184R GCA- ►CAA A55Q
V210 TTT ►ATT F209I GAA- >ACC E56T 705 735 102.97
ATG ►AGA M212R GAT- ►GCC D57A
AAT ►GAT N214D CAA- ►CGG Q58R
CAT ►GAT H219D ATT- >ATC 1921
TAC ►GTT Y221V TAT- >TAC Y532Y
GAG ►GAT E238D
AAA ►CAA K252Q
CAA ►AAA Q292K
CAA ►GCT Q321A
GAA ►GAT E333D
GCT ►ACA A345T
AAT ►ATT N369I
TCT ►TAC S377Y
ACA ■AGA T405R
AAT ►GGT N429G
GCA >TCT A436S
ACC ►CCA T501P
GAT ■GAA D536E
V21 1 AAA— >CAA K24Q ACT— >CGG T53R 706 736 112.23
CAA >AAT Q38N GAT→TGC D54C
ACA ►CGG T53 GCA→GTT A55V
GAT >TGC D54C GAA→CAG E56Q
GCT >GTT A55V GAT→CCA D57P
GAA >CAG E56Q CAA→GAG Q58E
GAT >CCA D57P GCT→GCC A263A
AAG >GAG K58E
GTT >ATT V60I
AAA >CAA K88Q
TAT ►CAT Y93H
AAT >GAT N97D
AGA >AAA R98K
AAG >CAA K125Q
AAG >CAA K173Q
AAG >AGA K184R
TTT ►ATT F209I
ATG ►AGA M212R
AAT >GAT N214D
CAT ►GAT H219D
TAC >GTT Y221V
GAG >GAT E238D
AAA >CAA K252Q
GCA >GCC A263A
CAA ►AAA Q292K
CAA >GCT Q321A
GAA >GAT E333D
GCT ►ACA A345T
AAT ATT N369I
TCT ►TAC S377Y
ACA ►AGA T405R
AAT >GGT N429G
GCA *TCT A436S
ACC >CCA T501P
GAT ►GAA D536E
d. V220, V221, V222, V223, V224, V225 and V226
CVS variants V220, V221, V222, V223, V224 and V225 were generated by a two- stage overlapping PCR protocol similar to that in Example 4.C.a., using the V75 gene as a template. V226 used the VI 9 gene as template as a comparison to variants produced using V75 as template. First stage PCR reactions used either mutagenic primer 21-140.1 with outer primer 7-10.4, or mutagenic primer 21-140.2 with outer primer 7-10.3 (see Table 18). These mutagenic primers simultaneously randomize the codons for amino acids 212-221 of CVS V19, or its derivatives, including V75. Second stage PCR reactions used primers 7-10.3 and 7-10.4. PCR cleanup, restriction digestion, ligations, transformations, and testing were performed as described in Section A above. The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 are set forth in Table 23 below. V223 does not contain the P281S mutation found in V75 and, V224 has an additional mutation of A319T. These mutations were introduced during PCR amplification.
Table 23. CVS Variants
Amino Amino
Nucleotide acid Nucleotide acid SEQ I D NO Valencene production %
Mutant changes vs. changes changes vs. changes nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
AAA ►CAA K24Q
CAA ►AAT Q38N
AAG ►CAA K58Q
GTT ►ATT V60I
AAA ►CAA K88Q
TAT ►CAT Y93H
AAT ►GAT N97D
AGA ►AAA 98K
AAG ►CAA K125Q
AAG ►CAA K173Q
AAG ►AGA K184R
TTA ■CTG L193L TTG- >CTG L193L
TTT ►ATT F209I AGA-►AAT R212N
ATG ►AAT M212N ATT- TAT I213Y
ATC ►TAT I213Y GAT- CTG D214L
AAT ►CTG N214L TCT— A.GG S215R
TCA ►AGG S215R ACT-►CGT T216R
ACA >CGT T216R TCT-►ATT S217I
AGT ATT S217I GAT- ccc D218P
GAT ►ccc D218P GAT- ►GCA D219A
CAT ►GCA H219A TTG-►GAT L220D
TTA ►GAT L220D GTT- >TCT V221 S 76
V220 718 747
TAC TCT Y221 S GGT- >GGG G276G (665 mg/L) GAG >GAT E238D CCA- TCA P281 S
AAA ►CAA K252Q TTG-►TGC L313C
CCT ►TCA P281 S TCT-►ACG S314T
CAA ►AAA Q292K TTG-►ATG L315M
CTC ►TGC L313C ACC-►AGT T317S
AGC ►ACG S314T GAC- >GAT D329D
CTC ►ATG L315M AAG- CGA K336R
ACT ►AGT T317S TTA-►ATT L337I
CAA >GCT Q321A GGT-►CGG G357R
GAA >GAT E333D
AAA ►CGA K336R
TTG ►ATT L337I
GCT ►ACA A345T
GGA ►CGG G357R
AAT ATT N369I
TCT ►TAC S377Y
ACA ►AGA T405R
AAT ►GGT N429G
GCA TCT A436S
ACC ►CCA T501P
GAT ►GAA D536E
AAA- ►CAA K24Q CAA- ►CGA Q113R
CAA-►AAT Q38N AGA- >GAC R212D
AAG-►CAA K58Q ATT- TAT I213Y
GTT-►ATT V60I GAT-►GAG D214E
AAA-►CAA K88Q TCT-►CAC S215H 75
V221 719 748
TAT-►CAT Y93H ACT-►CAA T216Q (656 mg/L) AAT-►GAT N97D GAT-►ATT D218I
AGA-►AAA R98K GAT-►TTA D219L
CAG-►CGA Q113R TTG- GTT L220V
AAG-►CAA K125Q GTT-►CAA V221Q
Table 23. CVS Variants
Amino Amino
Valencene
Nucleotide acid Nucleotide acid SEQ ID NO
production %
Mutant changes vs. changes changes vs. changes nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
AAG→CAA K173Q GGT→GGG G276G
AAG→AGA K184R CCA→TCA P281 S
TTT→ATT F209I TTG→TGC L313C
ATG→GAC M212D TCT→ACG S314T
ATC→TAT I213Y TTG→ATG L315M
AAT→GAG N214E ACC→AGT T317S
TCA→CAC S215H GAC→GAT D329D
ACA→CAA T216Q AAG→CGA K336R
AGT→TCT S217S TTA→ATT L337I
GAT→ATT D218I GGT→CGG G357R
CAT→TTA H219L
TTA→GTT L220V
TAC→CAA Y221Q
GAG→GAT E238D
AAA→CAA K252Q
CCT→TCA P281 S
CAA→AAA Q292K
CTC→TGC L313C
AGC→ACG S314T
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
ACC→CCA T501P
GAT→GAA D536E
AAA→CAA K24Q R212S
CAA→AAT Q38N AGA→TCC I213L
AAG→CAA K58Q ATT→CTG D214E
GTT→ATT V60I GAT→GAA S215P
AAA→CAA K88Q TCT→CCT T216P
TAT→CAT Y93H ACT→CCC S217F
AAT→GAT N97D TCT→TTC D218M
AGA→AAA R98K GAT→ATG D219H
AAG→CAA K125Q GAT→CAC L220P 80
V222 774 831
AAG→CAA K173Q TTG→CCC V221C (703 mg/L) AAG→AGA K184R GTT→TGC L313C
TTT→ATT F209I TTG→TGC S314T
ATG→TCC M212S TCT→ACG L315M
ATC→CTG I213L TTG→ATG T317S
AAT→GAA N214E ACC→AGT D329D
TCA→CCT S215P GAC→GAT K336R
ACA→CCC T216P AAG→CGA L337I
AGT→TTC S217F TTA→ATT G357R
Table 23. CVS Variants
Amino Amino
Valencene
Nucleotide acid Nucleotide acid SEQ ID NO
production %
Mutant changes vs. changes changes vs. changes nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
GAT→ATG D218M GGT→CGG
CAT→CAC H219H
TTA→CCC L220P
TAC→TGC Y221C
GAG→GAT E238D
AAA→CAA K252Q
GGG→GGT G276G
CAA→AAA Q292K
CTC→TGC L313C
AGC→ACG S314T
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
ACC→CCA T501P
GAT→GAA D536E
AAA→CAA K24Q
CAA→AAT Q38N
AAG→CAA K58Q
GTT→ATT V60I
AAA→CAA K88Q GAA→GAG E163E
TAT→CAT Y93H AGA→GCG R212A
AAT→GAT N97D ATT→ATC 12131
AGA→AAA R98K GAT→TAT D214Y
AAG→CAA K125Q TCT→GCA S215A
AAG→CAA K173Q ACT→AGG T216R
AAG→AGA K184R TCT→ACA S217T
GAA→GAG EJ63E GAT→GGA D218G
TTT→ATT F209I GAT→CGC D219R
ATG→GCG M212A TTG→ATG L220M 78.9
V223 775 832
AAT→TAT N214Y GTT→AAC V221N (688 mg/L) TCA→GCA S215A TTG→TGC L313C
ACA→AGG T216R TCT→ACG S314T
AGT→ACA S217T TTG→ATG L315M
GAT→GGA D218G ACC→AGT T317S
CAT→CGC H219R GAC→GAT D329D
TTA→ATG L220M AAG→CGA K336R
TAC→AAC Y221N TTA→ATT L337I
GAG→GAT E238D GGT→CGG G357R
AAA→CAA K252Q
GGG→GGT G276G
CAA→AAA Q292K
CTC→TGC L313C
AGC→ACG S314T
Table 23. CVS Variants
Amino Amino
ene
Nucleotide acid Nucleotide acid SEQ ID NO Valenc production %
Mutant changes vs. changes changes vs. changes nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
ACC→CCA T501P
GAT→GAA D536E
AAA→CAA K24Q
CAA→AAT Q38N
AAG→CAA K58Q
GTT→ATT V60I
AAA→CAA K88Q
TAT→CAT Y93H
AAT→GAT N97D
AGA→AAA R98K
AAG→CAA K125Q GAA→GAG E42E
AAG→CAA K173Q AGA→AAT R212N
AAG→AGA K184R ATT→ATG I213M
TTT→ATT F209I GAT→TCT D214S
ATG→AAT M212N TCT→TCG S215S
ATC→ATG I213M ACT→TAC T216Y
AAT→TCT N214S TCT→CGG S217R
TCA→TCG S215S GAT→GGG D218G
ACA→TAC T216Y GAT→TGC D219C
AGT→CGG S217R TTG→AGC L220S
77
V224 GAT→GGG D218G GTT→GTG V221 V 720 749
(675 mg/L)
CAT→TGC H219C GGT→GGG G276G
TTA→AGC L220S CCA→TCA P281 S
TAC→GTG Y221V TTG→TGC L313C
GAG→GAT E238D TCT→ACG S314T
AAA→CAA K252Q TTG→ATG L315M
CCT→TCA P281 S ACC→AGT T317S
CAA→AAA Q292K GCT→ACT A319T
CTC→TGC L313C GAC→GAT D329D
AGC→ACG S314T AAG→CGA K336R
CTC→ATG L315M TTA→ATT L337I
ACT→AGT T317S
GCA→ACT A319T
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→GGT G357G
Table 23. CVS Variants
Amino Amino
Nucleotide acid Nucleotide acid SEQ ID NO Valencene production %
Mutant changes vs. changes changes vs. changes nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
ACC→CCA T501P
GAT→GAA D536E
AAA→CAA K24Q
CAA→AAT Q38N
AAG→CAA K58Q
GTT→ATT V60I
AAA→CAA K88Q
TAT→ CAT Y93H
AAT→GAT N97D
AGA→AAA R98
AAG→CAA K125Q
AAG→CAA K173Q
AAG→AGA K184R
TTT→ATT F209I
AGA→GAT R212D
ATG→GAT M212D
ATT→GCA I213A
ATC→GCA I213A
GAT→AAC D214N
AAT→AAC N214N
TCT→GGT S215G
TCA→GGT S215G
ACT→GAA T216E
ACA→GAA T216E
TCT→AAG S217K
AGT→AAG S217K
GAT→GTC D218V
GAT→GTC D218V
GAT→TTG D219L
CAT→TTG H219L
TTG→AGT L220S
TTA→AGT L220S
GTT→TTT V221F 76
V225 TAC→TTT Y221F 721 750
GGT→GGG G276G (668 mg/L) GAG→GAT E238D
CCA→TCA P281 S
AAA→CAA 252Q
TTG→TGC L313C
CCT→TCA P281 S
TCT→ACG S314T
CAA→AAA Q292
TTG→ATG L315M
CTC→TGC L313C
ACC→AGT T317S
AGC→ACG S314T
GAC→GAT D329D
CTC→ATG L315M
AAG→CGA K336R
ACT→AGT T317S
TTA→ATT L337I
CAA→GCT Q321A
GGT→CGG G357R
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
ACC→CCA T501P
GAT→GAA D536E
AAA→CAA K24Q AGA→TCA R212S 98
V226 722 751
CAA→AAT Q38N ATT→CGT I213R (860 mg/L)
Table 23. CVS Variants
Amino Amino
Nucleotide acid Nucleotide acid SEQ I D NO Valencene production %
Mutant changes vs. changes changes vs. changes nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
AAG ►CAA K58Q GAT- ÷TCC D214S
GTT ►ATT V60I TCT-►AAG S215K
AAA ►CAA K88Q ACT- >CCG T216P
TAT ►CAT Y93H TCT- ^TTT S217F
AAT ►GAT N97D GAT- ^TGC D218C
AGA ►AAA 98K GAT- TGG D219W
AAG ►CAA K125Q TTG-►ACC L220T
AAG ►CAA K173Q GTT- *TCC V221 S
AAG ►AGA K184R TCT- ►rcc S401S
TTT ►ATT F209I
ATG ►TCA M212S
ATC ►CGT I213R
AAT >TCC N214S
TCA >AAG S215K
ACA ►CCG T216P
AGT *TTT S217F
GAT ►TGC D218C
CAT ►TGG H219W
TTA ►ACC L220T
TAC ►TCC Y221 S
GAG >GAT E238D
AAA ►CAA K252Q
CAA ►AAA Q292K
CAA >GCT Q321A
GAA >GAT E333D
GCT ►ACA A345T
AAT ATT N369I
TCT ►TAC S377Y
AGT TCC S401S
ACA ►AGA T405R
AAT ►GGT N429G
GCA TCT A436S
ACC ►CCA T501P
GAT ►GAA D536E
e. CVS variant V227
CVS variant V227 was generated by a single PCR reaction from the V75 gene usi i forward and reverse primers that introduce a mutation at amino acid residue F209. CVS variant V227, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 is set forth in Table 24 below.
Table 24. CVS Variant
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. % vs. V19 nt aa
wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AAA— >CAA K24Q CAA→CAG Q142Q
V227 CAA— > AAT Q38N ATT— >CAC I209H 800 857 85%
AAG— >CAA K58Q GGT→GGG G276G
Table 24. CVS Variant
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GTT ►ATT V60I CCA- ►TCA P281 S
AAA ►CAA K88Q TTG-►TGC L313C
TAT ►CAT Y93H TCT- >ACG S314T
AAT ►GAT N97D TTG-►ATG L315M
AGA ►AAA 98K ACC-►AGT T317S
AAG ►CAA K125Q GAC- >GAT D329D
CAA >CAG Q142Q AAG-►CGA K336R
AAG ►CAA K173Q TTA-►ATT L337I
AAG ►AGA K184R GGT-►CGG G357R
TTT ►CAC F209H
ATG ►AGA M212R
AAT ►GAT N214D
CAT ►GAT H219D
TAC ►GTT Y221V
GAG ►GAT E238D
AAA ►CAA K252Q
CCT ►TCA P281 S
CAA ►AAA Q292K
CTC ►TGC L313C
AGC ►ACG S314T
CTC ►ATG L315M
ACT ►AGT T317S
CAA >GCT Q321A
GAA >GAT E333D
AAA ►CGA K336R
TTG ►ATT L337I
GCT ►ACA A345T
GGA ►CGG G357R
AAT ATT N369I
TCT ►TAC S377Y
ACA ►AGA T405R
AAT ►GGT N429G
GCA TCT A436S
ACC ►CCA T501P
GAT ►GAA D536E
Example 5
Variants containing domains or regions from other terpene synthases
In this example, CVS variants were generated containing heterologies amino acids from 5-epi-aristolochene synthase from Nicotiana tabacum (TEAS, SEQ ID NO:941), premnaspirodiene synthase from Hyoscyamus muticus (HPS, SEQ ID NO:942) or valencene synthase from Vitis vinifera (SEQ ID NO:346). The mutants were generated as described below and in subsections a-k.
In general, the CVS variants were generated by a modification of the PCR method as described in Example 3.C.I . above, using primers that introduce mutations at multiple codon positions simultaneously.
- -
Overlapping PCR was used to generate multiple mutations in specific surface loops of V75, V19, or later derivatives of these variants. For each loop to be mutated, a pair of complementary mutagenic primers was synthesized, with each primer containing 15-20 base pairs of sequence identity on each side of the amino acid positions to be swapped. In some instances, random nucleotides were present at multiple codons in the loop targeted for mutagenesis.
Mutagenic primers for the desired loop change were used in PCR reactions with either the upstream primer 1 1-154.3 (SEQ ID NO:928) or the downstream primer 1 1-154.4 (SEQ ID NO:927) to generate two PCR products, each containing either random nucleotides or codons from heterologous valencene synthase genes at the desired codons. PCR conditions were one cycle at 96 °C for 2 minutes and then 20-30 cycles of 94 °C for 30 seconds, 50 °C for 30 seconds, and 72 °C for 2 minutes. Only a single stage of PCR was performed for each reaction. Each resulting PCR-generated gene fragment had 30-200 nucleotides of overlap with the YEp-CVS-ura vector on the outer end, and with the compatible PCR product on the inner end.
The PCR reactions were run on a 1 % agarose gel and the bands containing the designed fragment sizes were excised from the gel. The DNA was then eluted using a Qiaquick column (Qiagen). The YEp-CVS-ura vector was digested with restriction enzymes Kpn\ and Xba\ and purified on a 1% agarose gel and the bands containing the -6.4 kb fragment were excised from the gel. The DNA was then eluted using a Qiaquick column (Qiagen).
Approximately 250 ng of clean, digested, plasmid DNA and 250 ng of each clean PCR product were mixed, and the mixture was transformed directly into Saccharomyces cerevisiae strain A 1x7-95 using a lithium acetate yeast transformation kit from Sigma-Aldrich. Transformants having generated a complete plasmid by yeast homologous recombination were selected on SDE agar medium (0.67 % Bacto yeast nitrogen base without amino acids, 2 % glucose, 0.14 % yeast synthetic drop-out medium without uracil, leucine, histidine, tryptophan, 40 mg L ergosterol) after three days growth at 28-30 °C.
All of the generated mutants were screened in ALX7-95 using the microvial method described in Example 3.C.2, above, and mutants with >1 10 % valencene productivity of CVS V19 (i.e., 10 % increase in valencene versus CVS V19) were further screened in shake flask cultures. The identified mutants were sequenced. Tables 26-37 below sets forth the identified mutants, including the nucleic acid and amino acid mutations, and the percent (%) valencene production in initial microcultures and shake flask cultures relative to the valencene production of transformants containing the CVS V 19 gene.
RECTIFIED SHEET (RULE 91)
ISA/EP
In some instances, the nucleic acid mutation was silent such that the amino acid sequence of resulting valencene synthase was the same as that of CVS VI 9. In addition, the nucleic acid encoding the mutant CVS V19 (SEQ ID NO: 129) is codon optimized for yeast. Silent mutations that differ from those found in CVS VI 9 (see Table 11) are indicated in italic font. Several mutants contain the mutation Q58K. Parental gene CVS VI 9 contains the mutation K58Q. Thus, compared to wildtype CVS, this mutation is silent, albeit with a change in the nucleic acid codon (AAG in wildtype CVS, AAA in the mutant CVS). In the table below, dashes indicate deletions or insertions. For example, nucleotides corresponding to LI 75 and VI 76 are deleted in V232, thus the resulting variant is 2 amino acids shorter than wildtype CVS. Conversely, V239 contains 3 amino acid insertions at residues R91, A92 and
D93.
Table 25. Oligos for PCR
Primer Sequence SEQ ID
NO
TEAS53-58
downstream: 7- ACTTGACCAAACCTCTGGCG
339 10.4
upstream: 7-10.3 CCAAGCTGAATTCGAGCTCG 338
Mutagenic 1 : 21- GTTAGAAGAATGATTTTAGCAACCGGAAGGAAACCAATTCAAAAATT
342 108-3 G
Mutagenic 2: 21- CAATTTTTGAATTGGTTTCCTTCCGGTTGCTAAAATCATTCTTCTAA
343 108-4 C
Upstream and Downstream primers
downstream 11- AGCCGACAACCTTGATTGGAGACT
927 154.4
upstream 11- AATGAGCAACGGTATACGGC
928 154.3
CVS 85-99 with HPS 93-110
21-130.3 CATTTACAGAGCTGATCCTTATTTTGAGGCTCATGAATACAATGATT
929 TGCATACTGTTTC
21-130.4 AAATAAGGATCAGCTCTGTAAATGTGATCCAACATATCTTCAATTTC
930 TTTTTCAAAATGG
CVS 85-99 with Vitis 96-112
21-141.7 GAAAAAGAAATTGAAGATGCATTACAACATATTTGTAATAGTTTTCA
931 TGACTGCAATGATATGGATGGTGATTTGCATACTGTTTC
21-141.8 GAAACAGTATGCAAATCACCATCCATATCATTGCAGTCATGAAAACT
932 ATTACAAATATGTTGTAATGCATCTTCAATTTCTTTTTC
CVS90-99with Vitis 101-113
21-141.3 GCTATTCAACAATTGTGTAATAGTTTTCATGACTGCAATGAT
1002 ATGGATGGTGATTTGCATACTGTTTC
21-141.4 GAAACAGTATGCAAATCACCATCCATATCATTGCAGTCATGA
1003 AAACTATTACACAATTGTTGAATAGC
CVS 115-146 with Vitis 128-159
21-145.29 CATTTCAGATTGTTGAGACAACAAGGGTACACTATTTCATGTG 1004
21-145.30 CACATGAAATAGTGTACCCTTGTTGTCTCAACAATCTGAAATG 1005
21-145.39 GATGTAAGAGGCATGCTAGGCTTGTATGAAGCTGCTTATATG 1006
21-145.40 CATATAAGCAGCTTCATACAAGCCTAGCATGCCTCTTACATC 1007
CVS 174-184 with HPS 185-193 or TEAS 177-185
21-134.9 TCTGCAGCTCCACATTTGAAGTCACCTTTGGCTGAACAAATTAAC 933
21-134.10 AGGTGACTTCAAATGTGGAGCTGCAGATTGCAAATGAGTAGTAG 934
CVS 212-221 with HPS 221-228
21-141.5 GCAAGATACATTATGTCAATCTACGAAGAGGAGGAATTTAAGAACAA
935 GACTTTGTTAAATTTC
21-141.6 GAAATTTAACAAAGTCTTGTTCTTAAATTCCTCCTCTTCGTAGATTG
936 ACATAATGTATCTTGC
CVS 212-221 with TEAS 213-221
21-145.1 GCAAGATACATTATGTCATCAATCTATGACAAGGAACAATCGAAGAA
937 CAAGACTTTGTTAAATTTC
21-145.2 GAAATTTAACAAAGTCTTGTTCTTCGATTGTTCCTTGTCATAGATTG
938 ATGACATAATGTATCTTGC
CVS 212-221 with Vitis 223-230
21-145.3 GCAAGATACATTATGTCAGTCTACCAAGATGAAGCTTTCCATAACAA
939 GACTTTGTTAAATTTC
21-145.4 GAAATTTAACAAAGTCTTGTTATGGAAAGCTTCATCTTGGTAGACTG
940 ACATAATGTATCTTGC
CVS 212-221 random primer
21-140.1 GAAGCAAGATACATTATGTCANNNNNNNNNNNNNNNNNNNNNNNNNN
902 NNNNAAC AAGAC T T T G T TAAATT T C G
21-140.2 CGAAATTTAACAAAGTCTTGTTNNNNNNNNNNNNNNNNNNNNNNNNN
903 NNNNNTGACATAATGTATCTTGCTTC
a. V228, V229, V230 and V231
In CVS variants V228, V229, V230 and V231, amino acids 53-58 of CVS were replaced by amino acids 58-63 of TEAS (SEQ ID NO:295) as described above with primers 7-10.4 and 7-10.3 (see Table 25). CVS variant V229 was generated by recombination of
5 mutation in variants V228 and V73 using standard recombinant DNA and PCR methods.
CVS variants V230 and V231 were generated by recombination of mutations in variants
V228 and V75. The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 are set forth in
Tables 26-27 below.
Table 26. CVS Variant V228
Amino Amino SEQ ID Valencene
Initial
Nucleotide acid Nucleotide acid NO production micro-
Mutant changes vs. changes changes vs. changes nt aa % vs. V19 culture %
wildtype vs. CVS V19 vs. CVS (Shake vs. V19
wildtype V19 Flask)
AAA→CAA K24Q
CAA→AAT Q38N
ACA→ TTA T53L
GAT→ GCA D54A
GCT→ ACC A55T
GAA→ GGA E56G
ACT→ TTA T53L
GAT→ AGG D57R
GAT→ GCA D54A
AAG→ AAA K58K
GCA→ ACC A55T
V228 GTT→ATT V60I 203 67 102.52 ND
GAA→ GGA E56G
AAA→CAA K88Q
GAT→ AGG D57R
TAT→CAT Y93H
CAA→ AAA Q58K
AAT→GAT N97D
AGA→AAA R98K
AAG→CAA K125Q
AAG→CAA K173Q
AAG→AGA K184R
TTT→ATT F209I
ATG- >AGA M212
AAT-►GAT N214D
CAT-►GAT H219D
TAC- >GTT Y221V
GAG- >GAT E238D
AAA-►CAA K252Q
CAA-►AAA Q292K
CAA- >GCT Q321A
GAA- >GAT E333D
GCT- >ACA A345T
AAT- >ATT N369I
TCT- >TAC S377Y
ACA-►AGA T405R
AAT-►GGT N429G
GCA- TCT A436S
ACC-►CCA T501P
GAT- >GAA D536E
Table 27. CVS Variants
Amino Amino
Nucleotide acid Nucleotide acid SEQ I D NO Valencene production %
Mutant changes vs. changes changes vs. changes nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
AAA >CAA K24Q
CAA >AAT Q38N
ACA >TTA T53L
GAT ►GCA D54A
GCT ►ACC A55T
GAA >GGA E56G
GAT ►AGG D57R
AAG >AAA K58K
GTT >ATT V60I
AAA >CAA K88Q ACT- TTA T53L
TAT ►CAT Y93H GAT- GCA D54A
AAT >GAT N97D GCA- ACC A55T
AGA >AAA R98K GAA- >GGA E56G
AAG >CAA K125Q GAT-►AGG D57R
AAG >CAA K173Q CAA-►AAA Q58K
V229 AAG >AGA K184R GGT- >GGG G276G
(V228 TTT ►ATT F209I CCA- TCA P281 S
352 350 91.67 and ATG ►AGA M212R TTG- >TGC L313C
V73) AAT >GAT N214D TCT-►ACG S314T
CAT ►GAT H219D TTG-►ATG L315M
TAC >GTT Y221V ACC- >AGT T317S
GAG GAT E238D AAG- CGA K336R
AAA >CAA K252Q TTA-►ATA L337I
CCT ►TCA P281 S AAC- *TTG N347L
CAA ►AAA Q292K GGT- CGT G357R
CTC ►TGC L313C
AGC ►ACG S314T
CTC ►ATG L315M
ACT ►AGT T317S
CAA >GCT Q321A
GAA GAT E333D
AAA >CGA K336R
TTG ►ATA L337I
GCT ►ACA A345T
Table 27. CVS Variants
Amino Amino
Valencene
Nucleotide acid Nucleotide acid SEQ I D NO
production %
Mutant changes vs. changes changes vs. changes nt aa vs. V19 wildtype vs. CVS V19 vs. CVS
(Shake Flask) wildtype V19
AAT- TTG N347L
GGA- >CGT G357
AAT- ATT N369I
TCT-►TAC S377Y
ACA-►AGA T405R
AAT- >GGT N429G
GCA- *TCT A436S
ACC- >CCA T501P
GAT-►GAA D536E
AAA ^CAA K24Q
CAA →AAT Q38N
ACA ->TTA T53L
GAT *GCA D54A
GCT ÷ACC A55T
GAA ^GGA E56G
GAT >AGG D57R
AAG +AAA K58K
GTT ■ ATT V60I
AAA ^CAA K88Q
TAT ÷CAT Y93H
AAT ^GAT N97D
AGA ■ AAA R98K
AAG ^CAA K125Q ACT- TTA T53L
AAG ^CAA K173Q GAT- >GCA D54A
AAG ^AGA K184R GCA- >ACC A55T
TTT *ATT F209I GAA- >GGA E56G
ATG >AGA M212R GAT- >AGG D57R
AAT ^GAT N214D CAA- >AAA Q58K
V230
CAT ÷GAT H219D GGT- >GGG G276G
V231
TAC ->GTT Y221V CCA- >TCA P281 S
(V228 353 351 ND
GAG ->GAT E238D TTG- >TGC L313C
and
AAA ^CAA K252Q TCT-►ACG S314T
V75)
CAA AAA Q292K TTG- >ATG L315M
CCT ÷TCA P281 S ACC- >AGT T317S
CTC ÷TGC L313C GAC- *GAT D329D
AGC ÷ACG S314T AAG- >CGA K336R
CTC >ATG L315M TTA- >ATT L337I
ACT ÷AGT T317S GGT- >CGG G357R
CAA ^GCT Q321A
GAA ->GAT E333D
AAA ^CGA K336R
TTG ^ATT L337I
GCT *ACA A345T
GGA ^CGG G357R
AAT →ATT N369I
TCT *TAC S377Y
ACA *AGA T405R
AAT ^GGT N429G
GCA →TCT A436S
ACC ^CCA T501P
GAT >GAA D536E
b. V232, V233, V234, V235, V236, V237 and V238
In CVS variants V232, V233, V234, V235, V236, V237 and V238, amino acids 174- 184 were replaced by the equivalent amino acids from HPS (amino acids 185-193 of SEQ ID NO: 942) by the direct yeast recombination method as described above using mutagenic primers 21-134.9 and 21-134.10 with outer primers 11-154.3 and 11-54.4 (see Table 25).
CVS variants V232, V233, V234, V235 and V236 were generated using V75 (SEQ ID
NO: 130) as a template. CVS variant V237 was generated by recombination of mutations in V235 and V236. This variant additionally contained a mutation at E484 generated by a random PCR error. V237 was isolated from Alx7-95 and was sequenced. In parallel, V237 was transformed into Alxl 1-30 for testing in that strain. V238 was re-isolated from Alxl 1 -30. The variants, including amino acid and nucleotide changes versus both wildtype CVS and
CVS VI 9, and valencene production % versus CVS VI 9 are set forth in Table 28 below. All of these CVS variants contain two amino acid deletions since the corresponding sequence of
HPS is 2 amino acids shorter than that of CVS.
Table 21 3. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. % vs. V19 nt aa
wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AAA→CAA K24Q
CAA→AAT Q38N
AAG→CAA K58Q
GTT→ATT V60I
AAA→CAA K88Q
TAT→CAT Y93H
ACT→ACC T168T
AAT→GAT N97D
TCA→TCT S174S
AGA→AAA R98K
TTG→— L175→—
AAG→CAA K125Q
GTT→— V176→—
ACT→ACC T168T
CAA→GCT Q178→A176
AAG→CAA K173Q
GAT→CCA D179→P177
TCA→ TCT S174S
GTT→TTG V181→L179
TTG→— L175→—
V232 ACT→AAG T182→K180
GTA→— V176→— 90.00 V233 CCA→TCA P183→S181
CAG→GCT Q178→A176 ND V234 AGA→CCT R184→P182
GAT→CCA D179→P177 702 732 88.20 V235 GGT→GGG G276→G274
GTA→TTG V181→L179 82.15 V236 CCA→TCA P281→S279
ACC→AAG T182→K180 83.17 (546 aa) TTG→TGC L313→C311
CCT→TCA P183→S181
TCT→ACG S314→T312
AAG→CCT K184→P182
TTG→ATG L315→M313
TTT→ATT F209→I207
ACC→AGT T317→S315
ATG→AGA M212→R210
GAC→GAT D329→D327
AAT→GAT N214→D212
AAG→CGA K336→R334
CAT→GAT H219→D217
TTA→ATT L337→I335
TAC→GTT Y221→V219
GGT→CGG G357→R355
GAG→GAT E238→D236
AAA→CAA K252→Q250
CCT→TCA P281→S279
CAA→AAA Q292→K290
CTC→TGC L313→C311
AGC→ACG S314→T312
Table 28. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
CTC- ►ATG L315- ■M313
ACT- >AGT T317- >S315
CAA- >GCT Q321- >A319
GAA- >GAT E333- ►D331
AAA- >CGA K336- > 334
TTG- >ATT L337- ^1335
GCT-►ACA A345- >T343
GGA- >CGG G357- >R355
AAT- ATT N369- →I367
TCT-►TAC S377- ►Y375
ACA-►AGA T405- >R403
AAT- >GGT N429- >G427
GCA- *TCT A436- S434
ACC- >CCA T501- >P499
GAT-►GAA D536- E534
TCG ■CGG S2R
TCT GAC S3D
GGA >AAG G4K
GAA ►GGT E5G
ACA ACQ T6T
TTT ■TGT F7C
AAA ►CAA K24Q TCA ►CGG S2R
CAA >AAT Q38N TCT >GAC S3D
AAG ►CAA K58Q GGT ►AAG G4K
GTT >ATT V60I GAA >GGT E5G
AAA ►CAA K88Q ACT ACG T6T
TAT .CAT Y93H TTT ►TGT F7C
AAT ►GAT N97D TCA ► TCT S174S
AGA ►AAA R98K TTG L175→—
AAG ►CAA K125Q GTT V176→—
AAG ►CAA K173Q CAA >GCT Q178→A176
TCA TCT S174S GAT ►CCA D179→P177
TTG L175→— GTT ►TTG V181→L179 99.15
V237
GTA V176→— ACT ■AAG T182→K180 (Alx7-95) V238 703 733
CAG ►GCT Q178→A176 CCA >TCA P183→S181 121 (546 aa)
GAT ►CCA D179→P177 AGA >CCT R184→P182 (Alxl l-30) GTA ►TTG V181→L179 GGT ■GGG G276→G274
ACC AAG T182→K180 CCA >TCA P281→S279
CCT TCA P183→S181 TTG ►TGC L313→C311
AAG >CCT K184→P182 TCT ACG S314→T312
TTT ATT F209→I207 TTG ►ATG L315→M313
ATG AGA M212→R210 ACC ►AGT T317→S315
AAT ►GAT N214→D212 GAC GAT D329→D327
CAT >GAT H219→D217 AAG ►CGA K336→R334
TAC ►GTT Y221→V219 TTA ►ATT L337→I335
GAG ►GAT E238→D236 GGT ►CGG G357→R355
AAA ►CAA K252→Q250 GAG >GAT E484→D482
CCT TCA P281→S279
CAA ■AAA Q292→K290
CTC TGC L313→C311
AGC >ACG S314→T312
CTC ATG L315→M313
ACT AGT T317→S315
Table 213. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
CAA→GCT Q321→A319
GAA→GAT E333→D331
AAA→CGA K336→R334
TTG→ATT L337→I335
GCT→ACA A345→T343
GGA→CGG G357→R355
AAT→ATT N369→I367
TCT→TAC S377→Y375
ACA→AGA T405→R403
AAT→GGT N429→G427
GCA→TCT A436→S434
GAA→GAT E484→D482
ACC→CCA T501→P499
GAT→GAA D536→E 534
c. V239, V240, and V241
In CVS variants V239, V240, and V241, amino acids 53-58 were replaced by amino acids 58-63 of TEAS (SEQ ID NO:941), amino acids 85-99 were replaced by amino acids 93- 110 of HPS (SEQ ID NO:942) and amino acids 174-184 were replaced by amino acids 185- 193 of HPS (SEQ ID NO:942) or 177-185 of TEAS (SEQ ID NO:941) by direct yeast recombination as described above (see Table 25). Amino acids 185-193 of HPS are identical to amino acids 177-185 of TEAS. These mutants were generated from two PCR fragments. To generate the first fragment, the V228 variant was used as a template with oligos 11-154.3 and mutagenic primer 21-130.4. To generate the second fragment, V237/V238 was used as a template with outer oligo 11-154.4 and mutagenic primer 21 -130.3.
The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS V19, and valencene production % versus CVS V19 are set forth in Table 29 below. Use of the HPS loops to replace amino acids 85-99 and 174-184 results in the addition of three amino acid residues and the deletion of two amino acid residues, respectively, resulting in a protein that is one amino acid longer than wildtype CVS. In addition to the designed mutations from V228 and V237/V238, V239 contains a mutation at LI 11 that thought to be the result of a PCR error. Likewise, V240 also has a mutation at R19.
Table 29. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AAA→CAA K24Q ACT→TTA T53L
V239 CAA→AAT Q38N GAT→GCA D54A
713 743 87.5 (549 aa) ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
Table 29. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57 GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA — >R91
TTA→ATT L89I -— >GCT — >A92
TGT→TAC C90Y -— >GAT — >D93
>AGA >R91 CCA→CCT P91→P94 >GCT >A92 ATT→TAT I92→Y95 >GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98 TAT→TTT Y93→F96 TCT→CAT S96→H99 ATT→GAG I94→E97 GAT→GAA D97→E100 GAC→GCT D95→A98 AAA→TAC K98→Y101 AGT→CAT S96→H99 GCT→AAT A99→N102 AAT→GAA N97→E100 TTG→TCG L111→S114 AGA→TAC R98→Y101 TCA→TCT S174→S177 GCT→AAT A99→N102 TTG→— L175→- CTT→TCG L111→S114 GTT→— V176→- AAG→CAA K125→Q128 CAA→GCT Q178→A179 AAG→CAA K173→Q176 GAT→CCA D179→P180 TCA→ TCT S174→S177 GTT→TTG V181→L182 TTG→— L175→— ACT→AAG T182→K183 GTA→— V176→— CCA→TCA P183→S184 CAG→GCT Q178→A179 AGA→CCT R184→P185 GAT→CCA D179→P180 GGT→GGG G276→G277 GTA→TTG V181→L182 CCA→TCA P281→S282 ACC→AAG T182→K183 TTG→TGC L313→C314 CCT→TCA P183→S184 TCT→ACG S314→T315 AAG→CCT K184→P185 TTG→ATG L315→M316 TTT→ATT F209→I210 ACC→AGT T317→S318 ATG→AGA M212→R213 GAC→GAT D329→D330 AAT→GAT N214→D215 AAG→CGA K336→R337 CAT→GAT H219→D220 TTA→ATT L337→I338 TAC→GTT Y221→V222 GGT→CGG G357→R358 GAG→GAT E238→D239 GAG→GAT E484→D485 AAA→CAA K252→Q253
CCT→TCA P281→S282
CAA→AAA Q292→K293
ACT→ACC T303→T304
CTC→TGC L313→C314
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
CAA→GCT Q321→A322
GAA→GAT E333→D334
AAA→CGA K336→R337
TTG→ATT L337→I338
Table 29. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GCT- ►ACA A345- >T346
GGA- >CGG G357- > 358
AAT- ATT N369-■ I370
TCT-►TAC S377- >Y378
ACA-►AGA T405-►R406
AAT- >GGT N429-►G430
GCA- TCT A436- >S437
GAA- >GAT E484- >D485
ACC- >CCA T501- >P502
GAT-►GAA D536- >E537
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 TTT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
V240
TAT→TTT Y93→F96 TCT→CAT S96→H99 714 744 105 (549 aa)
ATT→GAG I94→E97 CAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→ TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→ TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 GGT→GGG G276→G277
GTA→TTG V181→L182 CCA→TCA P281→S282
ACC→AAG T182→K183 TTG→TGC L313→C314
CCT→TCA P183→S184 TCT→ACG S314→T315
AAG→CCT K184→P185 TTG→ATG L315→M316
TTT→ATT F209→I210 ACC→AGT T317→S318
ATG→AGA M212→R213 GAC→GAT D329→D330
AAT→GAT N214→D215 AAG→CGA K336→R337
CAT→GAT H219→D220 TTA→ATT L337→I338
Table 29. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TAC >GTT Y221 >V222 GGT→CGG G357→R358
GAG >GAT E238 ►D239 GAG→GAT E484→D485
AAA >CAA K252 >Q253
CCT ►TCA P281 >S282
CAA ►AAA Q292 >K293
ACT >ACC T303 >T304
CTC ►TGC L313 ►C314
AGC ►ACG S314 ►T315
CTC ►ATG L315 ■M316
ACT >AGT T317 >S318
CAA >GCT Q321 >A322
GAA >GAT E333 ►D334
AAA >CGA K336 >R337
TTG >ATT L337 ÷I338
GCT ►ACA A345 >T346
GGA >CGG G357 >R358
AAT ATT N369 ■»I370
TCT ►TAC S377 ►Y378
ACA ►AGA T405 ►R406
AAT >GGT N429 >G430
GCA *TCT A436 >S437
GAA >GAT E484 ►D485
ACC >CCA T501 >P502
GAT ►GAA D536 >E537
AAA- →CAA K24Q ACT→TTA T53L
CAA- →AAT Q38N GAT→GCA D54A
ACA- →TTA T53L GCA→ACC A55T
GAT- →GCA D54A GAA→GGA E56G
GCT- →ACC A55T GAT→AGG D57R
GAA- →GGA E56G CAA→AAA Q58K
GAT- →AGG D57R GCT→ATG A85M
AAG- →AAA K58K ATT→TTG I86L
GTT- →ATT V60I CAA→GAT Q87D
GCA- →ATG A85M CAA→CAC Q88H
ATA- →TTG I86L TTG→ATT L89I
CAA- →GAT Q87D TGT→TAC C90Y
AAA- →CAC K88H >AGA -— >R91
TTA- →ATT L89I -— >GCT -— >A92
V241
TGT- →TAC C90Y -— >GAT -— >D93 715 745 77.8 (549 aa)
AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
■GAT >D93 CAT→TTT H93→F96
CCA- →CCT P91→P94 ATT→GAG I94→E97
ATC- →TAT I92→Y95 GAT→GCT D95→A98
TAT- →TTT Y93→F96 TCT→CAT S96→H99
ATT- ->GAG I94→E97 GAT→GAA D97→E100
GAC- →GCT D95→A98 AAA→TAC K98→Y101
AGT- →CAT S96→H99 GCT→ AAT A99→N102
AAT- ->GAA N97→E100 TCA→TCT S174→S177
AGA- →TAC R98→Y101 TTG→— L175→—
GCT- →AAT A99→N102 GTT→— V176→—
AAG- →CAA K125→Q128 CAA→GCT Q178→A179
AAG- →CAA K173→Q176 GAT→CCA D179→P180
Table 29. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TCA TCT SI 74 ■SI 77 GTT- >TTG V181- L182
TTG L175 ACT-►AAG T182- ►K183
GTA V176 CCA- >TCA P183- >S184
CAG ►GCT Q178 >A179 AGA- ^CCT R184- P185
GAT >CCA D179 >P180 TTG- >CTG L193- L194
GTA ►TTG V181 ►LI 82 GGT- >GGG G276- G277
ACC AAG T182 ■K183 CCA- >TCA P281- >S282
CCT TCA P183 >S184 TTG- >TGC L313- ►C314
AAG >CCT K184 >P185 TCT- >ACG S314- ►T315
TTA CTG LI 93 >L194 TTG-►ATG L315- ■M316
TTT ATT F209 T210 ACC- >AGT T317- >S318
ATG AGA M212 >R213 GAC- >GAT D329- >D330
AAT >GAT N214 >D215 AAG- >CGA K336- >R337
CAT >GAT H219 >D220 TTA- >ATT L337- ^1338
TAC ►GTT Y221 V222 GGT-►CGG G357- >R358
GAG ►GAT E238 ■D239 GAA- >GAG E422- E423
AAA ►CAA K252 >Q253 GAG- >GAT E484- ►D485
CCT TCA P281 >S282
CAA ■AAA Q292 >K293
ACT ACC T303 >T304
CTC TGC L313 >C314
AGC >ACG S314 T315
CTC ATG L315 M316
ACT AGT T317 ►S318
CAA ►GCT Q321 >A322
GAA ►GAT E333 ■D334
AAA ►CGA K336 ►R337
TTG >ATT L337 I338
GCT ACA A345 ►T346
GGA ►CGG G357 ►R358
AAT ►ATT N369 ^1370
TCT TAC S377 •Y378
ACA AGA T405 .R406
AAT >GGT N429 >G430
GCA >TCT A436 ►S437
GAA ►GAT E484 ■D485
ACC >CCA T501 ►P502
GAT GAA D536 ►E537
d. V242
In CVS variant V242, amino acids 212-222 were replaced by amino acids 221-228 of HPS by direct yeast recombination as described above (see Table 25). This CVS variant was generated from V75 as a template using outer primers 11-154.3 with mutagenic primer 21- 141.6, and 11-154.4 with mutagenic primer 21-141.5. The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 are set forth in Table 30 below. This variant contains two amino acid deletions since the corresponding sequence of HPS is 2 amino acids shorter than that of CVS.
Screening of numerous clones showed that all but V242 had titers of -77% of VI 9, while V242 had a titer of 95% of the VI 9 titer. Sequencing revealed mutant V242 contained the sequence IYEEEGFK whereas amino acids 221-228 of HPS are IYEEEEFK. This discrepancy most likely occurred during oligo synthesis.
V243, V244, V245 and V255
In CVS variants V243, V244, V245 and V255, amino acids 53-58 were replaced by amino acids 58-63 of TEAS (SEQ ID NO:941), amino acids 85-99 were replaced by amino acids 93-110 of HPS (SEQ ID NO:942) and amino acids 174-184 were replaced by amino acids 185-193 of HPS (SEQ ID NO:942) or 177-185 of TEAS (SEQ ID NO:295) by direct yeast recombination as described above (see Table 27). These variants additionally contain mutations from V75. In addition, amino acids 212-221 were replaced by 1) amino acids 213- 221 of TEAS or 2) amino acids 223-230 of Vitis vinifera valencene synthase (SEQ ID
NO:346). These CVS variants were generated using V240 as a template, with primers set forth in Table 25 above.
V243 and V244 were generated using V240 as template, with mutagenic primers 21-145.1 and 21-145.5 together with outer oligos 11-154.3 and 11-154.4 (see Table 25). The V245 and V255 CVS variants were generated using V240 as a template, with mutagenic primers 21- 145.3 and 21-145.4, as set forth in Table 25 above.
The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS V19, and valencene production % versus CVS V19 are set forth in Table 31 below. V244 contains a mutation I325T that is not found in V243, presumably introduced during PCR. Variants V245 and V255, which each have the Vitis vinifera valencene synthase sequence at the CVS positions 212-221, differ by a single nucleotide change, presumably generated during PCR, that results in an unexpected Q448 to L447 mutation in V255.
Table 31 L CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AGA→AAA 19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
V243 GCA→ATG A85M CAA→CAC Q88H 777 834 78.93
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 TTT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
Table 31 L CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 CAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→ TCT S174→S177
AGA→TAC 98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→ TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TGG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T GAG→GAT E484D
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
AGA→AAA R19K AGA→AAA R19K
V244 AAA→CAA K24Q ACT→TTA T53L 778 835 77.75
CAA→AAT Q38N GAT→GCA D54A
Table 31 L CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57 GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA — >R91
TTA→ATT L89I -— >GCT — >A92
TGT→TAC C90Y -— >GAT — >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→ TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217-
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q ATT→ACT I325T
CCT→TCA P281 S GAC→GAT D329D
CAA→AAA Q292K AAG→CGA K336R
CTC→TGC L313C TTA→ATT L337I
AGC→ACG S314T GGT→CGG G357R
CTC→ATG L315M GGT→GGA G414G
Table 31 CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
ACT- >AGT T317S GAG→GAT E484D
CAA- >GCT Q321A
ATT-►ACT I325T
GAA- >GAT E333D
AAA- >CGA K336
TTG- >ATT L337I
GCT-►ACA A345T
GGA- >CGG G357R
AAT- ATT N369I
TCT-►TAC S377Y
ACA-►AGA T405R
GGC- GGA G414G
AAT- >GGT N429G
GCA- ^TCT A436S
GAA- GAT E484D
ACC- CCA T501P
GAT-►GAA D536E
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA — >R91
TTA→ATT L89I -— >GCT — >A92
TGT→TAC C90Y -— >GAT — >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
V245 779 836 81.30
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→GTC R212→V213
GTA→TTG V181→L182 ATT→TAC I213→Y214
Table 31 CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
ACC AAG T182 ►K183 GAT D214→- CCT TCA P183 ►S184 TCT S215→- AAG >CCT K184 P185 ACT CAA T216→Q215 TTT ATT F209 >I210 TCT GAT S217→D216 ATG ►GTC M212 >V213 GAT GAA D218→E217 ATC >TAC 1213 Y214 GAT ►GCT D219→A218 AAT N214 TTG ►TTC L220→F219 TCA S215 GTT ■CAT V221→H220 ACA CAA T216 Q215 GGT GGG G276→G275 AGT >GAT S217 D216 CCA ►TCA P281→S280 GAT GAA D218 ►E217 TTG ■TGC L313→C312 CAT >GCT H219 ►A218 TCT ACG S314→T313 TTA ►TTC L220 ►F219 TTG ATG L315→M314 TAC .CAT Y221 ►H220 ACC ■AGT T317→S316 GAG ►GAT E238 ■D237 GAC >GAT D329→D328 AAA ►CAA K252 ►Q251 AAG >CGA K336→R335 CCT TCA P281 ►S280 TTA >ATT L337→I336 CAA ■AAA Q292 ►K291 GGT ■CGG G357→R356 CTC TGC L313 ■C312 GAG ►GAT E484→D483 AGC ■ACG S314 ■T313
CTC ATG L315 M314
ACT AGT T317 ►S316
CAA ►GCT Q321 ►A320
GAA ►GAT E333 ■D332
AAA ►CGA K336 ►R335
TTG >ATT L337 >I336
GCT ACA A345 ►T344
GGA ►CGG G357 ►R356
AAT ►ATT N369 ÷I368
TCT ■TAC S377 Y376
ACA AGA T405 >R404
AAT >GGT N429 ►G428
GCA >TCT A436 >S435
GAA ►GAT E484 ■D483
ACC >CCA T501 ►P500
GAT GAA D536 ►E535
AGA- →AAA R19K AGA- →AAA R19K
AAA- →CAA K24Q ACT- →TTA T53L
CAA- →AAT Q38N GAT- →GCA D54A
ACA- →TTA T53L GCA- →ACC A55T
GAT- →GCA D54A GAA- →GGA E56G
GCT- →ACC A55T GAT- →AGG D57R
GAA- →GGA E56G CAA- →AAA Q58K
GAT- ->AGG D57R GCT- →ATG A85M
V255 AAG- →AAA K58K ATT- →TTG I86L 789 846
GTT- →ATT V60I CAA- →GAT Q87D
GCA- →ATG A85M CAA- →CAC Q88H
ATA- →TTG I86L TTG- →ATT L89I
CAA- →GAT Q87D TGT- →TAC C90Y
AAA- →CAC K88H AGA -— >R91
TTA- →ATT L89I ■GCT -— >A92
TGT- →TAC C90Y GAT -— >D93
AGA CCA- →<XT P91→P94
Table 31 CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
>GCT >A92 ATT ►TAT I92→Y95
>GAT >D93 CAT >TTT H93→F96
CCA→CCT P91→P94 ATT GAG I94→E97 ATC→TAT I92→Y95 GAT ►GCT D95→A98 TAT→TTT Y93→F96 TCT ■CAT S96→H99 ATT→GAG I94→E97 GAT GAA D97→E100 GAC→GCT D95→A98 AAA >TAC K98→Y101 AGT→CAT S96→H99 GCT AAT A99→N102 AAT→GAA N97→E100 TCA >TCT S174→S177 AGA→TAC 98→Y101 TTG L175→—
GCT→AAT A99→N102 GTT V176→—
AAG→CAA K125→Q128 CAA ►GCT Q178→A179 AAG→CAA K173→Q176 GAT >CCA D179→P180 TCA→TCT S174→S177 GTT ►TTG V181→L182 TTG→— L175→— ACT AAG T182→K183 GTA→— V176→— CCA ►TCA P183→S184 CAG→GCT Q178→A179 AGA >CCT R184→P185 GAT→CCA D179→P180 AGA ►GTC R212→V213 GTA→TTG V181→L182 ATT >TAC I213→Y214 ACC→AAG T182→K183 GAT D214→- CCT→TCA P183→S184 TCT S215→- AAG→CCT K184→P185 ACT CAA T216→Q215 TTT→ATT F209→I210 TCT GAT S217→D216 ATG→GTC M212→V213 GAT GAA D218→E217 ATC→TAC I213→Y214 GAT ►GCT D219→A218 AAT→— N214→ - TTG ►TTC L220→F219 TCA→— S215→- GTT CAT V221→H220 ACA→CAA T216→Q215 GGT GGG G276→G275 AGT→GAT S217→D216 CCA ►TCA P281→S280 GAT→GAA D218→E217 TTG TGC L313→C312 CAT→GCT H219→A218 TCT ACG S314→T313 TTA→TTC L220→F219 TTG ATG L315→M314 TAC→CAT Y221→H220 ACC >AGT T317→S316 GAG→GAT E238→D237 GAC >GAT D329→D328 AAA→CAA K252→Q251 AAG ►CGA K336→R335 CCT→TCA P281→S280 TTA ►ATT L337→I336 CAA→AAA Q292→K291 GGT CGG G357→R356 CTC→TGC L313→C312 CAA ►CTA Q448→L447 AGC→ACG S314→T313 GAG ►GAT E484→D483 CTC→ATG L315→M314
ACT→AGT T317→S316
CAA→GCT Q321→A320
GAA→GAT E333→D332
AAA→CGA K336→R335
TTG→ATT L337→I336
GCT→ACA A345→T344
GGA→CGG G357→R356
AAT→ATT N369→I368
TCT→TAC S377→Y376
ACA→AGA T405→R404
AAT→GGT N429→G428
GCA→TCT A436→S435
CAA→CTA Q448→L447
Table 31 L CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GAA→GAT E484→D483
ACC→CCA T501→P500
GAT→GAA D536→E535
f. V246, V247, V248, V249, V250, V251, V252, V253, V254 and V272
In CVS variants V246, V247, V248, V249, V250, V251, V252, V253, V254 and
V272, amino acids 53-58 were replaced by amino acids 58-63 of TEAS (SEQ ID NO:941), amino acids 85-99 were replaced by amino acids 93-110 of HPS (SEQ ID NO:942) and amino acids 174-184 were replaced by amino acids 185-193 of HPS (SEQ ID NO:942) or 177-185 of TEAS (SEQ ID NO:941) as described above. In addition, amino acids 212-222 were replaced by random amino acids.
CVS variants V246, V247, V248, V249, V250, V253 and V254 were generated as described in Example 4C.d., using V240 and VI 9 as templates for the two PCR reactions with oligos set forth in Table 25 above. For example, V246 was produced using random
mutagenic oligos 21-140.1 and 21-140.2 with outer oligos 11-154.3 and 11-154.4 to modify amino acid positions 212 to 221. The PCR reaction with 11-154.3 and 21-140.2 used V240 as template, but the second reaction used VI 9 as template. CVS variants V251 and V252 were generated as described in Example 4.C.a., using V241 and V19 as templates for the two PCR reactions. V272 was generated as in Example 4C.d., with the exception that V240 was used as template in both PCR reactions.
The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS V19, and valencene production % versus CVS V19 are set forth in Table 32 below. Several additional isolates were identified that produce approximately 77 % of the valencene titer of CVS V19, but additionally produce high amounts of b-elemene.
Table 32. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
V246 780 837 103.86
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
Table 32. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92 TGT→TAC C90Y -— >GAT -— >D93 >AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97 ATC→TAT I92→Y95 GAT→GCT D95→A98 TAT→TTT Y93→F96 TCT→CAT S96→H99 ATT→GAG I94→E97 GAT→GAA D97→E100 GAC→GCT D95→A98 AAA→TAC K98→Y101 AGT→CAT S96→H99 GCT→AAT A99→N102 AAT→GAA N97→E100 TCA→TCT S174→S177 AGA→TAC R98→Y101 TTG→— L175→- GCT→AAT A99→N102 GTT→— V176→- AAG→CAA K125→Q128 CAA→GCT Q178→A179 AAG→CAA K173→Q176 GAT→CCA D179→P180 TCA→ TCT S174→S177 GTT→TTG V181→L182 TTG→— L175→— ACT→AAG T182→K183 GTA→— V176→— CCA→TCA P183→S184 CAG→GCT Q178→A179 AGA→CCT R184→P185 GAT→CCA D179→P180 AGA→AGG R195→R196 GTA→TTG V181→L182 AGA→TAT R212→Y213 ACC→AAG T182→K183 ATT→TCA I213→S214 CCT→TCA P183→S184 GAT→CCT D214→P215 AAG→CCT K184→P185 TCT→AAC S215→N216 CGT→AGG R195→R196 ACT→GTT T216→V217 TTT→ATT F209→I210 TCT→ATC S217→I218 ATG→TAT M212→Y213 GAT→GAC D218→D219 ATC→TCA I213→S214 GAT→CTA D219→L220 AAT→CCT N214→P215 TTG→GCT L220→A221 TCA→AAC S215→N216 GTT→CCA V221→P222 ACA→GTT T216→V217
AGT→ATC S217→I218
GAT→GAC D218→D219
CAT→CTA H219→L220
TTA→GCT L220→A221
TAC→CCA Y221→P222
GAG→GAT E238→D239
AAA→CAA K252→Q253
CAA→AAA Q292→K293
CAA→GCT Q321→A322
GAA→GAT E333→D334
GCT→ACA A345→T346
AAT→ATT N369→I370
TCT→TAC S377→Y378
ACA→AGA T405→R406
AAT→GGT N429→G430
GCA→TCT A436→S437
ACC→CCA T501→P502
Table 32. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GAT→GAA D536→E537
AGA→AAA R19K
AAA→CAA K24Q
CAA→AAT Q38N
ACA→TTA T53L R19K
AGA→AAA
GAT→GCA D54A T53L
ACT→TTA
GCT→ACC A55T D54A
GAT→GCA
GAA→GGA E56G A55T
GCA→ACC
GAT→AGG D57R E56G
GAA→GGA
AAG→AAA K58K D57R
GAT→AGG
GTT→ATT V60I Q58K
CAA→AAA
GCA→ATG A85M A85M
GCT→ATG
ATA→TTG I86L I86L
ATT→TTG
CAA→GAT Q87D Q87D
CAA→GAT
AAA→CAC K88H Q88H
CAA→CAC
TTA→ATT L89I L89I
TTG→ATT
TGT→TAC C90Y C90Y
TGT→TAC
>AGA >R91 -— >R91
-— >AGA
>GCT >A92 -— >A92
-— >GCT
>GAT >D93 -— >D93
-— >GAT
CCA→CCT P91→P94 P91→P94
CCA→CCT
ATC→TAT I92→Y95 I92→Y95
ATT→TAT
TAT→TTT Y93→F96 H93→F96
CAT→TTT
ATT→GAG I94→E97 I94→E97
ATT→GAG
GAC→GCT D95→A98 D95→A98
GAT→GCT
AGT→CAT S96→H99 S96→H99
TCT→CAT
AAT→GAA N97→E100 D97→E100
V247 GAT→GAA 781 838 101.59
AGA→TAC R98→Y101 K98→Y101
AAA→TAC
GCT→AAT A99→N102 A99→N102
GCT→AAT
AAG→CAA K125→Q128 S174→S177
TCA→TCT
AAG→CAA K173→Q176 L175→—
TTG→—
TCA→TCT S174→S177 V176→—
GTT→—
TTG→— L175→— Q178→A179
CAA→GCT
GTA→— V176→— D179→P180
GAT→CCA
CAG→GCT Q178→A179 V181→L182
GTT→TTG
GAT→CCA D179→P180 T182→K183
ACT→AAG
GTA→TTG V181→L182 P183→S184
CCA→TCA
ACC→AAG T182→K183 R184→P185
AGA→CCT
CCT→TCA P183→S184 R212→K213
AGA→AAG
AAG→CCT K184→P185 I213→P214
ATT→CCT
TTT→ATT F209→I210 D214→V215
GAT→GTG
ATG→AAG M212→K213 S215→T216
TCT→ACG
ATC→CCT I213→P214 T216→R217
ACT→CGC
AAT→GTG N214→V215 S217→S218
TCT→AGC
TCA→ACG S215→T216 D218→L219
GAT→CTA
ACA→CGC T216→R217 D219→S220
GAT→TCG
AGT→AGC S217→S218 L220→A221
TTG→GCA
GAT→CTA D218→L219 V221→L222
GTT→CTG
CAT→TCG H219→S220 V320→A321
GTT→GCT
TTA→GCA L220→A221
TAC→CTG Y221→L222
GAG→GAT E238→D239
AAA→CAA K252→Q253
Table 32. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
CAA- ►AAA Q292- >K293
GTT-►GCT V320- >A321
CAA- >GCT Q321- >A322
GAA- >GAT E333-►D334
GCT-►ACA A345- >T346
AAT- ATT N369-■*I370
TCT-►TAC S377- >Y378
ACA-►AGA T405-► 406
AAT- >GGT N429- >G430
GCA- TCT A436- S437
ACC- >CCA T501- >P502
GAT-►GAA D536- >E537
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
V248 ATC→TAT I92→Y95 GAT→GCT D95→A98 782 839 94.32
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→ATG R212→M213
GTA→TTG V181→L182 ATT→CAG I213→Q214
ACC→AAG T182→K183 GAT→CAC D214→H215
CCT→TCA P183→S184 TCT→TTA S215→L216
AAG→CCT K184→P185 ACT→TGT T216→C217
TTT→ATT F209→I210 TCT→TTC S217→F218
ATC→CAG I213→Q214 GAT→TCC D218→S219
Table 32. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AAT- >CAC N214 >H215 GAT→CGT D219→R220
TCA- >TTA S215 ►L216 TTG→CAT L220→H221
ACA- >TGT T216 ►C217 GTT→AAA V221→K222
AGT- >TTC S217 >F218 AAA→AAG K499→K500
GAT- >TCC D218 >S219
CAT- >CGT H219 >R220
TTA-►CAT L220 >H221
TAC- >AAA Y221 >K222
GAG- >GAT E238 ►D239
AAA- >CAA K252 >Q253
CAA-►AAA Q292 >K293
CAA- >GCT Q321 >A322
GAA- >GAT E333 ►D334
GCT-►ACA A345 >T346
AAT- ATT N369 ÷I370
TCT-►TAC S377 •Y378
ACA-►AGA T405 ►R406
AAT- >GGT N429 >G430
GCA- *TCT A436 >S437
ACC- >CCA T501 >P502
GAT-►GAA D536 >E537
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q GAA→GAG E42E
CAA→AAT Q38N ACT→TTA T53L
ACA→TTA T53L GAT→GCA D54A
GAT→GCA D54A GCA→ACC A55T
GCT→ACC A55T GAA→GGA E56G
GAA→GGA E56G GAT→AGG D57R
GAT→AGG D57R CAA→AAA Q58K
AAG→AAA K58K GCT→ATG A85M
GTT→ATT V60I ATT→TTG I86L
GCA→ATG A85M CAA→GAT Q87D
ATA→TTG I86L CAA→CAC Q88H
CAA→GAT Q87D TTG→ATT L89I
AAA→CAC K88H TGT→TAC C90Y
TTA→ATT L89I -— >AGA -— >R91
TGT→TAC C90Y -— >GCT -— >A92
V249 783 840 100.75
>AGA >R91 -— >GAT -— >D93
>GCT >A92 CCA→CCT P91→P94
>GAT >D93 ATT→TAT I92→Y95
CCA→CCT P91→P94 CAT→TTT H93→F96
ATC→TAT I92→Y95 ATT→GAG I94→E97
TAT→TTT Y93→F96 GAT→GCT D95→A98
ATT→GAG I94→E97 TCT→CAT S96→H99
GAC→GCT D95→A98 GAT→GAA D97→E100
AGT→CAT S96→H99 AAA→TAC K98→Y101
AAT→GAA N97→E100 GCT→AAT A99→N102
AGA→TAC R98→Y101 TCA→TCT S174→S177
GCT→AAT A99→N102 TTG→— L175→—
AAG→CAA K125→Q128 GTT→— V176→—
AAG→CAA K173→Q176 CAA→GCT Q178→A179
TCA→TCT S174→S177 GAT→CCA D179→P180
TTG→— L175→— GTT→TTG V181→L182
Table 32. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
GTA V176 ACT- ■AAG T182- >K183 CAG ►GCT Q178 >A179 CCA-►TCA P183- ÷S184 GAT >CCA D179 *P180 AGA- >CCT R184-■*P185 GTA ►TTG V181 >L182 AGA- *TTT R212- ^F213 ACC AAG T182 ►K183 ATT- AAT 1213-►N214 CCT TCA P183 >S184 GAT- >TGT D214- ^C215 AAG >CCT K184 *P185 TCT—■GTA S215- >V216 TTT ATT F209 I210 ACT-■AAA T216- >K217 ATG >TTT M212 -*F213 TCT- >TAC S217- >Y218 ATC ■AAT 1213 •N214 GAT-►GCC D218- ÷A219 AAT ►TGT N214 >C215 GAT- >TTC D219- -*F220 TCA ■GTA S215 ►V216 TTG-►ACC L220- *T221 ACA ■AAA T216 ►K217 GTT-■CAG V221- ÷Q222 AGT ►TAC S217 ►Y218
GAT >GCC D218 >A219
CAT ►TTC H219 *F220
TTA ACC L220 >T221
TAC CAG Y221 >Q222
GAG ►GAT E238 ►D239
AAA ►CAA K252 >Q253
CAA ■AAA Q292 >K293
CAA ►GCT Q321 >A322
GAA ►GAT E333 ►D334
GCT ACA A345 >T346
AAT ►ATT N369 →I370
TCT ■TAC S377 ►Y378
ACA AGA T405 >R406
AAT >GGT N429 >G430
GCA >TCT A436 *S437
ACC >CCA T501 >P502
GAT GAA D536 >E537
AGA- →AAA R19K AGA- →AAA R19K
AAA- →CAA K24Q ACT- →TTA T53L
CAA- →AAT Q38N GAT- →GCA D54A
ACA- →TTA T53L GCA- →ACC A55T
GAT- →GCA D54A GAA- →GGA E56G
GCT- →ACC A55T GAT- →AGG D57R
GAA- →GGA E56G CAA- →AAA Q58K
GAT- →AGG D57R GCT- →ATG A85M
AAG- →AAA K58K ATT- →TTG I86L
GTT- →ATT V60I CAA- →GAT Q87D
GCA- →ATG A85M CAA- →CAC Q88H
V250 784 841
ATA- →TTG I86L TTG- →ATT L89I
CAA- →GAT Q87D TGT- →TAC C90Y
AAA- →CAC K88H AGA -— >R91
TTA- →ATT L89I ■GCT -— >A92
TGT- →TAC C90Y GAT -— >D93
AGA >R91 CCA- →CCT P91→P94
>GCT >A92 ATT- →TAT I92→Y95
■GAT >D93 CAT →TTT H93→F96
CCA- →CCT P91→P94 ATT- →GAG I94→E97 ATC- →TAT I92→Y95 GAT- →GCT D95→A98 TAT- →TTT Y93→F96 TCT- →CAT S96→H99
Table 32. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
ATT GAG 194 ►E97 GAT GAA D97→E100 GAC ►GCT D95 >A98 AAA ►TAC K98→Y101 AGT ►CAT S96 ►H99 GCT ■AAT A99→N102 AAT GAA N97 ■El 00 TCA >TCT S174→S177 AGA ►TAC 98 Y101 TTG L175→—
GCT AAT A99 N102 GTT V176→—
AAG ►CAA K125 >Q128 CAA ►GCT Q178→A179 AAG ►CAA K173 >Q176 GAT ■CCA D179→P180 TCA >TCT SI 74 >S177 GTT >TTG V181→L182 TTG L175 ACT AAG T182→K183 GTA V176 CCA ►TCA P183→S184 CAG ►GCT Q178 ►A179 AGA >CCT R184→P185 GAT >CCA D179 >P180 AGA ►TAC R212→Y213 GTA ►TTG V181 >L182 ATT ■CGT I213→R214 ACC AAG T182 ►K183 GAT ►CTA D214→L215 CCT TCA P183 ►S184 TCT AAT S215→N216 AAG >CCT K184 >P185 ACT ■GAT T216→D217 TTT ATT F209 >I210 TCT AAT S217→N218 ATG ►TAC M212 >Y213 GAT ►TAC D218→Y219 ATC ■CGT 1213 R214 GAT ■GCA D219→A220 AAT ►CTA N214 >L215 TTG GAA L220→E221 TCA ■AAT S215 ■N216 GTT ■TGG V221→W222 ACA >GAT T216 ►D217
AGT >AAT S217 ■N218
GAT ►TAC D218 ►Y219
CAT ■GCA H219 ►A220
TTA GAA L220 ►E221
TAC ■TGG Y221 ■W222
GAG ►GAT E238 ►D239
AAA ►CAA K252 ►Q253
CAA ■AAA Q292 ►K293
CAA ►GCT Q321 ►A322
GAA ►GAT E333 ►D334
GCT ACA A345 >T346
AAT ►ATT N369 ÷I370
TCT ■TAC S377 ■Y378
ACA AGA T405 ►R406
AAT >GGT N429 ►G430
GCA >TCT A436 >S437
ACC >CCA T501 >P502
GAT GAA D536 >E537
AAA- >CAA K24Q GAT- ►GGT D28G
GAT- >GGT D28G ACT- >TTA T53L
CAA- >AAT Q38N GAT-►GCA D54A
ACA- TTA T53L GCA- ACC A55T
GAT- ►GCA D54A GAA-►GGA E56G
GCT- ►ACC A55T GAT-►AGG D57R
V251 785 842
GAA- >GGA E56G CAA-►AAA Q58K
GAT- ►AGG D57R AAA-►AGA K62R
AAG- >AAA K58K GCT-►ATG A85M
GTT- >ATT V60I ATT- >TTG I86L
AAG- >AGA K62R CAA- >GAT Q87D
GCA- >ATG A85M CAA- CAC Q88H
Table 32. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94 >GCT >A92 ATT→TAT I92→Y95 >GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97 ATC→TAT I92→Y95 GAT→GCT D95→A98 TAT→TTT Y93→F96 TCT→CAT S96→H99 ATT→GAG I94→E97 GAT→GAA D97→E100 GAC→GCT D95→A98 AAA→TAC K98→Y101 AGT→CAT S96→H99 GCT→AAT A99→N102 AAT→GAA N97→E100 TCA→TCT S174→S177 AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179 AAG→CAA K173→Q176 GAT→CCA D179→P180 TCA→TCT S174→S177 GTT→TTG V181→L182 TTG→— L175→— ACT→AAG T182→K183 GTA→— V176→— CCA→TCA P183→S184 CAG→GCT Q178→A179 AGA→CCT R184→P185 GAT→CCA D179→P180 AGA→TCC R212→S213 GTA→TTG V181→L182 ATT→AAG I213→K214 ACC→AAG T182→K183 GAT→GCA D214→A215 CCT→TCA P183→S184 TCT→CAA S215→Q216 AAG→CCT K184→P185 ACT→GCA T216→A217 TTT→ATT F209→I210 TCT→CAT S217→H218 ATG→TCC M212→S213 GAT→AGC D218→S219 ATC→AAG I213→K214 GAT→CTC D219→L220 AAT→GCA N214→A215 TTG→GTG L220→V221 TCA→CAA S215→Q216 GTT→AGT V221→S222 ACA→GCA T216→A217
AGT→CAT S217→H218
GAT→AGC D218→S219
CAT→CTC H219→L220
TTA→GTG L220→V221
TAC→AGT Y221→S222
GAG→GAT E238→D239
AAA→CAA K252→Q253
CAA→AAA Q292→K293
CAA→GCT Q321→A322
GAA→GAT E333→D334
GCT→ACA A345→T346
AAT→ATT N369→I370
TCT→TAC S377→Y378
ACA→AGA T405→R406
AAT→GGT N429→G430
GCA→TCT A436→S437
ACC→CCA T501→P502
GAT→GAA D536→E537
V252 AAA→CAA K24Q ACT→TTA T53L 786 843
Table 32. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57 AAA→AGA K62R
AAG→AAA K58K GCT→ATG A85M
GTT→ATT V60I ATT→TTG I86L
AAG→AGA K62R CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91 TTA→ATT L89I >GCT >A92 TGT→TAC C90Y >GAT >D93 >AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97 ATC→TAT I92→Y95 GAT→GCT D95→A98 TAT→TTT Y93→F96 TCT→CAT S96→H99 ATT→GAG I94→E97 GAT→GAA D97→E100 GAC→GCT D95→A98 AAA→TAC K98→Y101 AGT→CAT S96→H99 GCT→AAT A99→N102 AAT→GAA N97→E100 TCA→TCT S174→S177 AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179 AAG→CAA K173→Q176 GAT→CCA D179→P180 TCA→TCT S174→S177 GTT→TTG V181→L182 TTG→— L175→— ACT→AAG T182→K183 GTA→— V176→— CCA→TCA P183→S184 CAG→GCT Q178→A179 AGA→CCT R184→P185 GAT→CCA D179→P180 AGA→AGT R212→S213 GTA→TTG V181→L182 ATT→TTG I213→L214 ACC→AAG T182→K183 GAT→GTG D214→V215 CCT→TCA P183→S184 TCT→CGG S215→R216 AAG→CCT K184→P185 ACT→TCT T216→S217 TTT→ATT F209→I210 TCT→GAG S217→E218 ATG→AGT M212→S213 GAT→AAA D218→K219 ATC→TTG I213→L214 TTG→CCA L220→P221 AAT→GTG N214→V215 GTT→AAT V221→N222 TCA→CGG S215→R216
ACA→TCT T216→S217
AGT→GAG S217→E218
GAT→AAA D218→K219
CAT→GAT H219→D220
TTA→CCA L220→P221
TAC→AAT Y221→N222
GAG→GAT E238→D239
AAA→CAA K252→Q253
CAA→AAA Q292→K293
CAA→GCT Q321→A322
Table 32. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GAA- >GAT E333- ►D334
GCT-►ACA A345- >T346
AAT- ATT N369-■^1370
TCT-►TAC S377- >Y378
ACA-►AGA T405-►R406
AAT- >GGT N429- >G430
GCA- *TCT A436- S437
ACC- >CCA T501- >P502
GAT-►GAA D536- >E537
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
V253 787 844 ND
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→CAT R212→H213
GTA→TTG V181→L182 ATT→CGC I213→R214
ACC→AAG T182→K183 GAT→ACT D214→T215
CCT→TCA P183→S184 TCT→CCA S215→P216
AAG→CCT K184→P185 ACT→GCT T216→A217
TTT→ATT F209→I210 TCT→TTC S217→F218
ATG→CAT M212→H213 GAT→TGC D218→C219
ATC→CGC I213→R214 GAT→AGA D219→R220
AAT→ACT N214→T215 TTG→GGC L220→G221
TCA→CCA S215→P216 GTT→GAA V221→E222
Table 32. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
ACA- >GCT T216 ►A217
AGT- >TTC S217 >F218
GAT- >TGC D218 >C219
CAT- >AGA H219 >R220
TTA- >GGC L220 >G221
TAC- >GAA Y221 >E222
GAG- >GAT E238 ►D239
AAA- >CAA K252 >Q253
CAA-►AAA Q292 >K293
CAA- >GCT Q321 >A322
GAA- >GAT E333 ►D334
GCT-►ACA A345 >T346
AAT- ATT N369 ÷I370
TCT-►TAC S377 •Y378
ACA-►AGA T405 ►R406
AAT- >GGT N429 >G430
GCA- *TCT A436 >S437
ACC- >CCA T501 >P502
GAT-►GAA D536 >E537
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
>AGA >R91 CCA→CCT P91→P94
V254 788 845 ND
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
Table 32. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
GAT >CCA D179 *P180 AGA- >CAG R212- >Q213 GTA TTG V181 >L182 ATT- >GTG 1213-►V214 ACC ►AAG T182 >K183 GAT- >AGG D214- *R215 CCT >TCA P183 >S184 TCT-►AAG S215- >K216 AAG *CCT K184 *P185 ACT-►CGG T216- R217 TTT ►ATT F209 ÷I210 TCT- >TGT S217- >C218 ATG ►CAG M212 *Q213 GAT- >GTA D218- >V219 ATC ►GTG 1213 •V214 GAT- >GAA D219- ÷E220 AAT ►AGG N214 >R215 TTG-►GCA L220- >A221 TCA ►AAG S215 ►K216 GTT- >GTG V221- >V222 ACA ►CGG T216 >R217
AGT TGT S217 ►C218
GAT >GTA D218 >V219
CAT ►GAA H219 >E220
TTA ►GCA L220 ►A221
TAC ►GTG Y221 >V222
GAG >GAT E238 >D239
AAA >CAA K252 >Q253
CAA ►AAA Q292 >K293
CAA >GCT Q321 >A322
GAA >GAT E333 >D334
GCT ►ACA A345 >T346
AAT ATT N369 ->I370
TCT ►TAC S377 ►Y378
ACA ►AGA T405 >R406
AAT >GGT N429 >G430
GCA *TCT A436 *S437
ACC >CCA T501 >P502
GAT ►GAA D536 >E537
AGA- →AAA R19K AGA- →AAA R19K
AAA- →CAA K24Q ACT- →TTA T53L
CAA- →AAT Q38N GAT- →GCA D54A
ACA- →TTA T53L GCA- →ACC A55T
GAT- →GCA D54A GAA- →GGA E56G
GCT- →ACC A55T GAT- →AGG D57R
GAA- →GGA E56G CAA- →AAA Q58K
GAT- →AGG D57R GCT- →ATG A85M
AAG- →AAA K58K ATT- →TTG I86L
GTT- →ATT V60I CAA- →GAT Q87D
GCA- →ATG A85M CAA- →CAC Q88H
ATA- →TTG I86L TTG- →ATT L89I
V272 805 862
CAA- →GAT Q87D TGT- →TAC C90Y
AAA- →CAC K88H AGA -— >R91
TTA- →ATT L89I GCT -— >A92
TGT- →TAC C90Y GAT -— >D93
AGA >R91 CCA- →CCT P91→P94
►GCT >A92 ATT- →TAT I92→Y95
■GAT >D93 CAT →TTT H93→F96
CCA- →ccr P91→P94 ATT- →GAG I94→E97 ATC- →TAT I92→Y95 GAT- →GCT D95→A98 TAT-→TTT Y93→F96 TCT- →CAT S96→H99 ATT- ->GAG I94→E97 GAT- →GAA D97→E100 GAC-→GCT D95→A98 AAA →TAC K98→Y101
Table 32. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa
wildtype wildtype CVS V19 CVS V19
AGT ►CAT S96 >H99 GCT AAT A99→N102
AAT GAA N97 ■El 00 TCA ■TCT S174→S177
AGA >TAC 98 Y101 TTG L175→—
GCT AAT A99 N102 GTT V176→—
AAG ►CAA K125 >Q128 CAA ►GCT Q178→A179
AAG ►CAA K173 >Q176 GAT >CCA D179→P180
TCA >TCT SI 74 >S177 GTT ►TTG V181→L182
TTG L175 ACT AAG T182→K183
GTA V176 CCA ►TCA P183→S184
CAG ►GCT Q178 ►A179 AGA >CCT R184→P185
GAT ►CCA D179 >P180 AGA ►GCC R212→A213
GTA ►TTG V181 >L182 ATT ►TTT I213→F214
ACC AAG T182 ►K183 GAT ►CTG D214→L215
CCT TCA P183 ►S184 TCT ■GCT S215→A216
AAG >CCT K184 P185 ACT ►TGC T216→C217
TTT ATT F209 >I210 TCT GGC S217→G218
ATG ►GCC M212 >A213 GAT ►CGT D218→R219
ATC >TTT 1213 ■F214 GAT ■CGA D219→R220
AAT ►CTG N214 >L215 TTG ■CCC L220→P221
TCA GCT S215 A216 GTT ACA V221→T222
ACA ►TGC T216 ►C217 TTG TGC L313→C314
AGT ■GGC S217 ■G218 TCT ACG S314→T315
GAT ►CGT D218 >R219 TTG ATG L315→M316
CAT ■CGA H219 >R220 ACC AGT T317→S318
TTA CCC L220 >P221 AAG ►CGA K336→R337
TAC ACA Y221 >T222 TTA ►ATT L337→I338
GAG ►GAT E238 ►D239 GGT ■CGG G357→R358
AAA ►CAA K252 >Q253
CAA AAA Q292 >K293
CTC TGC L313 ►C314
AGC ACG S314 ►T315
CTC ATG L315 •M316
ACT AGT T317 >S318
CAA ►GCT Q321 >A322
GAA ►GAT E333 ►D334
AAA ►CGA K336 >R337
TTG ►ATT L337 *I338
GCT ACA A345 >T346
GGA ►CGG G357 >R358
AAT ►ATT N369 ■*I370
TCT TAC S377 ►Y378
ACA AGA T405 ►R406
AAT ►GGT N429 >G430
GCA >TCT A436 >S437
ACC ►CCA T501 >P502
GAT GAA D536 >E537
V256, V257, V258, V259, V261, V263, V264, V262, V260, V265, V266 and V273
In CVS variants V256, V257, V258, V259, V261, V263, V264, V262, V260, V265, V266 and V273, amino acids 53-58 were replaced by amino acids 58-63 of TEAS (SEQ ID
NO:941), amino acids 85-99 were replaced by amino acids 93-110 of HPS (SEQ ID NO:942) and amino acids 174-184 were replaced by amino acids 185-193 of HPS (SEQ ID NO:942) or 177-185 of TEAS (SEQ ID NO:941) as described above. Some variants that were generated using V243 or V244 as templates also contained amino acids 212-221 replaced by amino acids 213-221 of TEAS. These variants additionally contain mutations from V75. In addition, amino acids 2-7 were replaced by random amino acids. These CVS variants were generated by direct yeast recombination using mutagenic primers mutCVS2-7 and revAA2- 7rnd (see Table 18) using V240, V243 or V244 as templates. The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 are set forth in Table 33 below.
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. % vs. V19 nt
wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TCG→CAA S2Q TCA→CAA S2Q
TCT→ACG S3T TCT→ACG S3T
GGA→TTT G4F GGT→TTT G4F
GAA→AAC E5N GAA→AAC E5N
ACA→TGT T6C ACT→TGT T6C
TTT→GCT F7A TTT→GCT F7A
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
V256 790 847 74.3
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— - ACT→AAG T182→K183
GTA→— V176→— - CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217-
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T GAG→GAT E484D
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
TCG→GCA S2A TCA→GCA S2A
TCT→GGC S3G TCT→GGC S3G
GGA→CGG G4R GGT→CGG G4R
GAA→GGG E5G GAA→GGG E5G
ACA→GCG T6A ACT→GCG T6A
TTT→TCC F7S TTT→TCC F7S
V257 791 848 ND
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57 GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217-
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T GAA→GAG E368E
CTC→ATG L315M GAG→GAT E484D
ACT→AGT T317S GCT→GCC A517A
CAA→GCT Q321A
GAA→GAT E333D
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GCA→GCC A517A
GAT→GAA D536E
TCG→GTT S2V TCA→GTT S2V
TCT→CTC S3L TCT→CTC S3L
GGA→AAA G4K GGT→AAA G4K
GAA→TCC E5S GAA→TCC E5S
ACA→AAG T6K ACT→AAG T6K
TTT→CGC F7R TTT→CGC F7R
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTG T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTG T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
V258 792 849 ND
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→-
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T GAG→GAT E484D
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
TCG→AAA S2K TCA→AAA S2K
TCT→GAA S3E TCT→GAA S3E
GGA→TGT G4C GGT→TGT G4C
GAA→ACG E5T GAA→ACG E5T
ACA→ATG T6M ACT→ATG T6M
TTT→TTA F7L TTT→TTA F7L
AGA→AAA R19K AGA→AAA R19K
V259an AAA→CAA K24Q ACT→TTA T53L
793 850 104.14 d V260 CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
-— >AGA -— >R91 CCA→CCT P91→P94
-— >GCT -— >A92 ATT→TAT I92→Y95
>GAT -— >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→ -
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→ - GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T AAA→AAG K468K
CTC→ATG L315M GAG→GAT E484D
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AAT- ATT N369I
TCT-►TAC S377Y
ACA-►AGA T405
AAT- >GGT N429G
GCA- *TCT A436S
GAA- >GAT E484D
ACC- >CCA T501P
GAT-►GAA D536E
TCG→CCA S2P TCA→CCA S2P
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
-— >AGA -— >R91 CCA→CCT P91→P94
-— >GCT -— >A92 ATT→TAT I92→Y95
>GAT -— >D93 CAT→TTT H93→F96
V261
CCA→CCT P91→P94 ATT→GAG I94→E97
and 794 851 ND ATC→TAT I92→Y95 GAT→GCT D95→A98
V262
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→ - ATG→TCA M212→S213 GAT→GAA D218E
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→ - GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T GAG→GAT E484D
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
TCG→TGC S2C TCA→TGC S2C
TCT→ATG S3M TCT→ATG S3M
GGA→ACA G4T GGT→ACA G4T
GAA→GGT E5G GAA→GGT E5G
ACA→GAA T6E ACT→GAA T6E
TTT→TCG F7S TTT→TCG F7S
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
V263 GCT→ACC A55T GAT→AGG D57R 795 852 114.57
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
-— >AGA -— >R91 CCA→CCT P91→P94
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
-— >GCT -— >A92 ATT→TAT I92→Y95
>GAT -— >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→ -
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→ - GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T GAG→GAT E484D
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GAT→GAA D536E
TCG→CAG S2Q TCA→CAG S2Q
TCT→AAT S3N TCT→AAT S3N
GGA→CTT G4L GGT→CTT G4L
GAA→GGC E5G GAA→GGC E5G
ACA→TAC T6Y ACT→TAC T6Y
TTT→TCG F7S TTT→TCG F7S
AGA→AAA 19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
-— >AGA -— >R91 CCA→CCT P91→P94
-— >GCT -— >A92 ATT→TAT I92→Y95
>GAT -— >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
V264 796 853 ND
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T GAG→GAT E484D
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
TCG→TTA S2L TCA→TTA S2L
TCT→AAC S3N TCT→AAC S3N
GGA→TCA G4S GGT→TCA G4S
GAA→ATC E5I GAA→ATC E5I
ACA→GAT T6D ACT→GAT T6D
TTT→TCG F7S TTT→TCG F7S
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
V265 797 854 ND
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCT→TCC S119→S122
AGA→TAC 98→Y101 TCA→TCT S174→S177
GCT→AAT A99→N102 TTG→— L175→—
TCA→TCC S119→S122 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T GAG→GAT E484D
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
TCG→CCT S2P TCA→CCT S2P
V266 TCT→GAC S3D TCT→GAC S3D 798 855 ND
GGA→CGC G4R GGT→CGC G4R
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GAA→ACC E5T GAA→ACC E5T
ACA→GGA T6G ACT→GGA T6G
TTT→CCA F7P TTT→CCA F7P
AGA→AAA 19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→ -
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T GAG→GAT E484D
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
TCG→GCA S2A TCA→GCA S2A
TCT→ACT S3T TCT→ACT S3T
GGA→TCT G4S GGT→TCT G4S
GAA→CAC E5H GAA→CAC E5H
ACA→AGT T6S ACT→AGT T6S
TTT→CAG F7Q TTT→CAG F7Q
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
V273 806 863 ND
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA -— >R91
TTA→ATT L89I -— >GCT -— >A92
TGT→TAC C90Y -— >GAT -— >D93
-— >AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
Table 33. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→-
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q ATT→ACT I325T
CCT→TCA P281 S GAC→GAT D329D
CAA→AAA Q292K AAG→CGA K336R
CTC→TGC L313C TTA→ATT L337I
AGC→ACG S314T GGT→CGG G357R
CTC→ATG L315M GGT→GGA G414G
ACT→AGT T317S GAG→GAT E484D
CAA→GCT Q321A
ATT→ACT I325T
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
GGC→GGA G414G
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
h. V267, V268, V269, V270 and V271
In CVS variants V267, V268, V269, V270 and V271, amino acids 53-58 were replaced by amino acids 58-63 of TEAS (SEQ ID NO:941), amino acids 85-99 were replaced
by amino acids 93-110 of HPS (SEQ ID NO: 942) and amino acids 174-184 were replaced by amino acids 185-193 of HPS (SEQ ID NO:942) or 177-185 of TEAS (SEQ ID NO:941) as described above. These variants additionally contain random mutations at LI 06 (V267), or F209 (V268-V271). CVS variants V267, V268, V269, V270 and V271 were generated using V240 as a template, with primers set forth in Table 25 above. The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 are set forth in Table 34 below.
Table 34. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. CVS changes vs. nt aa % vs. V19 wildtype wildtype V19 CVS V19 (Shake
Flask)
AGA→AAA 19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H — >AGA — >R91
TTA→ATT L89I — >GCT — >A92
TGT→TAC C90Y — >GAT — >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
V267 ATC→TAT I92→Y95 GAT→GCT D95→A98 799 856
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TTG→CTT L106→L109
AGA→TAC R98→Y101 TCA→TCT S174→S177
GCT→AAT A99→N102 TTG→— L175→—
AAG→CAA K125→Q128 GTT→— V176→—
AAG→CAA K173→Q176 CAA→GCT Q178→A179
TCA→TCT S174→S177 GAT→CCA D179→P180
TTG→— L175→— GTT→TTG V181→L182
GTA→— V176→— ACT→AAG T182→K183
CAG→GCT Q178→A179 CCA→TCA P183→S184
GAT→CCA D179→P180 AGA→CCT R184→P185
GTA→TTG V181→L182 GGT→GGG G276→G277
ACC→AAG T182→K183 CCA→TCA P281→S282
CCT→TCA P183→S184 TTG→TGC L313→C314
AAG→CCT K184→P185 TCT→ACG S314→T315
TTT→ATT F209→I210 TTG→ATG L315→M316
ATG→AGA M212→R213 ACC→AGT T317→S318
Table 34. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. CVS changes vs. nt aa % vs. V19 wildtype wildtype V19 CVS V19 (Shake
Flask)
AAT >GAT N214 >D215 GAC→GAT D329→D330
CAT ►GAT H219 >D220 AAG→CGA K336→R337
TAC >GTT Y221 >V222 TTA→ATT L337→I338
GAG >GAT E238 ►D239 GGT→CGG G357→R358
AAA >CAA K252 >Q253 GAG→GAT E484→D485
CCT ►TCA P281 >S282
CAA ►AAA Q292 >K293
CTC ►TGC L313 ►C314
AGC >ACG S314 ►T315
CTC ►ATG L315 ■M316
ACT ►AGT T317 >S318
CAA >GCT Q321 >A322
GAA >GAT E333 ►D334
AAA >CGA K336 >R337
TTG >ATT L337 ÷I338
GCT ►ACA A345 >T346
GGA >CGG G357 >R358
AAT >ATT N369 ■»I370
TCT ►TAC S377 ►Y378
ACA ►AGA T405 ►R406
AAT ►GGT N429 >G430
GCA >TCT A436 >S437
GAA >GAT E484 ►D485
ACC ►CCA T501 >P502
GAT ►GAA D536 >E537
AGA- →AAA R19K AGA→AAA R19K
AAA- →CAA K24Q ACT→TTA T53L
CAA- →AAT Q38N GAT→GCA D54A
ACA- →TTA T53L GCA→ACC A55T
GAT- →GCA D54A GAA→GGA E56G
GCT- →ACC A55T GAT→AGG D57R
GAA- →GGA E56G CAA→AAA Q58K
GAT- →AGG D57R GCT→ATG A85M
AAG- →AAA K58K ATT→TTG I86L
GTT- →ATT V60I CAA→GAT Q87D
GCA- →ATG A85M CAA→CAC Q88H
ATA- →TTG I86L TTG→ATT L89I
CAA- →GAT Q87D TGT→TAC C90Y
AAA- →CAC K88H -— >AGA >R91
V268 801 858 93
TTA- →ATT L89I -— >GCT >A92
TGT- →TAC C90Y >GAT >D93
AGA >R91 CCA→CCT P91→P94
GCT >A92 ATT→TAT I92→Y95
■GAT >D93 CAT→TTT H93→F96
CCA- →ccr P91→P94 ATT→GAG I94→E97
ATC- →TAT I92→Y95 GAT→GCT D95→A98
TAT-→TTT Y93→F96 TCT→CAT S96→H99
ATT- ->GAG I94→E97 GAT→GAA D97→E100
GAC-→GCT D95→A98 AAA→TAC K98→Y101
AGT-→CAT S96→H99 GCT→AAT A99→N102
AAT- ->GAA N97→E100 TCA→TCT S174→S177
AGA-→TAC R98→Y101 TTG→— L175→—
GCT-→AAT A99→N102 GTT→— V176→—
Table 34. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. CVS changes vs. nt aa wildtype wildtype V19 CVS V19
AAG ■CAA K125 ■Q128 CAA- >GCT Q178- ►A179 AAG ■CAA K173 ■Q176 GAT-►CCA D179- >P180 TCA ■TCT SI 74 ■SI 77 GTT-►TTG V181- L182 TTG L175 ACT-►AAG T182- ►K183 GTA V176 CCA-►TCA P183- ►S184 CAG ►GCT Q178 ►A179 AGA- *CCT R184- ►P185 GAT ►CCA D179 ►PI 80 ATT-►GAG 1209- ■E210 GTA >TTG V181 ►LI 82 GGT-►GGG G276- >G277 ACC ■AAG T182 ■K183 CCA-►TCA P281- ►S282 CCT ►TCA P183 ►S184 TTG-►TGC L313- ►C314 AAG >CCT K184 ►PI 85 TCT-■ACG S314- ►T315 TTT GAG F209 ■E210 TTG-►ATG L315- •M316 ATG ■AGA M212 ► 213 ACC-►AGT T317- ►S318 AAT ►GAT N214 ►D215 GAC- >GAT D329- D330 CAT ►GAT H219 ►D220 AAG-►CGA K336- ►R337 TAC ►GTT Y221 ►V222 TTA-►ATT L337- ÷L 38 GAG >GAT E238 ■D239 GGT-►CGG G357- ►R358 AAA ►CAA K252 ►Q253 GAG- >GAT E484- ►D485 CCT ►TCA P281 ►S282
CAA ►AAA Q292 ►K293
CTC ►TGC L313 ■C314
AGC ►ACG S314 ■T315
CTC ■ATG L315 M316
ACT ►AGT T317 ►S318
CAA ►GCT Q321 ►A322
GAA ►GAT E333 ■D334
AAA ►CGA K336 ►R337
TTG ►ATT L337 I338
GCT ■ACA A345 ►T346
GGA ►CGG G357 ►R358
AAT ►ATT N369 *L 70
TCT ■TAC S377 •Y378
ACA ►AGA T405 ■R406
AAT ►GGT N429 ►G430
GCA ►TCT A436 ►S437
GAA ►GAT E484 ■D485
ACC ►CCA T501 ►P502
GAT ■GAA D536 ►E537
AAA- ►CAA K24Q ACT- →TTA T53L
CAA- ►AAT Q38N GAT- →GCA D54A
ACA- TTA T53L GCA- →ACC A55T
GAT- ►GCA D54A GAA- →GGA E56G
GCT- ►ACC A55T GAT- →AGG D57R
GAA- ►GGA E56G CAA- →AAA Q58K
GAT- ►AGG D57R TTG- →TTA L72L
V269 AAG- >AAA K58K GCT- →ATG A85M 802 859
GTT- ►ATT V60I ATT- →TTG I86L
CTG- >TTA L72L CAA- →GAT Q87D
GCA- ►ATG A85M CAA- →CAC Q88H
ATA- ►TTG I86L TTG- →ATT L89I
CAA- ►GAT Q87D TGT- →TAC C90Y
AAA- ►CAC K88H AGA — >R91
TTA- ►ATT L89I ■GCT —A92
Table 34. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. CVS changes vs. nt aa wildtype wildtype V19 CVS V19
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94 >GCT >A92 ATT→TAT I92→Y95 >GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97 ATC→TAT I92→Y95 GAT→GCT D95→A98 TAT→TTT Y93→F96 TCT→CAT S96→H99 ATT→GAG I94→E97 GAT→GAA D97→E100 GAC→GCT D95→A98 AAA→TAC K98→Y101 AGT→CAT S96→H99 GCT→AAT A99→N102 AAT→GAA N97→E100 TTG→TCG L111→S114 AGA→TAC R98→Y101 TCA→TCT S174→S177 GCT→AAT A99→N102 TTG→— L175→—
CTT→TCG L111→S114 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179 AAG→CAA K173→Q176 GAT→CCA D179→P180 TCA→TCT S174→S177 GTT→TTG V181→L182 TTG→— L175→— ACT→AAG T182→K183 GTA→— V176→— CCA→TCA P183→S184 CAG→GCT Q178→A179 AGA→CCT R184→P185 GAT→CCA D179→P180 ATT→GAA I209→E210 GTA→TTG V181→L182 GGT→GGG G276→G277 ACC→AAG T182→K183 CCA→TCA P281→S282 CCT→TCA P183→S184 TTG→TGC L313→C314 AAG→CCT K184→P185 TCT→ACG S314→T315 TTT→GAA F209→E210 TTG→ATG L315→M316 ATG→AGA M212→R213 ACC→AGT T317→S318 AAT→GAT N214→D215 GAC→GAT D329→D330 CAT→GAT H219→D220 AAG→CGA K336→R337 TAC→GTT Y221→V222 TTA→ATT L337→I338 GAG→GAT E238→D239 GGT→CGG G357→R358 AAA→CAA K252→Q253 GAG→GAT E484→D485 CCT→TCA P281→S282
CAA→AAA Q292→K293
CTC→TGC L313→C314
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
CAA→GCT Q321→A322
GAA→GAT E333→D334
AAA→CGA K336→R337
TTG→ATT L337→I338
GCT→ACA A345→T346
GGA→CGG G357→R358
AAT→ATT N369→I370
TCT→TAC S377→Y378
ACA→AGA T405→R406
AAT→GGT N429→G430
GCA→TCT A436→S437
GAA→GAT E484→D485
ACC→CCA T501→P502
GAT→GAA D536→E537
V270 AGA→AAA R19K AGA→AAA R19K 803 860
Table 34. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. CVS changes vs. nt aa wildtype wildtype V19 CVS V19
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57 GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93 >AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97 ATC→TAT I92→Y95 GAT→GCT D95→A98 TAT→TTT Y93→F96 TCT→CAT S96→H99 ATT→GAG I94→E97 GAT→GAA D97→E100 GAC→GCT D95→A98 AAA→TAC K98→Y101 AGT→CAT S96→H99 GCT→AAT A99→N102 AAT→GAA N97→E100 TCA→TCT S174→S177 AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179 AAG→CAA K173→Q176 GAT→CCA D179→P180 TCA→TCT S174→S177 GTT→TTG V181→L182 TTG→— L175→— ACT→AAG T182→K183 GTA→— V176→— CCA→TCA P183→S184 CAG→GCT Q178→A179 AGA→CCT R184→P185 GAT→CCA D179→P180 ATT→TTA I209→L210 GTA→TTG V181→L182 GGT→GGG G276→G277 ACC→AAG T182→K183 CCA→TCA P281→S282 CCT→TCA P183→S184 TTG→TGC L313→C314 AAG→CCT K184→P185 TCT→ACG S314→T315 TTT→TTA F209→L210 TTG→ATG L315→M316 ATG→AGA M212→R213 ACC→AGT T317→S318 AAT→GAT N214→D215 GAC→GAT D329→D330 CAT→GAT H219→D220 AAG→CGA K336→R337 TAC→GTT Y221→V222 TTA→ATT L337→I338 GAG→GAT E238→D239 GGT→CGG G357→R358 AAA→CAA K252→Q253 GAG→GAT E484→D485 CCT→TCA P281→S282
CAA→AAA Q292→K293
CTC→TGC L313→C314
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
CAA→GCT Q321→A322
GAA→GAT E333→D334
Table 34. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. CVS changes vs. nt aa % vs. V19 wildtype wildtype V19 CVS V19 (Shake
Flask)
AAA- >CGA K336- > 337
TTG- >ATT L337- I338
GCT-►ACA A345- >T346
GGA- >CGG G357- >R358
AAT- >ATT N369- ■ I370
TCT-►TAC S377- >Y378
ACA-►AGA T405- ►R406
AAT- >GGT N429- ►G430
GCA- >TCT A436- >S437
GAA- >GAT E484- >D485
ACC-►CCA T501- >P502
GAT-►GAA D536- >E537
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA→CCT P91→P94 ATT→GAG I94→E97
V271 ATC→TAT I92→Y95 GAT→GCT D95→A98 804 861 93
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA→TCT S174→S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 ATT→ACG I209→T210
GTA→TTG V181→L182 GGT→GGG G276→G277
ACC→AAG T182→K183 CCA→TCA P281→S282
CCT→TCA P183→S184 TTG→TGC L313→C314
AAG→CCT K184→P185 TCT→ACG S314→T315
TTT→ACG F209→T210 TTG→ATG L315→M316
ATG→AGA M212→R213 ACC→AGT T317→S318
Table 34. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. CVS changes vs. nt aa % vs. V19 wildtype wildtype V19 CVS V19 (Shake
Flask)
AAT >GAT N214 >D215 GAC→GAT D329→D330
CAT ►GAT H219 >D220 AAG→CGA K336→R337
TAC >GTT Y221 >V222 TTA→ATT L337→I338
GAG >GAT E238 ►D239 GGT→CGG G357→R358
AAA >CAA K252 >Q253 GAG→GAT E484→D485
CCT ►TCA P281 >S282
CAA ►AAA Q292 >K293
CTC ►TGC L313 ►C314
AGC >ACG S314 ►T315
CTC ►ATG L315 ■M316
ACT ►AGT T317 >S318
CAA >GCT Q321 >A322
GAA >GAT E333 ►D334
AAA >CGA K336 >R337
TTG >ATT L337 ^1338
GCT ►ACA A345 >T346
GGA >CGG G357 >R358
AAT >ATT N369 -*I370
TCT ►TAC S377 ►Y378
ACA ►AGA T405 ►R406
AAT ►GGT N429 >G430
GCA >TCT A436 >S437
GAA >GAT E484 ►D485
ACC ►CCA T501 >P502
GAT ►GAA D536 >E537
i. V274 and V277
In CVS variants V274 and V277, amino acids 3-41 were replaced by amino acids 3- 51 of Vitis vinafera (SEQ ID NO:346), amino acids 53-58 were replaced by amino acids 58- 63 of TEAS (SEQ ID NO:941), amino acids 85-99 were replaced by amino acids 93-110 of HPS (SEQ ID NO:942) and amino acids 174-184 were replaced by amino acids 185-193 of HPS (SEQ ID NO:942) or 177-185 of TEAS (SEQ ID NO:941). CVS variant V274 was generated by direct yeast recombination using V240 as a template, with primers set forth in Table 25 above. CVS variant V277 was generated by direct yeast recombination using V245 as a template, with primers set forth in Table 25 above. The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 are set forth in Table 35 below.
Table 35. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TCG→TCT S2S TCA→TCT S2S
V274 TCT→ACT S3T TCT→ACT S3T 807 864 60.13
GGA→CAA G4Q GGT→CAA G4Q
Table 35. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
GAA→GTC E5V GAA→GTC E5V
>TCA >S6 >TCA -— >S6 >GCA >A7 -— >GCA -—A1 >TCT >S8 >TCT -— >S8 >TCT >S9 >TCT -— >S9 >CTA >L10 >CTA -— >L10 >GCC >Al 1 -— >GCC -— >A11
>CAG >Q12 -— >CAG -— >Q12 >ATT >I13 >ATT -— >I13
— >ccc >P14 -— >ccc >P14 >CAA >Q15 -—CAA -— >Q15
— >ccc >P16 -— >CCC >P16
ACA→AAA T6→K17 ACT→ AAA T6→K17
TTT→AAT F7→N18 TTT→AAT F7→N18 ACT→GTG T10→V21 AGA→CGT R8→R19 GAT→AAC D12→N23 CCA→CCT P9→P20
CAT→CAC H14→H25 ACT→GTG T10→V21 CCT→CCC P15→P26 GCT→GCA A11→A22 AGT→AAC S16→N27 GAT→AAC D12→N23 TTA→ATT L17→I28 CAT→CAC H14→H25 AGA→GGT 19→G30 CCA→CCC P15→P26 AAC→GAC N20→D31 TCT→AAC S16→N27 CAT→CAA H21→Q32 TTG→ATT L17→I28 CTC→ATC L23→I34 AGA→GGT R19→G30 AAA→ACC K24→T35 AAT→GAC N20→D31 GGT→TAC G25→Y36 CAT→CAA H21→Q32 GCT→ACT A26→T37 TTG→ATC L23→I34 TCT→CCT S27→P38 CAA→ACC Q24→T35 GAT→GAA D28→E39 GGT→TAC G25→Y36 TTC→GAC F29→D40 GCA→ACT A26→T37
ACA→— T31→— TCA→CCT S27→P38 GAT→ACT D33→T43 GAT→GAA D28→E39 CAT→CGT H34→R44 TTT→GAC F29→D40 ACT→GCC T35→A45 ACT→— T31→—
GCA→TGC A36→C46 GAT→ACT D33→T43 ACT→ AAA T37→K47 CAT→CGT H34→R44 CAA→GAG Q38→E48 ACA→GCC T35→A45 GAA→GAG E39→E49 GCT→TGC A36→C46 CGA→CAG R40→Q50 ACA→AAA T37→K47 CAC→ATT H41→I51 AAT→GAG N38→E48 ACA→TTA T53→L63 GAA→GAG E39→E49 GAT→GCA D54→A64 AGA→CAG R40→Q50 GCT→ACC A55→T65 CAT→ATT H41→I51 GAA→GGA E56→G66 ACT→TTA T53→L63 GAT→AGG D57→R67 GAT→GCA D54→A64 AAG→AAA K58→K68 GCA→ACC A55→T65 GTT→ATT V60→I70 GAA→GGA E56→G66 GCA→ATG A85→M95 GAT→AGG D57→R67 ATA→TTG I86→L96 CAA→AAA Q58→K68 CAA→GAT Q87→D97 GCT→ATG A85→M95 AAA→CAC K88→H98 ATT→TTG I86→L96 TTA→ATT L89→I99 CAA→GAT Q87→D97 TGT→TAC C90→Y100 CAA→CAC Q88→H98
Table 35. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
>AGA >R101 TTG→ATT L89→I99 >GCT >A102 TGT→TAC C90→Y100
>GAT >D103 -— >AGA >R101
CCA→CCT P91→P104 -— >GCT >A102 ATC→TAT I92→Y105 -— >GAT >D103 TAT→TTT Y93→F106 CCA→CCT P91→P104 ATT→GAG I94→E107 ATT→TAT I92→Y105 GAC→GCT D95→A108 CAT→TTT H93→F106 AGT→CAT S96→H109 ATT→GAG I94→E107 AAT→GAA N97→E110 GAT→GCT D95→A108 AGA→TAC R98→Y111 TCT→CAT S96→H109 GCT→AAT A99→N112 GAT→GAA D97→E110 AAG→CAA K125→Q138 AAA→TAC K98→Y111 AAG→CAA K173→Q186 GCT→AAT A99→N112 TCA→TCT S174→S187 TCA→TCT S174→S187 TTG→— L175→— TTG→— L175→—
GTA→— V176→— GTT→— V176→—
CAG→GCT Q178→A189 CAA→GCT Q178→A189 GAT→CCA D179→P190 GAT→CCA D179→P190 GTA→TTG V181→L192 GTT→TTG V181→L192 ACC→AAG T182→K193 ACT→AAG T182→K193 CCT→TCA P183→S194 CCA→TCA P183→S194 AAG→CCT K184→P195 AGA→CCT R184→P195 TTT→ATT F209→I220 GGT→GGG G276→G287 ATG→AGA M212→R223 CCA→TCA P281→S292 AAT→GAT N214→D225 TTG→TGC L313→C324 CAT→GAT H219→D230 TCT→ACG S314→T325 TAC→GTT Y221→V232 TTG→ATG L315→M326 GAG→GAT E238→D249 ACC→AGT T317→S328 AAA→CAA K252→Q263 GAC→GAT D329→D340 CCT→TCA P281→S292 AAG→CGA K336→R347 CAA→AAA Q292→K303 TTA→ATT L337→I348 CTC→TGC L313→C324 GGT→CGG G357→R368 AGC→ACG S314→T325 GAG→GAT E484→D495 CTC→ATG L315→M326
ACT→AGT T317→S328
CAA→GCT Q321→A332
GAA→GAT E333→D344
AAA→CGA K336→R347
TTG→ATT L337→I348
GCT→ACA A345→T356
GGA→CGG G357→R368
AAT→ATT N369→I380
TCT→TAC S377→Y388
ACA→AGA T405→R416
AAT→GGT N429→G440
GCA→TCT A436→S447
GAA→GAT E484→D495
ACC→CCA T501→P512
GAT→GAA D536→E547
TCG->TCT S2S TCA→TCT S2S
V277 TCT→ACT S3T TCT→ACT S3T 891 887
GGA→CAA G4Q GGT→CAA G4Q
Table 35. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
GAA→GTC E5V GAA→GTC E5V
>TCA >S6 >TCA -— >S6 >GCA >A7 -— >GCA -—A1 >TCT >S8 >TCT -— >S8 >TCT >S9 >TCT -— >S9 >CTA >L10 >CTA -— >L10 >GCC >Al 1 -— >GCC -— >A11
>CAG >Q12 -— >CAG -— >Q12 >ATT >I13 >ATT -— >I13
— >ccc >P14 -— >ccc >P14 >CAA >Q15 -—CAA -— >Q15
— >ccc >P16 -— >CCC >P16
ACA→AAA T6→K17 ACT→ AAA T6→K17
TTT→AAT F7→N18 TTT→AAT F7→N18 ACT→GTG T10→V21 AGA→CGT R8→R19 GAT→AAC D12→N23 CCA→CCT P9→P20
CAT->CAC H14->H25 ACT→GTG T10→V21 CCT->CCC P15->P26 GCT→GCA A11→A22 AGT→AAC S16→N27 GAT→AAC D12→N23 TTA→ATT L17→I28 CAT→CAC H14→H25 AGA→GGT 19→G30 CCA→CCC P15→P26 AAC→GAC N20→D31 TCT→AAC S16→N27 CAT→CAA H21→Q32 TTG→ATT L17→I28 CTC→ATC L23→I34 AGA→GGT R19→G30 AAA→ACC K24→T35 AAT→GAC N20→D31 GGT→TAC G25→Y36 CAT→CAA H21→Q32 GCT→ACT A26→T37 TTG→ATC L23→I34 TCT→CCT S27→P38 CAA→ACC Q24→T35 GAT→GAA D28→E39 GGT→TAC G25→Y36 TTC→GAC F29→D40 GCA→ACT A26→T37
ACA→— T31→— TCA→CCT S27→P38 GAT→ACT D33→T43 GAT→GAA D28→E39 CAT→CGT H34→R44 TTT→GAC F29→D40 ACT→GCC T35→A45 ACT→— T31→—
GCA→TGC A36→C46 GAT→ACT D33→T43 ACT→ AAA T37→K47 CAT→CGT H34→R44 CAA→GAG Q38→E48 ACA→GCC T35→A45 GAA->GAG E39->E49 GCT→TGC A36→C46 CGA→CAG R40→Q50 ACA→AAA T37→K47 CAC→ATT H41→I51 AAT→GAG N38→E48 ACA→TTA T53→L63 GAA→GAG E39→E49 GAT→GCA D54→A64 AGA→CAG R40→Q50 GCT→ACC A55→T65 CAT→ATT H41→I51 GAA→GGA E56→G66 ACT→TTA T53→L63 GAT→AGG D57→R67 GAT→GCA D54→A64 AAG→AAA K58→K68 GCA→ACC A55→T65 GTT→ATT V60→I70 GAA→GGA E56→G66 GCA→ATG A85→M95 GAT→AGG D57→R67 ATA→TTG I86→L96 CAA→AAA Q58→K68 CAA→GAT Q87→D97 GCT→ATG A85→M95 AAA→CAC K88→H98 ATT→TTG I86→L96 TTA→ATT L89→I99 CAA→GAT Q87→D97 TGT→TAC C90→Y100 CAA→CAC Q88→H98
Table 35. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
>AGA >R101 TTG→ATT L89→I99 >GCT >A102 TGT→TAC C90→Y100
>GAT >D103 -— >AGA >R101
CCA->CCT P91->P104 -— >GCT >A102 ATC→TAT I92→Y105 -— >GAT >D103 TAT→TTT Y93→F106 CCA→CCT P91→P104 ATT→GAG I94→E107 ATT→TAT I92→Y105 GAC→GCT D95→A108 CAT→TTT H93→F106 AGT→CAT S96→H109 ATT→GAG I94→E107 AAT→GAA N97→E110 GAT→GCT D95→A108 AGA→TAC R98→Y111 TCT→CAT S96→H109 GCT→AAT A99→N112 GAT→GAA D97→E110 AAG→CAA K125→Q138 AAA→TAC K98→Y111 AAG→CAA K173→Q186 GCT→AAT A99→N112 TCA->TCT S174->S187 TCA→TCT S174→S187 TTG→— L175→— TTG→— L175→— GTA→— V176→— GTT→— V176→— CAG→GCT Q178→A189 CAA→GCT Q178→A189 GAT→CCA D179→P190 GAT→CCA D179→P190 GTA→TTG V181→L192 GTT→TTG V181→L192 ACC→AAG T182→K193 ACT→AAG T182→K193 CCT→TCA P183→S194 CCA→TCA P183→S194 AAG→CCT K184→P195 AGA→CCT R184→P195 TTT→ATT F209→I220 AGA→GTC R212→V223 ATG→GTC M212→V223 ATT→TAC I213→Y224 ATC→TAC I213→Y224 GAT→— D214→—
AAT→— N214→— TCT→— S215→— TCA→— S215→— ACT→CAA T216→Q225 ACA→CAA T216→Q225 TCT→GAT S217→D226 AGT→GAT S217→D226 GAT→GAA D218→E227 GAT→GAA D218→E227 GAT→GCT D219→A228 CAT→GCT H219→A228 TTG→TTC L220→F229 TTA→TTC L220→F229 GTT→CAT V221→H230 TAC→CAT Y221→H230 TTG→CTG L270→L279 GAG→GAT E238→D247 GGT→GGG G276→G285 AAA→CAA K252→Q261 CCA→TCA P281→S290 TTA→CTG L270→L279 TTG→TGC L313→C322 CCT→TCA P281→S290 TCT→ACG S314→T323 CAA→AAA Q292→K301 TTG→ATG L315→M324 CTC→TGC L313→C322 ACC→AGT T317→S326 AGC→ACG S314→T323 GAC→GAT D329→D338 CTC→ATG L315→M324 AAG→CGA K336→R345 ACT→AGT T317→S326 TTA→ATT L337→I346 CAA→GCT Q321→A330 GGT→CGG G357→R366 GAA→GAT E333→D342 GAG→GAT E484→D493 AAA→CGA K336→R345 ATA→ATC I538→I547 TTG→ATT L337→I346
GCT→ACA A345→T354
GGA→CGG G357→R366
AAT→ATT N369→I378
TCT→TAC S377→Y386
ACA→AGA T405→R414
AAT→GGT N429→G438
Table 35. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GCA→TCT A436→S445
GAA→GAT E484→D493
ACC→CCA T501→P510
GAT→GAA D536→E545
ATT->ATC I538->I547
j. V275 and V276
In CVS variants V275 and V276, amino acids 85-99 were replaced by amino acids
96-113 of Vitis vinifera (SEQ ID NO:346) as described above (see Table 25). CVS Variants V275 and V276 were generated by direct yeast recombination using V75 as a template.
Mutagenic oligo 21-141.7 was used in a single PCR reaction with oligo 11-154.4 and mutagenic oligo 21-141.8 was used in a single PCR reaction with oligo 11-154.3, with oligos set forth in Table 25 above. The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 are set forth in Table 36 below. V275 and V276 differ by one mutation, Y387→C389 in V276.
Table 36. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AAA→CAA K24Q GCT→GCA A85A
CAA→AAT Q38N ATT→TTA I86L
AAG→CAA K58Q CAA→CAT Q88H
GTT→ATT V60I TTG→ATT L89I
ATA→TTA I86L CCA→AAT P91N
AAA→CAT K88H ATT→AAT I92N
TTA→ATT L89I CAT→TTT H93F
CCA→AAT P91N ATT→CAT I94H
ATC→AAT I92N GAT→GAC D95D
TAT→TTT Y93F TCT→TGC S96C
ATT→CAT I94H GAT→AAT D97N
AGT→TGC S96C AAA→GAT K98D
AGA→GAT R98D GCT→ATG A99M
V275 808 865 82.8
GCT→ATG A99M -— >GGT >G101
>GGT >G101 -— >GAT >D102
>GAT >D102 GGT→GGG G276→G278
AAG→CAA K125→Q127 CCA→TCA P281→S283
AAG→CAA K173→Q175 TTG→TGC L313→C315
AAG→AGA K184→R186 TCT→ACG S314→T316
TTT→ATT F209→I211 TTG→ATG L315→M317
ATG→AGA M212→R214 ACC→AGT T317→S319
AAT→GAT N214→D216 GAC→GAT D329→D331
CAT→GAT H219→D221 AAG→CGA K336→R338
TAC→GTT Y221→V223 TTA→ATT L337→I339
GAG→GAT E238→D240 GGT→CGG G357→R359
AAA→CAA K252→Q254
Table 36. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
CCT- >TCA P281- >S283
CAA-►AAA Q292- >K294
CTC-►TGC L313- ►C315
AGC- >ACG S314- ►T316
CTC-►ATG L315- •M317
ACT- >AGT T317- >S319
CAA- >GCT Q321- >A323
GAA- >GAT E333- ►D335
AAA- >CGA K336- >R338
TTG- >ATT L337- ÷I339
GCT-►ACA A345- >T347
GGA- >CGG G357- >R359
AAT- ATT N369- ->I371
TCT-►TAC S377- ►Y379
ACA-►AGA T405- >R407
AAT- >GGT N429- >G431
GCA- *TCT A436- *S438
ACC- >CCA T501- P503
GAT-►GAA D536- >E538
AAA- →CAA K24Q GCT- →GCA A85A
CAA-→AAT Q38N ATT- →TTA I86L
AAG-→CAA K58Q CAA- →CAT Q88H
GTT-→ATT V60I TTG- →ATT L89I
ATA→TTA I86L CCA- →AAT P91N
AAA→CAT K88H ATT- →AGT I92S
TTA-→ATT L89I CAT- →TTT H93F
CCA-→AAT P91N ATT- →CAT I94H
ATC- ->AGT I92S GAT- →GAC D95D
TAT→TTT Y93F TCT- →TGC S96C
ATT- ^CAT I94H GAT- →AAT D97N
AGT-→TGC S96C AAA- →GAT K98D
AGA→GAT R98D GCT- →ATG A99M
GCT-→ATG A99M GGT >G101
GGT >G101 GAT >D102
GAT >D102 TTG- →CTG L147→L149
AAG→CAA K125→Q127 GGT- ->GGG G276→G278
V276 866 809 107
TTG- >CTG L147->L149 CCA- →TCA P281→S283
AAG •CAA K173→Q175 TTG- →TGC L313→C315
AAG AGA K184→R186 TCT- →ACG S314→T316
TTT- ATT F209→I211 TTG- →ATG L315→M317
ATG- AGA M212→R214 ACC- →AGT T317→S319
AAT ■GAT N214→D216 GAC- →GAT D329→D331
CAT- GAT H219→D221 AAG- →CGA K336→R338
TAC ■GTT Y221→V223 TTA- →ATT L337→I339
GAG >GAT E238→D240 GGT- →CGG G357→R359
AAA ■CAA K252→Q254 TAT- →TGT Y387→C389
CCT TCA P281→S283 ATT- →ATC I440→I442
CAA- AAA Q292→K294
CTC TGC L313→C315
AGC ACG S314→T316
CTC- ATG L315→M317
ACT- AGT T317→S319
CAA >GCT Q321→A323
Table 36. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GAA- >GAT E333- ►D335
AAA- >CGA K336- > 338
TTG- >ATT L337- *I339
GCT-►ACA A345- >T347
GGA- >CGG G357- >R359
AAT- ATT N369-■+I371
TCT-►TAC S377- >Y379
TAC- >TGT Y387- >C389
ACA-►AGA T405-►R407
AAT- >GGT N429- >G431
GCA- *TCT A436- S438
ACC- >CCA T501- >P503
GAT-►GAA D536- >E538
k. V278, V279, V280 and V281
CVS variants V278, V279,V280 and V281 were generated by error-prone PCR as described in Example 3. a using V240 and V245 as templates, with the following exceptions. First, primers 11-154.3 and 11-154.4 (see Table 25) were used in the PCR reactions. Second, cloning was accomplished by direct yeast recombination as in Example 5.1. The variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9 are set forth in Table 37 below.
Table 37. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. % vs. V19 nt aa
wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
V278 AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG→AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H 888 892 66
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y -— >GAT >D93
>AGA >R91 CCA→CCT P91→P94
>GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
Table 37. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TAT→TTT Y93→F96 TCT CAC S96→H99
ATT→GAG I94→E97 GAT GAA D97→E100
GAC→GCT D95→A98 AAA >TAC K98→Y101
AGT→CAC S96→H99 GCT AAT A99→N102
AAT→GAA N97→E100 GCT ■GCA A150→A153
AGA→TAC R98→Y101 TCA >TCT S174→S177
GCT→AAT A99→N102 TTG L175→—
AAG→CAA K125→Q128 GTT V176→—
AAG→CAA K173→Q176 CAA ►GCT Q178→A179
TCA→ TCT S174→S177 GAT >CCA D179→P180
TTG→— L175→— GTT ►TTG V181→L182
GTA→— V176→— ACT AAG T182→K183
CAG→GCT Q178→A179 CCA ►TCA P183→S184
GAT→CCA D179→P180 AGA >CCT R184→P185
GTA→TTG V181→L182 AG A AGG R198→R199
ACC→AAG T182→K183 GAT ►GTT D214→V215
CCT→TCA P183→S184 GGT GGG G276→G277
AAG→CCT K184→P185 CCA ►TCA P281→S282
CGT->AGG R198->R199 TTG TGC L313→C314
TTT→ATT F209→I210 TCT ACG S314→T315
ATG→AGA M212→R213 TTG ATG L315→M316
AAT→GTT N214→V215 ACC >AGT T317→S318
CAT→GAT H219→D220 GAC >GAT D329→D330
TAC→GTT Y221→V222 AAG ►CGA K336→R337
GAG→GAT E238→D239 TTA ►ATT L337→I338
AAA→CAA K252→Q253 GGT CGG G357→R358
CCT→TCA P281→S282 GAG ►GAT E484→D485
ACT→ACC T303→T304 CCA ►TCA P506→S507
CAA→AAA Q292→K293
CTC→TGC L313→C314
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
CAA→GCT Q321→A322
GAA→GAT E333→D334
AAA→CGA K336→R337
TTG→ATT L337→I338
GCT→ACA A345→T346
GGA→CGG G357→R358
AAT→ATT N369→I370
TCT→TAC S377→Y378
ACA→AGA T405→R406
AAT→GGT N429→G430
GCA→TCT A436→S437
GAA→GAT E484→D485
ACC→CCA T501→P502
CCA→TCA P506→S507D
GAT→GAA 536→E537
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
V279 CAA→AAT Q38N GAT→GCA D54A 889 893 75
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
Table 37. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57 GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H -— >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y -— >GAT >D93
>AGA -— >R91 CCA→CCT P91→P94
-— >GCT -— >A92 ATT→TAT I92→Y95
>GAT -— >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 ACT→GCT T257→A258
GTA→TTG V181→L182 GGT→GGG G276→G277
ACC→AAG T182→K183 CCA→TCA P281→S282
CCT→TCA P183→S184 TTG→TGC L313→C314
AAG→CCT K184→P185 TCT→ACG S314→T315
TTT→ATT F209→I210 TTG→ATG L315→M316
ATG→AGA M212→R213 ACC→AGT T317→S318
AAT→GAT N214→D215 GAC→GAT D329→D330
CAT→GAT H219→D220 AAG→CGA K336→R337
TAC→GTT Y221→V222 TTA→ATT L337→I338
GAG→GAT E238→D239 GGT→CGG G357→R358
AAA→CAA K252→Q253 AAT→AGT N410→S411
ACT→GCT T257→A258 GAG→GAT E484→D485
CCT→TCA P281→S282
CAA→AAA Q292→K293
CTC→TGC L313→C314
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
CAA→GCT Q321→A322
GAA→GAT E333→D334
AAA→CGA K336→R337
TTG→ATT L337→I338
GCT→ACA A345→T346
Table 37. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GGA- ►CGG G357- >R358
AAT- >ATT N369-■^1370
TCT- >TAC S377- >Y378
ACA- >AGA T405-► 406
AAT-►AGT N410- >S411
AAT-►GGT N429- >G430
GCA- TCT A436- S437
GAA- >GAT E484-►D485
ACC-►CCA T501- >P502
GAT- >GAA D536- >E537
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R ATT→GTT I60V
AAG→AAA K58K GTT→CTT V69L
GTA→CTT V69L GCT→ATG A85M
GCA→ATG A85M ATT→TTG I86L
ATA→TTG I86L CAA→GAT Q87D
CAA→GAT Q87D CAA→CAC Q88H
AAA→CAC K88H TTG→ATT L89I
TTA→ATT L89I TGT→TAC C90Y
TGT→TAC C90Y -— >AGA >R91
>AGA >R91 -— >GCT >A92
>GCT >A92 -— >GAT >D93
>GAT >D93 CCA→CCT P91→P94
CCA->CCT P91->P94 ATT→TAT I92→Y95
ATC→TAT I92→Y95 CAT→TTT H93→F96
V280 TAT→TTT Y93→F96 ATT→GAG I94→E97 890 894 70
ATT→GAG I94→E97 GAT→GCT D95→A98
GAC→GCT D95→A98 TCT→CAT S96→H99
AGT→CAT S96→H99 GAT→GAA D97→E100
AAT→GAA N97→E100 AAA→TAC K98→Y101
AGA→TAC R98→Y101 GCT→AAT A99→N102
GCT→AAT A99→N102 ACT→ACC T103→T106
AAG→CAA K125→Q128 TCA→TCT S174→S177
AAG→CAA K173→Q176 TTG→— L175→—
TCA→ TCT S174→S177 GTT→— V176→—
TTG→— L175→— CAA→GCT Q178→A179
GTA→— V176→— GAT→CCA D179→P180
CAG→GCT Q178→A179 GTT→TTG V181→L182
GAT→CCA D179→P180 ACT→AAG T182→K183
GTA→TTG V181→L182 CCA→TCA P183→S184
ACC→AAG T182→K183 AGA→CCT R184→P185
CCT→TCA P183→S184 GGT→GGG G276→G277
AAG→CCT K184→P185 CCA→TCA P281→S282
TTT→ATT F209→I210 TTG→TGC L313→C314
ATG→AGA M212→R213 TCT→ACG S314→T315
AAT→GAT N214→D215 TTG→ATG L315→M316
CAT→GAT H219→D220 ACC→AGT T317→S318
Table 37. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TAC→GTT Y221- V222 GAC→GAT D329→D330
GAG→GAT E238- ÷D239 AAG→CGA K336→R337
AAA→CAA K252- ^Q253 TTA→ATT L337→I338
CCT→TCA P281- ^S282 GGT→CGG G357→R358
CAA→AAA Q292- ^K293 GAG→GAT E484→D485
CTC→TGC L313- ÷C314
AGC→ACG S314- VT315
CTC→ATG L315- >M316
ACT→AGT T317- →S318
CAA→GCT Q321- ^A322
GAA→GAT E333- ÷D334
AAA→CGA K336- -*R337
TTG→ATT L337- →I338
GCT->ACA A345- 346
GGA→CGG G357- ^R358
AAT→ATT N369- →I370
TCT→TAC S377- >Y378
ACA→AGA T405- ^R406
AAT→GGT N429- ÷G430
GCA→TCT A436- →S437
GAA→GAT E484- ÷D485
ACC→CCA T501- ^P502
GAT→GAA D536- →E537
AGA- →AAA R19K TTT→TTC F13F
AAA- →CCA K24P AGA→AAA R19K
CAA- →TAT Q38Y CAA→CCA Q24P
ACA- →TTA T53L AAT→TAT N38Y
GAT- →GCA D54A ACT→TTA T53L
GCT- →ACC A55T GAT→GCA D54A
GAA- →GGA E56G GCA→ACC A55T
GAT- →AGG D57R GAA→GGA E56G
AAG- >AAA K58K GAT→AGG D57R
GTT- →ATT V60I CAA→AAA Q58K
GCA- →ATG A85M GCT→ATG A85M
ATA- →TTG I86L ATT→TTG I86L
CAA- →GAT Q87D CAA→GAT Q87D
AAA- →CAC K88H CAA→CAC Q88H
TTA- →ATT L89I TTG→ATT L89I
V281 896 895 90.17
TGT- →TAC C90Y TGT→TAC C90Y
AGA -— >R91 -— >AGA >R91
GCT -— >A92 -— >GCT >A92
■GAT -— >D93 -— >GAT >D93
CCA- >CCT P91->P94 CCA→CCT P91→P94
ATC- →TAT I92→Y95 ATT→TAT I92→Y95
TAT →TTT Y93→F96 CAT→TTT H93→F96
ATT- →GAG I94→E97 ATT→GAG I94→E97
GAC →GCT D95→A98 GAT→GCT D95→A98
AGT- →CAT S96→H99 TCT→CAT S96→H99
AAT- →GAA N97→E100 GAT→GAA D97→E100
AGA →TAC R98→Y101 AAA→TAC K98→Y101
GCT- →AAT A99→N102 GCT→AAT A99→N102
AAG- →CAA K125→Q128 TCA→TCT S174→S177
AAG- →CAA K173→Q176 TTG→— L175→—
Table 37. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TCA->TCT S174->S177 GTT V176
TTG→— L175→— CAA ►GCT Q178 ►A179
GTA→— V176→— GAT >CCA D179 >P180
CAG→GCT Q178→A179 GTT TTG V181 >L182
GAT→CCA D179→P180 ACT AAG T182 ►K183
GTA→TTG V181→L182 CCA ►TCA P183 ►SI 84
ACC→AAG T182→K183 AGA >CCT R184 >P185
CCT→TCA P183→S184 AGA ►GTC R212 ►V213
AAG→CCT K184→P185 ATT TAC 1213 Y214
TTT→ATT F209→I210 GAT D214
ATG→GTC M212→V213 TCT S215
ATC→TAC I213→Y214 ACT CAA T216 ■Q215
AAT→— N214→— TCT GAT S217 D216
TCA→— S215→— GAT GAA D218 >E217
ACA→CAA T216→Q215 GAT ►GCT D219 ►A218
AGT→GAT S217→D216 TTG ►TTC L220 ►F219
GAT→GAA D218→E217 GTT CAT V221 ►H220
CAT→GCT H219→A218 GGT GGG G276 ►G275
TTA→TTC L220→F219 CCA ►TCA P281 ►S280
TAC→CAT Y221→H220 TTG TGC L313 >C312
GAG→GAT E238→D237 TCT ACG S314 313
AAA→CAA K252→Q251 TTG ATG L315 M314
CCT→TCA P281→S280 ACC >AGT T317 ►S316
CAA→AAA Q292→K291 GAC >GAT D329 >D328
CTC→TGC L313→C312 AAG ►CGA K336 ►R335
AGC→ACG S314→T313 TTA ►ATT L337 I336
CTC→ATG L315→M314 GGT CGG G357 ►R356
ACT→AGT T317→S316 GAG ►GAT E484 ■D483
CAA→GCT Q321→A320
GAA→GAT E333→D332
AAA→CGA K336→ 335
TTG→ATT L337→I336
GCT→ACA A345→T344
GGA→CGG G357→R356
AAT→ATT N369→I368
TCT→TAC S377→Y376
ACA→AGA T405→R404
AAT→GGT N429→G428
GCA→TCT A436→S435
GAA→GAT E484→D483
ACC→CCA T501→P500
GAT→GAA D536→E535
Example 6
Generation and Screening of Further Valencene Synthase Mutants
Further additional valencene synthase mutants were produced using a variety of methods. The mutants were generated as described below in subsections a-f.
Mutants were screened in ALX7-95 using the microvial method described in Example 3.C.2, above, and mutants with >110 % valencene productivity of CVS V19 (i.e., 10 % increase in valencene versus CVS VI 9) were further screened in shake flask cultures. Tables 38-40 below sets forth the amino acid changes based on the designed sequence, although attempts to sequence the mutants were not successful. The Tables also set forth the percent (%) valencene production in initial microcultures and shake flask cultures relative to the valencene production of transformants containing the CVS VI 9 gene.
a. V282
CVS V19 (SEQ ID NO: 129) was used as a template to generate V282. In CVS variant V282, amino acids 53-58 were replaced by amino acids 58-63 of TEAS (SEQ ID
NO:941), amino acids 85-99 were replaced by amino acids 93-110 of HPS (SEQ ID NO:942) and amino acids 174-184 were replaced by amino acids 185-193 of HPS (SEQ ID NO:942) or 177-185 of TEAS (SEQ ID NO:941), and amino acids 212-221 were replaced by random amino acids as described above (see Table 27). This mutant was prepared as described above in Example 5f.
b. V283
CVS variant V283 was generated as described in Example 5f above for CVS variant V246, using V241 as a template. Several additional isolates were identified that produce >77% valencene as compared to CVS VI 9, but additionally produce high amounts of b- elemene.
c. V284 and V285
CVS variants V284 and V285 were generated as described in Example 5f above for CVS variant V246, using V240 as a template. Several additional isolates were identified that produce greater than approximately 77 % of the valencene titer of CVS VI 9, but additionally produce high amounts of b-elemene.
- -
d. Variants containing randomized residues from amino acids 212-221
CVS V19 and V75 were used as templates to generate additional CVS variants containing randomized residues from amino acids 212-221. These mutants were generated as previously described in Example 5f above. Eight isolates generated using CVS V 19 as a template were identified as producing >80% valencene as compared to CVS V 1 . Twelve isolates generated using V75 as a template were identified as producing >74% valencene as compared to CVS V I .
e. Variants containing directed point mutations
Additional CVS variants were generated containing point mutations at positions L310, H360 or Q370 as set forth below by a single PCR reaction from the template gene using forward and reverse oligos set forth in Table 25 above.
Variants containing the point L310H were generated, whereby V75 and V240 were modified to have the mutation L310H. The variants were tested in microculture for production of valencene. The results showed that V75 + L310H averaged 95.5% of valencene production of variant V 19, while V240 +L31 OH averaged 77.7% valenence production of variant V 19. The results suggested that the L31 OH mutation did not have an positive impact in the V240 background.
Further, V19 was used as a template to generate point mutations at amino acid H360 or Q370, and 8 individual isolates were identified that produced 68-100 % valencene as compared to CVS V 19.
f. Variants containing swaps at the N-terminus
Additional CVS variants were generated containing swaps at the extreme N-terminus of CVS by replacement of nucleotides encoding residues 1-15 of CVS with corresponding sequence from each of three heterologous terpene synthase genes. The three heterologous terepene synthase genes were tr5-epi-aristolochene synthase from Nicotiana tabacum (TEAS, SEQ ID NO:941), premnaspirodiene synthase from Hyoscyamus muticus (HPS, SEQ ID N0.942) or valencene synthase from Vitis vinifera (SEQ ID NO:346). CVS variants V240, V243, and V245 were used as templates to generate the mutants. Production of valencene was determined, and the results showed tha the mutants resulted in reduced production of valencene compared to VI 9.
Example 7
Production of Nookatone
RECTIFIED SHEET (RULE 91)
ISA/EP
The valencene-containing soybean oil, produced by fermentation as described in Example 2, was concentrated and purified using wiped-film distillation at 100 °C and 350 mTorr to generate an oil that contained approximately 68 % valencene by weight. This material was converted to nootkatone by two different methods described below.
A. Oxidation of valencene to nootkatone using chromium trioxide
The valencene distillate produced as described above was oxidized to nootkatone using chromium trioxide and pyridine in dicholoromethane as follows. Chromium trioxide (369 g, 3.69 mol, 22 eq) was added in portions to a solution of pyridine (584 g, 7.4 mol, 44 eq) in 5 L of dicholoromethane. The mixture was stirred for 10 minutes, 50 grams of valencene distillate (68 % w/w, 0.167 mol, 1 eq) was added over four minutes, and the mixture was stirred at 22 °C for 18 hours. The liquor was drained from the vessel, and the solids were washed twice with 2 L of methyl tert-butyl ether (MTBE). The combined organic layers were further diluted with 2 L of MTBE and successively washed three times with 1.25 L of 5 % sodium hydroxide, twice with 2 L of 5 % hydrochloric acid, and once with 2 L of brine. The organic phase was dried over 200 grams of anhydrous sodium sulfate, filtered, and concentrated by evaporation to give 36.8 grams crude nootkatone (48 % w/w, 0.081 mol, 48 % yield).
B. Oxidation of valencene to nootkatone using silica phosphonate-immobilized chromium (III) catalyst
Silica phosphonate chromium (III) resin (48.9 g, PhosphonicS, Ltd.) was placed in a 5
L round bottom flask equipped with a condenser, thermowell, overhead stirrer, and sparge tube. Two (2) L of t-butanol and valencene distillate (68 %, 500 g, 1.67 moles, 1 eq) were added, the contents were heated to 45 °C, and the heterogeneous suspension was allowed to stir as oxygen was sparged through the solution (ca 1.5 L/min) and nitrogen flushed over the head-space. 70 % /-butyl hydroperoxide in water (TBHP, 315 g, 2.45 moles, 1.47 eq) was added to the solution over 2 hrs while the temperature of the reaction was heated and maintained at 60 ± 5 °C. The reaction was allowed to stir until >90% of the valencene was consumed, as determined by gas chromatography. The reaction was then allowed to cool to room temperature and the silica catalyst removed by filtration. The flask and resin were washed with 500 niL isopropanol. One (1) L of deionized water was added to the combined organic solution (t-butanol and isopropanol), and the mixture was concentrated under reduced pressure by evaporation to afford an amber colored oil. The oil was dissolved in 3 L of toluene and washed with 3.125 L of 15 % sulfuric acid for 15 minutes with vigorous agitation. The aqueous layer was removed and re-extracted with 1 L of toluene. The combined toluene layers were then washed three times with 2.5 L of 1 M sodium hydroxide, twice with 500 mL saturated sodium chloride, and dried over anhydrous mangnesium sulfate.
After filtration, the solvent was removed under reduced pressure by evaporation to afford 378 g of viscous amber oil (33 % nootkatone by weight, 0.57 moles, 34 % yield).
Example 8
Analysis of Terpene Product Distribution of CVS Variants In this example, gas chromatography (GC) was used to determine the product distribution of the terpenes produced by the variant valencene synthases. Analysis of the products produced by yeast strains expressing valencene synthase by gas chromatography indicates that the enzyme produces valencene as the primary product. A number of byproducts, including compounds referred to as Peak 1 (tentatively identified as β-selinene), Peak 2 (tentatively identified as x-selinene), Peak 3 (identified as eremophilene), Peak 4
(identified as 7-epz-a-selinene), and Peak 5 (unidentified), as well as β-elemene and a number of minor additional products were also produced. β-Elemene is almost certainly a degradation product of the mechanistic intermediate germacrene A, formed via Cope rearrangement (de Kraker et al. (2001) Plant Physiol. 125: 1930-1940).
The results are shown in Tables 41 and 42 below, which set forth the distribution of terpene products, as a percentage of the total amount of terpenes produced, defined herein as the sum of the amounts of valencene, β-elemene, and Peaks 1 through 5, as measured by GC peak area. Table 41 below sets forth the distribution of products for variants CVS VI 9, V71, V73, V75, V229 and V231 (see Tables 19 and 27 above) produced from shake flask cultures. In variants V71, V73, and V75 the amount of valencene produced as a percentage of the total amount of terpenes was about 71 %, as compared to 66 % for variant CVS VI 9. A corresponding decrease in the amount of β-elemene formed in these variants was observed, suggesting that the variant enzymes were more efficient at pushing the reaction to completion rather than stopping at the germacrene A intermediate. Distribution of the remaining byproducts from the valencene synthase variants were similar between the variant enzymes. In variants V229 and V231 , valencene again represented a larger proportion of the product mixture (72.8 %) than was produced by variant CVS V19 (67.66 %). With V229 and V231, decreases in the percentages of both β-elemene and Peak 3 were observed.
Table 42 below shows a similar comparison of yeast strains expressing valencene synthase variants grown in 3 L fermentation cultures. It was observed that the product distribution from variant CVS VI 9 was similar, but not identical, in fermentor cultivation to the product distribution seen in shake flask cultures. Variants V73 and V75 had altered product distributions leading to a larger percentage of the total product being represented by valencene. In each of these variants, the amount of β-elemene observed was less than that observed for variant CVS VI 9, again suggesting that the enzymes were more efficient at pushing the reaction to completion rather than stopping at intermediate germacrene A. The
amounts of Peaks 1 through 4 produced by these variants were all similar to the CVS VI 9 variant. Interestingly, more of the Peak 5 compound was produced by variant V75 compared to variant CVS VI 9, but less Peak 5 product was produced by V73. This suggested that variations in culture conditions might also influence product distribution with respect to this unidentified byproduct.
In general, it was observed that the proportion of products produced by some variant valencene synthase differ from those produced by the wild type enzyme or variants VI 8 and VI 9, whose product profiles are similar to the wild type valencene synthase. In particular, the proportion of valencene produced by some variants was higher than that observed in VI 9. These data indicated that variants with altered product selectivity can be produced by introducing mutations into valencene synthase and that some variants produce a greater proportion of valencene in the product mix.
Example 9
Additional Valencene Synthase Mutants
Additional valencene synthase mutants were produced using a valencene synthase above as a template to introduce further amino acid replacements or swaps using error prone PCR and overlapping PCR methods similar to those described above using primers that introduce mutations at multiple codon positions simultaneously. For example, some additional mutants were generated using valencene synthase VI 9, V240 or V245 as the template in a PCR reaction or reactions using primers set forth in Table 25. The generated
mutants were screened for valencene production as described above. The Table below set forth the generated variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valencene production % versus CVS VI 9.
CVS variants V293, V299, V300, V304, V305, V306, V307 and V308 were generated from V240 as a template sequence so that the variants have amino acids 53-58 replaced by amino acids 58-63 of TEAS (SEQ ID NO:941), amino acids 85-99 replaced by amino acids 93-110 of HPS (SEQ ID NO:942) and amino acids 174-184 replaced by amino acids 185-193 of HPS (SEQ ID NO:942) or 177-185 of TEAS (SEQ ID NO:941) as described above. In addition, the variants all were generated to contain one or more other amino acid replacements compared to V240 such as MIT, S2A, S3G, G4E, E5A, F7G, Al IT, N20D, L23S, Y152H (Y152→H155), E163D (E163→D166), K173E (K173→E176), M210T (M210→T211), C361R (C361→R362), Q448L (Q448→L449), C465S (C465→S466), K468Q (K468→Q469), K499E(K499→E500), P500L (P500→L501) and/or A539V
(A539→V540).
CVS variant V292 was generated from V245 as a template sequence so that the variant has amino acids 53-58 replaced by amino acids 58-63 of TEAS (SEQ ID NO:941), amino acids 85-99 replaced by amino acids 93-110 of HPS (SEQ ID NO:942), amino acids 174-184 replaced by amino acids 185-193 of HPS (SEQ ID NO:942) or 177-185 of TEAS (SEQ ID NO:941), and amino acids 212-221 were replaced by amino acids 223-230 of Vitis (SEQ ID NO:346) as described above. In addition, the variant was generated to contain an amino acid replacement V439L (V439→L438) compared to V245.
CVS variants V311 and V312 were generated from VI 9 as a template sequence. In addition, in the variants, amino acids 90-99 of CVS were replaced by amino acids 101-113 of Vitis vinifera set forth in SEQ ID NO:346 by direct yeast recombination as described above and using V19 as template (see Table 25). Mutagenic oligo 21-141.3 was used in a single PCR reaction with oligo 11-154.4 and mutagenic oligo 21-141.4 was used in a single PCR reaction with oligo 11-154.3, with oligos set forth in Table 25 above. V311 and V312 differ by two mutations, I82V and L399→S401 in V312.
In CVS variant V314, amino acids 3-41 were replaced by amino acids 3-51 of Vitis (SEQ ID NO:346), amino acids 53-58 were replaced by amino acids 58-63 of TEAS (SEQ ID NO:941), amino acids 85-99 were replaced by amino acids 96-112 of Vitis (SEQ ID NO:346) and amino acids 174-184 were replaced by amino acids 185-193 of HPS (SEQ ID NO:942) or 177-185 of TEAS (SEQ ID NO:941), and amino acids 212-221 were replaced by amino acids 223-230 of Vitis (SEQ ID NO:346) by direct yeast recombination as described above (see Table 25).
CVS variants V297 and V313 were generated using V240 or V314 as template, respectively, by replacing amino acids 115-146 by amino acids 128-159 of Vitis vinifera (SEQ ID NO:346 ). Three PCR fragments were combined by direct recombination as described above (see Table 25). The first PCR fragment used oligo 11-154.3 and mutagenic primer 21-145.30 with either V240 or V314 as template. The second PCR fragment used mutagenic primers 21-145.29 and 21-145.40 with Vitis vinifera (SEQ ID NO:346 ) as template. The third PCR fragment used oligo 11-154.4 and mutagenic oligo 21-145.39 with V240 as template. Thus, for CVS variant V313, in addition to the swaps described above for V314, in V313 amino acids 114-146 were replaced by amino acids 128-159 of Vitis (SEQ ID NO:346) by direct yeast recombination as described above (see Table 25). In addition, the variant was generated to contain an amino acid replacement H102Y (H102→Y114) compared to V314. CVS variant V297, which was generated from V240 as a template sequence, has amino acids 53-58 replaced by amino acids 58-63 of TEAS (SEQ ID NO:941), amino acids 85-99 replaced by amino acids 93-110 of HPS (SEQ ID NO:942), amino acids 114-146 replaced by amino aicds 128-159 of Vitis (SEQ ID NO:346) and amino acids 174-184 replaced by amino acids 185-193 of HPS (SEQ ID NO:942) or 177-185 of TEAS (SEQ ID NO:941).
V260 (V259), V263 and V277 were used as templates to generate point mutations at amino acids 196, 197, 198, 200, 348 or 399 to generate CVS variants V287, V288, V289, V290, V294, V295, V296, V298, V301, V302, V303, V309, V310, V315. Some of the resulting identified mutations generated by the designed mutation strategy resulted in no differences from the template, silent mutations or reversions to wiltype sequence.
Each of the above variants, including amino acid and nucleotide changes versus both wildtype CVS and CVS VI 9, and valence production % versus CVS 19 as assessed in shake flask cultures are set forth in Table 43. No data is provided for valencene production of variants V299, V300, V304, V305, V306, V307, V308 because these variants were tested only in microculture and not shake flask for valencene production.
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
V287 TCG→AAA S2K TCA→AAA S2K
TCT→GAA S3E TCT→GAA S3E
GGA→TGT G4C GGT→TGT G4C
945 944 75.8
GAA→ACG E5T GAA→ACG E5T
ACA→ATG T6M ACT→ATG T6M
TTT→TTA F7L TTT→TTA F7L
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TTG→CTG L161→L164
AGA→TAC R98→Y101 TCA→TCT S174→S177
GCT→AAT A99→N102 TTG→— L175→—
AAG→CAA K125→Q128 GTT→— V176→—
TTA->CTG L161->L164 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GAA→GAG E348E
AGC→ACG S314T GGT→CGG G357R
CTC→ATG L315M AAA→AAG K468K
ACT→AGT T317S GAG→GAT E484D
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336
TTG→ATT L337I
GCT→ACA A345T
GAA->GAG E348E
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
V288 TCG→AAA S2K TCA→AAA S2K
TCT→GAA S3E TCT→GAA S3E
GGA→TGT G4C GGT→TGT G4C
GAA→ACG E5T GAA→ACG E5T
ACA→ATG T6M ACT→ATG T6M
TTT→TTA F7L TTT→TTA F7L
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H 947 946
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→GCG S314A
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GAA→GCT E348A
AGC→GCG S314A GGT→CGG G357R
CTC→ATG L315M AAA→AAG K468K
ACT→AGT T317S GAG→GAT E484D
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336
TTG→ATT L337I
GCT→ACA A345T
GAA→GCT E348A
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
V289 TCG→TGC S2C TCA→TGC S2C
TCT→ATG S3M TCT→ATG S3M
GGA→ACA G4T GGT→ACA G4T
GAA→GGT E5G GAA→GGT E5G
949 948 83.2
ACA→GAA T6E ACT→GAA T6E
TTT→TCG F7S TTT→TCG F7S
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 TTG→CTG L197→L198
GTA→TTG V181→L182 TCA→TCG S211→S212
ACC→AAG T182→K183 AGA→TCA R212→S213
CCT→TCA P183→S184 ATT→ATC I213→I214
AAG→CCT K184→P185 GAT→TAT D214→Y215
CTT->CTG L197->L198 TCT→GAC S215→D216
TTT→ATT F209→I210 ACT→AAG T216→K217
TCC->TCG S211->S212 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
CTC- >TGC L313C GGT→CGG G357R
AGC- >ACG S314T GAG→GAT E484D
CTC- >ATG L315M
ACT- >AGT T317S
CAA- >GCT Q321A
GAA- ÷GAT E333D
AAA- ÷CGA K336
TTG- ►ATT L337I
GCT- >ACA A345T
GGA- ÷CGG G357R
AAT- >ATT N369I
TCT— TAC S377Y
ACA- >AGA T405R
AAT- >GGT N429G
GCA- TCT A436S
GAA- ^GAT E484D
ACC- >CCA T501P
GAT- >GAA D536E
V290 TCG→TGC S2C TCA→TGC S2C
TCT→ATG S3M TCT→ATG S3M
GGA→ACA G4T GGT→ACA G4T
GAA→GGT E5G GAA→GGT E5G
ACA→GAA T6E ACT→GAA T6E
TTT→TCG F7S TTT→TCG F7S
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I 951 950
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→CGT R198→R199
GTA→TTG V181→L182 AGA→TCA R212→S213
ACC→AAG T182→K183 ATT→ATC I213→I214
CCT→TCA P183→S184 GAT→TAT D214→Y215
AAG→CCT K184→P185 TCT→GAC S215→D216
TTT→ATT F209→I210 ACT→AAG T216→K217
ATG→TCA M212→S213 TCT→— S217→—
AAT→TAT N214→Y215 GAT→GAA D218E
TCA→GAC S215→D216 GAT→CAA D219Q
ACA→AAG T216→K217 TTG→TCG L220S
AGT→— S217→— GTT→AAG V221K
GAT→GAA D218E GGT→GGG G276G
CAT→CAA H219Q CCA→TCA P281 S
TTA→TCG L220S TTG→TGC L313C
TAC→AAG Y221K TCT→ACG S314T
GAG→GAT E238D TTG→ATG L315M
AAA→CAA K252Q ACC→AGT T317S
CCT→TCA P281 S GAC→GAT D329D
CAA→AAA Q292K AAG→CGA K336R
CTC→TGC L313C TTA→ATT L337I
AGC→ACG S314T GGT→CGG G357R
CTC→ATG L315M GAG→GAT E484D
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
V292 AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R 953 952 57.2
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCG D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCG D179→P180 GCT→GCA A192→A193
GTA→TTG V181→L182 AGA→GTC R212→V213
ACC→AAG T182→K183 ATT→TAC I213→Y214
CCT→TCA P183→S184 GAT→— D214→—
AAG→CCT K184→P185 TCT→— S215→-214
GCT->GCA A192->A193 ACT→CAA T216→Q215
TTT→ATT F209→I210 TCT→GAT S217→D216
ATG→GTC M212→V213 GAT→GAA D218→E217
ATC→TAC I213→Y214 GAT→GCT D219→A218
AAT→— N214→— TTG→TTC L220→F219
TCA→— S215→-214 GTT→CAT V221→H220
ACA→CAA T216→Q215 GGT→GGG G276→G275
AGT→GAT S217→D216 CCA→TCA P281→S280
GAT→GAA D218→E217 TTG→TGC L313→C312
CAT→GCT H219→A218 TCT→ACG S314→T313
TTA→TTC L220→F219 TTG→ATG L315→M314
TAC→CAT Y221→H220 ACC→AGT T317→S316
GAG→GAT E238→D237 GAC→GAT D329→D328
AAA→CAA K252→Q251 AAG→CGA K336→R335
CCT→TCA P281→S280 TTA→ATT L337→I336
CAA→AAA Q292→K291 GGT→CGG G357→R356
CTC→TGC L313→C312 GTT→CTT V439→L438
AGC→ACG S314→T313 GAG→GAT E484→D483
CTC→ATG L315→M314
ACT→AGT T317→S316
CAA→GCT Q321→A320
GAA→GAT E333→D332
AAA→CGA K336→R335
TTG→ATT L337→I336
GCT→ACA A345→T344
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GGA- ÷CGG G357- *R356
AAT- >ATT N369- ^1368
TCT— ■TAC S377- ►Y376
ACA- >AGA T405- > 404
AAT- >GGT N429- ^G428
GCA- >TCT A436- *S435
GTT- ►CTT V439- ^L438
GAA- ÷GAT E484- >D483
ACC- >CCA T501- >P500
GAT- >GAA D536- ^E535
V293 TCG→GCT S2A TCA→GCT S2A
TCT→GGA S3G TCT→GGA S3G
GGA→GAG G4E GGT→GAG G4E
GAA→GCG E5A GAA→GCG E5A
TTT→GGA F7G ACT→ AC A T6T
AGA→AAA R19K TTT→GGA F7G
AAA→CAA K24Q AGA→AAA R19K
CAA→AAT Q38N ACT→TTA T53L
ACA→TTA T53L GAT→GCA D54A
GAT→GCA D54A GCA→ACC A55T
GCT→ACC A55T GAA→GGA E56G
GAA→GGA E56G GAT→AGG D57R
GAT→AGG D57R CAA→AAA Q58K
AAG->AAA K58K GCT→ATG A85M
GTT→ATT V60I ATT→TTG I86L
GCA→ATG A85M CAA→GAT Q87D
ATA→TTG I86L CAA→CAC Q88H
CAA→GAT Q87D TTG→ATT L89I
AAA→CAC K88H TGT→TAC C90Y
TTA→ATT L89I >AGA >R91
TGT→TAC C90Y -— >GCT >A92
>AGA >R91 >GAT >D93 955 954 73.7
-— >GCT >A92 CCA→CCT P91→P94
>GAT >D93 ATT→TAT I92→Y95
CCA->CCT P91->P94 CAT→TTT H93→F96
ATC→TAT I92→Y95 ATT→GAG I94→E97
TAT→TTT Y93→F96 GAT→GCT D95→A98
ATT→GAG I94→E97 TCT→CAT S96→H99
GAC→GCT D95→A98 GAT→GAA D97→E100
AGT→CAT S96→H99 AAA→TAC K98→Y101
AAT→GAA N97→E100 GCT→AAT A99→N102
AGA→TAC R98→Y101 TCA→TCT S174→S177
GCT→AAT A99→N102 TTG→— L175→—
AAG→CAA K125→Q128 GTT→— V176→—
AAG→CAA K173→Q176 CAA→GCT Q178→A179
TCA->TCT S174->S177 GAT→CCA D179→P180
TTG→— L175→— GTT→TTG V181→L182
GTA→— V176→— ACT→AAG T182→K183
CAG→GCT Q178→A179 CCA→TCA P183→S184
GAT→CCA D179→P180 AGA→CCT R184→P185
GTA→TTG V181→L182 GAA→GAG E205→E206
ACC→AAG T182→K183 GGT→GGG G276→G277
CCT→TCA P183→S184 CCA→TCA P281→S282
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
AAG→CCT K184→P185 TTG→TGC L313→C314
TTT→ATT F209→I210 TCT→ACG S314→T315
ATG→AGA M212→R213 TTG→ATG L315→M316
AAT→GAT N214→D215 ACC→AGT T317→S318
CAT→GAT H219→D220 GAC→GAT D329→D330
TAC→GTT Y221→V222 AAG→CGA K336→R337
GAG→GAT E238→D239 TTA→ATT L337→I338
AAA→CAA K252→Q253 GGT→CGG G357→R358
CCT→TCA P281→S282 GAG→GAT E484→D485
CAA→AAA Q292→K293 AAA→GAA K499→E500
CTC→TGC L313→C314
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
CAA→GCT Q321→A322
GAA→GAT E333→D334
AAA→CGA K336→R337
TTG→ATT L337→I338
GCT→ACA A345→T346
GGA→CGG G357→R358
AAT→ATT N369→I370
TCT→TAC S377→Y378
ACA→AGA T405→R406
AAT→GGT N429→G430
GCA→TCT A436→S437
GAA→GAT E484→D485
AAG→GAA K499→E500
ACC→CCA T501→P502
GAT→GAA D536→E537
V294 TCG→TGC S2C TCA→TGC S2C
TCT→ATG S3M TCT→ATG S3M
GGA→ACA G4T GGT→ACA G4T
GAA→GGT E5G GAA→GGT E5G
ACA→GAA T6E ACT→GAA T6E
TTT→TCG F7S TTT→TCG F7S
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
957 956 79.3
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19 >GAT >D93 CAT >TTT H93→F96
CCA->CCT P91->P94 ATT >GAG I94→E97
ATC→TAT I92→Y95 GAT >GCT D95→A98
TAT→TTT Y93→F96 TCT >CAT S96→H99
ATT→GAG I94→E97 GAT >GAA D97→E100
GAC→GCT D95→A98 AAA ^TAC K98→Y101
AGT→CAT S96→H99 GCT >AAT A99→N102
AAT→GAA N97→E100 TCA ■TCT S174→S177
AGA→TAC 98→Y101 TTG L175→—
GCT→AAT A99→N102 GTT V176→—
AAG→CAA K125→Q128 CAA →GCT Q178→A179
AAG→CAA K173→Q176 GAT →CCA D179→P180
TCA->TCT S174->S177 GTT ÷TTG V181→L182
TTG→— L175→— ACT →AAG T182→K183
GTA→— V176→— CCA →TCA P183→S184
CAG→GCT Q178→A179 AGA →CCT R184→P185
GAT→CCA D179→P180 CCA >CCC P196→P197
GTA→TTG V181→L182 AGA →TCA R212→S213
ACC→AAG T182→K183 ATT ATC I213→I214
CCT→TCA P183→S184 GAT →TAT D214→Y215
AAG→CCT K184→P185 TCT >GAC S215→D216
CCT->CCC P196->P197 ACT →AAG T216→K217
TTT→ATT F209→I210 TCT >— S217→—
ATG→TCA M212→S213 GAT ->GAA D218E
AAT→TAT N214→Y215 GAT →CAA D219Q
TCA→GAC S215→D216 TTG ÷TCG L220S
ACA→AAG T216→K217 GTT ÷AAG V221K
AGT→— S217→— GOT +GGG G276G
GAT→GAA D218E CCA →TCA P281 S
CAT→CAA H219Q TTG ÷TGC L313C
TTA→TCG L220S TCT >ACG S314T
TAC→AAG Y221K TTG ÷ATG L315M
GAG→GAT E238D ACC →AGT T317S
AAA→CAA K252Q GAC ÷GAT D329D
CCT→TCA P281 S AAG →CGA K336R
CAA→AAA Q292K TTA *ATT L337I
CTC→TGC L313C GGT →CGG G357R
AGC→ACG S314T CAA >CAG Q448Q
CTC→ATG L315M GAG →GAT E484D
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
CAA->CAG Q448Q
GAA→GAT E484D
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
ACC→CCA T501P
GAT→GAA D536E
V295 TCG→AAA S2K TCA→AAA S2K
TCT→GAA S3E TCT→GAA S3E
GGA→TGT G4C GGT→TGT G4C
GAA→ACG E5T GAA→ACG E5T
ACA→ATG T6M ACT→ATG T6M
TTT→TTA F7L TTT→TTA F7L
AGA→AAA 19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97 959 958 81.6
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 CCA→CCC P196→P197
GTA→TTG V181→L182 AGA→TCA R212→S213
ACC→AAG T182→K183 ATT→ATC I213→I214
CCT→TCA P183→S184 GAT→TAT D214→Y215
AAG→CCT K184→P185 TCT→GAC S215→D216
CCT->CCC P196->P197 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
AGT S217→ GGT- >GGG G276G
GAT >GAA D218E CCA- ÷TCA P281 S
CAT >CAA H219Q TTG- >TGC L313C
TTA >TCG L220S TCT- ►ACG S314T
TAC ►AAG Y221K TTG- >ATG L315M
GAG ÷GAT E238D ACC- ÷AGT T317S
AAA ÷CAA K252Q GAC- >GAT D329D
CCT >TCA P281 S AAG- →CGA K336R
CAA >AAA Q292K TTA- >ATT L337I
CTC >TGC L313C GGT- ÷CGG G357R
AGC >ACG S314T CAT- ■CAC H360H
CTC >ATG L315M AAA- AAG K468K
ACT >AGT T317S GAG- ->GAT E484D
CAA >GCT Q321A
GAA ÷GAT E333D
AAA ÷CGA K336
TTG ►ATT L337I
GCT >ACA A345T
GGA ÷CGG G357R
AAT >ATT N369I
TCT TAC S377Y
ACA >AGA T405R
AAT >GGT N429G
GCA >TCT A436S
GAA ÷GAT E484D
ACC >CCA T501P
GAT >GAA D536E
V296 TCG→AAA S2K TCA→AAA S2K
TCT→GAA S3E TCT→GAA S3E
GGA→TGT G4C GGT→TGT G4C
GAA→ACG E5T GAA→ACG E5T
ACA→ATG T6M ACT→ATG T6M
TTT→TTA F7L TTT→TTA F7L
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
961 960
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC 98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T AAA→AAG K468K
CTC→ATG L315M GAG→GAT E484D
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
V297 AGA→AAA R19K AGA→AAA R19K 61.3 (avg of
963 962
AAA→CAA K24Q ACT→TTA T53L 4 flasks)
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57 GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 GGT→GGG G115→G118
AGA→TAC R98→Y101 ATT→TAC I116→Y119
GCT→AAT A99→N102 AAG→ACT K117→T120
GGA->GGG G115->G118 TCT→TCA S119→S122
ATC→TAC I116→Y119 GTT→ATA V122→I125
AAG→ACT K117→T120 GAA→AAC E124→N127
GTG→ATA V122→I125 CAA→AAG Q125→K128
GAG→AAC E124→N127 AAG→ACG K127→T130
AAA→ACG K127→T130 GAT→GAA D129→E132
GAT→GAA D129→E132 GAA→CGA E130→R133
GAG→CGA E130→R133 AAA→AAG K134→K137
TCA→GAA S135→E138 AGT→GAA S135→E138
TCG→GCT S136→A139 TCT→GCT S136→A139
ATA->ATC I138->1141 ATT→ATC I138→I141
AAC→AGC N139→S142 AAT→AGC N139→S142
GTT->GTA V141-> V144 GTT→GTA V141→V144
CAA→AGA Q142→R145 CAA→AGA Q142→R145
TTA->CTA L145->L148 TTG→CTA L145→L148
AGT→GGC S146→G149 TCT→GGC S146→G149
AAG→CAA K173→Q176 TCA→TCT S174→S177
TCA->TCT S174->S177 TTG→— L175→—
TTG→— L175→— GTT→— V176→—
GTA→— V176→— CAA→GCT Q178→A179
CAG→GCT Q178→A179 GAT→CCA D179→P180
GAT→CCA D179→P180 GTT→TTG V181→L182
GTA→TTG V181→L182 ACT→AAG T182→K183
ACC→AAG T182→K183 CCA→TCA P183→S184
CCT→TCA P183→S184 AGA→CCT R184→P185
AAG→CCT K184→P185 GGT→GGG G276→G277
TTT→ATT F209→I210 CCA→TCA P281→S282
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
ATG→AGA M212→R213 TTG→TGC L313→C314
AAT→GAT N214→D215 TCT→ACG S314→T315
CAT→GAT H219→D220 TTG→ATG L315→M316
TAC→GTT Y221→V222 ACC→AGT T317→S318
GAG→GAT E238→D239 GAC→GAT D329→D330
AAA→CAA K252→Q253 AAG→CGA K336→R337
CCT→TCA P281→S282 TTA→ATT L337→I338
CAA→AAA Q292→K293 GGT→CGG G357→R358
CTC→TGC L313→C314 GAG→GAT E484→D485
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
CAA→GCT Q321→A322
GAA→GAT E333→D334
AAA→CGA K336→R337
TTG→ATT L337→I338
GCT→ACA A345→T346
GGA→CGG G357→R358
AAT→ATT N369→I370
TCT→TAC S377→Y378
ACA→AGA T405→R406
AAT→GGT N429→G430
GCA→TCT A436→S437
GAA→GAT E484→D485
ACC→CCA T501→P502
GAT→GAA D536→E537
V298 TCG→AAA S2K TCA→AAA S2K
TCT→GAA S3E TCT→GAA S3E
GGA→TGT G4C GGT→TGT G4C
GAA→ACG E5T GAA→ACG E5T
ACA→ATG T6M ACT→ATG T6M
TTT→TTA F7L TTT→TTA F7L
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M 965 964 83
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC 98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 ACT→ACC T200→T201
GTA→TTG V181→L182 AGA→TCA R212→S213
ACC→AAG T182→K183 ATT→ATC I213→I214
CCT→TCA P183→S184 GAT→TAT D214→Y215
AAG→CCT K184→P185 TCT→GAC S215→D216
TTT→ATT F209→I210 ACT→AAG T216→K217
ATG→TCA M212→S213 TCT→— S217→—
AAT→TAT N214→Y215 GAT→GAA D218E
TCA→GAC S215→D216 GAT→CAA D219Q
ACA→AAG T216→K217 TTG→TCG L220S
AGT→— S217→— GTT→AAG V221K
GAT→GAA D218E GGT→GGG G276G
CAT→CAA H219Q CCA→TCA P281 S
TTA→TCG L220S TTG→TGC L313C
TAC→AAG Y221K TCT→ACG S314T
GAG→GAT E238D TTG→ATG L315M
AAA→CAA K252Q ACC→AGT T317S
CCT→TCA P281 S GAC→GAT D329D
CAA→AAA Q292K AAG→CGA K336R
CTC→TGC L313C TTA→ATT L337I
AGC→ACG S314T GGT→CGG G357R
CTC→ATG L315M GGT→GGC G457G
ACT→AGT T317S AAA→AAG K468K
CAA→GCT Q321A GAG→GAT E484D
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GGA->GGC G457G
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
V299 TCG->TCC S2S TCA→TCC S2S
967 966
GCA→ACT A11T GCT→ACT A11T
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
AGA→AAA 19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GTT→GTA V74V
AAG->AAA K58K GCT→ATG A85M
GTT→ATT V60I ATT→TTG I86L
GTG->GTA V74V CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 GGT→GGG G276→G277
GTA→TTG V181→L182 CCA→TCA P281→S282
ACC→AAG T182→K183 TTG→TGC L313→C314
CCT→TCA P183→S184 TCT→ACG S314→T315
AAG→CCT K184→P185 TTG→ATG L315→M316
TTT→ATT F209→I210 ACC→AGT T317→S318
ATG→AGA M212→R213 GAC→GAT D329→D330
AAT→GAT N214→D215 AAG→CGA K336→R337
CAT→GAT H219→D220 TTA→ATT L337→I338
TAC→GTT Y221→V222 GGT→CGG G357→R358
GAG→GAT E238→D239 GAG→GAT E484→D485
AAA→CAA K252→Q253
CCT→TCA P281→S282
CAA→AAA Q292→K293
CTC→TGC L313→C314
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
CAA- >GCT Q321- *A322
GAA- ÷GAT E333- >D334
AAA- ÷CGA K336- *R337
TTG- ►ATT L337- ►1338
GCT- >ACA A345- »T346
GGA- ÷CGG G357- *R358
AAT- >ATT N369- »I370
TCT— TAC S377- ►Y378
ACA- >AGA T405- >R406
AAT- >GGT N429- *G430
GCA- >TCT A436- *S437
GAA- ÷GAT E484- >D485
ACC- >CCA T501- >P502
GAT- >GAA D536- *E537
V300 ATG→ACG MIT ATG→ACG MIT
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96 969 968
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TAT→CAT Y152→H155
AGA→TAC R98→Y101 TCA→TCT S174→S177
GCT→AAT A99→N102 TTG→— L175→—
AAG→CAA K125→Q128 GTT→— V176→—
TAC→CAT Y152→H155 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 GGT→GGG G276→G277
GTA→TTG V181→L182 CCA→TCA P281→S282
ACC→AAG T182→K183 TTG→TGC L313→C314
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
CCT→TCA P183→S184 TCT→ACG S314→T315
AAG→CCT K184→P185 TTG→ATG L315→M316
TTT→ATT F209→I210 ACC→AGT T317→S318
ATG→AGA M212→R213 GAC→GAT D329→D330
AAT→GAT N214→D215 AAG→CGA K336→R337
CAT→GAT H219→D220 TTA→ATT L337→I338
TAC→GTT Y221→V222 GGT→CGG G357→R358
GAG→GAT E238→D239 TGT→CGT C361→R362
AAA→CAA K252→Q253 AAA→CAA K468→Q469
CCT→TCA P281→S282 GAG→GAT E484→D485
CAA→AAA Q292→K293
CTC→TGC L313→C314
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
CAA→GCT Q321→A322
GAA→GAT E333→D334
AAA→CGA K336→R337
TTG→ATT L337→I338
GCT→ACA A345→T346
GGA→CGG G357→R358
TGC→CGT C361→R362
AAT→ATT N369→I370
TCT→TAC S377→Y378
ACA→AGA T405→R406
AAT→GGT N429→G430
GCA→TCT A436→S437
AAG→CAA K468→Q469
GAA→GAT E484→D485
ACC→CCA T501→P502
GAT→GAA D536→E537
V301 TCG→TGC S2C TCA→TGC S2C
TCT→ATG S3M TCT→ATG S3M
GGA→ACA G4T GGT→ACA G4T
GAA→GGT E5G GAA→GGT E5G
ACA→GAA T6E ACT→GAA T6E
TTT→TCG F7S TTT→TCG F7S
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
971 970 80.22
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask) >AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 CCA→CCG P196→P197
GTA→TTG V181→L182 AGA→TCA R212→S213
ACC→AAG T182→K183 ATT→ATC I213→I214
CCT→TCA P183→S184 GAT→TAT D214→Y215
AAG→CCT K184→P185 TCT→GAC S215→D216
CCT->CCG P196->P197 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GGT→CGG G357R
AGC→ACG S314T GAG→GAT E484D
CTC→ATG L315M
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
V302 TCG→TGC S2C TCA→TGC S2C
TCT→ATG S3M TCT→ATG S3M
GGA→ACA G4T GGT→ACA G4T
GAA→GGT E5G GAA→GGT E5G
ACA→GAA T6E ACT→GAA T6E
TTT→TCG F7S TTT→TCG F7S
AGA→AAA 19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
973 972 90.8
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→CGG R198→R199
GTA→TTG V181→L182 AGA→TCA R212→S213
ACC→AAG T182→K183 ATT→ATC I213→I214
CCT→TCA P183→S184 GAT→TAT D214→Y215
AAG→CCT K184→P185 TCT→GAC S215→D216
CGT->CGG R198->R199 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
ACA >AAG T216→K217 GTT- ►AAG V221K
AGT >— S217→— GGT- >GGG G276G
GAT >GAA D218E CCA- >TCA P281 S
CAT >CAA H219Q TTG- ►TGC L313C
TTA >TCG L220S TCT— ACG S314T
TAC ►AAG Y221K TTG- ►ATG L315M
GAG ÷GAT E238D ACC- >AGT T317S
AAA ÷CAA K252Q GAC- >GAT D329D
CCT >TCA P281 S AAG- ÷CGA K336R
CAA >AAA Q292K TTA- >ATT L337I
CTC >TGC L313C GGT- >CGG G357R
AGC >ACG S314T GAG- ÷GAT E484D
CTC >ATG L315M
ACT >AGT T317S
CAA >GCT Q321A
GAA ÷GAT E333D
AAA ÷CGA K336
TTG ►ATT L337I
GCT >ACA A345T
GGA ÷CGG G357R
AAT >ATT N369I
TCT TAC S377Y
ACA >AGA T405R
AAT >GGT N429G
GCA >TCT A436S
GAA ÷GAT E484D
ACC >CCA T501P
GAT >GAA D536E
V303 TCG→AAA S2K TCA→AAA S2K
TCT→GAA S3E TCT→GAA S3E
GGA→TGT G4C GGT→TGT G4C
GAA→ACG E5T GAA→ACG E5T
ACA→ATG T6M ACT→ATG T6M
TTT→TTA F7L TTT→TTA F7L
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K 975 974
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
CCA->CCT P91->P94 ATT >GAG I94→E97
ATC→TAT I92→Y95 GAT >GCT D95→A98
TAT→TTT Y93→F96 TCT >CAT S96→H99
ATT→GAG I94→E97 GAT >GAA D97→E100
GAC→GCT D95→A98 AAA ^TAC K98→Y101
AGT→CAT S96→H99 GCT >AAT A99→N102
AAT→GAA N97→E100 TCA ■TCT S174→S177
AGA→TAC 98→Y101 TTG L175→—
GCT→AAT A99→N102 GTT V176→—
AAG→CAA K125→Q128 CAA →GCT Q178→A179
AAG→CAA K173→Q176 GAT →CCA D179→P180
TCA->TCT S174->S177 GTT ÷TTG V181→L182
TTG→— L175→— ACT →AAG T182→K183
GTA→— V176→— CCA →TCA P183→S184
CAG→GCT Q178→A179 AGA →CCT R184→P185
GAT→CCA D179→P180 ACT ^CAA T200→Q201
GTA→TTG V181→L182 AGA →TCA R212→S213
ACC→AAG T182→K183 ATT ATC I213→I214
CCT→TCA P183→S184 GAT →TAT D214→Y215
AAG→CCT K184→P185 TCT >GAC S215→D216
ACC→CAA T200→Q201 ACT →AAG T216→K217
TTT→ATT F209→I210 TCT >— S217-
ATG→TCA M212→S213 GAT ->GAA D218E
AAT→TAT N214→Y215 GAT →CAA D219Q
TCA→GAC S215→D216 TTG ÷TCG L220S
ACA→AAG T216→K217 GTT ÷AAG V221K
AGT→— S217→— GGT +GGG G276G
GAT→GAA D218E CCA →TCA P281 S
CAT→CAA H219Q TTG ÷TGC L313C
TTA→TCG L220S TCT ACG S314T
TAC→AAG Y221K TTG ^ATG L315M
GAG→GAT E238D ACC ->AGT T317S
AAA→CAA K252Q GAC ÷GAT D329D
CCT→TCA P281 S AAG →CGA K336R
CAA→AAA Q292K TTA ^ATT L337I
CTC→TGC L313C GGT →CGG G357R
AGC→ACG S314T AAA AAG K468K
CTC→ATG L315M GAG →GAT E484D
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
V304 AGA→AAA 19K
AAA→CAA K24Q
CAA→AAT Q38N
ACA→TTA T53L AGA→AAA R19K
GAT→GCA D54A ACT→TTA T53L
GCT→ACC A55T GAT→GCA D54A
GAA→GGA E56G GCA→ACC A55T
GAT→AGG D57R GAA→GGA E56G
AAG->AAA K58K GAT→AGG D57R
GTT→ATT V60I CAA→AAA Q58K
GCA→ATG A85M GCT→ATG A85M
ATA→TTG I86L ATT→TTG I86L
CAA→GAT Q87D CAA→GAT Q87D
AAA→CAC K88H CAA→CAC Q88H
TTA→ATT L89I TTG→ATT L89I
TGT→TAC C90Y TGT→TAC C90Y
>AGA >R91 >AGA >R91
-— >GCT >A92 -— >GCT >A92
>GAT >D93 >GAT >D93
CCA->CCT P91->P94 CCA→CCT P91→P94
ATC→TAT I92→Y95 ATT→TAT I92→Y95
TAT→TTT Y93→F96 CAT→TTT H93→F96
ATT→GAG I94→E97 ATT→GAG I94→E97
GAC→GCT D95→A98 GAT→GCT D95→A98
AGT→CAT S96→H99 TCT→CAT S96→H99
AAT→GAA N97→E100 GAT→GAA D97→E100
AGA→TAC R98→Y101 AAA→TAC K98→Y101 977 976
GCT→AAT A99→N102 GCT→AAT A99→N102
AAG→CAA K125→Q128 TCA→TCT S174→S177
AAG→CAA K173→Q176 TTG→— L175→—
TCA->TCT S174->S177 GTT→— V176→—
TTG→— L175→— CAA→GCT Q178→A179
GTA→— V176→— GAT→CCA D179→P180
CAG→GCT Q178→A179 GTT→TTG V181→L182
GAT→CCA D179→P180 ACT→AAG T182→K183
GTA→TTG V181→L182 CCA→TCA P183→S184
ACC→AAG T182→K183 AGA→CCT R184→P185
CCT→TCA P183→S184 GGT→GGG G276→G277
AAG→CCT K184→P185 CCA→TCA P281→S282
TTT→ATT F209→I210 TTG→TGT L313→C314
ATG→AGA M212→R213 TCT→ACG S314→T315
AAT→GAT N214→D215 TTG→ATG L315→M316
CAT→GAT H219→D220 ACC→AGT T317→S318
TAC→GTT Y221→V222 GAC→GAT D329→D330
GAG→GAT E238→D239 AAG→CGA K336→R337
AAA→CAA K252→Q253 TTA→ATT L337→I338
CCT→TCA P281→S282 GGT→CGG G357→R358
CAA→AAA Q292→K293 CAA→CTA Q448→L449
CTC→TGT L313→C314 GAG→GAT E484→D485
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
CAA→GCT Q321→A322
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GAA- ÷GAT E333- >D334
AAA- ÷CGA K336- *R337
TTG- ►ATT L337- ►1338
GCT- >ACA A345- »T346
GGA- ÷CGG G357- *R358
AAT- >ATT N369- »I370
TCT— TAC S377- ►Y378
ACA- >AGA T405- >R406
AAT- >GGT N429- *G430
GCA- >TCT A436- *S437
CAA- >CTA Q448- *L449
GAA- ÷GAT E484- >D485
ACC- >CCA T501- >P502
GAT- >GAA D536- *E537
V305 AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97 979 978
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 GAA→GAT E163→D166
AGA→TAC R98→Y101 TCA→TCT S174→S177
GCT→AAT A99→N102 TTG→— L175→—
AAG→CAA K125→Q128 GTT→— V176→—
GAA→GAT E163→D166 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→CTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 GGT→GGG G276→G277
GTA→CTG V181→L182 CCA→TCA P281→S282
ACC→AAG T182→K183 TTG→TGT L313→C314
CCT→TCA P183→S184 TCT→ACG S314→T315
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
AAG ^CCT K184 P185 TTG- •ATG L315- ►M316
TTT ATT F209 •1210 ACC- >AGT T317- ►S318
ATG >AGA M212 →R213 GAC- >GAT D329- >D330
AAT >GAT N214 D215 AAG- ÷CGA K336- >R337
CAT >GAT H219 D220 TTA- •ATT L337- ►1338
TAC >GTT Y221 >V222 GGT- >CGG G357- >R358
GAG ->GAT E238 ►D239 CAA- >CTA Q448- >L449
AAA ^CAA K252 >Q253 GAG- ÷GAT E484- ►D485
CCT ►TCA P281 •S282
CAA ^AAA Q292 >K293
CTC ►TGT L313 •C314
AGC ÷ACG S314 •T315
CTC ►ATG L315 •M316
ACT >AGT T317 ►S318
CAA ÷GCT Q321 >A322
GAA ->GAT E333 ►D334
AAA ^CGA K336 >R337
TTG >ATT L337 •1338
GCT >ACA A345 >T346
GGA ^CGG G357 >R358
AAT >ATT N369 I370
TCT •TAC S377 •Y378
ACA ÷AGA T405 ►R406
AAT >GGT N429 >G430
GCA ÷TCT A436 >S437
CAA ÷CTA Q448 >L449
GAA ->GAT E484 ►D485
ACC >CCA T501 ►P502
GAT >GAA D536 E537
V306 AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
981 980
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
AGT→CAT S96→H99 GCT >AAT A99 N102
AAT→GAA N97→E100 TCA ■TCT SI 74 S177
AGA→TAC 98→Y101 TTG L175
GCT→AAT A99→N102 GTT V176
AAG→CAA K125→Q128 CAA →GCT Q178 ÷A179
AAG→CAA K173→Q176 GAT ^CCA D179 ÷P180
TCA->TCT S174->S177 GTT >TTG V181 ÷L182
TTG→— L175→— ACT ÷AAG T182 >K183
GTA→— V176→— CCA ^TCA P183 ►SI 84
CAG→GCT Q178→A179 AGA →CCT R184 >P185
GAT→CCA D179→P180 ATG ^ACG M210 →T211
GTA→TTG V181→L182 TCA >TCT S211 >S212
ACC→AAG T182→K183 GGT *GGG G276 +G277
CCT→TCA P183→S184 CCA ^TCA P281 ►S282
AAG→CCT K184→P185 TTG >TGC L313 >C314
TTT→ATT F209→I210 TCT >ACG S314 ►T315
ATG→ACG M210→T211 TTG >ATG L315 >M316
TCC->TCT S2U->S212 ACC →AGT T317 >S318
ATG→AGA M212→R213 GAC *GAT D329 +D330
AAT→GAT N214→D215 AAG →CGA K336 ÷R337
CAT→GAT H219→D220 TTA ATT L337 >Γ338
TAC→GTT Y221→V222 GGT ^CGG G357 ÷R358
GAG→GAT E238→D239 TTT TTC F383 >F384
AAA→CAA K252→Q253 GAG →GAT E484 >D485
CCT→TCA P281→S282 CCA ^CTA P500 ►L501
CAA→AAA Q292→K293 TCT •TCC S531 >S532
CTC→TGC L313→C314
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
CAA→GCT Q321→A322
GAA→GAT E333→D334
AAA→CGA K336→R337
TTG→ATT L337→I338
GCT→ACA A345→T346
GGA→CGG G357→R358
AAT→ATT N369→I370
TCT→TAC S377→Y378
ACA→AGA T405→R406
AAT→GGT N429→G430
GCA→TCT A436→S437
GAA→GAT E484→D485
CCA→CTA P500→L501
ACC→CCA T501→P502
TCT->TCC S531->S532
GAT→GAA D536→E537
V307 AGA- >AAA R19K AGA- >AAA R19K
AAA- >CAA K24Q ACT- ►TTA T53L
CAA- >AAT Q38N GAT- >GCA D54A
ACA- >TTA T53L GCA- >ACC A55T 983 982 GAT- >GCA D54A GAA- >GGA E56G
GCT- ►ACC A55T GAT- ►AGG D57R
GAA- >GGA E56G CAA- >AAA Q58K
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
GAT→AGG D57 GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCA >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCA >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 CAA→CAG Q142→Q145
AGA→TAC R98→Y101 TCA→TCT S174→S177
GCT→AAT A99→N102 TTG→— L175→—
AAG→CAA K125→Q128 GTT→— V176→—
CAA->CAG Q142->Q145 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 GGT→GGG G276→G277
GTA→TTG V181→L182 CCA→TCA P281→S282
ACC→AAG T182→K183 TTG→TGC L313→C314
CCT→TCA P183→S184 TCT→ACG S314→T315
AAG→CCT K184→P185 TTG→ATG L315→M316
TTT→ATT F209→I210 ACC→AGT T317→S318
ATG→AGA M212→R213 GAC→GAT D329→D330
AAT→GAT N214→D215 AAG→CGA K336→R337
CAT→GAT H219→D220 TTA→ATT L337→I338
TAC→GTT Y221→V222 GGT→CGG G357→R358
GAG→GAT E238→D239 GAG→GAT E484→D485
AAA→CAA K252→Q253 GCA→GCG A539→A540
CCT→TCA P281→S282
CAA→AAA Q292→K293
CTC→TGC L313→C314
AGC→ACG S314→T315
CTC→ATG L315→M316
ACT→AGT T317→S318
CAA→GCT Q321→A322
GAA→GAT E333→D334
AAA→CGA K336→R337
TTG→ATT L337→I338
GCT→ACA A345→T346
GGA→CGG G357→R358
AAT→ATT N369→I370
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TCT→TAC S377- →Y378
ACA→AGA T405- →R406
AAT→GGT N429- →G430
GCA→TCT A436- →S437
GAA→GAT E484- →D485
ACC→CCA T501- →P502
GAT→GAA D536 →E537
GCT->GCG A539- >A540
V308 AGA→AAA R19K AGA→AAA R19K
AAC→GAC N20D AAT→GAC N20D
CTC→TCG L23S TTG→TCG L23S
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GAA→GAG E68E
AAG->AAA K58K GCT→ATG A85M
GTT→ATT V60I ATT→TTG I86L
GAA->GAG E68E CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97 985 984
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 CAA→GAA Q173→E176
AGA→TAC R98→Y101 TCA→TCT S174→S177
GCT→AAT A99→N102 TTG→— L175→-177
AAG→CAA K125→Q128 GTT→— V176→-177
AAG→GAA K173→E176 CAA→GCT Q178→A179
TCA->TCT S174->S177 GAT→CCA D179→P180
TTG→— L175→— GTT→TTG V181→L182
GTA→— V176→— ACT→AAG T182→K183
CAG→GCT Q178→A179 CCA→TCA P183→S184
GAT→CCA D179→P180 AGA→CCT R184→P185
GTA→TTG V181→L182 GGT→GGG G276→G277
ACC→AAG T182→K183 CCA→TCA P281→S282
CCT→TCA P183→S184 TTG→TGC L313→C314
AAG→CCT K184→P185 TCT→ACG S314→T315
TTT→ATT F209→I210 TTG→ATG L315→M316
ATG→AGA M212→R213 ACC→AGT T317→S318
AAT→GAT N214→D215 GAC→GAT D329→D330
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
CAT- →GAT H219- →D220 AAG→CGA K336→R337
TAC- →GTT Y221- →V222 TTA→ATT L337→I338
GAG →GAT E238- →D239 GGT→CGG G357→R358
AAA- →CAA K252- →Q253 TGC→AGC C465→S466
CCT- →TCA P281- →S282 GAG→GAT E484→D485
CAA- →AAA Q292- →K293 GGT→GGG G527→G528
CTC- →TGC L313- →C314 GCA→GTA A539→V540
AGC- →ACG S314- →T315
CTC- →ATG L315- →M316
ACT- →AGT T317- →S318
CAA- →GCT Q321- →A322
GAA- →GAT E333- →D334
AAA- →CGA K336- → 337
TTG- →ATT L337- →I338
GCT- →ACA A345- →T346
GGA →CGG G357- →R358
AAT- →ATT N369- →I370
TCT- ^TAC S377- →Y378
ACA- →AGA T405- →R406
AAT- →GGT N429- →G430
GCA- →TCT A436- →S437
TGT- →AGC C465- →S466
GAA- →GAT E484- →D485
ACC- →CCA T501- →P502
GGC- >GGG G527- >G528
GAT- →GAA D536- →E537
GCT- →GTA A539- →V540
V309 TCG→TGC S2C TCA→TGC S2C
TCT→ATG S3M TCT→ATG S3M
GGA→ACA G4T GGT→ACA G4T
GAA→GGT E5G GAA→GGT E5G
ACA→GAA T6E ACT→GAA T6E
TTT→TCG F7S TTT→TCG F7S
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
987 986 71
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC 98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GAA→GCT E348A
AGC→ACG S314T GGT→CGG G357R
CTC→ATG L315M GAG→GAT E484D
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GAA→GCT E348A
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
V310 TCG→TGC S2C TCA→TGC S2C 989 988 64
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TCT→ATG S3M TCT→ATG S3M
GGA→ACA G4T GGT→ACA G4T
GAA→GGT E5G GAA→GGT E5G
ACA→GAA T6E ACT→GAA T6E
TTT→TCG F7S TTT→TCG F7S
AGA→AAA R19K AGA→AAA R19K
AAA→CAA K24Q ACT→TTA T53L
CAA→AAT Q38N GAT→GCA D54A
ACA→TTA T53L GCA→ACC A55T
GAT→GCA D54A GAA→GGA E56G
GCT→ACC A55T GAT→AGG D57R
GAA→GGA E56G CAA→AAA Q58K
GAT→AGG D57R GCT→ATG A85M
AAG->AAA K58K ATT→TTG I86L
GTT→ATT V60I CAA→GAT Q87D
GCA→ATG A85M CAA→CAC Q88H
ATA→TTG I86L TTG→ATT L89I
CAA→GAT Q87D TGT→TAC C90Y
AAA→CAC K88H >AGA >R91
TTA→ATT L89I -— >GCT >A92
TGT→TAC C90Y >GAT >D93
>AGA >R91 CCA→CCT P91→P94
-— >GCT >A92 ATT→TAT I92→Y95
>GAT >D93 CAT→TTT H93→F96
CCA->CCT P91->P94 ATT→GAG I94→E97
ATC→TAT I92→Y95 GAT→GCT D95→A98
TAT→TTT Y93→F96 TCT→CAT S96→H99
ATT→GAG I94→E97 GAT→GAA D97→E100
GAC→GCT D95→A98 AAA→TAC K98→Y101
AGT→CAT S96→H99 GCT→AAT A99→N102
AAT→GAA N97→E100 TCA→TCT S174→S177
AGA→TAC R98→Y101 TTG→— L175→—
GCT→AAT A99→N102 GTT→— V176→—
AAG→CAA K125→Q128 CAA→GCT Q178→A179
AAG→CAA K173→Q176 GAT→CCA D179→P180
TCA->TCT S174->S177 GTT→TTG V181→L182
TTG→— L175→— ACT→AAG T182→K183
GTA→— V176→— CCA→TCA P183→S184
CAG→GCT Q178→A179 AGA→CCT R184→P185
GAT→CCA D179→P180 AGA→TCA R212→S213
GTA→TTG V181→L182 ATT→ATC I213→I214
ACC→AAG T182→K183 GAT→TAT D214→Y215
CCT→TCA P183→S184 TCT→GAC S215→D216
AAG→CCT K184→P185 ACT→AAG T216→K217
TTT→ATT F209→I210 TCT→— S217→—
ATG→TCA M212→S213 GAT→GAA D218E
AAT→TAT N214→Y215 GAT→CAA D219Q
TCA→GAC S215→D216 TTG→TCG L220S
ACA→AAG T216→K217 GTT→AAG V221K
AGT→— S217→— GGT→GGG G276G
GAT→GAA D218E CCA→TCA P281 S
CAT→CAA H219Q TTG→TGC L313C
TTA→TCG L220S TCT→ACG S314T
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TAC→AAG Y221K TTG→ATG L315M
GAG→GAT E238D ACC→AGT T317S
AAA→CAA K252Q GAC→GAT D329D
CCT→TCA P281 S AAG→CGA K336R
CAA→AAA Q292K TTA→ATT L337I
CTC→TGC L313C GAA→TCA E348S
AGC→ACG S314T GGT→CGG G357R
CTC→ATG L315M GAG→GAT E484D
ACT→AGT T317S
CAA→GCT Q321A
GAA→GAT E333D
AAA→CGA K336R
TTG→ATT L337I
GCT→ACA A345T
GAA→TCA E348S
GGA→CGG G357R
AAT→ATT N369I
TCT→TAC S377Y
ACA→AGA T405R
AAT→GGT N429G
GCA→TCT A436S
GAA→GAT E484D
ACC→CCA T501P
GAT→GAA D536E
V31 1 AAA→CAA K24Q
CAA→AAT Q38N
AAG→CAA K58Q
GTT→ATT V60I
AAA→CAA 88Q
CCA→AAT P91N
ATC→AGT 192 S
TAT→TTT Y93F
ATT→CAT I94H
CCA→AAT P91N
AGT→TGC S96C
ATT→AGT 192 S
AGA→GAT R98D
CAT→TTT H93F
GCT→ATG A99M
ATT→CAT I94H
-— >GGT >G101
GAT→GAC D95D
>GAT >D102
TCT→TGC S96C
AAG→CAA K125→Q127 991 990 104.3
GAT→AAT D97N
AAG→CAA K173→Q175
AAA→GAT 98D
AAG→AGA 184→R186
GCT→ATG A99M
TTT→ATT F209→I211
-— >GGT >G101
ATG→AGA M212→R214
>GAT >D102
AAT→GAT N214→D216
CAT→GAT H219→D221
TAC→GTT Y221→V223
GAG→GAT E238→D240
AAA→CAA K252→Q254
CAA→AAA Q292→K294
CAA→GCT Q321→A323
GAA→GAT E333→D335
GCT→ACA A345→T347
AAT→ATT N369→I371
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TCT→TAC S377→Y379
ACA→AGA T405→R407
AAT→GGT N429→G431
GCA→TCT A436→S438
ACC→CCA T501→P503
GAT→GAA D536→E538
V312 AAA→CAA 24Q
CAA→AAT Q38N
AAG→CAA K58Q
GTT→ATT V60I
ATA→GTT I82V
AAA→CAA K88Q
CCA→AAT P91N
ATC→AGT 192 S
TAT→TTT Y93F
ATT→CAT I94H
AGT→TGC S96C
AGA→GAT R98D
ATT→GTT I82V
GCT→ATG A99M
CCA→AAT P91N
-— >GGT >G101
ATT→AGT I92S
>GAT >D102
CAT→TTT H93F
AAG→CAA K125→Q127
ATT→CAT I94H
AAG→CAA K173→Q175
GAT→GAC D95D
AAG→AGA K184→R186
TCT→TGC S96C
TTT→ATT F209→I211 993 992 85.9
GAT→AAT D97N
ATG→AGA M212→R214
AAA→GAT K98D
AAT→GAT N214→D216
GCT→ATG A99M
CAT→GAT H219→D221
-— >GGT >G101
TAC→GTT Y221→V223
>GAT >D102
GAG→GAT E238→D240
TTG→TCG L399→S401
AAA→CAA 252→Q254
CAA→AAA Q292→ 294
CAA→GCT Q321→A323
GAA→GAT E333→D335
GCT→ACA A345→T347
AAT→ATT N369→I371
TCT→TAC S377→Y379
CTA→TCG L399→S401
ACA→AGA T405→R407
AAT→GGT N429→G431
GCA→TCT A436→S438
ACC→CCA T501→P503
GAT→GAA D536→E538
V313 TCG->TCT S2S TCA→TCT S2S 75 TCT→ACT S3T TCT→ACT S3T
GGA→CAA G4Q GGT→CAA G4Q
GAA→GTC E5V GAA→GTC E5V
>TCA -— >S6 >TCA -— >S6
995 994
-— >GCA -— >A7 -— >GCA -— >A7
>TCT -— >S8 >TCT -— >S8
>TCT -— >S9 >TCT -— >S9
>CTA >L10 >CTA >L10
-— >GCC >A1 1 -— >GCC >A1 1
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
-— >CAG >Q12 -— >CAG >Q12
>ATT >I13 >ATT >I13
-— >ccc >P14 -— >ccc >P14
>CAA >Q15 >CAA >Q15
-— >ccc >P16 -— >ccc >P16
ACA→AAA T6→K17 ACT→AAA T6→K17
TTT→AAT F7→N18 TTT→AAT F7→N18
ACT→GTG T10→V21 AGA→CGT R8→R19
GAT→AAC D12→N23 CCA→CCT P9→P20
CAT->CAC H14->H25 ACT→GTG T10→V21
CCT->CCC P15->P26 GCT→GCA A11→A22
AGT→AAC S16→N27 GAT→AAC D12→N23
TTA→ATT L17→I28 CAT→CAC H14→H25
AGA→GGT 19→G30 CCA→CCC P15→P26
AAC→GAC N20→D31 TCT→AAC S16→N27
CAT→CAA H21→Q32 TTG→ATT L17→I28
CTC→ATC L23→I34 AGA→GGT R19→G30
AAA→ACC K24→T35 AAT→GAC N20→D31
GGT→TAC G25→Y36 CAT→CAA H21→Q32
GCT→ACT A26→T37 TTG→ATC L23→I34
TCT→CCT S27→P38 CAA→ACC Q24→T35
GAT→GAA D28→E39 GGT→TAC G25→Y36
TTC→GAC F29→D40 GCA→ACT A26→T37
ACA→— T31→— TCA→CCT S27→P38
GAT→ACT D33→T43 GAT→GAA D28→E39
CAT→CGT H34→R44 TTT→GAC F29→D40
ACT→GCC T35→A45 ACT→— T31→—
GCA→TGC A36→C46 GAT→ACT D33→T43
ACT→AAA T37→K47 CAT→CGT H34→R44
CAA→GAG Q38→E48 ACA→GCC T35→A45
GAA->GAG E39->E49 GCT→TGC A36→C46
CGA→CAG R40→Q50 ACA→AAA T37→K47
CAC→ATT H41→I51 AAT→GAG N38→E48
GTA→ATT V48→I58 GAA→GAG E39→E49
ACA→TTA T53→L63 AGA→CAG R40→Q50
GAT→GCA D54→A64 CAT→ATT H41→I51
GCT→ACC A55→T65 GTT→ATT V48→I58
GAA→GGA E56→G66 ACT→TTA T53→L63
GAT→AGG D57→R67 GAT→GCA D54→A64
GTT→ATT V60→I70 GCA→ACC A55→T65
ATA→TTA I86→L96 GAA→GGA E56→G66
AAA→CAT K88→H98 GAT→AGG D57→R67
TTA→ATT L89→I99 CAA→AAA Q58→K68
CCA→AAT P91→N101 GCT→GCA A85→A95
ATC→AGT I92→S102 ATT→TTA I86→L96
TAT→TTT Y93→F103 CAA→CAT Q88→H98
ATT→CAT I94→H104 TTG→ATT L89→I99
AGT→TGC S96→C106 CCA→AAT P91→N101
AGA→GAT R98→D108 ATT→AGT I92→S102
GCT→ATG A99→M109 CAT→TTT H93→F103
-— >GGT >G111 ATT→CAT I94→H104
>GAT >D112 GAT→GAC D95→D105
CAC→TAT H102→Y114 TCT→TGC S96→C106
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
GGA->GGG GU5->G127 GAT→AAT D97→N107
ATC→TAC I116→Y128 AAA→GAT K98→D108
AAG→ACT K117→T129 GCT→ATG A99→M109
GTG→ATA V122→I134 -— >GGT >G111
GAG→AAC E124→N136 >GAT >D112
AAA→ACG K127→T139 CAT→TAT H102→Y114
GAT→GAA D129→E141 GGT→GGG GU5→G127
GAG→CGA E130→ 142 ATT→TAC I116→Y128
TCA→GAA S135→E147 AAG→ACT K117→T129
TCG→GCT S136→A148 TCT→TCA S119→S131
ATA->ATC I138->1150 GTT→ATA V122→I134
AAC→AGC N139→S151 GAA→AAC E124→N136
GTT->GTA V141-> V153 CAA→AAG Q125→K137
CAA→AGA Q142→R154 AAG→ACG K127→T139
TTA->CTA L145->L157 GAT→GAA D129→E141
AGT→GGC S146→G158 GAA→CGA E130→R142
AAG→CAA K173→Q185 AAA→AAG K134→K146
TCA->TCT S174->S186 AGT→GAA S135→E147
TTG→— L175→— TCT→GCT S136→A148
GTA→— V176→— ATT→ATC I138→I150
CAG→GCT Q178→A188 AAT→AGC N139→S151
GAT→CCA D179→P189 GTT→GTA V141→V153
GTA→TTG V181→L191 CAA→AGA Q142→R154
ACC→AAG T182→K192 TTG→CTA L145→L157
CCT→TCA P183→S193 TCT→GGC S146→G158
AAG→CCT K184→P194 TCA→TCT S174→S186
TTT→ATT F209→I219 TTG→— L175→—
ATG→GTC M212→V222 GTT→— V176→—
ATC→TAC I213→Y223 CAA→GCT Q178→A188
AAT→— N214→— GAT→CCA D179→P189
TCA→— S215→— GTT→TTG V181→L191
ACA→CAA T216→Q224 ACT→AAG T182→K192
AGT→GAT S217→D225 CCA→TCA P183→S193
GAT→GAA D218→E226 AGA→CCT R184→P194
CAT→GCT H219→A227 AGA→GTC R212→V222
TTA→TTC L220→F228 ATT→TAC I213→Y223
TAC→CAT Y221→H229 GAT→— D214→—
GAG→GAT E238→D246 TCT→— S215→—
AAA→CAA K252→Q260 ACT→CAA T216→Q224
TTA->CTG L270->L278 TCT→GAT S217→D225
CCT→TCA P281→S289 GAT→GAA D218→E226
CAA→AAA Q292→K300 GAT→GCT D219→A227
CTC→TGC L313→C321 TTG→TTC L220→F228
AGC→ACG S314→T322 GTT→CAT V221→H229
CTC→ATG L315→M323 TTG→CTG L270→L278
ACT→AGT T317→S325 GGT→GGG G276→G284
CAA→GCT Q321→A329 CCA→TCA P281→S289
GAA→GAT E333→D341 TTG→TGC L313→C321
AAA→CGA K336→R344 TCT→ACG S314→T322
TTG→ATT L337→I345 TTG→ATG L315→M323
GCT→ACA A345→T353 ACC→AGT T317→S325
GGA→CGG G357→R365 GAC→GAT D329→D337
AAT→ATT N369→I377 AAG→CGA K336→R344
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
TCT→TAC S377→Y385 TTA→ATT L337→I345
ACA→AGA T405→ 413 GGT→CGG G357→R365
AAT→GGT N429→G437 GAG→GAT E484→D492
GCA→TCT A436→S444 ATA→ATC I538→I546
GAA→GAT E484→D492
ACC→CCA T501→P509
GAT→GAA D536→E544
ATT->ATC I538->I546
V314 TCG->TCT S2S TCA→TCT S2S
TCT→ACT S3T TCT→ACT S3T
GGA→CAA G4Q GGT→CAA G4Q
GAA→GTC E5V GAA→GTC E5V
>TCA -— >S6 >TCA -— >S6
-— >GCA -— >A7 -— >GCA -— >A7
>TCT -— >S8 >TCT -— >S8
>TCT -— >S9 >TCT -— >S9
>CTA >L10 >CTA >L10
-— >GCC >Al 1 -— >GCC >Al 1
-— >CAG >Q12 -— >CAG >Q12
>ATT >I13 >ATT >I13
-— >ccc >P14 -— >ccc >P14
>CAA >Q15 CAA >Q15
-— >ccc >P16 -— >ccc >P16
ACA→AAA T6→K17 ACT→AAA T6→K17
TTT→AAT F7→N18 TTT→AAT F7→N18
ACT→GTG T10→V21 AGA→CGT R8→R19
GAT→AAC D12→N23 CCA→CCT P9→P20
CAT->CAC H14->H25 ACT→GTG T10→V21
CCT->CCC P15->P26 GCT→GCA A11→A22
AGT→AAC S16→N27 GAT→AAC D12→N23
TTA→ATT L17→I28 CAT→CAC H14→H25 997 996 101
AGA→GGT R19→G30 CCA→CCC P15→P26
AAC→GAC N20→D31 TCT→AAC S16→N27
CAT→CAA H21→Q32 TTG→ATT L17→I28
CTC→ATC L23→I34 AGA→GGT R19→G30
AAA→ACC K24→T35 AAT→GAC N20→D31
GGT→TAC G25→Y36 CAT→CAA H21→Q32
GCT→ACT A26→T37 TTG→ATC L23→I34
TCT→CCT S27→P38 CAA→ACC Q24→T35
GAT→GAA D28→E39 GGT→TAC G25→Y36
TTC→GAC F29→D40 GCA→ACT A26→T37
ACA→— T31→— TCA→CCT S27→P38
GAT→ACT D33→T43 GAT→GAA D28→E39
CAT→CGT H34→R44 TTT→GAC F29→D40
ACT→GCC T35→A45 ACT→— T31→—
GCA→TGC A36→C46 GAT→ACT D33→T43
ACT→AAA T37→K47 CAT→CGT H34→R44
CAA→GAG Q38→E48 ACA→GCC T35→A45
GAA->GAG E39->E49 GCT→TGC A36→C46
CGA→CAG R40→Q50 ACA→AAA T37→K47
CAC→ATT H41→I51 AAT→GAG N38→E48
ACA→TTA T53→L63 GAA→GAG E39→E49
GAT→GCA D54→A64 AGA→CAG R40→Q50
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
GCT→ACC A55→T65 CAT→ATT H41→I51
GAA→GGA E56→G66 ACT→TTA T53→L63
GAT→AGG D57→ 67 GAT→GCA D54→A64
AAG->AAA K58->K68 GCA→ACC A55→T65
GAA→GGA E56→G66
GTT→ATT V60→I70 GAT→AGG D57→R67
ATA→TTA I86→L96 CAA→AAA Q58→K68
AAA→CAT K88→H98 GCT→GCA A85→A95
TTA→ATT L89→I99 ATT→TTA I86→L96
CCA→AAT P91→N101 CAA→CAT Q88→H98
ATC→AGT I92→S102 TTG→ATT L89→I99
TAT→TTT Y93→F103 CCA→AAT P91→N101
ATT→CAT I94→H104 ATT→AGT I92→S102
AGT→TGC S96→C106 CAT→TTT H93→F103
AGA→GAT R98→D108 ATT→CAT I94→H104
GCT→ATG A99→M109 GAT→GAC D95→D105
-— >GGT >G111 TCT→TGC S96→C106
>GAT >D112 GAT→AAT D97→N107
AAG→CAA K125→Q137 AAA→GAT K98→D108
AAG→CAA K173→Q185 GCT→ATG A99→M109
TCA->TCT S174->S186 -— >GGT >G111
TTG→— L175→— >GAT >D112
GTA→— V176→— TCA→TCT S174→S186
CAG→GCT Q178→A188 TTG→— L175→-186
GAT→CCA D179→P189 GTT→— V176→-186
GTA→TTG V181→L191 CAA→GCT Q178→A188
ACC→AAG T182→K192 GAT→CCA D179→P189
CCT→TCA P183→S193 GTT→TTG V181→L191
AAG→CCT K184→P194 ACT→AAG T182→K192
TTT→ATT F209→I219 CCA→TCA P183→S193
ATG→GTC M212→V222 AGA→CCT R184→P194
ATC→TAC I213→Y223 AGA→GTC R212→V222
AAT→— N214→— ATT→TAC I213→Y223
TCA→— S215→— GAT→— D214→—
ACA→CAA T216→Q224 TCT→— S215→—
AGT→GAT S217→D225 ACT→CAA T216→Q224
GAT→GAA D218→E226 TCT→GAT S217→D225
CAT→GCT H219→A227 GAT→GAA D218→E226
TTA→TTC L220→F228 GAT→GCT D219→A227
TAC→CAT Y221→H229 TTG→TTC L220→F228
GAG→GAT E238→D246 GTT→CAT V221→H229
AAA→CAA K252→Q260 TTG→CTG L270→L278
TTA->CTG L270->L278 GGT→GGG G276→G284
CCT→TCA P281→S289 CCA→TCA P281→S289
CAA→AAA Q292→K300 TTG→TGC L313→C321
CTC→TGC L313→C321 TCT→ACG S314→T322
AGC→ACG S314→T322 TTG→ATG L315→M323
CTC→ATG L315→M323 ACC→AGT T317→S325
ACT→AGT T317→S325 GAC→GAT D329→D337
CAA→GCT Q321→A329 AAG→CGA K336→R344
GAA→GAT E333→D341 TTA→ATT L337→I345
AAA→CGA K336→R344 GGT→CGG G357→R365
TTG→ATT L337→I345 GAG→GAT E484→D492
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
GCT→ACA A345→T353 ATA→ATC I538→I546
GGA→CGG G357→ 365
AAT→ATT N369→I377
TCT→TAC S377→Y385
ACA→AGA T405→R413
AAT→GGT N429→G437
GCA→TCT A436→S444
GAA→GAT E484→D492
ACC→CCA T501→P509
GAT→GAA D536→E544
ATT->ATC I538->I546
V315 TCG->TCT S2S TCA→TCT S2S
TCT→ACT S3T TCT→ACT S3T
GGA→CAA G4Q GGT→CAA G4Q
GAA→GTC E5V GAA→GTC E5V
>TCA -— >S6 >TCA -— >S6
-— >GCA -— >A7 -— >GCA -— >A7
>TCT -— >S8 >TCT -— >S8
>TCT -— >S9 >TCT -— >S9
>CTA >L10 >CTA >L10
-— >GCC >Al 1 -—GCC >Al 1
-— >CAG >Q12 -— >CAG >Q12
>ATT >I13 >ATT >I13
-— >ccc >P14 -— >ccc >P14
>CAA >Q15 CAA >Q15
-— >ccc >P16 -— >ccc >P16
ACA→AAA T6→K17 ACT→AAA T6→K17
TTT→AAT F7→N18 TTT→AAT F7→N18
ACT→GTG T10→V21 AGA→CGT R8→R19
GAT→AAC D12→N23 CCA→CCT P9→P20
CAT->CAC H14->H25 ACT→GTG T10→V21
CCT->CCC P15->P26 GCT→GCA A11→A22
999 998
AGT→AAC S16→N27 GAT→AAC D12→N23
TTA→ATT L17→I28 CAT→CAC H14→H25
AGA→GGT R19→G30 CCA→CCC P15→P26
AAC→GAC N20→D31 TCT→AAC S16→N27
CAT→CAA H21→Q32 TTG→ATT L17→I28
CTC→ATC L23→I34 AGA→GGT R19→G30
AAA→ACC K24→T35 AAT→GAC N20→D31
GGT→TAC G25→Y36 CAT→CAA H21→Q32
GCT→ACT A26→T37 TTG→ATC L23→I34
TCT→CCT S27→P38 CAA→ACC Q24→T35
GAT→GAA D28→E39 GGT→TAC G25→Y36
TTC→GAC F29→D40 GCA→ACT A26→T37
ACA→— T31→— TCA→CCT S27→P38
GAT→ACT D33→T43 GAT→GAA D28→E39
CAT→CGT H34→R44 TTT→GAC F29→D40
ACT→GCC T35→A45 ACT→— T31→—
GCA→TGC A36→C46 GAT→ACT D33→T43
ACT→AAA T37→K47 CAT→CGT H34→R44
CAA→GAG Q38→E48 ACA→GCC T35→A45
GAA->GAG E39->E49 GCT→TGC A36→C46
CGA→CAG R40→Q50 ACA→AAA T37→K47
Table 43. CVS Variants
SEQ ID
Nucleotide Amino acid Nucleotide Amino acid NO
Mutant changes vs. changes vs. changes vs. changes vs. nt aa wildtype wildtype CVS V19 CVS V19
CAC→ATT H41→I51 AAT→GAG N38→E48
ACA→TTA T53→L63 GAA→GAG E39→E49
GAT→GCA D54→A64 AGA→CAG R40→Q50
GCT→ACC A55→T65 CAT→ATT H41→I51
GAA→GGA E56→G66 ACT→TTA T53→L63
GAT→AGG D57→ 67 GAT→GCA D54→A64
AAG->AAA K58->K68 GCA→ACC A55→T65
GTT→ATT V60→I70 GAA→GGA E56→G66
GCA→ATG A85→M95 GAT→AGG D57→R67
ATA→TTG I86→L96 CAA→AAA Q58→K68
CAA→GAT Q87→D97 GCT→ATG A85→M95
AAA→CAC K88→H98 ATT→TTG I86→L96
TTA→ATT L89→I99 CAA→GAT Q87→D97
TGT→TAC C90→Y100 CAA→CAC Q88→H98
>AGA >R101 TTG→ATT L89→I99
-— >GCT >A102 TGT→TAC C90→Y100
>GAT >D103 >AGA >R101
CCA->CCT P91->P104 -— >GCT >A102
ATC→TAT I92→Y105 >GAT >D103
TAT→TTT Y93→F106 CCA→CCT P91→P104
ATT→GAG I94→E107 ATT→TAT I92→Y105
GAC→GCT D95→A108 CAT→TTT H93→F106
AGT→CAT S96→H109 ATT→GAG I94→E107
AAT→GAA N97→E110 GAT→GCT D95→A108
AGA→TAC R98→Y111 TCT→CAT S96→H109
GCT→AAT A99→N112 GAT→GAA D97→E110
AAG→CAA K125→Q138 AAA→TAC K98→Y111
AAG→CAA K173→Q186 GCT→AAT A99→N112
TCA->TCT S174->S187 TCA→TCT S174→S187
TTG→— L175→— TTG→— L175→—
GTA→— V176→— GTT→— V176→—
CAG→GCT Q178→A189 CAA→GCT Q178→A189
GAT→CCA D179→P190 GAT→CCA D179→P190
GTA→TTG V181→L192 GTT→TTG V181→L192
ACC→AAG T182→K193 ACT→AAG T182→K193
CCT→TCA P183→S194 CCA→TCA P183→S194
AAG→CCT K184→P195 AGA→CCT R184→P195
TTT→ATT F209→I220 AGA→GTC R212→V223
ATG→GTC M212→V223 ATT→TAC I213→Y224
ATC→TAC I213→Y224 GAT→— D214→—
AAT→— N214→— TCT→— S215→—
TCA→— S215→— ACT→CAA T216→Q225
ACA→CAA T216→Q225 TCT→GAT S217→D226
AGT→GAT S217→D226 GAT→GAA D218→E227
GAT→GAA D218→E227 GAT→GCT D219→A228
CAT→GCT H219→A228 TTG→TTC L220→F229
TTA→TTC L220→F229 GTT→CAT V221→H230
TAC→CAT Y221→H230 TTG→CTG L270→L279
GAG→GAT E238→D247 GGT→GGG G276→G285
AAA→CAA K252→Q261 CCA→TCA P281→S290
TTA->CTG L270->L279 TTG→TGC L313→C322
CCT→TCA P281→S290 TCT→ACG S314→T323
CAA→AAA Q292→K301 TTG→ATG L315→M324
Table 43. CVS Variants
SEQ ID Valencene
Nucleotide Amino acid Nucleotide Amino acid NO production
Mutant changes vs. changes vs. changes vs. changes vs. nt aa % vs. V19 wildtype wildtype CVS V19 CVS V19 (Shake
Flask)
CTC→TGC L313→C322 ACC- →AGT T317- ÷S326
AGC→ACG S314→T323 GAC- *GAT D329- ^D338
CTC→ATG L315→M324 AAG- →CGA K336- →R345
ACT→AGT T317→S326 TTA- ATT L337- ^1346
CAA→GCT Q321→A330 GGT- ^CGG G357- →R366
GAA→GAT E333→D342 TTG- >CTG L399- >L408
AAA→CGA K336→ 345 GAG- →GAT E484- ^D493
TTG→ATT L337→I346 ATA- ATC 1538- ■1547
GCT→ACA A345→T354
GGA→CGG G357→R366
AAT→ATT N369→I378
TCT→TAC S377→Y386
CTA->CTG L399->L408
ACA→AGA T405→R414
AAT→GGT N429→G438
GCA→TCT A436→S445
GAA→GAT E484→D493
ACC→CCA T501→P510
GAT→GAA D536→E545
ATT->ATC I538->I547
Since modifications will be apparent to those of skill in this art, it is intended that this invention be limited only by the scope of the appended claims.
























