NOVEL HUMAN PROTEINS, POLYNUCLEOTIDES ENCODING THEM AND METHODS OF USING THE SAME
FIELD OF THE INVENTION
The present invention relates to nucleic acids encoding proteins that are new members of the following protein families: nuclear protein-like proteins, transforming acidic coiled-coil-containing protein-like proteins, thyroid hormone receptor interactor 6- Iike proteins, uroporphyrinogen-IIl synthase-like proteins, intracellular-like proteins, JLIM domain transcription factor-like proteins, voltage-dependent-calcium channel-like proteins, dihydropyridine-sensitive 1 -type-calcium channel-like proteins, beta-3-subunit-like proteins, nucleoporin-like proteins, BHLH protein DEC2-like proteins, kerain 18-like proteins, intracellular protein-like proteins, intracellular protein Tubby-like proteins, symplekin-like proteins, telethonin-Iike proteins, forkhead protein O3A-like proteins, cytochrome C-like proteins, troponin t-like proteins, XIN-like proteins, prostatic binding protein-like proteins, cyioplasmic protein like homo sapiens-like proteins, zinc-finger protein HZFI-like proteins, B4-2-like proteins, Maternal effect protein staufen-like proteins, desmin like homo sapiens-like proteins, hypothetical protein-like proteins, tropomysosin alpha chain-like proteins, heπnansky-pudlak syndrome-like proteins, NOT2P-like proteins, human selenium-binding-like proteins, EH domain-binding mitotic phosphoprotein-like proteins, hypothetical intracellular-like proteins, MHC class 1 region proline rich protein-like proteints, nebullin-like proteins, golgi matrix protein GM 130-like proteins, microspherule protein l -like proteins, AK016419 mus musculus adult male testis cDNA-like proteins, utrophin (dystroph in-related protein l )-like proteins, TPR domain-like proteins, LRR domain containing like homo sapiens-like proteins, G-rich sequence factor- l -like proteins, cytoplasmic protein-like proteins, meningioma-expressed antigen 6/1 1 (MEA6) (MEA1 l)-like proteins, ancient conserved domain protein l -like proteins, CDCRL-like proteins, HPRP-like proteins, PIBF1 protein-like proteins, cytoplasmic protein-like proteins, zinc-finger/KRAB domain containing protein-like proteins, RHO- Interactin Protein 3-like proteins, cardian-troponin l-like protein, guanine nucleotide- binding protein-like proteins, benzodiazpine receptor (BZRP) like homo sapiens-like proteins, ankyrin-repeat containing protein like homo sapiens-like proteins, acyltransferase
like homo sapiens-like proteins, GTP-binding-protein SAR I A like homo sapiens-like proteins, CGI-27 like homo sapiens-like proteins, FLJ20565 like homo sapiens-like proteins, 2410014PO7R1 K like homo sapiens-like proteins, multidomain presynaptic cytomatrix protein piccola like homo sapiens-like proteins, cytosolic-sorting protein PACS- 1 A-like-like proteins, formin 2 like homo sapiens-like proteins, novel 5' nucleotidase-like protein-like proteins, WW domain containing protein like homo sapiens-like proteins, gasdermin like homo sapiens-like proteins, Tubby super-family protein splice variant like homo sapiens-like proteins, synaptotagmin-like protein 3-A like homo sapiens-like proteins, copine I like homo sapiens-like proteins, selenoprotein XI like homo sapiens-like proteins, hypothetical WD-repeat like homo sapiens-like proteins, cytoplasmic protein-like proteins, TNFAIP l -like proteins, ribosomal protein L29-like proteins, paraneoplastic antigen-like proteins, GTF21 RD2 like homo sapiens-like proteins, glycolipid transfer protein-like proteins, novel copine Vll-like proteins, sperm membrane protein BS-63-like proteins, FIP-2-like proteins, PEXl O-like proteins. Included in the invention are polynucleotides and the polypeptides encoded by such polynucleotides, as well as vectors, host cells, antibodies and recombinant methods for producing the polypeptides and polynucleotides, as well as methods for using the same. Methods of use encompass diagnostic and prognostic assay procedures as well as methods of treating diverse pathological conditions.
BACKGROUND OF THE INVENTION
The invention generally relates to nucleic acids and polypeptides encoded therefrom. More specifically, the invention relates to nucleic acids encoding cytoplasmic, nuclear, membrane bound, and secreted polypeptides, as well as vectors, host cells, antibodies, and recombinant methods for producing these nucleic acids and polypeptides.
SUMMARY OF THE INVENTION
The present invention is based in part on nucleic acids encoding proteins that are members of the following protein families: nuclear protein-like proteins, transforming acidic coiled-coil-containing protein-like proteins, thyroid hormone receptor interactor 6-like proteins, uroporphyrinogen-Ill synthase-like proteins, intracellular-like proteins, LIM domain transcription factor-like proteins, voltage-dependent-calcium channel-like proteins, dihydropyridine-sensitive 1 -type-calcium channel-like proteins, beta-3-subunit-like proteins, nucleoporin-like proteins, BHLH protein DEC2-like proteins, kerain 18-like proteins, intracellular protein-like proteins, intracellular protein Tubby-like proteins, symplekin-like proteins, telethonin-like proteins, forkhead protein O3A-Iike proteins, cytochrome C-like proteins, troponin t-like proteins, XIN-like proteins, prostatic binding protein-like proteins, cyioplasmic protein like homo sapiens-like proteins, zinc-finger protein HZFI-like proteins, B4-2-like proteins, Maternal effect protein staufen-like proteins, desmin like homo sapiens- like proteins, hypothetical protein-like proteins, tropomysosin alpha chain-like proteins, hermansky-pudlak syndrome-like proteins, NOT2P-like proteins, human selenium-bindinglike proteins, EH domain-binding mitotic phosphoprotein-like proteins, hypothetical intracellular-like proteins, MHC class 1 region proline rich protein-like proteints, nebullin- like proteins, golgi matrix protein GM130-like proteins, microspherule protein l-like proteins, AK016419 mus musculus adult male testis cDNA-like proteins, utrophin (dystrophin-related protein l)-like proteins, TPR domain-like proteins, LRR domain containing like homo sapiens-like proteins, G-rich sequence factor-1-like proteins, cytoplasmic protein-like proteins, meningioma-expressed antigen 6/1 1 (MEA6) (MEA1 1)- like proteins, ancient conserved domain protein l-like proteins, CDCRL-like proteins, HPRP-like proteins, PIBF1 protein-like proteins, cytoplasmic protein-like proteins, zinc- finger/KRAB domain containing protein-like proteins, RHO-Interactin Protein 3-like proteins, cardian-troponin l-like protein, guanine nucleotide-binding protein-like proteins,
benzodiazpine receptor (BZRP) like homo sapiens-like proteins, ankyrin-repeat containing protein like homo sapiens-like proteins, acyltransferase like homo sapiens-like proteins, GTP- binding-protein SARI A like homo sapiens-like proteins, CGI-27 like homo sapiens-like proteins, FLJ20565 like homo sapiens-like proteins, 2410014PO7R1 K like homo sapiens-like proteins, multidomain presynaptic cytomatrix protein piccola like homo sapiens-like proteins, cytosolic-sorting protein PACS-1 A-like-like proteins, formin 2 like homo sapiens-like proteins, novel 5' nucleotidase-like protein-like proteins, WW domain containing protein like homo sapiens-like proteins, gasdermin like homo sapiens-like proteins, Tubby super-family protein splice variant like homo sapiens-like proteins, synaptotagmin-like protein 3-A like homo sapiens-like proteins, copine I like homo sapiens-like proteins, selenoprotein XI like homo sapiens-like proteins, hypothetical WD-repeat like homo sapiens-like proteins, cytoplasmic protein-like proteins, TNFA1P l -like proteins, ribosomal protein L29-like proteins, paraneoplastic antigen-like proteins, GTF21 RD2 like homo sapiens-like proteins, glycolipid transfer protein-like proteins, novel copine Vll-like proteins, sperm membrane protein BS-63-like proteins, FIP-2-like proteins, PEX l O-like proteins. The novel polynucleotides and polypeptides are referred to herein as NOV l a, NOV2a, NOV2b, NOV3a, NOV3b, NOV4a, NOV4b, NOV5a, NOV5b, NOV6a, NOV6b, NOV7a, NOV7b, NOV7c, NOV7d, NOV7e, NOV8a, NOV9a, NOV9b, NOVl Oa, NOVlOb, NOV1 l a, NOV 12a, NOV 12b, NOV13a, NOV 14a, NOV 1 5a, NOV 15b, NOV 16a, NOV 17a, NOV 18a, NOV 18b, NOV 18c, NOV 19a, NOV 19b, NO V20a, NO V20b, NO V20c, NOV20d, NOV20e, NOV20f, NOV20g, NOV21a, NOV21 b, NOV22a, NOV23a, NOV23b, NOV24a, NOV25a, NOV25b, NOV26a, NOV26b, NOV26c, NOV27a, NOV27b, NOV28a, NOV28b, NOV28c, NOV28d, NOV28e, NOV28f, NOV29a, NOV29b, NOV30a, NOV31a, NOV32a, NOV32b, NOV33a, NOV34a, NOV35a, NOV35b, NOV35c, NOV36a, NOV36b, NOV37a, NOV37b, NOV37c, NOV38a, NOV39a, NOV40a, NOV41 a, NOV42a, NOV42b, NOV43a, NOV44a, NOV44b, NOV44c, NOV45a, NOV46a, NOV47a, NOV48a, NOV48b, NOV49a, NOV49b, NOV50a, NOV50b, NOV50c, NOV51 a, NOV52a, NOV52b, NOV53a, NOV54a, NOV54b, NOV55a, NOV55b, NOV55c, NOV55d, NOV55e, NOV56a, NOV57a, NOV58a, NOV59a, NOV60a, NOV61a, NOV62a, NOV62b, NOV63a, NOV63b, NOV64a, NOV65a, NOV66a, NOV66b, NOV67a, NOV68a, NOV69a, NOV70a, NOV71 a, NOV72a, NOV72b, NOV72c, NOV73a, NOV73b, NOV74a, NOV75a, NOV76a, NOV77a, NOV78a, NOV79a, NOV80a, NOV81a, NOV81 b, NOV82a, NOV82b, NOV82c, NOV83a, NOV83b, NOV84a, NOV84b, NOV84c, NOV85a, NOV85b, NOV86a, NOV86b, NOV87a, NOV87b, NOV87c, NOV87d,
NOV87e, NOV88a, NOV88b, NOV89a, NOV89b, NOV90a, NOV90b. NOV91 a. NOV91 b, NOV91c, NOV91d, NOV92a, NOV92b, NOV92c and NOV92d. These nucleic acids and polypeptides, as well as derivatives, homologs, analogs and fragments thereof, will hereinafter be collectively designated as "NOVX" nucleic acid or polypeptide sequences. In one aspect, the invention provides an isolated NOVX nucleic acid disclosed in SEQ
ID NO:2n-l, wherein n is an integer between 1 and 172. In some embodiments, the NOVX nucleic acid molecule will hybridize under stringent conditions to a nucleic acid sequence complementary to a nucleic acid molecule that includes a protein-coding sequence of a NOVX nucleic acid sequence. The invention also includes an isolated nucleic acid that encodes a NOVX polypeptide, or a fragment, homolog, analog or derivative thereof. For example, the nucleic acid can encode a polypeptide at least 80% identical to a polypeptide comprising the amino acid sequences of SEQ ID NO:2n, wherein n is an integer between 1 and 172. The nucleic acid can be, for example, a genomic DNA fragment or a cDNA molecule that includes the nucleic acid sequence of any of SEQ ID NO:2n- l, wherein n is an integer between 1 and 172. Also included in the invention is an oligonucleotide, e.g., an oligonucleotide which includes at least 6 contiguous nucleotides of a NOVX nucleic acid (e.g., SEQ ID NO:2n- l , wherein n is an integer between 1 and 172) or a complement of said oligonucleotide.
The invention also encompasses isolated NOVX polypeptides (SEQ ID NO:2n, wherein n is an integer between 1 and 172). In certain embodiments, the NOVX polypeptides include an amino acid sequence that is substantially identical to the amino acid sequence of a human NOVX polypeptide.
The invention also features antibodies that immunoselectively bind to NOVX polypeptides, or fragments, homologs, analogs or derivatives thereof. In another aspect, the invention includes pharmaceutical compositions that include therapeutically- or prophylactically-effective amounts of a therapeutic and a pharmaceutical ly-acceptable carrier. The therapeutic can be, e.g., a NOVX nucleic acid, a NOVX polypeptide, or an antibody specific for a NOVX polypeptide. In a further aspect, the invention includes, in one or more containers, a therapeutically- or prophylactically-effective amount of this pharmaceutical composition.
In a further aspect, the invention includes a method of producing a polypeptide by culturing a cell that includes a NOVX nucleic acid, under conditions allowing for expression
of the NOVX polypeptide encoded by the DNA. If desired, the NOVX polypeptide can then be recovered.
In another aspect, the invention includes a method of detecting the presence of a NOVX polypeptide in a sample. In the method, a sample is contacted with a compound that selectively binds to the polypeptide under conditions allowing for formation of a complex between the polypeptide and the compound. The complex is detected, if present, thereby identifying the NOVX polypeptide within the sample.
The invention also includes methods to identify specific cell or tissue types based on their expression of a NOVX. Also included in the invention is a method of detecting the presence of a NOVX nucleic acid molecule in a sample by contacting the sample with a NOVX nucleic acid probe or primer, and detecting whether the nucleic acid probe or primer bound to a NOVX nucleic acid molecule in the sample.
In a further aspect, the invention provides a method for modulating the activity of a NOVX polypeptide by contacting a cell sample that includes the NOVX polypeptide with a compound that binds to the NOVX polypeptide in an amount sufficient to modulate the activity of said polypeptide. The compound can be, e.g., a small molecule, such as a nucleic acid, peptide, polypeptide, peptidomimetic, carbohydrate, lipid or other organic (carbon containing) or inorganic molecule, as further described herein. In another embodiment, the invention involves a method for identifying a potential therapeutic agent for use in treatment of a pathology, wherein the pathology is related to aberrant expression or aberrant physiological interactions of a polypeptide with an amino acid sequence selected from the group consisting of SEQ ID NO:2n, wherein n is an integer between 1 and 172, the method including providing a cell expressing the polypeptide of the invention and having a property or function ascribable to the polypeptide; contacting the cell with a composition comprising a candidate substance; and determining whether the substance alters the property or function ascribable to the polypeptide; whereby, if an alteration observed in the presence of the substance is not observed when the cell is contacted with a composition devoid of the substance, the substance is identified as a potential therapeutic agent.
Also within the scope of the invention is the use of a therapeutic in the manufacture of a medicament for treating or preventing disorders or syndromes including, e.g., adrenoleukodystrophy, congenital adrenal hyperplasia, hemophilia, hypercoagulation,
hypogonadism, idiopathic thrombocytopenic purpura, autoimmune disease,inflammatory bowel disease (1BD), rheumatoid arthritis, osteoarthritis, psoriasis, allergies, asthma, immunodeficiencies, Von Hippel-Lindau (VHL) syndrome, Alzheimer's disease, stroke, tuberous sclerosis, hypercalcemia, Parkinson's disease, Huntington's disease, cerebral palsy, epilepsy, Lesch-Nyhan syndrome, multiple sclerosis, schizophrenia, depression, ataxia-telangiectasia, leukodystrophies, behavioral disorders, addiction, anxiety, pain, obesity, diabetes, renal artery stenosis, interstitial nephritis, glomerulonephritis, polycystic kidney disease, systemic lupus erythematosus, renal tubular acidosis, IgA nephropathy, emphysema, scleroderma, adult respiratory distress syndrome (ARDS), lymphedema, graft versus host disease (GVHD), pancreatitis, ulcers, anemia, ataxia-telangiectasia, cancer, trauma, viral infections, bacterial infections, parasitic infections; and conditions related to transplantation, neuroprotection, fertility, or regeneration (in vitro and in vivo) and/or other pathologies and disorders of the like. Also within the scope of the invention is the use of a therapeutic in the manufacture of a medicament for treating or preventing conditions including, e.g., those associated with homologs of a NOVX sequence, such as those listed in Table A.
The therapeutic can be, e.g., a NOVX nucleic acid, a NOVX polypeptide, or a NOVX-specific antibody, or biologically-active derivatives or fragments thereof.
For example, the compositions of the present invention will have efficacy for treatment of patients suffering from the diseases and disorders disclosed above and/or other pathologies and disorders of the like. The polypeptides can be used as immunogens to produce antibodies specific for the invention, and as vaccines. They can also be used to screen for potential agonist and antagonist compounds. For example, a cDNA encoding NOVX may be useful in gene therapy, and NOVX may be useful when administered to a subject in need thereof.
The invention further includes a method for screening for a modulator of disorders or syndromes including, e.g., the diseases and disorders disclosed above and/or other pathologies and disorders of the like. The method includes contacting a test compound with a NOVX polypeptide and determining if the test compound binds to said NOVX polypeptide. Binding of the test compound to the NOVX polypeptide indicates the test compound is a modulator of activity, or of latency or predisposition to the aforementioned disorders or syndromes.
Also within the scope of the invention is a method for screening for a modulator of activity, or of latency or predisposition to disorders or syndromes including, e.g., the diseases and disorders disclosed above and/or other pathologies and disorders of the like by administering a test compound to a test animal at increased risk for the aforementioned disorders or syndromes. The test animal expresses a recombinant polypeptide encoded by a NOVX nucleic acid. Expression or activity of NOVX polypeptide is then measured in the test animal, as is expression or activity of the protein in a control animal which recombinantly-expresses NOVX polypeptide and is not at increased risk for the disorder or syndrome. Next, the expression of NOVX polypeptide in both the test animal and the control animal is compared. A change in the activity of NOVX polypeptide in the test animal relative to the control animal indicates the test compound is a modulator of latency of the disorder or syndrome.
In yet another aspect, the invention includes a method for determining the presence of or predisposition to a disease associated with altered levels of a NOVX polypeptide, a "NOVX nucleic acid, or both, in a subject (e.g., a human subject). The method includes measuring the amount of the NOVX polypeptide in a test sample from the subject and comparing the amount of the polypeptide in the test sample to the amount of the NOVX polypeptide present in a control sample. An alteration in the level of the NOVX polypeptide in the test sample as compared to the control sample indicates the presence of or predisposition to a disease in the subject. Preferably, the predisposition includes, e.g., the diseases and disorders disclosed above and/or other pathologies and disorders of the like. Also, the expression levels of the new polypeptides of the invention can be used in a method to screen for various cancers as well as to determine the stage of cancers.
In a further aspect, the invention includes a method of treating or preventing a pathological condition associated with a disorder in a mammal by administering to the subject a NOVX polypeptide, a NOVX nucleic acid, or a NOVX-specific antibody to a subject (e.g., a human subject), in an amount sufficient to alleviate or prevent the pathological condition. In preferred embodiments, the disorder, includes, e.g., the diseases and disorders disclosed above and/or other pathologies and disorders of the like. In yet another aspect, the invention can be used in a method to identity the cellular receptors and downstream effectors of the invention by any one of a number of techniques commonly employed in the art. These include but are not limited to the two-hybrid system, affinity purification, co-precipitation with antibodies or other specific-interacting molecules.
NOVX nucleic acids and polypeptides are further useful in the generation of antibodies that bind immuno-specifically to the novel NOVX substances for use in therapeutic or diagnostic methods. These NOVX antibodies may be generated according to methods known in the art, using prediction from hydrophobicity charts, as described in the "Anti-NOVX Antibodies" section below. The disclosed NOVX proteins have multiple hydrophilic regions, each of which can be used as an immunogen. These NOVX proteins can be used in assay systems for functional analysis of various human disorders, which will help in understanding of pathology of the disease and development of new drug targets for various disorders. The NOVX nucleic acids and proteins identified here may be useful in potential therapeutic applications implicated in (but not limited to) various pathologies and disorders as indicated below. The potential therapeutic applications for this invention include, but are not limited to: protein therapeutic, small molecule drug target, antibody target (therapeutic, diagnostic, drug targeting/cytotoxic antibody), diagnostic and/or prognostic marker, gene therapy (gene delivery/gene ablation), research tools, tissue regeneration in vivo and in vitro of all tissues and cell types composing (but not limited to) those defined here.
Unless otherwise defined, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs. Although methods and materials similar or equivalent to those described herein can be used in the practice or testing of the present invention, suitable methods and materials are described below. All publications, patent applications, patents, and other references mentioned herein are incorporated by reference in their entirety. In the case of conflict, the present specification, including definitions, will control. In addition, the materials, methods, and examples are illustrative only and not intended to be limiting. Other features and advantages of the invention will be apparent from the following detailed description and claims.
DETAILED DESCRIPTION OF THE INVENTION
The present invention provides novel nucleotides and polypeptides encoded thereby. Included in the invention are the novel nucleic acid sequences, their encoded polypeptides, antibodies, and other related compounds. The sequences are collectively referred to herein as "NOVX nucleic acids" or "NOVX polynucleotides" and the corresponding encoded polypeptides are referred to as "NOVX polypeptides" or "NOVX proteins." Unless indicated
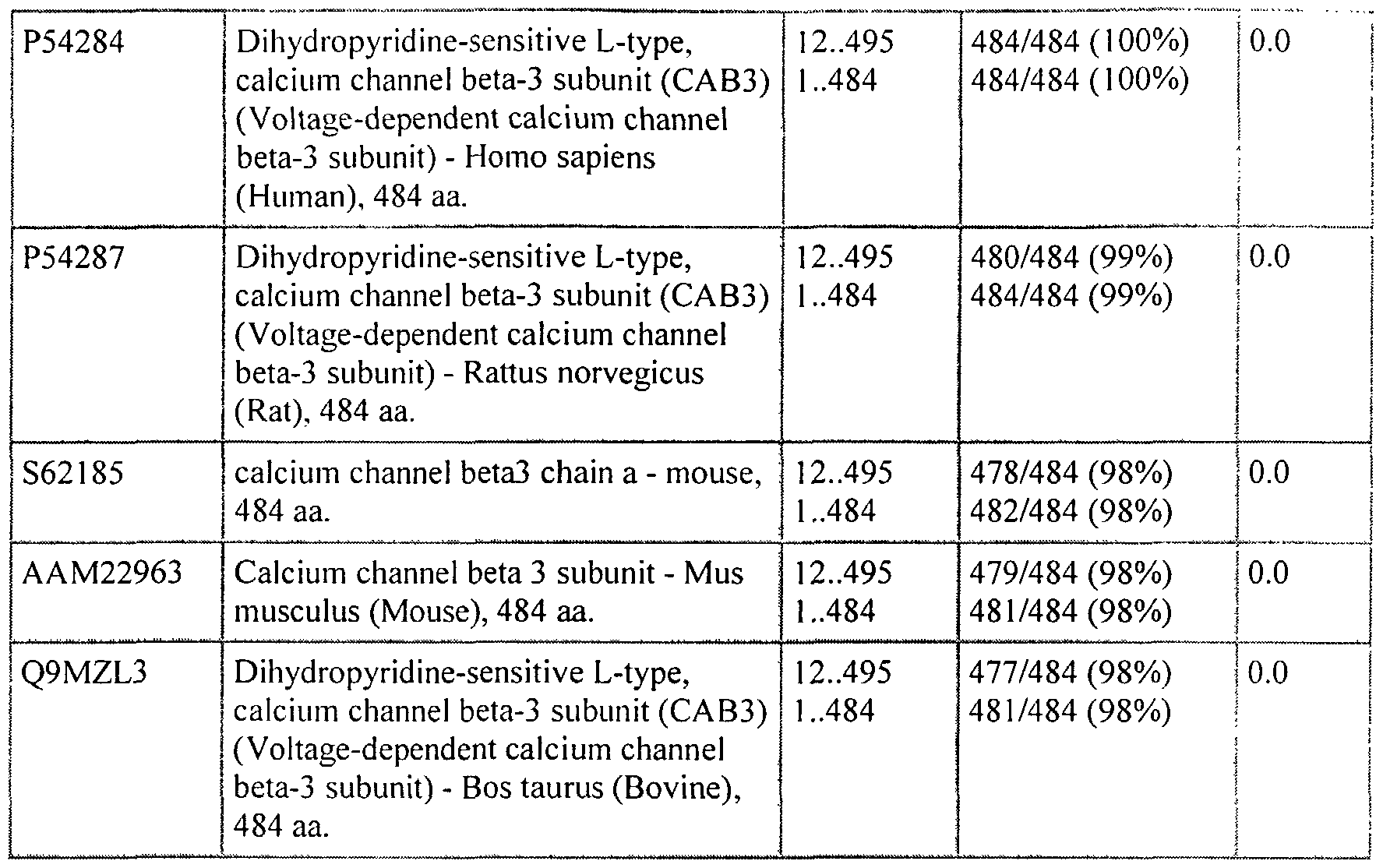
otherwise, "NOVX" is meant to refer to any of the novel sequences disclosed herein. Table A provides a summary of the NOVX nucleic acids and their encoded polypeptides. TABLE A. Sequences and Corresponding SEQ ID Numbers
Table A indicates the homology of NOV polypeptides to known protein families. Thus, the nucleic acids and polypeptides, antibodies and related compounds according to the invention corresponding to a NOVX as identified in column 1 of Table A will be useful in therapeutic and diagnostic applications implicated in, for example, pathologies and disorders associated with the known protein families identified in column 5 of Table A.
Pathologies, diseases, disorders and condition and the like that are associated with NOVX sequences include, but are not limited to: e.g., cardiomyopathy, atherosclerosis, hypertension, congenital heart defects, aortic stenosis, atrial septal defect (ASD), atrioventricular (A-V) canal defect, ductus arteriosus, pulmonary stenosis, subaortic stenosis, ventricular septal defect (VSD), valve diseases, tuberous sclerosis, scleroderma, obesity, metabolic disturbances associated with obesity, transplantation, adrenoleukodystrophy, congenital adrenal hyperplasia, prostate cancer, pancreatic cancer, gastric cancer, colon cancer, liver cancer, renal cancer, breast cancer, ovarian cancer, prostate cancer, squamous cell carcinoma, melanoma, brain cancer, allergies, asthma, emphysema, inflammatory bowel disease, rheumatoid arthritis, osteoarthritis, lupus erythematosus, diabetes, metabolic
disorders, neoplasm; adenocarcinoma, lymphoma, uterus cancer, fertility, hemophilia, hypercoagulation, idiopathic thrombocytopenic purpura, immunodeficiencies, graft versus host disease, AIDS, bronchial asthma, Crohn's disease; multiple sclerosis, schizophrenia, depression, treatment of Albright Hereditary Ostoeodystrophy, infectious disease, anorexia, cancer-associated cachexia, cancer, neurodegenerative disorders, epilepsy, Alzheimer's Disease, Parkinson's Disorder, Huntigton's Disease, immune disorders, hematopoietic disorders, and the various dyslipidemias, the metabolic syndrome X and wasting disorders associated with chronic diseases and various cancers, as well as conditions such as transplantation and fertility. NOVX nucleic acids and their encoded polypeptides are useful in a variety of applications and contexts. The various NOVX nucleic acids and polypeptides according to the invention are useful as novel members of the protein families according to the presence of domains and sequence relatedness to previously described proteins. Additionally, NOVX nucleic acids and polypeptides can also be used to identify proteins that are members of the family to which the NOVX polypeptides belong.
Consistent with other known members of the family of proteins, identified in column 5 of Table A, the NOVX polypeptides of the present invention show homology to, and contain domains that are characteristic of, other members of such protein families. Details of the sequence relatedness and domain analysis for each NOVX are presented in Example A. The NOVX nucleic acids and polypeptides can also be used to screen for molecules, which inhibit or enhance NOVX activity or function. Specifically, the nucleic acids and polypeptides according to the invention may be used as targets for the identification of small molecules that modulate or inhibit diseases associated with the protein families listed in Table A. The NOVX nucleic acids and polypeptides are also useful for detecting specific cell types. Details of the expression analysis for each NOVX are presented in Example C. Accordingly, the NOVX nucleic acids, polypeptides, antibodies and related compounds according to the invention will have diagnostic and therapeutic applications in the detection of a variety of diseases with differential expression in normal vs. diseased tissues, e.g. detection of a variety of cancers.
Additional utilities for NOVX nucleic acids and polypeptides according to the invention are disclosed herein.
NOVX clones
NOVX nucleic acids and their encoded polypeptides are useful in a variety of applications and contexts. The various NOVX nucleic acids and polypeptides according to the invention are useful as novel members of the protein families according to the presence of domains and sequence relatedness to previously described proteins. Additionally, NOVX nucleic acids and polypeptides can also be used to identify proteins that are members of the family to which the NOVX polypeptides belong.
The NOVX genes and their corresponding encoded proteins are useful for preventing, treating or ameliorating medical conditions, e.g., by protein or gene therapy. Pathological conditions can be diagnosed by determining the amount of the new protein in a sample or by determining the presence of mutations in the new genes. Specific uses are described for each of the NOVX genes, based on the tissues in which they are most highly expressed. Uses include developing products for the diagnosis or treatment of a variety of diseases and disorders. The NOVX nucleic acids and proteins of the invention are useful in potential diagnostic and therapeutic applications and as a research tool. These include serving as a specific or selective nucleic acid or protein diagnostic and/or prognostic marker, wherein the presence or amount of the nucleic acid or the protein are to be assessed, as well as potential therapeutic applications such as the following: (i) a protein therapeutic, (ii) a small molecule drug target, (iii) an antibody target (therapeutic, diagnostic, drug targeting/cytotoxic antibody), (iv) a nucleic acid useful in gene therapy (gene delivery/gene ablation), and (v) a composition promoting tissue regeneration in vitro and in vivo (vi) a biological defense weapon.
In one specific embodiment, the invention includes an isolated polypeptide comprising an amino acid sequence selected from the group consisting of: (a) a mature form of the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 172; (b) a variant of a mature form of the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 172, wherein any amino acid in the mature form is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence of the mature form are so changed; (c) an amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 172; (d) a variant of the amino acid sequence selected from the group consisting of SEQ ID NO:2n, wherein n is an integer
between 1 and 172 wherein any amino acid specified in the chosen sequence is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence are so changed; and (e) a fragment of any of (a) through (d).
In another specific embodiment, the invention includes an isolated nucleic acid molecule comprising a nucleic acid sequence encoding a polypeptide comprising an amino acid sequence selected from the group consisting of: (a) a mature form of the amino acid sequence given SEQ ID NO: 2n, wherein n is an integer between 1 and 172; (b) a variant of a mature form of the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 172 wherein any amino acid in the mature form of the chosen sequence is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence of the mature form are so changed; (c) the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 172; (d) a variant of the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 172, in which any amino acid specified in the chosen sequence is changed to a different amino acid, provided that no more than 15% of the amino acid residues in the sequence are so changed; (e) a nucleic acid fragment encoding at least a portion of a polypeptide comprising the amino acid sequence selected from the group consisting of SEQ ID NO: 2n, wherein n is an integer between 1 and 172 or any variant of said polypeptide wherein any amino acid of the chosen sequence is changed to a different amino acid, provided that no more than 10% of the amino acid residues in the sequence are so changed; and (f) the complement of any of said nucleic acid molecules.
In yet another specific embodiment, the invention includes an isolated nucleic acid molecule, wherein said nucleic acid molecule comprises a nucleotide sequence selected from the group consisting of: (a) the nucleotide sequence selected from the group consisting of SEQ ID NO: 2n-l , wherein n is an integer between 1 and 172; (b) a nucleotide sequence wherein one or more nucleotides in the nucleotide sequence selected from the group consisting of SEQ ID NO: 2n-l , wherein n is an integer between 1 and 172 is changed from that selected from the group consisting of the chosen sequence to a different nucleotide provided that no more than 15% of the nucleotides are so changed; (c) a nucleic acid fragment of the sequence selected from the group consisting of SEQ ID NO: 2n-l , wherein n is an integer between I and 172; and (d) a nucleic acid fragment wherein one or more nucleotides in the nucleotide sequence selected from the group consisting of SEQ ID NO: 2n-l , wherein n is an integer between 1 and 172 is changed from that selected from the
group consisting of the chosen sequence to a different nucleotide provided that no more than 15% of the nucleotides are so changed.
NOVX Nucleic Acids and Polypeptides
One aspect of the invention pertains to isolated nucleic acid molecules that encode NOVX polypeptides or biologically active portions thereof. Also included in the invention are nucleic acid fragments sufficient for use as hybridization probes to identify NOVX-encoding nucleic acids (e.g., NOVX mRNAs) and fragments for use as PCR primers for the amplification and/or mutation of NOVX nucleic acid molecules. As used herein, the term "nucleic acid molecule" is intended to include DNA molecules (e.g., cDNA or genomic DNA), RNA molecules (e.g., mRNA), analogs of the DNA or RNA generated using nucleotide analogs, and derivatives, fragments and homologs thereof. The nucleic acid molecule may be single-stranded or double-stranded, but preferably is comprised double-stranded DNA.
A NOVX nucleic acid can encode a mature NOVX polypeptide. As used herein, a "mature" form of a polypeptide or protein disclosed in the present invention is the product of a naturally occurring polypeptide or precursor form or proprotein. The naturally occurring polypeptide, precursor or proprotein includes, by way of nonlimiting example, the full-length gene product encoded by the corresponding gene. Alternatively, it may be defined as the polypeptide, precursor or proprotein encoded by an ORF described herein. The product "mature" form arises, by way of nonlimiting example, as a result of one or more naturally occurring processing steps that may take place within the cell (e.g., host cell) in which the gene product arises. Examples of such processing steps leading to a "mature" form of a polypeptide or protein include the cleavage of the N-terminal methionine residue encoded by the initiation codon of an ORF, or the proteolytic cleavage of a signal peptide or leader sequence. Thus a mature form arising from a precursor polypeptide or protein that has residues 1 to N, where residue 1 is the N-terminal methionine, would have residues 2 through N remaining after removal of the N-terminal methionine. Alternatively, a mature form arising from a precursor polypeptide or protein having residues 1 to N, in which an N-terminal signal sequence from residue 1 to residue M is cleaved, would have the residues from residue M+l to residue N remaining. Further as used herein, a "mature" form of a polypeptide or protein may arise from a step of post-translational modification other than a proteolytic cleavage event. Such additional processes include, by way of non-limiting
example, glycosylation, myristylation or phosphorylation. In general, a mature polypeptide or protein may result from the operation of only one of these processes, or a combination of any of them.
The term "probe", as utilized herein, refers to nucleic acid sequences of variable length, preferably between at least about 10 nucleotides (nt), about 100 nt, or as many as approximately, e.g., 6,000 nt, depending upon the specific use. Probes are used in the detection of identical, similar, or complementary nucleic acid sequences. Longer length probes are generally obtained from a natural or recombinant source, are highly specific, and much slower to hybridize than shorter-length oligomer probes. Probes may be single- stranded or double-stranded and designed to have specificity in PCR, membrane-based hybridization technologies, or ELISA-like technologies.
The term "isolated" nucleic acid molecule, as used herein, is a nucleic acid that is separated from other nucleic acid molecules which are present in the natural source of the nucleic acid. Preferably, an "isolated" nucleic acid is free of sequences which naturally flank the nucleic acid (i.e., sequences located at the 5'- and 3'-termini of the nucleic acid) in the genomic DNA of the organism from which the nucleic acid is derived. For example, in various embodiments, the isolated NOVX nucleic acid molecules can contain less than about 5 kb, 4 kb, 3 kb, 2 kb, 1 kb, 0.5 kb or 0.1 kb of nucleotide sequences which naturally flank the nucleic acid molecule in genomic DNA of the cell/tissue from which the nucleic acid is derived (e.g., brain, heart, liver, spleen, etc.). Moreover, an "isolated" nucleic acid molecule, such as a cDNA molecule, can be substantially free of other cellular material, or culture medium, or of chemical precursors or other chemicals.
A nucleic acid molecule of the invention, e.g., a nucleic acid molecule having the nucleotide sequence of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172, or a complement of this nucleotide sequence, can be isolated using standard molecular biology techniques and the sequence information provided herein. Using all or a portion of the nucleic acid sequence of SEQ ID NO:2«-l, wherein n is an integer between 1 and 172, as a hybridization probe, NOVX molecules can be isolated using standard hybridization and cloning techniques (e.g , as described in Sambrook, et al., (eds.), MOLECULAR CLONING: A LABORATORY MANUAL 2nd Ed., Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, 1989; and Ausubel, et al., (eds.), CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, New York, NY, 1993.)
A nucleic acid of the invention can be amplified using cDNA, mRNA or alternatively, genomic DNA, as a template with appropriate oligonucleotide primers according to standard PCR amplification techniques. The nucleic acid so amplified can be cloned into an appropriate vector and characterized by DNA sequence analysis. Furthermore, oligonucleotides corresponding to NOVX nucleotide sequences can be prepared by standard synthetic techniques, e.g., using an automated DNA synthesizer.
As used herein, the term "oligonucleotide" refers to a series of linked nucleotide residues. A short oligonucleotide sequence may be based on, or designed from, a genomic or cDNA sequence and is used to amplify, confirm, or reveal the presence of an identical, similar or complementary DNA or RNA in a particular cell or tissue. Oligonucleotides comprise a nucleic acid sequence having about 10 nt, 50 nt, or 100 nt in length, preferably about 15 nt to 30 nt in length. In one embodiment of the invention, an oligonucleotide comprising a nucleic acid molecule less than 100 nt in length would further comprise at least 6 contiguous nucleotides of SEQ ID NO:2«-l, wherein n is an integer between 1 and 1 2, or a complement thereof. Oligonucleotides may be chemically synthesized and may also be used as probes.
In another embodiment, an isolated nucleic acid molecule of the invention comprises a nucleic acid molecule that is a complement of the nucleotide sequence shown in SEQ ID NO:2«-l , wherein n is an integer between 1 and 172, or a portion of this nucleotide sequence (e.g., a fragment that can be used as a probe or primer or a fragment encoding a biologically-active portion of a NOVX polypeptide). A nucleic acid molecule that is complementary to the nucleotide sequence of SEQ ID NO:2/?-l , wherein n is an integer between 1 and 172, is one that is sufficiently complementary to the nucleotide sequence of SEQ ID NO:2/7-l , wherein n is an integer between 1 and 172, that it can hydrogen bond with few or no mismatches to the nucleotide sequence shown in SEQ ID NO:2«- l , wherein n is an integer between 1 and 172, thereby forming a stable duplex.
As used herein, the term "complementary" refers to Watson-Crick or Hoogsteen base pairing between nucleotides units of a nucleic acid molecule, and the term "binding" means the physical or chemical interaction between two polypeptides or compounds or associated polypeptides or compounds or combinations thereof. Binding includes ionic, non-ionic, van der Waals, hydrophobic interactions, and the like. A physical interaction can be either direct or indirect. Indirect interactions may be through or due to the effects of another polypeptide or compound. Direct binding refers to interactions that do not take place through, or due to,
the effect of another polypeptide or compound, but instead are without other substantial chemical intermediates.
A "fragment" provided herein is defined as a sequence of at least 6 (contiguous) nucleic acids or at least 4 (contiguous) amino acids, a length sufficient to allow for specific hybridization in the case of nucleic acids or for specific recognition of an epitope in the case of amino acids, and is at most some portion less than a full length sequence. Fragments may be derived from any contiguous portion of a nucleic acid or amino acid sequence of choice. A full-length NOVX clone is identified as containing an ATG translation start codon and an in-frame stop codon. Any disclosed NOVX nucleotide sequence lacking an ATG start codon therefore encodes a truncated C-terminal fragment of the respective NOVX polypeptide, and requires that the corresponding full-length cDNA extend in the 5* direction of the disclosed sequence. Any disclosed NOVX nucleotide sequence lacking an in-frame stop codon similarly encodes a truncated N-terminal fragment of the respective NOVX polypeptide, and requires that the corresponding full-length cDNA extend in the 3' direction of the disclosed sequence.
A "derivative" is a nucleic acid sequence or amino acid sequence formed from the native compounds either directly, by modification or partial substitution. An "analog"' is a nucleic acid sequence or amino acid sequence that has a structure similar to, but not identical to, the native compound, e.g. they differs from it in respect to certain components or side chains. Analogs may be synthetic or derived from a different evolutionary origin and may have a similar or opposite metabolic activity compared to wild type. A "homolog" is a nucleic acid sequence or amino acid sequence of a particular gene that is derived from different species.
Derivatives and analogs may be full length or other than full length. Derivatives or analogs of the nucleic acids or proteins of the invention include, but are not limited to, molecules comprising regions that are substantially homologous to the nucleic acids or proteins of the invention, in various embodiments, by at least about 70%, 80%, or 95% identity (with a preferred identity of 80-95%) over a nucleic acid or amino acid sequence of identical size or when compared to an aligned sequence in which the alignment is done by a computer homology program known in the art, or whose encoding nucleic acid is capable of hybridizing to the complement of a sequence encoding the proteins under stringent, moderately stringent, or low stringent conditions. See e.g. Ausubel, et al., CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, New York, NY, 1993, and below.
A "homologous nucleic acid sequence" or "homologous amino acid sequence." or variations thereof, refer to sequences characterized by a homology at the nucleotide level or amino acid level as discussed above. Homologous nucleotide sequences include those sequences coding for isoforms of NOVX polypeptides. Isoforms can be expressed in different tissues of the same organism as a result of, for example, alternative splicing of RNA. Alternatively, isoforms can be encoded by different genes. In the invention, homologous nucleotide sequences include nucleotide sequences encoding for a NOVX polypeptide of species other than humans, including, but not limited to: vertebrates, and thus can include, e.g., frog, mouse, rat, rabbit, dog, cat cow, horse, and other organisms. Homologous nucleotide sequences also include, but are not limited to, naturally occurring allelic variations and mutations of the nucleotide sequences set forth herein. A homologous nucleotide sequence does not, however, include the exact nucleotide sequence encoding human NOVX protein. Homologous nucleic acid sequences include those nucleic acid sequences that encode conservative amino acid substitutions (see below) in SEQ ID NO:2«-l , wherein n is an integer between 1 and 172, as well as a polypeptide possessing NOVX biological activity. Various biological activities of the NOVX proteins are described below.
A NOVX polypeptide is encoded by the open reading frame ("ORF") of a NOVX nucleic acid. An ORF corresponds to a nucleotide sequence that could potentially be translated into a polypeptide. A stretch of nucleic acids comprising an ORF is uninterrupted by a stop codon. An ORF that represents the coding sequence for a full protein begins with an ATG "start" codon and terminates with one of the three "stop" codons, namely, TAA, TAG, or TGA. For the purposes of this invention, an ORF may be any part of a coding sequence, with or without a start codon, a stop codon, or both. For an ORF to be considered as a good candidate for coding for a bonaβde cellular protein, a minimum size requirement is often set, e.g., a stretch of DNA that would encode a protein of 50 amino acids or more.
The nucleotide sequences determined from the cloning of the human NOVX genes allows for the generation of probes and primers designed for use in identifying and/or cloning NOVX homologues in other cell types, e.g. from other tissues, as well as NOVX homologues from other vertebrates. The probe/primer typically comprises substantially purified oligonucleotide. The oligonucleotide typically comprises a region of nucleotide sequence that hybridizes under stringent conditions to at least about 12, 25, 50, 100, 150, 200, 250, 300, 350 or 400 consecutive sense strand nucleotide sequence of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172; or an anti-sense strand nucleotide sequence of SEQ ID
NO:2/7- l , wherein n is an integer between 1 and 172; or of a naturally occurring mutant of SEQ ID NO:2/?-I , wherein n is an integer between I and 172.
Probes based on the human NOVX nucleotide sequences can be used to detect transcripts or genomic sequences encoding the same or homologous proteins. In various embodiments, the probe has a detectable label attached, e.g. the label can be a radioisotope, a fluorescent compound, an enzyme, or an enzyme co-factor. Such probes can be used as a part of a diagnostic test kit for identifying cells or tissues which mis-express a NOVX protein, such as by measuring a level of a NOVX-encoding nucleic acid in a sample of cells from a subject e.g., detecting NOVX mRNA levels or determining whether a genomic NOVX gene has been mutated or deleted.
"A polypeptide having a biologically-active portion of a NOVX polypeptide" refers to polypeptides exhibiting activity similar, but not necessarily identical to, an activity of a polypeptide of the invention, including mature forms, as measured in a particular biological assay, with or without dose dependency. A nucleic acid fragment encoding a "biologically-active portion of NOVX" can be prepared by isolating a portion of SEQ ID NO:2n-l , wherein n is an integer between 1 and 172, that encodes a polypeptide having a NOVX biological activity (the biological activities of the NOVX proteins are described below), expressing the encoded portion of NOVX protein (e.g., by recombinant expression in vitro) and assessing the activity of the encoded portion of NOVX. NOVX Nucleic Acid and Polypeptide Variants
The invention further encompasses nucleic acid molecules that differ from the nucleotide sequences of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172, due to degeneracy of the genetic code and thus encode the same NOVX proteins as that encoded by the nucleotide sequences of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172. In another embodiment, an isolated nucleic acid molecule of the invention has a nucleotide sequence encoding a protein having an amino acid sequence of SEQ ID NO:2/?, wherein n is an integer between 1 and 172.
In addition to the human NOVX nucleotide sequences of SEQ ID NO:2«- l , wherein n is an integer between 1 and 172, it will be appreciated by those skilled in the art that DNA sequence polymorphisms that lead to changes in the amino acid sequences of the NOVX polypeptides may exist within a population (e.g., the human population). Such genetic polymorphism in the NOVX genes may exist among individuals within a population due to
natural allelic variation. As used herein, the terms "gene" and "recombinant gene" refer to nucleic acid molecules comprising an open reading frame (ORF) encoding a NOVX protein, preferably a vertebrate NOVX protein. Such natural allelic variations can typically result in 1 -5% variance in the nucleotide sequence of the NOVX genes. Any and all such nucleotide variations and resulting amino acid polymorphisms in the NOVX polypeptides, which are the result of natural allelic variation and that do not alter the functional activity of the NOVX polypeptides, are intended to be within the scope of the invention.
Moreover, nucleic acid molecules encoding NOVX proteins from other species, and thus that have a nucleotide sequence that differs from a human SEQ ID NO:2«-l, wherein n is an integer between 1 and 172, are intended to be within the scope of the invention. Nucleic acid molecules corresponding to natural allelic variants and homologues of the NOVX cDNAs of the invention can be isolated based on their homology to the human NOVX nucleic acids disclosed herein using the human cDNAs, or a portion thereof, as a hybridization probe according to standard hybridization techniques under stringent hybridization conditions.
Accordingly, in another embodiment, an isolated nucleic acid molecule of the invention is at least 6 nucleotides in length and hybridizes under stringent conditions to the nucleic acid molecule comprising the nucleotide sequence of SEQ ID NO:2«-l, wherein n is an integer between 1 and 172. In another embodiment, the nucleic acid is at least 10, 25, 50, 100, 250, 500, 750, 1000, 1500, or 2000 or more nucleotides in length. In yet another embodiment, an isolated nucleic acid molecule of the invention hybridizes to the coding region. As used herein, the term "hybridizes under stringent conditions" is intended to describe conditions for hybridization and washing under which nucleotide sequences at least about 65%) homologous to each other typically remain hybridized to each other. Homologs (i.e., nucleic acids encoding NOVX proteins derived from species other than human) or other related sequences (e.g., paralogs) can be obtained by low, moderate or high stringency hybridization with all or a portion of the particular human sequence as a probe using methods well known in the art for nucleic acid hybridization and cloning.
As used herein, the phrase "stringent hybridization conditions" refers to conditions under which a probe, primer or oligonucleotide will hybridize to its target sequence, but to no other sequences. Stringent conditions are sequence-dependent and will be different in different circumstances. Longer sequences hybridize specifically at higher temperatures than shorter sequences. Generally, stringent conditions are selected to be about 5 °C lower than the
thermal melting point (Tm) for the specific sequence at a defined ionic strength and pH. The Tm is the temperature (under defined ionic strength, pH and nucleic acid concentration) at which 50% of the probes complementary to the target sequence hybridize to the target sequence at equilibrium. Since the target sequences are generally present at excess, at Tm, 50% of the probes are occupied at equilibrium. Typically, stringent conditions will be those in which the salt concentration is less than about 1.0 M sodium ion, typically about 0.01 to 1.0 M sodium ion (or other salts) at pH 7.0 to 8.3 and the temperature is at least about 30 °C for short probes, primers or oligonucleotides (e.g., 10 nt to 50 nt) and at least about 60 °C for longer probes, primers and oligonucleotides. Stringent conditions may also be achieved with the addition of destabilizing agents, such as formamide.
Stringent conditions are known to those skilled in the art and can be found in Ausubel, et al., (eds.), CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, N.Y. (1989), 6.3.1-6.3.6. Preferably, the conditions are such that sequences at least about 65%, 10%, 75%, 85%>, 90%), 95%>, 98%, or 99% homologous to each other typically remain hybridized to each other. A non-limiting example of stringent hybridization conditions are hybridization in a high salt buffer comprising 6X SSC, 50 mM Tris-HCl (pH 7.5), 1 mM EDTA, 0.02%) PVP, 0.02% FicoII, 0.02% BSA, and 500 mg/ml denatured salmon sperm DNA at 65°C, followed by one or more washes in 0.2X SSC, 0.01 % BSA at 50°C. An isolated nucleic acid molecule of the invention that hybridizes under stringent conditions to a sequence of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172, corresponds to a naturally-occurring nucleic acid molecule. As used herein, a "naturally-occurring" nucleic acid molecule refers to an RNA or DNA molecule having a nucleotide sequence that occurs in nature (e.g., encodes a natural protein).
In a second embodiment, a nucleic acid sequence that is hybridizable to the nucleic acid molecule comprising the nucleotide sequence of SEQ ID NO:2π-l , wherein n is an integer between 1 and 172, or fragments, analogs or derivatives thereof, under conditions of moderate stringency is provided. A non-limiting example of moderate stringency hybridization conditions are hybridization in 6X SSC, 5X Reinhardt's solution, 0.5% SDS and 100 mg/ml denatured salmon sperm DNA at 55 °C, followed by one or more washes in 1 X SSC, 0.1% SDS at 37 °C. Other conditions of moderate stringency that may be used are well-known within the art. See, e.g., Ausubel, et al. (eds.), 1993, CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, NY, and Krieger, 1990; GENE TRANSFER AND EXPRESSION, A LABORATORY MANUAL, Stockton Press, NY.
In a third embodiment, a nucleic acid that is hybridizable to the nucleic acid molecule comprising the nucleotide sequences of SEQ ID NO:2 7- l , wherein n is an integer between 1 and 172, or fragments, analogs or derivatives thereof, under conditions of low stringency, is provided. A non-limiting example of low stringency hybridization conditions are hybridization in 35% formamide, 5X SSC, 50 mM Tris-HCI (pH 7.5), 5 mM EDTA, 0.02% PVP, 0.02%) Ficoll, 0.2% BSA, 100 mg/ml denatured salmon sperm DNA, 10% (wt/vol) dextran sulfate at 40°C, followed by one or more washes in 2X SSC, 25 mM Tris-HCI (pH 7.4), 5 mM EDTA, and 0.1% SDS at 50°C. Other conditions of low stringency that may be used are well known in the art (e.g., as employed for cross-species hybridizations). See, e.g., Ausubel, et al. (eds.), 1993, CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, NY, and Kriegler, 1990, GENE TRANSFER AND EXPRESSION, A LABORATORY MANUAL, Stockton Press, NY; Shilo and Weinberg, 1981 . Proc Natl cadSci USA 78: 6789-6792.
Conservative Mutations
In addition to naturally-occurring allelic variants of NOVX sequences that may exist in the population, the skilled artisan will further appreciate that changes can be introduced by mutation into the nucleotide sequences of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172, thereby leading to changes in the amino acid sequences of the encoded NOVX protein, without altering the functional ability of that NOVX protein. For example, nucleotide substitutions leading to amino acid substitutions at "non-essential" amino acid residues can be made in the sequence of SEQ ID NO:2/7, wherein n is an integer between 1 and 172. A "non-essential" amino acid residue is a residue that can be altered from the wild-type sequences of the NOVX proteins without altering their biological activity, whereas an "essential" amino acid residue is required for such biological activity. For example, amino acid residues that are conserved among the NOVX proteins of the invention are predicted to be particularly non-amenable to alteration. Amino acids for which conservative substitutions can be made are well-known within the art.
Another aspect of the invention pertains to nucleic acid molecules encoding NOVX proteins that contain changes in amino acid residues that are not essential for activity. Such NOVX proteins differ in amino acid sequence from SEQ ID NO:2/?-l , wherein n is an integer between 1 and 172, yet retain biological activity. In one embodiment, the isolated nucleic acid molecule comprises a nucleotide sequence encoding a protein, wherein the protein comprises an amino acid sequence at least about 40% homologous to the amino acid
sequences of SEQ ID NO:2π, wherein n is an integer between I and 172. Preferably, the protein encoded by the nucleic acid molecule is at least about 60%) homologous to SEQ ID NO:2«, wherein n is an integer between 1 and 172; more preferably at least about 70%> homologous to SEQ ID NO:2«, wherein n is an integer between 1 and 172; still more preferably at least about 80%> homologous to SEQ ID NO:2/?, wherein n is an integer between 1 and 172; even more preferably at least about 90% homologous to SEQ ID NO:2», wherein n is an integer between 1 and 172; and most preferably at least about 95% homologous to SEQ ID NO:2n, wherein n is an integer between 1 and 172.
An isolated nucleic acid molecule encoding a NOVX protein homologous to the protein of SEQ ID NO:2«, wherein n is an integer between 1 and 172, can be created by introducing one or more nucleotide substitutions, additions or deletions into the nucleotide sequence of SEQ ID NO:2/7-l , wherein n is an integer between 1 and 172, such that one or more amino acid substitutions, additions or deletions are introduced into the encoded protein. Mutations can be introduced any one of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172, by standard techniques, such as site-directed mutagenesis and
PCR-mediated mutagenesis. Preferably, conservative amino acid substitutions are made at one or more predicted, non-essential amino acid residues. A "conservative amino acid substitution" is one in which the amino acid residue is replaced with an amino acid residue having a similar side chain. Families of amino acid residues having similar side chains have been defined within the art. These families include amino acids with basic side chains (e.g., lysine, arginine, histidine), acidic side chains (e.g., aspartic acid, glutamic acid), uncharged polar side chains (e.g., glycine, asparagine, glutamine, serine, threonine, tyrosine, cysteine), nonpolar side chains (e.g., alanine, valine, leucine, isoleucine, proline, phenylalanine, methionine, tryptophan), beta-branched side chains (e.g., threonine, valine, isoleucine) and aromatic side chains (e.g., tyrosine, phenylalanine, tryptophan, histidine). Thus, a predicted non-essential amino acid residue in the NOVX protein is replaced with another amino acid residue from the same side chain family. Alternatively, in another embodiment, mutations can be introduced randomly along all or part of a NOVX coding sequence, such as by saturation mutagenesis, and the resultant mutants can be screened for NOVX biological activity to identify mutants that retain activity. Following mutagenesis of a nucleic acid of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172, the encoded protein can be expressed by any recombinant technology known in the art and the activity of the protein can be determined.
The relatedness of amino acid families may also be determined based on side chain interactions. Substituted amino acids may be fully conserved "strong" residues or fully conserved "weak" residues. The "strong" group of conserved amino acid residues may be any one of the following groups: STA, NEQK, NHQK, NDEQ, QHRK, MILV, MILF. HY. FYW, wherein the single letter amino acid codes are grouped by those amino acids that may be substituted for each other. Likewise, the "weak" group of conserved residues may be any one of the following: CSA, ATV, SAG, STNK, STPA, SGND, SNDEQK, NDEQHK, NEQHRK, HFY, wherein the letters within each group represent the single letter amino acid code. In one embodiment, a mutant NOVX protein can be assayed for (/') the ability to form protei protein interactions with other NOVX proteins, other cell-surface proteins, or biologically-active portions thereof, (/'/') complex formation between a mutant NOVX protein and a NOVX ligand; or (iii) the ability of a mutant NOVX protein to bind to an intracellular target protein or biologically-active portion thereof; (e.g. avidin proteins). In yet another embodiment, a mutant NOVX protein can be assayed for the ability to regulate a specific biological function (e.g., regulation of insulin release).
Interfering RNA
In one aspect of the invention, NOVX gene expression can be attenuated by RNA interference. One approach well-known in the art is short interfering RNA (siRNA) mediated gene silencing where expression products of a NOVX gene are targeted by specific double stranded NOVX derived siRNA nucleotide sequences that are complementary to at least a 19- 25 nt long segment of the NOVX gene transcript, including the 5' untranslated (UT) region, the ORF, or the 3" UT region. See, e.g., PCT applications WO00/44895, W099/32619, WO01/75164, WO01/92513, WO 01/29058, WO01/89304, WO02/16620, and WO02/29858, each incorporated by reference herein in their entirety. Targeted genes can be a NOVX gene, or an upstream or downstream modulator of the NOVX gene. Nonlimiting examples of upstream or downstream modulators of a NOVX gene include, e.g., a transcription factor that binds the NOVX gene promoter, a kinase or phosphatase that interacts with a NOVX polypeptide, and polypeptides involved in a NOVX regulatory pathway. According to the methods of the present invention, NOVX gene expression is silenced using short interfering RNA. A NOVX polynucleotide according to the invention includes a siRNA polynucleotide. Such a NOVX siRNA can be obtained using a NOVX polynucleotide
sequence, for example, by processing the NOVX ribopolynucleotide sequence in a cell-free system, such as but not limited to a Drosophila extract, or by transcription of recombinant double stranded NOVX RNA or by chemical synthesis of nucleotide sequences homologous to a NOVX sequence. See, e.g., Tuschl, Zamore, Lehmann, Bartel and Sharp (1999), Genes & Dev. 13: 3191 -3197, incorporated herein by reference in its entirety. When synthesized, a typical 0.2 micromolar-scale RNA synthesis provides about 1 milligram of siRNA, which is sufficient for 1000 transfection experiments using a 24-well tissue culture plate format.
The most efficient silencing is generally observed with siRNA duplexes composed of a 21-nt sense strand and a 21-nt antisense strand, paired in a manner to have a 2-nt 3' overhang. The sequence of the 2-nt 3' overhang makes an additional small contribution to the specificity of siRNA target recognition. The contribution to specificity is localized' to the unpaired nucleotide adjacent to the first paired bases. In one embodiment, the nucleotides in the 3' overhang are ribonucleotides. In an alternative embodiment, the nucleotides in the 3' overhang are deoxyribonucleotides. Using 2'-deoxyribonucleotides in the 3' overhangs is as efficient as using ribonucleotides, but deoxyribonucleotides are often cheaper to synthesize and are most likely more nuclease resistant.
A contemplated recombinant expression vector of the invention comprises a NOVX DNA molecule cloned into an expression vector comprising operatively-linked regulatory sequences flanking the NOVX sequence in a manner that allows for expression (by transcription of the DNA molecule) of both strands. An RNA molecule that is antisense to NOVX mRNA is transcribed by a first promoter (e.g., a promoter sequence 3' of the cloned DNA) and an RNA molecule that is the sense strand for the NOVX mRNA is transcribed by a second promoter (e.g., a promoter sequence 5* of the cloned DNA). The sense and antisense strands may hybridize in vivo to generate siRNA constructs for silencing of the NOVX gene. Alternatively, two constructs can be utilized to create the sense and anti-sense strands of a siRNA construct. Finally, cloned DNA can encode a construct having secondary structure, wherein a single transcript has both the sense and complementary antisense sequences from the target gene or genes. In an example of this embodiment, a hairpin RNAi product is homologous to all or a portion of the target gene. In another example, a hairpin RNAi product is a siRNA. The regulatory sequences flanking the NOVX sequence may be identical or may be different, such that their expression may be modulated independently, or in a temporal or spatial manner.
In a specific embodiment, siRNAs are transcribed intracellularly by cloning the NOVX gene templates into a vector containing, e.g., a RNA pol 111 transcription unit from the smaller nuclear RNA (snRNA) U6 or the human RNase P RNA H 1. One example of a vector system is the GeneSuppressor™ RNA Interference kit (commercially available from Imgenex). The U6 and HI promoters are members of the type III class of Pol III promoters. The +1 nucleotide of the U6-like promoters is always guanosine, whereas the +1 for HI promoters is adenosine. The termination signal for these promoters is defined by five consecutive thymidines. The transcript is typically cleaved after the second uridine. Cleavage at this position generates a 3' UU overhang in the expressed siRNA, which is similar to the 3' overhangs of synthetic siRNAs. Any sequence less than 400 nucleotides in length can be transcribed by these promoter, therefore they are ideally suited for the expression of around 21 -nucleotide siRNAs in, e.g., an approximately 50-nucleotide RNA stem-loop transcript.
A siRNA vector appears to have an advantage over synthetic siRNAs where long term knock-down of expression is desired. Cells transfected with a siRNA expression vector would experience steady, long-term mRNA inhibition. In contrast, cells transfected with exogenous synthetic siRNAs typically recover from mRNA suppression within seven days or ten rounds of cell division. The long-term gene silencing ability of siRNA expression vectors may provide for applications in gene therapy.
In general, siRNAs are chopped from longer dsRNA by an ATP-dependent ribonuclease called DICER. DICER is a member of the RNase III family of double-stranded RNA-specific endonucleases. The siRNAs assemble with cellular proteins into an endonuclease complex. In vitro studies in Drosophila suggest that the siRNAs/protein complex (siRNP) is then transferred to a second enzyme complex, called an RNA-induced silencing complex (RISC), which contains an endoribonuclease that is distinct from DICER. RISC uses the sequence encoded by the antisense siRNA strand to find and destroy mRNAs of complementary sequence. The siRNA thus acts as a guide, restricting the ribonuclease to cleave only mRNAs complementary to one of the two siRNA strands.
A NOVX mRNA region to be targeted by siRNA is generally selected from a desired NOVX sequence beginning 50 to 100 nt downstream of the start codon. Alternatively, 5' or 3' UTRs and regions nearby the start codon can be used but are generally avoided, as these may be richer in regulatory protein binding sites. UTR-binding proteins and/or translation initiation complexes may interfere with binding of the siRNP or RISC endonuclease complex. An initial BLAST homology search for the selected siRNA sequence is done
against an available nucleotide sequence library to ensure that only one gene is targeted. Specificity of target recognition by siRNA duplexes indicate that a single point mutation located in the paired region of an siRNA duplex is sufficient to abolish target mRNA degradation. See, Elbashir e/ α/. 2001 EMBO J. 20(23):6877-88. Hence, consideration should be taken to accommodate SNPs, polymorphisms, allelic variants or species-specific variations when targeting a desired gene.
In one embodiment, a complete NOVX siRNA experiment includes the proper negative control. A negative control siRNA generally has the same nucleotide composition as the NOVX siRNA but lack significant sequence homology to the genome. Typically, one would scramble the nucleotide sequence of the NOVX siRNA and do a homology search to make sure it lacks homology to any other gene.
Two independent NOVX siRNA duplexes can be used to knock-down a target NOVX gene. This helps to control for specificity of the silencing effect. In addition, expression of two independent genes can be simultaneously knocked down by using equal concentrations of different NOVX siRNA duplexes, e.g., a NOVX siRNA and an siRNA for a regulator of a NOVX gene or polypeptide. Availability of siRNA-associating proteins is believed to be more limiting than target mRNA accessibility.
A targeted NOVX region is typically a sequence of two adenines (AA) and two thymidines (TT) divided by a spacer region of nineteen (N19) residues (e.g., AA(N 19)TT). A desirable spacer region has a G/C-content of approximately 30% to 70%, and more preferably of about 50%. Ifthe sequence AA(N 19)TT is not present in the target sequence, an alternative target region would be AA(N21). The sequence of the NOVX sense siRNA corresponds to (N19)TT or N21 , respectively. In the latter case, conversion of the 3' end of the sense siRNA to TT can be performed if such a sequence does not naturally occur in the NOVX polynucleotide. The rationale for this sequence conversion is to generate a symmetric duplex with respect to the sequence composition of the sense and antisense 3' overhangs. Symmetric 3' overhangs may help to ensure that the siRNPs are formed with approximately equal ratios of sense and antisense target RNA-cleaving siRNPs. See, e.g., Elbashir, Lendeckel and Tuschl (2001). Genes & Dev. 15: 188-200, incorporated by reference herein in its entirely. The modification of the overhang of the sense sequence of the siRNA duplex is not expected to affect targeted mRNA recognition, as the antisense siRNA strand guides target recognition.
Alternatively, if the NOVX target mRNA does not contain a suitable AA(N21 ) sequence, one may search for the sequence NA(N21 ). Further, the sequence of the sense strand and antisense strand may still be synthesized as 5' (N 19)TT, as it is believed that the sequence of the 3'-most nucleotide of the antisense siRNA does not contribute to specificity. Unlike antisense or ribozyme technology, the secondary structure of the target mRNA does not appear to have a strong effect on silencing. See, Harborth, et al. (2001) J. Cell Science 1 14: 4557-4565, incorporated by reference in its entirety.
Transfection of NOVX siRNA duplexes can be achieved using standard nucleic acid transfection methods, for example, OLIGOFECTAMINE Reagent (commercially available from Invitrogen). An assay for NOVX gene silencing is generally performed approximately 2 days after transfection. No NOVX gene silencing has been observed in the absence of transfection reagent, allowing for a comparative analysis of the wild-type and silenced NOVX phenotypes. In a specific embodiment, for one well of a 24-weIl plate, approximately 0.84 μg of the siRNA duplex is generally sufficient. Cells are typically seeded the previous day, and are transfected at about 50% confluence. The choice of cell culture media and conditions are routine to those of skill in the art, and will vary with the choice of cell type. The efficiency of transfection may depend on the cell type, but also on the passage number and the confluency of the cells. The time and the manner of formation of siRNA-liposome complexes (e.g. inversion versus vortexing) are also critical. Low transfection efficiencies are the most frequent cause of unsuccessful NOVX silencing. The efficiency of transfection needs to be carefully examined for each new cell line to be used. Preferred cell are derived from a mammal, more preferably from a rodent such as a rat or mouse, and most preferably from a human. Where used for therapeutic treatment, the cells are preferentially autologous, although non-autologous cell sources are also contemplated as within the scope of the present invention.
For a control experiment, transfection of 0.84 μg single-stranded sense NOVX siRNA will have no effect on NOVX silencing, and 0.84 μg antisense siRNA has a weak silencing effect when compared to 0.84 μg of duplex siRNAs. Control experiments again allow for a comparative analysis of the wild-type and silenced NOVX phenotypes. To control for transfection efficiency, targeting of common proteins is typically performed, for example targeting of lamin A/C or transfection of a CMV-driven EGFP-expression plasmid (e.g. commercially available from Clontech). In the above example, a determination of the fraction of lamin A/C knockdown in cells is determined the next day by such techniques as
immunofluorescence, Western blot, Northern blot or other similar assays for protein expression or gene expression. Lamin A/C monoclonal antibodies may be obtained from Santa Cruz Biotechnology.
Depending on the abundance and the half life (or turnover) of the targeted NOVX polynucleotide in a cell, a knock-down phenotype may become apparent after 1 to 3 days, or even later. In cases where no NOVX knock-down phenotype is observed, depletion of the NOVX polynucleotide may be observed by immunofluorescence or Western blotting. Ifthe NOVX polynucleotide is still abundant after 3 days, cells need to be split and transferred to a fresh 24-welI plate for re-transfection. If no knock-down of the targeted protein is observed, it may be desirable to analyze whether the target mRNA (NOVX or a NOVX upstream or downstream gene) was effectively destroyed by the transfected siRNA duplex. Two days after transfection, total RNA is prepared, reverse transcribed using a target-specific primer, and PCR-amplified with a primer pair covering at least one exon-exon junction in order to control for amplification of pre-mRNAs. RT/PCR of a non-targeted mRNA is also needed as control. Effective depletion of the mRNA yet undetectable reduction of target protein may indicate that a large reservoir of stable NOVX protein may exist in the cell. Multiple transfection in sufficiently long intervals may be necessary until the target protein is finally depleted to a point where a phenotype may become apparent. If multiple transfection steps are required, cells are split 2 to 3 days after transfection. The cells may be transfected immediately after splitting.
An inventive therapeutic method of the invention contemplates administering a NOVX siRNA construct as therapy to compensate for increased or aberrant NOVX expression or activity. The NOVX ribopolynucleotide is obtained and processed into siRNA fragments, or a NOVX siRNA is synthesized, as described above. The NOVX siRNA is administered to cells or tissues using known nucleic acid transfection techniques, as described above. A NOVX siRNA specific for a NOVX gene will decrease or knockdown NOVX transcription products, which will lead to reduced NOVX polypeptide production, resulting in reduced NOVX polypeptide activity in the cells or tissues.
The present invention also encompasses a method of treating a disease or condition associated with the presence of a NOVX protein in an individual comprising administering to the individual an RNAi construct that targets the mRNA of the protein (the mRNA that encodes the protein) for degradation. A specific RNAi construct includes a siRNA or a double stranded gene transcript that is processed into siRNAs. Upon treatment, the target
protein is not produced or is not produced to the extent it would be in the absence of the treatment.
Where the NOVX gene function is not correlated with a known phenotype, a control sample of cells or tissues from healthy individuals provides a reference standard for determining NOVX expression levels. Expression levels are detected using the assays described, e.g., RT-PCR, Northern blotting, Western blotting, ELISA, and the like. A subject sample of cells or tissues is taken from a mammal, preferably a human subject, suffering from a disease state. The NOVX ribopolynucleotide is used to produce siRNA constructs, that are specific for the NOVX gene product. These cells or tissues are treated by administering NOVX siRNA's to the cells or tissues by methods described for the transfection of nucleic acids into a cell or tissue, and a change in NOVX polypeptide or polynucleotide expression is observed in the subject sample relative to the control sample, using the assays described. This NOVX gene knockdown approach provides a rapid method for determination of a NOVX minus (NOVX") phenotype in the treated subject sample. The NOVX" phenotype observed in the treated subject sample thus serves as a marker for monitoring the course of a disease state during treatment.
In specific embodiments, a NOVX siRNA is used in therapy. Methods for the generation and use of a NOVX siRNA are known to those skilled in the art. Example techniques are provided below. .Production of RNAs
Sense RNA (ssRNA) and antisense RNA (asRNA) of NOVX are produced using known methods such as transcription in RNA expression vectors. In the initial experiments, the sense and antisense RNA are about 500 bases in length each. The produced ssRNA and asRNA (0.5 μM) in 10 mM Tris-HCI (pH 7.5) with 20 mM NaCI were heated to 95° C for 1 min then cooled and annealed at room temperature for 12 to 16 h. The RNAs are precipitated and resuspended in lysis buffer (below). To monitor annealing, RNAs are electrophoresed in a 2% agarose gel in TBE buffer and stained with ethidium bromide. See, e.g., Sambrook et al., Molecular Cloning. Cold Spring Harbor Laboratory Press, Plainview, N.Y. (1989).
Lysate Preparation Untreated rabbit reticulocyte lysate (Ambion) are assembled according to the manufacturer's directions. dsRNA is incubated in the lysate at 30° C for 10 min prior to the addition of mRNAs. Then NOVX mRNAs are added and the incubation continued for an
additional 60 min. The molar ratio of double stranded RNA and mRNA is about 200: 1. The NOVX mRNA is radiolabeled (using known techniques) and its stability is monitored by gel electrophoresis.
In a parallel experiment made with the same conditions, the double stranded RNA is internally radiolabeled with a 32P-ATP. Reactions are stopped by the addition of 2 X proteinase K buffer and deproteinized as described previously (Tuschl et al., Genes Dev., 13:3191-3197 (1999)). Products are analyzed by electrophoresis in 15% or 18% polyacrylamide sequencing gels using appropriate RNA standards. By monitoring the gels for radioactivity, the natural production of 10 to 25 nt RNAs from the double stranded RNA can be determined.
The band of double stranded RNA, about 21 -23 bps, is eluded. The efficacy of these 21 -23 mers for suppressing NOVX transcription is assayed in vitro using the same rabbit reticulocyte assay described above using 50 nanomolar of double stranded 21 -23 mer for each assay. The sequence of these 21-23 mers is then determined using standard nucleic acid sequencing techniques.
RNA Preparation
21 nt RNAs, based on the sequence determined above, are chemically synthesized using Expedite RNA phosphoramidites and thymidine phosphoramidite (Proligo, Germany). Synthetic oligonucleotides are deprotected and gel-purified (Elbashir, Lendeckel, & Tuschl, Genes & Dev. 15, 188-200 (2001)), followed by Sep-Pak CI 8 cartridge (Waters, Milford, Mass, USA) purification (Tuschl, et al. Biochemistry, 32: 1 1658-1 1668 ( 1993)).
These RNAs (20 μM) single strands are incubated in annealing buffer (100 mM potassium acetate, 30 mM HEPES-KOH at pH 7.4, 2 mM magnesium acetate) for 1 min at 90° C followed by 1 h at 37° C. Cell Culture
A cell culture known in the art to regularly express NOVX is propagated using standard conditions. 24 hours before transfection, at approx. 80% confluency, the cells are trypsinized and diluted 1 :5 with fresh medium without antibiotics (1 -3 X 105 cells/ml) and transferred to 24-well plates (500 ml/well). Transfection is performed using a commercially available lipofection kit and NOVX expression is monitored using standard techniques with positive and negative control. A positive control is cells that naturally express NOVX while a negative control is cells that do not express NOVX. Base-paired 21 and 22 nt siRNAs with
overhanging 3' ends mediate efficient sequence-specific mRNA degradation in lysates and in cell culture. Different concentrations of siRNAs are used. An efficient concentration for suppression in vitro in mammalian culture is between 25 nM to 100 nM final concentration. This indicates that siRNAs are effective at concentrations that are several orders of magnitude below the concentrations applied in conventional antisense or ribozyme gene targeting experiments.
The above method provides a way both for the deduction of NOVX siRNA sequence and the use of such siRNA for in vitro suppression. In vivo suppression may be performed using the same siRNA using well known in vivo transfection or gene therapy transfection techniques.
Antisense Nucleic Acids
Another aspect of the invention pertains to isolated antisense nucleic acid molecules that are hybridizable to or complementary to the nucleic acid molecule comprising the nucleotide sequence of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172, or fragments, analogs or derivatives thereof. An "antisense" nucleic acid comprises a nucleotide sequence that is complementary to a "sense" nucleic acid encoding a protein (e.g., complementary to the coding strand of a double-stranded cDNA molecule or complementary to an mRNA sequence). In specific aspects, antisense nucleic acid molecules are provided that comprise a sequence complementary to at least about 10, 25, 50, 100, 250 or 500 nucleotides or an entire NOVX coding strand, or to only a portion thereof. Nucleic acid molecules encoding fragments, homologs, derivatives and analogs of a NOVX protein of SEQ ID NO:2/7, wherein n is an integer between 1 and 172, or antisense nucleic acids complementary to a NOVX nucleic acid sequence of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172, are additionally provided. In one embodiment, an antisense nucleic acid molecule is antisense to a "coding region" of the coding strand of a nucleotide sequence encoding a NOVX protein. The term "coding region" refers to the region of the nucleotide sequence comprising codons which are translated into amino acid residues. In another embodiment, the antisense nucleic acid molecule is antisense to a "noncoding region" of the coding strand of a nucleotide sequence encoding the NOVX protein. The term "noncoding region" refers to 5' and 3' sequences which flank the coding region that are not translated into amino acids (i.e., also referred to as 5' and 3' untranslated regions).
Given the coding strand sequences encoding the NOVX protein disclosed herein, antisense nucleic acids of the invention can be designed according to the rules of Watson arid Crick or Hoogsteen base pairing. The antisense nucleic acid molecule can be complementary to the entire coding region of NOVX mRNA, but more preferably is an oligonucleotide that is antisense to only a portion of the coding or noncoding region of NOVX mRNA. For example, the antisense oligonucleotide can be complementary to the region surrounding the translation start site of NOVX mRNA. An antisense oligonucleotide can be, for example, about 5, 10, 15, 20, 25, 30, 35, 40, 45 or 50 nucleotides in length. An antisense nucleic acid of the invention can be constructed using chemical synthesis or enzymatic ligation reactions using procedures known in the art. For example, an antisense nucleic acid (e.g., an antisense oligonucleotide) can be chemically synthesized using naturally-occurring nucleotides or variously modified nucleotides designed to increase the biological stability of the molecules or to increase the physical stability of the duplex formed between the antisense and sense nucleic acids (e.g., phosphorothioate derivatives and acridine substituted nucleotides can be used).
Examples of modified nucleotides that can be used to generate the antisense nucleic acid include: 5-fluorouracil, 5-bromouracil, 5-chlorouracil, 5-iodouracil, hypoxanthine, xanthine, 4-acetylcytosine, 5-carboxymethylaminomethyl-2-thiouridine, 5-(carboxyhydroxylmethyl) uracil, 5-carboxymethylaminomethyluracil, dihydrouracil, beta-D-galactosylqueosine, inosine, N6-isopentenyladenine, 1 -methylguanine,
1-methylinosine, 2,2-dimethylguanine, 2-methyladenine, 2-methylguanine, 5-methoxyuraciI. 3-methylcytosine, 5-methylcytosine, N6-adenine, 7-methyIguanine,
5-methylaminomethyluracil, 5-methoxyaminomethyl-2-thiouracil, 2-thiouracil, 4-thiouracil, beta-D-mannosylqueosine, 5'-methoxycarboxymethyluraciI, 2-methylthio-N6-isopentenyladenine, uracil-5-oxyacetic acid (v), wybutoxosine, pseudouracil, queosine, 2-thiocytosine, 5-methyI-2-thiouracil, 5-methyluracil, uracil-5-oxyacetic acid methylester, uracil-5-oxyacetic acid (v), 5-methyl-2-thiouracil. 3-(3-amino-3-N-2-carboxypropyl) uracil, (acp3)w, and 2,6-diaminopurine. Alternatively, the antisense nucleic acid can be produced biologically using an expression vector into which a nucleic acid has been subcloned in an antisense orientation (i.e., RNA transcribed from the inserted nucleic acid will be of an antisense orientation to a target nucleic acid of interest, described further in the following subsection).
The antisense nucleic acid molecules of the invention are typically administered to a subject or generated in situ such that they hybridize with or bind to cellular mRNA and/or genomic DNA encoding a NOVX protein to thereby inhibit expression of the protein (e.g., by inhibiting transcription and/or translation). The hybridization can be by conventional nucleotide complementarity to form a stable duplex, or, for example, in the case of an antisense nucleic acid molecule that binds to DNA duplexes, through specific interactions in the major groove of the double helix. An example of a route of administration of antisense nucleic acid molecules of the invention includes direct injection at a tissue site. Alternatively, antisense nucleic acid molecules can be modified to target selected cells and then administered systemically. For example, for systemic administration, antisense molecules can be modified such that they specifically bind to receptors or antigens expressed on a selected cell surface (e.g., by linking the antisense nucleic acid molecules to peptides or antibodies that bind to cell surface receptors or antigens). The antisense nucleic acid molecules can also be delivered to cells using the vectors described herein. To achieve sufficient nucleic acid molecules, vector constructs in which the antisense nucleic acid molecule is placed under the control of a strong pol II or pol III promoter are preferred.
In yet another embodiment, the antisense nucleic acid molecule of the invention is an -anomeric nucleic acid molecule. An α-anomeric nucleic acid molecule forms specific double-stranded hybrids with complementary RNA in which, contrary to the usual β-units, the strands run parallel to each other. See, e.g., Gaultier, et al., 1987. Nucl. Acids Res. 15: 6625-6641. The antisense nucleic acid molecule can also comprise a
2'-o-methylribonucleotide (See, e.g., Inoue, et al. 1987. Nucl. Acids Res. 15: 6131 -6148) or a chimeric RNA-DNA analogue (See, e.g., Inoue, et al., 1987. FEBS Lett. 215: 327-330.
Ribozymes and PNA Moieties Nucleic acid modifications include, by way of non-limiting example, modified bases, and nucleic acids whose sugar phosphate backbones are modified or derivatized. These modifications are carried out at least in part to enhance the chemical stability of the modified nucleic acid, such that they may be used, for example, as antisense binding nucleic acids in therapeutic applications in a subject. In one embodiment, an antisense nucleic acid of the invention is a ribozyme.
Ribozymes are catalytic RNA molecules with ribonuclease activity that are capable of cleaving a single-stranded nucleic acid, such as an mRNA, to which they have a
complementary region. Thus, ribozymes (e.g., hammerhead ribozymes as described in Haselhoff and Gerlach 1988. Nature 334: 585-591 ) can be used to catalytically cleave NOVX mRNA transcripts to thereby inhibit translation of NOVX mRNA. A ribozyme having specificity for a NOVX-encoding nucleic acid can be designed based upon the nucleotide sequence of a NOVX cDNA disclosed herein (i.e., SEQ ID NO:2«-l , wherein n is an integer between 1 and 172). For example, a derivative of a Tetrahymena L-19 IVS RNA can be constructed in which the nucleotide sequence of the active site is complementary to the nucleotide sequence to be cleaved in a NOVX-encoding mRNA. See, e.g., U.S. Patent 4,987,071 to Cech, et al. and U.S. Patent 5,1 16,742 to Cech, et al. NOVX mRNA can also be used to select a catalytic RNA having a specific ribonuclease activity from a pool of RNA molecules. See, e.g., Bartel et al, (1993) Science 261 : 141 1 -1418.
Alternatively, NOVX gene expression can be inhibited by targeting nucleotide sequences complementary to the regulatory region of the NOVX nucleic acid (e.g., the NOVX promoter and/or enhancers) to form triple helical structures that prevent transcription of the NOVX gene in target cells. See, e.g., Helene, 1991. Anticancer Drug Des. 6: 569-84; Helene, et al. 1992. Ann. N Y. Acad. Sci. 660: 27-36; Maher, 1992. Bioassays 14: 807-15.
In various embodiments, the NOVX nucleic acids can be modified at the base moiety, sugar moiety or phosphate backbone to improve, e.g., the stability, hybridization, or solubility of the molecule. For example, the deoxyribose phosphate backbone of the nucleic acids can be modified to generate peptide nucleic acids. See, e.g., Hyrup, et al., 1996. Bioorg Med Chem 4: 5-23. As used herein, the terms "peptide nucleic acids" or "PNAs" refer to nucleic acid mimics (e.g., DNA mimics) in which the deoxyribose phosphate backbone is replaced by a pseudopeptide backbone and only the four natural nucleotide bases are retained. The neutral backbone of PNAs has been shown to allow for specific hybridization to DNA and RNA under conditions of low ionic strength. The synthesis of PNA oligomer can be performed using standard solid phase peptide synthesis protocols as described in Hyrup, et ai, 1996. supra; Perry-O'Keefe, et ai, 1996. Proc. Natl. Acad. Sci. USA 93: 14670-14675.
PNAs of NOVX can be used in therapeutic and diagnostic applications. For example, PNAs can be used as antisense or antigene agents for sequence-specific modulation of gene expression by, e.g., inducing transcription or translation arrest or inhibiting replication.
PNAs of NOVX can also be used, for example, in the analysis of single base pair mutations in a gene (e.g., PNA directed PCR clamping; as artificial restriction enzymes when used in combination with other enzymes, e.g., S\ nucleases (See, Hyrup, et al., 1996. upra); or as
probes or primers for DNA sequence and hybridization (See, Hyrup, et al., 1996, supra; Perry-O'Keefe, et al., 1996. supra).
In another embodiment, PNAs of NOVX can be modified, e.g., to enhance their stability or cellular uptake, by attaching lipophilic or other helper groups to PNA, by the formation of PNA-DNA chimeras, or by the use of liposomes or other techniques of drug delivery known in the art. For example, PNA-DNA chimeras of NOVX can be generated that may combine the advantageous properties of PNA and DNA. Such chimeras allow DNA recognition enzymes (e.g., RNase H and DNA polymerases) to interact with the DNA portion while the PNA portion would provide high binding affinity and specificity. PNA-DNA chimeras can be linked using linkers of appropriate lengths selected in terms of base stacking, number of bonds between the nucleotide bases, and orientation (see, Hyrup, et al, 1996. supra). The synthesis of PNA-DNA chimeras can be performed as described in Hyrup, et al., 1996. supra and Finn, et al., 1996. Nucl Acids Re 24: 3357-3363. For example, a DNA chain can be synthesized on a solid support using standard phosphoramidite coupling chemistry, and modified nucleoside analogs, e.g.,
5'-(4-rnethoxytrityl)amino-5'-deoxy-thymidine phosphoramidite, can be used between the PNA and the 5' end of DNA. See, e.g., Mag. et al., 1989. Nucl Acid Res 17: 5973-5988. PNA monomers are then coupled in a step ise manner to produce a chimeric molecule with a 5' PNA segment and a 3' DNA segment. See, e.g., Finn, et al., 1996. supra. Alternatively, chimeric molecules can be synthesized with a 5' DNA segment and a 3' PNA segment. See, e.g., Petersen, et al., 1975. Bioorg. Med. Chem. Lett. 5: 1 1 19-1 1 124.
In other embodiments, the oligonucleotide may include other appended groups such as peptides (e.g., for targeting host cell receptors in vivo), or agents facilitating transport across the cell membrane (see, e.g., Letsinger, et al., 1989. Proc. Natl. Acad. Sci. U.S.A. 86: 6553-6556; Lemaitre, et al., 1987. Proc. Natl. Acad. Sci. 84: 648-652; PCT Publication No. WO88/09810) or the blood-brain barrier (see, e.g., PCT Publication No. WO 89/10134). In addition, oligonucleotides can be modified with hybridization triggered cleavage agents (see, e.g., rol, et al., 1988. BioTechniques 6:958-976) or intercalating agents (see, e.g., Zon, 1988. Pharm. Res. 5: 539-549). To this end, the oligonucleotide may be conjugated to another molecule, e.g., a peptide, a hybridization triggered cross-linking agent, a transport agent, a hybridization-triggered cleavage agent, and the like.
NOVX Polypeptides
A polypeptide according to the invention includes a polypeptide including the amino acid sequence of NOVX polypeptides whose sequences are provided in any one of SEQ ID NO:2«, wherein n is an integer between 1 and 172. The invention also includes a mutant or variant protein any of whose residues may be changed from the corresponding residues shown in any one of SEQ ID NO:2«, wherein n is an integer between I and 172, while still encoding a protein that maintains its NOVX activities and physiological functions, or a functional fragment thereof.
In general, a NOVX variant that preserves NOVX-like function includes any variant in which residues at a particular position in the sequence have been substituted by other amino acids, and further include the possibility of inserting an additional residue or residues between two residues of the parent protein as well as the possibility of deleting one or more residues from the parent sequence. Any amino acid substitution, insertion, or deletion is encompassed by the invention. In favorable circumstances, the substitution is a conservative substitution as defined above.
One aspect of the invention pertains to isolated NOVX proteins, and biologically-active portions thereof, or derivatives, fragments, analogs or homologs thereof. Also provided are polypeptide fragments suitable for use as immunogens to raise anti-NOVX antibodies. In one embodiment, native NOVX proteins can be isolated from cells or tissue sources by an appropriate purification scheme using standard protein purification techniques. In another embodiment, NOVX proteins are produced by recombinant DNA techniques. Alternative to recombinant expression, a NOVX protein or polypeptide can be synthesized chemically using standard peptide synthesis techniques.
An "isolated" or "purified" polypeptide or protein or biologically-active portion thereof is substantially free of cellular material or other contaminating proteins from the cell or tissue source from which the NOVX protein is derived, or substantially free from chemical precursors or other chemicals when chemically synthesized. The language "substantially free of cellular material" includes preparations of NOVX proteins in which the protein is separated from cellular components of the cells from which it is isolated or recombinantly-produced. In one embodiment, the language "substantially free of cellular material" includes preparations of NOVX proteins having less than about 30% (by dry weight) of non-NOVX proteins (also referred to herein as a "contaminating protein"), more preferably less than about 20% of non-NOVX proteins, still more preferably less than about
10%) of non-NOVX proteins, and most preferably less than about 5% of non-NOVX proteins. When the NOVX protein or biologically-active portion thereof is recombinantly-produced, it is also preferably substantially free of culture medium, i.e., culture medium represents less than about 20%, more preferably less than about 10%, and most preferably less than about 5%> of the volume of the NOVX protein preparation.
The language "substantially free of chemical precursors or other chemicals" includes preparations of NOVX proteins in which the protein is separated from chemical precursors or other chemicals that are involved in the synthesis of the protein. In one embodiment, the language "substantially free of chemical precursors or other chemicals" includes preparations of NOVX proteins having less than about 30% (by dry weight) of chemical precursors or non-NOVX chemicals, more preferably less than about 20%) chemical precursors or non-NOVX chemicals, still more preferably less than about 10% chemical precursors or non-NOVX chemicals, and most preferably less than about 5%> chemical precursors or non-NOVX chemicals. Biologically-active portions of NOVX proteins include peptides comprising amino acid sequences sufficiently homologous to or derived from the amino acid sequences of the NOVX proteins (e.g., the amino acid sequence of SEQ ID NO:2n, wherein n is an integer between 1 and 172) that include fewer amino acids than the full-length NOVX proteins, and exhibit at least one activity of a NOVX protein. Typically, biologically-active portions comprise a domain or motif with at least one activity of the NOVX protein. A biologically-active portion of a NOVX protein can be a polypeptide which is, for example, 10, 25, 50, 100 or more amino acid residues in length.
Moreover, other biologically-active portions, in which other regions of the protein are deleted, can be prepared by recombinant techniques and evaluated for one or more of the functional activities of a native NOVX protein.
In an embodiment, the NOVX protein has an amino acid sequence of SEQ ID NO:2/?, wherein n is an integer between 1 and 172. In other embodiments, the NOVX protein is substantially homologous to SEQ ID NO:2n, wherein n is an integer between 1 and 172, and retains the functional activity of the protein of SEQ ID NO:2«, wherein n is an integer between 1 and 172, yet differs in amino acid sequence due to natural allelic variation or mutagenesis, as described in detail, below. Accordingly, in another embodiment, the NOVX protein is a protein that comprises an amino acid sequence at least about 45% homologous to the amino acid sequence of SEQ ID NO:2 ?, wherein n is an integer between 1 and 172, and
retains the functional activity of the NOVX proteins of SEQ ID NO:2«, wherein n is an integer between 1 and 1 72.
Determining Homology Between Two or More Sequences
To determine the percent homology of two amino acid sequences or of two nucleic acids, the sequences are aligned for optimal comparison purposes (e.g., gaps can be introduced in the sequence of a first amino acid or nucleic acid sequence for optimal alignment with a second amino or nucleic acid sequence). The amino acid residues or nucleotides at corresponding amino acid positions or nucleotide positions are then compared. When a position in the first sequence is occupied by the same amino acid residue or nucleotide as the corresponding position in the second sequence, then the molecules are homologous at that position (i.e., as used herein amino acid or nucleic acid "homology" is equivalent to amino acid or nucleic acid "identity").
The nucleic acid sequence homology may be determined as the degree of identity between two sequences. The homology may be determined using computer programs known in the art, such as GAP software provided in the GCG program package. See, Needleman and Wunsch, 1970. J Mol Biol 48: 443-453. Using GCG GAP software with the following settings for nucleic acid sequence comparison: GAP creation penalty of 5.0 and GAP extension. penalty of 0.3, the coding region of the analogous nucleic acid sequences referred to above exhibits a degree of identity preferably of at least 70%, 75%, 80%, 85%, 90%, 95%, 98%, or 99%, with the CDS (encoding) part of the DNA sequence of SEQ ID NO:2n-l , wherein n is an integer between 1 and 172.
The term "sequence identity" refers to the degree to which two polynucleotide or polypeptide sequences are identical on a residue-by-residue basis over a particular region of comparison. The term "percentage of sequence identity" is calculated by comparing two optimally aligned sequences over that region of comparison, determining the number of positions at which the identical nucleic acid base (e.g., A, T, C, G, U, or I, in the case of nucleic acids) occurs in both sequences to yield the number of matched positions, dividing the number of matched positions by the total number of positions in the region of comparison (i.e., the window size), and multiplying the result by 100 to yield the percentage of sequence identity. The term "substantial identity" as used herein denotes a characteristic of a polynucleotide sequence, wherein the polynucleotide comprises a sequence that has at least 80 percent sequence identity, preferably at least 85 percent identity and often 90 to 95 percent
sequence identity, more usually at least 99 percent sequence identity as compared to a reference sequence over a comparison region.
Chimeric and Fusion Proteins
The invention also provides NOVX chimeric or fusion proteins. As used herein, a NOVX "chimeric protein" or "fusion protein" comprises a NOVX polypeptide operatively-linked to a non-NOVX polypeptide. An "NOVX polypeptide" refers to a polypeptide having an amino acid sequence corresponding to a NOVX protein of SEQ ID NO:2/7, wherein n is an integer between I and 172, whereas a "non-NOVX polypeptide" refers to a polypeptide having an amino acid sequence corresponding to a protein that is not substantially homologous to the NOVX protein, e.g., a protein that is different from the NOVX protein and that is derived from the same or a different organism. Within a NOVX fusion protein the NOVX polypeptide can correspond to all or a portion of a NOVX protein. In one embodiment, a NOVX fusion protein comprises at least one biologically-active . portion of a NOVX protein. In another embodiment, a NOVX fusion protein comprises at least two biologically-active portions of a NOVX protein. In yet another embodiment, a NOVX fusion protein comprises at least three biologically-active portions of a NOVX protein. Within the fusion protein, the term "operatively-linked" is intended to indicate that the NOVX polypeptide and the non-NOVX polypeptide are fused in-frame with one another. The non-NOVX polypeptide can be fused to the N-terminus or C-terminus of the NOVX polypeptide.
In one embodiment, the fusion protein is a GST-NOVX fusion protein in which the NOVX sequences are fused to the C-terminus of the GST (glutathione S-transferase) sequences. Such fusion proteins can facilitate the purification of recombinant NOVX polypeptides. In another embodiment, the fusion protein is a NOVX protein containing a heterologous signal sequence at its N-terminus. In certain host cells (e.g., mammalian host cells), expression and/or secretion of NOVX can be increased through use of a heterologous signal sequence.
In yet another embodiment, the fusion protein is a NOVX-immunoglobulin fusion protein in which the NOVX sequences are fused to sequences derived from a member of the immunoglobulin protein family. The NOVX-immunoglobulin fusion proteins of the invention can be incorporated into pharmaceutical compositions and administered to a subject
to inhibit an interaction between a NOVX ligand and a NOVX protein on the surface of a cell, to thereby suppress NOVX-mediated signal transduction in vivo. The NOVX-immunoglobulin fusion proteins can be used to affect the bioavailability of a NOVX cognate ligand. Inhibition of the NOVX Iigand/NOVX interaction may be useful therapeutically for both the treatment of proliferative and differentiative disorders, as well as modulating (e.g. promoting or inhibiting) cell survival. Moreover, the NOVX-immunoglobulin fusion proteins of the invention can be used as immunogens to produce anti-NOVX antibodies in a subject, to purify NOVX ligands, and in screening assays to identify molecules that inhibit the interaction of NOVX with a NOVX ligand. A NOVX chimeric or fusion protein of the invention can be produced by standard recombinant DNA techniques. For example, DNA fragments coding for the different polypeptide sequences are ligated together in-frame in accordance with conventional techniques, e.g., by employing blunt-ended or stagger-ended termini for ligation, restriction enzyme digestion to provide for appropriate termini, filling-in of cohesive ends as appropriate, alkaline phosphatase treatment to avoid undesirable joining, and enzymatic ligation. In another embodiment, the fusion gene can be synthesized by conventional techniques including automated DNA synthesizers. Alternatively, PCR amplification of gene fragments can be carried out using anchor primers that give rise to complementary overhangs between two consecutive gene fragments that can subsequently be annealed and reamplified to generate a chimeric gene sequence (see, e.g., Ausubel, et al. (eds.) CURRENT PROTOCOLS IN MOLECULAR BIOLOGY, John Wiley & Sons, 1992). Moreover, many expression vectors are commercially available that already encode a fusion moiety (e.g., a GST polypeptide). A NOVX-encoding nucleic acid can be cloned into such an expression vector such that the fusion moiety is linked in-frame to the NOVX protein. NOVX Agonists and Antagonists
The invention also pertains to variants of the NOVX proteins that function as either NOVX agonists (i.e., mimetics) or as NOVX antagonists. Variants of the NOVX protein can be generated by mutagenesis (e.g., discrete point mutation or truncation of the NOVX protein). An agonist of the NOVX protein can retain substantially the same, or a subset of, the biological activities of the naturally occurring form of the NOVX protein. An antagonist of the NOVX protein can inhibit one or more of the activities of the naturally occurring form of the NOVX protein by, for example, competitively binding to a downstream or upstream
member of a cellular signaling cascade which includes the NOVX protein. Thus, specific biological effects can be elicited by treatment with a variant of limited function. In one embodiment, treatment of a subject with a variant having a subset of the biological activities of the naturally occurring form of the protein has fewer side effects in a subject relative to treatment with the naturally occurring form of the NOVX proteins.
Variants of the NOVX proteins that function as either NOVX agonists (i.e.. mimetics) or as NOVX antagonists can be identified by screening combinatorial libraries of mutants (e.g., truncation mutants) of the NOVX proteins for NOVX protein agonist or antagonist activity. In one embodiment, a variegated library of NOVX variants is generated by combinatorial mutagenesis at the nucleic acid level and is encoded by a variegated gene library. A variegated library of NOVX variants can be produced by, for example, enzymatically ligating a mixture of synthetic oligonucleotides into gene sequences such that a degenerate set of potential NOVX sequences is expressible as individual polypeptides, or alternatively, as a set of larger fusion proteins (e.g., for phage display) containing the set of NOVX sequences therein. There are a variety of methods which can be used to produce libraries of potential NOVX variants from a degenerate oligonucleotide sequence. Chemical synthesis of a degenerate gene sequence can be performed in an automatic DNA synthesizer, and the synthetic gene then ligated into an appropriate expression vector. Use of a degenerate set of genes allows for the provision, in one mixture, of all of the sequences encoding the desired set of potential NOVX sequences. Methods for synthesizing degenerate oligonucleotides are well-known within the art. See, e.g., Narang, 1983. Tetrahedron 39: 3; Itakura, et al., 1984. An u. Rev. Biochem. 53: 323; Itakura, et al., 1984. Science 198: 1056; Ike, et al., 1983. Nucl. Acids Res. 1 1 : 477.
Polypeptide Libraries In addition, libraries of fragments of the NOVX protein coding sequences can be used to generate a variegated population of NOVX fragments for screening and subsequent selection of variants of a NOVX protein. In one embodiment, a library of coding sequence fragments can be generated by treating a double stranded PCR fragment of a NOVX coding sequence with a nuclease under conditions wherein nicking occurs only about once per molecule, denaturing the double stranded DNA, renaturing the DNA to form double-stranded DNA that can include sense/antisense pairs from different nicked products, removing single stranded portions from reformed duplexes by treatment with Si nuclease, and ligating the
resulting fragment library into an expression vector By this method, expression libraries can be derived which encodes N-terminal and internal fragments of various sizes of the NOVX proteins.
Various techniques are known in the art for screening gene products of combinatorial libraries made by point mutations or truncation, and for screening cDNA libraries for gene products having a selected property. Such techniques are adaptable for rapid screening of the gene libraries generated by the combinatorial mutagenesis of NOVX proteins. The most widely used techniques, which are amenable to high throughput analysis, for screening large gene libraries typically include cloning the gene library into replicable expression vectors, transforming appropriate cells with the resulting library of vectors, and expressing the combinatorial genes under conditions in which detection of a desired activity facilitates isolation of the vector encoding the gene whose product was detected. Recursive ensemble mutagenesis (REM), a new technique that enhances the frequency of functional mutants in the libraries, can be used in combination with the screening assays to identify NOVX variants. See, e , Arkin and Yourvan, 1992. Proc Natl Acad Sci USA 89: 781 1 -7815; Delgrave, et al., 1993. Protein Engineering 6:327-33 1.
Anti-NOVX Antibodies
Included in the invention are antibodies to NOVX proteins, or fragments of NOVX proteins. The term "antibody" as used herein refers to immunoglobulin molecules and immunologically active portions of immunoglobulin (lg) molecules, / e , molecules that contain an antigen binding site that specifically binds (immunoreacts with) an antigen. Such antibodies include, but are not limited to, polyclonal, monoclonal, chimeric, single chain, Fa , Fab' and F(ab) fragments, and an Fab expression library. In general, antibody molecules obtained from humans relates to any of the classes IgG, IgM, IgA, IgE and IgD, which differ from one another by the nature of the heavy chain present in the molecule. Certain classes have subclasses as well, such as IgGi, IgG2, and others. Furthermore, in humans, the light chain may be a kappa chain or a lambda chain. Reference herein to antibodies includes a reference to all such classes, subclasses and types of human antibody species.
An isolated protein of the invention intended to serve as an antigen, or a portion or fragment thereof, can be used as an immunogen to generate antibodies that immunospecifically bind the antigen, using standard techniques for polyclonal and monoclonal antibody preparation. The full-length protein can be used or, alternatively, the
invention provides antigenic peptide fragments of the antigen for use as immunogens. An antigenic peptide fragment comprises at least 6 amino acid residues of the amino acid sequence of the full length protein, such as an amino acid sequence of SEQ ID NO:2n, wherein n is an integer between 1 and 172, and encompasses an epitope thereof such that an antibody raised against the peptide forms a specific immune complex with the full length protein or with any fragment that contains the epitope. Preferably, the antigenic peptide comprises at least 10 amino acid residues, or at least 15 amino acid residues, or at least 20 amino acid residues, or at least 30 amino acid residues. Preferred epitopes encompassed by the antigenic peptide are regions of the protein that are located on its surface; commonly these are hydrophilic regions.
In certain embodiments of the invention, at least one epitope encompassed by the antigenic peptide is a region of NOVX that is located on the surface of the protein, e.g., a hydrophilic region. A hydrophobicity analysis of the human NOVX protein sequence will indicate which regions of a NOVX polypeptide are particularly hydrophilic and, therefore, are likely to encode surface residues useful for targeting antibody production. As a means for targeting antibody production, hydropathy plots showing regions of hydrophilicity and hydrophobicity may be generated by any method well known in the art, including, for example, the Kyte Doolittle or the Hopp Woods methods, either with or without Fourier transformation. See, e.g., Hopp and Woods, 1981 , Proc. Nat. Acad. Sci. USA 78: 3824-3828; Kyte and Doolittle 1982, J. Mol. Biol. 157: 105-142, each incorporated herein by reference in their entirety. Antibodies that are specific for one or more domains within an antigenic protein, or derivatives, fragments, analogs or homologs thereof, are also provided herein.
The term "epitope" includes any protein determinant capable of specific binding to an immunoglobulin or T-cell receptor. Epitopic determinants usually consist of chemically active surface groupings of molecules such as amino acids or sugar side chains and usually have specific three dimensional structural characteristics, as well as specific charge characteristics. A NOVX polypeptide or a fragment thereof comprises at least one antigenic epitope. An anti-NOVX antibody of the present invention is said to specifically bind to antigen NOVX when the equilibrium binding constant (KD) is <1 μM, preferably < 100 nM, more preferably < 10 nM, and most preferably < 100 pM to about 1 pM, as measured by assays such as radioligand binding assays or similar assays known to those skilled in the art.
A protein of the invention, or a derivative, fragment, analog, homolog or ortholog thereof, may be utilized as an immunogen in the generation of antibodies that immunospecifically bind these protein components.
Various procedures known within the art may be used for the production of polyclonal or monoclonal antibodies directed against a protein of the invention, or against derivatives, fragments, analogs homologs or orthologs thereof (see, for example, Antibodies: A Laboratory Manual, Harlow E, and Lane D, 1988, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, NY, incorporated herein by reference). Some of these antibodies are discussed below. Polyclonal Antibodies
For the production of polyclonal antibodies, various suitable host animals (e.g., rabbit, goat, mouse or other mammal) may be immunized by one or more injections with the native protein, a synthetic variant thereof, or a derivative of the foregoing. An appropriate immunogenic preparation can contain, for example, the naturally occurring immunogenic protein, a chemically synthesized polypeptide representing the immunogenic protein, or a recombinantly expressed immunogenic protein. Furthermore, the protein may be conjugated to a second protein known to be immunogenic in the mammal being immunized. Examples of such immunogenic proteins include but are not limited to keyhole limpet hemocyanin, serum albumin, bovine thyroglobulin, and soybean trypsin inhibitor. The preparation can further include an adjuvant. Various adjuvants used to increase the immunological response include, but are not limited to, Freund's (complete and incomplete), mineral gels (e.g., aluminum hydroxide), surface active substances (e.g., lysolecithin, pluronic polyols, polyanions, peptides, oil emulsions, dinitrophenol, etc.), adjuvants usable in humans such as Bacille Calmette-Guerin and Corynebacterium parvum, or similar immunostimulatory agents. Additional examples of adjuvants which can be employed include MPL-TDM adjuvant (monophosphoryl Lipid A, synthetic trehalose dicorynomycolate).
The polyclonal antibody molecules directed against the immunogenic protein can be isolated from the mammal (e.g., from the blood) and further purified by well known techniques, such as affinity chromatography using protein A or protein G, which provide primarily the IgG fraction of immune serum. Subsequently, or alternatively, the specific antigen which is the target of the immunoglobulin sought, or an epitope thereof, may be immobilized on a column to purify the immune specific antibody by immunoaffinity
chromatography. Purification of immunoglobulins is discussed, for example, by D. Wilkinson (The Scientist, published by The Scientist, Inc, Philadelphia PA, Vol. 14, No. 8 (April 17, 2000), pp. 25-28).
Monoclonal Antibodies The term "monoclonal antibody" (MAb) or "monoclonal antibody composition", as used herein, refers to a population of antibody molecules that contain only one molecular species of antibody molecule consisting of a unique light chain gene product and a unique heavy chain gene product. In particular, the complementarity determining regions (CDRs) of the monoclonal antibody are identical in all the molecules of the population. MAbs thus contain an antigen binding site capable of immunoreacting with a particular epitope of the antigen characterized by a unique binding affinity for it.
Monoclonal antibodies can be prepared using hybridoma methods, such as those described by Kohler and Milstein, Nature, 256:495 (1975). In a hybridoma method, a mouse, hamster, or other appropriate host animal, is typically immunized with an immunizing agent to elicit lymphocytes that produce or are capable of producing antibodies that will specifically bind to the immunizing agent. Alternatively, the lymphocytes can be immunized in vitro.
The immunizing agent will typically include the protein antigen, a fragment thereof or a fusion protein thereof. Generally, either peripheral blood lymphocytes are used if cells of human origin are desired, or spleen cells or lymph node cells are used if non-human mammalian sources are desired. The lymphocytes are then fused with an immortalized cell line using a suitable fusing agent, such as polyethylene glycol, to form a hybridoma cell (Goding, Monoclonal Antibodies: Principles and Practice, Academic Press, (1986) pp. 59-103). Immortalized cell lines are usually transformed mammalian cells, particularly myeloma cells of rodent, bovine and human origin. Usually, rat or mouse myeloma cell lines are employed. The hybridoma cells can be cultured in a suitable culture medium that preferably contains one or more substances that inhibit the growth or survival of the unfused, immortalized cells. For example, ifthe parental cells lack the enzyme hypoxanthine guanine phosphoribosyl transferase (HGPRT or HPRT), the culture medium for the hybridomas typically will include hypoxanthine, aminopterin, and thymidine ("HAT medium"), which substances prevent the growth of HGPRT-deficient cells.
Preferred immortalized cell lines are those that fuse efficiently, support stable high level expression of antibody by the selected antibody-producing cells, and are sensitive to a medium such as HAT medium. More preferred immortalized cell lines are murine myeloma lines, which can be obtained, for instance, from the Salk Institute Cell Distribution Center, San Diego, California and the American Type Culture Collection, Manassas, Virginia.
Human myeloma and mouse-human heteromyeloma cell lines also have been described for the production of human monoclonal antibodies (Kozbor, J. Immunol, 133:3001 (1984); Brodeur et al. Monoclonal Antibody Production Techniques and Applications, Marcel Dekker, Inc, New York, (1987) pp. 51-63). The culture medium in which the hybridoma cells are cultured can then be assayed for the presence of monoclonal antibodies directed against the antigen. Preferably, the binding specificity of monoclonal antibodies produced by the hybridoma cells is determined by immunoprecipitation or by an in vitro binding assay, such as radioimmunoassay (RIA) or enzyme-linked immunoabsorbent assay (ELISA). Such techniques and assays are known in the art. The binding affinity of the monoclonal antibody can, for example, be determined by the Scatchard analysis of Munson and Pollard, Anal. Biochem, 107:220 ( 1980). It is an objective, especially important in therapeutic applications of monoclonal antibodies, to identify antibodies having a high degree of specificity and a high binding affinity for the target antigen. After the desired hybridoma cells are identified, the clones can be subcloned by limiting dilution procedures and grown by standard methods (Goding, 1986). Suitable culture media for this purpose include, for example, Dulbecco's Modified Eagle's Medium and RPMI-1640 medium. Alternatively, the hybridoma cells can be grown in vivo as ascites in a mammal. The monoclonal antibodies secreted by the subclones can be isolated or purified from the culture medium or ascites fluid by conventional immunoglobulin purification procedures such as, for example, protein A-Sepharose, hydroxylapatite chromatography, gel electrophoresis, dialysis, or affinity chromatography.
The monoclonal antibodies can also be made by recombinant DNA methods, such as those described in U.S. Patent No. 4,816,567. DNA encoding the monoclonal antibodies of the invention can be readily isolated and sequenced using conventional procedures (e.g., by using oligonucleotide probes that are capable of binding specifically to genes encoding the heavy and light chains of murine antibodies). The hybridoma cells of the invention serve as a
preferred source of such DNA. Once isolated, the DNA can be placed into expression vectors, which are then transfected into host cells such as simian COS cells, Chinese hamster ovary (CHO) cells, or myeloma cells that do not otherwise produce immunoglobulin protein, to obtain the synthesis of monoclonal antibodies in the recombinant host cells. The DNA also can be modified, for example, by substituting the coding sequence for human heavy and light chain constant domains in place of the homologous murine sequences (U.S. Patent No. 4,816,567; Morrison, Nature 368, 812-13 (1994)) or by covalently joining to the immunoglobulin coding sequence all or part of the coding sequence for a non-immunoglobulin polypeptide. Such a non-immunoglobulin polypeptide can be substituted for the constant domains of an antibody of the invention, or can be substituted for the variable domains of one antigen-combining site of an antibody of the invention to create a chimeric bivalent antibody.
Humanized Antibodies
The antibodies directed against the protein antigens of the invention can further comprise humanized antibodies or human antibodies. These antibodies are suitable for administration to humans without engendering an immune response by the human against the administered immunoglobulin. Humanized forms of antibodies are chimeric immunoglobulins, immunoglobulin chains or fragments thereof (such as Fv, Fab, Fab', F(ab')2 or other antigen-binding subsequences of antibodies) that are principally comprised of the sequence of a human immunoglobulin, and contain minimal sequence derived from a non-human immunoglobulin. Humanization can be performed following the method of Winter and co-workers (Jones et al. Nature, 321 :522-525 (1986); Riechmann et al. Nature, 332:323-327 (1988); Verhoeyen et al. Science, 239: 1534- 1536 (1988)), by substituting rodent CDRs or CDR sequences for the corresponding sequences of a human antibody. (See also U.S. Patent No. 5,225,539.) In some instances, Fv framework residues of the human immunoglobulin are replaced by corresponding non-human residues. Humanized antibodies can also comprise residues which are found neither in the recipient antibody nor in the imported CDR or framework sequences. In general, the humanized antibody will comprise substantially all of at least one, and typically two, variable domains, in which all or substantially all of the CDR regions correspond to those of a non-human immunoglobulin and all or substantially all of the framework regions are those of a human immunoglobulin consensus sequence. The humanized antibody optimally also will comprise at least a portion
of an immunoglobulin constant region (Fc), typically that of a human immunoglobulin (Jones et al, 1986; Riechmann et al., 1988; and Presta, Curr. Op. Struct. Biol, 2:593-596 ( 1992)).
Human Antibodies
Fully human antibodies essentially relate to antibody molecules in which the entire sequence of both the light chain and the heavy chain, including the CDRs, arise from human genes. Such antibodies are termed "human antibodies", or "fully human antibodies" herein. Human monoclonal antibodies can be prepared by the trioma technique; the human B-cell hybridoma technique (see Kozbor, et al, 1983 Immunol Today 4: 72) and the EBV hybridoma technique to produce human monoclonal antibodies (see Cole, et al, 1985 In: MONOCLONAL ANTIBODIES AND CANCER THERAPY, Alan R. Liss, Inc., pp. 77-96). Human monoclonal antibodies may be utilized in the practice of the present invention and may be produced by using human hybridomas (see Cote, et al, 1983. Proc Natl Acad Sci USA 80: 2026-2030) or by transforming human B-cells with Epstein Barr Virus in vitro (see Cole, et al, 1985 In: MONOCLONAL ANTIBODIES AND CANCER THERAPY, Alan R. Liss, Inc, pp. 77-96).
In addition, human antibodies can also be produced using additional techniques, including phage display libraries (Hoogenboom and Winter, J. Mol. Biol, 227:381 ( 1991 ); Marks et al, J. Mol. Biol, 222:581 ( 1991)). Similarly, human antibodies can be made by introducing human immunoglobulin loci into transgenic animals, e.g., mice in which the endogenous immunoglobulin genes have been partially or completely inactivated. Upon challenge, human antibody production is observed, which closely resembles that seen in humans in all respects, including gene rearrangement, assembly, and antibody repertoire. This approach is described, for example, in U.S. Patent Nos. 5,545,807; 5,545,806; 5,569,825; 5,625, 126; 5,633,425; 5,661 ,016, and in Marks et al. (Bio/Technology 10, 779-783 (1992)); Lonberg et al. (Nature 368 856-859 (1994)); Morrison ( Nature 368, 812- 13 ( 1994)); Fishwild et al,( Nature Biotechnology 14, 845-51 ( 1996)); Neuberger (Nature Biotechnology 14, 826 (1996)); and Lonberg and Huszar (Intern. Rev. Immunol. 13 65-93 (1995)).
Human antibodies may additionally be produced using transgenic nonhuman animals which are modified so as to produce fully human antibodies rather than the animal's endogenous antibodies in response to challenge by an antigen. (See PCT publication WO94/02602). The endogenous genes encoding the heavy and light immunoglobulin chains
in the nonhuman host have been incapacitated, and active loci encoding human heavy and light chain immunoglobulins are inserted into the host's genome. The human genes are incorporated, for example, using yeast artificial chromosomes containing the requisite human DNA segments. An animal which provides all the desired modifications is then obtained as progeny by crossbreeding intermediate transgenic animals containing fewer than the full complement of the modifications. The preferred embodiment of such a nonhuman animal is a mouse, and is termed the Xenomouse™ as disclosed in PCT publications WO 96/33735 and WO 96/34096. This animal produces B cells which secrete fully human immunoglobulins. The antibodies can be obtained directly from the animal after immunization with an immunogen of interest, as, for example, a preparation of a polyclonal antibody, or alternatively from immortalized B cells derived from the animal, such as hybridomas producing monoclonal antibodies. Additionally, the genes encoding the immunoglobulins with human variable regions can be recovered and expressed to obtain the antibodies directly, or can be further modified to obtain analogs of antibodies such as, for example, single chain Fv molecules.
An example of a method of producing a nonhuman host, exemplified as a mouse, lacking expression of an endogenous immunoglobulin heavy chain is disclosed in U.S. Patent No. 5,939,598. It can be obtained by a method including deleting the J segment genes from at least one endogenous heavy chain locus in an embryonic stem cell to prevent rearrangement of the locus and to prevent formation of a transcript of a rearranged immunoglobulin heavy chain locus, the deletion being effected by a targeting vector containing a gene encoding a selectable marker; and producing from the embryonic stem cell a transgenic mouse whose somatic and germ cells contain the gene encoding the selectable marker. A method for producing an antibody of interest, such as a human antibody, is disclosed in U.S. Patent No. 5,916,771. It includes introducing an expression vector that contains a nucleotide sequence encoding a heavy chain into one mammalian host cell in culture, introducing an expression vector containing a nucleotide sequence encoding a light chain into another mammalian host cell, and fusing the two cells to form a hybrid cell. The hybrid cell expresses an antibody containing the heavy chain and the light chain.
In a further improvement on this procedure, a method for identifying a clinically relevant epitope on an immunogen, and a correlative method for selecting an antibody that
binds immunospecifically to the relevant epitope with high affinity, are disclosed in PCT publication WO 99/53049.
Fah Fragments and Single Chain Antibodies
According to the invention, techniques can be adapted for the production of single-chain antibodies specific to an antigenic protein of the invention (see e.g., U.S. Patent No. 4,946,778). In addition, methods can be adapted for the construction of Fab expression libraries (see e.g., Huse, et al, 1989 Science 246: 1275-1281 ) to allow rapid and effective identification of monoclonal Fab fragments with the desired specificity for a protein or derivatives, fragments, analogs or homologs thereof. Antibody fragments that contain the idiotypes to a protein antigen may be produced by techniques known in the art including, but not limited to: (i) an F(ab')2 fragment produced by pepsin digestion of an antibody molecule; (ii) an Fab fragment generated by reducing the disulfide bridges of an F(a ')2 fragment; (iii) an Fab fragment generated by the treatment of the antibody molecule with papain and a reducing agent and (iv) Fv fragments. Bispecific Antibodies
Bispecific antibodies are monoclonal, preferably human or humanized, antibodies that have binding specificities for at least two different antigens. In the present case, one of the binding specificities is for an antigenic protein of the invention. The second binding target is any other antigen, and advantageously is a cell-surface protein or receptor or receptor subunit.
Methods for making bispecific antibodies are known in the art. Traditionally, the recombinant production of bispecific antibodies is based on the co-expression of two immunoglobulin heavy-chain/light-chain pairs, where the two heavy chains have different specificities (Milstein and Cuello, Nature, 305:537-539 (1983)). Because of the random assortment of immunoglobulin heavy and light chains, these hybridomas (quadromas) produce a potential mixture of ten different antibody molecules, of which only one has the correct bispecific structure. The purification of the correct molecule is usually accomplished by affinity chromatography steps. Similar procedures are disclosed in WO 93/08829, published 13 May 1993, and in Traunecker et al, EMBO J, 10:3655-3659 ( 1991 ). Antibody variable domains with the desired binding specificities (antibody-antigen combining sites) can be fused to immunoglobulin constant domain sequences. The fusion preferably is with an immunoglobulin heavy-chain constant domain, comprising at least part
of the hinge, CH2, and CH3 regions. It is preferred to have the first heavy-chain constant region (CH I ) containing the site necessary for light-chain binding present in at least one of the fusions. DNAs encoding the immunoglobulin heavy-chain fusions and, if desired, the immunoglobulin light chain, are inserted into separate expression vectors, and are co-transfected into a suitable host organism. For further details of generating bispecific antibodies see, for example, Suresh et al. Methods in Enzymology, 121 :210 ( 1986).
According to another approach described in WO 96/2701 1 , the interface between a pair of antibody molecules can be engineered to maximize the percentage of heterodimers which are recovered from recombinant cell culture. The preferred interface comprises at least a part of the CH3 region of an antibody constant domain. In this method, one or more small amino acid side chains from the interface of the first antibody molecule are replaced with larger side chains (e.g. tyrosine or tryptophan). Compensatory '"cavities" of identical or similar size to the large side chain(s) are created on the interface of the second antibody molecule by replacing large amino acid side chains with smaller ones (e.g. alanine or ® threonine). This provides a mechanism for increasing the yield of the heterodimer over other unwanted end-products such as homodimers.
Bispecific antibodies can be prepared as full length antibodies or antibody fragments (e.g. F(ab')2 bispecific antibodies). Techniques for generating bispecific antibodies from antibody fragments have been described in the literature. For example, bispecific antibodies can be prepared using chemical linkage. Brennan et al. Science 229:81 ( 1985) describe a procedure wherein intact antibodies are proteolytically cleaved to generate F(ab') fragments. These fragments are reduced in the presence of the dithiol complexing agent sodium arsenite to stabilize vicinal dithiols and prevent intermolecular disulfide formation. The Fab' fragments generated are then converted to thionitrobenzoate (TNB) derivatives. One of the Fab'-TNB derivatives is then reconverted to the Fab'-thiol by reduction with mercaptoethylamine and is mixed with an equimolar amount of the other Fab'-TNB derivative to form the bispecific antibody. The bispecific antibodies produced can be used as agents for the selective immobilization of enzymes.
Additionally, Fab' fragments can be directly recovered from E. coli and chemically coupled to form bispecific antibodies. Shalaby et al, J. Exp. Med. 175:21 7-225 ( 1992) describe the production of a fully humanized bispecific antibody F(ab')2 molecule. Each Fab' fragment was separately secreted from E. coli and subjected to directed chemical coupling in vitro to form the bispecific antibody. The bispecific antibody thus formed was
able to bind to cells overexpressing the ErbB2 receptor and normal human T cells, as well as trigger the lytic activity of human cytotoxic lymphocytes against human breast tumor targets.
Various techniques for making and isolating bispecific antibody fragments directly from recombinant cell culture have also been described. For example, bispecific antibodies have been produced using leucine zippers. Kostelny et al, J. Immunol. 148(5): 1547-1553 (1992). The leucine zipper peptides from the Fos and Jun proteins were linked to the Fab' portions of two different antibodies by gene fusion. The antibody homodimers were reduced at the hinge region to form monomers and then re-oxidized to form the antibody heterodimers. This method can also be utilized for the production of antibody homodimers. The "diabody" technology described by Hollinger et al, Proc. Natl. Acad. Sci. USA
90:6444-6448 (1993) has provided an alternative mechanism for making bispecific antibody fragments. The fragments comprise a heavy-chain variable domain (VH) connected to a light-chain variable domain (VL) by a linker which is too short to allow pairing between the two domains on the same chain. Accordingly, the VH and VL domains of one fragment are forced to pair with the complementary V and VH domains of another fragment, thereby forming two antigen-binding sites. Another strategy for making bispecific antibody fragments by the use of single-chain Fv (sFv) dimers has also been reported. See, Gruber et al, J. Immunol. 152:5368 ( 1994).
Antibodies with more than two valencies are contemplated. For example, trispecific antibodies can be prepared. Tutt et al., J. Immunol. 147:60 (1991 ).
Exemplary bispecific antibodies can bind to two different epitopes, at least one of which originates in the protein antigen of the invention. Alternatively, an anti-antigenic arm of an immunoglobulin molecule can be combined with an arm which binds to a triggering molecule on a leukocyte such as a T-cell receptor molecule (e.g. CD2, CD3, CD28, or B7), or Fc receptors for IgG (FcγR), such as FcγRI (CD64), FcγRII (CD32) and FcγRIII (CDl 6) so as to focus cellular defense mechanisms to the cell expressing the particular antigen. Bispecific antibodies can also be used to direct cytotoxic agents to cells which express a particular antigen. These antibodies possess an antigen-binding arm and an arm which binds a cytotoxic agent or a radionuclide chelator, such as EOTUBE, DPTA, DOTA, or TETA. Another bispecific antibody of interest binds the protein antigen described herein and further binds tissue factor (TF).
Heterocon jugate Antibodies
Heteroconjugate antibodies are also within the scope of the present invention. Heteroconjugate antibodies are composed of two covalently joined antibodies. Such antibodies have, for example, been proposed to target immune system cells to unwanted cells (U.S. Patent No. 4,676,980), and for treatment of HIV infection (WO 91/00360; WO
92/200373; EP 03089). It is contemplated that the antibodies can be prepared in vitro using known methods in synthetic protein chemistry, including those involving crosslinking agents. For example, immunotoxins can be constructed using a disulfide exchange reaction or by formjng a thioether bond. Examples of suitable reagents for this purpose include iminothiolate and methyl-4-mercaptobutyrimidate and those disclosed, for example, in U.S. Patent No. 4,676,980.
Effector Function Engineering
It can be desirable to modify the antibody of the invention with respect to effector function, so as to enhance, e.g., the effectiveness of the antibody in treating cancer. For example, cysteine residue(s) can be introduced into the Fc region, thereby allowing interchain disulfide bond formation in this region. The homodimeric antibody thus generated can have improved internalization capability and/or increased complement-mediated cell killing and antibody-dependent cellular cytotoxicity (ADCC). See Caron et al, J. Exp Med, 176: 1 191 -1 195 (1992) and Shopes, J. Immunol, 148: 2918-2922 (1992). Homodimeric antibodies with enhanced anti-tumor activity can also be prepared using heterobifunctional cross-linkers as described in Wolff et al. Cancer Research, 53: 2560-2565 (1993). Alternatively, an antibody can be engineered that has dual Fc regions and can thereby have enhanced complement lysis and ADCC capabilities. See Stevenson et al, Anti-Cancer Drug Design, 3: 219-230 (1989). Immunoconjugates
The invention also pertains to immunoconjugates comprising an antibody conjugated to a cytotoxic a*gent such as a chemotherapeutic agent, toxin (e.g., an enzymatically active toxin of bacterial, fungal, plant, or animal origin, or fragments thereof), or a radioactive isotope (i.e., a radioconjugate). Chemotherapeutic agents useful in the generation of such immunoconjugates have been described above. Enzymatically active toxins and fragments thereof that can be used include diphtheria A chain, nonbinding active fragments of diphtheria toxin, exotoxin A
chain (from Pseudomonas aeruginosa), ricin A chain, abrin A chain, modeccin A chain, alpha-sarcin, Aleurites fordii proteins, dianthin proteins, Phytolaca americana proteins (PAPI, PAPII, and PAP-S), momordica charantia inhibitor, curcin, crotin. sapaonaria officinalis inhibitor, gelonin, mitogellin, restrictocin, phenomycin, enomycin, and the tricothecenes. A variety of radionuclides are available for the production of radioconjugated antibodies. Examples include 2l2Bi, l3lI, 13lIn, 90N and l86Re.
Conjugates of the antibody and cytotoxic agent are made using a variety of bifunctional protein-coupling agents such as N-succinimidyl-3-(2-pyridyldithiol) propionate (SPDP), iminothiolane (IT), bifunctional derivatives of imidoesters (such as dimethyl adipimidate HCL), active esters (such as disuccinimidyl suberate), aldehydes (such as glutareldehyde), bis-azido compounds (such as bis (p-azidobenzoyl) hexanediamine),' bis-diazonium derivatives (such as bis-(p-diazoniumbenzoyl)-ethylenediamine), diisocyanates (such as tolyene 2,6-diisocyanate), and bis-active fluorine compounds (such as l ,5-diflιιoro-2,4-dinitrobenzene). For example, a ricin immunotoxin can be prepared as described in Vitetta et al.. Science, 238: 1098 (1987). Carbon- 14-labeled l -isothiocyanatobenzyl-3-methyldiethylene triaminepentaacetic acid (MX-DTPA) is an exemplary chelating agent for conjugation of radionucleotide to the antibody. See WO94/1 1026.
In another embodiment, the antibody can be conjugated to a "receptor" (such streptavidin) for utilization in tumor pretargeting wherein the antibody-receptor conjugate is administered to the patient, followed by removal of unbound conjugate from the circulation using a clearing agent and then administration of a "ligand" (e.g., avidin) that is in turn conjugated to a cytotoxic agent.
Immunoliposomcs The antibodies disclosed herein can also be formulated as immunoliposomes.
Liposomes containing the antibody are prepared by methods known in the art, such as described in Epstein et al, Proc. Natl. Acad. Sci. USA, 82: 3688 ( 1985); Hwang et al, Proc. Natl Acad. Sci. USA, 77: 4030 (1980); and U.S. Pat. Nos. 4,485,045 and 4,544,545. Liposomes with enhanced circulation time are disclosed in U.S. Patent No. 5,013,556. Particularly useful liposomes can be generated by the reverse-phase evaporation method with a lipid composition comprising phosphatidylcholine, cholesterol, and PEG-derivatized phosphatidylethanolamine (PEG-PE). Liposomes are extruded through
filters of defined pore size to yield liposomes with the desired diameter. Fab' fragments of the antibody of the present invention can be conjugated to the liposomes as described in Martin et al , J. Biol. Chem, 257: 286-288 (1982) via a disulfide-interchange reaction. A chemotherapeutic agent (such as Doxorubicin) is optionally contained within the liposome. See Gabizon et a/, J. National Cancer Inst, 81 (19): 1484 (1989).
Diagnostic Applications of Antibodies Directed Against the Proteins of the Invention
In one embodiment, methods for the screening of antibodies that possess the desired specificity include, but are not limited to, enzyme linked immunosorbent assay (ELISA) and other immunologically mediated techniques known within the art. In a specific embodiment, selection of antibodies that are specific to a particular domain of an NOVX protein is facilitated by generation of hybridomas that bind to the fragment of an NOVX protein possessing such a domain. Thus, antibodies that are specific for a desired domain within an NOVX protein, or derivatives, fragments, analogs or homologs thereof, are also provided herein.
Antibodies directed against a NOVX protein of the invention may be used in methods known within the art relating to the localization and/or quantitation of a NOVX protein (e.g., for use in measuring levels of the NOVX protein within appropriate physiological samples, for use in diagnostic methods, for use in imaging the protein, and the like). In a given embodiment, antibodies specific to a NOVX protein, or derivative, fragment, analog or homolog thereof, that contain the antibody derived antigen binding domain, are utilized as pharmacologically active compounds (referred to hereinafter as "Therapeutics").
An antibody specific for a NOVX protein of the invention (e.g, a monoclonal antibody or a polyclonal antibody) can be used to isolate a NOVX polypeptide by standard techniques, such as immunoaffinity, chromatography or immunoprecipitation. An antibody to a NOVX polypeptide can facilitate the purification of a natural NOVX antigen from cells, or of a recombinantly produced NOVX antigen expressed in host cells. Moreover, such an anti-NOVX antibody can be used to detect the antigenic NOVX protein (e.g., in a cellular lysate or cell supernatant) in order to evaluate the abundance and pattern of expression of the antigenic NOVX protein. Antibodies directed against a NOVX protein can be used diagnostically to monitor protein levels in tissue as part of a clinical testing procedure, e.g., to, for example, determine the efficacy of a given treatment regimen. Detection can be
facilitated by coupling (i.e., physically linking) the antibody to a detectable substance. Examples of detectable substances include various enzymes, prosthetic groups, fluorescent ' materials, luminescent materials, bioluminescent materials, and radioactive materials. Examples of suitable enzymes include horseradish peroxidase, alkaline phosphatase, β-galactosidase, or acetylcholinesterase; examples of suitable prosthetic group complexes include streptavidin/biotin and avidin/biotin; examples of suitable fluorescent materials include umbelliferone, fluorescein, fluorescein isothiocyanate, rhodamine, dichlorotriazinylamine fluorescein, dansyl chloride or phycoerythrin; an example of a luminescent material includes luminol; examples of bioluminescent materials include luciferase, luciferin, and aequorin, and examples of suitable radioactive material include '^I, 13, 1, 35S or 3H.
Antibody Therapeutics
Antibodies of the invention, including polyclonal, monoclonal, humanized and fully human antibodies, may used as therapeutic agents. Such agents will generally be employed to treat or prevent a disease or pathology in a subject. An antibody preparation, preferably one having high specificity and high affinity for its target antigen, is administered to the subject and will generally have an effect due to its binding with the target. Such an effect may be one of two kinds, depending on the specific nature of the interaction between the given antibody molecule and the target antigen in question. In the first instance, administration of the antibody may abrogate or inhibit the binding of the target with an endogenous ligand to which it naturally binds. In this case, the antibody binds to the target and masks a binding site of the naturally occurring ligand, wherein the ligand serves as an effector molecule. Thus the receptor mediates a signal transduction pathway for which ligand is responsible. Alternatively, the effect may be one in which the antibody elicits a physiological result by virtue of binding to an effector binding site on the target molecule. In this case the target, a receptor having an endogenous ligand which may be absent or defective in the disease or pathology, binds the antibody as a surrogate effector ligand, initiating a receptor-based signal transduction event by the receptor. A therapeutically effective amount of an antibody of the invention relates generally to the amount needed to achieve a therapeutic objective. As noted above, this may be a binding interaction between the antibody and its target antigen that, in certain cases, interferes with
the functioning of the target, and in other cases, promotes a physiological response. The amount required to be administered will furthermore depend on the binding affinity of the antibody for its specific antigen, and will also depend on the rate at which an administered antibody is depleted from the free volume other subject to which it is administered. Common ranges for therapeutically effective dosing of an antibody or antibody fragment of the invention may be, by way of nonlimiting example, from about 0.1 mg/kg body weight to about 50 mg/kg body weight. Common dosing frequencies may range, for example, from twice daily to once a week.
Pharmaceutical Compositions of Antibodies Antibodies specifically binding a protein of the invention, as well as other molecules identified by the screening assays disclosed herein, can be administered for the treatment of various disorders in the form of pharmaceutical compositions. Principles and considerations involved in preparing such compositions, as well as guidance in the choice of components are provided, for example, in Remington : The Science And Practice Of Pharmacy 19th ed. (Alfonso R. Gennaro, et al, editors) Mack Pub. Co, Easton, Pa. : 1995; Drug Absorption Enhancement : Concepts, Possibilities, Limitations, And Trends, Harwood Academic Publishers, Langhorne, Pa, 1994; and Peptide And Protein Drug Delivery (Advances In Parenteral Sciences, Vol. 4), 1991 , M. Dekker, New York.
If the antigenic protein is intracellular and whole antibodies are used as inhibitors, internalizing antibodies are preferred. However, liposomes can also be used to deliver the antibody, or an antibody fragment, into cells. Where antibody fragments are used, the smallest inhibitory fragment that specifically binds to the binding domain of the target protein is preferred. For example, based upon the variable-region sequences of an antibody, peptide molecules can be designed that retain the ability to bind the target protein sequence. Such peptides can be synthesized chemically and/or produced by recombinant DNA technology. See, e.g., Marasco et al, Proc. Natl. Acad. Sci. USA, 90: 7889-7893 (1993). The formulation herein can also contain more than one active compound as necessary for the particular indication being treated, preferably those with complementary activities that do not adversely affect each other. Alternatively, or in addition, the composition can comprise an agent that enhances its function, such as, for example, a cytotoxic agent, cytokine, chemotherapeutic agent, or growth-inhibitory agent. Such molecules are suitably present in combination in amounts that are effective for the purpose intended.
The active ingredients can also be entrapped in microcapsules prepared, for example, by coacervation techniques or by interfacial polymerization, for example, hydroxymethylcellulose or gelatin-microcapsules and poly-(methylmethacrylate) microcapsules, respectively, in colloidal drug delivery systems (for example, liposomes, albumin microspheres, microemulsions, nano-particles, and nanocapsules) or in macroemulsions.
The formulations to be used for in vivo administration must be sterile. This is readily accomplished by filtration through sterile filtration membranes.
Sustained-release preparations can be prepared. Suitable examples of sustained-release preparations include semipermeable matrices of solid hydrophobic polymers containing the antibody, which matrices are in the form of shaped articles, e.g, films, or microcapsules. Examples of sustained-release matrices include polyesters, hydrogels (for example, poly(2-hydroxyethyl-methacrylate), or poly(vinylalcohol)), polylactides (U.S. Pat. No. 3,773,919), copolymers of L-glutamic acid and γ ethyl-L-glutamate, non-degradable ethylene-vinyl acetate, degradable lactic acid-glycolic acid copolymers such as the LUPRON DEPOT ™ (injectable microspheres composed of lactic acid-glycolic acid copolymer and leuprolide acetate), and poly-D-(-)-3-hydroxybutyric acid. While polymers such as ethylene-vinyl acetate and lactic acid-glycolic acid enable release of molecules for over 100 days, certain hydrogels release proteins for shorter time periods.
ELISA Assay
An agent for detecting an analyte protein is an antibody capable of binding to an analyte protein, preferably an antibody with a detectable label. Antibodies can be polyclonal, or more preferably, monoclonal. An intact antibody, or a fragment thereof (e.g, Fab or F(ab)2) can be used. The term "labeled", with regard to the probe or antibody, is intended to encompass direct labeling of the probe or antibody by coupling (i.e., physically linking) a detectable substance to the probe or antibody, as well as indirect labeling of the probe or antibody by reactivity with another reagent that is directly labeled. Examples of indirect labeling include detection of a primary antibody using a fluorescently-labeled secondary antibody and end-labeling of a DNA probe with biotin such that it can be detected with fluorescently-labeled streptavidin. The term "biological sample" is intended to include tissues, cells and biological fluids isolated from a subject, as well as tissues, cells and fluids
present within a subject. Included within the usage of the term "biological sample", therefore, is blood and a fraction or component of blood including blood serum, blood plasma, or lymph. That is, the detection method of the invention can be used to detect an analyte mRNA, protein, or genomic DNA in a biological sample in vitro as well as in vivo. For example, in vitro techniques for detection of an analyte mRNA include Northern hybridizations and in situ hybridizations. In vitro techniques for detection of an analyte protein include enzyme linked immunosorbent assays (ELISAs), Western blots, immunoprecipitations, and immunofluorescence. In vitro techniques for detection of an analyte genomic DNA include Southern hybridizations. Procedures for conducting immunoassays are described, for example in "ELISA: Theory and Practice: Methods in Molecular Biology", Vol. 42, J. R. Crowther (Ed.) Human Press, Totowa, NJ, 1995; "Immunoassay", E. Diamandis and T. Christopoulus, Academic Press, Inc, San Diego, CA, 1996; and "Practice and Thory of Enzyme Immunoassays", P. Tijssen, Elsevier Science Publishers, Amsterdam, 1985. Furthermore, in vivo techniques for detection of an analyte protein include introducing into a subject a labeled anti-an analyte protein antibody. For example, the antibody can be labeled with a radioactive marker whose presence and location in a subject can be detected by standard imaging techniques.
NOVX Recombinant Expression Vectors and Host Cells
Another aspect of the invention pertains to vectors, preferably expression vectors, containing a nucleic acid encoding a NOVX protein, or derivatives, fragments, analogs or homologs thereof. As used herein, the term "vector" refers to a nucleic acid molecule capable of transporting another nucleic acid to which it has been linked. One type of vector is a "plasmid", which refers to a circular double stranded DNA loop into which additional DNA segments can be ligated. Another type of vector is a viral vector, wherein additional DNA segments can be ligated into the viral genome. Certain vectors are capable of autonomous replication in a host cell into which they are introduced (e.g., bacterial vectors having a bacterial origin of replication and episomal mammalian vectors). Other vectors (e g , non-episomal mammalian vectors) are integrated into the genome of a host cell upon introduction into the host cell, and thereby are replicated along with the host genome. Moreover, certain vectors are capable of directing the expression of genes to which they are operatively-linked. Such vectors are referred to herein as "expression vectors". In general, expression vectors of utility in recombinant DNA techniques are often in the form of
plasmids. In the present specification, "plasmid" and "vector" can be used interchangeably as the plasmid is the most commonly used form of vector. However, the invention is intended to include such other forms of expression vectors, such as viral vectors (e.g., replication defective retroviruses, adenoviruses and adeno-associated viruses), which serve equivalent functions.
The recombinant expression vectors of the invention comprise a nucleic acid of the invention in a form suitable for expression of the nucleic acid in a host cell, which means that the recombinant expression vectors include one or more regulatory sequences, selected on the basis of the host cells to be used for expression, that is operatively-linked to the nucleic acid sequence to be expressed. Within a recombinant expression vector, "operably-linked" is intended to mean that the nucleotide sequence of interest is linked to the regulatory ' sequence(s) in a manner that allows for expression of the nucleotide sequence (e.g., in an in vitro transcription/translation system or in a host cell when the vector is introduced into the host cell). The term "regulatory sequence" is intended to includes promoters, enhancers and other expression control elements (e.g., polyadenylation signals). Such regulatory sequences are described, for example, in Goeddel, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990). Regulatory sequences include those that direct constitutive expression of a nucleotide sequence in many types of host cell and those that direct expression of the nucleotide sequence only in certain host cells (e.g., tissue-specific regulatory sequences). It will be appreciated by those skilled in the art that the design of the expression vector can depend on such factors as the choice of the host cell to be transformed, the level of expression of protein desired, etc. The expression vectors of the invention can be introduced into host cells to thereby produce proteins or peptides, including fusion proteins or peptides, encoded by nucleic acids as described herein (e.g., NOVX proteins, mutant forms of NOVX proteins, fusion proteins, etc.).
The recombinant expression vectors of the invention can be designed for expression of NOVX proteins in prokaryotic or eukaryotic cells. For example, NOVX proteins can be expressed in bacterial cells such as Escherichia coli, insect cells (using baculovirus expression vectors) yeast cells or mammalian cells. Suitable host cells are discussed further in Goeddel, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990). Alternatively, the recombinant expression vector can be
transcribed and translated in vitro, for example using T7 promoter regulatory sequences and T7 polymerase.
Expression of proteins in prokaryotes is most often carried out in Escherichia coli with vectors containing constitutive or inducible promoters directing the expression of either fusion or non-fusion proteins. Fusion vectors add a number of amino acids to a protein encoded therein, usually to the amino terminus of the recombinant protein. Such fusion vectors typically serve three purposes: (i) to increase expression of recombinant protein; (ii) to increase the solubility of the recombinant protein; and (iii) to aid in the purification of the recombinant protein by acting as a ligand in affinity purification. Often, in fusion expression vectors, a proteolytic cleavage site is introduced at the junction of the fusion moiety and the recombinant protein to enable separation of the recombinant protein from the fusion moiety subsequent to purification of the fusion protein. Such enzymes, and their cognate recognition sequences, include Factor Xa, thrombin and enterokinase. Typical fusion expression vectors include pGEX (Pharmacia Biotech Inc; Smith and Johnson, 1988. Gene 67: 31 -40), pMAL (New England Biolabs, Beverly, Mass.) and pRIT5 (Pharmacia, Piscataway, N.J.) that fuse glutathione S-transferase (GST), maltose E binding protein, or protein A, respectively, to the target recombinant protein.
Examples of suitable inducible non-fusion E. coli expression vectors include pTrc (Amrann et al, (1988) Gene 69:301-315) and pET 1 Id (Studier et al., GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego. Calif. (1990) 60-89).
One strategy to maximize recombinant protein expression in E. coli is to express the protein in a host bacteria with an impaired capacity to proteolytically cleave the recombinant protein. See, e.g., Gottesman, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990) 1 19-128. Another strategy is to alter the nucleic acid sequence of the nucleic acid to be inserted into an expression vector so that the individual codons for each amino acid are those preferentially utilized in E. coli (see, e.g., Wada, et al., 1992. Nucl. Acids Res. 20: 21 1 1 -21 18). Such alteration of nucleic acid sequences of the invention can be carried out by standard DNA synthesis techniques. In another embodiment, the NOVX expression vector is a yeast expression vector.
Examples of vectors for expression in yeast Saccharomyces cerivisae include pYepSecl (Baldari, et al, 1987. EMBO J. 6: 229-234), pMFa (Kurjan and Herskowitz, 1982. Cell 30:
933-943), pJRY88 (Schultz et al, 1987. Gem 54: 1 13-123), pYES2 (Invitrogen Corporation, San Diego, Calif), and picZ (InVitrogen Corp, San Diego, Calif).
Alternatively, NOVX can be expressed in insect cells using baculovirus expression vectors. Baculovirus vectors available for expression of proteins in cultured insect cells (e.g., SF9 cells) include the pAc series (Smith, et al, 1983. Mol. Cell. Biol. 3: 2156-2165) and the pVL series (Lucklow and Summers, 1989. Virology 170: 31 -39).
In yet another embodiment, a nucleic acid of the invention is expressed in mammalian cells using a mammalian expression vector. Examples of mammalian expression vectors include pCDM8 (Seed, 1987. Nature 329: 840) and pMT2PC (Kaufman, et al, 1987. EMBO J. 6: 187-195). When used in mammalian cells, the expression vector's control functions are often provided by viral regulatory elements. For example, commonly used promoters are derived from polyoma, adenovirus 2, cytomegalovirus, and simian virus 40. For other suitable expression systems for both prokaryotic and eukaryotic cells see, e.g., Chapters 16 and 17 of Sambrook, et al, MOLECULAR CLONING: A LABORATORY MANUAL. 2nd ed. Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y, 1989.
In another embodiment, the recombinant mammalian expression vector is capable of directing expression of the nucleic acid preferentially in a particular cell type (e.g., tissue-specific regulatory elements are used to express the nucleic acid). Tissue-specific regulatory elements are known in the art. Non-limiting examples of suitable tissue-specific promoters include the albumin promoter (liver-specific; Pinkert, et al, 1987. Genes Dev. 1 : 268-277), lymphoid-specific promoters (Calame and Eaton, 1988. .JV. Immunol. 43: 235-275), in particular promoters of T cell receptors (Winoto and Baltimore, 1989. EMBO J. 8: 729-733) and immunoglobulins (Banerji, et al, 1983. Cell 33: 729-740; Queen and Baltimore, 1983. Cell 33: 741-748), neuron-specific promoters (e.g., the neurofilament promoter; Byrne and Ruddle, 1989. Proc. Natl. Acad. Sci. USA 86: 5473-5477), pancreas-specific promoters (Edlund, et al, 1985. Science 230: 912-916), and mammary gland-specific promoters (e.g., milk whey promoter; U.S. Pat. No. 4,873,3 16 and European Application Publication No. 264, 166). Developmentally-regulated promoters are also encompassed, e.g., the murine hox promoters (Kessel and Grass. 1990. Science 249: 374-379) and the α-fetoprotein promoter (Campes and Tilghman, 1989. Genes Dev. 3: 537-546).
The invention further provides a recombinant expression vector comprising a DNA molecule of the invention cloned into the expression vector in an antisense orientation. That is, the DNA molecule is operatively-linked to a regulatory sequence in a manner that allows for expression (by transcription of the DNA molecule) of an RNA molecule that is antisense to NOVX mRNA. Regulatory sequences operatively linked to a nucleic acid cloned in the antisense orientation can be chosen that direct the continuous expression of the antisense RNA molecule in a variety of cell types, for instance viral promoters and/or enhancers, or regulatory sequences can be chosen that direct constitutive, tissue specific or cell type specific expression of antisense RNA. The antisense expression vector can be in the form of a recombinant plasmid, phagemid or attenuated virus in which antisense nucleic acids are produced under the control of a high efficiency regulatory region, the activity of which can be determined by the cell type into which the vector is introduced. For a discussion of the regulation of gene expression using antisense genes see, e.g., Weintraub, et al, "Antisense RNA as a molecular tool for genetic analysis," Reviews-Trends in Genetics, Vol. 1 ( 1 )'ι 986. Another aspect of the invention pertains to host cells into which a recombinant expression vector of the invention has been introduced. The terms "host cell" and "recombinant host cell" are used interchangeably herein. It is understood that such terms refer not only to the particular subject cell but also to the progeny or potential progeny of such a cell. Because certain modifications may occur in succeeding generations due to either mutation or environmental influences, such progeny may not, in fact, be identical to the parent cell, but are still included within the scope of the term as used herein.
A host cell can be any prokaryotic or eukaryotic cell. For example, NOVX protein can be expressed in bacterial cells such as E. coli, insect cells, yeast or mammalian cells (such as Chinese hamster ovary cells (CHO) or COS cells). Other suitable host cells are known to those skilled in the art.
Vector DNA can be introduced into prokaryotic or eukaryotic cells via conventional transformation or transfection techniques. As used herein, the terms "transformation" and "transfection" are intended to refer to a variety of art-recognized techniques for introducing foreign nucleic acid (e g, DNA) into a host cell, including calcium phosphate or calcium chloride co-precipitation, DΕAΕ-dextran-mediated transfection, lipofection, or electroporation. Suitable methods for transforming or transfecting host cells can be found in Sambrook, et al. (MOLECULAR CLONING: A LABORATORY MANUAL. 2nd ed. Cold Spring
Harbor Laboratory, Cold Spring Harbor Laboratory Press. Cold Spring Harbor, N.Y, 1989), and other laboratory manuals.
For stable transfection of mammalian cells, it is known that, depending upon the expression vector and transfection technique used, only a small fraction of cells may integrate the foreign DNA into their genome. In order to identify and select these integrants, a gene that encodes a selectable marker (e.g., resistance to antibiotics) is generally introduced into the host cells along with the gene of interest. Various selectable markers include those that confer resistance to drugs, such as G418, hygromycin and methotrexate. Nucleic acid encoding a selectable marker can be introduced into a host cell on the same vector as that encoding NOVX or can be introduced on a separate vector. Cells stably transfected with the introduced nucleic acid can be identified by drug selection (e.g., cells that have incorporated the selectable marker gene will survive, while the other cells die).
A host cell of the invention, such as a prokaryotic or eukaryotic host cell in culture, can be used to produce (i.e., express) NOVX protein. Accordingly, the invention further provides methods for producing NOVX protein using the host cells of the invention. In one embodiment, the method comprises culturing the host cell of invention (into which a recombinant expression vector encoding NOVX protein has been introduced) in a suitable medium such that NOVX protein is produced. In another embodiment, the method further comprises isolating NOVX protein from the medium or the host cell. Transgenic NOVX Animals
The host cells of the invention can also be used to produce non-human transgenic animals. For example, in one embodiment, a host cell of the invention is a fertilized oocyte or an embryonic stem cell into which NOVX protein-coding sequences have been introduced. Such host cells can then be used to create non-human transgenic animals in which exogenous NOVX sequences have been introduced into their genome or homologous recombinant animals in which endogenous NOVX sequences have been altered. Such animals are useful for studying the function and/or activity of NOVX protein and for identifying and/or evaluating modulators of NOVX protein activity. As used herein, a "transgenic animal" is a non-human animal, preferably a mammal, more preferably a rodent such as a rat or mouse, in which one or more of the cells of the animal includes a transgene. Other examples of transgenic animals include non-human primates, sheep, dogs, cows, goats, chickens, amphibians, etc. A transgene is exogenous DNA that is integrated into the genome of a cell
from which a transgenic animal develops and that remains in the genome of the mature animal, thereby directing the expression of an encoded gene product in one or more cell types or tissues of the transgenic animal. As used herein, a "homologous recombinant animal" is a non-human animal, preferably a mammal, more preferably a mouse, in which an endogenous NOVX gene has been altered by homologous recombination between the endogenous gene and an exogenous DNA molecule introduced into a cell of the animal, e.g., an embryonic cell of the animal, prior to development of the animal.
A transgenic animal of the invention can be created by introducing NOVX-encoding nucleic acid into the male pronuclei of a fertilized oocyte (e.g., by microinjection, retroviral infection) and allowing the oocyte to develop in a pseudopregnant female foster animal. The human NOVX cDNA sequences, i.e., any one of SEQ ID NO:2w-l , wherein n is an integer between 1 and 172, can be introduced as a transgene into the genome of a non-human animal. Alternatively, a non-human homologue of the human NOVX gene, such as a mouse NOVX gene, can be isolated based on hybridization to the human NOVX cDNA (described further supra) and used as a transgene. Intronic sequences and polyadenylation signals can also be included in the transgene to increase the efficiency of expression of the transgene. A tissue-specific regulatory sequence(s) can be operably-linked to the NOVX transgene to direct expression of NOVX protein to particular cells. Methods for generating transgenic animals via embryo manipulation and microinjection, particularly animals such as mice, have become conventional in the art and are described, for example, in U.S. Patent Nos. 4,736,866; 4,870,009; and 4,873, 191 ; and Hogan, 1986. In: MANIPULA I INC. I I IE MOUSE EMBRYO, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. Similar methods are used for production of other transgenic animals. A transgenic founder animal can be identified based upon the presence of the NOVX transgene in its genome and/or expression of NOVX mRNA in tissues or cells of the animals. A transgenic founder animal can then be used to breed additional animals carrying the transgene. Moreover, transgenic animals carrying a transgene-encoding NOVX protein can further be bred to other transgenic animals carrying other transgenes.
To create a homologous recombinant animal, a vector is prepared which contains at least a portion of a NOVX gene into which a deletion, addition or substitution has been introduced to thereby alter, e.g., functionally disrupt, the NOVX gene. The NOVX gene can be a human gene (e , the cDNA of any one of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172), but more preferably, is a non-human homologue of a human NOVX
gene. For example, a mouse homologue of human NOVX gene of SEQ ID NO:2«- l , wherein n is an integer between 1 and 172, can be used to construct a homologous recombination vector suitable for altering an endogenous NOVX gene in the mouse genome. In one embodiment, the vector is designed such that, upon homologous recombination, the endogenous NOVX gene is functionally disrupted (i.e., no longer encodes a functional protein; also referred to as a "knock out" vector).
Alternatively, the vector can be designed such that, upon homologous recombination, the endogenous NOVX gene is mutated or otherwise altered but still encodes functional protein (e.g., the upstream regulatory region can be altered to thereby alter the expression of the endogenous NOVX protein). In the homologous recombination vector, the altered portion of the NOVX gene is flanked at its 5'- and 3'-termini by additional nucleic acid of the NOVX gene to allow for homologous recombination to occur between the exogenous NOVX gene carried by the vector and an endogenous NOVX gene in an embryonic stem cell. The additional flanking NOVX nucleic acid is of sufficient length for successful homologous recombination with the endogenous gene. Typically, several kilobases of flanking DNA
(both at the 5'- and 3'-termini) are included in the vector. See, e.g., Thomas, et al, 1987. Cell 51 : 503 for a description of homologous recombination vectors. The vector is ten introduced into an embryonic stem cell line (e.g., by electroporation) and cells in which the introduced NOVX gene has homologously-recombined with the endogenous NOVX gene are selected. See, e.g., i, et al, 1992. Cell 69: 915.
The selected cells arc then injected into a blastocyst of an animal (e.g., a mouse) to form aggregation chimeras. See, e.g., Bradley, 1987. In: TERATOCARCINOMAS AND EMBRYONIC STEM CELLS: A PRACTICAL APPROACH, Robertson, ed. IRL, Oxford, pp. 1 13-152. A chimeric embryo can then be implanted into a suitable pseudopregnant female foster animal and the embryo brought to term. Progeny harboring the homologously-recombined DNA in their germ cells can be used to breed animals in which all cells of the animal contain the homologously-recombined DNA by germline transmission of the transgene. Methods for constructing homologous recombination vectors and homologous recombinant animals are described further in Bradley, 1991. Curr. Opin. Biotechnol. 2: 823-829; PCT International Publication Nos.: WO 90/1 1354; WO 91/01 140; WO 92/0968: and WO 93/04169.
In another embodiment, transgenic non-humans animals can be produced that contain selected systems that allow for regulated expression of the transgene. One example of such a
system is the cre/loxP recombinase system of bacteriophage PI . For a description of the cre/loxP recombinase system, See, e.g., Lakso, et al., 1992. Proc. Natl. Acad. Sci. USA 89: 6232-6236. Another example of a recombinase system is the FLP recombinase system of Saccharomyces cerevisiae. See. O'Gorman, et al, 1991. Science 251 : 1351 -1355. If a cre/loxP recombinase system is used to regulate expression of the transgene, animals containing transgenes encoding both the Cre recombinase and a selected protein are required. Such animals can be provided through the construction of "double" transgenic animals, e.g., by mating two transgenic animals, one containing a transgene encoding a selected protein and the other containing a transgene encoding a recombinase. Clones of the non-human transgenic animals described herein can also be produced according to the methods described in Wilmut, et al., 1997. Nature 385: 810-813. In brief, a ceil (e.g., a somatic cell) from the transgenic animal can be isolated and induced to exit the growth cycle and enter Go phase. The quiescent cell can then be fused, e.g., through the use of electrical pulses, to an enucleated oocyte from an animal of the same species from which the quiescent cell is isolated. The reconstructed oocyte is then cultured such that it develops to morula or blastocyte and then transferred to pseudopregnant female foster animal. The offspring borne of this female foster animal will be a clone of the animal from which the cell (e.g., the somatic cell) is isolated.
Pharmaceutical Compositions The NOVX nucleic acid molecules, NOVX proteins, and anti-NOVX antibodies (also referred to herein as "active compounds") of the invention, and derivatives, fragments, analogs and homologs thereof, can be incorporated into pharmaceutical compositions suitable for administration. Such compositions typically comprise the nucleic acid molecule, protein, or antibody and a pharmaceutically acceptable carrier. As used herein, "pharmaceutically acceptable carrier" is intended to include any and all solvents, dispersion media, coatings, antibacterial and antifungal agents, isotonic and absorption delaying agents, and the like, compatible with pharmaceutical administration. Suitable carriers are described in the most recent edition of Remington's Pharmaceutical Sciences, a standard reference text in the field, which is incorporated herein by reference. Preferred examples of such carriers or diluents include, but are not limited to, water, saline, finger's solutions, dextrose solution, and 5%> human serum albumin. Liposomes and non-aqueous vehicles such as fixed oils may also be used. The use of such media and agents for pharmaceutically active substances is well
known in the art. Except insofar as any conventional media or agent is incompatible with the active compound, use thereof in the compositions is contemplated. Supplementary active compounds can also be incorporated into the compositions.
A pharmaceutical composition of the invention is formulated to be compatible with its intended route of administration. Examples of routes of administration include parenteral, e.g., intravenous, intradermal, subcutaneous, oral (e.g., inhalation), transdermal (i.e., topical), transmucosal, and rectal administration. Solutions or suspensions used for parenteral, intradermal, or subcutaneous application can include the following components: a sterile diluent such as water for injection, saline solution, fixed oils, polyethylene glycols, glycerine, propylene glycol or other synthetic solvents; antibacterial agents such as benzyl alcohol or methyl parabens; antioxidants such as ascorbic acid or sodium bisulfite; chelating agents such as ethylenediaminetetraacetic acid (EDTA); buffers such as acetates, citrates or phosphates, and agents for the adjustment of tonicity such as sodium chloride or dextrose. The pH can be adjusted with acids or bases, such as hydrochloric acid or sodium hydroxide. The parenteral preparation can be enclosed in ampoules, disposable syringes or multiple dose vials made of glass or plastic.
Pharmaceutical compositions suitable for injectable use include sterile aqueous solutions (where water soluble) or dispersions and sterile powders for the extemporaneous preparation of sterile injectable solutions or dispersion. For intravenous administration, suitable carriers include physiological saline, bacteriostatic water, Cremophor EL (BASF, Parsippany, N.J.) or phosphate buffered saline (PBS). In all cases, the composition must be sterile and should be fluid to the extent that easy syringeability exists. It must be stable under the conditions of manufacture and storage and must be preserved against the contaminating action of microorganisms such as bacteria and fungi. The carrier can be a solvent or dispersion medium containing, for example, water, ethanol, polyol (for example, glycerol, propylene glycol, and liquid polyethylene glycol, and the like), and suitable mixtures thereof. The proper fluidity can be maintained, for example, by the use of a coating such as lecithin, by the maintenance of the required particle size in the case of dispersion and by the use of surfactants. Prevention of the action of microorganisms can be achieved by various antibacterial and antifungal agents, for example, parabens, chlorobutanol, phenol, ascorbic acid, thimerosal, and the like. In many cases, it will be preferable to include isotonic agents, for example, sugars, polyalcohols such as manitol, sorbitol, sodium chloride in the composition. Prolonged absorption of the injectable compositions can be brought about by
including in the composition an agent which delays absorption, for example, aluminum monostearate and gelatin.
Sterile injectable solutions can be prepared by incorporating the active compound (e.g., a NOVX protein or anti-NOVX antibody) in the required amount in an appropriate solvent with one or a combination of ingredients enumerated above, as required, followed by filtered sterilization. Generally, dispersions are prepared by incorporating the active compound into a sterile vehicle that contains a basic dispersion medium and the required other ingredients from those enumerated above. In the case of sterile powders for the preparation of sterile injectable solutions, methods of preparation are vacuum drying and freeze-drying that yields a powder of the active ingredient plus any additional desired ingredient from a previously sterile-filtered solution thereof.
Oral compositions generally include an inert diluent or an edible carrier. They can be enclosed in gelatin capsules or compressed into tablets. For the purpose of oral therapeutic administration, the active compound can be incorporated with excipients and used in tne form of tablets, troches, or capsules. Oral compositions can also be prepared using a fluid carrier for use as a mouthwash, wherein the compound in the fluid carrier is applied orally and swished and expectorated or swallowed. Pharmaceutically compatible binding agents, and/or adjuvant materials can be included as part of the composition. The tablets, pills, capsules, troches and the like can contain any of the following ingredients, or compounds of a similar nature: a binder such as microcrystalline cellulose, gum tragacanth or gelatin; an excipient such as starch or lactose, a disintegrating agent such as alginic acid, Primogcl, or corn starch; a lubricant such as magnesium stearate or Sterotes; a glidant such as colloidal silicon dioxide; a sweetening agent such as sucrose or saccharin; or a flavoring agent such as peppermint, methyl salicylate, or orange flavoring. For administration by inhalation, the compounds are delivered in the form of an aerosol spray from pressured container or dispenser which contains a suitable propellant, e.g., a gas such as carbon dioxide, or a nebulizer.
Systemic administration can also be by transmucosal or transdermal means. For transmucosal or transdermal administration, penetrants appropriate to the barrier to be permeated are used in the formulation. Such penetrants are generally known in the art, and include, for example, for transmucosal administration, detergents, bile salts, and fusidic acid derivatives. Transmucosal administration can be accomplished through the use of nasal
sprays or suppositories. For transdermal administration, the active compounds are formulated into ointments, salves, gels, or creams as generally known in the art.
The compounds can also be prepared in the form of suppositories (e.g., with conventional suppository bases such as cocoa butter and other glycerides) or retention enemas for rectal delivery.
In one embodiment, the active compounds are prepared with carriers that will protect the compound against rapid elimination from the body, such as a controlled release formulation, including implants and microencapsulated delivery systems. Biodegradable, biocompatible polymers can be used, such as ethylene vinyl acetate, polyanhydrides, polyglycolic acid, collagen, polyorthoesters, and polylactic acid. Methods for preparation of such formulations will be apparent to those skilled in the art. The materials can also be obtained commercially from Alza Corporation and Nova Pharmaceuticals, Inc. Liposomal suspensions (including liposomes targeted to infected cells with monoclonal antibodies to viral antigens) can also be used as pharmaceutically acceptable carriers. These can be prepared according to methods known to those skilled in the art, for example, as described in U.S. Patent No. 4,522,81 1.
It is especially advantageous to formulate oral or parenteral compositions in dosage unit form for ease of administration and uniformity of dosage. Dosage unit form as used herein refers to physically discrete units suited as unitary dosages for the subject to be treated; each unit containing a predetermined quantity of active compound calculated to produce the desired therapeutic effect in association with the required pharmaceutical carrier. The specification for the dosage unit forms of the invention are dictated by and directly dependent on the unique characteristics of the active compound and the particular therapeutic effect to be achieved, and the limitations inherent in the art of compounding such an active compound for the treatment of individuals.
The nucleic acid molecules of the invention can be inserted into vectors and used as gene therapy vectors. Gene therapy vectors can be delivered to a subject by, for example, intravenous injection, local administration (see. e.g., U.S. Patent No. 5,328,470) or by stereotactic injection (see, e.g., Chen, et al, 1994. Proc. Natl. Acad. Sci. USA 91 : 3054-3057). The pharmaceutical preparation of the gene therapy vector can include the gene therapy vector in an acceptable diluent, or can comprise a slow release matrix in which the gene delivery vehicle is imbedded. Alternatively, where the complete gene delivery vector
can be produced intact from recombinant cells, e.g., retroviral vectors, the pharmaceutical preparation can include one or more cells that produce the gene delivery system.
The pharmaceutical compositions can be included in a container, pack, or dispenser together with instructions for administration. Screening and Detection Methods
The isolated nucleic acid molecules of the invention can be used to express NOVX protein (e.g., via a recombinant expression vector in a host cell in gene therapy applications), to detect NOVX mRNA (e.g., in a biological sample) or a genetic lesion in a NOVX gene, and to modulate NOVX activity, as described further, below. In addition, the NOVX proteins can be used to screen drugs or compounds that modulate the NOVX protein activity or expression as well as to treat disorders characterized by insufficient or excessive production of NOVX protein or production of NOVX protein forms that have decreased or aberrant activity compared to NOVX wild-type protein (e.g.; diabetes (regulates insulin release); obesity (binds and transport lipids); metabolic disturbances associated with obesity, the metabolic syndrome X as well as anorexia and wasting disorders associated with chronic diseases and various cancers, and infectious disease(possesses anti-microbial activity) and the various dyslipidemias. In addition, the anti-NOVX antibodies of the invention can be used to detect and isolate NOVX proteins and modulate NOVX activity. In yet a further aspect, the invention can be used in methods to influence appetite, absorption of nutrients and the disposition of metabolic substrates in both a positive and negative fashion.
The invention further pertains to novel agents identified by the screening assays described herein and uses thereof for treatments as described, supra.
Screening Assays
The invention provides a method (also referred to herein as a "screening assay") for identifying modulators, i.e., candidate or test compounds or agents (e.g., peptides, peptidomimetics, small molecules or other drugs) that bind to NOVX proteins or have a stimulatory or inhibitory effect on, e.g., NOVX protein expression or NOVX protein activity. The invention also includes compounds identified in the screening assays described herein. In one embodiment, the invention provides assays for screening candidate or test compounds which bind to or modulate the activity of the membrane-bound form of a NOVX protein or polypeptide or biologically-active portion thereof. The test compounds of the invention can be obtained using any of the numerous approaches in combinatorial library
methods known in the art, including: biological libraries; spatially addressable parallel solid phase or solution phase libraries; synthetic library methods requiring deconvolution; the "one-bead one-compound" library method; and synthetic library methods using affinity chromatography selection. The biological library approach is limited to peptide libraries, while the other four approaches are applicable to peptide, non-peptide oligomer or small molecule libraries of compounds. See, e.g., Lam, 1997. Anticancer Drug Design 12: 145.
A "small molecule" as used herein, is meant to refer to a composition that has a molecular weight of less than about 5 kD and most preferably less than about 4 kD. Small molecules can be, e.g., nucleic acids, peptides, polypeptides, peptidomimetics, carbohydrates, lipids or other organic or inorganic molecules. Libraries of chemical and/or biological mixtures, such as fungal, bacterial, or algal extracts, are known in the art and can be screened with any of the assays of the invention.
Examples of methods for the synthesis of molecular libraries can be found in the art, for example in: DeWitt, et al, 1993. Proc. Natl. Acad. Sci. U.S.A. 90: 6909; Erb, et al, 1994. Proc. Natl. Acad. Sci. U.S.A. 91 : 1 1422; Zuckermann, et al, 1994. J. Med. Chem. 37: 2678; Cho, et al., 1993. Science 261 : 1303; Carrel I, et al, \ 994. Angew. Chem. Int. Ed. Engl. 33: 2059; Carell, et al, 1994. Angew. Chem. Int. Ed. Engl. 33: 2061 ; and Gallop, et al, 1994. J. Med. Chem. 37: 1233.
Libraries of compounds may be presented in solution (e.g., Houghten, 1992. Biotechniques 13: 412-421), or on beads (Lam, 1991 . Nature 354: 82-84), on chips (Fodor, 1993. Nature 364: 555-556), bacteria (Ladner, U.S. Patent No. 5,223,409), spores (Ladner, U.S. Patent 5,233,409), plasmids (Cull, et al, 1992. Proc. Natl. Acad. Sci. USA 89: 1865-1869) or on phage (Scott and Smith, 1990. Science 249: 386-390; Devlin, 1990. Science 249: 404-406; Cwirla, et «/, 1990. Proc. Natl. Acad. Sci. U.S.A. 87: 6378-6382; Felici, 1991. J. Mol. Biol. 222: 301 -310; Ladner, U.S. Patent No. 5,233,409.).
In one embodiment, an assay is a cell-based assay in which a cell which expresses a membrane-bound form of NOVX protein, or a biologically-active portion thereof, on the cell surface is contacted with a test compound and the ability of the test compound to bind to a NOVX protein determined. The cell, for example, can of mammalian origin or a yeast cell. Determining the ability of the test compound to bind to the NOVX protein can be accomplished, for example, by coupling the test compound with a radioisotope or enzymatic label such that binding of the test compound to the NOVX protein or biologically-active portion thereof can be determined by detecting the labeled compound in a complex. For
example, test compounds can be labeled with % J3S, l4C, or 3H, either directly or indirectly, and the radioisotope detected by direct counting of radioemission or by scintillation counting. Alternatively, test compounds can be enzymatically-labeled with, for example, horseradish peroxidase, alkaline phosphatase, or luciferase, and the enzymatic label detected by determination of conversion of an appropriate substrate to product. In one embodiment, the assay comprises contacting a cell which expresses a membrane-bound form of NOVX protein, or a biologically-active portion thereof, on the cell surface with a known compound which binds NOVX to form an assay mixture, contacting the assay mixture with a test compound, and determining the ability of the test compound to interact with a NOVX protein, wherein determining the ability of the test compound to interact with a NOVX protein comprises determining the ability of the test compound to preferentially bind to NOVX protein or a biologically-active portion thereof as compared to the known compound.
In another embodiment, an assay is a cell-based assay comprising contacting a cell expressing a membrane-bound form of NOVX protein, or a biologically-active portion thereof, on the cell surface with a test compound and determining the ability of the test compound to modulate (e.g., stimulate or inhibit) the activity of the NOVX protein or biologically-active portion thereof. Determining the ability of the test compound to modulate the activity of NOVX or a biologically-active portion thereof can be accomplished, for example, by determining the ability of the NOVX protein to bind to or interact with a NOVX target molecule. As used herein, a "target molecule" is a molecule with which a NOVX protein binds or interacts in nature, for example, a molecule on the surface of a cell which expresses a NOVX interacting protein, a molecule on the surface of a second cell, a molecule in the extracellular milieu, a molecule associated with the internal surface of a cell membrane or a cytoplasmic molecule. A NOVX target molecule can be a non-NOVX molecule or a NOVX protein or polypeptide of the invention. In one embodiment, a NOVX target molecule is a component of a signal transduction pathway that facilitates transduction of an extracellular signal (e.g. a signal generated by binding of a compound to a membrane-bound NOVX molecule) through the cell membrane and into the cell. The target, for example, can be a second intercellular protein that has catalytic activity or a protein that facilitates the association of downstream signaling molecules with NOVX.
Determining the ability of the NOVX protein to bind to or interact with a NOVX target molecule can be accomplished by one of the methods described above for determining direct binding. In one embodiment, determining the ability of the NOVX protein to bind to or
interact with a NOVX target molecule can be accomplished by determining the activity of the target molecule. For example, the activity of the target molecule can be determined by detecting induction of a cellular second messenger of the target (i.e. intracellular Ca2+, diacylglycerol, IP3, etc.), detecting catalytic/enzymatic activity of the target an appropriate substrate, detecting the induction of a reporter gene (comprising a NOVX-responsive regulatory element operatively linked to a nucleic acid encoding a detectable marker, e.g., luciferase), or detecting a cellular response, for example, cell survival, cellular differentiation, or cell proliferation.
In yet another embodiment, an assay of the invention is a cell-free assay comprising contacting a NOVX protein or biologically-active portion thereof with a test compound and determining the ability of the test compound to bind to the NOVX protein or biologically-active portion thereof. Binding of the test compound to the NOVX protein can be determined either directly or indirectly as described above. In one such embodiment, the assay comprises contacting the NOVX protein or biologically-active portion thereof with a known compound which binds NOVX to form an assay mixture, contacting the assay mixture with a test compound, and determining the ability of the test compound to interact with a NOVX protein, wherein determining the ability of the test compound to interact with a NOVX protein comprises determining the ability of the test compound to preferentially bind to NOVX or biologically-active portion thereof as compared to the known compound. In still another embodiment, an assay is a cell-free assay comprising contacting
NOVX protein or biologically-active portion thereof with a test compound and determining the ability of the test compound to modulate (e.g. stimulate or inhibit) the activity of the NOVX protein or biologically-active portion thereof. Determining the ability of the test compound to modulate the activity of NOVX can be accomplished, for example, by determining the ability of the NOVX protein to bind to a NOVX target molecule by one of the methods described above for determining direct binding. In an alternative embodiment, determining the ability of the test compound to modulate the activity of NOVX protein can be accomplished by determining the ability of the NOVX protein further modulate a NOVX target molecule. For example, the catalytic/enzymatic activity of the target molecule on an appropriate substrate can be determined as described, supra.
In yet another embodiment, the cell-free assay comprises contacting the NOVX protein or biologically-active portion thereof with a known compound which binds NOVX protein to form an assay mixture, contacting the assay mixture with a test compound, and
determining the ability of the test compound to interact with a NOVX protein, wherein determining the ability of the test compound to interact with a NOVX protein comprises determining the ability of the NOVX protein to preferentially bind to or modulate the activity of a NOVX target molecule. The cell-free assays of the invention are amenable to use of both the soluble form or the membrane-bound form of NOVX protein. In the case of cell-free assays comprising the membrane-bound form of NOVX protein, it may be desirable to utilize a solubilizing agent such that the membrane-bound form of NOVX protein is maintained in solution. Examples of such solubilizing agents include non-ionic detergents such as n-octylglucoside, n-dodecylglucoside, n-dodecylmaltoside, octanoyl-N-methylglucamide, decanoyl-N-methylglucamide, Triton® X-100, Triton® X-l 14, Thesit®, lsotridecypoly(ethylene glycol ether)n, N-dodecyl~N,N-dimethyl-3-ammonio-1 -propane sulfonate, 3-(3-cholamidopropyl) dimethylamminiol-1 -propane sulfonate (CHAPS), or 3-(3-cholamidopropyl)dimethylamminiol-2-hydroxy-l -propane sulfonate (CHAPSO)._ In more than one embodiment of the above assay methods of the invention, it may be desirable to immobilize either NOVX protein or its target molecule to facilitate separation of complexed from uncomplexed forms of one or both of the proteins, as well as to accommodate automation of the assay. Binding of a test compound to NOVX protein, or interaction of NOVX protein with a target molecule in the presence and absence of a candidate compound, can be accomplished in any vessel suitable for containing the reactants. Examples of such vessels include microtiter plates, test tubes, and micro-centrifuge tubes. In one embodiment, a fusion protein can be provided that adds a domain that allows one or both of the proteins to be bound to a matrix. For example, GST-NOVX fusion proteins or GST-target fusion proteins can be adsorbed onto glutathione sepharose beads (Sigma Chemical, St. Louis, MO) or glutathione derivatized microtiter plates, that are then combined with the test compound or the test compound and either the non-adsorbed target protein or NOVX protein, and the mixture is incubated under conditions conducive to complex formation (e.g., at physiological conditions for salt and pH). Following incubation, the beads or microtiter plate wells are washed to remove any unbound components, the matrix immobilized in the case of beads, complex determined either directly or indirectly, for example, as described, supra. Alternatively, the complexes can be dissociated from the matrix, and the level of NOVX protein binding or activity determined using standard techniques.
Other techniques for immobilizing proteins on matrices can also be used in the screening assays of the invention. For example, either the NOVX protein or its target molecule can be immobilized utilizing conjugation of biotin and streptavidin. Biotinylated NOVX protein or target molecules can be prepared from biotin-NHS (N-hydroxy-succinimide) using techniques well-known within the art (e.g., biotinylation kit, Pierce Chemicals, Rockford, 111.), and immobilized in the wells of streptavidin-coated 96 well plates (Pierce Chemical). Alternatively, antibodies reactive with NOVX protein or target molecules, but which do not interfere with binding of the NOVX protein to its target molecule, can be derivatized to the wells of the plate, and unbound target or NOVX protein trapped in the wells by antibody conjugation. Methods for detecting such complexes, in addition to those described above for the GST-immobilized complexes, include immunodetection of complexes using antibodies reactive with the NOVX protein or target molecule, as well as enzyme-linked assays that rely on detecting an enzymatic activity associated with the NOVX protein or target molecule. In another embodiment, modulators of NOVX protein expression are identified in a method wherein a cell is contacted with a candidate compound and the expression of NOVX mRNA or protein in the cell is determined. The level of expression of NOVX mRNA or protein in the presence of the candidate compound is compared to the level of expression of NOVX mRNA or protein in the absence of the candidate compound. The candidate compound can then be identified as a modulator of NOVX mRNA or protein expression based upon this comparison. For example, when expression of NOVX mRNA or protein is greater (i.e., statistically significantly greater) in the presence of the candidate compound than in its absence, the candidate compound is identified as a stimulator of NOVX mRNA or protein expression. Alternatively, when expression of NOVX mRNA or protein is less (statistically significantly less) in the presence of the candidate compound than in its absence, the candidate compound is identified as an inhibitor of NOVX mRNA or protein expression. The level of NOVX mRNA or protein expression in the cells can be determined by methods described herein for detecting NOVX mRNA or protein.
In yet another aspect of the invention, the NOVX proteins can be used as "bait proteins" in a two-hybrid assay or three hybrid assay (see, e.g., U.S. Patent No. 5,283,3 17; Zervos, et al, 1993. Cell 72: 223-232; Madura, et al, 1993. J. Biol. Chem. 268: 12046-12054; Bartel, et al, 1993. Biotechniques 14: 920-924; Iwabuchi, et al, 1993. Oncogene 8: 1693- 1696; and Brent WO 94/10300), to identify other proteins that bind to or
interact with NOVX ("NOVX-binding proteins" or "NOVX-bp") and modulate NOVX activity. Such NOVX-binding proteins are also involved in the propagation of signals by the NOVX proteins as, for example, upstream or downstream elements of the NOVX pathway. The two-hybrid system is based on the modular nature of most transcription factors, which consist of separable DNA-binding and activation domains. Briefly, the assay utilizes two different DNA constructs. In one construct, the gene that codes for NOVX is fused to a gene encoding the DNA binding domain of a known transcription factor (e.g., GAL-4). In the other construct, a DNA sequence, from a library of DNA sequences, that encodes an unidentified protein ("prey" or "sample") is fused to a gene that codes for the activation domain of the known transcription factor. If the "bait" and the "prey" proteins are able to interact, in vivo, forming a NOVX-dependent complex, the DNA-binding and activation domains of the transcription factor are brought into close proximity. This proximity allows transcription of a reporter gene (e.g., LacZ) that is operably linked to a transcriptional regulatory site responsive to the transcription factor. Expression of the reporter gene can be detected and cell colonies containing the functional transcription factor can be isolated and used to obtain the cloned gene that encodes the protein which interacts with NOVX.
The invention further pertains to novel agents identified by the aforementioned screening assays and uses thereof for treatments as described herein.
Detection Assays Portions or fragments of the cDNA sequences identified herein (and the corresponding complete gene sequences) can be used in numerous ways as polynucleotide reagents. By way of example, and not of limitation, these sequences can be used to: (/) map their respective genes on a chromosome; and, thus, locate gene regions associated with genetic disease; (ii) identify an individual from a minute biological sample (tissue typing); and (iii) aid in forensic identification of a biological sample. Some of these applications are described in the subsections, below.
Chromosome Mapping
Once the sequence (or a portion of the sequence) of a gene has been isolated, this sequence can be used to map the location of the gene on a chromosome. This process is called chromosome mapping. Accordingly, portions or fragments of the NOVX sequences of SEQ ID NO:2«-l , wherein n is an integer between 1 and 172, or fragments or derivatives thereof, can be used to map the location of the NOVX genes, respectively, on a chromosome.
The mapping of the NOVX sequences to chromosomes is an important first step in correlating these sequences with genes associated with disease.
Briefly. NOVX genes can be mapped to chromosomes by preparing PCR primers (preferably 15-25 bp in length) from the NOVX sequences. Computer analysis of the NOVX, sequences can be used to rapidly select primers that do not span more than one exon in the genomic DNA, thus complicating the amplification process. These primers can then be used for PCR screening of somatic cell hybrids containing individual human chromosomes. Only those hybrids containing the human gene corresponding to the NOVX sequences will yield an amplified fragment. Somatic cell hybrids are prepared by fusing somatic cells from different mammals
(e.g., human and mouse cells). As hybrids of human and mouse cells grow and divide*, they gradually lose human chromosomes in random order, but retain the mouse chromosomes. By using media in which mouse cells cannot grow, because they lack a particular enzyme, but in which human cells can, the one human chromosome that contains the gene encoding the needed enzyme will be retained. By using various media, panels of hybrid cell lines can be established. Each cell line in a panel contains either a single human chromosome or a small number of human chromosomes, and a full set of mouse chromosomes, allowing easy mapping of individual genes to specific human chromosomes. See, e.g., D'Eustachio, et al, 1983. Science 220: 919-924. Somatic cell hybrids containing only fragments of human chromosomes can also be produced by using human chromosomes with translocations and deletions.
PCR mapping of somatic cell hybrids is a rapid procedure for assigning a particular sequence to a particular chromosome. Three or more sequences can be assigned per day using a single thermal cycler. Using the NOVX sequences to design oligonucleotide primers, sub-localization can be achieved with panels of fragments from specific chromosomes. Fluorescence in situ hybridization (FISH) of a DNA sequence to a metaphase chromosomal spread can further be used to provide a precise chromosomal location in one step. Chromosome spreads can be made using cells whose division has been blocked in metaphase by a chemical like colcemid that disrupts the mitotic spindle. The chromosomes can be treated briefly with trypsin, and then stained with Giemsa. A pattern of light and dark bands develops on each chromosome, so that the chromosomes can be identified individually. The FISH technique can be used with a DNA sequence as short as 500 or 600 bases. However, clones larger than 1 ,000 bases have a higher likelihood of binding to a unique
chromosomal location with sufficient signal intensity for simple detection. Preferably 1 ,000 bases, and more preferably 2,000 bases, will suffice to get good results at a reasonable amount of time. For a review of this technique, .see, Verma, et al, HUMAN CHROMOSOMES: A MANUAL OF BASIC TECHNIQUES (Pergamon Press, New York 1988). Reagents for chromosome mapping can be used individually to mark a single chromosome or a single site on that chromosome, or panels of reagents can be used for marking multiple sites and/or multiple chromosomes. Reagents corresponding to noncoding regions of the genes actually are preferred for mapping purposes. Coding sequences are more likely to be conserved within gene families, thus increasing the chance of cross hybridizations during chromosomal mapping.
Once a sequence has been mapped to a precise chromosomal location, the physical position of the sequence on the chromosome can be correlated with genetic map data. Such data are found, e.g., in McKusick, MITNDELIAN INHERITANCE IN MAN, available on-line through Johns Hopkins University Welch Medical Library). The relationship between genes and disease, mapped to the same chromosomal region, can then be identified through linkage analysis (co-inheritance of physically adjacent genes), described in, e.g., Egeland, et al, 1987. Nature, 325: 783-787.
Moreover, differences in the DNA sequences between individuals affected and unaffected with a disease associated with the NOVX gene, can be determined. If a mutation is observed in some or all of the affected individuals but not in any unaffected individuals, then the mutation is likely to be the causative agent of the particular disease. Comparison of affected and unaffected individuals generally involves first looking for structural alterations in the chromosomes, such as deletions or translocations that are visible from chromosome spreads or detectable using PCR based on that DNA sequence. Ultimately, complete sequencing of genes from several individuals can be performed to confirm the presence of a mutation and to distinguish mutations from polymorphisms.
Tissue Typing
The NOVX sequences of the invention can also be used to identify individuals from minute biological samples. In this technique, an individual's genomic DNA is digested with one or more restriction enzymes, and probed on a Southern blot to yield unique bands for identification. The sequences of the invention are useful as additional DNA markers for
RFLP ("restriction fragment length polymorphisms," described in U.S. Patent No. 5,272,057).
Furthermore, the sequences of the invention can be used to provide an alternative technique that determines the actual base-by-base DNA sequence of selected portions of an individual's genome. Thus, the NOVX sequences described herein can be used to prepare two PCR primers from the 5'- and 3'-termini of the sequences. These primers can then be used to amplify an individual's DNA and subsequently sequence it.
Panels of corresponding DNA sequences from individuals, prepared in this manner, can provide unique individual identifications, as each individual will have a unique set of such DNA sequences due to allelic differences. The sequences of the invention can be used to obtain such identification sequences from individuals and from tissue. The NOVX sequences of the invention uniquely represent portions of the human genome. Allelic variation occurs to some degree in the coding regions of these sequences, and to a greater degree in the noncoding regions. It is estimated that allelic variation between individual humans occurs with a frequency of about once per each 500 bases. Much of the allelic variation is due to single nucleotide polymorphisms (SNPs), which include restriction fragment length polymorphisms (RFLPs).
Each of the sequences described herein can, to some degree, be used as a standard against which DNA from an individual can be compared for identification purposes. Because greater numbers of polymorphisms occur in the noncoding regions, fewer sequences are necessary to differentiate individuals. The noncoding sequences can comfortably provide positive individual identification with a panel of perhaps 10 to 1 ,000 primers that each yield a noncoding amplified sequence of 100 bases. If coding sequences, such as those of SEQ JD NO:2«-I , wherein n is an integer between 1 and 172, are used, a more appropriate number of primers for positive individual identification would be 500-2,000.
Predictive Medicine
The invention also pertains to the field of predictive medicine in which diagnostic assays, prognostic assays, pharmacogenomics, and monitoring clinical trials are used for prognostic (predictive) purposes to thereby treat an individual prophylactically. Accordingly, one aspect of the invention relates to diagnostic assays for determining NOVX protein and/or nucleic acid expression as well as NOVX activity, in the context of a biological sample (e , blood, serum, cells, tissue) to thereby determine whether an individual is afflicted with a
disease or disorder, or is at risk of developing a disorder, associated with aberrant NOVX expression or activity. The disorders include metabolic disorders, diabetes, obesity, infectious disease, anorexia, cancer-associated cachexia, cancer, neurodegenerative disorders, Alzheimer's Disease, Parkinson's Disorder, immune disorders, and hematopoietic disorders, and the various dyslipidemias, metabolic disturbances associated with obesity, the metabolic syndrome X and wasting disorders associated with chronic diseases and various cancers. The invention also provides for prognostic (or predictive) assays for determining whether an individual is at risk of developing a disorder associated with NOVX protein, nucleic acid expression or activity. For example, mutations in a NOVX gene can be assayed in a biological sample. Such assays can be used for prognostic or predictive purpose to thereby prophylactically treat an individual prior to the onset of a disorder characterized by or associated with NOVX protein, nucleic acid expression, or biological activity.
Another aspect of the invention provides methods for determining NOVX protein, nucleic acid expression or activity in an individual to thereby select appropriate therapeutic or prophylactic agents for that individual (referred to herein as "pharmacogenomics"). Pharmacogenomics allows for the selection of agents (e.g., drugs) for therapeutic or prophylactic treatment of an individual based on the genotype of the individual (e.g., the genotype of the individual examined to determine the ability of the individual to respond to a particular agent.) Yet another aspect of the invention pertains to monitoring the influence of agents
(e.g., drugs, compounds) on the expression or activity of NOVX in clinical trials.
These and other agents are described in further detail in the following sections.
Diagnostic Assays
An exemplary method for detecting the presence or absence of NOVX in a biological sample involves obtaining a biological sample from a test subject and contacting the biological sample with a compound or an agent capable of detecting NOVX protein or nucleic acid (e.g., mRNA, genomic DNA) that encodes NOVX protein such that the presence of NOVX is detected in the biological sample. An agent for detecting NOVX mRNA or genomic DNA is a labeled nucleic acid probe capable of hybridizing to NOVX mRNA or genomic DNA. The nucleic acid probe can be, for example, a full-length NOVX nucleic acid, such as the nucleic acid of SEQ ID NO:2w-l , wherein n is an integer between 1 and 172, or a portion thereof, such as an oligonucleotide of at least 15, 30, 50, 100, 250 or 500
nucleotides in length and sufficient to specifically hybridize under stringent conditions to NOVX mRNA or genomic DNA. Other suitable probes for use in the diagnostic assays of the invention are described herein.
An agent for detecting NOVX protein is an antibody capable of binding to NOVX protein, preferably an antibody with a detectable label. Antibodies can be polyclonal, or more preferably, monoclonal. An intact antibody, or a fragment thereof (e.g, Fab or F(ab')2) can be used. The term "labeled", with regard to the probe or antibody, is intended to encompass direct labeling of the probe or antibody by coupling (i.e., physically linking) a detectable substance to the probe or antibody, as well as indirect labeling of the probe or antibody by reactivity with another reagent that is directly labeled. Examples of indirect labeling include detection of a primary antibody using a fluorescently-labeled secondary antibody and end-labeling of a DNA probe with biotin such that it can be detected with fluorescently-labeled streptavidin. The term "biological sample" is intended to include tissues, cells and biological fluids isolated from a subject, as well as tissues, cells and fluids present within a subject. That is, the detection method of the invention can be used to detect NOVX mRNA, protein, or genomic DNA in a biological sample in vitro as well as in vivo. For example, in vitro techniques for detection of NOVX mRNA include Northern hybridizations and in situ hybridizations. In vitro techniques for detection of NOVX protein include enzyme linked immunosorbent assays (ELISAs), Western blots, immunoprecipitations, and immunofluorescence. In vitro techniques for detection of NOVX genomic DNA include Southern hybridizations. Furthermore, in vivo techniques for detection of NOVX protein include introducing into a subject a labeled anti-NOVX antibody. For example, the antibody can be labeled with a radioactive marker whose presence and location in a subject can be detected by standard imaging techniques. In one embodiment, the biological sample contains protein molecules from the test subject. Alternatively, the biological sample can contain mRNA molecules from the test subject or genomic DNA molecules from the test subject. A preferred biological sample is a peripheral blood leukocyte sample isolated by conventional means from a subject.
In another embodiment, the methods further involve obtaining a control biological sample from a control subject, contacting the control sample with a compound or agent capable of detecting NOVX protein, mRNA, or genomic DNA, such that the presence of NOVX protein, mRNA or genomic DNA is detected in the biological sample, and comparing
the presence of NOVX protein, mRNA or genomic DNA in the control sample with the presence of NOVX protein, mRNA or genomic DNA in the test sample.
The invention also encompasses kits for detecting the presence of NOVX in a biological sample. For example, the kit can comprise: a labeled compound or agent capable of detecting NOVX protein or mRNA in a biological sample; means for determining the amount of NOVX in the sample; and means for comparing the amount of NOVX in the sample with a standard. The compound or agent can be packaged in a suitable container. The kit can further comprise instructions for using the kit to detect NOVX protein or nucleic acid. Prognostic Assays
The diagnostic methods described herein can furthermore be utilized to identify subjects having or at risk of developing a disease or disorder associated with aberrant NOVX expression or activity. For example, the assays described herein, such as the preceding diagnostic assays or the following assays, can be utilized to identify a subject having or at risk of developing a disorder associated with NOVX protein, nucleic acid expression or activity. Alternatively, the prognostic assays can be utilized to identify a subject having or at risk for developing a disease or disorder. Thus, the invention provides a method for identifying a disease or disorder associated with aberrant NOVX expression or activity in which a test sample is obtained from a subject and NOVX protein or nucleic acid (e.g., mRNA, genomic DNA) is detected, wherein the presence of NOVX protein or nucleic acid is diagnostic for a subject having or at risk of developing a disease or disorder associated with aberrant NOVX expression or activity. As used herein, a "test sample" refers to a biological sample obtained from a subject of interest. For example, a test sample can be a biological fluid (e.g., serum), cell sample, or tissue. Furthermore, the prognostic assays described herein can be used to determine whether a subject can be administered an agent (e.g., an agonist, antagonist, peptidomimetic, protein, peptide, nucleic acid, small molecule, or other drug candidate) to treat a disease or disorder associated with aberrant NOVX expression or activity. For example, such methods can be used to determine whether a subject can be effectively treated with an agent for a disorder. Thus, the invention provides methods for determining whether a subject can be effectively treated with an agent for a disorder associated with aberrant NOVX expression or activity in which a test sample is obtained and NOVX protein or nucleic acid is detected (e.g., wherein
the presence of NOVX protein or nucleic acid is diagnostic for a subject that can be administered the agent to treat a disorder associated with aberrant NOVX expression or activity).
The methods of the invention can also be used to detect genetic lesions in a NOVX gene, thereby determining if a subject with the lesioned gene is at risk for a disorder characterized by aberrant cell proliferation and/or differentiation. In various embodiments, the methods include detecting, in a sample of cells from the subject, the presence or absence of a genetic lesion characterized by at least one of an alteration affecting the integrity of a gene encoding a NOVX-protein, or the misexpression of the NOVX gene. For example, such genetic lesions can be detected by ascertaining the existence of at least one of: (/') a deletion of one or more nucleotides from a NOVX gene; (//') an addition of one or more nucleotides to a NOVX gene; (iii) a substitution of one or more nucleotides of a NOVX gene, (iv) a chromosomal rearrangement of a NOVX gene; (v) an alteration in the level of a messenger RNA transcript of a NOVX gene, (vi) aberrant modification of a NOVX gene, such as of the methylation pattern of the genomic DNA, (v/7) the presence of a non-wild-type splicing pattern of a messenger RNA transcript of a NOVX gene, (v/7/) a non-vvi Id-type level of a NOVX protein, (ix) allelic loss of a NOVX gene, and (x) inappropriate post-translational modification of a NOVX protein. As described herein, there are a large number of assay techniques known in the art which can be used for detecting lesions in a NOVX gene. A preferred biological sample is a peripheral blood leukocyte sample isolated by conventional means from a subject. However, any biological sample containing nucleated cells may be used, including, for example, buccal mucosal cells.
In certain embodiments, detection of the lesion involves the use of a probe/primer in a polymerase chain reaction (PCR) (see, e.g., U.S. Patent Nos. 4,683, 195 and 4,683,202), such as anchor PCR or RACE PCR, or, alternatively, in a ligation chain reaction (LCR) (see, e.g., Landegran, et al, 1988. Science 241 : 1077-1080; and Nakazawa, et al, 1994. Proc. Natl. Acad. Sci. USA 91 : 360-364), the latter of which can be particularly useful for detecting point mutations in the NOVX-gene (see, Abravaya, et al, 1995. Nucl Acids Res. 23: 675-682). This method can include the steps of collecting a sample of cells from a patient, isolating nucleic acid (e.g, genomic, mRNA or both) from the cells of the sample, contacting the nucleic acid sample with one or more primers that specifically hybridize to a NOVX gene under conditions such that hybridization and amplification of the NOVX gene (if present) occurs, and detecting the presence or absence of an amplification product, or detecting the
size of the amplification product and comparing the length to a control sample. It is anticipated that PCR and/or LCR may be desirable to use as a preliminary amplification step in conjunction with any of the techniques used for detecting mutations described herein.
Alternative amplification methods include: self sustained sequence replication (see, Guatelli, et al, 1990. Proc. Natl. Acad. Sci. USA 87: 1874-1878), transcriptional amplification system (see, Kwoh, et al, 1989. Proc. Natl. Acad. Sci. USA 86: 1 173-1 177); Qβ Replicase (.see, Lizardi, et al, 1988. BioTechnology 6: 1 197), or any other nucleic acid amplification method, followed by the detection of the amplified molecules using techniques well known to those of skill in the art. These detection schemes are especially useful for the detection of nucleic acid molecules if such molecules are present in very low numbers.
In an alternative embodiment, mutations in a NOVX gene from a sample cell can be identified by alterations in restriction enzyme cleavage patterns. For example, sample and control DNA is isolated, amplified (optionally), digested with one or more restriction endonucleases, and fragment length sizes are determined by gel electrophoresis and compared. Differences in fragment length sizes between sample and control DNA indicates mutations in the sample DNA. Moreover, the use of sequence specific ribozymes (see, e.g., U.S. Patent No. 5,493,531 ) can be used to score for the presence of specific mutations by development or loss of a ribozyme cleavage site.
In other embodiments, genetic mutations in NOVX can be identified by hybridizing a sample and control nucleic acids, e.g., DNA or RNA, to high-density arrays containing hundreds or thousands of oligonucleotides probes. See, e.g., Cronin, et al, 1996. Human Mutation 7: 244-255; Kozal, et al, 1996. Nat. Med. 2: 753-759. For example, genetic mutations in NOVX can be identified in two dimensional arrays containing light-generated DNA probes as described in Cronin, et al, supra. Briefly, a first hybridization array of probes can be used to scan through long stretches of DNA in a sample and control to identify base changes between the sequences by making linear arrays of sequential overlapping probes. This step allows the identification of point mutations. This is followed by a second hybridization array that allows the characterization of specific mutations by using smaller, specialized probe arrays complementary to all variants or mutations detected. Each mutation array is composed of parallel probe sets, one complementary to the wild-type gene and the other complementary to the mutant gene.
In yet another embodiment, any of a variety of sequencing reactions known in the art can be used to directly sequence the NOVX gene and detect mutations by comparing the
sequence of the sample NOVX with the corresponding wild-type (control) sequence. Examples of sequencing reactions include those based on techniques developed by Maxim ' and Gilbert, 1977. Proc. Natl. Acad. Sci. USA 74: 560 or Sanger, 1977. Proc. Natl Acad. Sci. USA 74: 5463. It is also contemplated that any of a variety of automated sequencing procedures can be utilized when performing the diagnostic assays (see, e.g., Naeve, et al, 1995. Biotechniques 19: 448), including sequencing by mass spectrometry (see, e.g., PCT International Publication No. WO 94/16101 ; Cohen, et al, 1996. Adv. Chromatography 36: 127- 162; and Griffin, et al, 1993. Appl Biochem. Biotechnol. 38: 147-159).
Other methods for detecting mutations in the NOVX gene include methods in which protection from cleavage agents is used to detect mismatched bases in RNA/RNA or
RNA/DNA heteroduplexes. See, e.g., Myers, et al, 1985. Science 230: 1242. In general, the art technique of "mismatch cleavage" starts by providing heteroduplexes of formed by hybridizing (labeled) RNA or DNA containing the wild-type NOVX sequence with potentially mutant RNA or DNA obtained from a tissue sample. The double-stranded duplexes are treated with an agent that cleaves single-stranded regions of the duplex such as which will exist due to basepair mismatches between the control and sample strands. For instance, RNA/DNA duplexes can be treated with RNase and DNA/DNA hybrids treated with Si nuclease to enzymatically digesting the mismatched regions. In other embodiments, either DNA/DNA or RNA/DNA duplexes can be treated with hydroxylamine or osmium tctroxide and with piperidine in order to digest mismatched regions. After digestion of the mismatched regions, the resulting material is then separated by size on denaturing polyacrylamide gels to determine the site of mutation. See, e.g., Cotton, et al, 1988. Proc. Natl. Acad. Sci. USA 85: 4397; Saleeba, et al, 1992. Methods Enzymol. 217: 286-295. In an embodiment, the control DNA or RNA can be labeled for detection. In still another embodiment, the mismatch cleavage reaction employs one or more proteins that recognize mismatched base pairs in double-stranded DNA (so called "DNA mismatch repair" enzymes) in defined systems for detecting and mapping point mutations in NOVX cDNAs obtained from samples of cells. For example, the mutY enzyme of E. coli cleaves A at G/A mismatches and the thymidine DNA glycosylase from HeLa cells cleaves T at G/T mismatches. See, e.g., Hsu, et al, 1994. Carcinogenesis 15: 1657- 1662. According to an exemplary embodiment, a probe based on a NOVX sequence, e.g., a wild-type NOVX sequence, is hybridized to a cDNA or other DNA product from a test cell(s). The duplex is
treated with a DNA mismatch repair enzyme, and the cleavage products, if any, can be detected from electrophoresis protocols or the like. See, e.g., U.S. Patent No. 5,459,039.
In other embodiments, alterations in electrophoretic mobility will be used to identify mutations in NOVX genes. For example, single strand conformation polymorphism (SSCP) may be used to detect differences in electrophoretic mobility between mutant and wild type nucleic acids. See, e.g., Orita, et al., 1989. Proc. Natl. Acad. Sci. USA: 86: 2766; Cotton, 1993. Mutat. Res. 285: 125-144; Hayashi, 1992. Genet. Anal. Tech. Appl. 9: 73-79. Single-stranded DNA fragments of sample and control NOVX nucleic acids will be denatured and allowed to renature. The secondary structure of single-stranded nucleic acids varies according to sequence, the resulting alteration in electrophoretic mobility enables the detection of even a single base change. The DNA fragments may be labeled or detected with labeled probes. The sensitivity of the assay may be enhanced by using RNA (rather than DNA), in which the secondary structure is more sensitive to a change in sequence. In one embodiment, the subject method utilizes heteroduplex analysis to separate double stranded heteroduplex molecules on the basis of changes in electrophoretic mobility. See, e.g., Keen, et al, 1991. Trends Genet. 7: 5.
In yet another embodiment, the movement of mutant or wild-type fragments in polyacrylamide gels containing a gradient of denaturant is assayed using denaturing gradient gel electrophoresis (DGGE). See, e.g., Myers, et al, 1985. Nature 313: 495. When DGGE is used as the method of analysis, DNA will be modified to insure that it does not completely denature, for example by adding a GC clamp of approximately 40 bp of high-melting GC-rich DNA by PCR. In a further embodiment, a temperature gradient is used in place of a denaturing gradient to identify differences in the mobility of control and sample DNA. See, e.g., Rosenbaum and Reissner, 1987. Biophys. Chem. 265: 12753. Examples of other techniques for detecting point mutations include, but are not limited to, selective oligonucleotide hybridization, selective amplification, or selective primer extension. For example, oligonucleotide primers may be prepared in which the known mutation is placed centrally and then hybridized to target DNA under conditions that permit hybridization only if a perfect match is found. See, e.g., Saiki, et al, 1986. Nature 324: 163; Saiki, et al, 1989. Proc. Natl. Acad. Sci. USA 86: 6230. Such allele specific oligonucleotides are hybridized to PCR amplified target DNA or a number of different mutations when the oligonucleotides are attached to the hybridizing membrane and hybridized with labeled target DNA.
Alternatively, allele specific amplification technology that depends on selective PCR amplification may be used in conjunction with the instant invention. Oligonucleotides used as primers for specific amplification may carry the mutation of interest in the center of the molecule (so that amplification depends on differential hybridization; see, e.g., Gibbs, et al, 1989. Nucl. Acids Res. 17: 2437-2448) or at the extreme 3'-terminus of one primer where, under appropriate conditions, mismatch can prevent, or reduce polymerase extension (see, e.g., Prossner, 1993. Tibtech. 1 1 : 238). In addition it may be desirable to introduce a novel restriction site in the region of the mutation to create cleavage-based detection. See, e.g., Gasparini, et al, 1992. Mol. Cell Probes 6: 1. It is anticipated that in certain embodiments amplification may also be performed using Taq ligase for amplification. See, e.g., Barany, 1991. Proc. Natl. Acad. Sci. USA 88: 189. In such cases, ligation will occur only if there is a perfect match at the 3'-terminus of the 5' sequence, making it possible to detect the presence of a known mutation at a specific site by looking for the presence or absence of amplification.
The methods described herein may be performed, for example, by utilizing pre-packaged diagnostic kits comprising at least one probe nucleic acid or antibody reagent described herein, which may be conveniently used, e.g., in clinical settings to diagnose patients exhibiting symptoms or family history of a disease or illness involving a NOVX gene.
Furthermore, any cell type or tissue, preferably peripheral blood leukocytes, in which NOVX is expressed may be utilized in the prognostic assays described herein. However, any biological sample containing nucleated cells may be used, including, for example, buccal mucosal cells.
Pharmacogenomics
Agents, or modulators that have a stimulatory or inhibitory effect on NOVX activity (e.g., NOVX gene expression), as identified by a screening assay described herein can be administered to individuals to treat (prophylactically or therapeutically) disorders. The disorders include but are not limited to, e.g., those diseases, disorders and conditions listed above, and more particularly include those diseases, disorders, or conditions associated with homologs of a NOVX protein, such as those summarized in Table A. In conjunction with such treatment, the pharmacogenomics (i.e., the study of the relationship between an individual's genotype and that individual's response to a foreign compound or drug) of the individual may be considered. Differences in metabolism of
therapeutics can lead to severe toxicity or therapeutic failure by altering the relation between dose and blood concentration of the pharmacologically active drug. Thus, the pharmacogenomics of the individual permits the selection of effective agents (e.g., drugs) for prophylactic or therapeutic treatments based on a consideration of the individual's genotype. Such pharmacogenomics can further be used to determine appropriate dosages and therapeutic regimens. Accordingly, the activity of NOVX protein, expression of NOVX nucleic acid, or mutation content of NOVX genes in an individual can be determined to thereby select appropriate agent(s) for therapeutic or prophylactic treatment of the individual. Pharmacogenomics deals with clinically significant hereditary variations in the response to drugs due to altered drug disposition and abnormal action in affected persons.
See e.g., Eichelbaum, 1996. Clin. Exp. Pharmacol. Physiol, 23: 983-985; Linder, 1997. Clin. Chem., 43: 254-266. In general, two types of pharmacogenetic conditions can be differentiated. Genetic conditions transmitted as a single factor altering the way drugs act on the body (altered drug action) or genetic conditions transmitted as single factors altering the way the body acts on drugs (altered drug metabolism). These pharmacogenetic conditions can occur either as rare defects or as polymorphisms. For example, glucose-6-phosphate dehydrogenase (G6PD) deficiency is a common inherited enzymopathy in which the main clinical complication is hemolysis after ingestion of oxidant drugs (anti-malarials, sulfonamides, analgesics, nitrofurans) and consumption of fava beans. As an illustrative embodiment, the activity of drug metabolizing enzymes is a major determinant of both the intensity and duration of drug action. The discovery of genetic polymorphisms of drug metabolizing enzymes (e.g, N-acetyltransferase 2 (NAT 2) and cytochrome pregnancy zone protein precursor enzymes CYP2D6 and CYP2C19) has provided an explanation as to why some patients do not obtain the expected drug effects or show exaggerated drug response and serious toxicity after taking the standard and safe dose of a drug. These polymorphisms are expressed in two phenotypes in the population, the extensive metabolizer (EM) and poor metabolizer (PM). The prevalence of PM is different among different populations. For example, the gene coding for CYP2D6 is highly polymorphic and several mutations have been identified in PM, which all lead to the absence of functional CYP2D6. Poor metabolizers of CYP2D6 and CYP2C 19 quite frequently experience exaggerated drug response and side effects when they receive standard doses. If a metabolite is the active therapeutic moiety, PM show no therapeutic response, as demonstrated for the analgesic effect of codeine mediated by its CYP2D6-formed metabolite
morphine. At the other extreme are the so called ultra-rapid metabolizers who do not respond to standard doses. Recently, the molecular basis of ultra-rapid metabolism has been identified to be due to CYP2D6 gene amplification.
Thus, the activity of NOVX protein, expression of NOVX nucleic acid, or mutation content of NOVX genes in an individual can be determined to thereby select appropriate agent(s) for therapeutic or prophylactic treatment of the individual. In addition, pharmacogenetic studies can be used to apply genotyping of polymorphic alleles encoding drug-metabolizing enzymes to the identification of an individual's drug responsiveness phenotype. This knowledge, when applied to dosing or drug selection, can avoid adverse reactions or therapeutic failure and thus enhance therapeutic or prophylactic efficiency when treating a subject with a NOVX modulator, such as a modulator identified by one of the exemplary screening assays described herein.
Monitoring of Effects During Clinical Trials
Monitoring the influence of agents (e.g., drugs, compounds) on the expression or activity of NOVX (e.g., the ability to modulate aberrant cell proliferation and/or differentiation) can be applied not only in basic drug screening, but also in clinical trials. For example, the effectiveness of an agent determined by a screening assay as described herein to increase NOVX gene expression, protein levels, or upregulate NOVX activity, can be monitored in clinical trails of subjects exhibiting decreased NOVX gene expression, protein levels, or downregulated NOVX activity. Alternatively, the effectiveness of an agent determined by a screening assay to decrease NOVX gene expression, protein levels, or downregulate NOVX activity, can be monitored in clinical trails of subjects exhibiting increased NOVX gene expression, protein levels, or upregulated NOVX activity. In such clinical trials, the expression or activity of NOVX and, preferably, other genes that have been implicated in, for example, a cellular proliferation or immune disorder can be used as a "read out" or markers of the immune responsiveness of a particular cell.
By way of example, and not of limitation, genes, including NOVX, that are modulated in cells by treatment with an agent (e.g., compound, drug or small molecule) that modulates NOVX activity (e.g., identified in a screening assay as described herein) can be identified. Thus, to study the effect of agents on cellular proliferation disorders, for example, in a clinical trial, cells can be isolated and RNA prepared and analyzed for the levels of expression of NOVX and other genes implicated in the disorder. The levels of gene
expression (i.e., a gene expression pattern) can be quantified by Northern blot analysis or RT-PCR, as described herein, or alternatively by measuring the amount of protein produced, by one of the methods as described herein, or by measuring the levels of activity of NOVX or other genes. In this manner, the gene expression pattern can serve as a marker, indicative of the physiological response of the cells to the agent. Accordingly, this response state may be determined before, and at various points during, treatment of the individual with the agent.
In one embodiment, the invention provides a method for monitoring the effectiveness of treatment of a subject with an agent (e.g., an agonist, antagonist, protein, peptide, peptidomimetic, nucleic acid, small molecule, or other drug candidate identified by the screening assays described herein) comprising the steps of (/) obtaining a pre-administration sample from a subject prior to administration of the agent; (ii) detecting the level of expression of a NOVX protein, mRNA, or genomic DNA in the preadministration sample; (///') obtaining one or more post-administration samples from the subject; (iv) detecting the level of expression or activity of the NOVX protein, mRNA, or genomic DNA in the post-administration samples; (v) comparing the level of expression or activity of the NOVX protein, mRNA, or genomic DNA in the pre-administration sample with the NOVX protein, mRNA, or genomic DNA in the post administration sample or samples; and (vi) altering the administration of the agent to the subject accordingly. For example, increased administration of the agent may be desirable to increase the expression or activity of NOVX to higher levels than detected, i.e., to increase the effectiveness of the agent. Alternatively, decreased administration of the agent may be desirable to decrease expression or activity of NOVX to lower levels than detected, i.e., to decrease the effectiveness of the agent.
Methods of Treatment
The invention provides for both prophylactic and therapeutic methods of treating a subject at risk of (or susceptible to) a disorder or having a disorder associated with aberrant NOVX expression or activity. The disorders include but are not limited to, e.g., those diseases, disorders and conditions listed above, and more particularly include those diseases, disorders, or conditions associated with homologs of a NOVX protein, such as those summarized in Table A. These methods of treatment will be discussed more fully, below.
Diseases and Disorders
Diseases and disorders that are characterized by increased (relative to a subject not suffering from the disease or disorder) levels or biological activity may be treated with Therapeutics that antagonize (i.e., reduce or inhibit) activity. Therapeutics that antagonize activity may be administered in a therapeutic or prophylactic manner. Therapeutics that may be utilized include, but are not limited to: (/) an aforementioned peptide, or analogs, derivatives, fragments or homologs thereof; (//') antibodies to an aforementioned peptide; (iii) nucleic acids encoding an aforementioned peptide; (iv) administration of antisense nucleic acid and nucleic acids that are "dysfunctional" (i.e., due to a heterologous insertion within the coding sequences of coding sequences to an aforementioned peptide) that are utilized to
"knockout" endogenous function of an aforementioned peptide by homologous recombination (.see, e.g., Capecchi, 1989. Science 244: 1288-1292); or (v) modulators ( i.e., inhibitors, agonists and antagonists, including additional peptide mimetic of the invention or antibodies specific to a peptide of the invention) that alter the interaction between an aforementioned peptide and its binding partner.
Diseases and disorders that are characterized by decreased (relative to a subject not suffering from the disease or disorder) levels or biological activity may be treated with Therapeutics that increase (i.e., are agonists to) activity. Therapeutics that upregulate activity may be administered in a therapeutic or prophylactic manner. Therapeutics that may be utilized include, but are not limited to, an aforementioned peptide, or analogs, derivatives, fragments or homologs thereof; or an agonist that increases bioavailability.
Increased or decreased levels can be readily detected by quantifying peptide and/or RNA, by obtaining a patient tissue sample (e.g., from biopsy tissue) and assaying it in vitro for RNA or peptide levels, structure and/or activity of the expressed peptides (or mRNAs of an aforementioned peptide). Methods that are well-known within the art include, but are not limited to, immunoassays (e.g., by Western blot analysis, immunoprecipitation followed by sodium dodecyl sulfate (SDS) polyacrylamide gel electrophoresis, immunocytochemistry, etc.) and/or hybridization assays to detect expression of mRNAs (e.g., Northern assays, dot blots, in situ hybridization, and the like). Prophylactic Methods
In one aspect, the invention provides a method for preventing, in a subject, a disease or condition associated with an aberrant NOVX expression or activity, by administering to
the subject an agent that modulates NOVX expression or at least one NOVX activity. Subjects at risk for a disease that is caused or contributed to by aberrant NOVX expression or activity can be identified by, for example, any or a combination of diagnostic or prognostic assays as described herein. Administration of a prophylactic agent can occur prior to the manifestation of symptoms characteristic of the NOVX aberrancy, such that a disease or disorder is prevented or, alternatively, delayed in its progression. Depending upon the type of NOVX aberrancy, for example, a NOVX agonist or NOVX antagonist agent can be used for treating the subject. The appropriate agent can be determined based on screening assays described herein. The prophylactic methods of the invention are further discussed in the following subsections.
Therapeutic Methods
Another aspect of the invention pertains to methods of modulating NOVX expression or activity for therapeutic purposes. The modulatory method of the invention involve^ contacting a cell with an agent that modulates one or more of the activities of NOVX protein activity associated with the cell. An agent that modulates NOVX protein activity can be an agent as described herein, such as a nucleic acid or a protein, a naturally-occurring cognate ligand of a NOVX protein, a peptide, a NOVX peptidomimetic, or other small molecule. In one embodiment, the agent stimulates one or more NOVX protein activity. Examples of such stimulatory agents include active NOVX protein and a nucleic acid molecule encoding NOVX that has been introduced into the cell. In another embodiment, the agent inhibits one or more NOVX protein activity. Examples of such inhibitory agents include antisense NOVX nucleic acid molecules and anti-NOVX antibodies. These modulatory methods can be performed in vitro (e.g., by culturing the cell with the agent) or, alternatively, in vivo (e.g., by administering the agent to a subject). As such, the invention provides methods of treating an individual afflicted with a disease or disorder characterized by aberrant expression or activity of a NOVX protein or nucleic acid molecule. In one embodiment, the method involves administering an agent (e.g, an agent identified by a screening assay described herein), or combination of agents that modulates (e.g., up-regulates or down-regulates) NOVX expression or activity. In another embodiment, the method involves administering a NOVX protein or nucleic acid molecule as therapy to compensate for reduced or aberrant NOVX expression or activity.
Stimulation of NOVX activity is desirable in situations in which NOVX is abnormally downregulated and/or in which increased NOVX activity is likely to have a beneficial effect. One example of such a situation is where a subject has a disorder characterized by aberrant cell proliferation and/or differentiation (e.g., cancer or immune associated disorders). Another example of such a situation is where the subject has a gestational disease (e.g., preclampsia).
Determination of the Biological Effect of the Therapeutic
In various embodiments of the invention, suitable in vitro or in vivo assays are performed to determine the effect of a specific Therapeutic and whether its administration is indicated for treatment of the affected tissue.
In various specific embodiments, in vitro assays may be performed with representative cells of the type(s) involved in the patient's disorder, to determine if a given Therapeutic exerts the desired effect upon the cell type(s). Compounds for use in therapy may be tested in suitable animal model systems including, but not limited to rats, mice, chicken, cows, monkeys, rabbits, and the like, prior to testing in human subjects. Similarly, for />7 vivo testing, any of the animal model system known in the art may be used prior to administration to human subjects.
Prophylactic and Therapeutic Uses of the Compositions of the Invention
The NOVX nucleic acids and proteins of the invention are useful in potential prophylactic and therapeutic applications implicated in a variety of disorders. The disorders include but are not limited to, e.g., those diseases, disorders and conditions listed above, and more particularly include those diseases, disorders, or conditions associated with homologs of a NOVX protein, such as those summarized in Table A.
As an example, a cDNA encoding the NOVX protein of the invention may be useful in gene therapy, and the protein may be useful when administered to a subject in need thereof. By way of non-limiting example, the compositions of the invention will have efficacy for treatment of patients suffering from diseases, disorders, conditions and the like, including but not limited to those listed herein.
Both the novel nucleic acid encoding the NOVX protein, and the NOVX protein of the invention, or fragments thereof, may also be useful in diagnostic applications, wherein the presence or amount of the nucleic acid or the protein are to be assessed. A further use could be as an anti-bacterial molecule (i.e., some peptides have been found to possess anti-bacterial
properties). These materials are further useful in the generation of antibodies, which immunospecifically-bind to the novel substances of the invention for use in therapeutic or diagnostic methods.
The invention will be further described in the following examples, which do not limit the scope of the invention described in the claims.
EXAMPLES
Example A: Polynucleotide and Polypeptide Sequences, and Homology Data
The NOV1 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 1 A.
Further analysis of the NOV l a protein yielded the following properties shown in Table I B.
! Table IB. Protein Sequence Properties NO VI a
PSort 0.5756 probability located in nucleus; 0.5070 probability located in mitochondria! I analysis: matrix space; 0.3000 probability located in microbody (peroxisome); 0.2297 probability located in mitochondπal inner membrane
1 SignalP No Known Signal Sequence Predicted
[ analysis:
A search of the NOV la protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table I C.
Table IC. Geneseq Results for NOVla
In a BLAST search of public sequence datbases, the NOVla protein was found to have homology to the proteins shown in the BLASTP data in Table 1 D.
Q9UJF2 Ras GTPase-activating protein nGAP 169..128 20/61 (32%) 0.19
(RAS protein activator like 1 ) - Homo j 938..998 32/61 (51 %) sapiens (Human). 1 139 aa. ;
PFam analysis predicts that the NOV la protein contains the domains shown in the Table I E.
; Table IE. Domain Analysis of NOVla
! Identities/
Pfam Domain NOVla Match Region j Similarities Expect Value j for the Matched Region
Example 2.
The NOV2 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 2A.
Table 2 A. NOV2 Sequence Analysis
SEQ ID NO: 3 I i1)0^7 b „
NOV2a, jCGGCTGCGCTTCTGCTGGAAACGCTTGCTGGCGCCTGTCACCGGTTCCCTCCATTTTGAAAGG CG I 01055- 01 DNA GAAAAAGGCTCTCCCCACCCATTCCCCTGCCCCTAGGAGCTGGAGCCGGAGGAGCCGCGCTCA
TGGCGTTCAGCCCGTGGCAGATCCTGTCCCCCGTGCAGTGGGCGAAATGGACGTGGTCTGCGG Sequence TACGCGGCGGGGCCGCCGGCGAGGACGAGGCTGGCGGGCCCGAGGGCGACCCCGAGGAGGAGG ATTCGCAAGCCGAGACCAAATCCTTGAGTTTCAGCTCGGATTCTGAAGGTAATTTTGAGACTC CTGAAGCTGAAACCCCGATCCGATCACCTTTCAAGGAGTCCTGTGATCCATCACTCGGATTGG CAGGACCTGGGGCCAAAAGCCAAGAATCACAAGAAGCTGATGAACAGCTTGTAGCAGAAGTGG TTGAAAAATGTTCATCTAAGACTTGTTCTAAACCTTCAGAAAATGAAGTGCCACAGCAGGCCA TTGACTCTCACTCAGTCAAGAATTTCAGAGAAGAACCTGAACATGATTTTAGCAAAATTTCCA TCGTGAGGCCATTTTCAATAGAAACGAAGGATTCCACGGATATCTCGGCAGTCCTCGGAACAA AAGTAGCTCATGGCTGTGTAACTGCAGTCTCAGGCAAGGCTCTGCCTTCCAGCCCGCCAGACG CCCTCCAGGACGAGGCGATGACAGAAGGCAGCATGGGGGTCACCCTCGAGGCCTCCGCAGAAG CTGATCTAAAAGCTGGCAACTCCTGTCCAGAGCTTGTGCCCAGCAGAAGAAGCAAGCTGAGAA AGCCCAAGCCTGTCCCCCTGAGGAAGAAAGCAATTGGAGGAGAGTTCTCAGACACCAACGCTG CTGTGGAGGGCACACCTCTCCCCAAGGCATCCTATCACTTCAGTCCTGAAGAGTTGGATGAGA ACACAAGTCCTTTGCTAGGAGATGCCAGGTTCCAGAAGTCTCCCCCTGACCTTAAAGAAACTC CCGGCACTCTCAGTAGTGACACCAACGACTCAGGGGTGGAGCTGGGGGCACGGTGAATG
ORF Start: ATG at 126 ΪORF Stop: TGA at 1062 r
I SEQ ID NO: 4 1312 aa iMW at 33130.0kD
NOV2a, MAFSPWQILSPVQWAKWTWSAVRGGAAGEDEAGGPEGDPEEEDSQAETKS SFSSDSEGNFET
CGI 01055-01 Protein PEAETPIRSPF ESCDPSLG AGPGAKSQESQEADEQLVAEWEKCSSKTCSKPSENEVPQQA IDSHSVKNFREEPEHDFSKISIVRPFSIETKDSTDISAV GTKVAHGCVTAVSGKALPSSPPD
Sequence ALQDEA TEGSMGVTLEASAEADLKAGNSCPELVPSRRSK RKPKPVP RKKAIGGEFSDTNA AVEGTP PKASYHFSPEELDENTSPL GDARFQKSPPDLKETPGTLSSDTNDSGVELGAR
SEQ ID NO: 5 (2731 bp
NOV2b, CAGAGGTCTAGCAGCCGGGCGCCGCGGGCCGGGGGCCTGAGGAGGCCACAGGACGGGCGTCTT
CGI 01055-02 DNA CCCGGCTAGTGGAGCCCGGCGCGGGGCCCGCTGCGGCCGCACCGTGAGGGGAGGAGGCCGAGG
AGGACGCGGCGCCGGCTGCCGGCGGGAGGAAGCGCTCCACCAGGGCCCCCGACGGCACTCGTT
Sequence TAACCACATCCGCGCCTCTGCTGGAAACGCTTGCTGGCGCCTGTCACCGGTTCCCTCCATTTT GAAAGGGAAAAAGGCTCTCCCCACCCATTCCCCTGCCCCTAGGAGCTGGAGCCGGAGGAGCCG
CGCTCATGGCGTTCAGCCCGTGGCAGATCCTGTCCCCCGTGCAGTGGGCGAAATGGACGTGGT
CTGCGGTACGCGGCGGGGCCGCCGGCGAGGACGAGGCTGGCGGGCCCGAGGGCGACCCCGAGG AGGAGGATTCGCAAGCCGAGACCAAATCCTTGAGTTTCAGCTCGGATTCTGAAGGTAATTTTG AGACTCCTGAAGCTGAAACCCCGATCCGATCACCTTTCAAGGAGTCCTGTGATCCATCACTCG GATTGGCAGGACCTGGGGCCAAAAGCCAAGAATCACAAGAAGCTGATGAACAGCTTGTAGCAG AAGTGGTTGAAAAATGTTCATCTAAGACTTGTTCTAAACCTTCAGAAAATGAAGTGCCACAGC AGGCCATTGACTCTCACTCAGTCAAGAATTTCAGAGAAGAACCTGAACATGATTTTAGCAAAA TTTCCATCGTGAGGCCATTTTCAATAGAAACGAAGGATTCCACGGATATCTCGGCAGTCCTCG GAACAAAAGCAGCTCATGGCTGTGTAACTGCAGTCTCAGGCAAGGCTCTGCCTTCCAGCCCGC CAGACGCCCTCCAGGACGAGGCGATGACAGAAGGCAGCATGGGGGTCACCCTCGAGGCCTCCG CAGAAGCTGATCTAAAAGCTGGCAACTCCTGTCCAGAGCTTGTGCCCAGCAGAAGAAGCAAGC TGAGAAAGCCCAAGCCTGTCCCCCTGAGGAAGAAAGCAATTGGAGGAGAGTTCTCAGACACCA ACGCTGCTGTGGAGGGCACACCTCTCCCCAAGGCATCCTATCACTTCAGTCCTGAAGAGTTGG ATGAGAACACAAGTCCTTTGCTAGGAGATGCCAGGTTCCAGAAGTCTCCCCCTGACATTAAAG AAACTCCCGGCACTCTCAGTAGTGACACCAACGACTCAGGGGTTGAGCTGGGGGAGGAGTCGA GGAGCTCACCTCTCAAGCTTGAGTTTGATTTCACAGAAGATACAGGAAACATAGAGGCCAGGA AAGCCCTTCCAAGGAAGCTTGGCAGGAAACTGGGTAGCACACTGACTCCCAAGATACAAAAAG ATGGCATCAGTAAGTCAGCAGGTTTAGAACAGCCTACAGACCCAGTGGCACGAGACGGGCCTC TCTCCCAAACATCTTCCAAGCCAGATCCTAGTCAGTGGGAGAGCCCCAGCTTCAACCCCTTTG GGAGCCACTCTGTTCTGCAGAACTCCCCACCCCTCTCTTCTGAGGGCTCCTACCACTTTGACC CAGATAACTTTGACGAATCCATGGATCCCTTTAAACCAACTACGACCTTAACAAGCAGTGACT TTTGTTCTCCCACTGGTAATCACGTTAATGAAATCTTAGAATCACCCAAGAAGGCAAAGTCGC GTTTAATAACGAGTGGCTGTAAGGTGAAGAAGCATGAAACTCAGTCTCTCGCCCTGGATGCAT GTTCTCGGGATGAAGGGGCAGTGATCTCCCAGATTTCAGACATTTCTAATAGGGATGGCCATG CTACTGATGAGGAGAAACTGGCATCCACGTCATGTGGTCAGAAATCAGCTGGTGCCGAGGTGA AAGGTGAGCCAGAGGAAGACCTGGAGTACTTTGAATGTTCCAATGTTCCTGTGTCTACCATAA ATCATGCGTTTTCATCCTCAGAAGCAGGCATAGAGAAGGAGACGTGCCAGAAGATGGAAGAAG ACGGGTCCACTGTGCTTGGGCTGCTGGAGTCCTCTGCAGAGAAGGCCCCTGTGTCGGTGTCCT GTGGAGGTGAGAGCCCCCTGGATGGGATCTGCCTCAGCGAATCAGACAAGACAGCCGTGCTCA CCTTAATAAGAGAAGAGATAATTACTAAAGAGATTGAAGCAAATGAATGGAAGAAGAAATACG AAGAGACCCGGCAAGAAGTTTTGGAGATGAGGAAAATTGTAGCTGAATATGAAAAGACTATTG CTCAAATGATTGAAGATGAACAAAGGACAAGTATGACCTCTCAGAAGAGCTTCCAGCAACTGA CCATGGAGAAGGAACAGGCCCTGGCTGACCTTAACTCTGTGGAAAGGTCCCTTTCTGATCTCT TCAGGAGATATGAGAACCTGAAAGGTGTTCTGGAAGGGTTCAAGAAGAATGAAGAAGCCTTGA AGAAATGTGCTCAGGATTACTTAGCCAGAGTTAAACAAGAGGAGCAGCGATACCAGGCCCTGA AAATCCACGCAGAAGAGAAACTGGACAAGTAAGAGCTTGTAAATGTTGAATTTCACTCTTCAT
GATGTTGTGGGAAGATTGAGAGAGGAAAACAAAATCACTGTTTCGCAACTCCAGGTTGTATTT
TTATGTGTGTGTTTATTTCACTTTTTAAACCCTTTTCCCATTGTTAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAACCCAAAAA
ORF Start: ATG at 321 ORF Stop: TAA at 2550
SEQ ID NO: 6 743 aa ;MW at 80863.4kD
NOV2b, MAFSPWQILSPVQWAKWTWSAVRGGAAGEDEAGGPEGDPEEEDSQAETKSLSFSSDSEGNFET
CG I 01055-02 Protein PEAETPIRSPFKESCDPSLGLAGPGAKSQESQEADEQLVAEWEKCSSKTCSKPSENEVPQQA IDSHSVKNFREEPEHDFSKISIVRPFSIETKDSTDISAVLGTKAAHGCVTAVSGKALPSSPPD
Sequence ALQDEAMTEGS GVTLEASAEADLKAGNSCPELVPSRRSKLRKPKPVPLRKKAIGGEFSDTNA AVEGTPLPKASYHFSPEELDENTΞPL GDARFQKSPPDIKETPGTLSSDTNDSGVE GEESRS SPLKLEFDFTEDTGNIEARKALPRK GRKLGSTLTPKIQKDGISKSAGLEQPTDPVARDGPLS QTSSKPDPSQ ESPSFNPFGSHSVLQNSPPLSSEGSYHFDPDNFDESMDPFKPTTTLTSSDFC SPTGNHVNEILESPKKAKSRLITSGCKVKKHETQSLALDACSRDEGAVISQISDISNRDGHAT DEEKLASTSCGQKSAGAEVKGEPEED EYFECSNVPVSTINHAFSSSEAGIEKETCQKMEEDG STV GLLESSAEKAPVSVSCGGESP DGICLSESDKTAV TLIREEIITKEIEA EWKKKYEE TRQEVLEMRKIVAEYEKTIAQMIEDEQRTSMTSQKSFQQ TMEKEQALAD NSVERS SDLFR RYENLKGVLEGFKKNEEALKKCAQDYLARVKQEEQRYQALKIHAEEKLDK
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 2B.
: Table 2B. Comparison of NOV2a against NOV2b. j NOV2a Residues/ Identities/
Protein Sequence i Match Residues Similarities for the Matched Region r. N0V2b 1..310 269/310 (86%) 1..310 270/310 (86%)
Further analysis of the NOV2a protein yielded the following properties shown in Table 2C.
Table 2C. Protein Sequence Properties NOV2a
PSort 0.8800 probability located in nucleus; 0.4612 probability located in mitochondrial j analysis: matrix space; 0.3000 probability located in microbody (peroxisome); 0.1582 probability located in mitochondrial inner membrane i SignalP Cleavage site between residues 21 and 22 ! analysis: x)
A search of the NOV2a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 2D.
In a BLAST search of public sequence datbases, the NOV2a protein was found to have homology to the proteins shown in the BLASTP data in Table 2E.
PFam analysis predicts that the NOV2a protein contains the domains shown in the
Table 2F.
Table 2F. Domain Analysis of NOV2a
Identities/
Pfam Domain NOV2a Match Region Similarities Expect Value for the Matched Region
Example 3. The NOV3 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 3A.
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 3B.
Further analysis of the NOV3a protein yielded the following properties shown in Table 3C.
Table 3C. Protein Sequence Properties NOV3a j PSort j 0.8486 probability located in lysosome (lumen); 0.4500 probability located in j analysis: I cytoplasm; 0.2583 probability located in microbody (peroxisome); 0.1000 ] ! probability located in mitochondrial matrix space
SignalP I No Known Signal Sequence Predicted analysis:
A search of the NOV3a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 3D.
1 Table 3D. Geneseq Results for NOV3a
NOV3a 1 Identities/
; Geneseq ! Protein/Organism/Length [Patent #, Residues/ ; Similarities for Expect j Identifier j Date] Match I the Matched Value Residues , Region
' AAM52307 Human TR1P6 - Homo sapiens, 476 aa. 1 ..36 1 36/36 ( 100%) 7e-17 [WO200171356-A2, 27-SEP-2001] 1..36 36/36 (100%)
, AAM52308 Murine TRIP6 - Mus musculus, 480 aa. 1..36 , 29/36 (80%) l e-12 [ WO200171356-A2. 27-SEP-2001 ] 1 ..36 I 32/36 (88%)
! AAR79480 Rat type II collagen - Rattus sp, 1442 1 ..79 ' 29/80 (36%) 0.01 1
I aa. [W0952261 1 -A2, 24-AUG-1995] 952..1029 ! 34/80 (42%)
I AAE16477 Human collagen alphal (II) protein - 1..79 ; 28/80 (35%) 0.024 Homo sapiens, 1418 aa. [US6323314- 928..1005 : 34/80 (42%) B 1 , 27-NOV-2001]
ABB09627 Amino acid sequence of human 1..79 28/80 (35%) 0.024 collagen type II alphal - Homo sapiens, 928..1005 34/80 (42%) 1418 aa. [US6342361 -B 1 , 29-JAN- 2002]
In a BLAST search of public sequence datbases, the NOV3a protein was found to have homology to the proteins shown in the BLASTP data in Table 3E.
PFam analysis predicts that the NOV3a protein contains the domains shown in the Table 3F.
; Table 3F. Domain Analysis of NOV3a
Identities/
Pfam Domain NOV3a Match Region Similarities Expect Value for the Matched Region
Example 4.
The NOV4 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 4A.
|SEQ ID NO: 12 |54 aa MW at 5975.9kD
NOV4a, MKVLLLKDAKEDDCGQDPYIRELG YGLEAT I PV SFEFLSLPSFSEKSGKGL ICG 102244-01 Protein Sequence
SEQ ID NO: 13 1086 bp
NOV4b, CCACAGAGGGCAGTCACGTGCCCGCTGTGTGCCAGGCCGGGTGCTGGGCACGGTCCCGCGAGT
CGI02244-02 DNA GCCCTATAAGGACTGCCAGGCAATAATGAAGGTTCTTTTACTGAAGGATGCGAAGGAAGATGA
CTGTGGCCAGGATCCGTATATCAGGGAATTAGGATTATATGGACTTGAAGCCACTTTGATCCC
Sequence TGTTTTATCGTTTGAGTTTTTGTCTCTTCCCAGTTTCTCTGAGAAGCTTTCTCATCCTGAAGA TTACGGGGGACTCATTTTTACCAGCCCCAGAGCAGTGGAAGCAGCAGAGTTATGTTTGGAGCA AAACAATAAAACTGAAGTCTGGGAAAGGTCTCTGAAAGAAAAATGGAATGCCAAGTCAGTGTA GTGGTTGGAAATGCTACTGCTTCTCTAGTGAGTAAAATTGGCCTGAATACAGAAGGAGAAAC CTGTGGAAATGCAGAAAAGCTTGCAGAATATATTTGTTCCAGGGAGTCCTCAGCACTGCCTCT TCTATTTCCCTGTGGAAACCTCAAAAGAGAAATCCTGCCAAAAGCGCTCAAGGACAAAGGGAT TGCCATGGAAAGCATAACTGTGTATCAGACAGTTGCACACCCAGGAATCCAAGGGAACCTGAA CAGCTACTATTCCCAGCAGGGGGTTCCAGCCAGCATCACATTTTTTAGTCCCTCTGGCCTCAC ATACAGTCTCAAGCACATTCAGGAGTTATCTGGTGACAATATCGATCAAATTAAGTTTGCAGC CATCGGCCCCACTACGGCTCGCGCGCTGGCCGCCCAGGGCCTTCCTGTAAGCTGCACTGCAGA GAGCCCCACGCCACAAGCCCTGGCCACTGGCATCAGGAAGGCTCTCCAGCCCCATGGCTGCTG CTGAGTCAGCCACCTAGCGCTGGCCCCATGCAGCCTCCCTGGGCTGGGCTGGCTCTGGATGGA
GCCAGGCATCGGCAAGGGCTCTCGGGAGCTGCTGCCGTCAGACTCCTGCCTCAAGCCTGAGTG
GAAGCACCTGAGGACCGGGGATCGGGACCTGACCTGGGGCTGGCCTCAGGCCCACGTGCACGT
GACTGCCCTCTGTGG
ORF Start: ATG at 89 jORF Stop: TGAj3t_884
SEQID NOΪM 265 aa IM W at 28626.3 kD
,NOV4b, MKVLLLKDAKEDDCGQDPYIRE GLYGLEATLIPVLSFEFLSLPSFSEKLSHPEDYGGLIFTS
ICG 102244-02 Protein PRAVEAAELCLEQNNKTEV ERSLKEKWNAKSVYWGNATASLVSKIGLNTEGETCGNAEKLA EYICSRESSALPLLFPCGNLKREILPKALKDKGIAMESITVYQTVAHPGIQGNLNSYYSQQGV iSequence PASITFFSPSGLTYSLKHIQELSGDNIDQIKFAAIGPTTARALAAQGLPVSCTAESPTPQALA TGIRKALQPHGCC
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 4B.
Further analysis of the NOV4a protein yielded the following properties shown in Table 4C.
f". Table 4C. Protein Sequence Properties NOV4a
PSort ; 0.6500 probability located in cytoplasm; 0.1000 probability located in mitochondrial analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0480 probability i located in microbody (peroxisome)
SignalP i No Known Signal Sequence Predicted analysis:
A search of the NOV4a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 4D.
Table 4D. Geneseq Results for NOV4a
NOV4a
Identities/
; Geneseq Protein/Organism/Length Residues/ : Expect ■ Similarities for the ' Identifier [Patent #, Date] Match ! Value I Matched Region Residues
In a BLAST search of public sequence datbases, the NOV4a protein was found to have homology to the proteins shown in the BLASTP data in Table 4E.
PFam analysis predicts that the NOV4a protein contains the domains shown in the Table 4F.
Example 5.
The NOV5 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 5A.
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 5B.
s Table 5B. Comparison of NOV5a against NOV5b. s NOV5a Residues/ Identities/ i Protein Sequence Match Residues Similarities for the Matched Region i NOV5b 1 1..293 245/283 (86%) 1 14.396 247/283 (86%)
Further analysis of the NOV5a protein yielded the following properties shown in Table 5C.
Table 5C. Protein Sequence Properties NOV5a
PSort 0.4500 probability located in cytoplasm; 0.3600 probability located in mitochondrial analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
: SignalP No Known Signal Sequence Predicted , analysis:
A search of the NOV5a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 5D.
Table 5D. Geneseq Results for NOV5a
NOV5a Identities/
I Geneseq Protein/Organism/Length [Patent #, Residues/ Similarities for Expect I Identifier Date] Match the Matched Value Residues Region
In a BLAST search of public sequence datbases, the NOV5a protein was found to have homology to the proteins shown in the BLASTP data in Table 5E.
PFam analysis predicts that the NOV5a protein contains the domains shown in the Table 5F.
13
Table 5F. Domain Analysis of NOV5a
Identities/
Pfam Domain NOV5a Match Region Similarities Expect Value for the Matched Region
Example 6.
The NOV6 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 6A.
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 6B.
Further analysis of the NOV6a protein yielded the following properties shown in Table 6C.
j Table 6C. Protein Sequence Properties NOVόa
; PSort 0.6500 probability located in cytoplasm; 0.1000 probability located in mitochondrial ! analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane) r~ SignalP No Known Signal Sequence Predicted
; analysis:
A search of the NOV6a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 6D.
15
In a BLAST search of public sequence datbases, the NOV6a protein was found to have homology to the proteins shown in the BLASTP data in Table 6E.
PFam analysis predicts that the NOV6a protein contains the domains shown in the Table 6F.
j Table 6F. Domain Analysis of NOVόa
Identities/
Pfam Domain NOVόa Match Region Similarities Expect Value for the Matched Region
LIM 23..82 24/62 (39%) 2.8e-18 50/62 (81%)
LIM 87..139 18/61 (30%) 4.4e-12 42/61 (69%)
Example 7.
The NOV7 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 7A.
16
jTable 7A. NOV7 Sequence Analysis
Γ JSEQID NOTZT J2532 bp
;NOV7a, CGGCGCCGCTCGCTCCCCCGACCCGGACTCCCCCATGTATGACGACTCCTACGTGCCCGGGTT
CGI 03764-01 DNA TGAGGACTCGGAGGCGGGTTCAGCCGACTCCTACACCAGCCGCCCATCTCTGGACTCAGACGT CTCCCTGGAGGAGGACCGGGAGAGTGCCCGGCGTGAAGTAGAGAGCCAGGCTCAGCAGCAGCT
Sequence CGAAAGGGCCAAGCACAAACCTGTGGCATTTGCGGTGAGGACCAATGTCAGCTACTGTGGCGT ACTGGATGAGGAGTGCCCAGTCCAGGGCTCTGGAGTCAACTTTGAGGCCAAAGATTTTCTGCA CATTAAAGAGAAGTACAGCAATGACTGGTGGATCGGGCGGCTAGTGAAAGAGGGCGGGGACAT CGCCTTCATCCCCAGCCCCCAGCGCCTGGAGAGCATCCGGCTCAAACAGGAGCAGAAGGCCAG GAGATCTGGGAACCCTTCCAGCCTGAGTGACATTGGCAACCGACGCTCCCCTCCGCCATCTCT AGCCAAGCAGAAGCAAAAGCAGGCGGAACATGTTCCCCCATATGACGTGGTGCCCTCCATGCG GCCTGTGGTGCTGGTGGGACCCTCTCTGAAAGGTTATGAGGTCACAGACATGATGCAGAAGGC TCTCTTCGACTTCCTCAAACACAGATTTGATGGCAGGATCTCCATCACCCGAGTCACAGCCGA CCTCTCCCTGGCAAAGCGATCTGTGCTCAACAATCCGGGCAAGAGGACCATCATTGAGCGCTC CTCTGCCCGCTCCAGCATTGCGGAAGTGCAGAGTGAGATCGAGCGCATATTTGAGCTGGCCAA ATCCCTGCAGCTAGTAGTGTTGGACGCTGACACCATCAACCACCCAGCACAGCTGGCCAAGAC CTCGCTGGCCCCCATCATCGTCTTTGTCAAAGTGTCCTCACCAAAGGTACTCCAGCGTCTCAT TCGCTCCCGGGGGAAGTCACAGATGAAGCACCTGACCGTACAGATGATGGCATATGATAAGCT GGTTCAGTGCCCACCGGAGTCATTTGATGTGATTCTGGATGAGAACCAGCTGGAGGATGCCTG TGAGCACCTGGCTGAGTACCTGGAGGTTTACTGGCGGGCCACGCACCACCCAGCCCCTGGCCC CGGACTTCTGGGTCCTCCCAGTGCCATCCCCGGACTTCAGAACCAGCAGCTGCTGGGGGAGCG TGGCGAGGAGCACTCCCCCCTTGAGCGGGACAGCTTGATGCCCTCTGATGAGGCCAGCGAGAG CTCCCGCCAAGCCTGGACAGGATCTTCACAGCGTAGCTCCCGCCACCTGGAGGAGGACTATGC AGATGCCTACCAGGACCTGTACCAGCCTCACCGCCAACACACCTCGGGGCTGCCTAGTGCTAA CGGGCATGACCCCCAAGACCGGCTTCTAGCCCAGGACTCAGAGCACAACCACAGTGACCGGAA CTGGCAGCGCAACCGGCCTTGGCCCAAGGATAGCTACTGACAGCCTCCTGCTGCCCTACCCTG
GCAGGCACAGGCGCAGCTGGCTGGGGGGCCCACTCCAGGCAGGGTGGCGTTAGACTGGCATCA
GGCTGGCACTAGGCTCAGCCCCCAAAACCCCCTGCCCAGCCCCAGCTTCAGGGCTGCCTGTGG
TCCCAAGGTTCTGGGAGAAACAGGGGACCCCCTCACCTCCTGGGCAGTGACCCCTACTAGGCT
CCCATTCCAGGTACTAGCTGTGTGTTCTGCACCCCTGGCACCTTCCTCTCCTCCCACACAGGA
AGCTGCCCCACTGGGCAGTGCCCTCAGGCCAGGATCCCCTTAGCAGGGTCCTTCCCACCAGAC
TCAGGGAAGGGATGCCCCATTAAAGTGACAAAAGGGTGGGGTGTGGGCACCATGGCATGAGGA
AGAAACAAGGTCCCTGAGCAGGCACAAGTCCTGACAGTCAAGGGACTGCTTTGGCATCCAGGG
CCTCCAGTCACCTCACTGCCATACATTAGAAATGAGACAATCAAAGCCCCCCCCAGGGTGGCA
CACCCATCCGTTTGCTGGGGTGTGGCAGCCACATCCAAGACTGGAGCAGCAGGCTGGCCACGC
ITCGGGCCAGAGAGAGCTCACAGCTGAAGCTCTTGGAGGGAAGGGCTCTCCTCACCCTGCCAGG
AAGCTTCTTAACATGTGACAGGACCAGGGACCAGGAGCATGGTGAAGCCAAGTGGCAGATGGG lAGCCAACCTGGATGGGGGTTTGGGGAAGGAGGGCATGTGTAGCAGAGAACTTAGGGGGGCCTC
.CTTGCCTTTCTCATTCTTTTGCCCTGCATCCTGTCATTTCTGTTCTTGTCCCTCATACATCTT
TGGAGAACCGGGCTCCAGACTTTGTTCCCTGACTCATAGCTGCCGCTTGTTAGGTTAGGGTTA
GATGGGGAGAGACAGGGCACAGAGGACCTGTCTCCCCGGCTACTCTTGCCTTATGGCTCTAGT
GTGTGACCTACAGAGCATGCTCCACAAGCCCCTGCCTCACCTCACTGTCATCACTAATAAACA
TCATGCACAGTC
ORF Start: at 2 ORF Stop: TGA at 1487 jSEQ ID NO: 24 495 aa MW at 55582.3 kD
NOV7a, GAARSPDPDSPMYDDSYVPGFEDSEAGSADSYTSRPSLDSDVSLEEDRESARREVESQAQQQL CGI 03764-01 Protein ERAKHKPVAFAVRTNVSYCGVLDEECPVQGSGVNFEAKDFLHIKEKYSNDWWIGRLVKEGGDI AFI PSPQRLESIRLKQEQKARRSGNPSSLSDIGNRRSPPPSLAKQKQKQAEHVPPYDVVPS R Sequence PWLVGPSL GYEVTDMMQKALFDFLKHRFDGRISITRVTADLSLAKRSVL PGKRTIIERS :SARSSIAEVQSEIERIFELAKSLQ WLDADTINHPAQLAKTSLAPI IVFVKVSSPKVLQR I RSRGKSQMKHLTVQMMAYDKLVQCPPESFDVILDENQLEDACEHLAEYLEVYWRATHHPAPGP GLLGPPSAIPGLQNQQL GERGEEHSPLERDSL PSDEASESSRQAWTGSSQRSSRHLEEDYA DAYQD YQPHRQHTSG PSANGHDPQDRLLAQDSEHNHSDRN QRNRP PKDSY
SEQ ID NO: 25 2532 bp
NOV7b, CGGCGCCGCTCGCTCCCCCGACCCGGACTCCCCCATGTATGACGACTCCTACGTGCCCGGGTT CG I 03764-01 DNA TGAGGACTCGGAGGCGGGTTCAGCCGACTCCTACACCAGCCGCCCATCTCTGGACTCAGACGT CTCCCTGGAGGAGGACCGGGAGAGTGCCCGGCGTGAAGTAGAGAGCCAGGCTCAGCAGCAGCT Sequence CGAAAGGGCCAAGCACAAACCTGTGGCATTTGCGGTGAGGACCAATGTCAGCTACTGTGGCGT ACTGGATGAGGAGTGCCCAGTCCAGGGCTCTGGAGTCAACTTTGAGGCCAAAGATTTTCTGCA CATTAAAGAGAAGTACAGCAATGACTGGTGGATCGGGCGGCTAGTGAAAGAGGGCGGGGACAT CGCCTTCATCCCCAGCCCCCAGCGCCTGGAGAGCATCCGGCTCAAACAGGAGCAGAAGGCCAG GAGATCTGGGAACCCTTCCAGCCTGAGTGACATTGGCAACCGACGCTCCCCTCCGCCATCTCT AGCCAAGCAGAAGCAAAAGCAGGCGGAACATGTTCCCCCATATGACGTGGTGCCCTCCATGCG
17
GCCTGTGGTGCTGGTGGGACCCTCTCTGAAAGGTTATGAGGTCACAGACATGATGCAGAAGGCi
TCTCTTCGACTTCCTCAAACACAGATTTGATGGCAGGATCTCCATCACCCGAGTCACAGCCGAJ
CCTCTCCCTGGCAAAGCGATCTGTGCTCAACAATCCGGGCAAGAGGACCATCATTGAGCGCTCj
CTCTGCCCGCTCCAGCATTGCGGAAGTGCAGAGTGAGATCGAGCGCATATTTGAGCTGGCCAAj
ATCCCTGCAGCTAGTAGTGTTGGACGCTGACACCATCAACCACCCAGCACAGCTGGCCAAGAC j
CTCGCTGGCCCCCATCATCGTCTTTGTCAAAGTGTCCTCACCAAAGGTACTCCAGCGTCTCAT
TCGCTCCCGGGGGAAGTCACAGATGAAGCACCTGACCGTACAGATGATGGCATATGATAAGCT
GGTTCAGTGCCCACCGGAGTCATTTGATGTGATTCTGGATGAGAACCAGCTGGAGGATGCCTG
TGAGCACCTGGCTGAGTACCTGGAGGTTTACTGGCGGGCCACGCACCACCCAGCCCCTGGCCC
CGGACTTCTGGGTCCTCCCAGTGCCATCCCCGGACTTCAGAACCAGCAGCTGCTGGGGGAGCG
TGGCGAGGAGCACTCCCCCCTTGAGCGGGACAGCTTGATGCCCTCTGATGAGGCCAGCGAGAG
CTCCCGCCAAGCCTGGACAGGATCTTCACAGCGTAGCTCCCGCCACCTGGAGGAGGACTATGC
AGATGCCTACCAGGACCTGTACCAGCCTCACCGCCAACACACCTCGGGGCTGCCTAGTGCTAA
CGGGCATGACCCCCAAGACCGGCTTCTAGCCCAGGACTCAGAGCACAACCACAGTGACCGGAA
CTGGCAGCGCAACCGGCCTTGGCCCAAGGATAGCTACTGACAGCCTCCTGCTGCCCTACCCTG
GCAGGCACAGGCGCAGCTGGCTGGGGGGCCCACTCCAGGCAGGGTGGCGTTAGACTGGCATCA
GGCTGGCACTAGGCTCAGCCCCCAAAACCCCCTGCCCAGCCCCAGCTTCAGGGCTGCCTGTGG
TCCCAAGGTTCTGGGAGAAACAGGGGACCCCCTCACCTCCTGGGCAGTGACCCCTACTAGGCT
CCCATTCCAGGTACTAGCTGTGTGTTCTGCACCCCTGGCACCTTCCTCTCCTCCCACACAGGA
AGCTGCCCCACTGGGCAGTGCCCTCAGGCCAGGATCCCCTTAGCAGGGTCCTTCCCACCAGAC
TCAGGGAAGGGATGCCCCATTAAAGTGACAAAAGGGTGGGGTGTGGGCACCATGGCATGAGGA
AGAAACAAGGTCCCTGAGCAGGCACAAGTCCTGACAGTCAAGGGACTGCTTTGGCATCCAGGG
CCTCCAGTCACCTCACTGCCATACATTAGAAATGAGACAATCAAAGCCCCCCCCAGGGTGGCA
CACCCATCCGTTTGCTGGGGTGTGGCAGCCACATCCAAGACTGGAGCAGCAGGCTGGCCACGC
TCGGGCCAGAGAGAGCTCACAGCTGAAGCTCTTGGAGGGAAGGGCTCTCCTCACCCTGCCAGG
AAGCTTCTTAACATGTGACAGGACCAGGGACCAGGAGCATGGTGAAGCCAAGTGGCAGATGGG jAGCCAACCTGGATGGGGGTTTGGGGAAGGAGGGCATGTGTAGCAGAGAACTTAGGGGGGCCTC
CTTGCCTTTCTCATTCTTTTGCCCTGCATCCTGTCATTTCTGTTCTTGTCCCTCATACATCTT
TGGAGAACCGGGCTCCAGACTTTGTTCCCTGACTCATAGCTGCCGCTTGTTAGGTTAGGGTTA
GATGGGGAGAGACAGGGCACAGAGGACCTGTCTCCCCGGCTACTCTTGCCTTATGGCTCTAGT
GTGTGACCTACAGAGCATGCTCCACAAGCCCCTGCCTCACCTCACTGTCATCACTAATAAACA
TCATGCACAGTC
ORF Start: at 2 JORF Stop: TGA at 487 SEQTD NO: 26 495 aa |MW at 55582.3 k ~
!NOV7b, GAARSPDPDSPMYDDSYVPGFEDSEAGSADSYTSRPSLDSDVSLEEDRESARREVESQAQQQL fCG 103764-01 Protein ERAKHKPVAFAVRTNVSYCGVLDEECPVQGSGVNFEAKDFLHIKEKYSNDWWIGRLVKEGGDI AFIPSPQRLESIRLKQEQKARRSGNPSSLSDIGNRRSPPPS AKQKQKQAEHVPPYDWPSMR
(Sequence PW VGPSLKGYEVTDMMQKALFDF KHRFDGRISITRVTADLSLAKRSVLNNPGKRTI IERS SARSSIAEVQSEIERIFELAKS QLW DADTINHPAQLAKTSLAPI IVFVKVSSPKVLQRLI RSRGKSQMKH TVQMMAYDKLVQCPPESFDVILDENQLEDACEHLAEY EVYWRATHHPAPGP GLLGPPSAIPGLQNQQLLGERGEEHSPLERDSLMPSDEASESSRQAWTGSSQRSSRHLEEDYA DAYQDLYQPHRQHTSGLPSANGHDPQDRL AQDSEHNHSDRNWQRNRPWP DSY
SEQ ID NO: 27 1822 bp
:NOV7c, TTCGTAACAACTCCGCCCCATTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGGTCTATA
212779035 DNA TAAGCAGAGCTCTCTGGCTAACTAGAGAACCCACTGCTTACTGGCTTATCGAAATTAATACGA
CTCACTATAGGGAGACCCAAGCTGGCTAGCGTTTAAACTTAAGCTTGGTACCGAGCTCGGATC
Sequence CACCATGTATGACGACTCCTACGTGCCCGGGTTTGAGGACTCGGAGGCGGGTTCAGCCGACTC CTACACCAGCCGCCCATCTCTGGACTCAGACGTCTCCCTGGAGGAGGACCGGGAGAGTGCCCG GCGTGAAGTAGAGAGCCAGGCTCAGCAGCAGCTCGAAAGGGCCAAGCACAAACCTGTGGCATT TGCGGTGAGGACCAATGTCAGCTACTGTGGCGTACTGGATGAGGAGTGCCCAGTCCAGGGCTC TGGAGTCAACTTTGAGGCCAAAGATTTTCTGCACATTAAAGAGAAGTACAGCAATGACTGGTG GATCGGGCGGCTAGTGAAAGAGGGCGGGGACATCGCCTTCATCCCCAGCCCCCAGCGCCTGGA GAGCATCCGGCTCAAACAGGAGCAGAAGGCCAGGAGATCTGGGAACCCTTCCAGCCTGAGTGA CATTGGCAACCGACGCTCCCCTCCGCCATCTCTAGCCAAGCAGAAGCAAAAGCAGGCGGAACA TGTTCCCCCATATGACGTGGTGCCCTCCATGCGGCCTGTGGTGCTGGTGGGACCCTCTCTGAA AGGTTATGAGGTCACAGACATGATGCAGAAGGCTCTCTTCGACTTCCTCAAACACAGATTTGA TGGCAGGATCTCCATCACCCGAGTCACAGCCGACCTCTCCCTGGCAAAGCGATCTGTGCTCAA CAATCCGGGCAAGAGGACCATCATTGAGCGCTCCTCTGCCCGCTCCAGCATTGCGGAAGTGCA GAGTGAGATCGAGCGCATATTTGAGCTGGCCAAATCCCTGCAGCTAGTAGTGTTGGACGCTGA CACCATCAACCACCCAGCACAGCTGGCCAAGACCTCGCTGGCCCCCATCATCGTCTTTGTCAA AGTGTCCTCACCAAAGGTACTCCAGCGTCTCATTCGCTCCCGGGGGAAGTCACAGATGAAGCA CCTGACCGTACAGATGATGGCATATGATAAGCTGGTTCAGTGCCCACCGGAGTCATTTGATGT GATTCTGGATGAGAACCAGCTGGAGGATGCCTGTGAGCACCTGGCTGAGTACCTGGAGGTTTA CTGGCGGGCCACGCACCACCCAGCCCCTGGCCCCGGACTTCTGGGTCCTCCCAGTGCCATCCC

SEQ ID NO: 31 1822 bp
NOV7e, TTCGTAACAACTCCGCCCCATTGACGCAAATGGGCGGTAGGCGTGTACGGTGGGAGGTCTATA
CGI 03764-03 DNA TAAGCAGAGCTCTCTGGCTAACTAGAGAACCCACTGCTTACTGGCTTATCGAAATTAATACGA
CTCACTATAGGGAGACCCAAGCTGGCTAGCGTTTAAACTTAAGCTTGGTACCGAGCTCGGATC
Sequence CACCATGTATGACGACTCCTACGTGCCCGGGTTTGAGGACTCGGAGGCGGGTTCAGCCGACTC CTACACCAGCCGCCCATCTCTGGACTCAGACGTCTCCCTGGAGGAGGACCGGGAGAGTGCCCG
GCGTGAAGTAGAGAGCCAGGCTCAGCAGCAGCTCGAAAGGGCCAAGCACAAACCTGTGGCATT

TGCGGTGAGGACCAATGTCAGCTACTGTGGCGTACTGGATGAGGAGTGCCCAGTCCAGGGCTC TGGAGTCAACTTTGAGGCCAAAGATTTTCTGCACATTAAAGAGAAGTACAGCAATGACTGGTG GATCGGGCGGCTAGTGAAAGAGGGCGGGGACATCGCCTTCATCCCCAGCCCCCAGCGCCTGGA GAGCATCCGGCTCAAACAGGAGCAGAAGGCCAGGAGATCTGGGAACCCTTCCAGCCTGAGTGA CATTGGCAACCGACGCTCCCCTCCGCCATCTCTAGCCAAGCAGAAGCAAAAGCAGGCGGAACA TGTTCCCCCATATGACGTGGTGCCCTCCATGCGGCCTGTGGTGCTGGTGGGACCCTCTCTGAA AGGTTATGAGGTCACAGACATGATGCAGAAGGCTCTCTTCGACTTCCTCAAACACAGATTTGA TGGCAGGATCTCCATCACCCGAGTCACAGCCGACCTCTCCCTGGCAAAGCGATCTGTGCTCAA CAATCCGGGCAAGAGGACCATCATTGAGCGCTCCTCTGCCCGCTCCAGCATTGCGGAAGTGCA GAGTGAGATCGAGCGCATATTTGAGCTGGCCAAATCCCTGCAGCTAGTAGTGTTGGACGCTGA CACCATCAACCACCCAGCACAGCTGGCCAAGACCTCGCTGGCCCCCATCATCGTCTTTGTCAA AGTGTCCTCACCAAAGGTACTCCAGCGTCTCATTCGCTCCCGGGGGAAGTCACAGATGAAGCA CCTGACCGTACAGATGATGGCATATGATAAGCTGGTTCAGTGCCCACCGGAGTCATTTGATGT GATTCTGGATGAGAACCAGCTGGAGGATGCCTGTGAGCACCTGGCTGAGTACCTGGAGGTTTA CTGGCGGGCCACGCACCACCCAGCCCCTGGCCCCGGACTTCTGGGTCCTCCCAGTGCCATCCC CGGACTTCAGAACCAGCAGCTGCTGGGGGAGCGTGGCGAGGAGCACTCCCCCCTTGAGCGGGA CAGCTTGATGCCCTCTGATGAGGCCAGCGAGAGCTCCCGCCAAGCCTGGACAGGATCTTCACA GCGTAGCTCCCGCCACCTGGAGGAGGACTATGCAGATGCCTACCAGGACCTGTACCAGCCTCA CCGCCAACACACCTCGGGGCTGCCTAGTGCTAACGGGCATGACCCCCAAGACCGGCTTCTAGC CCAGGACTCAGAACACAACCACAGTGACCGGAACTGGCAGCGCAACCGGCCTTGGCCCAAGGA TAGCTACTGAGCGGCCGCTCGAGTCTAGAGGGCCCGTTTAAACCCGCTGATCAGCCTCGACTG
TGCCTTCTAGTTGCCAGCCATCTGTTGTTTGCCCCTCCCCCGTGCCTTCCTTGACCCTGGAAG
GTGCCACTCCCACTGTCCTTTCCTAATAAAATGAGGAAATTGCATCGCATTGTCTGAG
ORF Start: ATG at 194 JORF Stop: TGA at 1646
SEQ ID NO: 32 484 aa MW at 54531.3kD
!NOV7e, MYDDSYVPGFEDSEAGSADSYTSRPSLDSDVSLEEDRESARREVESQAQQQ ERAKHKPVAFA
CGI 03764-03 Protein VRTNVSYCGVLDEECPVQGSGVNFEAKDFLHIKEKYS D IGRLVKEGGDIAFIPSPQRLES IRLKQEQKARRSGNPSSLSDIGNRRSPPPSLAKQKQKQAEHVPPYDWPSMRPWLVGPSLKG
Sequence YEVTDMMQKA FDFLKHRFDGRISITRVTADLSLAKRSVLNNPGKRTIIERSSARSSIAEVQS EIERIFELAKSLQLWLDADTINHPAQLAKTSLAPIIVFVKVSSPKV QRLIRSRGKSQMKHL TVQMMAYDKLVQCPPESFDVILDENQLEDACEHLAEYLEVYWRATHHPAPGPGLLGPPSAIPG LQNQQLLGERGEEHSPLERDSL PSDEASESSRQAWTGSSQRSSRHLEEDYADAYQDLYQPHR QHTSGLPSANGHDPQDRL AQDSEHNHSDRN QRNRP PKDSY
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 7B.
Further analysis of the NOV7a protein yielded the following properties shown in Table 7C.
Table 7C. Protein Sequence Properties NOV7a
PSort 0.6500 probability located in cytoplasm; 0.1000 probability located in mitochondrial analysis: , matrix space; 0.1000 probability located in lysosome (lumen); 0.1000 probability ; located in plasma membrane
■ SignalP No Known Signal Sequence Predicted j analysis:
A search of the NOV7a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 7D.
In a BLAST search of public sequence datbases, the NOV7a protein was found to have homology to the proteins shown in the BLASTP data in Table 7E.
PFam analysis predicts that the NOV7a protein contains the domains shown in the Table 7F.
Example 8.
The NOV8 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 8A.
Table 8A. NOV8 Sequence Analysis jSEQ ID NO: 33 2037 bp
NOV8a, CTACTTGGTCTCCTGCTTTCGCGACATGGCCTTCAATTTTGGGGCTCCCTCGGGCACCTCCGG CGI 04944-01 DNA TACCGCTGCAGCCACCGCGGCCCCCGGCTGGGTTTGGAGGATTTGGGACAACATCTACAACTG
CAGGTTCTGCATTCAGCTTTTCTGCCCCAACTAACACAGGCACTACTGGACTCTTTGGTGGTA Sequence CTCAGAACAAAGGTTTTGGATTTGGTACTGGTTTTGGCACAACAACGGGAACTAGTACTGGTT
TAGGTACTGGTTTGGGAACTGGACTGGGATTTGGAGGATTTAATACACAGCAGCAGCAGCAAA
CTAGCAGTAGGTTATAGTTGCATGCCCAGTAATAAAGATGAAGATGGGCTAGTGGTTTTAGTT TTCAACAAAAAAGAAACAGAGATTCGAAGCCAACAACAACAGTTGGTAGAATCATTGCATAAA JGTTTTGGGAGGAAACCAGACCCTTACTGTAAATGTAGAGGGCACTAAAACATTGCCAGATGAT
,CAGACAGAAGTTGTTATTTATGTTGTTGAGCGTTCGCCAAATGGTACTTCAAGAAGAGTTCCA IGCTACAACGCTATATGCCCATTTTGAACAAGCCAATATAAAAACACAATTGCAGCAACTTGGT IGTAACCCTTTCTATGACTAGAACAGAACTTTCTCCTGCACAGATCAGACAGCTTTTACAGAAT !CCTCCTGCTGGTGTTGATCCTATTATCTGGGAACAGGCCAAGGTAGATAACCCTGATTCTGAA AAGTTAATTCCTGTACCAATGGTGGGTTTTAAGGAACTTCTCCGAAGACTGAAGGTTCAAGAT JCAGATGACTAAGCAGCATCAAACCAGATTAGATATCATATCTGAAGATATTAGTGAGCTACAA AAGAATCAAACTACATCTGTAGCCAAAATTGCACAATACAAGAGGAAACTCATGGATCTTTCC CATAGAACTTTACAGGTCCTAATCAAACAGGAAATTCAAAGGAAGAGTGGTTATGCCATTCAG GCTGATGAAGAGCAGTTGCGAGTTCAGCTGGATACGATTCAGGGTGAACTAAATGCACCTACT CAGTTCAAGGGCCGACTAAATGAATTGATGTCTCAAATCAGGATGCAGAATCATTTTGGAGCA GTCAGATCTGAAGAAAGGTATTACATAGATGCAGATCTGTTACGAGAAATCAAGCAGCATTTG AAACAACAACAGGAAGGCCTTAGCCATTTGATTAGCATCATTAAAGACGATCTAGAAGATATA AAGCTGGTCGAACATGGATTGAATGAAACCATCCACATCAGAGGTGGTGTCTTTAGTTGACAG TTCACAAACTTGTGTAAAGGTTTGTGAAATGCATCTTCTTACTGCATCAGACCTTCCTTAAGA
ATGAAACCGACCACATGGAGGGAAAAAGAAAACAATTCTTTCTTGGATTGGTTTTTTGAGAAG
TTTACTGACAAATTACTGTTCATCAAATCTGAAATAGTCACCTCACAGCTCTTCAAAGAAAAC
CTTTGAAAGATTTATATCTAAAAGCTGTATTTACTTTAAAAGAAGTGCATAATTACCAAAATT
GTATGTACTATTGTACATTTTTACAACAGCATTTTCTTAAACATAATCTGTGTTTAATGATTA
TTGTCCATTGAGCCTGTACTCTGCTTTCCATACCAAGTAAATATGAAATAATCTACTTTGCAC
ATAACAGAAGAAACTATAATTACTTGGCTGTTGGAGATTTGTACTTGAGTATAAATGTACACC
AGTTTTTGTATTTGTGAACTCATCTGTGGGAGGAGTAAAGAAAATCCAAAAGCATTTAATGTT
TTGTTTTTGTTCTATAAAGATATGAAAATGTATTTTTATATTATTTTACTTATTTGGAATTTA
CAGAGCACACCTAAGCAATTAGGATATAACAAAACTACTTAACCATTTTTGCAACCATTTTGT
TTTTTAAGCCTTTTTATTTCTAAAAAGATGAAAACTTATAAATAAATTCTTAATTTGTAATTA ιCTTTTAAAAAAAAAAAAAAAA
ORF Start: ATG at 337 ;ORF Stop: TGA at 1318
SEQ ID NO: 34 327 aa M W at 37377.4kD
NOV8a, MPSNKDEDGLWLVFNKKETEIRSQQQQLVESLHKVLGGNQTLTVNVEGTKT PDDQTEWIY CG 104944-01 Protein WERS PNGTSRRVPATTLYAHFEQA I KTQ QQLGVTLSMTRTELSPAQIRQLLQNPPAGVDP IIWEQAKVDNPDSEK IPVPMVGFKELLRRLKVQDQMTKQHQTRLDI ISEDISE QKNQTTSV
Sequence AKIAQYKRKLMDLSHRTLQVLIKQEIQRKSGYAIQADEEQ RVQ DTIQGELNAPTQFKGRLN ELMSQIRMQNHFGAVRSEERYYIDADLLREI KQHLKQQQEGLSH ISI IKDDLEDIKLVEHGL NETIHIRGGVFS
Further analysis of the NOV8a protein yielded the following properties shown in Table 8B.
j Table 8B. Protein Sequence Properties NOV8a
, PSort 0.4500 probability located in cytoplasm; 0.3000 probability located in microbody ' analysis: (peroxisome); 0.1590 probability located in lysosome (lumen); 0.1000 probability located in mitochondrial matrix space
■ SignalP 1 No Known Signal Sequence Predicted analysis:
A search of the NOV8a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 8C.
! Table 8C. Geneseq Results for NOV8a
Geneseq Protein/Organism/Length [Patent #, NOV8a Identities/ Expect Identifier Date] Similarities for Value
P"
In a BLAST search of public sequence datbases, the NOV8a protein was found to have homology to the proteins shown in the BLASTP data in Table 8D.
: Table 8D. Public BLASTP Results for NOV8a
PFam analysis predicts that the N0V8a protein contains the domains shown in the Table 8E.
Table 8E. Domain Analysis of NOV8a
Identities/
Pfam Domain NOV8a Match Region Similarities Expect Value for the Matched Region
Example 9.
The NOV9 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 9A.
[Table 9A. NOV9 Sequence Analysis
I |SEQTD NO: 35 11471 bp
NOV9a, TTGAACATGGACGAAGGAATTCCTCATTTGCAAGAGAGACAGTTACTGGAACATAGAGATTTT CGI 06550-01 DNA ATAGGACTGGACTATTCCTCTTTGTATATGTGTAAACCCAAAAGGAGCATGAAACGAGACGAC ACCAAGGATACCTACAAATTACCGCACAGATTAATAGAAAAGAAAAGAAGAGACCGAATTAAT Sequence GAATGCATTGCTCAGCTGAAAGATTTACTGCCTGAACATCTGAAATTGACAACTCTGGGACAT CTGGAGAAAGCTGTAGTCTTGGAATTAACTTTGAAACACTTAAAAGCTTTAACCGCCTTAACC GAGCAACAGCATCAGAAGATAATTGCTTTACAGAATGGGGAGCGATCTCTGAAATCGCCCATT CAGTCCGACTTGGATGCGTTCCACTCGGGATTTCAAACATGCGCCAAAGAAGTCTTGCAATAC CTCTCCCGGTTTGAGAGCTGGACACCCAGGGAGCCGCGGTGTGTCCAGCTGATCAACCACTTG CACGCCGTGGCCACCCAGTTCTTGCCCACCCCGCAGCTGTTGACTCAACAGGTCCCTCTGAGC AAAGGCACCGGCGCTCCCTCGGCCGCCGGGTCCGCGGCCGCCCCCTGCCTGGAGCGCGCGGGG CAGAAGCTGGAGCCCCTCGCCTACTGCGTGCCCGTCATCCAGCGGACTCAGCCCAGCGCCGAG CTCGCCGCCGAGAACGACACGGACACCGACAGCGGCTACGGCGGCGAAGCCGAGGCCCGGCCG GACCGCGAGAAAGGCAAAGGCGCGGGGGCGAGCCGCGTCACCATCAAGCAGGAGCCTCCCGGG GAGGACTCGCCGGCGCCCAAGAGGATGAAGCTGGATTCCCGCGGCGGCGGCAGCGGCGGCGGC CCGGGGGGCGGCGCGGCGGCGGCGGCAGCCGCGCTTCTGGGGCCCGACCCTGCCGCCGCGGCC GCGCTGCTGAGACCCGACGCCGCCCTGCTCAGCTCGCTGGTGGCGTTCGGCGGAGGCGGAGGC GCGCCCTTCCCGCAGCCCGCGGCCGCCGCGGCCCCCTTCTGCCTGCCCTTCTGCTTCCTCTCG CCTTCTGCAGCTGCCGCCTACGTGCAGCCCTTCCTGGACAAGAGCGGCCTGGAGAAGTATCTG TACCCGGCGGCGGCTGCCGCCCCGTTCCCGCTGCTATACCCCGGCATCCCCGCCCCGGCGGCA GCCGCGGCAGCCGCCGCCGCCGCTGCCGCCGCCGCCGCCGCGTTCCCCTGCCTGTCCTCGGTG TTGTCGCCCCCTCCCGAGAAGGCGGGCGCCGCCGCCGCGACCCTCCTGCCGCACGAGGTGGCG CCCCTTGGGGCGCCGCACCCCCAGCACCCGCACGGCCGCACCCACCTGCCCTTCGCCGGGCCC CGCGAGCCGGGGAACCCGGAGAGCTCTGCTCAGGAAGATCCCTCGCAGCCAGGAAAGGAAGCT CCCTGAATCCTTGCGTCCCGAA
ORF Start: ATG at 7 jORF Stop: TGA at 1453
SEQ ID NO: 36 482 aa MW at 50496.7kD
NOV9a, MDEGIPHLQERQLLEHRDFIGLDYSSLYMCKPKRSMKRDDTKDTYKLPHRLIEKKRRDRINEC CGI 06550-01 Protein IAQ KD LPEHLKLTTLGH EKAWLE TLKHLKALTALTEQQHQKIIALQNGERS KSPIQS DLDAFHSGFQTCAKEVLQYLSRFESWTPREPRCVQ I HLHAVATQFLPTPQLLTQQVPLSKG Sequence TGAPSAAGSAAAPCLERAGQK EPLAYCVPVIQRTQPSAELAAENDTDTDSGYGGEAEARPDR EKGKGAGASRVTIKQEPPGEDSPAPKRMKLDSRGGGSGGGPGGGAAAAAAALLGPDPAAAAAL LRPDAA LSSLVAFGGGGGAPFPQPAAAAAPFCLPFCFLSPSAAAAYVQPFLDKSGLEKYLYP AAAAAPFPLLYPGIPAPAAAAAAAAAAAAAAAAFPCLSSVLSPPPEKAGAAAAT LPHEVAPL GAPHPQHPHGRTHLPFAGPREPGNPESSAQEDPSQPGKEAP
SEQ ID NO: 37 628 bp jNOV9b, TTGAACATGGACGAAGGAATTCCTCATTTGCAAGAGAGACAGTTACCGGAACATAGAGATTTT
ICG 106550-02 DNA ATAGGACTGGACTATTCCTCTTTGTATATGTGTAAACCCAAAAGGAGCATGAAACGAGACGAC j Sequence ACCAAGGATACCTACAAATTACCGCACAGATTAATAGAAAAGAAAAGAAGAGACCGAATTAAT j GAATGCATTGCTCAGCTGAAAGATTTACTGCCTGAACATCTGAAATTGACAACTCTGGGACATI CTGGAGAAAGCTGTAGTCTTGGAATTAACTTTGAAACACTTAAAAGCTTTAACCGCCTTAACC j GAGCAACAGCATCAGAAGATAATTGCTTTACAGAATGGGGAGCGATCTCTGAAATCGCCCATT j CAGTCCGACTTGGATGCGTTCCACTCGGGATTTCAAACATGCGCCAAAGAAGTCTTGCAATACi CTCTCCCGGTTTGAGGGCTGGACACCCAGGGAGCCGCGGTGTGTCCAGCTGATCAACCACTTGJ CACGCCGTGGCCACCCAGTTCCTGCCCTTCGCCGGGCCCCGCGAGCCGGGGAACCCGGAGAGc" TCTGCTCAAGAAGATCCCTCGCAGCCAGGAAAGGAAGCTCCCTGAATCCTTGCGTCCCGAA jORF Start: at 1 j |ORF Stop: TGA at 610 SEQ ID NO: 38 l203 aa "" "fiMW at"23298.4kD
NOV9b, JLNMDEGI PHLQERQLPEHRDFIGLDYSSLY CKPKRSMKRDDTKDTYKLPHRLIEKKRRDRIN
CGI 06550-02 Protein ECIAQLKD LPEHLKLTTLGHLEKAWLELTLKHLKA TALTEQQHQKI IA QNGERSLKSPI QSD DAFHSGFQTCAKEVLQYLSRFEGWTPREPRCVQ INHLHAVATQFLPFAGPREPGNPES
Sequence ISAQEDPSQPGKEAP
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 9B.
Table 9B. Comparison of NOV9a against NOV9b. entities/ Protein Sequence NOV9a Residues/ Id Match Residues Similarities for the Matched Region
! NOV9b 1..193 163/201 (81%) 3..203 165/201 (81%)
Further analysis of the NOV9a protein yielded the following properties shown in Table 9C.
i Table 9C. Protein Sequence Properties NOV9a
PSort 0.7000 probability located in plasma membrane; 0.3000 probability located in analysis: nucleus; 0.2000 probability located in endoplasmic reticulum (membrane); 0.1000 probability located in mitochondrial inner membrane
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV9a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 9D.
In a BLAST search of public sequence datbases, the NOV9a protein was found to have homology to the proteins shown in the BLASTP data in Table 9E.
1035185 j Class B basic helix-loop-helix protein 2 14..401 179/405 (44%) 4e-66 \ (bHLHB2) (Stimulated with retinoic acid 20.364 224/405 (55%) 13) (E47 interaction protein 1 ) (eipl) - Mus musculus (Mouse), 41 1 aa.
PFam analysis predicts that the NOV9a protein contains the domains shown in the Table 9F.
Example 10.
The NOV 10 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 10A.
j jTable 10A. NOV10 Seq -u_encDe A_na_lysis_
1344 bp jNOVlOa, TCGTCCGCAAAGCCTGAGTCCTGTCCTTTCTCTCTCCCCGGACAGCATGAGCTTCACCACTCG
JCG 106842-01 DNA CTCCACCTTCTCCACCAACTACCGGTCCCTGGGCTCTGTCCAGGCGCCCAGCTACGGCGCCCG GCCGGTCAGCAGCGCGGCCAGCGTCTATGCAGGCGCTGGGGGCCTGGCCACCGGGATAGCCGG
■Sequence GGGTCTGGCAGGAATGGGAGGCATCCAGAACGAGAAGGAGACCATGCAAAGCCTGAACGACCG CCTGGCCTCTTACCTGGACAGAGTGAGGAGCCTGGAGACCGAGAACCGGAGGCTGGAGAGCAA AATCCGGGAGCACTTGGAGAAGAAGGGACCCCAGGTCAGAGACTGGAGCCATTACTTCAAGAT CATCGAGGACCTGAGGGCTCAGATCTTCGCAAATACTGTGGACAATGCCCGCATCGTTCTGCA GATTGACAATGCCCGTCTTGCTGCTGATGACTTTAGAGTCAAGTATGAGACAGAGCTGGCCAT GCGCCAGTCTGTGGAGAACGACATCCATGGGCTCCGCAAGGTCATTGATGACACCAATATCAC ACGACTGCAGCTGGAGACAGAGATCGAGGCTCTCAAGGAGGAGCTGCTCTTCATGAAGAAGAA CCACGAAGAGGAAGTAAAAGGCCTACAAGCCCAGATTGCCAGCTCTGGGTTGACCGTGGAGGT AGATGCCCCCAAATCTCAGGACCTCGCCAAGATCATGGCAGACATCCGGGCCCAATATGACGA GCTGGCTCGGAAGAACCGAGAGGAGCTAGACAAGTACTGGTCTCAGCAGATTGAGGAGAGCAC CACAGTGGTCACCACACAGTCTGCTGAGGTTGGAGCTGCTGAGACGACGCTCACAGAGCTGAG ACGTACAGTCCAGTCCTTGGAGATCGACCTGGACTCCATGAGAAATCTGAAGGCCAGCTTGGA GAACAGCCTGAGGGAGGTGGAGGCCCGCTACGCCCTACAGATGGAGCAGCTCAACGGGATCCT GCTGCACCTTGAGTCAGAGCTGGCACAGACCCGGGCAGAGGGACAGCGCCAGGCCCAGGAGTA TGAGGCCCTGCTGAACATCAAGGTCAAGCTGGAGGCTGAGATCGCCACCTACCGCCGCCTGCT GGAAGATGGCGAGGACTTTAATCTTGGTGATGCCTTGGACAGCAGCAACTCCATGCAAACCAT CCAAAAGACCACCACCCGCCGGATAGTGGATGGCAAAGTGGTGTCTGAGACCAATGACACCAA AGTTCTGAGGCATTAAGCCAGCAGAAGCAGGGTACCCTTTGGGGAGCAGGAGGCCAATAAAAA
GTTCAGAGTTCATTGGATGTC
ORF Start: ATG at 47 jORF Stop: TAA at 1274 SEQ ID NO: 40 409 aa lMW at 46045.'ikb" jNOVIOa, MSFTTRSTFSTNYRSLGSVQAPSYGARPVSSAASVYAGAGGLATGIAGGLAGMGGIQNEKETM
,CG 106842-01 Protein QS NDRLASYLDRVRS ETENRRLESKIREHLEKKGPQVRD SHYFKIIEDLRAQIFANTVDN ARIVLQIDNARLAADDFRVKYETELAMRQSVENDIHG RKVIDDTNITRLQLETEIEALKEEL
[Sequence LFMKKNHEEEVKGLQAQIASSGLTVEVDAPKSQDLAKIMADIRAQYDELARKNREELDKYWSQ QIEESTTWTTQSAEVGAAETTLTE RRTVQS EIDLDS RNLKAS ENS REVEARYALQME
QLNGI LH ESELAQTRAEGQRQAQEYEALLNIKVKLEAEIATYRRLLEDGEDFNLGDALDSS
JNSMQTIQKTTTRRIVDGKWSETNDTKVLRH
"T i SEQ ID NO: 41 1412 bp jNOVlOb, JCGGGGTCGTCCGCAAAGCCTGAGTCCTGTCCTTTCTCTCTCCCCGGACAGCATGAGCTTCACC
CGI06842-02 DNA JACTCGCTCCACCTTCTCCACCAACTACCGGTCCCTGGGCTCTGTCCAGGCGCCCAGCTACGGC JGCCCGGCCGGTCAGCAGCGCGGCCAGCGTCTATGCAGGCGCTGGGGGCTCTGGTTCCCGGATC
Sequence JTCCGTGTCCCGCTCCACCAGCTTCAGGGGCGGCATGGGGTCCGGGGGCCTGGCCACCGGGATA JGCCGGGGGTCTGGCAGGAATGGGAGGCATCCAGAACGAGAAGGAGACCATGCAAAGCCTGAAC JGACCGCCTGGCCTCTTACCTGGACAGAGTGAGGAGCCTGGAGACCGAGAACCGGAGGCTGGAG JAGCAAAATCCGGGAGCACTTGGAGAAGAAGGGACCCCAGGTCAGAGACTGGAGCCATTACTTC 1AAGATCATCGAGGACCTGAGGGCTCAGATCTTCGCAAATACTGTGGACAATGCCCGCATCGTT JCTGCAGATTGACAATGCCCGTCTTGCTGCTGATGACTTTAGAGTCAAGTATGAGACAGAGCTG JGCCATGCGCCAGTCTGTGGAGAACGACATCCATGGGCTCCGCAAGGTCATTGATGACACCAAT JATCACACGACTGCAGCTGGAGACAGAGATCGAGGCTCTCAAGGAGGAGCTGCTCTTCATGAAG {AAGAACCACGAAGAGGAAGTAAAAGGCCTACAAGCCCAGATTGCCAGCTCTGGGTTGACCGTG 'GAGGTAGATGCCCCCAAATCTCAGGACCTCGCCAAGATCATGGCAGACATCCGGGCCCAATAT GACGAGCTGGCTCGGAAGAACCGAGAGGAGCTAGACAAGTACTGGTCTCAGCAGATTGAGGAG ΪAGCACCACAGTGGTCACCACACAGTCTGCTGAGGTTGGAGCTGCTGAGACGACGCTCACAGAG CTGAGACGTACAGTCCAGTCCTTGGAGATCGACCTGGACTCCATGAGAAATCTGAAGGCCAGC TTGGAGAACAGCCTGAGGGAGGTGGAGGCCCGCTACGCCCTACAGATGGAGCAGCTCAACGGG 'ATCCTGCTGCACCTTGAGTCAGAGCTGGCACAGACCCGGGCAGAGGGACAGCGCCAGGCCCAG JGAGTATGAGGCCCTGCTGAACATCAAGGTCAAGCTGGAGGCTGAGATCGCCACCTACCGCCGC ,CTGCTGGAAGATGGCGAGGACTTTAATCTTGGTGATGCCTTGGACAGCAGCAACTCCATGCAA JACCATCCAAAAGACCACCACCCGCCGGATAGTGGATGGCAAAGTGGTGTCTGAGACCAATGAC 'ACCAAAGTTCTGAGGCATTAAGCCAGCAGAAGCAGGGTACCCTTTGGGGAGCAGGAGGCCAAT
AAAAAGTTCAGAGTTCATTGGATGTC
ORF Start: ATG at 52 JORF Stop: TAA at 1342 SEQ 1D N0: 42 430 aa MW at 48057.2kD
NOV 10b, MSFTTRSTFSTNYRSLGSVQAPSYGARPVSSAASVYAGAGGSGSRISVSRSTSFRGGMGSGGL
CG I 06842-02 Protein ATGIAGGLAGMGGIQNEKETMQS NDR ASYLDRVRSLETENRRLESKIREHLEKKGPQVRDW SHYFKIIEDLRAQIFANTVDNARIVLQIDNAR AADDFRVKYETE A RQSVENDIHGLRKVI
Sequence DDTNITRLQLETEIEALKEELLFMKKNHEEEVKGLQAQIASSGLTVEVDAPKSQDLAKIMADI RAQYDELARKNREELDKYWSQQIEESTTWTTQSAEVGAAETTLTELRRTVQSLEIDLDSMR LKASLENSLREVEARYA QMEQLNGIL HLESELAQTRAEGQRQAQEYEA LNIKVKLEAEIA sTYRR EDGEDF LGDA DSSNSMQTIQKTTTRRIVDGKWSETNDTKVLRH
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 10B.
j Table 10B. Comparison of NOVIOa against NOVlOb.
NOVIOa Residues/ Identities/
I Protein Sequence Match Residues Similarities for the Matched Region
! NO VI 0b 1..409 381 /430 (88%) 1..430 381/430 (88%)
Further analysis of the NOV I Oa protein yielded the following properties shown in Table I OC.
Table IOC. Protein Sequence Properties NOVIOa
PSort 0.8477 probability located in mitochondrial intermembrane space; 0.7065 probability i analysis: located in mitochondrial matrix space; 0.3907 probability located in mitochondrial inner membrane; 0.3907 probability located in mitochondrial outer membrane
! SignalP No Known Signal Sequence Predicted ; analysis:
A search of the NOV I Oa protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 10D.
In a BLAST search of public sequence datbases, the NOV I Oa protein was found to have homology to the proteins shown in the BLASTP data in Table 10E.
Table 10E. Public BLASTP Results for NOVIOa
NOVIOa Identities/
Protein
Expect Accession Protein/Organism/Length Residues/ Similarities for Match the Matched Number \ Value Residues Portion
PFam analysis predicts that the NOVIOa protein contains the domains shown in the Table 10F.
Example 11.
The NOVl 1 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 1 1 A.
.Table 11 A. NOV11 Sequence Analysis " ' sEQΪbNbTϊi" " ' 1 197 bp
INOVl la, CCACTGGGACATATGTGGTGTTCCTTCCTAGCTCCTGTCTCCTCCTCATGCCTTTGTTGGGTA
CGI 07095-01 DNA TGGGCATGTTAGGGGGAAGGTCATTGCTGTCAGAGGGGCACTGACTTTCTAATGGTGTTACCC AAGGTGAATGTTGGAGACACAGTCGCGATGCTGCCCAAGTCCCGGCGAGCCCTAACTATCCAG
Sequence GAGATCGCTGCGCTGGCCAGGTCCTCCCTGCATGGTATTTCCCAGGTGGTGAAGGACCACGTG ACCAAGCCTACCGCCATGGCCCAGGGCCGAGTGGCTCACCTCATTGAGTGGAAGGGCTGGAGC AAGCCGAGTGACTCACCTGCTGCCCTGGAATCAGCCTTTTCCTCCTATTCAGACCTCAGCGAG GGCGAACAAGAGGCTCGCTTTGCAGCAGGAGTGGCTGAGCAGTTTGCCATCGCGGAAGCCAAG CTCCGAGCATGGTCTTCGGTGGATGGCGAGGACTCCACTGATGACTCCTATGATGAGGACTTT GCTGGGGGAATGGACACAGACATGGCTGGGCAGCTGCCCCTGGGGCCGCACCTCCAGGACCTG TTCACCGGCCACCGGTTCTCCCGGCCTGTGCGCCAGGGCTCCGTGGAGCCTGAGAGCGACTGC TCACAGACCATGTCCCCAGACACCCTGTGCTCTAGTCTGTGCAGCCTGGAGGATGGGTTGTTG GGCTCCCCGGCCCGGCTGGCCTCCCAGCTGCTGGGCGATGAGCTGCTTCTCGCCAAACTGCCC CCCAGCCGGGAAAGTGCCTTCCGCAGCCTGGGCCCACTGGAGGCCCAGGACTCACTCTACAAC TCGCCCCTCACAGAGTCCTGCCTTTCCCCCGCGGAGGAGGAGCCAGCCCCCTGCAAGGACTGC CAGCCACTCTGCCCACCACTAACGGGCAGCTGGGAACGGCAGCGGCAAGCCTCTGACCTGGCC TCTTCTGGGGTGGTGTCCTTAGATGAGGATGAGGCAGAGCCAGAGGAACAGTGACCCACATCA
TGCCTGGACAGTGACCCACATCATGCCTGGACAGTGACCCACATCATGCCTGGACAGTGACCC
ACATCATCCTGGACAGTGACCCACATCATGCCTGGACAGTGACCCACATCATGCCTGGACAGT
GACCCACATCATGCCTGGACAGTGACCCACATCATCCTGGACAGTGACCCACATGATGCCTGG
ORF Start: ATG at 1 15 JORF Stop: TGA at 997
SEQ ID NO: 44 294 aa MW at 3 l 502.5kD
NOVl la, MV PKVNVGDTVAMLPKSRRALTIQEIAALARSS HGISQWKDHVTKPTAAQGRVAHLIE
JCG 107095-01 Protein KGWSKPSDSPAALESAFSSYSDLSEGEQEARFAAGVAEQFAIAEAK RAWSSVDGEDSTDDSY DEDFAGGMDTDMAGQLPLGPHLQD FTGHRFSRPVRQGSVEPESDCSQTMSPDTLCSSLCSLE
(Sequence DGLLGSPAR ASQLLGDELLLAKLPPSRESAFRS GP EAQDS YNSPLTESCLSPAEEEPAP CKDCQPLCPP TGSWERQRQASDLASSGWSLDEDEAEPEEQ
Further analysis of the NOVl l a protein yielded the following properties shown in Table 1 I B.
Table 11B. Protein Sequence Properties NOVl la i PSort 0.3600 probability located in mitochondrial matrix space; 0.3000 probability located analysis: in microbody (peroxisome); 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
I SignalP No Known Signal Sequence Predicted ! analysis:
A search of the NOV l l a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 1 I C.
I AAB66099 Protein of the invention #1 1 - 37..294 257/258 (99%) e-149 Unidentified, 335 aa. [WO200078961 - 258/258 (99%) A1. 28-DEC-200O]
In a BLAST search of public sequence datbases, the NOV l la protein was found to have homology to the proteins shown in the BLASTP data in Table 1 I D.
PFam analysis predicts that the NOV l l a protein contains the domains shown in the Table H E.
! Table HE. Domain Analysis of NOVlla
J Identities/ • ' Pfam Domain NOVlla Match Region j Similarities Expect Value for the Matched Region lac i 20..47 7/28 (25%) 0.68 18/28 (64%)
Example 12.
The NOV 12 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 12A.
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 12B.
Table 12B. Comparison of NOV12a against NOV12b.
NOV12a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
, NOV 12b 1.34 31/34 (91%) 40..73 32/34 (93%)
Further analysis of the NOV 12a protein yielded the following properties shown in Table 12C.
^ ble 12C. Protein Sequence Properties NOV12a
; PSort 0.4859 probability located in mitochondrial matrix space; 0.4500 probability located j analysis: in cytoplasm; 0.1967 probability located in mitochondrial inner membrane; 0.1967 probability located in mitochondrial inte membrane space i SignalP No Known Signal Sequence Predicted j analysis:
A search of the NOV 12a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 12D.
In a BLAST search of public sequence datbases, the NOV 12a protein was found to have homology to the proteins shown in the BLASTP data in Table 12E.
Table 12E. Public BLASTP Results for NOV12a
NOV12a
Protein Identities/ Residues/ Expect
Accession Protein/Organism/Length Similarities for the Match
Number Value Matched Portion Residues
Q9BS43 | Similar to RIKE cDNA 1 ..151 151/151 (100%) '< 5e-83 j 170001 OH 15 gene - Flomo sapiens 1..151 151/151 ( 100%) j (Human), 151 aa.
Q9DAH9 j 170001 OH 15Rik protein - Mus 1..151 140/151 (92%) : 3e-77 j musculus (Mouse), 151 aa. 1..151 146/151 (95%)
Q8T888 1 Leucine-rich repeat dynein light I ..151 120/151 (79%) i 2e-64
1 ; chain - Ciona intestinalis, 190 aa. 40..190 132/151 (86%) !
044230 j Outer arm dynein light chain 2 - 1..151 1 10/151 (72%) , l e-57 | ' Anthocidaris crassispina (Sea 47..197 129/151 (84%)
\ i urchin), 199 aa.
Q9V573 j CG8800 protein - Drosophila 1..149 85/149 (57%) | 2e-43 i melanogaster (Fruit fly), 188 aa. 40..187 1 13/149 (75%) j
PFam analysis predicts that the NOVl 2a protein contains the domains shown in the Table 12F.
Table 12F. Domain Analysis of NOV12a *>
Identities/
Pfam Domain NOV12a Match Region j Similarities Expect Value i for the Matched Region
Example 13.
The NOV 13 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 13 A.
Table 13A. NOV13 Sequence Analysis
■SEQ ID NO: 49 :l644 bp_ j jNOV13a, GATATCCCGAGATTAGGTCCCCAGCTTCCAAAGAGAGGATCAGAATGTCTCAGGATAATGACA
CG 108707-01 DNA CATTGATGAGAGACATCCTGGGGCATGCGCTCGCTGCTATGAGGCTGCAGAAGCTGGAACAGC AGCGGCGGCTGTTTGAAAAGAAGCAGCGACAGAAGCGCCAGGAGCTCCTCATGGTTCAGGCCA
Sequence ATCCTGACGCTTCCCCGTGGCTTTGGCGCTCTTGTCTGCGGGAGGAGCGCCTTTTAGGTGACA GAGGCCTTGGGAACCCTTTCCTCCGGAAGAAAGTGTCAGAGGCACATCTGCCCTCTGGCATCC ACAGTGCCCTGGGCACCGTGAGCTGTGGTGGAGACGGCAGGGGCGAGCGCGGCCTCCCGACAC CGCGGACAGAAGCAGTGTTCAGGAATCTCGGTCTCCAGTCCCCTTTCTTATCCTGGCTCCCAG ACAATTCCGATGCAGAATTGGAGGAAGTCTCCGTGGAGAATGGTTCCGTCTCTCCCCCACCTT TTAAACAGTCTCCGAGAATCCGACGCAAGGGTTGGCAAGCCCACCAACGACCTGGGACCCGTG CAGAGGGTGAGAGTGACTCCCAGGATATGGGAGATGCACACAAGTCACCCAATATGGGACCAA ACCCTGGAATGGATGGTGACTGTGTATATGAAAACTTGGCCTTCCAAAAGGAAGAAGACTTGG AAAAGAAGAGAGAGGCCTCTGAGTCTACAGGGACGAACTCCTCAGCAGCACACAACGAAGAGT TGTCCAAGGCCCTGAAAGGCGAGGGTGGCACGGACAGCGACCATATGAGGCACGAAGCCTCCT TGGCAATCCGCTCCCCCTGCCCTGGGCTGGAGGAGGACATGGAAGCCTACGTGCTGCGGCCAG CGCTCCCGGGCACCATGATGCAGTGCTACCTCACCCGTGACAAGCACGGCGTGGACAAGGGCT TGTTCCCCCTCTACTACCTCTACCTGGAGACCTCTGACAGCCTGCAGCGCTCCCTCCTGGCTG GGCGAAAGAGAAGAAGGAGCAAAACTTCTAATTACCTCATCTCCCTGGATCCTACACACCTAT CTCGGGACGGGGACAATTTCGTGGGCAAAGTCAGATCCAATGTCTTCAGCACCAAGTTCACCA
Further analysis of the NOVl 3a protein yielded the following properties shown in Table 13B.
; Table 13B. Protein Sequence Properties NOV13a
; PSort 0.6000 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
'. SignalP No Known Signal Sequence Predicted '< analysis:
A search of the NOVl 3a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 13C.
In a BLAST search of public sequence datbases, the NOV 13a protein was found to have homology to the proteins shown in the BLASTP data in Table 13D.
PFam analysis predicts that the NOV 13a protein contains the domains shown in the Table 13E.
The NOV 14 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 14 A.
Table 14A. NOV14 Sequence Analysis
^ ^ ^Q— -
13937 bp
NOV 14a, TGCGCTGACAGCAGCCATGGCGAGCGGCAGTGGAGACAGCGTCACCCGTCGGAGCGTGGCATC
CGI 08791 -01 DNA ACAGTTTTTCACTCAAGAGGAGGGGCCGGGCATCGATGGCATGACCACCTCAGAGAGGGTGGT GGATCTTCTGAACCAGGCGGTGCTGATCACCAATGACTCAAAGATCACAGTGCTCAAACAGGT
Sequence CCAGGAGCTGATCATCAACAAAGACCCCACACTACTGGACAACTTCCTGGATGAGATCATCGC ATTCCAAGCAGACAAGTCAATCGAAGTGCGAAAATTTGTCATCGGCTTCATCGAGGAGGCATG CAAGCGAGACATCGAGTTGCTGCTGAAACTCATTGCAAACCTCAACATGCTCTTGAGGGACGA GAATGTGAACGTGGTGAAGAAGGCTATCCTCACCATGACCCAGCTCTACAAGGTGGCCCTGCA GTGGATGGTAAAGTCACGGGTCATTAGCGAGCTACAGGAGGCCTGCTGGGACATGGTATCTGC CATGGCGGGGGACATCATCCTGCTATTGGACTCTGACAATGACGGCATCCGCACCCACGCCAT CAAGTTTGTGGAGGGCCTCATTGTCACCCCGTCACCCCGCATGGCTGACTCAGAGATACCCCG ACGCCAGGAGCATGATATCAGCCTGGACCGCATCCCTCGTGACCACCCCTACATCCAGTACAA CGTGCTATGGGAAGAGGGCAAGGCAGCCTTGGAGCAGCTGCTTAAGTTCATGGTGCACCCTGC CATCTCCTCCATCAACCTGACCACAGCGCTGGGCTCCCTTGCCAATATCGCCCGCCAGAGACC CATGTTCATGTCTGAGGTGATCCAGGCCTATGAAACTCTGCATGCCAACCTGCCCCCGACGCT GGCCAAATCGCAGGTGAGCAGTGTGCGTAAGAATCTGAAGCTGCACCTGTTGAGTGTGCTGAA GCACCCGGCTTCCTTGGAGTTCCAGGCCCAGATCACCACCCTGCTGGTGGACCTGGGCACACC TCAGGCCGAGATCGCCCGCAACATGCCGAGCAGCAAGGACACCCGCAAGCGGCCCCGCGATGA CTCGGACTCCACACTCAAGAAGATGAAGCTGGAGCCCAACCTGGGGGAGGACGATGAGGACAA AGACTTGGAGCCAGGCCCGTCGGGGACCTCGAAGGCCTCAGCGCAGATCTCCGGCCAGTCAGA CACGGACATCACAGCTGAGTTCCTGCAGCCTCTGCTGACGCCTGATAATGTGGCTAATCTGGT CCTCATCAGCATGGTGTACCTACCCGAGGCCATGCCAGCCTCCTTCCAGGCCATCTACACCCC CGTGGAGTCAGCAGGCACGGAAGCCCAGATCAAGCACCTGGCTCGGCTCATGGCCACACAGAT GACAGCTGCCGGACTGGGACCAGGTGTAGAGCAGACCAAACAGTGCAAGGAGGAGCCCAAGGA GGAGAAGGTGGTGAAGACAGAGAGCGTCCTGATCAAGCGGCGCCTGTCAGCCCAGGGCCAAGC CATCTCGGTGGTGGGTTCCCTGAGCTCCATGTCCCCCCTGGAGGAAGAGGCACCGCAGGCCAA GAGGAGGCCAGAGCCCATTATCCCTGTCACTCAGCCCCGGCTGGCAGGCGCTGGTGGGCGCAA GAAAATTTTCCGTCTCAGCGACGTGCTGAAGCCCCTTACCGATGCCCAGGTGGAAGCCATGAA GCTGGGCGCTGTGAAGCGGATCCTGCGGGCTGAGAAGGCTGTGGCCTGCAGCGGGGCAGCCCA GGTCCGCATAAAGATCCTGGCCAGCCTGGTGACACAGTTCAACTCGGGCCTGAAGGCGGAGGT CCTGTCCTTCATCCTGGAGGATGTGCGGGCCCGCCTGGACCTGGCCTTCGCCTGGCTCTACCA GGAGTACAACGCCTACCTGGCCGCAGGTGCCTCGGGCTCCCTGGACAAGTATGAGGACTGCCT CATCCGCCTGTTGTCTGGCCTGCAGGAGAAACCAGACCAGAAGGATGGGATCTTCACCAAGGT TGTGCTGGAGGCGCCACTCATCACAGAGAGTGCCCTGGAGGTGGTCCGCAAGTACTGCGAGGA TGAGAGTCGCACCTATCTGGGCATGTCCACACTTCGAGACCTGATCTTCAAGCGCCCGTCCCG CCAGTTCCAGTACCTGCATGTCCTCCTCGACCTCAGCTCCCATGAGAAGGACAAGGTGCGCTC CCAGGCCCTGCTGTTCATCAAACGCATGTATGAGAAGGAGCAGCTGCGGGAGTATGTGGAGAA ATTTGCCCTCAACTACCTGCAGCTCCTGGTGCACCCCAACCCACCGTCTGTGCTGTTTGGAGC TGACAAGGACACAGAGGTGGCAGCACCCTGGACGGAGGAGACAGTGAAGCAGTGTCTGTACCT CTACCTGGCCCTCCTGCCTCAGAACCACAAGCTGATCCACGAACTGGCGGCCGTGTACACTGA AGCCATCGCCGACATCAAGCGGACGGTGCTGAGGGTCATTGAGCAGCCGATCCGAGGAATGGG CATGAACTCCCCGGAGCTGCTCCTGCTGGTGGAAAATTGTCCCAAGGGAGCAGAGACACTGGT CACGAGATGTCTGCACAGCCTCACAGACAAAGTCCCACCCTCCCCAGAGCTGGTGAAGCGGGT CCGGGATCTCTACCACAAGCGACTGCCAGACGTCCGCTTCCTCATCCCGGTGCTCAATGGGCT GGAGAAGAAAGAGGTGATCCAGGCCCTGCCTAAACTCATCAAACTCAACCCCATCGTGGTGAA GGAAGTCTTCAACCGCCTGCTGGGCACCCAGCATGGTGAGGGAAACTCAGCCTTGTCCCCGCT GAACCCTGGAGAGCTCCTGATCGCATTACACAACATTGACTCCGTGAAGTGCGACATGAAATC CATCATCAAAGCCACCAACCTGTGCTTTGCGGAGCGGAACGTGTACACGTCAGAGGTGCTGGC CGTGGTGATGCAGCAGCTGATGGAGCAGAGCCCCCTGCCCATGCTGCTCATGAGGACCGTCAT CCAGTCCCTGACCATGTACCCCCGCCTGGGGGGCTTCGTCATGAACATCCTGTCCCGCCTCAT CATGAAGCAGGTGTGGAAGTACCCCAAGGTGTGGGAGGGCTTCATCAAGTGCTGCCAGCGCAC AAAGCCCCAGAGCTTCCAGGTCATCCTGCAGCTGCCGCCCCAGCAGCTGGGAGCCGTCTTTGA CAAGTGCCCAGAGCTCCGGGAGCCCCTGCTGGCCCATGTCCGCTCCTTCACCCCCCACCAGCA AGCTCACATCCCTAACTCCATCATGACCATCTTGGAGGCCAGCGGCAAGCAGGAGCCAGAGGC CAAGGAGGCGCCTGCGGGGCCCTTGGAGGAGGATGATCTGGAGCCCCTGACCTTGGCCCCGGC CCCAGCACCCCGGCCCCCTCAGGACCTCATCGGCCTGCGACTGGCCCAGGAGAAGGCCTTAAA

Further analysis of the NOV 14a protein yielded the following properties shown in Table 14B.
Table 14B. Protein Sequence Properties NOV14a
PSort 0.8528 probability located in nucleus; 0.5806 probability located in mitochondrial analysis: matrix space; 0.3000 probability located in microbody (peroxisome); 0.2922 probability located in mitochondrial inner membrane
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV 14a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 14C.
In a BLAST search of public sequence datbases, the NOV 14a protein was found to have homology to the proteins shown in the BLASTP data in Table 14D.
PFam analysis predicts that the NOV 14a protein contains the domains shown in the Table 14E.
Example 15.
The NOV 15 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 15A.
Table 15A. NOV15 Sequence Analysis *>
SEQ i NoTo " " 959 bp"
|NOV15a, CGGCACGAGCATGGCTACCTCAGAGCTGAGCTGCGAGGTGTCGGAGGAGAACTGTGAGCGCCG
|CG 109247-01 DNA GGAGGCCTTCTGGGCAGAATGGAAGGATCTGACACTGTCCACACGGCCCGAGGAGGGCTGCTC CCTGCATGAGGAGGACACCCAGAGACATGAGACCTACCACCAGCAGGGGCAGTGCCAGGTGCT
^Sequence GGTGCAGCGCTCGCCCTGGCTGATGATGCGGATGGGCATCCTCGGCCGTGGGCTGCAGGAGTA CCAGCTGCCCTACCAGCGGGTACTGCCGCTGCCCATCTTCACCCCTGCCAAGATGGGCGCCAC CAAGGAGGAGCGTGAGGACACCCCCATCCAGCTTCAGGAGCTGCTGGCGCTGGAGACAGCCCT GGGTGGCCAGTGTGTGGACCGCCAGGAGGTGGCTGAGATCACAAAGCAGCTGCCCCCTGTGGT GCCTGTCAGCAAGCCCGGTGCACTTCGTCGCTCCCTGTCCCGCTCCATGTCCCAGGAAGCACA GAGAGGCTGAGAGGGACTGTGACTTGGGCTCCGCTGTGCCCGCCCTGGGCTGGGCCCTTCCTG
GCTAGGACTGTGGAGGGGAGCTGCTGGCCATGGCTGCTTTGTAGTTTGCCCAGAGTTGGGGGC
TAGGGGAGGGGGGAGCCAGAGGCCAGGATGCCTGAGCCCCCTGAGTTCCCAAAGGGAGGGTGG
CAGAGACAGTGGGCACTAAGGGTGGAGAGTTGGGGGCCAGCACAGCTGAGGACCCTCAGCCCC
AGGAGAAGGGACAAAAGGTACTGGTGAGGGCAAGAGGTGCCTGGGAGGAGTGGCCCTGATCCA
GGAAAATGTGAGGGGAATCTGGAACGCTCTAGGCAGAAGAAGCTGGGAGGGAGGGGGAGGTGA
AAAGGGCAGAGGCAAGGATGGTGGGGCCCCCAGCACCCTCTGTTAGTGCCGCAATAAATGCTC
AATCATGTGCCAGA
ORF Start: ATG at 11 jORF Stop: TGA at 512
SEQ ID NO: 54 167 aa MW at 19051 .5kD
|NOV15a. MATSELSCEVSEENCERREAF AEWKD TLSTRPEEGCSLHEEDTQRHETYHQQGQCQVLVQR
!CG 109247-01 Protein SPWLMMRMGILGRG QEYQLPYQRVLPLPIFTPAKMGATKEEREDTPIQLQELLALETALGGQ CVDRQEVAEITKQLPPWPVSKPGALRRSLSRSMSQEAQRG
Sequence
SEQ ID NO 55_ j672 bp j
NOV 15b, CGGCACGAGCATGGCTACCTCAGAGCTGAGCTGCGAGGTGTCGGAGGAGAACTGTGAGCGCCG
CG I 09247-02 DNA GGAGGCCTTCTGGGCAGAATGGAAGGATCTGACACTGTCCACACGGCCCGAGGAGGGCTGCTC CCTGCATGAGGAGGACACCCAGAGACATGAGACCTACCACCAGCAGGGGCAGTGCCAGGTGCT
.Sequence GGTGCAGCGCTCGCCCTGGCTGATGATGCGGATGGGCATCCTCGGCCGTGGGCTGCAGGAGTA CCAGCTGCCCTGGGCTGGGCCCTTCCTGGCTAGGACTGTGGAGGGGAGCTGCTGGCCATGGCT GCTTTGTAGTTTGCCCAGAGTTGGGGGCTAGGGGAGGGGGGAGCCAGAGGCCAGGATGCCTGA
GCCCCCTGAGTTCCCAAAGGGAGGGTGGCAGAGACAGTGGGCACTAAGGGTGGAGAGTTGGGG
GCCAGCACAGCTGAGGACCCTCAGCCCCAGGAGAAGGGACAAAAGGTACTGGTGAGGGCAAGA
GGTGCCTGGGAGGAGTGGCCCTGATCCAGGAAAATGTGAGGGGAATCTGGAACGCTCTAGGCA
GAAGAAGCTGGGAGGGAGGGGGAGGTGAAAAGGGCAGAGGCAAGGATGGTGGGGCCCCCAGCA
CCCTCTGTTAGTGCCGCAATAAATGCTCAATCATGTGCCAGA
ORF Start: ATG at 1 1 'fORF Stop: TAG at 344
SEQ ID NO: 56 1 1 1 aa MW at 12856.4kD
NOV 15b, MATSELSCEVSEENCERREAF AEWKDLTLSTRPEEGCSLHEEDTQRHETYHQQGQCQV VQR
CG I 09247-02 Protein SPWLMMR GILGRGLQEYQLPWAGPFLARTVEGSCWPWLLCSLPRVGG
Sequence
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 15B.
, Table 15B. Comparison of NOV15a against NOV15b.
\ NOV15a Residues/ Identities/
Protein Sequence : Match Residues Similarities for the Matched Region
NOV 15b ! 1..85 84/85 (98%) i 1..85 85/85 (99%)
Further analysis of the NOV l 5a protein yielded the following properties shown in Table 15C.
I Table 15C. Protein Sequence Properties NOV15a
PSort 0.6500 probability located in cytoplasm; 0.1000 probability located in mitochondrial analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
Signal P No Known Signal Sequence Predicted analysis:
A search of the NOV 15a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 15D.
AAW71560 Human hepatocyte nuclear factor 1 43..121
■ 20/79 (25%) 1.6 alpha (R131Q mutant) - Homo 90..164 39/79 (49%) sapiens, 630 aa. [ W0981 1254-A 1 , 19-
MAR-1998]
AAW71562 Human hepatocyte nuclear factor 1 43..121 19/79 (24%) 4.7 alpha (truncated mutant) - Homo 90. 164 39/79 (49%) sapiens, 415 aa. [ W0981 1254-A 1 , 19- *
MAR-1998]
AAW71561 Human hepatocyte nuclear factor 1 43..121 19/79 (24%) 4.7 alpha (truncated mutant) - Homo 90..164 39/79 (49%) sapiens, 314 aa. [W0981 1254-A 1 , 19-
MAR-1998]
In a BLAST search of public sequence datbases, the NOVl 5a protein was found to have homology to the proteins shown in the BLASTP data in Table 15E.
PFam analysis predicts that the NOV 15a protein contains the domains shown in the Table 15F.
Table 15F. Doma in Analysis of NOV15a
Identities/ i Pfam Domain NOV15a Match Region Similarities Expect Value for the Matched Region i
Example 16.
The NOV 16 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 16A.
Table 16A. NOV16 Sequence Analysis fSEQΪD NO^ 57 2067 bp
NOV 16a, : CGAGAGGAGAGCGCGAGAGCCCCAGCCGCGGGCGGGCGGGCGGTGAAGATGGCAGAGGCACCG
CGI 10410-01 DNA GCTTCCCCGGCCCCGCTCTCTCCGCTCGAAGTGGAGCTGGACCCGGAGTTCGAGCCCCAGAGC CGTCCGCGATCCTGTACGTGGCCCCTGCAAAGGCCGGAGCTCCAAGCGAGCCCTGCCAAGCCC
Sequence TCGGGGGAGACGGCCGCCGACTCCATGATCCCCGAGGAGGAGGACGATGAAGACGACGAGGAC GGCGGGGGACGGGCCGGGAACGCCTGGGGAAACCTGTCCTACGCGGACCTGATCACCCGCGCC ATCGAGAGCTCCCCGGACAAACGGCTCACTCTGTCCCAGATCTACGAGTGGATGGTGCGTTGC GTGCCCTACTTCAAGGATAAGGGCGACAGCAACAGCTCTGCCGGCTGGAAGAACTCCATCCGG CACAACCTGTCACTGCATAGTCGATTCATGCGGGTCCAGAATGAGGGAACTGGCAAGAGCTCT TGGTGGATCATCAACCCTGATGGGGGGAAGAGCGGAAAAGCCCCCCGGCGGCGGGCTGTCTCC ATGGACAATAGCAACAAGTATACCAAGAGCCGTGGCCGCGCAGCCAAGAAGAAGGCA cCCTG CAGACAGCCCCCGAATCAGCTGACGACAGTCCCTCCCAGCTCTCCAAGTGGCCTGGCAGCCCC ACGTCACGCAGCAGTGATGAGCTGGATGCGTGGACGGACTTCCGTTCACGCACCAATTCTAAC GCCAGCACAGTCAGTGGCCGCCTGTCGCCCATCATGGCAAGCACAGAGTTGGATGAAGTCCAG GACGATGATGCGCCTCTCTCGCCCATGCTCTACAGCAGCTCAGCCAGCCTGTCACCTTCAGTA AGCAAGCCGTGCACGGTGGAACTGCCACGGCTGACTGATATGGCAGGCACCATGAATCTGAAT GATGGGCTGACTGAAAACCTCATGGACGACCTGCTGGATAACATCACGCTCCCGCCATCCCAG CCATCGCCCACTGGGGGACTCATGCAGCGGAGCTCTAGCTTCCCGTATACCACCAAGGGCTCG GGCCTGGGCTCCCCAACCAGCTCCTTTAACAGCACGGTGTTCGGACCTTCATCTCTGAACTCC CTACGCCAGTCTCCCATGCAGACCATCCAAGAGAACAAGCCAGCTACCTTCTCTTCCATGTCA CACTATGGTAACCAGACACTCCAGGACCTGCTCACTTCGGACTCACTTAGCCACAGCGATGTC ATGATGACACAGTCGGACCCCTTGATGTCTCAGGCCAGCACCGCTGTGTCTGCCCAGAATTCC CGCCGGAACGTGATGCTTCGCAATGATCCGATGATGTCCTTTGCTGCCCAGCCTAACCAGGGA AGTTTGGTCAATCAGAACTTGCTCCACCACCAGCACCAAACCCAGGGCGCTCTTGGTGGCAGC CGTGCCTTGTCGAATTCTGTCAGCAACATGGGCTTGAGTGAGTCCAGCAGCCTTGGGTCAGCC AAACACCAGCAGCAGTCTCCTGTCAGCCAGTCTATGCAAACCCTCTCGGACTCTCTCTCAGGC TCCTCCTTGTACTCAACTAGTGCAAACCTGCCCGTCATGGGCCATGAGAAGTTCCCCAGCGAC TTGGACCTGGACATGTTCAATGGGAGCTTGGAATGTGACATGGAGTCCATTATCCGTAGTGAA CTCATGGATGCTGATGGGTTGGATTTTAACTTTGATTCCCTCATCTCCACACAGAATGTTGTT GGTTTGAACGTGGGGAACTTCACTGGTGCTAAGCAGGCCTCATCTCAGAGCTGGGTGCCAGGC TGAAGGATCACTGAGGAAGGGGAAGTGGGCAAAGCAGACCCTCAAACTGACACAAGACCTACA
GAGAAAACCCTTTGCCAAATCTGCTCTCAGCAAGTGGACAGTGATACCGTTTACAGCTTAACA
CCTTTGTGAATCCCACGCCATTTTCCTAACCCAGCAGAGACTGTTAATGGCCCCTTACCCTGG
GTGAAGCACTTACCCTTGGAACAGAACTCTAAAAAGTATGCAAAATCTTCC
ORF Start: ATG at 49 ORF Stop: TGA at 1828
SEQ ID NO: 58 593 aa MW at 63891.6kD
NOV 16a, MAEAPASPAPLSPLEVE DPEFEPQSRPRSCTWPLQRPELQASPAKPSGETAADSMIPEEEDD
CGI 10410-01 Protein EDDEDGGGRAGNAWGNLSYADLITRAIESSPDKRLTLSQIYEWMVRCVPYFKDKGDSNSSAGW KNSIRHNLSLHSRF RVQNEGTGKSS WIINPDGGKSGKAPRRRAVSMDNSNKYTKSRGRAAK
Sequence KKAALQTAPESADDSPSQLSKWPGSPTSRSSDELDAWTDFRSRTNSNASTVSGRLSPIMASTE LDEVQDDDAPLSPMLYSSSASLSPSVSKPCTVE PRLTDMAGT NLNDGLTENLMDDLLDNIT LPPSQPSPTGG MQRSSSFPYTTKGSGLGSPTSSFNSTVFGPSS NS RQSPMQTIQENKPAT FSSMSHYGNQTLQDLLTSDSLSHSDVMMTQSDPLMSQASTAVSAQNSRRNVM RNDPMMSFAA QPNQGSLVNQNLLHHQHQTQGALGGSRA SNSVS MGLSESSSLGSAKHQQQSPVSQSMQT S DSLSGSS YSTSANLPVMGHEKFPSDLDLDMF GSLECDMESIIRSE MDADGLDFNFDSLIS TQNWG NVGNFTGAKQASSQSWVPG
Further analysis of the NOV 16a protein yielded the following properties shown in
Table 16B.
Table 16B. Protein Sequence Properties NOVlόa
PSort 0.3000 probability located in nucleus; 0.1000 probability located in mitochondrial analysis: ' matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVl όa protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 16C.
In a BLAST search of public sequence datbases, the NOV 16a protein was found to have homology to the proteins shown in the BLASTP data in Table 16D.
Table 16D. Public BLASTP Results for NOVlόa
NOVlόa Identities/ j Protein Residues/ Similarities for Expect I Accession Protein/Organism/Length Match the Matched Value ! Number Residues Portion
PFam analysis predicts that the NOVl όa protein contains the domains shown in the Table 16E.
Example 17.
The NOV 17 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 17A.
NOV 17a, NAAHGKE YTQCQACHKPVENFVGPKHCGLIGRPAASVPGYDYSEGMKASGLTWDESTLDQFLJ
CG 1 10882-01 Protein TSPVAFV GTKMGFAGFDNPSDRADVIAWLRKMNDDPTICPKKS
Sequence
Further analysis of the NOVl 7a protein yielded the following properties shown in Table 17B.
Table 17B. Protein Sequence Properties NOV17a
PSort 0.4500 probability located in cytoplasm; 0.2852 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP I No Known Signal Sequence Predicted analysis:
A search of the NOV 17a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 17C.
In a BLAST search of public sequence datbases, the NOV 17a protein was found to have homology to the proteins shown in the BLASTP data in Table 1 7D.
PFam analysis predicts that the NOV 17a protein contains the domains shown in the Table 17E.
Example 18. The NOV 18 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 18A.
Sequence GTAATTTTCCTCTTCTTCTGGCTTTTCATGAAAGAAACATTATATGATGAAGTTCTTGCAAAA
CAGAAAAGAGAACAAAAGCTTATTCCTACCAAAACAGATAAAAAGAAAGCAGAAAAGAAAAAG
AATAAAAAGAAAGAAATCCAGAATGGAAACCTCCATGAATCCGACTCTGAGAGTGTACCTCGA
GACTTTAAATTATCAGATGCTTTGGCAGTAGAAGATGATCAAGTTGCACCTGTTCCATTGAAT
GTCGTTGAAACTTCAAGTAGTGTTAGGGAAAGAAAAAAGAAGGAAAAGAAACAAAAGCCTGTG
CTTGAAGAGCAGGTCATCAAAGAAAGTGACGCATCAAAGATTCCTGGCAAAAAAGTAGAACCT
GTCCCAGTTACTAAACAGCCCACCCCTCCCTCTGAAGCAGCTGCCTCGAAGAAGAAACCAGGG
CAGAAGAAGTCTAAAAATGGAAGCGATGACCAGGATAAAAAGGTGGAAACTCTCATGGTACCA
TCAAAAAGGCAAGAAGCATTGCCCCTCCACCAAGAGACTAAACAAGAAAGTGGATCAGGG AG
AAAGCTTCATCAAAGAAACAAAAGACAGAAAATGTCTTCGTAGATGAACCCCTTATTCATGCA
ACTACTTATATTCCTTTGATGGATAATGCTGACTCAAGTCCTGTGGTAGATAAGAGAGAGGTT
ATTGATTTGCTTAAACCTGACCAAGTAGAAGGGATCCAGAAATCTGGGACTAAAAAACTGAAG
ACCGAAACTGACAAAGAAAATGCTGAAGTGAAGTTTAAAGATTTTCTTCTGTCCTTGAAGACT
ATGATGTTTTCTGAAGATGAGGCTCTTTGTGTTGTAGACTTGCTAAAGGAGAAGTCTGGTGTA
ATACAAGATGCTTTAAAGAAGTCAAGTAAGGGAGAATTGACTACGCTTATACATCAGCTTCAA
GAAAAGGACAAGTTACTCGCTGCTGTGAAGGAAGATGCTGCTGCTACAAAGGATCGGTGTAAG
CAGTTAACCCAGGAAATGATGACAGAGAAAGAAAGAAGCAATGTGGTTATGACAAGGATGAAA
GATCGGATTGGAACATTAGAAAAGGAACATAATGTATTTCAAAACAAAATACATGTCAGTTAT
CAAGAGACTCAACAGATGCAGATGAAGTTTCAGCAAGTTCGTGAGCAGATGGAGGCAGAGATA
GCTCACTTGAAGCAGGAAAATGGTATACTGAGAGATGCAGTCAGCAACACTACAAATCAACTG
GAAAGCAAGCAGTCTGCAGAACTAAATAAACTACGCCAGGATTATGCTAGGTTGGTGAATGAG
CTGACTGAGAAAACAGGAAAGCTACAGCAAGAGGAAGTCCAAAAGAAGAATGCTGAGCAAGCA
GCTACTCAGTTGAAGGTTCAACTACAAGAAGCTGAGAGAAGGTGGGAAGAAGTTCAGAGCTAC
ATCAGGAAGAGAACAGCGGAACATGAGGCAGCACAGCAAGATTTACAGAGTAAATTTGTGGCC
AAAGAAAATGAAGTACAGAGTCTGCATAGTAAGCTTACAGATACCTTGGTATCAAAACAACAG
TTGGAGCAAAGACTAATGCAGTTAATGGAATCAGAGCAGAAAAGGGTGAACAAAGAAGAGTCT
CTACAAATGCAGGTTCAGGATATTTTGGAGCAGAATGAGGCTTTGAAAGCTCAAATTCAGCAG
TTCCATTCCCAGATAGCAGCCCAGACCTCCGCTTCAGTTCTAGCAGAAGAATTACATAAAGTG
ATTGCAGAAAAGGATAAGCAGATAAAACAGACTGAAGATTCTTTAGCAAGTGAACGTGATCGT
TTAACAAGTAAAGAAGAGGAACTTAAGGATATACAGAATATGAATTTCTTATTAAAAGCTGAA
GTGCAGAAATTACAGGCCCTGGCAAATGAGCAGGCTGCTGCTGCACATGAATTGGAGAAGATG
CAACAAAGTGTTTATGTTAAAGATGATAAAATAAGATTGCTGGAAGAGCAACTACAACATGAA
ATTTCAAACAAAATGGAAGAATTTAAGATTCTAAATGACCAAAACAAAGCATTAAAATCAGAA
GTTCAGAAGCTACAGACTCTTGTTTCTGAACAGCCTAATAAGGATGTTGTGGAACAAATGGAA
AAATGCATTCAAGAAAAAGATGAGAAGTTAAAGACTGTGGAAGAATTACTTGAAACTGGACTT
ATTCAGGTGGCAACTAAAGAAGAGGAGCTGAATGCAATAAGAACAGAAAATTCATCTCTGACA
AAAGAAGTTCAAGACTTAAAAGCTAAGCAAAATGATCAGGTTTCTTTTGCCTCTCTAGTTGAA
GAACTTAAGAAAGTGATCCATGAGAAAGATGGAAAGATCAAGTCTGTAGAAGAGCTTCTGGAG
GCAGAACTTCTCAAAGTTGCTAACAAGGAGAAAACTGTTCAGGATTTGAAACAGGAAATAAAG
GCTCTAAAAGAAGAAATAGGAAATGTCCAGCTTGAAAAGGCTCAACAGTTATCTATCACTTCC
AAAGTTCAGGAGCTTCAGAACTTATTAAAAGGAAAAGAGGAACAGATGAATACCATGAAGGCT GTTTTGGAAGAGAAAGAGAAAGACCTAGCCAATACAGGGAAGTGGTTACAGGATCTTCAAGAA
GAAAATGAATCTTTAAAAGCACATGTTCAGGAAGTAGCACAACATAACTTGAAAGAGGCCTCT TCTGCATCACAGTTTGAAGAACTTGAGATTGTGTTGAAAGAAAAGGGAAATGAATTGAAGAGG TTAGAAGCCATGCTAAAAGAGAGGGAGAGTGATCTTTCTAGCAAAACACAGCTGTTACAGGAT GTACAAGATGAAAACAAATTGTTTAAGTCCCAAATTGAGCAGCTTAAACAACAAAACTACCAA CAGGCATCTTCTTTTCCCCCTCATGAAGAATTATTAAAAGTAATTTCAGAAAGAGAGAAAGAA ATAAGTGGTCTCTGGAATGAGTTAGATTCTTTGAAGGATGCAGTTGAACACCAGAGGAAGAAA AACAATGACCTTCGGGAGAAAAACTGGGAAGCAATGGAAGCATTGGCATCAACTGAAAAAATG CTGCAGGACAAAGTGAACAAGACTTCCAAGGAAAGGCAGCAACAGGTGGAAGCTGTTGAGTTG GAGGCTAAAGAAGTTCTCAAAAAATTATTTCCAAAGGTGTCTGTCCCTTCTAATTTGAGTTAT GGTGAATGGTTGCATGGATTTGAAAAAAAGGCAAAAGAATGTATGGCTGGAACTTCAGGGTCA GAGGAGGTTAAGGTTCTAGAGCACAAGTTGAAAGAAGCTGATGAAATGCACACATTGTTACAG CTAGAGTGTGAAAAATACAAATCCGTCCTTGCAGAAACAGAAGGAATTTTACAGAAGCTACAG AGAAGTGTTGAGCAAGAAGAAAATAAATGGAAAGTTAAGGTCGATGAATCACACAAGACTATT AAACAGATGCAGTCATCATTTACATCTTCAGAACAAGAGCTAGAGCGATTAAGAAGCGAAAAT AAGGATATTGAAAATCTGAGAAGAGAACGAGAACATTTGGAAATGGAACTAGAAAAGGCAGAG ATGGAACGATCTACCTATGTTACAGAAGTCAGAGAGTTGAAGGCACAGTTAAATGAAACACTC ACAAAACTTAGAACTGAACAAAATGAAAGACAGAAGGTAGCTGGTGATTTGCATAAGGCTCAA CAGTCACTGGAGCTTATCCAGTCAAAAATAGTAAAAGCTGCTGGAGACACTACTGTTATTGAA AATAGTGATGTTTCCCCAGAAACGGAGTCTTCTGAGAAGGAGACAATGTCTGTAAGTCTAAAT CAGACTGTAACACAGTTACAGCAGTTGCTTCAGGCGGTAAACCAACAGCTCACAAAGGAGAAA GAGCACTACCAGGTGTTAGAGTGAAGTAATTGGGAAACTGTTCATTTGAGGATAAAAAAGGCA TTGTATTATATTTTGCCAAATTAAAGCCTTATTTATGTTTTCACCCTTTCTACTTTGTCAGAA ACACTGAACAGAGTTTTGTCTTTTCTAATCCTTGTTAGACTACTGATTTAAAGAAGGAAAAAA AAAAGCCAACTCTGTAGACACCTTCAGAGTTTAGTTTTATAATAAAAACTGTTTGAATAATTA

TGAACAGCCTAATAAGGATGTTGTGGAACAAATGGAAAAATGCATTCAAGAAAAAGATGAGAAj
GTTAAAGACTGTGGAAGAATTACTTGAAACTGGACTTATTCAGGTGGCAACTAAAGAAGAGGAJ
GCTGAATGCAATAAGAACAGAAAATTCATCTCTGACAAAAGAAGTTCAAGACTTAAAAGCTAAJ
GCAAAATGATCAGGTTTCTTTTGCCTCTCTAGTTGAAGAACTTAAGAAAGTGATCCATGAGAA]
AGATGGAAAGATCAAGTCTGTAGAAGAGCTTCTGGAGGCAGAACTTCTCAAAGTTGCTAACAAj
GGAGAAAACTGTTCAGGATTTGAAACAGGAAATAAAGGCTCTAAAAGAAGAAATAGGAAATGTj
CCAGCTTGAAAAGGCTCAACAGTTATCTATCACTTCCAAAGTTCAGGAGCTTCAGAACTTATT
AAAAGGAAAAGAGGAACAGATGAATACCATGAAGGCTGTTTTGGAAGAGAAAGAGAAAGACCT
AGCCAATACAGGGAAGTGGTTACAGGATCTTCAAGAAGAAAATGAATCTTTAAAAGCACATGT
TCAGGAAGTAGCACAACATAACTTGAAAGAGGCCTCTTCTGCATCACAGTTTGAAGAACTTGA
GATTGTGTTGAAAGAAAAGGAAAATGAATTGAAGAGGTTAGAAGCCATGCTAAAAGAGAGGGA
GAGTGATCTTTCTAGCAAAACACAGCTGTTACAGGATGTACAAGATGAAAACAAATTGTTTAA
GTCCCAAATTGAGCAGCTTAAACAACAAAACTACCAACAGGCATCTTCTTTTCCCCCTCATGA
AGAATTATTAAAAGTAATTTCAGAAAGAGAGAAAGAAATAAGTGGTCTCTGGAATGAGTTAGA
TTCTTTGAAGGATGCAGTTGAACACCAGAGGAAGAAAAACAATAGTTATGGTGAATGGTTGCA
TGGATTTGAAAAAAAGGCAAAAGAATGTATGGCTGGAACTTCAGGGTCAGAGGAGGTTAAGGT
TCTAGAGCACAAGTTGAAAGAAGCTGATGAAATGCACACATTGTTACAGCTAGAGTGTGAAAA
ATACAAATCCGTCCTTGCAGAAACAGAAGGAATTTTACAGAAGCTACAGAGAAGTGTTGAGCA
AGAAGAAAATAAATGGAAAGTTAAGGTCGATGAATCACACAAGACTATTAAACAGATGCAGTC
ATCATTTACATCTTCAGAACAAGAGCTAGAGCGATTAAGAAGCGAAAATAAGGATATTGAAAA
TCTGAGAAGAGAACGAGAACATTTGGAAATGGAACTAGAAAAGGCAGAGATGGAACGATCTAC
CTATGTTACAGAAGTCAGAGAGTTGAAGGCACAGTTAAATGAAACACTCACAAAACTTAGAAC
TGAACAAAATGAAAGACAGAAGGTAGCTGGTGATTTGCATAAGGCTCAACAGTCACTGGAGCT
TATCCAGTCAAAAATAGTAAAAGCTGCTGGAGACACTACTGTTATTGAAAATAGTGATGTTTC
CCCAGAAACGGAGTCTTCTGAGAAGGAGACAATGTCTGTAAGTCTAAATCAGACTGTAACACA
GTTACAGCAGTTGCTTCAGGCGGTAAACCAACAGCTCACAAAGGAGAAAGAGCACTACCAGGT
GTTAGAGTGAAGTAATTGGGAAACTGTTCATTTGAGGATAAAAAAGGCATTGTATTATATTTT
GCCAAATTAAAGCCTTATTTATGTTTTCACCCTTTCTACTTTGTCAGAAACACTGAACAGAGT
TTTGTCTTTTCTAATCCTTGTTAGACTACTGATTTAAAGAAGGAAAAAAAAAAGCCAACTCTG
TAGACACCTTCAGAGTTTAGTTTTATAATAAAAACTGTTTGAATAATTAGACCTTTACATTCC
TGAAGATAAACATGTAATCTTTTATCTTATTTTGCTCAATAAAATTGTTCAGAAGATCAAAGT
GGTAAAGACAATGTAAAATTTAACATTTTAATACTGATGTTGTACACTGTTTTACTTAACATT
TTGGGAAGTAACTGCCTCTGACTTCAACTCAAGAAAACACTTTTTTGTTGCTAATGTAATCGG
TTTTTGTAATGGCGTCAGCAAATAAAAGGATGCTTATTATTC
ORF Start: ATG at 41 jORF Stop: TGA at 3851 SEQ ID NO: 64 1270 aa ϊMW at l46190V7 b
NOVl 8b, MEFYESAYFIV IPSIVITVIFLFFWLFMKETLYDEVLAKQKREQKLIPTKTDKKKAEKKKNK
CG I 1 1 188-02 Protein KKEIQNGNLHESDSESVPRDFKLSDALAVEDDQVAPVPLNWETSSSVRERKKKEKKQKPVLE EQVIKESDASKIPGKKVEPVPVTKQPTPPSEAAASKKKPGQKKSKNGSDDQDKKVETLMVPSK
Sequence RQEALPLHQETKQESGSGKKKASSKKQKTENVFVDEPLIHATTYIP MDNADSSPWDKREVI D KPDQVEGIQKSGTKKLKTETDKENAEVKFKDFLLSLKTMMFSEDEA CWDL KEKSGVI QDALKKSSKGELTT IHQLQEKDKLLAAVKEDAAATKDRCKQLTQEMMTEKERSNWITRMKD RIGTLEKEHNVFQNKIHVSYQETQQMQMKFQQVREQ EAEIAHLKQENGILRDAVSNTTNQLE SKQSAELNKLRQDYAR VNELTEKTGKLQQEEVQKKNAEQAATQLKVQLQEAERRWEEVQSYI RKRTAEHEAAQQDLQSKFVAKENEVQSLHSKLTDTLVSKQQLEQRLMQ MESEQKRVNKEESL QMQVQDILEQNEALKAQIQQFHSQIAAQTSASVLAEELHKVIAEKDKQIKQTEDSLASERDRL TSKEEE KDIQNMNFLLKAEVQKLQALANEQAAAAHELEKMQQSVYVKDDKIRLLEEQLQHEI SNKMEEFKILNDQNKA KSEVQK QTLVSEQPNKDWEQMEKCIQEKDEKLKTVEE LETGLI QVATKEEELNAIRTENSSLTKEVQDLKAKQNDQVSFASLVEELKKVIHEKDGKIKSVEELLEA ELLKVANKEKTVQD KQEIKA KEEIGNVQLEKAQQLSITSKVQELQ LLKGKEEQMNTMKAV EEKEKDLANTGK QDLQEENESLKAHVQEVAQH LKEASSASQFEELEIVLKEKENELKR EAMLKERESDLSSKTQ LQDVQDENK FKSQIEQLKQQNYQQASSFPPHEELLKVISEREKEI SGLWNELDSLKDAVEHQRKK NSYGEWLHGFEKKAKEC AGTSGSEEVKVLEHK KEADEMHT LLQ ECEKYKSVLAETEGILQKLQRSVEQEENKWKVKVDESHKTIKQMQSSFTSSEQELERLR SENKDIENLRREREHLE ELEKAEMERSTYVTEVRELKAQLNETLTKLRTEQNERQKVAGDLH KAQQSLE IQSKIVKAAGDTTVIENSDVSPETESSEKETMSVSLNQTVTQLQQLLQAVNQQLT KEKEHYQVLE
SEQ ID NO: 65 14416 bp
NOV18c, GCCGCACAGGGTTTTATAGGATCACATTGACAAAAGTACCATGGAGTTTTATGAGTCAGCATA
CG I 1 1 188-03 DNA TTTTATTGTTCTTATTCCTTCAATAGTTATTACAGTAATTTTCCTCTTCTTCTGGCTTTTCAT GAAAGAAACATTATATGATGAAGTTCTTGCAAAACAGAAAAGAGAACAAAAGCTTATTCCTAC
Sequence CAAAACAGATAAAAAGAAAGCAGAAAAGAAAAAGAATAAAAAGAAAGAAATCCAGAATGGAAA CCTCCATGAATCCGACTCTGAGAGTGTACCTCGAGACTTTAAATTATCAGATGCTTTGGCAGT AGAAGATGATCAAGTTGCACCTGTTCCATTGAATGTCGTTGAAACTTCAAGTAGTGTTAGGGA
AAGAAAAAAGAAGGAAAAGAAACAAAAGCCTGTGCTTGAAGAGCAGGTCATCAAAGAAAGTGA CGCATCAAAGATTCCTGGCAAAAAAGTAGAACCTGTCCCAGTTACTAAACAGCCCACCCCTCC CTCTGAAGCAGCTGCCTCGAAGAAGAAACCAGGGCAGAAGAAGTCTAAAAATGGAAGCGATGA CCAGGATAAAAAGGTGGAAACTCTCATGGTACCATCAAAAAGGCAAGAAGCATTGCCCCTCCA CCAAGAGACTAAACAAGAAAGTGGATCAGGGAAGAAGAAAGCTTCATCAAAGAAACAAAAGAC AGAAAATGTCTTCGTAGATGAACCCCTTATTCATGCAACTACTTATATTCCTTTGATGGATAA TGCTGACTCAAGTCCTGTGGTAGATAAGAGAGAGGTTATTGATTTGCTTAAACCTGACCAAGT AGAAGGGATCCAGAAATCTGGGACTAAAAAACTGAAGACCGAAACTGACAAAGAAAATGCTGA AGTGAAGTTTAAAGATTTTCTTCTGTCCTTGAAGACTATGATGTTTTCTGAAGATGAGGCTCT TTGTGTTGTAGACTTGCTAAAGGAGAAGTCTGGTGTAATACAAGATGCTTTAAAGAAGTCAAG TAAGGGAGAATTGACTACGCTTATACATCAGCTTCAAGAAAAGGACAAGTTACTCGCTGCTGT GAAGGAAGATGCTGCTGCTACAAAGGATCGGTGTAAGCAGTTAACCCAGGAAATGATGACAGA GAAAGAAAGAAGCAATGTGGTTATAACAAGGATGAAAGATCGAATTGGAACATTAGAAAAGGA ACATAATGTATTTCAAAACAAAATACATGTCAGTTATCAAGAGACTCAACAGATGCAGATGAA GTTTCAGCAAGTTCGTGAGCAGATGGAGGCAGAGATAGCTCACTTGAAGCAGGAAAATGGTAT ACTGAGAGATGCAGTCAGCAACACTACAAATCAACTGGAAAGCAAGCAGTCTGCAGAACTAAA TAAACTACGCCAGGATTATGCTAGGTTGGTGAATGAGCTGACTGAGAAAACAGGAAAGCTACA GCAAGAGGAAGTCCAAAAGAAGAATGCTGAGCAAGCAGCTACTCAGTTGAAGGTTCAACTACA AGAAGCTGAGAGAAGGTGGGAAGAAGTTCAGAGCTACATCAGGAAGAGAACAGCGGAACATGA GGCAGCACAGCAAGATTTACAGAGTAAATTTGTGGCCAAAGAAAATGAAGTACAGAGTCTGCA TAGTAAGCTTACAGATACCTTGGTATCAAAACAACAGTTGGAGCAAAGACTAATGCAGTTAAT

GGAATCAGAGCAGAAAAGGGTGAACAAAGAAGAGTCTCTACAAATGCAGGTTCAGGATATTTT GGAGCAGAATGAGGCTTTGAAAGCTCAAATTCAGCAGTTCCATTCCCAGATAGCAGCCCAGAC CTCCGCTTCAGTTCTAGCAGAAGAATTACATAAAGTGATTGCAGAAAAGGATAAGCAGATAAA ACAGACTGAAGATTCTTTAGCAAGTGAACGTGATCGTTTAACAAGTAAAGAAGAGGAACTTAA GGATATACAGAATATGAATTTCTTATTAAAAGCTGAAGTGCAGAAATTACAGGCCCTGGCAAA TGAGCAGGCTGCTGCTGCACATGAATTGGAGAAGATGCAACAAAGTGTTTATGTTAAAGATGA TAAAATAAGATTGCTGGAAGAGCAACTACAACATGAAATTTCAAACAAAATGGAAGAATTTAA GATTCTAAATGACCAAAACAAAGCATTAAAATCAGAAGTTCAGAAGCTACAGACTCTTGTTTC TGAACAGCCTAATAAGGATGTTGTGGAACAAATGGAAAAATGCATTCAAGAAAAAGATGAGAA GTTAAAGACTGTGGAAGAATTACTTGAAACTGGACTTATTCAGGTGGCAACTAAAGAAGAGGA GCTGAATGCAATAAGAACAGAAAATTCATCTCTGACAAAAGAAGTTCAAGACTTAAAAGCTAA GCAAAATGATCAGGTTTCTTTTGCCTCTCTAGTTGAAGAACTTAAGAAAGTGATCCATGAGAA AGATGGAAAGATCAAGTCTGTAGAAGAGCTTCTGGAGGCAGAACTTCTCAAAGTTGCTAACAA GGAGAAAACTGTTCAGGATTTGAAACAGGAAATAAAGGCTCTAAAAGAAGAAATAGGAAATGT CCAGCTTGAAAAGGCTCAACAGTTATCTATCACTTCCAAAGTTCAGGAGCTTCAGAACTTATT AAAAGGAAAAGAGGAACAGATGAATACCATGAAGGCTGTTTTGGAAGAGAAAGAGAAAGACCT AGCCAATACAGGGAAGTGGTTACAGGATCTTCAAGAAGAAAATGAATCTTTAAAAGCACATGT TCAGGAAGTAGCACAACATAACTTGAAAGAGGCCTCTTCTGCATCACAGTTTGAAGAACTTGA GATTGTGTTGAAAGAAAAGGAAAATGAATTGAAGAGGTTAGAAGCCATGCTAAAAGAGAGGGA GAGTGATCTTTCTAGCAAAACACAGCTGTTACAGGATGTACAAGATGAAAACAAATTGTTTAA GTCCCAAATTGAGCAGCTTAAACAACAAAACTACCAACAGGCATCTTCTTTTCCCCCTCATGA AGAATTATTAAAAGTAATTTCAGAAAGAGAGAAAGAAATAAGTGGTCTCTGGAATGAGTTAGA TTCTTTGAAGGATGCAGTTGAACACCAGAGGAAGAAAAACAATGAAAGGCAGCAACAGGTGGA AGCTGTTGAGTTGGAGGCTAAAGAAGTTCTCAAAAAATTATTTCCAAAGGTGTCTGTCCCTTC TAATTTGAGTTATGGTGAATGGTTGCATGGATTTGAAAAAAAGGCAAAAGAATGTATGGCTGG AACTTCAGGGTCAGAGGAGGTTAAGGTTCTAGAGCACAAGTTGAAAGAAGCTGATGAAATGCA CACATTGTTACAGCTAGAGTGTGAAAAATACAAATCCGTCCTTGCAGAAACAGAAGGAATTTT ACAGAAGCTACAGAGAAGTGTTGAGCAAGAAGAAAATAAATGGAAAGTTAAGGTCGATGAATC ACACAAGACTATTAAACAGATGCAGTCATCATTTACATCTTCAGAACAAGAGCTAGAGCGATT AAGAAGCGAAAATAAGGATATTGAAAATCTGAGAAGAGAACGAGAACATTTGGAAATGGAACT AGAAAAGGCAGAGATGGAACGATCTACCTATGTTACAGAAGTCAGAGAGTTGAAGGCACAGTT AAATGAAACACTCACAAAACTTAGAACTGAACAAAATGAAAGACAGAAGGTAGCTGGTGATTT GCATAAGGCTCAACAGTCACTGGAGCTTATCCAGTCAAAAATAGTAAAAGCTGCTGGAGACAC TACTGTTATTGAAAATAGTGATGTTTCCCCAGAAACGGAGTCTTCTGAGAAGGAGACAATGTC TGTAAGTCTAAATCAGACTGTAACACAGTTACAGCAGTTGCTTCAGGCGGTAAACCAACAGCT CACAAAGGAGAAAGAGCACTACCAGGTGTTAGAGTGAAGTAATTGGGAAACTGTTCATTTGAG
GATAAAAAAGGCATTGTATTATATTTTGCCAAATTAAAGCCTTATTTATGTTTTCACCCTTTC
TACTTTGTCAGAAACACTGAACAGAGTTTTGTCTTTTCTAATCCTTGTTAGACTACTGATTTA
AAGAAGGAAAAAAAAAAGCCAACTCTGTAGACACCTTCAGAGTTTAGTTTTATAATAAAAACT GTTTGAATAATTAGACCTTTACATTCCTGAAGATAAACATGTAATCTTTTATCTTATTTTGCT CAATAAAATTGTTCAGAAGATCAAAGTGGTAAAGACAATGTAAAATTTAACATTTTAATACTG
ATGTTGTACACTGTTTTACTTAACATTTTGGGAAGTAACTGCCTCTGACTTCAACTCAAGAAA ACACTTTTTTGTTGCTAATGTAATCGGTTTTTGTAATGGCGTCAGCAAATAAAAGGATGCTTA TTATTC
ORF Start: ATG at 41 ORF Stop: TGA at 3941
SEQ ID NO: 66 i |300 aa •MW at 149609.6kD
NOVl 8c, MEFYESAYFIVLIPSIVITVIFLFFWLF KETLYDEVLAKQKREQKLIPTKTDKKKAEKKKNK
CG 1 1 1 188-03 Protein KKEIQNGNLHESDSESVPRDFKLSDALAVEDDQVAPVP NWETSSSVRERKKKEKKQKPVLE EQVIKESDASKIPGKKVEPVPVTKQPTPPSEAAASKKKPGQKKSKNGSDDQDKKVETLMVPSK
Sequence RQEALPLHQETKQESGSGKKKASSKKQKTENVFVDEPLIHATTYIPLMDNADSSPWDKREVI D LKPDQVEGIQKSGTKK KTETDKENAEVKFKDFLLSLKTM FSEDEALCWD LKEKSGVI QDA KKSSKGELTTLIHQ QEKDKLLAAVKEDAAATKDRCKQLTQEMMTEKERSNWITRMKD RIGTLEKEHNVFQNKIHVSYQETQQMQMKFQQVREQ EAEIAHLKQENGILRDAVSNTTNQLE SKQSAELNKLRQDYARLVNELTEKTGKLQQEEVQKKNAEQAATQLKVQLQEAERRWEEVQSYI RKRTAEHEAAQQDLQSKFVAKENEVQSLHSKLTDTLVSKQQLEQRLMQLMESEQKRVNKEES QMQVQDILEQNEALKAQIQQFHSQIAAQTSASVLAEELHKVIAEKDKQIKQTEDSLASERDRL TSKEEELKDIQNMNFLLKAEVQKLQA A EQAAAAHELEKMQQSVYVKDDKIRLLEEQLQHEI SNKMEEFKILNDQNKALKSEVQKLQTLVSEQPNKDWEQMEKCIQEKDEK KTVEELLETGLI QVATKEEELNAIRTENSSLTKEVQDLKAKQNDQVSFASLVEELKKVIHEKDGKIKSVEELLEA E LKVANKEKTVQDLKQEIKALKEEIGNVQLEKAQQLSITSKVQELQNLLKGKEEQM TMKAV LEEKEKDLANTGKWLQD QEENESLKAHVQEVAQH LKEASSASQFEELEIV KEKENE KRL EAMLKERESDLSSKTQL QDVQDENKLFKSQIEQLKQQNYQQASSFPPHEELLKVISEREKEI SGLWNELDSLKDAVEHQRKK NERQQQVEAVELEAKEVLKKLFPKVSVPSNLSYGEWLHGFEK KAKECMAGTSGSEEVKVLEHKLKEADEMHTL QLECEKYKSV AETEGILQK QRΞVEQEENK KVKVDESHKTIKQMQSSFTSSEQELERLRSENKDIENLRREREHLEMELEKAEMERSTYVTE VRE KAQLNET TKLRTEQNERQKVAGDLHKAQQSLELIQSKIVKAAGDTTVIENSDVSPETE SSEKETMSVSLNQTVTQLQQ LQAVNQQ TKEKEHYQVLE
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 18B.
Further analysis of the NOVl 8a protein yielded the following properties shown in Table 18C.
I Table 18C. Protein Sequence Properties NOVl 8a j PSort 0.8200 probability located in endoplasmic reticulum (membrane); 0.1900 probability : analysis: located in plasma membrane; 0.1800 probability located in nucleus; 0.1000 probability located in endoplasmic reticulum (lumen) j SignalP Cleavage site between residues 40 and 41 I analysis:
A search of the NOV 18a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 18D.
Table 18D. Geneseq Results for NOV18a
NOVl 8a
Identities/
Geneseq J Protein/Organism/Length [Patent #, Residues/ Expect .' Similarities for the Identifier j Date] Match Value Matched Region Residues
; ABB57163 j Mouse ischaemic condition related 1..1320 1 1072/1354 (79%) 0.0 protein sequence SEQ ID NO:396 - 1..1326 { 1 183/1354 (87%) Mus musculus, 1327 aa. j [ WO200188188-A2, 22-NO V-2001 ]
A AG67538 I Amino acid sequence of a human 50..1068 254/1069 (23%) le-63 pi 80 protein - Homo sapiens, 1240 aa. 235..1229 j 483/1069 (44%) [ WO200164947-A 1 , 07-SEP-2001 ]
I AAM79523 j Human protein SEQ ID NO 3169 - 21..1068 1261/1084 (24%) 3e-62 Homo sapiens, 1003 aa. 51 ..992 ' 482/1084 (44%) [ WO200157190- A2, 09- AUG-2001 ]
AAM78539 ; Human protein SEQ ID NO 1201 - 21 ..1068 : 261/1084 (24%) 3e-62 Homo sapiens, 977 aa. 25-966 82/1084 (44%) [WO200157190-A2, 09-AUG-2001] i AAW89721 ; Canine ribosome receptor - Canis 36-982 1 244/1006 (24%) : 4e-62 j familiaris, 1484 aa. [WO9901565-A1 51 1..1459 1 476/1006 (47%) j 14-JAN-1999]
In a BLAST search of public sequence datbases, the NOV 18a protein was found to have homology to the proteins shown in the BLASTP data in Table 18E.
PFam analysis predicts that the NOV 18a protein contains the domains shown in the Table 18F.
Example 19.
The NOV 19 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 19A.
AGGAGAAGTTCAAGCAGCAGAAATATGAGATCAATGTTCTCCGAAACAGGATCAACGATAACC AGAAAGTCTCCAAGACCCGCGGGAAGGCTAAAGTCACCGGGCGCTGGAAATAGAGCCTGGCCT
CCTTCACCAAAGATCTGCTCCTCGCTCGCACCTGCCTCCGGCCTGCACTCCCCCAGTTCCCGG
GCCCTCCTGGGCACCCCAGGCAGCTCCTGTTTGGAAATGGGGAGCTGGCCTAGGTGGGAGCCA
CCACTCCTGCCTGCCCCCACACCCACTCCACACCAGTAATAAAAAGCCACCACACACAAAAAA
AAAAAAAAAAAAACCCAAAA
ORF Start: ATG at 69 JORF Stop: TAG at 933 SEQ ID NO:7θ 288' aa ]MW at 34589.9kD
NOVl 9b, MSDIEEVVEEYEEEEQEEAAVEEQEEAAEEDAEAEAETEETRAEEDEEEEEAKEAEDGPMEES CGI 1 1473- 02 Protein KPKPRSFMPN VPPKIPDGERVDFDDIHRKRMEKD NELQA IEAHFENRKKEEEE VS KDR IERRRAERAEQQRIRNEREKERQNRLAEERARREEEENRRKAEDEARKKKALSNMMHFGGYIQ
Sequence KQAQTERKSGKRQTEREKKKKILAERRKVLAIDHLNEDQLREKAKELWQSIYNLEAEKFDLQE KFKQQKYEINVLRNRI DNQKVSKTRGKAKVTGRW
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 19B.
Table 19B. Comparison of NOV19a against NOV19b.
NOV19a Residues/
Protein Sequence Identities/ i Match Residues Similarities for the Matched Region
NOVl 9b 128..227 88/100 (88%) 190..288 93/100 (93%)
Further analysis of the NOV 19a protein yielded the following properties shown in Table 19C.
Table 19C. Protein Sequence Properties NOV19a
PSort 0.9725 probability located in nucleus; 0.1000 probability located in mitochondrial analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV 19a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 19D.
In a BLAST search of public sequence datbases, the NOV 19a protein was found to have homology to the proteins shown in the BLASTP data in Table 19E.
PFam analysis predicts that the NOV 19a protein contains the domains shown in the Table 19F.
Example 20.
The NOV20 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 20A.
Table 20A. NOV20 Sequence Analysis
SEQ ID NO: 71 '5382 bp
NOV20a, *AGGCTCCCAATCCCATCCTCATCTCTGCCCCTTCTTCTCAGAAGGATGGCCGACACCCAGACA
CG1 1 1501-01 DNA 'CAGGTGGCCCCCACACCAACCATGAGGATGGCAACTGCAGAGGACCTGCCCCTCCCTCCACCC sCCAGCCCTGGAGGACCTGCCACTGCCGCCACCCAAGGAATCCTTCTCCAAGTTCCATCAGCAG
Sequence JCGGCAAGCTAGTGAGCTCCGCCGCCTCTACAGGCACATCCACCCTGAGCTCCGCAAGAATCTG
^GCTGAGGCTGTGGCCGAGGATCTGGCTGAGGTCCTGGGCTCTGAGGAACCCACCGAGGGTGAC GTTCAGTGCATGCGCTGGATCTTTGAGAACTGGAGACTGGATGCCATTGGAGAACACGAGAGG ,CCAGCTGCCAAGGAGCCCGTGCTGTGTGGTGACGTCCAGGCCACCTCCCGCAAGTTTGAGGAA 'GGCTCCTTTGCCAACAGCACAGACCAGGAGCCAACCAGGCCCCAGCCAGGTGGAGGAGACGTT CGTGCAGCCCGCTGGCTATTTGAGACAAAGCCACTGGACGAGCTGACAGGGCAAGCCAAGGAA I ΪCTGGAGGCCACTGTGAGGGAGCCTGCAGCCAGCGGAGATGTGCAGGGTACCAGGATGCTCTTT J GAGACGCGGCCGCTGGACCGCCTGGGCTCCCGCCCCTCCCTGCAGGAGCAGAGCCCCTTGGAAJ .CTGCGCTCAGAGATCCAGGAGCTGAAGGGTGATGTGAAAAAGACAGTGAAGCTCTTCCAAACG J !GAGCCCCTGTGTGCCATCCAGGATGCAGAGGGCGCCATCCATGAGGTCAAGGCCGCATGCCGG; ,GAGGAGATCCAAAGCAACGCGGTGAGGTCTGCCCGCTGGCTCTTTGAGACCCGGCCTCTGGAC ,GCCATCAACCAGGACCCCAGCCAGGTGCGGGTGATCCGGGGGATTTCCCTGGAGGAGGGGGCC CGGCCCGACGTCAGTGCAACTCGCTGGATCTTTGAGACACAGCCCCTGGATGCCATCCGGGAG JATCTTGGTAGATGAGAAGGACTTCCAGCCATCCCCAGACCTTATCCCACCTGGTCCAGATGTT 'CAGCAGCAGCAGCATCTGTTTGAGACCCGAGCGCTGGACACTCTGAAGGGGGACGAAGAGGCT ;GGAGCAGAGGCCCCACCCAAGGAGGAAGTGGTCCCTGGTGATGTCCGCTCCACCCTGTGGCTA JTTTGAAACAAAGCCCCTGGATGCTTTCAGAGACAAGGTCCAAGTGGGTCACCTACAGCGAGTG ΪGATCCCCAGGACGGTGAGGGGCATCTATCCAGTGACAGCTCCTCAGCACTGCCCTTCTCTCAG SAGTGCCCCCCAGAGGGATGAGCTAAAGGGGGATGTGAAGACTTTTAAGAACCTTTTTGAGACC JCTTCCCTTGGACAGCATTGGACAGGGTGAGGTTCTGGCCCATGGGAGTCCAAGCAGAGAAGAA JGGAACTGATTCTGCTGGGCAGGCCCAGGGCATAGGGTCCCCAGTGTATGCCATGCAGGACAGC ;AAGGGCCGCCTCCATGCCCTGACCTCTGTTAGCAGAGAGCAGATAGTCGGAGGTGATGTGCAG JGGCTACAGGTGGATGTTTGAGACACAGCCCCTAGACCAGCTCGGCCGAAGCCCCAGTACCATC ^GACGTGGTGCGGGGCATCACCCGGCAGGAAGTGGTGGCTGGGGACGTTGGCACAGCTCGGTGG LCTTTTTGAGACCCAGCCCCTGGAGATGATCCACCAACGGGAGCAGCAGGAACGACAGAAAGAA 1GAAGGGAAGAGTCAGGGAGACCCCCAGCCTGAGGCACCCCCAAAGGGCGATGTGCAGACCATC ;CGGTGGTTGTTCGAGACTTGCCCAATGAGTGAGTTGGCCGAAAAGCAGGGGTCAGAGGTCACA IGATCCCACAGCCAAGGCTGAGGCACAGTCCTGCACCTGGATGTTCAAGCCCCAACCTGTGGAC JAGGCCAGTGGGCTCCAGGGAGCAGCACCTGCAGGTTAGCCAGGTCCCGGCTGGGGAAAGACAG JACAGACAGACACGTCTTTGAGACCGAGCCTCTTCAGGCCTCAGGCCGTCCCTGTGGAAGACGG "CCTGTGAGATACTGCAGCCGCGTGGAGATCCCTTCAGGGCAGGTGTCTCGTCAGAAAGAGGTT TTTCAGGCCCTGGAGGCAGGCAAGAAGGAAGAACAGGAGCCCCGGGTAATCGCTGGGTCCATC CCCGCGGGTTCTGTCCACAAGTTCACTTGGCTTTTTGAGAATTGTCCCATGGGCTCCCTGGCA GCTGAGAGCATCCAAGGGGGCAACCTCCTGGAAGAGCAGCCCATGAGCCCCTCAGGCAACAGG
'ATGCAAGAGAGCCAGGAGACTGCAGCTGAGGGGACCCTGCGGACTCTGCATGCCACACCTGGC 'ATCCTGCACCATGGAGGCATCCTCATGGAGGCCCGAGGGCCAGGGGAGCTCTGTCTTGCCAAG ;TATGTGCTCTCGGGCACAGGGCAGGGGCACCCTTATATACGAAAGGAGGAGCTGGTGTCAGGT iGAACTTCCCAGGATCATCTGCCAAGTCCTGCGCCGGCCAGATGTGGACCAGCAGGGGCTGCTG JGTGCAGGAAGACCCAACTGGCCAGCTCCAACTCAAGCCGCTGAGGCTGCCAACTCCAGGCAGC AGTGGGAATATTGAAGACATGGACCCTGAGCTCCAGCAGCTGCTGGCTTGCGGTCTTGGGACC TCCGTGGCAAGGACTGGGCTGGTGATGCAGGAGACAGAGCAGGGCCTGGTCGCACTGACTGCC TACTCTCTGCAGCCCCGGCTAACTAGCAAGGCCTCTGAGAGGAGCAGCGTGCAGCTGTTGGCC AGCTGCATAGATAAAGGAGACCTGAGTGGCCTGCACAGTCTGCGGTGGGAGCCCCCGGCTGAC JCCGAGTCCAGTGCCAGCCAGCGAGGGGGCCCAGAGCCTGCACCCAACTGAGAGCATCATCCAT 1GTTCCCCCACTGGACCCCAGCATGGGGATGGGGCATCTGAGAGCCTCAGGGGCCACCCCTTGC JCCTCCTCAGGCCATTGGAAAGGCAGTCCCTCTGGCTGGGGAAGCTGCAGCACCAGCCCAATTG •CAAAACACAGAAAAGCAGGAAGACAGTCACTCTGGACAGAAAGGGATGGCAGTCTTGGGAAAG jTCAGAAGGAGCCACGACTACCCCTCCGGGGCCTGGGGCCCCAGACCTCCTGGCCGCCATGCAG JAGTCTGCGGATGGCAACAGCTGAAGCCCAGAGCCTGCACCAGCAAGTTCTGAACAAGCACAAG CAGGGCCCCACCCCAACAGCCACTTCCAACCCCATCCAGGACGGTCTTCGGAAAGCTGGGGCT ACCCAAAGCAACATAAGGCCTGGGGGTGGAAGTGATCCCCGGATCCCAGCAGCCCCCAGAAAG
GTCAGTCCTGACTTTCCAGCTGGAGCCCACCGTGCTGAGGACTCCATCCAGCAAGCCTCTGAG
CCCCTGAAGGACCCCCTTCTTCACTCCCACAGCAGCCCTGCTGGCCAGAGAACCCCTGGAGGG TCACAGACAAAGACCCCAAAACTGGACCCCACCATGCCCCCAAAGAAGAAGCCGCAGCTGCCC CCTAAACCTGCACACCTAACCCAGAGCCACCCTCCTCAGAGGCTGCCCAAGCCCTTGCCTCTA ITCTCCCAGCTTTTCCTCGGAGGTGGGGCAAAGAGAACACCAACGAGGTGAGAGAGATACAGCC JATCCCTCAGCCAGCCAAGGTTCCCACTACTGTAGACCAGGGCCACATACCTCTGGCCAGATGT JCCCAGTGGACATAGCCAGCCCAGCTTACAACATGGCCTCAGCACCACGGCCCCCAGGCCCACC JAAGAATCAGGCTACAGGCAGCAATGCCCAGAGCTCTGAGCCCCCCAAGCTCAATGCCCTCAAC JCATGATCCCACCTCACCACAGTGGGGCCCCGGCCCCTCAGGAGAGCAGCCCATGGAAGGTTCC JCACCAAGGGGCCCCTGAGAGCCCTGACAGTCTGCAAAGAAACCAGAAAGAGCTCCAG ΪCCTC JCTGAACCAGGTGCAAGCCCTGGAGAAGGAGGCCGCAAGCAGTGTGGACGTGCAGGCCCTGCGG JAGGCTCTTTGAGGCCGTGCCCCAGCTGGGAGGGGCTGCTCCTCAGGCTCCTGCTGCCCACCAA JAAGCCCGAGGCCTCAGTGGAGCAGGCCTTTGGGGAGCTGACACGGGTCAGCACGGAAGTTGCT JCAACTGAAGGAACAGACCTTGGCAAGGCTGCTGGACATTGAAGAGGCTGTGCACAAGGCACTC AGCTCCATGTCTAGCCTCCAGCCTGAGGCCAGTGCCAGAGGCCATTTCCAGGGACCTCCAAAA GACCACAGTGCCCACAAGATCAGTGTCACAGTCAGCAGTAGCGCCAGGCCCAGTGGCTCAGGC JCAGGAGGTCGGAGGTCAAACTGCAGTCAAGAACCAAGCCAAGGTTGAATGCCACACTGAGGCC ICAGAGTCAAGTCAAGATCAGAAATCACACAGAGGCCAGAGGTCACACAGCCTCAACTGCCCCT JTCCACCAGGAGGCAGGAGACATCAAGAGAGTATTTGTGCCCTCCTCGGGTTTTACCTTCCAGC ΪCGAGATTCTCCCTCCTCCCCAACATTTATCTCCATCCAGTCGGCCACAAGGAAGCCTCTAGAG IACTCCCAGCTTTAAGGGCAACCCTGATGTCTCAGTGAAAAGCACACAACTGGCTCAGGACATA JGGCCAGGCCCTGCTCCACCAGAAAGGTGTCCAAGACAAAACTGGGAAGAAGGACATCACCCAG JTGCTCTGTGCAACCTGAACCTGCCCCTCCCTCAGCCAGTCCCCTGCCCAGAGGGTGGCAAAAG 'AGTGTTCTGGAGCTACAGACGGGGCCAGGGAGCTCACAACACTATGGAGCCATGAGAACCGTG JACTGAACAGTATGAGGAGGTGGACCAGTTTGGGAACACAGTCCTCATGTCTTCCACCACAGTC JACCGAGCAGGCAGAGCCACCCAGGAACCCAGGCTCCCACCTCGGGCTCCACGCCTCCCCCTTG JCTGAGGCAGTTCCTGCACAGCCCAGCTGGGTTCAGCAGTGACCTGACAGAAGCTGAGACGGTG JCAGGTGTCCTGCAGCTACTCCCAGCCAGCTGCCCAGTGAGGCCCACCGCCTCCCACCACACCT GCCACCTGTTCCTGGCCTCCACTGCCCCAGGACTGAAGTGGGTACCTGCCTCCTGTACACTGG AGCAAGGACCAAGAGGAAATGGCATCTTCAGAGGATTACTGTGGGCCATTTCCCTTTCGCAGT
■TCTTTCAATAGGCCCAGTTCTTCCAAATGGAAAAAGAAAGGTCTGGAAGAGGCCCACAGAGTT
IGCACAGGCGTGGGGGTAGGATGGGGGC
|ORF Start: ATG at 46 ,ORF Stop: TGA at 5140
I ιSEQ ID NO: 72 1698 aa jMW at 183686.6kD
NOV20a, MADTQTQVAPTPTMRMATAEDLPLPPPPA EDLPLPPPKESFSKFHQQRQASELRRLYRHIHP
CG I 1 1501 -01 Protein]ELRK LAEAVAEDLAEV GSEEPTEGDVQCMRWIFENWRLDAIGEHERPAAKEPV CGDVQAT SRKFEEGSFANSTDQEPTRPQPGGGDVRAARWLFETKP DELTGQAKELEATVREPAASGDVQ
{Sequence IGTR LFETRPLDRLGSRPSLQEQSPLELRSEIQELKGDVKKTVKLFQTEP CAIQDAEGAIHE VKAACREEIQSNAVRSARWLFETRPLDAINQDPSQVRVIRGISLEEGARPDVSATRWIFETQP LDAIREILVDEKDFQPSPD IPPGPDVQQQQHLFETRALDTLKGDEEAGAEAPPKEEVVPGDV RSTL LFETKP DAFRDKVQVGHLQRVDPQDGEGHLSSDSSSALPFSQSAPQRDELKGDVKTF
. KN FETLPLDSIGQGEVLAHGSPSREEGTDSAGQAQGIGSPVYAMQDSKGR HALTSVSREQI VGGDVQGYRWMFETQPLDQLGRSPS IDWRGITRQEWAGDVGTARWLFETQPLEMIHQREQ QERQKEEGKSQGDPQPEAPPKGDVQTIR LFETCPMSELAEKQGSEVTDPTAKAEAQSCTWMF KPQPVDRPVGSREQHLQVSQVPAGERQTDRHVFETEPLQASGRPCGRRPVRYCSRVEIPSGQV SRQKEVFQA EAGKKEEQEPRVIAGSIPAGSVHKFT LFENCPMGSLAAESIQGGNL EEQP SPSGNRMQESQETAAEGTLRTLHATPGI HHGGILMEARGPGELCLAKYVLSGTGQGHPYIRK EELVSGELPRIICQVLRRPDVDQQGLLVQEDPTGQLQLKPLR PTPGSSGNIEDMDPELQQL
JACGLGTSVARTGLVMQETEQGLVALTAYSLQPRLTSKASERSSVQLLASCIDKGDLSGLHSLR J JWEPPADPSPVPASEGAQSLHPTESIIHVPP DPSMGMGHLRASGATPCPPQAIGKAVPLAGEAJ LAAPAQLQNTEKQEDSHSGQKGMAVLGKSEGATTTPPGPGAPDLAAMQSLRMATAEAQSLHQQJ JVLNKHKQGPTPTATSNPIQDGLRKAGATQSNIRPGGGSDPRIPAAPRKVSPDFPAGAHRAEDS J JIQQASEP KDPL HSHSSPAGQRTPGGSQTKTPKLDPTMPPKKKPQLPPKPAH TQSHPPQRL , JPKPLPLSPSFSSEVGQREHQRGERDTAIPQPAKVPTTVDQGHIPLARCPSGHSQPSLQHGLST J JTAPRPTKNQATGSNAQSSEPPKLNALNHDPTSPQWGPGPSGEQPMEGSHQGAPESPDSLQRNQI IKELQG LNQVQALEKEAASSVDVQA RRLFEAVPQLGGAAPQAPAAHQKPEASVEQAFGELTR' IVSTEVAQLKEQTLARL DIEEAVHKALSSMSSLQPEASARGHFQGPPKDHSAHKISVTVSSSA RPSGSGQEVGGQTAVKNQAKVECHTEAQSQVKIRNHTEARGHTASTAPSTRRQETSREYLCPP RVLPSSRDSPSSPTFISIQSATRKPLETPSFKGNPDVSVKSTQAQDIGQALLHQKGVQDKTG KKDITQCSVQPEPAPPSASPLPRGWQKSVLELQTGPGSSQHYGAMRTVTEQYEEVDQFGNTVL MSSTTVTEQAEPPRNPGSHLGLHASPLLRQFLHSPAGFSSDLTEAETVQVSCSYSQPAAQ
]SEQ ID NO: 73 3333 bp j
NOV20b, TAGGCTCCCAATCCCATCCTCATCTCTGCCCCTTCTTCTCAGAAGGATGGCCGACACCCAGACA
CGI 1 1501-02 DNA CAGGTGGCCCCCACACCAACCATGAGGATGGCAACTGCAGAGGACCTGCCCCTCCCTCCACCC iCCAGCCCTGGAGGACCTGCCACTGCCGCCACCCAAGGAATCCTTCTCCAAGTTCCATCAGCAG
Sequence CGGCAAGCTAGTGAGCTCCGCCGCCTCTACAGGCACATCCACCCTGAGCTCCGCAAGAATCTG GCTGAGGCTGTGGCCGAGGATCTGGCTGAGGTCCTGGGCTCTGAGGAACCCACCGAGGGTGAC GTTCAGTGCATGCGCTGGATCTTTGAGAACTGGAGACTGGATGCCATTGGAGAACACGAGAGG CCAGCTGCCAAGGAGCCCGTGCTGTGTGGTGACGTCCAGGCCACCTCCCGCAAGTTTGAGGAA ^GGCTCCTTTGCCAACAGCACAGACCAGGAGCCAACCAGGCCCCAGCCAGGTGGAGGAGACGTT ICGTGCAGCCCGCTGGCTATTTGAGACAAAGCCACTGGACGAGCTGACAGGGCAAGCCAAGGAA iCTGGAGGCCACTGTGAGGGAGCCTGCAGCCAGCGGAGATGTGCAGGGTACCAGGATGCTCTTT JGAGACGCGGCCGCTGGACCGCCTGGGCTCCCGCCCCTCCCTGCAGGAGCAGAGCCCCTTGGAA ^CTGCGCTCAGAGATCCAGGAGCTGAAGGGTGATGTGAAAAAGACAGTGAAGCTCTTCCAAACG GAGCCCCTGTGTGCCATCCAGGATGCAGAGGGCGCCATCCATGAGGTCAAGGCCGCATGCCGG GAGGAGATCCAAAGCAACGCGGTGAGGTCTGCCCGCTGGCTCTTTGAGACCCGGCCTCTGGAC .GCCATCAACCAGGACCCCAGCCAGGTGCGGGTGATCCGGGGGATTTCCCTGGAGGAGGGGGCC ICGGCCCGACGTCAGTGCAACTCGCTGGATCTTTGAGACACAGCCCCTGGATGCCATCCGGGAG ATCTTGGTAGATGAGAAGGACTTCCAGCCATCCCCAGACCTTATCCCACCTGGTCCAGATGTT jCAGCAGCAGCAGCATCTGTTTGAGACCCGAGCGCTGGACACTCTGAAGGGGGACGAAGAGGCT iGGAGCAGAGGCCCCACCCAAGGAGGAAGTGGTCCCTGGTGATGTCCGCTCCACCCTGTGGCTA ?TTTGAAACAAAGCCCCTGGATGCTTTCAGAGACAAGGTCCAAGTGGGTCACCTACAGCGAGTG ^GATCCCCAGGACGGTGAGGGGCATCTATCCAGTGACAGCTCCTCAGCACTGCCCTTCTCTCAG JAGTGCCCCCCAGAGGGATGAGCTAAAGGGGGATGTGAAGACTTTTAAGAACCTTTTTGAGACC jCTTCCCTTGGACAGCATTGGACAGGGTGAGGTTCTGGCCCATGGGAGTCCAAGCAGAGAAGAA GGAACTGATTCTGCTGGGCAGGCCCAGGGCATAGGGTCCCCAGTGTATGCCATGCAGGACAGC AAGGGCCGCCTCCATGCCCTGACCTCTGTTAGCAGAGAGCAGATAGTCGGAGGTGATGTGCAG GGCTACAGGTGGATGTTTGAGACACAGCCCCTAGACCAGCTCGGCCGAAGCCCCAGTACCATc!
JGACGTGGTGCGGGGCATCACCCGGCAGGAAGTGGTGGCTGGGGACGTTGGCACAGCTCGGTGG JCTTTTTGAGACCCAGCCCCTGGAGATGATCCACCAACGGGAGCAGCAGGAACGACAGAAAGAA IGAAGGGAAGAGTCAGGGAGACCCCCAGCCTGAGGCACCCCCAAAGGGCGATGTGCAGACCATC ICGGTGGTTGTTCGAGACTTGCCCAATGAGTGAGTTGGCCGAAAAGCAGGGGTCAGAGGTCACA IGATCCCACAGCCAAGGCTGAGGCACAGTCCTGCACCTGGATGTTCAAGCCCCAACCTGTGGAC JAGGCCAGTGGGCTCCAGGGAGCAGCACCTGCAGGTTAGCCAGGTCCCGGCTGGGGAAAGACAG IACAGACAGACACGTCTTTGAGACCGAGCCTCTTCAGGCCTCAGGCCGTCCCTGTGGAAGACGG LCCTGTGAGATACTGCAGCCGCGTGGAGATCCCTTCAGGGCAGGTGTCTCGTCAGAAAGAGGTT ITTTCAGGCCCTGGAGGCAGGCAAGAAGGAAGAACAGGAGCCCCGGGTAATCGCTGGGTCCATC JCCCGCGGGTTCTGTCCACAAGTTCACTTGGCTTTTTGAGAATTGTCCCATGGGCTCCCTGGCA JGCTGAGAGCATCCAAGGGGGCAACCTCCTGGAAGAGCAGCCCATGAGCCCCTCAGGCAACAGG LATGCAAGAGAGCCAGGAGACTGCAGCTGAGGGGACCCTGCGGACTCTGCATGCCACACCTGGC JATCCTGCACCATGGAGGCATCCTCATGGAGGCCCGAGGGCCAGGGGAGCTCTGTCTTGCCAAG JTATGTGCTCTCGGGCACAGGGCAGGGGCACCCTTATATACGAAAGGAGGAGCTGGTGTCAGGT IGAACTTCCCAGGATCATCTGCCAAGTCCTGCGCCGGCCAGATGTGGACCAGCAGGGGCTGCTG JGTGCAGGAAGACCCAACTGGCCAGCTCCAACTCAAGCCGCTGAGGCTGCCAACTCCAGGCAGC JAGTGGGAATATTGAAGACATGGACCCTGAGCTCCAGCAGCTGCTGGCTTGCGGTCTTGGGACC JTCCGTGGCAAGGACTGGGCTGGTGATGCAGGAGACAGAGCAGGGCCTGGTCGCACTGACTGCC ITACTCTCTGCAGCCCCGGCTAACTAGCAAGGCCTCTGAGAGGAGCAGCGTGCAGCTGTTGGCC IAGCTGCATAGATAAAGGAGACCTGAGTGGCCTGCACAGTCTGCGGTGGGAGCCCCCGGCTGAC JCCGAGTCCAGTGCCAGCCAGCGAGGGGGCCCAGAGCCTGCACCCAACTGAGAGCATCATCCAT JGTTCCCCCACTGGACCCCAACAGCCACTTCCAACCCCATCCAGGACGGTCTTCGGAAAGCTGG JGGCTACCCAAAGCAACATAAGGCCTGGGGGTGGAAGTGATCCCCGGATCCCAGCAGCCCCCAG
IAAAGCTGCTGTGACAGGACCTGACTTTCCAGCTGGAGCCCACCGTGCTGAGGACTCCATCCAG jCAAGCCTCTGAGCCCCTGAAGGACCCCCTTCTTCACTCCCACAGCAGCCCTGCTGGCCAGAGA
lACCCCTGGAGGGTCACAGACAAAGACCCCAAAACTGGACCCCACCATGCCCCCAAAGAAGAAG ICCGCAGCTGCCCCCTATATCTGCACACCTAACCCAGAGCCCCCCTCCTCAGAGGCTG
ORF Start: ATG at 46 jORF Stop: TGA at 3061 jSEQ ID NO: 74 1005 aa ]MW at 110888.2kD sNOV20b ;MADTQTQVAPTPTMRMATAEDLPLPPPPALEDLPLPPPKESFSKFHQQRQASE RRLYRHIHP 'CGI 11501-02 Protein IELRKNLAEAVAEDLAEVLGSEEPTEGDVQCMRWIFENWRLDAIGEHERPAAKEPVLCGDVQAT JSRKFEEGSFANSTDQEPTRPQPGGGDVRAAR LFETKPLDELTGQAKELEATVREPAASGDVQ Sequence IGTRMLFETRPLDRLGSRPSLQEQSP ELRSEIQELKGDVKKTVKLFQTEP CAIQDAEGAIHE JVKAACREEIQSNAVRSARWLFETRPLDAINQDPSQVRVIRGISLEEGARPDVSATRWIFETQP JLDAIREILVDEKDFQPSPD IPPGPDVQQQQHLFETRALDTLKGDEEAGAEAPPKEEWPGDV JRSTL LFETKPLDAFRDKVQVGH QRVDPQDGEGHLSSDSSSALPFSQSAPQRDELKGDVKTF JKNLFETLPLDSIGQGEVLAHGSPSREEGTDSAGQAQGIGSPVYAMQDSKGR HALTSVSREQI JVGGDVQGYRW FETQPLDQLGRSPSTIDWRGITRQEWAGDVGTAR LFETQPLE IHQREQ JQERQKEEGKSQGDPQPEAPPKGDVQTIRWLFETCPMSELAEKQGSEVTDPTAKAEAQSCTWMF IKPQPVDRPVGSREQH QVSQVPAGERQTDRHVFETEPLQASGRPCGRRPVRYCSRVEIPSGQV 'SRQKEVFQALEAGKKEEQEPRVIAGSIPAGSVHKFT FENCPMGSLAAESIQGGNLLEEQPM "SPSGNRMQESQETAAEGTLRTLHATPGI HHGGIL EARGPGELCLAKYVLSGTGQGHPYIRK •EELVSGELPRIICQVLRRPDVDQQGLLVQEDPTGQLQLKPLRLPTPGSSGNIEDMDPELQQLL ^ACG GTSVARTGLVMQETEQGLVALTAYSLQPRLTSKASERSSVQLLASCIDKGDLSGLHSLR ΪWEPPADPSPVPASEGAQΞLHPTESIIHVPPLDPNSHFQPHPGRSSESWGYPKQHKAWGWK jSEQ ID NO: 75 1819 bp
NOV20c, ICACCAAGCTTATGGCCGACACCCAGACACAGGTGGCCCCCACACCAACCATGAGGATGGCAAC
249257832 DNA ITGCAGAGGACCTGCCCCTCCCTCCACCCCCAGCCCTGGAGGACCTGCCACTGCCGCCACCCAA ]GGAATCCTTCTCCAAGTTCCATCAGCAGCGGCAAGCTAGTGAGCTCCGCCGCCTCTACAGGCA
Sequence SCATCCACCCTGAGCTCCGCAAGAATCTGGCTGAGGCTGTGGCCGAGGATCTGGCTGAGGTCCT ΪGGGCTCTGAGGAACCCACCGAGGGTGACGTTCAGTGCATGCGCTGGATCTTTGAGAACTGGAG IACTGGATGCCATTGGAGAACACGAGAGGCCAGCTGCCAAGGAGCCCGTGCTGTGTGGTGACGT JCCAGGCCACCTCCCGCAAGTTTGAGGAAGGCTCCTTTGCCAACAGCACAGACCAGGAGCCAAC JCAGGCCCCAGCCAGGTGGAGGAGACGTTCGTGCAGCCCGCTGGCTATTTGAGACAAAGCCACT GGACGAGCTGACAGGGCAAGCCAAGGAACTGGAGGCCACTGTGAGGGAGCCTGCAGCCAGCGG JAGATGTGCAGGGTACCAGGATGCTCTTTGAGACGCGGCCGCTGGACCGCCTGGGCTCCCGCCC ICTCCCTGCAGGAGCAGAGCCCCTTGGAACTGCGCTCAGAGATCCAGGAGCTGAAGGGTGATGT JGAAAAAGACAGTGAAGCTCTTCCAAACGGAGCCCCTGTGTGCCATCCAGGATGCAGAGGGCGC ^CATCCATGAGGTCAAGGCCGCATGCCGGGAGGAGATCCAAAGCAACGCGGTGAGGTCTGCCCG JCTGGCTCTTTGAGACCCGGCCTCTGGACGCCATCAACCAGGACCCCAGCCAGGTGCGGGTGAT ICCGGGGGATTTCCCTGGAGGAGGGGGCCCGGCCCGACGTCAGTGCAACTCGCTGGATCTTTGA IGACACAGCCCCTGGATGCCATCCGGGAGATCTTGGTAGATGAGAAGGACTTCCAGCCATCCCC JAGACCTTATCCCACCTGGTCCAGATGTTCAGCAGCAGCGGCATCTGTTTGAGACCCGAGCGCT 'GGACACTCTGAAGGGGGACGAAGAGGCTGGAGCAGAGGCCCCACCCAAGGAGGAAGTGGTCCC JTGGTGATGTCCGCTCCACCCTGTGGCTATTTGAAACAAAGCCCCTGGATGCTTTCAGAGACAA GGTCCAAGTGGGTCACCTACAGCGAGTGGATCCCCAGGACGGTGAGGGGCATCTATCCAGTGA CAGCTCCTCAGCACTGCCCTTCTCTCAGAGTGCCCCCCAGAGGGATGAGCTAAAGGGGGATGT GAAGACTTTTAAGAACCTTTTTGAGACCCTTCCCTTGGACAGCATTGGACAGGGTGAGGTTCT GGCCCATGGGAGTCCAAGCAGAGAAGAAGGAACTGATTCTGCTGGGCAGGCCCAGGGCATAGG GTCCCCAGTGTATGCCATGCAGGACAGCAAGGGCCGCCTCCATGCCCTGACCTCTGTTAGCAG JAGAGCAGATAGTCGGAGGTGATGTGCAGGGCTACAGGTGGATGTTTGAGACACAGCCCCTAGA JCCAGCTCGGCCGAAGCCCCAGTACCATCGACGTGGTGCGGGGCATCACCCGGCAGGAAGTGGT JGGCTGGGGACGTTGGCACAGCTCGGTGGCTTTTTGAGACCCAGCCCCTGGAGATGATCCACCA ΪACGGGAGCAGCAGGAACGACAGAAAGAAGAAGGGAAGAGTCAGGGAGACCCCCAGCCTGAGGC IACCCCCAAAGGGCGATGTGCAGACCATCCGGTGGTTGTTCGAGACTCTCGAGGGC jORF Start: at 2 ORF Stop: end of sequence isEQlDNO:76" ]606 aa JMW at 67469.6kD
INOV20C, jTKLMADTQTQVAPTPTMRMATAEDLPLPPPPA EDLPLPPPKESFSKFHQQRQASELRRLYRH '249257832 Protein lHPELRKNLAEAVAEDLAEV GSEEPTEGDVQCMR IFEMWR DAIGEHERPAAKEPVLCGDV JQATSRKFEEGSFANSTDQEPTRPQPGGGDVRAARWLFETKP DELTGQAKELEATVREPAASG jSequence DVQGTR FETRPLDRLGSRPSLQEQSPLELRSEIQELKGDVKKTVKLFQTEPLCAIQDAEGA IHEVKAACREEIQSNAVRSARW FETRPLDAINQDPSQVRVIRGIS EEGARPDVSATRWIFE TQPLDAIREILVDEKDFQPSPDLIPPGPDVQQQRHLFETRALDTLKGDEEAGAEAPPKEEWP ΪGDVRST WLFETKP DAFRDKVQVGHLQRVDPQDGEGHLSSDSSSALPFSQSAPQRDELKGDV ΪKTFK FETLP DSIGQGEVLAHGSPSREEGTDSAGQAQGIGSPVYAMQDSKGRLHALTSVSR jEQIVGGDVQGYRW FETQP DQ GRSPSTIDWRGITRQEWAGDVGTARWLFETQPLEMIHQ JREQQERQKEEGKSQGDPQPEAPPKGDVQTIRWLFET EG
SEQ ID NO: 77 _ j 1216 bp _ ! j
;NOV20d, CACCAAGCTTTCAGGAGAGCAGCCCATGGAAGGTTCCCACCAAGGGGCCCCTGAGAGCCCTGA 249263153 DNA CAGTCTGCAAAGAAACCAGAAAGAGCTCCAGGGCCTCCTGAACCAGGTGCAAGCCCTGGAGAA GGAGGCCGCAAGCAGTGTGGACGTGCAGGCCCTGCGGAGGCTCTTTGAGGCCGTGCCCCAGCT Sequence GGGAGGGGCTGCTCCTCAGGCTCCTGCTGCCCACCAAAAGCCCGAGGCCTCAGTGGAGCAGGC iCTTTGGGGAGCTGACACGGGTCAGCACGGAAGTTGCTCAACTGAAGGAACAGACCTTGGCAAG GCTGCTGGACATTGAAGAGGCTGTGCACAAGGCACTCAGCTCCATGTCTAGCCTCCAGCCTGA GGCCAGTGCCAGAGGCCATTTCCAGGGACCTCCAAAAGACCACAGTGCCCACAAGATCAGTGT CACAGTCAGCAGTAGCGCCAGGCCCAGTGGCTCAGGCCAGGAGGTCAGAGGTCAAACTGCAGT CAAGAACCAAGCCAAGGTTGAATGCCACACTGAGGCCCAGAGTCAAGTCAAGATCAGAAATCA CACAGAGGCCAGAGGTCACACAGCCTCAACTGCCCCTTCCACCAGGAGGCAGGAGACATCAAG AGAGTATTTGTGCCCTCCTCGGGTTTTACCTTCCAGCCGAGATTCTCCCTCCTCCCCAACATT TATCTCCATCCAGTCGGCCACAAGGAAGCCTCTAGAGACTCCCAGCTTTAAGGGCAACCCTGA TGTCTCAGTGAAAAGCACACAACTGGCTCAGGACATAGGCCAGGCCCTGCTCCACCAGAAAGG TGTCCAAGACAAAACTGGGAAGAAGGACATCACCCAGTGCTCTGTGCAACCTGAACCTGCCCC JTCCCTCAGCCAGTCCCCTGCCCAGAGGGTGGCAAAAGAGTGTTCTGGAGCTACAGACGGGGCC JAGGGAGCTCACAACACTATGGAGCCATGAGAACCGTGACTGAACAGTATGAGGAGGTGGACCA 'GTTTGGGAACACAGTCCTCATGTCTTCCACCACAGTCACCGAGCAGGCAGAGCCACCCAGGAA CCCAGGCTCCCACCTCGGGCTCCACGCCTCCCCCTTGCTGAGGCAGTTCCTGCACAGCCCAGC TGGGTTCAGCAGTGACCTGACAGAAGCTGAGACGGTGCAGGTGTCCTGCAGCTACTCςCAGCC AGCTGCCCAGCTCGAGGGC
ORF Start: at 2 •ORF Stop: end of sequence
SEQ ID NO: 78 1405 aa MW at 43419.8kD
NOV20d, TKLSGEQPMEGSHQGAPESPDS QRNQKE QGL NQVQALEKEAASSVDVQALRRLFEAVPQL 249263153 Protein GGAAPQAPAAHQKPEAΞVEQAFGELTRVSTEVAQLKEQT ARLLDIEEAVHKALSSMSS QPE ASARGHFQGPPKDHSAHKISVTVSSSARPSGSGQEVRGQTAVKNQAKVECHTEAQSQVKIRNH Sequence TEARGHTASTAPSTRRQETSREYLCPPRV PSSRDSPSSPTFISIQSATRKPLETPSFKGNPD VSVKSTQLAQDIGQALLHQKGVQDKTGKKDITQCSVQPEPAPPSASPLPRGWQKSV ELQTGP GSSQHYGAMRTVTEQYEEVDQFGNTVLMSSTTVTEQAEPPRNPGSHLGLHASPLLRQFLHSPA GFSSDLTEAETVQVSCSYSQPAAQLEG
!SEQ ID NO: 79 j 1216 bp I
NOV20e, CACCAAGCTTTCAGGAGAGCAGCCCATGGAAGGTTCCCACCAAGGGGCCCCTGAGAGCCCTGA 249263166 DNA CAGTCTGCAAAGAAACCAGAAAGAGCTCCAGGGCCTCCTGAACCAGGTGCAAGCCCTGGAGAA
GGAGGCCGCAAGCAGTGTGGACGTGCAGGCCCTGCGGAGGCTCTTTGAGGCCGTGCCCCAGCT Sequence GGGAGGGGCTGCTCCTCAGGCTCCTGCTGCCCACCAAAAGCCCGAGGCCTCAGTGGAGCAGGC
CTTTGGGGAGCTGACACGGGTCAGCACGGAAGTTGCTCAACTGAAGGAACAGACCTTGGCAAG
GCTGCTGGACATTGAAGAGGCTGTGCACAAGGCACTCAGCTCCATGTCTAGCCTCCAGCCTGA
GGCCAGTGCCAGAGGCCATTTCCAGGGACCTCCAAAAGACCACAGTGCCCACAAGATCAGTGT
JCACAGTCAGCAGTAGCGCCAGGCCCAGTGGCTCAGGCCAGGAGGTCGGAGGTCAAACTGCAGT
;CAAGAACCAAGCCAAGGTTGAATGCCACACTGAGGCCCAGAGTCAAGTCAAGATCAGAAATCA
JCACAGAGGCCAGAGGTCACACAGCCTCAACTGCCCCTTCCACCAGGAGGCAGGAGACATCAAG
JAGAGTATTTGTGCCCTCCTCGGGTTTTACCTTCCAGCCGAGATTCTCCCTCCTCCCCAACATT
JTATCTCCATCCAGTCGGCCACAAGGAAGCCTCTAGAGACTCCCAGCTTTAAGGGCAACCCTGA
JTGTCTCAGTGAAAAGCACACAACTGGCTCAGGACATAGGCCAGGCCCTGCTCCACCAGAAAGG
ITGTCCAAGACAAAACTGGGAAGAAGGACATCACCCAGTGCTCTGTGCAACCTGAACCTGCCCC JTCCCTCAGCCAGTCCCCTGCCCAGAGGGTGGCAAAAGAGTGTTCTGGAGCTACAGACGGGGCC
JAGGGAGCTCACAACACTATGGAGCCATGAGAACCGTGACTGAACAGTATGAGGAGGTGGACCA JGTTTGGGAACACAGTCCTCATGTCTTCCACCACAGTCACCGAGCAGGCAGAGCCACCCAGGAA JCCCAGGCTCCCACCTCGGGCTCCACGCCTCCCCCTTGCTGAGGCAGTTCCTGCACAGCCCAGC JTGGGTTCAGCAGTGACCTGACAGAAGCTGAGACGGTGCAGGTGTCCTGCAGCTACTCCCAGCC 'AGCTGCCCAGCTCGAGGGC
ORF Start: at 2 jORF Stop: end of sequence
ISEQ ID NO: 80 405 aa MW at 43320.7kD
;NOV20e, JTKLSGEQPMEGSHQGAPESPDSLQRNQKELQGLLNQVQALEKEAASSVDVQALRRLFEAVPQ 249263166 Protein GGAAPQAPAAHQKPEASVEQAFGELTRVSTEVAQLKEQTLARLLDIEEAVHKALSS SSLQPE ASARGHFQGPPKDHSAHKISVTVSSSARPSGSGQEVGGQTAVKNQAKVECHTEAQSQVKIRNH jSequence iTEARGHTASTAPSTRRQETSREYLCPPRVLPSSRDSPSSPTFISIQSATRKPLETPSFKGNPD JVSVKSTQLAQDIGQALLHQKGVQDKTGKKDITQCSVQPEPAPPSASPLPRGWQKSV ELQTGP GSSQHYGAMRTVTEQYEEVDQFGNTVLMSSTTVTEQAEPPRNPGSHLGLHASPLLRQF HSPA GFSSDLTEAETVQVSCSYSQPAAQLEG
SEQ ID NO: 81 1216 bp I
,NOV20f, CACCAAGCTTTCAGGAGAGCAGCCCATGGAAGGTTCCCACCAAGGGGCCCCTGAGAGCCCTGA J249263170 DNA CAGTCTGCAAAGAAACCAGAAAGAGCTCCAGGGCCTCCTGAACCAGGTGCAAGCCCTGGAGAA GGAGGCCGCAAGCAGTGTGGACGTGCAGGCCCTGCGGAGGCTCTTTGAGGCCGTGCCCCAGCT 'Sequence GGGAGGGGCTGCTCCTCAGGCTCCTGCTGCCCACCAAAAGCCCGAGGCCTCAGTGGAGCAGGC CTTTGGGGAGCTGACACGGGTCAGCACGGAAGTTGCTCAACTGAAGGAACAGACCTTGGCAAG GCTGCTGGACATTGAAGAGGCTGTGCACAAGGCACTCAGCTCCATGTCTAGCCTCCAGCCTGA GGCCAGTGCCAGAGGCCATTTCCAGGGACCTCCAAAAGACCACAGTGCCCACAAGATCAGTGT CACAGTCAGCAGTAGCGCCAGGCCCAGTGGCTCAGGCCAGGAGGTCGGAGGTCAAACTGTAGT CAAGAACCAAGCCAAGGTTGAATGCCACACTGAGGCCCAGAGTCAAGTCAAGATCAGAAATCA CACAGAGGCCAGAGGTCACACAGCCTCAACTGCCCCTTCCACCAGGAGGCAGGAGACATCAAG AGAGTATTTGTGCCCTCCTCGGGTTTTACCTTCCAGCCGAGATTCTCCCTCCTCCCCAACATT TATCTCCATCCAGTCGGCCACAAGGAAGCCTCTAGAGACTCCCAGCTTTAAGGGCAACCCTGA TGTCTCAGTGAAAAGCACACAACTGGCTCAGGACATAGGCCAGGCCCTGCTCCACCAGAAAGG TGTCCAAGACAAAACTGGGAAGAAGGACATCACCCAGTGCTCTGTGCAACCTGAACCTGCCCC TCCCTCAGCCAGTCCCCTGCCCAGAGGGTGGCAAAAGAGTGTTCTGGAGCTACAGACGGGGCC AGGGAGCTCACAACACTATGGAGCCATGAGAACCGTGACTGAACAGTATGAGGAGGTGGACCA GTTTGGGAACACAGTCCTCATGTCTTCCACCACAGTCACCGAGCAGGCAGAGCCACCCAGGAA JCCCAGGCTCCCACCTCGGGCTCCACGCCTCCCCCTTGCTGAGGCAGTTCCTGCACAGCCCAGC JTGGGTTCAGCAGTGACCTGACAGAAGCTGAGACGGTGCAGGTGTCCTGCAGCTACTCCCAGCC FAGCTGCCCAGCTCGAGGGC
'ORF Start: at 2 ORF Stop: end of sequence
•SEQ ID NO: 82 1405 aa MW at 43348.7kD
NOV20f, JTKLSGEQPMEGSHQGAPESPDSLQRNQKELQGLLNQVQALEKEAASSVDVQALRRLFEAVPQL
249263170 Protein JGGAAPQAPAAHQKPEASVEQAFGELTRVSTEVAQLKEQTLARLLDIEEAVHKALSSMSSLQPE JASARGHFQGPPKDHSAHKISVTVSSSARPSGSGQEVGGQTWKNQAKVECHTEAQSQVKIRNH
Sequence ;TEARGHTASTAPSTRRQETSREYLCPPRVLPSSRDSPSSPTFISIQSATRKPLETPSFKGNPD VsVKSTQLAQDIGQALLHQKGVQDKTGKKDITQCSVQPEPAPPSASPLPRGWQKSVLELQTGP JGSSQHYGAMRTVTEQYEEVDQFGNTVLMSSTTVTEQAEPPRNPGSHLGLHASPLLRQFLHSPA ■GFSSDLTEAETVQVSCSYSQPAAQLEG
ISEQ ID NO: 83 21 15 bp
)NOV20g, ;CAAGAAGGTGTCTGTTGGAGCCAGCAGAACAGAACCAATTTGAACAAGAACCTCCAGAGGAAC jCG l 1 1501 -03 DNA JGACGAACCCTGAGACCACAGCTGCTACAGACCACAAACACCCCATCAGCCAAGAGAGACCCTT
GCTGCTGTGACAGGACCTGACTTTCCAGCTGGAGCCCACCGTGCTGAGGACTCCATCCAGCAA ϊSequence 'GCCTCTGAGCCCCTGAAGGACCCCCTTCTTCACTCCCACAGCAGCCCTGCTGGCCAGAGAACC
JCCTGGAGGGTCACAGACAAAGACCCCAAAACTGGACCCCACCATGCCCCCAAAGAAGAAGCCG ΪCAGCTGCCCCCTAAACCTGCACACCTAACCCAGAGCCACCCTCCTCAGAGGCTGCCCAAGCCC *TTGCCTCTATCTCCCAGCTTTTCCTCGGAGGTGGGGCAAAGAGAACACCAACGAGGTGAGAGA IGATACAGCCATCCCTCAGCCAGCCAAGGTTCCCACTACTGTAGACCGAGGCCACATACCTCTG GCCAGATGTCCCAGTGGACATAGCCAGCCCAGCTTACAACATGGCCTCAGCACCACGGCCCCC JAGGCCCACCAAGAATCAGGCTACAGGCAGCAATGCCCAGAGCTCTGAGCCCCCCAAGCTCAAT ;GCCCTCAACCATGATCCCACCTCACCACAGTGGGGCCCCGGCCCCTCAGGAGAGCAGCCCATG ;GAAGGTTCCCACCAAGGGGCCCCTGAGAGCCCTGACAGTCTGCAAAGAAACCAGAAAGAGCTC JCAGGGCCTCCTGAACCAGGTGCAAGCCCTGGAGAAGGAGGCCGCAAGCAGTGTGGACGTGCAG ΪGCCCTGCGGAGGCTCTTTGAGGCCGTGCCCCAGCTGGGAGGGGCTGCTCCTCAGGCTCCTGCT !GCCCACCAAAAGCCCGAGGCCTCAGTGGAGCAGGCCTTTGGGGAGCTGACACGGGTCAGCACG IGAAGTTGCTCAACTGAAGGAACAGACCTTGGCAAGGCTGCTGGACATTGAAGAGGCTGTGCAC LAAGGCACTCAGCTCCATGTCTAGCCTCCAGCCTGAGGCCAGTGCCAGAGGCCATTTCCAGGGA ICCTCCAAAAGACCACAGTGCCCACAAGATCAGTGTCACAGTCAGCAGTAGCGCCAGGCCCAGT
GGCTCAGGCCAGGAGGTCGGAGGTCAAACTGCAGTCAAGAACCAAGCCAAGGTTGAATGCCAC ACTGAGGCCCAGAGTCAAGTCAAGATCAGAAATCACACAGAGGCCAGAGGTCACACAGCCTCA ACTGCCCCTTCCACCAGGAGGCAGGAGACATCAAGAGAGTATTTGTGCCCTCCTCGGGTTTTA CCTTCCAGCCGAGATTCTCCCTCCTCCCCAACATTTATCTCCATCCAGTCGGCCACAAGGAAG CCTCTAGAGACTCCCAGCTTTAAGGGCAACCCTGATGTCTCAGTGAAAAGCACACAACTGGCT CAGGACATAGGCCAGGCCCTGCTCCACCAGAAAGGTGTCCAAGACAAAACTGGGAAGAAGGAC ATCACCCAGTGCTCTGTGCAACCTGAACCTGCCCCTCCCTCAGCCAGTCCCCTGCCCAGAGGG TGGCAAAAGAGTGTTCTGGAGCTACAGACGGGGCCAGGGAGCTCACAACACTATGGAGCCATG AGAACCGTGACTGAACAGTATGAGGAGGTGGACCAGTTTGGGAACACAGTCCTCATGTCTTCC ACCACAGTCACCGAGCAGGCAGAGCCACCCAGGAACCCAGGCTCCCACCTCGGGCTCCACGCC TCCCCCTTGCTGAGGCAGTTCCTGCACAGCCCAGCTGGGTTCAGCAGTGACCTGACAGAAGCT GAGACGGTGCAGGTGTCCTGCAGCTACTCCCAGCCAGCTGCCCAGTGAGGCCCACCGCCTCCC ACCACACCTGCCACCTGTTCCTGGCCTCCACTGCCCCAGGACTGAAGTGGGTACCTGCCTCCT GTACACTGGAGCAAGGACCAAGAGGAAATGGCATCTTCAGAGGATTACTGTGGGCCATTTCCC TTTCGCAGTTCTTTCAATAGGCCCAGTTCTTCCAAATGGAAAAAGAAAGGTCTGGAAGAGGCC CACAGAGTTGCACAGGCGTGGGGGTAGGATGGGGGC
'jORF Start: ATG at 295 ORF Stop: GA at 1873 ']SEQ ΪDN0784"' 1526 aa JMW at 56300.1 kD
NOV20g, IMPPKKKPQLPPKPAHLTQSHPPQRLPKPLPLSPSFSSEVGQREHQRGERDTAIPQPAKVPTTV
!CC 1 1 1501 -03 prote;n JDRVGHIPLARCPSGHΞQPSLQHGLSTTAPRPTKNQATGSNAQSSEPPKLNALNHDPTSPQWGPG iPSGEQPMEGSHQGAPESPDSLQRNQKELQGLLNQVQALEKEAASSVDVQALRRLFEAVPQLGG Sequence iAAPQAPAAHQKPEASVEQAFGELTRVSTEVAQLKEQTLARLLDIEEAVHKALSSMSSLQPEAS
IARGHFQGPPKDHSAHKISVTVSSSARPSGSGQEVGGQTAVKNQAKVECHTEAQSQVKIRNHTE ;ARGHTASTAPSTRRQETSREYLCPPRVLPSSRDSPSSPTFISIQSATRKPLETPSFKGNPDVS KSTQLAQDIGQALLHQKGVQDKTGKKDITQCSVQPEPAPPSASPLPRGWQKSVLELQTGPGS JSQHYGAMRTVTEQYEEVDQFGNTVLMSSTTVTEQAEPPRNPGSHLGLHASPLLRQFLHSPAGF ISSDLTEAETVQVSCSYSQPAAQ
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 20B.
Table 20B. Compai rison of NOV20a against NOV20b through NOV20g.
NOV20a Residues/ Identities/
Protein Sequence ■ Match Residues Similarities for the Matched Region
, NOV20b 1..979 893/979 (91 %) ■ 1 -979 894/979 (91 %)
I NOV20c 1..600 514/600 (85%) ; 4..603 515/600 (85%) i NOV20d 1300..1698 365/399 (91 %) 4..402 365/399 (91 %)
. NOV20e ; 1300..1698 366/399 (91 %) : 4..402 366/399 (91 %)
! NOV20f > 1300..1698 365/399 (91 %) ' 4..402 365/399 (91 %) i NOV20g 1 186..1698 460/513 (89%) | 14..526 461 /513 (89%)
Further analysis of the NOV20a protein yielded the following properties shown in Table 20C.
, Table 20C. Protein Sequence Properties NOV20a PSort 0.7000 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
, SignalP No Known Signal Sequence Predicted
' analysis:
A search of the NOV20a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 20D.
In a BLAST search of public sequence datbases, the NOV20a protein was found to have homology to the proteins shown in the BLASTP data in Table 20E.
BAC04783 CDNA FLJ39102 fιs, clone 1 173- 1698 j 525/526 (99%) 0.0 . NTONG2002948, moderately similar 1..526 I 526/526 (99%) I to Mus musculus Xin mRNA - Homo sapiens (Human). 526 aa.
BAC04655 1 CDNA FLJ38622 fis, clone 1305..1698 1 394/394 ( 100%) 0.0 ; HEART2008364, moderately similar 1.394 1 394/394 ( 100%) '. to Mus musculus Xin mRNA - Homo ' sapiens (Human), 394 aa.
Q91957 ' XIN - Gallus gallus (Chicken), 2562 20..746 398/793 (50%) 1 0.0 aa. 17..794 520/793 (65%)
PFam analysis predicts that the NOV20a protein contains the domains shown in the Table 20F.
Table 20F. Domain Analysis of NOV20a
Identities/
Pfa Domain j NOV20a Match Region Similarities Expect Value for the Matched Region
Example 21.
The NOV21 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 21 A.
JTable 21A. NOV21 Sequence Analysis
:SEQ ID NO: 85 _ i^18 bP_ :
NOV21 a, IGCCCTTCCATGCCAGACCTCAGCAAGTGGTCCGGGCCCTTGAGCCTGCAAGAAGTGGACGAGC
CG I 12595-01 DNA IAGCCGCAGCACCCGCTGCATGTCACCTACGCCGGGGCGGCGGTGGACGAGCTGGGCAAAGTGC TGACGCCCACCCAGGTTAAGAATAGACCCACCAGCATTTCGTGGGATGGTCTTGATTCAGGGA
Sequence ;AGCTCTACACCTTGGTCCTGACAGACCCGGATGCTCCCAGCAGGAAGGATCCCAAATACAGAG !AATGGCATCATTTCCTGGTGGTCAACATGAAGGGCAATGACATCAGCAGTGGCACAGTCCTCT ;CCGATTATGTGGGCTCGGGGCCTCCCAAGGGCACAGGCCTCCACCGCTATGTCTGGCTGGTTT ΪACGAGCAGGACAGGCCGCTAAAGTGTGACGAGCCCATCCTCAGCAACCGATCTGGAGACCACC IGTGGCAAATTCAAGGTGGCGTCCTTCCGTAAAAAGTATGAGCTCAGGGCCCCGGTGGCTGGCA ICGTGTTACCAGGCCGAGTGGGATGACTATGTGCCCAAACTGTACGAGCAGCTGTCTGGGAAGT LAGGGGGTTAGCTTGGGGACCTGAACTGTCCTGGAGGCCCCACCACACTCTG jORF Start: ATG at 9 [""""" ;ORF Stop: TAG at 567
'SEQ ID NO: 86 186aa MWat20957.5kD jNOV21a, MPDLSKWSGPLSLQEVDEQPQHPLHVTYAGAAVDELGKVLTPTQVKNRPTSIΞWDGLDSGKLY ICGl 12595- 01 Protein TLVLTDPDAPSRKDPKYREWHHFLWNMKGNDISSGTVLSDYVGSGPPKGTGLHRYV LVYEQ DRPLKCDEPILSNRSGDHRGKFKVASFRKKYELRAPVAGTCYQAEWDDYVPKLYEQLSGK
Sequence jSEQ ID NO: 87 1434 bp
NOV21 b, IGAGCCAGTGTGCTGAGCTCTCCGCGTCGCCTCTGTCGCCCGCGCCTGGCCTACCGCGGCACTC CG I 12595- 02 DNA ICCGGCTGCACGCTCTGCTTGGCCTCGCCATGCCGGTGGACCTCAGCAAGTGGTCCGGGCCCTT ;GAGCCTGCAAGAAGTGGACGAGCAGCCGCAGCACCCGCTGCATGTCACCTACGCCGGGGCGGC Sequence
IGGTGGACGAGCTGGGCAAAGTGCTGACGCCCACCCAGGTTAAGAATAGACCCACCAGCATTTC IGTGGGATGGTCTTGATTCAGGGAAGCTCTACACCTTGGTCCTGACAGACCCGGATGCTCCCAG ΪCAGGAAGGATCCCAAATACAGAGAATGGCATCATTTCCTGGTGGTCAACATGAAGGGCAATGA :CATCAGCAGTGGCACAGTCCTCTCCGATTATGTGGGCTCGGGGCCTCCCAAGGGCACAGGCCT SCCACCGCTATGTCTGGCTGGTTTACGAGCAGGACAGGCCGCTAAAGTGTGACGAGCCCATCCT JCAGCAACCGATCTGGAGACCACCGTGGCAAATTCAAGGTGGCGTCCTTCCGTAAAAAGTATGA IGCTCAGGGCCCCGGTGGCTGGCACGTGTTACCAGGCCGAGTGGGATGACTATGTGCCCAAACT 'GTACGAGCAGCTGTCTGGGAAGTAGGGGGTTAGCTTGGGGACCTGAACTGTCCTGGAGGCCCC
AAGCCATGTTCCCCAGTTCAGTGTTGCATGTATAATAGATTTCTCCTCTTCCTGCCCCCCTTG
JGCATGGGTGAGACCTGACCAGTCAGATGGTAGTTGAGGGTGACTTTTCCTGCTGCCTGGCCTT I'TATAATTTTACTCACTCACTCTGATTTATGTTTTGATCAAATTTGAACTTCATTTTGGGGGGT
*ATTTTGGTACTGTGATGGGGTCATCAAATTATTAATCTGAAAATAGCAACCCAGAATGTAAAA
AAGAAAAAGCTGGGGGGAAAAAGACCAGGTCTACAGTGATAGAGCAAAGCATCAAAGAATCTT
TAAGGGAGGTTTAAAAAAAAAAAAAAAAAAAAAGATTGGTTGCCTCTGCCTTTGTGATCCTGA
GTCCAGAATGGTACACAATGTGATTTTATGGTGATGTCACTCACCTAGACAACCAGAGGCTGG
ICATTGAGGCTAACCTCCAACACAGTGCATCTCAGATGCCTCAGTAGGCATCAGTATGTCACTC
TGGTCCCTTTAAAGAGCAATCCTGGAAGAAGCAGGAGGGAGGGTGGCTTTGCTGTTGTTGGGA
JCATGGCAATCTAGACCGGCAGCAGCGCTCGCTGACAGCTTGGGAGGAAACCTGAGATCTGTGT TTTTTAAATTGATCGTTCTTCATGGGGGTAAGAAAAGCTGGTCTGGAGTTGCTGAATGTTGCA
ΪTTAATTGTGCTGTTTGCTTGTAGTTGAATAAAAATAGAAACCTGAATG
;ORF Start: ATG at 92_ JORF Stop^TAG at 653 ~SEQIDNO:88 187 aa Irviw at 2l"θ~56.6kb
:NOV2 l b, "JMPVDLSK SGPLSLQEVDEQPQHPLHVTYAGAAVDELGKVLTPTQVKNRPTS I S DGLDSGKL CG I 12595- 02 Protein YTLVLTDPDAPSRKDPKYREWHHFLVVimKGiroisSGTVLSDYVGSGpDKGTGLHRYVWL^
JQDRPLKCDEP ILSNRSGDHRGKFKVASFRKKYELRAPVAGTCYQAE DDYVPKLYEQLSGK ISequence
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 21B.
Table 21B. Comparison of NOV21a against NOV21b.
; NOV21a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
NOV21b 3-186 184/184 ( 100%) ..187 184/184 (100%)
Further analysis of the NOV21a protein yielded the following properties shown in Table 2 IC.
Table 21C. Protein Sequence Properties NOV21a
PSort ! 0.4500 probability located in cytoplasm; 0.3603 probability located in microbody analysis: i (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 i ] probability located in lysosome (lumen)
, SignalP No Known Signal Sequence Predicted , ' analysis:
A search of the NOV21 a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 21 D.
In a BLAST search of public sequence datbases, the NOV21a protein was found to have homology to the proteins shown in the BLASTP data in Table 2 I E.
Table 21E. Public BLASTP Results for NOV21a j Protein NOV21a Identities/ Similarities for Expect j Accession Protein/Organism/Length Residues/ ! Number Match the Matched Value Residues Portion
I AAH31 102 Prostatic binding protein - Homo sapiens 3..186 184/184 (100%) e-109 (Human), 187 aa. 4..187 184/184 (100%)
PFam analysis predicts that the NOV21a protein contains the domains shown in the Table 2 I F.
f Table 21F. Domain Analysis of NOV21a j Identities/ j Pfam Domain NOV21a Match Region l Similarities Expect Value
1
1 : for the Matched Region
, PBP 1..171 '• 91/201 (45%) j l .le-84 i 1 162/201 (81 %) 1
Example 22.
The NOV22 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 22A.
Table 22A. NOV22 Sequence Analysis
SEQ ID NO: 89' 662 bp
NOV22a. CGCAGCCAGCACCGGGCGGAGAGGGCTACCATGGGGAAAATCGCGCTGCAACTCAAAGCCACG
ICG 1 12624-01 DNA CTGGAGAACATCACCAACCTCCGGCCCGTGGGCGAGGACTTCCGGTGGTACCTGAAGGACAGT GTGGCACTGAAGGGGGGCCGTGGCAGTGCTTCCATGGTCCAGAAGTGCAAGCTGTGTGCAAGA
.Sequence GAAAATTCCATCGAGATTTTAAGCAGCACCATCAAGCCTTACAATGCTGAAGACAATGAGAAC TCAAGACAATAGTGGAGTTTGAGTGCCGGGGCCTTGAACCAGTTGATTTCCAGCCGCAGGCT GGGTTTGCTGCTGAAGGTGTGGAGTCAGGGACAGCCTTCAGTGACATTAATCTGCAGGAGAAG GACTGGACTGACTATGATGAAAAGGCCCAGGAGTCTGTGGGAATCTATGAGGTCACCCACCAG TTTGTGAAGTGCTGATCCCTCTTCCTTCCCAGTTGCCCTTAAGAACTGAGAAAGGACAAAGTA
CTCTAAGCAGCAGAGCCCACAGAGGCTCGTTCCTTTGACCCTTGTCTCCTGGTGGCTATACGA
AACCTTCACAATCTGCATGCTGGACTTTATTACAGCTTCCCAAGCCCCATCAATAAAGCCCCT
GTTCACGCTGCACTGGTGCATGAAGGTGAAAT
ORF Start: ATG at 31 ORF Stop: TGA at 454
SEQ ID NO: 90 141 aa MW at 15790.6kD
Further analysis of the NOV22a protein yielded the following properties shown in Table 22B.
Table 22B. Protein Sequence Properties NOV22a j PSort 0.6500 probability located in cytoplasm; 0.1000 probability located in mitochondrial j analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability
I lnorcaarteedd i inn e ennHdnonpllaasςmmiirc r rfettiiπcuilliuimm ( (mmeemmhbrraannpel)
I SignalP No Known Signal Sequence Predicted . analysis:
A search of the NOV22a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 22C.
In a BLAST search of public sequence datbases, the NOV22a protein was found to have homology to the proteins shown in the BLASTP data in Table 22D.
Table 22D. Public BLASTP Results for NOV22a
NOV22a Identities/
Protein Residues/ Similarities for Expect
Accession i Protein/Organism/Length Match the Matched Value
Number Residues Portion Q9N WV4 , CDNA FLJ20580 fis, clone REC00516 1..141 141/160(88%) le-74 ] (Similar to hypothetical protein 1..160 141/160(88%) ' FLJ20580) - Homo sapiens (Human), '160aa.
JQ9DCH5 ;0610037L13Rik protein (RIKEN : 3..141 132/158(83%) 6e-70
;cDNA0610037L13 gene) -Mus J39..196 136/158(85%) musculus (Mouse), 196 aa.
Q9D1H2 ' 1110008H16Rik protein -Mus ! 1..133 114/154(74%) 9e-56 musculus (Mouse), 168 aa. j 1..154 122/154(79%)
'■ T22286 . hypothetical protein F46B6.3 - i 4..138 65/155(41%) -29
, Caenorhabditis elegans, 491 aa. j 328-482 95/155(60%)
AAF58406 CG4646-PA - Drosophila melanogaster I 1..140 63/160(39%) 6e-28 i (Fruit fly), 163 aa. il..l60 91/160(56%)
PFam analysis predicts that the NOV22a protein contains the domains shown in the Table 22E.
Table 22E. Doma in Analysis of NOV22a
1 Identities/
' Pfam Domain NOV22a Match Region Similarities Expect Value for the Matched Region
Example 23. The NOV23 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 23A.
GTAAGGAGTGTGGGAAAGCCTTCACCAGGTCTTGTCAACTTACTCAGCACAGAAAAACTCACA
1
CTGGAGAGAAACCTTATAAATGTAAGGATTGTGGGAGAGCCTTCACTGTTTCCTCTTGCTTAA
GTCAACATATGAAAATCCATGTGGGTGAGAAGCCTTATGAATGCAAGGAATGTGGGATAGCCT
TCACTAGATCTTCTCAACTTACTGAACATTTAAAAACTCACACTGCAAAGGATCCCTTTGAAT
GTAAGATATGTGGAAAATCCTTTAGAAATTCCTCATGCCTCAGTGATCACTTTCGAATTCACA
CTGGAATAAAACCCTATAAATGTAAGGATTGTGGGAAAGCCTTCACTCAGAACTCAGACCTTA
CTAAGCATGCACGAACTCACAGTGGAGAGAGGCCCTATGAATGTAAGGAATGTGGAAAGGCCT
TTGCCAGATCCTCTCGCCTTAGTGAACATACAAGAACTCACACTGGAGAGAAGCCTTTTGAAT
GTGTCAAATGTGGGAAAGCCTTTGCTATTTCTTCAAATCTTAGTGGACATTTGAGAATTCACA
CTGGAGAGAAGCCCTTTGAGTGCCTGGAATGTGGTAAAGCATTTACGCATTCCTCCAGTCTTA
ATAATCACATGCGGACCCACAGCGCCAAAAAACCATTCACGTGTATGGAATGTGGCAAAGCCT
TTAAGTTTCCCACGTGTGTTAACCTTCACATGCGGATTCACACTGGAGAAAACCCTACAATGT
AACAGTGTGGA
ORF Start ATG at 219 jORF Stop: TAA at 1008_ SEQ T Nolw 263 aa JMW at~2962C 6kb~ ""
NOV23a, MGTHTGDNPYECKECGKAFTRSCQLTQHRKTHTGEKPYKCKDCGRAFTVSSCLSQHIKIHVGE
CGI 13823-01 Protein KPYECKECGIAFTRSSQLTEHLKTHTAKDPFECKICGKSFRNSSCLSDHFRIHTGIKPYKCKD CGKAFTQNSDLTKHARTHSGERPYECKECGKAFARSSRLSEHTRTHTGEKPFECVKCGKAFAI
Sequence SS LSGHLRIHTGEKPFECLECGKAFTHSSSL NH RTHSAKKPFTCMECGKAFKFPTCVNLH MRIHTGENPTM
SEQ ID NO: 93 894 bp
|NOV23b, GCCCTTTGTGCGTATACAAACTCACAGGTCAGAAAAACCCTACAAATGTAAGGAATGTGGAAA CG I 13823- 02 DNA AGGATTTAGATATTCTGCATACCTTAATATTCACATGGGAACCCACACTGGAGACAATCCCTA
TGAGTGTAAGGAGTGTGGGAAAGCCTTCACCAGGTCTTGTCAACTTACTCAGCACAGAAAAAC
Sequence TCACACTGGAGAGAAACCTTATAAATGTAAGGATTGTGGGAGAGCCTTCACTGTTTCCTCTTG CTTAAGTCAACATATGAAAATCCATGTGGGTGAGAAGCCTTATGAATGCAAGGAATGTGGGAT AGCCTTCACTAGATCTTCTCAACTTACTGAACATTTAAAAACTCACACTGCAAAGGATCCCTT TGAATGTAAGATATGTGGAAAATCCTTTAGAAATTCCTCATGCCTCAGTGATCACTTTCGAAT TCACACTGGAATAAAACCCTATAAATGTAAGGATTGTGGGAAAGCCTTCACTCAGAACTCAGA CCTTACTAAGCATGCACGAACTCACAGTGGAGAGAGGCCCTATGAATGTAAGGAATGTGGAAA GGCCTTTGCCAGATCCTCTCGCCTTAGTGAACATACAAGAACTCACACTGGAGAGAAGCCTTT TGAATGTGTCAAATGTGGGAAAGCCTTTGCTATTTCTTCAAATCTTAGTGGACATTTGAGAAT TCACACTGGAGAGAAGCCCTTTGAGTGCCTGGAATGTGGTAAAGCATTTACGCATTCCTCCAG TCTTAATAATCACATGCGGACCCACAGCGCCAAAAAACCATTCACGTGTATGGAATGTGGCAA AGCCTTTAAGTTTCCCACGTGTGTTAACCTTCACATGCGGATCCACACTGGAGAAAACCCTAC AATGTAACAGTG
ORF Start: ATG at 98 ORF Stop: TAA at 887
SEQ ID NO: 94 263 aa MW at 29620.6kD
;NOV23b, MGTHTGDNPYECKECGKAFTRSCQLTQHRKTHTGEKPYKCKDCGRAFTVSSCLSQHMKIHVGE jCG l 13823-02 Protein KPYECKECGIAFTRSSQLTEHLKTHTAKDPFECKICGKSFRNSSCLSDHFRIHTGIKPYKCKD CGKAFTQNSDLTKHARTHSGERPYECKECGKAFARSSRLSEHTRTHTGEKPFECVKCGKAFAI jSequence SSNLSGHLRIHTGEKPFECLECGKAFTHSSSLNNHMRTHSAKKPFTCMECGKAFKFPTCVNLH MRIHTGENPTM
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 23B.
Table 23B. Comparison of NOV23a against NOV23b.
! NOV23a Residues/ Identities/
Protein Sequence ' Match Residues Similarities for the Matched Region
! NOV23b 1..263 263/263 ( 100%) 1..263 263/263 (100%)
Further analysis of the NOV23a protein yielded the following properties shown in Table 23C.
Table 23C. Protein Sequence Properties NOV23a i PSort 0.4500 probability located in cytoplasm; 0.3008 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability
i inn I lvycsΛoCsΛomme
SignalP ] No Known Signal Sequence Predicted analysis:
• A search of the NOV23a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 23D.
In a BLAST search of public sequence datbases, the NOV23a protein was found to have homology to the proteins shown in the BLASTP data in Table 23E.
Table 23E. Public BLASTP Results for NOV23a
PFam analysis predicts that the NOV23a protein contains the domains shown in the Table 23F.
Example 24.
The NOV24 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 24A.
jTable 24A. NOV24 Sequence Analysis
SEQ ID NO: 95 1945 bp
|NOV24a, GACAAGCTTCCTAGCGCTATGACTGTCGTCTCCGTCCCGCAGCGGGAGCCGCTCGTCCTGGGT
«CG 1 14098-01 DNA GGCCGCCTTGCGCCGCTTGGCTTTTCCTCCCGAGGTTACTTTGGGGCCCTCCCGATGGTGACC ACGGCTCCGCCTCCTTTACCCCGGATCCCGGACCCCCGGGCACTGCCCCCGACCCTCTTCCTC
(Sequence CCTCATTTCCTAGGGGGAGATGGCCCGTGTCTGACCCCCCAGCCTCGCGCTCCAGCAGCTCTG
I CCCAACCGCAGCCTCGCCGTGGCGGGAGGCACTCCTCGGGCAGCGCCGAAGAAGCGGCGAAAG AAGAAGGTGCGGGCCAGCCCCGCAGGGCAGCTGCCCAGCCGCTTCCACCAGTACCAGCAGCAC CGGAGCCCCGCGACCGGCCCGAGCGGAGCGCAGGAGGTCCCGGGCCCGGCCGCCGCCTTGGCC CCGAGTCCTGCAGCCGCAGCCGGCACGGAGGGAGCCAGCCCCGACCTTGCCCCGCTGCGGCCC GCGGCTCCCGGCCAAACCCCCCTCAGGAAAGAGGTTTTAAAATCAAAGATGGGAAAATCGGAG AAAATTGCCCTTCCCCATGGCCAGCTTGTTCATGGTATACACTTGTATGAGCAACCAAAGATA AACAGACAGAAAAGCAAATATAACTTGCCACTAACCAAGATCACCTCTGCAAAAAGAAATGAA AACAACTTTTGGCAGGATTCTGTTTCATCTGACAGAATTCAGAAGCAGGAAAAAAAGCCTTTT AAAAATACCGAGAACATTAAAAATTCGCATTTGAAGAAATCAGCATTTCTAACTGAAGTGAGC CAAAAGGAAAATTATGCTGGGGCAAAGTTTAGTGATCCACCTTCTCCTAGTGTTCTTCCAAAG CCTCCTAGTCACTGGATGGGAAGCACTGTTGAAAATTCCAACCAAAACAGGGAGCTGATGGCA GTACACTTAAAAACCCTCCTCAAAGTTCAAACTTAGATTTCAGATTTCAGTATGTGTGTAAAA
CATAATTTTTCCCATATCCCTGGACTCTTGAGAAAATTGGTACAGAAATGGAAATTTGCCTTG
TTGCAACATACAATTGCAAAAGATGAGTTTAAAAAATTACATACAAACAGCTTGTATTATATT
TTATATTTTGTAAATACTGTATACCATGTATTATGTGTATATTGTTCATACTTGAGAGGTATA
TTATAGTTTTGTTATGAAAGTATGTATTTTGCCCTGCCCACATTGCAGGTGTTTTGTATATAT
ACAATGGATAAATTTTAAGTGTGTGCTAAGGCACATGGAAGACCGATTTTATTTGCACAAGGT
ACTGAGATTTTTTTCAAGAAACAGCTGTCAAATCTCAAGGTGAAGATCTAAATGTGAACAGTT
TACTAATGCACTACTGAAGTTTAAATCTGTGGCACAATCAATGTAAGCATGGGGTTTGTTTCT
CTAAATTGATTTGTAATCTGAAATTACTGAACAACTCCTATTCCCATTTTTGCTAAACTCAAT
TTCTGGTTTTGGTATATATCCATTCCAGCTTAATGCCTCTAATTTTAATGCCAACAAAATTGG
TTGTAATCAAATTTTAAAATAATAATAATTTGGCCCCCCCTTTTAAAATAGTCTTGACTCTTT
GTGTGTGACTGTTTCTCATGTTTGAATGTGTGACTAGGAGATGATTTTGTGTGGTTGGATTTT
TTTGACTTCTACTTTACTGGCTGAGTGTGAGCCGCCATGCCTGGCCATAATCTACATTTTCTT
ACCAGGAGCAGCATTGAGGTTTTTGAGCATAGTACTTGACTACTCTAGAGGCTGAGACGGGAG
CATCTCTTGAGCCTGAGAAGTGGAGATTGCAATTGAGCTAGGATCAGGCCACTGCACTCCAGC
CTGGGTAACAGACGCTGTCTCAAAAAAAAGGCCAAGAGAAAGTAAGGGAGACAGA
ORF Start: ATG at 19 ORF Stop: TAG at 979
SEQ ID NO: 96 320 aa MW at 34527.4kD
NOV24a, MTWSVPQREPLVLGGRLAPLGFSSRGYFGALPMVTTAPPPLPRIPDPRALPPTLFLPHFLGG
CC 1 14098-01 Protein PGPCLTPQPRAPAALPNRSLAVAGGTPRAAPKKRRKKKVRASPAGQLPΞRFHQYQQHRSPATG
.Sequence PSGAQEVPGPAAALAPSPAAAAGTEGASPDLAPLRPAAPGQTPLRKEVLKSKMGKSEKIALPH GQLVHGIHLYEQPKINRQKSKYNLPLTKITSAKR EN FWQDSVSSDRIQKQEKKPFKNTENI KNSHLKKSAFLTEVSQKENYAGAKFSDPPSPSVLPKPPSHWMGSTVENSNQNRELMAVHLKTL
LKVQT
Further analysis of the NOV24a protein yielded the following properties shown in Table 24B.
Table 24B. Protein Sequence Properties NOV24a
- PSort 0.7000 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.2265 probability located in lysosome (lumen); 0.1000 probability located in mitochondrial matrix space
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV24a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 24C.
In a BLAST search of public sequence datbases, the N0V24a protein was found to have homology to the proteins shown in the BLASTP data in Table 24D.
PFam analysis predicts that the N0V24a protein contains the domains shown in the
Table 24E.
Table 24E. Domain Analysis of NOV24a
Identities/
Pfam Domain NOV24a Match Region Similarities Expect Value for the Matched Region
Example 25. The NOV25 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 25A.
Sequence AAGAACTCAAAGATACACAAAGTAATTTGAACCAAGGCTCAGAAGTTTTTGGAGCCGTGAGGG
ATACAGCAGTTTGGTCAATATTGTCTTAACATGCTTCAAATAAATCAGCTTCTCTCCAAGATA AATGGCAAACCCAAAAGAGAAAACTGCAATGTGTCTGGTAAATGAGTTAGCCCGTTTCAATA GAGTCCAACCCCAGTATAAACTTCTGAATGAAAGAGGGCCTGCTCATTCAAAGATGTTCTCAG TGCAGCTGAGTCTTGGTGAGCAGACATGGGAATCCGAAGGCAGCAGTATAAAGAAGGCTCAGC AGGCTGTTGCCAATAAAGCTTTGACTGAATCTACGCTTCCCAAACCAGTTCAGAAGCCACCCA AAAGTAATGTTAACAATAACCCAGGCAGTATAACTCCAACTGTGGAACTGAATGGGCTTGCTA TGAAAAGGGGAGAGCCTGCCATCTACAGGCCATTAGATCCAAAGCCATTCCCAAATTATAGAG CTAATTACAACTTTCGGGGCATGTACAATCAGAGGTATCATTGCCCAGTGCCTAAGATCTTTT ATGTTCAGCTCACTGTAGGAAATAATGAATTTTTTGGGGAAGGAAAGACTCGACAAGCTGCTA GACACAATGCTGCAATGAAAGCCCTCCAAGCACTGCAGAATGAACCTATTCCAGAAAGATCTC CTCAGAATGGTGAATCAGGAAAGGATATGGATGATGACAAAGATGCAAATAAGTCTGAGATCA GCTTAGTGTTTGAAATTGCTCTGAAGCGAAATATGCCTGTCAGTTTTGAGGTTATTAAAGAAA GTGGACCACCACATATGAAAAGCTTTGTTACTCGAGTGTCAGTAGGAGAGTTCTCTGCAGAAG GAGAAGGAAATAGCAAAAAACTCTCCAAGAAGCGCGCTGCGACCACCGTCTTACAGGAGCTTA AAAAACTTCCACCTCTTCCTGTGGTGGAAAAGCCAAAACTATTTTTTAAAAAACGCCCTAAAA CAATAGTAAAGGCCGGACCAGAATATGGCCAAGGGATGAACCCTATTAGCCGCCTGGCGCAAA TTCAACAGGCCAAAAAGGAAAAGGAGCCGGATTATGTTTTGCTTTCAGAAAGAGGAATGCCTC GACGTCGAGAATTTGTGATGCAGGTGAAGGTAGGCAATGAAGTTGCTACAGGAACAGGACCTA ATAAAAAGATAGCCAAAAAAAATGCTGCAGAAGCAATGCTGTTACAACTTGGTTATAAAGCAT CCACTAATCTTCAGGATCAACTTGAGAAGACAGGGGAAAACAAAGGATGGAGTGGTCCAAAGC CTGGGTTTCCTGAACCAACAAATAATACTCCAAAAGGAATTCTTCATTTGTCTCCTGATGTTT ATCAAGAGATGGAAGCCAGCCGCCACAAAGTAATCTCTGGCACTACTCTAGGCTATTTGTCAC CCAAAGATATGAACCAACCTTCAAGCTCTTTCTTCAGTATATCTCCCACATCGAATAGTTCAG CTACAATTGCCAGGGAACTCCTTATGAATGGAACATCTTCTACAGCTGAAGCCATAGGTTTAA AAGGAAGTTCTCCTACTCCCCCTTGTTCTCCAGTACAACCTTCAAAACAACTGGAATATTTAG CAAGGATTCAAGGCTTTCAGGTTCACTACTGTGATAGACAAAGTGGCAAAGAGTGTGTGACCT GTCTGACATTAGCCCCTGTGCAGATGACTTTCCATGCTATTGGAAGCTCCATTGAAGCCAGCC ATGATCAGGCAGCCTTAAGTGCCTTGAAACAATTTTCTGAACAAGGACTGGATCCAATCGATG GAGCAATGAATATCGAAAAAGGTTCTCTTGAAAAACAAGCCAAGCATCTGAGAGAGAAAGCGG ACAATAACCAGGCACCCCCGGGCTCCATCGCTCAGGACTGCAAGAAATCAAACTCGGCCGTCT AGCAGCTCCCAGAACCCGCGGCTGCCACCGCATCCTTATAAACCTGTCAGCACGCATGAGGGT
GTCTGTGTTCAGGGAAATGAATGACTAATACCATTATTTGAGTCTTATGTGAAGACAACACTA
TTCTAACACGAGAGATAATATACATGGTACTGTTTATTCCACTGGGGAAAAATAAACTTTGAG
CATTCCCTGGACTCGAGATCGATCTACTCATTGCCTGAGCGCGAAATTGTCCGGTCGGACTAA
ATAAGTAGAAATTGAAAAAGCAATTACTATTAATAAAAAAAAACAAATTACTTATAACCATCT
TTTCCTCATTTTTCTTATTACTTATATATTTTAAATATTATTTTTC
ORF Start: ATG at 255 4ORF Stop: TAG at 2079
SEQ ID NO: 98 |608 aa IMW at 66785".6kD "
NOV25a, MA PKEKTAMCLVNELARFNRVQPQYKLLNERGPAHSKMFSVQLSLGEQTWESEGSSIKKAQQ
,001 14308-01 Protein AVANKALTESTLPKPVQKPPKSNVN NPGSITPTVELNGLAMKRGEPAIYRPLDPKPFPNYRA NYNFRGMYNQRYHCPVPKIFYVQLTVGNNEFFGEGKTRQAARH AAMKALQALQNEPIPERSP jSequence QNGESGKDMDDDKDA KSEISLVFEIALKRNMPVSFEVIKESGPPHMKSFVTRVSVGEFSAEG EGNSKKLSKKRAATTVLQELKKLPPLPWEKPKLFFKKRPKTIVKAGPEYGQGMNPISRLAQI QQAKKEKEPDYVLLSERGMPRRREFVMQVKVGNEVATGTGPNKKIAKKNAAEAMLLQLGYKAS NLQDQLEKTGENKG SGPKPGFPEPT NTPKGILHLSPDVYQEMEASRHKVISGTTLGYLSP KDMNQPSSSFFSISPTSNSSATIARELLMNGTSSTAEAIGLKGSSPTPPCSPVQPSKQLEYLA RIQGFQVHYCDRQSGKECVTCLTLAPVQMTFHAIGSSIEASHDQAALSALKQFSEQGLDPIDG AMNIEKGSLEKQAKHLREKADNNQAPPGSIAQDCKKSNSAV
SEQ IDNO: 99 1899bp
NOV25b, TGTGAGGGATACAGCAGTTTGGTCAATATTGTCTTAACATGCTTCAAATAAATCAGATTGAAG
|CGI 14308-02 DNA AACTCCCTTCAGGATTTCTTGTAGAACAAGTCTGGTGTTGATGAAATCCTTCGGCTTTTGTTT
GTCTGGGAAAGACTTTATCTCTCCTTCATAATTAAAGGATATTTTCACCAGATATACTATTCT jSequence AGATGTTCTCAGTGCAGCTGAGTCTTGGTGAGCAGACATGGGAATCCGAAGGCAGCAGTATAA AGAAGGCTCAGCAGGCTGTTGCCAATAAAGCTTTGACTGAATCTACGCTTCCCAAACCAGTTC AGAAGCCACCCAAAAGTAATGTTAACAATAACCCAGGCAGTATAACTCCAACTGTGGAACTGA ATGGGCTTGCTATGAAAAGGGGAGAGCCTGCCATCTACAGGCCATTAGATCCAAAGCCATTCC CAAATTATAGAGCTAATTACAACTTTCGGGGCATGTACAATCAGAGGTATCATTGCCCAGTGC CTAAGATCTTTTATGTTCAGCTCACTGTAGGAAATAATGAATTTTTTGGGGAAGGAAAGACTC GACAAGCTGCTAGACACAATGCTGCAATGAAAGCCCTCCAAGCACTGCAGAATGAACCTATTC CAGAAAGATCTCCTCAGAATGGTGAATCAGGAAAGGATATGGATGATGACAAAGATGCAAATA AGTCTGAGATCAGCTTAGTGTTTGAAATTGCTCTGAAGCGAAATATGCCCGTCAGTTTTGAGG TTATTAAAGAAAGTGGACCACCACATATGAAAAGCTTTGTTACTCGAGTGTCAGTAGGAGAGT TCTCTGCAGAAGGAGAAGGAAATAGCAAAAAACTCTCCAAGAAGCGCGCTGCGACCACCGTCT
TACAGGAGCTTAAAAAACTTCCACCTCTTCCTGTGGTGGAAAAGCCAAAACTATTTTTTAAAA! AACGCCCTAAAACAATAGTAAAGGCCGGACCAGAATATGGCCAAGGGATGAACCCTATTAGCCI
GCCTGGCGCAAATTCAACAGGCCAAAAAGGAAAAGGAGCCGGATTATGTTTTGCTTTCAGAAAJ GAGGAATGCCTCGACGTCGAGAATTTGTGATGCAGGTGAAGGTAGGCAATGAAGTTGCTACAGJ GAACAGGACCTAATAAAAAGATAGCCAAAAAAAATGCTGCAGAAGCAATGCTGTTACAACTTG! GTTATAAAGCATCCACTAATCTTCAGGATCAACTTGAGAAGACAGGGGAAAACAAAGGATGGAJ GTGGTCCAAAGCCTGGGTTTCCTGAACCAACAAATAATACTCCAAAAGGAATTCTTCATTTGT
CTCCTGATGTTTATCAAGAGATGGAAGCCAGCCGCCACAAAGTAATCTCTGGCACTACTCTAGI
GCTATTTGTCACCCAAAGATATGAACCAACCTTCAAGCTCTTTCTTCAGTATATCTCCCACAT'
CGAATAGTTCAGCTACAATTGCCAGGGAACTCCTTATGAATGGAACATCTTCTACAGCTGAAG
CCATAGGTTTAAAAGGAAGTTCTCCTACTCCCCCTTGTTCTCCAGTACAACCTTCAAAACAAC
TGGAATATTTAGCAAGGATTCAAGGCTTTCAGGCAGCCTTAAGTGCCTTGAAACAATTTTCTG
AACAAGGACTGGATCCAATCGATGGAGCGATGAATATCGAAAAAGGTTCTCTTGAAAAACAAG
CCAAGCATCTGAGAGAGAAAGCGGACAATAACCAGGCACCCCCGGGCTCCATCGCTCAGGACT
GCAAGAAATCAAACTCGGCCGTCTAGCAGCTCCCAGAACCCGCGGCTGCCACCGCATCCTTAT
AAACCTGTCAGCACGCATGAGGGTGTCTGTGTTCAGGGAAATGAATGACTAATACCAAAGGGC
GAAATACTG
ORF Start: ATG at 192 jORF Stop: TAG at 1788
SEQ ID NO: 100 532 aa MW at 58273.9kD
|NOV25b, MFSVQLSLGEQT ESEGSSIKKAQQAVA KALTESTLPKPVQKPPKSNVNNNPGSITPTVELN
.'CG I 14308-02 Protein GLAMKRGEPAIYRPLDPKPFPNYRANYNFRGMYNQRYHCPVPKIFYVQLTVGNNEFFGEGKTR QAARHNAAMKALQALQNEPIPERSPQNGESGKDMDDDKDANKSEISLVFEIALKRNMPVSFEV jSequence IKESGPPHMKSFVTRVSVGEFSAEGEGNSKKLSKKRAATTVLQELKKLPPLPWEKPKLFFKK RPKTIVKAGPEYGQGMNPISRLAQIQQAKKEKEPDYVLLSERGMPRRREFVMQVKVGNEVATG TGPNKKIAKKNAAEAMLLQLGYKASTNLQDQLEKTGENKGWSGPKPGFPEPTNNTPKGILHLS PDVYQEMEASRHKVISGTTLGYLSPKDMNQPSSSFFSISPTSNSSATIARELLMNGTSSTAEA IGLKGSSPTPPCSPVQPSKQLEYLARIQGFQAALSALKQFSEQGLDPIDGAM IEKGSLEKQA KHLREKADNNQAPPGSIAQDCKKSNSAV
Sequence comparison ofthe above protein sequences yields the following sequence relationships shown in Table 25B.
Table 25B. Comparison ofNOV25a against NOV25b.
NOV25a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
NOV25b , 39-608 485/570 (85%) ; 1..532 485/570 (85%)
Further analysis of the NOV25a protein yielded the following properties shown in Table 25C.
Table 25C. Protein Sequence Properties NOV25a j PSort 0.7000 probability located in nucleus; 0.3000 probability located in microbody i analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP j No Known Signal Sequence Predicted analysis:
A search of the NOV25a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 25D.
In a BLAST search of public sequence datbases, the NOV25a protein was found to have homology to the proteins shown in the BLASTP data in Table 25E.
18 I
PFam analysis predicts that the NOV25a protein contains the domains shown in the Table 25F.
Example 26.
The NOV26 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 26A.
ACAATTTGGCTGCCTTCCGAGCGGACGTGGATGCAGCTACTCTAGCTCGCATTGACCTGGAGC GCAGAATTGAATCTCTCAACGAGGAGATCGCGTTCCTTAAGAAAGTGCATGAAGAGGAGATCC GTGAGTTGCAGGCTCAGCTTCAGGAACAGCAGGTCCAGGTGGAGATGGACATGTCTAAGCCAG ACCTCACTGCCGCCCTCAGGGATATCCGGGCTCAGTATGAGACCATCGCGGCTAAGAACATTT CTGAAGCTGAGGAGTGGTACAAGTCGAAGGTGTCAGACCTGACCCAGGCAGCCAACAAGAACA ACGACGCCCTGCGCCAGGCCAAGCAGGAGATGATGGAATACCGACACCAGATCCAGTCCTACA CCTGCGAGATTGACGCCCTCAAGGGCACTAACGATTCCCTGATGAGGCAGATGCGGGAATTGG AGGACCGATTTGCCAGTGAGGCCAGTGGCTACCAGGACAACATTGCGCGCCTGGAGGAAGAAA TCCGGCACCTCAAGGATGAGATGGCCCGCCATCTGCGCGAGTACCAGGACCTGCTCAACGTGA AGATGGCCCTGGATGTGGAGATTGCCACCTACCGGAAGCTGCTGGAGGGAGAGGAGAGCCGGA TCAATCTCCCCATCCAGACCTACTCTGCCCTCAACTTCCGAGAAACCAGCCCTGAGCAAAGGG GTTCTGAGGTCCATACCAAGAAGACGGTGATGATCAAGACCATCGAGACACGGGATGGGGAGG TCGTCAGTGAGGCGACACAGCAGCAGCATGAAGTGCTCTAAAGACGAGAGACCCTCTGCCACC
AGAGACCGTCCTCACCCCTGTCCTCACTGCTCCCTGAAGCCCAGCCTTCTTCCATCCCAGGAC
ACCACACCCAGCCTCAGTCCTCCCGTCACAGCCTCTGACCCCTCCTCACTGGCCATCCCTCGT
GGTCCCCAACAGCGACATAGCCCATCCCTGCCTGGTCACAGGCATGCCCCGGCCACCTCTGCG
GACCCCAGCTGTGAGCCTTGGCTGTTGGCAGTGAGTGAGCCTGGCTCTTGTGCTGGATGGAGC
CCAGGCGGGAGCGGTGGCCCTGTCCCTCCCACCTCTGTGACCTGAGGCCTACGCTTTGGCTCT
GGAGATAGCCCCAGAGCAGGGTGTTGGGATACTGCAGGGCCAGGACTGAGCCCCGCAGACCTC
CCCAGCCCCTAGCCCAGGAGAGAGAAAGCCAGGCAGGTAGCCTGGGGGACTAGCCCTGTGGAG
ACTGGGGGGCTTGAAATTGTCCCCGTGGTCTCTTACTTTCCTTTCCCCAGCCCAGGGΪGGACT
TAGAAAGCAGGGGCTACAAGAGGGAATCCCCGAAGGTGCTGGAGGTGGGAGCAGGAGATTGAG
AAGGAGAGAAAGTGGGTGAGATGCTGGAGAAGAGAGAGGAGGAGAGAGGCAGAGAGCGGTCTG;
AGGCTGGTGGGAGGGGCGCCCACCTCCCCACGCCCTCCCCCCCCCTGCTGCAGGGGCTCTGGA
GAGAAACAATAAA
ORF Start: ATG at 81 ORF Stop: TAA at 1488
SEQ ID NO: 102 469 aa MW at 53464.lkD fNOV26a, SQAYSSSQRVSSYRRTFGGAPGFPLGSPLSSPVFPRAGFGSKGSSSSVTSRVYQVSRTSGGA
|CG114349-01 Protein GGLGSLRASRLGTTRTPSSYGAGELLDFSLADAVNQEFLTTRTNEKVELQELNDRFANYIEKV RFLEQQNALAAEVNRLKGREPTRVAELYEEELRELRRQVEVLTNQRARVDVERDNLLDDLQRL jSequence KAKLQEEIQLKEEAE NLAAFRADVDAATLARIDLERRIESLNEEIAFLKKVHEEEIRELQAQ LQEQQVQVEMDMSKPDLTAALRDIRAQYETIAAKNISEAEEWYKSKVSDLTQAANKNNDALRQ AKQEMMEYRHQIQSYTCEIDALKGTNDSLMRQMRELEDRFASEASGYQDNIARLEEEIRHLKD EMARHLREYQDLLNVKMALDVEIATYRKLLEGEESRINLPIQTYSALNFRETSPEQRGSEVHT KKTV IKTIETRDGEWSEATQQQHEVL
SEQ ID NO: 103 : 1865 bp
'NOV26b, CCTCGCCGCATCCACTCTCCGGCCGGCCGCCTGCCCGCCGCCTCCTCCGTGCGCCCGCCAGCC
'CGI 14349-02 DNA TCGCCCGCGCCGTCACCATGAGCCAGGCCTACTCGTCCAGCCAGCGCGTGTCCTCCTACCGCC!
GCACCTTCGGCGGCGCCCCGGGCTTCCCGCTCGGCTCCCCGCTGAGCTCGCCCGTGTTCCCGC
{Sequence GGGCGGGTTTCGGCTCTAAGGGCTCCTCCAGCTCGGTGACGTCCCGCGTGTACCAGGTGTCGC GCACGTCGGGCGGGGCCGGGGGCCTGGGGTCGCTGCGGGCCAGCCGGCTGGGGACCACCCGCA CGCCCTCCTCCTACGGCGCAGGCGAGCTGCTGGACTTCTCACTGGCCGACGCGGTGAACCAGG AGTTTCTGACCACGCGCACCAACGAGAAGGTGGAGCTGCAGGAGCTCAATGACCGCTTCGCCA ACTACATCGAGAAGGTGCGCTTCCTGGAGCAGCAGAACGCGCTCGCCGCCGAAGTGAACCGGC TCAAGGGCCGCGAGCCGACGCGAGTGGCCGAGCTCTACGAGGAGGAGCTGCGGGAGCTGCGGC GCCAGGTGGAGGTGCTCACTAACCAGCGCGCGCGCGTCGACGTCGAGCGCGACAACCTGCTCG ACGACCTGCAGCGGCTCAAGGCCAAGCTGCAGGAGGAGATTCAGTTGAAGGAAGAAGCAGAGA ACAATTTGGCTGCCTTCCGAGCGGACGTGGATGCAGCTACTCTAGCTCGCATTGACCTGGAGC GCAGAATTGAATCTCTCAACGAGGAGATCGCGTTCCTTAAGAAAGTGCATGAAGAGGAGATCC GTGAGTTGCAGGCTCAGCTTCAGGAAATCCGGCACCTCAAGGATGAGATGGCCCGCCATCTGC GCGAGTACCAGGACCTGCTCAACGTGAAGATGGCCCTGGATGTGGAGATTGCCACCTACCGGA AGCTGCTGGAGGGAGAGGAGAGCCGGATCAATCTCCCCATCCAGACCTACTCTGCCCTCAACT TCCGAGAAACCAGCCCTGAGCAAAGGGGTTCTGAGGTCCATACCAAGAAGACGGTGATGATCA AGACCATCGAGACACGGGATGGGGAGGTCGTCAGTGAGGCCACACAGCAGCAGCATGAAGTGC TCTAAAGACAGAGACCCTCTGCCACCAGAGACCGTCCTCACCCCTGTCCTCACTGCTCCCTGA AGCCAGCCTTCTTCCATCCCAGGACACCACACCCAGCCTCAGTCCTCCCCTCACAGCCTCTGA CCCCTCCTCACTGGCCATCCCTCGTGGTCCCCAACAGCGACATAGCCCATCCCTGCCTGGTCA CAGGCATGCCCCGGCCACCTCTGCGGACCCCAGCTGTGAGCCTTGGCTGTTGGCAGTGAGTGA GCCTGGCTCTTGTGCTGGATGGAGCCCAGGCGGGAGCGGTGGCCCTGTCCCTCCCACCTCTGT GACCTGAGGCCTACGCTTTGGCTCTGGAGATAGCCCCAGAGCAGGGTGTTGGGATACTGCAGG GCCAGGACTGAGCCCCGCAGACCTCCCCAGCCCCTAGCCCAGGAGAGAGAAAGCCAGGCAGGT AGCCTGGGGGACTAGCCCTGTGGAGACTGGGGGGCTTGAAATTGTCCCCGTGGTCTCTTACTT TCCTTTCCCCAGCCCAGGGTGGACTTAGAAAGCAGGGGCTACAAGAGGGAATCCCCGAAGGTG CTGGAGGTGGGAGCAGGAGATTGAGAAGGAGAGAAAGTGGGTGAGATGCTGGAGAAGAGAGAG
GAGGAGAGAGGCAGAGAGCGGTCTGAGGCTGGTGGGAGGGGCGCCCACCTCCCCACGCCCTCC CCCCCCCTGCTGCAGGGGCTCTGGAGAGAAACAATAAA
ORF Start: ATG at 81 lORF Stop: TAA at 1 137
SEQ ID NO: 104 352 aa !MW at 39913.2kD
'NOV26b. MSQAYSSSQRVSSYRRTFGGAPGFPLGSPLSSPVFPRAGFGSKGSSSSVTSRVYQVSRTSGGA
CG I 14349-02 Protein GGLGSLRASRLGTTRTPSSYGAGELLDFSLADAVNQEFLTTRTNEKVELQELNDRFANYIEKV RFLEQQNALAAEVNRLKGREPTRVAELYEEELRELRRQVEVLTNQRARVDVERDNLLDDLQRL iSequence KAKLQEEIQLKEEAENNLAAFRADVDAATLARIDLERRIESLNEEIAFLKKVHEEEIRELQAQ LQEIRHLKDEMARHLREYQDLLNVKMALDVEIATYRKLLEGEESRINLPIQTYSALNFRETSP EQRGSEVHTKKTVMIKTIETRDGEWSEATQQQHEVL
SEQ ID NO: 105 1291 bp jNOV26c, ATGAGCCAGGCCTACTCGTCCAGCCAGCGCGTGTCCTCCTACCGCCGCACCTTCGGCGGGGCC iCG l 14349-03 DNA CCGGGCTTCCCGCTCGGCTCCCCGCTGAGCTCGCCCGTGTTCCCGCGGGCGGGTTTCGGCTCT AAGGGCTCCTCCAGCTCGGTGACGTCCCGCGTGTACCAGGTGTCGCGCACGTCGGGCGGGGCC
Sequence GGGGGCCTGGGGTCGCTGCGGGCCAGCCGGCTGGGGACCACCCGCACGCCCTCCTCCTACGGC GCAGGCGAGCTGCTGGACTTCTCACTGGCCGACGCGGTGAACCAGGAGTTTCTGACCACGCGC ACCAACGAGAAGGTGGAGCTGCAGGAGCTCAATGACCGCTTCGCCAACTACATCGAGAAGGTG CGCTTCCTGGAGCAGCAGAACGCGGCGCTCGCCGCCGAAGTGAACCGGCTCAAGGGCCGCGAG CCGACGCGAGTGGCCGAGCTCTACGAGAAGGAAGAGAACAATTTGGCTGCCTTCCGAGCGGAC GTGGATGCAGCTACTCTAGCTCGCATTGACCTGGAGCGCAGAATTGAATCTCTCAACGAGGAG ATCGCGTTCCTTAAGAAAGTGCATGAAGAGGAGATCCGTGAGTTGCAGGCTCAGCTTCAGGAA CAGCAGGTCCAGGTGGAGATGGACATGTCTAAGCCAGACCTCACTGCCGCCCTCAGGGACATC CGGGCTCAGTATGAGACCATCGCGGCTAAGAACATTTCTGAAGCTGAGGAGTGGTACAAGTCG AAGGTGTCAGACCTGACCCAGGCAGCCAACAAGAACAACGACGCCCTGCGCCAGGCCAAGCAG GAGATGATGGAATACCGACACCAGATCCAGTCCTACACCTGCGAGATTGACGCCCTGAAGGGC ACTAACGATTCCCTGATGAGGCAGATGCGGGAATTGGAGGACCGATTTGCCAGTGAGGCCAGT GGCTACCAGGACAACATTGCGCGCCTGGAGGAGGAAATCCGGCACCTCAAGGATGAGATGGCC CGCCATCTGCGCGAGTACCAGGACCTGCTCAACGTGAAGATGGCCCTGGATGTGGAGATTGCC ACCTACCGGAAGCTGCTGGAGGGAGAGGAGAGCCGGATCAATCTCCCCATCCAGACCTACTCT GCCCTCAACTTCCGAGAAACCAGCCCTGAGCAAAGGGGTTCTGAGGTCCATACCAAGAAGACG GTGATGATCAAGACCATGGAGACACGGGATGGGGAGGTCGTCAGTGAGGCCACACAGCAGCAG CATGAAGTGCTCTAAAGACGAGAGACCCTCT
ORF Start: ATG at 1 ORF Stop: TAA at 1273 SEQ ID NOT lOδ" " "1 424 aa ΪMW at 47999.0kD
NOV26c. MSQAYSSSQRVSSYRRTFGGAPGFPLGSPLSSPVFPRAGFGSKGSSSΞVTSRVYQVSRTSGGA
CG I 14349-03 Protein GGLGSLRASRLGTTRTPSSYGAGELLDFSLADAVNQEFLTTRTNEKVELQELNDRFANYIEKV RFLEQQNAALAAEVNRLKGREPTRVAELYEKEENNLAAFRADVDAATLARIDLERRIESLNEE
Sequence IAFLKKVHEEEIRELQAQLQEQQVQVEMDMSKPDLTAALRDIRAQYETIAAKNISEAEE YKS KVSDLTQAANKNNDALRQAKQEMMEYRHQIQSYTCEIDALKGTNDSLMRQMRELEDRFASEAS GYQDNIARLEEEIRHLKDEMARHLREYQDLLNVKMALDVEIATYRKLLEGEESRINLPIQTYS ALNFRETSPEQRGSEVHTKKTVMIKTMETRDGEWSEATQQQHEVL
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 26B.
Further analysis of the NOV26a protein yielded the following properties shown in Table 26C.
Table 26C. Protein Sequence Properties NOV26a
| PSort 0.5102 probability located in mitochondrial matrix space; 0.3000 probability located : analysis: in microbody (peroxisome); 0.2347 probability located in mitochondrial inner membrane; 0.2347 probability located in mitochondrial intermembrane space
; SignalP No Known Signal Sequence Predicted ! analysis:
A search of the NOV26a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 26D.
In a BLAST search of public sequence datbases, the NOV26a protein was found to have homology to the proteins shown in the BLASTP data in Table 26E.
PFam analysis predicts that the NOV26a protein contains the domains shown in the Table 26F.
Example 27.
The NOV27 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 27A.
Table 27A. NOV27 Sequence Analysis
SEQ ID NO: 107 _ 11903 bp j
NOV27a, CGGGGGCGGGGCCGGTAGTGGGAGTGCGGGGCGCGCGGTGACAGCGCGGGGTTGGCGGCGTGG
CG 1 14503-01 DNA GACCCAGGGGGCGACAGAGGCAGCAGCAGCCCGAGGCCTGAGGAGAGGAGACCGGCGGCGGCG
GCAATGCTGGAGACCTTTCGCGAGCGGCTGCTGAGCGTGCAGCAGGATTTCACCTCCGGGCTG
Sequence AAGACTTTAAGTGACAAGTCAAGAGAAGCAAAAGTGAAAAGCAAACCCAGGTATGAGGATACA TGGGCTGCACTTCACAGAAGAGCCAAAGACTGTGCAAGTGCTGGAGAGCTGGTGGATAGCGAG GTGGTCATGCTTTCTGCGCACTGGGAGAAGAAAAAGACAAGCCTCGTGGAGCTGCAAGAGCAG CTCCAGCAGCTCCCAGCTTTAATCGCAGACTTAGAATCCATGACAGCAAATCTGACTCATTTA GAGGCGAGTTTTGAGGAGGTAGAGAACAACCTGCTGCATCTGGAAGACTTATGTGGGCAGTGT GAATTAGAAAGATGCAAACATATGCAGTCCCAGCAACTGGAGAATTACAAGAAAAATAAGAGG
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 27B.
Table 27B. Comparison of NOV27a against NOV27b.
NOV27a Residues/ ] Identities/
Protein Sequence Match Residues j Similarities for the Matched Region
NOV27b 1..286 1273/303 (90%) 1.303 , 273/303 (90%)
Further analysis of the NOV27a protein yielded the following properties shown in Table 27C.
Table 27C. Protein Sequence Properties NOV27a
PSort i 0.4283 probability located in mitochondrial matrix space; 0.3000 probability located analysis: ' in nucleus; 0.1067 probability located in mitochondrial inner membrane; 0.1067 * probability located in mitochondrial intermembrane space j SignalP ; No Known Signal Sequence Predicted ', analysis:
A search of the NOV27a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 27D.
In a BLAST search of public sequence datbases, the NOV27a protein was found to have homology to the proteins shown in the BLASTP data in Table 27E.
Table 27E. Public BLASTP Results for NOV27a
NOV27a I Identities/
Protein
; Residues/ . Similarities for Expect
Accession Protein/Orga nism/Length Match 1 the Matched Value
Number j Residues 1 Portion
Q9H0U2 j Hypothetical 34.8 kDa protein - 1..286 j 285/303 (94%) e- 15- Homo sapiens (Human), 303 aa. 1.303 285/303 (94%) j Q96EV8 Unknown (protein for MGC:20210) j 1..254 i 252/271 (92%) e- 137 (Dysbindin) - Homo sapiens j 1..271 1 252/271 (92%)
(Human), 351 aa. \
J Q91 WZ8 ; Dysbindin (Dystrobrevin binding 1..253 217/270 (80%) ■ e- 1 18 protein 1 ) - Mus musculus (Mouse), j 1 ..270 232/270 (85%) 352 aa. j
Q96NV2 CDNA FLJ30031 fis, clone 65..254 189/190 (99%) e- 103 j 3NB692001349 - Homo sapiens ι 1 - 190 189/190 (99%) i (Human), 270 aa.
Q9D3I4 5430437B 18Rik protein - Mus ! 65-253 j 158/189 (83%) 3e-86 musculus (Mouse), 271 aa. I 1 -189 < 172/189 (90%)
PFam analysis predicts that the NOV27a protein contains the domains shown in the Table 27F.
Table 27F. Domain Analysis of NOV27a
Identities/
Pfam Domain NOV27a Match Region Similarities Expect Value for the Matched Region
Example 28.
The NOV28 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 28A.
AGCTTGAAGAAGAATTGAAAACTGTGACGAACAACTTGAAGTCACTGGAGGCTCAGGCTGAGA AGTACTCGCAGAAGGAAGACAGATATGAGGAAGAGATCAAGGTCCTTTCCGACAAGCTGAAGG AGGCTGAGACTCGGGCTGAGTTTGCGGAGAGGTCAGTAACTAAATTGGAGAAAAGCATTGATG ACTTAGAAGACGAGCTGTACGCTCAGAAACTGAAGTACAAAGCCATCAGCGAGGAGCTGGACC ACGCTCTCAACGATATGACTTCCATATAAGTTTCTTTGCTTCACTTCTCCCAAGACTCCCTCG TCGAGCTGGATGTCCCACCTCTCTGAGCTCTGCATTTGTCTATTCTCCAGCTGACCCTGGTTC
TCTCTCTTAGCATCCTGCCTTAGAGCCAGGCACACACTGTGCTTTCTATTGTACAGAAGCTCT
TCGTTTCAGTGTCAAATAAACACTGTGTAAGCTAAAAAAA
ORF Start: ATG at 57 j jORF Stop: TAA at 909
SEQ FD NOTTΪO*" ]284 aa MW at 32708. l kD
NOV28c, MDAIKKKMQMLKLDKENALDRAEQAEADKKAAEDRSKQLEDELVSLQKKLKGTEDELDKYSEA
CGI 14588-03 Protein LKDAQEKLELAEKKATDAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERG
MKVIESRAQKDEEKMEIQEIQLKEAKHIAEDADRKYEEVARKLVIIESDLERAEERAELΞEGK
Sequence CAELEEELKTVTNNLKSLEAQAEKYSQKEDRYEEEIKVLSDKLKEAETRAEFAERSVTKLEKS
IDDLEDELYAQKLKYKAISEELDHAL .N^D _MT_SI___ _ _
SEQ ID NO: 1 17
NOV28d, CCGCGCGCTCGCCCCGCCGCTCCTGCTGCAGCCCCAGGCCCCTCGCCGCCGCCACCATGGACG
CGI 14588-04 DNA CCATCAAGAAGAAGATGCAGATGCTGAAGCTCGACAAGGAGAACGCCTTGGATCGAGCTGAGC AGGCGGAGGCCGACAAGAAGGCGGCGGAAGACAGGAGCAAGCAGCTGGAAGATGAGCTGGTGT
Sequence CACTGCAAAAGAAACTCAAGGGCACCGAAGATGAACTGGACAAATACTCTGAGGCTCTCAAAG ATGCCCAGGAGAAGCTGGAGCTGGCAGAGAAAAAGGCCACCGATGCTGAAGCCGACGTAGCTT CTCTGAACAGACGCATCCAGCTGGTTGAGGAAGAGTTGGATCGTGCCCAGGAGCGTCTGGCAA CAGCTTTGCAGAAGCTGGAGGAAGCTGAGAAGGCAGCAGATGAGAGTGAGAGAGGTCAGTAAC TAAATTGGAGAAAAGCATTGATGACTTAGAAGACGAGCTGTACGCTCAGAAACTGAAGTACAA
AGCCATCAGCGAGGAGCTGGACCACGCTCTCAACGATATGACTTCCATATAAGTTTCTTTGCT
TCACTTCTCCCAAGACTCCCTCGTCGAGCTGGATGTCCCACCTCTCTGAGCTCTGCATTTGTC
TATTCTCCAGCTGACCCTGGTTCTCTCTCTTAGCATCCTGCCTTAGAGCCAGGCACACACTGT
GCTTTCTATTGTACAGAAGCTCTTCGTTTCAGTGTCAAATAAACACTGTGTAAGCTAAAAAAA
ORF Start: ATG at 57 jORF Stop: TAA at 438 SEQ ID NO: 1 18 127 aa MW at 14414.9kD
NOV28d, MDAIKKKMQMLKLDKENALDRAEQAEADKKAAEDRSKQLEDELVSLQKKLKGTEDELDKYSEA
CGI 14588-04 Protein LKDAQEKLELAEKKATDAEADVASLNRRIQLVEEELDRAQERLATALQKLEEAEKAADESERG Q
Sequence
SEQ ID NO: 1 19 1684 bp
NOV28e, CGCTCCTCCGCCCGACCGCGCGCTCGCCCCGCCGCTCCTGCTGCAGCCCCAGGGCCCCTCGCC
CGI 14588-05 DNA GCCGCCACCATGGACGCCATCAAGAAGAAGATGCAGATGCTGAAGCTCGACAAGGAGAACGCC
TTGGATCGAGCTGAGCAGGCGGAGGCCGACAAGAAGGCGGCGGAAGACAGGAGCAAGCAGCTC
Sequence GAGGAGGACATCGCGGCCAAGGAGAAGTTGCTGCGGGTGTCGGAGGACGAGCGGGACCGGGTG CTGGAGGAGCTGCACAAGGCGGAGGACAGCCTCCTGGCCGCCGAAGAGGCCGCCGCCAAGGCT GAAGCCGACGTAGCTTCTCTGAACAGACGCATCCAGCTGGTTGAGGAAGAGTTGGATCGTGCC CAGGAGCGTCTGGCAACAGCTTTGCAGAAGCTGGAGGAAGCTGAGAAGGCAGCAGATGAGAGT GAGAGAGGCATGAAAGTCATTGAGAGTCGAGCCCAAAAAGATGAAGAAAAAATGGAAATTCAG GAGATCCAACTGAAAGAGGCCAAGCACATTGCTGAAGATGCCGACCGCAAATATGAAGAGGTG GCCCGTAAGCTGGTCATCATTGAGAGCGACCTGGAACGTGCAGAGGAGCGGGCTGAGCTCTCA GAAGGCAAATGTGCCGAGCTTGAAGAAGAATTGAAAACTGTGACGAACAACTTGAAGTCACTG GAGGCTCAGGCTGAGAAGTACTCGCAGAAGGAAGACAGATATGAGGAAGAGATCAAGGTCCTT TCCGACAAGCTGAAGGAGGCTGAGACTCGGGCTGAGTTTGCGGAGAGGTCAGTAACTAAATTG GAGAAAAGCATTGATGACTTAGAAGAGAAAGTGGCTCATGCCAAAGAAGAAAACCTTAGTATG CATCAGATGCTGGATCAGACTTTACTGGAGTTAAACAACATGTGAAAACCTCCTTAGCTGCGA
CCACATTCTTTCGTTTTGTTTTGTTTTGTTTTTAAACACCTGCTTACCCCTTAAATGCAATTT
ATTTACTTTTACCACTGTCACAGAAACATCCACAAGATACCAGCTAGGTCAGGGGGTGGGGAA
AACACATACAAAAAGGCAAGCCCATGTCAGGGCGATCCTGGTTCAAATGTGCCATTTCCCGGG
TTGATGCTGCCACACTTTGTAGAGAGTTTAGCAACACAGTGTGCTTAGTCAGCGTAGGAATCC
TCACTAAAGCAGAAGAAGTTCCATTCAAAGTGCCAATGATAGAGTCAACAGGAAGGTTAATGT
TGGAAACACAATCAGGTGTGGATTGGTGCTACTTTGAACAAAAGGTCCCCCTGTGGTCTTTTG
TTCAACATTGTACAATGTAGAACTCTGTCCAACACTAATTTATTTTGTCTTGAGTTTTACTAC
AAGATGAGACTATGGATCCCGCATGCCTGAATTCACTAAAGCCAAGGGTCTGTAAGCCACGCT GCTCTTCCGAGACTTCCATTCCTTTCTGATTGGCACACGTGCAGCTCATGACAATCTGTAGGA TAACAATCAGTGTGGATTTCCACTCTTTTCAGTCCTTCATGTTAAAGATTTAGACACCACATA CAACTGGTAAAGGACGTTTTCTTGAGAGTTTTAACTATATGTAAACATTGTATAATGATATGG AATAAAATGCACATTGTAGGACATTTTCTAAAAAAAAAAAAAAAAA
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 28B.
I NOV28f I .. I 33 101/133 (75%)
I 27..259 109/133 (81 %)
Further analysis of the NOV28a protein yielded the following properties shown in Table 28C.
Table 28C. Protein Sequence Properties NOV28a
PSort 0.4500 probability located in cytoplasm; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV28a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 28D.
In a BLAST search of public sequence datbases, the NOV28a protein was found to have homology to the proteins shown in the BLASTP data in Table 28E.
PFam analysis predicts that the NOV28a protein contains the domains shown in the Table 28F.
Example 29.
The NOV29 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 29A.

>NOV29a, TTGACTGTATCGCCGGAATTCATGAAGTGCGTCTTGGTGGCCACTGAGGGCGCAGAGGTCCTC 'CG 1 14621 -01 DNA TTCTACTGGACAGATCAGGAGTTTGAAGAGAGTCTCCGGCTGAAGTTCGGGCAGTCAGAGAAT GAGGAAGAAGAGCTCCCTGCCCTGGAGGACCAGCTCAGCACCCTCCTAGCCCCGGTCATCATC Sequence TCCTCCATGACGATGCTGGAGAAGCTCTCGGACACCTACACCTGCTTCTCCACGGAAAATGGC AACTTCCTGTATGTCCTTCACCTGGTGCGGCCCCCAGACCTGGCGCAGCGTGTCCAGCTGTGG GAGCACTTCCAGAGCCTGCTGTGGACCTACAGCCGCCTGCGGGAGCAGGAGCAGTGCTTCGCC GTGGAGGCCCTGGAGCGACTGATTCACCCCCAGCTCTGTGAGCTGTGCATAGAGGCGCTGGAG CGGCACGTCATCCAGGCTGTCAACACCAGCCCCGAGCGGGGAGGCGAGGAGGCCCTGCATGCC TTCCTGCTCGTGCACTCCAAGCTGCTGGCATTCTACTCTAGCCACAGTGCCAGCTCCCTGCGC CCGGCCGACCTGCTTGCCCTCATCCTCCTGGTTCAGGACCTCTACCCCAGCGAGAGCACAGCA GAGGACGACATTCAGCCTTCCCCGCGGAGGGCCCGGAGCAGCCAGAACATCCCCGTGCAGCAG GCCTGGAGCCCTCACTCCACGGGCCCAACTGGGGGGAGCTCTGCAGAGACGGAGACAGACAGC TTCTCCCTCCCTGAGGAGTACTTCACACCAGCTCCTTCCCCTGGCGATCAGAGCTCAGGTAGC ACCATCTGGCTGGAGGGGGGCACCCCCCCCATGGATGCCCTTCAGATAGCAGAGGACACCCTC CAAACACTGGTTCCCCACTGCCCTGTGCCTTCCGGCCCCAGAAGGATCTTCCTGGATGCCAAC GTGAAGGAAAGCTACTGCCCCCTAGTGCCCCACACCATGTACTGCCTGCCCCTGTGGCAGGGC ATCAACCTGGTGCTCCTGACCAGGAGCCCCAGCGCGCCCCTGGCCCTGGTTCTGTCCCAGCTG ATGGATGGCTTCTCCATGCTGGAGAAGAAGCTGAAGGAAGGGCCGGAGCCCGGGGCCTCCCTG CGCTCCCAGCCCCTCGTGGGAGACCTGCGCCAGAGGATGGACAAGTTTGTCAAGAATCGAGGG GCACAGGAGATTCAGAGCACCTGGCTGGAGTTTAAGGCCAAGGCTTTCTCCAAAAGTGAGCCC GGATCCTCCTGGGAGCTGCTCCAGGCATGTGGGAAGCTGAAGCGGCAGCTCTGCGCCA CTAC CGGCTGAACTTTCTGACCACAGCCCCCAGCAGGGGAGGCCCACACCTGCCCCAGCACCTGCAG GACCAAGTGCAGAGGCTCATGCGGGAGAAGCTGACGGACTGGAAGGACTTCTTGCTGGTGAAG AGCAGGAGGAACATCACCATGGTGTCCTACCTAGAAGACTTCCCAGGCTTGGTGCACTTCATC TATGTGGACCGCACCACTGGGCAGATGGTGGCGCCTTCCCTCAACTGCAGTCAAAAGACCTCG TCGGAGTTGGGCAAGGGGCCGCTGGCTGCCTTTGTCAAAACTAAGGTCTGGTCTCTGATCCAG CTGGCGCGCAGATACCTGCAGAAGGGCTACACCACGCTGCTGTTCCGGGAGGGGGATTTCTAC TGCTCCTACTTCCTGTGGTTCGAGAATGACATGGGGTACAAACTCCAGATGATCGAGGTGCCC GTCCTCTCCGACGACTCAGTGCCTATCGGCATGCTGGGAGGAGACTACTACAGGAAGCTCCTG CGCTACTACAGCAAGAACCGCCCAACCGAGGCTGTCAGGTGCTACGAGCTGCTGGCCCTGCAC CTGTCTGTCATCCCCACTGACCTGCTGGTGCAGCAGGCCGGCCAGCTGGCCCGGCGCCTCTGG GAGGCCTCCCGTATCCCCCTGCTCTAGGCCAAGGTGGCCGCAGTCTGCCTTTGCATCCTGTCC
TCCAGCCACCCTTGCTTGCCACTGTTCCCCATGACGAGAGCCTCCTGTCTGCAGTGGCCATCC
TGAGGATAGGGCAGAGTGCCCAGGGTGGCCCCAGGGCTTCTAAAACCCCACCTAGACCACCCT
CCATGTCAGGTACTGAGCAAGGCCCCAGATCCTTCTCTCTGGAGGAAGAGGGAAGCCCAGGGG
TCCTGTTTGTAAAACAACGGTGGCAACAGCTCCTCTTCCAGAGCTGCCTCTGCCTTTATCCTG
GGAGATGGGGAGGAAGCCCCATCTCTGCTGTTCCCTGCGTGGAGGAAGCCCACCCAGCAAGCT
CTCTCCTACCCCAGGTAAAAGGTGCTCCTTTGCCTGGGTTTGAATTCCAGCGCTGCCACTTCC
TCTCTGCACCTCCTGGCAAGTTTCTTCTATTCCCCACGTTTAAAGCGATGGCACCTCCGTCCC
AGGGTGGTGTGAGGATTACCCAGTGTGGTAGGTGCTCAATAAATGTTGGTCATTGTTATCACT
GAAGCCCAACATGCTAGTGCTTCTAGACCCTTCTGTCAGTGCTGATAAGCCCTTGCTAAGTCC
CAGCCCCTTCATGCTTGGCTGGCGTCTGCCCTAGGGCTGGGGTTCTCAAGCCCCTGGCCCTGG
CCCAGAGATTTGGATTCCCTTGGCGGCCGTGGAGCCCAGGCTTTGATGTCTTTCAAAGCTTCT
GTGGTGCGCCCTGGATTGAGAACCACCACCCGAGGGGTACAGCCCCTCTCTTCCAACCGAGAA
GTTCCTGTCCAGAATGGACCCAGGGACAAGAGACCCTGAGAGCCCTGGGACTGGGAGTGTCTG
CTCCTCTGAGCCAGGAGGCCGGTGCTGGGCCAGAGAGGACGGCGTGGCGAAAGTCAGCGTCCA
CTGCAGCACAGGATCAGATGGCCGTGTGCTGTGCATGCAGGAGCCTCGCCTTCTGTGTCTTTA
GTCTTGAGCCAAAATTTGCTCAAAAGACTGATCTCTTCCTTGCAGGGAACAGCTTTGGGGCTG
GGGGAACTAGAACCCACATGTTGGTCTAAACCCTGAGAAGGTGGCAGTGAGGAAGTATCCCCT
CAGGTGACTGGATCTGTGTTCCTCCTTAACATCATCTGATGGAATGGCAATGAAAAGCGTGGA
TTGTGGAAAATACAGAAAAACATAAAGGAAAAAACTCCAATCCCCTGAGCCCACCACTGTTCA
GGACCCCTGCTTTTGTCACCTACTATTTCCCTTTAGTTTTTAGCAGCGGCTGGATGTGATATG
TCTAGTTTAACCAGTCCCCTTGATCTTTCTATATAATAAATAACACAGGAGTGAACATCCTGA
ATCAG
ORF Start: ATG at 22 t. ORF Stop: TAG at 1978
SEQ ID NO: 124 652 aa MW at 73743.7kD
NOV29a, MKCVLVATEGAEVLFY TDQEFEESLRLKFGQSENEEEELPALEDQLSTLLAPVIISSMTMLE .CG I 14621 -01 Protein KLSDTYTCFSTENGNFLYVLHLVRPPDLAQRVQLWEHFQSLLWTYSRLREQEQCFAVEALERL IHPQLCELCIEALERHVIQAVNTSPERGGEEALHAFLLVHSKLLAFYSSHSASSLRPADLLAL
"Sequence ILLVQDLYPSESTAEDDIQPSPRRARSSQNIPVQQAWSPHSTGPTGGSSAETETDSFSLPEEY FTPAPSPGDQSSGSTI LEGGTPPMDALQIAEDTLQTLVPHCPVPSGPRRIFLDANVKESYCP LVPHTMYCLPL QGINLVLLTRSPSAPLALVLSQLMDGFSMLEKKLKEGPEPGASLRSQPLVG DLRQRMDKFVKNRGAQEIQSTWLEFKAKAFSKSEPGSSWELLQACGKLKRQLCAIYRLNFLTT APSRGGPHLPQHLQDQVQRLMREKLTDWKDFLLVKSRRNITMVSYLEDFPGLVHFIYVDRTTG QMVAPSLNCSQKTSSELGKGPLAAFVKTKV SLIQLARRYLQKGYTTLLFREGDFYCSYFL F
ENDMGYKLQMIEVPVLSDDSVPIGMLGGDYYRKLLRYYSKNRPTEAVRCYELLALHLSVIPTD j LLVQQAGQLARRLWEASRIPLL !
SEQ ID NO: 125 ■2109 bp
NOV29b, GCCAAGATGAAGTGCGTCTTGGTGGCCACTGAGGGCGCAGAGGTCCTCTTCTACTGGACAGAT CG I 14621 -02 DNA CAGGAGTTTGAAGAGAGTCTCCGGCTGAAGTTCGGGCAGTCAGAGAATGAGGAAGAAGAGCTC CCTGCCCTGGAGGACCAGCTCAGCACCCTCCTAGCCCCGGTCATCATCTCCTCCATGACGATG Sequence CTGGAGAAGCTCTCGGACACCTACACCTGCTTCTCCACGGAAAATGGCAACTTCCTGTATGTC CTTCACCTGTTTGGAGAATGCCTGTTCATTGCCATCAATGGTGACCACACCGAGAGCGAGGGG GACCTGCGGCGGAAGCTGTATGTGCTCAAGTACCTGTTTGAAGTGCACTTTGGGCTGGTGACT GTGGACGGTCATCTTATCCGAAAGGAGCTGCGGCCCCCAGACCTGGCGCAGCGTGTCCAGCTG TGGGAGCACTTCCAGAGCCTGCTGTGGACCTACAGCCGCCTGCGGGAGCAGGAGCAGTGCTTC GCCGTGGAGGCCCTGGAGCGACTGATTCACCCCCAGCTCTGTGAGCTGTGCATAGAGGCGCTG GAGCGGCACGTCATCCAGGCTGTCAACACCAGCCCCGAGCGGGGAGGCGAGGAGGCCCTGCAT GCCTTCCTGCTCGTGCACTCCAAGCTGCTGGCATTCTACTCTAGCCACAGTGCCAGCTCCCTG CGCCCGGCCGACCTGCTTGCCCTCATCCTCCTGGTTCAGGACCTCTACCCCAGCGAGAGCACA GCAGAGGACGACATTCAGCCTTCCCCGCGGAGGGCCCGGAGCAGCCAGAACATCCCCGTGCAG CAGGCCTGGAGCCCTCACTCCACGGGCCCAACTGGGGGGAGCTCTGCAGAGACGGAGACAGAC AGCTTCTCCCTCCCTGAGGAGTACTTCACACCAGCTCCTTCCCCTGGCGATCAGAGCTCAGGT AGCACCATCTGGCTGGAGGGGGGCACCCCCCCCATGGATGCCCTTCAGATAGCAGAGGACACC CTCCAAACACTGGTTCCCCACTGCCCTGTGCCTTCCGGCCCCAGAAGGATCTTCCTGGATGCC AACGTGAAGGAAAGCTACTGCCCCCTAGTGCCCCACACCATGTACTGCCTGCCCCTGTGGCAG GGCATCAACCTGGTGCTCCTGACCAGGAGCCCCAGCGCGCCCCTGGCCCTGGTTCTGTCCCAG CTGATGGATGGCTTCTCCATGCTGGAGAAGAAGCTGAAGGAAGGGCCGGAGCCCGGGGCCTCC CTGCGCTCCCAGCCCCTCGTGGGAGACCTGCGCCAGAGGATGGACAAGTTTGTCAAGAATCGA GGGGCACAGGAGATTCAGAGCACCTGGCTGGAGTTTAAGGCCAAGGCTTTCTCCAAAAGTGAG CCCGGATCCTCCTGGGAGCTGCTCCAGGCATGTGGGAAGCTGAAGCGGCAGCTCTGCGCCATC TACCGGCTGAACTTTCTGACCACAGCCCCCAGCAGGGGAGGCCCACACCTGCCCCAGCACCTG CAGGACCAAGTGCAGAGGCTCATGCGGGAGAAGCTGACGGACTGGAAGGACTTCTTGCTGGTG AAGAGCAGGAGGAACATCACCATGGTGTCCTACCTAGAAGACTTCCCAGGCTTGGTGCACTTC ATCTATGTGGACCGCACCACTGGGCAGATGGTGGCGCCTTCCCTCAACTGCAGTCAAAAGACC TCGTCGGAGTTGGGCAAGGGGCCGCTGGCTGCCTTTGTCAAAACTAAGGTCTGGTCTCTGATC CAGCTGGCGCGCAGATACCTGCAGAAGGGCTACACCACGCTGCTGTTCCGGGAGGGGGATTTC TACTGCTCCTACTTCCTGTGGTTCGAGAATGACATGGGGTACAAACTCCAGATGATCGAGGTG CCCGTCCTCTCCGACGACTCAGTGCCTATCGGCATGCTGGGAGGAGACTACTACAGGAAGCTC CTGCGCTACTACAGCAAGAACCGCCCAACCGAGGCTGTCAGGTGCTACGAGCTGCTGGCCCTG CACCTGTCTGTCATCCCCACTGACCTGCTGGTGCAGCAGGCCGGCCAGCTGGCCCGGCGCCTC TGGGAGGCCTCCCGTATCCCCCTGCTCTAG
ORF Start: ATG at 7 ;ORF Stop: TAG at 2107 SEQTD NO: Ϊ 26 ~~ 700 aa MW at 79319.0kD jNOV29b, MKCVLVATEGAEVLFYWTDQEFEESLRLKFGQSENEEEELPALEDQLSTLLAPVIISSMTMLE
CG I 14621-02 Protein KLSDTYTCFSTENGNFLYVLHLFGECLFIAINGDHTESEGDLRRKLYVLKYLFEVHFGLVTVD GHLIRKELRPPDLAQRVQLWEHFQSLLWTYSRLREQEQCFAVEALERLIHPQLCELCIEALER
Sequence HVIQAVNTSPERGGEEALHAFLLVHSKLLAFYSSHSASSLRPADLLALILLVQDLYPSESTAE DDIQPSPRRARSSQNIPVQQAWSPHSTGPTGGSSAETETDSFSLPEEYFTPAPSPGDQSSGST IWLEGGTPPMDALQIAEDTLQTLVPHCPVPSGPRRIFLDANVKESYCPLVPHTMYCLPL QGI NLVLLTRSPSAPLALVLSQLMDGFSMLEKKLKEGPEPGASLRSQPLVGDLRQRMDKFVKNRGA QEIQSTWLEFKAKAFSKSEPGSSWELLQACGKLKRQLCAIYRLNFLTTAPSRGGPHLPQHLQD QVQRLMREKLTDWKDFLLVKSRRNITMVSYLEDFPGLVHFIYVDRTTGQMVAPSLNCSQKTSS ELGKGPLAAFVKTKVWSLIQLARRYLQKGYTTLLFREGDFYCSYFLWFENDMGYKLQMIEVPV LSDDSVPIGMLGGDYYRKLLRYYSKNRPTEAVRCYELLALHLSVIPTDLLVQQAGQLARRLWE ASRIPLL
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 29B.
Table 29B. Comparison of NOV29a against NOV29b.
NOV29a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
i NOV29b 1..652 617/700 (88%) 1..700 618/700 (88%)
Further analysis of the NOV29a protein yielded the following properties shown in Table 29C.
Table 29C. Protein Sequence Properties NOV29a
PSort 0.4500 probability located in cytoplasm; 0.3921 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP , No Known Signal Sequence Predicted analysis:
A search of the NOV29a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 29D.
In a BLAST search of public sequence datbases, the NOV29a protein was found to have homology to the proteins shown in the BLASTP data in Table 29E.
PFam analysis predicts that the NOV29a protein contains the domains shown in the Table 29F.
Example 30.
The NOV30 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 30A.
CGI 14649-01 DNA TCCTGTGACACGACCCTTGAGTGACAGTTCTATTTGATTGCCTCCGGTACTGTGAGGAAAGGA Sequence CACGACTCTATGGTGAGGACTGATGGACATACATTATCTGAGAAAAGAAACTACCAGGTGACA
AACAGCATGTTTGGTGCTTCAAGAAAGAAGTTTGTAGAGGGGGTCGACAGTGACTACCATGAC GAAAACATGTACTACAGCCAGTCTTCTATGTTTCCACATCGGTCAGAAAAAGATATGCTGGCA TCACCATCTACATCAGGTCAGCTGTCTCAGTTTGGGGCAAGTTTATACGGGCAACAAAACGGA AGTGAAAATGTGACAGGATTGGACCTTTCAGATTTCCCAGCATTAGCAGACCGAAACAGGAGG GAAGGAAGTGGTAACCCAACTCCATTAATAAACCCCTTGGCTGGAAGAGCTCCTTATGTTGGA ATGGTAACAAAACCAGCAAATGAACAATCCCAGGACTTCTCAATACACAATGAAGATTTTCCA GCATTACCAGGCTCCAGCTATAAAGATCCAACATCAAGTAATGATGACAGTAAATCTAATTTG AATACATCTGGCAAGACAACTTCAAGTACAGATGGACCCAAATTCCCTGGAGATAAAAGTTCA ACAACACAAAATAATAACCAGCAGAAAAAAGGGATCCAGGTGTTACCTGATGGTCGGGTTACT AACATTCCTCAAGGGATGGTGACGGACCAATTTGGAATGATTGGCCTGTTAACATTTATCAGG GCAGCAGAGACAGACCCAGGAATGGTACATCTTGCATTAGGAAGTGACTTAACAACATTAGGC CTCAATCTGAACTCTCCTGAAAATCTCTACCCCAAATTTGCGTCACCCTGGGCATCTTCACCT TGTCGACCTCAAGACATAGACTTCCATGTTCCATCTGAGTACTTAACGAACATTCACATTAGG GATAAGCTGGCTGCAATAAAACTTGGCCGATATGGTGAAGACCTTCTCTTCTATCTCTATTAC ATGAATGGAGGAGACGTATTACAACTTTTAGCTGCAGTGGAGCTTTTTAACCGTGATTGGAGA TACCACAAAGAAGAACGAGTATGGATTACCAGGGCACCAGGCATGGAGCCAACAATGAAAACC AATACCTATGAGAGGGGAACATATTACTTCTTTGACTGTCTTAACTGGAGGAAAGTAGCTAAG GAGTTCCATCTGGAATATGACAAATTAGAAGAACGGCCTCACCTGCCATCCACCTTCAACTAC AACCCTGCTCAGCAAGCCTTCTAAAAAAAAAAAAAAAAAAAAAAAAAAAGACTTCCCTTTTCT
TGGGGTATGGCTGTCTCAGCACAATACTCAACATAACTGCAGAACTGATGTGGCTCAGGCACC
CTGGTTTTAATTCCTTGAGGATCTGGCAATTGGCTTACGCAAAAGGTCACCATTTGAGGTCCT
GCCTTACTAATTATGTGCTGCCCAACAACTAAATTTGTAATTTGTTTTTCTCTAGTTTGAGCA
GGGTCTGAATTTTTTCATTTATTTCCTTTTTTGCCAGCAGACAGACTTGAGTCTGTAAAGACA
AGCAAATACACTGACAGAAGTTTACCATAGTTTCTAAAATGTAAAAAAGAAAACCCCCAAAAG
1ACTCAAGAAAATTAGACCACAAATTTTGCATTGTTCATTGTAGCACTATTGGTAATAAAATAA lCAAATGTTTGTGCATTTTTATGTGAAGATCCTTCTCGTATTTCATTTGGAAAGATGAGCAAGA
GGTCTGCTTCCTTCATTTTACTTCCCCTTCTGTTTTTGAAAGGCAGTTTCGCCAAGCTTAATG
CAAGAATATCTGACTGTTTAGAAGAAAGATATTGCCACAATCTCTGGATGGTTTTCCAGGGTT
GTGTTATTACTGAGCTTCATCTTTCCAGAATGAGCAAAACACTGTCCAGTCTTTGTTACGATT
TTGTAATAAATGTGTACATTTTTTTTAAATTTTTGGACATCACATGAATAAAGGTATGTATGT
ACGAATGTGTATATATTATATATATGACATCTATTTTGGAAAATGTTTGCCCTGCTGTACCTC
ATTTTTAGGAGGTGTGCATGGATGCAATATATGAAAATGGGACATTCTGGAACTGCTGGTCAG
GGGACTTTGTCGCCCTGTGCACTAAAAGGGCCAGATTTTCAGCAGCCAAGGACATCCATACCC
AAGTGAATGTGATGGGACTTAAAAGAAGTGAACTGAGACAATTCACTCTGGCTGTTTGAACAG
CAGCGTTTCATAGGAAGAGAAAAAAAGATCAATCTTGTATTTTCTGACCACATAAAGGCTTCT
TCTCTTTGTAATAAAGTAGAAAAGCTCTCCTCAAAAAAAAAAAAAAAAAACTCGAG jORF Start: ATG at 136 :ORF Stop: TAA at 1345
JSEQ ID NO: 128 (403 aa , 1M. W at~45257.9kD NOV30a, MVRTDGHTLSEKRNYQVTNSMFGASRKKFVEGVDSDYHDENMYYSQSSMFPHRSEKDMLASPS JCG 1 14649-01 Protein TSGQLSQFGASLYGQQNGSENVTGLDLSDFPALADRNRREGSGNPTPLINPLAGRAPYVGMVT KPANEQSQDFSIHNEDFPALPGSSYKDPTSSNDDSKSNLNTSGKTTSSTDGPKFPGDKSSTTQ JSequence NNNQQKKGIQVLPDGRVTNIPQGMVTDQFGMIGLLTFIRAAETDPGMVHLALGSDLTTLGLNL NSPENLYPKFASPWASSPCRPQDIDFHVPSEYLTNIHIRDKLAAIKLGRYGEDLLFYLYYMNG GDVLQLLAAVELFNRD RYHKEERVWITRAPGMEPTMKTNTYERGTYYFFDCLNWRKVAKEFH LEYDKLEERPHLPSTFNYNPAQQAF
Further analysis of the NOV30a protein yielded the following properties shown in Table 30B.
Table 30B. Protein Sequence Properties NOV30a
PSort 0.7600 probability located in nucleus; 0.2124 probability located in microbody analysis: (peroxisome); 0.1589 probability located in lysosome (lumen); 0.1000 probability located in mitochondrial matrix space
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV30a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 30C.
In a BLAST search of public sequence datbases, the NOV30a protein was found to have homology to the proteins shown in the BLASTP data in Table 30D.
PFam analysis predicts that the NOV30a protein contains the domains shown in the Table 30E.
Table 30E. Domain Analysis of NOV30a
Identities/
Pfa Domain NOV30a Match Region I Similarities Expect Value I for the Matched Region
Example 31.
The NOV3 1 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 31 A.
(Table 31A. NOV31 Sequence Analysis
1 JSEQ ID NO: 129 ;605 bp j_
,NOV31a, CTGACACCAGCACAGCAAACCCGCCGGGATCAAAGTGTACCAGTCGGCAGCATGGCTACGAAA
JCG 1 16785-01 DNA TGTGGGAATTGTGGACCCGGCTACTCCACCCCTCTGGAGGCCATGAAAGGACCCAGGGAAGAG ATCGTCTACCTGCCCTGCATTTACCGAAACACAGGCACTGAGGCCCCAGATTATCTGGCCACT jSequence GTGGATGTTGACCCCAAGTCTCCCCAGTATTGCCAGGTTAGGCGGGGCTTGGGCGCCAGCTAC TTTGAGACCATAGCTGCCCTCATCCCTGGCCCTGGGCCCCCCCTTCCCAGCTCCATCCTTCTT GGCCCTCCCTGGGGATGCTTGTGCACGCTCAACCTGGGACAAGGGGAGTGCTGAAATCCAGCC TGTGCCGTGCTTCCAAACCAAAATGAGTCCACAGGGGCGCCTCTTCCAAAAGTGGACAGAGGC
GTGGCCTGGGGGAGCACCACCTCTCCCCGCATCCTAGGTCATCCACCGGCTGCCCATGCCCAA
CCTGAAGGACGAGCTGCATCACTCAGGATGGAACACCTGCAGCAGCTGCTTCGGTGATAGCAC
CAAGTCGCGCACCAGGCTGGTGCTGCCAGTCTCATCTC
ORF Start: at 28 JORF Stop: at 343
SEQ 1D NO: 130 105 aa MW at 1 1074.6kD jNOV31a. DQSVPVGSMATKCGNCGPGYSTPLEAMKGPREEIVYLPCIYRNTGTEAPDYLATVDVDPKSPQ
JCG 1 16785-01 Protein YCQVRRGLGASYFETIAALIPGPGPPLPSSILLGPPWGCLCT jSequence
Further analysis of the NOV31 a protein yielded the following properties shown in Table 3 I B.
Table 31B. Protein Sequence Properties NOV31a
« PSort 0.6500 probability located in cytoplasm; 0.1873 probability located in lysosome ' analysis: (lumen); 0.1000 probability located in mitochondrial matrix space; 0.0000 probability located in endoplasmic reticulum (membrane)
: SignalP No Known Signal Sequence Predicted 1 analysis:
A search of the NOV31a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 3 I C.
In a BLAST search of public sequence datbases, the NOV31 a protein was found to have homology to the proteins shown in the BLASTP data in Table 3 I D.
PFam analysis predicts that the NOV3 l a protein contains the domains shown in the Table 3 I E.
; Table 31E. Domain Analysis of NOV31a
Identities/ Pfam Domain NOV31a Match Region j Similarities Expect Value for the Matched Region
Example 32.
The NOV32 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 32A.
jTable 32A. NOV32 Sequence Analysis
SEQ ID NO: 131 2620 bp
:NOV32a, iAATTCTTTCATTTCAGAGTTGAGCAAACTGTGTCTCAAGGAGGTGTGCGCTGCAGGTAGCTGA
CGI 18927-01 DNA TGTGGCCAGGATTTGAACCCACATTTTATATTCTTTGCCATTAGATTCCATTTTTCTTATCTC
TTATTTCTCAGCGCCAGGTCTCTTTTTGTTTCTGGGCCTCTTTCTTCCTTGGCCTCCTGCCTC
JSequence CCTGTCTTCCCATGTTCTTGTATCTGCTGCTGCCTGTGTTTTTCTCATTGTGTCTCTGCCTAG
CTCCCTCTGCCCAGGTTTCTATGTGTCTCTTTCTGTCAGAACTGTCTTCTATTTCTTCTCAGT
CCCCTTCTCTGCATTTGTTACATCATCTCTTCATCTTAATGTATTAGGCTGGGGCTGTTTTGG
GACTCCAGAGAGTTACTTTTTAACTAGCTACATCTGTCTTCAGGTGCCTGGCTTTCTGGCCTG
AGGTGGAAGCAGAGGCCAGCCTCTCTCCGTCATCCCTATCTCCCCTGGGCTTACATCATGGCG
GGGCTTTGAAAATCTCCCTCTGTGGCTTCTTGGAGCCGCATAGATGGGTGATCAGAGCTGGCT
CTGGAACCAGGCTGCTCCAGGAGTAAGGAGCCCAGTCTTTGCATGCAGTGTTGAAAAAGGTAA
TGTCCCTCTTGTGCTGAGCGAGCACCTGGCACACAGCAGGGACCCAGGCAGTGGGGCTGTTAG
GTTCCTTATCTCTCCTGAGCCTTGGGCTTCCGCTATCCTTGGGACGTCTGGTCTTCTGGCTTC
CCCGGTTCTTCCTGCCGCCCTGGATGCGGTGACCTGCCAGCACCTGCCGCAGCCTTCGTCCGG
GAGTCGCCCCATCTCTCCACGCAATCGGCCCTGTGCCCCTTGCTGCTGCAGCCGGGCACCATG
TCGACCTCGTCCTTGAGGCGCCAGATGAAGAACATCGTCCACAACTACTCAGAGGCGGAGATC AAGGTTCGAGAGGCCACGAGCAATGACCCCTGGGGCCCATCCAGCTCCCTCATGTCAGAGATT GCCGACCTCACCTACAACGTTGTCGCCTTCTCGGAGATCATGAGCATGATCTGGAAGCGGCTC AATGACCATGGCAAGAACTGGCGTCACGTTTACAAGGCCATGACGCTGATGGAGTACCTCATC AAGACCGGCTCGGAGCGCGTGTCGCAGCAGTGCAAGGAGAACATGTACGCCGTGCAGACGCTG AAGGACTTCCAGTACGTGGACCGCGACGGCAAGGACCAGGGCGTGAACGTGCGTGAGAAAGCT
AAGCAGCTGGTGGCCCTGCTGCGCGACGAGGACCGGCTGCGGGAAGAGCGGGCGCACGCGCTC AAGACCAAGGAAAAGCTGGCACAGACCGCCACGGCCTCATCAGCAGCTGTGGGCTCAGGCCCC CCTCCCGAGGCGGAGCAGGCGTGGCCGCAGAGCAGCGGGGAGGAGGAGCTGCAGCTCCAGCTG GCCCTGGCCATGAGCAAGGAGGAGGCCGACCAGGAGGAGCGGATCCGTCGCGGGGATGACCTG CGGCTGCAGATGGCAATCGAGGAGAGCAAGAGGGAGACTGGGGGCAAGGAGGAGTCGTCCCTC ATGGACCTTGCTGACGTCTTCACGGCCCCAGCTCCTGCCCCGACCACAGACCCCTGGGGGGGC CCAGCACCCATGGCTGCTGCCGTCCCCACGGCTGCCCCCACCTCGGACCCCTGGGGCGGCCCC CCTGTCCCTCCAGCTGCTGATCCCTGGGGAGGTCCAGCCCCCACGCCGGCCTCTGGGGACCCC TGGAGGCCTGCTGCCCCTGCAGGACCCTCAGTTGACCCTTGGGGTGGGACCCCAGCCCCTGCA GCTGGGGAGGGGCCCACGCCTGATCCATGGGGAAGTTCCGATGGTGGGGTCCCGGTCAGTGGG CCCTCAGCCTCCGATCCCTGGACACCGGCCCCGGCCTTCTCAGATCCCTGGGGAGGGTCACCT GCCAAGCCCAGCACCAATGGCACAACAGCAGCCGGGGGATTCGACACGGAGCCCGACGAGTTC TCTGACTTTGACCGACTCCGCACGGCACTGCCGACCTCCGGGAGCAGCGCAGGAGAGCTGGAG CTGCTGGCAGGAGAGGTGCCGGCCCGAAGCCCTGGGGCGTTTGACATGAGTGGGGTCAGGGGA TCTCTGGCTGAGGCTGTGGGCAGCCCCCCACCTGCAGCCACACCAACTCCCACGCCCCCCACC CGGAAGACGCCGGAGTCATTCCTGGGGCCCAATGCAGCCCTCGTCGACCTGGACTCGCTGGTG AGCCGGCCGGGCCCCACGCCGCCTGGAGCCAAGGCCTCCAACCCCTTCCTGCCAGGCGGAGGC CCAGCCACTGGCCCTTCCGTCACCAACCCCTTCCAGCCCGCGCCTCCCGCGACGCTCACCCTG AACCAGCTCCGTCTCAGTCCTGTGCCTCCCGTCCCTGGAGCGCCACCCACGTACATCTCTCCC CTTGGCGGGGGCCCTGGCCTGCCCCCCATGATGCCCCCGGGCCCCCCGGCCCCCAACACTAAT CCCTTCCTCCTATAATCCAGGGCGGAAGGGGGCCTGGCTCCATCCGGCTGCCCCATTCCGGCT
CCCTGGGAGATCAGTGTTGTGAGTGCATGTGAAATGG
ORF Start: ATG at 880 ,ORF Stop: TAA at 2533
SEQ ID NO:J32 551 aa 1MW at 57574.6kD
NOV32a, MSTSSLRRQMKNIVHNYSEAEIKVREATSNDP GPSSSLMSEIADLTYNWAFSEIMSMIWKR
CG 1 18927-01 Protein LNDHGKNWRHVYKAMTLMEYLIKTGSERVSQQCKENMYAVQTLKDFQYVDRDGKDQGVI REK
AKQLVALLRDEDRLREERAHALKTKEKLAQTATASSAAVGSGPPPEAEQA PQSSGEEELQLQ 'Sequence LALAMSKEEADQEERIRRGDDLRLQMAIEESKRETGGKEESSLMDLADVFTAPAPAPTTDPWG GPAPMAAAVPTAAPTSDPWGGPPVPPAADP GGPAPTPASGDPWRPAAPAGPSVDP GGTPAP AAGEGPTPDPWGSSDGGVPVSGPSASDP TPAPAFSDP GGSPAKPSTNGTTAAGGFDTEPDE FSDFDRLRTALPTSGSSAGELELLAGEVPARSPGAFDMSGVRGSLAEAVGSPPPAATPTPTPP TRKTPESFLGPNAALVDLDSLVSRPGPTPPGAKASNPFLPGGGPATGPSVTNPFQPAPPATLT LNQLRLSPVPPVPGAPPTYISPLGGGPGLPPMMPPGPPAPNTNPFLL
SEQ ID NO: 133 2449 bp
;NOV32b, AATTCTTTCATTTCAGAGTTGAGCAAACTGTGTCTCAAGGAGGTGTGCGCTGCAGGTAGCTGA CG118927-02 DNA TGTGGCCAGGATTTGAACCCACATTTTATATTCTTTGCCATTAGATTCCATTTTTCTTATCTC
TTATTTCTCAGCGCCAGGTCTCTTTTTGTTTCTGGGCCTCTTTCTTCCTTGGCCTCCTGCCTC
Sequence CCTGTCTTCCCATGTTCTTGTATCTGCTGCTGCCTGTGTTTTTCTCATTGTGTCTCTGCCTAG
CTCCCTCTGCCCAGGTTTCTATGTGTCTCTTTCTGTCAGAACTGTCTTCTATTTCTTCTCAGT
CCCCTTCTCTGCATTTGTTACATCATCTCTTCATCTTAATGTATTAGGCTGGGGCTGTTTTGG
GACTCCAGAGAGTTACTTTTTAACTAGCTACATCTGTCTTCAGGTGCCTGGCTTTCTGGCCTG
AGGTGGAAGCAGAGGCCAGCCTCTCTCCGTCATCCCTATCTCCCCTGGGCTTACATCATGGCG
GGGCTTTGAAAATCTCCCTCTGTGGCTTCTTGGAGCCGCATAGATGGGTGATCAGAGCTGGCT
CTGGAACCAGGCTGCTCCAGGAGTAAGGAGCCCAGTCTTTGCATGCAGTGTTGAAAAAGGTAA
TGTCCCTCTTGTGCTGAGCGAGCACCTGGCACACAGCAGGGACCCAGGCAGTGGGGCTGTTAG
GTTCCTTATCTCTCCTGAGCCTTGGGCTTCCGCTATCCTTGGGACGTCTGGTCTTCTGGCTTC
CCCGGTTCTTCCTGCCGCCCTGGATGCGGTGACCTGCCAGCACCTGCCGCAGCCTTCGTCCGG GAGTCGCCCCATCTCTCCACGCAATCGGCCCTGTGCCCCTTGCTGCTGCAGCCGGGCACCATG
TCGACCTCGTCCTTGAGGCGCCAGATGAAGAACATCGTCCACAACTACTCAGAGGCGGAGATC AAGGTTCGAGAGGCCACGAGCAATGACCCCTGGGGCCCATCCAGCTCCCTCATGTCAGAGATT GCCGACCTCACCTACAACGTTGTCGCCTTCTCGGAGATCATGAGCATGATCTGGAAGCGGCTC AATGACCATGGCAAGAACTGGCGTCACGTTTACAAGGCCATGACGCTGATGGAGTACCTCATC AAGACCGGCTCGGAGCGCGTGTCGCAGCAGTGCAAGGAGAACATGTACGCCGTGCAGACGCTG AAGGACTTCCAGTACGTGGACCGCGACGGCAAGGACCAGGGCGTGAACGTGCGTGAGAAAGCT AAGCAGCTGGTGGCCCTGCTGCTGGCCATGAGCAAGGAGGAGGCCGACCAGGAGGAGCGGATC CGTCGCGGGGATGACCTGCGGCTGCAGATGGCAATCGAGGAGAGCAAGAGGGAGACTGGGGGC AAGGAGGAGTCGTCCCTCATGGACCTTGCTGACGTCTTCACGGCCCCAGCTCCTGCCCCGACC ACAGACCCCTGGGGGGGCCCAGCACCCATGGCTGCTGCCGTCCCCACGGCTGCCCCCACCTCG GACCCCTGGGGCGGCCCCCCTGTCCCTCCAGCTGCTGATCCCTGGGGAGGTCCAGCCCCCACG CCGGCCTCTGGGGACCCCTGGAGGCCTGCTGCCCCTGCAGGACCCTCAGTTGACCCTTGGGGT GGGACCCCAGCCCCTGCAGCTGGGGAGGGGCCCACGCCTGATCCATGGGGAAGTTCCGATGGT GGGGTCCCGGTCAGTGGGCCCTCAGCCTCCGATCCCTGGACACCGGCCCCGGCCTTCTCAGAT CCCTGGGGAGGGTCACCTGCCAAGCCCAGCACCAATGGCACAACAGCAGCCGGGGGATTCGAC ACGGAGCCCGACGAGTTCTCTGACTTTGACCGACTCCGCACGGCACTGCCGACCTCCGGGAGC
AGCGCAGGAGAGCTGGAGCTGCTGGCAGGAGAGGTGCCGGCCCGAAGCCCTGGGGCGTTTGAC ATGAGTGGGGTCAGGGGATCTCTGGCTGAGGCTGTGGGCAGCCCCCCACCTGCAGCCACACCA ACTCCCACGCCCCCCACCCGGAAGACGCCGGAGTCATTCCTGGGGCCCAATGCAGCCCTCGTC GACCTGGACTCGCTGGTGAGCCGGCCGGGCCCCACGCCGCCTGGAGCCAAGGCCTCCAACCCC TTCCTGCCAGGCGGAGGCCCAGCCACTGGCCCTTCCGTCACCAACCCCTTCCAGCCCGCGCCT CCCGCGACGCTCACCCTGAACCAGCTCCGTCTCAGTCCTGTGCCTCCCGTCCCTGGAGCGCCA CCCACGTACATCTCTCCCCTTGGCGGGGGCCCTGGCCTGCCCCCCATGATGCCCCCGGGCCCC CCGGCCCCCAACACTAATCCCTTCCTCCTATAATCCAGGGCGGAAGGGGGCCTGGCTCCATCC
GGCTGCCCCATTCCGGCTCCCTGGGAGATCAGTGTTGTGAGTGCATGTGAAATGG
ORF Start: ATG at 880 ;ORF Stop: TAA at 2362
SEQ ID NO: 134 494 aa TMW at 51422.0k
;NOV32b, MSTSSLRRQMKNIVHNYSEAEIKVREATSNDPWGPSSSLMSEIADLTYNVVAFSEIMSMIWKR
CGI 18927-02 Protein LNDHGKNWRHVYKAMTLMEYLIKTGSERVSQQCKENMYAVQTLKDFQYVDRDGKDQGVNVREK AKQLVALLLAMSKEEADQEERIRRGDDLRLQMAIEESKRETGGKEESSLMDLADVFTAPAPAP
Sequence TTDPWGGPAPMAAAVPTAAPTSDPWGGPPVPPAADPWGGPAPTPASGDPWRPAAPAGPSVDPW GGTPAPAAGEGPTPDP GSSDGGVPVSGPSASDPWTPAPAFSDPWGGSPAKPSTNGTTAAGGF DTEPDEFSDFDRLRTALPTSGSSAGELELLAGEVPARSPGAFDMSGVRGSLAEAVGSPPPAAT PTPTPPTRKTPESFLGPNAALVDLDSLVSRPGPTPPGAKASNPFLPGGGPATGPSVTNPFQPA PPATLTLNQLRLSPVPPVPGAPPTYISPLGGGPGLPPMMPPGPPAPNTNPFLL
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 32B.
Table 32B. Comparison of NOV32a against NOV32b.
NOV32a Residues/ Identities/
■ Protein Sequence Match Residues Similarities for the Matched Region
NOV32b 1..551 360/551 (65%) 1..494 362/551 (65%)
Further analysis of the NOV32a protein yielded the following properties shown in Table 32C.
I Table 32C. Protein Sequence Properties NOV32a
; PSort 0.4600 probability located in mitochondrial matrix space; 0.4500 probability located
' analysis: in cytoplasm; 0.1903 probability located in lysosome (lumen); 0.1562 probability located in mitochondrial inner membrane
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV32a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 32D.
In a BLAST search of public sequence datbases, the NOV32a protein was found to have homology to the proteins shown in the BLASTP data in Table 32E.
! O95207 Epsin 2a - Homo sapiens (Human), 584 I 1..551 304/636 (47%) ! e- l 3ϊ aa. i 1 ..584 366/636 (56%) .
PFam analysis predicts that the NOV32a protein contains the domains shown in the Table 32F.
Example 33.
The NOV33 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 33A.
Further analysis of the NOV33a protein yielded the following properties shown in Table 33B.
1 Table 33B. Protein Sequence Properties NOV33a i PSort 0.8950 probability located in nucleus; 0.3000 probability located in microbody j analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV33a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 33C.
In a BLAST search of public sequence datbases, the NOV33a protein was found to have homology to the proteins shown in the BLASTP data in Table 33D.
! Table 33D. Public BLASTP Results for NOV33a
NOV33a
Protein Identities/ Residues/ Expect
Accession Protein/Organism/Length Similarities for the Match Value
Number Matched Portion Residues
PFam analysis predicts that the NOV33a protein contains the domains shown in the Table 33E.
Example 34.
The NOV34 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 34A.
Table 34A. NOV34 Sequence Analysis
L - "_"_ " "1 ' lSEQ DNb~l 7 |Ϊ955 bp
!NOV34a~ GGAAGGTGTGAGGTTGCCGCCATGCCTGGCAGAACGGAGGGAGGCAGTTGGCTCCGGAATGCG
JCG 119385-01 DNA GCCGCCGCAGATGTTCTCCGCAACCTTCCGGAAGTGGAATGGCGGGAGCCTCAGCATTGCTGC CCACCGACCCCCCGGAAGCGGAAACAGAATCCCCGCGTGCCCCTTCCTCACTACCCTCCAAAT
Sequence CCCGCTGCAGCCATTGCCGCAGACACGATGCCGAAACGAAAGAAGCAGAATCATCACCAGCCA CCGACACAGCAGCAGCCCCCGCTGCCCGAGCGGGAAGAGACTGGAGATGAGGAGGATGGGAGT CCCATCGCTCTTCACAGAGGTCCTCCAGGATCAAGGGGACCACTGATTCCACCACTGCTGAGT CTCCCACCTCCTCCTTGGGGTAGAGGCCCAATTCGGAGAGGGCTTGGCCCCAGGTCTAGCCCA TATGGTCGTGGTTGGTGGGGAGTCAATGCAGAACCTCCTTTTCCGGGGCCAGGCCATGGGGGT CCCACCAGGGGAAGCTTTCACAAGGAACAGAGAAACCCTCGAAGGCTCAAAAGCTGGTCTCTT ATCAAGAATACCTGCCCGCCCAAGGATGACCCCCAGGTTATGGAAGACAAATCCGACCGCCCT GTCTGCCGACATTTTGCCAAAAAGGGCCACTGTCGATATGAGGACCTCTGTGCCTTCTACCAT CCAGGCGTCAATGGACCTCCTCTGTGAGACTGTGCCTTCCCATCCAGGCTGGAAGGAGCTCTC TGTGACCTAGCGGCCATTTATTTCTCTGTAGCCCTATGATGGCTACTGTGAGGCTCTTCTAAC ACCCTCAGTCAGTGACACACCCATCCCATCCACCACTTCCCCCGTGTGGGGTCCAGAGTGGTG TTGCATCACTGGTGCGCGGCATACGCGCTTTCTTCTGATCCAGCCTGTAGAGACTCGCCTTTG GGACCCATCTTTGCTTCCTTTCAGTTGCCTCCTGGATCTTCTTTCCCGTCATCAAATGACTGC
TGAACAGGAAACCTCTTTGGTGCTGTTTCTTGTGCATCTGTCCACCTGTTCCCCAGTATTGCC
CTCAATTCCTGAGAGCCCTGGAGCGGTTTCCTACCATTCCCTTCTTTTAGCTGCTTGTTTTAA GTCCTTTTTATGTGACATTCCCTACCCCCAATGTTGTCAGCTGCTTGTGAAACTCAGCCAGGT TGTCTAACCTGGGGTCAAGTTTGGGTGACTGGTGCAGAGTTACTTCCTAAAAGGCCACTCTCC
CTGCCTTTGGATTTCATAGTTTCTCTGTCAGTAGCATGATCCCCACCGCTATGGTCTATCTAT GATCACCGTGCTTTGTGAAACTGTGCATCCCCTTGTAGCCTTTCTCAGTGTCCGTGGCATTTT
TGTGACTTCCCAGCACTAGAATAAGTTTTCCTGCCAAAATGAGTGAGGCGCTTGGTGCCCTCT
GGACTTTCCCACTTCCCAACATGGGAGAATTGTGAACTTTCCATCAGACTGCCTCCCTGGCCC
TCCCCATTCTTCTCCTGTTGGTTATTCTGAGTCTGACACAGACCCATGACATGTCTTATAAAG
CCTCCAATGGCTTTATCCTACCTAGATCCCTTCCAGCCCATTTTAATTAGACTATGTCATTGT
!GAGGCCACCAGTCCATTCATTTGAATTCTGTGAATCTCCACCTTGCCTATCTTTGGGTAGAAG
CTGGACAGTACTGTTGCCCTCTTCCAATCCTCTTCCCCTACATCCCTGGCACTGGTTGTTTTC
TGTGAAAACAGCAGTGAACAGGTTCAGTTTTGAACTGGCCCTGAGGAAATGGGTCAGGAGTTG
TATTGGCAAGAGGGAGGGGTGAGAGCTGTTGGAGAACTGAGAATGAGGTTTTTTTTTTTTTTT
TCTTTTTAACTTTTTTTATATTAGTAATAAATGCAGTGGAAACCAGCATTTTATTTAAAAAAA
AA
ORF Start: ATG at 22 ORF Stop: TGA at 718
SEQ ID NO: 138 232 aa MW at 25830. l kD
;NOV34a, MPGRTEGGS LRNAAAADVLRNLPEVE REPQHCCPPTPRKRKQNPRVPLPHYPPNPAAAIAA
CG 1 19385-01 Protein DTMPKRKKQNHHQPPTQQQPPLPEREETGDEEDGSPIALHRGPPGSRGPLIPPLLSLPPPPWG RGPIRRGLGPRSSPYGRGWWGVNAEPPFPGPGHGGPTRGSFHKEQRNPRRLKSWSLIKNTCPP iSequence KDDPQVMEDKSDRPVCRHFAKKGHCRYEDLCAFYHPGVNGPPL
Further analysis of the NOV34a protein yielded the following properties shown in Table 34B.
! Table 34B. Protein Sequence Properties NOV34a
: PSort 0.7000 probability located in nucleus; 0.2531 probability located in lysosome analysis: (lumen); 0.1000 probability located in mitochondrial matrix space; 0.0000 , probability located in endoplasmic reticulum (membrane)
I SignalP ; No Known Signal Sequence Predicted ' analysis:
A search of the NOV34a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 34C.
Table 34C. Geneseq Results for NOV34a
NOV34a Identities/
Geneseq Protein/Organism/Length [Patent #, Residues/ Similarities for Expect Identifier Date] Match the Matched Value Residues Region
AAM93213 j Human polypeptide, SEQ ID NO: 66-232 166/167 (99%) e- 105 2614 - Homo sapiens, 167 aa. 1..167 167/167 (99%) [EP1 130094-A2, 05-SEP-2001 ]
AAU28194 Novel human secretory protein, Seq 86-232 j 55/167 (32%) 8e- 13 ID No 363 - Homo sapiens, 940 aa. 799-939 1 63/167 (36%) [WO200166689-A2, 13-SEP-2001 ]
In a BLAST search of public sequence datbases, the NOV34a protein was found to have homology to the proteins shown in the BLASTP data in Table 34D.
PFam analysis predicts that the NOV34a protein contains the domains shown in the
Table 34E.
Table 34E. Domain Analysis of NOV34a
Identities/
Pfam Domain ] NOV34a Match Region Similarities Expect Value for the Matched Region zf-CCCH 200..226 10/27 (37%) 0.0031 j 20/27 (74%)
Example 35.
The NOV35 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 35A.
Table 35A. NOV35 Sequence Analysis
JSEQ ID NO: 139 ~]20566bp""" ]~
NOV35a, CCACTACTACTCTGAAAAATGGCAGATGACGAAGACTATGAGGAGGTGGTGGAGTACTACACA
CGI 19566-01 DNA GAAGAAGTGGTTTACGAAGAGGTGCCGGGAGAGACAATAACAAAAATTTATGAGACTACGACA
ACAAGGACATCTGACTATGAGCAATCAGAAACTTCCAAACCAGCTCTGGCACAGCCAGCACTG
Sequence GCACAGCCAGCATCAGCAAAGCCGGTGGAGAGGAGGAAGGTCATCCGGAAGAAAGTGGATCCT
TCAAAGTTCATGACCCCCTACATTGCACACAGTCAGAAAATGCAGGATCTTTTTAGCCCAAAT
AAATACAAGGAGAAGTTTGAGAAAACAAAAGGACAGCCATACGCCAGCACAACAGATACTCCA
GAACTTCGCAGAATCAAAAAAGTACAAGATCAACTCAGTGAGGTTAAGTATCGAATGGATGGT
GATGTTGCTAAGACTATATGTCACGTAGATGAAAAAGCAAAGGATATTGAACATGCAAAGAAA
GTGTCGCAGCAAGTCAGTAAGGTTTTATACAAGCAGAACTGGGAAGACACCAAGGATAAGTAC
CTGCTTCCTCCTGATGCCCCTGAACTTGTCCAGGCCGTTAAGAACACCGCCATGTTCAGCAAG
AAACTGTACACTGAAGACTGGGAAGCAGACAAAAGTTTGTTTTACCCCTATAATGATAGCCCG
GAACTGAGGAGAGTTGCCCAGGCCCAGAAAGCTCTCAGTGATGTTGCCTACAAAAAAGGTCTC
GCTGAACAGCAAGCTCAATTCACGCCTCTGGCCGATCCTCCAGATATAGAATTTGCCAAGAAA
GTAACCAATCAAGTGAGCAAGCAAAAATACAAAGAAGACTATGAAAATAAAATCAAAGGCAAA
TGGAGTGAGACACCTTGCTTTGAAGTTGCAAATGCCAGAATGAATGCTGATAACATTAGCACA
AGGAAATACCAGGAAGATTTTGAAAACATGAAAGACCAGATCTACTTCATGCAGACCGAAACA
CCAGAGTATAAAATGAATAAAAAAGCTGGTGTGGCAGCTAGCAAGGTAAAATACAAAGAAGAC
TATGAAAAGAATAAAGGAAAAGCAGATTATAATGTGCTTCCTGCTTCAGAGAACCCACAGCTT
AGGCAGCTGAAGGCAGCAGGAGATGCCCTAAGTGACAAACTATACAAGGAAAACTATGAAAAG
ACAAAAGCAAAGAGCATAAATTACTGCGAGACCCCCAAATTCAAGCTCGATACTGTTCTGCAG
AACTTCAGTAGTGATAAAAAATATAAAGATTCCTACTTAAAAGATATTTTGGGACATTATGTA
GGCAGCTTCGAGGATCCATACCATTCACACTGCATGAAAGTCACAGCTCAAAACAGTGATAAA
AACTACAAAGCAGAATACGAAGAAGACAGAGGCAAAGGCTTCTTCCCTCAGACCATAACTCAA
GAATATGAAGCAATTAAGAAACTAGATCAGTGTAAAGACCACACCTACAAAGTCCATCCAGAT
JAAGACAAAATTCACCCAAGTTACAGACTCTCCTGTTCTGCTACAAGCCCAAGTCAATTCCAAA
JCAACTGAGTGACTTAAATTACAAAGCAAAACATGAAAGTGAAAAGTTCAAGTGCCATATCCCC
JCCTGATACTCCTGCTTTTATCCAGCACAAAGTCAATGCCTATAACTTGAGTGATAATCTTTAT
(AAGCAAGACTGGGAGAAGAGCAAAGCCAAAAAGTTTGACATTAAAGTGGATGCCATTCCCCTG
CTGGCAGCCAAAGCCAACACCAAGAACACCAGCGATGTGATGTACAAGAAAGACTATGAAAAA
AACAAAGGGAAAATGATTGGAGTCCTCAGCATTAATGACGATCCCAAGATGCTGCACTCCTTG
AAGGTGGCCAAAAACCAGAGTGATAGATTATACAAGGAAAACTATGAGAAGACAAAGGCAAAG
AGTATGAATTACTGTGAGACCCCAAAATATCAACTTGATACTCAGCTGAAGAACTTCAGTGAG
GCTAGATATAAAGACTTATATGTAAAGGATGTTTTGGGACATTATGTAGGCAGCATGGAGGAC
CCATATCACACACACTGCATGAAAGTTGCAGCTCAAAACAGTGATAAAAGTTACAAAGCAGAA
TATGAAGAAGATAAAGGAAAATGCTATTTCCCTCAGACAATAACACAAGAATATGACGCAATC
AAGAAGCTGGACCAGTGTAAAGATCATACCTACAAAGTTCATCCAGATAAGACCAAATTCACG
GCAGTCACTGATTCTCCTGTACTGTTGCAAGCCCAGCTCAACACGAAACAGCTTAGTGATCTG
AATTACAAAGCAAAACATGAAGGTGAGAGGTTCAAGTGCCATATACCAGCAGATGCTCCACAG
TTTATCCAACACAGAGTCAATGCCTATAATCTGAGTGATAATGTTTATAAGCAAGACTGGGAG
AAGAGCAAAGCCAAGAAGTTTGACATTAAAGTGGACGCCATTCCCCTGTTGGCAGCCAAAGCC
AACACCAAGAACACCAGCGATGTGATGTACAAGAAAGACTATGAAAAGAGCAAAGGGAAAATG
ATTGGAGCCCTCAGCATTAATGACGATCCAAAGATGCTGCACTCCTTGAAGACAGCCAAAAAC
CAGAGTGATCGCGAATATCGAAAAGATTATGAAAAGTCAAAAACTATCTACACGGCACCTCTT
GATATGCTCCAAGTCACTCAAGCTAAGAAATCTCAGGCAATTGCCAGCGACGTTGATTATAAG
CACATCTTACACAGTTACAGCTACCCCCCTGATAGCATCAATGTGGACCTTGCCAAGAAGGCA
TATGCGCTGCAGAGCGATGTTGAATACAAAGCTGACTACAATAGCTGGATGAAAGGTTGTGGC
TGGGTGCCTTTTGGGTCCTTAGAAATGGAAAAGGCAAAGCGAGCTTCAGACATCCTCAATGAG
AAAAAATATCGCCAACATCCAGACACCCTCAAGTTTACCTCGATTGAAGATGCTCCAATTACA
GTACAGTCTAAAATTAACCAGGCCCAGAGGAGTGATATCGCTTACAAAGCCAAAGGAGAGGAA
ATTATTCACAATTACAACCTGCCACCAGACCTGCCCCAGTTCATCCAGGCTAAAGTTAATGCC
TACAATATCAGTGAGAATATGTACAAAGCAGACTTGAAAGACTTGAGCAAGAAGGGATATGAC
CTGAGAACTGATGCGATTCCCATCAGAGCTGCCAAAGCTGCCAGGCAGGCGGCGAGTGACGTT
CAGTACAAAAAAGACTATGAAAAGGCTAAAGGGAAAATGGTTGGCTTCCAAAGTCTTCAAGAT
GACCCTAAACTGGTTCATTATATGAACGTGGCCAAGATACAATCAGATCGGGAGTATAAAAAA
GACTATGAGAAGACAAAGTCCAAATACAACACGCCCCATGATATGTTCAATGTCGTGGCGGCT
AAGAAAGCCCAGGATGTGGTCAGCAATGTCAACTATAAGCATTCTCTCCATCATTACACCTAC TTGCCTGACGCCATGGACCTGGAGCTGTCTAAGAACATGATGCAGATACAGAGTGATAACGTC TACAAGGAAGACTACAACAACTGGATGAAAGGCATTGGCTGGATTCCTATTGGCAGTCTCGAC GTCGAAAAAGTTAAAAAGGCCGGTGATGCTCTGAATGAAAAGAAGTACAGGCAACATCCAGAC ACCCTCAAATTTACCAGCATTGTGGACTCCCCAGTTATGGTCCAGGCAAAACAGAACACGAAG CAAGTCAGTGATATCTTATACAAGGCTAAAGGAGAAGATGTGAAACATAAATACACCATGAGT CCTGATCTTCCTCAGTTTCTCCAGGCCAAGTGCAATGCTTACAGTATAAGTGACGTCTGTTAT AAACGGGATTGGCATGACTTAATACGCAAGGGCAACAATGTGCTGGGCGATGCTATTCCCATC ACTGCAGCCAAGGCATCGAGAAACATTGCCAGTGATTATAAATACAAGGAAGCTTATGAGAAG TCAAAGGGAAAGCATGTGGGTTTCAGAAGCCTCCAGGATGATCCCAAGCTGGTCCACTATATG AATGTGGCAAAGCTGCAGTCTGATCGTGAATACAAGAAGAACTATGAGAACACCAAAACCAGC TACCATACCCCTGGGGACATGGTTACGATCACAGCTGCAAAGATGGCCCAGGATGTCGCTACC AATGTCAACTACAAACAGCCATTGCATCATTACACATACCTACCTGACGCCATGAGTCTTGAG CATACGAGGAATGTCAATCAAATTCAGAGTGATAATGTGTATAAAGACGAGTATAACAGCTTC TTGAAGGGCATCGGATGGATCCCTATTGGTTCCCTGGAGGTGGAGAAGGTCAAGAAAGCAGGC GATGCATTAAATGAGAGGAAGTATCGACAGCACCCAGATACCGTCAAGTTCACAAGTGTGCCT GATTCCATGGGCATGATGTTGGCTCAGCATAACACAAAGCAGCTAAGTGATTTGAACTACAAG GTAGAGGGAGAGAAACTGAAGCACAAGTATACTATTGACCCTGAATTGCCTCAGTTTATTCAA GCCAAAGTCAACGCCCTCAACATGAGTGATGCTCATTATAAAGCAGATTGGAAGAAAACCATT CGCAAGGGCTATGATTTGAGACCAGATGCCATCCCAATTGTTGCTGCAAAAAGTTCAAGGAAT ATTGCTAGTGATTGCAAATATAAGGAGGCCTACGAGAAAGCCAAAGGCAAGCAAGTTGGATTT CTCAGTCTTCAGGATGATCCTAAACTGGTTCACTACATGAATGTGGCCAAAATCCAGTCTGAT CGTGAGTACAAAAAGGGCTATGAAGCCAGCAAGACCAAGTACCACACACCTCTGGATATGGTC AGTGTGACAGCTGCAAAGAAATCTCAGGAGGTTGCCACCAACGCCAACTACAGACAGTCATAC CACCACTACACTCTCCTGCCCGATGCCTTGAATGTGGAGCACTCCAGGAATGCCATGCAGATT CAGAGTGATAATCTGTACAAATCTGACTTCACCAATTGGATGAAAGGGATCGGCTGGGTGCCC ATAGAGTCCCTGGAGGTGGAGAAGGCAAAGAAAGCAGGAGAGATTCTTAGTGAGAAGAAGTAT CGCCAGCACCCCGAGAAGCTGAAGTTCACTTACGCCATGGACACAATGGAACAGGCACTTAAC AAGAGTAACAAACTGAACATGGACAAGAGGCTCTACACTGAAAAATGGAACAAGGACAAGACC ACCATTCATGTCATGCCTGACACACCGGATATTTTACTCTCCAGAGTAAACCAAATCACCATG AGTGATAAACTGTACAAAGCTGGCTGGGAAGAGGAAAAGAAGAAAGGATATGACCTGAGGCCT GATGCCATTGCAATAAAGGCTGCAAGAGCCTCTAGAGACATTGCCAGTGATTACAAATACAAG AAAGCCTATGAACAAGCCAAAGGGAAACACATTGGCTTCCGGAGCCTGGAAGATGACCCCAAG CTGGTGCACTTCATGCAAGTGGCCAAGATGCAGTCAGACCGGGAATACAAGAAGGGATATGAG AAATCCAAGACCTCCTTCCACACCCCGGTGGACATGCTCAGTGTGGTGGCAGCCAAGAAGTCT CAGGAAGTGGCCACCAATGCCAACTACAGGAACGTGATCCATACCTACAACATGCTTCCTGAT GCCATGAGCTTTGAATTGGCCAAAAATATGATGCAGATTCAAAGTGATAATCAGTACAAGGCT GACTATGCTGACTTCATGAAGGGCATTGGATGGCTCCCTCTGGGCTCCCTGGAAGCAGAGAAA AACAAGAAAGCCATGGAGATTATTAGTGAAAAGAAGTACCGCCAGCACCCAGACACTTTGAAG TATTCCACACTCATGGACTCGATGAACATGGTTTTGGCCCAGAATAATGCAAAAATTATGAAC GAACATCTCTACAAACAAGCATGGGAGGCTGACAAAACCAAAGTCCACATCATGCCTGATATC CCCCAGATTATTTTGGCAAAGGCAAATGCAATTAATATAAGTGATAAACTCTACAAACTTTCC TTGGAAGAGTCTAAAAAGAAAGGCTATGATCTCAGACCTGATGCAATTCCTATCAAAGCTGCC AAGGCTTCCAGAGATATTGCAAGTGATTATAAATACAAGTACAATTATGAAAAAGGGAAGGGG AAAATGGTTGGTTTCCGCAGTCTCGAGGATGATCCCAAATTAGTCCATTCCATGCAAGTGGCT AAGATGCAATCTGATCGGGAGTACAAGAAAAACTATGAGAACACAAAGACCAGCTACCACACC CCTGCCGACATGCTCAGTGTCACGGCTGCAAAGGATGCCCAAGCCAACATCACCAACACTAAC TACAAGCACCTGATTCACAAGTACATCCTCCTTCCAGATGCAATGAACATTGAGCTGACCAGG AATATGAATCGCATACAGAGTGATAATGAATATAAGCAAGATTACAATGAATGGTACAAAGGG CTTGGCTGGAGTCCAGCAGGTTCTCTGGAAGTGGAGAAGGCCAAGAAAGCAACTGAATATGCC AGTGATCAGAAATACCGCCAGCACCCGAGCAACTTCCAGTTTAAGAAGCTGACTGATTCCATG GACATGGTGCTTGCCAAGCAGAATGCACATACCATGAACAAGCATTTATACACCATTGATTGG AATAAAGATAAGACCAAGATTCATGTGATGCCTGATACACCAGATATTTTACAAGCCAAGCAG AATCAAACACTGTATAGTCAGAAACTCTATAAACTTGGATGGGAAGAAGCTTTGAAGAAAGGC TATGATCTCCCAGTTGATGCAATTTCTGTACAGCTAGCTAAAGCTTCAAGAGACATTGCTAGT GATTATAAATACAAACAAGGCTACCGAAAGCAACTTGGCCACCATGTTGGATTCCGGAGTCTG CAAGATGACCCAAAACTTGTGTTGTCCATGAATGTAGCCAAAATGCAGAGTGAAAGAGAATAC AAGAAGGACTTTGAGAAGTGGAAAACTAAGTTCTCCAGCCCAGTGGACATGTTGGGAGTGGTA CTGGCCAAGAAGTGTCAGGAGTTGGTTAGTGACGTGGACTACAAGAACTACCTGCATCAGTGG ACATGTCTGCCTGATCAGAACGATGTTGTGCAAGCTAAGAAAGTTTATGAACTGCAAAGTGAG AATCTATATAAATCTGACCTTGAGTGGCTGAGAGGCATAGGATGGAGTCCCTTGGGTTCTTTA GAGGCAGAAAAGAACAAGCGGGCTTCGGAAATCATCAGTGAGAAGAAATATCGTCAGCCTCCA GACAGAAACAAGTTCACCAGCATTCCTGATGCCATGGATATAGTTCTGGCAAAGACAAATGCC AAAAATAGGAGTGATAGACTTTATAGAGAAGCTTGGGACAAAGACAAGACTCAGATCCACATC ATGCCTGATACACCTGACATTGTTCTGGCTAAAGCAAACTTAATCAACACAAGTGATAAACTC TACCGAATGGGTTATGAGGAGCTGAAGAGAAAAGGTTACGATCTTCCTGTTGATGCCATACCA
ATCAAAGCAGCAAAAGCCTCCCGGGAAATTGCCAGTGAATACAAGTACAAGGAAGGCTTTCGC
AAGCAGCTCGGCCACCACATTGGTGCCCGGAACATTGAAGATGACCCCAAGATGATGTGGTCC
ATGCATGTGGCCAAGATCCAGAGTGACAGGGAGTACAAGAAGGACTTTGAGAAGTGGAAGACC
AAGTTCAGCAGCCCAGTGGACATGCTGGGGGTGGTGTTGGCCTATAAGTGCCAGACCTTAGTC
AGCGACGTGGACTACAAGAACTACCTGCACCAGTGGACATGCCTGCCCGACCAGAGCGATGTC
ATCCATGCTCGGCAGGCCTATGACCTCCAGAGCGATAATTTGTACAAGTCAGACCTTCAGTGG
CTAAAAGGCATTGGCTGGATGACTAGTGGTTCTCTCGAGGATGAGAAAAATAAACGAGCCACC
CAGATTTTGAGTGACCATGTTTACCGTCAGCACCCAGATCAATTTAAGTTTTCCAGCCTTATG
GATTCCATACCAATGGTTTTGGCAAAAAACAATGCTATTACCATGAATCATCGCCTCTATACA
GAAGCTTGGGATAAAGATAAAACCACTGTCCACATTATGCCAGATACCCCTGAAGTTTTATTA
GCTAAACAAAACAAAGTAAATTACAGTGAGAAATTGTATAAGCTTGGCCTAGAAGAAGCCAAG
AGGAAAGGTTATGACATGCGGGTAGATGCCATTCCTATCAAGGCAGCCAAGGCCTCCAGAGAT
ATTGCAAGTGAATTCAAGTACAAAGAAGGCTATCGTAAGCAGCTCGGCCACCACATTGGTGCC
CGAGCTATACGTGATGACCCCAAGATGATGTGGTCCATGCACGTGGCCAAGATCCAGAGTGAC
AGGGAGTACAAGAAGGACTTTGAGAAGTGGAAGACCAAGTTCAGCAGCCCAGTGGACATGCTG
GGGGTGGTGCTGGCCAAGAAGTGCCAGACCTTAGTCAGCGATGTGGACTACAAGAACTACCTG
CACCAGTGGACATGCCTGCCCGACCAGAGCGACGTCATCCATGCTCGGCAGGCCTATGACCTC
CAGAGCGATAATATGTACAAGTCTGATCTCCAGTGGATGAGAGGCATTGGCTGGGTGTCCATT
GGCTCTTTGGATGTGGAAAAATGCAAAAGGGCAACTGAAATTTTGAGTGATAAAATCTATCGC
CAGCCTCCAGACAGATTCAAATTTACCAGTGTGACTGACTCTCTGGAACAAGTGCTGGCCAAG
AACAATGCTCTCAACATGAATAAGCGTTTATACACAGAGGCCTGGGACAAAGACAAGACTCAA
ATTCACATAATGCCTGATACACCAGAGATTATGTTGGCAAGGCAGAACAAAATCAACTACAGT
GAGACTCTATACAAACTTGCCAATGAAGAAGCAAAAAAGAAAGGCTACGACTTGCGAAGTGAC
GCCATCCCCATCGTGGCTGCCAAGGCCTCCAGGGACGTTATCAGTGATTACAAATACAAAGAT
GGTTACCGCAAGCAGCTCGGCCACCACATTGGAGCCCGGAACATTGAAGATGACCCCAAGATG
ATGTGGTCCATGCATGTGGCCAAGATCCAGAGTGACAGGGAGTATAAGAAGGACTTTGAGAAG
TGGAAGACCAAGTTCAGCAGCCCAGTGGACATGCTGGGAGTGGTGTTAGCCAAGAAGTGCCAG
ACCTTAGTCAGCGATGTGGACTACAAGAACTACCTGCACGAGTGGACGTGCCTGCCCGACCAG
AATGATGTCATCCATGCTCGGCAGGCCTATGACCTCCAGAGCGATAACATTTACAAATCTGAT
CTCCAGTGGCTGAGAGGCATTGGCTGGGTCCCCATTGGGTCTATGGATGTGGTCAAGTGCAAG
AGAGCTGCTGAAATACTGAGTGATAACATCTACCGCCAGCCTCCGGACAAGCTGAAATTTACC
AGTGTGACTGACTCTCTAGAGCAGGTGCTGGCCAAGAACAATGCTCTCAATATGAACAAGCGC
TTATACACAGAAGCCTGGGACAAAGACAAGACCCAAGTCCATATTATGCCTGATACACCTGAA
ATCATGTTGGCAAGACAAAATAAAATAAATTATAGTGAGAGCCTCTATCGTCAGGCCATGGAA
GAAGCCAAGAAAGAAGGCTATGACTTGAGAAGTGATGCCATTCCCATTGTGGCTGCCAAGGCC
TCTCGGGATATTGCCAGTGATTACAAATACAAAGAAGCATATCGTAAGCAGTTGGGTCACCAC
ATTGGCGCCCGAGCAGTACACGATGACCCCAAGATAATGTGGTCCCTCCACATTGCCAAAGTG
CAGAGTGACCGTGAGTACAAGAAAGATTTTGAGAAATACAAGACAAGGTACAGCAGCCCAGTG
GACATGCTTGGTATCGTTTTGGCCAAGAAGTGTCAGACCTTGGTCAGCGATGTGGACTATAAA
CATCCTCTGCATGAATGCATCTGCCTGCCCGACCAGAATGACATCATTCATGCACGGAAAGCC
TATGACCTCCAGAGTGACAATTTGTATAAGTCAGACCTTGAATGGATGAAAGGCATTGGCTGG
GTTCCGATTGATTCCTTGGAAGTTGTTAGGGCCAAGAGAGCTGGAGAATTACTTAGTGATACT
ATCTACCGTCAGCGTCCAGAAACGCTGAAATTTACCAGTATAACGGACACTCCGGAGCAGGTG
CTGGCAAAAAACAATGCTTTAAACATGAATAAGCGCTTATATACTGAAGCCTGGGACAATGAC
AAGAAAACTATTCATGTCATGCCTGATACACCAGAAATCATGTTAGCCAAACTCAACCGAATA
AACTACAGTGATAAACTCTATAAACTTGCTTTGGAAGAGTCCAAGAAGGAAGGCTATGACTTG
CGTCTGGATGCCATTCCAATCCAAGCAGCCAAGGCTTCAAGAGATATTGCTAGTGATTACAAG
TACAAGGAAGGCTACCGCAAACAGCTTGGCCACCATATTGGGGCCCGGAACATTAAGGATGAC
CCGAAGATGATGTGGTCCATCCATGTGGCCAAGATCCAGAGTGACAGGGAGTACAAGAAGGAG
TTTGAGAAGTGGAAGACCAAGTTCAGCAGCCCAGTGGACATGCTGGGGGTGGTGCTGGCCAAG
AAGTGTCAGATCCTTGTAAGCGACATAGACTACAAGCATCCCCTGCATGAATGGACCTGCCTG
CCTGATCAGAATGACGTCATTCAGGCTCGGAAGGCCTATGACCTGCAGAGTGATGCTATTTAC
AAATCTGATCTTGAGTGGCTGAGAGGCATAGGATGGGTTCCCATTGGCTCTGTAGAGGTCGAG
AAAGTGAAGAGAGCTGGAGAAATCCTGAGTGACAGGAAGTATCGCCAGCCTGCAGACCAGCTC
AAATTCACATGCATTACCGACACTCCGGAAATTGTCCTAGCAAAGAATAATGCCCTGACAATG
AGCAAGCATTTATACACAGAAGCTTGGGATGCTGACAAAACCTCCATCCACGTGATGCCAGAC
ACCCCAGATATCCTGCTGGCCAAGAGTAATTCTGCCAATATCAGCCAAAAACTTTACACCAAG
GGATGGGATGAATCAAAGATGAAGGACTATGATCTGAGAGCAGATGCTATTTCCATCAAAAGT
GCCAAGGCCTCCAGGGACATCGCCAGTGACTACAAATACAAGGAAGCCTATGAGAAACAGAAA
GGCCACCACATTGGAGCCCAGAGCATTGAAGATGATCCCAAGATTATGTGTGCCATACATGCA
GAAAAAATTCAAAGTGAAAGGGAGTACAAGAAGGAATTCCAAAAGTGGAAAACCAAGTTCTCT
AGCCCAGTGGACATGTTAAGCATCTTGCTGGCCAAGAAATGTCAGACTTTGGTCACTGACATT
TATTATCGCAATTACCTGCATGAATGGACATGCATGCCGGATCAAAACGACATTATCCAAGCA
AAAAAGGCCTATGACCTGCAGAGTGATGCCCTCTACAAGGCTGACTTGGAGTGGTTGCGTGGC
ATTGGCTGGATGCCCCAAGGGTCTCCTGAAGTGTTGAGAGTCAAAAACGCCCAGAATATCTTT
TGTGACAGTGTCTATCGGACGCCTGTGGTGAACCTTAAGTACACAAGCATTGTTGACACACCT
GAAGTGGTCCTTGCTAAATCAAATGCTGAAAATATTAGTATTCCAAAGTACAGAGAGGTTTGG GACAAGGATAAAACTTCAATACACATAATGCCAGATACTCCAGAAATTAATCTCGCTAGAGCA AATGCTCTTAATGTGAGCAATAAACTTTACCGTGAGGGCTGGGATGAAATGAAGGCGGGCTGT GATGTCCGGCTGGATGCCATCCCCATCCAGGCTGCCAAGGCCTCCAGGGAGATTGCCAGTGAC TATAAATATAAGCTTGACCATGAGAAGCAGAAGGGACACTACGTGGGCACCCTCACAGCCAGG GATGACAACAAGATCCGCTGGGCCCTCATAGCTGACAAGCTCCAGAATGAACGAGAGTACCGG CTGGACTGGGCCAAATGGAAGGCCAAGATCCAGAGCCCTGTGGACATGCTTTCCATCCTGCAC TCTAAAAATTCCCAGGCTCTGGTCAGTGACATGGATTACCGCAATTACCTGCACCAGTGGACC TGCATGCCCGACCAGAACGATGTGATTCAGGCCAAGAAGGCCTACGAACTGCAGAGCGATAAT GTTTACAAGGCTGACTTGGAATGGTTGCGTGGAATTGGGTGGATGCCAAATGACTCCGTGTCC GTCAATCATGCCAAACATGCCGCGGACATCTTCAGTGAGAAAAAATATCGCACAAAAATAGAA ACTCTCAACTTTACGCCTGTGGATGACAGAGTTGATTATGTGACAGCGAAACAAAGTGGCGAG ATCCTCGATGATATTAAATACCGGAAAGACTGGAATGCCACCAAATCAAAGTACACCCTCACA GAAACCCCCCTGCTGCACACTGCCCAGGAGGCTGCTAGGATACTGGACCAGTATCTCTACAAG GAAGGCTGGGAGAGACAAAAAGCCACAGGTTACATTTTGCCTCCAGATGCTGTGCCATTTGTT CATGCCCATCACTGCAATGACGTTCAGAGTGAGCTGAAATACAAAGCTGAACATGTGAAGCAA AAAGGTCATTATGTTGGTGTCCCGACGATGAGAGATGATCCTAAGCTGGTTTGGTTTGAGCAT GCAGGCCAGATTCAGAATGAGAGACTATACAAAGAGGACTATCACAAAACAAAGGCCAAAATC AATATACCTGCTGATATGGTGTCAGTCTTGGCCGCCAAGCAGGGGCAGACCCTTGTCAGTGAT ATTGATTATCGTAATTACTTGCACCAATGGATGTGTCATCCTGACCAGAACGATGTTATTCAG GCAAGAAAGGCCTATGACCTACAGAGTGATAATGTCTACAGAGCTGACCTGGAGTGGCTCCGA GGCATTGGCTGGATCCCACTGGATTCTGTGGACCATGTAAGGGTTACTAAGAACCAGGAAATG ATGAGTCAGATCAAATATAAGAAAAATGCCCTTGAAAACTATCCTAACTTTACAAGTGTGGTG GATCCTCCAGAGATTGTTTTAGCCAAGATTAATTCTGTCAATCAAAGTGATGTAAAATATAAA GAAACATTTAATAAAGCAAAGGGCAAATATACGTTTTCACCAGATACACCACATATCTCCCAC TCCAAAGACATGGGAAAACTCTACAGTACTATACTGTATAAAGGGGCGTGGGAGGGCACCAAG GCCTATGGCTACACCCTGGATGAGCGCTACATTCCCATTGTTGGAGCCAAGCATGCTGATCTG GTGAACAGTGAGCTTAAATACAAAGAGACATATGAGAAGCAGAAAGGTCACTACCTGGCTGGA AAAGTGATCGGTGAATTCCCTGGTGTGGTTCACTGTCTGGATTTCCAAAAGATGAGGAGTGCG TTGAACTACAGAAAACATTATGAGGATACCAAAGCAAATGTTCATATCCCCAATGACATGATG AATCACGTGCTGGCTAAAAGGTGCCAGTACATCCTCAGTGACCTGGAGTATCGACACTATTTC CACCAGTGGACGTCTCTTCTGGAAGAACCCAATGTTATACGCGTCCGAAACGCCCAGGAGATC TTGAGTGATAATGTGTATAAAGATGACCTGAATTGGTTGAAAGGCATTGGTTGCTACGTTTGG GATACACCCCAAATCCTCCATGCCAAGAAATCATACGACCTTCAGAGTCAGCTACAATATACA GCAGCAGGTAAAGAAAATCTACAAAACTATAATCTGGTCACAGACACGCCCCTCTATGTGACT GCTGTTCAGAGTGGCATTAATGCCAGTGAGGTAAAATATAAAGAAAATTATCATCAGATTAAG GACAAATACACAACAGTTCTAGAAACAGTGGATTATGACAGAACCAGAAACCTGAAGAATCTT TACAGCAGTAACCTGTACAAGGAGGCCTGGGATAGAGTGAAAGCCACCAGCTACATCCTGCCT TCCAGCACCTTGTCCCTGACACACGCCAAGAACCAGAAGCATCTGGCCAGCCATATCAAATAT CGGGAAGAATATGAAAAGTTCAAAGCTCTTTATACGTTACCAAGAAGTGTTGACGATGATCCG AACACAGCACGGTGCCTCCGAGTTGGCAAGCTTAACATCGATCGCCTGTACAGATCAGTTTAT GAAAAGAACAAGATGAAAATCCACATCGTGCCCGACATGGTAGAGATGGTTACTGCCAAGGAT TCCCAGAAGAAAGTCAGTGAGATTGATTACCGCCTGCGCCTCCACGAATGGATTTGCCACCCC GACTTGCAAGTCAATGATCACGTCAGGAAAGTCACAGATCAGATCAGCGATATTGTATACAAG GATGACCTCAACTGGCTGAAAGGCATTGGTTGCTACGTCTGGGACACTCCTGAAATCCTCCAT GCCAAGCATGCTTATGATCTACGTGATGATATCAAGTATAAAGCTCACATGTTGAAAACAAGG AATGACTACAAGCTTGTCACAGATACACCAGTCTACGTGCAGGCTGTCAAAAGTGGGAAACAG CTAAGTGACGCTGTCTACCACTATGACTATGTGCACAGTGTCAGAGGCAAAGTGGCTCCAACT ACCAAAACCGTGGATCTGGACCGGGCCCTTCATGCATACAAGCTCCAGAGTTCGAATCTATAC AAAACCAGCCTGCGCACCCTGCCCACTGGATATAGACTTCCAGGTGACACTCCTCACTTCAAA CACATCAAGGACACCCGTTACATGAGCAGTTATTTCAAGTACAAAGAAGCCTATGAACACACC AAGGCATATGGGTATACACTTGGCCCCAAAGATGTTCCATTTGTCCACGTCCGGAGAGTCAAC AATGTTACCAGCGAGAGACTGTATCGGGAATTGTACCACAAACTGAAAGACAAGATCCATACA ACTCCCGATCCCCCTGAGATCCGCCAAGTCAAGAAGACACAAGAGGCTGTCAGTGAGTTGATC TACAAATCAGACTTCTTCAAGATGCAGGGCCACATGATCTCTCTGCCATACACACCCCAAGTG ATCCATTGCCGCTATGTGGGAGACATCACCAGTGATATTAAATACAAAGAGGACTTGCAGGTC CTGAAGGGATTTGGCTGCTTCCTGTATGACACTCCTGACATGGTCCGCTCCCGGCACCTGCGG AAGCTCTGGTCTAATTACCTATACACTGATAAGGCAAGGGAGATGCGAGACAAATACAAAGTG GTGCTTGACACTCCAGAATACAGAAAAGTGCAAGAACTGAAGACACATCTGAGTGAGCTGGTC TACAGAGCTGCAGGCAAGAAGCAGAAGTCAATCTTTACTTCAGTTCCTGATACTCCTGATCTT TTAAGAGCCAAGCGAGGGCAGAAGCTTCAGAGTCAGTATCTGTATGTTGAACTTGCCACCAAA GAGAGACCCCATCATCACGCTGGAAACCAGACCACAGCCTTGAAGCATGCTAAAGACGTGAAG GACATGGTCAGTGAGAAAAAGTACAAGATTCAATATGAAAAGATGAAAGACAAGTACACTCCG GTTCCAGATACGCCAATCCTCATCAGAGCCAAGAGGGCTTACTGGAATGCCAGTGATCTACGC TACAAAGAAACATTTCAAAAGACCAAAGGGAAATACCACACGGTGAAAGATGCCCTAGACATT GTCTATCATCGCAAAGTCACAGATGACATCAGTAAAATAAAATACAAGGAGAACTACATGAGC
CAGTTGGGTATCTGGAGGTCCATTCCTGATCGTCCAGAGCATTTCCACCACCGAGCAGTCACT GACACAGTCAGTGATGTAAAATATAAAGAAGACTTGACTTGGCTTAAAGGCATTGGTTGCTAT GCCTATGATACCCCTGATTTCACTCTGGCTGAAAAGAACAAGACTCTCTACAGCAAGTATAAG TATAAAGAAGTATTTGAAAGGACAAAGTCAGATTTCAAGTATGTTGCCGACTCTCCGATCAAT AGGCATTTCAAGTATGCAACTCAATTGATGAATGAGAAAAAATACAGAGCTGATTATGAGCAG CGGAAAGATAAATACCACCTGGTAGTCGATGAGCCTAGACATCTGCTGGCTAAGACCCGCAGC GACCAGATCAGTCAGATCAAATACAGGAAAAACTATGAAAAATCAAAGGACAAATTTACCTCA ATTGTGGATACTCCAGAACACCTGCGTACTACAAAAGTCAACAAACAAATCAGCGATATCCTT TATAAATTGGAATACAACAAGGCCAAACCCAGAGGCTACACCACAATCCACGACACGCCCATG TTGCTGCATGTCCGCAAGGTTAAAGATGAAGTCAGTGATCTGAAATACAAAGAAGTATACCAA AGAAATAAATCCAACTGCACCATTGAGCCAGATGCTGTTCATATCAAAGCAGCCAAGGACGCC TACAAAGTCAACACCAATCTGGACTATAAGAAACAGTACGAAGCCAACAAAGCCCACTGGAAG TGGACTCCTGACCGACCGGACTTCCTCCAGGCTGCCAAGTCATCCCTGCAGCAAAGCGATTTT GAATATAAGCTGGACCGGGAGTTCCTCAAGGGTTGCAAGCTTTCTGTCACTGATGACAAAAAC ACGGTGCTCGCCCTCAGGAATACTTTAATAGAAAGTGATCTGAAATACAAAGAGAAACATGTC AAGGAAAGAGGAACCTGTCATGCCGTACCTGACACGCCTCAGATCCTGCTGGCGAAGACTGTC AGCAACCTGGTGTCTGAGAACAAGTACAAGGACCATGTCAAGAAGCACTTGGCACAGGGCTCA TACACAACACTACCAGAGACCCGGGACACTGTTCACGTCAAGGAAGTGACCAAGCATGTCAGT GATACAAATTACAAAAAGAAGTTTGTCAAGGAGAAAGGAAAATCCAACTACTCCATCATGCTG GAGCCACCAGAGGTGAAACATGCTATGGAAGTGGCCAAGAAGCAAAGTGATGTCGCTTACAGA AAAGATGCCAAAGAGAAGCTGCATTACACCACAGTGGCTGATCGACCAGACATCAAGAAGGCC ACACAGGCAGCCAAACAGGCCAGTGAGGTGGAGTACAGAGCCAAGCACCGCAAGGAAGGCAGC JCATGGCTTAAGCATGCTCGGTCGCCCAGACATAGAAATGGCCAAGAAGGCAGCCAAGCTGAGC jAGCCAGGTTAAATACCGAGAAAATTTCGATAAAGAAAAGGGCAAGACACCAAAATACAATCCA AAAGACAGCCAGCTCTACAAAGTCATGAAAGATGCTAATAATCTTGCAAGTGAGGTTAAATAC AAGGCTGACCTGAAGAAACTTCACAAACCCGTGACTGACATGAAGGAGTCTCTGATCATGAAT CATGTCCTGAATACAAGCCAACTTGCCAGTTCTTACCAGTACAAGAAGAAGTATGAG? \GAGT AAAGGCCACTACCACACCATACCCGATAATCTGGAGCAGCTTCACCTAAAAGAGGCCACAGAA TTACAGAGTATAGTGAAATACAAAGAAAAGTATGAAAAGGAACGAGGAAAACCCATGCTGGAC TTTGAAACACCAACGTACATCACTGCCAAAGAGTCTCAGCAGATGCAGAGTGGGAAAGAATAT AGGAAAGATTATGAAGAGTCCATTAAAGGCAGAAACCTGACTGGCCTGGAGGTCACGCCAGCT TTGTTACATGTCAAATATGCAACTAAAATAGCAAGCGAGAAAGAGTACAGGAAAGATCTAGAG GAAAGCATCCGTGGGAAGGGCCTCACTGAAATGGAAGATACACCTGACATGCTAAGAGCAAAG AATGCCACTCAAATCCTCAATGAGAAAGAATATAAGCGAGACCTGGAACTGGAAGTCAAAGGA AGAGGCCTGAATGCCATGGCCAATGAAACTCCGGATTTTATGAGGGCCAGGAATGCTACTGAT

ATTGCCAGTCAGATTAAGTATAAGCAATCAGCAGAAATGGAGAAAGCCAATTTCACTTCTGTG GTTGATACTCCAGAGATCATTCATGCCCAACAAGTCAAGAATCTTTCAAGCCAGAAAAAGTAC AAGGAAGATGCTGAGAAGTCCATGTCGTATTATGAGACTGTTTTGGACACCCCAGAGATACAG AGAGTCCGGGAGAACCAAAAGAACTTCAGCCTTCTCCAATACCAGTGTGACCTTAAAAACAGT AAAGGAAAAATTACAGTTGTTCAAGACACGCCAGAAATACTGCGTGTAAAAGAAAATCAGAAG AATTTCAGCTCGGTTTTATATAAAGAGGATGTCTCACCAGGAACGGCTATCGGAAAGACACCT GAGATGATGAGAGTGAAACAAACACAGGACCACATTAGCTCGGTGAAGTATAAGGAAGCAATA GGACAAGGAACTCCAATCCCTGACCTGCCTGAAGTGAAACGTGTGAAGGAGACGCAGAAGCAC ATTAGCTCGGTTATGTACAAAGAAAACTTGGGAACAGGAATTCCAATCCCCATCACTCCTGAG ATTGAGAGAGTCAAACACAATCAAGAAAACCTTAGCTCGGTGTTATACAAAGAAAACATGGGC AAGGGAACCCCTTTACCTGTCACTCCCGAGATGGAAAGAGTCAAACACAATCAAGAAAATATT AGCTCGGTGTTATACAAAGAAAACATGGGCAAGGGAACCCCTCTACCTGTCACTCCTGAGATG GAGAGAGTCAAACACAATCAAGAAAATATTAGCTCGGTGTTATACAAAGAAAACATGGGCAAG GGAACTCCTTTACCTGTCACTCCCGAGATGGAGCGAGTCAAACACAATCAAGAAAATATTAGC TCGGTTTTGTACAAAGAAAATGTGGGGAAAGCCACCGCAACCACTGTGACTCCTGAGATGCAG AGAGTCAAACGCAATCAAGAAAACTTTAGCTCGGTGTTATACAAAGAGAACCTGGGGAAAGCA ACCCCCACACCCTTTACTCCCGAGATGGAGCGAGTCAAACGCAATCAAGAAAATATTAGCTCG GTTTTGTACAAAGAGAACATGAGAAAAGCAACTCCGACACCTGTTACTCCAGAGATGGAGAGA GCTAAGCGCAACCAAGAAAACATTAGCTCGGTTCTTTATTCTGATAGTTTCCGGAAACAAATA CAAGGCAAAGCTGCCTATGTATTGGATACCCCCGAGATGAGACGGGTGAGGGAGACCCAACGG CACATCTCAACGGTGAAATATCATGAAGACTTTGAGAAACACAAGGGTTGCTTCACACCAGTG GTGACAGATCCTATCACTGAACGAGTAAAGAAGAACATGCAGGACTTCAGTGACATTAACTAC CGAGGTATTCAGAGGAAAGTGGTAGAAATGGAACAAAAACGGAATGACCAAGATCAGGAGACT ATTACAGGTTTACGTGTCTGGCGTACTAATCCTGGTTCGGTTTTTGACTATGATCCAGCAGAA GACAACATCCAGTCCCGAAGCTTACACATGATTAATGTCCAAGCTCAGCGCCGGAGCCGGGAG CAGTCACGATCTGCCAGTGCACTAAGCGTCAGTGGGGGTGAGGAGAAGTCTGAGCATTCAGAA GCACCAGACCACCACCTTTCGACTTACAGCGACGGGGGTGTCTTTGCAGTCTCAACAGCTTAC AAACATGCAAAAACCACAGAGCTCCCACAACAACGATCATCTTCAGTTGCTACCCAACAGACA ACGGTATCTTCCATCCCATCTCATCCATCTACTGCTGGAAAAATCTTCCGTGCCATGTATGAC TATATGGCTGCTGATGCAGATGAGGTGTCCTTCAAGGATGGAGATGCCATCATAAATGTTCAA GCAATTGATGAAGGCTGGATGTATGGCACTGTGCAGAGGACTGGCAGGACCGGAATGCTCCCA
GCCAACTACGTTGAAGCTATTTAGGCATTTCAAAGCATCACACTTGTCTGCAGGACTTACAGA TCCTGCAGTCAATGTTTCGGTTTAGACTCTCCACTGTTACCTAAGTTCTCAAGCTGCCTATGG TTTTTCTGTGTCAATGTGATTTATGGTAGTACCATCCTTTCTCCTTTGGGTTTTAAAATAAGT
TGCAGAACAGACACTTTAAAAGCTTCTGCAATATTATTTCTGTGCCTAGAGTCTTTCTCCATT ATAAACATGTTTTAACATTATTTCTTTTCTAAAACAGGGATTTTGAATATGCCAAACACATTA AAGGAAAAATAGCAGAGATGTTCACCTTTTCCTTGCTGATTGCTAATGCTTATTATTTCTAAT TCAGTTCTGAAGTTATAAACTTATAATCAATACAAACCAGCAACTAATAAAACCTCTAATTCT GCAAAAAAAAAAAAAAAAAAAAAAGTCG
ORF Start: ATG at 19 jORF Stop: TAG at 20119
SEQ ID NO: 140 :6700 aa JMWatk ""
|NOV35a, ADDEDYEEVVEYYTEEWYEEVPGETITKIYETTTTRTSDYEQSETSKPALAQPALAQPASA
!CG 119566-01 Protein KPVERRKVIRKKVDPSKFMTPYIAHSQKMQDLFSPNKYKEKFEKTKGQPYASTTDTPELRRIK
KVQDQLSEVKYRMDGDVAKTICHVDEKAKDIEHAKKVSQQVSKVLYKQNWEDTKDKYLLPPDA jSequence PELVQAVKNTAMFSKKLYTED EADKSLFYPYNDSPELRRVAQAQKALSDVAYKKGLAEQQAQ
I FTPLADPPDIEFAKKVTNQVSKQKYKEDYENKIKGKWSETPCFEVANARMNADNISTRKYQED
FENMKDQIYFMQTETPEYKMNKKAGVAASKVKYKEDYEKNKGKADYNVLPASENPQLRQLKAA
GDALSDKLYKENYEKTKAKSINYCETPKFKLDTVLQNFSSDKKYKDSYLKDILGHYVGSFEDP
YHSHCMKVTAQNSDKNYKAEYEEDRGKGFFPQTITQEYEAIKKLDQCKDHTYKVHPDKTKFTQ
VTDSPVLLQAQVNSKQLSDLNYKAKHESEKFKCHIPPDTPAFIQHKVNAYNLSDNLYKQDWEK
SKAKKFDIKVDAIPLLAAKANTKNTSDVMYKKDYEKNKGKMIGVLSINDDPKMLHSLKVAKNQ
SDRLYKENYEKTKAKSMNYCETPKYQLDTQLKNFSEARYKDLYVKDVLGHYVGSMEDPYHTHC
MKVAAQNSDKSYKAEYEEDKGKCYFPQTITQEYDAIKKLDQCKDHTYKVHPDKTKFTAVTDSP
VLLQAQLNTKQLSDLNYKAKHEGERFKCHIPADAPQFIQHRVNAYNLSDNVYKQDWEKSKAKK
FDIKVDAIPLLAAKANTKNTSDVMYKKDYEKSKGKMIGALSINDDPKMLHSLKTAKNQSDREY
RKDYEKSKTIYTAPLDMLQVTQAKKSQAIASDVDYKHILHSYSYPPDSINVDLAKKAYALQSD
VEYKADYNSWMKGCGWVPFGSLEMEKAKRASDILNEKKYRQHPDTLKFTSIEDAPITVQSKIN
QAQRSDIAYKAKGEEIIHNYNLPPDLPQFIQAKVNAYNISENMYKADLKDLSKKGYDLRTDAI
PIRAAKAARQAASDVQYKKDYEKAKGKMVGFQSLQDDPKLVHYMNVAKIQSDREYKKDYEKTK
SKYNTPHDMFNWAAKKAQDWSNVNYKHSLHHYTYLPDAMDLELSKNMMQIQSDNVYKEDYN
N MKGIGWIPIGSLDVEKVKKAGDALNEKKYRQHPDTLKFTSIVDSPVMVQAKQNTKQVSDIL
YKAKGEDVKHKYTMSPDLPQFLQAKCNAYSISDVCYKRD HDLIRKGNNVLGDAIPITAAKAS
RNIASDYKYKEAYEKSKGKHVGFRSLQDDPKLVHYMNVAKLQSDREYKKNYENTKTSYHTPGD
MVTITAAKMAQDVATNVNYKQPLHHYTYLPDAMSLEHTRNVNQIQSDNVYKDEYNSFLKGIGW
IPIGSLEVEKVKKAGDALNERKYRQHPDTVKFTSVPDSMGMMLAQHNTKQLSDLNYKVEGEKL
KHKYTIDPELPQFIQAKVNALNMSDAHYKADWKKTIRKGYDLRPDAIPIVAAKSSRNIASDCK
YKEAYEKAKGKQVGFLSLQDDPKLVHYMNVAKIQSDREYKKGYEASKTKYHTPLDMVSVTAAK
KSQEVATNANYRQSYHHYTLLPDALNVEHSRNAMQIQSDNLYKSDFTNWMKGIG VPIESLEV
EKAKKAGEILSEKKYRQHPEKLKFTYAMDTMEQALNKSNKLNMDKRLYTEKWNKDKTTIHVMP
DTPDILLSRVNQITMSDKLYKAGWEEEKKKGYDLRPDAIAIKAARASRDIASDYKYKKAYEQA
KGKHIGFRSLEDDPKLVHFMQVAKMQSDREYKKGYEKSKTSFHTPVDMLSWAAKKSQEVATN
ANYRNVIHTYNMLPDAMSFELAKNMMQIQSDNQYKADYADFMKGIGWLPLGSLEAEKNKKAME
IISEKKYRQHPDTLKYSTLMDSMNMVLAQNNAKIMNEHLYKQAWEADKTKVHIMPDIPQIILA
KANAINISDKLYKLSLEESKKKGYDLRPDAIPIKAAKASRDIASDYKYKYNYEKGKGKMVGFR
SLEDDPKLVHSMQVAKMQSDREYKKNYENTKTSYHTPADMLSVTAAKDAQANITNTNYKHLIH
KYILLPDAMNIELTRNMNRIQSDNEYKQDYNEWYKGLGWSPAGSLEVEKAKKATEYASDQKYR
QHPSNFQFKKLTDSMDMVLAKQNAHTMNKHLYTIDWNKDKTKIHVMPDTPDILQAKQNQTLYS
QKLYKLG EEALKKGYDLPVDAISVQLAKASRDIASDYKYKQGYRKQLGHHVGFRSLQDDPKL
VLSMNVAKMQSEREYKKDFEKWKTKFSSPVDMLGWLAKKCQELVSDVDYKNYLHQ TCLPDQ
NDWQAKKVYELQΞENLYKSDLE LRGIGWSPLGSLEAEKNKRASEIISEKKYRQPPDRNKFT
SIPDAMDIVLAKTNAKNRSDRLYREAWDKDKTQIHIMPDTPDIVLAKANLINTSDKLYRMGYE
ELKRKGYDLPVDAIPIKAAKASREIASEYKYKEGFRKQLGHHIGARNIEDDPKMMWSMHVAKI
QSDREYKKDFEKWKTKFSSPVDMLGVVLAYKCQTLVSDVDYKNYLHQWTCLPDQSDVIHARQA
YDLQSDNLYKSDLQWLKGIG MTSGSLEDEKNKRATQILSDHVYRQHPDQFKFSSLMDSIPMV
LAKNNAITMNHRLYTEA DKDKTTVHIMPDTPEVLLAKQNKVNYSEKLYKLGLEEAKRKGYDM
RVDAIPIKAAKASRDIASEFKYKEGYRKQLGHHIGARAIRDDPKMMWSMHVAKIQSDREYKKD
FEKWKTKFSSPVDMLGWLAKKCQTLVSDVDYKNYLHQWTCLPDQSDVIHARQAYDLQSDNMY
KSDLQWMRGIGWVSIGSLDVEKCKRATEILSDKIYRQPPDRFKFTSVTDSLEQVLAKNNALNM
NKRLYTEAWDKDKTQIHIMPDTPEIMLARQNKINYSETLYKLANEEAKKKGYDLRSDAIPIVA
AKASRDVISDYKYKDGYRKQLGHHIGARNIEDDPKMMWSMHVAKIQSDREYKKDFEKWKTKFS
SPVDMLGWLAKKCQTLVSDVDYKNYLHEWTCLPDQNDVIHARQAYDLQSDNIYKSDLQ LRG
IGWVPIGSMDWKCKRAAEILSDNIYRQPPDKLKFTSVTDSLEQVLAKNNALNMNKRLYTEA
DKDKTQVHIMPDTPEIMLARQNKINYSESLYRQAMEEAKKEGYDLRSDAIPIVAAKASRDIAS
DYKYKEAYRKQLGHHIGARAVHDDPKIMWSLHIAKVQSDREYKKDFEKYKTRYSSPVDMLGIV
LAKKCQTLVSDVDYKHPLHECICLPDQNDIIHARKAYDLQSDNLYKSDLE MKGIG VPIDSL
EVVRAKRAGELLSDTIYRQRPETLKFTSITDTPEQVLAKNNALNMNKRLYTEAWDNDKKTIHV
MPDTPEIMLAKLNRINYSDKLYKLALEESKKEGYDLRLDAIPIQAAKASRDIASDYKYKEGYR KQLGHHIGARNIKDDPKMMWSIHVAKIQSDREYKKEFEKWKTKFSSPVDMLGVVLAKKCQI.LV SDIDYKHPLHEWTCLPDQNDVIQARKAYDLQSDAIYKSDLEWLRGIGWVPIGSVEVEKVKRAG EILSDRKYRQPADQLKFTCITDTPEIVLAKNNALTMSKHLYTEAWDADKTSIHVMPDTPDILL AKSNSANISQKLYTKGWDESKMKDYDLRADAISIKSAKASRDIASDYKYKEAYEKQKGHHIGA QSIEDDPKIMCAIHAEKIQSEREYKKEFQKWKTKFSSPVDMLSILLAKKCQTLVTDIYYRNYL HEWTCMPDQNDIIQAKKAYDLQSDALYKADLEWLRGIGWMPQGSPEVLRVKNAQNIFCDSVYR TPWNLKYTSIVDTPEWLAKSNAENISIPKYREVWDKDKTSIHIMPDTPEINLARANALNVS NKLYREGWDEMKAGCDVRLDAIPIQAAKASREIASDYKYKLDHEKQKGHYVGTLTARDDNKIR ALIADKLQNEREYRLDWAKWKAKIQSPVDMLSILHSKNΞQALVSDMDYRNYLHQWTCMPDQN DVIQAKKAYELQSDNVYKADLEWLRGIGWMPNDSVSVNHAKHAADIFSEKKYRTKIETLNFTP VDDRVDYVTAKQSGEILDDIKYRKDWNATKSKYTLTETPLLHTAQEAARILDQYLYKEGWERQ KATGYILPPDAVPFVHAHHCNDVQSELKYKAEHVKQKGHYVGVPTMRDDPKLVWFEHAGQIQN ERLYKEDYHKTKAKINIPADMVSVLAAKQGQTLVSDIDYRNYLHQWMCHPDQNDVIQARKAYD LQSDNVYRADLEWLRGIGWIPLDSVDHVRVTKNQEMMSQIKYKKNALENYPNFTSWDPPEIV LAKINSVNQSDVKYKETFNKAKGKYTFSPDTPHISHSKDMGKLYSTILYKGAWEGTKAYGYTL DERYIPIVGAKHADLVNSELKYKETYEKQKGHYLAGKVIGEFPGVVHCLDFQKMRSALNYRKH YEDTKA.WHIPNDMMNHVLAKRCQYILSDLEYRHYFHQWTSLLEEPNVIRVRNAQEILSDNVY KDDLNWLKGIGCYVWDTPQILHAKKSYDLQSQLQYTAAGKENLQNYNLVTDTPLYVTAVQSGI NASEVKYKENYHQIKDKYTTVLETVDYDRTRNLKNLYSSNLYKEAWDRVKATSYILPSΞTLSL THAKNQKHLASHIKYREEYEKFKALYTLPRSVDDDPNTARCLRVGKLNIDRLYRSVYEKNKMK IHIVPDMVEMVTAKDSQKKVSEIDYRLRLHEWICHPDLQVNDHVRKVTDQISDIVYKDDLNWL KGIGCYVWDTPEILHAKHAYDLRDDIKYKAHMLKTRNDYKLVTDTPVYVQAVKSGKQLSDAVY HYDYVHSVRGKVAPTTKTVDLDRALHAYKLQSSNLYKTSLRTLPTGYRLPGDTPHFKHIKDTR YMSSYFKYKEAYEHTKAYGYTLGPKDVPFVHVRRVNNVTSERLYRELYHKLKDKIHTTPDPPE IRQVKKTQEAVSELIYKSDFFKMQGHMISLPYTPQVIHCRYVGDITSDIKYKEDLQVLKGFGC FLYDTPDMVRSRHLRKLWSNYLYTDKAREMRDKYKWLDTPEYRKVQELKTHLSELVYRAAGK KQKSIFTSVPDTPDLLRAKRGQKLQSQYLYVELATKERPHHHAGNQTTALKHAKDVKDMVSEK KYKIQYEKMKDKYTPVPDTPILIRAKRAYWNASDLRYKETFQKTKGKYHTVKDALDIVYHRKV TDDISKIKYKENYMSQLGIWRSIPDRPEHFHHRAVTDTVSDVKYKEDLTWLKGIGCYAYDTPD FTLAEKNKTLYSKYKYKEVFERTKSDFKYVADSPINRHFKYATQLMNEKKYRADYEQRKDKYH LVVDEPRHLLAKTRSDQISQIKYRKNYEKSKDKFTSIVDTPEHLRTTKVNKQISDILYKLEYN KAKPRGYTTIHDTPMLLHVRKVKDEVSDLKYKEVYQRNKSNCTIEPDAVHIKAAKDAYKVNTN LDYKKQYEANKAHWKWTPDRPDFLQAAKSSLQQSDFEYKLDREFLKGCKLSVTDDKNTVLALR NTLIESDLKYKEKHVKERGTCHAVPDTPQILLAKTVSNLVSENKYKDHVKKHLAQGSYTTLPE TRDTVHVKEVTKHVSDTNYKKKFVKEKGKSNYSIMLEPPEVKHAMEVAKKQSDVAYRKDAKEK LHYTTVADRPDIKKATQAAKQASEVEYRAKHRKEGSHGLSMLGRPDIEMAKKAAKLSSQVKYR ENFDKEKGKTPKYNPKDSQLYKVMKDANNLASEVKYKADLKKLHKPVTDMKESLIMNHVLNTS QLASSYQYKKKYEKSKGHYHTIPDNLEQLHLKEATELQSIVKYKEKYEKERGKPMLDFETPTY ITAKESQQMQSGKEYRKDYEESIKGRNLTGLEVTPALLHVKYATKIASEKEYRKDLEESIRGK GLTEMEDTPDMLRAKNATQILNEKEYKRDLELEVKGRGLNAMANETPDFMRARNATDIASQIK YKQSAEMEKANFTSVVDTPEIIHAQQVKNLSSQKKYKEDAEKSMSYYETVLDTPEIQRVRENQ KNFSLLQYQCDLKNSKGKITVVQDTPEILRVKENQKNFSSVLYKEDVSPGTAIGKTPEMMRVK QTQDHISSVKYKEAIGQGTPIPDLPEVKRVKETQKHISSVMYKENLGTGIPIPITPEIERVKH NQENLSSVLYKENMGKGTPLPVTPEMERVKHNQENISSVLYKENMGKGTPLPVTPEMERVKHN QENISSVLYKENMGKGTPLPVTPEMERVKHNQENISSVLYKENVGKATATTVTPEMQRVKRNQ ENFSSVLYKENLGKATPTPFTPEMERVKRNQENISSVLYKENMRKATPTPVTPEMERAKRNQE NISSVLYSDSFRKQIQGKAAYVLDTPEMRRVRETQRHISTVKYHEDFEKHKGCFTPWTDPIT ERVKKNMQDFSDINYRGIQRKWEMEQKRNDQDQETITGLRVWRTNPGSVFDYDPAEDNIQSR SLHMI VQAQRRSREQSRSASALSVSGGEEKSEHSEAPDHHLSTYSDGGVFAVSTAYKHAKTT ELPQQRSSSVATQQTTVSSIPSHPSTAGKIFRAMYDYMAADADEVSFKDGDAIINVQAIDEGW MYGTVQRTGRTGMLPANYVEAI
SEQIDNO: 141 20881 bp 1
■NOV35b, CCCCACCTTTTGAGCAAGTTCAGCCTGGTTAAGTCCAAGCTGGTGATAAAACTACAAAGCAGA
■CG I 19566-02 DNA ATACGAAGAAGACAGAGGCAAAGGCTTCTTCCCTCAGACCATAACTCAAGAATATGGGGGTCT
CGCAGTAATTTATGCTCTTTGCTTTTGTCTTTTCATAGTTTTCCTTGTATAGTTTGTCACTTA
JSequence GGGCATCTCCTGCTGCCTTCAGCTGCCTAAGCTGTGGGTTCTCTGAAGCAGGAAGCACATTAT
AATCTGCTTTTCCTTTATTCTTTTCATAGTCTTCTTTGTATTTTGCTGCTGAGGAAATTTATT GGTAGATTGAAGGTTTGAACGAGAGCTACAGAAACGAAAGAAAAAGTCTGTATAAGCCAATG
GTGTTCGGGAAGAAAATAACCCCATTGCCTTGAGTTTGTAGGTGCCACTACTACTCTGAAAAA
TGGCAGATGACGAAGACTATGAGGAGGTGGTGGAGTACTACACAGAAGAAGTGGTTTACGAAG AGGTGCCGGGAGAGACAATAACAAAAATTTATGAGACTACGACAACAAGGACATCTGACTATG AGCAATCAGAAACTTCCAAACCAGCTCTGGCACAGCCAGCACTGGCACAGCCAGCATCAGCAA AGCCGGTGGAGAGGAGGAAGGTCATCCGGAAGAAAGTGGATCCTTCAAAGTTCATGACCCCCT ACATTGCACACAGTCAGAAAATGCAGGATCTTTTTAGCCCAAATAAATACAAGGAGAAGTTTG
AGAAAACAAAAGGACAGCCATACGCCAGCACAACAGATACTCCAGAACTTCGCAGAATCAAAA
AAGTACAAGATCAACTCAGTGAGGTTAAGTATCGAATGGATGGTGATGTTGCTAAGACTATAT
GTCACGTAGATGAAAAAGCAAAGGATATTGAACATGCAAAGAAAGTGTCGCAGCAAGTCAGTA
AGGTTTTATACAAGCAGAACTGGGAAGACACCAAGGATAAGTACCTGCTTCCTCCTGATGCCC
CTGAACTTGTCCAGGCCGTTAAGAACACCGCCATGTTCAGCAAGAAACTGTACACTGAAGACT
GGGAAGCAGACAAAAGTTTGTTTTACCCCTATAATGATAGCCCGGAACTGAGGAGAGTTGCCC
AGGCCCAGAAAGCTCTCAGTGATGTTGCCTACAAAAAAGGTCTCGCTGAACAGCAAGCTCAAT
TCACGCCTCTGGCCGATCCTCCAGATATAGAATTTGCCAAGAAAGTAACCAATCAAGTGAGCA
AGCAAAAATACAAAGAAGACTATGAAAATAAAATCAAAGGCAAATGGAGTGAGACACCTTGCT
TTGAAGTTGCAAATGCCAGAATGAATGCTGATAACATTAGCACAAGGAAATACCAGGAAGATT
TTGAAAACATGAAAGACCAGATCTACTTCATGCAGACCGAAACACCAGAGTATAAAATGAATA
AAAAAGCTGGTGTGGCAGCTAGCAAGGTAAAATACAAAGAAGACTATGAAAAGAATAAAGGAA
AAGCAGATTATAATGTGCTTCCTGCTTCAGAGAACCCACAGCTTAGGCAGCTGAAGGCAGCAG
GAGATGCCCTAAGTGACAAACTATACAAGGAAAACTATGAAAAGACAAAAGCAAAGAGCATAA
ATTACTGCGAGACCCCCAAATTCAAGCTCGATACTGTTCTGCAGAACTTCAGTAGTGATAAAA
AATATAAAGATTCCTACTTAAAAGATATTTTGGGACATTATGTAGGCAGCTTCGAGGATCCAT
ACCATTCACACTGCATGAAAGTCACAGCTCAAAACAGTGATAAAAACTACAAAGCAGAATACG
AAGAAGACAGAGGCAAAGGCTTCTTCCCTCAGACCATAACTCAAGAATATGAAGCAATTAAGA
AACTAGATCAGTGTAAAGACCACACCTACAAAGTCCATCCAGATAAGACAAAATTCACCCAAG
TTACAGACTCTCCTGTTCTGCTACAAGCCCAAGTCAATTCCAAACAACTGAGTGACTTAAATT
ACAAAGCAAAACATGAAAGTGAAAAGTTCAAGTGCCATATCCCCCCTGATACTCCTGGTTTTA
TCCAGCACAAAGTCAATGCCTATAACTTGAGTGATAATCTTTATAAGCAAGACTGGGAGAAGA
GCAAAGCCAAAAAGTTTGACATTAAAGTGGATGCCATTCCCCTGCTGGCAGCCAAAGCCAACA
CCAAGAACACCAGCGATGTGATGTACAAGAAAGACTATGAAAAAAACAAAGGGAAAATGATTG
GAGTCCTCAGCATTAATGACGATCCCAAGATGCTGCACTCCTTGAAGGTGGCCAAAAACCAGA
GTGATAGATTATACAAGGAAAACTATGAGAAGACAAAGGCAAAGAGTATGAATTACTGTGAGA
CCCCAAAATATCAACTTGATACTCAGCTGAAGAACTTCAGTGAGGCTAGATATAAAGACTTAT
ATGTAAAGGATGTTTTGGGACATTATGTAGGCAGCATGGAGGACCCATATCACACACACTGCA
TGAAAGTTGCAGCTCAAAACAGTGATAAAAGTTACAAAGCAGAATATGAAGAAGATAAAGGAA
AATGCTATTTCCCTCAGACAATAACACAAGAATATGACGCAATCAAGAAGCTGGACCAGTGTA
AAGATCATACCTACAAAGTTCATCCAGATAAGACCAAATTCACGGCAGTCACTGATTCTCCTG
TACTGTTGCAAGCCCAGCTCAACACGAAACAGCTTAGTGATCTGAATTACAAAGCAAAACATG
AAGGTGAGAGGTTCAAGTGCCATATACCAGCAGATGCTCCACAGTTTATCCAACACAGAGTCA
ATGCCTATAATCTGAGTGATAATGTTTATAAGCAAGACTGGGAGAAGAGCAAAGCCAAGAAGT
TTGACATTAAAGTGGACGCCATTCCCCTGTTGGCAGCCAAAGCCAACACCAAGAACACCAGCG
ATGTGATGTACAAGAAAGACTATGAAAAGAGCAAAGGGAAAATGATTGGAGCCCTCAGCATTA
ATGACGATCCAAAGATGCTGCACTCCTTGAAGACAGCCAAAAACCAGAGTGATCGCGAATATC
GAAAAGATTATGAAAAGTCAAAAACTATCTACACGGCACCTCTTGATATGCTCCAAGTCACTC
AAGCTAAGAAATCTCAGGCAATTGCCAGCGACGTTGATTATAAGCACATCTTACACAGTTACA
GCTACCCCCCTGATAGCATCAATGTGGACCTTGCCAAGAAGGCATATGCGCTGCAGAGCGATG
TTGAATACAAAGCTGACTACAATAGCTGGATGAAAGGTTGTGGCTGGGTGCCTTTTGGGTCCT
TAGAAATGGAAAAGGCAAAGCGAGCTTCAGACATCCTCAATGAGAAAAAATATCGCCAACATC
CAGACACCCTCAAGTTTACCTCGATTGAAGATGCTCCAATTACAGTACAGTCTAAAATTAACC
AGGCCCAGAGGAGTGATATCGCTTACAAAGCCAAAGGAGAGGAAATTATTCACAATTACAACC
TGCCACCAGACCTGCCCCAGTTCATCCAGGCTAAAGTTAATGCCTACAATATCAGTGAGAATA
TGTACAAAGCAGACTTGAAAGACTTGAGCAAGAAGGGATATGACCTGAGAACTGATGCGATTC
CCATCAGAGCTGCCAAAGCTGCCAGGCAGGCGGCGAGTGACGTTCAGTACAAAAAAGACTATG
AAAAGGCTAAAGGGAAAATGGTTGGCTTCCAAAGTCTTCAAGATGACCCTAAACTGGTTCATT
ATATGAACGTGGCCAAGATACAATCAGATCGGGAGTATAAAAAAGACTATGAGAAGACAAAGT
CCAAATACAACACGCCCCATGATATGTTCAATGTCGTGGCGGCTAAGAAAGCCCAGGATGTGG
TCAGCAATGTCAACTATAAGCATTCTCTCCATCATTACACCTACTTGCCTGACGCCATGGACC
TGGAGCTGTCTAAGAACATGATGCAGATACAGAGTGATAACGTCTACAAGGAAGACTACAACA
ACTGGATGAAAGGCATTGGCTGGATTCCTATTGGCAGTCTCGACGTCGAAAAAGTTAAAAAGG
CCGGTGATGCTCTGAATGAAAAGAAGTACAGGCAACATCCAGACACCCTCAAATTTACCAGCA
TTGTGGACTCCCCAGTTATGGTCCAGGCAAAACAGAACACGAAGCAAGTCAGTGATATCTTAT
ACAAGGCTAAAGGAGAAGATGTGAAACATAAATACACCATGAGTCCTGATCTTCCTCAGTTTC
TCCAGGCCAAGTGCAATGCTTACAGTATAAGTGACGTCTGTTATAAACGGGATTGGCATGACT
TAATACGCAAGGGCAACAATGTGCTGGGCGATGCTATTCCCATCACTGCAGCCAAGGCATCGA
GAAACATTGCCAGTGATTATAAATACAAGGAAGCTTATGAGAAGTCAAAGGGAAAGCATGTGG
GTTTCAGAAGCCTCCAGGATGATCCCAAGCTGGTCCACTATATGAATGTGGCAAAGCTGCAGT
CTGATCGTGAATACAAGAAGAACTATGAGAACACCAAAACCAGCTACCATACCCCTGGGGACA
TGGTTACGATCACAGCTGCAAAGATGGCCCAGGATGTCGCTACCAATGTCAACTACAAACAGC
CATTGCATCATTACACATACCTACCTGACGCCATGAGTCTTGAGCATACGAGGAATGTCAATC
AAATTCAGAGTGATAATGTGTATAAAGACGAGTATAACAGCTTCTTGAAGGGCATCGGATGGA
TCCCTATTGGTTCCCTGGAGGTGGAGAAGGTCAAGAAAGCAGGCGATGCATTAAATGAGAGGA
AGTATCGACAGCACCCAGATACCGTCAAGTTCACAAGTGTGCCTGATTCCATGGGCATGATGT
TGGCTCAGCATAACACAAAGCAGCTAAGTGATTTGAACTACAAGGTAGAGGGAGAGAAACTGA
AGCACAAGTATACTATTGACCCTGAATTGCCTCAGTTTATTCAAGCCAAAGTCAACGCCCTCA
ACATGAGTGATGCTCATTATAAAGCAGATTGGAAGAAAACCATTCGCAAGGGCTATGATTTGA
GACCAGATGCCATCCCAATTGTTGCTGCAAAAAGTTCAAGGAATATTGCTAGTGATTGCAAAT
ATAAGGAGGCCTACGAGAAAGCCAAAGGCAAGCAAGTTGGATTTCTCAGTCTTCAGGATGATC
CTAAACTGGTTCACTACATGAATGTGGCCAAAATCCAGTCTGATCGTGAGTACAAAAAGGGCT
ATGAAGCCAGCAAGACCAAGTACCACACACCTCTGGATATGGTCAGTGTGACAGCTGCAAAGA
AATCTCAGGAGGTTGCCACCAACGCCAACTACAGACAGTCATACCACCACTACACTCTCCTGC
CCGATGCCTTGAATGTGGAGCACTCCAGGAATGCCATGCAGATTCAGAGTGATAATCTGTACA
AATCTGACTTCACCAATTGGATGAAAGGGATCGGCTGGGTGCCCATAGAGTCCCTGGAGGTGG
AGAAGGCAAAGAAAGCAGGAGAGATTCTTAGTGAGAAGAAGTATCGCCAGCACCCCGAGAAGC
TGAAGTTCACTTACGCCATGGACACAATGGAACAGGCACTTAACAAGAGTAACAAACTGAACA
TGGACAAGAGGCTCTACACTGAAAAATGGAACAAGGACAAGACCACCATTCATGTCATGCCTG
ACACACCGGATATTTTACTCTCCAGAGTAAACCAAATCACCATGAGTGATAAACTGTACAAAG
CTGGCTGGGAAGAGGAAAAGAAGAAAGGATATGACCTGAGGCCTGATGCCATTGCAATAAAGG
CTGCAAGAGCCTCTAGAGACATTGCCAGTGATTACAAATACAAGAAAGCCTATGAACAAGCCA
AAGGGAAACACATTGGCTTCCGGAGCCTGGAAGATGACCCCAAGCTGGTGCACTTCATGCAAG
TGGCCAAGATGCAGTCAGACCGGGAATACAAGAAGGGATATGAGAAATCCAAGACCTCCTTCC
ACACCCCGGTGGACATGCTCAGTGTGGTGGCAGCCAAGAAGTCTCAGGAAGTGGCCACCAATG
CCAACTACAGGAACGTGATCCATACCTACAACATGCTTCCTGATGCCATGAGCTTTGAATTGG
CCAAAAATATGATGCAGATTCAAAGTGATAATCAGTACAAGGCTGACTATGCTGACTTCATGA
AGGGCATTGGATGGCTCCCTCTGGGCTCCCTGGAAGCAGAGAAAAACAAGAAAGCCATGGAGA
TTATTAGTGAAAAGAAGTACCGCCAGCACCCAGACACTTTGAAGTATTCCACACTCATGGACT
CGATGAACATGGTTTTGGCCCAGAATAATGCAAAAATTATGAACGAACATCTCTACAAACAAG
CATGGGAGGCTGACAAAACCAAAGTCCACATCATGCCTGATATCCCCCAGATTATTTTGGCAA
AGGCAAATGCAATTAATATAAGTGATAAACTCTACAAACTTTCCTTGGAAGAGTCTAAAAAGA
AAGGCTATGATCTCAGACCTGATGCAATTCCTATCAAAGCTGCCAAGGCTTCCAGAGATATTG
CAAGTGATTATAAATACAAGTACAATTATGAAAAAGGGAAGGGGAAAATGGTTGGTTTCCGCA
GTCTCGAGGATGATCCCAAATTAGTCCATTCCATGCAAGTGGCTAAGATGCAATCTGATCGGG
AGTACAAGAAAAACTATGAGAACACAAAGACCAGCTACCACACCCCTGCCGACATGCTCAGTG
TCACGGCTGCAAAGGATGCCCAAGCCAACATCACCAACACTAACTACAAGCACCTGATTCACA
AGTACATCCTCCTTCCAGATGCAATGAACATTGAGCTGACCAGGAATATGAATCGCATACAGA
GTGATAATGAATATAAGCAAGATTACAATGAATGGTACAAAGGGCTTGGCTGGAGTCCAGCAG
GTTCTCTGGAAGTGGAGAAGGCCAAGAAAGCAACTGAATATGCCAGTGATCAGAAATACCGCC
AGCACCCGAGCAACTTCCAGTTTAAGAAGCTGACTGATTCCATGGACATGGTGCTTGCCAAGC
AGAATGCACATACCATGAACAAGCATTTATACACCATTGATTGGAATAAAGATAAGACCAAGA
TTCATGTGATGCCTGATACACCAGATATTTTACAAGCCAAGCAGAATCAAACACTGTATAGTC
AGAAACTCTATAAACTTGGATGGGAAGAAGCTTTGAAGAAAGGCTATGATCTCCCAGTTGATG
CAATTTCTGTACAGCTAGCTAAAGCTTCAAGAGACATTGCTAGTGATTATAAATACAAACAAG
GCTACCGAAAGCAACTTGGCCACCATGTTGGATTCCGGAGTCTGCAAGATGACCCAAAACTTG
TGTTGTCCATGAATGTAGCCAAAATGCAGAGTGAAAGAGAATACAAGAAGGACTTTGAGAAGT
GGAAAACTAAGTTCTCCAGCCCAGTGGACATGTTGGGAGTGGTACTGGCCAAGAAGTGTCAGG
AGTTGGTTAGTGACGTGGACTACAAGAACTACCTGCATCAGTGGACATGTCTGCCTGATCAGA
ACGATGTTGTGCAAGCTAAGAAAGTTTATGAACTGCAAAGTGAGAATCTATATAAATCTGACC
TTGAGTGGCTGAGAGGCATAGGATGGAGTCCCTTGGGTTCTTTAGAGGCAGAAAAGAACAAGC
GGGCTTCGGAAATCATCAGTGAGAAGAAATATCGTCAGCCTCCAGACAGAAACAAGTTCACCA
GCATTCCTGATGCCATGGATATAGTTCTGGCAAAGACAAATGCCAAAAATAGGAGTGATAGAC
TTTATAGAGAAGCTTGGGACAAAGACAAGACTCAGATCCACATCATGCCTGATACACCTGACA
TTGTTCTGGCTAAAGCAAACTTAATCAACACAAGTGATAAACTCTACCGAATGGGTTATGAGG
AGCTGAAGAGAAAAGGTTACGATCTTCCTGTTGATGCCATACCAATCAAAGCAGCAAAAGCCT
CCCGGGAAATTGCCAGTGAATACAAGTACAAGGAAGGCTTTCGCAAGCAGCTCGGCCACCACA
TTGGTGCCCGGAACATTGAAGATGACCCCAAGATGATGTGGTCCATGCATGTGGCCAAGATCC
AGAGTGACAGGGAGTACAAGAAGGACTTTGAGAAGTGGAAGACCAAGTTCAGCAGCCCAGTGG
ACATGCTGGGGGTGGTGTTGGCCTATAAGTGCCAGACCTTAGTCAGCGACGTGGACTACAAGA
ACTACCTGCACCAGTGGACATGCCTGCCCGACCAGAGCGATGTCATCCATGCTCGGCAGGCCT
ATGACCTCCAGAGCGATAATTTGTACAAGTCAGACCTTCAGTGGCTAAAAGGCATTGGCTGGA
TGACTAGTGGTTCTCTCGAGGATGAGAAAAATAAACGAGCCACCCAGATTTTGAGTGACCATG
TTTACCGTCAGCACCCAGATCAATTTAAGTTTTCCAGCCTTATGGATTCCATACCAATGGTTT
TGGCAAAAAACAATGCTATTACCATGAATCATCGCCTCTATACAGAAGCTTGGGATAAAGATA
AAACCACTGTCCACATTATGCCAGATACCCCTGAAGTTTTATTAGCTAAACAAAACAAAGTAA
ATTACAGTGAGAAATTGTATAAGCTTGGCCTAGAAGAAGCCAAGAGGAAAGGTTATGACATGC
GGGTAGATGCCATTCCTATCAAGGCAGCCAAGGCCTCCAGAGATATTGCAAGTGAATTCAAGT
ACAAAGAAGGCTATCGTAAGCAGCTCGGCCACCACATTGGTGCCCGAGCTATACGTGATGACC
CCAAGATGATGTGGTCCATGCACGTGGCCAAGATCCAGAGTGACAGGGAGTACAAGAAGGACT
TTGAGAAGTGGAAGACCAAGTTCAGCAGCCCAGTGGACATGCTGGGGGTGGTGCTGGCCAAGA
AGTGCCAGACCTTAGTCAGCGATGTGGACTACAAGAACTACCTGCACCAGTGGACATGCCTGC
iCCGACCAGAGCGACGTCATCCATGCTCGGCAGGCCTATGACCTCCAGAGCGATAATATGTACA •AGTCTGATCTCCAGTGGATGAGAGGCATTGGCTGGGTGTCCATTGGCTCTTTGGATGTGGAAA JAATGCAAAAGGGCAACTGAAATTTTGAGTGATAAAATCTATCGCCAGCCTCCAGACAGATTCA jAATTTACCAGTGTGACTGACTCTCTGGAACAAGTGCTGGCCAAGAACAATGCTCTCAACATGA JATAAGCGTTTATACACAGAGGCCTGGGACAAAGACAAGACTCAAATTCACATAATGCCTGATA CACCAGAGATTATGTTGGCAAGGCAGAACAAAATCAACTACAGTGAGACTCTATACAAACTTG CCAATGAAGAAGCAAAAAAGAAAGGCTACGACTTGCGAAGTGACGCCATCCCCATCGTGGCTG CCAAGGCCTCCAGGGACGTTATCAGTGATTACAAATACAAAGATGGTTACCGCAAGCAGCTCG GCCACCACATTGGAGCCCGGAACATTGAAGATGACCCCAAGATGATGTGGTCCATGCATGTGG CCAAGATCCAGAGTGACAGGGAGTATAAGAAGGACTTTGAGAAGTGGAAGACCAAGTTCAGCA GCCCAGTGGACATGCTGGGAGTGGTGTTAGCCAAGAAGTGCCAGACCTTAGTCAGCGATGTGG ACTACAAGAACTACCTGCACGAGTGGACGTGCCTGCCCGACCAGAATGATGTCATCCATGCTC GGCAGGCCTATGACCTCCAGAGCGATAACATTTACAAATCTGATCTCCAGTGGCTGAGAGGCA TTGGCTGGGTCCCCATTGGGTCTATGGATGTGGTCAAGTGCAAGAGAGCTGCTGAAATACTGA GTGATAACATCTACCGCCAGCCTCCGGACAAGCTGAAATTTACCAGTGTGACTGACTCTCTAG AGCAGGTGCTGGCCAAGAACAATGCTCTCAATATGAACAAGCGCTTATACACAGAAGCCTGGG ACAAAGACAAGACCCAAGTCCATATTATGCCTGATACACCTGAAATCATGTTGGCAAGACAAA ATAAAATAAATTATAGTGAGAGCCTCTATCGTCAGGCCATGGAAGAAGCCAAGAAAGAAGGCT ATGACTTGAGAAGTGATGCCATTCCCATTGTGGCTGCCAAGGCCTCTCGGGATATTGCCAGTG ATTACAAATACAAAGAAGCATATCGTAAGCAGTTGGGTCACCACATTGGCGCCCGAGCAGTAC ACGATGACCCCAAGATAATGTGGTCCCTCCACATTGCCAAAGTGCAGAGTGACCGTGAGTACA AGAAAGATTTTGAGAAATACAAGACAAGGTACAGCAGCCCAGTGGACATGCTTGGTATCGTTT TGGCCAAGAAGTGTCAGACCTTGGTCAGCGATGTGGACTATAAACATCCTCTGCATGAATGCA TCTGCCTGCCCGACCAGAATGACATCATTCATGCACGGAAAGCCTATGACCTCCAGAGTGACA ATTTGTATAAGTCAGACCTTGAATGGATGAAAGGCATTGGCTGGGTTCCGATTGATTCCTTGG AAGTTGTTAGGGCCAAGAGAGCTGGAGAATTACTTAGTGATACTATCTACCGTCAGCGTCCAG AAACGCTGAAATTTACCAGTATAACGGACACTCCGGAGCAGGTGCTGGCAAAAAACAATGCTT TAAACATGAATAAGCGCTTATATACTGAAGCCTGGGACAATGACAAGAAAACTATTCATGTCA TGCCTGATACACCAGAAATCATGTTAGCCAAACTCAACCGAATAAACTACAGTGATAAACTCT ATAAACTTGCTTTGGAAGAGTCCAAGAAGGAAGGCTATGACTTGCGTCTGGATGCCATTCCAA TCCAAGCAGCCAAGGCTTCAAGAGATATTGCTAGTGATTACAAGTACAAGGAAGGCTACCGCA AACAGCTTGGCCACCATATTGGGGCCCGGAACATTAAGGATGACCCGAAGATGATGTGGTCCA TCCATGTGGCCAAGATCCAGAGTGACAGGGAGTACAAGAAGGAGTTTGAGAAGTGGAAGACCA AGTTCAGCAGCCCAGTGGACATGCTGGGGGTGGTGCTGGCCAAGAAGTGTCAGATCCTTGTAA GCGACATAGACTACAAGCATCCCCTGCATGAATGGACCTGCCTGCCTGATCAGAATGACGTCA TTCAGGCTCGGAAGGCCTATGACCTGCAGAGTGATGCTATTTACAAATCTGATCTTGAGTGGC ,TGAGAGGCATAGGATGGGTTCCCATTGGCTCTGTAGAGGTCGAGAAAGTGAAGAGAGCTGGAG AAATCCTGAGTGACAGGAAGTATCGCCAGCCTGCAGACCAGCTCAAATTCACATGCATTACCG ACACTCCGGAAATTGTCCTAGCAAAGAATAATGCCCTGACAATGAGCAAGCATTTATACACAG AAGCTTGGGATGCTGACAAAACCTCCATCCACGTGATGCCAGACACCCCAGATATCCTGCTGG CCAAGAGTAATTCTGCCAATATCAGCCAAAAACTTTACACCAAGGGATGGGATGAATCAAAGA TGAAGGACTATGATCTGAGAGCAGATGCTATTTCCATCAAAAGTGCCAAGGCCTCCAGGGACA TCGCCAGTGACTACAAATACAAGGAAGCCTATGAGAAACAGAAAGGCCACCACATTGGAGCCC AGAGCATTGAAGATGATCCCAAGATTATGTGTGCCATACATGCAGAAAAAATTCAAAGTGAAA GGGAGTACAAGAAGGAATTCCAAAAGTGGAAAACCAAGTTCTCTAGCCCAGTGGACATGTTAA GCATCTTGCTGGCCAAGAAATGTCAGACTTTGGTCACTGACATTTATTATCGCAATTACCTGC IATGAATGGACATGCATGCCGGATCAAAACGACATTATCCAAGCAAAAAAGGCCTATGACCTGC ^GAGTGATGCCCTCTACAAGGCTGACTTGGAGTGGTTGCGTGGCATTGGCTGGATGCCCCAAG GGTCTCCTGAAGTGTTGAGAGTCAAAAACGCCCAGAATATCTTTTGTGACAGTGTCTATCGGA CGCCTGTGGTGAACCTTAAGTACACAAGCATTGTTGACACACCTGAAGTGGTCCTTGCTAAAT CAAATGCTGAAAATATTAGTATTCCAAAGTACAGAGAGGTTTGGGACAAGGATAAAACTTCAA :TACACATAATGCCAGATACTCCAGAAATTAATCTCGCTAGAGCAAATGCTCTTAATGTGAGCA ATAAACTTTACCGTGAGGGCTGGGATGAAATGAAGGCGGGCTGTGATGTCCGGCTGGATGCCA TCCCCATCCAGGCTGCCAAGGCCTCCAGGGAGATTGCCAGTGACTATAAATATAAGCTTGACC
ΪATGAGAAGCAGAAGGGACACTACGTGGGCACCCTCACAGCCAGGGATGACAACAAGATCCGCT JGGGCCCTCATAGCTGACAAGCTCCAGAATGAACGAGAGTACCGGCTGGACTGGGCCAAATGGA AGGCCAAGATCCAGAGCCCTGTGGACATGCTTTCCATCCTGCACTCTAAAAATTCCCAGGCTC TGGTCAGTGACATGGATTACCGCAATTACCTGCACCAGTGGACCTGCATGCCCGACCAGAACG ATGTGATTCAGGCCAAGAAGGCCTACGAACTGCAGAGCGATAATGTTTACAAGGCTGACTTGG AATGGTTGCGTGGAATTGGGTGGATGCCAAATGACTCCGTGTCCGTCAATCATGCCAAACATG CCGCGGACATCTTCAGTGAGAAAAAATATCGCACAAAAATAGAAACTCTCAACTTTACGCCTG TGGATGACAGAGTTGATTATGTGACAGCGAAACAAAGTGGCGAGATCCTCGATGATATTAAAT ACCGGAAAGACTGGAATGCCACCAAATCAAAGTACACCCTCACAGAAACCCCCCTGCTGCACA CTGCCCAGGAGGCTGCTAGGATACTGGACCAGTATCTCTACAAGGAAGGCTGGGAGAGACAAA AAGCCACAGGTTACATTTTGCCTCCAGATGCTGTGCCATTTGTTCATGCCCATCACTGCAATG ACGTTCAGAGTGAGCTGAAATACAAAGCTGAACATGTGAAGCAAAAAGGTCATTATGTTGGTG
TCCCGACGATGAGAGATGATCCTAAGCTGGTTTGGTTTGAGCATGCAGGCCAGATTCAGAATG
AGAGACTATACAAAGAGGACTATCACAAAACAAAGGCCAAAATCAATATACCTGCTGATATGG
TGTCAGTCTTGGCCGCCAAGCAGGGGCAGACCCTTGTCAGTGATATTGATTATCGTAATTACT
TGCACCAATGGATGTGTCATCCTGACCAGAACGATGTTATTCAGGCAAGAAAGGCCTATGACC
TACAGAGTGATAATGTCTACAGAGCTGACCTGGAGTGGCTCCGAGGCATTGGCTGGATCCCAC
TGGATTCTGTGGACCATGTAAGGGTTACTAAGAACCAGGAAATGATGAGTCAGATCAAATATA
AGAAAAATGCCCTTGAAAACTATCCTAACTTTACAAGTGTGGTGGATCCTCCAGAGATTGTTT
TAGCCAAGATTAATTCTGTCAATCAAAGTGATGTAAAATATAAAGAAACATTTAATAAAGCAA
AGGGCAAATATACGTTTTCACCAGATACACCACATATCTCCCACTCCAAAGACATGGGAAAAC
TCTACAGTACTATACTGTATAAAGGGGCGTGGGAGGGCACCAAGGCCTATGGCTACACCCTGG
ATGAGCGCTACATTCCCATTGTTGGAGCCAAGCATGCTGATCTGGTGAACAGTGAGCTTAAAT
ACAAAGAGACATATGAGAAGCAGAAAGGTCACTACCTGGCTGGAAAAGTGATCGGTGAATTCC
CTGGTGTGGTTCACTGTCTGGATTTCCAAAAGATGAGGAGTGCGTTGAACTACAGAAAACATT
ATGAGGATACCAAAGCAAATGTTCATATCCCCAATGACATGATGAATCACGTGCTGGCTAAAA
GGTGCCAGTACATCCTCAGTGACCTGGAGTATCGACACTATTTCCACCAGTGGACGTCTCTTC
TGGAAGAACCCAATGTTATACGCGTCCGAAACGCCCAGGAGATCTTGAGTGATAATGTGTATA
AAGATGACCTGAATTGGTTGAAAGGCATTGGTTGCTACGTTTGGGATACACCCCAAATCCTCC
ATGCCAAGAAATCATACGACCTTCAGAGTCAGCTACAATATACAGCAGCAGGTAAAGAAAATC
TACAAAACTATAATCTGGTCACAGACACGCCCCTCTATGTGACTGCTGTTCAGAGTGGCATTA
ATGCCAGTGAGGTAAAATATAAAGAAAATTATCATCAGATTAAGGACAAATACACAACAGTTC
TAGAAACAGTGGATTATGACAGAACCAGAAACCTGAAGAATCTTTACAGCAGTAACCTGTACA
AGGAGGCCTGGGATAGAGTGAAAGCCACCAGCTACATCCTGCCTTCCAGCACCTTGTCCCTGA
CACACGCCAAGAACCAGAAGCATCTGGCCAGCCATATCAAATATCGGGAAGAATATGAAAAGT
TCAAAGCTCTTTATACGTTACCAAGAAGTGTTGACGATGATCCGAACACAGCACGGTGCCTCC
GAGTTGGCAAGCTTAACATCGATCGCCTGTACAGATCAGTTTATGAAAAGAACAAGATGAAAA
TCCACATCGTGCCCGACATGGTAGAGATGGTTACTGCCAAGGATTCCCAGAAGAAAGTCAGTG
AGATTGATTACCGCCTGCGCCTCCACGAATGGATTTGCCACCCCGACTTGCAAGTCA.-ΓGATC
ACGTCAGGAAAGTCACAGATCAGATCAGCGATATTGTATACAAGGATGACCTCAACTGGCTGA
AAGGCATTGGTTGCTACGTCTGGGACACTCCTGAAATCCTCCATGCCAAGCATGCTTATGATC
TACGTGATGATATCAAGTATAAAGCTCACATGTTGAAAACAAGGAATGACTACAAGCTTGTCA
CAGATACACCAGTCTACGTGCAGGCTGTCAAAAGTGGGAAACAGCTAAGTGACGCTGTCTACC
ACTATGACTATGTGCACAGTGTCAGAGGCAAAGTGGCTCCAACTACCAAAACCGTGGATCTGG
ACCGGGCCCTTCATGCATACAAGCTCCAGAGTTCGAATCTATACAAAACCAGCCTGCGCACCC
TGCCCACTGGATATAGACTTCCAGGTGACACTCCTCACTTCAAACACATCAAGGACACCCGTT
ACATGAGCAGTTATTTCAAGTACAAAGAAGCCTATGAACACACCAAGGCATATGGGTATACAC
TTGGCCCCAAAGATGTTCCATTTGTCCACGTCCGGAGAGTCAACAATGTTACCAGCGAGAGAC
TGTATCGGGAATTGTACCACAAACTGAAAGACAAGATCCATACAACTCCCGATCCCCCTGAGA
TCCGCCAAGTCAAGAAGACACAAGAGGCTGTCAGTGAGTTGATCTACAAATCAGACTTCTTCA
AGATGCAGGGCCACATGATCTCTCTGCCATACACACCCCAAGTGATCCATTGCCGCTATGTGG
GAGACATCACCAGTGATATTAAATACAAAGAGGACTTGCAGGTCCTGAAGGGATTTGGCTGCT
TCCTGTATGACACTCCTGACATGGTCCGCTCCCGGCACCTGCGGAAGCTCTGGTCTAATTACC
TATACACTGATAAGGCAAGGGAGATGCGAGACAAATACAAAGTGGTGCTTGACACTCCAGAAT
ACAGAAAAGTGCAAGAACTGAAGACACATCTGAGTGAGCTGGTCTACAGAGCTGCAGGCAAGAL
AGCAGAAGTCAATCTTTACTTCAGTTCCTGATACTCCTGATCTTTTAAGAGCCAAGCGAGGGC
AGAAGCTTCAGAGTCAGTATCTGTATGTTGAACTTGCCACCAAAGAGAGACCCCATCATCACG
CTGGAAACCAGACCACAGCCTTGAAGCATGCTAAAGACGTGAAGGACATGGTCAGTGAGAAAA
AGTACAAGATTCAATATGAAAAGATGAAAGACAAGTACACTCCGGTTCCAGATACGCCAATCC
TCATCAGAGCCAAGAGGGCTTACTGGAATGCCAGTGATCTACGCTACAAAGAAACATTTCAAA
AGACCAAAGGGAAATACCACACGGTGAAAGATGCCCTAGACATTGTCTATCATCGCAAAGTCA
CAGATGACATCAGTAAAATAAAATACAAGGAGAACTACATGAGCCAGTTGGGTATCTGGAGGT
CCATTCCTGATCGTCCAGAGCATTTCCACCACCGAGCAGTCACTGACACAGTCAGTGATGTAA
AATATAAAGAAGACTTGACTTGGCTTAAAGGCATTGGTTGCTATGCCTATGATACCCCTGATT
TCACTCTGGCTGAAAAGAACAAGACTCTCTACAGCAAGTATAAGTATAAAGAAGTATTTGAAA
GGACAAAGTCAGATTTCAAGTATGTTGCCGACTCTCCGATCAATAGGCATTTCAAGTATGCAA
CTCAATTGATGAATGAGAAAAAATACAGAGCTGATTATGAGCAGCGGAAAGATAAATACCACC
TGGTAGTCGATGAGCCTAGACATCTGCTGGCTAAGACCCGCAGCGACCAGATCAGTCAGATCA
AATACAGGAAAAACTATGAAAAATCAAAGGACAAATTTACCTCAATTGTGGATACTCCAGAAC
ACCTGCGTACTACAAAAGTCAACAAACAAATCAGCGATATCCTTTATAAATTGGAATACAACA
AGGCCAAACCCAGAGGCTACACCACAATCCACGACACGCCCATGTTGCTGCATGTCCGCAAGG
TTAAAGATGAAGTCAGTGATCTGAAATACAAAGAAGTATACCAAAGAAATAAATCCAACTGCA
CCATTGAGCCAGATGCTGTTCATATCAAAGCAGCCAAGGACGCCTACAAAGTCAACACCAATC
TGGACTATAAGAAACAGTACGAAGCCAACAAAGCCCACTGGAAGTGGACTCCTGACCGACCGG
ACTTCCTCCAGGCTGCCAAGTCATCCCTGCAGCAAAGCGATTTTGAATATAAGCTGGACCGGG
AGTTCCTCAAGGGTTGCAAGCTTTCTGTCACTGATGACAAAAACACGGTGCTCGCCCTCAGGA
ATACTTTAATAGAAAGTGATCTGAAATACAAAGAGAAACATGTCAAGGAAAGAGGAACCTGCC
ATGCCGTACCTGACACGCCTCAGATCCTGCTGGCGAAGACTGTCAGCAACCTGGTGTCTGAGA
ACAAGTACAAGGACCATGTCAAGAAGCACTTGGCACAGGGCTCATACACAACACTACCAGAGA CCCGGGACACTGTTCACGTCAAGGAAGTGACCAAGCATGTCAGTGATACAAATTACAAAAAGA AGTTTGTCAAGGAGAAAGGAAAATCCAACTACTCCATCATGCTGGAGCCACCAGAGGTGAAAC ATGCTATGGAAGTGGCCAAGAAGCAAAGTGATGTCGCTTACAGAAAAGATGCCAAAGAGAACC TGCATTACACCACAGTGGCTGATCGACCAGACATCAAGAAGGCCACACAGGCAGCCAAACAGG CCAGTGAGGTGGAGTACAGAGCCAAGCACCGCAAGGAAGGCAGCCATGGCTTAAGCATGCTCG GTCGCCCAGACATAGAAATGGCCAAGAAGGCAGCCAAGCTGAGCAGCCAGGTTAAATACCGAG AAAATTTCGATAAAGAAAAGGGCAAGACACCAAAATACAATCCAAAAGACAGCCAGCTCTACA AAGTCATGAAAGATGCTAATAATCTTGCAAGTGAGGTTAAATACAAGGCTGACCTGAAGAAAC TTCACAAACCCGTGACTGACATGAAGGAGTCTCTGATCATGAATCATGTCCTGAATACAAGCC AACTTGCCAGTTCTTACCAGTACAAGAAGAAGTATGAGAAGAGTAAAGGCCACTACCACACCA TACCCGATAATCTGGAGCAGCTTCACCTAAAAGAGGCCACAGAATTACAGAGTATAGTGAAAT ACAAAGAAAAGTATGAAAAGGAACGAGGAAAACCCATGCTGGACTTTGAAACACCAACGTACA TCACTGCCAAAGAGTCTCAGCAGATGCAGAGTGGGAAAGAATATAGGAAAGATTATGAAGAGT CCATTAAAGGCAGAAACCTGACTGGCCTGGAGGTCACGCCAGCTTTGTTACATGTCAAATATG CAACTAAAATAGCAAGCGAGAAAGAGTACAGGAAAGATCTAGAGGAAAGCATCCGTGGGAAGG GCCTCACTGAAATGGAAGATACACCTGACATGCTAAGAGCAAAGAATGCCACTCAAATCCTCA ATGAGAAAGAATATAAGCGAGACCTGGAACTGGAAGTCAAAGGAAGAGGCCTGAATGCCATGG CCAATGAAACTCCGGATTTTATGAGGGCCAGGAATGCTACTGATATTGCCAGTCAGATTAAGT ATAAGCAATCAGCAGAAATGGAGAAAGCCAATTTCACTTCTGTGGTTGATACTCCAGAGATCA TTCATGCCCAACAAGTCAAGAATCTTTCAAGCCAGAAAAAGTACAAGGAAGATGCTGAGAAGT CCATGTCGTATTATGAGACTGTTTTGGACACCCCAGAGATACAGAGAGTCCGGGAGAACCAAA AGAACTTCAGCCTTCTCCAATACCAGTGTGACCTTAAAAACAGTAAAGGAAAAATTACAGTTG TTCAAGACACGCCAGAAATACTGCGTGTAAAAGAAAATCAGAAGAATTTCAGCTCGGTTTTAT ATAAAGAGGATGTCTCACCAGGAACGGCTATCGGAAAGACACCTGAGATGATGAGAGTGAAAC AAACACAGGACCACATTAGCTCGGTGAAGTATAAGGAAGCAATAGGACAAGGAACTCCAATCC CTGACCTGCCTGAAGTGAAACGTGTGAAGGAGACGCAGAAGCACATTAGCTCGGTTATGTACA AAGAAAACTTGGGAACAGGCATTCCAACCACTGTGACTCCAGAGATTGAGAGAGTCAAACGCA ATCAAGAGAACTTTAGCTCGGTTTTGTACAAAGAAAATTTGGGGAAAGGAATCCCAACACCTA TCACTCCAGAGATGGAGAGAGTCAAACGCAATCAAGAGAACTTTAGCTCGGTGTTATACAAAG AAAACATGGGCAAGGGAACTCCTTTACCTGTCACTCCCGAGATGGAGCGAGTCAAACACAATC AAGAAAATATTAGCTCGGTTTTGTACAAAGAAAATGTGGGGAAAGCCACCGCAACCCCTGTCA CTCCTGAGATGCAGAGAGTCAAACGCAATCAAGAAAACATTAGCTCGGTGTTATACAAAGAGA ACCTGGGGAAAGCAACCCCCACACCCTTTACTCCTGAGATGGAAAGAGTGAAACGCAATCAAG AAAACTTTAGCTCGGTATTGTACAAAGAGAACATGAGAAAAGCAACTCCGACACCTGTTACTC CAGAGATGGAGAGAGCTAAGCGCAACCAAGAAAACATTAGCTCGGTTCTTTATTCTGATAGTT TCCGGAAACAAATACAAGGCAAAGCTGCCTATGTATTGGATACCCCCGAGATGAGACGGGTGA GGGAGACCCAACGGCACATCTCAACGGTGAAATATCATGAAGACTTTGAGAAACACAAGGGTT GCTTCACACCAGTGGTGACAGATCCTATCACTGAACGAGTAAAGAAGAACATGCAGGACTTCA GTGACATTAACTACCGAGGTATTCAGAGGAAAGTGGTAGAAATGGAACAAAAACGGAATGACC AAGATCAGGAGACTATTACAGGTTTACGTGTCTGGCGTACTAATCCTGGTTCGGTTTTTGACT ATGATCCAGCAGAAGACAACATCCAGTCCCGAAGCTTACACATGATTAATGTCCAAGCTCAGC GCCGGAGCCGGGAGCAGTCACGATCTGCCAGTGCACTAAGCGTCAGTGGGGGTGAGGAGAAGT CTGAGCATTCAGAAGCACCAGACCACCACCTTTCGACTTACAGCGACGGGGGTGTCTTTGCAG TCTCAACAGCTTACAAACATGCAAAAACCACAGAGCTCCCACAACAACGATCATCTTCAGTTG CTACCCAACAGACAACGGTATCTTCCATCCCATCTCATCCATCTACTGCTGGAAAAATCTTCC GTGCCATGTATGACTATATGGCTGCTGATGCAGATGAGGTGTCCTTCAAGGATGGAGATGCCA TCATAAATGTTCAAGCAATTGATGAAGGCTGGATGTATGGCACTGTGCAGAGGACTGGCAGGA CCGGAATGCTCCCAGCCAACTACGTTGAAGCTATTTAGGCATTTCAAAGCATCACACTTGTCT
GCAGGACTTACAGATCCTGCAGTCAATGTTTCGGTTTAGACTCTCCACTGTTACCTAAGTTCT
CAAGCTGCCTATGGTTTTTCTGTGTCAATGTGATTTATGGTAGTACCATCCTTTCTCCTTTGG
GTTTTAAAATAAGTTGCAGAACAGACACTTTAAAAGCTTCTGCAATATTATTTCTGTGCCTAG lAGTCTTTCTCCATTATAAACATGTTTTAACATTATTTCTTTTCTAAAACAGGGATTTTGAATA
TGCCAAACACATTAAAGGAAAAATAGCAGAGATGTTCACCTTTTCCTTGCTGATTGCTAATGC
TTATTATTTCTAATTCAGTTCTGAAGTTATAAACTTATAATCAATACAAACCAGCAACTAATA
AAACCTCTAATTCTGCAAAAAAAAAAAA
ORFjStart: ATG at 441 j Ϊ Stop: TAG at 20448
SEQB"Nθ7i42 :6669 aa "" "JMW at kD
NOV35b, MADDEDYEEWEYYTEEVVYEEVPGETITKIYETTTTRTSDYEQSETSKPALAQPALAQPASA
CGI 19566-02 Protein KPVERRKVIRKKVDPSKFMTPYIAHSQKMQDLFSPNKYKEKFEKTKGQPYASTTDTPELRRIK KVQDQLSEVKYRMDGDVAKTICHVDEKAKDIEHAKKVSQQVSKVLYKQNWEDTKDKYLLPPDA
Sequence PELVQAVKNTAMFSKKLYTEDWEADKSLFYPYNDSPELRRVAQAQKALSDVAYKKGLAEQQAQ FTPLADPPDIEFAKKVTNQVSKQKYKEDYENKIKGKWSETPCFEVANARMNADNISTRKYQED FENMKDQIYFMQTETPEYKMNKKAGVAASKVKYKEDYEKNKGKADYNVLPASENPQLRQLKAA GDALSDKLYKENYEKTKAKSINYCETPKFKLDTVLQNFSSDKKYKDSYLKDILGHYVGSFEDP
YHSHCMKVTAQNSDKNYKAEYEEDRGKGFFPQTITQEYEAIKKLDQCKDHTYKVHPDKTKFTQ
VTDSPVLLQAQVNSKQLSDLNYKAKHESEKFKCHIPPDTPAFIQHKVNAYNLSDNLYKQDWEK
SKAKKFDIKVDAIPLLAAKANTKNTSDVMYKKDYEKNKGKMIGVLSINDDPKMLHSLKVAKNQ
SDRLYKENYEKTKAKSMNYCETPKYQLDTQLKNFSEARYKDLYVKDVLGHYVGSMEDPYHTHC
MKVAAQNSDKSYKAEYEEDKGKCYFPQTITQEYDAIKKLDQCKDHTYKVHPDKTKFTAVTDSP
VLLQAQLNTKQLSDLNYKAKHEGERFKCHIPADAPQFIQHRVNAYNLSDNVYKQDWEKSKAKK
FDIKVDAIPLLAAKANTKNTSDVMYKKDYEKSKGKMIGALSINDDPKMLHSLKTAKNQSDREY
RKDYEKSKTIYTAPLDMLQVTQAKKSQAIASDVDYKHILHSYSYPPDSINVDLAKKAYALQSD
VEYKADYNSWMKGCGWVPFGSLEMEKAKRASDILNEKKYRQHPDTLKFTSIEDAPITVQSKIN
QAQRSDIAYKAKGEEIIHNYNLPPDLPQFIQAKVNAYNISENMYKADLKDLSKKGYDLRTDAI
PIRAAKAARQAASDVQYKKDYEKAKGKMVGFQSLQDDPKLVHYMNVAKIQSDREYKKDYEKTK
SKYNTPHDMFNWAAKKAQDWSNVNYKHSLHHYTYLPDAMDLELSKNMMQIQSDNVYKEDYN
NWMKGIGWIPIGSLDVEKVKKAGDALNEKKYRQHPDTLKFTSIVDSPVMVQAKQNTKQVSDIL
YKAKGEDVKHKYTMSPDLPQFLQAKCNAYSISDVCYKRDWHDLIRKGNNVLGDAIPITAAKAS
RNIASDYKYKEAYEKSKGKHVGFRSLQDDPKLVHYMNVAKLQSDREYKKNYENTKTSYHTPGD
MVTITAAKMAQDVATNVNYKQPLHHYTYLPDAMSLEHTRNVNQIQSDNVYKDEYNSFLKGIGW
IPIGSLEVEKVKKAGDALNERKYRQHPDTVKFTSVPDSMGMMLAQHNTKQLSDLNYKVEGEKL
KHKYTIDPELPQFIQAKVNALNMSDAHYKADWKKTIRKGYDLRPDAIPIVAAKSSRNIASDCK
YKEAYEKAKGKQVGFLSLQDDPKLVHYMNVAKIQSDREYKKGYEASKTKYHTPLDMVSVTAAK
KSQEVATNANYRQSYHHYTLLPDALNVEHSRNAMQIQSDNLYKSDFTNWMKGIGWVPIESLEV
EKAKKAGEILSEKKYRQHPEKLKFTYAMDTMEQALNKSNKLNMDKRLYTEKWNKDKTTIHVMP
DTPDILLSRVNQITMSDKLYKAGWEEEKKKGYDLRPDAIAIKAARASRDIASDYKYKKAYEQA
KGKHIGFRSLEDDPKLVHFMQVAKMQSDREYKKGYEKSKTSFHTPVDMLSWAAKKSQEVATN
ANYRNVIHTYNMLPDAMSFELAKNMMQIQSDNQYKADYADFMKGIGWLPLGSLEAEKNKKAME
IISEKKYRQHPDTLKYSTLMDSMNMVLAQNNAKIMNEHLYKQAWEADKTKVHIMPDIPQIILA
KANAINISDKLYKLSLEESKKKGYDLRPDAIPIKAAKASRDIASDYKYKYNYEKGKGKMVGFR
SLEDDPKLVHSMQVAKMQSDREYKKNYENTKTSYHTPADMLSVTAAKDAQANITNTNYKHLIH
KYILLPDAMNIELTRNMNRIQSDNEYKQDYNEWYKGLGWSPAGSLEVEKAKKATEYASDQKYR
QHPSNFQFKKLTDSMDMVLAKQNAHTMNKHLYTIDWNKDKTKIHVMPDTPDILQAKQNQTLYS
QKLYKLGWEEALKKGYDLPVDAISVQLAKASRDIASDYKYKQGYRKQLGHHVGFRSLQDDPKL
VLSMNVAKMQSEREYKKDFEKWKTKFSSPVDMLGWLAKKCQELVSDVDYKNYLHQWTCLPDQ
NDWQAKKVYELQSENLYKSDLEWLRGIGWSPLGSLEAEKNKRASEIISEKKYRQPPDRNKFT
SIPDAMDIVLAKTNAKNRSDRLYREAWDKDKTQIHIMPDTPDIVLAKANLINTSDKLYRMGYE
ELKRKGYDLPVDAIPIKAAKASREIASEYKYKEGFRKQLGHHIGARNIEDDPKMMWSMHVAKI
QSDREYKKDFEKWKTKFSSPVDMLGWLAYKCQTLVSDVDYKNYLHQWTCLPDQSDVIHARQA
YDLQSDNLYKSDLQWLKGIGWMTSGSLEDEKNKRATQILSDHVYRQHPDQFKFSSLMDSIPMV
LAKNNAITMNHRLYTEAWDKDKTTVHIMPDTPEVLLAKQNKVNYSEKLYKLGLEEAKRKGYDM
RVDAIPIKAAKASRDIASEFKYKEGYRKQLGHHIGARAIRDDPKMMWSMHVAKIQSDREYKKD
FEKWKTKFSSPVDMLGWLAKKCQTLVSDVDYKNYLHQWTCLPDQSDVIHARQAYDLQSDNMY
KSDLQWMRGIGWVSIGSLDVEKCKRATEILSDKIYRQPPDRFKFTSVTDSLEQVLAKNNALNM
NKRLYTEAWDKDKTQIHIMPDTPEIMLARQNKINYSETLYKLA EEAKKKGYDLRSDAIPIVA
AKASRDVISDYKYKDGYRKQLGHHIGARNIEDDPKMMWSMHVAKIQSDREYKKDFEKWKTKFS
SPVDMLGWLAKKCQTLVSDVDYKNYLHEWTCLPDQNDVIHARQAYDLQΞDNIYKSDLQWLRG
IGWVPIGSMDWKCKRAAEILSDNIYRQPPDKLKFTSVTDSLEQVLAKNNALNMNKRLYTEAW
DKDKTQVHIMPDTPEIMLARQNKINYSESLYRQAMEEAKKEGYDLRSDAIPIVAAKASRDIAS
DYKYKEAYRKQLGHHIGARAVHDDPKIMWSLHIAKVQSDREYKKDFEKYKTRYSSPVDMLGIV
LAKKCQTLVSDVDYKHPLHECICLPDQNDIIHARKAYDLQSDNLYKSDLEWMKGIGWVPIDSL
EVVRAKRAGELLSDTIYRQRPETLKFTSITDTPEQVLAKNNALNMNKRLYTEAWDNDKKTIHV
MPDTPEIMLAKLNRINYSDKLYKLALEESKKEGYDLRLDAIPIQAAKASRDIASDYKYKEGYR
KQLGHHIGARNIKDDPKMMWSIHVAKIQSDREYKKEFEKWKTKFSSPVDMLGVVLAKKCQILV
SDIDYKHPLHEWTCLPDQNDVIQARKAYDLQSDAIYKSDLEWLRGIGWVPIGSVEVEKVKRAG
EILSDRKYRQPADQLKFTCITDTPEIVLAKNNALTMSKHLYTEAWDADKTSIHVMPDTPDILL
AKSNSANISQKLYTKGWDESKMKDYDLRADAISIKSAKASRDIASDYKYKEAYEKQKGHHIGA
QSIEDDPKIMCAIHAEKIQSEREYKKEFQKWKTKFSSPVDMLSILLAKKCQTLVTDIYYRNYL
HEWTCMPDQNDIIQAKKAYDLQSDALYKADLEWLRGIGWMPQGSPEVLRVKNAQNIFCDSVYR
TPWNLKYTSIVDTPEWLAKSNAENISIPKYREVWDKDKTSIHIMPDTPEINLARANALNVS
NKLYREGWDEMKAGCDVRLDAIPIQAAKASREIASDYKYKLDHEKQKGHYVGTLTARDDNKIR
WALIADKLQNEREYRLDWAKWKAKIQSPVDMLSILHSKNSQALVSDMDYRNYLHQWTCMPDQN
DVIQAKKAYELQSDNVYKADLEWLRGIGWMPNDSVSVNHAKHAADIFSEKKYRTKIETLNFTP
VDDRVDYVTAKQSGEILDDIKYRKDWNATKSKYTLTETPLLHTAQEAARILDQYLYKEGWERQ
KATGYILPPDAVPFVHAHHCNDVQSELKYKAEHVKQKGHYVGVPTMRDDPKLVWFEHAGQIQN
ERLYKEDYHKTKAKINIPADMVSVLAAKQGQTLVSDIDYRNYLHQWMCHPDQNDVIQARKAYD
LQSDNVYRADLEWLRGIGWIPLDSVDHVRVTKNQEMMSQIKYKKNALENYPNFTSWDPPEIV
LAKINSVNQSDVKYKETFNKAKGKYTFSPDTPHISHSKDMGKLYSTILYKGAWEGTKAYGYTL
DERYIPIVGAKHADLVNSELKYKETYEKQKGHYLAGKVIGEFPGWHCLDFQKMRSALNYRKH
YEDTKANVHIPNDMMNHVLAKRCQYILSDLEYRHYFHQWTSLLEEPNVIRVRNAQEILSDNVY
AGTATGAATTACTGTGAGACCCCAAAATATCAACTTGATACTCAGCTGAAGAACTTCAGTGAG
GCTAGATATAAAGACTTATATGTAAAGGATGTTTTGGGACATTATGTAGGCAGCATGGAGGAC
CCATATCACACACACTGCATGAAAGTTGCAGCTCAAAACAGTGATAAAAGTTACAAAGCAGAA
TATGAAGAAGATAAAGGAAAATGCTATTTCCCTCAGACAATAACACAAGAATATGACGCAATC
AAGAAGCTGGACCAGTGTAAAGATCATACCTACAAAGTTCATCCAGATAAGACCAAATTCACG
GCAGTCACTGATTCTCCTGTACTGTTGCAAGCCCAGCTCAACACGAAACAGCTTAGTGATCTG
AATTACAAAGCAAAACATGAAGGTGAGAGGTTCAAGTGCCATATACCAGCAGATGCTCCACAG
TTTATCCAACACAGAGTCAATGCCTATAATCTGAGTGATAATGTTTATAAGCAAGACTGGGAG
AAGAGCAAAGCCAAGAAGTTTGACATTAAAGTGGACGCCATTCCCCTGTTGGCAGCCAAAGCC
AACACCAAGAACACCAGCGATGTGATGTACAAGAAAGACTATGAAAAGAGCAAAGGGAAAATG
ATTGGAGCCCTCAGCATTAATGACGATCCAAAGATGCTGCACTCCTTGAAGACAGCCAAAAAC
CAGAGTGATCGCGAATATCGAAAAGATTATGAAAAGTCAAAAACTATCTACACGGCACCTCTT
GATATGCTCCAAGTCACTCAAGCTAAGAAATCTCAGGCAATTGCCAGCGACGTTGATTATAAG
CACATCTTACACAGTTACAGCTACCCCCCTGATAGCATCAATGTGGACCTTGCCAAGAAGGCA
TATGCGCTGCAGAGCGATGTTGAATACAAAGCTGACTACAATAGCTGGATGAAAGGTTGTGGC
TGGGTGCCTTTTGGGTCCTTAGAAATGGAAAAGGCAAAGCGAGCTTCAGACATCCTCAATGAG
AAAAAATATCGCCAACATCCAGACACCCTCAAGTTTACCTCGATTGAAGATGCTCCAATTACA
GTACAGTCTAAAATTAACCAGGCCCAGAGGAGTGATATCGCTTACAAAGCCAAAGGAGAGGAA
ATTATTCACAATTACAACCTGCCACCAGACCTGCCCCAGTTCATCCAGGCTAAAGTTAATGCC ACAATATCAGTGAGAATATGTACAAAGCAGACTTGAAAGACTTGAGCAAGAAGGGATATGAC
CTGAGAACTGATGCGATTCCCATCAGAGCTGCCAAAGCTGCCAGGCAGGCGGCGAGTGACGTT
CAGTACAAAAAAGACTATGAAAAGGCTAAAGGGAAAATGGTTGGCTTCCAAAGTCTTCAAGAT
GACCCTAAACTGGTTCATTATATGAACGTGGCCAAGATACAATCAGATCGGGAGTATAAAAAA
GACTATGAGAAGACAAAGTCCAAATACAACACGCCCCATGATATGTTCAATGTCGTGGCGGCT
AAGAAAGCCCAGGATGTGGTCAGCAATGTCAACTATAAGCATTCTCTCCATCATTACACCTAC
TTGCCTGACGCCATGGACCTGGAGCTGTCTAAGAACATGATGCAGATACAGAGTGATAACGTC
TACAAGGAAGACTACAACAACTGGATGAAAGGCATTGGCTGGATTCCTATTGGCAGTCTCGAC
GTCGAAAAAGTTAAAAAGGCCGGTGATGCTCTGAATGAAAAGAAGTACAGGCAACATCCAGAC
ACCCTCAAATTTACCAGCATTGTGGACTCCCCAGTTATGGTCCAGGCAAAACAGAACACGAAG
CAAGTCAGTGATATCTTATACAAGGCTAAAGGAGAAGATGTGAAACATAAATACACCATGAGT
CCTGATCTTCCTCAGTTTCTCCAGGCCAAGTGCAATGCTTACAGTATAAGTGACGTCTGTTAT
AAACGGGATTGGCATGACTTAATACGCAAGGGCAACAATGTGCTGGGCGATGCTATTCCCATC
ACTGCAGCCAAGGCATCGAGAAACATTGCCAGTGATTATAAATACAAGGAAGCTTATGAGAAG
TCAAAGGGAAAGCATGTGGGTTTCAGAAGCCTCCAGGATGATCCCAAGCTGGTCCACTATATG
AATGTGGCAAAGCTGCAGTCTGATCGTGAATACAAGAAGAACTATGAGAACACCAAAACCAGC
TACCATACCCCTGGGGACATGGTTACGATCACAGCTGCAAAGATGGCCCAGGATGTCGCTACC
AATGTCAACTACAAACAGCCATTGCATCATTACACATACCTACCTGACGCCATGAGTCTTGAG
CATACGAGGAATGTCAATCAAATTCAGAGTGATAATGTGTATAAAGACGAGTATAACAGCTTC
TTGAAGGGCATCGGATGGATCCCTATTGGTTCCCTGGAGGTGGAGAAGGTCAAGAAAGCAGGC
GATGCATTAAATGAGAGGAAGTATCGACAGCACCCAGATACCGTCAAGTTCACAAGTGTGCCT
GATTCCATGGGCATGATGTTGGCTCAGCATAACACAAAGCAGCTAAGTGATTTGAACTACAAG
GTAGAGGGAGAGAAACTGAAGCACAAGTATACTATTGACCCTGAATTGCCTCAGTTTATTCAA
GCCAAAGTCAACGCCCTCAACATGAGTGATGCTCATTATAAAGCAGATTGGAAGAAAACCATT
CGCAAGGGCTATGATTTGAGACCAGATGCCATCCCAATTGTTGCTGCAAAAAGTTCAAGGAAT
ATTGCTAGTGATTGCAAATATAAGGAGGCCTACGAGAAAGCCAAAGGCAAGCAAGTTGGATTT
CTCAGTCTTCAGGATGATCCTAAACTGGTTCACTACATGAATGTGGCCAAAATCCAGTCTGAT
CGTGAGTACAAAAAGGGCTATGAAGCCAGCAAGACCAAGTACCACACACCTCTGGATATGGTC
AGTGTGACAGCTGCAAAGAAATCTCAGGAGGTTGCCACCAACGCCAACTACAGACAGTCATAC
CACCACTACACTCTCCTGCCCGATGCCTTGAATGTGGAGCACTCCAGGAATGCCATGCAGATT
CAGAGTGATAATCTGTACAAATCTGACTTCACCAATTGGATGAAAGGGATCGGCTGGGTGCCC
ATAGAGTCCCTGGAGGTGGAGAAGGCAAAGAAAGCAGGAGAGATTCTTAGTGAGAAGAAGTAT
CGCCAGCACCCCGAGAAGCTGAAGTTCACTTACGCCATGGACACAATGGAACAGGCACTTAAC
AAGAGTAACAAACTGAACATGGACAAGAGGCTCTACACTGAAAAATGGAACAAGGACAAGACC
ACCATTCATGTCATGCCTGACACACCGGATATTTTACTCTCCAGAGTAAACCAAATCACCATG
AGTGATAAACTGTACAAAGCTGGCTGGGAAGAGGAAAAGAAGAAAGGATATGACCTGAGGCCT
GATGCCATTGCAATAAAGGCTGCAAGAGCCTCTAGAGACATTGCCAGTGATTACAAATACAAG
AAAGCCTATGAACAAGCCAAAGGGAAACACATTGGCTTCCGGAGCCTGGAAGATGACCCCAAG
CTGGTGCACTTCATGCAAGTGGCCAAGATGCAGTCAGACCGGGAATACAAGAAGGGATATGAG
AAATCCAAGACCTCCTTCCACACCCCGGTGGACATGCTCAGTGTGGTGGCAGCCAAGAAGTCT
CAGGAAGTGGCCACCAATGCCAACTACAGGAACGTGATCCATACCTACAACATGCTTCCTGAT
GCCATGAGCTTTGAATTGGCCAAAAATATGATGCAGATTCAAAGTGATAATCAGTACAAGGCT
GACTATGCTGACTTCATGAAGGGCATTGGATGGCTCCCTCTGGGCTCCCTGGAAGCAGAGAAA
AACAAGAAAGCCATGGAGATTATTAGTGAAAAGAAGTACCGCCAGCACCCAGACACTTTGAAG
TATTCCACACTCATGGACTCGATGAACATGGTTTTGGCCCAGAATAATGCAAAAATTATGAAC
GAACATCTCTACAAACAAGCATGGGAGGCTGACAAAACCAAAGTCCACATCATGCCTGATATC
CCCCAGATTATTTTGGCAAAGGCAAATGCAATTAATATAAGTGATAAACTCTACAAACTTTCC
TTGGAAGAGTCTAAAAAGAAAGGCTATGATCTCAGACCTGATGCAATTCCTATCAAAGCTGCC
AAGGCTTCCAGAGATATTGCAAGTGATTATAAATACAAGTACAATTATGAAAAAGGGAAGGGG
AAAATGGTTGGTTTCCGCAGTCTCGAGGATGATCCCAAATTAGTCCATTCCATGCAAGTGGCT
AAGATGCAATCTGATCGGGAGTACAAGAAAAACTATGAGAACACAAAGACCAGCTACCACACC
CCTGCCGACATGCTCAGTGTCACGGCTGCAAAGGATGCCCAAGCCAACATCACCAACACTAAC
TACAAGCACCTGATTCACAAGTACATCCTCCTTCCAGATGCAATGAACATTGAGCTGACCAGG
AATATGAATCGCATACAGAGTGATAATGAATATAAGCAAGATTACAATGAATGGTACAAAGGG
CTTGGCTGGAGTCCAGCAGGTTCTCTGGAAGTGGAGAAGGCCAAGAAAGCAACTGAATATGCC
AGTGATCAGAAATACCGCCAGCACCCGAGCAACTTCCAGTTTAAGAAGCTGACTGATTCCATG
GACATGGTGCTTGCCAAGCAGAATGCACATACCATGAACAAGCATTTATACACCATTGATTGG
AATAAAGATAAGACCAAGATTCATGTGATGCCTGATACACCAGATATTTTACAAGCCAAGCAG
AATCAAACACTGTATAGTCAGAAACTCTATAAACTTGGATGGGAAGAAGCTTTGAAGAAAGGC
TATGATCTCCCAGTTGATGCAATTTCTGTACAGCTAGCTAAAGCTTCAAGAGACATTGCTAGT
GATTATAAATACAAACAAGGCTACCGAAAGCAACTTGGCCACCATGTTGGATTCCGGAGTCTG
CAAGATGACCCAAAACTTGTGTTGTCCATGAATGTAGCCAAAATGCAGAGTGAAAGAGAATAC
AAGAAGGACTTTGAGAAGTGGAAAACTAAGTTCTCCAGCCCAGTGGACATGTTGGGAGTGGTA
CTGGCCAAGAAGTGTCAGGAGTTGGTTAGTGACGTGGACTACAAGAACTACCTGCATCAGTGG
ACATGTCTGCCTGATCAGAACGATGTTGTGCAAGCTAAGAAAGTTTATGAACTGCAAAGTGAG
AATCTATATAAATCTGACCTTGAGTGGCTGAGAGGCATAGGATGGAGTCCCTTGGGTTCTTTA
GAGGCAGAAAAGAACAAGCGGGCTTCGGAAATCATCAGTGAGAAGAAATATCGTCAGCCTCCA
GACAGAAACAAGTTCACCAGCATTCCTGATGCCATGGATATAGTTCTGGCAAAGACAAATGCC
AAAAATAGGAGTGATAGACTTTATAGAGAAGCTTGGGACAAAGACAAGACTCAGATCCACATC
ATGCCTGATACACCTGACATTGTTCTGGCTAAAGCAAACTTAATCAACACAAGTGATAAACTC
TACCGAATGGGTTATGAGGAGCTGAAGAGAAAAGGTTACGATCTTCCTGTTGATGCCATACCA
ATCAAAGCAGCAAAAGCCTCCCGGGAAATTGCCAGTGAATACAAGTACAAGGAAGGCTTTCGC
AAGCAGCTCGGCCACCACATTGGTGCCCGGAACATTGAAGATGACCCCAAGATGATGTGGTCC
ATGCATGTGGCCAAGATCCAGAGTGACAGGGAGTACAAGAAGGACTTTGAGAAGTGGAAGACC
AAGTTCAGCAGCCCAGTGGACATGCTGGGGGTGGTGTTGGCCTATAAGTGCCAGACCTTAGTC
AGCGACGTGGACTACAAGAACTACCTGCACCAGTGGACATGCCTGCCCGACCAGAGCGATGTC
ATCCATGCTCGGCAGGCCTATGACCTCCAGAGCGATAATTTGTACAAGTCAGACCTTCAGTGG
CTAAAAGGCATTGGCTGGATGACTAGTGGTTCTCTCGAGGATGAGAAAAATAAACGAGCCACC
CAGATTTTGAGTGACCATGTTTACCGTCAGCACCCAGATCAATTTAAGTTTTCCAGCCTTATG
GATTCCATACCAATGGTTTTGGCAAAAAACAATGCTATTACCATGAATCATCGCCTCTATACA
GAAGCTTGGGATAAAGATAAAACCACTGTCCACATTATGCCAGATACCCCTGAAGTTTTATTA
GCTAAACAAAACAAAGTAAATTACAGTGAGAAATTGTATAAGCTTGGCCTAGAAGAAGCCAAG
AGGAAAGGTTATGACATGCGGGTAGATGCCATTCCTATCAAGGCAGCCAAGGCCTCCAGAGAT
ATTGCAAGTGAATTCAAGTACAAAGAAGGCTATCGTAAGCAGCTCGGCCACCACATTGGTGCC
CGAGCTATACGTGATGACCCCAAGATGATGTGGTCCATGCACGTGGCCAAGATCCAGAGTGAC
AGGGAGTACAAGAAGGACTTTGAGAAGTGGAAGACCAAGTTCAGCAGCCCAGTGGACATGCTG
GGGGTGGTGCTGGCCAAGAAGTGCCAGACCTTAGTCAGCGATGTGGACTACAAGAACTACCTG
CACCAGTGGACATGCCTGCCCGACCAGAGCGACGTCATCCATGCTCGGCAGGCCTATGACCTC
CAGAGCGATAATATGTACAAGTCTGATCTCCAGTGGATGAGAGGCATTGGCTGGGTGTCCATT:
GGCTCTTTGGATGTGGAAAAATGCAAAAGGGCAACTGAAATTTTGAGTGATAAAATCTATCGcl
CAGCCTCCAGACAGATTCAAATTTACCAGTGTGACTGACTCTCTGGAACAAGTGCTGGCCAAG
AACAATGCTCTCAACATGAATAAGCGTTTATACACAGAGGCCTGGGACAAAGACAAGACTCAA
ATTCACATAATGCCTGATACACCAGAGATTATGTTGGCAAGGCAGAACAAAATCAACTACAGT
GAGACTCTATACAAACTTGCCAATGAAGAAGCAAAAAAGAAAGGCTACGACTTGCGAAGTGAC
GCCATCCCCATCGTGGCTGCCAAGGCCTCCAGGGACGTTATCAGTGATTACAAATACAAAGAT
GGTTACCGCAAGCAGCTCGGCCACCACATTGGAGCCCGGAACATTGAAGATGACCCCAAGATG
ATGTGGTCCATGCATGTGGCCAAGATCCAGAGTGACAGGGAGTATAAGAAGGACTTTGAGAAG
TGGAAGACCAAGTTCAGCAGCCCAGTGGACATGCTGGGAGTGGTGTTAGCCAAGAAGTGCCAG
ACCTTAGTCAGCGATGTGGACTACAAGAACTACCTGCACGAGTGGACGTGCCTGCCCGACCAG
AATGATGTCATCCATGCTCGGCAGGCCTATGACCTCCAGAGCGATAACATTTACAAATCTGAT
CTCCAGTGGCTGAGAGGCATTGGCTGGGTCCCCATTGGGTCTATGGATGTGGTCAAGTGCAAG
AGAGCTGCTGAAATACTGAGTGATAACATCTACCGCCAGCCTCCGGACAAGCTGAAATTTACC
AGTGTGACTGACTCTCTAGAGCAGGTGCTGGCCAAGAACAATGCTCTCAATATGAACAAGCGC
TTATACACAGAAGCCTGGGACAAAGACAAGACCCAAGTCCATATTATGCCTGATACACCTGAA
ATCATGTTGGCAAGACAAAATAAAATAAATTATAGTGAGAGCCTCTATCGTCAGGCCATGGAA
GAAGCCAAGAAAGAAGGCTATGACTTGAGAAGTGATGCCATTCCCATTGTGGCTGCCAAGGCC
TCTCGGGATATTGCCAGTGATTACAAATACAAAGAAGCATATCGTAAGCAGTTGGGTCACCAC
ATTGGCGCCCGAGCAGTACACGATGACCCCAAGATAATGTGGTCCCTCCACATTGCCAAAGTG
CAGAGTGACCGTGAGTACAAGAAAGATTTTGAGAAATACAAGACAAGGTACAGCAGCCCAGTG
GACATGCTTGGTATCGTTTTGGCCAAGAAGTGTCAGACCTTGGTCAGCGATGTGGACTATAAA
CATCCTCTGCATGAATGCATCTGCCTGCCCGACCAGAATGACATCATTCATGCACGGAAAGCC
TATGACCTCCAGAGTGACAATTTGTATAAGTCAGACCTTGAATGGATGAAAGGCATTGGCTGG
GTTCCGATTGATTCCTTGGAAGTTGTTAGGGCCAAGAGAGCTGGAGAATTACTTAGTGATACT
ATCTACCGTCAGCGTCCAGAAACGCTGAAATTTACCAGTATAACGGACACTCCGGAGCAGGTG
CTGGCAAAAAACAATGCTTTAAACATGAATAAGCGCTTATATACTGAAGCCTGGGACAATGAC
AAGAAAACTATTCATGTCATGCCTGATACACCAGAAATCATGTTAGCCAAACTCAACCGAATA
AACTACAGTGATAAACTCTATAAACTTGCTTTGGAAGAGTCCAAGAAGGAAGGCTATGACTTG
CGTCTGGATGCCATTCCAATCCAAGCAGCCAAGGCTTCAAGAGATATTGCTAGTGATTACAAG
TACAAGGAAGGCTACCGCAAACAGCTTGGCCACCATATTGGGGCCCGGAACATTAAGGATGAC
CCGAAGATGATGTGGTCCATCCATGTGGCCAAGATCCAGAGTGACAGGGAGTACAAGAAGGAG
TTTGAGAAGTGGAAGACCAAGTTCAGCAGCCCAGTGGACATGCTGGGGGTGGTGCTGGCCAAG
AAGTGTCAGATCCTTGTAAGCGACATAGACTACAAGCATCCCCTGCATGAATGGACCTGCCTG
CCTGATCAGAATGACGTCATTCAGGCTCGGAAGGCCTATGACCTGCAGAGTGATGCTATTTAC
AAATCTGATCTTGAGTGGCTGAGAGGCATAGGATGGGTTCCCATTGGCTCTGTAGAGGTCGAG
AAAGTGAAGAGAGCTGGAGAAATCCTGAGTGACAGGAAGTATCGCCAGCCTGCAGACCAGCTC
AAATTCACATGCATTACCGACACTCCGGAAATTGTCCTAGCAAAGAATAATGCCCTGACAATG
AGCAAGCATTTATACACAGAAGCTTGGGATGCTGACAAAACCTCCATCCACGTGATGCCAGAC
ACCCCAGATATCCTGCTGGCCAAGAGTAATTCTGCCAATATCAGCCAAAAACTTTACACCAAG
GGATGGGATGAATCAAAGATGAAGGACTATGATCTGAGAGCAGATGCTATTTCCATCAAAAGT
GCCAAGGCCTCCAGGGACATCGCCAGTGACTACAAATACAAGGAAGCCTATGAGAAACAGAAA
GGCCACCACATTGGAGCCCAGAGCATTGAAGATGATCCCAAGATTATGTGTGCCATACATGCA
GAAAAAATTCAAAGTGAAAGGGAGTACAAGAAGGAATTCCAAAAGTGGAAAACCAAGTTCTCT
AGCCCAGTGGACATGTTAAGCATCTTGCTGGCCAAGAAATGTCAGACTTTGGTCACTGACATT
TATTATCGCAATTACCTGCATGAATGGACATGCATGCCGGATCAAAACGACATTATCCAAGCA
AAAAAGGCCTATGACCTGCAGAGTGATGCCCTCTACAAGGCTGACTTGGAGTGGTTGCGTGGC
ATTGGCTGGATGCCCCAAGGGTCTCCTGAAGTGTTGAGAGTCAAAAACGCCCAGAATATCTTT
TGTGACAGTGTCTATCGGACGCCTGTGGTGAACCTTAAGTACACAAGCATTGTTGACACACCT
GAAGTGGTCCTTGCTAAATCAAATGCTGAAAATATTAGTATTCCAAAGTACAGAGAGGTTTGG
GACAAGGATAAAACTTCAATACACATAATGCCAGATACTCCAGAAATTAATCTCGCTAGAGCA
AATGCTCTTAATGTGAGCAATAAACTTTACCGTGAGGGCTGGGATGAAATGAAGGCGC'SCTGT
GATGTCCGGCTGGATGCCATCCCCATCCAGGCTGCCAAGGCCTCCAGGGAGATTGCCAGTGAC
TATAAATATAAGCTTGACCATGAGAAGCAGAAGGGACACTACGTGGGCACCCTCACAGCCAGG
GATGACAACAAGATCCGCTGGGCCCTCATAGCTGACAAGCTCCAGAATGAACGAGAGTACCGG
CTGGACTGGGCCAAATGGAAGGCCAAGATCCAGAGCCCTGTGGACATGCTTTCCATCCTGCAC
TCTAAAAATTCCCAGGCTCTGGTCAGTGACATGGATTACCGCAATTACCTGCACCAGTGGACC
TGCATGCCCGACCAGAACGATGTGATTCAGGCCAAGAAGGCCTACGAACTGCAGAGCGATAAT
GTTTACAAGGCTGACTTGGAATGGTTGCGTGGAATTGGGTGGATGCCAAATGACTCCGTGTCC
GTCAATCATGCCAAACATGCCGCGGACATCTTCAGTGAGAAAAAATATCGCACAAAAATAGAA
ACTCTCAACTTTACGCCTGTGGATGACAGAGTTGATTATGTGACAGCGAAACAAAGTGGCGAG
ATCCTCGATGATATTAAATACCGGAAAGACTGGAATGCCACCAAATCAAAGTACACCCTCACA
GAAACCCCCCTGCTGCACACTGCCCAGGAGGCTGCTAGGATACTGGACCAGTATCTCTACAAG
GAAGGCTGGGAGAGACAAAAAGCCACAGGTTACATTTTGCCTCCAGATGCTGTGCCATTTGTT
CATGCCCATCACTGCAATGACGTTCAGAGTGAGCTGAAATACAAAGCTGAACATGTGAAGCAA
AAAGGTCATTATGTTGGTGTCCCGACGATGAGAGATGATCCTAAGCTGGTTTGGTTTGAGCAT
GCAGGCCAGATTCAGAATGAGAGACTATACAAAGAGGACTATCACAAAACAAAGGCCAAAATC
AATATACCTGCTGATATGGTGTCAGTCTTGGCCGCCAAGCAGGGGCAGACCCTTGTCAGTGAT
ATTGATTATCGTAATTACTTGCACCAATGGATGTGTCATCCTGACCAGAACGATGTTATTCAG
GCAAGAAAGGCCTATGACCTACAGAGTGATAATGTCTACAGAGCTGACCTGGAGTGGCTCCGA
GGCATTGGCTGGATCCCACTGGATTCTGTGGACCATGTAAGGGTTACTAAGAACCAGGAAATG
ATGAGTCAGATCAAATATAAGAAAAATGCCCTTGAAAACTATCCTAACTTTACAAGTGTGGTG
GATCCTCCAGAGATTGTTTTAGCCAAGATTAATTCTGTCAATCAAAGTGATGTAAAATATAAA
GAAACATTTAATAAAGCAAAGGGCAAATATACGTTTTCACCAGATACACCACATATCTCCCAC
TCCAAAGACATGGGAAAACTCTACAGTACTATACTGTATAAAGGGGCGTGGGAGGGCACCAAG
GCCTATGGCTACACCCTGGATGAGCGCTACATTCCCATTGTTGGAGCCAAGCATGCTGATCTG
GTGAACAGTGAGCTTAAATACAAAGAGACATATGAGAAGCAGAAAGGTCACTACCTGGCTGGA
AAAGTGATCGGTGAATTCCCTGGTGTGGTTCACTGTCTGGATTTCCAAAAGATGAGGAGTGCG
TTGAACTACAGAAAACATTATGAGGATACCAAAGCAAATGTTCATATCCCCAATGACATGATG
AATCACGTGCTGGCTAAAAGGTGCCAGTACATCCTCAGTGACCTGGAGTATCGACACTATTTC
CACCAGTGGACGTCTCTTCTGGAAGAACCCAATGTTATACGCGTCCGAAACGCCCAGGAGATC
TTGAGTGATAATGTGTATAAAGATGACCTGAATTGGTTGAAAGGCATTGGTTGCTACGTTTGG
GATACACCCCAAATCCTCCATGCCAAGAAATCATACGACCTTCAGAGTCAGCTACAATATACA
GCAGCAGGTAAAGAAAATCTACAAAACTATAATCTGGTCACAGACACGCCCCTCTATGTGACT
GCTGTTCAGAGTGGCATTAATGCCAGTGAGGTAAAATATAAAGAAAATTATCATCAGATTAAG
GACAAATACACAACAGTTCTAGAAACAGTGGATTATGACAGAACCAGAAACCTGAAGAATCTT
TACAGCAGTAACCTGTACAAGGAGGCCTGGGATAGAGTGAAAGCCACCAGCTACATCCTGCCT
TCCAGCACCTTGTCCCTGACACACGCCAAGAACCAGAAGCATCTGGCCAGCCATATCAAATAT
CGGGAAGAATATGAAAAGTTCAAAGCTCTTTATACGTTACCAAGAAGTGTTGACGATGATCCG
AACACAGCACGGTGCCTCCGAGTTGGCAAGCTTAACATCGATCGCCTGTACAGATCAGTTTAT
GAAAAGAACAAGATGAAAATCCACATCGTGCCCGACATGGTAGAGATGGTTACTGCCAAGGAT
TCCCAGAAGAAAGTCAGTGAGATTGATTACCGCCTGCGCCTCCACGAATGGATTTGCCACCCC
GACTTGCAAGTCAATGATCACGTCAGGAAAGTCACAGATCAGATCAGCGATATTGTATACAAG
GATGACCTCAACTGGCTGAAAGGCATTGGTTGCTACGTCTGGGACACTCCTGAAATCCTCCAT
GCCAAGCATGCTTATGATCTACGTGATGATATCAAGTATAAAGCTCACATGTTGAAAACAAGG
AATGACTACAAGCTTGTCACAGATACACCAGTCTACGTGCAGGCTGTCAAAAGTGGGAAACAG
CTAAGTGACGCTGTCTACCACTATGACTATGTGCACAGTGTCAGAGGCAAAGTGGCTCCAACT
ACCAAAACCGTGGATCTGGACCGGGCCCTTCATGCATACAAGCTCCAGAGTTCGAATCTATAC
AAAACCAGCCTGCGCACCCTGCCCACTGGATATAGACTTCCAGGTGACACTCCTCACTTCAAA
CACATCAAGGACACCCGTTACATGAGCAGTTATTTCAAGTACAAAGAAGCCTATGAACACACC
AAGGCATATGGGTATACACTTGGCCCCAAAGATGTTCCATTTGTCCACGTCCGGAGAGTCAAC
AATGTTACCAGCGAGAGACTGTATCGGGAATTGTACCACAAACTGAAAGACAAGATCCATACA
ACTCCCGATCCCCCTGAGATCCGCCAAGTCAAGAAGACACAAGAGGCTGTCAGTGAGTTGATC
TACAAATCAGACTTCTTCAAGATGCAGGGCCACATGATCTCTCTGCCATACACACCCCAAGTG
ATCCATTGCCGCTATGTGGGAGACATCACCAGTGATATTAAATACAAAGAGGACTTGCAGGTC
CTGAAGGGATTTGGCTGCTTCCTGTATGACACTCCTGACATGGTCCGCTCCCGGCACCTGCGG
AAGCTCTGGTCTAATTACCTATACACTGATAAGGCAAGGGAGATGCGAGACAAATACAAAGTG
GTGCTTGACACTCCAGAATACAGAAAAGTGCAAGAACTGAAGACACATCTGAGTGAGCTGGTC
TACAGAGCTGCAGGCAAGAAGCAGAAGTCAATCTTTACTTCAGTTCCTGATACTCCTGATCTT
TTAAGAGCCAAGCGAGGGCAGAAGCTTCAGAGTCAGTATCTGTATGTTGAACTTGCCACCAAA
GAGAGACCCCATCATCACGCTGGAAACCAGACCACAGCCTTGAAGCATGCTAAAGACGTGAAG
GACATGGTCAGTGAGAAAAAGTACAAGATTCAATATGAAAAGATGAAAGACAAGTACACTCCG
GTTCCAGATACGCCAATCCTCATCAGAGCCAAGAGGGCTTACTGGAATGCCAGTGATCTACGC
TACAAAGAAACATTTCAAAAGACCAAAGGGAAATACCACACGGTGAAAGATGCCCTAGACATT
GTCTATCATCGCAAAGTCACAGATGACATCAGTAAAATAAAATACAAGGAGAACTACATGAGC
CAGTTGGGTATCTGGAGGTCCATTCCTGATCGTCCAGAGCATTTCCACCACCGAGCAGTCACT
GACACAGTCAGTGATGTAAAATATAAAGAAGACTTGACTTGGCTTAAAGGCATTGGTTGCTAT
GCCTATGATACCCCTGATTTCACTCTGGCTGAAAAGAACAAGACTCTCTACAGCAAGTATAAG
TATAAAGAAGTATTTGAAAGGACAAAGTCAGATTTCAAGTATGTTGCCGACTCTCCGATCAAT
AGGCATTTCAAGTATGCAACTCAATTGATGAATGAGAAAAAATACAGAGCTGATTATGAGCAG
CGGAAAGATAAATACCACCTGGTAGTCGATGAGCCTAGACATCTGCTGGCTAAGACCCGCAGC
GACCAGATCAGTCAGATCAAATACAGGAAAAACTATGAAAAATCAAAGGACAAATTTACCTCA
ATTGTGGATACTCCAGAACACCTGCGTACTACAAAAGTCAACAAACAAATCAGCGATATCCTT
TATAAATTGGAATACAACAAGGCCAAACCCAGAGGCTACACCACAATCCACGACACGCCCATG
TTGCTGCATGTCCGCAAGGTTAAAGATGAAGTCAGTGATCTGAAATACAAAGAAGTATACCAA
AGAAATAAATCCAACTGCACCATTGAGCCAGATGCTGTTCATATCAAAGCAGCCAAGGACGCC
TACAAAGTCAACACCAATCTGGACTATAAGAAACAGTACGAAGCCAACAAAGCCCACTGGAAG
TGGACTCCTGACCGACCGGACTTCCTCCAGGCTGCCAAGTCATCCCTGCAGCAAAGCGATTTT
GAATATAAGCTGGACCGGGAGTTCCTCAAGGGTTGCAAGCTTTCTGTCACTGATGACAAAAAC
ACGGTGCTCGCCCTCAGGAATACTTTAATAGAAAGTGATCTGAAATACAAAGAGAAACATGTC
AAGGAAAGAGGAACCTGTCATGCCGTACCTGACACGCCTCAGATCCTGCTGGCGAAGACTGTC
AGCAACCTGGTGTCTGAGAACAAGTACAAGGACCATGTCAAGAAGCACTTGGCACAGGGCTCA
TACACAACACTACCAGAGACCCGGGACACTGTTCACGTCAAGGAAGTGACCAAGCATGTCAGT
GATACAAATTACAAAAAGAAGTTTGTCAAGGAGAAAGGAAAATCCAACTACTCCATCATGCTG
GAGCCACCAGAGGTGAAACATGCTATGGAAGTGGCCAAGAAGCAAAGTGATGTCGCTTACAGA
AAAGATGCCAAAGAGAAGCTGCATTACACCACAGTGGCTGATCGACCAGACATCAAGAAGGCC
ACACAGGCAGCCAAACAGGCCAGTGAGGTGGAGTACAGAGCCAAGCACCGCAAGGAAGGCAGC
CATGGCTTAAGCATGCTCGGTCGCCCAGACATAGAAATGGCCAAGAAGGCAGCCAAGCTGAGC
AGCCAGGTTAAATACCGAGAAAATTTCGATAAAGAAAAGGGCAAGACACCAAAATACAATCCA
AAAGACAGCCAGCTCTACAAAGTCATGAAAGATGCTAATAATCTTGCAAGTGAGGTTAAATAC
AAGGCTGACCTGAAGAAACTTCACAAACCCGTGACTGACATGAAGGAGTCTCTGATCATGAAT
CATGTCCTGAATACAAGCCAACTTGCCAGTTCTTACCAGTACAAGAAGAAGTATGAGAAGAGT
AAAGGCCACTACCACACCATACCCGATAATCTGGAGCAGCTTCACCTAAAAGAGGCCACAGAA
TTACAGAGTATAGTGAAATACAAAGAAAAGTATGAAAAGGAACGAGGAAAACCCATGCTGGAC
TTTGAAACACCAACGTACATCACTGCCAAAGAGTCTCAGCAGATGCAGAGTGGGAAAGAATAT
AGGAAAGATTATGAAGAGTCCATTAAAGGCAGAAACCTGACTGGCCTGGAGGTCACGCCAGCT
TTGTTACATGTCAAATATGCAACTAAAATAGCAAGCGAGAAAGAGTACAGGAAAGATCTAGAG
GAAAGCATCCGTGGGAAGGGCCTCACTGAAATGGAAGATACACCTGACATGCTAAGAGCAAAG
AATGCCACTCAAATCCTCAATGAGAAAGAATATAAGCGAGACCTGGAACTGGAAGTCAAAGGA
AGAGGCCTGAATGCCATGGCCAATGAAACTCCGGATTTTATGAGGGCCAGGAATGCTACTGAT
ATTGCCAGTCAGATTAAGTATAAGCAATCAGCAGAAATGGAGAAAGCCAATTTCACTTCTGTG
GTTGATACTCCAGAGATCATTCATGCCCAACAAGTCAAGAATCTTTCAAGCCAGAAAAAGTAC
AAGGAAGATGCTGAGAAGTCCATGTCGTATTATGAGACTGTTTTGGACACCCCAGAGATACAG
AGAGTCCGGGAGAACCAAAAGAACTTCAGCCTTCTCCAATACCAGTGTGACCTTAAAAACAGT
AAAGGAAAAATTACAGTTGTTCAAGACACGCCAGAAATACTGCGTGTAAAAGAAAATCAGAAG
AATTTCAGCTCGGTTTTATATAAAGAGGATGTCTCACCAGGAACGGCTATCGGAAAGACACCT
GAGATGATGAGAGTGAAACAAACACAGGACCACATTAGCTCGGTGAAGTATAAGGAAGCAATA
GGACAAGGAACTCCAATCCCTGACCTGCCTGAAGTGAAACGTGTGAAGGAGACGCAGAAGCAC ATTAGCTCGGTTATGTACAAAGAAAACTTGGGAACAGGCATTCCAACCACTGTGACTCCAGAG ATTGAGAGAGTCAAACGCAATCAAGAGAACTTTAGCTCGGTTTTGTACAAAGAAAATGTGGGG AAAGCCACCGCAACCCCTGTCACTCCTGAGATGCAGAGAGTCAAACGCAATCAAGAAAACATT AGCTCGGTATTGTACAAAGAGAACATGAGAAAAGCAACTCCGACACCTGTTACTCCAGAGATG GAGAGAGCTAAGCGCAACCAAGAAAACATTAGCTCGGTTCTTTATTCTGATAGTTTCCGGAAA CAAATACAAGGCAAAGCTGCCTATGTATTGGATACCCCCGAGATGAGACGGGTGAGGGAGACC CAACGGCACATCTCAACGGTGAAATATCATGAAGACTTTGAGAAACACAAGGGTTGCTTCACA CCAGTGGTGACAGATCCTATCACTGAACGAGTAAAGAAGAACATGCAGGACTTCAGTGACATT AACTACCGAGGTATTCAGAGGAAAGTGGTAGAAATGGAACAAAAACGGAATGACCAAGATCAG GAGACTATTACAGGTTTACGTGTCTGGCGTACTAATCCTGGTTCGGTTTTTGACTATGATCCA GCAGAAGACAACATCCAGTCCCGAAGCTTACACATGATTAATGTCCAAGCTCAGCGCCGGAGC CGGGAGCAGTCACGATCTGCCAGTGCACTAAGCGTCAGTGGGGGTGAGGAGAAGTCTGAGCAT TCAGAAGCACCAGACCACCACCTTTCGACTTACAGCGACGGGGGTGTCTTTGCAGTCTCAACA GCTTACAAACATGCAAAAACCACAGAGCTCCCACAACAACGATCATCTTCAGTTGCTACCCAA CAGACAACGGTATCTTCCATCCCATCTCATCCATCTACTGCTGGAAAAATCTTCCGTGCCATG TATGACTATATGGCTGCTGATGCAGATGAGGTGTCCTTCAAGGATGGAGATGCCATCATAAAT GTTCAAGCAATTGATGAAGGCTGGATGTATGGCACTGTGCAGAGGACTGGCAGGACCGGAATG CTCCCAGCCAACTACGTTGAAGCTATTTAGGCATTTCAAAGCATCACACTTGTCTGCAGGACT
TACAGATCCTGCAGTCAATGTTTCGGTTTAGACTCTCCACTGTTACCTAAGTTCTCAAGCTGC
CTATGGTTTTTCTGTGTCAATGTGATTTATGGTAGTACCATCCTTTCTCCTTTGGGTTTTAAA
ATAAGTTGCAGAACAGACACTTTAAAAGCTTCTGCAATATTATTTCTGTGCCTAGAGTCTTTC
TCCATTATAAACATGTTTTAACATTATTTCTTTTCTAAAACAGGGATTTTGAATATGCCAAAC
ACATTAAAGGAAAAATAGCAGAGATGTTCACCTTTTCCTTGCTGATTGCTAATGCTTATTATT
TCTAATTCAGTTCTGAAGTTATAAACTTATAATCAATACAAACCAGCAACTAATAAAACCTCT
AATTCTGCAAAAAAAAAAAAAAAAAAAAAAGTCG
ORF Start: ATG at 19 jORF Stop. TAG at 19747
SEQ ID NO: 144 6576 aa MW at kD jNOV35c, MADDEDYEEWEYYTEEWYEEVPGETITKIYETTTTRTSDYEQSETSKPALAQPALAQPASA
jCGl 19566-03 Protein KPVERRKVIRKKVDPSKFMTPYIAHSQKMQDLFSPNKYKEKFEKTKGQPYASTTDTPELRRIK KVQDQLSEVKYRMDGDVAKTICHVDEKAKDIEHAKKVSQQVSKVLYKQNWEDTKDKYLLPPDA jSequence PELVQAVKNTAMFSKKLYTEDWEADKSLFYPYNDSPELRRVAQAQKALSDVAYKKGLAEQQAQ FTPLADPPDIEFAKKVTNQVSKQKYKEDYENKIKGKWSETPCFEVANARMNADNISTRKYQED FENMKDQIYFMQTETPEYKMNKKAGVAASKVKYKEDYEKNKGKADYNVLPASENPQLRQLKAA GDALSDKLYKENYEKTKAKSINYCETPKFKLDTVLQNFSSDKKYKDSYLKDILGHYVGSFEDP YHSHCMKVTAQNSDKNYKAEYEEDRGKGFFPQTITQEYEAIKKLDQCKDHTYKVHPDKTKFTQ VTDSPVLLQAQVNSKQLSDLNYKAKHESEKFKCHIPPDTPAFIQHKVNAYNLSDNLYKQDWEK SKAKKFDIKVDAIPLLAAKANTKNTSDVMYKKDYEKNKGKMIGVLSINDDPKMLHSLKVAKNQ SDRLYKENYEKTKAKSMNYCETPKYQLDTQLKNFSEARYKDLYVKDVLGHYVGSMEDPYHTHC MKVAAQNSDKSYKAEYEEDKGKCYFPQTITQEYDAIKKLDQCKDHTYKVHPDKTKFTAVTDSP VLLQAQLNTKQLSDLNYKAKHEGERFKCHIPADAPQFIQHRVNAYNLSDNVYKQDWEKSKAKK FDIKVDAIPLLAAKANTKNTSDVMYKKDYEKSKGKMIGALSINDDPKMLHSLKTAKNQSDREY RKDYEKSKTIYTAPLDMLQVTQAKKSQAIASDVDYKHILHSYSYPPDSINVDLAKKAYALQSD VEYKADYNSWMKGCGWVPFGSLEMEKAKRASDILNEKKYRQHPDTLKFTSIEDAPITVQSKIN QAQRSDIAYKAKGEEIIHNYNLPPDLPQFIQAKVNAYNISENMYKADLKDLSKKGYDLRTDAI PIRAAKAARQAASDVQYKKDYEKAKGKMVGFQSLQDDPKLVHYMNVAKIQSDREYKKDYEKTK SKYNTPHDMFNWAAKKAQDVVSNVNYKHSLHHYTYLPDAMDLELSKNMMQIQSDNVYKEDYN NWMKGIGWIPIGSLDVEKVKKAGDALNEKKYRQHPDTLKFTSIVDSPVMVQAKQNTKQVSDIL YKAKGEDVKHKYTMSPDLPQFLQAKCNAYSISDVCYKRDWHDLIRKGNNVLGDAIPITAAKAS RNIASDYKYKEAYEKSKGKHVGFRSLQDDPKLVHYMNVAKLQSDREYKKNYENTKTSYHTPGD MVTITAAKMAQDVATNVNYKQPLHHYTYLPDAMSLEHTRNVNQIQSDNVYKDEYNSFLKGIGW IPIGSLEVEKVKKAGDALNERKYRQHPDTVKFTSVPDSMGMMLAQHNTKQLSDLNYKVEGEKL KHKYTIDPELPQFIQAKVNALNMSDAHYKADWKKTIRKGYDLRPDAIPIVAAKSSRNIASDCK YKEAYEKAKGKQVGFLSLQDDPKLVHYMNVAKIQSDREYKKGYEASKTKYHTPLDMVSVTAAK KSQEVATNANYRQSYHHYTLLPDALNVEHSRNAMQIQSDNLYKSDFTNWMKGIGWVPIESLEV EKAKKAGEILΞEKKYRQHPEKLKFTYAMDTMEQALNKSNKLNMDKRLYTEKWNKDKTTIHVMP DTPDILLSRVNQITMSDKLYKAGWEEEKKKGYDLRPDAIAIKAARASRDIASDYKYKKAYEQA KGKHIGFRSLEDDPKLVHFMQVAKMQSDREYKKGYEKSKTSFHTPVDMLSWAAKKSQEVATN ANYRNVIHTYNMLPDAMSFELAKNMMQIQSDNQYKADYADFMKGIGWLPLGSLEAEKNKKAME IISEKKYRQHPDTLKYSTLMDSMNMVLAQNNAKIMNEHLYKQAWEADKTKVHIMPDIPQIILA KANAINISDKLYKLSLEESKKKGYDLRPDAIPIKAAKASRDIASDYKYKYNYEKGKGKMVGFR SLEDDPKLVHSMQVAKMQSDREYKKNYENTKTSYHTPADMLSVTAAKDAQANITNTNYKHLIH KYILLPDAMNIELTRNMNRIQSDNEYKQDYNEWYKGLGWSPAGSLEVEKAKKATEYASDQKYR QHPSNFQFKKLTDSMDMVLAKQNAHTMNKHLYTIDWNKDKTKIHVMPDTPDILQAKQNQTLYS QKLYKLGWEEALKKGYDLPVDAISVQLAKASRDIASDYKYKQGYRKQLGHHVGFRSLQDDPKL
VLΞMNVAKMQSEREYKKDFEKWKTKFSSPVDMLGWLAKKCQELVSDVDYKNYLHQWTCLPDQ NDWQAKKVYELQSENLYKSDLEWLRGIGWSPLGSLEAEKNKRASEIISEKKYRQPPDRNKFT SIPDAMDIVLAKTNAKNRSDRLYREAWDKDKTQIHIMPDTPDIVLAKANLINTSDKLYRMGYE ELKRKGYDLPVDAIPIKAAKASREIASEYKYKEGFRKQLGHHIGARNIEDDPKMMWSMHVAKI JQSDREYKKDFEKWKTKFSSPVDMLGWLAYKCQTLVSDVDYKNYLHQWTCLPDQSDVIHARQA YDLQSDNLYKSDLQWLKGIGWMTSGSLEDEKNKRATQILSDHVYRQHPDQFKFSSLMDSIPMV LAKNNAITMNHRLYTEAWDKDKTTVHIMPDTPEVLLAKQNKVNYSEKLYKLGLEEAKRKGYDM RVDAIPIKAAKASRDIASEFKYKEGYRKQLGHHIGARAIRDDPKMMWSMHVAKIQSDREYKKD FEKWKTKFSSPVDMLGWLAKKCQTLVSDVDYKNYLHQWTCLPDQSDVIHARQAYDLQSDNMY KSDLQWMRGIGWVSIGSLDVEKCKRATEILSDKIYRQPPDRFKFTSVTDSLEQVLAKNNALNM NKRLYTEAWDKDKTQIHIMPDTPEIMLARQNKINYSETLYKLANEEAKKKGYDLRSDAIPIVA AKASRDVISDYKYKDGYRKQLGHHIGARNIEDDPKMMWSMHVAKIQSDREYKKDFEKWKTKFS SPVDMLGWLAKKCQTLVSDVDYKNYLHEWTCLPDQNDVIHARQAYDLQSDNIYKSDLQWLRG IGWVPIGSMDWKCKRAAEILSDNIYRQPPDKLKFTSVTDSLEQVLAKNNALNMNKRLYTEAW DKDKTQVHIMPDTPEIMLARQNKINYSESLYRQAMEEAKKEGYDLRSDAIPIVAAKASRDIAS DYKYKEAYRKQLGHHIGARAVHDDPKIMWSLHIAKVQSDREYKKDFEKYKTRYSSPVDMLGIV LAKKCQTLVSDVDYKHPLHECICLPDQNDIIHARKAYDLQSDNLYKSDLEWMKGIGWVPIDSL EVVRAKRAGELLSDTI RQRPETLKFTSITDTPEQVLAKNNALNMNKRLYTEAWDNDKKTIHV MPDTPEIMLAKLNRINYSDKLYKLALEESKKEGYDLRLDAIPIQAAKASRDIASDYKYKEGYR KQLGHHIGARNIKDDPKMMWSIHVAKIQSDREYKKEFEKWKTKFSSPVDMLGVVLAKKCQILV SDIDYKHPLHEWTCLPDQNDVIQARKAYDLQSDAIYKSDLEWLRGIGWVPIGSVEVEf-VKRAG EILSDRKYRQPADQLKFTCITDTPEIVLAKNNALTMSKHLYTEAWDADKTSIHVMPDTPDILL

AKSNSANISQKLYTKGWDESKMKDYDLRADAISIKSAKASRDIASDYKYKEAYEKQKGHHIGA QSIEDDPKIMCAIHAEKIQSEREYKKEFQKWKTKFSSPVDMLSILLAKKCQTLVTDIYYRNYL HEWTCMPDQNDIIQAKKAYDLQSDALYKADLEWLRGIGWMPQGSPEVLRVKNAQNIFCDSVYR TPWNLKYTSIVDTPEWLAKSNAENISIPKYREVWDKDKTSIHIMPDTPEINLARANALNVS NKLYREGWDEMKAGCDVRLDAIPIQAAKASREIASDYKYKLDHEKQKGHYVGTLTARDDNKIR WALIADKLQNEREYRLDWAKWKAKIQSPVDMLSILHSKNSQALVSDMDYRNYLHQWTCMPDQN DVIQAKKAYELQSDNVYKADLEWLRGIGWMPNDSVSVNHAKHAADIFSEKKYRTKIETLNFTP VDDRVDYVTAKQSGEILDDIKYRKDWNATKSKYTLTETPLLHTAQEAARILDQYLYKEGWERQ KATGYILPPDAVPFVHAHHCNDVQSELKYKAEHVKQKGHYVGVPTMRDDPKLVWFEHAGQIQN ERLYKEDYHKTKAKINIPADMVSVLAAKQGQTLVSDIDYRNYLHQWMCHPDQNDVIQARKAYD LQSDNVYRADLEWLRGIG IPLDSVDHVRVTKNQEMMSQIKYKKNALENYPNFTSWDPPEIV LAKINSVNQSDVKYKETFNKAKGKYTFSPDTPHISHSKDMGKLYSTILYKGAWEGTKAYGYTL DERYIPIVGAKHADLVNSELKYKETYEKQKGHYLAGKVIGEFPGVVHCLDFQKMRSALNYRKH YEDTKANVHIPNDMMNHVLAKRCQYILΞDLEYRHYFHQWTSLLEEPNVIRVRNAQEILSDNVY KDDLNWLKGIGCYVWDTPQILHAKKSYDLQSQLQYTAAGKENLQNYNLVTDTPLYVTAVQSGI NASEVKYKENYHQIKDKYTTVLETVDYDRTRNLKNLYSSNLYKEAWDRVKATSYILPSSTLSL THAKNQKHLASHIKYREEYEKFKALYTLPRSVDDDPNTARCLRVGKLNIDRLYRSVYEKNKMK jIHIVPDMVEMVTAKDSQKKVSEIDYRLRLHEWICHPDLQVNDHVRKVTDQISDIVYKDDLNWL KGIGCYVWDTPEILHAKHAYDLRDDIKYKAHMLKTRNDYKLVTDTPVYVQAVKSGKQLSDAVY jHYDYVHSVRGKVAPTTKTVDLDRALHAYKLQSSNLYKTSLRTLPTGYRLPGDTPHFKHIKDTR jYMSSYFKYKEAYEHTKAYGYTLGPKDVPFVHVRRVNNVTSERLYRELYHKLKDKIHTTPDPPE IRQVKKTQEAVSELIYKSDFFKMQGHMISLPYTPQVIHCRYVGDITSDIKYKEDLQVLKGFGC jFLYDTPDMVRSRHLRKLWSNYLYTDKAREMRDKYKWLDTPEYRKVQELKTHLSELVYRAAGK JKQKSIFTSVPDTPDLLRAKRGQKLQSQYLYVELATKERPHHHAGNQTTALKHAKDVKDMVSEK fKYKIQYEKMKDKYTPVPDTPILIRAKRAYWNASDLRYKETFQKTKGKYHTVKDALDIVYHRKV TDDISKIKYKENYMSQLGIWRSIPDRPEHFHHRAVTDTVSDVKYKEDLTWLKGIGCYAYDTPD FTLAEKNKTLYSKYKYKEVFERTKSDFKYVADSPINRHFKYATQLMNEKKYRADYEQRKDKYH 1LVVDEPRHLLAKTRSDQISQIKYRKNYEKSKDKFTSIVDTPEHLRTTKV KQISDILYKLEYN JKAKPRGYTTIHDTPMLLHVRKVKDEVSDLKYKEVYQRNKSNCTIEPDAVHIKAAKDAYKVNTN LDYKKQYEANKAHWKWTPDRPDFLQAAKSSLQQSDFEYKLDREFLKGCKLSVTDDKNTVLALR NTLIESDLKYKEKHVKERGTCHAVPDTPQILLAKTVSNLVSENKYKDHVKKHLAQGSYTTLPE TRDTVHVKEVTKHVSDTNYKKKFVKEKGKSNYSIMLEPPEVKHAMEVAKKQSDVAYRKDAKEK LHYTTVADRPDIKKATQAAKQASEVEYRAKHRKEGSHGLSMLGRPDIEMAKKAAKLSSQVKYR ENFDKEKGKTPKYNPKDSQLYKVMKDANNLASEVKYKADLKKLHKPVTDMKESLIMNHVLNTS QLASSYQYKKKYEKSKGHYHTIPDNLEQLHLKEATELQSIVKYKEKYEKERGKPMLDFETPTY ITAKESQQMQSGKEYRKDYEESIKGRNLTGLEVTPALLHVKYATKIASEKEYRKDLEESIRGK GLTEMEDTPDMLRAKNATQILNEKEYKRDLELEVKGRGLNAMANETPDFMRARNATDIASQIK YKQSAEMEKANFTSWDTPEIIHAQQVKNLSSQKKYKEDAEKSMSYYETVLDTPEIQRVRENQ KNFSLLQYQCDLKNSKGKITWQDTPEILRVKENQKNFSSVLYKEDVSPGTAIGKTPEMMRVK QTQDHISSVKYKEAIGQGTPIPDLPEVKRVKETQKHISSVMYKENLGTGIPTTVTPEIERVKR NQENFSSVLYKENVGKATATPVTPEMQRVKRNQENISSVLYKENMRKATPTPVTPEMERAKRN QENISSVLYSDSFRKQIQGKAAYVLDTPEMRRVRETQRHISTVKYHEDFEKHKGCFTPWTDP ITERVKKNMQDFSDINYRGIQRKWEMEQKRNDQDQETITGLRVWRTNPGSVFDYDPAEDNIQ SRSLHMINVQAQRRSREQSRSASALSVSGGEEKSEHSEAPDHHLSTYSDGGVFAVSTAYKHAK
TTELPQQRSSSVATQQTTVSSIPSHPSTAGKIFRAMYDYMAADADEVSFKDGDAIINVQAIDE; GWMYGTVQRTGRTGMLPANYVEAI |
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 35B.
Further analysis of the NOV35a protein yielded the following properties shown in Table 35C.
Table 35C. Protein Sequence Properties NOV35a
PSort 0.8800 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV35a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 35 D.
In a BLAST search of public sequence datbases, the NOV35a protein was found to have homology to the proteins shown in the BLASTP data in Table 35E.
PFam analysis predicts that the NOV35a protein contains the domains shown in the Table 35F.
j Table 35F. Domain Analysis of NOV35a i Identities/
I Pfam Domain NOV35a Match Region 1 Similarities Expect Value
Example 36.
The NOV36 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 36A.
Table 36A. NOV36 Sequence Analysis
;SEQ ID NO: 145 '2973 bp
NOV36a, jATGTCGGAAGAAACCCGACAGAGCAAATTGGCCGCAGCGAAGAAAAAGTTGAGAGAATATCAG
CGI 20166-01 DNA •CAGAGGAATAGCCCTGGTGTTCCTACAGGAGCGAAAAAGAAGAAGAAAATAAAAAATGGCAGT AACCCTGAGACAACCACTTCTGGTGGTTGCCACTCACCTGAGGATACACCCAAGGACAATGCT
Sequence GCTACTCTACAACCATCTGATGACACCGTGTTACCTGGCGGTGTCCCTTCCCCTGGTGCCAGT CTCACTAGCATGGCGGCATCTCAGAATCATGATGCTGACAATGTCCCTAATCTCATGGATGAA ACCAAGACTTTCTCATCAACCGAGAGCCTGCGACAACTCTCCCAACAGCTCAATGGTCTTGTT TGTGAGTCTGCGACATGTGTCAATGGGGAGGGCCCTGCATCGTCTGCTAACCTGAAGGATCTG GAGAGCCGGTACCAACAGCTAGCGGTAGCCCTGGACTCCAGCTATGTAACAAACAAACAACTC AATATCACGATAGAGAAATTGAAACAACAGAACCAAGAAATTACGGATCAGTTGGAAGAAGAA AAGAAAGAATGCCACCAAAAGCAGGGAGCCCTAAGGGAGCAGTTACAGGTTCACATTCAGACC ATAGGGATCCTCGTATCAGAGAAAGCTGAGTTACAGACAGCCCTGGCTCACACTCAGCATGCT GCCAGGCAGAAAGAAGGAGAGTCTGAAGATCTGGCCAGCCGCCTGCAGTATTCCCGGCGGCGT GTGGGAGAGTTGGAGCGGGCTCTCTCTGCTGTCTCCACGCAGCAGAAGAAGGCAGACAGGTAC AACAAGGAGTTAACCAAAGAGAGAGACGCCCTCAGGCTGGAGTTATACAAGAACACCCAAAGC AATGAGGACCTGAAGCAAGAGAAATCAGAATTGGAAGAGAAGCTTCGGGTCCTAGTGACTGAG AAGGCTGGCATGCAGCTTAACTTGGAAGAATTGCAAAAGAAGTTAGAGATGACGGAACTCCTG JCTTCAACAGTTTTCAAGCCGGTGTGAAGCCCCTGATGCTAACCAGCAGTTACAGCAGGCCATG 'GAGGAGCGGGCACAGCTGGAAGCACACCTGGGGCAGGTAATGGAGTCGGTTAGACAACTACAA 'ATGGAGAGAGATAAATATGCGGAGAATCTCAAAGGAGAGAGCGCCATGTGGCGGCAGAGGATG CAGCAGATGTCAGAGCAGGTGCACACATTGAGAGAGGAGAAGGAATGTAGCATGAGTCGGGTA CAGGAGCTGGAGACGAGCTTGGCTGAACTGAGGAACCAGATGGCTGAACCCCCGCCCCCAGAG CCCCCAGCAGGGCCCTCCGAGGTGGAGCAGCAGCTACAAGCGGAGGCTGAGCACCTGCGGAAG GAGCTGGAGGGTCTGGCAGGACAGCTTCAAGCCCAGGTGCAAGACAATGAGGGCTTGAGTCGC CTGAACCGGGAGCAGGAGGAGAGGCTGCTGGAGCTGGAGCGGGCGGCCGAGCTCTGGGGGGAG CAGGCGGAGGCGCGCAGGCAAATCCTGGAGACCATGCAGAACGACCGCACTACCATCAGCCGC GCACTCTCCCAGAACCGGGAGCTCAAGGAGCAGCTGGCTGAGCTGCAGAGCGGATTTGTAAAG CTGACTAATGAGAACATGGAGATCACCAGCGCACTGCAGTCGGAGCAGCACGTCAAGAGGGAG CTGGGAAAGAAGCTGGGCGAGCTGCAGGAGAAGCTGAGCGAGCTGAAGGAAACGGTGGAGCTG AAGAGCCAAGAGGCTCAAAGTCTGCAGCAGCAGCGAGACCAGTACCTGGGACACCTGCAGCAG TATGTGGCCGCCTATCAGCAGCTGACCTCTGAGAAGGAGGTGCTGCATAATCAGCTACTGCTG CAGACCCAGCTCGTGGACCAGCTGCAGCAGCAGGAAGCTCAGGGCAAAGCGGTGGCCGAGATG GCCCGCCAAGAGTTGCAGGAAACCCAGGAGCGCCTGGAAGCTGCCACCCAGCAGAATCAGCAG CTACGGGCCCAGTTGAGCCTCATGGCTCACCCTGGGGAAGGAGATGGACTGGACCGGGAGGAG GAGGAGGATGAGGAGGAGGAGGAGGAGGAGGCGGTGGCAGTACCTCAGCCCATGCCAAGCATC CCGGAGGACCTGGAGAGCCGGGAAGCCATGGTGGCATTTTTCAACTCAGCTGTAGCCAGTGCC GAGGAGGAGCAGGCAAGGCTACGTGGGCAGCTGAAGGAGCAAAGGGTGCGCTGCCGGCGCCTG GCTCACCTGCTGGCCTCGGCCCAGAAGGAGCCTGAGGCAGCAGCCCCAGCCCCAGGGACCGGG GGTGATTCTGTGTGTGGGGAGACCCACCGGGCCCTGCAGGGGGCCATGGAGAAGCTGCAGAGC CGCTTTATGGAGCTCATGCAGGAGAAGGCAGACCTGAAGGAGAGGGTAGAGGAACTGGAACAT CGCTGCATCCAGCTTTCTGGAGAGACAGACACCATTGGAGAGTACATTGCACTGTACCAGAGC CAGAGGGCAGTGCTGAAGGAGCGGCACCGGGAGAAGGAGGAGTACATCAGCAGGCTGGCCCAA GACAAGGAGGAGATGAAGGTGAAGCTGCTGGAGCTGCAGGAGCTGGTCTTACGGCTTGTGGGC GACCGCAACGAGTGGCATGGCAGATTCCTGGCAGCTGCCCAGAACCCTGCTGATGAGCCCACT
TCAGGGGCCCCAGCCCCCCAGGAACTTGGGGCTGCCAACCAGCAGGGTGATCTTTGCGAGGTG AGCCTCGCCGGCAGTGTGGAGCCTGCCCAAGGAGAGGCCAGGGAGGGTTCTCCCCGTGACAAC CCCACTGCACAGCAGATCATGCAGCTGCTTCGTGAGATGCAGAACCCCCGGGAGCGCCCAGGC TTGGGCAGCAACCCCTGCATTCCTTTTTTTTACCGGGCTGACGAGAATGATGAGGTGAAGATC ACTGTCATCTAA
ORF Start: ATG at 1 ;ORF Stop: TAA at 2971
SEQ ID NO: 146 Ϊ990 aa ΪMW aϊ 1 1 1657.5kD
;NOV36a, SEETRQSKLAAAKKKLREYQQRNSPGVPTGAKKKKKIKNGSNPETTTSGGCHSPEDTPKDNA
;CG 120166-01 Protein AT QPSDDTV PGGVPSPGASLTSMAASQNHDADNVPNL DETKTFSSTESLRQLSQQLNG V CESATCVNGEGPASSANLKDLESRYQQLAVALDSSYVTNKQLNITIEKLKQQNQEITDQLEEE
Sequence KKECHQKQGA REQLQVHIQTIGILVSEKAELQTALAHTQHAARQKEGESEDLASRLQYSRRR VGE ERALSAVSTQQKKADRYNKELTKERDALRLELYK TQSNEDLKQEKSELEEK RVLVTE KAGMQLNLEELQKKLEMTEL LQQFSSRCEAPDANQQLQQAMEERAQLEAHLGQVMESVRQLQ ERDKYAENLKGESAMWRQRMQQMSEQVHTLREEKECSMSRVQELETSLAELRNQMAEPPPPE PPAGPSEVEQQLQAEAEHLRKELEGLAGQLQAQVQDNEGLSRLNREQEERLLE ERAAE WGE QAEARRQILETMQ DRTTISRALSQNRELKEQLAELQSGFVKLTNENMEITSALQSEQHVKRE LGKKLGELQEKLSELKETVELKSQEAQSLQQQRDQYLGHLQQYVAAYQQLTSEKEVLHNQLL QTQLVDQLQQQEAQGKAVAEMARQE QETQERLEAATQQNQQLRAQLSLMAHPGEGDGLDREE EEDEEEEEEEAVAVPQPMPSIPEDLESREAMVAFFNSAVASAEEEQAR RGQLKEQRVRCRR AHLLASAQKEPEAAAPAPGTGGDSVCGETHRALQGAMEK QSRFMELMQEKADLKERVEELEH RCIQLSGETDTIGEYIALYQSQRAVLKERHREKEEYISR AQDKEEMKVKLLELQELVLRLVG DRNEWHGRFLAAAQNPADEPTSGAPAPQELGAANQQGDLCEVSLAGSVEPAQGEAREGSPRDN PTAQQIMQLLREMQNPRERPGLGSNPCIPFFYRADENDEVKITVI
SEQ ID NO: 147 :2886 bp
NOV36b. CCTCCCCGCCCCGCGATGTCGGAAGAAACCCGACAGAGCAAATTGGCCGCAGCGAAGAAAAAG CG I 20166-02 DNA TTGAGAGAATATCAGCAGAGGAATAGCCCTGGTGTTCCTACAGGAGCGAAAAAGAAGAAGAAA ATAAAAAATGGCAGTAACCCTGAGACAACCACTTCTGGTGGTTGCCACTCACCTGAGGATACA Sequence CCCAAGGACAATGCTGCTACTCTACAACCATCTGATGACACCGTGTTACCTGGCGGTGTCCCT TCCCCTGGTGCCAGTCTCACTAGCATGGCGGCATCTCAGAATCATGATGCTGACAATGTCCCT AATCTCATGGATGAAACCAAGACTTTCTCATCAACCGAGAGCCTGCGACAACTCTCCCAACAG CTCAATGGTCTTGTTTGTGAGTCTGCGACATGTGTCAATGGGGAGGGCCCTGCATCGTCTGCT AACCTGAAGGATCTGGAGAGCCGGTACCAACAGCTAGCGGTAGCCCTGGACTCCAGCTATGTA ACAAACAAACAACTCAATATCACGATAGAGAAATTGAAACAACAGAACCAAGAAATTACGGAT CAGTTGGAAGAAGAAAAGAAAGAATGCCACCAAAAGCAGGGAGCCCTAAGGGAGCAGTTACAG GTTCACATTCAGACCATAGGGATCCTCGTATCAGAGAAAGCTGAGTTACAGACAGCCCTGGCT CACACTCAGCATGCTGCCAGGCAGAAAGAAGGAGAGTCTGAAGATCTGGCCAGCCGCCTGCAG TATTCCCGGCGGCGTGTGGGAGAGTTGGAGCGGGCTCTCTCTGCTGTCTCCACGCAGCAGAAG AAGGCAGACAGGTACAACAAGGAGTTAACCAAAGAGAGAGACGCCCTCAGGCTGGAGTTATAC AAGAACACCCAAAGCAATGAGGACCTGAAGCAAGAGAAATCAGAATTGGAAGAGAAGCTTCGG GTCCTAGTGACTGAGAAGGCTGGCATGCAGCTTAACTTGGAAGAATTGCAAAAGAAGTTAGAG ATGACGGAACTCCTGCTTCAACAGTTTTCAAGCCGGTGTGAAGCCCCTGATGCTAACCAGCAG TTACAGCAGGCCATGGAGGAGCGGGCACAGCTGGAAGCACACCTGGGGCAGGTAATGGAGTCG GTTAGACAACTACAAATGGAGAGAGATAAATATGCGGAGAATCTCAAAGGAGAGAGCGCCATG TGGCGGCAGAGGATGCAGCAGATGTCAGAGCAGGTGCACACATTGAGAGAGGAGAAGGAATGT AGCATGAGTCGGGTACAGGAGCTGGAGACGAGCTTGGCTGAACTGAGGAACCAGATGGCTGAA CCCCCGCCCCCAGAGCCCCCAGCAGGGCCCTCCGAGGTGGAGCAGCAGCTACAAGCGGAGGCT GAGCACCTGCGGAAGGAGCTGGAGGGTCTGGCAGGACAGCTTCAAGCCCAGGTGCAAGACAAT GAGGGCTTGAGTCGCCTGAACCGGGAGCAGGAGGAGAGGCTGCTGGAGCTGGAGCGGGCGGCC GAGCTCTGGGGGGAGCAGGCGGAGGCGCGCAGGCAAATCCTGGAGACCATGCAGAACGACCGC ACTACCATCAGCCGCGCACTCTCCCAGAACCGGGAGCTCAAGGAGCAGCTGGCTGAGCTGCAG AGCGGATTTGTAAAGCTGACTAATGAGAACATGGAGATCACCAGCGCACTGCAGTCGGAGCAG CACGTCAAGAGGGAGCTGGGAAAGAAGCTGGGCGAGCTGCAGGAGAAGCTGAGCGAGCTGAAG GAAACGGTGGAGCTGAAGAGCCAAGAGGCTCAAAGTCTGCAGACCCAGCTCGTGGACCAGCTG CAGCAGCAGGAAGCTCAGGGCAAAGCGGTGGCCGAGATGGCCCGCCAAGAGTTGCAGGAAACC CAGGAGCGCCTGGAAGCTGCCACCCAGCAGAATCAGCAGCTACGGGCCCAGTTGAGCCTCATG GCTCACCCTGGGGAAGGAGATGGACTGGACCGGGAGGAGGAGGAGGATGAGGAGGAGGAGGAG GAGGAGGCGGTGGCAGTACCTCAGCCCATGCCAAGCATCCCGGAGGACCTGGAGAGCCGGGAA GCCATGGTGGCATTTTTCAACTCAGCTGTAGCCAGTGCCGAGGAGGAGCAGGCAAGGCTACGT GGGCAGCTGAAGGAGCAAAGGGTGCGCTGCCGGCGCCTGGCTCACCTGCTGGCCTCGGCCCAG AAGGAGCCTGAGGCAGCAGCCCCAGCCCCAGGGACCGGGGGTGATTCTGTGTGTGGGGAGACC CACCGGGCCCTGCAGGGGGCCATGGAGAAGCTGCAGAGCCGCTTTATGGAGCTCATGCAGGAG AAGGCAGACCTGAAGGAGAGGGTAGAGGAACTGGAACATCGCTGCATCCAGCTTTCTGGAGAG ACAGACACCATTGGAGAGTACATTGCACTGTACCAGAGCCAGAGGGCAGTGCTGAAGGAGCGG CACCGGGAGAAGGAGGAGTACATCAGCAGGCTGGCCCAAGACAAGGAGGAGATGAAGGTGAAG

Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 36B.
, Table 36B. Comparison of NOV36a against NOV36b.
: NOV36a Residues/ Identities/ s Protein Sequence j Match Residues Similarities for the Matched Region l NOV36b 1..990 790/990 (79%) 1..956 790/990 (79%)
Further analysis of the NOV36a protein yielded the following properties shown in Table 36C.
Table 36C. Protein Sequence Properties NOV36a
! PSort 0.6000 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
, SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV36a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 36D.
In a BLAST search of public sequence datbases, the NOV36a protein was found to have homology to the proteins shown in the BLASTP data in Table 36E.
PFam analysis predicts that the NOV36a protein contains the domains shown in the Table 36F.
Table 36F. Domain Analysis of NOV36a
I Identities/
Pfam Domain NOV36a Match Region j Similarities Expect Value j for the Matched Region
I--
Example 37.
The NOV37 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 37A.
Table 37A. NOV37 Sequence Analysis i [SEQ ΪD NO:' 149" J2490 bp •> jNOV37a, AAAAGGGCATTGAGACCNTGGGAGGTGACTTCATCAATTGCTCNTACCCCGGAGTTCTTAGAC JCG 120401 ■01 DNA AGACTTGGACCNATCCCCTACCTTGGGTGTGCACTTCTTGGGAAACGGAGGGGCCNGAGGGTC
CGAATCTCNTCTTCAGCCTTTTAAGCTTCACTTGGTCAGAATCCTTGGATGAGCNTGTGGGAC Sequence CGTTCCTCATAGCCCGGTGGTTTGANCCAGTGGCTTTGGGACTGTAAGAGGATGGACAAAGGT
AGTATGAGGCCGGGACAGCTCCCCAAATGCTCGGGCGCCAAGCATCTGCTGATTCCACTCTGT
GCCTGGCACGTGTGTCTTTCGGTCCTGGCTAGGCCTTGCCACCTCCCCCTGGGCCAGCACCAC
CCATGTACCTGTCGGCAGAGCCACAGTTGACTGACTTGCTGTTGAGCTGCTGCTCTTTAGCAC
GGCTGCATTTTGATGGCAGAGGGAGCAGTTATGCCCAGAGCCCAGCGTGTCGGCATCACCAGT
CTGACCTGAGCACCATGTGCTGCACGACATGACACGTGGCACCGGGGGAACTGCCCAGCGTGG
AAGGTCTGGGCCAGGTCTGAGCCCAGATGGGATCTGGATGGCCAAGGAACTCTACCTTAAAAC CTCAAGTGTCAAGGAGGCAGGGGAGGGGCCAAGAGGGCTGGCAGGGGAAGGGGGCTGGGGAGG GGTCCCATTTGCAGAGGCTCTTAGGATCTTAGGAGGCCCGAATCCCACCATTTCTCTACTTGG TAGATCTCAGGGGCTGCTAGATTCATCCCTGATGGCATCAGGCACTGCCAGCCGCTCAGAGGA TGAGGAGTCACTGGCAGGGCAGAAGCGAGCCTCCTCCCAGGCCTTGGGCACCATCCCTAAACG GAGAAGCTCCTCCAGGTTCATCAAGAGGAAGAAGTTCGATGATGAGCTGGTGGAGAGCAGCCT GGCAAAATCTTCTACCCGGGCAAAGGGGGCCAGTGGGGTGGAACCAGGGCGCTGTTCGGGGAG TGAACCCTCCTCCAGTGAGAAGAAGAAGGTATCCAAAGCCCCCAGCACTCCTGTGCCACCCAG CCCAGCCCCAGCCCCTGGACTCACCAAGCGTGTGAAGAAGAGTAAACAGCCACTTCAGGTGAC CAAGGATCTGGGCCGCTGGAAGCCTGCAGATGACCTCCTGCTCATAAATGCTGTGTTGCAGAC CAACGACCTGACCTCCGTCCACCTGGGCGTGAAATTCAGCTGCCGCTTCACCCTTCGGGAGGT CCAGGAGCGTTGGTACGCCCTGCTCTACGATCCTGTCATCTCCAAGTTGGCCTGTCAGGCCAT GAGGCAGCTGCACCCAGAGGCTATTGCAGCCATCCAGAGCAAGGCCCTGTTTAGCAAGGCTGA GGAGCAGCTGCTGAGCAAAGTGGGATCGACCAGCCAGCCCACCTTGGAGACCTTCCAGGACCT GCTGCACAGACACCCTGATGCCTTCTACCTGGCCCGTACCGCGAAGGCCCTGCAGGCCCACTG GCAGCTCATGAAGCAGTATTACCTGCTGGAGGACCAGACAGTGCAGCCGCTGCCCAAAGGGGA CCAAGTGCTGAACTTCTCTGATGCAGAGGACCTGATTGATGACAGTAAGCTCAAGGACATGCG AGATGAGGTCCTGGAACATGAGCTGATGGTGGCTGACCGGCGCCAGAAGCGAGAGATTCGGCA GCTGGAACAGGAACTGCATAAGTGGCAGGTGCTAGTGGACAGCATCACAGGCATGAGCTCTCC GGACTTCGACAACCAGACACTGGCAGTGCTGCGGGGCCGCATGGTGCGGTACCTGATGCGCTC GCGTGAGATCACCCTGGGCAGAGCAACCAAGGATAACCAGATTGATGTGGACCTGTCTCTGGA GGGTCCGGCCTGGAAGATATCCCGGAAACAAGGTGTCATCAAGCTGAAGAACAACGGTGATTT CTTCATTGCCAATGAGGGTCGACGGCCCATCTACATCGATGGACGGCCGGTGCTCTGTGGCTC CAAATGGCGCCTCAGCAACAACTCTGTGGTGGAGATCGCCAGCCTGCGATTCGTCTTCCTTAT CAACCAGGACCTCATTGCCCTCATCAGGGCTGAGGCTGCCAAGATCACACCACAGTGAGGAGT GGTGGCAGGACTCGTGGGCCCTCTCCGGCCTGTTTCCCCTGCCACTCCAGCCCCCTTGAGCTG GGAACTCAGGCTCCTGGAAAAACCTGGGCAGTGGGAGGCTCAGCTGCGGGCCATTGATTTGAG CCTTTGAGGGAGGATAGGGCTGGCCTTTGTGAAGCCAGCAGAGGCTGAGAACCTCAGGCTTCC CTAGATCCAGAGCCCCTCCCCATCTTCCTCTCTCTAAAAACAACCCTACCCCCCATTGCCACC TTCACTCCTGTGTCTCCAGCTGATTAGCCTCAGACTCTTCTTTTATTGTTTTTCTTTTGTAAA
TAAAAAGCACCAGGTTCAAAAAAAAAAAAAAAA
ORF Start: ATG at 533 j jORF Stop: TGA at 2135
SEQ ID NO: 150 J534 aa ΪMW at 590Ϊ6.8kD
JNOV37a, MTRGTGGTAQRGRSGPGLSPDGIWMAKE YLKTSSVKEAGEGPRG AGEGGWGGVPFAEALRI CGI 20401 -01 Protein LGGPNPTIS LARSQGLLDSSLMASGTASRSEDEESLAGQKRASSQALGTIPKRRSSSRFIKR KKFDDE VESSLAKSSTRAKGASGVEPGRCSGSEPSSSEKKKVSKAPSTPVPPSPAPAPGLTK Sequence RVKKSKQP QVTKDLGR KPADDLLLINAVLQTNDLTSVH GVKFSCRFTLREVQERWYAL Y DPVISKLACQAMRQLHPEAIAAIQSKALFSKAEEQLLSKVGSTSQPT ETFQDLLHRHPDAFY LARTAKA QAHWQLMKQYYLLEDQTVQPLPKGDQVLNFSDAEDLIDDSKLKDMRDEVLEHELM VADRRQKREIRQLEQELHK QVLVDSITGMSSPDFDNQTLAVLRGRMVRYLMRSREITLGRAT KDNQIDVDLSLEGPA KISRKQGVIK K GDFFIANEGRRPIYIDGRPVLCGSKWRLS SV VEIASLRFVFLINQDLIALIRAEAAKITPQ
SEQ ID NO: 151 1764 bp i
•NOV37b, TACCCCGAGAGTTCTTAGACAGACTTGGACCGATCCCCTACCTTGGGTGTGCACTCTTGGGAG CGI 20401 -02 DNA AACGAGGGGCGGAGGGTCCGAATCTCCTCTCAGCCTTTAAGCTCACCTGGTCAGAATCCTTGG
ATGAGCCTGTGGGACCGTTCCTCCTAGCCCGGTGGTTTGGAACCAGTGGCTTTGGGACTGTAA Sequence GAGGATGGACAAAGATTCTCAGGGGCTGCTAGATTCATCCCTGATGGCATCAGGCACTGCCAG
CCGCTCAGAGGATGAGGAGTCACTGGCAGGGCAGAAGCGAGCCTCCTCCCAGGCCTTGGGCAC CATCCCTAAACGGAGAAGCTCCTCCAGGTTCATCAAGAGGAAGAAGTTCGATGATGAGCTGGT GGAGAGCAGCCTGGCAAAATCTTCTACCCGGGCAAAGGGGGCCAGTGGGGTGGAACCAGGGCG CTGTTCGGGGAGTGAACCCTCCTCCAGTGAGAAGAAGAAGGTATCCAAAGCCCCCAGCACTCC TGTGCCACCCAGCCCAGCCCCAGCCCCTGGACTCACCAAGCGTGTGAAGAAGAGTAAACAGCC ACTTCAGGTGACCAAGGATCTGGGCCGCTGGAAGCCTGCAGATGACCTCCTGCTCATAAATGC TGTGTTGCAGACCAACGACCTGACCTCCGTCCACCTGGGCGTGAAACTCAGCTGCCGCTTCAC CCTTCGAGAGGTCCAGGAGCGTTGGTACGCCCTGCTCTACGATCCTGTCATCTCCAAGTTGGC CTGTCAGGCCATGAGGCAGCTGCACCCAGAGGCTATTGCAGCCATCCAGAGCAAGGCCCTGCA GGCCCACTGGCAGCTCATGAAGCAGTATTACCTGCTGGAGGACCAGACAGTGCAGCCGCTGCC CAAAGGGGACCAAGTGCTGAACTTCTCTGATGCAGAGGACCTGATTGATGACAGTAAGCTCAA GGACATGCGAGATGAGGTCCTGGAACATGAGCTGATGGTGGCTGACCGGCGCCAGAAGCGAGA GATTCGGCAGCTGGAACAGGAACTGCATAAGTGGCAGGTGCTAGTGGACAGCATCACAGGCAT GAGCTCTCCGGACTTCGACAACCAGACACTGGCAGTACTGCGGGGCCGCATGGTGCGGTACCT GATGCGCTCGCGTGAGATCACCCTGGGCAGAGCAACCAAGGATAACCAGATTGATGTGGACCT GTCTCTGGAGGGTCCGGCCTGGAAGATATCCCGGAAACAAGGTGTCATCAAGCTGAAGAACAA CGGTGATTTCTTCATTGCCAATGAGGGTCGACGGCCCATCTACATCGATGGACGGCCGGTGCT CTGTGGCTCCAAATGGCGCCTCAGCAACAACTCTGTGGTGGAGATCGCCAGCCTGCGATTCGT CTTCCTTATCAACCAGGACCTCATTGCCCTCATCAGGGCTGAGGCTGCCAAGATCACACCACA GTGAGGAGTGGTGGCAGGACTCGTGGGCCCTCTCCGGCCTGTTTCCCCTGCCACTCCAGCCCC
CTTGAGCTGGGAACTCAGGCTCCTGGAAAAACCTGGGCAGTGGGAGGCTCAGCTGCGGGCCAT
TGATTTGAGCCTTTGAGGGAGGATAGGGCTGGCCTTTGTGAAGCCAGCAGAGGCTGAGAACCT
CAGGCTTCCCTAGATCCAGAGCCCCTCCCCATCTTCCTCTCTCTAAAAACAACCCTACCCCCC
ATTGCCACCTTCACTCCTGTGTCTCCAGCTGATTAGCCTCAGACTCTTCTTTTATTGTTTTTC
ORF Start: ATG at 194 ■ORF Stop: TGA at 1451 SEQ D O: 152 " 419 aa |MW at 46940.2kD jNOV37b, MDKDSQGLLDSSLMASGTASRSEDEESLAGQKRASSQALGTIPKRRSSSRFIKRKKFDDE VE CG I 20401 -02 Protein SSLAKSSTRAKGASGVEPGRCSGSEPSSSEKKKVSKAPSTPVPPSPAPAPGLTKRV KSKQPL QVTKDLGR KPADDLLLINAVLQTNDLTSVHLGVKLSCRFTLREVQER YALLYDPVISKLAC Sequence QAMRQ HPEAIAAIQSKA QAH QLMKQYYLLEDQTVQPLPKGDQVLNFSDAEDLIDDSK KD MRDEVLEHE MVADRRQKREIRQ EQELHKWQVLVDSITGMSSPDFDNQT AVLRGRMVRYLM RSREIT GRATKDNQIDVDLSLEGPAWKISRKQGVIKLKNNGDFFIANEGRRPIYIDGRPVLC GSKWRLSNNSWEIASLRFVFLINQDLIA IRAEAAKITPQ
SEQ ID NO: 153 1914 bp t
NOV37c, CGCGGAGAAATTGTTGGATCTGGCAGTCTAGGAATGAATCTCCTCTCAGCCTTTAAGCTCACC ;CG 120401 -03 DNA TGGTCAGAATCCTTGGATGAGCCTGTGGGACCGTTCCTCCTAGCCCGGTGGTTTGGAACCAGT
GGCTTTGGGACTGTAAGAGGATGGACAAAGATTCTCAGGGGCTGCTAGATTCATCCCTGATGG jSequence CATCAGGCACTGCCAGCCGCTCAGAGGATGAGGAGTCACTGGCAGGGCAGAAGCGAGCCTCCT CCCAGGCCTTGGGCACCATCCCTAAACGGAGAAGCTCCTCCAGGTTCATCAAGAGGAAGAAGT TCGATGATGAGCTGGTGGAGAGCAGCCTGGCAAAATCTTCTACCCGGGCAAAGGGGGCCAGTG GGGTGGAACCAGGGCGCTGTTCGGGGAGTGAACCCTCCTCCAGTGAGAAGAAGAAGGTATCCA AAGCCCCCAGCACTCCTGTGCCACCCAGCCCAGCCCCAGCCCCTGGACTCACCAAGCGTGTGA AGAAGAGTAAACAGCCACTTCAGGTGACCAAGGATCTGGGCCGCTGGAAGCCTGCAGATGACC TCCTGCTCATAAATGCTGTGTTGCAGACCAACGACCTGACCTCCGTCCACCTGGGCGTGAAAT TCAGCTGCCGCTTCACCCTTCGGGAGGTCCAGGAGCGTTGGTACGCCCTGCTCTACGATCCTG
TCATCTCCAAGTTGGCCTGTCAGGCCATGAGGCAGCTGCACCCAGAGGCTATTGCAGCCATCC AGAGCAAGGCCCTGTTTAGCAAGGCTGAGGAGCAGCTGCTGAGCAAAGTGGGATCGACCAGCC AGCCCACCTTGGAGACCTTCCAGGACCTGCTGCACAGACACCCTGATGCCTTCTACCTGGCCC GTACCGCGAAGGCCCTGCAGGCCCACTGGCAGCTCATGAAGCAGTATTACCTGCTGGAGGACC AGACAGTGCAGCCGCTGCCCAAAGGGGACCAAGTGCTGAACTTCTCTGATGCAGAGGACCTGA TTGATGACAGTAAGCTCAAGGACATGCGAGATGAGGTCCTGGAACATGAGCTGATGGTGGCTG ACCGGCGCCAGAAGCGAGAGATTCGGCAGCTGGAACAGGAACTGCATAAGTGGCAGGTGCTAG TGGACAGCATCACAGGCATGAGCTCTCCGGACTTCGACAACCAGACACTGGCAGTGCTGCGGG GCCGCATGGTGCGGTACCTGATGCGCTCGCGTGAGATCACCCTGGGCAGAGCAACCAAGGATA ACCAGATTGATGTGGACCTGTCTCTGGAGGGTCCGGCCTGGAAGATATCCCGGAAACAAGGTG TCATCAAGCTGAAGAACAACGGTGATTTCTTCATTGCCAATGAGGGTCGACGGCCCATCTACA TCGATGGACGGCCGGTGCTCTGTGGCTCCAAATGGCGCCTCAGCAACAACTCTGTGGTGGAGA TCGCCAGCCTGCGATTCGTCTTCCTTATCAACCAGGACCTCATTGCCCTCATCAGGGCTGAGG CTGCCAAGATCACACCACAGTGAGGAATGGTGGCAGGACTCGTGGGCCCTCTCCGGCCTGTTT
CCCCTGCCACTCCAGCCCCCTTGAGCTGGGAACTCAGGCTCCTGGAAAAACCTGGGCAGTGGG
AGGCTCAGCTGCGGGCCATTGATTTGAGCCTTTGAGGGAGGATAGGGCTGGCCTTTGTGAAGC
CAGCAGAGGCTGAGAACCTCAGGCTTCCCTAGATCCAGAGCCCCTCCCCATCTTCCTCTCTCT
AAAAACAACCCTACCCCCCATTCTACCCCCCATTGCCACCTTCACTCCTGTGTCTCCAGCTGA
TTAGCCTCAGACTCTTCTTTTATTGTTTTTCTTTTGTAAATAAAAAGCACCAGGTTCCAAAGT
AAAAAAAAAAAAAAAAAACTCGAG
ORF Start: ATG at 147 10RF Stop: TGA at 1533
SEQ ID NO: 154 462 aa !MW at 51802.6kD
;NOV37c, MDKDSQGLLDSSLMASGTASRSEDEES AGQKRASSQALGTIPKRRSSSRFIKRKKFDDE VE
'CGI 20401-03 Protein SSLAKSSTRAKGASGVEPGRCSGSEPSSSEKKKVSKAPSTPVPPSPAPAPGLTKRVKKSKQPL QVTKDLGR KPADDLLLINAVLQTNDLTSVHLGVKFSCRFTLREVQERWYA LYDPVISKLAC jSequence QAMRQLHPEAIAAIQSKALFSKAEEQLLSKVGSTSQPTLETFQDL HRHPDAFYLARTAKALQ AHWQLMKQYYLLEDQTVQPLPKGDQVLNFSDAEDLIDDSKLKDMRDEVLEHELMVADRRQKRE IRQLEQELHK QVLVDSITGMSSPDFDNQTLAV RGR VRYLMRSREITLGRATKDNQIDVDL S EGPA KISRKQGVIKLKNNGDFFIANEGRRPIYIDGRPVLCGSKWRLS NSWEIASLRFV FLINQDLIA IRAEAAKITPQ
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 37B.
1 Table 37B. Comparison of NOV37a against NOV37b and NOV37c.
NOV37a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
1 NOV37b ! 77-534 371/458 (81 %) I 5..419 371/458 (81 %)
NOV37c 77-534 415/458 (90%) ! 5-462 415/458 (90%)
Further analysis of the NOV37a protein yielded the following properties shown in Table 37C.
I Table 37C. Protein Sequence Properties NOV37a i PSort 0.9600 probability located in nucleus; 0.3000 probability located in microbody ! analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted , analysis:
A search of the NOV37a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 37D.
In a BLAST search of public sequence datbases, the NOV37a protein was found to have homology to the proteins shown in the BLASTP data in Table 37E.
PFam analysis predicts that the NOV37a protein contains the domains shown in the Table 37F.
Table 37F. Domain Analysis of NOV37a
Identities/
Pfam Domain ϊ NOV37a Match Region Similarities Expect Value for the Matched Region
FHA ' 435..508 16/82 (20%) 6.2e- 14 62/82 (76%)
Example 38.
The NOV38 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 38A.
JTable 38A. NOV38 Sequence Analysis j " fSEQliO NO: 55 15142 bp
NOV38a, CCTGATGTGCAAGTACCAACATCTGTAAAAGATATGCGCTATTGCCAGGTTTCATTCCAAGAT
CGI 22125-01 DNA GATCATGTGTCTTTGGAAAGTGCGTTTACAGTAAGACCACTTCCTGATGAACCTAAACATTTA AAATGTGAAATGAAAGGAGGAAAAACAGTACAGATGGGCCAAGAGCTTCAAGGAGAAGTAGTT
Sequence ATAATAATTACAGATCAGTACGGAAATCAGATTCAAGCATTTTCACCAAGTTCTTTATCTTCT TTGTCAATTGCTGGGGTTGGACTTGATAGCTCAAATTTGAAAACAACCTTTCAGGAAAACACA CAGAGTATAAGTGTAAGAGGCATCAAATTTATTCCAGGTCCTCCTGGAAATAAGGATCTTTGT TTTACTTGGCGTGAGTTTTCTGACTTTATTCGAGTGCAACTAATTTCTGGACCTCCTGCTAAA CTTCTCCTTATAGACTGGCCAGAACTAAAGGAGTCCATTCCAGTGATTGGAAGAGATTTACAG AACCCTATTATTGTTCAACTTTGTGATCAGTGGGATAATCCAGCACCGGTACAACATGTTAAA ATAAGTCTTACAAAAGCTAGCAATTTAAAGCTCATGCCTTCAAACCAACAGCATAAAACAGAT GAGAAAGGCAGGGCTAATTTGGGAGTATTCAGTGTTTTTGCCCCTAGGGGAGAGCATACTCTT CAGGTTAAAGCCATCTATAACAAAAGTATCATAGAAGGACCTATAATTAAGTTAATGATTCTT CCAGACCCAGAAAAACCCGTTCGTCTCAATGTTAAATATGACAAAGATGCATCCTTCTTAGCA GGGGGTCTTTTCACTGATTTTATGATTAGTGTTATTTCTGAAGATGACAGTATCATTAAAAAC ATTAATCCAGCACGTATTTCCATGAAAATGTGGAAGCTGTCTACCAGTGGGAACCGACCCCCA GCAAATGCAGAAACATTTAGTTGTAATAAAATAAAAGATAATGACAAAGAAGATGGCTGCTTC TATTTCAGGGATAAAGTAATTCCTAATAAAGTGGGGACATATTGTATCCAGTTTGGTTTTATG ATGGATAAAACAAATATTCTCAACAGTGAACAGGTTATAGTTGAAGTCCTGCCTAATCAACCT GTGAAGTTAGTACCTAAAATTAAACCACCTACACCAGCTGTTTCAAATGTTCGCTCAGTTGCC AGTAGGACCTTGGTCAGAGATCTACATCTTAGTATCACGGATGACTACGACAACCATACTGGA ATTGATTTGGTTGGCACTATAATAGCCACCATTAAAGGCTCTAATGAGGAAGATACTGATACC CCACTTTTTATTGGGAAAGTTAGAACACTTGAATTCCCCTTCGTGAATGGTTCGGCTGAAATC ATGAGTCTGGTGCTGGCAGAAAGTAGTCCTGGAAGGGATAGTACTGAATATTTTATTGTATTT GAGCCCCGGCTACCACTTTTATCAAGAACCTTAGAACCATATATCCTACCGTTCATGTTTTAC AATGATGTTAAGAAGCAGCAACAAATGGCAGCACTTACAAAAGAAAAGGACCAATTATCTCAG TCTATTGTTATGTATAAAAGTTTATTTGAAGCCAGCCAACAGCTTCTTAATGAAATGAAATGT
CAAGTTGAAGAAGCAAGATTAAAAGAGGCCCAATTGCGAAATGAACTAAAAATACATAATATT GACATTCCTACAACACAACAGGTGCCACACATTGAAGCACTTCTGAAAAGAAAGCTATCAGAA CAAGAAGAACTGAAGAAAAAACCTAGAAGATCGTGTACTCTTCCAAACTATACTAAAGGCAGT GGAGATGTTTTGGGAAAGATTGCACATCTAGCACAAATTGAAGATGATAGAGCTGCGATGGTT ATTTCTTGGCATCTGGCAAGTGACATGGACTGTGTAGTCACCCTAACCACTGACGCTGCACGT CGTATCTATGATGAAACCCAAGGTCGTCAGCAGGTGTTGCCCCTTGATTCTATTTACAAGAAG ACTCTTCCAGATTGGAAAAGATCTCTACCTCATTTCCGAAATGGAAAATTGTATTTTAAACCC ATTGGAGATCCAGTCTTTGCTCGAGACTTGTTAACATTTCCAGATAATGTAGAACATTGTGAA ACAGTATTTGGTATGCTGTTAGGAGACACCATTATTTTGGATAATCTGGATGCGGCCAATCAT TATAGAAAAGAGGTTGTTAAAATTACACACTGTCCTACACTGCTGACCAGAGATGGAGATCGA ATTCGAAGTAATGGAAAGTTTGGGGGCCTTCAGAATAAAGCTCCTCCAATGGATAAACTTCGG GGAATGGTATTTGGAGCTCCAGTTCCAAAACAGTGTCTGATCTTAGGGGAACAAATAGATCTT CTTCAGCAGTATCGTTCTGCTGTGTGCAAACTAGACAGTGTGAATAAGGATCTTAACAGTCAA TTAGAGTACCTTCGCACTCCGGATATGAGGAAGAAAAAGCAAGAACTTGATGAACATGAGAAA AATCTCAAACTAATAGAGGAAAAACTAGGTATGACTCCCATACGTAAGTGTAATGACTCATTG CGTCATTCACCAAAGGTTGAGACGACAGATTGTCCAGTTCCTCCTAAAAGAATGAGACGAGAA GCTACAAGACAAAATAGGATTATAACCAAAACAGATGTATGAGAGGTGACAGAGAGAAGAGGC
CATTGGTCTCAGTAAGAATGCCCTGCTTTCTGCATCTCTGTTTCAGAAGACCAAGAGGGTGAC
TTACCAGACTGAGTATTTCTGGGGACAATACAAGTACCTGGGCATGAATTTCCATTTCGATTC
AGATGGGACTGGAAACAACCATTCAATTTTATGAATCTTACTGGACATTATGGATTTACTGGA lATTATTCCAGACATTATGCCCTTTGGTTGTCACTACCTTGCAAATGTGTAAGAGGAAAATGTG
CTAATGTGGCAGTGACTGTAAAACTGGCACATGGCATTTATTAATCCTGAAGAAAAGTACATG
TACTATTTTTCAGTATAAATATAATGAACATGTCAGAACTATTTCTTGAAAACCTTTTTATTA
CTTTTGCGTGAATTTATTTAACAAAGATGTTTTGTCTTTTGTGTAAGGGAGGTTCTAGAGGCT
AGATGTTTAATTGTAAATATGTGAGGAAACTCAATGCAGAATTCAGGATAAAAATTTTAAAAG
CACAGGTATTTGGGAATTGAAATGTTAAGATACCCAGAACAACATTAAATCAATGAGTGAACT
TGTGACAGTGGTAGCATTTCAAATTTCAAAAGACTTATCCTGTGTGTGTGTGTGTGTGTATAT
ATATATATATATATAAATATATATATATAAAATATTCAGCAGCACCAAGTTTTATAACTATTG
TTTGTTTGACTTTATTAATACTAGAATATGTAGTCTCAGCCTTAATTTTACATTTACATTATT
TTGTAATTTTTTATTACTATTTTTAAGGGGTTAAAGAGAACATACATTCTCACATTAGTGTAC
TTTCTGGTAGAAAGTTGCTGCAAAAACATTTGAAATGTATATTAACCTAATGTATGTCATATA
TATGTCTTTGTGTAAGTTCAAGACTATTGATCTGTGAAGTTATTTTGTAAGGACATACATTTG
GTAAGTAAGTTTGTGTCCCAGGAAATGTATGTGTTTTTAAACCCTTTCTAAATATGCAGGCCA
TTAATAAATAAGATTGTTTCTTCCCTACTGAATAGATAAGTGTTTTTCTTTTTTAAAATTGGA
AGCTTCATAAAAGTTATCTTGTTAAAAAACGATGATGATGTTAACCTATCTTTATAATTGGAA
ATTATTTAAACTGTTTGTTGTTACAGAAGAAACAAAATGGTAATTACAGAATTAGCTGTGGGG
AAGATTGGCTCCCATGGTACTACAGGTTGAGTATCCCTTATTCAAAATGGTTGGGACCTGAAG
TGTTTTGGATTTTGGTTTTTTGTGGGGTTTTTAAATTATTATTTTGGAATATTTGCATTATAT
TTACCAATTTAGCATCCCTAATCCAAAAATCTTTCATTAGAAATTGGAAATGCTTCAATGAGC
ATTTCCCTTATGTGTCATATCTGCGCTCAAATGTTTTGAATTTTGGAACATTTCTTGTTTCTG
ACTTTTAGATTAGGGATACTCACCCCGTACCAATATTTGGAGTCCTTAGACATTAGATTATAT
GAAAATGATTGATTGATAGGTAAGAAAGGTTAAAGAGAAATGACTTTTTAGGAACTAGACTTG
AACGTATAATTAATATGTGGAACTAGTTTGCTTTTATAATTCATTGTATCAAGAAGGAGTCAT
GTTTTAAATCCAAGGCATTGAGACTATCTAGAAGCAAAAAAGTTGGTTTTAAAAATTCTTTTT
ATTAGAAGTGTGTTTAAAAACATGTCTTTTTTTCCCTTGAGCGACAGTGGCCTCACTACATTG
CCCAGGCTAGTCTTGAACTCCTGGGTTCAAGCAGTCTTCCTGCCTTGGCCTCCTAAGTAGCAG
GGATTACAGGCATGCACCCACATGCCAATTTTTATTGCTTAAAATGGCGAGTTCTATGGATAT
TATCTAGCCCCAAGCCCATATCTGTACACTTTTGTTCATTTTATAATACCAGAAAGAATGTTC
TATCAGTAAAAGAAGGTTTTAAGTATGAATCTCCATTTTTGTGGAGTTTTTCTACCCTGTAAA lAATTAACTTTGTGGTTCCCAGTAATTACAGTAAGGAGTTTTTCTATATTTTCACAGTTGGATT
TATCTAAGGATATTTCTCAGCATATTAAGGAATCCTTTTCTACATTTGAGCAAATACTGAGGT
TCATGTTGTACCAAATAATAATAAATTGCTTTTGTGTTTAATATGTAACACGTAAGAACAATT
GAAATTTTCTTCTAAGATTTAATACTAGTCTTTTAGTATAAAGGAATGTAACTGGAGAAAAAA
ATTAATGCTACAGCCATTTATCCTGTGTTATGTGTTATATAATCTGAAATTTGTCACAATGTT
ACAATCAGGAAGTTTTTTTTCTGGTTTCTTCTTCCAAAGGAAAATAATAGCCTACTTGTATTT
TGAAGTAACTGAAATAAAACTCTCTCCAAGCCTTTTTGC
ORF Start: ATG at 34 jORF Stop: TGA at 2686 r SEQ D"N0: 156 884 aa "|M\ at 99946.2kD ""
'NOV38a~, MRYCQVSFQDDHVSLESAFTVRPLPDEPKHLKCEMKGGKTVQMGQELQGEWIIITDQYGNQI JCG 122125-01 Protein QAFSPSSLSSLSIAGVGLDSSNLKTTFQENTQSISVRGIKFIPGPPGNKDLCFTWREFSDFIR VQLISGPPAKLLLIDWPE KESIPVIGRD QNPIIVQLCDQWDNPAPVQHVKISLTKASN KL JSequence MPSNQQHKTDEKGRANLGVFSVFAPRGEHTLQVKAIYNKSIIEGPIIKLMILPDPEKPVR NV KYDKDASFLAGGLFTDFMISVISEDDS11KNINPARISMKMWKLSTSGNRPPANAETFSCNKI KDNDKEDGCFYFRDKVIPNKVGTYCIQFGFMMDKTNILNSEQVIVEVLPNQPVKLVPKIKPPT PAVSNVRSVASRTLVRDLHLSITDDYDNHTGIDLVGTIIATIKGSNEEDTDTP FIGKVRTLE
FPFV GSAEIMSLVLAESSPGRDSTEYFIVFEPRLPL SRT EPYILPFMFYNDVKKQQQMAA LTKEKDQLSQSIVMYKSLFEASQQLLNEMKCQVEEARLKEAQLRNE KIHNIDIPTTQQVPHI EALL RKLSEQEELKKKPRRSCTLPNYTKGSGDVLGKIAHLAQIEDDRAAMVISWHLASDMDC VVTLTTDAARRIYDETQGRQQVLPLDSIYKKT PDWKRSLPHFRNGKLYFKPIGDPVFARD L TFPD VEHCETVFGMLLGDTIILDNLDAANHYRKEWKITHCPTLLTRDGDRIRSNGKFGGLQ NKAPPMDKLRGMVFGAPVPKQCLILGEQIDLLQQYRSAVCKLDSVNKD NSQLEYLRTPDMRK KKQELDEHEKNLKLIEEKLGMTPIRKCNDSLRHSP VETTDCPVPPKRMRREATRQNRIITKT DV
Further analysis of the NOV38a protein yielded the following properties shown in Table 38B.
Table 38B. Protein Sequence Properties NOV38a
PSort I 0.9600 probability located in nucleus; 0.3000 probability located in microbody analysis: j (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
[Signal P No Known Signal Sequence Predicted j analysis:
A search of the NOV38a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 38C.
In a BLAST search of public sequence datbases, the NOV38a protein was found to have homology to the proteins shown in the BLASTP data in Table 38D.
PFam analysis predicts that the N0V38a protein contains the domains shown in the Table 38E.
Table 38E. Domain Analysis of NOV38a
Identities/
! Pfam Domain NOV38a Match Region j Similarities Expect Value for the Matched Region
Example 39.
The NOV39 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 39A.

Sequence jGCTCGATTTTCAAAGAGTGGGAAACCACCCATCAATGATATGTTCACAGACCTCAAAGATGGA jAGGAAGCTATTGGATCTTCTAGAAGGCCTCACAGGAACATCACTGCCAAAGGAACGTGGTTCC ACAAGGGTACATGCCTTAAATAACGTCAACAGAGTGCTGCAGGTTTTACATCAGAACAATGTG GAATTAGTGAATATAGGGGGAACTGACATTGTGGATGGAAATCACAAACTGACTTTGGGGTTA CTTTGGAGCATCATTTTGCACTGGCAGGTGAAAGATGTCATGAAGGATGTCATGTCGGACCTG CAGCAGACGAACAGTGAGAAGATCCTGCTCAGCTGGGTGCGTCAGACCACCAGGCCCTACAGC CAAGTCAACGTCCTCAACTTCACCACCAGCTGGACAGATGGACTCGCCTTTAATGCTGTCCTC CACCGACATAAACCTGATCTCTTCAGCTGGGATAAAGTTGTCAAAATGTCACCAATTGAGAGA CTTGAACATGCCTTCAGCAAGGCTCAAACTTATTTGGGAATTGAAAAGCTGTTAGATCCTGAA GATGTTGCCGTTCGGCTTCCTGACAAGAAATCCATAATTATGTATTTAACATCTTTGTTTGAG GTGCTACCTCAGCAAGTCACCATAGACGCCATCCGTGAGGTAGAGACACTCCCAAGGAAATAT AAAAAAGAATGTGAAGAAGAGGCAATTAATATACAGAGTACAGCGCCTGAGGAGGAGCATGAG AGTCCCCGAGCTGAAACTCCCAGCACTGTCACTGAGGTCGACATGGATCTGGACAGCTATCAG ATTGCGTTGGAGGAAGTGCTGACCTGGTTGCTTTCTGCTGAGGACACTTTCCAGGAGCAGGAT GATATTTCTGATGATGTTGAAGAAGTCAAAGACCAGTTTGCAACCCATGAAGCTTTTATGATG GAACTGACTGCACACCAGAGCAGTGTGGGCAGCGTCCTGCAGGCAGGCAACCAACTGATAACA CAAGGAACTCTGTCAGACGAAGAAGAATTTGAGATTCAGGAACAGATGACCCTGCTGAATGCT AGATGGGAGGCTCTTAGGGTGGAGAGTATGGACAGACAGTCCCGGCTGCACGATGTGCTGATG GAACTGCAGAAGAAGCAACTGCAGCAGCTCTCCGCCTGGTTAACACTCACAGAGGAGCGCATT CAGAAGATGGAAACTTGCCCCCTGGATGATGATGTAAAATCTCTACAAAAGCTGCTAGAAGAA CATAAAAGTTTGCAAAGTGATCTTGAGGCTGAACAGGTGAAAGTAAATTCACTAACTCACATG GTGGTCATTGTTGATGAAAACAGTGGTGAGAGCGCTACAGCTATCCTAGAAGACCAGTTACAG AAACTTGGTGAGCGCTGGACAGCAGTATGCCGTTGGACTGAAGAACGCTGGAATAGGTTACAA GAAATCAATATATTGTGGCAGGAATTATTGGAAGAACAGTGCTTGTTGAAAGCTTGGTTAACC GAAAAAGAAGAGGCTTTAAATAAAGTCCAGACAAGCAACTTCAAAGACCAAAAGGAACTAAGT GTCAGTGTTCGACGTCTGGCTATTTTGAAGGAAGACATGGAAATGAAGCGTCAAACATTGGAT CAGCTGAGTGAGATTGGCCAGGATGTGGGACAATTACTTGATAATTCCAAGGCATCTAAGAAG ATCAACAGTGACTCAGAGGAACTGACTCAAAGATGGGATTCTTTGGTTCAGAGACTAGAAGAT TCCTCCAACCAGGTGACTCAGGCTGTAGCAAAGCTGGGGATGTCTCAGATTCCTCAGAAGGAC CTTTTGGAGACTGTTCGTGTAAGAGAACAAGCAATTACAAAAAAATCTAAGCAGGAACTGCCT CCTCCTCCTCCCCCAAAGAAGAGACAGATCCATGTGGATATTGAAGCTAAGAAAAAGTTTGAT GCTATAAGTGCAGAGCTGTTGAACTGGATTTTGAAATGGAAAACTGCCATTCAGACCACAGAG ATAAAAGAGTATATGAAGATGCAAGACACTTCCGAAATGAAAAAGAAGTTGAAGGCATTAGAA AAAGAACAGAGAGAAAGAATCCCCAGAGCAGATGAATTAAACCAAACTGGACAAATCCTTGTG GAGCAAATGGGAAAAGAAGGCCTTCCTACTGAAGAAATAAAAAATGTTCTGGAGAAGGTTTCA TCAGAATGGAAGAATGTATCTCAACATTTGGAAGATCTAGAAAGAAAGATTCAGCTACAGGAA GATATAAATGCTTATTTCAAGCAGCTTGATGAGCTTGAAAAGGTCATCAAGACAAAGGAGGAG TGGGTAAAACACACTTCCATTTCTGAATCTTCCCGGCAGTCCTTGCCAAGCTTGAAGGATTCC TGTCAGCGGGAATTGACAAATCTTCTTGGCCTTCACCCCAAAATTGAAATGGCTCGTGCAAGC TGCTCGGCCCTGATGTCTCAGCCTTCTGCCCCAGATTTTGTCCAGCGGGGCTTCGATAGCTTT CTGGGCCGCTACCAAGCTGTACAAGAGGCTGTAGAGGATCGTCAACAACATCTAGAGAATGAA CTGAAGGGCCAACCTGGACATGCATATCTGGAAACATTGAAAACACTGAAAGATGTGCTAAAT GATTCAGAAAATAAGGCCCAGGTGTCTCTGAATGTCCTTAATGATCTTGCCAAGGTGGAGAAG GCCCTGCAAGAAAAAAAGACCCTTGATGAAATCCTTGAGAATCAGAAACCTGCATTACATAAA CTTGCAGAAGAAACAAAGGCTCTGGAGAAAAATGTTCATCCTGATGTAGAAAAATTATATAAG CAAGAATTTGATGATGTGCAAGGAAAGTGGAACAAGCTAAAGGTCTTGGTTTCCAAAGATCTA CATTTGCTTGAGGAAATTGCTCTCACACTCAGAGCTTTTGAGGCCGATTCAACAGTCATTGAG AAGTGGATGGATGGCGTGAAAGACTTCTTAATGAAACAGCAGGCTGCCCAAGGAGACGACGCA GGTCTACAGAGGCAGTTAGACCAGTGCTCTGCATTTGTTAATGAAATAGAAACAATTGAATCA TCTCTGAAAAACATGAAGGAAATAGAGACTAATCTTCGAAGTGGTCCAGTTGCTGGAATAAAA ACTTGGGTGCAGACAAGACTAGGTGACTACCAAACTCAACTGGAGAAACTTAGCAAGGAGATC GCTACTCAAAAAAGTAGGTTGTCTGAAAGTCAAGAAAAAGCTGCGAACCTGAAGAAAGACTTG GCAGAGATGCAGGAATGGATGACCCAGGCCGAGGAAGAATATTTGGAGCGGGATTTTGAGTAC AAGTCACCAGAAGAGCTTGAGAGTGCTGTGGAAGAGATGAAGAGGGCAAAAGAGGATGTGTTG CAGAAGGAGGTGAGAGTGAAGATTCTCAAGGACAACATCAAGTTATTAGCTGCCAAGGTGCCC TCTGGTGGCCAGGAGTTGACGTCTGAGCTGAATGTTGTGCTGGAGAATTACCAACTTCTTTGT AATAGAATTCGAGGAAAGTGCCACACGCTAGAGGAGGTCTGGTCTTGTTGGATTGAACTGCTT CACTATTTGGATCTTGAAACTACCTGGTTAAACACTTTGGAAGAGCGGATGAAGAGCACAGAG GTCCTGCCTGAGAAGACGGATGCTGTCAACGAAGCCCTGGAGTCTCTGGAATCTGTTCTGCGC CACCCGGCAGATAATCGCACCCAGATTCGAGAGCTTGGCCAGACTCTGATTGATGGGGGGATC CTGGATGATATAATCAGTGAGAAACTGGAGGCTTTCAACAGCCGATATGAAGATCTAAGTCAC CTGGCAGAGAGCAAGCAGATTTCTTTGGAAAAGCAACTCCAGGTGCTGCGGGAAACTGACCAG ATGCTTCAAGTCTTGCAAGAGAGCTTGGGGGAGCTGGACAAACAGCTCACCACATACCTGACT GACAGGATAGATGCTTTCCAAGTTCCACAGGAAGCTCAGAAAATCCAAGCAGAGATCTCAGCC CATGAGCTAACCCTAGAGGAGTTGAGAAGAAATATGCGTTCTCAGCCCCTGACCTCCCCAGAG AGTAGGACTGCCAGAGGAGGAAGTCAGATGGATGTGCTACAGAGGAAACTCCGAGAGGTGTCC
ACAAAGTTCCAGCTTTTCCAGAAGCCAGCTAACTTCGAGCAGCGCATGCTGGACTGCAAGCGT
GTGCTGGATGGCGTGAAAGCAGAACTTCACGTTCTGGATGTGAAGGACGTAGACCCTGACGTC
ATACAGACGCACCTGGACAAGTGTATGAAACTGTATAAAACTTTGAGTGAAGTCAAACTTGAA
GTGGAAACTGTGATTAAAACAGGAAGACATATTGTCCAGAAACAGCAAACGGACAACCCAAAA
GGGATGGATGAGCAGCTGACTTCCCTGAAGGTTCTTTACAATGACCTGGGCGCACAGGTGACA
GAAGGAAAACAGGATCTGGAAAGAGCATCACAGTTGGCCCGGAAAATGAAGAAAGAGGCTGCT
TCTCTCTCTGAATGGCTTTCTGCTACTGAAACTGAATTGGTACAGAAGTCCACTTCAGAAGGT
CTGCTTGGTGACTTGGATACAGAAATTTCCTGGGCTAAAAATGTTCTGAAGGATCTGGAAAAG
AGAAAAGCTGATTTAAATACCATCACAGAGAGTAGTGCTGCCCTGCAAAACTTGATTGAGGGC
AGTGAGCCTATTTTAGAAGAGAGGCTCTGCGTCCTTAACGCTGGGTGGAGCCGAGTTCGTACC
TGGACTGAAGATTGGTGCAATACCTTGATGAACCATCAGAACCAGCTAGAAATATTTGATGGG
AACGTGGCTCACATAAGTACCTGGCTTTATCAAGCTGAAGCTCTATTGGATGAAATTGAAAAG
AAACCAACAAGTAAACAGGAAGAAATTGTGAAGCGTTTAGTATCTGAGCTGGATGATGCCAAC
CTCCAGGTTGAAAATGTCCGCGATCAAGCCCTTATTTTGATGAATGCCCGTGGAAGCTCAAGC
AGGGAGCTTGTAGAACCAAAGTTAGCTGAGCTGAATAGGAACTTTGAAAAGGTGTCTCAACAT
ATCAAAAGTGCCAAATTGCTAATTGCTCAGGAACCATTATACCAATGTTTGGTCACCACTGAA
ACATTTGAAACTGGTGTGCCTTTCTCTGACTTGGAAAAATTAGAAAATGACATAGAAAATATG
TTAAAATTTGTGGAAAAACACTTGGAATCCAGTGATGAAGATGAAAAGATGGATGAGGAGAGT
GCCCAGATTGAGGAAGTTCTACAAAGAGGAGAAGAAATGTTACATCAACCTATGGAAGATAAT
AAAAAAGAAAAGATCCGTTTGCAATTATTACTTTTGCATACTAGATACAACAAAATTAAGGCA
ATCCCTATTCAACAGAGGAAAATGGGTCAACTTGCTTCTGGAATTAGATCATCACTTGTTCCT
ACAGATTATCTGGTTGAAATTAACAAAATTTTACTTTGCATGGATGATGTTGAATTATCGCTT
AATGTTCCAGAGCTCAACACTGCTATTTACGAAGACTTCTCTTTTCAGGAAGACTCTCTGAAG
AATATCAAAGACCAACTGGACAAACTTGGAGAGCAGATTGCAGTCATTCATGAAAAACAGCCA
GATGTCATCCTTGAAGCCTCTGGACCTGAAGCCATTCAGATCAGAGATACACTTACTCAGCAT
GGCGTTGAGCTAAGACAGCAGCAGCTTGAGGACATGATTATTGACAGTCTTCAGTGGGATGAC
CATAGGGAGGAGACTGAAGAACTGATGAGAAAATATGAGGCTCGACTCTATATTCTTCAGCAA
GCCCGACGGGATCCACTCACCAAACAAATTTCTGATAACCAAATACTGCTTCAAGAACTGGGT
CCTGGAGATGGTATCGTCATGGCGTTCGGATACGTCCTGCAGAAACTCTGGAGGGAATATGGG
AGTGATGACACAAGGAATGTGAAAGAAACCACAGAGTACTTAAAAACATCATGGATCAATCTC
AAACAAAGTATTGCTGACAGACAGAACGCCTTGGAGGCTGAGTGGAGGACGGTGCAGGCCTCT
CGCAGAGATCTGGAAAACTTCCTGAAGTGGATCCAAGAAGCAGAGACCACAGTGAATGTGCTT
GTGGATGCCTCTCATCGGGAGAATGCTCTTCAGGATAGTATCTTGGCCAGGGAACTCAAACAG
CAGATGCAGGACATCCAGGCAGAAATTGATGCCCACAATGACATATTTAAAAGCATTGACGGA
AACAGGCAGAAGATGGTAAAAGCTTTGGGAAATTCTGAAGAGGCTACTATGCTTCAACATCGA
CTGGATGATATGAACCAAAGATGGAATGACTTAAAAGCAAAATCTGCTAGCATCAGGGCCCAT
TTGGAGGCCAGCGCTGAGAAGTGGAACAGGTTGCTGATGTCCTTAGAAGAACTGATCAAATGG
CTGAATATGAAAGATGAAGAGCTTAAGAAACAAATGCCTATTGGAGGAGATGTTCCAGCCTTA!
CAGCTCCAGTATGACCATTGTAAGGCCCTGAGACGGGAGTTAAAGGAGAAAGAATATTCTGTC!
CTGAATGCTGTCGACCAGGCCCGAGTTTTCTTGGCTGATCAGCCAATTGAGGCCCCTGAAGAG
CCAAGAAGAAACCTACAATCAAAAACAGAATTAACTCCTGAGGAGAGAGCCCAAAAGATTGCC
AAAGCCATGCGCAAACAGTCTTCTGAAGTCAAAGAAAAATGGGAAAGTCTAAATGCTGTAACT
AGCAATTGGCAAAAGCAAGTGGACAAGGCATTGGAGAAACTCAGAGACCTGCAGGGAGCTATG
GATGACCTGGACGCTGACATGAAGGAGGCAGAGTCCGTGCGGAATGGCTGGAAGCCCGTGGGA
GACTTACTCATTGACTCGCTGCAGGATCACATTGAAAAAATCATGGCATTTAGAGAAGAAATT
GCACCAATCAACTTTAAAGTTAAAACGGTGAATGATTTATCCAGTCAGCTGTCTCCACTTGAC
CTGCATCCCTCTCTAAAGATGTCTCGCCAGCTAGATGACCTTAATATGCGATGGAAACTTTTA
CAGGTTTCTGTGGATGATCGCCTTAAACAGCTTCAGGAAGCCCACAGAGATTTTGGACCATCC
TCTCAGCATTTTCTCTCTACGTCAGTCCAGCTGCCGTGGCAAAGATCCATTTCACATAATAAA
GTGCCCTATTACATCAACCATCAAACACAGACCACCTGTTGGGACCATCCTAAAATGACCGAA
CTCTTTCAATCCCTTGCTGACCTGAATAATGTACGTTTTTCTGCCTACCGTACAGCAATCAAA
ATCCGAAGACTACAAAAAGCACTATGTTTGGATCTCTTAGAGTTGAGTACAACAAATGAAATT
TTCAAACAGCACAAGTTGAACCAAAATGACCAGCTCCTCAGTGTTCCAGATGTCATCAACTGT
CTGACAACAACTTATGATGGACTTGAGCAAATGCATAAGGACCTGGTCAACGTTCCACTCTGT
GTTGATATGTGTCTCAATTGGTTGCTCAATGTCTATGACACGGGTCGAACTGGAAAAATTAGA
GTGCAGAGTCTGAAGATTGGATTAATGTCTCTCTCCAAAGGTCTCTTGGAAGAAAAATACAGA
TATCTCTTTAAGGAAGTTGCGGGGCCGACAGAAATGTGTGACCAGAGGCAGCTGGGCCTGTTA
CTTCATGATGCCATCCAGATCCCCCGGCAGCTAGGTGAAGTAGCAGCTTTTGGAGGCAGTAAT
ATTGAGCCTAGTGTTCGCAGCTGCTTCCAACAGAATAACAATAAACCAGAAATAAGTGTGAAA
GAGTTTATAGATTGGATGCATTTGGAACCACAGTCCATGGTTTGGCTCCCAGTTTTACATCGA
GTGGCAGCAGCGGAGACTGCAAAACATCAGGCCAAATGCAACATCTGTAAAGAATGTCCAATT
GTCGGGTTCAGGTATAGAAGCCTTAAGCATTTTAACTATGATGTCTGCCAGAGTTGTTTCTTT
TCGGGTCGAACAGCAAAAGGTCACAAATTACATTACCCAATGGTGGAATATTGTATACCTACA
ACATCTGGGGAAGATGTACGAGACTTCACAAAGGTACTTAAGAACAAGTTCAGGTCGAAGAAG
TACTTTGCCAAACACCCTCGACTTGGTTACCTGCCTGTCCAGACAGTTCTTGAAGGTGACAAC
TTAGAGACTCCTATCACACTCATCAGTATGTGGCCAGAGCACTATGACCCCTCACAATCTCCT
CAACTGTTTCATGATGACACCCATTCAAGAATAGAACAATATGCCACACGACTGGCCCAGATG GAAAGGACTAATGGGTCTTTTCTCACTGATAGCAGCTCCACCACAGGAAGTGTGGAAGACGAG CACGCCCTCATCCAGCAGTATTGCCAAACACTCGGAGGAGAGTCCCCAGTGAGCCAGCCGCAG AGCCCAGCTCAGATCCTGAAGTCAGTAGAGAGGGAAGAACGTGGAGAACTGGAGAGGATCATT GCTGACCTGGAGGAAGAACAAAGAAATCTACAGGTGGAGTATGAGCAGCTGAAGGACCAGCAC CTCCGAAGGGGGCTCCCTGTCGGTTCACCGCCAGAGTCGATTATATCTCCCCATCACACGTCT GAGGATTCAGAACTTATAGCAGAAGCAAAACTCCTCAGGCAGCACAAAGGTCGGCTGGAGGCT AGGATGCAGATTTTAGAAGATCACAATAAACAGCTGGAGTCTCAGCTCCACCGCCTCCGACAG CTGCTGGAGCAGCCTGAATCTGATTCCCGAATCAATGGTGTTTCCCCATGGGCTTCTCCTCAG CATTCTGCACTGAGCTACTCGCTTGATCCAGATGCCTCCGGCCCACAGTTCCACCAGGCAGCG GGAGAGGACCTGCTGGCCCCACCGCACGACACCAGCACGGATCTCACGGAGGTCATGGAGCAG ATTCACAGCACGTTTCCATCTTGCTGCCCAAATGTTCCCAGCAGGCCACAGGCAATGTGA
ORF Start: ATG at 1 ORF Stop: TGA at 9193 r SEQ ID NO: 158 13064 aa MW at 352283.8kD
NOV39a, MAKYGEHEASPDNGQNEFSDIIKSRSDEHNDVQKKTFTKWINARFSKSGKPPINDMFTDLKDG
JCG 122195-01 Protein RKLLDLLEGLTGTSLPKERGSTRVHA NNV RVLQVLHQ NVELVNIGGTDIVDG HKLTLGL
LWSIILHWQVKDVMKDVMSDLQQTNSEKILLSWVRQTTRPYSQVNVLNFTTSWTDG AFNAVL
JSequence HRHKPDLFSWDKWKMSPIERLEHAFSKAQTYLGIEKL DPEDVAVR PDKKSIIMYLTSLFE
VLPQQVTIDAIREVETLPRKYKKECEEEAINIQSTAPEEEHESPRAETPSTVTEVDMDLDSYQ
IALEEVLTWLLSAEDTFQEQDDISDDVEEVKDQFATHEAFMMELTAHQSSVGSVLQAGNQLIT
QGTLSDEEEFEIQEQMTLLNARWEA RVESMDRQSRLHDVLMELQKKQLQQ SAWLTLTEERI
QKMETCPLDDDVKSLQKLLEEHKS QSDLEAEQVKVNSLTHMWIVDENSGESATAILEDQLQ
KLGERWTAVCRWTEERWNRLQEINILWQEL EEQCLLKAWLTEKEEA NKVQTSNFKDQKE S
VSVRRLAILKEDMEMKRQTLDQLSEIGQDVGQLLDNSKASKKINSDSEELTQRWDSLVQRLED
SSNQVTQAVAKLGMSQIPQKD LETVRVREQAITKKSKQELPPPPPPKKRQIHVDIEAKKKFD
AISAELLNWI KWKTAIQTTEIKEY KMQDTSEMKKK KALEKEQRERIPRADELNQTGQI V
EQMGKEGLPTEEIKNVLEKVSSE KNVSQHLEDLERKIQLQEDINAYFKQLDELEKVIKTKEE
WVKHTSISESSRQSLPSLKDSCQRELTNLLGLHPKIEMARASCSALMSQPSAPDFVQRGFDSF
LGRYQAVQEAVEDRQQHLENELKGQPGHAYLETLKTLKDVLNDSENKAQVSLNVLNDLAKVEK
ALQEKKTLDEILENQKPALHKLAEETKALEKNVHPDVEKLYKQEFDDVQGKW KLKVLVSKDL
HLLEEIALTLRAFEADSTVIEKWMDGVKDFL KQQAAQGDDAGLQRQLDQCSAFVNEIETIES
SLKNMKEIETNLRSGPVAGIKT VQTRLGDYQTQLEKLSKEIATQKSRLSESQEKAANLKKDL
AEMQEW1TQAEEEYLERDFEYKSPEELESAVEEMKRAKEDVLQKEVRVKILKDNIKLLAAKVP
SGGQELTSELNWLENYQLLCNRIRGKCHTLEEV SC IELLHYLDLETT LNTLEERMKSTE
VLPEKTDAVNEALESLESVLRHPADNRTQIRELGQTLIDGGILDDIISEKLEAFNSRYEDLSH
LAESKQISLEKQLQVLRETDQMLQVLQESLGELDKQLTTYLTDRIDAFQVPQEAQKIQAEISA
HELTLEELRRNMRSQPLTSPESRTARGGSQMDVLQRKLREVSTKFQLFQKPANFEQRMLDCKR
VLDGVKAELHVLDVKDVDPDVIQTHLDKCMKLYKTLSEVKLEVETVIKTGRHIVQKQQTDNPK
GMDEQLTSLKVLYNDLGAQVTEGKQDLERASQLARKMKKEAASLSEWLSATETELVQKSTSEG
LLGDLDTEISWAKNVLKDLEKRKADLNTITESSAALQNLIEGSEPILEERLCVLNAGWSRVRT TEDWCNTL NHQNQLEIFDGNVAHIST LYQAEALLDEIEKKPTSKQEEIVKRLVSELDDAN
LQVENVRDQALILMNARGSSSRELVEPKLAELNRNFEKVSQHIKSAKLLIAQEPLYQCLVTTE
TFETGVPFSDLEKLENDIENMLKFVEKHLESSDEDEKMDEESAQIEEVLQRGEEMLHQPMEDN
KKEKIRLQ LLLHTRYNKIKAIPIQQRKMGQLASGIRSSLLPTDYLVEINKILLCMDDVELSL VPELNTAIYEDFSFQEDSLKNIKDQLDKLGEQIAVIHEKQPDVILEASGPEAIQIRDTLTQH
GVELRQQQLEDMIIDSLQ DDHREETEELMRKYEARLYILQQARRDPLTKQISDNQILLQELG
PGDGIVAFGYVLQKLWREYGSDDTRNVKETTEYLKTSWINLKQSIADRQNALEAEWRTVQAS
RRDLENFLKWIQEAETTV VLVDASHRENALQDSILARELKQQMQDIQAEIDAHNDIFKSIDG
NRQKMVKALGNSEEATMLQHRLDDMNQRWNDLKAKSASIRAHLEASAEKWNRLLMSLEELIK
LNMKDEELKKQMPIGGDVPALQLQYDHCKALRRELKEKEYSVLNAVDQARVFLADQPIEAPEE
PRRNLQSKTELTPEERAQKIAKAMRKQSSEVKEKWESLNAVTSN QKQVDKALEKLRDLQGAM
DDLDADMKEAESVRNGWKPVGDLLIDSLQDHIEKI AFREEIAPINFKVKTVNDLSSQLSPLD
LHPSLKMSRQLDDLN RWKLLQVSVDDRLKQLQEAHRDFGPSSQHFLSTSVQLPWQRSISHNK
VPYYI HQTQTTCWDHPKMTELFQSLADL VRFSAYRTAIKIRRLQKALCLDLLELSTTNEI
FKQHKLNQNDQLLSVPDVINCLTTTYDGLEQMHKDLVNVPLCVD CLNWLLNVYDTGRTGKIR
VQSLKIGLMSLSKGLLEEKYRYLFKEVAGPTE CDQRQLGLLLHDAIQIPRQLGEVAAFGGSN
IEPSVRSCFQQNNNKPEISVKEFIDWMHLEPQSMVWLPVLHRVAAAETAKHQAKCNICKECPI
VGFRYRSLKHFNYDVCQSCFFSGRTAKGHKLHYPMVEYCIPTTSGEDVRDFTKVLKNKFRSKK
YFAKHPRLGYLPVQTVLEGDNLETPITLISMWPEHYDPSQSPQLFHDDTHSRIEQYATRLAQM
ERTNGSFLTDSSSTTGSVEDEHALIQQYCQTLGGESPVSQPQSPAQILKSVEREERGELERII
ADLEEEQRNLQVEYEQLKDQHLRRGLPVGSPPESIISPHHTSEDSELIAEAKLLRQHKGRLEA
RMQILEDHNKQLESQLHRLRQLLEQPESDSRINGVSPWASPQHSALSYSLDPDASGPQFHQAA
GEDLLAPPHDTSTDLTEV EQIHSTFPSCCPNVPSRPQAM
Further analysis of the NOV39a protein yielded the following properties shown in
Table 39B.
A search of the NOV39a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 39C.
In a BLAST search of public sequence datbases, the NOV39a protein was found to have homology to the proteins shown in the BLASTP data in Table 39D.
PFam analysis predicts that the NOV39a protein contains the domains shown in the Table 39E.
Example 40.
The NOV40 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 40A.
Table 40A. NOV40 Sequence Analysis
SEQ ID NOVl 59 " "]Ϊ677 bp"
NOV40a, GCCGCACCGGCAGCCATGAGCTCGGAGATGGAGCCGCTGCTCCTGGCCTGGAGCTATTTTAGG
CGI 22738-01 DNA CGCAGGAAGTTCCAGCTCTGCGCCGATCTATGCACGCAGATGCTGGAGAAGTCCCCTTATGAC CAGGCAGCTTGGATCTTAAAAGCAAGAGCGCTAACAGAAATGGTATACATAGATGAAATTGAT
Sequence GTAGATCAGGAAGGAATTGCAGAAATGATGCTGGATGAAAATGCTATAGCTCAAGTTCCACGT CCTGGAACGTCTTTGAAACTCCCTGGAACTAATCAGACAGGAGGGCCTAGCCAGGCCGTTAGG CCAATCACACAAGCTGGAAGACCCATTACAGGTTTCCTCAGGCCCAGCACGCAGAGTGGAAGG CCAGGCACTATGGAACAGGCTATCAGAACACCCAGAACCGCCTACACAGCCCGCCCTATCACC AGCTCCTCCGGAAGATTTGTCAGGCTGGGAACGGCTTCCATGCTTACAAGTCCTGATGGACCA TTTATAAATTTATCTAGGCTGAATTTAACAAAGTATTCCCAGAAACCTAAGTTGGCAAAGGCT TTGTTTGAGTATATCTTTCATCATGAAAATGATGTTAAGGCTTTGGATCTGGCTGCCCTCTCC ACAGAACATTCTCAGTACAAGGACTGGTGGTGGAAAGTACAGATTGGAAAATGTTACTACAGG TTGGGAATGTATCGTGAAGCAGAAAAACAGTTTAAATCAGCCCTGAAGCAGCAGGAAATGGTA GATACATTTCTGTACTTGGCAAAAGTATATGTCTCATTGGATCAACCTGTGACTGCTTTAAAT CTTTTCAAACAAGGCTTAGATAAGTTTCCAGGAGAAGTAACCCTGCTCTGTGGAATTGCAAGA
ATCTATGAGGAAATGAACAATATGTCATCAGCAGCAGAATATTACAAAGAAGTTTTGAAACAA GACAATACTCATGTGGAAGCCATCGCATGCATTGGAAGCAACCACTTCTATTCTGATCAGCCA GAAATAGCTCTCCGGTTTTACAGGCGGCTGCTGCAGATGGGCATTTATAACGGCCAGCTTTTT AACAATCTGGGGCTGTGTTGCTTCTATGCCCAGCAGTATGATATGACTCTGACCTCATTTGAA CGTGCCCTTTCTTTGGCTGAAAATGAAGAAGAGGCAGCTGATGTCTGGTACAACTTGGGACAT GTAGCTGTGGGAATAGGAGATACAAATTTGGCCCATCAGTGCTTCAGGCTGGCTCTGGTCAAC AACAACAACCACGCCGAGGCCTACAACAACCTGGCTGTGCTGGAGATGCGGAAGGGCCACGTT GAACAGGCAAGGGCACTATTACAAACTGCATCATCATTAGCACCCCATATGTATGAACCGCAT TTTAATTTTGCAACAATCTCTGATAAGATTGGAGATCTGCAGAGAAGCTATGTTGCTGCGCAG AAGTCTGAAGCAGCATTTCCAGACCATGTGGACACACAACATTTAATTAAACAATTAAGGCAG CATTTTGCTATGCTCTGATTGTTCCTTAGACCACATATGTTCTTATGAAGCAGCATTATGCAA
GGGGAAAAAAGCACTATGTCTGTGTATGTATGTATATAGTGTAATACGTATATTTTAACAAAC
CTGTCCTTGATATTAGTTAAGGTGACACATAAGGGTGAC
ORF Start: ATG at 16 . L JORF Stop: TGA at 1528 SEQ ΪD NO: 16θ" [504 aa lMW at 57182.6kD"
NOV40a, MSSEMEPLLLAWSYFRRRKFQ CADLCTQMLEKSPYDQAAWI KARALTEMVYIDEIDVDQEG CGI 22738- 01 Protein IAEMMLDENAIAQVPRPGTSLKLPGTNQTGGPSQAVRPITQAGRPITGF RPSTQSGRPGTME QAIRTPRTAYTARPITSSSGRFVR GTASMLTSPDGPFINLSRLNLTKYSQKPKLAKALFEYI Sequence FHHENDVKALDLAALSTEHSQYKDWWWKVQIGKCYYR GMYREAEKQFKSALKQQEMVDTFLY LAKVYVS DQPVTALN FKQG DKFPGEVTLLCGIARIYEEM MSSAAEYYKEVLKQDNTHV EAIACIGSNHFYSDQPEIALRFYRRL QMGIYNGQ FN GLCCFYAQQYDMTLTSFERA SL AENEEEAADVWYNLGHVAVGIGDTNLAHQCFR A VNN NHAEAY NLAVLEMRKGHVEQARA LLQTASSLAPHMYEPHFNFATISDKIGDLQRSYVAAQKSEAAFPDHVDTQHLIKQLRQHFAML.
Further ana lysis of the NOV40a protein yielded the following properties shown in Table 40B.
Table 40B. Protein Sequence Properties NOV40a
PSort 0.5944 probability located in mitochondrial matrix space; 0.3651 probability located analysis: in microbody (peroxisome); 0.3022 probability located in mitochondrial inner membrane; 0.3022 probability located in mitochondrial intermembrane space
Signal P No Known Signal Sequence Predicted analysis:
A search of the NOV40a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 40C.
In a BLAST search of public sequence datbases, the NOV40a protein was found to have homology to the proteins shown in the BLASTP data in Table 40D.
PFam analysis predicts that the NOV40a protein contains the domains shown in the Table 40E.
Example 41.
The NOV41 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 41 A.
Table 41A. NOV41 Sequence Analysis
SEQ ID NO: 161 :3397 bp
NOV41a, ■GCGGGACGCGCAGCGCTATGGCAGAGGGCAGCGGGGAAGTGGTCGCAGTGTCTGCGACCGGGG
CGI 23451 -01 DNA jCTGCCAACGGCCTCAACAATGGGGCAGGCGGGACCTCGGCGACGACCTGCAACCCGCTGTCGC JGCAAGCTGCATAAGATCCTGGAGACGCGGCTGGACAACGACAAGGAGATGTTAGAAGCTCTCA
Sequence AGGCACTTTCAACCTTTTTTGTTGAAAATAGTCTGCGGACTCGAAGAAATTTACGTGGAGATA TTGAACGTAAAAGTTTAGCCATCAATGAAGAATTTGTAAGCATTTTCAAGGAAGTGAAGGAGG AACTTGAAAGCATAAGCGAAGATGTTCAAGCAATGAGCAACTGTTGTCAAGATATGACAAGTC GCCTACAGGCAGCAAAGGAACAGACTCAAGATTTAATAGTTAAAACCACTAAGCTTCAATCTG AAAGCCAAAAATTAGAGATAAGAGCTCAAGTTGCAGATGCCTTCTTATCCAAGTTCCAACTGA CTTCTGATGAAATGAGTCTTCTTCGAGGTACAAGAGAAGGACCCATTACTGAGGATTTTTTCA AGGCACTGGGAAGAGTAAAACAGATTCATAATGATGTCAAAGTTCTCTTGCGTACAAATCAAC AAACGGCAGGTTTAGAAATTATGGAACAGATGGCCTTACTTCAAGAAACGGCTTATGAAAGAC TTTACCGATGGGCTCAAAGTGAATGCAGAACATTGACACAAGAATCATGTGACGTATCTCCAG TATTGACACAGGCAATGGAAGCCCTGCAGGACAGACCTGTCTTATATAAATATACCTTAGATG AATTTGGAACAGCCAGAAGAAGTACAGTTGTTCGTGGATTTATTGATGCGCTCACAAGAGGGG GCCCCGGAGGTACACCTAGACCAATTGAAATGCATTCTCATGACCCTTTGAGGTATGTAGGAG ATATGTTGGCTTGGCTCCATCAAGCTACTGCTTCTGAAAAGGAACACCTTGAAGCTCTCTTAA AGCATGTAACTACACAAGGTGTTGAAGAAAATATTCAAGAAGTTGTTGGGCATATCACTGAAG GTGTGTGCAGGCCTCTAAAGGTTCGAATTGAGCAAGTAATAGTTGCTGAACCTGGGGCAGTTT TATTATATAAAATTTCTAATCTCCTCAAATTTTATCACCATACAATCAGTGGTATTGTTGGAA ATAGTGCAACTGCATTATTGACTACCATTGAAGAAATGCATTTGCTAAGCAAAAAAATATTCT TCAATAGCTTGAGTCTTCATGCAAGTAAATTAATGGACAAGGTTGAACTCCCACCACCTGATC TTGGACCAAGTTCTGCACTAAATCAGACACTCATGTTGCTGCGTGAAGTTTTAGCATCTCACG ATTCTTCAGTTGTACCATTAGATGCTCGTCAAGCTGATTTTGTGCAGGTTTTATCATGTGTCT TGGATCCTCTCCTACAGATGTGTACTGTATCAGCCAGCAATTTAGGCACAGCTGACATGGCCA CTTTCATGGTCAATTCACTATATATGATGAAGACAACATTAGCTCTATTTGAATTCACTGACA GACGTCTGGAAATGCTACAGTTTCAGATCGAAGCACATTTGGACACACTTATAAATGAGCAAG CCTCTTATGTTTTAACTAGGGTAGGCTTGAGTTACATCTATAACACTGTACAGCAACATAAAC CTGAACAGGGCTCTTTAGCTAATATGCCCAACCTAGATTCTGTGACACTGAAGGCTGCAATGG TTCAGTTTGATCGTTATCTGTCAGCCCCAGACAACCTATTGATACCACAGCTGAACTTTCTTC TAAGTGCCACAGTGAAAGAGCAGATCGTAAAACAATCTACAGAATTAGTCTGCAGAGCCTATG
GTGAAGTGTATGCAGCCGTGATGAATCCAATCAATGAATACAAAGATCCAGAGAACATTCTTC ACCGATCGCCGCAGCAAGTGCAGACGCTTCTTTCCTGATTATCTTATTTCATTGTGTTAGCAA AATATGACCTCCCTAAAACACTGAAGGTTATTTTTTATTCTTTGAATTTTTACTTTATAATTT
GATAGTTACAGTTTTCTTTGTATCATAAGATTGTAAGTCCCGATAATTTTTTTTTTTTTGGTC TCAGTAACAGGGAAGTAAGTAACATGTTGACCTGAGCTAGTATTGCTGTGTATCTACTCTAAA TGAGATGATCTATTTTTTTGCTAGCCATCTCTCCAGCTCTGCAGTTTTCACTGTATTCAGGAA
GCATAAAGTAGTATGAAAGGTTTGAAGAATTTTTTTTTACAAGACTAGTTCTAAATTAACAGC TTATAAAAAATTTGTCTAAATTTAATAATTAGTATAAGGATATGACCTAATAAATGTCTCCTT ACCTAAAGATTCATTTGCTTTCTTTTAATATGAGTAGGCATACTTAGTAGCTTTTCTGAACCT
AGCCTATGTCTCTGTCCCCAAAATAGCTGCCCTTAAAGAGTTGTTAGCAGAGAGAAAAATAAC AGTGAATGTGCTCCTGGTGTATATGGCAGTGAATCTCCTTTCTGTTCTACTTTAGCATACTAT
ATATATTTGACTGTGTACATTCTTATGCAATTTTAAGTATACACTCAGCAATAATTAGAAAAA
AAGGAGAGAGAAAAGTGATTTAAACAGGGTGGATTCCACTCTGTGGGAGCCTTCGATGGAACT
CAAGGTGGAGCTCAGCCTTTCCAATGAGCTCTAAGCATGTAGATAGCCTGAGCTGTGTCTAAG
CCTGGTGTTTAAAGATGGGTATTTGTCATACAATATGGGTCCTAAATCCAACCAACTACACAT
TTTATCTGGTGTTCAAACCAAAGAAACAATGATCTACTCAAACATTGGAGAAAAAAACTGCCA
GAGGAGGAGTTGCCAATTGGCAGTGTGTCTTATCTCCATGTTGTAACTGGACTCTGACTTTAG
ACCATTACCTATTAGGAAGATTAAAAATGACTGTATTTTTAAAGGAATAAATCCCAGTGTGCC
TGATTTGACATTCTTGTCAGCAAAAAAAACTTAATTTCTAGTAAATCTATAAAAATGGGTAAG
TCCCTAAATTACAAATGAGAAAATTGAAGCACAAGGAAAAAAATAACTAGTTTGAAATATTTT
GAAAAGTAATAACATAAAACTAGTATTTGTAGAAGATTATGTGTTGTATATAACAAATTAGTA
TTTATAGAATATGACCTATTTATCTGAAGTTTATAATTGTTTATACCTAATACAGTTCTTTTT
GGAGTAAGAATGATTATATAATCGTTATCCATTTGGGTATAAATCTGTATTTTTAGTTTTTTC
CCTTTGATTAGTATGTGTTACATATAAAGACAGAAAATAAAGTATAAATCAAGAGCTT
ORF Start: ATG at 18 ORF Stop: TGA at 1989
SEQ ID NO: 162 657 aa 1MW at 73278.2kD
NOV41a, MAEGSGEWAVSATGAANGL NGAGGTSATTCNPLSRKLHKILETRLDNDKEMLEA KA STF
JCG 123451 -01 Protein FVENSLRTRRN RGDIERKSLAINEEFVSIFKEVKEELESISEDVQAMSNCCQDMTSRLQAAK EQTQDLIVKTTKLQSESQKLEIRAQVADAFLSKFQLTSDEMSLLRGTREGPITEDFFKALGRV
Sequence KQIHNDVKVLLRTNQQTAGLEIMEQMAL QETAYERLYR AQSECRTLTQESCDVSPVLTQAM EALQDRPVLYKYTLDEFGTARRSTWRGFIDALTRGGPGGTPRPIEMHSHDP RYVGDMLAWL HQATASEKEH EALLKHVTTQGVEENIQEWGHITEGVCRPLKVRIEQVIVAEPGAVLLYKIS N LKFYHHTISGIVGNSATALLTTIEEMHLLSKKIFFNS SLHASKLMDKVELPPPDLGPSSA LNQTLM LREVLASHDSSWPLDARQADFVQVLΞCVLDPLLQMCTVSASNLGTADMATFMVNS Y KTTLALFEFTDRR E LQFQIEAHLDTLINEQASYVLTRVGLSYIYMTVQQHKPEQGS ANMPNLDSVT KAAMVQFDRYLSAPDNLLIPQ NFLLSATVKEQIVKQSTE VCRAYGEVYAA VMNPINEYKDPENILHRSPQQVQTLLS
Further analysis of the NOV41 a protein yielded the following properties shown in Table 4 I B.
1 Table 41B. Protein Sequence Properties NOV41a j PSort 0.5500 probability located in endoplasmic reticulum (membrane); 0.1900 probability I analysis: located in lysosome (lumen); 0.1000 probability located in endoplasmic reticulum (lumen); 0.1000 probability located in outside
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV41a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 41C.
Table 41C. Geneseq Results for NOV41a
In a BLAST search of public sequence datbases, the NOV41 a protein was found to have homology to the proteins shown in the BLASTP data in Table 41 D.
PFam analysis predicts that the NOV41 a protein contains the domains shown in the Table 4 I E.
Table 41 E. Domain Analysis of NOV41a
Identities/
Pfa Domain NOV41a Match Region Similarities Expect Value for the Matched Region
Example 42.
The NOV42 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 42A.
TAGAGTTTGCCATCATGCGGATAGAAGCCCTGAAGCTGGCCAGGCAGATTGCTTTGGCTTCCC!
GCAGCCACCAGGATGCCAAGAGAGAGGCTGCTCACCCAACAGACGTCTCCATCTCCAAAACAG
CCTTGTACTCCCGCATCGGGACCGCTGAGGTGGAGAAACCTGCAGGCCTTCTGTTCCAGCAGC
CCGACCTGGACTCTGCCCTCCAGATCGCCAGAGCAGAGATCATAACCAAGGAGAGAGAGGTCT
CAGAATGGAAAGATAAATATGAAGAAAGCAGGCGGGAAGTGATGGAAATGAGGAAAATAGTGG
CCGAGTATGAGAAGACCATCGCTCAGATGATAGAGGACGAACAGAGAGAGAAGTCAGTCTCCC
ACCAGACGGTGCAGCAGCTGGTTCTGGAGAAGGAGCAAGCCCTGGCCGACCTGAACTCCGTGG
AGAAGTCTCTGGCCGACCTCTTCAGAAGATATGAGAAGATGAAGGAGGTCCTAGAAGGCTTCC
GCAAGAATGAAGAGGTGTTGAAGAGATGTGCGCAGGAGTACCTGTCCCGGGTGAAGAAGGAGG
AGCAGAGGTACCAGGCCCTGAAGGTGCACGCGGAGGAGAAACTGGACAGGGCCAATGCTGAGA
TTGCTCAGGTTCGAGGCAAGGCCCAGCAGGAGCAAGCCGCCCACCAGGCCAGCCTGCGGAAGG
AGCAGCTGCGAGTGGACGCCCTGGAAAGGACGCTGGAGCAGAAGAATAAAGAAATAGAAGAAC
TCACCAAGATTTGTGACGAACTGATTGCCAAAATGGGGAAAAGCTAACTCTGAACCGAATGTT
TTGGACTTAACTGTTGCGGCAATATGACCGTCGGCACACTGCTGTTCCTCCAGTTCCATGGAC
AGGTTCTGTTTTCACTTTTTCGTATGCACTACTGTATTTCCTTTCTAAATAAAATTGATTTGA
TTGTATGCAGTACTAAGGAGACTATCAGAATTTCTTGCTATTGGTTTGCATTTTCCTAGTATA
ATTCATAGCAAGTTGACCTCAGAGTTCCTGTATCAGGGAGATTGTCTGATTCTCTAATAAAAG
ACACATTGCTGACCTTGGCCTTGCCCTTTGTACACAAGTTCCCAGGGTGAGCAGCTTTTGGAT
TTAATATGAACATGTACAGCGTGCATAGGGACTCTTGCCTTAAGGAGTGTAAACTTGATCTGC
ATTTGCTGATTTGTTTTTAAAAAAACAAGAAATGCATGTTTCAAATAAAATTCTCTATTGTAA
ATAAAATTTTTTCTTTGGATCTTGAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
ORF Start: ATG at 87 ORF Stop: TAA at 3258
SEQ ID NO: 164 1057 aa MW at 115537.2kD
!NOV42a, GGSQSLQPAPASDLNLEASEAMSSDSEEAFETPESTTPVKAPPAPPPPPPEVIPEPEVSTQP
JCG 123660-01 Protein PPEEPGCGSETVPVPDGPRSDSVEGSPFRPPSHSFSAVFDEDKPIASSGTYNLDFDNIELVDT FQT EPRASDAKNQEGKVNTRRKSTDSVPISKSTLSRSLSLQASDFDGASSSGNPEAVALAPD jSequence AYSTGSSSASSTLKRTKKPRPPSLKKKQTTKKPTETPPVKETQQEPDEESLVPSGENLASETK TESAKTEGPSPALLEETPLEPAVGPKAACP DSESAEGWPPASGGGRVQNSPPVGRKTLP T TAPEAGEVTPSDSGGQEDSPAKGLSVRLEFDYSEDKSSWDNQQENPPPTKKIGKKPVAKMP R RPKMKKTPEK DNTPASPPRSPAEPNDIPIAKGTYTFDIDK DDPNFNPFSSTSKMQESPKLP QQSYNFDPDTCDESVDPFKTSSKTPSSPSKSPASFEIPASA EANGVDGDGNKPAKKKKTPL KTDTFRVKKSPKRSPLSDPPSQDPTPAATPETPPVISAWHATDEEKLAVTNQKWMCMTVDLE ADKQDYPQPSDLSTFVNETKFSSPTEGKQ CSQLDPHSASENPAPREPKARRETSQPELDYRN SYEIEY EKIGSS PQDDDAPKKQALYLMFDTSQESPVKSSPVRMSEΞPTPCSGSSFEETEAL VNTAAKNQHPVPRGLAPNQESHLQVPEKSSQKE EAMGLGTPSEAIEITAPEGSFASADA LS R AHPVSLCGALDYLEPDLAEKNPPLFAQKLQEELEFAIMRIEALKLARQIALASRSHQDAKR EAAHPTDVSISKTALYSRIGTAEVEKPAGLLFQQPDLDSALQIARAEIITKEREVSEWKDKYE ESRREVMEMRKIVAEYEKTIAQ IEDEQREKSVSHQTVQQLV EKEQALADLNSVEKSLADLF RRYEKMKEVLEGFRKNEEVLKRCAQEYLSRVKKEEQRYQALKVHAEEKLDRANAEIAQVRGKA QQEQAAHQASLRKEQLRVDA ERTLEQKNKEIEELTKICDELIAKMGKS
SEQ ID NO: 165 3686 bp
NOV42b, GCGGCCGCCCCGGCTCCCGGCTGCAGGAATCGCGCCAGGACGCTGGCCCCGCTCGCGGCTAGC
JCG 123660-02 DNA TTGCACGCCAGGGCACAGCGAGGATGGGAGGGTCGCAGTCCCTGCAGCCAGCCCCAGCCAGCG
ACCTGAACCTGGAGGCTTCCGAGGCAATGAGTTCCGATTCTGAAGAGGCATTTGAGACCCCGG jSequence AGTCAACGACCCCTGTCAAAGCTCCGCCAGCTCCACCCCCACCACCCCCCGAAGTCATCCCAG AACCCGAGGTCAGCACACAGCCACCCCCGGAAGAACCAGGATGTGGTTCTGAGACAGTCCCTG TCCCTGATGGCCCACGGAGCGACTCGGTGGAAGGAAGTCCCTTCCGTCCCCCGTCACACTCCT TCTCTGCCGTCTTCGATGAAGACAAGCCGATAGCCAGCAGTGGGACTTACAACTTGGACTTTG ACAACATTGAGCTTGTGGATACCTTTCAGACCTTGGAGCCTCGTGCCTCAGACGCTAAGAATC AGGAGGGCAAAGTGAACACACGGAGGAAGTCCACGGATTCCGTCCCCATCTCTAAGTCTACAC TGTCCCGGTCGCTCAGCCTGCAAGCCAGTGACTTTGATGGTGCTTCTTCCTCAGGCAATCCCG AGGCCGTGGCCCTTGCCCCAGATGCATATAGCACGGGTTCCAGCAGTGCTTCTAGTACCCTTA AGCGAACTAAAAAACCGAGGCCGCCTTCCTTAAAAAAGAAACAGACCACCAAGAAACCCACAG AGACCCCCCCAGTGAAGGAGACGCAACAGGAGCCAGATGAAGAGAGCCTTGTCCCCAGTGGGG AGAATCTAGCATCTGAGACGAAAACGGAATCTGCCAAGACGGAAGGTCCTAGCCCAGCCTTAT TGGAGGAGACGCCCCTTGAGCCCGCTGTGGGGCCCAAAGCTGCCTGCCCTCTGGACTCAGAGA GTGCAGAAGGGGTTGTCCCCCCGGCTTCTGGAGGTGGCAGAGTGCAGAACTCACCCCCTGTCG GGAGGAAAACGCTGCCTCTTACCACGGCCCCGGAGGCAGGGGAGGTAACCCCATCGGATAGCG GGGGGCAAGAGGACTCTCCAGCCAAAGGGCTCTCCGTAAGGCTGGAGTTTGACTATTCTGAGG ACAAGAGTAGTTGGGACAACCAGCAGGAAAACCCCCCTCCTACCAAAAAGATAGGCAAAAAGC CAGTTGCCAAAATGCCCCTGAGGAGGCCAAAGATGAAAAAGACACCCGAGAAACTTGACAACA CTCCTGCCTCACCTCCCAGATCCCCTGCTGAACCCAATGACATCCCCATTGCTAAAGGTACTT ACACCTTTGATATTGACAAGTGGGATGACCCCAATTTTAACCCTTTTTCTTCCACCTCAAAAA TGCAGGAGTCTCCCAAACTGCCCCAACAATCATACAACTTTGACCCAGACACCTGTGATGAGT
CCGTTGACCCCTTTAAGACATCCTCTAAGACCCCCAGCTCACCTTCTAAATCCCCAGCCTCCT TTGAGATCCCAGCCAGTGCTATGGAAGCCAATGGAGTGGACGGGGATGGGCTAAACAAGCCCG CCAAGAAGAAGAAGACGCCCCTAAAGACTGACACATTTAGGGTGAAAAAGTCGCCAAAACGGT CTCCTCTCTCTGATCCACCTTCCCAGGACCCCACCCCAGCTGCTACACCAGAAACACCACCAG TGATCTCTGCGGTGGTCCACGCCACAGATGAGGAAAAGCTGGCGGTCACCAACCAGAAGTGGA CGTGCATGACAGTGGACCTAGAGGCTGACAAACAGGACTACCCGCAGCCCTCGGACCTGTCCA CCTTTGTAAACGAGACCAAATTCAGTTCACCCACTGAGGAGTTGGATTACAGAAACTCCTATG AAATTGAATATATGGAGAAAATTGGCTCCTCCTTACCTCAGGACGACGATGCCCCGAAGAAGC AGGCCTTGTACCTTATGTTTGACACTTCTCAGGAGAGCCCTGTCAAGTCATCTCCCGTCCGCA TGTCAGAGTCCCCGACGCCGTGTTCAGGGTCAAGTTTTGAAGAGACTGAAGCCCTTGTGAACA CTGCTGCGAAAAACCAGCATCCTGTCCCACGAGGACTGGCCCCTAACCAAGAGTCACACTTGC AGGTGCCAGAGAAATCCTCCCAGAAGGAGCTGGAGGCCATGGGCTTGGGCACCCCTTCAGAAG CGATTGAAATTACAGCTCCCGAGGGCTCCTTTGCCTCTGCTGACGCCCTCCTCAGCAGGCTAG CTCACCCCGTCTCTCTCTGTGGTGCACTTGACTATCTGGAGCCCGACTTAGCAGAAAAGAACC CCCCACTATTCGCTCAGAAACTCCAGGAGGAGTTAGAGTTTGCCATCATGCGGATAGAAGCCC TGAAGCTGGCCAGGCAGATTGCTTTGGCTTCCCGCAGCCACCAGGATGCCAAGAGAGAGGCTG CTCACCCAACAGACGTCTCCATCTCCAAAACAGCCTTGTACTCCCGCATCGGGACCGCTGAGG TGGAGAAACCTGCAGGCCTTCTGTTCCAGCAGCCCGACCTGGACTCTGCCCTCCAGATCGCCA GAGCAGAGATCATAACCAAGGAGAGAGAGGTCTCAGAATGGAAAGATAAATATGAAGAAAGCA GGCGGGAAGTGATGGAAATGAGGAAAATAGTGGCCGAGTATGAGAAGACCATCGCTCAGATGA TAGAGGACGAACAGAGAGAGAAGTCAGTCTCCCACCAGACGGTGCAGCAGCTGGTTCTGGAGA AGGAGCAAGCCCTGGCCGACCTGAACTCCGTGGAGAAGTCTCTGGCCGACCTCTTCAGAAGAT ATGAGAAGATGAAGGAGGTCCTAGAAGGCTTCCGCAAGAATGAAGAGGTGTTGAAGAGATGTG CGCAGGAGTACCTGTCCCGGGTGAAGAAGGAGGAGCAGAGGTACCAGGCCCTGAAGGTGCACG CGGAGGAGAAACTGGACAGGGCCAATGCTGAGATTGCTCAGGTTCGAGGCAAGGCCCAGCAGG AGCAAGCCGCCCACCAGGCCAGCCTGCGGAAGGAGCAGCTGCGAGTGGACGCCCTGGAAAGGA CGCTGGAGCAGAAGAATAAAGAAATAGAAGAACTCACCAAGATTTGTGACGAACTGATTGCCA AAATGGGGAAAAGCTAACTCTGAACCGAATGTTTTGGACTTAACTGTTGCGGCAATATGACCG
TCGGCACACTGCTGTTCCTCCAGTTCCATGGACAGGTTCTGTTTTCACTTTTTCGTATGCACT
ACTGTATTTCCTTTCTAAATAAAATTGATTTGATTGTATGCAGTACTAAGGAGACTATCAGAA
TTTCTTGCTATTGGTTTGCATTTTCCTAGTATAATTCATAGCAAGTTGACCTCAGAGTTCCTG
TATCAGGGAGATTGTCTGATTCTCTAATAAAAGACACATTGCTGACCTTGGCCTTGCCCTTTG
ITACACAAGTTCCCAGGGTGAGCAGCTTTTGGATTTAATATGAACATGTACAGCGTGCATAGGG
ACTCTTGCCTTAAGGAGTGTAAACTTGATCTGCATTTGCTGATTTGTTTTTAAAAAAACAAGA
AATGCATGTTTCAAATAAAATTCTCTATTGTAAATAAAATTTTTTCTTTGGATCTTGAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
ORF Start:_ATG at 87 jORF Stop: TAA at 3165 SEQ Ϊb NόTTόό 1026 aa iMW at 1 12Ϊ09.5kD
;NOV42b, MGGSQSLQPAPASD NLEASEAMSSDSEEAFETPESTTPVKAPPAPPPPPPEVIPEPEVSTQP
ICG 123660-02 Protein PPEEPGCGSETVPVPDGPRSDSVEGSPFRPPSHSFSAVFDEDKPIASSGTYNLDFDNIELVDT FQTLEPRASDAKNQEGKVNTRRKSTDSVPISKSTLSRSLSLQASDFDGASSSGNPEAVALAPD
•Sequence AYSTGSSSASSTLKRTKKPRPPSLKKKQTTKKPTETPPVKETQQEPDEESLVPSGEN ASETK TESAKTEGPSPA LEETP EPAVGPKAACP DSESAEGWPPASGGGRVQNSPPVGRKTLP T TAPEAGEVTPSDSGGQEDSPAKGLSVRLEFDYSEDKSSWDNQQENPPPTKKIGKKPVAKMPLR RPKMKKTPEKLDNTPASPPRSPAEPNDIPIAKGTYTFDIDKWDDPNFNPFSSTSKMQESPK P QQSYNFDPDTCDESVDPFKTSSKTPSSPSKSPASFEIPASAMEANGVDGDGLNKPAKKKKTPL KTDTFRVKKSPKRSP SDPPSQDPTPAATPETPPVISAVVHATDEEKLAVTNQKWTCMTVDLE ADKQDYPQPSDLSTFVNETKFSSPTEELDYRNSYEIEYMEKIGSS PQDDDAPKKQALYLMFD TSQESPVKSSPVRMSESPTPCSGSSFEETEALVNTAAKNQHPVPRGLAPNQESHLQVPEKSSQ KE EAMGLGTPSEAIEITAPEGSFASADA LSRLAHPVSLCGALDYLEPDAEK PPLFAQKL QEELEFAIMRIEALK ARQIALASRSHQDAKREAAHPTDVSISKTA YSRIGTAEVEKPAGLL FQQPD DSALQIARAEIITKEREVSEWKDKYEESRREVMEMRKIVAEYEKTIAQMIEDEQREK SVSHQTVQQ VLEKEQALADLNSVEKS ADLFRRYEKMKEV EGFRKNEEVLKRCAQEYLSRV KKEEQRYQALKVHAEEKLDRANAEIAQVRGKAQQEQAAHQASLRKEQLRVDALERTLEQKNKE IEELTKICDELIAKMGKS
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 42B.
Table 42B. Comparison of NOV42a against NOV42b.
, NOV42a Residues/ Identities/
Protein Sequence ; Match Residues Similarities for the Matched Region
NOV42b I ..1057 916/1057 (86%) 1..1026 916/1057 (86%)
Further analysis of the NOV42a protein yielded the following properties shown in Table 42C.
Table 42C. Protein Sequence Properties NOV42a
PSort 0.9800 probability located in nucleus; 03000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
! SignalP ! No Known Signal Sequence Predicted ] analysis:
A search of the NOV42a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 42D.
In a BLAST search of public sequence datbases, the NOV42a protein was found to have homology to the proteins shown in the BLASTP data in Table 42E.
PFam analysis predicts that the N0V42a protein contains the domains shown in the Table 42F.
'< Table 42F. Domain Analysis of NOV42a
Identities/
: Pfam Domain NOV42a Match Region Similarities Expect Value for the Matched Region
Example 43. The N0V43 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 43A.

CG 123955-01 DNA CTGGCGAGCGCCCTGAGGAGGGATTCCGGGCAGGCGTTTTCCCTGGAGCAGCTCCGGCCGCTA Sequence CTAGCCAGCTCTCTGCCGCTAGCCGCCCGCTACCTGCAGCTGGACGCCGCACGCCTTGTCCGC TGCAACGCTCATGGGGAGCCCCGAAACTACCTCAACACCCTGTCCACGGCTCTGAACATCCTG GAGAAATACGGCCGCAACCTTCTCAGCCCTCAGCGGCCTCGGTACTGGCGTGGTGTCAAGTTT AATAACCCTGTCTTTCGCAGCACGGTGGATGCTGTGCAGCAGGGGGGCCGAGATGTGCTGCGA TTATATGGCTACACAGAGGAGCAACCAGATGGGTTGAGCTTCCCCGAAGGGCAGGAGGAGCCA GATGAGCACCAGGTTGCTACAGTCACACTGGAAGTACTGCTGCTTCGGACAGAGCTCAGCCTG CTATTGCAGAATACTCATCCAAGACAGCAGGCACTGGAGCAGCTGTTGGAAGACAAGGTTGAA GATATGCTGCAGCTTTCAGAATTTGACCCCCTATTGAGAGAGATTGCTCCTGGCCCCCTCACC ACACCCTCTGTCCCAGGCTCCACTCCTGGTCCCTGCTTCCTCTGTGGTTCTGCCCCAGGCACA CTGCACTGCCCATCCTGTAAACAGGCCCTGTGTCCAGCCTGTGACCACCTGTTCCATGGACAC CCATCCCGTGCTCATCACCTCCGCCAGACCCTGCCTGGGGTCCTGCAGGGTACCCACCTGAGC AGTTTACCTGCCTCAGCCCAACCACGGCCCCAGTCGACCTCCCTGCTGGCCCTGGGAGACAGC TCTCTTTCTTCCCCTAATCCTGCAAGTGCTCATTTGCCCTGGCACTGTGCTGCCTGTGCCATG CTAAATGAGCCTTGGGCAGTGCTCTGTGTGGCCTGTGATCGGCCCCGAGGCTGTAAGGGGTTG GGGTTGGGAACTGAGGGTCCCCAAGGAACTGGAGGCCTAGAACCTGATCTTGCACGGGGTCGG TGGGCCTGCCAGAGCTGTACCTTTGAGAATGAGGCAGCTGCTGTGCTATGTTCCATATGTGAG CGACCTCGGCTGGCCCAGCCTCCCAGCTTGGTGGTGGATTCCCGAGATGCTGGCATTTGCCTG CAACCCCTTCAGCAGGGGGATGCTTTGCTGGCCTCTGCCCAGAGTCAAGTCTGGTACTGTATT CACTGTACCTTCTGCAACTCGAGCCCTGGCTGGGTGTGTGTTATGTGCAACCGGACTAGTAGC CCCATTCCAGCACAACATGCCCCCCGGCCCTATGCCAGCTCTTTGGAAAAGGGACCCCCCAAG CCTGGGCCCCCACGACGCCTTAGTGCCCCCCTGCCCAGTTCCTGTGGAGATCCTGAGAAGCAG CGCCAAGACAAGATGCGGGAAGAAGGCCTCCAGCTAGTGAGCATGATCCGGGAAGGGGAAGCC GCAGGTGCCTGTCCAGAGGAGATCTTCTCGGCTCTGCAGTACTCGGGCACTGAGGTGCCTCTG CAGTGGTTGCGCTCAGAACTGCCCTACGTCCTGGAGATGGTGGCTGAGCTGGCTGGACAGCAG GACCCTGGGCTGGGTGCCTTTTCCTGTCAGGAGGCCCGGAGAGCCTGGCTGGATCGTCATGGC AACCTTGATGAAGCTGTGGAGGAGTGTGTGAGGACCAGGCGAAGGAAGGTACAGGAGCTCCAG TCTCTAGGCTTTGGGCCTGAGGAGGGGTCTCTCCAGGCATTGTTCCAGCACGGAGGTGATGTG TCACGGGCCCTGACTGAGCTACAGCGCCAACGCCTAGAGCCCTTCCGCCAGCGCCTCTGGGAC AGTGGCCCTGAGCCCACCCCTTCCTGGGATGGGCCAGACAAGCAGAGCCTGGTCAGGCGGCTT TTGGCAGTCTACGCACTCCCCAGCTGGGGCCGGGCAGAGCTGGCACTGTCACTGCTGCAGGAG ACACCCAGGAACTATGAGTTGGGGGATGTGGTAGAAGCTGTGAGGCACAGCCAGGACCGGGCC TTCCTGCGCCGCTTGCTTGCCCAGGAGTGTGCCGTGTGTGGCTGGGCCCTGCCCCACAACCGG ATGCAGGCCCTGACTTCCTGTGAGTGCACCATCTGTCCTGACTGCTTCCGCCAGCACTTCACC ATCGCCTTGAAGGAGAAGCACATCACAGACATGGTGTGCCCTGCCTGTGGCCGCCCCGACCTC ACCGATGACACACAGTTGCTCAGCTACTTCTCTACCCTTGACATCCAGCTTCGCGAGAGCCTA GAGCCAGATGCCTATGCGTTGTTCCATAAGAAGCTGACCGAGGGTGTGCTGATGCGGGACCCC AAGTTCTTGTGGTGTGCCCAGTGCTCCTTTGGCTTCATATATGAGCGTGAGCAGCTGGAGGCA ACTTGTCCCCAGTGTCACCAGACCTTCTGTGTGCGCTGCAAGCGCCAGTGTGAGGACTTCCAG AACTGGAAACGCATGAACGACCCAGAATACCAGGCCCAGGGCCTAGCAATGTATCTTCAGGAA AACGGCATTGACTGCCCCAAATGCAAGTTCTCGTACGCCCTGGCCCGAGGAGGCTGCATGCAC TTTCACTGTACCCAGTGCCGCCACCAGTTCTGCAGCGGCTGCTACAATGCCTTTTACGCCAAG AATAAATGTCCAGAGCCTAACTGCAGGGTGAAAAAGTCCCTGCACGGCCACCACCCTCGAGAC TGCCTCTTCTACCTGCGGGACTGGACTGCTCTCCGGCTTCAGAAGCTGCTACAGGACAATAAC GTCATGTTTAATACAGAGCCTCCAGCTGGGGCCCGGGCAGTCCCTGGAGGTGGCTGCCGAGTG ATAGAGCAGAAGGAGGTTCCCAATGGGCTCAGGGACGAAGCTTGTGGCAAGGAAACTCCAGCT GGCTATGCCGGCCTGTGCCAGGCACACTACAAAGAGTATCTTGTGAGCCTCATCAATGCCCAC TCGCTGGACCCAGCCACCTTGTATGAGGTGGAAGAGCTGGAGACGGCCACTGAGCGCTACCTG CACGTACGCCCCCAGCCTTTGGCTGGAGAGGATCCCCCTGCTTACCAGGCCCGCCTTCTGCAG AAGCTGACAGAAGAGGTACCCTTGGGACAGAGTATCCCCCGCAGGCGGAAGTAGCTGAGGGCA
AGGGTCCCGATGAGGGTCCCATGGCCTGCTCCCTCAGGAACAGCTCCAGCACCAATAAAGAGG
CATCTTACCACCCAGGCTTCTTGGTGGTCCTTCTTCCTGGTGCCACCATCTAGGGGCACCAGG
GAAAGAGCGGGG
ORF Start: ATG at 16 ORF Stop: TAG at 3202
SEQ ID NO: 168 11062 aa MW at 1 18400.2kD
!NOV43a, MPGEEEERAFLVAREELASALRRDSGQAFSLEQ RPLLASS PLAARYLQLDAARLVRCNAHG
JCG 123955-01 Protein EPRNYLNTLSTALNILEKYGRN LSPQRPRY RGVKFNNPVFRSTVDAVQQGGRDVLRLYGYT EEQPDGLSFPEGQEEPDEHQVATVTLEVLLLRTELSLL QNTHPRQQALEQL EDKVEDMLQL
Sequence SEFDP LREIAPGPLTTPSVPGSTPGPCFLCGSAPGT HCPSCKQALCPACDHLFHGHPSRAH HLRQTLPGVLQGTHLSSLPASAQPRPQSTSLLALGDSSLSSPNPASAHLPWHCAACAMLNEP AV CVACDRPRGCKGLGLGTEGPQGTGGLEPDLARGRWACQSCTFENEAAAVLCSICERPRLA QPPSLWDSRDAGICLQPLQQGDAL ASAQSQV YCIHCTFCNSSPGWVCV CNRTSSPIPAQ HAPRPYASSLEKGPPKPGPPRRLSAPLPSSCGDPEKQRQDKMREEGLQLVSMIREGEAAGACP EEIFSALQYSGTEVP QWLRSELPYVLEMVAELAGQQDPG GAFSCQEARRAWLDRHGN DEA VEECVRTRRRKVQELQSLGFGPEEGSLQALFQHGGDVSRALTELQRQRLEPFRQRLWDSGPEP
TPSWDGPDKQSLVRR LAVYA PSWGRAELA SLLQETPRNYE GDWEAVRHSQDRAFLRRL LAQECAVCGWALPHNRMQALTSCECTICPDCFRQHFTIALKEKHITDMVCPACGRPDLTDDTQ j LSYFSTLDIQLRESLEPDAYA FHKKLTEGVLMRDPKF WCAQCSFGFIYEREQLEATCPQC JHQTFCVRCKRQCEDFQN KRMNDPEYQAQG AMYLQENGIDCPKCKFSYA ARGGCMHFHCTQ IcRHQFCSGCYNAFYAKNKCPEPNCRVKKSLHGHHPRDCLFYLRD TALRLQKLLQDNNVMFNT jEPPAGARAVPGGGCRVIEQKEVPNG RDEACGKETPAGYAGLCQAHYKEY VSLINAHSLDPA T YEVEELETATERYLHVRPQP AGEDPPAYQARLLQK TEEVPLGQSIPRRRK
Further analysis of the NOV43a protein yielded the following properties shown in Table 43B.
i Table 43B. Protein Seque enπccee P rrroυpeerrtiiieess N πOjVv4t3ja j PSort 0.7000 probability located in nucleus; 0.3000 probability located in microbody « analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen) ,
I SignalP No Known Signal Sequence Predicted ' analysis:
A search of the NOV43a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 43C.
In a BLAST search of public sequence datbases, the NOV43a protein was found to have homology to the proteins shown in the BLASTP data in Table 43D.
PFam analysis predicts that the NOV43a protein contains the domains shown in the
Table 43E.
The NOV44 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 44A.
Table 44A. NOV44 Sequence Analysis
SEQ ID NO: 169 " 2847 bp
NOV44a, ACCTTTAAGCGTCACGGGTGGGGCTGCAGCTTCTGGACCTAGGACTTTGAACATGTCGCGCCT
CGI 24672-01 DNA GAAGCGGATAGCGGGGCAGGATCTCCGCGCTGGTTTCAAAGCAGGTGGAAGAGACTGCGGTAC CTCGGTACCCCAAGGGCTGTTGAAGGCAGCGAGGAAGAGCGGCCAGTTAAACCTGTCGGGTAG
Sequence AAACCTCAGTGAAGTGCCGCAGTGTGTCTGGAGAATAAATGTGGATATCCCTGAGGAAGCTAA TCAGAATCTTTCGTTTGGTGCTACTGAAAGATGGTGGGAGCAGACAGATTTGACCAAACTAAT AATATCAAACAATAAACTTCAGTCACTTACAGATGACCTGCGACTCTTGCCTGCACTGACTGT TCTTGATATACATGATAATCAGTTGACATCCCTTCCTTCTGCTATAAGAGAGCTAGAAAATCT TCAGAAACTTAATGTCAGCCATAATAAACTGAAAATACTCCCTGAAGAAATTACAAACCTAAG AAACCTGAAGTGCCTGTATCTCCAGCATAATGAATTAACCTGCATATCAGAGGGATTTGAACA ACTTTCCAATTTAGAAGATTTAGATCTTTCAAACAATCATCTTACAACTGTTCCTGCTAGTTT TTCTTCTCTGTCCAGTCTGGTGCGACTCAATCTTTCTAGTAATGAACTGAAGAGTTTGCCAGC AGAAATAAATAGAATGAAAAGGTTGAAGCATTTGGATTGTAATTCAAATCTCTTGGAAACTAT ACCTCCTGAATTGGCTGGCATGGAATCACTAGAATTGCTTTATTTGCGGAGGAATAAATTACG TTTTCTACCAGAATTTCCTTCTTGTAGTCTATTGAAGGAATTGCACGTAGGTGAAAACCAGAT TGAAATGTTAGAGGCAGAACATCTTAAACATCTGAATTCAATTCTTGTGCTAGACCTGAGGGA TAACAAGTTAAAATCTGTTCCAGATGAAATTATACTACTACGGTCCTTGGAAAGGCTTGACCT AAGCAACAATGATATTAGTAGTCTTCCCTATTCATTGGGGAACCTTCATTTGAAATTTTTGGC ATTAGAAGGAAATCCTTTGAGAACAATTCGAAGAGAAATTATAAGTAAAGGAACACAAGAAGT CCTAAAATATCTACGAAGCAAGATCAAAGATGATGGACCTAGCCAAAGTGAGTCTGCTACTGA GACTGCCATGACACTACCAAGTGAATCCAGAGTCAATATACATGCCATCATTACATTAAAAAT ATTAGACTATAGTGATAAACAAGCAACTTTGATTCCTGATGAGGTGTTTGATGCAGTAAAAAG CAACATCGTCACTTCTATTAACTTCAGTAAGAATCAACTATGTGAAATTCCAAAAAGGATGGT AGAACTGAAGGAAATGGTTTCTGATGTCGATCTCAGTTTTAATAAACTTTCCTTTATATCCTT GGAGTTATGTGTGCTTCAGAAATTGACTTTTTTAGATCTCAGGAACAATTTTTTAAATTCTTT GCCAGAAGAAATGGAATCACTGGTAAGACTGCAAACGATCAATCTTTCCTTTAATAGGTTTAA AATGCTACCTGAAGTTCTATATCGTATCTTCACACTTGAAACAATTCTGATTAGTAATAATCA GGTTGGATCTGTGGACCCTCAGAAAATGAAGATGATGGAAAATCTGACCACGTTGGACCTTCA AAATAATGACCTCTTACAAATTCCACCAGAGCTCGGTAATTGTGTAAACTTAAGAACATTACT ATTGGATGGAAATCCATTCCGAGTTCCTCGAGCAGCCATATTAATGAAAGGAACAGCTGCTAT ACTTGAATATTTGAGAGACCGAATTCCTACTTAACATGGAGTTGCTTTATAACCCTTGTCATG
TATTATTAACCCTGGTTAATTCTAAGGAGGATGTAACATTTGTTTTAGTATCATCTTAAAAGG
TGATTATTGTAATTGATCTTGTAGTTTCCCAGTATCACCTACCCGTTGGTATAATTAGCCTGG
GCCATATTCACTGCCAGTAAATATTTTTACATTTTTATTTAAGATTTTTGTAAGGTGTTGTGT
ACATTTGTAATGGTGATAACCACAATGTGTTCATACATTTGTTCTAAATGTTTTGCTTATGAT
TTATCCTGCTAACTTTCATTTTCTTATAGCAAGCAGTTTTTTCAAAAATGAATTTTTATTTAA
TGTGGTTCAGTATTATAATAACAAAGCATTTTTGTAGAACTGGTTTTTTTTCTCATTTATTTT
TGTATTCCATACAATGTGACCAATTGACTTGAATATGACTAGCCAGTTTCTATGTTTTTGTTA
GATATAAAATTAAATCGAATTTTGTTGAATACTGTTCTTTGGCATTTAAAAAATAAGACCTTC
TTATCTTGGGCCACATGTCAAAAGAAAAAGGAAACAAAAATATATTAAAAATAAGACTTTTCA
TTACCCATGATAGGACTTTTGTGATATGGCTAATCTCAGTACACATTTCAACTTAAAACCTTT TTATTTACAGCACCATAATTTTAAAATTTACTTGCAATCTTGGTAAGACTAAACTTGCAGTGT
TTTTCTAAAAGGGAATTTGATAGGTAAACTTGATTTAATAAAAATTAAATATCATTTTTGTTT
ACACCAAAATTATCAGAAGTAGGTTGATTAGTCATTATAACACTTACCATATGATTCTATTAA iGAAGTCAATTCAGTAGCATGTATATCAATTTATATAGATAGGTAGATAGCTTTTGGATGATTG
AGGCATGCTTATATTATGAAAAAAATTGCTAATAAAGATAAATACTACATGTTCAGAATAAAA
GTTACATTTTTC
ORF Start: ATG at 53 JORF Stop: TAA at 1859
SEQ ID NO: 170 602 aa MW at 68248.9kD
NOV44a, MSRLKRIAGQDLRAGFKAGGRDCGTSVPQGL KAARKSGQLNLSGRNLSEVPQCV RINVDIP
CGI 24672-01 Protein EEA QNLSFGATERWWEQTDLTKLIISNNKLQSLTDD R LPALTVLDIHDNQLTSLPSAIRE LEN QK NVSHNKLKI PEEITNLR KCLYLQHNELTCISEGFEQLSNLEDLDLSNNH TTV
Sequence PASFSSLSS VRLNLSSNELKSLPAEINRMKRLKHLDCNSNLLETIPPELAGMESLELLYLRR NKLRFLPEFPSCSLLKELHVGENQIE LEAEHLKHLNSILVLDLRDNKLKSVPDEII RSLE RLDLSNNDISSLPYSLGNLHLKFLALEGNPLRTIRREIISKGTQEVLKYLRSKIKDDGPSQSE
SATETAMTLPΞESRVNIHAIITLKILDYSDKQATLIPDEVFDAVKSNIVTSINFSKNQLCEIP KRMVE KEMVSDVDLSFNKLSFISLELCVLQKLTFLDLRNNFLNSLPEEMESLVRLQTINLΞF NRFKM PEVLYRIFTLETILISNNQVGSVDPQKMKMMEN TT DLQ NDLLQIPPELGNCVN RTLLLDGNPFRVPRAAILMKGTAAILEYLRDRIPT
SEQ ID NO: 171 ;2712 bp
NOV44b, ACCTTTAAGCGTCACGGGTGGGGCTGCAGCTTCTGGACCTAGGACTTTGAACATGTCGCGCCT
'CG I 24672-03 DNA GAAGCGGATAGCGGGGCAGGATCTCCGCGCTGGTTTCAAAGCAGGTGGAAGAGACTGCGGTAC CTCGGTACCCCAAGGGCTGTTGAAGGCAGCGAGGAAGAGCGGCCAGTTAAACCTGTCGGGTAG
.'Sequence AAACCTCAGTGAAGTGCCGCAGTGTGTCTGGAGAATAAATGTGGATATCCCTGAGGAAGCTAA TCAGAATCTTTCGTTTGGTGCTACTGAAAGATGGTGGGAGCAGACAGATTTGACCAAACTAAT AATATCAAACAATAAACTTCAGTCACTTACAGATGACCTGCGACTCTTGCCTGCACTGACTGT TCTTGATATACATGATAATCAGTTGACATCCCTTCCTTCTGCTATAAGAGAGCTAGAAAATCT TCAGAAACTTAATGTCAGCCATAATAAACTGAAAATACTCCCTGAAGAAATTACAAACCTAAG AAACCTGAAGTGCCTGTATCTCCAGCATAATGAATTAACCTGCATATCAGAGGGATTTGAACA ACTTTCCAATTTAGAAGATTTAGATCTTTCAAACAATCATCTTACAACTGTTCCTGCTAGTTT TTCTTCTCTGTCCAGTCTGGTGCGACTCAATCTTTCTAGTAATGAACTGAAGAGTTTGCCAGC AGAAATAAATAGAATGAAAAGGTTGAAGCATTTGGATTGTAATTCAAATCTCTTGGAAACTAT ACCTCCTGAATTGGCTGGCATGGAATCACTAGAATTGCTTTATTTGCGGAGGAATAAATTACG TTTTCTACCAGAATTTCCTTCTTGTAGTCTATTGAAGGAATTGCACGTAGGTGAAAACCAGAT TGAAATGTTAGAGGCAGAACATCTTAAACATCTGAATTCAATTCTTGTGCTAGACCTGAGGGA TAACAAGTTAAAATCTGTTCCAGATGAAATTATACTACTACGGTCCTTGGAAAGGCTTGACCT AAGCAACAATGATATTAGTAGTCTTCCCTATTCATTGGGGAACCTTCATTTGAAATTTTTGGC ATTAGAAGGAAATCCTTTGAGAACAATTCGAAGAGAAATTATAAGTAAAGGAACACAAGAAGT CCTAAAATATCTACGAAGCAAGATCAAAGATGATGGACCTAGCCAAAGTGAGTCTGCTACTGA GACTGCCATGACACTACCAAGTGAATCCAGAGTCAATATACATGCCATCATTACATTAAAAAT ATTAGACTATAGTGATAAACAAGCAACTTTGATTCCTGATGAGGTGTTTGATGCAGT-'}AAAG CAACATCGTCACTTCTATTAACTTCAGTAAGAATCAACTATGTGAAATTCCAAAAAGGATGGT AGAACTGAAGGAAATGGTTTCTGATGTCGATCTCAGTTTTAATAAACTTTCCTTTATATCCTT GGAGTTATGTGTGCTTCAGAAATTGACTTTTTTAGATCTCAGGAACAATTTTTTAAATTCTTT GCCAGAAGAAATGGAATCACTGGTAAGACTGCAAACGATCAATCTTTCCTTTAATAGGTTTAA AATGCTACCTGAAGTTCTATATCGTATCTTCACACTTGAAACAATTCTGATTAGTAATAATCA GGTTGGATCTGTGGACCCTCGAGCAGCCATATTAATGAAAGGAACAGCTGCTATACTTGAATA TTTGAGAGACCGAATTCCTACTTAACATGGAGTTGCTTTATAACCCTTGTCATGTATTATTAA
CCCTGGTTAATTCTAAGGAGGATGTAACATTTGTTTTAGTATCATCTTAAAAGGTGATTATTG
TAATTGATCTTGTAGTTTCCCAGTATCACCTACCCGTTGGTATAATTAGCCTGGGCCATATTC
ACTGCCAGTAAATATTTTTACATTTTTATTTAAGATTTTTGTAAGGTGTTGTGTACATTTGTA
ATGGTGATAACCACAATGTGTTCATACATTTGTTCTAAATGTTTTGCTTATGATTTATCCTGC
TAACTTTCATTTTCTTATAGCAAGCAGTTTTTTCAAAAATGAATTTTTATTTAATGTGGTTCA
GTATTATAATAACAAAGCATTTTTGTAGAACTGGTTTTTTTTCTCATTTATTTTTGTATTCCA
TACAATGTGACCAATTGACTTGAATATGACTAGCCAGTTTCTATGTTTTTGTTAGATATAAAA
TTAAATCGAATTTTGTTGAATACTGTTCTTTGGCATTTAAAAAATAAGACCTTCTTATCTTGG
GCCACATGTCAAAAGAAAAAGGAAACAAAAATATATTAAAAATAAGACTTTTCATTACCCATG
ATAGGACTTTTGTGATATGGCTAATCTCAGTACACATTTCAACTTAAAACCTTTTTATTTACA
GCACCATAATTTTAAAATTTACTTGCAATCTTGGTAAGACTAAACTTGCAGTGTTTTTCTAAA
AGGGAATTTGATAGGTAAACTTGATTTAATAAAAATTAAATATCATTTTTGTTTACACCAAAA
TTATCAGAAGTAGGTTGATTAGTCATTATAACACTTACCATATGATTCTATTAAGAAGTCAAT
TCAGTAGCATGTATATCAATTTATATAGATAGGTAGATAGCTTTTGGATGATTGAGGCATGCT
TATATTATGAAAAAAATTGCTAATAAAGATAAATACTACATGTTCAGAATAAAAGTTACATTT
TTC
ORF Start: ATG at 53 ]ORF Stop: TAA at 1724
SEQ ID NO: 172 557 aa MW at 631 14.9kD
,NOV44b, MSRLKRIAGQDLRAGFKAGGRDCGTSVPQGLLKAARKSGQLNLSGRNLSEVPQCVWRINVDIP
CG I 24672-03 Protein EEANQNLSFGATERWWEQTDLTK IISNNKLQSLTDDLRLLPALTVLDIHDNQLTS PSAIRE LENLQKLNVSHNKLKILPEEITNLRNL C YLQHNELTCISEGFEQ SNLEDLDLSNNHLTTV
.Sequence PASFSSLSSLVRLNLSSNELKSLPAEINRMKRLKHLDCNSNLLETIPPELAGMESLELLYLRR NKLRFLPEFPSCSLLKELHVGENQIEMLEAEHLKHLNSILVLDLRDNKLKSVPDEIILLRSLE RLDLS NDISSLPYSLGNLHLKFLALEGNPLRTIRREIISKGTQEVLKYLRSKIKDDGPSQSE SATETAMTLPSESRVNIHAIITLKILDYSDKQATLIPDEVFDAVKSNIVTSINFSKNQLCEIP KRMVELKEMVSDVDLSFNKLSFISLE CVLQK TFLDLRNNFLNSLPEEMESLVRLQTINLSF NRFKMLPEVLYRIFTLETILISNNQVGSVDPRAAILMKGTAAILEY RDRIPT
SEQ ID NO: 173 982 bp jNOV44c, CTGCAGCTTCTGGACCTAGGACTTTGAACATGTCGCGCCTGAAGCGGATAGCGGGGCAGGATC
|CG 124672-02 DNA TCCGCGCTGGTTTCAAAGCAGGTGGAAGAGACTGCGGTACCTCGGTACCCCAAGGGCTGTTGA
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 44B.
Further analysis of the NOV44a protein yielded the following properties shown in Table 44C.
Table 44C. Protein Sequence Properties NOV44a
PSort 0.4500 probability located in cytoplasm; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV44a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 44D.
In a BLAST search of public sequence datbases, the NOV44a protein was found to have homology to the proteins shown in the BLASTP data in Table 44E.
Table 44E. Public BLASTP Results for NOV44a
j Q9CRC8 2610040E 16 ik protein (Similar to 219..601 1321/383 (83%) i 0.0 hypothetical protein FLJ20331 ) - Mus 1.383 I 355/383 (91 %) musculus (Mouse), 384 aa.
PFam analysis predicts that the NOV44a protein contains the domains shown in the Table 44F.
Example 45.
The N0V45 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 45A.
GTCTCGGGCCGCCGCCGCCTGCTGCTGCTGCTCGGGGCCGCCGCGGCCGCTGCCTCCCAGACG
Sequence
CGTGGCCTCCAGACCGGGCCTGTGCCTCCCGGGAGGCTGGCGGGGCCTCCCGCTGTGGCCACC TCTGCCGCGGCCGCGGCCGCCGCGTCCTACCCTGCCCTCCGTGCCTCTCTGCTGCCGCAGTCG CTGGCGGCGGCGGCCGCCGTCCCGACGCGCAGCTACAGCCAGGAGTCCAAAACTACTTACCTG GAAGACCTTCCACCACCCCCTGAGTATGAATTGGCCCCGTCCAAGTTAGAAGAGGAAGTGGAT GATGTCTTTCTCATTCGAGCTCAAGGACTGCCCTGGTCATGCACTATGGAAGATGTGCTTAAC TTTTTTTCAGACTGCAGAATCCGCAACGGTGAGAATGGAATACATTTTCTCCTAAACAGAGAT GGGAAACGAAGGGGTGATGCCTTAATTGAAATGGAGTCAGAGCAGGATGTGCAGAAAGCCTTA GAGAAGCACCGCATGTACATGGGCCAGCGGTATGTGGAAGTATATGAGATAAACAATGAAGAT GTGGATGCCTTAATGAAGAGCTTGCAGGTCAAATCTTCGCCTGTGGTAAATGATGGTGTGGTT CGTTTGAGAGGACTTCCTTATAGTTGCAATGAGAAAGACATTGTAGACTTCTTTGCAGGACTG AATATAGTTGACATTACTTTTGTGATGGACTATAGAGGGAGGCGAAAAACAGGGGAAGCCTAT GTGCAATTTGAAGAACCAGAAATGGCCAACCAAGCCCTGTTGAAACACAGGGAAGAAATTGGT AATCGATACATCGAGATATTTCCAAGCAGAAGGAATGAAGTTCGAACACATGTCGGTTCTTAT AAGGGAAAGAAAATCGCATCTTTTCCTACTGCTAAGTATATAACTGAGCCAGAAATGGTCTTT GAAGAACATGAAGTAAATGAGGTATTTCAACCCATGACAGCTTTTGAAAGTGAGAAGGAAATA GAATTGCCTAAGGAGGTGCCAGAAAAGCTTCCAGAGGCTGCTGATTTTGGAACTACGTCTTCT CTGCATTTTGTCCACATGAGAGGATTACCTTTCCAAGCCAATGCCCAAGACATTATAAACTTT TTTGCTCCACTCAAGCCTGTTAGAATCACCATGGAATACAGCTCCAGTGGGAAGGCCACTGGA GAAGCTGATGTGCACTTTGAGACCCATGAGGATGCTGTTGCAGCGATGCTCAAGGATCGGTCC CACGTTCATCATAGGTATATTGAACTGTTCCTGAATTCATGTCCAAAAGGAAAATAAGACTCT
AGGGGCTCCAGATAATAAGGGTGAAGCAAGAAGCATTTCATTTGCACATCTTTCTTGGACTTG
GGATATACAGTTCCAGTTTATTAGCAGCAACTGCTAGGGAAATGATTTTGGTGTTTTGGGTTA
ATTGCTTCTAAGAAAAGTTTCATAGTGGACTGTTTAGAAGAAGAAATGAAAGATCCAGTTTGG
GATTATGAAATAAACCACAAATTAAAATTTTTGTTTAAACTGTCCAGGATCTGATTTAAAAAT
ATGGTCTTTGTTTTATATGATTAAATGGTTTGTTTTCATAGATGATATGTTACTCATTGTAAA
GACCACATATTTTTATTCAGCAGTGTTCTTTAAACGGTTTCATTTAAAAAGTAACTTTTTTTT
TTTGCCTGTGAATTGAGTGCTCTGATGTAAAACTTCTCATGGAGTGAAACAGTGATTTATTTT
AACCAAACATTCACCAAAGCAAAGAACGGTTTCAGACCTTTGAACTGGTATGGTTTGGCAGAA
TAGTTTTAAATTTTGCTGTATTTGATTACTTAGAGATAGGAATTTTTAAAAATCAAAACAAAA iAATACCACAGCTTAGTGTAAATGACAATTTGGCGGTTTTATGTCTTTAGAAATGTTTTGCCTT
TCTAAGCCTTGTGCTAAAGGCGTATAACGGTGGTGCCTATCTACTTAAGGGGGCATTCTAGTC
TTAACTTAAAAGTTGTCTAAACTGTCCCTCCCTGGCTTTTTTTGGTTTGGGGTAGACCTAAGG
GTGTTTGTTAGTCTCAAAACTGTGAAGTGACATGTCAGAACAGTCCAGACTGGTAAGAAAATT
AATGGCTTCACTTGAATTTAAACCAGCTCTAGATAGGAAAAAAATCAGTCTCCTCATTTGCTT
TTTAAATGGAGTAGTACATCCCATATTTTAGAACAAGTAGGGGTGCCTTGCTTAAATAAAAAT
AGCATTTAATGTATAATTGTGTGAAGGGTTTATGGATAAAGCTGTACTTCTGTCACAATGTGG
CAGTACTTTCTGCTTTAATATTAAACAGCTTGTTATTTAAATATTGGACAAAATGGCTGGCTT
CAAAATATAGTCATTAATAAACTAACTTTATGTGCACCTGTGTAGGAGAATCAAAATCCTGTA
TGCTTTCTTTGCCTTGTTCCTGTTCTCAGGGTGACGACTGCCACCAGGAGATGCAGTTCTAGT
TCTTAAAATTAAATTTGCCCAGGTTTCTGACAGGTGATACCTGGAAGAGAGACTATGTCTTCT
CTTACTTAATACATAACCATCTTTGATTACCAGCTAAGATGCGAAATCACTGTACTGTAGTCA
ATAAATGAAGACTTGTTTCAGGCTG
ORF Start: ATG at 1 jORF Stop: TAA at 1441
! SEQ ID NO: 176 480 aa MW at 53153.8kD
JNOV45a, MAGTRWVLGALLRGCGCNCSSCRRTGAACLPFYSAAGSIPSGVSGRRRLLLLLGAAAAAASQT
ICG 125900-01 Protein RGLQTGPVPPGRLAGPPAVATSAAAAAAASYPALRASLLPQSLAAAAAVPTRSYSQESKTTYL EDLPPPPEYELAPSKLEEEVDDVFLIRAQGLPWSCTMEDVLNFFSDCRIRNGENGIHFLLNRD jSequence GKRRGDALIEMESEQDVQKALEKHRMYMGQRYVEVYEIN EDVDALMKSLQVKSSPWNDGW RLRGLPYSCNEKDIVDFFAGLNIVDITFVMDYRGRRKTGEAYVQFEEPEMANQALLKHREEIG NRYIEIFPSRR EVRTHVGSYKGKKIASFPTAKYITEPEMVFEEHEVNEVFQPMTAFESEKEI ELPKEVPEKLPEAADFGTTSSLHFVHMRGLPFQANAQDIINFFAPLKPVRITMEYSSSGKATG EADVHFETHEDAVAAMLKDRSHVHHRYIELFLNSCPKGK
Further analysis of the NOV45a protein yielded the following properties shown in Table 45B.
Table 45B. Protein Sequence Properties NOV45a
' PSort 0.7929 probability located in mitochondrial intermembrane space; 0.7600 probability ', analysis: located in nucleus; 0.4699 probability located in mitochondrial matrix space; 0.3000 probability located in microbody (peroxisome)
, SignalP Cleavage site between residues 62 and 63 i analysis:
A search of the NOV45a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 45C.
In a BLAST search of public sequence datbases, the NOV45a protein was found to have homology to the proteins shown in the BLASTP data in Table 45D.
PFam analysis predicts that the NOV45a protein contains the domains shown in the Table 45E. >
Example 46.
The NOV46 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 46A.
Table 46A. NOV46 Sequence Analysis
SEQ ID NO: 177 2053 bp
NOV46a, CACCTGCTGCCCACCACCCCGGCAGCACCTTTCCCTGCCCAGGCTTCAGAGTGCCCTGTTGCT
CGI 26510-01 DNA GCTGCCACTGCCCCCCACACTCCAGGGCCATGTCAGAGCTCCCATCTACCCTCCACCAGCATG
CCGCTCCTGAAGATGCCCCCACCATTCTCGGGGTGCAGCCACCCCTGCAGCGGGCACTGTGGT
Sequence GGGCACTGCAGTGGGCCTCTCCTCCCACCCCCGAGCTCTCAGCCACTCCCTAGCACTCACAGG GATCCCGGGTGCAAGGGGCACAAGTTTGCACACAGTGGCCTGGCTTGCCAGCTGCCCCAGCCC TGCGAGGCAGATGAGGGGCTGGGTGAGGAAGAGGATAGCAGCTCTGAGCGAAGCTCCTGCACC TCATCCTCCACCCACCAGAGAGATGGGAAGTTCTGTGACTGCTGCTACTGTGAGTTCTTCGGC
CACAATGCGGAAAAGGAGAAGGCCCAGTTGGCAGCAGAAGCTCTAAAGCAGGCAAATCGTGTT TCTGGAAGCCGGGAGCCAAGGCCTGCCAGGGAGAGGCTCTTGGAGTGGCCCGACCGGGAACTG GATCGGGTCAACAGCTTCCTGAGCAGCCGTCTGCAGGAGATCAAAAACACTGTCAAAGACTCC ATCCGTGCCAGCTTCAGTGTGTGTGAGCTCAGCATGGACAGCAATGGCTTCTCTAAGGAGGGG GCTGCTGAGCCTGAGCCTCAGAGTCTACCCCCCTCAAACCTCAGTGGCTCCTCAGAGCAGCAG CCTGACATCAACCTTGACCTGTCCCCTTTGACTTTGGGCTCCCCTCAGAACCACACGTTACAA GCTCCAGGCGAGCCAGCCCCACCATGGGCAGAAATGAGAGGCCCCCACCCACCATGGACAGAG GTGAGGGGGCCCCCTCCCGGTATCGTCCCCGAGAACGGGCTCGTGAGGAGACTCAACACCGTG CCCAACCTATCCCGGGTGATCTGGGTCAAGACACCCAAGCCGGGCTACCCCAGCTCCGAGGAG CCAAGCTCAAAGGAAGTTCCCAGTTGCAAGCAGGAGCTGCCTGAGCCTGTGTCCTCAGGTGGG AAGCCACAGAAGGGCAAGAGGCAGGGCAGTCAGGCCAAGAAGAGCGAGGCAAGCCCAGCCCCC CGGCCCCCAGCCAGCCTAGAGGTTCCCAGTGCCAAGGGCCAGGTCGCTGGCCCCAAGCAGCCA GGCAGGGTCCTAGAGCTTCCCAAAGTAGGCAGCTGTGCTGAGGCTGGAGAGGGGAGCCGGGGG AGCCGGCCAGGACCAGGTTGGGCTGGCAGTCCCAAAACTGAGAAGGAGAAGGGCAGCTCCTGG CGAAACTGGCCAGGCGAGGCCAAGGCACGGCCTCAGGAGCAGGAGTCTGTGCAGCCCCCAGGC CCAGCAAGGCCACAGAGCTTGCCCCAGGGCAAGGGCCGCAGCCGCCGGAGCCGCAACAAGCAG GAGAAGCCAGCCTCCTCCTTGGACGATGTGTTCCTGCCCAAGGACATGGACGGGGTGGAGATG GATGAGACTGACCGAGAGGTGGAGTACTTTAAGAGGTTCTGTTTGGATTCTGCAAAGCAGACT CGTCAGAAAGTTGCTGTGAACTGGACCAACTTCAGCCTCAAGAAAACCACTCCTAGCACAGCT CAGTGAGGCCCTGCCCAGGCTGAGCTGCTTCAGGGCATCCTGAGGCCCTGACTGCCAGCTGAA
GGCGTATAATTTTTCCCTCCGTGTGCCCCACNTACCCGTCCAAGACCCTCTGTGCTCCCCACC
ATCCTGGACCAACCAAAAGCTGAACGGATGCCACACTGTGCTGGGGCCCCTTGACCTCAGCAG
AGCCGCTTCCTGGTGCTACGCAGCCTCCACACTCAGAGCCCGTGGACTGGGCTGGCCTAAGGG
CCAGGGCTGATGGTACTGCTGGCCCAACACTGCTCTCTTTGTGTTTGGTTTTTTTGTTTTTGT
TTTTATTTTGTTTTTTTCCAATTCTTTACTTTTGATACTGTGAAGATCTTTCGTGCCGAAAGA
TAAAGCAACATTTGGACACAGAAAAAAAAAAAAAAAA
ORF Start: ATG at 124 ORF Stop: TGA at 1642
SEQ ID NO: 178 506 aa JMW at 54743.6kD
NOV46a, MPLLKMPPPFSGCSHPCSGHCGGHCSGPLLPPPSSQPLPSTHRDPGCKGHKFAHSGLACQLPQ
CG I 26510-01 Protein PCEADEGLGEEEDSSSERSSCTSSSTHQRDGKFCDCCYCEFFGHNAEKEKAQLAAEALKQANR VSGSREPRPARERLLEWPDRELDRVNSFLSSRLQEIKNTVKDSIRASFSVCELSMDSNGFSKE
Sequence GAAEPEPQSLPPSNLSGSSEQQPDINLDLSPLTLGSPQNHTLQAPGEPAPPWAEMRGPHPPWT EVRGPPPGIVPENGLVRRLNTVPNLSRVI VKTPKPGYPSSEEPSSKEVPSCKQELPEPVSSG GKPQKGKRQGSQAKKSEASPAPRPPASLEVPSAKGQVAGPKQPGRVLELPKVGSCAEAGEGSR GSRPGPG AGSPKTEKEKGSS RWPGEAKARPQEQESVQPPGPARPQSLPQGKGRSRRSRNK QEKPASSLDDVFLPKDMDGVEMDETDREVEYFKRFCLDSAKQTRQKVAVNWTNFSLKKTTPST AQ
Further analysis of the NOV46a protein yielded the following properties shown in Table 46B.
j Table 46B. Protein Sequence Properties NOV46a j PSort ' 0.4500 probability located in cytoplasm; 0.3000 probability located in microbody j analysis: j (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 i probability located in lysosome (lumen)
Signal P j No Known Signal Sequence Predicted , analysis: i
A search of the NOV46a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 46C.
In a BLAST search of public sequence datbases, the NOV46a protein was found to have homology to the proteins shown in the BLASTP data in Table 46D.
PFam analysis predicts that the NOV46a protein contains the domains shown in the Table 46E.
Table 46E. Domain Analysis of NOV46a
Identities/
Pfa Domain j NOV46a Match Region Similarities Expect Value for the Matched Region
Example 47.
The NOV47 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 47A.
Table 47 A. NOV47 Sequence Analysis
SEQ ID NO: 179 3296 bp
NOV47a, CCGCCGTTTATTGTGGCCCCGACAGGCCGGGGTTACTGTGGCGACCACGAGAGCAGCTTTGGC
CGI 27106-01 DNA GCTATGGAGGAGCCCGGGGCTACCCCTCAACCGTATTTGGGGCTGCTCCTGGAGGAGCTACGC
AGGGTTAGGAGTCGGCTTTATGTGGGACGAGAGAAAAAGCTTGCTCTAATGCTTTCTGGACTA
Sequence ATTGAAGAAAAAAGTAAACTACTTGAAAAATTTAGCCTTGTTCAAAAAGAGTATGAAGGCTAT
GAAGTAGAGTCATCTTTAAAGGATGCCAGCTTTGAGAAGGAGGCAACAGAAGCACAAAGTTTG
GAGGCAACCTGTGAAAAGCTGAACAGGTCCAATTCTGAACTTGAGGATGAAATACTCTGTCTA
GAAAAAGAGTTAAAAGAAGAGAAATCCAAACATTCTGAACAAGATGAATTGATGGCGGATATT
TCAAAAAGGATACAGTCTCTAGAAGATGAGTCAAAATCCCTCAAATCACAAGTAGCTGAAGCC
AAAATGACCTTCAAGATATTTCAAATGAATGAAGAACGACTGAAGATAGCAATAAAAGATGCT
TTGAATGAAAATTCTCAACTTCAGGAAAGCCAGAAACAGCTTTTGCAAGAAGCTGAAGTATGG
AAAGAACAAGTGAGTGAACTTAATAAACAGAAAGTAACATTTGAAGACTCCAAAGTACATGCA
GAACAAGTTCTAAATGATAAAGAAAGTCACATCAAGACTCTGACTGAACGCTTGTTAAAGATG
AAAGATTGGGCTGCTATGCTTGGAGAAGACATAACGGATGATGATAACTTGGAATTAGAAATG
AACAGTGAATCGGAAAATGGTGCTTACTTAGATAATCCTCCAAAAGGAGCTTTGAAGAAACTG
ATTCATGCTGCTAAGTTAAATGCTTCTTTAAAAACCTTAGAAGGAGAAAGAAACCAAATTTAT
ATTCAGTTGTCTGAAGTTGATAAAACAAAGGAAGAGCTTACAGAGCATATTAAAAATCTTCAG
ACTGAACAAGCATCTTTGCAGTCAGAAAACACACATTTTGAAAATGAGAATCAGAAGCTTCAA
CAGAAACTTAAAGTAATGACTGAATTATATCAAGAAAATGAAATGAAACTCCACAGGAAATTA
ACAGTAGAGGAAAATTATCGGTTAGAGAAAGAAGAGAAACTTTCTAAAGTAGATGAAAAGATC
AGCCATGCCACTGAAGAGCTGGAGACCTATAGAAAGCGAGCCAAAGATCTTGAAGAAGAATTG
GAGAGAACTATTCATTCTTATCAAGGGCAGATTATTTCCCATGAGAAAAAAGCACATGATAAT
TGGTTGGCAGCTCGGAATGCTGAAAGAAACCTCAATGATTTAAGGAAAGAAAATGCTCACAAC
AGACAAAAATTAACTGAAACAGAGCTTAAATTTGAACTTTTAGAAAAAGATCCTTATGCACTC
GATGTTCCAAATACAGCATTTGGCAGAGAGCATTCCCCATATGGTCCCTCACCATTGGGTTGG
CCTTCATCTGAAACAAGAGCTTTTCTCTCTCCTCCAACTTTGTTGGAGGGTCCACTCACACTC
TCACCTTTGCTTCCAGGGGGAGGAGGAAGAGGCTCACGAGGCCCAGGGAATCCTTTGGACCAT
CAGATTACCAATGAAAGAGGAGAATCAAGCTGTGATAGGTTAACCGATCCTCATAGGGCTCTC
TCTGACACTGGGTTTCTGTCACCTCCATGGGACCAGGACCGTAGGATGATGTTTCCTCCGCCA
GGACAATCATATCCTGATTCAGCCCTTCCTCCACAAAGGCAAGACAGATTTTGTTCTAATTCT
GGTAGACTGTCTGGACCAGCAGAACTCAGAAGTTTTAATATGCCTTCTTTGGATAAAATGGAT
GGGTCAATGCCTTCAGAAATGGAATCCAGTAGAAATGATACCAAAGATGATCTTGGTAATTTA
AATGTGCCTGATTCATCTCTCCCTGCTGAAAATGAAGCCACTGGCCCTGGCTTTGTTCCTCCA
CCTCTTGCTCCAGTCAGAGGTCCATTGTTTCCAGTGGATGCAAGAGGCCCAT CTTGAGAAGA
GGACCTCCTTTCCCCCCACCTCCTCCAGGAGCCATGTTTGGAGCTTCTCGAGATTATTTTCCA
CCAGGGGATTTCCCAGGTCCACCACCTGCTCCATTTGCAATGAGAAATGTCTATCCACCGAGG GGTTTTCCTCCTTACCTTCCCCCAAGACCTGGATTTTTCCCCCCACCCCCACATTCTGAAGGT
AGAAGTGAGTTCCCCTCAGGTTTGATTCCACCTTCAAATGAGCCTGCTACTGAACATCCAGAA
CCACAGCAAGAAACCTGACAATATTTTTGCTCTCTTCAAAAGTAATTTTGACTGATCTCATTT TCAGTTTAAGTAACTGCTGTTACTTAAGTGATTACACTTTTGCTCAAATTGAAGCTTAATGGA
ATTATAATTCTCAGGATAGTATTTTGTAAATAAAGATGATTTAAATATGAATCTTATGAGTAA
ATTATTTCAATTTTATTTTAGACGGTATAACTATTTCAATTTGATTAATCCACTATTATATAA
ACAATAGTGGGAGTTTTATATATGTAATCTTGCAGGTGGGGAGGCTTTAAATTCTGAAGTCTG
TGTCTTTATGCCAAGAACTGTATTTACTGTGGTTGTGGACAAATGTGAAAGTAACTTTATGCT
TAAATAAATTATAGTTGATTTAAAGATTTGTTTGGCATTGATAATAATAAAATCAGTAGTTTT
TCTATAACTATGGCTCTATTAATTAACTTTTTTCCTTTTACCAATAACTTTGAGGTGCAAAAC
TCAAACTTATGTGGGTCTTTTGTGTTCAATTATGTTATGACAAATGTGCTCTCTTTCTTGTAA
ATAGACATGAGTGGCCCAAAGCAACAAATTAATACACTTTTAAAAGTCAAAATTGATTATATT
TTAAAGATAACCAGGATATTATCTAATGGTGAATTGTAGAATTTTGATCTTCTTATTCACTGA
GTTTCTTGCACGGTTTCTTTATTGCTTTTTTTCCCGCCTGTTCTTTTGTAAGGTATTTACTAT
TTTCTGTGGAGGATATTGAGATGTACTACAGGATAACTGTAGTGAATGATGTGTCATCATTTT
GAGCTTTGGACTCAATATCTTTAGTGTTTCCCTAAATCAGATTTGTAGGTCATGTTAAGCTTC TTGCACATTAATATGATTATGGAAGGAAAGGCAGTGAAGCATAACTAATAAACATCATAATAC
TTAAAAAAAAAAAAAAAAAA
ORF Start: ATG at 67 1 ORF Stop: TGA at 2347
SEQ ID NO: 180 760 aa MW at 86012.4kD
NOV47a, MEEPGATPQPYLGLLLEELRRVRSRLYVGREKKLALMLSGLIEEKSKLLEKFSLVQKEYEGYE
CG I 27106-01 Protein VESSLKDASFEKEATEAQSLEATCEKLNRSNSELEDEILCLEKELKEEKSKHSEQDEL ADIS KRIQSLEDESKSLKSQVAEAK TFKIFQMNEERLKIAIKDALNENSQLQESQKQLLQEAEVWK
Sequence EQVSELNKQKVTFEDSKVHAEQVLNDKESHIKTLTERLLKMKDWAAMLGEDITDDDNLELEMN SESENGAYLDNPPKGALKKLIHAAKLNASLKTLEGERNQIYIQLSEVDKTKEELTEHIKNLQT EQASLQSENTHFENENQKLQQKLKVMTELYQENEMKLHRKLTVEENYRLEKEEKLSKVDEKIS HATEELETYRKRAKDLEEELERTIHSYQGQIISHEKKAHDN LAAR AERNLNDLRKENAHNR QKLTETELKFELLEKDPYALDVPNTAFGREHSPYGPSPLGWPSSETRAFLSPPTLLEGPLTLS PLLPGGGGRGSRGPGNPLDHQITNERGESSCDRLTDPHRALSDTGFLSPPWDQDRRMMFPPPG QSYPDSALPPQRQDRFCSNSGRLSGPAELRSF MPSLDKMDGSMPSEMESSRNDTKDDLGNLN VPDSSLPAENEATGPGFVPPPLAPVRGPLFPVDARGPFLRRGPPFPPPPPGAMFGASRDYFPP GDFPGPPPAPFA RNVYPPRGFPPYLPPRPGFFPPPPHSEGRSEFPSGLIPPSNEPATEHPEP QQET
Further analysis of the NOV47a protein yielded the following properties shown in Table 47B.
; Table 47B. Protein Sequence Properties NOV47a
PSort 0.4500 probability located in cytoplasm; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV47a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 47C.
In a BLAST search of public sequence datbases, the NOV47a protein was found to have homology to the proteins shown in the BLASTP data in Table 47D.
PFam analysis predicts that the NOV47a protein contains the domains shown in the Table 47E.
Example 48.
The NOV48 clone was analyzed, and the nucleotide and encoded polypeptide ° sequences are shown in Table 48A.
jTable 48A. NOV48 Sequence Analysis
SEQ ID NO: 181 4797 bp iNOV48a, CTGGCTGGCTGGCTGTACACCTCGCTGCCGCCGGGCTTCGGGGGCACCGGGGAAGACTACAGC
JCG 127340-01 DNA GAAGAGGGGATCCACTTCCCGTGGCTGCCGGCGCTCGTGTGCACCGGCGCGGTATTCCTGGGC
GCCGAAATCTGCCCCTACTCAGTGTGTTCGCGGCACGGGCTGGCCATCGCCTCGCACAGCGTG
Sequence TGCCTGACCCGGCTTCTGATGGCAGCCGCCTTCCCCGTGTGCTACCCGCTGGGCCGCCTGCTG
GACTGGGCGCTGCGCCAGGAGATAAGCACCTTCTACACGCGGGAGAAGTTGCTGGAGACGTTG CGGGCCGCAGACCCCTACAGTGACCTGGTGAAGGAGGAGCTCAACATCATACAGGGTGCCCTG GAGCTGCGCACCAAAGTGGTGGAGGAGGTGCTGACCCCCCTGGGAGACTGCTTCATGCTGCGC TCAGACGCGGTGCTCGACTTCGCCACTGTCTCCGAGATCCTGCGCAGCGGCTACACTCGCATC CCAGTGTACGAGGGTGACCAGCGGCACAACATTGTGGACATTTTATTTGTCAAGGACTTGGCC TTCGTGGACCCCGACGACTGCACCCCGCTCCTCACTGTCACCCGCTTCTACAACCGGCCCCTG CATTGTGTTTTCAATGACACCCGACTGGACACGGTTCTGGAGGAGTTTAAGAAGGGAAAATCT CACCTGGCCATTGTCCAGCGGGTGAATAATGAGGGAGAAGGGGACCCTTTCTATGAGGTGATG GGCATTGTCACGCTGGAGGATATCATAGAGGAGATTATCAAGTCGGAGATCCTGGATGAAACT GATCTCTACACTGACAATCGGAAAAAGCAGAGGGTCCCGCAACGGGAGCGGAAGCGGCATGAC TTCTCCTTGTTTAAGCTTTCGGACACGGAGATGCGGGTGAAGATCTCACCACAGCTTCTGCTA GCCACACACCGCTTCATGGCCACAGAAGTGGAGCCCTTTAAGTCTCTGTACCTTTCGGAGAAG ATCCTGCTCCGGCTCCTGAAACATCCCAACGTGATCCAGGAGCTGAAGTTTGATGAGAAGAAC AAGAAGGCCCCGGAACACTACCTCTACCAGCGCAACCGCCCTGTGGACTACTTTGTGCTGCTT CTACAGGGTAAAGTGGAGGTGGAGGTTGGTAAGGAAGGCCTTCGCTTTGAAAATGGAGCCTTT ACTTACTATGGCGTCCCAGCCATCATGACCACTGCTTGCTCAGATAATGACGTGCGGAAGGTT GGAAGTCTGGCTGGATCTTCTGTCTTTCTAAACCGGTCCCCTTCTCGCTGCAGTGGGTTGAAT CGCTCTGAGTCTCCAAACCGAGAGCGCAGTGACTTTGGGGGCAGCAACACCCAGCTGTACAGC AGCAGCAACAACCTCTACATGCCTGACTACTCAGTCCACATCCTCAGCGATGTGCAGTTTGTG AAGATCACACGGCAGCAATATCAGAACGCACTCACTGCCTGCCACATGGACAGCTCACCTCAG TCCCCTGACATGGAGGCCTTCACAGACGGGGACTCCACTAAGGCCCCCACAACCCGGGGCACA CCCCAGACCCCTAAGGATGACCCCGCCATCACGCTCCTCAACAACAGGAACAGCCTGCCGTGC AGCCGCTCAGACGGGCTGAGAAGCCCCAGCGAGGTAGTGTACCTGAGGATGGAGGAGCTGGCC TTCACCCAGGAAGAAATGACTGACTTCGAGGAGCACAGCACACAGCAGCTCACGCTGTCTCCT GCAGCCGTTCCCACGAGAGCAGCATCAGATAGTGAATGTTGTAACATCAACCTGGATACAGAG ACCAGCCCCTGCAGTAGCGATTTTGAGGAAAACGTGGGCAAGAAGCTGCTGAGAACCTTGAGT GGCCAAAAAAGGAAGAGGTCACCAGAAGGAGAGAGAACCTCTGAGGACAACTCCAATTTAACA
jCCTCTGATCACATGACAGGGCAAAGCCAGCATTCACTGGGTGTGTGAAATTCCAGAGCTTTGG iGGGAGAATCCACCCTCCCATCATCTGCTTCCCCCAAGGCCTCCCACAGGTGACAGAATGTTCT
IGCCTTCCCTTCCATCTCTTCACCCCTAGCTGTCAGTTTGGCAGATTTTCCCTCGTTACCTCCA 'GTTCGACTCAGAACCTTGACATGGCCATAACAGAAGGAGGTGCCTCTGATAGAACATGCTAGA JAATGGTCTTTTCCACAGCATAGTCTGGGACTGGAAAAGAGATGTCTGACTGCAAGCTGACAAT
IGCCACTCTGGGACCCCTGATGCTCTTCTTTGTTCTTTGGGTCCCCTGATGCCATAGGAGACCT
ATCGTCTTGGAACTTGCCATTCTTTCCTCCAGAACAAAATGTTAACTTTCTAACACATTTCAT
GCATAGCTTGGCTCAGAAGGTGCCATTGGCAGACAGGCACATGGGAGGCTGGAGTAGGAGGTC
TGAAGATTAGTTCAGGGGATGGACCAAGAATTTCCCCCAGAGCTTTAAAGAAGTGGGACTCAG
CCATGTTGGCGCGTGATTGACATTACAGCACAGAAAACTGTTAGTGACTGGTTTCCTGTTAGA
TAAGGGTTCCAGCAGCCTGGGGCAGTATGTCTCAGCTGGAATGGAAAGAATGTGAGATGGAAC
CTCAAGTCACTGTTTTTACCAGGGACACATCTGTTTTGGCTCCCAATCAGCAGTCTTCAATCG
ATCAATAATTCTGCTCTGGAAGAGAAGGAACAGGGAGCAGAGAGACCCAACTGGGAGCCAGAG
ATGGAACTTCAGGTCTTAAGTGCAAATCAAAGCAAAAAACAAACAAAACTTACATGGAAAAAC
TGTAAGTGCTGAAAGCAAGTTTAGCCATGACAAACCAAAGAGTGCCCAGGTCAGCCAAGAAAG
ATACATAATCTCATGGGACTTCAGTGGGAGTTACACAGGAATGTTGAAGAATCATTCTTCTTT
ITTCATGCATTTGTCCTTCTCCCACCCCCTTACTACACCCTAGCAGATCAGCTGAGTGTACTTT
ATTCCAAGAACTTACTGGATCTCTGGTTTTTCTCCTGAAGTTGGGGCAGGTGCAATTCCAAGC
ATAACCACCAGATGGCAGAGTGACCGCGCATACCTGCTTCCAAGAATAAAACAGTTCTGAAAA
IGCAACCGCAAAGCCGGGCGCGGTGGCTCACACCTGTAATCCCAACAGTTTGGAAGACCGAGGC
GGGTGGATCACTTGAAGTCAGGAGTTTGAGACCAGCCTGGCCAACATGGTGAAACCCCCATCT
'CTCCTGGGCATGTAGTCCCAGCTACTCGGGAGGCTGAGGCAGGAGAATCGCTTGAACCTGGGA
IGGCAGAGGTTGCAGTGAGCTGAGATCACACCACTGCACTTCATCCTAGGCAACAGAGCGAGAC
TCTGTCTCCCCCCTCAAAAAAAAAAAAGAAAGAAAGAAAGAGAAAAGAAAAGAAAAGCAACCA jCAGCCAGCCTTAGGGAAAACTTGGAAGTAAGTGAAATTTGTCTTCAGAATAACTATCTCCCTT JTCTGATCTGTCTCCTACTCTTTAGATGTTCTCAGTCAAGTACTCACTGAACTCATTGATCGAG jTGCTGTCTGCTAAATCTCCAAACCATTCCCAAACCTTTCCCCGTAGTATACCATCCAGCTTCC
CTCCCCTTCCTCCAAAACCCTCCCTCCCACCTCCCCACACCCATTGAGTCATTCACAGGCAGG
AGGGAGACTGATCATTCCTCTGGGTTATCTGCATCTCAAAAGAAAATGCTTACCCACAGGAAC
JTGTTAACTCAGGGGTTCTTAACTTGGGGTCCATCACCCCAGGGGGTCCATAGTTGGACTTCAG lAGGGTCTATGAAACCCCTAAAACTGTCAGTATTTAATGTATTTATTCTTGTATGTTTTTTCCA
GAGCATTAAAGCTTTCATAAGGTTCTCAAAGGTCTCAGACCTACAAAGAGTTAAAACAAACAG
ACAAACAAAAAAAAACACTACTATTTTAAATAGTGGAACTTTCAGCCCAGCGTTTCTGCAATG
CAGAGTGAAGTGGATACTGGGCAGTTCGAGACAGGTTTTTAATCATAAGTGGTCTTTTCAAAT
GTCCATCAATTGATGGGGAAGGCTGGCACCCACCAAGAAGTGGAAGTCCTCAGAAATTCTCGG
CACACCCTAGAGTATTGTACAACCAACACCCCCACATAACTTTGTCCCCTCTTCCCCAACAAC
CCAGAGCAGGTGTTGCAGACAGGAGGGCCACAGCGTGTGGAAGTAAAGACTTTGGAGCTAGAG
ATGCCTTTTCCAGCAATGATTATTGACTTCACCACACCCCTTGCCTGGCCTGGCCTGAGGCTC
AGCAGTGCATGACTTCTCGTAGATAACTTCACAGTCATCCAGTCCCAACACCTGCTCTTGCCT
GGTAGGAACAGGCGAAGTGTCAGCCCTCAATGTTGGGTACTTAGACCCAAACCAATAAATGGT
GAGTTTTGAACAAGAACTACCATCATGCAGGCTTCTTGCCCAGCTGACCACTGGCCCCGGGGT
GCCTGCCTGGCTGGTCTTCATCACCTGAGGCCACCAGGCTCAAGCCACTGCTGTTGCATTACA
CCCATCCCTTTGCAAAATCCCTATGGAGCCTGTCACCACTCCCCTCCCTATATACCCCCACCC
CACAAAGATTTTCTTCAGGTTAAAAAAAAAGTTTAAAAAAAAGATTTTAAAATAAAGCATTTA
TGAAGGCTTAATAAATTGTAAATAATTTTTAAATAAAATGAAAATGCCTTTCCTGGAAAAAAA
AAAAAAAAA
ORF Start: ATG at 208 T JORF Stop: TGA at 1966
SEQ ID NO: 182 586 aa MW at 665583kD
NOV48a, MAAAFPVCYPLGRLLD ALRQEISTFYTREKLLETLRAADPYSDLVKEELNIIQGALELRTKV
CG I 27340-01 Protein VEEVLTPLGDCFMLRSDAVLDFATVSEILRSGYTRIPVYEGDQRHNIVDILFVKDLAFVDPDD CTPLLTVTRFYNRPLHCVF DTRLDTVLEEFKKGKSHLAIVQRVN EGEGDPFYEVMGIVTLE
Sequence DIIEE11KSEILDETDLYTDNRKKQRVPQRERKRHDFSLFKLSDTEMRVKISPQLLLATHRFM ATEVEPFKSLYLSEKILLRLLKHP VIQELKFDEKNKKAPEHYLYQRNRPVDYFVLLLQGKVE VEVGKEGLRFENGAFTYYGVPAIMTTACSDNDVRKVGSLAGSSVFLNRSPSRCSGLNRSESPN RERSDFGGSNTQLYSSSN LYMPDYSVHILSDVQFVKITRQQYQNALTACHMDSSPQSPDMEA FTDGDSTKAPTTRGTPQTPKDDPAITLL NRNSLPCSRSDGLRSPSEWYLRMEELAFTQEEM TDFEEHSTQQLTLSPAAVPTRAASDSECCNINLDTETSPCSSDFEENVGKKLLRTLSGQKRKR SPEGERTSEDNSNLTPLIT
SEQ ID NO: 183 371 1 bp
NOV48b, CTGGCTGGCTGGCTGTACACCTCGCTGCCGCCGGGCTTCGGGGGCACCGGGGAAGACTACAGC
CG I 27340-02 DNA GAAGAGGGGATCCACTTCCCGTGGCTGCCGGCGCTCGTGTGCACCGGCGCGGTATTCCTGGGC
GCCGAAATCTGCCCCTACTCAGTGTGTTCGCGGCACGGGCTGGCCATCGCCTCGCACAGCGTG
Sequence TGCCTGACCCGGCTTCTGATGGCAGCCGCCTTCCCCGTGTGCTACCCGCTGGGCCGCCTGCTG GACTGGGCGCTGCGCCAGGAGATAAGCACCTTCTACACGCGGGAGAAGTTGCTGGAGACGTTG
CGGGCCGCAGACCCCTACAGTGACCTGGTGAAGGAGGAGCTCAACATCATACAGGGTGCCCTG GAGCTGCGCACCAAAGTTGTGGAGGAGGTGCTGGCCCCCCTGGGAGACTGCTTCATGCTGCGC TCAGACGCGGTGCTCGACTTCGCCACTGTCTCCGAGATCCTGCGCAGCGGCTACACTCGCATC CCAGTGTACGAGGGTGACCAGCGGCACAACATTGTGGACATTTTATTTGTCAAGGACTTGGCC TTCGTGGACCCCGACGACTGCACCCCGCTCCTCACTGTCACCCGCTTCTACAACCGGCCCCTG CATTGTGTTTTCAATGACACCCGACTGGACACGGTTCTGGAGGAGTTTAAGAAGGCATCAGAT AGTGAATGTTGTAACATCAACCTGGATACAGAGACCAGCCCCTGCAGTAGCGATTTTGAGGAA AACGTGGGCAAGAAGCTGCTGAGAACCTTGAGTGGCCAAAAAAGGAAGAGGTCACCAGAAGGA GAGAGAACCTCTGAGGACAACTCCAATTTAACACCTCTGATCACATGACAGGGCAAAGCCAGC ATTCACTGGGTGTGTGAAATTCCAGAGCTTTGGGGGAGAATCCACCCTCCCATCATCTGCTTC
CCCCAAGGCCTCCCACAGGTGACAGAATGTTCTGCCTTCCCTTCCATCTCTTCACCCCTAGCT
GTCAGTTTGGCAGATTTTCCCTCGTTACCTCCAGTTCGACTCAGAACCTTGACATGGCCATAA
CAGAAGGAGGTGCCTCTGATAGAACATGCTAGAAATGGTCTTTTCCACAGCATAGTCTGGGAC
TGGAAAAGAGATGTCTGACTGCAAGCTGACAATGCCACTCTGGGACCCCTGATGCTCTTCTTT
GTTCTTTGGGTCCCCTGATGCCATAGGAGACCTATCGTCTTGGAACTTGCCATTCTTTCCTCC
AGAACAAAATGTTAACTTTCTAACACATTTCATGCATAGCTTGGCTCAGAAGGTGCCATTGGC jAGACAGGCACATGGGAGGCTGGAGTAGGAGGTCTGAAGATTAGTTCAGGGGATGGACCAAGAA
TTTCCCCCAGAGCTTTAAAGAAGTGGGACTCAGCCATGTTGGCGCGTGATTGACATTACAGCA
CAGAAAACTGTTAGTGACTGGTTTCCTGTTAGATAAGGGTTCCAGCAGCCTGGGGCAGTATGT
CTCAGCTGGAATGGAAAGAATGTGAGATGGAACCTCAAGTCACTGTTTTTACCAGGGACACAT
CTGTTTTGGCTCCCAATCAGCAGTCTTCAATCGATCAATAATTCTGCTCTGGAAGAGAAGGAA
CAGGGAGCAGAGAGACCCAACTGGGAGCCAGAGATGGAACTTCAGGTCTTAAGTGCAAATCAA
AGCAAAAAACAAACAAAACTTACATGGAAAAACTGTAAGTGCTGAAAGCAAGTTTAGCCATGA
CAAACCAAAGAGTGCCCAGGTCAGCCAAGAAAGATACATAATCTCATGGGACTTCAGTGGGAG
TTACACAGGAATGTTGAAGAATCATTCTTCTTTTTCATGCATTTGTCCTTCTCCCACCCCCTT
ACTACACCCTAGCAGATCAGCTGAGTGTACTTTATTCCAAGAACTTACTGGATCTCTGGTTTT
TCTCCTGAAGTTGGGGCAGGTGCAATTCCAAGCATAACCACCAGATGGCAGAGTGACCGCGCA
TACCTGCTTCCAAGAATAAAACAGTTCTGAAAAGCAACCGCAAAGCCGGGCGCGGTGGCTCAC
ACCTGTAATCCCAACAGTTTGGAAGACCGAGGCGGGTGGATCACTTGAAGTCAGGAGTTTGAG
ACCAGCCTGGCCAACATGGTGAAACCCCCATCTCTCCTGGGCATGTAGTCCCAGCTACTCGGG
AGGCTGAGGCAGGAGAATCGCTTGAACCTGGGAGGCAGAGGTTGCAGTGAGCTGAGATCACAC
CACTGCACTTCATCCTAGGCAACAGAGCGAGACTCTGTCTCCCCCCTCAAAAAAAAAAAAGAA
AGAAAGAAAGAGAAAAGAAAAGAAAAGCAACCACAGCCAGCCTTAGGGAAAACTTGGAAGTAA
GTGAAATTTGTCTTCAGAATAACTATCTCCCTTTCTGATCTGTCTCCTACTCTTTAGATGTTC
TCAGTCAAGTACTCACTGAACTCATTGATCGAGTGCTGTCTGCTAAATCTCCAAACCATTCCC
AAACCTTTCCCCGTAGTATACCATCCAGCTTCCCTCCCCTTCCTCCAAAACCCTCCCTCCCAC
CTCCCCACACCCATTGAGTCATTCACAGGCAGGAGGGAGACTGATCATTCCTCTGGGTTATCT
GCATCTCAAAAGAAAATGCTTACCCACAGGAACTGTTAACTCAGGGGTTCTTAACTTGGGGTC
CATCACCCCAGGGGGTCCATAGTTGGACTTCAGAGGGTCTATGAAACCCCTAAAACTGTCAGT
ATTTAATGTATTTATTCTTGTATGTTTTTTCCAGAGCATTAAAGCTTTCATAAGGTTCTCAAA
GGTCTCAGACCTACAAAGAGTTAAAACAAACAGACAAACAAAAAAAAACACTACTATTTTAAA
TAGTGGAACTTTCAGCCCAGCGTTTCTGCAATGCAGAGTGAAGTGGATACTGGGCAGTTCGAG
ACAGGTTTTTAATCATAAGTGGTCTTTTCAAATGTCCATCAATTGATGGGGAAGGCTGGCACC
CACCAAGAAGTGGAAGTCCTCAGAAATTCTCGGCACACCCTAGAGTATTGTACAACCAACACC
CCCACATAACTTTGTCCCCTCTTCCCCAACAACCCAGAGCAGGTGTTGCAGACAGGAGGGCCA
CAGCGTGTGGAAGTAAAGACTTTGGAGCTAGAGATGCCTTTTCCAGCAATGATTATTGACTTC
ACCACACCCCTTGCCTGGCCTGGCCTGAGGCTCAGCAGTGCATGACTTCTCGTAGATAACTTC
ACAGTCATCCAGTCCCAACACCTGCTCTTGCCTGGTAGGAACAGGCGAAGTGTCAGCCCTCAA
TGTTGGGTACTTAGACCCAAACCAATAAATGGTGAGTTTTGAACAAGAACTACCATCATGCAG
GCTTCTTGCCCAGCTGACCACTGGCCCCGGGGTGCCTGCCTGGCTGGTCTTCATCACCTGAGG
CCACCAGGCTCAAGCCACTGCTGTTGCATTACACCCATCCCTTTGCAAAATCCCTATGGAGCC
TGTCACCACTCCCCTCCCTATATACCCCCACCCCACAAAGATTTTCTTCAGGTTAAAAAAAAA
GTTTAAAAAAAAGATTTTAAAATAAAGCATTTATGAAGGCTTAATAAATTGTAAATAATTTTT
AAATAAAATGAAAATGCCTTTCCTGGAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
ORF Start: ATG at 208 ORF Stop: TGA at 865
SEQ ID NO: 184 219 aa 1MW at 24860.9kD
]NOV48b, MAAAFPVCYPLGRLLDWALRQEISTFYTREKLLETLRAADPYSDLVKEELNIIQGALELRTKV
CG I 27340-02 Protein VEEVLAPLGDCFMLRSDAVLDFATVSEILRSGYTRIPVYEGDQRHNIVDILFVKDLAFVDPDD CTPLLTVTRFYNRPLHCVFDTRLDTVLEEFKKASDSECCNINLDTETSPCSSDFEENVGKKL jSequence LRTLSGQKRKRSPEGERTSEDNSNLTPLIT
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 48B.
Further analysis of the NOV48a protein yielded the following properties shown in Table 48C.
j Table 48C. Protein Sequence Properties NOV48a
; PSort 0.6000 probability located in nucleus; 0.4644 probability located in mitochondrial analysis: matrix space; 0.3000 probability located in microbody (peroxisome); 0.1632 probability located in mitochondrial inner membrane
' SignalP Cleavage site between residues 21 and 22 analysis:
A search of the NOV48a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 48D.
Homo sapiens, 569 aa. [WO200218435- A1 , 07-MAR-2002]
In a BLAST search of public sequence datbases, the NOV48a protein was found to have homology to the proteins shown in the BLASTP data in Table 48E.
PFam analysis predicts that the NOV48a protein contains the domains shown in the Table 48F.
Example 49.
The NOV49 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 49A.
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 49B.
Table 49B. Comparison of NOV49a against NOV49b.
NOV49a Residues/
Protein Sequence Identities/ Match Residues Similarities for the Matched Region
NOV49b 27.378 336/352 (95%) 1 18.369 337/352 (95%)
Further analysis of the NOV49a protein yielded the following properties shown in
Table 49C.
Table 49C. Protein Sequence Properties NOV49a
PSort j 0.4500 probability located in cytoplasm; 0.3000 probability located in microbody analysis: j (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 I probability located in lysosome (lumen)
SignalP j No Known Signal Sequence Predicted analysis:
A search of the NOV49a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 49D.
In a BLAST search of public sequence datbases, the NOV49a protein was found to have homology to the proteins shown in the BLASTP data in Table 49E.
PFam analysis predicts that the NOV49a protein contains the domains shown in the Table 49F.
The NOV50 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 50A.
Table 50 A. NOV50 Sequence Analysis
SEQ ID NO: 189 1 122 bp
NOV50a, GAGCGGGAAACTGGAGCTTAAATTCTGGCGGCGAGATGGACATTCTGAAATCAGAGATCCTTC
CGI 28369-01 DNA GGAAGCGGCAGCTGGTGGAGGACAGGAACCTGCTGGTGGAAAATAAAAAATATTTCAAGCGTA GTGAGCTCGCAAAAAAAGAAGAGGAAGCATATTTTGAAAGATGTGGCTACAAGATACAGCCAA
Sequence AAGAGGAAGACACACAGAATGATCTGAAAGTTCATGAGGAAAACACCACAATTGAAGAGTTAG AGGCGCTTGGAGAGTCCTTAGGGAAAGGCGATGATCATAAAGACATGGACATCATCACCAAAT TCCTGAAGTTTCTTCTTGGCGTTTGGGCTAAAGAATTGAATGCCAGAGAAGATTATGTGAAAC GCAGTGTGCAGGGTAAACTGAACAGTGCGACCCAGAAACAGACCGAGTCCTACCTAAGACCAC TTTTTAGAAAGCTACGGAAAAGGAATCTTCCTGCTGATATTAAAGAATCAATAACGGATATTA TTAAATTCATGTTGCAGAGAGAATACGTGAAGGCAAATGATGCTTATCTTCAGATGGCCATTG GAAATGCGCCTTGGCCCATCGGTGTCACTATGGTTGGTATCCATGCCAGAACTGGCAGAGAAA AGATTTTTTCCAAGCATGTTGCACATGTTTTAAATGACGAAACTCAGCGGAAATATATTCAGG GATTGAAGAGGTTAATGACCATTTGCCAGAAACACTTTCCTACAGACCCATCCAAATGTGTGG AGTACAATGCACTGTGAGATCTGTGTATGGTGTGTTAATAACAATAAGAAACTTAGGGAAGCA
GGCTGTGGACTTCTGGAATTACCAACAGGAATGAGGAAAGAAGAAAACTGGAGTTTCCAGTCT
CTGAGTTCTACCTGATGTAACTCTTGATTGGTTTTAAGAACTTTGTTGGCCTTCATTTCATAT
CTGACTGCAAGCTGATTTTTCTTTCTTGCTTTCATTTTAATTAGTCCAAAATTAAGTTTTAAA
GATTTTTCCTCACAATTTAAATCCATAGACAACAGAAGGGGGTTTAAAATGACCTTTTTTTCA
GTTGACCCGAAAGTTGTGGTTAGATGATTAAAAAGAAACATTTGAAAAAAA
ORF Start: ATG at 36 ORF Stop: TGA at 771
SEQ ID NO: 190 245 aa MW at 28674.8kD
NOV50a, MDILKSEILRKRQLVEDRNLLVENKKYFKRSELAKKEEEAYFERCGYKIQPKEEDTQNDLKVH
CGI 28369-01 Protein EENTTIEELEALGESLGKGDDHKDMDIITKFLKFLLGVAKELNAREDYVKRSVQGKLNSATQ KQTESYLRPLFRKLRKR LPADIKESITDIIKFMLQREYVKANDAYLQMAIGNAPWPIGVTMV
Sequence GIHARTGREKIFSKHVAHVLNDETQRKYIQGLKRLMTICQKHFPTDPSKCVEYNAL
SEQ ID NO: 191 809 bp
NOV50b, GAGCGGGAAACTGGAGCTTAAATTCTGGCGGCGAGATGGACATTCTGAAATCAGAGATCCTTC
CGI 28369-02 DNA GGAAGCGGCAGCTGGTGGAGGACAGGAACCTGCTGGTGGAAAATAAAAAATATTTCAAGCGTA GTGAGCTCGCCAAAAAAGAAGAGGAAGCATATTTTGAAAGATGTGGCTACAAGATACAGCCAA
Sequence AAGAGGAGGACCAGAAACCATTAACTTCATCGAATCCAGTGTTAGAACTTGAACTGGCAGAGG AAAAATTACCTATGACGCTTTCTAGGCAAGAGTTAGAGGCGCTTGGAGAGTCCTTAGGGAAAG GCGATGATCATAAAGACATGGACATCATCACCAAATTCCTGAAGTTTCTTCTTGGCGTTTGGG CTAAAGAATTGAATGCCAGAGAAGATTATGTGAAACGCAGTGTGCAGGGTAAACTGAACAGTG CGACCCAGAAACAGACCGAGTCCTACCTAAGACCACTTTTTAGAAAGCTACGGAAAAGGAATC TTCCTGCTGATATTAAAGAATCAATAACGGATATTATTAAATTCATGTTGCAGAGAGAATACG TGAAGGCAAATGATGCTTATCTTCAGATGGCCATTGGAAATGCGCCTTGGCCCATCGGTGTCA CTATGGTTGGTATCCATGCCAGAACTGGCAGAGAAAAGATTTTTTCCAAGCATGTTGCACATG TTTTAAATGACGAAACTCAGCGGAAATATATTCAGGGATTGAAGAGGTTAATGACCATTTGCC AGAAACACTTTCCTACAGACCCATCCAAATGTGTGGAGTACAATGCACTGTGA
ORF Start: ATG at 36 ORF Stop: TGA at 807
SEQ ID NO: 192 257 aa MW at 29956.4kD
|NOV50b, MDILKSEILRKRQLVEDRNLLVENKKYFKRSELAKKEEEAYFERCGYKIQPKEEDQKPLTSSN jCG 128369-02 Protein PVLELELAEEKLPMTLSRQELEALGESLGKGDDHKDMDIITKFLKFLLGVWAKELNAREDYVK RSVQGKLNSATQKQTESYLRPLFRKLRKRNLPADIKESITDIIKFMLQREYVKANDAYLQMAI jSequence GNAPWPIGVTMVGIHARTGREKIFSKHVAHVLNDETQRKYIQGLKRLMTICQKHFPTDPSKCV EYNAL
SEQ ID NO: 193 843 bp lNOV50c, GAGCGGGAAACTGGAGCTTAAATTCTGGCGGCGAATGGACATTCTGAAATCAGAGATCCTTCG
JCG 128369-03 DNA GAAGCGGCAGCTGGTGGAGGACAGGAACCTGCTGGTGGAAAATAAAAAATATTTCAAGCGTAG TGAGCTCGCCAAAAAAGAAGAGGAAGCATATTTTGAAAGATGTGGCTACAAGATACAGCCAAA jSequence AGAGGAAAACACCACAATTGAAGAGTTAGAGGCGCTTGGAGAGTCCTTAGGGAAAGGCGATGA TCATAAAGACATGGACATCATCACCAAATTCCTGAAGTTTCTTCTTGGCGTTTGGGCTAAAGA
ATTGAATGCCAGAGAAGATTATGTGAAACGCAGTGTGCAGGGTAAACTGAACAGTGCGACCCA GAAACAGACCGAGTCCTACCTAAGACCACTTTTTAGAAAGCTACGGAAAAGGAATCTTCCTGC TGATATTAAAGAATCAATAACGGATATTATTAAATTCATGTTGCAGAGAGAATACGTGAAGGC AAATGATGCTTATCTTCAGATGGCCATTGGAAATGCGCCTTGGCCCATCGGTGTCACTGTGGT TGGTATCCATGCCAGAACTGGCAGAGAAAAGATTTTTTCCAAGCATGTTGCACATGTTTTAAA TGGCGAAACTCAGCGGAAATATATTCAGGGATTGAAGAGGTTAATGACCATTTGCCAGAAACA CTTTCCTACAGACCCATCCAAATGTGTGGAGTACAATGCACTGTGAGATCTGTGTATGGTGTG
TTAATAACAATAAGAAACTTAGGGAAGCAGGCTGTGGACTTCTGGAATTACCAACAGGAATGA
GGAAAGAAGAAAACTGGAAGGGCG
ORF Start: ATG at 35 ORF Stop: TGA at 737
SEQ ID NO: 194 234 aa MW at 27275.3kD
NOV50c, MDILKSEILRKRQLVEDR LLVENKKYFKRSELAKKEEEAYFERCGYKIQPKEENTTIEELEA
CGI 28369-03 Protein LGESLGKGDDHKDMDIITKFLKFLLGVWAKELNAREDYVKRSVQGKLNSATQKQTESYLRPLF RKLRKRNLPADIKESITDIIKF LQREYVKANDAYLQ AIGNAP PIGVTWGIHARTGREKI
Sequence FSKHVAHVLNGETQRKYIQGLKRLMTICQKHFPTDPSKCVEYNAL
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 50B.
Further analysis of the NOV50a protein yielded the following properties shown in Table 50C.
Table 50C. Protein Sequence Properties NOV50a
PSort 0.4500 probability located in cytoplasm; 0.3600 probability located in mitochondrial analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability
I lnorcaattpeHd i inn p ennHdnonpllaaςsmmiirc r rpettiiπcuillnumm t (mmpemmhbrraannpe)l
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV50a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 50D.
In a BLAST search of public sequence datbases, the NOV50a protein was found to have homology to the proteins shown in the BLASTP data in Table 50E.
PFam analysis predicts that the NOV50a protein contains the domains shown in the Table 50F.
Example 51.
The NOV5 1 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 51 A.
jTable 51A. NOV51 Sequence Analysis
SEQ ID NO: 195 2468 bp
NOV51a, GTAAAGCTCTGCCATAAACTTCTAGCGTGTGCCAATGGAATTCCAGCTTCGTGTTTTGCTTTC
CGI 28420-01 DNA CGCTCCTCGGAACATCCGGGAGAGTTGACTTCCGGCGGCTTGTGGGAGTGCTGGTTCTGTCCT
CCTTGCGGGTGCGGAGATGGTTGTCTTGGTTACGGGTCCTAACGGTCCCCTGCCTTGAAATCC
Sequence CTTGTTGAGGGCCTGCAACCTTGTGCTTCCGACTGGAGACGCCTTTGGTCCCTCGGTGTCTGC
ACTGGCTGCTGGTCAAGGCTTCAGTGTGGAGTAATTGACACTTTCGAGATTGAAGAATTGGAG
GAGAAACTTAATGATGCACTTCACCAGAAGCAGCTACTAACATTGAGATTAGACAACCAATTG
GCTTTTCAACAGAAAGATGCCAGCAAATATCAAGAATTAATGAAACAAGAAATGGAAACCATT
TTGTTGAGACAGAAACAACTAGAAGAGACAAATCTTCAGCTAAGAGAAAAAGCTGGAGATGTT CGTCGAAACCTGCGTGACTTTGAGTTGACAGAAGAGCAATATATTAAATTANAAGCTTTTCCT GAAGATCAGCTTTCTATTCCTGAATATGTATCTGTTCGCTTCTATGAGCTAGTGAATCCATTA AGAAAGGAAATCTGTGAACTACAAGTGAAAAAGAATATCCTAGCAGAAGAATTAAGTACAAAC AAAAACCAACTGAAGCAGCTGACAGAGACATATGAGGAAGATCGAAAAAACTACTCTGAAGTT CAAATTAGATGTCAACGTTTGGCCTTAGAATTAGCAGACACAAAACAGTTAATTCAGCAAGGT GACTACCGTCAAGAGAACTATGATAAAGTCAAGAGTGAACGTGATGCACTTGAACAGGAAGTA ATTGAGCTTAGGAGAAAACATGAAATACTTGAAGCCTCTCACATGATTCAAACAAAAGAACGA AGTGAATTATCAAAAGAGGTAGTCACCTTAGAGCAAACTGTTACTTTACTGCAAAAGGATAAA GAATATCTTAATCGCCAAAACATGGAGCTTAGTGTCTGCTGTGCTCATGAAGAGGATCGCCTT GAAAGACTTCAAGCTCAACTGGAAGAAAGCAAAAAGGCTAGAGAAGAGATGTATGAAAAATAT GTAGCATCCAGAGACCATTATAAAACAGAATATGAAAATAAACTACATGATGAACTAGAACAA ATCAGATTGAAAACCAACCAAGAAATTGATCAACTTCGAAATGCCTCTAGGGAAATGTATGAA CGAGAAAACAGAAATCTCCGAGAAGCAAGGGATAATGCTGTGGCTGAAAAGGAACGAGCAGTG ATGGCTGAAAAGGATGCTTTAGAAAAACACGATCAGCTCTTAGACAGGTACAGAGAACTACAA
CTTAGTACAGAAAGCAAAGTAACAGAATTTCTCCATCAAAGTAAATTAAAATCTTTTGAAAGT GAGCGTGTTCAACTTCTGCAAGAGGAAACAGCAAGAAATCTCACACAGTGTCAATTGGAATGT GAAAAATATCAGAAAAAATTGGAGGTTTTAACCAAAGAATTTTATAGTCTCCAAGCCTCTTCT GAAAAACGCATTACTGAACTTCAAGCACAGAACTCAGAGCATCAAGCAAGGCTAGACATTTAT GAGAAACTGGAAAAAGAGCTTGATGAAATAATAATGCAAACTGCAGAAATTGAAAATGAAGAT GAGGCTGAAAGGGTTCTTTTTTCCTACGGCTATGGTGCTAATGTTCCCACAACAGCCAAAAGA CGACTAAAGCAAAGTGTTCACTTGGCAAGAAGAGTGCTTCAATTAGAAAAACAAAACTCGCTG ATTNTTAAAAGATCTGGAACATCGAAAGGACCAAGTAACACAGCTTTCACCAGGAGCTTGACA GAGGCCAATTCGCTATTAAACCAGACTCAACAGCCTTACAGGTATCTCATTGAATCAGTGCGT CAGAGAGATTCTAAGATTGATTCACTGACGGAATCTATTGCACAACTTGAGAAAGATGTCAGC AACTTAAATAAAGAAAAGTCAGCTTTACTACAGACGAAGAATCAAATGGCATTAGATTTAGAA CAACTTCTAAATCATCGTGAGGAATTGGCAGCAATGAAACAGATTCTCGTTAAGATGCATAGT AAACATTCTGAGAACAGCTTACTTCTCACTAAAACAGAACCAAAACATGTGACAGAAAATCAG AAATCAAAGACTTTGAATGTGCCTAAAGAGCATGAAGACAATATATTTACACCTAAACCAACA CTCTTTACTAAAAAAGAAGCACCTGAGTGGTCTAAGAAACAAAAGATGAAGACCTAGTGTTTT
GGATGGGAAGCACCTGTAGACCATTATATACTCCTGAAGTTCTTTTTCTGATGGAAAACAAAA
TTCAGTTTAATCGTGTACTCAGCATTTTTTAAATAACAATGTTTATTTGAACTAATATTAAAT
TAACAAATTCG
ORF Start: ATG at 418 jORF Stop: TAG at 2323
SEQ ID NO: 196 635 aa MW at 74956.9kD
NOV51a, MKQEMETILLRQKQLEETNLQLREKAGDVRRNLRDFELTEEQYIKLXAFPEDQLSIPEYVSVR
CGI 28420-01 Protein FYELVNPLRKEICELQVKKNILAEELSTNKNQLKQLTETYEEDRKNYSEVQIRCQRLALELAD TKQLIQQGDYRQENYDKVKSERDALEQEVIELRRKHEILEASHMIQTKERSELSKEWTLEQT
Sequence VTLLQKDKEYLNRQNMELSVCCAHEEDRLERLQAQLEESKKAREEMYEKYVASRDHYKTEYEN KLHDELEQIRLKTNQEIDQLRNASREMYERENRNLREARDNAVAEKERAVMAEKDALEKHDQL LDRYRELQLSTES VTEFLHQSKLKSFESERVQLLQEETARNLTQCQLECEKYQKKLESVLTKE FYSLQASSEKRITELQAQNSEHQARLDIYEKLEKELDEIIMQTAEIENEDEAERVLFSYGYGA NVPTTAKRRLKQSVHLARRVLQLEKQNSLIXKRSGTSKGPSNTAFTRSLTEANSLLNQTQQPY RYLIESVRQRDSKIDSLTESIAQLEKDVSNLNKEKSALLQTKNQMALDLEQLLNHREELAAMK QILVKMHSKHSENSLLLTKTEPKHVTENQKSKTLNVPKEHEDNIFTPKPTLFTKKEAPE SKK QKMKT
Further analysis of the NOV51 a protein yielded the following properties shown in Table 5 I B.
Table 51B. Protein Sequence Properties NOVSla
PSort 0.3000 probability located in microbody (peroxisome); 0.3000 probability located in analysis: nucleus; 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV51 a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 51 C.
In a BLAST search of public sequence datbases, the NOV5 la protein was found to have homology to the proteins shown in the BLASTP data in Table 51 D.
PFam analysis predicts that the N0V51 a protein contains the domains shown in the Table 5 I E.
Example 52.
The NOV52 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 52A.
Table 52A. NOV52 Sequence Analysis
SEQ ID NO: 197 ~]fΪ08 bp
NOV52a, GACCCGTGTTGGGATGGGAGCCCGAACCCCCAGGCCTGGGGCGGGCCTCAGGGACCAGCAAAT
JCG 128519-01 DNA GGCCCCATCCGCTGCTCCTCAGGCCCCAGAAGCCTTCACACTCAAGGAGAAGGGGCACCTGCT GCGGCTGCCTGCGGCATTCAGGAAAGCAGCTTCCCAGAACTCGAGCCTGTGGGCCCAGCTCAG
.Sequence TTCCACACAGACCAGTGATTCCACGGATGCCGCCGCTGCCAAAACCCAGTTCCTCCAGAACAT GCAGACAGCTTCAGGCGGGCCCCAGCCCAGGCTCAGTGCTGTGGAGGTGGAGGCGGAGGCGGG GCGCCTGCGGAAGGCCTGCTCGCTGCTGAGACTGCGCATGAGGGAGGAGCTCTCAGCAGCCCC CATGGACTGGATGCAGGAGTACCGCTGCCTGCTCACGCTGGAGGGGCTGCAGGCCATGGTGGG CCAGTGTCTGCACAGGCTGCAGGAGCTGCGTGCAGCGGTGGCGGAACAGCCACCAAGACCATG TCCTGTGGGGAGGCCCCCCGGAGCCTCGCCGTCCTGTGGGGGTAGAGCGGAGCCTGCATGGAG CCCCCAGCTGCTTGTCTACTCCAGCACCCAGGAGCTGCAGACCCTGGCGGCCCTCAAGCTGCG JAGTGGCTGTGCTGGACCAGCAGATCCACTTGGAAAAGGTCCTGATGGCTGAACTCCTCCCCCT GGTAAGCGCTGCACAGCCGCAGGGGCCGCCCTGGCTGGCCCTGTGCCGGGCTGTGCACAGCCT GCTCTGCGAGGGAGGAGCACGTGTCCTTACCATCCTGCGGGATGAACCTGCAGTCTGAGCCTT
TCCCATGCTGCCCTCGGCCTGTTCAGATGGGGATTGGGGGTGTCTTCCCTGGCACTGTGCTCG
GGGACCCAGAGATGCCTGTGCTTCCCTGGGAAACCTGGTGAACTGGACCAGGTGGCCTCACTG
GCTCTTCTCAGGACAACTAAGCCTGCTGGTCAGGGCTGGCTTTCAGCCTTCCTAAGGCTCCTG
GACTCCAGAGGCCAGCGGGGAGCCTTTCCTGGCTCCCTCTGTTTTCTCTCACTGTAGACCAAA
GAGCCGCTTGTGTGATATTAAAGCCACTTTAGAAAGC
ORF Start: ATG at 14 ORF Stop: TGA at 812
SEQ ID NO: 198 266 aa MW at 28644.7kD
|NOV52a, MGARTPRPGAGLRDQQMAPSAAPQAPEAFTLKEKGHLLRLPAAFRKAASQNSSLWAQLSSTQT
JCG 128519-01 Protein SDSTDAAAAKTQFLQNMQTASGGPQPRLSAVEVEAEAGRLRKACSLLRLRMREELSAAP DWM QEYRCLLTLEGLQAMVGQCLHRLQELRAAVAEQPPRPCPVGRPPGASPSCGGRAEPAWSPQLL iSequence VYSSTQELQTLAALKLRVAVLDQQIHLEKVLMAELLPLVSAAQPQGPPWLALCRAVHSLLCEG GARVLTILRDEPAV
SEQ ID NO: 199 831 bp
NOV52b, GACCCGTGTTGGGATGGGAGCCCGAACCCCCAGGCCTGGGGCGGGCCTCAGGAACCAGCAAAT
CG I 28519-02 DNA GGCCCCATCCGCTGCTCCTCAGGCCCCAGAAGCCTTCACACTCAAGGAGAAGGGGCACCTGCT GCGGCTGCCTGCGGCATTCAGGAAAGCAGCTTCCCAGAACTCGAGCCTGTGGGCCCAGCTCAG
Sequence TTCCACACAGACCAGTGATTCCACGGATGCCGCCGCTGCCAAAACCCAGTTCCTCCAGAACAT GCAGACAGCTTCAGGCGGGCCCCAGCCCAGGCTCAGTGCTGTGGAGGTGGAGGCGGAGGCGGG GCGCCTGCGGAAGGCCTGCTCGCTGCTGAGACTGCGCATGAGGGAGGAGCTCTCGGCAGCCCC CATGGACTGGATGCAGGAGTACCGCTGCCTGCTCACGCTGGAGGGGCTGCAGGCCATGGTGGG CCAGTGTCTGCACAGGCTGCAGGAGCTGCGTGCAGCGGTGGCGGAACAGCCACCAAGACCATG TCCTGTGGGGAGGCCCCCCGGAGCCTCGCCGTCCTGTGGGGGTAGAGCGGAGCCTGCATGGAG CCCCCAGCTGCTTGTCTACTCCAGCACCCAGGAGCTGCAGACCCTGGCGGCCCTCAAGCTGCG
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 52B.
I Table 52B. Comparison of NOV52a against NOV52b.
NOV52a Residues/ Identities/
' Protein Sequence „ ^ _ Match Residues Similarities for the Matched Region
; NOV52b 1..266 212/266 (79%) 1..266 213/266 (79%)
Further analysis of the NOV52a protein yielded the following properties shown in Table 52C.
j Table 52C. Protein Sequence Properties NOV52a
PSort 0.6500 probability located in cytoplasm; 0.2413 probability located in lysosome analysis: (lumen); 0.1000 probability located in mitochondrial matrix space; 0.0000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV52a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 52D.
In a BLAST search of public sequence datbases, the NOV52a protein was found to have homology to the proteins shown in the BLASTP data in Table 52E.
PFam analysis predicts that the NOV52a protein contains the domains shown in the Table 52F.
Example 53.
The NOV53 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 53A.
Further analysis of the NOV53a protein yielded the following properties shown in Table 53B.
A search of the NOV53a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 53C.
In a BLAST search of public sequence datbases, the NOV53a protein was found to have homology to the proteins shown in the BLASTP data in Table 53D.
PFam analysis predicts that the NOV53a protein contains the domains shown in the Table 53E.
Table 53E. Domain Anal sis of NOV53a
Example 54.
The NOV54 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 54A.
JTable 54A. NOV54 Sequence Analysis
] SEQTD NO: 203 '3078 bp i
|NOV54a, ATGTCGGCAGCCAAGGAGAACCCGTGCAGGAAATTCCAGGCCAACATCTTCAACAAGAGCAAG
SCG 128852-01 DNA TGTCAGAACTGCTTCAAGCCCCGCGAGTCGCATCTGCTCAACGACGAGGACCTGACGCAGGCA AAACCCATTTATGGCGGTTGGCTGCTCCTGGCTCCAGATGGGACCGACTTTGACAACCCAGTG jSequence CACCGGTCTCGGAAATGGCAGCGACGGTTCTTCATCCTTTACGAGCACGGCCTCTTGCGCTAC GCCCTGGATGAGATGCCCACGACCCTTCCTCAGGGCACCATCAACATGAACCAGTGCACAGAT GTGGTGGATGGGGAGGGCCGCACGGGCCAGAAGTTCTCCCTGTGTATTCTGACGCCTGAGAAG GAGCATTTCATCCGGGCGGAGACCAAGGAGATCGTCAGTGGGTGGCTGGAGATGCTCATGGTC TATCCCCGGACCAACAAGCAGAATCAGAAGAAGAAACGGAAAGTGGAGCCCCCCACACCACAG GAGCCTGGGCCTGCCAAGGTGGCTGTTACCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGCAGC ATCCCCAGTGCTGAGAAAGTCCCCACCACCAAGTCCACACTCTGGCAGGAAGAAATGAGGACC AAGGACCAGCCAGATGGCAGCAGCCTGAGTCCAGCTCAGAGTCCCAGCCAGAGCCAGCCTCCT GCTGCCAGCTCCCTGCGGGAACCTGGGCTAGAGAGCAAAGAAGGTGAGAGCGCCATGAGTAGC GACCGCATGGACTGTGGCCGCAAAGTCCGGGTGGAGAGCGGCTACTTCTCTCTGGAGAAGACC AAACAGGACTTGAAGGCTGAAGAACAGCAGCTGCCCCCGCCGCTCTCCCCTCCCAGCCCCAGC ACCCCCAACCACAGGAGGTCCCAGGTGATTGAAAAGTTTGAGGCCTTGGACATTGAGAAGGCA GAGCACATGGAGACCAATGCAGTGGGGCCCTCACCATCCAGCGACACACGCCAGGGCCGCAGC GAGAAGAGGGCGTTCCCTAGGAAGCGGGACTTCACCAATGAAGCCCCCCCAGCTCCTCTCCCA GACGCCTCGGCTTCCCCCCTGTCTCCACACCGAAGAGCCAAGTCACTGGACAGGAGGTCCACG GAGCCCTCCGTGACGCCCGACCTGCTGAATTTCAAGAAAGGCTGGCTGACTAAGCAGTATGAG GACGGCCAGTGGAAGAAACACTGGTTTGTCCTCGCCGATCAAAGCCTGAGATACTACAGGGAT TCAGTGGCTGAGGAGGCAGCCGACTTGGATGGAGAAATTGACTTGTCCGCATGTTACGATGTC ACAGAGTATCCAGTTCAGAGAAACTATGGCTTCCAGATACATACAAAGGAGGGCGAGTTTACC CTGTCGGCCATGACATCTGGGATTCGGCGGAACTGGATCCAGACCATCATGAAGCACGTGCAC CCGACCACTGCCCCGGATGTGACCAGCTCGTTGCCAGAGGAAAAAAACAAGAGCAGCTGCTCT TTTGAGACCTGCCCGAGGCCTACTGAGAAGCAAGAGGCAGAGCTGGGGGAGCCGGACCCTGAG CAGAAGAGGAGCCGCGCACGGGAGCGGAGGCGAGAGGGCCGCTCCAAGACCTTTGACTGGGCT GAGTTCCGTCCCATCCAGCAGGCCCTGGCTCAGGAGCGGGTGGGCGGCGTGGGGCCTGCTGAC ACCCACGAGCCCCTGCGCCCTGAGGCGGAGCCTGGGGAGCTGGAGCGGGAGCGTGCACGGAGG CGGGAGGAGCGCCGCAAGCGCTTCGGGATGCTCGACGCCACAGACGGGCCAGGCACTGAGGAT GCAGCCCTGCGCATGGAGGTGGACCGGAGCCCAGGGCTGCCTATGAGCGACCTCAAAACGCAT AACGTCCACGTGGAGATTGAGCAGCGGTGGCATCAGGTGGAGACCACACCTCTCCGGGAAGAG AAGCAGGTGCCCATCGCGCCCGTCCACCTGTCTTCTGAAGATGGGGGTGACCGGCTCTCCACA CACGAGCTGACCTCTCTGCTCGAGAAGGAGCTGGAGCAGAGCCAGAAGGAGGCCTCAGACCTT CTGGAGCAGAACCGGCTCCTGCAGGACCAGCTGAGGGTGGCCCTGGGCCGGGAGCAGAGCGCC CGTGAGGGCTACGTGCTGCAGGCCACGTGCGAGCGAGGGTTTGCAGCAATGGAAGAAACGCAC CAGAAGAAGATTGAAGATCTCCAGAGGCAGCACCAGCGGGAGCTAGAGAAACTTCGAGAAGAG AAAGACCGCCTCCTAGCCGAGGAGACAGCGGCCACCATCTCAGCCATCGAAGCCATGAAGAAC GCCCACCGGGAGGAAATGGAGCGGGAGCTGGAGAAGAGCCAGCGGTCCCAGATCAGCAGCGTC AACTCGGATGTTGAGGCCCTGCGGCGCCAGTACCTGGAGGAGCTGCAGTCGGTGCAGCGGGAA CTGGAGGTCCTCTCGGAGCAGTACTCGCAGAAGTGCCTGGAGAATGCCCATCTGGCCCAGGCG CTGGAGGCCGAGCGGCAGGCCCTGCGGCAGTGCCAGCGTGAGAACCAGGAGCTCAATGCCCAC AACCAGGAGCTGAACAACCGCCTGGCTGCAGAGATCACACGGTTGCGGACGCTGCTGACTGGG GACGGCGGTGGGGAGGCCACTGGGTCACCCCTTGCACAGGGCAAGGATGCCTATGAACTAGAG
GTCTTATTGCGGGTAAAGGAATCGGAAATACAGTACCTGAAACAGGAGATTAGCTCCCTCAAG GATGAGCTGCAGACGGCACTGCGGGACAAGAAGTACGCAAGTGACAAGTACAAAGACATCTAC ACAGAGCTCAGCATCGCGAAGGCTAAGGCTGACTGTGACATCAGCAGGTTGAAGGAGCAGCTC IAAGGCTGCAACGGAAGCACTGGGGGAGAAGTCCCCTGACAGTGCCACGGTGTCCGGATATGAT ATAATGAAATCTAAAAGCAACCCTGACTTCTTGAAGAAAGACAGATCCTGTGTCACCCGGCAA CTCAGAAACATCAGGTCCAAGTCCGTAATTGAGCAGGTCTCGTGGGATACCTGA
ORF Start: ATG at 1 iORF Stop: TGA at 3076
SEQ ID NO: 204 1025 aa MWat 116459.8kD
NOV54a, MSAAKENPCRKFQANIF KSKCQNCFKPRESHLLNDEDLTQAKPIYGGWLLLAPDGTDFDNPV CGI 28852- 01 Protein HRSRKWQRRFFILYEHGLLRYALDEMPTTLPQGTINMNQCTDWDGEGRTGQKFSLCILTPEK EHFIRAETKEIVSGWLEMLMVYPRTNKQNQKKKRKVEPPTPQEPGPAKVAVTSSSSSSSSSSS Sequence IPSAEKVPTTKSTLWQEEMRTKDQPDGSSLSPAQSPSQSQPPAASSLREPGLESKEGESAMSS DR DCGRKVRVESGYFSLEKTKQDLKAEEQQLPPPLSPPSPSTPNHRRSQVIEKFEALDIEKA EHMETNAVGPSPSSDTRQGRSEKRAFPRKRDFTNEAPPAPLPDASASPLSPHRRAKSLDRRST EPSVTPDLLNFKKG LTKQYEDGQWKKHWFVLADQSLRYYRDSVAEEAADLDGEIDLSACYDV TEYPVQRNYGFQIHTKEGEFTLSAMTSGIRRN IQTIMKHVHPTTAPDVTSSLPEEKNKSSCS FETCPRPTEKQEAELGEPDPEQKRSRARERRREGRSKTFDWAEFRPIQQALAQERVGGVGPAD THEPLRPEAEPGELERERARRREERRKRFGMLDATDGPGTEDAALRMEVDRSPGLPMSDLKTH NVHVEIEQR HQVETTPLREEKQVPIAPVHLSSEDGGDRLSTHELTSLLEKELEQSQKEASDL LEQNRLLQDQLRVALGREQSAREGYVLQATCERGFAAMEETHQKKIEDLQRQHQRELEKLREE KDRLLAEETAATISAIEAMKNAHREEMERELEKSQRSQISSVNSDVEALRRQYLEELQSVQRE LEVLSEQYSQKCLENAHLAQALEAERQALRQCQRENQELNAHNQEL NRLAAEITRLRTLLTG DGGGEATGSPLAQGKDAYELEVLLRVKESEIQYLKQEISSLKDELQTALRDKKYASDKYKDIY TELSIAKAKADCDISRLKEQLKAATEALGEKSPDSATVSGYDIMKSKSNPDFLKKDRSCVTRQ LRNIRSKSVIEQVS DT
SEQ ID NO: 205 13990 bp
NOV54b, AGCCTGGAGCACTCCTACCAGAGGGTCTCCAGCCAGCTGCAGAGCATGCACACTCTGCTGAGA
CGI28852-02 DNA GAGAAGGAGGAAGAGCTGGAGCGCATTAAGGAAGCACATGAGAAGGTTCTGGAGAAGAAGGAG CAGGACCTCAATGAGGCTTTGGTTAAAATGGTTGCCTTGGGGAGCAGCTTAGAGGAAACAGAA
Sequence ATTAAGCTCCAGGCAAAAGAAGAGATTTTAAGGAAATTTGCAAGTGAATCTCCAAAGGACATG GAAGAGCCACGGAGTACCCCTGAAGAGACAGAAAGGGATGGCACTTTGCTCCCAGGCCAACCA GTCCAAGCCACTAGGGCACCTCTAGGCCTCCCACACACAAGGCTCGAGGATGAGGACGAGGAC CTGGGGGCTCCTCCGGGGGAAGAGTACGGTGATGGCAGCCCCAGTAGGGAAGACAGCATGGTG CCCCCAAAGTCAGTGGAAGTGCTTGACAGGGAGGGCCATCAGCAGGGCACAGCCAAACTCGAC CAAGGGGCACCTGGTGTTAAAAGGCAAAGAATCCGGTTCTCCACAATCCAGTGCCAAAGATAC ATTCACCCCGAAGGGTCTGAGAAGACCTGGACCAGCAGCACATCTTCCGACACCAGCCAGGAC CGGTCACCCTCGGAAGAAAGCATGTCCTCAGAGCCTGCACCCAGTGTACTGCCTGCAACTGGC JGACTCTGACACGTACGTCTCCATCATCCACTCCCTGGAGACCAAGCTCTACGTCACAGAGGAA AAGCTCAAAGACGTGACCGTGAGGCTGGAGAGCCAGCAGGGTCAGAGCCGTGAGGCACTGCTC GCACTGCACCACCAGTGGGCGGGCACCGAGGCCCAGCTGCGTGAGCAGCTCCGCGCCAGCCTG CTCCAGGTTGGCGCACTGGCCTCCCAGCTGGAGCAGGAGAGGCAGGAGAGGGCCAGGAGGGTT GAAGGGCATGTTGGAGAGCTTGGGGACTTCCAGGTCAAGAATAGTCAGGCCCTGATGTGCCTG GAAAATTGCCGAGAACAACTGAGATCTCTGCCTAGGGCCAGCCAGGAGGATGAGCAGGACGCA CGCGCAGCCTCCCTGGCCAGTGTGGAGAGTGCACTCGTCAGCGCCATCCAAGCCCTGCAGCAC TGGCCGGCCCCAGCCCATGGCGGGGCCCGTGCACAGCTGGAGACAGGTGGCACCGAGGAGAAT GGGAAGCCTGCCTCCCTGCAGCAGTGCTCCCAGTCTGAGTTGACAGAGCAGGAGCAGGTGAGG CTTCTTTCTGACCAGATTGCTCTGGAGGCCTCGCTGATCAGCCAGATAGCAGATTCCCTGAAG AACACAACATCAGATGTCTCCCGAATGCTCCATGAGATTTCTTGGTCAGGACAGCCACCGATG GAATCTGCTGGGGCCCCCGTAGACACCTGGGCCAGGAAGGTCCTAGTGGATGGTGAGTTCTGG AGCCAGGTTGAGTCTCTGAGGAAGCACTTGGGGACACTGGGAGGAGAGGCAGTCGGTGCCTCA GGAGACGGGCAGCAAAGCATCCCACAGGGCCTGGCCCCCATCCTGGCCAATGCCACATGGGTC AGGGCAGAGCTCAGCTTTGCCACACAGTCAGTGAGGGAGTCGTTCCACCGCAGGCTACAGAGC ATCCAGGAGACCCTGCGGGGCACCCAGACGGCCCTGCGGCAGCACAAATGCCTGCTGAGGGAA ATCCTGGGAGCCTACCAAACCCCAGACTTTGAAAGAGTGATGCAGCAGGTCTTGGAAGCCCTC AGGCTTCCAGCGGGCCATGAAGATGGTGTTCAGCTGTCCTGGGACCTGAGCCCCTTAGGAGAA GTCCTGGGCCGAGACTCAGACAGCTCTCAGGAGCCCTTCGATGTGTCTGACCAGAGCCCTGGG GCCTTTGTTGCTATTCAGGAGGAGCTTGCCCAGCAGCTGAAGGAGAAGGCCAGCCTCTTAGAG GAGATAGCGGCTGCCTTACCATCTCTGCCACCTGTGGAATCGCTGAGAGATTGCCAGAAGCTT CTCCAGGTGTCCCAGAGTCTCTCGTATAACACTTGTTTGGGAGGCCTCGGTCAGTATTCTTCA TTGTTGGTTCAGGATGCCATTATTCAGGCCCAGGTTTGCTATGCGTCCTGCAGAATCCGGCTA GAATATGAGAAGGAGCTCCAGCTCTGCAAGGAGTCCTGGCAAACCCGGGAGCCCTCCTGCTCA GAGCAGGCACAGGCAGCCCGGGCCCTGAGGGAGGAGTATGAGGAGCTTCTCCGCAAGCAGAAG AGCGAGTACCTGGATGTGATCGCCATTGTTGAAAGGGAGAATGCAGAGCTCAAGGCCAAGGCC GCCCAGCTAGACCATCAGCAGCAGTGTCTGGAGGATGCAGAGAGCAAGCACAGCATGAGCATG
TTCACCCTGCGGGGCAGGTATGAGGAGGAGATTCGGTGTGTGGTGGAGCAGCTGACCAGGACC GAGAGCACACTGCAGGCTGAGCGCAGCCGGGTCCTGAGCCAGCTGGATGCCTCGGTCAGAGAC AGGCAGGACATGGAGAGGCATCATGGTGAGCAGATACAGACCCTGGAGGACAGGTTCCAGCTC AAGGTCCGGGAGCTGCAGACGATCCACGAGGAGGAGCTGAGGACCCTGCAGGAGCACTACTCG CAGAGCCTGAGGTGCCTTCAGGACACCCTCTGCCTCCACCAGGGGCCACACCCCAAGGCCCTG CCAGCCCCTGCCCCCAACTGGCAGGCCACCCAGGGAGAGGCTGACTCCATGACGGGGCTGAGG GAGCGCATCCAGGAGCTGGAGGCCCAGATGGATGTCATGCGGGAGGAGCTGGGACACAAGGAC CTGGAGGGCGACGCGGCCACACTGCGTGAGAAGTACCAGAGGGACTTGGAGAGCCTTAAGGCC ACGTGCGAGCGAGGGTTTGCAGCAATGGAAGAAACGCACCAGAAGAAGATTGAAGATCTCCAG AGGCAGCACCAGCGGGAGCTAGAGAAACTTCGAGAAGAGAAAGACCGCCTCCTAGCCGAGGAG ACAGCGGCCACCATCTCAGCCATCGAAGCCATGAAGAACGCCCACCGGGAGGAAATGGAGCGG GAGCTGGAGAAGAGCCAGCGGTCCCAGATCAGCAGCGTCAACTCGGATGTTGAGGCCCTGCGG CGCCAGTACCTGGAGGAGCTGCAGTCGGTGCAGCGGGAACTGGAGGTCCTCTCGGAGCAGTAC TCGCAGAAGTGCCTGGAGAATGCCCATCTGGCCCAGGCGCTGGAGGCCGAGCGGCAGGCCCTG CGGCAGTGCCAGCGTGAGAACCAGGAGCTCAATGCCCACAACCAGGAGCTGAACAACCGCCTG GCTGCAGAGATCACACGGTTGCGGACGCTGCTGACTGGGGACGGCGGTGGGGAGGCCACTGGG TCACCCCTTGCACAGGGCAAGGATGCCTATGAACTAGAGGTCTTATTGCGGGTAAAGGAATCG GAAATACAGTACCTGAAACAGGAGATTAGCTCCCTCAAGGATGAGCTGCAGACGGCACTGCGG GACAAGAAGTACGCAAGTGACAAGTACAAAGACATCTACACAGAGCTCAGCATCGCGAAGGCT AAGGCTGACTGTGACATCAGCAGGTTGAAGGAGCAGCTCAAGGCTGCAACGGAAGCACTGGGG GAGAAGTCCCCTGACAGTGCCACGGTGTCCGGATATGATATAATGAAATCTAAAAGCAACCCT GACTTCTTGAAGAAAGACAGATCCTGTGTCACCCGGCAACTCAGAAACATCAGGTCCAAGAGT CTGAAGGAAGGCCTGACGGTGCAAGAACGGTTGAAGCTCTTTGAATCCAGGGACTTGAAGAAA GACTAGGTGTGTCCCATCCAAGTTGAGCACGCGCCTTCCCCAGCTTGCAGCAGCACACCCCAA
GCGCTGCTTTTCACCTGTACCTTTGTTTTATTATTATTATTATTATTGCTGTTGTTGTCATCG
TTAACTGTGGGCATGGAATGC
ORF Start: ATG at 46 ORF Stop: TAG at 3847
SEQ ID NO: 206 11267 aa MW at 142689.7kD
NOV54b, MHTLLREKEEELERIKEAHEKVLEKKEQDLNEALVKMVALGSSLEETEIKLQAKEEILRKFAS
CGI 28852-02 Protein ESPKDMEEPRSTPEETERDGTLLPGQPVQATRAPLGLPHTRLEDEDEDLGAPPGEEYGDGSPS REDSMVPPKSVEVLDREGHQQGTAKLDQGAPGVKRQRIRFSTIQCQRYIHPEGSEKTWTSSTS
Sequence SDTSQDRSPSEESMSSEPAPSVLPATGDSDTYLSIIHSLETKLYVTEEKLKDVTVRLESQQGQ SREALLALHHQ AGTEAQLREQLRASLLQVGALASQLEQERQERARRVEGHVGELGDFQVKNS QALMCLENCREQLRSLPRASQEDEQDARAAS ASVESALVSAIQALQH PAPAHGGARAQLET GGTEENGKPASLQQCSQSELTEQEQVRLLSDQIALEASLISQIADSLKNTTSDVSRMLHEISW SGQPPMESAGAPVDTWARKVLVDGEFWSQVESLRKHLGTLGGEAVGASGDGQQSIPQGLAPIL ANAT VRAELSFATQSVRESFHRRLQSIQETLRGTQTALRQHKCLLREILGAYQTPDFERVMQ QVLEALRLPAGHEDGVQLSWDLSPLGEVLGRDSDSSQEPFDVSDQSPGAFVAIQEELAQQLKE KASLLEEIAAALPSLPPVESLRDCQKLLQVSQSLSYNTCLGGLGQYSSLLVQDAIIQAQVCYA SCRIRLEYEKELQLCKESWQTREPSCSEQAQAARALREEYEELLRKQKSEYLDVIAIVERENA ELKAKAAQLDHQQQCLEDAESKHSMSMFTLRGRYEEEIRCWEQLTRTESTLQAERSRVLSQL DAΞVRDRQDMERHHGEQIQTLEDRFQLKVRELQTIHEEELRTLQEHYSQSLRCLQDTLCLHQG PHPKALPAPAPNWQATQGEADSMTGLRERIQELEAQMDVMREELGHKDLEGDAATLREKYQRD LESLKATCERGFAAMEETHQKKIEDLQRQHQRELEKLREEKDRLLAEETAATISAIEAMKNAH REEMERELEKSQRSQISSV SDVEALRRQYLEELQSVQRELEVLSEQYSQKCLENAHLAQALE AERQALRQCQRENQELNAHNQEL NRLAAEITRLRTLLTGDGGGEATGSPLAQGKDAYELEVL LRVKESEIQYLKQEISSLKDELQTALRDKKYASDKYKDIYTELSIAKAKADCDISRLKEQLKA ATEALGEKSPDSATVSGYDIMKSKSNPDFLKKDRSCVTRQLRNIRSKSLKEGLTVQERLKLFE
SRDLKKD
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 54B.
i Table 54B. Comparison of NOV54a against NOV54b.
Further analysis of the NOV54a protein yielded the following properties shown in Table 54C.
Table 54C. Protein Sequence Properties NOV54a
PSort 0.7000 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV54a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 54D.
In a BLAST search of public sequence datbases, the NOV54a protein was found to have homology to the proteins shown in the BLASTP data in Table 54E.
PFam analysis predicts that the NOV54a protein contains the domains shown in the Table 54F.
Example 55.
The NOV55 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 55A.
|CG 132650-01 DNA CGCTCCTCCAACTACCGCGCTTATGCCACGGAGCCGCACGCCAAGAAAAAATCTAAGATCTCC jSequence GCCTCGAGAAAATTGCAGCTGAAGACTCTGCTGCTGCAGATTGCAAAGCAAGAGCTGGAGCGA GAGGCGGAGGAGCGGCGCGGAGAGAAGGGGCGCGCTCTGAGCACCCGCTGCCAGCCGCTGGAG TTGGCCGGGCTGGGCTTCGCGGAGCTGCAGGACTTGTGCCGACAGCTCCACGCCCGTGTGGAC AAGGTGGATGAAGAGAGATACGACATAGAGGCAAAAGTCACCAAGAACATCACGGAGATTGCA GATCTGACTCAGAAGATCTTTGACCTTCGAGGCAAGTTTAAGCGGCCCACCCTGCGGAGAGTG AGGATCTCTGCAGATGCCATGATGCAGGCGCTGCTGGGGGCCCGGGCTAAGGAGTCCCTGGAC CTGCGGGCCCACCTCAAGCAGGTGAAGAAGGAGGACACCGAGAAGGAAAACCGGGAGGTGGGA GACTGGCGGAAGAACATCGATGCACTGAGTGGAATGGAGGGCCGCAAGAAAAAGTTTGAGAGC AAGAAAAAGAAAAAGAAACATCACCATCACCATGACTGA
ORF Start: ATG at 1 T ;ORF Stop: TGA at 667 SEQ PD NO: 208 J222 aa ~" fiMW at 255^77. ll b" "
NOV55a, MADGSSDAAREPRPAPAPIRRRSSNYRAYATEPHAK KSKISASRKLQLKTLLLQIAKQELER CGI 32650-01 Protein EAEERRGEKGRALSTRCQPLELAGLGFAELQDLCRQLHARVDKVDEERYDIEAKVTKNITEIA DLTQKIFDLRGKFKRPTLRRVRISADAMMQALLGARAKESLDLRAHLKQVKKEDTEKENREVG jSequence D RKNIDALSGMEGRKKKFESKKKKKKHHHHHD
SEQ ID NO: 209 J803 bp lNOV55b, TCAAGCAGCCCGGAGGAGACTGACGGTCCCTGGGACCCTGAAGGTCACCCGGGCGGCCCCCTC jCG 132650-05 DNA ACTGACCCTCCAAACGCCCCTGTCCTCGCCCTGCCTCCTGCCATTCCCGGCCTGAGTCTCAGC
ATGGCGGATGGGAGCAGCGATGCGGCTAGGGAACCTCGCCCTGCACCAGCCCCAATCAGACGC jSequence CGCTCCTCCAACTACCGCGCTTATGCCACGGAGCCGCACGCCAAGAAAAAATCTAAGATCTCC GCCTCGAGAAAATTGCAGCTGAAGACTCTGCTGCTGCAGATTGCAAAGCAAGAGCTGGAGCGA GAGGCGGAGGAGCGGCGCGGAGAGAAGGGGCGCGCTCTGAGCACCCGCTGCCAGCCGCTGGAG TTGGCCGGGCTGGGCTTCGCGGAGCTGCAGGACTTGTGCCGACAGCTCCACGCCCGTGTGGAC AAGGTGGATGAAGAGAGATACGACATAGAGGCAAAAGTCACCAAGAACATCACGAAGATCTTT GACCTTCGAGGCAAGTTTAAGCGGCCCACCCTGCGGAGAGTGAGGATCTCTGCAGATGCCATG ATGCAGGCGCTGCTGGGGGCCCGGGCTAAGGAGTCCCTGGACCTGCGGGCCCACCTCAAGCAG GTGAAGAAGGAGGACACCGAGAAGGAAAACCGGGAGGTGGGAGACTGGCGGAAGAACATCGAT GCACTGAGTGGAATGGAGGGCCGCAAGAAAAAGTTTGAGAGCTGAGCCTTCCTGCCTACTGCC CCTGCCCTGAGGAGGGCCACTGAGGAATAAAGCTTCTCTCTGAGCTG
ORF Start ATG at 127 jORF Stop: TGA at 736
SEQ ΪD NO: 210 "" |203 aa ΪMW at "23236.4kD"'
|NOV55b, MADGSSDAAREPRPAPAPIRRRSSNYRAYATEPHAKKKSKISASRKLQLKTLLLQIAKQELER
JCGl 32650-05 Protein EAEERRGEKGRALSTRCQPLELAGLGFAELQDLCRQLHARVDKVDEERYDIEAKVTKNITKIF DLRGKFKRPTLRRVRISADAMMQALLGARAKESLDLRAHLKQVKKEDTEKENREVGD RKNID
^Sequence ALSGMEGRKKKFES
SEQ ID NO: 21 1 ;689 bp jNOV55c, CCGGAGGAGACTGACGGTCCCTGGGACCCTGAAGGTCACCCGGGCGGCCCCCTCACTGACCCT jCG 132650-02 DNA CCAAACGCCCCTGTCCTCGCCCTGCCTCCTGCCATTCCCGGCCTGAGTCTCAGCATGGCGGAT
GGGAGCAGCGATGCGGCTAGGGAACCTCGCCCTGCACCAGCCCCAATCAGACGCCGCTCCTCC JSequence AACTACCGCGGAGAGAAGGGGCGCGCTCTGAGCACCCGCTGCCAGCCGCTGGAGTTGGCCGGG CTGGGCTTCGCGGAGCTGCAGGACTTGTGCCGACAGCTCCACGCCCGTGTGGACAAGGTGGAT GAAGAGAGATACGACATAGAGGCAAAAGTCACCAAGAACATCACGGAGATTGCAGATCTGACT CAGAAGATCTTTGACCTTCGAGGCAAGTTTAAGCGGCCCACCCTGCGGAGAGTGAGGATCTCT GCAGATGCCATGATGCAGGCGCTGCTGGGGGCCCGGGCTAAGGAGTCCCTGGACCTGCGGGCC CACCTCAAGCAGGTGAAGAAGGAGGACACCGAGAAGGAAAACCGGGAGGTGGGAGACTGGCGC AAGAACATCGATGCACTGAGTGGAATGGAGGGCCGCAAGAAAAAGTTTGAGAGCTGAGCCTTC CTGCCTACTGCCCCTGCCCTGAGGAGGGCCCTGAGGAATAAAGCTTCTCTCTGAGCTGA
ORF Start: ATG at 1 18 JORF Stop: TGA at 622
SEQ ΪD NO: 212 " " fl 68 aa [MW at 19133.6kD iNOV55c, MADGSSDAAREPRPAPAPIRRRSS YRGEKGRALSTRCQPLELAGLGFAELQDLCRQLHARVD iCG 132650-02 Protein KVDEERYDIEAKVTKNITEIADLTQKIFDLRGKFKRPTLRRVRISADAM QALLGARAKESLD LRAHLKQVKKEDTEKENREVGDWRKNIDALSGMEGRKKKFES jSequence
SEQ ID NO: 213 776 bp'""" " ~ '
)NOV55d, CTGAAGGTCACCCGGGCGGCCCCCTCACTGACCCTCCAAACGCCCCTGTCCTCGCCCTGCCTC
J jCCGG1133226655C0-03 DNA CTGCCATTCCCGGCCTGAGTCTCAGCATGGCGGATGGGAGCAGCGATGCGGCTAGGGAACCTC
GCCCTGCACCAGCCCCAATCAGACGCCGCTCCTCCAACTACCGCGCTTATGCCACGGAGCCGC jSequence ACGCCAAGAAAAAATCTAAGATCTCCGCCTCGAGAAAATTGCAGCTGAAGACTCTGCTGCTGC AGATTGCAAAGCAAGAGCTGGAGCGAGAGGCGGAGGAGCGGCGCGGAGAGAAGGGGCGCGCTC
TGAGCACCCGCTGCCAGTCGCTGGAGTTGGCCGGGCTGGGCTTCGCGGAGCTGCAGGACTTGT GCCGACAGCTCCACGCCCGTGTGGACAAGGTGGATGAAGAGAGATACGACATAGAGGCAAAAG TCACCAAGAACATCACGAAGATCTTTGACCTTCGAGGCAAGTTTAAGCGGCCCACCCTGCGGA GAGTGAGGATCTCTGCAGATGCCATGATGCAGGCGCTGCTGGGGGCCCGGGCTAAGGAGTCCC TGGACCTGCGGGCCCACCTCAAGCAGGTGAAGAAGGAGGACACCGAGAAGGAAAACCGGGAGG TGGGAGACTGGCGCAAGAACATCGATGCACTGAGTGGAATGGAGGGCCGCAAGAAAAAGTTTG AGAGCTGAGCCTTCCTGCCTACTGCCCCTGCCCTGAGGAGGGCCCTGAGGAATAAAGCTTCTC
TCTGAGCTGAAAAAAAAAAA
ORF Start: ATG at 90 j jORF Stop: TGA at 699
SEQ ID NOT2Ϊ4 " [203 aa JM W at'23226.3"kD iNOV55d, ADGSSDAAREPRPAPAPIRRRSSNYRAYATEPHAKKKSKISASRKLQLKTLLLQIAKQELER
,CG 132650-03 Protein EAEERRGEKGRALSTRCQSLELAGLGFAELQDLCRQLHARVDKVDEERYDIEAKVTKNITKIF DLRGKFKRPTLRRVRISADAMMQALLGARAKESLDLRAHLKQVKKEDTEKENREVGDWRKNID
^Sequence ALSG EGRKKKFES
SEQ ID NO: 215 |855 bp
JNOV55e, CGGCCGCGTCGACCCGGAGGAGACTGACGGTCCCTGGGACCCTGAAGGTCACCCGGGCGGCCC
ICG 132650-04 DNA CCTCACTGACCCTCCAAACGCCCCTGTCCTCGCCCTGCCTCCTGCCATTCCCGGCCTGAGTCT
CAGCATGGCGGATGGGAGCAGCGATGCGGCTAGGGAACCTCGCCCTGCACCAGCCCCAATCAG jSequence ACGCCGCTCCTCCAACTACCGCGCTTATGCCACGGAGCCGCACGCCAAGAAAAAATCTAAGAT CTCCGCCTCGAGAAAATTGCAGCTGAAGACTCTGCTGCTGCAGATTGCAAAGCAAGAGCTGGA GCGAGAGGCGGAGGAGCGGCGCGGAGAGAAGGGGCGCGCTCTGAGCACCCGCTGCCAGCCGCT GGAGTTGGCCGGGCTGGGCTTCGCGGAGCTGCAGGACTTGTGCCGACAGCTCCACGCCCGTGT GGACAAGGTGGATGAAGAGAGATACGACATAGAGGCAAAAGTCACCAAGAACATCACGGAGAT TGCAGATCTGACTCAGAAGATCTTTGACCTTCGAGGCAAGTTTAAGCGGCCCACCCTGCGGAG AGTGAGGATCTCTGCAGATGCCATGATGCAGGCGCTGCTGGGGGCCCGGGCTAAGGAGTCCCT GGACCTGCGGGCCCACCTCAAGCAGGTGAAGAAGGAGGACACCGAGAAGGAAAACCGGGAGGT GGGAGACTGGCGCAAGAACATCGATGCACTGAGTGGAATGGAGGGCCGCAAGAAAAAGTTTGA GAGCTGAGCCTTCCTGCCTACTGCCCCTGCCCTGAGGAGGGCCCTGAGGAATAAAGCTTCTCT
CTGAGCTGAAAAAAAAAAAAAAAAAAACCCAAAAAA
ORF Start: ATG at 131 jORF Stop: TGA at 761
SEQ ID NO: 216 210 aa JMW at 24007.2kD lNOV55e, MADGSSDAAREPRPAPAPIRRRSSNYRAYATEPHAKKKSKISASRKLQLKTLLLQIAKQELER jCG 132650-04 Protein EAEERRGEKGRALSTRCQPLELAGLGFAELQDLCRQLHARVDKVDEERYDIEAKVTKNITEIA DLTQKIFDLRGKFKRPTLRRVRIΞADAMMQALLGARAKESLDLRAHLKQVKKEDTEKENREVG
JSequence DWRKNIDALSGMEGRKKKFES
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 55B.
Further analysis of the NOV55a protein yielded the following properties shown in Table 55C.
! Table 55C. Protein Sequence Properties NOV55a
PSort 0.9855 probability located in nucleus; 0.3000 probability located in microbody : analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen) i SignalP No Known Signal Sequence Predicted 1 analysis:
A search of the NOV55a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 55D.
In a BLAST search of public sequence datbases, the NOV55a protein was found to have homology to the proteins shown in the BLASTP data in Table 55E.
Table 55E. Public BLASTP Results for NOV55a
PFam analysis predicts that the NOV55a protein contains the domains shown in the Table 55F.
Example 56.
The NOV56 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 56A.
Table 56A. NOV56 Sequence Analysis
" "" _ _ _" SEQ ID NOT 217 545 bp
NOviόaT" GGCGACTGGCTGCACGCGCCGCTGGAGCCCGACGTGCGCGCGGTGGTGGTGGGCTTTGACCCG
DNA CACTTCAGCTACATGAAGCTCACCAAGGCCCTGCGCTACCTGCAGCAGCCCGGCTGCCTGCTC
GTGGGCACCAACATGGACAACCGGCTTCCGCTTGAGAACGGCCGCTTCATCGCGGGTACCGGG jSequence TGTCTGGTCCGAGCCGTGGAGATGGCCGCCCAGCGCCAGGCCGACATCATCGGGAAGCCCAGC CGCTTCATTTTCGACTGCGTGTCCCAGGAATACGGCATCAACCCCGAGCGCACCGTCATGGTG GGAGACCGCCTGGACACAGACATCCTCCTAGGCGCCACCTGTGGCCTGAAGACCATCCTGACC CTCACCGGAGTCTCCACTCTAGGGGATGTGAAGAATAATCAGGAAAGTGACTGCGTGTCTAAG AAGAAAATGGTCCCTGACTTCTATGTTGACAGCATAGCCGACCTTTTGCCTGCCCTTCAAGGT TAAAGATTGAGTGTCTTTAATCTGCAGAATAAAAAAAAAAA
ORF Start: ATG at 76 ORF Stop: TAA at 505
SEQ ID NO: 218 143 aa MW at 15565.9kD
!NOV56a, M LTKALRYLQQPGCLLVGTNMDNRLPLENGRFIAGTGCLVRAVEMAAQRQADI IGKPSRFIF
JCG 133808-01 Protein DCVSQEYGINPERTVMVGDRLDTDILLGATCGLKTILTLTGVSTLGDVKNNQESDCVSKKKMV PDFYVDSIADLLPALQG
'Sequence
Further analysis of the NOV56a protein yielded the following properties shown in Table 56B.
i Table 56B. Protein Sequence Properties NOV56a j PSort 0.6500 probability located in cytoplasm; 0.2184 probability located in lysosome i analysis: (lumen); 0.1000 probability located in mitochondrial matrix space; 0.0000 probability located in endoplasmic reticulum (membrane)
S SignalP No Known Signal Sequence Predicted ! analysis:
A search of the NOV56a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 56C.
In a BLAST search of public sequence datbases, the NOV56a protein was found to have homology to the proteins shown in the BLASTP data in Table 56D.
l Table 56D. Public BLASTP Results for NOV56a
PFam analysis predicts that the NOV56a protein contains the domains shown in the Table 56E.
i Table 56E. Domain Analysis of NOV56a
I Identities/
Pfam Domain NOV56a Match Region ! Similarities Expect Value
1 for the Matched Region
Example 57. The NOV57 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 57A.
Further analysis of the NOV57a protein yielded the following properties shown in Table 57B.
; Table 57B. Protein Sequence Properties NOV57a
PSort 0.6500 probability .located in cytoplasm; 0.1000 probability located in mitochondrial analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
! SignalP No Known Signal Sequence Predicted i analysis:
A search of the NOV57a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 57C.
In a BLAST search of public sequence datbases, the NOV57a protein was found to have homology to the proteins shown in the BLASTP data in Table 57D.
PFam analysis predicts that the NOV57a protein contains the domains shown in the Table 57E.
The NOV58 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 58A.
Further analysis of the NOV58a protein yielded the following properties shown in
Table 58B.
Table 58B. Protein Sequence Properties NOV58a j PSort 0.4500 probability located in cytoplasm; 0.3000 probability located in microbody I analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
! SignalP No Known Signal Sequence Predicted • analysis:
A search of the NOV58a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 58C.
In a BLAST search of public sequence datbases, the NOV58a protein was found to have homology to the proteins shown in the BLASTP data in Table 58D.
, Q14704 KIAA0092 protein - Homo sapiens 51..402 137/375 (36%) 8e-60 (Human), 474 aa. , 65-436 212/375 (56%)
PFam analysis predicts that the NOV58a protein contains the domains shown in the Table 58E.
! Table 58E. Domain Analysis of NOV58a j Identities/
Pfam Domain NOV58a Match Region ! Similarities Expect Value for the Matched Region
Example 59.
The NOV59 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 59A.
iTable 59A. NOV59 Sequence Analysis
SEQ IDNO: 223 |1045 bp
NOV59a, TCTCCATGACATGTTGATGCTGGCTGAGCAGCAGCAGAAGCAGAAGTGGGCTGTGAATACTCA CGI36942 01 DNA AAACACTGCCTGGAGTAATGCTGATTCTAAATTTGGCCAGAGGATACTAGAGAAGATGGAATG GTCTAAAGGAAGGGGTTTAGGGGTTCAGGAGCAAGGAGGCCCAGATGATATTAAAGTTCAAGT Sequence TAAAAATAACGACCTGGGACTTCAAGCTACAATCAATAATGAAGCCAACTGGATTGCCCATCA AGATGATTTTAACTGGCTTCTGGCGGAACTGAACACTTGTCAGAGGCAGGAAACAGCAGACTC CTTAGACAACAAGAAAAAGAAATATTTTAGTCTTGAAGAAATTTCCAAAATCTTCAAAAACTG TGTTCATCATAGGAAATTTACAAAAGAAAAGGATCTATCATCTCGGAGCAAAACAGATCGTGA CTGCATTTTTGGGAAAAAACAGAGTAAGAAGACTCCCGAGGGTAATTCCAGTCCCTCCACTCC AGACCAGAACAAAACCACGATGACAACCCATGCCTTCACCATCCAGGAGCGTTTTGCCAAGCG AATGGCAGCACTGAAGAACAAGCCCCAGGTTGCAGCTCCAGGGCCTGACATTTCCAAGACCCA AGTGGAATGCAAAAGGGGGAAGAAAAGAAACAAAGAGGCAACAGGTAAAAATGGGGAGAGTTA CCCCCCAACACAGCCTAAGGCCAAGCGGCCTAAAGAGGGAAAGCCTAAGAGAGACAAGGTCCA GAAGTCGGCATCCAAGGAGAAAAGAGCACGGACAGACGGACAGTGCAGAGGCCTCTGCTGGGA AGAGAGTTCTGAGGCCTCTGCTCAGGGTGCAGGGAATTGTGTGCAGCCACCTGATGGCCAGGA TTTCACCCTGAAGCCCAAAAAGACAAGAGGAAAAAAAAAAGCTGCAAAGCCAGTAGAGGTAGC AATGGACACTACGCTGAAAGAAACACCAATGAAAAATAAGAAAAAGAAGAAAGGTTCCAAATG AATTCTCTCCAGCCAGGGCCTTCCGACCACTCAGCTT
ORF Start: ATG at 11 ORF Stop: TGA at 1007
SEQ ID NO: 224 332 aa MW at 37378.2kD
•NOV59a, MLMLAEQQQKQKWAVNTQNTAWSNADSKFGQRILEKMEWSKGRGLGVQEQGGPDDIKVQVKN
CG 136942-01 Protein DLGLQATI NEANWIAHQDDF LLAELNTCQRQETADSLDNKKKKYFSLEEISKIFKNCVHH RKFTKEKDLSSRSKTDRDCIFGKKQSKKTPEGNSSPSTPDQNKTTMTTHAFTIQERFAKRMAA
.Sequence LKNKPQVAAPGPDISKTQVECKRGKKRNKEATGKNGESYPPTQPKAKRPKEGKPKRDKVQKSA SKEKRARTDGQCRGLCWEESSEASAQGAGNCVQPPDGQDFTLKPKKTRGKKKAAKPVEVAMDT TLKETPMKNKKKKKGSK
Further analysis of the NOV59a protein yielded the following properties shown in Table 59B.
A search of the NOV59a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 59C.
In a BLAST search of public sequence datbases, the NOV59a protein was found to have homology to the proteins shown in the BLASTP data in Table 59D.
PFam analysis predicts that the NOV59a protein contains the domains shown in the Table 59E.
Example 60.
The NOV60 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 60A.
Further analysis of the NOV60a protein yielded the following properties shown in Table 60B.
Table 60B. Protein Sequence Properties NOVόOa
PSort 0.5297 probability located in microbody (peroxisome); 0.4657 probability located in analysis: mitochondrial matrix space; 0.1652 probability located in mitochondrial inner membrane; 0.1652 probability located in mitochondrial intermembrane space
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV60a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 60C.
In a BLAST search of public sequence datbases, the NOV60a protein was found to have homology to the proteins shown in the BLASTP data in Table 60D.
PFam analysis predicts that the NOVδOa protein contains the domains shown in the Table 60E.
Example 61.
The NOV6I clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 61 A.
jTable 61A. NOV61 Sequence Analysis
SEQ ID NO: 227 607 bp jNOVόla, CATTAATAATGTCTTTCATCTGTGAGTGGATCTACAATGGCTTCTACAGTGTGCTCCAGTTTC
JCG 137146-01 DNA TAGGACTCTACAAGAAATCTAGAAAACTTGTTCTCTTGGGTTGGGACAATGTGGATGAAACCA TTCTTCCTCATATGCTCAAAGATGGTGGATTGGGCCAACAGGCTCCAACACGACCTCTGCCAT jSequence CAGCAGAGCTGACAACTGCTAGCCTGGCTTTTACGACTTTTGATCTTCTGGGGCATAAGCAAA CACGTTGGTTTTGGAACAGTGATCTCCCAGCAACAAATGGGATTGCCTTTCTGGGTTACTGTG CAGATTGTCCTCAGATCCTGGAATCCAAAGAGGAGCTCAATGCTTTAATGACTGATGAAAGAA TATCCCATGTGCCAGTCCTTATCTTGATTAGCAAATTGGACAGAACAGGCACAATCAGTGAAG AAAAACTCTGTCTGCCATTTGGTCTTTATGGACAGACCACAGGAAAGGGAACTTGTGACCCTG AAGGAGCCAAATGCCTTTTCCAAGGAATCGTTCACGTTCAGTGTGTACAACAACAGGGCTATG GCAAGGGCTTCTGCTGGTTTGCCCAGTATATTGACTGATG
ORF Start: ATG at 9 ORF Stop: TGA at 603
SEQ ID NO: 228 198 aa ΪMW at 22Ϊ533kD lNOV61a, MSFICEWIYNGFYSVLQFLGLYKKSRKLVLLGWDNVDETILPHMLKDGGLGQQAPTRPLPSAE
;CG 137146-01 Protein LTTASLAFTTFDLLGHKQTRWFWNSDLPATNGIAFLGYCADCPQILESKEELNALMTDERISH VPVLILISKLDRTGTISEEKLCLPFGLYGQTTGKGTCDPEGAKCLFQGIVHVQCVQQQGYGKG
Sequence FCWFAQYID
Further analysis of the NOV61 a protein yielded the following properties shown in Table 61 B.
! Table 61B. Protein Sequence Properties NOVόla
PSort 0.7480 probability located in microbody (peroxisome); 0.1830 probability located in I analysis: lysosome (lumen); 0.1000 probability located in mitochondrial matrix space; 0.0000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVό l a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 61 C.
In a BLAST search of public sequence datbases, the NOVόla protein was found to have homology to the proteins shown in the BLASTP data in Table 6 ID.
P36536 GTP-binding protein SARI a - Mus 1..198 1 18/198 (59%) 8e-57 musculus (Mouse), 198 aa. 1..198 136/198 (68%)
PFam analysis predicts that the NOVόl a protein contains the domains shown in the Table 6 I E.
Table 61E. Domain Analysis of NOVόla
Identities/
Pfa Domain NOVόla Match Region Similarities Expect Value for the Matched Region arf 8..I98 55/193 (28%) l e-12 130/193 (67%)
Example 62.
The NOV62 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 62A.
JTable 62A. NOV62 Sequence Analysis
SEQ ID NO: 229 [545 bp"
NOV62a, GGAACGTGGCTGGTTGGAGGAGGTAGATCACCCTTTCTGCGGGGGACGATTTCGTCGGTGGTA
CG137566-01 DNA GGCTGCTACCATGAGGTTGAATCAGAACACCTTGCTGCTGGGGAAGAAGGTGGTCCTTGTACC
CTACACCTCGGAGCATGTGCCCAGGTACCACGAGTGGATGAAATCAGAGGAGCTGCAGCGTTT Sequence GACAGCCTCGGAGCCGCTGACCCTGGAGCAGGAGTATGCCATGCAGTGCAGCTGGCAGGAAGA TGCAGACAAGTGTACCTTCATTGTGCTGGATGCCGAGAAGTGGCAGGCCCAGCCAGGCGCCAC CGAAGAGAGCTGCATGGTGGGAGATGTGAACCTCTTCCTCACAGATCTAGAAGACCTCACCTT GGGGGAGATCGAGGTCATGATTGCAGAGCCCAGCTGCAGGGGTAAGGGCCTTGGCACTGAGGC CGTTCTCGCGATGCTGTCTTACGAAACTTCACTTTGAGCAGGTGGCTACGAGCAGTGTTTTTC
AGGAGGTGACCCTCAGACTGACAGTGAGTGAGTCCGAGCAT
ORF Start: ATG at 74 ORF Stop: TGA at 476
SEQ ID NO: 230 134 aa MW at 15130.1kD
|NOV62a, MRLNQNTLLLGKKWLVPYTSEHVPRYHEWMKSEELQRLTASEPLTLEQEYAMQCSWQEDADK
CGI 37566-01 Protein CTFIVLDAEK QAQPGATEESCMVGDVNLFLTDLEDLTLGEIEVMIAEPSCRGKGLGTEAVLA MLSYETSL
Sequence
SEQ ID NO: 231 709 bp
NOV62b, AGGCTGCTACCATGAGGTTGAATCAGAACACCTTGCTGCTGGGGAAGAAGGTGGTCCTTGTAC
CGI 37566-02 DNA CCTACACCTCGGAGCATGTCCCCAGCAGGTACCACGAGTGGATGAAATCAGAGGAGCTGCAGC GTTTGACAGCCTCGGAGCCGCTGACCCTGGAGCAGGAGTATGCCATGCAGTGCAGCTGGCAGG
Sequence AAGATGCAGACAAGTGTACCTTCATTGTGCTGGATGCCGAGAAGTGGCAGGCCCAGCCAGGCG CCACCGAAGAGAGCTGCATGGTGGGAGATGTGAACCTCTTCCTCACAGATCTAGAAGACCTCA CCTTGGGGGAGATCGAGGTCATGATTGCAGAGCCCAGCTGCAGGGGTAAGGGCCTTGGCACTG AGGCCGTTCTCGCGATGCTGTCTTACGGAGTGACCACGCTAGGTCTGACCAAGTTTGAGGCTA AAATTGGGCAAGGAAATGAACCAAGCATCCGGATGTTCCAGAAACTTCACTTTGAGCAGGTGG CTACGAGCAGTGTTTTTCAGGAGGTGACCCTCAGACTGACAGTGAGTGAGTCCGAGCATCAGT GGCTTCTGGAGCAGACCAGCCACGTGGAAGAGAAGCCTTACAGAGATGGGTCGGCAGAGCCCT GCTGATGGCTGGGCCTTGTGGGCAGCCACTCTGTGTGAGCAGGGTGTTGGGCCCATACACTTC
AAAGACCAGAGCCCTG
ORF Start: ATG at 12 ORF Stop: TGA at 633
SEQ ID NO: 232 207 aa MW at 23361.3kD ιNOV62b, MRLNQNTLLLGKKWLVPYTSEHVPSRYHEWMKSEELQRLTASEPLTLEQEYAMQCSWQEDAD
CG 1 "* 7566-02 Protein KCTFIVLDAEKWQAQPGA-ΓEESCMVGDVNLFLTDLEDLTLGEIEVMIAEPSCRGKGLGTEAVL i J " AMLSYGVTTLGLTKFEAKIGQGNEPSIRMFQKLHFEQVATSSVFQEVTLRLTVSESEHQWLLE
•Sequence QTSHVEEKPYRDGSAEPC
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 62B.
j Table 62B. Comparison of NOV62a against NOV62b.
NOV62a Residues/ i Identities/ j Protein Sequence Match Residues I Similarities for the Matched Region
NOV62b 1..130 j 130/131 (99%) 1..131 I 130/131 (99%)
Further analysis of the NOV62a protein yielded the following properties shown in Table 62C.
1 Table 62C. Protein Sequence Properties NOV62a j PSort 0.6500 probability located in cytoplasm; 0.1000 probability located in mitochondrial 1 analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
! SignalP No Known Signal Sequence Predicted , analysis:
A search of the NOV62a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 62D.
In a BLAST search of public sequence datbases, the NOV62a protein was found to have homology to the proteins shown in the BLASTP data in Table 62E.
PFam analysis predicts that the NOV62a protein contains the domains shown in the Table 62F.
The NOV63 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 63A.
JTable 63A. NOV63 Sequence Analysis j ]SEQ"ΪD NO: 233 683bp~ J jNOV63a, GGTGTGCTGCCAGAGATTTTGCCTCTTCAAGGTGAATGCGGCTTCAAGGGGCTATCTTTGTGC jCG137707-01 DNA TCCTGCCCCACCTGGGGCCCATCCTGGTCTGGCTGTTCACTCGTGATCACATGTCTGGTTGGT GTGAGGGCCCGAGGATGCTGTCCTGGTGCCCATTCTACAAAGTCTTATTGCTTGTACAGACAG
JSequence CCATCTACTCTGTCGTGGGGTATGCCTCCTACCTGGTGTGGAAGGACCTGGGAGGGGGCTTGG GGTGGCCCCTGGCCCTGCCTCTTGGCCTCTATGCTGTTCAGCTCACCATCAGCTGGACTGTCC TGGTTCTCTTTTTCACAGTCCACAACCCCGGCCTCTATGCCCAGGCCCTGCTGCACCTGCTGC TGCTGTATGGGCTGGTGGTGAGCACAGCACTGATCTGGCATCCCATCAACAAACTGGCTGCCC TGTTACTGCTGCCCTACCTAGCCTGGCTCACCGTGACTTCAGCCCTCACCTACCACCTGTGGA GGGACAGCCTTTGTCCAGTGCACCAGCCTCAGCCCACGGAGAAGAGTGACTGAGGCCCTAGGG
CATGGGAGAGGAGGGACGCCCAGGGTGGGGAGGAAGAGTCTGCAAGCAGGGCTGTGGAGTTAG
GGTTCACCCCAATGGGACCACCCTCCTGGGTCCCCTGGTGCCGTTTTTCCTTA
ORF Start: ATG at 36 ORF Stop: TGA at 555
SEQ ID NO: 234 173 aa IMW at 19491. l kD iNOV63a, MRLQGAIFVLLPHLGPILVWLFTRDH SG CEGPRMLS CPFYKVLLLVQTAIYSWGYASYL
JCG 137707-01 Protein V KDLGGGLGWPLALPLGLYAVQLTISWTVLVLFFTVHNPGLYAQALLHLLLLYGLWSTALI WHPINKLAALLLLPYLA LTVTΞALTYHL RDSLCPVHQPQPTEKSD jSequence
SEQ ID NO: 235 624 bp
JNOV63b, AGAGATTTGCCTCTTCAAGGTGAATGCGGCTTCAAGGGGCTATCTTTGTGCTCCTGCCCCACC jCG137707-02 DNA TGGGGCCCATCCTGGTCTGGCTGTTCACTCGTGATCACATGTCTGGTTGGTGTGAGGGCCCGA GGATGCTGTCCTGGTGCCCATTCTACAAAGTCTTATTGCTTGTACAGACAGCCATCTACTCTG iSequence CGTGGGCTATGCCTCCTACCTGGTGTGGAAGGACCTGGGAGGGGGCTTGGGGTGGCCCCTGG CCCTGCCTCTTGGCCTCTATGCTGTTCAGCTCACCATCAGCTGGACTGTCCTGGTTCTCTTTT TCACAGTCCACAACCCTGGTCTGGCCCTGCTGCACCTGCTGCTGCTGTATGGGCTGGTGGTGA GCACAGCACTGATCTGGCATCCCATCAACAAACTGGCTGCCCTGTTACTGCTGCCCTACCTAG CCTGGCTCACCGTGACTTCAGCCCTCACCTACCACCTGTGGAGGGACAGCCTTTGTCCAGTGC ACCAGCCTCAGCCCACGGAGAAGAGTGACTGAGGCCCTAGGGCATGGGAGAGGAGGGACGCCC
AGGGTGGGGAGGAAGAGTCTGCAAGCAGGGCTGTGGAGTTAGGGTTCACCCCAATGG
ORF Start: ATG at 24 ORF Stop: TGA at 534 r SEQ ID NO: 236 170 aa MW at 19128.7kD
!NOV63b, MRLQGAIFVLLPHLGPILVWLFTRDH SG CEGPRMLS CPFYKVLLLVQTAIYSWGYASYL
;CG 137707-02 Protein V KDLGGGLG PLALPLGLYAVQLTISWTVLVLFFTVHNPGLALLHLLLLYGLWSTALIWHP INKLAALLLLPYLAWLTVTSALTYHLWRDSLCPVHQPQPTEKSD
•Sequence
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 63B.
' Table 63B. Comparison of NOV63a against NOV63b.
NOV63a Residues/ Identities/
I Protein Sequence Match Residues Similarities for the Matched Region
NOV63b -173 130/173 (75%) \ 1..170 130/173 (75%)
Further analysis of the NOV63a protein yielded the following properties shown in Table 63C.
Table 63C. Protein Sequence Properties NOV63a
PSort 0.6850 probability located in endoplasmic reticulum (membrane); 0.6400 probability I analysis: located in plasma membrane; 0.4600 probability located in Golgi body; 0.1000 probability located in endoplasmic reticulum (lumen)
! i Si toen, alP . Cleavage site between residues 59 and 60
! analysis:
A search of the NOV63a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 63 D.
In a BLAST search of public sequence datbases, the NOV63a protein was found to have homology to the proteins shown in the BLASTP data in Table 63E.
PFam analysis predicts that the NOV63a protein contains the domains shown in the Table 63F.
Example 64.
The NOV64 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 64A.
CG138033-01 DNA ^CAGAAGATCCACAAGGCAGCTGTCAAGGGCGACGCTGCGGAGATGGAGCGCTGTCTGGCGCGC
Sequence JAGGAGCGGAGACCTTGACGCCCTGGACAAGCAGCACAGGACTGCTCTACATTTGGCCTGTGCC JAGTGGCCATGTGAAAGTGGTCACTCTCCTGGTTAACAGAAAATGCCAGATTGATATCTATGAC ΪAAAGAAAATAGAACGCCTTTGATACAGGCTGTCCATTGCCAGGAAGAGGCTTGTGCCGTTATT ICTGCTGGAACATGGTGCCAATCCAAACCTTAAGGATATCTACGGCAACACTGCTCTCCATTAT IGCTGTGTATAGTGAGAGCACCTCACTGGCAGAAAAACTGCTTTTCCATGGTGAAAATATTGAA IGCACTGGACAAGGACAGTAATACCCCACTTTTATTCGCTATAATTTGCAAGAAAGAGAAAATG JGTGGAATTTTTATTGAAAAACAAAGCAAGTACACATGCCGTTGATAGGCTGAGAAGAACAGCC ICTCATGCTTGCTGTGCACTATGACTCACTGGGTATTGTCAACATCCTTCTTAAGCAAAGTATT AATGTCTTTACTCAAGACATGTGTGGACGAGATGCAGAAGATTACGCTATTTCTTGCCGTTTG JACAAAGATTCAACAACAAATTTTGGAGCATAAAAAGATGATACTTAAAAATGACAAAATAGAT JGTTGGAAGTTCTGATGAATCTGCAGTCAGCATTTTCCATGAACTGTGTGTGGATTCATTGTCT IGCATTGGATGACGAACTCTTGAGTGTTGCTGCTAAGCAGTGTGTCCCCGAGAAAGTGTCAGAG JCCTTTACGTGGACCTTCCCATGGAAAAGGAAACAGAATAGTCAATGGAAAAGGAGAAGGTCCT JCCTGCAAAACATCCTTCCTTGAAGCCTAGCACTGAAATGGAAGATCCTGCTGTGAAAGGAGCA GTACAAAAAAGAATGTACATGAATTTGTCAACAGAACAAGCCTTACCAGTGGCTTCAGAGGAA GAACAGCAAAGGCGTGAAAGAAGTGAAAAGAAGCAACCACAGGTATATGAAGGAAATAATACA TACAAAAGTGAAAAAATACAACTATCAGAAAATATATGTCATAGTACATTTTCTGCTGCTGCT GACAGATTAACCCAACAAAGAAAGATTGGGAAAACATATCCTCAGCAATTTCCCAAGAAACTG JAAGGAAGAGCATGATAGGTGCACCTTAAAACAAGAAAATGAAGAAAAAACAAATGTTAATATG JCTGCACAAAAAAAATCGAGAAGAATTAGAAAGGAAAGAGAAACAATATAAGAAAGAAGTTGAA [GCAAAACAACTTGAACCAACTGTTCAATCACTAGAGATGAAACCAAAGACTGCAAGAAATACT JCCAAATCAGGATTTTCATAATCATGAAGAAGTGAAAGATCTGATGGATGAAAATTGCATTTTG AAGACAGATATTGCTATACTCAGACAGGAAATATGCACAATGAAAAATGACAACCTGGAAAAA GAAAATAAATATCTTAAGGACATTAAAATTGCTAAAGAAACAAATGCTGCCCTTGAAAAGTGT ATAAAACTCAATGAGGAAATGATAACAAAAACAGCATTCTGGTATCAACAAGAGCTTAATGAT CTCAAAGCTGAGAATACAAGGCTCAATTCTGAACTGTTGAAGGAAAAAGAAAGCAAGAAAAAA CTGGAAGCTGAAATTGAATCTTATCAGTCTAGACTGGCTGCTGCTATAAGTAAACACAGTGAA AATGTGAAAACAGAAAGAAACCTAAAACTTGCTTTAGAGAGAACACAAGATATTTCTGAGCAA GTAAAAATGAGTTCTGATATTTCCGAAATAGAAGATAAGAATGAGTTTCTTACTGAACAACTT TCTAAAATGCAAATTAAATTCAATACCTTAAAAGATAAGTTCCGTAAGACAAGAGATACTCTC AGAAAAAAGTCATTGGCTTTAGAAACTGTACAAAACGACCTAAGCCAAACACAGCAGCAAATA AAGGAAATGAAAGAGATGTATCAAAGTGCAGAAGCTAAAGTCAGTAAATCCACTGGAAAGTGG AACTGTGTGGAAGAGAGGATATGTCAACTCCAACGTGAAAATCCGTGGCTTGAACAGCAACTA GTTGATGTTCATCAGAAAGAGGATCATAAAGAGATAGTAATTAATATCCAAAGAGGCTTTATT GAGAGTAGAAAGAAAGACCTCATGCTAGAAGAGAAAAATAGAAAGCTAATGAATGAATATGAT CATTTAAAAGAAAGTCTCTTTCAATATGAGAGACAGAAAGCAGAAACAGTAGTAAGTATCAAG GAAGATAAATATTTTCAAACTTCTAGAAAGAAAGTTTAAACATTTGGTTCTGGATACATGTTG
AACCTAGTTGAATATAAAAATCAGTAGGATAAAAAGTGTG
ORF Start: ATG at 25 jORF Stop: TAA at 2494
SEQ ID NO: 238 823 aa MW at 94994.5kD
NOV64a, KLFGFRSRRGQTVLGSIDHLYTGSGYRIRYSELQKIHKAAVKGDAAEMERCLARRSGDLDAL
CG138033-01 Protein DKQHRTALHLACASGHVKWTLLVNRKCQIDIYDKENRTPLIQAVHCQEEACAVILLEHGANP NLKDIYGNTALHYAVYSESTSLAEKLLFHGENIEALDKDSNTPLLFAIICKKEKMVEFLLKNK Sequence ASTHAVDRLRRTALMLAVHYDSLGIVNILLKQSI VFTQDMCGRDAEDYAISCRLTKIQQQIL EHKKMILKNDKIDVGSSDESAVSIFHELCVDSLSALDDELLSVAAKQCVPEKVSEPLRGPSHG KGNRIVNGKGEGPPAKHPSLKPSTEMEDPAVKGAVQKRMYMNLSTEQALPVASEEEQQRRERS EKKQPQVYEGN TYKSEKIQLSENICHSTFSAAADRLTQQRKIGKTYPQQFPKKLKEEHDRCT LKQENEEKTNVNMLHKKNREELERKEKQYKKEVEAKQLEPTVQSLEMKPKTARNTPNQDFHNH EEVKDLMDENCILKTDIAILRQEICTMKNDNLEKENKYLKDIKIAKETNAALEKCIKLNEEMI TKTAF YQQELNDLKAENTRLNSELLKEKESKKKLEAEIESYQSRLAAAISKHSENVKTERNL KLALERTQDISEQVKMSSDISEIEDKNEFLTEQLSKMQIKFNTLKDKFRKTRDTLRKKSLALE TVQNDLSQTQQQIKEMKEMYQSAEAKVSKSTGKWNCVEERICQLQRENPWLEQQLVDVHQKED JHKEIVINIQRGFIESRKKDLMLEEKNRKLMNEYDHLKESLFQYERQKAETWSIKEDKYFQTS
RKKV
Further analysis of the NOV64a protein yielded the following properties shown in Table 64B.
PSort 0.7600 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV64a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 64C.
In a BLAST search of public sequence datbases, the NOV64a protein was found to have homology to the proteins shown in the BLASTP data in Table 64D.
PFam analysis predicts that the NOV64a protein contains the domains shown in the Table 64E.
Example 65.
The NOV65 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 65A.
AGGAGTCCTTCCACTATTAGCTTGAAAGAATCAAAGTCCAGAACTGATTTAAAGGAAGAGCAC
AAGTCTAGTATGATGCCTGGCTTCCTCTCAGAGGTTAACGCTTTAAGTGCTGTTTCCTCTGTT
GTAAATAAATTCAACCCTTTTGATTTGATATCAGACTCTGAGGCATCCCAGGAAGAAACCACC
AAGAAACAAAAAGTGGTTCAGAAGGAGCAAGGAAAACCTGAAGGAATCATAAAACCTCCTTTA
CAACAACAGCCACCCAAGCCGATTCCTAAGCAGCAAGGACCTGGTAGGGATCCGCTTCAGCAG
GATGGCACTCCCAAATCAATATCTTCTCAACAACCAGAAAAAATTAAATCACAACCTCCAGGT
ACAGGAAAGCCAATTCAGGGTCCTACCCAGACTCCTCAGACAGACCATGCAAAATTGCCACTT
CAACGAGATGCATCCAGGCCTCAGACTAAACAGGCAGACATAGTAAGGGGAGAATCAGTTAAA
CCCTCACTGCCAAGCCCATCCAAACCACCTATTCAGCAACCAACTCCTGGAAAACCTCCAGCA
CAGCAGCCTGGACATGAAAAATCACAGCCTGGGCCTGCAAAGCCCCCAGCTCAGCCCTCAGGG
CTAACAAAGCCATTGGCTCAACAACCAGGGACAGTGAAACCCCCAGTCCAGCCACCAGGGACA
ACAAAGCCTCCAGCTCAGCCTCTTGGTCCTGCTAAGCCTCCAGCTCAGCAGACTGGGTCAGAG
AAGCCTTCATCGGAGCAGCCTGGGCCAAAGGCTTTAGCTCAGCCTCCTGGAGTTGGAAAGACT
CCAGCTCAACAGCCAGGGCCAGCAAAGCCTCCAACCCAGCAGGTGGGGACACCAAAACCCCTA
GCTCAACAACCTGGGCTACAGTCTCCAGCTAAGGCACCTGGGCCTACAAAGACTCCAGCTCAG
ACAAAGCCCCCATCTCAACAGCCTGGCTCAACAAAACCCCCACCTCAACAGCCTGGCCCAGCA
AAGCCCTCACCTCAACAGCCTGGCTCAACAAAACCCCCATCTCAACAGCCTGGCTCAGCAAAA
CCCTCAGCTCAACAGCCTAGCCCAGCAAAGCCCTCGGCTCAGCAATTTACAAAACCAGTAAGC
CAAACAGGATTTGGAAAACCTCTGCAGCCACCAACAGTGTCTCCATCTGCAAAACAGCCTCCT
TCACAAGGCCTCCCTAAAACCATCTGTCCTCTTTGCAATACCACTGAACTTCTGTTGCATGTT
CCAGAAAAGGCCAATTTTAACACATGCACTGAGTGTCAAACCACTGTCTGTAGTCTCTGTGGT
TTTAATCCCAATCCTCATTTAACGGAGGCAAAAGAGTGGCTCTGTTTGAACTGTCAAATGAAA
AGAGCTCTAGGCGGGGATCTGGCTCCAGTTCCGTCATCACCCCAGCCCAAACTGAAGACTGCA
CCTGTTACCACTACATCAGCAGTGAGCAAATCATCCCCACAGCCACAGCAGACTTCCCCAAAG
AAGGATGCTGCACCAAAACAGGATCTCTCCAAGGCACCTGAGCCTAAAAAGCCACCACCGCTA
GTGAAACAACCAACCCTTCATGGCTCTCCTTCAGCCAAGGCCAAGCAGCCCCCTGAGGCAGAT
TCTTTGTCCAAGCCAGCCCCTCCCAAAGAACCTTCTGTCCCATCTGAGCAGGACAAGGCCCCT
GTTGCTGATGATAAACCAAAGCAGCCCAAGATGGTAAAGCCAACCACTGACCTTGTATCTTCA
TCATCAGCAACAACAAAACCTGATATTCCAAGCTCCAAAGTACAGTCACAAGCTGAAGAGAAA
ACAACCCCTCCTCTAAAAACAGACTCTGCCAAACCCTCACAGAGTTTTCCACCAACAGGGGAA
AAAGTCACCCCATTTGATTCTAAAGCCATACCTCGACCTGCATCAGATTCAAAAATTATTTCA
CATCCTGGTCCCAGTTCAGAGAGCAAAGGTCAAAAACAAGTTGACCCCGTACAAAAGAAGGAA
GAACCCAAGAAAGCACAAACCAAAATGAGTCCTAAACCAGATGCCAAGCCAATGCCAAAAGGG
TCACCAACACCCCCTGGCCCACGACCTACCGCTGGCCAAACTGTCCCCACACCTCAACAGTCC
CCAAAGCCTCAGGAGCAGTCAAGGCGTTTCAGTCTGAATCTGGGAAGTATTACTGATGCCCCC
AAATCACAGCCTACAACTCCTCAAGAGACCGTGACTGGGAAACTCTTTGGGTTTGGAGCATCA
ATCTTCAGCCAGGCATCAAATTTAATTTCCACTGCAGGCCAACCTGGACCTCATTCACAAAGT
GGACCAGGGGCCCCAATGAAACAAGCCCCTGCCCCTTCACAGCCACCTACTTCACAAGGGCCA
CCCAAATCCACAGGTCAAGCACCACCAGCACCTGCAAAAAGTATACCTGTGAAAAAGGAAACA
AAAGCCCCAGCAGCTGAAAAATTAGAGCCCAAAGCTGAACAAGCTCCAACAGTAAAAAGAACA
GAAACAGAAAAAAAGCCACCACCTATTAAGGATAGCAAATCTTTAACAGCTGAGCCTCAAAAG
GCTGTCCTTCCCACAAAACTGGAGAAATCGCCCAAACCAGAATCAACCTGTCCTCTCTGCAAA
ACTGAACTCAACATAGGTTCTAAGGATCCTCCTAACTTCAATACTTGCACTGAATGCAAGAAT
CAAGTGTGTAATCTCTGTGGATTTAACCCTACACCACATTTGACTGAGATTCAAGAATGGCTT
TGTTTAAATTGCCAAACCCAGAGAGCAATATCAGGACAGCTTGGAGACATACGCAAAATGCCA
CCTGCACCATCAGGACCCAAAGCATCTCCTATGCCTGTTCCTACAGAATCATCATCTCAGAAA
ACAGCAGTGCCTCCCCAAGTAAAATTAGTGAAAAAGCAAGAACAAGAAGTAAAAACGGAAGCT
GAAAAAGTCATTCTGGAAAAAGTAAAGGAAACACTATCAATGGAAAAAATTCCTCCTATGGTA
ACCACAGATCAAAAACAAGAAGAGAGTAAACTAGAGAAAGACAAAGCTTCAGCTCTTCAAGAA
AAAAAGCCACTCCCTGAAGAAAAAAAACTAATCCCTGAAGAAGAAAAGATACGTTCTGAAGAA
AAAAAGCCACTCCTAGAAGAAAAAAAGCCAACCCCTGAAGACAAAAAGCTACTCCCAGAGGCA
AAAACATCAGCCCCAGAAGAACAGAAACATGACTTACTTAAATCTCAAGTACAAATTGCTGAA
GAAAAGCTTGAAGGCAGAGTGGCTCCAAAGACAGTGCAAGAAGGGAAACAACCACAGACCAAG
ATGGAAGGTTTACCATCTGGCACACCTCAGAGTTTACCTAAAGAAGATGATAAGACAACCAAA
ACAATAAAAGAACAGCCACAGCCACCATGCACAGCAAAACCTGATCAGGAAAAGGAAGATGAC
AAATCAGACACCTCAAGTTCTCAGCAGCCTAAAAGCCCCCAAGGTCTGAGCGACACGGGATAT
TCTTCCGATGGAATATCAAGCTCACTTGGTGAAATTCCAAGTCTTATTCCAACTGATGAAAAG
GATATTCTCAAGGGACTCAAAAAGGACTCTTTTTCACAAGAAAGCAGCCCTTCCAGCCCCTCA
GATTTGGCTAAGTTAGAAAGTACAGTCCTATCTATTTTGGAAGCTCAAGCAAGTACACTTGCT
GATGAAAAGTCAGAAAAGAAAACACAACCCCATGAAGTTTCTCCTGAACAGCCTAAAGACCAA
GAGAAAACTCAGAGTTTATCTGAAACCTTGGAAATTACTATTTCAGAAGAGGAGATCAAAGAG
AGTCAAGAAGAAAGGAAAGACACTTTTAAAAAAGATAGCCAACAAGATATTCCTTCCAGCAAG
GACCATAAAGAGAAGTCTGAGTTTGTTGATGACATAACTACTAGAAGAGAGCCTTATGATTCA
GTTGAAGAGAGTAGTGAAAGTGAAAACTCACCTGTTCCACAAAGAAAACGAAGAACTAGTGTT
GGCTCATCAAGCAGTGATGAGTATAAACAGGAAGACAGCCAAGGATCAGGGGAAGAGGAGGAC
TTCATTCGAAAACAAATCATAGAAATGAGTGCTGATGAAGATGCTTCAGGTTCTGAAGATGAT
GAGTTCATCAGAAACCAGCTCAAAGAGATTAGTAGCAGTACTGAGAGCCAGAAGAAGGAAGAA
ACAAAGGGAAAAGGCAAAATAACAGCAGGGAAACACAGACGACTGACTCGAAAAAGTAGCACA
AGCATTGATGAAGATGCAGGAAGACGTCACTCATGGCATGATGAAGACGATGAAGCATTTGAT
GAAAGTCCTGAACTTAAATACAGAGAAACTAAAAGTCAGGAAAGTGAAGAACTTGTAGTTACT
GGAGGAGGAGGGCTACGCCGATTTAAAACAATTGAGCTCAACAGTACAATAGCAGATAAATAT
TCTGCAGAGTCATCACAGAAAAAAACAAGTTTGTATTTTGACGAAGAGCCAGAATTGGAAATG
GAAAGCCTGACAGACTCACCTGAAGATAGGTCAAGGGGAGAGGGATCTTCGAGTCTGCATGCT
TCCAGCTTCACTCCTGGTACATCCCCTACATCAGTATCATCACTTGATGAGGACAGTGACAGT
AGCCCGAGTCACAAAAAAGGAGAGAGCAAACAGCAACGCAAAGCTCGGCACAGACCACATGGC
CCTCTTTTGCCTACTATTGAAGATTCTTCAGAGGAAGAAGAATTGAGAGAGGAAGAAGAATTA
TTAAAGGAGCAAGAAAAGCAGAGGGAAATAGAACAGCAACAAAGAAAGAGTTCTAGTAAAAAA
TCAAAGAAAGACAAAGATGAACTTCGAGCTCAGAGAAGAAGGGAAAGGCCAAAGACACCACCT
AGTAATCTCTCTCCCATTGAAGATGCATCTCCGACAGAAGAGTTACGTCAGGCTGCAGAAATG
GAGGAGCTCCATAGATCTTCTTGTTCTGAATATTCACCTAGCATAGAGTCAGACCCAGAAGGT
TTTGAAATAAGCCCGGAAAAAATAATAGAAGTACAAAAAGTTTATAAATTGCCCACAGCTGTT
TCATTATACTCACCAACAGATGAGCAATCTATTATGCAGAAAGAAGGTAGCCAAAAGGCGTTA
AAAAGTGCTGAGGAGATGTATGAAGAAATGATGCATAAAACACACAAATACAAAGCTTTTCCA
GCTGCAAATGAACGAGATGAAGTGTTTGAAAAAGAGCCTTTGTATGGTGGGATGCTAATAGAG
GATTATATTTATGAATCTTTAGTAGAAGACACGTACAATGGATCGGTAGATGGCAGTCTGCTA
ACAAGGCAAGAAGAAGAAAATGGATTTATGCAGCAGAAAGGAAGAGAGCAAAAGATAAGACTT
TCAGAACAGATTTATGAAGATCCTATGCAGAAAATTACAGACCTCCAGAAAGAGTTTTATGAG
TTAGAAAGCTTACATTCTGTTGTGCCTCAGGAAGATATTGTTTCAAGCTCTTTTATCATCCCA
GAAAGCCATGAGATAGTGGACCTGGGTACTATGGTAACTTCTACAGAAGAAGAAAGGAAACTA
CTAGATGCTGATGCTGCCTATGAAGAACTTATGAAGAGGCAACAGATGCAATTAACACCTGGA
TCTAGCCCAACCCAGGCCCCCATTGGTGAGGATATGACAGAGTCCACCATGGACTTTGACAGA
ATGCCAGATGCCTCTTTGACATCAAGTGTTCTCTCAGGAGCGTCTCTTACAGATTCGACCAGC
AGTGCAACACTCTCTATCCCAGATGTTAAAATAACCCAACATTTTTCAACAGAAGAAAΓTGAG
GATGAATATGTAACCGATCATACAAGAGAAATTCAAGAGATAATTGCCCATGAATCGCTGATT
TTGACCTACTCGGAGCCTTCAGAAAGTGCTACATCTGTCCCACCCTCTGACACACCTTCTCTC
ACATCATCTGTTTCTTCGGTCTGTACCACAGATAGCTCTTCACCCATTACTACCCTGGATAGC
ATAACCACAGTTTATACAGAGCCAGTGGACATGATAACTAAATTTGAAGATTCTGAGGAAATT
TCTTCATCAACTTATTTTCCAGGCAGCATTATAGACTATCCAGAAGAAATAAGTGCATCTTTA
GATCGGACTGCCCCACCAGATGGTAGAGCTAGTGCTGATCATATTGTTATTTCCTTATCTGAT
ATGGCATCTTCTATCATAGAATCTGTAGTACCTAAACCTGAAGGGCCAGTTGCTGACACTGTT
TCTACTGACTTACTTATATCTGAAAAGGACCCAGTGAAGAAAGCCAAGAAGGAAACTGGGAAT
GGAATCATTCTGGAAGTTTTGGAAGCTTACAGAGATAAAAAGGAGTTGGAGGCCGAACGAACA
AAAAGTAGCTTATCCGAAACCGTGTTTGATCACCCACCTTCTTCTGTAATAGCCCTTCCAATG
AAAGAGCAGCTTTCAACTACATACTTTACATCTGGAGAGACCTTTGGTCAGGAAAAACCTGCA
TCTCAGTTACCATCTGGCAGTCCTTCTGTTTCCTCTCTTCCAGCTAAACCTCGCCCATTCTTT
AGAAGTTCTTCTTTGGATATATCAGCTCAACCTCCTCCCCCTCCTCCCCCTCCCCCTCCTCCT
CCTCCTCCACCACCACCCCCTCCTCCCCCACCACTTCCTCCACCAACTTCACCTAAACCAACT
ATTCTTCCTAAAAAAAAGTTAACAGTTGCATCTCCAGTGACTACAGCTACACCTCTGTTTGAT
GCTGTTACTACTCTAGAGACCACAGCTGTTCTGAGAAGTAATGGATTACCTGTTACAAGAATA
TGTACTACTGCACCTCCTCCTGTTCCTCCTAAGCCATCTTCAATTCCATCTGGACTTGTATTT
ACCCACAGGCCTGAGCCAAGCAAACCTCCAATCGCCCCCAAACCAGTGATTCCTCAGCTTCCA
ACAACTACACAAAAACCAACAGATATACACCCCAAACCAACAGGCCTATCTTTAACTTCAAGT
ATGACCTTAAATTCAGTGACTTCAGCAGATTATAAATTGCCTTCCCCTACCTCCCCACTTTCC
CCACACTCCAACAAGTCTTCACCAAGATTTTCCAAATCCCTCACAGAAACTTATGTAGTTATT
ACATTGCCATCTGAACCAGGGACTCCAACAGATTCTTCTGCTAGTCAAGCAATTACCAGTTGG
CCCTTGGGATCACCCTCCAAAGATCTGGTTTCTGTTGAACCTGTGTTTTCTGTAGTTCCTCCT
GTGACAGCTGTAGAAATTCCAATTTCTTCAGAACAGACCTTCTACATCTCTGGAGCTTTACAG
ACATTTTCTGCTACCCCTGTCACAGCACCCTCTTCATTTCAAGCAGCTCCCACATCAGTTACA
CAGTTTCTCACTACTGAAGTTTCCAAGACTGAGGTTTCAGCAACCAGAAGTACAGCTCCTAGT
GTTGGTCTCAGCAGCATTTCCATAACAATTCCTCCAGAGCCTCTTGCTCTAGATAACATACAT
TTAGAGAAGCCTCAGTATAAAGAAGATGGAAAATTGCAACTTGTTGGTGATGTAATTGATTTG
CGTACAGTACCAAAGGTAGAAGTTAAAACAACTGATAAATGTATTGATCTTTCTGCTTCTACA
JATGGATGTGAAAAGGCAGATCACAGCAAATGAAGTTTATGGGAAACAAATTAGTGCTGTCCAA
JCCCTCTATTATAAATCTTAGTGTGACATCATCAATAGTGACTCCTGTATCTCTGGCCACTGAG
JACAGTGACCTTTGTCACATGCACAGCTAGTGCAAGTTACACTACAGGCACAGAAAGCCTAGTG
GGTGCAGAACATGCAATGACAACACCACTCCAACTTACAACATCAAAGCATGCTGAGCCCCCA
TACAGGATACCAAGTGACCAGGTCTTTCCTATAGCTAGGGAAGAAGCACCAATAAACTTATCT
CTAGGTACTCCAGCACATGCAGTGACATTGGCTATTACAAAACCTGTCACTGTGCCTCCTGTT
GGTGTCACAAATGGATGGACTGATAGCACCGTATCCCAGGGAATCACTGATGGGGAAGTAGTG
GATCTCAGTACAACCAAGTCTCACAGAACAGTCGTAACAATGGATGAGTCTACTTCAAGTGTG
ATGACCAAAATAATAGAAGATGAAAAACCCGTTGATTTAACCGCAGGGAGAAGAGCTGTGTGC
TGTGATGTGGTTTATAAATTACCATTTGGAAGGAGCTGCACAGCACAGCAGCCTGCAACTACT
CTTCCTGAGGATCGTTTTGGTTATAGGGATGACCACTATCAGTATGATCGATCAGGGCCATAT
GGTTATAGAGGGATTGGGGGAATGAAGCCTTCCATGTCTGACACAAATTTAGCAGAAGCTGGA
CATTTTTTCTATAAAAGTAAGAATGCTTTTGATTATTCTGAAGGAACTGACACAGCAGTAGAT
CTGACTTCAGGGAGAGTTACTACAGGTGAGGTAATGGATTATTCAAGCAAGACTACAGGTCCA
TATCCAGAAACACGACAAGTCATTTCAGGAGCTGGGATTAGTACCCCACAGTATTCCACAGCA
AGAATGACACCACCACCAGGACCCCAGTATTGTGTGGGGAGTGTTTTGAGGTCATCTAATGGT
GTTGTCTATTCTTCAGTAGCAACTCCAACACCCTCTACATTTGCTATCACCACACAACCTGGC
TCCATTTTCAGCACCACAGTGAGGGATTTGTCTGGTATTCATACGGCTGATGCAGTGACTTCA
TTACCTGCCATGCACCATAGCCAGCCAATGCCTAGATCATATTTTATAACAACAGGTGCATCT
GAAACGGACATTGCAGTAACTGGTATTGATATCAGTGCCAGTTTGCAAACTATTACTATGGAG
TCTCTTACTGCTGAGACGATAGACTCTGTTCCCACTTTAACCACAGCATCCGAAGTGTTTCCT
GAAGTGGTGGGAGATGAAAGTGCTCTTTTAATTGTCCCTGAAGAAGATAAACAACAGCAGCAG
CTAGACTTGGAGCGTGAGCTCCTGGAACTGGAGAAAATTAAGCAACAGCGCTTTGCTGAGGAA
TTGGAGTGGGAACGTCAGGAAATTCAAAGGTTCCGAGAACAAGAAAAGATCATGGTTCAGAAA
AAGTTGGAGGAGCTGCAGTCTATGAAGCAACACCTTCTCTTTCAGCAAGAAGAAGAGCGGCAA
GCCCAGTTCATGATGAGGCAGGAGACGTTAGCTCAGCAACAGTTACAGCTTGAGCAGATCCAA
CAGCTGCAACAACAGCTTCACCAGCAGCTGGAGGAGCAAAAGATTCGGCAGATCTACCAGTAT
AACTATGACCCTTCTGGAACTGCTTCTCCACAAACCACTACAGAGCAGGCAATTTTGGAAGGT
CAGTATGCTGCTCTGGAAGGCAGCCAATTTTGGGCAACTGAAGATGCAACCACCACAGCTTCA
GCTGTTGTGGCAATTGAAATACCACAAAGCCAAGGATGGTACACCGTTCAGTCTGATGGTGTT
ACTCAGTACATTGCCCCACCTGGTATCCTGAGCACTGTTTCAGAAATACCTCTAACAGATGTT
GTTGTGAAAGAGGAAAAACAACCCAAAAAGAGAAGTTCTGGAGCTAAAGTCCGAGGACAGTAT
GATGACATGGGAGAAAATATGACAGATGATCCCCGAAGTTTTAAAAAGATAGTGGACAGTGGT
GTACAAACGGATGACGAAGATGCCACAGATCGGAGCTATGTGAGTAGGAGAAGGAGAACTAAA
AAGAGTGTGGATACAAGCGTCCAAACTGATGATGAAGATCAGGATGAGTGGGATATGCCTACT
AGATCAAGGAGGAAAGCTCGTGTAGGGAAATATGGTGACAGCATGACAGAGGCTGACAAGACC
AAACCCCTTTCCAAAGTCTCCAGCATAGCAGTTCAAACGGTAGCAGAGATATCTGTGCAAACT
GAACCAGTTGGAACCATAAGAACACCCTCCATACGGGCACGAGTGGATGCCAAGGTAGAAATA
ATTAAACACATTTCAGCACCTGAAAAGACTTACAAAGGGGGCAGTTTAGGATGTCAAACAGAA
GCAGATTCAGACACACAAAGTCCTCAATATCTGAGTGCCACATCTCCACCCAAAGACAAGAAA
CGCCCAACACCTTTAGAGATTGGTTATTCATCTCACCTCCGGGCAGATTCCACAGTACAGCTG
GCTCCTTCCCCACCCAAATCCCCCAAAGTCCTTTACTCACCCATCTCACCACTTTCACCAGGC
AAAGCCTTAGAATCAGCCTTTGTACCTTATGAAAAACCCCTCCCTGATGATATAAGTCCACAG
AAAGTACTGCATCCAGATATGGCTAAAGTTCCCCCAGCAAGTCCTAAGACAGCCAAGATGATG
CAGCGTTCTATGTCTGACCCCAAGCCTCTGAGTCCAACAGCAGACGAAAGTTCCAGGGCTCCT
TTTCAGTATACCGAGGGCTATACGACTAAAGGTTCTCAAACCATGACATCCTCTGGAGCCCAG
AAAAAAGTTAAAAGAACTCTGCCAAATCCACCTCCTGAGGAGATTTCCACAGGAACTCAATCC
ACATTCAGCACAATGGGCACAGTTTCCAGGAGAAGGATCTGCAGAACCAACACAATGGCACGA
GCCAAGATTCTCCAGGACATAGACAGAGAGCTTGATCTTGTGGAAAGGGAGTCTGCAAAACTT
CGAAAGAAACAAGCAGAGCTTGATGAAGAAGAAAAGGAGATTGATGCTAAGCTACGATACCTG
GAAATGGGAATTAACAGGAGGAAAGAGGCCCTATTAAAGGAGAGAGAAAAGAGAGAACGAGCC
TACCTCCAGGGAGTAGCTGAGGATCGTGATTACATGTCTGACAGTGAAGTGAGTAGCACAAGA
CCAACCCGAATAGAAAGTCAGCATGGCATTGAGCGACCAAGAACTGCTCCCCAAACTGAATTC
AGCCAGTTTATACCACCACAAACCCAAACAGAATCTCAACTAGTTCCTCCGACAAGTCCTTAC
ACACAATACCAGTACTCTTCCCCTGCTCTTCCTACCCAAGCACCCACCTCATACACTCAACAG
TCTCATTTTGAGCAACAAACTTTGTACCATCAGCAAGTTTCACCTTATCAGACTCAGCCAACA
TTCCAAGCTGTGGCAACAATGTCCTTCACACCTCAAGTTCAACCTACACCAACCCCACAGCCT
TCTTATCAGTTACCTTCACAGATGATGGTGATACAACAGAAGCCACGGCAAACTACATTATAT
TTGGAGCCCAAGATAACCTCAAACTATGAAGTGATTCGCAACCAACCCCTTATGATAGCACCT
GTTTCTACGGATAACACATTTGCTGTTTCCCATCTTGGTAGTAAGTACAATAGTTTAGACTTG
AGAATAGGTTTGGAGGAAAGAAGTAGCATGGCAAGCAGTCCAATATCAAGCATATCTGCAGAT
TCTTTCTATGCAGATATTGATCACCATACTCCACGAAATTATGTCCTAATTGACGACATTGGA
GAGATCACCAAAGGAACAGCGGCATTAAGCACCGCATTTAGCCTTCATGAAAAGGATCTGTCA
AAAACAGACCGTCTCCTTCGAACCACTGAGACACGCCGGTCTCAAGAAGTGACAGATTTCCTA
GCACCTTTACAGTCTTCCTCTAGATTGCATAGTTATGTGAAGGCGGAGGAAGACCCAATGGAG
GATCCTTACGAGTTAAAGCTTCTGAAACATCAGATTAAACAGGAATTTCGTAGAGGGACAGAG
AGCTTAGATCACCTTGCTGGTCTTTCTCATTATTACCATGCTGATACTAGCTACAGACATTTT
CCAAAATCTGAGAAGTATAGCATCAGTAGACTCACACTTGAAAAACAAGCAGCAAAACAACTG
CCAGCAGCCATACTTTATCAAAAGCAGTCAAAGCATAAGAAATCACTAATTGACCCTAAAATG
TCAAAATTTTCACCTATTCAAGAAAGTAGAGACCTTGAACCTGATTATTCAAGCTATATGACT
TCTAGCACTTCATCTATTGGTGGCATTTCCTCCAGGGCAAGGCTCCTTCAAGATGACATCACT
TTTGGCCTCAGAAAAAATATTACAGACCAACAAAAATTTATGGGATCTTCTCTTGGCACAGGA
CTGGGCACATTAGGAAATACCATACGCTCAGCTCTGCAGGATGAAGCGGATAAGCCATACAGT
AGTGGCAGCAGGTCCAGACCTTCCTCCAGACCTTCCTCTGTCTATGGGCTTGATTTATCAATT
AAAAGGGATTCTTCTAGCTCTTCCCTAAGACTGAAAGCTCAAGAGGCTGAAGCTCTAGATGTT
TCCTTTAGTCATGCATCATCCTCTGCCAGAACTAAGCCGACCAGTTTGCCAATTAGTCAAAGT
AGAGGAAGAATACCAATTGTGGCCCAGAATTCTGAAGAAGAAAGCCCACTCAGTCCTGTTGGC CAGCCAATGGGAATGGCCAGGGCTGCAGCTGGACCCCTGCCACCAATATCTGCAGACACCAGG GATCAGTTTGGATCAAGCCACTCATTGCCTGAAGTTCAGCAACACATGAGGGAAGAATCACGG ACTCGAGGCTATGACCGTGACATAGCATTCATCATGGATGACTTCCAACATGCCATGTCAGAC AGTGAAGCCTATCATCTGCGTCGTGAGGAAACAGATTGGTTTGATAAACCCAGGGAGTCTCGT TTGGAAAATGGACATGGTCTGGACCGAAAACTGCCGGAAAGATTGGTCCACTCTAGACCACTC AGTCAACATCAAGAGCAAATTATACAGATGAACGGGAAAACTATGCACTACATCTTTCCTCAC GCAAGGATAAAAATAACAAGAGACTCAAAGGATCACACAGTTTCAGGTAATGGATTAGGAATT AGAATTGTGGGTGGTAAAGAAATCCCGGGACATAGTGGAGAAATTGGAGCCTATATTGCCAAG ATTCTTCCTGGGGGAAGTGCGGAACAGACGGGGAAGCTTATGGAAGGGATGCAAGTATTGGAA TGGAATGGAATTCCCTTGACTTCTAAAACATATGAAGAAGTTCAGAGTATCATTAGTCAGCAA AGTGGGGAAGCAGAAATATGTGTAAGACTGGACCTCAATATGCTATCAGATTCTGAAAATTCC CAGCATCTGGAACTTCATGAGCCACCAAAAGCTGTGGATAAGGCGAAATCCCCAGGGGTTGAT CCTAAGCAGTTGGCAGCAGAACTCCAGAAGGTTTCACTACAGCAGTCACCGCTGGTTCTGTCA TCAGTTGTTGAAAAAGGATCTCATGTTCATTCAGGTCCTACATCAGCAGGATCCAGTTCCGTT CCCAGCCCTGGGCAACCAGGGTCCCCCTCAGTGAGCAAAAAGAAGCACGGCAGCAGCAAGCCT ACCGATGGAACAAAGGTTGTCTCTCATCCAATTACAGGAGAAATTCAGCTTCAAATTAACTAT GATCTTGGAAATCTCATAATACATATTCTCCAAGCAAGAAATCTTGTTCCTCGAGACAACAAT GGTTATTCTGACCCTTTTGTGAAAGTGTACCTTCTTCCAGGGAGAGGTCAAGTCATGGTTGTC CAGAATGCAAGTGCTGAGTACAAGAGAAGGACTAAACATGTCCAGAAAAGTCTTAATCCTGAG TGGAATCAAACAGTAATTTATAAAAGTATTTCCATGGAACAGCTCAAGAAGAAAACACTGGAG GTGACAGTTTGGGATTATGATAGATTTTCATCCAACGACTTCCTTGGGGAGGTATTGATTGAT TTATCTAGCACATCTCACCTCGATAACACTCCAAGGTGGTATCCTCTCAAAGAACAGACTGAA AGCATTGATCATGGCAAGTCTCATTCCAGTCAGAGCAGCCAGCAGTCCCCAAAGCCATCTGTT ATCAAAAGCAGAAGCCATGGTATCTTCCCTGACCCATCAAAGGACATGCAGGTTCCCACCATT GAGAAATCCCATAGTAGTCCTGGTAGCTCAAAATCATCATCAGAAGGCCATCTCCGTTCTCAT GGACCATCTCGCAGTCAAAGCAAAACCAGCGTCACTCAGACCCACCTGGAAGATGCAGGGGCT GCCATAGCTGCTGCCGAAGCTGCCGTGCAACAACTCCGCATTCAACCAAGTAAAAGACGCAAA TAAATTCCTCAGCATGGCAGCTTAATGTTCATCTGTTGCCTTTCTTTCCTGCTGTCCTTTCCT
GTTTGCTTTCAGTTTTCAACATCCTCTGCTCACCCTGTTCTCTGTCCCTTTGTCTGTGTAAGA
ACGATATAAATACATTAATATGCTCTTTCTTATTTAGATTTTTTTTATTTACATAGACTGAAA
TAAAACTGGCTGTTTCTCCTTTGTTTCCACCATCCATCCAACCTGGCTCATAGCATTTGATAC
AGTGTCTGTGATGTTTGGAAGCAAAGCAATGTTGTGTGTCCTTTTTGTTTGCGCTTAAATATC
ORF Start: ATG at 61 jORF Stop: TAA at_l 4680 SEQ ID NO: 240" " 4873 aa "]i W at 53 H66.4kD
;NOV65a, MGNEASLEGEGLPEGLAAAAAAGGGASGAGSPSHTAIPAGMEADLSQLSEEERRQIAAVMSRA
JCG 138043-01 Protein QGLPKGSVPPAAAESPSMHRKQELDSSHPPKQSGRPPDPGRPAQPGLSKSRTTDTFRSEQKLP GRSPSTISLKESKSRTDLKEEHKSSMMPGFLSEVNALSAVSSWNKFNPFDLISDSEASQEET fSequence TKKQKWQKEQGKPEGIIKPPLQQQPPKPIPKQQGPGRDPLQQDGTPKSISSQQPEKIKSQPP GTGKPIQGPTQTPQTDHAKLPLQRDASRPQTKQADIVRGESVKPSLPSPSKPPIQQPTPGKPP AQQPGHEKSQPGPAKPPAQPSGLTKPLAQQPGTVKPPVQPPGTTKPPAQPLGPAKPPAQQTGS EKPSSEQPGPKALAQPPGVGKTPAQQPGPAKPPTQQVGTPKPLAQQPGLQSPAKAPGPTKTPA QTKPPSQQPGSTKPPPQQPGPAKPSPQQPGSTKPPSQQPGSAKPSAQQPSPAKPSAQQFTKPV SQTGFGKPLQPPTVSPSAKQPPSQGLPKTICPLCNTTELLLHVPEKANFNTCTECQTTVCSLC GFNPNPHLTEAKEWLCLNCQMKRALGGDLAPVPSSPQPKLKTAPVTTTSAVSKSSPQPQQTSP KKDAAPKQDLSKAPEPKKPPPLVKQPTLHGSPSAKAKQPPEADSLSKPAPPKEPSVPSEQDKA PVADDKPKQPKMVKPTTDLVSSSSATTKPDIPSSKVQSQAEEKTTPPLKTDSAKPSQSFPPTG EKVTPFDSKAIPRPASDSKIISHPGPSSESKGQKQVDPVQKKEEPKKAQTKMSPKPDAKPMPK GSPTPPGPRPTAGQTVPTPQQSPKPQEQSRRFSLNLGSITDAPKSQPTTPQETVTGKLFGFGA SIFSQASNLISTAGQPGPHSQSGPGAPMKQAPAPSQPPTSQGPPKSTGQAPPAPAKSIPVKKE TKAPAAEKLEPKAEQAPTVKRTETEKKPPPIKDSKSLTAEPQKAVLPTKLEKSPKPESTCPLC KTELNIGSKDPPNFNTCTECKNQVCNLCGFNPTPHLTEIQEWLCLNCQTQRAISGQLGDIRKM PPAPSGPKASPMPVPTESSSQKTAVPPQVKLVKKQEQEVKTEAEKVILEKVKETLSMEKIPPM VTTDQKQEESKLEKDKASALQEKKPLPEEKKLIPEEEKIRSEEKKPLLEEKKPTPEDKKLLPE AKTSAPEEQKHDLLKSQVQIAEEKLEGRVAPKTVQEGKQPQTKMEGLPSGTPQSLPKEDDKTT KTIKEQPQPPCTAKPDQEKEDDKSDTSSSQQPKSPQGLSDTGYSSDGISSSLGEIPSLIPTDE KDILKGLKKDSFSQESSPSSPSDLAKLESTVLSILEAQASTLADEKSEKKTQPHEVSPEQPKD QEKTQSLSETLEITISEEEIKESQEERKDTFKKDSQQDIPSSKDHKEKSEFVDDITTRREPYD SVEESSESENSPVPQRKRRTSVGSSSSDEYKQEDSQGSGEEEDFIRKQIIE SADEDASGSED DEFIRNQLKEISSSTESQKKEETKGKGKITAGKHRRLTRKSSTSIDEDAGRRHSWHDEDDEAF DESPELKYRETKSQESEELWTGGGGLRRFKTIELNSTIADKYSAESSQKKTSLYFDEEPELE MESLTDSPEDRSRGEGSSSLHASSFTPGTSPTSVSSLDEDSDSSPSHKKGESKQQRKARHRPH GPLLPTIEDSSEEEELREEEELLKEQEKQREIEQQQRKSSSKKSKKDKDELRAQRRRERPKTP PSNLSPIEDASPTEELRQAAEMEELHRSSCSEYSPSIESDPEGFEISPEKIIEVQKVYKLPTA VSLYSPTDEQSIMQKEGSQKALKSAEEMYEEM HKTHKYKAFPAANERDEVFEKEPLYGGMLI
EDYIYESLVEDTYNGSVDGSLLTRQEEENGFMQQKGREQKIRLSEQIYEDPMQKITDLQKEFY ELESLHSWPQEDIVSSSFIIPESHEIVDLGTMVTSTEEERKLLDADAAYEELMKRQQMQLTP GSSPTQAPIGEDMTESTMDFDRMPDASLTSSVLSGASLTDSTSSATLSIPDVKITQHFSTEEI EDEYVTDHTREIQEIIAHESLILTYSEPSESATSVPPSDTPSLTSSVSSVCTTDSSSPITTLD SITTVYTEPVDMITKFEDSEEISSSTYFPGSIIDYPEEISASLDRTAPPDGRASADHIVISLS DMASSIIESVVPKPEGPVADTVSTDLLISEKDPVKKAKKETGNGIILEVLEAYRDKKELEAER TKSSLSETVFDHPPSSVIALPMKEQLSTTYFTSGETFGQEKPASQLPSGSPSVSSLPAKPRPF FRSSSLDISAQPPPPPPPPPPPPPPPPPPPPPPLPPPTSPKPTILPKKKLTVASPVTTATPLF DAVTTLETTAVLRSNGLPVTRICTTAPPPVPPKPSSIPSGLVFTHRPEPSKPPIAPKPVIPQL PTTTQKPTDIHPKPTGLSLTSSMTLNSVTSADYKLPSPTSPLSPHSNKSSPRFSKSLTETYW ITLPSEPGTPTDSSASQAITS PLGSPSKDLVSVEPVFSWPPVTAVEIPISSEQTFYISGAL QTFSATPVTAPSSFQAAPTSVTQFLTTEVSKTEVSATRSTAPSVGLSSISITIPPEPLALDNI HLEKPQYKEDGKLQLVGDVIDLRTVP VEVKTTDKCIDLSASTMDVKRQITANEVYGKQISAV QPSIINLSVTSSIVTPVSLATETVTFVTCTASASYTTGTESLVGAEHAMTTPLQLTTSKHAEP PYRIPSDQVFPIAREEAPINLSLGTPAHAVTLAITKPVTVPPVGVTNG TDSTVSQGITDGEV VDLSTTKSHRTWTMDESTSSVMTKIIEDEKPVDLTAGRRAVCCDWYKLPFGRSCTAQQPAT TLPEDRFGYRDDHYQYDRSGPYGYRGIGGMKPSMSDTNLAEAGHFFYKSKNAFDYSEGTDTAV DLTSGRVTTGEVMDYSSKTTGPYPETRQVISGAGISTPQYSTARMTPPPGPQYCVGSVLRSSN GWYSSVATPTPSTFAITTQPGSIFSTTVRDLSGIHTADAVTSLPAMHHSQPMPRSYFITTGA SETDIAVTGIDISASLQTITMESLTAETIDSVPTLTTASEVFPEWGDESALLIVPEEDKQQQ QLDLERELLELEKIKQQRFAEELE ERQEIQRFREQEKIMVQKKLEELQSMKQHLLFC-QEEER QAQFMMRQETLAQQQLQLEQIQQLQQQLHQQLEEQKIRQIYQYNYDPSGTASPQTTTEQAILE GQYAALEGSQFWATEDATTTASAWAIEIPQSQGWYTVQSDGVTQYIAPPGILSTVSEIPLTD WVKEEKQPKKRSSGAKVRGQYDDMGE MTDDPRSFKKIVDSGVQTDDEDATDRSYVSRRRRT KKSVDTSVQTDDEDQDE DMPTRSRRKARVGKYGDΞMTEADKTKPLSKVSSIAVQTVAEISVQ TEPVGTIRTPSIRARVDAKVEIIKHISAPEKTYKGGSLGCQTEADSDTQSPQYLSATSPPKDK KRPTPLEIGYSSHLRADSTVQLAPSPPKSPKVLYSPISPLSPGKALESAFVPYEKPLPDDISP QKVLHPDMAKVPPASPKTAKM QRSMSDPKPLSPTADESSRAPFQYTEGYTTKGSQT TSSGA QKKVKRTLPNPPPEEISTGTQSTFSTMGTVSRRRICRTNTMARAKILQDIDRELDLVERESAK LRK QAELDEEEKEIDAKLRYLEMGINRRKEALLKEREKRERAYLQGVAEDRDYMSDSEVSST RPTRIESQHGIERPRTAPQTEFSQFIPPQTQTESQLVPPTSPYTQYQYSSPALPTQAPTSYTQ QSHFEQQTLYHQQVSPYQTQPTFQAVATMSFTPQVQPTPTPQPSYQLPSQMMVIQQKPRQTTL YLEPKITSNYEVIRNQPLMIAPVSTDNTFAVSHLGSKYNSLDLRIGLEERSSMASSPISSISA DSFYADIDHHTPR YVLIDDIGEITKGTAALSTAFSLHEKDLSKTDRLLRTTETRRSQEVTDF LAPLQSSSRLHSYVKAEEDPMEDPYELKLLKHQIKQEFRRGTESLDHLAGLSHYYHADTSYRH FPKSEKYSISRLTLEKQAAKQLPAAILYQKQSKHKKSLIDPKMSKFSPIQESRDLEPDYSSYM TSSTSSIGGISSRARLLQDDITFGLRKNITDQQKFMGSSLGTGLGTLGNTIRSALQDEADKPY SSGSRSRPSSRPSSVYGLDLSIKRDSSSSSLRLKAQEAEALDVSFSHASSSARTKPTSLPISQ SRGRIPIVAQNSEEESPLSPVGQPMGMARAAAGPLPPISADTRDQFGSSHSLPEVQQHMREES RTRGYDRDIAFIMDDFQHAMSDSEAYHLRREETDWFDKPRESRLENGHGLDRKLPERLVHSRP LSQHQEQIIQMNGKTMHYIFPHARIKITRDSKDHTVSGNGLGIRIVGGKEIPGHSGEIGAYIA KILPGGSAEQTGKLMEGMQVLEWNGIPLTSKTYEEVQSIISQQSGEAEICVRLDLNMLSDSEN SQHLELHEPPKAVDKAKSPGVDPKQLAAELQKVSLQQSPLVLSSVVEKGSHVHSGPTSAGSSS VPSPGQPGSPSVSKKKHGSSKPTDGTKWSHPITGEIQLQINYDLGNLIIHILQARNLVPRDN NGYSDPFVKVYLLPGRGQVMVVQNASAEYKRRTKHVQKSLNPEWNQTVIYKSIS EQLKKKTL EVTV DYDRFSSNDFLGEVLIDLSSTSHLDNTPR YPLKEQTESIDHGKSHSSQSSQQSPKPS VIKSRSHGIFPDPSKDMQVPTIEKSHSSPGSSKSSSEGHLRSHGPSRSQSKTSVTQTHLEDAG AAIAAAEAAVQQLRIQPSKRRK
Further analysis of the NOV65a protein yielded the following properties shown in Table 65B.
i Table 65B. Protein Sequence Properties NOV65a
PSort 0.9800 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space, 0.1000 probability located in lysosome (lumen)
SignaiP No Known Signal Sequence Predicted j analysis:
A search of the NOV65a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 65C.
In a BLAST search of public sequence datbases, the NOV65a protein was found to have homology to the proteins shown in the BLASTP data in Table 65D.
! Q9JKS6 Piccolo protein (Multidomain j 1..4870 4060/4924 (82%) : o.o presynaptic cytomatrix protein) - j 1..4877 4317/4924 (87%) Rattus norvegicus (Rat), 5085 aa. ]
; Q9QYX7 Piccolo protein (Presynaptic 1..4870 4047/4922 (82%) 0.0 j cytomatrix protein) (Aczonin) 1..4830 4293/4922 (86%)
I (Brain- derived HLMN protein) -
I Mus musculus (Mouse), 5038 aa.
Q9PU36 Piccolo protein (Aczonin) - Gallus j 87-4872 j 3260/4986 (65%) 0.0 gallus (Chicken), 5120 aa (fragment), j 1..4853 I 3724/4986 (74%)
I T00332 hypothetical protein KIAA0559 - j 3662-4873 1212/1212 (100%) 0.0
I human, 1212 aa (fragment). j 1..1212 1212/1212 ( 100%)
PFam analysis predicts that the NOV65a protein contains the domains shown in the Table 65E.
Example 66.
The NOV66 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 66A.

TGTGGCCCTCCTGAAGCGGTTTAAAGTTTCAGATGAGGTGGGCTTTGGGCTGGAGCATGTGTC CCGCGAGCAGATCCGGGAAGTGGAAGAGGACTTGGATGAATTGTATGACAGTCTGGAGATGTA CAACCCCAGCGACAGTGGCCCTGAGATGGAGGAGACAGAAAGCATCCTCAGCACGCCAAAGCC CAAGCTCAAGCCTTTCTTTGAGGGGATGTCGCAGTCCAGCTCCCAGACGGAGATTGGCAGCCT CAACAGCAAAGGCAGCCTCGGAAAAGACACCACCAGCCCTATGGAATTGGCTGCTCTAGAAAA AATTAAATCTACTTGGATTAAAAACCAAGATGACAGCTTGACTGAAACAGACACTCTGGAAAT CACTGACCAGGACATGTTTGGAGATGCCAGCACGAGTCTGGTTGTGCCGGAGAAAGTCAAAAC TCCCATGAAGTCCAGTAAAACGGATCTCCAGGGCTCTGCCTCCCCCAGCAAAGTGGAGGGGGT GCACACACCCCGGCAGAAGAGGAGCACGCCCCTGAAGGAGCGGCAGCTCTCCAAGCCCCTAAG TGAGAGGACCAACAGTTCCGACAGCGAGCGCTCCCCAGATCTGGGCCACAGCACGCAGATTCC AAGAAAGGTGGTGTATGACCAGCTCAATCAGATCCTGGTGTCAGATGCAGCCCTCCCAGAAAA TGTCATTCTGGTGAACACCACTGACTGGCAGGGCCAGTATGTGGCTGAGCTGCTCCAGGACCA GCGGAAGCCTGTGGTGTGCACCTGCTCCACCGTGGAGGTCCAGGCCGTGCTGTCCGCCCTGCT CACCCGGATCCAGCGCTACTGCAACTGCAACTCTTCCATGCCGAGGCCAGTGAAGGTGGCTGC TGTGGGAGGCCAGAGCTACCTGAGCTCCATCCTCAGGTTCTTTGTCAAGTCCCTGGCCAACAA GACCTCCGACTGGCTTGGCTACATGCGCTTCCTCATCATCCCCCTCGGTTCTCACCCTGTGGC CAAATACTTGGGGTCAGTCGACAGTAAATACAGTAGTTCCTTCCTGGATTCTGGTTGGAGAGA TCTGTTCAGTCGCTCGGAGCCACCAGTGTCAGAGCAACTGGACGTGGCAGGGCGGGTGATGCA GTACGTCAACGGGGCAGCCACGACACACCAGCTTCCCGTGGCCGAAGCCATGCTGACTTGCCG GCATAAGTTCCCTGATGAAGACTCCTATCAGAAGTTTATTCCCTTCATTGGCGTGGTGAAGGT GGGTCTGGTTGAAGACTCTCCCTCCACAGCAGGCGATGGGGACGATTCTCCTGTGGTCAGCCT TACTGTGCCCTCCACATCACCACCCTCCAGCTCGGGCCTGAGCCGAGACGCCACGGCCACCCC TCCCTCCTCCCCATCTATGAGCAGCGCCCTGGCCATCGTGGGGAGCCCTAATAGCCCATATGG GGACGTGATTGGCCTCCAGGTGGACTACTGGCTGGGCCACCCCGGGGAGCGGAGGAGGGAAGG CGACAAGAGGGACGCCAGCTCGAAGAACACCCTCAAGAGTGTCTTCCGCTCAGTGCAGGTGTC CCGCCTGCCCCATAGTGGGGAGGCCCAGCTTTCTGGCACCATGGCCATGACTGTGGTCACCAA AGAAAAGAACAAGAAAGTTCCCACCATCTTCCTGAGCAAGAAACCCCGAGAAAAGGAGiTGGA TTCTAAGAGCCAGGTCATTGAAGGCATCAGCCGCCTCATCTGCTCAGCCAAGCAGCAGCAGAC TATGCTGAGAGTGTCCATCGATGGGGTCGAGTGGAGTGACATCAAGTTCTTCCAGCTGGCAGC CCAGTGGCCCACCCATGTCAAGCACTTTCCAGTGGGACTCTTCAGTGGCAGCAAGGCCACCTG AGGCCCTGTCTCCCAG
ORF Start: ATG at 8 ,ORF Stop: TGA at_2897
! SEQ ID NO: 242 """ " 1963 aa MW'at 1048973 kD " " jNOVόόa, " MAERGGAGGGPGGAGGGSGQRGSGVAQSPQQPPPQQQQQQPPQQPTPPKLAQATSSSSSTSAA
|CG 138208-01 Protein AASΞSSSSTSTSMAVAVASGSAPPGGPGPGRTPAPVQMNLYAT EVDRSSSSCVPRLFSLTLK KLV LKE DKDLNSWIAVKLQGSKRILRSNEIVLPASGLVETELQLTFSLQYPHFLKRDANK •Sequence LQIMLQRRKRYKNRTILGYKTLAVGLINMAEVMQHPNEGALVLGLHSNVKDVSVPVAEIKIYS LSSQPIDHEGIKSKLSDRSPDIDNYSEEEEESFSSEQEGSDDPLHGQDLFYEDEDLRKVKKTR RKLTSTSAITRQPNIKQKFVALLKRFKVSDEVGFGLEHVSREQIREVEEDLDELYDSLEMYNP SDSGPEMEETESILSTPKPKLKPFFEGMSQSSSQTEIGSLNSKGSLGKDTTSPMELAALEKIK STWIKNQDDSLTETDTLEITDQDMFGDASTSLWPEKVKTPMKSSKTDLQGSASPSKVEGVHT PRQKRSTPLKERQLSKPLSERTNSSDSERSPDLGHSTQIPRKWYDQLNQILVSDAALPENVI LVNTTDWQGQYVAELLQDQRKPWCTCSTVEVQAVLSALLTRIQRYCNCNSSMPRPVKVAAVG GQSYLSSILRFFVKSLANKTSD LGYMRFLIIPLGSHPVAKYLGSVDSKYSSSFLDSGWRDLF SRSEPPVSEQLDVAGRVMQYV GAATTHQLPVAEAMLTCRHKFPDEDSYQKFIPFIGWKVGL VEDSPSTAGDGDDSPWSLTVPSTSPPSSSGLSRDATATPPSSPSMSSALAIVGSPNSPYGDV IGLQVDYWLGHPGERRREGDKRDASSKNTLKSVFRSVQVSRLPHSGEAQLSGTMAMTWTKEK NKKVPTIFLSK PREKEVDSKSQVIEGISRLICSAKQQQTMLRVSIDGVEWSDIKFFQLAAQ PTHVKHFPVGLFSGSKAT
SEQ ID NO: 243 3225 bp
NOV66b, CGGCCTCCGTAACCCCCGCCTAGCCGGGCCATGGCGGAACGCGGAGGGGCGGGCGGTGGTCCC
CG 138208-02 DNA GGAGGCGCCGGGGGCGGCAGCGGCCAGCGGGGATCCGGGGTCGCCCAGTCCCCTCAGCAGCCG CCGCCGCAGCAGCAGCAGCAGCAGCCGCCGCAGCAGCCGACGCCCCCCAAGCTGGCCCAGGCC
.Sequence ACCTCGTCGTCCTCGTCCACCTCGGCGGCGGCTGCCTCCTCCTCGTCCTCGTCTACCTCCACC TCCATGGCCGTGGCGGTGGCCTCGGGCTCCGCGCCTCCCGGTGGCCCGGGGCCAGGCCGCACC CCCGCCCCGGTGCAGATGAACCTGTACGCCACCTGGGAGGTGGACCGGAGCTCGTCCAGCTGC GTGCCTAGGCTATTCAGCTTGACCCTGAAGAAACTCGTCATGCTAAAAGAAATGGACAAAGAT CTTAACTCAGTGGTCATCGCTGTGAAGCTGCAGGGTTCAAAAAGAATTCTTCGCTCCAACGAG ATCGTCCTTCCAGCTAGTGGACTGGTGGAAACAGAGCTCCAATTAACCTTCTCCCTTCAGTAC CCTCATTTCCTTAAGCGAGATGCCAACAAGCTGCAGATCATGCTGCAAAGGAGAAAACGTTAC AAGAATCGGACCATCTTGGGCTATAAGACCTTGGCCGTGGGACTCATCAACATGGCAGAGGTG ATGCAGCATCCTAATGAAGGCGCACTGGTGCTTGGCCTACACAGCAACGTGAAGGATGTCTCT GTGCCTGTGGCAGAAATAAAGATCTACTCCCTGTCCAGCCAACCCATTGACCATGAAGGAATC AAATCCAAGCTTTCTGATCGTTCTCCTGATATTGACAATTATTCTGAGGAAGAGGAAGAGAGT
TTCTCATCAGAACAGGAAGGCAGTGATGATCCATTGCATGGGCAGGACTTGTTCTACGAAGAC GAAGATCTCCGGAAAGTGAAGAAGACCCGGAGGAAACTAACCTCAACCTCTGCCATCACAAGG CAACCTAACATCAAACAGAAGTTTGTGGCCCTCCTGAAGCGGTTTAAAGTTTCAGATGAGGTG

GGCTTTGGGCTGGAGCATGTGTCCCGCGAGCAGATCCGGGAAGTGGAAGAGGACTTGGATGAA TTGTATGACAGTCTGGAGATGTACAACCCCAGCGACAGTGGCCCTGAGATGGAGGAGACAGAA AGCATCCTCAGCACGCCAAAGCCCAAGCTCAAGCCTTTCTTTGAGGGGATGTCGCAGTCCAGC TCCCAGACGGAGATTGGCAGCCTCAACAGCAAAGGCAGCCTCGGAAAAGACACCACCAGCCCT ATGGAATTGGCTGCTCTAGAAAAAATTAAATCTACTTGGATTAAAAACCAAGATGACAGCTTG ACTGAAACAGACACTCTGGAAATCACTGACCAGGACATGTTTGGAGATGCCAGCACGAGTCTG GTTGTGCCGGAGAAAGTCAAAACTCCCATGAAGTCCAGTAAAACGGATCTCCAGGGCTCTGCC TCCCCCAGCAAAGTGGAGGGGGTGCACACACCCCGGCAGAAGAGGAGCACGCCCCTGAAGGAG CGGCAGCTCTCCAAGCCCCTAAGTGAGAGGACCAACAGTTCCGACAGCGAGCGCTCCCCAGAT CTGGGCCACAGCACGCAGATTCCAAGAAAGGTGGTGTATGACCAGCTCAATCAGATCCTGGTG TCAGATGCAGCCCTCCCAGAAAATGTCATTCTGGTGAACACCACTGACTGGCAGGGCCAGTAT GTGGCTGAGCTGCTCCAGGACCAGCGGAAGCCTGTGGTGTGCACCTGCTCCACCGTGGAGGTC CAGGCCGTGCTGTCCGCCCTGCTCACCCGGATCCAGCGCTACTGCAACTGCAACTCTTCCATG CCGAGGCCAGTGAAGGTGGCTGCTGTGGGAGGCCAGAGCTACCTGAGCTCCATCCTCAGGTTC TTTGTCAAGTCCCTGGCCAACAAGACCTCCGACTGGCTTGGCTACATGCGCTTCCTCATCATC CCCCTCGGTTCTCACCCTGTGGCCAAATACTTGGGGTCAGTCGACAGTAAATACAGTAGTTCC TTCCTGGATTCTGGTTGGAGAGATCTGTTCAGTCGCTCGGAGCCACCAGTGTCAGAGCAACTG GACGTGGCAGGGCGGGTGATGCAGTACGTCAACGGGGCAGCCACGACACACCAGCTTCCCGTG GCCGAAGCCATGCTGACTTGCCGGCATAAGTTCCCTGATGAAGACTCCTATCAGAAGTTTATT CCCTTCATTGGCGTGGTGAAGGTGGGTCTGGTTGAAGACTCTCCCTCCACAGCAGGCGATGGG GACGATTCTCCTGTGGTCAGCCTTACTGTGCCCTCCACATCACCACCCTCCAGCTCGGGCCTG AGCCGAGACGCCACGGCCACCCCTCCCTCCTCCCCATCTATGAGCAGCGCCCTGGCCATCGTG GGGAGCCCTAATAGCCCATATGGGGACGTGATTGGCCTCCAGGTGGACTACTGGCTGGGCCAC CCCGGGGAGCGGAGGAGGGAAGGCGACAAGAGGGACGCCAGCTCGAAGAACACCCTCAAGAGT GTCTTCCGCTCAGTGCAGGTGTCCCGCCTGCCCCATAGTGGGGAGGCCCAGCTTTCTGGCACC ATGGCCATGACTGTGGTCACCAAAGAAAAGAACAAGAAAGTTCCCACCATCTTCCTGAGCAAG AAACCCCGAGAAAAGGAGGTGGATTCTAAGAGCCAGGTCATTGAAGGCATCAGCCGCCTCATC TGTTCTTCCCCCTCCTTAGGCCCCAGCCTGGGCCCAGACCCATCCTCCCAGCCAGGTTTCCCT CCAGCAGGCTCCTTCCCTCCCTGTCACCTCCCTCTCACCAACCCGGGGTCTGAGCCCCTCATT CCTGACCGTCCGTGTTCTCAGGAGTGGTTGAGGACACAGGGCCCCAGCCCAGCCCTCTGCACC CCCCAGCCCGGCCATCTGCGCCCCACAGCCCCTTTGGAGCTTTTCTCTTGTCCTCTCACTCCT TCCCAGAAGTTTTTGCACAGAACTTCATTTTGAAAGTGTTTTTCTCATTCTCCATACCTCCCC
CAAGCTCTCCTCCAGCCCTTCCCAGGGCTCAGCCCTGCTGTCCTGAGCGTCTCCTGGGCCAGA
GAGAGGAGATGGGGGTGGGAGGGACTGAGTTGATGTTGGGTTTTTCATTCAATAAATTGGTGA
TTTCTTACCGAC
T l,ORF Start: ATG at 31 ]ORF Stop: TGA at 3055 SEQ ID NO: "244 1008 aa MW at 109341.2kD
>NOV66b, MAERGGAGGGPGGAGGGSGQRGSGVAQSPQQPPPQQQQQQPPQQPTPPKLAQATSΞSSSTSAA
;CG 138208-02 Protein AASSSSSSTSTS AVAVASGSAPPGGPGPGRTPAPVQMNLYATWEVDRSSSSCVPRLFSLTLK KLVMLKEMDKDLNSWIAVKLQGSKRILRSNEIVLPASGLVETELQLTFSLQYPHFLKRDANK
■Sequence LQIMLQRRKRYKNRTILGYKTLAVG INMAEVMQHPNEGALVLGLHSNVKDVSVPVAEIKIYS LSSQPIDHEGIKSKLSDRSPDIDNYSEEEEESFSSEQEGSDDPLHGQDLFYEDEDLRKVKKTR RKLTSTSAITRQPNIKQKFVALLKRFKVSDEVGFGLEHVSREQIREVEEDLDELYDSLEMYNP SDSGPEMEETESILSTPKPKLKPFFEGMSQSSSQTEIGSLNSKGSLGKDTTSPMELAALEKIK STWIKNQDDSLTETDTLEITDQDMFGDASTSLWPEKVKTPMKSSKTDLQGSASPSKVEGVHT PRQKRSTPLKERQLSKPLSERTNSSDSERSPDLGHSTQIPRKWYDQLNQILVSDAALPENVI LVNTTDWQGQYVAELLQDQRKPWCTCSTVEVQAVLSALLTRIQRYCNCNSS PRPVKVAAVG GQSYLSSILRFFVKSLANKTSD LGYMRFLIIPLGSHPVAKYLGSVDSKYSSSFLDSGWRDLF SRSEPPVSEQLDVAGRVMQYVNGAATTHQLPVAEAMLTCRHKFPDEDSYQKFIPFIGVVKVGL VEDSPSTAGDGDDSPWSLTVPSTSPPSSSGLSRDATATPPSSPSMSSALAIVGSPNSPYGDV IGLQVDYWLGHPGERRREGDKRDASSKNTLKSVFRSVQVSRLPHSGEAQLSGTMAMTWTKEK NKKVPTIFLSKKPREKEVDSKSQVIEGISRLICSSPSLGPSLGPDPSSQPGFPPAGSFPPCHL PLTNPGSEPLIPDRPCSQEWLRTQGPSPALCTPQPGHLRPTAPLELFSCPLTPSQKFLHRTSF
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 66B.
j Table 66B. Comparison of NOVόόa against NOV66b.
NOVόόa Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
NOV66b 100-915 738/816 (90%) 100..915 738/816 (90%)
Further analysis of the NOV66a protein yielded the following properties shown in Table 66C.
I Table 66C. Protein Sequence Properties NOVόόa j PSort 0.9700 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVόόa protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 66D.
gene 19 clone HCUGE72 - Homo 65..102 132/38 (83%) sapiens, I 04 aa. [WO200055371-A1 , 21-SEP-2000]
In a BLAST search of public sequence datbases, the NOVόόa protein was found to have homology to the proteins shown in the BLASTP data in Table 66E.
LASTP Results for N V
PFam analysis predicts that the NOVόόa protein contains the domains shown in the Table 66F.
! Table 66F. Domain Analysis of NOVόόa
Identities/
Pfam Domain NOVόόa Match Region Similarities Expect Value for the Matched Region
Example 67.
The NOV67 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 67A.
Table 67 A. NOV67 Sequence Analysis SEQΪDNO: 245 J5634 bp
NOV67a. CGGGATTGCACCATGGGGAACCAGGATGGGAAGCTGAAGAGGAGCGCAGGTGATGCTTTGCAC
CGI 38303-01 DNA GAAGGCGGCGGTGGCGCCGAGGATGCGCTGGGGCCCAGGGATGTGGAAGCCACAAAGAAGGGG AGCGGGGGCAAGAAGGCGCTAGGCAAGCACGGCAAGGGGGGAGGGGGCGGCGGCGGCGGCGGG
Sequence GAGTCGGGCAAGAAGAAGAGCAAGTCCGACTCCAGAGCCTCGGTGTTTTCCAACCTGCGGATC AGGAAGAATCTGTCCAAGGGGAAAGGCGCCGGCGGCTCCCGCGAAGATGTACTGGATTCCCAG GCCCTGCAGACCGGGGAGCTGGACAGCGCTCACTCCCTGCTCACCAAGACTCCAGACCTCAGC CTCTCGGCGGACGAGGCCGGCCTGTCGGATACCGAGTGTGCGGACCCTTTTGAGGTGACCGGT CCAGGGGGTCCTGGGCCTGCCGAGGCTAGGGTCGGGGGCCGGCCGATCGCCGAGGATGTGGAA ACTGCAGCAGGGGCGCAGGATGGACAAAGGACCAGCTCGGGCTCGGACACGGACATCTATAGC TTCCATTCGGCTACGGAGCAAGAGGATTTGCTTTCAGACATCCAGCAGGCGATCCGCCTGCAG CAGCAGCAGCAGCAGCAGCTCCAGCTCCAGCTCCAGCAACAGCAGCAGCAGCAGCAGCTCCAG GGCGCCGAGGAGCCTGCAGCGCCCCCCACTGCCGTCTCCCCTCAGCCCGGGGCCTTCCTGGGC CTGGACCGGTTCCTGCTGGGGCCGGTCTCCGAGGCGCCCAGTCTCCCGGCAGCGCAACCCGCG GCCAAAGACTCGCCCTCCTCCACGGCTTTCCCATTTCCCGAGGCCGGGCCGGGGGAGGAAGCG GCCGGAGCCCCCGTGCGAGGGGCTGGGGACACGGATGAGGAGGGTGAGGAGGATGCTTTTGAG GATGCGCCCCGGGGCTCTCCGGGGGAGGAGTGGGCCCCGGAGGTGGGAGAGGACGCCCCGCAG AGGCTGGGGGAAGAGCCGGAGGAGGAGGCGCAAGGACCTGACGCCCCCGCGGCCGCTTCCCTG CCCGGCAGCCCCGCGCCTAGCCAGCGCTGTTTCAAGCCCTACCCGCTCATCACCCCCTGCTAC ATCAAGACCACCACCCGGCAGCTCAGCTCGCCCAATCACTCCCCGTCTCAGTCCCCTAATCAG AGCCCCAGGATCAAGAGGCGGCCGGAACCCTCCCTGAGCCGAGGGTCCAGAACTGCCCTGGCC TCCGTAGCCGCCCCGGCCAAGAAGCACCGGGCCGACGGCGGCCTTGCGGCCGGCCTGAGCCGC TCGGCTGACTGGACGGAGGAGCTAGGCGCCCGCACGCCCCGGGTGGGAGGCTCCGCGCACCTG CTGGAGCGCGGGGTGGCGAGTGACAGCGGCGGTGGGGTGTCCCCAGCACTGGCCGCCAAGGCG TCTGGGGCCCCCGCGGCTGCGGATGGCTTCCAGAACGTGTTCACAGGTGAGCGCGGGCGAACG CTGTTGGAGAAGCTGTTCAGCCAGCAGGAGAACGGGCCTCCAGAAGAAGCAGAGAAGTTTTGC TCCCGGATCATTGCCATGGGTCTTCTCCTTCCTTTTAGTGATTGCTTCAGGGAACCGTGTAAT CAGAATGCCCAAGATCAACTTTATACCTGGGCTGCAGTTAGTCAACCCACACACTCATTGGAC TATTCAGAAGGGCAGTTTCCTAGGCGAGTTCCATCCATGGGGCCACCATCCAAACCTCCCGAT GAGGAACACAGGCTCGAGGATGCTGAAACAGAATCTCAATCTGCTGTTTCAGAAACTCCCCAA AAACGCTCAGATGCTGTCCAGCAGGAAGTTGTTGACATGAAGTCTGAGGGACAGGCCACTGTA ATTCAGCAGCTGGAACAGACTATTGAGGATCTGAGAACCAAAATAGCTGAACTAGAGAGGCAG TATCCTGCCCTGGACACAGAGGTGGCCAGTGGTCATCAAGGGCTTGAGAATGGAGTGACAGCC TCAGGCGATGTCTGTCTCGAAGCTCTCAGGTTAGAAGAAAAGGAAGTACGGCATCATAGGATT TTAGAGGCGAAATCGATACAGACTTCCCCCACGGAAGAGGGCGGGGTGCTGACACTGCCTCCT GTGGATGGGCTGCCAGGGCGTCCTCCATGCCCCCCTGGGGCTGAAAGTGGACCTCAGACAAAG TTCTGTTCAGAGATTTCTTTGATTGTGTCTCCAAGGCGAATATCAGTCCAGCTCGACAGCCAT CAGCCCACACAGAGCATCTCACAGCCTCCACCACCTCCATCCCTTCTGTGGTCTGCTGGGCAA GGACAGCCTGGGTCACAGCCGCCCCATTCTATTTCTACCGAGTTTCAAACCAGCCACGAACAC TCTGTTTCCTCTGCCTTTAAAAACAGCTGTAACATCCCATCTCCACCACCTCTGCCTTGCACA GAGTCCTCCAGCTCCATGCCTGGCCTGGGCATGGTGCCTCCCCCACCTCCCCCTCTCCCTGGC ATGACAGTGCCTACTCTGCCCAGTACAGCCATTCCCCAACCTCCTCCTCTGCAGGGTACAGAA ATGCTGCCACCCCCTCCCCCTCCTCTTCCCGGAGCGGGCATACCTCCTCCGCCGCCTCTACCC GGAGCAGGCATACTCCCTCTGGGAGCGGGCATACCCCCACCTCCCCCTCTACCCGGAGCGGGC ATACCCCCTCCGCCCCCTCTACCCGGAGTGGGCATACCTCCTCCGCCCCCTCTACCCGGAGCG GGCATACCCCCTCCTCCCCCTCTACCCGGAGCGGGCATACCCCCTCCTCCCCCTCTTCCCGGA GCGGGCATACCTCCTCCACCCCCTCTACCCAGAGTGGGCATACCCCCTCCGCCCCCACTTCCC GGAGCGGGCATACCCCCACCTCCCCCTCTACCCGGAGCGGGCATACCCCCTCCGCCCCCTCTA CCTGGAGTGGGAATACCTCCTCCGCCCCCTCTACCTGGAGTGGGAATACCTCCTCCGCCCCCT CTACCTGGTGCTGGGATTCCCCCACCTCCTCCCTTGCCAGGTATGGGGATTCCACCTGCTCCA GCTCCCCCACTCCCTCCACCTGGGACAGGAATCCCACCGCCCCCTCTGCTTCCTGTATCAGGC CCTCCACTCCTCCCACAAGTTGGGAGTAGCACTTTACCAACCCCACAGGTGTGTGGATTTCTT CCTCCTCCATTGCCAAGTGGCTTGTTTGGATTAGGGATGAATCAGGACAAAGGGAGTAGGAAG CAGCCCATAGAGCCTTGTCGACCAATGAAGCCTCTTTACTGGACCAGGATTCAACTACATAGT AAAAGAGACTCCAGTACTTCACTTATTTGGGAAAAAATTGAAGAGCCATCCATAGATTGTCAT GAATTTGAGGAATTATTTTCTAAAACTGCTGTAAAGGAGAGAAAGAAACCTATCTCTGATACT

Further analysis of the NOV67a protein yielded the following properties shown in Table 67B.
j Table 67B. Protein Sequence Properties NOV67a
PSort 0.7000 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
• SignalP No Known Signal Sequence Predicted ', analysis:
A search of the NOV67a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 67C.
In a BLAST search of public sequence datbases, the NOV67a protein was found to have homology to the proteins shown in the BLASTP data in Table 67D.
PFam analysis predicts that the NOV67a protein contains the domains shown in the Table 67E.
Example 68.
The NOV68 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 68A.

GAATATAATAAACTGAAGGAACGTCTACATCAACTTGTTATGAACAAGAAAGATAAGAAAATA GCTATGGACATTTTGAATTATGTCGGGAGAGCTGATGGAAAAAGAGGCTCCTGGAGGACTGGT AAAACTGAAGCCAGGAATGAAGATGAAATGTATAAAATTCTCTTGAATGATTATGAATATCGT CAGAAACAAATCCTAATGGAAAATGCAGAACTTAAGAAGGTTCTTCAACAAATGAAAAAGGAA ATGATTTCTCTTCTTTCTCCCCAAAAGAAGAAACCTAGAGAAAGAGTAGATGATAGTACAGGA ACTGTTATTTCCGATGTTGAAGAAGATGCCGGGGAACTAAGCAGAGAGAGTATGTGGGACCTT TCCTGTGAAACTGTGAGAGAGCAGCTTACAAACAGCATCAGAAAACAGTGGAGAATTTTGAAA AGTCATGTAGAAAAGCTTGATAACCAAGTTTCAAAGGTACACCTGGAAGGTTTTAATGATGAA GATGTAATCTCACGACAAGACCATGAACAAGAAACTGAAAAACTCGAGTTAGAAATTCAGCAG TGTAAAGAAATGATTAAAACTCAGCAACAGCTTTTACAGCAGCAGCTCGCTACTGCATATGAT GATGATACCACTTCACTATTACGAGACTGTTATTTGTTGGAAGAAAAGGAACGTCTCAAAGAA GAATGGTCCCTTTTTAAAGAGCAGAAAAAGAATTTTGAGAGGGAGAGACGAAGCTTTACAGAA GCCGCTATTCGCCTGGGATTGGAGAGAAAGGCATTTGAAGAAGAAAGAGCCAGTTGGTTAAAG CAGCAGTTTCTAAATATGACTACCTTTGACCACCAGAACTCAGAAAATGTGAAACTTTTCAGT GCCTTCTCAGGAAGTTCTGATTGGGACAATCTTATAGTGCACTCGAGGCAGCCGCAAAAGAAG CCTCACAGTGTGTCTAATGGGTCTCCAGTTTGCATGTCTAAACTTACTAAATCTCTTCCTGCT TCACCTTCCACTTCAGACTTTTGCCAGACACGTTCCTGCATATCTGAACATAGTTCAATCAAT GTACTGAATATAACTGCTGAAGAAATTAAACCAAATCAGGTTGGAGGAGAACGTACAAATCAA AAATGGAGTGTGGCGTCAAGACCTGGATCACAGGAAGGTTGCTATAGTGGATGCTCCTTGAGC TACACAAATTCTCATGTAGAAAAAGATGACTTACCTTAGACATGTGGACTGGAATTTTTTTCA TTAATGTGTTCATCAAGTTTCACATCTAAGTTGAAACAGGGTGTGTCATAAAGTCAGTTATCT CTAATAACTTAAGATGGTCTGAGTTGTTTGTTTGGACTTCCCTGTCTTCCCCCAAAGAGTTGA AATCTTAAATCTATTTAAAAGGATATAAAAGCTTTGGATATGTATTTTTAGTAACAGAAGCAT CTGGTTCTGTGAATAAAGGAATGTATAGATGTTTGGATGGAAACAAAAGCACTAGACTGAGTT TCCTCTTATAGGTATTAAAAATAGCACTTTTAGGAAACTGATTATTGTAAATGTTTAATTTTG TCTCAAATATAGTTGGCATTGGAAGTTTAGCCTTTACTTGAATGTATACTGTAGATTTTTAAC AAAGCGAGTTCTATATTTATTATGTTTAGTGTGGTTTGAAATTACCTCTTTCATATGTTTTAA ATAAAGTGAAATTTATGTATGTTTTGTACATAGATACACATGATTATGTTAAGAGGCTTTAAG ATTTAAAAGTTTCACACAACCATAAGTATAGTATTTCATGCCAGTAAAATTTTTTTAGTGGTA TTCTGTTTACAGATGTATTAGGACCATTGATGCATTACATTTAAGAATTCTCTTTAATACATC TGGGCAATAAATATTGAAAGGTATTCCATGAAGCTGAGTTCTTTAGATAATCAACACTACTAA CATTACATTTTTGAGATTTTTATGACATTAGATTTTTATTTTGTATATGTAGAATATTATAAT TTTTAAAAGGACTATTGATGATAGAAGAATAGGGGCAAGACGACAAAAGTACCTTTGAATAAA ACAATTTAAGAAATTGGTTTAAGATATTGGATGATAGAAGATATTTAAGATATCTAGATGGTG
ATATTTTCCTTACAAGATGGGTACCAGTATAGTAATATCTGTATACTAACTAGGGCTTTGTAT
TGTCAATAATTTTTTAATAATTTTTTAATGAGGTATTTACCACTGAAGAAATATGATAATATA
AAACCATCAAATTTTATAATTGAGATGATACTCTGGAAAAACATGTCATTTCATTTTCAGAAA
ACTCTTAAGCTCTCTTCAGTCTCTGTAATGTTTCTGATTGCATGTTTCTTCATGAAAAGTATG
TTGTTGTTTTGATAGTAATAATAATAAATGTAGGCTCAGCTCTTTCCCAGGATTTTCATCAAA
AAGCTTTAAGTGCCTAACCCTGCTTGTCTCTGTACATAGAAGCCTGCACAGATCCAACCCTTG
CTAGGTATCATAGTTTAGGCCCATTTACCTTCCCCTGTACTGGCAGTTCAGCCGCTTACATGC
ACTCACCCTGTTTGTGGCTATTTTAAATTCATATTATTAAAAAACAAAAAAAACCCACCTATT
TGTGTTGTCCATTCACTATACGTAACTATGTAACTCTTTGGAGTTGCATAGCAGCAGCCATTT
TTTCAGGGCTGATAGGATATCATTAAGAGTGTCTTATGAGACATTAGTGGATATACTCATAGT
AACCATATTTATAGTTTTAAAGAGCTAGCTCTTGAGCATTAGTCACTACCTTCAGCTTGATGC
ATGGTCACTTCTTTACTATTTAAAATACTACACATTGTACAAAATATCGAAGACACTACCATA
TGCTAAAGGAAGAAATCTAGCTGGGATATAGGATTTTTGTTGTTTTTGTTTTTGTTTGTTTTG
CTATTTAGCAATAACATGGTCAAAAAGGCAATCAGAAATTTTAAATACAGTTAATGGATACAT
TTGGCAACAATTTTCCCCCGAGGGTTTTCCATGGTGTACTTTGCAAGAAATAAGCACTCTAAT
TTTTAAAGTAAATCTCTTATTTTAGCAAATATTATATTTCATGACAATGGAGTTCTAGAAAGC
AGCATCTGTTTTTTGTTGCGTGTTTCCATTTTAAAGTGAGTTGAGTTCTCAAATTGGAAAGAA
AGATTCCTTGAGACGTACTTTTAAAATCTAAAGTGTGAAAGAAACAGCAGAGTAAAAGCCAGA
CTCATTGCACCTTCAATGTCTGCATAGATCCAGAAGTTGTACATTTTACCTAACAACATCACT
TTTGTTGAACATTCCAACTCCAGAATGATCCCCAATCACCCTAATCTCAGAATGCTGGAATGA
TGTCTGTTGGAAAACCCAGGACTCCACACACAAAACTCCTGGGATTTTGTTTCCCATCTCTTT
CTAGGTGTTTGCAATGTACAAATAATACAGCTGTGCTAATCTCACATTTAGCCATGATAGATG
ATGGTTCTAGAGTGTACTTCCATTTGTAAGTCCTCCTGATAAGTGCTTTCTTGTTTATCACTA
TGTAAATCTGAAATATTTTGTACTTCATTTGTTTTTATCCATTCTGAATTTTCAAAGCATAAA
AATGTCAAAGAAAAATTGAGATAAACATTTTGTTCACCATTAAATGTTTGCATCTGCAGTCTA
TGATGAGAAACAATGAAATTATGACTAAAATTTAACAAATAGTATTTTCTTATAGAAGCAATG
TATTAAATGATTAGATACACAGGACAGTTCACAGCAAATTGTTTACTTACATGGCATAATTGA
AATACTGTTATTTGTAAAGAGTTCTATACTGCCTACCTTAGCTAACCAGAATTGTTCATAGAC
TTGTGATAATATGGTGTTATGGGAAAACACATTTTGTGCGCATGATGAAGAGAGCACCGTGAA
TCTAGTCTTGACTGCCCCTGGTGGAACATTTGAAAGCCCTTGGGACTCCAGGAGAGATGTTTT
TGCAGCATGTATGCTAAATTTGTGAGTTAGCAAGACCCTGCTGTGATTACTATGTTGTACAGA TCTTCAAAGTATATTGCCTAATATGAGTCATGTTATTTCTAGATTGAATTTAAAGTAAGTATG
GATTATGGAAGTCTAGTAAATATACTTTTCCCTATTTTTGTCCTTTTTCAGTCTTTTGGTAAG
CATTTATTAAGTACCTGCTGTATGTCAAGGCTTACTACTGCTTTCCAATCCTTGGTGATATGA AGACAGATAAGCACGCTGCCTGCTATTAGGAATCTGAGCTGAGTGGAAGGCCAACTATTAAAC CTACATTGTAATAAACAATGGTGGATGCTACGGACACATTCAGTCTGTTCATAAAACATGGAC
TGATGGGTCTGCTCCAGGCCACATTTGTTTTTTAACAGTAACGTGGCTAGGCTTCCATTTATA
AGTCTTAGCATTATTTCCTTTGTGAAGTACTATGTAACAGATGATTGTTTGCTAGATTTTGTT
TTCTACAATCAAAATGTTGACCTGCAAAGCAGTGTAGGATTTTCTCTCCTCAAGAGCGTGTAT
TATTATCTAGTAGAAAAAGCATTCCCAAAGACTTGGTCCATGCAGATAAGGATAATGAAATTG
CTCACTCTAATCCTTTTTCTAAATACAGTGTTTTTCAAGCTGGATGTAAATTAGAGTGGGTGG
ATATTGATTAAATTATTTGATTTATATGAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
ORF Start: ATG at 166 j ;ORF Stop: TAG at 1927
SEQ ID NO: 248 " J587 aa "MW at 68326.4kD
!NOV68a, SPSSLYSQQVLCSSIPLSKNVHSFFSAFCTEDNIEQSISYLDQELTTFGFPSLYEESKGKET
CG138362-01 Protein KRELNIVAVLNCM ELLVLQRKNLLAQENVETQNLKLGSDMDHLQSCYSKLKEQLETSRREMI GLQERDRQLQCKNRNLHQLLKNEKDEVQKLQNIIASRATQYNHDMKRKEREYNKLKERLHQLV Sequence MNKKDKKIAMDILNYVGRADGKRGS RTGKTEARNEDE YKILL DYEYRQKQILMENAELKK VLQQMKKEMISLLSPQKKKPRERVDDSTGTVISDVEEDAGELSRESMWDLSCETVREQLTNSI RKQ RILKSHVEKLDNQVSKVHLEGFNDEDVISRQDHEQETEKLELEIQQCKE IKTQQQLLQ QQLATAYDDDTTSLLRDCYLLEEKERLKEEWSLFKEQKKNFERERRSFTEAAIRLGLE.RKAFE EERASWLKQQFLNMTTFDHQNSENVKLFSAFSGSSDWDNLIVHSRQPQKKPHSVSNGSPVCMS KLTKSLPASPSTSDFCQTRSCISEHSSINVLNITAEEIKPNQVGGERTNQKWSVASRPGSQEG CYSGCSLSYTNSHVEKDDLP
Further analysis of the NOV68a protein yielded the following properties shown in Table 68B.
i Table 68B. Protein Sequence Properties NOV68a j PSort 0.5500 probability located in endoplasmic reticulum (membrane); 0.1900 probability ' analysis: located in lysosome (lumen); 0.1800 probability located in nucleus; 0.1000 probability located in endoplasmic reticulum (lumen) i SignalP No Known Signal Sequence Predicted ! analysis:
A search of the NOV68a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 68C.
In a BLAST search of public sequence datbases, the NOV68a protein was found to have homology to the proteins shown in the BLASTP data in Table 68D.
PFam analysis predicts that the NOV68a protein contains the domains shown in the Table 68E.
The N0V69 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 69A.
Further analysis of the NOV69a protein yielded the following properties shown in Table 69B.
Table 69B. Protein Sequence Properties NOV69a
PSort 0.4500 probability located in cytoplasm; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 p prroobbaabbiilliittyy llooccaatteedd iinn llyyssoossoommee ( (lluummeenn))
SignalP , No Known Signal Sequence Predicted analysis:
A search of the NOV69a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 69C.
In a BLAST search of public sequence datbases, the NOV69a protein was found to have homology to the proteins shown in the BLASTP data in Table 69D.
Table 69D. Public BLASTP Results for NOV69a
NOV69a
Protein Identities/ " Residues/
Accession Protein/Organism/Length Similarities for the ! ' j Match
Number Matched Portion Residues
Q8TB52 ; Similar to RIKEN cDNA 1..745 745/745 (100%) 1 0.0
; 1700026A 16 gene - Homo sapiens 1..745 745/745 (100%) (Human). 745 aa.
Q9D9X5 1700026A 16Rik protein - Mus 1..745 653/749 (87%) ! 0.0 musculus (Mouse), 746 aa. 1..746 696/749 (92%)
Q9BXZ7 F-box domain protein - Homo 356-745 388/390 (99%) 0.0
, sapiens (Human), 390 aa. 1.390 389/390 (99%)
Q9UH90 Muscle disease-related protein - 7-733 254/745 (34%) i e-1 1 1
' Homo sapiens (Human), 709 aa. 12..693 376/745 (50%)
Q9ULM5 KIAA 1 195 protein - Homo sapiens 7-733 251/745 (33%) ! e- 109 (Human), 717 aa (fragment). 20..701 375/745 (49%)
PFam analysis predicts that the NOV69a protein contains the domains shown in the Table 69E.
Example 70.
The NOV70 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 70A.
jTablc 70A. NOV70 Sequence Analysis
SEQ ID NO: 251 753 bp
NOV70a, ATGCAGGACCCCAACGCAGACACTGAGTGGAATGACATCTTACGCAAAAAGGGTTTCTTACCC
CG I 38781 -01 DNA GCCAAGGAAGAATTGGAAGAATTGGAAGAGGAGGCAGAAGAGGAGCAGCGCATCCTCCAGCAG TCAGTGGTGAAAACATATGAAGATATGACTTTGGAAGAGCTGGAGGATCACGAAGGCGAGTTT
Sequence .AATGAGGAGGATGAATGTGCTATTGAAATGTACAGACAGCAGAGACTGGCTGAGTGGAAAGCA
ACTAAACTGAAGAATAAATCTGGAAAAGTTTTGGAGATCTCAGGGAAGGATTATGTTCAAGAA GTTACCAAAGCTGGCGAGGGCTTGTGGGTCATCTTGCACCTTTACAAACAAGGAATTCCCCTC TGTGCCCTGATAAATCAGCACCTCAGTGGACTTGCCAGGAAGTTTCCTGATGTCAAATTTATC AAAGCCATTTCAACAACCTGCATACCCAATTATACTGATAGGAATCTGCCCACGATATTTGTT TACCTGGAAGGAGATATCAAGGCTCAGTTTATTGGTCCTCTGGTGTTTGGCGGCATGAACCTG ACAAGAGATGAGTTGGAATGGAAACTGTCTGAATCTGGAGCAATTACGACAGACCTGGAGGAA AACCCTAAGAAGCCGATTGAAGACGTGTTGCTCTCCTCAGTGCGGCGCTCTGTCCTCATGAAG
AGGGACAGCGATTCCAAGGGTGACTGAGGCTACAGCTGCTATCCCATGCCGAACTTTCTT
ORF Start: ATG at 1 j ORF Stop: TGA at* 718 SEQ ID N0. 252 J239 aa {MW at 27409.8kD lNOV70a, MQDPNADTEW DILRKKGFLPAKEELEELEEEAEEEQRILQQSWKTYEDMTLEELEDHEGEF
JCG 138781 -01 Protein NEEDECAIEMYRQQRLAE KATKLKNKSGKVLEISGKDYVQEVTKAGEGLWVILHLYKQGIPL CALINQHLSGLARKFPDVKFIKAISTTCIPNYTDRNLPTIFVYLEGDIKAQFIGPLVFGGMNL JSequence TRDELEWKLSESGAITTDLEENPKKPIEDVLLSSVRRSVLMKRDSDSKGD
Further analysis of the NOV70a protein yielded the following properties shown in Table 70B.
I Table 70B. Protein Sequence Properties NOV70a j PSort 0.6500 probability located in cytoplasm; 0.1000 probability located in mitochondrial I analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane) j Signal P No Known Signal Sequence Predicted [ analysis:
A search of the NOV70a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 70C.
In a BLAST search of public sequence datbases, the NOV70a protein was found to have homology to the proteins shown in the BLASTP data in Table 70D.
PFam analysis predicts that the NOV70a protein contains the domains shown in the Table 70E.
Example 71.
The NOV71 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 71 A.
,CG 138808-01 DNA ATTACTGGTGCTAAGCAAATTCCTTGCTCCCTGAAAATACGTGGCATTCATGCAAAAGAGGAA
Sequence AAGTCATTGCATGGATGGGGTCACGGAAGCAACGGAGCAGGTTACAAGTCCAGGTCCCTGGCC
CGAAGCTGCCTTTCTCACTTTAAGAGTAACCAGCCTTACGCATCGAGACTCGGTGGCCCCACA
TGCAAGGTCTCCAGAGGTGTTGCCTACTCCACGCACAGGACAAATGCCCCAGGGAAGGATTTC
CAGGGCATCAGTGCTGCTTTCTCAACTGAGAATGGCTTCCACTCTGTTGGCCACGAGCTGGCA
GATAACCACATCACCTCCAGAGACTGCAACGGACACCTTCTCAACTGCTACGGGAGGAATGAG
AGCATTGCCTCCACCCCACCGGGCGAAGACCGCAAGAGCCCCCGAGTGCTCATCAAAACGCTG
GGGAAGCTGGATGGGTGTTTAAGGGTCGAGTTCCACAATGGTGGCAACCCCAGCAAAGTGCCT
GCAGAGGACTGCAGTGAGCCGGTGCAGCTGCTGAGGTACTCACCTACCTTAGCATCGGAAACC
TCCCCTGTGCCTGAAGCCAGGAGGGGGTCCAGCGCCGATTCCCTGCCCAGCCATCGCCCCTCT
CCCACGGACTCTCGCCTGCGGTCCAGCAAAGGCAGCTCCCTGAGTTCTGAGTCATCCTGGTAC
GACTCCCCTTGGGGCAATGCTGGAGAGCTGAGCGAGGCTGAGGGCTCCTTCCTGGCCCCCGGC
ATGCCTGACCCCAGTCTCCATGCCAGCTTCCCACCTGGCGATGCCAAAAAGCCTTTCAACCAA
AGCTCTTCCCTCTCCTCCCTCCGGGAACTGTACAAAGATGCCAACCTGGGGAGCCTCTCCCCC
TCAGGTATCCGCCTTTCTGATGAATACATGGGCACGCATGCCAGCCTGAGCAACCGTGTCTCT
TTTGCTTCCGACATTGATGTGCCCTCCAGAGTGGCACACGGGGACCCCATCCAGTACAGTTCC
TTCACTCTCCCCTGTCGGAAGCCCAAAGCCTTTGTTGAGGATACTGCGAAGAAGGACTCCCTC
AAAGCCAGGATGCGACGGATCAGTGACTGGACGGGAAGCCTCTCAAGGAAGAAAAGGAAACTC
CAGGAGCCGAGGTCCAAGGAGGGCAGTGACTACTTTGACAGTCGCTCTGATGGACTGAATACA
GATGTGCAGGGATCCTCCCAGGCATCTGCTTTTCTGTGGTCAGGGGGCTCTACTCAGATCCTG
TCTCAGAGAAGTGAATCCACACATGCGATTGGCAGCGATCCCCTCCGGCAGAACATTTATGAG
AATTTCATGCGAGAGTTGGAAATGAGCAGGACCAACACTGAGAACATAGAAACATCTACAGAA
ACCGCCGAGTCCAGCAGCGAGTCACTCAGCTCTCTGGAACAGCTGGATCTGCTCTTTGAGAAG
GAACAGGGGGTGGTCCGGAAGGCCGGGTGGCTCTTCTTCAAGCCCCTGGTCACTGTGCAGAAG
GAAAGGAAGCTTGAGCTGGTGGCACGAAGGAAATGGAAACAGTACTGGGTAACGCTGAAAGGT
TGCACGCTGCTGTTTTATGAGACCTATGGGAAGAATTCCATGGATCAGAGCAGTGCCCCTCGG
TGTGCTCTGTTTGCAGAAGACAGCATAGTGCAGTCTGTTCCAGAGCATCCCAAGAAAGAAAAT
GTGTTCTGCCTCAGCAACTCCTTTGGAGATGTCTACCTTTTCCAGGCCACCAGCCAGACAGAT
CTAGAAAACTGGGTCACTGCTGTACACTCTGCTTGTGCATCCCTTTTTGCAAAGAAGCATGGG
AAAGAGGACACGCTGCGGCTGCTGAAGAACCAGACCAAAAACCTGCTTCAGAAGATAGACATG
GACAGCAAGATGAAGAAGATGGCAGAGCTGCAGCTGTCCGTGGTGAGCGACCCAAAGAACAGG
AAAGCCATAGAGAACCAGATCCAGCAATGGGAGCAGAATCTTGAGAAATTTCACATGGATCTG
TTCAGGATGCGCTGCTATCTGGCCAGCCTACAAGGTGGGGAGTTACCGAACCCAAAGAGTCTC
CTTGCAGCCGCCAGCCGCCCCTCCAAGCTGGCCCTCGGCAGGCTGGGCATCTTGTCTGTTTCC
TCTTTCCATGCTCTGGTATGTTCTAGAGATGACTCTGCTCTCCGGAAAAGGACACTGTCACTG
ACCCAGCGAGGGAGAAACAAGAAGGGAATATTTTCTTCGTTAAAAGGGCTGGACACACTGGCCj
AGAAAAGGCAAGGAGAAGAGACCTTCTATAACTCAGGTGTTTGATTCAAGTGGCAGCCATGGA
TTTTCTGGAACTCAGCTACCTCAAAACTCCAGTAACTCCAGTGAGGTCGATGAACTTCTGCAT
ATATATGGTTCAACAGTAGACGGTGTTCCCCGAGACAATACATGGGAAATCCAGACTTATGTC
CACTTTCAGGACAATCACGGAGTTACTGTAGGGATCAAGCCAGAGCACAGAGTAGAAGATATT
TTGACTTTGGCATGCAAGATGAGGCAGTTGGAACCCAGCCATTATGGCCTACAGCTTCGAAAA
TTAGTAGATGACAATGTTGAGTATTGCATCCCTGCACCATATGAATATATGCAACAACAGGTT
TATGATGAAATAGAAGTCTTTCCACTAAATGTTTATGACGTGCAGCTCACGAAGACTGGGAGT
GTGTGTGACTTTGGGTTTGCAGTTACAGCGCAGGTGGATGAGCGTCAGCATCTCAGCCGGATA
TTTATAAGCGACGTTCTTCCCGATGGCCTGGCGTATGGGGAAGGGCTGAGAAAGGGCAATGAG
ATCATGACCTTAAATGGGGAAGCTGTGTCTGATCTTGACCTTAAGCAGATGGAGGCCCTGTTT
TCTGAGAAGAGCGTCGGACTCACTCTGATTGCCCGGCCTCCGGACACAAAAGCAACCCTGTGT
ACATCCTGGTCAGACAGTGACCTGTTCTCCAGGGACCAGAAGAGTCTGCTGCCCCCTCCTAAC
CAGTCCCAACTGCTGGAGGAATTCCTGGATAACTTTAAAAAGAATACAGCCAATGATTTCAGC
AACGTCCCTGATATCACAACAGGTCTGAAAAGGAGTCAGACAGATGGCACTCTGGATCAGGTT
TCCCACAGGGAGAAAATGGAGCAGACATTCAGGAGTGCTGAGCAGATCACTGCACTGTGCAGG
AGTTTTAACGACAGTCAGGCCAACGGCATGGAAGGACCGCGGGAGAATCAGGATCCTCCTCCG
AGGCCTCTGGCCCGCCACCTGTCTGATGCAGACCGCCTCCGCAAAGTCATCCAGGAGCTTGTG
GACACAGAGAAGTCCTACGTGAAGGATTTGAGCTGCCTCTTTGAATTATACTTGGAGCCACTT
CAGAATGAGACCTTTCTTACCCAAGATGAGATGGAGTCACTTTTTGGAAGTTTGCCAGAGATG
CTTGAGTTTCAGAAGGTGTTTCTGGAGACCCTGGAGGATGGGATTTCAGCATCATCTGACTTT
AACACCCTAGAAACCCCCTCACAGTTTAGAAAATTACTGTTTTCCCTTGGAGGCTCTTTCCTT
TATTACGCGGACCACTTTAAACTGTACAGTGGATTCTGTGCTAACCATATCAAAGTACAGAAG
GTTCTGGAGCGAGCTAAAACTGACAAAGCCTTCAAGGCTTTTCTGGACGCCCGGAACCCCACC
AAGCAGCATTCCTCCACGCTGGAGTCCTACCTCATCAAGCCGGTTCAGAGAGTGCTCAAGTAC
CCGCTGCTGCTCAAGGAGCTGGTGTCCCTGACGGACCAGGAGAGCGAGGAGCACTACCACCTG
ACGGAAGCACTAAAGGCAATGGAGAAAGTAGCGAGCCACATCAATGAGATGCAGAAGATCTAT
GAGGATTATGGGACCGTGTTTGACCAGCTAGTAGCTGAGCAGAGCGGAACAGAGAAGGAGGTA
ACAGAACTTTCGATGGGAGAGCTTCTGATGCACTCTACGGTTTCCTGGTTGAATCCATTTCTG
TCTCTAGGAAAAGCTAGAAAGGACCTTGAGCTCACAGTATTTGTTTTTAAGAGAGCCGTCATA
CTGGTTTATAAAGAAAACTGCAAACTGAAAAAGAAATTGCCCTCGAATTCCCGGCCTGCACAC
AACTCTACTGACTTGGACCCATTTAAATTCCGCTGGTTGATCCCCATCTCCGCGCTTCAAGTC AGACTGGGGAATCCAGCAGGGACAGAAAATAATTCCATATGGGAACTGATCCATACGAAGTCA GAAATAGAAGGACGGCCAGAAACCATCTTTCAGTTGTGTTGCAGTGACAGTGAAAGCAAAACC AACATTGTTAAGGTGATTCGTTCTATTCTGAGGGAGAACTTCAGGCGTCACATAAAGTGTGAA TTACCACTGGAGAAAACGTGTAAGGATCGCCTGGTACCTCTTAAGAACCGAGTTCCTGTTTCG GCCAAATTAGCTTCATCCAGGTCTTTAAAAGTCCTGAAGAATTCCTCCAGCAACGAGTGGACC GGTGAGACTGGCAAGGGAACCTTGCTGGACTCTGACGAGGGCAGCTTGAGCAGCGGCACCCAG AGCAGCGGCTGCCCCACGGCTGAGGGCAGGCAGGACTCCAAGAGCACTTCTCCCGGGAAATAC CCACACCCCGGCTTGGCAGATTTTGCTGACAATCTCATCAAAGAGAGTGACATCCTGAGCGAT GAAGATGATGACCACCGTCAGACTGTGAAGCAGGGCAGCCCTACTAAAGACATCGAAATTCAG TTCCAGAGACTGAGGATTTCCGAGGACCCAGACGTTCACCCCGAGGCTGAGCAGCAGCCTGGC CCGGAGTCGGGTGAGGGTCAGAAAGGAGGAGAGCAGCCCAAACTGGTCCGGGGGCACTTCTGC CCCATTAAACGAAAAGCCAACAGCACCAAGAGGGACAGAGGAACTTTGCTCAAGGCGCAGATC CGTCACCAGTCCCTTGACAGTCAGTCTGAAAATGCCACCATCGACCTAAATTCTGTTCTAGAG CGAGAATTCAGTGTCCAGAGTTTAACATCTGTTGTCAGTGAGGAGTGTTTTTATGAAACAGAG AGCCACGGAAAATCATAGTATGATTCAATCCAGATATGGGTTAAATTCCTCATTTTACTTTTA
AACTGGTGGTAAAGTGGAAATTGCAAAAAAAAAAAAAAAAAAACTGTTCATTCCTGGGTTTTG
TGCAGTATACATTTTCCCACAAAATGGTTGTAAAGATTTAAGTTATTTTAATTTATTGTGGAT
CAGAAACCTAGATGAAACTGGTCAGAATCTGTAAATTACTTAGTTTATATCCACTTTGAGCAG
GTATCAAATGATTTAGGATCCTTAAAATTACATTCTAATAATTAAGTTATGTGGAAAAAGTAA
GGCTGGGAAGTCGTGATTAATAGTTTTCAAAGGCCATTTTTTAAAATCCTCTGGGCATTTTCT
TTCAGCTGTTTGTTAGTTTTTGCTTTATTTAAAGCATATTTAAGTTATTTTAATGTGGTTTAG
GGGCAAAATGTGCAGATACTTCATTTTTGTAAGATAGATTGTAATAGATGCTGTTTATACTAA
ACATGTCATAACTATCTATACAGTATATATTAAAAGAAAGCTTGTACTGTATCTTATTTGATG
ATATTTATTTTCTCTGCCAAGCTGTATAGTAAAAGGAAAATAAGTCACATCTGGTCATTGGCA
TTTGTATCGTCATTCTGTAAAGACAAAAGAGTACCTATATAAGAAGCTCCACGTAGTGCAAAT
CGACATCTGGTAGGCTGCTCGCCCCCAGGCAGCAGCTAGAGTCTGTAATTCTCTGCGTCATCC
TCTTCTTTTTCTTCATTTTTGCTTTTTCTTCGCTTGAGTTCTTCTCTGAAATTATATGCAAAG
AGTTGTGGGTCTTCATCACACATTTTTCTGTATACATCACAGAGGCTCTTAAAGTGTGAGATG
GAGAGCTGGTGGGGCCGAAGAGTAGGGTCTATGTCTGCCAACTCTAACAGCCTGCCCGTGCTT
TCCAAGCGCTGCGCTTCAGGGAATAACATTCTGAGCCCTCGATGGCAGTATTTCCTTCGGAAC
TGAAATACATTCTGAACCACTTTTTCCACCAGCTTGAATGGCTGCTCTATCTTGGGCTGTATC
AAGGGAGTGAAGTGCACCACGCCCACGTCCACCTTCGTTGTAAGCAAACATATTATCATTCTG
TGGCATGATATGTGGCATAGTGTGATCAATCAACTCATCCTTGTAAAACAGGAAGATGGGCTG
TCAACAGCCTGTTTTCATAAACAGACCTTTCCACGTACTTCGGTTTCATCTCTAGGCATGGAA
GATGGTACATTCTGGATTCGCAAATGACATGGAGAAATCAGCCGGCTGCACCTGTTCTCTAAT
GACATCCACCAGACCTGTGCTTGATGGTCACTTAATTTTAAAACACAGTTTCACAATGGCTTA
;AAAATCAATCCAAATCAGTAAAGTCAGTCAGCAGATAATAGATGGCATTAGAATATTTTAGTT
TTTGAATGAGGAAAAAAATAAGCTGCAGCAGCAGCTTCAAGACACAGAGAGATGGCAGACAGG
CCCCCAGGGACCACTCAGTGCTAAACTTCCCAGATAGAGACACCACTTATTTTCGGTAGACAC
TGATTAATCAGCTGGACTGAATTC
ORF Start: ATG at 7 ORF Stop: TAG at 5182
SEQ ID NO: 254 1725 aa MW at 192579. l kD
|NOV71 a, GNSDSQYTLQGSKNHSNTITGAKQIPCSLKIRGIHAKEEKSLHGWGHGSNGAGYKSRSLARS
;CG 138808-01 Protein CLSHFKSNQPYASRLGGPTCKVSRGVAYSTHRTNAPGKDFQGISAAFSTENGFHSVGHELADN HITSRDCNGHLLNCYGRNESIASTPPGEDRKSPRVLIKTLGKLDGCLRVEFHNGGNPSKVPAE
.Sequence DCSEPVQLLRYSPTLASETSPVPEARRGSSADSLPSHRPSPTDSRLRSSKGSSLSSESSWYDS PWGNAGELSEAEGSFLAPGMPDPSLHASFPPGDAKKPFNQSSSLSSLRELYKDANLGSLSPSG IRLSDEYMGTHASLSNRVSFASDIDVPSRVAHGDPIQYSSFTLPCRKPKAFVEDTAKKDSLKA RMRRISDWTGSLSRKKRKLQEPRSKEGSDYFDSRSDGLNTDVQGSSQASAFLWSGGSTQILSQ RSESTHAIGSDPLRQNIYENFMRELEMSRTNTENIETSTETAESSSESLSSLEQLDLLFEKEQ GVVRKAGWLFFKPLVTVQKERKLELVARRKWKQYWVTLKGCTLLFYETYGKNSMDQSSAPRCA LFAEDSIVQSVPEHPKKEsVFC SNSFGDVYLFQATSQTDLENWVTAVHSACASLFAKKHGKE DTLRLLKNQTKNLLQKIDMDSKMKKMAELQLSVVSDPKNRKAIENQIQQ EQNLEKFHMDLFR RCYLASLQGGELPNPKSLLAAASRPSKLALGRLGILSVSSFHALVCSRDDSALRKRTLSLTQ RGRNKKGIFSSLKGLDTLARKGKEKRPSITQVFDSSGSHGFSGTQLPQNSSNSSEVDELLHIY GSTVDGVPRDNT EIQTYVHFQDNHGVTVGIKPEHRVEDILTLACKMRQLEPSHYGLQLRKLV DDNVEYCIPAPYEYMQQQVYDEIEVFPLNVYDVQLTKTGSVCDFGFAVTAQVDERQHLSRIFI SDVLPDGLAYGEGLRKGNEIMTLNGEAVSDLDLKQMEALFSEKSVGLTLIARPPDTKATLCTS WSDSDLFSRDQKSLLPPPNQSQLLEEFLDNFKK TANDFS VPDITTGLKRSQTDGTLDQVSH REKMEQTFRSAEQITALCRSFNDSQA GMEGPRENQDPPPRPLARHLSDADRLRKVIQELVDT EKSYVKDLSCLFELYLEPLQNETFLTQDEMESLFGSLPEMLEFQKVFLETLEDGISASSDFNT LETPSQFRKLLFSLGGSFLYYADHFKLYSGFCANHIKVQKVLERAKTDKAFKAFLDARNPTKQ HSSTLESYLIKPVQRVLKYPLLLKELVSLTDQESEEHYHLTEALKAMEKVASHINEMQKIYED YGTVFDQLVAEQSGTEKEVTELSMGELLMHSTVS LNPFLSLGKARKDLELTVFVFKRAVILV

Further analysis of the NOV71 a protein yielded the following properties shown in Table 7 I B.
Table 71B. Protein Sequence Properties NOV71a
PSort 0.9800 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV71a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 71C.
AAB07494 A T-cell lymphoma invasion and \ 1 100..1725 626/626 (100%) 1 0.0 metastasis 2 (TIAM2) protein - Homo | 1..626 626/626 (100%) sapiens, 626 aa. [WO200040607-A2, ! 13-JUL-2000] !
In a BLAST search of public sequence datbases, the NOV71a protein was found to have homology to the proteins shown in the BLASTP data in Table 7 I D.
PFam analysis predicts that the NOV71 a protein contains the domains shown in the Table 71 E.
The NOV72 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 72A.
JTable 72A. NOV72 Sequence Analysis
SEQ ID NO: 255 |4172 bp
;NOV72a, GCGGCCGCCCGGGCTAAGAGCGGCCGGCTGGAGCCGCTGAGCCCCCGCTGCGGCCGGGAGCTG
JCG 139224-01 DNA CATGGGGGAGCGCCGGCAGCGCTTGGGAAGATGCCCCGGCCGGAGCTGCCCCTGCCGGAGGGC
TGGGAGGAGGCGCGCGACTTCGACGGCAAGGTCTACTACATAGACCACACGAACCGCACCACC
(Sequence AGCTGGATCGACCCGCGGGACAGGTACACCAAACCGCTCACCTTTGCTGACTGCATTAGTGAT GAGTTGCCGCTAGGATGGGAAGAGGCATATGACCCACAGGTTGGAGATTACTTCATAGACCAC AACACCAAAACCACTCAGATTGAGGATCCTCGAGTACAATGGCGGCGGGAGCAGGAACATATG CTGAAGGATTACCTGGTGGTGGCCCAGGAGGCTCTGAGTGCACAAAAGGAGATCTACCAGGTG AAGCAGCAGCGCCTGGAGCTTGCACAGCAGGAGTACCAGCAACTGCATGCCGTCTGGGAGCAT AAGCTGGGCTCCCAGGTCAGCGTGGTCTCTGGTTCATCATCCAGCTCCAAGTATGACCCTGAG ATCCTGAAAGCTGAAATTGCCACTGCAAAATCCCGGGTAAACAAGCTGAAGAGAGAGATGGTT CACCTCCAGCACGAGCTGCAGTTCAAAGAGCGTGGCTTTCAGACCCTGAAGAAGATCGATAAG AAAATGTCTGATGCTCAGGGCAGCTACAAACTGGATGAAGCTCAGGCTGTCTTGAGAGAAACA AAAGCCATCAAAAAGGCTATTACCTGTGGGGAAAAGGAAAAGCAAGATCTCATTAAGAGCCTT GCCATGTTGAAGGACGGCTTCCGCACTGACAGGGGGTCTCACTCAGACCTGTGGTCCAGCAGC AGCTCTCTGGAGAGTTCGAGTTTCCCGCTACCGAAACAGTACCTGGATGTGAGCTCCCAGACA GACATCTCGGGAAGCTTCGGCATCAACAGCAACAATCAGTTGGCAGAGAAGGTCAGATTGCGC CTTCGATATGAAGAGGCTAAGAGAAGGATCGCCAACCTGAAGATCCAGCTGGCCAAGCTTGAC AGTGAGGCCTGGCCTGGGGTGCTGGACTCAGAGAGGGACCGGCTGATCCTTATCAACGAGAAG GAGGAGCTGCTGAAGGAGATGCGCTTCATCAGCCCCCGCAAGTGGACCCAGGGGGAGGTGGAG CAGCTGGAGATGGCCCGGAAGCGGCTGGAAAAGGACCTGCAGGCAGCCCGGGACACCCAGAGC AAGGCGCTGACGGAGAGGTTAAAGTTAAACAGTAAGAGGAACCAGCTTGTGAGAGAACTGGAG GAAGCCACCCGGCAGGTGGCAACTCTGCACTCCCAGCTGAAAAGTCTCTCAAGCAGCATGCAG TCCCTGTCCTCAGGCAGCAGCCCCGGATCCCTCACGTCCAGCCGGGGCTCCCTGGTTGCATCC AGCCTGGACTCCTCCACTTCAGCCAGCTTCACTGACCTCTACTATGACCCCTTTGAGCAGCTG GACTCAGAGCTGCAGAGCAAGGTGGAGTTCCTGCTCCTGGAGGGGGCCACCGGCTTCCGGCCC TCAGGCTGCATCACCACCATCCACGAGGATGAGGTGGCCAAGACCCAGAAGGCAGAGGGAGGT GGCCGCCTGCAGGCTCTGCGTTCCCTGTCTGGCACCCCAAAGTCCATGACCTCCCTATCCCCA CGTTCCTCTCTCTCCTCCCCCTCCCCACCCTGTTCCCCTCTCATGGCTGACCCCCTCCTGGCT GGTGATGCCTTCCTCAACTCCTTGGAGTTTGAAGACCCGGAGCTGAGTGCCACTCTTTGTGAA CTGAGCCTTGGTAACAGCGCCCAGGAAAGATACCGGCTGGAGGAACCAGGAACGGAGGGCAAG CAGCTGGGCCAAGCTGTGAATACGGCCCAGGGGTGTGGCCTGAAAGTGGCCTGTGTCTCAGCC GCCGTATCGGACGAGTCAGTGGCTGGAGACAGTGGTGTGTACGAGGCTTCCGTGCAGAGACTG GGTGCTTCAGAAGCTGCTGCATTTGACAGTGACGAATCGGAAGCAGTGGGTGCGACCCGAATT CAGATTGCCCTGAAGTATGATGAGAAGAATAAGCAATTTGCAATATTAATCATCCAGCTGAGT AACCTTTCTGCTCTGTTGCAGCAACAAGACCAGAAAGTGAATATCCGCGTGGCTGTCCTTCCT TGCTCTGAAAGCACAACCTGCCTGTTCCGGACCCGGCCTCTGGACGCCTCAGACACTCTAGTG TTCAATGAGGTGTTCTGGGTATCCATGTCCTATCCAGCCCTTCACCAGAAGACCTTAAGAGTC GATGTCTGTACCACCGACAGGAGCCATCTGGAAGAGTGCCTGGGAGGCGCCCAGATCAGCCTG GCGGAGGTCTGCCGGTCTGGGGAGAGGTCGACTCGCTGGTACAACCTTCTCAGCTACAAATAC TTGAAGAAGCAGAGCAGGGAGCTCAAGCCAGTGGGAGTTATGGCCCCTGCCTCAGGGCCTGCC AGCACGGACGCTGTGTCTGCTCTGTTGGAACAGACAGCAGTGGAGCTGGAGAAGAGGCAGGAG GGCAGGAGCAGCACACAGACACTGGAAGACAGCTGGAGGTATGAGGAGACCAGTGAGAATGAG GCAGTAGCCGAGGAAGAGGAGGAGGAGGTGGAGGAGGAGGAGGGAGAAGAGGATGTTTTCACC GAGAAAGCCTCACCTGATATGGATGGGTACCCAGCATTAAAGGTGGACAAAGAGACCAACACG GAGACCCCGGCCCCATCCCCCACAGTGGTGCGACCTAAGGACCGGAGAGTGGGCACCCCGTCC CAGGGGCCATTTCTTCGAGGGAGCACCATCATCCGCTCTAAGACCTTCTCCCCAGGACCCCAG AGCCAGTACGTGTGCCGGCTGAATCGGAGTGATAGTGACAGCTCCACTCTGTCCAAAAAGCCA CCTTTTGTTCGAAACTCCCTGGAGCGACGCAGCGTCCGGATGAAGCGGCCTTCCTCGGTCAAG TCGCTGCGCTCCGAGCGTCTGATCCGTACCTCGCTGGACCTGGAGTTAGACCTGCAGGCGACA AGAACCTGGCACAGCCAACTGACCCAGGAGATCTCGGTGCTGAAGGAGCTCAAGGAGCAGCTG GAACAAGCCAAGAGCCACGGGGAGAAGGAGCTGCCACAGTGGTTGCGTGAGGACGAGCGTTTC CGCCTGCTGCTGAGGATGCTGGAGAAGCGGATGGACCGAGCGGAGCACAAGGGTGAGCTTCAG ACAGACAAGATGATGAGGGCAGCTGCCAAGGATGTGCACAGGCTCCGAGGCCAGAGCTGTAAG GAACCCCCAGAAGTTCAGTCTTTCAGGGAGAAGATGGCATTTTTCACCCGGCCTCGGATGAAT ATCCCAGCTCTCTCTGCAGATGACGTCTAATCGCCAGAAAAGTATTTCCTTTGTTCCACTGAC
CAGGCTGTGAACATTGACTGTGGCTAAAGTTATTTATGTGGTGTTATATGAAGGTACTGAGTC
ACAAGTCCTCTAGTGCTCTTGTTGGTTTGAAGATGAACCGACTTTTTAGTTTGGGTCCTACTG TTGTTATTAAAAACAGAACAAAAACAAAACACACACACACACAAAAACAGAAACAAAAAAAAC
CAGCATTAAAATAATAAGATTGTATAGTTTGTATATTTAGGAGTGTATTTTTGGGAAAGAAAA
TTTAAATGAACTAAAGCAGTATTGAGTTGCTGCTCTTCTTAAAATCGTTTAGATTTTTTTTGG
TTTGTACAGCTCCACCTTTTAGAGGTCTTACTGCAATAAGAAGTAATGCCTGGGGGACGGTAA TCCTAATAGGACGTCCCGCACTTGTCACAGTACAGCTAATTTTTCCTAGTTAACATATTTTGT jACAATATTAAAAAAATGCACAGAAACCATTGGGGGGGATTCAGAGGTGCATCCACGGATCTTC
TTGAGCTGTGACGTGTTTTTATGTGGCTGCCCAACGTGGAGCGGGCAGTGTGATAGGCTGGGT
GGGCTAAGCAGCCTAGTCTATGTGGGTGACAGGCCACGCTGGTCTCAGATGCCCAGTGAAGCC
ACTAACATGAGTGAGGGGAGGGCTGTGGGGAACTCCATTCAGTTTTATCTCCATCAATAAAGT iGGCCTTTCAAAAAG
ORF Start: ATG at 94 : _ |ORF Stop: TAA at 3430
SEQ ID NO: 256_ ' 1 1 12 aa ~ JMW ιt_ 2_5i 7T'kD
NOV72a, MPRPELPLPEGWEEARDFDGKVYYIDHTNRTTSWIDPRDRYTKPLTFADCISDELPLG EEAY
CGI 39224-01 Protein DPQVGDYFIDHNTKTTQIEDPRVQWRREQEHMLKDYLWAQEALSAQKEIYQVKQQRLELAQQ EYQQLHAV EHKLGSQVSWSGSSSSSKYDPEILKAEIATAKSRVNKLKREMVHLQHELQFKE
Sequence RGFQTLKKIDKKMSDAQGSYKLDEAQAVLRETKAIKKAITCGEKEKQDLIKSLAMLKDGFRTD RGSHSDLWSSSSSLESSSFPLPKQYLDVSSQTDISGSFGINS NQLAEKVRLRLRYEEAKRRI ANLKIQLAKLDSEAWPGVLDSERDRLILINEKEELLKEMRFISPRKWTQGEVEQLE ARKRLE KDLQAARDTQSKALTERLKLNSKRNQLVRELEEATRQVATLHSQLKSLSSSMQSLSSGSSPGS LTSSRGSLVASSLDSSTSASFTDLYYDPFEQLDSELQSKVEFLLLEGATGFRPSGCITTIHED EVAKTQKAEGGGRLQALRSLSGTPKSMTSLSPRSSLSSPSPPCSPLMADPLLAGDAFLNΞLEF EDPELSATLCELSLGNSAQERYRLEEPGTEGKQLGQAVNTAQGCGLKVACVSAAVSDESVAGD SGVYEASVQRLGASEAAAFDSDESEAVGATRIQIALKYDEKNKQFAILIIQLSNLSALLQQQD QKVNIRVAVLPCSESTTCLFRTRPLDASDTLVFNEVF VSMSYPALHQKTLRVDVCTTDRSHL EECLGGAQISLAEVCRSGERSTRWY LLSYKYLKKQSRELKPVGVMAPASGPASTDAVSALLE QTAVELEKRQEGRSSTQTLEDSWRYEETSENEAVAEEEEEEVEEEEGEEDVFTEKASPDMDGY PALKVDKETNTETPAPSPTWRPKDRRVGTPSQGPFLRGSTIIRSKTFSPGPQSQYVCRLNRS DSDSSTLSKKPPFVRNSLERRSVRMKRPSSVKSLRSERLIRTSLDLELDLQATRTWHSQLTQE ISVLKELKEQLEQAKΞHGEKELPQ LREDERFRLLLRMLEKRMDRAEHKGELQTDKM RAAAK DVHRLRGQSCKEPPEVQSFREKMAFFTRPRMNIPALSADDV
SEQ ID NO: 257 3062 bp
NOV72b, GCGGCCGCCCGGGCTAAGAGCGGCCGGCTGGAGCCGCTGAGCCCCCGCTGCGGCCGGGAGCTG CGI 39224- 02 DNA CATGGGGGAGCGCCGGCAGCGCTTGGGAAGATGCCCCGGCCGGAGCTGCCCCTGCCGGAGGGC
TGGGAGGAGGCGCGCGACTTCGACGGCAAGGTCTACTACATAGACCACACGAACCGCACCACC Sequence AGCTGGATCGACCCGCGGGACAGGTACACCAAACCGCTCACCTTTGCTGACTGCATTAGTGAT GAGTTGCCGCTAGGATGGGAAGAGGCATATGACCCACAGGTTGGAGATTACTTCATAGACCAC AACACCAAAACCACTCAGATTGAGGATCCTCGAGTACAATGGCGGCGGGAGCAGGAACATATG CTGAAGGATTACCTGGTGGTGGCCCAGGAGGCTCTGAGTGCACAAAAGGAGATCTACCAGGTG AAGCAGCAGCGCCTGGAGCTTGCACAGCAGGAGTACCAGCAACTGCATGCCGTCTGGGAGCAT AAGCTGGGCTCCCAGGTCAGCGTGGTCTCTGGTTCATCATCCAGCTCCAAGTATGACCCTGAG ATCCTGAAAGCTGAAATTGCCACTGCAAAATCCCGGGTAAACAAGCTGAAGAGAGAGATGGTT CACCTCCAGCACGAGCTGCAGTTCAAAGAGCGTGGCTTTCAGACCCTGAAGAAGATCGATAAG AAAATGTCTGATGCTCAGGGCAGCTACAAACTGGATGAAGCTCAGGCTGTCTTGAGAGAAACA AAAGCCATCAAAAAGGCTATTACCTGTGGGGAAAAGGAAAAGCAAGATCTCATTAAGAGCCTT GCCATGTTGAAGGACGGCTTCCGCACTGACAGGGGGTCTCACTCAGACCTGTGGTCCAGCAGC AGCTCTCTGGAGAGTTCGAGTTTCCCGCTACCGAAACAGTACCTGGATGTGAGCTCCCAGACA GACATCTCGGGAAGCTTCGGCATCAACAGCAACAATCAGTTGGCAGAGAAGGTCAGATTGCGC CTTCGATATGAAGAGGCTAAGAGAAGGATCGCCAACCTGAAGATCCAGCTGGCCAAGCTTGAC AGTGAGGCCTGGCCTGGGGTGCTGGACTCAGAGAGGGACCGGCTGATCCTTATCAACGAGAAG GAGGAGCTGCTGAAGGAGATGCGCTTCATCAGCCCCCGCAAGTGGACCGACCCCCTCCTGGCT GGTGATGCCTTCCTCAACTCCTTGGAGTTTGAAGACCCGGAGCTGAGTGCCACTCTTTGTGAA CTGAGCCTTGGTAACAGCGCCCAGGAAAGATACCGGCTGGAGGAACCAGGAACGGAGGGCAAG CAGCTGGGCCAAGCTGTGAATACGGCCCAGGGGTGTGGCCTGAAAGTGGCCTGTGTCTCAGCC GCCGTATCGGACGAGTCAGTGGCTGGAGACAGTGGTGTGTACGAGGCTTCCGTGCAGAGACTG GGTGCTTCAGAAGCTGCTGCATTTGACAGTGACGAATCGGAAGCAGTGGGTGCGACCCGAATT CAGATTGCCCTGAAGTATGATGAGAAGAATAAGCAATTTGCAATATTAATCATCCAGCTGAGT AACCTTTCTGCTCTGTTGCAGCAACAAGACCAGAAAGTGAATATCCGCGTGGCTGTCCTTCCT TGCTCTGAAAGCACAACCTGCCTGTTCCGGACCCGGCCTCTGGACGCCTCAGACACTCTAGTG TTCAATGAGGTGTTCTGGGTATCCATGTCCTATCCAGCCCTTCACCAGAAGACCTTAAGAGTC GATGTCTGTACCACCGACAGGAGCCATCTGGAAGAGTGCCTGGGAGGCGCCCAGATCAGCCTG GCGGAGGTCTGCCGGTCTGGGGAGAGGTCGACTCGCTGGTACAACCTTCTCAGCTACAAATAC TTGAAGAAGCAGAGCAGGGAGCTCAAGCCAGTGGGAGTTATGGCCCCTGCCTCAGGGCCTGCC
AGCACGGACGCTGTGTCTGCTCTGTTGGAACAGACAGCAGTGGAGCTGGAGAAGAGGCAGGAG GGCAGGAGCAGCACACAGACACTGGAAGACAGCTGGAGGTATGAGGAGACCAGTGAGAATGAG GCAGTAGCCGAGGAAGAGGAGGAGGAGGTGGAGGAGGAGGAGGGAGAAGAGGATGTTTTCACC GAGAAAGCCTCACCTGATATGGATGGGTACCCAGCATTAAAGGTGGACAAAGAGACCAACACG GAGACCCCGGCCCCATCCCCCACAGTGGTGCGACCTAAGGACCGGAGAGTGGGCACCCCGTCC CAGGGGCCATTTCTTCGAGGGAGCACCATCATCCGCTCTAAGACCTTCTCCCCAGGACCCCAG AGCCAGTACGTGTGCCGGCTGAATCGGAGTGATAGTGACAGCTCCACTCTGTCCAAAAAGCCA CCTTTTGTTCGAAACTCCCTGGAGCGACGCAGCGTCCGGATGAAGCGGCCTTCCTCGGTCAAG TCGCTGCGCTCCGAGCGTCTGATCCGTACCTCGCTGGACCTGGAGTTAGACCTGCAGGCGACA AGAACCTGGCACAGCCAACTGACCCAGGAGATCTCGGTGCTGAAGGAGCTCAAGGAGCAGCTG GAACAAGCCAAGAGCCACGGGGAGAAGGAGCTGCCACAGTGGTTGCGTGAGGACGAGCGTTTC CGCCTGCTGCTGAGGATGCTGGAGAAGCGGATGGACCGAGCGGAGCACAAGGGTGAGCTTCAG ACAGACAAGATGATGAGGGCAGCTGCCAAGGATGTGCACAGGCTCCGAGGCCAGAGCTGTAAG GAACCCCCAGAAGTTCAGTCTTTCAGGGAGAAGATGGCATTTTTCACCCGGCCTCGGATGAAT ATCCCAGCTCTCTCTGCAGATGACGTCTAATCGCCAGAAAAGTATTTCCTTTGTTCCACTGAC
CAGGCTGTGAACATTGACTGTGGCTAAAGTTATTTATGTGGTGTTATATGAAGGTACTGAGTC
ACAAGTCCTCTAGTGCTCTTGTTGGTTTGAAGATGAACCGACTTTTTAGTTTGGGTCCTACTG
TTGTTATTAAAAACAGAACAAAAACAAAACACACACAC
ORF Start: ATG at 94 ORF Stop: TAA at 2863
SEQ ID NO: 258 923 aa MW at 104821.7kD
,NOV72b, IMPRPELPLPEGWEEARDFDGKVYYIDHTNRTTSWIDPRDRYTKPLTFADCIΞDELPLGWEEAY iCG 139224- ■02 Protein !DPQVGDYFIDHNTKTTQIEDPRVQ RREQEH LKDYLWAQEALSAQKEIYQVKQQRLELAQQ JEYQQLHAVWEHKLGSQVSWSGSSSSSKYDPEILKAEIATAKSRVNKLKREMVHLQHELQFKE jSequence IRGFQTLKKIDKKMSDAQGSYKLDEAQAVLRETKAIKKAITCGEKEKQDLIKSLAMLKDGFRTD JRGSHSDLWSSSSSLESSSFPLPKQYLDVSSQTDISGSFGINSNNQLAEKVRLRLRYEEAKRRI ANLKIQLAKLDSEAWPGVLDSERDRLILINEKEELLKEMRFISPRKWTDPLLAGDAFLNSLEF EDPELSATLCELSLGNSAQERYRLEEPGTEGKQLGQAVNTAQGCGLKVACVSAAVSDESVAGD JSGVYEASVQRLGASEAAAFDSDESEAVGATRIQIALKYDEKNKQFAILIIQLSNLSALLQQQD JQKVNIRVAVLPCSESTTCLFRTRPLDASDTLVFNEVFWVSMSYPALHQKTLRVDVCTTDRSHL IEECLGGAQISLAEVCRSGERSTRWYNLLSYKYLKKQSRELKPVGVMAPASGPASTDAVSALLE QTAVELEKRQEGRSSTQTLEDSWRYEETSENEAVAEEEEEEVEEEEGEEDVFTEKASPDMDGY PALKVDKETNTETPAPSPTWRPKDRRVGTPSQGPFLRGSTIIRSKTFSPGPQSQYVCRLNRS DSDSSTLSKKPPFVRNSLERRSVRMKRPSSVKSLRSERLIRTSLDLELDLQATRTWHSQLTQE ISVLKELKEQLEQAKSHGEKELPQWLREDERFRLLLRMLEKRMDRAEHKGELQTDKMMRAAAK IDVHRLRGQSCKEPPEVQSFREKMAFFTRPRMNIPALSADDV
|SEQ ID NO: 259 3698 bp
!NOV72c. JGCGGCCGCCCGGGCTAAGAGCGGCCGGCTGGAGCCGCTGAGCCCCCGCTGCGGCCGGGAGCTG
JCG 139224-03 DNA jCATGGGGGAGCGCCGGCAGCGCTTGGGAAGATGCCCCGGCCGGAGCTGCCCCTGCCGGAGGGC 'TGGGAGGAGGCGCGCGACTTCGACGGCAAGGTCTACTACATAGACCACACGAACCGCACCACC
Sequence AGCTGGATCGACCCGCGGGACAGGTACACCAAACCGCTCACCTTTGCTGACTGCATTAGTGAT GAGTTGCCGCTAGGATGGGAAGAGGCATATGACCCACAGGTTGGAGATTACTTCATAGACCAC AACACCAAAACCACTCAGATTGAGGATCCTCGAGTACAATGGCGGCGGGAGCAGGAACATATG CTGAAGGATTACCTGGTGGTGGCCCAGGAGGCTCTGAGTGCACAAAAGGAGATCTACCAGGTG AAGCAGCAGCGCCTGGAGCTTGCACAGCAGGAGTACCAGCAACTGCATGCCGTCTGGGAGCAT AAGCTGGGCTCCCAGGTCAGCGTGGTCTCTGGTTCATCATCCAGCTCCAAGTATGACCCTGAG ATCCTGAAAGCTGAAATTGCCACTGCAAAATCCCGGGTAAACAAGCTGAAGAGAGAGATGGTT CACCTCCAGCACGAGCTGCAGTTCAAAGAGCGTGGCTTTCAGACCCTGAAGAAGATCGATAAG AAAATGTCTGATGCTCAGGGCAGCTACAAACTGGATGAAGCTCAGGCTGTCTTGAGAGAAACA AAAGCCATCAAAAAGGCTATTACCTGTGGGGAAAAGGAAAAGCAAGATCTCATTAAGAGCCTT GCCATGTTGAAGGACGGCTTCCGCACTGACAGGGGGTCTCACTCAGACCTGTGGTCCAGCAGC AGCTCTCTGGAGAGTTCGAGTTTCCCGCTACCGAAACAGTACCTGGATGTGAGCTCCCAGACA GACATCTCGGGAAGCTTCGGCATCAACAGCAACAATCAGTTGGCAGAGAAGGTCAGATTGCGC CTTCGATATGAAGAGGCTAAGAGAAGGATCGCCAACCTGAAGATCCAGCTGGCCAAGCTTGAC AGTGAGGCCTGGCCTGGGGTGCTGGACTCAGAGAGGGACCGGCTGATCCTTATCAACGAGAAG GAGGAGCTGCTGAAGGAGATGCGCTTCATCAGCCCCCGCAAGTGGACCCAGGGGGAGGTGGAG CAGCTGGAGATGGCCCGGAAGCGGCTGGAAAAGGACCTGCAGGCAGCCCGGGACACCCAGAGC AAGGCGCTGACGGAGAGGTTAAAGTTAAACAGTAAGAGGAACCAGCTTGTGAGAGAACTGGAG JGAAGCCACCCGGCAGGTGGCAACTCTGCACTCCCAGCTGAAAAGTCTCTCAAGCAGCATGCAG TCCCTGTCCTCAGGCAGCAGCCCCGGATCCCTCACGTCCAGCCGGGGCTCCCTGGTTGCATCC AGCCTGGACTCCTCCACTTCAGCCAGCTTCACTGACCTCTACTATGACCCCTTTGAGCAGCTG GACTCAGAGCTGCAGAGCAAGGTGGAGTTCCTGCTCCTGGAGGGGGCCACCGGCTTCCGGCCC TCAGGCTGCATCACCACCATCCACGAGGATGAGGTGGCCAAGACCCAGAAGGCAGAGGGAGGT GGCCGCCTGCAGGCTCTGCGTTCCCTGTCTGGCACCCCAAAGTCCATGACCTCCCTATCCCCA CGTTCCTCTCTCTCCTCCCCCTCCCCACCCTGTTCCCCTCTCATGGCTGACCCCCTCCTGGCT
GGTGATGCCTTCCTCAACTCCTTGGAGTTTGAAGACCCGGAGCTGAGTGCCACTCTTTGTGAA CTGAGCCTTGGTAACAGCGCCCAGGAAAGATACCGGCTGGAGGAACCAGGAACGGAGGGCAAG CAGCTGGGCCAAGCTGTGAATACGGCCCAGGGGTGTGGCCTGAAAGTGGCCTGTGTCTCAGCG GCCGTATCGGACGAGTCAGTGGCTGGAGACAGTGGTGTGTACGAGGCTTCCGTGCAGAGACTG GGTGCTTCAGAAGCTGCTGCATTTGACAGTGACGAATCGGAAGCAGTGGGTGCGACCCGAATT CAGATTGCCCTGAAGTATGATGAGAAGAATAAGCAATTTGCAATATTAATCATCCAGCTGAGT AACCTTTCTGCTCTGTTGCAGCAACAAGACCAGAAAGTGAATATCCGCGTGGCTGTCCTTCCT TGCTCTGAAAGCACAACCTGCCTGTTCCGGACCCGGCCTCTGGACGCCTCAGACACTCTAGTG TTCAATGAGGTGTTCTGGGTATCCATGTCCTATCCAGCCCTTCACCAGAAGACCTTAAGAGTC GATGTCTGTACCACCGACAGGAGCCATCTGGAAGAGTGCCTGGGAGGCGCCCAGATCAGCCTG GCGGAGGTCTGCCGGTCTGGGGAGAGGTCGACTCGCTGGTACAACCTTCTCAGCTACAAATAC TTGAAGAAACAGAGCAGGGAGCTCAAGCCAGTGGGAGTCATGGCCCCTGCCTCAGGGCCTGCC GGATGAAGCGGCCTTCCTCGGTTAAGTCGCTGCGCTCCGAGCGTCTGATCCGTACCTCGCTG GACCTGGAGTTAGACCTGCAGGCGACAAGAACCTGGCACAGCCAATTGACCCAGGAGATCTCG GTGCTGAAGGAGCTCAAGGAGCAGCTGGAACAAGCCAAGAGCCACGGGGAGAAGGAGCTGCCA CAGTGGTTGCGTGAGGACGAGCGTTTCCGCCTGCTGCTGAGGATGCTGGAGAAGCGGCAGATG GACCGAGCGGAGCACAAGGGTGAGCTTCAGACAGACAAGATGATGAGGGCAGCTGCCAAGGAT GTGCACCAGCTCCGAGGCCAGAGCTGTAAGGAACCCCCAGAAGTTCAGTCTTTCAGGGAGAAG ATGGCATTTTTCACCCGGCCTCGGATGAATATCCCAGCTCTCTCTGCAGATGACGTCTAATCG CCAGAAAAGTATTTCCTTTGTTCCACTGACCAGGCTGTGAACATTGACTGTGGCTAAAGTTAT
TTATGTGGTGTTATATGAAGGTACTGAGTCACAAGTCCTCTAGTGCTCTTGTTGGTTTGAAGA
TGAACCGACTTTTTAGTTTGGGTCCTACTGTTGTTATTAAAAACAGAACAAAAACAAAACACA
CACACACACAAAAACAGAAACAAAAAAAACCAGCATTAAAATAATAAGATTGTATAGTTTGTA
TATTTAGGAGTGTATTTTTGGGAAAGAAAATTTAAATGAACTAAAGCAGTATTGAGTTGCTGC
TCTTCTTAAAATCGTTTAGATTTTTTTTGGTTTGTACAGCTCCACCTTTTAGAGGTCTTACTG
CAATAAGAAGTAATGCCTGGGGGACGGTAATCCTAATAGGACGTCCCGCACTTGTCACAGTAC
AGCTAATTTTTCCTAGTTAACATATTTTGTACAATATTAAAAAAATGCACAGAAACCATTGGG
GGGGATTCAGAGGTGCATCCACGGATCTTCTTGAGCTGTGACGTGTTTTTATGTGGCTGCCCA
ACGTGGAGCGGGCAGTGTGATAGGCTGGGTGGGCTAAGCAGCCTAGTCTATGTGGGTGACAGG
CCACGCTGGTCTCAGATGCCCAGTGAAGCCACTAACATGAGTGAGGGGAGGGCTGTGGGGAAC
TCCATTCAGTTTTATCTCCATCAATAAAGTGGCCTTTCAAAAAG
ORF Start: ATG at 94 JORF Stop: TAA at 2956 SEQ ID NO: 260 Ϊ954 aa :MW at 107489.2kD
]NOV72c, MPRPELPLPEGWEEARDFDGKVYYIDHTNRTTS IDPRDRYTKPLTFADCISDELPLGWEEAY
JCG 139224-03 Protein DPQVGDYFIDHNTKTTQIEDPRVQWRREQEHMLKDYLWAQEALSAQKEIYQVKQQRLELAQQ EYQQLHAVWEHKLGSQVSWSGSSSSSKYDPEILKAEIATAKSRVNKLKREMVHLQHELQFKE jSequence RGFQTLKKIDKKMSDAQGSYKLDEAQAVLRETKAIKKAITCGEKEKQDLIKSLAMLKDGFRTD RGSHSDLWSSSSSLESSSFPLPKQYLDVSSQTDISGSFGINSNNQLAEKVRLRLRYEEAKRRI ANLKIQLAKLDSEAWPGVLDSERDRLILINEKEELLKEMRFISPRK TQGEVEQLEMARKRLE KDLQAARDTQSKALTERLKLNSKRNQLVRELEEATRQVATLHSQLKSLSSSMQSLSSGSSPGS LTSSRGSLVASSLDSSTSASFTDLYYDPFEQLDSELQSKVEFLLLEGATGFRPSGCITTIHED EVAKTQKAEGGGRLQALRSLSGTPKSMTSLSPRSSLSSPSPPCSPLMADPLLAGDAFLNSLEF EDPELSATLCELSLGNSAQERYRLEEPGTEGKQLGQAVNTAQGCGLKVACVSAAVSDESVAGD SGVYEASVQRLGASEAAAFDSDESEAVGATRIQIALKYDEKNKQFAILIIQLSNLSALLQQQD QKVNIRVAVLPCSESTTCLFRTRPLDASDTLVFNEVFWVSMSYPALHQKTLRVDVCTTDRSHL EECLGGAQISLAEVCRSGERSTR YNLLSYKYLKKQSRELKPVGVMAPASGPARMKRPSSVKS LRSERLIRTSLDLELDLQATRTWHSQLTQEISVLKELKEQLEQAKSHGEKELPQWLREDERFR LLLRMLEKRQMDRAEHKGELQTDKMMRAAAKDVHQLRGQSCKEPPEVQSFREKMAFFTRPRMN IPALSADDV
Sequence comparison ofthe above protein sequences yields the following sequence relationships shown in Table 72B.
Table 72B. Comparison ofNOV72a against NOV72b and NOV72c.
NOV72a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
NOV72b 553-1 1 12 483/560 (86%) 364-923 483/560 (86%)
"T
NOV72c .870 678/871 (77%) .871 6 1/871 (78%)
Further analysis of the NOV72a protein yielded the following properties shown in Table 72C.
: Table 72C. Protein Sequence Properties NOV72a
. PSort 0.7600 probability located in nucleus; 0.3000 probability located in microbody ' analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
; SignalP No Known Signal Sequence Predicted ' analysis:
A search of the NOV72a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 72D.
In a BLAST search of public sequence datbases, the NOV72a protein was found to have homology to the proteins shown in the BLASTP data in Table 72E.
PFam analysis predicts that the NOV72a protein contains the domains shown in the Table 72F.
Example 73. The NOV73 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 73A.
Table 73A. NOV73 Sequence Analysis ]SEQ ID O: 261 .1455 bp
NOV73a, TCCTTGGCAGCCTTGGCAGCCACCTTGACACTCTCCTGTCTCCCCACCTCCACAGAGACAATG
CG I 40088-01 DNA ACCATGTTTGAAAATGTCACCCGGGCCCTGGCCAGACAGCTAAACCCTCGAGGGGACCTGACA CCACTTGACAGCCTCATCGACTTCAAGCGCTTCCATCCCTTCTGCCTGGTGCTGAGGAAGAGG
Sequence AAGAGCACGCTCTTCTGGGGGGCCCGGTACGTCCGCACCGACTACACGCTGCTGGATGTGCTT GAGCCCGGCAGCTCACCTTCAGACCCAACAGACACTGGGAATTTTGGCTTTAAGAATATGCTG GACACCCGAGTGGAGGGAGATGTGGATGTACCAAAGACGGTGAAGGTGAAGGGAACGGCAGGG CTCTCGCAGAACAGCACTCTGGAGGTCCAGACACTCAGTGTGGCTCCCAAGGCCCTGGAGACC GTGCAGGAGAGGAAGCTGGCAGCAGACCACCCATTCCTGAAGGAGATGCAAGATCAAGGGGAG AACCTGTATGTGGTGATGGAGGTGGTGGAGACGGTGCAGGAGGTCACACTGGAGCGAGCCGGC AAGGCAGAGGCCTGCTTCTCCCTCCCCTTCTTCGCCCCATTGGGGCTACAGGGATCCATAAAT CACAAGGAGGCTGTAACCATCCCCAAGGGCTGCGTCCTGGCCTTTCGAGTGAGACAGCTGATG GTCAAAGGCAAAGATGAGTGGGATATTCCACATATCTGCAATGATAACATGCAAACCTTCCCT CCTGGAGAGGAAGGTGCCCGATGGAGGGCTGTGTGTCCCATTATTGTCCCCATAGGGGACGTA CACGAAGGCTTCAGGACACTAAAAGAAGAAGTTCAGAGAGAGACCCAACAAGTGGAGAAGCTG AGCCGAGTAGGGCAAAGCTCCCTGCTCAGCTCCCTCAGCAAACTTCTAGGGAAGAAAAAGGAG CTACAAGACCTTGAGCTCGCACTTGAAGGGGCTCTAGACAAGGGACATGAAGTGACCCTGGAG GCACTCCCAAAAGATGTCCTGCTATCAAAGGAGGCCGTGGGCGCCATCCTCTATTTCGTTGGA GCCCTAACAGAGCTAAGTGAAGCCCAACAGAAGCTGCTGGTGAAATCCATGGAGAAAAAGATC CTACCCGTGCAGCTAAAGCTGGTGGAGAGCACGATGGAACAGAACTTCCTGCTGGATAAAGAG GGTGTTTTCCCCCTGCAACCTGAGCTGCTCTCCTCCCTTGGGGACGAGGAGCTGACCCTCACG GAGGCTCTAGTCGGGCTGAGTGGCCTGGAAGTGCAGAGATCGGGCCCCCAATATATGTGGGAC CCAGACACCCTCCCTCGCCTCTGTGCTCTTTATGCAGGCCTCTCTCTCCTTCAGCAGCTTACC AAGGCCTCCTAATTTGCCTTTTACGTCTGCTTCATGACTCCCTAATGCCTTCCCAACCTCGTG GTGCTG
ORF Start: ATG at 61 ORF Stop: TAA at 1396
SEQ ID NO: 262 445 aa }MW at 49428.5kD
NOV73a, MTMFENVTRALARQLNPRGDLTPLDSLIDFKRFHPFCLVLRKRKSTLF GARYVRTDYTLLDV
CGI 40088-01 Protein EPGSSPSDPTDTGNFGFP MLDTRVEGDVDVPKTVKVKGTAGLSQNSTLEVQTLSVAPKALE TVQERKLAADHPFLKEMQDQGENLYWMEWETVQEVTLERAGKAEACFSLPFFAPLGLQGSI
Sequence NHKEAVTIPKGCVLAFRVRQLMVKGKDEWDIPHICNDNMQTFPPGEEGARWRAVCPIIVPIGD VHEGFRTLKEEVQRETQQVEKLSRVGQSSLLSSLSKLLGKKKELQDLELALEGALDKGHEVTL EALPKDVLLSKEAVGAILYFVGALTELSEAQQKLLVKS EKKILPVQLKLVEST EQNFLLDK EGVFPLQPELLSSLGDEELTLTEALVGLSGLEVQRSGPQYMWDPDTLPRLCALYAGLSLLQQL
TKAS
SEQ ID NO: 263 1386 bp |
NOV73b, CTCCACAGAGACAATGACCATGTTTGAAAATGTCACCCGGGCCCTGGCCAGACAGCTAAACCC
:CG 140088-02 DNA TCGAGGGGACCTGACACCACTTGACAGCCTCATCGACTTCAAGCGCTTCCATCCCTTCTGCCT GGTGCTGAGGAAGAGGAAGAGCACGCTCTTCTGGGGGGCCCGGTACGTCCGCACCGACTACAC
Sequence GCTGCTGGATGTGCTTGAGCCCGGCAGCTCACCTTCAGACCCAACAGACACTGGGAATTTTGG CTTTAAGAATATGCTGGACACCCGAGTGGAGGGAGATGTGGATGTACCAAAGACGGTGAAGGT GAAGGGAACGGCAGGGCTCTCGCAGAACAGCACTCTGGAGGTCCAGACACTCAGTGTGGCTCC CAAGGCCCTGGAGACCTTGCAGAAGAGGAAGCTGGCAGCAGACCACCCATTCCTGAAGGAGAT GCAAGATCAAGGGGAGAACCTGTATGTGGTGATGGAGGTGGTGGAGACGGTGCAGGAGGTCAC ACTGGAGCGAGCCGGCAAGGCAGAGGCCTGCTTCTCCCTCCCCTTCTTCGCCCCATTGGGGCT ACAGGGATCCATAAATCACAAGGAGGCTGTAACCATCCCCAAGGGCTGCGTCCTGGCCTTTCG AGTGAGACAGCTGATGGTCAAAGGCAAAGATGAGTGGGATATTCCACATATCTGCAATGATAA CATGCAAACCTTCCCTCCTGGAGAAAAGTCAGGAGAGGAGAAGGTCATCCTTATCCAGGCATC TGATGTTGGGGACGTACACGAAGGCTTCAGGACACTAAAAGAAGAAGTTCAGAGAGAGACCCA ACAAGTGGAGAAGCTGAGCCGAGTAGGGCAAAGCTCCCTGCTCAGCTCCCTCAGCAAACTTCT AGGGAAGAAAAAGGAGCTACAAGACCTTGAGCTCGCACTTGAAGGGGCTCTAGACAAGGGACA TGAAGTGACCCTGGAGGCACTCCCAAAAGATGTCCTGCTATCAAAGGAGGCCGTGGGCGCCAT CCTCTATTTCGTTGGAGCCCTAACAGAGCTAAGTGAAGCCCAACAGAAGCTGCTGGTGAAATC CATGGAGAAAAAGATCCTACCCGTGCAGCTAAAGCTGGTGGAGAGCACGATGGAACAGAACTT CCTGCTGGATAAAGAGGGTGTTTTCCCCCTGCAACCTGAGCTGCTCTCCTCCCTTGGGGACGA GGAGCTGACCCTCACGGAGGCTCTAGTCGGGCTGAGTGGCCTGGAAGTGCAGAGATCGGGCCC CCAATATATGTGGGACCCAGACACCCTCCCTCGCCTCTGTGCTCTTTATGCAGGCCTCTCTCT CCTTCAGCAGCTTACCAAGGCCTCCTAATTTGCCTTTTACGTCTGCTTCATGACTCCCTAATG
ORF Start: ATG at 14 ORF Stop: TAA at 1349
SEQ ID NO: 264 445 aa MW at 49377.4kD
*NOV73b, MT FENVTRALARQLNPRGDLTPLDSLIDFKRFHPFCLVLRKRKSTLFWGARYVRTDYTLLDV
CG 140088-02 Protein LEPGSSPSDPTDTGNFGFKNMLDTRVEGDVDVPKTVKVKGTAGLSQNSTLEVQTLSVAPKALE TLQKRKLAADHPFLKEMQDQGENLYVVMEWETVQEVTLERAGKAEACFSLPFFAPLGLQGSI
Sequence NHKEAVTIPKGCVLAFRVRQLMVKGKDEWDIPHICNDNMQTFPPGEKSGEEKVILIQASDVGD VHEGFRTLKEEVQRETQQVEKLSRVGQSSLLSSLSKLLGKKKELQDLELALEGALDKGHEVTL EALPKDVLLSKEAVGAILYFVGALTELSEAQQKLLVKSMEKKILPVQLKLVESTMEQNFLLDK EGVFPLQPELLSSLGDEELTLTEALVGLSGLEVQRSGPQYMWDPDTLPRLCALYAGLSLLQQL TKAS
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 73B.
; Table 73B. Comparison of NOV73a against NOV73b.
NOV73a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
NOV73b 1..445 398/445 (89%) 1..445 404/445 (90%)
Further analysis of the NOV73a protein yielded the following properties shown in Table 73C.
! Table 73C. Protein Sequence Properties NOV73a
; PSort 0.3600 probability located in mitochondrial matrix space; 0.3000 probability located analysis: j in microbody (peroxisome); 0.3000 probability located in nucleus; 0.1000 : ! probability located in lysosome (lumen)
, SignalP j No Known Signal Sequence Predicted ' analysis:
A search of the NOV73a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 73D.
In a BLAST search of public sequence datbases, the NOV73a protein was found to have homology to the proteins shown in the BLASTP data in Table 73E.
! Table 73E. Public BLASTP Results for NOV73a
PFam analysis predicts that the NOV73a protein contains the domains shown in the Table 73F.
The NOV74 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 74A.
Table 74A. NOV74 Sequence Analysis SEQ Ϊb NO: 265" 1 124 bp jNOV74a, IGAAATTTTAATTTA"T ^TTCCCCCCTTTTTTTCCTGCATCTATAGGATAATATTGTAAAATAG
,CG 140170-01 DNA CAATTGAAACCAATAATCATTAAATAAATATCAAGGAAAATCCAAGCAAAGCTTTCTTTTTGT
TGGACTAGTGGTGTGGTGTTTGGAGACAGTCTCTGAATGTGAACAGGAAAGCACCCATCAGCA
JSequence AAACACGATCACTCTCTAGGGAGACAGCTGGGGGAATCTGACTCTGGCTTCTGCTTTTGTTTT
AAGGGATTAACTTCCCTGTCAAGTCCAAGAAGACTTGCGTATGAGAAGATTACCTGATGGACT
TAATTCTAAGATTAGCTTTTTTCATCAAGATGGAAAAAGATCTTTAGGAGCAGAAAAGGGGAG
TGCTAACTGGGGGAGCGAGAAGGGAGACGAGCAAAAGAAACAAAATCTTGCCACGTGGCTCTG
TTTTGTCAGCAAGAGGATTTAAGACTCACCCAGGGCAAACACTGGGACCACTGTAAGAGCGCT
GGAACATTCTGCCTCTTGAGTGAAGGGGCCTTCTTTCTAGCCTCTATGGCACTGAGGGGTGCG
CCGGCTGGTGGAGGAGTAGTCCGATGGAGCCCTGCGTTCCCCGGGGACACAGGGCCAAGCTTT
GAGGTGGAAAGTTTCTGGTTCTGAAACAACAAGGAGAGAGTCTGTTTTTCTTCCTAAAATTTG
GACTCTTGTCTGCACAAACTCTGGTCTGTTTTGCACGGTTTGTGTGCCTTTTTTTCCCTTTAT
GCAATCTTTTTCAGCTTTAGCAGCAGAAATTTGTCTAGTTCAGGAAACATGCTAGAGGGTGGC
TTCAGAAGGAAGATGATCCTGTGTATTCTGTCTCTGCATCCGAACTTTTGAAGAGAAAAATTC
GAGCTAGAGGGATTCTTAAAGCCTTAAGTTACTTGAAATCTATGTATTTGCAACCCTTTGTCT
CTGGAATCATATTACACTAAACTGGAATCTCAGGCTGAATGAGAATAACCAAGTGGAGTAAAA
AGAAGAAAACCGTTTCTTGATCACCACTTAATTAACGATGCTCTTTCTCCAAAGGATCAGCAC
GTTCTTCCTCTGAGAACTTGAAAATACAAATGGACCCCATGTTTTTTTAAGCATTACCTTTTC
TTAGAAGACTGCCATCATCTTTTATAGAGGAATTTTTTCACTATGCATTCAGTGGATCTTTAT
AAAATACTGACCTTCTAATTAGATTCAGGTCAGTCTTAATTAAAGGGGGAAAAAAGCAACGCA
AGCCAACCACAAAAACACATATACCAATGAAAGAAATTGGTTTAAATTTCACAGCATTAACAT
TACTTTTTAAGTAAAACAGTTCATTGAAGAAAGTATGTATGCAGCAGTGGAACATGGGCCTGT
GCTTTGCAGTGACTCCAACATCCTGTGCCTGTCCTGGAAGGGGCGTGTCCCCAAGAGTGAGAA GGAGAAGCCTGTGTGCAGGAGACGCTACTATGAGGAAGGCTGGCTGGCCACGGGCAACGGGCG AGGAGTGGTTGGGGTGACTTTCACCTCTAGTCACTGTCGCAGGGACAGGAGTACTCCACAGAG GATAAATTTCAACCTCCGGGGCCACAATAGCGAGGTTGTGCTGGTGAGGTGGAATGAGCCCTA CCAGAAACTGGCCACGTGCGATGCGGACGGAGGCATATTCGTGTGGATTCAGTACGAGGGCAG GTGGTCTGTGGAGCTGGTCAACGACCGCGGGGCGCAGGTGAGTGATTTCACGTGGAGCCATGA TGGAACTCAAGCACTTATTTCCTATCGAGATGGGTTTGTCCTGGTTGGGTCTGTCAGTGGACA AAGACACTGGTCATCCGAAATCAACTTGGAAAGTCAAATTACGTGTGGCATATGGACTCCTGA CGACCAACAGGTGCTGTTTGGCACGGCCGATGGGCAGGTGATTGTCATGGATTGCCACGGCAG AATGCTGGCCCACGTCCTCTTGCACGAGTCAGACGGTGTCCTCGGCATGTCCTGGAACTACCC GATCTTCCTGGTGGAGGACAGCAGCGAGAGCGACACGGACTCAGATGACTACGCCCCTCCCCA AGATGGTCCGGCAGCATATCCCATCCCAGTGCAGAACATCAAGCCTCTGCTCACCGTCAGCTT CACCTCGGGAGACATCAGCTTAATGAACAACTACGATGACTTGTCTCCCACGGTCATCCGCTC AGGGCTGAAAGAGGTGGTAGCCCAGTGGTGCACACAGGGGGACTTGCTGGCAGTCGCTGGGAT GGAACGGCAGACCCAGCTTGGTGAGCTTCCCAATGGTCCCCTTCTGAAGAGTGCCATGGTCAA GTTCTACAATGTTCGTGGGGAGCACATCTTCACACTGGACACTCTCGTGCAGCGCCCCATCAT CTCCATCTGCTGGGGTCACCGGGATTCGAGGCTGTTGATGGCATCAGGACCAGCCCTGTACGT GGTGCGTGTGGAGCACCGGGTGTCCAGCCTGCAGCTGCTGTGCCAGCAGGCCATCGCCAGCAC CTTGCGTGAGGACAAGGACGTCAGCAAGCTGACTCTGCCCCCCCGCCTCTGCTCCTACCTCTC CACTGCCTTCATCCCCACCATCAAGCCCCCAATTCCAGATCCGAACAACATGAGAGACTTTGT CAGCTACCCATCAGCCGGCAACGAGCGGCTGCACTGCACCATGAAGCGCACAGAGGACGACCC GGAGGTGGGCGGCCCGTGCTACACGCTCTACCTGGAGTACCTGGGCGGGCTTGTGCCCATCCT CAAAGGGCGGCGCATCAGCAAGCTGCGGCCAGAGTTCGTCATCATGGACCCGCGGACAGATAG CAAACCAGATGAAATCTATGGGAACAGCTTGATTTCTACTGTGATCGACAGCTGCAACTGCTC AGACTCCAGTGACATTGAGCTGAGTGATGACTGGGCTGCCAAGAAATCTCCCAAAATCTCCAG AGCTAGCAAATCACCCAAACTCCCAAGGATCAGCATTGAGGCCCGCAAGTCACCCAAGCTGCC CCGGGCTGCTCAGGAGCTCTCCCGGTCCCCACGGTTGCCCCTGCGCAAGCCCTCTGTGGGCTC GCCCAGCCTGACTCGGAGAGAGTTTCCTTTTGAAGACATCACTCACCCCACCTATCTTGCTCA GGTCACGTCTAATATCTGGGGAACCAAATTTAAGATTGTGGGCTTGGCTGCTTTCCTGCCAAC CAACCTCGGTGCAGTAATCTATAAAACCAGCCTCCTGCATCTCCAGCCGCGGCAGATGACCAT TTATCTCCCAGAAGTTCGGAAAATTTCCATGGACTATATTAATTTACCTGTCTTCAACCCAAA TGTTTTCAGTGAAGATGAAGATGATTTACCAGTGACAGGAGCATCTGGTGTCCCTGAGAACAG CCCACCTTGTACCGTGAACATCCCTATTGCACCGATCCACAGCTCGGCTCAGGCTATGTCCCC
CACGCAGAGCATAGGGCTGGTGCAGTCCCTACTGGCCAATCAGAATGTGCAGCTAGATGTCCT
GACCAACCAGACGACAGCTGTAGGGACAGCAGAACATGCAGGTGACAGTGCCACCCAGTACCC
AGTCTCCAACCGGTACTCCAATCCTGGACAGGTGATTTTCGGAAGCGTGGAAATGGGCCGCAT
CATTCAGAACCCCCCTCCACTGTCCCTGCCTCCCCCGCCGCAGGGGCCCATGCAGCTGTCCAC
GGTGGGCCATGGAGACCGAGACCACGAACACCTGCAGAAGTCAGCCAAGGCCCTGCGGCCAAC
ACCGCAGCTGGCAGCTGAGGGGGACGCAGTGGTCTTTAGTGCCCCCCAGGAGGTCCAGGTGAC
CAAGATAAACCCTCCACCCCCGTACCCAGGAACCATCCCCGCTGCCCCCACCACAGCAGCACC
CCCGCCCCCTCTGCCGCCCCCACAGCCCCCAGTGGATGTGTGCTTGAAGAAGGGCGACTTCTC
CCTCTACCCCACGTCAGTGCACTACCAGACCCCCCTGGGCTATGAGAGGATCACCACCTTCGA
CAGCAGTGGCAACGTGGAGGAGGTGTGCCGGCCCCGCACCCGGATGCTGTGCTCCCAGAACAC
CTACACCCTCCCCGGCCCGGGTAGCTCTGCCACCTTGAGGCTCACGGCCACTGAGAAGAAGGT
CCCTCAGCCCTGCAGCAGTGCCACCCTGAACCGCCTGACCGTCCCTCGCTACTCCATCCCCAC
CGGGGACCCACCCCCGTATCCTGAAATTGCCAGCCAGCTGGCCCAGGGGCGGGGGGCTGCCCA
GAGGTCCGACAATAGCCTCATCCACGCTACCCTGCGGAGGAACAACCGTGAGGCTACGCTCAA
GATGGCCCAGCTGGCCGACAGCCCGCGGGCCCCCCTGCAGCCCCTGGCCAAGTCCAAGGGCGG
GCCCGGGGGGGTGGTGACACAGCTCCCAGCGCGGCCCCCACCTGCCCTGTACACCTGCAGTCA
GTGCAGTGGCACAGGGCCCAGCTCACAGCCCGGAGCCTCCCTGGCCCATACCGCCAGCGCCTC
CCCGTTGGCCTCCCAGTCCTCCTACAGCCTCCTGAGCCCACCCGACAGCGCCCGCGACCGCAC
CGACTACGTCAACTCGGCCTTCACGGAGGACGAGGCCCTGTCCCAGCACTGTCAGCTTGAGAA
GCCCTTGAGGCACCCTCCCCTGCCTGAAGCTGCTGTCACCCTGAAACGGCCACCCCCTTACCA
GTGGGACCCCATGCTGGGTGAGGACGTTTGGGTTCCTCAAGAAAGGACAGCACAGACTTCAGG
GCCCAACCCCTTAAAACTGTCCTCTCTGATGCTGAGTCAGGGCCAGCACCTGGACGTGTCCCG
ACTGCCCTTCATCTCCCCCAAGTCTCCTGCCAGCCCCACTGCCACTTTCCAAACAGGCTATGG
GATGGGAGTGCCATATCCAGGAAGCTATAACAACCCCCCTTTGCCTGGAGTGCAGGCTCCCTG
CTCTCCCAAAGATGCCCTGTCCCCAACGCAGTTTGCACAACAGGAGCCTGCTGTGGTCCTTCA
GCCGCTGTACCCACCCAGCCTCTCCTATTGCACCCTGCCCCCCATGTACCCAGGAAGCAGCAC
GTGCTCTAGTTTACAGCTGCCACCTGTCGCCTTGCATCCATGGAGTTCCTACAGCGCCl'GCCC
GCCCATGCAGAACCCCCAGGGCACTCTCCCCCCAAAGCCACACTTGGTGGTGGAGAAGCCCCT
TGTGTCCCCACCACCTGCCGACCTCCAAAGCCACTTGGGCACAGAGGTGATGGTAGAGACTGC
AGACAACTTCCAGGAAGTCCTCTCCCTGACCGAAAGCCCAGTCCCCCAGCGGACAGAAAAATT
TGGAAAGAAGAACCGGAAGCGCCTGGACAGCCGAGCAGAAGAAGGCAGCGTTCAGGCCATCAC
TGAGGGCAAAGTGAAGAAGGAGGCTAGGACTTTGAGTGACTTTAATTCCCTAATCTCCAGCCC
ACACCTGGGGAGAGAGAAGAAGAAAGTGAAGAGTCAGAAAGACCAACTGAAGTCAAAGAAGTT
GAATAAGACAAACGAGTTCCAGGACAGCTCCGAGAGCGAGCCTGAGCTGTTCATCAGCGGGGA
TGAGCTCATGAACCAGAGCCAGGGCAGCAGAAAGGGCTGGAAAAGCAAGCGCTCCCCACGGGC
CGCCGGCGAGCTGGAGGAGGCCAAGTGCCGGCGGGCCAGTGAGAAGGAGGACGGGCGGCTGGG
CAGCCAAGGCTTCGTGTACGTGATGGCCAACAAGCAGCCGCTGTGGAACGAGGCCACCCAGGT
CTACCAGCTGGACTTCGGGGGGCGGGTGACCCAGGAGTCCGCCAAGAACTTCCAGATTGAGTT
AGAGGGGCGGCAGGTGATGCAGTTTGGACGGATTGATGGCAGTGCGTACATTCTAGACTTCCA
GTATCCGTTCTCAGCCGTGCAGGCCTTTGCAGTTGCCCTGGCCAACGTGACTCAGCGCCTCAA
ATGAAGAGACTGGTGTGGGGAGGAGAGAGATGCAGAGAGCCTTTGGAAGAGGTCTTCGGAGAT
GCCAGAGGAGCCCTCTAGGGGTCCGATGCCTGGGAGGACCAGAAGCCAACAGCAAAACTGGAA
AAGCCCGGCAGGCCCAGGAGAGGGCGCTGACCTGTGGTCGTCATTTATTTGGTTGGGTTTTAT
TACCTTTTATTGTCTGTTCTTCTTTTCTTCTTTCATTTCAGTGGCATTTGGAAGCAAAGAGTG
CTAGGCACCTGCAGTTCTTTCAGGAAACAGCTTGGCTGTGGTAATGCTCTACTGGGCCCTTCA
GAATGAAGACAGTCTGCCTTAGAGCCTGCTATTCTTTTAGACATAGGGAGGATGCATTATCCT
GTATTCTCCTCCAACATCACCACTAGCGTAAAAGCAAAAAGCTTTTACAAAACACAGCCAAAA
ATTCTCAAGATGCAGGTTCTTGGGGAATGGGATGGGGACAGCATTTGATTTACACTGATTATG
TTACTCCCCAAAAGGTGACTTAATTAATAAAGGGCATTTGGGCAGACACACTGTGTTGGACCA
ACAAAGTAGGCTCTTTACAGGGGTGTTCTCACCAGGTAGAAATGCGATTTGCTCACTGAGGAT
GTTGGGGAAGGGACGAAGGGTAAAGAAGAAACTGCACCGTATACACAGGTTCACATCACTCTG
CAGACAGCAATGTGACTCAGCGTGTGACTTGTAGCAGCAGTACGAGGGCTACACTCCTCTGCT
GAGGATGTCTACATTGAAAGCCTCCACTAGTTTCATCGTTTGTCAAGTTCCGTAGATCAGTGA
TGGTCATTCAGCATGACTGGTTCTGGGAGAAGGTGAGAGACAAAAATGGAAAGATCCTGGCCT
GTGGTAGTGGTAGCAGTTTTCTCAAATAATGTGGTGACAGTCACTAGATCCTCACATGCTGAG
AAACAGCCTCTACTCTCTCTGCCCCTTTTACTTTTTAATCTGGAATGCATTACTGTAAACATG
ATCTTTCCCATGAGATACCATGTTCTATGCCTTCCCATTCTAAAAGTGTGGACAACGCTTGAT
TTGAAACCACTCCTTTTCTCCTCTTGGCTACATTAAAATTCAGTTGACTACAAATGCTTTCTA
TCAAATTAGAAATGTAACCAAAAAAATGTTAAGTGTTCACCAGGGTATTAAAATACAGAGGGA
GTATGGTCAAATCTTTTGACAAAATTTTCATGATCTTCTCTAACAAAAAAAGTTGTTTATTAA
CTGTACAGACTGTTTACTAAGGAGCTAAACCACTGAGAAAACGTTATTAAAATTGTAATACCT
AGGTAGTTGGTTGATCACAGTTTGTTAATTGTATAAAAAAAAATTACCTAGAATATCTCTTCC
CACTTCCTCGTCCTCGTGAGAACCTGTGGGCAGTATTCAAGCCCTGATGACAAAACCCAGTGT
TTTTTGTTGTTGTTTTTTGTTGTTGTTTTTTGTTTTTGTTTTTGTTTTTCTCAGTCTTACCTG
TGATGTTGTTTAGGATCAGGCCCCTCTCCTGGGCCTGCTGTGCAGGAGCACAGGAACTATCTG
CTGGCGTTGGGTTCCAAATTTGCATTTTATTTGGAAACAGACAAGTAGAAGATGCTACAGAAA
AGTATTTTCAAATTTAAACGTTTTTTAATCCCCTGTTTTAGTTAAAAAATTGGAAAAGAAACC IGACCCATTTTTTTCCCAGATCAAGATGACATGACATCACTCCCAATTCTCTCCAAACCCCAGA JGAAATACTGACGAAGTTTTCTGATGTGGCAAAGGATATTTCCCATCTAATACCAGTTTCTCAT
I. TTATATTTAACGTATTGGACCTGATATTTTTAGTGGGTGCATTCTTCCAGAAAGAATTCAGCA
IATGTTATCAGAATTAATTCTTTTATATGAGTTTATGTAGCTTGATATGGTGTTTCAGTGCTTA
JTTGGTTGTGCAATAATGGTTATAGCCTGTTAGATAATCTAAATGCAATTCCCCTGTTTTGTCG TTTAGGAGATAATTATTTATCTTGCTTTTCATAGTGTTCTTAGGAATTATTTTGTTGTTACGT
TTTGGTGAGTTATACCCATTTTATTTATTTAGAAAAATAGTATCTTTGTTAACGACTTACATG
GTCACAGTATATTTTGCTGCAAGAAATAAAGAGGATATGATAGAAGGTTTTTTTTTTTTTTTT
TTTTTTTTTTTGAGACGGAGTCCCACTCTTGTCGCCCAACTAGAGTGTAGTGGCACAATCTCG
GCTCCCCACAACCTCTGACTCCAGGGTTCAGGTGATTATTTTGCCTCAGCCTCCCAAGCAGCT
GGGATTATAGACACCCGCCAACACGCCAGGCTAATGTTTTTGTATTTTTAATAGAGATGGGGT
TTTGCCATGTTGGCCAGGCTGGTCTTGAACTCCTGACCTCAGGTGATCCGCCCGCCTCGGCCT
CCCAAAGTGCTGGGATTACAGACGTGAGCCACCACTCCCGGCCCATAGAAGGTTTTTTGCTGG
ΪATAATTTGTAACTTTTCTAATTGGGAAAAAATTCCTATTAATCACTTAAAAATTTTTTTTTGT
ATTTTGTGTTATTGATTATATACAAAGGAGACTTTTTTTTTGAGATAACACTCAAATAGTATT
CTCTTCTTTTGAAAATTTTATTTTTATCTGAAAATAACAGTTGATCTGAAATAAAAAGGGGAG
ACCTATTAGAATGAGAGTAGCCAAGGAAAGAGTTACTAGGTAATAAGCTTCACTTTTTGTGTT
CTAATTGTTTTTGAGATATAAAGACCCTGAAAAAGCCCATTTTAGAACCTGTTTAATAAGAGC
AAATATAGGGGAAAATCTTTGAAATGAAAGCTACAAATACATGTGAGAAGAAAAAAATGGATT
TTTTTAGCAAATAATTAACTAAGCTTCTAAATGCCTAGCTCCCTCCCCCAAAGGCGCTTTCCC
CCGATGGAGGCACAGGCTTCTGTCTCGGATGTTTGGCGCACGTGAGTTTGTATGAGTTTGTAC
CGGAGTGACCCCGGCAGCCACTGCCCACCTCCCCTCTACCCAGGGGCCTGAAAAGAGGGGCTG
CCCTCCTGCGCCAAGGCAGACACAAGCTGCGGGCTGTGCGGTCCTAGTAGTGTGACGTTTCAG
TTAATAGTGGTGGTCTTATTTTCAACTATGCTTTCATTCAGTCAGTCTCTGTTGACTAAATAC
GACGAAAATTCATACTTTATGCAGGAGATTTCTAAAAATTTAATGTTTATTAATAGTTTATGA lATATCAAGATACCTCATTGAATCCCTAAATTTAAAAGCAGTCCAGTAAAAGGTTAACTGTATA
AAGAATCTATGACTTTTTGAGGGAAGTGTGATATATTAACAAATATAACCAATTCTAAATTTG
TTTTAGCTCTAACCTCATCAAACCAAAGGCACAGATTTGTGTACAATATACCCATTGAATGTA
TATCCTGAGAAAAATTGGGGCCAAAGAAGCAGGAAAATCTCAAAGCTCTAATGGCAGCATAAA
TCAAAGAATTTCACAGGCTAGTGTTTTTATCCATAGCCATTGCTCCCTTGTCAAGTGTCTCAC
AAGGACATGGAAGAATGTGTTATGTTCATCTTGTAATCATAGCAAAAAGTCTGCAAACCCCAG
GGTCAAGCCTGCTCTGCCACAGGGTTGGATGGTGACCTTGGGCAAGTCCCTGGGGCTGGCTAG
GCCTCCACTTGTCCATCTGTGAAATGAAAGGATCAGCCTGGACAGCCCTCTAAACTCCCTTAC
AGCTCTCAGCCTAAGAGCGCAGCACTGAACAGCCTCATCATTCCACTTTTCATGGGAAATATA
TTTCACACCATTGCCTTTGTGTAGAGAAATATTTCTTTTCCTGTGTTAATGAGCTATGTACTG
AATATAAACCAGTGCATTTAAAGTAATATCTTTTGTGCACCTCTAAATGTGTTTGGAATTGTG
TTTGTTCTCATAGAATATACAAAAGTACTGATTCTAGGTAAGAAGGAGTCTCCACGGGTGTGC
CCTGCTCAGCTGGATGTCCATGAGAACAGCCATGAAATAAGTCACTACTTGTCCCCAAAACCA
CAGGAATATATACCTAGGTCACCTCAAATTCCTGAGTGTGCTCTGCCATGTTACACGGTCTTC
AAATTGAAAAGGTTTCTTGAAAAGGAAAGTTTGGCCCAGCAACTGGAGAAGGAGTCCATGGTG jTCGCTGTGTGCCTGTATCATTTGGCCAAGTCAATGGTTGTAAGCAAAGTTAGTGGAGACAAAA
ATGTGTCCAAAATGTCGTTTGAGTTCCTGGGATTTCTGTAATAGCACACAACTCAGAACTCTT
CAGCATTTGTGTGATTCCTTACCTCTGGCTGATAAAACTCTAATGGGTTGTGGCTTACTTTGT
TTCCATTTTCTTTGGCTTTGTGCAATTTTTGTGTAACTTTACTTGTACCTATATTTTCTGTTT
ACAGTTCTTTTTAAGGGGAGGGGTAGGGTTCTAAGATCTTGTTGTTTATTGTAGATAAAAATT
TTTTCGTGTTGTAGAAAAGCATGGGTTATGCGTTTGACTGAAAAAGACACTGTATTATTTACC
AAAGGGGTATTGTTTTTGCATTTGTTTATAAATGCATTATTTTGGTACTGTAAATTTGGACAT
AATTTCTGAGTTTATTACTACTGGCATTTTCTTTTTCCCTTTTTTTTTTTTTTAACCGTAAGT
GCACGATGCAGGTGCATAGGCCCCAGACCAAACTAGACCACCAGCATGTTCATGTCCAGACCT
CGGCAGTGGCGTGCACTGCTTGTGCACCTCAGTTCCTCCAGTGTTGGTTTGTTTGTTTTTTAA
TTCAGCATCCTGCTGGTTTTACTTTCCAAGCAAGATCTGTTGCGACTCCCAAATGCGTTTTAA
TGAGCTCATCCTTATTTGCCTTTCTTCTTACGTATTTTGTGTATTAGATTGTGCAGGAGATAT
TCTAGAAGGCATTAATGGTTTGCATTCAAAACGATGTGGTTTGTCCAAGTTATTTTCTGTCTT
TATTACTGAGACGGATTAATCTCCTTATTTTTTTCTTGATGATTTGAAGTTGTAAGAGTTGTC
CAGCTATTGCTTAATAAAATTTTGCAGATCAAAAAA
ORF Start: ATG at 1358 _ |ORF Stop: TGA at 5987
SEQ ID NO: 266 J1543 aa ]iMW at 168953.6kb
NOV74a, MYAAVEHGPVLCSDSNILCLS KGRVPKSEKEKPVCRRRYYEEGWLATGNGRGWGVTFTSSH
CG I 40170-01 Protein CRRDRSTPQRINFNLRGHNSEWLVR NEPYQKLATCDADGGIFVWIQYEGRWSVELVNDRGA QVSDFT SHDGTQALISYRDGFVLVGSVSGQRHWSSEINLESQITCGI TPDDQQVLFGTADG
Sequence QVIVMDCHGRMLAHVLLHESDGVLGMSWNYPIFLVEDSSESDTDSDDYAPPQDGPAAYPIPVQ NIKPLLTVSFTSGDISLM NYDDLSPTVIRSGLKEWAQWCTQGDLLAVAGMERQTQLGELPN GPLLKSAMVKFYNVRGEHIFTLDTLVQRPIISIC GHRDSRLLMASGPALYWRVEHRVSSLQ LLCQQAIASTLREDKDVSKLTLPPRLCSYLSTAFIPTIKPPIPDPNN RDFVSYPSAGNERLH
CTMKRTEDDPEVGGPCYTLYLEYLGGLVPILKGRRISKLRPEFVIMDPRTDSKPDEIYGNSLI STVIDSCNCSDSSDIELSDDWAA KSPKISRASKSPKLPRISIEARKSPKLPRAAQELSRSPR LPLRKPSVGSPSLTRREFPFEDITHPTYLAQVTSNIWGTKFKIVGLAAFLPTNLGAVIYKTSL LHLQPRQMTIYLPEVRKISMDYINLPVF PNVFSEDEDDLPVTGASGVPENSPPCTVNIPIAP IHSSAQA SPTQSIGLVQSLLANQNVQLDVLTNQTTAVGTAEHAGDSATQYPVSNRYSNPGQV IFGSVEMGRIIQNPPPLSLPPPPQGPMQLSTVGHGDRDHEHLQKSAKALRPTPQLAAEGDAW FSAPQEVQVTKINPPPPYPGTIPAAPTTAAPPPPLPPPQPPVDVCLKKGDFSLYPTSVHYQTP LGYERITTFDSSGNVEEVCRPRTR LCSQNTYTLPGPGSSATLRLTATEKKVPQPCSSATLNR LTVPRYSIPTGDPPPYPEIASQLAQGRGAAQRSDNSLIHATLRR REATLKMAQLADSPRAP LQPLAKSKGGPGGWTQLPARPPPALYTCSQCSGTGPSSQPGASLAHTASASPLASQSSYSLL SPPDSARDRTDYVNSAFTEDEALSQHCQLEKPLRHPPLPEAAVTLKRPPPYQWDPMLGEDVWV PQERTAQTSGPNPLKLSSLMLSQGQHLDVSRLPFISPKSPASPTATFQTGYGMGVPYPGSY N PPLPGVQAPCSPKDALSPTQFAQQEPAWLQPLYPPSLSYCTLPPMYPGSSTCSSLQLPPVAL HPWSSYSACPPMQNPQGTLPPKPHLVVEKPLVSPPPADLQSHLGTEVMVETADNFQEVLSLTE SPVPQRTEKFGKKNRKRLDSRAEEGSVQAITEGKVKKEARTLSDFNSLISSPHLGREKKKVKS QKDQLKSKKLNKTNEFQDSSESEPELFISGDEL NQSQGSRKGWKSKRSPRAAGELEEAKCRR ASEKEDGRLGSQGFVYVMA KQPLWNEATQVYQLDFGGRVTQESAKNFQIELEGRQVMQFGRI DGSAYILDFQYPFSAVQAFAVALANVTQRLK
Further analysis of the NOV74a protein yielded the following properties shown in Table 74B.
; Table 74B. Protein Sequence Properties NOV74a
PSort 0.8800 probability located in nucleus; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
J SignalP No Known Signal Sequence Predicted 1 analysis:
A search of the NOV74a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 74C.
In a BLAST search of public sequence datbases, the NOV74a protein was found to have homology to the proteins shown in the BLASTP data in Table 74D.
PFam analysis predicts that the NOV74a protein contains the domains shown in the Table 74E.
The NOV75 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 75A.
Table 75A. NOV75 Sequence Analysis
.. SEQ ID NO: 267 ; 1838 bp
NOV75a, AAATGGCCCAAGAAATAGATCTGAGTGCTCTCAAGGAGTTAGAACGCGAGGCCATTCTCCAGG
CGI 40179-01 DNA TCCTGTACCGAGACCAGGCGGTTCAAAACACAGAGGAGGAGAGGACACGGAAACTGAAAACAC ACCTGCAGCATCTCCGGTGGAAAGGAGCGAAGAACACGGACTGGGAGCACAAAGAGAAGTGCT
Sequence GTGCGCGCTGCCAGCAGGTGCTGGGGTTCCTGCTGCACCGGGGCGCCGTGTGCCGGGGCTGCA GCCACCGCGTGTGTGCCCAGTGCCGAGTGTTCCTGAGGGGGACCCATGCCTGGAAGTGCACGG TGTGCTTCGAGGACAGGAATGTCAAAATAAAAACTGGAGAATGGTTCTATGAGGAACGAGCCA AGAAATTTCCAACTGCAGGCAAACATGAGACAGTTGGAGGGCAGCTCTTGCAATCTTATCAGA AGCTGAGCAAAATTTCTGTGGTTCCTCCTACTCCACCTCCTGTCAGCGAGAGCCAGTGCAGCC GCAGTAGGCTCCAGGAGTTTGGTCAGTTTAGAGGATTTAATAAGTCCGTGGAAAATTTGTTTC TGTCTCTTGCTACCCACGTGAAAGAGCTCTCCAAATCCCAGAATGATATGACTTCTGAGAAGC ATCTTCTCGCCACGGGCCCCAGGCAGTGTGTGGGACAGACAGAGAGACGGAGCCAGTCTGACA CTGCGGTCAACGTCACCACCAGGAAGGTCAGTGCACCAGATATTCTGAAACCTCTCAATCAAG AGGATCCCAAATGCTCTACTAACCCTATTTTGAAGCAACAGAATCTCCCATCCAGTCCGGCAC CCAGTACCATATTCTCTGGAGGTTTTAGACACGGAAGTTTAATTAGCATTGACAGCACCTGTA CAGAGATGGGCAATTTTGACAATGCTAATGTCACTGGAGAAATAGAATTTGCCATTCATTATT GCTTCAAAACCCATTCTTTAGAAATATGCATCAAGGCCTGTAAGAACCTTGCCTATGGAGAAG AAAAGAAGAAAAAGTGCAATCCGTATGTGAAGACCTACCTGTTGCCCGACAGATCCTCCCAGG GAAAGCGCAAGACTGGAGTCCAAAGGAACACCGTGGACCCGACCTTTCAGGAGACCTTGAAGT ATCAGGTGGCCCCTGCCCAGCTGGTGACCCGGCAGCTGCAGGTCTCGGTGTGGCATCTGGGCA CGCTGGCCCGGAGAGTGTTTCTTGGAGAAGTGATCATTCCTCTGGCCACGTGGGACTTTGAAG ACAGCACAACACAGTCCTTCCGCTGGCATCCGCTCCGGGCCAAGGCGGAGAAATACGAAGACA GCGTTCCTCAGAGTAATGGAGAGCTCACAGTCCGGGCTAAGCTGGTTCTCCCTTCACGGCCCA GAAAACTCCAAGAGGCTCAAGAAGGTCAGCCATCACTTCATGGTCAACTTTGTTTGGTAGTGC TAGGAGCCAAGAATTTACCTGTGCGGCCAGATGGCACCTTGAACTCATTTGTTAAGGGGTGTC TCACTCTGCCAGACCAACAAAAACTGAGACTGAAGTCGCCAGTCCTGAGGAAGCAGGCTTGCC CCCAGTGGAAACACTCATTTGTCTTCAGTGGCGTAACCCCAGCTCAGCTGAGGCAGTCAAGCT TGGAGTTAACTGTCTGGGATCAGGCCCTCTTTGGAATGAACGACCGCTTGCTTGGAGGAACCA GACTTGGTTCAGAGGGAGACACAGCTGTTGGCGGGGATGCATGCTCACTATCGAAGCTCCAGT GGCAGAAAGTCCTTTCCAGCCCCAATCTATGGACAGACATGACTCTTGTCCTGCACTGACATG AAGGCCTCAAG
ORF Start: ATG at : ORF Stop: TGA at 1821
SEQ ID NO: 268 606 aa MW at 68204.5kD
NOV75a, AQEIDLSALKELEREAILQVLYRDQAVQNTEEERTRKLKTHLQHLRWKGAKNTD EHKEKCC
CG I 40179-01 Protein ARCQQVLGFLLHRGAVCRGCSHRVCAQCRVFLRGTHA KCTVCFEDRNVKIKTGEWFYEERAK KFPTAGKHETVGGQLLQSYQKLSKISWPPTPPPVSESQCSRSRLQEFGQFRGFNKSVENLFL
Sequence SLATHVKELSKSQNDMTSEKHLLATGPRQCVGQTERRSQSDTAVNVTTRKVSAPDILKPLNQE DPKCSTNPILKQQNLPSSPAPSTIFSGGFRHGSLISIDSTCTEMGNFDNANVTGEIEFAIHYC FKTHSLEICIKACKNLAYGEEKKKKCNPYVKTYLLPDRSSQGKRKTGVQRNTVDPTFQETLKY QVAPAQLVTRQLQVSVWHLGTLARRVFLGEVIIPLATWDFEDSTTQSFRWHPLRAKAEKYEDS VPQSNGELTVRAKLVLPΞRPRKLQEAQEGQPSLHGQLCLWLGAKNLPVRPDGTLNSFVKGCL TLPDQQKLRLKSPVLRKQACPQWKHSFVFSGVTPAQLRQSSLELTVWDQALFGMNDRLLGGTR LGSEGDTAVGGDACSLSKLQWQKVLSSPNLWTDMTLVLH
Further analysis of the NOV75a protein yielded the following properties shown in
Table 75B.
; Table 75B. Protein Sequence Properties NOV75a
PSort 0.6000 probability located in nucleus; 0.3000 probability located in microbody ! analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
I SignalP No Known Signal Sequence Predicted j analysis:
A search of the NOV75a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 75C.
In a BLAST search of public sequence datbases, the NOV75a protein was found to have homology to the proteins shown in the BLASTP data in Table 75D.
PFam analysis predicts that the NOV75a protein contains the domains shown in the Table 75E.
Example 76.
The NOV76 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 76A.
jTable 76A. NOV76 Sequence Analysis
""JSΕQ"TD"NO7269 11545 bp
|NOV76a, TACTGAGGCTTTCGGGACGGCGGCGGGAAGATGGCGGCCTCCAGGAATGGGTTTGAAGCCGTG j . GAGGCAGAGGGCAGCGCAGGGTGCCGGGGAAGCTCGGGAATGGAGGTGGTGCTTCCTTTGGAT
Further analysis of the NOV76a protein yielded the following properties shown in Table 76B.
; Table 76B. Protein Sequence Properties NOV76a
' PSort 0.9800 probability located in nucleus; 0.3725 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen) SignalP No Known Signal Sequence Predicted [ analysis:
A search of the NOV76a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 76C.
In a BLAST search of public sequence datbases, the NOV76a protein was found to have homology to the proteins shown in the BLASTP data in Table 76D.
PFam analysis predicts that the NOV76a protein contains the domains shown in the Table 76E.
Example 77.
The NOV77 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 77A.
CGI40727-01 Protein ILEYRFETVQKLRFGIYDIDNKTPELRDDDFLGGAECSLGQIVSSQVLTLPLMLKPGKPAGRGT
Sequence JITVSAQELKDNRVVTMEVEARNLDKKDFLGKSDPFLEFFRQGDGKWHLVYRSEVIKNNLNPTW JKRFSVPVQHFCGGNPSTPIQVQCSDYDSDGSHDLIGTFHTSLAQLQAVPAEFECIHPEKQQKK IKSYKNSGTIRVKICRVETEYSFLDYVMGGCQINFTVGVDFTGSNGDPSSPDSLHYLSPTGV E |YLMAL SVGSWQDYDSDKLFPAFGFGAQVPPD QVSHEFALNFNPSNPYCAGIQGIVDAYRQ IALPQVRLYGPTNFAPIINHVARFAAQAAHQGTASQYFMLLLLTDGAVTDVEATREAWRASNL JPMSVIIVGVGGADFEAMEQLDADGGPLHTRSGQAAARDIVQFVPYRRFQNVSRCKFDLGVYPF
TFP
Further analysis of the NOV77a protein yielded the following properties shown in Table 77B.
Table 77B. Protein Sequence Properties NOV77a
PSort * 0.4500 probability located in cytoplasm; 0.3359 probability located in microbody analysis: ; (peroxisome); 0.1756 probability located in lysosome (lumen); 0.1000 probability located in mitochondrial matrix space
SignalP , Cleavage site between residues 14 and 15 analysis:
A search of the NOV77a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 77C.
AAU19854 Human novel extracellular matrix 57..440 259/389 (66%) e-160 protein, Seq ID No 504 - Homo 6.394 318/389 (81%) sapiens, 399 aa. [ WO200155368-A 1 02-AUG-2001]
In a BLAST search of public sequence datbases, the NOV77a protein was found to have homology to the proteins shown in the BLASTP data in Table 77D.
PFam analysis predicts that the NOV77a protein contains the domains shown in the Table 77E.
The NOV78 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 78A.
Further analysis of the NOV78a protein yielded the following properties shown in Table 78B.
A search of the NOV78a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 78C.
In a BLAST search of public sequence datbases, the NOV78a protein was found to have homology to the proteins shown in the BLASTP data in Table 78D.
PFam analysis predicts that the NOV78a protein contains the domains shown in the Table 78E.
The NOV79 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 79A.
Table 79 A. NOV79 Sequence Analysis
; _ _"__ " " "fSEQ" iD N"θ: 275 1044 bp
;Nθ"V79a, " CACGTCCCCTGTGCGGCCAGCGTCAGAGCCATGGCGATGGAGGAGAGGAAGCCCGAGACCGAG
'CG 141395-01 DNA GCAACGAGAGCACAGCCGACCCCTTCGTCATCCACCACTCAGAGCAAGCCTACGCCCGTGAAG CCAAACTATGCTCTCAAGTTCACCCTTGCTGGCCACACCAAAGCAGTGTCCTCCGTGAAATTC ■Sequence AGCCCGAATGGAGAGTGGCTGGCAAGTTCATCTGCTGATAAACTCATTAAAATTTGGGGGTCA TATGATGGGAAATTTGAGAAAACCATGTCTGGTCACAGCCTGTGGTCGTCAGATTCTAACCTT TTTGTTTCCGCCTCAGATGACAAAACCTTGAAGATACGGGACGTGAGCTCGGGAAAGTGTCTG AAAACCCTGAAGGGACACAGTAATTATGTCTTTTGCTGTAACTTCAATCCCCAGTCCAGCCTT ACTGTCTCAGGATCCTTTGATGAAAGTGTGAGGATATGGGTTGTGAAAACAGGGAAGTGCCAC AAGACTCTGCTAGCTCACTCCGATCCAGTCTCGGCCATTCATTTTAATCGTGATGGATTCTTG ATAGTTTCAAGTAGCTATGATGGTCTCTGTCACATCTGGGACACCGCCTCAGGCCAGTGCCTG AAAACGCTCACTGATGATGACAACCCCCTGGTGTCTTTCGTGAAGCTCTCCCCGAAGGGTGGA TACATCGTGGCTGCCACGCTGGGCAACACACTCAAGCTCTGGGACTACAGCAAGGGGAAGTGC CTGAAGACATACACTGGCCACAAGAACGAGAAATACTGCATATTTGCTAATTTCTCTGTTACT GGCGGGAAGTGGATTGTGTCTGGCTCGGAGGATAACCTTCTTTACATCTGGAAACTTCAGACG AAAGAGATTGTACAGAAATTAGAAGGCCACACAGATGTTGTGACCTCAACAGCTTGTCACCCA ACAGAAAACATCATCACCTCTGCCGCGCTAGAAAATGACAAAACAATTAAACTGTGGAAGAGT GACTGTTAAGTCCCTTTGCTCCCACATGCGATAGAC
ORF Start: ATG at 31 jORF Stop: TAA at 1015
SEQ ID NO: 276 328 aa iMW at 36088.6kD
<NOV79a, I AMEERKPETEATRAQPTPSSSTTQSKPTPVKPNYALKFTLAGHTKAVSSVKFSPNGE LASS
CG 141395-01 Protein SADKLIKIWGSYDGKFEKTMSGHSLWSSDSNLFVSASDDKTLKIRDVSSGKCLKTLKGHSNYV FCCNFNPQSSLTVSGSFDESVRIWWKTGKCHKTLLAHSDPVSAIHFNRDGFLIVSSSYDGLC
!Sequence HI WDTASGQCLKTLTDDDNPLVS FVKLS PKGGY I VAATLGNTLKLWDYS KGKCLKTYTGHKNE KYCIFANFSVTGGKWIVSGSEDNLLYIWKLQTKEIVQKLEGHTDVVTSTACHPTENIITSAAL ENDKTIKLWKSDC
Further analysis of the NOV79a protein yielded the following properties shown in Table 79B.
Table 79B. Protein Sequence Properties NOV79a
PSoil 0.4500 probability located in cytoplasm; 0.4206 probability located in microbody , analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 j probability located in lysosome (lumen)
SignalP I No Known Signal Sequence Predicted analysis:
A search of the NOV79a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 79C.
Table 79C. Geneseq Results for NOV79a
In a BLAST search of public sequence datbases, the NOV79a protein was found to have homology to the proteins shown in the BLASTP data in Table 79D.
Q9D7H2
~[2310009C03Rik protein - Mus musculus ] 12.328 j 235/323 (72%) j e-139
(Mouse), 328 aa. 8.328 1 271/323 (83%)
PFam analysis predicts that the NOV79a protein contains the domains shown in the Table 79E.
Table 79E. Doma in Analysis of NOV79a
Identities/
Pfam Domain NOV79a Match Region Similarities Expect Value for the Matched Region
WD40 37-73 17/37 (46%) 4.3e-06 30/37 (81 %)
1 WD40 1 15..151 17/37 (46%) 8.2e-06 31 /37 (84%)
WD40 157..193 15/37 (41 %) 9.4e-06 29/37 (78%)
^040 242..281 10/40 (25%) 0.04 32/40 (80%)
, WD40 287.325 12/39 (3 1 %) 0.18 29/39 (74%)
Example 80.
The NOV80 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 80A.
jTablc 80A. NOV80 Sequence Analysis
SEQ ID NO: 277 1602 bp
]NOV80a, GGAGCCATGCGGCGATCGAGGAGCTCTGCGGCCGCCAAGCTGCGCGGGCAGAAGCGGTCCGGG
.CG 191018-01 DNA GCCTCCGCGGCCCCCGCGGCCTCCGCGGCCGCTGCCTTGGCACCCAGCGCCACCCGCACACGG CGCTCCGCTAGCCAGGCCGGGAGCAAGAGCCAGGCGGTGGAGAAGCCGCCGTCGGAGAAGCCG iSequence CGGCTGAGGCGCTCGTCGCCGCGGGCCCAGGAGGAGGGCCCGGGGGAGCCGCCGCCGCCTGAG CTGGCGTTGCTCCCGCCACCGCCGCCGCCGCCGCCGACTCCCGCGACCCCGACGTCCTCGGCG TCCAACCTGGACCTGGGCGAGCAGCGGGAGCGCTGGGAGACGTTCCAGAAGCGGCAGAAGCTT ACCTCCGAGGGTGCCGCCAAGCTCCTGCTAGACACCTTTGAATACCAGGGCCTGGTGAAGCAC ACAGGAGGCTGCCACTGTGGAGCAGTTCGTTTTGAAGTTTGGGCCTCAGCAGACTTGCATATA TTTGACTGCAATTGCAGCATTTGCAAGAAGAAGCAGAATAGACACTTCATTGTTCCAGCTTCT CGCTTCAAGCTCCTGAAGGGAGCTGAGCACATAACGACTTACACGTTCAATACTCACAAAGCC CAGCATACCTTCTGTAAGAGATGTGGCGTTCAGAGCTTCTATACTCCACGATCAAACCCCGGA GGCTTCGGAATTGCCCCCCACTGCCTGGATGAGGGCACTGTGCGGAGTATGGTCACTGAGGAA TTCAATGGCAGCGATTGGGAGAAGGCCATGAAAGAGCACAAGACCATCAAGAACATGTCTAAA GAGTGAGCTTCTGCCTCTCCTGCCCTGAAAAGGAGGAATGATTGGGGCCAGCAACTTTGCTCT CCCTGCCGTGCCTCGGTGGTGCTCCTGAATGTGGCTGACCTGGGCTGCTGGTTCCGTTGACTA GGGTCATCTTGATCTCTGCAGTTTGCTCCAGCTACCAGTTTCTTTAGGCAGCTCTTTGTCCTC CCTCTGCCCAGATTTTGATGTAGTCTAATTGACATCCTTCTCTTCCCAACTTTTGTGTGATCC AGCAGAGCATGTGAGACTCTTTGATATGCACCTTCATGTATTATCTTGTTCAGTTCTCTGAGG TTGGGATCATTATTATTTCCCATTTTGCAGATGAGAGAATTGAGGCAGAGAAAGGTTCAGCAC
CTTGCCTTTGGTTACACAGCTGGTCATTCTGGCTTCAATCGCAGGACTACCAGCCTGTGCTCT
TCACCACTTAGCTTCCCTGACTCAGGCCACTTCCCTGGAGCGTTAGCTGGATTCTGAGAGTAG
TTTCCAAGCCAGAGCTTTCAGAGAGCTTTTGTTCGTAGGACAATTTTAAGACATCAGGTTCTT
GAATGTTTTGTGTTTTTTTAAGTCTCAGATTTATCTTCCTACTTCCTACTTCTCCAAAAAGAC TGAGAGCTGACATATTTGATTGTAAGCTCTTTGAGGCAGAGTTCTTGTAATCGTCTCTGTATA
AAACAGTGCCCACCCCAGTGACCTGTACTTGGATGCTTCAATCAGAGCTGTCCTGTTAAATAG
AGCAAGTTTTTCCTAGACCCACATTCT
ORF Start: ATG at 7 jORF Stop: TGA at 823
SEQ ID NO: 278 272 aa jMW at 297303kD
|NOV80a, MRRSRSSAAAKLRGQKRSGASAAPAASAAAALAPSATRTRRSASQAGSKSQAVEKPPSEKPRL
CGI 91018-01 Protein RRSSPRAQEEGPGEPPPPELALLPPPPPPPPTPATPTSSASNLDLGEQRERWETFQKRQKLTS EGAAKLLLDTFEYQGLVKHTGGCHCGAVRFEVWASADLHIFDCNCSICKKKQNRHFIVPASRF
Sequence KLLKGAEHITTYTFNTHKAQHTFCKRCGVQSFYTPRSNPGGFGIAPHCLDEGTVRSMVTEEFN GSDWEKA KEHKTIKNMSKE
Further analysis of the NOV80a protein yielded the following properties shown in Table 80B.
Table 80B. Protein Sequence Properties NOV80a Sort 0.7941 probability located in mitochondrial matrix space; 0.6305 probability located I analysis: in mitochondrial intermembrane space; 0.4722 probability located in mitochondrial inner membrane; 0.4722 probability located in mitochondrial outer membrane i SignalP No Known Signal Sequence Predicted j analysis:
A search of the NOV80a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 80C.
In a BLAST search of public sequence datbases, the NOV80a protein was found to have homology to the proteins shown in the BLASTP data in Table 80D.
PFam analysis predicts that the NOV80a protein contains the domains shown in the Table 80E.
Example 81.
The NOV81 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 81 A.
jTable 81A. NOV81 Sequence Analysis j " " JSEQ ID N0: 279 1051 bp iNOVδla, CCGCTGCTACCCGGCATGTCGGCGGAGGCCTCGGGCCCGGCTGCCGCCGCGGCCCCGTCCCTG
!CG56125-01 DNA GAAGCCCCCAAGCCCTCGGGTCTCGAGCCTGGCCCCGCCGCCTACGGTCTCAAGCCGCTGACC CCGAACAGCAAATACGTGAAGCTGAACGTGGGCGGCTCGTTGCACTACACCACGCTGCGCACC jSequence CTCACGGGACAGGACACCATGCTCAAAGCCATGTTCAGCGGCCGCGTGGAGGTGCTGACCGAT GCCGGAGGTTGGGTGCTGATTGACCGGAGCGGCCGTCACTTTGGTACAATCCTCAATTACCTG CGGGATGGGTCTGTGCCACTGCCGGAGAGTACGAGAGAACTGGGGGAGCTGCTGGGCGAAGCA CGCTACTACCTGGTGCAGGGCCTGATTGAGGACTGCCAGCTGGCGCTGCAGCAAAAAAGGGAG ACGCTGTCCCCGCTGTGCCTCATCCCCATGGTGACATCTCCCCGGGAGGAGCAGCAGCTCCTG GCCAGCACCTCCAAGCCCGTGGTGAAGCTCCTGCACAACCGCAGTAACAACAAGTACTCCTAC ACCAGCACTTCAGATGACAACCTACTTAAGAACATCGAGCTGTTCGACAAGCTGGCCCTGCGC TTCCACGGGCGGCTACTCTTCCTCAAGGATGTCCTGGGGGACGAGATCTGCTGCTGGTCTTTC TACGGGCAGGGCCGCAAAATCGCCGAGGTGTGCTGCACCTCCATTGTCTATGCTACGGAGAAG AAGCAGACCAAGGTGGAATTTCCAGAGGCCCGGATCTTCGAGGAGACCCTGAACATCCTCATC TACGAGACTCCCCGGGGCCCAGACCCAGCCCTCCTGGAGGCCACAGGGGGAGCAGCTGGAGCT GGTGGGGCTGGCCGCGGGGAGGATGAAGAGAACCGAGAGCACCGTGTCCGCAGGATCCATGTC CGGCGCCATATCACCCACGACGAGCGTCCTCATGGCCAACAAATTGTCTTCAAGGACTGACCT CTGACCCTCCCCCTGCCTTCCTCTTGCCTTGGGACCCAGTCCC
ORF Start: ATG at 16 [ORF Stop: TGA at 1003
SEQ ID NO: 280 329 aa TMW a. 36357.0kD """"
INOVδla, MSAEASGPAAAAAPSLEAPKPSGLEPGPAAYGLKPLTPNSKYVKLNVGGSLHYTTLRTLTGQD
CG56125-01 Protein TMLKAMFSGRVEVLTDAGGWVLIDRSGRHFGTILNYLRDGSVPLPESTRELGELLGEARYYLV QGLIEDCQLALQQKRETLSPLCLIPMVTSPREEQQLLASTSKPWKLLHNRS NKYSYTSTSD jSequence DNLLKNIELFDKLALRFHGRLLFLKDVLGDEICCWSFYGQGRKIAEVCCTSIVYATEKKQTKV EFPEARIFEETLNILIYETPRGPDPALLEATGGAAGAGGAGRGEDEENREHRVRRIHVRRHIT HDERPHGQQIVFKD
SEQ ID NO: 281 .852 bp
NOVδlb, TTTTTTTTAGTTTCTCAACTTAACTTTATTTCAATAATTTAATAGAAAATTAAAATAATAAAT CG56125-02 DNA AATATGAAACAGACTGATAACGCTGAGCTGGGCAGGCCCAGGCCAGTCTAGTACAAAGTTAAG
GAGGTAGGGAGGATGGTGGGGAGGAGGGGGCGGACTACCCTGCAGGACGCGGGAGGCTGCTCA
ISequence GACTGTGGTGATGTCAGGAAGGGCCGCACACTTTGGCATGGACGATGCACTAAAAAAAGAGAA
AGGGAATTCTAAATCCCTCTTAACCAGCTGGAGAGGGAAGGACGCAGGGCCAGGGTGGGGACA
AGTGTTGGCTTCGGAAGGCTCTGAGTGGTGGGGCCGGAATGTACCATGTTGTTAGCAATGGGG
TTGGGACGGGTGGAGAAGGGCCAAAGTGAGCTGTGCCATGCAATGAAGGGACAGAGGAGGACC CACGACTTGGCCAGCAGAGCCGGGGCAAAAGTCTGGGAAGGGGAGGGAAAGAGAGAGGGACTG GGTCCCAAGGCAAGAGGAAGGCAGGGGGAGGGTCAGAGGTCAGTCCTTGAAGACAATTTGTTG GCCATGAGGACGCTCGTCGTGGGTGATATGGCGCCGGACATGGATCCTGCGGACACGGTGCTC TCGGTTCTCTTCATCCTCCCCGCGGCCAGCCCCACCAGCTCCAGCTGCTCCCCCTGTGGCCTC CAGGAGGGCTGGGTCTGGGCCCCGGGGAGTCTCGTAGATGAGGATGTTCAGGGTCTCCTCGAA GATCCGGGCCTCTGGAAATTCCACCTGCAAAAGGCCAGCCGGCCCCAGCTCCTTCCTTCTGGT GCAGTCACGCAGGGCCATCCCCCTGCCTAGGNN
ORF Start: ATG at 361 ORF Stop: TAG at 847
SEQ ID NO: 282 62 aa W at 17258.6kD
•NOV81 b, MLLAMGLGRVEKGQSELCHAMKGQRRTHDLASRAGAKVWEGEGKREGLGPKARGRQGEGQRSV
CG56125-02 Protein LEDNLLAMRTLWGDMAPDMDPADTVLSVLFILPAASPTSSSCSPCGLQEGWV APGSLVDED VQGLLEDPGLWKFHLQKASRPQLLPSGAVTQGHPPA
•Sequence
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 8 I B.
Table 81B. Comparison of NOV81a against NOV81b.
Protein Sequence NOV81a Residues/ Identities/ Match Residues Similarities for the Matched Region
- NOV81 b 126..132 6/7 (85%) 127..133 7/7 (99%)
Further analysis of the NOVδ l a protein yielded the following properties shown in Table 81C.
j Table 81C. Protein Sequence Properties NOV81a
PSort 0.6500 probability located in cytoplasm; 0.1000 probability located in mitochondrial analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVδla protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table δ l D.
In a BLAST search of public sequence datbases, the NOVδla protein was found to have homology to the proteins shown in the BLASTP data in Table δ 1 E.
PFam analysis predicts that the NOVδl a protein contains the domains shown in the Table 8 IF.
Table 81F. Domain Analysis of NOV81a
] Identities/
Pfam Domain NOV81a Match Region i Similarities Expect Value
1 for the Matched Region
K etra 141..138 i 35/1 1 1 (32%) 2.8e-27 j 71/1 1 1 (64%)
Example 82. The NOV82 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table δ2A.
Sequence AGGGGGTGGACCCCAAGTTCCTGAGGAACATGCGCTTTGCCAAGAAGCACAACAAAAAGGGCC TAAAGAAGATGCAGGCCAACAATGCCAAGGCCATGAGTGCACGTGCCGAGGCTATCAAGGCCC TCGTAAAGCCCAAGGAGGTTAAGCCCAAGATCCCAAAGGGTGTCAGCCGCAAGCTCGATCGAC TTGCCTACATTGCCCACCCCAAGCTTGGGAAGCGTGCTCGTGCCCGTATTGCCAAGGGGCTCA GGCTGTGCCGGCCAAAGGCCAAGGCCAAGGCCAAGGCCAAGGATCAAACCAAGGCCCAGGCTG CAGCCCCAGCTTCAGTTCCAGCTCAGGCTCCCAAACGTACCCAGGCCCCTACAAAGGCTTCAG AGTAGATATCTCTGCCAACATGAGGACAGAAGGACTGGTGCGACCCCCCACCCCCGCCCCTGG
GCTACCATCTGCATGGGGCTGGGGTCCTCCTGTGCTACTGGTACAAATAAACCTGAGGCAGGA
ORF Start: ATG at 30 )ORF_Stop: TAG at 507
SEQ ID NO: 284 159 aa ΪM W at" 1775Ϊ.9kD
,NOV82a, MAKSKNHTTHNQSRKWHRNGIKKPRSQRYESLKGVDPKFLRN RFAKKHNKKGLKKMQANNAK
;CG571 13-01 Protein AMSARAEAIKALVKPKEVKPKIPKGVSRKLDRLAYIAHPKLGKRARARIAKGLRLCRPKAKAK AKAKDQTKAQAAAPASVPAQAPKRTQAPTKASE
'Sequence
SEQ ID NO: 285 600 bp
|NOV82b, CGCGGCTTATGGTGCAGACATGGCCAAGTCCAAGAACCACACCACACACAACCAGTCCCGAAA JCG571 13-03 DNA ATGGCACAGAAATGGTATCAAGAAACCCCGATCACAAAGATACGAATCTCTTAAGGGGGTGGA CCCCAAGTTCCTGAGGAACATGCGCTTTGCCAAGAAGCACAACAAAAAGGGCCTAAAGAAGAT 'Sequence GCAGGCCAACAATGCCAAGGCCATGAGTGCACGTGCCGAGGCTATCAAGGCCCTCGTAAAGCC CAAGGAGGTTAAGCCCAAGATCCCAAAGGGTGTCAGCCGCAAGCTCGATCGACTTGCCTACAT TGCCCACCCCAAGCTTGGGAAGCGTGCTCGTGCCCGTATTGCCAAGGGGCTCAGGCTGTGCCG GCCAAAGGCCAAGGCCAAGGCCAAGGCCAAGGCCAAGGATCAAACCAAGGCCCAGGCTGCAGC CCCAGCTTCAGTTCCAGCTCAGGCTCCCAAACGTACCCAGGCCCCTACAAAGGCTTCAGAGTA GATATCTCTGCCAACATGAGGACAGAAGGACTGGTGCGACCCCCCACCCCCGCCCCTGGGCTA
CCATCTGCATGGGGCTGGGGTCCTCCTGTGCTA )
ORF Start: ATG at 20 JORF Stop: TAG at 503
SEQ ID NO: 286 161 aa MW at 17951. l kD
NOV82b, MAKSKNHTTHNQSRK HRNGIKKPRSQRYESLKGVDPKFLR MRFAKKHNKKGLKKMQANNAK
CG571 13-03 Protein AMSARAEAIKALVKPKEVKPKIPKGVSRKLDRLAYIAHPKLGKRARARIAKGLRLCRPKAKAK AKAKAKDQTKAQAAAPASVPAQAPKRTQAPTKASE
^Sequence
SEQ ID NO: 287 _ (579 bp j
;NOV82c, ACTCACTATAGGGCTCGAGCGGCGCTTCGGGAGCCGCGGCTTATGGTGCAGACATGGCCAAGT .CG571 13-02 DNA CCAAGAACCACACCACACACAACCAGTCCCGAAAATGGCACAGAAATGGTATCAAGAAACCCC GATCACAAAGATACGAATCTCTTAAGGGGGTGGACCCCAAGTTCCTGAGGAACATGCGCTTTG Sequence CCAAGAAGCACAACAAAAAGGGCCTAAAGAAGATGCAGGCCAACAATGCCAAGGCCATGAGTG CACGTGCCGAGGCTATCAAGGCCCTCGTAAAGCCCAAGGAGGTTAAGCCCAAGATCCCAAAGG GTGTCAGCCGCAAGCTCGATCGACTTGCCTACATTGCCCACCCCAAGCTTGGGAAGCGTGCTC GTGCCCGTATTGCCAAGGGGCTCAGGCTGTGCCGGCCAAAGGCCAAGGCCAAGGCCAAGGCCA AGGCCAAGGATCAAACCAAGGCCCAGGCTGCAGCCCCAGCTTCAGTTCCAGCTCAGGCTCCCA AACGTACCCAGGCCCCTACAAAGGCTTCAGAGTAGATATCTCTGCCAACATGAGGACAGAAGG GCCTGGTGTCCA
ORF Start: ATG at 54 jORF Stop: TAG at 537
SEQ ID NO: 288 161 aa MW at 17951. l kD
,NOV82c. AKSKNHTTH QSRK HRNGIKKPRSQRYESLKGVDPKFLRNMRFAKKH KKGLKKMQAN AK
'CG571 13-02 Protein AMSARAEAIKALVKPKEVKPKIPKGVSRKLDRLAYIAHPKLGKRARARIAKGLRLCRP AKAK AKAKAKDQTKAQAAAPASVPAQAPKRTQAPTKASE
Sequence
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 82B.
Table 82B. Comparison of NOV82a against NOV82b and NOV82c.
NOV82a Residues/ Identities/
Protein Sequence Match Residues Similarities for the Matched Region
NOV82b 1..159 1 16/161 (72%) 1..161 1 16/161 (72%)
NOV82c 1..159 1 16/161 (72%) 1..161 1 16/161 (72%)
Further analysis of the NOV82a protein yielded the following properties shown in Table δ2C.
A search of the NOV82a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 82D.
! Table 82D. Geneseq Results for NOV82a j
In a BLAST search of public sequence datbases, the NOV82a protein was found to have homology to the proteins shown in the BLASTP data in Table δ2E.
PFam analysis predicts that the NOV82a protein contains the domains shown in the Table δ2F.
Example 83.
The NOV83 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 83A.
Table 83A. NOV83 Sequence Analysis
SEQ ID NO: 289 ]l 409 bp
,NOV83a, GGCACAGCCCAGGAACGTTGCTTTGGAGAATCCTGCAGATAAGGCTTTTCCAAAAAGCGCGAG ;CG59536-01 DNA CATCTTGTTGTATTCAGATACCCTATCGTCGTCAGTCATGGCTAGCATCACTGCGTGTGTGGG
TAACAGCAGGCAGCAGAATGCACCTTTGCCGCCTTGGGCCCATTCCATGTTGAGGTCTCTGGG ^Sequence GAGGAGTCTCTGTCCTTTAGTGGTCAAAATGGCAGAGAGAAACATGAAGTTGTTCTCAGGAAG AGTGGTGCCAGCCCAGGGGAAAGAAACCTTTGAAAACTGGCTGATCCAAGTCAATGAGGTCCT GCCAGATTGGAGTATGTCTGAGGAGGAAAAACTCAAGCGCTTGATGAAAACACTTAGGGGCCC TGCCCGGGAGGTCATGCGTTTGCTTCAGGCGGCCAACCCCAACCTAAGTGTAGCAGATTTCTT GCGGGCAATGAAATTGGTGTTTGGGGAGTCTGAAAGCAGTGTGACTGCCCATGGTAAATTTTT TAACACCCTGCAGGCACAAGGGGAGAAAGCCTCCCTTTATGTGATCCGTTTAGAGGTGCAGCT CCAGAATGCTATTCAGGCAGGCATCCTAGCTGAGAAAGATGCAAACCAGACTCGCTTGCAACA GCTTCTTTTAGGCGCTGAGCTGAATAGGGACCTGCGCTTCAGGCTTAAGCATCTTCTCAGGAT GTATGCAAATAAGCAGGAGCGGCTTCCCAATTTCCTGGAGTTAATCAAGATGATAAGGGAGGA AGAGGATTGGGATGATGCTTTTATTAAACGGAAGCGGCCGAAAAGGTCTGAGCCAATAATGGA GAGGGCAGCCAGCCCTGTGGCATTTCAGGGCGCCCAGCCAATAGCAATCAGCAGTGCTGACTG TAACTGCAACGTGATAGAAATAGATGATACCCTTGATGACTCTGATGAGGATGTGATCCTGGT GGTGTCTCTGTACCCTTCACTGACACCTACAGGTGCCCCTCCCTTCAGAGGAAGAGCCAGACC TCTGGATCAAGTGCTGGTTATTGATTCCCCCAACAATTCTGGGGCTCAGTCTCTTTCTACCAG TGGTGGTTCTGGGTATAAGAATGATGGTCCTGGGAATATTCGTAGAGCCAGGAAGCGAAAATA CACAACCCGCTGTTCATATTGTGGGGAGGAGGGCCACTCAAAAGAAACCTGTGACAATGAGAG CAACAAGGCCCAGGTTTTTGAGAATCTGATCATCACCCTGCAGGAGCTGACACATACAGAGGA GAGGTCAAAAGAGGTCCCTGGAGAACACAGTGATGCTTCTGAGCCACAGTAAGGATCTAGTCC
AGCCCTAAATGAGTCCTTGACTGTATTCAGAGTCTGGTAATGGGAATAACAGGAGAGGGGGGT
GGGTTTCTAACTGCATGAATTAA
ORF Start: ATG at 101 'ORF Stop: TAA at 1310
SEQ ID NO: 290 403 aa MW at 45159.8kD
;NOV83a, MASITACVGNSRQQNAPLPP AHSMLRSLGRSLCPLVVKMAERNMKLFSGRWPAQGKETFEN jCG59536-01 Protein WLIQVNEVLPDWSMSEEEKLKRLMKTLRGPAREVMRLLQAANPNLSVADFLRA KLVFGESES SVTAHGKFFNTLQAQGEKASLYVIRLEVQLQNAIQAGILAEKDANQTRLQQLLLGAELNRDLR JSequence FRLKHLLRMYANKQERLPNFLELIKMIREEEDWDDAFIKRKRPKRSEPIMERAASPVAFQGAQ PIAISSADCNCNVIEIDDTLDDSDEDVILWSLYPSLTPTGAPPFRGRARPLDQVLVIDSPNN SGAQSLSTSGGSGYKNDGPGNIRRARKRKYTTRCSYCGEEGHSKETCDNESNKAQVFENLIIT LQELTHTEERSKEVPGEHSDASEPQ
SEQ ID NO: 291 I 360 bp iNOV83b, GTTGCTTTGGAGAATCCTGCAGATAAGGCTTTTCCAAAAAGCGCGAGCATCTTGTTGTATTCA CG59536-02 DNA GATACCCTACCGTCGTCAGTCATGGCTAGCATCACTGCGCGTGTGGGTAACAGCAGGCAGCAG
AATGCACCTTTGCCGCCTTGGGCCCATTCCATGTTGAGGTCTCTGGGGAGGAGTCTCTGTCCT Sequence TTAGTGGTCAAAATGGCAGAGAGAAACATGAAGTTGTTCTCAGGAAGAGTGGTGCCAGCCCAG GGGAAAGAAACCTTTGAAAACTGGCTGATCCAAGTCAATGAGGTCCTGCCAGATTGGAGTATG
! TCTGAGGAGGAAAAACTCAAGCGCTTGATGAAAACACTTAGGGGCCCTGCCCGGGAGGTCATG CGTTTGCTTCAGGCGGCCAACCCCAACCTAAGTGTAGCAGATTTCTTGCGGGCAATGAAATTG GTGTTTGGGGAGTCTGAAAGCAGTGTGACTGCCCATGGTAAATTTTTTAACACCCTGCAGGCA CAAGGGGAGAAAGCCTCCCTTTATGTGATCCGTTTAGAGGTGCAGCTCCAGAATGCTATTCAG GCAGGCATCCTAGCTGAGAAAGGTGCAAACCAGACTCGCTTGCAACAGCTTCTTTTAGGCGCT GAGCTGAATAGGGACCTGCGCTTCAGGCTTAAGCATCTTCTCAGGATGTATGCAAATAAGCAG GAGCGGCTTCCCAATTTCCTGGAGTTAATCAAGATGATAAGGGAGGAAGAGGATTGGGATGAT GCTTTTATTAAACGGAAGCGGCCGAAAAGGTCTGAGCCAATAATGGAGAGGGCAGCCAGCCCT GTGGCATTTCAGGGCGCCCAGCCAATAGCAATCAGCAGTGCTGACTGTAACTGCAACGTGATA GAAATAGATGATACCCTTGATGACTCTGATGAGGATGTGATCCTGGTGGTGTCTCTGTACCCT TCACTGACACCTACAGGTGCCCCTCCCTTCAGAGGAAGAGCCAGACCTCTGGATCAAGTGCTG GTTATTGATTCCCCCAACAATTCTGGGGCTCAGTCTCTTTCTACCAGTGGTGGTTCTGGGTAT AAGAATGATGGTCCTGGGAATATTCGTAGAGCCAGGAAGCGAAAATACACAACCCGCTGTTCA TATTGTGGGGAGGAGGGCCACTCAAAAGAAACCTGTGACAATGAGAGCAACAAGGCCCAGGTT TTTGAGAATCTGATCATCACCCTGCAGGAGCTGACACATACAGAGGAGAGGTCAAAAGAGGTC CCTGGAGAACACAGTGATGCTTCTGAGCCACAGTAAGGATCTAGTCCAGCCCTAAATGAGTCC TTGACTGTATTCAGAGTCTGGTAATGGGAATAACAGG
ORF Start: ATG at 85 ORF Stop: TAA at 1294
SEQ ID NO: 292 403 aa MW at 45154.9kD
|NOV83b, MASITARVGNSRQQNAPLPP AHSMLRSLGRSLCPLWKMAERNM LFSGRWPAQGKETFEN 1CG59536-02 Protein LIQVNEVLPDWSMSEEEKLKRLMKTLRGPAREVMRLLQAANPNLSVADFLRAMKLVFGESES SVTAHGKFFNTLQAQGEKASLYVIRLEVQLQNAIQAGILAEKGANQTRLQQLLLGAELNRDLR
iSequence FRLKHLLRMYANKQERLPNFLELIK IREEEDWDDAFIKRKRPKRSEPIMERAASPVAFQGAQ PIAISSADCNCNVIEIDDTLDDSDEDVILWSLYPSLTPTGAPPFRGRARPLDQVLVIDSPNN
ISGAQSLSTSGGSGYKNDGPGNIRRARKRKYTTRCSYCGEEGHSKETCDNESNKAQVFENLI IT
ILQELTHTEERSKEVPGEHSDASEPQ
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 83B.
Further analysis of the NOV83a protein yielded the following properties shown in Table δ3C.
[ Table 83C. Protein Sequence Properties NOV83a j PSort 0.7000 probability located in nucleus; 0.1000 probability located in mitochondrial ' analysis: matrix space; 0.1000 probability located in lysosome (lumen); 0.0000 probability located in endoplasmic reticulum (membrane)
! SignalP No Known Signal Sequence Predicted ; analysis:
A search of the NOVδ3a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table δ3D.
In a BLAST search of public sequence datbases, the NOV83a protein was found to have homology to the proteins shown in the BLASTP data in Table 83E.
PFam analysis predicts that the NOV83a protein contains the domains shown in the Table δ3F.
The NOVδ4 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table δ4A.


ACAGACGTGTTTGTCGTCGGAACCGAGAGAGGATGCGCTTTTGTTAATGCCAGGACGGATTTT CAGAAAGATTTTGCAAAATACTGCGTTGCAGAGGGACTGTGTGAGGTGAAACCTCCCTGCCCT GTGAACGGGATGCAGGTCCACTCGGGCGAAACGGAAATACTCAGGAAGGCAGTGGAGGACTAT TTCTGCTTTTGTTATCAGAAAGCCTTAGGGACAACAGTGATGGTGCCTGTTCCCTATGAGAAG ATGCTGCGAGACCAGTCGGCTGTGGTAGTGCAGGGGCTTCCGGAAGGCGTTGCCTTTCAACAC CCTGAGAATTACGACCTTGCAACCCTGAAATGGATTTTGGAGAACAAAGCAGGGATTTCATTC ATCATAAATAGGAGACCCTTCCTAGGACCAGAGAGTCAGCTGGGTGGCCCTGGGATGGTAACA GATGCGGAGAGATCCATAGTATCACCAAGTGAAAGCTGCGGCCCCATCAATGTGAAAACTGAA CCCATGGAAGATTCTGGCATTTCACTGAAAGCAGAAGCTGTCTCAGTCAAGAAAGAATCAGAA GATCCTAATTACTATCAATATAATATGCAAGGTAATAGCCACCCTTCTTCCACAAGCAATGAA GTAATAGAAATGGAATTACCAATGGAACAAGATTCCACTCCGCTGGTCCCTTCAGAAGAACCA AATGAGGACCCTGAAGCCGAGGTGAAAATCGAAGGTGGAAACACAAATTCATCCAGTGTTACA AATTCTGCAGCAGGTGTTGAAGATCTTAACATCGTTCAAGTGACTGTTGATAATGAGAAGGAA AGATTATCAAGCATTGAAAAGATTAAACAGCTAAGAGAACAAGTTAATGACCTCTTTAGCCGA AAATTTGGTAAAGCAATTGGCGTGGATTTCCCTGTGAAAGTTCCCTACAGGAAGATCACATTC AACCCTGGCTGTGTGGTGATTGATGGCATGCCCCCGGGGGTGGTATTCAAGGCCCCCGGCTAT CTGGAAATCAGTTCCATGAGGAGGATCTTGGAGGCAGCTGAGTTTATCAAATTCACAGTCATC AGGCCGCTTCCAGGGCTTGAGCTCAGTAATGTGGGAAAACGCAAGATAGACCAGGAGGGCCGT GTGTTTCAAGAAAAGTGGGAGAGAGCGTATTTCTTCGTGGAAGTACAGAATATTCCAACATGT CTCATATGCAAACAAAGCATGTCTGTGTCCAAAGAATATAACCTAAGACGCCACTATCAAACC AATCACAGCAAGCATTATGACCAGTATATGGAAAGAATGCGTGACGAGAAGCTTCACGAGCTG AAAAAAGGGCTCAGGAAGTATCTCTTAGGCTTGTCAGACACCGAGTGTCCCGAGCAAAAACAA GTGTTTGCAAACCCAAGTCCAACCCAGAAATCCCCCGTGCAGCCTGTAGAGGACCTAGCTGGG AACTTATGGGAGAAGTTACGTGAAAAAATCAGGTCTTTTGTGGCATATTCTATCGCAATCGAT GAGATCACGGATATAAATAATACCACCCAGTTGGCCATATTCATCCGTGGTGTCGATGAGAAT TTCGATGTGTCCGAAGAACTTCTGGACACGGTGCCCATGACGGGTACAAAATCTGGCAACGAG ATCTTTTCGCGTGTTGAGAAGAGCCTGAAAAAGTTCTGTATCGACTGGTCGAAATTAGTAAGC GTGGCCTCCACTGGCACCCCAGCGATGGTGGATGCCAATAACGGGCTTGTCACAAAACTGAAG TCCAGGGTGGCGACGTTCTGCAAGGGTGCGGAACTGAAGTCCATCTGTTGTATAATTCATCCG GAATCACTCTGTGCTCAGAAGTTGAAGATGGACCACGTCATGGACGTGGTAGTGAAGTCCGTG AACTGGATATGCTCCCGGGGACTGAACCACAGTGAGTTCACAACCTTGCTCTATGAGCTGGAC AGCCAGTATGGTAGCCTCCTGTACTACACGGAGATTAAGTGGCTCAGTCGCGGGCTCGTGCTA AAGAGATTTTTCGAATCCTTGGAAGAAATCGACTCCTTCATGTCATCCAGAGGGAAACCCCTG CCTCAACTGAGCTCCATAGATTGGATCCGAGACCTGGCCTTCTTGGTTGACATGACGATGCAT CTGAACGCTTTGAACATCTCTCTCCAAGGACACTCCCAAATCGTCACGCAGATGTATGACCTG ATCCGGGCGTTCCTAGCAAAACTGTGCCTCTGGGAGACTCATTTGACGAGGAATAATCTGGCC CACTTTCCCACCCTGAAATTGGCTTCCAGAAATGAAAGCGATGGCCTGAACTACATTCCCAAA ATCGCGGAACTCAAGACCGAATTCCAGAAAAGGCTGTCTGATTTCAAACTCTACGAAAGCGAA CTGACTCTGTTCAGCTCCCCGTTCTCCACGAAGATCGACAGTGTGCACGAGGAGCTCCAGATG GAGGTTATCGACCTGCAATGCAACACGGTCCTGAAGACGAAATACGACAAGGTGGGAATACCA GAATTCTACAAGTACCTCTGGGGTAGCTACCCGAAATACAAGCACCATTGCGCAAAGATTCTT TCCATGTTCGGGAGCACCTACATTTGCGAACAGCTGTTCTCCATTATGAAACTGAGCAAAACA AAATACTGCTCCCAGTTAAAGGATTCCCAGTGGGATTCTGTACTCCACATCGCAACGTGATGG AGAGAAAACTCCTGGCAGGGCCCTATGGTGGGAAAGGCTGGAGTCTTCTAGTCCCAAGGGATT
GGGAGATGACAAAATGAATTTTTTTTTCTTTTTTGA r~ ORF Start ATG at 163 .ORF Stop: TGA at 3019
SEQ ID NO: 298 1952 aa MW at 107635.4kD
,NOV84c, MAQVAVSTLPVEEESSSETRMWTFLVSALESMCKELAKSKAEVACIAVYETDVFWGTERGC
CG59794-03 Protein AFVNARTDFQKDFAKYCVAEGLCEVKPPCPV GMQVHSGETEILR AVEDYFCFCYQKALGTT VMVPVPYEKMLRDQSAWVQGLPEGVAFQHPENYDLATLKWILENKAGISFIINRRPFLGPES Sequence QLGGPGMVTDAERSIVSPSESCGPINVKTEPMEDSGISLKAEAVSVKKESEDPNYYQYNMQGN SHPSSTSNEVIEMELP EQDSTPLVPSEEPNEDPEAEVKIEGGNTNSSSVTNSAAGVEDLNIV QVTVDNEKERLSSIEKIKQLREQVNDLFSRKFGKAIGVDFPVKVPYRKITFNPGCWIDGMPP GWFKAPGYLEISSMRRILEAAEFIKFTVIRPLPGLELSNVGKRKIDQEGRVFQEKWERAYFF VEVQNIPTCLICKQSMSVSKEYNLRRHYQTNHSKHYDQYMERMRDEKLHELKKGLRKYLLGLS DTECPEQKQVFA PSPTQKSPVQPVEDLAGNL EKLREKIRSFVAYSIAIDEITDINNTTQLA IFIRGVDENFDVSEELLDTVPMTGTKSGNEIFSRVEKSLKKFCIDWSKLVSVASTGTPAMVDA NNGLVTKLKSRVATFCKGAELKSICCIIHPESLCAQKLKMDHVMDWVKSVNWICSRGLNHSE FTTLLYELDSQYGSLLYYTEIKWLSRGLVLKRFFESLEEIDSFMSSRGKPLPQLSSID IRDL AFLVDMTMHLNALNISLQGHSQIVTQMYDLIRAFLAKLCLWETHLTRNLAHFPTLKLASRNE SDGLNYIPKIAELKTEFQKRLSDFKLYESELTLFSSPFSTKIDSVHEELQMEVIDLQCNTVLK KYDKVGIPEFYKYLWGSYPKYKHHCAKILSMFGSTYICEQLFSIMKLSKTKYCSQLKDSQWD
SVLHIAT
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 84B.
Further analysis of the NOV84a protein yielded the following properties shown in
Table δ4C.
Table 84C. Protein Sequence Properties NOV84a
PSort 0.3600 probability located in mitochondrial matrix space; 0.3000 probability located analysis: in microbody (peroxisome); 0.1000 probability located in lysosome (lumen); 0.1000 probability located in nucleus
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV84a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 84D.
In a BLAST search of public sequence datbases, the NOV84a protein was found to have homology to the proteins shown in the BLASTP data in Table 84E.
PFam analysis predicts that the NOV84a protein contains the domains shown in the Table δ4F.
The NOV85 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 85A.
Table 85A. NOV85 Sequence Analysis _ _ ^
SEQ T6 NO: 299
NOV85a, CAGGATGAACGCTGCTTTCCAAGATGGCGACGGAGGGAGGAGGGAAGGAGATGAACGAGATTA CG59821-01 DNA AGACCCAATTCACCACCCGGGAAGGTCTGTACAAGCTGCTGCCGCACTCGGAGTACAGCCGGC CCAACCGGGTGCCCTTCAACTCGCAGGGATCCAACCCTGTCCGCGTCTCCTTCGTAAACCTCA Sequence ACGACCAGTCTGGCAACGGCGACCGCCTCTGCTTCAATGTGGGCCGGGAGCTGTACTTCTATA TCTACAAGGGGGTCCGCAAGGCTGCTGACTTGAGTAAACCAATAGATAAAAGGATATACAAAG GAACACAGCCTACTTGTCATGACTTCAACCACCTAACAGCCACAGCAGAAAGTGTCTCTCTCC TAGTGGGCTTTTCCGCAGGCCAAGTCCAGCTTATAGACCCAATCAAAAAAGAAACTAGCAAAC TTTTTAATGAGGAAGGCTCATTGTCATCCCCAAGCCAGGCCAGTTCTCCAGGTGGAACTGTAG TGTAGCGACCTCACTGCTGCGCGCAC
ORF Start: ATG at 24 ORF Stop: TAG at 507
SEQ ID NO: 300 161 aa jMW at 17692.7kD
!NOV85a, MATEGGGKEMNEIKTQFTTREGLYKLLPHSEYSRPNRVPFNSQGSNPVRVSFVNLNDQSGNGD
:CG59821-01 Protein RLCFNVGRELYFYIYKGVRKAADLSKPIDKRIYKGTQPTCHDFHLTATAESVSLLVGFSAGQ VQLIDPIKKETSKLFNEEGSLSSPSQASSPGGTW JSequence
SEQ ID NO: 301 519 bp NOV85b, AGGATGAACGCTGCTTTCCAAGATGGCGACGGAGGGAGGAGGGAAGGAGATGAACGAGATTAA JCG59821-02 DNA GACCCAATTCACCACCCGGGAAGGTCTGTACAAGCTGCTGCCGCACTCGGAGTACAGCCGGCC CAACCGGGTGCCCTTCAACTCGCAGGGATCCAACCCTGTCCGCGTCTCCTTCGTAAACCTCAA jSequence CGACCAGTCTGGCAACGGCGACCGCCTCTGCTTCAATGTGGGCCGGGAGCTGTACTTCTATAT CTACAAGGGGGTCCGCAAGGCTGCTGACTTGAGTAAACCAATAGATAAAAGGATATACAAAGG AACACAGCCTACTTGTCATGACTTCAACCACCTAACAGCCACAGCAGAAAGTGTCTCTCTCCT AGTGGGCTTTTCCGCAGGCCAAGTCCAGCTTATAGACCCAATCAAAAAAGAAACTAGCAAACT TTTTAATGAGGAAGGCTCATTGTCATCCCCAAGCCAGGCCAGTTCTCCAGGTGGAACTGTAGT GTAGCGACCTCACTG
ORF Start: ATG at 23 ORF Stop: TAG at 506
SEQ ID NO: 302 161 aa SMW at 17692.7kD
!NOV85b, MATEGGGKEMNEIKTQFTTREGLYKLLPHSEYSRPNRVPFNSQGSNPVRVSFVNLNDQSGNGD
[ JCCGG5599882211--02 Protein RLCFNVGRELYFYIYKGVRKAADLSKPIDKRIYKGTQPTCHDFNHLTATAESVSLLVGFSAGQ VQLIDPIKKETSKLFNEEGSLSSPSQASSPGGTW jSequence
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 85B.
Further analysis of the NOV85a protein yielded the following properties shown in
Table 85C.
! Table 85C. Protein Sequence Properties NOV85a
PSort 10.4500 probability located in cytoplasm; 0.3000 probability located in microbody analysis: I (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 ' probability located in lysosome (lumen)
SignalP I No Known Signal Sequence Predicted ' analysis:
A search of the NOV85a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table δ5D.
In a BLAST search of public sequence datbases, the NOV85a protein was found to have homology to the proteins shown in the BLASTP data in Table δ5E.
PFam analysis predicts that the NOV85a protein contains the domains shown in the Table δ5F.
: Table 85F. Domain Analysis of NOV85a
Identities/
Pfam Domain NOV85a Match Region Similarities Expect Value for the Matched Region
Example 86.
The NOV86 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 86A.
JGCCCTTGAGGACCTCTTATTGTCATCCAATATGTTGCAACAATTGCCTGATTCTATAGGTGGA
'CTTTTGAAAAAACTAACAACTCTAAAAGTAGATGACAATCAACTTACAATGCTACCCAATACA
JATTGGAAGTTTATCTTTATTAGAAGAATTTGACTGTAGCTGTAATGAACTGGAGTCACTACCT
ITCTACTATTGGCTACCTTCATAGTCTTCGGACATTAGCAGTTGATGAGAATTTCCTTCCAGAA
TTACCCAGAGAAATTGGAAGTTGTAAGAATGTAACAGTCATGTCTCTACGCTCCAACAAATTA
GAATTTCTTCCTGAAGAGATTGGACAGATGCAGAAACTAAGAGTCCTAAATTTGAGTGACAAC
AGGTTGAAGAATTTACCATTCTCATTTACCAAACTTAAAGAGCTTGCAGCTTTGTGGCTTTCT
GACAATCAGTCCAAAGCCCTTATCCCTTTACAAACAGAAGCCCATCCAGAAACAAAGCAAAGA
GTATTGACTAACTACATGTTTCCCCAGCAGCCTCGTGGTGATGAAGATTTCCAGTCAGACAGT
GACAGCTTTAACCCTACACTGTGGGAAGAGCAGAGACAACAACGCATGACTGTTGCCTTTGAA
TTTGAAGACAAAAAAGAAGATGACGAAAATGCTGGGAAAGTTAAGCTCTCCTGCCAAGCCCCC
TGGGAAAGGGGCCAGCGTGGGATTACTCTCCAACCTGCCAGACTGTCTGGCGATTGCTGCACA
CCATGGGCCAGGTGTGATCAGCAGATCCAAGATATGCCCGTCCCCCAGAATGACCCACAGCTG
GCATGGGGTTGTATAAGTGGCCTCCAGCAGGAAAGGAGCATGTGTACTCCATTGCCAGTTGCA
GCACAATCCACCACTCTTCCCTCTCTAAGTGGCAGACAGGTTGAAATAAACCTAAAACGATAT
CCAACTCCTTACCCAGAGGATTTAAAGAATATGGTAAAATCTGTTCAAAATTTGGTGGGTAAG
CCAAGCCATGGAGTGCGTGTTGAGAATTCAAATCCAACTGCTAACACGGAGCAAACTGTGAAA
GAAAAATATGAACACAAGTGGCCGGTAGCCCCAAAGGAGATTACAGTGGAGGATTCTTTTGTT
CATCCAGCTAATGAAATGAGGATTGGGGAACTTCACCCTTCATTAGCTGAGACCCCTCTGTAC
CCACCCAAACTTGTTCTGCTAGGGAAGGACAAAAAAGAATCAACTGATGAGTCTGAAGTTGAC
AAAACTCACTGTCTGAATAACAGTGTTTCCTCAGGCACTTACTCAGACTACTCGCCTTCCCAG
GCTTCCTCAGGATCCTCTAATACCCGGGTTAAAGTGGGGTCCTTGCAGACAACAGCTAAAGAT
GCAGTACATAATTCTTTGTGGGGTAACAGGATTGCACCATCTTTCCCACAGCCTCTTGATTCA
AAGCCATTACTCAGCCAGCGGGAGGCTGTTCCCCCAGGCAATATACCACAGCGTCCTGACCGG
CTGCCCATGAGTGATACTTTCACTGACAACTGGACTGATGGCTCGCATTATGACAACACAGGG
TTTGTTGCTGAGGAAACCACAGCCGAGAATGCCAACAGTAATCCTCTCTTAAGTTCGAAATCT
AGAAGCACATCTTCGCATGGACGCAGGCCTTTGATCAGGCAAGACAGGATTGTTGGTGTTCCC
CTGGAACTCGAGCAGTCTACACACAGACACACACCAGAAACAGAAGTGCCTCCTTCCAATCCT
TGGCAGAATTGGACCAGAACCCCTAGTCCGTTTGAAGACAGGACCGCTTTTCCTTCCAAATTA
GAGACAACCCCCACTACCAGCCCATTGCCTGAAAGGAAAGAACATATAAAGGAATCTACTGAA
ATACCTAGTCCTTTTTCTCCAGGCGTACCATGGGAGTATCATGATTCCAATCCCAACAGGAGT
CTTAGTAATGTCTTTTCTCAAATCCATTGCCGCCCGGAATCTTCTAAAGGTGTTATTTCAATT
AGCAAAAGCACAGAGAGGCTTTCCCCCCTAATGAAAGATATCAAGTCTAATAAATTCAAAAAG
TCACAGAGTATCGATGAGATTGACATTGGTACATATAAGGTGTATAACATACCATTAGAAAAC
TATGCTTCTGGGAGTGATCACTTAGGAAGCCACGAACGACCGGATAAGATGCTGGGACCAGAG
CATGGTATGTCCAGTATGTCTCGAAGCCAGTCAGTCCCAATGCTGGATGATGAGATGCTCACC
TACGGAAGTAGTAAGGGGCCACAACAACAAAAAGCTTCTATGACAAAAAAAGTCTATCAGTTT
GACCAAAGCTTCAATCCTCAAGGATCAGTGGAAGTGAAAGCCGAAAAGAGGATACCACCCCCT
TTTCAACACAATCCCGAGTACGTGCAACAGGCCAGCAAAAACATCGCCAAGGATTTGATTAGT
CCTAGAGCTTACAGAGGATACCCACCGATGGAGCAAATGTTTTCATTTTCTCAGCCATCTGTG
AATGAGGATGCTGTGGTGAATGCCCAGTTCGCAAGCCAAGGGGCCAGGGCGGGCTTCCTGAGA
AGGGCCGACTCCCTGGTGAGCGCCACAGAAATGGCCATGTTTAGAAGGGTCAATGAGCCTCAT
GAGCTGCCCCCAACTGATAGGTACGGCAGACCCCCATATAGGGGAGGGCTGGATCGCCAAAGC
AGCGTTACAGTGACTGAGTCCCAGTTCCTGAAAAGGAATGGCAGGTATGAAGATGAACACCCT
TCATATCAAGAAGTGAAAGCTCAGGCGGGAAGTTTTCCGGTTAAAAACCTTACCCAAAGGAGG
CCATTGTCTGCGAGAAGCTACAGTACAGAGAGTTACGGTGCCTCCCAAACCAGGCCAGTTTCA
GCTAGGCCTACTATGGCAGCTCTTTTGGAAAAAATACCATCTGACTATAACTTGGGTAACTAT
GGTGACAAGCCATCAGATAACAGTGATTTAAAGACGAGGCCTACTCCTGTGAAGGGAGAGGAG
AGCTGTGGTAAAATGCCTGCAGACTGGAGACAACAGCTGCTTAGACATATAGAAGCTAGACGG
TTAGACAGGACCCCGTCCCAGCAAAGCAACATTTTAGACAATGGACAAGAAGATGTATCTCCT
AGTGGCCAATGGAATCCTTATCCACTTGGGAGGCGGGATGTACCTCCGGACACCATTACTAAG
AAGGCAGGCAGCCACATCCAGACGTTGATGGGGTCCCAAAGCCTTCAGCATCGCAGCCGGGAG
CAGCAGCCGTATGAAGGAAATATAAACAAAGTGACCATCCAGCAATTTCAGTCACCATTGCCT
(ATTCAGATCCCCTCTTCACAGGCCACCCGGGGACCTCAGCCTGGACGGTGCTTAATTCAAACT
AAAGGGCAAAGGAGTATGGATGGATATCCAGAGCAGTTTTGTGTGAGAATAGAAAAGAATCCT
GGCCTTGGATTTAGTATCAGTGGTGGAATTAGTGGACAAGGAAATCCATTCAAACCTTCTGAC
AAGGGTATCTTTGTTACTAGGGTTCAGCCTGATGGGCCAGCATCAAACCTACTGCAGCCTGGT
GATAAGATCCTTCAGGCAAATGGACACAGTTTTGTACATATGGAACATGAAAAAGCTGTATTA
CTACTGAAGAGTTTCCAGAACACAGTAGACCTAGTTATTCAACGTGAGCTTACTGTCTAAATA
JTTTTTTATAAATAGTGAAGATACGTCTAGCCAGACCTAATGTTCAAAAATAAATTTATACATA
JGAAACAAATTTTGCCAATTGCTGGACCAATGGCAAACATTAGTGCCAAATGTATAATACTATA
ITGTTAGCACTGACCATCCTTAAAAAATGTTAACTCTATAAATATGATGTTCATGTGGTTATGT
IATTAGTTTTAATTGTCAGCCTCTGGCTGTGCATTGGTGCAGTTTTGTTTCTGTTTTTGTTTTT
GTTTTTAATCAAATAAGTTTCTTCTCAAAATGGATTTCATATAATTTCGGAGCACGGAAGCAC
ACACAAGCTCTTTATGAATTCTGCTCTCCATCAGAAACACTGCCTCAAAGTTGTATATGCCTT
TATATAGAAAATACAAATATAAAGAATTGTAATTCCCATAAAATATTTCTAGCACAAGGTATA
TGTTGGCATATATACAAAAAGAATATAGAGAAAAACAATATTTTCATAAACTAAACATCTCAG
ATAGAGAAAAAATATATCTTAAAATAAGACTTTACTATATTGAATCTTTTTCAATAAAAATTA CATGATAATGCCTTATGAAAGTAACTGTACATATGGTATAAAGTGTTTATATTTGGTTCCATA
TTCATTTGCTAAATTCTCATGACACAGAGTGAAATATTTCATAAATTAGCCATTTATCTCTGG
GACCCAAATAAAAATAGGATGAACTAATTTGTTCAATGCCTTTAGCTAATTACAATACATGCA GAGTTTAGAAACAGACTAAAGGTCATTGTAGTTAAGTCTTTTTCACCACAAATTTAAGCAGTG
GATGATGGGTGGCAGGAAAGGTATTGCTTTATTTCTTTCAAGTTCATGTTGATTATAAACTGT
AGCCCCTGTGATTTCTTTACTTGTAAATGTGGAATTTATTTGTGTGTTGCTTAATCTAATTTG
CTGCTTTTTAAATTATTTAAAACGAATTTTGGAAATTGATAAAATTTATCATTACGAAAGACT
GCTGTTAGAAAGTTATGGTAGGTGATTTTAAATCCTTGGTATTTAAATATGAAACTTCAAATA
TAATTTCTCAGAGCTGTGGTCTACCTGTATCATTAATTTCAATGGCTGTTTTTCTGGGCAGAA
ATAGATAAAATACTTTTTTTCCAAAAACAGTTTCAAGGTATGTAAAATCCTGAATGCTTTTTC
ACTGAAGAGAAAGACAAGCATGGTTAATGTAGAATTATTTACTTTTCCATTGAAACTATTTTC jCTGCATAAATGATCAAAATTTATTTTATAATCCTTTAAAATACTTATCTTTCATATTAGTCAT
TAATTTAATTACAATATTAATTTGAATTTCCAGGATAATTTCCCGGAGTTGGTTGCATGCATT
ATCTTTCATAATTTTACATAGTTCTTTTGTTATATAATGAATTTACTTTACATGCTAGTGTTT
CAAGTATTGTATGAGGATTTTCACAATAGTATCACTGAATGATGTCACCAGAGCTCTGAGAAT lAATATTTGTAAGTTAACTGTTTTATGGGGACATTGAAAATATTGTATTTTTGTAGGGTCTATT
AAAATGAGTGTCACTT
ORF Start: ATG at 1 ,ORF Stop: TAA at 4468
SEQ ID NO: 304 1489 aa MW at 167241.9kD
NOV86a, MTTKRKIIGRLVPCRCFRGEEEIISVLDYSHCSLQQVPKEVFNFERTLEELYLDANQIEELPK
CG59849-01 Protein QLFNCQALRKLSIPDNDLSNLPTTIASLVNLKELDISKNGVQEFPENIKCCKCLTIIEASVNP ISKLPDGFTQLLNLTQLYLNDAFLEFLPANFGRLVKLRILELRENHLKTLPKMHKLAQLERLD Sequence LGNNEFSELPEVLDQIQNLRELW D NALQVLPGSIGKLKMLVYLDMSKNRIETVDMDISGCE ALEDLLLSSNMLQQLPDSIGGLLKKLTTLKVDDNQLTMLPNTIGSLSLLEEFDCSCNELESLP STIGYLHSLRTLAVDENFLPELPREIGSCKNVTVMSLRSNKLEFLPEEIGQMQKLRVLNLSDN RLKNLPFSFTKLKELAAL LSDNQSKALIPLQTEAHPETKQRVLTNYMFPQQPRGDEDFQSDS DSFNPTLWEEQRQQRMTVAFEFEDKKEDDENAGKVKLSCQAPWERGQRGITLQPARLSGDCCT PWARCDQQIQDMPVPQ DPQLAWGCISGLQQERS CTPLPVAAQSTTLPSLSGRQVEINLKRY PTPYPEDLKNMVKSVQNLVGKPSHGVRVENSNPTANTEQTVKEKYEHK PVAPKEITVEDSFV HPANEMRIGELHPSLAETPLYPPKLVLLGKDKKESTDESEVDKTHCLNNSVSSGTYSDYSPSQ ASSGSSNTRVKVGSLQTTAKDAVHNSLWGNRIAPSFPQPLDSKPLLSQREAVPPGNIPQRPDR LPMSDTFTDNWTDGSHYDNTGFVAEETTAENANSNPLLSSKSRSTSSHGRRPLIRQDRIVGVP LELEQSTHRHTPETEVPPSNPWQNWTRTPSPFEDRTAFPSKLETTPTTSPLPERKEHIKESTE IPSPFSPGVP EYHDSNPNRSLS VFSQIHCRPESSKGVISISKSTERLSPLMKDIKSNKFKK SQSIDEIDIGTYKVYNIPLENYASGSDHLGSHERPDKMLGPEHGMSS SRSQΞVPMLDDEMLT YGSSKGPQQQKASMTKKVYQFDQSFNPQGSVEVKAEKRIPPPFQHNPEYVQQASKNIAKDLIS PRAYRGYPP EQMFSFSQPSVNEDAVVNAQFASQGARAGFLRRADSLVSATEMAMFRRVNEPH ELPPTDRYGRPPYRGGLDRQSSVTVTESQFLKRNGRYEDEHPSYQEVKAQAGSFPVKNLTQRR PLSARSYSTESYGASQTRPVSARPTMAALLEKIPSDYNLGNYGDKPSDNSDLKTRPTPVKGEE SCGKMPADWRQQLLRHIEARRLDRTPSQQSNILDNGQEDVSPSGQWNPYPLGRRDVPPDTITK KAGSHIQTLMGSQSLQHRSREQQPYEGNINKVTIQQFQSPLPIQIPSSQATRGPQPGRCLIQT KGQRSMDGYPEQFCVRIEKNPGLGFSISGGISGQGNPFKPSDKGIFVTRVQPDGPASNLLQPG DKILQA GHSFVHMEHEKAVLLLKSFQNTVDLVIQRELTV
SEQ ID NO: 305 1260 bp
<NOV86b, ATGACCACCAAACGGAAAATCATCGGCCGTCTGGTGCCATGCCGATGTTTCCGAGGTGAAGAA {CG59849-02 DNA GAAATCATCGCAGTTTTAGATTACTCCCACTGCAGTCTTCAGCAGGTGCCAAAGGAGGTCTTT AACTTCGAACGAACATTAGAGGAGCTTTATCTAGATGCCAATCAAATTGAAGAACTACCCAAG jSequence CAATTGTTCAACTGTCAAGCTCTACGAAAACTAAGTATTCCTGATAACGACCTTTCAAATCTG CCAACCACTATTGCTAGTTTAGTTAATCTTAAAGAACTCGACATCAGTAAAAATGGTGTACAA GAATTTCCAGAAAACATAAAGTGCTGTAAGTGTTTAACAATTATTGAAGCCAGTGTCAATCCC ATTTCTAAACTACCTGATGGCTTCACACAGCTCCTAAACCTGACCCAGCTCTACCTGAATGAC GCCTTTCTTGAATTTCTTCCAGCCAATTTTGGAAGACTTGTCAAATTGCGGATCTTGGAGTTA AGAGAAAATCACTTGAAAACTCTACCAAAGTCAATGCACAAACTGGCCCAGTTGGAAAGACTT GACCTAGGCAATAATGAATTCGGTGAGCTGCCTGAAGTTCTGGATCAAATACAAAATTTGAGG GAGTTATGGATGGATAATAATGCATTACAAGTGTTACCTGGGGCAGGCAGCCACATCCAGACG TTGATGGGGTCCCAAAGCCTTCAGCATCGCAGCCGGGAGCAGCAGCCGTATGAAGGAAATATA AACAAAGTGACCATCCAGCAATTTCAGTCACCATTGCCTATTCAGATCCCCTCTTCACAGGCC ACCCGGGGACCTCAGCCTGGACGGTGCTTAATTCAAAATAAAGGGCAAAGGAGTATGGATGGA TATCCAGAGCAGTTTTGTGTGAGAATAGAAAAGAATCCTGGCCTTGGATTTAGTATCAGTGGT GGAATTAGTGGACAAGGAAATCCATTCAAACCTTCTGACAAGGGTATCTTTGTTACTAGGGTT CAGCCTGATGGGCCAGCATCAAACCTACTGCAGCCTGGTGATAAGATCCTTCAGGCAAATGGA CACAGTTTTGTACATATGGAACATGAAAAAGCTGTATTACTACCGAAGAGTTTCCAGAACACA
41
IGTAGACCTAGTTATTCAACGTGAGCTTACTGTCTAAATATTTTTTATAAATAGTGAAGATACG ITCTAGCCAGACCTAATGTTCAAAAATAAATTTATACATAGAAACAAATTTTGCCAATTGCTGG iORF Start: ATG at 1 iORF Stop: TAA at 1 168
SEQ ID NO: 306 389 aa MW at 43792.9kD
NOV86b, MTTKRKIIGRLVPCRCFRGEEEIIAVLDYSHCSLQQVPKEVFNFERTLEELYLDANQIEELPK
CG59849-02 Protein QLFNCQALRKLSIPDNDLSNLPTTIASLVNLKELDISKNGVQEFPENIKCCKCLTIIEASVNP ISKLPDGFTQLL LTQLYL DAFLEFLPANFGRLVKLRILELRENHLKTLPKSMHKLAQLERL Sequence DLGNNEFGELPEVLDQIQNLRELWMDNNALQVLPGAGSHIQTL GSQSLQHRSREQQPYEGNI NKVTIQQFQSPLPIQIPSSQATRGPQPGRCLIQNKGQRSMDGYPEQFCVRIEKNPGLGFSISG GISGQGNPFKPSDKGIFVTRVQPDGPASNLLQPGDKILQANGHSFVHMEHEKAVLLPKSFQNT VDLVIQRELTV
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 86B.
Table 86B. Comparison of NOV86a against NOV86b
NOV86a Residues/ Identities/ Protein Sequence Match Residues Similarities for the Matched Region
NOV86b 1..232 210/233 (90%) 1..233 215/233 (92%)
Further analysis of the NOVδόa protein yielded the following properties shown in Table δ6C.
Table 86C. Protein Sequence Properties NOV86a
PSort 0.5192 probability located in mitochondrial matrix space; 0.3000 probability located analysis: in microbody (peroxisome); 0.2487 probability located in mitochondrial inner membrane; 0.2487 probability located in mitochondrial intermembrane space
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOVδόa protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 86D.
In a BLAST search of public sequence datbases, the NOV86a protein was found to have homology to the proteins shown in the BLASTP data in Table 86E.
PFam analysis predicts that the NOV86a protein contains the domains shown in the Table 86F.
Example 87.
The NOV87 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table δ7A.
GAGCAGAGCAGGCAGGGGTGGGGGCCGGGCCCGCAAGAGCCCGAAAGGTCGCCACCCCCTAGC
CTGTGGGGTGCATCTGCGAACCAGGGTGAAGTCACAGGTCCCGGGGTGTGGAGGCTCCATCCT TTCTCCTTTCTGCCAGCCGATGTGTCCTCATCTCAGGCCCGTGCCTGGGACCCCGTGTCTGCC CAGGTGGGCAGCCTTGAGCCCAGGGGACTCAGTGCCCTCCATGCCCTGGCTGGCAGAAACCCT
CAACAGCAGTCTGGGCACTGTGGGGCTCTCCCCGCCTCTCCTGCCTTGTTTGCCCCTCAGCGT GCCAGGCAGACTGGGGGCAGGACAGCCGGAAGCTGAGACCAAGGCTCCTCACAGAAGGGCCCA GGAAGTCCCCGCCCTTGGGACAGCCTCCTCCGTAGCCCCTGCACGGCACCAGTTCCCCGAGGG
ACGCAGCAGGCCGCCTCCCGCAGCGGCCGTGGGTCTGCACAGCCCAGCCCAGCCCAAGGCCCC CAGGAGCTGGGACTCTGCTACACCCAGTGAAATGCTGTGTCCCTTCTCCCCCGTGCCCCTTGA TGCCCCCTCCCCACAGTGCTCAGGAGACCCGTGGGGCACGGAACAGGAGGGTCTGGACCCTGT
GGCCCAGCCAAAGGCTACCAGACAGCCACAACCAGCCCAGCCACCATCCAGTGCCTGGGGCCT GGCCACTGGCTCTTCACAGTGGACCCCAGCACCTCGGGGTGGCAGAGGGACGGCCCCCACGGC CCAGCAGACATGCGAGCTTCCAGAGTGCAATCTATGTGATGTCTTCCAACGTTAATAAATCAC ACAGCCTCCCAGGAGGGAGACGCTGGGGTGCAAAAAAAAAGCAAAA
ORF Start^ATG at ; [ORF Stop: TAG at 913 SEQ ΪD NO: 308 214 aa ]MW at 24265.6kD
NOV87a, MDDSETGFNLKWLVSFKQCLDEKEEVLLDPYIASWKGLVRFL SLGTIFSFISKDWSKLRI
CG59920-01 Protein MERLRGGPQSEHYRSLQA VAHELSNRLVDLEGRSHHPESGCRTVLRLHRALH LQLFLEGLR TSPEDARTSALCADSYNASLAAYHP WRRAVTVAFCTLPTREVFLEAMNVGPPEQAVQMLGE Sequence ALPFIQRVYNVSQKLYAEHSLLDLP
NOV87d, GAGGGGACGTCGTCGTAGAGGGCCGGAGCGGGCGGGCGGCGACGGACCCGGCTCCCGCGCAGG CG59920-0 I DNA ACGGAGCCGTGGCTCAGGTCGGCCCCTCCCCAACACCACCCCGGGCCTCCGCCCCTTCCTGGG
CCTCTCGGTGGAGCAGGGACCCGAACCGGTGCCCATCCAGTCCGGTGCCATCTGAAGCCCCCT Sequence TCCCAGAAAATGAGCCACAGAGCAAGCTGACCCCAGCGACACAGCCCCCCAGCCCTACTATAT
TTCCGTTCCTATCAAAAAATGGATGACTCGGAGACAGGTTTCAATCTGAAAGTCGTCCTGGTC
AGTTTCAAGCAGTGTCTCGATGAGAAGGAAGAGGTCTTGCTGGACCCCTACATTGCCAGCTGG AAGGGCCTGGTCAGGTTTCTGAACAGCCTGGGCACCATCTTCTCATTCATCTCCAAGGACGTG GTCTCCAAGCTGCGGATCATGGAGCGCCTCAGGGGCGGCCCGCAGAGCGAGCACTACCGCAGC CTGCAGGCCATGGTGGCCCACGAGCTGAGCAACCGGCTGGTGGACCTGGAGGGCCGCTCCCAC CACCCGGAGTCTGGCTGCCGGACGGTGCTGCGCCTGCACCGCGCCCTGCACTGGCTGCAGCTG TTCCTGGAGGGCCTGCGTACCAGCCCCGAGGACGCACGCACCTCCGCACTCTGCGCCGACTCC TACAACGCCTCGCTGGCCGCCTACCACCCCTGGGTCGTGCGCCGTGCCGTCACCGTGGCCTTC TGCACGCTGCCCACACGCGAGGTCTTCCTGGAGGCCATGAACGTGGGGCCCCCGGAGCAGGCC GTGCAGATGCTAGGCGAGGCCCTCCCCTTCATCCAGCGTGTCTACAACGTCTCCCAGAAGCTC TACGCCGAGCACTCCCTGCTGGACCTGCCCTAGAGGCGGGAAGCCAGGGCCGCACCGGCTTTC
CTGCTGCAGATCTGGGCTGCGGTGGCCAGGGCCGTGAGTCCCGTGGCAGAGCCTTCTGGGCGC
TGCGGGAACAGGAGATCCTCTGTCGCCCCTGTGAGCTGAGCTGGTTAGGAACCACAGACTGTG
ACAGAGAAGGTGGCGACCAGCCCAGAAGAGGCCCACCCTCTCGGTCCGGAACAAGACGCCTCA
GCCACGGCTCCCCCTCGGCCTATTACACGCGTGCGCAGCCAGGCCTCGCCAGGGTGCGGTGCA
GAGCAGAGCAGGCAGGGGTGGGGGCCGGGCCCGCAAGAGCCCGAAAGGTCGCCACCCCCTAGC
CTGTGGGGTGCATCTGCGAACCAGGGTGAAGTCACAGGTCCCGGGGTGTGGAGGCTCCATCCT
TTCTCCTTTCTGCCAGCCGATGTGTCCTCATCTCAGGCCCGTGCCTGGGACCCCGTGTCTGCC
CAGGTGGGCAGCCTTGAGCCCAGGGGACTCAGTGCCCTCCATGCCCTGGCTGGCAGAAACCCT
CAACAGCAGTCTGGGCACTGTGGGGCTCTCCCCGCCTCTCCTGCCTTGTTTGCCCCTCAGCGT
GCCAGGCAGACTGGGGGCAGGACAGCCGGAAGCTGAGACCAAGGCTCCTCACAGAAGGGCCCA
GGAAGTCCCCGCCCTTGGGACAGCCTCCTCCGTAGCCCCTGCACGGCACCAGTTCCCCGAGGG
IACGCAGCAGGCCGCCTCCCGCAGCGGCCGTGGGTCTGCACAGCCCAGCCCAGCCCAAGGCCCC
CAGGAGCTGGGACTCTGCTACACCCAGTGAAATGCTGTGTCCCTTCTCCCCCGTGCCCCTTGA
TGCCCCCTCCCCACAGTGCTCAGGAGACCCGTGGGGCACGGAACAGGAGGGTCTGGACCCTGT
GGCCCAGCCAAAGGCTACCAGACAGCCACAACCAGCCCAGCCACCATCCAGTGCCTGGGGCCT
GGCCACTGGCTCTTCACAGTGGACCCCAGCACCTCGGGGTGGCAGAGGGACGGCCCCCACGGC
CCAGCAGACATGCGAGCTTCCAGAGTGCAATCTATGTGATGTCTTCCAACGTTAATAAATCAC
ACAGCCTCCCAGGAGGGAGACGCTGGGGTGCAAAAAAAAAGCAAAA
ORF Start: ATG at 271 ; JORF Stop: TAG at 913
"1.
SEQTD NOT3Ϊ4 "~1|214 aa MW at"24265.6kD " "
|NOV87d, MDDSETGFNLKWLVSFKQCLDEKEEVLLDPYIAS KGLVRFLNSLGTI FSFISKDWSKLRI
CG59920-01 Protein MERLRGGPQSEHYRSLQAMVAHELSNRLVDLEGRSHHPESGCRTVLRLHRALH LQLFLEGLR TSPEDARTSALCADSYNASLAAYHPWWRRAVTVAFCTLPTREVFLEAMNVGPPEQAVQMLGE Sequence ALPFIQRVYNVSQKLYAEHSLLDLP
SEQ ID NO: 315 11279 bp
NOV87e, GCCCTCGAGGTAGGGGTGATTCAGGGTGTGCTCCATGATGGTCAGAAGCGCCAGCCACGTCTC 308559628 DNA CTTGGCTGTGGGGATGATCTGGGAGGCTGGCAGCAGGAAGCCATAGCGCCCAGTGTCCCGGAG
CTCGAAGGTGAAGGAGTACTTGATGCCCTGGCTGTAGGTCCAGTCAATAGTGCTTCCACTGGC Sequence TTGATAAATTGCCTTGATGATGCTGCCATAGTTGAACTTGGTCCCGTAGAGAGAGGCCAGGGC
TGTCACAGCAGCCTTGGAAAGCTGATCCAGCTCATCCTGGTCAGGGACTGGTTCTGTTTTGTA
GCCATAGGGATACATGAGGAGCTGGGAGTAGCTGTGGATGGAGATGAAGGCCTTGATGTTCCC
ATGGTCCTTCACAAAGTCTACAATGGACTTGACCTCCACTTCGGAATTGGCAAACTTGCCGTG
GTAAGTCTCCGAGCAGGGGTTACTGCTGGCTCCGGACAACCCAAAGCCAGCGTCCCAGTTCCT
GTTGGGGTCCACGCCAATACAGAGGGAGCCTGCTGTGTGGGACCGAGTCTTGCGCCACATGCG ATTCGTGCTGTGCGTGAAGGCAAAGCCATCAGGGTTGGTGACGATCTCCAGGAAGATGTCCAA GGTGTCGAGAATGGCGGTGAAAGCTGCATCCTGCCCGTAGTCTTGAGTGATCTTCTTTGCAAA
CCAGACCCCACTGGCCTGGGTGACCCACTCCCGGGAATGGATGCCCGTGTCGATCCAGATGGC
TGGACGCTTACTGCCCCCCGTGCTGAACTTCAGCACGTAAATGGGACGCCCTTCATAGGTGTT
GCCAATCTGGATCTTGCTGACAAGGTGCGGGTTCTCCGCCACCAGCAGGTCCAGGAAGTCATA
IGATCTCCTCCAGGGTGTGGTAGGTGGCGTAGTTAAAAGTGTCGGTGGAGCGCGCCCGGGACCG
GAAGGCGAACATCTGCTCCTGCTCCTCGTCCAGCAGCGACTGCACGTCCTCGATCATGGTCTC
ATAGCTGATGCCGTGGGACTCCAGAAAGATCTTGACCGCCTGGATGCTGGGGAAGGGCACTCG
GACGTCGATGGGGGAGCCAGGGTGGGCAGGCCCCCGCCAGAAGTCCAGCTGCAGGTGCTCCAG
GTCCTCCAGCTCCTTCACCTTCTGTACCTGGGCCTCATCGGCTACAGAGATTCGGAGCACCTG
ATGCCCCACAAAGTCCTCCTTGCCAAAGACAGCCCCCAACAGGACACTCAACACCAGCAACCC
CCGCATGGTGGATCCGGTG
ORF Start: at 446 jORF Stop: TAG at 668
SEQ ID NO: 316 74 aa MW at 8100.6kD
,NOV87e. VSEQGLLLAPDNPKPASQFLLGSTPIQREPAVWDRVLRHMRFVLCVKAKPSGLVTISRKMSKV 308559628 Protein SRMAVKAASCP [Sequence
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 87B.
Further analysis of the NOV87a protein yielded the following properties shown in Table 87C.
i Table 87C. Protein Sequence Properties NOV87a
PSort 0.4500 probability located in cytoplasm; 03577 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV87a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table δ7D.
In a BLAST search of public sequence datbases, the NOV87a protein was found to have homology to the proteins shown in the BLASTP data in Table δ7E.
PFam analysis predicts that the NOV87a protein contains the domains shown in the Table 87F.
Table 87F. Domain Analysis of NOV87a
Identities/
Pfam Domain j NOV87a Match Region Similarities Expect Value j for the Matched Region
Example 88.
The NOVδδ clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table δδA.
Table 88A. NOV88 Sequence Analysis
!SEQ ID NO: 317 1911 bp
NOV88a, ICGGCGAGTGAATCTACCCAGGAGCTGAAGCTTCCCTTGGCAACTTGGGGACACCAGGGCCACA
CG59983-01 DNA !GTGACTTTGTGGCTTGGCTTTAGATAAATTTGACCATGGGCTGTAGAACCCAGCAGCTCAGAA
JTCCATTAAAAGGAGAGCTGGGAGGAGAATGAAGAAGATGAGCAACATTTATGAGTCCGCTGCC
Sequence JAACACACTGGGAATCTTTAACAGCCCCTGCCTGACCAAAGTTGAGCTGCGTGTGGCGTGCAAA GGCATTTCTGACAGAGATGCCCTTTCCAAACCAGGCCCCTGTGTCATCCTCAAGATGCAGTCT CATGGGCAGTGGTTTGAGGTTGACAGGACTGAGGTGATTCGCACCTGCATAAACCCAGTGTAC TCAAAACTGTTTACTGTGGACTTTTACTTTGAGGAGGTGCAGCGCCTGCGGTTTGAAGTCCAT GACATCAGCAGCAACCACAATGGGCTGAAGGAGGCCGACTTCCTTGGTGGCATGGAGTGCACA CTTGGCCAGATTGTTTCCCAGAGAAAGCTGTCCAAATCCTTGCTGAAGCATGGGAACACAGCA GGGAAATCTTCCATCGCGGTGATTGCTGAAGAATTATCTGGCAATGACGACTATGTTGAGCTT GCATTCAATGCACGGAAATTGGATGACAAGGATTTCTTCAGTAAATCTGACCCATTTCTGGAA ATTTTTCGTATGAATGATGATGCAACTCAGCAGCTGGTGCACCGAACTGAGGTTGTGATGAAT AACTTAAGCCCAGCCTGGAAATCATTCAAAGTATCTGTAAATTCTCTATGCAGCGGAGACCCA GACCGCCGGCTAAAGTGCATAGTATGGGACTGGGACTCCAATGGCAAGCATGACTTCATTGGA GAATTCACCTCGACATTCAAGGAGATGAGAGGAGCAATGGAAGGGAAACAGGTGCAGTGGGAG TGCATCAATCCCAAGTACAAAGCCAAGAAGAAGAATTACAAGAACTCAGGCACTGTGATTCTG AATCTGTGCAAGATTCACAAGATGCATTCTTTCTTGGACTACATCATGGGTGGCTGCCAAATC CAGTTTACAGTAGCTATAGATTTCACTGCCTCAAACGGGGACCCCAGGAACAGCTGTTCCTTG CACTACATCCACCCTTACCAACCCAATGAGTATCTGAAAGCTTTGGTAGCTGTGGGGGAGATT TGCCAAGACTATGACAGTGACAAAATGTTCCCTGCCTTTGGGTTTGGCGCCAGGATACCTCCA GAGTACACGGTCTCTCATGACTTTGCAATCAACTTTAATGAAGAACAACCCAAATGTGCAGGA ATTCAAGGAGTTGTGGAAGCCTATCAGAGCTGTCTTCCTAAGCTCCAACTCTACGGTCCCACC AACATTGCCCCCATCATCCAGAAGGTTGCCAAGTCAGCGTCAGAGGAAACTAACACCAAGGAG GCATCGCAATACTTCATCCTGCTGATCCTGACAGATGGTGTTATCACAGACATGGCCGACACC CGGGAGGCCATTGTCCATGCCTCCCACCTCCCCATGTCAGTCATCATCGTGGGAGTAGGGAAC GCTGACTTCAGTGACATGCAGATGCTGGACGGTGATGATGGGATTCTGAGGTCACCCAAGGGA GAGCCTGTTCTTCGAGACATCGTCCAGTTCGTGCCCTTCAGGAACTTCAAACACGCATCTCCA GCTGCCCTGGCAAAGAGCGTGCTGGCTGAAGTCCCAAACCAAGTTGTGGACTATTACAATGGC AAAGGAATTAAACCAAAATGTTCATCAGAAATGTATGAATCTTCCAGCACACTAGCACCATGA ACTCCCCACACAGTTTTACAGAGTTCTGAAATACTATTCCTGCTAATATTTCATATTTAATAC
TTCTACTATTCCTGCAAATGG
ORF Start: ATG at 154 ORF Stop: TGA at 1825
SEQ ID NO: 318 557 aa MW at 62264.4kD
NOV88a, KKMSNIYESAANTLGIFNSPCLTKVELRVACKGISDRDALSKPGPCVILKMQSHGQWFEVDR
CG59983-01 Protein TEVIRTCINPVYSKLFTVDFYFEEVQRLRFEVHDISSNHNGLKEADFLGGMECTLGQIVSQRK LSKSLLKHGNTAGKSSIAVIAEELSGNDDYVELAFNARKLDDKDFFSKSDPFLEIFRMNDDAT Sequence QQLVHRTEWMNNLSPAWKSFKVSVNSLCSGDPDRRLKCIVWDWDSNGKHDFIGEFTSTFKE RGAMEGKQVQWECINPKYKAKKKNYKNSGTVILNLCKIHKMHSFLDYIMGGCQIQFTVAIDFT ASNGDPRNSCSLHYIHPYQPNEYLKALVAVGEICQDYDSDKMFPAFGFGARIPPEYTVSHDFA INFNEEQPKCAGIQGWEAYQSCLPKLQLYGPTNIAPIIQKVAKSASEETNTKEASQYFILLI LTDGVITDMADTREAIVHASHLPMSVIIVGVGNADFSD QMLDGDDGILRSPKGEPVLRDIVQ FVPFRNFKHASPAALAKSVLAEVPNQWDYYNGKGIKPKCSSEMYESSSTLAP
SEQ ID NO: 319 1795 bp
NOV88b, ^GTGACTTTGTGGCTTGGCTTTAGATAAATTTGACCATGGCTGTAGAACCCAGCAGCTCAGAA
CG59983-02 DNA TCCATTAAAAGGAGAGCTGGGAGGAGAATGAAGAAGATGAGCAACATTTATGAGTCCGCTGCC Sequence AACACACTGGGAATCTTTAACAGCCCCTGCCTGACCAAAGTTGAGCTGCGTGTGGCGTGCAAA GGCATTTCTGACAGAGATGCCCTTTCCAAACCAGACCCCTGTGTCATCCACAAGATGCAGTCT CATGGGCAGTGGTTTGAGGTTGACAGGACTGAGGTGATTCGCACCTGCATAAACCCAGTGTAC TCAAAACTGTTTACTGTGGACTTTTACTTTGAGGAGGTGCAGCGCCTGCGGTTTGAAGTCCAT GACATCAGCAGCAACCACAATGGGCTGAAGGAGGCCGACTTCCTTGGTGGCATGGAGTGCACA CTTGGCCAGATTGTTTCCCAGAGAAAGCTGTCCAAATCCTTGCTGAAGCATGGGAACACAGCA GGGAAATCTTCCATCACGGTGATTGCTGAAGAATTATCTGGCAATGACGACTATGTTGAGCTT GCATTCAATGCACGGAAATTGGATGACAAGGATTTCTTCAGTAAATCTGACCCATTTCTGGAA ATTTTTCGTATGAATGATGATGCAACTCAGCAGCTGGTGCACCGAACTGAGGTTGTGATGAAT AACTTAAGCCCAGCCTGGAAATCATTCAAAGTATCTGTAAATTCTCTATGCAGCGGAGACCCA GACCGCCGGCTAAAGTGCATAGTATGGGACTGGGACTCCAATGGCAAGCATGACTTCATTGGA GAATTCACCTCGACATTCAAGGAGATGAGAGGAGCAATGGAAGGGAAACAGGTGCAGTGGGAG TGCATCAATCCCAAGTACAAAGCCAAGAAGAAGAATTACAAGAACTCAGGCACTGTGATTCTG AATCTGTGCAAGATTCACAAGATGCATTCTTTCTTGGACTACATCATGGGTGGCTGCCAAATC CAGTTTACAGTAGCTATAGATTTCACTGCCTCAAACGGGGACCCCAGGAACAGCTGTTCCTTG CACTACATCCACCCTTACCAACCCAATGAGTATCTGAAAGCTTTGGTAGCTGTGGGGGAGATT TGCCAAGACTATGACAGTGACAAAATGTTCCCTGCCTTTGGGTTTGGCGCCAGGATACCTCCA GAGTACACGGTCTCTCATGACTTTGCAATCAACTTTAATGAAGACAACCCAGAATGTGCAGGA ATTCAAGGAGTTGTGGAAGCCTATCAGAGCTGTCTTCCTAAGCTCCAACTCTACGGTCCCACC AACATTGCCCCCATCATCCAGAAGGTTGCCAAGTCGGCGTCAGAGGAAACTAACACCAAGGAG GCATCGCAATACTTCATCCTGCTGATCCTGACAGATGGTGTTATCACAGACATGGCCGACACC CGGGAGGCCATTGTCCATGCCTCCCACCTCCCCATGTCAGTCATCATCGTGGGAGTAGGGAAC GCTGACTTCAGTGACATGCAGATGCTGGACGGTGATGATGGGATTCTGAGGTCACCCAAGGGA GAGCCTGTTCTTCGAGACATCGTCCAGTTCGTGCCCTTCAGGAACTTCAAACATGCATCTCCA GCTGCCCTGGCAAAGAGCGTGCTGGCTGAAGTCCCAAACCAAGTTGTGGACTATTACAATGGC AAAGGAATTAAACCAAAATGTTCATCAGAAATGTATGAATCTTCCAGAACACTAGCAC'ATGA ACTCCCCACACAGTTTTACAGAGTTCTGAAA
ORF Start: ATG at 91 ORF Stop: TGA at 1762
SEQ ID NO: 320 557 aa ]MW at 62418.4kD jNOV88b, MKKMSNIYESAANTLGIFNSPCLTKVELRVACKGISDRDALSKPDPCVIHKMQSHGQWFEVDR
JCG59983-02 Protein TEVIRTCINPVYSKLFTVDFYFEEVQRLRFEVHDISSNHNGLKEADFLGGMECTLGQIVSQRK LSKSLLKHGNTAGKSSITVIAEELSGNDDYVELAFNARKLDDKDFFSKSDPFLEIFRMNDDAT iSequence QQLVHRTEWMNNLSPAWKSFKVSVNSLCSGDPDRRLKCIV DWDSNGKHDFIGEFTSTFKEM RGAMEGKQVQWECINPKYKAKKKNYKNSGTVILNLCKIHKMHSFLDYIMGGCQIQFTVAIDFT ASNGDPRNSCSLHYIHPYQPNEYLKALVAVGEICQDYDSDKMFPAFGFGARIPPEYTVSHDFA INFNEDNPECAGIQGWEAYQSCLPKLQLYGPTNIAPIIQKVAKSASEETNTKEASQYFILLI LTDGVITD ADTREAIVHASHLPMSVIIVGVGNADFSDMQMLDGDDGILRSPKGEPVLRDIVQ FVPFRNFKHASPAALAKSVLAEVPNQWDYYNGKGIKPKCSSEMYESSRTLAP
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 8δB.
Table 88B. Compai ison of NOV88a against NOV88b. j NOV88a Residues/ Identities/
Protein Sequence 1 Match Residues Similarities for the Matched Region
NOV88b , 1 -557 529/557 (94%) j 1 -557 531/557 (94%)
Further analysis of the NOVδδa protein yielded the following properties shown in Table 8δC.
! Table 88C. Protein Sequence Properties NOV88a j PSort 0.4500 probability located in cytoplasm; 0.3000 probability located in microbody j analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
SignalP ! No Known Signal Sequence Predicted analysis:
A search of the NOVδδa protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table δδD.
In a BLAST search of public sequence datbases, the NOV88a protein was found to have homology to the proteins shown in the BLASTP data in Table 88E.
PFam analysis predicts that the NOVδδa protein contains the domains shown in the Table δδF.
Example 89.
The N0V89 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 89A.
jTable 89A. NOV89 Sequence Analysis " fSEQΪD~NO: 32 ,724 bp
NOV89a, ICAGGAGGCGGGTGGGTCAAGGTAACTCTGGGCTACAGAGTCCTTGCTGGGGGTTCGGGGAGCG CG93335-01 DNA CTTGGACCCCGGCTTCTGGGACGCGTCAGAATATTATCCAGCAATGCAAATGAACAAACTATA
ACTACACACAGCTGCATGGATAAATGTCAGAAACATGACGTTGAGTGTGAGAAGCCAGATGCA Sequence JAACGAGGACTCACTGTGCAATTCTGTGCATGTACAGTGGCCAGGAGAAGGGAGCACTGGCTTT jGCTTTCATCAGGCCAAAGATGCCTTTCTTTGGGAATACGTTCAGTCCGAAGAAGACACCTCCT CGGAAGTCGGCATCTCTCTCCAACCTGCATTCTTTGGATCGATCAACCCGGGAGGTGGAGCTG GGCTTGGAATACGGATCCCCGACTATGAACCTGGCAGGGCAAAGCCTGAAGTTTGAAAATGGC CAGTGGATAGCAGAGACAGGGGTTAGTGGCGGTGTGGACCGGAGGGAGGTTCAGCGCCTTCGC AGGCGGAACCAGCAGTTGGAGGAAGAGAACAATCTCTTGCGGCTGAAAGTGGACATCTTATTA GACATGCTTTCAGAGTCCACTGCTGAATCCCACTTAATGGAGAAGGAACTGGATGAACTGAGG ATCAGCCGGAAGAGAAAATGAAGACCCCAGAGACATTTATTGGGGAGTAGGATGTGGCTGAGT
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 89B.
Further analysis of the NOV89a protein yielded the following properties shown in Table 89C.
j Table 89C. Protein Sequence Properties NOV89a
- PSort 0.4600 probability located in nucleus; 0.3000 probability located in microbody I analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen) j SignalP No Known Signal Sequence Predicted j analysis:
A search of the NOV89a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 89D.
In a BLAST search of public sequence datbases, the NOV89a protein was found to have homology to the proteins shown in the BLASTP data in Table δ9E.
PFam analysis predicts that the NOV89a protein contains the domains shown in the Table δ9F.
Example 90.
The NOV90 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 90A.
|Table 90A. NOV90 Sequence Analysis
SEQ ID NO: 325 10677 bp
]NOV90a, GGATCGAATCGCGGCCGCGTCGACGGTTTGCAGGCGCTTTCCTCTTGGAAGTGGCGACTGCTG JCG94377-01 DNA CGGGCCTGAGCGCTGGTCTCACGCGCCTCGGGAGCCAGGTTGGCGGCGCGATGAGGCGCAGCA
AGGCTGACGTGGAGCGGTACATCGCCTCGGTGCAGGGCTCCACCCCGTCGCCTCGACAGAAGT JSequence CAATGAAAGGATTCTATTTTGCAAAGCTGTATTATGAAGCTAAAGAATATGATCTTGCTAAAA AATACATATGTACTTACATTAATGTGCAAGAGAGGGATCCCAAAGCTCACAGATTTCTGGGTC TTCTTTATGAATTGGAAGAAAACACAGACAAAGCCGTTGAATGTTACAGGCGTTCAGTGGAAT TAAACCCAACACAAAAAGATCTTGTGTTGAAGATTGCAGAATTGCTTTGTAAAAATGATGTTA CTGATGGAAGAGCAAAATACTGGCTTGAAAGAGCAGCCAAACTTTTCCCAGGAAGTCCTGCAA TTTATAAACTAAAGGAACAGCTTCTAGATTGTGAAGGTGAAGATGGATGGAATAAACTTTTTG ACTTGATTCAGTCAGAACTTTATGTAAGACCTGATGACGTCCATGTGAACATCCGGCTAGTGG AGGTGTATCGCTCAACTAAAAGATTGAAGGATGCTGTGGCCCACTGCCATGAGGCAGAGAGGA ACATAGCTTTGCGTTCAAGTTTAGAATGGAATTCGTGTGTTGTACAGACCCTTAAGGAATATC TGGAGTCTTTACAGTGTTTGGAGTCTGATAAAAGTGACTGGCGAGCAACCAATACAGACTTAC TGCTGGCCTATGCTAATCTTATGCTTCTTACGCTTTCCACTAGAGATGTGCAGGAAAGTAGAG AATTACTGCAAAGTTTTGATAGTGCTCTTCAGTCTGTGAAATCTTTGGGTGGAAATGATGAAC TGTCAGCTACTTTCTTAGAAATGAAAGGACATTTCTACATGCATGCTGGTTCTCTGCTTTTGA AGATGGGTCAGCATAGTAGTAATGTTCAATGGCGAGCTCTTTCTGAGCTGGCTGCATTGTGCT ATCTCATAGCATTTCAGGTTCCAAGACCAAAGATTAAATTAATAAAAGGTGAAGCTGGACAAA ATCTGCTGGAAATGATGGCCTGTGACCGACTGAGCCAATCAGGGCACATGTTGCTAAACTTAA GTCGTGGCAAGCAAGATTTTTTAAAAGAGATTGTTGAAACTTTTGCCAACAAAAGCGGGCAGT CTGCATTATATGATGCTCTGTTTTCTAGTCAGTCACCTAAGGATACATCTTTTCTTGGTAGCG ATGATATTGGAAACATTGATGTACGAGAACCAGAGCTTGAAGATTTGACTAGATACGATGTTG GTGCTATTCGAGCACATAATGGTAGTCTTCAGCACCTTACTTGGCTTGGCTTACAGTGGAATT CATTGCCTGCTTTACCTGGAATCCGAAAATGGCTAAAACAGCTTTTCCATCATTTGCCCCATG AAACCTCAAGGCTTGAAACAAATGCACCTGAATCAATATGTATTTTAGATCTTGAAGTATTTC
TCCTTGGAGTAGTATATACCAGCCACTTACAATTAAAGGAGAAATGTAATTCTCACCACAGCT
CCTATCAGCCGTTATGCCTGCCCCTTCCTGTGTGTAAACAGCTTTGTACAGAAAGACAAAAAT
CTTGGTGGGATGCGGTTTGTACTCTGATTCACAGAAAAGCAGTACCTGGAAACGTAGCAAAAT
TGAGACTTCTAGTTCAGCATGAAATAAACACTCTAAGAGCCCAGGAAAAACATGGCCTTCAAC
CTGCTCTGCTTGTACATTGGGCAGAATGCCTTCAGAAAACGGGCAGCGGTCTTAATTCTTTTT
ATGATCAACGAGAATACATAGGGAGAAGTGTTCATTATTGGAAGAAAGTTTTGCCATTGTTGA
AGATAATAAAAAAGAAGAACAGTATTCCTGAACCTATTGATCCTCTGTTTAAACATTTTCATA
GTGTAGACATTCAGGCATCAGAAATTGTTGAATATGAAGAAGACGCACACATAACTTTTGCTA
TATTGGATGCAGTAAATGGAAATATAGAAGATGCTGTGACTGCTTTTGAATCTATAAAAAGTG
TTGTTTCTTATTGGAATCTTGCACTGATTTTTCACAGGAAGGCAGAAGACATTGAAAATGATG
CCCTTTCTCCTGAAGAACAAGAAGAATGCAAAAATTATCTGAGAAAGACCAGGGACTACCTAA
TAAAGATTATAGATGACAGTGATTCAAATCTTTCAGTGGTCAAGAAATTGCCTGTGCCCCTGG
AGTCTGTAAAAGAGATGCTTAATTCAGTCATGCAGGAACTCGAAGACTATAGTGAAGGAGGTC
CTCTCTATAAAAATGGTTCTTTGCGAAATGCAGATTCAGAAATAAAACGTTCTACACCGTCTC
CTACCAGATATTCACTATCACCAAGTAAAAGTTACAAGTATTCTCCCAAAACACCACCTCGAT
GGGCAGAAGATCAGAATTCTTTACTGAAAATGATTTGCCAACAAGTAGAGGCCATTAAGAAAG
AAATGCAGGAGTTGAAACTAAATAGCAGTAACTCAGCATCCCCTCATCGTTGGCCCACAGAGA
ATTATGGACCAGACTCGGTGCCTGATGGATATCAGGGGTCACAGACATTTCATGGGGCTCCAC
TAACAGTTGCAACTACTGGCCCTTCAGTATATTATAGTCAGTCACCAGCATATAATTCCCAGT
ATCTTCTCAGACCAGCAGCTAATGTTACTCCCACAAAGGGCCCAGTCTATGGCATGAATAGGC
TTCCACCCCAACAGCATATTTATGCCTATCCGCAACAGATGCACACACCGCCAGTGCAAAGCT
CATCTGCTTGTATGTTCTCTCAGGAGATGTATGGTCCTCCTGCATTGCGTTTTGAGTCTCCTG
CAACGGGAATTCTATCGCCCAGGGGTGATGATTACTTTAATTACAATGTTCAACAGACAAGCA
CAAATCCACCTTTGCCAGAACCAGGATATTTCACAAAACCTCCGATTGCAGCTCATGCTTCAA
GATCTGCAGAATCTAAGACTATAGAATTTGGGAAAACTAATTTTGTTCAGCCCATGCCGGGTG
AAGGATTAAGGCCATCTTTGCCAACACAAGCACACACAACACAGCCAACTCCTTTTAAATTTA
ACTCAAATTTCAAATCAAATGATGGTGACTTCACGTTTTCCTCACCACAGGTTGTGACΛCAGC
CCCCTCCTGCAGCTTACAGTAACAGTGAAAGCCTTTTAGGTCTCCTGACTTCAGATAAACCCT
TGCAAGGAGATGGCTATAGTGGAGCCAAACCAATTCCTGGTGGTCAAACCATTGGGCCTCGAA
ATACATTCAATTTTGGAAGCAAAAATGTGTCTGGAATTTCATTTACAGAAAACATGGGGTCGA
GTCAGCAAAAGAATTCTGGTTTTCGGCGAAGTGATGATATGTTTACTTTCCATGGTCCAGGGA
AATCAGTATTTGGAACACCCACTTTAGAGACAGCAAACAAGAATCATGAGACAGATGGAGGAA
GTGCCCATGGGGATGATGATGATGACGGTCCTCACTTTGAGCCTGTAGTACCTCTTCCTGATA
AGATTGAAGTAAAAACTGGTGAGGAAGATGAAGAAGAATTCTTTTGCAACCGCGCGAAATTGT
TTCGTTTCGATGTAGAATCCAAAGAATGGAAAGAACGTGGGATTGGCAATGTAAAAATACTGA
GGCATAAAACATCTGGTAAAATTCGCCTTCTAATGAGACGAGAGCAAGTATTGAAAATCTGTG
CAAATCATTACATCAGTCCAGATATGAAATTGACACCAAATGCTGGATCAGACAGATCTTTTG
TATGGCATGCCCTTGATTATGCAGATGAGTTGCCAAAACCAGAACAACTTGCTATTAGGTTCA
AAACTCCTGAGGAAGCAGCACTTTTTAAATGCAAGTTTGAAGAAGCCCAGAGCATTTTAAAAG
CCCCAGGAACAAATGTAGCCATGGCGTCAAATCAGGCTGTCAGAATTGTAAAAGAACCCACAA
GTCATGATAACAAGGATATTTGCAAATCTGATGCTGGAAACCTGAATTTTGAATTTCAGGTTG
CAAAGAAAGAAGGGTCTTGGTGGCATTGTAACAGCTGCTCATTAAAGAATGCTTCAACTGCTA
AGAAATGTGTATCATGCCAAAATCTAAACCCAAGCAATAAAGAGCTCGTTGGCCCACCATTAG
CTGAAACTGTTTTTACTCCTAAAACCAGCCCAGAGAATGTTCAAGATCGATTTGCATTGGTGA
CTCCAAAGAAAGAAGGTCACTGGGATTGTAGTATTTGTTTAGTAAGAAATGAACCTACTGTAT
CTAGGTGCATTGCGTGTCAGAATACAAAATCTGCTAACAAAAGTGGATCTTCATTTGTTCATC
AAGCTTCATTTAAATTTGGCCAGGGAGATCTTCCTAAACCTATTAACAGTGATTTCAGATCTG
TTTTTTCTACAAAGGAAGGACAGTGGGATTGCAGTGCATGTTTGGTACAAAATGAGGGGAGCT
CTACAAAATGTGCTGCTTGTCAGAATCCGAGAAAACAGAGTCTACCTGCTACTTCTATTCCAA
CACCTGCCTCTTTTAAGTTTGGTACTTCAGAGACAAGTAAAACTCTAAAAAGTGGATTTGAAG
ACATGTTTGCTAAGAAGGAAGGACAGTGGGATTGCAGTTCATGCTTAGTGCGAAATGAAGCAA
ATGCTACAAGATGTGTTGCTTGTCAGAATCCGGATAAACCAAGTCCATCTACTTCTGTTCCAG
CTCCTGCCTCTTTTAAGTTTGGTACTTCAGAGACAAGCAAGGCTCCAAAGAGCGGATTTGAGG
GAATGTTCACTAAGAAGGAGGGACAGTGGGATTGCAGTGTGTGCTTAGTAAGAAATGAAGCCA
GTGCTACCAAATGTATTGCTTGTCAGAATCCAGGTAAACAAAATCAAACTACTTCTGCAGTTT
CAACACCTGCCTCTTCAGAGACAAGCAAGGCTCCAAAGAGCGGATTTGAGGGAATGTTCACTA
AGAAGGAGGGACAGTGGGATTGCAGTGTGTGCTTAGTAAGAAATGAAGCCAGTGCTACCAAAT
GTATTGCTTGTCAGAATCCAGGTAAACAAAATCAAACTACTTCTGCAGTTTCAACACCTGCCT
CTTCAGAGACAAGCAAGGCTCCAAAGAGCGGATTTGAGGGAATGTTCACTAAGAAGGAAGGAC
AGTGGGATTGCAGTGTGTGCTTAGTAAGAAATGAAGCCAGTGCTACCAAATGTATTGCTTGTC
AGTGTCCAAGTAAACAAAATCAAACAACTGCAATTTCAACACCTGCCTCTTCGGAGATAAGCA
AGGCTCCAAAGAGTGGATTTGAAGGAATGTTCATCAGGAAAGGACAGTGGGATTGTAGTGTTT
GCTGTGTACAAAATGAGAGTTCTTCCTTAAAATGTGTGGCTTGTGATGCCTCTAAACCAACTC
ATAAACCTATTGCAGAAGCTCCTTCAGCTTTCACACTGGGCTCAGAAATGAAGTTGCATGACT
CTTCTGGAAGTCAGGTGGGAACAGGATTTAAAAGTAATTTCTCAGAAAAAGCTTCTAAGTTTG
GCAATACAGAGCAAGGATTCAAATTTGGGCATGTGGATCAAGAAAATTCACCTTCATTTATGT
TTCAGGGTTCTTCTAATACAGAATTTAAGTCAACCAAAGAAGGATTTTCCATCCCTGTGTCTG
CTGATGGATTTAAATTTGGCATTTCGGAACCAGGAAATCAAGAAAAGAAAAGTGAAAAGCCTC
TTGAAAATGGTACTGGCTTCCAGGCTCAGGATATTAGTGGCCAGAAGAATGGCCGTGGTGTGA
TTTTTGGCCAAACAAGTAGCACTTTTACATTTGCAGATCTTGCAAAATCAACTTCAGGAGAAG
GATTTCAGTTTGGCAAAAAAGACCCCAATTTCAAGGGATTTTCAGGTGCTGGAGAAAAATTAT
TCTCATCACAATACGGTAAAATGGCCAATAAAGCAAACACTTCCGGTGACTTTGAGAAAGATG
ATGATGCCTATAAGACTGAGGACAGCGATGACATCCATTTTGAACCAGTAGTTCAAATGCCCG
AAAAAGTAGAACTTGTAACAGGAGAAGAAGATGAAAAAGTTCTGTATTCACAGCGGGTAAAAC
TATTTAGATTTGATGCTGAGGTAAGTCAGTGGAAAGAAAGGGGCTTGGGGAACTTAAAAATTC
TCAAAAACGAGGTCAATGGCAAACTAAGAATGCTGATGCGAAGAGAACAAGTACTAAAAGTGT
GTGCTAATCATTGGATAACGACTACGATGAACCTGAAGCCTCTCTCTGGATCAGATAGAGCAT
GGATGTGGTTAGCCAGTGATTTCTCTGATGGTGATGCCAAACTAGAGCAGTTGGCAGCAAAAT
TTAAAACACCAGAGCTGGCTGAAGAATTCAAGCAGAAATTTGAGGAATGCCAGCGGCTTCTGT
TAGACATACCACTTCAAACTCCCCATAAACTTGTAGATACTGGCAGAGCTGCCAAGTTAATAC
AGAGAGCTGAAGAAATGAAGAGTGGACTGAAAGATTTCAAAACATTTTTGACAAATGATCAAA
CAAAAGTCACTGAGGAAGAAAATAAGGGTTCAGGTACAGGTGCGGCCGGTGCCTCAGACACAA
CAATAAAACCCAATCCTGAAAACACTGGGCCCACATTAGAATGGGATAACTATGATTTAAGGG
AAGATGCTTTGGATGATAGTGTCAGTAGTAGCTCAGTACATGCTTCTCCATTGGCAAGTAGCC
CTGTGAGAAAAAATCTTTTCCGTTTTGGTGAGTCAACAACAGGATTTAACTTCAGTTTTAAAT
CTGCTTTGAGTCCATCTAAGTCTCCTGCCAAGTTGAATCAGAGTGGGACTTCAGTTGGCACTG
ATGAAGAATCTGATGTTACTCAAGAAGAAGAGAGAGATGGACAGTACTTTGAACCTGTTGTTC
CTTTACCTGATCTAGTTGAAGTATCCAGTGGTGAGGAAAATGAACAAGTTGTTTTTAGTCACA
GGGCAAAACTCTACAGATATGATAAAGATGTTGGTCAATGGAAAGAAAGGGGCATTGGTGATA
TAAAGATTTTACAGAATTATGATAATAAGCAAGTTCGTATAGTGATGAGAAGGGACCAAGTAT
TAAAACTTTGTGCCAATCACAGAATAACTCCAGACATGACTTTGCAAAATATGAAAGGGACAG
AAAGAGTATGGTTGTGGACTGCATGTGATTTTGCAGATGGAGAAAGAAAAGTAGAGCATTTAG
CTGTTCGTTTTAAACTACAGGATGTTGCAGACTCGTTTAAGAAAATTTTTGATGAAGCAAAAA
CAGCCCAGGAAAAAGATTCTTTGATAACACCTCATGTTTCTCGGTCAAGCACTCCCAGAGAGT
CACCATGTGGCAAAATTGCTGTAGCTGTATTAGAAGAAACCACAAGAGAGAGGACAGATGTTA
TTCAGGGTGATGATGTAGCAGATGCAACTTCAGAAGTTGAAGTGTCTAGCACATCTGAAACAA
CACCAAAAGCAGTGGTTTCTCCTCCAAAGTTTGTATTTGGTTCAGAGTCTGTTAAAAGCATTT
TTAGTAGTGAAAAATCAAAACCATTTGCATTCGGCAACAGTTCAGCCACTGGGTCTTTGTTTG
GATTTAGTTTTAATGCACCTTTGAAAAGTAACAATAGTGAAACTAGTTCAGTAGCCCAGAGTG
GATCTGAAAGCAAAGTGGAACCTAAAAAATGTGAACTGTCAAAGAACTCTGATATCGAACAGT
CTTCAGATAGCAAAGTCAAAAATCTCTTTGCTTCCTTTCCAACGGAAGAATCTTCAATCAACT
ACACATTTAAAACACCAGAAAAGGCAAAAGAGAAGAAAAAACCTGAAGATTCTCCCTCAGATG
ATGATGTTCTCATTGTATATGAACTAACTCCAACCGCTGAGCAGAAAGCCCTTGCAACCAAAC
TTAAACTTCCTCCAACTTTCTTCTGCTACAAGAATAGACCAGATTATGTTAGTGAAGAAGAGG
AGGATGATGAAGATTTCGAAACAGCTGTCAAGAAACTTAATGGAAAACTATATTTGGATGGCT
CAGAAAAATGTAGACCCTTGGAAGAAAATACAGCAGATAATGAGAAAGAATGTATTATTGTTT
GGGAAAAGAAACCAACAGTTGAAGAGAAGGCAAAAGCAGATACGTTAAAACTTCCACCTACAT
TTTTTTGTGGAGTCTGTAGTGATACTGATGAAGACAATGGAAATGGGGAAGACTTTCAATCAG
AGCTTCAAAAAGTTCAGGAAGCTCAAAAATCTCAGACAGAAGAAATAACTAGCACAACTGACA
GTGTATATACAGGTGGGACTGAAGTGATGGTACCTTCTTTCTGTAAATCTGAAGAACCTGATT
CTATTACCAAATCCATTAGTTCACCATCTGTTTCCTCTGAAACTATGGACAAACCTGTAGATT
TGTCAACTAGAAAGGAAATTGATACAGATTCTACAAGCCAAGGGGAAAGCAAGATAGTTTCAT
TTGGATTTGGAAGTAGCACAGGGCTCTCATTTGCAGACTTGGCTTCCAGTAATTCTGGAGATT
TTGCTTTTGGTTCTAAAGATAAAAATTTCCAATGGGCAAATACTGGAGCAGCTGTGTTTGGAA
CACAGTCAGTCGGAACCCAGTCAGCCGGTAAAGTTGGTGAAGATGAAGATGGTAGTGATGAAG
AAGTAGTTCATAATGAAGATATCCATTTTGAACCAATAGTGTCACTACCAGAGGTAGAAGTAA
AATCTGGAGAAGAAGATGAAGAAATTTTGTTTAAAGAGAGAGCCAAACTTTATAGATGGGATC
GGGATGTCAGTCAGTGGAAGGAGCGCGGTGTTGGAGATATAAAGATTCTTTGGCATACAATGA
AGAATTATTACCGGATCCTAATGAGAAGAGACCAGGTTTTTAAAGTGTGTGCAAACCACGTTA
TTACTAAAACAATGGAATTAAAGCCCTTAAATGTTTCAAATAATGCTTTAGTTTGGACTGCCT
CAGATTATGCTGATGGAGAAGCAAAAGTAGAACAGCTTGCAGTGAGATTTAAAACTAAAGAAG
TAGCTGATTGTTTCAAGAAAACATTTGAAGAATGTCAGCAGAATTTAATGAAACTCCAGAAAG
GACATGTATCACTGGCAGCAGAATTATCAAAGGAGACCAATCCTGTGGTGTTTTTTGATGTTT
GTGCGGACGGTGAACCTCTAGGGCGGATAACTATGGAATTATTTTCAAACATTGTTCCTCGGA
CTGCTGAGAACTTCAGAGCACTATGCACTGGAGAGAAAGGCTTTGGTTTCAAGAATTCCATTT
TTCACAGAGTAATTCCAGATTTTGTTTGCCAAGGAGGAGATATCACCAAACATGATGGAACAG
GCGGACAGTCCATTTATGGAGACAAATTTGAAGATGAAAATTTTGATGTGAAACATACTGGTC
CTGGTTTACTATCCATGGCCAATCAAGGCCAGAATACCAATAATTCTCAATTTGTTATAACAC
TGAAGAAAGCAGAACATTTGGACTTTAAGCATGTAGTATTTGGGTTTGTTAAGGATGGCATGG
ATACTGTGAAAAAGATTGAATCATTTGGTTCTCCCAAAGGGTCTGTTTGTCGAAGAATAACTA
TCACAGAATGTGGACAGATATAAAATCATTGTTGTTCATAGAAAATTTCATCTGTATAAGCAG
TTGGATTGAAGCTTAGCTATTACAATTTGATAGTTATGTTCAGCTTTTGAAAATGGACGTTTC
CGATTTACAAATGTAAAATTGCAGCTTATAGCTGTTGTCACTTTTTAATGTGTTATAATTGAC
CTTGCATGGTGTGAAATAAAAGTTTAAACACTGGTGTATTTCAGGTGTACTTGTGTTTATGTA
CTCCTGACGTATTAAAATGGAATAATACTAATCTTGTTAAAAGCAATAGACCTCAAACTATTG
AAGGAATATGATATATGCAATTTAATTTTAATTCCTTTTAAGATATTTGGACTTCCTGCATGG
ATATACTTACCATTTGAATAAAGGGACCACAACTTGGATAATTTAATTTTAGGTTTGAAATAT
ATTTGGTAATCTTAACTATTGGTGTACTCATTTATGCATAGAGACTCGTTTATGAATGGGTAG
AGCCACAGAACGTATAGAGTTAACCAAAGTGCTCTTCTCTAGAATCTTTACACCTCCTGTGTG
GTTACAAGTTAACTTTGTAAGTAGCGTACCTTCCTTCCTTAAAATATCTAGCTTCCTGTGCCC
TTTCATAGATATTCGATTAATTTTTACATTTTAAACAAGTTGACTATTTCCTTTAGGGGTTTT
GTTTCAAACTTTTCTGTCATCTGTCTCTACTACCTCAGAAACTGCAGCTTGGTTCTGATGATA
GAAATTGAATTTTTCCTTGTAGTTATTGTGATAAAGTATGAATATTTTTAGAAAGTCTATACC
ATGTTCTTTCGTTAAAGATTTGCTTTATACAAGATTGTTGCAGTACCTTTTTCTGGTAAATTT
TGTAGCAGAAATAAAATGACAATTCCTAAG
ORF Start: ATG at lj 4 \ |ORF Stop: TAA at 9786 sΕΪQ ID N0. 326 " "' " " [3224 aa ]MW at 358214.5kD " "
|NOV90a, MRRSKADVERYIASVQGSTPSPRQKSMKGFYFAKLYYEAKEYDLAKKYICTYINVQERDPKAH JCG94377-01 Protein RFLGLLYELEENTDKAVECYRRSVELNPTQKDLVLKIAELLCKNDVTDGRAKYWLERAAKLFP
! GSPAIYKLKEQLLDCEGEDG NKLFDLIQSELYVRPDDVHVNIRLVEVYRSTKRLKDAVAHCH jSequence EAERNIALRSSLE NSCWQTLKEYLESLQCLESDKSDWRATNTDLLLAYANLMLLTLSTRDV
QESRELLQSFDSALQSVKSLGGNDELSATFLEMKGHFYMHAGSLLLKMGQHSSNVQWRALSEL
AALCYLIAFQVPRPKIKLIKGEAGQNLLEMMACDRLSQSGHMLLNLSRGKQDFLKEIVETFAN
KΞGQSALYDALFSSQSPKDTSFLGSDDIGNIDVREPELEDLTRYDVGAIRAHNGSLQHLTWLG
LQWNSLPALPGIRK LKQLFHHLPHETSRLETNAPESICILDLEVFLLGVVYTSHLQLKEKCN
SHHSSYQPLCLPLPVCKQLCTERQKSW DAVCTLIHRKAVPGNVAKLRLLVQHEINTLRAQEK
HGLQPALLVHWAECLQKTGSGLNSFYDQREYIGRSVHYWKKVLPLLKIIKKKNSIPEPIDPLF
KHFHSVDIQASEIVEYEEDAHITFAILDAVNGNIEDAVTAFESIKSVVSYWNLALIFHRKAED
IENDALSPEEQEECKNYLRKTRDYLIKIIDDSDSNLSWKKLPVPLESVKEMLNSVMQELEDY
SEGGPLYKNGSLRNADSEIKRSTPSPTRYSLSPSKSYKYSPKTPPRWAEDQNSLLKMICQQVE
AIKKEMQELKLNSSNSAΞPHR PTENYGPDSVPDGYQGSQTFHGAPLTVATTGPSVYYSQSPA
YNSQYLLRPAANVTPTKGPVYGMNRLPPQQHIYAYPQQMHTPPVQSSSACMFSQEMYGPPALR
FESPATGILSPRGDDYFNYNVQQTSTNPPLPEPGYFTKPPIAAHASRSAESKTIEFGKTNFVQ
PMPGEGLRPSLPTQAHTTQPTPFKFNSNFKSNDGDFTFSSPQWTQPPPAAYSNSESLLGLLT
SDKPLQGDGYSGAKPIPGGQTIGPRNTFNFGSKNVSGISFTENMGSSQQKNSGFRRSDDMFTF
HGPGKSVFGTPTLETANKNHETDGGSAHGDDDDDGPHFEPWPLPDKIEVKTGEEDEEEFFCN
RAKLFRFDVESKEWKERGIGNVKILRHKTSGKIRLLMRREQVLKICANHYISPDMKLTPNAGS
DRSFV HALDYADELPKPEQLAIRFKTPEEAALFKCKFEEAQSILKAPGTNVAMASNQAVRIV
KEPTSHDNKDICKSDAGNLNFEFQVAKKEGSW HCNSCSLKNASTAKKCVSCQNLNPSNKELV
GPPLAETVFTPKTSPENVQDRFALVTPKKEGHWDCSICLVRNEPTVSRCIACQNTKSANKSGS
SFVHQASFKFGQGDLPKPINSDFRSVFSTKEGQWDCSACLVQNEGSSTKCAACQNPRKQSLPA
TSIPTPASFKFGTSETSKTLKSGFEDMFAKKEGQWDCSSCLVRNEANATRCVACQNPDKPSPS
TSVPAPASFKFGTSETSKAPKSGFEGMFTKKEGQWDCSVCLVRNEASATKCIACQNPGKQNQT
TSAVSTPASSETSKAPKSGFEGMFTKKEGQWDCSVCLVRNEASATKCIACQNPGKQNQTTSAV
STPASSETSKAPKSGFEGMFTKKEGQWDCSVCLVRNEASATKCIACQCPSKQNQTTAISTPAS
SEISKAPKSGFEGMFIRKGQWDCSVCCVQNESSSLKCVACDASKPTHKPIAEAPSAFTLGSEM
KLHDSSGSQVGTGFKSNFSEKASKFGNTEQGFKFGHVDQENSPSFMFQGSSNTEFKSTKEGFS
IPVSADGFKFGISEPGNQEKKSEKPLENGTGFQAQDISGQKNGRGVIFGQTSSTFTFADLAKS
TSGEGFQFGKKDPNFKGFSGAGEKLFSSQYGKANKANTSGDFEKDDDAYKTEDSDDIHFEPV
VQMPEKVELVTGEEDEKVLYSQRVKLFRFDAEVSQ KERGLGNLKILKNEVNGKLRMLMRREQ
VLKVCANH ITTTMNLKPLSGSDRAWMWLASDFSDGDAKLEQLAAKFKTPELAEEFKQKFEEC
QRLLLDIPLQTPHKLVDTGRAAKLIQRAEEMKSGLKDFKTFLTNDQTKVTEEENKGSGTGAAG
ASDTTIKPNPENTGPTLEWDNYDLREDALDDSVSSSSVHASPLASSPVRKNLFRFGESTTGFN
FSFKSALSPSKSPAKLNQSGTSVGTDEESDVTQEEERDGQYFEPWPLPDLVEVSSGEENEQV
VFSHRAKLYRYDKDVGQ KERGIGDIKILQNYDNKQVRIVMRRDQVLKLCANHRITPDMTLQN
MKGTERVWLWTACDFADGERKVEHLAVRFKLQDVADSFKKIFDEAKTAQEKDSLITPHVSRSS
TPRESPCGKIAVAVLEETTRERTDVIQGDDVADATSEVEVSSTSETTPKAWSPPKFVFGSES
VKSIFSSEKSKPFAFGNSSATGSLFGFSFNAPLKSNNSETSSVAQSGSESKVEPKKCELSKNS
DIEQSSDSKVKNLFASFPTEESSINYTFKTPEKAKEKKKPEDSPSDDDVLIVYELTPTAEQKA
LATKLKLPPTFFCYKNRPDYVSEEEEDDEDFETAVKKLNGKLYLDGSEKCRPLEENTADNEKE
CIIV EKKPTVEEKAKADTLKLPPTFFCGVCSDTDEDNGNGEDFQSELQKVQEAQKSQTEEIT
STTDSVYTGGTEVMVPSFCKSEEPDSITKSISSPSVSSETMDKPVDLSTRKEIDTDSTSQGES
KIVSFGFGSSTGLSFADLASSNSGDFAFGSKDKNFQWANTGAAVFGTQSVGTQSAGKVGEDED
GSDEEWHNEDIHFEPIVSLPEVEVKSGEEDEEILFKERAKLYRWDRDVSQWKERGVGDIKIL
WHTMKNYYRILMRRDQVFKVCANHVITKTMELKPLNVSNNALV TASDYADGEAKVEQLAVRF
KTKEVADCFKKTFEECQQNLMKLQKGHVSLAAELSKETNPWFFDVCADGEPLGRITMELFSN
IVPRTAENFRALCTGEKGFGFKNSIFHRVIPDFVCQGGDITKHDGTGGQSIYGDKFEDENFDV
KHTGPGLLSMANQGQNTNNSQFVITLKKAEHLDFKHVVFGFVKDG DTVKKIESFGSPKGSVC RRITITECGQI
|SEQ ID NO: 327 5332 bp
NOV90b, ACGCGTCTCGGGAGCCAGGTTGGCGGCGCGATGAGGCGCAGCAAGGCCGATGTGGAGCGGTAC CG94377-02 DNA GTCGCCTCGGTGCTGGGTCTCACCCCGTCGCCTCGACAGAAGTCAATGAAAGGATTCTATTTT
GCAAAGCTGTATTATGAAGCTAAAGAATATGATCTTGCTAAAAAGTACGTATGTACTTACCTT Sequence AGTGTGCAAGAGAGGGATCCCAGAGCTCACAGATTTCTGGGTCTTCTTTATGAATTGGAAGAA
AACACAGAGAAAGCCGTTGAATGTTACAGGCGTTCACTGGAATTAAACCCACCACAAAAAGAT
CTTGTGTTGAAGATTGCAGAATTGCTTTGTAAAAATGATGTTACTGATGGAAGAGCAAAATAC
TGGGTTGAAAGGGCAGCGAAACTTTTCCCAGGAAGTCCTGCAATTTATAAACTAAAGCATCTT
CTAGATTGTGAAGGTGAAGATGGATGGAATAAACTTTTTGACTGGATTCAGTCAGAACTTTAT
GTAAGACCTGATGACGTCCATATGAACATCCGGCTAGTGGAGTTGTATCGCTCAAATAAAAGA
TTGAAGGATGCTGTGGCCCGCTGCCATGAGGCAGAGAGGAACATAGCTTTGCGTTCAAGTTTA
GAGTGGAATTCGTGTGTTGTACAGACCCTTAAGGAATATCTGGAGTCTTTACAGTGTTTGGAG
TCTGATAAAAGTGACTGGCGAGCAACCAATACAGACTTACTGCTGGCCTATGCTAATCTTATG
CTTCTTACGCTTTCCACTAGAGATGTGCAGGAAAGTAGAGAATTACTGGAAAGTTTTGATAGT
GCTCTTCAGTCTGCAAAATCTTCTTTGGGTGGAAATGATGAACTGTCAGCTACTTTCTTAGAA
ATGAAAGGACATTTCTACATGCATGCTGGTTCTCTGCTCTTGAAGATGGGTCAGCATGGTAAT
AATGTTCAATGGCAAGCTCTTTCTGAGCTGGCTGCATTGTGCTATGTCATAGCATTTCAGGTT
CCAAGACCAAAGATTAAATTAATAAAAGGTGAAGCTGGACAAAATCTGCTGGAAATGATGGCC
TGTGACCGACTGAGCCAATCAGGGCATATGTTGCTAAACTTAAGTCGTGGCAAGCAAGATTTT
TTAAAAGAGGTTGTTGAAACTTTTGCCAACAAAAGCGGGCAGTCTGTGTTATATAATGCTCTG
TTTTCTAGTCAGTCATCTAAGGATACATCTTTTCTTGGTAGCGATGATATTGGAAACATTGAT
GTACAAGAACCAGAGCTTGAAGATTTGGCTAGATACGATGTTGGTGCTATTCAAGCACATAAT
GGTAGTCTTCAGCACCTTACTTGGCTTGGCTTACAGTGGAATTCATTGCCTGCTTTACCTGGA
ATCCGAAAATGGCTAAAACAGCTTTTCCATCATTTGCCCCAGGAAACCTCAAGGCTTGAAACA
AATGCACCTGAATCAATATGTATTTTAGATCTTGAAGTATTTCTCCTTGGAGTAGTATATACC
AGCCACTTACAATTAAAGGAGAAATGTAATTCTCACCACAGCTCCTATCAGCCGTTATGCCTG
CCCCTTCCTGTGTGTAAACGGCTTTGTACAGAGAGACAAAAATCTTGGTGGGATGCGGTTTGT
ACTCTGATTCACAGAAAAGCAGTGAACTCAGCAGAATTGAGACTTGTAGTTCAGCATGAAATA
AACACTCTAAGAGCCCAGGAAAAACATGGCCTTCAACCTGCTCTGCTTGTACATTGGGCAAAA
TGCCTTCAGAAAGGCAGGGGTCTTAATTCTTCTTATGATCAACAAGAATACATAGGGAGAAGT
GTTCATTATTGGAAGAAAGTTTTGCCATTGTTGAAGATAATAAAGAAGAACAGTATTCCTGAA
CCTATTGATCCTCTGTTTAAACATTTTCATAGTGTAGACATTCAGGCATCAGAAATTGTTGAG
TATGAAGAAGATGCACACATAACTTTTGCTATATTGGATGCAGTACATGGAAATATAGAAGAT
GCTGTGACTGCTTTTGAATCTATAAAAAGTGTTGTTTCTTATTGGAATCTTGCACTGATTTTT
CACAGGAAAGCAGAAGACATTGAAAATGATGCCGTTTTTCCTGAAGAACAAGAAGAATGCAAA
AATTATCTGAGAAAGACCAGGGACTACCTAATAAAGATTATAGATGACAGTGATTCAAATCTT
TCAGTGGTCAAGAAAGTAAGTGTGCCCCTGGAGTCTGTAAAAGAGATGCTTAAGTCAGTCATG
CAGGAACTCGAAGACTATAGTGAAGGAGGTCCTCTCTATAAAAATGGTTCTTTGCGAAATGCA
GATTCAGAAATAAAACATTCTACACCATCTCCTACCAAATATTCACTATCACCAAGTAAAAGT
TACAAGTATTCTCCCAAAACACCACCTCGATGGGCAGAAGATCAGAATTCTTTACGGAAAATG
ATTTGCCAAGAAGTAAAGGCCATTAAGAAAGAAATGCAGGAGTTGAAACTAAATAGCAGTAAG
TCAGCATCCCGTCATCGTTGGCCCACAGAGAATTATGGACCAGACTCGGTGCCTGATGGATAT
CAGGGGTCACAGACATTTCATGGGGCTCCACTAACAGTTGCAACTACTGGCCCTTCAGTATAT
TATAGTCAGTCACCAGCATATAATTCCCAGTATCTTCTCAGACCAGCAGCTAATGTTACTCCC
ACAAAGGGTTCTTCTAATACAGAATTTAAGTCAACCAAAGAAGGATTTTCCATCCCTGTGTCT
GCTGATGGATTTAAATTTGGCATTTCGGAACCAGGAAATCAAGAAAAGAAAAGTGAAAAGCCT
CTTGAAAATGATACTGGCTTCCAGGCTCAGGATATTAGTGGCCAGAAGAATGGCCGTGGTGTG
ATTTTTGGCCAAACAAGTAGCACTTTTACATTTGCAGATGTTGCAAAATCAACTTCAGGAGAA
GGATTTCAGTTTGGCAAAAAAGACCCCAATTTCAAGGGATTTTCAGGTGCTGGAGAAAAATTA
TTCTCATCACAATGCGGTAAAATGGCCAATAAAGCAAACACTTCCGGTGACTTTGAGAAAGAT
GATGATGCCTGTAAGACTGAGGACAGCGATGACATCCATTTTGAACCAGTAGTTCAAATGCCT
GAAAAAGTAGAACTTGTAACAGGAGAAGAAGGTGAAAAAGTTCTGTATTCACAGGGGGTAAAA
CTATTTAGATTTGATGCTGAGATAAGTCAGTGGAAAGAAAGGGGCTTGGGGAACTTAAAAATT
CTCAAAAATGAGGTCAATGGCAAACCAAGAATGCTGATGCGAAGAGACCAAGTACTAAAAGTG
TGTGCTAATCATTGGATAACAACTACAATGAACCTGAAGCCCCTCTCTGGATCAGATAGAGCA
TGGATGTGGTTAGCCAGTGATTTCTCTGATGGTGATGCCAAACTAGAGCGGTTGGCAGCACAA
TTTAAAACACCAGAGCTGGCTGAAGAATTCAAGCAGAAATTTGAGGAATGCCAGCGGCTTCTG
TTAGACATACCACTTCAAACTCCCCATAAACTTGTAGATACTGGCAGAGCTGCCAAGCTAATA
CAGAGAGCTGAAGAAATGAAGAGTGGACTGAAAGATTTCAAAACGTTTTTGACAAATGATCAA
ACAAAAGTCACTGAGGAAGAAAATAAGGGTTCAGGTACAGGTGCAGCCGGTGCCTCAGACACA
ACAATAAAACCCAATCCTGAAAACACTGGGCCCACATTAGAATGGGATAACTATGATTTAAGG
GAAGATGCTTTGGATGATAATGTTAGTAGTAGCTCAGTACATGATTCTCCGTTGGCAAGTAGC
CCTGTGAGAAAAAATATTTTCCGCTTTGATGAGTCAACAACAGGATTTAACTTCAGTTTTAAA
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 90B.
j Table 90B. Comparison of NOV90a against NOV90b.
NOV90a Residues/ Identities/ j Protein Sequence Match Residues Similarities for the Matched Region ! NOV90b I ..900 795/901 (88%) 1 1 ..906 823/901 (91 %)
Further analysis of the NOV90a protein yielded the following properties shown in Table 90C.
; Table 90C. Protein Sequence Properties NOV90a
PSort 0.6000 probability located in endoplasmic reticulum (membrane); 0.3000 probability analysis: located in microbody (peroxisome); 0.2525 probability located in mitochondrial inner membrane; 0.1000 probability located in nucleus i SignalP No Known Signal Sequence Predicted ' analysis:
A search of the NOV90a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 90D.
I Table 90D. Geneseq Results for NOV90a
NOV90a
Identities/ , „ r j Geneseq Protein/Organism/Length [Patent Residues/
Similarities for the j .. ! Identifier #, Date] Match i Value Matched Region Residues
AAW54235 ; Human Nup358 protein - Homo 1.3224 3224/3224 (100%) 0.0
! sapiens, 3224 aa. [WO9809170-A2, 1.3224 3224/3224 (100%) : 05-MAR-1998]
! AAM03867 ' Peptide #2549 encoded by probe for 1885-2048 157/164 (95%) 2e-85 j ; measuring breast gene expression - I ..164 159/164 (96%)
I ; Homo sapiens, 164 aa.
I [WO200157270-A2, 09-AUG-2001 ]
AAM28631 ] Peptide #2668 encoded by probe for 1885..2048 157/164 (95%) 2e-85 measuring placental gene expression 1..164 159/164 (96%) - Homo sapiens, 164 aa. [WO200157272-A2, 09-AUG-2001 ]
AAM 16137 Peptide #2571 encoded by probe for 1885-2048 157/164 (95%) 2e-85 ; measuring cervical gene expression - 1..164 159/164 (96%) j Homo sapiens, 164 aa. 1 [WO200157278-A2, 09-AUG-2001 ]
AAM68322 2e-85
probe encoded protein SEQ ID NO: 1..164 159/164 (96%) 28628 - Homo sapiens, 164 aa. [WO200157276-A2, 09-AUG-2001]
In a BLAST search of public sequence datbases, the NOV90a protein was found to have homology to the proteins shown in the BLASTP data in Table 90E.
PFam analysis predicts that the NOV90a protein contains the domains shown in the Table 90F.
Example 91.
The NOV91 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 91 A.
jTable 91A. NOV91 Sequence Analysis
SEQ ID O: 329"" 1908 bp
ΪNOV91a. ACAGGTGACTTTTCCACAGGAACTTCTGCAATGTCCCATCAACCTCTCAGCTGCTGGAATTCG SCG97090-01 DNA CCCTTATCCTCCCACCTGGATCTCCCAAACCTGGACACATTTACCCCGGAGGAGCTGCTGCAG CAGATGAAAGAGCTCCTGACCGAGAACCACCAGCTGAAAGAAGCCATGAAGCTAAATAATCAA Sequence GCCATGAAAGGGAGATTTGAGGAGCTTTCGGCCTGGACAGAGAAACAGAAGGAAGAACGCCAG TTTTTTGAGATACAGAGCAAAGAAGCAAAAGAGCGTCTAATGGCCTTGAGTCATGAGAATGAG AAATTGAAGGAAGAGCTTGGAAAACTAAAAGGGAAATCAGAAAGGTCATCTGAGGACCCCACT GATGACTCCAGGCTTCCCAGGGCCGAAGCGGAGCAGGAAAAGGACCAGCTCAGGACCCAGGTG GTGAGGCTACAAGCAGAGAAGGCAGACCTGTTGGGCATCGTGTCTGAACTGCAGCTCAAGCTG AACTCCAGCGGCTCCTCAGAAGATTCCTTTGTTGAAATTAGGATGGCTGAAGGAGAAGCAGAA GGGTCAGTAAAAGAAATCAAGCATAGTCCTGGGCCCACGAGAACAGTCTCCACTGGCACGAGC AGATCTGCAGATGGGGCCAAGAATTACTTCGAACATGAGGAGTTAACTGTGAGCCAGCTCCTG CTGTGCCTAAGGGAAGGGAATCAGAAGGTGGAGAGACTTGAAGTTGCACTCAAGGAGGCCAAA GAAAGAGTTTCAGATTTTGAAAAGAAAACAAGTAATCGTTCTGAGATTGAAACCCAGACAGAG GGGAGCACAGAGAAAGAGAATGATGAAGAGAAAGGCCCGGAGACTGTTGGAAGCGAAGTGGAA
)GCACTGAACCTCCAGGTGACATCTCTGTTTAAGGAGCTTCAAGAGGCTCATACAAAACTCAGC IGAAGCTGAGCTAATGAAGAAGAGACTTCAAGAAAAGTGTCAGGCCCTTGAAAGGAAAAATTCT jGCAATTCCATCAGAGTTGAATGAAAAGCAAGAGCTTGTTTATACTAACAAAAAGTTAGAGCTA CAAGTGGAAAGCATGCTATCAGAAATCAAAATGGAACAGGCTAAAACAGAGGATGAAAAGTCC AAATTAACTGTGCTACAGATGACACACAACAAGCTTCTTCAAGAACATAATAATGCATTGAAA ACAATTGAGGAACTAACAAGAAAAGAGTCAGAAAAAGTGGACAGGGCAGTGCTGAAGGAACTG AGTGAAAAACTGGAACTGGCAGAGAAGGCTCTGGCTTCCAAACAGCTGCAAATGGATGAAATG AAGCAAACCATTGCCAAGCAGGAAGAGGACCTGGAAACCATGACCATCCTCAGGGCTCAGATG GAAGTTTACTGTTCTGATTTTCATGCTGAAAGAGCAGCGAGAGAGAAAATTCATGAGGAAAAG GAGCAACTGGCATTGCAGCTGGCAGTTCTGCTGAAAGAGAATGATGCTTTCGAAGACGGAGGC AGGCAGTCCTTGATGGAGATGCAGAGTCGTCATGGGGCGAGAACAAGTGACTCTGACCAGCAG GCTTACCTTGTTCAAAGAGGAGCTGAGGACAGGGACTGGCGGCAACAGCGGAATATTCCGATT CATTCCTGCCCCAAGTGTGGAGAGGTTCTGCCTGACATAGACACGTTACAGATTCACGTGATG GATTGCATCATTTAAGTGTTGATGTATCACCTCCCCAAAACTGTTGGTAAATGTCAGATTTTT
TCCTCCAAGAGTTGTGCTTTTGTGTTATTTGTTTTCACTCAAATATTTTGCCTCATTATTCTT
GTTTTAAAAGAAAGAAAACAGGCCGGGCACAGTGGCTCATGCCTGTAATCCCAGCACTTTGGG
AGATCCAGGTGGGAGGAT
ORF Start: ATG at 31 ORF Stop: TAA at 1714
SEQ ID NO: 330 561 aa MW at 64267.6kD
NOV91a, MSHQPLSCWNSPLSSHLDLPNLDTFTPEELLQQMKELLTENHQLKEAMKLNNQAMKGRFEELS
CG97090-01 Protein AWTEKQKEERQFFEIQSKEAKERLMALSHENEKLKEELGKLKGKSERSSEDPTDDSRLPRAEA EQEKDQLRTQWRLQAEKADLLGIVSELQLKLNSSGSSEDSFVEIRMAEGEAEGSVKEIKHSP Sequence GPTRTVSTGTSRSADGAKNYFEHEELTVSQLLLCLREGNQKVERLEVALKEAKERVSDFEKKT SNRSEIETQTEGSTEKENDEEKGPETVGSEVEALNLQVTSLFKELQEAHTKLSEAELMKKRLQ EKCQALERKNSAIPSELNEKQELVYTNKKLELQVEΞMLSEIKMEQAKTEDEKSKLTVLQMTHN KLLQEHNNALKTIEELTRKESEKVDRAVLKELSEKLELAEKALASKQLQMDEMKQTIAKQEED LETMTILRAQMEVYCSDFHAERAAREKIHEEKEQLALQLAVLLKENDAFEDGGRQSLMEMQSR HGARTSDSDQQAYLVQRGAEDRDWRQQRNIPIHSCPKCGEVLPDIDTLQIHVMDCII
SEQ ID NO: 331 1858 bp
NOV91 b, ATCCTCCCACCTGGATCTCCCAAACCTGGACACGTTTACCCCGGAGGAGCTGCTGCAGCAGAT CG97090-04 DNA GAAAGAGCTCCTGACCGAGAACCACCAGCTGAAAGAAGCCATGAAGCTAAATAATCAAGCCAT GAAAGGGAGATTTGAGGAGCTTTCGGCCTGGACAGAGAAACAGAAGGAAGAACGCCAGTTTTT Sequence TGAGATACAGAGCAAAGAAGCAAAAGAGCGTCTAATGGCCTTGAGTCATGAGAATGAGAAATT GAAGGAAGAGCTTGGAAAACTAAAAGGGAAATCAGAAAGGTCATCTGAGGACCCCACTGATGA CTCCAGGCTTCCCAGGGCCGAAGCGGAGCAGGAAAAGGACCAGCTCAGGACCCAGGTGGTGAG GCTACAAGCAGAGAAGGCAGACCTGTTGGGCATCGTGTCTGAACTGCAGCTCAAGCTGAACTC CAGCGGCTCCTCAGAAGATTCCTTTGTTGAAATTAGGATGGCTGAAGGAGAAGCAGAAGGGTC AGTAAAAGAAATCAAGCATAGTCCTGGGCCCACGAGAACAGTCTCCACTGGCACGGCATTGTC TAAATATAGGAGCAGATCTGCAGATGGGGCCAAGAATTACTTCGAACATGAGGAGTTAACTGT GAGCCAGCTCCTGCTGTGCCTAAGGGAAGGGAATCAGAAGGTGGAGAGACTTGAAGTTGCACT CAAGGAGGCCAAAGAAAGAGTTTCAGATTTTGAAAAGAAAACAAGTAATCGTTCTGAGATTGA AACCCAGACAGAGGGGAGCACAGAGAAAGAGAATGATGAAGAGAAAGGCCCGGAGACTGTTGG AAGCGAAGTGGAAGCACTGAACCTCCAGGTGACATCTCTGTTTAAGGAGCTTCAAGAGGCTCA TACAAAACTCAGCGAAGCTGAGCTAATGAAGAAGAGACTTCAAGAAAAGTGTCAGGCCCTTGA AAGGAAAAATTCTGCAATTCCATCAGAGTTGAATGAAAAGCAAGAGCTTGTTTATACTAACAA AAAGTTAGAGCTACAAGTGGAAAGCATGCTATCAGAAATCAAAATGGAACAGGCTAAAACAGA GGATGAAAAGTCCAAATTAACTGTGCTACAGATGACACACAACAAGCTTCTTCAAGAACATAA TAATGCATTGAAAACAATTGAGGAACTAACAAGAAAAGAGTCAGAAAAAGTGGACAGGGCAGT GCTGAAGGAACTGAGTGAAAAACTGGAACTGGCAGAGAAGGCTCTGGCTTCCAAACAGCTGCA AATGGATGAAATGAAGCAAACCATTGCCAAGCAGGAAGAGGACCTGGAAACCATGACCATCCT CAGGGCTCAGATGGAAGTTTACTGTTCTGATTTTCATGCTGAAAGAGCAGCGAGAGAGAAAAT TCATGAGGAAAAGGAGCAACTGGCATTGCAGCTGGCAGTTCTGCTGAAAGAGAATGATGCTTT CGAAGACGGAGGCAGGCAGTCCTTGATGGAGATGCAGAGTCGTCATGGGGCGAGAACAAGTGA CTCTGACCAGCAGGCTTACCTTGTTCAAAGAGGAGCTGAGGACAGGGACTGGCGGCAACAGCG GAATATTCCGATTCATTCCTGCCCCAAGTGTGGAGAGGTTCTGCCTGACATAGACACGTTACA GATTCACGTGATGGATTGCATCATTTAAGTGTTAATGTATCACCTCCCCAAAACTGTTGGTAA ATGTCAGATTTTTTCCTCCAAGAGTTGTGCTTTTGTGTTATTTGTTTTCACTCAAATATTTTG
CCTCATTATTCTTGTTTTAAAAGAAAGAAAACAGGCCGGGCACAGTGGCTCATGCCTGTAATC
CCAGCACTTTGGGAGATCCAGGTGGGAGGAT
ORF Start: ATG at 62 |ORF Stop: TAA at 1664
SEQ ID NO: 332 534 aa MW at 612253kD
,NOV91b, MKELLTENHQLKEAMKLNNQAMKGRFEELSAWTEKQKEERQFFEIQSKEAKERLMALSHENEK LKEELGKLKGKSERSSEDPTDDSRLPRAEAEQEKDQLRTQWRLQAEKADLLGIVSELQLKLN
CG97090-04 Protein |SSGSSEDSFVEIRMAEGEAEGSVKEIKHSPGPTRTVSTGTALSKYRSRSADGAKNYFEHEELT Sequence VSQLLLCLREGNQKVERLEVALKEAKERVSDFEKKTSNRSEIETQTEGSTEKENDEEKGPETV GSEVEALNLQVTSLFKELQEAHTKLSEAELMKKRLQEKCQALERKNSAIPSELNEKQELVYTN KKLELQVESMLSEIKMEQAKTEDEKSKLTVLQMTHNKLLQEHNNALKTIEELTRKESEKVDRA VLKELSEKLELAEKALASKQLQMDEMKQTIAKQEEDLETMTILRAQMEVYCSDFHAERAAREK IHEEKEQLALQLAVLLKENDAFEDGGRQSLMEMQSRHGARTSDSDQQAYLVQRGAEDRDWRQQ RNIPIHSCPKCGEVLPDIDTLQIHVMDCII
SEQ ID NO: 333 1857 bp
NOV91c, TGCTGGAATTCGCCCTTATCCTCCCACCTGGATCTCCCAAACCTGGACACATTTACCCCGGAG CG97090-03 DNA GAGCTGCTGCAGCAGATGAAAGAGCTCCTGACCGAGAACCACCAGCTGAAAGAAGCCATGAAG
CTAAATAATCAAGCCATGAAAGGGAGATTTGAGGAGCTTTCGGCCTGGACAGAGAAACAGAAG Sequence GAAGAACGCCAGTTTTTTGAGATACAGAGCAAAGAAGCAAAAGAGCGTCTAATGGCCTTGAGT CATGAGAATGAGAAATTGAAGGAAGAGCTTGGAAAACTAAAAGGGAAATCAGAAAGGTCATCT GAGGACCCCACTGATGACTCCAGGCTTCCCAGGGCCGAAGCGGAGCAGGAAAAGGACCAGCTC AGGACCCAGGTGGTGAGGCTACAAGCAGAGAAGGCAGACCTGTTGGGCATCGTGTCTGAACTG CAGCTCAAGCTGAACTCCAGCGGCTCCTCAGAAGATTCCTTTGTTGAAATTAGGATGGCTGAA GGAGAAGCAGAAGGGTCAGTAAAAGAAATCAAGCATAGTCCTGGGCCCACGAGAACAGTCTCC ACTGGCACGAGCAGATCTGCAGATGGGGCCAAGAATTACTTCGAACATGAGGAGTTAACTGTG AGCCAGCTCCTGCTGTGCCTAAGGGAAGGGAATCAGAAGGTGGAGAGACTTGAAGTTGCACTC AAGGAGGCCAAAGAAAGAGTTTCAGATTTTGAAAAGAAAACAAGTAATCGTTCTGAGATTGAA ACCCAGACAGAGGGGAGCACAGAGAAAGAGAATGATGAAGAGAAAGGCCCGGAGACTGTTGGA AGCGAAGTGGAAGCACTGAACCTCCAGGTGACATCTCTGTTTAAGGAGCTTCAAGAGGCTCAT ACAAAACTCAGCGAAGCTGAGCTAATGAAGAAGAGACTTCAAGAAAAGTGTCAGGCCCTTGAA AGGAAAAATTCTGCAATTCCATCAGAGTTGAATGAAAAGCAAGAGCTTGTTTATACTAACAAA AAGTTAGAGCTACAAGTGGAAAGCATGCTATCAGAAATCAAAATGGAACAGGCTAAAACAGAG GATGAAAAGTCCAAATTAACTGTGCTACAGATGACACACAACAAGCTTCTTCAAGAACATAAT AATGCATTGAAAACAATTGAGGAACTAACAAGAAAAGAGTCAGAAAAAGTGGACAGGGCAGTG CTGAAGGAACTGAGTGAAAAACTGGAACTGGCAGAGAAGGCTCTGGCTTCCAAACAGCTGCAA ATGGATGAAATGAAGCAAACCATTGCCAAGCAGGAAGAGGACCTGGAAACCATGACCATCCTC AGGGCTCAGATGGAAGTTTACTGTTCTGATTTTCATGCTGAAAGAGCAGCGAGAGAGAAAATT CATGAGGAAAAGGAGCAACTGGCATTGCAGCTGGCAGTTCTGCTGAAAGAGAATGATGCTTTC GAAGACGGAGGCAGGCAGTCCTTGATGGAGATGCAGAGTCGTCATGGGGCGAGAACAAGTGAC TCTGACCAGCAGGCTTACCTTGTTCAAAGAGGAGCTGAGGACAGGGACTGGCGGCAACAGCGG AATATTCCGATTCATTCCTGCCCCAAGTGTGGAGAGGTTCTGCCTGACATAGACACGTTACAG ATTCACGTGATGGATTGCATCATTTAAGTGTTGATGTATCACCTCCCCAAAACTGTTGGTAAA
TGTCAGATTTTTTCCTCCAAGAGTTGTGCTTTTGTGTTATTTGTTTTCACTCAAATATTTTGC
CTCATTATTCTTGTTTTAAAAGAAAGAAAACAGGCCGGGCACAGTGGCTCATGCCTGTAATCC
CAGCACTTTGGGAGATCCAGGTGGGAGGAT
ORF Start: ATG at 79 jORF Stop: TAA at 1663
JSEQ ID NOT334 528 aa ΪMW at 60506.5kD
NOV91c, MKELLTENHQLKEAMKLNNQAMKGRFEELSAWTEKQKEERQFFEIQSKEAKERLMALSHENEK
CG97090-03 Protein LKEELGKLKGKSERSSEDPTDDSRLPRAEAEQEKDQLRTQ RLQAEKADLLGIVSELQLKLN SSGSSEDSFVEIRMAEGEAEGSVKEIKHSPGPTRTVSTGTSRSADGAKNYFEHEELTVSQLLL Sequence CLREGNQKVERLEVALKEAKERVSDFEKKTSNRSEIETQTEGSTEKENDEEKGPETVGSEVEA LNLQVTSLFKELQEAHTKLSEAELMKKRLQEKCQALERKNSAIPSELNEKQELVYTNKKLELQ VESMLSEIKMEQAKTEDEKSKLTVLQMTHNKLLQEHNNALKTIEELTRKESEKVDRAVLKELS EKLELAEKALASKQLQMDEMKQTIAKQEEDLETMTILRAQMEVYCSDFHAERAAREKIHEEKE QLALQLAVLLKENDAFEDGGRQSLMEMQSRHGARTSDSDQQAYLVQRGAEDRDWRQQRNIPIH SCPKCGEVLPDIDTLQIHVMDCII
SEQ ID NO: 335 [908 bp
NOV91d, JACAGGTGACTTTTCCACAGGAACTTCTGCAATGTCCCATCAACCTCTCAGATCCTCCCACCTG CG97090-02 DNA JGATCTCCCAAACCTGGACACGTTTACCCCGGAGGAGCTGCTGCAGCAGATGAAAGAGCTCCTG LACCGAGAACCACCAGCTGAAAGAAGCCATGAAGCTAAATAATCAAGCCATGAAAGGGAGATTT Sequence JGAGGAGCTTTCGGCCTGGACAGAGAAACAGAAGGAAGAACGCCAGTTTTTTGAGATACAGAGC JAAAGAAGCAAAAGAGCGTCTAATGGCCTTGAGTCATGAGAATGAGAAATTGAAGGAAGAGCTT JGGAAAACTAAAAGGGAAATCAGAAAGGTCATCTGAGGACCCCACTGATGACTCCAGGCTTCCC AGGGCCGAAGCGGAGCAGGAAAAGGACCAGCTCAGGACCCAGGTGGTGAGGCTACAAGCAGAG AAGGCAGACCTGTTGGGCATCGTGTCTGAACTGCAGCTCAAGCTGAACTCCAGCGGCTCCTCA GAAGATTCCTTTGTTGAAATTAGGATGGCTGAAGGAGAAGCAGAAGGGTCAGTAAAAGAAATC AAGCATAGTCCTGGGCCCACGAGAACAGTCTCCACTGGCACGGCATTGTCTAAATATAGGAGC AGATCTGCAGATGGGGCCAAGAATTACTTCGAACATGAGGAGTTAACTGTGAGCCAGCTCCTG CTGTGCCTAAGGGAAGGGAATCAGAAGGTGGAGAGACTTGAAGTTGCACTCAAGGAGGCCAAA GAAAGAGTTTCAGATTTTGAAAAGAAAACAAGTAATCGTTCTGAGATTGAAACCCAGACAGAG
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 9 IB.
Further analysis of the NOV9 l a protein yielded the following properties shown in Table 91C.
Table 91C. Protein Sequence Properties NOV91a
PSort 0.4500 probability located in cytoplasm; 0.3000 probability located in microbody analysis: (peroxisome); 0.1000 probability located in mitochondrial matrix space; 0.1000 probability located in lysosome (lumen)
Signal P , No Known Signal Sequence Predicted i analysis:
A search of the NOV91 a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 9 I D.
In a BLAST search of public sequence datbases, the NOV91 a protein was found to have homology to the proteins shown in the BLASTP data in Table 91 E.
Table 91 E. Public BLASTP Results for NOV91a
NOV91a Identities/
Protein Residues/ Similarities for Expect
Accession Protein/Organism/Length Match the Matched Value
Number Residues Portion
AAH32762 Similar to optineurin - Homo sapiens 1..561 555/571 (97%) 0.0 (Human), 571 aa. 1..571 556/571 (97%)
PFam analysis predicts that the NOV91 a protein contains the domains shown in the Table 9 IF.
Example 92.
The NOV92 clone was analyzed, and the nucleotide and encoded polypeptide sequences are shown in Table 92A.
CACGTACGCGCTGAGGCCAGATCCCCTCAGGGTCCTGATGAGTGTGGCGCCATCTGCCTTACA GCTCCGTGTCCGCAGCCTGCCCGGAGAGGACCTGAGGGCCCGTGTTAGCTACAGGCTGCTGGG GGTCATCTCACTGCTGCACCTGGTGCTGTCCATGGGGCTGCAGCTGTACGGTTTCAGGCAGCG GCAGCGAGCCAGGAAGGAGTGGAGGCTGCACCGCGGCCTGTCTCACCGCAGGGCCTCCTTGGA GGAGAGAGCCGTTTCCAGAAACCCCCTGTGCACCCTGTGCCTGGAGGAGCGCAGGCACCCAAC AGCCACGCCCTGCGGCCACCTGTTCTGCTGGGAGTGCATCACCGCGTGGTGCAGCAGCAAGGC GGAGTGTCCCCTCTGCCGGGAGAAGTTCCCTCCCCAGAAGCTCATCTACCTTCGGCACTACCG CTGAGCCGGCGCCCGGGTGGGCCTGGACACAGATGACCTCTACGGGAGTCTGAACGCCAAGAT
TTAGTCTCAGGATTAACCTTGCTTGCACAGAAGTTAGAACACTCTCAGTTTTTTGTCATGTAA
GATACTAACCTAGCCACCCTGGGAGAGAACAGAAAGCTGTCCCTGGCTGCACTTTCTCAGCCC
TGGGAGGGGCGCCTGAACCCAGAACATTTCCCTAACCCCAACCTGGTAGGACTCAGCCACTTC
TTCAGGAATTTCACTTATTTGGACGGGATTTTAGGTTTCCCTCCCTTCCCCAAACCATACAGT
TGAGAAGTAATTCAGAAGTAGGCCAGAAGACACTTTATTCGTTTATATTGTGAGAAAACAGCC CCATCAGGCTTGTGTTAAGGCAATGGACTGAATGAGTGCGTGCTGGGTGGGGTGGGGCACGGA
GGCTGGCGGGTTGCTTCAGCCAGTGCAGTGAGAACAGCAGCCCCACGGCCCCATGGGAGGCGG
CGCTGCTCTCCCCGAGGGCGGCTGGGCAGAGCACATCCCCCAGGACTTGATGACCACACGGGG
CAGAGAGAAACCAACCAAGGCCAGCACCTCCGTCGGAAGCATTTGGCACACACACCTTCAATA
CACGTCAAGGTCGCTTCCAGTTTTAGAAAACAGAAATCTGCATCTCAGCCTGAGACGCACAGA
IGAGGTCTCTTCCTGACCCAGACGCACTCACGAGCCAGGTCCTGGGGGTATGGGGGCTGCCAGG
GGCGCCCGAGCCCTCTCCTGGGGGGCCTGCTGGGCAGGCGACCTGCTGACCCACGGTCACTGC
TGTGTTCAGCCCCTCAGCTCGGCCCCAGCCTATTTCCCGCCTCCATTTGATGTTTCCAGGTTT
TCAAAACTGCATTTAACCTGCGCCAGAGAGTTCACCGTAGGCATCTTTAATAAACTAACTCCA
GCAAAATGTGGGTACGTTACTAAAAAAAAAAAAAAAAAAAAAA
ORF Start: ATG at 38 ORF Stop: TGA at 1073
SEQ ID NO: 344 345 aa MW at 39085.0kD
NOV92d, MAPAAASPPEVIRAAQKDEYYRGGLRSAAGGALHSLAGARKWLEWRKEVELLSDVAYFGLTTL
CG97966-04 Protein AGYQTLGEEYVSIIQVDPSRIHVPSSLRRGVLVTLHAVLPYLLDKALLPLEQELQADPDSGRP LQGSLGPGGRGCSGARRWMRHHTATLTEQQRRALLRAVFVLRQGLACLQRLHVAWFYIHGVFY Sequence HLAKRLTGITYALRPDPLRVLMSVAPSALQLRVRSLPGEDLRARVSYRLLGVISLLHLVLSMG LQLYGFRQRQRARKEWRLHRGLSHRRASLEERAVSRNPLCTLCLEERRHPTATPCGHLFCWEC ITAWCSSKAECPLCREKFPPQKLIYLRHYR
Sequence comparison of the above protein sequences yields the following sequence relationships shown in Table 92B.
Further analysis of the NOV92a protein yielded the following properties shown in Table 92C.
Table 92C. Protein Sequence Properties NOV92a
, PSort 0.4500 probability located in cytoplasm; 0.3774 probability located in microbody analysis: ■ (peroxisome); 0.2542 probability located in lysosome (lumen); 0.1000 probability located in mitochondrial matrix space
, »..__ .
SignalP No Known Signal Sequence Predicted analysis:
A search of the NOV92a protein against the Geneseq database, a proprietary database that contains sequences published in patents and patent publication, yielded several homologous proteins shown in Table 92D.
In a BLAST search of public sequence datbases, the NOV92a protein was found to have homology to the proteins shown in the BLASTP data in Table 92E.
PFam analysis predicts that the NOV92a protein contains the domains shown in the Table 92F.
Table 92F. Doma in Analysis of NOV92a i Identities/
< Pfam Domain NOV92a Match Region Similarities Expect Value for the Matched Region
; zf-C3HC4 185-205 9/29 (31 %) 0.01 1
1 16/29 (55%)
Example B: Sequencing Methodology and Identification of NOVX Clones
1. GeneCalling™ Technology: This is a proprietary method of performing differential gene expression profiling between two or more samples developed at CuraGen and described by Shimkets, et al., "Gene expression analysis by transcript profiling coupled to a gene database query" Nature Biotechnology 17: 198-δ03 ( 1999). cDNA was derived from various human samples representing multiple tissue types, normal and diseased states, physiological states, and developmental states from different donors. Samples were obtained
as whole tissue, primary cells or tissue cultured primary cells or cell lines. Cells and cell lines may have been treated with biological or chemical agents that regulate gene expression, for example, growth factors, chemokines or steroids. The cDNA thus derived was then digested with up to as many as 120 pairs of restriction enzymes and pairs of linker-adaptors specific for each pair of restriction enzymes were ligated to the appropriate end. The restriction digestion generates a mixture of unique cDNA gene fragments. Limited PCR amplification is performed with primers homologous to the linker adapter sequence where one primer is biotinylated and the other is fluorescently labeled. The doubly labeled material is isolated and the fluorescently labeled single strand is resolved by capillary gel electrophoresis. A computer algorithm compares the electropherograms from an experimental and control group for each of the restriction digestions. This and additional sequence-derived information is used to predict the identity of each differentially expressed gene fragment using a variety of genetic databases. The identity of the gene fragment is confirmed by additional, gene-specific competitive PCR or by isolation and sequencing of the gene fragment. 2. SeqCalling™ Technology: cDNA was derived from various human samples representing multiple tissue types, normal and diseased states, physiological states, and developmental states from different donors. Samples were obtained as whole tissue, primary cells or tissue cultured primary cells or cell lines. Cells and cell lines may have been treated with biological or chemical agents that regulate gene expression, for example, growth factors, chemokines or steroids. The cDNA thus derived was then sequenced using CuraGen's proprietary SeqCalling technology. Sequence traces were evaluated manually and edited for corrections if appropriate. cDNA sequences from all samples were assembled together, sometimes including public human sequences, using bioinformatic programs to produce a consensus sequence for each assembly. Each assembly is included in CuraGen Corporation's database. Sequences were included as components for assembly when the extent of identity with another component was at least 95%> over 50 bp. Each assembly represents a gene or portion thereof and includes information on variants, such as splice forms single nucleotide polymorphisms (SNPs), insertions, deletions and other sequence variations.
3. PathCalling™ Technology: The NOVX nucleic acid sequences are derived by laboratory screening of cDNA library by the two-hybrid approach. cDNA fragments covering either the full length of the DNA sequence, or part of the sequence, or both, are sequenced. In silico prediction was based on sequences available in CuraGen Corporation's
proprietary sequence databases or in the public human sequence databases, and provided either the full length DNA sequence, or some portion thereof.
The laboratory screening was performed using the methods summarized below: cDNA libraries were derived from various human samples representing multiple tissue types, normal and diseased states, physiological states, and developmental states from different donors. Samples were obtained as whole tissue, primary cells or tissue cultured primary cells or cell lines. Cells and cell lines may have been treated with biological or chemical agents that regulate gene expression, for example, growth factors, chemokines or steroids. The cDNA thus derived was then directional ly cloned into the appropriate two-hybrid vector (Gal4-activation domain (GaI4-AD) fusion). Such cDNA libraries as well as commercially available cDNA libraries from Clontech (Palo Alto, CA) were then transferred from E.coli into a CuraGen Corporation proprietary yeast strain (disclosed in U. S. Patents 6,057, 101 and 6,083,693, incorporated herein by reference in their entireties).
Gal4-binding domain (Gal4-BD) fusions of a CuraGen Corportion proprietary library of human sequences was used to screen multiple Gal4-AD fusion cDNA libraries resulting in the selection of yeast hybrid diploids in each of which the Gal4-AD fusion contains an individual cDNA. Each sample was amplified using the polymerase chain reaction (PCR) using non-specific primers at the cDNA insert boundaries. Such PCR product was sequenced; sequence traces were evaluated manually and edited for corrections if appropriate. cDNA sequences from all samples were assembled together, sometimes including public human sequences, using bioinformatic programs to produce a consensus sequence for each assembly. Each assembly is included in CuraGen Corporation's database. Sequences were included as components for assembly when the extent of identity with another component was at least 95%o over 50 bp. Each assembly represents a gene or portion thereof and includes information on variants, such as splice forms single nucleotide polymorphisms (SNPs), insertions, deletions and other sequence variations.
Physical clone: the cDNA fragment derived by the screening procedure, covering the entire open reading frame is, as a recombinant DNA, cloned into pACT2 plasmid (Clontech) used to make the cDNA library. The recombinant plasmid is inserted into the host and selected by the yeast hybrid diploid generated during the screening procedure by the mating of both CuraGen Corporation proprietary yeast strains N 106' and YULH (U. S. Patents 6,057, 101 and 6,083,693).
4. RACE: Techniques based on the polymerase chain reaction such as rapid amplification of cDNA ends (RACE), were used to isolate or complete the predicted sequence of the cDNA of the invention. Usually multiple clones were sequenced from one or more human samples to derive the sequences for fragments. Various human tissue samples from different donors were used for the RACE reaction. The sequences derived from these procedures were included in the SeqCalling Assembly process described in preceding paragraphs.
5. Exon Linking: The NOVX target sequences identified in the present invention were subjected to the exon linking process to confirm the sequence. PCR primers were designed by starting at the most upstream sequence available, for the forward primer, and at the most downstream sequence available for the reverse primer. In each case, the sequence was examined, walking inward from the respective termini toward the coding sequence, until a suitable sequence that is either unique or highly selective was encountered, or, in the case of the reverse primer, until the stop codon was reached. Such primers were designed based on in silico predictions for the full length cDNA, part (one or more exons) of the DNA or protein sequence of the target sequence, or by translated homology of the predicted exons to closely related human sequences from other species. These primers were then employed in PCR amplification based on the following pool of human cDNAs: adrenal gland, bone marrow, brain - amygdala, brain - cerebellum, brain - hippocampus, brain - substantia nigra, brain - thalamus, brain -whole, fetal brain, fetal kidney, fetal liver, fetal lung, heart, kidney, lymphoma - Raji, mammary gland, pancreas, pituitary gland, placenta, prostate, salivary gland, skeletal muscle, small intestine, spinal cord, spleen, stomach, testis, thyroid, trachea, uterus. Usually the resulting amplicons were gel purified, cloned and sequenced to high redundancy. The PCR product derived from exon linking was cloned into the pCR2.1 vector from Invitrogen. The resulting bacterial clone has an insert covering the entire open reading frame cloned into the pCR2.1 vector. The resulting sequences from all clones were assembled with themselves, with other fragments in CuraGen Corporation's database and with public ESTs. Fragments and ESTs were included as components for an assembly when the extent of their identity with another component of the assembly was at least 95%> over 50 bp. In addition, sequence traces were evaluated manually and edited for corrections if appropriate. These procedures provide the sequence reported herein.
6. Physical Clone: Exons were predicted by homology and the intron/exon boundaries were determined using standard genetic rules. Exons were further selected and
refined by means of similarity determination using multiple BLAST (for example, tBlastN, BlastX, and BlastN) searches, and, in some instances, GeneScan and Grail. Expressed sequences from both public and proprietary databases were also added when available to further define and complete the gene sequence. The DNA sequence was then manually corrected for apparent inconsistencies thereby obtaining the sequences encoding the full-length protein.
The PCR product derived by exon linking, covering the entire open reading frame, was cloned into the pCR2.1 vector from Invitrogen to provide clones used for expression and screening purposes. Example C: Quantitative expression analysis of clones in various cells and tissues
The quantitative expression of various clones was assessed using microtiter plates containing RNA samples from a variety of normal and pathology-derived cells, cell lines and tissues using real time quantitative PCR (RTQ PCR). RTQ PCR was performed on an Applied Biosystems ABI PRISM® 7700 or an ABI PRISM® 7900 HT Sequence Detection System. Various collections of samples are assembled on the plates, and referred to as Panel 1 (containing normal tissues and cancer cell lines), Panel 2 (containing samples derived from tissues from normal and cancer sources), Panel 3 (containing cancer cell lines), Panel 4 (containing cells and cell lines from normal tissues and cells related to inflammatory conditions), Panel 5D/5I (containing human tissues and cell lines with an emphasis on metabolic diseases), AI_comprehensive_panel (containing normal tissue and samples from autoimmune/autoinflammatory diseases), Panel CNSD.01 (containing samples from normal and diseased brains) and CNS_neurodegeneration_panel (containing samples from normal and Alzheimer's diseased brains).
RNA integrity from all samples is controlled for quality by visual assessment of agarose gel electropherograms using 28S and 18S ribosomal RNA staining intensity ratio as a guide (2: 1 to 2.5: 1 28s: 18s) and the absence of low molecular weight RNAs that would be indicative of degradation products. Samples are controlled against genomic DNA contamination by RTQ PCR reactions run in the absence of reverse transcriptase using probe and primer sets designed to amplify across the span of a single exon. First, the RNA samples were normalized to reference nucleic acids such as constitutively expressed genes (for example, β-actin and GAPDH). Normalized RNA (5 ul) was converted to cDNA and analyzed by RTQ-PCR using One Step RT-PCR Master Mix
Reagents (Applied Biosystems; Catalog No. 4309169) and gene-specific primers according to the manufacturer's instructions.
In other cases, non-normalized RNA samples were converted to single strand cDNA (sscDNA) using Superscript II (Invitrogen Corporation; Catalog No. 18064-147) and random hexamers according to the manufacturer's instructions. Reactions containing up to 10 μg of total RNA were performed in a volume of 20 μl and incubated for 60 minutes at 42 °C. This reaction can be scaled up to 50 μg of total RNA in a final volume of 100 μl. sscDNA samples are then normalized to reference nucleic acids as described previously, using IX TaqMan® Universal Master mix (Applied Biosystems; catalog No. 4324020), following the manufacturer's instructions.
Probes and primers were designed for each assay according to Applied Biosystems Primer Express Software package (version I for Apple Computer's Macintosh Power PC) or a similar algorithm using the target sequence as input. Default settings were used for reaction conditions and the following parameters were set before selecting primers: primer concentration = 250 nM, primer melting temperature (Tm) range = 58 °-60 °C, primer optimal Tm = 59 °C, maximum primer difference = 2 °C, probe does not have 5'G, probe Tm must be 10 °C greater than primer Tm, amplicon size 75bp to l OObp. The probes and primers selected (see below) were synthesized by Synthegen (Houston, TX, USA). Probes were double purified by HPLC to remove uncoupled dye and evaluated by mass spectroscopy to verify coupling of reporter and quencher dyes to the 5' and 3' ends of the probe, respectively. Their final concentrations were: forward and reverse primers, 900nM each, and probe, 200nM. PCR conditions: When working with RNA samples, normalized RNA from each tissue and each cell line was spotted in each well of either a 96 well or a 384-well PCR plate (Applied Biosystems). PCR cocktails included either a single gene specific probe and primers set, or two multiplexed probe and primers sets (a set specific for the target clone and another gene-specific set multiplexed with the target probe). PCR reactions were set up using TaqMan® One-Step RT-PCR Master Mix (Applied Biosystems, Catalog No. 4313803) following manufacturer's instructions. Reverse transcription was performed at 48°C for 30 minutes followed by amplification/PCR cycles as follows: 95°C 10 min, then 40 cycles of 95 °C for 15 seconds, 60 °C for 1 minute. Results were recorded as CT values (cycle at which a given sample crosses a threshold level of fluorescence) using a log scale, with the difference in RNA concentration between a given sample and the sample with the lowest CT value
being represented as 2 to the power of delta CT. The percent relative expression is then obtained by taking the reciprocal of this RNA difference and multiplying by 100.
When working with sscDNA samples, normalized sscDNA was used as described previously for RNA samples. PCR reactions containing one or two sets of probe and primers were set up as described previously, using 1 X TaqMan® Universal Master mix (Applied Biosystems; catalog No. 4324020), following the manufacturer's instructions. PCR amplification was performed as follows: 95 °C 10 min, then 40 cycles of 95 °C for 15 seconds, 60 °C for 1 minute. Results were analyzed and processed as described previously.
Panels 1, 1.1, 1.2, and 1.3D The plates for Panels 1 , 1.1, 1.2 and 1.3D include 2 control wells (genomic DNA control and chemistry control) and 94 wells containing cDNA from various samples. The samples in these panels are broken into 2 classes: samples derived from cultured cell lines and samples derived from primary normal tissues. The cell lines are derived from cancers of the following types: lung cancer, breast cancer, melanoma, colon cancer, prostate cancer, CNS cancer, squamous cell carcinoma, ovarian cancer, liver cancer, renal cancer, gastric cancer and pancreatic cancer. Cell lines used in these panels are widely available through the American Type Culture Collection (ATCC), a repository for cultured cell lines, and were cultured using the conditions recommended by the ATCC. The normal tissues found on these panels are comprised of samples derived from all major organ systems from single adult individuals or fetuses. These samples are derived from the following organs: adult skeletal muscle, fetal skeletal muscle, adult heart, fetal heart, adult kidney, fetal kidney, adult liver, fetal liver, adult lung, fetal lung, various regions of the brain, the spleen, bone marrow, lymph node, pancreas, salivary gland, pituitary gland, adrenal gland, spinal cord, thymus, stomach, small intestine, colon, bladder, trachea, breast, ovary, uterus, placenta, prostate, testis and adipose.
In the results for Panels 1 , 1.1 , 1.2 and 1 D, the following abbreviations are used: ca. = carcinoma, * = established from metastasis, met = metastasis, s cell var = small cell variant, non-s = non-sm = non-small, squam = squamous,
pi. eff = pi effusion = pleural effusion, glio = glioma, astro = astrocytoma, and neuro = neuroblastoma. General_screening_panel_vl.4, vl.5 and vl.6
The plates for Panels 1.4, vl .5 and vl .6 include two control wells (genomic DNA control and chemistry control) and 94 wells containing cDNA from various samples. The samples in Panels 1.4, vl .5 and v l .6 are broken into 2 classes: samples derived from cultured cell lines and samples derived from primary normal tissues. The cell lines are derived from cancers of the following types: lung cancer, breast cancer, melanoma, colon cancer, prostate cancer, CNS cancer, squamous cell carcinoma, ovarian cancer, liver cancer, renal cancer, gastric cancer and pancreatic cancer. Cell lines used in Panels 1.4, vl .5 and vl .6 are widely available through the American Type Culture Collection (ATCC), a repository for cultured cell lines, and were cultured using the conditions recommended by the ATCC. The normal tissues found on Panels 1.4, vl .5 and v l .6 are comprised of pools of samples derived from all major organ systems from 2 to 5 different adult individuals or fetuses. These samples are derived from the following organs: adult skeletal muscle, fetal skeletal muscle, adult heart, fetal heart, adult kidney, fetal kidney, adult liver, fetal liver, adult lung, fetal lung, various regions of the brain, the spleen, bone marrow, lymph node, pancreas, salivary gland, pituitary gland, adrenal gland, spinal cord, thymus, stomach, small intestine, colon, bladder, trachea, breast, ovary, uterus, placenta, prostate, testis and adipose. Abbreviations are as described for Panels 1, 1.1 , 1.2, and 1.3D.
Panels 2D, 2.2, 2.3 and 2.4
The plates for Panels 2D, 2.2, 2.3 and 2.4 generally include two control wells and 94 test samples composed of RNA or cDNA isolated from human tissue procured by surgeons working in close cooperation with the National Cancer Institute's Cooperative Human Tissue Network (CHTN) or the National Disease Research Initiative (NDRI) or from Ardais or Clinomics. The tissues are derived from human malignancies and in cases where indicated many malignant tissues have "matched margins" obtained from noncancerous tissue just adjacent to the tumor. These are termed normal adjacent tissues and are denoted "NAT" in the results below. The tumor tissue and the "matched margins" are evaluated by two independent pathologists (the surgical pathologists and again by a pathologist at NDRI/
CHTN/Ardais/Clinomics). Unmatched RNA samples from tissues without malignancy (normal tissues) were also obtained from Ardais or Clinomics This analysis provides a gross histopathological assessment of tumor differentiation grade. Moreover, most samples include the original surgical pathology report that provides information regarding the clinical stage of the patient. These matched margins are taken from the tissue surrounding (/ e immediately proximal) to the zone of surgery (designated "NAT", for normal adjacent tissue, in Table RR). In addition, RNA and cDNA samples were obtained from various human tissues derived from autopsies performed on elderly people or sudden death victims (accidents, etc ). These tissues were ascertained to be free of disease and were purchased from various commercial sources such as Clontech (Palo Alto, CA), Research Genetics, and Invitrogen. General oncology screening panel_v_2.4 is an updated version of Panel 2D.
HASS Panel v 1.0
The HASS panel v 1.0 plates are comprised of 93 cDNA samples and two controls. Specifically, 81 of these samples are derived from cultured human cancer cell lines that had been subjected to serum starvation, acidosis and anoxia for different time periods as well as controls for these treatments, 3 samples of human primary cells, 9 samples of malignant brain cancer (4 medulloblastomas and 5 glioblastomas) and 2 controls. The human cancer cell lines are obtained from ATCC (American Type Culture Collection) and fall into the following tissue groups: breast cancer, prostate cancer, bladder carcinomas, pancreatic cancers and CNS cancer cell lines. These cancer cells are all cultured under standard recommended conditions. The treatments used (serum starvation, acidosis and anoxia) have been previously published in the scientific literature. The primary human cells were obtained from Clonetics (Walkersville, MD) and were grown in the media and conditions recommended by Clonetics. The malignant brain cancer samples are obtained as part of a collaboration (Henry Ford Cancer Center) and are evaluated by a pathologist prior to CuraGen receiving the samples . RNA was prepared from these samples using the standard procedures. The genomic and chemistry control wells have been described previously.
ARDAIS Panel v 1.0
The plates for ARDAIS panel v 1.0 generally include 2 control wells and 22 test samples composed of RNA isolated from human tissue procured by surgeons working in close cooperation with Ardais Corporation. The tissues are derived from human lung malignancies (lung adenocarcinoma or lung squamous cell carcinoma) and in cases where
indicated many malignant samples have "matched margins" obtained from noncancerous lung tissue just adjacent to the tumor. These matched margins are taken from the tissue surrounding (i.e. immediately proximal) to the zone of surgery (designated "NAT", for normal adjacent tissue) in the results below. The tumor tissue and the "matched margins" are evaluated by independent pathologists (the surgical pathologists and again by a pathologist at Ardais). Unmatched malignant and non-malignant RNA samples from lungs were also obtained from Ardais. Additional information from Ardais provides a gross histopathological assessment of tumor differentiation grade and stage. Moreover, most samples include the original surgical pathology report that provides information regarding the clinical state of the patient.
Panels 3D and 3.1
The plates of Panels 3D and 3.1 are comprised of 94 cDNA samples and two control samples. Specifically, 92 of these samples are derived from cultured human cancer cell lines, 2 samples of human primary cerebellar tissue and 2 controls. The human cell lines are generally obtained from ATCC (American Type Culture Collection), NCI or the German tumor cell bank and fall into the following tissue groups: Squamous cell carcinoma of the tongue, breast cancer, prostate cancer, melanoma, epidermoid carcinoma, sarcomas, bladder carcinomas, pancreatic cancers, kidney cancers, leukemias/lymphomas, ovarian/uterine/cervical, gastric, colon, lung and CNS cancer cell lines. In addition, there are two independent samples of cerebellum. These cells are all cultured under standard recommended conditions and RNA extracted using the standard procedures. The cell lines in panel 3D and 1.3D are of the most common cell lines used in the scientific literature. Oncology_cell_line_screening_panel_v3.2 is an updated version of Panel 3. The cell lines in panel 3D, 3.1 , 1.3D and oncology_cell_!ine_screening_panel_v3.2 are of the most common cell lines used in the scientific literature.
Panels 4D, 4R, and 4.1D
Panel 4 includes samples on a 96 well plate (2 control wells, 94 test samples) composed of RNA (Panel 4R) or cDNA (Panels 4D/4.1 D) isolated from various human cell lines or tissues related to inflammatory conditions. Total RNA from control normal tissues such as colon and lung (Stratagene, La Jolla, CA) and thymus and kidney (Clontech) was employed. Total RNA from liver tissue from cirrhosis patients and kidney from lupus patients was obtained from BioChain (Biochain Institute, Inc., Hayward, CA). Intestinal tissue for
RNA preparation from patients diagnosed as having Crohn's disease and ulcerative colitis was obtained from the National Disease Research Interchange (NDRI) (Philadelphia, PA).
Astrocytes, lung fibroblasts, dermal fibroblasts, coronary artery smooth muscle cells, small airway epithelium, bronchial epithelium, microvascular dermal endothelial cells, microvascular lung endothelial cells, human pulmonary aortic endothelial cells, human umbilical vein endothelial cells were all purchased from Clonetics (Walkersville, MD) and grown in the media supplied for these cell types by Clonetics. These primary cell types were activated with various cytokines or combinations of cytokines for 6 and/or 12-14 hours, as indicated. The following cytokines were used; IL-1 beta at approximately l-5ng/ml, TNF alpha at approximately 5-10ng/ml, IFN gamma at approximately 20-50ng/ml, IL-4 at approximately 5-10ng/ml, IL-9 at approximately 5- 10ng/ml, IL-13 at approximately 5- 10ng/ml. Endothelial cells were sometimes starved for various times by culture in the basal media from Clonetics with 0.1 % serum.
Mononuclear cells were prepared from blood of employees at CuraGen Corporation, using Ficoll. LAK cells were prepared from these cells by culture in DMEM 5% FCS
(Hyclone), l OOμM non essential amino acids (Gibco/Life Technologies, Rockville, MD), I mM sodium pyruvate (Gibco), mercaptoethanol 5.5x10°M (Gibco), and lOmM Hepes (Gibco) and Interleukin 2 for 4-6 days. Cells were then either activated with 10-20ng/ml PMA and l -2μg/ml ionomycin, IL-12 at 5-10ng/ml, IFN gamma at 20-50ng/ml and IL-18 at 5-1 Ong/ml for 6 hours. In some cases, mononuclear cells were cultured for 4-5 days in DMEM 5% FCS (Hyclone), l OOμM non essential amino acids (Gibco), I mM sodium pyruvate (Gibco), mercaptoethanol 5.5x10"5M (Gibco), and l OmM Hepes (Gibco) with PHA (phytohemagglutinin) or PWM (pokeweed mitogen) at approximately 5μg/ml. Samples were taken at 24, 4δ and 72 hours for RNA preparation. MLR (mixed lymphocyte reaction) samples were obtained by taking blood from two donors, isolating the mononuclear cells using Ficoll and mixing the isolated mononuclear cells 1 : 1 at a final concentration of approximately 2xl 06cells/ml in DMEM 5% FCS (Hyclone). l OOμM non essential amino acids (Gibco), I mM sodium pyruvate (Gibco), mercaptoethanol (5.5x 10"5M) (Gibco), and l OmM Hepes (Gibco). The MLR was cultured and samples taken at various time points ranging from 1 - 7 days for RNA preparation.
Monocytes were isolated from mononuclear cells using CD14 Miltenyi Beads, +ve VS selection columns and a Vario Magnet according to the manufacturer's instructions. Monocytes were differentiated into dendritic cells by culture in DMEM 5% fetal calf serum
(FCS) (Hyclone, Logan, UT), l OOμM non essential amino acids (Gibco), I mM sodium pyruvate (Gibco), mercaptoethanol 5.5x10'5M (Gibco), and l OmM Hepes (Gibco), 50ng/mf GMCSF and 5ng/ml IL-4 for 5-7 days. Macrophages were prepared by culture of monocytes for 5-7 days in DMEM 5%> FCS (Hyclone), l OOμM non essential amino acids (Gibco), I mM sodium pyruvate (Gibco), mercaptoethanol 5.5x10°M (Gibco), l OmM Hepes (Gibco) and 10% AB Human Serum or MCSF at approximately 50ng/ml. Monocytes, macrophages and dendritic cells were stimulated for 6 and 12-14 hours with lipopolysaccharide (LPS) at l OOng/ml. Dendritic cells were also stimulated with anti-CD40 monoclonal antibody (Pharmingen) at l Oμg/ml for 6 and 12-14 hours. CD4 lymphocytes, CDδ lymphocytes and NK cells were also isolated from mononuclear cells using CD4, CD8 and CD56 Miltenyi beads, positive VS selection columns and a Vario Magnet according to the manufacturer's instructions. CD45RA and CD45RO CD4 lymphocytes were isolated by depleting mononuclear cells of CDδ, CD56, CD14 and CD 19 cells using CDδ, CD56, CD14 and CDl 9 Miltenyi beads and positive selection. CD45RO beads were then used to isolate the CD45RO CD4 lymphocytes with the remaining cells being CD45RA CD4 lymphocytes. CD45RA CD4, CD45RO CD4 and CD8 lymphocytes were placed in DMEM 5% FCS (Hyclone), l OOμM non essential amino acids (Gibco), I mM sodium pyruvate (Gibco), mercaptoethanol 5.5x10°M (Gibco), and l OmM Hepes (Gibco) and plated at 106cells/ml onto Falcon 6 well tissue culture plates that had been coated overnight with 0.5μg/ml anti-CD28 (Pharmingen) and 3ug/ml anti-CD3 (OKT3, ATCC) in PBS. After 6 and 24 hours, the cells were harvested for RNA preparation. To prepare chronically activated CD8 lymphocytes, we activated the isolated CD8 lymphocytes for 4 days on anti-CD28 and anti-CD3 coated plates and then harvested the cells and expanded them in DMEM 5%> FCS (Hyclone), l OOμM non essential amino acids (Gibco), I mM sodium pyruvate (Gibco), mercaptoethanol 5.5x10°M (Gibco), and l OmM Hepes (Gibco) and IL-2. The expanded CD8 cells were then activated again with plate bound anti-CD3 and anti-CD2δ for 4 days and expanded as before. RNA was isolated 6 and 24 hours after the second activation and after 4 days of the second expansion culture. The isolated NK cells were cultured in DMEM 5% FCS (Hyclone), l OOμM non essential amino acids (Gibco), I mM sodium pyruvate (Gibco), mercaptoethanol 5.5x I 0°M (Gibco), and l OmM Hepes (Gibco) and IL-2 for 4-6 days before RNA was prepared.
To obtain B cells, tonsils were procured from NDRI. The tonsil was cut up with sterile dissecting scissors and then passed through a sieve. Tonsil cells were then spun down
and resupended at IO6 cells/ml in DMEM 5% FCS (Hyclone), lOOμM non essential amino acids (Gibco), I mM sodium pyruvate (Gibco), mercaptoethanol 5.5x10°M (Gibco), and l OmM Hepes (Gibco). To activate the cells, we used PWM at 5μg/ml or anti-CD40 (Pharmingen) at approximately l Oμg/ml and IL-4 at 5-10ng/ml. Cells were harvested for RNA preparation at 24, 4δ and 72 hours.
To prepare the primary and secondary Thl/Th2 and Trl cells, six-well Falcon plates were coated overnight with l Oμg/ml anti-CD2δ (Pharmingen) and 2μg/ml 0KT3 (ATCC), and then washed twice with PBS. Umbilical cord blood CD4 lymphocytes (Poietic Systems, German Town, MD) were cultured at 105-106cells/ml in DMEM 5% FCS (Hyclone), l OOμM non essential amino acids (Gibco), ImM sodium pyruvate (Gibco), mercaptoethanol
5.5xlO"5M (Gibco), l OmM Hepes (Gibco) and IL-2 (4ng/ml). IL-12 (5ng/ml) and anti-IL4 ( 1 μg/ml) were used to direct to Th 1 , while IL-4 (5ng/ml) and anti-IFN gamma ( I μg/ml) were used to direct to Th2 and IL- 10 at 5ng/ml was used to direct to Trl . After 4-5 days, the activated Th l , Th2 and Trl lymphocytes were washed once in DMEM and expanded for 4-7 days in DMEM 5% FCS (Hyclone), l OOμM non essential amino acids (Gibco), I mM sodium pyruvate (Gibco), mercaptoethanol 5.5x10_:>M (Gibco), l OmM Hepes (Gibco) and IL-2 (1 ng/ml). Following this, the activated Th l , Th2 and Trl lymphocytes were re-stimulated for 5 days with anti-CD2δ/0KT3 and cytokines as described above, but with the addition of anti-CD95L (1 μg/ml) to prevent apoptosis. After 4-5 days, the Thl , Th2 and Trl lymphocytes were washed and then expanded again with IL-2 for 4-7 days. Activated Th l and Th2 lymphocytes were maintained in this way for a maximum of three cycles. RNA was prepared from primary and secondary Th l , Th2 and Trl after 6 and 24 hours following the second and third activations with plate bound anti-CD3 and anti-CD2δ mAbs and 4 days into the second and third expansion cultures in Interleukin 2. The following leukocyte cells lines were obtained from the ATCC: Ramos, EOL-1 ,
KU-δl 2. EOL cells were further differentiated by culture in O. lmM dbcAMP at Sxl O^cells/ml for 8 days, changing the media every 3 days and adjusting the cell concentration to Sxl O^cells/ml. For the culture of these cells, we used DMEM or RPMI (as recommended by the ATCC), with the addition of 5%> FCS (Hyclone), l OOμM non essential amino acids (Gibco), I mM sodium pyruvate (Gibco), mercaptoethanol 5.5x10°M (Gibco), lOmM Hepes (Gibco). RNA was either prepared from resting cells or cells activated with PMA at l Ong/ml and ionomycin at 1 μg/ml for 6 and 14 hours. Keratinocyte line CCD 106 and an airway epithelial tumor line NCI-H292 were also obtained from the ATCC. Both were
cultured in DMEM 5% FCS (Hyclone), l OOμM non essential amino acids (Gibco), I mM sodium pyruvate (Gibco), mercaptoethanol 5.5x10°M (Gibco), and l OmM Hepes (Gibco). CCDl 106 cells were activated for 6 and 14 hours with approximately 5 ng/ml TNF alpha and 1 ng/ml IL-I beta, while NCI-H292 cells were activated for 6 and 14 hours with the following cytokines: 5ng/ml IL-4, 5ng/ml IL-9, 5ng/ml IL-13 and 25ng/ml IFN gamma.
For these cell lines and blood cells, RNA was prepared by lysing approximately 107cells/ml using Trizol (Gibco BRL). Briefly, 1/10 volume of bromochloropropane (Molecular Research Corporation) was added to the RNA sample, vortexed and after 10 minutes at room temperature, the tubes were spun at 14,000 rpm in a Sorvall SS34 rotor. The aqueous phase was removed and placed in a 15ml Falcon Tube. An equal volume of isopropanol was added and left at -20 °C overnight. The precipitated RNA was spun down at 9,000 rpm for 15 min in a Sorvall SS34 rotor and washed in 70% ethanol. The pellet was redissolved in 300μl of RNAse-free water and 35μl buffer (Promega) 5μl DTT, 7μl RNAsin and δμl DNAse were added. The tube was incubated at 37 °C for 30 minutes to remove contaminating genomic DNA, extracted once with phenol chloroform and re-precipitated with 1/10 volume of 3M sodium acetate and 2 volumes of 100% ethanol. The RNA was spun down and placed in RNAse free water. RNA was stored at -80 °C.
Al comprehensive panel_vl.O
The plates for AI_comprehensive panel vl .0 include two control wells and 89 test samples comprised of cDNA isolated from surgical and postmortem human tissues obtained from the Backus Hospital and Clinomics (Frederick, MD). Total RNA was extracted from tissue samples from the Backus Hospital in the Facility at CuraGen. Total RNA from other tissues was obtained from Clinomics.
Joint tissues including synovial fluid, synovium, bone and cartilage were obtained from patients undergoing total knee or hip replacement surgery at the Backus Hospital.
Tissue samples were immediately snap frozen in liquid nitrogen to ensure that isolated RNA was of optimal quality and not degraded. Additional samples of osteoarthritis and rheumatoid arthritis joint tissues were obtained from Clinomics. Normal control tissues were supplied by Clinomics and were obtained during autopsy of trauma victims. Surgical specimens of psoriatic tissues and adjacent matched tissues were provided as total RNA by Clinomics. Two male and two female patients were selected between the ages
of 25 and 47. None of the patients were taking prescription drugs at the time samples were isolated.
Surgical specimens of diseased colon from patients with ulcerative colitis and Crohns disease and adjacent matched tissues were obtained from Clinomics. Bowel tissue from three female and three male Crohn's patients between the ages of 41 -69 were used. Two patients were not on prescription medication while the others were taking dexamethasone, phenobarbital, or tylenol. Ulcerative colitis tissue was from three male and four female patients. Four of the patients were taking lebvid and two were on phenobarbital.
Total RNA from post mortem lung tissue from trauma victims with no disease or with emphysema, asthma or COPD was purchased from Clinomics. Emphysema patients ranged in age from 40-70 and all were smokers, this age range was chosen to focus on patients with cigarette-linked emphysema and to avoid those patients with alpha- l anti-trypsin deficiencies. Asthma patients ranged in age from 36-75, and excluded smokers to prevent those patients that could also have COPD. COPD patients ranged in age from 35-δ0 and included both smokers and non-smokers. Most patients were taking corticosteroids, and bronchodilators. In the labels employed to identify tissues in the AI_comprehensive panel_vl .0 panel, the following abbreviations are used: AI = Autoimmunity Syn = Synovial Normal = No apparent disease
Rep22 /Rep20 = individual patients RA = Rheumatoid arthritis Backus = From Backus Hospital OA = Osteoarthritis (SS) (BA) (MF) = Individual patients
Adj = Adjacent tissue Match control = adjacent tissues -M = Male -F = Female COPD = Chronic obstructive pulmonary disease
Panels 5D and 51
The plates for Panel 5D and 51 include two control wells and a variety of cDNAs isolated from human tissues and cell lines with an emphasis on metabolic diseases. Metabolic tissues were obtained from patients enrolled in the Gestational Diabetes study. Cells were obtained during different stages in the differentiation of adipocytes from human mesenchymal stem cells. Human pancreatic islets were also obtained.
In the Gestational Diabetes study subjects are young (l δ - 40 years), otherwise healthy women with and without gestational diabetes undergoing routine (elective) Caesarean section. After delivery of the infant, when the surgical incisions were being repaired/closed, the obstetrician removed a small sample (<1 cc) of the exposed metabolic tissues during the closure of each surgical level. The biopsy material was rinsed in sterile saline, blotted and fast frozen within 5 minutes from the time of removal. The tissue was then flash frozen in liquid nitrogen and stored, individually, in sterile screw-top tubes and kept on dry ice for shipment to or to be picked up by CuraGen. The metabolic tissues of interest include uterine wall (smooth muscle), visceral adipose, skeletal muscle (rectus) and subcutaneous adipose. Patient descriptions are as follows:
Patient 2 Diabetic Hispanic, overweight, not on insulin
Patient 7-9 Nondiabetic Caucasian and obese (BMI>30) Patient 10 Diabetic Hispanic, overweight, on insulin Patient 1 1 Nondiabetic African American and overweight
Patient 12 Diabetic Hispanic on insulin Adipocyte differentiation was induced in donor progenitor cells obtained from Osirus (a division of Clonetics/BioWhittaker) in triplicate, except for Donor 3U which had only two replicates. Scientists at Clonetics isolated, grew and differentiated human mesenchymal stem cells (HuMSCs) for CuraGen based on the published protocol found in Mark F. Pittenger, et al., Multilineage Potential of Adult Human Mesenchymal Stem Cells Science Apr 2 1999: 143-147. Clonetics provided Trizol lysates or frozen pellets suitable for mRNA isolation and ds cDNA production. A general description of each donor is as follows:
Donor 2 and 3 U: Mesenchymal Stem cells, Undifferentiated Adipose Donor 2 and 3 AM: Adipose, AdiposeMidway Differentiated
Donor 2 and 3 AD: Adipose, Adipose Differentiated Human cell lines were generally obtained from ATCC (American Type Culture Collection), NCI or the German tumor cell bank and fall into the following tissue groups:
kidney proximal convoluted tubule, uterine smooth muscle cells, small intestine, liver HepG2 cancer cells, heart primary stromal cells, and adrenal cortical adenoma cells. These cells are all cultured under standard recommended conditions and RNA extracted using the standard procedures. All samples were processed at CuraGen to produce single stranded cDNA. Panel 51 contains all samples previously described with the addition of pancreatic islets from a 5δ year old female patient obtained from the Diabetes Research Institute at the University of Miami School of Medicine. Islet tissue was processed to total RNA at an outside source and delivered to CuraGen for addition to panel 51.
In the labels employed to identify tissues in the 5D and 51 panels, the following abbreviations are used:
GO Adipose = Greater Omentum Adipose SK = Skeletal Muscle UT = Uterus PL = Placenta AD = Adipose Differentiated
AM = Adipose Midway Differentiated U = Undifferentiated Stem Cells
Panel CNSD.01
The plates for Panel CNSD.01 include two control wells and 94 test samples comprised of cDNA isolated from postmortem human brain tissue obtained from the Harvard Brain Tissue Resource Center. Brains are removed from calvaria of donors between 4 and 24 hours after death, sectioned by neuroanatomists, and frozen at -δ0°C in liquid nitrogen vapor. All brains are sectioned and examined by neuropathologists to confirm diagnoses with clear associated neuropathology. Disease diagnoses are taken from patient records. The panel contains two brains from each of the following diagnoses: Alzheimer's disease, Parkinson's disease, Huntington's disease, Progressive Supernuclear Palsy, Depression, and "Normal controls". Within each of these brains, the following regions are represented: cingulate gyrus, temporal pole, globus palladus, substantia nigra, Brodman Area 4 (primary motor strip), Brodman Area 7 (parietal cortex), Brodman Area 9 (prefrontal cortex), and Brodman area 17 (occipital cortex). Not all brain regions are represented in all cases; e.g., Huntington's disease is characterized in part by neurodegeneration in the globus palladus, thus this region is impossible to obtain from
45δ
confirmed Huntington's cases. Likewise Parkinson's disease is characterized by degeneration of the substantia nigra making this region more difficult to obtain. Normal control brains were examined for neuropathology and found to be free of any pathology consistent with neurodegeneration. In the labels employed to identify tissues in the CNS panel, the following abbreviations are used:
PSP = Progressive supranuclear palsy
Sub Nigra = Substantia nigra
Glob Palladus= Globus palladus Temp Pole = Temporal pole
Cing Gyr = Cingulate gyrus
BA 4 = Brodman Area 4
Panel CNSJNeurodegeneration Vl.O
The plates for Panel CNS_Neurodegeneration_Vl .0 include two control wells and 47 test samples comprised of cDNA isolated from postmortem human brain tissue obtained from the Harvard Brain Tissue Resource Center (McLean Hospital) and the Human Brain and Spinal Fluid Resource Center (VA Greater Los Angeles Healthcare System). Brains are removed from calvaria of donors between 4 and 24 hours after death, sectioned by neuroanatomists, and frozen at -δ0°C in liquid nitrogen vapor. All brains are sectioned and examined by neuropathologists to confirm diagnoses with clear associated neuropathology. Disease diagnoses are taken from patient records. The panel contains six brains from Alzheimer's disease (AD) patients, and eight brains from "Normal controls" who showed no evidence of dementia prior to death. The eight normal control brains are divided into two categories: Controls with no dementia and no Alzheimer's like pathology (Controls) and controls with no dementia but evidence of severe Alzheimer's like pathology, (specifically senile plaque load rated as level 3 on a scale of 0-3; 0 = no evidence of plaques, 3 = severe AD senile plaque load). Within each of these brains, the following regions are represented: hippocampus, temporal cortex (Brodman Area 21), parietal cortex (Brodman area 7), and occipital cortex (Brodman area 17). These regions were chosen to encompass all levels of neurodegeneration in AD. The hippocampus is a region of early and severe neuronal loss in AD; the temporal cortex is known to show neurodegeneration in AD after the hippocampus; the parietal cortex shows moderate neuronal death in the late stages of the disease; the
occipital cortex is spared in AD and therefore acts as a "control" region within AD patients. Not all brain regions are represented in all cases.
In the labels employed to identify tissues in the CNS_Neurodegeneration_V l .0 panel, the following abbreviations are used:
AD = Alzheimer's disease brain; patient was demented and showed AD-like pathology upon autopsy
Control = Control brains; patient not demented, showing no neuropathology
Control (Path) = Control brains; pateint not demented but showing sever AD-like pathology
SupTemporal Ctx = Superior Temporal Cortex
Inf Temporal Ctx = Inferior Temporal Cortex
A. NOV7a: Hsapiens CAB3
Expression of gene NOV7a was assessed using the primer-probe set Ag4264, described in Table AA. Results of the RTQ-PCR runs are shown in Tables AB and AC. Table AA. Probe Name Ag4264
Table AB. General screening panel yl.4
General_screening_panel_vl.4 Summary: Ag4264 Highest expression of this gene is detected in breast cancer T47D cell line (CT=27). High to moderate levels of expression of this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene
may be effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at moderate levels in pancreas, adipose, adrenal gland, thyroid, pituitary gland, skeletal muscle, heart, fetal liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
In addition, this gene is expressed at moderate levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Panel 5 Islet Summary: Ag4264 Highest expression of this gene is detected in islet cells (CT=32.3). Moderate to low levels of expression of this gene is also seen in uterus, mesenchymal stem cells, adipose and kidney.
This gene codes for the L-type calcium channel beta-3 subunit. The beta subunit of voltage-dependent calcium channels contributes to the function of the calcium channel by increasing peak calcium current, shifting the voltage dependencies of activation and inactivation, modulating G protein inhibition and controlling the alpha-1 subunit membrane targeting. Therefore, therapeutic modulation of this gene may be useful as a treatment for the enhancement of insulin secretion in Type 2 diabetes.
B. NOV9b: BHLH PROTEIN DEC2 Expression of full-length physical clone NOV9b was assessed using the primer-probe set Ag6927, described in Table BA. Results of the RTQ-PCR runs are shown in Table BB. Table BA. Probe Name Ag6927
Table BB. General screening panel yl.6
JLiver ;0.0 .Brain (Thalamus) Pool 160.7 JFetal Liver ;o.o Brain (whole) j Ϊ4.5
~ " ' [Liver ca. HepG2 {13 'Spinal Cord Pool !89.5
JKidney Pool ;21 .9 Adrenal Gland J 15.8
{Fetal Kidney [ 1.4 - [Pituitary gland Pool |25.2
JRenal ca. 786-0 [6.3 Salivary Gland !9.3 JRenal ca. A498 IO.O Thyroid (female) """ "j9.9
JRenal ca. ACHN 112.9 [Pancreatic ca. CAPAN2 i lθ.1
•Renal ca. UO-31 |80.7 jPancreas Pool 114.7
General_screening_panel_vl.6 Summary: Ag6927 Highest expression of this gene is detected in a ovarian cancer OVCAR-3 cell line (CT=33). Significant expression of this gene is also seen in number of cell lines derived from brain, colon, renal, lung and ovarian cancers. Therefore, expression of this gene may be used as marker to detect these cancers. Furthermore, therapeutic modulation of this gene may be useful in the treatment of these cancers.
In addition, low levels of expression of this gene is also seen in most of the regions of the central nervous system examined, including amygdala, hippocampus, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
C. NOVlόa: FORKHEAD PROTEIN 03A Expression of gene NOV 16a was assessed using the primer-probe set Ag3742, described in Table CA. Results of the RTQ-PCR runs are shown in Table CB. Table CA. Probe Name Ag3742
Panel 5D Summary: Ag3742 Highest expression of this gene is detected in liver HepG2 cell line (CT=28.8). This gene shows a wide expression in tissues with metabolic/endocrine function. Moderate to low levels of expression of this gene is seen in adipose, uterus, placenta, skeletal muscle, small intestine and kidney. Therefore, therapeutic
modulation of this gene may be useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
D. NOV18a: kinectin like
Expression of gene NOVl 8a was assessed using the primer-probe set Ag6564, described in Table DA. Results of the RTQ-PCR runs are shown in Tables DB and DC. Table DA. Probe Name Ag6564
Table DB. AI comprehensive panel yl.O
Table DC. General screening panel yl.6
AI_comprehensive panel_vl.0 Summary: Ag6564 Highest expression of this gene is detected in control psoriasis sample (CT=24). This gene shows wide expression in this panel with high levels of expression of in samples derived from bone, cartilage, synovium and synovial fluid samples from osteoarthritis, and rheumatoid arthritis patients, as well as, in samples derived from normal lung samples, COPD lung, emphysema, atopic asthma, asthma, allergy, Crohn's disease (normal matched control and diseased), ulcerative colitis (normal matched control and diseased), and psoriasis (normal matched control and diseased). Therefore, therapeutic modulation of this gene product may ameliorate symptoms/conditions associated with autoimmune and inflammatory disorders including psoriasis, allergy, asthma, inflammatory bowel disease, rheumatoid arthritis and osteoarthritis
General_screening_panel_vl.6 Summary: Ag6564 Highest expression of this gene is seen in ovarian cancer SK-OV-3 cell line (CT=24.4). High levels of expression of this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at high levels in pancreas, adipose, adrenal gland, thyroid, pituitary gland, skeletal muscle, heart, fetal liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
Interestingly, this gene is expressed at much higher levels in fetal (CT=27) when compared to adult liver (CT=40). This observation suggests that expression of this gene can be used to distinguish fetal from adult liver. In addition, the relative overexpression of this gene in fetal tissue suggests that the protein product may enhance liver growth or development in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of liver related diseases.
In addition, this gene is expressed at high levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum,
cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
E. NOV20a: XIN
Expression of gene NOV20a was assessed using the primer-probe set Ag3459, described in Table EA. Results of the RTQ-PCR runs are shown in Tables EB, EC and ED. Table EA. Probe Name Ag3459
Table EB. General screening panel yl.4
Table EC. Panel 4D
{HUVEC none 0.0_ Kidney
■0.3 iHUVEC starved
"jo.o
"
Table ED. general oncology screening panel v 2.4
General_screening_panel_vl.4 Summary: Ag3459 Highest expression of this gene is detected in skeletal muscle (CT=23.7). Interestingly, expression of this gene is higher in adult as compared to fetal skeletal muscle (CT=26.7). Therefore, expression of this gene may be used to distinguish between the adult and fetal skeletal muscle.
Moderate to low levels of expression of this gene is also seen in tissues with metabolic functions including adipose, skeletal muscle, heart, and liver. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of metabolically related diseases, such as obesity and diabetes.
Panel 4D Summary: Ag3459 Highest expression of this gene is detected in PMA/ionomycin stimulated LAK cells (CT=24.9). Moderate to low levels of expression of this gene is seen in activated polarized T cells, memory and naive T cells, actived B cells, two way MLR, LAK, eosinophils, dendritic cells, lung and dermal fibroblasts, colon, lung, kidney, liver cirrhosis and lupus kidney. Interestingly, expression of this gene is upregulated in cytokine activated LAK cells, polarized T cells, PBMC, eosinophils, macrophage, basophils, keratinocytes and HPAEC endothelial cells. Therefore, modulation of the gene product with a functional therapeutic may lead to the alteration of functions associated with these cell types and lead to improvement of the symptoms of patients suffering from autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis. general oncology screening panel_v_2.4 Summary: Ag3459 Highest expression of this gene is detected in normal adjacent prostate sample (CT=32.7). Expression of this gene is higher in normal tissue as compared to prostate cancer (CTs=36-40). Therefore, expression of this gene may be used to distinguish the cancerous region from normal prostate.
In addition, moderate to low levels of expression of this gene is also seen in malignant colon cancer and lung cancers. Expression of this gene is higher in cancer as compared to the corresponding normal adjacent tissue. Therefore, expression of this gene may be used as marker to detect the presence of colon and lung cancer. In addition, therapeutic modulation of this gene may be useful in the treatment of these cancers.
F. NOV21a: PROSTATIC BINDING PROTEIN
Expression of full-length physical clone NOV21a was assessed using the primer- probe set Ag4464, described in Table FA. Results of the RTQ-PCR runs are shown in Tables FB, FC and FD. Table FA. Probe Name Ag4464
Table FB. General screening panel yl.4
jFetal Liver 48.6 Brain (whole) {30.8 {Liver ca. HepG2 39.8 Spinal Cord Pool 147.6
[Kidney Pool 16.7 Adrenal Gland •100.0
[Fetal Kidney 8.6 Pituitary gland Pool 17.4
[Renal ca. 786-0 26.8 Salivary Gland "- |9T- JRenal ca. A498 5O ~ Thyroid (female) 131.0
[Renal ca. ACHN Pancreatic ca. CAPAN2 ι6.7
{Renal ca. UO-31 233 Pancreas Pool 114.7
Table FC. Panel CNS 1
JBA9 Huntington's2 28.1 Temp Pole PSP2 112.3 JBA9 PSP 25.2 Temp Pole Depression2
"{8.5
"
JBA9 PSP2 8.0 Cing Gyr Control 166.9
|BA9 Depression 14.2 Cing Gyr Control2 40.3 _,
JBA9 Depression2 1 1.8 Cing Gyr Alzheimer's 44.4 [BA 17 Control 48.6 """ " Cing Gyr Alzheimer's2 { 14.4 JBA 17 Control2 57.~8 Cing Gyr Parkinson's ~" "33O
JBA 17 Alzheimer's2 8.2 Cing Gyr Parkinson's2 {52.5
[BA17 Parkinson's 38.7 Cing Gyr Huntington's 100.0
JBA 17 Parkinson's2 49.3 Cing Gyr Huntington's2 '33.7
{BA 17 Huntington's 40.1 Cing Gyr PSP 136.6
JBA17 Huntington's2 15.6 Cing Gyr PSP2 J15.7
JBA 17 Depression 13.3 Cing Gyr Depression 110.2 _. _
{BA 17 Depression2 33.7 Cing Gyr Depression2 ι I 7.6
Table FD. Panel CNS 1.1
General_screening_panel_vl.4 Summary: Ag4464 Highest expression of this gene is seen in adrenal gland (CT=23.4). In addition, this gene is also expressed at high levels in pancreas, adipose, thyroid, pituitary gland, skeletal muscle, heart, liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
In addition, this gene is expressed at high levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
High levels of expression of this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of pancreatic, gastric,
colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
Panel CNS_1 Summary: Ag4464 This panel confirms the expression of this gene at significant levels in the brains of an independent group of individuals. Please see Panel 1 .4 for a discussion of the potential use of this gene in treatment of central nervous system disorders.
Panel CNS_1.1 Summary: Ag4464 This panel confirms the expression of this gene at significant levels in the brains of an independent group of individuals. Please see Panel 1.4 for a discussion of the potential use of this gene in treatment of central nervous system disorders.
G. NOV32b: EH DOMAIN-BINDING MITOTIC PHOSPHOPROTEIN
Expression of gene NOV32b was assessed using the primer-probe set Ag3088, described in Table GA. Results of the RTQ-PCR runs are shown in Tables GB, GC and GD. Table GA. Probe Name Ag3088
Table GB. CNS neurodegeneration vl.O
AD 4 Temporal Ctx 34.2 Control (Path) 1 Occipital Ctx [69.3
AD 5 Inf Temporal Ctx 84.7 Control (Path) 2 Occipital Ctx 116.8
AD 5 Sup Temporal Ctx |47.6 Control (Path) 3 Occipital Ctx 7.1
AD 6 Inf Temporal Ctx 165.5 Control (Path) 4 Occipital Ctx :247
AD 6 Sup Temporal Ctx 60.3 Control 1 Parietal Ctx ;13.9
Control 1 Temporal Ctx JlO.O Control 2 Parietal Ctx Ϊ66.9 Control 2 Temporal Ctx 69.3 Control 3 Parietal Ctx {Ϊ9.9
Control 3 Temporal Ctx 33.9 Control (Path) 1 Parietal Ctx '63.7
Control 3 Temporal Ctx |17.9 Control (Path) 2 Parietal Ctx 33.2 Control (Path) 1 Temporal Ctx "" ""[678'" Control (Path) 3 Parietal Ctx " "{8"."7 """
Control (Path) 2 Temporal Ctx 52.5 Control (Path) 4 Parietal Ctx {59.5
Table GC. Panel 1.3D
Table GD. Panel 2.2
CNS_neurodegeneration_vl.0 Summary: Ag3088 This panel confirms the expression of this gene at low levels in the brains of an independent group of individuals. However, no differential expression of this gene was detected between Alzheimer's diseased postmortem brains and those of non-demented controls in this experiment. Please see Panel 1.3 for a discussion of the potential utility of this gene in treatment of central nervous system disorders.
Panel 1.3D Summary: Ag3088 This gene is widely expressed in many of the samples in this panel, with highest expression in a brain cancer U- 1 18-MG cell line (CT = 26). This gene is also highly expressed in all the regions of the central nervous system, including the amygdala, cerebellum, hippocampus, substantia nigra, thalamus, cerebral cortex and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression. This gene codes for a homolog of epsin, which is involved in the phagocytosis of macromolecules, and interacts with Huntingtin-interacting protein. Therefore, this gene may play a critical role in the endocytosis of Huntingtin protein and the etiology of Huntington's disease. Downregulation of this gene or its protein product may be of therapeutic benefit in the treatment of Huntington's disease.
This gene is also expressed in many tissues with metabolic function, including pancreas, adrenal, thyroid, and pituitary glands, skeletal muscle, heart, liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
This gene is highly expressed in cell lines derived from melanoma, renal, breast, brain, ovarian, lung, colon, kidney, pancreatic and prostate cancers. Expression of this gene is higher in cancer cell lines when compared to corresponding normal tissues. Based on this expression profile, the expression of this gene may be used as a marker to detect these cancers. Furthermore, therapeutic modulation of this gene may be useful in the treatment of these cancers. Panel 2.2 Summary: Ag3088 Highest expression of this gene is detected in normal liver tissue (CT = 27.3). In addition, the level of expression in some lung, breast, liver and kidney cancer tissue samples is higher than the corresponding adjacent control normal tissue.
The reverse appears to be true for colon, ovary and stomach tissue, where expression is slightly higher in normal tissue than the matched cancer tissues. Thus, based upon its profile, the expression of this gene may be used to distinguish between these cancers and the normal adjacent tissue. Please see panel 1.3 for further discussion on the utility of this gene.
H. NOV57a: GUANINE NUCLEOTIDE-BINDING PROTEIN GAMMA-7 SUBUNIT
Expression of gene NOV57a was assessed using the primer-probe set Ag4907, described in Table HA. Results of the RTQ-PCR runs are shown in Tables HB, HC and HD. Table HA. Probe Name Ag4907
Table HB. CNS neurodegeneration yl.0
Control 3 Temporal Ctx 23.0 {Control (Path) 2 Parietal Ctx 20.2
Control (Path) 1 Temporal Ctx 27.9 {Control (Path) 3 Parietal Ctx 1 1.8
Control (Path) 2 Temporal Ctx 32".8" {Control (Path) 4 Parietal Ctx 24.1
Table HC. General screening panel yl.5
{Rel. Rel.
!Exp.(%) Exp.(%)
Tissue Name [Ag4907, Tissue Name ,Ag4907, {Run Run [228829503 228829503
Adipose 5.5 Renal ca. TK- 10 ,38.2
Melanoma* Hs688(A).T 'J 1747.T6 " Bladder { 16.7 Melanoma* Hs688(B).T Gastric ca. (liver met.) NCI-N87 Ϊ00.0
Melanoma* Ml 4 " 2Ϊ .6 Gastric ca. KATO III 43.5
Melanoma* LOXIMVI [7.6 Colon ca. SW-948 ; 1 1.7
Melanoma* SK-MEL-5 22.5 Colon ca. SW480 ;26.6
Squamous cell carcinoma SCC-4 {5.9 Colon ca.* (SW480 met) SW620 ,28.7
Testis Pool [24.1 Colon ca. HT29 1204
Prostate ca.* (bone met) PC-3 | 19.5 Colon ca. HCT-1 16 30.4 Prostate Pool " "'3.6 Colon ca. CaCo-2 3379 " "
Placenta [6.0 Colon cancer tissue 15.8
Uterus Pool {7.5 Colon ca. SW1 1 16 4.7
Ovarian ca. OVCAR-3 i43;r Colon ca. Colo-205 [ΠTΓ
Ovarian ca. SK-OV-3 [42.3 Colon ca. SW-48 Ό.O
Ovarian ca. OVCAR-4 {15.6 Colon Pool '22.5 Ovarian ca. OVCAR-5 ]67Ϊ4 Small Intestine Pool Fl4.2 "
Ovarian ca. IGROV- 1 [ 13.0 Stomach Pool 13.6
Ovarian ca. OVCAR-8 15.3 Bone Marrow Pool ,477 "
Ovary 144 Fetal Heart (6.0
Breast ca. MCF-7 39.0 Heart Pool Ϊ2.7"""'
Breast ca. MDA-MB-231 "137.6 1 Lymph Node Pool 13.9
Breast ca. BT 549 J32.8 Fetal Skeletal Muscle 12.7
Breast ca. T47D " |23".0 Skeletal Muscle Pool "5.7
Breast ca. MDA-N "]20.9 " Spleen Pool 1.6 " " """
Breast Pool ] 15.8 Thymus Pool 19.8
Trachea |4.9'7" - CNS cancer (glio/astro) U87-MG "34.9
Lung ]2.5 CNS cancer (glio/astro) U-1 18-MG 737
Fetal Lung 35.4 CNS cancer (neuro;mef) SK-N-AS 50.3
Lung ca. NCI-N417 [20.6 CNS cancer (astro) SF-539 1 1.9 Lung ca. LX-1 41.8 j CNS cancer (astro) SNB-75 51.4
Lung ca. NCI-HI 46 26.2 CNS cancer (glio) SNB- 19 13.9
Lung ca. SHP-77 ]63.7 1 CNS cancer (glio) SF-295 72.7
Lung ca. A549 {17.1 Brain (Amygdala) Pool 5.5
Lung ca. NCI-H526 6.3 Brain (cerebellum) 147.3 :L"ung""ca7NCl"-"H"23 ~ 327Ϊ "" Brain (fetal) "" " " [3Ϊ.0 jLung ca. NCI-H460 15.1 Brain (Hippocampus) Pool 112.9
Lung ca. HOP-62 15.0 Cerebral Cortex Pool (10.0
Lung ca. NCI-H522 933 Brain (Substantia nigra) Pool (10.7 Liver 0.9 Brain (Thalamus) Pool ]7l2
Fetal Liver Brain (whole) " " " 1Ϊ278
Liver ca. HepG2 19.5 Spinal Cord Pool {2.3
Kidney Pool 31.0 Adrenal Gland { 127 Fetal Kidney 423 Pituitary gland Pool ] 13.7
Renal ca. 786-0 21.9 Salivary Gland 16.6
Renal ca. A498 1 1.9 Thyroid (female) {7.8
Renal ca. ACHN 30.8 Pancreatic ca. CAPAN2 "J40.9
Renal ca. UO-31 9.4 Pancreas Pool {34.6 '
Table HD. Panel 4.1D
CNS_neurodcgeneration_vl.0 Summary: Ag4907 This panel confirms the expression of this gene at low levels in the brains of an independent group of individuals. However, no differential expression of this gene was detected between Alzheimer's diseased postmortem brains and those of non-demented controls in this experiment. Please see Panel 1.5 for a discussion of the potential use of this gene in treatment of central nervous system disorders.
General_screening_panel_vl.5 Summary: Ag4907 Highest expression of this gene is detected in gastric cancer NCI-N87 cell line (CT=31.3). Moderate levels of expression of
this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at moderate to low levels in pancreas, adrenal gland, thyroid, pituitary gland, skeletal muscle, fetal liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
In addition, this gene is expressed at low levels in most regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, and cerebral cortex. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Interestingly, this gene is expressed at much higher levels in fetal (CTs=32.8-34.8) when compared to adult lung and liver (CTs=36-38). This observation suggests that expression of this gene can be used to distinguish fetal from adult lung and liver. In addition, the relative overexpression of this gene in fetal tissue suggests that the protein product may enhance growth or development of lung and liver in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of lung and liver related diseases.
Panel 4. ID Summary: Ag4907 Low levels of expression of this gene are detected mainly in IL-9 treated mucoepidermoid cell line NCI-H292. The expression of this gene in this mucoepidermoid cell line that is often used as a model for airway epithelium (NCI-H292 cells) suggests that this gene may be important in the proliferation or activation of airway epithelium. Therefore, therapeutics designed with the protein encoded by this gene may reduce or eliminate symptoms caused by inflammation in lung epithelia in chronic obstructive pulmonary disease, asthma, allergy, and emphysema.
I. NOV58a: Novel 2410017P07RIK Protein - Like Gene
Expression of gene NOV58a was assessed using the primer-probe set Ag4913, described in Table IA. Results of the RTQ-PCR runs are shown in Tables IB and IC.
Table IA. Probe Name Ag4913
Table IB. General screening panel yl.5
[Fetal Lung (41.2 CNS cancer (neuro;met) SK-N-AS 114.2 [Lung ca.
~NCI-N417
")5O
""" """"" CNS cancer (astro) SF-539 ( 193
"" "" {Lung ca. LX- 1 {23.8 CNS cancer (astro) SNB-75
"158.2
JLung ca. NCI-H 146 i" -9 .. CNS cancer (glio) SNB- 19 (8.7
{Lung ca. SHP-77 32.1 CNS cancer (glio) SF-295 (30.1
Lung ca. A549 16.3 Brain (Amygdala) Pool Ϊ7.2 " " "
Lung ca. NCI-H526 1 14 Brain (cerebellum) {39.2
Lung ca. NCI-H23 19.5 Brain (fetal) ( 18.7
Lung ca. NCI-H460 17.4 Brain (Hippocampus) Pool Lung ca. HOP-62 J5.6 Cerebral Cortex Pool ft 4.0
Lung ca. NCI-H522 36.6 Brain (Substantia nigra) Pool (6.4
Liver 0.8 Brain (Thalamus) Pool [ 15.8 Fetal Liver J31.6 Brain (whole) 76.5" """"
Liver ca. HepG2 5.8 Spinal Cord Pool 17.8
Kidney Pool [25.3 Adrenal Gland 13.6 Fetal Kidney {30.8 Pituitary gland Pool {4.9 Renal ca. 786-0 [26.8 Salivary Gland ~]f.~l
Renal ca. A498 {4.0 Thyroid (female) {4.5
Renal ca. ACHN J5.4 Pancreatic ca. CAPAN2 ;9.9
(Renal ca. UO-3 1 |12.9 Pancreas Pool 713.7"
Table IC. Panel 4.1D
General_screening_panel_vl.5 Summary: Ag4913 Highest expression of this gene is detected in breast cancer BT 549 cell line (CT=26.4). Moderate to high levels of expression of this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain
cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Among tissues with metabolic or endocrine function, this gene is expressed at moderate levels in pancreas, adipose, adrenal gland, thyroid, pituitary gland, skeletal muscle, heart, liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes. Interestingly, this gene is expressed at much higher levels in fetal (CTs=27.7-28) when compared to adult lung and liver (CTs=31 -33). This observation suggests that expression of this gene can be used to distinguish fetal from adult lung and liver. In addition, the relative overexpression of this gene in fetal tissue suggests that the protein product may enhance growth or development of liver and lung in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of lung and liver related diseases.
In addition, this gene is expressed at moderate levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as
Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Panel 4.1D Summary: Ag4913 Highest expression of this gene is detected in basophils (Cts=29). This gene is expressed at high to moderate levels in a wide range of cell types of significance in the immune response in health and disease. These cells include members of the T-cell, B-cell, endothelial cell, macrophage/monocyte, and peripheral blood mononuclear cell family, as well as epithelial and fibroblast cell types from lung and skin, and normal tissues represented by colon, lung, thymus and kidney. This ubiquitous pattern of expression suggests that this gene product may be involved in homeostatic processes for these and other cell types and tissues. This pattern is in agreement with the expression profile in General_screening_panel_vl .5 and also suggests a role for the gene product in cell survival and proliferation. Therefore, modulation of the gene product with a functional
therapeutic may lead to the alteration of functions associated with these cell types and lead to improvement of the symptoms of patients suffering from autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis.
J. NOV59a: Novel FLJ20565 Like Gene
Expression of gene NOV59a was assessed using the primer-probe set Ag4914, described in Table JA. Results of the RTQ-PCR runs are shown in Table JB. Table JA. Probe Name Ag4914
Table JB. General screening panel yl.5
Breast ca. MDA-MB-231 {0.0 Lymph Node Pool 0.0 Breast ca. BT 549 [0.0 Fetal Skeletal Muscle ,0.0
Breast ca. T47D 10.0 Skeletal Muscle Pool 0.0
Breast ca. MDA-N jo.o Spleen Pool 0.0
Breast Pool J35.1 Thymus Pool 0.0
Trachea jό.ό CNS cancer (glio/astro) U87-MG "b o" -
Lung [24.1 CNS cancer (glio/astro) U-1 18-MG 74.7 "
Fetal Lung jo.o CNS cancer (neuro;met) SK-N-AS 0.0
Lung ca. NCI-N417 {0.0 CNS cancer (astro) SF-539 0.0 Lung ca. LX-1 TOO "" CNS cancer (astro) SNB-75 ; 144
Lung ca. NCI-H 146 0.0 CNS cancer (glio) SNB- 19 ,0.0
Lung ca. SHP-77 [69.7 CNS cancer (glio) SF-295 0.0
Lung ca. A549 0.0 Brain (Amygdala) Pool 0.0
Lung ca. NCI-H526 (o.o Brain (cerebellum) ■0.0
Lung ca. NCI-H23 [0.0 Brain (fetal) 0.0 Lung ca. NCΪ-H460 {0.0 Brain (Hippocampus) Pool .oT ' Lung ca. HOP-62 jo.o Cerebral Cortex Pool olo"
Lung ca. NCI-H522 0.0 Brain (Substantia nigra) Pool Ό.O
Liver [o.o Brain (Thalamus) Pool 0.0 Fetal Liver 0.0 Brain (whole) Ό.O ""
Liver ca. HepG2 lo.o Spinal Cord Pool ,0.0
Kidney Pool il8.8 Adrenal Gland 0.0 Fetal Kidney jo.o Pituitary gland Pool 0.0
Renal ca. 786-0 Ό.O Salivary Gland ;0.0
Renal ca. A498 lo.o Thyroid (female) Ό.O
Renal ca. ACHN [o.o Pancreatic ca. CAPAN2 "loo.o" Renal ca. UO-31 {0.0 Pancreas Pool "lo.o
General_screening_panel_vl.5 Summary: Ag4914 Low levels of expression of this gene are restricted to pancreatic cancer cell line (CT=34.5). Therefore, expression of this gene may be used to distinguish this sample from other samples in this panel and also as diagnostic marker for detection of pancreatic cancer. Furthermore, therapeutic modulation of this gene may be useful in the treatment of this cancer.
K. NOV60a: CGI-27 Protein Like Gene
Expression of gene NOV60a was assessed using the primer-probe set Ag4915, described in Table KA. Results of the RTQ-PCR runs are shown in Tables KB and KC. Table KA. Probe Name Ag4915
{Probe jTET-5'-ctcaggaccacagctgaatgcacag-3'-TAMRA {25 {57 216 ! Reverse J5'-tacttgtgaaagccaaccttct-3' [22
|84 311
Table KB. General screening panel yl.5
Table KC. Panel 4.1D
General_screening_panel_vl.5 Summary: Ag4915 Highest expression of this gene is detected in testis (CT=34.3). Thus, expression of this gene could be used to differentiate between this sample and other samples on this panel and as a marker of testicular tissue. Therapeutic modulation of the expression or function of this gene may be useful in the treatment of male infertility and hypogonadism.
In addition, low levels of expression of this gene is also seen in number of cancer cell lines derived from ovarian, lung and colon. Therefore, therapeutic modulation of this gene may be useful in the treatment of ovarian, lung and colon cancer. Furthermore, expression of
this gene may be used as diagnostic marker for the detection of colon, lung and ovarian cancers.
Panel 4. ID Summary: Ag4915 Moderate levels of expression of this gene is restricted to secondary Trl cells (CT=28.8). Thus, expression of this gene may be used to distinguish Trl cell from other samples used in this panel. Furhtermore, expression of this gene in resting Trl cells suggest a role for this gene in T lymphocyte activation. Therefore, therapeutic modulation of this gene or its protein product may be useful in the treatment of T cell-mediated autoimmune and inflammatory diseases.
L. NOV64a: Ankyrin-repeat containing protein
Expression of gene NOV64a was assessed using the primer-probe set Ag4950, described in Table LA. Results of the RTQ-PCR runs are shown in Tables LB and LC. Table LA. Probe Name Ag4950
Table LB. General screening panel yl.5
Ovarian ca. OVCAR-5 46.7 Small Intestine Pool J63 Ovarian ca. IGROV-1 0.0 Stomach Pool
Ovarian ca. OVCAR-8 4.5 Bone Marrow Pool "W {3.2
Ovary 1 .5 Fetal Heart i l .7
Breast ca. MCF-7 14-6" " Heart Pool { 1.2
Breast ca. MDA-MB-231 22.2 Lymph Node Pool { 1.7 Breast ca. BT 549 0.5 Fetal Skeletal Muscle jo.o
Breast ca. T47D 1 1 .4 Skeletal Muscle Pool 118.3
Breast ca. MDA-N 9.3 Spleen Pool (10.7 Breast Pool -, 3 " " Thymus Pool " "31.9"
Trachea 9.0 CNS cancer (glio/astro) U87-MG 3.5
Lung 0.0 CNS cancer (glio/astro) U-1 18-MG (41.5
Fetal Lung 12.9 CNS cancer (neuro;met) SK-N-AS (0.1
Lung ca. NCI-N417 0.0 CNS cancer (astro) SF-539 (6.0
Lung ca. LX-1 7.3 CNS cancer (astro) SNB-75 ! 15.1 |Lung ca. NCI-H146 0.0 CNS cancer" (gli"o "SNB'-l' 9 Ό.O
Lung ca. SHP-77 0.2 CNS cancer (glio) SF-295 33.9
Lung ca. A549 20.4 Brain (Amygdala) Pool {5.8
Lung ca. NCI-H526 0.1 Brain (cerebellum) (0.1 Lung ca. NCI-H23 5.5 Brain (fetal) 12.0
(Lung ca. NCI-H460 10.2 Brain (Hippocampus) Pool I2.1
Lung ca. HOP-62 3.6 Cerebral Cortex Pool { 10.0
Lung ca. NCI-H522 Brain (Substantia nigra) Pool (6.0
Liver 0.0 Brain (Thalamus) Pool [8.7
Fetal Liver 0.0 Brain (whole) .O
Liver ca. HepG2 o.o"" " Spinal Cord Pool " 14/9 "
Kidney Pool 3.4 Adrenal Gland , 1.6
Fetal Kidney 4.4 Pituitary gland Pool ( 1.8
Renal ca. 786-0 10.4 Salivary Gland I1-6 , Renal ca. A498 472 " Thyroid (female) ( 1.8
Renal ca. ACHN 6.1 Pancreatic ca. CAPAN2 i8.9
{Renal ca. UO-31 10.6 Pancreas Pool 4.9
Table LC. Panel 4.1D
Monocytes rest .O {Neutrophils rest 13
Monocytes LPS [o.O jcolon O.O
Macrophages rest l ._> Lung :63
Macrophages LPS JO.O (Thymus '52.5
(HUVEC none " " "]07θ "[Kidney " _ " 9.2 " "i
(HUVEC starved " " " "[θ.O " " I "" " . " , .. " " < ]
General_screcning_panel_vl.5 Summary: Ag4950 Highest expression of this gene is detected in testis (CT=29.3). Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of male infertility and hypogonadism. Moderate to low levels of expression of this gene is also seen in number of cancer cell lines derived from pancreatic, gastric, colon, lung, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of pancreatic, garlic, colon, lung, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at moderate to low levels in pancreas, adipose, skeletal muscle, and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
In addition, this gene is expressed at low levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Interestingly, this gene is expressed at much higher levels in fetal (CT=32) when compared to adult lung (CT=40). This observation suggests that expression of this gene can be used to distinguish fetal from adult lung. In addition, the relative overexpression of this gene in fetal tissue suggests that the protein product may enhance lung growth or development in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of lung related diseases.
Panel 4. I D Su mmary: Ag4950 Highest expression of this gene is detected in activated secondary Trl cells (CT=32). In addition, moderate to low levels of expression of this gene is also seen in activated polarized T cells, memory T cells, LAK cells, activated PBMC, mucoepidermoid NCI-H292 cells, and thymus. Expression of this gene is upregulated in activated secondary polarized T cells as wel l as in PBMC cells. Thus, this gene may be involved in activation T and B cells. Therefore, modulation of the gene product with a functional therapeutic may lead to the alteration of functions associated with these cell types and lead to improvement of the symptoms of patients suffering from autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis.
M. NOV65a: MULTIDOMAIN PRESYNAPTIC CYTOMATRIX PROTEIN PICCOLO
Expression of gene NOV65a was assessed using the primer-probe set Ag495 1 , described in Table MA. Results of the RTQ-PCR runs are shown in Tables MB and MC.
Table MA. Probe Name Ag4951
Table MB. CNS neurodeseneration vl.O
Rel. Rel.
|Exp.(%) Exp.(%)
'Tissue Name (Ag4951, Tissue Name :Ag4951, [Run Run {249286336 ,249286336 r
AD 1 Hippo 18.4 Control (Path) 3 Temporal Ctx 3-9
IAD 2 Hippo 125.7 Control (Path) 4 Temporal Ctx ;57.4 'AD 3 Hippo AD l Occipital Ctx 18.4 iAD 4 Hippo {6.6 AD 2 Occipital Ctx (Missing) 10.0
<AD 5 Hippo 177.9" AD 3 Occipital Ctx 76.0 ""
[AD 6 Hippo (53.2 {AD 4 Occipital Ctx 25.5 Control 2 Hippo [43.2 [AD 5 Occipital Ctx 53.6
[Control 4 Hippo 3.4 AD 6 Occipital Ctx ;24.1
{Control (Path) 3 Hippo 3.8 Control 1 Occipital Ctx 11 .3
»AD 1 Temporal Ctx [ l 7.4 Control 2 Occipital Ctx 42.9
IAD 2 Temporal Ctx 3 1 .4 Control 3 Occipital Ctx 127.0 AD 3 Temporal Ctx 6.6 " Control 4 Occipital Ctx 3.4
,AD 4 Temporal Ctx 22.1 Control (Path) 1 Occipital Ctx '98.6
AD 5 Inf Temporal Ctx 62.4 Control (Path) 2 Occipital Ctx ■ 17.8
AD 5 Sup Temporal Ctx 34.4 Control (Path) 3 Occipital Ctx (0.8 AD 6 Inf Temporal Ctx 52.1 " Control (Path) 4 Occipital Ctx 3 1 .9 AD 6 Sup Temporal Ctx 58.6 Control 1 Parietal Ctx 4.7
Control 1 Temporal Ctx 3.5 Control 2 Parietal Ctx 363 Control 2 Temporal Ctx 32.8 Control 3 Parietal Ctx ' 13.3 27 '' 4- - Control 3 Temporal Ctx Control (Path) 1 Parietal Ctx 92.0
Control 3 Temporal Ctx 4.0 Control (Path) 2 Parietal Ctx 28.5
Control (Path) 1 Temporal Ctx 100.0 Control (Path) 3 Parietal Ctx :2.5
Control (Path) 2 Temporal Ctx 54.3 Control (Path) 4 Parietal Ctx "1653
Table MC. Panel 4.1D
,2ry Th l /Th2/Trl anti-CD95
0.0 CCD l 106 (Keratinocytes) none 44.4 CH 1 1
CCDl 106 (Keratinocytes) TNFalpha +
'LAK cells rest 0.0 136.6 IL- l beta
|LAK cells IL-2 0.0 Liver ciirhosis 125.0 lLAK cells IL-2+IL-12 0.0 NCI-H292 none ' 14.4
■LAK cells IL-2+IFN gamma 0.0 NCI-H292 IL-4 """ " 18.7
LAK cells IL-2+ IL-18 0.0 NCI-H292 IL-9 39.0
•LAK cells PMA/ionomycin 0.0 JNCI-H292 IL- 13 26.8 INK Cells IL-2 rest 0.0 JNCI-H292 IFN gamma 123.3
Two Way MLR 3 day 0.0 HPAEC none
JTwo Way MLR 5 day 0.0 HPAEC TNF alpha + IL-1 beta 10.0
[Two Way MLR 7 day 0.4 Lung fibroblast none (0.0
!PBMC rest 0.0 Lung fibroblast TNF alpha + IL-1 beta " {0/7 7
!PBMC PWM 0.0 Lung fibroblast IL-4 0.0
{PBMC PHA-L 0.0 Lung fibroblast IL-9 Ό.O Ramos (B cell) none 42.3 Lung fibroblast IL- 13 "o.o
'Ramos (B cell) ionomycin 47.0 Lung fibroblast IFN gamma 0.0
B lymphocytes PWM 0.0 Dermal fibroblast CCDl 070 rest (4.6 IB lymphocytes CD40L and IL-4 0.0 Dermal fibroblast CCD1070 TNF alpha iilo
■EOL-1 dbcAMP 0.0 "" Dermal fibroblast CCDl 070 IL-1 beta Ό.O
•EOL-1 dbcAMP
0.0 Dermal fibroblast IFN gamma 10.8 (PMA/ionomycin
{Dendritic cells none 0.0 Dermal fibroblast IL-4 Ό'Ό
•Dendritic cells LPS 0.0 Dermal Fibroblasts rest ,0.0
Dendritic cells anti-CD40 0.0 Neutrophils TNFa+LPS 0.0 Monocytes rest OΌ Neutrophils rest .Monocytes LPS olo" Colon ,5.7
Macrophages rest 0.8 Lung "j l 7.8 iMacrophages LPS 0.0 Thymus (38.2
ΗUVEC none 2.2 Kidney (100.0
[HUVEC starved 275"" " " "
CNS_neurodegeneration_vl.0 Summary: Ag4951 Expression of this gene is ubiquitous throughout the samples in this panel, with highest expression in the temporal cortex of a control patient with pathological condition (CT=26.4). While no association between the expression of this gene and the presence of Alzheimer's disease is detected in this panel, these results confirm the expression of this gene in areas that degenerate in Alzheimer's disease, including the cortex, hippocampus, amygdala and thalamus. Expression of this gene in brain suggests that this gene may play a role in central nervous system
disorders such as Alzheimer's disease. Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Panel 4. ID Summary: Ag4951 Highest expression of this gene is detected in kidne> (CT=30.1). In addition, moderate to low levels of expression of this gene is also seen in colon, lung, thymus, Ramos B cells, lung microvascular endothelial cells, cytokine activated small airway epithelium, keratinocytes, mucoepidermoid NCI-H292 cells and liver cirrhosis samples. Therefore, therapeutic modulation of this gene may be useful in the treatment of autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, osteoarthritis and liver cirrhosis.
N. NOV66a and NOV66b: human ortholog of rat CYTOSOLIC SORTING PROTEIN PACS-1A
Expression of gene NOV66a and variant NOV66b was assessed using the primer- probe sets Ag4956 and Ag4960. described in Tables NA and NB. Results of the RTQ-PCR runs are shown in Tables NC and ND.
Table NA. Probe Name Ag4956
Table NB. Probe Name Ag4960
Table NC. General screening panel yl.5
Lun ca. A549 81.2 !78.5 .Brain (Amygdala) Pool [ 14.2 ,8.0
.Lungca. NCI-H526 7.4 :9.0 Brain (cerebellum) {45.4 129.9
Lungca. NCI-H23 19.5 '24.5 Brain (fetal) lioo.o (77.4
.Brain (Hippocampus) 1
Lungca. NCI-H460 1)1.5 ,12.6 ! 15.6 il7.0 Pool i
(Lung ca. HOP-62 ,26.2 [22.5 Cerebral Cortex Pool [23.0 (18.4
Brain (Substantia nigra)
!Lungca. NC1-H522 38.4 39.2 {16.6 112.7 i Pool ϊ
Liver U.9 11.5 ;Brain (Thalamus) Pool [25.5 (20.2 iFetal Liver :127 32.2 Brain (whole) [48.3 ■31.2 - r -- - -
Liver ca. HepG2 12.9 Spinal Cord Pool f ll .0 """ " :9.5
{Kidney Pool |25.5 !25.5 ΪAdrenal Gland 17.3 (12.9
[Fetal Kidney 11.0 18.7 Pituitary gland Pool 4.1 3.9
(Renal ca.786-0 35.6 34.9 .Salivary Gland [57.O 42.0
Renal ca. A498 10.2 (8.7 Thyroid (female) jlθ.3 ιH.2
.Renal ca. ACHN 37.1 39.2 Pancreatic ca. CAPAN2 J35.6 36.3
Renal ca. UO-31 '86.5 79.0 Pancreas Pool 121.0 ■21.6
Table ND. Panel 4.1D
General_screening_pancl_vl.5 Summary: Ag4956/Ag4960 Two experiments with same probe and primer sets are in excellent agreement with highest expression of this gene seen in fetal brain and breast cancer MDA-MB-231 cell line (CTs=25). Moderate to high levels of expression of this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at high to moderate levels in pancreas, adipose, adrenal gland, thyroid, pituitary gland, skeletal muscle, heart, liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
In addition, this gene is expressed at high levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Panel 4.1D Summary: Ag4956/Ag4960 Two experiments with same probe and primer sets are in excellent agreement with highest expression of this gene seen in TNF alpha treated dermal fibroblast (CTs=27-27.5). This gene is expressed at high to moderate levels in a wide range of cell types of significance in the immune response in health and disease. These cells include members of the T-cell, B-cell, endothelial cell, macrophage/monocyte,
and peripheral blood mononuclear cell family, as well as epithelial and fibroblast cell types from lung and skin, and normal tissues represented by colon, lung, thymus and kidney. This ubiquitous pattern of expression suggests that this gene product may be involved in homeostatic processes for these and other cell types and tissues. This pattern is in agreement with the expression profile in General_screening_panel_vl .5 and also suggests a role for the gene product in cell survival and proliferation. Therefore, modulation of the gene product with a functional therapeutic may lead to the alteration of functions associated with these cell types and lead to improvement of the symptoms of patients suffering from autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis.
O. NOV67a: Formin 2
Expression of gene NOV67a was assessed using the primer-probe set Ag4959, described in Table OA. Results of the RTQ-PCR runs are shown in Tables OB and OC. Table OA. Probe Name Ag4959
Table OB. CNS neurodegeneration yl.O
(AD 4 Temporal Ctx 13.5 Control (Path) 1 Occipital Ctx (41 .5 AD 5 Inf Temporal Ctx ]48.0 Control (Path) 2 Occipital Ctx
" "(2.9
"
,AD 5 SupTemporal Ctx { 17.6 (Control (Path) 3 Occipital Ctx [ό.o
JAD 6 Inf Temporal Ctx (27.7 Control (Path) 4 Occipital Ctx ■5.8
'AD 6 Sup Temporal Ctx {26.6 lControl 1 Parietal Ctx ( 1.4 jControl 1 Temporal Ctx i l .O Control 2 Parietal Ctx " l l 7.6" jControl 2 Temporal Ctx J 19.2 Control 3 Parietal Ctx ■4.6
Control 3 Temporal Ctx [57 _ Control (Path) 1 Parietal Ctx (46.0
(Control 4 Temporal Ctx " I2I0 " Control (Path) 2 Parietal Ctx (4.8 ;Control (Path) 1 Temporal Ctx """ (22.5 Control (Path) 3 Parietal Ctx 2.2"
(Control (Path) 2 Temporal Ctx {25.9 Control (Path) 4 Parietal Ctx '23.5
Table OC. General sc reening pji inel vl.5
Rel. { Rel. ■Exp.(%) { Exp.(%)
{Tissue Name lAg4959, iTissue Name Ag4959, Run 1 Run
1 (228886990 { 228886990 iAdipose .o IRenal ca. TK-10 ,0.0
Melanoma* Hs688(A).T 123 " ;Bladder " ";"o7o [Melanoma* Hs688(B).f (Gastric ca. (liver met.) NCI-N87 0.0
(Melanoma* M14 (0.0 IGastric ca. KATO III ,0.0 [Melanoma* LOXIMVI 15.0 (Colon ca. SW-948 Ό.O " M ' elanoma .* . S.K-MEL-5 {100.0 " Colon ca." SW480 """ 0.0
JSquamous cell carcinoma SCC-4 ,0.0 iColon ca.* (SW480 met) SW620 0.0 jTestis Pool (0.0 (Colon ca. HT29 0.0 "
(Prostate ca.* (bone met) PC-3 ,0.0 (Colon ca. HCT- 1 16
_ - __ - " o7o "" " " (Prostate Pool iColon ca. CaCo-2 0.0 "~
(Placenta {0.0 (Colon cancer tissue "0.0 'Uterus Pool " io.o """ (Colon ca. SWl 1 16 "" " lo.o
Ovarian ca. OVCAR-3 IO.O iColon ca. Colo-205 Ό.O
.Ovarian ca. SK-OV-3 10.0 ,Colon ca. SW-48 0.0 Ovarian ca. OVCAR-4 io.o (Colon Pool lo.o
(Ovarian ca. OVCAR-5 io.o iSmall Intestine Pool "" Ό'.O"
(Ovarian ca. IGROV-1 0.0 'Stomach Pool 0.0 Ovarian ca. OVCAR-8 [04 Bone Marrow Pool ,0.0 .Ovary ""io.o" "" " !Fetal Heart " ΌΌ
{Breast ca. MCF-7 " [0.0 .Heart Pool 10.0
(Breast ca. MDA-MB-23 1 ,0.0 Lymph Node Pool Ό.O Εreast ca. BT 549 [o7o iFetal Skeletal Muscle "(0.0
[Breast ca. T47D Jo.o {Skeletal Muscle Pool (0.0
[Breast ca. MDA-N 10.6 (Spleen Pool (0.0
{Breast Pool jo.o (Thymus Pool .o
Trachea ,0.0 {CNS cancer (glio/astro) U87-MG 0.0
(Lung 0.0 _ {CNS cancer (glio/astro) U-1 18-MG 1 .3
)Fetal Lung 0.0 *"" {CNS cancer (neurojmet) SK-N-AS 0.0
Lung ca. NCI-N417 0.0 {CNS cancer (astro) SF-539 O.O
(Lung ca. LX-1 0.0 {CNS cancer (astro) SNB-75 Ό.O
[Lung ca. NCI-H 146 [0.0 (CNS cancer (glio) SNB- 19 Ό.O
(Lung ca. SHP-77 jθ.4 JCNS cancer (glio) SF-295 0.0
(Lung ca. A549 'OΌ (Brain (Amygdala) Pool 0.8
[Lung ca. NCI-H526 Ό"Ό " " {Brain (cerebellum) 4.7
{Lung ca. NCI-H23 O.o (Brain (fetal) ■ 1 .2
(Lung ca. NCI-H460 ,0.7 Brain (Hippocampus) Pool 1.2
JLung ca. HOP-62 10.0 (Cerebral Cortex Pool 12.3
[Lung ca. NCI-H522 Ό jBrain (Substantia nigra) Pool , 1.0
(Liver O.O [Brain (Thalamus) Pool 2.3
(Fetal Liver lo.o" jBrain (whole) 2.3
{Liver ca. HepG2 0.0 Spinal Cord Pool 0.8 !
'Kidney Pool 0.0 (Adrenal Gland o.o ;
.Fetal Kidney .O |Pituitary gland Pool 0.4 {
[Renal ca. 786-0 (0.0 (Salivary Gland 0.0 i iRenal ca. A498 0.0 {Thyroid (female) Ό.O !
[Renal ca. ACHN ,0.0 Pancreatic ca. CAPAN2 0.0 {
(Renal ca. UO-31 0.0 Pancreas Pool 0.0 {
CNS_neurodegeneration_vl.O Summary: Ag4959 Low levels of expression of this gene is seen throughout the samples in this panel, with highest expression in the hippocampus of a patient with Alzheimer's disease (CT=33.3). While no association between the expression of this gene and the presence of Alzheimer's disease is detected in this panel, these results confirm the expression of this gene in areas that degenerate in Alzheimer's disease, including the cortex, hippocampus, amygdala and thalamus.
General_screening_pancl_vl .5 Summary: Ag4959 Moderate levels of expression of this gene are restricted to melanoma SK-MEL-5 cell line (CT=31.7). Therefore, expression of this gene may be used to distinguish this sample from other samples used in this panel and also as marker to detect the presence of melanoma. Furthermore, therapeutic modulation of this gene may be useful in the treatment of melanoma.
P. NOV69a: F-box domain containing protein
Expression of gene NOV69a was assessed using the primer-probe set Ag4961 , described in Table PA. Results of the RTQ-PCR runs are shown in Tables PB, PC and PD. Table PA. Probe Name Ag4961
iSEQ ID
Primers (Sequences Length Start Position
[No
'Forward 5'-cagaggtgccctttagcttact-3' {22 1671 (393 _ Probe TET-5'-ttctcagcgtagattttgtccatcaa-3'-TA M RA [26 1706 ]394
(Reverse 5'-caaatggcggtcatgtataatc-3' [22 1745 395'"
Table PB. CNS neurodegeneration yl.O
Table PC. General screening panel yl.5
Renal ca. 786-0 11 1.0 iSalivary Gland 1.6 Renal ca. A498 16.2 Thyroid (female) 7.7 [ enai ca. ACHN 7.6 {Pancreatic ca. CAPAN2 112.2
Renal ca. UO-31 16.8 (Pancreas Pool 18.7
Table PP. Panel 4.1D
.Two Way MLR 3 day 32.3 HPAEC none 125.3
fTwo Way MLR 5 day 18.6 HPAEC TNF alpha + IL- 1 beta 44.8
{Two Way MLR 7 day 17.9 Lung fibroblast none -30.6 "
■PBMC rest 4.9 Lung fibroblast TNF alpha + IL- 1 beta 18.7
(PBMC PWM 17.0 Lung fibroblast IL-4 ;24.1
(PBMC PHA-L 18.4 Lung fibroblast IL-9 ;29.9 j
(Ramos (B cell) none 44.8 Lung fibroblast IL- 13 (52.9
'Ramos (B cell) ionomycin 58.6 Lung fibroblast IFN gamma ,57.0
{B lymphocytes PWM 27.9 Dermal fibroblast CCD 1070 rest 58.6 jB lymphocytes CD40L and IL-4 264 Dermal fibroblast CCDl 070 TNF alpha !62.9
[EOL-1 dbcAMP 36.3 Dermal fibroblast CCD1070 IL-1 beta (31.0 .J 1 l ιEOL-1 dbcAMP
56.3 Dermal fibroblast IFN gamma l
116.5
'PMA/ionomycin •
{Dendritic cells none 25.9 Dermal fibroblast IL-4 28.1 ' I
!Dendritic cells LPS 32.8 Dermal Fibroblasts rest ■ 17.0 I I
Dendritic cells anti-CD40 25.9 Neutrophils TNFa+LPS 17.2 i
]Monocytes rest 25.7 Neutrophils rest 10.2 !
I
{Monocytes LPS 50.3 Colon ,9.6 !
{Macrophages rest 34.4 Lung 15.4 iMacrophages LPS 13.2 Thymus 24.5
-
.HUVEC none 33.2 Kidney 19.8
'HUVEC starved 25.9
CNS_neurodegeneration_vl.O Summary: Ag4961 This panel confirms the expression of this gene at low levels in the brains of an independent group of individuals. However, no differential expression of this gene was detected between Alzheimer's diseased postmortem brains and those of non-demented controls in this experiment. Please see Panel 1 .5 for a discussion of the potential role of this gene in treatment of central nervous system disorders.
General_screening_panel_vL5 Summary: Ag4961 Highest expression of this gene is detected in brain cancer SNB-75 cell line (CT=28.6). Moderate levels of expression of this gene is also seen in cluster of cancer cell lines derived from pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers. Thus, expression of this gene could be used as a marker to detect the presence of these cancers. Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of pancreatic, gastric, colon, lung, liver, renal, breast, ovarian, prostate, squamous cell carcinoma, melanoma and brain cancers.
Among tissues with metabolic or endocrine function, this gene is expressed at moderate to low levels in pancreas, adipose, adrenal gland, thyroid, pituitary gland, skeletal muscle, heart, fetal liver and the gastrointestinal tract. Therefore, therapeutic modulation of the activity of this gene may prove useful in the treatment of endocrine/metabolically related diseases, such as obesity and diabetes.
Interestingly, this gene is expressed at much higher levels in fetal (CT=30.2) when compared to adult liver (CT=37). This observation suggests that expression of this gene can be used to distinguish fetal from adult liver. In addition, the relative overexpression of this gene in fetal tissue suggests that the protein product may enhance liver growth or development in the fetus and thus may also act in a regenerative capacity in the adult. Therefore, therapeutic modulation of the protein encoded by this gene could be useful in treatment of liver related diseases.
In addition, this gene is expressed at moderate levels in all regions of the central nervous system examined, including amygdala, hippocampus, substantia nigra, thalamus, cerebellum, cerebral cortex, and spinal cord. Therefore, therapeutic modulation of this gene product may be useful in the treatment of central nervous system disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
Panel 4.1D Summary: Ag4961 Highest expression of this gene is detected in PMA/ionomycin stimulated basophil (CT=30.4). This gene is expressed at high to moderate levels in a wide range of cell types of significance in the immune response in health and disease. These cells include members of the T-cell, B-cell, endothelial cell, macrophage/monocyte, and peripheral blood mononuclear cell family, as well as epithelial and fibroblast cell types from lung and skin, and normal tissues represented by colon, lung, thymus and kidney. This ubiquitous pattern of expression suggests that this gene product may be involved in homeostatic processes for these and other cell types and tissues. This pattern is in agreement with the expression profile in General_screening_panel_v l .5 and also suggests a role for the gene product in cell survival and proliferation. Therefore, modulation of the gene product with a functional therapeutic may lead to the alteration of functions associated with these cell types and lead to improvement of the symptoms of patients suffering from autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis.
Q. NOV72a: WW domain containing protein
Expression of gene NOV72a was assessed using the primer-probe set Λg4977, described in Table QA. Results of the RTQ-PCR runs are shown in Tables QB and QC. Table QA. Probe Name Ag4977
SEQ ID
Primers {Sequences Length Start Position
[No jForward |5'-taggatgggaagaggcatatg-3' 21 263 3~96
{Probe ιTET-5'-cttcatagaccacaacaccaaaacca-3'-TAMRA 26 303 397 "
Reverse {5'-tactcgaggatcctcaatctga-3' 22 398
Table QB. General screening panel yl.5
rachea 47 (CNS cancer (glio/astro) U87-MG 0.7
.Lung 10.0 (CNS cancer (glio/astro) U- 1 18-MG (0.0
(Fetal Lung 4.9 (CNS cancer (neuro;met) SK-N-AS {3. 1 jLung ca. NCI-N417 ,03 JCNS cancer (astro) SF-539 ■0.3
{Lung ca. LX- 1 ,6.7 (CNS cancer (astro) SNB-75 (0.9
(Lung ca. NCI-H 146 (2.4 (CNS cancer (glio) SNB- 19 | 1 8.6 Lung ca. SHP-77 10.9 [CNS cancer (glio) SF-295 ■2.2 jLung ca. A549 ( 16.7 (Brain (Amygdala) Pool 3.8
Lung ca. NCI-H526 2.0 jBrain (cerebellum) :8.0 Lung ca. NCI-H23 3.2 (Brain (fetal) ■' 15.9
Lung ca. NCI-H460 , 1 .6 (Brain (Hippocampus) Pool 3.0 Lung ca. HOP-62 (1.8 {Cerebral Cortex Pool 13.9 Lung ca.'NCI-H522 [6.6 jBrain (Substantia nigra) Pool "{4.2
Liver '0.5 iBrain (Thalamus) Pool (6.3
Fetal Liver ■2.5 (Brain (whole) 4.8 Liver ca. HepG2 4.6 (Spinal Cord Pool ,5.0 Kidney Pool ' 0.1 Adrenal Gland O.4
Fetal Kidney — •- 2 (Pituitary gland Pool 10.4
Renal ca. 786-0 :9.8 (Salivary Gland (21.0 Renal ca. A498 17.9 Thyroid (female) .3.9
Renal ca. ACHN (23.0 (Pancreatic ca. CAPAN2 33.2
Renal ca. UO-31 34.2 (Pancreas Pool •5.1
Table OC. Panel 4.1D
General_screening_panel_vl.5 Summary: Ag4977 Highest expression of this gene is seen in an ovarian cancer cell line (CT=25.8). This gene is widely expressed in this panel,
with high to moderate expression seen in brain, colon, gastric, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in cell survival and proliferation. Modulation of this gene product may be useful in the treatment of cancer, specifically in ovarian, colon and renal cancers. In addition, this gene is expressed at much higher levels in fetal lung tissue (CT=30) when compared to expression in the adult counterpart (CT=37). Thus, expression of this gene may be used to differentiate between the fetal and adult source of this tissue.
Among tissues with metabolic function, this gene is expressed at moderate to low levels in pituitary, adipose, adrenal gland, pancreas, thyroid, and adult and fetal liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
This gene is also expressed at moderate levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex.
Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Panel 4. ID Summary: Ag4977 Highest expression of this gene is seen in IL-9 treated NCI-H292 cells (CT=28.5). Expression of this gene is also seen at moderate levels in activated and resting keratinocytes, small airway epithelium, bronchial epithelium, and astrocytes, a cluster of samples derived from NCI-H292 cells, and normal kidney. Low but significant levels of expression are seen in treated and untreated dermal and lung fibroblasts. The expression of this gene in cells derived from the lung and skin suggests that this gene may be involved in normal conditions as well as pathological and inflammatory lung and skin disorders that include chronic obstructive pulmonary disease, asthma, allergy, psoriasis and emphysema.
R. NOV73a and NOV73b: GASDERMIN
Expression of gene N0V73a and full length physical clone N0V73b was assessed using the primer-probe set Ag4981 , described in Table RA. Results of the RTQ-PCR runs are shown in Tables RB and RC. Please note that NOV73b represents a full-length physical clone of the NOV73a gene, validating the prediction of the gene sequence.
Table RA. Probe Name Ag4981
Table RB. General screening panel yl.5
Table RC. Panel 4.1D
General_screening_panel_vl.5 Summary: Ag4981 Highest expression is seen in colon cancer tissue (CT=28.4), with prominent expression also detected in a lung cancer cell line. Thus, expression of this gene could be used to differentiate between these samples and other samples on this panel and as a marker to detect the presence of colon cancer.
Furthermore, therapeutic modulation of the expression or function of this gene may be effective in the treatment of colon cancer.
Low but significant levels of expression are seen in pancreas, metabolic, and adrenal suggesting that modulation of the expression or function of this gene may be useful in the treatment of metabolic disease, including obesity and diabetes.
Panel 4.1D Summary: Ag4981 Highest expression of this gene is seen in small airway epithelium (CT=31.2). Low but significant levels of expression are detected in TNF-a and 11-1 beta treated keratinocytes and small airway epithelium, primary T cells, dendritic cells, macrophages and normal lung.
S. NOV75a: Synaptotagmin-Like Protein 3-A
Expression of gene NOV75a was assessed using the primer-probe set Ag4993, described in Table SA. Results of the RTQ-PCR runs are shown in Tables SB and SC. Table SA. Probe Name Ag4993
Table SB. General screening panel yl.5
Table SC. Panel 4. ID
Dendritic cells LPS 14.1 {Dermal Fibroblasts rest 1.6
Dendritic cells anti-CD40 (2.1 Neιιtrophils TNFa+LPS 1.8
Monocytes rest j l47 [Neutrophils rest Ϊ3.5 ' iMonocytes LPS '6.8 Colon
Macrophages rest " 1775 [Lung 3.0
Macrophages LPS (7.5 [Thymus 22.7
HUVEC none [0.5 JKidney 1.4
HUVEC starved {0.5
Gencral_screening_panel_vl.5 Summary: Ag4993 Highest expression of this gene is seen in a colon cancer cell line (CT=25.3). High levels of expression are also seen in a renal cancer cell line. Thus, expression of this gene could be used to differentiate between these samples and other samples on this panel and as a marker of these cancers. In addition, therapeutic modulation of the expression or function of this gene may be useful in the treatment of these cancers.
In addition, this gene is expressed at much higher levels in fetal lung tissue (CT=29.4) when compared to expression in the adult counterpart (CT=33.3). Thus, expression of this gene may be used to differentiate between the fetal and adult source of this tissue. In addition, modulation of the expression or function of this gene may be useful in the treatment of diseases that affect this tissue.
Among tissues with metabolic function, this gene is expressed at moderate levels in pituitary, adipose, adrenal gland, pancreas, thyroid, and adult and fetal skeletal muscle, heart. and liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
This gene is also expressed at moderate levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex.
Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Panel 4.1D Summary: Ag4993 Highest expression of this gene is seen in chronically activated Th2 cells (Ct=26.2). This gene is widely expressed on this panel, but is more prominently expressed in T cells, B cells and LAK cells. Therefore, the putative protein
encoded by this gene could potentially be used diagnostically to identify B or T cells. In addition, the gene product could also potentially be used therapeutically in the treatment of asthma, emphysema, IBD, lupus or arthritis and in other diseases in which T cells and B cells are involved.
T. NOV76a: Hypothetical Intracellular
Expression of gene NOV76a was assessed using the primer-probe set Ag5023, described in Table TA. Results of the RTQ-PCR runs are shown in Tables TB, TC and TD. Table TA. Probe Name Ag5023
Table TB. CNS neurodegeneration vl.O
[Control 4 Temporal Ctx [4.2 Control (Path) 2 Parietal Ctx ( 1 7.4
.Control (Path) 1 Temporal Ctx 35.6 Control (Path) 3 Parietal Ctx 15.7
(Control (Path) 2 Temporal Ctx |29.3 Control (Path) 4 Parietal Ctx ,38.7
Table TC. General screening panel vl.5
Rel. (Rel.
:Eχp.(%) >Exp.(%)
Tissue Name (Ag5023, Tissue Name ■Ag5023,
Run Run
1228959376 1228959376
Adipose ;2.3 (Renal ca. TK- 10 ;57
Melanoma* Hs688(A).T J2.3 (Bladder 3.6
JMelanoma* Hs688(B).T 3.0 ;Gastric ca. (liver met.) NCI-N87 7.9 jMelanoma* M 14 12.1 (Gastric ca. KATO III ■8.4 jMelanoma* LOX1MVI ■2.7 Colon ca. SW-948 2l
{Melanoma* SK-MEL-5 3.3 (Colon ca. SW480 ; 1 .9
JSquamous cell carcinoma SCC-4 (2.5 Colon ca.* (SW480 met) SW620 "li .3
{Testis Pool 12.0 IColon ca. HT29 Ϊ13 jProstate ca.* (bone met) PC-3 4.2 .Colon ca. HCT-1 16 fProstate Pool 12.5 Colon ca. CaCo-2
{Placenta 0.7 Colon cancer tissue ; 1 .5 " "';
[Uterus Pool (2-4 Colon ca. SW1 1 16 O.5 ,'
[Ovarian ca. OVCAR-3 4.5 Colon ca. Colo-205 1 .1 1
[Ovarian ca. SK-OV-3 lϊ'ϊ "" Colon ca. SW-48 0.5
[Ovarian ca. OVCΛR-4 11.3 Colon Pool ,5.3
[Ovarian ca. OVCAR-5 '5.2 Small Intestine Pool 5.0
'Ovarian ca. IGROV- 1 3.2 Stomach Pool 3.0 {
[Ovarian ca. OVCAR-8 12.4 Bone Marrow Pool i l .5 j jOvary ■3.0 Fetal Heart 3.1 J
{Breast ca. MCF-7 14.5 Heart Pool :2.5 1
[Breast ca. MDA-MB-23 1 (9.9 Lymph Node Pool (4.9 ! iBreast ca. BT 549 j5.1 Fetal Skeletal Muscle 4.5
{Breast ca. T47D ( 1 .4 Skeletal Muscle Pool , 10.7 1
(Breast ca. MDA-N ( 1.8 Spleen Pool (2. 1 !
'Breast Pool ;4.1 Thymus Pool .2.. j
{Trachea 11.4 CNS cancer (glio/astro) U87-MG 1 16.6 j
Lung [0.0 CNS cancer (glio/astro) U-1 18-MG ( 1 1.2 j
Tetal Lung ,r8.0 CNS cancer (neuro;met) SK-N-AS [7.1 " j
[Lung ca. NCI-N417 [ 1.1 CNS cancer (astro) SF-539 (23 ]
Lung ca. LX-1 (4.2 CNS cancer (astro) SNB-75 ■5.9
(Lung ca. NCI-H 146 " θ.6 CNS cancer (glio) SNB-19 ■Ϊ3 -6 J
Lung ca. SHP-77 '>2. \ CNS cancer (glio) SF-295 1 12.1 i
Lung ca. A549 jl .6 "1 Brain (Amygdala) Pool T1.3 " !
Lung ca. NCI-H526 , 1 .0 • Brain (cerebellum) 4.4 Lung ca. NCI-H23 12.1 iBrain (fetal) (2.1 Lung caTllclTTHlό " Brain (Hippocampus) Pool " O7
,Lung ca. HOP-62 ( 1 3 jCerebral Cortex Pool ■0.6
Lung ca. NCI-H522 (Brain (Substantia nigra) Pool 10.6
{Liver [0.0 Brain (Thalamus) Pool O.9 iFetal Liver ; 100.0 iBrain (whole) 10.2
[Liver ca. HepG2 (2.2 jSpinal Cord Pool (2.2
(Kidney Pool [7-4 (Adrenal Gland , 1.8
{Fetal Kidney 4.6 Pituitary gland Pool 1 -0
Renal ca. 786-0 :6.2 'Salivary Gland ,0.9
Renal ca. A498 10.7 Thyroid (female) ( 1.4
JRenal ca. ACHN J2.4 iPancreatic ca. CAPAN2 74.6
JRenal ca. UO-31 (4.5 i Pancreas Pool
Table TD. Panel 4.1D
CNS_neurodegeneration_vl.0 Summary: Ag5023 This gene appears to be slightly upregulated in the temporal cortex of Alzheimer's disease patients. Therefore, therapeutic modulation of the expression or function of this gene may decrease neuronal death and be of use in the treatment of this disease.
General_scrcening_panel_vl.5 Summary: Ag5023 This gene is widely expressed in this panel, with highest expression in fetal liver (CT=26.8). In addition, this gene is expressed at much higher levels in fetal lung and lung tissue (CT=30) when compared to expression in the adult counterparts (CTs=40). Thus, expression of this gene may be used to
differentiate between the fetal and adult sources of these tissues. In addition, therapeutic modulation of the expression or function of this gene may be useful in the treatment of diseases that affect these organs.
Moderate to low expression is seen in brain, colon, gastric, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in cell survival and proliferation. Modulation of this gene product may be useful in the treatment of cancer.
Among tissues with metabolic function, this gene is expressed at moderate levels in pituitary, adipose, adrenal gland, pancreas, thyroid, and adult and fetal skeletal muscle, heart, and liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
This gene is also expressed at moderate levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex.
Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Panel 4. ID Summary: Ag5023 Highest expression of this gene is seen in chronically activated Th2 cells (CT=30). This gene is also expressed at moderate levels in a wide range of cell types of significance in the immune response in health and disease. These cells include members of the T-cell, B-cell, endothelial cell, macrophage/monocyte, and peripheral blood mononuclear cell family, as well as epithelial and fibroblast cell types from lung and skin, and normal tissues represented by colon, lung, thymus and kidney. This ubiquitous pattern of expression suggests that this gene product may be involved in homeostatic processes for these and other cell types and tissues. This pattern is in agreement with the expression profile in General_screening_panel_vl .5 and also suggests a role for the gene product in cell survival and proliferation. Therefore, modulation of the gene product with a functional therapeutic may lead to the alteration of functions associated with these cell types and lead to improvement of the symptoms of patients suffering from autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis.
U. NOV78a: Selenoprotein X 1
Expression of gene NOV78a was assessed using the primer-probe set Ag5042, described in Table UA.
Table UA. Probe Name Ag5042
V. NOV79a: Hypothetical WD-repeat
Expression of gene NOV79a was assessed using the primer-probe set Ag5050, described in Table VA. Results of the RTQ-PCR runs are shown in Tables VB and VC.
Table VA. Probe Name Ag5050
Table VB. CNS neurodegeneration yl.O
■AD 4 Temporal Ctx 23.5
"JControl (Path) 1 Occipital Ctx ,70.2
AD 5 Inf Temporal Ctx 100.0 [Control (Path) 2 Occipital Ctx • 10.2
AD 5 Sup Temporal Ctx 51.4 |Controϊ (Path) 3 Occipital Ctx 54 "
AD 6 Inf Temporal Ctx 74.7 [Control (Path) 4 Occipital Ctx , 17.2
,AD 6 Sup Temporal Ctx 85.9 ""[Control 1 Parietal Ctx (6.9
Control 1 Temporal Ctx 7.5 jControl 2 Parietal Ctx 42.9
Control 2 Temporal Ctx 47.6 [Control 3 Parietal Ctx ,21.9
Control 3 Temporal Ctx 17.9 [Control (Path) 1 Parietal Ctx (68.8 iControl 3 Temporal Ctx 12.2 (Control (Path) 2 Parietal Ctx '22.2
Control (Path) 1 Temporal Ctx 55.9 [Control (Path) 3 Parietal Ctx 6.4 iControl (Path) 2 Temporal Ctx 34.2 Control (Path) 4 Parietal Ctx 36.9
Table VC. Panel 4. ID
CNS_neurodegeneration_vL0 Summary: Ag5050 This gene appears to be slightly upregulated in the temporal cortex of Alzheimer's disease patients. Therefore, therapeutic modulation of the expression or function of this gene may decrease neuronal death and be of use in the treatment of this disease.
Panel 4.1D Summary: Ag5050 Highest expression of this gene is seen in keratinocytes (CT=29). This gene is also expressed at moderate levels in a wide range of cell types of significance in the immune response in health and disease. These cells include members of the T-cell, B-cell, endothelial cell, macrophage/monocyte, and peripheral blood mononuclear cell family, as well as epithelial and fibroblast cell types from lung and skin,
and normal tissues represented by colon, lung, thymus and kidney. This ubiquitous pattern of expression suggests that this gene product may be involved in homeostatic processes for these and other cell types and tissues also suggests a role for the gene product in cell survival and proliferation. Therefore, modulation of the gene product with a functional therapeutic may lead to the alteration of functions associated with these cell types and lead to improvement of the symptoms of patients suffering from autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis.
W. NOV84a and NOV84b: GTF2IRD1
Expression of gene NOV84a and full-length physical clone NOV84b was assessed using the primer-probe set Ag3588, described in Table WA. Results of the RTQ-PCR runs are shown in Tables WB and WC. Please note that NOV84b represents a full-length physical clone of the NOV84a gene, validating the prediction of the gene sequence.
Table WA. Probe Name Ag3588
Table WB. CNS neurodegeneration vl.O
AD 4 Temporal Ctx [28.7 Control (Path) 1 Occipital Ctx (77.4
AD 5 Inf Temporal Ctx (100.0 Control (Path) 2 Occipital Ctx ( 13.5
AD 5 SupTemporal Ctx [50.3 Control (Path) 3 Occipital Ctx (3.6
;AD 6 Inf Temporal Ctx [58.2 Control (Path) 4 Occipital Ctx 115.3
AD 6 Sup Temporal Ctx [44.1 Control 1 Parietal Ctx ( 12.9
{Control 1 Temporal Ctx :9.6 Control 2 Parietal Ctx (49.3
Control 2 Temporal Ctx [28.7 Control 3 Parietal Ctx ( 14.9
(Control 3 Temporal Ctx (20.9 Control (Path) 1 Parietal Ctx '52.5
Control 4 Temporal Ctx { 16.4 Control (Path) 2 Parietal Ctx " " ]25~.2
[Control (Path) 1 Temporal Ctx {46.7 Control (Path) 3 Parietal Ctx 7.5
(Control (Path) 2 Temporal Ctx [28.3 Control (Path) 4 Parietal Ctx 43.8
Table WC. general onco logv screening panel v 2.4
CNS_neurodegeneration_vl.O Summary: Ag3588 This gene appears to be slightly upregulated in the temporal cortex of Alzheimer's disease patients. Therefore, therapeutic
modulation of the expression or function of this gene may decrease neuronal death and be of use in the treatment of this disease. general oncology screening panel_v_2.4 Summary: Ag3588 This gene is widely expressed in this panel, with highest expression in melanoma (CT=28.6). In addition, this gene is more highly expressed in lung cancer than in the corresponding normal adjacent tissue. Thus, expression of this gene could be used as a marker of these cancers. Furthemore, therapeutic modulation of the expression or function of this gene product may be useful in the treatment of lung and melanoma cancer.
X. NOV85a and NOV85b: Intracellular Protein
Expression of gene NOV85a and full-length physical clone NOV85b was assessed using the primer-probe sets Ag3597 and Ag3679, described in Tables XA and XB. Results of the RTQ-PCR runs are shown in Tables XC, XD, XE and XF. Please note that NOV85b represents a ful l-length physical clone of the NOV85a gene, validating the prediction of the gene sequence.
Table XA. Probe Name Ag3597
Table XB. Probe Name Ag3679
(SEQ ID
IPri ers Sequences Length (Start Position
[No _
•Forward 5'-acaaaggaacacagcctacttg-3' {22 , 190 [420
.Probe TET-5'-cttcaaccacctaacagccacagcag-3'-TAMRA J26 ; 158 421
(Reverse 5'-gcccactaggagagagacactt-3' (22 ' 135 422
Table XC. CNS neurodegeneration vl .O
AD 4 Hippo i
7-
1 ,AD 2 Occipital Ctx (Missing) [0.0 AD 5 hippo 172.7 1AD 3 Occipital Ctx j l l .3 D 6 Hippo 47.6 (AD 4 Occipital Ctx i 18.0
sControl 2 Hippo [Ϊ9.5 AD 5 Occipital Ctx 132.3
Control 4 Hippo [9.8 lAD 6 Occipital Ctx |30.8 •Control (Path) 3 Hippo 11 1 .3 (Control 1 Occipital Ctx ;7.9 ;AD 1 Temporal Ctx "[26.6 (Control 2 Occipital Ctx 133.0 " ""
AD 2 Temporal Ctx {32.3 Control 3 Occipital Ctx ( 18.7
AD 3 Temporal Ctx {7.0 ■Control 4 Occipital Ctx (8.8 (AD 4 Temporal Ctx 1-29".1 Control (Path) 1 Occipital Ctx "" """"" {55.9"""
;AD 5 Inf Temporal Ctx (100.0 (Control (Path) 2 Occipital Ctx ( 12.5
]AD 5 SupTemporal Ctx (497 (Control (Path) 3 Occipital Ctx { 1 1.3 {AD 6 Inf Temporal Ctx " ]47.δ " """ (Control (Path) 4 Occipital Ctx ( 1476
AD 6 Sup Temporal Ctx 142.9 Control 1 Parietal Ctx ( 13. r
Control 1 Temporal Ctx "lio.o ontrol 2 Parietal Ctx (54.0 Control 2 Temporal Ctx 125-2 ' •Control 3 Parietal: Ctx 1 .5.9 .Control 3 Temporal Ctx [17.1 Control (Path) 1 Parietal Ctx 143.2
IControl 4 Temporal Ctx _ 1__2__._7_ (Control (Path) 2 Parietal Ctx 122.4
Control (Path) 1 Temporal Ctx IControl (Path) 3 Parietal Ctx ( 10.7 - - j — Control (Path) 2 Temporal Ctx [27.9 " Control (Path) 4 Parietal Ctx
Table XD. General screening panel yl.4
Renal ca. A498
'4.2 4.6 (Thyroid (female)
" J13
".4
~~ ' 13.2 iRenal ca. ACHN 17.6 118.8 (Pancreatic ca. CAPAN2 _ [_2_7___.7_ 27.5
Renal ca. UO-31 '24.7 22.1 ; Pancreas Pool '27.9
Table XE. Panel 4.1D
Table XF. general oncology screening panel v 2.4
General_screening_panel_vl.4 Summary: Ag3597/Ag3679 Two experiments with the same probe and primer produce results that are in excellent agreement. Highest expression of this gene is seen in a breast cancer cell line. Higher levels of expression are also seen in breast, prostate, ovarian and lung tissues when compared to expression in normal
tissue. Thus, expression of this gene could be used as a marker of these cancers and therapeutic modulation of the activity of this gene may be effective in their treatment.
Among tissues with metabolic function, this gene is expressed at high to moderate levels in pituitary, adipose, adrenal gland, pancreas, thyroid, and adult and fetal skeletal muscle, heart, and liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
- This gene is also expressed at high to moderate levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex.
Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
This gene codes for variant of DMR protein and a homologue of mouse dystrophia myotonica-containing WD repeat motif protein (DMR-N9 protein). DMR-N9 has been implicated in myotonic dystrophy (MD). Therefore, therapeutic modulation of this gene could be useful in the treatment of MD
Panel 4. ID Summary: Ag3597/Ag3679 Two experiments with the same probe and primer produce results that are in excellent agreement. Flighest expression of this gene is seen in cytokine activated LAK cells. In addition, this gene is expressed at high to moderate levels in a wide range of cell types of significance in the immune response in health and disease. These cells include members of the T-cell, B-cell, endothelial cell, macrophage/monocyte, and peripheral blood mononuclear cell family, as well as epithelial and fibroblast cell types from lung and skin, and normal tissues represented by colon, lung, thymus and kidney. This ubiquitous pattern of expression suggests that this gene product may be involved in homeostatic processes for these and other cell types and tissues. This pattern is in agreement with the expression profile in General_screening_panel_v l .4 and also suggests a role for the gene product in cell survival and proliferation. Therefore, modulation of the gene product with a functional therapeutic may lead to the alteration of functions associated with these cell types and lead to improvement of the symptoms of patients suffering from autoimmune and inflammatory diseases such as asthma, allergies, inflammatory bowel disease, lupus erythematosus, psoriasis, rheumatoid arthritis, and osteoarthritis.
general oncology screening panel_v_2.4 Summary: Ag3597/Ag3679 Two experiments produce results that are in very good agreement, with highest expression in a kidney cancer and a melanoma (CT=27.3-28.7). In addition, this gene is more highly expressed in lung and kidney cancer than in the corresponding normal adjacent tissue. In addition, consistent prominent expression is seen in melanoma and prostate cancer. Thus, expression of this gene could be used as a marker of these cancers. Furthemore, therapeutic modulation of the expression or function of this gene product may be useful in the treatment of lung, melanoma, prostate and kidney cancer.
Y. NOV87a and NOV87b: Glycolipid Transfer Protein-like
Expression of gene NOV87a and full-length physical clone NOV87b was assessed using the primer-probe set Ag6896, described in Table YA. Results of the RTQ-PCR runs are shown in Table YB. Please note that NOV87b represents a full-length physical clone of the NOV87a gene, validating the prediction of the gene sequence. Table YA. Probe Name Ag6896 jPrimers {Sequences (Length iSrart Position SEQ ID No
[Forward ]5'-cgtcaccgtggccttct-3' [l 7 [741 "423
Probe TET-5'-cacgctgcccacacgcgagg-3'-TAMRA ]20 __.9_ 424
Reverse j5'-gttcatggcctccaggaaga-3' T2θ" 779 425
Table YB. General screening panel yl.6
1 Rel. Rel.
(Exp.(%) Exp.(%)
Tissue Name [Ag6896, Tissue Name Ag6896,
1 i •Run Run
278388389 ,278388389
Adipose 16.8 Renal ca. TK- 10 ( 19.6 rMeIanoma* Hs688(A).T (33.9 Bladder ""1.7.6
•Melanoma* Hs688(B).T (29.1 Gastric ca. (liver met.) NCI-N87 (69.3 Melanoma* M 14 [507 Gastric ca. KATO I II 55.1
Melanoma* LOXIMV1 I2O.9 'Colon ca. SW-948 64.2
•Melanoma* SK-MEL-5 {20.6 Colon ca. SW480 165.5
'Squamous cell carcinoma SCC-4 ;53.2 Colon ca.* (SW480 met) SW620 , 17.2 Testis Pool "j35."l" Colon ca. HT29 [22. I
Prostate ca.* (bone met) PC-3 "[97.9 Colon ca. HCT- 1 16 (36.6
'Prostate Pool J9:l Colon ca. CaCo-2 (26. 1
'Placenta {26.2 Colon cancer tissue """"{33 O
Uterus Pool .4.1 Colon ca. SW1 1 16 17.9
■Ovarian ca. OVCAR-3 (99.3 Colon ca. Colo-205 17.4
(Ovarian ca. SK-OV-3 194.0 Colon ca. SW-48 25.0
Ovarian ca. OVCAR-4 158.6 Colon Pool 19.1 lOvarian ca. OVCAR-5 (60.3 Small Intestine Pool 15.6
(Ovarian ca. IGROV-1 157.8 Stomach Pool 8.7
[Ovarian ca. OVCAR-8 [66.9 Bone Marrow Pool 6.9
{Ovary (8.8 Fetal Heart 18.8
(Breast ca. MCF-7 [363 Heart Pool 16.2""
[Breast ca. MDA-MB-231 j 100.0 Lymph Node Pool 14.6
[Breast ca. BT 549 [79.0 Fetal Skeletal Muscle 10.3
(Breast ca. T47D J18.8 Skeletal Muscle Pool 15.9
JBreast ca. MDA-N 160.3 Spleen Pool 16.2
(Breast Pool 117.8 Thymus Pool 19.3
,Trachea 128.7 CNS cancer (glio/astro) U87-MG 47.6
[Lung ; 1 .4 CNS cancer (glio/astro) U-1 18-MG 75.8
• Fetal Lung J21.9 CNS cancer (neuro;met) SK-N-AS 38.4
.Lung ca. NCI-N4Ϊ 7" J33.7 CNS cancer (astro) SF-539 34.6
,Lung ca. LX-1 {22.2 CNS cancer (astro) SNB-75 79.6
Lung ca. NCI-H 146 113.3 CNS cancer (glio) SNB- 19 60.7
[Lung ca. SHP-77 (33.2 CNS cancer (glio) SF-295 40.6
Lung ca. A549 [24.5 Brain (Amygdala) Pool 20.0
[Lung ca. NCI-H526 [27.0 Brain (cerebellum) 12.5
Lung ca. NCf-H23 {32.5 Brain (fetal) 40.1
,Lung ca. NCI-H460 [9.9 Brain (Hippocampus) Pool ϊ 8.2 "
'Lung ca. HOP-62 ( 15.8 Cerebral Cortex Pool 19.1
Lung ca. NCI-H522 (54.7 Brain (Substantia nigra) Pool 21.0
{Liver 121.8 Brain (Thalamus) Pool 19.2
(Fetal Liver [ 14.3 J Brain (whole) 35.6
{Liver ca. HepG2 ( 19.6 Spinal Cord Pool 16.5
(Kidney Pool (21.9 Adrenal Gland 35.1
Fetal Kidney | l 4.4 Pituitary gland Pool J .J iRenal ca. 786-0 (28.5 j Salivary Gland 46.7 rRenal ca. A498 l?-9 . .. Thyroid (female) 1 1.4
Renal ca. ACHN l l 8.9 f Pancreatic ca. CAPAN2 51.4
Renal ca. UO-3 1 {24.8 { Pancreas Pool 1 1.0
General_screening_pancl_vl.6 Summary: Ag6896 Highest expression of this gene is seen in a breast cancer cell line (CT=27.8). This gene is ubiqutously expressed in this panel, with moderate expression seen in brain, colon, gastric, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in
cell survival and proliferation. Modulation of this gene product may be useful in the treatment of cancer.
In addition, this gene is expressed at much higher levels in fetal lung tissue (CT=29.8) when compared to expression in the adult counterpart (CT=33.8). Thus, expression of this gene may be used to differentiate between the fetal and adult source of these tissue
Among tissues with metabolic function, this gene is expressed at moderate levels in pituitary, adipose, adrenal gland, pancreas, thyroid, and adult and fetal skeletal muscle, heart, and liver. This widespread expression among these tissues suggests that this gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
This gene is also expressed at moderate levels in the CNS, including the hippocampus, thalamus, substantia nigra, amygdala, cerebellum and cerebral cortex. Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
Z. NOV88a: Copine VII
Expression of gene NOV88a was assessed using the primer-probe set Ag3641. described in Table ZA. Results of the RTQ-PCR runs are shown in Tables ZB and ZC. Table ZA. Probe Name Ag3641
Table ZB. CNS neurodegeneration yl.O
(AD 5 hippo 100.0 AD 3 Occipital Ctx 11.0 (AD 6 Hippo 24.8 ,AD 4 Occipital Ctx 17.5
Control 2 Hippo 6.5 AD 5 Occipital Ctx 16.0
Control 4 Hippo 1 .0 AD 6 Occipital Ctx • 18.9 jControl (Path) 3 Hippo 0.3 Control 1 Occipital Ctx (0.0 (AD 1 Temporal Ctx l79""" " Control 2 Occipital Ctx _ " T _25_..2" (AD 2 Temporal Ctx 9.0 Control 3 Occipital Ctx
(AD 3 Temporal Ctx 1.2 Control 4 Occipital Ctx U .2
[AD 4 Tempora. Ctx 2.7 Control (Path) 1 Occipital Ctx 26.4 "- , . -_ - " " (AD 5 Inf Temporal Ctx 31.6 Control (Path) 2 Occipital Ctx
[AD 5 SupTemporal Ctx 19.6 Control (Path) 3 Occipital Ctx 0.4
[AD 6 Inf Temporal Ctx 7.6 ■'Control (Path) 4 Occipital Ctx {6.0 JAD 6 Sup Temporal Ctx IT, " (Control 1 Parietal Ctx (0.5
(Control 1 Temporal Ctx 0.4 Control 2 Parietal Ctx 1 1.6
(Control 2 Temporal Ctx 6.1 •Control 3 Parietal Ctx 4.5 [Control 3 Temporal Ctx 4.1 Control (Path) 1 Parietal Ctx .15.7 (Control 4 Temporal Ctx 13 " Control (Path) 2 Parietal Ctx 12.7 "
JControl (Path) 1 Temporal Ctx 26.6 Control (Path) 3 Parietal Ctx 0.2
[Control (Path) 2 Temporal Ctx 1 1.7 Control (Path) 4 Parietal Ctx 115.7
Table ZC. General screening panel yl.4
Rel. Rel.
Exp.(%) Exp.(%)
'Tissue Name Ag3641, Tissue Name Ag3641,
Run Run
218306189 (218306189
Adipose "ό7"o" (Renal ca. TK- 10 __ 0_._0_
[Melanoma* Hs688(A).f 1.1 jBladder
{Melanoma* Hs688(B).T 1 .2 {Gastric ca. (liver met.) NCI-N87 11 7 JMelanoma* M14 ol - [Gastric ca. KATO III Ό.O
Melanoma* LOXIMVI 0.0 iColon ca. SW-948 0.0
(Melanoma* SK-MEL-5 0.0 .Colon ca. SW480 (0.0 JSquamous cell carcinoma SCC-4 OΌ " (Colon ca.* (SW480 met) SW620 "" lo.o Testis Pool 474" {Colon ca. HT29 (0.0
.Prostate ca.* (bone met) PC-3 ' •2 (Colon ca. HCT-1 16 (0.0 Prostate Pool 100.0 (Colon ca. CaCo-2 " "Ό.O {Placenta 0 0 [Colon cancer tissue '0.0 "
:Uterus Pool 0.0 {Colon ca. SW1 1 16 .O
•Ovarian ca. OVCAR-3 66.9 jColon ca. Colo-205 (0.0 Ovarian ca. SK-OV-3 0.0 (Colon ca. SW-48 jo.o" " "_[["
Ovarian ca. OVCAR-4 3.0 Colon Pool id.o jOvarian ca. OVCAR-5 0.0 {Small Intestine Pool [0.0 iOvarian ca. IGROV-1 14.0 Stomach Pool !ό"7ό
CNS_neurodegeneration_vl .O Summary: Ag3641 This panel does not show differential expression of this gene in Alzheimer's disease. However, this profile confirms the expression of this gene at moderate levels in the brain. Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurological disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
General_screening_panel_vl.4 Summary: Ag3641 Highest expression is seen in the prostate (CT=33). Prominent expression of this gene is seen in cells lines from ovarian and lung cancer as well as all regions of the brain in this panel. Therefore, therapeutic
modulation of this gene may be useful in the treatment of prostate related diseases, as well as, lung and ovarian cancers.
In addition, moderate to low levels of expression of this gene is also seen in all the regions of brain. Therefore, therapeutic modulation of this gene product may be useful in the treatment of neurological disorders such as Alzheimer's disease, Parkinson's disease, epilepsy, multiple sclerosis, schizophrenia and depression.
AA. NOV89b: intracellular protein
Expression of full-length physical clone NOV89b was assessed using the primer- probe set Ag691 1 , described in Table AAA. Results of the RTQ-PCR runs are shown in Table AAB.
Table AAA. Probe Name Ag6911
Table AAB. General screening panel yl.6
.Ovarian ca. IGROV-l (26.6 [Stomach Pool .4.1 [Ovarian ca. OVCAR-8 [21 .8 (Bone Marrow Pool .Ovary 5.6
■Fetal Heart •
:6l4
""
Breast ca. MCF-7 117.3 JHeart Pool :8.7
(Breast ca. MDA-MB-231 {66.9 Lymph Node Pool 10.6 Breast ca. BT 549 T160.0 Fetal Skeletal Muscle 3.2"" (Breast ca. T47D " I17.7 Skeletal Muscle Pool 2.7 iBreast ca. MDA-N 114.7 Spleen Pool ■6.5 Breast Pool 19.9 " Thymus Pool 7.5 ~ {Trachea 11276 CNS cancer (glio/astro) U87-MG 43.8
Lung |4.8 CNS cancer (glio/astro) U- 1 18-MG 29.
Fetal Lung {17.1 CNS cancer (neuro;met) SK-N-AS 1293 Lung ca. NCI-N4J7 j8".ϊ" CNS cancer (astro) SF-539 "!2Ϊ70~ [Lun ca. LX-1 39.5 CNS cancer (astro) SNB-75 !58.2 [" mg'ca NCI-1.146 10.2 jCNS cancer (glio) SNB- 19 26.1 Lung ca. SHP-77 61.6 (CNS cancer (glio) SF-295 34.2 Lung ca. A549 39.2 JBrain (Amygdala) Pool 2.6"
JLung ca. NCI-H526 113.4 jBrain (cerebellum) 5.5 (Lung ca. NCI-H23" "" {57.8 Brain (fetal) Lung ca. NCI-H460 112.2 Brain (Hippocampus) Pool 3.7
(Lung ca. HOP-62 Cerebral Cortex Pool 4.3
{Lung ca. NCI-H522 39.8 Brain (Substantia nigra) Pool 2. jLiver 1.3" " Brain (Thalamus) Pool 4.5" Fetal Liver 6.4 (Brain (whole) Liver ca. HepG2 (8.4 [Spinal Cord Pool 3.4 .Kidney Pool ll"57_" !Adrenal Gland 9.7 [Fetal Kidney "iTTT (Pituitary gland Pool ;5.2 '
(Renal ca. 786-0 (507 [Salivary Gland 1 1.1
[Renal ca. A498 [17.6 {Thyroid (female) ( 10.0 .Renal ca. ACHN {26.6 " [Pancreatic ca. CAPAN2 126.1 iRenal ca. UO-31 {44.1 [Pancreas Pool 4.9
General_screening_panel_vl.6 Summary: Ag691 1 Highest expression of this gene is seen in a breast cancer cell line (CT=29.8). This gene is widely expressed in this panel, with moderate expression seen in brain, colon, gastric, lung, breast, ovarian, and melanoma cancer cell lines. This expression profile suggests a role for this gene product in cell survival and proliferation. Modulation of this gene product may be useful in the treatment of cancer.
Among tissues with metabolic function, this gene is expressed at low but significant levels in pituitary, adipose, adrenal gland, pancreas, thyroid, fetal liver and adult and fetal skeletal muscle and heart. This widespread expression among these tissues suggests that this
gene product may play a role in normal neuroendocrine and metabolic function and that disregulated expression of this gene may contribute to neuroendocrine disorders or metabolic diseases, such as obesity and diabetes.
This gene is also expressed at low but significant levels in the CNS. including the hippocampus, thalamus, substantia nigra, cerebellum and cerebral cortex. Therefore, therapeutic modulation of the expression or function of this gene may be useful in the treatment of neurologic disorders, such as Alzheimer's disease, Parkinson's disease, schizophrenia, multiple sclerosis, stroke and epilepsy.
AB. NOV91c and NOV91b: FIP-2 like
Expression of full-length physical clones NOV91c and variant NOV91 b was assessed using the primer-probe set Ag6162, described in Table ABA. Table ABA. Probe Name Ag6162
. IPrimers Sequences Length Start Position (N
.Forward 5'-ttgtgtgtcatctgtagcacagtta-3' 25 _ 7-_4_6_ 432 """" "
{Probe |TET-5'-tggacttttcatcctctgttttagcc-3'-TAMRA 26
Reverse j5'-gctatcagaaatcaaaatggaaca-3' 24 T800" 434
Example D: Identification of Single Nucleotide Polymorphisms in NOVX nucleic acid sequences
Variant sequences are also included in this application. A variant sequence can include a single nucleotide polymorphism (SNP). A SNP can, in some instances, be referred to as a "cSNP" to denote that the nucleotide sequence containing the SNP originates as a cDNA. A SNP can arise in several ways. For example, a SNP may be due to a substitution of one nucleotide for another at the polymorphic site. Such a substitution can be either a transition or a transversion. A SNP can also arise from a deletion of a nucleotide or an insertion of a nucleotide, relative to a reference allele. In this case, the polymorphic site is a site at which one allele bears a gap with respect to a particular nucleotide in another allele. SNPs occurring within genes may result in an alteration of the amino acid encoded by the gene at the position of the SNP. Intragenic SNPs may also be silent, when a codon including a SNP encodes the same amino acid as a result of the redundancy of the genetic code. SNPs occurring outside the region of a gene, or in an intron within a gene, do not result in changes in any amino acid sequence of a protein but may result in altered regulation of the expression
pattern. Examples include alteration in temporal expression, physiological response regulation, cell type expression regulation, intensity of expression, and stability of transcribed message.
SeqCalling assemblies produced by the exon linking process were selected and extended using the following criteria. Genomic clones having regions with 98% identity to all or part of the initial or extended sequence were identified by BLASTN searches using the relevant sequence to query human genomic databases. The genomic clones that resulted were selected for further analysis because this identity indicates that these clones contain the genomic locus for these SeqCalling assemblies. These sequences were analyzed for putative coding regions as well as for similarity to the known DNA and protein sequences. Programs used for these analyses include Grail, Genscan, BLAST, HMMER, FASTA, Hybrid and other relevant programs.
Some additional genomic regions may have also been identified because selected SeqCalling assemblies map to those regions. Such SeqCalling sequences may have overlapped with regions defined by homology or exon prediction. They may also be included because the location of the fragment was in the vicinity of genomic regions identified by similarity or exon prediction that had been included in the original predicted sequence. The sequence so identified was manually assembled and then may have been extended using one or more additional sequences taken from CuraGen Corporation's human SeqCalling database. SeqCalling fragments suitable for inclusion were identified by the Cura Tools™ program
SeqExtend or by identifying SeqCalling fragments mapping to the appropriate regions of the genomic clones analyzed.
The regions defined by the procedures described above were then manually integrated and corrected for apparent inconsistencies that may have arisen, for example, from miscalled bases in the original fragments or from discrepancies between predicted exon junctions, EST locations and regions of sequence similarity, to derive the final sequence disclosed herein. When necessary, the process to identify and analyze SeqCalling assemblies and genomic clones was reiterated to derive the full length sequence (Alderborn et al., Determination of Single Nucleotide Polymorphisms by Real-time Pyrophosphate DNA Sequencing. Genome Research. 10 (8) 1249-1265, 2000).
Variants are reported individually but any combination of all or a select subset of variants are also included as contemplated NOVX embodiments of the invention.
NOVla SNP data:
NOV l a has 4 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 1 and 2, respectively. The nucleotide sequence of the NOVla variants differ as shown in Table DA.
NOV2a SNP data:
NOV2a has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 3 and 4, respectively. The nucleotide sequence of the NOV2a variants differ as shown in Table DB.
NOV6a SNP data:
NOVόa has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 19 and 20, respectively. The nucleotide sequence of the NOVόa variants differ as shown in Table DC.
NOV7a SNP data:
NOV7a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs:23 and 24, respectively. The nucleotide sequence of the NOV7a variants differ as shown in Table DD.
NOV8a SNP data:
NOV8a has 8 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 33 and 34, respectively. The nucleotide sequence of the NOV8a variants differ as shown in Table DE.
NOB9b has 7 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 37 and 38, respectively. The nucleotide sequence of the NOV9b variants differ as shown in Table DF.
NOVIOa SNP data:
NOVI Oa has 24 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 39 and 40, respectively. The nucleotide sequence of the NOV I Oa variants differ as shown in Table DO
NOVlla SNP data:
NOV l l a has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 43 and 44, respectively. The nucleotide sequence of the NOVl l a variants differ as shown in Table DH.
NOV 12b has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 47 and 48, respectively. The nucleotide sequence of the NOV 12b variants differ as shown in Table DI.
NOV13a SNP data:
NOV 13a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 49 and 50, respectively. The nucleotide sequence of the NOV 13a variants differ as shown in Table DJ.
NOVl 4a SNP data:
NOV 14a has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 51 and 52. respectively. The nucleotide sequence of the NOV14a variants differ as shown in Table DK.
NOV l όa has 5 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 57 and 58, respectively. The nucleotide sequence of the NOV] 6a variants differ as shown in Table DL.
NOVl 8a SNP data: NOVl 8a has 5 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 61 and 62, respectively. The nucleotide sequence of the NOVl 8a variants differ as shown in Table DM.
NOVl 9a SNP data:
NOV19a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 67 and 68, respectively. The nucleotide sequence of the NOV 19a variants differ as shown in Table DN.
NOV20a SNP data:
NOV20a has 4 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 71 and 72, respectively. The nucleotide sequence of the NOV20a variants differ as shown in Table DO.
NOV21a SNP data:
NOV21a has 9 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 85 and 86, respectively. The nucleotide sequence of the NOV21 a variants differ as shown in Table DP.
NOV22a SNP data:
NOV22a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 89 and 90, respectively. The nucleotide sequence of the NOV22a variants differ as shown in Table DQ.
NOV23a SNP data:
NOV23a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 91 and 92, respectively. The nucleotide sequence of the NOV23a variants differ as shown in Table DR.
NOV24a has 4 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 95 and 96, respectively. The nucleotide sequence of the NOV24a variants differ as shown in Table DS.
NOV25a SNP data: s )
NOV25a has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 97 and 98, respectively. The nucleotide sequence of the NOV25a variants differ as shown in Table DT.
NOV27a SNP data:
NOV27a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 107 and 108, respectively. The nucleotide sequence of the NOV27a variants differ as shown in Table DU.
NOV28a SNP data:
NOV28a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 1 1 1 and 1 12, respectively. The nucleotide sequence of the NOV28a variants differ as shown in Table DV.
NOV29a SNP data:
NOV29a has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 123 and 124, respectively. The nucleotide sequence of the NOV29a variants differ as shown in Table DW.
NOV31a SNP data:
NOV31a has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 129 and 130, respectively. The nucleotide sequence of the NOV3 l a variants differ as shown in Table DX.
Table DX. cSNP and Coding Variants for NOV31a
Variant Nucleotides Amino Acids
NOV32b SNP data:
NOV32b has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 133 and 134. respectively. The nucleotide sequence of the NOV32b variants differ as shown in Table DY.
NOV34a SNP data:
NOV34a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 137 and 138, respectively. The nucleotide sequence of the NOV34a variants differ as shown in Table DZ.
NOV36b SNP data:
NOV36b has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 147 and 148, respectively. The nucleotide sequence of the NOV36b variants differ as shown in Table DAA.
Table DAA. cSNP and Coding Variants for NOV36b
Variant Nucleotides Amino Acids
NOV37b SNP data:
NOV37b has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 151 and 152, respectively. The nucleotide sequence of the NOV37b variants differ as shown in Table DAB.
NOV38a SNP data:
NOV38a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 155 and 156, respectively. The nucleotide sequence of the NOV38a variants differ as shown in Table DAC.
NOV41a SNP data:
NOV41 a has 4 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 161 and 162, respectively. The nucleotide sequence of the NOV41a variants differ as shown in Table DAD.
NOV42a SNP data:
NOV42a has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 163 and 164. respectively. The nucleotide sequence of the NOV42a variants differ as shown in Table DAE.
NOV43a SNP data: NOV43a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 167 and 168, respectively. The nucleotide sequence of the NOV43a variants differ as shown in Table DAF.
NOV44c has I SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 173 and 174, respectively. The nucleotide sequence of the NOV44c variants differ as shown in Table DAG.
NOV45a SNP data:
NOV45a has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 175 and 176, respectively. The nucleotide sequence of the NOV45a variants differ as shown in Table DAH.
NOV46a SNP data:
NOV46a has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 177 and 178, respectively. The nucleotide sequence of the NOV46a variants differ as shown in Table DAI.
NOV47a SNP data: NOV47a has 9 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 1 79 and 1 80, respectively. The nucleotide sequence of the NOV47a variants differ as shown in Table DAJ.
NOV48b SNP data:
NOV48b has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 183 and 1 84, respectively. The nucleotide sequence of the NOV48b variants differ as shown in Table DAK. w)
NOV49a SNP data:
NOV49a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 185 and 1 86, respectively. The nucleotide sequence of the NOV49a variants differ as shown in Table DAL.
NOV50a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 189 and 190, respectively. The nucleotide sequence of the NOV50a variants differ as shown in Table DAM.
NOV54a SNP data:
NOV54a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 203 and 204, respectively. The nucleotide sequence of the NOV54a variants differ as shown in Table DAN.
NOV52a SNP data:
NOV52a has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 197 and 198, respectively. The nucleotide sequence of the NOV52a variants differ as shown in Table DAO.
NOVό l a has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 227 and 228, respectively. The nucleotide sequence of the NOVόla variants differ as shown in Table DAP.
NOV62a SNP data:
NOV62a has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 229 and 230, respectively. The nucleotide sequence of the NOV62a variants differ as shown in Table DAQ.
NOVόόa SNP data:
NOVόόa has 2 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 241 and 242, respectively. The nucleotide sequence of the NOV66a variants differ as shown in Table DAR.
NOV67a has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 245 and 246. respectively. The nucleotide sequence of the NOV67a variants differ as shown in Table DAS.
NOV71a SNP data:
NOV71 a has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 253 and 254, respectively. The nucleotide sequence of the NOV71 a variants differ as shown in Table DAT.
NOV72a SNP data:
NOV72a has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 255 and 256. respectively. The nucleotide sequence of the NOV72a variants differ as shown in Table DAU.
NOV74a SNP data: NOV74a has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 265 and 266, respectively. The nucleotide sequence of the NOV74a variants differ as shown in Table DAV.
NOV77a SNP data:
NOV77a has 4 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 271 and 272, respectively. The nucleotide sequence of the NOV77a variants differ as shown in Table DAW.
NOV80a SNP data:
NOV80a has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 277 and 278, respectively. The nucleotide sequence of the NOV80a variants differ as shown in Table DAX.
NOV81 has I SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 281 and 282, respectively. The nucleotide sequence of the NOV81 b variants differ as shown in Table DAY.
NOV82b SNP data:
NOV82b has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 285 and 286, respectively. The nucleotide sequence of the NOV82b variants differ as shown in Table DAZ.
NOV83b SNP data:
NOV83b has 1 SNP variant, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 291 and 292, respectively. The nucleotide sequence of the NOV83b variants differ as shown in Table DBA.
NOV84a has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 293 and 294, respectively. The nucleotide sequence of the NOV84a variants differ as shown in Table DBB.
NOV86b SNP data:
NOVδόb has 6 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 305 and 306, respectively. The nucleotide sequence of the NOV86b variants differ as shown in Table DBC.
NOV87a SNP data:
NOV87a has 6 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 307 and 308, respectively. The nucleotide sequence of the NOV87a variants differ as shown in Table DBD.
NOV88a SNP data:
NOV88a has 5 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOa: 317 and 3 1 8, respectively. The nucleotide sequence of the NOV88a variants differ as shown in Table DBE.
NOV91c SNP data:
NOV91 c has 3 SNP variants, whose variant positions for its nucleotide and amino acid sequences is numbered according to SEQ ID NOs: 333 and 334, respectively. The nucleotide sequence of the NOV91c variants differ as shown in Table DBF.
OTHER EMBODIMENTS
Although particular embodiments have been disclosed herein in detail, this has been done by way of example for purposes of illustration only, and is not intended to be limiting with respect to the scope of the appended claims, which follow. In particular, it is contemplated by the inventors that various substitutions, alterations, and modifications may be made to the invention without departing from the spirit and scope of the invention as defined by the claims. The choice of nucleic acid starting material, clone of interest, or library type is believed to be a matter of routine for a person of ordinary skill in the art with knowledge of the embodiments described herein. Other aspects, advantages, and modifications considered to be within the scope of the following claims. The claims presented are representative of the inventions disclosed herein. Other, unclaimed inventions are also contemplated. Applicants reserve the right to pursue such inventions in later claims.