US10521224B2 - Automatic identification of relevant software projects for cross project learning - Google Patents
Automatic identification of relevant software projects for cross project learning Download PDFInfo
- Publication number
- US10521224B2 US10521224B2 US15/908,346 US201815908346A US10521224B2 US 10521224 B2 US10521224 B2 US 10521224B2 US 201815908346 A US201815908346 A US 201815908346A US 10521224 B2 US10521224 B2 US 10521224B2
- Authority
- US
- United States
- Prior art keywords
- candidate target
- project
- projects
- target projects
- subject
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images










Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/70—Software maintenance or management
- G06F8/71—Version control; Configuration management
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/30—Creation or generation of source code
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/30—Creation or generation of source code
- G06F8/33—Intelligent editors
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/70—Software maintenance or management
- G06F8/75—Structural analysis for program understanding
-
- G06K9/6215—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/20—Software design
Definitions
- the application relates generally to automatic identification of relevant software projects for cross project learning.
- Cross-project learning enables modification of a subject project based on a review of existing projects. For instance, a review of the existing projects may enable identification of problems in the subject project, which may then be repaired in the subject project. Further, in cross-project learning, existing solutions incorporated in existing projects may be used to repair the problems in the subject project. Thus, an amount of re-work may decrease. For example, efficiency in repairing the problems in the subject project may be improved by using work already performed for existing projects.
- a method of cross-project learning for improvement of a subject project may include accessing, from a candidate target project database, features including feature information of one or more candidate target projects.
- the method may include accessing, from a server, features including feature information of a subject project.
- the candidate target projects and the subject project may include software programs.
- the method may include determining a similarity score between the feature information of each of the candidate target projects and the feature information of the subject project. A similarity score may be determined for each feature of each of the candidate target projects.
- the method may include aggregating the similarity scores of each feature in the candidate target projects to create an aggregate similarity score for each of the candidate target projects.
- the method may include sorting the candidate target projects by the aggregate similarity scores.
- the method may include filtering the candidate target projects that have an aggregate similarity score below a particular threshold.
- the method may include generating a set of similar target projects that includes the candidate target projects that have an aggregate similarity score equal to or above the particular threshold.
- the method may include identifying a defect in the subject project based on the similar target projects.
- the method may include recommending code, based on the similar target projects, to repair the defect in the subject project.
- the method may include modifying the subject project by implementing the recommended code in the subject project to repair the defect.
- FIG. 1 illustrates a first example cross-project learning environment in which cross-project learning of a subject project may be implemented
- FIG. 2 illustrates a second example cross-project learning environment in which cross-project learning of a subject project may be implemented
- FIG. 3 illustrates an example schematic of determining a similarity score between projects
- FIG. 4 illustrates an example application of cross-project learning using the process of FIG. 3 ;
- FIG. 5 illustrates example results of the example application of FIG. 4 ;
- FIG. 6 is a flow diagram of an example method of extracting feature information of features
- FIG. 7 is a flow diagram of an example method of preprocessing feature information
- FIG. 8 is a flow diagram of an example method of constructing and comparing vectors
- FIG. 9 is a flow diagram of an example method of relevant feature information retrieval.
- FIG. 10 is a flow diagram of an example method of test data generation and modified subject project validation
- cross-project learning may be used to solve software problems more efficiently.
- solutions to current software problems are not recreated in their entirety. Instead, the solutions to current software problems are based on solutions implemented to past software problems. For example, a software developer or an automated tool may solve a software bug by learning how similar software bugs in relevant, previous projects have been solved.
- a database of software programs may be used to learn more about a current software program, which may be referred to as a subject project.
- this single database is a fixed repository of software programs, which may be used regardless of the subject project. Accordingly, code-searching implemented using the database may result in identification of multiple candidate target projects.
- the multiple candidate target projects may include relevant and irrelevant programs as well as programs having a range in purpose, functionality, language, domain, etc.
- the breadth and scope of the candidate target projects introduce an inefficiency into cross-project learning and waste computing resources.
- code-search applications may help determine a desirable corpus.
- general code-search applications such as applications in which developer's habits are predicted, may benefit from a corpus having multiple, different program types and languages.
- some code-search applications may benefit from a corpus with multiple programming languages such as C, C++, JAVA, and other programming languages.
- Other cases may benefit from a corpus having a single language.
- language-specific applications such as repairing Null-Pointer-Exception (NPE) bugs may benefit from a corpus of only JAVA projects.
- NPE Null-Pointer-Exception
- some domain-specific applications may benefit from a corpus of only relevant software projects. For example, fixing a bug related to an application programming interface (API) may benefit from a corpus of only relevant software projects.
- API application programming interface
- some embodiments in the present disclosure include a method of cross-project learning for improvement of a subject project using relevant software projects.
- Embodiments described in the present disclosure may include a method for cross-project learning in which learning is performed using a corpus of relevant projects.
- the corpus of relevant projects may be selected from a broader set of projects stored in a database.
- the broader set of projects stored in the database may include irrelevant projects in addition to the relevant projects that are selected as the corpus of the relevant projects.
- Some embodiments improve the functioning of computers and network environments. For instance, some embodiments may include identifying a defect in the subject project based on similar target projects; recommending code, based on the similar target projects, to repair the defect in the subject project; and modifying the subject project by implementing the recommended code in the subject project to repair the defect.
- the modified subject project may lead to higher quality code patches; reduced computational overhead and network congestion; reduced down-time; better efficiency during code execution; removal of unnecessary code; consolidation of loops or lengthy calculations; protection or repairs from worms, viruses and malware; more efficient or more appropriate use of call functions; lower error margins in analytic output; reduced sizing of required computational power in processors or servers; increased speed of network functionality, or combinations thereof.
- some embodiments may include: determining a similarity score between the feature information of each of the candidate target projects and the feature information of the subject project, in which a similarity score may be determined for each feature of each of the candidate target projects; aggregating the similarity scores of each feature in the candidate target projects to create an aggregate similarity score for each of the candidate target projects; sorting the candidate target projects by the aggregate similarity scores; filtering the candidate target projects that have an aggregate similarity score below a particular threshold; and generating a set of similar target projects that includes the candidate target projects that have an aggregate similarity score equal to or above the particular threshold.
- One or more of the above example steps may lead to faster search results in cross-project learning, decreased search costs, more effective code patches, decreased executable errors, and/or reduced computational overhead.
- methods described herein may improve the technical field of software development, analytics, defect prediction, defect repair, and/or test generation. For example, some embodiments may include identifying a defect in the subject project based on similar target projects; recommending code, based on the similar target projects, to repair the defect in the subject project; and modifying the subject project by implementing the recommended code in the subject project to repair the defect.
- the modified subject project based on methods described in this disclosure may lead to more efficient cross-project learning and, in turn, more rapid software development, code debugging, code analysis, and other software improvements.
- Such methods of modifying the subject project are an improvement over conventional methods which may be inefficient due to use of a fixed repository of computer software programs, which in some applications or examples may lead to an unnecessarily oversized search-result output potentially causing excess computational overhead, decreased performance (e.g., speed performance), or unnecessary/forced parameters limiting compatibility (e.g., for installation on embedded devices) or functionality for a given objective such as those that are domain-specific.
- Some embodiments described in this disclosure may include a method for cross-project learning in which learning (with respect to a subject project) may be performed using a corpus of relevant projects.
- a large corpus of candidate projects may first be analyzed for similarity to the subject project. Based on the similarity of the candidate projects to the subject project, each candidate project may be given a similarity score, which may then be used to filter out dissimilar candidate projects. For example, candidate projects with the top similarity scores may be selected. Based on the selected candidate projects, a defect in the subject project may be identified, and code may be recommended to repair the defect. The subject project may then be modified by implementing the recommended code in the subject project to repair the defect.
- the analysis for similarity may be based on features.
- the features may include, for example, a project description, a class name, a method name, a variable name, a comment, and a dependent API name.
- the feature information of the subject project and the candidate projects may be compared based on the similarity such that a similarity score may be provided on a feature level.
- each feature of each candidate project may have a similarity score with respect to the features of the subject project.
- the similarity scores of each feature in each candidate project may be added together to form a composite or aggregate similarity score for the candidate project as a whole. Based on the aggregate similarity score, candidate projects that are most relevant or most similar to the subject project may be selected.
- FIG. 1 illustrates a first example cross-project learning environment (first environment) 100 arranged in accordance with at least one embodiment described in the present disclosure.
- the first environment 100 may include a server 102 and a subject project 105 .
- the subject project 105 may include source code 110 , readme files 115 , and one or more test cases 120 .
- the first environment 100 may include a computing device 121 having a search module 122 with components therein communicatively coupled via a bus 123 .
- the search module 122 may include a candidate target project database (in FIG. 1 “candidate target projects”) 125 , a filter 130 , similar target projects 135 , and a processor 137 .
- the first environment 100 may also include candidate patches 140 , a computing device 141 having a test module 145 , and a plausible patch 150 .
- cross-project learning and/or defect repair may occur automatically or semi-automatically as described with reference to the embodiments below.
- the subject project 105 may be identified as problematic or otherwise in need of code repair.
- the subject project 105 may be a software program, that when executed, results in an error.
- information from the subject project 105 may be accessed from the server 102 by the search module 122 .
- the information accessed from the server 102 may be used to identify candidate target projects that include similar features and potentially similar code repairs, which have already been performed.
- the subject project 105 may include a defect, which may be located in one or more potential locations in the source code 110 , which may be referred to as buggy locations.
- a user may select one or more of the buggy locations in the source code 110 for code-searching performed by the search module 122 .
- the code-searching may lead to potential repairs or patches for the buggy source code 110 .
- the search module 122 may access information regarding the subject project 105 and candidate target projects in the candidate target project database 125 and compare the accessed information for similarity via the filter 130 .
- one or more of textual information in the source code 110 , the readme files 115 , and the test cases 120 of the subject project 105 may be accessed from the server 102 by the search module 122 .
- textual information of one or more of the candidate target projects in the candidate target project database 125 may be accessed, including any or all of source code, readme files, and test cases for one or more of the candidate target projects.
- one or both of the subject project 105 and the candidate target projects of the candidate target project database 125 may be software programs (partial software programs or entire software programs).
- the accessed textual information of the subject project 105 and the candidate target projects may be compared for similarity via the filter 130 .
- the candidate target projects with a particular value or amount of similarity, in relation to the subject project 105 may be selected by the processor 137 using the filter 130 .
- the degree of similarity between the subject project 105 and the candidate target projects may be based on a textual similarity and may be determined using various expressions.
- the selected candidate target projects may include the similar target projects 135 .
- the candidate patches 140 may be determined by the search module 122 as potentially beneficial in repairing the defect in the subject project 105 .
- the search module 122 may determine the candidate patches 140 .
- code-searching techniques may include ssFix, a program repair tool that leverages program syntax to fix bugs.
- the test module 145 may then test the candidate patches 140 .
- the plausible patch 150 may be identified amongst the candidate patches 140 .
- Predetermined performance standards may include industry standards, speed requirements, accuracy requirements, computation overhead requirements, client-driven or end user-driven requirements, etc. Additionally or alternatively, the predetermined performance standards may be based on a performance of the subject project 105 with the defect unrepaired versus a performance of the subject project 105 with the plausible patch 150 applied to the subject project 105 (e.g., a modified subject project 105 ).
- the defect in the subject project 105 may be repaired, for example, automatically or semi-automatically. Additionally or alternatively, any or all of the following may be performed: prediction of other defects in the subject project 105 , recommending code based on the similar target projects 135 to repair one or more defects in the subject project 105 , generating test data to test the modified subject project 105 , pushing downloads with the modified subject project 105 to end users, and the like. These examples may be active steps performed in response to, for example, determining relevant code in the in similar target projects 135 or determining the candidate patches 140 .
- methods described herein may cause the processor 137 to prompt a user (e.g., via a graphical user interface (GUI)) to confirm, select, post-pone, ignore, or deny one of the candidate patches 140 being applied to the subject project 105 .
- GUI graphical user interface
- methods described herein may cause the processor 137 to predict additional needed repairs and recommend to a user that the additional repairs be performed in view of the similar target projects 135 .
- FIG. 2 illustrates a second example environment 200 that may be arranged in accordance with at least one embodiment described in the present disclosure.
- the second environment 200 may include software developers 205 , software end-users 210 , a candidate target project database 215 , developer input 220 , user input 225 , crawler 230 , raw data 235 , a computing device 237 having a decision module 240 and a similar target project database 245 , a computing device 247 having a retrieval module 250 , a computing device 252 having an application module 255 , and a human developer 260 .
- the second environment 200 may illustrate a broader context of the first environment 100 .
- the software developers 205 may generate the developer input 220 .
- the developer input 220 may include, for example, documentation, metadata, readme files, test cases, psuedo code, source code, discussion, notes, comments, tags, patches, and the like.
- the software end-users 210 may generate the user input 225 .
- the user input 225 may include, for example, bug-reports, user reviews, analytic reports, error messages, back-up files, recovery files, visual displays, charts, graphs, spreadsheets, other suitable input and combinations thereof.
- the developer input 220 and the user input 225 may be generated to the candidate target project database 215 .
- the crawler 230 may crawl and scrape information from the candidate target project database 215 to generate the raw data 235 .
- the raw data 235 may continue to be associated with one of the candidate target projects.
- the decision module 240 may derive suitable abstractions from the raw data 235 .
- the decision module 240 may extract various portions of the raw data 235 and perform various operations, such as preprocessing.
- Preprocessing discussed further below in the disclosure, may include splitting an identifying name, removing a stop word, and stemming one or more remaining terms.
- the preprocessing may include a bag-of-words approach in which grammar and/or order of words may be disregarded.
- the decision module 240 may determine which information from the raw data 235 is appropriate to index and archive in the similar target project database 245 . For example, the decision module 240 may compare for similarity information of a subject project (such as the subject project 105 ) with the raw data 235 associated with one or more candidate target projects. If the degree of similarity is determined to be sufficient, then the decision module 240 may generate a set of similar target projects for storing in the similar target project database 245 . Generation of the set of similar target projects may be based on the raw data 235 and associated candidate target projects, which have sufficient similarity to the subject project.
- a subject project such as the subject project 105
- Information from the similar target projects may be appropriately indexed and archived in the similar target project database 245 , in which each feature of each similar target project may be associated with a particular index.
- feature may be interpreted as a measurable property or characteristic within a software program that may be used in discriminatory fashion to identify relevant software programs.
- the retrieval module 250 may perform software program analysis, code-searching, and/or artificial intelligence functions such as machine learning (including deep learning) for iterative improvement to the subject project. Additionally or alternatively, the retrieval module 250 may perform a code search in which the set of similar target projects is the searched corpus.
- candidate patches may be determined and/or tested for use in the application module 255 .
- the human developer 260 may perform performance tests or otherwise manage the candidate patches in the application module.
- the application module 255 may include an integrated development environment (IDE) and may receive inputs from one or both of the retrieval module 250 and the human developer 260 . Additionally or alternatively, the application module 255 may generate output to one or both of the retrieval module 250 and the human developer 260 .
- IDE integrated development environment
- defects may be predicted. Such defect prediction may be useful for use in the application module 255 .
- a defect may be explicitly identified or, in other cases, a defect may be predicted as likely present.
- a defect may be predicted, with a degree of probability, as present.
- the defect may be predicted as present at a certain line, section, function, and/or location within the subject project.
- the defect prediction may include candidate patches, while in other embodiments, no candidate patches may be included with the defect prediction.
- each of the modules may be implemented as software including one or more routines configured to perform one or more operations.
- the modules may include a set of instructions executable by a processor to provide the functionality described below.
- the modules may be stored in or at least temporarily loaded into corresponding memory of the computing device 121 , the computing device 141 , the computing device 237 , the computing device 247 , and the computing device 252 .
- the modules may be accessible and executable by one or more processors.
- One or more of the modules may be adapted for cooperation and communication with the one or more processors and components of the computing devices 121 , 141 , 237 , 247 , and 252 via a bus, such as the bus 123 .
- FIG. 3 illustrates a schematic 300 of determining a similarity score between projects that may be implemented in the first environment 100 of FIG. 1 .
- the process represented by the schematic 300 may be implemented to improve a subject project 310 .
- the schematic 300 may include candidate target projects (in FIG. 3 “candidate projects”) 305 , the subject project 310 , target features 315 , subject features 320 , preprocessing 325 , BM25-based vector space model 330 , similarity scores 335 (in FIG. 3 , S 1 -S 6 ), an aggregate similarity score 340 , sorting module 345 , threshold 350 , selection module 355 , and similar target projects 360 .
- the schematic 300 may depict what information is accessed within the candidate target projects 305 and the subject project 310 .
- target features 315 which belong to one of the candidate target projects 305
- subject features 320 which belong to the subject project 310 , may be accessed.
- the schematic 300 may depict what is done with the accessed information prior to a similarity comparison (such as the preprocessing 325 ), and how the similarity comparison is performed (such as the BM25-based vector space model 330 ). Once the similarity comparison is performed, the schematic 300 may depict what some example results may include (such as similarity scores 335 , aggregate similarity score 340 , and similar target projects 360 ) and/or what may be accomplished using the example results.
- the candidate target projects 305 and the subject project 310 may be software programs, may include software programs, or may be otherwise tied to software programs.
- the candidate target projects 305 and the subject project 310 may include a subset of features (e.g., the target features 315 or the subject features 320 ).
- one of the candidate target projects 305 may include a subset of features such as the target features 315 a - 315 f .
- another of the candidate target projects 305 may include a different subset of features.
- the subject project 310 may include a subset of features such as subject features 320 a - 320 f.
- examples of the target features 315 may include a project description 315 a , a class name 315 b , a method name 315 c , a variable name 315 d , a comment 315 e , and a dependent API name 315 f .
- examples of the subject features 320 may include a project description 320 a , a class name 320 b , a method name 320 c , a variable name 320 d , a comment 320 e , and a dependent API name 320 f .
- more or less information may comprise the target features 315 and/or the subject features 320 .
- one or both of the target features 315 and the subject features 320 may include textual or structural information based on documentation, metadata, readme files, test cases, psuedo code, source code, discussion, notes, comments, tags, patches, and the like.
- the target features 315 and the subject features 320 may be preprocessed via preprocessing 325 .
- Preprocessing may include one or more of splitting an identifier name, removing a stop word, and stemming one or more remaining terms.
- a variable name may include “termsInDocument.” Splitting the identifying name may thus include splitting as follows: “terms in document” in which spaces are provided between words. Removing stop words may then appear as follows: “terms document” in which the term “in” is struck through or removed.
- a stop word may be any commonly used word such as the word “the” that a search engine might be programmed to ignore.
- entities called a query and a document may be constructed and populated in preparation for comparing the target features 315 with the subject features 320 in the BM25-based vector space model 330 .
- the query may be constructed and populated with the preprocessed feature information of the subject features 320
- the document may be constructed and populated with the preprocessed feature information of the target features 315 .
- the preprocessed feature information in both of the query and the document may be indexed and vector representations created.
- the query vector and the document vector may be calculated according to example BM25 expressions:
- the parameter x′ 1 may represent a BM25-based weight of a term in a document of one of the candidate target projects 305 .
- the parameter y′ 1 may represent a BM25-based weight of a term in a query of the subject project 310 .
- the parameter tf d (x i ) may represent a smoothed term frequency of an i th term in a document of one of the candidate target projects 305 , in which the term “smoothed” may be interpreted as modification of data points (e.g., term frequency) to reduce noise such as rapid changes, random changes, or outliers.
- the parameter tf q (y i ) may represent a smoothed term frequency of an i th term in a query of the subject project 310 , in which the term “smoothed” may be interpreted as modification of data points (e.g., term frequency) to reduce noise such as rapid changes, random changes, or outliers.
- the parameter idf(t i ) may represent an inverse document frequency of an i th term t.
- the parameter x may represent a term frequency.
- the parameter y may represent a term frequency.
- the parameter b may represent a scaling factor.
- the parameter l d may represent a document length.
- the parameter l C may represent an average document length.
- the parameter n t may represent a number documents in the candidate target projects having a term t.
- the parameter N may represent a total number of words in a dictionary.
- the operator ⁇ is a scalar multiplier.
- s( ) may represent a function for computing a similarity score at feature level. The remaining parameters are as described above.
- an output of the BM25-based vector space model 330 may include similarity scores 335 .
- the similarity scores 335 may be representative of a similarity between the query vector and the document vector, or representative of a similarity between the subject features 320 and the target features 315 .
- the similarity scores 335 may include any quantity of similarity scores 335 (e.g., S 1 -Sn), depending on the quantity of features extracted from one or both of the candidate target projects 305 and the subject project 310 .
- the similarity scores 335 may have a one-to-one relationship.
- S 1 of the similarity scores 335 may correspond to a similarity between the project description 315 a and the project description 320 a .
- the relationship between the similarity scores 335 may not be one-to-one.
- the class name 320 b may be compared for similarity with not only the class name 315 b , but also the method name 315 c and the variable name 315 d .
- S 2 of the similarity scores 335 may be representative of a similarity between the class name 320 b and multiple target features 315 .
- the similarity scores 335 may be added together to create an aggregate similarity score 340 for one of the candidate target projects 305 .
- the aggregate similarity score 340 may be equal to or between 0 and 1, while in other embodiments varied by one to four orders of magnitude. In other embodiments, the aggregate similarity score 340 may be any positive number.
- the function s′( ) may represent an aggregate similarity score.
- the parameter w f may represent a weighting factor.
- the parameter fields may represent features.
- multiple candidate target projects 305 may be preprocessed in preprocessing 325 and compared with the subject project 310 in the BM25-based vector space model 330 . For example, when there are no additional candidate target projects 305 remaining to be analyzed and compared, a sorting module 345 may sort the candidate target projects 305 according to the aggregate similarity score 340 .
- the candidate target projects 305 may be filtered according to a threshold 350 .
- the candidate target projects 305 that have an aggregate similarity score 340 below the threshold 350 may not be selected by the selection module 355 .
- the selection module 355 may generate a set of similar target projects 360 , which may be the selected candidate target projects 305 that have an aggregate similarity score 340 equal to or above the threshold 350 .
- the generated set of similar target projects 360 may include one or more of: candidate target projects 305 having aggregate similarity scores 340 ranked in a top percentile; candidate target projects 305 having aggregate similarity scores 340 ranked in a top number of all the aggregate similarity scores 340 ; and candidate target projects 305 having an aggregate similarity score 340 equal to or above a threshold aggregate similarity score.
- the similar target projects 360 may be used for determining a plausible patch (such as the plausible patch 150 ).
- a plausible patch such as the plausible patch 150.
- FIG. 4 illustrates an example application 400 of the process 300 of FIG. 3 that may be used to determine a bug fix.
- the application 400 may be an example bug fix from Commons Lang (Bug ID: LANG-677) and may include an error line 405 , which includes errors 410 and 415 , and a replacement line 420 , which includes corrections 425 and 430 .
- a fix involves multiples edits. For instance, the fix involves changing parameters in two APIs. In such cases involving multiple edits, synthesis-based program repair may be costly due to, for example, trial and error.
- a code-search-based approach may be suitable to fix the error line 405 if the code related to the bug-fix may be found elsewhere in the same project or in some other relevant projects.
- an appropriate patch as indicated in correction line 420 may be found in a project called “adempiere” from the candidate target project database hosted on sourceforge.net (as described below with reference to FIG. 5 ).
- FIG. 5 illustrates example preliminary results 500 of the application of FIG. 4 .
- the preliminary results 500 may include summary results 501 and a table of specific results 503 .
- the summary results 501 may identify a number of projects in a corpus or database. In FIG. 5 , the number of projects is 980. In other circumstances, the number of projects may include another number of projects.
- the summary result 501 may also identify a project that includes a correct code and a rank of the project that includes the correct code. For instance, in FIG. 5 , the project that includes the correct code is named “Adempiere,” and is ranked in a 24th position in the table of specific results 503 , which is in the top 3% of the 980 projects when ranked by similarity score.
- the table of specific results 503 may include a rank 505 , a project name 510 , and an aggregate similarity score (in FIG. 5 “score”) 515 for each of the projects in the corpus or database.
- the projects in the corpus or database may be substantially similar to and correspond to the candidate target projects 305 described elsewhere in the presented embodiments.
- the similar target projects 360 may include the candidate target projects 305 with a rank 505 equal to or above a particular number such as 30 or with a score 515 equal to or above 0.330.
- the project that includes the correct code e.g., “Adempiere”
- FIG. 6 illustrates a flow diagram of an example method 600 of extracting feature information arranged in accordance with at least one embodiment described in the present disclosure. Although illustrated as discrete blocks, various blocks may be divided into additional blocks, combined into fewer blocks, or eliminated, depending on the desired implementation.
- the method 600 may begin at block 605 , in which features of candidate target projects and of a subject project may be accessed.
- the features of the candidate target projects in a candidate project database may be accessed.
- the features of the subject project in a server may be accessed.
- the features may include feature information.
- one or more of source code, test cases, and readme files may be parsed.
- the parsing may include a textual parsing, a structural parsing, a visual parsing, and the like.
- the parsing may be performed by bots and/or by parsing algorithms.
- Some example parsing algorithms may include Eclipse JDT Parser or ANTLR.
- textual information and structural information may be extracted.
- the textual information and the structural information may be extracted from the parsed source code, test cases, and readme files.
- a document and a query may be constructed using the extracted textual information and structural information. For example, the textual information and the structural information from the features of the subject project may be indexed and placed in the query. Similarly, the textual information and the structural information from the features of one of the candidate projects may be indexed and placed in the document.
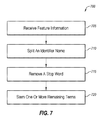
- FIG. 7 is a flow diagram of an example method 700 of preprocessing feature information in accordance with at least one embodiment described in the present disclosure.
- the method 700 may be performed prior to a determination of a similarity score.
- various blocks may be divided into additional blocks, combined into fewer blocks, or eliminated, depending on the desired implementation.
- the method 700 may begin at block 705 , in which feature information is received.
- an identifier name may be split. For example, an identifier name with multiple words formed as a single name may be split apart with spaces therebetween.
- a stop word may be removed.
- the stop word may be a commonly used term that a search engine or algorithm may discard or otherwise discount for lack of importance to a query. Some examples of stop words are “in” and “the.”
- one or more remaining terms may be stemmed.
- remaining terms in non-root form may be modified to arrive at the root of the word.
- Some examples of non-root forms are plural terms (documents versus document), gerund (run versus running), or participle terms (gone versus go).
- FIG. 8 is a flow diagram of an example method 800 of constructing and comparing vectors arranged in accordance with at least one embodiment described in the present disclosure. Although illustrated as discrete blocks, various blocks may be divided into additional blocks, combined into fewer blocks, or eliminated, depending on the desired implementation.
- the method 800 may begin at block 805 , in which a query vector may be constructed.
- the query vector may include query terms from the feature information of the subject project.
- the query vector may be based at least partially on query terms that have been indexed in a query.
- a document vector may be constructed.
- the document vector may include document terms from the feature information of the candidate target projects.
- the document vector may be based at least partially on document terms that have been indexed in a document.
- a feature within a candidate target project may be selected.
- the selected feature may include document terms in the document vector.
- a cosine similarity may be determined between the query vector and the document vector.
- the cosine similarity of the selected feature of the candidate target project may be added to an aggregate score.
- at least blocks 815 and 820 may be repeated as desired for a predetermined amount of features and type of features.
- the predetermined amount of features may be about 6 features, about 10 features, or some other suitable number of features.
- the predetermined amount of features may be determined based on the various types of features and/or the degree to which the various types of features are discriminatory (e.g., features that aid classification, identification, or narrowing).
- FIG. 9 is a flow diagram of an example method 900 of retrieving relevant feature information arranged in accordance with at least one embodiment described in the present disclosure. Although illustrated as discrete blocks, various blocks may be divided into additional blocks, combined into fewer blocks, or eliminated, depending on the desired implementation.
- the method 900 may begin at block 905 , in which target features of one or more candidate target projects may be accessed.
- the target features may be accessed from a candidate target project database.
- the target features may include target feature information.
- Target features of a candidate target project may include a project description, a class name, a method name, a variable name, a dependent API name, a comment, an external library, other features, or combinations thereof.
- subject features of a subject project may be accessed from a server.
- Subject features of the subject project may include one or more of a project description, a class name, a method name, a variable name, a dependent API name, a comment, an external library, other features, or combinations thereof.
- a similarity score may be determined.
- the similarity score may be determined between the target feature information of one or more or each of the candidate target projects and the subject feature information of the subject project. In some embodiments, the similarity score may be determined for each target feature of each of the candidate target projects.
- the similarity scores may be aggregated. The similarity scores may be aggregated to create an aggregate similarity score for each of the candidate target projects. For instance, in some embodiments, similarity scores of each target feature in the candidate target projects may be aggregated.
- the candidate target projects may be sorted.
- the candidate target projects may be sorted by the aggregate similarity scores. For example, the candidate target projects having the highest aggregate similarity scores (e.g., largest numbers) may be sorted in a top portion or top ranking with respect to many or all of the candidate target projects.
- candidate target projects may be filtered. For instance, the candidate target projects that have an aggregate similarity score below a particular threshold may be filtered.
- a set of similar target projects may be generated.
- the set of similar target projects may include the candidate target projects that have an aggregate similarity score equal to or above the particular threshold.
- the particular threshold may include a particular percentile (e.g., a top 25%, top 15%, or another suitable percentile), a particular number (e.g., a top five, seven, or another suitable number), or a particular aggregate similarity score (e.g., 0.7, 0.55, or another suitable similarity score) when the candidate target projects are ranked according to the aggregate similarity scores.
- a defect in the subject project may be identified.
- the defect may be identified based on the similar target projects. For example, a documented defect in one or more of the similar target projects (which may repaired in the database), may be identified as textually or structurally similar to a portion of the subject project. Accordingly, documented defect may be identified as a defect in the subject project.
- code may be recommended. The code may be recommended based on the similar target projects. The code may be recommended to repair the identified defect in the subject project. For instance, code used to repair the documented defect in the similar target projects may be recommended for application to the subject project.
- the subject project may be modified. The subject project may be modified by implementing the recommended code in the subject project to repair the identified defect.
- FIG. 10 is a flow diagram of an example method 1000 of generating test data and validating a modified subject project arranged in accordance with at least one embodiment described in the present disclosure. Although illustrated as discrete blocks, various blocks may be divided into additional blocks, combined into fewer blocks, or eliminated, depending on the desired implementation.
- the method 1000 may begin at block 1005 , in which new data may be generated.
- the new data may be generated to test a modified subject project.
- the subject project may have been modified due to implementation of a plausible patch to repair a defect.
- the generated new data may include new test cases used to test the subject project that includes the plausible patch.
- the modified subject project may be validated.
- the modified subject project may be validated using predetermined performance standards.
- the predetermined performance standards may be based on a performance of the subject project before the subject project was modified.
- the predetermined performance standards may include industry standards, speed requirements, accuracy requirements, computation overhead requirements, client-driven, end user-driven requirements, other performance standards, or combinations thereof.
- a defect may be predicted in the subject project.
- a defect may be explicitly identified in the subject project, or, in other cases, a defect may be predicted as likely present in the subject project.
- a defect may be predicted, with a degree of probability, as present.
- the defect may be predicted as present at a certain line, section, function, and/or location within the subject project.
- the defect prediction may include candidate patches, while in other embodiments, no candidate patches may be included with the defect prediction.
- the methods 600 , 700 , 800 , 900 , and 1000 may be performed, in whole or in part, in some embodiments in a network environment, such as the environments 100 and 200 . Additionally or alternatively, the methods 600 , 700 , 800 , 900 , and 1000 may be performed by a processor, such as the processor 137 , as described with respect to FIG. 1 . In these and other embodiments, some or all of the steps of the methods 600 , 700 , 800 , 900 , and 1000 may be performed based on the execution of instructions stored on one or more non-transitory computer-readable media.
- a processor may include any suitable special-purpose or general-purpose computer, computing entity, or processing device including various computer hardware or software modules and may be configured to execute instructions stored on any applicable computer-readable storage media.
- the processor may include a microprocessor, a microcontroller, a digital signal processor (DSP), an application-specific integrated circuit (ASIC), a Field-Programmable Gate Array (FPGA), or any other digital or analog circuitry configured to interpret and/or to execute program instructions and/or to process data.
- DSP digital signal processor
- ASIC application-specific integrated circuit
- FPGA Field-Programmable Gate Array
- the processor may include any number of processors distributed across any number of networks or physical locations that are configured to perform individually or collectively any number of operations described herein.
- the processor may interpret and/or execute program instructions and/or processing data stored in the memory.
- the device may perform operations, such as the operations performed by the processor 137 of FIG. 1 .
- memory as found in servers, databases, and the like may include computer-readable storage media or one or more computer-readable storage mediums for carrying or having computer-executable instructions or data structures stored thereon.
- Such computer-readable storage media may be any available media that may be accessed by a general-purpose or special-purpose computer, such as the processor.
- such computer-readable storage media may include non-transitory computer-readable storage media including Random Access Memory (RAM), Read-Only Memory (ROM), Electrically Erasable Programmable Read-Only Memory (EEPROM), Compact Disc Read-Only Memory (CD-ROM) or other optical disk storage, magnetic disk storage or other magnetic storage devices, flash memory devices (e.g., solid state memory devices), or any other storage medium which may be used to carry or store desired program code in the form of computer-executable instructions or data structures and which may be accessed by a general-purpose or special-purpose computer. Combinations of the above may also be included within the scope of computer-readable storage media.
- RAM Random Access Memory
- ROM Read-Only Memory
- EEPROM Electrically Erasable Programmable Read-Only Memory
- CD-ROM Compact Disc Read-Only Memory
- flash memory devices e.g., solid state memory devices
- Combinations of the above may also be included within the scope of computer-readable storage media.
- non-transitory should be construed to exclude only those types of transitory media that were found to fall outside the scope of patentable subject matter in the Federal Circuit decision of In re Nuijten, 500 F.3d 1346 (Fed. Cir. 2007).
- computer-executable instructions may include, for example, instructions and data configured to cause the processor to perform a certain operation or group of operations as described in the present disclosure.
- any disjunctive word or phrase presenting two or more alternative terms, whether in the description, claims, or drawings, should be understood to contemplate the possibilities of including one of the terms, either of the terms, or both terms.
- the phrase “A or B” should be understood to include the possibilities of “A” or “B” or “A and B.”
- first,” “second,” “third,” etc. are not necessarily used herein to connote a specific order or number of elements.
- the terms “first,” “second,” “third,” etc. are used to distinguish between different elements as generic identifiers. Absence a showing that the terms “first,” “second,” “third,” etc., connote a specific order, these terms should not be understood to connote a specific order. Furthermore, absence a showing that the terms “first,” “second,” “third,” etc., connote a specific number of elements, these terms should not be understood to connote a specific number of elements.
- a first widget may be described as having a first side and a second widget may be described as having a second side.
- the use of the term “second side” with respect to the second widget may be to distinguish such side of the second widget from the “first side” of the first widget and not to connote that the second widget has two sides.
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Computer Security & Cryptography (AREA)
- Artificial Intelligence (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Debugging And Monitoring (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
In the above expressions, the parameter x′1 may represent a BM25-based weight of a term in a document of one of the candidate target projects 305. The parameter y′1 may represent a BM25-based weight of a term in a query of the
s({right arrow over (d f)},{right arrow over (q f)})=Σi=1 n tf d(x i)×tf q(y i)×idf(t i)2.
In the second BM25 equation, s( ) may represent a function for computing a similarity score at feature level. The remaining parameters are as described above.
s′({right arrow over (d)},{right arrow over (q)})=Σf∈fields w f ×s({right arrow over (d f)},{right arrow over (q f)}),
In the aggregate similarity score expression, the function s′( ) may represent an aggregate similarity score. The parameter wf may represent a weighting factor. The parameter fields may represent features.
Claims (20)
s′({right arrow over (d)},{right arrow over (q)})=Σf∈fields w f ×s({right arrow over (d f)},{right arrow over (q f)}),
s′({right arrow over (d)},{right arrow over (q)})=Σf∈fields w f ×s({right arrow over (d f)},{right arrow over (q f)}),
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US15/908,346 US10521224B2 (en) | 2018-02-28 | 2018-02-28 | Automatic identification of relevant software projects for cross project learning |
| JP2018156256A JP7131199B2 (en) | 2018-02-28 | 2018-08-23 | Automatic identification of related software projects for cross-project learning |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US15/908,346 US10521224B2 (en) | 2018-02-28 | 2018-02-28 | Automatic identification of relevant software projects for cross project learning |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| US20190265970A1 US20190265970A1 (en) | 2019-08-29 |
| US10521224B2 true US10521224B2 (en) | 2019-12-31 |
Family
ID=67684519
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US15/908,346 Active US10521224B2 (en) | 2018-02-28 | 2018-02-28 | Automatic identification of relevant software projects for cross project learning |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US10521224B2 (en) |
| JP (1) | JP7131199B2 (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10782941B1 (en) * | 2019-06-20 | 2020-09-22 | Fujitsu Limited | Refinement of repair patterns for static analysis violations in software programs |
| US11403304B2 (en) | 2020-09-02 | 2022-08-02 | Fujitsu Limited | Automatically curating existing machine learning projects into a corpus adaptable for use in new machine learning projects |
| US11551151B2 (en) | 2020-09-02 | 2023-01-10 | Fujitsu Limited | Automatically generating a pipeline of a new machine learning project from pipelines of existing machine learning projects stored in a corpus |
| US12039419B2 (en) | 2020-09-02 | 2024-07-16 | Fujitsu Limited | Automatically labeling functional blocks in pipelines of existing machine learning projects in a corpus adaptable for use in new machine learning projects |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20200371778A1 (en) * | 2019-05-21 | 2020-11-26 | X Development Llc | Automated identification of code changes |
| US20210089992A1 (en) * | 2019-09-20 | 2021-03-25 | Nec Laboratories America, Inc. | Method for automated code reviewer recommendation |
| CN110751186B (en) * | 2019-09-26 | 2022-04-08 | 北京航空航天大学 | Cross-project software defect prediction method based on supervised expression learning |
| US11416245B2 (en) * | 2019-12-04 | 2022-08-16 | At&T Intellectual Property I, L.P. | System and method for syntax comparison and analysis of software code |
| KR102156931B1 (en) * | 2020-01-16 | 2020-09-16 | 주식회사 소프트센 | Appratus of estimating program coded by using block coding, method and system thereof and computer program stored in recoring medium |
| CN111367801B (en) * | 2020-02-29 | 2024-07-12 | 杭州电子科技大学 | Data transformation method for cross-company software defect prediction |
| US11630649B2 (en) | 2020-06-02 | 2023-04-18 | International Business Machines Corporation | Intelligent application library management |
| CN111966586A (en) * | 2020-08-05 | 2020-11-20 | 南通大学 | Cross-project defect prediction method based on module selection and weight updating |
| CN113176998A (en) * | 2021-05-10 | 2021-07-27 | 南通大学 | Cross-project software defect prediction method based on source selection |
| CN113392184A (en) * | 2021-06-09 | 2021-09-14 | 平安科技(深圳)有限公司 | Method and device for determining similar texts, terminal equipment and storage medium |
| EP4364062A1 (en) * | 2021-07-01 | 2024-05-08 | Google LLC | Detecting inactive projects based on usage signals and machine learning |
| CN118095294B (en) * | 2024-04-25 | 2024-07-09 | 广东汉佳信息技术有限公司 | Project document generation method and device based on artificial intelligence and electronic equipment |
Citations (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030172058A1 (en) * | 2002-03-07 | 2003-09-11 | Fujitsu Limited | Document similarity calculation apparatus, clustering apparatus, and document extraction apparatus |
| US20070130561A1 (en) * | 2005-12-01 | 2007-06-07 | Siddaramappa Nagaraja N | Automated relationship traceability between software design artifacts |
| US20070266367A1 (en) * | 2004-01-07 | 2007-11-15 | International Business Machines Corporation | Relationship Management For Data Modeling In An Integrated Development Environment |
| US20110202385A1 (en) * | 2010-02-15 | 2011-08-18 | Matsui Takaharu | Method and its apparatus for supporting project and program for carrying out the method |
| US20120054117A1 (en) * | 2010-08-27 | 2012-03-01 | Christopher Peltz | Identifying an individual in response to a query seeking to locate personnel with particular experience |
| US20120197674A1 (en) * | 2011-01-27 | 2012-08-02 | Maher Rahmouni | Estimating a future project characteristic based on the similarity of past projects |
| US20130041711A1 (en) * | 2011-08-09 | 2013-02-14 | Bank Of America Corporation | Aligning project deliverables with project risks |
| US20130268916A1 (en) * | 2012-04-09 | 2013-10-10 | Accenture Global Services Limited | Component discovery from source code |
| US20140115565A1 (en) * | 2012-10-18 | 2014-04-24 | Microsoft Corporation | Test similarity detection with method call sequence analysis |
| US20160378445A1 (en) * | 2015-06-26 | 2016-12-29 | Mitsubishi Electric Corporation | Similarity determination apparatus, similarity determination method and similarity determination program |
| US20170242782A1 (en) | 2016-02-23 | 2017-08-24 | Fujitsu Limited | Textual similarity based software program repair |
| US20170366568A1 (en) * | 2016-06-21 | 2017-12-21 | Ebay Inc. | Anomaly detection for web document revision |
| US20180137189A1 (en) * | 2016-11-11 | 2018-05-17 | International Business Machines Corporation | Efficiently finding potential duplicate values in data |
| US20190004790A1 (en) * | 2017-06-29 | 2019-01-03 | Red Hat, Inc. | Measuring similarity of software components |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6024448B2 (en) * | 2012-12-26 | 2016-11-16 | 富士通株式会社 | Information processing program, information processing method and apparatus |
| JP6528669B2 (en) * | 2015-12-14 | 2019-06-12 | 富士通株式会社 | Predictive detection program, apparatus, and method |
-
2018
- 2018-02-28 US US15/908,346 patent/US10521224B2/en active Active
- 2018-08-23 JP JP2018156256A patent/JP7131199B2/en active Active
Patent Citations (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20030172058A1 (en) * | 2002-03-07 | 2003-09-11 | Fujitsu Limited | Document similarity calculation apparatus, clustering apparatus, and document extraction apparatus |
| US20070266367A1 (en) * | 2004-01-07 | 2007-11-15 | International Business Machines Corporation | Relationship Management For Data Modeling In An Integrated Development Environment |
| US20070130561A1 (en) * | 2005-12-01 | 2007-06-07 | Siddaramappa Nagaraja N | Automated relationship traceability between software design artifacts |
| US20110202385A1 (en) * | 2010-02-15 | 2011-08-18 | Matsui Takaharu | Method and its apparatus for supporting project and program for carrying out the method |
| US20120054117A1 (en) * | 2010-08-27 | 2012-03-01 | Christopher Peltz | Identifying an individual in response to a query seeking to locate personnel with particular experience |
| US20120197674A1 (en) * | 2011-01-27 | 2012-08-02 | Maher Rahmouni | Estimating a future project characteristic based on the similarity of past projects |
| US20130041711A1 (en) * | 2011-08-09 | 2013-02-14 | Bank Of America Corporation | Aligning project deliverables with project risks |
| US20130268916A1 (en) * | 2012-04-09 | 2013-10-10 | Accenture Global Services Limited | Component discovery from source code |
| US20140115565A1 (en) * | 2012-10-18 | 2014-04-24 | Microsoft Corporation | Test similarity detection with method call sequence analysis |
| US20160378445A1 (en) * | 2015-06-26 | 2016-12-29 | Mitsubishi Electric Corporation | Similarity determination apparatus, similarity determination method and similarity determination program |
| US20170242782A1 (en) | 2016-02-23 | 2017-08-24 | Fujitsu Limited | Textual similarity based software program repair |
| US20170366568A1 (en) * | 2016-06-21 | 2017-12-21 | Ebay Inc. | Anomaly detection for web document revision |
| US20180137189A1 (en) * | 2016-11-11 | 2018-05-17 | International Business Machines Corporation | Efficiently finding potential duplicate values in data |
| US20190004790A1 (en) * | 2017-06-29 | 2019-01-03 | Red Hat, Inc. | Measuring similarity of software components |
Non-Patent Citations (9)
| Title |
|---|
| He et al., "Simplification of Training Data for Cross-Project Defect Prediction" (Year: 2014). * |
| He et al., "TDSelector: A Training Data Selection Method for Cross-Project Defect Prediction" (Year: 2016). * |
| Mill, "Automating Traceability Link Recovery through Classification", FSE 2017, Aug. 21, 2017. |
| Nguyen et al., "Using Topic Model to Suggest Fine-grained Source Code Changes" (Year: 2016). * |
| Saha et al., "An Information Retrieval Approach for Regression Test Prioritization Based on Program Changes", ICSE 2015, REPiR, May 16, 2015. |
| Xin and Reiss, "Leveraging Syntax-Related Code for Automated Program Repair" ASE 2017: ssFix, Oct. 30, 2017. |
| Zhang et al., "Cross-project Defect Prediction Using a Connectivity-based Unsupervised Classifier" (Year: 2016). * |
| Zhou et al., "Where Should the Bugs Be Fixed?", ICSE 2012, Jun. 2, 2012. |
| Zimmermann et al, "Cross-project Defect Prediction", FSE, Aug. 24, 2009. |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10782941B1 (en) * | 2019-06-20 | 2020-09-22 | Fujitsu Limited | Refinement of repair patterns for static analysis violations in software programs |
| US11403304B2 (en) | 2020-09-02 | 2022-08-02 | Fujitsu Limited | Automatically curating existing machine learning projects into a corpus adaptable for use in new machine learning projects |
| US11551151B2 (en) | 2020-09-02 | 2023-01-10 | Fujitsu Limited | Automatically generating a pipeline of a new machine learning project from pipelines of existing machine learning projects stored in a corpus |
| US12039419B2 (en) | 2020-09-02 | 2024-07-16 | Fujitsu Limited | Automatically labeling functional blocks in pipelines of existing machine learning projects in a corpus adaptable for use in new machine learning projects |
Also Published As
| Publication number | Publication date |
|---|---|
| US20190265970A1 (en) | 2019-08-29 |
| JP2019153270A (en) | 2019-09-12 |
| JP7131199B2 (en) | 2022-09-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10521224B2 (en) | Automatic identification of relevant software projects for cross project learning | |
| US11221832B2 (en) | Pruning engine | |
| Jiang et al. | Shaping program repair space with existing patches and similar code | |
| Nguyen et al. | A study of repetitiveness of code changes in software evolution | |
| Wang et al. | Amalgam+: Composing rich information sources for accurate bug localization | |
| Higo et al. | Incremental code clone detection: A PDG-based approach | |
| US9298453B2 (en) | Source code analytics platform using program analysis and information retrieval | |
| EP3674918B1 (en) | Column lineage and metadata propagation | |
| US9542176B2 (en) | Predicting software build errors | |
| Roy | Detection and analysis of near-miss software clones | |
| EP2801906B1 (en) | Source code flow analysis using information retrieval | |
| CN108197306B (en) | SQL statement processing method and device, computer equipment and storage medium | |
| Dou et al. | CACheck: detecting and repairing cell arrays in spreadsheets | |
| Xia et al. | An effective change recommendation approach for supplementary bug fixes | |
| JP2020126641A (en) | Api mash-up exploration and recommendation | |
| US20210182293A1 (en) | Candidate projection enumeration based query response generation | |
| US20160292062A1 (en) | System and method for detection of duplicate bug reports | |
| CN112148595A (en) | Software change level defect prediction method for removing repeated change | |
| Zhang et al. | Fusing multi-abstraction vector space models for concern localization | |
| Magalhães et al. | Automatic selection of test cases for regression testing | |
| Hegedűs et al. | Static code analysis alarms filtering reloaded: A new real-world dataset and its ML-based utilization | |
| CN112631925B (en) | Method for detecting single-variable atom violation defect | |
| CN113760864A (en) | Data model generation method and device | |
| Nguyen et al. | Using topic model to suggest fine-grained source code changes | |
| Udagawa | Source code retrieval using sequence based similarity |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| FEPP | Fee payment procedure |
Free format text: ENTITY STATUS SET TO UNDISCOUNTED (ORIGINAL EVENT CODE: BIG.); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY |
|
| AS | Assignment |
Owner name: FUJITSU LIMITED, JAPAN Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:SAHA, RIPON K.;PRASAD, MUKUL R.;REEL/FRAME:045079/0197 Effective date: 20180226 |
|
| STPP | Information on status: patent application and granting procedure in general |
Free format text: NOTICE OF ALLOWANCE MAILED -- APPLICATION RECEIVED IN OFFICE OF PUBLICATIONS |
|
| STPP | Information on status: patent application and granting procedure in general |
Free format text: NOTICE OF ALLOWANCE MAILED -- APPLICATION RECEIVED IN OFFICE OF PUBLICATIONS |
|
| STCF | Information on status: patent grant |
Free format text: PATENTED CASE |
|
| MAFP | Maintenance fee payment |
Free format text: PAYMENT OF MAINTENANCE FEE, 4TH YEAR, LARGE ENTITY (ORIGINAL EVENT CODE: M1551); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY Year of fee payment: 4 |