US9245034B2 - Recommending content - Google Patents
Recommending content Download PDFInfo
- Publication number
- US9245034B2 US9245034B2 US13/517,449 US201013517449A US9245034B2 US 9245034 B2 US9245034 B2 US 9245034B2 US 201013517449 A US201013517449 A US 201013517449A US 9245034 B2 US9245034 B2 US 9245034B2
- Authority
- US
- United States
- Prior art keywords
- content
- input
- probability
- increase
- response
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



Classifications
-
- G06F17/30867—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9535—Search customisation based on user profiles and personalisation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/048—Interaction techniques based on graphical user interfaces [GUI]
Definitions
- the present invention relates to content recommendation, in particular content recommendation to a user.
- StumbleUpon implements a toolbar, giving websurfers the option between two buttons. The first, labeled “Stumble!”, generates a randomly selected website. The second, labeled “I like this” allows surfers to indicate they like the website they see. Websurfers are thus presented with a sequence of different websites, until one that matches their interests is found.
- StumbleUpon learns through a registered user's feedback (i.e., clicks of the “I like this” button) which websites she or he likes; recommendations are then made by showing the user websites that have been recommended by other registered users with similar preferences. StumbleUpon also leverages social-networking information to make recommendations. In particular, registered users can declare their friends. Assuming that friends should have common interests, StumbleUpon exploits this information to recommend websites to users when selected by their friends.
- search engines like Google and Blogoscope [N. Banshal and N. Koudas. “ Searching the Blogosphere ”, in WebDB, 2007].
- WEbsurfers submit queries to such engines, requesting specific content. These engines regularly crawl the World Wide Web and store information about the content published in every website. This information is stored and processed, and answers to a user's queries are given by matching these queries to relevant websites obtained through crawling the web.
- Digg relies on the participation of websurfers through tag submission, which they may not always be able or willing to perform.
- Digg, Delicious and Reddit lack personalization: the recommendations made are collective, and are not designed to meet the needs of any particular websurfer.
- StumbleUpon and El-Arini et al. personalize the search for content to a particular websurfer. Moreover, they do so with minimal feedback. Tagging is not required; instead, users need only declare which sites they like and, in StumbleUpon, optionally provide social networking information.
- El Arini et al. solve an optimization problem, in which they try to match websites to each websurfer's personal interests. Their solution is not optimal, but is within a constant factor of the optimal. Nonetheless, the approach proposed by El Arini et al. is not content-agnostic. It requires knowledge of the nature of the content published by websites. To obtain this information, a central server must crawl the web periodically and discover and analyse what type of content is published at different websites. This server needs to have considerable storage capacity to store and analyse the data it collects.
- StumbleUpon The exact mechanism employed by StumbleUpon is proprietary, so it is not possible to assess its operation. However, it is certainly a centralized mechanism: the preferences of users are aggregated and stored at a central server. Moreover, it is not possible to know whether the method used by StumbleUpon indeed matches websites to each individual interests optimally, or simple heuristics are used to offer website suggestions.
- Search engines like Google and Blogscope have the following disadvantages.
- First, like El-Arini et al. they are by definition content-aware, and require extensive, frequent crawling of the web, and the storage and processing of terabytes of information.
- eliciting a websurfer's interests is not always straightforward: the websurfer may not be able to declare what type of content she or he is interested in before actually being presented with it, and that is the reason why recommendation engines like StumbleUpon have been proposed as alternatives.
- a method for recommending content items to a user including: (i) receiving one of at least a first input and a second input from a user in relation to content presented to the user; (ii) in response to a first input, rendering the presented content, or in response to a second input, selecting fresh content for presentation; and, (iii) repeating steps (i) and (ii) until a first input is received, wherein content has a probability associated therewith, and content is selected in dependence on the associated probability of that content, the first and second inputs being received at a user interface of a user device, the selection of the content being performed locally at the user device.
- the first input can be regarded as an acceptance of the content
- the second input can be regarded as a rejection of the content, the rejected content preferably being discarded.
- the probably associated with a given content is increased each time a first input is received from the user for that content.
- the magnitude of the increase in the probability associated with given content is dependent at least in part on said probability before the increase.
- a measure of system performance (that is, a measure of how the system performs in giving user satisfaction) is obtained in dependence on the number of times a user enters a second input before entering a first input.
- the measure is preferably obtained from a functional relationship between performance and the number of second inputs received before a first input is received.
- the functional relationship may but need not be obtained empirically from user experiments. In fact, it has been found that there is more than one decreasing function that can be used, and that the function, also referred to as a rating function, can be seen as a system parameter.
- the decrease if any, in the predicted system performance that would have occurred had the user entered a further second command instead of a first command is determined.
- the decrease is simple the system performance after Y+1 second inputs relative to the system performance after Y second inputs. This, in effect, can be seen as a measure of a predicted reduction in user satisfaction associated with an additional second input.
- the magnitude of the increase in the probability of a given content can be dependent on the number of second inputs entered by the user before the user enters a first input in respect of that content.
- a counter is preferably provided to count the number of second inputs, the counter having a counter value that is incremented each time a user enters a second input.
- the counter value reached when a first input is entered can then used to update the probability associated with the content rendered in response to the first input.
- the counter value is preferably re-set.
- the magnitude of the increase in probability is dependent on previous recommendation probabilities.
- a user device for recommending content to a user including: display means arranged to present content to a user; a user interface arranged to receive one of at least a first input and a second input in relation to content presented to a user, the display means being arranged to display the presented content in response to a first input; and, section means arranged, in response to a second input, to select fresh content for presentation, each content having a probability associated therewith, the selection means being arranged to select content in dependence on the associated probability of that content.
- the selection means is preferably arranged to increase the probably associated with a given content each time a first input is received from the user for that content. Yet more preferably, the magnitude of the increase is dependent at least in part on said probability before the increase. This allows the interest a user has in content to be taken into account when presenting the same or similar content to that user again.
- a method for recommending content items to users said method using a user interface comprising at least two options, one option allowing users to approve a content item and the other option allowing users to discard a content item, wherein a new content item is presented to the users when they select option and discard a content item, characterized in that said method uses probabilistic rules for recommending content items to users, in that said probabilistic rules for recommending content items to users are updated when a user selects option and approves a content item, with the approved content item's probability being increased and in that the magnitude of the increase is evaluated as a function of previous recommendation probabilities and the number of content items viewed and discarded by said user before it approved said content item.
- a counter is increased each time a user selects option discarding a content item, and in that, when said user selects option and approves a content item, the value of said counter is read, is used to compute the probabilities of displaying a particular content item to a user and is reset to zero.
- the computation of new content display probabilities is performed by one or more of the following:
- communities of users are formed and the recommendation of content items to users is performed based on the membership of users to said communities.
- a common set of probabilities of displaying a particular content is used for all users members of a community.
- said set of probabilities is updated based on a counter of all users members of the community.
- users designate at least one content category that interests them and in the recommendation of content items to users is performed based on the interest of users in this content category.
- a set of probabilities is maintained per user and content category.
- FIG. 1 shows a diagram representing the method according to the present invention.
- FIG. 2 shows a system for recommending content.
- the web is modeled as a set of N websites. These websites maintain content that covers M different topics, such as, e.g., sports, politics, movies, health, etc.
- more than one topic e.g., sports and health
- more than one topic can be covered by a certain website at a given point in time; the expected number of topics covered by w will be ⁇ f p w,f .
- the surfer visits websites daily by using a mechanism that works as follows: the mechanism recommends a sequence of websites to the surfer, and the surfer keeps viewing these sites until she or he finds a website covering the topic that interests her or him.
- the method according to the present invention can, according to an embodiment, be implemented as a toolbar on the surfer's web-browser: the surfer would be presented with two different buttons, one called “next” and the other called “select”. Clicking the first would generate a new website, while clicking the second would indicate that a topic the surfer is interested in is found.
- R(Y) be a function rating the performance of the system, given that the topic is found within Y steps.
- the mechanism should choose a surfing strategy that maximizes the expected rating, by making the latter appropriately small.
- the optimization problem described by (1) preferably relates to surfing strategies in which sites are each visited with probability at least ⁇ , i.e., the feasible domain is restricted to
- ⁇ right arrow over (x) ⁇ N For ⁇ right arrow over (x) ⁇ N , let
- ⁇ D ⁇ ⁇ ( x -> ) argmin y -> ⁇ D ⁇ ⁇ ⁇ y -> - x -> ⁇ 2 . ( 3 ) be the orthogonal projection to the domain D ⁇ . Since D ⁇ is closed and convex, ⁇ D ⁇ is well defined—there exists a unique ⁇ right arrow over (y) ⁇ D ⁇ minimizing the distance from ⁇ right arrow over (x) ⁇ .
- D ⁇ is a convex polyhedron
- ⁇ right arrow over (y) ⁇ can be computed by a quadratic program.
- ⁇ (k) ⁇ + is a gain factor; if it decreases with k, feedback given later has smaller impact on the surfing strategy.
- ⁇ right arrow over (g) ⁇ (k) ⁇ ⁇ N is the vector forcing the change on the surfing strategy based the surfer's feedback.
- ⁇ right arrow over (g) ⁇ (k) has the following coordinates:
- the rating function R is a system parameter, while ⁇ right arrow over (x) ⁇ is maintained by the mechanism and used to recommend websites.
- Y the mechanism needs to keep track of how many websites it has shown to the surfer; the only feedback given by the surfer is the indication that her or his interests have been met.
- the mechanism does not need to know—and the surfer does not need to declare—which is the interesting topic covered by website w.
- the system 10 can be viewed as having a display 12 , a user interface 14 , selection means 16 for selecting content to present to a user and a counter 18 for counting the number of times a user clicks “next” before clicking “select”, the selection means being arranged to select content as explained above.
- the selection means has a processor for processing data and a memory for storing, for example, the probability associated with each content.
- the system will preferably be implemented in a hand held user device, for example a device having wireless connectivity for downloading content to be displayed.
- the content may be downloaded through an opportunistic network.
- the common surfing strategy is updated as in (4), the only difference being that, instead of the individual vectors ⁇ right arrow over (g) ⁇ s , the community average ⁇ right arrow over (g) ⁇ c is used.
- ⁇ c the maximum l 1 distance between the interest profiles of surfers in the community, i.e.,
- ⁇ c the diameter of the community. Intuitively, we will be interested in the case where the diameter is small, as surfers in the same community should have similar interests.
- our mechanism should avoid visiting such sites more than once, e.g., through blacklisting them if the surfer does not approve them during a search.
- the mechanism according to the present invention maintains a vector ⁇ right arrow over (x) ⁇ whose dimension is N, the number of websites. Given the number of websites on the Internet, this is clearly impractical. One way to avoid this is to restrict the mechanism to a subset of all websites; this is not satisfactory, as it would limit the surfer's choices.
- the embodiments described above are aimed at solving the drawbacks of the prior art solutions. They can be seen as proving a way to design a probabilistic strategy for recommending content items to users so that users access content of interest quickly
- the embodiments illustrate a method for recommending content items to a user. It includes: (i) receiving one of at least an acceptance input and a rejection input from a user in relation to content presented to the user; (ii) in response to an acceptance input, rendering the presented content, or in response to a rejection input, selecting fresh content for presentation; and, (iii) repeating steps (i) and (ii) until a acceptance input is received.
- Content is selected in dependence on a associated probability associated with that content. The probability is increased in response to an acceptance input, the increase being determined in part on a measure of to predicted reduction in user satisfaction that would be associated with an additional rejection input.
Abstract
Description
-
- assuming that user satisfaction is a decreasing function of the number of times it selects the option discarding a content item before accessing an approved content item;
- posing an optimization problem, in which user satisfaction is to be maximized, as a function of the content display probabilities; and
- updating the content display probabilities every time the option is selected so that the quantities reflecting the content display probabilities automatically adapt and converge to the content display probabilities that maximize user satisfaction.
-
- The method according to the present invention is decentralized: it is implemented as an application running at each individual user's machine.
- The method according to the present invention makes recommendations to websurfers in a manner that reduces the number of websites viewed before one that the websurfer likes is presented.
- The method according to the present invention reduces the need for tagging content. Moreover, it does not require that users explicitly state their interests on a given day—though such information can be used to improve the performance of our mechanism.
- The method according to the present invention is content-oblivious: it does reduces the need for a priori knowledge of the nature of the content stored at each website. It does not require frequent crawling of the web and the subsequent storage and processing of terabytes of data.
- The performance of the method according to the present invention may be improved through the use of social networking information.
- Assumption 1. The rating function R:→
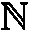 is (a) non-increasing and (b) summable, i.e., Σk=1 ∞|R(k)|<∞.
is (a) non-increasing and (b) summable, i.e., Σk=1 ∞|R(k)|<∞.
Note that
be the orthogonal projection to the domain Dε. Since Dε is closed and convex, ΠD
{right arrow over (x)}(k+1)=ΠD
where Y(k), k=1, 2, . . . is the number of sites a surfer visits on the k-th day until it locates a topic she or he is interested in, and
Note that, to compute this, all the mechanism needs to know is Y, R and {right arrow over (x)}.
-
- 1) The system is installed, in one embodiment, at the user's browser
- 2) The system displays two buttons to the user, a “next” button and a “select” button
- 3) To use the system, the user clicks the “next” button and is displayed a new website. The user keeps clicking “next” until a website he or she likes is displayed by the system.
- 4) Once a website that the user likes is shown, the user lets the system know about this by clicking the “select” button.
- 5) The system stores a vector of probabilities x_w, that sum up to one. We call this the “surfing strategy of the system”.
- 6) Each time the user clicks the next button, the system displays a website selected at random according to the vector of probabilities x_w. That is, it shows website w with probability x_w
- 7) The system maintains a counter Y, keeping track of how many times the user has clicked the next button since the last click of the select button
- 8) The system contains, as a design parameter, a function R that satisfies Assumption 1. This is a design parameter: intuitively R(Y) gives a numerical value how satisfied the user will if he or she has to see Y websites before being presented with a website that she likes. Any R that satisfies Assumption 1 can be used, so a wide range of user preferences with respect to their level of satisfaction after Y viewings are captured by the system. We call this R the “rating function”.
- 9) Each time the user clicks the “select” button, the system uses the counter Y to update the vector of probabilities x in the following manner:
- a. Let w be the website at which the user clicked “select”
- b. The mechanism creates a vector g, of the same length as the vector of probabilities x, such that g_w is equal to −Y*(R(Y+1)−R(Y))/x_w and zero everywhere else (equation 5)
- c. In words, the formula −Y*(R(Y+1)−R(Y))/x_w means
- i. Compute R(Y+1), R(Y) where R is the design parameter function capturing how satisfied the user is when he or she has viewed Y websites it does not like before viewing a website he or she views a website that she likes, and Y is the counter keeping track of how many times the viewer has clicked next before clicking select.
- ii. Subtract R(Y) from R(Y+1).
- iii. Multiply the result by Y
- iv. Divide the result by x_w, where x_w is the probability that website w is selected
- v. Multiply the result by −1
- d. The above vector g, which is zero everywhere except at g_w, where it is equal to −Y*(R(Y+1)−R(Y))/x_w, this quantity being computed as in c. above, is multiplied to a numerical value gamma and added to x
- e. The numerical value gamma (known to the person skilled in the art as a gain factor) can be any value, that decreases every time that the surfing vector is updated.
- f. The result of the addition of these two vectors, (that is the sum of the vector of probabilities x and the vector g multiplied by the gain factor gamma) is projected to the set of all vectors x whose coordinates are (a) larger than a parameter epsilon, which is arbitrary but small and (b) sum up to one (see formula (4))
- g. The projection to the above set of vectors, known to the man skilled in the art as the orthogonal projection to a closed convex polyhedral set, can be computed through several methods. In one embodiment, it can be computed by the solution of what is called by the man skilled in the art a quadratic program. There are other, alternatives, all of which are well known to the man skilled in the art.
- h. The above description of how the vector of probabilities is updated can be understood through following equations: Eq. (2), defining the set of vectors summing up to one whose coordinates are larger than epsilon, Eq. (3), defining the orthogonal projection, which is a known definition, (4), defining how the vector of probabilities is adapted, and (5) and (6), defining how the vector g is computed
With regard to the function R of Equation (5), R(Y+1) can be seen as being the user satisfaction that the user would have at finding the web site W after Y+1 clicks (that is Y+1 second inputs). That is, it is the notional satisfaction predicted after one more click than was actually needed to find the web site W (which was accepted with a first input after Y clicks). If the benefit in finding the site in Y rather than Y+1 clicks is large, then the user would be particularly dissatisfied at not finding it in Y clicks but only in Y+1 clicks. Consequently, the value R(Y)−R(Y+1) is of large magnitude, and the probability associated with the website W is increased by a large amount. Otherwise, if the benefit is small, W is only increased by a small amount.
the average change vector and the average system rating among all surfers in the community.
{right arrow over (x)}(k+1)=ΠD
Claims (14)
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP09306291 | 2009-12-21 | ||
| EP09306291A EP2348424A1 (en) | 2009-12-21 | 2009-12-21 | Method for recommending content items to users |
| EP09306291.7 | 2009-12-21 | ||
| PCT/EP2010/070232 WO2011080138A1 (en) | 2009-12-21 | 2010-12-20 | Recommending content |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| US20120260165A1 US20120260165A1 (en) | 2012-10-11 |
| US9245034B2 true US9245034B2 (en) | 2016-01-26 |
Family
ID=42111850
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US13/517,449 Active US9245034B2 (en) | 2009-12-21 | 2010-12-20 | Recommending content |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US9245034B2 (en) |
| EP (1) | EP2348424A1 (en) |
| WO (1) | WO2011080138A1 (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5182178B2 (en) * | 2009-03-18 | 2013-04-10 | ソニー株式会社 | Information processing apparatus and information processing method |
| WO2014008502A1 (en) * | 2012-07-06 | 2014-01-09 | Block Robert S | Advanced user interface |
| US11868354B2 (en) * | 2015-09-23 | 2024-01-09 | Motorola Solutions, Inc. | Apparatus, system, and method for responding to a user-initiated query with a context-based response |
| CN107798147B (en) * | 2017-12-05 | 2021-05-25 | 深圳市敏思跃动科技有限公司 | News client and message pushing method thereof |
Citations (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6374145B1 (en) * | 1998-12-14 | 2002-04-16 | Mark Lignoul | Proximity sensor for screen saver and password delay |
| US20040177110A1 (en) | 2003-03-03 | 2004-09-09 | Rounthwaite Robert L. | Feedback loop for spam prevention |
| US20070106672A1 (en) * | 2005-11-08 | 2007-05-10 | Sony Netservices Gmbh | Method of providing content items |
| US20070288965A1 (en) * | 2006-03-30 | 2007-12-13 | Kabushiki Kaisha | Recommended program information providing method and apparatus |
| US20080189232A1 (en) * | 2007-02-02 | 2008-08-07 | Veoh Networks, Inc. | Indicator-based recommendation system |
| US20090006442A1 (en) | 2007-06-27 | 2009-01-01 | Microsoft Corporation | Enhanced browsing experience in social bookmarking based on self tags |
| EP2060983A1 (en) | 2007-11-19 | 2009-05-20 | Core Logic, Inc. | Content recommendation apparatus and method using tag cloud |
| US20090132459A1 (en) | 2007-11-16 | 2009-05-21 | Cory Hicks | Processes for improving the utility of personalized recommendations generated by a recommendation engine |
| US20090300547A1 (en) * | 2008-05-30 | 2009-12-03 | Kibboko, Inc. | Recommender system for on-line articles and documents |
| US20110016431A1 (en) * | 2009-07-20 | 2011-01-20 | Aryk Erwin Grosz | Method for Automatically Previewing Edits to Text Items within an Online Collage-Based Editor |
| US20110035674A1 (en) * | 2009-08-06 | 2011-02-10 | Oracle International Corporation | Recommendations matching a user's interests |
| US20110061076A1 (en) * | 1999-12-21 | 2011-03-10 | Kamal Ali | Intelligent system and methods of recommending media content items based on user preferences |
| US20110289075A1 (en) * | 2010-05-24 | 2011-11-24 | Nelson Erik T | Music Recommender |
-
2009
- 2009-12-21 EP EP09306291A patent/EP2348424A1/en not_active Withdrawn
-
2010
- 2010-12-20 WO PCT/EP2010/070232 patent/WO2011080138A1/en active Application Filing
- 2010-12-20 US US13/517,449 patent/US9245034B2/en active Active
Patent Citations (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6374145B1 (en) * | 1998-12-14 | 2002-04-16 | Mark Lignoul | Proximity sensor for screen saver and password delay |
| US20110061076A1 (en) * | 1999-12-21 | 2011-03-10 | Kamal Ali | Intelligent system and methods of recommending media content items based on user preferences |
| US20120084818A1 (en) * | 1999-12-21 | 2012-04-05 | Kamal Ali | Intelligent System and Methods of Recommending Media Content Items Based on User Preferences |
| US20040177110A1 (en) | 2003-03-03 | 2004-09-09 | Rounthwaite Robert L. | Feedback loop for spam prevention |
| US20070106672A1 (en) * | 2005-11-08 | 2007-05-10 | Sony Netservices Gmbh | Method of providing content items |
| US20070288965A1 (en) * | 2006-03-30 | 2007-12-13 | Kabushiki Kaisha | Recommended program information providing method and apparatus |
| US20080189232A1 (en) * | 2007-02-02 | 2008-08-07 | Veoh Networks, Inc. | Indicator-based recommendation system |
| US20090006442A1 (en) | 2007-06-27 | 2009-01-01 | Microsoft Corporation | Enhanced browsing experience in social bookmarking based on self tags |
| US20090132459A1 (en) | 2007-11-16 | 2009-05-21 | Cory Hicks | Processes for improving the utility of personalized recommendations generated by a recommendation engine |
| EP2060983A1 (en) | 2007-11-19 | 2009-05-20 | Core Logic, Inc. | Content recommendation apparatus and method using tag cloud |
| US20090300547A1 (en) * | 2008-05-30 | 2009-12-03 | Kibboko, Inc. | Recommender system for on-line articles and documents |
| US20110016431A1 (en) * | 2009-07-20 | 2011-01-20 | Aryk Erwin Grosz | Method for Automatically Previewing Edits to Text Items within an Online Collage-Based Editor |
| US20110035674A1 (en) * | 2009-08-06 | 2011-02-10 | Oracle International Corporation | Recommendations matching a user's interests |
| US20110289075A1 (en) * | 2010-05-24 | 2011-11-24 | Nelson Erik T | Music Recommender |
Non-Patent Citations (13)
| Title |
|---|
| Adomavicius et al., "New Recommendation Techniques for Multicriteria Rating Systems", IEEE Intelligent Systems, vol. 22, No. 3, May 1, 2007, pp. 48-55. |
| Aneiros et al., "Recommendation-Based Collaborative Browsing Using Bookmarks", Proceedings of the 2004 Iadis International Conference e-Society, Avila, Spain, Jul. 16, 2004, pp. 718-725. |
| Anonymous, "Digg-What the Internet is talking about right now", http://digg.com, Feb. 10, 2015, pp. 1-37. |
| Anonymous, "Discover, share, and organize the hottest links online", http://delicious.com, Feb. 10, 2015, pp. 1-2. |
| Anonymous, "reddit: the front page of the intemet", http://reddit.com, Feb. 10, 2015, pp. 1-4. |
| Anonymous, "Stumble Upon is a giant collection of the best pages on the Internet", http://www.stumbleupon.com, Feb. 10, 2015, pp. 1-2. |
| Anonymous, "StumbleUpon's Recommendation Technology", http://www.stumbleupon.com/technology/, Feb. 10, 2015, pp. 1-2. |
| Bahshal el al, "Searching the Blogosphere", Preceeding of the 10th International Workshop of Web and Databases, Beijing, China, Jun. 15, 2007. |
| El-Arini et al. "Turning Down the Noise in the Dlogosphere", KOD, Paris, France, Jun. 28-Jul. 1, 2009. |
| http://google.com, Feb. 10, 2015, p. 1. |
| Ioannidis et al., "Surfing the Blogosphere: Optimal Personalized Strategies for Searching the Web," INFOCOM, 2010 Proceedings IEEE, Mar. 14, 2010, pp. 1-9. |
| Phatak et al., "Clustering for Personalized Mobile Web Usage", Proceedings of the 2002 IEEE International Conference on Fuzzy Systems, vol. 1, (2002), pp. 705-710. |
| Search Report Dated May 19, 2011. |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2011080138A1 (en) | 2011-07-07 |
| EP2348424A1 (en) | 2011-07-27 |
| US20120260165A1 (en) | 2012-10-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Yin et al. | Social influence-based group representation learning for group recommendation | |
| Abrahao et al. | Reputation offsets trust judgments based on social biases among Airbnb users | |
| TWI636416B (en) | Method and system for multi-phase ranking for content personalization | |
| Christensen et al. | Social group recommendation in the tourism domain | |
| US20200068034A1 (en) | Method and system for measuring user engagement using click/skip in content stream | |
| US7457768B2 (en) | Methods and apparatus for predicting and selectively collecting preferences based on personality diagnosis | |
| US9270767B2 (en) | Method and system for discovery of user unknown interests based on supplemental content | |
| US8909626B2 (en) | Determining user preference of items based on user ratings and user features | |
| Rana et al. | A study of the dynamic features of recommender systems | |
| US6345264B1 (en) | Methods and apparatus, using expansion attributes having default, values, for matching entities and predicting an attribute of an entity | |
| US6353813B1 (en) | Method and apparatus, using attribute set harmonization and default attribute values, for matching entities and predicting an attribute of an entity | |
| US20150051973A1 (en) | Contextual-bandit approach to personalized news article recommendation | |
| US8346749B2 (en) | Balancing the costs of sharing private data with the utility of enhanced personalization of online services | |
| US20140280890A1 (en) | Method and system for measuring user engagement using scroll dwell time | |
| JP5805548B2 (en) | Information processing apparatus and information processing method | |
| US20090216639A1 (en) | Advertising selection and display based on electronic profile information | |
| US20140280550A1 (en) | Method and system for measuring user engagement from stream depth | |
| US20150095271A1 (en) | Method and apparatus for contextual linear bandits | |
| Javari et al. | Recommender systems based on collaborative filtering and resource allocation | |
| US9245034B2 (en) | Recommending content | |
| Kim et al. | Folkommender: a group recommender system based on a graph-based ranking algorithm | |
| Zhao et al. | Service objective evaluation via exploring social users' rating behaviors | |
| WO2006054276A1 (en) | Mobile device internet access | |
| CN110222257A (en) | A kind of method, apparatus and data-link node for recommending business information | |
| KR20220094824A (en) | Method for suggesting fashion goods by using artificial intelligence stylist |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment |
Owner name: THOMSON LICENSING, FRANCE Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:MASSOULIE, LAURENT;IOANNDIS, EFSTRATIOS;SIGNING DATES FROM 20120515 TO 20120525;REEL/FRAME:031280/0415 |
|
| STCF | Information on status: patent grant |
Free format text: PATENTED CASE |
|
| AS | Assignment |
Owner name: THOMSON LICENSING DTV, FRANCE Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:THOMSON LICENSING;REEL/FRAME:041370/0433 Effective date: 20170113 |
|
| AS | Assignment |
Owner name: THOMSON LICENSING DTV, FRANCE Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:THOMSON LICENSING;REEL/FRAME:041378/0630 Effective date: 20170113 |
|
| AS | Assignment |
Owner name: INTERDIGITAL MADISON PATENT HOLDINGS, FRANCE Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:THOMSON LICENSING DTV;REEL/FRAME:046763/0001 Effective date: 20180723 |
|
| MAFP | Maintenance fee payment |
Free format text: PAYMENT OF MAINTENANCE FEE, 4TH YEAR, LARGE ENTITY (ORIGINAL EVENT CODE: M1551); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY Year of fee payment: 4 |
|
| MAFP | Maintenance fee payment |
Free format text: PAYMENT OF MAINTENANCE FEE, 8TH YEAR, LARGE ENTITY (ORIGINAL EVENT CODE: M1552); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY Year of fee payment: 8 |