WO2011148524A1 - アプリケーションサーバの切替方法、管理計算機及びプログラムを格納した記憶媒体 - Google Patents
アプリケーションサーバの切替方法、管理計算機及びプログラムを格納した記憶媒体 Download PDFInfo
- Publication number
- WO2011148524A1 WO2011148524A1 PCT/JP2010/064460 JP2010064460W WO2011148524A1 WO 2011148524 A1 WO2011148524 A1 WO 2011148524A1 JP 2010064460 W JP2010064460 W JP 2010064460W WO 2011148524 A1 WO2011148524 A1 WO 2011148524A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- switching
- application server
- information
- failure
- switching pattern
- Prior art date
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2023—Failover techniques
- G06F11/2025—Failover techniques using centralised failover control functionality
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2023—Failover techniques
- G06F11/203—Failover techniques using migration
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2038—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant with a single idle spare processing component
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/16—Error detection or correction of the data by redundancy in hardware
- G06F11/20—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements
- G06F11/202—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant
- G06F11/2046—Error detection or correction of the data by redundancy in hardware using active fault-masking, e.g. by switching out faulty elements or by switching in spare elements where processing functionality is redundant where the redundant components share persistent storage
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F2201/00—Indexing scheme relating to error detection, to error correction, and to monitoring
- G06F2201/815—Virtual
Definitions
- the present invention relates to a computer system having a failover configuration, and particularly to a server switching technique including a procedure for determining a server switching pattern.
- Server switching means exists as a business recovery method when a server failure occurs (for example, Patent Document 1, Patent Document 2, and Patent Document 3).
- a method related to effective use of a spare server in a failover configuration including such server switching means, development on a spare server, testing, and temporary allocation to a Web server are known.
- a task for example, a software development task
- the standby server is temporarily stopped to prevent the occurrence of I / O (Input / Output) failures and to update WWN (World Wide Name) and BIOS (Basic Input / Output System) settings. It is necessary.
- the above will affect the operations on the standby or active server when switching servers. For example, when the standby server is forcibly stopped for quick switching, hardware failure or business data corruption may occur. When a server is switched after waiting for a business stop on the standby server, the business recovery on the active server may be delayed and the SLA (Service Level Agreement) may not be satisfied. This problem is particularly noticeable in situations where a standby server is shared by a plurality of tasks having different requirements.
- SLA Service Level Agreement
- the problem to be solved by the present invention is to provide a server switching method for stopping a standby server as safely as possible at the time of server switching in order to satisfy business requirements and suppress the influence of server switching on the standby server. It is to determine the failure sign of the active server and stop the standby server in advance.
- a typical example of the invention disclosed in this specification is as follows. That is, a first application server that provides a first task, a second application server that provides a second task, and a management computer connected to the first application server and the second application server include: An application server switching method for transferring a first job provided by the first application server to the second application server, wherein the management computer transfers the first job to a second application server.
- An application server switching method for transferring a first job provided by the first application server to the second application server wherein the management computer transfers the first job to a second application server.
- a first step of setting a safety level for each switching pattern with reference to switching level information in which a switching pattern for switching to is set, and the management computer refers to the switching level information and performs the switching The first job is switched to the second application server for each pattern.
- a second step of setting a switching time required for the first operation, and a stop time allowed when the management computer switches the first job to the second application server is set for each first job.
- Fig. 1 shows the configuration of the computer system.
- the computer system includes a management server device 100, one or more server devices 110-A and 110-B, an SVP (Service Processor) 111, a server chassis 112 that houses the server devices 110-A and 110-B, and the SVP 111, and a storage device. 120, one or more network switches 130, and one or more storage switches 140.
- the server apparatus 110-A functions as an active system
- the server apparatus 110-B functions as a standby system.
- the server device 110 is a generic term for the plurality of server devices 110-A and 110-B.
- the management server device 100 is a computer that operates under program control, and connects an input device 150 and an output device 151 used by a user (administrator of the computer system) of the management server device 100, and connects to the network switch 130.
- Network Interface Card Network Interface Card
- HBA Hyper Bus Adapter
- the management server device 100 is connected to each server device 110, SVP 111, and storage device 120 via the network switch 130 and the storage switch 140.
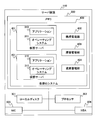
- the management server device 100 operates the failure recovery management unit 101 and has a table group 102 necessary for the operation of the failure recovery management unit 101. Each table included in the table group 102 will be described later using a table configuration example shown in FIG.
- the server device 110 is a computer that operates under program control, and includes a NIC (Network Interface Card) connected to the network switch 130 and an HBA (Host Bus Adapter) connected to the storage switch 140.
- the server device 110 is connected to the management server device 100, another server device 110, the SVP 111, and the storage device 120 via the network switch 130 and the storage switch 140.
- the storage apparatus 120 includes an FC (Fibre Channel) and a LAN interface, is connected to the storage switch 140 and the network switch 130, and includes a management server apparatus 100 and one or more disks 121 used by each server apparatus 110. It is.
- FC Fibre Channel
- the network switch 130 is one or more network devices.
- the network device is specifically a network switch, a router, a load balancer, a firewall, or the like.
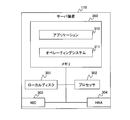
- FIG. 2 is a block diagram showing the configuration of the management server device 100.
- the management server device 100 includes a processor (CPU) 241 that performs arithmetic processing, a memory 242 that stores data and programs, a local disk 243 that holds data and programs, a NIC 245 connected to the network switch 130, and a storage switch HBA 244 connected to 140 is provided.
- the local disk 243 functions as a medium for storing each program.
- the memory 242 is loaded with the failure recovery management unit 101, the table group 102, and the server management unit 200.
- the failure recovery management unit 101 includes a switching level table generation unit 210, a switching execution unit 212, a switching method determination unit 213, and a failure sign information table generation unit 214.
- the failure recovery management unit 101 and the server management unit 200 are described as programs executed by the processor 241, but are implemented by hardware or firmware installed in the management server device 100, or a combination thereof. May be. Further, the failure recovery management unit 101 and the server management unit 200 are stored in an auxiliary storage device such as the local disk 243 provided in the management server device 100, loaded into the memory 242 at the time of execution, and then executed by the processor 241.
- the failure management unit 232 detects a failure (CPU temperature rise, fan rotation speed abnormality, memory ECC correction error, etc.) that has occurred in each server device 110 based on information transmitted from each server device 110 or SVP 111.
- the table group 102 includes a business requirement table 220, a switching level table 221, a switching information table group 222, a failure constraint table 223, and a failure predictor information table 224.
- the failure constraint table 223 is a table used in the second embodiment.
- the failure sign information table 224 is a table used in the third embodiment.
- the server management unit 200 includes a failure management unit 230, a configuration management unit 231, a resource management unit 232, a log management unit 233, and a business management unit 234.
- the configuration management unit 231 collects and holds configuration information (host name, operating system type, device information, etc.) regarding each server device 110 from each server device 110.
- the resource management unit 232 collects and holds the load information (CPU usage rate, memory usage, etc.) of each server device 110 from each server device 110.
- the log management unit 233 holds a history of switching performed in the past (switching method 602 (switching pattern)) identifier, start time, end time, target server device, target business, and the like.
- the business management unit 234 collects and holds information on business running on each server device 110.
- the log management unit 233 may include an identifier of the switching method 602 (switching pattern) and the time required for switching (required time) as information indicating the results of switching performed in the past.
- the average value for every switching pattern implemented in the past can be used for the time required for switching, as will be described later.
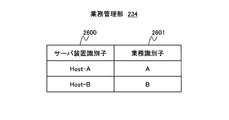
- FIG. 26 shows an example of information held by the business management unit 234.
- a column 2600 is an identifier for identifying the server device 110. Specifically, the host name and IP address set in the operating system running on the server apparatus 110, the UUID (Universally Unique Identifier) set in the server apparatus 110, and the like.
- a column 2601 is an identifier for identifying a business running on each server device 110. Specifically, the name of the business and the name defined by the user (or system administrator).
- FIG. 3 is a block diagram showing the configuration of the server device 110.
- the server apparatuses 110-A and 110-B stored in the blade server chassis 112 have the same configuration.
- the server device 110 includes a memory 300, a local disk 301, a processor (CPU) 302, a NIC 303, and an HBA 304.
- the local disk 301 is used as an auxiliary storage device.
- the server device 110 may use a flash memory or the like as an auxiliary storage device.
- the server device 110 may have a plurality of NICs and HBAs.
- the memory 300 holds a program for operating the operating system 311.
- the processor 302 executes programs such as the operating system 311 and the application (business) 310 loaded into the memory 300.
- the server device 110 includes a BMC (Baseboard Management Controller) (not shown), and can control power and monitor hardware such as the temperature of the processor 302 and the fan rotation speed in response to a command from the SVP 111. .
- BMC Baseboard Management Controller
- the virtualization system may be operated in the server device 110.
- the configuration of the server device 110 provided with a virtualization system will be described later with reference to FIG.
- FIG. 4 shows the configuration of the server device 110 when a virtualization system is provided.
- the memory 300 holds a program for operating the virtualization system 400.
- a hypervisor As the virtualization system 400, a hypervisor, a VMM (Virtual Machine Monitor), or the like can be employed.
- a virtual server 401, a configuration management unit 402, a failure management unit 403, and a resource management unit 404 operate.
- the virtual server 401 is a logical computer that emulates a physical computer, and programs such as an OS (Operating System) 311 and an application 310 are executed in the virtual server 401 using virtual resources allocated by the virtualization system 400. Make it work.
- OS Operating System
- the configuration management unit 402 collects configuration information (host name, virtual server name, etc.) regarding the virtualization system 400 and each virtual server 401, shapes the collected information, and transmits the shaped information to the management server device 100.
- the failure management unit 403 detects a failure (CPU temperature increase, fan speed abnormality, etc.) that has occurred in the server device 110 and the virtualization system 400, shapes information indicating the failure content, and converts the shaped information to the management server device 100. Send to.
- a failure CPU temperature increase, fan speed abnormality, etc.
- the resource management unit 404 measures the load information (CPU usage rate, memory usage, etc.) of the server device 110 and the virtual server 401, shapes the current load information, and transmits the shaped load information to the management server device 100. .
- the information that the resource management unit 404 transmits to the management server device 100 may include information measured in the past.
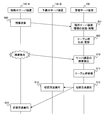
- FIG. 5 is a sequence diagram illustrating an example of processing among the active server device 110-A, the spare server device 110-B, and the management server device 100.
- the active server device 110-A manages configuration information, failure information, and resource information related to the active server device 110-A and the virtualization system 400 operating on the OS 311 or the virtualization system 400 operating on the server device 110-A. It transmits to the server apparatus 100 (process 500). Note that the process 500 is repeatedly executed at predetermined intervals. Further, the BMC (not shown) of the server device 110 may transmit configuration information, failure information, and resource information to the management server device 100.
- the management server device 100 receives the information transmitted from the active server device 110, and notifies the failure management unit 230, the configuration management unit 231 and the resource management unit 232 of the server management unit 200 of the information (processing 501) ).
- the management server device generates the contents of the business requirement table 220 and the switching level table 221 of the table group 102 based on the information of the failure management unit 230, the configuration management unit 231, the resource management unit 232, and the log management unit 233. Or it updates (process 502).
- the management server device 100 triggers the detection of a failure of the active server device 110 (processing 510), refers to the table group 102 (processing 511), and the active server in which the failure has occurred based on the referenced information.
- a switching method (or switching pattern) of the server apparatus 110 is selected (processing 512). Based on the switching method selected in process 512, the management server apparatus 100 performs switching to take over the work of the active server apparatus 110-A to the spare server apparatus 110-B (process 513).
- the switching of the server device 110 is first stopped according to the selected switching method for the job (second job) provided (or executed) by the spare server device 110-B, and the active server device 110-A. This is performed by providing the backup server apparatus 110-B with the job provided in (1).
- the trigger detected in the processing 510 is described as a failure of the active server device 110 (such as a server stop due to a hardware failure).
- the maintenance and hardware of the hardware configuring the active server device 110 are described.
- event notification from software and information set by a user through GUI (Graphical User Interface) by the input device 150 and the output device 151 may be used as a trigger.
- FIG. 6 is an explanatory diagram showing an example of the switching level table 221.
- the switching level table 221 is generated or updated by the switching level table generation unit 210 and holds information regarding the switching method (or switching pattern) of the server apparatus 110 and its features.
- Level 601 is information for digitizing and comparing non-numeric items such as the degree of safety in the switching method. In the present embodiment, the information on the level 601 is described as the degree of safety described later, but other information may be used.
- the safety level means that the management server device 100 switches the switching pattern based on hardware consumption, business continuity, data corruption, etc. when system switching is performed on the active spare server device 110-B. This information is determined every time. In the present embodiment, the switching pattern having a higher safety level can take over the work of the active server apparatus 110-A while suppressing the influence on the work of the spare server apparatus 110-B.
- the level 601 stores values determined by the management server device 100 based on the contents of the switching method feature table 900, the control target rate table 901, the resource release rate table 902, and the business restart rate table 903 shown in FIG.
- the switching method (or switching pattern) 602 is an identifier for identifying a switching method (switching pattern) for taking over the work of the active server device 110-A to the spare server device 110-B. Specifically, the name of the switching method and the name defined by the user (or system administrator).
- a column 603 is a required time 603 required for execution for each switching method. The required time 603 is determined by the management server device 100 based on information in the log management unit 233 and information set by a user through a GUI (Graphical User Interface) by the input device 150 and the output device 151.
- GUI Graphic User Interface
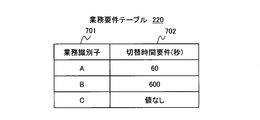
- FIG. 7 is an explanatory diagram showing an example of the business requirement table 220.
- the business requirement table 700 is a switching time requirement based on the SLA such as a business down allowable time when the server device 110 is switched.
- a column (business identifier) 701 is an identifier for identifying a business executed on the server apparatus 110. As this identifier, an identifier associated with the business identifier 2601 held by the business management unit 234 is used.
- a column (switching time requirement) 702 is a stop time permitted when a task is switched from the active server device 110-A to the spare server device 110-B.
- the value in the column 702 is 60 seconds
- a switching method (or switching pattern) in which the required time exceeds 60 seconds is not permitted due to business requirements.
- the unit of the column 702 is described as seconds, but other units may be used.
- the value in the column 702 may be set to no value (no requirement in particular) when there is no definition regarding the stop time with the client receiving the provision of business.
- the business requirement table 700 can be set in advance by an administrator or the like.
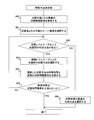
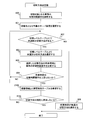
- FIG. 8 is a flowchart illustrating an example of processing performed by the switching method determination unit 213 included in the failure recovery management unit 101.
- the switching method determination unit 213 operates when the failure recovery management unit 101 determines a switching method (or switching pattern) (processing 512 in FIG. 5).
- the switching method determination unit 213 refers to the task requirement table 220 and refers to the switching time requirement 702 of the task to be switched with respect to the task being executed on the active server device 110 -A to be switched.
- the business to be switched is a business associated with the active server device 110-A in which the management server device 100 has detected a failure.
- the virtualization system 400 is operated on the active server device 110-A and a plurality of tasks are associated, the lowest switching time requirement 702 is referred to among the switching times requirement 702 of the plurality of tasks. (Step 800).
- the switching method determination unit 213 selects the spare server device 110-B that is the switching destination of the active server device 110-A.
- the operation status of each spare server apparatus 110-B is referred to by the resource management unit 232, and is selected as a switching destination of an inactive or another active server apparatus (not shown).
- the server device 110 that has not been selected is selected.
- the server device 110 to be selected as the switching destination is selected from information (priority or spare server device directly designated by the user) set by the user through a GUI (Graphical User Interface) by the input device 150 and the output device 151. (Step 801).
- the switching method determination unit 213 determines from the switching level table 221 whether there is a switching method 602 that has never been selected in this process, and if there is a switching method 602 that has never been selected, step 802. If all switching methods 602 have been selected, the process moves to step 806 (step 805).
- the switching method determination unit 213 selects the switching method 602 that has the highest level 601 (the value is large) and has never been selected in this process from the switching level table 221 (step 802).
- the switching method determination unit 213 compares the required time 603 of the switching method 602 selected in Step 802 with the task switching time requirement 702 referred to in Step 800 (Step 803).
- Step 803 If the switching time requirement 702 does not exceed the required time 603 as a result of the comparison in step 803, the switching method determination unit 213 assumes that even if the business is down due to the execution of the switching method 602 selected in step 802, it does not violate the business requirement. It judges, and the process of the switching method determination part 213 is complete
- the switching time requirement 702 allowed for the business to be switched and the standby server device 110-B to be switched to are selected. Then, by repeating steps 802, 803, 804, and 805 for the number of entries in the switching level table 221, the switching method 602 (or switching pattern) satisfies the switching time requirement 702 and the value of the level 601 is the largest. A switching method 602 is selected. If the number of NO in step 804 exceeds the number of entries in the switching level table 221, the switching method 602 with the shortest required time 603 can be selected.
- FIG. 9 is an explanatory diagram showing the configuration of the switching information table group 222.
- the switching information table group 222 includes a switching method feature table 900, a control target rate table 901, a resource release rate table 902, and a business restart rate table 903.
- the switching information table group 222 is used for determining the level 601 of the switching level table 221.
- FIG. 10 is an explanatory diagram showing the configuration of the switching method feature table 900.
- the switching method feature table 900 shows the characteristics of the operation of the spare server device 110-B when executing each switching method (switching pattern) and the operations already executed on the spare server device 110-B. Hold information about impacts.
- the switching method feature table 900 is a table preset by a user or the like.
- Column (switching method) 1000 is an identifier for identifying the switching method of the server apparatus 110. Specifically, the name of the switching method and the name defined by the user (or system administrator).
- a column 1001 is information serving as a determination element of information indicated by the level 601 (safety level in the present embodiment). In other words, when the switching method 1000 is executed, the contents of the control commanded to the spare server apparatus 110-B are set for each control item.
- the column 1001 includes a control target 1010, a resource securing method 1011 and a business restart 1012 as sub columns (control items).
- the control target 1010 is a component (OS, hardware, virtualization system, etc.) in the spare server apparatus 110-B that is a transmission destination of a control command when the switching method (switching pattern) 1000 is executed.
- the resource release method 1011 is a method of releasing the resources of the spare server device 110-B in order to allocate the work on the active server device 110-A when the switching method 1000 is executed (server device stop, resource allocation rate). Change).
- the business restart 1012 indicates whether or not the business on the spare server device 110-B is restarted when the switching method 1000 is executed.
- FIG. 11 is an explanatory diagram showing the configuration of the control target rate table 901.
- the control target rate table 901 indicates information for associating the control target 1010 with information (level of safety in the present embodiment) indicated by the level 601.
- the control target rate table 901 is a table preset by a user or the like.
- Column 1100 is an identifier for associating the control target rate table 901 with the control target 1010.
- the column 1101 is information for comparing information (level of safety in the present embodiment) indicated by the level 601 between the columns 1100. For example, when FIG. 11 is used as an example, a case where a control command such as shutdown is transmitted to software such as an OS or a virtualization system is compared with a case where a control command such as power stop is transmitted to hardware. Because the burden on hardware can be reduced, safety is high. In addition, when the hardware is forcibly stopped, problems such as a case where the server apparatus 110 cannot be recognized from the management server apparatus 100 when the power is turned on again may occur. For this reason, the safety degree of the switching pattern (switching method) including the procedure for forcibly stopping the hardware power supply is set low.
- FIG. 12 shows the configuration of the resource release rate table 902.
- the resource release rate table 902 indicates information for associating the resource release method 1011 with the information indicated by the level 601 (safety level in this embodiment).
- the resource release rate table 902 is a table preset by a user or the like.
- Column 1200 is an identifier for associating the resource release rate table 902 with the resource release method 1011.
- a column 1201 is information for comparing information (level of safety in the present embodiment) indicated by the level 601 between the columns 1200. For example, using FIG. 12 as an example, the resource allocation rate is greater when the spare server device 110-B is stopped and the entire spare server device 110-B is allocated to the work on the active server device 110-A. Compared with the case where a part of the spare server device 110-B is allocated to the work on the active server device 110-A, the necessary resources can be prepared, and the degree of safety is high in terms of business continuity.
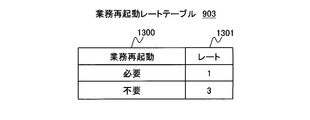
- FIG. 13 is an explanatory diagram showing the configuration of the business restart rate table 903.
- the business restart rate table 903 indicates information for associating the business restart 1012 with information (level of safety in the present embodiment) indicated by the level 601.
- the business restart rate table 903 is a table preset by a user or the like.
- Column 1300 is an identifier for associating the business restart rate table 903 with the business restart 1012.
- the column 1301 is information for comparing information (level of safety in this embodiment) indicated by the level 601 between the columns 1300. For example, when FIG. 13 is used as an example, the degree of safety in terms of data loss is higher when the business restart is not required than when the business restart is required.
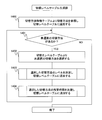
- FIG. 14 is a flowchart illustrating an example of processing performed by the switching level table generation unit 210. This process is executed in process 502 of FIG.
- the switching level table generation unit 210 operates when the failure recovery management unit 101 generates the switching level table 221 (process 502).
- the switching level table generation unit 210 refers to the switching method 1000 from the switching method feature table 900 and adds it to the switching method 602 of the switching level table 221 (step 1400).
- the switching level table generation unit 210 determines whether there is a selection method that has never been selected in this processing among the switching methods added in step 1400, and there is a selection method that has never been selected. Advances to step 1402, and if not, the process ends (step 1401). It should be noted that a flag (not shown) or the like is provided in the switching level table 221 and the above determination may be made by setting a flag when the switching method 602 is selected.
- the switching level table generating unit 210 selects one switching method that has never been selected in this process from among the switching methods 602 in the switching level table 221 (step 1402).
- the switching level table generating unit 210 determines the level of the switching method 602 selected in step 1402 and adds it to the level 601 of the corresponding record in the switching level table 221 (step 1403).
- a detailed processing flowchart of step 1403 is shown in FIG.
- the switching level table generation unit 210 determines the time required for the switching method 602 selected in step 1402, adds it to the level 601 of the corresponding record in the switching level table 221, and moves to step 1401 (step 1404).
- a detailed processing flowchart of step 1404 is shown in FIG.
- FIG. 15 shows a flowchart of processing for determining the level 601 of the switching method 602 in step 1403 shown in FIG.
- the control target 1010 corresponding to the selected switching method 602 is read from the switching method feature table 900 of FIG. 10, and the rate 1101 of the control target rate table 901 shown in FIG.
- step 1501 the resource release method 1011 corresponding to the selected switching method 602 is read from the switching method feature table 900 of FIG. 10, and the rate 1201 of the resource release rate table 902 is referred to.
- step 1502 the business restart 1012 of the selected switching method 602 is read from the switching method feature table 900 of FIG. 10, and the rate 1301 of the business restart rate table 903 is referred to.
- step 1503 the level 601 of the switching level table 221 is determined from the information referenced in step 1500, step 1501, and step 1502.
- the determination method in step 1502 is described as the sum of rate 1101, rate 1201, and rate 1301, but the highest rate value and the order in the switching level table 221 (for example, the sum value is switched). If the level table 221 is the second highest, another determination method such as 2) may be used.
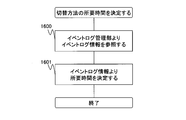
- FIG. 16 shows a flowchart of processing for determining the required time 603 of the selected switching method 602 in step 1404 shown in FIG.
- the log management unit 233 refers to event log information indicating an execution history such as start and end of the selected switching method 602.
- step 1601 the required time is determined from the event log information referenced in step 1600.
- the determination method in step 1601 will be described as the difference between the latest end time and start time related to the switching method 602 (switching pattern) selected in step 1404. Another determination method such as a value or an average value may be used.
- the acquisition of information related to the switching method 602 (switching pattern) from the event log information is performed by comparing the identifier of the switching method selected in step 1404 with the identifier of the switching method 602 (switching pattern) included in the event log information. I will do it.
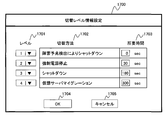
- FIG. 17 shows an example of a GUI (Graphical User Interface) as an example of a UI (User Interface) that the failure recovery management unit 101 provides to allow the user to set the contents of the switching level table 221.
- GUI Graphic User Interface
- UI User Interface
- This GUI is displayed on the output device 151 connected to the management server device 100, the display device of another terminal connected to the management server device 100 via the network switch 130, or the like using a browser, a dedicated program, text, or the like. indicate.
- the switching level information setting window 1700 displays switching level information, buttons for operation, and the like.
- the switching level information displayed in the window 1700 is based on the contents of the switching level table 221.
- level 1701 information on level 601 is displayed.
- switching method 1702 information on the switching method 602 is displayed.
- required time 1703 information in the column 603 is displayed.
- the user inputs values for level 1701 and required time 1703.
- the failure recovery management unit 101 reflects the information input in the level 1701 and the required time 1703 in the switching level table 221.
- FIG. 18 shows an example of a GUI (Graphical User Interface) as an example of a UI (User Interface) provided by the failure recovery management unit 101 to allow the user to set the contents of the business requirement table 220.
- GUI Graphic User Interface
- This GUI is displayed on the output device 151 connected to the management server device 100, the display device of another terminal connected to the management server device 100 via the network switch 130, or the like using a browser, a dedicated program, text, or the like. indicate.
- the business requirement information setting window 1800 displays business requirement information and buttons for operation.
- the business requirement information displayed in the window 1800 is based on the content of the business requirement table 220.
- information in the column 701 is displayed.
- information in the column 702 is displayed.
- the user enters a value in the switching time requirement 1802.
- the failure recovery management unit 101 reflects the information input in the switching time requirement 1802 in the business requirement table 220.
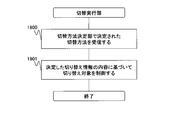
- FIG. 19 is a flowchart illustrating an example of processing performed by the switching execution unit 212.
- the switching execution unit 212 starts its operation by the failure recovery management unit 101 after the processing of the switching method determination unit 213 at the time of switching method selection (processing 512 in FIG. 5).
- the switching execution unit 212 receives the switching method determined by the switching method determination unit 213 from the failure recovery management unit 101 (step 1900).
- the switching execution unit 212 controls the active and standby server apparatuses 110 based on the switching method received in Step 1900 (Step 1901). For example, if the received switching method is a forced power supply stop, a power supply stop command is transmitted to the hardware of the spare server apparatus 110-B, and after the power supply stop is determined, the system switchover of the current server apparatus 110-A is performed. carry out.
- the failure recovery management unit 101 determines a server switching method (switching procedure) for stopping the spare server device 110-B as safely as possible during server switching according to the level, By performing server switching based on the determined switching method, it is possible to recover the business.
- a server switching method switching procedure
- the server device 110 is switched, it becomes possible to satisfy the business requirements, which are restrictions until the standby system takes over the active system, and to stop the standby server device 110-B as safely as possible. It is possible to prevent the data of the business (development and test) executed on the server apparatus 110-B from being damaged.
- the spare server device 110-A can be used effectively when a failure occurs in the active server device 110-A while effectively utilizing the resources of the computer system. It is possible to switch from the active system to the standby system while satisfying predetermined business conditions while minimizing the influence on the business being executed by the apparatus 110-B.
- the switching method including the step of selecting the switching method from the level 601 for each switching method and the requirements of the business to be switched has been described.
- a switching method including a step of selecting a switching method in consideration of the content of a failure that has occurred in the active server apparatus 110-A will be described.
- the failure constraint table 223 is newly used.
- another structure it is the same as that of the said 1st Embodiment, The description of those structures and steps is abbreviate
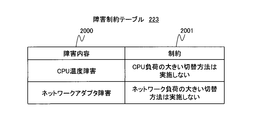
- FIG. 20 shows the configuration of the failure constraint table 223.
- the failure constraint table 223 is included in the table group 102 of FIG. 2, and is used for the content of a failure (failure factor) that has occurred in the active server device 110-A (and the OS 311 and the virtualization system 400 running on the server device 110-A).
- Constraints for determining the switching method for example, when a temperature failure occurs in a CPU (processor), a moving means that overuses the CPU such as virtual server migration is not used frequently
- a column 2000 is an identifier for identifying failure contents. Specifically, the name is defined by the user (or server administrator).
- a column 2001 shows the content of the constraint that the failure gives to the determination of the switching method. Taking FIG. 20 as an example, when a network adapter failure occurs and the network bandwidth decreases, the switching method is determined so as not to implement a switching method with a large network load such as virtual server migration.
- the failure factor can be specified based on a log or notification acquired by the management server device 100 from the BMC or OS of the server device 110.
- Known or well-known techniques can be used for specifying the cause of the failure.
- FIG. 21 shows a processing flowchart of the switching method determination unit 213 of the second embodiment.
- FIG. 21 shows processing in which the switching method determination unit 213 shown in FIG. 8 of the first embodiment is changed for the present embodiment. 21 is different from FIG. 8 in that step 2105 and step 2106 are added. The other steps are the same as those in FIG. 8 of the first embodiment.
- the switching method determination unit 213 refers to the failure content 2000 of the failure constraint table 223 based on the failure information of the active server device 110-A received by the management server device 100 (step 2105).
- the switching method determination unit 213 determines whether or not the constraint acquired in Step 2105 is not violated by executing the switching method selected in Step 2102 (Step 2106). On the other hand, if the acquired constraint is violated, the process moves to step 2102.
- the failure recovery management unit 101 can determine the switching method of the server device 110 in consideration of the content of the failure that has occurred in the active server device 110-A. As a result, it is possible to avoid problems such as that the switching method of the server device 110 induces a failure, or that a resource necessary for switching the server device 110 cannot be used due to the failure and the switching fails.
- FIG. 22 shows an example of a processing sequence among the active server device 110-A, the spare server device 110-B, and the management server device 100 in the third embodiment. Note that the process of FIG. 22 is executed in addition to the processes 500 to 502 shown in FIG. 5 of the first embodiment. About another structure, it is the same as that of the said 1st Embodiment, The description of those structures and steps is abbreviate
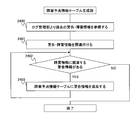
- the management server device 100 generates the failure sign information table 224 based on the information of the failure management unit 230 and the log management unit 233 of the server management unit 200 (processing 2207).
- the active server device 110 sends warning information (for example, CPU temperature rise, fan rotation rise, memory collect error, resource tightness, etc.) related to the server device 110, the OS 311 operating on the server device 110, or the virtualization system 400 to the management server device 100. Transmit (process 2200). Note that the process 2200 is repeatedly executed at predetermined intervals.
- warning information for example, CPU temperature rise, fan rotation rise, memory collect error, resource tightness, etc.
- the management server device 100 receives the warning information transmitted from the active server device 110-A, and detects a failure sign of the active server device 110-A from the content (processing 2201). When the management server apparatus 100 detects a failure sign of the active server apparatus 110-A, the management server apparatus 100 transmits a stop command (such as OS shutdown) to the spare server apparatus 110-B (process 2202). When the backup server apparatus 110-B receives the stop command from the management server apparatus 100, the backup server apparatus 110-B stops the server apparatus 110-B based on the content (process 2203).
- a stop command such as OS shutdown
- the management server device 100 detects a failure of the active server device 110-A (process 2204). After detecting the failure, the management server device 100 starts switching from the active server device 110-A to the spare server device 110-B (processing 2205). The active and spare server apparatuses 110 perform switching in response to a request from the management server apparatus 100 (process 2206).
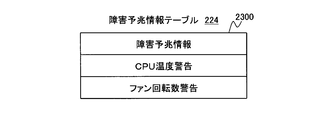
- FIG. 23 is an explanatory diagram showing the structure of the failure sign information table 224.
- the failure sign information table 224 is generated by a failure sign information table generation unit 214 (to be described later), and the failure recovery management unit 101 holds information for determining a failure sign of the server device 110.
- a column 2300 indicates information related to a failure sign of the server apparatus 110. Taking FIG. 23 as an example, when the management server device 100 receives status information related to the CPU temperature warning from the active server device 110-A, the failure recovery management unit 101 will cause a failure in the active server device 110-A in the future. Determined to occur and stop.
- FIG. 24 is a flowchart illustrating an example of processing performed in the failure sign information table generation unit 214.
- the failure predictor information table generation unit 214 operates when the failure recovery management unit 101 generates failure predictor information (processing 2207).
- the failure sign information table generation unit 214 refers to the warning information and the failure information for the past active server device 110-A from the log management unit 233 (step 2400).
- the failure sign information table generation unit 214 associates the warning information and the failure information referred to in Step 2400 (Step 2401).
- This association includes a part that is directly related (for example, CPU (processor) failure information and CPU (processor) warning information are related), and a part that is indirectly related (for example, CPU warning information If it occurs, there is a possibility that a performance failure of the OS, virtualization system, application, etc., which are related parts), reception time (for example, the closer the reception time is, the more related).
- the failure sign information table generation unit 214 determines whether or not there is warning information related to the failure information in Step 2401. If there is warning information related to the failure information, the process proceeds to Step 2403, and if not, the process ends. (Step 2402). The failure sign information table generation unit 214 adds the warning information related to the failure information in step 2401 to the failure sign information table and moves to step 2402 (step 2403).
- FIG. 25 shows an example of a GUI (Graphical User Interface) as an example of a UI (User Interface) that the failure recovery management unit 101 provides to allow the user to set the contents of the failure predictor information table 224.
- This GUI is displayed on the output device 151 connected to the management server device 100, the display device of another terminal connected to the management server device 100 via the network switch 130, or the like using a browser, a dedicated program, text, or the like. indicate.
- the failure sign information setting window 2500 displays failure sign information and buttons for operation.
- the failure sign information displayed in the window 2500 is based on the contents of the failure sign information table 224.
- the failure predictor 2501 displays information in the column 2300.
- the user can select information to be treated as a failure sign from the information regarding the state of the server device 110 provided in the management server device 100 in 2501.
- the failure recovery management unit 101 reflects the information input in the switching time requirement 2501 in the failure predictor information table 224.
- the failure recovery management unit 101 can detect a failure sign of the active server device 110-A and stop the spare server device 110-B before a failure actually occurs. As a result, it is possible to avoid problems such as the forced stop of the active server device 110-A and the spare server device 110-B due to the occurrence of a failure and the data corruption on the spare server device 110-B due to the forced stop.
- the present invention can be applied to a computer system or a management server that switches to a standby server when a failure occurs in an active server.
- the present invention is suitable for a computer system in which tasks such as tests and system development are allocated to a standby server and the computer system's computing resources are effectively used.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Quality & Reliability (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Hardware Redundancy (AREA)
Abstract
管理計算機が、第1の業務を第2のアプリケーションサーバへ切り替える際の切替パターンを設定した切替レベル情報を参照して、前記切替パターン毎に安全度のレベルと切替時間を設定し、第1の業務を第2のアプリケーションサーバへ切り替える際に許容された停止時間を参照し、前記切替レベル情報の切替時間が第1の業務に設定された停止時間より短く、かつ、切替レベル情報の前記安全度のレベルが最も高い切替パターンを選択する。
Description
本発明は、フェイルオーバー構成を備える計算機システムに係り、特にサーバの切替パターンを決定する手順を含むサーバ切替の技術に関する。
サーバの障害発生時の業務復旧方法として、サーバの切替手段が存在する(例えば、特許文献1、特許文献2、特許文献3)。このようなサーバの切替手段を備えたフェイルオーバー構成における、予備サーバの有効活用に関する方法として、予備サーバでの開発、テスト、Webサーバなどへの一時的な割当が知られている。
しかし、上記従来の方法では、サーバの切替を実施する際に予備系サーバ上で稼動する業務(例えば、ソフトウェアの開発業務等)が一旦停止されてしまう。これは、切替の際に、I/O(Input/Output)障害発生の防止、WWN(World Wide Name)やBIOS(Basic Input/Output System)設定の更新などのため、予備系サーバを一旦停止させる必要があるからである。
上記は、サーバの切替において、予備系または現用系サーバ上の業務に影響を与えることとなる。例えば、迅速な切替のために予備系サーバを強制停止した場合、ハードウェアの故障や、業務データの破損などが発生する場合がある。予備系サーバ上の業務停止を待ってからサーバを切り替えた場合、現用系サーバ上の業務復旧が遅延しSLA(Service Level Agreement)を満たせない場合が発生する。この問題は、要件の異なる複数の業務で予備系サーバを共有する状況にて特に顕著となる。
そこで、本発明が解決しようとする課題は、業務要件を満たしかつサーバ切替の予備系サーバへの影響を抑えるために、サーバ切替時に予備系サーバを可能な限り安全に停止させるサーバの切替方法を決定すること、また現用系サーバの障害予兆を検出し事前に予備系サーバを停止させることである。
本明細書において開示される発明の代表的な一例を示せば以下の通りである。すなわち、第1の業務を提供する第1のアプリケーションサーバと、第2の業務を提供する第2のアプリケーションサーバと、前記第1のアプリケーションサーバ及び第2のアプリケーションサーバに接続された管理計算機が、前記第1のアプリケーションサーバで提供される第1の業務を、前記第2のアプリケーションサーバに引き継がせるアプリケーションサーバの切り替え方法であって、前記管理計算機が、前記第1の業務を第2のアプリケーションサーバへ切り替える際の切替パターンが設定された切替レベル情報を参照し、前記切替パターン毎に安全度のレベルを設定する第1のステップと、前記管理計算機が、前記切替レベル情報を参照し、前記切替パターン毎に前記第1の業務を第2のアプリケーションサーバへ切り替えるために必要な切替時間を設定する第2のステップと、前記管理計算機が、前記第1の業務を第2のアプリケーションサーバへ切り替える際に許容された停止時間が前記第1の業務毎に設定された業務要件情報を参照する第3のステップと、前記管理計算機が、前記参照した第1の業務に設定された業務要件情報の停止時間と、前記切替レベル情報の前記切替パターンに設定された前記切替時間とを比較し、前記第1の業務に設定された前記業務要件情報の停止時間より短く、かつ、前記切替レベル情報の前記切替パターンのうち前記安全度のレベルが最も高い切替パターンを選択する第4のステップと、前記管理計算機が、前記選択された切替パターンで、前記第2のアプリケーションサーバの第2の業務を停止させた後、前記第1の業務を前記第2のアプリケーションサーバで提供させる第5のステップと、を含む。
したがって、本発明の一実施形態によれば、サーバ切替時に第2のアプリケーションサーバ(予備サーバ)を可能な限り安全に停止させるサーバの切替パターンを決定することができる。
以下、本発明の一実施形態を添付図面に基づいて説明する。
<第1の実施形態>
図1は、計算機システムの構成を示す。この計算機システムは、管理サーバ装置100、1つ以上のサーバ装置110-A、110-B、SVP(Service Processor)111、サーバ装置110-A、110-B及びSVP111を収めるサーバシャーシ112、ストレージ装置120、1つ以上のネットワークスイッチ130、1つ以上のストレージスイッチ140を有する。なお、図1において、サーバ装置110-Aは現用系として機能し、サーバ装置110-Bは予備系として機能する。また、複数のサーバ装置110-A,110-Bの総称をサーバ装置110とする。
管理サーバ装置100は、プログラム制御により動作するコンピュータであり、管理サーバ装置100のユーザ(本計算機システムの管理者)が使用する入力装置150及び出力装置151を接続し、ネットワークスイッチ130に接続するNIC(Network Interface Card)、及びストレージスイッチ140に接続するHBA(Host Bus Adapter)を備える。
管理サーバ装置100は、ネットワークスイッチ130、ストレージスイッチ140を介して、各サーバ装置110、SVP111、及びストレージ装置120に接続する。管理サーバ装置100は、障害復旧管理部101を動作させ、また障害復旧管理部101の動作に必要なテーブル群102を有する。テーブル群102に含まれる各テーブルは、図6以降のテーブル構成例を用いて後述する。
サーバ装置110は、プログラム制御により動作するコンピュータであり、ネットワークスイッチ130に接続するNIC(Network Interface Card)、及びストレージスイッチ140に接続するHBA(Host Bus Adapter)を備える。サーバ装置110は、ネットワークスイッチ130、ストレージスイッチ140を介して、管理サーバ装置100、他のサーバ装置110、SVP111、及びストレージ装置120に接続する。
ストレージ装置120は、FC(Fibre Channel)及びLANインタフェースを備えてストレージスイッチ140、ネットワークスイッチ130に接続され、管理サーバ装置100及び各サーバ装置110が使用する1つ以上のディスク121を含む記憶装置システムである。
ネットワークスイッチ130は、1つ以上のネットワーク機器である。ネットワーク機器は、具体的にはネットワークスイッチやルータ、ロードバランサ、及びファイアウォールなどである。
図2は、管理サーバ装置100の構成を示すブロック図である。管理サーバ装置100は、演算処理を行うプロセッサ(CPU)241と、データやプログラムを格納するメモリ242と、データやプログラムを保持するローカルディスク243と、ネットワークスイッチ130に接続されるNIC245と、ストレージスイッチ140に接続されるHBA244を備える。なお、ローカルディスク243は、各プログラムを記憶する媒体として機能する。メモリ242には、障害復旧管理部101、テーブル群102、サーバ管理部200がロードされる。
障害復旧管理部101は、切替レベルテーブル生成部210、切り替え実行部212、切替方法決定部213、障害予兆情報テーブル生成部214を含む。尚、本実施形態では、障害復旧管理部101、及びサーバ管理部200は、プロセッサ241により実行されるプログラムとして説明するが、管理サーバ装置100に搭載するハードウェアやファームウェア、またはそれらの組み合わせにより実装してもよい。また、障害復旧管理部101、及びサーバ管理部200は、管理サーバ装置100が備えるローカルディスク243等の補助記憶装置に格納され、実行時にはメモリ242にロードされてから、プロセッサ241によって実行される。
障害管理部232は、各サーバ装置110で発生した障害(CPU温度上昇、ファン回転数異常、メモリECCコレクトエラーなど)を、各サーバ装置110またはSVP111から送信される情報によって検知する。
テーブル群102は、業務要件テーブル220、切替レベルテーブル221、切替情報テーブル群222、障害制約テーブル223、障害予兆情報テーブル224を含む。なお、障害制約テーブル223は第2の実施形態で使用するテーブルである。また、障害予兆情報テーブル224は第3の実施形態で使用するテーブルである。
サーバ管理部200は、障害管理部230、構成管理部231、資源管理部232、ログ管理部233及び業務管理部234を含む。構成管理部231は、各サーバ装置110に関する構成情報(ホスト名、オペレーティングシステムの種別、デバイス情報など)を、各サーバ装置110より収集して保持する。
資源管理部232は、各サーバ装置110の負荷情報(CPU使用率、メモリ使用量など)を、各サーバ装置110より収集して保持する。ログ管理部233は、過去に実施した切替の履歴(切替方法602(切り替えパターン))の識別子、開始時刻、終了時刻、対象サーバ装置、対象業務など)を保持する。業務管理部234は、各サーバ装置110上で稼動する業務の情報を収集して保持する。なお、ログ管理部233は、過去に実施した切替の実績を示す情報として、切替方法602(切り替えパターン)の識別子と、切り替えに要した時間(所要時間)を含んでもよい。また、切り替えの所要時間は、後述するように過去に実施した切り替えパターン毎の平均値を用いることができる。
図26は、業務管理部234が保持する情報の例を示す。カラム2600は、サーバ装置110を識別するための識別子である。具体的には、サーバ装置110上で稼動するオペレーティングシステムに設定されたホスト名、IPアドレス、サーバ装置110に設定されたUUID(Universally Unique Identifier)などである。カラム2601は、各サーバ装置110上で稼動する業務を識別するための識別子である。具体的には、業務の名称、及びユーザ(またはシステム管理者)が定義した名称である。
図3は、サーバ装置110の構成を示すブロック図である。ブレードサーバシャーシ112に格納されるサーバ装置110-A、110-Bは同一の構成である。サーバ装置110は、メモリ300、ローカルディスク301、プロセッサ(CPU)302、NIC303、HBA304を有する。ローカルディスク301は、補助記憶装置として使用する。尚、サーバ装置110は補助記憶装置としてフラッシュメモリなどを使用してもよい。またサーバ装置110は複数のNIC及びHBAを有してもよい。
メモリ300は、オペレーティングシステム311を動作させるプログラムを保持する。サーバ装置110内では、プロセッサ302がメモリ300にロードしたオペレーティングシステム311、アプリケーション(業務)310などのプログラムを実行する。
また、サーバ装置110は、図示しないBMC(Baseboard Management Controller)を備えており、SVP111からの指令に応じて電源の制御や、プロセッサ302の温度やファン回転数などハードウェアの監視を行うことができる。
また、サーバ装置110内では仮想化システムを動作させてもよい。仮想化システムを備える場合のサーバ装置110の構成は、図4を用いて後述する。
図4は、仮想化システムを備える場合のサーバ装置110の構成を示す。メモリ300は、仮想化システム400を動作させるプログラムを保持する。仮想化システム400としては、ハイパバイザやVMM(Virtual Machine Monitor)等を採用することができる。仮想化システム400内では、仮想サーバ401、構成管理部402、障害管理部403、資源管理部404が動作する。
仮想サーバ401は、物理コンピュータをエミュレートした論理コンピュータであり、仮想化システム400によって割当てられた仮想資源を使用して、仮想サーバ401内で、OS(Operating System)311、アプリケーション310などのプログラムを動作させる。
構成管理部402は、仮想化システム400及び各仮想サーバ401に関する構成情報(ホスト名、仮想サーバ名など)を収集し、収集した情報を整形し、整形した情報を管理サーバ装置100へ送信する。
障害管理部403は、サーバ装置110及び仮想化システム400で発生した障害(CPU温度上昇、ファン回転数異常など)を検知し、障害内容を示す情報を整形し、整形した情報を管理サーバ装置100へ送信する。
資源管理部404は、サーバ装置110及び仮想サーバ401の負荷情報(CPU使用率、メモリ使用量など)を計測し、現況の負荷情報を整形し、整形した負荷情報を管理サーバ装置100へ送信する。尚、資源管理部404が、管理サーバ装置100へ送信する情報には、過去に計測した情報を含んでもよい。
図5は、現用のサーバ装置110-A、予備のサーバ装置110-B、及び管理サーバ装置100間の処理の一例を示すシーケンス図である。現用のサーバ装置110-Aは、その上で動作するOS311または仮想化システム400を通じて、現用のサーバ装置110-A及びその上で稼動する仮想化システム400に関する構成情報、障害情報、資源情報を管理サーバ装置100に送信する(処理500)。なお、処理500は、所定の周期毎に繰り返して実行される。また、サーバ装置110のBMC(図示省略)が構成情報、障害情報、資源情報を管理サーバ装置100に送信するようにしてもよい。
管理サーバ装置100は、現用のサーバ装置110から送信された情報を受信し、その内容をサーバ管理部200の、障害管理部230、構成管理部231、及び資源管理部232に通知する(処理501)。
管理サーバ装置は、障害管理部230、構成管理部231、資源管理部232、及びログ管理部233の情報を元に、テーブル群102の、業務要件テーブル220、及び切替レベルテーブル221の内容を生成または更新する(処理502)。
管理サーバ装置100は、現用のサーバ装置110の障害を検知することなどを契機とし(処理510)、テーブル群102の参照を行い(処理511)、参照した情報を元に障害が発生した現用のサーバ装置110の切替方法(または切り替えパターン)を選択する(処理512)。管理サーバ装置100は、処理512で選択した切替方法に基づいて、現用のサーバ装置110-Aの業務を予備のサーバ装置110-Bへ引き継ぐ切替を実施する(処理513)。サーバ装置110の切替は、まず、予備のサーバ装置110-Bで提供(または実行)されている業務(第2の業務)を選択した切替方法に応じて停止させ、現用のサーバ装置110-Aで提供されていた業務(第1の業務)を、予備のサーバ装置110-Bで提供させることで行われる。
尚、本実施形態では、処理510で検知する契機を現用のサーバ装置110の障害(ハードウェア故障によるサーバ停止など)として説明するが、現用のサーバ装置110を構成するハードウェアの保守、ハードウェアまたはソフトウェアからのイベント通知、及びユーザが入力装置150及び出力装置151によるGUI(Graphical User Interface)を通して設定した情報を契機として用いてもよい。
図6は、切替レベルテーブル221の例を示す説明図である。切替レベルテーブル221は、切替レベルテーブル生成部210によって生成または更新され、サーバ装置110の切り替え方法(または切り替えパターン)とその特徴に関する情報を保持する。レベル601は、切り替え方法を安全度などの非数値項目を数値化し、比較するための情報である。尚、本実施形態ではレベル601の情報を後述する安全度として説明するが他の情報を用いてもよい。安全度とは、稼働中の予備のサーバ装置110-Bに対して系切り替えを実施した場合の、ハードウェアの消費、業務継続性、データ破損、などに基づいて管理サーバ装置100が、切り替えパターン毎に決定する情報である。本実施形態では、安全度の数値がより高い切り替えパターンの方が、予備のサーバ装置110-Bの業務に与える影響を抑制しながら現用のサーバ装置110-Aの業務を引き継ぐことができる。
レベル601は、後述する図9の、切替方法特徴テーブル900、制御対象レートテーブル901、資源解放レートテーブル902、及び業務再起動レートテーブル903の内容より、管理サーバ装置100が決定する値が格納される。切替方法(または切り替えパターン)602は、現用のサーバ装置110-Aの業務を予備のサーバ装置110-Bへ引き継ぐ切り替え方法(切り替えパターン)を識別するための識別子である。具体的には、切替方法の名称、及びユーザ(またはシステム管理者)が定義した名称である。カラム603は、切り替え方法毎の実施に要する所要時間603である。所要時間603は、ログ管理部233の情報や、ユーザが入力装置150及び出力装置151によるGUI(Graphical User Interface)を通して設定した情報を元に、管理サーバ装置100が決定する。
図7は、業務要件テーブル220の例を示す説明図である。業務要件テーブル700は、サーバ装置110を切り替える際に業務ダウン許容時間などのSLAに基づいた切り替え時間要件である。カラム(業務識別子)701は、サーバ装置110で実行される業務を識別するための識別子である。この識別子には、業務管理部234が保持する業務識別子2601と関連付けられるものを使用する。カラム(切替時間要件)702は、業務を現用のサーバ装置110-Aから予備のサーバ装置110-Bへの切り替える際に許可される停止時間である。例えば、カラム702の値が60秒である場合、所要時間が60秒を超える切り替え方法(または切り替えパターン)は業務要件上許可されないこととなる。尚、本実施形態ではカラム702の単位を秒として説明するが他の単位を用いてもよい。また、カラム702の値は、業務の提供を受けるクライアントとの間に停止時間に関する定めがない場合には、値なし(要件が特にない)とすることもできる。また、業務要件テーブル700は、管理者などが予め設定しておくことができる。
図8は、障害復旧管理部101に含まれる切替方法決定部213で行われる処理の一例を示すフローチャートである。切替方法決定部213は、障害復旧管理部101が切替方法(または切り替えパターン)を決定する(図5の処理512)際に動作する。切替方法決定部213は、切り替え対象の現用系のサーバ装置110-Aで実行されている業務について、業務要件テーブル220を参照して切替対象となる業務の切替時間要件702を参照する。切替対象となる業務とは、管理サーバ装置100が障害を検出した現用のサーバ装置110-Aに関連付けられている業務である。現用のサーバ装置110-A上で仮想化システム400が稼動することで、複数の業務が関連付けられている場合は、複数の業務の切替時間要件702の中から最も低い切替時間要件702を参照する(ステップ800)。
切替方法決定部213は、現用のサーバ装置110-Aの切替先となる予備のサーバ装置110-Bを選択する。予備のサーバ装置110-Bが複数ある場合は、各予備のサーバ装置110-Bの稼動状態を資源管理部232より参照し、未稼働または別の現用サーバ装置(図示省略)の切替先として選択されていないサーバ装置110から選択する。なお、切替先として選択するサーバ装置110は、ユーザが入力装置150及び出力装置151によるGUI(Graphical User Interface)を通して設定した情報(優先度や、ユーザが直接指定した予備サーバ装置)から選択してもよい(ステップ801)。
切替方法決定部213は、切替レベルテーブル221より、本処理にてまだ一度も選択されていない切替方法602があるか否かを判定し、一度も選択されていない切替方法602があればステップ802へ移動し、全ての切替方法602が選択されていればステップ806に移動する(ステップ805)。
切替方法決定部213は、切替レベルテーブル221より、最もレベル601が高く(値が大きい)、本処理にて一度も選択されていない切替方法602を選択する(ステップ802)。切替方法決定部213は、ステップ802において選択した切替方法602の所要時間603と、ステップ800で参照した業務の切替時間要件702を比較する(ステップ803)。
切替方法決定部213は、ステップ803の比較により切替時間要件702が所要時間603を上回らない場合、ステップ802で選択した切替方法602の実行によって業務がダウンしてもそれは業務要件を違反しないものとして判定し、切替方法決定部213の処理を終了する。切替時間要件702が所要時間603を上回る場合、当該切替方法は業務要件に対し利用できないと判定しステップ805に移動する(ステップ804)。ステップ806は、切替時間要件702を満足する切替方法602が無い場合の処理である。ステップ806では、所要時間603が最も早い切替方法602を選択する。
上記処理により、まず切り替え対象の業務に許される切替時間要件702と、切り替え先の予備系のサーバ装置110-Bが選択される。そして、ステップ802、803、804、805を切替レベルテーブル221のエントリの数だけ繰り返し行うことで、切替方法602(または切り替えパターン)の内、切替時間要件702を満たしかつ最もレベル601の値が大きい切替方法602を選択する。また、ステップ804でNOとなった回数が切替レベルテーブル221のエントリの数を超えた場合には、所要時間603が最も短い切替方法602を選択することができる。
図9は、切替情報テーブル群222の構成を示す説明図である。切替情報テーブル群222は、切替方法特徴テーブル900、制御対象レートテーブル901、資源解放レートテーブル902、業務再起動レートテーブル903を有する。切替情報テーブル群222は、切替レベルテーブル221のレベル601の判定に用いる。
図10は、切替方法特徴テーブル900の構成を示す説明図である。切替方法特徴テーブル900は、各切替方法(切り替えパターン)を実施する際の、予備のサーバ装置110-Bの動作の特徴、及び予備のサーバ装置110-B上で既に実行されている業務への影響に関する情報を保持する。切替方法特徴テーブル900はユーザなどが予め設定したテーブルである。
カラム(切替方法)1000は、サーバ装置110の切替方法を識別するための識別子である。具体的には、切替方法の名称、及びユーザ(またはシステム管理者)が定義した名称である。カラム1001は、レベル601が示す情報(本実施形態では安全度)の判定要素となる情報である。換言すれば、切替方法1000を実行する際に、予備のサーバ装置110-Bに指令する制御の内容を、制御の項目毎に設定したものである。
カラム1001は、サブカラム(制御の項目)として制御対象1010、資源確保方法1011、業務再起動1012を備える。制御対象1010は、切替方法(切り替えパターン)1000を実施する際の、制御命令の送信先となる、予備のサーバ装置110-B内の構成要素(OS、ハードウェア、仮想化システムなど)である。資源解放方法1011は、切替方法1000を実施する際の、現用のサーバ装置110-A上の業務を割り当てるために予備のサーバ装置110-Bの資源を解放する方法(サーバ装置停止、資源割当率変更など)を示す。業務再起動1012は、切替方法1000を実施する際に、予備のサーバ装置110-B上の業務の再起動の有無を示す。
図11は、制御対象レートテーブル901の構成を示す説明図である。制御対象レートテーブル901は、制御対象1010をレベル601が示す情報(本実施形態では安全度)に関連付けるための情報を示す。制御対象レートテーブル901はユーザなどが予め設定したテーブルである。
カラム1100は、制御対象レートテーブル901を制御対象1010と関連付けるための識別子である。カラム1101は、カラム1100間でレベル601が示す情報(本実施形態では安全度)を比較するための情報である。例えば、図11を例として用いると、ハードウェアに対して電源停止などの制御命令を送信する場合と比べて、OSや仮想化システムなどのソフトウェアにシャットダウンなどの制御命令を送信する場合の方が、ハードウェアの負担を低減できるため安全度が高い。なお、ハードウェアを強制的に電源停止させた場合、再度通電したときに管理サーバ装置100からサーバ装置110を認識できない場合などの不具合が発生することがある。このため、ハードウェアの電源を強制的に停止する手順を含む切り替えパターン(切り替え方法)の安全度を低く設定しておく。
図12は、資源解放レートテーブル902の構成を示す。資源解放レートテーブル902は、資源解放方法1011をレベル601が示す情報(本実施形態では安全度)に関連付けるための情報を示す。資源解放レートテーブル902はユーザなどが予め設定したテーブルである。
カラム1200は、資源解放レートテーブル902を資源解放方法1011と関連付けるための識別子である。カラム1201は、カラム1200間でレベル601が示す情報(本実施形態では安全度)を比較するための情報である。例えば、図12を例として用いると、予備のサーバ装置110-Bを停止し、予備のサーバ装置110-B全体を現用のサーバ装置110-A上の業務に割り当てる場合の方が、資源割当率を変更して予備のサーバ装置110-Bの一部を現用のサーバ装置110-A上の業務に割り当てる場合と比べて、必要な資源を用意できるため業務継続性の面で安全度が高い。
図13は、業務再起動レートテーブル903の構成を示す説明図である。業務再起動レートテーブル903は、業務再起動1012をレベル601が示す情報(本実施形態では安全度)に関連付けるための情報を示す。業務再起動レートテーブル903はユーザなどが予め設定したテーブルである。
カラム1300は、業務再起動レートテーブル903を業務再起動1012と関連付けるための識別子である。カラム1301は、カラム1300間でレベル601が示す情報(本実施形態では安全度)を比較するための情報である。例えば、図13を例として用いると、業務の再起動が必要な場合と比べて、業務再起動が不要な場合の方がデータ損失性の面で安全度が高い。
図14は、切替レベルテーブル生成部210で行われる処理の一例を示すフローチャートである。この処理は、図5の処理502で実行される。
切替レベルテーブル生成部210は、障害復旧管理部101が切替レベルテーブル221を生成する(処理502)際に動作する。切替レベルテーブル生成部210は、切替方法特徴テーブル900より切替方法1000を参照し、切替レベルテーブル221の切替方法602に追加する(ステップ1400)。
切替レベルテーブル生成部210は、ステップ1400で追加した切替方法の内、本処理にて一度も選択されていない選択方法があるか否かを判定し、一度も選択されていない選択方法がある場合はステップ1402へ進み、無い場合は処理を終了する(ステップ1401)。なお、切替レベルテーブル221には、図示しないフラグなどを設けておき、切替方法602が選択されたときにフラグをセットすることで、上記判定を行うようにすればよい。
切替レベルテーブル生成部210は、切替レベルテーブル221の切替方法602のうち本処理にて一度も選択されていない切替方法を1つ選択する(ステップ1402)。切替レベルテーブル生成部210は、ステップ1402にて選択した切替方法602のレベルを決定し、切替レベルテーブル221の該当するレコードのレベル601に追加する(ステップ1403)。ステップ1403の詳細な処理フローチャートは図15に示す。
切替レベルテーブル生成部210は、ステップ1402にて選択した切替方法602の所要時間を決定し、切替レベルテーブル221の該当するレコードのレベル601に追加し、ステップ1401に移動する(ステップ1404)。ステップ1404の詳細な処理フローチャートは図17に示す。
図15は、図14に示したステップ1403の、切替方法602のレベル601を決定する処理のフローチャートを示す。ステップ1500では、選択した切替方法602に対応する制御対象1010を図10の切替方法特徴テーブル900より読み込んで、図11に示した制御対象レートテーブル901のレート1101を参照する。
ステップ1501では、選択した切替方法602に対応する資源解放方法1011を図10の切替方法特徴テーブル900より読み込んで、資源解放レートテーブル902のレート1201を参照する。
ステップ1502では、選択した切替方法602の業務再起動1012を図10の切替方法特徴テーブル900より読み込んで、業務再起動レートテーブル903のレート1301を参照する。
ステップ1503では、ステップ1500、ステップ1501、ステップ1502で参照した情報より切替レベルテーブル221のレベル601を決定する。尚、本実施形態ではステップ1502の決定方法を、レート1101、レート1201、レート1301の和として説明するが、最も高いレートの値や、切替レベルテーブル221における順位(例えば、前記和の値が切替レベルテーブル221において2番目に高い場合は2)など、別の決定方法を用いてもよい。
図16は、図14に示したステップ1404の、選択した切替方法602の所要時間603を決定する処理のフローチャートを示す。ステップ1600では、ログ管理部233から上記選択した切替方法602の開始、終了といった実行履歴を示すイベントログ情報を参照する。
ステップ1601では、ステップ1600で参照したイベントログ情報より、所要時間を決定する。尚、本実施形態ではステップ1601の決定方法を、ステップ1404にて選択した切替方法602(切り替えパターン)に関する直近の終了時刻と開始時刻の差として説明するが、過去N回分の実施に関する差の最悪値や平均値など、別の決定方法を用いてもよい。尚、イベントログ情報からの切替方法602(切り替えパターン)に関する情報の取得は、ステップ1404にて選択した切替方法の識別子と、イベントログ情報に含まれる切替方法602(切り替えパターン)の識別子の比較によって行うこととする。
図17は、障害復旧管理部101が、ユーザに切替レベルテーブル221の内容を設定させるために提供するUI(User Interface)の例として、GUI(Graphical User Interface)の例を示す。このGUIは、管理サーバ装置100に接続した出力装置151や、管理サーバ装置100にネットワークスイッチ130を介して接続された他の端末の表示装置等にブラウザや専用のプログラム、及びテキストなどを用いて表示する。
切替レベル情報設定ウィンドウ1700には、切替レベル情報と、操作のためのボタン等が表示される。ウィンドウ1700に表示される切替レベル情報は、切替レベルテーブル221の内容に基づいている。
レベル1701には、レベル601の情報が表示される。切替方法1702には、切替方法602の情報が表示される。所要時間1703には、カラム603の情報が表示される。ユーザは、レベル1701、所要時間1703に値を入力する。ユーザは、設定を更新する場合、ボタン1704をクリックし、キャンセルする場合はボタン1705をクリックする。ボタン1704をクリックすると、障害復旧管理部101は、レベル1701、所要時間1703に入力された情報を切替レベルテーブル221に反映する。
図18は、障害復旧管理部101が、ユーザに業務要件テーブル220の内容を設定させるために提供するUI(User Interface)の例として、GUI(Graphical User Interface)の例を示す。このGUIは、管理サーバ装置100に接続した出力装置151や、管理サーバ装置100にネットワークスイッチ130を介して接続された他の端末の表示装置等にブラウザや専用のプログラム、及びテキストなどを用いて表示する。
業務要件情報設定ウィンドウ1800には、業務要件情報と、操作のためのボタン等が表示される。ウィンドウ1800に表示される業務要件情報は、業務要件テーブル220の内容に基づいている。業務1801には、カラム701の情報が表示される。切替時間要件1802には、カラム702の情報が表示される。ユーザは切替時間要件1802に値を入力する。ユーザは、設定を更新する場合、ボタン1803をクリックし、キャンセルする場合はボタン1804をクリックする。ボタン1803をクリックすると、障害復旧管理部101は、切替時間要件1802に入力された情報を業務要件テーブル220に反映する。
図19は、切替実行部212で行われる処理の一例を示すフローチャートである。切替実行部212は、切替方法選択(図5の処理512)の際に、切替方法決定部213の処理の後に、障害復旧管理部101によって動作が開始される。
切替実行部212は、切替方法決定部213で決定された切替方法を障害復旧管理部101より受け取る(ステップ1900)。切替実行部212は、ステップ1900で受け取った切替方法に基づいて、現用及び予備のサーバ装置110を制御する(ステップ1901)。例えば、受け取った切替方法が強制電源停止の場合、予備のサーバ装置110-Bのハードウェアに対し電源停止命令を送信し、電源停止を判定した後、現用のサーバ装置110-Aの系切替を実施する。
本実施形態によれば、障害復旧管理部101は、サーバ切替時に予備のサーバ装置110-Bを可能な限り安全に停止させるためのサーバの切替方法(切替手順)をレベルに応じて決定し、決定した切替方法に基づいてサーバ切替を実施することで業務の復旧が可能となる。サーバ装置110の切り替え時には、予備系が現用系を引き継ぐまでの制約である業務要件を満たし、かつ、予備系のサーバ装置110-Bを可能な限り安全に停止させることが可能となり、予備系のサーバ装置110-Bで実行していた業務(開発やテスト)のデータが破損するのを防ぐことができる。
以上のように、本実施形態によれば、サーバ切替時に予備系のサーバ装置を可能な限り安全に停止させるサーバの切替パターンを決定することができる。すなわち、予備のサーバ装置110-Bで開発やテストなどの業務を実行することで、計算機システムのリソースを有効に活用しながら、現用のサーバ装置110-Aに障害が発生したときには、予備のサーバ装置110-Bで実行していた業務に与える影響を最小にしながら、所定の業務条件を満たして現用系から予備系に切り替えを実施することが可能となる。
<第2の実施形態>
前記第1の実施形態では、切替方法毎のレベル601と切替対象となる業務の要件から切替方法を選択するステップを含む切替方法について述べた。本第2の実施形態では、現用のサーバ装置110-Aで発生した障害の内容を考慮して切替方法を選択するステップを含む切替方法について述べる。本実施形態では、障害制約テーブル223を新たに用いる。その他の構成については、前記第1の実施形態と同じであり、それらの構成、ステップの説明は省略する。
図20は、障害制約テーブル223の構成を示す。障害制約テーブル223は、図2のテーブル群102に含まれ、現用のサーバ装置110-A(また、その上で稼動するOS311や仮想化システム400など)で発生した障害内容(障害要因)に対する、切替方法決定の際の制約(例えば、CPU(プロセッサ)に温度障害が発生した場合は、仮想サーバマイグレーションなどCPUを酷使する移動手段を多用しない、など)を示す。カラム2000は、障害内容を識別するための識別子である。具体的には、ユーザ(またはサーバ管理者)が定義した名称である。カラム2001は、障害が切替方法の決定に与える制約の内容を示す。図20を例とすると、ネットワークアダプタ障害が発生しネットワーク帯域が低下した場合は、仮想サーバマイグレーションなどネットワーク負荷の大きい切替方法は実施しないよう切替方法を決定する。
なお、障害要因の特定は、管理サーバ装置100がサーバ装置110のBMCやOS等から取得したログや通知に基づいて行うことができる。障害要因の特定については、公知または周知の技術を用いることができる。
図21は、本第2の実施形態の切替方法決定部213の処理フローチャートを示す。図21は、前記第1の実施形態の図8に示した切替方法決定部213を本実施形態のために変更した処理である。図21が図8と異なる箇所は、ステップ2105、ステップ2106の追加である。その他のステップは、前記第1の実施形態の図8と同じである。
切替方法決定部213は、管理サーバ装置100が受信した現用のサーバ装置110-Aの障害情報より、障害制約テーブル223の障害内容2000を参照する(ステップ2105)。切替方法決定部213は、ステップ2102で選択した切替方法を実行することによって、ステップ2105で取得した制約に違反しない否かを判定する(ステップ2106)。一方、取得した制約に違反するならば、ステップ2102に移動する。
本実施形態によれば、障害復旧管理部101は、現用のサーバ装置110-Aに発生した障害の内容を考慮し、サーバ装置110の切替方法を決定することができる。その結果、サーバ装置110の切替方法が障害を誘発することや、障害によりサーバ装置110の切替に必要な資源が使用できず切替失敗となるなどの問題を回避することができる。
<第3の実施形態>
本第3の実施形態では、特徴的な切替方法として現用のサーバ装置110-Aの障害予兆検出に基づいた切替方法について述べる。図22では、本第3実施形態における、現用のサーバ装置110-A、予備のサーバ装置110-B、及び管理サーバ装置100間の処理シーケンスの例を示す。なお、図22の処理は、前記第1の実施形態の図5に示した処理500~502に加えて実行される。その他の構成については、前記第1の実施形態と同じであり、それらの構成、ステップの説明は省略する。
管理サーバ装置100は、サーバ管理部200の障害管理部230、ログ管理部233の情報に基づいて、障害予兆情報テーブル224を生成する(処理2207)。
現用のサーバ装置110は、サーバ装置110、その上で動作するOS311または仮想化システム400に関する警告情報(例えば、CPU温度上昇、ファン回転上昇、メモリコレクトエラー、リソース逼迫など)を管理サーバ装置100に送信する(処理2200)。なお、処理2200は、所定の周期毎に繰り返して実行される。
管理サーバ装置100は、現用のサーバ装置110-Aから送信された警告情報を受信し、その内容より現用のサーバ装置110-Aの障害予兆を検出する(処理2201)。管理サーバ装置100は、現用のサーバ装置110-Aの障害予兆を検出すると予備のサーバ装置110-Bに対して停止命令(OSシャットダウンなど)を送信する(処理2202)。予備のサーバ装置110-Bは、管理サーバ装置100から停止命令を受信するとその内容に基づいてサーバ装置110-Bを停止する(処理2203)。
その後、現用のサーバ装置110-Aが障害発生により停止すると、管理サーバ装置100は、現用のサーバ装置110-Aの障害を検知する(処理2204)。管理サーバ装置100は、障害検知後に、現用のサーバ装置110-Aから予備のサーバ装置110-Bへの切替を開始する(処理2205)。現用及び予備のサーバ装置110は、管理サーバ装置100からの要求に対し切替を実施する(処理2206)。
図23は、障害予兆情報テーブル224の構成を示す説明図である。障害予兆情報テーブル224は、後述の障害予兆情報テーブル生成部214によって生成され、障害復旧管理部101が、サーバ装置110の障害予兆を判定するための情報を保持する。カラム2300は、サーバ装置110の障害予兆に関する情報を示す。図23を例とすると、現用のサーバ装置110-AよりCPU温度警告に関する状態情報を、管理サーバ装置100が受信した場合、障害復旧管理部101は現用のサーバ装置110-Aに、今後障害が発生し停止すると判定する。
図24は、障害予兆情報テーブル生成部214で行われる処理の一例を示すフローチャートである。障害予兆情報テーブル生成部214は、障害復旧管理部101が障害予兆情報を生成する(処理2207)際に動作する。
障害予兆情報テーブル生成部214は、ログ管理部233より過去の現用のサーバ装置110-Aについて警告情報及び障害情報を参照する(ステップ2400)。障害予兆情報テーブル生成部214は、ステップ2400で参照した警告情報及び障害情報を関連付ける(ステップ2401)。
この関連付けは、直接的な関連がある部位(例えば、CPU(プロセッサ)の障害情報とCPU(プロセッサの)警告情報は関連がある)、間接的な関連がある部位(例えば、CPUの警告情報が発生すると、その関連部位であるOS、仮想化システム、アプリケーションの性能障害などが発生する可能性がある)、受信時刻(例えば、受信時刻が近いほど関連がある)などより行う。
障害予兆情報テーブル生成部214は、ステップ2401により障害情報に関連する警告情報があるか否かを判定し、障害情報に関連する警告情報がある場合はステップ2403へ進み、無い場合は処理を終了する(ステップ2402)。障害予兆情報テーブル生成部214は、ステップ2401により障害情報に関連する警告情報を、障害予兆情報テーブルに追加してステップ2402に移動する(ステップ2403)。
図25は、障害復旧管理部101が、ユーザに障害予兆情報テーブル224の内容を設定させるために提供するUI(User Interface)の例として、GUI(Graphical User Interface)の例を示す。このGUIは、管理サーバ装置100に接続した出力装置151や、管理サーバ装置100にネットワークスイッチ130を介して接続された他の端末の表示装置等にブラウザや専用のプログラム、及びテキストなどを用いて表示する。
障害予兆情報設定ウィンドウ2500には、障害予兆情報と、操作のためのボタン等が表示される。ウィンドウ2500に表示される障害予兆情報は、障害予兆情報テーブル224の内容に基づいている。障害予兆2501には、カラム2300の情報が表示される。ユーザは、2501に、管理サーバ装置100が備える、サーバ装置110の状態に関する情報より、障害予兆として扱う情報を選択することができる。ユーザは、新しい障害予兆2501を追加する場合、ボタン2505をクリックする。ユーザは、既存の障害予兆2501を削除する場合、ボタン2502をクリックする。ユーザは、設定を更新する場合、ボタン2503をクリックし、キャンセルする場合はボタン2504をクリックする。ボタン2503をクリックすると、障害復旧管理部101は、切替時間要件2501に入力された情報を障害予兆情報テーブル224に反映する。
本実施形態によれば、現用のサーバ装置の障害予兆を検出し事前に予備のサーバ装置を停止させることで、サーバ切替時に予備のサーバ装置で稼動する業務への影響を抑えることができる。すなわち、障害復旧管理部101は、現用のサーバ装置110―Aの障害予兆を検出して、実際に障害が発生する前に予備のサーバ装置110-Bを停止させることができる。その結果、障害発生による現用サーバ装置110-A及び予備サーバ装置110-Bの強制停止、及び強制停止による予備サーバ装置110-B上のデータの破損などの問題を回避することができる。
以上、本発明を添付の図面を参照して詳細に説明したが、本発明はこのような具体的構成に限定されるものではなく、添付した請求の範囲の趣旨内における様々な変更及び同等の構成を含むものである。
以上のように、本発明は、現用系のサーバに障害が発生したときに予備系のサーバに切り替える計算機システムや、管理サーバに適用することができる。特に、予備系のサーバにテストやシステム開発などの業務を割り当てて、計算機システムの計算資源を有効活用する計算機システムに好適である。
Claims (15)
- 第1の業務を提供する第1のアプリケーションサーバと、第2の業務を提供する第2のアプリケーションサーバと、前記第1のアプリケーションサーバ及び第2のアプリケーションサーバに接続された管理計算機が、前記第1のアプリケーションサーバで提供される第1の業務を、前記第2のアプリケーションサーバに引き継がせるアプリケーションサーバの切り替え方法であって、
前記管理計算機が、前記第1の業務を第2のアプリケーションサーバへ切り替える際の切替パターンが設定された切替レベル情報を参照し、前記切替パターン毎に安全度のレベルを設定する第1のステップと、
前記管理計算機が、前記切替レベル情報を参照し、前記切替パターン毎に前記第1の業務を第2のアプリケーションサーバへ切り替えるために必要な切替時間を設定する第2のステップと、
前記管理計算機が、前記第1の業務を第2のアプリケーションサーバへ切り替える際に許容された停止時間が前記第1の業務毎に設定された業務要件情報を参照する第3のステップと、
前記管理計算機が、前記参照した第1の業務に設定された業務要件情報の停止時間と、前記切替レベル情報の前記切替パターンに設定された前記切替時間とを比較し、前記第1の業務に設定された前記業務要件情報の停止時間より短く、かつ、前記切替レベル情報の前記切替パターンのうち前記安全度のレベルが最も高い切替パターンを選択する第4のステップと、
前記管理計算機が、前記選択された切替パターンで、前記第2のアプリケーションサーバの第2の業務を停止させた後、前記第1の業務を前記第2のアプリケーションサーバで提供する第5のステップと、
を含むことを特徴とするアプリケーションサーバの切替方法。 - 請求項1に記載のアプリケーションサーバの切替方法であって、
前記第1のステップでは、前記管理計算機は、前記切替レベル情報の切替パターン毎に設定された前記第2のアプリケーションサーバに対する複数の制御項目と前記制御項目毎の数値情報が設定された切替特徴情報を参照し、前記安全度のレベルを算出するための前記数値情報を前記制御項目毎に取得し、前記切替パターンに含まれる前記制御項目の数値情報から当該切替パターンの安全度のレベルを設定し、
前記第2のステップでは、前記管理計算機は、前記切替パターン毎の過去に切り替えに要した時間の実績を格納したログ情報を参照して、前記切替時間を設定することを特徴とするアプリケーションサーバの切替方法。 - 請求項1に記載のアプリケーションサーバの切替方法であって、
前記管理計算機が、前記第1のアプリケーションサーバの障害を検知する第6のステップをさらに含み、
前記第1のアプリケーションサーバの障害の検知を契機に、前記第3のステップ、第4のステップ及び第5のステップを行うことを特徴とするアプリケーションサーバの切替方法。 - 請求項3に記載のアプリケーションサーバの切替方法であって、
前記第4のステップでは、前記管理計算機は、前記第1のアプリケーションサーバの障害要因を特定し、障害要因毎に制限すべき切替パターンが設定された障害制約情報を参照して、前記特定された障害要因に対応する制限すべき切替パターンを取得して、前記切替レベル情報の切替パターンに設定された前記切替時間が、前記第1の業務に設定された前記業務要件情報の停止時間より短く、かつ、前記制限すべき切替パターン以外の切替パターンのうち、前記切替レベル情報の安全レベルが最も高い前記切替パターンを選択することを特徴とするアプリケーションサーバの切替方法。 - 請求項1に記載のアプリケーションサーバの切替方法であって、
前記管理計算機が、前記第1のアプリケーションサーバの障害の予兆を検知する第7のステップをさらに含み、
前記第1のアプリケーションサーバの障害の予兆の検知を契機に、前記第3のステップ、第4のステップ及び第5のステップを行うことを特徴とするアプリケーションサーバの切替方法。 - プロセッサと、メモリとを有し、第1の業務を提供する第1のアプリケーションサーバと第2の業務を提供する第2のアプリケーションサーバとに接続されて、前記第1のアプリケーションサーバで提供される第1の業務を、前記第2のアプリケーションサーバに引き継がせる障害復旧部を備えた管理計算機であって、
前記障害復旧部は、
前記第1の業務を第2のアプリケーションサーバへ切り替える際の切替パターンと、前記切替パターン毎の安全度のレベルと、前記切替パターン毎に前記第1の業務を第2のアプリケーションサーバへ切り替えるために必要な切替時間とを設定する切替レベル情報生成部と、
前記第1の業務を第2のアプリケーションサーバへ切り替える際に許容された停止時間を予め設定した業務要件情報と、
前記参照した第1の業務に設定された業務要件情報の停止時間と、前記切替レベル情報の前記切替パターンに設定された前記切替時間とを比較し、前記第1の業務に設定された前記業務要件情報の停止時間より短く、かつ、前記切替レベル情報の前記切替パターンのうち前記安全度のレベルが最も高い切替パターンを選択する切り替えパターン選択部と、
前記選択された切替パターンで、前記第2のアプリケーションサーバの第2の業務を停止させた後、前記第1の業務を前記第2のアプリケーションサーバで提供させるための切り替え実行部と、
を備えたことを特徴とする管理計算機。 - 請求項6に記載の管理計算機であって、
前記切替レベル情報生成部は、
前記切替レベル情報の切替パターン毎に設定された前記第2のアプリケーションサーバに対する複数の制御項目と前記制御項目毎の数値情報が設定された切替特徴情報を参照し、前記安全度のレベルを算出するための前記数値情報を前記制御項目毎に取得し、
前記切替パターンに含まれる前記制御項目の数値情報から当該切替パターンのレベルを設定し、
前記切替パターン毎の過去に切り替えに要した時間の実績を格納したログ情報を参照して、前記切替時間を設定することを特徴とする管理計算機。 - 請求項6に記載の管理計算機であって、
前記第1のアプリケーションサーバの障害を検知する障害管理部をさらに有し、
前記切り替えパターン選択部は、障害管理部が前記第1のアプリケーションサーバの障害の検知を契機に、前記切り替えパターンを選択することを特徴とする管理計算機。 - 請求項8に記載の管理計算機であって、
前記切り替えパターン選択部は、
前記障害管理部が検知した前記第1のアプリケーションサーバの障害要因を特定し、
障害要因毎に制限すべき切替パターンが設定された障害制約情報を参照して、前記特定された障害要因に対応する制限すべき切替パターンを取得して、
前記切替レベル情報の切替パターンに設定された前記切替時間が、前記第1の業務に設定された前記業務要件情報の停止時間より短く、かつ、前記制限すべき切替パターン以外の切替パターンのうち、前記切替レベル情報の安全レベルが最も高い前記切替パターンを選択することを特徴とする管理計算機。 - 請求項8に記載の管理計算機であって、
前記第1のアプリケーションサーバの障害の予兆を検知する障害管理部をさらに有し、
前記切り替えパターン選択部は、障害管理部が前記第1のアプリケーションサーバの障害の予兆の検知を契機に、前記切り替えパターンを選択することを特徴とする管理計算機。 - 第1の業務を提供する第1のアプリケーションサーバと、第2の業務を提供する第2のアプリケーションサーバと、前記第1のアプリケーションサーバ及び第2のアプリケーションサーバに接続されて、プロセッサとメモリを備えた管理計算機を制御するプログラムが格納された記憶媒体であって、
前記第1の業務を第2のアプリケーションサーバへ切り替える際の切替パターンが設定された切替レベル情報を参照し、前記切替パターン毎に安全度のレベルを設定する第1の手順と、
前記切替レベル情報を参照し、前記切替パターン毎に前記第1の業務を第2のアプリケーションサーバへ切り替えるために必要な切替時間を設定する第2の手順と、
前記第1の業務を第2のアプリケーションサーバへ切り替える際に許容された停止時間が前記第1の業務毎に設定された業務要件情報を参照する第3の手順と、
前記参照した第1の業務に設定された業務要件情報の停止時間と、前記切替レベル情報の前記切替パターンに設定された前記切替時間とを比較し、前記第1の業務に設定された前記業務要件情報の停止時間より短く、かつ、前記切替レベル情報のレベルが最も高い切替パターンを選択する第4の手順と、
前記選択された切替パターンで、前記第2のアプリケーションサーバの第2の業務を停止させた後、前記第1の業務を前記第2のアプリケーションサーバで提供させる第5の手順と、
を前記プロセッサに実行させることを特徴とする記憶媒体。 - 請求項11に記載のプログラムが格納された記憶媒体であって、
前記第1の手順では、前記切替レベル情報の切替パターン毎に設定された前記第2のアプリケーションサーバに対する複数の制御項目と前記制御項目毎の数値情報が設定された切替特徴情報を参照し、前記安全度のレベルを算出するための前記数値情報を前記制御項目毎に取得し、前記切替パターンに含まれる前記制御項目の数値情報から当該切替パターンのレベルを設定し、
前記第2の手順では、前記切替パターン毎に切り替えに要した時間の過去の実績を格納したログ情報を参照して、前記切替時間を設定することを特徴とする記憶媒体。 - 請求項11に記載のプログラムが格納された記憶媒体であって、
前記第1のアプリケーションサーバの障害を検知する第6の手順をさらに含み、
前記第1のアプリケーションサーバの障害の検知を契機に、前記第3の手順、第4の手順及び第5の手順を行うことを特徴とする記憶媒体。 - 請求項13に記載のプログラムが格納された記憶媒体であって、
前記第4の手順は、
前記第1のアプリケーションサーバの障害要因を特定し、障害要因毎に制限すべき切替パターンが設定された障害制約情報を参照して、前記特定された障害要因に対応する制限すべき切替パターンを取得して、前記切替レベル情報の切替パターンに設定された前記切替時間が、前記第1の業務に設定された前記業務要件情報の停止時間より短く、かつ、前記制限すべき切替パターン以外の切替パターンのうち、前記切替レベル情報の安全レベルが最も高い前記切替パターンを選択することを特徴とする記憶媒体。 - 請求項11に記載のプログラムが格納された記憶媒体であって、
前記第1のアプリケーションサーバの障害の予兆を検知する第7の手順をさらに含み、
前記第1のアプリケーションサーバの障害の予兆の検知を契機に、前記第3の手順、第4の手順及び第5の手順を行うことを特徴とする記憶媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/695,050 US8880936B2 (en) | 2010-05-28 | 2010-08-26 | Method for switching application server, management computer, and storage medium storing program |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010122884A JP5305040B2 (ja) | 2010-05-28 | 2010-05-28 | サーバ計算機の切替方法、管理計算機及びプログラム |
| JP2010-122884 | 2010-05-28 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2011148524A1 true WO2011148524A1 (ja) | 2011-12-01 |
Family
ID=45003528
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2010/064460 WO2011148524A1 (ja) | 2010-05-28 | 2010-08-26 | アプリケーションサーバの切替方法、管理計算機及びプログラムを格納した記憶媒体 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US8880936B2 (ja) |
| JP (1) | JP5305040B2 (ja) |
| WO (1) | WO2011148524A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9317394B2 (en) | 2011-12-19 | 2016-04-19 | Fujitsu Limited | Storage medium and information processing apparatus and method with failure prediction |
| US20240036989A1 (en) * | 2022-07-27 | 2024-02-01 | Hitachi, Ltd. | Storage system and management method |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013105926A1 (en) | 2011-03-22 | 2013-07-18 | Aerovironment Inc. | Invertible aircraft |
| US8667340B2 (en) * | 2011-03-29 | 2014-03-04 | Hewlett-Packard Development Company, L.P. | Method and system for distributed processing of alerts |
| US20120259956A1 (en) * | 2011-04-07 | 2012-10-11 | Infosys Technologies, Ltd. | System and method for implementing a dynamic change in server operating condition in a secured server network |
| JP2013156963A (ja) * | 2012-01-31 | 2013-08-15 | Fujitsu Ltd | 制御プログラム、制御方法、情報処理装置、制御システム |
| JP5983746B2 (ja) * | 2012-07-05 | 2016-09-06 | 富士通株式会社 | 処理装置、処理システム、及びプログラム |
| US20150234720A1 (en) * | 2012-09-27 | 2015-08-20 | Nec Corporation | Standby system device, active system device, and load dispersion method |
| JP6179119B2 (ja) * | 2013-02-19 | 2017-08-16 | 日本電気株式会社 | 管理装置、管理方法、及び管理プログラム |
| KR101444783B1 (ko) | 2013-05-16 | 2014-09-26 | 국방과학연구소 | 시스템 가용성 향상을 위한 시스템 운용 방법 |
| CN104898435B (zh) * | 2015-04-13 | 2019-01-15 | 惠州Tcl移动通信有限公司 | 家庭服务系统及其故障处理方法、家电设备、服务器 |
| US11429398B2 (en) | 2017-06-14 | 2022-08-30 | Nec Corporation | Change procedure generation device, change procedure generation method, and change procedure generation program |
| JP2019008548A (ja) * | 2017-06-23 | 2019-01-17 | 三菱電機株式会社 | 切替管理装置、監視制御システム、切替管理方法および切替管理プログラム |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1125023A (ja) * | 1997-07-08 | 1999-01-29 | Yokogawa Electric Corp | 協調自律分散システム |
| JPH1185555A (ja) * | 1997-09-10 | 1999-03-30 | Mitsubishi Electric Corp | コールドスタンバイ型二重系システム |
| JP2004030363A (ja) * | 2002-06-27 | 2004-01-29 | Hitachi Ltd | 論理計算機システム、論理計算機システムの構成制御方法および論理計算機システムの構成制御プログラム |
| JP2007207219A (ja) * | 2006-01-06 | 2007-08-16 | Hitachi Ltd | 計算機システムの管理方法、管理サーバ、計算機システム及びプログラム |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7496794B1 (en) * | 2006-01-13 | 2009-02-24 | Network Appliance, Inc. | Creating lightweight fault analysis records |
| JP5032191B2 (ja) * | 2007-04-20 | 2012-09-26 | 株式会社日立製作所 | サーバ仮想化環境におけるクラスタシステム構成方法及びクラスタシステム |
| US7698598B1 (en) * | 2007-04-24 | 2010-04-13 | Netapp, Inc. | Automatic generation of core files and automatic generation of support information with generation of core files |
| JP5286942B2 (ja) * | 2008-05-30 | 2013-09-11 | 富士通株式会社 | 制御方法、制御プログラム及び情報処理装置 |
-
2010
- 2010-05-28 JP JP2010122884A patent/JP5305040B2/ja not_active Expired - Fee Related
- 2010-08-26 WO PCT/JP2010/064460 patent/WO2011148524A1/ja active Application Filing
- 2010-08-26 US US13/695,050 patent/US8880936B2/en not_active Expired - Fee Related
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1125023A (ja) * | 1997-07-08 | 1999-01-29 | Yokogawa Electric Corp | 協調自律分散システム |
| JPH1185555A (ja) * | 1997-09-10 | 1999-03-30 | Mitsubishi Electric Corp | コールドスタンバイ型二重系システム |
| JP2004030363A (ja) * | 2002-06-27 | 2004-01-29 | Hitachi Ltd | 論理計算機システム、論理計算機システムの構成制御方法および論理計算機システムの構成制御プログラム |
| JP2007207219A (ja) * | 2006-01-06 | 2007-08-16 | Hitachi Ltd | 計算機システムの管理方法、管理サーバ、計算機システム及びプログラム |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9317394B2 (en) | 2011-12-19 | 2016-04-19 | Fujitsu Limited | Storage medium and information processing apparatus and method with failure prediction |
| US20240036989A1 (en) * | 2022-07-27 | 2024-02-01 | Hitachi, Ltd. | Storage system and management method |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2011248735A (ja) | 2011-12-08 |
| US8880936B2 (en) | 2014-11-04 |
| US20130138998A1 (en) | 2013-05-30 |
| JP5305040B2 (ja) | 2013-10-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5305040B2 (ja) | サーバ計算機の切替方法、管理計算機及びプログラム | |
| US7802127B2 (en) | Method and computer system for failover | |
| US8156490B2 (en) | Dynamic migration of virtual machine computer programs upon satisfaction of conditions | |
| EP2972870B1 (en) | Coordinating fault recovery in a distributed system | |
| JP5851503B2 (ja) | 高可用性仮想機械環境におけるアプリケーションの高可用性の提供 | |
| JP5074274B2 (ja) | 計算機システム及び通信経路の監視方法 | |
| US7992032B2 (en) | Cluster system and failover method for cluster system | |
| WO2011074284A1 (ja) | 仮想計算機の移動方法、仮想計算機システム及びプログラムを格納した記憶媒体 | |
| JP4572250B2 (ja) | 計算機切り替え方法、計算機切り替えプログラム及び計算機システム | |
| JP2010244524A (ja) | 仮想サーバの移動方法の決定方法及びその管理サーバ | |
| US20200150946A1 (en) | System and method for the dynamic expansion of a cluster with co nodes before upgrade | |
| EP2518627B1 (en) | Partial fault processing method in computer system | |
| JP2007207219A (ja) | 計算機システムの管理方法、管理サーバ、計算機システム及びプログラム | |
| WO2012004902A1 (ja) | 計算機システム及び計算機システムの系切替制御方法 | |
| WO2012168995A1 (ja) | I/oスイッチの制御方法、仮想計算機の制御方法及び計算機システム | |
| WO2013190694A1 (ja) | 計算機の復旧方法、計算機システム及び記憶媒体 | |
| JP5998577B2 (ja) | クラスタ監視装置、クラスタ監視方法、及びプログラム | |
| JP5316616B2 (ja) | 業務引き継ぎ方法、計算機システム、及び管理サーバ | |
| WO2022009438A1 (ja) | サーバメンテナンス制御装置、システム、制御方法及びプログラム | |
| JP4883492B2 (ja) | 仮想マシン管理システムおよび計算機、並びに、プログラム | |
| JP2015095151A (ja) | 起動制御プログラム、装置、及び方法 | |
| JP4877368B2 (ja) | ディスク引き継ぎによるフェイルオーバ方法 | |
| US20140040447A1 (en) | Management system and program product |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 10852190 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 13695050 Country of ref document: US |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 10852190 Country of ref document: EP Kind code of ref document: A1 |