US20030135372A1 - Hybrid dual/single talker speech synthesizer - Google Patents
Hybrid dual/single talker speech synthesizer Download PDFInfo
- Publication number
- US20030135372A1 US20030135372A1 US10/242,466 US24246602A US2003135372A1 US 20030135372 A1 US20030135372 A1 US 20030135372A1 US 24246602 A US24246602 A US 24246602A US 2003135372 A1 US2003135372 A1 US 2003135372A1
- Authority
- US
- United States
- Prior art keywords
- lpc
- melp
- frame
- tdvc
- gain
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Abandoned
Links
- 230000009977 dual effect Effects 0.000 title claims abstract description 54
- 238000000034 method Methods 0.000 claims abstract description 150
- 238000005259 measurement Methods 0.000 claims 2
- 230000007704 transition Effects 0.000 abstract description 19
- 238000006243 chemical reaction Methods 0.000 description 81
- 238000001228 spectrum Methods 0.000 description 59
- 230000008569 process Effects 0.000 description 49
- 230000003595 spectral effect Effects 0.000 description 38
- 230000000694 effects Effects 0.000 description 25
- 230000006870 function Effects 0.000 description 24
- 230000005540 biological transmission Effects 0.000 description 20
- 238000013139 quantization Methods 0.000 description 17
- 238000010586 diagram Methods 0.000 description 16
- 230000003044 adaptive effect Effects 0.000 description 15
- 238000012937 correction Methods 0.000 description 15
- 230000015572 biosynthetic process Effects 0.000 description 13
- 238000003786 synthesis reaction Methods 0.000 description 13
- 238000012545 processing Methods 0.000 description 11
- 238000004458 analytical method Methods 0.000 description 10
- 230000006835 compression Effects 0.000 description 10
- 238000007906 compression Methods 0.000 description 10
- 230000005284 excitation Effects 0.000 description 10
- 230000009466 transformation Effects 0.000 description 10
- 238000000844 transformation Methods 0.000 description 10
- 238000004891 communication Methods 0.000 description 8
- 101100421536 Danio rerio sim1a gene Proteins 0.000 description 7
- 101100495431 Schizosaccharomyces pombe (strain 972 / ATCC 24843) cnp1 gene Proteins 0.000 description 7
- 230000008901 benefit Effects 0.000 description 7
- 238000009499 grossing Methods 0.000 description 7
- 241000194293 Apopestes spectrum Species 0.000 description 5
- 238000001514 detection method Methods 0.000 description 5
- 238000005516 engineering process Methods 0.000 description 5
- 238000010183 spectrum analysis Methods 0.000 description 5
- 206010019133 Hangover Diseases 0.000 description 4
- 238000007667 floating Methods 0.000 description 4
- 230000006872 improvement Effects 0.000 description 4
- 230000001755 vocal effect Effects 0.000 description 4
- 230000008859 change Effects 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 239000003623 enhancer Substances 0.000 description 3
- 238000011524 similarity measure Methods 0.000 description 3
- 241000501308 Conus spectrum Species 0.000 description 2
- 238000005311 autocorrelation function Methods 0.000 description 2
- 238000004364 calculation method Methods 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 230000006837 decompression Effects 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 238000013507 mapping Methods 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 230000000644 propagated effect Effects 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 238000007493 shaping process Methods 0.000 description 2
- 230000001131 transforming effect Effects 0.000 description 2
- 206010002953 Aphonia Diseases 0.000 description 1
- 238000012935 Averaging Methods 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 238000013459 approach Methods 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 230000008570 general process Effects 0.000 description 1
- 238000013178 mathematical model Methods 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000010355 oscillation Effects 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 238000012913 prioritisation Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000005070 sampling Methods 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 210000001260 vocal cord Anatomy 0.000 description 1
Images













Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04W—WIRELESS COMMUNICATION NETWORKS
- H04W88/00—Devices specially adapted for wireless communication networks, e.g. terminals, base stations or access point devices
- H04W88/18—Service support devices; Network management devices
- H04W88/181—Transcoding devices; Rate adaptation devices
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G10L19/173—Transcoding, i.e. converting between two coded representations avoiding cascaded coding-decoding
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/78—Detection of presence or absence of voice signals
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/0204—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders using subband decomposition
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/06—Determination or coding of the spectral characteristics, e.g. of the short-term prediction coefficients
Definitions
- the present invention relates to speech synthesizers. More specifically, the present invention relates to a system and method for decoding a digital audio stream containing encoded parameters describing either a single talker's voice input or encoded parameters describing two simultaneous talker's voice inputs.
- speech coding refers to the process of compressing and decompressing human speech.
- a speech coder is an apparatus for compressing (also referred to herein as coding) and decompressing (also referred to herein as decoding) human speech.
- Storage and transmission of human speech by digital techniques has become widespread.
- digital storage and transmission of speech signals is accomplished by generating a digital representation of the speech signal and then storing the representation in memory, or transmitting the representation to a receiving device for synthesis of the original speech.
- Digital compression techniques are commonly employed to yield compact digital representations of the original signals.
- Information represented in compressed digital form is more efficiently transmitted and stored and is easier to process. Consequently, modem communication technologies such as mobile satellite telephony, digital cellular telephony, land-mobile telephony, Internet telephony, speech mailboxes, and landline telephony make extensive use of digital speech compression techniques to transmit speech information under circumstances of limited bandwidth.
- Compression is typically accomplished by extracting parameters of successive sample sets, also referred to herein as “frames”, of the original speech waveform and representing the extracted parameters as a digital signal.
- the digital signal may then be transmitted, stored or otherwise provided to a device capable of utilizing it.
- Decompression is typically accomplished by decoding the transmitted or stored digital signal. In decoding the signal, the encoded versions of extracted parameters for each frame are utilized to reconstruct an approximation of the original speech waveform that preserves as much of the perceptual quality of the original speech as possible.
- Coders which perform compression and decompression functions by extracting parameters of the original speech are generally referred to as parametric coders or vocoders. Instead of transmitting efficiently encoded samples of the original speech waveform itself, parametric coders map speech signals onto a mathematical model of the human vocal tract. The excitation of the vocal tract may be modeled as either a periodic pulse train (for voiced speech), or a white random number sequence (for unvoiced speech).
- voiced speech refers to speech sounds generally produced by vibration or oscillation of the human vocal cords.
- unvoiced speech refers to speech sounds generated by forming a constriction at some point in the vocal tract, typically near the end of the vocal tract at the mouth, and forcing air through the constriction at a sufficient velocity to produce turbulence.
- Speech coders which employ parametric algorithms to map and model
- LPC-10 Linear Prediction Coding: a Federal Standard, having a transmission rate of 2400 bits/sec. LPC-10 is described, e.g., in T. Tremain, “The Government Standard Linear Prediction Coding Algorithm: LPC-10,” Speech Technology Magazine, pp. 40-49, April 1982).
- MELP Mated Excitation Linear Prediction: another Federal Standard, also having a transmission rate of 2400 bits/sec.
- a description of MELP can be found in A. McCree, K. Truong, E. George, T. Barnwell, and V. Viswanathan, “A 2.4 kb/sec MELP Coder Candidate for the new U.S. Federal Standard,” Proc. IEEE Conference on Acoustics, Speech and Signal Processing, pp. 200-203, 1996.
- TDVC Time Domain voicingng Cutoff
- TDVC A high quality, ultra low rate speech coding algorithm developed by General Electric and Lockheed Martin having a transmission rate of 1750 bits/sec.
- TDVC is described in the following U.S. Pat. Nos. 6,138,092; 6,119,082; 6,098,036; 6,094,629; 6,081,777; 6,081,776; 6,078,880; 6,073,093; 6,067,511.
- TDVC is also described in R. Zinser, M. Grabb, S. Koch and G. Brooksby, “Time Domain voicingng Cutoff (TDVC): A High Quality, Low Complexity 1.3-2.0 kb/sec Vocoder,” Proc. IEEE Workshop on Speech Coding for Telecommunications, pp. 25-26, 1997.
- transcoders are needed (both ways, A-to-B and B-to-A) to communicate between and amongst the units.
- a communication unit employing LPC-10 speech coding can not communicate with a communication unit employing TDVC speech coding unless there is an LPC-to-TDVC transcoder to translate between the two speech coding standards.
- Many commercial and military communication systems in use today must support multiple coding standards. In many cases, the vocoders are incompatible with each other.
- FIG. 1 A tandem connection is illustrated in FIG. 1.
- Vocoder decoder 102 and D/A 104 decodes an incoming bit stream representing parametric data of a first speech coding algorithm into an analog speech sample.
- A/D 106 and vocoder encoder 108 reencodes the analog speech sample into parametric data encoded by a second speech coding algorithm.
- the system and method of the present invention comprises a compressed domain universal transcoder architecture that greatly improves the transcoding process.
- the compressed domain transcoder directly converts the speech coder parametric information in the compressed domain without converting the parametric information to a speech waveform representation during the conversion.
- the parametric model parameters are decoded, transformed, and then re-encoded in the new format.
- the process requires significantly less computing resources than a tandem connection. In some cases, the CPU time and memory savings can exceed an order of magnitude.
- the method more-generally comprises transcoding a bit stream representing frames of data encoded according to a first compression standard (MELP coding standard) to a bit stream representing frames of data according to a second compression standard (TDVC coding standard).
- the bit stream is decoded into a first set of parameters compatible with a first compression standard.
- the first set of parameters are transformed into a second set of parameters compatible with a second compression standard without converting the first set of parameters to an analog or digital waveform representation.
- the second set of parameters are encoded into a bit stream compatible with the second compression standard.
- FIG. 1 depicts a block diagram illustrating a conventional tandem connection.
- FIG. 2 depicts a block diagram illustrating the general architecture of the compressed domain universal transcoder of the present invention.
- FIG. 3 depicts a block diagram illustrating an LPC-to-MELP transcoding process.
- FIG. 4 depicts a block diagram illustrating a MELP-to-LPC transcoding process.
- FIG. 5 depicts a block diagram illustrating a LPC-to-TDVC transcoding process.
- FIG. 6 depicts a block diagram illustrating a MELP-to-TDVC transcoding process.
- FIG. 7 depicts a block diagram illustrating a TDVC-to-LPC transcoding process.
- FIG. 8 depicts a block diagram illustrating a TDVC-to-MELP transcoding process.
- FIG. 9 depicts a block diagram illustrating a Compressed Domain Conference Bridge.
- FIG. 10 depicts a dual synthesizer state diagram.
- FIG. 11 depicts a Compressed Domain Voice Activation Detector (CDVAD).
- CDVAD Compressed Domain Voice Activation Detector
- FIG. 12A depicts a block diagram illustrating a multi-frame encoding and decoding process.
- FIG. 12B depicts 5-bit and 4-bit quantizer tables used for multi-frame gain encoding and decoding.
- the transcoding technology of the present invention greatly improves the transcoding process.
- the transcoder directly converts the speech coder parametric information in the compressed domain without converting the parametric information to an analog speech signal during the conversion.
- the parametric model parameters are decoded, transformed, and then re-encoded in the new format.
- the process requires significantly less computing resources than the tandem connection illustrated in FIG. 1. In some cases, the CPU time and memory savings can exceed an order of magnitude.
- the transcoder of the present invention performs the following steps: 1) decode the incoming bit stream into the vocoder parameters, 2) transform the vocoder parameters into a new set of parameters for the target output vocoder, and 3) encode the transformed parameters into a bit stream compatible with the target output coder.
- FIG. 2 is a block diagram illustrating the general transcoding process 200 of the present invention.
- the process 200 shown in FIG. 2 is the general conversion process that is used to convert an incoming bit stream encoded with a first coding standard to an output bit stream encoded with a second coding standard.
- an incoming bit stream encoded with the LPC coding standard could be converted to the MELP coding standard, or an incoming bit stream encoded in MELP coding standard could be converted to the TDVC coding standard.
- the process shown in FIG. 2 illustrates the general process of the present invention that applies to all of the possible conversions (e.g. LPC to MELP, LPC to TDVC, MELP to LPC, etc).
- Each of the six individual transcoder conversions between LPC, MELP, and TDVC will later be described individually in more detail below with respect to sections 2-7 below and FIGS. 3 - 8 .
- an incoming bit stream is received by demultiplexing and FEC (forward error correction decoding) step 201 .
- the incoming bit stream represents frames containing parameters of a first coding standard such as LPC-10, MELP, or TDVC. This first coding standard will also be referred to as the “input coding standard.”
- FEC forward error correction decoding
- step 201 forward error correction decoding is performed on the incoming data frames, and the copies of each frame are distributed to steps 202 , 204 , 206 , and 208 , respectively.
- FEC adds redundant bits to a block of information to protect from errors.
- each coding standard employs different numbers and kinds of parameters.
- LPC-10 employs one voicing parameter comprised of only a single voicing bit per half-frame of data
- MELP employs a total of seven voicing parameters per frame (five voicing parameters representing bandpass voicing strengths, one overall voiced/unvoiced flag, and one voicing parameter called the “jitter flag”) in an effort to enhance speech quality.
- steps 202 the spectral parameters of the first coding standard are decoded from the incoming data frames.
- step 204 the voicing parameters of the first coding standard are decoded from the incoming data frames.
- step 206 the pitch parameters of the first coding standard are decoded from the incoming data frames.
- step 208 the gain parameters of the first coding standard are decoded from the incoming data frames.
- step 210 , 212 , 214 , and 216 the decoded parameters of the input coding standard are converted to spectrum, voicing, pitch and gain parameters, respectively, of the output coding standard.
- Each type of conversion is described in detail in the sections below for each specific type of transcoder conversion.
- the conversion from input coding standard parameters to output coding standard parameters is not always a simple one to one conversion of parameters.
- the output voicing parameters could be a function of both the input voicing parameters and the input spectrum parameters (this is true, for example, for the MELP to LPC transcoding conversion, described below).
- Other operations are also used in the conversion process to improve the output sound quality such as interpolation operations, smoothing operations, and formant enhancement described further in sections 2-7 below.
- the parameters produced by the conversion steps 210 , 212 , 214 , and 216 will be either floating point numbers or fixed point numbers, depending on the particular output coding standard.
- the MELP and TDVC standards use floating point numbers
- the LPC-10 standard uses fixed point numbers.
- Encoding steps 218 , 220 , 222 , and 224 encode and quantize the output spectrum, voicing, pitch and gain parameters, respectively, using the standard quantization/encoding algorithms of the output coding standard.
- step 226 the output parameters are combined into frames, forward error correction encoding is performed, and the output bit stream representing frames of the output coding standard are transmitted.
- the general transcoding method illustrated in FIG. 2 and the conversion techniques described below can also be applied to create trancoders for conversion between other coding standards besides LPC, MELP, and TDVC that are currently in usage or being developed.
- FIG. 3 illustrates a transcoding method 300 for converting a bit stream representing frames encoded with the LPC-10 coding standard to a bit stream representing frames encoded with the MELP coding standard.
- step 302 an incoming bit stream is received.
- the incoming bit stream represents LPC-10 frames containing LPC-10 parameters.
- Forward error correction (FEC) decoding is performed on the incoming bit stream.
- the incoming bit stream is also decoded by extracting LPC-10 spectrum, pitch, voicing, and gain parameters from the incoming bit stream.
- the parameters are then distributed to spectrum conversion step 304 , voicing conversion step 312 , pitch conversion step 316 and gain conversion step 322 .
- FEC Forward error correction
- the LPC-10 spectrum parameters are referred to as “reflection coefficients” (RCs) whereas the MELP spectrum parameters are referred to as “line spectrum frequencies” (LSFs).
- RCs reflection coefficients
- LSFs line spectrum frequencies
- step 304 the LPC-10 reflection coefficients (RC) are first converted to their equivalent normalized autocorrelation coefficients (R).
- the LPC-10 reflection coefficients (RC) are also converted to their equivalent predictor filter coefficients (A); the predictor filter coefficients (A) are saved for later use in formant enhancement step 308 .
- Both of these conversions (RC ⁇ R, RC ⁇ A) are performed by using well known transformations.
- the autocorrelation conversion (RC ⁇ R) recursion is carried out to 50 lags (setting RCs above order 10 to zero).
- the resulting values for the autocorrelation coefficients (R) are stored symmetrically in a first array.
- step 306 the “preemphasis” is removed from the LPC-10 autocorrelation (R) coefficients.
- R LPC-10 autocorrelation
- Newer speech coding algorithms such as MELP and TDVC do not perform preemphasis because they were designed for modem signal processing hardware that has wider data paths. Therefore, a MELP synthesizer expects spectral coefficients that were produced directly from the sampled speech signal without preemphasis.
- step 306 the preemphasis effects are removed from the LPC-10 spectral coefficients.
- Preemphasis removal is performed as follows.
- the symmetrical autocorrelation coefficients (HH) of a deemphasis filter are calculated beforehand and stored in a second array matching the format of the first array of autocorrelation coefficients (R) created in step 304 .
- the deemphasis filter is a single pole IIR filter and is generally the inverse of the preemphasis filter used by LPC-10, but different preemphasis and deemphasis coefficients may be used.
- the LPC-10 standard uses 0.9375 for preemphasis and 0.75 for deemphasis. Because the deemphasis filter has IIR characteristics, the autocorrelation function is carried out to 40 time lags. The autocorrelation values are obtained by convolving the impulse response of the filter.
- the resulting modified autocorrelation coefficients R′ will be referred to herein as “deemphasized” autocorrelation coefficients, meaning that the LPC-10 preemphasis effects have been removed. Note that by removing the preemphasis in the correlation domain (i.e. removing the preemphasis from autocorrelation coefficients rather than the reflection coefficients or filter coefficients), computational complexity can be reduced.
- the deemphasized autocorrelation coefficients R′ are then converted to deemphasized reflection coefficients (RC′) and deemphasized predictor filter coefficients (A′), using well known conversion formulas.
- the stability of the synthesis filter formed by the coefficients is checked; if the filter is unstable, the maximum order stable model is used (e.g. all RC′ coefficients up to the unstable coefficient are used for the conversion to A′ coefficients).
- the RC and RC′ values are saved for use by the “Compute LPC Gain Ratio” step 320 , described further below.
- step 308 formant enhancement is performed.
- the perceptual quality produced by low rate speech coding algorithms can be enhanced by attenuating the output speech signal in areas of low spectral amplitude. This operation is known as formant enhancement.
- Formant enhancement sharpens up the spectral peaks and depresses the valleys to produce a crisper sound that is more intelligible.
- Format enhancement is conventionally performed during the process of decoding the bit stream into an analog speech signal. However, according to the present invention, it has been found that formant enhancement can be used to in the transcoding process 300 to produce a better sounding speech output.
- Section 12 describes a method of formant enhancement performed in the correlation domain.
- Section 13 describes a second method of formant enhancement performed in the frequency domain.
- the formant enhancement method performed in the correlation domain utilizes both the non-deemphasized filter coefficients (A) and the deemphasized filter coefficients (A′). Both methods of formant enhancement produce good results. Which one is preferable is a subjective determination made by the listener for the particular application.
- Formant enhancement step 310 outputs “enhanced” deemphasized LPC-10 filter coefficients (A′′), wherein the term “enhanced” means that formant enhancement has been performed.
- the transcoding process of the present invention illustrated in FIG. 3 could potentially be performed without formant enhancement step 308 .
- formant enhancement has been found to substantially improve the speech quality and understandability of the MELP output.
- step 310 the enhanced deemphasized LPC-10 filter coefficients (A′′) are converted to MELP line spectrum frequencies (LSFs). This conversion is made by using well known transformations.
- the MELP LSFs are then adaptively smoothed.
- modem vocoders like MELP and TDVC, because of the way the quantization error is handled, the voice often obtains an undesirable vibrato-like sound if smoothing is not performed.
- a smoothing function is applied to reduce this undesirable vibrato effect.
- the smoothing function is designed to reduce small fluctuations in the spectrum when there are no large frame-to-frame spectrum changes. Large fluctuations are allowed to pass with minimum smoothing.
- the following C-code segment is an example of such a smoother.
- lsp[i] are the current frame's LSF coefficients
- oldlsp[i] are the previous frame's LSF coefficients
- delta is a floating point temporary variable
- MELP also has the provision for encoding the first 10 harmonic amplitudes for voiced speech.
- These harmonic amplitudes can either be set to zero or generated as follows.
- Further enhancement may be achieved by utilizing the method described in Grabb, et al., U.S. Pat. No. 6,081,777, “Enhancement of Speech Signals Transmitted Over a Vocoder Channel”, and modifying the first three harmonic amplitudes amp(k) according to the values given in FIG. 5 and the accompanying equation.
- the smoothed LSFs are encoded according to the MELP quantization standard algorithm.
- step 312 the LPC-10 voicing parameters are converted into MELP voicing parameters. This is not a simple one-to-one conversion because LPC-10 uses only a single voicing parameter, whereas MELP uses several voicing parameters. Thus, a method has been devised according to the present invention for assigning MELP parameters based on the LPC-10 parameters which produces superior sound quality.
- the LPC-10 coding standard uses only a single voicing bit per half-frame representing either voiced or unvoiced; i.e., each half-frame is either voiced or unvoiced.
- the newer MELP coding standard uses seven different voicing parameters: five bandpass voicing strengths, one overall voiced/unvoiced flag, and one voicing parameter called the “jitter flag” which is used to break up the periodicity in the voiced excitation to make the speech sound less buzzy during critical transition periods.
- the conversion process of the present invention uses the expanded voicing features of the MELP synthesizer to advantage during transitional periods such as voicing onset, described as follows.
- the LPC voicing bits are converted to MELP voicing parameters according to three different situations:
- the method is illustrated by the piece of C code below. Testing has found that this method provides the superior sound performance. This method tends to provide a smoother transition from voiced to unvoiced transitions.
- melp-> jitter is the MELP jitter flag
- melp-> bpvc[i] are the MELP bandpass voicing strengths. Note that for the transition from unvoiced to voiced, the top two MELP voicing bands are forced to be unvoiced. This reduces perceptual buzziness in the output speech.
- step 314 the MELP voicing and jitter parameters are encoded according to the MELP quantization standard algorithm.
- step 316 the LPC-10 pitch parameters are converted to MELP pitch parameters.
- the LPC-10 coding standard encodes pitch by a linear method whereas MELP encodes pitch logarithmically. Therefore, in step 316 , the logarithm is taken of the LPC-10 pitch parameters to convert to the MELP pitch parameters.
- step 318 the MELP pitch parameters are encoded using the MELP quantization standard algorithm.
- step 322 The conversion from LPC-10 RMS gain parameters to MELP gain parameters begins in step 322 .
- step 322 the LPC-10 RMS gain parameters are scaled to account for the preemphasis removal performed on the LPC-10 spectral coefficients in step 306 .
- LPC-10 coding adds preemphasis to the sampled speech signal prior to spectral analysis.
- the preemphasis operation in addition to attenuating the bass and increasing the treble frequencies, also reduces the power level of the input signal. The power level is reduced in a variable fashion depending on the spectrum. Therefore, the effect of removing the preemphasis in step 306 must be accounted for accordingly when converting the gains from LPC to MELP.
- the preemphasis removal is accounted for by scaling the gains in step 322 .
- an “LPC gain ratio” is calculated for each new frame of parametric data.
- the factor of 8 is included to accommodate the 13 bit input and output sample scaling in LPC-10 (MELP utilizes 16 bit input and output samples).
- the LPC RMS gain parameter is scaled by the LPC Gain Ratio calculated in step 320 .
- Steps 324 addresses another difficulty in the gain conversion process which is that MELP uses two gain parameters per frame, whereas LPC uses only one gain parameter per frame.
- MELP employs a first gain parameter for the first half frame, and a second gain parameter for the second half frame. There thus needs to be a method for assigning the two half-frame MELP gains which produce a good quality sounding output.
- a simple method of assigning MELP gains would be to simply set both of the MELP gains equal to the LPC RMS gain. However, it has been found that a better result is obtained if the two MELP gains are generated by taking a logarithmic average of the LPC RMS gains from frame to frame. This is performed in steps 324 and 326 . As illustrated by the C-code segment below, the first MELP frame gain is assigned to be equal to the logarithmic average of the old LPC RMS gain from the last frame and the new LPC RMS gain from the current frame. The second MELP gain is set equal to the LPC RMS gain for the current frame. This method of assigning MELP gains provides a smooth transition.
- LPCrms and LPCrmsold represent the scaled LPC RMS gains computed in step 322 .
- LPCrms is the current frame's gain
- LPCrmsold is the previous frame's scaled gain.
- melp-> gain[0] and melp-> gain[1] are the MELP half frame gains
- pow( ) is the C library power function
- log10( ) is the C-library base-10 logarithm function.
- step 326 the logarithmic value of the two MELP gains are provided to encoding step 328 .
- step 328 the MELP half-frame gains are encoded using the standard MELP logarithmic quantization algorithm.
- step 330 the encoded MELP spectrum, voicing, pitch, and gain parameters are inserted into MELPs frame and forward error correction (FEC) coding is performed. An output bit stream representing the MELP frames is then transmitted to a desired recipient.
- FEC forward error correction
- FIG. 4 illustrates a transcoding method 400 for converting a bit stream representing frames encoded with the MELP coding standard to a bit stream representing frames encoded with the LPC-10 coding standard.
- an incoming bit stream is received.
- the incoming bit stream represents MELP frames containing MELP parameters.
- forward error correction (FEC) decoding is performed on the incoming bit stream.
- the MELP frames are also decoded by extracting the MELP spectrum, pitch, voicing, and gain parameters from the MELP frames.
- the MELP parameters are then distributed to steps 404 , 412 , 416 and 420 for conversion to LPC-10 spectrum, voicing, pitch and gain parameters, respectively.
- step 404 the MELP LSFs are converted to their equivalent normalized autocorrelation coefficients R using well known transformations.
- preemphasis is added to the autocorrelation coefficients R.
- LPC-10 speech encoders add preemphasis to the originally sampled (nominal) speech signal before the LPC-10 spectral analysis and encoding is performed.
- transcoder 400 must modify the autocorrelation coefficients R to produce modified autocorrelation coefficients which are equivalent to autocorrelation coefficients that would have been produced had the original nominal speech signal been preemphasized prior to LPC-10 encoding.
- the LPC-10 0.9375 preemphasis coefficient must be superimposed on the spectrum. This is performed in the correlation domain by performing the following operation on the autocorrelation (R) coefficients:
- R ′( i ) R ( i ) ⁇ 0.9375[ R (
- R′(i) are the preemphasized autocorrelation coefficients. Note that the input set of R(i)s must be computed out to 11 lags to avoid truncation.
- the preemphasized autocorrelation coefficients R′ are then transformed to preemphasized predictor filter coefficients A′ using well known transformations. As noted in section 2, above, performing the preemphasis addition in the correlation domain reduces computational complexity.
- step 408 formant enhancement is performed.
- the purpose of formant enhancement step 408 is the same as formant enhancement step 308 described above for the LPC-10 to MELP transcoder.
- Two methods of formant enhancement are described in detail in sections 12 and 13 below. Section 12 describes a method of formant enhancement performed in the correlation domain. Section 13 describes a second method of formant enhancement performed in the frequency domain. Both methods of formant enhancement produce good results. Which one is preferable is a subjective determination made by the listener for the particular application. For the MELP to LPC-10 transcoder, the majority of listeners polled showed a slight preference frequency domain method.
- step 410 the formant enhanced preemphasized filter coefficients A′′ are converted to LPC-10 reflection coefficients RC′′ using well known transformations. Also in step 410 , the reflection coefficients RC′′ are encoded according to the LPC-10 quantizer tables.
- the MELP voicing parameters are converted to LPC voicing parameters.
- the LPC-10 coding standard uses only a single voicing bit per half-frame, whereas the MELP coding standard uses seven different voicing parameters: five bandpass voicing strengths, one overall voiced/unvoiced flag, and one voicing parameter called the “jitter flag.”
- step 412 achieves better perceptual performance by assigning values to the LPC voicing bits based on the MELP bandpass voicing strengths, the MELP overall voicing bit, and the first reflection coefficient RC′[0] (after preemphasis addition) received from preemphasis addition unit 406 .
- flag is an integer temporary variable
- rc′[0] is the first reflection coefficient (computed from the spectrum after preemphasis addition).
- both LPC voicing bits are set to one (voiced) if the MELP overall unvoiced flag equals zero (voiced). Otherwise, the LPC voicing bits are set to one (unvoiced).
- both LPC voicing bits are set to zero (unvoiced) if the first reflection coefficient RC′[0] is negative, and the total number of MELP bands which are voiced is less than or equal to four. The reason this last improvement is performed is as follows.
- the MELP voicing analysis algorithm will occasionally set a partially voiced condition (lower bands voiced, upper bands unvoiced) when the input signal is actually unvoiced. Unvoiced signals typically have a spectrum that is increasing in magnitude with frequency.
- the first reflection coefficient RC′[0] provides an indication the spectral slope, and when it is negative, the spectral magnitudes are increasing with frequency. Thus, this value can be used to correct the error.
- step 414 pitch and voice are encoded together using the standard LPC-10 quantization algorithm. According to the LPC standard, pitch and voicing are encoded together.
- step 416 the MELP pitch parameter is converted to an LPC-10 pitch parameter by taking the inverse logarithm of the MELP pitch parameter (since the MELP algorithm encodes pitch logarithmically).
- step 418 the resulting LPC-10 pitch parameter is quantized according to the LPC-10 pitch quantization table.
- step 414 pitch and voice are encoded together using the standard LPC-10 quantization algorithm.
- the MELP algorithm produces two half-frame logarithmically encoded gain (RMS) parameters per frame, whereas LPC produces a single RMS gain parameter per frame.
- step 420 the inverse logarithm of each MELP half-frame gain parameter is taken.
- step 424 both gain values are scaled by the above scaling value.
- the output of step 424 will be referred to as the “scaled MELP gains.”
- the LPC gain parameter is nominally set to the logarithmic average of the two scaled MELP gains.
- An adaptive combiner algorithm is then used to preserve plosive sounds by utilizing the LPC-10 synthesizer's ability to detect and activate the “impulse doublet” excitation mode.
- LPC-10 synthesizers use an “impulse doublet” excitation mode which preserves plosive sounds like the sounds of the letters ‘b’ and ‘p’. If the LPC synthesizer senses a strong increase in gain, it produces an impulse doublet. This keeps the ‘b’ and ‘p’ sounds from sounding like ‘s’ or ‘f’ sounds.
- the algorithm used in step 426 is described as follows. First, the LPC gain parameter is nominally set to the logarithmic average of the two scaled MELP gains. Next, if it is determined that there is a large increase between the first and second half-frame scaled MELP gains, and the current and last transcoded frames are unvoiced, then the LPC gain parameter is set equal to the second half-frame scaled MELP gain.
- This emulates the adaptively-positioned analysis window used in LPC analysis and preserves LPC-10 synthesizer's ability to detect and activate the “impulse doublet” excitation mode for plosives. In other words, this method preserves sharp changes in gain to allow the LPC synthesizer to reproduce the ‘b’ and ‘p’ type sounds effectively.
- step 428 the LPC gain parameter is then quantized and encoded according to the quantizer tables for the LPC-10 standard algorithm.
- step 430 the encoded LPC spectrum, voicing, pitch, and gain parameters are inserted into a LPC frame and forward error correction (FEC) coding is added. An output bit stream representing the LPC frames is produced.
- FEC forward error correction
- FIG. 5 illustrates a transcoding method 300 for converting a bit stream representing LPC-10 encoded frames to a bit stream representing TDVC encoded frames.
- an incoming bit stream is received.
- the incoming bit stream represents LPC-10 frames containing LPC-10 parameters.
- forward error correction (FEC) decoding is performed on the incoming bit stream.
- the LPC-10 frames are also decoded by extracting the LPC-10 spectrum, pitch, voicing, and gain parameters from the LPC-10 frames.
- the LPC-10 parameters are then distributed to steps 504 , 514 , and 526 for conversion to LPC-10 spectrum, voicing, and gain parameters, respectively (no conversion of pitch is necessary as described below).
- the method of transcoding from LPC-10 parameters to TDVC parameters can be divided into 2 types of operations: 1) conversion from LPC-10 parameters to TDVC parameters, and 2) frame interpolation to synchronize the different frame sizes.
- the frame interpolation operations are performed in steps 508 , 516 , 520 , and 528 for interpolation of spectrum, voicing, pitch, and gain parameters, respectively.
- the conversion steps will be discussed first, followed by a discussion of the frame interpolation steps.
- step 504 the LPC-10 reflection coefficients (RC) are converted to their equivalent normalized autocorrelation coefficients (R) using well known transformations.
- the autocorrelation conversion recursion is carried out to 50 lags (setting RCs above order 10 to zero).
- the resulting values for the autocorrelation coefficients (R) are stored symmetrically in a first array.
- the preemphasis is removed in the correlation domain, described as follows.
- the symmetrical autocorrelation coefficients (HH) of the deemphasis filter are calculated beforehand and stored in an array.
- the deemphasis filter is a single pole IIR filter and is generally the inverse of the preemphasis filter, but different preemphasis and deemphasis coefficients may be used.
- the LPC-10 standard uses 0.9375 for preemphasis and 0.75 for deemphasis. Because the deemphasis filter has IIR characteristics, the autocorrelation function is carried out to 40 lags.
- the autocorrelation values (HH) are obtained by convolving the impulse response of the filter.
- a modified set of spectral autocorrelation coefficients is calculated via convolving the R values with the HH values:
- R ′ ⁇ ( k ) ⁇ i ⁇ R ⁇ ( i + k ) * HH ⁇ ( i )
- the resulting modified autocorrelation coefficients R′ are converted to both reflection coefficients (RC′) and predictor filter coefficients (A′).
- the stability of the synthesis filter formed by the coefficients is checked; if the filter is unstable, the maximum order stable model is used (e.g. all RC's up to the unstable coefficient are used for the conversion to A′ coefficients).
- the RC′ values are saved for use by step 524 in calculating the TDVC gain, discussed further below.
- the final step in the preemphasis removal process is to convert the deemphasized predictor filter coefficients (A′) to line spectrum frequencies (LSF) in preparation for frame interpolation in step 508 .
- LSF line spectrum frequencies
- step 514 LPC-10 voicing parameters are converted to TDVC voicing parameters.
- the TDVC voicing cutoff frequency parameter fsel indicates a frequency above which the input frame is judged to contain unvoiced content, and below which the input frame is judged to contain voiced speech.
- LPC-10 uses a simple, half-frame on/off voicing bit.
- Step 514 takes advantage of the expanded fsel voicing feature of the TDVC synthesizer during transitional periods such as voicing onset.
- fselnew is the TDVC fsel parameter.
- the effect of the method illustrated by the above code is that when a mid-frame transition from the LPC unvoiced to voiced state occurs, the TDVC voicing output changes in a gradual fashion in the frequency domain (by setting fsel to an intermediate value of 2). This prevents a click sound during voicing onset and thereby reduces perceptual buzziness in the output speech.
- step 526 an adjustment for preemphasis removal must be made to the LPC gain parameter before it can be used in a TDVC synthesizer. This preemphasis removal process is described as follows.
- the LPC gain parameter is scaled by the LPC gain ratio.
- the LPC gain ratio is calculated in step 524 for each new frame of data.
- This scale factor is the LPC Gain Ratio.
- the factor of 8 is included to accommodate the 13 bit input and output sample scaling in LPC-10 (TDVC utilizes 16 bit input and output samples).
- the scaling performed by step 526 is required because the LPC RMS gain is measured from the preemphasized input signal, while the TDVC gain is measured from the nominal input signal.
- Isf ( i ) wold*lsfold ( i )+ wnew*lsfnew ( i )
- lsfnew( ) and Isfold( ) correspond to the “new” and “old” LSF data sets described above.
- the voicing parameter fsel is also linearly interpolated in step 516 :
- TDVCpitch wold*LPCpitchold+wnew*LPCpitchnew
- the gain (RMS) is logarithmically interpolated in step 528 .
- the TDVC gain can be computed using the following C-code segment:
- TDVCgain pow (10.0, wold*log 10( LPCscaledRMSold )+ wnew*log 10( LPCscaledRMSnew ));
- the interpolated spectrum, voicing, pitch and gain parameters are then quantized and encoded according to the TDVC standard algorithm in steps 512 , 528 , 522 , and 530 , respectively.
- step 532 the encoded TDVC spectrum, voicing, pitch, and gain parameters are inserted into a TDVC frame and forward error correction (FEC) coding is added.
- FEC forward error correction
- FIG. 6 illustrates a transcoding method 600 for converting a bit stream representing MELP encoded frames to a bit stream representing TDVC encoded frames.
- an incoming bit stream is received.
- the incoming bit stream represents MELP frames containing MELP parameters.
- forward error correction (FEC) is decoding performed on the incoming bit stream.
- the MELP frames are also decoded by extracting the MELP spectrum, pitch, voicing, and gain parameters from the MELP frames.
- the MELP parameters are then distributed to steps 604 , 612 , 618 and 624 for conversion to TDVC spectrum, voicing, pitch and gain parameters, respectively.
- the method of transcoding from MELP to TDVC can be divided into 2 types of operations: 1) conversion from MELP parameters to TDVC parameters, and 2) frame interpolation to synchronize the different frame sizes.
- the frame interpolation operations are performed in steps 606 , 614 , 620 , and 628 for interpolation of spectrum, voicing, pitch, and gain parameters, respectively.
- the conversion steps will be discussed first, followed by a discussion of the frame interpolation steps.
- step 604 the MELP LSFs are scaled to convert to TDVC LSFs. Since MELP and TDVC both use line spectrum frequencies (LSFs) to transmit spectral information, no conversion is necessary except for a multiplication by a scaling factor of 0.5 (to accommodate convention differences).
- LSFs line spectrum frequencies
- step 612 the MELP voicing parameters are converted to TDVC voicing parameters.
- the TDVC voicing cutoff frequency parameter fsel (also referred to as the voicing cutoff frequency “flag”) indicates a frequency above which the input frame is judged to contain unvoiced content, and below which the input frame is judged to contain voiced speech.
- the value of the voicing cutoff flag ranges from 0 for completely unvoiced to 7 for completely voiced.
- r0 is a temporary floating point variable
- fselnew is the TDVC fsel parameter.
- the highest voiced frequency band in MELP is first identified.
- the frequency cutoffs for the MELP frequency bands are located at 500 Hz, 1000 Hz, 2000 Hz, and 3000 Hz.
- the frequency cutoff of the highest voiced band in MELP is used to choose the nearest corresponding value of fsel.
- step 618 the MELP pitch parameters-are converted to TDVC parameter. Since MELP pitch is logarithmically encoded, the TDVC pitch parameter (pitchnew) is obtained by taking an inverse logarithm of the MELP pitch parameter, as illustrated the following equation:
- the MELP gain parameters are converted to TDVC.
- melp-> gain[0] and melp-> gain[1] are the first and second MELP half-frame gains (respectively)
- gainnew is the “new” gain (described below in the section on frame interpolation)
- pow( ) is the C library power function
- log10 is the C library base-10 logarithm function.
- MELP and TDVC use different frame sizes (22.5 and 20 msec, respectively).
- an interpolation operation must be performed.
- 8 frames of MELP parameter data must be converted to 9 frames of TDVC parameter data.
- a smooth interpolation function is used for this process, based on a master clock counter 608 that counts MELP frames on a modulo-8 basis from 0 to 7. At startup, the master clock counter 608 is initialized at 0.
- TDVClsf ( i ) wold*lsfold ( i )+ wnew*lsfnew ( i )
- lsfnew( ) and lsfold( ) correspond to the “new” and “old” LSF sets described above.
- the voicing parameter fsel is also linearly interpolated in step 614 :
- TDVCfsel wold*fselold+wnew*fselnew
- TDVCpitch wold*pitchold+wnew*pitchnew
- the gain (RMS) is logarithmically interpolated in step 628 .
- the TDVC gain can be computed using the following C-code segment in step 628 :
- TDVCgain pow (10.0, wold*log 10( gainold )+ wnew*log 10( gainnew ));
- the interpolated spectrum, voicing, pitch, and gain parameters may now be quantized and encoded according to the TDVC standard algorithms in steps 610 , 616 , 622 , and 630 , respectively.
- step 632 the encoded TDVC spectrum, voicing, pitch, and gain parameters are inserted into a TDVC frame and forward error correction (FEC) coding is added.
- FEC forward error correction
- FIG. 7 illustrates a transcoding method 700 for converting from TDVC encoded frames to LPC-10 encoded frames.
- the transcoding conversion from TDVC to LPC-10 consists of 2 operations: 1) conversion from MELP parameters to TDVC parameters, and 2) frame interpolation to synchronize the different frame sizes.
- step 702 an incoming bit stream is received.
- the incoming bit stream represents TDVC frames containing TDVC parameters.
- forward error correction (FEC) decoding is performed on the incoming bit stream.
- the TDVC frames are also decoded by extracting the TDVC spectrum, pitch, voicing, and gain parameters from the TDVC frames.
- step 704 the TDVC line spectrum frequencies (LSFs) are transformed into predictor filter coefficients (A) using well known transformations.
- adaptive bandwidth expansion is removed from the TDVC predictor filter coefficients A.
- Adaptive bandwidth expansion is used by TDVC but not by LPC (i.e., adaptive bandwidth expansion is applied during TDVC analysis but not by LPC analysis).
- LPC line spectrum frequencies
- removing the adaptive bandwidth expansion effects from the spectral coefficients sharpens up the LPC spectrum and makes the resulting output sound better.
- the adaptive bandwidth expansion is removed by the following process:
- pitch is the TDVC pitch parameter.
- the new coefficient set a′(i) is checked for stability. If they form a stable LPC synthesis filter, then the modified coefficients a′(i) are used for further processing; if not, the original coefficients a(i) are used.
- the Interpolation Controller 708 handles this adjustment and changes the weighting coefficients wnew and wold for all four interpolation steps 706 , 714 , 720 , and 724 .
- master clock 708 is at the beginning portion of the interpolation cycle (less than or equal to three) then the LPC output parameters (including spectrum, voicing, pitch and gain) will be fixed to the old LPC output. If the clock is at the end portion of the interpolation cycle (greater than three), then the LPC output (spectrum, voicing, pitch and gain) is fixed to the new LPC set.
- This adjustment emulates the adaptively-positioned analysis window used in LPC analysis and preserves LPC-10 synthesizer's ability to detect and activate the “impulse doublet” excitation mode for plosives. This preserves the sharp difference of plosive sounds and produces a crisper sound.
- step 706 interpolation of the spectral coefficients is performed.
- the LSFs are linearly interpolated using the wnew and wold coefficients described above:
- preemphasis is added.
- the LPC-10 0.9375 preemphasis coefficient must be superimposed on the spectrum, since TDVC does not use preemphasis. This is performed in the correlation domain via transforming the interpolated LSFs into predictor coefficients (A) and then transforming the predictor coefficients into their equivalent normalized autocorrelation (R) coefficients and then employing the following operation:
- R ′( i ) R ( i ) ⁇ 0.9375[ R (
- R′(i) are the preemphasized autocorrelation coefficients. Note that the input set of R( )s must be computed out to 11 lags to avoid truncation. The modified autocorrelation coefficients R′(i) are now transformed back to predictor coefficients A′(i) for further processing.
- step 710 formant enhancement is performed on the predictor filter coefficients A′(i).
- Formant enhancement has been found to improve the quality of the transcoded speech.
- Two methods of formant enhancement are described in detail in sections 12 and 13 below. Section 12 describes a method of formant enhancement performed in the correlation domain. Section 13 describes a second method of formant enhancement performed in the frequency domain. Both methods of formant enhancement produce good results. Which one is preferable is a subjective determination made by the listener for the particular application. For the TDVC to LPC-10 transcoder, the majority of listeners polled showed a slight preference frequency domain method.
- the predictor filter coefficients A′(i) are converted to reflection coefficients (RCs) by well known transformations and quantized according to the LPC-10 quantizer tables in step 712 .
- voicing conversion uses the TDVC fsel voicing parameter and the first reflection coefficient RC.
- the TDVC fsel voicing cutoff frequency parameter is linearly interpolated using the wnew and wold coefficients described above:
- fselold is the “old” value of fsel
- fselnew is the “new” value of fsel
- step 716 the fsel voicing parameter is converted to an LPC voicing parameter. Simply using fsel voicing parameter bit to determine both half frame LPC voicing bits is inadequate. Additional information is required for the best perceptual performance.
- rc[0] is the first reflection coefficient (computed from the spectrum after preemphasis addition in step 708 ).
- both LPC half frame voicing bits are set to zero (unvoiced). If fsel is greater than 2, then both LPC half frame voicing bits are set to one (voiced).
- Unvoiced signals typically have a spectrum that is increasing in magnitude with frequency.
- the first reflection coefficient RC′[0] provides an indication the spectral slope, and when it is negative, the spectral magnitudes are increasing with frequency. Thus, this value can be used to correct the error.
- step 718 pitch and voicing are encoded together using the standard LPC-10 encoding algorithm.
- step 720 pitch is converted by linearly interpolating the “new” and “old” values of the TDVC pitch to form a single LPC pitch:
- step 718 pitch and voicing are encoded together using the standard LPC-10 quantization algorithm.
- the first step in converting the TDVC gain to LPC RMS is to logarithmically interpolate the the “new” and “old” values of the TDVC gain in step 724 (C-code example):
- LPCrms pow (10.0, wold*log 10( TDVCgainold )+ wnew*log 10( TDVCgainnew ));
- LPCrms is the intermediate LPC RMS gain
- pow( ) is the C-library power function
- log10 is the C-library base 10 logarithm function.
- step 728 the gain is scaled to account for the preemphasis addition performed on the spectral coefficients in step 708 .
- the following steps are performed to account for preemphasis.
- the factor of 8 is included to accommodate the 13 bit input and output sample scaling in LPC-10 (TDVC utilizes 16 bit input and output samples). This step is required because the LPC gain is measured from the preemphasized input signal, while the TDVC gain is measured from the nominal input signal.
- step 730 the LPC RMS gain is then quantized and encoded according to the quantizer tables for the LPC-10 algorithm.
- step 732 the encoded LPC-10 spectrum, voicing, pitch, and gain parameters are inserted into a LPC frame and forward error correction (FEC) is added. An output bit stream representing the LPC frames is produced.
- FEC forward error correction
- FIG. 8 illustrates a transcoding method 800 for converting a bit stream representing TDVC encoded frames to a bit stream representing MELP encoded frames.
- an incoming bit stream is received.
- the incoming bit stream represents TDVC frames containing TDVC parameters.
- forward error correction (FEC) decoding is performed on the incoming bit stream.
- the TDVC frames are also decoded by extracting the TDVC spectrum, pitch, voicing, and gain parameters from the TDVC frames.
- the TDVC parameters are then distributed to steps 604 , 612 , 618 and 624 for conversion to MELP spectrum, voicing, pitch and gain parameters, respectively.
- FEC forward error correction
- the LSFs are linearly interpolated in step 806 using the wnew and wold coefficients described above:
- the scaling factor of 2.0 is included (scaling is performed in step 809 ) because the MELP scaling convention is different than that of TDVC.
- the interpolated LSFs are then quantized and encoded in step 810 according to the MELP standard.
- the MELP standard also transmits 10 harmonic amplitude values that are used by the MELP synthesizer for generating voiced speech.
- U.S. Pat. No. 6,098,036 to Zinser et al., “Speech Coding System and Method Including Spectral Formant Enhancer,” (incorporated-by reference herein) discloses a spectral formant enhancement algorithm to generate these harmonic amplitudes.
- step 808 the calculated harmonic amplitudes are encoded by a MELP harmonic amplitude encoder.
- This method of generating harmonic amplitudes for provision to the MELP synthesizer could also be used with the LPC-to-MELP transcoder described in section 2, above.
- the fsel parameter is linearly interpolated in step 812 using the wnew and wold coefficients described above:
- fsel is interpolated TDVC fsel voicing parameter
- nint( ) is the nearest integer function
- tmp is an integer temporary variable.
- all of the MELP bands below the TDVC voicing cutoff frequency are set to voiced.
- the overall voicing bit and the bandpass strengths are then encoded according the MELP standard in step 816 .
- Pitch is converted by linearly interpolating the “new” and “old” values of the TDVC pitch to form a single LPC pitch in step 818 :
- step 820 the logarithm of the pitch is taken.
- step 822 the resulting pitch value is then encoded according to the MELP standard.
- the MELP algorithm has the capability to transmit 2 half-frame gains per frame.
- an adaptive dual gain interpolation is performed. This adaptive interpolation is a modification of the wnew/wold interpolation algorithm described above.
- the wnew/wold interpolation algorithm has been modified to generate these two gains by moving the wnew/wold interpolation weights slightly backward in the clock schedule for the first MELP gain, and slightly forward for the second MELP gain. These modified weights are used for logarithmic interpolation.
- melp-> gain[0] and melp-> gain[1] are the first and second MELP half-frame gains (respectively)
- tdvc-> gain[1] and tdvc-> gain[2] are the “old” and “new” TDVC gains (respectively)
- pow( ) is the C library power function
- log10 is the C library base-10 logarithm function.
- step 830 the encoded MELP spectrum, voicing, pitch, and gain parameters are inserted into a MELP frame and forward error correction (FEC) coding is added. An output bit stream representing the MELP frames is produced.
- FEC forward error correction
- Conference bridging technology has been available for many years to users of the Public Switched Telecommunications Network (PSTN). This technology enables multiple users in remote locations to participate in group discussions.
- PSTN Public Switched Telecommunications Network
- a conventional bridge uses a summation matrix that supplies an adaptive combination of the incoming signals to each conference participant.
- the adaptive combination algorithm is designed to attenuate signals from incoming lines that are not actively carrying a voice signal. Therefore, only a signal voice will be carried at any one time in the conventional bridge system.
- bridge systems must support multiple coding standards.
- the vocoders are incompatible with each other (e.g. LPC-10, MELP, TDVC). For this reason, direct input to output bitstream transfers cannot be used for interconnection, and the above-mentioned tandem connection is clearly less-than-optimal.
- This present invention includes an architecture for a compressed domain conference bridge that surmounts the problems described above. Central to the conference bridge structure is the concept of transcoding between different coding standards, as described in sections 1-7 above.
- the compressed domain bridge of the present invention is designed to be of low computational complexity in order to keep power consumption as low as possible. This is especially important for space-based applications such as use on satellites.
- the basic idea of the compressed domain conference bridge of the present invention is to perform most bridging operations in the compressed (rather than signal) domain.
- the compressed domain conference bridge is designed to provide most of the services available on a conventional bridge, but maintain full intelligibility for all users (even when there are multiple simultaneous talkers).
- multiple types of low-rate vocoder algorithms are supported, including a special hybrid-dual/single talker receiver that will allow a user to hear 2 simultaneous talkers over a single 2400 bit/second channel. This hybrid-dual/single talker receiver is described in detail in section 9, below, and FIG. 10.
- FIG. 9 depicts a block diagram illustrating a typical compressed domain conference bridge 900 .
- the incoming bit streams from N different conference participants (users) are first decoded into vocoder parametric model data by respective parameter decoder units 902 (User 1 's transmission bit stream is decoded by decoder unit 902 - 1 , User 2 's transmission bit stream is decoded by decoder unit 902 - 2 , and so forth).
- the parameters for each stream are then analyzed to determine which stream(s) carry an active voice signal by a corresponding Compressed Domain Voice Activity Detector (CDVAD) 904 .
- CDVAD Compressed Domain Voice Activity Detector
- CDVAD 904 determines which incoming bit streams contain a real voice signal; this information is used by Bridge Control Algorithm 950 to determine which channels contain speech, and thus which channels should be transmitted to the User receivers, as described further below.
- frame interpolators 906 perform frame interpolation. For example, suppose a user with a 20 msec frame size has to be connected to another user with a 22.5 msec frame size. In this case, frame interpolator unit 104 converts 9 frames of 20 msec parameter data to 8 frames of 22.5 msec data. This is accomplished in a smooth, continuous manner by frame interpolator 906 . See the frame interpolation sections in sections 4-7 above for a description of this type of interpolation algorithm.
- FIG. 9 shows a frame interpolator 906 on the decoding side of the conference bridge (i.e. to the left of primary/secondary talker bus 910 ) and a frame interpolator 912 on the encoding side of the conference bridge (i.e. to the right of primary/secondary talker bus 910 ). Only one of these frame interpolators is necessary. Whether to use a frame interpolator on the encoding side or decoding side of the conference is bridge is a choice based on which location produces the best perceptual quality in the output speech.
- Bridge control algorithm 950 next determines which incoming channels will be converted for transmission over the bridge to the receivers.
- This design also yields significant savings in computational complexity, because a maximum of 2 users per vocoder type must be encoded for transmission.
- the current implementation of the bridge is designed to work with several different types of vocoders (e.g. LPC-10, MELP, and TDVC), including the hybrid-dual/single talker (D/ST) receiver mentioned above and described in section 9, below.
- the D/ST receiver is capable of receiving and decoding a single talker bitstream (at approximately 2400 b/sec) or a dual talker bitstream (2 ⁇ 1200 b/sec), and dynamically switching between the two formats as the call progresses. The switching is accomplished without artifacts or noticeable degradation.
- the bridge sends the D/ST receiver a single talker stream. If two participants are speaking simultaneously, the bridge will send the D/ST receiver the vocoder parameters for both participants in the 2 ⁇ 1200 b/sec dual talker format.
- the reason for designing the system in this fashion is that the reproduction quality for the 1200 b/sec format is not as good as the 2400 b/sec single talker format.
- Another desirable feature for a conference bridge is the ability to assign priorities to the participants to regulate access to retransmission over the bridge.
- a participant with a higher priority will take precedence over a lower priority user when both are talking at the same time.
- the talker channels are selected using 1) the pre-set priority of each user for retransmission, and 2) which users are actually talking (as indicated by the CDVAD units 904 ).
- the bridge control algorithm 950 selects the primary and secondary talkers using the following algorithm: No user talking: highest priority user is primary second highest priority user is secondary 1 user talking: talking user is primary non-talking user with highest priority is secondary 2 users talking: highest priority talking user is primary other user who is talking is secondary >2 users talking: highest priority talking user is primary second highest priority talking user is secondary
- the first rule is that the primary talker's audio is never transmitted back to his/her receiver. The primary talker will always receive the secondary talker's audio. In a similar fashion, the secondary talker will always receive the primary talker's audio. To minimize potential user confusion, a primary or secondary talker is not allowed to receive a dual-talker bitstream (this would require a third talker path through the bridge if the first 2 rules are applied, and some participants would be receiving different streams than others).
- the decoded vocoder parameters for the primary and secondary talker channels can be loaded into associated parameter structures for transcoding by transcoders 908 .
- Transcoding is necessary when there are users with different vocoder types are participating in the conference. Some different types of transcoding operations in the compressed domain are fully described in sections 1-7.
- Transcoding is performed by the transcoder 908 in the corresponding primary talker channel and the transcoder 908 in the corresponding secondary talker channel. For example, if bridge control algorithm 950 determines that user 2 is the primary talker channel, and user 7 is the secondary talker channel, then transcoder 908 - 2 performs transcoding of channel 2 and transcoder 908 - 7 performs transcoding of channel 7 , if transcoding is necessary.
- Each transcoder 908 can be configured by bridge control algorithm 950 to perform one or more desired transcoding conversions. For example, suppose user 1 is determined to be the primary talker channel, and user 1 is transmitting a MELP-encoded bit stream. One of the user receivers connected to the conference bridge is an LPC receiver, and one user receiver is a TDVC receiver. Bridge control algorithm 950 then configures transcoder 908 - 1 to convert user 1 's bit stream from MELP to LPC, and from MELP to TDVC. Thus two versions of user 1 's bit stream are created: one encoded with LPC and one encoded with TDVC. In this example, transcoder 908 - 1 is said to have two “transcoder structures.” One transcoder structure converts MELP to LPC, and the other structure converts MELP to TDVC.
- the maximum number of transcoder structures required for each transcoder 908 is dependent on the number of different vocoder types on the system and whether any users have dual speaker capability. Because of the primary/secondary talker channel architecture, the number of transcoder structures is not dependent on the number of users. This feature yields a significant memory savings in implementation.
- the table below gives the maximum number of transcoder structures, taking into account the rules given in the last paragraph. 1 coder type 2 coder types 3 coder types in call in call in call no D/ST users 0 2 3 at least 1 D/ST user 0 2 4
- a hash table may be used to keep track of conversion operations handled by each allocated transcoder structure. These structures have a 1-frame vocoder parameter memory. When the configuration changes, the memory must be preserved under certain conditions. If the user who was assigned to secondary talker channel is reassigned to the primary talker channel, the memory from the secondary structure must be transferred to that of the primary. In a similar fashion, if the primary structure memory must be copied to that of the secondary if the opposite switch occurs. Finally, if a “new” user is selected for the primary or secondary talker channel, the associated structure memory is reinitialized.
- the bit streams from the primary talker and secondary talker channels are distributed to the receivers via primary/secondary talker bus 910 .
- the bridge control algorithm 950 checks to see if there are any valid D/ST users on the system who are eligible to receive a dual-talker format. If the dual-talker conditions (described above) are satisfied, then the eligible users receive both the primary and secondary talkers in the dual-talker format. If a receiver does not have D/ST capability, then only the primary talker is received.
- D/ST encoder 914 - 1 For each D/ST eligible receiver, D/ST encoder 914 - 1 encodes the bit streams for the primary and second talker channels into a dual-talker format.
- the dual-talker format consists of two 1200 b/sec channels, one each for the primary and secondary talker channels.
- the low bit rate for each channel is achieved by utilizing three frames of vocoder parameter data and encoding the most recent two frames at one time. The details of this encoding technique is described in section 11, below.
- the relative loudness of each talker can be adjusted through manipulation of the vocoder gain or RMS parameter. Because the gain parameters may represent different quantities for different vocoder algorithms, they must be compared on an equal basis. Sections 1 through 7 above (transcoder descriptions) describe how to convert from one gain format to another.
- a “tone” control function can be applied to emphasize one talker over another. This can be accomplished through correlation domain convolution of the spectral prediction coefficients with the desired “tone” shaping filter. For an example of how this is preformed, see section 2a, above (the preemphasis removal in section 2a is performed by correlation domain convolution of the spectral prediction coefficients, and the same technique can be applied here using a tone shaping filter).
- the TDVC encoder uses a predictive mode spectral LSF quantizer, special care must be taken when the primary and/or secondary talkers are changed and when there are dual to single talker transitions. Continuity is preserved with memory interchanges and predictor state resets, as described in sections d and e, above.
- a hybrid dual/single talker 2400 b/sec speech synthesizer hereafter referred to as the “dual synthesizer,” produces a digital audio stream by decoding a compressed bit stream that contains, on a frame by frame basis, encoded parameters describing either a single talker's voice input or encoded parameters describing two simultaneous talker's voice inputs.
- the means by which a dual talker compressed bit stream is generated is described in section 11, below.
- the dual synthesizer is able to decode such dual-talker bit streams and handle transitions from dual-talker to single-talker modes and vice versa without introducing objectionable artifacts (audible defects) in the output audio.
- the dual synthesizer is described below in the context of TDVC, although the dual synthesizer could use any other coding standards such as LPC-10 or MELP.
- the compressed bit stream that is input to Dual Synthesizer 1000 is divided into “packets” of two different types: an “S” packet type and a “D” packet type.
- the two types of packets are structured as follows:
- ‘S’ and ‘D’ represent a one bit tag for either a Single or Dual Talker packet.
- a packet contains bits representing a single 20 ms segment of speech.
- a packet contains a 48-bit “sub-packet” for each talker that actually represents two consecutive 20 ms segments of speech.
- the dual synthesizer contains two independent TDVC synthesizers (referred to as primary and secondary synthesizers), and is operating in either Single or Dual Talker mode at any given time.
- the primary synthesizer is active for both Single and Dual Talker mode, while the secondary synthesizer is active only for Dual Talker mode.
- the Dual Synthesizer operates according to the state diagram 1000 shown in FIG. 10.
- the initial operating mode is assumed to be Single state 1002 .
- the Dual Synthesizer stays in this mode.
- the operating mode is switched to Dual state 1004 .
- Special processing to accomplish the transition is described below.
- the operating mode is Dual mode 1004 .
- the operating mode switches to “Ringdown” mode 1006 for a small number of frames, sufficient to let the output of the synthesis filter for the discontinued talker to ring down. Special transition processing for this transition is also described below.
- LSFs Line Spectral Frequencies coefficients
- pitch and gain parameters for both Dual Mode Talkers are decoded.
- sim1 and sim2 are the similarity measures for Dual Mode talkers 1 and 2, respectively.
- sim1 is the smaller of the two, nothing needs to be done, since the Single Mode talker parameters and Dual Mode talker 1 parameters are both processed by the primary synthesizer.
- sim2 is smaller, the state of the secondary synthesizer is copied over that of the primary before any processing takes place. The secondary synthesizer is reinitialized to a quiescent state before processing in both cases.
- the procedure for handling the Dual to Single Mode transition is very similar to the procedure for the Single to Dual Mode transition. In this case, it is assumed that one of the Dual Mode talkers will continue as the Single Mode talker. Once again, parameters are decoded, and similarity measures are computed in precisely the same manner as illustrated above. If it appears that Dual Mode talker 1 has become the Single Mode talker, then nothing need be done; however if it appears that Dual Mode talker 2 has become the Single Mode talker, the state of the secondary synthesizer is copied over the state of the primary synthesizer.
- VAD Voice Activity Detection
- vocoder digital voice compression
- the purpose of a VAD is to detect the presence or absence of voice activity in a digital input signal.
- the task is quite simple when the input signal can be guaranteed to contain no background noise, but quite challenging when the input signal may include varying types and levels of background noise.
- Many types of VAD have been designed and implemented.
- Some VAD algorithms also attempt to classify the type of speech that is present in a short time interval as being either voiced (e.g. a vowel sound, such as long e) or unvoiced (e.g. a fricative, such as ‘sh’).
- voiced e.g. a vowel sound, such as long e
- unvoiced e.g. a fricative, such as ‘sh’
- the vocoder can tailor its operation to the classification. For example, depending on the classification, a vocoder might encode an input signal interval with more, less, or even no bits (in the case of silence).
- the object of the compressed domain voice activity detector (CDVAD) of the present invention as described herein is to perform the Voice Activity Detection function given a compressed bit stream (produced by a vocoder) as input, rather than a time domain waveform.
- Conventional VAD algorithms operate on a time domain waveform. For an example of a conventional VAD algorithm which operates in the signal domain, see Vahatalo, A., and Johansson, I., “Voice Activity Detection for GSM Adaptive Multi-Rate Codec,” ICASSP 1999, pp. 55-57.
- the Compressed Domain VAD (CDVAD) of the present invention decodes the compressed bit stream only to the level of vocoder parametric model data, rather than decoding to a speech waveform.
- Decoding to vocoder parameters has the advantage of requiring much less computation than decoding to a speech waveform.
- the CDVAD can be used in conjunction with the Compressed Domain Conference Bridge 900 , described above in section 8.
- the bridge and by extension the VAD component, must be of low computational complexity in order to keep power consumption as low as possible on the satellite.
- the bridge receives a plurality of compressed voice bit streams (which need not have been produced by the same type of vocoder), determines which bit streams contain voice activity, and use decision logic to select which bit stream(s) to transmit to the conference participants.
- the CDVAD disclosed herein incorporates a modem, fairly conventional VAD algorithm, but adapts it to operate using compressed voice parameters rather than a time domain speech waveform.
- the CDVAD can be adapted to operate with compressed bit streams for many different vocoders including TDVC, MELP and LPC-10.
- FIG. 11 depicts a block diagram illustrating a CDVAD method 1100 .
- CDVAD method 1100 will first be described with respect to a bit stream representing TDVC parameters.
- Each frame of TDVC parameters represents 20 ms segment of speech.
- the CDVAD In adapting the CDVAD to the other vocoder types (e.g. LPC and MELP), only minor transformations of their native parameter sets are required, as described below.
- CDVAD 1100 receives 4 types of TDVC parameters as inputs: 1) a set of 10 short term filter coefficients in LSF (Line Spectral Frequency) form, 2) frame gain, 3) TDVC-style voicing cutoff flag, and 4) pitch period.
- LSF Line Spectral Frequency
- the TDVC-style voicing cutoff flag 1106 indicates a frequency above which the input frame is judged to contain unvoiced content, and below which the input frame is judged to contain voiced speech. The value of the voicing cutoff flag ranges from 0 for completely unvoiced to 7 for completely voiced.
- LPC-10's short term filter coefficients are converted from reflection coefficients to LSFs, the frame gain is scaled to adjust for pre-emphasis and different system scaling conventions, and LPC-10's half-frame voicing flags are boolean-OR'ed to make them compatible with the TDVC-style voicing cutoff flag.
- MELP & TDVC both use the LSF representation of short term filter coefficients.
- MELP uses two half-frame gains rather than a single frame gain value as in TDVC; the larger of MELP's two half-frame gain values is used as the overall frame gain by the CDVAD.
- MELP's band pass voicing information is converted to a TDVC-style voicing cutoff flag using a simple mapping similar to the conversion described in section 5b, above (MELP to TDVC transcoder).
- the CDVAD operation is based on spectral estimation, periodicity detection, and frame gain.
- the basic idea of the CDVAD shown in FIG. 11 is to make the VAD decision based on a comparison between input signal level and a background noise estimate for each of a plurality of frequency bands, while also taking into account overall frame gain, voicing cutoff frequency, and pitch information.
- the spectral envelope for a frame is computed from the input short term filter coefficients (LSFs). From the spectral envelope, signal levels are computed for each of a number of frequency sub-bands. The signal levels are then normalized by both the overall frame gain and the gain of the short term filter.
- LSFs short term filter coefficients
- a “pitch flag” is set for the current frame only if the pitch has been relatively constant over the current and 2 or more immediately preceding frames.
- the voicing cutoff flag fsel must be greater than 0 (i.e. not fully unvoiced).
- step 1106 the background noise level is estimated for each sub-band.
- the normalized sub-band levels from step 1102 and intermediate VAD decision for the current frame (produce by step 1108 , discussed below) for the current frame are received as inputs to step 1106 .
- the background noise sub-band levels are updated with a weighted sum of their current value and the input sub-band levels. However, the weights for the summation are varied, depending on several conditions:
- step 1110 hangover addition is performed.
- Hangover addition applies some smoothing to the intermediate VAD decision, to try to ensure that the ends of utterances, some of which are quite low amplitude, are not cut off by the VAD.
- Described as follows is a method for ultra-low rate encoding and decoding of the parameters used in predictive-style parametric vocoders (e.g. MELP, LPC, TDVC).
- the method of ultra-low rate encoding described herein produces a degradation in sound quality, it is very useful for applications where an ultra-low rate is needed.
- one application for this ultra-low rate encoding method is for use in a dual-talker system that will allow a user to hear 2 simultaneous talkers over a single 2400 bit/second channel (the dual-talker format consists of two 1200 b/sec channels within the 2400 b/sec channel).
- FIG. 12A A method of multi-frame pitch encoding and decoding will now be described as illustrated by FIG. 12A.
- every two frames of pitch data are combined into a single frame which is transmitted.
- the transmitted frame is received by the decoder, the single received frame is converted back to two frames of pitch data.
- the method described below converts two frames of TDVC pitch information (a total of 12 pitch bits) into a single transmitted frame containing a pitch value P consisting of one mode bit and six pitch bits. Thus, the method reduces the number of pitch bits from 12 to 7 (per every two TDVC frames encoded).
- each frame contains a quantized pitch value which was previously generated by an optimal quantizer.
- the pitch information from Frame 1 and Frame 2 is combined into a single pitch value P which will be included in the transmitted frame T.
- P the pitch value from the Frame 0
- the frame received immediately prior to Frame 1 is required.
- Frames 0′, 1′, and 2′ Three frames of decoded data are shown: Frames 0′, 1′, and 2′.
- Frame T is converted to two frames: Frame 1′ and 2′ according to the methods described below.
- the pitch information from Frame 1 and the pitch information from Frame 2 are converted to a single pitch value P according to two methods: a Mode 0 method, and a Mode 1 method.
- a distortion value D is then calculated for both the Mode 0 P value, and the Mode 1 P value, as described further below.
- the transmitted value of P which is encoded into the transmitted frame T is determined by which mode produces the lowest a lowest distortion value D. If Mode 0 produces a lower distortion value D then a Mode 0-encoded frame is transmitted. If Mode 1 produces a lower distortion value D, then a Mode 1-encoded frame is transmitted.
- the decoder reads the mode bit of the frame to determine whether the received frame T is a Mode 0-encoded frame or a Mode 1-encoded frame. If frame T is a Mode 0-encoded frame, a Mode 0 decoding method is used. If frame T is a Mode 1 encoded frame, a Mode 1 decoding method is used. The frame T is thereby decoded into two Frames: Frame 1′ and Frame 2′.
- Mode 0 encoding P is set equal to the Frame 1 six-bit pitch value.
- Mode 1 encoding P is set equal to the Frame 2 six-bit pitch value.
- Mode 0 decoding P is used as the six-bit pitch value for both Frame 1′ and Frame 2′.
- Mode 1 decoding The pitch value from Frame 0′ is repeated for Frame 1′, and P is used for Frame 2′.
- F1 is the 6-bit quantized pitch value for frame 1
- F2 is the 6-bit quantized pitch value for frame 2
- P is the pitch value that is transmitted.
- Mode 0 simply chose P to be equal to the F2 six-bit pitch value (or, alternatively, to the average of the F1 and F2 six-bit pitch values) the same equation for D 0 , above, would result. Because P is quantized with the same table as F1 or F2, it is computationally more efficient to use the individual values of F1 or F2 instead of the average.
- the gain encoding algorithm assumes that an optimal, non-uniform scalar quantizer has already been developed for encoding a single frame of gain.
- a 5-bit quantizer is in use.
- the value of the first frame's gain (Frame 1) is encoded using this 5-bit quantizer.
- a 4-bit custom quantizer table is generated for the second frame (Frame 2).
- the first 9 output levels for the table consist of fixed sparse samples of the 5-bit table (e.g. every 3 rd entry in the table).
- the next seven output levels are delta-referenced from the Frame 1 value.
- Delta referencing refers to quantizing the Frame 2 value as an offset in the quantization table from the Frame 1 value.
- the seven delta values supported are 0, +1, +2, +3, ⁇ 1, ⁇ 2, and ⁇ 3.
- FIG. 12B shows an example of how the quantizer tables for the 5- and 4-bit algorithms may be constructed.
- the quantization index for the Frame 2 gain all entries in the Frame 2 table are compared to the gain, and the index corresponding to the lowest distortion is transmitted. For example, if the Frame 1 gain was quantized to level L18, and the Frame 2 gain is closest in value to L19, them the D+1 quantization level would be selected for Frame 2. As a second example, suppose the Frame 1 gain was at level L28, but the Frame 2 gain was closest in value to L4. In this case the L3 quantization level would be selected Frame 2.
- the spectrum is encoded two frames at a time using an interpolative algorithm such as the one described in U.S. Pat. No. 6,078,880 “Speech Coding System and Method Including voicingng Cut Off Frequency Analyzer”, which is incorporated herein by reference.
- the description of the algorithm begins in column 10, line 32.
- a 25 bit MSVQ algorithm is for the non-interpolated frames.
- a 3 bit interpolation flag is used for the interpolated frames. If a parametric vocoder does not use LSFs for spectral quantization, the spectral parameters can be converted to the LSF format before interpolation.
- voicing is encoded by requantizing the TDVC fsel voicing parameter from a 3 bit value (0 to 7) to a 2 bit value with the following mapping: input fsel value transmitted index output fsel value 0 0 0 1 1 2 2 1 2 3 1 2 4 2 5 5 2 5 6 2 5 7 3 7
- the parametric vocoder does not use the TDVC-style voicing parameter (fsel), then the voicing parameter must be converted to TDVC format first.
- the perceptual quality produced by low rate speech coding algorithms can often be enhanced by attenuating the output speech signal in areas of low spectral amplitude. This operation is commonly known as formant enhancement.
- formant enhancement typically, the formant enhancement function is performed in the speech decoder. However, it would be desirable to perform this formant enhancement function using an existing standardized algorithm that has no built in capability in the decoder.
- the formant method described below can dramatically improve the subjective quality of speech when using an existing standardized speech coding algorithm with no changes in existing equipment.
- the following method can be applied in a speech decoder, a speech encoder or a transcoder like the ones described in Sections 1 through 7, above.
- the use of this formant enhancement method requires no extra overhead for transmission.
- Formant enhancement is used by the LPC-to-MELP transcoder 300 (FIG. 3, Step 308 ), MELP-to-LPC transcoder 400 (FIG. 4, Step 408 ), and TDVC-to-LPC-10 transcoder 700 (FIG. 7, Step 710 ).
- formant enhancement is performed on the coefficients A′, the filter coefficients following preemphasis addition.
- formant enhancement method utilizes both the coefficient sets A and A′, the filter coefficients before and after preemphasis removal.
- the process begins with a set of predictor coefficients A(i) that represent the all-pole model of the speech spectrum. If the process is being applied to the specific case of transcoding from LPC-to-MELP (step 308 shown in FIG. 3), then the non-deemphasized predictor coefficients A(i) are used (coefficients prior to preemphasis removal in step 306 ). For the MELP-to-LPC and TDVC-to-LPC transcoders, coefficients A′(i) are used (coefficients A following preemphasis addition).
- a second set of bandwidth-expanded coefficients A2(i) is generated according to:
- a 2( i ) ⁇ i A ′( i ): for MELP-to-LPC and TDVC-to-LPC, or
- ⁇ is the bandwidth expansion factor (approximately 0.4).
- the autocorrelation coefficient set R′(k) (autocorrelation coefficients after preemphasis removal) is convolved with R2(k) to produce a set of 10 enhanced coeffcients R′′(k):
- R ′′ ⁇ ( k ) ⁇ i ⁇ R ′ ⁇ ( i + k ) * R2 ⁇ ( i )
- a significant benefit of this formant enhancement method is that it produces a 10 th order filter that has formant enhancement characteristics similar to the underlying 20 th order filter (that would have been obtained by simply convolving the two sets of predictor coefficients). Because there is no change in filter order, there is no additional overhead involved in transmission.
- An adaptive frequency-domain formant enhancement method is described below. As with the correlation-domain method described above in Section 12, the following method can dramatically improve the subjective quality of speech when using an existing standardized speech coding algorithm with no changes in existing equipment. The method can also be applied in a speech decoder, a speech encoder or transcoder, and requires no extra overhead for transmission.
- a The process begins with a set of predictor coefficients a(i) that represent the all-pole model of the speech spectrum.
- a(i) are the predictor coefficients
- m is the filter order
- j is ⁇ square root ⁇ square root over ( ⁇ 1) ⁇ .
- the present invention includes a transcoder which converts parametric encoded data in the compressed domain.
- a transcoder which converts parametric encoded data in the compressed domain.
- Six individual specific transcoder structures and two formant enhancement methods are described in detail.
- a Voice Activity Detector which operates in the compressed domain is also disclosed.
- a Dual Talker synthesizer which uses a method of low-rate encoding is also disclosed.
- a Compressed Domain Conference Bridge is disclosed which utilizes the compressed domain transcoder, the compressed domain voice activity detector, and the dual talker synthesizer.
- the inventions are described with respect to speech coding applications, the inventions and the techniques described above are not limited to speech coding. More generally, the inventions can be applied to any other type of compressed data transmission.
- the transcoders described in sections 1-7 could be used to convert any compressed data stream from a first compressed format to a second compressed format in the compressed domain.
- the conference bridge, the voice activity detector, the dual talker, and the formant enhancement methods could all be applied to other types of compressed data transmission other than compressed speech.
Landscapes
- Engineering & Computer Science (AREA)
- Signal Processing (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computer Networks & Wireless Communication (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
Description
- This application is a continuation of U.S. patent application Ser. No. 09/822,503 filed Apr. 2, 2001 (“Compressed Domain Universal Transcoder”).
- The present invention relates to speech synthesizers. More specifically, the present invention relates to a system and method for decoding a digital audio stream containing encoded parameters describing either a single talker's voice input or encoded parameters describing two simultaneous talker's voice inputs.
- The term speech coding refers to the process of compressing and decompressing human speech. Likewise, a speech coder is an apparatus for compressing (also referred to herein as coding) and decompressing (also referred to herein as decoding) human speech. Storage and transmission of human speech by digital techniques has become widespread. Generally, digital storage and transmission of speech signals is accomplished by generating a digital representation of the speech signal and then storing the representation in memory, or transmitting the representation to a receiving device for synthesis of the original speech.
- Digital compression techniques are commonly employed to yield compact digital representations of the original signals. Information represented in compressed digital form is more efficiently transmitted and stored and is easier to process. Consequently, modem communication technologies such as mobile satellite telephony, digital cellular telephony, land-mobile telephony, Internet telephony, speech mailboxes, and landline telephony make extensive use of digital speech compression techniques to transmit speech information under circumstances of limited bandwidth.
- A variety of speech coding techniques exist for compressing and decompressing speech signals for efficient digital storage and transmission. It is the aim of each of these techniques to provide maximum economy in storage and transmission while preserving as much of the perceptual quality of the speech as is desirable for a given application.
- Compression is typically accomplished by extracting parameters of successive sample sets, also referred to herein as “frames”, of the original speech waveform and representing the extracted parameters as a digital signal. The digital signal may then be transmitted, stored or otherwise provided to a device capable of utilizing it. Decompression is typically accomplished by decoding the transmitted or stored digital signal. In decoding the signal, the encoded versions of extracted parameters for each frame are utilized to reconstruct an approximation of the original speech waveform that preserves as much of the perceptual quality of the original speech as possible.
- Coders which perform compression and decompression functions by extracting parameters of the original speech are generally referred to as parametric coders or vocoders. Instead of transmitting efficiently encoded samples of the original speech waveform itself, parametric coders map speech signals onto a mathematical model of the human vocal tract. The excitation of the vocal tract may be modeled as either a periodic pulse train (for voiced speech), or a white random number sequence (for unvoiced speech). The term “voiced” speech refers to speech sounds generally produced by vibration or oscillation of the human vocal cords. The term “unvoiced” speech refers to speech sounds generated by forming a constriction at some point in the vocal tract, typically near the end of the vocal tract at the mouth, and forcing air through the constriction at a sufficient velocity to produce turbulence. Speech coders which employ parametric algorithms to map and model
- There are several types of vocoders on the market and in common usage, each having its own set of algorithms associated with the vocoder standard. Three of these vocoder standards are:
- 1. LPC-10 (Linear Prediction Coding): a Federal Standard, having a transmission rate of 2400 bits/sec. LPC-10 is described, e.g., in T. Tremain, “The Government Standard Linear Prediction Coding Algorithm: LPC-10,” Speech Technology Magazine, pp. 40-49, April 1982).
- 2. MELP (Mixed Excitation Linear Prediction): another Federal Standard, also having a transmission rate of 2400 bits/sec. A description of MELP can be found in A. McCree, K. Truong, E. George, T. Barnwell, and V. Viswanathan, “A 2.4 kb/sec MELP Coder Candidate for the new U.S. Federal Standard,” Proc. IEEE Conference on Acoustics, Speech and Signal Processing, pp. 200-203, 1996.
- 3. TDVC (Time Domain Voicing Cutoff): A high quality, ultra low rate speech coding algorithm developed by General Electric and Lockheed Martin having a transmission rate of 1750 bits/sec. TDVC is described in the following U.S. Pat. Nos. 6,138,092; 6,119,082; 6,098,036; 6,094,629; 6,081,777; 6,081,776; 6,078,880; 6,073,093; 6,067,511. TDVC is also described in R. Zinser, M. Grabb, S. Koch and G. Brooksby, “Time Domain Voicing Cutoff (TDVC): A High Quality, Low Complexity 1.3-2.0 kb/sec Vocoder,” Proc. IEEE Workshop on Speech Coding for Telecommunications, pp. 25-26, 1997.
- When different units of a communication system use different vocoder algorithms, transcoders are needed (both ways, A-to-B and B-to-A) to communicate between and amongst the units. For example, a communication unit employing LPC-10 speech coding can not communicate with a communication unit employing TDVC speech coding unless there is an LPC-to-TDVC transcoder to translate between the two speech coding standards. Many commercial and military communication systems in use today must support multiple coding standards. In many cases, the vocoders are incompatible with each other.
- Two conventional solutions that have been implemented to interconnect communication units employing different speech coding algorithms consist of the following:
- 1) Make all new terminals support all existing algorithms. This “lowest common denominator” approach means that newer terminals cannot take advantage of improved voice quality offered by the advanced features of the newer speech coding algorithms such as TDVC and MELP when communicating with older equipment which uses an older speech coding algorithm such as LPC.
- 2) Completely decode the incoming bits to analog or digital speech samples from the first speech coding standard, and then reencode the analog speech samples using the second speech coding standard. This process is known a tandem connection. The problem with a tandem connection is that it requires significant computing resources and usually results in a significant loss of both subjective and objective speech quality. A tandem connection is illustrated in FIG. 1.
Vocoder decoder 102 and D/A 104 decodes an incoming bit stream representing parametric data of a first speech coding algorithm into an analog speech sample. A/D 106 andvocoder encoder 108 reencodes the analog speech sample into parametric data encoded by a second speech coding algorithm. - What is needed is a system and method for transcoding compressed speech from a first coding standard to a second coding standard which 1) retains a high degree of speech quality in the transcoding process, 2) takes advantage of the improved voice quality features provided by newer coding standards, and 3) minimizes the use of computing resources. The minimization of computing resources is especially important for space-based transcoders (such as for use in satellite applications) in order to keep power consumption as low as possible.
- The system and method of the present invention comprises a compressed domain universal transcoder architecture that greatly improves the transcoding process. The compressed domain transcoder directly converts the speech coder parametric information in the compressed domain without converting the parametric information to a speech waveform representation during the conversion. The parametric model parameters are decoded, transformed, and then re-encoded in the new format. The process requires significantly less computing resources than a tandem connection. In some cases, the CPU time and memory savings can exceed an order of magnitude.
- The method more-generally comprises transcoding a bit stream representing frames of data encoded according to a first compression standard (MELP coding standard) to a bit stream representing frames of data according to a second compression standard (TDVC coding standard). The bit stream is decoded into a first set of parameters compatible with a first compression standard. Next, the first set of parameters are transformed into a second set of parameters compatible with a second compression standard without converting the first set of parameters to an analog or digital waveform representation. Lastly, the second set of parameters are encoded into a bit stream compatible with the second compression standard.
- FIG. 1 depicts a block diagram illustrating a conventional tandem connection.
- FIG. 2 depicts a block diagram illustrating the general architecture of the compressed domain universal transcoder of the present invention.
- FIG. 3 depicts a block diagram illustrating an LPC-to-MELP transcoding process.
- FIG. 4 depicts a block diagram illustrating a MELP-to-LPC transcoding process.
- FIG. 5 depicts a block diagram illustrating a LPC-to-TDVC transcoding process.
- FIG. 6 depicts a block diagram illustrating a MELP-to-TDVC transcoding process.
- FIG. 7 depicts a block diagram illustrating a TDVC-to-LPC transcoding process.
- FIG. 8 depicts a block diagram illustrating a TDVC-to-MELP transcoding process.
- FIG. 9 depicts a block diagram illustrating a Compressed Domain Conference Bridge.
- FIG. 10 depicts a dual synthesizer state diagram.
- FIG. 11 depicts a Compressed Domain Voice Activation Detector (CDVAD).
- FIG. 12A depicts a block diagram illustrating a multi-frame encoding and decoding process.
- FIG. 12B depicts 5-bit and 4-bit quantizer tables used for multi-frame gain encoding and decoding.
- 1. Compressed Domain Universal Transcoder
- The transcoding technology of the present invention greatly improves the transcoding process. The transcoder directly converts the speech coder parametric information in the compressed domain without converting the parametric information to an analog speech signal during the conversion. The parametric model parameters are decoded, transformed, and then re-encoded in the new format. The process requires significantly less computing resources than the tandem connection illustrated in FIG. 1. In some cases, the CPU time and memory savings can exceed an order of magnitude.
- In general terms, the transcoder of the present invention performs the following steps: 1) decode the incoming bit stream into the vocoder parameters, 2) transform the vocoder parameters into a new set of parameters for the target output vocoder, and 3) encode the transformed parameters into a bit stream compatible with the target output coder.
- FIG. 2 is a block diagram illustrating the
general transcoding process 200 of the present invention. Theprocess 200 shown in FIG. 2 is the general conversion process that is used to convert an incoming bit stream encoded with a first coding standard to an output bit stream encoded with a second coding standard. For example, an incoming bit stream encoded with the LPC coding standard could be converted to the MELP coding standard, or an incoming bit stream encoded in MELP coding standard could be converted to the TDVC coding standard. The process shown in FIG. 2 illustrates the general process of the present invention that applies to all of the possible conversions (e.g. LPC to MELP, LPC to TDVC, MELP to LPC, etc). Each of the six individual transcoder conversions between LPC, MELP, and TDVC will later be described individually in more detail below with respect to sections 2-7 below and FIGS. 3-8. - As shown in FIG. 2, an incoming bit stream is received by demultiplexing and FEC (forward error correction decoding)
step 201. The incoming bit stream represents frames containing parameters of a first coding standard such as LPC-10, MELP, or TDVC. This first coding standard will also be referred to as the “input coding standard.”Instep 201, forward error correction decoding is performed on the incoming data frames, and the copies of each frame are distributed tosteps - There are four basic types of parameters used in low rate vocoders: 1) gross spectrum, 2) pitch, 3) RMS power (or gain), and 4) voicing. Within these four categories of parameter types, each coding standard employs different numbers and kinds of parameters. For example, LPC-10 employs one voicing parameter comprised of only a single voicing bit per half-frame of data, whereas MELP employs a total of seven voicing parameters per frame (five voicing parameters representing bandpass voicing strengths, one overall voiced/unvoiced flag, and one voicing parameter called the “jitter flag”) in an effort to enhance speech quality.
- In
steps 202, the spectral parameters of the first coding standard are decoded from the incoming data frames. Instep 204, the voicing parameters of the first coding standard are decoded from the incoming data frames. Instep 206, the pitch parameters of the first coding standard are decoded from the incoming data frames. Instep 208, the gain parameters of the first coding standard are decoded from the incoming data frames. - In
step - The parameters produced by the conversion steps 210, 212, 214, and 216 will be either floating point numbers or fixed point numbers, depending on the particular output coding standard. For example, the MELP and TDVC standards use floating point numbers, whereas the LPC-10 standard uses fixed point numbers.
- Encoding
steps step 226, the output parameters are combined into frames, forward error correction encoding is performed, and the output bit stream representing frames of the output coding standard are transmitted. - Each of the following individual transcoding processes will now be described in detail.
- 1. LPC to MELP Transcoder
- 2. LPC to TDVC Transcoder
- 3. MELP to LPC Transcoder
- 4. MELP to TDVC Transcoder
- 5. TDVC to LPC Transcoder
- 6. TDVC to MELP Transcoder
- The general transcoding method illustrated in FIG. 2 and the conversion techniques described below can also be applied to create trancoders for conversion between other coding standards besides LPC, MELP, and TDVC that are currently in usage or being developed.
- 2. LPC-to-MELP Transcoder
- FIG. 3 illustrates a
transcoding method 300 for converting a bit stream representing frames encoded with the LPC-10 coding standard to a bit stream representing frames encoded with the MELP coding standard. Instep 302, an incoming bit stream is received. The incoming bit stream represents LPC-10 frames containing LPC-10 parameters. Forward error correction (FEC) decoding is performed on the incoming bit stream. The incoming bit stream is also decoded by extracting LPC-10 spectrum, pitch, voicing, and gain parameters from the incoming bit stream. The parameters are then distributed tospectrum conversion step 304, voicingconversion step 312,pitch conversion step 316 and gainconversion step 322. Each of these conversion processes will now be described in detail. - a. Spectrum Conversion
- The LPC-10 spectrum parameters are referred to as “reflection coefficients” (RCs) whereas the MELP spectrum parameters are referred to as “line spectrum frequencies” (LSFs). The conversion of RCs to LSFs is performed in
steps - In
step 304, the LPC-10 reflection coefficients (RC) are first converted to their equivalent normalized autocorrelation coefficients (R). The LPC-10 reflection coefficients (RC) are also converted to their equivalent predictor filter coefficients (A); the predictor filter coefficients (A) are saved for later use informant enhancement step 308. Both of these conversions (RC→R, RC→A) are performed by using well known transformations. In order to avoid truncation effects in subsequent steps, the autocorrelation conversion (RC→R) recursion is carried out to 50 lags (setting RCs aboveorder 10 to zero). The resulting values for the autocorrelation coefficients (R) are stored symmetrically in a first array. - In
step 306, the “preemphasis” is removed from the LPC-10 autocorrelation (R) coefficients. To explain why this is performed, first an explanation of preemphasis is provided as follows. When encoding speech according to the LPC speech coding algorithm standard, an operation known as “preemphasis” is performed on the sampled speech signal prior to spectral analysis. Preemphasis is performed by applying a first order FIR filter prior to spectral analysis. This preemphasis operation attenuates the bass frequencies and boosts the treble frequencies. The purpose of preemphasis is to aid in the computations associated with a fixed point processor; preemphasis makes it less likely for the fixed point processor to get an instability from an underflow or an overflow condition. - Newer speech coding algorithms such as MELP and TDVC do not perform preemphasis because they were designed for modem signal processing hardware that has wider data paths. Therefore, a MELP synthesizer expects spectral coefficients that were produced directly from the sampled speech signal without preemphasis.
- Because LPC uses preemphasis, while MELP does not, in
step 306 the preemphasis effects are removed from the LPC-10 spectral coefficients. Preemphasis removal is performed as follows. The symmetrical autocorrelation coefficients (HH) of a deemphasis filter are calculated beforehand and stored in a second array matching the format of the first array of autocorrelation coefficients (R) created instep 304. The deemphasis filter is a single pole IIR filter and is generally the inverse of the preemphasis filter used by LPC-10, but different preemphasis and deemphasis coefficients may be used. The LPC-10 standard uses 0.9375 for preemphasis and 0.75 for deemphasis. Because the deemphasis filter has IIR characteristics, the autocorrelation function is carried out to 40 time lags. The autocorrelation values are obtained by convolving the impulse response of the filter. - A modified set of spectral autocorrelation coefficients is calculated via convolving the R values with the HH values as follows:

- The resulting modified autocorrelation coefficients R′ will be referred to herein as “deemphasized” autocorrelation coefficients, meaning that the LPC-10 preemphasis effects have been removed. Note that by removing the preemphasis in the correlation domain (i.e. removing the preemphasis from autocorrelation coefficients rather than the reflection coefficients or filter coefficients), computational complexity can be reduced.
- The deemphasized autocorrelation coefficients R′ are then converted to deemphasized reflection coefficients (RC′) and deemphasized predictor filter coefficients (A′), using well known conversion formulas. The stability of the synthesis filter formed by the coefficients is checked; if the filter is unstable, the maximum order stable model is used (e.g. all RC′ coefficients up to the unstable coefficient are used for the conversion to A′ coefficients). The RC and RC′ values are saved for use by the “Compute LPC Gain Ratio”
step 320, described further below. - In
step 308, formant enhancement is performed. The perceptual quality produced by low rate speech coding algorithms can be enhanced by attenuating the output speech signal in areas of low spectral amplitude. This operation is known as formant enhancement. Formant enhancement sharpens up the spectral peaks and depresses the valleys to produce a crisper sound that is more intelligible. Format enhancement is conventionally performed during the process of decoding the bit stream into an analog speech signal. However, according to the present invention, it has been found that formant enhancement can be used to in thetranscoding process 300 to produce a better sounding speech output. - Two methods of formant enhancement are described in detail in sections 12 and 13 below. Section 12 describes a method of formant enhancement performed in the correlation domain. Section 13 describes a second method of formant enhancement performed in the frequency domain. The formant enhancement method performed in the correlation domain utilizes both the non-deemphasized filter coefficients (A) and the deemphasized filter coefficients (A′). Both methods of formant enhancement produce good results. Which one is preferable is a subjective determination made by the listener for the particular application.
-
Formant enhancement step 310 outputs “enhanced” deemphasized LPC-10 filter coefficients (A″), wherein the term “enhanced” means that formant enhancement has been performed. The transcoding process of the present invention illustrated in FIG. 3 could potentially be performed withoutformant enhancement step 308. However, formant enhancement has been found to substantially improve the speech quality and understandability of the MELP output. - In
step 310, the enhanced deemphasized LPC-10 filter coefficients (A″) are converted to MELP line spectrum frequencies (LSFs). This conversion is made by using well known transformations. Instep 310, the MELP LSFs are then adaptively smoothed. With modem vocoders like MELP and TDVC, because of the way the quantization error is handled, the voice often obtains an undesirable vibrato-like sound if smoothing is not performed. Thus, instep 310, a smoothing function is applied to reduce this undesirable vibrato effect. The smoothing function is designed to reduce small fluctuations in the spectrum when there are no large frame-to-frame spectrum changes. Large fluctuations are allowed to pass with minimum smoothing. The following C-code segment is an example of such a smoother. Note that this segment is only an example, and any algorithm having a smoothing effect similar to that described above could be used.for (i=0; i<10; i++) { delta = 10.0*(lsp[i] − oldlsp[i]); if (delta < 0.0) delta = −delta; if (delta > 0.5) delta = 0.5; lsp[i] = lsp[i]*(0.5+delta) + oldlsp[i]*(0.5−delta); } - where lsp[i] are the current frame's LSF coefficients, oldlsp[i] are the previous frame's LSF coefficients, and delta is a floating point temporary variable.
- MELP also has the provision for encoding the first 10 harmonic amplitudes for voiced speech. These harmonic amplitudes can either be set to zero or generated as follows. U.S. Pat. No. 6,098,036 to Zinser et al., “Speech Coding System and Method Including Spectral Formant Enhancer,” discloses a spectral formant enhancement algorithm to generate these harmonic amplitudes. In particular, the process described in columns 17 and 18 can be used to generate 10 amplitudes (amp(k), k=1 . . . 10) from Equation 7 in column 18. Further enhancement may be achieved by utilizing the method described in Grabb, et al., U.S. Pat. No. 6,081,777, “Enhancement of Speech Signals Transmitted Over a Vocoder Channel”, and modifying the first three harmonic amplitudes amp(k) according to the values given in FIG. 5 and the accompanying equation.
- It was found that generating harmonic amplitudes in this manner produced a superior output quality sound for the TDVC to MELP transcoder (described in section 7, below). However, the improvement for the LPC-10 to MELP transcoder was not as significant. Therefore, for the LPC-10 to MELP transcoder, it may be desirable to simply set the MELP harmonic amplitudes to zero, to reduce computational complexity.
- After multiplication by a factor of 2 (to match scaling conventions), the smoothed LSFs are encoded according to the MELP quantization standard algorithm.
- b. Voicing Conversion and Jitter Factor Conversion
- In
step 312, the LPC-10 voicing parameters are converted into MELP voicing parameters. This is not a simple one-to-one conversion because LPC-10 uses only a single voicing parameter, whereas MELP uses several voicing parameters. Thus, a method has been devised according to the present invention for assigning MELP parameters based on the LPC-10 parameters which produces superior sound quality. - The LPC-10 coding standard uses only a single voicing bit per half-frame representing either voiced or unvoiced; i.e., each half-frame is either voiced or unvoiced. In order to provide improved sound quality, the newer MELP coding standard uses seven different voicing parameters: five bandpass voicing strengths, one overall voiced/unvoiced flag, and one voicing parameter called the “jitter flag” which is used to break up the periodicity in the voiced excitation to make the speech sound less buzzy during critical transition periods.
- The conversion process of the present invention uses the expanded voicing features of the MELP synthesizer to advantage during transitional periods such as voicing onset, described as follows. The LPC voicing bits are converted to MELP voicing parameters according to three different situations:
- (1) mid-frame onset (the first LPC half-frame is unvoiced and the second half-frame is voiced).
- (2) fully voiced (both half-frames are voiced).
- (3) fully un-voiced mid-frame unvoiced transition (either both half-frames are unvoiced or the first frame is voiced and the second half-frame is unvoiced).
- The method is illustrated by the piece of C code below. Testing has found that this method provides the superior sound performance. This method tends to provide a smoother transition from voiced to unvoiced transitions. The following C-code segment illustrates the method of converting LPC-10 voicing bits to the MELP voicing parameters:
/* mid-frame onset */ if ((lpc->voice[0]==0) && (lpc->voice[1]==1)) { melp->uv_flag = 0; melp->jitter = 0.25; for (i=0; i<NUM_BANDS-2; i++) melp->bpvc[i] = 1.0; melp->bpvc[NUM_BANDS-2] = 0.0; melp->bpvc[NUM_BANDS-1] = 0.0; } /* fully voiced */ else if ((lpc->voice[0]==1) && (lpc->voice[1]==1)) { melp->uv_flag = 0; melp->jitter = 0.0; for (i=0; i<NUM_BANDS; i++) melp->bpvc[i] = 1.0; } /* fully unvoiced and mid-frame unvoiced transition */ else { melp->uv_flag = 1; melp->jitter = 0.25; for (i=0; i<NUM_BANDS; i++) melp->bpvc[i] = 0.0; } - where lpc-> voice[0] and lpc-> voice[1] are the half-frame LPC voicing bits (0=unvoiced), melp-> uv_flag is the MELP overall unvoiced flag (0=unvoiced), melp-> jitter is the MELP jitter flag, and melp-> bpvc[i] are the MELP bandpass voicing strengths. Note that for the transition from unvoiced to voiced, the top two MELP voicing bands are forced to be unvoiced. This reduces perceptual buzziness in the output speech.
- In
step 314, the MELP voicing and jitter parameters are encoded according to the MELP quantization standard algorithm. - c. Pitch Conversion
- In
step 316, the LPC-10 pitch parameters are converted to MELP pitch parameters. The LPC-10 coding standard encodes pitch by a linear method whereas MELP encodes pitch logarithmically. Therefore, instep 316, the logarithm is taken of the LPC-10 pitch parameters to convert to the MELP pitch parameters. Instep 318, the MELP pitch parameters are encoded using the MELP quantization standard algorithm. - d. Gain (RMS) Conversion
- The conversion from LPC-10 RMS gain parameters to MELP gain parameters begins in
step 322. Instep 322, the LPC-10 RMS gain parameters are scaled to account for the preemphasis removal performed on the LPC-10 spectral coefficients instep 306. To explain, as mentioned previously, LPC-10 coding adds preemphasis to the sampled speech signal prior to spectral analysis. The preemphasis operation, in addition to attenuating the bass and increasing the treble frequencies, also reduces the power level of the input signal. The power level is reduced in a variable fashion depending on the spectrum. Therefore, the effect of removing the preemphasis instep 306 must be accounted for accordingly when converting the gains from LPC to MELP. The preemphasis removal is accounted for by scaling the gains instep 322. - In
step 320, an “LPC gain ratio” is calculated for each new frame of parametric data. The LPC gain ratio is the ratio of the LPC predictor gains derived from the spectrum before and after preemphasis removal (deemphasis addition) instep 306. If,
- is defined as the synthesis filter gain before preemphasis removal and:

- is defined as the synthesis filter gain after preemphasis removal, then the scaling factor (i.e., the LPC Gain Ratio) to be used for the LPC-10 gain is

- The factor of 8 is included to accommodate the 13 bit input and output sample scaling in LPC-10 (MELP utilizes 16 bit input and output samples). In
step 322, the LPC RMS gain parameter is scaled by the LPC Gain Ratio calculated instep 320. -
Steps 324 addresses another difficulty in the gain conversion process which is that MELP uses two gain parameters per frame, whereas LPC uses only one gain parameter per frame. MELP employs a first gain parameter for the first half frame, and a second gain parameter for the second half frame. There thus needs to be a method for assigning the two half-frame MELP gains which produce a good quality sounding output. - A simple method of assigning MELP gains would be to simply set both of the MELP gains equal to the LPC RMS gain. However, it has been found that a better result is obtained if the two MELP gains are generated by taking a logarithmic average of the LPC RMS gains from frame to frame. This is performed in
steps - The following C-code segment illustrates this method of calculating the gains:
- melp-> gain[0]=pow(10.0, 0.5*log10(LPCrmsold)+0.5*log10(LPCrms));
- melp-> gain[1]=LPCrms;
- LPCrms and LPCrmsold represent the scaled LPC RMS gains computed in
step 322. LPCrms is the current frame's gain, while LPCrmsold is the previous frame's scaled gain. melp-> gain[0] and melp-> gain[1] are the MELP half frame gains, pow( ) is the C library power function, and log10( ) is the C-library base-10 logarithm function. - In
step 326, the logarithmic value of the two MELP gains are provided to encodingstep 328. Instep 328, the MELP half-frame gains are encoded using the standard MELP logarithmic quantization algorithm. - In
step 330, the encoded MELP spectrum, voicing, pitch, and gain parameters are inserted into MELPs frame and forward error correction (FEC) coding is performed. An output bit stream representing the MELP frames is then transmitted to a desired recipient. - 3. MELP to LPC Transcoder
- FIG. 4 illustrates a
transcoding method 400 for converting a bit stream representing frames encoded with the MELP coding standard to a bit stream representing frames encoded with the LPC-10 coding standard. Instep 402, an incoming bit stream is received. The incoming bit stream represents MELP frames containing MELP parameters. Instep 402, forward error correction (FEC) decoding is performed on the incoming bit stream. The MELP frames are also decoded by extracting the MELP spectrum, pitch, voicing, and gain parameters from the MELP frames. The MELP parameters are then distributed tosteps - a. Spectrum Conversion
- In step 404, the MELP LSFs are converted to their equivalent normalized autocorrelation coefficients R using well known transformations. In
step 406, preemphasis is added to the autocorrelation coefficients R. As mentioned previously for the LPC to MELP transcoder (section 2, above), LPC-10 speech encoders add preemphasis to the originally sampled (nominal) speech signal before the LPC-10 spectral analysis and encoding is performed. Thus,transcoder 400 must modify the autocorrelation coefficients R to produce modified autocorrelation coefficients which are equivalent to autocorrelation coefficients that would have been produced had the original nominal speech signal been preemphasized prior to LPC-10 encoding. - The LPC-10 0.9375 preemphasis coefficient must be superimposed on the spectrum. This is performed in the correlation domain by performing the following operation on the autocorrelation (R) coefficients:
- R′(i)=R(i)−0.9375[R(|i−1|)+R(i+1)]+0.93752 R(i)
- where R′(i) are the preemphasized autocorrelation coefficients. Note that the input set of R(i)s must be computed out to 11 lags to avoid truncation. The preemphasized autocorrelation coefficients R′ are then transformed to preemphasized predictor filter coefficients A′ using well known transformations. As noted in
section 2, above, performing the preemphasis addition in the correlation domain reduces computational complexity. - In
step 408, formant enhancement is performed. The purpose offormant enhancement step 408 is the same asformant enhancement step 308 described above for the LPC-10 to MELP transcoder. Two methods of formant enhancement are described in detail in sections 12 and 13 below. Section 12 describes a method of formant enhancement performed in the correlation domain. Section 13 describes a second method of formant enhancement performed in the frequency domain. Both methods of formant enhancement produce good results. Which one is preferable is a subjective determination made by the listener for the particular application. For the MELP to LPC-10 transcoder, the majority of listeners polled showed a slight preference frequency domain method. - In
step 410, the formant enhanced preemphasized filter coefficients A″ are converted to LPC-10 reflection coefficients RC″ using well known transformations. Also instep 410, the reflection coefficients RC″ are encoded according to the LPC-10 quantizer tables. - b. Voicing Conversion
- In
step 412, the MELP voicing parameters are converted to LPC voicing parameters. As mentioned previously, the LPC-10 coding standard uses only a single voicing bit per half-frame, whereas the MELP coding standard uses seven different voicing parameters: five bandpass voicing strengths, one overall voiced/unvoiced flag, and one voicing parameter called the “jitter flag.” - Simply using the MELP overall voicing bit to determine both half frame LPC voicing bits does not provide good performance. The voicing conversion process performed in
step 412 achieves better perceptual performance by assigning values to the LPC voicing bits based on the MELP bandpass voicing strengths, the MELP overall voicing bit, and the first reflection coefficient RC′[0] (after preemphasis addition) received frompreemphasis addition unit 406. A preferred decision algorithm is described by the following C-code segment:lpc->voice[0] = lpc->voice[1] = (melp->uv_flag+1)%2; flag = 0; for (i=0; i<NUM_BANDS; i++) flag += (int)melp->bpvc[i]; if ((flag <= 4) && (rc'[0] < 0.0)) lpc->voice[0] = lpc->voice[1] = 0; - where lpc-> voice[ ] are the half-frame LPC voicing bits (1=voiced), flag is an integer temporary variable, melp-> uv_flag is the MELP overall unvoiced flag (0=voiced), melp-> bpvc[ ] are the bandpass voicing strengths (0.0 or 1.0, with 1.0=voiced), and rc′[0] is the first reflection coefficient (computed from the spectrum after preemphasis addition).
- As illustrated by the above code, initially both LPC voicing bits are set to one (voiced) if the MELP overall unvoiced flag equals zero (voiced). Otherwise, the LPC voicing bits are set to one (unvoiced). To improve the output sound performance, both LPC voicing bits are set to zero (unvoiced) if the first reflection coefficient RC′[0] is negative, and the total number of MELP bands which are voiced is less than or equal to four. The reason this last improvement is performed is as follows. The MELP voicing analysis algorithm will occasionally set a partially voiced condition (lower bands voiced, upper bands unvoiced) when the input signal is actually unvoiced. Unvoiced signals typically have a spectrum that is increasing in magnitude with frequency. The first reflection coefficient RC′[0] provides an indication the spectral slope, and when it is negative, the spectral magnitudes are increasing with frequency. Thus, this value can be used to correct the error.
- Note that this type of voicing error is generally not apparent when a MELP speech decoder is used, since the signal power from the unvoiced bands masks the (incorrect) voiced excitation. However, if the error is propagated into the LPC speech decoder, it results in a perceptually annoying artifact.
- In
step 414, pitch and voice are encoded together using the standard LPC-10 quantization algorithm. According to the LPC standard, pitch and voicing are encoded together. - c. Pitch Conversion
- In
step 416, the MELP pitch parameter is converted to an LPC-10 pitch parameter by taking the inverse logarithm of the MELP pitch parameter (since the MELP algorithm encodes pitch logarithmically). Instep 418, the resulting LPC-10 pitch parameter is quantized according to the LPC-10 pitch quantization table. - In
step 414, pitch and voice are encoded together using the standard LPC-10 quantization algorithm. - d. Gain (RMS) Conversion
- As described previously, the MELP algorithm produces two half-frame logarithmically encoded gain (RMS) parameters per frame, whereas LPC produces a single RMS gain parameter per frame. In
step 420, the inverse logarithm of each MELP half-frame gain parameter is taken. Instep 424, the two resulting values are scaled to account for preemphasis addition which occurred in step 406 (similar to thegain scaling step 320 for the LPC-to-MELP transcoder described above). More specifically, both gain values are scaled by the ratio of the LPC predictor gain parameters derived from the spectrum before and after preemphasis addition. This LPC gain ratio is calculated instep 422 for each new frame of parametric data. If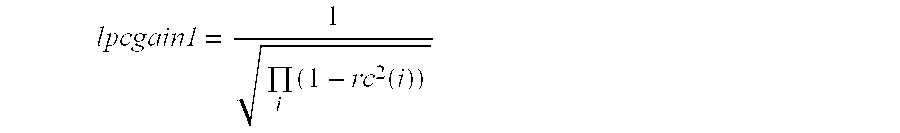
- is defined as the synthesis filter gain before preemphasis addition and

- is defined as the synthesis filter gain after preemphasis addition, then the scaling factor to be used for both MELP gains is

- The factor of 8 is included to accommodate the 13 bit input and output sample scaling in LPC-10 (MELP utilizes 16 bit input and output samples). In
step 424, both gain values are scaled by the above scaling value. The output ofstep 424 will be referred to as the “scaled MELP gains.” - In
step 426, the LPC gain parameter is nominally set to the logarithmic average of the two scaled MELP gains. An adaptive combiner algorithm is then used to preserve plosive sounds by utilizing the LPC-10 synthesizer's ability to detect and activate the “impulse doublet” excitation mode. To explain, LPC-10 synthesizers use an “impulse doublet” excitation mode which preserves plosive sounds like the sounds of the letters ‘b’ and ‘p’. If the LPC synthesizer senses a strong increase in gain, it produces an impulse doublet. This keeps the ‘b’ and ‘p’ sounds from sounding like ‘s’ or ‘f’ sounds. - The algorithm used in
step 426 is described as follows. First, the LPC gain parameter is nominally set to the logarithmic average of the two scaled MELP gains. Next, if it is determined that there is a large increase between the first and second half-frame scaled MELP gains, and the current and last transcoded frames are unvoiced, then the LPC gain parameter is set equal to the second half-frame scaled MELP gain. This emulates the adaptively-positioned analysis window used in LPC analysis and preserves LPC-10 synthesizer's ability to detect and activate the “impulse doublet” excitation mode for plosives. In other words, this method preserves sharp changes in gain to allow the LPC synthesizer to reproduce the ‘b’ and ‘p’ type sounds effectively. - In
step 428, the LPC gain parameter is then quantized and encoded according to the quantizer tables for the LPC-10 standard algorithm. - In
step 430, the encoded LPC spectrum, voicing, pitch, and gain parameters are inserted into a LPC frame and forward error correction (FEC) coding is added. An output bit stream representing the LPC frames is produced. - 4. LPC to TDVC Transcoder
- FIG. 5 illustrates a
transcoding method 300 for converting a bit stream representing LPC-10 encoded frames to a bit stream representing TDVC encoded frames. Instep 502, an incoming bit stream is received. The incoming bit stream represents LPC-10 frames containing LPC-10 parameters. Instep 302, forward error correction (FEC) decoding is performed on the incoming bit stream. The LPC-10 frames are also decoded by extracting the LPC-10 spectrum, pitch, voicing, and gain parameters from the LPC-10 frames. The LPC-10 parameters are then distributed tosteps steps - a. Spectrum Conversion
- While the LPC-10 analysis algorithm applies preemphasis before spectral analysis, the TDVC analysis does not, so the TDVC synthesizer expects spectral coefficients that were extracted from a nominal input signal. Thus, the preemphasis effects must be removed from the LPC spectral parameters.
- In
step 504, the LPC-10 reflection coefficients (RC) are converted to their equivalent normalized autocorrelation coefficients (R) using well known transformations. In order to avoid truncation effects in subsequent steps, the autocorrelation conversion recursion is carried out to 50 lags (setting RCs aboveorder 10 to zero). The resulting values for the autocorrelation coefficients (R) are stored symmetrically in a first array. - In
step 506, the preemphasis is removed in the correlation domain, described as follows. The symmetrical autocorrelation coefficients (HH) of the deemphasis filter are calculated beforehand and stored in an array. The deemphasis filter is a single pole IIR filter and is generally the inverse of the preemphasis filter, but different preemphasis and deemphasis coefficients may be used. The LPC-10 standard uses 0.9375 for preemphasis and 0.75 for deemphasis. Because the deemphasis filter has IIR characteristics, the autocorrelation function is carried out to 40 lags. The autocorrelation values (HH) are obtained by convolving the impulse response of the filter. - A modified set of spectral autocorrelation coefficients is calculated via convolving the R values with the HH values:

- The resulting modified autocorrelation coefficients R′ are converted to both reflection coefficients (RC′) and predictor filter coefficients (A′). The stability of the synthesis filter formed by the coefficients is checked; if the filter is unstable, the maximum order stable model is used (e.g. all RC's up to the unstable coefficient are used for the conversion to A′ coefficients). The RC′ values are saved for use by
step 524 in calculating the TDVC gain, discussed further below. - The final step in the preemphasis removal process is to convert the deemphasized predictor filter coefficients (A′) to line spectrum frequencies (LSF) in preparation for frame interpolation in
step 508. Frame interpolation, instep 508, is described in section e. below. - b. Voicing Conversion
- In
step 514, LPC-10 voicing parameters are converted to TDVC voicing parameters. The TDVC voicing parameter is called the “voicing cutoff frequency parameter” fsel (0=fully unvoiced, 7=fully voiced). The TDVC voicing cutoff frequency parameter fsel indicates a frequency above which the input frame is judged to contain unvoiced content, and below which the input frame is judged to contain voiced speech. On the other hand, LPC-10 uses a simple, half-frame on/off voicing bit. -
Step 514 takes advantage of the expanded fsel voicing feature of the TDVC synthesizer during transitional periods such as voicing onset. The following C-code segment illustrates a method of converting LPC-10 voicing bits to TDVC voicing cutoff frequency parameter fsel:/* mid-frame onset */ if ((lpc->voice[0]==0) && (lpc->voice[1]==1)) fselnew = 2; /* fully voiced */ else if ((lpc->voice[0]==1) && (lpc->voice[1]==1)) fselnew = 7; /* full unvoiced and mid-frame unvoiced transition */ else fselnew = 0; - where lpc-> voice[0] and lpc-> voice[1] are the half-frame LPC voicing bits (0=unvoiced), and fselnew is the TDVC fsel parameter. According to the TDVC standard, fselnew=0 corresponds to 0 Hz (DC) and fselnew=7 corresponds to 4 KHz, with each fselnew value equally spaced 562 Hz apart. The effect of the method illustrated by the above code is that when a mid-frame transition from the LPC unvoiced to voiced state occurs, the TDVC voicing output changes in a gradual fashion in the frequency domain (by setting fsel to an intermediate value of 2). This prevents a click sound during voicing onset and thereby reduces perceptual buzziness in the output speech.
- c. Pitch Conversion
- No conversion is required to convert from the LPC-10 pitch parameter to TDVC pitch parameter; the LPC-10 pitch parameter is simply copied to a temporary register for later interpolation in
step 520, described below. - d. Gain (RMS) Conversion
- In
step 526, an adjustment for preemphasis removal must be made to the LPC gain parameter before it can be used in a TDVC synthesizer. This preemphasis removal process is described as follows. - The LPC gain parameter is scaled by the LPC gain ratio. The LPC gain ratio is calculated in
step 524 for each new frame of data. The LPC gain ratio is the ratio of LPC predictor gains derived from the spectrum before and after preemphasis removal (deemphasis addition). If
- is defined as the synthesis filter gain before preemphasis addition and

- is defined as the synthesis filter gain after preemphasis addition, then the scaling factor (LPC Gain Ratio) to be used for the LPC RMS is

- This scale factor is the LPC Gain Ratio. The factor of 8 is included to accommodate the 13 bit input and output sample scaling in LPC-10 (TDVC utilizes 16 bit input and output samples). The scaling performed by
step 526 is required because the LPC RMS gain is measured from the preemphasized input signal, while the TDVC gain is measured from the nominal input signal. - e. Frame Interpolation
- Because LPC-10 and TDVC use different frame sizes (22.5 and 20 msec, respectively), a frame interpolation operation must be performed. To keep time synchronization, 8 frames of LPC parameter data must be converted to 9 frames of TDVC parameter data. A smooth interpolation function is used for this process, based on a
master clock counter 510 that counts LPC frames on a modulo-8 basis from 0 to 7. At startup, themaster clock counter 510 is initialized at 0. A new frame of LPC parameter data is read for each count; after all interpolation operations (described below), then “new” LPC parameter data is copied into the “old” parameter data area, and themaster clock counter 510 is incremented by 1, with modulo 8 addition. The following interpolation weights are used to generate a set of TDVC parameter data from the “new” and “old” transformed LPC data:
- wnew=1.0−wold
- Note that at startup (clock=0), wold is set to zero, while wnew is set to 1.0. This is consistent with the LPC frame read schedule, as the contents of the “old” data area are undefined at startup. When the
master clock counter 510 reaches 7, two frames of TDVC data are written. The first frame is obtained by interpolating the “old” and “new” transformed LPC data using the weights given by the equations above. The second frame is obtained by using the “old” transformed LPC data only (the same result as ifmaster clock 510 were set to 8). Themaster clock 510 is then reset to 0 and the process begins again. - The interpolation equations for each TDVC parameter are as follows. Linear interpolation is used for line spectrum frequencies in step 508:
- Isf(i)=wold*lsfold(i)+wnew*lsfnew(i)
- where lsfnew( ) and Isfold( ) correspond to the “new” and “old” LSF data sets described above. The voicing parameter fsel is also linearly interpolated in step 516:
- fsel=wold*fselold+wnew*fselnew
- Likewise for the pitch in step 520:
- TDVCpitch=wold*LPCpitchold+wnew*LPCpitchnew
- Finally, the gain (RMS) is logarithmically interpolated in
step 528. Using the scaled LPC RMS values derived above, the TDVC gain can be computed using the following C-code segment: - TDVCgain=pow(10.0, wold*log10(LPCscaledRMSold)+wnew*log10(LPCscaledRMSnew));
- The interpolated spectrum, voicing, pitch and gain parameters are then quantized and encoded according to the TDVC standard algorithm in
steps step 532, the encoded TDVC spectrum, voicing, pitch, and gain parameters are inserted into a TDVC frame and forward error correction (FEC) coding is added. An output bit stream representing the TDVC frames is transmitted. - 5. MELP to TDVC Transcoder
- FIG. 6 illustrates a
transcoding method 600 for converting a bit stream representing MELP encoded frames to a bit stream representing TDVC encoded frames. Instep 602, an incoming bit stream is received. The incoming bit stream represents MELP frames containing MELP parameters. Instep 602, forward error correction (FEC) is decoding performed on the incoming bit stream. The MELP frames are also decoded by extracting the MELP spectrum, pitch, voicing, and gain parameters from the MELP frames. The MELP parameters are then distributed tosteps - The method of transcoding from MELP to TDVC can be divided into 2 types of operations: 1) conversion from MELP parameters to TDVC parameters, and 2) frame interpolation to synchronize the different frame sizes. The frame interpolation operations are performed in
steps - a. Spectrum Conversion
- In
step 604, the MELP LSFs are scaled to convert to TDVC LSFs. Since MELP and TDVC both use line spectrum frequencies (LSFs) to transmit spectral information, no conversion is necessary except for a multiplication by a scaling factor of 0.5 (to accommodate convention differences). - b. Voicing Conversion
- In
step 612, the MELP voicing parameters are converted to TDVC voicing parameters. As described previously, TDVC employs a single voicing cutoff frequency parameter (fsel: 0=fully unvoiced, 7=fully voiced) while MELP uses an overall voicing bit and five bandpass voicing strengths. The TDVC voicing cutoff frequency parameter fsel (also referred to as the voicing cutoff frequency “flag”) indicates a frequency above which the input frame is judged to contain unvoiced content, and below which the input frame is judged to contain voiced speech. The value of the voicing cutoff flag ranges from 0 for completely unvoiced to 7 for completely voiced. - The following C-code segment illustrates a conversion of the MELP voicing data to the TDVC fsel parameter by selecting a voicing cutoff frequency fsel that most closely matches the upper cutoff frequency of the highest frequency voiced band in MELP:
if (melp->uv_flag == 1) fselnew = 0; else { for (i=4; i>=0; i−−) if (melp->bpvc[i] == 1.0) break; r0 = 1000.0*(float)i; if (r0 == 0.0) r0 = 500.0; if (r0 < 0.0) r0 = 0.0; for (i=0; i<=7; i++) if (abs((int)((float)i*571.4286 − r0)) < 286) break; fselnew = i; } - where melp-> uv_flag is the MELP overall unvoiced flag (0=voiced), melp-> bpvc[ ] are the bandpass voicing strengths (0.0 or 1.0, with 1.0=voiced), r0 is a temporary floating point variable, and fselnew is the TDVC fsel parameter.
- As illustrated by the above code, the highest voiced frequency band in MELP is first identified. The frequency cutoffs for the MELP frequency bands are located at 500 Hz, 1000 Hz, 2000 Hz, and 3000 Hz. The frequency cutoff of the highest voiced band in MELP is used to choose the nearest corresponding value of fsel.
- c. Pitch Conversion
- In
step 618, the MELP pitch parameters-are converted to TDVC parameter. Since MELP pitch is logarithmically encoded, the TDVC pitch parameter (pitchnew) is obtained by taking an inverse logarithm of the MELP pitch parameter, as illustrated the following equation: - pitchnew=10MELPpitch
- d. Gain Conversion
- In
steps 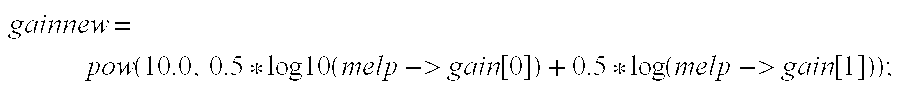
- where melp-> gain[0] and melp-> gain[1] are the first and second MELP half-frame gains (respectively), gainnew is the “new” gain (described below in the section on frame interpolation), pow( ) is the C library power function, and log10 is the C library base-10 logarithm function.
- e. Frame Interpolation
- Because MELP and TDVC use different frame sizes (22.5 and 20 msec, respectively), an interpolation operation must be performed. To keep time synchronization, 8 frames of MELP parameter data must be converted to 9 frames of TDVC parameter data. A smooth interpolation function is used for this process, based on a
master clock counter 608 that counts MELP frames on a modulo-8 basis from 0 to 7. At startup, themaster clock counter 608 is initialized at 0. A new frame of MELP data is read for each count; after all interpolation operations (described below), then “new” MELP data is copied into the “old” data area, and themaster clock counter 608 is incremented by 1, with modulo 8 addition and “old” transformed MELP data:
- wnew=1.0−wold
- Note that at startup (master clock=0), wold is set to zero, while wnew is set to 1.0. This is consistent with the MELP frame read schedule, as the contents of the “old” data are is undefined at startup. When the
master clock counter 608 reaches 7, two frames of TDVC data are written. The first frame is obtained by interpolating the “old” and “new” transformed MELP data using the weights given by the equations above. The second frame is obtained by using the “old” transformed MELP data only (the same result as if clock were set to 8). Themaster clock 608 is then reset to 0 (via the modulo-8 addition) and the process begins again. - The interpolation equations for each TDVC parameter are as follows. Linear interpolation is used for line spectrum frequencies in step 606:
- TDVClsf(i)=wold*lsfold(i)+wnew*lsfnew(i)
- where lsfnew( ) and lsfold( ) correspond to the “new” and “old” LSF sets described above. The voicing parameter fsel is also linearly interpolated in step 614:
- TDVCfsel=wold*fselold+wnew*fselnew
- Likewise for the pitch in step 620:
- TDVCpitch=wold*pitchold+wnew*pitchnew
- Finally, the gain (RMS) is logarithmically interpolated in
step 628. Using the scaled LPC RMS gain values derived above, the TDVC gain can be computed using the following C-code segment in step 628: - TDVCgain=pow(10.0, wold*log10(gainold)+wnew*log10(gainnew));
- The interpolated spectrum, voicing, pitch, and gain parameters may now be quantized and encoded according to the TDVC standard algorithms in
steps step 632, the encoded TDVC spectrum, voicing, pitch, and gain parameters are inserted into a TDVC frame and forward error correction (FEC) coding is added. An output bit stream representing the TDVC frames is transmitted. - 6. TDVC to LPC Transcoder
- FIG. 7 illustrates a
transcoding method 700 for converting from TDVC encoded frames to LPC-10 encoded frames. The transcoding conversion from TDVC to LPC-10 consists of 2 operations: 1) conversion from MELP parameters to TDVC parameters, and 2) frame interpolation to synchronize the different frame sizes. - In
step 702, an incoming bit stream is received. The incoming bit stream represents TDVC frames containing TDVC parameters. Instep 702, forward error correction (FEC) decoding is performed on the incoming bit stream. The TDVC frames are also decoded by extracting the TDVC spectrum, pitch, voicing, and gain parameters from the TDVC frames. - a. Spectrum Conversion, Part 1 (Step 704)
- In
step 704, the TDVC line spectrum frequencies (LSFs) are transformed into predictor filter coefficients (A) using well known transformations. Next, adaptive bandwidth expansion is removed from the TDVC predictor filter coefficients A. Adaptive bandwidth expansion is used by TDVC but not by LPC (i.e., adaptive bandwidth expansion is applied during TDVC analysis but not by LPC analysis). When converting from TDVC to LPC, removing the adaptive bandwidth expansion effects from the spectral coefficients sharpens up the LPC spectrum and makes the resulting output sound better. The adaptive bandwidth expansion is removed by the following process: - 1) The original bandwidth expansion parameter gamma is calculated via:

- where pitch is the TDVC pitch parameter.
- 2) Next, the reciprocal of gamma is calculated (rgamma=1.0/gamma).
- 3) The predictor filter coefficients A are then scaled according to
- a′(i)=(rgamma)i a(i)
- 4) The new coefficient set a′(i) is checked for stability. If they form a stable LPC synthesis filter, then the modified coefficients a′(i) are used for further processing; if not, the original coefficients a(i) are used.
- 5) The selected coefficient set (either a(i) or a′(i)) is then converted back into LSFs for interpolation using well known transformations.
- b. Frame Interpolation
- Because LPC-10 and TDVC use different frame sizes (22.5 and 20 msec, respectively), an interpolation operation must be performed. Interpolation of the spectrum, voicing, pitch, and gain parameters is performed in
steps - To keep time synchronization, 9 frames of TDVC parameter data must be converted to 8 frames of TDVC parameter data. A smooth interpolation function is used for this process, based on a
master clock counter 708 that counts LPC frames on a modulo-8 basis from 0 to 7. At startup, the count is initialized to zero. On master clock=0, two sequential TDVC data frames are read and labeled as “new” and “old”. On subsequent counts, the “new” frame data is copied into the “old” frame data area, and the next TDVC frame is read into the “new” data area. All TDVC parameters are interpolated using the following weighting coefficients:
- wold=1.0−wnew
- Note that all parameters are interpolated in their TDVC format (e.g. spectrum in LSFs and voicing in fsel units). This produces better superior sound quality output, than if interpolation is performed in the LPC format.
- The following adaptive interpolation technique is also used to improve plosive sounds. If a large change is detected in the TDVC parameters, an adjustment is made to the interpolation weighting coefficients. Specifically, 1) if the spectral difference between the “new” and “old” LSF sets is greater than 5 dB and 2) if the absolute difference between the “new” and “old” fsel parameters is greater than or equal to 5, and 3) the ratio of the “new” and “old” TDVC gain parameters is greater than 10 or less than 0.1, the following adjustment is performed (C-code):
if (master_clock <= 3) { wnew = 0.0; wold = 1.0; } else { wnew = 1.0; wold = 0.0; } - The
Interpolation Controller 708 handles this adjustment and changes the weighting coefficients wnew and wold for all fourinterpolation steps master clock 708 is at the beginning portion of the interpolation cycle (less than or equal to three) then the LPC output parameters (including spectrum, voicing, pitch and gain) will be fixed to the old LPC output. If the clock is at the end portion of the interpolation cycle (greater than three), then the LPC output (spectrum, voicing, pitch and gain) is fixed to the new LPC set. This adjustment emulates the adaptively-positioned analysis window used in LPC analysis and preserves LPC-10 synthesizer's ability to detect and activate the “impulse doublet” excitation mode for plosives. This preserves the sharp difference of plosive sounds and produces a crisper sound. - c. Spectrum Conversion—
Part 2 - In
step 706, interpolation of the spectral coefficients is performed. To generate a single set of LPC spectral coefficients from the “new” and “old” TDVC LSFs, the LSFs are linearly interpolated using the wnew and wold coefficients described above: - lsf(i)=wold*lsfold(i)+wnew*lsfnew(i)
- To complete the conversion of the spectral parameters, in
step 708, preemphasis is added. The LPC-10 0.9375 preemphasis coefficient must be superimposed on the spectrum, since TDVC does not use preemphasis. This is performed in the correlation domain via transforming the interpolated LSFs into predictor coefficients (A) and then transforming the predictor coefficients into their equivalent normalized autocorrelation (R) coefficients and then employing the following operation: - R′(i)=R(i)−0.9375[R(|i−1|)+R(i+1)]+0.93752 R(i)
- where R′(i) are the preemphasized autocorrelation coefficients. Note that the input set of R( )s must be computed out to 11 lags to avoid truncation. The modified autocorrelation coefficients R′(i) are now transformed back to predictor coefficients A′(i) for further processing.
- In
step 710, formant enhancement is performed on the predictor filter coefficients A′(i). Formant enhancement has been found to improve the quality of the transcoded speech. Two methods of formant enhancement are described in detail in sections 12 and 13 below. Section 12 describes a method of formant enhancement performed in the correlation domain. Section 13 describes a second method of formant enhancement performed in the frequency domain. Both methods of formant enhancement produce good results. Which one is preferable is a subjective determination made by the listener for the particular application. For the TDVC to LPC-10 transcoder, the majority of listeners polled showed a slight preference frequency domain method. - After the formant enhancement has been applied, the predictor filter coefficients A′(i) are converted to reflection coefficients (RCs) by well known transformations and quantized according to the LPC-10 quantizer tables in
step 712. - d. Voicing Conversion and Jitter Factor Conversion
- Voicing conversion uses the TDVC fsel voicing parameter and the first reflection coefficient RC. First, in
step 714, the TDVC fsel voicing cutoff frequency parameter is linearly interpolated using the wnew and wold coefficients described above: - fsel=wold*fselold+wnew*fselnew
- where fselold is the “old” value of fsel, and fselnew is the “new” value of fsel.
- In
step 716, the fsel voicing parameter is converted to an LPC voicing parameter. Simply using fsel voicing parameter bit to determine both half frame LPC voicing bits is inadequate. Additional information is required for the best perceptual performance. The preferred decision algorithm is described by the following C-code segment:if (fsel <= 2) lpc->voice[0] = lpc->voice[1] = 0; else lpc->voice[0] = lpc->voice[1] = 1; if ((fsel <= 4) && (rc[0] < 0.0)) lpc->voice[0] = lpc->voice[1] = 0; - where lpc-> voice[ ] are the half-frame LPC voicing bits (1=voiced), fsel is the interpolated TDVC fsel voicing parameter (0=fully unvoiced 7=fully voiced), and rc[0] is the first reflection coefficient (computed from the spectrum after preemphasis addition in step 708).
- As illustrated by the above code, if the TDVC voicing cutoff frequency parameter fsel is less than or equal to 2, then both LPC half frame voicing bits are set to zero (unvoiced). If fsel is greater than 2, then both LPC half frame voicing bits are set to one (voiced). The exception occurs when fsel <=4 and the first reflection coefficient RC′(0) (after preemphasis addition) is less than zero. In this case, both LPC half frame voicing bits are set to zero (unvoiced). This last exception is implemented to improve the output sound performance. The reason this last improvement is performed is as follows. The TDVC voicing analysis algorithm will occasionally set a partially voiced condition (fsel>0 but fsel <=4) when the input signal is actually unvoiced. Unvoiced signals typically have a spectrum that is increasing in magnitude with frequency. The first reflection coefficient RC′[0] provides an indication the spectral slope, and when it is negative, the spectral magnitudes are increasing with frequency. Thus, this value can be used to correct the error.
- Note that this type of voicing error is generally not apparent when a TDVC speech decoder is used, since the signal power from the unvoiced portion of the excitation masks the (incorrect) voiced excitation. However, if the error is propagated into the LPC speech decoder, it results in a perceptually annoying artifact.
- In
step 718, pitch and voicing are encoded together using the standard LPC-10 encoding algorithm. - e. Pitch Conversion
- In
step 720, pitch is converted by linearly interpolating the “new” and “old” values of the TDVC pitch to form a single LPC pitch: - LPCpitch=wold*TDVCpitchold+wnew*TDVCpitchnew
- In
step 718, pitch and voicing are encoded together using the standard LPC-10 quantization algorithm. - f. Gain (RMS) Conversion
- The first step in converting the TDVC gain to LPC RMS is to logarithmically interpolate the the “new” and “old” values of the TDVC gain in step 724 (C-code example):
- LPCrms=pow(10.0, wold*log10(TDVCgainold)+wnew*log10(TDVCgainnew));
- where LPCrms is the intermediate LPC RMS gain, pow( ) is the C-library power function and log10 is the C-
library base 10 logarithm function. - In
step 728, the gain is scaled to account for the preemphasis addition performed on the spectral coefficients instep 708. The following steps are performed to account for preemphasis. First, the intermediate LPC RMS gain value is adjusted by the ratio of the LPC predictor gains derived from the spectrum before and after preemphasis addition. This LPC gain ratio is calculated instep 726 for each new frame of data. If
- is defined as the synthesis filter gain before preemphasis addition and

- is defined as the synthesis filter gain after preemphasis addition, then the scaling factor to be used for the intermediate LPC gain parameter is

- The factor of 8 is included to accommodate the 13 bit input and output sample scaling in LPC-10 (TDVC utilizes 16 bit input and output samples). This step is required because the LPC gain is measured from the preemphasized input signal, while the TDVC gain is measured from the nominal input signal.
- Additional quality improvements may be obtained by providing a small boost factor for unvoiced signals by utilizing a modified scaling factor:

- In
step 730, the LPC RMS gain is then quantized and encoded according to the quantizer tables for the LPC-10 algorithm. - In
step 732, the encoded LPC-10 spectrum, voicing, pitch, and gain parameters are inserted into a LPC frame and forward error correction (FEC) is added. An output bit stream representing the LPC frames is produced. - 7. TDVC to MELP Transcoder
- FIG. 8 illustrates a
transcoding method 800 for converting a bit stream representing TDVC encoded frames to a bit stream representing MELP encoded frames. Instep 802, an incoming bit stream is received. The incoming bit stream represents TDVC frames containing TDVC parameters. Instep 802, forward error correction (FEC) decoding is performed on the incoming bit stream. The TDVC frames are also decoded by extracting the TDVC spectrum, pitch, voicing, and gain parameters from the TDVC frames. The TDVC parameters are then distributed tosteps - a. Frame Interpolation
- The process for converting from TDVC to MELP is shown in FIG. 8. Because MELP and TDVC use different frame sizes (22.5 and 20 msec, respectively), an interpolation operation must be performed. To keep time synchronization, 9 frames of TDVC parameter data must be converted to 8 frames of LPC parameter data. A smooth interpolation function is used for this process, based on a
master clock counter 804 that counts MELP frames on a modulo-8 basis from 0 to 7. On count=0, two sequential TDVC data frames are read and labeled as “new” and “old”. On subsequent counts, the “new” frame data is copied into the “old” frame data area, and the next TDVC frame is read into the “new” data area. All TDVC parameters are interpolated using the following weighting coefficients:
- wold=1.0−wnew
- Note that all parameters are interpolated in their TDVC format (e.g. voicing in fsel units). This was found to produce superior output sound performance.
- b. Spectrum Conversion
- To generate a single set of MELP LSFs from the “new” and “old” TDVC LSFs, the LSFs are linearly interpolated in
step 806 using the wnew and wold coefficients described above: - lsf(i)=2.0*[wold*lsfold(i)+wnew*lsfnew(i)]
- The scaling factor of 2.0 is included (scaling is performed in step 809) because the MELP scaling convention is different than that of TDVC. The interpolated LSFs are then quantized and encoded in
step 810 according to the MELP standard. - The MELP standard also transmits 10 harmonic amplitude values that are used by the MELP synthesizer for generating voiced speech. U.S. Pat. No. 6,098,036 to Zinser et al., “Speech Coding System and Method Including Spectral Formant Enhancer,” (incorporated-by reference herein) discloses a spectral formant enhancement algorithm to generate these harmonic amplitudes. The process described in columns 17 and 18 of the above patent can be used to generate 10 amplitudes (amp(k), k=1 . . . 10) from Equation 7 in column 18. Further enhancement may be achieved by utilizing the method described in Grabb, et al., U.S. Pat. No. 6,081,777, “Enhancement of Speech Signals Transmitted Over a Vocoder Channel” (also incorporated herein by reference) and modifying the first three harmonic amplitudes amp(k) according to the values given in FIG. 5 and the accompanying equation. This calculation of harmonic amplitudes is performed in
step 807. - In
step 808, the calculated harmonic amplitudes are encoded by a MELP harmonic amplitude encoder. This method of generating harmonic amplitudes for provision to the MELP synthesizer could also be used with the LPC-to-MELP transcoder described insection 2, above. - c. Voicing Conversion
- Voicing conversion uses the TDVC fsel voicing parameter (fscl=0 indicates fully unvoiced speech, while fsel=7 indicates fully voiced speech). First, the fsel parameter is linearly interpolated in
step 812 using the wnew and wold coefficients described above: - fsel=wold*fselold+wnew*fselnew
- Next, the interpolated fsel parameter is converted to the MELP overall voicing bit and bandpass strengths in
step 814 using the C-code segment below:if(fsel == 0) melp->uv_flag = 1; else melp->uv_flag = 0; tmp = nint((float)fsel*571.4286/1000.0); tmp = tmp + 1; if (fsel < 2) tmp = fsel; tmp = tmp − 1; for (i=0; i<=tmp; i++) melp->bpvc[i] = 1.0; for (i=tmp+1; i<=4; i++) melp->bpvc[i] = 0.0; - where fsel is interpolated TDVC fsel voicing parameter, melp-> uv_flag is the MELP overall unvoiced flag (0=voiced), melp-> bpvc[ ] are the bandpass voicing strengths (0.0 or 1.0, with 1.0=voiced), nint( ) is the nearest integer function, and tmp is an integer temporary variable. As illustrated by the above code, all of the MELP bands below the TDVC voicing cutoff frequency are set to voiced. The overall voicing bit and the bandpass strengths are then encoded according the MELP standard in
step 816. - d. Pitch Conversion
- Pitch is converted by linearly interpolating the “new” and “old” values of the TDVC pitch to form a single LPC pitch in step 818:
- MELPpitch=wold*TDVCpitchold+wnew*TDVCpitchnew
- In
step 820, the logarithm of the pitch is taken. Instep 822, the resulting pitch value is then encoded according to the MELP standard. - e. Gain Conversion
- The MELP algorithm has the capability to transmit 2 half-frame gains per frame. In
step 824, an adaptive dual gain interpolation is performed. This adaptive interpolation is a modification of the wnew/wold interpolation algorithm described above. The wnew/wold interpolation algorithm has been modified to generate these two gains by moving the wnew/wold interpolation weights slightly backward in the clock schedule for the first MELP gain, and slightly forward for the second MELP gain. These modified weights are used for logarithmic interpolation. The following C-code segment illustrates one way to implement this method:wold = wold + 0.1; /* back up a bit */ if(wold > 1.0) wo1d = 1.0; wnew = 1.0 − wold; melp->gain[0] = pow(10.0, wold*log10(0.01 + tdvc->gain[1]) + wnew*log10(0.01 + tdvc->gain[2])); wold = wold − 0.2; /* go forward a bit */ if(wold < 0.0) wold = 0.0; wnew = 1.0 − wold; melp->gain[1] = pow(10.0, wold*log10(0.01 + tdvc->gain[1]) + wnew*log10(0.01 + tdvc->gain[2])); - where melp-> gain[0] and melp-> gain[1] are the first and second MELP half-frame gains (respectively), tdvc-> gain[1] and tdvc-> gain[2] are the “old” and “new” TDVC gains (respectively), pow( ) is the C library power function, and log10 is the C library base-10 logarithm function. In
steps - In
step 830, the encoded MELP spectrum, voicing, pitch, and gain parameters are inserted into a MELP frame and forward error correction (FEC) coding is added. An output bit stream representing the MELP frames is produced. - 8. Compressed Domain Conference Bridge with Multi-Talker Capability
- Conference bridging technology has been available for many years to users of the Public Switched Telecommunications Network (PSTN). This technology enables multiple users in remote locations to participate in group discussions. Generally, a conventional bridge uses a summation matrix that supplies an adaptive combination of the incoming signals to each conference participant. The adaptive combination algorithm is designed to attenuate signals from incoming lines that are not actively carrying a voice signal. Therefore, only a signal voice will be carried at any one time in the conventional bridge system.
- In both commercial and military applications, it is desirable to have conference bridge functionality available when using very low rate (2.4 kb/sec and below) digital communication channels. Because each conference participant is allotted a maximum of 2.4 kb/sec, the design and implementation of such a bridge poses several challenges. Most of these challenges are caused by the limitations of vocoders operating at low rates. The major issues are:
- 1. Current-generation 2.4 kb/sec vocoders are unable to transmit multiple talkers simultaneously without near total loss of intelligibility. This precludes use of the conventional summation matrix described above.
- 2. Conventional conference bridge designs require decoding the incoming 2.4 kb/sec bit stream to a speech waveform for processing (such as speech activity detection). The speech must then be re-encoded for transmission to the participants. This encode/decode/encode/decode process is known a tandem connection and greatly decreases the subjective quality of the speech.
- 3. To be useful, bridge systems must support multiple coding standards. In most cases, the vocoders are incompatible with each other (e.g. LPC-10, MELP, TDVC). For this reason, direct input to output bitstream transfers cannot be used for interconnection, and the above-mentioned tandem connection is clearly less-than-optimal.
- This present invention includes an architecture for a compressed domain conference bridge that surmounts the problems described above. Central to the conference bridge structure is the concept of transcoding between different coding standards, as described in sections 1-7 above. The compressed domain bridge of the present invention is designed to be of low computational complexity in order to keep power consumption as low as possible. This is especially important for space-based applications such as use on satellites.
- The basic idea of the compressed domain conference bridge of the present invention is to perform most bridging operations in the compressed (rather than signal) domain. The compressed domain conference bridge is designed to provide most of the services available on a conventional bridge, but maintain full intelligibility for all users (even when there are multiple simultaneous talkers). In addition, multiple types of low-rate vocoder algorithms are supported, including a special hybrid-dual/single talker receiver that will allow a user to hear 2 simultaneous talkers over a single 2400 bit/second channel. This hybrid-dual/single talker receiver is described in detail in section 9, below, and FIG. 10.
- a. Parameter Decoding and CDVAD
- FIG. 9 depicts a block diagram illustrating a typical compressed
domain conference bridge 900. The incoming bit streams from N different conference participants (users) are first decoded into vocoder parametric model data by respective parameter decoder units 902 (User 1's transmission bit stream is decoded by decoder unit 902-1,User 2's transmission bit stream is decoded by decoder unit 902-2, and so forth). The parameters for each stream are then analyzed to determine which stream(s) carry an active voice signal by a corresponding Compressed Domain Voice Activity Detector (CDVAD) 904. The Compressed Domain Voice Activity Detector according to the present invention is described in detail insection 10, below. -
CDVAD 904 determines which incoming bit streams contain a real voice signal; this information is used byBridge Control Algorithm 950 to determine which channels contain speech, and thus which channels should be transmitted to the User receivers, as described further below. - b. Frame Interpolation
- Because users of the conference bridge may be using different vocoder algorithms that do not necessarily have the same frame size, frame
interpolators 906 perform frame interpolation. For example, suppose a user with a 20 msec frame size has to be connected to another user with a 22.5 msec frame size. In this case,frame interpolator unit 104 converts 9 frames of 20 msec parameter data to 8 frames of 22.5 msec data. This is accomplished in a smooth, continuous manner byframe interpolator 906. See the frame interpolation sections in sections 4-7 above for a description of this type of interpolation algorithm. - Note that FIG. 9 shows a
frame interpolator 906 on the decoding side of the conference bridge (i.e. to the left of primary/secondary talker bus 910) and aframe interpolator 912 on the encoding side of the conference bridge (i.e. to the right of primary/secondary talker bus 910). Only one of these frame interpolators is necessary. Whether to use a frame interpolator on the encoding side or decoding side of the conference is bridge is a choice based on which location produces the best perceptual quality in the output speech. - c. Bridge Control and Multi-Talker Capability
-
Bridge control algorithm 950 next determines which incoming channels will be converted for transmission over the bridge to the receivers. Here we introduce the concept of the primary and secondary talker channels. Previous research has shown that during typical voice conferences, there are rarely more than two participants talking at once. Consequently, thecompressed domain bridge 900 has been designed around this factor, with-the capability to transmit two simultaneous talkers to participants. This design also yields significant savings in computational complexity, because a maximum of 2 users per vocoder type must be encoded for transmission. - A note on the conference participant's equipment is in order here. The current implementation of the bridge is designed to work with several different types of vocoders (e.g. LPC-10, MELP, and TDVC), including the hybrid-dual/single talker (D/ST) receiver mentioned above and described in section 9, below. The D/ST receiver is capable of receiving and decoding a single talker bitstream (at approximately 2400 b/sec) or a dual talker bitstream (2×1200 b/sec), and dynamically switching between the two formats as the call progresses. The switching is accomplished without artifacts or noticeable degradation.
- During the course of a conference call, if only one participant is speaking, then the bridge sends the D/ST receiver a single talker stream. If two participants are speaking simultaneously, the bridge will send the D/ST receiver the vocoder parameters for both participants in the 2×1200 b/sec dual talker format. The reason for designing the system in this fashion is that the reproduction quality for the 1200 b/sec format is not as good as the 2400 b/sec single talker format. By switching dynamically between the two formats, the system can continuously provide each user with the highest quality reproduction given the input conditions.
- Another desirable feature for a conference bridge is the ability to assign priorities to the participants to regulate access to retransmission over the bridge. A participant with a higher priority will take precedence over a lower priority user when both are talking at the same time. To accommodate prioritization and the dual speaker mode of operation described above, the concept of primary and secondary talker channels has been developed. The talker channels are selected using 1) the pre-set priority of each user for retransmission, and 2) which users are actually talking (as indicated by the CDVAD units 904). The
bridge control algorithm 950 selects the primary and secondary talkers using the following algorithm:No user talking: highest priority user is primary second highest priority user is secondary 1 user talking: talking user is primary non-talking user with highest priority is secondary 2 users talking: highest priority talking user is primary other user who is talking is secondary >2 users talking: highest priority talking user is primary second highest priority talking user is secondary - Note that there are always primary and secondary talker channels selected, even if there are no users actively talking. This ensures that the conference bridge will always function like a normal full-duplex telephone call if there are only 2 users. For calls with more than 2 users, all non-talking users on the bridge will receive either the primary or the combined primary and secondary signals (if they have D/ST capability).
- There are a few special rules applying to the selected primary and secondary talkers. The first rule is that the primary talker's audio is never transmitted back to his/her receiver. The primary talker will always receive the secondary talker's audio. In a similar fashion, the secondary talker will always receive the primary talker's audio. To minimize potential user confusion, a primary or secondary talker is not allowed to receive a dual-talker bitstream (this would require a third talker path through the bridge if the first 2 rules are applied, and some participants would be receiving different streams than others).
- d. Transcoding
- After the primary and secondary talker channels are selected by
bridge control algorithm 950, the decoded vocoder parameters for the primary and secondary talker channels can be loaded into associated parameter structures for transcoding bytranscoders 908. Transcoding is necessary when there are users with different vocoder types are participating in the conference. Some different types of transcoding operations in the compressed domain are fully described in sections 1-7. - Transcoding is performed by the
transcoder 908 in the corresponding primary talker channel and thetranscoder 908 in the corresponding secondary talker channel. For example, ifbridge control algorithm 950 determines thatuser 2 is the primary talker channel, and user 7 is the secondary talker channel, then transcoder 908-2 performs transcoding ofchannel 2 and transcoder 908-7 performs transcoding of channel 7, if transcoding is necessary. - Each
transcoder 908 can be configured bybridge control algorithm 950 to perform one or more desired transcoding conversions. For example, supposeuser 1 is determined to be the primary talker channel, anduser 1 is transmitting a MELP-encoded bit stream. One of the user receivers connected to the conference bridge is an LPC receiver, and one user receiver is a TDVC receiver.Bridge control algorithm 950 then configures transcoder 908-1 to convertuser 1's bit stream from MELP to LPC, and from MELP to TDVC. Thus two versions ofuser 1's bit stream are created: one encoded with LPC and one encoded with TDVC. In this example, transcoder 908-1 is said to have two “transcoder structures.” One transcoder structure converts MELP to LPC, and the other structure converts MELP to TDVC. - The maximum number of transcoder structures required for each
transcoder 908 is dependent on the number of different vocoder types on the system and whether any users have dual speaker capability. Because of the primary/secondary talker channel architecture, the number of transcoder structures is not dependent on the number of users. This feature yields a significant memory savings in implementation. The table below gives the maximum number of transcoder structures, taking into account the rules given in the last paragraph.1 coder type 2 coder types 3 coder types in call in call in call no D/ ST users 0 2 3 at least 1 D/ ST user 0 2 4 - Because the selection of primary and secondary talkers changes during the course of the call, the transcoding operation also changes dynamically. A hash table may be used to keep track of conversion operations handled by each allocated transcoder structure. These structures have a 1-frame vocoder parameter memory. When the configuration changes, the memory must be preserved under certain conditions. If the user who was assigned to secondary talker channel is reassigned to the primary talker channel, the memory from the secondary structure must be transferred to that of the primary. In a similar fashion, if the primary structure memory must be copied to that of the secondary if the opposite switch occurs. Finally, if a “new” user is selected for the primary or secondary talker channel, the associated structure memory is reinitialized.
- e. Dual/Single Talker Encoding
- After transcoding, the bit streams from the primary talker and secondary talker channels are distributed to the receivers via primary/
secondary talker bus 910. Thebridge control algorithm 950 checks to see if there are any valid D/ST users on the system who are eligible to receive a dual-talker format. If the dual-talker conditions (described above) are satisfied, then the eligible users receive both the primary and secondary talkers in the dual-talker format. If a receiver does not have D/ST capability, then only the primary talker is received. - For each D/ST eligible receiver, D/ST encoder 914-1 encodes the bit streams for the primary and second talker channels into a dual-talker format. The dual-talker format consists of two 1200 b/sec channels, one each for the primary and secondary talker channels. The low bit rate for each channel is achieved by utilizing three frames of vocoder parameter data and encoding the most recent two frames at one time. The details of this encoding technique is described in section 11, below.
- Care must be taken when switching between dual and single talker modes. Because two frames are encoded at a time in dual-talker mode, a switch to single-talker mode cannot occur during every other frame. Additional concerns arise when the users assigned to the primary talker channel and secondary talker channel change. Because there are 2 frames of vocoder parameter memory in the dual-talker encoder, primary/secondary memory interchanges or re-initialization must be performed to ensure continuity (as described above in section d).
- f. Other Bridge Functions and Notes
- The relative loudness of each talker can be adjusted through manipulation of the vocoder gain or RMS parameter. Because the gain parameters may represent different quantities for different vocoder algorithms, they must be compared on an equal basis.
Sections 1 through 7 above (transcoder descriptions) describe how to convert from one gain format to another. - A “tone” control function can be applied to emphasize one talker over another. This can be accomplished through correlation domain convolution of the spectral prediction coefficients with the desired “tone” shaping filter. For an example of how this is preformed, see section 2a, above (the preemphasis removal in section 2a is performed by correlation domain convolution of the spectral prediction coefficients, and the same technique can be applied here using a tone shaping filter).
- Because the TDVC encoder uses a predictive mode spectral LSF quantizer, special care must be taken when the primary and/or secondary talkers are changed and when there are dual to single talker transitions. Continuity is preserved with memory interchanges and predictor state resets, as described in sections d and e, above.
- 9. Hybrid Dual/Single Talker 2400 b/sec Speech Synthesizer
- A hybrid dual/single talker 2400 b/sec speech synthesizer, hereafter referred to as the “dual synthesizer,” produces a digital audio stream by decoding a compressed bit stream that contains, on a frame by frame basis, encoded parameters describing either a single talker's voice input or encoded parameters describing two simultaneous talker's voice inputs. The means by which a dual talker compressed bit stream is generated is described in section 11, below. The dual synthesizer is able to decode such dual-talker bit streams and handle transitions from dual-talker to single-talker modes and vice versa without introducing objectionable artifacts (audible defects) in the output audio.
- For the purposes of description, the dual synthesizer is described below in the context of TDVC, although the dual synthesizer could use any other coding standards such as LPC-10 or MELP.
- The compressed bit stream that is input to
Dual Synthesizer 1000 is divided into “packets” of two different types: an “S” packet type and a “D” packet type. The two types of packets are structured as follows: - S<35 bits>
- D<48
bits Talker 1><48bits Talker 2> - ‘S’ and ‘D’ represent a one bit tag for either a Single or Dual Talker packet. In the context of Single Talker TDVC, a packet contains bits representing a single 20 ms segment of speech. For Dual Talker mode, however, a packet contains a 48-bit “sub-packet” for each talker that actually represents two consecutive 20 ms segments of speech.
- The dual synthesizer contains two independent TDVC synthesizers (referred to as primary and secondary synthesizers), and is operating in either Single or Dual Talker mode at any given time. The primary synthesizer is active for both Single and Dual Talker mode, while the secondary synthesizer is active only for Dual Talker mode.
- The Dual Synthesizer operates according to the state diagram 1000 shown in FIG. 10. In state diagram 1000, the initial operating mode is assumed to be
Single state 1002. As long as ‘S’ packets are received, the Dual Synthesizer stays in this mode. When a ‘D’ packet is received, the operating mode is switched toDual state 1004. Special processing to accomplish the transition is described below. As long as ‘D’ packets are received, the operating mode isDual mode 1004. When an ‘S’ packet is received, the operating mode switches to “Ringdown”mode 1006 for a small number of frames, sufficient to let the output of the synthesis filter for the discontinued talker to ring down. Special transition processing for this transition is also described below. - a. Single to Dual State Transition Processing
- It is assumed that the Single Mode talker becomes one of the Dual Mode talkers, as will be the case in the great majority of instances. Because no bits are transmitted to identify whether the Single Mode talker becomes
Dual Mode talker - Line Spectral Frequencies coefficients (LSFs), pitch, and gain parameters for both Dual Mode Talkers are decoded. A similarity measure is computed between the decoded parameters for each Dual Mode talker and the last set of Single Mode parameters, as illustrated by the following code excerpt:
sim1 = sim2 = 0.0; d1 = euclidian_distance( singlemode_1sf, talker1_1sf, MM ); d2 = euclidian_distance( singlemode_1sf, talker2_1sf, MM ); sim1 = d1/(d1+d2); sim2 = d2/(d1+d2); sim1 += (float)abs(singlemode_pitch − talker1_pitch) /(float)(singlemode_pitch + talker1_pitch); sim2 += (float)abs(singlemode_ipitch − talker2_pitch) /(float)(singlemode_ipitch + talker2_pitch); d1 = fabs(log(singlemode_gain+20.) − log(talker1_gain+20.)); d2 = fabs(log(singlemode_gain+20.) − log(talker2_gain+20.)); sim1 += d1/(d1+d2); sim2 += d2/(d1+d2); if(sim1 > sim2) { /* Single Mode talker has become Dual Mode talker 2 */swap_synthesizer_states(); } - In the code excerpt above, sim1 and sim2 are the similarity measures for
Dual Mode talkers Dual Mode talker 1 parameters are both processed by the primary synthesizer. However, when sim2 is smaller, the state of the secondary synthesizer is copied over that of the primary before any processing takes place. The secondary synthesizer is reinitialized to a quiescent state before processing in both cases. - b. Dual to Single State Transition Processing
- The procedure for handling the Dual to Single Mode transition is very similar to the procedure for the Single to Dual Mode transition. In this case, it is assumed that one of the Dual Mode talkers will continue as the Single Mode talker. Once again, parameters are decoded, and similarity measures are computed in precisely the same manner as illustrated above. If it appears that
Dual Mode talker 1 has become the Single Mode talker, then nothing need be done; however if it appears thatDual Mode talker 2 has become the Single Mode talker, the state of the secondary synthesizer is copied over the state of the primary synthesizer. - 10. Compressed Domain Voice Activity Detector
- Voice Activity Detection (VAD) algorithms are integral parts of many digital voice compression (vocoder) algorithms which are used for communication and voice storage applications. The purpose of a VAD is to detect the presence or absence of voice activity in a digital input signal. The task is quite simple when the input signal can be guaranteed to contain no background noise, but quite challenging when the input signal may include varying types and levels of background noise. Many types of VAD have been designed and implemented. Some VAD algorithms also attempt to classify the type of speech that is present in a short time interval as being either voiced (e.g. a vowel sound, such as long e) or unvoiced (e.g. a fricative, such as ‘sh’). Once the VAD has classified an interval of the input signal, the vocoder can tailor its operation to the classification. For example, depending on the classification, a vocoder might encode an input signal interval with more, less, or even no bits (in the case of silence).
- The object of the compressed domain voice activity detector (CDVAD) of the present invention as described herein is to perform the Voice Activity Detection function given a compressed bit stream (produced by a vocoder) as input, rather than a time domain waveform. Conventional VAD algorithms operate on a time domain waveform. For an example of a conventional VAD algorithm which operates in the signal domain, see Vahatalo, A., and Johansson, I., “Voice Activity Detection for GSM Adaptive Multi-Rate Codec,” ICASSP 1999, pp. 55-57.
- The Compressed Domain VAD (CDVAD) of the present invention decodes the compressed bit stream only to the level of vocoder parametric model data, rather than decoding to a speech waveform. Decoding to vocoder parameters has the advantage of requiring much less computation than decoding to a speech waveform.
- The CDVAD can be used in conjunction with the Compressed
Domain Conference Bridge 900, described above in section 8. The bridge, and by extension the VAD component, must be of low computational complexity in order to keep power consumption as low as possible on the satellite. As described previously, the bridge receives a plurality of compressed voice bit streams (which need not have been produced by the same type of vocoder), determines which bit streams contain voice activity, and use decision logic to select which bit stream(s) to transmit to the conference participants. - The CDVAD disclosed herein incorporates a modem, fairly conventional VAD algorithm, but adapts it to operate using compressed voice parameters rather than a time domain speech waveform. The CDVAD can be adapted to operate with compressed bit streams for many different vocoders including TDVC, MELP and LPC-10.
- FIG. 11 depicts a block diagram illustrating a
CDVAD method 1100.CDVAD method 1100 will first be described with respect to a bit stream representing TDVC parameters. Each frame of TDVC parameters represents 20 ms segment of speech. In adapting the CDVAD to the other vocoder types (e.g. LPC and MELP), only minor transformations of their native parameter sets are required, as described below. - As shown in FIG. 11,
CDVAD 1100 receives 4 types of TDVC parameters as inputs: 1) a set of 10 short term filter coefficients in LSF (Line Spectral Frequency) form, 2) frame gain, 3) TDVC-style voicing cutoff flag, and 4) pitch period. As described previously, the TDVC-style voicingcutoff flag 1106 indicates a frequency above which the input frame is judged to contain unvoiced content, and below which the input frame is judged to contain voiced speech. The value of the voicing cutoff flag ranges from 0 for completely unvoiced to 7 for completely voiced. - To adapt LPC-10's parameters to the CDVAD, three conversions must be performed. LPC-10's short term filter coefficients are converted from reflection coefficients to LSFs, the frame gain is scaled to adjust for pre-emphasis and different system scaling conventions, and LPC-10's half-frame voicing flags are boolean-OR'ed to make them compatible with the TDVC-style voicing cutoff flag.
- To adapt MELP's parameters to the CDVAD is somewhat easier, because MELP & TDVC both use the LSF representation of short term filter coefficients. MELP uses two half-frame gains rather than a single frame gain value as in TDVC; the larger of MELP's two half-frame gain values is used as the overall frame gain by the CDVAD. MELP's band pass voicing information is converted to a TDVC-style voicing cutoff flag using a simple mapping similar to the conversion described in section 5b, above (MELP to TDVC transcoder).
- The CDVAD operation is based on spectral estimation, periodicity detection, and frame gain. The basic idea of the CDVAD shown in FIG. 11 is to make the VAD decision based on a comparison between input signal level and a background noise estimate for each of a plurality of frequency bands, while also taking into account overall frame gain, voicing cutoff frequency, and pitch information.
- In
step 1102, the spectral envelope for a frame is computed from the input short term filter coefficients (LSFs). From the spectral envelope, signal levels are computed for each of a number of frequency sub-bands. The signal levels are then normalized by both the overall frame gain and the gain of the short term filter. - In
step 1104, a “pitch flag” is set for the current frame only if the pitch has been relatively constant over the current and 2 or more immediately preceding frames. In addition, for the pitch parameter to be considered valid, the voicing cutoff flag fsel must be greater than 0 (i.e. not fully unvoiced). - In
step 1106, the background noise level is estimated for each sub-band. The normalized sub-band levels fromstep 1102 and intermediate VAD decision for the current frame (produce bystep 1108, discussed below) for the current frame are received as inputs to step 1106. The background noise sub-band levels are updated with a weighted sum of their current value and the input sub-band levels. However, the weights for the summation are varied, depending on several conditions: - 1) If the intermediate VAD decision=1, indicating the probable presence of speech, the weights are set such that the background noise sub-band levels can only be updated downwards, to avoid corruption of the background noise estimate.
- 2) If the last several (e.g. 4) frames' intermediate VAD decision=0, indicating the probable absence of speech, the weights are set such that the background noise sub-band levels update (upwards or downwards) relatively quickly.
- 3) If the VAD decision has been=1 for a large number of frames, but the input sub-band levels have shown little variation, the weights are set such that the background noise sub-band levels update relatively slowly. This case is exercised both at startup, and when there is an abrupt increase in background noise levels.
- In
step 1108, an intermediate VAD decision for the current frame is made. Given the normalized sub-band levels fromstep 1102, and the background noise estimate fromstep 1106, a signal to noise ratio is computed for each sub-band. The ratios are then summed and compared against an experimentally determined threshold. The threshold is set higher for high background noise situations, and lower for low background noise situations. If the sum is greater than the threshold, voice activity is detected and the intermediate VAD decision is set=1, otherwise it is set=0. The intermediate VAD decision is provided tosteps - In
step 1110, hangover addition is performed. Hangover addition applies some smoothing to the intermediate VAD decision, to try to ensure that the ends of utterances, some of which are quite low amplitude, are not cut off by the VAD. Hangover addition also removes isolated VAD=0 decisions from the middle of active speech regions. If a sufficient number Hi, of consecutive frames have an intermediate VAD decision=1, hangover is enabled, and the final VAD decision will be held=1 until H2 consecutive frames with intermediate VAD decision=0 are encountered. - 11. Low Rate Multi-Frame Encoder and Decoder
- Described as follows is a method for ultra-low rate encoding and decoding of the parameters used in predictive-style parametric vocoders (e.g. MELP, LPC, TDVC). Although the method of ultra-low rate encoding described herein produces a degradation in sound quality, it is very useful for applications where an ultra-low rate is needed. As described previously, one application for this ultra-low rate encoding method is for use in a dual-talker system that will allow a user to hear 2 simultaneous talkers over a single 2400 bit/second channel (the dual-talker format consists of two 1200 b/sec channels within the 2400 b/sec channel).
- These encoding and decoding methods are described in the following four sections for pitch, gain, spectrum and voicing parameters. The encoding and decoding methods are described below with respect to the TDVC coding standard. However, the methods can be applied to any coding standards using pitch gain, spectrum and frequency parameters.
- a. Pitch Encoding and Decoding
- A method of multi-frame pitch encoding and decoding will now be described as illustrated by FIG. 12A. During encoding, every two frames of pitch data are combined into a single frame which is transmitted. When the transmitted frame is received by the decoder, the single received frame is converted back to two frames of pitch data.
- The method described below converts two frames of TDVC pitch information (a total of 12 pitch bits) into a single transmitted frame containing a pitch value P consisting of one mode bit and six pitch bits. Thus, the method reduces the number of pitch bits from 12 to 7 (per every two TDVC frames encoded).
- At 1202, three frames of data, Frames 0, 1, and 2, are shown prior to encoding. Each frame contains a quantized pitch value which was previously generated by an optimal quantizer. During the encoding process, the pitch information from
Frame 1 andFrame 2 is combined into a single pitch value P which will be included in the transmitted frame T. In order to determine a value for P, knowledge of the pitch value from theFrame 0, the frame received immediately prior toFrame 1, is required. - At 1204, three frames of decoded data are shown:
Frames 0′, 1′, and 2′. During the decoding process, Frame T is converted to two frames:Frame 1′ and 2′ according to the methods described below. - With regards to the encoding process, the pitch information from
Frame 1 and the pitch information fromFrame 2 are converted to a single pitch value P according to two methods: aMode 0 method, and aMode 1 method. A distortion value D is then calculated for both the Mode 0 P value, and the Mode 1 P value, as described further below. The transmitted value of P which is encoded into the transmitted frame T is determined by which mode produces the lowest a lowest distortion valueD. If Mode 0 produces a lower distortion value D then a Mode 0-encoded frame is transmitted. IfMode 1 produces a lower distortion value D, then a Mode 1-encoded frame is transmitted. - With regards to the decoding process, when the transmitted frame T is received by the decoder, the decoder reads the mode bit of the frame to determine whether the received frame T is a Mode 0-encoded frame or a Mode 1-encoded frame. If frame T is a Mode 0-encoded frame, a
Mode 0 decoding method is used. If frame T is aMode 1 encoded frame, aMode 1 decoding method is used. The frame T is thereby decoded into two Frames:Frame 1′ andFrame 2′. - The 2 encoding modes and 2 decoding modes are as follows:
-
Mode 0 encoding: P is set equal to theFrame 1 six-bit pitch value. -
Mode 1 encoding: P is set equal to theFrame 2 six-bit pitch value. -
Mode 0 decoding: P is used as the six-bit pitch value for bothFrame 1′ andFrame 2′. -
Mode 1 decoding: The pitch value fromFrame 0′ is repeated forFrame 1′, and P is used forFrame 2′. - For
Mode 0, the distortion value (D0) is calculated by: - D 0 =|F1−P|+|F2−P|
- where F1 is the 6-bit quantized pitch value for
frame 1, F2 is the 6-bit quantized pitch value forframe 2, and P is the pitch value that is transmitted. - For
Mode 0, since P has been set to the value of F1, the distortion equation reduces to: - D 0 =|F2−F1|
- For
Mode 1, the distortion is: - D 1 =|F1−F0′|
- since P is set to the value of F2. To select the transmission mode, choose
Mode 0 if D0 is less than D1; chooseMode 1 otherwise. - Note that if
Mode 0 simply chose P to be equal to the F2 six-bit pitch value (or, alternatively, to the average of the F1 and F2 six-bit pitch values) the same equation for D0, above, would result. Because P is quantized with the same table as F1 or F2, it is computationally more efficient to use the individual values of F1 or F2 instead of the average. - b. Gain Encoding
- The gain encoding algorithm assumes that an optimal, non-uniform scalar quantizer has already been developed for encoding a single frame of gain. For the purposes of illustration, assume a 5-bit quantizer is in use. The value of the first frame's gain (Frame 1) is encoded using this 5-bit quantizer. For the second frame (Frame 2), a 4-bit custom quantizer table is generated. The first 9 output levels for the table consist of fixed sparse samples of the 5-bit table (e.g. every 3 rd entry in the table). The next seven output levels are delta-referenced from the
Frame 1 value. Delta referencing refers to quantizing theFrame 2 value as an offset in the quantization table from theFrame 1 value. The seven delta values supported are 0, +1, +2, +3, −1, −2, and −3. FIG. 12B shows an example of how the quantizer tables for the 5- and 4-bit algorithms may be constructed. - To select the quantization index for the
Frame 2 gain, all entries in theFrame 2 table are compared to the gain, and the index corresponding to the lowest distortion is transmitted. For example, if theFrame 1 gain was quantized to level L18, and theFrame 2 gain is closest in value to L19, them the D+1 quantization level would be selected forFrame 2. As a second example, suppose theFrame 1 gain was at level L28, but theFrame 2 gain was closest in value to L4. In this case the L3 quantization level would be selectedFrame 2. - c. Spectrum Encoding
- The spectrum is encoded two frames at a time using an interpolative algorithm such as the one described in U.S. Pat. No. 6,078,880 “Speech Coding System and Method Including Voicing Cut Off Frequency Analyzer”, which is incorporated herein by reference. The description of the algorithm begins in
column 10, line 32. For this application, a 25 bit MSVQ algorithm is for the non-interpolated frames. A 3 bit interpolation flag is used for the interpolated frames. If a parametric vocoder does not use LSFs for spectral quantization, the spectral parameters can be converted to the LSF format before interpolation. - d. Voicing Encoding
- Voicing is encoded by requantizing the TDVC fsel voicing parameter from a 3 bit value (0 to 7) to a 2 bit value with the following mapping:
input fsel value transmitted index output fsel value 0 0 0 1 1 2 2 1 2 3 1 2 4 2 5 5 2 5 6 2 5 7 3 7 - If the parametric vocoder does not use the TDVC-style voicing parameter (fsel), then the voicing parameter must be converted to TDVC format first.
- 12. Adaptive Correlation-Domain Zero Overhead Formant Enhancement
- The perceptual quality produced by low rate speech coding algorithms can often be enhanced by attenuating the output speech signal in areas of low spectral amplitude. This operation is commonly known as formant enhancement. Typically, the formant enhancement function is performed in the speech decoder. However, it would be desirable to perform this formant enhancement function using an existing standardized algorithm that has no built in capability in the decoder.
- The formant method described below can dramatically improve the subjective quality of speech when using an existing standardized speech coding algorithm with no changes in existing equipment. The following method can be applied in a speech decoder, a speech encoder or a transcoder like the ones described in
Sections 1 through 7, above. The use of this formant enhancement method requires no extra overhead for transmission. - Formant enhancement is used by the LPC-to-MELP transcoder 300 (FIG. 3, Step 308), MELP-to-LPC transcoder 400 (FIG. 4, Step 408), and TDVC-to-LPC-10 transcoder 700 (FIG. 7, Step 710). For the MELP-to-
LPC transcoder 400 and the TDVC-to-LPC-10transcoder 700, formant enhancement is performed on the coefficients A′, the filter coefficients following preemphasis addition. For the LPC-to-MELP transcoder 300, formant enhancement method utilizes both the coefficient sets A and A′, the filter coefficients before and after preemphasis removal. - a. The process begins with a set of predictor coefficients A(i) that represent the all-pole model of the speech spectrum. If the process is being applied to the specific case of transcoding from LPC-to-MELP (step 308 shown in FIG. 3), then the non-deemphasized predictor coefficients A(i) are used (coefficients prior to preemphasis removal in step 306). For the MELP-to-LPC and TDVC-to-LPC transcoders, coefficients A′(i) are used (coefficients A following preemphasis addition). A second set of bandwidth-expanded coefficients A2(i) is generated according to:
- A2(i)=γi A′(i): for MELP-to-LPC and TDVC-to-LPC, or
- A2(i)=γi A(i): for LPC-to-MELP
- where γ is the bandwidth expansion factor (approximately 0.4).
- b. For the MELP-to-LPC and TDVC-to-LPC transcoders, the non-expanded A(i) coefficients and the expanded A2(i) coefficients are converted to their corresponding normalized autocorrelation coefficients R(k) and R2(k). In order to avoid truncation effects in subsequent steps, the autocorrelation conversion recursion is carried out to 50 lags. For the LPC-to-MELP transcoder, only the expanded A2(i) coefficients are converted to their corresponding normalized autocorrelation coefficients R2(k).
- c. Next, for the MELP-to-LPC and TDVC-to-LPC transcoders, the two sets of autocorrelation coefficients R(k) and R2(k) are convolved to produce a set of 10 enhanced coefficients R″(k):

- For the LPC-to-MELP transcoder, the autocorrelation coefficient set R′(k) (autocorrelation coefficients after preemphasis removal) is convolved with R2(k) to produce a set of 10 enhanced coeffcients R″(k):

- d. The enhanced autocorrelation coefficients R″ are then converted to 10 reflection coefficients RC″(i).
- e. The reflection coefficients RC″(i) are examined to ensure that none have a value lying outside the range (−1.0, +1.0). If any values lie outside this range, the maximum order stable model is used (e.g. all RC″(i)s up to the first out-of-range coefficient are retained; the out-of-range coefficient and all others following are set to zero).
- f. The resulting RC″(i) set is converted back to enhanced prediction coefficients A″(i) for quantization and transmission.
- A significant benefit of this formant enhancement method is that it produces a 10 th order filter that has formant enhancement characteristics similar to the underlying 20th order filter (that would have been obtained by simply convolving the two sets of predictor coefficients). Because there is no change in filter order, there is no additional overhead involved in transmission.
- 13. Adaptive Frequency-Domain Zero Overhead Formant Enhancement Method
- An adaptive frequency-domain formant enhancement method is described below. As with the correlation-domain method described above in Section 12, the following method can dramatically improve the subjective quality of speech when using an existing standardized speech coding algorithm with no changes in existing equipment. The method can also be applied in a speech decoder, a speech encoder or transcoder, and requires no extra overhead for transmission.
- a. The process begins with a set of predictor coefficients a(i) that represent the all-pole model of the speech spectrum. An amplitude spectrum H(ω) is extracted from the coefficients using:

- where H(ω) is the spectral amplitude at digital frequency ω(=2πf/8000 for a system with 8 kHz sampling rate), a(i) are the predictor coefficients, m is the filter order and j is {square root}{square root over (−1)}. Amplitude values H(w) are computed every 50 Hz from 0-4000 Hz and stored in an array ampsav(k)=H(2πk50/8000), k=0 . . . 39.
- b. The set of amplitude values computed in step a are used to calculate a set of enhancement values amp(k) according to the method described in U.S. Pat. No. 6,098,036, “Speech Coding System and Method Including Spectral Formant Enhancer”, column 18 with ω o=2π50/8000 and fo=50.
- c. Set amp(k)=amp(k)*ampsav(k)
- d. Compute a set of enhanced autocorrelation coefficients from the enhanced amplitude set amp(k) using:

- e. The enhanced autocorrelation coefficients are then converted to 10 reflection coefficients rc(i).
- f. The reflection coefficients are examined to ensure that none have a value lying outside the range (−1.0, +1.0). If any values lie outside this range, the maximum order stable model is used (e.g. all rc( )s up to the first out-of-range coefficient are retained; the out-of-range coefficient and all others following are set to zero).
- g. The resulting rc( ) set is converted back to prediction coefficients for quantization and transmission.
- h. A significant benefit of this algorithm is that it produces a 10 th order filter that has similar formant enhancement characteristics to those produced using the method of U.S. Pat. No. 6,098,036. Because there is no requirement to separately transmit the amplitude values, there is no additional overhead involved.
- 14. Conclusion
- As described above, the present invention includes a transcoder which converts parametric encoded data in the compressed domain. Six individual specific transcoder structures and two formant enhancement methods are described in detail. A Voice Activity Detector which operates in the compressed domain is also disclosed. A Dual Talker synthesizer which uses a method of low-rate encoding is also disclosed. Lastly, a Compressed Domain Conference Bridge is disclosed which utilizes the compressed domain transcoder, the compressed domain voice activity detector, and the dual talker synthesizer.
- It should be noted that while the inventions are described with respect to speech coding applications, the inventions and the techniques described above are not limited to speech coding. More generally, the inventions can be applied to any other type of compressed data transmission. For example, the transcoders described in sections 1-7 could be used to convert any compressed data stream from a first compressed format to a second compressed format in the compressed domain. Additionally, the conference bridge, the voice activity detector, the dual talker, and the formant enhancement methods could all be applied to other types of compressed data transmission other than compressed speech.
- Although the systems and methods of the present invention has been described in connection with preferred embodiments, it is not intended to be limited to the specific form herein. On the contrary, it is intended to cover such alternatives, and equivalents, as can be reasonably included within the spirit and scope of the invention as defined by the appended claims.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/242,466 US20030135372A1 (en) | 2001-04-02 | 2002-09-13 | Hybrid dual/single talker speech synthesizer |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/822,503 US20030028386A1 (en) | 2001-04-02 | 2001-04-02 | Compressed domain universal transcoder |
| US10/242,466 US20030135372A1 (en) | 2001-04-02 | 2002-09-13 | Hybrid dual/single talker speech synthesizer |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US09/822,503 Continuation US20030028386A1 (en) | 2001-04-02 | 2001-04-02 | Compressed domain universal transcoder |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| US20030135372A1 true US20030135372A1 (en) | 2003-07-17 |
Family
ID=25236208
Family Applications (19)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US09/822,503 Abandoned US20030028386A1 (en) | 2001-04-02 | 2001-04-02 | Compressed domain universal transcoder |
| US09/991,695 Expired - Fee Related US6678654B2 (en) | 2001-04-02 | 2001-11-26 | TDVC-to-MELP transcoder |
| US10/242,452 Abandoned US20030115046A1 (en) | 2001-04-02 | 2002-09-13 | TDVC-to-LPC transcoder |
| US10/242,465 Expired - Lifetime US7062434B2 (en) | 2001-04-02 | 2002-09-13 | Compressed domain voice activity detector |
| US10/242,429 Abandoned US20030135368A1 (en) | 2001-04-02 | 2002-09-13 | Compressed domain conference bridge |
| US10/242,433 Abandoned US20030105628A1 (en) | 2001-04-02 | 2002-09-13 | LPC-to-TDVC transcoder |
| US10/242,431 Abandoned US20030135366A1 (en) | 2001-04-02 | 2002-09-13 | Compressed domain voice activity detector |
| US10/242,466 Abandoned US20030135372A1 (en) | 2001-04-02 | 2002-09-13 | Hybrid dual/single talker speech synthesizer |
| US10/242,427 Abandoned US20030125939A1 (en) | 2001-04-02 | 2002-09-13 | MELP-to-LPC transcoder |
| US10/242,428 Abandoned US20030125935A1 (en) | 2001-04-02 | 2002-09-13 | Pitch and gain encoder |
| US10/242,434 Abandoned US20030093268A1 (en) | 2001-04-02 | 2002-09-13 | Frequency domain formant enhancement |
| US10/242,467 Abandoned US20030144835A1 (en) | 2001-04-02 | 2002-09-13 | Correlation domain formant enhancement |
| US11/007,922 Expired - Lifetime US7165035B2 (en) | 2001-04-02 | 2004-12-09 | Compressed domain conference bridge |
| US11/051,664 Abandoned US20050159943A1 (en) | 2001-04-02 | 2005-02-04 | Compressed domain universal transcoder |
| US11/451,290 Expired - Fee Related US7421388B2 (en) | 2001-04-02 | 2006-06-12 | Compressed domain voice activity detector |
| US11/513,729 Expired - Fee Related US7529662B2 (en) | 2001-04-02 | 2006-08-31 | LPC-to-MELP transcoder |
| US11/513,804 Expired - Lifetime US7430507B2 (en) | 2001-04-02 | 2006-08-31 | Frequency domain format enhancement |
| US11/514,574 Expired - Fee Related US7668713B2 (en) | 2001-04-02 | 2006-09-01 | MELP-to-LPC transcoder |
| US11/514,573 Abandoned US20070067165A1 (en) | 2001-04-02 | 2006-09-01 | Correlation domain formant enhancement |
Family Applications Before (7)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US09/822,503 Abandoned US20030028386A1 (en) | 2001-04-02 | 2001-04-02 | Compressed domain universal transcoder |
| US09/991,695 Expired - Fee Related US6678654B2 (en) | 2001-04-02 | 2001-11-26 | TDVC-to-MELP transcoder |
| US10/242,452 Abandoned US20030115046A1 (en) | 2001-04-02 | 2002-09-13 | TDVC-to-LPC transcoder |
| US10/242,465 Expired - Lifetime US7062434B2 (en) | 2001-04-02 | 2002-09-13 | Compressed domain voice activity detector |
| US10/242,429 Abandoned US20030135368A1 (en) | 2001-04-02 | 2002-09-13 | Compressed domain conference bridge |
| US10/242,433 Abandoned US20030105628A1 (en) | 2001-04-02 | 2002-09-13 | LPC-to-TDVC transcoder |
| US10/242,431 Abandoned US20030135366A1 (en) | 2001-04-02 | 2002-09-13 | Compressed domain voice activity detector |
Family Applications After (11)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US10/242,427 Abandoned US20030125939A1 (en) | 2001-04-02 | 2002-09-13 | MELP-to-LPC transcoder |
| US10/242,428 Abandoned US20030125935A1 (en) | 2001-04-02 | 2002-09-13 | Pitch and gain encoder |
| US10/242,434 Abandoned US20030093268A1 (en) | 2001-04-02 | 2002-09-13 | Frequency domain formant enhancement |
| US10/242,467 Abandoned US20030144835A1 (en) | 2001-04-02 | 2002-09-13 | Correlation domain formant enhancement |
| US11/007,922 Expired - Lifetime US7165035B2 (en) | 2001-04-02 | 2004-12-09 | Compressed domain conference bridge |
| US11/051,664 Abandoned US20050159943A1 (en) | 2001-04-02 | 2005-02-04 | Compressed domain universal transcoder |
| US11/451,290 Expired - Fee Related US7421388B2 (en) | 2001-04-02 | 2006-06-12 | Compressed domain voice activity detector |
| US11/513,729 Expired - Fee Related US7529662B2 (en) | 2001-04-02 | 2006-08-31 | LPC-to-MELP transcoder |
| US11/513,804 Expired - Lifetime US7430507B2 (en) | 2001-04-02 | 2006-08-31 | Frequency domain format enhancement |
| US11/514,574 Expired - Fee Related US7668713B2 (en) | 2001-04-02 | 2006-09-01 | MELP-to-LPC transcoder |
| US11/514,573 Abandoned US20070067165A1 (en) | 2001-04-02 | 2006-09-01 | Correlation domain formant enhancement |
Country Status (2)
| Country | Link |
|---|---|
| US (19) | US20030028386A1 (en) |
| WO (1) | WO2002080147A1 (en) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030065508A1 (en) * | 2001-08-31 | 2003-04-03 | Yoshiteru Tsuchinaga | Speech transcoding method and apparatus |
| US20030125935A1 (en) * | 2001-04-02 | 2003-07-03 | Zinser Richard L. | Pitch and gain encoder |
| US20030195745A1 (en) * | 2001-04-02 | 2003-10-16 | Zinser, Richard L. | LPC-to-MELP transcoder |
| US20050143984A1 (en) * | 2003-11-11 | 2005-06-30 | Nokia Corporation | Multirate speech codecs |
| US20080059166A1 (en) * | 2004-09-17 | 2008-03-06 | Matsushita Electric Industrial Co., Ltd. | Scalable Encoding Apparatus, Scalable Decoding Apparatus, Scalable Encoding Method, Scalable Decoding Method, Communication Terminal Apparatus, and Base Station Apparatus |
| US20090299737A1 (en) * | 2005-04-26 | 2009-12-03 | France Telecom | Method for adapting for an interoperability between short-term correlation models of digital signals |
| US20130332165A1 (en) * | 2012-06-06 | 2013-12-12 | Qualcomm Incorporated | Method and systems having improved speech recognition |
Families Citing this family (139)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3489735B2 (en) * | 2000-08-16 | 2004-01-26 | 松下電器産業株式会社 | Deblocking filter operation unit |
| JP2002202799A (en) * | 2000-10-30 | 2002-07-19 | Fujitsu Ltd | Voice transcoder |
| US6996522B2 (en) * | 2001-03-13 | 2006-02-07 | Industrial Technology Research Institute | Celp-Based speech coding for fine grain scalability by altering sub-frame pitch-pulse |
| US7941313B2 (en) * | 2001-05-17 | 2011-05-10 | Qualcomm Incorporated | System and method for transmitting speech activity information ahead of speech features in a distributed voice recognition system |
| US7203643B2 (en) * | 2001-06-14 | 2007-04-10 | Qualcomm Incorporated | Method and apparatus for transmitting speech activity in distributed voice recognition systems |
| US6757648B2 (en) * | 2001-06-28 | 2004-06-29 | Microsoft Corporation | Techniques for quantization of spectral data in transcoding |
| KR100434275B1 (en) * | 2001-07-23 | 2004-06-05 | 엘지전자 주식회사 | Apparatus for converting packet and method for converting packet using the same |
| KR100460109B1 (en) * | 2001-09-19 | 2004-12-03 | 엘지전자 주식회사 | Conversion apparatus and method of Line Spectrum Pair parameter for voice packet conversion |
| US20030195006A1 (en) * | 2001-10-16 | 2003-10-16 | Choong Philip T. | Smart vocoder |
| US6941265B2 (en) * | 2001-12-14 | 2005-09-06 | Qualcomm Inc | Voice recognition system method and apparatus |
| FI112016B (en) * | 2001-12-20 | 2003-10-15 | Nokia Corp | Conference Call Events |
| WO2003058407A2 (en) * | 2002-01-08 | 2003-07-17 | Dilithium Networks Pty Limited | A transcoding scheme between celp-based speech codes |
| US6829579B2 (en) | 2002-01-08 | 2004-12-07 | Dilithium Networks, Inc. | Transcoding method and system between CELP-based speech codes |
| US7231345B2 (en) * | 2002-07-24 | 2007-06-12 | Nec Corporation | Method and apparatus for transcoding between different speech encoding/decoding systems |
| US20040073690A1 (en) | 2002-09-30 | 2004-04-15 | Neil Hepworth | Voice over IP endpoint call admission |
| US7359979B2 (en) * | 2002-09-30 | 2008-04-15 | Avaya Technology Corp. | Packet prioritization and associated bandwidth and buffer management techniques for audio over IP |
| US7363218B2 (en) * | 2002-10-25 | 2008-04-22 | Dilithium Networks Pty. Ltd. | Method and apparatus for fast CELP parameter mapping |
| US7486719B2 (en) | 2002-10-31 | 2009-02-03 | Nec Corporation | Transcoder and code conversion method |
| US7928310B2 (en) * | 2002-11-12 | 2011-04-19 | MediaLab Solutions Inc. | Systems and methods for portable audio synthesis |
| US7263481B2 (en) * | 2003-01-09 | 2007-08-28 | Dilithium Networks Pty Limited | Method and apparatus for improved quality voice transcoding |
| US7634399B2 (en) * | 2003-01-30 | 2009-12-15 | Digital Voice Systems, Inc. | Voice transcoder |
| PL377355A1 (en) * | 2003-02-06 | 2006-02-06 | Dolby Laboratories Licensing Corporation | Continuous backup audio |
| US7318027B2 (en) * | 2003-02-06 | 2008-01-08 | Dolby Laboratories Licensing Corporation | Conversion of synthesized spectral components for encoding and low-complexity transcoding |
| US7747431B2 (en) * | 2003-04-22 | 2010-06-29 | Nec Corporation | Code conversion method and device, program, and recording medium |
| US20040234067A1 (en) * | 2003-05-19 | 2004-11-25 | Acoustic Technologies, Inc. | Distributed VAD control system for telephone |
| US6963352B2 (en) * | 2003-06-30 | 2005-11-08 | Nortel Networks Limited | Apparatus, method, and computer program for supporting video conferencing in a communication system |
| US7469209B2 (en) * | 2003-08-14 | 2008-12-23 | Dilithium Networks Pty Ltd. | Method and apparatus for frame classification and rate determination in voice transcoders for telecommunications |
| US7433815B2 (en) * | 2003-09-10 | 2008-10-07 | Dilithium Networks Pty Ltd. | Method and apparatus for voice transcoding between variable rate coders |
| FR2863797B1 (en) * | 2003-12-15 | 2006-02-24 | Cit Alcatel | LAYER TWO COMPRESSION / DECOMPRESSION FOR SYNCHRONOUS / ASYNCHRONOUS MIXED TRANSMISSION OF DATA FRAMES WITHIN A COMMUNICATIONS NETWORK |
| KR20060132697A (en) * | 2004-02-16 | 2006-12-21 | 코닌클리케 필립스 일렉트로닉스 엔.브이. | Transcoder and Transcoding Methods |
| EP1569200A1 (en) * | 2004-02-26 | 2005-08-31 | Sony International (Europe) GmbH | Identification of the presence of speech in digital audio data |
| US20050232497A1 (en) * | 2004-04-15 | 2005-10-20 | Microsoft Corporation | High-fidelity transcoding |
| US20050258983A1 (en) * | 2004-05-11 | 2005-11-24 | Dilithium Holdings Pty Ltd. (An Australian Corporation) | Method and apparatus for voice trans-rating in multi-rate voice coders for telecommunications |
| US7978827B1 (en) | 2004-06-30 | 2011-07-12 | Avaya Inc. | Automatic configuration of call handling based on end-user needs and characteristics |
| US8010353B2 (en) * | 2005-01-14 | 2011-08-30 | Panasonic Corporation | Audio switching device and audio switching method that vary a degree of change in mixing ratio of mixing narrow-band speech signal and wide-band speech signal |
| US7983906B2 (en) * | 2005-03-24 | 2011-07-19 | Mindspeed Technologies, Inc. | Adaptive voice mode extension for a voice activity detector |
| JP4793539B2 (en) * | 2005-03-29 | 2011-10-12 | 日本電気株式会社 | Code conversion method and apparatus, program, and storage medium therefor |
| CA2602804C (en) * | 2005-04-01 | 2013-12-24 | Qualcomm Incorporated | Systems, methods, and apparatus for highband burst suppression |
| WO2006116024A2 (en) | 2005-04-22 | 2006-11-02 | Qualcomm Incorporated | Systems, methods, and apparatus for gain factor attenuation |
| US8170875B2 (en) * | 2005-06-15 | 2012-05-01 | Qnx Software Systems Limited | Speech end-pointer |
| ATE409937T1 (en) * | 2005-06-20 | 2008-10-15 | Telecom Italia Spa | METHOD AND APPARATUS FOR SENDING VOICE DATA TO A REMOTE DEVICE IN A DISTRIBUTED VOICE RECOGNITION SYSTEM |
| US20070115949A1 (en) * | 2005-11-17 | 2007-05-24 | Microsoft Corporation | Infrastructure for enabling high quality real-time audio |
| WO2007084254A2 (en) * | 2005-11-29 | 2007-07-26 | Dilithium Networks Pty Ltd. | Method and apparatus of voice mixing for conferencing amongst diverse networks |
| JP3981399B1 (en) * | 2006-03-10 | 2007-09-26 | 松下電器産業株式会社 | Fixed codebook search apparatus and fixed codebook search method |
| US7805292B2 (en) * | 2006-04-21 | 2010-09-28 | Dilithium Holdings, Inc. | Method and apparatus for audio transcoding |
| US7805532B2 (en) * | 2006-04-29 | 2010-09-28 | 724 Software Solutions, Inc. | Platform for interoperability |
| US8327024B2 (en) * | 2006-04-29 | 2012-12-04 | 724 Solutions Software, Inc. | System and method for SMS/IP interoperability |
| US8078153B2 (en) * | 2006-04-29 | 2011-12-13 | 724 Solutions Software, Inc. | System and method for dynamic provisioning of contextual-based identities |
| EP1855271A1 (en) * | 2006-05-12 | 2007-11-14 | Deutsche Thomson-Brandt Gmbh | Method and apparatus for re-encoding signals |
| WO2007138511A1 (en) * | 2006-05-30 | 2007-12-06 | Koninklijke Philips Electronics N.V. | Linear predictive coding of an audio signal |
| US8589151B2 (en) * | 2006-06-21 | 2013-11-19 | Harris Corporation | Vocoder and associated method that transcodes between mixed excitation linear prediction (MELP) vocoders with different speech frame rates |
| US20080006685A1 (en) * | 2006-07-06 | 2008-01-10 | Firethorn Holdings, Llc | Methods and Systems For Real Time Account Balances in a Mobile Environment |
| US8467766B2 (en) * | 2006-07-06 | 2013-06-18 | Qualcomm Incorporated | Methods and systems for managing payment sources in a mobile environment |
| US20080010204A1 (en) * | 2006-07-06 | 2008-01-10 | Firethorn Holdings, Llc | Methods and Systems For Making a Payment Via a Paper Check in a Mobile Environment |
| US8489067B2 (en) * | 2006-07-06 | 2013-07-16 | Qualcomm Incorporated | Methods and systems for distribution of a mobile wallet for a mobile device |
| US8160959B2 (en) * | 2006-07-06 | 2012-04-17 | Firethorn Mobile, Inc. | Methods and systems for payment transactions in a mobile environment |
| US8121945B2 (en) * | 2006-07-06 | 2012-02-21 | Firethorn Mobile, Inc. | Methods and systems for payment method selection by a payee in a mobile environment |
| US8510220B2 (en) * | 2006-07-06 | 2013-08-13 | Qualcomm Incorporated | Methods and systems for viewing aggregated payment obligations in a mobile environment |
| US20080010191A1 (en) * | 2006-07-06 | 2008-01-10 | Firethorn Holdings, Llc | Methods and Systems For Providing a Payment in a Mobile Environment |
| US8145568B2 (en) * | 2006-07-06 | 2012-03-27 | Firethorn Mobile, Inc. | Methods and systems for indicating a payment in a mobile environment |
| US8725499B2 (en) * | 2006-07-31 | 2014-05-13 | Qualcomm Incorporated | Systems, methods, and apparatus for signal change detection |
| WO2008017076A2 (en) * | 2006-08-03 | 2008-02-07 | The Regents Of The University Of California | Iterative methods for dose reduction and image enhancement in tomography |
| KR100883652B1 (en) * | 2006-08-03 | 2009-02-18 | 삼성전자주식회사 | Speech section detection method and apparatus, and speech recognition system using same |
| US8169983B2 (en) * | 2006-08-07 | 2012-05-01 | Pine Valley Investments, Inc. | Transcoder architecture for land mobile radio systems |
| WO2008026754A1 (en) * | 2006-08-30 | 2008-03-06 | Nec Corporation | Voice mixing method, multipoint conference server using the method, and program |
| US7725311B2 (en) * | 2006-09-28 | 2010-05-25 | Ericsson Ab | Method and apparatus for rate reduction of coded voice traffic |
| US7826561B2 (en) * | 2006-12-20 | 2010-11-02 | Icom America, Incorporated | Single sideband voice signal tuning method |
| US8036886B2 (en) * | 2006-12-22 | 2011-10-11 | Digital Voice Systems, Inc. | Estimation of pulsed speech model parameters |
| US20080195381A1 (en) * | 2007-02-09 | 2008-08-14 | Microsoft Corporation | Line Spectrum pair density modeling for speech applications |
| JP5140684B2 (en) * | 2007-02-12 | 2013-02-06 | ドルビー ラボラトリーズ ライセンシング コーポレイション | Improved ratio of speech audio to non-speech audio for elderly or hearing-impaired listeners |
| JP5530720B2 (en) | 2007-02-26 | 2014-06-25 | ドルビー ラボラトリーズ ライセンシング コーポレイション | Speech enhancement method, apparatus, and computer-readable recording medium for entertainment audio |
| US7937076B2 (en) * | 2007-03-07 | 2011-05-03 | Harris Corporation | Software defined radio for loading waveform components at runtime in a software communications architecture (SCA) framework |
| US8655650B2 (en) * | 2007-03-28 | 2014-02-18 | Harris Corporation | Multiple stream decoder |
| WO2009001292A1 (en) * | 2007-06-27 | 2008-12-31 | Koninklijke Philips Electronics N.V. | A method of merging at least two input object-oriented audio parameter streams into an output object-oriented audio parameter stream |
| JP2009063928A (en) * | 2007-09-07 | 2009-03-26 | Fujitsu Ltd | Interpolation method, information processing apparatus |
| DE602008005477D1 (en) * | 2007-09-12 | 2011-04-21 | Dolby Lab Licensing Corp | LANGUAGE EXPANSION WITH ADJUSTMENT OF NOISE LEVEL ESTIMATIONS |
| WO2009035614A1 (en) * | 2007-09-12 | 2009-03-19 | Dolby Laboratories Licensing Corporation | Speech enhancement with voice clarity |
| WO2009035615A1 (en) * | 2007-09-12 | 2009-03-19 | Dolby Laboratories Licensing Corporation | Speech enhancement |
| WO2009054141A1 (en) * | 2007-10-26 | 2009-04-30 | Panasonic Corporation | Conference terminal device, relay device, and coference system |
| US8457958B2 (en) | 2007-11-09 | 2013-06-04 | Microsoft Corporation | Audio transcoder using encoder-generated side information to transcode to target bit-rate |
| US7970603B2 (en) * | 2007-11-15 | 2011-06-28 | Lockheed Martin Corporation | Method and apparatus for managing speech decoders in a communication device |
| JP5229234B2 (en) * | 2007-12-18 | 2013-07-03 | 富士通株式会社 | Non-speech segment detection method and non-speech segment detection apparatus |
| US7782802B2 (en) * | 2007-12-26 | 2010-08-24 | Microsoft Corporation | Optimizing conferencing performance |
| RU2473140C2 (en) | 2008-03-04 | 2013-01-20 | Фраунхофер-Гезелльшафт цур Фёрдерунг дер ангевандтен | Device to mix multiple input data |
| AU2012202581B2 (en) * | 2008-03-04 | 2012-10-11 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Mixing of input data streams and generation of an output data stream therefrom |
| US8164862B2 (en) * | 2008-04-02 | 2012-04-24 | Headway Technologies, Inc. | Seed layer for TMR or CPP-GMR sensor |
| US8831936B2 (en) * | 2008-05-29 | 2014-09-09 | Qualcomm Incorporated | Systems, methods, apparatus, and computer program products for speech signal processing using spectral contrast enhancement |
| JP5050158B2 (en) * | 2008-06-02 | 2012-10-17 | 株式会社メガチップス | Transcoder |
| US9357075B1 (en) | 2008-06-05 | 2016-05-31 | Avaya Inc. | Conference call quality via a connection-testing phase |
| US20090316870A1 (en) * | 2008-06-19 | 2009-12-24 | Motorola, Inc. | Devices and Methods for Performing N-Way Mute for N-Way Voice Over Internet Protocol (VOIP) Calls |
| US8538749B2 (en) * | 2008-07-18 | 2013-09-17 | Qualcomm Incorporated | Systems, methods, apparatus, and computer program products for enhanced intelligibility |
| JP2010060989A (en) * | 2008-09-05 | 2010-03-18 | Sony Corp | Operating device and method, quantization device and method, audio encoding device and method, and program |
| JP4702645B2 (en) * | 2008-09-26 | 2011-06-15 | ソニー株式会社 | Arithmetic apparatus and method, quantization apparatus and method, and program |
| JP2010078965A (en) * | 2008-09-26 | 2010-04-08 | Sony Corp | Computation apparatus and method, quantization device and method, and program |
| US8218751B2 (en) | 2008-09-29 | 2012-07-10 | Avaya Inc. | Method and apparatus for identifying and eliminating the source of background noise in multi-party teleconferences |
| US9947340B2 (en) | 2008-12-10 | 2018-04-17 | Skype | Regeneration of wideband speech |
| GB0822537D0 (en) * | 2008-12-10 | 2009-01-14 | Skype Ltd | Regeneration of wideband speech |
| GB2466201B (en) * | 2008-12-10 | 2012-07-11 | Skype Ltd | Regeneration of wideband speech |
| KR101622950B1 (en) * | 2009-01-28 | 2016-05-23 | 삼성전자주식회사 | Method of coding/decoding audio signal and apparatus for enabling the method |
| US8311115B2 (en) * | 2009-01-29 | 2012-11-13 | Microsoft Corporation | Video encoding using previously calculated motion information |
| US8396114B2 (en) * | 2009-01-29 | 2013-03-12 | Microsoft Corporation | Multiple bit rate video encoding using variable bit rate and dynamic resolution for adaptive video streaming |
| US9202456B2 (en) * | 2009-04-23 | 2015-12-01 | Qualcomm Incorporated | Systems, methods, apparatus, and computer-readable media for automatic control of active noise cancellation |
| US8270473B2 (en) * | 2009-06-12 | 2012-09-18 | Microsoft Corporation | Motion based dynamic resolution multiple bit rate video encoding |
| KR101251045B1 (en) * | 2009-07-28 | 2013-04-04 | 한국전자통신연구원 | Apparatus and method for audio signal discrimination |
| CN101989429B (en) | 2009-07-31 | 2012-02-01 | 华为技术有限公司 | Method, device, equipment and system for transcoding |
| US8340965B2 (en) * | 2009-09-02 | 2012-12-25 | Microsoft Corporation | Rich context modeling for text-to-speech engines |
| US9773511B2 (en) * | 2009-10-19 | 2017-09-26 | Telefonaktiebolaget Lm Ericsson (Publ) | Detector and method for voice activity detection |
| US8521520B2 (en) | 2010-02-03 | 2013-08-27 | General Electric Company | Handoffs between different voice encoder systems |
| JP5424936B2 (en) * | 2010-02-24 | 2014-02-26 | パナソニック株式会社 | Communication terminal and communication method |
| US9053697B2 (en) | 2010-06-01 | 2015-06-09 | Qualcomm Incorporated | Systems, methods, devices, apparatus, and computer program products for audio equalization |
| US8705616B2 (en) | 2010-06-11 | 2014-04-22 | Microsoft Corporation | Parallel multiple bitrate video encoding to reduce latency and dependences between groups of pictures |
| CN103229235B (en) * | 2010-11-24 | 2015-12-09 | Lg电子株式会社 | Speech signal coding method and voice signal coding/decoding method |
| US20120143604A1 (en) * | 2010-12-07 | 2012-06-07 | Rita Singh | Method for Restoring Spectral Components in Denoised Speech Signals |
| US8594993B2 (en) | 2011-04-04 | 2013-11-26 | Microsoft Corporation | Frame mapping approach for cross-lingual voice transformation |
| US9591318B2 (en) | 2011-09-16 | 2017-03-07 | Microsoft Technology Licensing, Llc | Multi-layer encoding and decoding |
| WO2013046139A1 (en) * | 2011-09-28 | 2013-04-04 | Marvell World Trade Ltd. | Conference mixing using turbo-vad |
| FR2984580A1 (en) * | 2011-12-20 | 2013-06-21 | France Telecom | METHOD FOR DETECTING A PREDETERMINED FREQUENCY BAND IN AN AUDIO DATA SIGNAL, DETECTION DEVICE AND CORRESPONDING COMPUTER PROGRAM |
| US11089343B2 (en) | 2012-01-11 | 2021-08-10 | Microsoft Technology Licensing, Llc | Capability advertisement, configuration and control for video coding and decoding |
| CN103325385B (en) * | 2012-03-23 | 2018-01-26 | 杜比实验室特许公司 | Speech communication method and device, method and device for operating jitter buffer |
| US9064503B2 (en) | 2012-03-23 | 2015-06-23 | Dolby Laboratories Licensing Corporation | Hierarchical active voice detection |
| US9589570B2 (en) | 2012-09-18 | 2017-03-07 | Huawei Technologies Co., Ltd. | Audio classification based on perceptual quality for low or medium bit rates |
| WO2014138539A1 (en) * | 2013-03-08 | 2014-09-12 | Motorola Mobility Llc | Conversion of linear predictive coefficients using auto-regressive extension of correlation coefficients in sub-band audio codecs |
| RU2639952C2 (en) | 2013-08-28 | 2017-12-25 | Долби Лабораторис Лайсэнзин Корпорейшн | Hybrid speech amplification with signal form coding and parametric coding |
| KR20150032390A (en) * | 2013-09-16 | 2015-03-26 | 삼성전자주식회사 | Speech signal process apparatus and method for enhancing speech intelligibility |
| FR3020732A1 (en) * | 2014-04-30 | 2015-11-06 | Orange | PERFECTED FRAME LOSS CORRECTION WITH VOICE INFORMATION |
| CN106486129B (en) * | 2014-06-27 | 2019-10-25 | 华为技术有限公司 | A kind of audio coding method and device |
| US9385751B2 (en) * | 2014-10-07 | 2016-07-05 | Protein Metrics Inc. | Enhanced data compression for sparse multidimensional ordered series data |
| CN104320385A (en) * | 2014-10-10 | 2015-01-28 | 中麦通信网络有限公司 | Mobile terminal voice communication implementation method and device |
| US9972334B2 (en) | 2015-09-10 | 2018-05-15 | Qualcomm Incorporated | Decoder audio classification |
| CN106098072B (en) * | 2016-06-02 | 2019-07-19 | 重庆邮电大学 | A 600bps Very Low Rate Speech Coding and Decoding Method Based on Hybrid Excitation Linear Prediction |
| GB201801664D0 (en) | 2017-10-13 | 2018-03-21 | Cirrus Logic Int Semiconductor Ltd | Detection of liveness |
| CN109102811B (en) * | 2018-07-27 | 2021-03-30 | 广州酷狗计算机科技有限公司 | Audio fingerprint generation method and device and storage medium |
| US10692490B2 (en) | 2018-07-31 | 2020-06-23 | Cirrus Logic, Inc. | Detection of replay attack |
| TW202008800A (en) * | 2018-07-31 | 2020-02-16 | 塞席爾商元鼎音訊股份有限公司 | Hearing aid and hearing aid output voice adjustment method thereof |
| US11270714B2 (en) | 2020-01-08 | 2022-03-08 | Digital Voice Systems, Inc. | Speech coding using time-varying interpolation |
| US12254895B2 (en) | 2021-07-02 | 2025-03-18 | Digital Voice Systems, Inc. | Detecting and compensating for the presence of a speaker mask in a speech signal |
| US11990144B2 (en) | 2021-07-28 | 2024-05-21 | Digital Voice Systems, Inc. | Reducing perceived effects of non-voice data in digital speech |
| CN114007109B (en) * | 2021-10-28 | 2023-05-12 | 广州华多网络科技有限公司 | Mixed stream transcoding processing method and device, equipment, medium and product thereof |
| US11900961B2 (en) * | 2022-05-31 | 2024-02-13 | Microsoft Technology Licensing, Llc | Multichannel audio speech classification |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4479211A (en) * | 1982-10-29 | 1984-10-23 | At&T Bell Laboratories | Method and apparatus for controlling ports in a digital conference arrangement |
| US5150410A (en) * | 1991-04-11 | 1992-09-22 | Itt Corporation | Secure digital conferencing system |
| US5623539A (en) * | 1994-01-27 | 1997-04-22 | Lucent Technologies Inc. | Using voice signal analysis to identify authorized users of a telephone system |
| US6466550B1 (en) * | 1998-11-11 | 2002-10-15 | Cisco Technology, Inc. | Distributed conferencing system utilizing data networks |
| US6633632B1 (en) * | 1999-10-01 | 2003-10-14 | At&T Corp. | Method and apparatus for detecting the number of speakers on a call |
| US6728222B1 (en) * | 1998-12-08 | 2004-04-27 | Nec Corporation | Conference terminal control device |
Family Cites Families (74)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US535362A (en) * | 1895-03-12 | Vertical rotary swing | ||
| JPS58140798A (en) * | 1982-02-15 | 1983-08-20 | 株式会社日立製作所 | Voice pitch extraction |
| US4696040A (en) | 1983-10-13 | 1987-09-22 | Texas Instruments Incorporated | Speech analysis/synthesis system with energy normalization and silence suppression |
| US5241650A (en) * | 1989-10-17 | 1993-08-31 | Motorola, Inc. | Digital speech decoder having a postfilter with reduced spectral distortion |
| JP2776050B2 (en) * | 1991-02-26 | 1998-07-16 | 日本電気株式会社 | Audio coding method |
| US5680508A (en) * | 1991-05-03 | 1997-10-21 | Itt Corporation | Enhancement of speech coding in background noise for low-rate speech coder |
| US5173941A (en) | 1991-05-31 | 1992-12-22 | Motorola, Inc. | Reduced codebook search arrangement for CELP vocoders |
| US5390177A (en) * | 1993-03-24 | 1995-02-14 | At&T Corp. | Conferencing arrangement for compressed information signals |
| GB2281680B (en) * | 1993-08-27 | 1998-08-26 | Motorola Inc | A voice activity detector for an echo suppressor and an echo suppressor |
| US5325362A (en) * | 1993-09-29 | 1994-06-28 | Sun Microsystems, Inc. | Scalable and efficient intra-domain tunneling mobile-IP scheme |
| US5457685A (en) * | 1993-11-05 | 1995-10-10 | The United States Of America As Represented By The Secretary Of The Air Force | Multi-speaker conferencing over narrowband channels |
| PL174216B1 (en) * | 1993-11-30 | 1998-06-30 | At And T Corp | Transmission noise reduction in telecommunication systems |
| US5657422A (en) * | 1994-01-28 | 1997-08-12 | Lucent Technologies Inc. | Voice activity detection driven noise remediator |
| US5537536A (en) * | 1994-06-21 | 1996-07-16 | Intel Corporation | Apparatus and method for debugging electronic components through an in-circuit emulator |
| US5555017A (en) * | 1994-07-08 | 1996-09-10 | Lucent Technologies Inc. | Seamless multimedia conferencing system using an enhanced multipoint control unit |
| US5825240A (en) * | 1994-11-30 | 1998-10-20 | Massachusetts Institute Of Technology | Resonant-tunneling transmission line technology |
| JP2993396B2 (en) * | 1995-05-12 | 1999-12-20 | 三菱電機株式会社 | Voice processing filter and voice synthesizer |
| DE69628103T2 (en) * | 1995-09-14 | 2004-04-01 | Kabushiki Kaisha Toshiba, Kawasaki | Method and filter for highlighting formants |
| DE69620967T2 (en) * | 1995-09-19 | 2002-11-07 | At & T Corp., New York | Synthesis of speech signals in the absence of encoded parameters |
| US5826023A (en) * | 1996-06-03 | 1998-10-20 | International Business Machines Corporation | Communications tunneling |
| TW416044B (en) * | 1996-06-19 | 2000-12-21 | Texas Instruments Inc | Adaptive filter and filtering method for low bit rate coding |
| US6067093A (en) * | 1996-08-14 | 2000-05-23 | Novell, Inc. | Method and apparatus for organizing objects of a network map |
| US5987327A (en) * | 1996-09-16 | 1999-11-16 | Motorola, Inc. | Method for establishing communications in wireless communication systems having multiple switching centers |
| US5806027A (en) * | 1996-09-19 | 1998-09-08 | Texas Instruments Incorporated | Variable framerate parameter encoding |
| GB2320166A (en) * | 1996-12-09 | 1998-06-10 | Motorola Ltd | method of reverting to tandem operation between transcoders of a communication system |
| US5845251A (en) * | 1996-12-20 | 1998-12-01 | U S West, Inc. | Method, system and product for modifying the bandwidth of subband encoded audio data |
| US6049543A (en) * | 1996-12-27 | 2000-04-11 | Motorola, Inc. | Transcoder for use in an ATM-based communications system |
| US5890126A (en) * | 1997-03-10 | 1999-03-30 | Euphonics, Incorporated | Audio data decompression and interpolation apparatus and method |
| US6104716A (en) * | 1997-03-28 | 2000-08-15 | International Business Machines Corporation | Method and apparatus for lightweight secure communication tunneling over the internet |
| US5995923A (en) * | 1997-06-26 | 1999-11-30 | Nortel Networks Corporation | Method and apparatus for improving the voice quality of tandemed vocoders |
| US6026356A (en) * | 1997-07-03 | 2000-02-15 | Nortel Networks Corporation | Methods and devices for noise conditioning signals representative of audio information in compressed and digitized form |
| US6385195B2 (en) * | 1997-07-21 | 2002-05-07 | Telefonaktiebolaget L M Ericsson (Publ) | Enhanced interworking function for interfacing digital cellular voice and fax protocols and internet protocols |
| US6138022A (en) * | 1997-07-23 | 2000-10-24 | Nortel Networks Corporation | Cellular communication network with vocoder sharing feature |
| TW408298B (en) * | 1997-08-28 | 2000-10-11 | Texas Instruments Inc | Improved method for switched-predictive quantization |
| US6097726A (en) * | 1997-09-18 | 2000-08-01 | Ascend Communications, Inc. | Virtual path merging in a multipoint-to-point network tunneling protocol |
| US6044070A (en) * | 1997-10-15 | 2000-03-28 | Ericsson Inc. | Remote connection control using a tunneling protocol |
| US6172974B1 (en) * | 1997-10-31 | 2001-01-09 | Nortel Networks Limited | Network element having tandem free operation capabilities |
| US6003004A (en) * | 1998-01-08 | 1999-12-14 | Advanced Recognition Technologies, Inc. | Speech recognition method and system using compressed speech data |
| FI980132A7 (en) * | 1998-01-21 | 1999-07-22 | Nokia Mobile Phones Ltd | Adaptive post-filter |
| KR100269216B1 (en) | 1998-04-16 | 2000-10-16 | 윤종용 | Pitch determination method with spectro-temporal auto correlation |
| US6295302B1 (en) * | 1998-04-24 | 2001-09-25 | Telefonaktiebolaget L M Ericsson (Publ) | Alternating speech and data transmission in digital communications systems |
| CA2239294A1 (en) * | 1998-05-29 | 1999-11-29 | Majid Foodeei | Methods and apparatus for efficient quantization of gain parameters in glpas speech coders |
| US6094629A (en) * | 1998-07-13 | 2000-07-25 | Lockheed Martin Corp. | Speech coding system and method including spectral quantizer |
| US6098036A (en) * | 1998-07-13 | 2000-08-01 | Lockheed Martin Corp. | Speech coding system and method including spectral formant enhancer |
| US6067511A (en) * | 1998-07-13 | 2000-05-23 | Lockheed Martin Corp. | LPC speech synthesis using harmonic excitation generator with phase modulator for voiced speech |
| US6078880A (en) * | 1998-07-13 | 2000-06-20 | Lockheed Martin Corporation | Speech coding system and method including voicing cut off frequency analyzer |
| US6138092A (en) * | 1998-07-13 | 2000-10-24 | Lockheed Martin Corporation | CELP speech synthesizer with epoch-adaptive harmonic generator for pitch harmonics below voicing cutoff frequency |
| US6119082A (en) * | 1998-07-13 | 2000-09-12 | Lockheed Martin Corporation | Speech coding system and method including harmonic generator having an adaptive phase off-setter |
| US6081776A (en) * | 1998-07-13 | 2000-06-27 | Lockheed Martin Corp. | Speech coding system and method including adaptive finite impulse response filter |
| US6453289B1 (en) * | 1998-07-24 | 2002-09-17 | Hughes Electronics Corporation | Method of noise reduction for speech codecs |
| US6188980B1 (en) * | 1998-08-24 | 2001-02-13 | Conexant Systems, Inc. | Synchronized encoder-decoder frame concealment using speech coding parameters including line spectral frequencies and filter coefficients |
| US6192335B1 (en) * | 1998-09-01 | 2001-02-20 | Telefonaktieboiaget Lm Ericsson (Publ) | Adaptive combining of multi-mode coding for voiced speech and noise-like signals |
| US6081777A (en) * | 1998-09-21 | 2000-06-27 | Lockheed Martin Corporation | Enhancement of speech signals transmitted over a vocoder channel |
| US5918022A (en) * | 1998-09-28 | 1999-06-29 | Cisco Technology, Inc. | Protocol for transporting reservation system data over a TCP/IP network |
| US6493666B2 (en) | 1998-09-29 | 2002-12-10 | William M. Wiese, Jr. | System and method for processing data from and for multiple channels |
| US6073093A (en) * | 1998-10-14 | 2000-06-06 | Lockheed Martin Corp. | Combined residual and analysis-by-synthesis pitch-dependent gain estimation for linear predictive coders |
| US6539355B1 (en) * | 1998-10-15 | 2003-03-25 | Sony Corporation | Signal band expanding method and apparatus and signal synthesis method and apparatus |
| US6453287B1 (en) * | 1999-02-04 | 2002-09-17 | Georgia-Tech Research Corporation | Apparatus and quality enhancement algorithm for mixed excitation linear predictive (MELP) and other speech coders |
| US6260009B1 (en) | 1999-02-12 | 2001-07-10 | Qualcomm Incorporated | CELP-based to CELP-based vocoder packet translation |
| US6253171B1 (en) * | 1999-02-23 | 2001-06-26 | Comsat Corporation | Method of determining the voicing probability of speech signals |
| US6377915B1 (en) * | 1999-03-17 | 2002-04-23 | Yrp Advanced Mobile Communication Systems Research Laboratories Co., Ltd. | Speech decoding using mix ratio table |
| US6325362B1 (en) * | 1999-05-26 | 2001-12-04 | Raymond O. Massey | Cooling and misting apparatus for evaporative cooling of open-air vehicle occupants |
| JP2001067092A (en) * | 1999-08-26 | 2001-03-16 | Matsushita Electric Ind Co Ltd | Voice detection device |
| US6604070B1 (en) * | 1999-09-22 | 2003-08-05 | Conexant Systems, Inc. | System of encoding and decoding speech signals |
| US7315815B1 (en) | 1999-09-22 | 2008-01-01 | Microsoft Corporation | LPC-harmonic vocoder with superframe structure |
| US6510407B1 (en) | 1999-10-19 | 2003-01-21 | Atmel Corporation | Method and apparatus for variable rate coding of speech |
| CA2391382A1 (en) * | 1999-11-15 | 2001-05-25 | Parker Hughes Institute | Phorboxazole derivatives for treating cancer |
| JP3487250B2 (en) * | 2000-02-28 | 2004-01-13 | 日本電気株式会社 | Encoded audio signal format converter |
| US6615170B1 (en) * | 2000-03-07 | 2003-09-02 | International Business Machines Corporation | Model-based voice activity detection system and method using a log-likelihood ratio and pitch |
| JP2001326952A (en) * | 2000-05-15 | 2001-11-22 | Nec Corp | Broadcast confirmation system, method and device for broadcast confirmation, and recording medium with broadcast confirmation program recorded thereon |
| US6678651B2 (en) | 2000-09-15 | 2004-01-13 | Mindspeed Technologies, Inc. | Short-term enhancement in CELP speech coding |
| JP2002202799A (en) | 2000-10-30 | 2002-07-19 | Fujitsu Ltd | Voice transcoder |
| US7096009B2 (en) * | 2001-03-09 | 2006-08-22 | Research In Motion Limited | Advanced voice and data operations in a mobile data communication device |
| US20030028386A1 (en) | 2001-04-02 | 2003-02-06 | Zinser Richard L. | Compressed domain universal transcoder |
-
2001
- 2001-04-02 US US09/822,503 patent/US20030028386A1/en not_active Abandoned
- 2001-11-26 US US09/991,695 patent/US6678654B2/en not_active Expired - Fee Related
-
2002
- 2002-04-02 WO PCT/US2002/010187 patent/WO2002080147A1/en active Application Filing
- 2002-09-13 US US10/242,452 patent/US20030115046A1/en not_active Abandoned
- 2002-09-13 US US10/242,465 patent/US7062434B2/en not_active Expired - Lifetime
- 2002-09-13 US US10/242,429 patent/US20030135368A1/en not_active Abandoned
- 2002-09-13 US US10/242,433 patent/US20030105628A1/en not_active Abandoned
- 2002-09-13 US US10/242,431 patent/US20030135366A1/en not_active Abandoned
- 2002-09-13 US US10/242,466 patent/US20030135372A1/en not_active Abandoned
- 2002-09-13 US US10/242,427 patent/US20030125939A1/en not_active Abandoned
- 2002-09-13 US US10/242,428 patent/US20030125935A1/en not_active Abandoned
- 2002-09-13 US US10/242,434 patent/US20030093268A1/en not_active Abandoned
- 2002-09-13 US US10/242,467 patent/US20030144835A1/en not_active Abandoned
-
2004
- 2004-12-09 US US11/007,922 patent/US7165035B2/en not_active Expired - Lifetime
-
2005
- 2005-02-04 US US11/051,664 patent/US20050159943A1/en not_active Abandoned
-
2006
- 2006-06-12 US US11/451,290 patent/US7421388B2/en not_active Expired - Fee Related
- 2006-08-31 US US11/513,729 patent/US7529662B2/en not_active Expired - Fee Related
- 2006-08-31 US US11/513,804 patent/US7430507B2/en not_active Expired - Lifetime
- 2006-09-01 US US11/514,574 patent/US7668713B2/en not_active Expired - Fee Related
- 2006-09-01 US US11/514,573 patent/US20070067165A1/en not_active Abandoned
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4479211A (en) * | 1982-10-29 | 1984-10-23 | At&T Bell Laboratories | Method and apparatus for controlling ports in a digital conference arrangement |
| US5150410A (en) * | 1991-04-11 | 1992-09-22 | Itt Corporation | Secure digital conferencing system |
| US5623539A (en) * | 1994-01-27 | 1997-04-22 | Lucent Technologies Inc. | Using voice signal analysis to identify authorized users of a telephone system |
| US6466550B1 (en) * | 1998-11-11 | 2002-10-15 | Cisco Technology, Inc. | Distributed conferencing system utilizing data networks |
| US6728222B1 (en) * | 1998-12-08 | 2004-04-27 | Nec Corporation | Conference terminal control device |
| US6633632B1 (en) * | 1999-10-01 | 2003-10-14 | At&T Corp. | Method and apparatus for detecting the number of speakers on a call |
Cited By (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7668713B2 (en) | 2001-04-02 | 2010-02-23 | General Electric Company | MELP-to-LPC transcoder |
| US20070094018A1 (en) * | 2001-04-02 | 2007-04-26 | Zinser Richard L Jr | MELP-to-LPC transcoder |
| US20030135370A1 (en) * | 2001-04-02 | 2003-07-17 | Zinser Richard L. | Compressed domain voice activity detector |
| US20030195745A1 (en) * | 2001-04-02 | 2003-10-16 | Zinser, Richard L. | LPC-to-MELP transcoder |
| US20050102137A1 (en) * | 2001-04-02 | 2005-05-12 | Zinser Richard L. | Compressed domain conference bridge |
| US7529662B2 (en) | 2001-04-02 | 2009-05-05 | General Electric Company | LPC-to-MELP transcoder |
| US7430507B2 (en) | 2001-04-02 | 2008-09-30 | General Electric Company | Frequency domain format enhancement |
| US7062434B2 (en) | 2001-04-02 | 2006-06-13 | General Electric Company | Compressed domain voice activity detector |
| US20070094017A1 (en) * | 2001-04-02 | 2007-04-26 | Zinser Richard L Jr | Frequency domain format enhancement |
| US7165035B2 (en) | 2001-04-02 | 2007-01-16 | General Electric Company | Compressed domain conference bridge |
| US20070067165A1 (en) * | 2001-04-02 | 2007-03-22 | Zinser Richard L Jr | Correlation domain formant enhancement |
| US20070088545A1 (en) * | 2001-04-02 | 2007-04-19 | Zinser Richard L Jr | LPC-to-MELP transcoder |
| US20030125935A1 (en) * | 2001-04-02 | 2003-07-03 | Zinser Richard L. | Pitch and gain encoder |
| US20030065508A1 (en) * | 2001-08-31 | 2003-04-03 | Yoshiteru Tsuchinaga | Speech transcoding method and apparatus |
| US7092875B2 (en) * | 2001-08-31 | 2006-08-15 | Fujitsu Limited | Speech transcoding method and apparatus for silence compression |
| US6940967B2 (en) * | 2003-11-11 | 2005-09-06 | Nokia Corporation | Multirate speech codecs |
| US20050143984A1 (en) * | 2003-11-11 | 2005-06-30 | Nokia Corporation | Multirate speech codecs |
| US7848925B2 (en) | 2004-09-17 | 2010-12-07 | Panasonic Corporation | Scalable encoding apparatus, scalable decoding apparatus, scalable encoding method, scalable decoding method, communication terminal apparatus, and base station apparatus |
| US20080059166A1 (en) * | 2004-09-17 | 2008-03-06 | Matsushita Electric Industrial Co., Ltd. | Scalable Encoding Apparatus, Scalable Decoding Apparatus, Scalable Encoding Method, Scalable Decoding Method, Communication Terminal Apparatus, and Base Station Apparatus |
| US20110040558A1 (en) * | 2004-09-17 | 2011-02-17 | Panasonic Corporation | Scalable encoding apparatus, scalable decoding apparatus, scalable encoding method, scalable decoding method, communication terminal apparatus, and base station apparatus |
| US8712767B2 (en) | 2004-09-17 | 2014-04-29 | Panasonic Corporation | Scalable encoding apparatus, scalable decoding apparatus, scalable encoding method, scalable decoding method, communication terminal apparatus, and base station apparatus |
| US20090299737A1 (en) * | 2005-04-26 | 2009-12-03 | France Telecom | Method for adapting for an interoperability between short-term correlation models of digital signals |
| US8078457B2 (en) * | 2005-04-26 | 2011-12-13 | France Telecom | Method for adapting for an interoperability between short-term correlation models of digital signals |
| US20130332165A1 (en) * | 2012-06-06 | 2013-12-12 | Qualcomm Incorporated | Method and systems having improved speech recognition |
| US9881616B2 (en) * | 2012-06-06 | 2018-01-30 | Qualcomm Incorporated | Method and systems having improved speech recognition |
Also Published As
| Publication number | Publication date |
|---|---|
| US20050159943A1 (en) | 2005-07-21 |
| US20030135370A1 (en) | 2003-07-17 |
| US20030115046A1 (en) | 2003-06-19 |
| US20050102137A1 (en) | 2005-05-12 |
| US20030050775A1 (en) | 2003-03-13 |
| US7430507B2 (en) | 2008-09-30 |
| US20030125935A1 (en) | 2003-07-03 |
| US7668713B2 (en) | 2010-02-23 |
| US20070067165A1 (en) | 2007-03-22 |
| US20070094017A1 (en) | 2007-04-26 |
| US7062434B2 (en) | 2006-06-13 |
| US6678654B2 (en) | 2004-01-13 |
| US20030144835A1 (en) | 2003-07-31 |
| US20030105628A1 (en) | 2003-06-05 |
| US20030135368A1 (en) | 2003-07-17 |
| US7529662B2 (en) | 2009-05-05 |
| US7165035B2 (en) | 2007-01-16 |
| US7421388B2 (en) | 2008-09-02 |
| US20030093268A1 (en) | 2003-05-15 |
| US20070055512A1 (en) | 2007-03-08 |
| US20030028386A1 (en) | 2003-02-06 |
| US20030135366A1 (en) | 2003-07-17 |
| US20030125939A1 (en) | 2003-07-03 |
| US20070088545A1 (en) | 2007-04-19 |
| WO2002080147A1 (en) | 2002-10-10 |
| US20070094018A1 (en) | 2007-04-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7529662B2 (en) | LPC-to-MELP transcoder | |
| JP4870313B2 (en) | Frame Erasure Compensation Method for Variable Rate Speech Encoder | |
| US20030195745A1 (en) | LPC-to-MELP transcoder | |
| JP4390803B2 (en) | Method and apparatus for gain quantization in variable bit rate wideband speech coding | |
| US7613607B2 (en) | Audio enhancement in coded domain | |
| JPH09152900A (en) | Speech signal quantization method using human auditory model in predictive coding | |
| JPH09152895A (en) | Perceptual noise masking measurement method based on frequency response of synthesis filter | |
| JP2002528775A (en) | Method and apparatus for adaptive band pitch search in wideband signal coding | |
| JP2010181891A (en) | Control of adaptive codebook gain for speech encoding | |
| JPH09152898A (en) | A method for synthesizing speech signals without coded parameters. | |
| JP2006525533A5 (en) | ||
| KR100351484B1 (en) | Speech coding apparatus and speech decoding apparatus | |
| KR20190139872A (en) | Non-harmonic speech detection and bandwidth extension in multi-source environments | |
| US6424942B1 (en) | Methods and arrangements in a telecommunications system | |
| JP2003517157A (en) | Method and apparatus for subsampling phase spectral information | |
| JP2003504669A (en) | Coding domain noise control | |
| EP1544848B1 (en) | Audio enhancement in coded domain | |
| JP4108396B2 (en) | Speech coding transmission system for multi-point control equipment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment |
Owner name: LOCKHEED MARTIN CORPORATION, MARYLAND Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:GENERAL ELECTRIC COMPANY;REEL/FRAME:013296/0742 Effective date: 20020722 Owner name: LOCKHEED MARTIN CORPORATION, MARYLAND Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:CHOONG, PHILIP T.;REEL/FRAME:013296/0755 Effective date: 20020523 Owner name: GENERAL ELECTRIC COMPANY, NEW YORK Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:KOCH, STEVEN R.;ZINSER, JR, RICHARD L.;REEL/FRAME:013296/0773 Effective date: 20020710 |
|
| STCB | Information on status: application discontinuation |
Free format text: ABANDONED -- FAILURE TO RESPOND TO AN OFFICE ACTION |