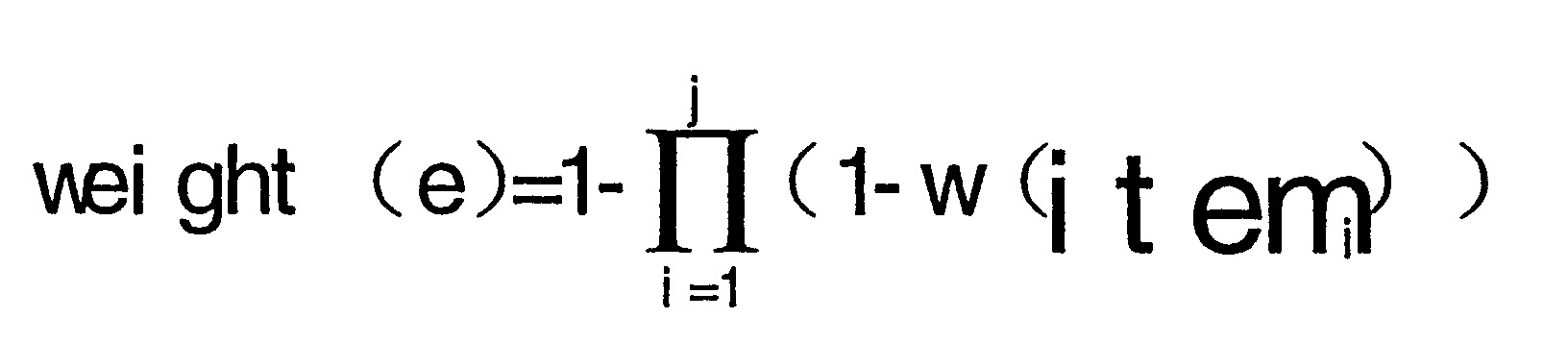本說明書一個或多個實施例提供一種異常群體識別方法及裝置,用以解決現有技術中異常群體識別準確率較低的問題。
為了使本技術領域的人員更好地理解本說明書一個或多個實施例中的技術方案,下面將結合本說明書一個或多個實施例中的圖式,對本說明書一個或多個實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本說明書一部分實施例,而不是全部的實施例。基於本說明書一個或多個實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都應當屬於本說明書一個或多個實施例保護的範圍。
圖1為本發明實施例提供的異常群體識別方法的流程示意圖,該方法的執行主體例如可以為終端設備或伺服器,其中,終端設備例如可以為個人電腦等,伺服器例如可以為獨立的一個伺服器,也可以是由多個伺服器組成的伺服器集群,本示例性實施例對此不做特殊限定。如圖1所示,該方法可以包括以下步驟:
步驟S102、獲取多個待分析用戶中的各待分析用戶的特徵值。
在本發明實施例中,可以首先獲取多個待分析用戶的原始個人資料,然後,對多個待分析用戶的原始個人資料進行離散化,以得到各待分析用戶的特徵值。其中,獲取多個待分析用戶的原始個人資料包括:可以透過一獲取模組獲取各待分析用戶的原始個人資料,並將各待分析用戶的原始個人資料進行集合得到多個待分析用戶的原始個人資料。每個待分析用戶的原始個人資料均可以包括個人基本資料、行為資料、設備資料等,本示例性實施例對此不做特殊限定。個人基本資料中可以包括年齡、性別、職業、收入、學歷、籍貫、聯繫方式、帳號等特徵的資料,本示例性實施例對此不做特殊限定。例如,個人基本資料可以包括:女(性別)、18歲(年齡)、本科(學歷)、律師(職業)、陝西(籍貫)。行為資料可以包括多個行為特徵的資料,具體的,行為資料中包括的行為特徵的資料可以根據應用場景的不同進行設定。例如,在保險場景下,行為資料可以包括:2018.10.03號投保(投保時間)、意外險(投保種類)、2019.2.1號出險(出險特徵)等。設備資料例如可以包括:設備型號、設備歸屬地、使用設備的常用位址、更換設備的頻率等特徵的資料,本示例性實施例對此不做特殊限定。
對多個待分析用戶的原始個人資料進行離散化,以得到各待分析用戶的特徵值可以包括:根據多個待分析用戶的原始個人資料中的各特徵的資料分析各特徵的資料的分佈,再根據各特徵的資料的分佈並結合分箱方式對各特徵的資料進行分箱,並將各特徵的資料分箱後對應的區間確定為對應的各特徵的資料的特徵值,以及根據各特徵的資料的特徵值並結合各待分析用戶的原始個人資料確定各待分析用戶的特徵值。
分箱方式可以根據特徵所屬的性質進行確定,對於連續型的特徵(例如年齡、收入、交易金額等),可以根據業務經驗和資料分佈確定採用等頻、等寬等分箱方式。對於類別型的特徵(例如,性別、學歷、職業等),可以根據特徵的具體類別對類別型的特徵的資料進行分箱。對於文字型的特徵(例如位址等),可以採用將模式一致的文字聚成一類的方式進行分箱。
需要說明的是,可以根據待分析用戶的唯一標識對待分析用戶進行標記,用以區分待分析用戶。唯一標識例如可以為:身分證、軍官證、帳號id等,本示例性實施例對此不做特殊限定。
步驟S104、確定各待分析用戶的特徵值中的高頻特徵值和低頻特徵值。
在本示例性實施例中,可以透過以下兩種方式確定待分析用戶的特徵值中的高頻特徵值和低頻特徵值,其中:
方式一、統計每個特徵值在多個待分析用戶的特徵值中出現的次數,並根據下述確定規則在特徵值中確定高頻特徵值和低頻特徵值,其中,確定規則為:若特徵值在多個待分析用戶的特徵值中出現的次數符合公式T2i
≥Xi
>T1i
,則特徵值為低頻特徵值,其中,Xi
為第i個特徵值在多個待分析用戶的特徵值中出現的次數,T2i
為第i個特徵值對應的第二預設出現次數,T1i
為第i個特徵值對應的第一預設出現次數,T2i
>T1i
,且T2i
和T1i
的具體數值可以根據第i個特徵值所屬的特徵進行確定,即特徵不同,對應的T2i
和T1i
的具體數值也不同;若特徵值在多個待分析用戶的特徵值中出現的次數符合公式T3i
≥Xi
>T2i
,則特徵值為高頻特徵值,其中,Xi
為第i個特徵值在多個待分析用戶的特徵值中出現的次數,T2i
為第i個特徵值對應的第二預設出現次數,T3i
為第i個特徵值對應的第三預設出現次數,T3i
>T2i
,且T2i
和T3i
的具體數值可以根據第i個特徵值所屬的特徵進行確定,即特徵不同,對應的T2i
和T3i
的具體數值也不同。
在確定出高頻特徵值和低頻特徵值後,可以透過將高頻特徵值和低頻特徵分別與各待分析用戶的特徵值進行匹配,以得到各待分析用戶的高頻特徵值和低頻特徵值。例如,高頻特徵值包括:A、B、D,低頻特徵值包括C、E,若待分析用戶的特徵值包括:A、B、C、E,則該待分析用戶的高頻特徵值包括A、B,該待分析用戶的低頻特徵值包括C、E;若待分析用戶的特徵值包括:A、E、F,則該待分析用戶的高頻特徵值包括A,該待分析用戶的低頻特徵值包括E。
方式二、如圖2所示,可以包括以下步驟:
步驟S202、根據各待分析用戶的特徵值構建第一二部圖,其中,第一二部圖包括與各待分析用戶對應的節點、與各特徵值對應的節點、以及各待分析用戶對應的節點與其特徵值對應的節點之間的邊。
在本發明實施例中,將每個待分析用戶分別轉化為節點,每個待分析用戶僅對應一個節點,並將各待分析用戶的特徵值轉化為節點,每個特徵值僅對應一個節點,即在轉化的過程中,若一個特徵值對應的節點已經存在,則複用該節點,無需再設置與該特徵值對應的節點,其中,與各待分析用戶對應的節點位於第一二部圖的一側,與各特徵值對應的節點位於第一二部圖的另一側,且在與各待分析用戶對應的節點與其特徵值對應的節點之間添加邊。例如,待分析用戶為5個,分別為第一待分析用戶至第五待分析用戶,其中,第一待分析用戶的特徵值包括:A、B、D,第二待分析用戶的特徵值包括:B、C、F,第三待分析用戶的特徵值包括:A、C、D、F,第四待分析用戶的特徵值包括:B、D、F,第五待分析用戶的特徵值包括:C、D、E、F,基於此,構建的第一二部圖如圖3所示,其中,第一待分析用戶對應的節點1、第二待分析用戶對應的節點2、第三待分析用戶對應的節點3、第四待分析用戶對應的節點4以及第五待分析用戶對應的節點5位於圖3的左側,特徵值A對應的節點、特徵值B對應的節點、特徵值C對應的節點、特徵值D對應的節點、特徵值E對應的節點、特徵值F對應的節點位於圖3的右側,且在各待分析用戶對應的節點和其特徵值對應的節點之間設置邊。
步驟S204、在第一二部圖中獲取各特徵值對應的節點的度,並根據各特徵值對應的節點的度在特徵值中確定高頻特徵值和低頻特徵值。
在本發明實施例中,特徵值對應的節點的度指與特徵值對應的節點連接的邊的數量,例如,在圖3中,特徵值A對應的節點的度為2、特徵值B對應的節點的度為3、特徵值C對應的節點的度為3、特徵值D對應的節點的度為4、特徵值E對應的節點的度為1、特徵值F的度為4。
根據各特徵值對應的節點的度在特徵值中確定高頻特徵值和低頻特徵值的過程可以包括:根據各特徵值並結合下述確定規則確定高頻特徵值和低頻特徵值,其中確定規則可以為:若特徵值對應的節點的度滿足公式K2i
≥degree(Vi
)>1,則特徵值為低頻特徵值,其中,degree(Vi
)為第i個特徵值Vi
對應的節點的度,K2i
為第i個特徵值Vi
對應的第一預設度,K2i
>1,且K2i
的具體數值可以根據第i個特徵值Vi
所屬的特徵進行確定,即特徵不同,對應的K2i
的具體數值也不同;若特徵值對應的節點的度滿足公式K1i
≥degree(Vi
)>K2i
,則特徵值為高頻特徵值,其中,degree(Vi
)為第i個特徵值Vi
對應的節點的度,K2i
為第i個特徵值Vi
對應的第一預設度,K1i
為第i各特徵值Vi
對應的第二預設度,K1i
>K2i
,且K2i
和K1i
的具體數值可以根據第i個特徵值Vi
所屬的特徵進行確定,即特徵不同,對應的K2i
和K1i
的具體數值也不同。
例如,如圖3所示,若K2i
為2,K1i
為3,則特徵值A為低頻特徵值,特徵值B、特徵值C為高頻特徵值。
步驟S206、根據高頻特徵值和低頻特徵值確定各待分析用戶的特徵值中的高頻特徵值和低頻特徵值。
在本發明實施例中,將高頻特徵值分別與各待分析用戶的特徵值進行匹配,並將各待分析用戶中的與高頻特徵值匹配成功的特徵值確定為對應的各待分析用戶的高頻特徵值;將低頻特徵值分別與各待分析用戶中的特徵值進行匹配,並將各待分析用戶中的與低頻特徵值匹配成功的特徵值確定為對應的各待分析用戶的低頻特徵值。例如,如圖3所示,若K2i
為2,K1i
為3,則特徵值A為低頻特徵值,特徵值B、特徵值C為高頻特徵值。基於此,第一待分析用戶的低頻特徵值包括特徵值A、第一待分析用戶的高頻特徵值包括特徵值B,第二待分析用戶沒有低頻特徵值,第二待分析用戶的高頻特徵值包括:特徵值B、特徵值C,第三待分析用戶的低頻特徵值包括特徵值A,第三待分析用戶的高頻特徵值包括特徵值C,第四待分析用戶沒有低頻特徵值,第四待分析用戶的高頻特徵值包括特徵值B,第五待分析用戶沒有低頻特徵值,第五待分析用戶的高頻特徵值包括特徵值C。
步驟S106、根據各待分析用戶的高頻特徵值和預設的頻繁項集挖掘策略挖掘最大頻繁項集,獲取最大頻繁項集中的低頻最大頻繁特徵值。
在本發明實施例中,預設的頻繁項集挖掘策略例如可以為Apriori(挖掘關聯規則的頻繁項集)策略,還可以為FP-Growth等,本示例性實施例對此不做特殊限定。下面,以預設的頻繁項集挖掘策略為FP-Growth為例,對上述過程進行說明,其中,如圖4所示,可以包括以下步驟:
步驟S402、根據各待分析用戶的高頻特徵值並結合FP-Growth方法,挖掘支援度滿足預設支援度的頻繁多項集,並在頻繁多項集中確定最大頻繁項集。
在本發明實施例中,支持度為高頻特徵值在多個待分析用戶中的出現次數,預設支援度的具體數值可以自行設定,例如可以為1、也可以為2等,本示例性實施例對此不做特殊限定。頻繁多項集指至少包括兩個高頻特徵值的集合。支持度滿足預設支持度的頻繁多項集指頻繁多項集中的每個高頻特徵值的支持度均大於預設支援度。
具體的挖掘頻繁多項集的過程包括:定義預設支援度,掃描各待分析用戶的高頻特徵值,以得到每個高頻特徵值在多個待分析用戶中的出現次數(即支持度),並在各待分析用戶的高頻特徵值中篩除支持度小於預設支持度的高頻特徵值,以及根據各待分析用戶中剩餘的高頻特徵值構建FP樹,並在FP樹中挖掘頻繁多項集。在頻繁多項集中獲取無超集合條件的頻繁多項集,並將頻繁多項集中的無超集合條件的頻繁多項集確定為最大頻繁項集。需要說明的是,每個最大頻繁項集中包括多個高頻特徵值,此處,將最大頻繁項集中包括的高頻特徵值命名為最大頻繁特徵值,即每個最大頻繁項集中包括多個最大頻繁特徵值。
步驟S404、將各待分析用戶的特徵值與最大頻繁項集中的最大頻繁特徵值進行匹配,以得到各待分析用戶的最大頻繁特徵值。
在本發明實施例中,將各待分析用戶的特徵值與最大頻繁項集中的最大頻繁特徵值進行匹配,並將各待分析用戶中與最大頻繁項集中的最大頻繁特徵值匹配成功的特徵值確定為對應的各待分析用戶的最大頻繁特徵值。
步驟S406、在待分析用戶的最大頻繁特徵值中確定低頻最大頻繁特徵值。
在本發明實施例中,可以透過以下兩種方式確定低頻最大頻繁特徵值,其中:
方式一、根據各待分析用戶的最大頻繁特徵值統計各最大頻繁特徵值在多個待分析用戶中的出現次數,並根據各最大頻繁特徵值在多個待分析用戶中的出現次數並結合下述確定規則在最大頻繁特徵值中確定低頻最大頻繁特徵值,其中,確定規則為:若最大頻繁特徵值在多個待分析用戶中的出現次數符合公式P2i
≥Si
,則最大頻繁特徵值為低頻最大頻繁特徵值,其中,P2i
為第i個最大頻繁特徵值對應的預設出現次數,且P2i
的具體數值可以根據第i個最大頻繁特徵值所屬的特徵進行確定,即特徵不同,對應的P2i
的具體數值也不同,Si
為第i個最大頻繁特徵值在多個待分析用戶中的出現次數。
方式二、如圖5所示,可以包括以下步驟:
步驟S502、根據各待分析用戶的最大頻繁特徵值構建第二二部圖,其中,第二二部圖包括與各待分析用戶對應的節點、與各最大頻繁特徵值對應的節點、以及各待分析用戶對應的節點與其最大頻繁特徵值對應的節點之間的邊。
在本發明實施例中,將每個待分析用戶分別轉化為節點,每個待分析用戶僅對應一個節點,並將各待分析用戶的最大頻繁特徵值轉化為節點,每個最大頻繁特徵值僅對應一個節點,其中,與各待分析用戶對應的節點位於第二二部圖的一側,與各最大頻繁特徵值對應的節點位於第二二部圖的另一側,且在各待分析用戶對應的節點與其最大頻繁特徵值對應的節點之間添加邊,以完成對第二二部圖的構建。
步驟S504、在第二二部圖中獲取各最大頻繁特徵值對應的節點的度,並根據各最大頻繁特徵值對應的節點的度在最大頻繁特徵值中確定低頻最大頻繁特徵值。
在本發明實施例中,最大頻繁特徵值對應的節點的度為二部圖中與該最大頻繁特徵值對應的節點相連的邊的數量。確定低頻最大頻繁特徵值的過程可以包括:根據各最大頻繁特徵值對應的節點的度並結合下述確定規則確定低頻最大頻繁特徵值,其中確定規則可以為:若最大頻繁特徵值對應的節點的度滿足公式L2i
≥degree(Vi
),則最大頻繁特徵值為低頻最大頻繁特徵值,其中,degree(Vi
)為第i個最大頻繁特徵值對應的節點的度,L2i
第i個最大頻繁特徵值Vi
對應的預設度,且L2i
的具體數值可以根據第i個最大頻繁特徵值Vi
所屬的特徵進行確定,即特徵不同,對應的L2i
的具體數值也不同。
步驟S108、根據各待分析用戶的特徵值中的低頻最大頻繁特徵值和低頻特徵值構建目標二部圖,並定義目標二部圖中的邊的權重。
在本發明實施例中,將低頻最大頻繁特徵值與各待分析用戶中的特徵值進行匹配,並將各待分析用戶中與低頻最大頻繁特徵值匹配成功的特徵值確定為對應的各待分析用戶的低頻最大頻繁特徵值。根據各待分析用戶的低頻最大頻繁特徵值以及步驟S104中獲取的各待分析用戶的低頻特徵值構建目標二部圖的過程可以包括:將各待分析用戶分別轉化為節點,並將各低頻特徵值轉化為節點,將各低頻最大頻繁特徵值轉化為節點,以及在各待分析用戶對應的節點與其低頻特徵值對應的節點之間添加邊,並在各待分析用戶對應的節點與其低頻最大頻繁特徵值對應的節點之間添加邊,以完成對目標二部圖的構建。
定義目標二部圖中的邊的權重可以包括:定義目標二部圖中各待分析用戶對應的節點與其低頻特徵值對應的節點之間的邊的權重,以及定義目標二部圖中各待分析用戶對應的節點與其低頻最大頻繁特徵值對應的節點之間的邊的權重。其中,定義目標二部圖中各待分析用戶對應的節點與其低頻特徵值對應的節點之間的邊的權重可以包括:根據各低頻特徵值所屬的特徵確定各低頻特徵值的權重,具體地,低頻特徵值的權重越高,同時包括該低頻特徵值的待分析用戶為一個異常群體的概率越高,低頻特徵值的權重越低,同時包括該低頻特徵值的待分析用戶為一個異常群體的概率越低。在確定各低頻特徵值的權重後,將與各低頻特徵值對應的節點連接的邊的權重均設定為對應的各低頻特徵值的權重。例如,若低頻特徵值包括頻繁出險(出險特徵對應的特徵值)、無業(職業特徵對應的特徵值),且頻繁出險的權重為0.5、無業的權重為0.1,則,與頻繁出險對應的節點連接的邊的權重均設定為0.5,與無業對應的節點連接的邊的權重均設定為0.1。同理,定義目標二部圖中各待分析用戶對應的節點與其低頻最大頻繁特徵值對應的節點之間的邊的權重可以包括:根據各低頻最大頻繁特徵值所屬的特徵確定各低頻最大頻繁特徵值的權重,具體地,低頻最大頻繁特徵值的權重越高,同時包括該低頻最大頻繁特徵值的待分析用戶為一個異常群體的概率越高,低頻最大頻繁特徵值的權重越低,同時包括該低頻最大頻繁特徵值的待分析用戶為一個異常群體的概率越低。將與各低頻最大頻繁特徵值對應的節點連接的邊的權重設定為對應的各低頻最大頻繁特徵值的權重。
步驟S110、根據目標二部圖中的邊的權重,以及透過對目標二部圖進行圖聚類所得到的多個待分析用戶的聚類結果,確定待分析用戶中的異常群體。
在本發明實施例中,可以透過以下兩種方式確定待分析用戶中的異常群體,其中:
方式一、在目標二部圖中刪除權重小於第一預設權重的邊,以得到待聚類二部圖,並對待聚類二部圖採用聯通演算法得到至少一個最大連通子圖,以及將每個最大連通子圖中的節點對應的待分析用戶確定為一個異常群體。
在本發明實施例中,第一預設權重的具體數值可以自行設定,本示例性實施例對此不做特殊限定。將目標二部圖中的每個邊的權重依次與第一預設權重進行比較,若邊的權重小於第一預設權重,則在目標二部圖中刪除該邊,若邊的權重不小於第一預設權重,則在目標二部圖中保留該邊,將篩除權重小於預設權重的邊的目標二部圖確定為待聚類二部圖。對待聚類二部圖採用聯通演算法以得到至少一個最大連通子圖,在每個最大連通子圖中篩除與低頻特徵值對應的節點和與低頻最大頻繁特徵值對應的節點,並將每個最大連通子圖中剩餘的節點對應的待分析用戶進行集合,以得到每個最大連通子圖對應的待分析用戶集合,以及將每個最大連通子圖對應的待分析用戶集合分別確定為一個異常群體。
方式二、在目標二部圖中刪除權重小於第一預設權重的邊,以得到待聚類二部圖,並透過社區發現演算法對待聚類二部圖中的節點進行劃分,以得到多個節點集合,以及將每個節點集合中的節點對應的待分析用戶確定為一個異常群體。
在本發明實施例中,由於在二部圖中刪除權重小於第一預設權重的邊,以得到待聚類二部圖的原理與上述方式一中的原理相同,因此此處不在贅述。社區發現演算法例如可以為louvain演算法等,本示例性實施例對此不做特殊限定。在透過社區發現演算法對待聚類二部圖中的節點進行劃分得到多個節點集合後,首先在每個節點集合中篩除與低頻特徵值對應的節點和低頻最大頻繁特徵值對應的節點,並分別將每個節點集合中剩餘的節點對應的待分析用戶進行集合,以得到每個節點集合對應的待分析用戶集合,並將每個節點集合對應的待分析用戶集合分別確定為一個異常群體。
進一步地,在得到異常群體之後,為了進一步對異常群體進行驗證,進而進一步的提高異常群體識別的準確度,可以獲取每個異常群體中的待分析用戶的總數量,並在異常群體中篩除待分析用戶的總數量少於預設數量的異常群體,並將剩餘的異常群體確定為最終識別出的異常群體;還可以計算每個異常群體對應的最大連通子圖的模組度,並將每個異常群體對應的最大連通子圖的模組度確定為對應的異常群體的模組度,以及在異常群體中篩除模組度小於預設模組度的異常群體,將剩餘的異常群體確定為最終識別出的異常群體。需要說明的是,上述兩種驗證方式僅為示例性的,並不用於限定本發明,其還可以透過分析異常群體中的每個待分析用戶的業務特徵對異常群體進行驗證。
為了更加準確的對待分析用戶進行聚類,以得到更加準確的異常群體,如圖6所示,根據目標二部圖中的邊的權重,以及透過對目標二部圖進行圖聚類所得到的多個待分析用戶的聚類結果,確定待分析用戶中的異常群體可以包括以下步驟:
步驟S602、根據目標二部圖中的邊的權重計算任意兩個待分析用戶之間的權重。
在本發明實施例中,在目標二部圖中獲取與任意兩個待分析用戶對應的節點共同連接的與低頻特徵值對應的節點和與低頻最大頻繁特徵值對應的節點,並將與任意兩個待分析用戶對應的節點共同連接的與低頻特徵值對應的節點和與低頻最大頻繁特徵值對應的節點確定為目標節點;根據任意兩個待分析用戶中的任何一個待分析用戶對應的節點與每個目標節點之間的邊的權重並結合下述公式計算任意兩個待分析用戶之間的權重,上述公式為:
其中,為任意兩個待分析用戶之間的權重,j為目標節點的總數量,為第i個目標節點與任意兩個待分析用戶中的任意一個待分析用戶對應的節點之間的邊的權重。
步驟S604、將各待分析用戶轉化為節點,並在任意兩個節點之間設置邊,並將任意兩個節點的邊的權重設定為對應的任意兩個待分析用戶之間的權重,以構建目標聚類圖。
在本發明實施例中,將各待分析用戶轉化為節點,即一個待分析用戶僅對應一個節點,並在任意兩個節點之間設置邊,以及將任意兩個待分析用戶之間的權重設定為該任意兩個待分析用戶對應的兩個節點之間的邊的權重,以完成目標聚類圖的構建。由上可知,透過步驟S602和步驟S604將包括待分析用戶對應的節點和低頻特徵值對應的節點以及低頻最大頻繁特徵值對應的節點的目標二部圖轉化為僅包括待分析用戶對應的節點的目標聚類圖。
步驟S606、透過對目標聚類圖進行圖聚類所得到的多個待分析用戶的聚類結果,確定待分析用戶中的異常群體。
在本發明實施例中,可以透過以下兩種方式確定異常群體,其中:
方式一、在目標聚類圖中刪除權重小於第二預設權重的邊,以得到待聚類圖,並對待聚類圖採用聯通演算法得到至少一個最大連通子圖,以及將每個最大連通子圖中的節點對應的待分析用戶分別確定為一個異常群體。
在本發明實施例中,第二預設權重的具體數值可以自行設定,本示例性實施例對此不做特殊限定。將目標聚類圖中的每個邊的權重分別與第二預設權重進行比較,並在目標聚類圖中刪除權重小於第二預設權重的邊,以將目標聚類圖轉化為待聚類圖。將每個最大連通子圖中的節點對應的待分析用戶進行集合,以得到每個最大連通子圖對應的待分析用戶集合,並將每個最大連通子圖對應的待分析用戶集合分別確定為一個異常群體。
方式二、在目標聚類圖中刪除權重小於第二預設權重的邊,以得到待聚類圖,並透過社區發現演算法對待聚類圖進行劃分,以得到多個節點集合,以及將每個節點集合對應的待分析用戶分別確定為一個異常群體。
在申請實施例中,第二預設權重已經在上文中進行了說明,因此此處不在贅述。將目標聚類圖中的每個邊的權重分別與第二預設權重進行比較,並在目標聚類圖中刪除權重小於第二預設權重的邊,以將目標聚類圖轉化為待聚類圖。社區發現演算法例如可以為louvain演算法等,本示例性實施例對此不做特殊限定。在透過社區發現演算法對待聚類圖中的節點進行劃分得到多個節點集合後,分別將每個節點集合中的節點對應的待分析用戶進行集合,以得到每個節點集合對應的待分析用戶集合,並將每個節點集合對應的待分析用戶集合分別確定為一個異常群體。
由上可知,透過根據目標二部圖中的邊的權重計算任意兩個待分析用戶之間的權重,並根據任意兩個待分析用戶之前的權重構建目標聚類圖,以將目標二部圖轉化為目標聚類圖,使得目標聚類圖更加準確且更加直觀的反應待分析用戶之間的關係,進而使得根據目標聚類圖得到的異常群體更加準確。
需要說明的是,上述兩種確定異常群體的方式進行示例性的,並不用於限定本發明。
進一步地,在得到異常群體之後,為了進一步對異常群體進行驗證,進而進一步的提高異常群體識別的準確度,可以獲取每個異常群體中的待分析用戶的總數量,並在異常群體中篩除待分析用戶的總數量少於預設數量的異常群體,並將剩餘的異常群體確定為最終識別出的異常群體;還可以計算每個異常群體對應的最大連通子圖的模組度,並將每個異常群體對應的最大連通子圖的模組度確定為對應的異常群體的模組度,以及在異常群體中篩除模組度小於預設模組度的異常群體,將剩餘的異常群體確定為最終識別出的異常群體。需要說明的是,上述兩種驗證方式僅為示例性的,並不用於限定本發明,其還可以透過分析異常群體中的每個待分析用戶的業務特徵對異常群體進行驗證。
綜上所述,透過對各待分析用戶的高頻特徵值進行預設的頻繁項集挖掘策略挖掘最大頻繁項集,並獲取最大頻繁項集中的低頻最大頻繁特徵值,以挖掘待分析用戶的行為序列,進而使得異常群體的識別更加準確;此外,僅透過獲取各待分析用戶的低頻特徵值和低頻最大頻繁特徵值,並根據各待分析用戶的低頻特徵值和低頻最大頻繁特徵值構建目標二部圖,並定義目標二部圖中的邊的權重,以及根據目標二部圖中的邊的權重並對目標二部圖進行圖聚類,以得到異常群體,步驟簡單,且易於執行。
對應上述異常群體識別方法,基於相同的技術構思,本發明實施例還提供了一種異常群體識別裝置,圖7為本發明實施例提供的異常群體識別裝置700的組成示意圖,該裝置用於執行上述異常群體識別方法,如圖7所示,該裝置700可以包括:獲取模組701、確定模組702、挖掘模組703、構建模組704、聚類別模組705,其中:
獲取模組701,用於獲取多個待分析用戶中的各所述待分析用戶的特徵值;
確定模組702,用於確定各所述待分析用戶的特徵值中的高頻特徵值和低頻特徵值;
挖掘模組703,用於根據各所述待分析用戶的高頻特徵值和預設的頻繁項集挖掘策略挖掘最大頻繁項集,獲取所述最大頻繁項集中的低頻最大頻繁特徵值;
構建模組704,用於根據各所述待分析用戶的特徵值中的所述低頻最大頻繁特徵值和所述低頻特徵值構建目標二部圖,並定義所述目標二部圖中的邊的權重;
聚類別模組705,用於根據所述目標二部圖中的邊的權重,以及透過對所述目標二部圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體。
可選地,所述獲取模組701可以包括:
獲取單元,用於獲取所述多個待分析用戶的原始個人資料;
離散化單元,用於對所述多個待分析用戶的原始個人資料進行離散化,以得到各所述待分析用戶的特徵值。
可選地,所述確定模組702可以包括:
第一構建單元,用於根據各所述待分析用戶的特徵值構建第一二部圖,其中,所述第一二部圖包括與各所述待分析用戶對應的節點、與各所述特徵值對應的節點、以及各所述待分析用戶對應的節點與其特徵值對應的節點之間的邊;
第一確定單元,用於在所述第一二部圖中獲取各所述特徵值對應的節點的度,並根據各所述特徵值對應的節點的度在所述特徵值中確定高頻特徵值和低頻特徵值;
第二確定單元,用於根據所述高頻特徵值和所述低頻特徵值確定各所述待分析用戶的特徵值中的高頻特徵值和低頻特徵值。
可選地,所述挖掘模組703可以包括:
挖掘單元,用於根據各所述待分析用戶的高頻特徵值並結合FP-Growth方法,挖掘支援度滿足預設支援度的頻繁多項集,並在所述頻繁多項集中確定最大頻繁項集;
匹配單元,用於將各所述待分析用戶的特徵值與所述最大頻繁項集中的最大頻繁特徵值進行匹配,以得到各所述待分析用戶的最大頻繁特徵值;
第三確定單元,用於在所述待分析用戶的最大頻繁特徵值中確定低頻最大頻繁特徵值。
可選地,所述第三確定單元可以包括:
構建子單元,用於根據各所述待分析用戶的最大頻繁特徵值構建第二二部圖,其中,所述第二二部圖包括與各所述待分析用戶對應的節點、與各所述最大頻繁特徵值對應的節點、以及各所述待分析用戶對應的節點與其最大頻繁特徵值對應的節點之間的邊;
確定子單元,用於在所述第二二部圖中獲取各所述最大頻繁特徵值對應的節點的度,並根據各所述最大頻繁特徵值對應的節點的度在所述最大頻繁特徵值中確定低頻最大頻繁特徵值。
可選地,所述聚類別模組705可以包括:
第一聚類單元,用於在所述目標二部圖中刪除權重小於第一預設權重的邊,以得到待聚類二部圖,並對所述待聚類二部圖採用聯通演算法得到至少一個最大連通子圖,以及將每個所述最大連通子圖中的節點對應的待分析用戶確定為一個所述異常群體;或者
第二聚類單元,用於在所述目標二部圖中刪除權重小於第一預設權重的邊,以得到待聚類二部圖,並透過社區發現演算法對所述待聚類二部圖中的節點進行劃分,以得到多個節點集合,以及將每個所述節點集合中的節點對應的待分析用戶確定為一個所述異常群體。
可選地,所述聚類別模組705可以包括:
計算單元,用於根據所述目標二部圖中的邊的權重計算任意兩個所述待分析用戶之間的權重;
第二構建單元,用於將各所述待分析用戶轉化為節點,並在任意兩個節點之間設置邊,並將任意兩個節點的邊的權重設定為對應的任意兩個所述待分析用戶之間的權重,以構建目標聚類圖;
第三聚類單元,用於透過對所述目標聚類圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體。
可選地,所述第三聚類單元可以包括:
第一聚類子單元,用於在所述目標聚類圖中刪除權重小於第二預設權重的邊,以得到待聚類圖,並對所述待聚類圖採用聯通演算法得到至少一個最大連通子圖,以及將每個所述最大連通子圖中的節點對應的待分析用戶分別確定為一個所述異常群體;或者
第二聚類子單元,用於在所述目標聚類圖中刪除權重小於第二預設權重的邊,以得到待聚類圖,並透過社區發現演算法對所述待聚類圖進行劃分,以得到多個節點集合,以及將每個所述節點集合對應的待分析用戶分別確定為一個所述異常群體。
本發明實施例中的異常群體識別裝置,透過對各待分析用戶的高頻特徵值進行預設的頻繁項集挖掘策略挖掘最大頻繁項集,並獲取最大頻繁項集中的低頻最大頻繁特徵值,以挖掘待分析用戶的行為序列,進而使得異常群體的識別更加準確;此外,僅透過獲取各待分析用戶的低頻特徵值和低頻最大頻繁特徵值,並根據各待分析用戶的低頻特徵值和低頻最大頻繁特徵值構建目標二部圖,並定義目標二部圖中的邊的權重,以及根據目標二部圖中的邊的權重並對目標二部圖進行圖聚類,以得到異常群體,步驟簡單,且易於執行。
應上述異常群體識別方法,基於相同的技術構思,本發明實施例還提供了一種異常群體識別設備,圖8為本發明實施例提供的異常群體識別設備的結構示意圖,該設備用於執行上述的異常群體識別方法。
如圖8所示,異常群體識別設備可因配置或性能不同而產生比較大的差異,可以包括一個或一個以上的處理器801和記憶體802,記憶體802中可以儲存有一個或一個以上儲存應用程式或資料。其中,記憶體802可以是短暫儲存或持久儲存。儲存在記憶體802的應用程式可以包括一個或一個以上模組(圖示未顯示),每個模組可以包括對異常群體識別設備中的一系列電腦可執行指令。更進一步地,處理器801可以設定為與記憶體802通訊,在異常群體識別設備上執行記憶體802中的一系列電腦可執行指令。異常群體識別設備還可以包括一個或一個以上電源803、一個或一個以上有線或無線網路介面804、一個或一個以上輸入輸出介面805、一個或一個以上鍵盤806等。
在一個具體的實施例中,異常群體識別設備包括有記憶體,以及一個或一個以上的程式,其中,一個或者一個以上程式儲存於記憶體中,且一個或者一個以上程式可以包括一個或一個以上模組,且每個模組可以包括對異常群體識別設備中的一系列電腦可執行指令,且經配置以由一個或者一個以上處理器執行該一個或者一個以上套裝程式含用於進行以下電腦可執行指令:
獲取多個待分析用戶中的各所述待分析用戶的特徵值;
確定各所述待分析用戶的特徵值中的高頻特徵值和低頻特徵值;
根據各所述待分析用戶的高頻特徵值和預設的頻繁項集挖掘策略挖掘最大頻繁項集,獲取所述最大頻繁項集中的低頻最大頻繁特徵值;
根據各所述待分析用戶的特徵值中的所述低頻最大頻繁特徵值和所述低頻特徵值構建目標二部圖,並定義所述目標二部圖中的邊的權重;
根據所述目標二部圖中的邊的權重,以及透過對所述目標二部圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體。
可選地,電腦可執行指令在被執行時,所述獲取多個待分析用戶中的各所述待分析用戶的特徵值包括:
獲取所述多個待分析用戶的原始個人資料;
對所述多個待分析用戶的原始個人資料進行離散化,以得到各所述待分析用戶的特徵值。
可選地,電腦可執行指令在被執行時,所述確定各所述待分析用戶的特徵值中的高頻特徵值和低頻特徵值包括:
根據各所述待分析用戶的特徵值構建第一二部圖,其中,所述第一二部圖包括與各所述待分析用戶對應的節點、與各所述特徵值對應的節點、以及各所述待分析用戶對應的節點與其特徵值對應的節點之間的邊;
在所述第一二部圖中獲取各所述特徵值對應的節點的度,並根據各所述特徵值對應的節點的度在所述特徵值中確定高頻特徵值和低頻特徵值;
根據所述高頻特徵值和所述低頻特徵值確定各所述待分析用戶的特徵值中的高頻特徵值和低頻特徵值。
可選地,電腦可執行指令在被執行時,所述根據各所述待分析用戶的高頻特徵值和預設的頻繁項集挖掘策略挖掘最大頻繁項集,獲取所述最大頻繁項集中的低頻最大頻繁特徵值包括:
根據各所述待分析用戶的高頻特徵值並結合FP-Growth方法,挖掘支援度滿足預設支援度的頻繁多項集,並在所述頻繁多項集中確定最大頻繁項集;
將各所述待分析用戶的特徵值與所述最大頻繁項集中的最大頻繁特徵值進行匹配,以得到各所述待分析用戶的最大頻繁特徵值;
在所述待分析用戶的最大頻繁特徵值中確定低頻最大頻繁特徵值。
可選地,電腦可執行指令在被執行時,所述在所述待分析用戶的最大頻繁特徵值中確定低頻最大頻繁特徵值包括:
根據各所述待分析用戶的最大頻繁特徵值構建第二二部圖,其中,所述第二二部圖包括與各所述待分析用戶對應的節點、與各所述最大頻繁特徵值對應的節點、以及各所述待分析用戶對應的節點與其最大頻繁特徵值對應的節點之間的邊;
在所述第二二部圖中獲取各所述最大頻繁特徵值對應的節點的度,並根據各所述最大頻繁特徵值對應的節點的度在所述最大頻繁特徵值中確定低頻最大頻繁特徵值。
可選地,電腦可執行指令在被執行時,,所述根據所述目標二部圖中的邊的權重,以及透過對所述目標二部圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體包括:
在所述目標二部圖中刪除權重小於第一預設權重的邊,以得到待聚類二部圖,並對所述待聚類二部圖採用聯通演算法得到至少一個最大連通子圖,以及將每個所述最大連通子圖中的節點對應的待分析用戶確定為一個所述異常群體;或者
在所述目標二部圖中刪除權重小於第一預設權重的邊,以得到待聚類二部圖,並透過社區發現演算法對所述待聚類二部圖中的節點進行劃分,以得到多個節點集合,以及將每個所述節點集合中的節點對應的待分析用戶確定為一個所述異常群體。
可選地,電腦可執行指令在被執行時,所述根據所述目標二部圖中的邊的權重,以及透過對所述目標二部圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體包括:
根據所述目標二部圖中的邊的權重計算任意兩個所述待分析用戶之間的權重;
將各所述待分析用戶轉化為節點,並在任意兩個節點之間設置邊,並將任意兩個節點的邊的權重設定為對應的任意兩個所述待分析用戶之間的權重,以構建目標聚類圖;
透過對所述目標聚類圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體。
可選地,電腦可執行指令在被執行時,所述透過對所述目標聚類圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體包括:
在所述目標聚類圖中刪除權重小於第二預設權重的邊,以得到待聚類圖,並對所述待聚類圖採用聯通演算法得到至少一個最大連通子圖,以及將每個所述最大連通子圖中的節點對應的待分析用戶分別確定為一個所述異常群體;或者
在所述目標聚類圖中刪除權重小於第二預設權重的邊,以得到待聚類圖,並透過社區發現演算法對所述待聚類圖進行劃分,以得到多個節點集合,以及將每個所述節點集合對應的待分析用戶分別確定為一個所述異常群體。
本發明實施例中的異常群體識別設備,透過對各待分析用戶的高頻特徵值進行預設的頻繁項集挖掘策略挖掘最大頻繁項集,並獲取最大頻繁項集中的低頻最大頻繁特徵值,以挖掘待分析用戶的行為序列,進而使得異常群體的識別更加準確;此外,僅透過獲取各待分析用戶的低頻特徵值和低頻最大頻繁特徵值,並根據各待分析用戶的低頻特徵值和低頻最大頻繁特徵值構建目標二部圖,並定義目標二部圖中的邊的權重,以及根據目標二部圖中的邊的權重並對目標二部圖進行圖聚類,以得到異常群體,步驟簡單,且易於執行。
對應上述異常群體識別方法,基於相同的技術構思,本發明實施例還提供了一種儲存媒體,用於儲存電腦可執行指令,在一個具體的實施例中,該儲存媒體可以為隨身碟、光碟、硬碟等,該儲存媒體儲存的電腦可執行指令在被處理器執行時,能實現以下流程:
獲取多個待分析用戶中的各所述待分析用戶的特徵值;
確定各所述待分析用戶的特徵值中的高頻特徵值和低頻特徵值;
根據各所述待分析用戶的高頻特徵值和預設的頻繁項集挖掘策略挖掘最大頻繁項集,獲取所述最大頻繁項集中的低頻最大頻繁特徵值;
根據各所述待分析用戶的特徵值中的所述低頻最大頻繁特徵值和所述低頻特徵值構建目標二部圖,並定義所述目標二部圖中的邊的權重;
根據所述目標二部圖中的邊的權重,以及透過對所述目標二部圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體。
可選地,該儲存媒體儲存的電腦可執行指令在被處理器執行時,所述獲取多個待分析用戶中的各所述待分析用戶的特徵值包括:
獲取所述多個待分析用戶的原始個人資料;
對所述多個待分析用戶的原始個人資料進行離散化,以得到各所述待分析用戶的特徵值。
可選地,該儲存媒體儲存的電腦可執行指令在被處理器執行時,所述確定各所述待分析用戶的特徵值中的高頻特徵值和低頻特徵值包括:
根據各所述待分析用戶的特徵值構建第一二部圖,其中,所述第一二部圖包括與各所述待分析用戶對應的節點、與各所述特徵值對應的節點、以及各所述待分析用戶對應的節點與其特徵值對應的節點之間的邊;
在所述第一二部圖中獲取各所述特徵值對應的節點的度,並根據各所述特徵值對應的節點的度在所述特徵值中確定高頻特徵值和低頻特徵值;
根據所述高頻特徵值和所述低頻特徵值確定各所述待分析用戶的特徵值中的高頻特徵值和低頻特徵值。
可選地,該儲存媒體儲存的電腦可執行指令在被處理器執行時,所述根據各所述待分析用戶的高頻特徵值和預設的頻繁項集挖掘策略挖掘最大頻繁項集,獲取所述最大頻繁項集中的低頻最大頻繁特徵值包括:
根據各所述待分析用戶的高頻特徵值並結合FP-Growth方法,挖掘支援度滿足預設支援度的頻繁多項集,並在所述頻繁多項集中確定最大頻繁項集;
將各所述待分析用戶的特徵值與所述最大頻繁項集中的最大頻繁特徵值進行匹配,以得到各所述待分析用戶的最大頻繁特徵值;
在所述待分析用戶的最大頻繁特徵值中確定低頻最大頻繁特徵值。
可選地,該儲存媒體儲存的電腦可執行指令在被處理器執行時,所述在所述待分析用戶的最大頻繁特徵值中確定低頻最大頻繁特徵值包括:
根據各所述待分析用戶的最大頻繁特徵值構建第二二部圖,其中,所述第二二部圖包括與各所述待分析用戶對應的節點、與各所述最大頻繁特徵值對應的節點、以及各所述待分析用戶對應的節點與其最大頻繁特徵值對應的節點之間的邊;
在所述第二二部圖中獲取各所述最大頻繁特徵值對應的節點的度,並根據各所述最大頻繁特徵值對應的節點的度在所述最大頻繁特徵值中確定低頻最大頻繁特徵值。
可選地,該儲存媒體儲存的電腦可執行指令在被處理器執行時,所述根據所述目標二部圖中的邊的權重,以及透過對所述目標二部圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體包括:
在所述目標二部圖中刪除權重小於第一預設權重的邊,以得到待聚類二部圖,並對所述待聚類二部圖採用聯通演算法得到至少一個最大連通子圖,以及將每個所述最大連通子圖中的節點對應的待分析用戶確定為一個所述異常群體;或者
在所述目標二部圖中刪除權重小於第一預設權重的邊,以得到待聚類二部圖,並透過社區發現演算法對所述待聚類二部圖中的節點進行劃分,以得到多個節點集合,以及將每個所述節點集合中的節點對應的待分析用戶確定為一個所述異常群體。
可選地,該儲存媒體儲存的電腦可執行指令在被處理器執行時,所述根據所述目標二部圖中的邊的權重,以及透過對所述目標二部圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體包括:
根據所述目標二部圖中的邊的權重計算任意兩個所述待分析用戶之間的權重;
將各所述待分析用戶轉化為節點,並在任意兩個節點之間設置邊,並將任意兩個節點的邊的權重設定為對應的任意兩個所述待分析用戶之間的權重,以構建目標聚類圖;
透過對所述目標聚類圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體。
可選地,該儲存媒體儲存的電腦可執行指令在被處理器執行時,所述透過對所述目標聚類圖進行圖聚類所得到的所述多個待分析用戶的聚類結果,確定所述待分析用戶中的異常群體包括:
在所述目標聚類圖中刪除權重小於第二預設權重的邊,以得到待聚類圖,並對所述待聚類圖採用聯通演算法得到至少一個最大連通子圖,以及將每個所述最大連通子圖中的節點對應的待分析用戶分別確定為一個所述異常群體;或者
在所述目標聚類圖中刪除權重小於第二預設權重的邊,以得到待聚類圖,並透過社區發現演算法對所述待聚類圖進行劃分,以得到多個節點集合,以及將每個所述節點集合對應的待分析用戶分別確定為一個所述異常群體。
本發明實施例中的儲存媒體儲存的電腦可執行指令在被處理器執行時,透過對各待分析用戶的高頻特徵值進行預設的頻繁項集挖掘策略挖掘最大頻繁項集,並獲取最大頻繁項集中的低頻最大頻繁特徵值,以挖掘待分析用戶的行為序列,進而使得異常群體的識別更加準確;此外,僅透過獲取各待分析用戶的低頻特徵值和低頻最大頻繁特徵值,並根據各待分析用戶的低頻特徵值和低頻最大頻繁特徵值構建目標二部圖,並定義目標二部圖中的邊的權重,以及根據目標二部圖中的邊的權重並對目標二部圖進行圖聚類,以得到異常群體,步驟簡單,且易於執行。
在20世紀90年代,對於一個技術的改進可以很明顯地區分是硬體上的改進(例如,對二極體、電晶體、開關等電路結構的改進)還是軟體上的改進(對於方法流程的改進)。然而,隨著技術的發展,當今的很多方法流程的改進已經可以視為硬體電路結構的直接改進。設計人員幾乎都透過將改進的方法流程程式設計到硬體電路中來得到對應的硬體電路結構。因此,不能說一個方法流程的改進就不能用硬體實體模組來實現。例如,可程式設計邏輯器件(Programmable Logic Device,PLD)(例如現場可程式設計閘陣列(Field Programmable Gate Array,FPGA))就是這樣一種積體電路,其邏輯功能由用戶對器件程式設計來確定。由設計人員自行程式設計來把一個數位系統“整合”在一片PLD上,而不需要請晶片製造廠商來設計和製作專用的積體電路晶片。而且,如今,取代手工地製作積體電路晶片,這種程式設計也多半改用“邏輯編譯器(logic
Compiler)”軟體來實現,它與程式開發撰寫時所用的軟體編譯器相類似,而要編譯之前的原始代碼也得用特定的程式設計語言來撰寫,此稱之為硬體描述語言(Hardware Description Language,HDL),而HDL也並非僅有一種,而是有許多種,如ABEL(Advanced Boolean Expression Language)、AHDL(Altera Hardware Description Language)
、Confluence、CUPL(Cornell University Programming
Language)、HDCal、JHDL(Java Hardware Description
Language)、Lava、Lola、MyHDL、PALASM、RHDL(
Ruby Hardware Description Language)等,目前最普遍使用的是VHDL(Very-High-Speed Integrated Circuit Hardware Description Language)與Verilog。本領域技術人員也應該清楚,只需要將方法流程用上述幾種硬體描述語言稍作邏輯程式設計並程式設計到積體電路中,就可以很容易得到實現該邏輯方法流程的硬體電路。
控制器可以按任何適當的方式來實現,例如,控制器可以採取例如微處理器或處理器以及儲存可由該(微)處理器執行的電腦可讀程式碼(例如軟體或韌體)的電腦可讀媒體、邏輯閘、開關、專用積體電路(Application Specific Integrated Circuit,ASIC)、可程式設計邏輯控制器和嵌入微控制器的形式,控制器的例子包括但不限於以下微控制器:ARC 625D、Atmel AT91SAM、Microchip
PIC18F26K20以及Silicone Labs C8051F320,記憶體控制器還可以被實現為記憶體的控制邏輯的一部分。本領域技術人員也知道,除了以純電腦可讀程式碼方式實現控制器以外,完全可以透過將方法步驟進行邏輯程式設計來使得控制器以邏輯閘、開關、專用積體電路、可程式設計邏輯控制器和嵌入微控制器等的形式來實現相同功能。因此這種控制器可以被認為是一種硬體部件,而對其內包括的用於實現各種功能的裝置也可以視為硬體部件內的結構。或者甚至,可以將用於實現各種功能的裝置視為既可以是實現方法的軟體模組又可以是硬體部件內的結構。
上述實施例闡明的系統、裝置、模組或單元,具體可以由電腦晶片或實體實現,或者由具有某種功能的產品來實現。一種典型的實現設備為電腦。具體地,電腦例如可以為個人電腦、膝上型電腦、蜂巢式電話、相機電話、智慧型電話、個人數位助理、媒體播放器、導航設備、電子郵件設備、遊戲控制台、平板電腦、穿戴式設備或者這些設備中的任何設備的組合。
為了描述的方便,描述以上裝置時以功能分為各種單元分別描述。當然,在實施本發明時可以把各單元的功能在同一個或多個軟體和/或硬體中實現。
本領域內的技術人員應明白,本發明的實施例可提供為方法、系統、或電腦程式產品。因此,本發明可採用完全硬體實施例、完全軟體實施例、或結合軟體和硬體方面的實施例的形式。而且,本發明可採用在一個或多個其中包含有電腦可用程式碼的電腦可用儲存媒體(包括但不限於磁碟記憶體、CD-ROM、光學記憶體等)上實施的電腦程式產品的形式。
本發明是參照根據本發明實施例的方法、設備(系統)、和電腦程式產品的流程圖和/或方塊圖來描述的。應理解可由電腦程式指令實現流程圖和/或方塊圖中的每一流程和/或方塊、以及流程圖和/或方塊圖中的流程和/或方塊的結合。可提供這些電腦程式指令到通用電腦、專用電腦、嵌入式處理機或其他可程式設計資料處理設備的處理器以產生一個機器,使得透過電腦或其他可程式設計資料處理設備的處理器執行的指令產生用於實現在流程圖一個流程或多個流程和/或方塊圖一個方塊或多個方塊中指定的功能的裝置。
這些電腦程式指令也可儲存在能引導電腦或其他可程式設計資料處理設備以特定方式工作的電腦可讀記憶體中,使得儲存在該電腦可讀記憶體中的指令產生包括指令裝置的製造品,該指令裝置實現在流程圖一個流程或多個流程和/或方塊圖一個方塊或多個方塊中指定的功能。
這些電腦程式指令也可裝載到電腦或其他可程式設計資料處理設備上,使得在電腦或其他可程式設計設備上執行一系列操作步驟以產生電腦實現的處理,從而在電腦或其他可程式設計設備上執行的指令提供用於實現在流程圖一個流程或多個流程和/或方塊圖一個方塊或多個方塊中指定的功能的步驟。
在一個典型的配置中,計算設備包括一個或多個處理器(CPU)、輸入/輸出介面、網路介面和記憶體。
記憶體可能包括電腦可讀媒體中的非永久性記憶體,隨機存取記憶體(RAM)和/或非易失性記憶體等形式,如唯讀記憶體(ROM)或快閃記憶體(flash RAM)。記憶體是電腦可讀媒體的示例。
電腦可讀媒體包括永久性和非永久性、可移動和非可移動媒體可以由任何方法或技術來實現資訊儲存。資訊可以是電腦可讀指令、資料結構、程式的模組或其他資料。電腦的儲存媒體的例子包括,但不限於相變記憶體(PRAM)、靜態隨機存取記憶體(SRAM)、動態隨機存取記憶體(DRAM)、其他類型的隨機存取記憶體(RAM)、唯讀記憶體(ROM)、電可抹除可程式設計唯讀記憶體(EEPROM)、快閃記憶體或其他記憶體技術、唯讀光碟唯讀記憶體(CD-ROM)、數位多功能光碟(DVD)或其他光學儲存、磁盒式磁帶,磁帶磁片儲存或其他磁性儲存設備或任何其他非傳輸媒體,可用於儲存可以被計算設備訪問的資訊。按照本文中的界定,電腦可讀媒體不包括暫態式電腦可讀媒體(transitory media),如調變的資料訊號和載波。
還需要說明的是,術語“包括”、“包含”或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、商品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、商品或者設備所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,並不排除在包括所述要素的過程、方法、商品或者設備中還存在另外的相同要素。
本領域技術人員應明白,本發明的實施例可提供為方法、系統或電腦程式產品。因此,本發明可採用完全硬體實施例、完全軟體實施例或結合軟體和硬體方面的實施例的形式。而且,本發明可採用在一個或多個其中包含有電腦可用程式碼的電腦可用儲存媒體(包括但不限於磁碟記憶體、CD-ROM、光學記憶體等)上實施的電腦程式產品的形式。
本發明可以在由電腦執行的電腦可執行指令的一般上下文中描述,例如程式模組。一般地,程式模組包括執行特定任務或實現特定抽象資料類型的常式、程式、物件、元件、資料結構等等。也可以在分散式運算環境中實踐本發明,在這些分散式運算環境中,由透過通訊網路而被連接的遠端處理設備來執行任務。在分散式運算環境中,程式模組可以位於包括儲存設備在內的本地和遠端電腦儲存媒體中。
本說明書中的各個實施例均採用漸進的方式描述,各個實施例之間相同相似的部分互相參見即可,每個實施例重點說明的都是與其他實施例的不同之處。尤其,對於系統實施例而言,由於其基本相似於方法實施例,所以描述的比較簡單,相關之處參見方法實施例的部分說明即可。
以上所述僅為本發明的實施例而已,並不用於限制本發明。對於本領域技術人員來說,本發明可以有各種更改和變化。凡在本發明的精神和原理之內所作的任何修改、等同替換、改進等,均應包含在本發明的申請專利範圍的範疇之內。One or more embodiments of this specification provide a method and device for identifying abnormal groups to solve the problem of low accuracy of abnormal group recognition in the prior art. In order to enable those skilled in the art to better understand the technical solutions in one or more embodiments of this specification, the following will combine the drawings in one or more embodiments of this specification to compare the The technical solution is described clearly and completely. Obviously, the described embodiments are only a part of the embodiments in this specification, rather than all the embodiments. Based on one or more embodiments of this specification, all other embodiments obtained by a person of ordinary skill in the art without creative work shall fall within the protection scope of one or more embodiments of this specification. Figure 1 is a schematic flow chart of an abnormal group identification method provided by an embodiment of the present invention. The execution subject of the method can be, for example, a terminal device or a server. The terminal device can be, for example, a personal computer, and the server can be, for example, an independent one. The server may also be a server cluster composed of multiple servers, which is not particularly limited in this exemplary embodiment. As shown in Fig. 1, the method may include the following steps: Step S102: Obtain a characteristic value of each user to be analyzed among a plurality of users to be analyzed. In the embodiment of the present invention, the original personal data of multiple users to be analyzed may be obtained first, and then the original personal data of the multiple users to be analyzed are discretized to obtain the characteristic value of each user to be analyzed. Among them, obtaining the original personal data of multiple users to be analyzed includes: obtaining the original personal data of each user to be analyzed through an obtaining module, and collecting the original personal data of each user to be analyzed to obtain the original personal data of multiple users to be analyzed personal information. The original personal data of each user to be analyzed may include basic personal data, behavior data, equipment data, etc., which are not particularly limited in this exemplary embodiment. The basic personal data may include data with characteristics such as age, gender, occupation, income, educational background, hometown, contact information, account number, etc. This exemplary embodiment does not specifically limit this. For example, basic personal information can include: female (gender), 18 years old (age), undergraduate (education), lawyer (occupation), Shaanxi (hometown). The behavior data may include data of multiple behavior characteristics. Specifically, the data of behavior characteristics included in the behavior data can be set according to different application scenarios. For example, in an insurance scenario, the behavioral data may include: 2018.10.03 insurance (insured time), accident insurance (insurance type), 2019.2.1 insurance (insurance characteristics), etc. The device data may include, for example, the device model, the home location of the device, the common address of the used device, the frequency of replacing the device, and other characteristic data, which is not specifically limited in this exemplary embodiment. Discretizing the original personal data of multiple users to be analyzed to obtain the characteristic value of each user to be analyzed may include: analyzing the distribution of the data of each feature according to the data of each feature in the original personal data of the multiple users to be analyzed, Then according to the distribution of the data of each feature and combined with the binning method, the data of each feature is binned, and the corresponding interval after the data of each feature is binned is determined as the feature value of the corresponding data of each feature, and according to each feature The characteristic value of each user to be analyzed is combined with the original personal data of each user to be analyzed to determine the characteristic value of each user to be analyzed. The binning method can be determined according to the nature of the feature. For continuous features (such as age, income, transaction amount, etc.), the equal frequency, equal width and other binning methods can be determined according to business experience and data distribution. For categorical features (for example, gender, education, occupation, etc.), the categorical feature data can be binned according to the specific category of the feature. For text-based features (such as addresses, etc.), the texts with the same pattern can be grouped into one category for binning. It should be noted that the user to be analyzed can be marked according to the unique identifier of the user to be analyzed to distinguish the user to be analyzed. The unique identifier may be, for example, an identity card, an officer card, an account id, etc., which are not specifically limited in this exemplary embodiment. Step S104: Determine the high-frequency characteristic value and the low-frequency characteristic value among the characteristic values of each user to be analyzed. In this exemplary embodiment, the high-frequency characteristic value and the low-frequency characteristic value of the characteristic values of the user to be analyzed can be determined in the following two ways, among which: Method 1: Count the characteristics of each characteristic value in multiple users to be analyzed The number of occurrences in the value, and determine the high-frequency characteristic value and the low-frequency characteristic value in the characteristic value according to the following determination rule, where the determination rule is: if the characteristic value appears in the characteristic value of multiple users to be analyzed, the number of times conforms to the formula T2 i ≥X i> T1 i, wherein the value of low-frequency characteristic value, wherein, X-i is the i-th eigenvalue in the eigenvalues of the number of occurrences of a plurality of users to be analyzed, T2 i is the i-th eigenvalue of T1 i is the first preset number of occurrences corresponding to the i-th feature value, T2 i > T1 i , and the specific values of T2 i and T1 i can be based on the feature to which the i-th feature value belongs Make a determination, that is, if the characteristics are different, the corresponding specific values of T2 i and T1 i are also different; if the number of times the characteristic value appears in the characteristic values of multiple users to be analyzed conforms to the formula T3 i ≥X i >T2 i , then the characteristic value Is a high-frequency feature value, where X i is the number of times the i-th feature value appears in the feature values of multiple users to be analyzed, T2 i is the second preset number of occurrences corresponding to the i-th feature value, and T3 i is The third preset number of occurrences corresponding to the i-th eigenvalue, T3 i > T2 i , and the specific values of T2 i and T3 i can be determined according to the feature to which the i-th eigenvalue belongs, that is, if the feature is different, the corresponding T2 i The specific values of i and T3 are also different. After determining the high-frequency feature value and low-frequency feature value, the high-frequency feature value and low-frequency feature can be matched with the feature value of each user to be analyzed to obtain the high-frequency feature value and low-frequency feature value of each user to be analyzed . For example, the high-frequency feature values include: A, B, D, and the low-frequency feature values include C and E. If the feature values of the user to be analyzed include: A, B, C, E, then the high-frequency feature values of the user to be analyzed include A and B, the low-frequency characteristic value of the user to be analyzed includes C and E; if the characteristic value of the user to be analyzed includes: A, E, F, the high-frequency characteristic value of the user to be analyzed includes A, and the Low-frequency characteristic values include E. Manner two, as shown in Figure 2, may include the following steps: Step S202, construct a first two-part graph according to the characteristic value of each user to be analyzed, where the first two-part graph includes nodes corresponding to each user to be analyzed, and The node corresponding to each feature value and the edge between the node corresponding to each user to be analyzed and the node corresponding to the feature value. In the embodiment of the present invention, each user to be analyzed is converted into a node, each user to be analyzed corresponds to only one node, and the characteristic value of each user to be analyzed is converted into a node, and each characteristic value corresponds to only one node. That is, during the conversion process, if the node corresponding to a feature value already exists, the node is reused, and there is no need to set the node corresponding to the feature value. Among them, the node corresponding to each user to be analyzed is located in the first two parts of the graph. On one side of, the node corresponding to each feature value is located on the other side of the first bipartite graph, and an edge is added between the node corresponding to each user to be analyzed and the node corresponding to the feature value. For example, there are 5 users to be analyzed, which are the first user to be analyzed to the fifth user to be analyzed, wherein the characteristic values of the first user to be analyzed include: A, B, and D, and the characteristic values of the second user to be analyzed include : B, C, F, the characteristic value of the third user to be analyzed includes: A, C, D, F, the characteristic value of the fourth user to be analyzed includes: B, D, F, the characteristic value of the fifth user to be analyzed includes : C, D, E, F, based on this, the first two-part graph constructed is as shown in Figure 3, where the node corresponding to the first user to be analyzed 1, the node corresponding to the second user to be analyzed 2, the third The node 3 corresponding to the analysis user, the node 4 corresponding to the fourth user to be analyzed, and the node 5 corresponding to the fifth user to be analyzed are located on the left side of Fig. 3, the node corresponding to feature value A, the node corresponding to feature value B, and the node corresponding to feature value C The nodes of, the nodes corresponding to the characteristic value D, the nodes corresponding to the characteristic value E, and the nodes corresponding to the characteristic value F are located on the right side of Fig. 3, and edges are set between the nodes corresponding to each user to be analyzed and the nodes corresponding to the characteristic values. Step S204: Obtain the degree of the node corresponding to each feature value in the first two-part graph, and determine the high-frequency feature value and the low-frequency feature value in the feature value according to the degree of the node corresponding to each feature value. In the embodiment of the present invention, the degree of the node corresponding to the characteristic value refers to the number of edges connected to the node corresponding to the characteristic value. For example, in Figure 3, the degree of the node corresponding to the characteristic value A is 2, and the degree corresponding to the characteristic value B is 2. The degree of the node is 3, the degree of the node corresponding to the characteristic value C is 3, the degree of the node corresponding to the characteristic value D is 4, the degree of the node corresponding to the characteristic value E is 1, and the degree of the characteristic value F is 4. The process of determining the high-frequency characteristic value and the low-frequency characteristic value in the characteristic value according to the degree of the node corresponding to each characteristic value may include: determining the high-frequency characteristic value and the low-frequency characteristic value according to each characteristic value in combination with the following determination rules, wherein the determining rule may be: If the feature value of the node corresponding to satisfy the equation K2 i ≥degree (V i)> 1, the value of the low-frequency characteristic feature value, wherein, degree (V i) is the i th value V i corresponding to the feature node degrees, the first predetermined value of K2 i V i corresponding to the i-th feature, K2 i> 1, and the specific numerical value of the characteristic may K2 i V i belongs is determined according to the i-th feature, i.e., features of the different , The specific values of the corresponding K2 i are also different; if the degree of the node corresponding to the eigenvalue satisfies the formula K1 i ≥degree(V i )>K2 i , the eigenvalue is a high-frequency eigenvalue, where degree(V i ) is node of the i-th feature value corresponding to V i, K2 i is the i-th feature value V i corresponding to a first predetermined degree, K1 i of the i-th second predetermined value V i of each corresponding feature, K1 i> i K2, K2 and Kl specific values i and i may be performed according to the i-th eigenvalue V i belongs is determined, i.e. the different characteristics, the specific values corresponding to Kl and K2 i i are different. For example, as shown in Fig. 3, if K2 i is 2 and K1 i is 3, then the characteristic value A is a low-frequency characteristic value, and the characteristic value B and the characteristic value C are high-frequency characteristic values. Step S206: Determine the high-frequency characteristic value and the low-frequency characteristic value among the characteristic values of each user to be analyzed according to the high-frequency characteristic value and the low-frequency characteristic value. In the embodiment of the present invention, the high-frequency feature value is matched with the feature value of each user to be analyzed, and the feature value of each user to be analyzed that is successfully matched with the high-frequency feature value is determined as the corresponding user to be analyzed The high-frequency feature value of the user; the low-frequency feature value is matched with the feature value of each user to be analyzed, and the feature value of each user to be analyzed that is successfully matched with the low-frequency feature value is determined as the low frequency of the corresponding user to be analyzed Eigenvalues. For example, as shown in Fig. 3, if K2 i is 2 and K1 i is 3, then the characteristic value A is a low-frequency characteristic value, and the characteristic value B and the characteristic value C are high-frequency characteristic values. Based on this, the low-frequency feature value of the first user to be analyzed includes feature value A, the high-frequency feature value of the first user to be analyzed includes feature value B, the second user to be analyzed does not have low-frequency feature values, and the high-frequency feature value of the second user to be analyzed The feature value includes: feature value B, feature value C, the low-frequency feature value of the third user to be analyzed includes feature value A, the high-frequency feature value of the third user to be analyzed includes feature value C, and the fourth user to be analyzed has no low-frequency feature value , The high-frequency characteristic value of the fourth user to be analyzed includes the characteristic value B, the fifth user to be analyzed has no low-frequency characteristic value, and the high-frequency characteristic value of the fifth user to be analyzed includes the characteristic value C. Step S106: Mining the maximum frequent item set according to the high frequency feature value of each user to be analyzed and the preset frequent itemset mining strategy, and obtain the low frequency maximum frequent feature value in the maximum frequent item set. In the embodiment of the present invention, the preset frequent itemset mining strategy may be, for example, an Apriori (frequent itemsets mining association rule) strategy, or FP-Growth, etc., which is not specifically limited in this exemplary embodiment. In the following, taking the preset frequent itemset mining strategy as FP-Growth as an example, the above process will be described. As shown in FIG. 4, the following steps may be included: Step S402, according to the high-frequency feature value of each user to be analyzed Combined with the FP-Growth method, it mines frequent multinomial sets whose support degree meets the preset support degree, and determines the maximum frequent itemset in the frequent multinomial set. In the embodiment of the present invention, the support degree is the number of occurrences of high-frequency feature values in multiple users to be analyzed. The specific value of the preset support degree can be set by yourself, for example, it can be 1, or 2, etc. This exemplary The embodiment does not specifically limit this. Frequent polynomial sets refer to sets that include at least two high-frequency feature values. The frequent multinomial set whose support degree meets the preset support degree means that the support degree of each high-frequency feature value in the frequent multinomial set is greater than the preset support degree. The specific process of mining frequent polynomial sets includes: defining the preset support degree, scanning the high-frequency feature value of each user to be analyzed, to obtain the number of occurrences of each high-frequency feature value in multiple users to be analyzed (ie, the degree of support) , And filter out the high-frequency feature values whose support is less than the preset support from the high-frequency feature values of the users to be analyzed, and construct the FP tree based on the remaining high-frequency feature values of the users to be analyzed, and put it in the FP tree Mining frequent multinomial sets. Obtain frequent polynomial sets without superset conditions in frequent polynomial sets, and determine frequent polynomial sets without superset conditions in frequent polynomial sets as the maximum frequent itemsets. It should be noted that each maximum frequent item set includes multiple high-frequency feature values. Here, the high-frequency feature value included in the maximum frequent item set is named the maximum frequent feature value, that is, each maximum frequent item set includes multiple Maximum frequent feature value. Step S404: Match the feature value of each user to be analyzed with the maximum frequent feature value in the maximum frequent item set to obtain the maximum frequent feature value of each user to be analyzed. In the embodiment of the present invention, the feature value of each user to be analyzed is matched with the maximum frequent feature value in the maximum frequent item set, and the feature value of each user to be analyzed that is successfully matched with the maximum frequent feature value in the maximum frequent item set Determined as the corresponding maximum frequent feature value of each user to be analyzed. Step S406: Determine the low-frequency maximum frequent feature value from the maximum frequent feature value of the user to be analyzed. In the embodiment of the present invention, the low-frequency maximum frequent feature value can be determined in the following two ways, among which: Method 1: Count the occurrence of each maximum frequent feature value in multiple users to be analyzed according to the maximum frequent feature value of each user to be analyzed According to the number of occurrences of each maximum frequent feature value in multiple users to be analyzed and combined with the following determination rules, determine the low frequency maximum frequent feature value from the maximum frequent feature value. The determination rule is: if the maximum frequent feature value is If the number of occurrences in multiple users to be analyzed meets the formula P2 i ≥S i , the maximum frequent feature value is the low frequency maximum frequent feature value, where P2 i is the preset number of occurrences corresponding to the i-th maximum frequent feature value, and P2 The specific value of i can be determined according to the feature to which the i-th largest frequent feature value belongs, that is, the specific value of P2 i corresponding to different features is also different. S i is the i-th largest frequent feature value among multiple users to be analyzed The number of occurrences of. The second method, as shown in FIG. 5, may include the following steps: Step S502: Construct a second bipartite graph according to the maximum frequent feature value of each user to be analyzed, where the second bipartite graph includes nodes corresponding to each user to be analyzed , The node corresponding to each maximum frequent feature value, and the edge between the node corresponding to each user to be analyzed and the node corresponding to the maximum frequent feature value. In the embodiment of the present invention, each user to be analyzed is converted into a node, each user to be analyzed corresponds to only one node, and the maximum frequent feature value of each user to be analyzed is converted into a node, and each maximum frequent feature value is only Corresponding to a node, where the node corresponding to each user to be analyzed is located on one side of the second bipartite graph, and the node corresponding to each maximum frequent feature value is located on the other side of the second bipartite graph, and in each user to be analyzed An edge is added between the corresponding node and the node corresponding to the maximum frequent feature value to complete the construction of the second bipartite graph. Step S504: Obtain the degree of the node corresponding to each maximum frequent feature value in the second two-part graph, and determine the low-frequency maximum frequent feature value from the maximum frequent feature value according to the degree of the node corresponding to each maximum frequent feature value. In the embodiment of the present invention, the degree of the node corresponding to the maximum frequent feature value is the number of edges connected to the node corresponding to the maximum frequent feature value in the bipartite graph. The process of determining the low-frequency maximum frequent feature value may include: determining the low-frequency maximum frequent feature value according to the degree of the node corresponding to each maximum frequent feature value in combination with the following determination rule, where the determination rule may be: if the node corresponding to the maximum frequent feature value is If the degree satisfies the formula L2 i ≥ degree(V i ), the maximum frequent feature value is the low-frequency maximum frequent feature value, where degree(V i ) is the degree of the node corresponding to the i-th maximum frequent feature value, and L2 i is the i-th frequent preset maximum eigenvalue of the corresponding V i, and the specific numerical value of the characteristic L2 of i V i may be determined according to the relevant i-th maximum frequent feature, i.e. different characteristics, i L2 of the corresponding specific values are different. Step S108: Construct a target bipartite graph according to the low-frequency maximum frequent feature value and the low-frequency feature value among the feature values of each user to be analyzed, and define the weights of edges in the target bipartite graph. In the embodiment of the present invention, the low-frequency maximum frequent feature value is matched with the feature value of each user to be analyzed, and the feature value of each user to be analyzed that successfully matches the low-frequency maximum frequent feature value is determined as the corresponding each to be analyzed The user's low frequency maximum frequent feature value. The process of constructing the target bipartite graph according to the low-frequency maximum frequent feature value of each user to be analyzed and the low-frequency feature value of each user to be analyzed obtained in step S104 may include: converting each user to be analyzed into a node, and converting each low-frequency feature Values are converted into nodes, each low-frequency maximum frequent feature value is converted into nodes, and edges are added between the node corresponding to each user to be analyzed and the node corresponding to the low-frequency feature value, and the node corresponding to each user to be analyzed and its low-frequency maximum frequent Add edges between the nodes corresponding to the eigenvalues to complete the construction of the target bipartite graph. Defining the weights of the edges in the target bipartite graph may include: defining the weights of the edges between the nodes corresponding to each user to be analyzed in the target bipartite graph and the nodes corresponding to the low-frequency eigenvalues, and defining the weights of the edges in the target bipartite graph to be analyzed The weight of the edge between the node corresponding to the user and the node corresponding to the low-frequency maximum frequent feature value. Wherein, defining the weight of the edge between the node corresponding to each user to be analyzed in the target bipartite graph and the node corresponding to the low-frequency feature value may include: determining the weight of each low-frequency feature value according to the feature to which each low-frequency feature value belongs, specifically, The higher the weight of the low-frequency feature value, the higher the probability that the user to be analyzed that includes the low-frequency feature value is an abnormal group, and the lower the weight of the low-frequency feature value. At the same time, the user to be analyzed that includes the low-frequency feature value is an abnormal group. The lower the probability. After the weight of each low-frequency feature value is determined, the weight of the edge connected to the node corresponding to each low-frequency feature value is set as the weight of each corresponding low-frequency feature value. For example, if the low-frequency feature values include frequent risks (feature values corresponding to the features of risks), unemployed (feature values corresponding to the features of occupations), and the weight of frequent risks is 0.5, and the weight of unemployed is 0.1, then the node corresponding to frequent risks The weights of connected edges are all set to 0.5, and the weights of edges connected to unemployed nodes are all set to 0.1. Similarly, defining the weight of the edge between the node corresponding to each user to be analyzed in the target bipartite graph and the node corresponding to the low-frequency maximum frequent feature value may include: determining each low-frequency maximum frequent feature according to the feature to which each low-frequency maximum frequent feature value belongs The weight of the low-frequency maximum frequent feature value, specifically, the higher the weight of the low-frequency maximum frequent feature value, and the higher the probability that the user to be analyzed that includes the low-frequency maximum frequent feature value is an abnormal group, the lower the weight of the low-frequency maximum frequent feature value, and also includes The lower the probability that the user to be analyzed with the low-frequency maximum frequent feature value is an abnormal group. The weight of the edge connected to the node corresponding to each low-frequency maximum frequent feature value is set as the weight of each corresponding low-frequency maximum frequent feature value. Step S110, according to the weights of the edges in the target bipartite graph and the clustering results of multiple users to be analyzed obtained by graph clustering on the target bipartite graph, determine the abnormal group of users to be analyzed. In the embodiment of the present invention, the abnormal group of users to be analyzed can be determined in the following two ways. Among them: Method 1: Delete edges with a weight less than the first preset weight in the target bipartite graph to obtain the second cluster to be clustered. Partial graphs, and using the Unicom algorithm to obtain at least one largest connected subgraph for the bipartite graph to be clustered, and determine the to-be-analyzed user corresponding to the node in each largest connected subgraph as an abnormal group. In the embodiment of the present invention, the specific value of the first preset weight can be set by itself, which is not particularly limited in this exemplary embodiment. Compare the weight of each edge in the target bipartite graph with the first preset weight in turn. If the weight of the edge is less than the first preset weight, delete the edge in the target bipartite graph. If the weight of the edge is not less than With the first preset weight, the edge is retained in the target bipartite graph, and the target bipartite graph whose weight is less than the preset weight is determined as the bipartite graph to be clustered. For the bipartite graph to be clustered, the Unicom algorithm is used to obtain at least one maximum connected subgraph, the nodes corresponding to the low-frequency eigenvalues and the nodes corresponding to the low-frequency maximum frequent eigenvalues are filtered out in each of the maximum connected subgraphs, and each The users to be analyzed corresponding to the remaining nodes in the largest connected subgraphs are set to obtain the set of users to be analyzed corresponding to each of the largest connected subgraphs, and the set of users to be analyzed corresponding to each of the largest connected subgraphs is determined as one Anomalous groups. Method 2: Delete edges with weights less than the first preset weight in the target bipartite graph to obtain the bipartite graph to be clustered, and divide the nodes in the bipartite graph to be clustered through the community discovery algorithm to obtain multiple A set of nodes, and the users to be analyzed corresponding to the nodes in each set of nodes are determined as an abnormal group. In the embodiment of the present invention, since edges with weights less than the first preset weight are deleted in the bipartite graph, the principle of obtaining the bipartite graph to be clustered is the same as the principle in the above-mentioned way 1, so it will not be repeated here. The community discovery algorithm may be, for example, the louvain algorithm, which is not specifically limited in this exemplary embodiment. After dividing the nodes in the bipartite graph to be clustered through the community discovery algorithm to obtain multiple node sets, firstly filter out the nodes corresponding to the low-frequency feature value and the node corresponding to the low-frequency maximum frequent feature value in each node set. The users to be analyzed corresponding to the remaining nodes in each node set are respectively collected to obtain the user set to be analyzed corresponding to each node set, and the user set to be analyzed corresponding to each node set is determined as an abnormal group. . Further, after obtaining the abnormal group, in order to further verify the abnormal group and further improve the accuracy of the abnormal group identification, the total number of users to be analyzed in each abnormal group can be obtained and screened out from the abnormal group The total number of users to be analyzed is less than the preset number of abnormal groups, and the remaining abnormal groups are determined as the finally identified abnormal groups; the module degree of the largest connected subgraph corresponding to each abnormal group can also be calculated, and the The module degree of the largest connected subgraph corresponding to each abnormal group is determined as the module degree of the corresponding abnormal group, and the abnormal group whose module degree is smaller than the preset module degree is screened out from the abnormal group, and the remaining abnormal group Determined as the finally identified anomalous group. It should be noted that the above two verification methods are only exemplary and are not used to limit the present invention. They can also verify the abnormal group by analyzing the business characteristics of each user to be analyzed in the abnormal group. In order to cluster the analyzed users more accurately to obtain a more accurate abnormal group, as shown in Figure 6, according to the weight of the edges in the target bipartite graph and the result obtained by graph clustering on the target bipartite graph From the clustering results of multiple users to be analyzed, determining the abnormal group among users to be analyzed may include the following steps: Step S602: Calculate the weight between any two users to be analyzed according to the weights of edges in the target bipartite graph. In the embodiment of the present invention, the node corresponding to the low-frequency feature value and the node corresponding to the low-frequency maximum frequent feature value that are commonly connected to the nodes corresponding to any two users to be analyzed are obtained in the target bipartite graph, and the node corresponding to any two The node corresponding to the low-frequency characteristic value and the node corresponding to the low-frequency maximum frequent characteristic value that are connected together by the nodes corresponding to the users to be analyzed are determined as the target node; according to any two users to be analyzed, the node corresponding to any one of the users to be analyzed is determined to be the target node. The weight of the edge between each target node is combined with the following formula to calculate the weight between any two users to be analyzed. The above formula is: among them, Is the weight between any two users to be analyzed, j is the total number of target nodes, Is the i-th target node The weight of the edge between the nodes corresponding to any one of the two users to be analyzed. Step S604: Convert each user to be analyzed into a node, set an edge between any two nodes, and set the weight of the edge of any two nodes to the corresponding weight between any two users to be analyzed to construct Target cluster map. In the embodiment of the present invention, each user to be analyzed is converted into a node, that is, a user to be analyzed corresponds to only one node, an edge is set between any two nodes, and the weight between any two users to be analyzed is set Is the weight of the edge between the two nodes corresponding to any two users to be analyzed to complete the construction of the target cluster graph. It can be seen from the above that, through steps S602 and S604, the target bipartite graph including the node corresponding to the user to be analyzed and the node corresponding to the low-frequency feature value and the node corresponding to the low-frequency maximum frequent feature value is transformed into a target bipartite graph that includes only the node corresponding to the user to be analyzed Target cluster map. Step S606: Determine an abnormal group of users to be analyzed through clustering results of multiple users to be analyzed obtained by performing graph clustering on the target cluster graph. In the embodiment of the present invention, the abnormal group can be determined in the following two ways, among which: Method one, delete edges with a weight less than the second preset weight in the target clustering graph to obtain the graph to be clustered, and treat the clustering The graph uses the Unicom algorithm to obtain at least one maximum connected subgraph, and the users to be analyzed corresponding to the nodes in each maximum connected subgraph are respectively determined as an abnormal group. In the embodiment of the present invention, the specific value of the second preset weight can be set by itself, which is not particularly limited in this exemplary embodiment. The weight of each edge in the target clustering graph is compared with the second preset weight, and the edges with a weight less than the second preset weight are deleted in the target clustering graph to convert the target clustering graph into a cluster to be clustered. Class Diagram. Collect the to-be-analyzed users corresponding to the nodes in each largest connected sub-graph to obtain the to-be-analyzed user set corresponding to each largest connected sub-graph, and determine the to-be-analyzed user set corresponding to each largest connected sub-graph as An anomalous group. Method 2: Delete edges with a weight less than the second preset weight in the target cluster graph to obtain the cluster graph to be clustered, and divide the cluster graph to obtain multiple node sets through the community discovery algorithm. The users to be analyzed corresponding to each set of nodes are respectively determined as an abnormal group. In the application embodiment, the second preset weight has been described above, so it will not be repeated here. The weight of each edge in the target clustering graph is compared with the second preset weight, and the edges with a weight less than the second preset weight are deleted in the target clustering graph to convert the target clustering graph into a cluster to be clustered. Class Diagram. The community discovery algorithm may be, for example, the louvain algorithm, which is not specifically limited in this exemplary embodiment. After dividing the nodes in the cluster graph through the community discovery algorithm to obtain multiple node sets, collect the users to be analyzed corresponding to the nodes in each node set to obtain the users to be analyzed corresponding to each node set Set, and determine the set of users to be analyzed corresponding to each node set as an abnormal group. It can be seen from the above that the weight between any two users to be analyzed is calculated based on the weights of the edges in the target bipartite graph, and the target clustering graph is constructed based on the previous weights of any two users to be analyzed, so that the target bipartite graph The conversion into a target cluster map makes the target cluster map more accurate and more intuitive to reflect the relationship between the users to be analyzed, and thereby makes the abnormal groups obtained from the target cluster map more accurate. It should be noted that the above two methods of determining abnormal groups are exemplary and are not intended to limit the present invention. Further, after obtaining the abnormal group, in order to further verify the abnormal group and further improve the accuracy of the abnormal group identification, the total number of users to be analyzed in each abnormal group can be obtained and screened out from the abnormal group The total number of users to be analyzed is less than the preset number of abnormal groups, and the remaining abnormal groups are determined as the finally identified abnormal groups; the module degree of the largest connected subgraph corresponding to each abnormal group can also be calculated, and the The module degree of the largest connected subgraph corresponding to each abnormal group is determined as the module degree of the corresponding abnormal group, and the abnormal group whose module degree is smaller than the preset module degree is screened out from the abnormal group, and the remaining abnormal group Determined as the finally identified anomalous group. It should be noted that the above two verification methods are only exemplary and are not used to limit the present invention. They can also verify the abnormal group by analyzing the business characteristics of each user to be analyzed in the abnormal group. In summary, the maximum frequent itemsets are mined through the frequent itemset mining strategy preset for the high-frequency feature values of the users to be analyzed, and the low-frequency and maximum frequent feature values in the maximum frequent itemsets are obtained to mine the user’s features to be analyzed. Behavior sequence, which makes the identification of abnormal groups more accurate; in addition, only by obtaining the low-frequency feature value and low-frequency maximum frequent feature value of each user to be analyzed, and construct the target based on the low-frequency feature value and low-frequency maximum frequent feature value of each user to be analyzed The bipartite graph defines the weights of the edges in the target bipartite graph, and performs graph clustering on the target bipartite graph according to the weights of the edges in the target bipartite graph to obtain anomalous groups. The steps are simple and easy to execute. Corresponding to the above-mentioned abnormal group identification method, based on the same technical concept, an embodiment of the present invention also provides an abnormal group identification device. FIG. 7 is a schematic diagram of the composition of an abnormal group identification device 700 provided by an embodiment of the present invention. An abnormal group identification method, as shown in FIG. 7, the device 700 may include: an acquisition module 701, a determination module 702, a mining module 703, a construction module 704, and a clustering module 705, in which: the acquisition module 701, It is used to obtain the characteristic value of each of the users to be analyzed; the determination module 702 is used to determine the high-frequency characteristic value and the low-frequency characteristic value of the characteristic values of the user to be analyzed; mining model The group 703 is used to mine the maximum frequent itemsets according to the high-frequency feature values of the users to be analyzed and the preset frequent itemset mining strategy, and obtain the low-frequency and maximum frequent feature values in the maximum frequent itemsets; building module 704 , For constructing a target bipartite graph according to the low-frequency maximum frequent feature value and the low-frequency feature value in the feature values of each user to be analyzed, and defining the weights of edges in the target bipartite graph; clustering categories The module 705 is configured to determine the weight of the edges in the target bipartite graph and the clustering results of the multiple users to be analyzed obtained by performing graph clustering on the target bipartite graph Anomalous groups of users to be analyzed. Optionally, the acquisition module 701 may include: an acquisition unit, configured to acquire the original personal data of the multiple users to be analyzed; a discretization unit, configured to perform processing on the original personal data of the multiple users to be analyzed Discretization to obtain the characteristic value of each user to be analyzed. Optionally, the determining module 702 may include: a first constructing unit, configured to construct a first two-part picture according to the characteristic value of each user to be analyzed, wherein the first two-part picture includes the same The node corresponding to the user to be analyzed, the node corresponding to each of the characteristic values, and the edge between the node corresponding to each of the users to be analyzed and the node corresponding to the characteristic value; Acquire the degree of the node corresponding to each of the characteristic values in a two-part graph, and determine the high-frequency characteristic value and the low-frequency characteristic value in the characteristic value according to the degree of the node corresponding to each characteristic value; a second determining unit, It is used to determine the high-frequency characteristic value and the low-frequency characteristic value of the characteristic values of each user to be analyzed according to the high-frequency characteristic value and the low-frequency characteristic value. Optionally, the mining module 703 may include: a mining unit for mining frequent multinomial sets whose support degree meets the preset support degree according to the high-frequency feature value of each user to be analyzed and combined with the FP-Growth method, And determine the maximum frequent item set in the frequent item set; a matching unit, used to match the feature value of each user to be analyzed with the maximum frequent feature value in the maximum frequent item set to obtain each of the to be analyzed The maximum frequent characteristic value of the user; the third determining unit is configured to determine the maximum frequent characteristic value of low frequency among the maximum frequent characteristic values of the users to be analyzed. Optionally, the third determining unit may include: a constructing subunit for constructing a second bipartite graph according to the maximum frequent feature value of each user to be analyzed, wherein the second bipartite graph includes the The node corresponding to the user to be analyzed, the node corresponding to each of the maximum frequent eigenvalues, and the edge between each node corresponding to the user to be analyzed and the node corresponding to the maximum frequent eigenvalue; determining a subunit for Acquire the degree of the node corresponding to each of the maximum frequent feature values in the second two-part graph, and determine the low-frequency maximum frequent feature in the maximum frequent feature value according to the degree of the node corresponding to each of the maximum frequent feature value value. Optionally, the clustering module 705 may include: a first clustering unit, configured to delete edges with a weight less than a first preset weight in the target bipartite graph to obtain the bipartite graph to be clustered, And use the Unicom algorithm for the bipartite graph to be clustered to obtain at least one largest connected subgraph, and determine the user to be analyzed corresponding to a node in each of the largest connected subgraphs as one of the abnormal groups; or The two-part clustering unit is used to delete edges with a weight less than the first preset weight in the target bipartite graph to obtain the bipartite graph to be clustered, and to perform the community discovery algorithm on the bipartite graph to be clustered The nodes in the node are divided to obtain multiple node sets, and the users to be analyzed corresponding to the nodes in each node set are determined as one of the abnormal groups. Optionally, the clustering module 705 may include: a calculation unit, configured to calculate the weight between any two users to be analyzed according to the weight of the edge in the target bipartite graph; a second construction unit, Used to convert each user to be analyzed into a node, set an edge between any two nodes, and set the weight of the edge of any two nodes to the corresponding weight between any two users to be analyzed , To construct a target clustering graph; the third clustering unit is used to determine the clustering results of the multiple users to be analyzed obtained by performing graph clustering on the target clustering graph Of anomalous groups. Optionally, the third clustering unit may include: a first clustering subunit, configured to delete edges with a weight less than a second preset weight in the target cluster graph to obtain the graph to be clustered, and The Unicom algorithm is used for the graph to be clustered to obtain at least one largest connected subgraph, and the users to be analyzed corresponding to the nodes in each of the largest connected subgraphs are respectively determined as one of the abnormal groups; or the second cluster The class subunit is used to delete edges with a weight less than the second preset weight in the target clustering graph to obtain a to-be-clustered graph, and to divide the to-be-clustered graph through a community discovery algorithm to obtain A plurality of node sets, and the users to be analyzed corresponding to each of the node sets are respectively determined as one abnormal group. The abnormal group identification device in the embodiment of the present invention mines the maximum frequent item set through a preset frequent itemset mining strategy for the high frequency feature value of each user to be analyzed, and obtains the low frequency maximum frequent feature value in the maximum frequent item set, In order to mine the behavior sequence of the users to be analyzed, the identification of abnormal groups is more accurate; in addition, only by obtaining the low-frequency feature value and low-frequency maximum frequent feature value of each user to be analyzed, and according to the low-frequency feature value and low-frequency feature value of each user to be analyzed Construct the target bipartite graph with the maximum frequent feature value, and define the weight of the edge in the target bipartite graph, and perform graph clustering on the target bipartite graph according to the weight of the edge in the target bipartite graph to obtain anomalous groups, steps Simple and easy to implement. In response to the above abnormal group identification method, based on the same technical concept, an embodiment of the present invention also provides an abnormal group identification device. FIG. 8 is a schematic structural diagram of an abnormal group identification device provided by an embodiment of the present invention. The device is used to perform the above-mentioned Methods of identifying abnormal groups. As shown in FIG. 8, the abnormal group identification device may have relatively large differences due to different configurations or performances, and may include one or more processors 801 and a memory 802, and the memory 802 may store one or more memories. Application or data. Among them, the memory 802 may be short-term storage or permanent storage. The application program stored in the memory 802 may include one or more modules (not shown in the figure), and each module may include a series of computer-executable instructions in the device for identifying abnormal groups. Furthermore, the processor 801 may be configured to communicate with the memory 802 and execute a series of computer executable instructions in the memory 802 on the abnormal group identification device. The abnormal group identification device may also include one or more power sources 803, one or more wired or wireless network interfaces 804, one or more input and output interfaces 805, one or more keyboards 806, and the like. In a specific embodiment, the abnormal group identification device includes a memory and one or more programs, wherein one or more programs are stored in the memory, and the one or more programs may include one or more Modules, and each module may include a series of computer executable instructions in the equipment for identifying abnormal groups, and is configured to be executed by one or more processors to execute the one or more package programs. Execution instruction: Obtain the characteristic value of each of the users to be analyzed; determine the high-frequency characteristic value and the low-frequency characteristic value among the characteristic values of the users to be analyzed; According to the characteristic value of each user to be analyzed The high-frequency feature value and the preset frequent itemset mining strategy mine the maximum frequent itemset, and obtain the low-frequency and maximum frequent feature values in the maximum frequent itemset; according to the low-frequency and maximum frequentness among the feature values of the users to be analyzed The eigenvalues and the low-frequency eigenvalues construct a target bipartite graph, and define the weights of edges in the target bipartite graph; according to the weights of the edges in the target bipartite graph, and by comparing the target bipartite graph The clustering results of the multiple users to be analyzed obtained by graph clustering determine the abnormal group among the users to be analyzed. Optionally, when the computer-executable instruction is executed, the obtaining the characteristic value of each of the plurality of users to be analyzed includes: obtaining the original personal data of the plurality of users to be analyzed; The original personal data of a plurality of users to be analyzed are discretized to obtain the characteristic value of each user to be analyzed. Optionally, when the computer-executable instructions are executed, the determining the high-frequency characteristic value and the low-frequency characteristic value of the characteristic values of each user to be analyzed includes: constructing a first characteristic value according to the characteristic value of each user to be analyzed A two-part graph, wherein the first two-part graph includes nodes corresponding to each of the users to be analyzed, nodes corresponding to each of the characteristic values, and nodes corresponding to each of the users to be analyzed and corresponding to their characteristic values Edges between nodes; acquiring the degree of the node corresponding to each of the feature values in the first two-part graph, and determining the high-frequency feature value in the feature value according to the degree of the node corresponding to each of the feature value And a low-frequency characteristic value; determining a high-frequency characteristic value and a low-frequency characteristic value among the characteristic values of each user to be analyzed according to the high-frequency characteristic value and the low-frequency characteristic value. Optionally, when the computer-executable instructions are executed, the maximum frequent itemsets are mined according to the high-frequency feature values of the users to be analyzed and a preset frequent itemset mining strategy, and the most frequent itemsets in the maximum frequent itemsets are obtained. The low-frequency maximum frequent feature value includes: According to the high-frequency feature value of each user to be analyzed and combined with the FP-Growth method, mining the frequent polynomial set whose support degree meets the preset support degree, and determining the maximum frequent item in the frequent polynomial set Set; match the feature value of each user to be analyzed with the maximum frequent feature value in the maximum frequent item set to obtain the maximum frequent feature value of each user to be analyzed; in the maximum frequent feature value of the user to be analyzed In the eigenvalue, determine the maximum frequent eigenvalue of low frequency. Optionally, when the computer-executable instructions are executed, the determining the low-frequency maximum frequent feature value from the maximum frequent feature values of the users to be analyzed includes: constructing a second feature value according to the maximum frequent feature values of the users to be analyzed A two-part graph, wherein the second two-part graph includes nodes corresponding to each of the users to be analyzed, nodes corresponding to each of the maximum frequent feature values, and nodes corresponding to each of the users to be analyzed and their maximum frequent Edges between nodes corresponding to eigenvalues; acquiring the degree of each node corresponding to the maximum frequent eigenvalue in the second bipartite graph, and obtaining the degree of each node corresponding to the maximum frequent eigenvalue in the second bipartite graph Determine the low-frequency maximum frequent feature value in the maximum frequent feature value. Optionally, when the computer-executable instructions are executed, the weights of the edges in the target bipartite graph and the multiple waits obtained by clustering the target bipartite graph Analyzing the clustering results of users and determining the abnormal groups among the users to be analyzed includes: deleting edges with a weight less than a first preset weight in the target bipartite graph to obtain the bipartite graph to be clustered, and comparing all The bipartite graph to be clustered uses the Unicom algorithm to obtain at least one maximum connected subgraph, and the user to be analyzed corresponding to the node in each of the maximum connected subgraphs is determined as one of the abnormal groups; or in the target Delete edges with weights less than the first preset weight in the bipartite graph to obtain the bipartite graph to be clustered, and divide the nodes in the bipartite graph to be clustered through the community discovery algorithm to obtain multiple nodes Set, and determine the users to be analyzed corresponding to the nodes in each of the node sets as one of the abnormal groups. Optionally, when the computer-executable instructions are executed, the weights of edges in the target bipartite graph and the multiple to-be-analyzed obtained by performing graph clustering on the target bipartite graph According to the clustering results of users, determining the abnormal group among the users to be analyzed includes: calculating the weight between any two users to be analyzed according to the weights of the edges in the target bipartite graph; The user is converted into a node, and an edge is set between any two nodes, and the weight of the edge of any two nodes is set to the corresponding weight between any two users to be analyzed, so as to construct a target cluster graph; Determine the abnormal group among the users to be analyzed through clustering results of the multiple users to be analyzed obtained by performing graph clustering on the target cluster graph. Optionally, when the computer-executable instructions are executed, the clustering results of the plurality of users to be analyzed obtained by performing graph clustering on the target cluster graph are determined to determine which of the users to be analyzed is The abnormal group includes: deleting edges with a weight less than a second preset weight in the target clustering graph to obtain a to-be-clustered graph, and applying a Unicom algorithm to the to-be-clustered graph to obtain at least one largest connected subgraph, And determining the users to be analyzed corresponding to the nodes in each of the largest connected subgraphs as one of the abnormal groups; or deleting edges with a weight less than a second preset weight in the target clustering graph to obtain Cluster graphs, and divide the graphs to be clustered through a community discovery algorithm to obtain multiple node sets, and determine the users to be analyzed corresponding to each of the node sets as one of the abnormal groups. The abnormal group identification device in the embodiment of the present invention mines the maximum frequent item set through a preset frequent item set mining strategy for the high frequency feature value of each user to be analyzed, and obtains the low frequency maximum frequent feature value in the maximum frequent item set, In order to mine the behavior sequence of the users to be analyzed, the identification of abnormal groups is more accurate; in addition, only by obtaining the low-frequency feature value and low-frequency maximum frequent feature value of each user to be analyzed, and according to the low-frequency feature value and low-frequency feature value of each user to be analyzed Construct the target bipartite graph with the maximum frequent feature value, and define the weight of the edge in the target bipartite graph, and perform graph clustering on the target bipartite graph according to the weight of the edge in the target bipartite graph to obtain anomalous groups, steps Simple and easy to implement. Corresponding to the above-mentioned abnormal group identification method, based on the same technical concept, an embodiment of the present invention also provides a storage medium for storing computer executable instructions. In a specific embodiment, the storage medium may be a flash drive, an optical disc, Hard disk, etc., when the computer executable instructions stored in the storage medium are executed by the processor, the following process can be realized: acquiring the characteristic value of each of the plurality of users to be analyzed; determining each user to be analyzed The high-frequency feature value and the low-frequency feature value in the feature values of, mining the maximum frequent item set according to the high-frequency feature value of each user to be analyzed and the preset frequent item set mining strategy, and obtain the low frequency in the maximum frequent item set Maximum frequent feature value; construct a target bipartite graph according to the low frequency maximum frequent feature value and the low frequency feature value in the feature values of each user to be analyzed, and define the weights of edges in the target bipartite graph; According to the weights of the edges in the target bipartite graph and the clustering results of the multiple users to be analyzed obtained by performing graph clustering on the target bipartite graph, the abnormality in the users to be analyzed is determined group. Optionally, when the computer-executable instructions stored in the storage medium are executed by the processor, the obtaining the characteristic value of each of the plurality of users to be analyzed includes: obtaining the information of the plurality of users to be analyzed Original personal data; discretize the original personal data of the multiple users to be analyzed to obtain the characteristic value of each user to be analyzed. Optionally, when the computer-executable instructions stored in the storage medium are executed by the processor, the determining the high-frequency characteristic value and the low-frequency characteristic value of the characteristic values of the users to be analyzed includes: according to each of the characteristic values to be analyzed The first two-part graph is constructed from the characteristic values of users, wherein the first two-part graph includes nodes corresponding to each of the users to be analyzed, nodes corresponding to each of the characteristic values, and corresponding to each of the users to be analyzed The edge between the node and the node corresponding to its feature value; obtain the degree of the node corresponding to each of the feature values in the first two-part graph, and obtain the degree of the node corresponding to each of the feature values in the feature The high-frequency characteristic value and the low-frequency characteristic value are determined in the value; the high-frequency characteristic value and the low-frequency characteristic value among the characteristic values of each user to be analyzed are determined according to the high-frequency characteristic value and the low-frequency characteristic value. Optionally, when the computer-executable instructions stored in the storage medium are executed by the processor, the maximum frequent itemsets are mined according to the high-frequency feature values of the users to be analyzed and a preset frequent itemset mining strategy to obtain The low-frequency maximum frequent feature value in the maximum frequent item set includes: according to the high-frequency feature value of each user to be analyzed and combined with the FP-Growth method, mining frequent polynomial sets whose support degree meets the preset support degree, and Determine the maximum frequent item set in a frequent multinomial set; match the feature value of each user to be analyzed with the maximum frequent feature value in the maximum frequent item set to obtain the maximum frequent feature value of each user to be analyzed; The maximum frequent feature value of the low frequency is determined from the maximum frequent feature value of the user to be analyzed. Optionally, when the computer-executable instructions stored in the storage medium are executed by the processor, the determining the low-frequency maximum frequent feature value from the maximum frequent feature values of the users to be analyzed includes: The maximum frequent feature value constructs a second two-part graph, wherein the second two-part graph includes nodes corresponding to each of the users to be analyzed, nodes corresponding to each of the maximum frequent feature values, and each of the to-be-analyzed The edge between the node corresponding to the user and the node corresponding to the maximum frequent feature value; obtain the degree of each node corresponding to the maximum frequent feature value in the second bipartite graph, and correspond to each of the maximum frequent feature values Determine the low-frequency maximum frequent feature value from the maximum frequent feature value in the degree of the node of. Optionally, when the computer-executable instructions stored in the storage medium are executed by the processor, the weights of edges in the target bipartite graph are obtained by clustering the target bipartite graph. The clustering results of the plurality of users to be analyzed, and determining the abnormal group among the users to be analyzed includes: deleting edges with a weight less than a first preset weight in the target bipartite graph to obtain the two to be clustered Part of the graph, the Unicom algorithm is used for the bipartite graph to be clustered to obtain at least one maximum connected subgraph, and the users to be analyzed corresponding to the nodes in each of the maximum connected subgraphs are determined as one of the abnormal groups Or delete edges with a weight less than the first preset weight in the target bipartite graph to obtain the bipartite graph to be clustered, and divide the nodes in the bipartite graph to be clustered through a community discovery algorithm , To obtain a plurality of node sets, and determine the users to be analyzed corresponding to the nodes in each of the node sets as one of the abnormal groups. Optionally, when the computer-executable instructions stored in the storage medium are executed by the processor, the weights of edges in the target bipartite graph are obtained by clustering the target bipartite graph. The clustering results of the plurality of users to be analyzed, determining the abnormal group among the users to be analyzed includes: calculating a weight between any two users to be analyzed according to the weights of edges in the target bipartite graph ; Convert each user to be analyzed into a node, set an edge between any two nodes, and set the weight of the edge of any two nodes to the corresponding weight between any two users to be analyzed, To construct a target cluster map; and determine an abnormal group among the users to be analyzed through clustering results of the plurality of users to be analyzed obtained by performing graph clustering on the target cluster map. Optionally, when the computer-executable instructions stored in the storage medium are executed by the processor, the clustering results of the plurality of users to be analyzed obtained by performing graph clustering on the target cluster graph are determined The abnormal group among the users to be analyzed includes: deleting edges with a weight less than a second preset weight in the target clustering graph to obtain a to-be-clustered graph, and to obtain the to-be-clustered graph by using a Unicom algorithm At least one largest connected subgraph, and the users to be analyzed corresponding to the nodes in each of the largest connected subgraphs are respectively determined as one of the abnormal groups; or the deletion weight in the target clustering graph is less than a second preset Weighted edges to obtain the graph to be clustered, and divide the graph to be clustered through the community discovery algorithm to obtain multiple node sets, and determine the users to be analyzed corresponding to each of the node sets as One of the abnormal populations. When the computer-executable instructions stored in the storage medium in the embodiment of the present invention are executed by the processor, the maximum frequent itemsets are mined through the preset frequent itemset mining strategy of the high-frequency feature values of the users to be analyzed, and the maximum frequent itemsets are obtained. The low-frequency maximum frequent feature value in the frequent item set can be used to mine the behavior sequence of the users to be analyzed, thereby making the identification of abnormal groups more accurate; in addition, only by obtaining the low-frequency feature value and the low-frequency maximum frequent feature value of each user to be analyzed, and according to Construct a target bipartite graph with the low-frequency feature value and low-frequency maximum frequent feature value of each user to be analyzed, and define the weight of the edge in the target bipartite graph, and perform the target bipartite graph based on the weight of the edge in the target bipartite graph. Graph clustering to obtain anomalous groups, the steps are simple and easy to execute. In the 1990s, the improvement of a technology can be clearly distinguished from the improvement of the hardware (for example, the improvement of the circuit structure of diodes, transistors, switches, etc.) or the improvement of the software (for the process of the method). Improve). However, with the development of technology, the improvement of many methods and processes of today can be regarded as a direct improvement of the hardware circuit structure. Designers almost always get the corresponding hardware circuit structure by programming the improved method flow into the hardware circuit. Therefore, it cannot be said that the improvement of a method flow cannot be realized by the hardware entity module. For example, a Programmable Logic Device (PLD) (such as a Field Programmable Gate Array (FPGA)) is such an integrated circuit whose logic function is determined by the user's programming of the device. It is designed by the designer to "integrate" a digital system on a PLD without having to ask the chip manufacturer to design and produce a dedicated integrated circuit chip. Moreover, nowadays, instead of manually making integrated circuit chips, this kind of programming is mostly realized by using "logic compiler" software, which is similar to the software compiler used in program development and writing. The original code before compilation must also be written in a specific programming language, which is called Hardware Description Language (HDL), and HDL is not only one, but there are many, such as ABEL (Advanced Boolean Expression Language), AHDL (Altera Hardware Description Language), Confluence, CUPL (Cornell University Programming Language), HDCal, JHDL (Java Hardware Description Language), Lava, Lola, MyHDL, PALASM, RHDL (Ruby Hardware Description Language), etc., Currently the most commonly used are VHDL (Very-High-Speed Integrated Circuit Hardware Description Language) and Verilog. Those skilled in the art should also be aware that only a little logic programming of the method flow using the above hardware description languages and programming into an integrated circuit can easily obtain a hardware circuit that implements the logic method flow. The controller can be implemented in any suitable manner. For example, the controller can take the form of a microprocessor or a processor and a computer readable code (such as software or firmware) that can be executed by the (micro) processor. Reading media, logic gates, switches, application specific integrated circuits (ASIC), programmable logic controllers and embedded microcontrollers. Examples of controllers include but are not limited to the following microcontrollers: ARC 625D , Atmel AT91SAM, Microchip PIC18F26K20 and Silicon Labs C8051F320, the memory controller can also be implemented as part of the memory control logic. Those skilled in the art also know that, in addition to implementing the controller in a purely computer-readable code, it is entirely possible to design the method steps with logic programming to enable the controller to be controlled by logic gates, switches, dedicated integrated circuits, and programmable logic. The same function can be realized in the form of an embedded microcontroller and a microcontroller. Therefore, such a controller can be regarded as a hardware component, and the devices included in it for realizing various functions can also be regarded as a structure within the hardware component. Or even, the device for realizing various functions can be regarded as both a software module for realizing the method and a structure within a hardware component. The systems, devices, modules, or units explained in the above embodiments may be implemented by computer chips or entities, or implemented by products with certain functions. A typical implementation device is a computer. Specifically, the computer can be, for example, a personal computer, a laptop computer, a cellular phone, a camera phone, a smart phone, a personal digital assistant, a media player, a navigation device, an email device, a game console, a tablet computer, a wearable Device or any combination of these devices. For the convenience of description, when describing the above device, the functions are divided into various units and described separately. Of course, when implementing the present invention, the functions of each unit can be implemented in the same or multiple software and/or hardware. Those skilled in the art should understand that the embodiments of the present invention can be provided as a method, a system, or a computer program product. Therefore, the present invention can take the form of a completely hardware embodiment, a completely software embodiment, or an embodiment combining software and hardware. Moreover, the present invention can be in the form of a computer program product implemented on one or more computer-usable storage media (including but not limited to disk memory, CD-ROM, optical memory, etc.) containing computer-usable program codes. . The present invention is described with reference to flowcharts and/or block diagrams of methods, equipment (systems), and computer program products according to embodiments of the present invention. It should be understood that each process and/or block in the flowchart and/or block diagram, and the combination of processes and/or blocks in the flowchart and/or block diagram can be realized by computer program instructions. These computer program instructions can be provided to the processors of general-purpose computers, dedicated computers, embedded processors, or other programmable data processing equipment to generate a machine that can be executed by the processor of the computer or other programmable data processing equipment A device for realizing the functions specified in a flow or multiple flows in the flowchart and/or a block or multiple blocks in the block diagram is generated. These computer program instructions can also be stored in a computer-readable memory that can guide a computer or other programmable data processing equipment to work in a specific manner, so that the instructions stored in the computer-readable memory generate a manufactured product including the instruction device , The instruction device realizes the functions specified in one process or multiple processes in the flowchart and/or one block or multiple blocks in the block diagram. These computer program instructions can also be loaded on a computer or other programmable data processing equipment, so that a series of operation steps are executed on the computer or other programmable equipment to generate computer-implemented processing, so that the computer or other programmable equipment The instructions executed above provide steps for implementing functions specified in a flow or multiple flows in the flowchart and/or a block or multiple blocks in the block diagram. In a typical configuration, the computing device includes one or more processors (CPUs), input/output interfaces, network interfaces, and memory. Memory may include non-permanent memory in computer-readable media, random access memory (RAM) and/or non-volatile memory, such as read-only memory (ROM) or flash memory ( flash RAM). Memory is an example of computer-readable media. Computer-readable media include permanent and non-permanent, removable and non-removable media, and information storage can be realized by any method or technology. Information can be computer-readable instructions, data structures, program modules, or other data. Examples of computer storage media include, but are not limited to, phase change memory (PRAM), static random access memory (SRAM), dynamic random access memory (DRAM), and other types of random access memory (RAM) , Read-only memory (ROM), electrically erasable programmable read-only memory (EEPROM), flash memory or other memory technologies, read-only CD-ROM (CD-ROM), digital multi-function Optical discs (DVD) or other optical storage, magnetic cassettes, tape-to-disk storage or other magnetic storage devices, or any other non-transmission media, can be used to store information that can be accessed by computing devices. According to the definition in this article, computer-readable media does not include transient computer-readable media (transitory media), such as modulated data signals and carrier waves. It should also be noted that the terms "include", "include" or any other variants thereof are intended to cover non-exclusive inclusion, so that a process, method, commodity or equipment including a series of elements not only includes those elements, but also includes Other elements that are not explicitly listed, or they also include elements inherent to such processes, methods, commodities, or equipment. If there are no more restrictions, the element defined by the sentence "including a..." does not exclude the existence of other identical elements in the process, method, commodity, or equipment that includes the element. Those skilled in the art should understand that the embodiments of the present invention can be provided as a method, a system, or a computer program product. Therefore, the present invention can take the form of a completely hardware embodiment, a completely software embodiment, or an embodiment combining software and hardware. Moreover, the present invention can be in the form of a computer program product implemented on one or more computer-usable storage media (including but not limited to disk memory, CD-ROM, optical memory, etc.) containing computer-usable program codes. . The invention can be described in the general context of computer-executable instructions executed by a computer, such as a program module. Generally, program modules include routines, programs, objects, components, data structures, etc. that perform specific tasks or implement specific abstract data types. The present invention can also be practiced in distributed computing environments in which tasks are performed by remote processing devices connected through a communication network. In a distributed computing environment, program modules can be located in local and remote computer storage media including storage devices. The various embodiments in this specification are described in a progressive manner, and the same or similar parts between the various embodiments can be referred to each other, and each embodiment focuses on the differences from other embodiments. In particular, as for the system embodiment, since it is basically similar to the method embodiment, the description is relatively simple, and for related parts, please refer to the part of the description of the method embodiment. The foregoing descriptions are merely embodiments of the present invention, and are not intended to limit the present invention. For those skilled in the art, the present invention can have various modifications and changes. Any modification, equivalent replacement, improvement, etc. made within the spirit and principle of the present invention should be included in the scope of the patent application of the present invention.