WO2010131318A1 - Video-sound output device and method for localizing sound - Google Patents
Video-sound output device and method for localizing sound Download PDFInfo
- Publication number
- WO2010131318A1 WO2010131318A1 PCT/JP2009/058744 JP2009058744W WO2010131318A1 WO 2010131318 A1 WO2010131318 A1 WO 2010131318A1 JP 2009058744 W JP2009058744 W JP 2009058744W WO 2010131318 A1 WO2010131318 A1 WO 2010131318A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- speaker
- voice
- video
- background sound
- sound
- Prior art date
Links
Images















Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N7/00—Television systems
- H04N7/14—Systems for two-way working
- H04N7/141—Systems for two-way working between two video terminals, e.g. videophone
- H04N7/147—Communication arrangements, e.g. identifying the communication as a video-communication, intermediate storage of the signals
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/439—Processing of audio elementary streams
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/44—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream, rendering scenes according to MPEG-4 scene graphs
- H04N21/44008—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream, rendering scenes according to MPEG-4 scene graphs involving operations for analysing video streams, e.g. detecting features or characteristics in the video stream
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Stereophonic System (AREA)
Abstract
A video-sound output device (1) is provided with a video analysis unit (11) that analyzes a video image to specify the position of a speaker, a sound separation unit (12) that separates a mixed speaker and background sound into a speaker sound and a background sound, and a localization unit (13) localizes the speaker sound separated by the sound separation unit (12) to the speaker position specified by the audio-sound analysis unit (11).
Description
本発明は、映像及び音声を含むコンテンツデータを出力する映像音声出力装置の音声定位技術に関し、特に、話者位置に応じた音声定位を行う音声定位技術に関する。音声定位技術に関する。
The present invention relates to an audio localization technology for a video / audio output device that outputs content data including video and audio, and more particularly, to an audio localization technology for performing audio localization according to a speaker position. Related to sound localization technology.
テレビ放送などの番組コンテンツを受信して、ディスプレイに映像を表示するとともにスピーカから音声を出力する場合、モノラル音声においてはスピーカの位置から人の声が聞こえるようになっている。また、ステレオ/サラウンド音声においては、多くの場合、画面中央に人の声を定位させて、画面中央から人の声が聞こえるようになっている。
When receiving program content such as TV broadcast, displaying video on a display and outputting sound from a speaker, in monaural sound, a human voice can be heard from the position of the speaker. In stereo / surround sound, in many cases, a human voice is localized at the center of the screen so that the human voice can be heard from the center of the screen.
しかしながら、一般に、ディスプレイ上の話者位置に人の声が定位していると臨場感が増すことが知られているため、従来においては、映像解析により話者位置を特定し、話者位置に音声を定位させる音声定位技術が開示されている。
However, since it is generally known that the presence of a person's voice is localized at the speaker position on the display, it is known that the sense of presence increases. An audio localization technique for localizing audio is disclosed.
例えば、特許文献1では、話者の位置を検出し、検出した位置に応じて、複数のスピーカから出力する音声の音量を制御している。また、特許文献2では、発話者の位置を特定し、特定した位置に応じて、エフェクトや音量調整を行い、最適なスピーカから音声データを出力している。
For example, in Patent Document 1, the position of a speaker is detected, and the volume of sound output from a plurality of speakers is controlled according to the detected position. Moreover, in patent document 2, the position of a speaker is specified, an effect and volume adjustment are performed according to the specified position, and audio | speech data is output from the optimal speaker.
しかしながら、上述した特許文献1においては、シーンの内容を考慮せずに、話者位置に音声を定位させているため、シーンによっては、臨場感を高めるどころか、却ってストレスを感じてしまう場合がある。例えば、効果音やBGMなどの背景音が流れるシーンにおいても、効果音やBGMなどの背景音を話者位置から出力するため、当該シーンを視聴している視聴者は、却ってストレスを感じてしまうという問題がある。また、特許文献2においては、背景音を話者音声と背景音が別の音声チャンネルに収録されている場合には、話者音声のみを話者位置に定位させることができるが、話者音声と背景音が同じ音声チャンネルに収録されている場合には、話者音声のみを話者位置に定位させることができず、却って違和感を生じるという問題がある。
However, in Patent Document 1 described above, since the sound is localized at the speaker position without considering the contents of the scene, depending on the scene, there is a case where stress is felt instead of enhancing the sense of reality. . For example, even in a scene where background sounds such as sound effects and BGM flow, since background sounds such as sound effects and BGM are output from the speaker position, viewers who watch the scene feel stress on the contrary. There is a problem. Further, in Patent Document 2, when the background sound is recorded in different audio channels, the speaker sound can be localized at the speaker position. When the background sound and the background sound are recorded on the same audio channel, there is a problem in that only the speaker's voice cannot be localized at the speaker position, which causes a sense of incongruity.
本発明は上記の事情を鑑みてなされたものであり、その課題の一例としては、話者音声と背景音が同一音声チャンネルに収録されていても、違和感を生じない音声定位技術を提供することにある。
The present invention has been made in view of the above circumstances, and an example of the problem is to provide a sound localization technique that does not cause a sense of incongruity even when the speaker sound and the background sound are recorded in the same sound channel. It is in.
上記の課題を達成するため、本発明の一態様に係る映像音声出力装置は、映像を解析して、話者の位置を特定する話者位置特定手段と、話者の音声と背景音が混じった混合音声を、話者の音声と背景音に分離する音声分離手段と、前記話者位置特定手段が特定した話者の位置に、前記音声分離手段が分離した話者の音声を定位させる音声定位手段と、を備えている。
In order to achieve the above object, a video / audio output device according to an aspect of the present invention includes a speaker position specifying unit that analyzes video and specifies a speaker's position, and the speaker's voice and background sound are mixed. Voice separation means for separating the mixed voice into the voice of the speaker and the background sound, and voice for localizing the voice of the speaker separated by the voice separation means at the position of the speaker specified by the speaker position specifying means Localization means.
また、本発明の一態様に係る音声定位方法は、映像を解析して、話者の位置を特定する話者位置特定ステップと、話者の音声と背景音が混じった混合音声を、話者の音声と背景音に分離する音声分離ステップと、前記話者位置特定ステップで特定した話者の位置に、音声分離ステップで分離した話者の音声を定位させる音声定位ステップと、を備えている。
In addition, the sound localization method according to one aspect of the present invention includes a speaker position specifying step of analyzing a video to specify a speaker position, and a mixed sound in which a speaker's voice and a background sound are mixed. And a sound localization step of localizing the voice of the speaker separated in the voice separation step at the position of the speaker identified in the speaker position identification step. .
以下、本発明の実施の形態を図面を用いて説明する。
Hereinafter, embodiments of the present invention will be described with reference to the drawings.
<第1の実施の形態>
図1は、本発明の実施の形態に係る映像音声出力装置1の概略構成図である。映像音声出力装置1は、話者位置に合わせた音声定位で音声を出力する装置である。本実施の形態においては、話者音声と背景音が同一チャンネルに収録されているので、同一チャンネルに収録されている話者音声と背景音を分離し、分離した話者音声だけを話者位置に合わせて定位変更している。 <First Embodiment>
FIG. 1 is a schematic configuration diagram of a video / audio output apparatus 1 according to an embodiment of the present invention. The video / audio output device 1 is a device that outputs audio with audio localization in accordance with the speaker position. In this embodiment, since the speaker voice and background sound are recorded on the same channel, the speaker voice and background sound recorded on the same channel are separated, and only the separated speaker voice is The panorama has been changed to match.
図1は、本発明の実施の形態に係る映像音声出力装置1の概略構成図である。映像音声出力装置1は、話者位置に合わせた音声定位で音声を出力する装置である。本実施の形態においては、話者音声と背景音が同一チャンネルに収録されているので、同一チャンネルに収録されている話者音声と背景音を分離し、分離した話者音声だけを話者位置に合わせて定位変更している。 <First Embodiment>
FIG. 1 is a schematic configuration diagram of a video / audio output apparatus 1 according to an embodiment of the present invention. The video / audio output device 1 is a device that outputs audio with audio localization in accordance with the speaker position. In this embodiment, since the speaker voice and background sound are recorded on the same channel, the speaker voice and background sound recorded on the same channel are separated, and only the separated speaker voice is The panorama has been changed to match.
なお、以下において、「話者」とは、映像データ(画面上)において発話している者をいい、「話者音声」とは、発話している者の声をいう。また、「背景音」とは、話者音声以外の音をいい、具体的には、BGM、環境音、騒音、発話者以外の声など意味する。「話者位置」とは、話者の画面上の位置をいうが、より正確には話者の顔(特に口)付近の位置をいう。「話者位置に合わせた音声定位で音声を出力する」とは、話者の位置から音声が聞こえてくるように音声を出力することをいい、例えば、図2に示すように、話者Aが画面上左側に存在する場合には、画面d10の左側に設けたスピーカSP1から出力される話者音声の音量を大きくし、画面d10の右側に設けたスピーカSP2から出力される話者音声の音量を小さくして、画面左側にいる話者の位置から音声が聞こえてくるように音声を出力することをいう。
In the following, “speaker” refers to a person speaking in the video data (on the screen), and “speaker voice” refers to the voice of the person speaking. The “background sound” means a sound other than the speaker's voice, and specifically means BGM, environmental sound, noise, voice other than the speaker, and the like. “Speaker position” refers to a position on the screen of the speaker, but more precisely, a position near the face (especially mouth) of the speaker. “Output the voice with the voice localization in accordance with the speaker position” means outputting the voice so that the voice can be heard from the position of the speaker. For example, as shown in FIG. Is present on the left side of the screen, the volume of the speaker voice output from the speaker SP1 provided on the left side of the screen d10 is increased, and the volume of the speaker voice output from the speaker SP2 provided on the right side of the screen d10 is increased. This means that the sound is output so that the sound can be heard from the position of the speaker on the left side of the screen at a reduced volume.
ここで、映像音声出力装置1は、外部から入力された映像及び音声を含むコンテンツデータを再生して外部に出力する機能を有する装置であれば何であってもよく、例えば、具体的には、テレビジョン(TV)、DVDプレーヤ及びレコーダ、BDプレーヤ及びレコーダ、パーソナルコンピュータ(PC)などが想定される。
Here, the video / audio output device 1 may be any device as long as it has a function of reproducing content data including video and audio input from the outside and outputting the content data to the outside. A television (TV), a DVD player and recorder, a BD player and recorder, a personal computer (PC), and the like are assumed.
映像音声出力装置1は、詳しくは、映像解析部11、音声分離部12、定位処理部13、映像表示部14、及び音声出力部15を備えている。
Specifically, the video / audio output device 1 includes a video analysis unit 11, an audio separation unit 12, a localization processing unit 13, a video display unit 14, and an audio output unit 15.
映像解析部11は、入力した映像データを映像表示部14に出力する(音声データと同期させるため、必要に応じて映像データを遅延させて映像表示部14に出力する)とともに、入力した映像データから話者位置を特定するようになっている。話者位置の特定方法については、公知の技術を用いて行われる。例えば、映像データから人の顔面の領域を検出し、顔面の中の口の動きを検出することで、話者を特定するようにしてもよい。この際、口の動きの検出においては、前後数フレームの映像データを用いて、口領域の輝度などの差分を特徴量として算出し、算出した特徴量の値が最も大きい口領域を持った人を話者と判定とすれば、複数の顔面が検出された場合であっても、話者を特定することができる。
The video analysis unit 11 outputs the input video data to the video display unit 14 (to synchronize with the audio data, the video data is delayed and output to the video display unit 14 as necessary) and the input video data The speaker position is specified from the above. The method for specifying the speaker position is performed using a known technique. For example, a speaker may be specified by detecting a region of a human face from video data and detecting a mouth movement in the face. At this time, in detecting the movement of the mouth, using the video data of several frames before and after, the difference such as the brightness of the mouth area is calculated as a feature amount, and the person with the mouth region having the largest feature value is calculated. Is determined as a speaker, the speaker can be specified even when a plurality of faces are detected.
また、映像解析部11は、特定した話者の位置を定位処理部13に出力するようになっている。
Further, the video analysis unit 11 outputs the specified speaker position to the localization processing unit 13.
音声分離部12は、入力した音声データ(話者音声と背景音が混合した音声データ)を周波数パラメータP1に基づいて、話者音声と背景音に分離するようになっている。周波数パラメータP1は、人間の声の一般的な周波数帯域を示すパラメータであり、本実施形態においては、図3に示すように、下限周波数f1として80Hz、上限周波数f2として3000Hzが設定されている。詳しくは、話者音声は、入力した音声データを周波数パラメータP1が設定された帯域通過フィルタに通すことで得ることができる。すなわち、本実施の形態においては、80Hzから3000Hzの間の周波数帯域の音声を話者音声として分離する。また、背景音は、入力した音声データを周波数パラメータP1が設定された帯域阻止フィルタに通すことで得ることができる。すなわち、本実施の形態においては、80Hz未満、または3000Hzを超えた周波数帯域の音声を背景音として分離する。なお、図3に示す周波数パラメータP1は好適な一例の値を示したものであり、周波数パラメータP1は必ずしも図3に示す値に限定されるものではない。
The voice separation unit 12 separates the input voice data (voice data in which the speaker voice and the background sound are mixed) into the speaker voice and the background sound based on the frequency parameter P1. The frequency parameter P1 is a parameter indicating a general frequency band of a human voice. In the present embodiment, as shown in FIG. 3, the lower limit frequency f1 is set to 80 Hz, and the upper limit frequency f2 is set to 3000 Hz. Specifically, the speaker voice can be obtained by passing the input voice data through a band-pass filter in which the frequency parameter P1 is set. That is, in the present embodiment, the voice in the frequency band between 80 Hz and 3000 Hz is separated as the speaker voice. The background sound can be obtained by passing the input audio data through a band rejection filter in which the frequency parameter P1 is set. That is, in the present embodiment, the voice in the frequency band of less than 80 Hz or more than 3000 Hz is separated as the background sound. Note that the frequency parameter P1 shown in FIG. 3 shows a preferable example value, and the frequency parameter P1 is not necessarily limited to the value shown in FIG.
また、音声分離部12は、分離した話者音声を定位処理部13に出力し、分離した背景音を音声出力部15に出力するようになっている。
The voice separation unit 12 outputs the separated speaker voice to the localization processing unit 13 and outputs the separated background sound to the voice output unit 15.
定位処理部13は、映像解析部11から出力された話者位置に基づいて、音声分離部12から出力された話者音声の定位変更処理を行うようになっている。すなわち、画面上の話者位置に話者音声を定位させるように音量の調整を行っている。例えば、図2に示すように、話者Aが画面上左側に存在する場合には、画面左側に設けたスピーカSP1から出力される話者音声の音量を大きくし、画面右側に設けたスピーカSP2から出力される話者音声の音量を小さくする。具体的には、話者Aが画面上、水平方向の比がC:Dとなる位置に存在する場合には、スピーカSP1とスピーカSP2の話者音声の音量の比をD:Cに設定するようにしてもよい。
The localization processing unit 13 performs localization change processing of the speaker voice output from the voice separation unit 12 based on the speaker position output from the video analysis unit 11. That is, the volume is adjusted so that the speaker voice is localized at the speaker position on the screen. For example, as shown in FIG. 2, when the speaker A exists on the left side of the screen, the volume of the speaker voice output from the speaker SP1 provided on the left side of the screen is increased, and the speaker SP2 provided on the right side of the screen. Decrease the volume of the speaker voice output from. Specifically, when the speaker A is present on the screen at a position where the horizontal ratio is C: D, the volume ratio of the speaker voices of the speakers SP1 and SP2 is set to D: C. You may do it.
なお、話者音声の定位変更処理の際には、再生環境を考慮してもよい。再生環境とは、例えば、ディスプレイ等の表示画面の大きさやスピーカの位置などである。例えば、画面の上下左右方向それぞれにスピーカを備える場合には、図2に示すように左右スピーカの音量の調整だけでなく、話者の上下方向の位置に応じて上下スピーカの音量の調整を行うようにしてもよい。
Note that the playback environment may be taken into account in the process of changing the localization of the speaker voice. The reproduction environment is, for example, the size of a display screen such as a display or the position of a speaker. For example, in the case where speakers are provided in the upper, lower, left and right directions of the screen, the volume of the upper and lower speakers is adjusted not only according to the volume of the left and right speakers as shown in FIG. You may do it.
また、定位処理部13は、定位変更処理した話者音声を音声出力部15に出力するようになっている。
Also, the localization processing unit 13 outputs the speaker voice subjected to the localization change process to the voice output unit 15.
映像表示部14は、映像解析部11から出力された映像データをディスプレイ等に表示するようになっている。
The video display unit 14 displays the video data output from the video analysis unit 11 on a display or the like.
音声出力部15は、定位変更処理された話者音声と音声分離部12から出力された背景音を混合してスピーカに出力するようになっている。
The voice output unit 15 mixes the speaker voice subjected to the localization change process and the background sound output from the voice separation unit 12 and outputs the mixed sound to the speaker.
い。
Yes.
次に、図4を参照して、本実施の形態の映像音声出力装置1の映像音声出力処理について説明する。図4は、映像音声出力装置1の映像音声出力処理の流れを示すフローチャートである。
Next, the video / audio output processing of the video / audio output device 1 of the present embodiment will be described with reference to FIG. FIG. 4 is a flowchart showing the flow of the video / audio output process of the video / audio output device 1.
まず、映像音声出力装置1の映像解析部11は、入力された映像データを解析して、画面上の話者位置を特定する映像解析処理を行う(ステップS2)。
First, the video analysis unit 11 of the video / audio output device 1 analyzes the input video data and performs video analysis processing for specifying the speaker position on the screen (step S2).
次に、映像音声出力装置1の音声分離部12は、入力された音声データを話者音声と背景音に分離する音声分離処理を行う(ステップS4)。
Next, the audio separation unit 12 of the video / audio output device 1 performs an audio separation process for separating the input audio data into the speaker sound and the background sound (step S4).
ここで、図5を参照して、音声分離処理について詳しく説明する。図5は、図4のステップS4の音声分離処理を詳しく示すフローチャートである。
Here, the speech separation process will be described in detail with reference to FIG. FIG. 5 is a flowchart showing in detail the speech separation process in step S4 of FIG.
音声分離部12は、周波数パラメータP1の下限周波数f1及び上限周波数f2を設定する(ステップS12)。具体的には、f1=80Hz、f2=3000Hzである。なお、周波数パラメータP1の値に関しては、映像音声出力装置1が予め固定的な値を保持するようにしてもよいし、ユーザが映像音声出力装置1に指示をして可変的な値を設定可能としてもよい。
The voice separation unit 12 sets the lower limit frequency f1 and the upper limit frequency f2 of the frequency parameter P1 (step S12). Specifically, f1 = 80 Hz and f2 = 3000 Hz. As for the value of the frequency parameter P1, the video / audio output apparatus 1 may hold a fixed value in advance, or the user can instruct the video / audio output apparatus 1 to set a variable value. It is good.
次に、音声分離部12は、入力された音声データを、周波数パラメータP1が設定された帯域通過フィルタに通して、話者音声を分離する(ステップS14)。
Next, the voice separator 12 passes the input voice data through a band-pass filter in which the frequency parameter P1 is set, and separates the speaker voice (step S14).
次に、音声分離部12は、入力された音声データを、周波数パラメータP1が設定された帯域阻止フィルタに通して、背景音を分離する(ステップS16)。
Next, the sound separation unit 12 passes the input sound data through a band rejection filter in which the frequency parameter P1 is set, and separates the background sound (step S16).
図4に戻って、次に、映像音声出力装置1の定位処理部13は、特定された話者位置に分離された話者音声を定位変更する音声定位処理を行う(ステップS6)。
Referring back to FIG. 4, next, the localization processing unit 13 of the video / audio output device 1 performs audio localization processing for changing the localization of the speaker voice separated to the specified speaker position (step S6).
ここで、図6を参照して、音声定位処理について詳しく説明する。図6は、図4のステップS6の音声定位処理を詳しく示すフローチャートである。
Here, the sound localization process will be described in detail with reference to FIG. FIG. 6 is a flowchart showing in detail the sound localization process in step S6 of FIG.
定位処理部13は、画面内に話者がいるか否かを判定する(ステップS22)。画面内に話者がいるか否かは、映像解析部11が解析した話者位置の有無により判断し、話者位置が存在するときは画面内に話者がいると判断する。
The localization processing unit 13 determines whether or not there is a speaker on the screen (step S22). Whether or not there is a speaker in the screen is determined based on the presence or absence of the speaker position analyzed by the video analysis unit 11. When the speaker position exists, it is determined that there is a speaker in the screen.
画面内に話者がいる場合には(ステップS22:YES)、話者位置に近いスピーカの話者音声の出力値を上げて(ステップS24)、話者位置に遠いスピーカの話者音声の出力値を下げる(ステップS26)。例えば、図2に示すように話者Aが画面上の左側にいる場合には、スピーカSP1の音量を上げて、スピーカSP2の音量を下げる。
If there is a speaker on the screen (step S22: YES), the speaker voice output value near the speaker position is raised (step S24), and the speaker voice output from the speaker far from the speaker position is output. The value is lowered (step S26). For example, as shown in FIG. 2, when the speaker A is on the left side of the screen, the volume of the speaker SP1 is increased and the volume of the speaker SP2 is decreased.
画面内に話者がいない場合には(ステップS22:NO)、音声定位を変更する処理を行わない。
If there is no speaker on the screen (step S22: NO), the process of changing the sound localization is not performed.
図4に戻って、次に、映像音声出力装置1の映像表示部14は、映像データをディスプレイ等に表示する映像表示処理を行い(ステップS8)、音声出力部15は、音声データをスピーカから出力する音声出力処理を行う(ステップS10)。
Returning to FIG. 4, next, the video display unit 14 of the video / audio output device 1 performs video display processing for displaying the video data on a display or the like (step S8), and the audio output unit 15 transmits the audio data from the speaker. A sound output process is performed (step S10).
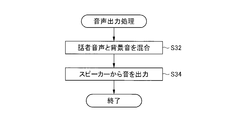
ここで、図7を参照して、音声出力処理について詳しく説明する。図7は、図4のステップS10の音声出力処理を詳しく示すフローチャートである。
Here, the audio output processing will be described in detail with reference to FIG. FIG. 7 is a flowchart showing in detail the audio output process in step S10 of FIG.
映像表示部14は、定位変更処理された話者音声と背景音を混合して(ステップS32)、混合した音声データをスピーカから出力する(ステップS34)。例えば、図2に示すように話者Aが画面上の左側にいる場合には、話者音声に関しては、スピーカSP1の音量を上げるとともにスピーカSP2の音量を下げて出力し、背景音に関しては、スピーカSP1及びSP2の音量を同じにして出力する。この結果、話者音声は人の位置から聞こえ、背景音は入力音声情報の定位を維持させることができる。
The video display unit 14 mixes the speaker voice subjected to the localization change process and the background sound (step S32), and outputs the mixed voice data from the speaker (step S34). For example, as shown in FIG. 2, when the speaker A is on the left side of the screen, the speaker sound is output by increasing the volume of the speaker SP1 and decreasing the volume of the speaker SP2, and the background sound is The speakers SP1 and SP2 are output at the same volume. As a result, the speaker voice can be heard from the position of the person, and the background sound can maintain the localization of the input voice information.
以上説明したように、本実施の形態に係る映像音声出力装置1によれば、話者音声と背景音が同一の音声チャンネルに収録された映像コンテンツであっても、話者音声だけを話者位置に定位変更させることが可能なので、視聴者は違和感を生じることがなく、より自然で臨場感のある視聴が可能となる。
As described above, according to the video / audio output device 1 according to the present embodiment, even if the video content includes the speaker audio and the background sound recorded in the same audio channel, only the speaker audio is transmitted to the speaker. Since the position can be changed to the position, the viewer does not feel uncomfortable and more natural and realistic viewing is possible.
なお、本実施の形態の音声分離部12は、人間の声の一般的な周波数帯域を示す周波数パラメータP1を用いて、話者音声と背景音の分離を行ったが、話者音声と背景音の分離方法はこれに限定されるものではなく、他の方法でもよい。例えば、ステレオ音声の場合には、左右それぞれの音声を周波数領域に変換し、変換した周波数領域における左右それぞれの音声のスペクトルパワーを比較することで話者音声を分離するようにしてもよい。この方法の場合には、ステレオ音声における話者の音声は中央に定位しているので、左右のスペクトルパワーの差の小さい周波数帯域を話者の周波数帯域として、話者の音声を分離することができる。
Note that the voice separation unit 12 according to the present embodiment separates the speaker voice and the background sound using the frequency parameter P1 indicating the general frequency band of the human voice. The separation method is not limited to this, and other methods may be used. For example, in the case of stereo speech, the left and right speech may be converted into the frequency domain, and the speaker speech may be separated by comparing the spectral power of the left and right speech in the converted frequency domain. In the case of this method, since the speaker's voice in stereo sound is localized in the center, the speaker's voice can be separated using the frequency band having a small difference in spectral power between the left and right as the speaker's frequency band. it can.
なお、本実施の形態においては、人の声の周波数帯域と重なる周波数帯域を有する背景音(80~3000Hzの背景音。以下、背景音1という)が存在する場合には、背景音が話者音声の中に混じってしまい、話者音声に混じった背景音も同時に人の位置に音声定位変更されてしまう。そのため、このような場合には、話者音声に混じった背景音の音声定位を打ち消すように分離された背景音(80Hz未満、または3000Hzを超えた背景音。以下、背景音2という)を音声定位変更するようにしてもよい。
In the present embodiment, when there is a background sound having a frequency band that overlaps the frequency band of the human voice (background sound of 80 to 3000 Hz; hereinafter referred to as background sound 1), the background sound is the speaker. The sound is mixed in the voice, and the background sound mixed in the speaker's voice is simultaneously changed to the position of the person. Therefore, in such a case, the background sound separated to cancel the sound localization of the background sound mixed with the speaker sound (background sound less than 80 Hz or more than 3000 Hz; hereinafter referred to as background sound 2) The localization may be changed.
例えば、図2に示すように話者Aが画面上左側にいる場合には、話者音声に関しては、スピーカSP1の音量を上げるとともにスピーカSP2の音量を下げて出力するが、この話者音声の中には背景音1が含まれているので、背景音1も人の位置、つまり画面上の左側から聞こえてしまう。そのため、背景音2に関しては、画面上の右側から聞こえるようにスピーカSP1の音量を下げ、スピーカSP2の音量を下げて出力する。この結果、背景音1と背景音2を合わせた背景音全体は、人の位置に定位させることなく、入力音声情報の定位を維持させることができる。
For example, as shown in FIG. 2, when the speaker A is on the left side of the screen, the speaker sound is output with the volume of the speaker SP1 raised and the volume of the speaker SP2 lowered. Since the background sound 1 is included, the background sound 1 is also heard from the position of the person, that is, the left side on the screen. Therefore, the background sound 2 is output with the volume of the speaker SP1 lowered and the volume of the speaker SP2 lowered so that it can be heard from the right side of the screen. As a result, the entire background sound including the background sound 1 and the background sound 2 can be localized in the input voice information without being localized in the position of the person.
図8は、話者音声の中に背景音が含まれることを考慮した映像音声出力装置1Aの概略構成図である。映像音声出力装置1Aは、映像音声出力装置1と略同一の構成であるが、定位処理部13Aの機能だけが異なっている。
FIG. 8 is a schematic configuration diagram of the video / audio output device 1A in consideration of the background sound included in the speaker voice. The video / audio output device 1A has substantially the same configuration as the video / audio output device 1, but only the function of the localization processing unit 13A is different.
定位処理部13Aは、映像解析部11から出力された話者位置に基づいて、音声分離部12から出力された分離された話者音声(背景音1を含む)の定位変更処理を行うようになっている。すなわち、画面上の話者位置に、分離した話者音声(背景音1を含む)を定位させるように音量の調整を行っている。
Based on the speaker position output from the video analysis unit 11, the localization processing unit 13 </ b> A performs a localization change process of the separated speaker voice (including background sound 1) output from the voice separation unit 12. It has become. That is, the volume is adjusted so that the separated speaker voice (including background sound 1) is localized at the speaker position on the screen.
また、定位処理部13Aは、音声分離部12から出力された分離された背景音(背景音2)の定位変更処理を行うようになっている。すなわち、画面上の話者位置と反対の方向に(画面上の中心に対して)、分離した背景音(背景音2)を定位させるように音量の調整を行っている。
In addition, the localization processing unit 13A performs a localization changing process for the separated background sound (background sound 2) output from the voice separation unit 12. That is, the volume is adjusted so that the separated background sound (background sound 2) is localized in the direction opposite to the speaker position on the screen (with respect to the center on the screen).
この結果、定位処理部13Aは、定位変更処理した話者音声及び定位変更処理した背景音を音声出力部15に出力するようになっている。
As a result, the localization processing unit 13A outputs the speaker voice subjected to the localization change process and the background sound subjected to the localization change process to the voice output unit 15.
図9は、映像音声出力装置1Aの音声定位処理の流れを詳しく示すフローチャートである。
FIG. 9 is a flowchart showing in detail the flow of audio localization processing of the video / audio output device 1A.
定位処理部13Aは、画面内に話者がいるか否かを判定する(ステップS42)。
The localization processing unit 13A determines whether or not there is a speaker on the screen (step S42).
画面内に話者がいる場合には(ステップS42:YES)、定位処理部13Aは、話者位置に近いスピーカの話者音声(背景音1を含む)の出力値を上げて(ステップS44)、話者位置に遠いスピーカの話者音声(背景音1を含む)の出力値を下げる(ステップS46)。例えば、図2に示すように話者SPが画面の左側にいる場合には、話者音声(背景音1を含む)のスピーカSP1の音量を上げて、スピーカSP2の音量を下げる。
When there is a speaker in the screen (step S42: YES), the localization processing unit 13A increases the output value of the speaker voice (including background sound 1) of the speaker close to the speaker position (step S44). Then, the output value of the speaker voice (including background sound 1) from the speaker far from the speaker position is lowered (step S46). For example, as shown in FIG. 2, when the speaker SP is on the left side of the screen, the volume of the speaker SP1 for speaker voice (including background sound 1) is increased and the volume of the speaker SP2 is decreased.
次いで、定位処理部13Aは、話者位置に近いスピーカの背景音2の出力値を下げ(ステップS48)、定位処理部13Aは、話者位置に遠いスピーカの背景音2の出力値を上げる(ステップS50)。例えば、図2に示すように話者SPが画面上左側にいる場合には、背景音2のスピーカSP1の音量を下げて、スピーカSP2の音量を上げる。
Next, the localization processing unit 13A decreases the output value of the background sound 2 of the speaker close to the speaker position (step S48), and the localization processing unit 13A increases the output value of the background sound 2 of the speaker far from the speaker position ( Step S50). For example, as shown in FIG. 2, when the speaker SP is on the left side of the screen, the volume of the speaker SP1 of the background sound 2 is lowered and the volume of the speaker SP2 is raised.
一方、画面内に話者がいない場合には(ステップS42:NO)、音声定位を変更する処理を行わない。
On the other hand, when there is no speaker on the screen (step S42: NO), the process of changing the sound localization is not performed.
以上、本変形例に係る映像音声出力装置1Aによれば、話者音声を話者位置に定位変更させることができる。また、映像音声出力装置1Aによれば、話者音声と背景音の周波数帯域が重なり、話者音声に背景音が混じることがあったとしても、話者音声と分離された背景音を画面中央から話者がいない方向に音声定位させるので、背景音全体は、入力音声情報の定位を維持させることができる。この結果、視聴者は違和感を生じることがなく、より自然で臨場感のある視聴が可能となる。
As described above, according to the video / audio output device 1A according to the present modification, it is possible to change the localization of the speaker voice to the speaker position. Further, according to the video / audio output device 1A, even if the frequency band of the speaker voice and the background sound overlaps and the background sound is mixed with the speaker voice, the background sound separated from the speaker voice is displayed at the center of the screen. Therefore, the entire background sound can maintain the localization of the input voice information. As a result, the viewer does not feel uncomfortable, and more natural and realistic viewing is possible.
<第2の実施の形態>
図10は、本発明の第2の実施の形態に係る映像音声出力装置2の概略構成図である。映像音声出力装置2は、話者位置に合わせた音声定位で音声を出力する装置である。なお、以下においては、第1の実施の形態と異なる構成、機能及び処理のみ説明し、その他の構成、機能及び処理に関しては同一部位には同一符号を付して説明を省略する。 <Second Embodiment>
FIG. 10 is a schematic configuration diagram of the video /audio output device 2 according to the second embodiment of the present invention. The video / audio output device 2 is a device that outputs audio with audio localization in accordance with the speaker position. In the following description, only configurations, functions, and processes different from those of the first embodiment will be described, and with regard to other configurations, functions, and processes, the same portions are denoted by the same reference numerals and description thereof is omitted.
図10は、本発明の第2の実施の形態に係る映像音声出力装置2の概略構成図である。映像音声出力装置2は、話者位置に合わせた音声定位で音声を出力する装置である。なお、以下においては、第1の実施の形態と異なる構成、機能及び処理のみ説明し、その他の構成、機能及び処理に関しては同一部位には同一符号を付して説明を省略する。 <Second Embodiment>
FIG. 10 is a schematic configuration diagram of the video /
映像解析部21は、入力した映像データを映像表示部14に出力する(音声データと同期させるため、必要に応じて映像データを遅延させて映像表示部14に出力する)とともに、入力した映像データから話者位置を特定するようになっている。
The video analysis unit 21 outputs the input video data to the video display unit 14 (to synchronize with the audio data, the video data is delayed and output to the video display unit 14 as necessary), and the input video data The speaker position is specified from the above.
また、映像解析部21は、話者の顔特徴を抽出し、抽出した顔特徴から話者の属性を解析するようになっている。顔特徴の抽出は、公知の技術を用いて行われる。本実施の形態では、顔の主要な部位に対してその特徴量を検出する方法を採用しており、顔輪郭、両眉、両眼、鼻、口などの位置関係を示す特徴量を顔特徴として抽出する。また、話者の属性とは、年齢や性別を意味し、本実施の形態においては、男性または女性の判定、子供であるか否かの判定を行うようになっている。
Also, the video analysis unit 21 extracts the speaker's facial features and analyzes the speaker's attributes from the extracted facial features. Facial features are extracted using a known technique. In this embodiment, a method for detecting the feature amount of a major part of the face is adopted, and the feature amount indicating the positional relationship between the face contour, both eyebrows, both eyes, nose, mouth and the like is used as the facial feature. Extract as In addition, the attribute of the speaker means age and sex, and in the present embodiment, determination of a man or a woman and determination of whether or not a child is performed.
また、映像解析部21は、特定した話者の位置を定位処理部13に出力し、解析した属性を音声分離部22に出力するようになっている。
Also, the video analysis unit 21 outputs the identified speaker position to the localization processing unit 13 and outputs the analyzed attribute to the voice separation unit 22.
属性データベース(以下、属性DBという)23は、属性ごとの顔特徴に関するデータ(以下、顔特徴データという)を記憶しているデータベースで、本実施の形態では、男性または女性の顔特徴データ、及び子供の顔特徴データを備えている。映像解析部21は、抽出した話者の顔特徴と属性DB23に記憶されている顔特徴データとを比較して話者の属性を解析するようになっている。
The attribute database (hereinafter referred to as attribute DB) 23 is a database that stores data relating to facial features for each attribute (hereinafter referred to as facial feature data), and in this embodiment, male or female facial feature data, and It has child face feature data. The video analysis unit 21 analyzes the speaker's attributes by comparing the extracted speaker's facial features with the facial feature data stored in the attribute DB 23.
なお、本実施の形態においては、映像音声出力装置2が属性DB23を備える構成としたが、映像音声出力装置2が属性DB23を備えない構成でもよく、映像音声出力装置2が、通信ネットワークを介して属性DB23にアクセスし、属性DB23に記憶された顔特徴データを参照する構成としてもよい。
In the present embodiment, the video / audio output device 2 includes the attribute DB 23. However, the video / audio output device 2 may not include the attribute DB 23, and the video / audio output device 2 may be connected via a communication network. The attribute DB 23 may be accessed to refer to the facial feature data stored in the attribute DB 23.
音声分離部22は、入力した音声データ(話者音声と背景音が混合した音声データ)を、周波数パラメータP1に属性を加味した周波数パラメータP2に従って、話者音声と背景音に分離するようになっている。本実施の形態においては、周波数パラメータP2は、例えば、男性の場合には、上限周波数f2の値を補正値αだけ下げた値とし、女性の場合には、下限周波数f1の値を補正値βだけ上げた値としている。男性は女性に比べて一般に声が低いと考えられるので、男女差を周波数パラメータP2に反映したものである。また、子供の場合には、男女間の補正に加えて、下限周波数f1をさらに補正値γだけ上げた値としている。子供は大人に比べて一般に声が高いと考えられるので、年齢差を周波数パラメータP2に反映したものである。なお、この補正方法は、好適な一方法を示したものであり、これに限定されるものではない。
The voice separation unit 22 separates input voice data (voice data in which speaker voice and background sound are mixed) into speaker voice and background sound according to a frequency parameter P2 in which an attribute is added to the frequency parameter P1. ing. In the present embodiment, for example, in the case of a male, the frequency parameter P2 is a value obtained by reducing the value of the upper limit frequency f2 by the correction value α, and in the case of a female, the value of the lower limit frequency f1 is the correction value β. Only the value is raised. Since men are generally considered to have lower voice than women, the difference between men and women is reflected in the frequency parameter P2. In the case of a child, in addition to the correction between men and women, the lower limit frequency f1 is further increased by a correction value γ. Since the child is generally considered to be louder than the adult, the age difference is reflected in the frequency parameter P2. In addition, this correction method shows one suitable method, and is not limited to this.
また、音声分離部22は、分離した話者音声を定位処理部13に出力し、分離した背景音を音声出力部15に出力するようになっている。
Also, the voice separation unit 22 outputs the separated speaker voice to the localization processing unit 13 and outputs the separated background sound to the voice output unit 15.
図11は本実施の形態に係る映像音声出力装置2の音声分離処理の流れを詳しく示すフローチャートである。
FIG. 11 is a flowchart showing in detail the flow of the audio separation process of the video / audio output apparatus 2 according to the present embodiment.
音声分離部22は、周波数パラメータP2の下限周波数f1及び上限周波数f2を設定する(ステップS52)。具体的には、周波数パラメータP1の値をそのまま設定し、f1=80Hz、f2=3000Hzとする。
The voice separation unit 22 sets the lower limit frequency f1 and the upper limit frequency f2 of the frequency parameter P2 (step S52). Specifically, the value of the frequency parameter P1 is set as it is, and f1 = 80 Hz and f2 = 3000 Hz.
次に、音声分離部22は、話者が男性であるか否かを判定する(ステップS54)。話者が男性である場合には(ステップS52:YES)、音声分離部22は、周波数パラメータP2の上限周波数f2を補正し(ステップS56)、話者が女性である場合には(ステップS54:NO)、音声分離部22は、周波数パラメータP2の下限周波数f1を補正する(ステップS58)。詳しくは、話者が男性である場合には、周波数パラメータP2の上限周波数f2から補正値αを減算し、話者が女性である場合には、周波数パラメータP2の下限周波数f1に補正値βを加算する。
Next, the voice separation unit 22 determines whether or not the speaker is a male (step S54). If the speaker is a male (step S52: YES), the speech separation unit 22 corrects the upper limit frequency f2 of the frequency parameter P2 (step S56). If the speaker is a female (step S54: NO), the voice separation unit 22 corrects the lower limit frequency f1 of the frequency parameter P2 (step S58). Specifically, when the speaker is a male, the correction value α is subtracted from the upper limit frequency f2 of the frequency parameter P2, and when the speaker is a female, the correction value β is added to the lower limit frequency f1 of the frequency parameter P2. to add.
次に、音声分離部22は、話者が子供であるか否かを判定する(ステップS60)。話者が子供である場合には(ステップS60:YES)、音声分離部22は、周波数パラメータP2の下限周波数f1をさらに補正する(ステップS62)。詳しくは、話者が子供である場合には、周波数パラメータP2の下限周波数f1に補正値γを加算する。
Next, the voice separation unit 22 determines whether or not the speaker is a child (step S60). When the speaker is a child (step S60: YES), the voice separation unit 22 further corrects the lower limit frequency f1 of the frequency parameter P2 (step S62). Specifically, when the speaker is a child, the correction value γ is added to the lower limit frequency f1 of the frequency parameter P2.
次に、音声分離部22は、入力された音声データを、周波数パラメータP2が設定された帯域通過フィルタに通して、話者音声を分離する(ステップS64)。
Next, the voice separator 22 passes the input voice data through a band-pass filter in which the frequency parameter P2 is set, and separates the speaker voice (step S64).
次に、音声分離部22は、入力された音声データを、周波数パラメータP2が設定された帯域阻止フィルタに通して、背景音を分離する(ステップS66)。
Next, the voice separation unit 22 passes the inputted voice data through a band rejection filter in which the frequency parameter P2 is set, and separates the background sound (step S66).
以上説明したように、本実施の形態に係る映像音声出力装置2によれば、話者の属性を解析し、属性による声の相違を反映した周波数パラメータP2に基づいて音声を分離するので話者音声と背景音の分離の精度をさらに上げることができる。
As described above, according to the video / audio output device 2 according to the present embodiment, the speaker's attributes are analyzed, and the voice is separated based on the frequency parameter P2 reflecting the voice difference due to the attributes. The accuracy of separating the sound and the background sound can be further increased.
その結果、視聴者は違和感を生じることがなく、さらに自然で臨場感のある視聴を楽しむことができる。
As a result, viewers can enjoy a more natural and realistic viewing experience without feeling uncomfortable.
<第3の実施の形態>
図12は、本発明の第3の実施の形態に係る映像音声出力装置3の概略構成図である。映像音声出力装置3は、話者位置に合わせた音声定位で音声を出力する装置である。 <Third Embodiment>
FIG. 12 is a schematic configuration diagram of a video /audio output device 3 according to the third embodiment of the present invention. The video / audio output device 3 is a device that outputs audio with audio localization in accordance with the speaker position.
図12は、本発明の第3の実施の形態に係る映像音声出力装置3の概略構成図である。映像音声出力装置3は、話者位置に合わせた音声定位で音声を出力する装置である。 <Third Embodiment>
FIG. 12 is a schematic configuration diagram of a video /
映像解析部31は、入力した映像データを映像表示部14に出力する(音声データと同期させるため、必要に応じて映像データを遅延させて映像表示部14に出力する)とともに、入力した映像データから話者位置を特定するようになっている。
The video analysis unit 31 outputs the input video data to the video display unit 14 (to synchronize with the audio data, the video data is delayed and output to the video display unit 14 as necessary), and the input video data The speaker position is specified from the above.
また、映像解析部31は、入力した映像データから話者の顔特徴を抽出するようになっている。顔特徴の抽出は、公知の技術を用いて行われる。本実施の形態では、顔の主要な部位に対してその特徴量を検出する方法を採用しており、顔輪郭、両眉、両眼、鼻、口などの複数の顔特徴点の位置座標を顔特徴として抽出する。
Also, the video analysis unit 31 extracts the speaker's facial features from the input video data. Facial features are extracted using a known technique. In the present embodiment, a method for detecting the feature amount of a major part of the face is adopted, and the position coordinates of a plurality of facial feature points such as a face outline, brows, both eyes, nose, and mouth are used. Extract as facial features.
また、映像解析部31は、特定した話者の位置を定位処理部13に出力し、抽出した顔特徴を音声分離部32に出力するようになっている。
Also, the video analysis unit 31 outputs the position of the identified speaker to the localization processing unit 13 and outputs the extracted facial features to the voice separation unit 32.
特徴DB33は、顔特徴と声特徴を対応付けた特徴データを記憶しているデータベースである。図13に特徴データのデータ構成を示す。特徴データは、図13に示すように、複数の顔特徴の座標(具体的には、目や鼻や口の位置を示す)と、声特徴(具体的には、下限周波数f1及び上限周波数f2を示す)を対応付けている。特徴データは、例えば、TVや映画などの動画コンテンツに出演する俳優などのデータで構成される。後述する音声分離部32は、映像解析部31が抽出した話者の顔特徴と特徴DB33に記憶されている特徴データとを比較して、一致する特徴データが存在する場合には、話者の顔特徴に対応する声特徴を取得するようになっている。
The feature DB 33 is a database that stores feature data in which face features and voice features are associated with each other. FIG. 13 shows the data structure of feature data. As shown in FIG. 13, the feature data includes coordinates of a plurality of facial features (specifically, the positions of eyes, nose, and mouth) and voice features (specifically, a lower limit frequency f1 and an upper limit frequency f2). Is shown). The feature data is composed of data such as actors appearing in moving image contents such as TV and movies. The voice separation unit 32 described later compares the speaker's facial features extracted by the video analysis unit 31 with the feature data stored in the feature DB 33, and if there is matching feature data, Voice features corresponding to the facial features are acquired.
なお、本実施の形態においては、映像音声出力装置3が特徴DB33を備える構成としたが、映像音声出力装置3が特徴DB33を備えない構成でもよく、映像音声出力装置3が、通信ネットワークを介して特徴DB33にアクセスし、特徴DB33に記憶されたデータを参照する構成としてもよい。また、特徴DB33に記憶される特徴データは、最新の映像コンテンツの内容に合わせて随時更新されるようにしてもよい。
In the present embodiment, the video / audio output device 3 includes the feature DB 33. However, the video / audio output device 3 may not include the feature DB 33, and the video / audio output device 3 may be connected via a communication network. The feature DB 33 may be accessed and the data stored in the feature DB 33 may be referred to. Further, the feature data stored in the feature DB 33 may be updated as needed according to the latest video content.
音声分離部32は、入力した音声データ(話者音声と背景音が混合した音声データ)を、周波数パラメータP1または周波数パラメータP3に従って、話者音声と背景音に分離するようになっている。詳しくは、音声分離部32は、映像解析部31が出力した顔特徴に基づいて特徴DB33から声特徴を取得できる場合には、取得した声特徴を周波数パラメータP3として設定し、設定した周波数パラメータP3に従って、音声データを分離するようになっている。一方、映像解析部31が出力した顔特徴に基づいて特徴DB33から声特徴を取得できない場合には、周波数パラメータP1に従って、音声データを分離するようになっている。例えば、図13に示す特徴データの中から話者Aの声特徴を取得できた場合には、周波数パラメータP3の下限周波数f1=3000Hz、上限周波数f2=5000Hzを設定し、この周波数パラメータP3に従って、話者音声と背景音を分離する。
The voice separation unit 32 separates the input voice data (voice data in which the speaker voice and the background sound are mixed) into the speaker voice and the background sound according to the frequency parameter P1 or the frequency parameter P3. Specifically, when the voice separation unit 32 can acquire a voice feature from the feature DB 33 based on the facial feature output from the video analysis unit 31, the voice separation unit 32 sets the acquired voice feature as the frequency parameter P3, and the set frequency parameter P3. The voice data is separated according to the above. On the other hand, when the voice feature cannot be acquired from the feature DB 33 based on the facial feature output by the video analysis unit 31, the audio data is separated according to the frequency parameter P1. For example, when the voice feature of the speaker A can be acquired from the feature data shown in FIG. 13, the lower limit frequency f1 = 3000 Hz and the upper limit frequency f2 = 5000 Hz of the frequency parameter P3 are set. Separate speaker and background sounds.
また、音声分離部32は、分離した話者音声を定位処理部13に出力し、分離した背景音を音声出力部15に出力するようになっている。
Also, the voice separation unit 32 outputs the separated speaker voice to the localization processing unit 13 and outputs the separated background sound to the voice output unit 15.
図14は本実施の形態に係る映像音声出力装置3の音声分離処理の流れを詳しく示すフローチャートである。
FIG. 14 is a flowchart showing in detail the flow of audio separation processing of the video / audio output device 3 according to the present embodiment.
音声分離部32は、周波数パラメータP1の下限周波数f1及び上限周波数f2を設定する(ステップS72)。具体的には、f1=80Hz、f2=3000Hzである。
The voice separation unit 32 sets the lower limit frequency f1 and the upper limit frequency f2 of the frequency parameter P1 (step S72). Specifically, f1 = 80 Hz and f2 = 3000 Hz.
次に、音声分離部22は、特徴DB33に顔特徴が一致する特徴データがあるか否かを判定する(ステップS74)。特徴DB33に一致する特徴データがある場合には(ステップS74:YES)、一致した特徴データの声特徴を取得して、周波数パラメータP3の下限周波数f1及び上限周波数f2を設定する(ステップS76)。
Next, the voice separation unit 22 determines whether or not there is feature data with matching facial features in the feature DB 33 (step S74). If there is matching feature data in the feature DB 33 (step S74: YES), the voice feature of the matched feature data is acquired, and the lower limit frequency f1 and the upper limit frequency f2 of the frequency parameter P3 are set (step S76).
次に、音声分離部22は、周波数パラメータP3が設定されている場合には周波数パラメータP3に基づいて、周波数パラメータP3が設定されていない場合には周波数パラメータP1に基づいて、入力された音声データを帯域通過フィルタにかけて、話者音声を分離する(ステップS78)。
Next, the voice separation unit 22 inputs the voice data based on the frequency parameter P3 when the frequency parameter P3 is set, and based on the frequency parameter P1 when the frequency parameter P3 is not set. Is applied to a band pass filter to separate the speaker voice (step S78).
次に、音声分離部22は、周波数パラメータP3が設定されている場合には周波数パラメータP3に基づいて、周波数パラメータP3が設定されていない場合には周波数パラメータP1に基づいて、入力された音声データを帯域阻止フィルタにかけて、背景音を分離する(ステップS80)。
Next, the voice separation unit 22 inputs the voice data based on the frequency parameter P3 when the frequency parameter P3 is set, and based on the frequency parameter P1 when the frequency parameter P3 is not set. Is applied to the band rejection filter to separate the background sound (step S80).
以上説明したように、本実施の形態に係る映像音声出力装置3によれば、話者の顔特徴から個人を特定し、特定した個人の声特徴を反映した周波数パラメータP3に基づいて音声を分離することができるので、話者音声と背景音の分離の精度をさらに上げることができる。
As described above, according to the video / audio output device 3 according to the present embodiment, an individual is identified from the speaker's facial features, and the speech is separated based on the frequency parameter P3 reflecting the identified individual's voice features. Therefore, the accuracy of separating the speaker voice and the background sound can be further increased.
<第4の実施の形態>
図15は、本発明の第4の実施の形態に係る映像音声出力装置4の概略構成図である。映像音声出力装置4は、話者位置に合わせた音声定位で音声を出力する装置である。 <Fourth embodiment>
FIG. 15 is a schematic configuration diagram of a video /audio output device 4 according to the fourth embodiment of the present invention. The video / audio output device 4 is a device that outputs audio with audio localization in accordance with the speaker position.
図15は、本発明の第4の実施の形態に係る映像音声出力装置4の概略構成図である。映像音声出力装置4は、話者位置に合わせた音声定位で音声を出力する装置である。 <Fourth embodiment>
FIG. 15 is a schematic configuration diagram of a video /
映像解析部41は、入力した映像データを映像表示部14に出力する(音声データと同期させるため、必要に応じて映像データを遅延させて映像表示部14に出力する)とともに、入力した映像データから話者位置を特定するようになっている。
The video analysis unit 41 outputs the input video data to the video display unit 14 (to synchronize with the audio data, the video data is delayed and output to the video display unit 14 as necessary), and the input video data The speaker position is specified from the above.
また、映像解析部41は、シーンの特徴を解析する機能を有しており、入力された映像データのシーン特徴を取得するようになっている。詳しくは、映像データのRGBヒストグラム、RGBヒストグラムの時間変化、単位ブロックでの動きベクトルの分散等から、シーン特徴を取得するようになっている。
Further, the video analysis unit 41 has a function of analyzing the features of the scene, and acquires the scene features of the input video data. Specifically, the scene feature is acquired from the RGB histogram of the video data, the temporal change of the RGB histogram, the distribution of the motion vector in the unit block, and the like.
また、映像解析部41は、特定した話者の位置を定位処理部13に出力し、取得したシーン特徴を音声分離部42に出力するようになっている。
Also, the video analysis unit 41 outputs the specified speaker position to the localization processing unit 13 and outputs the acquired scene feature to the audio separation unit 42.
音声分離部42は、入力した音声データ(話者音声と背景音が混合した音声データ)を、周波数パラメータP1または周波数パラメータP4に従って、話者音声と背景音に分離するようになっている。詳しくは、音声分離部42は、映像解析部41が取得したシーン特徴から、背景音の推定が可能である場合には、シーン特徴の背景音の特徴(周波数パラメータP4)を取得する。例えば、シーン特徴が「降雨シーン」である場合には、入力した音声データから雨の音を除くことで話者音声を得ることができる。具体的には、雨の音はホワイトノイズに近い特性を持っているので、すべての周波数帯域から一定のパワーを差し引くことにより、話者音声を分離することができる。一方、映像解析部41が背景音の推定が可能でない場合には、周波数パラメータP1に従って、音声データを分離するようになっている。
The voice separation unit 42 separates the input voice data (voice data in which the speaker voice and the background sound are mixed) into the speaker voice and the background sound according to the frequency parameter P1 or the frequency parameter P4. Specifically, when the background sound can be estimated from the scene feature acquired by the video analysis unit 41, the sound separation unit 42 acquires the background sound feature (frequency parameter P4) of the scene feature. For example, when the scene feature is “rainfall scene”, the speaker voice can be obtained by removing the rain sound from the input voice data. Specifically, since the sound of rain has characteristics close to white noise, the speaker's voice can be separated by subtracting a certain power from all frequency bands. On the other hand, when the video analysis unit 41 cannot estimate the background sound, the audio data is separated according to the frequency parameter P1.
図16は本実施の形態に係る映像音声出力装置4の音声分離処理の流れを詳しく示すフローチャートである。
FIG. 16 is a flowchart showing in detail the flow of the audio separation process of the video / audio output device 4 according to the present embodiment.
音声分離部42は、算出したシーン特徴から背景音の推定が可能であるか否かを判定する(ステップS82)。背景音の推定が可能である場合には(ステップS82:YES)、音声分離部42は、推定した背景音に適した周波数パラメータP4を設定して、話者音声及び背景音を取得する(ステップS84)。一方、背景音の推定が可能でない場合には(ステップS82:NO)、音声分離部42は、周波数パラメータP1の下限周波数f1及び上限周波数f2を設定する(ステップS86)。具体的には、f1=80Hz、f2=3000Hzである。
The sound separation unit 42 determines whether the background sound can be estimated from the calculated scene feature (step S82). When the background sound can be estimated (step S82: YES), the speech separation unit 42 sets the frequency parameter P4 suitable for the estimated background sound and acquires the speaker sound and the background sound (step S82). S84). On the other hand, when the background sound cannot be estimated (step S82: NO), the sound separation unit 42 sets the lower limit frequency f1 and the upper limit frequency f2 of the frequency parameter P1 (step S86). Specifically, f1 = 80 Hz and f2 = 3000 Hz.
次に、音声分離部42は、周波数パラメータP1に基づいて、入力された音声データに帯域通過フィルタをかけて、話者音声を分離し(ステップS88)、周波数パラメータP1に基づいて、入力された音声データに帯域阻止フィルタをかけて、背景音を分離する(ステップS90)。
Next, the voice separator 42 applies a band-pass filter to the input voice data based on the frequency parameter P1 to separate the speaker voice (step S88), and the input is performed based on the frequency parameter P1. A band rejection filter is applied to the audio data to separate background sounds (step S90).
以上説明したように、本実施の形態に係る映像音声出力装置4によれば、シーン特徴を解析し、解析したシーン特徴から背景音の推定を行うので、話者音声と背景音の分離の精度をさらに上げることができる。
As described above, according to the video / audio output device 4 according to the present embodiment, the scene feature is analyzed, and the background sound is estimated from the analyzed scene feature. Can be further increased.
以上、本発明の実施の形態について説明してきたが、本発明は、上述した実施の形態に限られるものではなく、本発明の要旨を逸脱しない範囲において、本発明の実施の形態に対して種々の変形や変更を施すことができ、そのような変形や変更を伴うものもまた、本発明の技術的範囲に含まれるものである。
Although the embodiments of the present invention have been described above, the present invention is not limited to the above-described embodiments, and various modifications can be made to the embodiments of the present invention without departing from the gist of the present invention. Such modifications and changes can be made, and those accompanying such modifications and changes are also included in the technical scope of the present invention.
1,1A,2,3,4 映像音声出力装置
11,21,31,41 映像解析部
12,22,32,42 音声分離部
13,13A 定位処理部
14 映像表示部
15 音声出力部
23 属性DB
33 特徴DB
P1,P2,P3,P4 周波数パラメータ
f1 下限周波数
f2 上限周波数
1, 1A, 2, 3, 4 Video / audio output device 11, 21, 31, 41 Video analysis unit 12, 22, 32, 42 Audio separation unit 13, 13A Localization processing unit 14 Video display unit 15 Audio output unit 23 Attribute DB
33 Feature DB
P1, P2, P3, P4 Frequency parameter f1 Lower limit frequency f2 Upper limit frequency
11,21,31,41 映像解析部
12,22,32,42 音声分離部
13,13A 定位処理部
14 映像表示部
15 音声出力部
23 属性DB
33 特徴DB
P1,P2,P3,P4 周波数パラメータ
f1 下限周波数
f2 上限周波数
1, 1A, 2, 3, 4 Video /
33 Feature DB
P1, P2, P3, P4 Frequency parameter f1 Lower limit frequency f2 Upper limit frequency
Claims (7)
- 映像を解析して、話者の位置を特定する話者位置特定手段と、
話者の音声と背景音が混じった混合音声を、話者の音声と背景音に分離する音声分離手段と、
前記話者位置特定手段が特定した話者の位置に、前記音声分離手段が分離した話者の音声を定位させる音声定位手段と、
を備えることを特徴とする映像音声出力装置。 A speaker position specifying means for analyzing a video and specifying a speaker position;
A voice separation means for separating the mixed voice mixed with the speaker's voice and the background sound into the speaker's voice and the background sound;
Voice localization means for localizing the voice of the speaker separated by the voice separation means at the position of the speaker identified by the speaker position identification means;
A video / audio output device comprising: - 前記音声分離手段は、
話者の音声の上限周波数及び下限周波数に関する第1のパラメータを備え、
前記第1のパラメータに基づいて、前記混合音声を話者の音声と背景音に分離することを特徴とする請求項1記載の映像音声出力装置。 The voice separation means is
A first parameter for the upper and lower frequency limits of the speaker's voice;
The video / audio output apparatus according to claim 1, wherein the mixed sound is separated into a speaker's voice and a background sound based on the first parameter. - 映像を解析して、話者の属性を検出する属性検出手段と、
前記属性検出手段が検出した話者の属性に応じて、前記第1のパラメータの値を調整する音声パラメータ調整手段と、
をさらに備え、
前記音声分離手段は、
前記音声パラメータ調整手段により調整された前記第1のパラメータの値に基づいて、前記混合音声を話者の音声と背景音に分離することを特徴とすることを特徴とする請求項2記載の映像音声出力装置。 Attribute detection means for analyzing the video and detecting speaker attributes;
Voice parameter adjustment means for adjusting the value of the first parameter according to the speaker attribute detected by the attribute detection means;
Further comprising
The voice separation means is
3. The video according to claim 2, wherein the mixed sound is separated into a speaker's voice and a background sound based on the value of the first parameter adjusted by the voice parameter adjusting means. Audio output device. - 映像を解析して、話者の顔特徴を検出する顔特徴検出手段と、
人の顔特徴と、その人の音声の上限周波数及び下限周波数に関する第2のパラメータとを対応付けて記憶しているデータベースと、
前記データベースに前記顔特徴検出手段が検出した顔特徴が存在する場合には、前記顔特徴検出手段が検出した顔特徴に対応付けられた第2のパラメータを取得するパラメータ取得手段と、
をさらに備え、
前記音声分離手段は、
前記データベースに前記顔特徴検出手段が検出した顔特徴が存在する場合には、前記第2のパラメータに基づいて、前記データベースに前記顔特徴検出手段が検出した顔特徴が存在しない場合には、記第1のパラメータに基づいて、前記混合音声を話者の音声と背景音に分離することを特徴とする請求項2記載の映像音声出力装置。 Facial feature detection means for analyzing the video and detecting the facial features of the speaker;
A database that stores the facial features of the person and the second parameters related to the upper limit frequency and the lower limit frequency of the voice of the person in association with each other;
Parameter acquisition means for acquiring a second parameter associated with the facial feature detected by the facial feature detection means when the facial feature detected by the facial feature detection means exists in the database;
Further comprising
The voice separation means is
If the facial feature detected by the facial feature detection means exists in the database, the facial feature detected by the facial feature detection means does not exist in the database based on the second parameter. 3. The video / audio output device according to claim 2, wherein the mixed sound is separated into a speaker's sound and a background sound based on the first parameter. - 映像を解析して、シーン特徴を検出するシーン特徴検出手段と、
検出したシーン特徴から背景音を推定する背景音推定手段と、
をさらに備え、
前記音声分離手段は、
前記背景音推定手段が背景音を推定できた場合には、推定した背景音に適した周波数に関するパラメータに基づいて、前記背景音推定手段が背景音を推定できない場合には、前記第1のパラメータに基づいて、前記混合音声を話者の音声と背景音に分離することを特徴とする請求項2記載の映像音声出力装置。 Scene feature detection means for analyzing a video and detecting a scene feature;
A background sound estimation means for estimating a background sound from the detected scene feature;
Further comprising
The voice separation means is
When the background sound estimation means can estimate the background sound, based on the parameter relating to the frequency suitable for the estimated background sound, when the background sound estimation means cannot estimate the background sound, the first parameter The video / audio output apparatus according to claim 2, wherein the mixed sound is separated into a speaker's voice and a background sound based on the above. - 前記音声定位手段は、
前記話者位置特定手段が特定した話者の位置に対して、画面の中心から遠ざける方向に、前記音声分離手段が分離した背景音を定位させることを特徴とする請求項1乃至5のいずれか1項に記載の映像音声出力装置。 The voice localization means includes
6. The background sound separated by the voice separation unit is localized in a direction away from the center of the screen with respect to the speaker position specified by the speaker position specifying unit. The video / audio output device according to Item 1. - 映像を解析して、話者の位置を特定する話者位置特定ステップと、
話者の音声と背景音が混じった混合音声を、話者の音声と背景音に分離する音声分離ステップと、
前記話者位置特定ステップで特定した話者の位置に、音声分離ステップで分離した話者の音声を定位させる音声定位ステップと、
を備えることを特徴とする音声定位方法。 A speaker location step for analyzing the video and identifying the speaker location;
A voice separation step of separating the mixed voice mixed with the speaker's voice and the background sound into the speaker's voice and the background sound;
A voice localization step of localizing the voice of the speaker separated in the voice separation step to the position of the speaker identified in the speaker position identification step;
A sound localization method comprising:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2009/058744 WO2010131318A1 (en) | 2009-05-11 | 2009-05-11 | Video-sound output device and method for localizing sound |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2009/058744 WO2010131318A1 (en) | 2009-05-11 | 2009-05-11 | Video-sound output device and method for localizing sound |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2010131318A1 true WO2010131318A1 (en) | 2010-11-18 |
Family
ID=43084708
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2009/058744 WO2010131318A1 (en) | 2009-05-11 | 2009-05-11 | Video-sound output device and method for localizing sound |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2010131318A1 (en) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05191896A (en) * | 1992-01-13 | 1993-07-30 | Pioneer Electron Corp | Pseudo stereo device |
| JP2000295700A (en) * | 1999-04-02 | 2000-10-20 | Nippon Telegr & Teleph Corp <Ntt> | Method and system for sound source localization using image information and storage medium storing program to realize the method |
-
2009
- 2009-05-11 WO PCT/JP2009/058744 patent/WO2010131318A1/en active Application Filing
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05191896A (en) * | 1992-01-13 | 1993-07-30 | Pioneer Electron Corp | Pseudo stereo device |
| JP2000295700A (en) * | 1999-04-02 | 2000-10-20 | Nippon Telegr & Teleph Corp <Ntt> | Method and system for sound source localization using image information and storage medium storing program to realize the method |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10142759B2 (en) | Method and apparatus for processing audio with determined trajectory | |
| US5548346A (en) | Apparatus for integrally controlling audio and video signals in real time and multi-site communication control method | |
| JP5067595B2 (en) | Image display apparatus and method, and program | |
| US20100302401A1 (en) | Image Audio Processing Apparatus And Image Sensing Apparatus | |
| JP2019523902A (en) | Method and apparatus for generating a virtual or augmented reality presentation using 3D audio positioning | |
| CN102111601A (en) | Content-based adaptive multimedia processing system and method | |
| JP2011250100A (en) | Image processing system and method, and program | |
| KR20070034462A (en) | Video-Audio Synchronization | |
| JP5085769B1 (en) | Acoustic control device, acoustic correction device, and acoustic correction method | |
| US20090154896A1 (en) | Video-Audio Recording Apparatus and Video-Audio Reproducing Apparatus | |
| KR20150001521A (en) | Display apparatus and method for providing a stereophonic sound service | |
| CN102055941A (en) | Video player and video playing method | |
| US11211074B2 (en) | Presentation of audio and visual content at live events based on user accessibility | |
| US20120301030A1 (en) | Image processing apparatus, image processing method and recording medium | |
| CN114830233A (en) | Adjusting audio and non-audio features based on noise indicator and speech intelligibility indicator | |
| US20110109722A1 (en) | Apparatus for processing a media signal and method thereof | |
| US20220053282A1 (en) | Apparatus and method for processing audiovisual data | |
| US20090304088A1 (en) | Video-sound signal processing system | |
| CN111787464B (en) | Information processing method and device, electronic equipment and storage medium | |
| WO2010140254A1 (en) | Image/sound output device and sound localizing method | |
| JP2010124391A (en) | Information processor, and method and program for setting function | |
| WO2010131318A1 (en) | Video-sound output device and method for localizing sound | |
| JP2015018079A (en) | Subtitle voice generation apparatus | |
| KR20220117057A (en) | Method and apparatus for video quality assessment according to the presence and absence of audio | |
| JP2011234139A (en) | Three-dimensional audio signal generating device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 09844592 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| 122 | Ep: pct application non-entry in european phase |
Ref document number: 09844592 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: JP |