USRE42481E1 - Semiconductor yield management system and method - Google Patents
Semiconductor yield management system and method Download PDFInfo
- Publication number
- USRE42481E1 USRE42481E1 US10/972,115 US97211504A USRE42481E US RE42481 E1 USRE42481 E1 US RE42481E1 US 97211504 A US97211504 A US 97211504A US RE42481 E USRE42481 E US RE42481E
- Authority
- US
- United States
- Prior art keywords
- node
- variables
- prediction
- split
- variable
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images




Classifications
-
- H—ELECTRICITY
- H01—ELECTRIC ELEMENTS
- H01L—SEMICONDUCTOR DEVICES NOT COVERED BY CLASS H10
- H01L22/00—Testing or measuring during manufacture or treatment; Reliability measurements, i.e. testing of parts without further processing to modify the parts as such; Structural arrangements therefor
- H01L22/20—Sequence of activities consisting of a plurality of measurements, corrections, marking or sorting steps
Definitions
- This invention relates generally to a system and method for managing a semiconductor process and in particular to a system and method for managing yield in a semiconductor process.
- the semiconductor industry is continually pushing toward smaller and smaller geometries of the semiconductor devices being produced since smaller devices generate less heat and operate at a higher speed than larger devices.
- a single chip may contain over one billion patterns.
- the semiconductor manufacturing process is extremely complicated since it involves hundreds of processing steps. A mistake or small error at any of the process steps or tool specifications may cause lower yield in the final semiconductor product, wherein yield may be defined as the number of functional devices produced by the process as compared to the theoretical number of devices that could be produced assuming no bad devices. Improving yield is a critical problem in the semiconductor industry and has a direct economic impact to the semiconductor industry. In particular, a higher yield translates into more devices that may be sold by the manufacturer.
- the yield management system and method in accordance with the invention may provide many advantages over conventional methods and systems which make the yield management system and method more useful to semiconductor device manufacturers.
- the system may be fully automated and easy to use so that no extra training is necessary to make use of the yield management system.
- the system handles both continuous (e.g., temperature) and categorical (e.g., Lot 1 , Lot 2 , etc.) variables.
- the system also automatically handles missing data during a pre-processing step.
- the system can rapidly search through hundreds of yield parameters and generate an output indicating the one or more key yield factors/parameters.
- the system generates an output (a decision tree) that is easy to interpret and understand.
- the system is also very flexible in that it permits prior yield parameter knowledge (from users) to be easily incorporated into the building of the model in accordance with the invention. Unlike conventional systems, if there is more than one yield factor/parameter affecting the yield of the process, the system can identify all of the parameters/factors simultaneously so that the multiple factors are identified during a single pass through the yield data.
- the yield management method may receive a yield data set.
- a data set comes in, it first goes through a data preprocessing step in which the validity of the data in the data set is checked and cases or parameters with missing data are eliminated.
- a Yield Mine model is built during a model building step.
- the model may be modified by one or more users based on their experience or prior knowledge of the data set.
- the data set may be processed using various statistical analysis tools to help the user better understand the relationship between the response and predict variables.
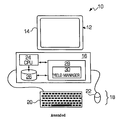
- FIG. 1 is a diagram illustrating an example of a yield management system in accordance with the invention implemented on a personal computer;
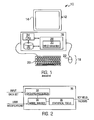
- FIG. 2 is a block diagram illustrating more details of the yield management system in accordance with the invention.
- FIG.3 is a flowchart illustrating an example of a yield management method in accordance with the invention.
- FIG. 4 is a diagram illustrating the data preprocessing procedure in accordance with the invention.
- FIG. 5 illustrates an example of a yield parameter being selected by the user and a tree node being automatically split or manually split in accordance with the invention
- FIG. 6 is a flowchart illustrating a recursive node splitting method in accordance with the invention.
- FIG. 7 illustrateillustrates an example of a yield parameter being selected by the user and a tree being automatically generated by the system based on the user selected parameter in accordance with the invention
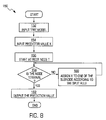
- FIG. 8 is a flowchart illustrating a method for tree prediction in accordance with the invention.
- FIG. 9 illustrates an example of the statistical tools available to the user in accordance with the invention.
- the invention is particularly applicable to a computer-implemented software-based yield management system and it is in this context that the invention will be described. It will be appreciated, however, that the system and method in accordance with the invention has greater utility since it may be implemented in hardware or may incorporate other modules or functionality not described herein.
- FIG. 1 is a block diagram illustrating an example of a yield management system 10 in accordance with the invention implemented on a personal computer 12 .
- the personal computer may include a display unit 14 , that may be a cathode ray tube (CRT), a liquid crystal display or the like, a processing unit 16 and one or more input/output devices 18 that permit a user to interact with the software application being executed by the personal computer.
- the input/output devices may include a keyboard 20 and a mouse 22 , but may also include other peripheral devices such as printers, scanners and the like.
- the processing unit 16 may further include a central processing unit (CPU) 24 , a persistent storage device 26 , such as a hard disk, a tape drive, an optical disk system, a removable disk system or the like and a memory 28 .
- the CPU may control the persistent storage device and memory.
- a software application may be permanently stored in the persistent storage device and then may be loaded into the memory 28 when the software application is going to be executed by the CPU.
- the memory 28 may contain a yield manager 30 .
- the yield manager may be implemented as one or more software applications that are executed by the CPU.
- the yield management system may also be implemented using hardware and may be implemented on different types of computer systems, such as client/server systems, web servers, mainframe computers, workstations and the like. Now, more details of the implementation of the yield management system in software will be described.
- FIG. 2 is block diagram illustrating more details of the yield management system 30 in accordance with the invention.
- the yield management system may receive a data set containing various types of semiconductor process data including continuous/numerical data, such as temperature or pressure, and categorical data, such as the lot number of the particular device.
- the yield management system in accordance with the invention may process the data set, generate a model, apply one or more statistical tools to the model and data set and generate an output that may indicate, for example, the key factors/parameters that affected the yield of the devices that generated the current data set.
- the data may be input to a data preprocessor 32 that may validate the data and remove any missing data records.
- the output from the data preprocessor may be fed into a model builder 34 so that a model of the data set may be automatically generated by the system.
- the user may enter model modifications into the model builder to modify the model based on, for example, past experience with the particular data set.
- a final model is output and made available to a statistical tool library 36 .
- the library may contain one or more different statistical tools that may be used to analyze the final model.
- the output of the system may be, for example, a listing of one or more factors/parameters that contributed to the yield of the devices that generated the data set being analyzed. As described above, the system is able to simultaneously identify multiple yield factors. Now, a yield management method in accordance with the invention will be described.
- FIG. 3 is a flowchart illustrating an example of a yield management method 40 in accordance with the invention.
- the method may include receiving an input data set in step 41 and preprocessing the input data set in step 42 to clean up the data set (e.g., validate the data and remove any data records containing missing, erroneous or invalid data elements).
- the cleaned up data set may be used to build a model and the user may enter model modifications in step 46 .
- the model Once the model is complete, it may be analyzed in step 48 using a variety of different statistical tools to generate yield management information such as key yield factors.
- the data preprocessing step 42 helps to clean up the incoming data set so that the later analysis may be more fruitful.
- the yield management system in accordance with the invention can handle data sets with complicated data structures.
- a yield data set typically has hundreds of different variables. These variables may include both a response variable, Y, and predictor variables, X 1 , X 2 , . . . , X m , that may be of a numerical type or a categorical type.
- a variable is a numerical type variable if its values are real numbers, such as different temperatures at different time times during the process.
- a variable is a categorical type variable if its values are of a set of finite elements not necessarily having any natural ordering. For example, a categorical variable could takes take values in a set of ⁇ MachineA, MachineB, MachineC ⁇ or values of (Lot 1 , Lot 2 or Lot 3 ).
- the data pre-processing step removes the cases or variables having missing values.
- the preprocessing first may remove all predictor variables that are “bad”. By “bad”, it is understood that either a variable has too much missing data, ⁇ MS, or, for a categorical variable, if the variable has too many distinct classes, ⁇ DC.
- both MS and DC are user defined thresholds so that the user may set these values and control the preprocessing of the data.
- data preprocessing may remove all cases with missing data. If one imagines that the original data set is a matrix with each column representing a single variable, then data preprocessing first removes all “bad” columns (variables) and then removes “bad rows” (missing data) in the remaining data set with the “good” columns.
- FIG. 4 is a diagram illustrating an example of the data preprocessing procedure in accordance with the invention.
- the MS variable is set to 2.
- FIG. 4 shows an original data set 50 , a data set 52 once bad columns have been removed and a data set 54 once the bad rows have been removed.
- the original data set 50 may include three predictor variables (Pred 1 , Pred 2 and Pred 3 ) and a numerical variable (Response) wherein three values for Pred 3 are unknown and one value for Pred 2 is unknown. Since the MS is set to 2 in this example, any predictor variables that have more than two unknown values are removed. Thus, as shown in the processed data set 52 , the column containing the Pred 3 variable is removed from the data set.
- the Pred 2 variable Since the Pred 2 variable have has only one missing value, it is not removed from the data set in this step. Next, any bad rows of data are removed from the data set. In the example shown in FIG. 4 , the row with a Pred 1 value of 0.5 is removed since the row contained an unknown value for variable Pred 2 . Thus, once the preprocessing has been completed, the data set 54 contains no missing values so that the statistical analysis may produce better results. Now, the model building step in accordance with the invention will be described in more detail.
- the yield management system uses a decision tree-based method.
- the method partitions the data set, D, into sub-regions.
- the tree structure may be a hierarchical way to describe a partition of D. It is constructed by successively splitting nodes (as described below), starting with the root node (D), until some stopping criteria are met and the node is declared a terminal node. For each terminal node, a value or a class is assigned to all the cases within the node.
- FIG. 5 shows an example of a Yield Mine model decision tree 100 generated by the system.
- the data set contains 233 process step variables, 233 time variables corresponding to each process step, and 308 parametric test variables. All of the variables are not shown in FIG. 5 for clarity. All of these variables are used in the Yield Mine model building as predictor variables.
- the response variable in this example is named “Good DielRing” and represents the number of good dies around the edge of a wafer produced during a particular process run.
- the Yield Mine system using the decision tree prediction identifies one or more variables as key yield factors.
- the key yield factor variables are PWELLASH, FINISFI, TI_TIN_RTP_, and VTPSP_.
- PWELLASH and FINISFI are time variables associated with the process variables PWELLASH_and FINISFI_and TI 13 TIN_RTP_ TI — TIN — RTP_and VTPSP_are process variables. Note that, for each terminal node 102 in the decision tree, the value of the response variable at that terminal node is shown so that the user can view the tree and easily determine which terminal node (and thus which predictor variables) result in the best value of the response variable.
- a tree node if a tree node is not terminal, it has a splitting criterion for the construction of its sub-nodes as will be described in more detail below with reference to FIG. 6 .
- the root node is split into two sub-nodes depending on the criterion of whether PWELLASH is before or after 3:41:00 am, 07/03/98. If PWELLASH is before 3:41:00 am, 07/03/98, the case is put in the left sub-node. Otherwise, it is put in the right sub-node.
- the left sub-node is further split into its sub-nodes using the criterion FINISFI ⁇ 07/17/98 4:40:00 pm.
- TI_TIN_RTP — 2RTP
- n 0 max ⁇ 5, floor(0.02 ⁇ N) ⁇ where N is the total number of cases in D, and the function floor(x) gives the biggest integer that is less than or equal to x.
- FIG. 6 is a flowchart illustrating a method 110 for splitting nodes of a decision tree in accordance with the invention.
- step 112 a particular node of the decision tree, T, is selected. The process is then repeated for each node of the tree.
- i 1, . . . n ⁇ . In step 122 , the method may determine if ⁇ j >V wherein V is a user-defined threshold value as described below. If ⁇ j is not greater than the threshold value, then in step 124 , the splitting process for the particular node is stopped and the processing begins with the next node.
- step 126 the node, T, is split into one or more sub-nodes, T 1 , T 2 , . . . , T m , based on the variable j.
- a decision tree is built to find relations between the response variable and the predictor variables.
- Each split, S, of a node, T partitions the node into m subnodes T 1 , T 2 , . . . , T m , in hopes that the subnodes are less “noisy” than T as defined below.
- a real-value function that measures the noisiness of a node T, g(T) may be defined wherein N T denotes the number of cases in T, and N T i denotes the number of cases in the ith sub-node T i .
- the method may define ⁇ (S) to be the goodness of split function for a split, S, wherein:
- a node split depends only on one predictor variable.
- the method may search through all predictor variables, X 1 , X 2 , . . . , X n , one by one to find the best split based on each predictor variable. Then, the best split is the one to be used to split the node. Therefore, it is sufficient to explain the method by describing how to find the best split for a single predictor variable.
- Y and the predictor variable, X, as being either categorical or numerical, there are four possible scenarios. Below, details for each scenario on how the split is constructed and how to assign a proper value or a class to a terminal node is described. Now, the case when Y and X are both categorical variables is described.
- Y is Categorical and X is Ategorical Categorical
- a split rule has the form of a question: Is x ⁇ B S , where B S is a subset of B. If the answer to the question is yes, then the case is put in the left sub-node T L . Otherwise it is put in the right sub-node T R .
- N i T denote the number of class i cases in node T.
- the function which measure measures the noisiness of the node, g(T) is defined as:
- ⁇ ⁇ ( s ) g ⁇ ( T ) - N T L N T ⁇ g ⁇ ( T L ) - ⁇ N T R N T ⁇ g ⁇ ( T R ) ( 3 )
- the method searches through all positions 2 l splits to find the one that minimizes ⁇ (S). Now, the case where Y is categorical and X is numerical will be described.
- the split in this case is also binary as above.
- T L and T R to denote the two sub-nodes of T.
- a split rule takes one of the two forms.
- N T and g(T) in the same way as in the previous scenario. Since a split in this case has one more parameter than a split in the first case above, the method may define
- ⁇ ⁇ ( S ) ⁇ g ⁇ ( T ) - N T L N T ⁇ g ⁇ ( T L ) - N T R N T ⁇ g ⁇ ( T R ) if ⁇ ⁇ S ⁇ ⁇ has ⁇ ⁇ form ⁇ ⁇ ( 1 ) c ⁇ ( g ⁇ ( T ) - N T L N T ⁇ g ⁇ ( T L ) - N T R N T ⁇ g ⁇ ( T R ) ) if ⁇ ⁇ S ⁇ ⁇ has ⁇ ⁇ form ⁇ ⁇ ( 2 )
- the split rule is the same as the first case.
- the only difference is the way in which the noiseness function, g(T), is defined.
- g(T) since Y is numerical, let y 1 , y 2 , . . . , y N T denote the response variable for all cases in T.
- g(T) is then defined as the L P norm of the empirical distribution function of Y in T.
- ⁇ (S) may be defined as:
- ⁇ ⁇ ( s ) g ⁇ ( T ) - N T L N T ⁇ g ⁇ ( T L ) - ⁇ N T R N T ⁇ g ⁇ ( T R )
- the split rule is defined the same way as in the second case above, and g(T) is defined the same way as in the third case.
- the method may search through all possible splits to come up with the split, S*, which minimizes ⁇ (S), where:
- ⁇ ⁇ ( S * ) ⁇ g ⁇ ( T ) - N T L N T ⁇ g ⁇ ( T L ) - ⁇ N T R N T ⁇ g ⁇ ( T R ) if ⁇ ⁇ S * ⁇ ⁇ has ⁇ ⁇ form ⁇ ⁇ ( 1 ) c ⁇ ( g ⁇ ( T ) - N T L N T ⁇ g ⁇ ( T L ) - ⁇ N T R N T ⁇ g ⁇ ( T R ) ) if ⁇ ⁇ S * ⁇ ⁇ has ⁇ ⁇ form ⁇ ⁇ ( 2 )
- the node T is split into d sub-nodes, T 1 , T 2 , . . . , T d .
- T 1 , T 2 , . . . , T d Let ⁇ circumflex over (x) ⁇ 1 , ⁇ circumflex over (x) ⁇ 2 , . . . , ⁇ circumflex over (x) ⁇ N T denote the ordered values of x 1 , x 2 , . . . , x N T in an increasing order.
- (x, y) ⁇ T i if ⁇ circumflex over (x) ⁇ L 1 ⁇ x ⁇ circumflex over (x) ⁇ R i
- h 2 ⁇ 1 if ⁇ ⁇ i ⁇ N T ⁇ ⁇ mod ⁇ ⁇ d 0 Otherwise
- ⁇ (T) is assigned to the biggest class in the node.
- ⁇ (T) is picked arbitrarily among those classes.
- the cost function is the same function g(T) which measure measures the “noisiness” of the node as described above.
- ⁇ (T) is assigned to the value which minimizes the cost. It can be easily shown that, when g(T) is the L 2 norm of the node, ⁇ (T) equals to the mean value of the node. Now, the pruning of the decision tree will be described.
- An n-fold cross validation procedure starts with dividing the data set into n subsets, D 1 ,D 2 , . . . , D n .
- the division is random and each subset contains as nearly as possible, the same number of cases.
- D i c denote the compliment set of D i .
- TR 1 , TR 2 , . . . , TR n are built using the D 1 c , D 2 c , . . . , D n c .
- T T denote the set of terminal nodes of a tree node T.
- C(t) be the cost function of node t if all nodes under t are pruned.
- g ⁇ ( T ) ⁇ ( C ⁇ ( T ) - C ⁇ ( T T ) ⁇ T T ⁇ - 1 if ⁇ ⁇ T ⁇ ⁇ is ⁇ ⁇ not ⁇ ⁇ a ⁇ ⁇ terminal ⁇ ⁇ node 0 if ⁇ ⁇ T ⁇ ⁇ is ⁇ ⁇ a ⁇ ⁇ terminal ⁇ ⁇ node
- T T is the cardinality of T T .
- TR N be the tree obtained by pruning off T 0 from TR. Every node T N in tree TR N comes from the node T in TR. If we can show that, for every T N , g(T N ) ⁇ g(T), then, by definition, g(TR N ) ⁇ g(TR).
- T N For node T N , its counter part counterpart T contains T 0 as one of its sub-node sub-nodes. 2) For node T N , its counter part counterpart T does not contain T 0 as a sub-node.
- g ⁇ ( T N ) C ⁇ ( T N ) - C ⁇ ( T T N ) ⁇ T T N ⁇ - 1
- g ⁇ ( T ) C ⁇ ( T ) - C ⁇ ( T T ) ⁇ T T ⁇ - 1 .
- This theorem establishes a relationship between the size of a tree structure model and its complexity g(TR). In general, the bigger the complexity the more the number of nodes of the tree.
- Cross validation can point out which complexity value v is likely to produce the most accurate tree structure. Using this v, we can prune the tree generated from the whole data set until its complexity is just below v. This pruned tree is used as the final tree structure model. Now, the model modification step will be described.
- the predictor variables can be correlated with each other.
- the splits of a node based on different parameters can produce similar results. In such cases, it is really up to the process engineer who uses the software to identify which parameter is the real cause of the Yield problem.
- all predictor variables are ranked according to their relative significance if the split were based on them.
- X i be the variable picked by the method which the split, S*, is based on.
- FIG. 7 illustrates two trees 130 , 140 wherein the first tree 130 is built using the PWELLASH variable selected by the method and the second tree 140 is built using the user-selected parameter PWELLCB.
- FIG. 8 is a flowchart illustrating a method 150 for tree prediction in accordance with the invention.
- step 152 the previously generated tree model is input.
- the prediction value, X, of interest is input.
- step 156 the prediction using the tree starts at the root node, T.
- step 158 the method may determine if the node is terminal. If the current node is not terminal, then the method may assign X to one of the sub-nodes in step 160 according to the split rule described above. After the assignment in step 160 , the method loops back to step 158 to test if the next node is a terminal node. If the node is terminal, then the method outputs the prediction value in step 162 and the method is completed. Now, the analysis step in accordance with the invention will be described.
- All the basic statistical analysis tools are available to help the user to validate the model and identify the yield problem.
- a right click of the mouse produces a list of tools available as shown in FIG. 9 . Every analysis is done at the node level (i.e., it only uses the data from that particular node).
- An example of the analysis tools available at the right node after the first split is shown in FIG. 9 .
- those analysis tools may include box-whisker chart, Cumsum control chart, Shewhet control chart, histogram, one-way ANOVA, two sample comparison and X-Y correlation analysis.
- the particular tools available to the user depend upon the nature of the X and Y parameters (e.g., continuous vs. categorical).
- the tree After each model is built, the tree can be saved for future predictions. If a new set of parameter values is available, it can be fed into the model and generate prediction of the response value for each case. This functionality can be very handy for the user.
Abstract
A system and method for yield management is disclosed wherein a data set containing one or more prediction variable values and one or more response values is input into the system. The system can pre-process the input data set to remove prediction variables with missing values and data sets with missing values. The pre-processed data can then be used to generate a model that may be a decision tree. The system can accept user input to modify the generated model. Once the model is complete, one or more statistical analysis tools can be used to analyze the data and generate a list of the key yield factors for the particular data set.
Description
This invention relates generally to a system and method for managing a semiconductor process and in particular to a system and method for managing yield in a semiconductor process.
The semiconductor industry is continually pushing toward smaller and smaller geometries of the semiconductor devices being produced since smaller devices generate less heat and operate at a higher speed than larger devices. Currently, a single chip may contain over one billion patterns. The semiconductor manufacturing process is extremely complicated since it involves hundreds of processing steps. A mistake or small error at any of the process steps or tool specifications may cause lower yield in the final semiconductor product, wherein yield may be defined as the number of functional devices produced by the process as compared to the theoretical number of devices that could be produced assuming no bad devices. Improving yield is a critical problem in the semiconductor industry and has a direct economic impact to the semiconductor industry. In particular, a higher yield translates into more devices that may be sold by the manufacturer.
Semiconductor manufacturing companies have been collecting data for a long time about various process parameters in an attempt to improve the yield of the semiconductor process. Today, an explosive growth of database technology has contributed to the yield analysis that each company follows. In particular, the database technology has far outpaced the yield management ability when using conventional statistical methods to interpret and relate yield to major yield factors. This has created a need for a new generation of tools and techniques for automated and intelligent database analysis for yield management.
Current conventional yield management systems have a number of limitations and disadvantages which make them less desirable to the semiconductor industry. For example, the conventional systems may require some manual processing which slows the analysis and makes it susceptible to human error. In addition, these conventional systems may not handle both continuous and categorical yield management variables. Some conventional systems cannot handle missing data elements and do not permit rapid searching through hundreds of yield parameters to identify key yield factors. Some conventional systems output data that is difficult to understand or interpret even by knowledgeable semiconductor yield management people. In addition, the conventional systems typically process each yield parameter separately, which is time consuming and cumbersome and cannot identify more than one parameter at a time.
Thus, it is desirable to provide a yield management system and method which solves the above limitations and disadvantages of the conventional systems and it is to this end that the present invention is directed.
The yield management system and method in accordance with the invention may provide many advantages over conventional methods and systems which make the yield management system and method more useful to semiconductor device manufacturers. In particular, the system may be fully automated and easy to use so that no extra training is necessary to make use of the yield management system. In addition, the system handles both continuous (e.g., temperature) and categorical (e.g., Lot 1, Lot 2, etc.) variables. The system also automatically handles missing data during a pre-processing step. The system can rapidly search through hundreds of yield parameters and generate an output indicating the one or more key yield factors/parameters. The system generates an output (a decision tree) that is easy to interpret and understand. The system is also very flexible in that it permits prior yield parameter knowledge (from users) to be easily incorporated into the building of the model in accordance with the invention. Unlike conventional systems, if there is more than one yield factor/parameter affecting the yield of the process, the system can identify all of the parameters/factors simultaneously so that the multiple factors are identified during a single pass through the yield data.
In accordance with a preferred embodiment of the invention, the yield management method may receive a yield data set. When a data set comes in, it first goes through a data preprocessing step in which the validity of the data in the data set is checked and cases or parameters with missing data are eliminated. Using the cleaned up data set, a Yield Mine model is built during a model building step. Once the model is generated automatically by the yield management system, the model may be modified by one or more users based on their experience or prior knowledge of the data set. Once the model has been modified, the data set may be processed using various statistical analysis tools to help the user better understand the relationship between the response and predict variables.
The invention is particularly applicable to a computer-implemented software-based yield management system and it is in this context that the invention will be described. It will be appreciated, however, that the system and method in accordance with the invention has greater utility since it may be implemented in hardware or may incorporate other modules or functionality not described herein.
In accordance with the invention, the yield management system may also be implemented using hardware and may be implemented on different types of computer systems, such as client/server systems, web servers, mainframe computers, workstations and the like. Now, more details of the implementation of the yield management system in software will be described.
In more detail, the data may be input to a data preprocessor 32 that may validate the data and remove any missing data records. The output from the data preprocessor may be fed into a model builder 34 so that a model of the data set may be automatically generated by the system. Once the system has generated a model, the user may enter model modifications into the model builder to modify the model based on, for example, past experience with the particular data set. Once the user modifications have been incorporated into the model, a final model is output and made available to a statistical tool library 36. The library may contain one or more different statistical tools that may be used to analyze the final model. The output of the system may be, for example, a listing of one or more factors/parameters that contributed to the yield of the devices that generated the data set being analyzed. As described above, the system is able to simultaneously identify multiple yield factors. Now, a yield management method in accordance with the invention will be described.
The data preprocessing step 42 helps to clean up the incoming data set so that the later analysis may be more fruitful. The yield management system in accordance with the invention can handle data sets with complicated data structures. A yield data set typically has hundreds of different variables. These variables may include both a response variable, Y, and predictor variables, X1, X2, . . . , Xm, that may be of a numerical type or a categorical type. A variable is a numerical type variable if its values are real numbers, such as different temperatures at different time times during the process. A variable is a categorical type variable if its values are of a set of finite elements not necessarily having any natural ordering. For example, a categorical variable could takes take values in a set of {MachineA, MachineB, MachineC} or values of (Lot1, Lot2 or Lot3).
It is very common for a yield data set to have missing values. The data pre-processing step removes the cases or variables having missing values. In particular, the preprocessing first may remove all predictor variables that are “bad”. By “bad”, it is understood that either a variable has too much missing data, ≧MS, or, for a categorical variable, if the variable has too many distinct classes, ≧DC. In accordance with the invention, both MS and DC are user defined thresholds so that the user may set these values and control the preprocessing of the data. In a preferred embodiment, the default value values are MS=0.05×N, DC=32, where N is the total number of cases in the data set.
Once the “bad” predictor variables are removed, then, for the remaining data set, data preprocessing may remove all cases with missing data. If one imagines that the original data set is a matrix with each column representing a single variable, then data preprocessing first removes all “bad” columns (variables) and then removes “bad rows” (missing data) in the remaining data set with the “good” columns.
The yield management system uses a decision tree-based method. In particular, the method partitions the data set, D, into sub-regions. The tree structure may be a hierarchical way to describe a partition of D. It is constructed by successively splitting nodes (as described below), starting with the root node (D), until some stopping criteria are met and the node is declared a terminal node. For each terminal node, a value or a class is assigned to all the cases within the node. Now, the node splitting method and example of the decision tree will be described in more detail.
In this example, out of all 774 predictor variables, the Yield Mine system using the decision tree prediction, identifies one or more variables as key yield factors. In this example, the key yield factor variables are PWELLASH, FINISFI, TI_TIN_RTP_, and VTPSP_. In this example, PWELLASH and FINISFI are time variables associated with the process variables PWELLASH_and FINISFI_and TI13 TIN_RTP_ TI—TIN—RTP_and VTPSP_are process variables. Note that, for each terminal node 102 in the decision tree, the value of the response variable at that terminal node is shown so that the user can view the tree and easily determine which terminal node (and thus which predictor variables) result in the best value of the response variable.
In the tree structure model in accordance with the invention, if a tree node is not terminal, it has a splitting criterion for the construction of its sub-nodes as will be described in more detail below with reference to FIG. 6 . For example, the root node is split into two sub-nodes depending on the criterion of whether PWELLASH is before or after 3:41:00 am, 07/03/98. If PWELLASH is before 3:41:00 am, 07/03/98, the case is put in the left sub-node. Otherwise, it is put in the right sub-node. The left sub-node is further split into its sub-nodes using the criterion FINISFI <07/17/98 4:40:00 pm. The right sub-node is also further split into its sub-nodes using the criterion TI_TIN_RTP—=2RTP, where TI13TIN_RTP_ TI—TIN—RTP_is a process step parameter and 2RTP is one of its specification if the variable is continuous. For a terminal node, the average value of all cases under the node is shown. In this example, it is pretty clear to the user that when PWELLASH<07/03/98 3:41:00 am, the yield is higher, especially when the criterion FINISFI<07/17/98 4:40:00 pm is also satisfied. The worst case happens when PWELLASH>07/03/98 3:41:00 am, and TI_TIN_RTP—<>1RTP, and VTPSPE—ε{23STEP, 25STEP, 26STEP}.
To find the proper stopping criteria for tree construction is a difficult problem. To deal with the problem we first over-grow the tree and then apply cross validation techniques to prune the tree. Pruning the tree is described in detail in the following sections. To grow an over sized tree, the method may keep splitting nodes in the tree until all cases in the node having the same response value, or the number of cases in the node is less than a user defined threshold, n0. The default in our algorithm is n0=max{5, floor(0.02×N)} where N is the total number of cases in D, and the function floor(x) gives the biggest integer that is less than or equal to x. Now, the construction of the decision tree and the method for splitting tree nodes in accordance with the invention will be described.
If Φj>V, then in step 126, the node, T, is split into one or more sub-nodes, T1, T2, . . . , Tm, based on the variable j. In step 128, for each sub-node, Tk where k=1, . . . , m, the same node splitting method is applied. In this manner, each node is processed to determine if splitting is appropriate and then each sub-node created during a split is also checked for susceptibility to splitting as well. Thus, the nodes of the decision tree are split in accordance with the invention. Now, more details of the decision tree construction and node splitting method will be described.
A decision tree is built to find relations between the response variable and the predictor variables. Each split, S, of a node, T, partitions the node into m subnodes T1, T2, . . . , Tm, in hopes that the subnodes are less “noisy” than T as defined below. To quantify this idea, a real-value function that measures the noisiness of a node T, g(T), may be defined wherein NT denotes the number of cases in T, and NT i denotes the number of cases in the ith sub-node Ti. The partition of T is exclusive, therefore, Σi=1 mNT i =NT. Next, the method may define Φ(S) to be the goodness of split function for a split, S, wherein:
We say that the subnodes are less noisy than their ancestor if Φ(S)>0. In Yield Mine, a node split depends only on one predictor variable. The method may search through all predictor variables, X1, X2, . . . , Xn, one by one to find the best split based on each predictor variable. Then, the best split is the one to be used to split the node. Therefore, it is sufficient to explain the method by describing how to find the best split for a single predictor variable. Depending on the types of the response variable, Y, and the predictor variable, X, as being either categorical or numerical, there are four possible scenarios. Below, details for each scenario on how the split is constructed and how to assign a proper value or a class to a terminal node is described. Now, the case when Y and X are both categorical variables is described.
Y is Categorical and X is Ategorical Categorical
Suppose that Y takes values in the set A={A1, A2 , . . . , Ak}, and X takes values in the set B={B1,B2, . . . , Bl}. In this case, only binary splits are allowed. That is, if a node is split, it produces 2 sub-nodes, a left sub-node, TL, and a right sub-node, TR. A split rule has the form of a question: Is xΣBS, where BS is a subset of B. If the answer to the question is yes, then the case is put in the left sub-node TL. Otherwise it is put in the right sub-node TR. There are 2l different subsets of B. Therefore, there are 2l different splits.
Let Ni T denote the number of class i cases in node T. The function which measure measures the noisiness of the node, g(T), is defined as:
Since there are only two sub-nodes, the goodness of split function, Φ(S), is:
The method thus searches through all positions 2l splits to find the one that minimizes Φ(S). Now, the case where Y is categorical and X is numerical will be described.
Y is Categorical and X is Numerical
Suppose that Y takes values in the set A={A1,A2, . . . , Ak} and x1,x2, . . . , xN T denotes the numerical predictor variable in each case. The split in this case is also binary as above. We will again use TL and TR to denote the two sub-nodes of T. A split rule takes one of the two forms.
-
- 1) Is x≦α?
- 2) Is α<x≦β?
- where α and β take values from the set {x1, x2, . . . , xN
T }. For each case, if the answer to the split rule is true, it is put in TL. Otherwise it is put in TR.
- where α and β take values from the set {x1, x2, . . . , xN
Now, we define NT and g(T) in the same way as in the previous scenario. Since a split in this case has one more parameter than a split in the first case above, the method may define
-
-
- wherein c is between 0 and 1 and can be set by the user. The default is 0.9. There are only finite split rules of form (1) and (2). The method thus searches through all possible splits to find the one that minimizes Φ(S). Now, the case where Y is numerical and X is categorical will be described.
-
Y is Numerical and X is Categorical
In this case, the split rule is the same as the first case. The only difference is the way in which the noiseness function, g(T), is defined. In particular, since Y is numerical, let y1, y2, . . . , yN T denote the response variable for all cases in T. g(T) is then defined as the LP norm of the empirical distribution function of Y in T. In particular,
Then, Φ(S) may be defined as:
As in the first case, there are only a finite number of possible splits and the method searches through all possible splits to find the one that minimizes Φ(S). Now, a fourth case where Y and X are both numerical will be described.
Y is Numerical and X is Numerical
In this case, the split rule is defined the same way as in the second case above, and g(T) is defined the same way as in the third case. Thus, the method may search through all possible splits to come up with the split, S*, which minimizes Φ(S), where:
Then, a linear regression model, as set forth below, is fit
y=a0+a1x+ε, (5)
y=a0+a1x+ε, (5)
-
- where ε is assumed to be i.i.d. Gaussian with mean 0 and variance σ2
Now, let ŷi denote the fitted value of the model for case i. Let r be the LP norm of the residuals. That is,
- where ε is assumed to be i.i.d. Gaussian with mean 0 and variance σ2
If Φ(S*)<cxr , then S* is the best split. Otherwise, the linear model fits better than split form 1 and 2. In this case, the node T is split into d sub-nodes, T1, T2, . . . , Td. Let {circumflex over (x)}1,{circumflex over (x)}2, . . . , {circumflex over (x)}N T denote the ordered values of x1, x2, . . . , xN T in an increasing order. Then a case (x, y)εTi if
{circumflex over (x)}L1 ≦x<{circumflex over (x)}R i
where
{circumflex over (x)}L
where
h1=max{i, (NT mod d)},
-
-
- where d is a user defined parameter. The default value of d is 4. Now, assigning a value or class to a terminal node will be described.
-
When a terminal node is reached, a value or a class, ƒ(T), is assigned to all cases in the node depending on the type of the response variable. If the type of the response variable is numerical, ƒ(T) is a real value number. Otherwise, ƒ(T) is set to be a class member of the set A={A1, A2 , . . . , Ak}. Now, the cost function may be determined if Y is categorical or numerical.
Y is Categorical
Assume Y takes values in set A={A1, A2, . . . , Ak}. T is a terminal node with NT cases. Let Ni T be the number, Y, equal to Ai in T, iε{1,2, . . . , L}. If the node is pure (i.e., all the cases in the node has the same response Aj), then, ƒ(T)=Aj. Otherwise, the node is not pure. No matter which class, ƒ(T), is assigned to, there is at least one case misclassified in the node. Let u(i|j) be the cost of assigning a class j case to class i. Then the total cost of assigning ƒ(T) to node T is
-
- where ƒ(T)=Aj, such that U(Aj)=min(U(Ai), iε{1,2, . . . , l})
If u(i|j) is constant for all i and j, then ƒ(T) is assigned to the biggest class in the node. When there is a tie for the best choice of ƒ(T) among several classes, ƒ(T) is picked arbitrarily among those classes. Now, the case where Y is numerical is described.
Y is Numerical
In this case, the cost function is the same function g(T) which measure measures the “noisiness” of the node as described above. ƒ(T) is assigned to the value which minimizes the cost. It can be easily shown that, when g(T) is the L2 norm of the node, ƒ(T) equals to the mean value of the node. Now, the pruning of the decision tree will be described.
By growing an oversized tree as described above, one encounters the problem of over fitting. To deal with this problem, cross validation is used to find the right size of the model. Then, the tree can be pruned to the proper size. Ideally, one would like to split the data into two sets. One for constructing the model and one for testing. But, unless the data set is sufficiently large, using only part of the data set to build the model reduces its accuracy. Therefore, cross validation is the preferred procedure.
An n-fold cross validation procedure starts with dividing the data set into n subsets, D1,D2, . . . , Dn. The division is random and each subset contains as nearly as possible, the same number of cases. Let Di c denote the compliment set of Di. Then n tree structure models TR1, TR2, . . . , TRn are built using the D1 c, D2 c, . . . , Dn c. Now we can use the cases in Di c to test the validity of TRi and to find out what is the right size of the tree model.
A measure of the size of a tree structure model, g(TR), the complexity of TR, is defined as follows. Let TT denote the set of terminal nodes of a tree node T. Let C(t) be the cost function of node t if all nodes under t are pruned. Thus,
where |TT| is the cardinality of TT, and
where P(t) is the probability function.
Next, one can define
g(TR)=max(g(T)|T is a node of TR)
g(TR)=max(g(T)|T is a node of TR)
Theorem: Let T0 be the node, such that g(T0)=g(TR). Then, pruning off all sub-nodes of T0 will not increase the complexity of the tree.
Proof
Let TRN be the tree obtained by pruning off T0 from TR. Every node TN in tree TRN comes from the node T in TR. If we can show that, for every TN, g(TN)≦g(T), then, by definition, g(TRN)≦g(TR).
There are two scenarios. 1) For node TN, its counter part counterpart T contains T0 as one of its sub-node sub-nodes. 2) For node TN, its counter part counterpart T does not contain T0 as a sub-node. In the second scenario, TN and T has have the same structure. Therefore, g(TN)=g(T). Now, let us consider the first scenario. If TN has no sub-node, then, g(TN)=0≦g(T). Otherwise, by definition,
Since, C(TN)=C(T), C(T)−C(TT)−(C(TN)−C(TT N))=C(T0)−C(T0T), |TT|−1−(|TT N|−1)=|T0|−1, and g(T0)=g(TR), therefore, g(T)≦g(T0). Hence, g(TN)≦g(T).
This theorem establishes a relationship between the size of a tree structure model and its complexity g(TR). In general, the bigger the complexity the more the number of nodes of the tree.
Cross validation can point out which complexity value v is likely to produce the most accurate tree structure. Using this v, we can prune the tree generated from the whole data set until its complexity is just below v. This pruned tree is used as the final tree structure model. Now, the model modification step will be described.
In some cases, the predictor variables can be correlated with each other. The splits of a node based on different parameters can produce similar results. In such cases, it is really up to the process engineer who uses the software to identify which parameter is the real cause of the Yield problem. To help the engineer to identify the possible candidates of parameters at any node split, all predictor variables are ranked according to their relative significance if the split were based on them. To be more precise, let Xi be the variable picked by the method which the split, S*, is based on.
For any j≠i let Sj denote the best split based on Xj. Then, define
Since S* is the best split 0≦q(i)≦1 . Then, when double clicking on a node, a list of all predictor variables ranked by their q values is shown as illustrated in FIG. 5 . If the user decides it is more appropriate to split on a predictor variable other than the one picked by the method, the user can then highlight it from the list, and a single click of the mouse will reproduce the tree and force node T to be split based on user picked parameters. For example, FIG. 7 illustrates two trees 130, 140 wherein the first tree 130 is built using the PWELLASH variable selected by the method and the second tree 140 is built using the user-selected parameter PWELLCB. Now, a method for tree prediction in accordance with the invention will be described in more detail.
All the basic statistical analysis tools are available to help the user to validate the model and identify the yield problem. At each node, a right click of the mouse produces a list of tools available as shown in FIG. 9 . Every analysis is done at the node level (i.e., it only uses the data from that particular node). An example of the analysis tools available at the right node after the first split is shown in FIG. 9 . In this example, those analysis tools may include box-whisker chart, Cumsum control chart, Shewhet control chart, histogram, one-way ANOVA, two sample comparison and X-Y correlation analysis. The particular tools available to the user depend upon the nature of the X and Y parameters (e.g., continuous vs. categorical).
After each model is built, the tree can be saved for future predictions. If a new set of parameter values is available, it can be fed into the model and generate prediction of the response value for each case. This functionality can be very handy for the user.
While the foregoing has been with reference to a particular embodiment of the invention, it will be appreciated by those skilled in the art that changes in this embodiment may be made without departing from the principles and spirit of the invention, the scope of which is defined by the appended claims.
Claims (34)
1. A computerized yield management system, comprising:
pre-processing computing device means executed by a data pre-processor in a computer processing unit for pre-processing an input data set comprising one or more prediction variables and one or more response variables containing data about a particular semiconductor process, the pre-processing computing device means further comprising means for removing one or more prediction variables from the input data set having more than a predetermined number of missing values, means for removing one or more prediction variables from the input data set having more than a predetermined number of classes, and means for removing data having more than a predetermined number of missing values to generate pre-processed data;
model generating computer device means executed by a model builder in the computer processing unit, the model builder being in communication with the data pre-processor, for generating a model based on the pre-processed data, the model being a decision tree;
computing device means executed by the model builder for modifying the model based on user input; and
computing device means executed by a statistical tool library in the computer processing unit, the statistical tool library being in communication with the model builder, for analyzing the model using a statistical tool to generate one or more key yield factors based on the input data set.
2. The system of claim 1 , wherein the model generating computing device means further comprises means for building a decision tree containing a root node, one or more intermediate nodes and one or more terminal nodes wherein a response value at the one or more terminal nodes is presented to the user and splitting means for splitting a node in the tree into one or more sub-nodes based on prediction variables contained in the node.
3. The system of claim 2 , wherein the splitting means further comprises means for determining if a number of data cases in a node are less than a predetermined threshold value, means for calculating a goodness of split value for splitting the node based on each predictor prediction variable in the node, means for selecting prediction variables having a maximum goodness of split value and means for splitting the node into one or more sub-nodes based on the prediction variables having the maximum goodness of split value.
4. The system of claim 3 , wherein the one or more prediction variables and the one or more response variables are categorical variables.
5. The system of claim 4 , wherein the splitting means further comprises a splitting rule and a goodness of split rule, the splitting rule comprising means for placing a case into a left sub-node if the case is included in the values of the predictor prediction variable and wherein the goodness of split rule is of the form:
where Φ(s) represents a goodness of split rule for a split, s; g(T) represents noisiness of a node T; g(TL) represents noisiness of a left sub-node of node T; g(TR) represents noisiness of a right sub-node of node T; NT is a number of cases in node T; NT L is a number of cases in a left sub-node of node T; and NT R is a number of cases in a right sub-node of node T.
6. The system of claim 3 , wherein the one or more prediction variables and the one or more response variables are numerical.
7. The system of claim 6 , wherein the splitting means further comprises a splitting rule and a goodness of split rule, the splitting rule comprising means for placing a case into a left sub-node if the value of the predictor prediction variable for a particular case is less than or equal to a first predetermined value of the predictor prediction variables or if the value of the predictor prediction variable for the particular case is between the first predetermined value and a second predetermined value of the predictor prediction variables and wherein the goodness of split rule is of the form:
where Φ(S*) represents a goodness of split rule for a split, S*; g(T) represents noisiness of a node T; g(TL) represents noisiness of a left sub-node of node T; g(TR) represents noisiness of a right sub-node of node T; NT is a number of cases in node T; NT L is a number of cases in a left sub-node of node T; NT R is a number of cases in a right sub-node of node T; c is a user-selectable variable between 0 and 1.
8. The system of claim 3 , wherein the a response variable from the one or more response variables is a categorical variable and the a prediction variable from the one or more prediction variables is a numerical variable.
9. The system of claim 8 , wherein the splitting means further comprises a splitting rule and a goodness of split rule, the splitting rule comprising means for placing a case into a left sub-node if the value of the predictor prediction variable for a particular case is less than or equal to a first predetermined value of the predictor prediction variables or if the value of the predictor prediction variable for the particular case is between the first predetermined value and a second predetermined value of the predictor prediction variables and wherein the goodness of split rule is of the form:
where Φ(S) represents a goodness of split rule for a split, S; g(T) represents noisiness of a node T; g(TL) represents noisiness of a left sub-node of node T; g(TR) represents noisiness of a right sub-node of node T; NT is a number of cases in node T; NT L is a number of cases in the left sub-node of node T; NT R is a number of cases in the right sub-node of node T; c is a user-selectable variable between 0 and 1.
10. The system of claim 3 , wherein the a response variable from the one or more response variables is a numerical variable and the a prediction variable from the one or more prediction variables is a categorical variable.
11. The system of claim 10 , wherein the splitting means further comprises a splitting rule and a goodness of split rule, the splitting rule comprising means for placing a case into a left sub-node if the case is included in the values of the predictor prediction variable and wherein the goodness of split rule is of the form:
where Φ(s) represents a goodness of split rule for a split, s; g(T) represents noisiness of a node T; g(TL) represents noisiness of a left sub-node of node T; g(TR) represents noisiness of a right sub-node of node T; NT is a number of cases in node T; NT L is a number of cases in the left sub-node of node T; and NT R is a number of cases in the right sub-node of node T.
12. A yield management method, comprising:
pre-processing, via a computing device, an input data set comprising one or more prediction variables and one or more response variables containing data about a particular semiconductor process, the pre-processing further comprising removing one or more prediction variables from the input data set having more than a predetermined number of missing values, removing one or more prediction variables from the input data set having more than a predetermined number of classes and removing data having more than a predetermined number of missing values to generate pre-processed data;
generating, via the computing device, a model based on the pre-processed data, the model being a decision tree;
modifying, via the computing device, the model based on user input; and
analyzing, via the computing device, the model using statistical tools to examine one or more key yield factors based on the input data set.
13. The method of claim 12 , wherein the generated model further comprises building a decision tree containing a root node, one or more intermediate nodes and one or more terminal nodes wherein a response value at the one or more terminal nodes is presented to the user and splitting a node in the tree into one or more sub-nodes based on prediction variables contained in the node.
14. The method of claim 13 , wherein the splitting further comprises determining if a number of data cases in a node are less than a predetermined threshold value, calculating a goodness of split value for splitting the node based on each predictor prediction variable in the node, selecting prediction variables having a maximum goodness of split value and splitting the node into one or more sub-nodes based on the prediction variables having the maximum goodness of split value.
15. The method of claim 14 , wherein the one or more prediction variables and the one or more response variables are categorical variables.
16. The method of claim 15 , wherein the splitting further comprises a splitting rule and a goodness of split rule, the splitting rule comprising placing a case into a left sub-node if the case is included in the values of the predictor prediction variable and wherein the goodness of split rule is of the form:
where Φ(s) represents a goodness of split rule for a split, s; g(T) represents noisiness of a node T; g(TL) represents noisiness of a left sub-node of node T; g(TR) represents noisiness of a right sub-node of node T; NT is a number of cases in node T; NT L is a number of cases in the left sub-node of node T; and NT R is a number of cases in the right sub-node of node T.
17. The method of claim 14 , wherein the one or more prediction variables and the one or more response variables are numerical.
18. The method of claim 17 , wherein the splitting further comprises a splitting rule and a goodness of split rule, the splitting rule comprising placing a case into a left sub-node if the value of the predictor prediction variable for a particular case is less than or equal to a first predetermined value of the predictor prediction variables or if the value of the predictor prediction variable for the particular case is between the first predetermined value and a second predetermined value of the predictor prediction variables and wherein the goodness of split rule is of the form:
where Φ(S*) represents a goodness of split rule for a split, S*; g(T) represents noisiness of a node T; g(TL) represents noisiness of a left sub-node of node T; g(TR) represents noisiness of a right sub-node of node T; NT is a number of cases in node T; NT L is a number of cases in a left sub-node of node T; NT R is a number of cases in a right sub-node of node T; c is a user-selectable variable between 0 and 1.
19. The method of claim 14 , wherein the a response variable from the one or more response variables is a categorical variable and the a prediction variable from the one or more prediction variables is a numerical variable.
20. The method of claim 19 , wherein the splitting further comprises a splitting rule and a goodness of split rule the splitting rule comprising placing a case into a left sub-node if the value of the predictor prediction variable for a particular case is less than or equal to a first predetermined value of the predictor prediction variables or if the value of the predictor prediction variable for the particular case is between the first predetermined value and a second predetermined value of the predictor prediction variables and wherein the goodness of split rule is of the form:
where Φ(S) represents a goodness of split rule for a split, S; g(T) represents noisiness of a node T; g(TL) represents noisiness of a left sub-node of node T; g(TR) represents noisiness of a right sub-node of node T; NT is a number of cases in node T; NT L is a number of cases in the left sub-node of node T; NT R is a number of cases in the right sub-node of node T; c is a user-selectable variable between 0 and 1.
21. The method of claim 14 , wherein the a response variable from the one or more response variables is a numerical variable and the a prediction variable from the one or more prediction variables is a categorical variable.
22. The method of claim 21 , wherein the splitting further comprises a splitting rule and a goodness of split rule, the splitting rule comprising placing a case into a left sub-node if the case is included in the values of the predictor prediction variable and wherein the goodness of split rule is of the form:
where Φ(s) represents a goodness of split rule for a split, s; g(T) represents noisiness of a node T; g(TL) represents noisiness of a left sub-node of node T; g(TR) represents noisiness of a right sub-node of node T; NT is a number of cases in node T; NT L is a number of cases in the left sub-node of node T; and NT R is a number of cases in the right sub-node of node T.
23. A computerized yield management system, comprising:
pre-processing computing device means executed by a data pre-processor in a computer processing unit for pre-processing an input data set comprising one or more prediction variables and one or more response variables containing data about a particular semiconductor process to remove data having at least a predetermined number of missing values to generate pre-processed data, and the pre-processing computing device means comprising means for removing one or more prediction variables from the input data set having more than a predetermined number of classes;
computing device means executed by a model builder in the computer processing unit, the model builder being in communication with the data pre-processor, for generating a model based on the pre-processed data, the model being a decision tree identifying one or more variables as key yield factors; and
computing device means executed by a statistical tool library in the computer processing unit, the statistical tool library being in communication with the model builder, for analyzing the model using a statistical tool to examine one or more key yield factors based on the input data set.
24. The system of claim 23 wherein the pre-processing computing device means further comprises means for removing one or more prediction variables from the input data set having more than a predetermined number of missing values.
25. The system of claim 23 wherein the pre-processing computing device means further comprises means for removing data having more than a predetermined number of missing values.
26. The system of claim 23, further comprising means for modifying the model based on user input.
27. A yield management method, comprising:
pre-processing, via a computing device, an input data set comprising one or more prediction variables and one or more response variables containing data about a particular semiconductor process to remove data having at least a predetermined number of missing values to generate pre-processed data, the pre-processing further comprising removing one or more prediction variables from the input data set having more than a predetermined number of classes;
generating, via the computing device, a model based on the pre-processed data, the model being a decision tree identifying one or more variables as key yield factors; and
analyzing the model using a statistical tool to examine one or more key yield factors based on the input data set.
28. The method of claim 27 wherein the pre-processing further comprises removing one or more prediction variables from the input data set having more than a predetermined number of missing values.
29. The method of claim 27 wherein the pre-processing further comprises removing data having more than a predetermined number of missing values.
30. The method of claim 27, further comprising modifying the model based on user input.
31. A computerized yield management system, comprising:
pre-processing computing device means executed by a data pre-processor in a computer processing unit for pre-processing an input data set comprising one or more prediction variables and one or more response variables containing data about a particular semiconductor process to remove data having at least a predetermined number of missing values to generate pre-processed data, and the pre-processing computing device means comprising means for removing one or more prediction variables from the input data set having more than a predetermined number of classes;
computing device means executed by a model builder in the computer processing unit, the model builder being in communication with the data pre-processor, for generating a model based on the pre-processed data, the model being a decision tree identifying one or more variables as key yield factors; and
computing device means executed by a statistical tool in the computer processing unit, the statistical tool being in communication with the model builder, for analyzing the model using the statistical tool to generate yield management information.
32. The system of claim 31 wherein the pre-processing computing device means further comprises means for removing data containing erroneous values.
33. The system of claim 31 wherein the pre-processing computing device means further comprises means for removing data containing invalid values.
34. The system of claim 31, further comprising means for modifying the model based on user input.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/972,115 USRE42481E1 (en) | 1999-12-08 | 2004-10-22 | Semiconductor yield management system and method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/458,185 US6470229B1 (en) | 1999-12-08 | 1999-12-08 | Semiconductor yield management system and method |
| US10/972,115 USRE42481E1 (en) | 1999-12-08 | 2004-10-22 | Semiconductor yield management system and method |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US09/458,185 Reissue US6470229B1 (en) | 1999-12-08 | 1999-12-08 | Semiconductor yield management system and method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| USRE42481E1 true USRE42481E1 (en) | 2011-06-21 |
Family
ID=23819718
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US09/458,185 Ceased US6470229B1 (en) | 1999-12-08 | 1999-12-08 | Semiconductor yield management system and method |
| US10/972,115 Expired - Lifetime USRE42481E1 (en) | 1999-12-08 | 2004-10-22 | Semiconductor yield management system and method |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US09/458,185 Ceased US6470229B1 (en) | 1999-12-08 | 1999-12-08 | Semiconductor yield management system and method |
Country Status (1)
| Country | Link |
|---|---|
| US (2) | US6470229B1 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9645097B2 (en) | 2014-06-20 | 2017-05-09 | Kla-Tencor Corporation | In-line wafer edge inspection, wafer pre-alignment, and wafer cleaning |
| US9885671B2 (en) | 2014-06-09 | 2018-02-06 | Kla-Tencor Corporation | Miniaturized imaging apparatus for wafer edge |
Families Citing this family (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7337149B2 (en) * | 2000-12-12 | 2008-02-26 | International Business Machines Corporation | System and methodology for calculating the cost of future semiconductor products using regression analysis of historical cost data |
| US7155421B1 (en) * | 2002-10-16 | 2006-12-26 | Sprint Spectrum L.P. | Method and system for dynamic variation of decision tree architecture |
| AU2003296939A1 (en) * | 2002-12-10 | 2004-06-30 | Stone Investments, Inc | Method and system for analyzing data and creating predictive models |
| US6998866B1 (en) * | 2004-07-27 | 2006-02-14 | International Business Machines Corporation | Circuit and method for monitoring defects |
| US20060095237A1 (en) * | 2004-10-28 | 2006-05-04 | Weidong Wang | Semiconductor yield management system and method |
| US7685481B2 (en) * | 2005-06-23 | 2010-03-23 | Mks Instruments, Inc. | Bitmap cluster analysis of defects in integrated circuits |
| US7363098B2 (en) * | 2005-12-19 | 2008-04-22 | Tech Semiconductor Singapore Pte Ltd | Method to identify machines causing excursion in semiconductor manufacturing |
| US7533313B1 (en) * | 2006-03-09 | 2009-05-12 | Advanced Micro Devices, Inc. | Method and apparatus for identifying outlier data |
| US8577717B2 (en) * | 2006-05-25 | 2013-11-05 | Taiwan Semiconductor Manufacturing Company, Ltd. | Method and system for predicting shrinkable yield for business assessment of integrated circuit design shrink |
| US8615691B2 (en) * | 2006-10-13 | 2013-12-24 | Advantest (Singapore) Pte Ltd | Process for improving design-limited yield by localizing potential faults from production test data |
| US7494893B1 (en) | 2007-01-17 | 2009-02-24 | Pdf Solutions, Inc. | Identifying yield-relevant process parameters in integrated circuit device fabrication processes |
| US7954018B2 (en) * | 2007-02-02 | 2011-05-31 | Rudolph Technologies, Inc | Analysis techniques for multi-level memory |
| US20080312875A1 (en) * | 2007-06-12 | 2008-12-18 | Yu Guanyuan M | Monitoring and control of integrated circuit device fabrication processes |
| US7539585B2 (en) | 2007-06-14 | 2009-05-26 | International Business Machines Corporation | System and method for rule-based data mining and problem detection for semiconductor fabrication |
| TW200929412A (en) * | 2007-12-18 | 2009-07-01 | Airoha Tech Corp | Model modification method for a semiconductor device |
| US7974723B2 (en) * | 2008-03-06 | 2011-07-05 | Applied Materials, Inc. | Yield prediction feedback for controlling an equipment engineering system |
| US9275334B2 (en) * | 2012-04-06 | 2016-03-01 | Applied Materials, Inc. | Increasing signal to noise ratio for creation of generalized and robust prediction models |
| EP3746946A1 (en) * | 2018-01-31 | 2020-12-09 | ASML Netherlands B.V. | Method to label substrates based on process parameters |
| TWI695280B (en) * | 2018-10-08 | 2020-06-01 | 財團法人資訊工業策進會 | Apparatus and method for determining a target adjustment route for a preset control condition set of a production line |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4754410A (en) * | 1986-02-06 | 1988-06-28 | Westinghouse Electric Corp. | Automated rule based process control method with feedback and apparatus therefor |
| US5727128A (en) * | 1996-05-08 | 1998-03-10 | Fisher-Rosemount Systems, Inc. | System and method for automatically determining a set of variables for use in creating a process model |
| US5897627A (en) | 1997-05-20 | 1999-04-27 | Motorola, Inc. | Method of determining statistically meaningful rules |
| US6098063A (en) * | 1994-02-15 | 2000-08-01 | R. R. Donnelley & Sons | Device and method for identifying causes of web breaks in a printing system on web manufacturing attributes |
| US6336086B1 (en) * | 1998-08-13 | 2002-01-01 | Agere Systems Guardian Corp. | Method and system for analyzing wafer processing order |
-
1999
- 1999-12-08 US US09/458,185 patent/US6470229B1/en not_active Ceased
-
2004
- 2004-10-22 US US10/972,115 patent/USRE42481E1/en not_active Expired - Lifetime
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4754410A (en) * | 1986-02-06 | 1988-06-28 | Westinghouse Electric Corp. | Automated rule based process control method with feedback and apparatus therefor |
| US6098063A (en) * | 1994-02-15 | 2000-08-01 | R. R. Donnelley & Sons | Device and method for identifying causes of web breaks in a printing system on web manufacturing attributes |
| US5727128A (en) * | 1996-05-08 | 1998-03-10 | Fisher-Rosemount Systems, Inc. | System and method for automatically determining a set of variables for use in creating a process model |
| US5897627A (en) | 1997-05-20 | 1999-04-27 | Motorola, Inc. | Method of determining statistically meaningful rules |
| US6336086B1 (en) * | 1998-08-13 | 2002-01-01 | Agere Systems Guardian Corp. | Method and system for analyzing wafer processing order |
Non-Patent Citations (18)
| Title |
|---|
| "Quadrillion: Q-Yield Product Overview," Quadrillion Corporation (last accessed at http://web.archive.org/web/19971210064219/www.quadrillion.com/qyov... Feb. 5, 2009) 2 pages. |
| "Quadrillion: Training Services," Quadrillion Corporation (last accessed at http://web.archive.org/web/19971210064511/www.quadrillion.com/train.html Feb. 5, 2009) 2 pages. |
| Bergendahl, et al., "Optimization of Plasma Processing, etc." IBM. J. Res. Develop., Sep. 1982, pp. 580-589, vol. 26, No. 5, IBM, US. |
| Data Mining and the Case for Sampling: Solving Business Problems Using SAS Enterprise Miner Software, 1998, pp. 1-35, Sas Institute Inc., US. |
| Email from Dave Garrod at PDF Solutions, Inc. enclosing prior art for the yield analysis and data mining tool called Q-Yield, 1 page (Sent Feb. 5, 2009). |
| Famili et al., "Data Preprocessing and Intelligent Data Analysis," Intelligent Data Analysis Journal, pp. 1-28 (Mar. 24, 1997). |
| Friedhoff, et al., "Analysis of Intra-Level Isolation Test Structure, etc." Proc. IEEE 1989 Int. Conf. Micro. Test Struc., Mar, 1989, pp. 217-221,vol. 2, No. 1, Pittsburgh, PA. |
| Irani et al. Expert, IEEE vol. 8, Issue 1, "Applying machine learning to semiconductor manufacturing", Feb. 1993, pp. 41-47. * |
| Ison et al., Semiconductor Manufacturing Conference Proceedings, 1997 IEEE Symposium on "Fault diagnosis of plasma etch equipment", San Francisco, Ca. published Oct. 6-8, 1997, pp. B49-B52. * |
| Lee et al., "Yield Analysis and Data Management Using Yield Manager(TM)," IEEE/SEMI Advanced Semiconductor Manufacturing Conference, pp. 19-30 (1998). |
| Lee et al., "Yield Analysis and Data Management Using Yield Manager™," IEEE/SEMI Advanced Semiconductor Manufacturing Conference, pp. 19-30 (1998). |
| Lee, et al., "RTSPC: A Sofware Utility for Real-Time SPC, etc." IEEE Trans. Semicon. Mfg., Feb, 1995, pp. 17-25, vol. 8, No. 1, US. |
| Lee, F., et al., Yield Analysis and Data Management Using Yield Manager, 1998 IEEE/Semi Adv. Semi. Manuf. Conf., 1998, pp. 19-30, US. |
| Murthy, S., Automatic Construction of Decision Trees from Data: A Multi-Disciplinary Survey, Data Mining and Knowledge Dscovery, 1998, pp. 345-389, v. 2, Kluwer Aca. Pub., US. |
| Perez, R., et al., Machine Learning for a Dynamic Manufacturing Environment, ACM SIGICE Bulletin, 1994, pp. 5-9, v. 19, US. |
| Quinlan, J., Unknown Attribute Values in Induction in Segre, A. (Ed.), Proc. Sixth Intl. Machine Learning Workshop, 1989, Morgan Kaufmann, US. |
| Turney, P., "Data Engineering for the Analysis of Semiconductor Manufacturing Data," Workshop on Data Engineering for Inductive Learning, pp. 1-10 (Apr. 3, 1995). |
| Yang, Y-K., "EPAS: An Emitter Piloting Advisory Expert System, etc." IEEE Trans. Semicon. Mfg., May 1990, pp. 45-53, vol. 3, No. 2, US. |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9885671B2 (en) | 2014-06-09 | 2018-02-06 | Kla-Tencor Corporation | Miniaturized imaging apparatus for wafer edge |
| US9645097B2 (en) | 2014-06-20 | 2017-05-09 | Kla-Tencor Corporation | In-line wafer edge inspection, wafer pre-alignment, and wafer cleaning |
Also Published As
| Publication number | Publication date |
|---|---|
| US6470229B1 (en) | 2002-10-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| USRE42481E1 (en) | Semiconductor yield management system and method | |
| Collin et al. | Extending approximate Bayesian computation with supervised machine learning to infer demographic history from genetic polymorphisms using DIYABC Random Forest | |
| US20080270088A1 (en) | Method and system for causal modeling and outlier detection | |
| US8380472B2 (en) | Semiconductor yield management system and method | |
| Idri et al. | COCOMO cost model using fuzzy logic | |
| US6990486B2 (en) | Systems and methods for discovering fully dependent patterns | |
| Davey et al. | The development of a software clone detector | |
| US6466929B1 (en) | System for discovering implicit relationships in data and a method of using the same | |
| US20060161403A1 (en) | Method and system for analyzing data and creating predictive models | |
| Last et al. | Automated detection of outliers in real-world data | |
| EP1208480A1 (en) | Data mining assists in a relational database management system | |
| JP2006507558A (en) | Viewing multidimensional data through hierarchical visualization | |
| US7251636B2 (en) | Scalable methods for learning Bayesian networks | |
| US7562054B2 (en) | Method and apparatus for automated feature selection | |
| Huang | Dimensionality reduction in automatic knowledge acquisition: a simple greedy search approach | |
| Duan et al. | Root cause analysis approach based on reverse cascading decomposition in QFD and fuzzy weight ARM for quality accidents | |
| Kulkarni et al. | Evolve systems using incremental clustering approach | |
| Su et al. | Intelligent scheduling controller for shop floor control systems: a hybrid genetic algorithm/decision tree learning approach | |
| Jin et al. | Effective and efficient itemset pattern summarization: regression-based approaches | |
| US6519591B1 (en) | Vertical implementation of expectation-maximization algorithm in SQL for performing clustering in very large databases | |
| Tan et al. | Building verified neural networks with specifications for systems | |
| US6922692B2 (en) | Directed non-cyclic graph walking system and method | |
| Ong et al. | A manufacturing failure root cause analysis in imbalance data set using pca weighted association rule mining | |
| Vesanto et al. | An automated report generation tool for the data understanding phase | |
| Last et al. | Data mining for process and quality control in the semiconductor industry |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment |
Owner name: MKS INSTRUMENTS, INC., MASSACHUSETTS Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:YIELD DYNAMICS, INC.;REEL/FRAME:021489/0065 Effective date: 20080903 |
|
| AS | Assignment |
Owner name: RUDOLPH TECHNOLOGIES, INC., NEW JERSEY Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:MKS INSTRUMENTS, INC.;REEL/FRAME:024946/0388 Effective date: 20100811 |
|
| FPAY | Fee payment |
Year of fee payment: 12 |