WO2004074468A1 - Novel pectinases and uses thereof - Google Patents
Novel pectinases and uses thereof Download PDFInfo
- Publication number
- WO2004074468A1 WO2004074468A1 PCT/EP2003/005726 EP0305726W WO2004074468A1 WO 2004074468 A1 WO2004074468 A1 WO 2004074468A1 EP 0305726 W EP0305726 W EP 0305726W WO 2004074468 A1 WO2004074468 A1 WO 2004074468A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- pec
- polypeptide
- group
- polynucleotide
- Prior art date
Links
- 108010059820 Polygalacturonase Proteins 0.000 title claims abstract description 90
- 108010093305 exopolygalacturonase Proteins 0.000 title claims abstract description 88
- 238000000034 method Methods 0.000 claims abstract description 90
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 63
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 63
- 239000002157 polynucleotide Substances 0.000 claims abstract description 63
- 125000003275 alpha amino acid group Chemical group 0.000 claims abstract description 45
- 239000002773 nucleotide Substances 0.000 claims abstract description 37
- 125000003729 nucleotide group Chemical group 0.000 claims abstract description 37
- 230000014509 gene expression Effects 0.000 claims abstract description 30
- 241000228245 Aspergillus niger Species 0.000 claims abstract description 24
- 238000004519 manufacturing process Methods 0.000 claims abstract description 24
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 216
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 195
- 229920001184 polypeptide Polymers 0.000 claims description 160
- 239000013598 vector Substances 0.000 claims description 50
- 102000037865 fusion proteins Human genes 0.000 claims description 25
- 108020001507 fusion proteins Proteins 0.000 claims description 25
- 241000233866 Fungi Species 0.000 claims description 10
- 230000001105 regulatory effect Effects 0.000 claims description 10
- 238000012258 culturing Methods 0.000 claims description 3
- 230000001131 transforming effect Effects 0.000 claims description 3
- 239000001963 growth medium Substances 0.000 claims description 2
- 108090000623 proteins and genes Proteins 0.000 abstract description 175
- 102000004169 proteins and genes Human genes 0.000 abstract description 137
- 102000004190 Enzymes Human genes 0.000 abstract description 70
- 108090000790 Enzymes Proteins 0.000 abstract description 70
- 239000002299 complementary DNA Substances 0.000 abstract description 21
- 230000000694 effects Effects 0.000 abstract description 21
- 108091026890 Coding region Proteins 0.000 abstract description 8
- 206010017533 Fungal infection Diseases 0.000 abstract description 2
- 208000031888 Mycoses Diseases 0.000 abstract description 2
- 235000018102 proteins Nutrition 0.000 description 134
- 150000007523 nucleic acids Chemical group 0.000 description 80
- 210000004027 cell Anatomy 0.000 description 77
- 229940088598 enzyme Drugs 0.000 description 70
- 102000039446 nucleic acids Human genes 0.000 description 66
- 108020004707 nucleic acids Proteins 0.000 description 66
- 239000012634 fragment Substances 0.000 description 43
- 108020004414 DNA Proteins 0.000 description 38
- 241001465754 Metazoa Species 0.000 description 37
- 229920001277 pectin Polymers 0.000 description 37
- 239000001814 pectin Substances 0.000 description 35
- 235000010987 pectin Nutrition 0.000 description 35
- 235000001014 amino acid Nutrition 0.000 description 34
- 241000196324 Embryophyta Species 0.000 description 30
- 229940024606 amino acid Drugs 0.000 description 30
- 150000001413 amino acids Chemical class 0.000 description 30
- 238000011282 treatment Methods 0.000 description 27
- 235000005911 diet Nutrition 0.000 description 26
- 108091028043 Nucleic acid sequence Proteins 0.000 description 25
- 239000000523 sample Substances 0.000 description 25
- 239000013604 expression vector Substances 0.000 description 24
- 239000000203 mixture Substances 0.000 description 24
- 230000037213 diet Effects 0.000 description 22
- 239000000463 material Substances 0.000 description 22
- 238000012545 processing Methods 0.000 description 20
- 235000013399 edible fruits Nutrition 0.000 description 18
- 230000001976 improved effect Effects 0.000 description 17
- 241000287828 Gallus gallus Species 0.000 description 16
- 235000011389 fruit/vegetable juice Nutrition 0.000 description 15
- 238000003752 polymerase chain reaction Methods 0.000 description 15
- 230000008569 process Effects 0.000 description 15
- 238000002474 experimental method Methods 0.000 description 14
- 230000004927 fusion Effects 0.000 description 14
- 238000009396 hybridization Methods 0.000 description 14
- 238000002360 preparation method Methods 0.000 description 14
- 239000000047 product Substances 0.000 description 14
- 230000000890 antigenic effect Effects 0.000 description 13
- 239000013615 primer Substances 0.000 description 13
- 239000002987 primer (paints) Substances 0.000 description 13
- 108010076504 Protein Sorting Signals Proteins 0.000 description 12
- 235000019621 digestibility Nutrition 0.000 description 12
- 238000000746 purification Methods 0.000 description 12
- 235000010469 Glycine max Nutrition 0.000 description 11
- 238000007792 addition Methods 0.000 description 11
- 230000027455 binding Effects 0.000 description 11
- 239000000758 substrate Substances 0.000 description 11
- 241000228212 Aspergillus Species 0.000 description 10
- 108091007433 antigens Proteins 0.000 description 10
- 102000036639 antigens Human genes 0.000 description 10
- 238000003556 assay Methods 0.000 description 10
- 230000000295 complement effect Effects 0.000 description 10
- 230000002163 immunogen Effects 0.000 description 10
- 108091034117 Oligonucleotide Proteins 0.000 description 9
- 125000000539 amino acid group Chemical group 0.000 description 9
- 230000001580 bacterial effect Effects 0.000 description 9
- 238000006243 chemical reaction Methods 0.000 description 9
- 239000007787 solid Substances 0.000 description 9
- 239000000126 substance Substances 0.000 description 9
- 238000006467 substitution reaction Methods 0.000 description 9
- 244000068988 Glycine max Species 0.000 description 8
- 230000002378 acidificating effect Effects 0.000 description 8
- 239000000427 antigen Substances 0.000 description 8
- 230000004071 biological effect Effects 0.000 description 8
- 210000002421 cell wall Anatomy 0.000 description 8
- 235000013305 food Nutrition 0.000 description 8
- 235000015203 fruit juice Nutrition 0.000 description 8
- 235000015097 nutrients Nutrition 0.000 description 8
- 238000012216 screening Methods 0.000 description 8
- 210000001519 tissue Anatomy 0.000 description 8
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 7
- 101150007523 32 gene Proteins 0.000 description 7
- 102000053602 DNA Human genes 0.000 description 7
- 108020004511 Recombinant DNA Proteins 0.000 description 7
- 238000004458 analytical method Methods 0.000 description 7
- 230000002788 anti-peptide Effects 0.000 description 7
- 239000003623 enhancer Substances 0.000 description 7
- 239000000284 extract Substances 0.000 description 7
- 210000004408 hybridoma Anatomy 0.000 description 7
- 239000003550 marker Substances 0.000 description 7
- 230000035772 mutation Effects 0.000 description 7
- 239000013612 plasmid Substances 0.000 description 7
- 238000003786 synthesis reaction Methods 0.000 description 7
- 238000005406 washing Methods 0.000 description 7
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 7
- 241000894006 Bacteria Species 0.000 description 6
- 241000588724 Escherichia coli Species 0.000 description 6
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 6
- 108010038807 Oligopeptides Proteins 0.000 description 6
- 102000015636 Oligopeptides Human genes 0.000 description 6
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 6
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 6
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 6
- 241000700605 Viruses Species 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 230000003247 decreasing effect Effects 0.000 description 6
- 238000001514 detection method Methods 0.000 description 6
- 235000012055 fruits and vegetables Nutrition 0.000 description 6
- 230000006870 function Effects 0.000 description 6
- 230000028327 secretion Effects 0.000 description 6
- 238000010561 standard procedure Methods 0.000 description 6
- 241000220225 Malus Species 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 239000000872 buffer Substances 0.000 description 5
- 238000010367 cloning Methods 0.000 description 5
- 238000012217 deletion Methods 0.000 description 5
- 230000037430 deletion Effects 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 238000003018 immunoassay Methods 0.000 description 5
- 230000006872 improvement Effects 0.000 description 5
- 208000015181 infectious disease Diseases 0.000 description 5
- 238000002347 injection Methods 0.000 description 5
- 239000007924 injection Substances 0.000 description 5
- 210000004962 mammalian cell Anatomy 0.000 description 5
- 239000011159 matrix material Substances 0.000 description 5
- 108020004999 messenger RNA Proteins 0.000 description 5
- 238000010369 molecular cloning Methods 0.000 description 5
- 235000016709 nutrition Nutrition 0.000 description 5
- 239000002245 particle Substances 0.000 description 5
- 108020004410 pectinesterase Proteins 0.000 description 5
- 229920001282 polysaccharide Polymers 0.000 description 5
- 238000003259 recombinant expression Methods 0.000 description 5
- 230000002829 reductive effect Effects 0.000 description 5
- 230000003248 secreting effect Effects 0.000 description 5
- 239000002002 slurry Substances 0.000 description 5
- 239000000243 solution Substances 0.000 description 5
- 238000001890 transfection Methods 0.000 description 5
- 238000013519 translation Methods 0.000 description 5
- 235000013311 vegetables Nutrition 0.000 description 5
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 4
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 4
- 238000002965 ELISA Methods 0.000 description 4
- MHAJPDPJQMAIIY-UHFFFAOYSA-N Hydrogen peroxide Chemical compound OO MHAJPDPJQMAIIY-UHFFFAOYSA-N 0.000 description 4
- 229920002230 Pectic acid Polymers 0.000 description 4
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 4
- 239000002671 adjuvant Substances 0.000 description 4
- 235000021016 apples Nutrition 0.000 description 4
- 235000014590 basal diet Nutrition 0.000 description 4
- 239000012472 biological sample Substances 0.000 description 4
- 230000015556 catabolic process Effects 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 150000001875 compounds Chemical class 0.000 description 4
- 238000007796 conventional method Methods 0.000 description 4
- 230000000378 dietary effect Effects 0.000 description 4
- 230000002255 enzymatic effect Effects 0.000 description 4
- 238000000605 extraction Methods 0.000 description 4
- 210000003608 fece Anatomy 0.000 description 4
- 150000004676 glycans Chemical class 0.000 description 4
- 230000002209 hydrophobic effect Effects 0.000 description 4
- 238000000338 in vitro Methods 0.000 description 4
- 238000003780 insertion Methods 0.000 description 4
- 230000037431 insertion Effects 0.000 description 4
- 108010045069 keyhole-limpet hemocyanin Proteins 0.000 description 4
- 239000007788 liquid Substances 0.000 description 4
- 239000002609 medium Substances 0.000 description 4
- 244000005700 microbiome Species 0.000 description 4
- 238000002703 mutagenesis Methods 0.000 description 4
- 231100000350 mutagenesis Toxicity 0.000 description 4
- 239000010318 polygalacturonic acid Substances 0.000 description 4
- 239000005017 polysaccharide Substances 0.000 description 4
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 4
- 238000012163 sequencing technique Methods 0.000 description 4
- 241000894007 species Species 0.000 description 4
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 4
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 3
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 3
- 102000011632 Caseins Human genes 0.000 description 3
- 108010076119 Caseins Proteins 0.000 description 3
- 108020004635 Complementary DNA Proteins 0.000 description 3
- 241000238631 Hexapoda Species 0.000 description 3
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 3
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 3
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 3
- 241000699670 Mus sp. Species 0.000 description 3
- 208000010359 Newcastle Disease Diseases 0.000 description 3
- 101710163270 Nuclease Proteins 0.000 description 3
- 241000283973 Oryctolagus cuniculus Species 0.000 description 3
- 108010029182 Pectin lyase Proteins 0.000 description 3
- 206010035226 Plasma cell myeloma Diseases 0.000 description 3
- 241000700159 Rattus Species 0.000 description 3
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 3
- 239000004473 Threonine Substances 0.000 description 3
- 238000001042 affinity chromatography Methods 0.000 description 3
- 230000037396 body weight Effects 0.000 description 3
- 229940098773 bovine serum albumin Drugs 0.000 description 3
- 206010006451 bronchitis Diseases 0.000 description 3
- BECPQYXYKAMYBN-UHFFFAOYSA-N casein, tech. Chemical compound NCCCCC(C(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(CC(C)C)N=C(O)C(CCC(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(C(C)O)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(COP(O)(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(N)CC1=CC=CC=C1 BECPQYXYKAMYBN-UHFFFAOYSA-N 0.000 description 3
- 235000021240 caseins Nutrition 0.000 description 3
- -1 charged amino acids Chemical class 0.000 description 3
- 230000002759 chromosomal effect Effects 0.000 description 3
- 238000003776 cleavage reaction Methods 0.000 description 3
- 239000012141 concentrate Substances 0.000 description 3
- 238000006731 degradation reaction Methods 0.000 description 3
- 239000006047 digesta Substances 0.000 description 3
- 239000003814 drug Substances 0.000 description 3
- 210000003527 eukaryotic cell Anatomy 0.000 description 3
- 238000000855 fermentation Methods 0.000 description 3
- 230000004151 fermentation Effects 0.000 description 3
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 3
- 230000002538 fungal effect Effects 0.000 description 3
- 238000001114 immunoprecipitation Methods 0.000 description 3
- 230000001939 inductive effect Effects 0.000 description 3
- 230000002458 infectious effect Effects 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 230000001404 mediated effect Effects 0.000 description 3
- 229930182817 methionine Natural products 0.000 description 3
- 230000000813 microbial effect Effects 0.000 description 3
- 235000013384 milk substitute Nutrition 0.000 description 3
- 201000000050 myeloid neoplasm Diseases 0.000 description 3
- 108010087558 pectate lyase Proteins 0.000 description 3
- 229920000642 polymer Polymers 0.000 description 3
- 238000003825 pressing Methods 0.000 description 3
- 210000001236 prokaryotic cell Anatomy 0.000 description 3
- 230000010076 replication Effects 0.000 description 3
- 230000007017 scission Effects 0.000 description 3
- 239000004455 soybean meal Substances 0.000 description 3
- 241000701161 unidentified adenovirus Species 0.000 description 3
- 241000701447 unidentified baculovirus Species 0.000 description 3
- 241001515965 unidentified phage Species 0.000 description 3
- 238000001262 western blot Methods 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- 229920000936 Agarose Polymers 0.000 description 2
- 108010078791 Carrier Proteins Proteins 0.000 description 2
- 102000014914 Carrier Proteins Human genes 0.000 description 2
- 108010084185 Cellulases Proteins 0.000 description 2
- 102000005575 Cellulases Human genes 0.000 description 2
- 229920000742 Cotton Polymers 0.000 description 2
- 239000003155 DNA primer Substances 0.000 description 2
- 238000012286 ELISA Assay Methods 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 108010093488 His-His-His-His-His-His Proteins 0.000 description 2
- 102000004157 Hydrolases Human genes 0.000 description 2
- 108090000604 Hydrolases Proteins 0.000 description 2
- 102100034349 Integrase Human genes 0.000 description 2
- 239000007836 KH2PO4 Substances 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 241000699666 Mus <mouse, genus> Species 0.000 description 2
- 238000000636 Northern blotting Methods 0.000 description 2
- 102000004316 Oxidoreductases Human genes 0.000 description 2
- 108090000854 Oxidoreductases Proteins 0.000 description 2
- 229930182555 Penicillin Natural products 0.000 description 2
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 2
- 240000004713 Pisum sativum Species 0.000 description 2
- 235000010582 Pisum sativum Nutrition 0.000 description 2
- 239000004793 Polystyrene Substances 0.000 description 2
- 108091034057 RNA (poly(A)) Proteins 0.000 description 2
- 108020005091 Replication Origin Proteins 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 235000019764 Soybean Meal Nutrition 0.000 description 2
- PPBRXRYQALVLMV-UHFFFAOYSA-N Styrene Chemical compound C=CC1=CC=CC=C1 PPBRXRYQALVLMV-UHFFFAOYSA-N 0.000 description 2
- WGLPBDUCMAPZCE-UHFFFAOYSA-N Trioxochromium Chemical compound O=[Cr](=O)=O WGLPBDUCMAPZCE-UHFFFAOYSA-N 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000000433 anti-nutritional effect Effects 0.000 description 2
- 230000000692 anti-sense effect Effects 0.000 description 2
- 239000006030 antibiotic growth promoter Substances 0.000 description 2
- 230000005875 antibody response Effects 0.000 description 2
- 102000005936 beta-Galactosidase Human genes 0.000 description 2
- 108010005774 beta-Galactosidase Proteins 0.000 description 2
- 238000007068 beta-elimination reaction Methods 0.000 description 2
- 230000008827 biological function Effects 0.000 description 2
- 229940041514 candida albicans extract Drugs 0.000 description 2
- 239000005018 casein Substances 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- 238000004587 chromatography analysis Methods 0.000 description 2
- 239000000470 constituent Substances 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- 230000029087 digestion Effects 0.000 description 2
- 229940079919 digestives enzyme preparation Drugs 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 238000003912 environmental pollution Methods 0.000 description 2
- 239000003797 essential amino acid Substances 0.000 description 2
- 235000020776 essential amino acid Nutrition 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 210000001035 gastrointestinal tract Anatomy 0.000 description 2
- RWSXRVCMGQZWBV-WDSKDSINSA-N glutathione Chemical compound OC(=O)[C@@H](N)CCC(=O)N[C@@H](CS)C(=O)NCC(O)=O RWSXRVCMGQZWBV-WDSKDSINSA-N 0.000 description 2
- 230000013595 glycosylation Effects 0.000 description 2
- 238000006206 glycosylation reaction Methods 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 230000003100 immobilizing effect Effects 0.000 description 2
- 230000003053 immunization Effects 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 229910052500 inorganic mineral Inorganic materials 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 238000002803 maceration Methods 0.000 description 2
- WRUGWIBCXHJTDG-UHFFFAOYSA-L magnesium sulfate heptahydrate Chemical compound O.O.O.O.O.O.O.[Mg+2].[O-]S([O-])(=O)=O WRUGWIBCXHJTDG-UHFFFAOYSA-L 0.000 description 2
- 239000011707 mineral Substances 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- 229910000402 monopotassium phosphate Inorganic materials 0.000 description 2
- 230000007935 neutral effect Effects 0.000 description 2
- 230000001717 pathogenic effect Effects 0.000 description 2
- 229940049954 penicillin Drugs 0.000 description 2
- 238000002823 phage display Methods 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- 239000000419 plant extract Substances 0.000 description 2
- 229920002223 polystyrene Polymers 0.000 description 2
- GNSKLFRGEWLPPA-UHFFFAOYSA-M potassium dihydrogen phosphate Chemical compound [K+].OP(O)([O-])=O GNSKLFRGEWLPPA-UHFFFAOYSA-M 0.000 description 2
- 125000001500 prolyl group Chemical group [H]N1C([H])(C(=O)[*])C([H])([H])C([H])([H])C1([H])[H] 0.000 description 2
- 239000012857 radioactive material Substances 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 238000010188 recombinant method Methods 0.000 description 2
- 239000011347 resin Substances 0.000 description 2
- 229920005989 resin Polymers 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 230000001177 retroviral effect Effects 0.000 description 2
- 238000010839 reverse transcription Methods 0.000 description 2
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 210000000813 small intestine Anatomy 0.000 description 2
- 238000010532 solid phase synthesis reaction Methods 0.000 description 2
- 238000003153 stable transfection Methods 0.000 description 2
- 210000002784 stomach Anatomy 0.000 description 2
- 229960005322 streptomycin Drugs 0.000 description 2
- 239000006228 supernatant Substances 0.000 description 2
- 230000009469 supplementation Effects 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 238000013518 transcription Methods 0.000 description 2
- 230000035897 transcription Effects 0.000 description 2
- 230000009466 transformation Effects 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 238000000108 ultra-filtration Methods 0.000 description 2
- 241001430294 unidentified retrovirus Species 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- 239000013603 viral vector Substances 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- 235000019786 weight gain Nutrition 0.000 description 2
- 239000012138 yeast extract Substances 0.000 description 2
- DIGQNXIGRZPYDK-WKSCXVIASA-N (2R)-6-amino-2-[[2-[[(2S)-2-[[2-[[(2R)-2-[[(2S)-2-[[(2R,3S)-2-[[2-[[(2S)-2-[[2-[[(2S)-2-[[(2S)-2-[[(2R)-2-[[(2S,3S)-2-[[(2R)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[2-[[(2S)-2-[[(2R)-2-[[2-[[2-[[2-[(2-amino-1-hydroxyethylidene)amino]-3-carboxy-1-hydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1,5-dihydroxy-5-iminopentylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]hexanoic acid Chemical compound C[C@@H]([C@@H](C(=N[C@@H](CS)C(=N[C@@H](C)C(=N[C@@H](CO)C(=NCC(=N[C@@H](CCC(=N)O)C(=NC(CS)C(=N[C@H]([C@H](C)O)C(=N[C@H](CS)C(=N[C@H](CO)C(=NCC(=N[C@H](CS)C(=NCC(=N[C@H](CCCCN)C(=O)O)O)O)O)O)O)O)O)O)O)O)O)O)O)N=C([C@H](CS)N=C([C@H](CO)N=C([C@H](CO)N=C([C@H](C)N=C(CN=C([C@H](CO)N=C([C@H](CS)N=C(CN=C(C(CS)N=C(C(CC(=O)O)N=C(CN)O)O)O)O)O)O)O)O)O)O)O)O DIGQNXIGRZPYDK-WKSCXVIASA-N 0.000 description 1
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 1
- ASWBNKHCZGQVJV-UHFFFAOYSA-N (3-hexadecanoyloxy-2-hydroxypropyl) 2-(trimethylazaniumyl)ethyl phosphate Chemical compound CCCCCCCCCCCCCCCC(=O)OCC(O)COP([O-])(=O)OCC[N+](C)(C)C ASWBNKHCZGQVJV-UHFFFAOYSA-N 0.000 description 1
- 125000006701 (C1-C7) alkyl group Chemical group 0.000 description 1
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 1
- UFBJCMHMOXMLKC-UHFFFAOYSA-N 2,4-dinitrophenol Chemical compound OC1=CC=C([N+]([O-])=O)C=C1[N+]([O-])=O UFBJCMHMOXMLKC-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- LJGHYPLBDBRCRZ-UHFFFAOYSA-N 3-(3-aminophenyl)sulfonylaniline Chemical compound NC1=CC=CC(S(=O)(=O)C=2C=C(N)C=CC=2)=C1 LJGHYPLBDBRCRZ-UHFFFAOYSA-N 0.000 description 1
- QRYXYRQPMWQIDM-UHFFFAOYSA-N 3-benzoyl-3-(2,5-dioxopyrrol-1-yl)-1-hydroxypyrrolidine-2,5-dione Chemical compound O=C1N(O)C(=O)CC1(C(=O)C=1C=CC=CC=1)N1C(=O)C=CC1=O QRYXYRQPMWQIDM-UHFFFAOYSA-N 0.000 description 1
- 108010011619 6-Phytase Proteins 0.000 description 1
- CJIJXIFQYOPWTF-UHFFFAOYSA-N 7-hydroxycoumarin Natural products O1C(=O)C=CC2=CC(O)=CC=C21 CJIJXIFQYOPWTF-UHFFFAOYSA-N 0.000 description 1
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 1
- 108010022752 Acetylcholinesterase Proteins 0.000 description 1
- 102000012440 Acetylcholinesterase Human genes 0.000 description 1
- 108010013043 Acetylesterase Proteins 0.000 description 1
- 108010000239 Aequorin Proteins 0.000 description 1
- 102100024321 Alkaline phosphatase, placental type Human genes 0.000 description 1
- 244000291564 Allium cepa Species 0.000 description 1
- 235000002732 Allium cepa var. cepa Nutrition 0.000 description 1
- 101710101545 Alpha-xylosidase Proteins 0.000 description 1
- 244000099147 Ananas comosus Species 0.000 description 1
- 235000007119 Ananas comosus Nutrition 0.000 description 1
- 108010032595 Antibody Binding Sites Proteins 0.000 description 1
- 240000007087 Apium graveolens Species 0.000 description 1
- 235000015849 Apium graveolens Dulce Group Nutrition 0.000 description 1
- 235000010591 Appio Nutrition 0.000 description 1
- 101100433757 Arabidopsis thaliana ABCG32 gene Proteins 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 201000002909 Aspergillosis Diseases 0.000 description 1
- 101000709143 Aspergillus aculeatus Rhamnogalacturonate lyase A Proteins 0.000 description 1
- 208000036641 Aspergillus infections Diseases 0.000 description 1
- 241000122821 Aspergillus kawachii Species 0.000 description 1
- 241000351920 Aspergillus nidulans Species 0.000 description 1
- 240000006439 Aspergillus oryzae Species 0.000 description 1
- 235000002247 Aspergillus oryzae Nutrition 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 231100000699 Bacterial toxin Toxicity 0.000 description 1
- 241001513358 Billardiera scandens Species 0.000 description 1
- 108010017384 Blood Proteins Proteins 0.000 description 1
- 102000004506 Blood Proteins Human genes 0.000 description 1
- 241000167854 Bourreria succulenta Species 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- 101710132601 Capsid protein Proteins 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 229920003043 Cellulose fiber Polymers 0.000 description 1
- 241000736839 Chara Species 0.000 description 1
- 108091062157 Cis-regulatory element Proteins 0.000 description 1
- 241000207199 Citrus Species 0.000 description 1
- 235000008733 Citrus aurantifolia Nutrition 0.000 description 1
- 235000005979 Citrus limon Nutrition 0.000 description 1
- 244000131522 Citrus pyriformis Species 0.000 description 1
- 241001672694 Citrus reticulata Species 0.000 description 1
- 101710094648 Coat protein Proteins 0.000 description 1
- 108091033380 Coding strand Proteins 0.000 description 1
- 241000186216 Corynebacterium Species 0.000 description 1
- 244000241257 Cucumis melo Species 0.000 description 1
- 235000015510 Cucumis melo subsp melo Nutrition 0.000 description 1
- 244000007835 Cyamopsis tetragonoloba Species 0.000 description 1
- 235000017788 Cydonia oblonga Nutrition 0.000 description 1
- 241000701022 Cytomegalovirus Species 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- 108010008286 DNA nucleotidylexotransferase Proteins 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 102100029764 DNA-directed DNA/RNA polymerase mu Human genes 0.000 description 1
- XPDXVDYUQZHFPV-UHFFFAOYSA-N Dansyl Chloride Chemical compound C1=CC=C2C(N(C)C)=CC=CC2=C1S(Cl)(=O)=O XPDXVDYUQZHFPV-UHFFFAOYSA-N 0.000 description 1
- 244000000626 Daucus carota Species 0.000 description 1
- 235000002767 Daucus carota Nutrition 0.000 description 1
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 101001096557 Dickeya dadantii (strain 3937) Rhamnogalacturonate lyase Proteins 0.000 description 1
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 1
- 108010061142 Endo-arabinase Proteins 0.000 description 1
- 108010013369 Enteropeptidase Proteins 0.000 description 1
- 102100029727 Enteropeptidase Human genes 0.000 description 1
- 101710091045 Envelope protein Proteins 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- 241000701959 Escherichia virus Lambda Species 0.000 description 1
- 108010074860 Factor Xa Proteins 0.000 description 1
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 1
- 241000710198 Foot-and-mouth disease virus Species 0.000 description 1
- 241000700662 Fowlpox virus Species 0.000 description 1
- 240000009088 Fragaria x ananassa Species 0.000 description 1
- IAJILQKETJEXLJ-UHFFFAOYSA-N Galacturonsaeure Natural products O=CC(O)C(O)C(O)C(O)C(O)=O IAJILQKETJEXLJ-UHFFFAOYSA-N 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- 206010071602 Genetic polymorphism Diseases 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- 102000006395 Globulins Human genes 0.000 description 1
- 108010073178 Glucan 1,4-alpha-Glucosidase Proteins 0.000 description 1
- 102100022624 Glucoamylase Human genes 0.000 description 1
- 108010015776 Glucose oxidase Proteins 0.000 description 1
- 239000004366 Glucose oxidase Substances 0.000 description 1
- 108010060309 Glucuronidase Proteins 0.000 description 1
- 102000053187 Glucuronidase Human genes 0.000 description 1
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- 108010024636 Glutathione Proteins 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 102100021181 Golgi phosphoprotein 3 Human genes 0.000 description 1
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 1
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 1
- HVLSXIKZNLPZJJ-TXZCQADKSA-N HA peptide Chemical compound C([C@@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HVLSXIKZNLPZJJ-TXZCQADKSA-N 0.000 description 1
- 101710154606 Hemagglutinin Proteins 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 1
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 1
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 1
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- 101710203526 Integrase Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 240000006240 Linum usitatissimum Species 0.000 description 1
- 235000004431 Linum usitatissimum Nutrition 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 1
- 235000007688 Lycopersicon esculentum Nutrition 0.000 description 1
- 101710125418 Major capsid protein Proteins 0.000 description 1
- 101710141347 Major envelope glycoprotein Proteins 0.000 description 1
- 229920002774 Maltodextrin Polymers 0.000 description 1
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 240000003183 Manihot esculenta Species 0.000 description 1
- 235000016735 Manihot esculenta subsp esculenta Nutrition 0.000 description 1
- 108010036176 Melitten Proteins 0.000 description 1
- 102000003792 Metallothionein Human genes 0.000 description 1
- 108090000157 Metallothionein Proteins 0.000 description 1
- 102000014171 Milk Proteins Human genes 0.000 description 1
- 108010011756 Milk Proteins Proteins 0.000 description 1
- 102100036617 Monoacylglycerol lipase ABHD2 Human genes 0.000 description 1
- 108010021466 Mutant Proteins Proteins 0.000 description 1
- 102000008300 Mutant Proteins Human genes 0.000 description 1
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 101000728666 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) Putative rhamnogalacturonase Proteins 0.000 description 1
- 108091005461 Nucleic proteins Chemical group 0.000 description 1
- 101710141454 Nucleoprotein Proteins 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 101710093908 Outer capsid protein VP4 Proteins 0.000 description 1
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 description 1
- 238000012408 PCR amplification Methods 0.000 description 1
- 101150048253 PHYA gene Proteins 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 108010004729 Phycoerythrin Proteins 0.000 description 1
- 235000008331 Pinus X rigitaeda Nutrition 0.000 description 1
- 235000011613 Pinus brutia Nutrition 0.000 description 1
- 241000018646 Pinus brutia Species 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 101710083689 Probable capsid protein Proteins 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 101710176177 Protein A56 Proteins 0.000 description 1
- 101710188315 Protein X Proteins 0.000 description 1
- 244000141353 Prunus domestica Species 0.000 description 1
- 101100084022 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) lapA gene Proteins 0.000 description 1
- 241000220324 Pyrus Species 0.000 description 1
- 206010037742 Rabies Diseases 0.000 description 1
- 235000016954 Ribes hudsonianum Nutrition 0.000 description 1
- 240000001890 Ribes hudsonianum Species 0.000 description 1
- 235000001466 Ribes nigrum Nutrition 0.000 description 1
- 244000281247 Ribes rubrum Species 0.000 description 1
- 235000016911 Ribes sativum Nutrition 0.000 description 1
- 235000002355 Ribes spicatum Nutrition 0.000 description 1
- 235000016897 Ribes triste Nutrition 0.000 description 1
- 241000714474 Rous sarcoma virus Species 0.000 description 1
- 240000007651 Rubus glaucus Species 0.000 description 1
- 241000293869 Salmonella enterica subsp. enterica serovar Typhimurium Species 0.000 description 1
- 229920002684 Sepharose Polymers 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 240000003768 Solanum lycopersicum Species 0.000 description 1
- 244000061456 Solanum tuberosum Species 0.000 description 1
- 235000002595 Solanum tuberosum Nutrition 0.000 description 1
- 241000256248 Spodoptera Species 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- 241000701093 Suid alphaherpesvirus 1 Species 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 1
- 239000005864 Sulphur Substances 0.000 description 1
- 210000001744 T-lymphocyte Anatomy 0.000 description 1
- GKLVYJBZJHMRIY-OUBTZVSYSA-N Technetium-99 Chemical compound [99Tc] GKLVYJBZJHMRIY-OUBTZVSYSA-N 0.000 description 1
- 108020005038 Terminator Codon Proteins 0.000 description 1
- 108010022394 Threonine synthase Proteins 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 235000011941 Tilia x europaea Nutrition 0.000 description 1
- 240000006909 Tilia x europaea Species 0.000 description 1
- 235000021307 Triticum Nutrition 0.000 description 1
- 244000098338 Triticum aestivum Species 0.000 description 1
- YZCKVEUIGOORGS-NJFSPNSNSA-N Tritium Chemical compound [3H] YZCKVEUIGOORGS-NJFSPNSNSA-N 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- 240000001717 Vaccinium macrocarpon Species 0.000 description 1
- ZVNYJIZDIRKMBF-UHFFFAOYSA-N Vesnarinone Chemical compound C1=C(OC)C(OC)=CC=C1C(=O)N1CCN(C=2C=C3CCC(=O)NC3=CC=2)CC1 ZVNYJIZDIRKMBF-UHFFFAOYSA-N 0.000 description 1
- 241000219094 Vitaceae Species 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 239000002250 absorbent Substances 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 239000008351 acetate buffer Substances 0.000 description 1
- 229940022698 acetylcholinesterase Drugs 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 238000005377 adsorption chromatography Methods 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- AEMOLEFTQBMNLQ-BKBMJHBISA-N alpha-D-galacturonic acid Chemical compound O[C@H]1O[C@H](C(O)=O)[C@H](O)[C@H](O)[C@H]1O AEMOLEFTQBMNLQ-BKBMJHBISA-N 0.000 description 1
- 102000005840 alpha-Galactosidase Human genes 0.000 description 1
- 108010030291 alpha-Galactosidase Proteins 0.000 description 1
- 108010061314 alpha-L-Fucosidase Proteins 0.000 description 1
- 102000012086 alpha-L-Fucosidase Human genes 0.000 description 1
- 108010061261 alpha-glucuronidase Proteins 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 1
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 1
- 238000012870 ammonium sulfate precipitation Methods 0.000 description 1
- 235000011130 ammonium sulphate Nutrition 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 150000001450 anions Chemical class 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 235000015197 apple juice Nutrition 0.000 description 1
- 239000003125 aqueous solvent Substances 0.000 description 1
- 108010076955 arabinogalactan endo-1,4-beta-galactosidase Proteins 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 235000019568 aromas Nutrition 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 125000000613 asparagine group Chemical class N[C@@H](CC(N)=O)C(=O)* 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 239000000688 bacterial toxin Substances 0.000 description 1
- 108010040482 beta-apiosidase Proteins 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 239000003833 bile salt Substances 0.000 description 1
- 239000013060 biological fluid Substances 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 229940021722 caseins Drugs 0.000 description 1
- 238000005277 cation exchange chromatography Methods 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 239000012707 chemical precursor Substances 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 235000019693 cherries Nutrition 0.000 description 1
- 210000002987 choroid plexus Anatomy 0.000 description 1
- 239000013611 chromosomal DNA Substances 0.000 description 1
- 235000020971 citrus fruits Nutrition 0.000 description 1
- 235000021448 clear apple juice Nutrition 0.000 description 1
- 238000012411 cloning technique Methods 0.000 description 1
- 239000003224 coccidiostatic agent Substances 0.000 description 1
- 238000002742 combinatorial mutagenesis Methods 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 235000021019 cranberries Nutrition 0.000 description 1
- 238000004132 cross linking Methods 0.000 description 1
- 101150081158 crtB gene Proteins 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 230000000593 degrading effect Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000002405 diagnostic procedure Methods 0.000 description 1
- 230000001079 digestive effect Effects 0.000 description 1
- 102000004419 dihydrofolate reductase Human genes 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 239000000975 dye Substances 0.000 description 1
- 235000013601 eggs Nutrition 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 1
- 230000007515 enzymatic degradation Effects 0.000 description 1
- 238000001976 enzyme digestion Methods 0.000 description 1
- 125000004185 ester group Chemical group 0.000 description 1
- 230000032050 esterification Effects 0.000 description 1
- 238000005886 esterification reaction Methods 0.000 description 1
- 238000012869 ethanol precipitation Methods 0.000 description 1
- 230000029142 excretion Effects 0.000 description 1
- 108010038658 exo-1,4-beta-D-xylosidase Proteins 0.000 description 1
- 235000019620 fat digestibility Nutrition 0.000 description 1
- 239000000706 filtrate Substances 0.000 description 1
- 239000012467 final product Substances 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 230000037433 frameshift Effects 0.000 description 1
- 230000005714 functional activity Effects 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 238000001879 gelation Methods 0.000 description 1
- 238000007429 general method Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 229940116332 glucose oxidase Drugs 0.000 description 1
- 235000019420 glucose oxidase Nutrition 0.000 description 1
- 230000006377 glucose transport Effects 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 229960003180 glutathione Drugs 0.000 description 1
- 235000021021 grapes Nutrition 0.000 description 1
- 239000005090 green fluorescent protein Substances 0.000 description 1
- 238000000227 grinding Methods 0.000 description 1
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical class O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 229910001385 heavy metal Inorganic materials 0.000 description 1
- 239000000185 hemagglutinin Substances 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 210000003917 human chromosome Anatomy 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 238000004191 hydrophobic interaction chromatography Methods 0.000 description 1
- 238000012872 hydroxylapatite chromatography Methods 0.000 description 1
- 230000008105 immune reaction Effects 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 239000012133 immunoprecipitate Substances 0.000 description 1
- 238000007901 in situ hybridization Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- APFVFJFRJDLVQX-UHFFFAOYSA-N indium atom Chemical compound [In] APFVFJFRJDLVQX-UHFFFAOYSA-N 0.000 description 1
- 206010022000 influenza Diseases 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000009698 intestinal cell proliferation Effects 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 239000011630 iodine Substances 0.000 description 1
- 229910052740 iodine Inorganic materials 0.000 description 1
- BAUYGSIQEAFULO-UHFFFAOYSA-L iron(2+) sulfate (anhydrous) Chemical compound [Fe+2].[O-]S([O-])(=O)=O BAUYGSIQEAFULO-UHFFFAOYSA-L 0.000 description 1
- SURQXAFEQWPFPV-UHFFFAOYSA-L iron(2+) sulfate heptahydrate Chemical compound O.O.O.O.O.O.O.[Fe+2].[O-]S([O-])(=O)=O SURQXAFEQWPFPV-UHFFFAOYSA-L 0.000 description 1
- 229910000359 iron(II) sulfate Inorganic materials 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 101150066555 lacZ gene Proteins 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 235000021374 legumes Nutrition 0.000 description 1
- 239000004571 lime Substances 0.000 description 1
- 238000012417 linear regression Methods 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- HWYHZTIRURJOHG-UHFFFAOYSA-N luminol Chemical compound O=C1NNC(=O)C2=C1C(N)=CC=C2 HWYHZTIRURJOHG-UHFFFAOYSA-N 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- SQQMAOCOWKFBNP-UHFFFAOYSA-L manganese(II) sulfate Chemical compound [Mn+2].[O-]S([O-])(=O)=O SQQMAOCOWKFBNP-UHFFFAOYSA-L 0.000 description 1
- 229910000357 manganese(II) sulfate Inorganic materials 0.000 description 1
- CDUFCUKTJFSWPL-UHFFFAOYSA-L manganese(II) sulfate tetrahydrate Chemical compound O.O.O.O.[Mn+2].[O-]S([O-])(=O)=O CDUFCUKTJFSWPL-UHFFFAOYSA-L 0.000 description 1
- 235000013372 meat Nutrition 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- VDXZNPDIRNWWCW-JFTDCZMZSA-N melittin Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(N)=O)CC1=CNC2=CC=CC=C12 VDXZNPDIRNWWCW-JFTDCZMZSA-N 0.000 description 1
- 230000031864 metaphase Effects 0.000 description 1
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 235000021239 milk protein Nutrition 0.000 description 1
- 238000003801 milling Methods 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- ZTLGJPIZUOVDMT-UHFFFAOYSA-N n,n-dichlorotriazin-4-amine Chemical compound ClN(Cl)C1=CC=NN=N1 ZTLGJPIZUOVDMT-UHFFFAOYSA-N 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 230000035764 nutrition Effects 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 235000021017 pears Nutrition 0.000 description 1
- LCLHHZYHLXDRQG-ZNKJPWOQSA-N pectic acid Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)O[C@H](C(O)=O)[C@@H]1OC1[C@H](O)[C@@H](O)[C@@H](OC2[C@@H]([C@@H](O)[C@@H](O)[C@H](O2)C(O)=O)O)[C@@H](C(O)=O)O1 LCLHHZYHLXDRQG-ZNKJPWOQSA-N 0.000 description 1
- 108010072638 pectinacetylesterase Proteins 0.000 description 1
- 102000004251 pectinacetylesterase Human genes 0.000 description 1
- 238000010647 peptide synthesis reaction Methods 0.000 description 1
- 125000001151 peptidyl group Chemical group 0.000 description 1
- 210000001322 periplasm Anatomy 0.000 description 1
- 230000002688 persistence Effects 0.000 description 1
- 101150009573 phoA gene Proteins 0.000 description 1
- 229940080469 phosphocellulose Drugs 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 229940085127 phytase Drugs 0.000 description 1
- 108010031345 placental alkaline phosphatase Proteins 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 229920001983 poloxamer Polymers 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 229920000447 polyanionic polymer Polymers 0.000 description 1
- 102000054765 polymorphisms of proteins Human genes 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- 230000001323 posttranslational effect Effects 0.000 description 1
- OTYBMLCTZGSZBG-UHFFFAOYSA-L potassium sulfate Chemical compound [K+].[K+].[O-]S([O-])(=O)=O OTYBMLCTZGSZBG-UHFFFAOYSA-L 0.000 description 1
- 229910052939 potassium sulfate Inorganic materials 0.000 description 1
- 244000144977 poultry Species 0.000 description 1
- 235000013594 poultry meat Nutrition 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000009145 protein modification Effects 0.000 description 1
- 230000006337 proteolytic cleavage Effects 0.000 description 1
- 239000012264 purified product Substances 0.000 description 1
- 238000012205 qualitative assay Methods 0.000 description 1
- 238000012207 quantitative assay Methods 0.000 description 1
- 235000021013 raspberries Nutrition 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 239000012465 retentate Substances 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 108010035322 rhamnogalacturonan acetylesterase Proteins 0.000 description 1
- 108010016615 rhamnogalacturonan rhamnohydrolase Proteins 0.000 description 1
- 238000009991 scouring Methods 0.000 description 1
- 238000007423 screening assay Methods 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 239000004460 silage Substances 0.000 description 1
- 230000037432 silent mutation Effects 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 238000002791 soaking Methods 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 235000020712 soy bean extract Nutrition 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 210000004989 spleen cell Anatomy 0.000 description 1
- 210000004988 splenocyte Anatomy 0.000 description 1
- 230000003019 stabilising effect Effects 0.000 description 1
- 238000012409 standard PCR amplification Methods 0.000 description 1
- 238000012289 standard assay Methods 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 235000021012 strawberries Nutrition 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 235000019640 taste Nutrition 0.000 description 1
- 238000012956 testing procedure Methods 0.000 description 1
- 229960000814 tetanus toxoid Drugs 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000005820 transferase reaction Methods 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 229910052722 tritium Inorganic materials 0.000 description 1
- ORHBXUUXSCNDEV-UHFFFAOYSA-N umbelliferone Chemical compound C1=CC(=O)OC2=CC(O)=CC=C21 ORHBXUUXSCNDEV-UHFFFAOYSA-N 0.000 description 1
- HFTAFOQKODTIJY-UHFFFAOYSA-N umbelliferone Natural products Cc1cc2C=CC(=O)Oc2cc1OCC=CC(C)(C)O HFTAFOQKODTIJY-UHFFFAOYSA-N 0.000 description 1
- 241000712461 unidentified influenza virus Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 238000011514 vinification Methods 0.000 description 1
- 210000002268 wool Anatomy 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23C—DAIRY PRODUCTS, e.g. MILK, BUTTER OR CHEESE; MILK OR CHEESE SUBSTITUTES; MAKING OR TREATMENT THEREOF
- A23C11/00—Milk substitutes, e.g. coffee whitener compositions
- A23C11/02—Milk substitutes, e.g. coffee whitener compositions containing at least one non-milk component as source of fats or proteins
- A23C11/10—Milk substitutes, e.g. coffee whitener compositions containing at least one non-milk component as source of fats or proteins containing or not lactose but no other milk components as source of fats, carbohydrates or proteins
- A23C11/103—Milk substitutes, e.g. coffee whitener compositions containing at least one non-milk component as source of fats or proteins containing or not lactose but no other milk components as source of fats, carbohydrates or proteins containing only proteins from pulses, oilseeds or nuts, e.g. nut milk
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23K—FODDER
- A23K20/00—Accessory food factors for animal feeding-stuffs
- A23K20/10—Organic substances
- A23K20/189—Enzymes
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23K—FODDER
- A23K30/00—Processes specially adapted for preservation of materials in order to produce animal feeding-stuffs
- A23K30/10—Processes specially adapted for preservation of materials in order to produce animal feeding-stuffs of green fodder
- A23K30/15—Processes specially adapted for preservation of materials in order to produce animal feeding-stuffs of green fodder using chemicals or microorganisms for ensilaging
- A23K30/18—Processes specially adapted for preservation of materials in order to produce animal feeding-stuffs of green fodder using chemicals or microorganisms for ensilaging using microorganisms or enzymes
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23K—FODDER
- A23K50/00—Feeding-stuffs specially adapted for particular animals
- A23K50/70—Feeding-stuffs specially adapted for particular animals for birds
- A23K50/75—Feeding-stuffs specially adapted for particular animals for birds for poultry
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23L—FOODS, FOODSTUFFS OR NON-ALCOHOLIC BEVERAGES, NOT OTHERWISE PROVIDED FOR; PREPARATION OR TREATMENT THEREOF
- A23L11/00—Pulses, i.e. fruits of leguminous plants, for production of food; Products from legumes; Preparation or treatment thereof
- A23L11/30—Removing undesirable substances, e.g. bitter substances
- A23L11/33—Removing undesirable substances, e.g. bitter substances using enzymes; Enzymatic transformation of pulses or legumes
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23L—FOODS, FOODSTUFFS OR NON-ALCOHOLIC BEVERAGES, NOT OTHERWISE PROVIDED FOR; PREPARATION OR TREATMENT THEREOF
- A23L11/00—Pulses, i.e. fruits of leguminous plants, for production of food; Products from legumes; Preparation or treatment thereof
- A23L11/60—Drinks from legumes, e.g. lupine drinks
- A23L11/65—Soy drinks
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23L—FOODS, FOODSTUFFS OR NON-ALCOHOLIC BEVERAGES, NOT OTHERWISE PROVIDED FOR; PREPARATION OR TREATMENT THEREOF
- A23L19/00—Products from fruits or vegetables; Preparation or treatment thereof
- A23L19/09—Mashed or comminuted products, e.g. pulp, purée, sauce, or products made therefrom, e.g. snacks
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23L—FOODS, FOODSTUFFS OR NON-ALCOHOLIC BEVERAGES, NOT OTHERWISE PROVIDED FOR; PREPARATION OR TREATMENT THEREOF
- A23L2/00—Non-alcoholic beverages; Dry compositions or concentrates therefor; Preparation or treatment thereof
- A23L2/70—Clarifying or fining of non-alcoholic beverages; Removing unwanted matter
- A23L2/84—Clarifying or fining of non-alcoholic beverages; Removing unwanted matter using microorganisms or biological material, e.g. enzymes
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23L—FOODS, FOODSTUFFS OR NON-ALCOHOLIC BEVERAGES, NOT OTHERWISE PROVIDED FOR; PREPARATION OR TREATMENT THEREOF
- A23L29/00—Foods or foodstuffs containing additives; Preparation or treatment thereof
- A23L29/06—Enzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y302/00—Hydrolases acting on glycosyl compounds, i.e. glycosylases (3.2)
- C12Y302/01—Glycosidases, i.e. enzymes hydrolysing O- and S-glycosyl compounds (3.2.1)
- C12Y302/01015—Polygalacturonase (3.2.1.15)
Definitions
- the invention relates to newly identified polynucleotide sequences comprising genes that encode novel pectinases isolated from Aspergillus niger.
- the invention features the full length nucleotide sequences of the novel genes, the cDNA sequences comprising the full length coding sequences of the novel pectinases as well as the amino acid sequences of the full-length functional proteins and functional equivalents thereof.
- the invention also relates to methods of using these enzymes in industrial processes and methods of diagnosing fungal infections. Also included in the invention are cells transformed with a polynucleotide according to the invention and cells wherein a pectinase according to the invention is genetically modified to enhance or reduce its activity and/or level of expression.
- Pectin polymers are important constituents of plant primary cell walls. They are composed of chains of 1 ,4-linked alpha-D-galacturonic acid and methylated derivatives thereof. Enzymes that are able to degrade the above- defined pectin polymers are called pectinases. Degradation in this respect means that at least one sugar residue or estergroup has been removed from the pectin molecule.
- Pectinases such as polygalacturonase, pectin methylesterase, pectin lyase or pectate lyase are important for the food and feed industry, such as in the art of fruit and vegetable processing such as fruit juice production or wine making, where their ability to catalyse the degradation of the backbone of the pectin polymer is utilised.
- pectinases in particular pectin methyl esterase, is the firming of fruit and vegetables.
- the seeds of leguminicaeae like soybeans and other types of peas also contain pectin. This pectin, however, is quite different from pectins described for fruits like apple berries etc.
- soybea pectin A large part of soybea pectin is water- unsoluble.
- soybea pectin consists mainly of xylogalacturonan and rhamnogalacturonan and contains only minor amounts of homogalacturonan.
- the CDTA-soluble pectic substances from soybean meal are composed of rhamnogalacturonan and xylogalacturonan but not homogalacturonan. Due to these structural differences soybea pectin is much more difficult to degrade by pectinases as compared to fruit pectin.
- pectin degrading enzymes An assortment of different pectin degrading enzymes is known to be present in various microorganisms such as Aspergillus niger.
- beta-fucosidase 3.2.1.38 beta-apiosidase 3.2.1.x alpha-rhamnosidase 3.2.1.40 beta-rhamnosidase 3.2.1.43 alpha-arabinopyranosidase 3.2.1.x beta-glucuronidase 3.2.1.31
- Pectin methylesterase catalyses the removal of methanol from pectin, resulting in the formation of pectic acid (polygalacturonic acid).
- Pectate lyase cleaves glycosidic bonds in polygalacturonic acid by beta-elimination
- pectin lyase cleaves the glycosidic bonds of highly methylated pectins by beta- elimination
- polygalacturonase hydrolyses the glycosidic linkages in the polygalacturonic acid chain.
- pectinases such as Rapidase Press ® are actually a mixture of enzymes, which, along with other enzymes such as cellulases, are used in the fruit industry to help extract, clarify and modify fruit juices.
- Pectinases have already been cloned in a variety of different microorganisms. Molecular cloning of pectinases in fungi has also been described. The DNA and deduced amino acid sequences of several pectinases from Aspergillus oryzae, Aspergillus kawachii and Emericella nidulans are known. However, there is still a need for other pectinases with different properties so that feed, fruit and vegetable processing may be optimized.
- One of the disadvantages of the currently available enzymes is that they have pH optima above pH 4.0. Many fruit juices are more acidic and a pH optimum below 3.8 would be desirable. Fruit juices may become as acidic as pH 2.0 and it is therefore an object of the present invention to provide pectinases with a more acidic pH optimum. Pectinases with a pH optimum below 3.8 would be especially advantageous. Fruit processing is also often performed at more extreme temperatures. Use of pectinases with lower temperature optima would improve yield and quality of the juice because more aromas would be released. The currently available enzymes have a very low efficiency at temperatures below 15 °C. Also, at high temperatures the currently available enzymes are easily inactivated. This is a disadvantage for those fruit juices that have to be pasteurized.
- Enzymes according to the invention also provide a better temperature stability and may withstand more extreme temperatures in comparison with pectinases according to the prior art. Also, the specificity of conventional enzymes leaves to be desired. Fruit juice that needs to be filtrated after or during processing tends to clot the filters after some time. This is due to the inability of prior art enzymes to properly digest fruit polysaccharides which causes the fouling of the filters.
- a further object is to provide naturally and recombinantly produced pectinases as well as recombinant strains producing these.
- fusion polypeptides are part of the invention as well as methods of making and using the polynucleotides and polypeptides according to the invention. Summary of the invention
- the invention provides for novel polynucleotides encoding novel pectinases. These pectinases were found to digest pectinases from various sources in a better way than conventional pectinases. Such better performance was especially evident when the pectinases according to the invention were used to prevent filter fouling in fruit juice applications. Also, pectinases according to the invention may advantageously be employed for improving the nutritional value of soybean extracts. Moreover, the availability of improved, isolated enzymes allows a cocktail of enzymes to be be prepared which is optimized for the digestion of pectin from a particular feed, fruit or juice.
- the invention provides for polynucleotides having a nucleotide sequence that hybridises preferably under highly stringent conditions to a sequence selected from the group consisting of SEQ ID NO: 33 - 64 or from the group consisting of SEQ ID NO: 1 - 32.
- sequences revealed herein are shown in the accompanying sequence listing. For clarity reasons, the group consisting of sequences according to SEQ ID NO: 1 , SEQ ID NO: 2, SEQ ID NO: 3, SEQ ID NO: 4, SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 7, SEQ ID NO: 8, SEQ ID NO: 9; SEQ ID NO: 10, SEQ ID NO: 11 , SEQ ID NO: 12, SEQ ID NO: 13, SEQ ID NO: 14, SEQ ID NO: 15, SEQ ID NO: 16, SEQ ID NO: 17, SEQ ID NO: 18, SEQ ID NO: 19; SEQ ID NO: 20, SEQ ID NO: 21 , SEQ ID NO: 22, SEQ ID NO: 23, SEQ ID NO: 24, SEQ ID NO: 25, SEQ ID NO: 26, SEQ ID NO: 27, SEQ ID NO: 28, SEQ ID NO: 29; SEQ ID NO: 30, SEQ ID NO: 31 , SEQ ID NO: 32, SEQ ID NO: 33, SEQ ID NO: 34, SEQ ID NO: 35, SEQ
- SEQ ID NO: 1 The group consisting of sequences according to SEQ ID NO: 1 , SEQ ID NO: 2, SEQ ID NO: 3, SEQ ID NO: 4, SEQ ID NO: 5, SEQ ID NO: 6, SEQ ID NO: 7, SEQ ID NO: 8, SEQ ID NO: 9; SEQ ID NO: 10, SEQ ID NO: 11 , SEQ ID NO: 12, SEQ ID NO: 13, SEQ ID NO: 14, SEQ ID NO: 15, SEQ ID NO: 16, SEQ ID NO: 17, SEQ ID NO: 18, SEQ ID NO: 19; SEQ ID NO: 20, SEQ ID NO: 21, SEQ ID NO: 22, SEQ ID NO: 23, SEQ ID NO: 24, SEQ ID NO: 25, SEQ ID NO: 26, SEQ ID NO: 27, SEQ ID NO: 28, SEQ ID NO: 29; SEQ ID NO: 30, SEQ ID NO: 31 and SEQ ID NO: 32 is hereinafter collectively termed the group consisting of SEQ ID NO: 1 - 32
- SEQ ID NO: 33 The group consisting of sequences according to SEQ ID NO: 33, SEQ ID NO: 34, SEQ ID NO: 35, SEQ ID NO: 36, SEQ ID NO:37, SEQ ID NO: 38, SEQ ID NO: 39; SEQ ID NO: 40, SEQ ID NO: 41 , SEQ ID NO: 42, SEQ ID NO: 43, SEQ ID NO: 44, SEQ ID NO: 45, SEQ ID NO: 46, SEQ ID NO: 47, SEQ ID NO: 48, SEQ ID NO: 49; SEQ ID NO: 50, SEQ ID NO: 51 , SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, SEQ ID NO: 55, SEQ ID NO: 56, SEQ ID NO: 57, SEQ ID NO: 58, SEQ ID NO: 59; SEQ ID NO: 60, SEQ ID NO: 61, SEQ ID NO: 62, SEQ ID NO: 63 and SEQ ID NO: 64 is hereinafter collectively termed
- SEQ ID NO: 65 The group consisting of sequences according to SEQ ID NO: 65, SEQ ID NO: 66, SEQ ID NO: 67, SEQ ID NO: 68, SEQ ID NO: 69; SEQ ID NO: 70, SEQ ID NO: 71 , SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79; SEQ ID NO: 80, SEQ ID NO: 81 , SEQ ID NO: 82, SEQ ID NO: 83, SEQ ID NO: 84, SEQ ID NO: 85, SEQ ID NO: 86, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89; SEQ ID NO: 90, SEQ ID NO: 91 , SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID
- SEQ ID NO: 6 The group consisting of sequences according to SEQ ID NO: 6, SEQ ID NO: 7, SEQ ID NO: 8, SEQ ID NO: 9; SEQ ID NO: 10, SEQ ID NO: 11 , SEQ ID NO: 12, SEQ ID NO: 13, SEQ ID NO: 14, SEQ ID NO: 15, SEQ ID NO: 16, SEQ ID NO: 17, SEQ ID NO: 18, SEQ ID NO: 19; SEQ ID NO: 20, SEQ ID NO: 21 , SEQ ID NO: 22, SEQ ID NO: 23, SEQ ID NO: 24, SEQ ID NO: 25, SEQ ID NO: 26, SEQ ID NO: 27, SEQ ID NO: 28, SEQ ID NO: 29; SEQ ID NO: 30, SEQ ID NO: 31 and SEQ ID NO: 32 is hereinafter collectively termed the group consisting of SEQ ID NO: 6 - 32
- SEQ ID NO: 38 SEQ ID NO: 39; SEQ ID NO: 40, SEQ ID NO: 41, SEQ ID NO: 42, SEQ ID NO: 43, SEQ ID NO: 44, SEQ ID NO: 45, SEQ ID NO: 46, SEQ ID NO: 47, SEQ ID NO: 48, SEQ ID NO: 49; SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52, SEQ ID NO: 53, SEQ ID NO: 54, SEQ ID NO: 55, SEQ ID NO: 56, SEQ ID NO: 57, SEQ ID NO: 58, SEQ ID NO: 59; SEQ ID NO: 60, SEQ ID NO: 61, SEQ ID NO: 62, SEQ ID NO: 63 and SEQ ID NO: 64 is hereinafter collectively termed the group consisting of SEQ ID NO: 38 - 64.
- SEQ ID NO: 70 The group consisting of sequences according to SEQ ID NO: 70, SEQ ID NO: 71, SEQ ID NO: 72, SEQ ID NO: 73, SEQ ID NO: 74, SEQ ID NO: 75, SEQ ID NO: 76, SEQ ID NO: 77, SEQ ID NO: 78, SEQ ID NO: 79; SEQ ID NO: 80, SEQ ID NO: 81, SEQ ID NO: 82, SEQ ID NO: 83, SEQ ID NO: 84, SEQ ID NO: 85, SEQ ID NO: 86, SEQ ID NO: 87, SEQ ID NO: 88, SEQ ID NO: 89; SEQ ID NO: 90, SEQ ID NO: 91 , SEQ ID NO: 92, SEQ ID NO: 93, SEQ ID NO: 94, SEQ ID NO: 95 and SEQ ID NO: 96 is hereinafter collectively termed the group consisting of SEQ ID NO: 70 - 96.
- SEQ ID NO: 1 - 21 The group consisting of sequences according to SEQ ID NO:
- SEQ ID NO: 34 SEQ ID NO: 35, SEQ ID NO: 36, SEQ ID NO:37, SEQ ID NO: 38, SEQ ID NO: 39
- SEQ ID NO: 40 SEQ ID NO: 41, SEQ ID NO: 42, SEQ ID NO: 43, SEQ ID NO: 44, SEQ ID NO: 45, SEQ ID NO: 46, SEQ ID NO: 47, SEQ ID NO: 48, SEQ ID NO: 49
- SEQ ID NO: 50, SEQ ID NO: 51, SEQ ID NO: 52 and SEQ ID NO: 53 is hereinafter collectively termed the group consisting of SEQ ID NO: 33 - 53.
- SEQ ID NO: 80, SEQ ID NO: 81, SEQ ID NO: 82, SEQ ID NO: 83, SEQ ID NO: 84 and SEQ ID NO: 85 is hereinafter collectively termed the group consisting of SEQ ID NO: 65 - 85.
- the invention provides nucleic acids that are more than 40% such as about 60%, preferably 65%, more preferably 70%, even more preferably 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% or 99% homologous to the sequences selected from the group consisting of SEQ ID NO: 33 - 64 or from the group consisting of SEQ ID NO: 1 - 32.
- the invention provides for a polynucleotide comprising the coding sequence of the polynucleotides according to the invention, preferred is a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1 - 32.
- the invention also relates to vectors comprising a polynucleotide sequence according to the invention and primers, probes and fragments that may be used to amplify or detect the DNA according to the invention.
- a vector is provided wherein the polynucleotide sequence according to the invention is functionally linked with regulatory sequences suitable for expression of the encoded amino acid sequence in a suitable host cell, such as A. niger or A. oryzea.
- the invention also provides methods for preparing polynucleotides and vectors according to the invention.
- the invention also relates to recombinantly produced host cells that contain heterologous or homologous polynucleotides according to the invention.
- the invention provides recombinant host cells wherein the expression of a pectinase according to the invention is significantly increased or wherein the activity of the pectinase is increased.
- polypeptides according to the invention include the polypeptides encoded by the polynucleotides according to the invention. Especially preferred is a polypeptide selected from the group consisting of SEQ ID NO: 65 - 96 or functional equivalents thereof.
- the present invention provides polynucleotides encoding a number of novel pectinases, collectively called PEC 1 - PEC 32, having an amino acid sequence selected from the group consisting of SEQ ID NO: 65 - 96 or functional equivalents thereof.
- PEC1 - PEC 32 is hereinafter used to refer to any polypeptide with pectinase activity selected from the group consisiting of SEQ ID NO: 65 - 96.
- the sequences of the genes encoding PEC 1 - PEC 32 were determined by sequencing genomic clones obtained from Aspergillus niger.
- polynucleotides may be obtained from filamentous fungi, in particular from Aspergillus niger. More specifically, the invention relates to an isolated polynucleotide having a nucleotide sequence selected from the group consisting of SEQ ID NO: 33 - 64 or from the group consisting of SEQ ID NO: 1 - 32.
- the invention also relates to an isolated polynucleotide encoding at least one functional domain of a polypeptide selected from the group consisting of SEQ ID NO: 65 - 96 or functional equivalents thereof.
- a nucleic acid molecule of the present invention such as a nucleic acid molecule selected from the group consisting of SEQ ID NO: 33 - 64 or from the group consisting of SEQ ID NO: 1 - 32 or a functional equivalent thereof, may be isolated using standard molecular biology techniques and the sequence information provided herein. For example, using all or portion of a nucleic acid selected from the group consisting of SEQ ID NO: 33 - 64 or from the group consisting of SEQ ID NO: 1 - 32 as a hybridization probe, nucleic acid molecules according to the invention may be isolated using standard hybridization and cloning techniques (e. g., as described in Sambrook, J., Fritsh, E. F., and Maniatis, T. Molecular Cloning: A Laboratory Manual.2nd, ed., Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, 1989).
- nucleic acid molecule encompassing all or a portion of a nucleotide sequence selected from the group consisting of SEQ ID NO: 33 - 64 or from the group consisting of SEQ ID NO: 1 - 32 may be isolated by the polymerase chain reaction (PCR) using synthetic oligonucleotide primers designed based upon the sequence information contained herein.
- a nucleic acid according to the invention may be amplified using cDNA, mRNA or alternatively, genomic DNA, as a template and appropriate oligonucleotide primers according to standard PCR amplification techniques. The nucleic acid thus amplified may be cloned into an appropriate vector and characterized by DNA sequence analysis.
- oligonucleotides corresponding to or hybridisable to nucleotide sequences according to the invention may be prepared by standard synthetic techniques, e.g., using an automated DNA synthesizer.
- an isolated nucleic acid molecule of the invention comprises the nucleotide sequence selected from the group consisting of SEQ ID NO: 1 - 32.
- the sequences of the cDNAs selected from the group consisting of SEQ ID NO: 1 - 32 correspond to the coding region of the A. niger PEC 1 - PEC 32 pectinases.
- Pectinases PEC 1 - PEC 32 correspond to polypeptides selected from the group consisting of SEQ ID NO: 65 - 96.
- a nucleic acid molecule which is complementary to another nucleotide sequence is one which is sufficiently complementary to the other nucleotide sequence to such an extent that it may hybridize to the other nucleotide sequence thereby forming a stable duplex.
- One aspect of the invention pertains to isolated nucleic acid molecules that encode a polypeptide of the invention or a functional equivalent thereof such as a biologically active fragment or domain, as well as nucleic acid molecules sufficient for use as hybridisation probes to identify nucleic acid molecules encoding a polypeptide of the invention and fragments of such nucleic acid molecules suitable for use as PCR primers for the amplification or mutation of nucleic acid molecules.
- An "isolated polynucleotide” or “isolated nucleic acid” is a DNA or RNA that is not immediately contiguous with both of the coding sequences with which it is immediately contiguous (one on the 5' end and one on the 3' end) in the naturally occurring genome of the organism from which it is derived.
- an isolated nucleic acid includes some or all of the 5' non-coding (e.g., promotor) sequences that are immediately contiguous to the coding sequence.
- the term therefore includes, for example, a recombinant DNA that is incorporated into a vector, into an autonomously replicating plasmid or virus, or into the genomic DNA of a prokaryote or eukaryote, or which exists as a separate molecule (e.g., a cDNA or a genomic DNA fragment produced by PCR or restriction endonuclease treatment) independent of other sequences.
- nucleic acid molecule As used herein, the terms “polynucleotide” or “nucleic acid molecule” are intended to include DNA molecules (e.g., cDNA or genomic DNA) and RNA molecules (e.g., mRNA) and analogs of the DNA or RNA generated using nucleotide analogs.
- the nucleic acid molecule may be single-stranded or double-stranded, but preferably is double-stranded DNA.
- the nucleic acid may be synthesized using oligonucleotide analogs or derivatives (e.g., inosine or phosphorothioate nucleotides).
- oligonucleotides may be used, for example, to prepare nucleic acids that have altered base-pairing abilities or increased resistance to nucleases.
- Another embodiment of the invention provides an isolated nucleic acid molecule which is antisense to a PEC 1 - PEC 32 nucleic acid molecule, e.g., the coding strand of a PEC 1 - PEC 32 nucleic acid molecule. Also included within the scope of the invention are the complement strands of the nucleic acid molecules described herein.
- sequence information as provided herein should not be so narrowly construed as to require inclusion of erroneously identified bases.
- the specific sequences disclosed herein may be readily used to isolate the complete gene from filamentous fungi, in particular A. niger which in turn may easily be subjected to further sequence analyses thereby identifying sequencing errors.
- all nucleotide sequences determined by sequencing a DNA molecule herein were determined using an automated DNA sequencer and all amino acid sequences of polypeptides encoded by DNA molecules determined herein were predicted by translation of a DNA sequence determined as above. Therefore, as is known in the art for any DNA sequence determined by this automated approach, any nucleotide sequence determined herein may contain some errors.
- Nucleotide sequences determined by automation are typically at least about 90% identical, more typically at least about 95% to at least about 99.9% identical to the actual nucleotide sequence of the sequenced DNA molecule.
- the actual sequence may be more precisely determined by other approaches including manual DNA sequencing methods well known in the art.
- a single insertion or deletion in a determined nucleotide sequence compared to the actual sequence will cause a frame shift in translation of the nucleotide sequence such that the predicted amino acid sequence encoded by a determined nucleotide sequence will be completely different from the amino acid sequence actually encoded by the sequenced DNA molecule, beginning at the point of such an insertion or deletion.
- a nucleic acid molecule according to the invention may comprise only a portion or a fragment of the nucleic acid sequence selected from the group consisting of SEQ ID NO: 33 - 64 or from the group consisting of SEQ ID NO: 1 - 32, for example a fragment which may be used as a probe or primer or a fragment encoding a portion of a PEC 1 - PEC 32 protein.
- the nucleotide sequence determined from the cloning of the PEC 1 - PEC 32 gene and cDNA allows for the generation of probes and primers designed for use in identifying and/or cloning other PEC 1 - PEC 32 family members, as well as PEC 1 - PEC 32 homologues from other species.
- the probe/primer typically comprises substantially purified oligonucleotide which typically comprises a region of nucleotide sequence that hybridizes preferably under highly stringent conditions to at least about 12 or 15, preferably about 18 or 20, preferably about 22 or 25, more preferably about 30, 35, 40, 45, 50, 55, 60, 65, or 75 or more consecutive nucleotides of a nucleotide sequence selected from the group consisting of SEQ ID NO: 33 - 64 or from the group consisting of SEQ ID NO: 1 - 32 or a functional equivalent thereof.
- Probes based on the PEC 1 - PEC 32 nucleotide sequences may be used to detect transcripts or genomic PEC 1 - PEC 32 sequences encoding the same or homologous proteins for instance in other organisms.
- the probe further comprises a label group attached thereto, e.g., the label group may be a radioisotope, a fluorescent compound, an enzyme, or an enzyme cofactor.
- the label group may be a radioisotope, a fluorescent compound, an enzyme, or an enzyme cofactor.
- Such probes may also be used as part of a diagnostic test kit for identifying cells which express a PEC 1 - PEC 32 protein.
- the terms “homology” or “percent identity” are used interchangeably herein. For the purpose of this invention, it is defined here that in order to determine the percent identity of two amino acid sequences or of two nucleic acid sequences, the sequences are aligned for optimal comparison purposes (e.g., gaps may be introduced in the sequence of a first amino acid or nucleic acid sequence for optimal alignment with a second amino or nucleic acid sequence). The amino acid residues or nucleotides at corresponding amino acid positions or nucleotide positions are then compared. When a position in the first sequence is occupied by the same amino acid residue or nucleotide as the corresponding position in the second sequence, then the molecules are identical at that position.
- % identity number of identical positions/total number of positions (i.e. overlapping positions) x 100).
- the two sequences are the same length.
- the skilled person will be aware of the fact that several different computer programms are available to determine the homology between two sequences. For instance, a comparison of sequences and determination of percent identity between two sequences may be accomplished using a mathematical algorithm. In a preferred embodiment, the percent identity between two amino acid sequences is determined using the Needleman and Wunsch (J. Mol. Biol. (48):444-453 (1970)) algorithm which has been incorporated into the GAP program in the GCG software package (available at http://www.gcg.com), using either a Blossom 62 matrix or a PAM250 matrix, and a gap weight of 16, 14, 12, 10, 8, 6, or 4 and a length weight of 1 , 2, 3, 4, 5, or 6. The skilled person will appreciate that all these different parameters will yield slightly different results but that the overall percentage identity of two sequences is not significantly altered when using different algorithms.
- the percent identity between two nucleotide sequences is determined using the GAP program in the GCG software package (available at http://www.gcg.com), using a NWSgapdna.CMP matrix and a gap weight of 40, 50, 60, 70, or 80 and a length weight of 1 , 2, 3, 4, 5, or 6.
- the percent identity two amino acid or nucleotide sequence is determined using the algorithm of E. Meyers and W.
- the nucleic acid and protein sequences of the present invention may further be used as a "query sequence" to perform a search against public databases to, for example, identify other family members or related sequences.
- search may be performed using the NBLAST and XBLAST programs (version 2.0) of Altschul, et al. (1990) J. Mol. Biol. 215:403—10.
- Gapped BLAST may be utilized as described in Altschul et al., (1997) Nucleic Acids Res. 25(17):3389-3402.
- the default parameters of the respective programs e.g., XBLAST and NBLAST
- hybridizing is intended to describe conditions for hybridization and washing under which nucleotide sequences at least about 50%, at least about 60%, at least about 70%, more preferably at least about 80%, even more preferably at least about 85% to 90%, more preferably at least 95%) homologous to each other typically remain hybridized to each other.
- a preferred, non-limiting example of such hybridization conditions are hybridization in 6X sodium chloride/sodium citrate (SSC) at about 45 °C, followed by one or more washes in 1 X SSC, 0.1 % SDS at 50 °C, preferably at 55 °C, preferably at 60 °C and even more preferably at 65 °C.
- Highly stringent conditions include, for example, hybridizing at 68 °C in 5x SSC/5x Denhardt's solution / 1.0% SDS and washing in 0.2x SSC/0.1% SDS at room temperature. Alternatively, washing may be performed at 42 °C.
- the skilled artisan will know which conditions to apply for stringent and highly stringent hybridisation conditions. Additional guidance regarding such conditions is readily available in the art, for example, in Sambrook et al., 1989, Molecular Cloning, A Laboratory Manual, Cold Spring Harbor Press, N.Y.; and Ausubel et al. (eds.), 1995, Current Protocols in Molecular Biology, (John Wiley & Sons, N.Y.).
- cDNA libraries constructed from other organisms e.g. filamentous fungi, in particular from the species Aspergillus may be screened.
- Homologous gene sequences may be isolated, for example, by performing PCR using two degenerate oligonucleotide primer pools designed on the basis of nucleotide sequences as taught herein.
- the template for the reaction may be cDNA obtained by reverse transcription of mRNA prepared from strains known or suspected to express a polynucleotide according to the invention.
- the PCR product may be subcloned and sequenced to ensure that the amplified sequences represent the sequences of a new PEC 1 - PEC 32 nucleic acid sequence, or a functional equivalent thereof.
- the PCR fragment may then be used to isolate a full length cDNA clone by a variety of known methods.
- the amplified fragment may be labeled and used to screen a bacteriophage or cosmid cDNA library.
- the labeled fragment may be used to screen a genomic library.
- RNA may be isolated, following standard procedures, from an appropriate cellular or tissue source.
- a reverse transcription reaction may be performed on the RNA using an oligonucleotide primer specific for the most 5' end of the amplified fragment for the priming of first strand synthesis.
- RNA/DNA hybrid may then be "tailed" (e.g., with guanines) using a standard terminal transferase reaction, the hybrid may be digested with RNase H, and second strand synthesis may then be primed (e.g., with a poly-C primer).
- second strand synthesis may then be primed (e.g., with a poly-C primer).
- vectors preferably expression vectors, containing a nucleic acid encoding a PEC 1 - PEC 32 protein or a functional equivalent thereof.
- vector refers to a nucleic acid molecule capable of transporting another nucleic acid to which it has been linked.
- plasmid refers to a circular double stranded DNA loop into which additional DNA segments may be ligated.
- viral vector is another type of vector, wherein additional DNA segments may be ligated into the viral genome.
- plasmid and "vector” may be used interchangeably herein as the plasmid is the most commonly used form of vector.
- the invention is intended to include such other forms of expression vectors, such as viral vectors (e.g., replication defective retroviruses, adenoviruses and adeno-associated viruses), which serve equivalent functions.
- viral vectors e.g., replication defective retroviruses, adenoviruses and adeno-associated viruses
- the recombinant expression vectors of the invention comprise a nucleic acid of the invention in a form suitable for expression of the nucleic acid in a host cell, which means that the recombinant expression vector includes one or more regulatory sequences, selected on the basis of the host cells to be used for expression, which is operatively linked to the nucleic acid sequence to be expressed.
- operatively linked is intended to mean that the nucleotide sequence of interest is linked to the regulatory sequence(s) in a manner which allows for expression of the nucleotide sequence (e.g., in an in vitro transcription/translation system or in a host cell when the vector is introduced into the host cell).
- regulatory sequence is intended to include promoters, enhancers and other expression control elements (e.g., polyadenylation signal). Such regulatory sequences are described, for example, in Goeddel; Gene Expression Technology: Methods in Enzymologyl 85, Academic Press, San Diego, CA (1990).
- Regulatory sequences include those which direct constitutive expression of a nucleotide sequence in many types of host cells and those which direct expression of the nucleotide sequence only in a certain host cell (e.g. tissue-specific regulatory sequences). It will be appreciated by those skilled in the art that the design of the expression vector may depend on such factors as the choice of the host cell to be transformed, the level of expression of protein desired, etc.
- the expression vectors of the invention may be introduced into host cells to thereby produce proteins or peptides, encoded by nucleic acids as described herein (e.g. PEC 1 - PEC 32 proteins, mutant forms of PEC 1 - PEC 32 proteins, fragments, variants or functional equivalents thereof, fusion proteins, etc.).
- Expression vectors useful in the present invention include chromosomal-, episomal- and virus-derived vectors e.g., vectors derived from bacterial plasmids, bacteriophage, yeast episome, yeast chromosomal elements, viruses such as baculoviruses, papova viruses, vaccinia viruses, adenoviruses, fowl pox viruses, pseudorabies viruses and retroviruses, and vectors derived from combinations thereof, such as those derived from plasmid and bacteriophage genetic elements, such as cosmids and phagemids.
- vectors derived from bacterial plasmids, bacteriophage, yeast episome, yeast chromosomal elements viruses such as baculoviruses, papova viruses, vaccinia viruses, adenoviruses, fowl pox viruses, pseudorabies viruses and retroviruses
- vectors derived from combinations thereof such as those derived from plasmid and bacteriophage
- Vector DNA may be introduced into prokaryotic or eukaryotic cells via conventional transformation or transfection techniques.
- transformation and “transfection” are intended to refer to a variety of art-recognized techniques for introducing foreign nucleic acid (e.g., DNA) into a host cell, including calcium phosphate or calcium chloride co-percipitation, DEAE- dextran-mediated transfection, transduction, infection, lipofection, cationic lipidmediated transfection or electroporation.
- Suitable methods for transforming or transfecting host cells may be found in Sambrook, et al. (Molecular Cloning: A Laboratory Manual, 2 nd , ed. Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, 1989), Davis et al., Basic Methods in Molecular Biology (1986) and other laboratory manuals.
- a gene that encodes a selectable marker (e.g., resistance to antibiotics) is generally introduced into the host cells along with the gene of interest.
- selectable markers include those which confer resistance to drugs, such as G418, hygromycin and methatrexate.
- Nucleic acid encoding a selectable marker may be introduced into a host cell on the same vector as that encoding a PEC 1 - PEC 32 protein or may be introduced on a separate vector. Cells stably transfected with the introduced nucleic acid may be identified by drug selection (e.g. cells that have incorporated the selectable marker gene will survive, while the other cells die).
- Fusion vectors add a number of amino acids to a protein encoded therein, e.g. to the amino terminus of the recombinant protein.
- Such fusion vectors typically serve three purposes: 1) to increase expression of recombinant protein; 2) to increase the solubility of the recombinant protein; and 3) to aid in the purification of the recombinant protein by acting as a ligand in affinity purification.
- a proteolytic cleavage site is introduced at the junction of the fusion moiety and the recombinant protein to enable separation of the recombinant protein from the fusion moiety subsequent to purification of the fusion protein.
- enzymes, and their cognate recognation sequences include Factor Xa, thrombin and enterokinase.
- the expression vectors will preferably contain selectable markers. Such markers include dihydrofolate reductase or neomycin resistance for eukarotic cell culture and tetracyline or ampicilling resistance for culturing in E. coli and other bacteria. Representative examples of appropriate host include bacterial cells, such as E.
- coli Streptomyces and Salmonella typhimurium
- fungal cells such as yeast
- insect cells such as Drosophila S2 and Spodoptera Sf9
- animal cells such as CHO, COS and Bowes melanoma
- plant cells Appropriate culture mediums and conditions for the above-described host cells are known in the art.
- vectors preferred for use in bacteria are pQE70, pQE60 and PQE-9, available from Qiagen; pBS vectors, Phagescript vectors, Bluescript vectors, pNH8A, pNH16A, pNH18A, pNH46A, available from Stratagene; and ptrc99a, pKK223-3, pKK233-3, pDR540, pRIT5 available from Pharmacia.
- preferred eukaryotic vectors are PWLNEO, pSV2CAT, pOG44, pZT1 and pSG available from Stratagene; and pSVK3, pBPV, pMSG and pSVL available from Pharmacia.
- Other suitable vectors will be readily apparent to the skilled artisan.
- bacterial promotors for use in the present invention include E. coli lad and lacZ promoters, the T3 and T7 promoters, the gpt promoter, the lambda PR, PL promoters and the trp promoter, the HSVthymidine kinase promoter, the early and late SV40 promoters, the promoters of retroviral LTRs, such as those of the Rous sarcoma virus ("RSV”), and metallothionein promoters, such as the mouse metallothionein-l promoter.
- retroviral LTRs such as those of the Rous sarcoma virus ("RSV")
- metallothionein promoters such as the mouse metallothionein-l promoter.
- Enhancers are cis-acting elements of DNA, usually about from 10 to 300 bp that act to increase transcriptional activity of a promoter in a given host cell-type.
- enhancers include the SV40 enhancer, which is located on the late side of the replication origin at bp 100 to 270, the cytomegalovirus early promoter enhancer, the polyoma enhancer on the late side of the replication origin, and adenovirus enhancers.
- secretation signal may be incorporated into the expressed polypeptide.
- the signals may be endogenous to the polypeptide or they may be heterologous signals.
- the polypeptide may be expressed in a modified form, such as a fusion protein, and may include not only secretion signals but also additional heterologous functional regions.
- a region of additional amino acids, particularly charged amino acids may be added to the N-terminus of the polypeptide to improve stability and persistence in the host cell, during purification or during subsequent handling and storage.
- peptide moieties may be added to the polypeptide to facilitate purification.
- the invention provides an isolated polypeptide having an amino acid sequence selected from the group consisting of SEQ ID NO: 65 - 96, an amino acid sequence obtainable by expressing a polynucleotide selected from the group consisting of SEQ ID NO: 33 - 64 in an appropriate host, as well as an amino acid sequence obtainable by expressing a polynucleotide sequence selected from the group consisting of SEQ ID NO: 1 - 32 in an appropriate host. Also, a peptide or polypeptide comprising a functional equivalent of the above polypeptides is comprised within the present invention.
- polypeptides are collectively comprised in the term "polypeptides according to the invention"
- peptide and oligopeptide are considered synonymous (as is commonly recognized) and each term may be used interchangeably as the context requires to indicate a chain of at least two amino acids coupled by peptidyl linkages.
- the word “polypeptide” is used herein for chains containing more than seven amino acid residues. All oligopeptide and polypeptide formulas or sequences herein are written from left to right and in the direction from amino terminus to carboxy terminus. The one-letter code of amino acids used herein is commonly known in the art and may be found in Sambrook, et al. (Molecular Cloning: A Laboratory Manual, 2 nd , ed. Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, 1989)
- isolated polypeptide or protein is intended a polypeptide or protein removed from its native environment.
- recombinantly produced polypeptides and proteins expressed in host cells are considered isolated for the purpose of the invention as are native or recombinant polypeptides which have been substantially purified by any suitable technique such as, for example, the single-step purification method disclosed in Smith and Johnson, Gene 67:31-40 (1988).
- the PEC 1 - PEC 32 pectinase according to the invention may be recovered and purified from recombinant cell cultures by well-known methods including ammonium sulfate or ethanol precipitation, acid extraction, anion or cation exchange chromatography, phosphocellulose chromatography, hydrophobic interaction chromatography, affinity chromatography, hydroxylapatite chromatography and lectin chromatography. Most preferably, high performance liquid chromatography ("HPLC”) is employed for purification.
- Polypeptides of the present invention include naturally purified products, products of chemical synthetic procedures, and products produced by recombinant techniques from a prokaryotic or eukaryotic host, including, for example, bacterial, yeast, higher plant, insect and mammalian cells.
- polypeptides of the present invention may be glycosylated or may be non-glycosylated.
- polypeptides of the invention may also include an initial modified methionine residue, in some cases as a result of host-mediated processes.
- the invention also features nucleic acid fragments which encode the above biologically active fragments of the PEC 1 - PEC 32 protein.
- a "PEC 1 - PEC 32 polypeptide” refers to a polypeptide having an amino acid sequence corresponding to PEC 1 - PEC 32
- a “non-PEC 1 - PEC 32 polypeptide” refers to a polypeptide having an amino acid sequence corresponding to a protein which is not substantially homologous to the PEC 1 - PEC 32 protein, e.g., a protein which is different from the PEC 1 - PEC 32 protein and which is derived from the same or a different organism.
- the PEC 1 - PEC 32 polypeptide may correspond to all or a portion of a PEC 1 - PEC 32 protein.
- the fusion protein is a GST- PEC 1 - PEC 32 fusion protein in which the PEC 1 - PEC 32 sequences are fused to the C-terminus of the GST sequences.
- Such fusion proteins may facilitate the purification of recombinant PEC 1 - PEC 32.
- the fusion protein is a PEC 1 - PEC 32 protein containing a heterologous signal sequence at its N-terminus.
- expression and/or secretion of PEC 1 - PEC 32 may be increased through use of a hetereologous signal sequence.
- the gp67 secretory sequence of the baculovirus envelope protein may be used as a heterologous signal sequence (Current Protocols in Molecular Biology, Ausubel et al., eds., John Wiley & Sons, 1992).
- Other examples of eukaryotic heterologous signal sequences include the secretory sequences of melittin and human placental alkaline phosphatase (Stratagene; La Jolla, California).
- useful prokarytic heterologous signal sequences include the phoA secretory signal (Sambrook et al., supra) and the protein A secretory signal (Pharmacia Biotech; Piscataway, New Jersey).
- a signal sequence may be used to facilitate secretion and isolation of a protein or polypeptide of the invention.
- Signal sequences are typically characterized by a core of hydrophobic amino acids which are generally cleaved from the mature protein during secretion in one or more cleavage events.
- Such signal peptides contain processing sites that allow cleavage of the signal sequence from the mature proteins as they pass through the secretory pathway.
- the signal sequence directs secretion of the protein, such as from a eukaryotic host into which the expression vector is transformed, and the signal sequence is subsequently or concurrently cleaved.
- the protein may then be readily purified from the extracellular medium by art recognized methods.
- the signal sequence may be linked to the protein of interest using a sequence which facilitates purification, such as with a GST domain.
- the sequence encoding the polypeptide may be fused to a marker sequence, such as a sequence encoding a peptide, which facilitates purification of the fused polypeptide.
- the marker sequence is a hexa-histidine peptide, such as the tag provided in a pQE vector (Qiagen, Inc.), among others, many of which are commercially available. As described in Gentz et al, Proc. Natl. Acad. Sci.
- PCR amplification of gene fragments may be carried out using anchor primers which give rise to complementary overhangs between two consecutive gene fragments which may subsequently be annealed and reamplified to generate a chimeric gene sequence (see, for example, Current Protocols in Molecular Biology, eds. Ausubel et al. John Wiley & Sons: 1992).
- anchor primers which give rise to complementary overhangs between two consecutive gene fragments which may subsequently be annealed and reamplified to generate a chimeric gene sequence
- many expression vectors are commercially available that already encode a fusion moiety (e.g, a GST polypeptide).
- a nucleic acid encoding a PEC 1 - PEC 32 polypeptide may be cloned into such an expression vector such that the fusion moiety is linked in-frame to the PEC 1 - PEC 32 polypeptide.
- Functional equivalents and “functional variants” are used interchangeably herein.
- Functional equivalents of PEC 1 - PEC 32 DNA are isolated DNA fragments that encode a polypeptide that exhibits a particular function of a PEC 1 - PEC 32 A. niger pectinase as defined herein.
- a functional equivalent of a PEC 1 - PEC 32 polypeptide according to the invention is a polypeptide that exhibits at least one function of an A. niger pectinase as defined herein. Functional equivalents therefore also encompass biologically active fragments.
- Functional protein or polypeptide equivalents may contain only conservative substitutions of one or more amino acids of a sequence selected from the group consisting of SEQ ID NO: 65 - 96 or substitutions, insertions or deletions of non-essential amino acids.
- a non-essential amino acid is a residue that may be altered in a sequence selected from the group consisting of SEQ ID NO: 65 - 96 without substantially altering the biological function.
- amino acid residues that are conserved within their own family among any of the PEC 1 - PEC 32 proteins of the present invention are predicted to be particularly unamenable to alteration.
- substitution is intended to mean that a substitution in which the amino acid residue is replaced with an amino acid residue having a similar side chain.
- These families are known in the art and include amino acids with basic side chains (e.g. lysine, arginine and hystidine), acidic side chains (e.g.
- aspartic acid glutamic acid
- uncharged polar side chains e.g., glycine, asparagines, glutamine, serine, threonine, tyrosine, cysteine
- non- polar side chains e.g., alanine, valine, leucine, isoleucine, proline, phenylalanine, methionine, tryptophan
- beta-branched side chains e.g., threonine, valine, isoleucine
- aromatic side chains e.g., tyrosine, phenylalanine tryptophan, histidine
- Functional nucleic acid equivalents may typically contain silent mutations or mutations that do not alter the biological function of encoded polypeptide. Accordingly, the invention provides nucleic acid molecules encoding PEC 1 - PEC 32 proteins that contain changes in amino acid residues that are not essential for a particular biological activity. Such PEC 1 - PEC 32 proteins differ in amino acid sequence from a sequence selected from the group consisting of SEQ ID NO: 65 - 96 yet retain at least one biological activity.
- the isolated nucleic acid molecule comprises a nucleotide sequence encoding a protein, wherein the protein comprises a substantially homologous amino acid sequence of at least about 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%), 98%, 99% or more homologous to an amino acid sequence selected from the group consisting of SEQ ID NO: 65 - 96.
- An isolated nucleic acid molecule encoding a PEC 1 - PEC 32 protein homologous to the protein selected from the group consisting of SEQ ID NO: 65 - 96 may be created by introducing one or more nucleotide substitutions, additions or deletions into the coding nucleotide sequences selected from the group consisting SEQ ID NO: 65 - 963 - 64 or from the group consisting of SEQ ID NO: 1 - 32 such that one or more amino acid substitutions, deletions or insertions are introduced into the encoded protein.
- Such mutations may be introduced by standard techniques, such as site-directed mutagenesis and PCR-mediated mutagenesis.
- orthologues of the A. niger PEC 1 - PEC 32 protein are proteins that may be isolated from other strains or species and possess a similar or identical biological activity. Such orthologues may readily be identified as comprising an amino acid sequence that is substantially homologous to a sequence selected from the group consisting of SEQ ID NO: 65 - 96.
- substantially homologous refers to a first amino acid or nucleotide sequence which contains a sufficient or minimum number of identical or equivalent (e.g., with similar side chain) amino acids or nucleotides to a second amino acid or nucleotide sequence such that the first and the second amino acid or nucleotide sequences have a common domain.
- amino acid or nucleotide sequences which contain a common domain having about 60%, preferably 65%, more preferably 70%, even more preferably 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98% or 99% identity or more are defined herein as sufficiently identical.
- nucleic acids encoding other PEC 1 - PEC 32 family members which thus have a nucleotide sequence that differs from a sequence selected from the group consisting of SEQ ID NO: 33 - 64 or from the group consisting of SEQ ID NO: 1 - 32, are within the scope of the invention.
- nucleic acids encoding PEC 1 - PEC 32 proteins from different species which thus may have a nucleotide sequence which differs from a sequence selected from the group consisting of SEQ ID NO: 33 - 64.or from the group consisting of SEQ ID NO: 1 - 32 are within the scope of the invention.
- Nucleic acid molecules corresponding to variants (e.g. natural allelic variants) and homologues of the PEC 1 - PEC 32 DNA of the invention may be isolated based on their homology to the PEC 1 - PEC 32 nucleic acids disclosed herein using the cDNAs disclosed herein or a suitable fragment thereof, as a hybridisation probe according to standard hybridisation techniques preferably under highly stringent hybridisation conditions.
- improved PEC 1 - PEC 32 proteins are provided.
- Improved PEC 1 - PEC 32 proteins are proteins wherein at least one biological activity is improved. Such proteins may be obtained by randomly introducing mutations along all or part of the PEC 1 - PEC 32 coding sequence, such as by saturation mutagenesis, and the resulting mutants may be expressed recombinantly and screened for biological activity. For instance, the art provides for standard assays for measuring the enzymatic activity of pectinases and thus improved proteins may easily be selected.
- the PEC 1 - PEC 32 protein has an amino acid sequence selected from the group consisting of SEQ ID NO: 65 - 96.
- the PEC 1 - PEC 32 polypeptide is substantially homologous to the amino acid sequence selected from the group consisting of SEQ ID NO: 65 - 96 and retains at least one biological activity of a polypeptide selected from the group consisting of SEQ ID NO: 65 - 96, yet differs in amino acid sequence due to natural variation or mutagenesis as described above.
- the PEC 1 - PEC 32 protein has an amino acid sequence encoded by an isolated nucleic acid fragment capable of hybridising to a nucleic acid selected from the group consisting of SEQ ID NO: 33 - 64 or from the group consisting of SEQ ID NO: 1 - 32, preferably under highly stringent hybridisation conditions.
- the PEC 1 - PEC 32 protein is a protein which comprises an amino acid sequence at least about 60%), 65%, 70%, 75%, 80%, 85%o, 90%), 95%), 96%., 97%>, 98%, 99% or more homologous to the amino acid sequence selected from the group consisting of SEQ ID NO: 65 - 96 and retains at least one functional activity of a polypeptide selected from the group consisting of SEQ ID NO: 65 - 96.
- Functional equivalents of a protein according to the invention may also be identified e.g. by screening combinatorial libraries of mutants, e.g. truncation mutants, of the protein of the invention for pectinase activity.
- a variegated library of variants is generated by combinatorial mutagenesis at the nucleic acid level.
- a variegated library of variants may be produced by, for example, enzymatically ligating a mixture of synthetic oligonucleotides into gene sequences such that a degenerate set of potential protein sequences is expressible as individual polypeptides, or alternatively, as a set of larger fusion proteins (e.g., for phage display).
- libraries of fragments of the coding sequence of a polypeptide of the invention may be used to generate a variegated population of polypeptides for screening a subsequent selection of variants.
- a library of coding sequence fragments may be generated by treating a double stranded PCR fragment of the coding sequence of interest with a nuclease under conditions wherein nicking occurs only about once per molecule, denaturing the double stranded DNA, renaturing the DNA to form double stranded DNA which may include sense/antisense pairs from different nicked products, removing single stranded portions from reformed duplexes by treatment with S1 nuclease, and ligating the resulting fragment library into an expression vector.
- an expression library may be derived which encodes N-terminal and internal fragments of various sizes of the protein of interest.
- REM Recursive ensemble mutagenesis
- REM Recursive ensemble mutagenesis
- a technique which enhances the frequency of functional mutants in the libraries may be used in combination with the screening assays to identify variants of a protein of the invention.
- PEC 1 - PEC 32 gene sequence selected from the group consisting of SEQ ID NO: 33 - 64 it will be apparent for the person skilled in the art that DNA sequence polymorphisms that may lead to changes in the amino acid sequence of the PEC 1 - PEC 32 protein may exist within a given population. Such genetic polymorphisms may exist in cells from different populations or within a population due to natural allelic variation. Allelic variants may also include functional equivalents.
- Fragments of a polynucleotide according to the invention may also comprise polynucleotides not encoding functional polypeptides. Such polynucleotides may function as probes or primers for a PCR reaction. Nucleic acids according to the invention irrespective of whether they encode functional or non-functional polypeptides, may be used as hybridization probes or polymerase chain reaction (PCR) primers. Uses of the nucleic acid molecules of the present invention that do not encode a polypeptide having a PEC 1 - PEC 32 activity include, inter alia, (1) isolating the gene encoding the PEC 1 - PEC 32 protein, or allelic variants thereof from a cDNA library e.g. from other organisms than A.
- in situ hybridization e.g. FISH
- metaphase chromosomal spreads to provide precise chromosomal location of the PEC 1 - PEC 32 gene as described in Verma et al., Human Chromosomes: a Manual of Basic Techniques, Pergamon Press, New York (1988);
- Northern blot analysis for detecting expression of PEC 1 - PEC 32 mRNA in specific tissues and/or cells and 4) probes and primers that may be used as a diagnostic tool to analyse the presence of a nucleic acid hybridisable to the PEC 1 - PEC 32 probe in a given biological (e.g. tissue) sample.
- Also encompassed by the invention is a method of obtaining a functional equivalent of a PEC 1 - PEC 32 gene or cDNA.
- a method entails obtaining a labelled probe that includes an isolated nucleic acid which encodes all or a portion of the sequence selected from the group consisting of SEQ ID NO: 65 - 96 or a variant thereof; screening a nucleic acid fragment library with the labelled probe under conditions that allow hybridisation of the probe to nucleic acid fragments in the library, thereby forming nucleic acid duplexes, and preparing a full-length gene sequence from the nucleic acid fragments in any labelled duplex to obtain a gene related to the PEC 1 - PEC 32 gene.
- a PEC 1 - PEC 32 nucleic acid of the invention is at least 60%, 65%, 70%, 75%, 80%, 85%, 90%, 91%, 92%, 93%, 94%), 95%>, 96%o, 97% » 98%., 99%, or more homologous to a nucleic acid sequence selected from the group consisting of SEQ ID NO: 33 - 64 , from the group consisting of SEQ ID NO: 1 - 32 or the complement thereof.
- a PEC 1 - PEC 32 polypeptide according to the invention is at least 60%, 65%, 70%, 75%, 80%, 85%>, 90%>, 91%, 92%o, 93%, 94%, 95%, 96%, 97%, 98%, 99%>, or more homologous to an amino acid sequence selected from the group consisting of SEQ ID NO: 65 - 96.
- a host cell may be chosen that modulates the expression of the inserted sequences, or modifies and processes the gene product in a specific, desired fashion. Such modifications (e.g., glycosylation) and processing (e.g., cleavage) of protein products may facilitate optimal functioning of the protein.
- Various host cells have characteristic and specific mechanisms for post-translational processing and modification of proteins and gene products.
- Appropriate cell lines or host systems familiar to those of skill in the art of molecular biology and/or microbiology may be chosen to ensure the desired and correct modification and processing of the foreign protein expressed.
- eukaryotic host cells that possess the cellular machinery for proper processing of the primary transcript, glycosylation, and phosphorylation of the gene product may be used.
- Such host cells are well known in the art.
- Host cells also include, but are not limited to, mammalian cell lines such as CHO, VERO, BHK, HeLa, COS, MDCK, 293, 3T3, WI38, and choroid plexus cell lines.
- mammalian cell lines such as CHO, VERO, BHK, HeLa, COS, MDCK, 293, 3T3, WI38, and choroid plexus cell lines.
- the polypeptides according to the invention may be produced by a stably-transfected cell line.
- a number of vectors suitable for stable transfection of mammalian cells are available to the public, methods for constructing such cell lines are also publicly known, e.g., in Ausubel et al. (supra).
- the invention further features antibodies, such as monoclonal or polyclonal antibodies, that specifically bind PEC 1 - PEC 32 proteins according to the invention.
- antibody or “monoclonal antibody” (Mab) is meant to include intact molecules as well as antibody fragments (such as, for example, Fab and F(ab') 2 fragments) which are capable of specifically binding to PEC 1 - PEC 32 protein.
- Fab and F(ab') 2 fragments lack the Fc fragment of intact antibody, clear more rapidly from the circulation, and may have less non-specific tissue binding of an intact antibody (Wahl et al., J. Nucl. Med. 24:316-325 (1983)). Thus, these fragments are preferred.
- the antibodies of the present invention may be prepared by any of a variety of methods. For example, cells expressing the PEC 1 - PEC 32 protein or an antigenic fragment thereof may be administered to an animal in order to induce the production of sera containing polyclonal antibodies.
- a preparation of PEC 1 - PEC 32 protein is prepared and purified to render it substantially free of natural contaminants. Such a preparation is then introduced into an animal in order to produce polyclonal antisera of greater specific activity.
- the antibodies of the present invention are monoclonal antibodies (or PEC 1 - PEC 32 protein binding fragments thereof).
- any suitable myeloma cell line may be employed in accordance with the present inventoin; however, it is preferably to employ the parent myeloma cell line (SP 2 O), available from the American Type Culture Collection, Rockville, Maryland.
- SP 2 O myeloma cell line
- the resulting hybridoma cells are selectively maintained in HAT medium, and then cloned by limiting dilution as described by Wands et al. (Gastro-enterology 80:225-232 (1981)).
- the hybridoma cells obtained through such a selection are then assayed to identify clones which secrete antibodies capable of binding the PEC 1 - PEC 32 protein antigen.
- the polypeptides may be coupled to a carrier protein, such as KLH, as described in Ausubel et al., supra, mixed with an adjuvant, and injected into a host mammal.
- various host animals may be immunized by injection of a polypeptide of interest.
- suitable host animals include rabbits, mice, guinea pigs, and rats.
- Various adjuvants may be used to increase the immunological response, depending on the host species, including but not limited to Freund's (complete and incomplete), adjuvant mineral gels such as aluminum hydroxide, surface actve substances such as lysolecithin, pluronic polyols, polyanions, peptides, oil emulsions, keyhole limpet hemocyanin, dinitrophenol, BCG (bacille Calmette-Guerin) and Corynebacterium parvum.
- Polyclonal antibodies are heterogeneous populations of antibody molecules derived from the sera of the immunized animals.
- Such antibodies may be of any immunoglobulin class including IgG, IgM, IgE, IgA, IgD, and any subclass thereof.
- the hybridomas producing the mAbs of this invention may be cultivated in vitro or in vivo. Once produced, polyclonal or monoclonal antibodies are tested for specific recognition of a PEC 1 - PEC 32 polypeptide or functional equivalent thereof in an immunoassay, such as a Western blot or immunoprecipitation analysis using standard techniques, e.g., as described in Ausubel et al., supra.
- Antibodies that specifically bind to PEC 1 - PEC 32 proteins or functional equivalents thereof are useful in the invention. For example, such antibodies may be used in an immunoassay to detect PEC 1 - PEC 32 in pathogenic or non- pathogenic strains of Aspergillus (e.g., in Aspergillus extracts).
- the antisera are checked for their ability to immunoprecipitate a recombinant PEC 1 - PEC 32 polypeptide or functional equivalents thereof whereas unrelated proteins may serve as a control for the specificity of the immune reaction.
- techniques decribed for the production of single chain antibodies (U.S. Patent 4,946,778 and 4,704,692) may be adapted to produce single chain antibodies against a PEC 1 - PEC 32 polypeptide or functional equivalents thereof.
- Kits for generating and screening phage display libraries are commercially available e.g. from Pharmacia.
- examples of methods and reagents particularly amenable for use in generating and screening antibody display library may be found in, for example, U.S. Patent No.
- PEC 1 - PEC 32 polypeptides of functional equivalents thereof may be used, for example, to detect expression of a PEC 1 - PEC 32 gene or a functional equivalent thereof e.g. in another strain of Aspergillus.
- PEC 1 - PEC 32 polypeptide may be readily detected in conventional immunoassays of Aspergillus cells or extracts. Examples of suitable assays include, without limitation, Western blotting, ELISAs, radioimmune assays, and the like.
- an antibody recognizes and binds a particular antigen, e.g., a PEC 1 - PEC 32 polypeptide, but does not substantially recognize and bind other unrelated molecules in a sample.
- Antibodies may be purified, for example, by affinity chromatography methods in which the polypeptide antigen is immobilized on a resin.
- An antibody directed against a polypeptide of the invention may be used to isolate the polypeptide by standard techniques, such as affinity chromatography or immunoprecipitation. Moreover, such an antibody may be used to detect the protein (e.g., in a cellular lysate or cell supernatant) in order to evaluate the abundance and pattern of expression of the polypeptide.
- the antibodies may also be used diagnostically to monitor protein levels in cells or tissue as part of a clinical testing procedure, e.g., to, for example, determine the efficacy of a given treatment regimen or in the diagnosis of Aspergillosis..
- Detection may be facilitated by coupling the antibody to a detectable substance.
- detectable substances include various enzymes, prosthetic groups, fluorescent materials, luminescent materials, bioluminescent materials, and radioactive materials.
- suitable enzymes include horseradish peroxidase, alkaline phosphatase, ⁇ -galactosidase, or acetylcholinesterase;
- suitable fluorescent materials include umbelliferone, fluorescein, fluorescein isothiocyanate, rhodamine, dichlorotriazinylamine fluorescein, dansyl chloride or phycoerythrin;
- an example of a luminescent material includes luminol;
- bioluminescent materials include luciferase, luciferin, and aequorin, and examples of suitable radioactive materials include 125 l, 131 l, 35 S or 3 H.
- Preferred epitopes encompassed by the antigenic peptide are regions that are located on the surface of the protein, e.g., hydrophilic regions. Hydrophobicity plots of the proteins of the invention may be used to identify hydrophilic regions.
- the antigenic peptide of a protein of the invention comprises at least 7 (preferably 10, 15, 20, or 30) contiguous amino acid residues of the amino acid sequense of a sequence selected from the group consisting of SEQ ID NO: 65 - 96 and encompasses an epitope of the protein such that an antibody raised against the peptide forms a specific immune complex with the protein.
- Preferred epitopes encompassed by the antigenic peptide are regions of PEC 1 - PEC 32 that are located on the surface of the protein, e.g., hydrophilic regions, hydrophobic regions, alpha regions, beta regions, coil regions, turn regions and flexible regions.
- Immunoassavs Qualitative or quantitative determination of a polypeptide according to the present invention in a biological sample may occur using any art- known method.
- Antibody-based techniques provide special advantages for assaying specific polypeptide levels in a biological sample. In these, the specific recognition is provided by the primary antibody (polyclonal or monoclonal) but the secondary detection system may utilize fluorescent, enzyme, or other conjugated secondary antibodies. As a result, an immunocomplex is obtained.
- the invention provides a method for diagnosing whether a certain organism is infected with Aspergillus comprising the steps of:
- Tissues may also be extracted, e.g., with urea and neutral detergent, for the liberation of protein for Western-blot or dot/slot assay. This technique may also be applied to body fluids.
- PEC 1 - PEC 32-specific monoclonal antibodies may be used both as an immunoabsorbent and as an enzyme-labeled probe to detect and quantify the PEC 1 - PEC 32 protein.
- the amount of PEC 1 - PEC 32 protein present in the sample may be calculated by reference to the amount present in a standard preparation using a linear regression computer algorithm.
- two distinct specific monoclonal antibodies may be used to detect PEC 1 - PEC 32 protein in a biological fluid. In this assay, one of the antibodies is used as the immuno-absorbent and the other as the enzyme-labeled probe.
- the above techniques may be conducted essentially as a "one- step” or “two-step” assay.
- the "one-step” assay involves contacting PEC 1 - PEC 32 protein with immobilized antibody and, without washing, contacting the mixture with the labeled antibody.
- the "two-step” assay involves washing before contacting the mixture with the labeled antibody.
- Other conventional methods may also be employed as suitable. It is usually desirable to immobilize one component of the assay system on a support, thereby allowing other components of the system to be brought into contact with the component and readily removed from the sample.
- Suitable enzyme labels include, for example, those from the oxidase group, which catalyze the production of hydrogen peroxide by reacting with substrate. Activity of an oxidase label may be assayed by measuring the concentration of hydrogen peroxide formed by the enzyme-labelled antibody/substrate reaction.
- the microtitre plates may be coated with a PEC 1 - PEC 32 polypeptide by adding the polypeptide in a solution (typically, at a concentration of 0.05 to 1 mg/ml in a volume of 1-100 ul) to each well, and incubating the plates at room temperature to 37 °C for 0.1 to 36 hours.
- Polypeptides that are not bound to the plate may be removed by shaking the excess solution from the plate, and then washing the plate (once or repeatedly) with water or a buffer.
- the polypeptide is contained in water or a buffer. The plate is then washed with a buffer that lacks the bound polypeptide.
- the plates are blocked with a protein that is unrelated to the bound polypeptide.
- a protein that is unrelated to the bound polypeptide 300 ul of bovine serum albumin (BSA) at a concentration of 2 mg/ml in Tris-HCl is suitable.
- BSA bovine serum albumin
- Suitable substrates include those substrates that contain a defined cross-linking chemistry (e.g., plastic substrates, such as polystyrene, styrene, or polypropylene substrates from Corning Costar Corp. (Cambridge, MA), for example) .
- a beaded particle e.g., beaded agarose or beaded sepharose, may be used as the substrate.
- Suitable antigens include enzymes (e.g., horse radish peroxidase, alkaline phosphatase, and a-galactosidase) and non-enzymatic polypeptides (e.g., serum proteins, such as BSA and globulins, and milk proteins, such as caseins).
- enzymes e.g., horse radish peroxidase, alkaline phosphatase, and a-galactosidase
- non-enzymatic polypeptides e.g., serum proteins, such as BSA and globulins, and milk proteins, such as caseins.
- the invention provides a peptide or polypeptide comprising an epitope-bearing portion of a polypeptide of the invention.
- the epitope of this polypeptide portion is an immunogenic or antigenic epitope of a polypeptide of the invention.
- An "immunogenic epitope" is defined as a part of a protein that elicits an antibody response when the whole protein is the immunogen. These immunogenic epitopes are believed to be confined to a few loci on the molecule.
- a region of a protein molecule to which an antibody may bind is defined as an "antigenic epitope.”
- the number of immunogenic epitopes of a protein generally is less than the number of antigenic epitopes. See, for instance, Geysen, H. M. et al., Proc. Natl. Acad. Sci. USA 81 :3998-4002 (1984).
- Peptides capable of eliciting protein-reactive sera are frequently represented in the primary sequence of a protein, may be characterized by a set of simple chemical rules, and are confined neither to immunodominant regions of intact proteins (i.e., immunogenic epitopes) nor to the amino or carboxyl terminals. Peptides that are extremely hydrophobic and those of six or fewer residues generally are ineffective at inducing antibodies that bind to the mimicked protein; longer, soluble peptides, especially those containing proline residues, usually are effective. Sutcliffe et al., supra, at 661.
- 18 of 20 peptides designed according to these guidelines containing 8- 39 residues covering 75% of the sequence of the influenza virus hemagglutinin HAI polypeptide chain, induced antibodies that reacted with the HA1 protein or intact virus; and 12/12 peptides from the MuLV polymerase and 18/18 from the rabies glycoprotein induced antibodies that precipitated the respective proteins.
- Antigenic epitope-bearing peptides and polypeptides of the invention are therefore useful to raise antibodies, including monoclonal antibodies, that bind specifically to a polypeptide of the invention.
- a high proportion of hybridomas obtained by fusion of spleen cells from donors immunized with an antigen epitope-bearing peptide generally secrete antibody reactive with the native protein.
- the antibodies raised by antigenic epitope bearing peptides or polypeptides are useful to detect the mimicked protein, and antibodies to different peptides may be used for tracking the fate of various regions of a protein precursor which undergoes posttranslation processing.
- the peptides and anti-peptide antibodies may be used in a variety of qualitative or quantitative assays for the mimicked protein, for instance in competition assays since it has been shown that even short peptides (e.g., about 9 amino acids) may bind and displace the larger peptides in immunoprecipitation assays. See, for instance, Wilson, I A et al., Cell 37:767-778 at 777 (1984).
- the anti-peptide antibodies of the invention also are useful for purification of the mimicked protein, for instance, by adsorption chromatography using methods well known in the art.
- Antigenic epitope-bearing peptides and polypeptides of the invention designed according to the above guidelines preferably contain a sequence of at least seven, more preferably at least nine and most preferably between about 15 to about 30 amino acids contained within the amino acid sequence of a polypeptide of the invention.
- peptides or polypeptides comprising a larger portion of an amino acid sequence of a polypeptide of the invention, containing about 30 to about 50 amino acids, or any length up to and including the entire amino acid sequence of a polypeptide of the invention also are considered epitope-bearing peptides or polypeptides of the invention and also are useful for inducing antibodies that react with the mimicked protein.
- the amino acid sequence of the epitope-bearing peptide is selected to provide substantial solubility in aqueous solvents (i.e., the sequence includes relatively hydrophilic residues and highly hydrophobic sequences are preferably avoided); and sequences containing proline residues are particularly preferred.
- the epitope-bearing peptides and polypeptides of the invention may be produced by any conventional means for making peptides or polypeptides including recombinant means using nucleic acid molecules of the invention.
- a short epitope-bearing amino acid sequence may be fused to a larger polypeptide which acts as a carrier during recombinant production and purification, as well as during immunization to produce anti-peptide antibodies.
- Epitope-bearing peptides also may be synthesized using known methods of chemical synthesis. For instance, Houghten has described a simple method for synthesis of large numbers of peptides, such as 10-20 mg of 248 different 13 residue peptides representing single amino acid variants of a segment of the HAI polypeptide which were prepared and characterized (by ELISA-type binding studies) in less than four weeks. Houghten, R. A., Proc. Natl. Acad. Sci. USA 82:5131-5135 (1985). This "Simultaneous Multiple Peptide Synthesis
- Epitope-bearing peptides and polypeptides of the invention are used to induce antibodies according to methods well known in the art. See, for instance, Sutcliffe et al., supra; Wilson et al., supra; Chow, M. et al., Proc. Natl. Acad. Sci. USA 82:910-914; and Bittle, F.J. et al., J. Gen. Virol. 66:2347-2354 (1985).
- animals may be immunized with free peptide; however, anti-peptide antibody titer may be boosted by coupling of the peptide to a macromolecular carrier, such as keyhole limpet hemocyanin (KLH) or tetanus toxoid.
- KLH keyhole limpet hemocyanin
- peptides containing cysteine may be coupled to carrier using a linker such as maleimidobenzoyl-N-hydroxysuccinimide ester (MBS), while other peptides may be coupled to carrier using a more general linking agent such as glutaraldehyde.
- Animals such as rabbits, rats and mice are immunized with either free or carriercoupled peptides, for instance, by intraperitoneal and/or intradermal injection of emulsions containing about 100 ug peptide or carrier protein and Freund's adjuvant. Several booster injections may be needed, for instance, at intervals of about two weeks, to provide a useful titer of anti-peptide antibody which may be detected, for example, by ELISA assay using free peptide adsorbed to a solid surface.
- the titer of anti-peptide antibodies in serum from an immunized animal may be increased by selection of anti-peptide antibodies, for instance, by adsorption to the peptide on a solid support and elution of the selected antibodies according to methods well known in the art.
- U.S. Patent No. 5,194,392 to Geysen (1990) describes a general method of detecting or determining the sequence of monomers (amino acids or other compounds) which is a topological equivalent of the epitope (i.e., a "mimotope") which is complementary to a particular paratope (antigen binding site) of an antibody of interest. More generally, U.S. Patent No. 4,433,092 to
- Geysen (1989) describes a method of detecting or determining a sequence of monomers which is a topographical equivalent of a ligand which is complementary to the ligand binding site of a particular receptor of interest.
- U.S. Patent No. 5,480,971 to Houghten, R. A. et al. (1996) on Peralkylated Oligopeptide Mixtures discloses linear C1-C7-alkyl peralkylated oligopeptides and sets and libraries of such peptides, as well as methods for using such oligopeptide sets and libraries for determining the sequence of a peralkylated oligopeptide that preferentially binds to an acceptor molecule of interest.
- non-peptide analogs of the epitope-bearing peptides of the invention also may be made routinely by these methods.
- Pectins and pectinases play an important role in the food industry. Pectinases are used in the production of fruit and vegetable juices and purees, and in the extraction of useful components, like arome compounds, or even pharmaceuticals, from plant materials.
- pectinases One of the main applications of pectinases is in the production of clear fruit and vegetable juice.
- the production of juices from fruit and vegetables typically involves, after an optional washing step, grinding, crushing or otherwise destroying the integrity of the fruit or vegetables thus obtaining a fruit or vegetable pulp.
- the pulp may be treated with enzymes to decrease soluble pectin, a process generally referred to as maceration.
- maceration the pulp is ready for pressing, leading to a juice fraction and a residue fraction, the latter being referred to as the pomace.
- the juice obtained after pressing is usually pasteurised, optionally with recovery of the aroma, which may then be added back at the end of the process.
- the pasteurised juice is enzymatically depectinized with the aid of pectinases, optionally pre- concentrated, filtrated, optionally ultra-filtrated and concentrated to obtain a clear concentrate or juice which is ready for shipping and/or blending to obtain a clear apple juice for the consumer market
- pectinases are useful in all production processes in which the integrity of the cell wall should be destroyed in order to release materials from the inside of the cells, or from the cell walls. Pectinases may also be used to destroy the connection between cells without affecting the integrity of the separate cells. When cells should remain intact, e.g.
- PEC 1 - PEC 32 pectinases may advantageously be used to release the structural connection between the cells.
- PEC 1 - PEC 32 pectinases are also able to decrease the water- binding and hence the viscosity of pectin-containing slurries, e.g. fruit or vegetable pulps, which improves the pressability/processability of the pulp.
- PEC 1 - PEC 32 pectinases may also be used in the retting of flax (to release the cellulose fibres from the plant tissue) and the scouring of cotton (to increase the water absorbance and dye uptake of the cotton fibres).
- Plant and pectin-containing materials include plant pulp, parts of plants and plant extracts.
- an extract from a plant material is any substance which may be derived from plant material by extraction (mechanical and/or chemical), processing or by other separation techniques.
- the extract may be juice, nectar, base, or concentrates made thereof.
- the plant material may comprise or be derived from vegetables, e.g., carrots, celery, onions, legumes or leguminous plants (soy, soybean, peas) or fruit, e.g., pome or seed fruit (apples, pears, quince etc.), grapes, tomatoes, citrus (orange, lemon, lime, mandarin), melons, prunes, cherries, black currants, redcurrants, raspberries, strawberries, cranberries, pineapple and other tropical fruits, trees and parts thereof (e.g. pollen, from pine trees).
- Fruit juice that needs to be filtrated after or during processing tends to clot the filters after some time.
- PEC 1 - PEC 32 pectinases may conveniently be produced in microorganisms.
- Microbial pectinases are available from a variety of sources; Bacillus spec, are a common source of bacterial enzymes, whereas fungal enzymes are commonly produced in Aspergillus spec.
- pectinases that are obtained by recombinant DNA techniques.
- Such recombinant enzymes have a number of advantages over their traditionally purified counterparts.
- Recombinant enzymes may be produced at a low cost price, high yield, free from contaminating agents like bacteria or viruses but also free from bacterial toxins or contaminating other enzyme activities.
- the polypeptides of the invention may be used to treat plant material including plant pulp and plant extracts. For example, they may be used to treat apple pulp and/or raw juice during the production of apple juice. They may also be used to treat liquid or solid foodstuffs or edible foodstuff ingredients. Conveniently the polypeptide of the invention is combined with suitable (solid or liquid) carriers or diluents including buffers to produce a composition or enzyme preparation.
- suitable (solid or liquid) carriers or diluents including buffers to produce a composition or enzyme preparation.
- the polypeptide is typically stably formulated either in liquid r dry form.
- the product is made as a composition which will optionally include, for example, a stabilising buffer and/or preservative.
- compositions may also include other enzymes capable of digesting plant material or pectin, for example other pectinases such as an endo-arabinanase, rhamnogalacturonases, and/or polygalacturonase.
- pectinases such as an endo-arabinanase, rhamnogalacturonases, and/or polygalacturonase.
- immobilization of the enzyme on a solid matrix or incorporation on or into solid carrier particles may be preferred.
- the composition may also include a variety of other plant material-degrading enzymes, for example cellulases and other pectinases.
- polypeptides and compositions of the invention may therefore be used in a method of processing plant material to degrade or modify the pectin constituents of the cell walls of the plant material
- the polypeptides of the invention are used as a composition/ enzyme preparation as described above.
- the composition will generally be added to plant pulp obtainable by, for example mechanical processing such as crushing or milling plant material. Incubation of the composition with the plant material will typically be carried out for a time of from 10 minutes to 5 hours, such as 30 minutes to 2 hours, preferably for about 1 hour.
- the processing temperature is preferably 10-55°C, e.g. from 15 to 25°C, optimally about 20°C and one may use 10-300g, preferably 30-70g, optimally about 50g of enzyme per ton of material to be treated. All the enzyme(s) or their compositions used may be added sequentially or at the same time to the plant pulp.
- the plant material may first be macerated (e.g. to a puree) or liquefied.
- processing parameters such as the yield of the extraction, viscosity of the extract and/or quality of the extract may be improved.
- a polypeptide of the invention may be added to raw juice obtained from pressing or liquefying the plant pulp. Treatment of raw juice may be carried out in a similar manner to the plant pulp in respect of dosage, temperature and holding time. Again, other enzymes than pectinases may be included.
- a composition containing a polypeptide of the invention may also be used during the preparation of fruit or vegetable purees. The end product of these processes is typically heat-treated at 85°C for a time of from 1 minute to 1 hour, under conditions to partially or fully inactivate the polypeptides of the invention. Due to the highly specific action on pectins the polypeptides of the invention may also be used to prepare pectins with modified chara dsristics, e.g. modified gelation capacities for specific applications.
- the polypeptides of the invention may be added to animal feeds rich in pectin, e.g. soy-containing food, to improve the breakdown of the plant cell wall leading to improved utilisation of the plant nutrients by the animal.
- the polypeptides of the invention may be added to the feed or silage if pre-soaking or wet diets are preferred.
- the polypeptides of the invention may continue to degrade pectins in the feed in vivo.
- Polypeptides according to the invention have low pH optima and are capable of releasing important nutrients in such acidic environments as the stomach of an animal. The invention thus also provides (e.g.
- PEC 1 - PEC 32 pectinases may also be advantageously used during the production of milk substitutes (or replacers) from soy bean. These milk substitutes may be consumed by both humans and animals. A typical problem during the preparation of these milk substitutes is the high viscosity of the soy bean slurry, resulting in the need for an undesirable dilution of the slurry to a concentration of dry solids of 10 to 15%.
- An enzyme preparation containing a polypeptide according to the invention may be added to the slurry, either before or during the processing, enabling processing at a higher concentration (typically 40 to 50%) dry solids.
- Addition of pectinases according to the invention to a soy suspension as described in WO 95/29598 results in a decrease in waterbinding and a concommitant decrease in viscosity of the slurry.
- the enzyme may also be used in the preparation of savoury product(s), e.g. from soy bean.
- the invention also relates to the use of PEC 1 - PEC 32 pectinases in a selected number of industrial and pharmaceutical processes.
- the pectinase according to the invention features a number of significant advantages over the prior art enzymes. Depending on the specific application, these advantages may include aspects like lower production costs, higher specificity towards the substrate, less antigenic, less undesirable side activities, higher yields when produced in a suitable microorganism, more suitable pH and temperature ranges, better tastes of the final product as well as food grade and kosher aspects.
- An important aspect of the pectinases according to the invention is that they cover a whole range of pH and temperature optima which are ideally suited for a variety of applications. For example many large scale processes benefit from relatively high processing temperatures of 50 degrees C or higher, e.g. to control the risks of microbial infections.
- pectinases according to the invention comply with this demand but at the same time they are not that heat stable that they resist attempts to inactivate the enzyme by an additional heat treatment. The latter feature allows production routes that yield final products free of residual enzyme activity. Similarly many feed and food products have slightly acidic pH values so that pectinases with acidic or near neutral pH optima are preferred for their processing. A PEC 1 - PEC 32 pectinase complies with this requirement as well.
- polypeptides of the invention may also be added to animal feeds rich in pectin or xylogalacturonan, to reduce anti-nutritional effects of plant pectins and consequently improve production performances and welfare of the animals, as well as reducing environmental pollution.
- Advantagous is that these fungal derived polypeptides of the invention have generally lower pH optima and their activities are therefore (more) capable of hydrolysis in such acidic environments as the stomach of an animal. With that, anti-nutritional properties of the plant cell wall fractions are already reduced early on in the digestive tract of the animal.
- PEC 1 - PEC 32 were expressed in A. niger by cloning of cDNAs acco ding to SEQ ID NO: 1 - 32.
- the resulting enzyme preparations were subsequently purified by ultrafiltration and used in food and feed conversion as described in the examples. It was found that PEC 1 - PEC 32, when added to animal feed, were able to increase the nutritional value of the feed, as measured by an improved body weight gain in the range of 1 to 5%> and in an improvement of the feed conversion ration of 1.5 to 6%>.
- PEC 1 - PEC 21 corresponding to polypeptides with SEQ ID NO: 65 - 85 were found especially useful.
- DNA fragments having a sequence according to SEQ ID NO: 1 - 32 were cloned under the control of the glucoamylase promoter.
- the Aspergillus niger phytase (phyA) gene described in international patent application WO 98/46772 was replaced with the pectinase genes described above, yielding the vectors pPECTI - 32 respectively.
- the expression vectors pPECTI - 32 were introduced into Aspergillus niger CBS 646.97 (described in WO 98/46772). Using PCR, transformants containing pPECTI - 32 were selected.
- An experime t was designed to establish whether PEC 1 - PEC 32 pectinases, expressed as described above, could improve the nutritional value of soybean-based feed.
- the experiment was performed using male broilers (Ross 308) housed in floor pens. Directly after arrival from the hatchery, the animals were randomly distributed over 40 pens, each pen containing 20 broilers. Eight pens were allocated to each treatment. The pens were set up in an artificially heated, illuminated and ventilated broiler house, applying conditions similar to those found in practice. Animals were vaccinated according to the normal vaccination program. The experiment was performed till day 35 of age.
- Table 1 Feed composition and contents of main nutrients of diet 1.
- Rapidase Press improved performance (treatment 2 compared to treatment 1 ), especially the growth of the animals. Additional supplementation with any enzyme chosen from PEC 1 - PEC 32, (treatments 3 - 5) further improved the performance of the animals, in particular supplementation with an enzyme chosen from PEC 1 - PEC 21 (corresponding to SEQ ID NO: 65 - 85) lead to a 1 - 4% gain in body weight and improved the feed conversion ratio with 1.5 - 6%.
- Example 2 Example 2.
- AME apparent metabolisable energy
- Male broilers (Ross 308) of seven days of age were randomly distributed over 18 cages, each cage housing 8 broilers.
- Six cages were allocated to each treatment.
- the cages were set up in an artificially heated, illuminated and ventilated broiler house, using a three-tier cage system. Tiers were blocked over the treatments.
- the room was illuminated 24 hours/day, but the light intensity was gradually decreased during the trial. Also the temperature was decreased gradually during the experiment, according to a practical schedule.
- the humidity during the trial was kept at approximately 60%.
- the treatments were: 1. basal diet (table 1 [example 1]), without enzyme was added (control), 2. addition of Rapidase Press, and 5. as diet 2, but with the addition of 25 ppm of additional pectinases PEC 1 - PEC 32.
- the feeds were pelleted without the addition of steam in the process. Feed and water were offered ad libitum o the animals. Analytical procedures applied were similar to those typically applied in animal experimentation institutes, usually AOAC-methods.
- Rapidase Press improved digestibility, especially of protein.
- Addition of PEC 1 - PEC 32 had a large effect on energy metabolisability and on faecal digestibility of fat and protein, in particular PEC 1 - PEC 21 showed significant improvements in the order of 2 to 5%.
- a next experiment was performed using mixed-sex broilers (Ross) fed a maize-soybean meal-based diet.
- the animals were housed in floor pens. Directly after arrival from the hatchery, the animals were randomly distributed over 48 pens, each pen containing 24 broilers; eight pens (four pens of males and four pens of females) were allocated to each treatment.
- the pens were set up in an artificially heated, illuminated and ventilated broiler house, applying conditions similar to those found in practice. Animals were vaccinated according to the normal vaccination program against Infectious Bronchitis and New Castle Disease. The experiment was performed up to day 42 of age.
- Rapidase Press improved growth by 1.8% (treatment 2 compared to treatment 1).
- a single enzyme selected from PEC 1 - 32 (treatment 3) showed a similar effect, but improved FCR as well (average 1.4%).
- Supple entation with both enzymes, Rapidase Press and an enzyme selected from PEC 1 - PEC 32 in different doses (treatments 4 - 6) showed the best results.
- PEC 1 - PEC 21 were found to be useful enzymes in this respect.
- the treatments were:
- Modified hairy regions (MHR) from apples were isolated as a filter retentate after treatment of apples with Rapidase Press, a commercially available pectinase preparation, and subsequently the MHR was saponified resulting in MHR-S.
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Polymers & Plastics (AREA)
- Food Science & Technology (AREA)
- Zoology (AREA)
- Microbiology (AREA)
- Organic Chemistry (AREA)
- Nutrition Science (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Botany (AREA)
- Animal Husbandry (AREA)
- Agronomy & Crop Science (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Birds (AREA)
- Medicinal Chemistry (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- Oil, Petroleum & Natural Gas (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
Abstract
Description



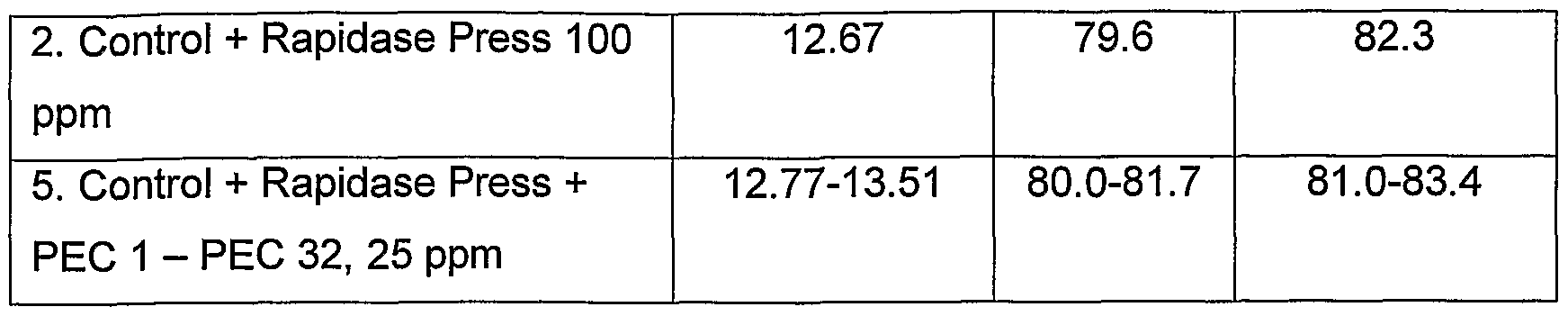




Claims
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| AU2003303934A AU2003303934A1 (en) | 2002-05-30 | 2003-05-28 | Novel pectinases and uses thereof |
| EP03815949A EP1507857A1 (en) | 2002-05-30 | 2003-05-28 | Novel pectinases and uses thereof |
Applications Claiming Priority (62)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP02100594 | 2002-05-30 | ||
| EP02100590.5 | 2002-05-30 | ||
| EP02100606 | 2002-05-30 | ||
| EP02100597.0 | 2002-05-30 | ||
| EP02100600 | 2002-05-30 | ||
| EP02100605.1 | 2002-05-30 | ||
| EP02100589 | 2002-05-30 | ||
| EP02100602 | 2002-05-30 | ||
| EP02100598.8 | 2002-05-30 | ||
| EP02100601.0 | 2002-05-30 | ||
| EP02100598 | 2002-05-30 | ||
| EP02100592 | 2002-05-30 | ||
| EP02100602.8 | 2002-05-30 | ||
| EP02100590 | 2002-05-30 | ||
| EP02100583 | 2002-05-30 | ||
| EP02100588.9 | 2002-05-30 | ||
| EP02100594.7 | 2002-05-30 | ||
| EP02100587.1 | 2002-05-30 | ||
| EP02100597 | 2002-05-30 | ||
| EP02100588 | 2002-05-30 | ||
| EP02100591 | 2002-05-30 | ||
| EP02100589.7 | 2002-05-30 | ||
| EP02100603.6 | 2002-05-30 | ||
| EP02100586.3 | 2002-05-30 | ||
| EP02100604 | 2002-05-30 | ||
| EP02100591.3 | 2002-05-30 | ||
| EP02100605 | 2002-05-30 | ||
| EP02100592.1 | 2002-05-30 | ||
| EP02100603 | 2002-05-30 | ||
| EP02100583.0 | 2002-05-30 | ||
| EP02100604.4 | 2002-05-30 | ||
| EP02100606.9 | 2002-05-30 | ||
| EP02100601 | 2002-05-30 | ||
| EP02100587 | 2002-05-30 | ||
| EP02100586 | 2002-05-30 | ||
| EP02100593.9 | 2002-05-30 | ||
| EP02100600.2 | 2002-05-30 | ||
| EP02100593 | 2002-05-30 | ||
| EP02100622 | 2002-06-03 | ||
| EP02100629.1 | 2002-06-03 | ||
| EP02100624.2 | 2002-06-03 | ||
| EP02100645.7 | 2002-06-03 | ||
| EP02100624 | 2002-06-03 | ||
| EP02100623 | 2002-06-03 | ||
| EP02100644 | 2002-06-03 | ||
| EP02100629 | 2002-06-03 | ||
| EP02100645 | 2002-06-03 | ||
| EP02100613.5 | 2002-06-03 | ||
| EP02100625 | 2002-06-03 | ||
| EP02100621.8 | 2002-06-03 | ||
| EP02100623.4 | 2002-06-03 | ||
| EP02100644.0 | 2002-06-03 | ||
| EP02100613 | 2002-06-03 | ||
| EP02100625.9 | 2002-06-03 | ||
| EP02100621 | 2002-06-03 | ||
| EP02100622.6 | 2002-06-03 | ||
| EP02100730.7 | 2002-06-20 | ||
| EP02100730 | 2002-06-20 | ||
| EP02102522 | 2002-11-01 | ||
| EP02102523 | 2002-11-01 | ||
| EP02102523.4 | 2002-11-01 | ||
| EP02102522.6 | 2002-11-01 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2004074468A1 true WO2004074468A1 (en) | 2004-09-02 |
Family
ID=32913473
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2003/005726 WO2004074468A1 (en) | 2002-05-30 | 2003-05-28 | Novel pectinases and uses thereof |
Country Status (3)
| Country | Link |
|---|---|
| EP (1) | EP1507857A1 (en) |
| AU (1) | AU2003303934A1 (en) |
| WO (1) | WO2004074468A1 (en) |
Cited By (39)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009033244A1 (en) * | 2007-09-12 | 2009-03-19 | Poli-Nutrí Alimentos Ltda. | Nutritional formulation for post hatched birds |
| WO2010102976A1 (en) | 2009-03-10 | 2010-09-16 | Dsm Ip Assets B.V. | Pregastric esterase and derivatives thereof |
| WO2010122141A1 (en) | 2009-04-24 | 2010-10-28 | Dsm Ip Assets B.V. | Carbohydrate degrading polypeptide and uses thereof |
| WO2011026877A1 (en) | 2009-09-03 | 2011-03-10 | Dsm Ip Assets B.V. | Baking enzyme composition as ssl replacer |
| WO2011048852A1 (en) * | 2009-10-19 | 2011-04-28 | バイオアイ株式会社 | Pectin lyase, pectin lyase gene, enzyme preparation, and method for production of single cells of plant tissue |
| WO2011098580A1 (en) | 2010-02-11 | 2011-08-18 | Dsm Ip Assets B.V. | Polypeptide having cellobiohydrolase activity and uses thereof |
| WO2012000888A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having acetyl xylan esterase activity and uses thereof |
| WO2012000890A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having beta-glucosidase activity and uses thereof |
| WO2012000891A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having carbohydrate degrading activity and uses thereof |
| WO2012000887A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having swollenin activity and uses thereof |
| WO2012000886A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having beta-glucosidase activity and uses thereof |
| WO2012000892A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having or assisting in carbohydrate material degrading activity and uses thereof |
| WO2012093149A2 (en) | 2011-01-06 | 2012-07-12 | Dsm Ip Assets B.V. | Novel cell wall deconstruction enzymes and uses thereof |
| WO2012130950A1 (en) | 2011-04-01 | 2012-10-04 | Dsm Ip Assets B.V. | Novel cell wall deconstruction enzymes of talaromyces thermophilus and uses thereof |
| WO2012130964A1 (en) | 2011-04-01 | 2012-10-04 | Dsm Ip Assets B.V. | Novel cell wall deconstruction enzymes of thermomyces lanuginosus and uses thereof |
| EP2620496A1 (en) | 2012-01-30 | 2013-07-31 | DSM IP Assets B.V. | Alpha-amylase |
| EP2662444A1 (en) | 2007-04-20 | 2013-11-13 | DSM IP Assets B.V. | Asparaginase enzyme variants and uses thereof |
| WO2013182669A2 (en) | 2012-06-08 | 2013-12-12 | Dsm Ip Assets B.V. | Novel cell wall deconstruction enzymes of myriococcum thermophilum and uses thereof |
| WO2013182670A2 (en) | 2012-06-08 | 2013-12-12 | Dsm Ip Assets B.V. | Novel cell wall deconstruction enzymes of scytalidium thermophilum and uses thereof |
| WO2013182671A1 (en) | 2012-06-08 | 2013-12-12 | Dsm Ip Assets B.V. | Cell wall deconstruction enzymes of aureobasidium pullulans and uses thereof |
| WO2014060378A1 (en) | 2012-10-16 | 2014-04-24 | Dsm Ip Assets B.V. | Cell wall deconstruction enzymes of pseudocercosporella herpotrichoides and|uses thereof |
| WO2014060380A1 (en) | 2012-10-16 | 2014-04-24 | Dsm Ip Assets B.V. | Cell wall deconstruction enzymes of thermoascus aurantiacus and uses thereof |
| WO2014028772A3 (en) * | 2012-08-16 | 2014-05-08 | Bangladesh Jute Research Institute | Pectin degrading enzymes from macrophomina phaseolina and uses thereof |
| WO2014118360A2 (en) | 2013-02-04 | 2014-08-07 | Dsm Ip Assets B.V. | Carbohydrate degrading polypeptide and uses thereof |
| WO2014140165A1 (en) | 2013-03-14 | 2014-09-18 | Dsm Ip Assets B.V. | Cell wall deconstruction enzymes of paecilomyces byssochlamydoides and uses thereof |
| WO2014140167A1 (en) | 2013-03-14 | 2014-09-18 | Dsm Ip Assets B.V. | Cell wall deconstruction enzymes of malbranchea cinnamomea and uses thereof |
| WO2014202622A2 (en) | 2013-06-19 | 2014-12-24 | Dsm Ip Assets B.V. | Rasamsonia gene and use thereof |
| WO2014202620A2 (en) | 2013-06-19 | 2014-12-24 | Dsm Ip Assets B.V. | Rasamsonia gene and use thereof |
| WO2014202621A1 (en) | 2013-06-20 | 2014-12-24 | Dsm Ip Assets B.V. | Carbohydrate degrading polypeptide and uses thereof |
| WO2014202624A2 (en) | 2013-06-19 | 2014-12-24 | Dsm Ip Assets B.V. | Rasamsonia gene and use thereof |
| WO2015107050A1 (en) | 2014-01-14 | 2015-07-23 | Dsm Ip Assets B.V. | Improved enzyme variants of lactase from kluyveromyces lactis |
| WO2016056913A1 (en) | 2014-10-10 | 2016-04-14 | Enzypep B.V. | Peptide fragment condensation and cyclisation using a subtilisin variant with improved synthesis over hydrolysis ratio |
| WO2017007324A1 (en) | 2015-07-09 | 2017-01-12 | Enzypep B.V. | Designing an enzymatic peptide fragment condensation strategy |
| WO2018019948A1 (en) | 2016-07-29 | 2018-02-01 | Dsm Ip Assets B.V. | Polypeptides having cellulolytic enhancing activity and uses thereof |
| WO2019193102A1 (en) | 2018-04-05 | 2019-10-10 | Dsm Ip Assets B.V. | Variant maltogenic alpha-amylase |
| WO2019243312A1 (en) | 2018-06-19 | 2019-12-26 | Dsm Ip Assets B.V. | Lipolytic enzyme variants |
| WO2023222614A1 (en) | 2022-05-16 | 2023-11-23 | Dsm Ip Assets B.V. | Lipolytic enzyme variants |
| WO2024121357A1 (en) * | 2022-12-08 | 2024-06-13 | Novozymes A/S | Fiber-degrading enzymes for animal feed comprising an oil seed material |
| WO2025012325A1 (en) | 2023-07-11 | 2025-01-16 | Dsm Ip Assets B.V. | Protein arginine deiminase |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1994014966A1 (en) * | 1992-12-24 | 1994-07-07 | Gist-Brocades N.V. | CLONING AND EXPRESSION OF THE EXO-POLYGALACTURONASE GENE FROM $i(ASPERGILLUS) |
| US5447862A (en) * | 1987-02-04 | 1995-09-05 | Ciba-Geigy Corporation | Pectin lyase genes of aspergillus niger |
| US6197566B1 (en) * | 1993-03-31 | 2001-03-06 | Novo Nordisk A/S | α-galactosidase enzyme |
-
2003
- 2003-05-28 EP EP03815949A patent/EP1507857A1/en not_active Withdrawn
- 2003-05-28 AU AU2003303934A patent/AU2003303934A1/en not_active Abandoned
- 2003-05-28 WO PCT/EP2003/005726 patent/WO2004074468A1/en not_active Application Discontinuation
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5447862A (en) * | 1987-02-04 | 1995-09-05 | Ciba-Geigy Corporation | Pectin lyase genes of aspergillus niger |
| WO1994014966A1 (en) * | 1992-12-24 | 1994-07-07 | Gist-Brocades N.V. | CLONING AND EXPRESSION OF THE EXO-POLYGALACTURONASE GENE FROM $i(ASPERGILLUS) |
| US6197566B1 (en) * | 1993-03-31 | 2001-03-06 | Novo Nordisk A/S | α-galactosidase enzyme |
Non-Patent Citations (4)
| Title |
|---|
| HARA T ET AL: "CLARIFICATION OF APPLE JUICE WITH POLYGALACTURONASE OF ASPERGILLUS-NIGER AND PECTINESTERASE OF ASPERGILLUS-ORYZAE AND THEIR PROTOPECTIN ADSORPTION AND DEGRADATION BEHAVIOR", JOURNAL OF THE JAPANESE SOCIETY FOR FOOD SCIENCE AND TECHNOLOGY, vol. 33, no. 5, 1986, pages 336 - 341, XP009018288, ISSN: 0029-0394 * |
| MILL P J: "The pectic enzymes of Aspergillus niger. A mercury-activated exopolygalacturonase.", THE BIOCHEMICAL JOURNAL. ENGLAND JUN 1966, vol. 99, no. 3, June 1966 (1966-06-01), pages 557 - 561, XP009018280, ISSN: 0264-6021 * |
| MILL P J: "The pectic enzymes of Aspergillus niger. A second exopolygalacturonase.", THE BIOCHEMICAL JOURNAL. ENGLAND, vol. 99, no. 3, - June 1966 (1966-06-01), pages 562 - 565, XP009018279 * |
| OMRAN H ET AL: "SOME RESULTS OF THE ISOLATION OF DISCRETE ENZYMES EXOPOLYGALACTURONASE AND PECTINESTERASE FROM A COMMERCIAL PECTIC ENZYME PREPARATION I. ISOLATION PURIFICATION AND CHARACTERIZATION OF AN EXOPOLYGALACTURONASE EXOPG", LEBENSMITTEL-WISSENSCHAFT & TECHNOLOGIE, vol. 19, no. 6, 1986, pages 457 - 463, XP009018347, ISSN: 0023-6438 * |
Cited By (48)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2662444A1 (en) | 2007-04-20 | 2013-11-13 | DSM IP Assets B.V. | Asparaginase enzyme variants and uses thereof |
| EP2662443A1 (en) | 2007-04-20 | 2013-11-13 | DSM IP Assets B.V. | Asparaginase enzyme variants and uses thereof |
| WO2009033244A1 (en) * | 2007-09-12 | 2009-03-19 | Poli-Nutrí Alimentos Ltda. | Nutritional formulation for post hatched birds |
| WO2010102976A1 (en) | 2009-03-10 | 2010-09-16 | Dsm Ip Assets B.V. | Pregastric esterase and derivatives thereof |
| WO2010122141A1 (en) | 2009-04-24 | 2010-10-28 | Dsm Ip Assets B.V. | Carbohydrate degrading polypeptide and uses thereof |
| WO2011026877A1 (en) | 2009-09-03 | 2011-03-10 | Dsm Ip Assets B.V. | Baking enzyme composition as ssl replacer |
| WO2011048852A1 (en) * | 2009-10-19 | 2011-04-28 | バイオアイ株式会社 | Pectin lyase, pectin lyase gene, enzyme preparation, and method for production of single cells of plant tissue |
| US8691536B2 (en) | 2009-10-19 | 2014-04-08 | Bio-I Co., Ltd. | Pectin lyase, pectin lyase polynucleotide, enzyme preparation, and method for producing single cells of plant tissue |
| EP2492343A4 (en) * | 2009-10-19 | 2012-10-24 | Bio I Co Ltd | PECTINLYASE, PECTINLYASEGEN, ENZYMPRÄPARAT AND PROCESS FOR THE PRODUCTION OF INDIVIDUAL CELLS FROM PLANT TISSUE |
| JP5266394B2 (en) * | 2009-10-19 | 2013-08-21 | バイオアイ株式会社 | Pectin lyase, pectin lyase gene, enzyme preparation, and method for unicellularization of plant tissue |
| WO2011098580A1 (en) | 2010-02-11 | 2011-08-18 | Dsm Ip Assets B.V. | Polypeptide having cellobiohydrolase activity and uses thereof |
| WO2012000890A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having beta-glucosidase activity and uses thereof |
| WO2012000891A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having carbohydrate degrading activity and uses thereof |
| WO2012000887A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having swollenin activity and uses thereof |
| WO2012000886A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having beta-glucosidase activity and uses thereof |
| WO2012000892A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having or assisting in carbohydrate material degrading activity and uses thereof |
| WO2012000888A1 (en) | 2010-06-29 | 2012-01-05 | Dsm Ip Assets B.V. | Polypeptide having acetyl xylan esterase activity and uses thereof |
| WO2012093149A2 (en) | 2011-01-06 | 2012-07-12 | Dsm Ip Assets B.V. | Novel cell wall deconstruction enzymes and uses thereof |
| WO2012130964A1 (en) | 2011-04-01 | 2012-10-04 | Dsm Ip Assets B.V. | Novel cell wall deconstruction enzymes of thermomyces lanuginosus and uses thereof |
| WO2012130950A1 (en) | 2011-04-01 | 2012-10-04 | Dsm Ip Assets B.V. | Novel cell wall deconstruction enzymes of talaromyces thermophilus and uses thereof |
| EP2620496A1 (en) | 2012-01-30 | 2013-07-31 | DSM IP Assets B.V. | Alpha-amylase |
| WO2013113665A1 (en) | 2012-01-30 | 2013-08-08 | Dsm Ip Assets B.V. | Alpha-amylase |
| WO2013182669A2 (en) | 2012-06-08 | 2013-12-12 | Dsm Ip Assets B.V. | Novel cell wall deconstruction enzymes of myriococcum thermophilum and uses thereof |
| WO2013182670A2 (en) | 2012-06-08 | 2013-12-12 | Dsm Ip Assets B.V. | Novel cell wall deconstruction enzymes of scytalidium thermophilum and uses thereof |
| WO2013182671A1 (en) | 2012-06-08 | 2013-12-12 | Dsm Ip Assets B.V. | Cell wall deconstruction enzymes of aureobasidium pullulans and uses thereof |
| KR102043363B1 (en) * | 2012-08-16 | 2019-11-11 | 방글라데시 주트 리서치 인스티튜트 | Pectin degrading enzymes from Macrophomina phaseolina and uses thereof |
| CN104837991A (en) * | 2012-08-16 | 2015-08-12 | 孟加拉朱特研究所 | Pectin degrading enzymes from macrophomina phaseolina and uses thereof |
| KR20150042849A (en) * | 2012-08-16 | 2015-04-21 | 방글라데시 주트 리서치 인스티튜트 | Pectin degrading enzymes from Macrophomina phaseolina and uses thereof |
| WO2014028772A3 (en) * | 2012-08-16 | 2014-05-08 | Bangladesh Jute Research Institute | Pectin degrading enzymes from macrophomina phaseolina and uses thereof |
| US9765322B2 (en) | 2012-08-16 | 2017-09-19 | Bangladesh Jute Research Institute | Pectin degrading enzymes from macrophomina phaseolina and uses thereof |
| WO2014060380A1 (en) | 2012-10-16 | 2014-04-24 | Dsm Ip Assets B.V. | Cell wall deconstruction enzymes of thermoascus aurantiacus and uses thereof |
| WO2014060378A1 (en) | 2012-10-16 | 2014-04-24 | Dsm Ip Assets B.V. | Cell wall deconstruction enzymes of pseudocercosporella herpotrichoides and|uses thereof |
| WO2014118360A2 (en) | 2013-02-04 | 2014-08-07 | Dsm Ip Assets B.V. | Carbohydrate degrading polypeptide and uses thereof |
| WO2014140167A1 (en) | 2013-03-14 | 2014-09-18 | Dsm Ip Assets B.V. | Cell wall deconstruction enzymes of malbranchea cinnamomea and uses thereof |
| WO2014140165A1 (en) | 2013-03-14 | 2014-09-18 | Dsm Ip Assets B.V. | Cell wall deconstruction enzymes of paecilomyces byssochlamydoides and uses thereof |
| WO2014202620A2 (en) | 2013-06-19 | 2014-12-24 | Dsm Ip Assets B.V. | Rasamsonia gene and use thereof |
| WO2014202624A2 (en) | 2013-06-19 | 2014-12-24 | Dsm Ip Assets B.V. | Rasamsonia gene and use thereof |
| WO2014202622A2 (en) | 2013-06-19 | 2014-12-24 | Dsm Ip Assets B.V. | Rasamsonia gene and use thereof |
| WO2014202621A1 (en) | 2013-06-20 | 2014-12-24 | Dsm Ip Assets B.V. | Carbohydrate degrading polypeptide and uses thereof |
| WO2015107050A1 (en) | 2014-01-14 | 2015-07-23 | Dsm Ip Assets B.V. | Improved enzyme variants of lactase from kluyveromyces lactis |
| WO2016056913A1 (en) | 2014-10-10 | 2016-04-14 | Enzypep B.V. | Peptide fragment condensation and cyclisation using a subtilisin variant with improved synthesis over hydrolysis ratio |
| WO2017007324A1 (en) | 2015-07-09 | 2017-01-12 | Enzypep B.V. | Designing an enzymatic peptide fragment condensation strategy |
| WO2018019948A1 (en) | 2016-07-29 | 2018-02-01 | Dsm Ip Assets B.V. | Polypeptides having cellulolytic enhancing activity and uses thereof |
| WO2019193102A1 (en) | 2018-04-05 | 2019-10-10 | Dsm Ip Assets B.V. | Variant maltogenic alpha-amylase |
| WO2019243312A1 (en) | 2018-06-19 | 2019-12-26 | Dsm Ip Assets B.V. | Lipolytic enzyme variants |
| WO2023222614A1 (en) | 2022-05-16 | 2023-11-23 | Dsm Ip Assets B.V. | Lipolytic enzyme variants |
| WO2024121357A1 (en) * | 2022-12-08 | 2024-06-13 | Novozymes A/S | Fiber-degrading enzymes for animal feed comprising an oil seed material |
| WO2025012325A1 (en) | 2023-07-11 | 2025-01-16 | Dsm Ip Assets B.V. | Protein arginine deiminase |
Also Published As
| Publication number | Publication date |
|---|---|
| EP1507857A1 (en) | 2005-02-23 |
| AU2003303934A1 (en) | 2004-09-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2004074468A1 (en) | Novel pectinases and uses thereof | |
| US5876997A (en) | Phytase | |
| CN102046784B (en) | Proline-specific protease from penicillium chrysogenum | |
| DK175538B1 (en) | Process for producing an alpha-amidating enzyme, genetically engineered microorganism or host cell and recombinant DNA molecule, ............. | |
| US7323327B2 (en) | Genes encoding novel proteolytic enzymes | |
| JP2009183302A (en) | New phospholipase and use of the same | |
| PT1319079E (en) | Talaromyces xylanase | |
| JP2005535352A (en) | Novel lipases and their use | |
| De Caro et al. | Characterization of pancreatic lipase-related protein 2 isolated from human pancreatic juice | |
| US20090275079A1 (en) | Novel genes encoding novel proteolytic enzymes | |
| BRPI0912975B1 (en) | USE OF PECTINOLYTIC ENZYME, PROCESS FOR ENZYMATIC TREATMENT OF FRUIT OR VEGETABLE PUZZLE, PROCESS FOR PREPARING FRUIT OR VEGETABLE JUICE, VECTOR, TRANSFORMED HOSPITAL CELL, AND PREPARED PIPE PREPARED | |
| WO1986001532A1 (en) | Polypeptide and polypeptide composition | |
| JP5977936B2 (en) | Glycopeptides, antibodies derived from pancreatic structures and their applications in diagnosis and therapy | |
| EP1394176A1 (en) | Novel mucin binding polypeptides derived from Lactobacillus johnsonii | |
| US20050032059A1 (en) | Novel amylases and uses thereof | |
| US6303766B1 (en) | Soybean phytase and nucleic acid encoding the same | |
| RU2423525C2 (en) | New genes coding new proteolytic enzymes | |
| US5801031A (en) | Human and rat gamma glutamyl hydrolase genes | |
| RU2291901C2 (en) | Polypeptide and composition having xylanase activity, polypeptide application, polynucleotide encoding polypeptide, expression vector containing polynucleotide, method for production of polynucleotide, and method for treatment of plant or xylan-containing material | |
| CA2294045C (en) | Gene encoding a protein having aurone synthesis activity | |
| AU719444B2 (en) | Endoglucanases | |
| AU2007203496B2 (en) | Novel phytase | |
| EP1382970A1 (en) | Novel mucin binding polypeptides | |
| NZ560367A (en) | Novel genes encoding novel proteolytic enzymes |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AK | Designated states |
Kind code of ref document: A1 Designated state(s): AE AG AL AM AT AU AZ BA BB BG BR BY BZ CA CH CN CO CR CU CZ DE DK DM DZ EC EE ES FI GB GD GE GH GM HR HU ID IL IN IS JP KE KG KP KR KZ LC LK LR LS LT LU LV MA MD MG MK MN MW MX MZ NI NO NZ OM PH PL PT RO RU SC SD SE SG SK SL TJ TM TN TR TT TZ UA UG US UZ VC VN YU ZA ZM ZW |
|
| AL | Designated countries for regional patents |
Kind code of ref document: A1 Designated state(s): GH GM KE LS MW MZ SD SL SZ TZ UG ZM ZW AM AZ BY KG KZ MD RU TJ TM AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HU IE IT LU MC NL PT RO SE SI SK TR BF BJ CF CG CI CM GA GN GQ GW ML MR NE SN TD TG |
|
| DFPE | Request for preliminary examination filed prior to expiration of 19th month from priority date (pct application filed before 20040101) | ||
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | ||
| WWE | Wipo information: entry into national phase |
Ref document number: 200408943 Country of ref document: ZA |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2003815949 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2003303934 Country of ref document: AU |
|
| WWP | Wipo information: published in national office |
Ref document number: 2003815949 Country of ref document: EP |
|
| WWW | Wipo information: withdrawn in national office |
Ref document number: 2003815949 Country of ref document: EP |
|
| NENP | Non-entry into the national phase |
Ref country code: JP |
|
| WWW | Wipo information: withdrawn in national office |
Country of ref document: JP |