RU2485605C2 - Improved method for coding and parametric presentation of coding multichannel object after downmixing - Google Patents
Improved method for coding and parametric presentation of coding multichannel object after downmixing Download PDFInfo
- Publication number
- RU2485605C2 RU2485605C2 RU2011102416A RU2011102416A RU2485605C2 RU 2485605 C2 RU2485605 C2 RU 2485605C2 RU 2011102416 A RU2011102416 A RU 2011102416A RU 2011102416 A RU2011102416 A RU 2011102416A RU 2485605 C2 RU2485605 C2 RU 2485605C2
- Authority
- RU
- Russia
- Prior art keywords
- audio
- parameters
- channels
- matrix
- output
- Prior art date
Links
- 230000005236 sound signal Effects 0.000 claims abstract description 22
- 238000009826 distribution Methods 0.000 claims abstract description 15
- 239000011159 matrix material Substances 0.000 claims description 235
- 238000002156 mixing Methods 0.000 claims description 45
- 230000000875 corresponding Effects 0.000 claims description 12
- 230000002194 synthesizing Effects 0.000 claims description 8
- 230000001131 transforming Effects 0.000 claims description 8
- 238000004590 computer program Methods 0.000 claims description 4
- 238000003860 storage Methods 0.000 claims description 3
- 230000018109 developmental process Effects 0.000 claims description 2
- 241000382509 Vania Species 0.000 claims 1
- 230000000694 effects Effects 0.000 abstract description 4
- 238000005516 engineering process Methods 0.000 abstract description 4
- 239000000126 substance Substances 0.000 abstract 1
- 239000000203 mixture Substances 0.000 description 136
- 238000009877 rendering Methods 0.000 description 71
- 238000010586 diagram Methods 0.000 description 25
- 238000006243 chemical reaction Methods 0.000 description 24
- 238000004422 calculation algorithm Methods 0.000 description 21
- 230000015572 biosynthetic process Effects 0.000 description 15
- 238000000034 method Methods 0.000 description 12
- 230000036850 Cld Effects 0.000 description 10
- 238000005755 formation reaction Methods 0.000 description 10
- 238000004364 calculation method Methods 0.000 description 8
- 230000004807 localization Effects 0.000 description 5
- 238000003786 synthesis reaction Methods 0.000 description 5
- 230000005540 biological transmission Effects 0.000 description 3
- 230000004069 differentiation Effects 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 238000000926 separation method Methods 0.000 description 3
- 238000007792 addition Methods 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 238000007906 compression Methods 0.000 description 2
- 230000002596 correlated Effects 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 238000005457 optimization Methods 0.000 description 2
- 238000007781 pre-processing Methods 0.000 description 2
- 102100001231 CLDN1 Human genes 0.000 description 1
- 101700052649 CLDN1 Proteins 0.000 description 1
- 101700045458 CPC-1 Proteins 0.000 description 1
- 101700022029 GBLP Proteins 0.000 description 1
- 230000002159 abnormal effect Effects 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 230000003111 delayed Effects 0.000 description 1
- 230000005520 electrodynamics Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000011049 filling Methods 0.000 description 1
- 238000009434 installation Methods 0.000 description 1
- 230000002452 interceptive Effects 0.000 description 1
- 238000011068 load Methods 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000000051 modifying Effects 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 238000000638 solvent extraction Methods 0.000 description 1
- 238000003892 spreading Methods 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- 230000001755 vocal Effects 0.000 description 1
- 238000005303 weighing Methods 0.000 description 1
Images








Abstract
Description
Изобретение относится к декодированию множественных объектов путем преобразования закодированного многообъектного сигнала на базе доступного многоканального понижающего микширования и вспомогательных управляющих данных.The invention relates to decoding multiple objects by converting an encoded multi-object signal based on available multi-channel down-mix and auxiliary control data.
Последние разработки в области технологии обработки звука делают возможным воссоздание многоканального аудиосигнала на базе стерео- (или моно-) сигнала и соответствующих управляющих данных. Эти методы параметрического кодирования звукового окружения обычно включают в себя параметризацию. Параметрический многоканальный аудиодекодер (например, MPEG Surround стандарта ISO/TEC 23003-1, L.Villemoes, J.Herre, J.Breebaart, G.Hotho, S.Disch, H.Pumhagen, and K.Kjorling, "MPEG Surround: The Forthcoming ISO Standard for Spatial Audio Coding," in 28th International AES Conference, The Future of Audio Technology Surround and Beyond, Pitea, Sweden, June 30-July 2, 2006; J.Breebaart, J.Herre, L.Villemoes, C.Jin,, K.Kjorling, J.Plogsties, and J.Koppens, "Multi-Channels goes Mobile: MPEG Surround Binaural Rendering," in 29th International AES Conference, Audio for Mobile and Handheld Devices, Seoul, Sept 2-4,2006) реконструирует M каналов на базе K принятых каналов, где М>K, с использованием управляющих данных. Управляющие данные представляют собой параметризацию многоканального сигнала на базе разности интенсивности сигнала между каналами (IID) и межканальной когерентности, согласованности (ICC). Как правило, такие параметры выделяются на стадии кодирования и описывают отношения мощностей и корреляцию между парами каналов используемых при повышающем микшировании. Применение такого алгоритма кодирования позволяет выполнять кодирование при скорости передачи данных, значительно более низкой, чем передача всей совокупности М каналов, при высокой эффективности кодирования и одновременной гарантии совместимости как с устройствами каналов K, так и с устройствами каналов М.Recent developments in the field of sound processing technology make it possible to recreate a multi-channel audio signal based on a stereo (or mono) signal and the corresponding control data. These methods for parametric coding of the surround sound environment typically include parameterization. Parametric multi-channel audio decoder (e.g., MPEG Surround ISO / TEC 23003-1, L. Villemoes, J. Herre, J. Breebaart, G. Hotho, S. Disch, H. Pumhagen, and K. Kjorling, "MPEG Surround: The Forthcoming ISO Standard for Spatial Audio Coding, "in the 28th International AES Conference, The Future of Audio Technology Surround and Beyond, Pitea, Sweden, June 30-July 2, 2006; J. Breebaart, J. Herre, L. Villemoes, C. Jin ,, K.Kjorling, J.Plogsties, and J.Koppens, "Multi-Channels goes Mobile: MPEG Surround Binaural Rendering," in the 29th International AES Conference, Audio for Mobile and Handheld Devices, Seoul, Sept 2-4,2006 ) reconstructs M channels based on K received channels, where M> K, using control data. The control data is a parameterization of a multi-channel signal based on the difference in signal intensity between channels (IID) and inter-channel coherence, consistency (ICC). As a rule, such parameters are distinguished at the coding stage and describe the power ratios and the correlation between the pairs of channels used in upmixing. The use of such a coding algorithm allows coding at a data rate much lower than the transmission of the entire set of M channels, with high coding efficiency and at the same time guarantee compatibility with both K channel devices and M channel devices.
Схожую систему кодирования осуществляет соответствующий кодер аудиообъекта [С.Faller, "Parametric Joint-Coding of Audio Sources," Convention Paper 6752 presented at the 120th AES Convention, Paris, France, May 20-23, 2006], [C.Faller, "Parametric Joint-Coding of Audio Sources," Patent application PCT/EP2006/050904, 2006], где несколько аудиообъектов микшируются "вниз" кодером, а позже микшируются "вверх" с использованием управляющих команд. Процесс повышающего микширования может также рассматриваться как разделение объектов, смешанных при понижающем микшировании. Полученный в результате повышающего микширования сигнал может быть преобразован для воспроизведения в одно- или многоканальный вид. Определяя точнее, упомянутые выше публикации представляют метод синтеза звуковых каналов на основании результатов понижающего микширования (именуемых суммарным сигналом), статистической информации об источниках и характеристик, задающих необходимый выходной формат. Если используются несколько сигналов, полученных понижающим микшированием, эти сигналы состоят из подмножеств различных объектов, и повышающее микширование должно осуществляться по каждому каналу понижающего микширования индивидуально. Новизна предлагаемого метода заключается в осуществлении повышающего микширования одновременно по всем каналам понижающего микширования. Методы кодирования объекта, представленные до настоящего изобретения, не предлагали вариант декодирования результатов понижающего микширования по нескольким каналам одновременно.A similar coding system is implemented by the corresponding encoder of an audio object [C. Faller, "Parametric Joint-Coding of Audio Sources," Convention Paper 6752 presented at the 120th AES Convention, Paris, France, May 20-23, 2006], [C. Faller, " Parametric Joint-Coding of Audio Sources, "Patent application PCT / EP2006 / 050904, 2006], where several audio objects are mixed down by the encoder and later mixed up using the control commands. The upmixing process can also be considered as the separation of objects mixed in the downmix. The signal obtained as a result of upmixing can be converted for reproduction to a single or multichannel form. Determining more precisely, the publications mentioned above present a method for synthesizing sound channels based on the results of down-mixing (referred to as the sum signal), statistical information about the sources, and characteristics that specify the required output format. If several signals obtained by down-mixing are used, these signals consist of subsets of different objects, and up-mixing should be carried out individually for each down-mixing channel. The novelty of the proposed method lies in the implementation of up-mix simultaneously on all channels of down-mix. The object coding methods presented prior to the present invention did not offer the option of decoding the downmix results on several channels simultaneously.
Первый аспект изобретения относится к кодеру аудиообъекта, генерирующему закодированный сигнал аудиообъекта с использованием совокупности аудиообъектов, включая:A first aspect of the invention relates to an audio object encoder generating an encoded audio object signal using a plurality of audio objects, including:
генератор информации (данных) понижающего микширования, генерирующий параметры распределения множества аудиообъектов, по крайней мере, по двум каналам понижающего микширования;a downmix information (data) generator generating distribution parameters of a plurality of audio objects over at least two downmix channels;
генератор параметров аудиообъектов и выходной интерфейс для генерирования кодированного сигнала аудиообъекта с использованием характеристик понижающего микширования и параметров объекта.an audio object parameter generator and an output interface for generating an encoded audio object signal using downmix characteristics and object parameters.
Второй аспект изобретения относится к методу кодирования аудиообъекта. обеспечивающему генерирование кодированного сигнала аудиообъекта с использованием совокупности аудиообъектов, включая:A second aspect of the invention relates to a method for encoding an audio object. generating a coded signal of an audio object using a combination of audio objects, including:
генерирование данных понижающего микширования, характеризующих порядок распределения совокупности аудиообъектов, по крайней мере, по двум каналам понижающего микширования;generating down-mix data characterizing the distribution order of a plurality of audio objects over at least two down-mix channels;
генерирование параметров аудиообъектов и генерирование кодированных сигналов аудиообъекта с использованием данных понижающего микширования и параметров объекта.generating parameters of audio objects and generating encoded signals of an audio object using downmix data and object parameters.
Третий аспект изобретения относится к звуковому синтезатору (аудиосинтезатору), генерирующему выходные данные с использованием кодированного сигнала аудиообъекта, включая:A third aspect of the invention relates to a sound synthesizer (audio synthesizer) generating output using an encoded audio object signal, including:
синтезатор выходных данных, используемых для представления множества выходных каналов с заданной конфигурацией выходного аудиосигнала, отображающего совокупность аудиообъектов, где синтезатор выходных данных распознает характеристики понижающего микширования для распределения множества аудиообъектов, по крайней мере, по двум каналам понижающего микширования и параметры аудиообъекта.an output synthesizer used to represent a plurality of output channels with a given configuration of an output audio signal representing a plurality of audio objects, where the output synthesizer recognizes down-mix characteristics for distributing a plurality of audio objects over at least two down-mix channels and audio object parameters.
Четвертый аспект изобретения относится к методу синтезирования звука, позволяющего генерировать выходные данные с использованием кодированного сигнала аудиообъекта, включая:A fourth aspect of the invention relates to a method for synthesizing sound, which allows generating output using an encoded signal of an audio object, including:
генерирование выходных данных для формирования множества выходных каналов с заданной конфигурацией выходного аудиосигнала, отображающей совокупность аудиообъектов, с применением синтезатора выходных данных, способным считывать характеристики понижающего микширования для распределения множества аудиообъектов, по крайней мере, по двум каналам понижающего микширования и параметры аудиообъекта.generating output data for generating a plurality of output channels with a given configuration of an output audio signal representing a plurality of audio objects using an output synthesizer capable of reading down-mix characteristics to distribute a plurality of audio objects over at least two down-mix channels and audio object parameters.
Пятый аспект изобретения относится к кодированному сигналу аудиообъекта, содержащему характеристики понижающего микширования, указывающие порядок распределения множества аудиообъектов, по крайней мере, по двум каналам понижающего микширования, и параметры объектов, позволяющие реконструировать аудиообъекты с использованием параметров объектов и, по крайней мере, двух каналов понижающего микширования.A fifth aspect of the invention relates to an encoded audio object signal comprising downmix characteristics indicating the distribution order of a plurality of audio objects over at least two downmix channels, and object parameters allowing reconstruction of audio objects using object parameters and at least two downmix channels mixing.
Шестой аспект изобретения относится к компьютерному программному обеспечению, предназначенному для осуществления метода кодирования аудиообъекта или метода декодирования аудиообъекта на компьютере.A sixth aspect of the invention relates to computer software for implementing a method for encoding an audio object or a method for decoding an audio object on a computer.
Далее изобретение будет представлено иллюстративным материалом, не ограничивающим его ни по форме, ни по существу, с пояснениями прилагаемых чертежей, где:Further, the invention will be presented by illustrative material, not limiting it either in form or in essence, with explanations of the accompanying drawings, where:
на фиг.1а представлена блок-схема алгоритма кодирования пространственного аудиообъекта, включая кодирование и декодирование;on figa presents a block diagram of the encoding algorithm for a spatial audio object, including encoding and decoding;
на фиг.1b представлена блок-схема алгоритма кодирования пространственного аудиообъекта с использованием декодера MPEG Surround;on fig.1b presents a block diagram of the encoding algorithm for a spatial audio object using the MPEG Surround decoder;
на фиг.2 представлен алгоритм работы кодера пространственного аудиообъекта;figure 2 presents the algorithm of the encoder spatial audio object;
на фиг.3 представлена схема алгоритма работы экстрактора (выделителя) параметров аудиообъекта в режиме дифференциации мощности;figure 3 presents a diagram of the algorithm of the extractor (separator) parameters of the audio object in the mode of power differentiation;
на фиг.4 представлена схема алгоритма работы экстрактора (выделителя) параметров аудиообъекта в режиме предсказания;figure 4 presents a diagram of the algorithm of the extractor (extractor) parameters of the audio object in the prediction mode;
на фиг.5 представлена схема устройства транскодера SAOC - MPEG Surround;figure 5 presents a diagram of the device transcoder SAOC - MPEG Surround;
на фиг.6 схематически представлены различные режимы работы понижающего микшера для понижающего микширования;figure 6 schematically shows the various modes of operation of the down-mixer for down-mixing;
на фиг.7 представлена принципиальная схема декодера MPEG Surround для нисходящего микширования стереосигнала;7 is a schematic diagram of an MPEG Surround decoder for down-mixing a stereo signal;
на фиг.8 дана схема частного случая реализации с использованием кодера SAOC;on Fig is a diagram of a special case of implementation using the SAOC encoder;
на фиг.9 представлена схема варианта осуществления кодера;Fig.9 is a diagram of an embodiment of an encoder;
на фиг.10 представлена схема варианта осуществления декодера;10 is a diagram of an embodiment of a decoder;
на фиг.11 представлена таблица оптимальных режимов работы декодера/синтезатора;figure 11 presents a table of optimal modes of operation of the decoder / synthesizer;
на фиг.12 представлена блок-схема методики расчета некоторых пространственных параметров повышающего микширования;on Fig presents a block diagram of a methodology for calculating some spatial parameters of the up-mix;
на фиг.13а представлена блок-схема методики расчета дополнительных пространственных параметров повышающего микширования;on figa presents a block diagram of a methodology for calculating additional spatial parameters up-mixing;
на фиг.13b представлена блок-схема методики расчетов с применением параметров предсказания;on fig.13b presents a block diagram of a calculation method using prediction parameters;
на фиг.14 дана общая принципиальная схема системы кодер/декодер;Fig. 14 is a general schematic diagram of an encoder / decoder system;
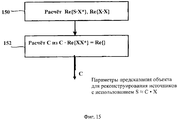
на фиг.15 представлена блок-схема алгоритма расчета прогностических параметров объекта; иon Fig presents a block diagram of an algorithm for calculating the prognostic parameters of the object; and
фиг.16 иллюстрирует способ стерео представления (рендеринга).Fig. 16 illustrates a stereo presentation (rendering) method.
Описанные ниже варианты осуществления изобретения являются не более чем иллюстрацией принципов усовершенствованного метода кодирования и параметрического представления кодирования многоканального объекта после понижающего микширования. Подразумевается, что для специалистов в данной области возможность внесения изменений и усовершенствований в компоновку и элементы описанной конструкции очевидна. В силу этого представленные описания и пояснения вариантов реализации изобретения ограничиваются только рамками патентных требований, но не конкретными деталями.Embodiments of the invention described below are nothing more than an illustration of the principles of an improved encoding method and a parametric representation of the encoding of a multi-channel object after downmixing. It is understood that for specialists in this field, the possibility of making changes and improvements to the layout and elements of the described construction is obvious. Therefore, the presented descriptions and explanations of the embodiments of the invention are limited only by the scope of patent requirements, but not by specific details.
Предпочтительные варианты осуществления предусматривают метод кодирования, который сочетает в себе функциональные возможности алгоритма кодирования объекта с возможностями аудио представления (аудиорендеринга) многоканального декодера. Пересылаемые управляющие данные относятся к индивидуальным объектам и в силу этого позволяют управлять при воспроизведении пространственным положением и уровнем сигнала. Таким образом, управляющая информация непосредственно связана с так называемым 'описанием сцены', дающим информацию о расположении объектов в окружающем пространстве. Описанием сцены можно управлять или со стороны декодера в интерактивном режиме со слушателем или со стороны кодера от источника звука.Preferred embodiments provide an encoding method that combines the functionality of an object encoding algorithm with the capabilities of the audio presentation (audio rendering) of a multi-channel decoder. Forwarded control data refers to individual objects and, therefore, allows you to control the spatial position and signal level during playback. Thus, the control information is directly related to the so-called 'scene description', which gives information about the location of objects in the surrounding space. The scene description can be controlled either from the decoder side in interactive mode with the listener or from the encoder side from the sound source.
Суть изобретения заключается в том, что вводится транскодер для того, чтобы преобразовать (перекодировать) относящуюся к объекту управляющую информацию и сигнал понижающего микширования в управляющие данные и сигнал понижающего микширования, предназначенные для системы воспроизведения, например, декодера MPEG Surround. В представленном методе кодирования объекты могут быть произвольно распределены по имеющимся в наличии каналам нисходящего микширования кодера. Транскодер точно использует многоканальные параметры нисходящего микширования, обеспечивая перекодированный сигнал понижающего микширования и относящиеся к объекту управляющие данные. Благодаря этому повышающее микширование на декодере выполняется не для каждого канала индивидуально, как предложено в [С.Faller, "Parametric Joint-Coding of Audio Sources," Convention Paper 6752 presented at the 120th AES Convention, Paris, France, May 20-23, 2006], а все каналы понижающего микширования обрабатываются одновременно за один процесс повышающего микширования. По новой схеме параметры многоканального понижающего микширования должны быть частью управляющих данных и кодируются кодером объекта.The essence of the invention lies in the fact that a transcoder is introduced in order to convert (transcode) the object-related control information and the down-mix signal into control data and the down-mix signal intended for a reproduction system, for example, an MPEG Surround decoder. In the presented encoding method, objects can be arbitrarily distributed over the available channels of the downstream mixing of the encoder. The transcoder accurately utilizes multi-channel down-mix parameters, providing a transcoded down-mix signal and object-related control data. Due to this, up-mixing on the decoder is not performed individually for each channel, as suggested in [C. Faller, "Parametric Joint-Coding of Audio Sources," Convention Paper 6752 presented at the 120th AES Convention, Paris, France, May 20-23, 2006], and all downmix channels are processed simultaneously in a single upmix process. According to the new scheme, the parameters of multichannel down-mixing should be part of the control data and encoded by the object encoder.
Распределение объектов по каналам понижающего микширования может выполниться автоматически, или это может быть конструктивное решение, связанное с кодером. В последнем случае систему понижающего (нисходящего) микширования можно включить в уже существующую многоканальную систему воспроизведения (например, в стереоустановку), делая упор на воспроизведение, опуская стадию перекодирования и многоканального декодирования. Это еще одно преимущество перед более ранними алгоритмами кодирования, известными из уровня техники, предусматривавшими один канал понижающего микширования или множественные каналы понижающего микширования, содержащие подмножества объектов-источников.The distribution of objects on the down-mix channels can be performed automatically, or it can be a constructive decision related to the encoder. In the latter case, the system of down (down) mixing can be included in an existing multi-channel playback system (for example, in stereo), emphasizing playback, omitting the stage of transcoding and multi-channel decoding. This is another advantage over earlier coding algorithms known in the art for a single downmix channel or multiple downmix channels containing subsets of source objects.
В то время как алгоритмы кодирования объекта известного уровня техники описывают технологию декодирования, используя исключительно единственный канал понижающего микширования, данное изобретение не имеет такого ограничения, поскольку предлагает метод одновременного декодирования материала понижающего микширования, содержащего сигналы понижающего микширования по нескольким каналам. Качество разделения объектов возрастает по мере увеличения числа каналов понижающего микширования. Таким образом, изобретение успешно заполняет пробел между алгоритмом кодирования объекта по одиночному моноканалу понижающего микширования и алгоритмом многоканального кодирования, где каждый объект передается по выделенному каналу. Таким образом, предлагаемый метод дает возможность гибкого управления качеством при разделении объектов в зависимости от предъявляемых, прикладных требований и эксплуатационных свойств системы передачи (таких, как емкость канала).While encoding algorithms of an object of the prior art describe decoding technology using only a single downmix channel, the present invention does not have such a limitation, since it offers a method for simultaneously decoding downmix material containing downmix signals on several channels. The quality of object separation increases as the number of down-mix channels increases. Thus, the invention successfully fills the gap between the object coding algorithm for a single mono channel down-mix and the multi-channel coding algorithm, where each object is transmitted on a dedicated channel. Thus, the proposed method allows flexible quality management when separating objects depending on the requirements, application requirements and operational properties of the transmission system (such as channel capacity).
В дополнение к этому, преимущество использования более чем одного канала заключается в том, что оно позволяет также принимать во внимание корреляцию между различными объектами в отличие от описания, учитывающего лишь разницу в интенсивности звуковых сигналов, как в алгоритмах кодирования объекта в более ранней практике. Более ранняя практика исходила из предпосылки, что все объекты независимы друг от друга и взаимно не согласованы (нулевая взаимная корреляция), в то время как в действительности маловероятно, что объекты не могут быть коррелированы, как, например, левый и правый каналы стереофонического сигнала. В соответствии с концепцией данного изобретения включение параметров корреляции в описание (управляющие данные) делает его более полным и таким образом способствует созданию дополнительной возможности разделения объектов. Предпочтительные варианты осуществления включают в себя, по крайней мере, один из следующих отличительных признаков.In addition, the advantage of using more than one channel is that it also allows you to take into account the correlation between different objects, as opposed to a description that takes into account only the difference in the intensity of sound signals, as in object encoding algorithms in earlier practice. Earlier practice proceeded from the premise that all objects are independent from each other and mutually inconsistent (zero cross-correlation), while in reality it is unlikely that objects cannot be correlated, such as the left and right channels of a stereo signal. In accordance with the concept of the present invention, the inclusion of correlation parameters in the description (control data) makes it more complete and thus contributes to the creation of an additional possibility of separation of objects. Preferred embodiments include at least one of the following features.
Система для передачи и создания множества отдельных аудиообъектов с использованием многоканального понижающего микширования и вспомогательных управляющих данных, описывающих эти объекты, включающая в себя:A system for transmitting and creating many separate audio objects using multi-channel down-mixing and auxiliary control data describing these objects, including:
кодер пространственных аудиообъектов, кодирующий множество аудиообъектов для многоканального понижающего микширования, информацию о многоканальном понижающем микшировании и параметры объекта; или декодер пространственных аудиообъектов, расшифровывающий данные многоканального понижающего микширования, информацию о многоканальном понижающем микшировании, параметры объекта и матрицу аудиорендеринга (матрицу представления) объекта во второй многоканальный аудиосигнал, применимый для аудиовоспроизведения.a spatial audio object encoder encoding a plurality of audio objects for multi-channel down-mix, multi-channel down-mix information and object parameters; or a spatial audio object decoder that decrypts the multi-channel down-mix data, the multi-channel down-mix information, the object parameters and the audio rendering matrix (presentation matrix) of the object into a second multi-channel audio signal suitable for audio playback.
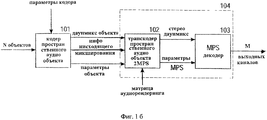
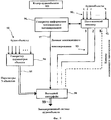
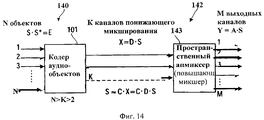
На фиг.1а показан алгоритм кодирования пространственного аудиообъекта (SAOC), включающий в себя кодер SAOC 101 и декодер SAOC 104. Кодер пространственных аудиообъектов 101 кодирует N объектов в данные понижающего микширования объекта о K>1 аудиоканалах в соответствии с параметрами кодера. Информация о примененной весовой матрице понижающего микширования D выводится кодером SAOC вместе со вспомогательными данными относительно мощности и корреляции понижающего микширования. Матрица D часто, но не обязательно всегда, постоянна по времени и по частоте и поэтому содержит относительно мало информации. В завершение, кодер SAOC фиксирует параметры каждого объекта как частотно-временную функцию с глубиной разрешения, определяемой на основе принципов восприятия (перцептуального кодирования). Декодер пространственных аудиообъектов 104 принимает вводимые в него данные каналов понижающего микширования объектов, информацию о понижающем микшировании и параметры объектов (сгенерированные кодером) и генерирует выходные данные, содержащие М аудиоканалов для представления пользователю. Аудиорендеринг N объектов в М аудиоканалов производится посредством матрицы аудиорендеринга, представляющей собой набор параметров, вводимых пользователем в декодер SAOC.Fig. 1a shows a spatial audio object (SAOC) encoding algorithm including an
На фиг.1b показана блок-схема алгоритма кодирования пространственного аудиообъекта с последующим применением декодера MPEG Surround. Декодер SAOC 104, примененный в настоящем изобретении, может быть реализован в виде транскодера SAOC - MPEG Surround 102 в сочетании с декодером MPEG Surround 103 с понижающим микшированием до стереосигнала. Управляемая пользователем матрица аудиорендеринга А размерности M×N определяет заданное соотношение преобразования N объектов в М аудиоканалов. Функции этой матрицы могут зависеть как от настроек, так и от частотных показателей, и это окончательный результат наиболее дружественного интерфейса для управления аудиообъектами (куда, кроме того, извне может быть введено описание сцены). В случае применения настроек для акустической системы 5. 1, количество выходных аудиоканалов будет М=6. Задача декодера SAOC заключается в перцептуальном воссоздании исходных аудиообъектов как конечного результата аудиорендеринга. На входе транскодер SAOC - MPEG Surround 102 получает матрицу аудиорендеринга А, данные понижающего микширования объекта, результаты понижающего микширования, включая весовую матрицу понижающего микширования D, и описание объекта, и генерирует понижающее микширование стереосигнала и информацию MPEG Surround. Если транскодер реализуется в соответствии с настоящим изобретением, следующий за ним декодер MPEG Surround 103, получив на входе эти данные, на выходе дает М-канальный акустический сигнал с требуемыми характеристиками.Fig. 1b shows a block diagram of an encoding algorithm for a spatial audio object followed by the use of an MPEG Surround decoder. The
Декодер SAOC, вводимый в настоящем изобретении, состоит из транскодера SAOC - MPEG Surround 102 и декодера MPEG Surround 103 с нисходящим микшированием до стереосигнала. Управляемая пользователем матрица аудиорендеринга А размерности M×N определяет заданное соотношение преобразования N объектов в M аудиоканалов. Эта матрица может зависеть как от настроек, так и от частоты, что является показателем более дружественного интерфейса управления аудиообъектами. При применении настроек для акустической системы 5.1 количество выходных аудиоканалов будет М=6. Декодер SAOC предназначен для перцептуального воссоздания исходных аудиообъектов как конечного результата аудиорендеринга. На входе транскодер SAOC - MPEG Surround 102 получает матрицу аудиорендеринга А, данные понижающего микширования объекта, результаты понижающего микширования, включая весовую матрицу понижающего микширования D, и описание объекта и генерирует понижающее микширование стереосигнала и информацию MPEG Surround. Если транскодер реализуется в соответствии с настоящим изобретением, следующий за ним декодер MPEG Surround 103, получив на входе эти данные, на выходе дает М-канальный акустический сигнал с требуемыми характеристиками.The SAOC decoder introduced in the present invention consists of a SAOC transcoder -
На фиг.2 представлен алгоритм работы кодера пространственного аудиообъекта (SAOC) 101, вводимого настоящим изобретением. N аудиообъектов вводятся в блок понижающего микширования 201, а также в экстрактор (выделитель) параметров аудиообъекта 202. Блок понижающего микширования 201 смешивает объекты в поток итоговых данных понижающего микширования объекта, состоящий из K>1 аудиоканалов, в соответствии с параметрами кодера, а также выводит информацию о понижающем микшировании. Эта информация включает в себя описание примененной весовой матрицы понижающего микширования D и дополнительно, если последовательно задействуемый экстрактор параметров аудиообъекта работает в режиме предсказания, параметры, описывающие мощность и корреляцию результатов понижающего микширования объекта.Figure 2 presents the algorithm of the encoder spatial audio object (SAOC) 101, introduced by the present invention. N audio objects are input into the downmixing unit 201, as well as into the extractor (extractor) of the parameters of the
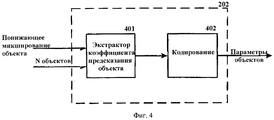
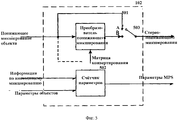
Как будет обсуждаться в одном из следующих параграфов, роль подобных дополнительных параметров заключается в предоставлении доступа к энергетическим и корреляционным показателям подмножеств преобразуемых аудиоканалов в тех случаях, когда параметры объектов выражены только относительно понижающего микширования, и главным примером здесь являются синхросигналы "тыльный/фронтальный" для акустических систем 5.1. Экстрактор параметров аудиообъектов 202 выделяет параметры объекта в соответствии с параметрами кодера. Средства управления кодером по частотно-временным изменениям определяют, какой из двух режимов кодера применен, на энергетической или прогностической основе. В режиме дифференциации мощности параметры кодера далее содержат информацию о группировании N аудиообъектов в Р стереообъектов и N-2P монообъектов. Каждый режим будет описан далее на фиг.3 и 4.As will be discussed in one of the following paragraphs, the role of such additional parameters is to provide access to the energy and correlation indicators of the subsets of the converted audio channels in those cases when the parameters of the objects are expressed only with respect to the downmix, and the main example here is the rear / front signals for acoustic systems 5.1. An audio
На фиг.3 представлена схема алгоритма работы экстрактора параметров аудиообъекта 202 в режиме дифференциации мощности. Группирование 301 в Р стереообъектов и N-2P монообъектов осуществляется согласно информации о группировании, содержавшейся в параметрах кодера. Для каждого заданного частотно-временного интервала тогда выполняются следующие операции. Два показателя мощности объекта и одна нормализованная корреляция выделяются экстрактором стереопараметров 302 для каждого из Р стереообъектов. Один энергетический показатель выделяется экстрактором параметров 303 для каждого из N-2Р монообъектов. Затем полный набор из N параметров мощности и Р параметров нормализованной корреляции кодируются в 304 вместе с данными группирования, формируя параметры объекта. Кодирование может включать в себя операцию нормализации с учетом самого высокого показателя мощности объекта или с учетом суммы выделенных мощностей объекта.Figure 3 presents a diagram of the algorithm of the extractor parameters of the
На фиг.4 представлена схема алгоритма работы экстрактора параметров аудиообъекта 202 в режиме предсказания. Для каждого заданного частотно-временного интервала тогда выполняются следующие операции. Для каждого из N объектов выводится линейная комбинация из K каналов понижающего микширования объектов, которая соответствует данному объекту по методу наименьших квадратов. K весов этой линейной комбинации называются коэффициентами предсказания объекта (ОРС), и они вычисляются экстрактором ОРС 401. Полный набор ОРС в количестве N-K кодируется в 402 с формированием параметров объекта. Кодирование может включать сокращение общего числа ОРС на основании линейных взаимозависимостей. Отличительной особенностью данного изобретения является то, что это общее число может быть сокращено максимально до {K·(N-K),0}, ест весовая матрица понижающего микширования D имеет полный ранг.Figure 4 presents a diagram of the algorithm of the extractor parameters of the
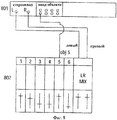
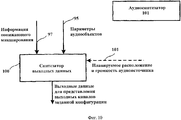
На фиг.5 представлена схема устройства транскодера SAOC - MPEG Surround 102 согласно настоящему изобретению. Для каждого частотно-временного интервала информация о понижающем микшировании и параметры объекта объединяются с матрицей аудиорендеринга счетчиком параметров 502 с формированием параметров MPEG Surround типа CLD (разность уровней каналов), СРС (коэффициент предсказания канала) и ICC (межканальная согласованность) и матрицы G преобразователя нисходящего микширования размерности 2×K. Преобразователь результатов понижающего микширования 501 преобразует понижающее микширование объекта в стерео понижающего микширования с помощью матричной операции в соответствии с матрицей G. В упрощенном режиме транскодера для K-2 эта матрица работает как единичная матрица, и понижающее микширование объекта проходит без изменения как стерео понижающего микширования. На схеме этот режим показан в виде переключателя 503 в положении А, тогда как при нормальном режиме работы переключатель находится в положении В. Дополнительное преимущество транскодера - его пригодность к использованию в качестве автономного устройства там, где игнорируются параметры MPEG Surround, и выходные данные преобразователя понижающего микширования используются непосредственно как стереоаудиорендеринг.FIG. 5 is a schematic diagram of a device of a SAOC-
На фиг.6 схематически представлены различные режимы работы преобразователя 501 данных понижающего микширования согласно настоящему изобретению. Учитывая, что переданный объект понижающего микширования в формате битстрима является выходом K-канального аудиокодера, этот битстрим сначала дешифруется аудиодекодером 601 в K аудиосигналов временной области. Затем все эти сигналы преобразуются в частотную область гибридным банком фильтров QMF (квадратурный зеркальный фильтр) MPEG Surround в блоке T/F (время/частота) 602. Работа матрицы варьирования времени и частоты, определяемая данными матрицы преобразователя, осуществляется на результирующих сигналах гибридной области QMF блоком матрицирования 603, который выводит стереосигнал в гибридной области QMF. Гибридный блок синтеза 604 преобразует стереосигнал гибридной области QMF в стереосигнал области QMF. Гибридная область QMF задана для улучшения частотного разрешения в сторону низких частот путем последующей фильтрации поддиапазонов QMF. При выполнении в дальнейшем такой фильтрации с использованием банков фильтров Nyquist преобразование из гибридной в стандартную область QMF состоит в простом суммировании групп сигналов гибридных поддиапазонов, см. [Е.Schuijers, J.Breebart, and H.Purnhagen "Low complexity parametric stereo coding" Proc 116th AES convention Berlin. Germany 2004, Preprint 6073]. Этот сигнал является первым возможным выходным форматом преобразователя понижающего микширования, что соответствует положению А переключателя 607. Подобный сигнал домена QMF может быть подан непосредственно на соответствующий интерфейс области QMF декодера MPEG Surround, и это является наиболее предпочтительным режимом работы с точки зрения задержки, сложности и качества. Другой возможностью является формирование стереосигнала временной области с применением синтеза банка фильтров QMF 605. При положении В переключателя 607 преобразователь выдает цифровой стереосигнал, который также может быть введен в интерфейс временной области последующего декодера MPEG Surround или подан напрямую на воспроизводящее стереоустройство. Третьей возможностью при положении С переключателя 607 является кодирование стереосигнала музыкального домена с помощью стерео аудиокодера 606. В этом случае выходным форматом преобразователя понижающего микширования будет стерео аудиобитстрим, совместимый с центральным декодером, являющимся компонентом MPEG-декодера. Этот третий режим работы применим в случае, когда транскодер SAOC - MPEG Surround блокирован MPEG-декодером из-за соединения, ограничивающего скорость передачи данных, или когда пользователю необходимо сохранить образ определенного объекта для будущего воспроизведения.6 schematically illustrates various modes of operation of the
На фиг.7 представлена принципиальная схема декодера MPEG Surround для понижающего микширования стереосигнала. Стерео понижающего микширования с помощью окна "два-к-трем" (ТТТ) делится на три промежуточных канала. Далее каждый промежуточный канал с помощью трех окон "один-к-двум" (ОТТ) делится на два с образованием шести каналов 5.1-канальной конфигурации.7 is a schematic diagram of an MPEG Surround decoder for downmixing a stereo signal. The stereo down-mix using the two-to-three window (TTT) is divided into three intermediate channels. Next, each intermediate channel using three one-to-two windows (OTT) is divided into two with the formation of six channels 5.1-channel configuration.
На фиг.8 дана схема частного случая реализации с использованием кодера SAOC. Аудиомикшер 802 дает на выходе стереосигнал (левый и правый), который обычно создается путем смешения сигналов на входе микшера (здесь - входные каналы 1-6) и произвольных дополнительных входных данных от электронных эффектов типа ревербератора и т.п. Кроме того, микшер имеет один индивидуальный выходной канал (здесь канал 5). Этот канал может использоваться, например, для обычных функций микшера, таких как "прямой выход" или "дополнительная пересылка" для вывода индивидуальных данных без задействования каких-либо промежуточных процессов (таких как динамическая обработка и эквалайзер). Стереосигнал (левый и правый) и индивидуальный выходной канал (obj5) являются вводом в кодер SAOC 801, который представляет собой лишь частный случай кодера SAOC 101 на фиг.1. Однако он служит типичным примером применения, когда аудиообъект obj5 (содержащий, например, речь) должен быть полностью подконтролен пользователю с правом внесения корректировок на входе декодера, оставаясь, однако, частью смешанной стереофонограммы (с правым и левым каналами). Из концепции также очевидно, что к панели "object input" ("вход объекта") в рамке 801 может быть подключено два или более аудиообъектов, и в дополнение к этому, стереофонограмма может быть расширена за счет многоканального соединения, например 5.1-канального устройства.On Fig given a diagram of a special case of implementation using the encoder SAOC. The 802 audio mixer produces a stereo signal (left and right), which is usually created by mixing the signals at the mixer input (here, input channels 1-6) and arbitrary additional input from electronic effects such as a reverb, etc. In addition, the mixer has one individual output channel (here channel 5). This channel can be used, for example, for normal mixer functions, such as "direct output" or "additional transfer" to output individual data without involving any intermediate processes (such as dynamic processing and equalizer). The stereo signal (left and right) and the individual output channel (obj5) are input to the
Далее представлено краткое математическое описание изобретения. Для дискретных комплексных сигналов х, y комплексное внутреннее произведение и возведенная в квадрат норма (энергия) определяются по:The following is a brief mathematical description of the invention. For discrete complex signals x, y, the complex internal product and the squared norm (energy) are determined by:
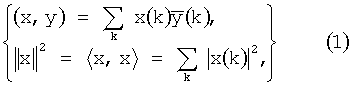
где y(k) обозначает комплексно сопряженный сигнал y(k). Все рассматриваемые здесь сигналы представляют собой отсчеты поддиапазонов из модулированного банка фильтров или оконного анализа БПФ (быстрое преобразование Фурье) дискретных сигналов времени. Подразумевается, что эти поддиапазоны должны быть преобразованы обратно в дискретную временную область с помощью соответствующих операций банка фильтров синтеза. Блок сигналов из L отсчетов представляет сигнал в частотно-временном интервале, являющемся частью перцептуально мотивированного мозаичного заполнения (тайлинга) частотно-временной плоскости, используемой для описания свойств сигнала. При таком разбиении определенные аудиообъекты могут быть представлены как N рядов длины L в матрице,where y (k) denotes the complex conjugate signal y (k). All the signals considered here are subband samples from a modulated filter bank or FFT window analysis (fast Fourier transform) of discrete time signals. It is understood that these subbands must be converted back to a discrete time domain using the appropriate synthesis filter bank operations. A block of signals from L samples represents a signal in the time-frequency interval, which is part of the perceptually motivated mosaic filling (tiling) of the time-frequency plane used to describe the properties of the signal. With this partitioning, certain audio objects can be represented as N rows of length L in the matrix,
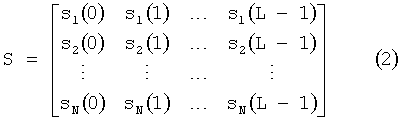
Весовая матрица понижающего микширования D размерности K×N,Downmix weight matrix D of dimension K × N,
где K>1 определяет K-канальный сигнал нисходящего микширования в форме матрицы с K рядами матричного умноженияwhere K> 1 defines the K-channel down-mix signal in the form of a matrix with K rows of matrix multiplication
![]()
![]()
Управляемая пользователем матрица аудиорендеринга объекта А размерности М×N определяет М-канальный аудиорендеринг с заданными показателями аудиообъектов в форме матрицы с М рядами матричного умноженияUser-controlled audio rendering matrix of object A of dimension M × N defines an M-channel audio rendering with specified performance of audio objects in the form of a matrix with M rows of matrix multiplication
![]()
![]()
Если временно не принимать во внимание эффекты основного потока аудиокодирования, задача декодера SAOC состоит в том, чтобы генерировать близкий к желаемому восприятию Y как результат аудиорендеринга первоначальных аудиообъектов на базе матрицы аудиорендеринга А, результатов понижающего микширования X, матрицы понижающего микширования D и параметров объекта.Unless temporarily taking into account the effects of the main audio coding stream, the task of the SAOC decoder is to generate close to the desired perception Y as a result of audio rendering of the original audio objects based on the audio rendering matrix A, the downmix X, the downmix D, and the object parameters.
Параметры объекта в энергетическом режиме согласно настоящему изобретению несут информацию о ковариации оригинальных объектов. В детерминированной версии, удобной для последовательного получения результатов, а также наглядной для описания типичных операций кодера, ковариация представляется в ненормализованной форме произведением матриц SS*, где звездочка обозначает операцию с комплексной сопряженной транспонированной матрицей. Таким образом, параметры объекта, полученные в энергетическом режиме, обеспечивают положительную полуопределенную матрицу А размерностью N×N таким образом, что, возможно до коэффициента масштабирования,The parameters of the object in the energy mode according to the present invention carry information about the covariance of the original objects. In the deterministic version, convenient for obtaining sequential results, as well as visual for describing typical encoder operations, covariance appears in an abnormal form as the product of SS * matrices, where the asterisk denotes an operation with a complex conjugate transposed matrix. Thus, the parameters of the object obtained in the energy mode provide a positive semidefinite matrix A of dimension N × N in such a way that, possibly up to the scaling factor,
![]()
![]()
Известный уровень техники кодирования аудиообъектов часто рассматривает модель объекта, где все объекты не коррелируют. В таком случае матрица Е является диагональной и содержит лишь аппроксимацию к энергиям объекта Sn=||Sn||2 для n=1, 2, …, N. Согласно фиг.3 экстрактор параметров объекта вносит существенную корректировку в эту идею, что особенно актуально в случаях, когда объекты представлены стереофоническими сигналами, для которых предположение об отсутствии корреляции не действует. Группирование Р отобранных стереопар объектов описывается наборами индексов {(np, mp), р=1, 2, Р}. Для этих стереопар корреляция <Sn, Sm> вычислена, и комплексная, реальная или абсолютная величина нормализованной корреляции (ICC)The prior art coding of audio objects often considers an object model where all objects are not correlated. In this case, the matrix E is diagonal and contains only an approximation to the energies of the object S n = || S n || 2 for n = 1, 2, ..., N. According to figure 3, the object parameter extractor makes a significant adjustment to this idea, which is especially true in cases where objects are represented by stereo signals for which the assumption of the absence of correlation does not work. The grouping P of selected stereo pairs of objects is described by sets of indices {(n p , m p ), p = 1, 2, P}. For these stereopairs, the correlation <S n , S m > is calculated, and the complex, real or absolute value of the normalized correlation (ICC)

выделена экстрактором стереопараметров 302. После этого в декодере данные ICC могут быть объединены с энергетическими показателями для формирования матрицы Е, на 2Р отстоящей от диагональных элементов. Например, для общего числа объектов N=3, из которых первые два составляют единую пару (1, 2), переданные энергетические и корреляционные данные имеют вид:highlighted by the
S1, S2, S3 и p1.S 1 , S 2 , S 3 and p 1 .
В этом случае объединение в матрицу Е дает:In this case, combining into matrix E gives:
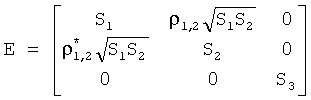
Параметры объекта в режиме предсказания согласно настоящему изобретению предназначены для формирования матрицы С коэффициента предсказания объекта (ОРС) размерностью N×K, доступной для декодера таким образом, чтоThe parameters of the object in the prediction mode according to the present invention are intended to form an object prediction coefficient (OPC) matrix C of dimension N × K, accessible to the decoder in such a way that
![]()
![]()
Другими словами, для каждого объекта существует линейная комбинация каналов нисходящего микширования таким образом, что объект может быть восстановлен приблизительно согласно:In other words, for each object, there is a linear combination of the down-mix channels so that the object can be restored approximately according to:
![]()
![]()
В предпочтительном варианте реализации экстрактор коэффициента предсказания объекта (ОРС) 401 решает нормальные уравненияIn a preferred embodiment, an object prediction coefficient (OPC)
![]()
![]()
или, для более привлекательной реальной оценки коэффициента предсказания объекта (ОРС), он решает:or, for a more attractive real estimate of the object prediction coefficient (OPC), it decides:
![]()
![]()
В обоих случаях, если принять реально оцененную весовую матрицу понижающего микширования D и несингулярную ковариацию понижающего микширования, то из умножения слева с D следует, чтоIn both cases, if we take the really estimated weight matrix of the downmix D and the non-singular covariance of the downmix, then from the left multiplication with D it follows that
![]()
![]()
где I - единичная матрица размерностью K.where I is the identity matrix of dimension K.
Если D имеет полный ранг, то согласно элементарной линейной алгебре набор решений для (9) может быть параметрирован макс {K·(N-K),0} параметрами. Этот принцип задействован в 402 при совместном кодировании данных ОРС. Полная матрица предсказания С может быть восстановлена в декодере из сокращенного набора параметров и матрицы понижающего микширования.If D has full rank, then, according to elementary linear algebra, the set of solutions for (9) can be parameterized with max {K · (N-K), 0} parameters. This principle is used in 402 when jointly encoding OPC data. The full prediction matrix C can be reconstructed in the decoder from a reduced set of parameters and a downmix matrix.
Для примера рассмотрим случай понижающего микширования с получением стерео понижающего микширования (K=2), включающего в себя три объекта (N=3>) - музыкальную стереофонограмму (s1,s2) и центральный панорамированный одиночный музыкальный инструмент или трек вокала s3.As an example, consider the case of down-mix with obtaining a stereo down-mix (K = 2), which includes three objects (N = 3>) - a stereo music record (s 1 , s 2 ) and a central panned single musical instrument or s 3 vocal track.
Матрица понижающего микширования имеет вид:The downmix matrix has the form:
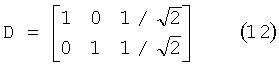
То есть левый канал понижающего микширования представляет собой x1=s1+s3/√2, и правый канал - х2=s2+s3/√2.That is, the left channel of the downmix is x 1 = s 1 + s 3 / √2, and the right channel is x 2 = s 2 + s 3 / √2.
Коэффициенты предсказания объекта (ОРС) для одиночного трека стремятся приблизиться к s3≈c31x1+c32x2, и в этом случае уравнение (11) может быть решено с получением с11=1-c31/√2, с12=-с32/√2, с21=-c31/√2 и с22=1-c32/√2.The object prediction coefficients (OPC) for a single track tend to approach s 3 ≈c 31 x 1 + c 32 x 2 , in which case equation (11) can be solved to obtain with 11 = 1-c 31 / √2, s 12 = -
Отсюда следует, что достаточное количество коэффициентов предсказания объекта (ОРС) определяется через K(N-K)=2·(3-2)=2.It follows that a sufficient number of prediction coefficients of the object (OPC) is determined through K (N-K) = 2 · (3-2) = 2.
ОРС c31, c32 могут быть найдены из нормальных уравненийOPC c 31 , c 32 can be found from normal equations
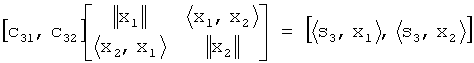
Транскодер SAOC - MPEG SurroundSAOC Transcoder - MPEG Surround
Что касается фигуры 7, М=6 выходных каналов конфигурации 5.1 представляют собойAs for figure 7, M = 6 output channels of the configuration 5.1 are
(y1, y2, …, y6)=(If,Is,rf,rs,c,lfe).(y 1 , y 2 , ..., y 6 ) = (I f , I s , r f , r s , c, lfe).
Транскодер должен давать на выходе стерео понижающего микширования (l0,r0) и параметры для конфигураций ТТТ и ОТТ. Поскольку внимание теперь сосредоточено на стерео понижающем микшировании, в дальнейшем будет принято, что K=2. Поскольку и параметры объекта, и параметры MPS ТТТ существуют и в энергетическом, и в прогностическом режиме, необходимо рассматривать все четыре комбинации.The transcoder should give the output of the stereo down-mix (l 0 , r 0 ) and parameters for the TTT and OTT configurations. Since attention is now focused on stereo downmix, it will be assumed that K = 2. Since both the object parameters and the MPS TTT parameters exist both in the energy and in the prognostic mode, it is necessary to consider all four combinations.
Энергетический режим эффективен, например, когда аудиокодер понижающего микширования не является волновым кодером в рассматриваемом частотном диапазоне. Подразумевается, что параметры MPEG Surround, речь о которых пойдет ниже, перед их пересылкой должны пройти надлежащее квантование и кодировку. Для дальнейшего разъяснения четырех вышеупомянутых комбинаций следует напомнить, что это:The power mode is effective, for example, when the down-mix audio encoder is not a wave encoder in the frequency range in question. It is understood that the parameters of MPEG Surround, which will be discussed below, must be properly quantized and encoded before being sent. To further clarify the four above combinations, it should be recalled that these are:
1) параметры объекта в энергетическом режиме и транскодер в режиме предсказания;1) the parameters of the object in the energy mode and the transcoder in the prediction mode;
2) параметры объекта в энергетическом режиме и транскодер в энергетическом режиме;2) the parameters of the object in the energy mode and the transcoder in the energy mode;
3) параметры объекта в режиме предсказания (коэффициент предсказания объекта ОРС) и транскодер в режим предсказания;3) the parameters of the object in the prediction mode (prediction coefficient of the OPC object) and the transcoder in the prediction mode;
4) параметры объекта в режиме предсказания (ОРС) и транскодер в энергетическом режиме.4) the parameters of the object in the prediction mode (OPC) and the transcoder in the energy mode.
Если в рассматриваемом интервале частот аудиокодер понижающего микширования представляет собой кодер волнового типа, параметры объекта могут фиксироваться как в энергетическом режиме, так и в режиме предсказания, при этом транскодер должен предпочтительно работать в режиме предсказания. Если в рассматриваемом интервале частот аудиокодер понижающего микширования не является кодером волнового типа, кодер объекта и транскодер оба должны работать в энергетическом режиме. Четвертая комбинация менее актуальна, вследствие чего дальнейшее описание затронет только первые три комбинации.If in the frequency range under consideration the down-mix audio encoder is a wave-type encoder, the object parameters can be fixed both in the energy mode and in the prediction mode, while the transcoder should preferably operate in the prediction mode. If in the considered frequency range the down-mix audio encoder is not a wave-type encoder, both the object encoder and the transcoder should work in the energy mode. The fourth combination is less relevant, as a result of which the further description will affect only the first three combinations.
Параметры объекта в энергетическом режимеObject parameters in energy mode
В энергетическом режиме данные, доступные для транскодера, описываются тройкой матриц (D, Е, А). Параметры ОТТ MPEG Surround формируются путем оценки энергетических и корреляционных показателей при виртуальном аудиорендеринге переданных параметров и матрицы аудиорендеринга А размерностью 6×N. Заданная шестиканальная ковариация представляется какIn the energy mode, the data available for the transcoder is described by a triple of matrices (D, E, A). The OTT MPEG Surround parameters are formed by evaluating the energy and correlation indicators during virtual audio rendering of the transferred parameters and the audio rendering matrix A with a dimension of 6 × N. The given six-channel covariance is represented as
![]()
![]()
Введение (5) в (13) дает приближениеIntroduction (5) to (13) gives an approximation
![]()
![]()
которое полностью определяется доступными данными. Пусть fa обозначает элементы F. Тогда параметры CLD и ICC определяются из:which is completely determined by the available data. Let f a denote the elements of F. Then the parameters CLD and ICC are determined from:
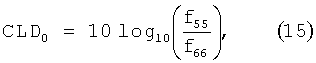
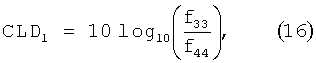
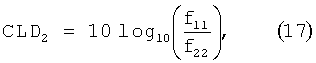
![]()
![]()
![]()
![]()
где J> - или абсолютная величина <р(z)=\z\, или оператор действительного значения <р(z)-Ре{z}. В качестве наглядного примера рассмотрим случай с тремя объектами, описанный ранее в отношении уравнения (12). Представим матрицу аудиорендеринга в видеwhere J> is either the absolute value <p (z) = \ z \, or the operator of the real value <p (z) -Pe {z}. As an illustrative example, consider the case with three objects described earlier in relation to equation (12). Imagine the audio rendering matrix as

Таким образом, задача аудиорендеринга состоит в размещении объекта 1 между правой фронтальной и правой панорамной позициями, объекта 2 - между левой фронтальной и левой панорамной позициями и объекта 3 - впереди справа, в центре и по каналу оптимизации низких частот (lfe). Для упрощения предположим также, что все эти три объекта некоррелированы и обладают одинаковой энергией так, чтоThus, the task of audio rendering is to place

В таком случае правая сторона формулы (14) приобретает видIn this case, the right side of the formula (14) takes the form
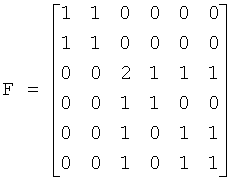
Подстановкой соответствующих значений в формулы (15)-(19) получаем:Substituting the corresponding values in formulas (15) - (19) we obtain:

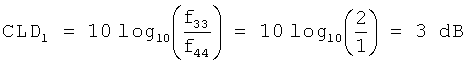

![]()
![]()
![]()
![]()
В качестве реакции декодер MPEG Surround получит инструкцию на введение некоторой декорреляции между правой фронтальной и правой панорамной позициями, но не допускать декорреляцию между левым фронтальным и левым панорамным позиционированием.As a reaction, the MPEG Surround decoder will be instructed to introduce some decorrelation between the right front and right panoramic positions, but not allow decorrelation between the left front and left panoramic positions.
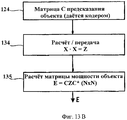
Для ТТТ-параметров MPEG Surround в режиме предсказания первым шагом должно быть формирование сокращенной матрицы аудиорендеринга А3 размерностью 3×N для комбинированных каналов (l,r,qc), где q=1/√2. Это подразумевает, что А3=D36A, где матрица частичного понижающего микширования от 6 до 3 определяется с помощьюFor the TTT parameters of MPEG Surround in prediction mode, the first step is to form a 3 × N reduced audio rendering matrix A 3 for combined channels (l, r, qc), where q = 1 / √2. This implies that A 3 = D 36 A, where the partial downmix matrix from 6 to 3 is determined using
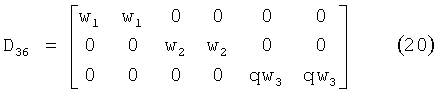
Веса неполного понижающего микширования wp, р=1, 2, 3 корректируются таким образом, что энергия wp(y2p-1+y2p) равна сумме энергий ||y2p-1||2+||y2p||2 до предельного коэффициента. Все данные, необходимые для выведения матрицы частичного понижающего микширования, D36 доступны в F. Затем формируется матрица предсказания С3 размерностью 3×2 таким образом, чтоThe incomplete down-mix weights w p , p = 1, 2, 3 are adjusted so that the energy w p (y 2p-1 + y 2p ) is equal to the sum of the energies || y 2p-1 || 2 + || y 2p || 2 to the limit coefficient. All the data necessary to derive a partial downmix matrix, D 36, is available in F. Then a 3 × 3 prediction matrix C 3 is formed so that
![]()
![]()
Более предпочтительно такую матрицу выводить, предварительно принимая во внимание нормальные уравнения C3(DED*)=A3S.It is more preferable to derive such a matrix, previously taking into account the normal equations C 3 (DED *) = A 3 S.
Результат решения нормальных уравнений наилучшим образом удовлетворяет форме сигнала для (21), принимая во внимание модель ковариации объекта Е. Рекомендуется выполнить некоторую постобработку матрицы С3, включая рядные коэффициенты, для полной или выборочной компенсации прогнозируемых потерь по каналам.The result of solving the normal equations best suits the waveform for (21), taking into account the covariance model of object E. It is recommended to perform some post-processing of the C 3 matrix, including in-line coefficients, for full or selective compensation of the predicted channel losses.
Чтобы проиллюстрировать и пояснить указанные выше шаги, необходимо продолжить рассмотрение примера аудиорендеринга определенных ранее шести каналов. При рассмотрении элементов матрицы F следует учитывать, что веса понижающего микширования представляют собой решения уравненийIn order to illustrate and clarify the above steps, it is necessary to continue consideration of the example of audio rendering of the six channels identified earlier. When considering the elements of the matrix F, it should be taken into account that the downmix weights are solutions of the equations
![]()
![]()
что в частном примере приобретает вид,which in a particular example takes the form
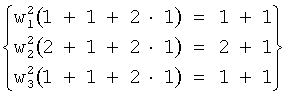
Таким образом, что (w1,w2,w3)=(1/√1,√3/5,1/√2).Thus, (w 1 , w 2 , w 3 ) = (1 / √1, √3 / 5.1 / √2).
Подстановка в (20) дает:Substitution in (20) gives:
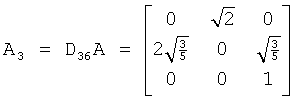
После чего решением системы уравнений С3(DED*)=A3ED* находим (переключаясь теперь на достижение конечной точности),After which, by solving the system of equations C 3 (DED *) = A 3 ED * we find (switching now to achieve the ultimate accuracy),

Матрица С3 содержит лучшие веса для аппроксимации к желаемому результату аудиорендеринга объекта по комбинированным каналам (l,r,qc) в ходе нисходящего микширования. Этот общий тип матричной операции не может выполняться декодером MPEG Surround, который связан ограниченным пространством матриц ТТТ из-за использования всего двух параметров. Цель преобразователя понижающего микширования (результата понижающего микширования), относящегося к данному изобретению, стоит в предварительной обработке понижающего микширования объекта таким образом, чтобы комбинированный эффект от предварительной обработки и от матрицы ТТТ MPEG Surround соответствовал желаемому результату повышающего микширования (upmix), описанного с помощью С3.The C 3 matrix contains the best weights to approximate the desired result of the audio rendering of the object through the combined channels (l, r, qc) during downstream mixing. This general type of matrix operation cannot be performed by the MPEG Surround decoder, which is bound by the limited TTT matrix space due to the use of only two parameters. The purpose of the down-mix converter (down-mix result) of this invention is to pre-process the down-mix of an object so that the combined effect of the pre-processing and the TTT MPEG Surround matrix matches the desired up-mix result (upmix) described with C 3 .
В MPEG Surround матрица ТТТ для предсказания (l,r,qc) на основании (l0, r0) параметризуется по трем параметрам (α,β,γ) черезIn MPEG Surround, the TTT matrix for predicting (l, r, qc) based on (l 0 , r 0 ) is parameterized in three parameters (α, β, γ) through
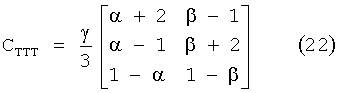
Матрица G преобразователя понижающего микширования (результатов нисходящего микширования) согласно настоящему изобретению формируется выбором 7=1 и решением системы уравненийThe matrix G of the down-mix converter (down-mix results) according to the present invention is formed by selecting 7 = 1 and solving the system of equations
![]()
![]()
Легко подтверждается, что DTTTCTTT=I, где I - единичная матрица два-на-два иIt is easily confirmed that D TTT C TTT = I, where I is the two-on-two identity matrix and
![]()
![]()
Таким образом, перемножение матриц слева на DTTT обеих сторон (23) дает в результатеThus, multiplying the matrices on the left by D TTT of both sides (23) yields
![]()
![]()
В общем случае G обратима, и (23) имеет единственное решение для CTTT, удовлетворяющее условию CTTTGTTT=I.In the general case, G is invertible, and (23) has a unique solution for C TTT satisfying the condition C TTT G TTT = I.
Параметры ТТТ (α,β) определяются этим решением.TTT parameters (α, β) are determined by this solution.
Для рассмотренного ранее частного примера можно легко подтвердить, что решения соответствуютFor the particular example considered earlier, one can easily confirm that the solutions correspond
![]()
![]()
Следует обратить внимание на то, что основной объем потока стерео понижающего микширования при этой матрице преобразования меняет положение между левой и правой сторонами, отражая тот факт, что в процессе приведенного в примере аудиорендеринга объекты, проходящие по левому каналу понижающего микширования, перемещаются в правую часть акустической сцены, и наоборот. Подобное явление невозможно при использовании декодера MPEG Surround в режиме стерео.It should be noted that the main volume of the stereo down-mix stream with this transformation matrix changes position between the left and right sides, reflecting the fact that during the audio rendering shown in the example, the objects passing through the left down-mix channel are moved to the right side of the acoustic scenes and vice versa. A similar phenomenon is not possible when using the MPEG Surround decoder in stereo.
При отсутствии возможности использования преобразователя понижающего микширования может быть выработан описываемый далее, близкий к оптимальному, метод. При работе в энергетическом режиме для параметров ТТТ MPEG Surround требуется распределение энергии объединенных каналов (α,β). Поэтому соответствующие параметры разности уровней каналов CLD могут быть выведены непосредственно из элементов F черезIf it is not possible to use a down-mix converter, the method described below, which is close to optimal, can be developed. When operating in power mode, the TTT MPEG Surround parameters require the distribution of energy of the combined channels (α, β). Therefore, the corresponding parameters of the channel level difference CLD can be derived directly from the elements F through


В данном случае целесообразно использовать только диагональную матрицу G с положительными ячейками для преобразователя понижающего микширования. Функционально важно достичь правильного распределения энергии каналов нисходящего микширования до начала восходящего микширования (upmix) ТТТ. При наличии матрицы понижающего микширования с шести каналов до двух D26=DTTTD36 и определений изIn this case, it is advisable to use only the diagonal matrix G with positive cells for the down-mix converter. It is functionally important to achieve the correct energy distribution of the downmix channels before the upmix of the TTT. With a downmix matrix from six channels to two D 26 = D TTT D 36 and definitions from
![]()
![]()
![]()
![]()
просто выбираетсяjust get out
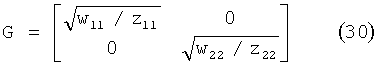
Дальнейшее наблюдение показывает, что подобный диагональный преобразователь понижающего микширования может быть пропущен на пути от объекта к транскодеру MPEG Surround и реализован введением в действие параметров произвольного усиления понижающего микширования (ADG) декодера MPEG Surround. В этом случае приращения в логарифмической области будут соответствовать ADGi=10log10(wn/zn) при i=1, 2.Further observation shows that such a diagonal down-mix converter can be skipped on the way from the object to the MPEG Surround transcoder and implemented by setting the parameters of the arbitrary amplification of the down-mix (ADG) of the MPEG Surround decoder. In this case, the increments in the logarithmic region will correspond to ADG i = 10log 10 (w n / z n ) for i = 1, 2.
Параметры объекта, в режиме предсказания (ОРС)Object parameters in prediction mode (OPC)
В режиме предсказания объекта доступные данные представляются тремя матрицами (D, С, А), где С - матрица N×2, содержащая N пар коэффициентов предсказания объекта ОРС. В силу относительности коэффициентов предсказания далее для оценки энергетических параметров MPEG Surround будет необходим доступ к показателям аппроксимации к матрице ковариации 2×2 понижающего микширования объекта,In the object prediction mode, the available data is represented by three matrices (D, C, A), where C is an N × 2 matrix containing N pairs of OPC object prediction coefficients. Due to the relative nature of the prediction coefficients, in order to estimate the energy parameters of MPEG Surround, access to the approximation indices for the covariance matrix of a 2 × 2 downmixing object will be necessary
![]()
![]()
Предпочтительнее, если эта информация поступит от кодера объекта как часть сведений о нисходящем микшировании, однако она может также быть оценена на транскодере, исходя из измерений принятого понижающего микширования, или косвенно выведена из (D, С) через анализ приближенной модели объекта. При наличии Z ковариация объекта может быть оценена путем введения модели предсказания Y=СХ, давая в результатеIt is preferable if this information comes from the object encoder as part of the down-mix information, however, it can also be evaluated on the transcoder based on the measurements of the adopted down-mix, or indirectly derived from (D, C) through analysis of an approximate model of the object. In the presence of Z, the covariance of the object can be estimated by introducing the prediction model Y = CX, resulting in
![]()
![]()
и все параметры ОТТ MPEG Surround и ТТТ энергетического режима могут быть оценены, исходя из Е, как и в случае с энергетическими параметрами объекта. Однако наибольшее преимущество применения коэффициентов предсказания объекта ОРС проявляется в сочетании с параметрами ТТТ MPEG Surround в режиме предсказания. В этом случае аппроксимация формы сигнала D36Y≈А3СХ сразу же дает редуцированную матрицу предсказания:and all the parameters of the OTT MPEG Surround and the TTT of the energy mode can be estimated based on E, as is the case with the energy parameters of the object. However, the greatest advantage of using the OPC object prediction coefficients is manifested in combination with the TTT MPEG Surround parameters in the prediction mode. In this case, the approximation of the waveform D 36 Y≈А 3 СХ immediately gives a reduced prediction matrix:
С3=А3С,C 3 = A 3 C,
при опоре на которую остающиеся шаги к формированию параметров ТТТ (α,β) и преобразователя понижающего микширования аналогичны получению параметров объекта в энергетическом режиме. Фактически, шаги от формулы (22) к формуле (25) полностью идентичны.based on which, the remaining steps to the formation of the TTT parameters (α, β) and the down-mix converter are similar to obtaining the object parameters in the energy mode. In fact, the steps from formula (22) to formula (25) are completely identical.
Результирующая матрица G подается на преобразователь результатов понижающего микширования, и параметры ТТТ (α,β) пересылаются на декодер MPEG Surround.The resulting matrix G is fed to the down-mixer, and the TTT parameters (α, β) are sent to the MPEG Surround decoder.
Автономное применение преобразователя понижающего микширования для стерео понижающего микшированияStandalone downmix converter for stereo downmix
Во всех описанных выше случаях преобразователь 501 объекта в стерео понижающего микширования на выходе предоставляет данные, приближенные к 5.1-канальному стерео понижающего микширования как результату аудиорендеринга исходных аудиообъектов. Этот стереоаудиорендеринг может быть выражен матрицей А2 размерностью 2×N, определяемой как А2=D26A. Во многих реализациях это понижающее микширование представляет самостоятельный интерес, при этом внимание привлекает возможность прямого управления стереоаудиорендерингом А2. В качестве наглядного примера опять рассмотрим случай стереофонограммы с наложением по центру панорамированной монофонической голосовой дорожки, закодированной по частному случаю методики, кратко изложенной при описании фигуры 8 с пояснениями в контексте формулы (12). Регулирование пользователем динамического диапазона голоса может осуществляться через аудиорендеринг согласноIn all of the cases described above, the stereo down-
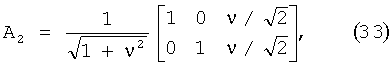
где ν - регулирование соотношения голос-музыка. Структура матрицы преобразования результатов понижающего микширования основывается на выраженииwhere ν is the regulation of the voice-music ratio. The structure of the transformation matrix of the downmix results is based on the expression
![]()
![]()
Для параметров объекта, полученных на базе предсказания, следует лишь подставить приближение S≈CDS и получать матрицу преобразователя G=А2С. Для параметров объекта на базе энергетических показателей следует решить нормальные уравненияFor the parameters of the object obtained on the basis of the prediction, it is only necessary to substitute the approximation S≈CDS and obtain the transducer matrix G = A 2 C. For the parameters of the object based on energy indicators, normal equations
![]()
![]()
На фиг.9 представлена схема предпочтительного варианта осуществления кодера аудиообъектов в соответствии с одним из аспектов настоящего изобретения. Кодер аудиообъектов 101 в целом уже был описан при пояснении предшествующих графических схем. Кодер аудиообъектов, генерирующий закодированный сигнал объекта, использует множество аудиообъектов 90, обозначенных на фиг.9 как входные данные понижающего микшера 92 и генератора параметров объекта 94. Кроме того, кодер аудиообъектов 101 включает в себя генератор информации понижающего микширования 96, генерирующий параметры понижающего микширования 97, фиксируя порядок распределения множества аудиообъектов по крайней мере по двум каналам понижающего микширования, обозначенным на схеме как тракты 93, исходящие из понижающего микшера 92.FIG. 9 is a diagram of a preferred embodiment of an audio object encoder in accordance with one aspect of the present invention. The encoder audio objects 101 as a whole has already been described in the explanation of the previous graphic schemes. An audio object encoder generating an encoded object signal uses a plurality of
Генератор параметров объекта предназначен для генерирования параметров аудиообъектов 95, причем параметры объекта рассчитываются таким образом, что реконструкция аудиообъекта возможна с использованием параметров объекта и, по крайней мере, двух каналов понижающего микширования 93. При этом важно, что реконструкция осуществляется не со стороны кодера, а со стороны декодера. Однако полноценная реконструкция со стороны декодера возможна благодаря расчету параметров объектов 95, выполняемому генератором параметров объектов кодера.The object parameter generator is designed to generate the parameters of
Кроме того, кодер аудиообъектов 101 включает в себя выходной интерфейс 98 для генерирования закодированного сигнала аудиообъекта 99 с использованием данных понижающего микширования 97 и параметров объекта 95. В зависимости от назначения каналы понижающего микширования 93 могут, кроме того, использоваться и кодироваться как сигнал аудиообъекта. При этом могут возникать ситуации, при которых выходной интерфейс 98 генерирует кодированный сигнал аудиообъекта 99, который не содержит каналы понижающего микширования. Такая ситуация может возникнуть, когда какие-либо каналы понижающего микширования, которые должны быть использованы декодером, уже находятся в распоряжении декодера таким образом, что информация по понижающему микшированию и параметры аудиообъекта передаются по каналам понижающего микширования раздельно. Пользу из такой ситуации можно извлечь, когда каналы понижающего микширования объектов 93 могут быть куплены отдельно от параметров объектов и информации по нисходящему микшированию за меньшую сумму денег, а параметры объектов и информация по понижающему микшированию могут быть куплены за дополнительные средства с целью предоставления пользователю на стороне декодера возможности получить добавленную стоимость.In addition, the
При отсутствии параметров объекта и информации по понижающему микшированию пользователь может преобразовывать каналы понижающего микширования в стерео- или многоканальный сигнал в зависимости от количества каналов, задействованных в понижающем микшировании. Естественно, пользователь может также сформировать монофонический сигнал простым добавлением, по крайней мере, двух переданных каналов понижающего микширования объектов.In the absence of object parameters and downmix information, the user can convert the downmix channels into a stereo or multichannel signal depending on the number of channels involved in the downmix. Naturally, the user can also generate a monophonic signal by simply adding at least two transmitted down-mix channels of objects.
Параметры объекта и данные понижающего микширования обеспечивают пользователю гибкость акустических преобразований и повышение качества и полноценности звучания акустических объектов, позволяя осуществлять многоцелевой аудиорендеринг для воспроизведения в дальнейшем аудиоматериала на звуковой аппаратуре любого типа - на стереосистемах, на многоканальных системах или даже на системах синтеза волнового поля. Если установки синтеза волнового поля еще не очень популярны, то многоканальные системы формата 5.1 или 7.1 все шире распространяются на потребительском рынке.Object parameters and down-mix data provide the user with the flexibility of acoustic transformations and increase the quality and sound quality of acoustic objects, allowing for multi-purpose audio rendering for later playback of audio material on any type of audio equipment - on stereo systems, on multi-channel systems or even on wave field synthesis systems. If the installation of wave field synthesis is still not very popular, then multichannel systems of the 5.1 or 7.1 format are increasingly spreading to the consumer market.
На фиг.10 представлена схема звукового синтезатора для генерирования выходных данных. Для осуществления своих функций аудиосинтезатор содержит синтезатор выходных данных 100. Синтезатор выходных данных принимает на входе данные понижающего микширования 97 и параметры аудиообъекта 95, а также, возможно, характеристики предполагаемого источника звука, такие как пространственное расположение источников звука или определяемый пользователем динамический диапазон конкретного источника в результате аудиорендеринга с использованием 101.Figure 10 presents a diagram of a sound synthesizer for generating output data. To perform its functions, the audio synthesizer contains an
Синтезатор выходных данных 100 предназначен для генерирования выходных данных, необходимых для формирования множества выходных каналов с заданной конфигурацией выходного аудиосигнала, реконструирующих множество аудиообъектов. Наилучшим образом синтезатор выходных данных 100 реализует свои функциональные возможности, используя параметры понижающего микширования 97 и параметры аудиообъекта 95. Согласно пояснениям к фиг.11, данным ниже, выходные данные представляют собой многочисленные показатели различного назначения, включая специфический рендеринг выходных каналов или простое воссоздание исходных сигналов, или же перекодирование параметров в характеристики пространственного преобразования с формированием пространственной конфигурации для повышающего микширования без какого-либо аудиорендеринга выходных каналов, например для хранения или пересылки этих пространственных параметров.The
Общая схема реализации данного изобретения отображена на фиг.14. Здесь блок кодера 140 включает в себя кодер аудиообъектов 101, который принимает на входе N аудиообъектов.The General implementation scheme of the present invention is shown in Fig.14. Here, the
На выходе преимущественного варианта технического исполнения кодера аудиообъектов кроме информации по понижающему микшированию и параметров объекта, не показанных на фиг.14, формируется число К каналов понижающего микширования. В соответствии с настоящим изобретением количество каналов понижающего микширования должно быть больше или равно двум.At the output of the preferred embodiment of the audio object encoder, in addition to the down-mix information and the object parameters not shown in Fig. 14, the number K of down-mix channels is formed. In accordance with the present invention, the number of downmix channels should be greater than or equal to two.
Каналы понижающего микширования передаются на блок декодера 142, в состав которого входит пространственный повышающий микшер 143. Пространственный повышающий микшер 143 может включать в себя аудиосинтезатор, являющийся частью данного изобретения, если аудиосинтезатор работает в режиме транскодера. Однако, если аудиосинтезатор 101, как показано на фиг.10, работает в режиме пространственного повышающего микширования, то в данной реализации и пространственный повышающий микшер 143, и аудиосинтезатор представляют собой одно и то же устройство. Пространственный повышающий микшер генерирует М выходных каналов для воспроизведения через М динамиков. Эти динамики размещаются в заранее определенных точках окружающего пространства и совокупно формируют выходной акустический сигнал заданной конфигурации. Выходной канал выходного аудиосигнала заданной конфигурации может рассматриваться как цифровой или аналоговый электродинамический акустический сигнал, транслируемый от выхода пространственного повышающего микшера 143 на вход громкоговорителя с заданным позиционированием в среде определенным образом сконфигурированного множества источников выходных аудиосигналов. В зависимости от конкретной ситуации, если выполняется стереоаудиорендеринг, количество М выходных каналов может быть равным двум. При выполнении многоканального аудиорендеринга число М выходных каналов будет больше двух.The downmix channels are transmitted to a
Чаще всего распространена ситуация, при которой количество каналов понижающего микширования меньше числа выходных каналов из-за технических требований трактов передачи данных. В подобных случаях число М может быть значительно большим, чем число K, превышая его в два или даже более раз.The most common situation is when the number of down-mix channels is less than the number of output channels due to the technical requirements of data transmission paths. In such cases, the number M can be significantly larger than the number K, exceeding it by two or even more times.
На фиг.14 дополнительно дано матричное представление функций, выполняемых блоком кодера и блоком декодера в рамках данного изобретения. В большинстве случаев обрабатываются блоки величин отсчетов. Поэтому, как видно из уравнения (2), аудиообъект отображается в виде ряда L величин отсчетов. Матрица S содержит N строк, соответствующих количеству объектов, и L столбцов, соответствующих количеству отсчетов. Матрица Е рассчитана по уравнению (5) и включает в себя N колонок и N строк. Матрица Е содержит параметры объекта, когда параметры объекта даются в энергетическом режиме. Для некоррелированных объектов матрица Е, как показано в контексте уравнения (6), имеет только основные диагональные элементы, каждый из которых отображает энергию аудиообъекта. Все недиагональные элементы, как было указано ранее, представляют корреляцию двух аудиообъектов, что особенно важно, когда несколько объектов представляют собой два канала стереофонического сигнала.On Fig additionally given a matrix representation of the functions performed by the encoder unit and the decoder unit in the framework of the present invention. In most cases, blocks of sample values are processed. Therefore, as can be seen from equation (2), the audio object is displayed in the form of a series of L sample values. Matrix S contains N rows corresponding to the number of objects, and L columns corresponding to the number of samples. Matrix E is calculated according to equation (5) and includes N columns and N rows. Matrix E contains the parameters of the object when the parameters of the object are given in the energy mode. For uncorrelated objects, the matrix E, as shown in the context of equation (6), has only the main diagonal elements, each of which displays the energy of the audio object. All off-diagonal elements, as mentioned earlier, represent the correlation of two audio objects, which is especially important when several objects represent two channels of a stereo signal.
В зависимости от особенностей конструктивного исполнения уравнение (2) представляет сигнал временной области. После этого генерируется единый энергетический показатель для всего диапазона аудиообъектов. Однако предпочтительнее, если аудиообъекты обрабатываются частотно-временным преобразователем на основе, например, какого-либо алгоритма преобразования или банка фильтров, причем, в последнем случае, уравнение (2) справедливо для каждого поддиапазона, в результате чего обеспечивается формирование матрицы Е для каждого поддиапазона и, безусловно, для каждого интервала времени.Depending on the design features, equation (2) represents a time-domain signal. After that, a single energy indicator is generated for the entire range of audio objects. However, it is preferable if the audio objects are processed by a time-frequency converter based, for example, on a conversion algorithm or a filter bank, and, in the latter case, equation (2) is valid for each subband, as a result of which matrix E is generated for each subband and definitely for every time interval.
Матрица X каналов понижающего микширования имеет K строк и L столбцов и рассчитывается по уравнению (3). Как видно из уравнения (4), М выходных каналов рассчитаны, исходя из N объектов с использованием так называемой матрицы аудиорендеринга А для N объектов. В зависимости от ситуации N объектов могут быть реконструированы блоком декодера с использованием результатов понижающего микширования и параметров объекта, при этом аудиорендеринг может быть применен непосредственно к сигналам реконструируемых объектов.The matrix of X down-mix channels has K rows and L columns and is calculated by equation (3). As can be seen from equation (4), the M output channels are calculated based on N objects using the so-called audio rendering matrix A for N objects. Depending on the situation, N objects can be reconstructed by a decoder unit using the results of down-mixing and object parameters, while audio rendering can be applied directly to the signals of reconstructed objects.
С другой стороны, массив понижающего микширования может быть напрямую преобразован в сигналы выходных каналов без точного расчета сигналов источника. Матрица аудиорендеринга А, главным образом, индивидуально позиционирует источники в соответствии с заданной конфигурацией выходных аудиосигналов. Предположим, имеется шесть объектов и шесть выходных каналов, тогда каждый объект можно ассоциировать с каждым выходным каналом, и эта схема будет отражена матрицей аудиорендеринга. Однако при необходимости расположить все объекты внутри акустического пространства между двумя динамиками матрица аудиорендеринга А, отражая новое позиционирование, примет иной вид.On the other hand, the down-mix array can be directly converted to the output channel signals without accurately calculating the source signals. The audio rendering matrix A mainly individually positions the sources in accordance with a predetermined configuration of the output audio signals. Suppose there are six objects and six output channels, then each object can be associated with each output channel, and this scheme will be reflected in the audio rendering matrix. However, if necessary, arrange all objects inside the acoustic space between two speakers, the audio rendering matrix A, reflecting the new positioning, will take a different look.
Матрица аудиорендеринга, или в более общем смысле, планируемая пространственная локализация объектов, как и предполагаемое соотношение динамических диапазонов источников звука, могут в целом быть рассчитаны кодером и переданы декодеру в виде так называемого описания сцены. Однако в других вариантах осуществления такое описание сцены может быть выполнено непосредственно пользователем с целью генерировать заданное им самим повышающее микширование для получения заданной им самим конфигурации выходных акустических сигналов. Таким образом, передача описания сцены не является обязательной процедурой, такое описание сцены может быть реализовано пользователем с достижением удовлетворения его собственных запросов. Пользователь может, например, по своему желанию локализовать некоторые аудиообъекты в местах, отличных от позиций, в которых эти объекты изначально находились и которые были для них сгенерированы. Возможны также случаи, когда аудиообъекты внедрены как таковые, без наличия "оригинала" и его месторасположения относительно других, реальных, объектов. В подобных ситуациях источники звука изначально позиционируются относительно друг друга пользователем.The audio rendering matrix, or in a more general sense, the planned spatial localization of objects, as well as the estimated ratio of the dynamic ranges of sound sources, can generally be calculated by the encoder and transmitted to the decoder in the form of a so-called scene description. However, in other embodiments, such a description of the scene can be performed directly by the user in order to generate a boost mixing set by himself to obtain a configuration of acoustic output signals set by himself. Thus, the transfer of the description of the scene is not a mandatory procedure, such a description of the scene can be implemented by the user to achieve the satisfaction of his own requests. The user can, for example, optionally localize some audio objects in places other than the positions in which these objects were originally located and which were generated for them. There are also cases when audio objects are implemented as such, without the presence of the “original” and its location relative to other, real, objects. In such situations, sound sources are initially positioned relative to each other by the user.
Возвращаясь к фиг.9, рассмотрим понижающий микшер 92. Он предназначен для сокращения при микшировании фонограммы множества аудиообъектов до количества каналов понижающего микширования, причем количество аудиообъектов превосходит количество каналов понижающего микширования, при этом понижающий микшер сопряжен с генератором информации понижающего микширования так, что распределение множества аудиообъектов по множеству каналов понижающего микширования выполняется в соответствии с показателями понижающего микширования. Показатели понижающего микширования, генерируемые генератором информации понижающего микширования 96 на фиг.9, могут создаваться автоматически или управляться вручную. Рекомендуется данные понижающего микширования обрабатывать с меньшей разрешающей способностью, чем параметры объектов. Благодаря этому биты служебной информации могут быть сохранены без потери качества, поскольку фиксированные показатели понижающего микширования для отдельных частей фонограммы или одиночное медленно изменяющееся состояние понижающего микширования, не требующее обязательной частотной избирательности, оказываются вполне достаточными. Возможен вариант осуществления изобретения, при котором информация о понижающем микшировании представляет собой матрицу понижающего микширования, имеющую K строк и N столбцов.Returning to Fig. 9, we consider a
Показатель в строке матрицы понижающего микширования имеет определенное значение, когда аудиообъект, соответствующий этому показателю в матрице понижающего микширования, присутствует в канале понижающего микширования, представленном в ряду матрицы понижающего микширования. Когда аудиообъект включен в более чем один канал понижающего микширования, конкретное значение имеют более одного ряда матрицы понижающего микширования. При этом предпочтенее, если квадратичные значения при сложении для отдельного аудиообъекта дают в сумме не более 1,0. Тем не менее, возможны и другие значения.The indicator in the row of the downmix matrix has a definite value when an audio object corresponding to this indicator in the downmix matrix is present in the downmix channel presented in the row of the downmix matrix. When an audio object is included in more than one downmix channel, more than one row of the downmix matrix has a specific value. Moreover, it is preferable if the quadratic values during addition for a single audio object give a total of no more than 1.0. However, other meanings are possible.
Кроме того, аудиообъекты могут быть введены в один или более каналов понижающего микширования с различными уровнями, и эти уровни могут быть обозначены внутри матрицы понижающего микширования весами, отличными от единицы и не составляющими в целом 1,0 для конкретного аудиообъекта.In addition, audio objects can be introduced into one or more downmix channels with different levels, and these levels can be indicated within the downmix matrix by weights other than unity and not totaling 1.0 for a particular audio object.
Когда каналы понижающего микширования включаются в закодированный сигнал аудиообъекта, сгенерированный выходным интерфейсом 98, закодированный сигнал аудиообъекта может представлять собой, например, мультиплексный сигнал с временным уплотнением в определенном формате. И наоборот, закодированный сигнал аудиообъекта может быть любым сигналом, который позволяет с помощью блока декодера разделять параметры объектов 95, параметры понижающего микширования 97 и каналы понижающего микширования 93. В дополнение к этому, интерфейс вывода данных 98 может включать в себя кодеры параметров объектов, информацию по понижающему микшированию или каналы понижающего микширования. Кодеры для параметров объектов и для данных по понижающему микшированию могут быть дифференциальными кодерами и/или энтропийными кодерами, а кодеры для каналов понижающего микширования могут представлять собой моно- или стереоаудиокодеры, такие как кодеры МР3 или ААС (усовершенствованный аудиокодек). Все эти операции кодирования дают в результате дополнительное сжатие данных с целью последующего уменьшения скорости передачи данных, необходимой для кодированного сигнала аудиообъекта 99.When the downmix channels are included in the encoded audio object signal generated by the
В зависимости от конкретного применения понижающего микшера 92 его функции предусматривают стереофоническое представление музыкального фона, по меньшей мере, по двум каналам понижающего микширования и введение в эти, по крайней мере, два канала понижающего микширования голосовой фонограммы в предварительно заданном соотношении. При такой версии реализации первый канал музыкального фона проходит по первому каналу понижающего микширования и второй канал музыкального фона - по второму каналу понижающего микширования. Результатом подобной компоновки является оптимальное стереофоническое воспроизведение музыкального фона на стереоаппаратуре. При этом пользователь имеет возможность позиционировать голосовую фонограмму между левым стереодинамиком и правым стереодинамиком. В качестве варианта первый и второй каналы музыкального фона могут проходить по одному каналу понижающего микширования, а голосовая фонограмма может быть проведена по другому каналу понижающего микширования.Depending on the particular application of the
Таким образом, исключая один канал понижающего микширования, можно полностью отделить голосовую фонограмму от фона музыкального сопровождения, что, в частности, отвечает требованиям караоке. Однако при этом качество воспроизведения каналов стереофонограммы музыкального сопровождения страдает из-за параметризации объекта, которая, безусловно, является методом сжатия с потерями.Thus, excluding one channel of down-mixing, you can completely separate the voice phonogram from the background of musical accompaniment, which, in particular, meets the requirements of karaoke. However, at the same time, the quality of reproduction of the channels of the stereo soundtrack of musical accompaniment suffers due to the parameterization of the object, which, of course, is a lossy compression method.
Понижающий микшер 92 имеет конфигурацию, позволяющую суммировать во временной области отсчет за отсчетом. Для такого суммирования используются отсчеты аудиообъектов, предназначенных для понижающего микширования до одного канала понижающего микширования. Если аудиообъект вводится в канал понижающего микширования в определенном процентном отношении, перед суммированием отсчетов должно выполняться предварительное взвешивание. Кроме того, суммирование может выполняться и в частотной области, или в поддиапазоне, то есть в области, следующей за частотно-временным преобразованием. Таким образом, понижающее микширование может выполняться даже в области банка фильтров, когда частотно-временное преобразование осуществляется в банке фильтров, или в области преобразования, когда частотно-временное преобразование представляет собой FFT (быстрое преобразование Фурье, БПФ), MDCT (модифицированное дискретное косинусное преобразование, МДКП), или любое другое преобразование.The
Согласно одному из аспектов настоящего изобретения генератор параметров объекта 94 генерирует энергетические параметры и дополнительно - параметры корреляции между двумя объектами, когда два аудиообъекта совокупно представляют стереосигнал, что видно из последующего уравнения (6). С другой стороны, параметры объекта являются параметрами режима предсказания.According to one aspect of the present invention, the
На фиг.15 представлена блок-схема алгоритма или способа расчета прогностических параметров аудиообъекта. Как уже пояснялось относительно уравнений с (7) по (12), расчету подлежат некоторая статистическая информация относительно каналов понижающего микширования в матрице X и аудиообъекты в матрице S. В частности, блок 150 показывает первый шаг вычисления действительной части S·X* и действительной части X·X*. Эти действительные части - не просто числа, а матрицы, и эти матрицы в одном из вариантов реализации определяются через системы обозначений в уравнении (1) при рассмотрении реализации, следующей за уравнением (12). В большинстве случаев значения шага 150 могут быть рассчитаны с использованием данных, доступных в кодере аудиообъектов 101. Затем, как показано в шаге 152, рассчитывается матрица предсказания С. В частности, как принято на существующем уровне техники, необходимо решить систему уравнений таким образом, чтобы были получены все значения матрицы предсказания С размерностью N строк и K столбцов. Главным образом, весовые множители cn,i, как в уравнении (8), рассчитаны так, что взвешенное линейное суммирование всех каналов понижающего микширования реконструирует соответствующий аудиообъект с возможно высоким качеством. Подобная матрица предсказания дает тем лучший результат реконструкции аудиообъектов, чем большее количество каналов понижающего микширования задействуется.On Fig presents a block diagram of an algorithm or method for calculating the prognostic parameters of an audio object. As already explained with respect to equations (7) through (12), some statistical information regarding down-mix channels in matrix X and audio objects in matrix S are subject to calculation. In particular, block 150 shows the first step of calculating the real part S · X * and the real part X X *. These real parts are not just numbers, but matrices, and these matrices in one of the implementation options are determined through the notation system in equation (1) when considering the implementation following equation (12). In most cases, the values of
Далее более подробно будет рассмотрена фиг.11. В частности, на фиг.7 отображены несколько видов выходных данных, используемых для создания множества выходных каналов с заданной конфигурацией выходного сигнала. В строке 111 отображена ситуация, в которой выходными данными синтезатора выходных данных 100 являются реконструированные источники звука.Next, in more detail will be considered 11. In particular, FIG. 7 shows several types of output data used to create a plurality of output channels with a given output signal configuration.
Входные данные, необходимые синтезатору выходных данных 100 для реконструирования аудиоисточников, включают в себя информацию по понижающему микшированию, каналы понижающего микширования и параметры аудиообъекта. При этом для дальнейшего воспроизведения реконструированных источников нет необходимости создавать конфигурацию выходного сигнала и предварительно позиционировать сами акустические источники внутри пространственной конфигурации выходного аудиосигнала. В режиме, обозначенном на фиг.11 номером 1, на выходе синтезатора выходных данных 100 будут формироваться реконструированные источники звуковых сигналов. В случае использования в качестве параметров аудиообъекта параметров предсказания синтезатор выходных данных 100 работает согласно определению, сформулированному в уравнении (7). Когда параметры объекта фиксируются в энергетическом режиме, для воссоздания исходных сигналов синтезатор выходных данных использует инверсию матрицы понижающего микширования и энергетическую матрицу.The input data required by the
В качестве альтернативы синтезатор выходных данных 100 может выполнять функции транскодера, как показано, например, в блоке 102 на фиг.1b. При работе синтезатора выходного сигнала в режиме транскодера, генерирующего параметры микшера пространственного звучания, требуются данные понижающего микширования, параметры аудиообъекта, конфигурация выходного сигнала и планируемая пространственная локализация источников звука. В частности, конфигурация выходного сигнала и планируемое пространственное позиционирование обеспечиваются с помощью матрицы аудиорендеринга А. При этом для генерирования параметров микшера пространственного звучания нет необходимости в наличии каналов понижающего микширования, более подробное объяснение чему будет дано в контексте фиг.12. В зависимости от ситуации параметры микшера пространственного звучания, сгенерированные синтезатором выходных данных 100, в дальнейшем могут быть напрямую использованы микшером пространственного звучания типа MPEG Surround для повышающего микширования каналов нисходящего микширования. При такой версии конструктивного исполнения корректировка каналов понижающего микширования объектов не обязательна, достаточно применение простой матрицы преобразования, имеющей только диагональные элементы, что описывалось в отношении уравнения (13). В формате 2 в строке 112 на фиг.11 синтезатор выходных данных 100 выдавает параметры микшера пространственного звучания и, предпочтительно, матрицу конверсии G согласно уравнению (13), включающую в себя показатели усиления, которые могут быть использованы как параметры произвольного усиления понижающего микширования (ADG) декодера MPEG-surround.Alternatively, the
В формате 3 в строке 113 на фиг.11 выходные данные содержат параметры микшера пространственного звучания в виде конверсионной матрицы, такой как показана в контексте уравнения (25). В этом контексте синтезатор выходных данных 100 не обязательно должен фактически конвертировать понижающее микширование объекта в стерео понижающего микширования. Номером 4 в строке 114 на фиг.11 обозначен другой формат работы синтезатора выходных данных 100, представленный на фиг.10. В данном случае транскодер работает, как элемент 102 на фиг.1b, и выдает на выходе не только параметры микшера пространственного звучания, но и дополнительные преобразованные результаты понижающего микширования.In
При этом отпадает необходимость вывода конверсионной матрицы G в дополнение к преобразованному понижающему микшированию. Вывода преобразованного понижающего микширования и параметров микшера пространственного звучания достаточно, что очевидно из фиг.1b.This eliminates the need for outputting the conversion matrix G in addition to the converted downmix. The output of the converted downmix and surround mixer parameters are sufficient, which is obvious from fig.1b.
Формат 5 характеризует еще одно приложение синтезатора выходных данных 100, показанное на фиг.10. В условиях, обозначенных в строке 115 на фиг.11, выходные данные, сгенерированные синтезатором выходных данных, не содержат никакие параметры микшера пространственного звучания, а только включают в себя, например, матрицу конверсии G согласно уравнению (35) или фактически содержат непосредственно выходные стереофонические сигналы, как показано в строке 115. При таком варианте реализации интерес представляет только стереоаудиорендеринг, а какие-либо параметры микшера пространственного звучания не требуются. Однако для генерирования стереовыхода требуется вся имеющаяся в наличии входная информация, как показано на фиг.11.
Еще один режим работы синтезатора выходных данных отображен в формате 6 в строке 116. В данном случае синтезатор выходных данных 100 генерирует многоканальный выход и является аналогом компонента 104 на фиг.1b. Для этого синтезатору выходных данных 100 необходима вся доступная входная информация, на основе которой он формирует многоканальный выходной сигнал, состоящий из более чем двух выходных каналов, подлежащих воспроизведению с использованием соответствующего количества акустических динамиков, локализованных в пространстве в соответствии с заданной конфигурацией выходного аудиосигнала. Таким многоканальным выходным сигналом может быть 5.1-канальный выход, 7.1-канальный выход или 3.0-канальный выход при наличии левого, центрального и правого громкоговорителей.Another mode of operation of the output synthesizer is displayed in
Далее дается ссылка на фиг.11 для наглядности пояснения примера вычисления нескольких параметров, снятых с декодера MPEG-surround, на основании принципа параметризации, представленного на фиг.7. Как уже сказано, фиг.7 иллюстрирует процесс параметризации с использованием блока декодера MPEG-Surround, начиная с ввода стерео понижающего микширования 70, содержащего левый I0 и правый r0 каналы понижающего микширования. Схематически оба канала понижающего микширования вводятся в так называемый блок "два-к-трем" 71. Блок "два-к-трем" управляется несколькими входными параметрами 72. Блок 71 генерирует три выходных канала 73а, 73b, 73с. Каждый выходной канал вводится в блок "один-к-двум". Это означает, что канал 73а вводится в блок 74а, канал 73b вводится в блок 74b, и канал 73с вводится в блок 74с. Каждый блок имеет два выходных канала. Блок 74а выводит левый фронтальный lf и левый панорамный ls каналы. Одновременно блок 74b выводит правый фронтальный rf и правый панорамный rs каналы. Вместе с тем блок 74с дает на выходе центральный канал с и канал оптимизации низких частот (lfe). Важно, что весь процесс повышающего микширования от каналов понижающего микширования 70 до выходных каналов осуществляется с использованием матричной операции, и древовидная структура, показанная на фиг.7, не обязательно должна реализовываться шаг-за-шагом, а может быть осуществлена через одну или через несколько операций над матрицами. Более того, промежуточные сигналы, обозначенные как 73а, 73b и 73с, не рассчитываются определенно каким-либо конкретным реализованным устройством, а показаны на фиг.7 только для наглядности. Вместе с тем, блоки 74а, 74b принимают некоторые остаточные сигналы res1 OTT, res2 OTT, которые могут использоваться для введения в выходные сигналы определенного момента случайности.Next, reference is made to FIG. 11 for the purpose of explaining an example of calculating several parameters taken from an MPEG-surround decoder based on the parameterization principle presented in FIG. 7. As already mentioned, FIG. 7 illustrates a parameterization process using an MPEG-Surround decoder unit, starting from inputting a stereo down-
Как известно из описания декодера MPEG-surround, управление блоком 71 осуществляется с использованием или параметров предсказания СРС, или энергетических параметров CLDrrr. Для повышающего микширования с двух каналов на три канала требуются, по крайней мере, два параметра предсказания СРС1, СРС2 или, по крайней мере, два энергетических параметра ![]()
![]()
![]()
![]()
Естественно, что подобный специальный расчет параметров для данного конкретного технического решения может быть адаптирован к другим форматам вывода сигнала или разновидностям параметризации в соответствии с концепцией данного изобретения. Более того, последовательность шагов алгоритма или компоновка средств на фиг.12 и 13а, b даны лишь в качестве наглядного примера и могут претерпевать изменения в границах логики математических уравнений.Naturally, such a special calculation of the parameters for this particular technical solution can be adapted to other signal output formats or types of parameterization in accordance with the concept of the present invention. Moreover, the sequence of steps of the algorithm or the layout of the funds in FIGS. 12 and 13a, b are given only as a good example and can undergo changes in the boundaries of the logic of mathematical equations.
Шаг 120 обеспечивает функционирование матрицы аудиорендеринга А. Матрица аудиорендеринга позиционирует в акустическом пространстве каждый источник из множества источников с учетом предварительно заданной конфигурации выходного сигнала.Step 120 provides the functioning of the audio rendering matrix A. The audio rendering matrix positions each source from a plurality of sources in the acoustic space, taking into account a predetermined output signal configuration.
Шаг 121 обеспечивает образование матрицы частичного понижающего микширования D36 в соответствии с уравнением (20). Эта матрица обеспечивает возможность нисходящего микширования с шести выходных каналов до трех каналов и имеет размерность 3×N. При необходимости генерировать большее число выходных каналов, чем при конфигурации 5.1, например, при создании 8-канального формата выходного сигнала (7.1), матрица, представленная в блоке 121, станет матрицей D38.Step 121 provides the formation of a partial downmix matrix D 36 in accordance with equation (20). This matrix allows downstream mixing from six output channels to three channels and has a 3 × N dimension. If necessary, generate a larger number of output channels than with 5.1 configuration, for example, when creating an 8-channel output signal format (7.1), the matrix presented in
Шаг 122 обеспечивает формирование редуцированной матрицы аудиорендеринга А3 путем перемножения матрицы D36 и полной матрицы аудиорендеринга, как определено в шаге 120.Step 122 provides the formation of a reduced matrix of audio rendering A 3 by multiplying the matrix D 36 and the full matrix of audio rendering, as defined in
Шаг 123 обеспечивает введение матрицы понижающего микширования D. Эта матрица понижающего микширования D может быть извлечена из закодированного сигнала аудиообъекта, когда матрица целиком содержится в этом сигнале. Или же матрица понижающего микширования может быть параметризирована, например, для введения специальных данных по понижающему микшированию и формирования матрицы понижающего микширования G.Step 123 provides the introduction of the downmix matrix D. This downmix matrix D can be extracted from the encoded signal of the audio object when the matrix is entirely contained in this signal. Alternatively, the downmix matrix can be parameterized, for example, to introduce special downmix data and generate the downmix matrix G.
Шаг 124 обеспечивает в дополнение к этому энергетическую матрицу объекта. Эта энергетическая матрица объекта отражена в параметрах объекта для N объектов и может быть выделена из импортируемых аудиообъектов или реконструирована с использованием определенного набора правил. Такой набор правил восстановления может включать в себя энтропийное декодирование и т.п.Step 124 provides in addition to this an energy matrix of the object. This energy matrix of the object is reflected in the object parameters for N objects and can be extracted from imported audio objects or reconstructed using a specific set of rules. Such a set of recovery rules may include entropy decoding and the like.
Шаг 125 обеспечивает формирование "сокращенной" матрицы предсказания С3. Значения этой матрицы могут быть рассчитаны путем решения системы линейных уравнений согласно шагу 125. В частности, элементы матрицы С3 могут быть вычислены умножением обеих частей уравнения на инверсию (DED*).Step 125 provides the formation of a “reduced” C 3 prediction matrix. The values of this matrix can be calculated by solving a system of linear equations according to
Шаг 126 обеспечивает расчет конверсионной матрицы G. Конверсионная матрица G размерностью K*K сформирована согласно уравнению (25). Для решения уравнения на шаге 126 необходима специальная матрица DTTT, формируемая на шаге 127. Пример для этой матрицы дан в уравнении (24), а определение можно получить, исходя из соответствующего уравнения для CTTT, что описано уравнением (22). Таким образом, уравнение (22) определяет порядок действий на шаге 128. Шаг 129 определяет уравнения для расчета матрицы CTTT. Как только на основании уравнения блока 129 будет определена матрица CTTT, могут быть выведены параметры α, β и γ, являющиеся параметрами СРС (коэффициента предсказания канала). Рекомендуется задать γ значение, равное 1, после чего единственными входными параметрами СРС в блок 71 останутся α и β.Step 126 provides the calculation of the conversion matrix G. The conversion matrix G of dimension K * K is formed according to equation (25). To solve the equation in
Остальные параметры, необходимые для алгоритма на фиг.7, представляют собой параметры, вводимые в блоки 74а, 74b и 74с. Расчет этих параметров описан в контексте фиг.13а. Шаг 130 обеспечивает формирование матрицы аудиорендеринга А. Размерность матрицы аудиорендеринга А составляет N строк для числа аудиообъектов и М столбцов для числа выходных каналов. Эта матрица аудиорендеринга содержит информацию, основанную на векторе сцены, когда вектор сцены используется. Чаще всего матрица аудиорендеринга включает в себя информацию об определенном местоположении в заданной конфигурации выходного сигнала. Если рассматривать матрицу аудиорендеринга А, например, в контексте ниже уравнения (19), становится понятно, каким образом может быть закодирована определенная локализация объектов в структуре матрицы аудиорендеринга. Естественно, могут использоваться и другие способы строго определенного позиционирования, такие как по значениям, не равным 1. Кроме того, используя значения, с одной стороны, меньше 1 и, с другой стороны, больше 1, можно управлять уровнем громкости конкретных аудиообъектов.The remaining parameters necessary for the algorithm in Fig. 7 are the parameters input to
Возможен вариант конструктивного исполнения, при котором матрица аудиорендеринга формируется модулем декодера без использования какой-либо информации со стороны кодера.A design variant is possible in which the audio rendering matrix is formed by the decoder module without using any information from the encoder.
Это дает возможность пользователю размещать аудиообъекты произвольно по своему желанию, без учета их взаимного пространственного расположения, зафиксированного данными кодера.This enables the user to place audio objects arbitrarily at will, without taking into account their mutual spatial location, recorded by the encoder data.
Возможна также версия технического решения, при которой относительное или абсолютное позиционирование акустических источников может быть закодировано модулем кодера и передано на декодер в виде определенного вектора сцены. Затем, на модуле декодера информация относительно локализации источников звука, предпочтительно не зависящая от заданных установок аудиорендеринга, обрабатывается с формированием в результате матрицы аудиорендеринга, отражающей пространственное расположение аудиоисточников, сориентированных на специфическую конфигурацию выходного аудиосигнала.A version of the technical solution is also possible in which the relative or absolute positioning of the acoustic sources can be encoded by the encoder module and transmitted to the decoder in the form of a certain scene vector. Then, on the decoder module, information regarding the localization of sound sources, preferably independent of the specified audio rendering settings, is processed to form an audio rendering matrix reflecting the spatial arrangement of the audio sources oriented to the specific configuration of the output audio signal.
Шаг 131 обеспечивает формирование матрицы Е энергетических показателей объекта, которая уже рассматривалась в связи с шагом 124 на фиг.12. Эта матрица имеет размерность N×N и содержит параметры аудиообъекта. Один из вариантов осуществления изобретения предусматривает подобную матрицу энергетических параметров объекта для каждого поддиапазона и каждого модуля временных отсчетов или отсчетов поддиапазонов.Step 131 provides the formation of the matrix E of energy indicators of the object, which has already been considered in connection with
Шаг 132 обеспечивает расчет матрицы энергетических параметров выходного сигнала F.Step 132 provides a calculation of the matrix of energy parameters of the output signal F.
F - матрица ковариации выходных каналов. Поскольку при этом выходные каналы сохраняют неопределенность, матрица F энергетических параметров выходного сигнала рассчитывается с использованием матрицы аудиорендеринга и матрицы энергетических характеристик. Эти матрицы формируются при выполнении шагов 130 и 131 с непосредственным доступом к матрицам в модуле декодера. После этого с применением специальных уравнений (15), (16), (17), (18) и (19) производится расчет показателей разности уровней каналов CLD0, CLD1, CLD2 и характеристик межканальной когерентности ICC1 и ICC2 с целью получения параметров для блоков 74а, 74b, 74с. Важно, что пространственные характеристики рассчитываются путем комбинирования специфических элементов матрицы энергетических показателей выходного сигнала F.F is the covariance matrix of the output channels. Since the output channels remain uncertain in this case, the matrix F of energy parameters of the output signal is calculated using the matrix of audio rendering and the matrix of energy characteristics. These matrices are formed in
По выполнении шага 133 все параметры для пространственного повышающего микшера, такого, например, какой схематично показан на фиг.7, подготовлены.In
В описанных ранее реализациях изобретения параметры объекта представлялись как энергетические характеристики. Однако когда параметры объектов даются в прогностическом представлении, то есть в виде матрицы С предсказания объектов, показанной под пунктом 124а на фиг.12, для расчета сокращенной матрицы предсказания С3 достаточно простого перемножения матриц согласно иллюстрации блока 125а и пояснениям в контексте уравнения (32). Матрица, использованная в блоке 125а, является той же самой матрицей A3, которая упоминается в блоке 122 на фиг.12.In the previously described implementations of the invention, the parameters of the object were presented as energy characteristics. However, when the parameters of the objects are given in the prognostic representation, that is, in the form of an object prediction matrix C, shown under
Когда матрица С предсказания объектов генерируется кодером аудиообъектов и передается на декодер, требуются дополнительные вычисления для подготовки параметров для блоков 74а, 74b, 74с. Эти вспомогательные шаги представлены на фиг.13b. Вновь матрица С предсказания объекта формируется как блок 124а на фиг.13b, что аналогично описанию блока 124а на фиг.12. Затем, как описывалось в связи с уравнением (31), матрица ковариации Z понижающего микширования объекта рассчитывается с использованием переданного понижающего микширования или генерируется и передается как дополнительная служебная информация. После передачи данных о матрице Z декодер не должен выполнять какие-либо расчеты энергетических параметров, ведущие, по существу, к возобновлению отсроченной обработки некоторых данных и увеличению совокупной загрузки блока декодера. Однако, когда эти вопросы не являются решающими для того или иного приложения, полоса частот пропускания может быть сохранена, и матрица ковариации Z понижающего микширования объекта также может быть рассчитана с использованием отсчетов понижающего микширования, которые, безусловно, доступны в модуле декодера. Как только действия шага 134 будут завершены и матрица ковариации понижающего микширования объекта будет готова, матрица Е энергетических параметров объекта может быть рассчитана согласно указаниям шага 135 с использованием матрицы предсказания С и матрицы ковариации понижающего микширования или матрицы Z "энергии понижающего микширования". По завершении шага 135 могут быть выполнены все описанные выше шаги, относящиеся к фиг.13а, а именно - 132, 133, с целью формирования всех необходимых параметров для блоков 74а, 74b, 74с на фиг.7.When the object prediction matrix C is generated by the audio object encoder and transmitted to the decoder, additional calculations are required to prepare the parameters for
На фиг.16 представлено еще одно конструктивное решение, реализующее только стереоаудиорендеринг. Стереоаудиорендеринг - это формирование выходного сигнала в соответствии с режимом номер 5 или строкой 115 фиг.11. Здесь синтезатору выходных данных 100 на фиг.10 не требуются какие-либо пространственные параметры восходящего микширования, главным образом ему необходима специальная конверсионная матрица G, чтобы преобразовать понижающее микширование объекта в функциональное и, безусловно, быстро настраиваемое и легко управляемое стерео понижающее микширование.On Fig presents yet another design solution that implements only stereo audio rendering. Stereo audio rendering is the formation of an output signal in accordance with
Шаг 160 на фиг.16 содержит в себе расчет матрицы частичного понижающего микширования с М до 2 каналов. При варианте с шестью выходными каналами матрица частичного понижающего микширования будет выполнять функции матрицы понижающего микширования с шести до двух каналов, сохраняя возможность применения других матриц понижающего микширования. Расчет такой матрицы частичного понижающего микширования может быть выполнен, например, путем выведения из матрицы частичного понижающего микширования D36, как это имело место на шаге 121, и матрицы DTTT, как это было сделано на ступени 127 фиг.12.Step 160 in FIG. 16 includes calculating a partial downmix matrix from M to 2 channels. In the variant with six output channels, the partial downmix matrix will act as a downmix matrix from six to two channels, while maintaining the possibility of using other downmix matrices. The calculation of such a partial downmix matrix can be performed, for example, by deducing from the partial downmix matrix D 36 , as was the case in
В дополнение к этому, на основании результата шага 160 генерируется матрица стереоаудиорендеринга А2, и на шаге 161 представлена "большая" матрица аудиорендеринга А. Матрица аудиорендеринга А - это та же самая матрица, которая рассматривалась в связи с блоком 120 фиг.12.In addition, based on the result of
Далее, на шаге 162, матрица стереоаудиорендеринга может быть параметрирована показателями локализации µ и κ. При задании и для µ, и для κ значения 1 получается уравнение (33), которое дает возможность варьировать динамический диапазон голоса, что уже описывалось в примере, приведенном в контексте уравнения (33). Вместе с тем, при изменении других параметров, таких как µ и κ, может варьироваться также расположение источников.Next, at
Затем, как показано на шаге 163, рассчитывается матрица конверсии G с применением уравнения (33).Then, as shown in
Исправления, внесенные в описаниеCorrections made to the description
В частности, матрица (DED*) может быть рассчитана, инвертирована, и инвертированная матрица может быть умножена на правую часть уравнения блока 163. Безусловно, могут быть применены и другие способы решения уравнения блока 163. После того как получена матрица конверсии G, понижающее микширование объекта X может быть преобразовано путем умножения матрицы конвертирования и понижающего микширования объекта, что отображено в блоке 164. После этого может быть выполнен стереоаудиорендеринг конвертированного понижающего микширования X' с использованием двух акустических стереосистем. В зависимости от технического решения для µ, ν и κ могут быть заданы определенные значения для расчета матрицы конвертирования G. Или же конверсионная матрица G может быть рассчитана с использованием всех этих трех параметров в качестве переменных таким образом, что параметры будут задаваться в соответствии с требованиями пользователя после прохождения шага 163.In particular, the matrix (DED *) can be calculated, inverted, and the inverted matrix can be multiplied by the right side of the equation of
В предпочтительных вариантах реализации изобретения были найдены решения проблемы передачи нескольких самостоятельных аудиообъектов (с использованием многоканального понижающего микширования и вспомогательных управляющих данных, описывающих объектыи аудиорендеринга объектов для заданной воспроизводящей системы (конфигурации громкоговорителей)). Вводится способ преобразования относящихся к объекту управляющих данных в управляющие данные, совместимые с системой воспроизведения. Далее предлагаются соответствующие методы кодирования, основанные на алгоритме кодирования MPEG Surround.In preferred embodiments of the invention, solutions have been found to the problem of transmitting several independent audio objects (using multi-channel downmixing and auxiliary control data describing objects and audio rendering of objects for a given playback system (speaker configuration)). A method for converting object-related control data into control data compatible with a reproduction system is introduced. The following are suitable coding methods based on the MPEG Surround coding algorithm.
В зависимости от технических требований конкретного варианта конструктивного исполнения вводимые методы и результирующий сигнал могут иметь форму реализации в аппаратных средствах или в программном обеспечении. Данная часть изобретения может быть осуществлена с использованием цифрового носителя информации, в частности диска или CD, предназначенного для хранения в электронно считываемом виде управляющих сигналов, совместимого с программируемой компьютерной системой таким образом, чтобы могли быть выполнены вводимые методы. Таким образом, в общем смысле настоящее изобретение представляет собой компьютерный программный продукт с присвоенным ему программным кодом, хранящимся на машинно-считываемом накопителе, и предназначенный для выполнения, по меньшей мере, одного из изобретенных методов при запуске данного программного продукта на компьютере. Формулируя иначе, изобретенные методы являются, таким образом, программой для компьютера, имеющей программный код, предназначенной для осуществления изобретенных методов при запуске данной программы на компьютере.Depending on the technical requirements of a particular embodiment, the input methods and the resulting signal may take the form of implementation in hardware or in software. This part of the invention can be implemented using a digital storage medium, in particular a disk or CD, designed to store control signals in an electronically readable form compatible with a programmable computer system so that the input methods can be performed. Thus, in a general sense, the present invention is a computer program product with software code assigned to it stored on a machine-readable drive, and designed to perform at least one of the invented methods when starting this software product on a computer. Stated differently, the invented methods are, therefore, a computer program having program code designed to implement the invented methods when running this program on a computer.
Другими словами, конструктивное исполнение предлагаемого изобретения представляет собой кодер аудиообъектов, предназначенный для генерирования закодированного сигнала аудиообъекта как одного из множества аудиообъектов, включающий в свою конструкцию генератор информации понижающего микширования для формирования информации понижающего микширования, отображающей порядок распределения множества аудиообъектов, по меньшей мере, между двумя каналами понижающего микширования;In other words, the embodiment of the present invention is an audio object encoder for generating an encoded audio object signal as one of a plurality of audio objects, including a downmix information generator for generating downmix information showing a distribution order of a plurality of audio objects between at least two downmix channels;
генератор параметров аудиообъектов; и выходной интерфейс для генерирования кодированного сигнала аудиообъекта с использованием информации понижающего микширования и параметров объекта.generator of audio object parameters; and an output interface for generating a coded signal of the audio object using downmix information and object parameters.
Как вариант, интерфейс вывода данных может генерировать закодированный аудиосигнал, дополнительно используя множество каналов понижающего микширования.Alternatively, the data output interface may generate an encoded audio signal, additionally using a plurality of downmix channels.
Кроме этого, или вместо этого, генератор параметров отличается тем, что способен формировать характеристики объекта с первичным временным и частотным разрешением, а в случаях, когда генератор информации понижающего микширования имеет функцию генерирования информации понижающего микширования с вторичным временным и частотным разрешением, вторичная разрешающая способность по времени и частоте ниже, чем первичная.In addition, or instead, the parameter generator is characterized in that it is capable of generating object characteristics with primary time and frequency resolution, and in cases where the down-mixing information generator has the function of generating down-mixing information with secondary time and frequency resolution, the secondary resolution is time and frequency lower than the primary.
Кроме того, генератор информации понижающего микширования отличается тем, что способен генерировать информацию понижающего микширования таким образом, что параметры понижающего микширования равномерно охватывают весь диапазон частот аудиообъектов.In addition, the down-mix information generator is characterized in that it is able to generate down-mix information so that the down-mix parameters uniformly cover the entire frequency range of audio objects.
Кроме того, генератор информации понижающего микширования отличается тем, что способен генерировать информацию понижающего микширования таким образом, что информация понижающего микширования может содержать матрицу понижающего микширования, определяемую как:In addition, the downmix information generator is characterized in that it is capable of generating downmix information such that the downmix information may comprise a downmix matrix, defined as:
X=DS,X = DS
где S - матрица, представляющая аудиообъекты и содержащая число строк, равное количеству аудиообъектов,where S is a matrix representing audio objects and containing the number of rows equal to the number of audio objects,
где D - матрица понижающего микширования, иwhere D is a downmix matrix, and
где X - матрица, представляющая множество каналов понижающего микширования и содержащая число строк, равное количеству каналов понижающего микширования.where X is a matrix representing a plurality of downmix channels and containing a number of lines equal to the number of downmix channels.
Кроме того, информация о части объекта может иметь показатель, меньший чем 1 и больший чем 0.In addition, information about a part of an object may have an indicator less than 1 and greater than 0.
Кроме того, понижающий микшер отличается тем, что способен формировать стереофоническое представление музыкального фона, по крайней мере, по двум каналам понижающего микширования и вводить голосовую фонограмму, по крайней мере, в эти два канала понижающего микширования в заданном соотношении.In addition, the downmixer is characterized in that it is able to generate a stereo background representation of the musical background through at least two downmix channels and enter a voice phonogram in at least these two downmix channels in a predetermined ratio.
Кроме того, понижающий микшер отличается тем, что способен выполнять сложение отсчетов сигналов для дальнейшего введения в канал понижающего микширования согласно данным по понижающему микшированию.In addition, the downmixer is characterized in that it is capable of adding up the signal samples for further introduction into the downmix channel according to the downmix data.
Кроме того, интерфейс вывода данных отличается тем, что способен выполнять сжатие данных по понижающему микшированию и параметров объекта перед генерированием закодированного сигнала аудиообъекта.In addition, the data output interface is characterized in that it is capable of compressing downmix data and object parameters before generating an encoded audio object signal.
Кроме того, множество аудиообъектов может включать в себя стереофонический объект, представленный двумя аудиообъектами с некоторой ненулевой корреляцией и содержащий данные о группировании, сформированные генератором информации понижающего микширования, указывающие на эти два аудиообъекта, образующие данный стереофонический объект.In addition, a plurality of audio objects may include a stereo object represented by two audio objects with some non-zero correlation and containing grouping data generated by a downmix information generator pointing to these two audio objects forming this stereo object.
Кроме того, генератор параметров объекта отличается тем, что способен формировать параметры предсказания аудиообъектов, рассчитывая их таким образом, что взвешенное добавление каналов понижающего микширования к исходному объекту, регулируемому с помощью параметров предсказания, или просто к исходному объекту дает в результате аппроксимацию объекта-источника.In addition, the object parameter generator is characterized in that it is able to generate the prediction parameters of audio objects, calculating them in such a way that a weighted addition of down-mix channels to the original object controlled by the prediction parameters, or simply to the original object, results in an approximation of the source object.
Кроме того, параметры предсказания могут формироваться на основе полосы частот, причем аудиообъекты охватывают весь частотный диапазон.In addition, the prediction parameters can be formed based on the frequency band, and audio objects cover the entire frequency range.
Кроме того, количество аудиообъектов может быть равным N, количество каналов понижающего микширования равно K, а число параметров предсказания объектов, вычисляемое генератором параметров объектов, равно или меньше чем N·K.In addition, the number of audio objects can be equal to N, the number of down-mix channels is K, and the number of object prediction parameters calculated by the object parameter generator is equal to or less than N · K.
Кроме того, генератор параметров объекта отличается тем, что способен рассчитывать наибольшее число параметров предсказания объектов K·(N-K).In addition, the object parameter generator is characterized in that it is able to calculate the largest number of object prediction parameters K · (N-K).
Кроме того, генератор параметров объекта может включать в себя повышающий микшер для увеличения числа каналов, полученных понижающим микшированием с использованием различных сочетаний контролируемых параметров предсказания объектов;In addition, the object parameter generator may include an upmixer to increase the number of channels obtained by downmixing using various combinations of controlled object prediction parameters;
при этом входящий в состав повышающего микшера кодер аудиообъектов включает в свою конструкцию итеративный контроллер, предназначенный для обнаружения параметров предсказания объекта, подлежащих тестированию, в результате чего сводятся к минимуму отклонения сигнала, реконструируемого повышающим микшером, от соответствующего оригинального сигнала среди различных наборов контролируемых параметров предсказания объекта.at the same time, the encoder of audio objects included in the upmixer includes an iterative controller designed to detect the prediction parameters of the object to be tested, which minimizes the deviation of the signal reconstructed by the upmixer from the corresponding original signal among various sets of monitored object prediction parameters .
Кроме того, синтезатор выходных данных отличается тем, что способен определять матрицу конвертирования, используя информацию по понижающему микшированию, причем матрица преобразования рассчитывается таким образом, что, по крайней мере, частично меняется расположение каналов понижающего микширования, когда аудиообъект, содержащийся в первом канале нисходящего микширования, представляющий первую половину стереоплоскости, должен быть воспроизведен во второй половине стереоплоскости.In addition, the output synthesizer is characterized in that it is able to determine the conversion matrix using the downmix information, the conversion matrix being calculated in such a way that the arrangement of the downmix channels is at least partially changed when the audio object contained in the first downmix channel representing the first half of the stereoscopic plane should be reproduced in the second half of the stereoscopic plane.
Кроме того, аудиосинтезатор может включать в себя аудиорендерер каналов, предназначенный для выполнения аудиорендеринга выходных аудиоканалов с получением акустического сигнала предварительно заданной конфигурации благодаря использованию пространственных параметров и, по меньшей мере, двух каналов понижающего микширования или конвертированных каналов понижающего микширования.In addition, the audio synthesizer may include an audio renderer of channels designed to perform audio rendering of the output audio channels to produce an acoustic signal of a predetermined configuration through the use of spatial parameters and at least two down-mix channels or converted down-mix channels.
Кроме того, синтезатор выходных данных отличается тем, что способен формировать выходные аудиоканалы заданной конфигурации, дополнительно задействуя, по крайней мере, два канала понижающего микширования.In addition, the output data synthesizer is characterized in that it is capable of generating output audio channels of a given configuration, additionally involving at least two down-mix channels.
Кроме того, синтезатор выходных данных отличается тем, что способен вычислять фактические веса понижающего микширования для матрицы частичного понижающего микширования таким образом, что энергия взвешенной суммы двух каналов равна энергиям каналов в пределах ограничения.In addition, the output synthesizer is characterized in that it is able to calculate the actual downmix weights for the partial downmix matrix so that the energy of the weighted sum of the two channels is equal to the energies of the channels within the constraint.
Кроме того, веса понижающего микширования для матрицы частичного понижающего микширования могут быть определены следующим образом:In addition, the downmix weights for the partial downmix matrix can be determined as follows:
![]()
![]()
где wp - вес понижающего микширования, р - целочисленная переменная индекса, fj,i - ячейка матрицы энергетических характеристик, представляющая приближение матрицы ковариации выходных каналов, предварительно заданной конфигурации выходного сигнала.where w p is the weight of the downmix, p is an integer index variable, f j, i is the cell of the energy characteristics matrix, representing the approximation of the covariance matrix of the output channels, a predefined output signal configuration.
Кроме того, синтезатор выходных данных отличается тем, что способен вычислять отдельные коэффициенты матрицы предсказания путем решения системы линейных уравнений.In addition, the output synthesizer is characterized in that it is able to calculate the individual coefficients of the prediction matrix by solving a system of linear equations.
Кроме того, синтезатор выходных данных отличается тем, что способен решать систему линейных уравнений, основываясь на:In addition, the output synthesizer is different in that it is able to solve a system of linear equations based on:
C3(DED*)=A3ED*,C 3 (DED *) = A 3 ED *,
где С3 - матрица предсказания "два-к-трем", D - матрица понижающего микширования, полученная, исходя из информации по нисходящему микшированию, Е - матрица энергетических характеристик, выведенная на основании исходных аудиообъектов, и А3 - сокращенная матрица понижающего микширования, и где "*" обозначает комплексно сопряженную операцию.where C 3 is a two-to-three prediction matrix, D is a down-mix matrix derived from down-mix information, E is an energy characteristics matrix derived from the original audio objects, and A 3 is a reduced down-mix matrix, and where "*" denotes a complex conjugate operation.
Кроме того, параметры предсказания для повышающего микширования "два-к-трем" могут быть получены параметризацией матрицы предсказания таким образом, что матрица предсказания определяется всего двумя параметрами, иIn addition, the prediction parameters for up-mixing two-to-three can be obtained by parameterizing the prediction matrix so that the prediction matrix is determined by only two parameters, and
при этом синтезатор выходных данных отличается тем, что способен предварительно обрабатывать, по меньшей мере, два канала понижающего микширования таким образом, что результат воздействия предварительной обработки и матрицы параметризированного предсказания соответствует желаемой матрице повышающего микширования.the output synthesizer is characterized in that it is able to pre-process at least two down-mix channels in such a way that the result of the pre-processing and the parameterized prediction matrix correspond to the desired up-mix matrix.
Кроме того, параметризация матрицы предсказания может иметь следующий вид:In addition, the parameterization of the prediction matrix can be as follows:

где индекс ТТТ - матрица параметризированного предсказания, a α, β и γ - коэффициенты.where the TTT index is the parameterized prediction matrix, and α, β, and γ are the coefficients.
Кроме того, матрица конверсии G понижающего микширования может быть рассчитана следующим образом:In addition, the downmix conversion matrix G can be calculated as follows:
G=DTTTC3 G = D TTT C 3
где С3 - матрица предсказания "два-к-трем", где DTTT и CTTT равны I, где I - единичная матрица "два-к-двум", и где CTTT основывается на:where C 3 is a two-to-three prediction matrix, where D TTT and C TTT are equal to I, where I is a two-to-two prediction matrix, and where C TTT is based on:
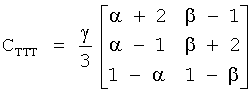
где α, β, γ - постоянные коэффициенты.where α, β, γ are constant coefficients.
Далее, прогностические параметры для повышающего микширования "два-к-трем" могут быть определены как α и β, при этом γ задан как 1.Further, the prognostic parameters for up-mixing two-to-three can be defined as α and β, with γ being set as 1.
Кроме того, синтезатор выходных данных отличается тем, что способен рассчитывать энергетические параметры для повышающего микширования "три-к-шести" с использованием матрицы энергетических характеристик F на основании:In addition, the output synthesizer is characterized in that it is able to calculate the energy parameters for up-mixing three-to-six using the matrix of energy characteristics F based on:
YY*≈F=AEA*,YY * ≈F = AEA *,
где A - матрица аудиорендеринга, E - матрица энергетических характеристик, сформированная на основании аудиообъектов-источников, Y - матрица выходного канала, а "*" служит указателем комплексно сопряженной операции.where A is the matrix of audio rendering, E is the matrix of energy characteristics formed on the basis of audio source objects, Y is the matrix of the output channel, and "*" is an indicator of a complex conjugate operation.
Кроме того, синтезатор выходных данных отличается тем, что способен рассчитывать энергетические параметры, комбинируя элементы матрицы энергетических характеристик.In addition, the output data synthesizer is characterized in that it is able to calculate energy parameters by combining elements of the matrix of energy characteristics.
Кроме того, синтезатор выходных данных отличается тем, что способен вычислять энергетические параметры на основании приведенных ниже уравнений:In addition, the output synthesizer is characterized in that it is able to calculate energy parameters based on the equations below:
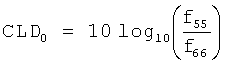

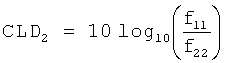
![]()
![]()
![]()
![]()
где φ - абсолютная величина φ(z)=|z| или оператор действительного значения φ(z)=Pe{z},where φ is the absolute value of φ (z) = | z | or the operator of the real value φ (z) = Pe {z},
где CLD0 - первый энергетический параметр разности уровней каналов, где CLD1 - второй энергетический параметр разности уровней каналов, где CLD2 - третий энергетический параметр разности уровней каналов, где ICC1 - первый энергетический параметр межканальной когерентности, a ICC2 - второй энергетический параметр межканальной когерентности, и где fi,j - элементы матрицы энергетических характеристик F в позициях i, j в этой матрице.where CLD 0 is the first energy parameter of the channel level difference, where CLD 1 is the second energy parameter of the channel level difference, where CLD 2 is the third energy parameter of the channel level difference, where ICC 1 is the first energy parameter of interchannel coherence, and ICC 2 is the second energy parameter inter-channel coherence, and where f i, j are the elements of the matrix of energy characteristics F at positions i, j in this matrix.
Кроме того, первая группа параметров может содержать энергетические параметры, и при этом синтезатор выходных данных отличается тем, что способен формировать энергетические параметры, комбинируя элементы матрицы энергетических характеристик F.In addition, the first group of parameters may contain energy parameters, and the output data synthesizer is characterized in that it is able to generate energy parameters by combining elements of the matrix of energy characteristics F.
Кроме того, энергетические параметры могут быть получены, исходя из того, что:In addition, energy parameters can be obtained on the basis that:
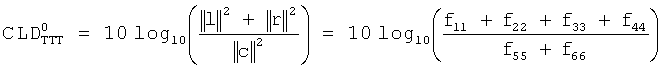
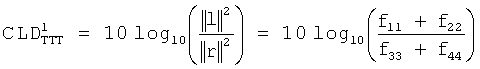
где ![]()
![]()
![]()
![]()
Кроме того, синтезатор выходных данных отличается тем, что способен рассчитывать весовые коэффициенты для взвешивания каналов понижающего микширования, весовые коэффициенты для управления коэффициентами произвольного усиления понижающего микширования (ADG) пространственного декодера.In addition, the output synthesizer is characterized in that it is able to calculate weights for weighting the down-mix channels, weights for controlling the arbitrary down-mix gain (ADG) of the spatial decoder.
Кроме того, синтезатор выходных данных отличается тем, что способен рассчитывать весовые коэффициенты, исходя из:In addition, the output data synthesizer is characterized in that it is able to calculate weighting factors based on:
Z=DED*,Z = DED *,
W=D26ED*26,W = D 26 ED * 26 ,
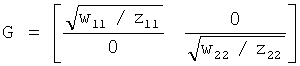
где D - матрица понижающего микширования, Е - матрица энергетических характеристик, полученная на основании аудиообъектов-источников, где W - промежуточная матрица, где D26 - матрица частичного понижающего микширования для сокращения числа каналов с 6 до 2 с заданной конфигурацией выходного сигнала, и где G - матрица преобразования, содержащая коэффициенты произвольного усиления понижающего микширования пространственного декодера.where D is the down-mix matrix, E is the energy characteristics matrix obtained from the source audio objects, where W is the intermediate matrix, where D 26 is the partial down-mix matrix to reduce the number of channels from 6 to 2 with the given output signal configuration, and where G is a transformation matrix containing arbitrary gain coefficients of the down-mix of the spatial decoder.
Кроме того, синтезатор выходных данных отличается тем, что способен рассчитать матрицу энергетических характеристик, исходя из:In addition, the output data synthesizer is characterized in that it is able to calculate the matrix of energy characteristics based on:
E=CZC*,E = CZC *,
где Е - матрица энергетических характеристик, С - матрица параметра предсказания, и Z - матрица ковариации, по меньшей мере, двух каналов нисходящего микширования.where E is the matrix of energy characteristics, C is the matrix of the prediction parameter, and Z is the covariance matrix of at least two downstream channels.
Кроме того, синтезатор выходных данных отличается тем, что способен рассчитать матрицу конвертирования, исходя из:In addition, the output data synthesizer is characterized in that it is able to calculate the conversion matrix based on:
G=A2·C,G = A 2 · C,
где G - матрица преобразования, А2 - неполная матрица аудиорендеринга, и С - матрица параметров предсказания.where G is the transformation matrix, A 2 is the incomplete matrix of audio rendering, and C is the matrix of prediction parameters.
Кроме того, синтезатор выходных данных отличается тем, что способен рассчитать матрицу конвертирования, исходя из:In addition, the output data synthesizer is characterized in that it is able to calculate the conversion matrix based on:
G(DED*)=A2ED*,G (DED *) = A 2 ED *,
где G - матрица энергетических характеристик, сформированная на базе источника звука на фонограмме, D - матрица понижающего микширования, полученная на основании информации по понижающему микшированию, А2 - редуцированная матрица аудиорендеринга, а "*" служит указателем полной сопряженной операции.where G is the matrix of energy characteristics formed on the basis of the sound source in the phonogram, D is the matrix of downmixing, obtained on the basis of information on downmixing, A 2 is the reduced matrix of audio rendering, and "*" is an indicator of the complete conjugate operation.
Кроме того, параметризованная матрица стереоаудиорендеринга А2 может быть сформирована следующим образом:In addition, a parametrized stereo audio rendering matrix A 2 can be formed as follows:
![]()
![]()
где µ, ν и κ - действительные параметры, задаваемые в соответствии с расположением и динамическим диапазоном одного или большего количества исходных аудиообъектов.where µ, ν, and κ are actual parameters specified in accordance with the location and dynamic range of one or more source audio objects.
Claims (13)
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US82964906P | 2006-10-16 | 2006-10-16 | |
| US60/829.649 | 2006-10-16 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| RU2009113055/09A Division RU2430430C2 (en) | 2006-10-16 | 2007-10-05 | Improved method for coding and parametric presentation of coding multichannel object after downmixing |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| RU2011102416A RU2011102416A (en) | 2012-07-27 |
| RU2485605C2 true RU2485605C2 (en) | 2013-06-20 |
Family
ID=
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2646320C1 (en) * | 2014-04-11 | 2018-03-02 | Самсунг Электроникс Ко., Лтд. | Method and device for rendering sound signal and computer-readable information media |
| US9947325B2 (en) | 2013-11-27 | 2018-04-17 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Decoder, encoder and method for informed loudness estimation employing by-pass audio object signals in object-based audio coding systems |
| RU2658888C2 (en) * | 2014-03-24 | 2018-06-25 | Долби Интернэшнл Аб | Method and device of the dynamic range compression application to the higher order ambiophony signal |
Cited By (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10497376B2 (en) | 2013-11-27 | 2019-12-03 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Decoder, encoder, and method for informed loudness estimation in object-based audio coding systems |
| US9947325B2 (en) | 2013-11-27 | 2018-04-17 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Decoder, encoder and method for informed loudness estimation employing by-pass audio object signals in object-based audio coding systems |
| RU2651211C2 (en) * | 2013-11-27 | 2018-04-18 | Фраунхофер-Гезелльшафт Цур Фердерунг Дер Ангевандтен Форшунг Е.Ф. | Decoder, encoder and method of informed volume evaluation using bypass signals of audio objects in systems basing on audio encoding objects |
| US11423914B2 (en) | 2013-11-27 | 2022-08-23 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Decoder, encoder and method for informed loudness estimation employing by-pass audio object signals in object-based audio coding systems |
| US10891963B2 (en) | 2013-11-27 | 2021-01-12 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Decoder, encoder, and method for informed loudness estimation in object-based audio coding systems |
| US10699722B2 (en) | 2013-11-27 | 2020-06-30 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Decoder, encoder and method for informed loudness estimation employing by-pass audio object signals in object-based audio coding systems |
| US10567899B2 (en) | 2014-03-24 | 2020-02-18 | Dolby Laboratories Licensing Corporation | Method and device for applying dynamic range compression to a higher order ambisonics signal |
| US10362424B2 (en) | 2014-03-24 | 2019-07-23 | Dolby Laboratories Licensing Corporation | Method and device for applying dynamic range compression to a higher order ambisonics signal |
| RU2760232C2 (en) * | 2014-03-24 | 2021-11-23 | Долби Интернэшнл Аб | Method and device for applying dynamic range compression to higher-order ambiophony signal |
| RU2658888C2 (en) * | 2014-03-24 | 2018-06-25 | Долби Интернэшнл Аб | Method and device of the dynamic range compression application to the higher order ambiophony signal |
| RU2698775C1 (en) * | 2014-04-11 | 2019-08-29 | Самсунг Электроникс Ко., Лтд. | Method and device for rendering an audio signal and a computer-readable medium |
| RU2646320C1 (en) * | 2014-04-11 | 2018-03-02 | Самсунг Электроникс Ко., Лтд. | Method and device for rendering sound signal and computer-readable information media |
| US10674299B2 (en) | 2014-04-11 | 2020-06-02 | Samsung Electronics Co., Ltd. | Method and apparatus for rendering sound signal, and computer-readable recording medium |
| US10873822B2 (en) | 2014-04-11 | 2020-12-22 | Samsung Electronics Co., Ltd. | Method and apparatus for rendering sound signal, and computer-readable recording medium |
| RU2676415C1 (en) * | 2014-04-11 | 2018-12-28 | Самсунг Электроникс Ко., Лтд. | Method and device for rendering of sound signal and computer readable information media |
| US11245998B2 (en) | 2014-04-11 | 2022-02-08 | Samsung Electronics Co.. Ltd. | Method and apparatus for rendering sound signal, and computer-readable recording medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| RU2430430C2 (en) | Improved method for coding and parametric presentation of coding multichannel object after downmixing | |
| JP5133401B2 (en) | Output signal synthesis apparatus and synthesis method | |
| RU2558612C2 (en) | Audio signal decoder, method of decoding audio signal and computer program using cascaded audio object processing stages | |
| JP2009503615A (en) | Control of spatial audio coding parameters as a function of auditory events | |
| Hotho et al. | A backward-compatible multichannel audio codec | |
| RU2485605C2 (en) | Improved method for coding and parametric presentation of coding multichannel object after downmixing | |
| BRPI0715559B1 (en) | IMPROVED ENCODING AND REPRESENTATION OF MULTI-CHANNEL DOWNMIX DOWNMIX OBJECT ENCODING PARAMETERS |