TW201804345A - Method, system and computer-readable medium for automatic chinese ontology generation based on structured web knowledge - Google Patents
Method, system and computer-readable medium for automatic chinese ontology generation based on structured web knowledge Download PDFInfo
- Publication number
- TW201804345A TW201804345A TW106125119A TW106125119A TW201804345A TW 201804345 A TW201804345 A TW 201804345A TW 106125119 A TW106125119 A TW 106125119A TW 106125119 A TW106125119 A TW 106125119A TW 201804345 A TW201804345 A TW 201804345A
- Authority
- TW
- Taiwan
- Prior art keywords
- concept
- aforementioned
- interest
- chinese text
- text corpus
- Prior art date
Links
Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
Abstract
Description
本發明關於自動生成本體庫的方法及系統,特別是基於結構化網路知識自動中文本體庫建構。 The invention relates to a method and a system for automatically generating an ontology library, in particular to an automatic Chinese ontology library construction based on structured network knowledge.
在訊息技術的時代,大量的數據每天被上載至網路、企業計算機網路或其他資料庫或者從此等之處被下載。數據用戶總是期待從網路、企業計算機網路或資料庫獲得他們所需要的各種訊息,但是並非每次均能獲得正確的訊息。本體表示的是不同概念之間特有的相似性及連接關係,可以用來幫助對網路、企業計算機網路或任何其他資料庫獲得的訊息或文件進行語義搜索。 In the age of information technology, large amounts of data are uploaded to or downloaded from the Internet, corporate computer networks, or other databases every day. Data users always expect to get all the information they need from the Internet, corporate computer networks, or databases, but not every time they get the right information. Ontology represents the unique similarity and connection relationship between different concepts, which can be used to help the semantic search of information or files obtained by the network, corporate computer network or any other database.
傳統的本體生成通常是專家通過手動輸入概念之間的關係來完成的,因此需要耗費許多人力。當前,不同的計算機實現程式,諸如人工神經網路(ANN)可以用於發現語料庫中詞語之間的語義相關性。然而,ANN需要預先進行訓練,因此仍然需要大量人力準備具有多種輸入模式的數據。因此採用ANN可能未必能夠有效的跟上網路、企業計算機網路或任 何資料庫數據的更新速度。 Traditional ontology generation is usually done by experts manually entering relationships between concepts, so it requires a lot of manpower. Currently, different computer-implemented programs, such as artificial neural networks (ANN), can be used to discover semantic correlations between words in a corpus. However, ANN needs to be trained in advance, so it still requires a lot of manpower to prepare data with multiple input modes. Therefore, the use of ANN may not be able to effectively keep up with the Internet, corporate computer networks or any Any database data update speed.
本體可以從各種語言的知識中產生。無論運用何種語言,使用者必須以該種語言來處理語料庫並且提煉關鍵字段用於本體生成。某些語言諸如中文,在詞語之間沒有明確的分隔符,與英文相比在語言處理方面更加困難或復雜,使關鍵詞提取更困難。因此,中文文字語料庫的語義內容很不容易理解。自然語言處理(NLP)和潛在語義分析(LSA)在計算機科學中被用於涉及計算機和人類語言之間互動的領域。結合NLP和LSA可對中文文字語料庫進行詞法、語法、句法和語義分析。這種分析特別涉及詞語切分、詞性標註、詞例提煉、統計分析和詞例相關性的確定。然而,由於中文語言的復雜性,NLP和LSA可能未必有效且準確地提煉用於本體生成的正確關鍵詞或概念。 Ontology can be generated from knowledge in various languages. Regardless of the language used, users must process the corpus in that language and refine key fields for ontology generation. Some languages, such as Chinese, have no clear delimiter between words, which is more difficult or complicated in terms of language processing compared to English, making keyword extraction more difficult. Therefore, the semantic content of the Chinese text corpus is not easy to understand. Natural language processing (NLP) and latent semantic analysis (LSA) are used in computer science in areas involving interaction between computers and human languages. Combining NLP and LSA can perform lexical, grammatical, syntactic, and semantic analysis on Chinese text corpora. This kind of analysis especially involves word segmentation, part-of-speech tagging, word extraction, statistical analysis, and determination of word relevance. However, due to the complexity of the Chinese language, NLP and LSA may not necessarily effectively and accurately refine the correct keywords or concepts for ontology generation.
總之,需要一種更有效率的系統和方法,理想地需要一種電腦自動實現的方法和系統,用於中文本體庫生成,以應對快速發展的數據世界和滿足數據用戶的需求。 In short, there is a need for a more efficient system and method. Ideally, a computer-implemented method and system is needed for the generation of Chinese ontology libraries to meet the rapidly developing data world and meet the needs of data users.
利用結構化網路知識可以自動中文本體庫建構。結構化網路知識是儲存在網路上的結構化訊息資料庫。例如,具有許多基於網路的中文百科全書,諸如百度百科和中文維基百科,這些是流行的由幾百萬條文章組成的公眾知識庫。每條文章包含一個主題,該主題通常由具有該主題知識的數據用戶手工編輯。如果發現錯誤或者無效的訊息,可以向基於網 路的百科全書的主辦方匯報,以糾正那些錯誤或無效的訊息。因此每個主題可以被認為是手工編輯的,並且由專家刪選的,因此可以被認為是該主題的專家意見。在用於生成本體時,每個主題可以被進一步當作一個概念。此外,數據用戶可以通過在文章中插入鏈結展示相關聯的文章。這種鏈結可以被認為是概念中的結合點,因此表示不同概念之間的語義關係。由於結構化的網路知識是基於包括眾多數量的概念以及概念之間的關係而建立的,與ANN需要預先訓練不同,使用結構化網路知識的生成本體可以自動完成,而無需大量的人力準備數據。因此,本發明不需要任何人力介入,因此在本體生成方面更有效率。 The use of structured network knowledge can automatically construct the Chinese ontology library. Structured network knowledge is a database of structured messages stored on the network. For example, there are many web-based Chinese encyclopedias, such as Baidu Encyclopedia and Chinese Wikipedia, which are popular public knowledge bases consisting of millions of articles. Each article contains a topic, which is usually manually edited by a data user with knowledge of the topic. If you find an error or invalid message, you can Lu's encyclopedia reports to correct those errors or invalid messages. Therefore, each topic can be considered to be edited manually and selected by an expert, and therefore can be considered to be an expert opinion on the topic. Each topic can be further treated as a concept when used to generate an ontology. In addition, data users can display related articles by inserting links into the articles. This kind of link can be considered as the connection point in the concept, and thus represents the semantic relationship between different concepts. Because structured network knowledge is based on the inclusion of a large number of concepts and the relationships between concepts, unlike ANN, which requires pre-training, the generation of ontology using structured network knowledge can be done automatically without a lot of human preparation data. Therefore, the present invention does not require any human intervention and is therefore more efficient in terms of ontology generation.
由於中文語言在詞語之間沒有明確的分隔符,生成中文本體庫中提煉的知識的準確性通常依賴於句子分割的方式以及選擇哪些詞例進行提煉。生成中文本體庫通常使用NLP和LSA進行知識提取。NLP和LSA是計算機執行的程式,這些程式進行中文文字語料庫的詞法、語法、句法和語義分析。NLP和LSA可以被認為使用計算機語言對人的語言進行理解,並且與中文母語的人對中文語料庫的理解相比,這種理解可能不夠準確有效。考慮到這一點,本發明使用結構化知識網路中的超鏈結來發現相關聯的概念,以有效地提取中文知識。由於這些超鏈結已經被專家審查過,因此可以認為它們能更準確地描述概念之間的關係。 Since the Chinese language has no clear delimiters between words, the accuracy of generating the extracted knowledge in the Chinese ontology database usually depends on the way of sentence segmentation and which word examples are selected for extraction. To generate Chinese ontology libraries, NLP and LSA are usually used for knowledge extraction. NLP and LSA are computer-executable programs that perform lexical, grammatical, syntactic, and semantic analysis of Chinese text corpora. NLP and LSA can be considered to use computer language to understand human language, and this understanding may not be accurate and effective compared to the understanding of Chinese corpus by native Chinese speakers. With this in mind, the present invention uses hyperlinks in a structured knowledge network to discover related concepts to effectively extract Chinese knowledge. Since these hyperlinks have been reviewed by experts, it can be said that they can more accurately describe the relationship between concepts.
下文描述的是一種用於基於結構化的網路知識自動中文本體庫建構的方法及電腦可讀媒體,其編碼在處理器執行時能使處理器實現 該方法的指示,包括下列步驟,從一結構化知識網路中抓取結構化知識,其中的結構化知識包括至少一個用於自動中文本體庫生成所關注的概念;過濾無關的鏈結;提取與前述所關注的概念相關的知識;發現前述所關注的概念的相關聯概念;通過餘弦相似性的度量推斷出前述所關注的概念以及其相關聯概念的語義相關性;並且儲存推斷出的前述語義相關性數據。 Described below is a method and computer-readable medium for the construction of an automatic Chinese ontology library based on structured network knowledge, and its coding enables the processor to implement The instructions of the method include the following steps: grabbing structured knowledge from a structured knowledge network, where the structured knowledge includes at least one concept for automatic Chinese ontology library generation; filtering irrelevant links; extracting Knowledge related to the aforementioned concept of interest; discovering related concepts of the aforementioned concept of interest; inferring the aforementioned concept of interest and the semantic relevance of its associated concept through a measure of cosine similarity; and storing the inferred aforementioned Semantic relevance data.
理想地,從結構化知識網路抓取的結構化知識的步驟包括下列步驟:通過超文本傳輸協議(“HTTP”)協議瀏覽前述的結構化知識;使用廣度優先搜索方法訪問結構化知識分類頁中的超鏈結,直到訪問完所有鏈結的中文文本語料;從前述結構化知識網路取得至少一個中文文本語料,其中前述中文文本語料的主題、摘要和內容由包含前述中文文本語料的靜態超文本標記語言(“HTML”)頁面中的HTML頭部,標題和主體標簽來確定;並且對取得的每個中文文本語料生成鏈結記錄。 Ideally, the steps of structured knowledge captured from a structured knowledge network include the following steps: browsing the aforementioned structured knowledge through a Hypertext Transfer Protocol ("HTTP") protocol; accessing the structured knowledge classification page using a breadth-first search method Link in the Chinese text until all the linked Chinese text corpora are accessed; at least one Chinese text corpus is obtained from the aforementioned structured knowledge network, wherein the subject, abstract, and content of the aforementioned Chinese text corpus consist of the aforementioned Chinese text The HTML header, title, and body tags in the static Hypertext Markup Language ("HTML") page of the corpus are determined; and a link record is generated for each Chinese text corpus obtained.
進一步,從結構化知識網路抓取的結構化知識的步驟包括下列步驟:對取得的每個中文文本語料生成唯一標識符。 Further, the step of structured knowledge captured from the structured knowledge network includes the following steps: generating a unique identifier for each Chinese text corpus obtained.
進一步,從結構化知識網路中抓取的結構化知識的步驟包括下列步驟:對取得的每個中文文本語料儲存網址(“URL”),標識符及/或最後修改時間。 Further, the step of capturing the structured knowledge from the structured knowledge network includes the following steps: storing a URL ("URL"), an identifier, and / or a last modification time for each Chinese text corpus obtained.
進一步,從結構化知識網路中抓取的結構化知識的步驟包括下列步驟:以預先設定的時間間隔掃描所有取得的中文文本語料;通過檢索是否存在具有相同最後修改時間的匹配記錄來產生或更新中文文本語料記錄;並且消除所有重復的中文文本語料。 Further, the step of capturing the structured knowledge from the structured knowledge network includes the following steps: scanning all the acquired Chinese text corpora at a preset time interval; generating by retrieving whether there are matching records with the same last modification time Or update Chinese text corpus records; and eliminate all duplicate Chinese text corpora.
進一步,消除重復的中文文本語料的步驟包括下列步驟:對 每個中文文本語料僅保留一個識別符;並且將相同中文文本語料所有其他不同的識別符轉換為重定向識別符。 Further, the steps of eliminating duplicate Chinese text corpora include the following steps: Each Chinese text corpus retains only one identifier; and all other different identifiers of the same Chinese text corpus are converted into redirection identifiers.
理想地,過濾無關鏈結的步驟包括下列步驟:對連接到外部網頁的無關鏈結、訪問菜單中不涉及前述所關注的概念知識的無關鏈結、以及在前述結構化知識網路中重復出現的鏈結進行噪聲過濾。 Ideally, the steps of filtering irrelevant links include the following steps: irrelevant links to external web pages, irrelevant links in the access menu that do not involve the aforementioned conceptual knowledge of interest, and recurrence in the aforementioned structured knowledge network The links are filtered for noise.
理想地,提取與前述所關注的概念相關的知識的步驟包括下列步驟:從描述所關注概念的中文文本語料中提取相關名詞術語。 Ideally, the step of extracting knowledge related to the aforementioned concept of interest includes the following steps: extracting relevant noun terms from a Chinese text corpus describing the concept of interest.
理想地,發現前述所關注的概念的相關聯概念的步驟包括如下步驟:從所關注的概念的中文文本語料中提取超鏈結列表,其中每個超鏈結的中文文本語料表示與前述所關注的概念相關的概念。 Ideally, the step of discovering related concepts of the aforementioned concept of interest includes the following steps: extracting a list of hyperlinks from the Chinese text corpus of the concept of interest, where the Chinese text corpus of each hyperlink represents the same Concept related to the concept of interest.
理想地,通過餘弦相似性的度量推斷出前述所關注的概念以及其相關聯概念的語義相關性的步驟包括如下步驟:計算前述所關注概念的術語頻率權重向量V1;訪問前述所關注概念的中文文本語料中的超級鏈結,從而定位前述所關注的概念的相關聯概念;計算每個前述相關聯概念的術語頻率權重向量,其中每個前述相關聯概念的前述術語頻率權重向量代表每個相關聯概念的唯一語義;並計算所關注概念和每個相關聯概念的術語頻率權重向量之間的餘弦相似性。 Ideally, the step of inferring the semantic relevance of the aforementioned concept of interest and its associated concepts through a measure of cosine similarity includes the steps of: calculating the term frequency weight vector V1 of the aforementioned concept of interest; accessing the Chinese of the aforementioned concept of interest Superlinks in the text corpus to locate the associated concepts of the aforementioned concepts of interest; compute the term frequency weight vector for each of the aforementioned associated concepts, where the aforementioned term frequency weight vector for each of the aforementioned associated concepts represents each The unique semantics of the associated concepts; and calculate the cosine similarity between the concept of interest and the term frequency weight vector for each associated concept.
進一步,由下列方程來計算術語頻率權重向量V1:V1=(tf(t1,c1),tf(t2,c1),....tf(tn,c1)) Further, the term frequency weight vector V1 is calculated by the following equation: V1 = (tf (t1, c1), tf (t2, c1), ... tf (tn, c1))
其中tf(t1,c1)為所關注概念c1的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c1)為所關注概念c1的中文文本語料中的第二個相關術語的術語 頻率;並且tf(tn,c1)為所關注概念c1的中文文本語料中的第n個相關術語的術語頻率。 Where tf (t1, c1) is the term frequency of the first related term in the Chinese text corpus of the concept c1 of interest; tf (t2, c1) is the second correlation in the Chinese text corpus of the concept of interest c1 Terminology Frequency; and tf (tn, c1) is the term frequency of the nth related term in the Chinese text corpus of the concept c1 of interest.
進一步,由下列方程來計算每個相關聯概念的術語頻率權重向量:V2=(tf(t1,c2),tf(t2,c2),....tf(tn,c2)) Further, the term frequency weight vector for each associated concept is calculated by the following equation: V2 = (tf (t1, c2), tf (t2, c2), ...... tf (tn, c2))
其中V2為相關聯概念c2的術語頻率權重向量;tf(t1,c2)為前述相關聯概念c2的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c2)為前述相關聯概念c2的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c2)為前述相關聯概念c2的中文文本語料中的第n個相關術語的術語頻率。 Where V2 is the term frequency weight vector of the related concept c2; tf (t1, c2) is the term frequency of the first related term in the Chinese text corpus of the aforementioned related concept c2; tf (t2, c2) is the aforementioned related The term frequency of the second related term in the Chinese text corpus of the related concept c2; and tf (tn, c2) is the term frequency of the nth related term in the Chinese text corpus of the related concept c2.
此外,由下列方程來計算所關注的概念及每個相關聯概念的術語頻率權重向量之間的餘弦相似性的步驟:

其中V1和V2分別為所關注概念c1和相關聯概念c2的術語頻率權重向量。 Where V1 and V2 are the term frequency weight vectors of the concept of interest c1 and the associated concept c2, respectively.
此外,儲存推斷出的前述語義相關性數據的步驟包括:用網路本體語言儲存語義相關性;並對前述語義相關性的訊息建立索引。 In addition, the step of storing the inferred aforementioned semantic relevance data includes: storing semantic relevance in a web ontology language; and indexing the aforementioned semantic relevance information.
理想地,使用的網路本體語言是資源描述框架(“RDF”)。 Ideally, the web ontology language used is a resource description framework ("RDF").
理想地,對前述語義相關性的訊息建立索引的步驟包括建立 包括所關注概念、相關聯概念、相關聯概念的數量和RDF圖標的概念圖。 Ideally, the step of indexing the aforementioned semantically relevant messages includes establishing Includes concept maps of concepts of interest, related concepts, number of related concepts, and RDF icons.
理想地,從結構化知識網路抓取結構化知識的步驟包括下列步驟:從基於網路的中文百科全書中抓取結構化知識。 Ideally, the steps to capture structured knowledge from a structured knowledge network include the following steps: Grab structured knowledge from a web-based Chinese encyclopedia.
理想地,從結構化知識網路抓取結構化知識的步驟包括下列步驟:從百度百科或中文維基百科抓取結構化知識。 Ideally, the step of capturing structured knowledge from a structured knowledge network includes the following steps: Grab structured knowledge from Baidu Encyclopedia or Chinese Wikipedia.
另外關於一種基於結構化網路知識自動中文本體庫建構的系統,包括:網路爬行模組,配置為從結構化知識網路抓取結構化知識;噪聲過濾模組,配置為過濾無關鏈結;知識提取模組,配置為提取中文文本語料中與所關注的概念相關的知識;儲存從結構化網路知識中下載的中文文本語料的資料庫;以及關係發現模組,配置為提取所關注概念的相關聯概念,並且利用餘弦相似性的度量計算所關注的概念和相關聯的概念之間的語義相關性。 In addition, a system for constructing an automatic Chinese ontology library based on structured network knowledge includes: a web crawling module configured to capture structured knowledge from a structured knowledge network; a noise filtering module configured to filter unrelated links A knowledge extraction module configured to extract knowledge related to the concept of interest in the Chinese text corpus; a database storing Chinese text corpora downloaded from structured network knowledge; and a relationship discovery module configured to extract A related concept of the concept of interest, and a measure of cosine similarity is used to calculate the semantic correlation between the concept of interest and the related concept.
理想地,該無關鏈結是連接到外部網頁的無關鏈結、訪問菜單中不涉及前述所關注的概念知識的無關鏈結、以及在前述結構化知識網路中重復出現的鏈結。 Ideally, the irrelevant link is an irrelevant link connected to an external webpage, an irrelevant link in the access menu that does not involve the aforementioned conceptual knowledge of interest, and a recurring link in the aforementioned structured knowledge network.
此外,該系統包括一顯示概念圖的可視化界面,其中前述概念圖包括所關注的概念,相關聯概念,相關聯概念的數量和RDF圖標,其中相關聯概念的數量為涉及前述所關注概念的前述相關聯概念的總數,前述的RDF圖標允許用戶下載前述所關注概念的RDF三元組。 In addition, the system includes a visual interface displaying a concept map, wherein the aforementioned concept map includes the concerned concept, related concepts, the number of related concepts, and RDF icons, wherein the number of related concepts is the aforementioned related to the aforementioned concerned concept. For the total number of related concepts, the aforementioned RDF icon allows the user to download the RDF triples of the aforementioned concepts of interest.
理想地,語義相關性由RDF所編碼。 Ideally, semantic relevance is encoded by RDF.
本發明提供一種更有效率的自動中文本體庫生成的系統及方法,以應對快速發展的數位世界並迎合數據用戶的需求。 The present invention provides a more efficient system and method for automatic Chinese ontology library generation, in order to cope with the rapidly developing digital world and meet the needs of data users.
1‧‧‧靜態HTML網頁 1‧‧‧ static HTML page
2‧‧‧基於結構化網路知識自動中文本體庫建構的系統 2‧‧‧Automatic Chinese Ontology Library Construction System Based on Structured Network Knowledge
21‧‧‧網路爬行模組 21‧‧‧Web Crawl Module
22‧‧‧噪聲過濾模組 22‧‧‧Noise Filter Module
23‧‧‧知識提取模組 23‧‧‧Knowledge Extraction Module
24‧‧‧資料庫 24‧‧‧Database
25‧‧‧關係發現模組 25‧‧‧ Relationship Discovery Module
26‧‧‧可視化模組 26‧‧‧Visualization Module
51‧‧‧關注的概念 51‧‧‧Concerned concepts
52‧‧‧相關聯概念 52‧‧‧related concepts
【圖1】為基於結構化網路知識自動中文本體庫建構的系統的可能實施方式的方框圖。 [Figure 1] A block diagram of a possible implementation of a system for building an automatic Chinese ontology library based on structured network knowledge.
【圖2】為展示基於結構化網路知識自動中文本體庫建構主要步驟的流程圖。 [Figure 2] A flowchart showing the main steps of constructing an automatic Chinese ontology library based on structured network knowledge.
【圖3】為展示關係發現的進一步步驟的流程圖。 [Fig. 3] A flowchart showing further steps of relationship discovery.
【圖4】為概念「三國」的概念圖。 [Figure 4] is a conceptual diagram of the concept "Three Kingdoms".
【圖5】為以RDF格式顯示的主題和相互語義相關性。 [Figure 5] is the theme and mutual semantic relevance displayed in RDF format.
參照附圖中所示的示例,具體描述示範性實施方式的細節,其中全文相似的附圖標記涉及相似的元素。 The details of the exemplary embodiments are described in detail with reference to the examples shown in the accompanying drawings, wherein like reference numerals refer to like elements throughout.
僅通過示意性的方式,附圖及以下描述較佳的實施方式。應該註意到的是,根據下文的討論,這裏公開的結構和方法的替代實施方式將毫無疑問地被認為是可行的替代方案,不會偏離要求保護的原則。 By way of illustration only, the preferred embodiments are described in the drawings and below. It should be noted that according to the discussion below, alternative embodiments of the structures and methods disclosed herein will undoubtedly be considered as viable alternatives without departing from the principles claimed.
在此所記載之系統、方法及電腦可讀媒體的實施方式基於結構化的網路知識自動中文本體庫建構。 The implementation of the systems, methods, and computer-readable media described herein is based on a structured network knowledge automatic Chinese ontology library construction.
從圖1中可見,基於結構化網路知識自動中文本體庫建構的系統2包括網路爬行模組21,噪聲過濾模組22,知識提取模組23,資料庫24, 關係發現模組25和可視化模組26。圖2中展示基於結構化的網路知識自動中文本體庫建構的流程圖。 It can be seen from FIG. 1 that the system 2 based on the structured online knowledge automatic Chinese ontology library construction includes a web crawling module 21, a noise filtering module 22, a knowledge extraction module 23, a database 24, Relationship discovery module 25 and visualization module 26. Figure 2 shows a flowchart of the construction of a structured online knowledge-based automatic Chinese ontology library.
在步驟S21,可以通過網路爬行模組21,從網路抓取諸如基於網路的中文百科全書的結構化知識網路的靜態HTML網頁1。例如,基於網路的中文百科全書可以是著名的百度百科和中文維基百科。每個靜態HTML網頁1描述一個特定概念,並且有連到相關網頁的鏈結。為了從結構化知識網頁抓取所有的靜態HTML網頁1(包括所有鏈結的網頁),網路爬行模組21通過HTTP協議瀏覽結構化知識網路中的目錄,並使用廣度優先搜索方法訪問目錄網頁中的超鏈結,直到所有鏈結的目錄均被訪問。網路爬行模組21接著從鏈結的靜態HTML網頁1中僅取得並提取中文文本語料,其中主題、摘要和內容由被取得的靜態HTML頁面上的HTML標簽(例如頭部,標題和主體標簽)來確定。 In step S21, a static HTML webpage 1 of a structured knowledge network such as a web-based Chinese encyclopedia can be crawled from the web through the web crawling module 21. For example, web-based Chinese encyclopedias can be the well-known Baidu Encyclopedia and Chinese Wikipedia. Each static HTML page 1 describes a specific concept and has links to related web pages. In order to crawl all the static HTML pages 1 (including all linked pages) from the structured knowledge pages, the web crawler module 21 browses the directories in the structured knowledge network through the HTTP protocol, and uses the breadth-first search method to access the directories Hyperlinks in a web page until all linked directories are accessed. The web crawling module 21 then obtains and extracts only the Chinese text corpus from the linked static HTML webpage 1, where the subject, abstract, and content are the HTML tags (such as the header, title, and body) on the acquired static HTML page. Label).
下文描述了網路爬行模組21一種可能的實施方式。網路爬行模組21可使用正規表示法"<a(.*?)</a>"從結構化的知識網路中找到所有可能的鏈結,對每個取得的中文文本語料建立鏈結記錄、並將該鏈結記錄和取得的中文文本語料存入資料庫24中。每個從抓取的靜態HTML網頁1中取得的中文文本語料可以由該被抓取的靜態HTML網頁1的網址來識別。為了便於識別,基於代表該中文文字語料的網址(“URL”),可為該中文文字語料生成唯一的識別符。例如,如果從URL為http://baike.baidu.com/view/2347.htm抓取的靜態HTML網頁1中取得了中文文本語料A,那麽該中文文本語料A將具有的標識符為2347。如果從URL為http://baike.baidu.com/view/10088.htm抓取的的靜態HTML網頁1取得了中文 文本語料B,那麽該該中文文本語料B將具有的標識符為10088。將每個中文文本語料的URL,標識符和最後修改時間儲存在資料庫24中。 A possible implementation manner of the web crawling module 21 is described below. The web crawling module 21 can use the regular notation "<a (. *?) </ A>" to find all possible links from the structured knowledge network, and establish a link for each acquired Chinese text corpus Make a record, and save the link record and the Chinese text corpus obtained in the database 24. Each Chinese text corpus obtained from the captured static HTML webpage 1 can be identified by the URL of the captured static HTML webpage 1. For easy identification, a unique identifier may be generated for the Chinese text corpus based on a web address ("URL") representing the Chinese text corpus. For example, if a Chinese text corpus A is obtained from the static HTML webpage 1 captured at the URL http://baike.baidu.com/view/2347.htm, then the Chinese text corpus A will have an identifier of 2347. If the static HTML webpage 1 captured from the URL http://baike.baidu.com/view/10088.htm is obtained in Chinese Text corpus B, then the Chinese text corpus B will have an identifier of 10088. The URL, identifier and last modification time of each Chinese text corpus are stored in the database 24.
網路爬行模組21以預先設定的時間間隔掃描所有下載的中文文本,通過檢索下載的中文文本語料的最後修改時間是否與現存鏈結記錄中的最後修改時間是否相匹配,來建立或者更新儲存的鏈結記錄。網路爬行模組21還可以在兩個或多個抓取的具有不同網址的靜態HTML網頁1中掃描並找出相同的中文文本語料。例如,相同的中文文本語料可能存在於抓取的具有以下不同網址的靜態HTML網頁1的瀏覽頁和子瀏覽頁下:(瀏覽頁下)http://baike.baidu.com/view/1005619.htm(子瀏覽頁下)http://baike.baidu.com/subview/1005619/1005619.htm這種從不同網址取得的中文文本語料的複製將產生不同的識別符並使標識符不唯一。為了消除資料庫24中重復的中文文本語料,網路爬行模組21可將次瀏覽頁中的中文文本語料的標識符定為一個重定向標識符,將該中文文本語料重定向至瀏覽頁下的標識符。因此,每個中文文本語料只有一個標識符,從而保持鏈結記錄中標識符的唯一性。 The web crawler module 21 scans all downloaded Chinese texts at a preset time interval, and establishes or updates by retrieving whether the last modified time of the downloaded Chinese text corpus matches the last modified time in the existing link record. Stored link records. The web crawling module 21 can also scan and find the same Chinese text corpus in two or more captured static HTML webpages 1 with different URLs. For example, the same Chinese text corpus may exist under the browse page and sub-browse page of the crawled static HTML webpage 1 with the following different URLs: (under the browse page) http://baike.baidu.com/view/1005619. htm (under the sub-browsing page) http: //baike.baidu.com/subview/1005619/1005619.htm This copy of Chinese text corpora obtained from different URLs will generate different identifiers and make the identifiers not unique. In order to eliminate the duplicate Chinese text corpus in the database 24, the web crawling module 21 may set the identifier of the Chinese text corpus in the second page as a redirection identifier, and redirect the Chinese text corpus to Browse the identifiers below the page. Therefore, each Chinese text corpus has only one identifier, thereby maintaining the uniqueness of the identifiers in the linked records.
總之,網路爬行模組21能掃描所有用上述正規表示法提取的鏈結記錄,通過<a>標簽中匹配的“href”屬性值從鏈結中提取標識符,將該標識符用於尋找資料庫24記錄的儲存在語料中的唯一標識符,並在鏈結記錄重定向標識符存在時對其進行更新。接著,在資料庫24中建立所有下載的中文文本語料的鏈結記錄。 In short, the web crawling module 21 can scan all the link records extracted by the above-mentioned regular representation, extract the identifier from the link by matching the "href" attribute value in the <a> tag, and use the identifier to find The unique identifier stored in the corpus recorded by the database 24 is updated when the link record redirection identifier exists. Next, link records of all downloaded Chinese text corpora are created in the database 24.
在步驟S22,噪聲過濾模組22過濾所有連接到外部網頁的無關鏈結、與中文文本語料中描述的知識無關的訪問菜單中的無關鏈結,和 結構化知識網路中重復出現的鏈結。 In step S22, the noise filtering module 22 filters all the irrelevant links connected to the external webpage, the irrelevant links in the access menu unrelated to the knowledge described in the Chinese text corpus, and Recurring links in a structured network of knowledge.
每個取得的中文文本語料可以代表一個概念,並且這個概念經常是該中文文本語料的主題。概念是一個抽象的想法。通過審視與該概念相關的細節訊息,與這個概念相關的事件、人物、物體、地點、時間、特性和特點等等,人們能夠理解這個概念。所有上述訊息均可以認為是概念的知識。在步驟S23,知識提取模組23提取中文文本語料中的概念知識。有很多提取概念知識的方法。其中一個方法是,提取描述這個概念的中文文本語料中的相關名詞術語。可以理解的是,不偏離本發明的精神和範圍,可以採取從所有已知或今後發展的手段中衍生出的任何本質上準確的知識提取措施。 Each obtained Chinese text corpus can represent a concept, and this concept is often the subject of the Chinese text corpus. Concept is an abstract idea. By examining the detailed information related to the concept, people can understand the concept related to the event, person, object, place, time, characteristics and characteristics and so on. All of the above messages can be considered conceptual knowledge. In step S23, the knowledge extraction module 23 extracts the conceptual knowledge in the Chinese text corpus. There are many ways to extract conceptual knowledge. One method is to extract relevant noun terms from the Chinese text corpus describing the concept. It can be understood that, without departing from the spirit and scope of the present invention, any essentially accurate knowledge extraction measures derived from all known or future-developed means can be taken.
從中文文本語料中提取的知識可以用於計算前述中文文本語料的術語頻率權重向量。既然每個中文文本語料代表一個概念,中文文本語料的術語頻率權重向量也可以是一個概念的術語頻率權重向量。V1是所關注概念c1的術語頻率權重向量,並且計算如下:V1=(tf(t1,c1),tf(t2,c1),....tf(tn,c1)) The knowledge extracted from the Chinese text corpus can be used to calculate the term frequency weight vector of the aforementioned Chinese text corpus. Since each Chinese text corpus represents a concept, the term frequency weight vector of the Chinese text corpus can also be a term frequency weight vector of a concept. V1 is the term frequency weight vector for the concept c1 of interest and is calculated as follows: V1 = (tf (t1, c1), tf (t2, c1), ... tf (tn, c1))
其中tf(t1,c1)為所關注概念c1的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c1)為所關注概念c1的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c1)為所關注概念c1的中文文本語料中的第n個相關術語的術語頻率。 Where tf (t1, c1) is the term frequency of the first related term in the Chinese text corpus of the concept c1 of interest; tf (t2, c1) is the second correlation in the Chinese text corpus of the concept of interest c1 The term frequency of terms; and tf (tn, c1) is the term frequency of the nth related term in the Chinese text corpus of the concept c1 of interest.
中文文本語料中具有連接到其他中文文本語料的超鏈結。這 些超鏈結中文文本語料代表與原始所關注概念相關聯的概念。在步驟S24,關係發現模組25通過計算中文文本語料(代表所關注的概念)和超鏈結文本語料(代表相關聯的概念)上得到的術語頻率權重向量,和計算中文文本語料和超鏈結中文文本語料術語頻率權重向量的餘弦相似性來發現概念之間的聯繫。 Chinese text corpora has hyperlinks to other Chinese text corpora. This These hyperlinked Chinese text corpora represent concepts associated with the original concept of interest. In step S24, the relationship discovery module 25 calculates the term frequency weight vectors obtained on the Chinese text corpus (representing the concept of interest) and the hyperlink text corpus (representing the associated concept), and calculates the Chinese text corpus And the cosine similarity of the frequency weight vector of the hypertext Chinese corpus term to discover the connection between the concepts.
如圖3中進一步說明的,對關係發現模組25一個可能的實施方式進行如下描述。在步驟S31,執行從概念c1的已抓取的靜態HTML網頁1提取超鏈結列表的步驟。中文文本語料中的每個超鏈結代表一個相關聯的概念。在步驟S32,通過訪問所關注概念的中文文本語料中找到的超鏈結,識別相關聯的概念。還可以找到相關聯概念的相應術語頻率權重向量。例如,可以在所關注概念c1的中文文本語料中找到的相關聯概念c2和c3,而相關聯概念c2和c3的術語頻率權重向量可以進行如下計算:V2=(tf(t1,c2),tf(t2,c2),....tf(tn,c2)) As further illustrated in FIG. 3, a possible implementation manner of the relationship discovery module 25 is described as follows. In step S31, a step of extracting a hyperlink list from the captured static HTML webpage 1 of the concept c1 is performed. Each hyperlink in the Chinese text corpus represents an associated concept. In step S32, the related concepts are identified by accessing the hyperlinks found in the Chinese text corpus of the concept of interest. The corresponding term frequency weight vector for associated concepts can also be found. For example, the related concepts c2 and c3 can be found in the Chinese text corpus of the concept c1 of interest, and the term frequency weight vectors of the related concepts c2 and c3 can be calculated as follows: V2 = (tf (t1, c2), tf (t2, c2), ...... tf (tn, c2))
V3=(tf(t1,c3),tf(t2,c3),....tf(tn,c3))其中V2是相關聯概念c2的術語頻率權重向量;V3是相關聯概念c3的術語頻率權重向量;tf(t1,c2)為相關聯概念c2的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c2)為相關聯概念c2的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c2)為相關聯概念c2的中文文本語料中的第n個相關術語的術語頻率;
tf(t1,c3)為相關聯概念c3的中文文本語料中的第一個相關術語的術語頻率;tf(t2,c3)為相關聯概念c3的中文文本語料中的第二個相關術語的術語頻率;並且tf(tn,c3)為相關聯概念c3的中文文本語料中的第n個相關術語的術語頻率;在步驟S33,每個相關聯的概念就具有代表其唯一語義的術語頻率權重向量。在步驟S34,由餘弦相似性度量來推斷相關聯概念的語義相關性。通過一個概念和其相關聯概念的餘弦相似性可以推斷這兩個概念之間的相近程度,即度量一個概念和相關聯概念的術語頻率權重向量的餘弦角:
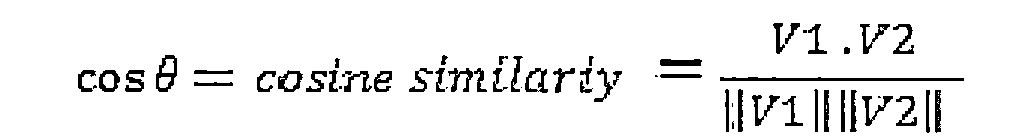
其中V1和V2分別是所關注概念c1和相關聯概念c2的術語頻率權重向量。 Where V1 and V2 are the term frequency weight vectors of the concept of interest c1 and the associated concept c2, respectively.
如果兩個概念之間的餘弦相似性接近1,那麽這兩個概念之間的內容很大程度上彼此相似。換句話說,這兩個概念很大程度上可能是語義相關的。如果兩個概念之間的餘弦相似性等於0,那麽這兩個概念具有完全不同的內容,意味著從語義角度來說可能是完全無關的。因此餘弦相似性有助於相關聯概念相似性的量化。 If the cosine similarity between two concepts is close to 1, then the content between the two concepts is largely similar to each other. In other words, these two concepts may be largely semantically related. If the cosine similarity between two concepts is equal to zero, then the two concepts have completely different content, meaning that they may be completely irrelevant from a semantic point of view. Therefore cosine similarity helps to quantify the similarity of related concepts.
從資料庫24中能取得所有的中文文本語料記錄,其中每一個代表一個概念,並且計算每個中文文本語料的術語頻率權重向量。推導出每個中文文本語料記錄和所有與其通過超鏈結相連的中文文本語料記錄之 間的餘弦相似性。主要的主體可以由正式語言進行編碼,例如網路本體語言“OWL”,資源描述框架(“RDF”或“RDFS”)。也可以使用其他本體語言。在本實施方式中,如圖5所示,中文文本語料轉換為RDF三元組。所有具有術語頻率權重的相關聯概念也以RDF三元組的方式被記錄下來。例如,具有語義相關性的中文文本語料的所有相關聯的概念以RDF格式在步驟S35進行儲存,而在步驟S36為具有語義相關性訊息的RDF文件建立索引。生成的RDF三元組和儲存的RDF數據可以用於進一步的查詢和操作。 All Chinese text corpus records can be obtained from the database 24, each of which represents a concept, and the term frequency weight vector of each Chinese text corpus is calculated. Derive a record of each Chinese text corpus record and all Chinese text corpus records connected to it through a hyperlink Cosine similarity between. The main body can be coded in a formal language, such as the web ontology language "OWL", the resource description framework ("RDF" or "RDFS"). Other ontology languages can also be used. In this embodiment, as shown in FIG. 5, the Chinese text corpus is converted into RDF triples. All related concepts with the term frequency weighting are also recorded as RDF triples. For example, all related concepts of a Chinese text corpus with semantic relevance are stored in RDF format at step S35, and an index of RDF files with semantic relevance information is established at step S36. The generated RDF triples and stored RDF data can be used for further queries and operations.
為了便於在生成中文本體庫時進行概念的檢索,可以建立標題和摘要的索引。可以通過度量概念的相關性來實現概念檢索和展示相關聯概念在概念圖中。 In order to facilitate the retrieval of concepts when generating the Chinese ontology library, indexes of titles and abstracts can be established. Conceptual retrieval can be achieved by measuring the relevance of concepts and showing the associated concepts in the concept map.
在一個實施方式中,以如圖4中顯示的概念圖用戶界面的形式,系統2包括可視化界面26,從而便於展開搜索。可視化界面26展示一個概念圖,其中所關注的概念51(即本實施方式中指“三國”)展示在圖中央,周邊展示所有相關聯的概念52。所關注的概念51下的一個數字代表與所關注概念51相關聯概念52的總數目。如圖4所顯示的,與“三國”相關聯的概念共有707個。該可視化界面26還可以展示RDF圖標,允許用戶下載所關注概念51的RDF三元組。不偏離本公開的範圍,所關注的概念、相關聯概念、RDF圖標數目的位置和方向可以變化。 In one embodiment, in the form of a concept map user interface as shown in FIG. 4, the system 2 includes a visual interface 26 to facilitate the search. The visual interface 26 shows a concept map, in which the concerned concepts 51 (referred to as “three kingdoms” in this embodiment) are displayed in the center of the figure, and all associated concepts 52 are displayed in the periphery. A number under the concept of interest 51 represents the total number of concepts 52 associated with the concept of interest 51. As shown in Figure 4, there are 707 concepts associated with the "Three Kingdoms." The visualization interface 26 can also display RDF icons, allowing users to download RDF triples of the concept 51 of interest. Without departing from the scope of the present disclosure, the concepts and associated concepts, the position and direction of the number of RDF icons may vary.
在此提供特別參考示例性實施方式的描述和示例,但是可以理解的是在申請專利範圍的精神和範圍下的變體和修正也是有效的。上述具體實施方式展示說明書可能的範圍,但不限於該公開的範圍。 Specific reference is made herein to the description and examples of exemplary embodiments, but it will be understood that variations and modifications within the spirit and scope of the scope of the patent application are also valid. The above specific embodiments show possible scopes of the description, but are not limited to the scope of the disclosure.
1‧‧‧靜態HTML網頁 1‧‧‧ static HTML page
2‧‧‧基於結構化網路知識自動中文本體庫建構的系統 2‧‧‧Automatic Chinese Ontology Library Construction System Based on Structured Network Knowledge
21‧‧‧網路爬行模組 21‧‧‧Web Crawl Module
22‧‧‧噪聲過濾模組 22‧‧‧Noise Filter Module
23‧‧‧知識提取模組 23‧‧‧Knowledge Extraction Module
24‧‧‧資料庫 24‧‧‧Database
25‧‧‧關係發現模組 25‧‧‧ Relationship Discovery Module
26‧‧‧可視化模組 26‧‧‧Visualization Module
Claims (42)


Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| HK16109078.8 | 2016-07-29 | ||
| HK16109078.8A HK1220319A2 (en) | 2016-07-29 | 2016-07-29 | Method, system and computer-readable medium for automatic chinese ontology generation based on structured web knowledge |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| TW201804345A true TW201804345A (en) | 2018-02-01 |
Family
ID=58633644
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| TW106125119A TW201804345A (en) | 2016-07-29 | 2017-07-26 | Method, system and computer-readable medium for automatic chinese ontology generation based on structured web knowledge |
Country Status (4)
| Country | Link |
|---|---|
| CN (1) | CN109643315B (en) |
| HK (1) | HK1220319A2 (en) |
| TW (1) | TW201804345A (en) |
| WO (1) | WO2018019289A1 (en) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018232290A1 (en) * | 2017-06-16 | 2018-12-20 | Elsevier, Inc. | Systems and methods for automatically generating content summaries for topics |
| CN111859975A (en) * | 2019-04-22 | 2020-10-30 | 广东小天才科技有限公司 | Method and system for expanding corpus regular form of sample corpus |
| CN110502640A (en) * | 2019-07-30 | 2019-11-26 | 江南大学 | A kind of extracting method of the concept meaning of a word development grain based on construction |
| CN110851612B (en) * | 2019-08-29 | 2023-08-18 | 国家计算机网络与信息安全管理中心 | Mobile application knowledge graph composite completion method and device based on encyclopedia knowledge |
| CN111783422B (en) | 2020-06-24 | 2022-03-04 | 北京字节跳动网络技术有限公司 | Text sequence generation method, device, equipment and medium |
| CN115658931B (en) * | 2022-12-27 | 2023-04-07 | 清华大学 | Encyclopedic knowledge graph dynamic updating method, device, equipment and medium |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN100568230C (en) * | 2004-07-30 | 2009-12-09 | 国际商业机器公司 | Multilingual network information search method and system based on hypertext |
| CN102609512A (en) * | 2012-02-07 | 2012-07-25 | 北京中机科海科技发展有限公司 | System and method for heterogeneous information mining and visual analysis |
| US20150019174A1 (en) * | 2013-07-09 | 2015-01-15 | Honeywell International Inc. | Ontology driven building audit system |
| US11250203B2 (en) * | 2013-08-12 | 2022-02-15 | Microsoft Technology Licensing, Llc | Browsing images via mined hyperlinked text snippets |
| US9672197B2 (en) * | 2014-10-14 | 2017-06-06 | Sugarcrm Inc. | Universal rebranding engine |
| US9842102B2 (en) * | 2014-11-10 | 2017-12-12 | Oracle International Corporation | Automatic ontology generation for natural-language processing applications |
| CN105488105B (en) * | 2015-11-19 | 2019-11-05 | 百度在线网络技术(北京)有限公司 | The treating method and apparatus of the method for building up of information extraction template, knowledge data |
| CN105843965B (en) * | 2016-04-20 | 2019-06-04 | 广东精点数据科技股份有限公司 | A kind of Deep Web Crawler form filling method and apparatus based on URL subject classification |
-
2016
- 2016-07-29 HK HK16109078.8A patent/HK1220319A2/en unknown
-
2017
- 2017-07-26 TW TW106125119A patent/TW201804345A/en unknown
- 2017-07-28 CN CN201780046326.XA patent/CN109643315B/en active Active
- 2017-07-28 WO PCT/CN2017/094881 patent/WO2018019289A1/en active Application Filing
Also Published As
| Publication number | Publication date |
|---|---|
| CN109643315A (en) | 2019-04-16 |
| WO2018019289A1 (en) | 2018-02-01 |
| HK1220319A2 (en) | 2017-04-28 |
| CN109643315B (en) | 2024-05-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Auer et al. | Dbpedia: A nucleus for a web of open data | |
| CN109643315B (en) | Method, system, computer device and computer readable medium for automatically generating Chinese ontology based on structured network knowledge | |
| US20090070322A1 (en) | Browsing knowledge on the basis of semantic relations | |
| Bedi et al. | Focused crawling of tagged web resources using ontology | |
| AU2019201531A1 (en) | An in-app conversational question answering assistant for product help | |
| JP2009048441A (en) | Information retrieval system and method and program, and information retrieval service provision method | |
| US20100005088A1 (en) | Using An Encyclopedia To Build User Profiles | |
| Grigalis | Towards web-scale structured web data extraction | |
| Al-Khalifa et al. | Folksonomies versus automatic keyword extraction: An empirical study | |
| Belozerov et al. | Semantic web technologies: Issues and possible ways of development | |
| Wasim et al. | Extracting and modeling user interests based on social media | |
| Posea et al. | Bringing the social semantic web to the personal learning environment | |
| Kramár et al. | Disambiguating search by leveraging a social context based on the stream of user’s activity | |
| Maree | Multimedia context interpretation: a semantics-based cooperative indexing approach | |
| CN114117242A (en) | Data query method and device, computer equipment and storage medium | |
| JP2006164086A (en) | Online knowledge search support system and online knowledge search support method | |
| Alfred et al. | A robust framework for web information extraction and retrieval | |
| Fung et al. | Discover information and knowledge from websites using an integrated summarization and visualization framework | |
| Roberson et al. | Semi-automatic ontology extraction to create draft topic maps | |
| WO2009035871A1 (en) | Browsing knowledge on the basis of semantic relations | |
| Khatavkar et al. | Use of noun phrases in identification of a website | |
| Blanco-Fernández et al. | Automatically Assembling a Custom-Built Training Corpus for Improving the Learning of In-Domain Word/Document Embeddings | |
| Menemencioğlu et al. | A Review on Semantic Text and Multimedia Retrieval and Recent Trends | |
| Yokoo et al. | Semantics-based news delivering service | |
| Alkwai et al. | Making Recommendations from Web Archives for" Lost" Web Pages |