WO2007107315A1 - Multisensorieller hypothesen-basierter objektdetektor und objektverfolger - Google Patents
Multisensorieller hypothesen-basierter objektdetektor und objektverfolger Download PDFInfo
- Publication number
- WO2007107315A1 WO2007107315A1 PCT/EP2007/002411 EP2007002411W WO2007107315A1 WO 2007107315 A1 WO2007107315 A1 WO 2007107315A1 EP 2007002411 W EP2007002411 W EP 2007002411W WO 2007107315 A1 WO2007107315 A1 WO 2007107315A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- hypotheses
- sensor signal
- stream
- hypothesis
- search
- Prior art date
Links
Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/103—Static body considered as a whole, e.g. static pedestrian or occupant recognition
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/214—Generating training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/25—Fusion techniques
- G06F18/253—Fusion techniques of extracted features
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/10—Image acquisition
- G06V10/12—Details of acquisition arrangements; Constructional details thereof
- G06V10/14—Optical characteristics of the device performing the acquisition or on the illumination arrangements
- G06V10/147—Details of sensors, e.g. sensor lenses
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/774—Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/80—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level
- G06V10/806—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level of extracted features
Definitions
- the invention relates to a method for multi-sensor object detection.
- driver assistance systems for road vehicles which detect and track vehicles ahead by means of radar, for example, to automatically regulate the speed and the distance of the own vehicle to the preceding traffic.
- various types of sensors such as radar, laser and camera sensors are already known for use in the vehicle environment. These sensors are very different in their properties and have different advantages and disadvantages. For example, such sensors differ in their resolution or in the spectral sensitivity. It would therefore be particularly advantageous if several different sensors would be used simultaneously in a driver assistance system.
- the invention is therefore based on the object to provide a method for multi-sensor object detection, which objects can be detected and tracked in a simple and reliable manner.
- a method for multi-sensor object detection wherein sensor information from at least two different sensor signal currents with different
- Sensor signal properties are used for joint evaluation.
- the sensor signal currents are not adapted to each other for evaluation and / or imaged each other.
- object hypotheses are first of all generated and, on the basis of these object hypotheses, features for at least one classifier are then generated.
- the object hypotheses are then evaluated by means of the at least one classifier and assigned to one or more classes. At least two classes are defined, one of the two classes being assigned objects.
- the sensor information from the at least two sensor signal streams is combined directly with one another or fused together. This considerably simplifies the evaluation and enables shorter calculation times. The fact that no additional steps for the adaptation of the individual sensor signal currents are needed, the number of possible sources of error in the evaluation is minimized.
- the object hypotheses can either be clearly assigned to a class, or they are assigned to several classes, the respective assignment is occupied with a probability.
- the object hypotheses are independently generated individually in each sensor signal stream, the object hypotheses of different sensor signal currents are then assigned to each other via assignment rules.
- the object hypotheses are generated in each sensor signal stream by means of search windows in a previously defined 3D state space, which is defined by physical variables. Due to the defined 3D state space, the object hypotheses generated in the individual sensor signal streams can later be assigned to one another.
- the object hypotheses from two different sensor signal streams are paired later in the subsequent classification, forming an object-hypothesis-out-of-a-search-window pair if there are more than two sensor signal streams Accordingly, from each sensor signal stream in each case a search window used and formed from an object hypothesis, which is then passed to the classifier for joint evaluation.
- the physical quantities for spanning the 3D state space can be, for example, one or more component (s) of the object extent, a speed and / or acceleration parameter, a time, etc.
- the state space can also be made higher dimensional.
- object hypotheses are generated in a sensor signal stream (primary stream) and the object hypotheses of the primary stream are then projected into other image streams (secondary streams), wherein an object hypothesis of the primary stream generates one or more object hypotheses in the secondary stream.
- the object hypotheses in the primary stream are generated, for example, by means of a search window within the image recordings recorded by means of the camera sensor.
- the object hypotheses generated in the primary stream are then computationally projected into one or more other sensor streams.
- the projection of object hypotheses of the primary current into a secondary current is based on the sensor models used and / or the positions of search windows within the primary current or on the epipolar geometry of the sensors used.
- Projection can also create ambiguity in this context.
- An object hypothesis / search window of the primary stream generates, for example, due to different object distances of the individual sensors, several -Ob ⁇ j ⁇ e ⁇ kthypot-hesen - / - Suchfenst_e_r in the secondary stream.
- the object hypotheses generated with it are then preferably pass in pairs to the classifier. In each case, pairs are formed from the object hypothesis of the primary stream and in each case one object hypothesis of the secondary stream and then transferred to the classifier.
- all object hypotheses or parts thereof generated in the secondary flows are also passed to the classifier.
- object hypotheses are profitably determined by their object type, object position, object extent, object orientation, object motion parameters such as direction of motion and velocity,
- Object hazard potential or any combination thereof can also be any other parameter that describes the object properties.
- an object associated speed and / or acceleration values is particularly advantageous if the inventive method is used in addition to the object recognition in addition to the object tracking and the evaluation includes tracking.
- object hypotheses are randomly scattered in a physical search space or generated in a grid.
- search windows are varied with a predetermined step size within the search space using a grid.
- search windows are used only within predetermined regions of the state space at which objects occur with high probability and thus object hypotheses are generated.
- the object hypotheses in a physical search space can also be determined by a physical search space Model originated.
- the search space may be adaptively constrained by external constraints such as aperture angles, range ranges, statistical characteristics obtained locally in the image, and / or measurements from other sensors.
- the different sensor signal properties in the sensor signal currents are based essentially on different positions and / or orientations and / or sensor variables of the sensors used.
- deviations in the sensor variables used mainly cause different sensor signal properties in the individual sensor signal currents.
- camera sensors having a different resolving power cause differences in sizes in image capturing.
- different sized image areas are often detected.
- the physical properties of the camera chips can be completely different, so that, for example, one camera captures environmental information in the visible wavelength spectrum and another camera acquires environmental information in the infrared spectrum, wherein the image recordings can have a completely different resolution.
- each object hypothesis is individually classified for themselves and the results of the individual classifications are combined, at least one classifier is provided. If several classifiers are used, e.g. for each different
- the grid in which the object hypotheses are generated is adaptively adjusted depending on the classification result.
- the grid width is adapted adaptively as a function of the classification result, object hypotheses being generated only at the grid points or search windows being positioned only at grid points.
- the screen ruling is preferably chosen to be smaller.
- the grid size is larger if object hypotheses are increasingly assigned to an object class or if the probability of object class membership increases.
- a hierarehi.s.chen Structure-for-the-hypothesis grid possible.
- the grid in Depending on the classification result of a previous time step adaptively adapted, possibly taking into account a dynamic system model.
- the evaluation method by means of which the object hypotheses are evaluated, is adjusted automatically as a function of at least one previous evaluation.
- the last preceding classification result or several previous classification results are taken into account.
- only individual parameters of an evaluation method and / or a plurality of evaluation methods are selected here for a suitable evaluation method.
- the most varied evaluation methods are possible in this connection, which can be based, for example, on statistical and / or model-based approaches.
- the type of evaluation method provided for the selection also depends on the type of sensors used.
- both the grid is adapted adaptively, and the evaluation method used for the evaluation is adapted.
- the raster is refined in a profitable manner only at the positions in the search space where the probability or score for the presence of objects is high enough, with the score being derived from the last raster levels.
- the different sensor signal currents can also be used zi-tgie-i-eh- 7 -a-be-r-auch_zei_tv_ers_e £, zt.
- a single Sensor signal stream together with at least one time-shifted version of the same can be used.
- the inventive method can be used except for object detection and tracking of detected objects.
- the inventive method can be used in particular for environmental detection and / or object tracking in a road vehicle.
- a combination of a color camera sensitive in the visible wavelength spectrum and a camera sensitive in the infrared wavelength spectrum is suitable for use in a road vehicle.
- persons and, on the other hand, the colored signal lights of traffic lights in the vicinity of the road vehicle can be reliably detected at night.
- the information provided by the two sensors is evaluated by the method according to the invention for multisensorial object recognition in order to recognize and track, for example, persons contained therein.
- the sensor information is thereby preferably presented to the driver on a display unit arranged in the vehicle cockpit in the form of image data, persons and signal lights of traffic light installations being highlighted in the displayed image information.
- FIG. 1 shows on the left a surrounding scene detected by means of an NIR camera and on the right a scene detected by means of an FIR camera
- FIG. 2 shows a suboptimal assignment of two sensor signal streams
- FIG. 3 the feature formation in connection with FIG
- FIG. 4 shows the geometric determination of the search space.
- FIG. 5 shows a resulting set of hypotheses for a
- FIG. 6 shows the epipolar geometry of a two-camera system.
- FIG. 7 shows the epipolar geometry using the example of FIG.
- Pedestrian Detection Fig. 8 shows the cause of scaling differences in
- Fig. 10 shows the relaxation of the correspondence condition Fig. 11 correspondence error between label and
- FIG. 12 shows how multi-stream hypotheses arise
- FIG. 13 Comparison of detection rates with different ones
- Grid width Fig. 14 shows the detector response as a function of the achieved
- FIG. 15 shows a coarse-to-fine search in the one-dimensional case.
- FIG. 16 shows by way of example the neighborhood definition
- FIG. 17 a hypothesis tree
- the two camera sensors and the recorded intensity images differ greatly.
- the NIR image shown on the left has a high variance depending on the lighting conditions and surface properties.
- the heat rays detected by the FIR camera which are shown in the right-hand part of the picture, are almost exclusively direct emissions of the objects. Due to their intrinsic heat, pedestrians in particular generate a pronounced signature in thermal images and stand out greatly from the background in country road scenarios.
- this obvious advantage of the FIR sensor is contrasted with its resolution: it is four times smaller in the X and Y direction than that of the NIR camera. Due to this rough sampling, important high-frequency signal components are lost. For example, a pedestrian 50 meters away in the FIR image only has a height of 10 pixels.
- the quantization also differs, although both cameras deliver 12-bit gray value images, however, the dynamic range relevant for the detection task extends to 9 bits for the NIR camera and to only 6 bits for the FIR camera. This results in an 8 times larger quantization error.
- the NIR camera image object structures are clearly visible, the image is dependent on lighting and surface structure and it has a high intensity variance.
- the FIR camera image object structures are difficult to detect, the image is dependent on emissions, with the pedestrian stands out clearly from the cold background. Due to the fact that both sensors have various advantages, namely that the strengths of one are the weaknesses of the other, the use of these sensors in the context of the inventive method is particularly advantageous. Here are the advantages of both sensors in one. Combine classifier, which significantly exceeds the detection performance of single-stream classifiers.
- sensor fusion refers to the use of multiple sensors and the generation of a common representation. The goal is to increase the accuracy of the information obtained. Characteristic here is the union of measured data in a perceptual system.
- the sensor integration refers to the use of different sensors for several subtasks, such as image recognition for localization and haptic sensors for subsequent manipulation with actuators.
- Fusion approaches can be categorized based on their resulting representations. For example, the following four fusion levels are distinguished:
- Pixel-level fusion In contrast to the signal plane, the spatial reference of pixels to objects in space is considered. Examples are extraction of depth information with stereo cameras or the calculation of optical flow in image sequences.
- Feature-level fusion Feature-level fusion independently extracts features from both sensors. These are combined, for example, in a classifier or a localization method.
- Symbol-level fusion For example, symbolic representations are words or phrases used in speech recognition. Grammars create logical relationships between words. These in turn can control the interpretation of acoustic and visual signals.
- classifier fusion Another form of fusion is the classifier fusion.
- the results of several classifiers are united.
- the data sources or the sensors are not necessarily different.
- the goal here is to reduce the classification error by redundancy.
- the decisive factor is that the individual classifiers have errors that are as uncorrelated as possible.
- Weighted majority decision A simple principle is the majority decision, ie the choice of class issued by most classifiers. Each classifier can be weighted according to its reliability. Using learning data ideal weights can be determined.
- Bayes combination For each classifier a confusion matrix can be calculated. This is a confusion matrix indicating the frequency of all classifier results for each actual class. It can be used to approximate conditional probabilities for resulting classes. Now all classifications are mapped to probabilities for class membership using the Bayes theorem. As the final result, the maximum is then selected.
- the further classifier can be trained with the vector of the results and the label of the first classifier.
- Possible fusion concepts in the detection of pedestrians are the detector fusion and a merger on feature level. There are already acceptable solutions to the detection problem with only one sensor, so combining by classifier fusion is possible. In the case of two classifiers and a two class problem considered here, a merger by weighted majority vote or Bayesian combination results in either a simple and operation or an or operation of the single detectors.
- the AND operation has the consequence that (with the same parameterization) the number of detections and thus the detection rate can only be reduced. With an OR operation, the false alarm rate can not get better. How meaningful the respective links are can be determined by determining the confusion matrices and analyzing the correlations.
- the detector result of the cascade classifier can be interpreted as a probability of inference by mapping the achieved level and the last activation to a detection probability. This allows a decision function to be defined on nonbinary values.
- Another possibility is to use the one classifier for attention control and the other classifier for detection. The former should be parameterized so that the detection rate (ate Fa-1-sch-aia-rmr be borne de ⁇ r ⁇ -) - is high.
- Feature-level fusion is mainly due to the availability of boosting techniques.
- the concrete combination of features from both streams can thus be done automatically with the already used method based on the training data.
- the result represents approximately an optimal choice and weighting of the features from both streams.
- An advantage here is the extended feature space. If certain subsets of the data can only be easily separated in one of the individual flow feature spaces, then the combination can simplify the separation of all data. For example, the pedestrian silhouette is clearly visible in the NIR image, whereas the FIR image shows an illumination-independent contrast between the pedestrian and the background. In practice, it has been shown that feature-level fusion can drastically reduce the number of features required.
- the resulting detector will be used in the form of a real-time system and with live data from the two cameras.
- the training uses labeled data.
- An extensive database of sequences and labels is available for this purpose, which includes country road scenes with pedestrians running by the roadside, cars and cyclists.
- the two sensors used record approx. 25 pictures per second, the temporal sampling is done asynchronously due to the hardware, the times of both pictures are independent. Because of fluctuations. At the recording times even a significant difference in the number of images of the two cameras for a sequence is common. An application of the detector is not possible as soon as only one feature is not available.
- ⁇ 3 should be chosen as a function of the distribution of t s (i + 1) -t s (i) and should be about 3 ⁇ .
- mapping is sub-optimal with respect to minimizing the mean timestamp difference.
- the assignment algorithm can be used in this form for the application, there are advantageously no delays due to waiting for potential assignment candidates.
- the concept for the search window plays a central role in the feature formation, especially in the extension of the detector for multi-sensorial use, with multiple sensor signal currents are present.
- the localization of all objects in a picture consists of examining a set of hypotheses.
- a hypothesis stands for a position and scaling of the object in the image. This results in the search window, ie the image section, which is used for the feature calculation.
- one hypothesis consists of a search window pair, that is, one search window in each stream. It should be noted that for a single search window in one stream due to the parallax problem, different combinations of search windows in the other stream may occur. Thus, a very large number of multi-stream hypotheses can arise.
- FIG. 3 shows the feature formation in connection with a multi-stream detector.
- a multi-stream feature set corresponds to the union of the two feature sets that result for the single-stream detectors.
- a multi-stream feature is defined by filter type, position, scaling and sensor flow. Smaller filters can be used in the NIR search window due to the higher image resolution-ais-im- PIR search window. The number of NIR features is thus higher than the number of FIR features. In this embodiment, approximately 7000 NIR features and approximately 3000 FIR features were used.
- new training examples are continuously selected during the training process.
- a new example set is generated using all stages already trained.
- the training examples like the hypotheses, consist of a search window in each stream. Positive examples result from labels that are present in each stream.
- a mapping problem occurs: The randomly selected search windows must be consistent with respect to the projection geometry of the camera system so that the training examples match the multistrom hypotheses of the later application.
- a specific hypothesis generator which will be described in detail below, is used in the determination of the negative examples. Instead of selecting the position and size of the search window from negative examples independently and randomly, a random set of hypotheses is now used.
- the set of hypotheses has a smarter, world model-based distribution of the hypotheses in the image.
- This hypothesis generator can also be used for single-stream training.
- the negative examples are determined with the same search strategy, which later serves in the application of the detector for generating hypotheses.
- the example set for the multi-stream training is made up of positive and negative examples, which include-again-by-the-next-search windows in both streams.
- AdaBoost is used, and all features of each example are calculated. In the feature selection, only the number of features changes compared to the single-stream training, as it is abstracted due to its definition and the associated multistrom data source.
- the architecture of a multi-stream detector application is very similar to that of a single-stream detector.
- the required modifications to the system are on the one hand adaptations for the general handling of multiple sensor signal streams, which changes are required at almost all points of the implementation.
- the hypothesis generator is extended.
- For the generation of multi-stream hypotheses a correspondence condition for search windows of both streams is necessary, which is based on world and camera models.
- a multi-stream camera calibration must be integrated into the hypothesis generation.
- the fusion approach pursued in connection with this exemplary embodiment corresponds to a merger at feature level.
- Ada-Boost a combination of features of both streams is chosen.
- Other methods could be used here for feature selection and fusion.
- the required changes to the detector are an extended feature set, a synchronization of the data as well as the generation of a hypothesis set, which takes into account the geometric relationships of the camera models.
- the derivation of a correspondence rule, the search space sampling and further profitable optimizations are presented below.
- the trained single-stream cascade classifier evaluates individual search windows one after the other. As a result, the classifier provides a statement as to whether an object was detected in exactly this position and scaling.
- hypotheses are defined via a search window pair, that is to say via a search window in each stream.
- search windows can be generated in two streams with two single-stream hypothesis generators, the link to the multistrom hypothesis set is not trivial due to the parallax.
- the step size of the scanning in the u and v directions in FIG. 4 are chosen to be proportional to the height of the hypothesis, that is to say the scaling, and in this example amounts to approximately 5% of the hypothesis height.
- the search window heights themselves are the result of a series of scaling, each increasing by 5% starting with 25 pixels in the NIR image (8 pixels in FIR image).
- This type of quantization can be motivated with a property of the detector, namely the fact that the size scaling of the features also increases the blurring of their localization in the image, as is the case, for example, with a Haarwavelet or similar filters.
- the features are defined here in a fixed grid and are scaled according to the size of the hypothesis. With the hypothesis generation described, a reduction of the 64 million hypotheses of the complete search space to 320,000 results in this case in the NIR image. Due to the low image resolution in the FIR image, there are 50,000 hypotheses. Reference is also made to FIG. 5. For the consideration of the restrictions defined in three-dimensional space, a transformation between image coordinates and world coordinates is necessary. The basis for this are the intrinsic and extrinsic camera parameters determined by the calibration.
- FIG. 4 illustrates the geometric determination of the search space.
- the search area is displayed, which results in a fixed scaling.
- An upper and lower limit is calculated for the upper search window edge in the image.
- the limits (v m i n and v max ) arise when the object is projected onto the image plane once with the smallest and once with the largest expected object size (obj m i n or obj ma ⁇ ).
- the distance (z m i n and Zma x ) is chosen so that the correct scaling arises in the image. Due to the relaxed restriction of the ground plane assumption, the spatial position lies between the dashed planes. The smallest and the largest object are moved up and down to calculate the limits.
- FIG. 5 shows the resulting hypothesis set of the single-stream hypothesis generator.
- search windows with a grid-like arrangement are generated.
- different square lattices are created with adapted lattice spacings and own area restrictions.
- only one search window for each scaling as well as the centers of all other hypotheses is visualized in FIG.
- the illustration is exemplary, with large scaling and position increments selected.
- FIG. 6 shows the epipolar geometry of a two-camera system.
- the epipolar marginal number specifies the set of possible correspondence points for a point in an image plane.
- Epipolar lines and an epipolar plane can be constructed for every point p in the image.
- the possible correspondence points for points of an epipolar line in an image are exactly the same on the corresponding epipolar line of the other image plane.
- FIG. 6 shows in particular the geometry of a multi-camera system with two arbitrarily arranged cameras with the centers Oi e R 3 and O 2 e R 3 and an arbitrary point P e R 3 .
- Oi, O 2 and P span the so-called epipolar plane. It cuts the image planes in the epipolar lines.
- the epipoles are the intersections of the image planes with the line OiO 2 . 0i0 2 is contained in all epipolar planes of all possible points P. All occurring epipolar lines thus intersect in the respective epipole.
- the Epipolarlinien have the following meaning in the correspondence finding: Epipolar lines and an epipolar plane can be constructed for each point p in the picture.
- the possible correspondence points for points of an epipolar line in one image are exactly those on the corresponding epipolar line of the other image plane.
- R and T are clearly defined by the relative extrinsic parameters of the camera system.
- Pi, T and Pi- T are coplanar, i.
- the set of all possible pixels p2 in the second image which may correspond to a point pi of the first image, is exactly the one for which equation (5.6) is erf-ü-1-lt. Mrt of this correspondence condition for individual pixels can now consistent search window pairs from the Single-stream hypotheses are formed as follows:
- the aspect ratio of the search window is preferably fixed by definition, ie a search window can be uniquely described by the midpoints of the upper and lower edge.
- FIG. 7 shows the epipolar geometry using the example of pedestrian detection.
- an ambiguous projection of a search window from the image of the right camera into that of the left camera takes place.
- the correspondence search windows result from the epipolar lines of the centers of the search window bottom and top edges.
- the set of possible search window pairs should include all those search window pairs that describe objects of realistic size. If one calculates the backprojection of the objects into the space, the position and size of the object can be determined by means of triangulation. The range of epipolar lines is then reduced to correspondences with valid object size, as shown by the dotted line in Figure 7.
- FIG. 8 shows, in particular, the cause of the scaling differences arising in the correspondence search windows, and in the projection of a search window from the first to the second sensor stream, a plurality of correspondence search windows with different scaling results.
- the geometric relationship between camera arrangement, object sizes and scaling differences is shown in detail.
- h 2 min or h 2 max is the minimum or maximum occurring scaling of the correspondence search window in the second sensor current to the search window h x in the first sensor current.
- Z ⁇ mxn , Z 1 1 "**, Z 2 min and Z 2 max be the object distances of both objects to both cameras, then follows
- the scaling ratio goes to 1.
- the offset of the cameras is about 2m in the test carrier.
- the correspondence space for a search window in the first stream that is to say the set of corresponding search windows in the second stream, can be simplified as follows:
- the scaling of all corresponding search windows is standardized.
- the scaling h 2 used for all correspondences is the mean of the minimum and maximum scaling:
- FIG. 9 shows resultant correspondences in the NIR image for a search window in the FIR image.
- a unified scaling is used for all corresponding search windows.
- a correspondence error there is an unknown error in the camera model. This creates a fuzziness for both the position and the scaling of the correlated search window, it is referred to below as a correspondence error.
- the scaling error is neglected for the following reasons: First, the influence of the dynamics on the scaling is very small if the object is at least 20m away. Secondly, a significant insensitivity of the detector response can be seen in terms of the accuracy of the hypothesis scaling. This can be seen by multiple detections, whose centers hardly vary, but the scales vary greatly. To compensate for the translational error, a relaxation of the correspondence condition is introduced. For this purpose, a tolerance range for the position of the correlated search window is defined.
- an ellipse-shaped tolerance range is defined in the image with the radii e x and e y , in which further correspondences arise, as shown with reference to FIG.
- the correspondence error is identical for each search window scaling.
- the resulting tolerance range is therefore glejLc_h__selected-t- for each scaling.
- FIG. 10 shows the relaxation of the correspondence condition.
- the positions of the correlating search windows are not limited to one route only. You can now lie within an elliptical area around this distance. In the NIR image, only the center points of the search windows are drawn.
- data labeled with the radii are used.
- the radii of the elliptical tolerance range are determined as follows:
- the correspondence search window that comes closest to the label search window in the second stream is used for error determination.
- the proximity of two search windows can be defined here either by the overlap, in particular by the ratio of the intersection of two rectangles to their union surface (also called coverage) or by the spacing of the search window center points. The latter definition was chosen in this embodiment, since this neglects the scaling error that is uncritical for the detector response.
- the distance in the X and Y directions is determined between the label search window and the closest correspondence search window. This results in a frequency distribution for the X and Y distances.
- the next step after defining the correspondence space for a search window is the search space scan. As with single-stream subsampling, the number of hypotheses should also be minimized with as little loss as possible in the detection performance.
- FIG. 11 shows the correspondence error between label and correspondence search window.
- the illustrated correspondence error is the smallest pixel distance of a label search window to the correspondent search windows of the corresponding label, so the projected label of the other sensor signal stream.
- FIR labels are projected into the NIR image and a histogram is formed over the distances of the search window centers.
- the method for the search space sampling proceeds as follows: In both streams, single-stream hypotheses, ie search windows, are scattered with the single-stream hypothesis generator. In this case, the resulting scaling stages must be matched to one another, wherein in the first stream the scalings are determined by the hypothesis generator. For each of these scaling levels, the correspondence space of a prototypical search window is then determined. The scaling of the second stream results from the scaling of the correspondence spaces of all prototypical search windows. This creates the same number of scaling levels in both streams. Now, search window pairs are formed, resulting in the multi-stream hypotheses. It is then possible to select one of the two streams in order to select the respective one for each search window
- FIG. 12 shows the resulting multistrom hypotheses.
- three search windows in the FIR image and their correspondence regions in the NIR image are drawn. Couples are formed with the search windows scattered by single-stream hypothesis generators. A multi-stream hypothesis corresponds to a search window pair.
- a stronglearner H k of the cascade stage k is defined by:
- Weaklearners with features of a stream include:
- the number of hypotheses per image and the number of all features are decisive.
- the number of hypotheses can be reduced by the number of search windows R 3 in the streams, s cc-protected by O (R1-R2).
- the factor hidden in the O notation is very small here, since the correspondence area is small is opposite to the entire image area.
- the number of calculated features is then in the worst case O (R1-R2- (M1 + M2)) where Ms is the number of features in each stream s.
- each feature in each search window is calculated at most once per image.
- the number of calculated features is at most O (Rl -M1 + R2 -M2).
- the effort is reduced in the worst case by the factor min (Rl, R2).
- a complexity analysis for the average case is more complex because the relationship between the average number of calculated features per hypothesis or search window in the first case and in the second case is not linear.
- the search space of the multistrom detector was detected in this example with two single-stream hypothesis generators and a relaxed correspondence relationship. In this case, however, it is difficult to find an optimal parameterization, especially the finding of the appropriate sampling step sizes. On the one hand, they have a major influence on the detection performance and, on the other hand, on the resulting computational effort.
- acceptable compromises could be found in a practical experiment, which could ensure a real-time capability in the FIR case because of the lower image resolution, but in the NIR case this was not possible with the hardware used.
- the performance of the experimental computer used was also insufficient when using a fusion detector with Weaklearner cache and resulted in longer response times in complex scenes. Of course, these problems can be solved with more powerful hardware.
- FIG. 13 shows the comparison of the detection rates of different screen rulings, wherein four different hypothesis grid densities are compared.
- the detection rate of a fusion detector is plotted against the number of stages used.
- the detection rate is defined by the number of pedestrians found divided by the number of pedestrians.
- the reason for the phenomenon that has occurred is the following property of the detector:
- the detector response, ie the cascade stage reached, is at most a hypothesis which is positioned exactly on the pedestrian. If one pushes the hypothesis step by step away from the pedestrian, the detector result does not drop abruptly to zero, but there is an area in which the detector result varies greatly and tends to decrease. This behavior of the cascade detector is referred to below as a characteristic detector response.
- An experiment in which an image is scanned in pixel steps is visualized in FIG. It uses a multistrom detector and fixed scale hypotheses. You can do that
- FIG. 14 shows the detector response as a function of the achieved detection stage.
- a multistrom detector is applied to a set of hypotheses in a scaling with pixel-precise grid.
- the last cascade level reached is plotted for each hypothesis at its midpoint.
- no training examples slightly offset to a label are used. Only exact positive examples are used as well as negative examples, which have a large distance to each positive example.
- the behavior of the detector is undefined in hypotheses that are slightly offset from an object. Therefore, the characteristic detector response is experimentally investigated for each detector.
- the central idea for reducing the number of hypotheses is a coarse-to-fine search, whereby each image is searched in the first step with a roughly resolved set of hypotheses.
- hypotheses with higher density are scattered in the image.
- the local neighborhood is searched for hypotheses that suggest an object in its vicinity.
- the achieved number of stages can be taken as criteria for the refinement of the search.
- the local neighborhood of the new hypotheses can then be searched again until the finest hypothesis grid is reached.
- a threshold is used with which the achieved cascade level of each hypothesis is compared.
- FIG. 15 shows a coarse-to-fine search in the one-dimensional case.
- an image line from the image acquisition shown in FIG. 14 was used, which is shown in the form of a function in FIG. From left to right you can see the steps of the search process.
- the hypothesis results are horizontal and the thresholds for local refinement are shown horizontally.
- the threshold value is the maximum level for which the affected screen density still has almost the same detection rate as the maximum achievable.
- ⁇ in this example mainly values between 0.98 and 0.999 are suitable.
- the Hypothesian is considered.
- the hypothesis space is now not one-dimensional but in the case of the single-stream detector three-dimensional or six-dimensional in the fusion detector.
- the problem of gradual refinement in all dimensions is solved with the hypothesis generator.
- There are two possibilities for defining the neighborhood of which the second is used in this embodiment.
- a minimum value for the coverage of two adjacent search windows can be defined. In this case, however, it is not clear how to choose the minimum value, since gaps can arise in the refined sets of hypotheses, that is, areas that are not close enough to any hypothesis of the coarse set of hypotheses. Therefore, different thresholds must be set for each grid density.
- the neighborhood can be defined with a modified checkerboard distance. Thus, the mentioned gaps are avoided and it can be defined a uniform threshold for all screen densities.
- the chessboard distance is defined by
- the array density of a current is defined by r x, r y, r h e R.
- the grid spacings are for a search window height h then in the x direction r x • h and in the y direction r y • h.
- For a search window height hi the next largest search window height h is 2 hi- (1 + rh).
- the neighborhood criterion for a search window with position S 1 e R 2 and search window height Ia 1 to a search window S 2 e R 2 of a finer hypothesis set with height h? is with _a_scalar ⁇ ? DEFINE-t ⁇ Max ⁇ ⁇ h 2 e [h x ⁇ + r h ) - ⁇ , hfi + r h y ⁇ ⁇ . r x 'K (5.14)
- Grid intervals have. Then by choosing ⁇ > 0.5 it must be achieved that the neighborhoods of adjacent coarse set hypotheses overlap and the fine grid hypotheses overlap several coarse hypotheses
- the neighborhood definition is shown in FIG. 16: the neighborhood is drawn for three of the hypotheses of the same scaling level, and on the right side there are three different scalings and their resultant
- the generation of the refined hypothesis wanren ⁇ ⁇ er application would be too time-consuming and may as well Preprocessing step done.
- the generation of all refined hypothesis sets is done by means of the hypothesis generator. First, the set of hypotheses for each refinement level is generated. Then the hypotheses are linked to the neighborhood criterion, each hypothesis being compared to each hypothesis of the next finer set of hypotheses. If these are close, they are linked. This results in a tree-like structure whose roots correspond to the hypotheses of the coarsest stage. In FIG. 17, the edges represent the calculated neighborhood relationships. Since a certain search effort is associated with the generation of the hypothesis tree, the calculations required for this purpose are preferably realized via a separate tool and stored in the form of a file.
- FIG. 17 shows the resulting hypothesis tree.
- the hypothesis tree / search tree has several roots and is searched from the roots to the leaf level, if the detection result of a node is greater than the threshold value.
- the hypothesis tree is traversed. Beginning with the first tree root, the tree is searched with a depth or breadth first search. The hypothesis of the root is evaluated. As long as the corresponding threshold value is exceeded, the tree is descended and the respective child node hypotheses are examined. Then the search continues at the next tree root. Along with the backtracking method described below, the depth search is most effective.
- node may have multiple parent node, care must be taken that each nodecycle._ only once examined by the use of a multi-grid tree hypothesis here results in advantageous manner a reduction in d ⁇ he ⁇ Hypothesis number, which affects the detection performance.
- the number of multiple detections is very high in the multi-stream detector and in the FIR detector. Multiple detections therefore have a major impact on computation time as they traverse the entire cascade. Therefore, a so-called backtracking method is used.
- a so-called backtracking method is used.
- the search in the hypothesis tree is aborted and continued at the next tree root. This will locally reduce the density of hypotheses as soon as an object is found.
- all child nodes are randomly permuted so that their order does not correlate with their order in the image. For example, if the first child hypotheses are always in the upper left corner of the neighborhood, detection tends to shift in that direction.
- multiraster hypothesis tree is not only in the context of multi-sensor fusion of great advantage, but is particularly suitable for interaction with cascade classifiers in general and this leads to significantly better classification results.
Abstract
Es wird ein Verfahren zur multisensoriellen Objekterkennung gezeigt, welches Sensorinformationen aus mehreren unterschiedlichen Sensorsignalströmen mit unterschiedlichen Sensorsignaleigenschaften gemeinsam auswertet. Zur Auswertung werden die wenigstens zwei Sensorsignalströme dabei nicht aneinander angepasst und/oder aufeinander abgebildet, sondern in jedem der wenigstens zwei Sensorsignalströme Objekthypothesen generiert und auf der Grundlage dieser Objekthypothesen Merkmale für wenigstens einen Klassifikator generiert. Die Objekthypothesen werden anschließend mittels eines Klassifikators bewertet und einer oder mehreren Klassen zugeordnet, wobei wenigstens zwei Klassen definiert sind und einer der beiden Klassen Objekte zuzuordnen sind,
Description
MuItisensorieller Hypothesen-basierter Objektdetektor und Objektverfolger
[0001] Die Erfindung betrifft ein Verfahren zur multisensoriellen Objekterkennung .
[0002] Die rechnerbasierte Auswertung von Sensorsignalen zur Objekterkennung und Objektverfolgung ist bereits aus dem Stand der Technik bekannt. Beispielsweise sind Fahrerassistenzsysteme für Straßenfahrzeuge erhältlich, welche vorausfahrende Fahrzeuge mittels Radar erkennen und nach verfolgen, um z.B. die Geschwindigkeit und den Abstand des eigenen Fahrzeugs zum vorausfahrenden Verkehr automatisch zu regeln. Für den Einsatz im Fahrzeugumfeld sind darüber hinaus unterschiedlichste Arten von Sensoren, wie z.B. Radar, Laser- und Kamerasensoren bereits bekannt . Diese Sensoren sind in ihren Eigenschaften sehr unterschiedlich und besitzen unterschiedliche Vor- und Nachteile. Beispielsweise unterscheiden sich derartige Sensoren in ihrem Auflösungsvermögen oder in der spektralen Empfindlichkeit. Besonders vorteilhaft wäre es daher, falls mehrere unterschiedliche Sensoren gleichzeitig in einem Fahrerassistenzsystem zum Einsatz kommen würden. Ein multisensorieller Einsatz ist derzeit jedoch kaum möglich, da sich mittels unterschiedlicher Arten von Sensoren erfasste Größen nur mit erheblichem Aufwand bei der Signalauswertung direkt vergleichen oder in geeigneter Weise kombinieren lassen.
[0003] Bei den aus dem Stand der Technik bekannten Systemen werden daher die einzelnen Sensorströme zunächst aneinander angepasst, bevor diese miteinander fusioniert werden. Beispielsweise werden die Bilder zweier Kameras mit unterschiedlichem Auflösungsvermögen zunächst in aufwendiger Weise pixelgenau aufeinander abgebildet und erst dann miteinander fusioniert.
[0004] Der Erfindung liegt daher die Aufgabe zu Grunde ein Verfahren zur multisensoriellen Objekterkennung zu schaffen, womit Objekte auf eine einfache und zuverlässige Weise erkannt und verfolgt werden können.
[0005] Die Aufgabe wird gemäß der Erfindung durch ein Verfahren mit den Merkmalen des Patentanspruchs 1 gelöst . Vorteile Ausgestaltungen und Weiterbildungen werden in den Unteransprüchen aufgezeigt .
[0006] Gemäß der Erfindung wird ein Verfahren zur multisensoriellen Objekterkennung bereitgestellt, wobei Sensorinformationen aus wenigstens zwei unterschiedlichen Sensorsignalströmen mit unterschiedlichen
Sensorsignaleigenschaften zur gemeinsamen Auswertung herangezogen werden. Die Sensorsignalströme werden dabei zur Auswertung nicht aneinander angepasst und/oder aufeinander abgebildet. Anhand der wenigstens zwei Sensorsignalströme werden zunächst Objekthypothesen generiert und auf der Grundlage dieser Objekthypothesen werden sodann Merkmale für wenigstens einen Klassifikator generiert. Die Objekthypothesen werden anschließend mittels dem wenigstens einen Klassifikator bewertet und einer oder mehreren Klassen zugeordnet. Dabei sind wenigstens zwei Klassen definiert, wobei einer der beiden Klassen Objekte zuzuordnen sind. Mit dem erfindungsgemäßen Verfahren wird somit eine einfache und
zuverlässige Objekterkennung erst möglich. Eine aufwendige Anpassung unterschiedlicher Sensorsignalströme aneinander bzw. eine Abbildung aufeinander entfällt hierbei in besonders gewinnbringender Weise komplett . Im Rahmen des erfindungsgemäßen Verfahrens werden die Sensorinformationen aus den wenigstens zwei Sensorsignalströmen vielmehr direkt miteinander kombiniert bzw. miteinander fusioniert. Dadurch wird die Auswertung deutlich vereinfacht und kürzere Rechenzeiten sind möglich. Dadurch dass keine zusätzlichen Schritte für die Anpassung der einzelnen Sensorsignalströme benötigt werden, wird die Anzahl möglicher Fehlerquellen bei der Auswertung minimiert .
[0007] Die Objekthypothesen können entweder eindeutig einer Klasse zugeordnet werden, oder sie werden mehreren Klassen zugeordnet, wobei die jeweilige Zuordnung mit einer Wahrscheinlichkeit belegt ist.
[0008] In einer gewinnbringenden Weise werden die Objekthypothesen unabhängig voneinander einzeln in jedem Sensorsignalstrom generiert, wobei die Objekthypothesen unterschiedlicher Sensorsignalströme sodann über Zuordnungsvorschriften einander zuordenbar sind. Zunächst werden dabei in jedem Sensorsignalstrom mittels Suchfenstern in einem zuvor definierten 3D-Zustandsraum, welcher durch physikalische Größen Aufgespannt wird, die Objekthypothesen generiert. Aufgrund des definierten 3D-Zustandsraums sind die in den einzelnen Sensorsignalströmen generierten Objekthypothesen später einander zuordenbar. Beispielsweise werden die Objekthypothesen aus zwei unterschiedlichen Sensorsignalströmen später bei der sich anschließenden Klassifikation paarweise klassifiziert, wobei eine Obj-ekt-hypot-hese—aus—einem—Such-fens-terpaar—gebildet—wird— Falls mehr als zwei Sensorsignalströme vorhanden sind, wird
dem entsprechend aus jedem Sensorsignalstrom jeweils ein Suchfenster herangezogen und daraus eine Objekthypothese gebildet, welche sodann zur gemeinsamen Auswertung an den Klassifikator übergeben wird. Bei den physikalischen Größen zum Aufspannen des 3D-Zustandsraums kann es sich beispielsweise um eine oder mehrere Komponente (n) der Objektausdehnung, einen Geschwindigkeits- und/oder Beschleunigungsparameter, um eine Zeitangabe usw. handeln. Der Zustandsraum kann dabei auch höher dimensional ausgestaltet sein.
[0009] In einer weiteren gewinnbringenden Weise der Erfindung werden Objekthypothesen in einem Sensorsignalstrom (Primärstrom) generiert und die Objekthypothesen des Primärstroms sodann in andere Bildströme (Sekundärströme) projiziert, wobei eine Objekthypothese des Primärstroms eine oder mehrere Objekthypothesen im Sekundärstrom erzeugt. Bei der Verwendung eines Kamerasensors werden die Objekthypothesen im Primärstrom dabei beispielsweise anhand eines Suchfensters innerhalb der mittels des Kamerasensors aufgezeichneten Bildaufnahmen generiert . Die im Primärstrom generierten Objekthypothesen werden anschließend rechnerisch in einen oder mehrere andere Sensorströme projiziert. In einer weiteren vorteilhaften Weise basiert die Projektion von Objekthypothesen des Primärstroms in einen Sekundärstrom dabei auf den verwendeten Sensormodellen und/oder der Positionen von Suchfenstern innerhalb des Primärstroms bzw. auf der Epipolargeometrie der verwendeten Sensoren. Bei der Projektion können in diesem Zusammenhang auch Mehrdeutigkeiten entstehen. Eine Objekthypothese/Suchfenster des Primärstroms generiert, z.B. aufgrund unterschiedlicher Objektabstände der einzelnen Sensoren, mehrere -Ob~j~e~kthypot-hesen-/-Suchfenst_e_r im Sekundärstrom. Die damit generierten Objekthypothesen werden sodann vorzugsweise
paarweise dem Klassifikator übergeben. Wobei jeweils Paare aus der Objekthypothese des Primärstroms und jeweils einer Objekthypothese des Sekundärstroms gebildet werden und sodann dem Klassifikator übergeben werden. Es besteht aber auch die Möglichkeit, dass neben der Objekthypothese des Primärstroms auch alle in den Sekundärströmen generierten Objekthypothesen oder Teile davon dem Klassifikator übergeben werden.
[0010] Im Zusammenhang mit der Erfindung werden Objekthypothesen in gewinnbringender Weise durch deren Objekttyp, Objektposition, Objektausdehnung, Objektorientierung, Objektbewegungsparameter wie Bewegungsrichtung und Geschwindigkeit,
Objektgefahrenpotential oder einer beliebigen Kombination daraus beschrieben werden. Es kann sich darüber hinaus auch um beliebige weitere Parameter handeln, welche die Objekteigenschaften beschreiben. Beispielsweise einem Objekt zugeordnete Geschwindigkeits- und/oder Beschleunigungswerte. Dies ist insbesondere dann von Vorteil, falls das erfindungsgemäße Verfahren neben der reinen Objekterkennung zusätzlich zur Objektnachverfolgung eingesetzt wird und die Auswertung ein Tracking mit umfasst .
[0011] In einer weiteren vorteilhaften Weise der Erfindung werden Objekthypothesen in einem physikalischen Suchraum zufällig gestreut oder in einem Raster erzeugt. Beispielsweise werden Suchfenster mit einer vorgegebenen Schrittweite innerhalb des Suchraums anhand eines Rasters variiert. Es besteht aber auch die Möglichkeit, dass Suchfenster nur innerhalb von vorbestimmten Bereichen des Zustandsraums an denen Objekte mit hoher Wahrscheinlichkeit auftreten eingesetzt werde und damit Objekthypothesen generieri werden. Außerdem können die Objekthypothesen in einem physikalischen Suchraum auch durch ein physikalisches
Modell entstanden sein. Der Suchraum kann durch externe Vorgaben wie Öffnungswinkel, Entfernungsbereiche, statistische Kenngrößen, die lokal im Bild gewonnen werden, und/oder Messungen anderer Sensoren adaptiv eingeschränkt werden .
[0012] Im Zusammenhang mit der Erfindung basieren die unterschiedlichen Sensorsignaleigenschaften in den Sensorsignalströmen im Wesentlichen auf unterschiedlichen Positionen und/oder Orientierungen und/oder Sensorgrößen der verwendeten Sensoren. Neben Positions- und/oder Orientierungsabweichungen oder einzelnen Komponenten davon verursachen hauptsächlich Abweichungen bei den verwendeten Sensorgrößen unterschiedliche Sensorsignaleigenschaften in den einzelnen Sensorsignalströmen. Beispielsweise verursachen Kamerasensoren mit einem unterschiedlichen Auflösungsvermögen unterschiede in den Größen bei den Bildaufnahmen. Auch werden häufig aufgrund unterschiedlicher Kameraoptiken unterschiedlich große Bildbereiche erfasst . Weiterhin können z.B. die physikalischen Eigenschaften der Kamerachips völlig unterschiedlich sein, sodass beispielsweise eine Kamera Umgebungsinformationen im sichtbaren Wellenlängenspektrum und eine weitere Kamera Umgebungsinformationen im Infraroten Spektrum erfasst, wobei die Bildaufnahmen ein völlig unterschiedliches Auflösungsvermögen aufweisen können.
[0013] Im Rahmen der Auswertung besteht in vorteilhafter Weise die Möglichkeit, dass jede Objekthypothese einzeln für sich klassifiziert wird und die Ergebnisse der einzelnen Klassifikationen kombiniert werden, wobei wenigstens ein Klassifikator vorgesehen ist. Falls mehrere Klassifikatoren zum Einsatz kommen, kann dabei z.B. für jede unterschiedliche
Art—von—Θbj-ekt—-j-ewe-i-1-s—ein—K-lassif-ikat.or viox.ge.sjehen sein.
Falls lediglich ein Klassifikator vorgesehen ist, wird
zunächst jede Objekthypothese mittels des Klassifikators klassifiziert und sodann die Ergebnisse mehrerer einzelner Klassifikationen zu einem Gesamtergebnis kombiniert. Hierzu sind dem Fachmann auf dem Gebiet der Mustererkennung und Klassifikation unterschiedliche Auswertestrategien bekannt. Bei einer weiteren vorteilhaften Weise der Erfindung ist es jedoch auch möglich, dass in dem wenigstens einen Klassifikator Merkmale von Objekthypothesen unterschiedlicher Sensorsignalströme gemeinsam bewertet und zu einem Klassifikationsergebnis zusammengefasst werden. Für die zuverlässige Erkennung eines bestimmten Objekts muss hierbei beispielsweise eine vorbestimmte Anzahl an Objekthypothesen eine Mindestwahrscheinlichkeit bei der Klassenzugehörigkeit zu dieser bestimmten Objektklasse erreichen. Auch sind dem Fachmann auf dem Gebiet der Mustererkennung und Klassifikation in diesem Zusammenhang unterschiedlichste Auswertestrategien bekannt .
[0014] Weiterhin ist es von großem Vorteil, falls das Raster, in welchem die Objekthypothesen erzeugt werden, in Abhängigkeit des Klassifikationsergebnisses adaptiv angepasst wird. Beispielsweise wird die Rasterweite in Abhängigkeit des Klassifikationsergebnisses adaptiv angepasst, wobei Objekthypothesen nur an den Rasterpunkten generiert werden bzw. Suchfenster nur an Rasterpunkten positioniert werden. Falls Objekthypothesen zunehmend keiner Objektklasse zugeordnet werden oder gar keine Objekthypothesen generiert werden, wird die Rasterweite vorzugsweise kleiner gewählt. Im Gegensatz dazu wird die Rasterweite größer gewählt falls Objekthypothesen zunehmend einer Objektklasse zugeordnet werden bzw. die Wahrscheinlichkeit für eine Objektklassenzugehörigkeit steigt. Auch ist in diesem Zusammenhang ein Einsatz einer hierarehi.s.chen. Struktur—f-ür- das Hypothesenraster möglich. Außerdem kann das Raster in
Abhängigkeit des Klassifikationsergebnisses eines vorangegangenen ZeitSchrittes adaptiv angepasst werden, eventuell unter Berücksichtigung eines dynamischen Systemmodells .
[0015] In einer weiteren vorteilhaften Weise wird das Auswerteverfahren, mittels welchem die Objekthypothesen bewertet werden, in Abhängigkeit von wenigstens einer vorangegangenen Bewertung automatisch angepasst wird. Hierbei wird beispielsweise lediglich das zuletzt vorangegangene Klassifikationsergebnis oder aber mehrere vorangegangene Klassifikationsergebnisse berücksichtigt. Beispielsweise werden hierbei lediglich einzelne Parameter eines Auswerteverfahren und/oder aus mehreren Auswerteverfahren ein geeignetes Auswerteverfahren ausgewählt. Grundsätzlich sind in diesem Zusammenhang die unterschiedlichsten Auswerteverfahren möglich, welche beispielsweise auf statistischen und/oder modellbasierten Ansätzen beruhen können. Die Art der für die Auswahl zur Verfügung gestellten Auswerteverfahren hängt dabei auch von der Art der eingesetzten Sensoren ab.
[0016] Weiterhin besteht auch die Möglichkeit, dass in Abhängigkeit des Klassifikationsergebnisses sowohl das Raster adaptiv angepasst wird, als auch das für die Bewertung herangezogene Auswerteverfahren angepasst wird. Das Raster wird in einer gewinnbringenden Weise nur an den Positionen im Suchraum verfeinert, wo die Wahrscheinlichkeit oder Bewertung für das Vorhandensein von Objekten hoch genug ist, wobei die Bewertung aus den letzten Rasterstufen abgeleitet wird.
[0017] Die unterschiedlichen Sensorsignalströme können zei-tgie-i-eh-7—a-be-r—auch_zei_tv_ers_e£,zt verwendet werden. Genauso kann in vorteilhafter Weise auch ein einzelner
Sensorsignalstrom gemeinsam mit wenigstens einer zeitversetzten Version desselben verwendet werden.
[0018] Das erfindungsgemäße Verfahren kann außer zur Objekterkennung auch zur Verfolgung von erkannten Objekten verwendet werden.
[0019] Das erfindungsgemäße Verfahren kann insbesondere zur Umgebungserfassung und/oder Objektverfolgung bei einem Straßenfahrzeug verwendet werden. Beispielsweise eignet sich für den Einsatz bei einem Straßenfahrzeug eine Kombination aus einer im sichtbaren Wellenlängenspektrum empfindlichen Farbkamera und einer im infraroten Wellenlängenspektrum empfindlichen Kamera. Damit können bei Nacht einerseits Personen und andererseits die farbigen Signalleuchten von Verkehrsampeln im Umfeld des Straßenfahrzeugs auf zuverlässige Weise erfasst werden. Die von den beiden Sensoren gelieferten Informationen werden dabei mit dem erfindungsgemäßen Verfahren zur multisensoriellen Objekterkennung ausgewertet, um beispielsweise darin enthaltene Personen zu erkennen und nachzuverfolgen. Die Sensorinformationen werden dem Fahrer dabei vorzugsweise auf einer im Fahrzeugcockpit angeordneten Anzeigeeinheit in der Form von Bilddaten präsentiert, wobei Personen und Signalleuchten von Ampelanlagen in den angezeigten Bildinformationen hervorgehoben sind. Für den Einsatz bei einem Straßenfahrzeug eignen sich im Zusammenhang mit dem erfindungsgemäßen Verfahren als Sensoren neben Kameras vor allem auch Radar- und Lidarsensoren. Das Erfindungsgemäße verfahren ist darüber hinaus für den Einsatz unterschiedlichster Arten von Bildsensoren und beliebigen anderen aus dem Stand der Technik bekannten Sensoren g^eϊgϊτet~
[0020] Weitere Merkmale und Vorteile der Erfindung ergeben sich aus der folgenden Beschreibung von bevorzugten Ausführungsbeispielen anhand der Figuren. Dabei zeigen:
Fig. 1 links eine mittels einer NIR-Kamera und rechts eine mittels einer FIR-Kamera erfasste Umgebungsszene Fig. 2 eine suboptimale Zuordnung zweier Sensorsignalströme Fig. 3 die Merkmalsbildung im Zusammenhang mit einem
Multistrom-Detektor
Fig. 4 die geometrische Bestimmung des Suchraumes Fig. 5 eine resultierende Hypothesenmenge bei einem
Einzelstrom-Hypothesengenerator
Fig. 6 die Epipolargeometrie eines Zweikamerasystems Fig. 7 die Epipolargeometrie am Beispiel einer
Fußgängerdetektion Fig. 8 die Ursache für Skalierungsunterschiede in
Korrespondenzsuchfenstern Fig. 9 resultierende Korrespondenzen im NIR-BiId für ein
Suchfenster im FIR-BiId
Fig. 10 die Relaxation der Korrespondenzbedingung Fig. 11 Korrespondenzfehler zwischen Label- und
Korrespondenzsuchfenster
Fig. 12 wie Multistrom-Hypothesen entstehen Fig. 13 Vergleich von Detektionsraten bei unterschiedlicher
Rasterweite Fig. 14 die Detektorantwort in Abhängigkeit der erreichten
Detektionsstufe
Fig. 15 eine Grob-Zu-Fein-Suche im eindimensionalen Fall Fig. 16 beispielhaft die Nachbarschaftsdefinition Fig. 17 einen Hypothesenbaum
[0021] In der Figur 1 ist links eine mittels einer NIR-Kamera
_und rechts- e-i-ne- -mi-trfee-1-s- einer FTR-^Kamera erf'a~s~ste"~
Umgebungsszene dargestellt. Die beiden Kamerasensoren und die
damit aufgezeichneten Intensitätsbilder unterscheiden sich dabei stark. Das auf der linken Seite gezeigte NIR-BiId weist eine hohe Varianz in Abhängigkeit der Beleuchtungsverhältnisse und Oberflächeneigenschaften auf. Dem entgegen sind die von der FIR-Kamera erfassten Wärmestrahlen, welche im rechten Teilbild dargestellt sind, fast ausschließlich direkte Emissionen der Objekte. Gerade Fußgänger erzeugen durch ihre Eigenwärme eine ausgeprägte Signatur in Wärmebildern und heben sich in Landstraßenszenarien stark vom Hintergrund ab. Diesem offensichtlichen Vorteil des FIR-Sensors steht aber dessen Auflösung gegenüber: Sie ist in X- und Y-Richtung jeweils um den Faktor 4 kleiner als die der NIR-Kamera. Durch diese grobe Abtastung gehen wichtige hochfrequente Signalanteile verloren. Beispielsweise hat ein Fußgänger in 50m Entfernung im FIR-BiId nur noch eine Höhe von 10 Pixeln. Auch die Quantisierung unterscheidet sich dabei, wobei beide Kameras zwar 12 Bit Grauwertbilder liefern, jedoch erstreckt sich der für die Detektionsaufgäbe relevante Dynamikbereich bei der NIR-Kamera auf 9 Bit und bei der FIR-Kamera auf nur 6 Bit. Daraus resultiert ein 8-fach größerer Quantisierungsfehler. Bei dem NIR-Kamerabild sind Objektstrukturen gut zu erkennen, die Abbildung ist dabei abhängig von Beleuchtung und Oberflächenstruktur und es weist eine hohe Intensitätsvarianz auf. Im Gegensatz dazu sind bei dem FIR-Kamerabild Objektstrukturen schlecht zu erkennen, die Abbildung ist hierbei von Emissionen abhängig, wobei sich der Fußgänger vom kalten Hintergrund deutlich abhebt. Aufgrund der Tatsache, dass beide Sensoren verschiedenartige Vorteile aufweisen, und zwar geradeso, dass die Stärken des einen die Schwächen des anderen sind, ist der Einsatz dieser Sensoren im Zusammenhang bei dem erfindungsgemäßen Verfahren besonders vorteilhaft. Dabei lassen sich die Vorteile beider Sensoren in einem.
Klassifikator vereinen, welcher die Detektionsleistung von Einzelstrom-Klassifikatoren deutlich übertrifft.
[0022] Der Begriff Sensorfusion bezeichnet die Nutzung mehrerer Sensoren und die Erzeugung einer gemeinsamen Repräsentation. Das Ziel ist dabei, die Genauigkeit der gewonnenen Informationen zu erhöhen. Bezeichnend ist hierbei die Vereinigung von Messdaten in einem perzeptuellen System. Die Sensorintegration dagegen bezeichnet die Nutzung verschiedener Sensoren für mehrere Teilaufgaben, wie etwa Bilderkennung zur Lokalisierung und haptische Sensorik zur nachfolgenden Manipulation mit Aktoren.
[0023] Fusionsansätzen lassen sich anhand ihrer resultierenden Repräsentationen in Kategorien einteilen. Es werden dabei beispielsweise folgende vier Fusionsebenen unterschieden :
• Fusion auf Signalebene: Hierbei werden direkt die Rohsignale betrachtet. Ein Beispiel ist die Lokalisierung von akustischen Quellen aufgrund von Phasenverschiebungen.
• Fusion auf Pixelebene: Im Gegensatz zur Signalebene wird der räumliche Bezug von Pixeln zu Objekten im Raum betrachtet. Beispiele sind Extraktion von Tiefeninformation mit Stereokameras oder auch die Berechnung des optischen Flusses in Bildfolgen.
• Fusion auf Merkmalsebene: Bei der Fusion auf Merkmalsebene werden unabhängig Merkmale beider Sensoren extrahiert. Diese werden z.B. in einem Klassifikator oder einem Lokalisierungsverfahren kombiniert .
• Fusion auf Symbolebene: Symbolische Repräsentationen sind beispielsweise Wörter oder Sätze bei der Spracherkennung. Durch Grammatiken entstehen logische Beziehungen zwischen Wörtern. Diese wiederum können die Interpretation von akustischen und visuellen Signalen steuern.
[0024] Eine weitere Form der Fusion ist die Klassifikatorfusion. Hierbei werden die Ergebnisse mehrerer Klassifikatoren vereint . Dabei sind die Datenquellen oder die Sensoren nicht zwingend verschieden. Das Ziel ist es hierbei, den Klassifikationsfehler durch Redundanz zu verkleinern. Entscheidend ist, dass die Einzelklassifikatoren möglichst unkorrelierte Fehler aufweisen. Einige Methoden zur Fusion von Klassifikatoren sind beispielsweise:
• Gewichtete Mehrheitsentscheidung: Ein einfaches Prinzip ist die Mehrheitsentscheidung, also die Wahl der Klasse die von den meisten Klassifikatoren ausgegeben wurde. Jeder Klassifikator kann entsprechend seiner Zuverlässigkeit gewichtet werden. Mittels Lerndaten können ideale Gewichte ermittelt werden.
• Bayes-Kombination: Für jeden Klassifikator kann eine Konfusionsmatrix berechnet werden. Das ist eine Verwechslungsmatrix, die die Häufigkeit von allen Klassifikatorergebnissen für jede tatsächliche Klasse angibt. Mit ihr können bedingte Wahrscheinlichkeiten für resultierende Klassen approximiert werden. Nun werden alle Klassifikationen mit Hilfe des Bayes-Theorems auf Wahrscheinlichkeiten für Klassenzugehörigkeiten abgebildet. Als Endresultat wird sodann das Maximum gewählt.
• Stacked Generalizatioju_j3le__I_dee_j3_eji. di.esem_Ansatz_ist—die_
Verwendung der Klassifikatorergebnisse als Eingänge bzw.
Merkmale eines weiteren Klassifikators . Der weitere Klassifikator kann dabei mit dem Vektor der Ergebnisse und dem Label des ersten Klassifikators trainiert werden.
[0025] Mögliche Fusionskonzepte bei der Detektion von Fußgängern sind die Detektorfusion und eine Fusion auf Merkmalsebene. Es existieren bereits akzeptable Lösungen für das Detektionsproblem mit nur einem Sensor, daher ist eine Kombination durch Klassifikatorfusion möglich. Bei dem hier betrachteten Fall mit zwei Klassifikatoren und einem Zweiklassenproblem führt eine Fusion durch gewichtete Mehrheitsentscheidung oder Bayes-Kombination entweder zu einer einfachen Und-Operation oder zu einer Oder-Operation der Einzeldetektoren. Die Und-Verknüpfung hat zur Folge, dass sich (bei gleicher Parametrisierung) die Zahl der Detektionen und damit die Detektionsrate nur verkleinern können. Bei einer Oder-Verknüpfung kann die Falschalarmrate nicht besser werden. Wie sinnvoll die jeweiligen Verknüpfungen sind, kann mit der Bestimmung der Konfusionsmatrizen und Analyse der Korrelationen ermittelt werden. Es kann aber eine Aussage über den entstehenden Aufwand gemacht werden: Im Falle der Oder-Verknüpfung müssen die Bilder beider Ströme abgetastet werden, der Aufwand ist mindestens die Summe des Aufwands beider Einzelstrom-Detektoren. Alternativ zur Und- bzw. Oder- Verknüpfung kann das Detektorergebnis des Kaskadenklassifikators als Rückschlusswahrscheinlichkeit interpretiert werden, indem die erreichte Stufe und die letzte Aktivierung auf eine Detektionswahrscheinlichkeit abgebildet werden. Damit lässt sich eine Entscheidungsfunktion auf nicht -binären Werten definieren. Eine andere Möglichkeit sieht vor, den einen Klassifikator zur Aufmerksamkeitssteuerung und den anderen Klassifikator zur_ Detektion zu nutzen. Ersterer sollte so parametrisiert sein, dass die Detektionsrate (zu Lasten de~r~Fa-1-sch-aia-rmr-ate-)—
hoch ist. Dadurch reduziert sich möglicherweise die Datenmenge des detektierenden Klassifikators, sodass diese leichter zu klassifizieren ist. Eine Fusion auf Merkmalsebene bietet sich hauptsächlich wegen der Verfügbarkeit von Boosting-Verfahren an. Die konkrete Kombination von Merkmalen aus beiden Strömen kann also mit der bereits genutzten Methode automatisiert auf Basis der Trainingsdaten geschehen. Das Resultat stellt näherungsweise eine optimale Wahl und Gewichtung der Merkmale aus beiden Strömen dar. Ein Vorteil ist hierbei der erweiterte Merkmalsraum. Sind bestimmte Teilmengen der Daten jeweils nur in einem der Einzelstrom- Merkmalsräume leicht zu trennen, dann kann durch die Kombination eine Trennung aller Daten vereinfacht werden. Beispielsweise ist im NIR-BiId die Fußgängersilhouette gut zu erkennen, dagegen ist im FIR-BiId ein beleuchtungsunabhängiger Kontrast zwischen Fußgänger und Hintergrund abgebildet. In der Praxis hat sich gezeigt, dass mit der Fusion auf Merkmalsebene die Zahl der notwendigen Merkmale drastisch gesenkt werden kann.
[0026] Nachfolgend wird die Architektur des verwendeten MuItistromklassifikators beschrieben. Für die Erweiterung des Einzelstrom-Klassifikators zum Multistrom-Klassifikator ist es erforderlich, dass viele Teile der Klassifikatorarchitektur überarbeitet werden. Eine Ausnahme ist dabei der Kernalgorithmus z.B. AdaBoost, welcher nicht notwendigerweise modifiziert werden muss. Dennoch können einige implementierungstechnische Optimierungen vorgenommen werden, welche die Dauer eines NIR-Trainingslaufes mit einer vorbestimmten Parametrisierung um ein Vielfaches senken. Es wird dabei die vollständige Tabelle der Merkmalswerte für alle Beispiele im Speicher gehalten. Ein weiterer Punkt ist die Optimierungen bei der Beispielgenerierung . Damit konnten beim praktischen Einsatz TrainingsTäufe πdrt 1"& Sequen-z-en i-n
ca. 24 Stunden beendet werden. Vor dieser Optimierung dauerte ein Training mit nur drei Sequenzen zwei Wochen. Die Integration von weiteren Strömen in die Anwendung erfolgt im Zuge eines Redesigns der Implementierungen. Bei der Erweiterung des Hypothesengenerators sind dabei die meisten Modifikationen und Innovationen nötig.
[0027] Im Folgenden werden die wesentlichen Erweiterungen hinsichtlich der Datenvorverarbeitung beschrieben. Der resultierende Detektor soll in Form eines Echtzeitsystems und mit Live-Daten der beiden Kameras zur Anwendung kommen. Für das Training werden gelabelte Daten herangezogen. Dafür steht eine umfangreiche Datenbank mit Sequenzen und Labels zur Verfügung, welche Landstraßenszenen mit am Straßenrand laufenden Fußgängern, Autos und Radfahrern beinhalten. Zwar zeichnen die Beiden verwendeten Sensoren ca. 25 Bildern pro Sekunde auf, die zeitliche Abtastung erfolgt dabei jedoch hardwarebedingt asynchron, die Zeitpunkte beider Aufnahmen sind dabei unabhängig. Wegen Schwankungen .bei den Aufnahmezeitpunkten ist sogar eine deutliche Differenz der Bilderanzahl der beiden Kameras für eine Sequenz üblich. Eine Anwendung des Detektors ist nicht möglich, sobald auch nur ein Merkmal nicht zur Verfügung steht . Würde man beispielsweise bei fehlenden Merkmalen die jeweiligen Terme in der Stronglearnergleichung durch Nullen ersetzen, ist das Verhalten Undefiniert. Dies macht das sequenzielle Abarbeiten der einzelnen Bilder der Multistrom-Daten unmöglich und verlangt sowohl für das Training als auch für die Anwendung eines Mulistrom-Detektors eine Synchronisierung der Sensordatenströme. In diesem Fall müssen also Bildpaare gebildet werden. Da die Aufnahmezeitpunkte der Bilder eines Paares nicht exakt gleich sind, ist jeweils ein anderer Zustand der Umgebung abgejoildet_i__p_._h die- Bos-i-fe-i-βn—des¬ Fahrzeugs und die des Fußgängers ist jeweils eine andere. Um
jeglichen Einfluss der Umgebungsdynamik zu minimieren, müssen die Bildpaare so gebildet werden, dass die Differenzen der beiden ZeitStempel minimal werden. Wegen der erwähnten unterschiedlichen Anzahl Messungen pro Zeiteinheit müssen entweder Bilder aus einem Strom mehrmals verwendet werden, oder es werden Bilder ausgelassen. Zwei Gründe sprechen für die letztere Methode: Erstens minimiert sie die durchschnittliche Zeitstempeldifferenz und zweitens würde die Mehrfachverwendung im Onlinebetrieb zu gelegentlichen Spitzen beim Rechenaufwand führen. Der nachfolgende Algorithmus beschreibt die Datensynchronisierung:
I Gegeben : 2
3 Bildsequenzen Is(i) für jeden Strom s e {l, 2}
4
5 Zeitstempel ts(i) für alle Bilder für jeden Strom s
6
7 Erwartete Zeitstempeldifferenz E(ts(i + l)-ts(i)) für jeden Strom s 8 9 Größte erwartete Zeitstempeldifferenz-Abweichung ε s für jeden Strom s 10
II Initialisierung : 12
13 Beginne mit den ersten Bildern der Ströme: 14
15 i = 1
16 j = 1 17 P = O 18
19 Algorithmus : -20 21 Solange die Bilder I l ( i) und 12 (j ) existieren :
22
23 Wenn It1(D - t2(j)| > mins ( ~ (E (ts (i+1) -ts (i) ) + ^8))
24
25 Wenn t1(±) < t2 (j)
26 i = i + 1
27 Sonst
28 j = j + 1
29 Sonst 30
31 Bilde ein Paar (i,j) : 32
33 P = P^ (i, j)
34 i = i + 1
35 j = j + 1 36
37 Ergebnis :
38
39 Bildpaare P
Hierbei sollte ε 3 in Abhängigkeit der Verteilung von ts (i+1) -ts (i) gewählt werden und etwa 3σ betragen. Bei kleinen ^3 besteht die Möglichkeit, dass manche Bildpaare nicht gefunden werden, für große ε s steigt die erwartete Zeitstempeldifferenz. Die Zuordnungsvorschrift entspricht einer Greedy-Strategie und ist damit im Allgemeinen suboptimal bezüglich der Minimierung der mittleren Zeitstempeldifferenz. Sie ist dadurch aber sowohl im Training als auch im Online-Betrieb der Anwendung einsetzbar. Für den Fall V ar(ta(i + 1) - ta(i)) = 0 und ε s = 0 V3 ist sie in vorteilhafter Weise optimal .
[-0Θ2-8-]—I-n—der E-igur__2__wird__beispielhaft eine suboptimale
Zuordnung zweier Sensorsignalströme gezeigt. Hierbei ist
insbesondere das Ergebnis des zuvor gezeigten Zuordnungsalgorithmus dargestellt. In diesem Beispiel ist die Zuordnung suboptimal bezüglich der Minimierung der mittleren Zeitstempeldifferenz. Der Zuordnungsalgorithmus ist in dieser Form für die Anwendung einsetzbar, es entstehen in vorteilhafter Weise keine Verzögerungen durch Warten auf potentielle Zuordnungskandidaten.
[0029] Das Konzept für das Suchfenster spielt bei der Merkmalsbildung eine zentrale Rolle, insbesondere bei der Erweiterung des Detektors für den multisensoriellen Einsatz, wobei mehrere Sensorsignalströme vorhanden sind. Bei einem Einzelstrom-Detektor besteht die Lokalisation aller Objekte in einem Bild aus der Untersuchung einer Menge an Hypothesen. Eine Hypothese steht dabei für eine Position und Skalierung des Objekts im Bild. Daraus ergibt sich das Suchfenster, also der Bildausschnitt, welcher für die Merkmalsberechnung herangezogen wird. Im Multistrom-Fall besteht eine Hypothese aus einem Suchfenster-Paar, also aus je einem Suchfenster in jedem Strom. Dabei ist zu beachten, dass für ein einzelnes Suchfenster im einen Strom aufgrund des Parallaxenproblems verschiedene Kombinationen mit Suchfenstern im anderen Strom auftreten können. Somit kann sich eine sehr große Anzahl an Multistrom-Hypothesen ergeben. Eine Hypothesengenerierung für beliebige Kameraanordnungen wird im weiteren Verlauf noch aufgezeigt. Die Klassifikation basiert auf Merkmalen aus zwei Suchfenstern, wie dies anhand der Figur 3 verdeutlicht wird. Die Figur 3 zeigt dabei die Merkmalsbildung im Zusammenhang mit einem Multistrom-Detektor . Eine Multistrom-Merkmalsmenge entspricht der Vereinigung der beiden Merkmalsmengen, die sich für die Einzelstrom-Detektoren ergeben. Ein Multistrom- Merkmal ist definiert durch Filtertyp, Position, Skalierung und Sensorström. Im NIR-Suchfenster können aufgrund der höheren Bildauflösung kleinere Filter verwendet werden—ais—i-m-
PIR-Suchfenster . Die Zahl der NIR-Merkmale ist somit höher als die Zahl der FIR-Merkmale . Bei diesem Ausführungsbeispiel wurden ca. 7000 NIR-Merkmale und ca. 3000 FIR-Merkmale verwendet .
[0030] In einer vorteilhaften Weise werden während des Trainingsprozesses kontinuierlich neue Trainingsbeispiele gewählt. Vor dem Training mittels jeder Klassifikatorstufe wird unter Verwendung aller bereits trainierten Stufen eine neue Beispielmenge erzeugt. Im Multistrom-Training bestehen die Trainingsbeispiele wie die Hypothesen aus einem Suchfenster in jedem Strom. Positivbeispiele ergeben sich aus Labels, welche in jedem Strom vorhanden sind. Im Zusammenhang mit automatisch generierten Negativbeispielen kommt hierbei ein Zuordnungsproblem auf: Die zufällig gewählten Suchfenster müssen konsistent bezüglich der Projektionsgeometrie des Kamerasystems sein, sodass die Trainingsbeispiele mit den Multistrom-Hypothesen der späteren Anwendung übereinstimmen. Um dies zu erreichen, wird ein spezieller Hypothesengenerator, welcher nachfolgend noch detailliert beschrieben wird, bei der Bestimmung der Negativbeispiele verwendet . Anstatt wie bisher die Position und Größe des Suchfensters von Negativbeispielen unabhängig und zufällig zu wählen, wird nun zufällig in eine Hypothesenmenge gegriffen. Dabei weist die Hypothesenmenge neben konsistenten Suchfensterpaaren eine intelligentere, auf Weltmodellen basierende Verteilung der Hypothesen im Bild auf. Auch für das Einzelstrom-Training kann dieser Hypothesengenerator eingesetzt werden. Hierbei werden die Negativbeispiele mit der gleichen Suchstrategie bestimmt, welche später bei der Anwendung des Detektors zur Hypothesengenerierung dient . Die Beispielsmenge für das Multistrom-Training besteht also aus Positiv- und Negativbeispi_el_en., welche—wiede-r-um—j-eweüs—ern- Suchfenster in beiden Strömen beinhalten. Für das Training
wird beispielsweise AdaBoost eingesetzt, wobei alle Merkmale aller Beispiele berechnet werden. Bei der Merkmalsselektion ändert sich gegenüber dem Einzelstrom-Training lediglich die Zahl der Merkmale, da aufgrund ihrer Definition und der damit verbundenen Multistrom-Datenquelle abstrahiert wird.
[0031] Die Architektur einer Multistrom-Detektoranwendung ist der eines Einzelstrom-Detektors sehr ähnlich. Die erforderlichen Modifikationen am System sind zum einen Anpassungen für das generelle Handling von mehreren Sensorsignalströmen, wodurch an fast allen Stellen der Implementierung Änderungen erforderlich sind. Zum anderen wird der Hypothesengenerator erweitert . Für die Generierung von Multistrom-Hypothesen ist eine Korrespondenzbedingung für Suchfenster beider Ströme notwendig, welche auf Welt- und Kameramodellen basiert. Somit muss eine Multistrom- Kamerakalibration in die Hypothesengenerierung integriert werden. Die für Einzelstrom-Detektoren verwendete Brüte- Force-Suche im Hypothesenraum lässt sich zwar auf Multistrom- Detektoren übertragen, sie erweist sich dann aber häufig als zu ineffizient. Der Suchraum vergrößert sich dabei deutlich und die Zahl der Hypothesen vervielfacht sich. Um dennoch echtzeitfähig zu bleiben, muss die Hypothesenmenge wieder verkleinert werden und es sind intelligentere Suchstrategien erforderlich. Der im Zusammenhang mit diesem Ausführungsbeispiel verfolgte Fusionsansatz entspricht einer Fusion auf Merkmalsebene. Mittels Ada-Boost wird dabei eine Kombination aus Merkmalen beider Ströme gewählt. Auch andere Verfahren könnten hier zur Merkmalsauswahl und Fusion herangezogen werden. Die erforderlichen Änderungen am Detektor ist eine erweiterte Merkmalsmenge, eine Synchronisierung der Daten sowie die Erzeugung einer Hypothesenmenge, welche geometrische Zusammenhänge der Kameramodelle mit berücksicncig€ .
[0032] Nachfolgend wird die Herleitung einer Korrespondenzvorschrift, die Suchraumabtastung und weitere gewinnbringende Optimierungen vorgestellt. Mit dem trainierten Einzelstrom-Kaskadenklassifikator werden nacheinander einzelne Suchfenster evaluiert . Der Klassifikator liefert als Ergebnis eine Aussage, ob ein Objekt in genau dieser Position und Skalierung detektiert wurde. In jedem Bild können Fußgänger an unterschiedlichen Positionen mit verschiedenen Skalierungen erscheinen. Deshalb muss bei der Verwendung des Klassifikators als Detektor in jedem Bild eine große Menge an Positionen bzw. Hypothesen geprüft werden. Diese Hypothesenmenge kann durch Unterabtastung und Suchbereichseinschränkungen reduziert werden. Damit kann der Berechnungsaufwand ohne Beeinträchtigung der Detektionsleistung vermindert werden. Aus dem Stand der Technik sind hierfür Hypothesengeneratoren für Einzelstrom-Anwendungen bereit bekannt. Bei dem im Zusammenhang mit diesem Ausführungsbeispiel vorgestellten Multistrom-Detektor werden Hypothesen über ein Suchfensterpaar, also über ein Suchfenster in jedem Strom definiert . Die Suchfenster lassen sich zwar in beiden Strömen mit zwei Einzelstrom-Hypothesengeneratoren erzeugen, die Verknüpfung zur Multistrom-Hypothesenmenge ist aber aufgrund der Parallaxe nicht trivial. Die Zuordnung von zwei Suchfenstern aus verschiedenen Strömen zu einer Multistrom- Hypothese muss dabei bestimmte geometrische Bedingungen erfüllen. Um eine Robustheit gegen Kalibrationsfehler und Dynamikeinflüsse zu erreichen, werden des Weiteren Relaxationen dieser geometrischen Korrespondenzbedingungen eingeführt. Schließlich wird eine konkrete Abtast- und Zuordnungsstrategie gewählt. Es entstehen hierbei sehr viel mehr Hypothesen als bei___Einz.els-trom=-Detek-feo-ren— Um- d±e~ Echtzeitfähigkeit des Multistrom-Detektors zu gewährleisten,
werden nachfolgend weitere Optimierungsstrategien aufgezeigt, unter anderem auch eine sehr effektive Methode zur Hypothesenreduktion über eine dynamische lokale Steuerung der Hypothesendichte, welche gleichsam auch im Zusammenhang mit Einzelstrom-Detektoren einsetzbar ist. Die einfachste Suchstrategie zum Auffinden von Objekten an allen Positionen im Bild ist das pixelweise Abtasten des gesamten Bildes in allen möglichen Suchfenstergrößen. Das ergibt bei einem Bild mit 640 x 480 Pixeln eine Hypothesenmenge mit ca. 64 Millionen Elementen. Diese Hypothesenmenge wird im Folgenden als vollständiger Suchraum des Einzelstrom-Detektors bezeichnet. Mit Hilfe einer im Folgenden beschriebenen Bereichseinschränkung auf Basis eines einfachen Weltmodells sowie einer skalierungsabhängigen Unterabtastung des Suchraums, kann die Zahl der zu untersuchenden Hypothesen in besonders vorteilhafter Weise auf ca. 320.000 reduziert werden. Grundlage für die Bereichsbeschränkung ist zum einen die sogenannte "Ground-Plane-Assumption" , die Annahme, dass die Welt eben ist, wobei sich die zu detektierenden Objekte und das Fahrzeug auf gleicher Ebene befinden. Zum anderen kann aufgrund der Objektgröße im Bild und einer Annahme bezüglich der realen Objektgröße eine eindeutige Position im Raum abgeleitet werden. Damit liegen alle Hypothesen einer Skalierung im Bild auf einer waagrechten Geraden. Beide Annahmen, also die "Ground-Plane-Assumption" sowie die bzgl . einer festen realen Objektgröße treffen in der Regel nicht zu. Die Einschränkungen werden deswegen relaxiert, so dass für die Objektposition als auch für deren Größe im Raum ein gewisser Toleranzbereich zugelassen wird, dieser Sachverhalt ist in der Figur 4 veranschaulicht. Die Relaxation der "Ground-Plane-Assumption" wird dabei durch einen Winkel ε angegeben, der bei diesem Ausführungsbeispiel z.B. 1° beträgt . Damit werden auch Or-i-enfe-i-erungsfehl~e~f iπT
Kameramodell kompensiert, welche beispielsweise durch
Nickbewegungen des Fahrzeugs entstehen können. Neben der beschriebenen Bereichsbeschränkung wird durch eine skalierungsabhängige Unterabtastung die Anzahl der zu untersuchenden Hypothesen weiter reduziert. Die Schrittweite der Abtastung in u- und v-Richtung in der Figur 4 werden dabei proportional zur Hypothesenhöhe, also der Skalierung, gewählt und beträgt in diesem Beispiel etwa 5% der Hypothesenhöhe. Die Suchfensterhöhen selbst ergeben sich aus einer Reihe von Skalierungen, die beginnend mit 25 Pixeln im NIR-BiId (8 Pixel in FIR-BiId) jeweils um 5% größer werden. Diese Art der Quantisierung lässt sich mit einer Eigenschaft des Detektors motivieren, nämlich der Tatsache, dass mit der Größenskalierung der Merkmale auch die Unscharfe ihrer Lokalisation im Bild zunimmt, wie dies z.B. bei einem Haarwavelet oder ähnlichen Filtern der Fall ist. Die Merkmale sind hierbei in einem festen Raster definiert und werden entsprechend der Größe der Hypothese mitskaliert. Mit der beschriebenen Hypothesengenerierung ergibt sich in diesem Fall im NIR-BiId eine Reduktion der 64 Millionen Hypothesen des vollständigen Suchraumes auf 320.000. Im FIR-BiId sind es aufgrund der niedrigen Bildauflösung 50.000 Hypothesen, hierzu wird auch auf Figur 5 verwiesen. Für die Berücksichtigung der im dreidimensionalen Raum definierten Einschränkungen ist eine Transformation zwischen Bildkoordinaten und Weltkoordinaten notwendig. Basis dafür sind die durch die Kalibration ermittelten intrinsischen und extrinsischen Kameraparameter. Die geometrischen Zusammenhänge für die Projektion eines 3D-Punktes auf die Bildebene sind dem Fachmann auf dem Gebiet der Bildauswertung bekannt. Aufgrund der geringen Verzeichnungen bei beiden Kameras kann in diesem Ausführungsbeispiel ein Lochkameramodell verwendet werden.
[0033] Die Figur 4 veranschaulicht die geometrische Bestimmung des Suchraumes. Es wird hierbei der Suchbereich dargestellt, der sich für eine feste Skalierung ergibt. Berechnet wird eine Ober- und Untergrenze für die obere Suchfensterkante im Bild. Die Grenzen (vmin und vmax) ergeben sich, wenn das Objekt einmal mit der kleinsten und einmal mit der größten erwarteten Objektgröße (objmin bzw. objmaχ) auf die Bildebene projiziert wird. Hierbei wird der Abstand (zmin und Zmax) so gewählt, dass die richtige Skalierung im Bild entsteht. Durch die relaxierte Einschränkung der Ground- Plane-Assumption liegt die räumliche Position zwischen den gestrichelt eingezeichneten Ebenen. Das kleinste und das größte Objekt werden für die Berechnung der Grenzen dabei entsprechend nach oben und unten verschoben.
[0034] In der Figur 5 wird die resultierende Hypothesenmenge des Einzelstrom-Hypothesengenerators gezeigt . Es werden hierbei Suchfenster mit quadratgitterartiger Anordnung generiert. Für verschiedene Skalierungen entstehen unterschiedliche Quadratgitter mit angepassten Gitterabständen und eigenen Bereichsbeschränkungen. Im Sinne einer übersichtlichen Darstellung wird in der Figur 5 nur ein Suchfenster für jede Skalierung sowie die Mittelpunkte aller anderen Hypothesen visualisiert . Die Darstellung ist exemplarisch, es wurden dabei große Skalierungs- und Positionsschrittweiten gewählt.
[0035] Aus den Einzelstrom-Hypothesen entstehen somit durch geeignete Paarbildung Multistrom-Hypothesen. Die Epipolargeometrie ist dabei Grundlage für die Paarbildung, womit die geometrischen Zusammenhänge beschrieben werden. In der Figur 6 wird die Epipolargeometrie eines Zweikamerasystems gezeigt Die Epipolargeomefe-rie—beschreltnr die Menge der möglichen Korrespondenzpunkte für einen Punkt
in einer Bildebene. Für jeden Punkt p im Bild lassen sich Epipolarlinien und eine Epipolarebene konstruieren. Die möglichen Korrespondenzpunkte für Punkte einer Epipolarlinie in einem Bild sind dabei genau die auf der entsprechenden Epipolarlinie der anderen Bildebene. In der Figur 6 wird insbesondere die Geometrie eines Multikamerasystems mit zwei beliebig angeordneten Kameras mit den Zentren Oi e R3 und O2 e R3 und einem beliebigen Punkt P e R3 gezeigt. Oi, O2 und P spannen dabei die sogenannte Epipolarebene auf. Sie schneidet die Bildebenen in den Epipolarlinien. Die Epipole sind die Schnittpunkte der Bildebenen mit der Geraden OiO2. 0i02 ist in allen Epipolarebenen aller möglichen Punkte P enthalten. Alle auftretenden Epipolarlinien schneiden sich also im jeweiligen Epipol . Die Epipolarlinien haben bei der Korrespondenzfindung die folgende Bedeutung: Für jeden Punkt p im Bild lassen sich Epipolarlinien und eine Epipolarebene konstruieren. Die möglichen Korrespondenzpunkte für Punkte einer Epipolarlinie in einem Bild sind genau die auf der entsprechenden Epipolarlinie der anderen Bildebene.
[0036] Es sei nun Punkt P e R3 ein Punkt im Raum. Pl, P2 e R3 sei die Darstellung von P in den Kamerakbordinatensystemen mit Ursprung O1 bzw. O2. Dann gibt es eine Rotationsmatrix R e R3x3 und einen Translationsvektor T e R3 für die gilt:
P2=R[Px-T). (5.1)
R und T sind dabei durch die relativen extrinsischen Parameter des Kamerasystems eindeutig festgelegt. Pi, T und Pi- T sind koplanar, d.h.
(P1 -T)τ ■ (TxP,)= 0. (5.2)
Mit Gleichung (5.1) und der Orthonormalität der Rotationsmatrix ergibt sich:
,(5.1)
O = (P1-T)7"(TxP1) = (A-1Pj(T-XP1J=(^pJ(TxP1). (5.3)
Das Kreuzprodukt kann nun in ein Skalarprodukt umgeschrieben werden :

Damit ergibt sich aus Gleichung (5.3)
o = (RV2 J (SP1 ) = (PfRXsP1 ) = Pl (RS)P1 = P2 TEPX , '.5.5)
mit E : = RS der Essentiellen Matrix. Nun ist eine Beziehung zwischen Pi und P2, hergestellt. Projiziert man sie mittels

0 = plEpl (5.6)

Hierbei ist fi,2 die fokale Länge und Zi,2 die Z-Komponente von P1^. Damit ist die Menge aller möglichen Bildpunkte p2 im zweiten Bild, die mit einem Punkt pi des ersten Bildes korrespondieren können genau die, für die die Gleichung (5.6) e-r-f-ü-1-l-t ist . Mrt dieser Korrespondenzbedingung für einzelne Bildpunkte können nun konsistente Suchfensterpaare aus den
Einzelstrom-Hypothesen wie folgt gebildet werden: Das Seitenverhältnis der Suchfenster ist vorzugsweise per Definition fest, d.h. ein Suchfenster lässt sich eindeutig durch die Mittelpunkte der oberen und unteren Kante beschreiben. Mit der Korrespondenzbedingung für Bildpunkte ergeben sich so zwei Epipolarlinien im Bild der zweiten Kamera für die möglichen Mittelpunkte der Ober- und Unterkanten aller korrespondierenden Suchfenster, wie dies z.B. in der Figur 7 dargestellt wird. Die Figur 7 zeigt die Epipolargeometrie am Beispiel einer Fußgängerdetektion. Hierbei findet eine mehrdeutige Projektion eines Suchfensters vom Bild der rechten Kamera in das der linken Kamera statt. Die Korrespondenzsuchfenster ergeben sich dabei aus den Epipolarlinien der Mittelpunkte der Suchfensterunter- und -Oberkanten. Die Darstellung ist im Sinne der Übersichtlichkeit hier nur illustrativ. Die Menge an möglichen Suchfensterpaaren soll all diejenigen Suchfensterpaaren beinhalten, welche Objekte mit realistischer Größe beschreiben. Berechnet man die Rückprojektion der Objekte in den Raum, kann mittels Triangulation Position und Größe des Objektes bestimmt werden. Der Bereich der Epipolarlinien wird dann auf Korrespondenzen mit gültiger Objektgröße reduziert, wie dies anhand der gepunkteten Linie in Abbildung 7 gezeigt ist.
[0037] Es wird nun die Optimierung des Korrespondenzraumes beschrieben, wobei sich bei der Projektion eines Suchfensters von einem Sensorstrom in den anderen Sensorstrom mehrere Korrespondenzsuchfenster mit unterschiedlicher Skalierung ergeben. Dieser Skalierungsunterschied verschwindet jedoch, falls die Kamerapositionen und -ausrichtungen bis auf einen lateralen Versatz gleich sind. Für die Skalierung ist also nur___ein Versatz d zwischen den Zentren Oi und O2 in Längsrichtung des Kamerasystems relevant, wie i-i-e-s—i-n—der.
Figur 8 gezeigt wird. Der Orientierungsunterschied beider Kameras ist in diesem Beispiel vernachlässigbar. In der Figur 8 wird dabei insbesondere die Ursache für die in den Korrespondenzsuchfenstern entstehenden Skalierungsunterschiede gezeigt und wobei bei der Projektion eines Suchfensters vom ersten in den zweiten Sensorstrom sich mehrere Korrespondenzsuchfenster mit unterschiedlicher Skalierung ergeben. Hierbei ist der geometrische Zusammenhang zwischen Kameraanordnung, Objektgrößen und Skalierungsunterschieden detailliert dargestellt.
[0038] Es ist eine feste Suchfenstergröße hi im ersten Bild vorgegeben. Im Folgenden soll das Verhältnis
T min H2

untersucht werden, wobei h2 min bzw. h2 max die minimale bzw. maximale auftretende Skalierung der Korrespondenzsuchfenster im zweiten Sensorstrom zum Suchfenster hx im ersten Sensorstrom ist. Es seien Hmin = Im die Höhe eines nahen Fußgängers und Hmax = 2m die Höhe eines weit entfernten Fußgängers, wobei hier nur Fußgänger betrachtet werden, welche eine minimale Größe von Im und eine maximale Größe von 2m aufweisen. Beide Fußgänger seien so weit entfernt, dass sie im Bild der ersten Kamera die Höhe hx aufweisen. Seien weiterhin Zλ mxn, Z1 1"**, Z2 min und Z2 max die Objektabstände beider Objekte zu beiden Kameras, dann folgt
Z min.max •-/ min.max j
' 22 = Zi ~ d ( 5 . 7 ) und
Λ x rr min H ma
(5 8) ^ mm Z y
A2 max z >j,2 min y max rr min (57) 2'mω T T mm r r min _ Λ 2
Λ y min
A7 mm T T man y min T T man. y mm £■ max (5.9)
Tj max ■^ 1 z y,2 max
Für große Entfernungen geht das Skalierungsverhältnis gegen 1. Für eine Anwendung des Klassifikators als Frühwarnsystem in Landstraßenszenarien, kann man sich bei der Wahl von Zimin auf Werte größer 20m beschränken. Der Versatz der Kameras ist im Versuchsträger ca. 2m. Zusammen mit den oben vorgeschlagenen Werten für die Fußgängergrößen ergibt sich, dass
.max
gilt. Es lässt sich somit der Korrespondenzraum für ein Suchfenster im ersten Strom, also die Menge der korrespondierenden Suchfenster im zweiten Strom folgendermaßen vereinfachen: Die Skalierung aller korrespondierenden Suchfenster wird vereinheitlicht. Die verwendete Skalierung h2 für alle Korrespondenzen ist der Mittelwert der minimal und maximal auftretenden Skalierung:
max
K= 2 • (5.10)
Der verursachte Skalierungsfehler beträgt dabei maximal 2,75%. In der Figur 9 werden Resultierende Korrespondenzen im NIR-BiId für ein Suchfenster im FIR-BiId gezeigt. Es wird dabei eine vereinheitlichte Skalierung für alle Korrespondierenden Suchfenster verwendet .
[0039] Zur Modellierung des Korrespondenzfehlers ist in realen Anwendungen die oben beschriebene Paarbildung zur Erzeugung von Multistrom-Hypothesen häufig unzureichend. In gewinnbringender Weise werden folgende Faktoren darüber hinaus mit berücksichtigt:
• Fehler in den extrinsischen und intrinsischen Kameraparametern, verursacht durch Messfehler während der Kamerakalibrierung.
• Einflüsse der Umgebungsdynamik.
[0040] Es besteht also ein unbekannter Fehler im Kameramodell. Dadurch entsteht eine Unscharfe sowohl für die Position als auch die Skalierung der korrelierenden Suchfenster, sie wird im Folgenden als Korrespondenzfehler bezeichnet. Der Skalierungsfehler wird aus folgenden Gründen vernachlässigt: Erstens ist der Einfluss der Dynamik auf die Skalierung sehr gering, wenn das Objekt mindestens 20m entfernt ist. Zweitens ist eine deutliche Unempfindlichkeit der Detektorantwort zu erkennen, was die Exaktheit der Hypothesenskalierung betrifft. Dies wird anhand von Mehrfachdetektionen sichtbar, deren Mittelpunkte zwar kaum variieren, jedoch variieren die Skalierungen dabei stark. Zur Kompensation des translativen Fehlers wird eine Relaxation der Korrespondenzbedingung eingeführt . Hierfür wird ein Toleranzbereich für die Position der korrelierenden Suchfenster definiert. Für jede dieser Korrespondenzen wird im Bild ein ellipsenförmiger Toleranzbereich mit den Radien ex und ey definiert, in dem weitere Korrespondenzen entstehen, wie dies anhand der Figur 10 gezeigt wird. Dabei ist der Korrespondenzfehler für jede Suchfensterskalierung identisch. Der resultierende Toleranzbereich wird daher für jede Skalierung glejLc_h__gewähl-t-.
[0041] In der Figur 10 wird die Relaxation der Korrespondenzbedingung gezeigt. Die Positionen der korrelierenden Suchfenster sind hierbei nicht nur auf eine Strecke beschränkt . Sie können nun innerhalb eines elliptischen Bereiches um diese Strecke herum liegen. Im NIR- BiId sind dabei nur die Mittelpunkte der Suchfenster eingezeichnet. In Bezug auf diesen Korrespondenzfehler werden zur Bestimmung der Radien gelabelte Daten herangezogen. Die Radien des elliptischen Toleranzbereichs werden folgendermaßen bestimmt :
• Für jedes Multistrom-Label werden die Suchfenster in beiden Strömen bestimmt .
• Zu dem jeweiligen Suchfenster im ersten Strom werden alle möglichen Korrespondenzsuchfenster im zweiten Strom berechnet. Dabei wird eine nicht-relaxierte Korrespondenzbedingung verwendet .
• Das Korrespondenzsuchfenster, das dem Labelsuchfenster im zweiten Strom am nächsten kommt, wird für die Fehlerbestimmung herangezogen. Die Nähe zweier Suchfenster kann hier entweder durch die Überdeckung definiert sein, insbesondere durch das Verhältnis der Schnittfläche zweier Rechtecke zu deren Vereinigungsfläche (auch Coverage genannt) oder durch den Abstand der Suchfenstermittelpunkte. Letztere Definition wurde bei diesem Ausführungsbeispiel gewählt, da so der für die Detektorantwort unkritische Skalierungsfehler vernachlässigt wird.
• Für alle Labels wird der Abstand in X- und Y-Richtung zwischen dem Labelsuchfenster und dem am nächsten gelegenen Korrespondenzsuchfenster bestimmt. Es entsteht dabei eine Häufigkeitsverteilung für die X- und Y-Abstände. Ein Histogramm über den Abstand in X- und Y-Richtung ist in der Figur 11 dargestellt .
• Nun werden die Radien ex und ey von der Verteilung der Abstände abgeleitet. In dieser Arbeit wurde ex = 2σx und ey = 2ery gewählt. Der nächste Schritt nach der Definition des Korrespondenzraumes für ein Suchfenster ist die Suchraumabtastung. Wie bei der Einzelstrom-Unterabtastung soll auch hier die Hypothesenzahl bei möglichst geringen Einbußen bei der Detektionsleistung minimiert werden.
[0042] Figur 11 zeigt den Korrespondenzfehler zwischen Label - und Korrespondenzsuchfenster. Der dargestellte Korrespondenzfehler ist dabei der kleinste Pixelabstand eines Labelsuchfensters zu den Korrespondenzsuchfenstern des korrespondierenden Labels, also zum projizierten Label des anderen Sensorsignalstroms. Bei der dargestellten Messung werden FIR-Labels ins NIR-BiId projiziert und ein Histogramm über die Abstände der Suchfenstermittelpunkte gebildet.
[0043] Das Verfahren für die Suchraumabtastung läuft folgendermaßen ab: In beiden Strömen werden mit dem Einzelstrom-Hypothesengenerator Einzelstrom-Hypothesen, also Suchfenster gestreut . Es müssen dabei die entstehenden Skalierungsstufen aufeinander abgestimmt werden, wobei im ersten Strom die Skalierungen mit dem Hypothesengenerator bestimmt werden. Für jede dieser Skalierungsstufen wird sodann der Korrespondenzraum eines prototypischen Suchfensters bestimmt. Die Skalierungen des zweiten Stromes ergeben sich aus den Skalierungen der Korrespondenzräume aller prototypischen Suchfenster. Dadurch entsteht in beiden Strömen die gleiche Anzahl an Skalierungsstufen. Nun werden Suchfensterpaare gebildet, wodurch die Multistrom-Hypothesen entstehen. Es kann anschließend einer der beiden Ströme gewählt werden, um für jedes Suchfenster den jeweiligen
Korresponden-z-be-r-eich im__anderen Strom zu bestimmen. Alle
Suchfenster des zweiten Stromes, welche die ricntige
Skalierung aufweisen, die innerhalb dieses Bereiches liegen, werden zusammen mit dem festen Suchfenster des ersten Stromes zur Paarbildung herangezogen, dies wird anhand der Figur 12 verdeutlicht. Dabei zeigt die Figur 12 die entstehenden Multistrom-Hypothesen. Es sind hierbei drei Suchfenster im FIR-BiId und ihre Korrespondenzbereiche im NIR-BiId eingezeichnet. Mit den von Einzelstrom-hypothesengeneratoren gestreuten Suchfenstern werden Paare gebildet. Eine Multistrom-Hypothese entspricht dabei einem Suchfensterpaar.
[0044] Wählt man für die intern verwendeten Einzelstrom- Hpothesengeneratoren Positions- und Skalierungsschrittweiten von 5% der Suchfensterhöhe, so ergeben sich im NIR-BiId ca. 400.000 Einzelstrom-Hypothesen, im FIR-BiId ca. 50.000. Es ergeben sich dabei jedoch ca. 1,2 Millionen Multistrom- Hypothesen. Im praktischen Einsatz konnte eine Verarbeitungsgeschwindigkeit mit 2 Bildern pro Sekunde erzielt werden. Um die Echtzeitfähigkeit der Anwendung zu gewährleisten, werden nachfolgend weitere Optimierungen vorgestellt. Zum einen wird ein sogenannter Weaklearner-Cache beschrieben, der die Zahl der notwendigen Merkmalsberechnungen vermindert. Darüber hinaus wird ein Verfahren zur dynamischen Reduktion der Hypothesenmenge vorgestellt, im Folgenden mit Multiraster-Hypothesenbaum bezeichnet. Die dritte Optimierung, welche mit Backtracking bezeichnet wird, reduziert im Falle einer Detektion unnötigen Aufwand in Zusammenhang mit Mehrfachdetektionen.
[0045] Das Evaluieren von mehreren Multistrom-Hypothesen, die ein Suchfenster gemeinsam haben, führt dazu, dass Weaklearner mehrmals auf den gleichen Daten berechnet werden. Zur Vermeidung aller redundanten Berechnungen wird nun ein Cachingverfahren_e,ing.esetzt—Dabei—w-i-r-d—f-ü-r—jedes~Such'feTϊs~ter~ in beiden Strömen und für jeden Stronglearner partielle
Summen der Stronglearner-Berechnung in Tabellen abgelegt. Ein Stronglearner Hk der Kaskadenstufe k ist definiert durch:
"'WH | — ! 1 : : s Sotn{sxt)≥ @t »«s'M-i "XtfM (5.1D
k mit den Weaklearnern h, e{-l, l} und Hypothese x.
Sk (x) kann aufgetrennt werden in zwei Summen, die nur
Weaklearner mit Merkmalen eines Stromes beinhalten:
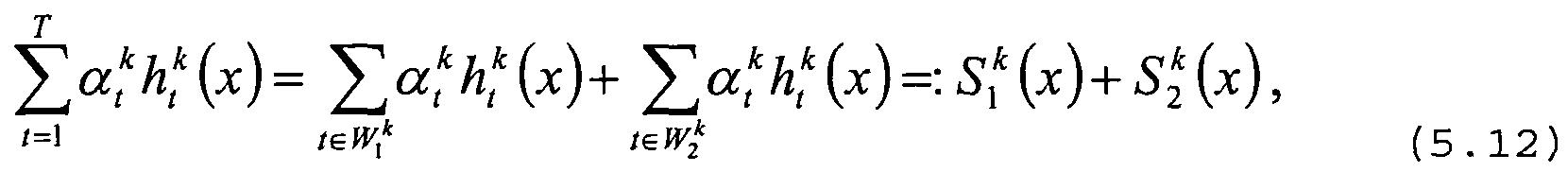
Falls mehrere Hypothesen xi in einem Strom s das gleiche Suchfenster besitzen, dann ist in jeder Stufe k für den Strom s die Summe S5 (xi) gleich für alle xi . Das Ergebnis wird vorzugsweise zwischengespeichert und mehrmals verwendet. Sofern für eine Stronglearner-Berechnung auf bereits berechnete Werte zurückgegriffen werden kann, reduziert sich der Aufwand in gewinnbringender Weise auf eine Summen- und eine Schwellwertoperation. Was die Größe der Tabellen betrifft, ergeben sich bei diesem Ausführungsbeispiel für insgesamt 500.000 Suchfenster und 25 Kaskadenstufen 12,5 Millionen Einträge. Mit 64Bit-Fließkommazahlen werden 100 MB dabei Speicher benötigt. Für eine Aufwandsabschätzung kann die Zahl der Merkmalsberechnungen sowohl mit als auch ohne Weaklearner-Cache betrachtet werden. Im ersteren Fall ist die Zahl der Hypothesen pro Bild und die Anzahl aller Merkmale ausschlaggebend. Die Zahl der Hypothesen kann durch die Anzahl der Suchfenster R3 in den Strömen, s abgesc-hä-t-z-t—we-rderr mit O(R1-R2). Der in der O-Notation versteckte Faktor ist hier allerdings sehr klein, da der Korrespondenzbereich klein
gegenüber der gesamten Bildfläche ist. Die Zahl der berechneten Merkmale ist dann im schlechtesten Fall O(R1-R2-(M1 +M2)) wobei Ms die Zahl der Merkmale in jedem Strom s ist. Im zweiten Fall wird jedes Merkmal in jedem Suchfenster höchstens einmal pro Bild berechnet . Somit ist die Zahl der berechneten Merkmale höchstens O (Rl -M1+R2 -M2) . Der Aufwand wird im schlechtesten Fall um den Faktor min(Rl,R2) reduziert. Eine Komplexitätsanalyse für den durchschnittlichen Fall ist dagegen aufwändiger, da der Zusammenhang zwischen der mittleren Zahl berechneter Merkmale pro Hypothese bzw. Suchfenster im ersten Fall und im zweiten Fall nicht linear ist.
[0046] Es folgen Ausführungen zum Multiraster-Hypothesenbaum. Der Suchraum des Multistrom-Detektors wurde bei diesem Beispiel mit zwei Einzelstrom-Hypothesengeneratoren und einer relaxierten Korrespondenzbeziehung erfasst . Hierbei ist es jedoch schwierig eine optimale Parametrisierung zu finden, speziell das Finden der geeigneten Abtast-Schrittweiten. Sie haben zum einen großen Einfluss auf die Detektionsleistung und zum anderen auf den entstehenden Rechenaufwand. Für die Einzelstrom-Detektoren konnten bei einem praktischen Versuch akzeptable Kompromisse gefunden werden, die im FIR-FaIl wegen der geringeren Bildauflösung eine Echtzeitfähigkeit gewährleisten konnten, im NIR-FaIl war dies mit der eingesetzten Hardware allerdings nicht möglich. Die Leistung des verwendeten Versuchsrechners war auch beim Einsatz eines Fusionsdetektors mit Weaklearner-Cache nicht ausreichend und führte in komplexen Szenen zu längeren Reaktionszeiten. Diese Probleme lassen sich aber natürlich mit leistungsfähigerer Hardware lösen.
F0047_1 Beim. praktischen- 3-i-nsa-fe-z- wurden- ve-rschi-edene- Parametrisierungen des Hypothesengenerators und des Detektors
getestet. Mehrere Suchrasterdichten und verschiedene Stufenbeschränkungen wurden dabei evaluiert . Es hat sich gezeigt, dass auch bei sehr grober Abtastung jeder zu detektierende Fußgänger bereits mit den ersten Stufen des Detektors erkannt wird. Hierbei wurden die hinteren Kaskadenstufen sukzessive abgeschaltet, was eine hohe Falschalarmrate zur Folge hat. Die beim praktischen Einsatz aufgezeichneten Messwerte sind in der Abbildung 13 dargestellt. Die Zahl der Hypothesen waren beginnend mit der feinsten Rasterdichte: ca. 1.200.000, 200.000, 7.000 und 2.000.
[0048] Die Figur 13 zeigt dabei den Vergleich der Detektionsraten verschiedener Rasterweiten, wobei vier verschiedene Hypothesenrasterdichten verglichen werden. Für jede Rasterweite ist die Detektionsrate eines Fusionsdetektors über die Zahl der verwendeten Stufen aufgetragen. Die Detektionsrate ist definiert durch die Zahl der gefundenen Fußgänger dividiert durch die Zahl aller Fußgänger. Der Grund für das aufgetretene Phänomen ist folgende Eigenschaft des Detektors: Die Detektorantwort, also die erreichte Kaskadenstufe, ist maximal für eine Hypothese, welche exakt auf dem Fußgänger positioniert ist. Schiebt man die Hypothese nun schrittweise vom Fußgänger weg, fällt das Detektorergebnis nicht abrupt auf null ab, sondern es existiert ein Bereich, indem das Detektorergebnis stark variiert und tendenziell absinkt. Dieses Verhalten des Kaskadendetektors wird im Folgenden als charakteristische Detektorantwort bezeichnet. Ein Experiment, bei dem ein Bild in Pixelschritten abgetastet wird, ist in der Figur 14 visualisiert . Dabei werden ein Multistrom-Detektor und Hypothesen mit fixer Skalierung verwendet. Man kann den
Bereich, für den—d-ie—Defeekfeoranfewort—verzögert—abfä~l~ϊt~; gut" erkennen. Weiterhin hat sich gezeigt, dass der Detektor
ähnliche Charakteristiken bei einem Experiment mit fixer Position und variierender Skalierung aufweist. Damit ist die Detektionsleistung des verkürzten Detektors angewandt auf ein grobes Hypothesenraster zu erklären, denn die "Trefferfläche" für einen Fußgänger vergrößert sich für niedrigere Stufen.
[0049] In der Figur 14 wird die Detektorantwort in Abhängigkeit der erreichten Detektionsstufe gezeigt. Dabei wird ein Multistrom-Detektor auf eine Hypothesenmenge in einer Skalierung mit pixelgenauem Raster angewandt. Die letzte erreichte Kaskadenstufe ist für jede Hypothese an ihrem Mittelpunkt eingezeichnet. Während des Trainings werden keine zu einem Label leicht versetzten Trainingsbeispiele verwendet. Es werden ausschließlich exakte Positivbeispiele verwendet sowie Negativbeispiele, welche einen großen Abstand zu jedem Positivbeispiel aufweisen. Somit ist das Verhalten des Detektors Undefiniert bei Hypothesen, die zu einem Objekt leicht versetzt sind. Es wird daher für jeden Detektor experimentell die charakteristische Detektorantwort untersucht. Die zentrale Idee zur Reduktion der Hypothesenzahl ist dabei eine Grob-Zu-Fein-Suche, wobei jedes Bild im ersten Schritt mit einer grob aufgelösten Hypothesenmenge abgesucht wird. In Abhängigkeit des Detektorergebnisses werden nun weitere Hypothesen mit höherer Dichte im Bild gestreut . Außerdem wird die lokale Nachbarschaft derjenigen Hypothesen durchsucht, die ein Objekt in ihrer Nähe vermuten lassen. Durch das oben beschriebene Verhalten des Detektors, kann die erreichte Stufenzahl als Kriterium für die Verfeinerung der Suche genommen werden. Nach dem gleichen Prinzip kann sodann erneut die lokale Nachbarschaft der neuen Hypothesen durchsucht werden, bis das feinste Hypothesenraster erreicht ist. Für ieden Verfeinerungsschritt wird ein Schwellwert verwendet,
mit dem die erreichte Kaskadenstufe jeder Hypothese verglichen wird.
[0050] Figur 15 zeigt eine Grob-Zu-Fein-Suche im eindimensionalen Fall. Hierfür wurde eine Bildzeile aus der in Figur 14 gezeigten Bildaufnahme herangezogen, welche in der Form einer Funktion in der Figur 15 dargestellt ist. Von links nach rechts sind die Schritte des Suchverfahrens zu sehen. Senkrecht sind die Hypothesenresultate und waagerecht die Schwellwerte zur lokalen Verfeinerung eingezeichnet. Für die Schwellwertbestimmung kann das eingangs beschriebene Experiment verwendet werden. Die Detektionsrate jeder Rasterdichte ist für die ersten Stufen des Detektors fast identisch. Als Schwellwert wird die maximale Stufe gewählt, für die die betroffene Rasterdichte immer noch beinahe die gleiche Detektionsrate hat wie die maximal erreichbare. Für die Schwellwertstufe k einer Rasterdichte L wird eine
L
Detektionsrate D t gefordert , sodass
≥a-D?.
D"
Ok kennzeichnet hierbei die Detektionsrate der feinsten Rasterdichte H in Stufe k. Wenn n die Zahl der Verfeinerungen ist, dann ergibt sich für die letzte Stufe K des Detektors eine Detektionsrate
Dκ=a"-DK H
Für α sind in diesem Beispiel hauptsächlich Werte zwischen 0,98 und 0,999 geeignet.
[0051] Bei der Definition der Nachbarschaft wird der Hypothesenrautn betrachtet. Der Hypothesenraum ist nun nicht eindimensional sondern im Falle des Einzelstrom-Detektors dreidimensional oder sechsdimensional beim Fusionsdetektor. Das Problem einer Schrittweisen Verfeinerung in allen Dimensionen wird mit dem Hypothesengenerator gelöst. Zur Definition der Nachbarschaft gibt es dabei zwei Möglichkeiten, von denen in diesem Ausführungsbeispiel die zweite verwendet wird. Zum einen kann ein Minimalwert für die Überdeckung (Coverage) zweier benachbarter Suchfenster festgelegt werden. In diesem Fall ist jedoch nicht klar, wie der Minimalwert zu wählen ist, da in den verfeinerten Hypothesenmengen Lücken entstehen können, also Bereiche, die keiner Hypothese der groben Hypothesenmenge nahe genug sind. Es müssen daher verschiedene Schwellwerte für jede Rasterdichte festgelegt werden. Zum anderen kann die Nachbarschaft mit einer modifizierten Schachbrett -Distanz definiert werden. Damit werden die erwähnten Lücken vermieden und es kann ein einheitlicher Schwellwert für alle Rasterdichten definiert werden. Die Schachbrett -Distanz ist definiert durch
dύt(pι,p2)=max\plιX-p2ιX\,\pUy-p2ty\) mit pλ,p2 e <R2. (5.13)
Die Rasterdichte für einen Strom ist durch rx,ry,rh eR definiert . Die Rasterabstände sind für eine Suchfensterhöhe h dann in X-Richtung rx • h und in Y-Richtung ry • h. Für eine Suchfensterhöhe hi ist die nächst größere Suchfensterhöhe h2 hi- (1 + rh) . Das Nachbarschaftskriterium für ein Suchfenster mit Position S1 e R2 und Suchfensterhöhe Ia1 zu einem Suchfenster S2 e R2 einer feineren Hypothesenmenge mit Höhe h? ist mit _einem_Skalar <? definier-t^
max
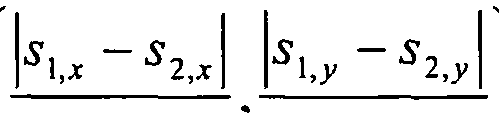 < δ Λ h2 e [hx{\ + rh)-δ,hfi + rhyδ}. rx ' K (5.14)
< δ Λ h2 e [hx{\ + rh)-δ,hfi + rhyδ}. rx ' K (5.14)
A,
Die entstehenden Intervallgrenzen sind in der Figur 16 visualisiert . Im Multistrom-Fall gilt in jedem Strom ein dreidimensionales Nachbarschaftskriterium. Für benachbarte Multistrom-Hypothesen muss die Nachbarschaftsbedingung in beiden Strömen erfüllt sein. Wählt man rx = ry und δ = 0,5, so sind alle Nachbarschaftsbereiche bis auf die Ränder disjunkt. Sofern die Schrittweiten r* und für die
Verfeinerungs-Hypothesenmengen sukzessive halbiert werden und die hinzukommenden Hypothesen genau auf die Grenzen der
Nachbarschaftsbereiche fallen, ist dieser Wert für δ sinnvoll, da die feineren Hypothesen mit allen angrenzenden gröberen Hypothesen verknüpft werden. Dies gilt jedoch nicht, falls die verfeinerten Hypothesenmengen beliebige
Rasterabstände aufweisen. Dann muss durch Wahl von ^>0,5 erreicht werden, dass sich die Nachbarschaftsbereiche von benachbarten Hypothesen der groben Menge überlappen und die Hypothesen des feinen Rasters mehreren Hypothesen des groben
Rasters zugeordnet werden. Der erforderliche Wert für δ muss durch Experimente ermittelt werden, d.h. er muss an die charakteristische Detektorantwort angepasst werden.
[0052] In der Figur 16 wird die Nachbarschaftsdefinition gezeigt : Die Nachbarschaft ist für drei der Hypothesen gleicher Skalierungsstufe eingezeichnet, außerdem sind rechts drei verschiedene Skalierungen und deren resultierende
Skalierungs-Nachbarschaft abgebildet. Für δ wurde hierbei 0,75 gewählt .
[0053] Die Erzeugung der verfeinerten Hypothesen wanrenα αer Anwendung wäre zu zeitintensiv und kann genauso gut als
Vorverarbeitungsschritt erfolgen. Das Generieren aller verfeinerten Hypothesenmengen erfolgt mittels des Hypothesengenerators . Es wird zunächst die Hypothesenmenge für jede Verfeinerungsstufe generiert. Anschließend werden die Hypothesen mit dem Nachbarschaftskriterium verknüpft, wobei Jede Hypothese mit jeder Hypothese der nächsten feineren Hypothesenmenge verglichen wird. Sind diese sich nahe, werden sie verknüpft. Es entsteht hierbei eine baumartige Struktur, deren Wurzeln den Hypothesen der gröbsten Stufe entsprechen. In der Figur 17 stellen die Kanten die berechneten Nachbarschaftsbeziehungen dar. Da mit der Generierung des Hypothesenbaumes ein gewisser Suchaufwand verbunden ist, werden die dafür erforderlichen Berechnungen vorzugsweise über ein separates Tool realisiert und in Form einer Datei gespeichert .
[0054] Figur 17 zeigt den resultierenden Hypothesenbaum. Der Hypothesenbaum/Suchbaum weist dabei mehrere Wurzeln auf und wird von den Wurzeln aus bis auf die Blattebene abgesucht, sofern das Detektionsergebnis eines Knotens größer als der Schwellwert ist. Bei der Verarbeitung eines Bildes (bzw. Bildpaares beim Multistrom-Detektor) wird der Hypothesenbaum durchlaufen. Beginnend mit der ersten Baumwurzel wird der Baum mit einer Tiefen- oder Breitensuche abgesucht. Die Hypothese der Wurzel wird dabei evaluiert . Solange der entsprechende Schwellwert überschritten ist, wird im Baum abgestiegen und die jeweiligen Kindknoten-Hypothesen untersucht . Dann wird die Suche bei der nächsten Baumwurzel fortgesetzt. Zusammen mit dem nachfolgend beschriebenen Backtracking-Verfahren ist die Tiefensuche am effektivsten. Da Knoten mehrere Vaterknoten aufweisen können, muss darauf geachtet werden, dass jeder Knoten nur einmal untersucht wird._ Durch den Einsatz eines Multiraster-Hypothesenbaum resultiert dabei in gewinnbringender Weise eine Reduktion d~er~
Hypothesenzahl, welche sich auf die Detektionsleistung auswirkt .
[0055] Die Zahl der Mehrfachdetektionen ist beim Multistrom- Detektor und beim FIR-Detektor sehr hoch. Mehrfachdetektionen haben daher großen Einfluss auf die Rechenzeit, da sie die gesamte Kaskade durchlaufen. Es wird daher ein sogenanntes Backtracking-Verfahren eingesetzt. Mit einer Änderung der Suchstrategie kann dabei ein Großteil der Mehrfachdetektionen vermieden werden, wobei im Falle einer Detektion die Suche in dem Hypothesenbaum abgebrochen und bei der nächsten Baumwurzel fortgesetzt wird. Dadurch wird die Hypothesendichte lokal vermindert, sobald ein Objekt gefunden wird. Um keinen systematischen Fehler zu erzeugen, werden alle Kindknoten zufällig permutiert, so dass ihre Reihenfolge nicht mit ihrer Anordnung im Bild korreliert. Wenn die ersten Kind-Hypothesen beispielsweise immer links oben im Nachbarschaftsbereich liegen, so kann die Detektion tendenziell in diese Richtung verschoben werden.
[0056] Anhand dieses Ausführungsbeispiels wurde somit ausgehend vom Einzelstrom-Hyothesengenerator, durch Modellierung eines relaxierten Korrespondenzbereiches und schließlich durch verschiedene Optimierungen ein Verfahren entwickelt, welches trotz des komplexen Suchraumes der Multistrom-Daten sehr wenig Rechenzeit erfordert . Einen wichtigen Beitrag leistet dabei der Multiraster- Hypothesenbaum .
[0057] Die Verwendung des Multiraster-Hypothesenbaums ist nicht nur im Rahmen der Multisensorfusion von großem Vorteil, sondern eignet sich in besonderer Weise auch zum Zusammenspiel mit Kaskadenklassifikatoren im Allgemeinen und führt hierbei zu signifikant besseren Klassifikationsergebnissen.
Claims
1. Verfahren zur multisensoriellen Objekterkennung, wobei Sensorinformationen aus wenigstens zwei unterschiedlichen Sensorsignalströmen mit unterschiedlichen Sensorsignaleigenschaften zur gemeinsamen Auswertung herangezogen werden, wobei die wenigstens zwei Sensorsignalströme zur Auswertung nicht aneinander angepasst und/oder aufeinander abgebildet werden, wobei hierbei in jedem der wenigstens zwei Sensorsignalströme Objekthypothesen generiert werden, wobei auf der Grundlage dieser Objekthypothesen Merkmale für wenigstens einen Klassifikator generiert werden und wobei die Objekthypothesen mittels dem wenigstens einen Klassifikator bewertet und einer oder mehreren Klassen zugeordnet werden, wobei wenigstens zwei Klassen definiert sind und einer der beiden Klassen Objekte zuzuordnen sind.
2. Verfahren nach Anspruch 1 , dadurch gekennzeichnet, dass die Objekthypothesen eindeutig einer Klasse zugeordnet werden.
3. Verfahren nach Anspruch 1 , dadurch gekennzeichnet, dass die Objekthypothesen mehreren Klassen zugeordnet werden, wobei die jeweilige Zuordnung mit einer Wahrscheinlichkeit belegt ist.
4. Verfahren nach einem der vorstehenden Ansprüche, dadurch gekennzeichnet, dass die Objekthypothesen unabhängig voneinander in jedem Sensorsignalstrom einzeln generiert werden, wobei die Objekthypothesen unterschiedlicher Sensorsignalströme sodann über Zuordnungsvorschriften einander zuordenbar sind.
5. Verfahren nach einem der Ansprüche 1 bis 3, dadurch gekennzeichnet, dass Objekthypothesen in einem Sensorsignalstrom (Primärstrom) generiert werden und Objekthypothesen des
Primärstroms in andere Sensorsignalströme (Sekundärströme) projiziert werden, wobei eine
Objekthypothese des Primärstroms eine oder mehrere
Objekthypothesen im Sekundärstrom erzeugt.
6. Verfahren nach Anspruch 5, dadurch gekennzeichnet, dass die Projektion von Objekthypothesen des Primärstroms in einen Sekundärstrom auf den verwendeten Sensormodellen und/oder der Positionen von Suchfenstern innerhalb des Primärstroms bzw. auf der Epipolargeometrie basiert.
7. Verfahren nach einem der vorstehenden Ansprüche, dadurch gekennzeichnet, dass Objekthypothesen durch deren Objektt_yp_,_ Objektposition, Objektausdehnung, ObjektOrientierung, Objektbewegungsparameter wie Bewegungsrichtung und Geschwindigkeit, Objektgefahrenpotential oder einer beliebigen Kombination daraus beschrieben werden.
8. Verfahren nach einem der vorstehenden Ansprüche, dadurch gekennzeichnet, dass Objekthypothesen in einem physikalischen Suchraum zufällig gestreut oder in einem Raster erzeugt werden oder durch ein physikalisches Modell erzeugt werden.
9. Verfahren nach Anspruch 8, dadurch gekennzeichnet, dass der Suchraum durch externe Vorgaben wie Öffnungswinkel, Entfernungsbereiche, statistische Kenngrößen, die lokal im Bild gewonnen werden, und/oder Messungen anderer Sensoren adaptiv eingeschränkt wird.
10. Verfahren nach einem der vorstehenden Ansprüche, dadurch gekennzeichnet, dass die unterschiedlichen Sensorsignaleigenschaften in den Sensorsignalströmen auf unterschiedlichen Positionen und/oder Orientierungen und/oder Sensorgrößen der verwendeten Sensoren basieren.
11. Verfahren nach Anspruch 10, dadurch gekennzeichnet, dass jede Objekthypothese einzeln für sich klassifiziert wird und die Ergebnisse der einzelnen Klassifikationen kombiniert werden, wobei wenigstens ein Klassifikator vorgesehen ist .
12. Verfahren nach Anspruch 10, dadurch gekennzeichnet, dass in dem wenigstens einen Klassifikator Merkmale von Objekthypothesen unterschiedlicher Sensorsignalströme gemeinsam bewertet und zu einem Klassifikationsergebnis zusammengefasst werden.
13. Verfahren nach einem der vorstehenden Ansprüche, dadurch gekennzeichnet, dass das Raster, in welchem die Objekthypothesen erzeugt werden, in Abhängigkeit des Klassifikationsergebnisses adaptiv angepasst wird.
14. Verfahren nach einem der Ansprüche 1 bis 12, dadurch gekennzeichnet, dass das Raster, in welchem die Objekthypothesen erzeugt werden, in Abhängigkeit des Klassifikationsergebnisses eines vorangegangenen Zeitschrittes adaptiv angepasst wird .
15. Verfahren nach einem der vorstehenden Ansprüche, dadurch gekennzeichnet, dass das Auswerteverfahren, mittels welchem die Objekthypothesen bewertet werden, in Abhängigkeit von wenigstens einer vorangegangenen Bewertung automatisch angepasst wird.
16. Verfahren nach einem der vorstehenden Ansprüche, dadurch gekennzeichnet, dass mindestens zwei unterschiedliche Sensorsignalströme zeitversetzt verwendet werden oder dass ein einzelner Sensorsignalstrom gemeinsam mit wenigstens einer zeitversetzten Version desselben verwendet wird.
17. Verwendung des Verfahrens nach ejnem__der_jv:ors-teh.enden- Ansprüche zur Verfolgung von erkannten Objekten.
8. Verwendung des Verfahrens nach einem oder mehreren der Ansprüche 1 bis 16 zur Umgebungserfassung und/oder Objektverfolgung bei einem Straßenfahrzeug.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US12/294,021 US20090103779A1 (en) | 2006-03-22 | 2007-03-19 | Multi-sensorial hypothesis based object detector and object pursuer |
| EP07723378A EP2005361A1 (de) | 2006-03-22 | 2007-03-19 | Multisensorieller hypothesen-basierter objektdetektor und objektverfolger |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE102006013597.0 | 2006-03-22 | ||
| DE102006013597 | 2006-03-22 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2007107315A1 true WO2007107315A1 (de) | 2007-09-27 |
Family
ID=38255131
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2007/002411 WO2007107315A1 (de) | 2006-03-22 | 2007-03-19 | Multisensorieller hypothesen-basierter objektdetektor und objektverfolger |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US20090103779A1 (de) |
| EP (1) | EP2005361A1 (de) |
| WO (1) | WO2007107315A1 (de) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210286044A1 (en) * | 2018-12-03 | 2021-09-16 | Lac Camera Systems Oy | Self-positioning method, self-positioning system and tracking beacon unit |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8280901B2 (en) * | 2008-01-03 | 2012-10-02 | Masterfile Corporation | Method and system for displaying search results |
| US8687898B2 (en) * | 2010-02-01 | 2014-04-01 | Toyota Motor Engineering & Manufacturing North America | System and method for object recognition based on three-dimensional adaptive feature detectors |
| US8855911B2 (en) | 2010-12-09 | 2014-10-07 | Honeywell International Inc. | Systems and methods for navigation using cross correlation on evidence grids |
| US8799201B2 (en) | 2011-07-25 | 2014-08-05 | Toyota Motor Engineering & Manufacturing North America, Inc. | Method and system for tracking objects |
| US11288472B2 (en) * | 2011-08-30 | 2022-03-29 | Digimarc Corporation | Cart-based shopping arrangements employing probabilistic item identification |
| US8818722B2 (en) | 2011-11-22 | 2014-08-26 | Honeywell International Inc. | Rapid lidar image correlation for ground navigation |
| DE102012207203A1 (de) * | 2012-04-30 | 2013-10-31 | Robert Bosch Gmbh | Verfahren und Vorrichtung zur Bestimmung eines Umfelds |
| EP2662828B1 (de) * | 2012-05-11 | 2020-05-06 | Veoneer Sweden AB | Sichtsystem und -verfahren für ein Kraftfahrzeug |
| US9157743B2 (en) | 2012-07-18 | 2015-10-13 | Honeywell International Inc. | Systems and methods for correlating reduced evidence grids |
| US10043067B2 (en) * | 2012-12-03 | 2018-08-07 | Harman International Industries, Incorporated | System and method for detecting pedestrians using a single normal camera |
| US9881380B2 (en) * | 2016-02-16 | 2018-01-30 | Disney Enterprises, Inc. | Methods and systems of performing video object segmentation |
| US10257501B2 (en) * | 2016-04-06 | 2019-04-09 | Facebook, Inc. | Efficient canvas view generation from intermediate views |
| CN110019899B (zh) * | 2017-08-25 | 2023-10-03 | 腾讯科技(深圳)有限公司 | 一种目标对象识别方法、装置、终端及存储介质 |
| RU2688253C2 (ru) * | 2017-10-21 | 2019-05-21 | Вячеслав Михайлович Агеев | Устройство различения гипотез |
| CN109271892A (zh) * | 2018-08-30 | 2019-01-25 | 百度在线网络技术(北京)有限公司 | 一种物体识别方法、装置、设备、车辆和介质 |
| US11017513B1 (en) * | 2019-03-28 | 2021-05-25 | Amazon Technologies, Inc. | Active sensor fusion systems and methods for object detection |
| DE102020206660A1 (de) | 2019-05-30 | 2020-12-03 | Robert Bosch Gesellschaft mit beschränkter Haftung | Redundante umgebungswahrnehmungsverfolgung für automatisierte fahrsysteme |
| DE102020206659A1 (de) | 2019-05-30 | 2020-12-03 | Robert Bosch Gesellschaft mit beschränkter Haftung | Multi-hypothesen-objektverfologung für automatisierte fahrsysteme |
| CN111768433A (zh) * | 2020-06-30 | 2020-10-13 | 杭州海康威视数字技术股份有限公司 | 一种移动目标追踪的实现方法、装置及电子设备 |
| EP4047516A1 (de) * | 2021-02-19 | 2022-08-24 | Aptiv Technologies Limited | Verfahren und systeme zur bestimmung einer entfernung eines objekts |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102004007049A1 (de) * | 2004-02-13 | 2005-09-01 | Robert Bosch Gmbh | Verfahren zur Klassifizierung eines Objekts mit einer Stereokamera |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6188777B1 (en) * | 1997-08-01 | 2001-02-13 | Interval Research Corporation | Method and apparatus for personnel detection and tracking |
| US7778328B2 (en) * | 2003-08-07 | 2010-08-17 | Sony Corporation | Semantics-based motion estimation for multi-view video coding |
| US20050089213A1 (en) * | 2003-10-23 | 2005-04-28 | Geng Z. J. | Method and apparatus for three-dimensional modeling via an image mosaic system |
| WO2005060640A2 (en) * | 2003-12-15 | 2005-07-07 | Sarnoff Corporation | Method and apparatus for object tracking prior to imminent collision detection |
| JP4424031B2 (ja) * | 2004-03-30 | 2010-03-03 | 株式会社日立製作所 | 画像生成装置、システムまたは画像合成方法。 |
| US7769228B2 (en) * | 2004-05-10 | 2010-08-03 | Siemens Corporation | Method for combining boosted classifiers for efficient multi-class object detection |
| WO2005114557A2 (en) * | 2004-05-13 | 2005-12-01 | Proximex | Multimodal high-dimensional data fusion for classification and identification |
| US7742641B2 (en) * | 2004-12-06 | 2010-06-22 | Honda Motor Co., Ltd. | Confidence weighted classifier combination for multi-modal identification |
-
2007
- 2007-03-19 WO PCT/EP2007/002411 patent/WO2007107315A1/de active Application Filing
- 2007-03-19 US US12/294,021 patent/US20090103779A1/en not_active Abandoned
- 2007-03-19 EP EP07723378A patent/EP2005361A1/de not_active Withdrawn
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102004007049A1 (de) * | 2004-02-13 | 2005-09-01 | Robert Bosch Gmbh | Verfahren zur Klassifizierung eines Objekts mit einer Stereokamera |
Non-Patent Citations (9)
| Title |
|---|
| CHECKA, NEAL: "Fast Pedestrian Detection from a moving vehicle", ONLINE DOCUMENT, 2004, MIT, USA, XP007902696, Retrieved from the Internet <URL:http://sow.csail.mit.edu/2004/proceedings/Checka.pdf> [retrieved on 20070727] * |
| FRANKE U ET AL: "AUTONOMOUS DRIVING GOES DOWNTOWN", IEEE EXPERT, IEEE SERVICE CENTER, NEW YORK, NY, US, vol. 13, no. 6, November 1998 (1998-11-01), pages 40 - 48, XP000848997, ISSN: 0885-9000 * |
| GANDHI T ET AL: "Vehicle Mounted Wide FOV Stereo for Traffic and Pedestrian Detection", IMAGE PROCESSING, 2005. ICIP 2005. IEEE INTERNATIONAL CONFERENCE ON GENOVA, ITALY 11-14 SEPT. 2005, PISCATAWAY, NJ, USA,IEEE, 11 September 2005 (2005-09-11), pages 121 - 124, XP010851343, ISBN: 0-7803-9134-9 * |
| GAVRILA D M ET AL: "Vision-based pedestrian detection: the protector system", INTELLIGENT VEHICLES SYMPOSIUM, 2004 IEEE PARMA, ITALY JUNE 14-17, 2004, PISCATAWAY, NJ, USA,IEEE, 14 June 2004 (2004-06-14), pages 13 - 18, XP010727435, ISBN: 0-7803-8310-9 * |
| JAHARD F ET AL: "Far/near infrared adapted pyramid-based fusion for automotive night vision", IMAGE PROCESSING AND ITS APPLICATIONS, 1997., SIXTH INTERNATIONAL CONFERENCE ON DUBLIN, IRELAND 14-17 JULY 1997, LONDON, UK,IEE, UK, vol. 2, 14 July 1997 (1997-07-14), pages 886 - 890, XP006508423, ISBN: 0-85296-692-X * |
| LUO R C ET AL: "A tutorial on multisensor integration and fusion", SIGNAL PROCESSING AND SYSTEM CONTROL, FACTORY AUTOMATION. PACIFIC GROVE, NOV. 27 - 30, 1990, PROCEEDINGS OF THE ANNUAL CONFERENCE OF THE INDUSTRIAL ELECTRONICS SOCIETY. (IECON), NEW YORK, IEEE, US, vol. VOL. 1 CONF. 16, 27 November 1990 (1990-11-27), pages 707 - 722, XP010038257, ISBN: 0-87942-600-4 * |
| PAUL VIOLA ET AL: "Detecting Pedestrians Using Patterns of Motion and Appearance", INTERNATIONAL JOURNAL OF COMPUTER VISION, KLUWER ACADEMIC PUBLISHERS, BO, vol. 63, no. 2, 1 July 2005 (2005-07-01), pages 153 - 161, XP019216468, ISSN: 1573-1405 * |
| VIOLA P ET AL: "Rapid object detection using a boosted cascade of simple features", PROCEEDINGS 2001 IEEE CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION. CVPR 2001. KAUAI, HAWAII, DEC. 8 - 14, 2001, PROCEEDINGS OF THE IEEE COMPUTER CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION, LOS ALAMITOS, CA, IEEE COMP. SOC, US, vol. VOL. 1 OF 2, 8 December 2001 (2001-12-08), pages 511 - 518, XP010583787, ISBN: 0-7695-1272-0 * |
| WENDER S ET AL: "Multiple classifier Cascades for Vehicle Occupant Monitoring Using and Omni-directional Camera", FORTSCHRITT-BERICHTE VDI. REIHE 10, KOMMUNIKATIONSTECHNIK, DUESSELDORF, DE, no. 37-46, 2004, XP007902695, ISSN: 0178-9627 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210286044A1 (en) * | 2018-12-03 | 2021-09-16 | Lac Camera Systems Oy | Self-positioning method, self-positioning system and tracking beacon unit |
| US11774547B2 (en) * | 2018-12-03 | 2023-10-03 | Lac Camera Systems Oy | Self-positioning method, self-positioning system and tracking beacon unit |
Also Published As
| Publication number | Publication date |
|---|---|
| US20090103779A1 (en) | 2009-04-23 |
| EP2005361A1 (de) | 2008-12-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2007107315A1 (de) | Multisensorieller hypothesen-basierter objektdetektor und objektverfolger | |
| DE102007013664A1 (de) | Multisensorieller Hypothesen-basierter Objektdetektor und Objektverfolger | |
| DE19636028C1 (de) | Verfahren zur Stereobild-Objektdetektion | |
| EP1634243B1 (de) | Verfahren und vorrichtung zur objektortung für kraftfahrzeuge | |
| DE112009000949T5 (de) | Detektion eines freien Fahrpfads für ein Fahrzeug | |
| DE102007019491B4 (de) | Fahrzeugumgebungs-Überwachungsvorrichtung, Fahrzeug, Fahrzeugumgebungs-Überwachungsverfahren und Fahrzeugumgebungs-Überwachungsprogramm | |
| DE102009048699A1 (de) | Pixelbasierte Detektion einer nicht vorhandenen Struktur eines freien Pfads | |
| DE102009048892A1 (de) | Pixelbasierte strukturreiche Detektion eines freien Pfads | |
| WO2013029722A2 (de) | Verfahren zur umgebungsrepräsentation | |
| DE102004018813A1 (de) | Verfahren zur Erkennung und/oder Verfolgung von Objekten | |
| DE102012000459A1 (de) | Verfahren zur Objektdetektion | |
| DE102021002798A1 (de) | Verfahren zur kamerabasierten Umgebungserfassung | |
| DE102018133441A1 (de) | Verfahren und System zum Bestimmen von Landmarken in einer Umgebung eines Fahrzeugs | |
| DE102018123393A1 (de) | Erkennung von Parkflächen | |
| WO2020178198A1 (de) | Schätzung der bewegung einer bildposition | |
| DE102008036219A1 (de) | Verfahren zur Erkennung von Objekten im Umfeld eines Fahrzeugs | |
| DE102006037600B4 (de) | Verfahren zur auflösungsabhängigen Darstellung der Umgebung eines Kraftfahrzeugs | |
| EP3663881B1 (de) | Verfahren zur steuerung eines autonomen fahrzeugs auf der grundlage von geschätzten bewegungsvektoren | |
| EP3543901B1 (de) | Vorrichtung und verfahren zur robusten ermittlung der position, ausrichtung, identität und ausgewählter zustandsinformationen von objekten | |
| DE102008059551B4 (de) | Verfahren zum Ermitteln der Lageänderung eines Kamerasystems und Vorrichtung zum Erfassen und Verarbeiten von Bildern | |
| DE102019127283A1 (de) | System und Verfahren zum Erfassen eines Objekts in einer dreidimensionalen Umgebung eines Trägerfahrzeugs | |
| WO2009101030A1 (de) | Verfahren zur rechnergestützten berechnung der bewegung eines objekts aus sensordaten | |
| DE102022201679A1 (de) | Verfahren und Vorrichtung zum Trainieren eines neuronalen Netzes | |
| EP3663800B1 (de) | Verfahren zur objekterfassung mit einer 3d-kamera | |
| DE102021206625A1 (de) | Computerimplementiertes Verfahren und System zur Unterstützung einer Installation eines bildgebenden Sensors und Trainingsverfahren |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 07723378 Country of ref document: EP Kind code of ref document: A1 |
|
| DPE1 | Request for preliminary examination filed after expiration of 19th month from priority date (pct application filed from 20040101) | ||
| WWE | Wipo information: entry into national phase |
Ref document number: 2007723378 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2009500754 Country of ref document: JP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 12294021 Country of ref document: US |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |