RU2421798C2 - Модель данных для объектно-реляционных данных - Google Patents
Модель данных для объектно-реляционных данных Download PDFInfo
- Publication number
- RU2421798C2 RU2421798C2 RU2006102530/08A RU2006102530A RU2421798C2 RU 2421798 C2 RU2421798 C2 RU 2421798C2 RU 2006102530/08 A RU2006102530/08 A RU 2006102530/08A RU 2006102530 A RU2006102530 A RU 2006102530A RU 2421798 C2 RU2421798 C2 RU 2421798C2
- Authority
- RU
- Russia
- Prior art keywords
- entity
- type
- name
- data
- association
- Prior art date
Links
Images















































Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/25—Integrating or interfacing systems involving database management systems
- G06F16/252—Integrating or interfacing systems involving database management systems between a Database Management System and a front-end application
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/40—Data acquisition and logging
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Computer Hardware Design (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
- Stored Programmes (AREA)
Abstract
Изобретение относится к области доступа к базам данных. Техническим результатом является повышение эффективности доступа к базам данных. Система для определения отношения между первой и второй объектными сущностями данных содержит процессор и память, соединенную с процессором, хранящую компоненты объектной сущности и компоненты отношения, причем первый компонент объектной сущности и второй компонент объектной сущности, предоставляют первую объектную сущность данных и вторую объектную сущность данных, причем каждая объектная сущность данных обладает унифицированной идентичностью на большом количестве разнородных приложений, при этом каждая объектная сущность данных приводится в соответствие к лежащим в основе данным в хранилище данных; и компонент отношения, явным образом определяет отношение между первой и второй объектными сущностями данных, причем отношение представляет собой ассоциацию, содержащую две стороны, так что первая сторона представляет первую объектную сущность данных, а вторая сторона представляет вторую объектную сущность данных, при этом первая объектная сущность данных независима от второй объектной сущности данных в ассоциации. 3 н. и 12 з.п. ф-лы, 33 ил.
Description
Эта заявка испрашивает приоритет на основании предварительной заявки на выдачу патента США №60/657295, озаглавленной «DATA MODEL FOR OBJECT-RELATIONAL DATA» («МОДЕЛЬ ДАННЫХ ДЛЯ ОБЪЕКТНО-РЕЛЯЦИОННЫХ ДАННЫХ») и поданной 28 февраля 2005 года, а также имеет отношение к находящейся на рассмотрении заявке на выдачу патента США №11/171905, озаглавленной «PLATFORM FOR DATA SERVICES ACROSS DISPARATE APPLICATION FRAMEWORKS» («ПЛАТФОРМА ДЛЯ СЛУЖБЫ ПЕРЕДАЧИ ДАННЫХ ЧЕРЕЗ РАЗНОРОДНЫЕ КАРКАСЫ ПРИЛОЖЕНИЙ»), поданной 30 июня 2005 года.
УРОВЕНЬ ТЕХНИКИ
Устойчивость данных является ключевым требованием в любом приложении, будь то потребительское приложение или важное коммерческое приложение (LOB). Например, командные и аудиовизуальные приложения сохраняют документы, музыку и фотографии, приложения электронной почты сохраняют объекты сообщений и календарные объекты, а пакеты бизнес-приложений сохраняют объекты потребителей и заказов. Почти все эти приложения определяют объектную модель для данных и прописывают свои собственные механизмы устойчивости.
Стандартным механизмом для описания, запрашивания и манипулирования данными является система управления реляционной базой данных (RDBMS), основанная на SQL (языке структурированных запросов). Моделью данных SQL является язык, используемый для декларативного описания структуры данных в виде таблиц, ограничительных условий и так далее. Однако информационно-емкие приложения, такие как LOB-приложения, обнаруживают, что SQL оказывается недостаточным при удовлетворении их потребностей в некоторых отношениях. Во первых, структура их данных является более сложной, чем могущая быть описанной с помощью SQL. Во вторых, они создают свои приложения с использованием объектно-ориентированных языков, которые, к тому же, богаче, чем SQL, по информационным структурам, которые они могут представлять.
Разработчики этих приложений справляются с этими недостатками, описывая данные с использованием объектно-ориентированного проектирования, реализованного на языках программирования, таких как C#. Они, в таком случае, переносят SQL-данные в и из объектов либо вручную, либо с использованием некоторой разновидности объектно-реляционной технологии. К сожалению, не каждый объектно-ориентированный проект может быть легко приведен в соответствие заданной SQL-реализации или, в некоторых случаях, какой бы то ни было SQL-реализации, порождая значительный объем работ ручного программирования ввиду того, что разработчикам приходится иметь дело с различиями.
Другая проблема состоит в том, что возможностей, которые разработчикам приходится узнавать и принимать во внимание из SQL, нет в их распоряжении, когда их данные находятся в виде объектов. Например, выражение запроса должно быть сделано в терминах лежащей в основе базы данных, а не объектов, которые они используют для других задач.
Решение состоит в том, чтобы предоставить более обогащенную модель данных, которая поддерживается объектным каркасом и сервером базы данных или поддерживающей средой исполнения. Для разработчика она будет выглядеть просто подобной базе данных с более богатыми возможностями для описания и манипулирования данными. Общая и простая, но обогащенная модель данных могла бы сделать возможной общую модель программирования для этих приложений и предоставляет прикладным платформам возможность рационализировать основу доступа к общим данным. Следовательно, существует неудовлетворенная потребность в обогащенной модели данных, которая предоставляет возможность общей модели программирования для многочисленных разнородных приложений.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Последующее представляет упрощенное краткое изложение для того, чтобы обеспечить базовое понимание некоторых аспектов раскрытого изобретения. Это краткое изложение не является исчерпывающим обзором, и оно не имеет намерением идентифицировать его ключевые/критические элементы или установить рамки изобретения. Его единственной целью является представить в упрощенном виде некоторые концепции, в качестве вступления к более подробному описанию, которое представлено ниже.
Раскрытым изобретением является обогащенная модель данных, названная Общей моделью данных (CDM). Она поддерживается платформой, которая ее реализует, названной Общей платформой данных (CDP). CDM является моделью данных, общей для многочисленных специфичных приложений моделей данных. Например, она может поддерживать как PIM-данные (организатора персональной информации) приложения конечного пользователя, так и важные коммерческие (LOB) данные. Подобным образом, приложение со своей собственной моделью данных, такой как SDM (модель описания системы) Microsoft Windows™, может задавать свою модель поверх CDM. CDM делает возможной улучшенную функциональную совместимость между приложениями.
Существует значительное количество концепций устойчивости и моделирования данных, широко применяемых в приложениях, которые могут быть вынесены в общую модель данных, тем самым, предоставляя обогащенный каркас устойчивости, который может быть заимствован большими количествами приложений. Возможности CDM включают в себя отнесение к категории реляционных понятий, определение обогащенной объектной абстракции для данных, моделирование богатой семантики (например, отношений), минимизацию несоответствия между приложением и CDM, согласование с системой типов CLR (общеязыковой среды исполнения), поддержку поведений, чтобы сделать возможной разработку среднеуровневых и клиентских приложений, и обеспечение логических понятий. Концепции моделирования фиксируют семантику, независимую от информационных хранилищ.
Один из примеров, где CDM превосходит SQL, заключается в определении отношений. В SQL отношение между потребителем (Customer) и заказом (Order) не может быть выражено явным образом. Является допустимым выражать ограничение внешнего ключа, из которого может быть выведено отношение, но внешний ключ является только одним из многих способов для реализации отношений. В CDM отношение может быть выражено явным образом и обладает атрибутами, таким же образом, как содержит атрибуты описание таблицы. Отношения являются первоклассным участником. Второй пример состоит в том, что CDM содержит систему типов для объектов, которая позволяет ей более естественно осуществлять интеграцию с CLR.
В еще одном ее аспекте предусмотрена альтернативная реализация CDM, в которой отношения определены на высшем уровне с использованием элементов <Association> или <Composition>. Соответственно, нет необходимости определять свойство по источнику (или родителю) для того, чтобы определить ссылочную (Ref) ассоциацию (или композицию).
Для достижения вышеизложенных и родственных целей некоторые иллюстративные аспекты раскрытого изобретения описаны в материалах настоящей заявки в связи с последующим описанием и прилагаемыми чертежами. Эти аспекты, однако, являются указывающими только на несколько различных способов, которыми могут быть использованы принципы, раскрытые в материалах настоящей заявки, и имеют намерением включать в себя все такие аспекты и их эквиваленты. Другие преимущества и новые признаки станут очевидными из последующего подробного описания при рассмотрении в соединении с чертежами.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 иллюстрирует архитектуру общей модели данных (CDM) в соответствии со связанным изобретением.
Фиг.2 иллюстрирует способ предоставления CDM в соответствии с новым аспектом.
Фиг.3 иллюстрирует компонент отношения и его разновидности.
Фиг.4 иллюстрирует компонент объектной сущности, его членов и типы членов.
Фиг.5 иллюстрирует окно LOB-приложения для изображения основных признаков модели данных изобретения.
Фиг.6 иллюстрирует окно LOB-приложения и каким образом структурные отношения между объектными сущностями отражены в окне LOB-приложения по фиг.5.
Фиг.7 иллюстрирует композицию объектных сущностей в виде наложенного на окно LOB-приложения по фиг.5.
Фиг.8 иллюстрирует примерную LOB-модель, использующую концепции CDM, которая использует отношения объектных сущностей, сводные таблицы и их адресацию, и ограничительные условия в соответствии с изобретением.
Фиг.9 иллюстрирует использование ключей и идентификаторов объектной сущности в соответствии с CDM.
Фиг.10 иллюстрирует UML-представление некоторых подставляемых типов.
Фиг.11 иллюстрирует UML-представление некоторых типов объектной сущности.
Фиг.12 иллюстрирует UML-представление некоторых типов при композиции.
Фиг.13 иллюстрирует визуализацию экземпляра D в TS.TableD.
Фиг.14 иллюстрирует SQL-таблицы, которые соответствуют таблицам объектных сущностей по фиг.13.
Фиг.15 иллюстрирует платформу данных, которая может использовать CDM раскрытого изобретения.
Фиг.16 иллюстрирует фрагменты метамодели CDM, которые проясняют семантику модели, имеющую отношение к типам.
Фиг.17 иллюстрирует фрагменты метамодели CDM, которые проясняют семантику модели, имеющую отношение к свойствам.
Фиг.18 иллюстрирует фрагменты метамодели CDM, которые проясняют семантику модели, имеющую отношение к ассоциациям.
Фиг.19 иллюстрирует четыре основных концепции альтернативной реализации CDM.
Фиг.20 иллюстрирует, что CDM поддерживает понятие наследования типа.
Фиг.21 иллюстрирует таксономию типов CDM для этой реализации.
Фиг.22 иллюстрирует общее представление типов и экземпляров в этой реализации CDM.
Фиг.23 иллюстрирует, каким образом типы объектной сущности и подставляемые типы объявляются с использованием SDL.
Фиг.24 иллюстрирует многие виды отношений, поддерживаемых CDM.
Фиг.25 иллюстрирует структурную организацию для сделанных устойчивыми объектных сущностей в CDM.
Фиг.26 иллюстрирует использование расширений объектной сущности в этой реализации CDM.
Фиг.27 иллюстрирует фрагменты метамодели CDM альтернативной реализации, которые проясняют семантику модели, имеющую отношение к типам.
Фиг.28 иллюстрирует фрагменты метамодели CDM альтернативной реализации, которые проясняют некоторую семантику модели, имеющую отношение к свойствам.
Фиг.29 иллюстрирует фрагменты метамодели CDM альтернативной реализации, которые проясняют некоторую семантику модели, имеющую отношение к ассоциациям.
Фиг.30 иллюстрирует UML-диаграмму композиции по фиг.29, которая иллюстрирует некоторые аспекты отношения, показанного на нем.
Фиг.31 иллюстрирует усовершенствованные отношения альтернативной реализации.
Фиг.32 иллюстрирует структурную схему компьютера, работоспособного для приведения в исполнение CDM-архитектуры.
Фиг.33 иллюстрирует схематичную структурную схему примерной вычислительной среды, в которой CDM может быть использована.
ПОДРОБНОЕ ОПИСАНИЕ
Изобретение далее описано со ссылкой на чертежи, на всем протяжении которых одинаковые ссылочные номера использованы, чтобы указывать ссылкой на идентичные элементы. В последующем описании, в целях пояснения, изложены многочисленные характерные детали, чтобы обеспечить его исчерпывающее понимание. Может быть очевидным, однако, что изобретение может быть осуществлено на практике без этих характерных деталей. В других случаях хорошо известные конструкции и устройства показаны в виде структурной схемы, для того чтобы облегчить его описание.
В качестве использованных в этой заявке, термины «компонент» и «система» предназначены для указания ссылкой на связанный с применением компьютера объект, любое из аппаратных средств, сочетания аппаратных средств и программного обеспечения, программного обеспечения или программного обеспечения при его выполнении. Например, компонент может быть, но не ограничивается настоящим, процессом, выполняющимся на процессоре, процессором, накопителем на жестком диске, многочисленными запоминающими накопителями (оптического и/или магнитного запоминающего носителя), объектом, исполняемым файлом, потоком управления, программой и/или компьютером. В качестве иллюстрации, как приложение, работающее на сервере, так и сервер могут быть компонентами. Один или более компонентов могут находиться в пределах процесса и/или потока управления, и компонент может быть локализован на одном компьютере и/или распределен между двумя или более компьютерами.
Несмотря на то, что определенные способы отображения информации для пользователей показаны и описаны по некоторым чертежам как моментальные снимки экрана, специалисты в соответствующей области техники будут осознавать, что могут быть использованы другие разнообразные альтернативные варианты. Термины «экран», «веб-страница» и «страница» в материалах настоящей заявки, как правило, использованы взаимозаменяемым образом. Страницы или экраны сохраняются и/или передаются в качестве описаний отображения, как графические интерфейсы пользователя, или посредством других способов изображения информации на экране (например, любого из персонального компьютера, PDA (персонального цифрового ассистента), мобильного телефона или другого пригодного устройства), где формат и информация или контент, который должен быть отображен на странице, сохраняется в памяти, базе данных или другом хранилище.
Первоначально, со ссылкой на чертежи, фиг.1 иллюстрирует архитектуру 100 общей модели данных (CDM) в соответствии со связанным изобретением. CDM 100 включает в себя компонент 102 объектной сущности, который предоставляет объектную сущность данных, обладающую унифицированной идентичностью на всем большом количестве разнородных приложений. Компонент 104 отношения определяет отношение между двумя или более объектными сущностями данными.
CDM 100 является моделью данных, общей для многочисленных специфичных приложений моделей данных. Например, она может поддерживать как PIM-данные (организатора персональной информации) приложения конечного пользователя, так и важные коммерческие (LOB) данные. Подобным образом, приложение SDM-типа (модели описания системы Windows™) может задавать свою модель поверх CDM 100. CDM 100 делает возможной улучшенную функциональную совместимость между приложениями.
Существует значительное количество концепций устойчивости и моделирования данных, которые могут быть вынесены в CDM, в силу этого, используя общий словарь для описания данных и делая возможным общий набор служб, которые могут приносить пользу всем приложениям, такой как объектно-реляционный каркас устойчивости. Косвенной целью CDM 100 является освободить приложения от определения их собственного каркаса устойчивости и к тому же сделать возможными более высокие уровни функциональной совместимости приложения по разным информационным хранилищам. Другие цели включают в себя отнесение к категории реляционных понятий, определение обогащенной объектной абстракции для данных, моделирование обогащенной семантики (например, отношений), минимизацию несоответствия между приложением и CDM, согласование с системой CLR-типов (общеязыковой среды исполнения), поддержку поведений, чтобы дать возможность разработки среднеуровневых и клиентских приложений, и логические понятия. Концепции моделирования фиксируют семантику, независимую от информационных хранилищ.
CDM связанного изобретения предусматривает по меньшей мере следующие новые аспекты.
• Система типов пополнена типами объектной сущности (Entity Type), подставляемыми типами (Inline Type), таблицами объектных сущностей (Entity Table), наборами таблиц (Table Set) и отношениями (Relationship)
• Проведение различий между типами объектной сущности и подставляемыми типами
• Типы объектной сущности включают в себя понятие идентичности и ключей (вместо определения их таблицами, как имеет место в SQL)
○ Явное объявление ключей, составленных из комбинаций свойств объектной сущности
• Разные виды отношений между объектными сущностями (ассоциации)
○ Компонуемость ассоциации объектной сущности с другими типами ассоциации
○ Ассоциации общего значения (Common Value)
○ Условные (Conditional) ассоциации (предусматривают более сложные отношения типа соединения)
• Факторизация атрибутов, заданных в объектной сущности (описания свойств), в зависимости от того, что задано в отношении (Relationship) (как такие свойства используются для соотнесения объектных сущностей)
• Вложенные таблицы (композиции)
• Расширения
○ Специфичные типу
○ Основанные на экземпляре или классе
○ Возможность порождения из других расширений
○ Возможность задавать таблицу-хранилище
• Расширяемые перечисления
• Объявление свойств навигации (Navigation) для отношений
• Задание области ассоциаций, чтобы применять только к конкретной таблице
• Группирование таблиц объектных сущностей (Entity Table) и отношений (Relationship) в наборы таблиц (Table Set)
• Возможность задавать таблицу, которая должна быть использована в описании объектной сущности (Entity), ассоциации или наборе таблиц
• Наборы атрибутов каждого описания типа
• Представление проекций в качестве анонимных типов
○ Возможность описывать анонимные типы подстановкой
• Задание ограничений типов
Последующее является текстовым описанием системы типов CDM, над которыми будет выполняться какая бы то ни была алгебра. Отступ указывает, что тип с отступом является разновидностью «выступающего» типа; например, тип Array (массива) является подставляемым (Inline) типом.
Type (тип) - абстрактная основа всех типов
Тип Entity (объектная сущность) - допускающий указание ссылкой тип (обладает уникальной идентичностью) со свойствами подставляемого (Inline) именованного типа
Подставляемый (Inline) тип - не обладает идентичностью
Тип Collection (коллекции)
Тип Array (массива) - однородное множество экземпляров подставляемого (Inline) типа
Тип Entity Table (таблицы объектных сущностей) - набор объектных сущностей
Тип Scalar (скалярный)
Тип Entity Ref (ссылки объектной сущности) - ссылка на объектную сущность
Тип Table Ref (ссылки таблицы) - это требуется для алгебры обновлений; он не должен использоваться в качестве типа свойства.
Тип Simple (простой) - примитивные типы без других членов, такие как int (целочисленный), string (строковый), Xml, FileStream (файлового потока)
Тип Enumeration (перечислимый)
Тип Array (массива) - однородное множество экземпляров подставляемого (Inline) типа; им является RowSet<I> (набор строк, возвращаемый по аргументу I)
Тип Complex (составной)
Тип Structured (структурированный) - тип с определяемыми пользователем свойствами; свойствами подставляемого (Inline) типа
Тип Anonymous (анонимный) - неименованный; переопределяемый при каждом использовании; имеет свойства подставляемого (Inline) типа
Тип Row Set (набора строк) - совокупность экземпляров подставляемого (Inline) типа или типа объектной сущности (Entity).
Тип Entity Table (таблицы объектных сущностей) - набор экземпляров типа Entity; им является сайт (место, где сохраняются экземпляры)
Тип Relational Table (реляционной таблицы) - однородное множество экземпляров анонимного (Anonymous) типа; он является сайтом
Фиг.2 иллюстрирует способ предоставления CDM в соответствии с новым аспектом. Несмотря на то, что, в целях простоты пояснения, один или более способов, показанных в материалах настоящей заявки, например, в виде блок-схемы алгоритма или диаграммы последовательности операций, показаны и описаны как последовательность действий, должно быть понято и принято во внимание, что связанное изобретение не ограничено очередностью действий, так как некоторые действия могут, в соответствии с ним, происходить в ином порядке и/или одновременно с другими действиями из тех, что показаны и описаны в материалах настоящей заявки. Например, специалисты в данной области техники будут понимать и принимать во внимание, что способ, в качестве альтернативы, мог бы быть представлен как последовательность взаимосвязанных состояний или событий, таких как на диаграмме состояний. Более того, не все проиллюстрированные действия могут потребоваться для реализации способа в соответствии с изобретением.
На 200 предоставлена схема, которая определяет пространство имен для задания области определений схемы. На 202 определяются типы объектных сущностей для группирования свойств и методов. На 204 определяется объектная сущность набора таблиц, чьими свойствами являются таблицы. На 206 семантические связи между объектными сущностями выражаются с использованием отношений (например, ассоциаций, композиций, …).
Объектные сущности моделируют объекты реального мира. Объектной сущностью является объект данных, который является уникально идентифицируемым в CDM с использованием его идентичности (ключа). Объектная сущность является наименьшей единицей, которая может быть совместно использована (указана ссылкой) с использованием ее идентичности. Объектная сущность обладает структурой (например, свойствами) и поведением (например, методами). Некоторыми примерами разных типов объектных сущностей являются заказ (Order), потребитель (Customer), деловой контакт (Contact), документ (Document), и тому подобное. Объектные сущности подобны типизированным строкам на SQL99 или объектам в ODBMS-системах. Объектные сущности определены как экземпляры типов объектной сущности. Ниже, только в целях примера, изложен синтаксис для описания объектной сущности:
<EntityType Name="Order" Key="OrderId">
<Property Name="OrderId" Type="Guid" Nullalbe="false"/>
<Property Name="Date" Type="DateTime" Nullalbe="false"/>
…
</EntityType>
Каждая объектная сущность обладает уникальной идентичностью, которая пополнена значениями ключей объектной сущности. Эта идентичность является основой для формирования ссылки на объектную сущность. Ключом объектной сущности является набор из одного или более свойств объектной сущности. Каждая объектная сущность обладает уникальной идентичностью, которая пополнена значениями ключей объектной сущности. Эта идентичность является основой для формирования ссылки на объектную сущность. Ключом объектной сущности является набор из одного или более свойств объектной сущности. Каждое описание объектной сущности неабстрактного типа должно задавать ключевые свойства или наследовать ключевые характеристики от базового типа объектной сущности. Значения ключевых свойств могут быть определяемыми пользователем или вырабатываемыми системой.
Идентификатор объектной сущности формируется из ключа объектной сущности плюс идентификатора содержащей или родительской объектной сущности для данной объектной сущности. Родительской объектной сущностью является объектная сущность, содержащая таблицу, в которой сохранена дочерняя объектная сущность - потомок. Ключу объектной сущности необходимо быть уникальным только в пределах ее таблицы - другая таблица может содержать объектную сущность с таким же значением ключа объектной сущности. Таким образом, идентификатор объектной сущности является уникальным согласно комбинированию значения ее ключа с идентификатором ее родителя. В некоторых случаях ключ может быть уникальным в масштабе всего хранилища, к примеру, при использовании глобально уникального идентификатора (GUID). CDM требует, чтобы идентификатор был уникален лишь в пределах элемента (например, EntitySet).
Идентичность полностью идентифицирует объектную сущность и может быть разыменована, чтобы возвратить экземпляр объектной сущности. Ссылка использует идентичность. При заданной объектной сущности может быть получено значение ее ссылки. Две объектные сущности тождественны тогда и только тогда, когда тождественны их идентичности. Синтаксисом ссылочного типа в CDM является «Ref(<entity_type>)», а свойства могут быть типа «ref»; такое свойство названо ссылочным свойством. Ссылочные значения могут быть сделаны устойчивыми; они являются долговременными ссылками на объектные сущности. Копирование ссылочных значений не копирует объектные сущности, на которые они ссылаются. Ссылочные значения, к тому же, могли бы обеспечивать навигацию в пределах языка запросов, например, посредством операторов Ref и Deref.
Ссылки дают возможность совместного использования объектных сущностей. Например, объектная сущность заказа может содержать ссылочное свойство потребителя (Customer). Все заказы для одного и того же потребителя будут иметь одинаковое значение для ссылочного свойства потребителя. Структура ссылки является определяемой реализацией. Ссылки и ключи могут быть открыты для воздействия в качестве типов в API (прикладном интерфейсе программирования). Реализация ссылки включает в себя информацию идентификатора для объектной сущности, на которую она ссылается, в том числе значения ключей и, возможно, таблицу, в которой объектная сущность находится. Она могла бы хранить ссылку в качестве значений индивидуальных ключей (давая возможность рационального объединения) или в качестве единого непрозрачного значения. Функции могли бы открывать для воздействия структуры ссылок, чтобы получать значения ключей или таблицу, содержащую объектную сущность.
CDM состоит из следующих основных понятий: объектная сущность и отношение. Объектной сущностью является набор непосредственно связанных данных с единой идентичностью. Отношением является механизм, который соотносит две или более объектных сущностей. Фиг.3 иллюстрирует компонент 102 отношения и его разновидности. Отношения описывают, каким образом соотносятся две или более объектных сущностей. Отношения 300 принимают одну из следующих форм.
Ассоциация 302 (Association) - наиболее общая форма отношения 300 между двумя или более объектными сущностями. Объектные сущности, названные сторонами, соотносятся одна с другой через явно заданное отношение источник-цель (подобное внешнему - первичному ключу) или посредством запроса. Каждая из сторон в отношении остается независимой от других сторон. Является допустимым обязывать одну сторону быть удаленной, когда удаляется другая сторона, или предохранять одну сторону от того, чтобы быть удаленной до тех пор, пока существует другая сторона.
Композиция 304 - родительская объектная сущность, которая соотнесена дочерней объектной сущности (или объектным сущностям) таким образом, что дочерняя объектная сущность на понятийном уровне является неотъемлемой частью родительской объектной сущности. Дочерняя объектная сущность существует в точности в одной родительской и поэтому всегда должна удаляться, когда удаляется родительская объектная сущность. Кроме того, ее идентичности необходимо быть уникальной среди других дочерних объектных сущностей в такой композиции.
Объектная сущность 306 ассоциации (Association Entity) определена там, где две или более объектных сущностей, сторон, связаны вместе отношениями по отдельной объектной сущности, объектные сущности ассоциации, которая сама может иметь свойства. Каждая из сторон на понятийном уровне остается независимой от других.
Фиг.4 иллюстрирует компонент 100 объектной сущности и его члены, и типы членов. Компонент 100 объектной сущности использует объектную сущность 400, которая является состоящей из членов объектной сущности. Поддерживаются следующие разновидности членов. Свойство 402 (Property) выделяет хранилище для экземпляра конкретного типа. Свойство 404 навигации (Navigation Property) упрощает запрашивание по всем объектным сущностям, соотнесенным ассоциацией. Расчетное свойство (Calculated Property) представляет рассчитываемые значения в качестве противопоставленных хранимому значению. Метод 408 представляет операцию, которая может быть выполнена.
Члены объектной сущности имеют типы членов и/или вмещают типизированные параметры. Следующие разновидности типов, подставляемые типы 412 (Inline Type) и табличные типы 414 (Table Type), имеются в распоряжении при описании членов объектной сущности. Подставляемым типом (Inline Type) является тип, чьи данные сохраняются внутри текста в объектной сущности. Подобно типам объектной сущности, подставляемые типы являются состоящими из членов. В отличие от типов объектной сущности, подставляемые типы не имеют идентичности сверх той, что наложена объектной сущностью, в пределах которой они находятся. Подставляемые типы могут быть объявлены непосредственно и охватывают некоторые другие разновидности типов в модели данных. Подставляемые типы (Inline Type) включают в себя следующие.
Простой подставляемый тип 416 (Simple Inline Type) - подставляемый тип, который не имеет внутренней структуры, которая является видимой в общей модели данных. Типы значений CLR являются простыми типами в общей модели данных. Перечислимый тип 418 (Enumeration Type) - набор именованных значений. Перечислимые типы 418 являются простыми типами, которые могут быть независимо и одновременно расширены многочисленными разработчиками без опасения конфликта. Тип 420 ссылки объектной сущности (Entity Reference Type) - долговременная ссылка на одиночную объектную сущность, возможно, включающая в себя ссылку на таблицу, в которой находится объектная сущность. Ссылки объектной сущности используются в соединении с ассоциациями, чтобы соотносить две объектные сущности. Тип 422 табличной ссылки (Table Reference Type) - долговременная ссылка на таблицу. Тип 424 массива (Array Type) - упорядоченная коллекция экземпляров подставляемого типа, иного чем массив.
Табличный тип 414 (Table Type) - неупорядоченная коллекция экземпляров заданного типа объектной сущности. Таблицы используются в соединении с композициями, чтобы соотносить две объектные сущности. Все из типов, перечисленных выше, являются содержимыми типами; то есть, значения этих типов могут содержаться объектной сущностью.
Тип объектной сущности описывает членов объектной сущности. Типы объектной сущности могут быть порождены от базового типа объектной сущности, в каковом случае порожденный тип объектной сущности содержит все члены базового типа наряду с членами, описанными для порожденного типа. Типы объектной сущности могут быть независимо и одновременно расширены многочисленными разработчиками без опасения конфликта. Такие типы расширения объектной сущности не зависят от наследования типа. Типы объектной сущности и расширения объектной сущности не являются содержимыми типами.
Набор таблиц - экземпляр типа объектной сущности, который содержит нормированные таблицей свойства. Объявление набора таблиц создает одиночный именованный экземпляр типа и, таким образом, каждой из таблиц, которые он содержит. Набор таблиц создает место для хранения данных подобно способу, при котором создание базы данных создает место для хранения данных.
Далее, со ссылкой на фиг.5, проиллюстрировано окно LOB-приложения для изображения основных признаков модели данных изобретения. Объектная сущность заказа на покупку (Sales Order Entry) иллюстрирует данные, такие как номер заказа (Order Number), номер потребителя (Customer Number), имя потребителя (Customer Name) и информация о товаре заказа, такая как номер изделия (Item Number), описание (Description), количество (Quantity), и другую значимую информацию.
Фиг.6 иллюстрирует, каким образом структурные отношения между объектными сущностями отражены в окне LOB-приложения по фиг.5. Как указано ранее, двумя основными понятиями CDM являются объектная сущность и отношение. Объектной сущностью является объект с данными свойств и идентичности, которые уникально его идентифицируют. Отношением является способ для соотнесения объектных сущностей. На фиг.6 заказ (Order) и потребитель (Customer) являются двумя объектными сущностями, соотнесенными посредством ассоциации. Здесь, объектная сущность заказа (Order) ассоциативно связана только с одной («1») объектной сущностью потребителя (Customer). Интуитивно, потребитель может относиться к нулю или более («*») заказов. Объектные сущности обладают свойствами и могут наследовать друг от друга. Ассоциации реализуются разными способами: в качестве ссылки (например, Order.Customer), в качестве соединения между свойствами, в качестве объектной сущности, и т.д.
Ассоциации могут быть реализованы некоторым количеством разных способов. Один из подходов заключается в том, чтобы использовать ссылку (которая подобна указателю). В предыдущем примере по фиг.6 есть одна ссылка, которая является указателем из заказа (Order) на потребителя (Customer). Это просто реализует ограничение, при котором может быть один потребитель, соотнесенный с заказом. В одной из реализаций свойство ссылки может содержать в нем только одну ссылку.
Еще один подход заключается в том, чтобы использовать условную ассоциацию, которая является отношением, описанным на основе свойств. Есть два свойства, соотнесенные вместе некоторым образом, или набор свойств, взаимосвязанных некоторым образом. Отношение общего значения - отношение, при котором, если две объектные сущности содержат одинаковое значение, они являются соотнесенными. Примером является документ (объектная сущность), который содержит имя (свойство) автора, и другая объектная сущность, названная деловым контактом, и она содержит свойство наименования делового контакта. Отношение может быть установлено между свойством имени автора объектной сущности документа и свойством наименования делового контакта объектной сущности делового контакта. Если значения таких свойств являются одинаковыми, то имеет место отношение между такими двумя объектными сущностями. Это может быть обобщено, чтобы сформировать некоторое произвольное выражение, которое говорит: «если выражение истинно, то эти объектные сущности соотнесены». Например, если первая объектная сущность содержит первое свойство прямоугольника, а вторая объектная сущность содержит второе свойство прямоугольника, отношение может быть определено из условия, что первая и вторая объектные сущности соотнесены, если прямоугольник второй объектной сущности полностью вмещает прямоугольник первой объектной сущности.
Третьим подходом является объектная сущность ассоциации, где объектная сущность используется, чтобы создавать связь. Это может быть использовано, чтобы иметь в распоряжении свойства на ассоциации.
Фиг.7 иллюстрирует композицию объектных сущностей в соответствии с изобретением, которые наложены на окно LOB-приложения по фиг.5. Композиция является включением, где один предмет заключает в себе другой, и таким образом, является не только отношением. Например, заказ (Order) содержит или заключает в себе набор объектных сущностей товаров заказа (OrderLine). Родительская идентичность плюс дочерняя идентичность вместе составляют полную идентичность потомка. Композиция изображается свойством таблицы объектных сущностей в родительской объектной сущности. Эта возможность повторного использования в пределах CDM табличного понятия для изображения композиции является полезной. Композиция (которая показана черным ромбом) ассоциативно связывает две объектные сущности как родителя, так и потомка. Каждый заказ (Order) содержит таблицу многих («*») объектных сущностей товара заказа (OrderLine) (или их производных). Родитель управляет временем существования потомка, так как потомок «живет» в пределах родителя, удаление родителя должно удалять потомка. Дочерней объектной сущности необходимо быть уникальной только среди других потомков в той же самой композиции.
Фиг.8 иллюстрирует примерную LOB-модель, использующую концепции CDM, которая использует отношения объектных сущностей, их сводные таблицы и адресацию, и ограничения в соответствии с изобретением. Линия со стрелкой изображает ассоциацию (например, ссылочное свойство), черный ромб указывает композицию (табличное свойство), а набор таблиц аналогичен базе данных. Набор таблиц является корнем дерева данных приложения. Набор таблиц является экземпляром типа набора таблиц. Типы набора таблиц содержат только нормированные таблицей свойства. То есть, типы набора таблиц участвуют только в композициях. Тип набора таблиц является разновидностью типа объектной сущности. Приложение создает данные посредством определения экземпляра типа набора таблиц, названного «набор таблиц» («table set») (например, определяет «Northwind» типа «NorthwindData»). Набор таблиц также описывает набор данных, которые устанавливаются в службе и, в конечном счете, в базе данных. Он является автономной и компонуемой единицей данных.
Когда объектная сущность (например, SalesData (данные продаж)) определена, она может быть соотнесена со многими иными объектными сущностями. Например, компания будет иметь набор заказов внутри нее и набор потребителей внутри нее. Это иллюстрирует пару разных композиций. Заказ (Order) будет содержать товары заказа внутри него так, что начинает оформляться дерево. В вершине дерева находится специальная объектная сущность, названная объектной сущностью набора таблиц. Набором таблиц является одиночный экземпляр некоторого типа объектной сущности. (Эта конструкция аналогична SQL-понятию базы данных). Набор таблиц предусматривает средство объявления данных. На чертеже он изображен в белом цвете (до некоторой степени, в сравнении с затушеванным прямоугольником), так как он является отличным от других объектных сущностей. Пример LOB показывает набор таблиц данных продаж (SalesData) (или «базу данных») с одной или более компаниями, адресами, потребителями или заказами. Объектная сущность потребителя (Customer), например, может быть частью единственной компании за раз, например, компании, представляющей связанное с местом жительства предпринимательство, либо компании, представляющей торговое предпринимательство. Чтобы проиллюстрировать понятие отношений объектной сущности в модели LOB по фиг.8, родительская объектная сущность компании (Company) содержит две дочерние объектные сущности - заказ (Order) и потребитель (Customer). CDM логически выстраивает таблицы потомков, которые являются непересекающимися друг с другом в объектной сущности компании (Company). Линия от объектной сущности заказа (Order) к объектной сущности адреса (Address) является ассоциацией с потомком.
Понятие композиции в CDM состоит в том, что если компания набирает заказы, такой набор заказов является отдельным от набора заказов другой компании. Например, заказы из розничной продажи никогда не пересекаются с или не совпадают с заказами от машиностроения. Композиция означает, что эти наборы являются раздельными, не перекрываются, и они не используют совместный ресурс. Как указано ранее, ассоциации изображены линиями со стрелками. Так, заказ ссылается на потребителя, и может быть сформирован другой заказ (не показан), который ссылается на того же самого потребителя. Здесь, заказ (Order) не имеет необходимости ссылаться на своего прямого равноправного участника (Customer), но может ссылаться непосредственно на содержащуюся объектную сущность адреса (Address). Более чем один заказ может ссылаться на адрес (Address), который является помеченным адресом рассылки счетов (BillingAddress). На понятийном уровне, заказ будет предъявлен к оплате действующему лицу по такому адресу. Однако, каждый товар заказа (OrderLine) может быть отгружен в отдельные адреса отгрузки, снабженные ссылкой вне каждого товара. Каждый из таких адресов происходит от того же самого потребителя, который указан ссылкой заказом, который является родителем товара заказа. Следовательно, ссылки расширяют адреса, которые принадлежат потребителю.
Еще один аспект CDM предоставляет возможность ввода ограничения. Рассмотрим линии ассоциаций дерева: от заказа (Order) к потребителю (Customer); от заказа (Order) к адресу (Address); и от товара заказа (OrderLine) к адресу (Address). Ничто не требует, что адреса потребителей, указываемые ссылкой заказом или его товаром, должны принадлежать потребителю заказа. Является возможным обязать адреса ссылаться на адрес другого потребителя. Однако в CDM есть ограничения, которые могут быть применены, чтобы гарантировать, что адрес является адресом надлежащего потребителя. Это упоминается как «задание области» ассоциаций. Что касается ассоциации между объектной сущностью заказа (Order) и объектной сущностью заказчика (Customer), ограничение состоит в том, что заказ (Order) может ссылаться только на потребителя (Customer) в той же самой компании (Company). То есть, они имеют «общего предка».
Что касается ассоциации между объектной сущностью заказа (Order) и объектной сущностью адреса (Address), ограничение состоит в том, что заказ (Order) может ссылаться только на адрес (Address) в сводной таблице /SalesData/Company/Customer/Address. Сводные таблицы являются адресами в ограничениях и запросах согласно пути свойства. Здесь, тип набора таблиц данных продаж (SalesData) содержит табличное свойство 800, названное «Companies» («Компании»). Каждая объектная сущность потребителя (Customer) имеет свою собственную таблицу объектных сущностей адресов (Address). Совокупность таких таблиц (фактически, их объединение) адресуется наименованием таблицы (Table Name): SalesData/Companies/Customers/Addresses (ДанныеПродаж/Компании/Потребители/Адреса) в объектной сущности адреса (Address).
Фиг.9 иллюстрирует использование ключей и идентификаторов объектной сущности в соответствии с CDM. Ключом являются одно или более свойств в объектной сущности, которые уникально ее идентифицируют в конкретной таблице, где, к тому же, таблицы сформированы посредством отношения композиции. Например, кто-нибудь может определить свойство социального страхования в качестве ключа для потребителя. Ключ гарантирует, что, например, никакие два потребителя в пределах таблицы не имеют одинакового номера социального страхования. Второй частью идентичности объектной сущности является таблица, в которой объектная сущность присутствует. Если бы кто-нибудь хотел иметь в распоряжении двух потребителей с одинаковым наименованием, он мог бы либо определить ключ идентичным свойством, иным, чем наименование (как здесь описано), или он мог бы поместить каждого потребителя в разные таблицы, чтобы избежать конфликта имен. Таблица объектных сущностей идентифицируется посредством предоставления идентификатора объектной сущности, который содержит табличное свойство, плюс наименование свойства из таблицы. Таким образом, это является рекурсивным определением.
На фиг.9 есть две таблицы А (таблица А (ATable) в B и таблица А (ATable) в С). При заданной А ее идентификатор состоит из AID (<<ключ>> AID), который также указывает, в какой она таблице. Одна из возможностей состоит в том, что она в конкретной объектной сущности B в свойстве ATable. Другая возможность состоит в том, что она в конкретной объектной сущности C в свойстве ATable. Практическим примером является ключ товара заказа, который типично является порядковым номером. Наименованием свойства является порядковый номер, который помечен как ключ. Может быть много разных заказов с одинаковым порядковым номером. Таким образом, порядковому номеру необходимо быть уникальным только в пределах такого заказа, а не по всем заказам.
Как указано ранее, еще одним аспектом, предусмотренным согласно CDM, являются сводные таблицы. Например, таблица товаров заказа для одного заказа является отдельной от другой таблицы товаров заказа для другого заказа. Однако может быть интересным знать, сколько было заказано определенного изделия, независимо от заказа. Таким образом, есть потребность просматривать все товары заказа, независимо от заказа, ради заказанного количества в штуках. Сводные таблицы являются средством, в пределах которого это следует делать. То есть, является возможным просматривать все товары заказа по многим разным заказам или другим типам объектной сущности.
Последующее является более подробным описанием CDM раскрытого изобретения. В CDM ключи определены в типе; в противоположность, в SQL99 ключи определены, скорее, в таблицах, чем в описании типа строки. Несмотря на то, что отделение описания ключа от описания типа объектной сущности может показаться гибким (или расширяемым), оно, как ни странно, ограничивает возможность повторного использования и переносимость типов. Если ключи определены в таблице, то специфичное типу поведение не может работать по разным таблицам. То есть, имеет место отсутствие гарантии, что некоторая бизнес-логика (скажем, создание потребителей, заказов и их соотнесение), записанная по типам объектной сущности, будет работать по разным хранилищам типов объектной сущности, в соответствии с чем происходит ослабление возможности повторного использования типов. В SQL99 это не является проблемой, так как он не задает, каким образом типы приведены в соответствие клиентским/среднеуровневым средам прикладного программирования. Отсутствие идентичности по типам объектной сущности в SQL99 вынуждает приводить таблицы типов в соответствие объектам (классам (Classes)) языка программирования вместо приведения в соответствие типам объектных сущностей. В дополнение, ассоциативное связывание идентичности с таблицами не обеспечивает поддержку переходных объектных сущностей. Идентичность ассоциативно связывается с типом объектной сущности для того, чтобы поддерживать допускающие повторное использование типы и агностические типы поведения.
Устойчивость объектной сущности. Объектные сущности могут быть созданы посредством вызова метода конструктора (new) типа объектной сущности; объектные сущности делаются устойчивыми добавлением их в таблицу. В CDM таблица объектных сущностей является типизированной коллекцией объектных сущностей. Таблицы объектных сущностей подобны типизированным таблицам SQL99, но они являются логическими. То есть, таблица объектных сущностей может быть приведена в соответствие одной или более физическим SQL-таблицам. Таблица типа объектной сущности указывается ссылкой в качестве таблицы объектной сущности типа.
Время существования объектной сущности является зависимым от времени существования таблицы, членом которой она является. Когда таблица удаляется, объектные сущности в ней удаляются тоже. Объектные сущности, к тому же, могут быть удалены явным образом.
Таблицы объектных сущностей определяются посредством определения композиции или задания свойства в типе объектной сущности. Логически, экземпляр таблицы создается, когда создается экземпляр типа объектной сущности, а удаляется тогда, когда удаляется экземпляр объектной сущности (однако, физическая SQL-таблица обычно создается, когда устанавливается схема, которая определяет тип, и существует до тех пор, пока установленная схема не удаляется).
<EntityType Name="Order" …>
<Property Name="Lines" Type="Table(OrderLine)" …/>
…
</EntityType>
<EntityType Name="OrderLine" …>
…
</EntityType>
Такие свойства определяют отношение композиции между родительским и дочерним типами объектной сущности (соответственно, Order и OrderLine, в этом случае).
Любое количество таблиц может быть создано, чтобы сохранять экземпляры данного типа объектной сущности. Каждая таблица является совершенно независимой (ключи уникальны только в области одиночной таблицы, и т.д.). Глобальный «экстент» (непрерывная область) всех экземпляров заданного типа, который может быть запрошен, отсутствует.
Тип объектной сущности может быть ограничен одиночной таблицей посредством включения атрибута Table (таблица) в элемент <EntityType>. Это полезно, когда объектная сущность будет содержать поведения, которые зависят от существования таблиц других типов объектных сущностей. Например, тип заказа (Order), вероятно, должен зависеть от существования таблицы потребителей (Customer) (и наоборот), и это отражено включением атрибутов Table в примере, изложенном ниже:
<EntityType Name="Order" Table="SalesData.Orders" …>
…
</EntityType>
<EntityType Name="Customer" Table="SalesData.Customers" …>
…
…
</EntityType>
<EntityType Name="SalesData" …>
<Property Name="Orders" Type="Table(Order)" …/>
<Property Name="Customer" Type="Table(Customer)" …/>
</EntityType>
Наложение табличного ограничения на объектную сущность исключает обладание более чем одной таблицей такого типа. Менее запретительный подход заключается в том, чтобы накладывать ограничение на ассоциацию, как описано в разделе Ассоциация в главе об отношениях.
Наборы таблиц (Table Set). Тип набора таблиц является ограниченной формой типа объектной сущности. Типы набора таблиц могут содержать только ссылку и нормированные таблицей свойства, расчетные свойства и/или методы. Например:
<TableSetType Name="SalesData">
<Property Name="Orders" Type="Table(Order)" …/>
<Property Name="Customer" Type="Table(Customer)" …/>
</TableSetType>
Набор таблиц является экземпляром типа набора таблиц. Каждый экземпляр набора таблиц имеет наименование, которое является уникальным в пределах данного хранилища. Экземпляры набора таблиц могут быть объявлены в схеме или созданы динамически с использованием операций, предусмотренных хранилищем. Примерное объявление экземпляра набора таблиц из схемы показано далее:
<TableSet Name="Sales" Type="SalesData"/>
Наименование набора таблиц вместе с наименованием табличного свойства может быть использовано в операторе FROM запроса. Например:
SELECT OrderID, Date FROM Sales.Orders
Тип набора таблиц может объявлять установленный по умолчанию экземпляр набора таблиц. Например:
<TableSetType Name="WinFSData" DefaultTableSet="WinFS">
…
</TableSetType>
<TableSet Name="Sales" Type="SalesData"/>
Также является допустимым объединять ранее определенные наборы таблиц в новый набор таблиц. Это полезно при комбинировании данных из двух отдельных приложений в единое приложение. Заметим, что тип объектной сущности данных товарооборота (SalesData) в примере, изложенном выше, является абстрактным. Это происходит потому, что неабстрактные типы объектной сущности должны задавать ключевые свойства, а свойства простых типов не разрешены в типе объектной сущности, используемом для набора таблиц. Является допустимым объединять ранее определенные наборы таблиц в новый набор таблиц. Это полезно при комбинировании данных из двух отдельных приложений в единое приложение.
Типы объектной сущности (Entity Type) по сравнению с подставляемыми типами (Inline Type). Подставляемый тип не является типом объектной сущности. Подставляемые типы подобны типам структуры; они являются просто значениями. Они не обладают какой бы то ни было идентичностью; каждый экземпляр подставляемого типа является другим, даже если они имеют идентичные значения. В CDM подставляемые типы могут быть использованы только в качестве типа свойств объектной сущности. Значения подставляемого типа сохраняются внутри вместе объектной сущностью, частью которой являются. Так как экземпляр подставляемого типа не имеет своей собственной идентичности, он не является допускающим указание ссылкой. Он является пригодным для указания ссылкой посредством свойства объектной сущности, удерживающего экземпляр подставляемого типа. Изложенное ниже является примерным описанием подставляемого типа:
<InlineType Name="Address">
<Property Name="Street" Type="String"
Nullable="false"/>
<Property Name="City" Type="String" Nullable="false"/>
…
</InlineType>
Тем не менее, как типы объектной сущности, так и подставляемые типы, являются строго типизированными и имеют схожую структуру, они обладают несовпадающей семантикой устойчивости, совместного использования и операционной семантикой. Экземпляры подставляемого типа не делаются устойчивыми сами по себе; они являются структурной частью типа объектной сущности. Экземпляры подставляемого типа не могут быть совместно используемыми; использование каждого экземпляра является исключительным. Экземпляры подставляемого типа не являются целевыми для большинства операций, аналогичных копированию, перемещению, удалению, резервированию, восстановлению, и т.п.
Вследствие вышеизложенных семантических различий является важным предусмотреть разные понятия подставляемого типа и типа объектной сущности, с тем чтобы приложения могли осуществлять объявления в программе надлежащим образом. В SQL99 понятия подставляемого типа и типа объектной сущности явным образом не моделируются. В SQL99 есть только «определяемые пользователем типы». Если тип использован как тип столбца, он ведет себя как подставляемый тип; если он использован для определения таблицы, он действует как тип объектной сущности (тип строки). Так как ключи определены в таблице, только строки типизированной таблицы обладают идентичностью. Так как типы не имеют ключей, в SQL, наряду с размышлением об экземплярах типа, приходится вести разговор в терминах экземпляров типа с ключами и экземпляров без ключей.
В CDM типы объектной сущности и подставляемые типы моделируются явным образом в качестве отдельных понятий с раздельной спецификацией синтаксиса.
Взаимосовместимость данных. Взаимосовместимость данных может управляться либо оптимистичным образом, либо пессимистичным образом. В любом случае единицей управления взаимосовместимостью является объектная сущность, либо ради обнаружения конфликта при оптимистической взаимосовместимости, либо блокирования при пессимистической взаимосовместимости. Модель данных допускает, что могут быть использованы разные схемы обнаружения конфликта, и этим учитывает стратегическое решение реализации модели данных и разработчика, если реализация модели данных дает им такую гибкость (например, реализация могла бы игнорировать конфликты, если никакие из свойств, являющихся обновляемыми, не были изменены).
При пессимистической взаимосовместимости принимаются к использованию блокировки всей объектной сущности, исключающие ее вложенные таблицы. Так, если объектная сущность подвергается чтению с блокировкой, чтение будет терпеть неудачу, если другой пользователь имеет в распоряжении блокированную объектную сущность. Однако, если только дочерняя объектная сущность блокирована, чтение родительской будет удаваться. Модель данных допускает, что могут быть использованы разные схемы блокирования, и этим учитывает стратегическое решение реализации модели данных и разработчика, если реализация модели данных снабжает их такой гибкостью.
Отношения. Отношение соотносит две или более объектных сущностей. Например, деловой контакт (Contact) определяет автора документа (Document), или заказ (Order) содержит товары заказа (OrderLines). Отношение может быть ассоциацией (Association) или композицией (Composition). Ассоциации описывают «равноправные» отношения между объектными сущностями, тогда как композиция описывает отношение родителя/потомка между двумя объектными сущностями.
Сами отношения не сохраняются в качестве экземпляров типов в хранилище, но представляются данными в соотнесенных объектных сущностях. Одно из конкретных использований ассоциаций задает тип объектной сущности, объектная сущность ассоциации, в качестве объектной сущности, которая олицетворяет отношение и, необязательно, может сохранять дополнительные данные как часть отношения. Каждая ассоциация имеет наименование; наименование играет роль семантического отношения между объектными сущностями. Например, DocAuthor (автор документа) является наименованием отношения между документом и деловым контактом; ассоциация DocAuthor устанавливает отношение делового контакта как автора документа; подобным образом, OrderCustomer (потребитель заказа) является ассоциацией, которая ассоциативно связывает потребителя с заказом; при заданном заказе может быть проведена ассоциативная связь, чтобы определить его потребителя.
Заметим, что понятия ассоциации и композиции являются согласующимися с понятиями ассоциации и композиции UML (унифицированного языка моделирования). Построение диаграмм, определяющих отношения объектных сущностей, и UML-терминология (например, роль, кратность, …) сохранены настолько, насколько возможно.
Понятие отношений явным образом в реляционной модели не поддерживается. Внешние и первичные ключи и ссылочная целостность предоставляют инструментальные средства для реализации отношений ограниченным образом. SQL99 содержит дополнительные объектно-реляционные расширения, аналогичные ссылочным (Ref) и табличным (Table) типам, чтобы поддерживать регламентированные одиночной и множественной объектной сущностью свойства, но формально отношения не моделируются.
CDM сочетает ссылочные и табличные свойства SQL99 и понятия ассоциации и композиции UML. Этот подход привносит обогащенные отношения и навигацию в SQL и возможность использования запросов в приложения, моделируемые с использованием UML.
Ассоциации. Ассоциации олицетворяют равноправные связи между объектными сущностями. Они могут быть основаны на использовании типизированных ссылочным типом свойств или типизированных нессылочным типом свойств. Они также могут включать в себя объектную сущность ассоциации, которая играет конкретную роль. Каждая описана по очереди.
Ассоциации, использующие типизированные ссылочным типом свойства. Рассмотрим следующую примерную схему.
<EntityType Name="Customer" …>
…
</EntityType>
<EntityType Name="Order" …>
<Property Name="CustRef" Type="Ref(Customer)"
Nullable="false"
Association="OrderCustomer" />
…
</EntityType>
<TableSetType Name="SalesData">
<Property Name="Orders" Type="Table(Order)" …/>
<Property Name="Customers" Type="Table(Customer)" …/>
<Property Name="BadCustomers" Type="Table(Customer)" …/>
</TableSetType>
<Association Name="OrderCustomer" >
<End Role="OrderRole" Type="Order" Multiplicity="*" Table="SalesData.Customers" />
<End Role="CustomerRole" Type="Customer" OnDelete="Cascade”
Multiplicity="1" />
<Reference FromRole=”OrderRole” ToRole=”CustomerRole” Property=”CustRef”/>
</Association>
Ассоциация имеет две стороны, каждая из которых представляет соотнесенную объектную сущность. Каждая сторона предусматривает следующую информацию:
• Role (роль): Роль именует конечную точку, которая описывает роль или функцию, которую экземпляр типа объектной сущности играет на этой стороне. Она является наименованием, которое используется объектной сущностью на другой стороне ассоциации. В CDM наименование роли должно быть явно задано, хотя часто оно будет наименованием типа объектной сущности стороны.
• Type (Тип): Тип задает наименование типа объектной сущности стороны. Например, в ассоциации OrderCustomer (потребитель заказа) типом для стороны с ролью потребителя (CustomerRole) является тип потребителя (Customer). Типом для роли заказа (OrderRole) является тип объектной сущности заказа (Order). Тип должен быть типом объектной сущности (он не может быть подставляемым типом).
• Multiplicity (кратность): Кратность задает диапазон разрешенных значений мощности множества для стороны ассоциации. Мощность множества стороны отношения является фактическим количеством экземпляров объектной сущности, вовлеченных в отношение на этой стороне. В примере ассоциации OrderCustomer (потребитель заказа), заказ (Order) поступает от ровно одного потребителя (Customer), и каждый заказ (Order) должен быть размещен в соответствии с потребителем (Customer). Итак, кратностью является «единица». Это ограничение зафиксировано как Multiplicity = “1” на стороне с ролью потребителя (CustomerRole). С другой стороны, потребитель (Customer) может обладать неограниченным количеством заказов (Order), ассоциированных с ним. Multiplicity = “*” на стороне с ролью заказа (OrderRole) фиксирует такое ограничение мощности множества.
Типичными значениями кратности являются “0..1” (нуль или один), “1” (ровно один), “*” (нуль или более) и “1..*” (один или более). В более общем смысле, значения кратности могут задавать значения «n» (ровно n) или диапазон значений «n..m» (между n и m, включительно, где n является меньшим или равным m). Типично, кратность обеих сторон ассоциации упоминается совместно, к примеру: 1:1 (один к одному), 1:* (один ко многим), *:1 (многие к одному), и *:* (многие ко многим). В примере ассоциации OrderCustomer (потребитель заказа), приведенном выше, может быть нуль или более заказов с тем же потребителем (имеющим то же самое значение свойства CustRef). Отметим, что ограничительная семантика целостности ссылочных данных может быть смоделирована установлением надлежащим образом кратности на сторонах. Там, где нижним граничным значением кратности является 1, принудительно применяется традиционная ограничительная (Restrict) семантика. То есть, для каждого заказа должен существовать потребитель. Следовательно, заказ не может быть создан, пока нет потребителя; подобным образом, потребитель не может быть удален, если потребитель внесен в заказ.
• Table (таблица): Накладывает ограничение на таблицу, где могут быть найдены экземпляры типа (Type). Это необходимо для целевого объекта основанной на ссылке ассоциации, чтобы таблица не задавалась прямо в описании типа целевой объектной сущности. В примере, приведенном выше, указано, что потребители (Customer) по заказам (Order) могут быть найдены только в таблице SalesData.Customers, но не в таблице SalesData.BadCustomers. Задание Table=”” указывает, что ссылка может ссылаться на объектную сущность в любой таблице надлежащего типа.
• OnDelete (по удалении): Атрибут OnDelete задает, что должно быть сделано, когда объектная сущность на этой стороне удаляется. В этом примере, разрешенными значениями могли бы быть: Cascade, SetNull, or Restrict (каскадировать, установить нуль или ограничить). В этом примере:
■ Так как было задано Cascade (каскадировать), когда объектная сущность потребителя (Customer) удаляется, объектная сущность заказа (Order) удаляется тоже.
■ Если было задано SetNull (установить нуль), когда объектная сущность потребителя (Customer) удаляется, свойство CustRef объектной сущности заказа (Order) на другой стороне, будет установлено в Null (нуль). Свойство должно быть обнуляемым.
■ Если было задано Restrict (ограничить), объектная сущность потребителя (Customer) не может быть удалена, если объектная сущность заказа (Order) ассоциирована с ним.
Элемент <Reference> указывает, что это ассоциация, основанная на ссылке. Этот элемент задает следующую информацию: FromRole (исходная роль) - роль, которая содержит ссылочное свойство, которое реализует ассоциацию; ToRole (целевая роль) - роль, которая является целевым объектом ссылки; и Property (свойство) - наименование ссылочного свойства.
В ассоциации OrderCustomer (потребитель заказа) свойство CustRef стороны с ролью заказа (OrderRole) соотнесено идентификатором объектной сущности с ролью потребителя (CustomerRole); свойство CustRef действует подобно внешнему ключу.
Ассоциации, использующие типизированные нессылочным типом свойства. Ассоциация OrderCustomer (потребитель заказа), приведенная выше, соотносит типы объектной сущности заказа и потребителя по идентичности потребителя. Вообще, допустимо соотносить два типа объектной сущности по любым свойствам сторон. Например, рассмотрим следующую ассоциацию DocumentAuthor (автор документа), где свойство Document.Author соотнесено с Contact.Name. Так как Contact.Name не является уникальным, эта ассоциация может возвращать многочисленные деловые контакты для документа.
<EntityType Name="Contact" Key="ContactId">
<Property Name="ContactId" Type="String" Nullable="false">
<Property Name="Name" Type="String" Nullable="false"/>
</EntityType>
<EntityType Name="Document" Key="DocId">
<Property Name="DocId" Type="String" Nullable="false"/>
<Property Name="Title" Type="String" Nullable="false">
<Property Name="Author" Type=”String" Nullable="true">
</EntityType>
<Association Name="DocumentAuthor" >
<End Role="DocRole" Type="Document" Multiplicity="*" />
<End Role="ContactRole" Type="Contact" Multiplicity="1"/>
<Condition>
DocRole.Author = ContactRole.Name
</Condition >
</Association>
Одно из отличий между этим примером и примером потребителя/заказа (Customer/Order) состоит в том, что вместо задания элемента <Reference> предусмотрено булево выражение внутри элемента <Condition>. Так как <Condition> может содержать в себе выражение произвольной сложности, это очень гибкая форма ассоциации. Она на самом деле делает удобным повторное использование соединения в приложениях согласно ее добавлению в качестве первоклассной части моделей запроса и программирования.
В случаях, когда требуется только простая эквивалентность между двумя свойствами, поддерживается упрощенный синтаксис. В таких случаях, элемент <CommonValue> может быть использован вместо элемента <Condition>. Пример, приведенный ниже, содержит тот же смысл, как и предыдущий пример (за исключением поведения OnUpdate (по обновлению), описанного ниже):
<Association Name="DocumentAuthor" >
<End Role="DocRole" Type="Document" Multiplicity="*"/>
<End Role="ContactRole" Type="Contact" Multiplicity="1"
OnUpdate=”Cascade”/>
<CommonValue Property1=”DocRole.Author”
Property2=”ContactRole.Name”/>
</Association>
Поскольку свойства явным образом перечислены и всегда имеют одно и то же значение, имеется в распоряжении один дополнительный признак: атрибут OnUpdate (по обновлению). Возможными значениями этого атрибута являются: Cascade, SetNull или Restrict (каскадировать, установить нуль или ограничить). В этом примере значение атрибута “Cascade” указывает, что если свойство на стороне с ролью делового контакта (ContactRole) обновляется, то значение распространяется на свойство на другой стороне; если OnUpdate=”Restrict”, то это свойство не может быть изменено, если есть объектная сущность, ассоциированная с другой стороной; если OnUpdate=”SetNull”, то, когда свойство на этой стороне обновляется, свойство на другой стороне устанавливается в нуль.
Объектные сущности ассоциации. Является общепринятым ассоциативно связывать свойства отношением. Например, типично, трудовые отношения между организацией и лицом несут свойства, подобные периоду трудоустройства (EmploymentPeriod). Часть свойства типа организации (Organization) или лица (Person) может быть создана, но свойство ничего не означает без отношений. Например, свойство периода трудоустройства (EmploymentPeriod) в организации (Organization) является бессмысленным, пока, к тому же, не присутствует трудоустроенное лицо; подобным образом свойство не является значащим в объектной сущности лица (Person).
В CDM сделаны устойчивыми только объектные сущности (экземпляры типа объектной сущности). Только объектные сущности (фактически, таблицы объектных сущностей) являются пригодными для запрашивания. Ассоциации и композиции сохраняются в качестве метаданных. Поэтому свойства в ассоциациях должны быть сохранены в объектной сущности. Такая объектная сущность является объектной сущностью ассоциации. Это играет такую же роль, как класс ассоциации в UML. Тип объектной сущности ассоциации аналогичен промежуточной таблице (связи или объединения) в реляционных системах, со ссылками (внешними ключами) на объектные сущности, которые она продолжает связывать. Ключ объектной сущности ассоциации, как правило, включает в себя ссылки на соотнесенные объектные сущности. Например, рассмотрим следующее:
<EntityType Name="Product" …>
…
</EntityType>
<EntityType Name="Supplier" …>
…
</EntityType>
<EntityType Name="PSLink" Key="ProductRef, SupplierRef" …>
<Property Name="ProductRef" Type="Ref(Product)"
Nullable="false" …/>
<Property Name="SupplierRef" Type="Ref(Supplier)"
Nullable="false" …/>
<Property Name="Price" Type="Decimal" Nullable="false">
<Decimal Precision="6" Scale="2"/>
</Property>
<Property Name="Quantity" Type="int" Nullable="false"/>
</EntityType>
PSLink - тип объектной сущности, который является связывающим продукцию и поставщиков. PSLink соотносит типы продукта (Product) и поставщика (Supplier), задавая два ссылочных свойства, ProductRef и SupplierRef, для типов продукта (Product) и поставщика (Supplier), соответственно. В дополнение к соотнесению продукции и поставщиков она содержит свойства цены (Price) и количества (Quantity), значимые для отношения.
Возможные ассоциации между продуктом (Product), поставщиком (Supplier) и PSLink существуют между: PSLink и Product, PSLink и Supplier, и Product и Supplier. Эти ассоциации могли бы быть определены явно, как изложено ниже:
<Association Name="PSLinkProduct" >
<End Role="PSLink" Type="PSLink"/>
<End Role="Product" Type="Product" />
<Reference FromRole=”PSLink” ToRole=”Product”
Property=”ProductRef”/>
</Association>
<Association Name="PSLinkSupplier" >
<End Role="PSLink" Type="PSLink" EndProperty="SupplierRef”/>
<End Role="Supplier" Type="Supplier" />
<Reference FromRole=”PSLink” ToRole=”Supplier”
Property=”SupplierRef”/>
</Association>
<Association Name="ProductSupplier">
<End Role="Product" Type="Product"/>
<End Role="Supplier" Type="Supplier"/>
<Uses Role="PSLink" Type="PSLink"/>
<Condition>
PSLink.ProductRef = Product AND PSLink.SupplierRef = Supplier
</Condition>
</Association>
В вышеприведенном примере факт того, что PSLink - объектная сущность ассоциации, не является явно заданным, следовательно, не мог бы быть использован в описаниях ассоциаций. Разработчик схемы обязан утомительно определять все необходимые описания ассоциации. Однако этого можно избежать введением понятия явно заданной объектной сущности ассоциации в качестве части описания ассоциации. Вышеприведенный пример ниже переписан с заданием PSLink в качестве объектной сущности ассоциации:
<EntityType Name="Product" …>
…
</EntityType>
<EntityType Name="Supplier" …>
…
</EntityType>
<EntityType Name="PSLink" Key="ProductRef,SupplierRef"
Association=”ProductSupplier”>
<Property Name="ProductRef" Type="Ref(Product)"
Nullable="false" Role=”Product”/>
<Property Name="SuplierRef" Type="Ref(Supplier)"
Nullable="false" Role=”Supplier”/>
<Property Name="Price" Type="Decimal" Nullable="false">
<Decimal Precision="6" Scale="2"/>
</Property>
<Property Name="Quantity" Type="int" Nullable="false"/>
</EntityType>
<Association Name="ProductSupplier">
<AssociationEntity Type="PSLink">
<End Role=”Link” Type=”PSLink”/>
<Reference FromRole=”Link” ToRole=”Product”
Property=”ProductRef”/>
<Reference FromRole=”Link” ToRole=”Supplier”
Property=”SupplierRef”/>
</AssociationEntity>
<End Role="Product" Type="Product"
OnDelete=”CascadeToAssociationEntity”/>
<End Role="Supplier" Type="Supplier"
OnDelete=”CascadeToAssociationEntity” />
</Association>
Отметим следующие аспекты касательно этого примера:
• Он является более чем укороченной формой другого определения, потому что он предоставляет информацию о типе, которая не может быть логически выведена, когда объектную сущность ассоциации выявляется неявным образом.
• Атрибут Association (ассоциации) в определении <EntityType> PSLink идентифицирует этот тип как объектная сущность ассоциации и идентифицирует ассоциацию, которая использует тип.
• Атрибуты Role (роли) в элементах свойств ProductRef и SupplierRef идентифицируют роли в пределах ассоциации, которая использует эти свойства.
• Элемент End (сторона), вложенный внутри AssociationEntity (объектная сущность ассоциации), предоставляет наименование для роли, выполняемой самой объектной сущностью ассоциации. По многим аспектам объектная сущность ассоциации фактически является конечной точкой многопозиционной ассоциации, но по другим аспектам она выполняет специальную функцию в ассоциации.
• Элементы <Reference> описывают, каким образом объектная сущность ассоциации ассоциативно связана с объектными сущностями продукта и поставщика. Они являются вложенными, поскольку они подчинены общей ассоциации.
• Атрибуты OnDelete (по удалению) элементов End указывают, что если любая сторона удаляется, объектная сущность ассоциации, а следовательно, отношение, удаляется тоже. Однако удаление одной стороны не служит причиной того, чтобы быть удаленной другой стороне (то есть, удаление поставщика не служит причиной того, чтобы быть удаленным поставляемому продукту). Другими возможными значениями для этих атрибутов могли бы быть: Cascade (каскадировать), который мог бы служить причиной того, чтобы быть удаленными всем сторонам (заключенным объектной сущностью ассоциации); SetNull (установить нуль), который мог бы служить причиной для того, чтобы быть установленным в нуль ссылочному свойству в объектной сущности ассоциации; или Restrict (ограничить), который мог бы служить причиной того, чтобы удалению терпеть неудачу до тех пор, пока существует экземпляр PSLink.
Объектные сущности ассоциации также могут быть использованы в ассоциациях, использующих типизированные нессылочным типом свойства. Полные описания ассоциаций смотрите дальше в этом документе.
Задание области ассоциаций. Задание области ассоциаций определяет, что объектные сущности на обеих сторонах ассоциации являются потомками одного и того же экземпляра объектной сущности. Область ассоциации задается посредством размещения в атрибуте Scope (область) наименования типа объектной сущности, который содержит в себе обе стороны. Атрибут Table (таблица) на сторонах в таком случае должен начинаться таким типом. Рассмотрим следующий пример, в котором автомобиль (Car) содержит двигатель (Engine), колеса (Wheel) и трансмиссию (DriveTrain).
<EntityType Name="Car" Key="Model">
<Property Name="Model" Type="String">
<Property Name="Wheels" Type="Array(Ref(Wheel))"/>
<Occurs Minimum="4" Maximum="4"/>
</Property>
<Property Name="Engine" Type="Ref(Motor)"/>
<Property Name="DriveTrain" Type="Ref(DriveTrain)"/>
</EntityType>
<EntityType Name="Motor" … > … </EntityType>
<EntityType Name="Wheel" … > … </EntityType>
Двигатель (Engine) и колеса (Wheel) соединены посредством трансмиссии (DriveTrain).
<EntityType Name="DriveTrain" Association="DriveTrain">
<Property Name="Engine" Type="Ref(Motor)" Role="Engine"/>
<Property Name="Wheels" Type="Array(Ref(Wheel))"
Role="Wheels">
<Check>Count(*) = 2 OR Count(*) = 4</Check>
</Property>
</EntityType>
<Association Name="DriveTrain" Scope="Car">
<End Role="Engine" Type="Motor" Table="Car.Engine"/>
<End Role="Wheels" Type="Wheel" Table="Car.Wheels"/>
<AssociationEntity Type="DriveTrain"/>
<End Role="DriveTrain"
Type="DriveTrain" Table="Car.DriveTrain"/>
<Reference FromRole="DriveTrain" ToRole="Engine"
Property="Engine"/>
<Reference FromRole="DriveTrain" ToRole="Wheels"
Property="Wheels"/>
</AssociationEntity>
</Association>
Вышеприведенный пример показывает, что трансмиссия (DriveTrain) соединяет двигатель (Engine) и колеса (Wheel) из одного и того же автомобиля (Car). Недопустимо для двигателя (Engine) из одного автомобиля (Car) быть прикрепленным к колесам (Wheel) из другого автомобиля (Car). Любые атрибуты Table (таблиц) в элементах <End> должны начинаться с задающей область объектной сущности. Элемент <End> может указывать, что установление области к нему не следует применять, посредством добавления атрибута Scoped=”false”.
Композиция. Композиция является понятием моделирования, которое определяет композиционное отношение между двумя объектными сущностями. Снова рассмотрим пример заказа (Order); свойство товара (Line) и отношение OrderLines (товары заказа) определяют композицию между типами объектной сущности заказа (Order) и товара (Line). Есть структурное отношение между типами заказа (Order) и товара (Line); товары являются частью (или скомпонованы в) заказа. Объектная сущность товара принадлежит единственной объектной сущности заказа; объектная сущность товара исключительно является частью заказа; заказ и его товары формируют операционную единицу.
В противоположность, в вышеприведенных примерах заказ (Order) и потребитель (Customer) являются независимыми объектными сущностями. Таблицы заказов (Orders) и потребителей (Customers) независимы друг от друга. Ассоциация OrderCustomer (потребитель заказа) соотносит заказы и потребителей. Пока OnDelete=Cascade не задано в ассоциации, времена существования заказов и потребителей независимы друг от друга. OnDelete=Cascade добавляет поведенческое ограничение, которое требует от заказов, ассоциативно связанных с потребителями, быть удаленными, когда удаляется потребитель. Однако, структурное отношение между типами объектных сущностей заказа и потребителя отсутствует. Например, выборка объектной сущности потребителя не осуществляет доступ к каким бы то ни было заказам, и наоборот. В дополнение, является допустимым, чтобы заказ (Order) мог участвовать в другой, но подобной ассоциации с поставщиком (Supplier); скажем, есть свойство SupplierRef в заказе (Order) и ассоциация OrderSupplier (поставщик заказа). Эта ассоциация могла бы также задавать OnDelete=”Cascade”, означающее, что время существования заказа (Order) контролируется либо потребителем, который размещал заказ, либо поставщиком, который осуществлял поставку заказа. Однако, заказ (Order) и потребитель (Customer), или заказ (Order) и поставщик (Supplier) не составляют операционных единиц для операций, аналогичных копированию, перемещению, резервированию, восстановлению и т.д.
<EntityType Name="Order" …>
<Property Name="Lines" Type="Table(OrderLine)"
Composition="OrderLines"/>
…
</EntityType>
<EntityType Name=”OrderLine” …>
…
</EntityType>
<Composition Name="OrderLines">
<ParentEnd Role="ParentOrder" Type="Order"
EndProperty="Lines"/>
<ChildEnd Role="LineItems" Type="OrderLine" Multiplicity="*"/>
</Composition>
Несмотря на истинность того, что такая композиция является дополнительной конкретизацией понятия ассоциации, она является фундаментальным понятием, особенно в структурном и операционном ракурсе. Отношение между заказом (Order) и товарами (Line) является совершенно отличным от такового между заказом (Order) и потребителем (Customer). Поэтому в CDM композиция является особым, самым высокоуровневым понятием.
Объектные сущности композиции и ассоциации. Одно из конкретных использований объектных сущностей ассоциации компонует саму объектную сущность ассоциации в одну из ассоциируемых объектных сущностей. Рассмотрим пример, приведенный ниже:
<EntityType Name="Item" …>
<Property Name="Links" Type="Table(Link)"
Association="ItemLinkRelation"/>
…
</EntityType>
<EntityType Name="Link" Association="ItemLinkRelation" …>
<Property Name="Target" Type="Ref(Item)" Role="Target"/>
…
</EntityType>
<Association Name="ItemLinkRelation">
<AssociationEntity Type="Link"/>
<End Role=”Link” Type=”PSLink”/>
<Composition ParentRole=”Source” ChildRole=”Link”
Property=”Links”/>
<Reference FromRole=”Link” ToRole=”Target”
Property=”Target”/>
</AssociationEntity>
<End Role="Source" Type="Item"/>
<End Role="Target" Type="Item"/>
</Association>
Здесь мы имеем тип объектной сущности, предмет (Item), который содержит вложенную таблицу типа объектной сущности связь (Link). Сам тип связи (Link) является объектной сущностью ассоциации, в которой он располагается между двумя соотнесенными объектными сущностями (двумя предметами в этом случае) и содержит специфичные отношению свойства. Факт того, что композиция должна соотносить предметы (Item) и связи (Link), не отменяет того факта, что истинное отношение, являющееся моделируемым, находится между двумя предметами (Item).
Навигация. Одним из преимуществ моделирования отношений явным образом является возможность осуществлять навигацию от одной из объектных сущностей до соотнесенных объектных сущностей с использованием описания отношения. Такая навигация может поддерживаться через запросы по отношению к CDM или посредством использования классов API-интерфейсов, сформированных из описаний типа объектной сущности и отношения. В примере OrderCustomer (потребителя заказа), при заданной объектной сущности заказа можно осуществлять навигацию до его потребителя с использованием свойства CustRef и описания ассоциации. Описание ассоциации также может быть использовано, чтобы осуществлять навигацию от потребителя до его заказов. Метаданные ассоциации могут быть использованы, чтобы формировать основанный на объединении запрос, чтобы переходить от потребителя к заказам. Подобным образом, в DocumentAuthor (авторе документа) ассоциация может быть использована, чтобы формировать навигацию от документа до делового контакта и наоборот.
В CDM является допустимым предварительно определять основанные на ассоциации свойства навигации с использованием описаний отношения. Пример такого свойства навигации показан ниже:
<EntityType Name="Customer" …>
<NavigationProperty Name=”Orders”
Association=”OrderCustomer”
FromRole=”Customer” ToRole=”Order”/>
…
</EntityType>
<EntityType Name="Order" …>
<Property Name="CustRef" Type="Ref(Customer)"
Nullable="false"
Association="OrderCustomer" />
…
</EntityType>
<Association Name="OrderCustomer" >
<End Role="OrderRole" Type="Order" Multiplicity="*" />
<End Role="CustomerRole" Type="Customer" OnDelete="Cascade”
Multiplicity="1" />
<Reference FromRole=”OrderRole” ToRole=”CustomerRole”
Property=”CustRef”/>
</Association>
Элемент NavigationProperty (свойства навигации) в объектной сущности потребителя (Customer) задает путь навигации от потребителя (или потребителей) до заказов, ассоциированных с потребителем(ями). Это свойство могло бы быть представлено в моделях запроса и программирования в качестве виртуальной (нематериальной) и допускающей запрашивание, только для чтения, коллекцией ссылок на объектной сущности заказа (Order).
Последующее является описанием языка схемы CDM. Все определения объектной сущности, отношения и набора таблиц совершаются в контексте схемы. Схема определяет пространство имен, которое задает область наименований содержимого, описанных в пределах схемы. Элемент <Schema> является корневым элементом документа схемы. Элемент <Schema> может содержать следующие атрибуты:
• Namespace (пространство имен) - обязательный. Уникальное пространство имен для схемы. Пространство имен подчиняется правилам CLR для наименований пространств имен. В дополнение, также должны соблюдаться руководящие принципы именования пространств имен, определенные для пространств имен CLR. Благодаря следованию этим соглашениям, существует обоснованная гарантия уникальности при выборе наименования пространства имен.
Например:
<Schema Namespace=”MyCompany.MySchema”>
</Schema>
Схема может ссылаться на типы, определенные в другой схеме с использованием полностью уточненных наименований типа (namespace-name.type-name) (пространство имен-наименование.тип-наименование). Например:
<Schema Namespace=”MyCompany.MySchema”>
<InlineType Name=”MyType”
BaseType=”YourCompany.YourSchema.YourType” …>
</InlineType>
</Schema>
Схема может включать в себя элемент <Using>, чтобы вносить наименования типов, определенные во внешней схеме, в область. Элемент <Using>может иметь следующие атрибуты:
• Namespace (пространство имен) - обязательный. Пространство имен схемы, чье содержимое внесено в область.
• Alias (псевдоним) - необязательный. Наименование, которое может быть использовано в качестве подстановки для пространства имен.
Например:
<Schema Namespace=”MyCompany.MySchema”>
<Using Namespace=”YourCompany.YourSchema”/>
<Using Namespace=”AnotherCompany.AnotherSchema”
Alias=”Another”/>
<InlineType Name=”Type1” BaseType=”YourType”>
</InlineType>
<InlineType Name=”Type2” BaseType=”Another.AnotherType”>
</InlineType>
</Schema>
Правила именования. Все наименования типа, отношения и набора таблиц должны подчиняться правилам CLR для наименований типов. Наименования также должны следовать руководящим принципам именования типов инфраструктуры .Net. Наименования типов и отношений должны быть уникальными. То есть, тип и отношение не могут иметь одинаковое полностью уточненное наименование, и никакие два типа или два отношения не могут иметь одинаковое полностью уточненное наименование. Все наименования наборов таблиц должны быть уникальными (никакие два набора таблиц не могут иметь одинаковое полностью уточненное наименование), но набор таблиц может иметь такое же наименование, как тип или отношение.
Простые типы. Простой тип представляет одиночное значение без какой-либо внутренней структуры, видимой в модели данных. CLR-типы значений используются в качестве простых типов в CDM. Некоторое количество типов значения, определенных в пространстве имен CLR System, System.Storage и System.Data.SqlTypes, изначально поддерживаются для использования в модели данных. Этими типами являются:
| System.Data.SqlTypes.SqlString | System.String | System.Storage.ByteCollection |
| System.Data.SqlTypes.SqlBinary | System.Boolean | System.Storage.StorageStreamReference |
| System.Data.SqlTypes.SqlBoolean | System.Byte | System.Storage.StorageXmlReference |
| System.Data.SqlTypes.SqlByte | System.Int16 | |
| System.Data.SqlTypes.SqlInt16 | System.Int32 | |
| System.Data.SqlTypes.SqlInt32 | System.Int64 | |
| System.Data.SqlTypes.SqlInt64 | System.Single | |
| System.Data.SqlTypes.SqlSingle | System.Double | |
| System.Data.SqlTypes.SqlDouble | System.Decimal | |
| System.Data.SqlTypes.SqlDecimal | System.DateTime | |
| System.Data.SqlTypes.SqlDateTime | System.Guid | |
| System.Data.SqlTypes.SqlGuid | System.Uri | |
| и т.д. | System.TimeSpan |
Любой тип значения, который удовлетворяет набору требований, также мог бы быть способен использоваться в качестве простого типа в модели данных. Условия, которым такому типу необходимо удовлетворять, либо будут предоставлять ему возможность быть сохраненным и использованным прямо в запросе (к примеру, UDT), или будут снабжать метаданными, необходимыми, чтобы обеспечивать преобразования хранилища и запроса, через CLR-атрибуты.
Ограничения простого типа. Является возможным ограничивать значения простого типа с использованием одного из ограничительных элементов, определенных ниже. Эти элементы могут быть вложены внутрь различных элементов, которые ссылаются на простые типы (т.е. элемент <Property> в элементе <EntityType> или <InlineType>).
Length (длина). Ограничительный элемент <Length> может быть применен к типам System.String, System.Storage.ByCollection и System.Data.SqlTypes.String, чтобы ограничивать длину значения. Этот элемент может содержать в себе следующие атрибуты:
• Minimum (минимум) - Минимальная длина значения. Значение по умолчанию - нуль.
• Maximum (максимум) - максимальная длина значения. Значение “unbounded” («неограниченный») указывает, что никакого заданного максимума нет. Значением по умолчанию является “unbounded”.
Чтобы быть совместимым с ограничением, заданным в базовом типе, значение, заданное для Minimum, должно быть равным или большим, чем прежнее значение, а значение, заданное для Maximum, должно быть равным или меньшим, чем прежнее значение.
Decimal (десятичное число). Ограничительный элемент <Decimal> может быть применен к типам System.Decimal и System.SqlDecimal, чтобы ограничить точность и шкалу допустимых значений. Этот элемент может содержать в себе атрибуты Precision (точность) и Scale (шкала).
Default (значение по умолчанию). Ограничительный элемент <Default> может быть применен к любому простому типу, чтобы задать значение по умолчанию, которое должно быть использовано для свойства. Этот элемент может содержать следующие атрибуты: Value (значение) - обязательный. Значение по умолчанию для свойства. Значение этого атрибута должно быть конвертируемым в значение собственного типа. Отметим, что элемент <Default> в действительности не задает ограничение. Любое значение является совместимым со значением, заданным в базовом типе.
Check (проверка). Ограничительный элемент <Check> может содержать в себе булево выражение запроса. Чтобы значение свойства было действительным, это выражение должно обращаться в истинное значение. Выражение не должно иметь никаких побочных эффектов. Когда ограничение проверки задано в обоих, базовом и производном, типах, оба ограничения проверяются на действительность.
Перечислимые типы. Перечислимый тип определяет набор наименований, которые представляют уникальные значения. Тип лежащих в основе значений, но не сами хранимые значения, является видимым в CDM. Когда используются заказные преобразования хранилища, лежащий в основе тип определяется этим преобразованием. Для проскриптивного хранилища лежащий в основе тип будет выбран автоматически или мог бы быть предоставлен посредством специфичной хранилищу рекомендации. Перечислимый тип объявляется с использованием элемента <EnumerationType>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование перечислимого типа.
• Extensible (расширяемый) - необязательный. Значение “true” указывает, что перечислимый тип может быть расширен с использованием элемента <EnumerationExtension> (см. ниже). Значение “false” указывает, что никакие расширения не разрешены. Значением по умолчанию является “false”.
Элемент <EnumerationType> может содержать нуль или более элементов <EnumerationMember>. Эти элементы могут содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование используется, чтобы представлять специфичное перечислению значение. Это наименование должно быть уникальным внутри объявляющего элемента <EnumerationType>. При ссылке на члена перечисления это наименование всегда уточняется наименованием типа перечисления.
• AliasesMember (определяет псевдоним члена) - необязательный. Содержит наименование другого члена перечисления. Указывает, что этот член перечисления является псевдонимом для именованного члена (например, оба наименования представляют одно и то же значение).
Примерное перечисление определено ниже:
<Schema Name=”MyCompany.MySchema”>
<EnumerationType Name=”A”>
<EnumerationMember Name=”P” />
<EnumerationMember Name=”Q” />
<EnumerationMember Name=”R” AliasesMember=”Q”/>
</EnumerationType>
</Schema>
Отметим, что перечисления в стиле «битового флажка» не могут быть описаны с использованием перечислимого типа. Взамен, необходимо использовать массив перечислимого типа.
Расширяемые перечисления. Когда элемент <EnumerationType> задает Extensible=”true”, является возможным расширять перечисление дополнительными значениями. Свойство перечислимого типа может содержать в себе любое из значений, заданных в <EnumerationType> или в любом расширении такого типа.
Значения, определенные в каждом расширении, являются обособленными от значений, определенных в базовом перечислимом типе и всех других расширениях. Это предоставляет перечислимому типу возможность быть независимо расширенным многочисленными разработчиками без возможности конфликтов.
Тип расширения перечисления определяется с использованием элемента <EnumerationExtensionType>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование типа расширения перечисления.
• ExtendsType (расширяет тип)- обязательный. Наименование перечислимого типа, который является расширяемым.
Элемент <EnumerationExtensionType> может содержать в себе нуль или более элементов <EnumerationMember>. Эти элементы могут содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование используется, чтобы представлять специфичное перечислению значение. Это наименование должно быть уникальным внутри объявляющего элемента <EnumerationExtensionType>.
Наименование, однако, может дублировать наименование в типе расширения перечисления. В таком случае значение, определенное в расширении, все же является отдельным от значения, определенного в расширенном перечислении.
При осуществлении ссылки на члена перечисления, это наименование всегда уточняется наименованием типа расширения перечисления.
• AliasesMember (определяет псевдоним члена) - необязательный. Содержит полное наименование (enumeration-type-name.enumeration-member-name (перечисление-тип-наименование.перечисление-член-наименование)) другого члена перечисления, в одном из этого расширения, другом расширении к тому же самому перечислимому типу или самом расширенном перечислимом типе. Указывает, что этот член перечисления является псевдонимом для именованного члена (например, оба наименования представляют одно и то же значение).
Примерное перечисление определено ниже:
<Schema Name=”MyCompany.MySchema”>
<!--
Сочетание перечислимого типа C и типов D и E расширения определяют следующие отдельные значения, которые могут быть сохранены в свойстве типа C: C.P, C.Q, D.Q, D.S, E.T и E.U. Перечислимые члены C.R, D.T и E.U являются псевдонимами для C.Q и поэтому не представляют уникальных значений.
-->
<EnumerationType Name=”C” Extensible=”true”>
<EnumerationMember Name=”P”/>
<EnumerationMember Name=”Q”/>
<EnumerationMember Name=”R” AliasesMember=”Q”/>
</EnumerationType>
<EnumerationExtensionType Name=”D” ExtendsType=”C”>
<EnumerationMember Name=”Q”/>
<EnumerationMember Name=”S”/>
<EnumerationMember Name=”T” AliasesMember=”C.R”/>
</EumerationExtension>
<EnumerationExtension Name=”E” ExtendsType=”C”>
<EnumerationMember Name=”T”/>
<EnumerationMember Name=”U” AliasesMember=”D.T”/>
</EnumerationExtension>
</Schema>
Типы массива. Экземпляры типов массива могут хранить многочисленные экземпляры заданного типа: простого, подставляемого, перечислимого, ссылки объектной сущности или ссылки таблицы (массивы массивов не разрешены). Эти экземпляры являются элементами массива. Порядок элементов фиксируется и может поддерживаться приложением явным образом. Приложения могут вставлять элементы в массив и удалить элементы из массива. Типы массива задаются с использованием синтаксиса:
Array(element-type)
где element-type - наименование типа элемента.
Ограничения типа массива. Является возможным ограничивать значения типа массива с использованием одного из ограничительных элементов, определенных ниже. Эти элементы могут быть вложенными внутри различных элементов, которые ссылаются на типы массива (например, элемент <Property> в элементе <EntityType> или <InlineType>).
ElementConstraint (ограничение элемента). Ограничительный элемент <ElementConstraint> может быть использован, чтобы накладывать ограничения на элементы в массиве. Любой ограничительный элемент, который является действительным для типа элемента, может быть задан внутри элемента <ElementConstraint>.
Occurs (встречается). Ограничительный элемент <Occurs> может быть использован, чтобы ограничивать количество элементов в массиве. Этот элемент может содержать следующие атрибуты:
• Minimum (минимум) - необязательный. Задает минимальное количество компонент в массиве. Значением по умолчанию является нуль.
• Maximum (максимум) - необязательный. Задает максимальное количество компонент в массиве. Значение “unbounded” («неограниченный») означает, что никаких ограничений нет. Значением по умолчанию является “unbounded”.
Чтобы быть совместимым с ограничением, заданным в базовом типе, значение, заданное для Minimum, должно быть равным или большим, чем прежнее значение, а значение, заданное для Maximum, должно быть равным или меньшим, чем прежнее значение.
Unique (уникальный). Ограничительный элемент <Unique> может быть использован, чтобы задавать свойство или свойства типа элемента, который должен содержать уникальное значение в массиве. Этот элемент может содержать следующие атрибуты: Properties (свойства) - обязательный. Разделенный запятыми список наименований свойств элемента.
Check (проверка). Ограничительный элемент <Check> содержит в себе булево выражение запроса. Чтобы значение свойства было действительным, это выражение должно обращаться в истинное значение. Выражение не должно иметь никаких побочных эффектов. Когда ограничение проверки задано в обоих, базовом и порожденном, типах, оба ограничения проверяются на действительность. Отметим, что ограничение проверки по свойству массива применяется к свойству как целому. Например, оно может быть использовано, чтобы проверить, что сумма свойства элемента является меньшей, чем некоторое предельное значение. В качестве альтернативы, ограничение проверки, помещенное внутри элемента <ElementConstraint>, могло бы применяться к каждому значению индивидуально.
Табличные типы. Экземпляры табличных типов могут хранить неупорядоченную коллекцию экземпляров заданного типа объектной сущности. Заданный тип объектной сущности, или тип в иерархии своего базового типа, должен задавать ключевые свойства. Заметим, что это не обязательно означает, что тип объектной сущности не может быть абстрактным типом. Ключевые свойства типа объектной сущности, сохраненные во вложенной таблице, должны быть уникальными в любом экземпляре таблицы. Таблица может удерживать любую объектную сущность заданного типа или типа, порожденного от такого типа. Приложения могут вставлять объектные сущности в таблицу и удалять объектные сущности из таблицы. Табличные типы задаются с использованием синтаксиса:
Table(entity-type)
Типы объектной сущности (и только типы объектной сущности) могут определять свойства табличных типов. Такие свойства представляют вложенные таблицы. Вложенные таблицы определяют ячейку хранилища, которая является зависимой от экземпляра содержащей объектной сущности. Объектные сущности, сохраненные во вложенной таблице, считаются частью образующего единое целое блока данных, определенного содержащей объектной сущностью (например, они удаляются, когда удаляется содержащая объектная сущность). Однако отсутствует гарантия устойчивости касательно превращений в контейнер и содержащиеся объектные сущности, ожидаемых в качестве явным образом управляемых через приложение с использованием транзакций. Является ошибкой определять рекурсивные таблицы. То есть, объектная сущность не может определять таблицу своего типа, своих надтипов или своих подтипов, также объектная сущность не может объявлять таблицу некоторого другого типа объектной сущности, содержащего таблицу ее типа. Типизированные табличным типом свойства определяют отношения композиции между двумя объектными сущностями (родительской объектной сущностью со свойством и дочерними объектными сущностями, содержащимися в таблице).
Ссылочные типы объектной сущности. Экземпляры ссылочных типов хранят ссылки на объектную сущность заданного типа. Ссылка инкапсулирует ссылку на таблицу, которая содержит в себе объектную сущность и значения ключевого свойства объектной сущности. Ссылка может быть разрешена в объектную сущность, которая является целевым объектом ссылки. Ссылочные типы задаются с использованием синтаксиса:
Ref(entity-type)
Типы объектной сущности и подставляемые типы могут определять свойства ссылочных типов. Типизированные ссылочным типом свойства определяют отношения ассоциации между двумя объектными сущностями (исходная объектная сущность со свойством и целевая объектная сущность, указанная ссылкой свойством).
Типы ссылки таблицы. Экземпляры типов ссылки таблицы хранят ссылку на таблицу. Целевая таблица могла бы быть «самой высокоуровневой» таблицей в наборе таблиц или вложенной таблицей. Ссылка может быть разрешена в таблицу, которая является целевым объектом ссылки. Типы ссылки таблицы задаются с использованием синтаксиса:
TableRef(entity-type)
Типы объектной сущности и подставляемые типы могут определять свойства ссылочных типов.
Свойства. Свойства используются в типах объектной сущности и подставляемых, чтобы выделять хранилище. Свойство определяется с использованием элемента <Property>. В дополнение к общим элементам члена, определенным выше, этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование члена. Наименование должно быть уникальным в области определяющего типа. Наименование должно подчиняться правилам CLR для наименований членов класса и должно следовать руководящим принципам именования каркаса .Net.
• DuplicateName (дублировать наименование) - необязательный. Наименования членов также должны быть уникальными по иерархии базового типа, пока атрибут DuplicateName не предусмотрен или не имеет значение “true”. Значение “false”, значение по умолчанию, указывает, что наименование члена подразумевается уникальным.
Роль этого атрибута состоит в том, чтобы а) документировать тот факт, что наименование члена дублирует свойство в базовом типе и b) вынуждает разработчика схемы предпочитать дублировать наименование преднамеренно (то есть он играет ту же роль, что и ключевое слово «new» в C#).
• Type (тип) - обязательный. Тип свойства. Это может быть любой тип: простой, подставляемый, массива, ссылки объектной сущности или ссылки таблицы. Для свойств, определенных в объектных сущностях, табличные типы также разрешены.
• Nullable (обнуляемый) - обязателен для свойств всех типов, за исключением массивов и вложенных таблиц, не разрешен для свойств с типами массива и вложенной таблицы. Значение “true” означает, что свойство может хранить нулевое значение. Значение “false” означает, что свойство не может хранить нулевое значение.
• Association (ассоциация) - обязателен, если тип свойства является ссылочным или массивом ссылочного типа. Задает наименование ассоциации, в которой это свойство участвует. Дополнительно смотрите Ассоциации.
• Composition (композиция) - обязателен, если тип свойства является табличным типом. Задает наименование ассоциации или композиции, в которой это свойство участвует. Дополнительно смотрите Композиции.
• Role (роль) - Задает роль ассоциации, в которой это свойство участвует. Смотрите раздел по ассоциациям об описании того, когда этот атрибут обязателен.
Некоторые примерные определения свойства показаны ниже:
<Schema Namespace=”MyCompany.MySchema”>
<Using Namespace=”System”/>
<InlineType Name=”A”>
<Property Name=”One” Type=”Int32”/>
</InlineType>
<InlineType Name=”B” BaseType=”A”>
<Property Name=”One” Type=”String” DuplicateName=”true”/>
<Property Name=”Two” Type=”Int32”/>
</InlineType>
</Schema>
Ограничения свойства. Значение, которое может быть сохранено в свойстве, может быть ограничено с использованием ограничительного элемента внутри элемента <Property>. Набор разрешенных ограничительных элементов является зависимым от типа свойства и определяется так, как каждый тип, который обсужден. В дополнение, свойство может быть дополнительно ограничено в производном типе посредством размещения ограничительных элементов внутри элемента <PropertyConstraint>. Этот элемент может содержать следующие атрибуты:
• Property (свойство) - обязательный. Наименование ограничиваемого свойства. В случаях, когда существуют дубликатные наименования свойства, это наименование может быть уточнено с использованием наименования типа. Если наименование дублировано и не уточнено, предполагается свойство в наиболее производном типе.
• Type (тип) - необязательный. Тип, которым ограничено свойство. Тип может быть задан, только если исходным типом свойства был Array(T), Table(T), Ref(T) или TableRef(T). В таких случаях новый тип должен быть Array(S), Table(S) Ref(S) или TableRef(S), соответственно, а S должен быть подтипом T.
При использовании элемента <PropertyConstraint>, необходимо, чтобы заданные ограничения были совместимы с любыми ограничениями, определенными в базовом типе. Определение каждого ограничительного элемента включает в себя описание того, что влечет за собой совместимость. Некоторые простые примеры показаны ниже:
<Schema Namespace=”MyCompany.MySchema”>
<Using Namespace=”System”/>
<InlineType Name=”A”>
<Property Name=”X” Type=”Int32”>
<Range Minimum=”10” Maximum=”1000”/>
</Property>
<Property Name=”Y” Type=”String”>
<Length Maximum=”100”/>
</Property>
</InlineType>
<InlineType Name=”B” BaseType=”A”>
<PropertyConstraint Property=”Y”>
<Length Maximum=”50”/>
</PropertyConstraint>
</InlineType>
</Schema>
Наложение ограничения на целевые типы. При порождении типа от типа, который содержит ссылочное свойство, является допустимым дополнительно ограничивать тип объектной сущности, который может быть задан. Это делается с использованием элемента внутри элемента <PropertyConstraint> и заданием значения для атрибута Type (тип), как описано в материалах настоящей заявки. Например:
<Schema Namespace=”MyCompany.MySchema>
<EntityType Name=”A” Key=”ID”>
<Property Name=”ID” Type=”Int32”/>
</EntityType>
<EntityType Name=”B” BaseType=”A”>
</EntityType>
<InlineType Name=”C”>
<Property Name=”ARef” Type=”Ref(A)”/>
</InlineType>
<InlineType Name=”D” BaseType=”C”>
<PropertyConstraint Property=”ARef” Type=”Ref(B)”/>
</InlineType>
</Schema>
Расчетные свойства. Расчетные свойства используются в типах объектной сущности и подставляемых типах, чтобы представлять, скорее, рассчитываемое, чем хранимое, значение. Алгоритм, используемый для вычисления значения свойства, не рассматривается частью модели данных. Может быть описано свойство, которое возвращает запрос в качестве части модели данных. Расчетное свойство объявляется с использованием элемента <ComputedProperty>. В дополнение к общим атрибутам члена, определенным выше, этот элемент может содержать следующие атрибуты:
• ReadOnly (только чтение) - необязательный. Указывает, когда свойство только для чтения. Значением по умолчанию является “true”, означающее, что свойство только для чтения и не может быть использовано при обновлениях.
• Static (статический) - необязательный. Указывает, является ли свойство статическим или свойством экземпляра. Значением по умолчанию является “false”, указывающее, что это - свойство экземпляра.
Пример, приведенный ниже, объявляет расчетное свойство, именованное «X» с типом «Int32»:
<Schema Namespace=”MyCompany.MySchema”>
<InlineType Name=”A”>
<ComputedProperty Name=”X” Type=”Int32”/>
</InlineType>
</Schema>
Ограничения расчетного свойства. Значение, которое может быть сохранено в свойстве, может быть ограничено с использованием ограничительного элемента внутри элемента <ComputedProperty>. Набор разрешенных ограничительных элементов является зависимым от типа свойства и определяется так, как каждый тип, который обсужден. В одной из реализаций, элементы <PropertyConstraint> также работают с расчетными свойствами.
Методы. Методы используются в подставляемых типах и типах объектной сущности, чтобы олицетворять операцию, которая может быть выполнена. Алгоритм, используемый для реализации метода, не рассматривается частью модели данных. В одной из реализаций, в качестве части модели данных, может быть описан метод, который принимает запрос как входные данные и возвращает запрос в качестве выходных данных. Ассоциации, по существу, определяют такие методы. Метод объявляется с использованием элемента <Method>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование члена. Наименование должно быть уникальным в области определяющего типа. Наименование должно подчиняться правилам CLR для наименований членов класса и должно следовать руководящим принципам именования каркаса .Net.
• DuplicateName (дублировать наименование) - необязательный. Наименования членов также должны быть уникальными по иерархии базового типа, пока атрибут DuplicateName не предусмотрен или не имеет значение “true”. Значение “false”, значение по умолчанию, указывает, что наименование члена подразумевается уникальным.
Роль этого атрибута состоит в том, чтобы а) документировать тот факт, что наименование члена дублирует свойство в базовом типе, и b) вынуждает разработчика схемы предпочитать дублировать наименование преднамеренно (то есть он играет ту же роль, что и ключевое слово «new» в C#).
• ReturnType (возвращаемый тип) - обязательный. Тип значения возвращаемого методом. Это может быть тип: простой, подставляемый, массива, ссылки объектной сущности, ссылки таблицы или табличный, или он может быть пустой строкой, указывающей, что не возвращается никаких значений.
• Static (статический) - необязательный. Указывает, является ли метод статическим или методом экземпляра. Значением по умолчанию является “false”, указывающее, что это метод экземпляра.
• Association (ассоциация) - обязателен, если возвращаемый тип является ссылочным или массивом ссылочного типа. Задает наименование ассоциации, в которой этот метод участвует. Дополнительно смотрите раздел по ассоциациям.
• Composition (композиция) - обязателен, если возвращаемый тип является табличным типом. Задает наименование ассоциации или композиции, в которой этот метод участвует. Дополнительно смотрите раздел по композициям.
• Role (роль) - Задает роль ассоциации, в которой этот метод участвует. Смотрите раздел по ассоциациям касательно описания того, когда этот атрибут обязателен.
Элемент <ReturnTypeConstraints> может быть вложенным внутри элемента <Method>. Ограничительные элементы, которые применяются к возвращаемому типу метода, могут быть вложенными внутри элемента <ReturnTypeConstraints>. Элемент <Method> может содержать нуль или более вложенных элементов <Parameter> для задания параметров, принимаемых методом. Элемент <Parameter> может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование параметра.
• Type (тип) - обязательный. Тип параметра.
• Out (выходной) - необязательный. Значение “true”, если это выходной параметр, или “false”, значение по умолчанию, если это входной параметр.
Ограничительные элементы, которые применяются к типу параметра, могут быть вложенными внутри элемента <Parameter>. Пример, приведенный ниже, объявляет расчетное свойство, именованное “X”, с типом “Int32”, и метод, именованный “Y”, с параметром, именованным “a” типа “Int32”, и который возвращает значение типа “Int32”.
<Schema Namespace=”MyCompany.MySchema”>
<InlineType Name=”Foo”>
<Method Name=”Y” Type=”Int32”>
<Parameter Name=”a” Type=”String”>
<Length Maximum=”100”/>
</Parameter>
</Method>
</InlineType>
</Schema>
Подставляемые типы. Экземпляры подставляемых типов могут быть сделаны устойчивыми только в качестве компонентов одного и только одного экземпляра объектной сущности. Экземпляры подставляемых типов не обладают явно заданной идентичностью (идентичность является неявно выраженной в том, каким образом он расположен внутри своей содержащей объектной сущности). Экземпляры подставляемых типов считаются частью образующего единое целое блока данных, определенного содержащей объектной сущностью (например, они удаляются, когда удаляется содержащая объектную сущность). Также есть гарантия, что непротиворечивость по всем подставляемым данным, которые являются частью объектной сущности, будет обеспечиваться без каких-либо явных действий приложения. Заметим, что это не устраняет признаки, подобные единицам изменения и синхронизации WinFS, от снабжения разработчика схемы более изящным разветвленным контролем над непротиворечивостью.
Разработчики схем могут определять новые подставляемые типы со структурой, состоящей из набора свойств. Такой подставляемый тип может быть порожден от отдельного подставляемого базового типа. Такие типы определяются с использованием элемента <InlineType> внутри элемента <Schema> (вложенные подставляемые типы не разрешены). Элемент <InlineType> может содержать следующие атрибуты:
• Name (наименование) - обязательный. Задает наименование типа.
• BaseType (базовый тип) - необязательный. Определяет подставляемый тип, типизированный этим типом как подтип. Если никакой базовый тип не задан, предполагается анонимный абстрактный базовый тип, который не определяет никаких свойств.
• Abstract (абстрактный) - необязательный. “true” - если тип является абстрактным, “false” - если он является конкретным. Экземпляры только неабстрактных типов могут быть созданы. Значением по умолчанию является “false”.
• Sealed (изолированный) - необязательный. “true” - если тип является изолированным, “false” - если не является, или “external” - если изолирован только при использованиях, внешних по отношению к определяющей схеме. Значением по умолчанию является “false”.
• FriendSchemas (дружественные схемы) - необязательный. Разделенный запятыми список пространств имен схемы, которые рассматриваются “друзьями” определяющего типа. Эти схемы не подвергаются ограничениям, наложенным значением атрибута Sealed=”external” (однако, они подвергаются ограничению Sealed=”true”).
Некоторыми примерными описаниями подставляемого (Inline) типа являются:
<Schema Namespace=”MyCompany.MySchema”>
<InlineType Name=”A” Abstract=”true”>
<Property Name=”One” Type=”Int32”/>
</InlineType>
<InlineType Name=”B” BaseType=”A”>
<Property Name=”Two” Type=”Int32”/>
</InlineType>
<InlineType Name=”C” BaseType=”B”>
<Property Name=”Three” Type=”Int32”/>
</InlineType>
</Schema>
Фиг.10 иллюстрирует UML-представление 1100 некоторых из вышеприведенных подставляемых типов.
Ограничения подставляемого типа. Экземпляры подставляемого типа могут быть ограничены с использованием следующих ограничительных элементов. Эти элементы могут быть вложенными внутри различных элементов, которые ссылаются на подставляемые типы (например, элемент <Property> в элементе <EntityType> или <InlineType>).
Check (проверка). Ограничительный элемент <Check> может содержать в себе булево выражение запроса. Чтобы значение свойства было действительным, это выражение должно обращаться в истинное значение. Выражение не должно иметь никаких побочных эффектов. Когда ограничение проверки задано в обоих, базовом и порожденном, типах, оба ограничения проверяются на действительность.
Типы объектной сущности. Тип объектной сущности определяет образующий единое целое блок данных. Экземпляры типов объектной сущности могут быть сделаны устойчивыми в одной и только одной таблице. Экземпляры типов объектной сущности обладают явно заданной идентичностью. Является возможным сохранять долговременную ссылку на экземпляр типа объектной сущности с использованием ссылочного типа.
Разработчики схемы могут определять новые типы объектной сущности со структурой, состоящей из набора свойств. Тип объектной сущности может быть порожден из одиночного базового типа объектной сущности. Такие типы объявляются с использованием элемента <EntityType> внутри элемента <Schema> (вложенные типы объектной сущности не разрешены). Элемент <EntityType> может содержать следующие атрибуты:
• Name (наименование) - обязательный. Задает наименование типа. Наименование должно быть уникальным среди всех наименований типа (оба наименования, подставляемого типа и типа объектной сущности), определенных в объемлющей схеме.
• BaseType (базовый тип) - необязательный. Определяет тип объектной сущности, типизированный этим типом как подтип. Если никакой базовый тип не задан, предполагается анонимный абстрактный базовый тип, который не определяет никаких свойств.
• Abstract (абстрактный) - необязательный. “true” - если тип является абстрактным, “false” - если он является конкретным. Экземпляры только неабстрактных типов могут быть созданы. Значением по умолчанию является “false”.
• Sealed (изолированный) - необязательный. “true” - если тип является изолированным, “false” - если не является, или “external” - если изолирован только при использованиях, внешних по отношению к определяющей схеме. Значением по умолчанию является “false”.
• FriendSchemas (дружественные схемы) - необязательный. Разделенный запятыми список пространств имен схемы, которые рассматриваются “друзьями” определяющего типа. Эти схемы не подвергаются ограничениям, наложенным согласно Internal=”true” или Sealed=”external” (однако, они подвергаются ограничению Sealed=”true”).
• Table (таблица) - необязательный. Задает наименование одной и только одной самой высокоуровневой или вложенной таблицы, которая будет содержать в себе экземпляры этого типа объектной сущности, с использованием синтаксиса entity-type-name.table-property-name (объектная сущность-тип-наименование.таблица-свойство-наименование). Установленным по умолчанию является то, что любое количество таблиц может быть определено, чтобы содержать экземпляры типа объектной сущности.
• Extensible (расширяемый) - необязательный. Значение “true”, значение по умолчанию, указывает, что объектная сущность может быть расширена с использованием элементов <EntityExtensionType>, как описано ниже. Значение “false” указывает, что объектная сущность не может быть расширена.
• Association (ассоциация) - если объектная сущность обладает ролью объектной сущности ассоциации в описании ассоциации, этот атрибут обязателен и должен задавать наименование ассоциации. В ином случае, этот атрибут не может быть представлен.
• Key (ключ) - разделенный запятыми список одного или более наименований свойств, определенных в типе объектной сущности или базовом типе. Только один тип в иерархии типа объектной сущности может задавать атрибут Key. Все типы в такой типовой базовой иерархии типа должны быть абстрактными типами. Заданные свойства могут быть взяты из типа или его базовых типов. Заданные свойства устанавливают часть идентичности объектной сущности. Остаток идентичности неявным образом берется из родителя объектной сущности (например, экземпляра объектной сущности, который определяет табличное свойство, в котором находится дочерняя объектная сущность). Только свойства с подставляемым не обнуляемым типом, исключая массивы, могут быть заданы в качестве ключевого свойства. Если свойство определяемого пользователем подставляемого типа, все свойства этого типа рассматриваются ключевыми свойствами и все должны быть однозначными и необнуляемыми. Вложенные свойства (свойства у свойства составного типа) также могут быть заданы в качестве ключевых свойств.
Некоторыми примерными определениями типа объектной сущности являются:
<Schema Namespace=”MyCompany.MySchema”>
<EntityType Name=”A” Abstract=”true”>
<Property Name=”One” Type=”Int32”/>
</EntityType>
<EntityType Name=”B” BaseType=”A” Key=”Two”>
<Property Name=”Two” Type=”Int32”/>
</EntityType>
<EntityType Name=”C” BaseType=”B”>
<Property Name=”Three” Type=”Int32”/>
</EntityType>
<InlineType Name=”D”>
<Property Name=”X” Type=”Int32”/>
<Property Name=”Y” Type=”Int32”/>
</InlineType>
<EntityType Name=”E” Key=”D”>
<Property Name=”D” Type=”D”/>
</EntityType>
<EntityType Name=”F” Key=”D.X”>
<Property Name=”D” Type=”D”/>
</EntityType>
</Schema>
Фиг.11 иллюстрирует UML-представление некоторых типов 1100 объектной сущности, описанных выше.
Ограничения типа объектной сущности. Экземпляры типа объектной сущности могут быть ограничены с использованием следующих ограничительных элементов. Эти элементы могут быть вложенными внутри различных элементов, которые ссылаются на типы объектной сущности (например, элемент <Property> в элементе <EntityType>).
Check (проверка). Ограничительный элемент <Check> может содержать в себе булево выражение запроса. Чтобы значение свойства было действительным, это выражение должно обращаться в истинное значение. Выражение не должно иметь никаких побочных эффектов. Когда ограничение проверки задано в обоих, базовом и порожденном, типах, оба ограничения проверяются на действительность.
Типы расширения объектной сущности. Чтобы обращаться к сценариям WinFS и MBF, должно быть возможным расширять данный набор типов, фактически не модифицируя схемы, где такие типы были описаны. Хотя это может быть выполнено заимствованием одного из некоторого количества шаблонов (к примеру, снабжением базового класса таблицей типа объектной сущности расширения (Extension)), желательно сделать такую концепцию первоклассной частью модели данных. Это предоставляет специальным API-шаблонам возможность быть сформированными для расширений и является более простым для разработчика типа для понимания и использования.
Типы объектной сущности, которые задают атрибут Extensible=”true”, могут быть расширены. Расширение объектной сущности объявляется с использованием элемента <EntityExtensionType> внутри элемента <Schema>. Элемент <EntityExtensionType> может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование типа расширения.
• ExtendsType (расширить тип)- обязательный. Наименование типа объектной сущности, являющейся расширяемой.
• InstanceManagement (управление экземплярами) - обязательный. Значение “Implicit” указывает, что экземпляры расширения добавляются и удаляются в/из расширенной объектной сущности неявным образом. Значение “Explicit” указывает, что экземпляры расширения должны быть добавлены и удалены приложением явным образом.
• Table (таблица) - необязательный. Задает таблицу, в которой следует сохранять расширения.
Могло бы быть недопустимым порождать один тип расширения из другого типа расширения. Элемент <EntityExtensionType> может содержать в себе любой элемент, который может быть помещен внутри элемента <EntityType>. Типично это включает в себя элементы <Property>. Не является необходимым для наименований свойств быть уникальными по всем расширениям или даже по свойствам расширенного типа. Если InstanceManagement=”Implicit”, все из свойств, определенных в расширении, должны быть обнуляемыми, или задавать значение по умолчанию, либо иметь тип массива, коллекции или табличный с минимальным ограничением вхождения нуля. Заметим, что типизированное одноэлементным подставляемым типом свойство не может задавать значение по умолчанию и, значит, должно быть обнуляемым. Это предоставляет запросам возможность быть выполненными, несмотря на расширение, как если оно присутствовало всегда.
Если InstanceManagement=”Explicit”, приложение явным образом добавляет и удаляет расширение в/из экземпляра объектной сущности, используя операции, определенные в языке запросов для CDM. Средство, чтобы проверять наличие расширения, также предусмотрено. Экземпляры расширения объектной сущности подразумеваются частью образующего единое целое блока данных, определенного содержащей объектной сущностью (например, они удаляются, когда удаляется содержащая объектная сущность). Однако, нет гарантии устойчивости касательно изменений по отношению к объектной сущности и расширению, предполагаемых в качестве явным образом управляемых через приложение с использованием транзакций.
Все расширения объектной сущности (EntityExtension) содержат свойство по умолчанию, именованное “Entity” типа Ref(T), где T - значение типа ExtendsType, которое указывает на экземпляр объектной сущности, с которым ассоциативно связано расширение. Примерные тип и расширение объектной сущности показаны ниже:
<Schema Namespace=”MyCompany.MySchema”>
<EntityType Name=”A” Key=”ID”>
<Property Name=”ID” Type=”Int32”/>
<Property Name=”X” Type=”Int32”/>
</EntityType>
<EntityExtension Name=”B” ExtendsType=”A”
InstanceManagement=”Implicit”>
<Property Name=”X” Type=”String”/>
<Property Name=”Y” Type=”Int32”/>
</EntityExtension>
</Schema>
Ассоциация. Ассоциация предоставляет возможность двум или более объектным сущностям, объектным сущностям сторон, быть соотнесенными друг с другом. Каждая из сторон на понятийном уровне остается независимой от других. Ассоциации изображаются с использованием элемента <Association>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование ассоциации.
• Scope (область) - необязательный. Задает наименование типа объектной сущности. Ассоциацией задается область до экземпляра объектной сущности заданного типа и ее действительность может быть проверена относительно экземпляра.
Элемент <Association> имеет два или более вложенных элемента <End>, каждый описывает одну из сторон ассоциации. Заметим, что более чем два элемента <End> могут быть заданы, только если также задан элемент <AssociationEntity>. Элемент <End> может содержать следующие атрибуты:
• Role (роль) - обязательный. Именует роль, которую это сторона играет в ассоциации.
• PluralRole (множественная роль) - необязательный. Обеспечивает форму множественного числа наименования роли. Это наименование используется в модели запроса и каноническом объектном преобразовании. Если не задано, взамен используется наименование формы roleEntities (ролевые объектные сущности).
• Type (тип) - обязательный. Тип объектной сущности представлен стороной.
• Multiplicity (кратность) - необязательный. Кратность этой стороны ассоциации, которая устанавливает нижнее и верхнее граничное значение касательно мощности множества. Она задается в качестве целочисленного диапазона вида <lower_bound>..<upper_bound> (<нижнее_граничное значение>..<верхнее_граничное значение>), или в качестве одиночного целочисленного значения, если нижнее и верхнее граничные значения являются одинаковыми. Верхним граничным значением может быть “*”, которое указывает неограниченное значение. Взятое в отдельности “*” является синонимичным с “0..*”. Значения по умолчанию и правила касательно того, могут ли быть подменены эти значения по умолчанию, зависят от вида ассоциации.
■ Ссылка (Reference): “*” на указывающей ссылкой стороне, “0..1” на указываемой ссылкой стороне.
■ Композиция (Composition): “1” на родительской стороне (фиксированное), “*” на дочерней стороне.
■ Условие (Condition) и общее значение (Common Value): “*” на обеих сторонах (фиксированное)
■ Объектная сущность ассоциации (Association Entity): “*” на обеих сторонах
Кратность, большая, чем 1, является допустимой, но также может интерпретироваться как * в целях принудительного применения.
• Table (таблица) - обязательный для целевого объекта основанной на ссылке ассоциации, в ином случае - необязательный. Задает табличное свойство типа объектной сущности, заданного Type (типом) или одним из предков типа (Type). Сторона ограничивается из условия, что ассоциативно связанная объектная сущность появляется в заданной таблице. Синтаксис задает путь, который начинается типом объектной сущности и заканчивается табличным свойством собственного типа. Каждый сегмент пути приводится к типу объектной сущности одним из двух способов:
а. Он задает ссылочное или табличное свойство по типу объектной сущности (либо приводит к лежащему в основе типу объектной сущности). Этот синтаксис имеет вид: <entity-type>/<property-name>. Если использовано ссылочное свойство, то его соответствующая сторона ассоциации должна содержать заданное наименование таблицы.
b. Он задает роль в ассоциации или композиции (либо приводит к типу стороны). Этот синтаксис имеет вид: <entity-type>/<relationship-name>.<role-name>. Если используется ассоциация, то сторона, заданная наименованием роли, должна содержать заданное наименование таблицы.
На основанной на ссылке ассоциации могут присутствовать кавычки (“”), указывающие, что ссылка может быть в любой таблице корректного типа. Если был задан атрибут Scope (область), то путь может начинаться с указанного типа объектной сущности. Если атрибут Table (таблица) задан по описанию Type (типа), то этот путь должен быть с ним совместим.
• Scoped (ограничен областью) - необязательный. Указывает, ограничена ли область этой стороны экземпляром этой объектной сущности, указанной в атрибуте Scope (области) элемента <Association>. По умолчанию является истинным значением.
• OnDelete (по удалении) - необязательный. Задает действие, которое должно быть предпринято, когда удаляется объектная сущность в пределах этой роли. Может быть задано, только когда эта сторона перечислена в элементе <Reference> или <CommonValue>. Возможными значениями являются:
• Restrict (ограничить) - предохраняет объектную сущность от удаления. Это значение по умолчанию.
• Cascade (каскадировать) - служит причиной того, чтобы были удалены объектные сущности в ролях других сторон.
• CascadeToAssociationEntity (каскадировать до объектной сущности ассоциации) - служит причиной того, чтобы была удалена только объектная сущность ассоциации.
• SetNull (установить нуль) - служит причиной того, чтобы было установлено в нуль свойство на другой стороне ассоциации. В тех случаях, когда свойство является коллекцией ссылок, ссылки удаляются из коллекции. Нижнее граничное значение кратности на другой стороне ассоциации должно быть нулевым. Допускает задание, только если эта сторона перечислена в одном из свойств элемента <CommonValue> или ToRole (для роли) элемента <Reference>.
• OnUpdate (по обновлению) - необязательный. Задает действие, которое должно быть предпринято, когда обновляется свойство общего значения объектной сущности в роли стороны. Может быть задано, только когда эта сторона перечислена в элементе <CommonValue>. Когда OnUpdate (по обновлению) не задано, то обновление свойства на одной стороне не оказывает никакого влияния на свойство на другой стороне. Возможными значениями являются:
• Restrict (ограничить) - предохраняет объектную сущность от обновления.
• Cascade (каскадировать) - служит причиной того, чтобы свойство общего значения объектной сущности в другой роли стороны было обновлено тем же самым значением.
• SetNull (установить в нуль) - служит причиной того, чтобы было установлено в нуль свойство общего значения объектной сущности в роли другой стороны. Нижнее граничное значение кратности на другой стороне ассоциации должно быть нулевым.
Виды ассоциации. Вид ассоциации указывает, каким образом связаны стороны. Каждая ассоциация является одним из четырех видов, указанных вложенностью одного из следующих элементов под элементом <Association>.
• <Reference> - две стороны связаны с использованием ссылочного свойства на одной из сторон.
• <Condition> - две стороны связаны посредством произвольного соединения по сторонам.
• <CommonValue> - две стороны связаны посредством объединения эквивалентностью по свойству с каждой стороны.
• <AssociationEntity> - две или более сторон связаны с использованием дополнительной объектной сущности. Только когда использован этот элемент, могут быть заданы более чем два элемента <End>.
Элемент <Reference> описывает ассоциацию ссылочного вида. Элемент может содержать следующие атрибуты:
• FromRole (исходная роль) - обязательный. Наименование роли, которая содержит типизированное ссылочным типом свойство. Для объектных сущностей ассоциации это должно быть наименование роли объектной сущности ассоциации.
• ToRole (целевая роль) - обязательный. Наименование роли, на которую нацелено ссылочное свойство. Идентифицированная роль не должна задавать атрибут OnUpdate (по обновлению).
• Property (свойство) - обязательный. Наименование свойства ссылки в объектной сущности FromRole (исходной роли). Элемент <Property>, определяющий это свойство, должен иметь атрибут Role (роль), задающий содержащую ассоциацию. Если верхним граничным значением кратности является единица, то тип свойства должен быть ссылкой, и такая ссылка должна быть обнуляемой, если нижним граничным значением является нуль. Если больше, чем единица, типом свойства должен быть массив ссылок.
Ниже показан пример ссылочной ассоциации “AtoB” («A к B»), соотносящей объектные сущности А и В.
<EntityType Name="A" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="BRef" Type="Ref(B)" Association = "AtoB"/>
</EntityType>
<EntityType Name="B" Key="ID">
<Property Name="ID" Type="Int32">
</EntityType>
<Association Name="AtoB">
<End Role="ARole" Type="A"/>
<End Role="BRole" Type="B"/>
<Reference FromRole="ARole" ToRole="BRole" Property="BRef"/>
</Association>
Элемент <CommonValue> описывает ассоциацию вида общего значения. Элемент может содержать следующие атрибуты:
• Property1 (свойство1) - обязательный. Идентифицирует свойство на одной из сторон с использованием строки с форматом role-name.property-name (роль-наименование.свойство-наименование).
• Property2 (свойство2) - обязательный. Идентифицирует свойство на одной из сторон с использованием строки с форматом role-name.property-name (роль-наименование.свойство-наименование).
Для объектной сущности ассоциации одно из Property1 (свойство1) и Property2 (свойство2) задает роль объектной сущности ассоциации, а другой - задает роль стороны. Заданная сторона может содержать атрибут OnUpdate (по обновлению) и/или OnDelete (по удалении). Ниже показан пример ассоциации “AtoB” («A к B») общего значения, соотносящей объектные сущности А и В.
<EntityType Name="A" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="X" Type="String"/>
</EntityType>
<EntityType Name="B" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="Y" Type="String"/>
</EntityType>
<Association Name="AtoB">
<End Role="ARole" Type="A"/>
<End Role="BRole" Type="B"/>
<CommonValue Property1="ARole.X" Property2="BRole.Y"/>
</Association>
Элемент <Condition> описывает ассоциацию, основанную на произвольном соединении между двумя сторонами. Элемент должен содержать выражение, которое обращается в истинное значение для соотнесенных объектных сущностей. Наименования ролей, заданные в элементах <End> и <Using>, могут быть использованы в этом выражении. Если элемент <Association> содержит элемент <Condition>, он также может содержать нуль или более элементов <Using>. Эти элементы описывают дополнительные объектные сущности, которые используются для определения отношения между сторонами. Элементы <Using> могут содержать следующие атрибуты:
• Role (роль) - обязательный. Именует роль стороны, используемой в отношении.
• Type (тип) - обязательный. Тип объектной сущности, используемой в отношении.
• Table (таблица) - смотрите описание атрибута по элементу <End> ассоциации.
С использованием элементов <End>, <Using> и <Condition> конструируется полный запрос. Этот запрос имеет вид:
SELECT end-role-1, end-role-2
FROM end-table-1 AS end-role-1, end-table-2 AS end-role-2,
using-table-n AS using-role-n, …
WHERE condition
Следующий пример показывает две объектные сущности А и В, соотнесенные с использованием выражения, включающего в себя третью объектную сущность С.
<EntityType Name="A" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="X" Type="String"/>
</EntityType>
<EntityType Name="B" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="Y" Type="String"/>
</EntityType>
<EntityType Name="C" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="Z1" Type="String"/>
<Property Name="Z2" Type="String"/>
</EntityType>
<Association Name="AtoB">
<End Role="ARole" Type="A"/>
<End Role="BRole" Type="B"/>
<Using Role="CRole" Type="C" Table="CTable"/>
<Condition>
ARole.X=CRole.Z1 AND BRole.Y=CRole.Z2
</Condition>
</Association>
Элемент <AssociationEntity> указывает, что стороны ассоциации связаны посредством объектной сущности ассоциации. Элемент <AssociationEntity> может содержать следующие атрибуты:
• Role (роль) - обязательный. Именует роль, которую объектная сущность ассоциации играет в ассоциации.
• PluralRole (множественная роль) - необязательный. Предусматривает множественную форму наименования роли. Это наименование используется в модели запроса и каноническом объектном преобразовании. Если не задан, взамен используется наименование формы roleEntities (ролевые объектные сущности).
• Type (тип) - обязательный. Тип объектной сущности ассоциации. Элемент <EntityType>, который определяет этот тип, должен задавать атрибут Association (ассоциация), который идентифицирует охватывающий элемент <Association>.
• Table (таблица) - смотрите описание атрибута по элементу <End> ассоциации.
Элемент <AssociationEntity> содержит один вложенный элемент <End>. Объектная сущность ассоциации определяет ассоциацию между этим элементом <End> и каждым из элементов <End>, вложенных под элементом <Association>. Вид этих ассоциаций описывается элементом <Reference>, <Condition> или <CommonValue>. Одна из ассоциаций взамен может быть описана элементом <Composition>:
• <Composition> - объектная сущность ассоциации является потомком одной из сторон композиции.
Role (роль) по каждому <End> элемента <Association> должна быть указана ссылкой одной из двух ролей в одном из этих элементов вида; другая роль ссылается на <End> элемента <AssociationEntity>.
Элемент <Composition> вписывает композицию объектной сущности ассоциации в одну из ролей сторон. Он должен быть вложенным внутри <AssociationEntity>. Элемент <Composition> содержит следующие атрибуты:
• ParentRole (родительская роль) - обязательный. Наименование роли стороны, которая содержит в себе вложенную таблицу типа объектной сущности ассоциации. Это не должно быть ролью объектной сущности ассоциации. Атрибут OnDelete (по удалении) в элементе <End>, указываемый ссылкой этой ролью, должен задавать Cascade (каскадировать) или CascadeToAssocationEntity (каскадировать до объектной сущности ассоциации). Атрибут OnUpdate (по обновлению) не может быть задан.
• ChildRole (дочерняя роль) - обязательный. Наименование роли, которая содержится в родительской объектной сущности. Это должно быть ролью <End> объектной сущности ассоциации.
• Property (свойство) - обязательный. Наименование табличного свойства в родительской объектной сущности. Элемент <Property>, который определяет это свойство, должен содержать атрибут Association (ассоциация), который задает вмещающую ассоциацию.
Элемент <Condition> должен содержать следующий атрибут, когда он вложен под элементом <AssociationEntity>:
• JoinedRoles (объединенные роли) - обязательный. Общий разделенный перечень из двух или более наименований ролей. Этот перечень включает в себя наименование роли <End> из <AssociationEntity> и одно из наименований ролей сторон. Перечисленные роли не должны задавать атрибут OnDelete (по удалении) или OnUpdate (по обновлению).
Следующий пример показывает ассоциацию "AtoB" («A к B») объектной сущности, соотносящую А и В и использующую сущность С ассоциации, где С скомпонована в А и содержит ссылку на В.
<EntityType Name="A" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="CTable" Type="Table(C)"/>
</EntityType>
<EntityType Name="B" Key="ID">
<Property Name="ID" Type="Int32">
</EntityType>
<EntityType Name="C" Key="ARef, BRef" Association="AtoB">
<Property Name="BRef" Type="Ref(B)" Role="BRole"/>
</EntityType>
<Association Name="AtoB">
<AssociationEntity Type="C">
<End Role="CRole" Type="C"/>
<Composition ParentRole="ARole" ChildRole="CRole"
Property="CTable"/>
<Reference FromRole="CRole" ToRole="BRole"
Property="BRef"/>
</AssociationEntity>
<End Role="ARole" Type="A"/>
<End Role="BRole" Type="B"/>
</Association>
Композиция. Каждая вложенная таблица определяет композицию (composition) между объектными сущностями двух типов: типом объектной сущности, который содержит типизированное табличным типом свойство, и типом объектной сущности, который содержится таблицей. Композиция описывается с использованием элемента <Composition>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование композиции.
Элемент <Composition> содержит элемент <ParentEnd>. Этот элемент может содержать следующие атрибуты:
• Role (роль) - обязательный. Именует роль родительской объектной сущности.
• Type (тип) - обязательный. Задает тип родительской объектной сущности.
• Property (свойство) - обязательный. Задает свойство в родительской объектной сущности, которое определяет композицию.
• PluralRole (множественная роль) - необязательный. Предусматривает множественную форму наименования роли. Это наименование используется в модели запроса и каноническом объектном преобразовании. Если не задан, взамен используется наименование формы roleEntities (ролевые объектные сущности).
Элемент <Composition> также должен содержать элемент <ChildEnd>. Этот элемент может содержать следующие атрибуты:
• Role (роль) - обязательный. Именует роль дочерней объектной сущности.
• Type (тип) - обязательный. Задает тип дочерней объектной сущности.
• Multiplicity (кратность) - необязательный. Кратность потомка (дочерней объектной сущности) в композиции. Смотрите также атрибут Multiplicity (кратность) элемента <End> ассоциации.
• PluralRole (множественная роль) - необязательный. Предусматривает множественную форму наименования роли. Это наименование используется в модели запроса и каноническом объектном преобразовании. Если не задан, взамен используется наименование формы roleEntities (ролевые объектные сущности).
Схема, приведенная ниже, определяет две независимых вложенных таблицы, которые могут содержать экземпляры А: В.АTable (таблица В.А) и С.АTable (таблица С.А). Также есть вложенная таблица, которая может содержать экземпляры В, D.BTable (таблица D.B), и вложенная таблица, которая может содержать экземпляры С, D.CTable (таблица D.С). Экземпляры D содержатся в самой высокоуровневой таблице, названной DTable (таблицей D).
<Schema Namespace=”MyCompany.MySchema”>
<EntityType Name=”A” Key=”AID”>
<Property Name=”AID” Type=”String”>
<Length Maximum=”2”/>
</Property>
</EntityType>
<EntityType Name=”B” Key=”BID”>
<Property Name=”BID” Type=”String”>
<Length Maximum=”2”/>
</Property>
<Property Name=”TableA” Type="Table(A)"
Composition=”BA”/>
</EntityType>
<Composition Name=”BA”>
<ParentEnd Role=”RoleB” Type="B" Property="TableA"/>
<ChildEnd Role=”RoleA” Type="A"/>
</Composition>
<EntityType Name=C” Key=CID”>
<Property Name=”CID” Type=”String”>
<Length Maximum=”2”/>
</Property>
<Property Name=”TableA” Type=”Table(A)”
Composition=”CA”/>
</EntityType>
<Composition Name=”CA”>
<ParentEnd Role=”RoleC” Type="C" Property="TableA"/>
<ChildEnd Role=”RoleA” Type="A"/>
</Composition>
<EntityType Name=”D” Key=”DID”>
<Property Name=”DID” Type=”String”>
<Length Maximum=”2”/>
</Property>
<Property Name=”TableB” Type=”Table(B)”
Composition=”DB”/>
<Property Name=”TableC” Type=”Table(C)”
Composition=”DC”/>
</EntityType>
<Composition Name=”DB”>
<ParentEnd Role=”RoleD” Type="D" Property="TableB"/>
<ChildEnd Role=”RoleB” Type="B"/>
</Composition>
<Composition Name=”DC”>
<ParentEnd Role=”RoleD” Type="D" Property="TableC"/>
<ChildEnd Role=”RoleC” Type="C"/>
</Composition>
<TableSet Name=”TS”>
<Table Name=”TableD” Type=”D”/>
</TableSet>
</Schema>
Фиг.12 иллюстрирует UML-представление 1200 некоторых из идентичных типов, подчиненных композиции.
Фиг.13 иллюстрирует визуализацию 1300 экземпляра D в TS.TableD.
Фиг.14 иллюстрирует SQL-таблицы 1400, которые соответствуют таблицам объектных сущностей по фиг.13.
Ограничения типа вложенной таблицы. Является допустимым ограничивать значения типа коллекции и массива с использованием одного из ограничительных элементов, определенных ниже. Эти элементы могут быть вложенными внутри различных элементов, которые ссылаются на табличные типы (например, элемент <Property> в элементе <EntityType> или <InlineType>).
EntityConstraint (ограничение объектной сущности). Ограничительный элемент <EntityConstraint> может быть использован, чтобы размещать ограничения по объектным сущностям в таблице. Любой ограничительный элемент, который является действительным для типа объектной сущности, может быть задан внутри элемента <EntityConstraint>.
Occurs (встречается). Ограничительный элемент <Occurs> может быть использован, чтобы ограничивать количество объектных сущностей в таблице. Этот элемент может содержать следующие атрибуты:
• Minimum (минимум) - необязательный. Задает минимальное количество вхождений в таблице. Значением по умолчанию является нуль.
• Maximum (максимум) - необязательный. Задает максимальное количество таблицы вхождений. Значение “unbounded” (“не ограничено”) означает, что ограничений нет. Значением по умолчанию является “unbounded”.
Чтобы быть совместимым с ограничением, заданным в базовом типе, значение, заданное для Minimum (минимума) должно быть равным или большим, чем прежнее значение, а значение, заданное для Maximum (максимума), должно быть равным или меньшим, чем прежнее значение.
Unique (уникальный). Ограничительный элемент <Unique> может быть использован, чтобы задавать свойство или свойства типа объектной сущности, которые должны содержать уникальное значение в таблице. Этот элемент может содержать следующие атрибуты: Properties (свойства) - обязательный. Разделенный запятыми список наименований свойств объектной сущности.
Check (проверить). Ограничительный элемент <Check> может содержать булево выражение запроса. Для таблицы, которая должна быть действительной, это выражение обращается в истинное значение. Выражение не должно иметь никаких побочных эффектов. Когда ограничение проверки задано и в базовом, и порожденном типах, оба ограничения проверяются на действительность. Заметим, что ограничение проверки по таблице применяется к свойству как единому целому. Например, оно могло бы быть использовано, чтобы проверять, что сумма значения конкретного свойства является меньшей, чем некоторое предельное значение. В качестве альтернативы, ограничение проверки, помещенное внутри элемента <EntityConstraint> могло бы применяться к каждому значению индивидуально.
Свойства навигации. Свойство навигации по выбору может быть размещено в объектной сущности, заданной любой стороной отношения. Это свойство предоставляет средство навигации от одной стороны до другой стороны отношения. Свойства навигации представлены с использованием элемента <NavigationProperty> в пределах описания <Entity>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование члена. Наименование должно быть уникальным в области определяющего типа. Наименование должно соблюдать CLR-правила для наименований членов класса и должно следовать руководящим принципам именования каркаса .Net.
• DuplicateName (дублировать наименование) - необязательный. Наименования членов также должны быть уникальными по всей иерархии базового типа, если не предусмотрен атрибут DuplicateName (дублировать наименование) или не обладает значением “true”. Значение “false”, устанавливаемое по умолчанию, указывает, что предполагается, что наименование члена должно быть уникальным.
Роль этого атрибута заключается в том, чтобы а) документировать тот факт, что наименование члена дублирует свойство в базовом типе, и b) принуждает разработчика схемы предпочитать дублировать наименование целенаправленно (т.е. он играет такую же роль, как ключевое слово new в С#).
• Association (ассоциация) - должен присутствовать атрибут либо Association (ассоциации), либо Composition (композиции). Задает наименование ассоциации, олицетворенной этим свойством.
• Composition (композиция) - должен присутствовать атрибут либо Association (ассоциации), либо атрибут Composition (композиции). Задает наименование композиции, олицетворенной этим свойством.
• FromRole (исходная роль) - обязательный. Роль стороны, представленной этой объектной сущностью со свойством навигации.
• ToRole (целевая роль) - обязательный. Роль стороны, представленной свойством.
Псевдонимы типа. Псевдоним типа дает уникальное наименование типу: простому, коллекции, массива, табличному или ссылочному, и набору ограничений. Псевдоним типа определяется с использованием элемента <TypeAlias>, который допускает следующие атрибуты:
• Name (наименование) - обязательный. Наименование псевдонима.
• AliasedType (именуемый псевдонимом тип) - обязательный. Наименование именуемого псевдонимом типа. Это должен быть тип: простой, коллекции, массива, табличный или ссылочный.
Элемент <TypeAlias> может содержать любой ограничительный элемент, разрешенный для именованного псевдонимом типа. Определенное наименование псевдонима может быть использовано везде, где может быть использовано наименование именованного псевдонимом типа. Некоторые примерные псевдонимы показаны ниже:
<Schema Namespace=”MyCompany.MySchema”>
<TypeAlias Name=”Name” AliasedType=”String”>
<Length Maximum=”1000”/>
</TypeAlias>
<TypeAlias Name=”PersonRef” BaseType=”Ref(PersonItem)”>
</TypeAlias >
<TypeAlias Name=”Keywords” AliasedType=”Collection(String)”>
<Length Maximum=”100”/>
<Occurs Minimum=”0” Maximum=”unbounded”/>
</TypeAlias>
</Schema>
Наборы таблиц и типы набора таблиц. Тип набора таблиц является ограниченной формой типа объектной сущности. Тип набора таблиц определяется с использованием элемента <TableSetType>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование типа набора таблиц. Это наименование должно быть уникальным среди всех типов и отношений в определяющей схеме.
• DefaultTableSet (набор таблиц по умолчанию) - необязательный. Задает набор таблиц по умолчанию типа набора таблиц. Если не задан, то значения по умолчанию нет.
Элементы <TableSetType> могут содержать элементы <Property>, которые задают ссылочные и табличные типы. Ссылочное свойство может задавать только типы набора таблиц. Элементы <TableSetType> также могут содержать элементы <ComputedProperty> и <Method>.
Экземпляры набора таблиц. Набор таблиц является экземпляром типа набора таблиц. Наборы таблиц образуют “высший уровень” модели данных. Вся память хранилища прямым или косвенным образом выделяется посредством создания набора таблиц. Набор таблиц описывается с использованием элемента <TableSet>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование набора таблиц. Это наименование должно быть уникальным среди всех наборов таблиц в определяющей схеме.
• Type (тип) - обязательный. Наименование типа набора таблиц.
Объединение наборов таблиц. Элемент <TableSet> содержит элемент <AggregatedTableSet> для каждого типизированного ссылочным типом свойства в заданном типе объектной сущности. Это предоставляет предварительно определенным наборам таблиц возможность быть объединенными в новый набор таблиц. Это полезно при комбинировании данных из двух раздельных приложений в единое приложение. Элемент <AggregatedTableSet> может содержать следующие атрибуты:
• Property (свойство) - обязательный. Наименование заданного ссылочным типом свойства.
• TableSet (набор таблиц) - обязательный. Наименование набора таблиц, который будет указан ссылкой свойством.
Пример, приведенный ниже, иллюстрирует это:
Из Sales Schema (схемы продаж)
<TableSetType Name="SalesData">
…
</TableSetType>
<TableSet Name="Sales" Type="SalesData"/>
Из схемы WinFS (файловой системы Windows)
<TableSetType Name="WinFSData" DefaultTableSet="WinFS">
…
</TableSetType>
<TableSet Name="WinFS" Type="WinFSData"/>
Из (третьей) схемы Third
<TableSetType Name="ThirdAppData">
<Property Name="Sales" Type="Ref(SalesData)" …/>
<Property Name="WinFS" Type="Ref(WinFSData)" …/>
…
</TableSetType>
<TableSet Name="ThirdApp" Type="ThirdAppData">
<AggregatedTableSet Property="WinFS" TableSet="WinFS"/>
<AggregatedTableSet Property="Sales" TableSet="Sales"/>
</TableSet>
Язык запросов. Может быть задан язык запросов для CDM. Язык запросов может быть основан на SQL-нацеливании CDM-понятий, подобных объектным сущностям и отношениям.
Использование композиций в запросах. Последующие шаблоны работают при определении набора таблиц, на котором основана введенная таблица. Композиция может сделать следующие функции доступными для использования в запросе:
• Table(parent-type) composition.Getparent-role-p(Table(child-type)) - возвращает родителей введенных потомков.
• parent-type composition.Getparent-role-s(child-type) - Родитель введенного потомка.
• Table(parent-type) composition.Filterparent-role-p(Table(parent-type), Table(child-type)) - возвращает набор родителей, отфильтрованных по наличию потомка во введенном наборе потомков.
• Table(child-type) composition.Getchild-role-p(Table(parent-type)) - возвращает потомков введенных родителей.
• Table(child-type) composition.Getchild-role-p(parent-type) - возвращает потомков введенного родителя.
• Table(child-type) composition.Filterchild-role-p(Table(child-type), Table(parent-type)) - возвращает набор потомков, отфильтрованный по наличию потомка во введенном наборе родителей.
Где: composition (композиция) представляет наименование композиции; parent-role-s представляет форму единственного числа наименования родительской роли; parent-role-p представляет форму множественного числа наименования родительской роли; child-role-s представляет форму единственного числа наименования дочерней роли; child-role-p представляет форму множественного числа наименования дочерней роли; parent-type представляет тип родительской объектной сущности; child-type представляет тип дочерней объектной сущности; и Table(type) представляет запрос по таблице конкретного типа.
Использование ассоциаций в запросах. Эти шаблоны могут работать при определении набора таблиц, на которых основана введенная таблица. Ассоциация делает следующие функции доступными для использования в запросе:
• Table(end-1-type) association.Getend-1-role-p(Table(end-2-type)) - возвращает объектные сущности end-1, ассоциативно связанные с заданными объектными сущностями end-2.
• Table(end-1-type) association.Getend-1-role-p(end-2-type) - возвращает объектные сущности end-1, ассоциативно связанные с заданной объектной сущностью end-2.
• Table(end-1-type) association.Filterend-1-role-p(Table(end-1-type), Table(end-2-type)) - возвращает набор объектных сущностей end-1, отфильтрованных по наличию ассоциативно связанной объектной сущности end-2 во введенном наборе объектных сущностей end-2.
• Вышеприведенные методы повторяются для всех сочетаний сторон, в том числе объектной сущности ассоциации, если присутствует.
Где: association (ассоциация) представляет наименование ассоциации; end-1-role-s представляет форму единственного числа наименования роли стороны; end-1-role-p представляет форму множественного числа наименования роли стороны; end-2-role-s представляет форму единственного числа наименования роли стороны; end-2-role-p представляет форму множественного числа наименования роли стороны; end-1-type представляет тип исходной объектной сущности; end-2-type представляет тип целевой объектной сущности; и Table(type) представляет запрос по таблице конкретного типа.
Интерфейсы. Интерфейсы обеспечивают CLR-подобные интерфейсы для типов объектных сущностей и подставляемых типов. Они могут быть использованы для решения большинства из тех же самых задач, которые интерфейсы решают в объектных системах типов. Интерфейс объявляется с использованием элемента <Interface>. Элемент <Interface> может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование интерфейса. Должно быть уникальным среди всех типов и самых высокоуровневых таблиц, определенных в схеме.
• BaseInterfaces (базовые интерфейсы) - необязательный. Разделенный запятыми список интерфейсов, от которых порожден этот интерфейс.
Элемент <EntityType> или <InlineType> может использовать атрибут ImplementedInterfaces (реализованный интерфейс), для того чтобы задавать разделенный запятыми список интерфейсов, которые он реализует. Каждое из свойств, определенных в перечисленном интерфейсе, должно быть определено в типе. Как с интерфейсом в С#, свойство, определенное в интерфейсе, реализуется неявным образом в типе простым объявлением свойства с таким же наименованием и типом. Ограничения по свойству могут быть сужены, когда оно объявлено. Свойство также может быть реализовано неявным образом. Это достигается включением наименования типа интерфейса в наименование свойства (в точности, как для С#). Это предоставляет разным ограничениям возможность быть примененными к свойствам, которые имеют одну и ту же сигнатуру, но унаследованы от разных интерфейсов. Например:
<Schema Namespace=”MyCompany.MySchema”>
<Interface Name=”IA”>
<Property Name=”X” Type=”Int32”/>
<Property Name=”Y” Type=”Int32”/>
</Interface>
<Interface Name=”IB”>
<Property Name=”X” Type=”Int32”/>
<Property Name=”Y” Type=”Int32”/>
</Interface>
<EntityType Name=”C” ImplementedInterfaces=”IA, IB”
Key=”ID”>
<Property Name=”ID” Type=”Int32”/>
<Property Name=”X” Type=”Int32”/>
<Property Name=”IA.Y” Type=”Int32”>
<RangeConstraint Maximum=”100”/>
</Property>
<Property Name=”IB.Y” Type=”Int32”>
<RangeConstraint Maximum=”10”/>
</Property>
</EntityType>
</Schema>
Последующее является примером завершенной схемы. Пример, приведенный ниже, определяет типы объектной сущности Customer (потребителя), Order (заказа), OrderLine (товара заказа), Product (продукта) и Supplier (поставщика) вместе с ассоциациями, описывающими, каким образом соотнесены эти объектные сущности.
<Schema Namespace="MyLOB">
<InlineType Name="Address">
<Property Name="Line1" Type="String" Nullable="false">
<Length Maximum="100"/>
</Property>
<Property Name="Line2" Type="String" Nullable="true">
<Length Maximum="100"/>
</Property>
<Property Name="City" Type="String" Nullable="false">
<Length Maximum="50"/>
</Property>
<Property Name="State" Type="String" Nullable="false">
<Length Minimum="2" Maximum="2"/>
</Property>
<Property Name="ZipCode" Type="String" Nullable="false">
<Length Minimum="5" Maximum="5"/>
</Property>
</InlineType>
<EntityType Name="Customer" Key="CustomerId">
<Property Name="CustomerId" Type="String" Nullable="false">
<Length Minimum="10" Maximum="10"/>
</Property>
<Property Name="Name" Type="String" Nullable="false">
<Length Maximum="200"/>
</Property>
<Property Name="Addresses" Type="Array(Address)">
<Occurs Minimum="1" Maximum="3"/>
</Property>
<NavigationProperty Name="Orders"
Association="OrderCustomer"
FromRole="Customer" ToRole="Orders"/>
</EntityType>
<EntityType Name="Order" Key="OrderId">
<Property Name="OrderId" Type="String" Nullable="false">
<Length Minimum="10" Maximum="10"/>
</Property>
<Property Name="Date" Type="DateTime" Nullable="false"/>
<Property Name="Customer" Type="Ref(Customer)"
Association="OrderCustomer"/>
<Property Name="Lines" Type="Table(OrderLine)"
Composition="OrderOrderLine"/>
<Property Name="ShippingAddress" Type="Address"
Nullable="false"/>
</EntityType>
<Composition Name="OrderOrderLine">
<ParentEnd Role="Order" Type="Order" PluralRole="Orders"
Property="Lines"/>
<ChildEnd Role="OrderLine" Type="OrderLine"
PluralRole="OrderLines"
Multiplicity="100"/>
</Composition>
<Association Name="OrderCustomer">
<End Role="Order" Type="Order" PluralRole="Orders"/>
<End Role="Customer" Type="Customer" PluralRole="Customers"
OnDelete="Cascade" Table=""/>
</Association>
<EntityType Name="OrderLine" Key="LineId">
<Property Name="LineId" Type="Byte" Nullable="false"/>
<Property Name="Product" Type="Ref(Product)"
Nullable="false"
Association="OrderLineProduct"/>
<Property Name="Quantity" Type="Int16" Nullable="false">
<Range Minimum="1" Maximum="100"/>
</Property>
<Property Name="Price" Type="Decimal" Nullable="false">
<Decimal Precision="6" Scale="2"/>
</Property>
<NavigationProperty Name="Order"
Composition="OrderOrderLine"
FromRole="Line" ToRole="Order"/>
</EntityType>
<Association Name="OrderLineProduct">
<End Role="OrderLine" PluralRole="OrderLines"/>
<End Role="Product" Type="Product" PluralRole="Products"
Table=""/>
<Reference FromRole="OrderLine" ToRole="Product"
Property="Product"/>
</Association>
<EntityType Name="Product" Key="ProductId">
<Property Name="ProductId" Type="Guid" Nullable="false"/>
<Property Name="Title" Type="String" Nullable="false">
<Length Maximum="100"/>
</Property>
<Property name="Description" Type="String"
Nullable="false">
<Length Maximum="1000"/>
</Property>
</EntityType>
<Association Name="CustomerProduct">
<End Role=="Customer" PluralRole=="Customers"
Type=="Customer"/>
<End Role="Product" PluralRole="Products" Type="Product"/>
<Uses Role="Order" Type="Order"/>
<Uses Role="Line" Type="Lines"/>
<Condition>
Order.Customer = Customer AND OrderLine.Product = Product
</Condition>
</Association>
<EntityType Name="Supplier" Key="SupplierId">
<Property Name="SupplierId" Type="String" Nullable="false">
<Length Minimum="10" Maximum="10"/>
</Property>
<Property Name="Name" Type="String" Nullable="false">
<Length Maximum="200"/>
</Property>
<Property Name="Addresses" Type="Array(Address)">
<Occurs Minimum="1" Maximum="3"/>
</Property>
<NavigationProperty Name="Products"
Association="ProductSupplier"
FromRole="Supplier" ToRole="Product"/>
</EntityType>
<EntityType Name="ProductSupplierLink" Key="Product,
Supplier"
Association="ProductSupplier">
<Property Name="Product" Type="Ref(Product)"
Nullable="false"
Role="Product"/>
<Property Name="Supplier" Type="Ref(Supplier)"
Nullable="false"
Role="Supplier"/>
<Property Name="Price" Type="Decimal" Nullable="false">
<Decimal Precision="6" Scale="2"/>
</Property>
</EntityType>
<Association Name="ProductSupplier">
<AssociationEntity Type="ProductSupplierLink">
<End Role="Link" Type="ProductSupplierLink"/>
<Reference FromRole="Link" ToRole="Product"
Property="Product"/>
<Reference FromRole="Link" ToRole="Supplier"
Property="Supplier"/>
</AssociationEntity>
<End Role="Product" Type="Product" PluralRole="Products"
Table="" />
<End Role="Supplier" Type="Supplier" PluralRole="Suppliers"
Table="" />
</Association>
<TableSetType Name="LOBData">
<Property Name="Orders" Type="Table(Order)"/>
<Property Name="Customers" Type="Table(Customer)"/>
<Property Name="Products" Type="Table(Product)"/>
<Property Name="Suppliers" Type="Table(Supplier)"/>
<Property Name="PSLinks" Type="Table(ProductSupplierLink)"/>
</TableSetType>
<TableSet Name="LOB" Type="TableSetType"/>
</Schema>
SQL99 и CDM. SQL99 определяет несколько расширений объектов до основной реляционной модели данных (например, SQL92). Некоторыми ключевыми аспектами SQL99 являются: Определяемые пользователем типы, которые включают в себя как индивидуальные (Distinct) типы, так и структурированные (Structured) типы; методы (Method) (поведения (Behaviors)); типизированные таблицы (Typed Tables); и ссылки (Refs).
SQL 99 определяет часть или всю полную систему типов, замкнутую в пределах SQL-модели данных. Несмотря на то, что объекты в языках программирования могут быть преобразованы в SQL-объекты, определять сильную связь с языком программирования (например, Java, C#) не является целью SQL99. Например, методы в SQL99 лучше описываются на процедурном языке SQL, чем на стандартном языке программирования. Цель CDM состоит в том, чтобы задавать точное согласование как с SQL, так и с CLR.
Определяемые пользователем типы. Типы, простые и составные, в CDM сопоставляются почти один к одному с определяемыми пользователем типами в SQL99. Простые типы и псевдонимы простых типов соответствуют скалярным типам и индивидуальным типам SQL99. Составные (Complex) типы соответствуют структурированному типу данных SQL99. Главным различием между структурированным типом SQL и составным типом является разграничение между подставляемыми (Inline) типами и типами объектной сущности (Entity). В CDM понятие идентичности/ключа определяется во время описания типа. В SQL99 идентичность определяется, когда тип используется для определения типизированной таблицы. Поэтому в SQL99 не было необходимости проводить различие между типами с и без идентичности, в соответствии с этим имела место поддержка повторного использования типа как для таблицы (допускающих ссылку объектов), так и для описания столбца (непригодных для ссылки, подставленных объектов). Такое повторное использование типа действует именно на хранение, так как идентичность может быть определена во время описания таблицы. Однако, один и тот же тип не может быть сопоставлен подставляемому классу, так же как пригодному для указания ссылкой классу. Так как целью CDM является предоставить объектный каркас приложения и каркас устойчивости, разграничение между подставляемыми типами и типами объектной сущности является важным.
Методы/поведения. В CDM поведения определяются с использованием каркаса CLR. SQL99 определяет свой собственный каркас методов/поведений. Несмотря на то, что он является близким к большинству современных (объектно-ориентированных) OO-языков, он по-прежнему является иным и не предусматривает подходящей среды программирования для приложений. Типично, приложения (или серверы приложений) преодолевают пробел между средой программирования и средой баз данных.
Типизированные таблицы по сравнению с таблицами объектных сущностей. Таблицы объектных сущностей в CDM подобны типизированным таблицам SQL99. Однако, экстент является логическим - он является логической коллекцией объектов. Физическое хранилище, ассоциативно связанное с экстентом, отсутствует. Таблица типов является SQL-таблицей со всеми атрибутами хранения, разрешенными в таблицах. Непрерывные области памяти могут быть приведены в соответствие одной или более физическим таблицам.
Ссылки. Ссылки в CDM и в SQL99 очень похожи. В CDM ссылке задается область посредством задания экстента для ссылки; в SQL99 ссылке задается область посредством задания таблицы типов в качестве целевого объекта для ссылки. В обоих случаях ссылка разрешается в объект.
Фиг.15 иллюстрирует схематическую диаграмму платформы 1500 данных, которая может использовать CDM подчиненной архитектуры. Должно быть принято во внимание, что расстановка любых компонентов и/или блоков в схеме не подразумевает (и не обязательно не допускает) любое своеобразное размещение по другую сторону границ процесса/машины. Платформа 1500 данных может использовать оптимистическую модель взаимосовместимости, с тем чтобы, если изменения должны быть сохранены, а другие изменения уже были произведены по отношению к лежащим в основе данным, обнаружение конфликта разрешало это специфичным для приложения образом. Чтобы быть эффективной платформой, платформа 1500 данных содержит признаки, такие как интеграция языка программирования, обогащенное моделирование данных, каркас устойчивости, службы и так далее. API 1502 содействует языковой интеграции и доступу к данным посредством приложения 1504 через среду исполнения 1506 платформы данных по отношению к хранилищу 1508. Платформа 1500 данных предусматривает следующие признаки.
CDM. В центре среды исполнения 1506 платформы 1500 данных находится CDM 1510. Цель CDM 1510 состоит в том, чтобы факторизовать концепции моделирования, общие по многочисленным прикладным областям, от приложений, работающих главным образом с пользовательскими данными (PIM, документы и т.д.), до данных LOB и коммерческих. В дополнение, чтобы предоставить обогащенную абстракцию объектов и отношений, CDM 1510 предусматривает поддержку для структур, неструктурированных и частично структурированных данных.
Данные строки/объектной сущности. CDM 1510 поддерживает обогащенную модель объектную сущность-отношение (Entity-Relationship) для фиксирования структуры и поведения структурированных данных (например, коммерческой информации). CDM 1510 является надмножеством основной реляционной модели, с расширениями для обогащенной объектной абстракции и моделирования отношений (например, отношение Author (автора) между документами (Document) и деловыми контактами (Contact), отношение Lines (товары) между заказами на покупку (Purchase Order) и товарами заказов (Order Lines)).
Файловые данные. CDM 1510 поддерживает тип данных (“file stream” (“файловый поток”) для сохранения и манипулирования неструктурированными (файловыми) данными. Тип данных файлового потока может хранить данные в виде файла и поддерживает API-интерфейсы файлового доступа. Тип данных файлового потока естественным образом поддерживается в SQL Server, приведенным в соответствие файловому потоку NTFS (файловой системы новой технологии), и поддерживает все основанные на файловом описателе/потоке операции. В дополнение к моделированию неструктурированного контента в виде файлового потока, в CDM 1510, с использованием типов объектной сущности, полезный контент может быть поддержан в виде структурированных свойств. Основанные на базах данных файловые системы хранения определяют понятие имеющей файловую основу записи, каковая является объектной сущностью, которая моделирует структурированные свойства наряду с файловым потоком неструктурированного контента. Имеющая файловую основу запись предусматривает обогащенное запрашивание наряду с основанными на потоке операциями над ассоциированным файловым потоком.
XML-данные: XML-документы могут быть промоделированы в CDM 1510 двумя основными способами: (1) сохранением их в качестве типа XML-данных; (2) приведением XML-документа в соответствие одной или более объектным сущностям (например, подобно информационным контрактам). CDM 1510 поддерживает тип XML-данных в качестве поддерживаемого в SQL Server. Тип XML-данных может быть типом любого свойства объектной сущности. Тип XML-данных предусматривает нетипизированные или типизированные XML-документы, которые должны быть сохранены. Строгая типизация обеспечивается посредством ассоциативного связывания одной или более XML-схем со свойствами XML-документа.
Интеграция языка программирования, в том числе Query (запросов), в API 1502. Компоненты признаков платформы 1500 данных сеансов и транзакций 1512, запроса 1514, устойчивости 1516, указателей 1515, служб 1520, объектного кэша 1522 и ведению 1524 бизнес-логики инкапсулированы в нескольких классах “среды исполнения”, имеющихся в распоряжении в API 1502 платформы данных.
Объектная сущность 1516 устойчивости включает в себя механизм устойчивости, который предусматривает декларативные описания преобразований, которые точно описывают, каким образом объекты компонуются из частей компонентов, которые поступают из реляционных хранилищ. Механизм включает в себя компонент (не показан) формирования запроса, который берет выражение, определенное процессором запросов, в терминах выражения объектного запроса и затем комбинирует его с декларативным преобразованием. Это превращается в эквивалентные запросные выражения, которые осуществляют доступ к лежащим в основе таблицам в базе данных. Компонент (не показан) формирования обновления проверяет службы отслеживания изменений и с помощью метаданных преобразования описывает, каким образом преобразовать такие изменения в пространстве объектов в изменения в пространстве таблиц.
Механизм устойчивости может включать в себя объектно-реляционные преобразования. Другими словами, абстракции моделирования, доступа и запроса, предусмотренные платформой 1500 данных, основаны на объектах. Основная технология хранения, используемая платформой 1500 данных, является реляционной. Механизм устойчивости использует объектно-реляционные преобразования (также указываемые ссылкой как “O-R-преобразования”), в которых механизм устойчивости может приводить языковые классы в соответствие лежащему в основе табличному представлению.
Запрашивание/поиск файловых (File) и XML-данных. CDM 402 сохраняет неструктурированные и частично структурированные данные с использованием типов файлового потока и XML-данных, соответственно. CQL является допускающим запрашивание этих типов данных. Для файлового контента, переведенного в структурированные сущности (например, в имеющие WinFS-файловую основу записи), реляционные операторы CQL могут запрашивать эти объектные сущности. Неструктурированные данные, сохраненные в качестве файлового потока, могут быть запрошены с использованием полнотекстового поиска. XML-контент может быть запрошен с использованием XPath или XQuery.
Объектно-реляционные преобразования. Так как платформа 1500 данных предусматривает основанную на объектах абстракцию поверх реляционного (табличного) хранилища, она предусматривает компонент O-R-преобразования. Платформа 1500 данных поддерживает как предписывающие преобразования, так и не предписывающие преобразования (разработчик типа имеет в распоряжении некоторую гибкость в задании преобразований). Заметим, что основанная на базе данных реализация системы файлового хранения в настоящее время использует директивные (предписывающие) преобразования, тогда как более общие O-R-каркасы устойчивости требуют недирективных преобразований.
Кэширование. Среда исполнения платформы 1506 данных поддерживает в рабочем состоянии кэш результатов запросов (например, указателей) и незаверенных обновлений. Это называется кэшем сеанса. Платформа 1500 данных также предусматривает явный кэш, который дает приложению возможность работать в режиме разъединения. Платформа 1500 данных предусматривает различные гарантии совместимости для данных в явном кэше. Кэш выполняет управление идентичностью посредством сопоставления идентичности данных на диске с объектами в памяти. Среда исполнения платформы 1506 данных обслуживает кэш 1522 результатов запросов (например, указателей, подробно обсужденных ранее) и незаверенных обновлений, при этом такой кэш может быть упомянут как сеансовый кэш, так как он привязан к сеансам, транзакциям 1512. В дополнение, он начинает существовать, когда сеанс создается, и прекращает, когда сеанс завершается.
Платформа 1500 данных также может открывать для воздействия другой вид кэша, названный явным кэшем. Явный кэш предусматривает кэш данных из одного или более запросов. Как только данные материализуются в явный кэш, могут быть обеспечены следующие гарантии непротиворечивости данных: 1) только чтение, не аутентичное; 2) сквозная запись, аутентичная, и 3) автоматическая регенерация через внешние уведомления. Модель программирования и запросов, несмотря на явный кэш, может быть, по существу, подобной той, которая покрывает данные хранилища.
Процессор запросов. Доступ к базе данных происходит через процессор запросов. Процессор запросов предоставляет многочисленным внешним интерфейсам возможность управлять многочисленными языками запросов, которые должны быть выражены, а затем преобразованы во внутренний канонический формат. Это делается исходя из модели предметной области и объектов приложения, на котором она продолжает работать. Запросы затем переправляются в процессор, который является конвейером, и затем конвертируются в специфичные для серверного средства управления базой данных запросы.
Курсоры. Платформа 1500 данных может обеспечивать как однонаправленные курсоры, так и курсоры прокрутки. Курсоры поддерживают уведомления, многоуровневое группирование с состоянием расширения/сжатия, динамическую сортировку и фильтрацию. Курсор, линейки 1515 являются механизмами, которые предоставляют набору объектных сущностей данных, возвращенных из СQL, быть обработанными по одному за раз. Приложение может создавать курсор на наборе результатов посредством простого копирования полного набора результатов в память и наложения шаблона прокрутки поверх этой структуры памяти. Но повсеместность этого требования и сложность, которая иногда связана с реализацией курсора (особенно, когда учитываются обновления, страничная организация и т.п.), означает, что любая платформа данных должна предусматривать модель указывания курсором. В дополнение к основным функциональным возможностям просмотра и прокрутки курсоры платформы данных могут предусматривать следующие признаки: 1) внешние уведомления и обслуживание, 2) многоуровневое группирование с состоянием расширения/сжатия, и 3) динамическую сортировку и фильтрацию (например, “последующую обработку”). Должно быть принято во внимание и понято, что курсоры могут не быть особым механизмом для задания набора результатов. Результирующие наборы задаются запросами, а курсоры находятся поверх этих запросов.
Ведущий узел 1524 бизнес-логики. Платформа 1500 данных предусматривает среду выполнения для ведения централизованной информационной логики над типами/экземплярами и над операциями. Такая информационная централизованная бизнес логика отличается от логики приложения/бизнес-процесса, которая может вестись на сервере приложений. Объекты не являются просто строками в базе данных. Когда объекты становятся материализованными в памяти, они фактически являются объектами, которые обладают поведениями, каковые может активизировать приложение. В системе есть точки расширения, которые преимущественно являются событиями и обратными вызовами, все из которых действуют, чтобы расширять платформу 1500 данных во время выполнения. Эти объекты являются не просто объектами, а CLR-объектами, объектами .NET и т.д. Платформа 1500 данных предоставляет возможность перехватывать вызовы методов проверки операционной готовности свойств в этих объектах. Приложения могут настраивать по специальным требованиям поведение этих объектов.
Платформа 1500 данных предусматривает несколько механизмов для создания бизнес-логики. Эти механизмы могут быть разделены на следующие 5 категорий: ограничения, обработчики событий, статические/экземплярные методы, связываемые поведения и статические служебные методы, каждая из которых далее обсуждена более подробно. Объектная сущность 1526 ограничений/безопасности может быть декларативной и процедурной. Эти ограничения могут быть выполнены в хранилище, в непосредственной близости к данным. Таким образом, считается, что ограничения 1526 должны быть в пределах доверительной границы. Более того, ограничения могут быть авторизованы разработчиком типа.
Ведение 1524 бизнес-логики может использовать обработчик событий. API 1502 платформы данных формирует несколько событий по операциям изменения данных. Авторы бизнес-логики могут обязать действовать эти события через код обработчика. Например, рассмотрим приложение управления заказами. Когда поступает новый заказ, приложению необходимо убедиться, что стоимость заказа является меньшей, чем кредитный лимит, санкционированный для потребителя. Эта логика может быть частью кода обработчика событий, который выполняется перед тем, как заказ помещается в хранилище.
Службы. Платформа 1500 данных предусматривает базовый набор служб, которые доступны для всех клиентов платформы данных. Эти службы включают в себя правила, отслеживание изменений, обнаружение конфликтов, формирование событий и уведомления. Формирование событий расширяет среду 1506 исполнения платформы данных от служб уровня каркаса, или для приложений, чтобы добавлять дополнительные поведения, а также используется для связывания данных в пользовательском интерфейсе.
Ограничения. Платформа 1500 данных предусматривает компонент 1526 ограничений/безопасности для, по меньшей мере, предоставления разработчику типа возможности декларативно создавать ограничения. Эти ограничения выполняются в хранилище. Типично, область ограничений платформы данных охватывает понятия, такие как длина, точность, шкала, значение по умолчанию, проверка и так далее. Эти ограничения принудительно применяются механизмом 1526 ограничения платформы данных во время выполнения.
Безопасность. Платформа 1500 данных предусматривает основанную на роли модель безопасности - пользовательские полномочия определяют ее «роль» (такие как администратор, опытный пользователь, подтверждающий субъект и т.д.). Каждой роли назначен набор прав доступа. Механизм 1526 безопасности платформы данных принудительно применяет эти политики безопасности. В дополнение, платформа 1500 данных предусматривает модель безопасности для контроля доступа к объектным сущностям в платформе 1500 данных. Модель безопасности может поддерживать аутентификацию пользователя операционной системы, уровень авторизации объектных сущностей (например, с раздельными правами для чтения и обновления), и т.д.
Заметим, что компонент 1526 ограничений/безопасности проиллюстрирован отдельно от компонента 1506 среды исполнения платформы данных, так как он может действовать в качестве отдельной от него объектной сущности. В качестве альтернативы, и возможно, более эффективно, компонент 1526 ограничений/безопасности комбинируется с компонентом 1508 хранилища, который может быть системой базы данных.
На последующих фиг.16-18 каждый класс на диаграмме является элементом модели или схемы. Элементы, обозначенные “S”, являются элементами в SDL. Другие элементы являются структурными элементами, неявно структурированными элементами (такими как ссылочные типы) или встроенными элементами (такими как простые типы, которые расширяются посредством импортирования CLR-типов, а не через прямое объявление).
Фиг.16 иллюстрирует фрагменты метамодели CDM, которые проясняют некоторую семантику модели, имеющую отношение к типам. Эти модели, скорее, описывают действие схемы, чем моделирование ее точного синтаксиса. Например, атрибут, который использует наименование роли стороны ассоциации, изображен в качестве ссылки на сторону ассоциации в этих моделях. Комментарии и дополнительные ограничения:
Объявление типа объектной сущности неявным образом определяет тип коллекции объектных сущностей (EntityCollectionType) и ссылочный тип (ReferenceType). Объявление составного типа неявным образом определяет подставляемую коллекцию (InlineCollection). На практике эти типы могут быть реализованы групповыми признаками, такими как Ref<T>, EntityCollection<T>, InlineCollection<T>.
• Cвойства могут быть объявлены только в объявлениях подставляемого типа и типа объектной сущности.
• typeof(InlineCollectionType.ElementType)!= InlineCollectionType
Фиг.17 иллюстрирует фрагменты метамодели CDM, которые проясняют некоторую семантику модели, имеющую отношение к свойствам. Комментарии и дополнительные ограничения:
Property.Kind делает ограничения ассоциации более удобными для чтения, так как метакласс Property (свойства) обладает типом, и свойство, которое он представляет, обладает типом. Kind устраняет любую путаницу, которая могла бы вноситься.
• AssociationEnd.Property является свойством, которое указывает ссылкой на объектную сущность на той же самой стороне ассоциации. Другими словами, оно является свойством в объектной сущности на противоположной стороне ассоциации.
• Свойства набора ссылок или объектных сущностей являются свойствами ассоциации, которые обладают лежащим в основе типом обьъектной сущности.
• Свойства навигации возвращают запрос.
Фиг.18 иллюстрирует фрагменты метамодели CDM, которые проясняют некоторую семантику модели, имеющую отношение к ассоциациям. Большинство из ограничений здесь просто утверждают, что такие свойства на стороне ассоциации должны быть правильным типом, где правильный тип является достаточно очевидным. Например, ассоциация ссылочного (Reference) вида должна содержать свойство со ссылочным типом. Комментарии и дополнительные ограничения:
AssociationEnd.Property является свойством в типе объектной сущности на другой стороне ассоциации. Оно обозначает свойство, указывающее ссылкой объектную сущность на этой стороне ассоциации. Более формально по ассоциации, последующее удерживает:
Ends[0].Property.UnderlyingType=Ends[1].Type и
Ends[1].Property.UnderlyingType=Ends[0].Type
• Одно из CommonValue.Properties происходит от каждой из двух объектных сущностей в ассоциации общего значения.
АЛЬТЕРНАТИВНЫЕ РЕАЛИЗАЦИЯ И СИНТАКСИС
Последующее является альтернативной реализацией модели данных для объектно-реляционных данных. Описание этой альтернативной реализации использует язык описания схем, который является одной из многих возможных форм выражения для этой альтернативной реализации. Также отметим, что есть множество сходств с предыдущей реализацией, описанной ранее, например, по-прежнему заметные различия в форме именования и синтаксиса.
В этом альтернативном описании отношения уже могут быть определены на высшем уровне с использованием элементов <Association> или <Composition>. Нет необходимости определять свойство в источнике (или родителе) для того, чтобы определить ссылочную (Ref) ассоциацию (или композицию). Последующие являются действующими поведениями, которые вводятся на отношениях: OnCopy (по копированию), OnSerialize (по сериализации), OnSecure (по защите) и OnLock (по блокированию). Наборы объектных сущностей (EntitySets) определяются только в пределах типа контейнера объектных сущностей (EntityContainerType) - и не определяются в пределах типа объектной сущности (EntityType). Свойство навигации (NavigationProperty) больше не используется, а свойство отношения (RelationshipProperty) используется с немного другой семантикой.
Типизированные явным ссылочным (Ref) типом свойства являются неограниченными областью ссылками на объектную сущность, и не создают отношение. Свойство отношения (RelationshipProperty) неявным образом является свойством типа ссылки (Ref) (или коллекции ссылок (Collection (Ref))). Область действия отношения задается в пределах оператора <Scope> типа контейнера объектных сущностей.
Отношения сделаны более абстрактными. В предыдущей реализации отношения были определены неявно посредством регламентированных ссылкой (Ref) или коллекцией свойствами в пределах объектной сущности - которая требует в качестве предварительного условия способ реализации отношений. Здесь, отношения определены на высшем уровне. Это удаляет метаданные отношения из объявления типа, тем самым, делая возможным повторное использование типа.
Иерархическое представление. Ссылочные ассоциации, условные ассоциации и объектные сущностные ассоциации - все определяются в пределах элемента <Association>. Это является отражением того факта, что метамодель содержит центральное понятие ассоциации между двумя объектными сущностями; основана ли она на ссылке, условии или соотнесена через объектную сущность ассоциации, задается различными тегами и под-элементами в пределах <Association>. Специализированные понятия (ссылка, условие, объектная сущность ассоциации) наслаиваются поверх центрального понятия (ассоциации).
Разделение основного моделирования и устойчивости. Понятие коллекции объектных сущностей было использовано в предыдущей реализации ради двух целей. Во-первых, в качестве способа для именования и указания ссылкой на сделанные устойчивыми группы объектных сущностей, а во-вторых, в качестве способа определения композиции. Таким образом, она должна была иметь дело с устойчивостью, только чтобы моделировать композиции. Теперь коллекции объектных сущностей являются понятием строгого группирования/задания области; они не разрешены в качестве полей в пределах типа объектной сущности. Композиция определяется на высшем уровне посредством задания абстрактных метаданных об участвующих объектных сущностях. При отделении устойчивости от композиций модель является более гибкой и ортогональной (пригодной для использования в качестве базиса).
Упрощение коллекций. Так как коллекция объектных сущностей теперь разрешена только в пределах типа контейнера объектных сущностей (EntityContainerType) (прежде известном как тип базы данных объектных сущностей (EntityDatabaseType)), только подставляемые коллекции могут быть свойствами типа объектной сущности или составного типа. Это привело к упрощению семантики коллекции. Больше нет необходимости проводить различие между коллекциями объектных сущностей и подставляемыми коллекциями. Есть просто “коллекции”, и они используются, чтобы собирать в коллекцию подставляемые типы.
Возможность задавать операционную семантику. Эта реализация задает отношения - ассоциации или композиции - и ортогонально задает операционное поведение по любому отношению, независимо от его типа. Следовательно, теперь является возможным задавать поведения OnCopy (по копированию), OnSerialize (по сериализации), OnSecure (по защите), OnLock (по блокированию) на любом отношении. К тому же, это обеспечивает большую гибкость и захватывает больший набор сценариев.
Произвольное группирование объектных сущностей. Понятие “записи” WinFS, вообще говоря, является операционным группированием по крайней мере нескольких объектных сущностей (например, объектные сущности записи (Item), объектные сущности фрагмента записи (ItemFragment) и содержащихся объектных сущностей). Композиция, как определено ранее, была чрезмерно ограничивающей для моделирования этого понятия. С возможностью задания операционной семантики и отделения коллекций объектных сущностей от описания отношения делает возможным собирание и выбор операционного поведения и позволяет ему применяться к произвольному группированию объектных сущностей.
Переименование. Некоторые наименования были изменены для лучшего отражения их семантики. Например: (а) коллекция объектных сущностей (EntityCollection) была заменена на набор объектных сущностей (EntitySet), так как теперь это является неупорядоченным группированием объектных сущностей; она также является совместимой с терминологией, используемой при классическом ER-моделировании; (b) тип базы данных объектных сущностей (EntityDatabaseType) был заменен на тип контейнера объектных сущностей (EntityContainerType), чтобы ликвидировать термин “база данных”, так как он имеет много дополнительных оттенков значения устойчивости/операционных/административных; (с) подставляемая коллекция (InlineCollection) была заменена на коллекцию (Collection), поскольку это является единственной разновидностью коллекций, разрешенных в этой модели реализации.
База данных объектных сущностей (EntityDatabase) больше не используется, но теперь является экземпляром типа базы данных объектных сущностей (EntityDatabaseType). <AssociationEntityType> теперь определяется в пределах элемента <Association>.
Таким образом, модель данных описывает конфигурацию и семантику (ограничения, поведения), и отношения между различными частями данных, в которых заинтересовано приложение.
Фиг.19 иллюстрирует четыре основных концепции альтернативной реализации CDM. Как и раньше, четырьмя понятиями являются типы, экземпляры, объектные сущности и отношения. Фиг.19 показывает подмножество данных, которые могут быть ассоциативно связаны с LOB-приложением, каковое, типично, может иметь дело со следующими разными видами данных: заказ, потребитель, товары заказа, адрес, поставщик, продукт, служащий и так далее. Рассмотрим прямоугольник, маркированный Customer (потребителем). В CDM это указывается ссылкой как объектная сущность и изображает самую высокоуровневую единицу данных, с которой работает приложение. Потребитель (Customer) имеет несколько полей: CustomerID (идентификатор потребителя), CompanyName (наименование компании), ContactName (наименование делового контакта), Address (адрес) и Phone (телефон). Каждое поле имеет тип, который определяет структуру данных, которые входят в такое поле. Можно легко увидеть, что идентификатор потребителя (CustomerID) является строкой фиксированной длины. Поля CompanyName (наименование компании) и ContactName (наименование делового контакта) также являются типами строки. Потребитель (Customer) сам имеет тип. Так как потребитель (Customer) является объектной сущностью, то этот тип может указываться ссылкой как тип объектной сущности. Также отметим, что поле Address (адреса) отличается от других полей: оно обладает внутренней структурой в виде других полей. В CDM тип такого поля называется составным типом. В противоположность, типы полей CustomerID (идентификатора потребителя), CompanyName (наименования компании) и ContactName (наименование делового контакта) - все являются простыми типами. Поле Phone (телефона) состоит из нескольких телефонных номеров, каждый из которых является строкой. Это названо как тип коллекции. Тип задает структуру (и определенные ограничения на значения); реальные данные сохраняются в экземплярах этих типов. Типы и экземпляры являются подобными классам и объектам, соответственно. Фиг.19 показывает экземпляры потребителя (Customer), заказа (Order) и детализации заказа (OrderDetail).
Оба, потребитель (Customer) и адрес (Address), похожи в том смысле, что они оба имеют внутреннюю структуру (скомпонованную из многочисленных полей). Но семантически и операционно потребитель (Customer) отличается от адреса (Address). Customer действует как единица для запроса, операций изменения данных, транзакций, устойчивости и совместного использования. Адрес (Address), с другой стороны, всегда существует в пределах потребителя (Customer) и не может быть независимо указан ссылкой или подвергнут воздействию иным образом. В CDM такие самые высокоуровневые единицы данных названы объектными сущностями. Все другие данные подразумеваются подставляемыми в объектной сущности.
Далее, глядя на заказ (Order), бизнес-правила требуют, чтобы каждый заказ имел соответствующего потребителя. Это моделируется отношением между объектной сущностью заказа (Order) и объектной сущностью потребителя (Customer). Есть разные виды отношений, поддерживаемые CDM. Одно, между заказом (Order) и потребителем (Customer), названо как ассоциация. Ассоциации типично используются, чтобы моделировать равноправные отношения между объектными сущностями. Каждый заказ составлен из нескольких товаров заказа (если у продавца книг заказаны пять книг, то информация о каждой книге является товаром заказа). Это моделируется как другой вид отношения - композиция. Каждый товар заказа (OrderLine) в пределах композиции является объектной сущностью.
Конфигурация данных описана определяющими типами. Концептуально тип является наименованием, данным набору значений. Например, если нечто является типом int, задан диапазон значений, который в точности является диапазоном целых чисел. Точное определение понятия типа требует экскурса в теорию категорий, которая находится за пределами объема этого документа. Таким образом, понятие типа постулируется в этом документе формально примитивным понятием. Система типов является механизмом для описания типов и ассоциативного связывания их с языковыми конструкциями.
Центральной по отношению к CDM является ее система типов. Данные, определенные с использованием этой системы типов, считаются строго типизированными, подобно CLR. Другими словами, есть предположение, что реализация предусматривает строгое принудительное применение правил типов без исключений; что все типы известны к моменту компиляции; и что любые преобразования типов являются предсказуемыми по их результату.
На высшем уровне, система типов CDM определяет две разновидности типов: типы объектной сущности и подставляемые типы. Типы объектных сущностей обладают уникальной идентичностью и формируют операционный блок непротиворечивости. Интуитивно, объектные сущности используются для моделирования “самых высокоуровневых” понятий, например, потребителей (Customer), заказов (Order), поставщиков (Supplier), и т.п. Подставляемые типы являются содержимыми типами. Они содержатся в пределах типа объектной сущности. Они существуют и уничтожаются совместно, совместно подвергаются действию транзакций и указываются ссылкой только в пределах контекста содержащей объектные сущности. Очень приближенно, тип объектной сущности подобен ссылочному типу в CLR, в то время как подставляемый тип подобен типу значения. Это является ограниченной аналогией и применяется только в том смысле, что подставляемые типы, подобно типам значения CLR, не обладают способностью независимого существования, тогда как типы объектных сущностей, подобно ссылочным типам CLR, могут существовать независимо и могут быть независимо указаны ссылкой.
Есть несколько разновидностей подставляемых типов: скалярные типы, составные типы, тип XML, тип FILESTREAM и коллекции этих типов. Некоторые из этих типов более подробно описаны ниже.
Язык описания схем (SDL) используется в качестве синтаксиса для описания типов. SDL является аналогичным подмножеству C# для описания классов или подмножеству языка описания данных (DDL) SQL. SDL выражается на XML (но он не является основанным на XSD). На всем протяжении этого описания SDL-фрагменты будут использоваться для иллюстрации концепции, являющейся описываемой.
Скалярные типы, в некотором смысле, являются простейшими типами имеющимися в распоряжении в системе типов. Они не имеют внутренней структуры, видимой системе. Скалярный тип представляет одиночное значение. CDM определяет три вида скалярных типов: простые типы (Simple Type), перечислимые типы (Enumeration Type) и ссылочные (Ref) типы.
Простые типы (Simple Type) являются встраиваемыми, примитивными типами, предусмотренными системой. Типы значения CLR используются в качестве простых типов CDM, таких как System.String, System.Boolean, System.Byte, System.Int16 и т.д. CDM также поддерживает некоторое количество типов, определенных в пространствах имен System.Storage и System.Data.SqlTypes (System.Storage.ByteCollection, System.Data.SqlTypes.SqlSingle…).
Перечислимый (Enumeration) тип определяет набор символических наименований, таких как (красный, синий, зеленый) или (весна, лето, осень, зима). Экземпляр перечислимого типа имеет значение, которое находится в пределах этого набора.
Экземпляр ссылочного (Ref) типа является значением, которое идентифицирует объектную сущность. Описание ссылочных (Ref) типов предоставлено ниже.
Простые типы могут быть использованы для построения более сложных (составных) типов. Составной тип может иметь наименование или может оставаться анонимным.
Именованный составной тип имеет наименование и набор членов. Член может быть таким же простым, как наименование и скалярный тип. Каждый член является скалярным типом (в этом случае, простым типом). Информационные члены, такие как эти, указываются ссылкой как свойства.
Две других разновидности членов могут существовать в составных типах: методы и расчетные свойства, которые будут описаны ниже. Составной тип также может содержать другие составные типы.
Анонимный составной тип, как подразумевает наименование, является структурно подобным составному типу, но не может быть использован для объявления свойств, основанных на нем. Анонимные составные типы возвращаются как результаты запросов (к примеру, в запросах, которые конструируют подмножество полей из объектных сущностей). Они существуют в CDM, чтобы гарантировать закрытие запроса. SDL не содержит синтаксиса для объявления этих типов.
Отметим одно различие между именованными и анонимными составными типами: два именованных составных типа с совершенно одинаковой структурой, но с разными наименованиями, подразумеваются индивидуальным типом. Но два анонимных составных типа с совершенно одинаковой структурой подразумеваются одним и тем же типом.
Тип объектной сущности является структурно похожим на составной тип тем, что он является типом, построенным из скалярных типов и других составных типов. Однако семантически и операционно он является совершенно другим - объектная сущность является допускающей уникальное указание ссылкой посредством идентичности, единицей непротиворечивости для различных операций, и так далее. Типы объектной сущности (Entity Type) определяются до некоторой степени подобно составным типам (Complex Type).
Коллекции сохраняют нулевое количество или более экземпляров подставляемых типов. В последующем примере, рассмотрим тип Person (действующего лица): этот тип сохраняет контактную информацию о человеке. Типично, сохраняются имя, домашний адрес, рабочий адрес, домашний телефон, рабочий телефон, мобильный телефон и идентификатор (ID) электронной почты (чтобы взять наиболее общее подмножество). Заметим, что в этом перечне существуют два адреса и три телефонных номера. Таковые могут быть смоделированы в качестве коллекций с использованием CDM, как показано в примере, приведенном ниже.
1. <ComplexType Name=”Person”>
2. <Property Name=”Name” Type=”String” />
3. <Property Name=”EmailID” Type=”String” />
4. <Property Name=”Addresses” Type=”Collection(Address)” />
5. <Property Name=”PhoneNumbers” Type=”Collection(String)” />
6. </ComplexType>
Строка 4 определяет коллекцию элементов Address (адреса) для поля Addresses (адресов). Строка 5 определяет коллекцию элементов String (строки) для поля PhoneNumbers (телефонные номера). Таким образом, действующее лицо может иметь, например, две коллекции под объектом Person (действующего лица) - Addresses (адресов) и PhoneNumbers (телефонных номеров). Коллекция Addresses (адресов) содержит два экземпляра типа Address (адреса), в то время как коллекция PhoneNumbers (телефонных номеров) содержит два экземпляра типа String (строки). В CDM коллекции могут быть определены для простых и составных типов.
Часто является желательным для коллекции обладать семантикой массива. Массив является коллекцией, где элементы упорядочены и проиндексированы. Заметим, что массив упорядочен, но не обязательно отсортирован. Например, [1,4,5,3] - упорядоченная коллекция, но неотсортированная. Она является упорядоченной, потому что можно потребовать второй элемент и будет гарантировано (в отсутствие явных изменений) возвращение «4».
Атрибут Array (массива) под-элемента <Collection> в <Property>, типизированном типом коллекции, когда установлен в истинное значение, превращает ее в массив. Array (массив) - необязательный атрибут, чье значение по умолчанию устанавливается в “false”.
Типично, модель данных, используемая приложением, содержит много разных типов. Некоторые из этих типов моделируют абсолютно разные понятия, например, потребителя (Customer) и заказа (Order). Такие типы не используют совместно никаких членов. Но другие типы моделируют понятия, которые обладают частицей сходства друг с другом, но по-прежнему являются разными. Например, рассмотрим потребителя (Customer) и служащего (Employee). Даже если они моделируют разные понятия, есть лежащая в основе нить общности между ними - оба содержат свойства для адреса, номера телефона и имени. Она является информацией, необходимой, чтобы с кем-нибудь связываться. Другими словами, она является контактной информацией.
Фиг.20 иллюстрирует, что CDM поддерживает понятие наследования типа. Наследование предоставляет типу возможность наследовать свойства, методы и расчетные свойства от другого типа. В примере Employee (служащий) и Customer (потребитель) наследуют от Contact (делового контакта). Здесь, Contact (деловой контакт) назван супертипом или базовым типом. Employee (служащий) и Customer (потребитель) названы подтипами или порожденными типами. Заданию подтипов нет необходимости останавливаться на единственном уровне. Является допустимым для подтипа быть родителем другого типа - например, Employee (служащий) может быть базовым у Manager (руководителя), Customer (потребитель) - базовым у PreferredCustomer (привилегированного потребителя) и так далее. Таким образом, целые иерархии наследования могут быть сформированы, как показано на фиг.20.
Хотя вышеприведенный пример показывает только наследование свойств, порожденные типы также наследуют методы и расчетные свойства от своего базового типа. CDM следует семантике CLR для наследования методов (поведения). SDL-спецификация (частичная) для вышеизложенной иерархии наследования показана в примере, приведенном ниже.
1. <ComplexType Name=”Contact”>
2. <Property Name=”Name” Type=”String” />
3. <Property Name=”Address” Type=”Address” />
4. <Property Name=”Phone” Type=”String” />
5. </ComplexType>
6. <ComplexType Name=”Customer” BaseType=”Contact”>
7. <Property Name=”CustomerID” Type=”String” />
8. <Property Name=”CompanyName” Type=”String” />
9. </ComplexType>
10. <ComplexType Name=”PreferredCustomer” BaseType=”Customer”>
11. <Property Name=”PreferenceCode” Type=”String” />
12. <Property Name=”CreditLimit” Type=”Decimal” />
13. </ComplexType>
14. <!-- Похожие объявления для Employee (служащего) и Manager (руководителя) -->
Как иллюстрировалось прежде, одна из целей наследования состоит в том, чтобы совместно использовать групповое понятие среди многочисленных типов. Еще одним назначением наследования является расширяемость. Даже после того как ISV (независимый поставщик программного обеспечения) реализует и развертывает иерархию наследования, потребители могут расширять типы, чтобы приспособить их назначения, посредством наследования. Ключом к становлению работы этой расширяемости является понятие замещаемости значения (также известное как полиморфизм): каждый экземпляр порожденного типа также является экземпляром базового типа. Так, если Manager (руководитель) является порожденным от Employee (служащего), то каждый экземпляр Manager (руководителя) также является экземпляром Employee (служащего). Значит, при запрашивании всех служащих (базового типа) возвращаются также и все руководители (порожденные типы).
Фиг.21 иллюстрируют таксономию CDM-типов для этой реализации. В этом разделе предоставляется уместная классификация типов в пределах системы типов CDM. Почти все данные, когда рассматриваются в пределах своего более широкого семантического контекста, будут тем или иным образом ограничены по области определения их типа. CDM делает возможной спецификацию различных ограничений по разным типам.
Ограничения простого типа. Набор допустимых значений для простого типа может быть ограничен многообразием способов, таких как ограничение длины (строчной или бинарной), точности, шкалы (десятичной) и так далее. Установленное по умолчанию ограничение дает возможность задания значения по умолчанию. Проверочное ограничение задает булево выражение по значению свойства. Если это выражение обращается в ложное значение, то значение свойства является недействительным.
Ограничения типа коллекции. Следующие ограничения поддерживаются по коллекциям: ограничение ElementOccurs (элемент встречается) задает минимальную и максимальную мощность множества коллекции. Ограничение Unique (уникальное) может быть использовано, чтобы гарантировать уникальность значений элемента коллекции. ElementConstraint (ограничение элемента) может быть использовано, чтобы задавать ограничения по типу, лежащему в основе коллекции (например, если определяют коллекцию типа Decimal (десятичного числа), то это <ElementConstraint> может быть использовано, чтобы задавать точность и шкалу).
Ограничение Check (проверка) задает булево выражение запроса. Это выражение должно обращаться в истинное значение для того, чтобы коллекция считалась действительной. Заметим, что это ограничение применяется к свойству коллекции как единому целому, а не к отдельному элементу в пределах коллекции.
Рекомендуется, чтобы разработчики типов всегда определяли уникальные ограничения по Collections (коллекциям), особенно, если ожидается, что коллекция будет содержать большое количество элементов. Во время работы, когда обновляется один элемент коллекции, ограничение уникальности дает возможность реализации делать целевым этот одиночный элемент для обновления, вместо переписывания всей коллекции. Это сокращает время обновления и сетевой трафик.
Ограничения порожденных типов. Является возможным ограничивать свойства базового типа в пределах порожденного типа посредством использования ограничений порожденных типов. Рассмотрим программу поощрения авиапассажиров, предлагаемую различными авиакомпаниями. United Airlines, например, имеет в распоряжении программу, названную Mileage Plus («преимущество расстояния в милях»). Эта программа имеет несколько уровней членства - член 1К, член Premier Executive, член Premier и «просто» член. Чтобы быть членом Premier, вы должны налетать, по меньшей мере, 25000 миль или 30 оплачиваемых участков; для Premier Executive и 1K, этими значениями соответственно являются 50000/60 и 100000/100. Заметим, что при определении ограничений порожденных типов ограничения должны быть совместимыми с ограничениями базовых типов. Например, если ограничение ElementOccurs (элемент встречается) в поле коллекции в базовом типе задает минимальное значение единицей и максимальное значение пятидесятью, то ограничение порожденных типов должно иметь минимальное значение, большее чем единица, а максимальное значение, меньшее чем пятьдесят.
Ограничение обнуляемости. Как простые, так и составные типы могут задавать ограничение обнуляемости. Это означает, что экземпляр этого типа может хранить значение NULL (нуля). Это задается посредством атрибута Nullable (обнуляемый) в элементе <Property>.
Заметим, что свойства коллекции могли бы не быть установлены в Nullable и что Nullable допускается даже в типизированных составным типом свойствах. Значением по умолчанию атрибута Nullable является “true”.
До сих пор предоставлялись основные возможности моделирования, предусмотренные системой типов CDM этой альтернативной реализации. CDM является обогащенным набором встроенных типов, имеющим возможности определять составные типы, создавать перечисления, выражать ограничения, наследование и замещаемость значений (полиморфизм).
Как только эти типы спроектированы и развернуты в системе, приложение начинает создавать и манипулировать экземплярами этих типов. Различные операции, такие как копирование, перемещение, запрашивание, удаление, резервирование/восстановление (для сделанных устойчивыми данных) и так далее, выполняются над экземплярами типов. В последующем описана операционная семантика CDM.
Типы и экземпляры. Тип определяет структуру данных. Реальные данные сохраняются в экземплярах типов. В объектно-ориентированных языках, например, тип и экземпляры названы классами и объектами.
Фиг.22 иллюстрирует понятие типов и экземпляров в этой реализации CDM. Эллипсами на фиг.22 являются реальные данные, тогда как параллелепипедами являются типы, то есть метаданные.
Типы объектной сущности и подставляемые типы. Еще раз посмотрев на данные, используемые гипотетическим LOB-приложением, с одной стороны, они содержат типы, такие как Customers (потребители) и Orders (заказы), а с другой стороны, они также содержат типы, такие как Address (адрес) и AddressLine (строка адреса). Каждый из этих типов имеет структуру, то есть каждый может быть разложен на многочисленные поля. Однако, есть два ключевых различия между типом потребителя (Customer) и типом адреса (Address). Экземпляры типа потребителя (Customer) обладают независимым существованием, тогда как экземпляры типа адреса (AddressType) существуют только в пределах (например) экземпляра типа потребителя (Customer).
В этом смысле, потребитель (Customer) является самым высокоуровневым типом; экземпляры этого типа существуют независимо, независимо указываются ссылкой («покажите мне потребителя (Customer), чьим наименованием компании (CompanyName) является …») и независимо подвергаются действию транзакций. Адрес (Address), с другой стороны, является содержимым типом - его экземпляры существуют только в пределах контекста экземпляра самого высокоуровневого типа, например, «адрес потребителя» или «адрес отгрузки заказа», и так далее.
Тип потребителя (Customer) обладает идентичностью, тогда как тип адреса (Address) - нет. Каждый экземпляр потребителя (Customer) может быть уникально идентифицирован, и может быть предпринято указание его ссылкой. Тип адреса (Address) не может быть отдельно идентифицирован вне типа, к примеру, потребителя (Customer). Это основополагающее различие формализовано в CDM посредством понятия типов объектной сущности (Entity Type) и подставляемых типов (Inline Types). В примере LOB, приведенном выше, потребитель (Customer) является типом объектной сущности (Entity), тогда как адрес является подставляемым (Inline) типом.
Характеристики объектных сущностей. Хотя тип объектной сущности является структурно похожим на составной тип, он обладает несколькими характеристиками, которые отличают его от подставляемых типов. Эти характеристики наделяют экземпляр объектной сущности особой операционной семантикой. Объектная сущность (Entity) является экземпляром типа объектной сущности. Объектная сущность является наименьшей единицей данных CDM, которая может независимо существовать. Это подразумевает следующие характеристики:
Идентичность: каждая объектная сущность обладает идентичностью. Гарантировано, что эта идентичность ссылается на объектную сущность и только эту объектную сущность в течение времени ее существования. Наличие идентичностей подразумевает, что может быть предпринято указание ссылкой на их объектные сущности.
Идентичность объектной сущности является причиной того, почему объектная сущность является «самой высокоуровневой» единицей данных - каждая объектная сущность является пригодной для указания ссылкой и, следовательно, может быть использована при запрашивании, обновлении и других операциях.
Единица непротиворечивости: гарантировано, что запросы и обновления являются непротиворечивыми на уровне объектных сущностей. Объектная сущность является целевым объектом большинства CDP-операций, таких как копирование, перемещение, удаление, резервирование, восстановление, и т.п. Эти операции не нацеливаются на подставляемые типы.
Единица транзакций: транзакции происходят на уровне объектной сущности. Сформулировав иначе, объектные сущности могут быть подвергнуты транзакции порознь, но подставляемые типы всегда подвергаются транзакции в пределах контекста содержащей объектные сущности.
Единица для отношений: отношения задаются на уровне объектных сущностей, а не подставляемых типов. Объектные сущности могут сотноситься друг с другом посредством композиции и ссылочной ассоциации. Экземпляр подставляемого типа не может быть источником или целевым объектом отношения.
Единица устойчивости: объектная сущность является единицей устойчивости. Подставляемые типы не делаются устойчивыми сами по себе, но находятся в устойчивом состоянии всего лишь как части объектной сущности. По существу, подставляемые типы действуют по значению - отсюда, они должны быть сохранены как часть объектной сущности.
Заметим, однако, что сама CDM как не подразумевает, так и не требует, чтобы объектные сущности делались устойчивыми. CDM остается непротиворечивой, независимо от того, находятся ли объектные сущности в памяти или сделаны устойчивыми.
Единица совместного использования: объектная сущность является единицей совместного использования в пределах модели данных. Например, LOB-приложение содержит понятие продукта (Product). Поставщик (Supplier) поставляет один или более продуктов. Заказ (Order) содержит один или более продуктов. Для того чтобы предотвратить избыточное хранение информации о продукте, может быть определена объектная сущность продукта (Product), а ссылки на экземпляры этой объектной сущности могут быть помещены в пределах объектных сущностей заказа (Order) и поставщика (Supplier). Если, с другой стороны, Product (продукт) является подставляемым типом, то как заказ (Order), так и поставщик (Supplier) должны содержать экземпляры продукта (Product), приводя к избыточному хранению и аномалиям вставки, удаления и обновления, которые являются следствием этого.
Фиг.23 иллюстрирует, каким образом типы объектной сущности и подставляемые типы объявляются с использованием SDL. Объектные сущности объявляются с использованием элемента <EntityType>, как показано в строках 14-27. Свойства типа объектной сущности являются свойствами подставляемого типа (по определению). Есть несколько разновидностей подставляемых типов. Скалярные типы: напомним, что скалярные типы могут быть дополнительно подразделены на простые, ссылочные (Ref) и перечислимые типы. Простые подставляемые типы встроены в каркас CDM - в некотором смысле они уже объявлены и доступны для использования. В примере по фиг.23, использование таких типов изображено в строках 8, 9, 10, 11, 12, 15 и 18.
Перечислимые типы объявляются с использованием элемента <EnumerationType>, как показано в строках 1-5. Как только эти типы объявлены, они могут быть использованы в пределах любого составного (Complex Type) или типа объектной сущности (Entity Type) (см. строку 8).
Типы XML и FILESTREAM (не показаны в этом примере) являются встроенными типами, но не совсем скалярными (то есть, модель данных может делать вывод о содержимом этих типов до ограниченной степени).
Составные типы объявляются с использованием элемента <ComplexType>, как показано в строках 7-13. Свойства составного (Complex) типа могут быть любым подставляемым типом - типом скалярным, коллекции или составным. Как только объявлен, составной (Complex) тип может быть использован в пределах любых составных (Complex) типов или типов объектной сущности (Entity).
Типы коллекций объявляются с использованием ключевого слова Collection (коллекция), сопровождаемого наименованием подставляемого типа. Коллекция типов адреса (AddressType) показана в строке 22.
Как описывалось ранее, основополагающей характеристикой объектной сущности является тот факт, что она обладает уникальной идентичностью. Гарантируется, что идентичность объектной сущности должна выдерживать обновления объектной сущности и продолжать идентифицировать одну и ту же объектную сущность на всем протяжении ее времени существования. Объектная сущность также обладает ключевым атрибутом. Этот ключ является состоящим из одного или более свойств. Требуется, чтобы ключи объектной сущности были уникальными в пределах набора объектных сущностей (EntitySet). Ключи объектной сущности могут быть использованы реализацией, чтобы формировать идентичность объектной сущности. Ключи объектной сущности задаются с использованием атрибута «Key» элемента <EntityType>. Любой набор типизированных скалярным (в том числе ссылочными (Ref) типами) или составным типом свойств может служить в качестве ключа по отношению к типу объектной сущности до тех пор, пока по меньшей мере одно свойство в ключе является необнуляемым. Типизированные типом коллекции (Collection) свойства не должны быть частью ключа.
Заметим, что только базовый тип иерархии типов объектной сущности может задавать ключ. Порожденные типы автоматически наследуют ключи от базового типа. Это осуществляет поддержку, заставляя замещаемость значения (полиморфизм) работать детерминировано.
Ссылки объектной сущности. Поскольку объектная сущность обладает идентичностью, является возможным иметь в распоряжении ссылки объектной сущности. В этой реализации CDM ссылки объектной сущности используются главным образом для навигации отношений. Например, объектная сущность потребителя (Customer) соотнесена с объектной сущностью заказа (Order) посредством отношения Customer_Order (потребитель_заказ). Задавшись заказом (Order), возможно находить ассоциативно связанного потребителя (Customer) с использованием особого свойства в объектной сущности заказа (Order) (известного как свойство отношения). Это свойство типа Ref(Customer). Ключевое слово Ref обозначает, что это ссылка на другой тип объектной сущности.
Также является возможным явным образом определять типизированное ссылочным (Ref) типом свойство в пределах типа объектной сущности или составного типа. Это свойство служит в качестве «указателя» на указываемую ссылкой объектную сущность. Существование типизированного ссылочным (Ref) типом свойства не определяет и не подразумевает отношения между содержащими и указываемыми ссылкой типами объектной сущности. Отношения должны быть определены явным образом. В случае со сделанными устойчивыми объектными сущностями, ссылки являются долговременными.
Подставляемые типы. Объектная сущность либо существует сама по себе на высшем уровне, или содержится в пределах набора объектных сущностей. Объектная сущность не может быть встроенной непосредственно в пределах другой объектной сущности или составного типа. Составной тип, с другой стороны, может быть встроенным в другом составном типе или типе объектной сущности. То есть, как объектные сущности, так и составные типы могут содержать свойства, чьим типом является составной тип.
Скалярные типы и коллекции также могут быть встроены в другие составные типы или типы объектной сущности. Это является причиной того, почему составные типы, коллекции и скалярные типы совместно упоминаются как подставляемые типы.
Наборы объектных сущностей и контейнеры объектных сущностей. Предусмотрены два сценария, которые помогают описать, где существуют экземпляры объектной сущности. Экземпляры объектной сущности делаются устойчивыми в некотором хранилище данных. Сама CDM предусмотрительно создана агностической относительно хранилища. Она теоретически может быть реализована посредством многообразия технологий хранения. Объектные сущности также обладают промежуточным существованием в памяти. CDM не задает, каким образом они материализуются в памяти и делаются доступными приложению. Приложение типично имеет дело с многочисленными экземплярами объектных сущностей различных типов. Эти экземпляры могут либо жить сами по себе на высшем уровне, или быть содержащимися в пределах наборов объектных сущностей. Набор объектных сущностей содержит экземпляры объектных сущностей данного типа (или его подтипа). Ключ объектной сущности является значащим в пределах набора объектных сущностей. Каждая объектная сущность в пределах набора объектных сущностей должна иметь уникальный ключ.
Контейнером объектных сущностей (Entity Container) является группа из одного или более наборов объектных сущностей. Контейнер объектных сущностей используется для задания области отношений ассоциации и композиции. Контейнер объектных сущностей также является единицей устойчивости и административной единицей, по которой определены резервирование, восстановление, пользователи, роли и другая подобная семантика.
Схема является организационной структурой для хранения типов, отношений и других наименований. Она предоставляет пространство имен, в пределах которого применяются обычные правила уникальности наименований. Схема определяется с использованием элемента <Schema> и является самым высокоуровневым элементом SDL-файла. Все типы объектной сущности, отношения, составные и так далее, должны быть определены в пределах схемы. Схемы, определенные где-либо в другом месте, могут быть импортированы с использованием элемента <Using>, а типы, определенные в них, могут быть указаны ссылкой с использованием их полностью уточненного наименования. Также является возможным использовать типы непосредственно в другой схеме (например, без включения элемента <Using>, посредством использования полностью уточненного синтаксиса: Namespace.Type-name (Пространство имен.типа-наименование). <Using> является синтаксическим сокращением, чтобы сократить набор текста. Тип, определенный в любой развернутой схеме, может быть использован посредством предоставления полностью уточненного наименования этого типа.
Спецификация CDM умалчивает о том, что должно происходить с того момента, когда типы записаны на SDL. Что касается типов, которые записаны на SDL, CDP - которая реализует CDM, предоставляет инструментальные средства, которые принимают SDL-описание и развертывают эти типы в хранилище. В зависимости от природы хранилища, это развертывание может включать в себя создание абстракций уровня хранилища. Например, если хранилищем является RDBMS, то развертывание создавало бы базы данных и таблицы, соответствующие схемам и типам. Оно также могло бы создавать SQL-код для принудительного применения модели ограничений и данных. В качестве альтернативы, CDP может быть использована с существующей базой данных посредством приведения таблиц базы данных в соответствие с CDM-типами.
В дополнение к создаваемым записям уровня хранилища инструментальные средства CDP также сформируют CLR-классы, соответствующие типам и отношениям. Реализация может использовать атрибут Namespace (пространство имен) элемента <Schema>, чтобы создавать пространства имен CLR для задания области этих классов. CDP также поддерживает приведение существующих объектных моделей в соответствие CDM-типам. Заметим, что CDM-типы не требуют хранилища. Являются возможными развертывания в оперативной памяти.
Любой значащий набор реальных данных всегда содержит отношения между своими составляющими частями. Например: Потребитель размещает один или более заказов, заказ содержит детализации заказа, продукт имеется в наличии у одного или более поставщиков и так далее. В этой фразе данные показаны курсивом, а отношения между ними - в качестве подчеркнутых. Ясно, что понятие отношений является неотъемлемым для любой попытки информационного моделирования. Реляционная модель не поддерживает отношения явным образом. Первичные ключи, внешние ключи и целостность ссылочных данных предоставляют инструментальные средства, чтобы реализовать некоторые из ограничений, подразумеваемых отношениями. Ключевым значением CDM является ее поддержка отношений в качестве первоклассного понятия в пределах самой модели данных. Это предусматривает более простые и богатые возможности моделирования. Поддержка отношений также распространяется на CDM-запросы, которые предоставляют взаимоотношениям возможность быть явным образом указанными ссылкой в запросе и предоставляют возможность осуществлять навигацию на основании отношений.
Фиг.24 иллюстрирует многие разновидности отношений, поддерживаемых CDM. В реальных сценариях моделирования есть много разных видов отношений - они обладают разными порядками (одинарное, бинарное …), кратностью (1-1, 1-многие, многие-многие) и семантикой (включения, равноправия …). CDM обладает возможностью моделировать все эти разные типы отношений. В CDM отношения определяются на уровне объектных сущностей. Есть два способа соотнесения объектных сущностей: ассоциации и композиции. Ассоциации (Association) моделируют «равноправные» отношения, а композиции (Composition) моделируют отношения «родитель-потомок».
Семантика моделирования может потребовать, чтобы соотнесенные объектные сущности действовали в качестве единиц для различных операций. Например, рассмотрим отношение Contains (содержит) между заказом (Order) и товаром заказа (OrderLine) по фиг.24. Является обоснованным ожидать, что операция копирования или сериализации над заказом (Order) будет иметь результатом также и копирование или сериализацию ассоциативно связанных товаров заказа (OrderLines). CDM определяет по меньшей мере пять операций: удалить, копировать, сериализовать, защитить и блокировать. Поведение может быть задано по соотнесенным объектным сущностям в ответ на эти операции. Заметим, что, в дополнение к ссылочным ассоциациям и композициям, могут существовать два других способа соотнесения объектных сущностей: условные ассоциации и объектные сущности ассоциации.
Ассоциации являются одним из наиболее общих и полезных отношений при моделировании данных. Классическим примером ассоциации является отношение между объектными сущностями потребителя (Customer) и заказа (Order). Типично, это отношение включает в себя кратность, где каждый заказ (Order) ассоциативно связан в точности с одним потребителем (Customer). Каждый потребитель (Customer) имеет нуль или более заказов (Order). Отношение также может включать в себя операционное поведение: полезно оперировать соотнесенными объектными сущностями, как если бы они были единым целым. Например, когда потребитель (Customer) с неоплаченными заказами (Order) удаляется, копируется или сериализуется, для соответствующих заказов (Order) может быть желательным также становиться удаленными, скопированными или сериализованными. Элемент <Association> используется, чтобы моделировать это отношение.
1. <EntityType Name="Order" Key="OrderId">
2. <Property Name="OrderId"
3. Type="String"/>
4. <!--Other Properties-->
5. </EntityType>
6.
7. <EntityType Name="Customer" Key="CustomerId">
8. <Property Name="CustomerId"
9. Type="String"/>
10. <!--Other Properties-->
11. </EntityType>
12.
13. <Association Name=”Order_Customer”>
14. <End Type=”Order” Multiplicity=”*” />
15. <End Type=”Customer” Multiplicity=”1”>
16. <OnDelete Action=”Cascade” />
17. </End>
18. </Association>
Атрибут «Type» в <End> определяет тип объектной сущности, участвующий в отношении.
Атрибут «Multiplicity» определяет мощность множества стороны. В этом примере задано, что есть в точности один потребитель (Customer) (значением в строке 15 является “1”) для нуля или более заказов (значением в строке 14 является “*”). Другими значениями для этого атрибута являются:
"0..1" - нуль или один
• "1" - в точности один
• "*" - нуль или более
• "1..*" - один или более
• "n" - в точности n
• "n..m" - между n и m включительно, где n является меньшим или равным m.
Элемент <OnDelete> в строке 16 задает операционное поведение для операций удаления. Он содержит один атрибут, “Action”, который может иметь одно из 3 значений. Cascade (каскадировать) - удалять все заказы (Order), принадлежащие потребителю (Customer). Это является тем, что показано в примере, изложенном выше. Restrict (ограничить) - предотвратить удаление потребителя (Customer), когда существуют неоплаченные заказы (Order). RemoveAssociation (удалить ассоциацию) - удалить отношение между заказами (Order) и потребителем (Customer). Заметим, что для того, чтобы иметь в распоряжении непротиворечивую семантику, элемент <OnDelete> разрешен только на одной из сторон отношения.
CDM делает возможным задание поведения по другим операциям: копирования, сериализации, защиты и блокирования. Они все придерживаются того же самого шаблона, который проиллюстрирован для поведения удаления - посредством использования под-элемента вида <OnOperation Action=”…”>. Спецификация операционного поведения может быть выполнена как по ассоциациям, так и композициям.
Ассоциации моделируют равноправные отношения. Композиции моделируют отношения строгого включения (родитель-потомок). Классическим примером композиции является отношение между заказом (Order) и вхождениями товаров (Line), ему соответствующих. Заказной товар полностью управляется своим родительским заказом. Семантически он не имеет значимого существования вне содержащего заказа. Удаление заказа принудительно применяет удаление всех заказных товаров. Таким образом, объектные сущности заказа (Order) и товара (Line) указываются ссылкой как являющиеся соотнесенными посредством композиции (то есть, заказ (Order) является скомпонованным из одной или более объектных сущностей товара (Line)).
Отношение композиции обладает тремя следующими характеристиками:
Уникальность: Потомки данного родителя должны обладать между собой уникальным ключом. Например, товар (Line), принадлежащий заказу (Order), должен иметь уникальный ключ, чтобы отличать его от всех других товаров (Line) для того же самого заказа (Order). Общий способ реализации этого мог бы состоять в том, чтобы получать идентичность потомка посредством комбинирования его ключа и идентичности родителя.
Каскадное удаление: Удаление родителя удаляет потомка.
Кратность: Кратностью родителя является единица. Это выражает семантику, что товар (Line) не может существовать без заказа (Order).
Элемент <Composition> используется, чтобы моделировать композицию.
Заметим, что нет необходимости задавать «Multiplicity» («кратность»)) для родителя, потому что она всегда является единицей для композиции. Фактически, является ошибкой задавать «Multiplicity» иную, чем единица для родителя композиции. Кратность может быть задана для дочерней стороны, и она может иметь любое из значений, приведенных ниже.
Операционные поведения могут быть заданы по композициям - для операций копирования, сериализации, защиты и блокирования. Заметим, что нет необходимости задавать <OnDelete>, потому что композиция всегда обладает семантикой каскадного удаления. Является ошибкой: задавать <OnDelete Action=”x”>, где x является не равным “Cascade”, и задавать <OnDelete> на дочерней стороне.
Часто является полезным оперировать соотнесенными объектными сущностями, как если бы они были единым целым. Например, при копировании объектной сущности заказа (Order), обычно желательно, чтобы соответствующие объектные сущности товара (Line) также копировались. CDM дает возможность задания этих поведений для различных операций: удаления, копирования, сериализации, защиты и блокирования. Используемый общий шаблон должен определять под-элемент вида <OnOperation Action=”value”/>. Operation (операция) может быть одной из Delete (удалить), Copy (копировать), Serialize (сериализовать), Secure (защитить) или Lock (блокировать). В зависимости от операции (Operation), значение "Action" может быть Cascade (каскадировать), Restrict (ограничить), RemoveAssociation (удалить ассоциацию), и т.д.
Следующие моменты должны быть приняты во внимание при задании операционной семантики: все элементы <OnOperation.../> должны быть заданы только на одной из сторон отношения. Может быть недопустимым (например) задавать <OnDelete> по потребителю (Customer) и <OnCopy> по заказу (Order). Концептуальная модель здесь состоит в том, что одна из сторон отношения находится в управляющей роли; операционная семантика ниспадает от такой объектной сущности ко всем другим сторонам. Нет необходимости задавать <OnDelete…/> для композиции. По определению, удаление родителя композиции каскадирует операцию вниз, до потомка. Все элементы <OnOperation…/> должны быть заданы по родителю композиции. Сторона, которая задает <OnDelete> или <OnSecure> при Action=”Cascade”, должна обладать кратностью “1”. В ином случае, семантика становится противоречивой.
Отношения в CDM определяются вне типов, которые в них участвуют. Сами типы не обязаны содержать специального свойства, чтобы установить отношение. Например, отношение Order_Customer (Заказ_Потребитель) может быть задано с использованием самого высокоуровневого элемента <Association>; типы Customer (потребителя) и Order (заказа) не содержат свойства или другие идентифицирующие метки внутри них, чтобы указывать, что они участвуют в отношении друг с другом.
Различные механизмы в запросе или API могут быть выдуманы для осуществления навигации от одной стороны отношения до другой. Например, CDP API содержит статический класс для каждого отношения, класс содержит методы, которые могут быть использованы для навигации. Возьмем пример Order_Customer (Заказ_Потребитель), класс мог бы быть назван Order_Customer, и методами могли бы быть GetOrdersGivenCustomer(…) (получить заказы данного потребителя) и так далее.
Однако наиболее наглядным способом было бы фактически иметь свойство на каждой стороне отношения. Например, если бы Order (заказ) содержал свойство, названное Customer (потребитель), то навигация была бы такой же простой, как осуществление доступа к свойству. Чтобы сделать возможным этот простой шаблон для навигации отношений, CDM содержит понятие свойств отношения. Они могут быть определены в объектной сущности в целях выражения осуществления навигации до соотнесенной объектной сущности. Свойства отношения определяются с использованием элемента <RelationshipProperty>. Элемент <RelationshipProperty> содержит три атрибута. “Name” определяет наименование свойства. Это наименование может быть использовано в запросах или API, чтобы осуществлять навигацию до другой стороны отношения. “Relationship” задает наименование ассоциации или композиции. “End” идентифицирует целевой объект навигации. Свойства отношения могут быть определены для отношений как ассоциации, так и композиции, и могут быть определены на каждой стороне отношения.
Заметим, что в отличие от «обычных» свойств, свойства отношения не содержат атрибута “Type”. Это происходит потому, что они неявным образом приведены к типу ссылки объектной сущности (Entity Ref) (или коллекции ссылок объектной сущности). Эта ссылка объектной сущности используется, чтобы осуществлять навигацию до целевой объектной сущности.
Свойство отношения является либо одиночной ссылкой объектной сущности (Entity Ref) или коллекцией ссылок объектной сущности, в зависимости от кратности стороны, на которую она нацеливается. Следующая таблица показывает возможные значения для “Multiplicity” («кратности») и типы соответствующих свойств отношения:
| Кратность | Тип свойства отношения |
| "0..1" | Ref(тип объектной сущности), Nullable=”true” |
| "1" | Ref(тип объектной сущности), Nullable=”false” |
| "*" | Collection(Ref(entity-type)), <ElementOccurs Minimum=”0” Maximum=”unbounded”/> |
| "1..*" | Collection(Ref(тип объектной сущности)), <ElementOccurs Minimum=”1” Maximum=”unbounded” /> |
| "n" | Collection(Ref(тип объектной сущности)), <ElementOccurs Minimum=”n”, Maximum=”n” /> |
| "n..m" | Collection(Ref(тип объектной сущности)), <ElementOccurs Minimum=”n”, Maximum=”m” /> |
Как описывалось ранее, объектная сущность может либо существовать «сама по себе» на высшем уровне, или находиться в пределах набора объектных сущностей (который сам находится в пределах контейнера объектных сущностей). Рассмотрим ситуацию в пределах контекста двух сторон отношения. В случае «свободно плавающих» объектных сущностей обе стороны отношения существуют где-то в пределах «океана» объектных сущностей. Рассмотрим, когда объектные сущности группируются в многочисленные наборы объектных сущностей. Например, рассмотрим следующий фрагмент схемы:
1. <EntityContainerType Name=”LOBData”>
2. <Property Name="Orders" Type="EntitySet(Order)"/>
3. <Property Name="GoodCustomers"
Type="EntitySet(Customer)"/>
4. <Property Name="BadCustomers"
Type="EntitySet(Customer)"/>
5. </EntityContainerType>
6. <EntityType Name="Customer" Key="CustomerId">
7. …
8. </EntityType>
9. <EntityType Name="Order" Key="OrderId">
10. …
11. </EntityType>
12. <Association Name=”Order_Customer”>
13. <End Type=”Order” Multiplicity=”*” />
14. <End Type=”Customer” Multiplicity=”1”>
15. <OnDelete Action=”Cascade” />
16. </End>
17. </Association>
Контейнер (LOBData) объектных сущностей содержит три набора объектных сущностей: Orders (заказы), GoodCustomers (хорошие потребители) и BadCustomers (плохие потребители). Все объектные сущности Customer (потребителя) в GoodCustomers (хороших потребителях) обладают весьма хорошим доверием и, следовательно, считаются достойными размещения заказов. BadCustomers (плохие потребители) не выполнили обязательства по своим платежам. Очевидное бизнес-правило здесь состоит в том, чтобы требовать только хороших потребителей (GoodCustomers) для размещения заказа (Order). Другими словами, ограничить область отношения Customer_Order (Потребитель_Заказ) из условия, что только объектные сущности хороших потребителей (GoodCutomers) могут приобретать заказы (Orders). Кроме того, все заказы (Order) должны находиться в наборе объектных сущностей заказов (Orders). Это делается посредством использования элемента <Scope> внутри <EntityContainerType>, как показано ниже:
1. <EntityContainerType Name="LOBData">
2. <Property Name="Orders" Type="EntitySet(Order)"/>
3. <Property Name="GoodCustomers"
Type="EntitySet(Customer)"/>
4. <Property Name="BadCustomers" Type="EntitySet(Customer)"/>
5. <Scope Relationship=”Order_Customer”>
6. <End Type=”Customer” EntitySet=”GoodCustomers” />
7. <End Type=”Order” EntitySet=”Orders” />
8. </Scope>
9. </EntityContainerType>
Элемент <Scope> (строка 5) содержит один атрибут “Relationship”, который идентифицирует ассоциацию или композицию, чьи стороны являются ограниченными областью. Под-элементы <End>, один для каждой стороны отношения, используются, чтобы задавать набор объектных сущностей, до которой эта сторона ограничена областью. По строке 6 видно, что сторона потребителя (Customer) ограничена область набора объектных сущностей хороших потребителей (GoodCustomers); а по строке 7 сторона заказа (Order) ограничена областью набора объектных сущностей заказов (Orders).
Если развернутая схема содержит контейнер объектных сущностей, то каждая сторона каждого отношения ограничивается по области одним и только одним набором объектных сущностей в пределах контейнера объектных сущностей. Если явно заданный оператор <Scope> отсутствует для данной ассоциации или композиции, то реализация ограничивает область сторон установленными по умолчанию наборами объектных сущностей. Способ, которым производится неявное задание области, является определяемой реализацией.
CDM делает возможным специфицирование более строгих правил задания области для композиций. Рассмотрим композицию между заказом (Order) и товаром (Line). Для товара (Line) не имеет смысла существовать без соответствующего заказа (Order). Таким образом, набор объектных сущностей, который содержит объектные сущности товара (Line), должен принудительно применять бизнес-правило, что каждый товар (Line) должен быть потомком одного и только одного заказа (Order). Это делается с использованием элемента <Requires>.
Следующие требования задания области удовлетворяются вышеприведенным примером: Сторона Line (товара) у Shipment_Line (Отгрузка_Товар) должна быть ограничена областью набора объектных сущностей ShipmentLines (товары отгрузки) (строка 16). Каждый товар (Line) в товарах отгрузки (ShipmentLines) должен быть стороной композиции Shipment_Line (Товар_Отгрузка). Это сделано в строке 7 с использованием элемента <Requires>. Этот элемент содержит один атрибут “Relationship”, который идентифицирует композицию. Сторона товара (Line) у Order_Line (Заказ_Товар) должна быть ограничена областью набора объектных сущностей товаров заказа (OrderLines) (строка 12). Каждый товар (Line) в товарах заказа (OrderLines) должен быть стороной композиции Order_Line (Заказ_Товар) (строка 4). Если элемент <Requires> отсутствует в наборе объектных сущностей, то он не ограничен содержанием объектных сущностей, принадлежащих любой данной композиции. Это может быть важным требованием во многих сценариях моделирования. Заметим, что элемент <Requires> может быть использован, чтобы задавать только одно наименование композиции.
Альтернативное описание CDM до сих пор было агностическим относительно того, где в точности находятся объектные сущности. Объектные сущности могут находиться в памяти или быть фактически сделанными долговременно устойчивыми в хранилище. Основная CDM не подразумевает, не требует и не заботится о том, где находятся объектные сущности - объектные сущности могут находиться в памяти или делаться устойчивыми. Последующее является описанием сделанных устойчивыми объектных сущностей и каким образом CDM поддерживает понятие устойчивости.
Контейнер объектных сущностей является самой высокоуровневой организационной единицей для объектных сущностей и является уровнем, на котором определяется семантика устойчивости. Объектная сущность является наименьшей единицей данных, которая может быть сделана устойчивой. Типично, сделанные устойчивыми объектные сущности обладают операционной семантикой, ассоциативно связанной с ними, такой как копировать, переместить, резервировать, восстановить, сериализовать и т.п. Контейнер объектных сущностей является единицей устойчивости, на которой эта семантика может быть определена. Он также является организационной единицей, в которой определяются административные понятия, такие как резервирование, восстановление, пользователи, роли и т.д. В этом смысле, контейнер объектных сущностей подобен базе данных SQL.
Контейнер объектных сущностей содержит один или более наборов объектных сущностей, в пределах которых находятся все объектные сущности. Таким образом, определение экземпляра контейнера объектной сущности дает толчок процессу выделения хранилища. Типично, разработчик типов определяет тип контейнера объектных сущностей. Сама CDM не определяет, каким образом экземпляр контейнера объектных сущностей получен из типа и каким образом этот экземпляр приводится в соответствие лежащим в основе структурам хранения (таким как EntityContainer->Database (контейнер объектных сущностей -> база данных), Entity set -> table(s) (набор объектных сущностей -> таблица(ы)), и т.д.). CDP определяет набор директивных преобразований между контейнером объектных сущностей (и типами, содержащимися в нем) и SQL-хранилищем. CDP также делает возможными недирективные (определяемые пользователем) преобразвания для того же самого.
Вообще, приложения вольны организовывать объектные сущности любым способом, который они избирают - CDM не навязывает никакой конкретной организационной структуры. При разговоре о сделанных устойчивыми объектных сущностях, тем не менее, семантика объектных сущностей, наборов объектных сущностей и контейнера объектных сущностей (Entity Container) подразумевает определенную структурную организацию. Когда объектные сущности сделаны устойчивыми: каждая объектная сущность должна существовать в пределах набора объектных сущностей; каждый набор объектных сущностей должен существовать в пределах контейнера объектных сущностей (Entity Container), а контейнер объектных сущностей (Entity Container) должен существовать на высшем уровне.
Фиг.25 иллюстрирует структурную организацию для делаемых устойчивыми объектных сущностей в CDM. Это является логическим представлением данных, а не физическим. Каждый показанный набор объектных сущностей может быть приведен в соответствие, например, таблице. Эта таблица почти достоверно могла бы иметь дополнительные столбцы для представления отношений. Можно вообразить себе набор объектных сущностей заказов (Orders) являющийся преобразуемым в таблицу заказов (Orders), которая содержит столбец идентификатора потребителя (CustomerID). Поскольку CDM не предписывает распределение хранилища, описание оставлено на логическом уровне. Можно увидеть, что каждая объектная сущность является резидентной в пределах набора объектных сущностей. Дополнительно, каждый набор объектных сущностей содержится в пределах контейнера объектной сущности (EntityContainer) (MyLobDB в примерном представлении). Чтобы завершить это описание структурной организации, заметим, что CDM-хранилище состоит из одного или более контейнеров объектных сущностей (EntityContainer).
Не все разработчики приложений определяют типы; большинство из них используют типы, которые были описаны и развернуты другими ISV-поставщиками. В материалах настоящей заявки предусмотрен механизм, чтобы пользователь был способен расширять предопределенный тип специальными способами, не причиняя ущерба верности исходного типа. Расширения объектной сущности (Entity Extensions) и расширяемые перечисления (Extensible Enumerations) - два средства, предусмотренные в CDM, чтобы сделать возможной независимую расширяемость типов.
Фиг.26 иллюстрирует использование расширений объектной сущности в этой реализации CDM. Чтобы мотивировать необходимость и использование для расширений объектной сущности, рассмотрим тип делового контакта (ContactType). Он содержит стандартные свойства для имени (Name), адреса (Address), и телефонного номера (PhoneNumber). Допустим, что ISV программного обеспечения GPS (глобальной системы местоопределения) желает добавить информацию широты и долготы к этому типу. Один из способов сделать это мог бы состоять в том, чтобы модифицировать действующий тип делового контакта (ContactType); это нежелательно, потому что есть много других пользователей этого типа в системе. Другой способ мог бы заключаться в том, чтобы задать подтип нового класса от типа делового контакта (ContactType), названный ContactWithGPSType (тип делового контакта с GPS). Это могло бы означать, что все пользователи типа адреса (AddressType) теперь будут должны изменить свой код, чтобы использовать ContactWithGPSType; кроме того, GPS-информация не может быть добавлена к существующим деловым контактам в системе - они должны быть переделаны в этот новый тип.
CDM изящно решает эту проблему посредством понятия расширения объектной сущности. Расширения объектной сущности являются пригодными для указания ссылкой структурированными типами; они могут содержать любой член, который объектную сущность может содержать, - свойства, методы и расчетные свойства. Расширение определяется с использованием элемента <EntityExtensionType>. Типы расширения не пользуются наследованием. <EntityExtensionType> может содержать любой элемент, который может быть представлен в <EntityType>. Для наименований свойств не является обязательным быть уникальными по всем расширениям или даже по свойствам типа, являющегося расширяемым.
Управление временем существования. Расширение тесно привязано к объектной сущности, потому что каждый тип расширения задает тип объектной сущности, который он расширяет. Все расширения объектной сущности содержат свойство по умолчанию, названное “Entity” типа Ref(T), где T - значение ExtendsType (расширяет тип), которое указывает на экземпляр объектной сущности, расширением которого таковое является. Это показано схематично на фиг.26 в виде ключа объектной сущности в пределах расширения.
Расширение не обладает способностью независимого существования вне объектной сущности, которую оно расширяет. CDM требует, чтобы управление временем существования расширений было частью реализации - то есть, реализация должна удалять все расширения, когда удаляется соответствующая объектная сущность. В этом смысле, расширения ведут себя так, как будто они являются композициями соответствующей объектной сущности. Хотя экземпляры расширения объектных сущностей считаются частью образующего единое целое блока данных, определенных содержащей объектной сущностью, отсутствует гарантия непротиворечивости касательно изменений по отношению к объектной сущности и расширению, кроме тех случаев, когда управляются явным образом через приложение, использющее транзакции.
Управление экземплярами. Если InstanceManagement=”Implicit”, все свойства, определенные в расширении, должны либо быть обнуляемыми, задавать значение по умолчанию, или иметь тип коллекции (Collection) с ограничением минимального вхождения нулем. Заметим, что типизированное одноэлементным подставляемым типом свойство не может задавать значение по умолчанию, а значит, обязано быть обнуляемым. Это предоставляет запросам возможность быть выполненными по отношению к расширению, как если бы оно всегда присутствовало.
Если InstanceManagement=”Explicit”, приложения должны явным образом добавлять и удалять расширение в/из экземпляра объектной сущности с использованием операций, описанных на языке запросов для общей модели данных. Средство для проверки присутствия расширения также предусмотрено.
Предотвращение расширяемости. Разработчики типов могут пожелать предотвратить создание расширений для данного типа. Это может быть сделано посредством атрибута “Extensible” в элементах <EntityType> или <AssociationEntityType>. Когда установлено в “true” (каковое является значением по умолчанию), элементы <EntityExtensionType> могут быть определены для этой объектной сущности. Это может быть переведено в “false”, чтобы предотвратить расширения для этого типа.
Расширяемые перечисления и псевдонимы перечислений. Так как производители или их потребители развивают набор развернутых типов, иногда становится необходимым добавлять наименования к существующему перечислению. Например, рассмотрим перечисление, названное ToyotaCarModels (модели машин Тойота), которое, вероятно, содержало бы следующие наименования в 2795 году: [Corolla, Camry, MR2, Celica, Avalon]. Однако, в 2005 году ему требуется содержать эти дополнительные наименования: Prius, Echo, Matrix и Solara.
Перечисления могут быть расширены с использованием элемента <EnumerationExtensionType>. Это показано в примере, приведенном ниже:
1. <EnumerationType Name=”C” Extensible=”true”>
2. <EnumerationMember Name=”P”/>
3. <EnumerationMember Name=”Q”/>
4. <EnumerationMember Name=”R” AliasesMember=”Q”/>
5. </EnumerationType>
6.
7. <EnumerationExtensionType Name=”D” ExtendsType=”C”>
8. <EnumerationMember Name=”Q”/>
9. <EnumerationMember Name=”S”/>
10. <EnumerationMember Name=”T” AliasesMember=”C.R”/>
11. </EumerationExtensionType>
12. <EnumerationExtensionType Name=”E” ExtendsType=”C”>
13. <EnumerationMember Name=”T”/>
14. <EnumerationMember Name=”U” AliasesMember=”D.T”/>
15. </EnumerationExtensionType>
В строке 7, перечислимый тип 'C' расширен, чтобы добавить наименования 'Q', 'S' и 'T'. В строке 12, отдельное расширение выполнено по отношению к 'C' посредством добавления наименований 'T' и 'U'. Поскольку члены перечисления всегда уточняются наименованием лежащего в основе базового или перечислимого типа расширения, дублированные наименования в расширениях являются допустимыми (D.T и E.Т в этом примере).
Часто является полезным иметь в распоряжении псевдоним для существующего наименования члена перечисления. Классический пример этого встречается в перечислении времен года (Seasons). В Соединенных Штатах временами года являются [spring (весна), summer (лето), fall (время листопада), winter (зима)]. В Соединенном Королевстве или Индии “fall” («время листопада») называется “autumn” («осенью»). В этом случае является желательным быть способным определить оба наименования, но заставить их на понятийном уровне соответствовать одному и тому же члену перечисления. Атрибут “AliasesMember” в элементе <EnumerationMember> определяет псевдоним для существующего наименования. В этом примере, С.R, D.T и E.U - все являются псевдонимами для C.Q и, следовательно, не представляют уникальные наименования.
Фиг.27 иллюстрирует фрагменты метамодели CDM альтернативной реализации, которые проясняют семантику модели, имеющую отношение к типам.
Фиг.28 иллюстрирует фрагменты метамодели CDM альтернативной реализации, которые проясняют некоторую семантику модели, имеющую отношение к свойствам.
Фиг.29 иллюстрирует фрагменты метамодели CDM альтернативной реализации, которые проясняют некоторую семантику модели, имеющую отношение к ассоциациям.
Фиг.30 иллюстрирует UML-диаграмму композиции по фиг.29, которая иллюстрирует несколько аспектов отношения, показанного на ней.
Фиг.31 иллюстрирует развитые отношения альтернативной реализации.
СИСТЕМА ТИПОВ CDM
Следующая таблица представляет систему типов CDM в виде абстрактного синтаксиса, показывающего рекурсивную структуру системы: бесконечное множество разрешенных выражений, следующих из конечной грамматики. Сначала система типов представлена целиком, затем повторно, с пояснительным текстом и небольшими примерами.
Структурные типы
structuralType ::= simpleType|tupleType|collectionType
simpleType ::= scalar|enum|cname|sname|Ref<ename>
tupleType ::= {…,structuralType aname [ # ],…}
collectionType ::= (List|Set|Multiset|…)<structuralType>
Нарицательные типы
declaration ::= typeSynonym|complexType|entityType| entitySet|entityContainer|binaryRelation
typeSynonym ::= Type sname=structuralType
complexType ::= ComplexType cname [extends cname][constraint] structuralType
entityType ::= EntityType ename [extends ename][constraint][rname] structuralType
entitySet ::= EntitySet esname <ename>
entityContainer ::= EntityContainer ecname <…,(esname|collectionType),…>
binaryRelation ::= Relation rname <(ename|rname),(ename| rname)> constraint
Базовые типы
aname Символические наименования атрибутов (то есть, наименования членов)
ename Символические наименования типа объектной сущности
cname Символические наименования составных типов
sname Символические синонимы других типов
rname Символические наименования бинарных отношений
esname Символические наименования наборов объектных сущностей
ecname Символические наименования коллекций объектных сущностей
scalar Базовый тип без значимой внутренней структуры
enum Тип пронумерованных символов
constraint Выражения в исчислении предикатов первого порядка
Структурные типы. Первый блок описаний является рекурсивно замкнутой субграмматикой, содержащей структурные типы CDM. Предложения в этой субграмматике могут указывать ссылкой только на (1) другие термины в той же самой субграмматике, (2) нарицательные типы, только по имени, (3) термины в последнем блоке - базовые типы. Базовые типы включают в себя только различные пространства имен и непосредственные типы, которые будут разработаны где-то в другом месте. С одним исключением (типы коллекций в контейнерах объектных сущностей), структурные типы не могут быть конкретизированы непосредственно. Точнее, они накапливают типы объектных сущностей, которые являются разновидностью нарицательного типа и являются основополагающим способом конкретизировать данные.
structuralType ::= simpleType|tupleType|collectionType
structuralType (структурный тип) является simpleType (простым типом), tupleType (кортежным типом) или collectionType (типом коллекции).
simpleType (простой тип) является любым из scalar, enum, cname, sname, или ссылкой на ename. Scalar является базовым типом без значимой внутренней структуры, аналогичный машинному примитивному Integer (целочисленному), или Decimal (десятичному) SQL, либо String (строковому) или DateTime (даты и времени) .NET. Очень важной разновидностью скалярного типа является GUID (глобально уникальный идентификатор). Этот тип обладает таким свойством, что каждый экземпляр является уникальным повсюду по пространству и времени. Его первичное использование происходит в качестве типа вырабатываемых системой или свернутых ключей. enum является простым перечислимым типом, который встречается в C#, Visual Basic, или других языках программирования .NET. cname является наименованием complexType (составного типа), одним из нарицательных типов, определенных ниже. sname является typeSynonym (синонимом типа), семантически таким же, как запись определения именованного типа в строку. Заметим, что snames не могут ссылаться на нарицательные типы: они являются всего лишь синонимами для структурных типов. Наконец, ename является наименованием entityType (типа объектной сущности), основной разновидностью нарицательного типа. ename-типы заключены в литеральном условном обозначении Ref<>, чтобы подчеркнуть, что только типы объектной сущности содержат первоклассные ссылки. Ссылки на объектные сущности могут моделировать внешние ключи в реляционных базах данных. CDM формализует это использование посредством основанных на типе отношений (Relationship).
Есть два аспекта равенства вообще: первый, обозначают ли два выражения типа один и тот же тип; второй, являются ли одинаковыми два экземпляра данного единственного типа. Терминология «равенства по типам» использована для первого, а «равенство по значениям» или «равенство по экземплярам» - для последнего.
Равенство по простым типам является непосредственным: два простых типа являются либо очевидно одинаковыми, либо нет (enum-типы должны содержать одинаковые символические теги в одинаковом порядке). Равенство по значениям простых типов, в принципе, определяется побитовым сравнением. На практике, некоторые из типов .NET будут подвергаться более сложным операциям проверки на равенство. Достаточно сказать, что каждый простой тип должен предоставлять оператор равенства, принимающий два экземпляра типа и возвращающий булево значение.
tupleType (кортежный тип) является одной или более пар вида structuralType aname (структурный тип - наименование атрибута), каждая сопровождается необязательным знаком диеза, все заключены в фигурные скобки. Кортежный тип является подобным полезной нагрузке описания класса C#, состоящего из членов или атрибутов, каждый из которых рекурентно содержит наименование и один из структурных типов (structuralTypes), соответственно. Наименования атрибутов имеют тип aname, то есть, получены из области определения символических имен, отличных от ename, cname, и т.д. Любая ссылка на атрибут по наименованию должна быть однозначной.
Равенство по кортежным типам определяется, как изложено ниже: два кортежных типа равны, тогда и только тогда, когда их атрибуты имеют одинаковые наименования и типы и фигурируют в одинаковом порядке. Значит, {TA A, TB B} и {TB B, TA A} являются несовпадающими кортежными типами. Причина заключается в том, что следует поддерживать синтаксис позиционного доступа в реализациях CDM. Два экземпляра кортежного типа равны, если типы и значения их атрибутов являются рекурентно равными.
Знаки диеза обозначают атрибуты, которые составляют ключевые характеристики, означая, что при определенных обстоятельствах значения помеченных знаком диеза атрибутов, в собирательном значении, должны быть уникальными в пределах наборов типа коллекции или в пределах наборов объектных сущностей (entitySets). Если более чем один атрибут в типе содержит знаки диеза, то ключ является составным ключом, состоящим из всех помеченных атрибутов, сцепленных в том порядке, в котором они были описаны в тексте. Составные ключи могут распространяться на многочисленные кортежные типы, так, например, в
{TA A {TB B #} {TC C #}}
Ключевой характеристикой является {B,C}. В качестве более длинного примера рассмотрим:
{String personName,
{Int a, Int b, Int c} socialSecurityNumber #,
{String street,
String city,
String state,
{Int station, Int block} zipCode} address}
Это является миниатюрным кортежным типом для карточки делового контакта с тремя атрибутами, названными personName (имя лица), socialSecurityNumber (номер социального страхования) и address (адрес). Эти атрибуты соответственно имеют следующие три типа: строка произвольной формы для имени действующего лица; вложенный кортеж, содержащий три части номера социального страхования, помеченного знаком диеза, с тем чтобы действовать в качестве уникального ключа в наборе объектных сущностей или коллекции наборов; вложенный кортеж, содержащий улицу, город, штат и почтовый индекс из двух частей, вновь представленный как более глубоко вложенный кортеж.
collectionType (типом коллекции) является либо List (список), Set (набор), Multiset (кратный набор) или некоторые другие, каждый параметризирован другим структурным типом. В большинстве случаев типы коллекций косвенно конкретизируются в качестве компонентов или объектных сущностей. Однако, они могут быть непосредственно конкретизированы внутри контейнеров объектных сущностей, как документируется ниже.
Списки. Список является упорядоченной коллекцией экземпляров structuralType (структурного типа). «Упорядоченный» означает, что есть преобразование из положительных целых чисел 1, 2, … в элементы коллекции. «Упорядоченный» не должно быть перепутано с «отсортированный»: Список [1, 3, 2] упорядочен, но не отсортирован; [1, 2, 3] и упорядочен, и отсортирован. Особый случай пары является обычным. Пара является просто списком с длиной в два.
Равенство по списочным типам является рекурентным по структурному типу членов списка. Два экземпляра списочного типа равны, если (1) имеет место одинаковое количество членов; (2) значения членов рекурентно равны; и (3) члены фигурируют в одинаковом порядке. Пример: List<Int> - тип списка целых чисел.
Наборы. Набором является неупорядоченная коллекция экземпляров structuralType (структурного типа), в которой не разрешены дубликаты. Set<Int> мог бы быть типом набора целых чисел. Операции предназначены для вставки членов, проверки членства и вычисления объединений, пересечений, и т.п.
Равенство по типам набора является рекурентным по структурному типу членов набора. Два экземпляра типа набора равны, если они содержат одинаковое количество членов, и значения членов рекурентно равны, независимо от порядка.
Счет в сторону увеличения от единицы является математической условностью. Языки программирования имеют тенденцию производить счет в сторону увеличения от нуля. Однако, отсутствие уверенности, считать ли от единицы или от нуля, имеет место даже в математике. Нечто, столь же фундаментальное, как множество натуральных чисел, пишется N, иногда определяется как 0, 1, …, а иногда как 1, 2, ….
Кратные наборы. Кратный набор является неупорядоченной коллекцией экземпляров structuralType, в которой разрешены дубликаты. Например,
Multiset<Set<String>>
мог бы быть типом кратного набора наборов строк, а
Multiset<{String personName, DateTime birthdate}>
мог бы быть типом кратного набора экземпляров анонимного кортежного типа имен и дат рождения действующих лиц.
Равенство по типам кратного набора является рекурентным по структурному типу членов кратного набора. Два экземпляра типа кратного набора равны, если (1) они содержат одинаковое количество членов; и (2) значения членов рекурентно равны, независимо от порядка, но касательно количеств дубликатов. Так, [1, 1, 2, 3] и [2, 1, 3, 1] равны как кратные наборы, а [1, 1, 2, 3] и [1, 2, 2, 3] - нет. Математически, наиболее наглядным представлением кратного набора является набор пар количеств и значений кратности. Если кратные наборы представлены таким образом, то их равенство является автоматическим, полагающимся только на равенство наборов и равенство пар.
Нарицательные типы. Нарицательные типы имеют отличительный признак по той причине, что они должны быть уникально именованы в пределах своих областей определения. Два нарицательных типа участвуют в выделении подтипов отношений. Этими двумя являются complexType (составной тип) и entityType (тип объектной сущности). Выделение подтипов для структурных типов теоретически является гораздо более сложным, поэтому не разрешено в CDM.
Наборы объектных сущностей являются нарицательными и потому, что их наименования являются частью ссылок объектной сущности, типа Ref<e>, и потому, что они являются одним из способов сформировать корень дерева экземпляров. В такой роли, они должны иметь наименования, с тем чтобы приложения могли извлекать данные экземпляра. Коллекции объектных сущностей также должны быть именованными, поскольку они также формируют корень дерева экземпляров. Синонимы типа являются нарицательными типами, потому что их существо состоит в присваивании имен. Наконец, отношения являются нарицательными, с тем чтобы Association Entities (объектные сущности ассоциации) могли совместно использовать их и ссылаться на них по наименованию.
Равенство по нарицательным типам, в некотором смысле, является более легким, чем равенство по структурным типам. Является ошибкой в ее наиболее суровой форме для двух типов обладать одинаковыми наименованиями и содержать какое-нибудь различие, даже синтаксическое, в их описаниях.
Равенство по значениям нарицательных типов также может получить преимущество именования. В частности, два экземпляра типа объектной сущности равны тогда и только тогда, когда равны их ссылки. Это является обоснованием для называния ссылки на объектную сущность ее идентичностью.
Таковыми являются шесть разных видов объявлений нарицательных типов. Синоним типа вводит конкретный sname в область определения snames. Когда такое sname используется где-то в другом месте, structuralType (структурный тип), к которому оно относится, заменяется на sname. Например,
Type toyContactCard =
{String personName,
{Int a, Int b, Int c} socialSecurityNumber #,
{String street, String city, String state,
{Int station, Int block} zipCode} address}
определяет синоним типа для типа карточки делового контакта, показанного выше. Такой синоним типа, toyContactCard, мог бы быть использован в любом месте, где кто-нибудь в ином случае был бы вынужден копировать-вставлять или вводить на клавиатуре дословное описание.
complexType (составной тип) вводит cname, которое (1) по желанию расширяет другой составной тип; где (2) каждый экземпляр соблюдает необязательное ограничение, выраженное в исчислении предикатов первого порядка; и (3) содержит дополнительную структуру, обозначенную посредством structuralType (структурного типа), означающего, что данный структурный тип добавлен к структурным типам предков, а коллизии атрибутов не допускаются.
CDM допускает единичное наследование, означающее, что составной тип может расширять самое большее один другой составной тип, но рекурсия допустима, с тем чтобы прямой предок мог, в свою очередь, расширять самое большее один другой составной тип.
Составные типы являются наиболее обогащенной разновидностью структурированного подставляемого типа CDM. Подставляемые типы имеют отличительный признак, что, несмотря на то, что является возможным ссылаться на них по наименованию в других описаниях типа, невозможно ни конкретизировать их напрямую, ни предпринять ссылку на экземпляры, которые могут появляться в объектных сущностях. Также является фактом, что встроенные ключевые характеристики, в виде помеченных знаком диеза атрибутов в кортежных типах, игнорируются в контексте составных типов.
Различие между составными типами и синонимами типа состоит в том, что первые могут пользоваться наследованием и претерпевать ограничения. В качестве отступления заметим, что некоторые ограничения могут быть проверены статически, во время компиляции, посредством технологий доказательства теорем или проверки моделей. Другие ограничения должны быть проверены во время выполнения, в каковом случае компилятор должен порождать код проверки ограничений. Пример:
ComplexType betterContactCard toyContactCard
описывает составной тип с полезной нагрузкой, заданной синонимом типа, приведенным выше.
ComplexType employeeRecord extends betterContactCard
{Int employeeNumber, Int departmentNumber}
описывает составной тип для записей о служащем, основанных на карточке лучшего делового контакта, уже определенной. Он содержит все атрибуты betterContactCard (карточки лучшего делового контакта) и явно заданного кортежа, записанного в строку.
entityType (тип объектной сущности) вводит ename, которое (1) по выбору расширяет другой тип объектной сущности; где (2) каждый экземпляр подчиняется необязательному ограничению; которое (3) по выбору ссылается на отношение посредством его rname; и (4) содержит дополнительную структуру, обозначенную посредством structuralType (структурного типа), означающую, что данный структурный тип линейно сцеплен со структурными типами типов объектной сущности предка, а коллизии атрибутов не допускаются.
Ключевые характеристики (знаки диеза) также являются сцепленными, означая, что ключевая характеристика типа объектной сущности с предками является сцеплением в линейном порядке ключевых характеристик содержащихся кортежных типов.
Тип объектной сущности должен содержать ключевую характеристику. Это подразумевает, что тип объектной сущности должен содержать, по меньшей мере, один кортежный тип с, по меньшей мере, одним знаком диеза в своей цепи наследования. Это ограничение принудительно применяется семантически, с тем чтобы не переусложнять синтаксис.
Необязательное rname отвечает за Association Entities (объектной сущности ассоциации) CDM, которые являются бинарными отношениями с дополнительными атрибутами. Дополнительные подробности следует искать в разделе об отношениях, приведенном ниже.
CDM допускает единичное наследование, означающее, что тип объектной сущности может рекурсивно расширять самое большее один другой тип объектной сущности, соответственно. Типы объектной сущности не могут расширять составные типы, а составные типы не могут расширять типы объектной сущности. Другими словами, составные типы и типы объектной сущности заполняют обособленные, выделяющие подтипы универсумы.
Типы объектной сущности являются наиболее обогащенной разновидностью структурированных типов CDM, которые участвуют в entitySets (наборах объектных сущностей), где помеченные знаком диеза атрибуты в кортежах составляют первичные ключи в обычном смысле реляционных баз данных. Дополнительно, экземпляры объектной сущности обладают идентичностями, которые являются их ключевыми значениями, сцепленными с идентичностями их наборов объектных сущностей. 3 этих идентичности составляют значения терминов явно заданных Ref<ename>, которые фигурируют в блочной единице грамматики.
Типы объектной сущности являются первичной разновидностью CDM-типа, который может быть непосредственно конкретизирован, всегда в контексте набора объектных сущностей, который является моделью CDM для реляций или таблиц, снова в обычном смысле реляционных баз данных. Пример:
EntityType employeeEntity employeeRecord
определяет тип объектной сущности, основанный на составном типе employeeRecord (запись о служащем), определенном выше. На этой стадии помеченные знаком диеза атрибуты, игнорируемые до этого, снова обретают значимость. Вспомним, что employeeRecord (запись о служащем) расширяет betterContactCard (карточку лучшего делового контакта), который использует синоним типа toyContactCard (карточка модельного делового контакта), который содержит встроенный атрибут
{Int a, Int b, Int c} socialSecurityNumber #
Знак диеза в этом атрибуте подразумевает, что номер социального страхования будет первичным ключом в наборах объектных сущностей экземпляров employeeEntity (объектные сущности служащего). Если бы пользователь оказал предпочтение номеру служащего над номером социального страхования для ключей, могло бы быть необходимым определять новые кортежные типы с номером служащего, помеченным знаком диеза, и номером социального страхования, не помеченным знаком диеза, или использовать операции манипулирования знаком диеза, приведенные ниже, чтобы создать новые типы из старых.
entitySet (набор объектных сущностей) является именованной коллекцией объектных сущностей типа ename. Дублированные экземпляры объектных сущностей не допускаются в наборах объектных сущностей, и типы объектной сущности должны содержать ключевые характеристики, то есть, один или более атрибутов, помеченных знаками диеза. Наименование esname набора объектных сущностей вводится в обособленную область определения esnames.
EntitySet employees<employeeEntity>
мог бы быть типом набора объектных сущностей из объектных сущностей служащих, использующего номер социального страхования в качестве ключа.
entityContainer (контейнер объектных сущностей) является именованной коллекцией одного или более терминов, каждый из которых является либо набором объектных сущностей, обозначенным своим esname или анонимным типом коллекции.
EntityContainer <employees>
мог бы быть типом контейнера объектных сущностей, удерживающего экземпляр набора объектных сущностей, названного employees («служащие»). Метод конкретизации типов коллекции в контейнерах объектных сущностей подлежит определению. Иначе, контейнер объектных сущностей является просто оболочкой для одного или более наборов объектных сущностей.
Отношения. CDM нуждается в следующих канонических формах отношений: (1) Ассоциация (Association), (2) условная ассоциация (Conditional Association), (3) объектная сущность ассоциативная (Association Entity), (4) композиция (Composition). Все они являются вариантами одного и того же низкоуровневого уровня понятия математического отношения, и мы формализуем их в качестве таковых.
Математическое отношение является подмножеством декартова произведения наборов, из условия, что все члены подмножества удовлетворяют некоторому ограничению. Рассмотрим список одного или более наборов (A1, A2, …, An), также записываемый как Ai, i = 1..n. Декартово произведение этих наборов, записываемое C = A1 × A2 ×…×·An, является набором n-арных, упорядоченных кортежей.
C = {(a1, a2, …, an)|a1 ∈ A1, a2 ∈ A2, …, an ∈ An}
Декартово произведение является наибольшим отношением, которое может быть образовано из списка наборов, поскольку ограничение не отфильтровывает никаких членов.
Чтобы сформировать отношение с меньшим количеством членов, чем полное декартово произведение, ограничение должно отфильтровать некоторых. Например, рассмотрим набор номеров служащих, от 1 до 100, записанный 1..100, и набор номеров отделов, от 1 до 10. Одним из способов соотнесения служащих с отделами мог бы выглядеть, как изложено ниже, при определении символа  в качестве наименования отношения:
в качестве наименования отношения:
где 'div' является арифметическим целочисленным делением. Это соотносит служащих от 1 до 10 с отделом 1, служащих от 11 до 20 с отделом 2, и так далее. Предикат является конъюнкцией трех частей e ∈ 1..100, d ∈ 1..10, и (e - 1)div10 = d - 1.
Этот пример в неявном виде происходит, чтобы задавать отношение многие к одному между служащими и отделами. Стандартным условным обозначением для использования наименования отношения в качестве инфиксного «оператора» является:
(e, d)∈  e d
e d
Исчисление предикатов первого порядка является достаточным, чтобы выражать все практически интересные ограничения, в том числе уникальности, кратности, ссылки и условного членства. CDM дает наименования определенным шаблонам ограничений, которые являются важными или очень распространенными на практике. Например, системы реляционных баз данных зачастую реализуют отношения «один ко многим» посредством внешних ключей. Ссылочное ограничение CDM является утверждением, что значение внешнего ключа должно появляться в качестве первичного ключа в целевом наборе объектных сущностей. Значение этого внешнего ключа является экземпляром типа Ref<ename>. Шаблон в исчислении предикатов может быть сделан абстрактным, чтобы символизировать класс ссылочных ограничений.
Неформально, ограничение является композицией отдельных термов через логические функции, аналогичные 'and', 'or' и 'not' ('И', 'Или' и 'Не'). Каждый терм является выражением булева типа, который может ссылаться на атрибуты объектных сущностей посредством ename и aname; на константы; на операторы сравнения, подобные ≤; на переменные, введенные кванторами, подобными ∀ и ∃; и на некоторые особые, вызывающие изменение ориентации операционные ограничения, ввиду того, что предусмотрен синтаксис:
operationalConstraint ::= On (Delete|Copy|Serialize) <ename>
(Cascade|Restrict|Remove)
Каждый из девяти видов операционного ограничения ссылается на один из двух типов объектной сущности в бинарном отношении по его ename. Cascade (каскадировать) означает, что операция Delete (удаления), Copy (копирования) или Serialize (сериализации) должна распространяться на экземпляры другого типа объектной сущности в отношении. Restrict (ограничить) означает, что операция должна иметь место, только если экземпляры другого типа объектной сущности независимо выполняют совместимую операцию. Remove (удалить) означает, что само отношение должно быть удалено, когда операция завершается.
Другой особой формой ограничения является ограничение кратности:
multiplicityConstraint ::= (multiplicity (one|many|n1..m1) ename1 to
(one|many|n2..m2) ename2)
где ni≤mi - натуральные числа, большие чем нуль. Эта форма является синтаксической копилкой для эквивалентных выражений в исчислении предикатов и предлагается здесь, поскольку они являются традиционными сценариями моделирования. Эти именованные типы объектной сущности должны быть таковыми, также названными в отношении.
CDM использует термин условное ограничение (conditional constraint) для ограничений, которые не попадают ни в какую из категорий, приведенных выше. До сих пор является обсуждаемым, должен ли быть идентифицирован класс композиционных ограничений.
entitySet (набор объектных сущностей), выражаясь логически, является унарным(одинарным) отношением, где декартово произведение является тривиальным, состоящим только из одного набора. Бинарное отношение (binaryRelation) является бинарным отношением, где декартово произведение именует два набора. Тернарное, кватернарное и т.д. отношения являются поддающимися расчету, с еще большими декартовыми произведениями. Но бинарные отношения удовлетворяют фактически всем практическим сценариям плюс все большие отношения заведомо могут быть построены как композиции бинарных отношений.
binaryRelation ::= Relation rname <(ename|rname),
(ename|rname)> constraint
binaryRelation (бинарное отношение) вводит rname (наименование отношения) в область определения rnames (наименований отношений) и определяет бинарное отношение на паре объектных сущностей или другие отношения, которые удовлетворяют обязательному ограничению (constraint). В исходном случае, где пары являются объектными сущностями, а не другими отношениями, пары являются членами декартова произведения универсумов типов объектной сущности. Рекурсивный случай, где одна или обе соотнесенных разновидностей являются другими отношениями, поддерживает композиционное построение отношений большей арности.
EntityType department {String deptName, Int deptNo #}
EntitySet departments <department>
Relation empDepts <department,employeeEntity>
(кратность - один департамент (department) ко многим объектным сущностям служащих (employeeEntity))
добавляет тип объектной сущности и набор объектных сущностей для отделов и объявляет отношение один ко многим от отделов к объектным сущностям служащих. Есть варианты выбора для реализации такого отношения. Например, оно могло бы быть реализовано либо таблицей соединений, либо ограничительным условием внешнего ключа.
Ассоциация. CDM-ассоциация (Association) является бинарным отношением, как определено выше.
Условная ассоциация. Все бинарные отношения являются условными, подразумевая, что ограничительное условие является обязательным. Поэтому условные ассоциации (Conditional Associations) CDM являются бинарными отношениями, как определено выше.
Ассоциация объектной сущности. Тип объектной сущности по выбору может ссылаться на бинарное отношение посредством rname. Такая объектная сущность принимает во внимание ассоциации объектной сущности (Association Entities) CDM.
Композиция. Бинарное отношение, которое удовлетворяет следующим двум критериям, является CDM-композицией (Composition): имеет место ограничение кратности, при котором, по меньшей мере, один из типов объектной сущности обладает кратностью в единицу, и есть операционное ограничение по такому типу объектной сущности, вида On Delete ename Cascade (по удалении расширенного наименования, каскадировать).
Операции на уровне типа
(cname|ename) drop → structuralType
конвертирует составной тип или тип объектной сущности в структурный тип. Он обращает объявления complexType и entityType (составного типа и типа объектной сущности).
Запись ответвления betterContactCard (карточки лучшего делового контакта) является такой же как запись toyContactCard (карточки модельного делового контакта), так как betterContactCard была построена из toyContactCard посредством объявления сложного типа (ComplexType) betterContactCard toyContactCard.
(tupleType|sname) ++ (tupleType|sname) → tupleType
определяет бинарную операцию ++, которая конкатенирует (сцепляет) два кортежных типа - или синонимы, которые их именуют - чтобы создать другой. Запись
{String personName} ++ {{Int a, Int b, Int c} socialSecurityNumber #}
является тем же самым, что и запись
{String personName, {Int a, Int b, Int c} socialSecurityNumber #}.
(tupleType|sname) -- aname → tupleType
удаляет именованный атрибут из кортежного типа. Это является пустой операцией, если входной кортежный тип не имеет именованного атрибута. Запись
{String personName, Address address} -- personName
является тем же самым, что и запись
{Address address}.
(tupleType|sname)StripHashes → tupleType
изымает все ненужные пометки решеткой из всех атрибутов в кортежном типе своего аргумента. Запись
{String personName, {Int a, Int b, Int c} socialSecurityNumber #}
StripHashes
является тем же самым, что и запись
{String personName, {Int a, Int b, Int c} socialSecurityNumber}
(tupleType|sname) aname AddHash -! tupleType
имеет результатом кортежный тип с именованным атрибутом, помеченным решеткой. Если такой атрибут уже был помечен решеткой, он остается таковым. Запись
{String personName, {Int a, Int b, Int c} socialSecurityNumber}
personName AddHash
является тем же самым, что и запись
{String personName #, {Int a, Int b, Int c} socialSecurityNumber}
Далее, со ссылкой на фиг.32, проиллюстрирована структурная схема компьютера, функционирующего для выполнения CDM-архитектуры. Для того чтобы предусмотреть дополнительный контекст для различных аспектов связанного изобретения, фиг.32 и дальнейшее обсуждение предназначены для предоставления краткого общего описания подходящей вычислительной среды 3200, в которой различные аспекты изобретения могут быть реализованы. Несмотря на то, что изобретение ранее было описано в общем контексте машинно-исполняемых инструкций, которые могут работать на одном или более компьютерах, специалисты в данной области техники будут осознавать, что изобретение также может быть реализовано в сочетании с другими программными модулями и/или в виде сочетания аппаратных средств и программного обеспечения.
Как правило, программные модули включают в себя процедуры, программы, компоненты, структуры данных и т.п., которые выполняют конкретные задачи и/или реализуют конкретные абстрактные типы данных. Более того, специалисты в данной области техники будут принимать во внимание, что изобретенные способы могут быть осуществлены на практике с другими конфигурациями компьютерных систем, в том числе однопроцессорными или многопроцессорными компьютерными системами, миникомпьютерами, универсальными электронно-вычислительными машинами, а также персональными компьютерами, «карманными» вычислительными устройствами, основанной на микропроцессорах и/или программируемой бытовой электронной аппаратурой и тому подобным, каждые из которых могут оперативно связываться с одним или более связанными устройствами.
Проиллюстрированные аспекты изобретения также могут быть осуществлены на практике в распределенных вычислительных средах, в которых определенные задачи выполняются удаленными обрабатывающими устройствами, которые связаны через сеть передачи данных. В распределенной вычислительной среде, программные модули могут быть размещены как в локальном, так и в удаленном запоминающих устройствах памяти.
Компьютер типично включает в себя многообразие машиночитаемых носителей. Машиночитаемые носители могут быть любыми имеющимися в распоряжении носителями, к которым может быть осуществлен доступ компьютером, и включают в себя как энергозависимые и энергонезависимые носители, так и съемные и несъемные носители. В качестве примера, но не ограничения, машиночитаемые носители могут содержать компьютерные запоминающие ностители и среду передачи данных. Компьютерные запоминающие носители включают в себя как энергозависимые и энергонезависимые, так и съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Компьютерные запоминающие носители включают в себя, но не в качестве ограничения, ОЗУ (оперативное запоминающее устройство, RAM), ПЗУ (постоянное запоминающее устройство, ROM), ЭСППЗУ (электрически стираемое и программируемое ПЗУ, EEPROM), флэш-память, или другую технологию памяти, CD-ROM (ПЗУ на компакт диске), цифровой видеодиск (DVD) или другое оптическое дисковое запоминающее устройство, магнитные кассеты, магнитную ленту, накопитель на магнитных дисках или другие магнитные запоминающие устройства, или любой другой носитель, который может быть использован для хранения желаемой информации и к которому может быть осуществлен доступ компьютером.
Снова, со ссылкой на фиг.32, примерная среда 3200 для реализации различных аспектов изобретения включает в себя компьютер 3202, компьютер 3202 включает в себя устройство 3204 обработки данных, системную память 3206 и системную шину 3208. Системная шина 3208 присоединяет системные компоненты, в том числе, но не в качестве ограничения, системную память 3206 к устройству 3204 обработки данных. Устройство 3204 обработки данных может быть любым из различных доступных для приобретения процессоров. Архитектуры с двумя микропроцессорами и другие многопроцессорные архитектуры также могут быть использованы в качестве устройства 3204 обработки данных.
Системная шина 3208 может быть любой из некоторых типов шинных структур, которые могут содействовать взаимосвязи с шиной памяти (с или без контроллера памяти), периферийной шиной и локальной шиной, использующей любую из многообразия доступных для приобретения шинных архитектур. Системная память 3206 включает в себя постоянное запоминающее устройство (ПЗУ) 3210 и оперативное запоминающее устройство (ОЗУ) 3212. Базовая система ввода/вывода (BIOS), сохраняемая в энергонезависимой памяти 3210, такой как ПЗУ, СППЗУ (стираемое программируемое ПЗУ, EPROM), ЭСППЗУ, каковой BIOS содержит в себе базовые процедуры, которые помогают передавать информацию между элементами в пределах компьютера 3202, к примеру, во время запуска. ОЗУ 3212 также может включать в себя высокоскоростное ОЗУ, такое как статическое ОЗУ для кэширования данных.
Компьютер 3202 дополнительно включает в себя внутренний накопитель 3214 на магнитном диске (НЖМД, HDD) (например, EIDE (с интерфейсом усовершенствованных электронных схем управления встроенным дисководом), SATA (с интерфейсом SATA), каковой внутренний накопитель 3214 на жестком диске также может быть сконфигурирован для внешнего использования в подходящем шасси (не показано), накопитель 3216 на гибких магнитных дисках (НЖМД, FDD) (например, для считывания с или записи на съемную дискету 3218) и накопитель 3220 на оптических дисках (например, осуществляющий считывание диска 3222 CD-ROM, или для считывания с или записи на другие оптические носители большой емкости, такие как DVD). Накопитель 3214 на жестком диске, накопитель 3216 на магнитных дисках и накопитель 3220 на оптических дисках могут быть подключены к системной шине 3208 посредством, соответственно, интерфейса 3224 накопителя на жестком диске, интерфейса 3226 накопителя на магнитных дисках, и интерфейса 3228 накопителя на оптических дисках. Интерфейс 3224 для реализаций с внешним накопителем включает в себя по меньшей мере одну или обе из интерфейсных технологий универсальной последовательной шины (USB) или IEEE 1394 (FireWire). Другие технологии связи внешнего накопителя находятся в пределах рассмотрения связанного изобретения.
Накопители и их ассоциируемые машиночитаемые носители предусматривают энергонезависимое хранение данных, структур данных, машинно-исполняемых инструкций и так далее. Касательно компьютера 3202, накопители и носители обеспечивают хранение данных в надлежащем цифровом формате. Несмотря на то, что описание машиночитаемых носителей, приведенных выше, ссылается на НЖМД, съемную магнитную дискету и съемные оптические диски, такие как CD или DVD, специалистами в данной области техники должно быть принято во внимание, что другие типы носителей, которые являются пригодными для считывания компьютером, такие как zip-дисководы, магнитные кассеты, карты флэш-памяти, картриджи и тому подобное, также могут быть использованы в примерной операционной среде и, кроме того, что любые такие носители могут содержать в себе машинно-исполняемые инструкции для выполнения способов изобретения.
Некоторое количество программных модулей может быть сохранено в накопителях и ОЗУ 3212, в том числе операционная система 3230, одна или более прикладных программ 3232, другие программные модули 3234 и данные 3236 программ. Взятые в целом или части операционной системы, приложений, модулей и/или данных также могут быть кэшированы в ОЗУ 3212. Принято во внимание, что изобретение может быть реализовано с различными доступными для приобретения операционными системами или сочетаниями операционных систем.
Пользователь может вводить команды и информацию в компьютер 3202 через одно или более проводных/беспроводных устройств ввода, например, клавиатуру 3238 и указательное устройство, такое как мышь 3240. Другие устройства ввода (не показаны) могут включать в себя микрофон, (инфракрасный, IR) ИК-пульт дистанционного управления, джойстик, игровую панель, перо-стилус, сенсорный экран или подобное. Эти и другие устройства ввода часто подключены к устройству 3204 обработки данных через интерфейс 3242 устройства ввода, который присоединен к системной шине 3208, но может быть подключен посредством других интерфейсов, таких как параллельный порт, последовательный порт стандарта IEEE 1394, игровой порт, порт USB, ИК-интерфейс и т.п.
Монитор 3244 или другой вид устройства отображения также подключен к системной шине 3208 через интерфейс, такой как видеоадаптер 3246. В дополнение к монитору 3244, персональный компьютер типично включают в себя другие периферийные устройства вывода (не показаны), такие как динамики, принтеры и т.п.
Компьютер 3202 может работать в сетевой среде с использованием логических соединений, посредством проводной и/или беспроводной связи, с одним или более удаленных компьютеров, таких как удаленный компьютер(ы) 3248. Удаленный компьютер(ы) 3248 может быть рабочей станцией, серверным компьютером, маршрутизатором, персональным компьютером, портативным компьютером, основанным на микропроцессоре развлекательным приспособлением, одноранговым устройством или другим общим узлом сети, и типично включает в себя многие или все из элементов, описанных касательно компьютера 3202, хотя, в целях краткости, проиллюстрировано только устройство 3250 памяти/хранения. Изображенные логические соединения включают в себя проводную/беспроводную возможность связи с локальной сетью (LAN) 3252 и/или сетью большего масштаба, например, глобальной сетью (WAN) 3254. Такие сетевые среды LAN и WAN являются обычным явлением в офисах и компаниях и содействуют корпоративным компьютерным сетям, таким как интранет (локальная сеть, использующая технологии Интернет), все из которых могут подключаться к глобальной сети связи, например, сети Интернет.
При использовании в сетевой среде LAN, компьютер 3202 подключен к локальной сети 3252 через сетевой интерфейс или адаптер 3256 проводной/беспроводной связи. Адаптер 3256 может способствовать проводной или беспроводной связи с LAN 3252, которая также может включать в себя точку беспроводного доступа, размещенную в ней для поддерживания связи с беспроводным адаптером 3256.
При использовании в сетевой среде WAN, компьютер 3202 может включать в себя модем 3258, или подключен к серверу связи в WAN 3254, или обладает другим средством для установления связи через WAN 3254, к примеру, в виде сети Интернет. Модем 3258, который может быть внутренним или внешним и проводным или беспроводным, подключен к системной шине 3208 через интерфейс 3242 последовательного порта. В сетевой среде программные модули, изображенные касательно компьютера 3202, или их части, могут быть сохранены в удаленном устройстве 3250 памяти/хранения. Будет принято во внимание, что показанные сетевые соединения являются примерными, и может быть использовано другое средство установления линии связи между компьютерами.
Компьютер 3202 выполнен с возможностью поддержания связи с любыми беспроводными устройствами или объектами, настроенными на обмен информацией по беспроводной связи, например, принтером, сканером, настольным или портативным компьютером, портативным цифровым секретарем, спутником связи, любой единицей оборудования или местоположением, ассоциируемым с беспроводным образом обнаруживаемой маркировкой (например, киоском, новостным стендом, помещением для отдыха), и телефоном. Это включает в себя по меньшей мере беспроводные технологии Wi-Fi и Bluetooth™. Так, связь может быть предопределенной структурой, как с традиционной сетью, или просто подходящей для данного случая связью между по меньшей мере двумя устройствами.
Wi-Fi, или Wireless Fidelity («беспроводная точность»), предоставляет возможность подключения к сети Интернет с дивана дома, кровати в номере отеля или из конференц-зала на работе при отсутствии проводов. Wi-Fi - беспроводная технология, подобная используемой в сотовом телефоне, которая дает возможность таким устройствам, например, компьютерам, отправлять и принимать данные внутри или вне помещения; где угодно в пределах зоны покрытия базовой станции. Сети Wi-Fi используют радиотехнологии, названные IEEE 802.11 (a, b, g и т.д.), чтобы предоставлять возможность защищенного, надежного высокоскоростного беспроводного соединения. Сеть Wi-Fi может быть использована, чтобы связывать компьютеры друг с другом, с сетью Интернет и с проводными сетями (которые используют стандарт IEEE 802.3 или Ethernet). Сети Wi-Fi работают в нелицензируемых радиодиапазонах 2,4 и 5 ГГц, например, при скорости передачи данных 11 Мбит/с (802.11a) или 54 Мбит/с (802.11b), или с изделиями, которые содержат в себе оба диапазона (двухдиапазонными), поэтому сети могут обеспечивать практическую производительность, аналогичную базовым проводным сетям Ethernet 10BaseT (на неэкранированной витой паре), используемым во многих офисах.
Далее, со ссылкой на фиг.33, проиллюстрирована схематичная структурная схема примерной вычислительной среды 3300, в которой CDM может быть использована. Система 3300 включает в себя одного или более клиентов(а) 3302. Клиент(ы) 3302 может быть аппаратными средствами и/или программным обеспечением (например, потоками, процессами, вычислительными устройствами). Клиент(ы) 3302 может, например, вставлять куки-файл(ы) и/или контекстную информацию посредством использования изобретения.
Система 3300 также включает в себя один или более серверов 3304. Сервер(ы) 3304 также могут быть аппаратными средствами и/или программным обеспечением (например, потоками, процессами, вычислительными устройствами). Серверы 3304, например, могут обеспечивать содержание потоков для выполнения преобразований, посредством применения изобретения. Одна из возможных связей между клиентом 3302 и сервером 3304 может быть в виде пакета данных, приспособленного, чтобы быть переданным между двумя или более компьютерными процессами. Пакет данных, например, может включать в себя куки-файл и/или ассоциируемую контекстную информацию. Система 3300 включает в себя инфраструктуру 3306 связи (например, глобальную сеть передачи данных, такую как сеть Интернет), которая может быть использована, чтобы содействовать связи между клиентом(ами) 3302 и сервером(ами) 3304.
Связь может быть облегчена посредством проводной (в том числе оптоволоконной) и/или беспроводной технологии. Клиент(ы) 3302 подключены с возможностью взаимодействия к одному или более клиентским хранилищам 3308 данных, которые могут быть использованы, чтобы сохранять информацию, локальную по отношению к клиенту(ам) 3302 (например, куки-файл(ы) и/или ассоциированную контекстную информацию). Подобным образом, серверы 3304 подключены с возможностью взаимодействия к одному или более серверному хранилищу(ам) 3310 данных, которые могут быть использованы, чтобы сохранять информацию, локальную по отношению к серверам 3304.
То, чтобы было описано выше, включает в себя примеры раскрытого изобретения. Конечно, невозможно описать каждое мыслимое сочетание компонентов или способов, но рядовой специалист в данной области техники может осознать, что возможны многие дополнительные сочетания и перестановки. Следовательно, изобретение имеет намерением охватить все такие преобразования, модификации и варианты, которые попадают в пределы объектной сущности и объема прилагаемой формулы изобретения. Более того, в тех пределах, в которых термин «включает в себя» использован либо в подробном описании, либо в формуле изобретения, этот термин предполагается включающим, в некоторой степени аналогичным термину «содержащий», как интерпретируется «содержащий», когда используется в качестве переходного слова в формуле изобретения.
2420-135044RU/051
Приложение A
Общая модель данных
| Содержание | |
| 1. ВВЕДЕНИЕ | 4 |
| 1.1 Основные понятия | 6 |
| 1.1.1 Объектная сущность | 7 |
| 1.1.2 Отношение | 9 |
| 1.2 Сфера применения общей модели данных | 10 |
| 1.3 Схема документа | 11 |
| 1.4 Почему общая модель данных? | 13 |
| 1.4.1 Почему не SQL99? | 14 |
| 1.4.2 Почему не CLR?? | 15 |
| 1.4.3 Почему не UML? | 18 |
| 1.4.4 Почему не XML? | 19 |
| 1.5 Краткое содержание документа | 20 |
| 2. ОПИСАНИЕ ПРОЕКТА | 20 |
| 2.1 Объектные сущности | 20 |
| 2.1.1 Ключи, идентичность и ссылки объектной сущности | 21 |
| 2.1.1.1 Логическое обоснование | 23 |
| 2.1.2 Устойчивость объектной сущности | 24 |
| 2.1.2.1 Наборы таблиц | 26 |
| 2.1.3 Типы объектной сущности по сравнению с подставляемыми типами | 28 |
| 2.1.4 Взаимосовместимость данных | 31 |
| 2.2 Отношения | 33 |
| 2.2.1 Ассоциации | 35 |
| 2.2.1.1 Ассоциации, использующие типизированные ссылочным типом свойства | 35 |
| 2.2.1.2 Ассоциации, использующие типизированные нессылочным типом свойства | 39 |
| 2.2.1.3 Объектные сущности ассоциации | 41 |
| 2.2.1.4 Задание области ассоциаций | 47 |
| 2.2.2 Композиция | 48 |
| 2.2.2.1 Объектные сущности композиции и ассоциации | 50 |
| 2.2.3 Навигация | 52 |
| 3. ПОДРОБНОСТИ ПРОЕКТА | 53 |
| 3.1 Схемы | 53 |
| 3.1.1 Правила именования | 55 |
| 3.2 Простые типы | 56 |
| 3.2.1 Ограничения простого типа | 57 |
| 3.2.1.1 Length | 57 |
| 3.2.1.2 Decimal | 58 |
| 3.2.1.3 Default | 58 |
| 3.2.1.4 Check | 59 |
| 3.3 Перечислимые типы | 59 |
| 3.3.1 Расширяемые перечисления | 61 |
| 3.4 Типы массива | 63 |
| 3.4.1. Ограничения типа массива | 63 |
| 3.4.1.1 ElementConstraint | 64 |
| 3.4.1.2 Occurs | 64 |
| 3.4.1.3 Unique | 64 |
| 3.4.1.4 Check | 65 |
| 3.5 Табличные типы | 65 |
| 3.6 Типы ссылки объектной сущности | 67 |
| 3.7 Типы ссылки таблицы | 67 |
| 3.8 Свойства | 68 |
| 3.8.1 Ограничения свойств | 70 |
| 3.8.2 Наложение ограничений на целевые типы | 71 |
| 3.9 Расчетные свойства | 72 |
| 3.9.1 Ограничения расчетных свойств | 73 |
| 3.10 Методы | 73 |
| 3.11 Подставляемые типы | 76 |
| 3.11.1 Ограничения подставляемых типов | 79 |
| 3.11.1.1 Check | 79 |
| 3.12 Типы объектной сущности | 79 |
| 3.12.1 Ограничения типа объектной сущности | 83 |
| 3.12.1.1 Check | 83 |
| 3.12.2 Типы расширения объектной сущности | 84 |
| 3.13 Ассоциация | 87 |
| 3.13.1 Виды ассоциаций | 91 |
| 3.14 Композиция | 99 |
| 3.14.1 Ограничения типа вложенной таблицы | 103 |
| 3.14.1.1 EntityConstraint | 103 |
| 3.14.1.2 Occurs | 103 |
| 3.14.1.3 Unique | 104 |
| 3.14.1.4 Check | 104 |
| 3.15 Свойства навигации | 105 |
| 3.16 Псевдонимы типа | 106 |
| 3.17 Наборы таблиц и типы набора таблиц | 107 |
| 3.17.1 Типы набора таблиц | 107 |
| 3.17.2 Экземпляры набора таблиц | 108 |
| 3.17.3 Объединение наборов таблиц | 108 |
| 4. ОБЩЕДОСТУПНЫЕ РЕЗУЛЬТАТЫ | 110 |
| 4.1.1 Язык запросов | 110 |
| 4.1.1.1 Использование композиций в запросах | 110 |
| 4.1.1.2 Использование ассоциаций в запросах | 112 |
| 4.1.2 Интерфейсы | 113 |
| 5. ПРИЛОЖЕНИЯ | 115 |
| 5.1 Завершенная примерная схема | 115 |
| 5.2 SQL 99 и Общая модель данных | 119 |
| 5.2.1 Определяемые пользователем типы | 120 |
| 5.2.2 Методы/Поведения | 121 |
| 5.2.3 Типизированные таблицы против таблиц объектных сущностей | 121 |
| 5.2.4 Ссылки | 122 |
| 5.2.5 Примерная простая LOB-схема | 122 |
| 5.3 Структурная семантика | 124 |
| 5.3.1 Типы | 125 |
| 5.3.2 Свойства | 126 |
1. ВВЕДЕНИЕ
Устойчивость данных является ключевым требованием в любом приложении, будь то потребительское приложение или бизнес-приложение. Командные и аудиовизуальные приложения сохраняют документы, музыку и фотографии; приложения электронной почты, аналогичные Outlook и Exchange, сохраняют объекты сообщений и календарные объекты; пакеты бизнес-приложений, аналогичных MBS ERP, сохраняют объекты потребителей и заказов. Почти все эти приложения определяют объектную модель для данных и прописывают свои собственные механизмы устойчивости.
Общая и простая, но обогащенная, модель данных делает возможной общую модель программирования для этих приложений и предоставляет прикладным платформам возможность рационализировать основу доступа к общим данным. Она, к тому же, является предпосылкой к выполнению видения WinFS унифицированным хранилищем для Windows-приложений. Начальное сосредоточение WinFS произошло на клиентских и потребительских приложениях. Однако, полная ценность унифицированного хранилища претворяется в жизнь, когда все приложения, потребительские и промышленные приложения, используют в своих целях лежащее в основе хранилище.
Общая модель данных, описанная в этом документе, является общей моделью данных для многочисленных специфичных приложениям моделей данных. Например, она может поддерживать как PIM-данные (модель данных WinFS), так и LOB-данные (MBF). Подобным образом, SDM (модель описания системы) может задавать свою модель поверх общей модели данных. Тем не менее, общая модель данных не пытается моделировать каждое специфичное приложению понятие. Общая модель данных делает возможной лучшую функциональную совместимость между приложениями. Но это не означает, что приложения могут свободно перемещаться по всем прикладным моделям; например, приложение, написанное для WinFS, не может работать на фоне SDM, так как оно наслаивает специфичные приложению концепции поверх общей модели данных.
Есть значительное количество концепций устойчивости и моделирования данных, которые могут быть вынесены в общую модель, тем самым, предоставляя обогащенный каркас устойчивости, который может быть заимствован большими количествами приложений. Целью общей модели данных является освободить приложения от определения их собственного каркаса устойчивости и к тому же сделать возможными более высокие уровни прикладной функциональной совместимости, охватывающей разные хранилища данных.
Ключевыми задачами общей модели данных являются:
1. Осуществлять отнесение с реляционными понятиями
2. Определять обогащенную объектную абстракцию для данных
3. Моделировать обогащенную семантику, аналогичную отношениям
4. Минимизировать несоответствия между приложением и моделью данных
5. Осуществлять согласование с системой типов CLR
6. Поддержка поведения. Давать возможность разработки среднеуровневых и клиентских приложений
7. Логические понятия. Концепции моделирования фиксируют семантику, независимую от хранилищ данных.
1.1 Основные понятия
Общая модель данных является состоящей из следующих основных понятий:
• Объектная сущность (Entity) - набор непосредственно связанных данных с единой идентичностью.
• Отношение (Relationship) - механизм для соотнесения двух или более объектных сущностей.
Структуры модели данных описаны с использованием XML-грамматики в документах схем.
1.1.1 Объектная сущность
Объектные сущности являются состоящими из членов. Поддерживаются следующие разновидности членов.
• Свойство (Property) - выделяет хранилище для экземпляра конкретного типа.
• Свойство навигации (Navigation Property) - упрощает запрашивание по объектным сущностям, соотнесенным ассоциацией.
• Расчетное свойство (Calculated Property) - представляет рассчитываемое значение в противоположность хранимому.
• Метод (Method) - представляет операцию, которая может быть выполнена.
Члены объектной сущности имеют типы и/или принимают типизированные параметры. Следующие разновидности типов имеются в распоряжении при описании членов объектной сущности:
• Подставляемый тип (Inline Type) - типы, чьи данные сохраняются внутри объектной сущности. Подобно типам объектной сущности, подставляемые типы являются состоящими из членов. В отличие от типов объектной сущности, подставляемые типы не имеют идентичности сверх той, что наложена объектной сущностью, в пределах которой они находятся. Подставляемые типы могут быть объявлены непосредственно и охватывают несколько других разновидностей типов в модели данных.
1. Простой подставляемый тип (Simple Inline Type) - подставляемый тип, который не имеет внутренней структуры, которая является видимой в общей модели данных. Типы значений CLR являются простыми типами в общей модели данных.
2. Перечислимый тип (Enumeration Type) - набор именованных значений. Перечислимые типы являются простыми типами, которые могут быть независимо и одновременно расширены многочисленными разработчиками без опасения конфликта.
3. Тип ссылки объектной сущности (Entity Reference Type) - долговременная ссылка на одиночную объектную сущность, возможно включающая в себя ссылку на таблицу, в которой находится объектная сущность. Ссылки объектной сущности используются в соединении с ассоциациями, чтобы соотносить две объектные сущности.
4. Тип ссылки таблицы (Table Reference Type) - долговременная ссылка на таблицу.
5. Тип массива (Array Type) - упорядоченная коллекция экземпляров подставляемого типа, иного чем массив.
• Табличный тип (Table Type) - неупорядоченная коллекция экземпляров заданного типа объектной сущности. Таблицы используются в соединении с композициями, чтобы соотносить две объектные сущности.
Все из типов, перечисленных выше, являются содержимыми типами; то есть, значения этих типов могут содержаться объектной сущностью.
Тип объектной сущности описывает членов объектной сущности. Типы объектной сущности могут быть порождены от базового типа объектной сущности, в каковом случае порожденный тип объектной сущности содержит все члены базового типа наряду с членами, описанными для порожденного типа.
Типы объектной сущности могут быть независимо и одновременно расширены многочисленными разработчиками без опасения конфликта. Такие типы расширения объектной сущности не зависят от наследования типа.
Типы объектной сущности и расширения объектной сущности не являются содержимыми типами.
Набор таблиц - экземпляр типа объектной сущности, который содержит нормированные таблицей свойства. Объявление набора таблиц создает одиночный именованный экземпляр типа и, таким образом, каждую из таблиц, которые он содержит. Набор таблиц создает место для хранения данных подобно способу, при котором создание базы данных создает место для хранения данных.
1.1.2 Отношение
Отношения описывают, каким образом соотносятся две или более объектных сущностей. Отношения принимают одну из следующих форм:
• Ассоциация (Association) - наиболее общая форма отношения между двумя или более объектными сущностями. Объектные сущности, названные сторонами, соотносятся одна с другой через явно заданное отношение источник-цель (подобное внешнему - первичному ключу) или посредством запроса. Каждая из сторон в отношении остается независимой от других сторон. Является допустимым заставлять одну сторону быть удаленной, когда удаляется другая сторона, или предохранять одну сторону от того, чтобы быть удаленной, до тех пор, пока существует другая сторона.
• Композиция (Composition) - родительская объектная сущность, которая соотнесена с дочерней объектной сущностью (или объектными сущностями) таким образом, что дочерняя объектная сущность (потомок) на понятийном уровне является неотъемлемой частью родительской объектной сущности. Дочерняя объектная сущность удаляется всегда, когда удаляется родительская объектная сущность.
• Ассоциация объектной сущности (Entity Association) - две или более объектных сущностей, сторон, связаны вместе отношениями по отдельной объектной сущности, ассоциации объектной сущности. Каждая из сторон на понятийном уровне остается независимой от других.
1.2 Сфера применения общей модели данных
Что могла бы покрывать общая модель данных? Должна модель данных отражать каждый семантический аспект лежащего в основе хранилища данных? Например, в WinFS, когда мы говорим о модели данных WinFS, мы учитываем систему типов, операционную семантику (например, копировать, переместить, удалить и экспортировать), элементарные правила безопасности, а также службы совместного использования и синхронизации. Модель данных WinFS задает все (то есть, все службы), которые хранилище WinFS должно приводить в исполнение. С другой стороны, спецификация SQL 99 включает в себя систему типов, язык запросов, правила транзакций и безопасности. Спецификация SQL не включает в себя операции, подобные импортированию, экспортированию, резервированию, восстановлению и так далее. Сфера применения общей модели данных должна покрывать
• Основную модель данных - систему типов, отношения и таблицы
• Язык запросов
• Общие API-интерфейсы
• Транзакции
• Аспекты безопасности
По существу, общая модель данных будет покрывать концепции, которые находятся в сфере интересов разработчика приложений. Семантика служб, подобная операциям уведомления, синхронизации, администрирования¸ и усовершенствованная безопасность не покрываются спецификацией общей модели данных.
Настоящий документ, главным образом, фокусируется на "основной" модели данных. Есть сопроводительные спецификации для языка запросов и API-интерфейсов.
1.3 Схема документа
Связанные с CDM функциональные возможности могут быть разбиты на шесть компонентов:
• Сама модель данных (описанная в этом документе). Модель данных является независимой от конкретной реализации модели данных
• Язык запросов для общей модели данных
• Хранилище WinFS, которое непосредственно реализует хранилище CDM-моделей данных
• Отличные от WinFS хранилища, которые требуют от CDM-моделей данных быть приведенными в соответствие SQL-конструкциям явным образом.
• API System.Storage, который предусматривает CLR-модель программирования для CDM-моделей данных.
• Инструментальные средства для проектирования CDM-моделей данных
Документ [WinFSDM] описывает, каким образом используется CDM в первом выпуске WinFS. Ожидается, что этот выпуск Acadia SQL Server предоставит обоим, реляционным и WinFS, типам возможность быть в состоянии сосуществовать в одном и том же хранилище.
Чтобы поддержать отличные от WinFS хранилища, необходима технология объектного реляционного (O/R) преобразования, которая является частью API System.Storage. Заметим, что API System.Storage объединил в себе функциональные возможности, ранее предоставляемые ObjectSpaces. Первый выпуск API System.Storage может не поддерживать приведение CDM-конструкций в соответствие реляционным хранилищам. Поддержка API System.Storage для табличных хранилищ описана в документе [RelationalProvider].
API System.Storage состоит из инструментальных средств, которые генерируют классы данных из CDM-схем и каркас среды исполнения, который поддерживает извлечение, модифицирование и сохранение объектов, которые олицетворяют сделанные устойчивыми CDM-данные. Архитектура API System.Storage описана в документе [API Arch].
Инструментальные средства для проектирования CDM-моделей данных являются разрабатываемыми и встраиваются в Visual Studio.
Заметим, что реализации CDM, которые не заимствуют хранилище WinFS, API-интерфейсы System.Storage и/или средства проектирования, возможны и подразумеваются.
1.4 Почему общая модель данных?
Есть по меньшей мере четыре других кандидата на модель данных: SQL99, CLR, UML и XSD. Ни один из них не является непосредственно используемым, поскольку ни один не обладает исчерпывающей привилегией абстракций для построения приложений с долговременными данными. CLR не задумана как информационная модель базы данных. SQL 99 не испытывает недостаток высокоуровневых абстракций, таких как отношения. XSD не имеет поведенческих компонентов и перекрывается, главным образом, с системой типов CLR. UML является языком общего характера без четко выраженной семантики хранения. И CLR и XSD обладают признаками, которые, как следует, не соответствуют серверу базы данных.
Однако, общая модель данных четко соответствует CLR-реализации. Ее правила описывают поведение основанного на CLR каркаса. Она также четко соответствует SQL Server, к тому же, добавляет дополнительные абстракции, которых ему недостает. Приложения могут моделироваться с использованием UML-подобного языка моделирования. В заключение, данные в модели могут быть ясно выражены на XML.
Комбинируя модели SQL 99, CLR и E/R (UML), общая модель данных предлагает обогащенную модель данных для разработки приложений.
Остаток этого раздела дополнительно обсуждает эти прочие модели.
1.4.1 Почему не SQL99?
Разработчики баз данных часто спрашивают, почему не использовать SQL 99 в качестве общей модели данных. Ведь SQL 99 добавил определяемые пользователем типы (UDT) и объектную ориентацию. Язык SQL усовершенствован для запрашивания типизированных таблиц и столбцов. Итак, почему, в самом деле, не использовать SQL 99? Несмотря на то, что SQL 99 добавлял объектно-ориентированные расширения к SQL, он по-прежнему не удовлетворяет многим из требований общей модели данных. К тому же, SQL-модель излишне специфична реализации касательно абстракции, которую используют приложения. Последующее является недостатками текущей SQL 99-модели:
1. UDT-типы SQL 99 фиксируют, главным образом, структуры. Поведение типа привязано к типам и таблицам. Например, идентичность задается в таблице вместо того, чтобы в типе; подобным образом, операционная семантика (например, копирования, резервирования, восстановления) определена в таблицах. Следовательно, приложения не могут полагаться только на типы, чтобы развивать логику. Такие приложения не могут быть независимыми от источников данных, тем самым ограничивая переносимость.
2. Есть несоответствие между системой типов SQL 99 и системами типов языков программирования (например, C#). SQL 99 определяет свой собственный язык хранимых процедур и методов. Несмотря на то, что SQL99 действительно специфицирует связывание с другими языками программирования, он, большей частью, скорее, фокусируется на связывании языка запросов, чем установлении соответствия между концепциями моделей данных. Например, SQL-J, скорее, определяет, каким образом язык запросов SQL может быть объединен с Java (более строго, нежели JDBC), чем каким образом классы и иерархии классов Java приводятся в соответствие SQL-концепциям.
3. SQL 99 не поддерживает понятия, подобные отношениям, ограничениям отношений UML, и т.п.
4. Понятия SQL 99 являются слишком низкоуровневыми и ориентированными на реализацию. Например, понятия внешнего ключа и первичного ключа могут быть использованы для реализации определенных высокоуровневых понятий отношений.
Общая модель данных сочетает SQL99-манеру моделирования ссылок и вложенных таблиц с UML-понятиями ассоциаций и композиций. Этот подход привносит понятия отношений в SQL-модель и делает возможным осуществление SQL-запросов в общей модели данных.
1.4.2 Почему не CLR??
Разработчики CLR иногда спрашивают, почему мы не могли бы использовать CLR в качестве общей модели данных. Безусловно, приложения, описанные с использованием общей модели данных, должны иметь результатом естественную CLR-реализацию.
Но немногие приложения (и даже еще более немногие приложения баз данных) непосредственно вписываются в CLR. Разработчики баз данных, в частности, обычно конструируют каркасы и тратят деньги на дополнительные функциональные возможности, чтобы повысить уровень абстракции данных, которыми они управляют. Посредством каркасов они используют богатство системы типов CLR, наряду с ее ограничением и усовершенствованием в отношении своей проблемной области. Общая модель данных описывает семантику такого каркаса. Она направляет усилия на некоторые заботы, на которые не направляет CLR.
1. Модель должна перекрыть возможности обеих, SQL и CLR, сред исполнения. Невозможно вводить в обращение хоть какие-то типы в SQL Server; определенного рода правила и аннотирование метаданными являются необходимыми, чтобы быть определяемым пользователем типом данных с полным набором свойств. CLR имеет в распоряжении иной подход для чистки памяти, чем SQL. SQL оптимизирован, чтобы иметь дело с взаимосовместимостью.
2. CLR-типы значения и ссылки оптимизированы для другого набора ограничений. Типы значений должны быть небольшими, чтобы сделать прохождение по значению эффективным, и стабильными по своей структуре, отвергая использование наследования. Соответственно, большинством типов являются ссылочные типы. Данные базы данных к тому же обладают различием между типами значения и ссылки, но требования, которые оно накладывает на них, препятствует использованию CLR-типов значения и ссылки для их реализации во всех случаях.
3. CLR не рассчитана для устойчивости. Например, ссылки не являются долговременными. Их значение значимо только в пределах одиночного интервала памяти, делая ее физической и недолговечной, в отличие от ключей, которые являются логическими и долговременными. И она не предусматривает никаких ориентированных на множества возможностей запроса.
4. Понятия CLR являются слишком низкоуровневыми и ориентированными на реализацию. Например, коллекции могут быть использованы для реализации определенных высокоуровневых понятий отношений.
5. Система типов CLR не поддерживает отношения, ограничения, долговременные коллекции или большие типы данных, такие как (большие двоичные) BLOB-объекты, файловые потоки. Таковые являются необходимыми, чтобы моделировать неструктурированные и структурированные данные.
Это говорит о том, что каждое O-R-решение, доступное в качестве каркаса внутри или вне Microsoft, является каркасом (Примеры в Microsoft включают в себя MBF, ObjectSpaces, Object Persistence и интегрированную в язык последовательных операторов работу запроса). Эти каркасы накладывают ограничения на авторов типов и снабжают их дополнительными функциональными возможностями, недоступными в среде исполнения. Общая модель данных формализует правила и поведение для таких каркасов.
Основная структура типа общей модели данных непосредственно согласуется с CLR касательно экстента, при котором является возможным реализовать устойчивость по отношению к обыкновенным CLR-классам, если требуется.
1.4.3 Почему не UML?
UML в большинстве случаев используется для проектирования приложений баз данных. В дополнение, некоторые части общности UML осуществляют активизацию, что иногда называется исполняемым UML. Разработчики иногда спрашивают, почему не использовать UML в качестве общей модели данных.
UML является языком моделирования общего применения. Он становится интересным для моделирования приложений с опорой на конкретную модель данных и каркас, названный специфичным для области определения языком моделирования (DSL), в то время как было усовершенствовано преобразование между UML и DSL. Завершение такого преобразования обнаружило определенного рода проблемы, связанные с использованием UML для этой цели.
1. Неформальное моделирование с помощью UML является весьма эффективным. Группы разработки назначают смысл разным UML-символам. Но то, что необходимо в модели данных, является формальным описанием, которое понятно повсюду. UML не всегда обеспечивает это.
2. В тех случаях, когда UML обладает понятной семантикой, она не всегда является правильной. Например, UML не четко соответствует CLR, поскольку он не содержит того же самого набора модификаторов доступа и не поддерживает свойства.
3. UML испытывает недостаток в способе для выражения некоторых понятий, таких как ассоциации условного вида. Он предусматривает механизмы расширяемости, однако, инструментальные средства будут обеспечивать для них разную поддержку. Приобретение большого опыта разработки требует большей точности, чем эта.
Взамен непосредственного использования UML, общая модель данных использует понятия, из которых он возникает и задает им точный смысл. Инструментальные средства будут использовать UML-подобный язык, чтобы моделировать приложения общей модели данных. Этим способом UML обеспечивает большую ценность общей модели данных.
1.4.4 Почему не XML?
Модели данных CDM выражены на XML, поэтому люди иногда спрашивают, почему XSD не используется в качестве общей модели данных.
Несмотря на то, что грамматика файла CDM-схемы может быть описана на XSD, является некорректным делать из этого вывод, что семантика CDM является такой же, как XSD. Это могло бы быть истинным, только если бы CDM изначально была описывающей XML-хранилище, каковое не является ее целью, поскольку система типов XSD не удовлетворяет требованиям общей модели данных. Проблемы заключаются в том, что
1. XSD испытывает недостаток во многих основных понятиях общей модели данных, к примеру, в отношениях.
2. XSD имеет в распоряжении конструкции, которые не являются полезными для общей модели данных и удобно приводимыми в соответствие средам исполнения CLR и SQL Server, в том числе разные наборы скалярных типов и многочисленные механизмы для расширения типа, ни один из которых не совместим с CLR.
CDM поддерживает правильные, описанные на XSD типы XML-данных, а сериализация ее данных в XML и обратно, также является значимой и полезной. Таким образом, CDM объединяется с XML, но она не является синонимичной с ним.
1.5 Краткое содержание документа
Глава 2 описывает основные понятия CDM и логическое обоснование проекта; глава 3 предоставляет формальные синтаксические и семантические правила для концепций модели данных. Глава 4 перечисляет некоторые общедоступные результаты. Приложения включают в себя связанный материал (подобный обсуждению SQL 99).
2. ОПИСАНИЕ ПРОЕКТА
2.1. Объектные сущности
Объектные сущности моделируют объекты реального мира. Объектной сущностью является информационный объект, который является уникально идентифицируемым в общей модели данных с использованием его идентичности (ключа). Объектная сущность является наименьшей единицей, которая может быть совместно использована (пригодной для указания ссылкой) с использованием ее идентичности.
Объектная сущность обладает структурой (например, свойствами) и поведением (например, методами). Некоторыми примерами разных типов объектных сущностей являются заказ (Order), потребитель (Customer), деловой контакт (Contact), документ (Document), и т.п. Объектные сущности подобны типизированным строкам в SQL 99 или объектам в ODBMS-системах. Объектные сущности определены как экземпляры типов объектных сущностей. Приведенное ниже является примерным описанием объектной сущности:
<EntityType Name="Order" Key="OrderId">
<Property Name="OrderId" Type="Guid" Nullalbe="false"/>
<Property Name="Date" Type="DateTime" Nullalbe="false"/>
…
</EntityType>
2.1.1 Ключи, идентичность и ссылки объектной сущности
Каждая объектная сущность обладает уникальной идентичностью, которая пополнена значениями ключей объектной сущности. Эта идентичность является основой для формирования ссылки на объектную сущность.
Ключом объектной сущности является набор из одного или более свойств объектной сущности. Каждое описание объектной сущности неабстрактного типа должно задавать ключевые свойства или наследовать ключевые характеристики от базового типа объектной сущности. Значения ключевых свойств могут быть определяемыми пользователем или вырабатываемыми системой.
Идентификатор объектной сущности формируется из ключа объектной сущности плюс идентификатора содержащей или родительской (порождающей) объектной сущности для данной объектной сущности. Родительской объектной сущностью (предком) является объектная сущность, содержащая таблицу, в которой сохранена (дочерняя) объектная сущность. Ключу объектной сущности необходимо быть уникальным только в пределах ее таблицы - другая таблица может содержать объектную сущность с таким же значением ключа объектной сущности. Таким образом, идентификатор объектной сущности является уникальным, комбинируя значения ее ключей с идентификатором ее родителя. (Несмотря на то, что в WinFS ключи объектной сущности уникальны в масштабе хранилища, так как каждый тип объектной сущности (запись) совместно использует единую таблицу в пределах WinFS-хранилища, вообще, требуется, чтобы ключи объектной сущности были уникальными только в пределах таблицы).
Ссылка является значением, которое полностью идентифицирует объектную сущность и которое может быть разыменовано, чтобы возвратить экземпляр объектной сущности. При заданной объектной сущности может быть получено значение ее ссылки. Две объектные сущности тождественны тогда и только тогда, когда тождественны значения их ссылок. Синтаксисом ссылочного типа в общей модели данных является «Ref(<entity_type>)», а свойства могут быть ссылочного типа. Ссылочные значения могут быть сделаны устойчивыми; они являются долговременными ссылками на объектные сущности. Копирование ссылочных значений не копирует объектные сущности, на которые они ссылаются. Язык запросов будет поддерживать и осуществлять навигацию ссылочных значений (подобно SQL 99-операторам DEREF и →).
Ссылки дают возможность совместного использования объектных сущностей. Например, объектная сущность заказа может содержать ссылочное свойство потребителя (Customer). Все заказы для одного и того же потребителя будут иметь одинаковое значение для ссылочного свойства потребителя.
Структура ссылки определяется реализацией. (Ссылки и ключи являются типами в API, который не определяется моделью данных). Реализация ссылки наглядно включает в себя информацию идентификатора для объектной сущности, на которую она ссылается, в том числе значения ключей и, возможно, таблицу, в которой объектная сущность находится. Она могла бы хранить ссылку в качестве значений индивидуальных ключей (делая возможным рациональное объединение) или в качестве единого непрозрачного значения. Функции могли бы открывать для воздействия структуры ссылок, чтобы получать значения ключей или таблицу, содержащую объектную сущность.
2.1.1.1 Логическое обоснование
В общей модели данных ключи определены по типу; в противоположность, в SQL99 ключи определены, скорее, по таблицам, чем по описанию типа строки. Несмотря на то, что отделение определения ключа от описания типа объектной сущности может показаться гибким (или расширяемым), оно, как ни странно, ограничивает возможность повторного использования и переносимость типов. Если ключи определены в таблице, то специфичное типу поведение не может работать в разных таблицах. То есть, имеет место отсутствие гарантии, что некоторая бизнес-логика (скажем, создание потребителей, заказов и их соотнесение), записанная по типам объектной сущности, будет работать в разных хранилищах типов объектной сущности, в соответствии с чем - ослабление возможности повторного использования типов. В SQL99 это не является проблемой, так как он не задает, каким образом типы приводятся в соответствие клиентским/среднеуровневым средам прикладного программирования. Отсутствие идентичности по типам объектной сущности в SQL 99 вынуждает приводить таблицы типов в соответствие объектам (классам (Classes)) языка программирования вместо приведения в соответствие типам объектной сущности. В дополнение, ассоциативное связывание идентичности с таблицами не обеспечивает поддержку переходных объектных сущностей.
Идентичность ассоциативно связывается с типом объектной сущности для того, чтобы поддерживать допускающие многократное использование типы и уровневые агностические поведения типа.
2.1.2 Устойчивость объектной сущности
Объектные сущности создаются посредством вызова метода конструктора (new) типа объектной сущности; объектные сущности делаются устойчивыми добавлением их в таблицу. В общей модели данных таблица объектных сущностей является типизированной коллекцией объектных сущностей. Таблицы объектных сущностей подобны типизированным SQL99-таблицам, но они являются логическими. То есть, таблица объектных сущностей может быть приведена в соответствие одной или более физическим SQL-таблицам. Мы указываем ссылкой таблицу типа объектной сущности как таблицу объектных сущностей типа.
Время существования объектной сущности является зависимым от времени существования таблицы, членом которой она является. Когда таблица удаляется, объектные сущности в ней также удаляются. Объектные сущности, к тому же, могут быть удалены явным образом.
Таблицы объектных сущностей определяются посредством задания свойства в типе объектной сущности. Логически, экземпляр таблицы создается, когда создается экземпляр типа объектной сущности, а удаляется, когда удаляется экземпляр объектной сущности (однако, физическая SQL-таблица создается, когда устанавливается схема, которая определяет тип, и существует до тех пор, пока установленная схема не удаляется).
<EntityType Name="Order" …>
<Property Name="Lines" Type="Table(OrderLine)" …/>
…
</EntityType>
<EntityType Name="OrderLine" …>
…
</EntityType>
Такие свойства определяют отношение композиции между родительским и дочерним типами объектной сущности (соответственно, Order и OrderLine, в этом случае). Смотрите раздел 2.2.1.3, приведенный ниже для дополнительных сведений.
Любое количество таблиц может быть создано, чтобы сохранять экземпляры данного типа объектной сущности. Каждая таблица является совершенно независимой (ключи уникальны только в области одиночной таблицы, и т.д.). Глобальный экстент всех экземпляров заданного типа, который может быть запрошен, отсутствует.
Тип объектной сущности может быть ограничен одиночной таблицей посредством включения атрибута Table (таблица) в элемент <EntityType>. Это полезно, когда объектная сущность будет содержать поведения, которые зависят от существования таблиц других типов объектных сущностей. Например, тип заказа (Order), вероятно, должен зависеть от существования таблицы потребителей (Customer) (и наоборот), и это отражено включением атрибутов Table в примере, изложенном ниже:
<EntityType Name="Order" Table="SalesData.Orders" …>
….
</EntityType>
<EntityType Name="Customer" Table="SalesData.Customers" …>
…
</EntityType>
<EntityType Name="SalesData" …>
<Property Name="Orders" Type="Table(Order)" …/>
<Property Name="Customer" Type="Table(Customer)" …/>
</EntityType>
Наложение табличного ограничения на объектную сущность исключает обладание более чем одной таблицей такого типа. Менее запретительный подход заключается в том, чтобы накладывать ограничение на ассоциацию, как описано в параграфе Ассоциация в разделе об отношениях.
2.1.2.1 Наборы таблиц
Тип набора таблиц является ограниченной формой типа объектной сущности. Типы набора таблиц могут содержать только ссылку и нормированные таблицей свойства, расчетные свойства и/или методы. Например:
<TableSetType Name="SalesData">
<Property Name="Orders" Type="Table(Order)" …/>
<Property Name="Customer" Type="Table(Customer)" …/>
</TableSetType>
Набор таблиц является экземпляром типа набора таблиц. Каждая объектная сущность набора таблиц обладает наименованием, которое является уникальным в пределах данного хранилища. Экземпляры набора таблиц могут быть объявлены в схеме или созданы динамически с использованием операций, предусмотренных хранилищем. Примерное объявление экземпляра набора таблиц из схемы показано ниже:
<TableSet Name="Sales" Type="SalesData"/>
Наименование набора таблиц вместе с наименованием табличного свойства может быть использовано в операторе FROM запроса. Например:
SELECT OrderID, Date FROM Sales.Orders
Тип набора таблиц может объявлять устанавливаемый по умолчанию экземпляр набора таблиц. Например:
<TableSetType Name="WinFSData" DefaultTableSet="WinFS">
…
</TableSetType>
<TableSet Name="Sales" Type="SalesData"/>
Также является допустимым объединять ранее определенные наборы таблиц в новый набор таблиц. Это полезно при комбинировании данных из двух раздельных приложений в единое приложение.
Заметим, что тип объектной сущности данных продаж (SalesData) в примере, изложенном выше, является абстрактным. Это происходит потому, что неабстрактные типы объектной сущности должны задавать ключевые свойства, а свойства простых типов не разрешены в типе объектной сущности, используемом для набора таблиц.
Также является допустимым объединять ранее определенные наборы таблиц в новый набор таблиц. Это полезно при комбинировании данных из двух раздельных приложений в единое приложение.
2.1.3 Типы объектной сущности
по сравнению с подставляемыми типами
Подставляемый тип является ничтожным типом (не являющимся типом объектной сущности). Подставляемые типы подобны типам структуры; они являются просто значениями. Они не обладают какой бы то ни было идентичностью; каждый экземпляр подставляемого типа является другим, даже если они имеют идентичные значения. В общей модели данных подставляемые типы могут быть использованы только в качестве типа свойств объектной сущности. Значения подставляемого типа сохраняются внутри вместе с объектной сущностью, частью которой являются. Так как экземпляр подставляемого типа не имеет своей собственной идентичности, он не является пригодным для указания ссылкой. Он является пригодным для указания ссылкой только посредством свойства объектной сущности, удерживающего экземпляр подставляемого типа. Изложенное ниже является примерным описанием подставляемого типа:
<InlineType Name="Address">
<Property Name="Street" Type="String" Nullable="false"/>
<Property Name="City" Type="String" Nullable="false"/>
…
</InlineType>
Тем не менее, как типы объектной сущности, так и подставляемые типы, являются строго типизированными и имеют схожую структуру, они обладают несовпадающей семантикой устойчивости, совместного использования и операционной семантикой.
• Экземпляры подставляемого типа не делаются устойчивыми сами по себе; они являются структурной частью типа объектной сущности.
• Экземпляры подставляемого типа не могут быть разделяемыми; использование каждого экземпляра является исключительным.
• Экземпляры подставляемого типа не являются целевыми для большинства операций, аналогичных копированию, перемещению, удалению, резервированию, восстановлению, и т.п. В WinFS отдельные свойства подставляемых типов не могут быть независимо подвергнуты отслеживанию изменений (для синхронизации).
Вследствие вышеизложенных семантических различий является важным предусмотреть разные понятия подставляемого типа и типа объектной сущности, с тем чтобы приложения могли осуществлять объявления в программе надлежащим образом. В SQL99 понятия подставляемого типа и типа объектной сущности явным образом не моделируются. В SQL99 есть только «определяемые пользователем типы». Если тип использован как тип столбца, он ведет себя как подставляемый тип; если он использован для определения таблицы, он действует как тип объектной сущности (тип строки). Так как ключи определены в таблице, только строки типизированной таблицы обладают идентичностью. Так как типы не имеют ключей, в SQL, наряду с размышлением об экземплярах типа, приходится вести разговор в терминах экземпляров типа с ключами и экземпляров типа без ключей.
Наряду с определением общей модели данных, мы обсуждали за и против описания типа в SQL99-стиле. Несмотря на то, что SQL99 предоставляет типу возможность быть использованным как в качестве типа строки, так и столбца, без необходимости описывать два раздельных типа, есть несколько недостатков, ассоциативно связанных с такой спецификацией. Сторонники могли бы привести доводы, что такой подход является гибким, но он служит причиной неудобств программирования по отношению к приложениям. Последующее является некоторыми из проблем, связанных со слиянием понятий типов объектной сущности и подставляемых типов в единое понятие.
1. Приложения обязаны быть осведомленными, происходит экземпляр типа от строки или от свойства. Такие приложения редко являются переносимыми. Возможно, что тот же самый тип используется как в качестве типа объектной сущности, так и в качестве подставляемого типа. Трудно описать поведения типа, которые действуют в обоих случаях, тем самым ограничивается переносимость.
2. Так как один и тот же тип может быть использован, чтобы определить две разные таблицы с двумя разными ключами, трудно описать поведения типа, которые являются независимыми от его хранилища.
3. Так как тип может быть использован в качестве совместно используемых экземпляров (объектных сущностей) и не используемых совместно значений (экземпляры подставляемого типа), принудительное применение семантики совместного использования в приложениях становится сложным. Например, приложения не могли бы предпринимать ссылки на классы, соответствующие подставляемым экземплярам.
4. Приложения не могут делать выводы об операционной семантике, просто проверяя тип (например, отслеживании изменений или защите).
5. Вследствие причин, изложенных выше, является затруднительным генерировать прикладные классы из описаний типов. Прикладные классы могут быть сгенерированы из описаний таблиц и табличных свойств, чтобы зафиксировать правильную семантику совместного использования и операционную.
В общей модели данных, типы объектной сущности и подставляемые типы моделируются явным образом в качестве отдельных понятий с раздельной спецификацией синтаксиса.
2.1.4 Взаимосовместимость данных
Взаимосовместимость данных может управляться либо оптимистическим образом, либо пессимистическим образом. В любом случае, единицей управления взаимосовместимостью является объектная сущность, либо для обнаружения конфликта при оптимистичной взаимосовместимости, либо блокирования при пессимистичной взаимосовместимости.
При оптимистической взаимосовместимости, по умолчанию, конфликты обнаруживаются касательно полной объектной сущности, исключая ее вложенные таблицы. Так, если объектная сущность считывается, а затем обновляется, обновление будет терпеть неудачу, если было произведено изменение любого вида, типизированные подставляемым типом свойства объектной сущности после этого были считаны, но до этого были обновлены. Однако, если обновление было произведено в отношении к любым дочерним объектным сущностям этой объектной сущности, оно не будет терпеть неудачу. Модель данных допускает, что могут быть использованы разные схемы обнаружения конфликтов, и этим учитывает стратегическое решение реализации модели данных и разработчика, если реализация модели данных снабжает их такой гибкостью. (Например, реализация могла бы игнорировать конфликты, если ни одно из свойств, являющихся обновляемыми, не было изменено).
При пессимистической взаимосовместимости, принимаются к использованию блокировки полной объектной сущности, исключающие ее вложенные таблицы. Так, если объектная сущность подвергается чтению с блокировкой, чтение будет терпеть неудачу, если другой пользователь имеет в распоряжении блокированную объектную сущность. Однако, если только дочерняя объектная сущность блокирована, чтение родительской будет удаваться. Модель данных допускает, что могут быть использованы разные схемы блокирования, и этим учитывает стратегическое решение реализации модели данных и разработчика, если реализация модели данных снабжает их такой гибкостью. Однако, блокировки не будут приниматься к использованию при более мелкой степени структурированности, чем объектная сущность. (Например, SQL Server предусматривает уровни изоляции и проводит различие между блокировками чтения и обновления. Кроме того, реализация может предусматривать механизм для блокирования потомков, когда подвергается чтению родитель.)
Заметим, что реализация, которая предполагает оптимистическую взаимосовместимость, тоже будет работать, когда используется пессимистическая взаимосовместимость, но реализация, предполагающая пессимистическую взаимосовместимость не будет работать, когда используется оптимистическая взаимосовместимость).
2.2 Отношения
Отношение соотносит две или более объектных сущностей. Например, деловой контакт (Contact) определяет автора документа (Document), или заказ (Order) содержит товары заказа (OrderLines). Отношение может быть ассоциацией (Association) или композицией (Composition). Ассоциации описывают «равноправные» отношения между объектными сущностями, тогда как композиция описывает отношение родителя/потомка между двумя объектными сущностями.
Сами отношения не сохраняются в качестве экземпляров типов в хранилище, но олицетворяются данными в соотнесенных объектных сущностях. Одно из конкретных использований ассоциаций задает тип объектной сущности, объектная сущность ассоциации, в качестве объектной сущности, которая олицетворяет отношение и, по выбору, может сохранять дополнительные данные как часть отношения.
Каждая ассоциация имеет наименование; наименование играет роль семантического отношения между объектными сущностями. Например, DocAuthor (автор документа) является наименованием отношения между документом и деловым контактом; ассоциация DocAuthor устанавливает отношение делового контакта как автора документа; подобным образом, OrderCustomer (потребитель заказа) является ассоциацией, которая ассоциативно связывает потребителя с заказом; при заданном заказе может быть проведена ассоциативная связь, чтобы определить его потребителя.
Заметим, что понятия ассоциации и композиции являются согласующимися с понятиями ассоциации и композиции UML. Мы сохранили построение диаграмм объектная сущность-связь и UML-терминологию (например, роль, кратность и т.п.) настолько, насколько это возможно.
Понятие отношений явным образом в реляционной модели не поддерживается. Внешние и первичные ключи и целостность ссылочных данных предоставляют инструментальные средства для реализации отношений ограниченным образом. SQL99 содержит дополнительные объектные реляционные расширения, аналогичные ссылочным (Ref) и табличным (Table) типам, чтобы поддерживать регламентированные одиночной и множественной объектной сущностью свойства, но, формально, отношения не моделируются.
Общая модель данных сочетает ссылочные и табличные свойства SQL 99 и понятия ассоциации и композиции UML. Этот подход привносит обогащенные отношения и навигацию в SQL и возможность использования запросов в приложения, моделируемые с использованием UML.
2.2.1 Ассоциации
Ассоциации олицетворяют равноправные связи между объектными сущностями. Они могут быть основаны на использовании типизированных ссылочным типом свойств или типизированных нессылочным типом свойств. Они также могут включать в себя объектную сущность ассоциации, которая играет конкретную роль. Каждая описана по очереди.
2.2.1.1 Ассоциации,
использующие типизированные ссылочным типом свойства
Рассмотрим следующую примерную схему.
<EntityType Name="Customer" …>
…
</EntityType>
<EntityType Name="Order" …>
<Property Name="CustRef" Type="Ref(Customer)" Nullable="false"
Association="OrderCustomer" />
…
</EntityType>
<TableSetType Name="SalesData">
<Property Name="Orders" Type="Table(Order)" …/>
<Property Name="Customers" Type="Table(Customer)" …/>
<Property Name="BadCustomers" Type="Table(Customer)" …/>
</TableSetType>
<Association Name="OrderCustomer" >
<End Role="OrderRole" Type="Order" Multiplicity="*"
Table="SalesData.Customers" />
<End Role="CustomerRole" Type="Customer" OnDelete="Cascade”
Multiplicity="1" />
<Reference FromRole=”OrderRole” ToRole=”CustomerRole”
Property=”CustRef”/>
</Association>
Ассоциация имеет две стороны, каждая из которых представляет соотнесенную объектную сущность. Каждая сторона предусматривает следующую информацию:
• Role (роль): Роль именует конечную точку, которая описывает роль или функцию, которую экземпляр типа объектной сущности играет на этой стороне. Она является наименованием, которое используется объектной сущностью на другой стороне ассоциации. В CDM, наименование роли должно быть явно задано, хотя, часто оно будет наименованием типа объектной сущности стороны.
• Type (Тип): Тип задает наименование типа объектной сущности стороны. Например, в ассоциации OrderCustomer (потребитель заказа), типом для стороны с ролью потребителя (CustomerRole) является тип потребителя (Customer). Типом для роли заказа (OrderRole) является тип объектной сущности заказа (Order). Тип должен быть типом объектной сущности (он не может быть подставляемым типом).
• Кратность (Multiplicity): Кратность задает диапазон разрешенных значений мощности множества для стороны ассоциации. Мощность множества стороны отношения является фактическим количеством экземпляров объектной сущности, вовлеченных в отношение на этой стороне. В примере ассоциации OrderCustomer (потребитель заказа), заказ (Order) поступает от ровно одного потребителя (Customer), и каждый заказ (Order) должен быть размещен в соответствии с потребителем (Customer). Итак, кратностью является «единица». Это ограничение зафиксировано как Multiplicity = “1” на стороне роли потребителя (CustomerRole). С другой стороны, потребитель (Customer) может обладать неограниченным количеством заказов (Order), ассоциированных с ним. Multiplicity = “*” на стороне с ролью заказа (OrderRole) фиксирует такое ограничение мощности множества.
Типичными значениями кратности являются “0..1” (нуль или один), “1” (ровно один), “*” (нуль или более) и “1..*” (один или более). В более общем смысле, значения кратности могут задавать значения «n» (ровно n) или диапазон значений «n..m» (между n и m, включительно, где n является меньшим или равным m). Типично, кратность обеих сторон ассоциации упоминается совместно, к примеру: 1:1 (один к одному), 1:* (один ко многим), *:1 (многие к одному), и *:* (многие ко многим). В примере ассоциации OrderCustomer (потребитель заказа), приведенном выше, может быть нуль или более заказов с тем же потребителем (т.е. имеющим то же самое значение свойства CustRef).
Заметим, что ограничительная семантика ограничений целостности ссылочных данных может быть смоделирована установлением надлежащим образом кратности на сторонах. Там, где нижним граничным значением кратности является 1, принудительно применяется традиционная ограничительная (Restrict) семантика. То есть, для каждого заказа должен существовать потребитель. Следовательно, заказ не может быть создан, пока нет потребителя; подобным образом, потребитель не может быть удален, если потребитель внесен в заказ.
• Table (таблица): Накладывает ограничение на таблицу, где могут быть найдены экземпляры типа (Type). Это необходимо для целевого объекта основанной на ссылке ассоциации, чтобы таблица не задавалась прямо в описании типа целевой объектной сущности. В примере, приведенном выше, указано, что потребители (Customer) по заказам (Order) могут быть найдены только в таблице SalesData.Customers, но не в таблице SalesData.BadCustomers. Задание Table=”” указывает, что ссылка может ссылаться на объектную сущность в любой таблице надлежащего типа.
• OnDelete (по удалению): Атрибут OnDelete задает, что должно быть сделано, когда объектная сущность на этой стороне удаляется. В этом примере разрешенными значениями могли бы быть: Cascade, SetNull или Restrict (каскадировать, установить в нуль или ограничить). В этом примере:
• Так как было задано Cascade (каскадировать), когда объектная сущность потребителя (Customer) удаляется, объектная сущность заказа (Order) удаляется тоже.
• Если было задано SetNull (установить нуль), когда объектная сущность потребителя (Customer) удаляется, свойство CustRef объектной сущности заказа (Order) на другой стороне будет установлено в Null (нуль). Свойство должно быть обнуляемым.
• Если было задано Restrict (ограничить), объектная сущность потребителя (Customer) не может быть удалена, если объектная сущность заказа (Order) ассоциирована с ним.
Элемент <Reference> указывает, что это ассоциация, основанная на ссылке. Этот элемент задает следующую информацию:
• FromRole (исходная роль): Роль, которая содержит ссылочное свойство, которое реализует ассоциацию.
• ToRole (целевая роль): Роль, которая является целевым объектом ссылки.
• Property (свойство): Наименование ссылочного свойства.
В ассоциации OrderCustomer (потребитель заказа), свойство CustRef стороны с ролью заказа (OrderRole) соотнесено с идентификатором объектной сущности с ролью потребителя (CustomerRole); свойство CustRef действует подобно внешнему ключу.
2.2.1.2 Ассоциации, использующие типизированные нессылочным типом свойства
Ассоциация OrderCustomer (потребитель заказа), приведенная выше, соотносит типы объектной сущности заказа и потребителя по идентичности потребителя. Вообще, допустимо соотносить два типа объектной сущности по любым свойствам сторон. Например, рассмотрим следующую ассоциацию DocumentAuthor (автор документа), где свойство Document.Author соотнесено с Contact.Name. Так как Contact.Name не является уникальным, эта ассоциация может возвращать многочисленные деловые контакты для документа.
<EntityType Name="Contact" Key="ContactId">
<Property Name="ContactId" Type="String" Nullable="false">
<Property Name="Name" Type="String" Nullable="false"/>
</EntityType>
<EntityType Name="Document" Key="DocId">
<Property Name="DocId" Type="String" Nullable="false"/>
<Property Name="Title" Type="String" Nullable="false">
<Property Name="Author" Type=”String" Nullable="true">
</EntityType>
<Association Name="DocumentAuthor" >
<End Role="DocRole" Type="Document" Multiplicity="*" />
<End Role="ContactRole" Type="Contact" Multiplicity="1"/>
<Condition>
DocRole.Author = ContactRole.Name
</Condition>
</Association>
Одно из важных различий между этим примером и примером потребителя/заказа (Customer/Order) состоит в том, что вместо задания элемента <Reference> предусмотрено булево выражение внутри элемента <Condition> (<условие>). Так как <Condition> может содержать в себе выражение произвольной сложности, это очень гибкая форма ассоциации. Она в самом деле делает удобным повторное использование соединения в приложениях, добавляя его в качестве первоклассной части моделей запроса и программирования.
В случаях, когда требуется только простая эквивалентность между двумя свойствами, поддерживается упрощенный синтаксис. В таких случаях, элемент <CommonValue> может быть использован вместо элемента <Condition>. Пример, приведенный ниже, содержит тот же смысл, как и предыдущий пример (за исключением поведения OnUpdate (по обновлению), описанного ниже):
<Association Name="DocumentAuthor">
<End Role="DocRole" Type="Document" Multiplicity="*"/>
<End Role="ContactRole" Type="Contact" Multiplicity="1"
OnUpdate=”Cascade”/>
<CommonValue Property1=”DocRole.Author”
Property2=”ContactRole.Name”/>
</Association>
Поскольку свойства явным образом перечислены и всегда имеют одно и то же значение, имеется в распоряжении один дополнительный признак: атрибут OnUpdate (по обновлению). Возможными значениями этого атрибута являются: Cascade, SetNull или Restrict (каскадировать, установить в нуль или ограничить). В этом примере значение атрибута “Cascade” указывает, что если свойство на стороне роли делового контакта (ContactRole) обновляется, то значение распространяется на свойство на другой стороне; если OnUpdate=”Restrict”, то это свойство не может быть изменено, если есть объектная сущность, ассоциированная с другой стороной; если OnUpdate=”SetNull”, то когда свойство на этой стороне обновляется, свойство на другой стороне устанавливается в нуль.
2.2.1.3 Объектные сущности ассоциации
Является общепринятым ассоциативно связывать отношением свойства. Например, типично, трудовые отношения между организацией и лицом несут свойства, подобные периоду трудоустройства (EmploymentPeriod). Мы могли бы создать часть свойства типа организации (Organization) или лица (Person), но свойство ничего не означает без отношения. Например, свойство периода трудоустройства (EmploymentPeriod) в организации (Organization) является бессмысленным, пока, к тому же, не присутствует трудоустроенное лицо; подобным образом свойство не является значащим в объектной сущности лица (Person).
В общей модели данных, делаются устойчивыми только объектные сущности (экземпляры типа объектной сущности). Только объектные сущности (фактически, таблицы объектных сущностей) являются пригодными для запрашивания. Ассоциации и композиции сохраняются в качестве метаданных. Поэтому свойства в ассоциациях должны быть сохранены в объектной сущности. Такая объектная сущность является объектной сущностью ассоциации. Это играет такую же роль, как класс ассоциации в UML. Тип объектной сущности ассоциации аналогичен промежуточной таблице (связи или объединения) в реляционных системах, со ссылками (внешними ключами) на объектные сущности, которые она продолжает связывать. Ключ объектной сущности ассоциации, как правило, включает в себя ссылки на соотнесенные объектные сущности. Например, рассмотрим следующее:
<EntityType Name="Product" …>
…
</EntityType>
<EntityType Name="Supplier" …>
…
</EntityType>
<EntityType Name="PSLink" Key="ProductRef, SupplierRef" …>
<Property Name="ProductRef" Type="Ref(Product)" Nullable="false"
…/>
<Property Name="SupplierRef" Type="Ref(Supplier)"
Nullable="false"…/>
<Property Name="Price" Type="Decimal" Nullable="false">
<Decimal Precision="6" Scale="2"/>
</Property>
<Property Name="Quantity" Type="int" Nullable="false"/>
</EntityType>
PSLink - тип объектной сущности, который является связывающим продукцию и поставщиков. PSLink соотносит типы продукта (Product) и поставщика (Supplier), задавая два ссылочных свойства, ProductRef и SupplierRef, для типов продукта (Product) и поставщика (Supplier), соответственно. В дополнение к соотнесению продукции и поставщиков, она содержит свойства цены (Price) и количества (Quantity), значащие для отношения.
Возможные ассоциации между продуктом (Product), поставщиком (Supplier) и PSLink существуют между PSLink и Product, PSLink и Supplier, и Product и Supplier. Эти ассоциации могли бы быть определены явным образом, как изложено ниже:
<Association Name="PSLinkProduct" >
<End Role="PSLink" Type="PSLink"/>
<End Role="Product" Type="Product" />
<Reference FromRole=”PSLink” ToRole=”Product”
Property=”ProductRef”/>
</Association>
<Association Name="PSLinkSupplier" >
<End Role="PSLink" Type="PSLink" EndProperty="SupplierRef”/>
<End Role="Supplier" Type="Supplier" />
<Reference FromRole=”PSLink” ToRole=”Supplier”
Property=”SupplierRef”/>
</Association>
<Association Name="ProductSupplier">
<End Role="Product" Type="Product"/>
<End Role="Supplier" Type="Supplier"/>
<Uses Role="PSLink" Type="PSLink"/>
<Condition>
PSLink.ProductRef = Product AND PSLink.SupplierRef =
Supplier
</Condition>
</Association>
В вышеприведенном примере факт того, что PSLink - объектная сущность ассоциации, не является явно заданным и, следовательно, не мог бы быть использован в описаниях ассоциаций. Разработчик схемы обязан утомительно определять все необходимые описания ассоциации. Однако этого можно избежать введением понятия явно заданной объектной сущности ассоциации в качестве части описания ассоциации. Вышеприведенный пример ниже переписан с заданием PSLink в качестве объектной сущности ассоциации:
<EntityType Name="Product" …>
…
</EntityType>
<EntityType Name="Supplier" …>
…
</EntityType>
<EntityType Name="PSLink" Key="ProductRef,SupplierRef"
Association=”ProductSupplier”>
<Property Name="ProductRef" Type="Ref(Product)" Nullable="false" Role=”Product”/>
<Property Name="SuplierRef" Type="Ref(Supplier)"
Nullable="false" Role=”Supplier”/>
<Property Name="Price" Type="Decimal" Nullable="false">
<Decimal Precision="6" Scale="2"/>
</Property>
<Property Name="Quantity" Type="int" Nullable="false"/>
</EntityType>
<Association Name="ProductSupplier">
<AssociationEntity Type="PSLink">
<End Role=”Link” Type=”PSLink”/>
<Reference FromRole=”Link” ToRole=”Product”
Property=”ProductRef”/>
<Reference FromRole=”Link” ToRole=”Supplier”
Property=”SupplierRef”/>
</AssociationEntity>
<End Role="Product" Type="Product"
OnDelete=”CascadeToAssociationEntity”/>
<End Role="Suppier" Type="Supplier"
OnDelete=”CascadeToAssociationEntity” />
</Association>
Отметим следующие обстоятельства касательно этого примера:
• Он является более чем укороченной формой другого определения, потому что он предоставляет информацию о типе, которая не может быть логически выведена, когда объектная сущность ассоциации вызвана неявным образом.
• Атрибут Association в определении <EntityType> PSLink идентифицирует этот тип как объектную сущность ассоциации и идентифицирует ассоциацию, которая использует тип.
• Атрибуты Role в элементах свойств ProductRef и SupplierRef идентифицируют роли в пределах ассоциации, которая использует эти свойства.
• Элемент End, вложенный внутри AssociationEntity (объектная сущность ассоциации), предоставляет наименование для роли, выполняемой самой объектной сущностью ассоциации. По многим аспектам, объектная сущность ассоциации на самом деле является конечной точкой многопозиционной ассоциации, но по другим аспектам, она выполняет специальную функцию в ассоциации.
• Элементы <Reference> описывают, каким образом объектная сущность ассоциации ассоциативно связана с объектными сущностями продукта и поставщика. Они являются вложенными, поскольку они являются подчиненными общей ассоциации.
• Атрибуты OnDelete элементов End указывают, что если любая сторона удаляется, объектная сущность ассоциации, а следовательно, отношение, удаляется тоже. Однако, удаление одной стороны не служит причиной того, чтобы быть удаленной другой стороне (то есть, удаление поставщика не служит причиной того, чтобы быть удаленным поставляемому продукту). Другими возможными значениями для этих атрибутов могли бы быть Cascade (каскадировать), который мог бы служить причиной того, чтобы быть удаленными всем сторонам (заключенные объектной сущностью ассоциации); SetNull (установить нуль), который мог бы служить причиной для того, чтобы быть установленным в нуль ссылочному свойству в объектной сущности ассоциации; или Restrict (ограничить), который мог бы служить причиной того, что удаление терпит неудачу до тех пор, пока существует объектная сущность PSLink.
Объектные сущности ассоциации также могут быть использованы в ассоциациях, использующих типизированные нессылочным типом свойства. Полные описания ассоциаций смотрите дальше в этом документе.
2.2.1.4 Задание области ассоциаций
Задание области ассоциации определяет, что объектные сущности на обеих сторонах ассоциации являются потомками одного и того же экземпляра объектной сущности. Ассоциации задается область посредством размещения в атрибуте Scope (область) наименования типа объектной сущности, который содержит в себе обе стороны. Атрибут Table (таблица) на сторонах в таком случае должен начинаться таким типом. Рассмотрим следующий пример, в котором автомобиль (Car) содержит двигатель (Engine), колеса (Wheel) и трансмиссию (DriveTrain).
<EntityType Name="Car" Key="Model">
<Property Name="Model" Type="String">
<Property Name="Wheels" Type="Array(Ref(Wheel))"/>
<Occurs Minimum="4" Maximum="4"/>
</Property>
<Property Name="Engine" Type="Ref(Motor)"/>
<Property Name="DriveTrain" Type="Ref(DriveTrain)"/>
</EntityType>
<EntityType Name="Motor" … > … </EntityType>
<EntityType Name="Wheel" … > … </EntityType>
Двигатель (Engine) и колеса (Wheel) соединены посредством трансмиссии (DriveTrain).
<EntityType Name="DriveTrain" Association="DriveTrain">
<Property Name="Engine" Type="Ref(Motor)" Role="Engine"/>
<Property Name="Wheels" Type="Array(Ref(Wheel))" Role="Wheels">
<Check>Count(*) = 2 OR Count(*) = 4</Check>
</Property>
</EntityType>
<Association Name="DriveTrain" Scope="Car">
<End Role="Engine" Type="Motor" Table="Car.Engine"/>
<End Role="Wheels" Type="Wheel" Table="Car.Wheels"/>
<AssociationEntity Type="DriveTrain"/>
<End Role="DriveTrain"
Type="DriveTrain" Table="Car.DriveTrain"/>
<Reference FromRole="DriveTrain" ToRole="Engine"
Property="Engine"/>
<Reference FromRole="DriveTrain" ToRole="Wheels"
Property="Wheels"/>
</AssociationEntity>
</Association>
Вышеприведенный пример показывает, что трансмиссия (DriveTrain) соединяет двигатель (Engine) и колеса (Wheel) из одного и того же автомобиля (Car). Недопустимо для двигателя (Engine) из одного автомобиля (Car) быть прикрепленным к колесам (Wheel) из другого автомобиля (Car). Любые атрибуты Table в элементах <End> должны начинаться с задающей область объектной сущности. Элемент <End> может указывать, что установление области к нему применять не следует, посредством добавления атрибута Scoped=”false”.
2.2.2 Композиция
Композиция является понятием моделирования, которое определяет композиционное отношение между двумя объектными сущностями. Снова рассмотрим пример заказа (Order); свойство товаров (Lines) и отношение OrderLines (товары заказа) определяют композицию между типами объектной сущности заказа (Order) и товара (Line). Есть структурное отношение между типами заказа (Order) и товара (Line); товары являются частью (или скомпонованы в) заказа. Объектная сущность товара принадлежит единственной объектной сущности заказа; объектная сущность товара исключительно является частью заказа; заказ и его товары формируют операционную единицу.
В противоположность, в вышеприведенных примерах заказ (Order) и потребитель (Customer) являются независимыми объектными сущностями. Таблицы заказов (Orders) и потребителей (Customers) являются независимыми друг от друга. Ассоциация OrderCustomer (потребитель заказа) соотносит заказы и потребителей. Пока OnDelete=Cascade не задано в ассоциации, времена существования заказов и потребителей являются независимыми друг от друга. OnDelete=Cascade добавляет поведенческое ограничение, которое требует от заказов, ассоциативно связанных с потребителями, быть удаленными, когда удаляется потребитель. Однако, структурное отношение между типами объектных сущностей заказа и потребителя отсутствует. Например, выборка объектной сущности потребителя не осуществляет доступ к каким бы то ни было заказам и наоборот.
В дополнение, является допустимым, чтобы заказ (Order) мог участвовать в другой, но подобной ассоциации с поставщиком (Supplier); скажем, есть свойство SupplierRef в заказе (Order) и ассоциация OrderSupplier (поставщик заказа). Эта ассоциация могла бы также задавать OnDelete=”Cascade”, означающее, что время существования заказа (Order) контролируется либо потребителем, который размещал заказ, либо поставщиком, который осуществлял поставку заказа. Однако заказ (Order) и потребитель (Customer) или заказ (Order) и поставщик (Supplier) не составляют операционных единиц для операций, аналогичных копированию, перемещению, резервированию, восстановлению и т.д.
EntityType Name="Order" …>
<Property Name="Lines" Type="Table(OrderLine)"
Composition="OrderLines"/>
…
</EntityType>
<EntityType Name=”OrderLine” …>
…
</EntityType>
<Composition Name="OrderLines">
<ParentEnd Role="ParentOrder" Type="Order" EndProperty="Lines"/>
<ChildEnd Role="LineItems" Type="OrderLine" Multiplicity="*"/>
</Composition>
Несмотря на истинность того, что такая композиция является дополнительной конкретизацией понятия ассоциации, она является фундаментальным понятием, особенно в структурном и операционном ракурсе. Отношение между заказом (Order) и товарами (Line) является совершенно отличным от такового между заказом (Order) и потребителем (Customer). Поэтому в общей модели данных композиция является обособленным, самым высокоуровневым понятием.
2.2.2.1 Объектные сущности композиции и ассоциации
Одно из конкретных использований объектных сущностей ассоциации компонует саму объектную сущность ассоциации в одну из ассоциируемых объектных сущностей. Рассмотрим пример, приведенный ниже:
<EntityType Name="Item" …>
<Property Name="Links" Type="Table(Link)"
Association="ItemLinkRelation"/>
…
</EntityType>
<EntityType Name="Link" Association="ItemLinkRelation" …>
<Property Name="Target" Type="Ref(Item)" Role="Target"/>
…
</EntityType>
<Association Name="ItemLinkRelation">
<AssociationEntity Type="Link"/>
<End Role=”Link” Type=”PSLink”/>
<Composition ParentRole=”Source” ChildRole=”Link”
Property=”Links”/>
<Reference FromRole=”Link” ToRole=”Target”
Property=”Target”/>
</AssociationEntity>
<End Role="Source" Type="Item"/>
<End Role="Target" Type="Item"/>
</Association>
Здесь мы имеем тип объектной сущности, предмета (Item), который содержит вложенную таблицу типа объектной сущности связи (Link). Сам тип связи (Link) является объектной сущностью ассоциации, в которой он располагается между двумя соотнесенными объектными сущностями (двумя предметами в этом случае) и содержит специфичные отношению свойства. Факт того, что композиция должна соотносить предметы (Item) и связи (Link), не отменяет того факта, что истинное отношение, являющееся моделируемым, находится между двумя предметами (Item).
2.2.3 Навигация
Одним из преимуществ моделирования отношений явным образом является возможность осуществлять навигацию от одной из объектных сущностей до соотнесенных объектных сущностей с использованием описания отношения. Такая навигация может поддерживаться через запросы по отношению к общей модели данных или посредством использования классов API-интерфейсов, сформированных из описаний типа объектной сущности и отношения. В примере потребителя заказа (OrderCustomer), при заданной объектной сущности заказа можно осуществлять навигацию до его потребителя с использованием свойства CustRef и описания ассоциации. Описание ассоциации также может быть использовано, чтобы осуществлять навигацию от потребителя до его заказов. Метаданные ассоциации могут быть использованы, чтобы формировать основанный на объединении запрос, чтобы переходить от потребителя к заказам. Подобным образом, в DocumentAuthor (авторе документа), ассоциация может быть использована, чтобы формировать навигацию от документа до делового контакта и наоборот.
В общей модели данных является допустимым заранее определять основанные на ассоциации свойства навигации с использованием описаний отношения. Пример такого свойства навигации показан ниже:
<EntityType Name="Customer" …>
<NavigationProperty Name=”Orders” Association=”OrderCustomer”
FromRole=”Customer” ToRole=”Order”/>
…
</EntityType>
<EntityType Name="Order" …>
<Property Name="CustRef" Type="Ref(Customer)" Nullable="false"
Association="OrderCustomer" />
…
</EntityType>
<Association Name="OrderCustomer" >
<End Role="OrderRole" Type="Order" Multiplicity="*" />
<End Role="CustomerRole" Type="Customer" OnDelete="Cascade”
Multiplicity="1" />
<Reference FromRole=”OrderRole” ToRole=”CustomerRole”
Property=”CustRef”/>
</Association>
Элемент NavigationProperty в объектной сущности потребителя (Customer) задает путь навигации от потребителя (или потребителей) до заказов, ассоциированных с потребителем(ями). Это свойство могло бы быть представлено в моделях запроса и программирования в качестве виртуальной (нематериальной) и допускающей запрашивание, только для чтения, коллекцией ссылок на объектные сущности заказа (Order).
3. ПОДРОБНОСТИ ПРОЕКТА
Этот раздел подробно описывает язык схемы общей модели данных.
3.1 Схемы
Все описания объектной сущности, отношения и набора таблиц происходят в контексте схемы. Схема определяет пространство имен, которое задает область наименований содержимого, описанных в пределах схемы.
Элемент <Schema> является корневым элементом документа схемы. Элемент <Schema> может иметь следующие атрибуты:
• Namespace (пространство имен) - обязательный. Уникальное пространство имен для схемы. Пространство имен должно подчиняться правилам CLR для наименований пространств имен. В дополнение, также должны соблюдаться руководящие принципы именования пространств имен, определенные для пространств имен CLR. Благодаря следованию этим соглашениям Microsoft и ISV-поставщиков, существует обоснованная гарантия уникальности при выборе наименования пространства имен.
Например:
<Schema Namespace=”MyCompany.MySchema”>
</Schema>
Схема может ссылаться на типы, определенные в другой схеме с использованием полностью уточненных наименований типа (namespace-name.type-name) (пространство имен-наименование.тип-наименование). Например:
<Schema Namespace=”MyCompany.MySchema”>
<InlineType Name=”MyType”
BaseType=”YourCompany.YourSchema.YourType”…>
…
</InlineType>
</Schema>
Схема может включать в себя элемент <Using>, чтобы вносить наименования типов, определенные во внешней схеме, в область. Отсутствие означает, что нет схем, которые автоматически вносятся в область. Элемент <Using> может иметь следующие атрибуты:
• Namespace (пространство имен) - обязательный. Пространство имен схемы, чье содержимое внесено в область.
• Alias (псевдоним) - необязательный. Наименование, которое может быть использовано в качестве подстановки для пространства имен.
Например:
<Schema Namespace=”MyCompany.MySchema”>
<Using Namespace=”YourCompany.YourSchema”/>
<Using Namespace=”AnotherCompany.AnotherSchema”
Alias=”Another”/>
<InlineType Name=”Type1” BaseType=”YourType”>
…
</InlineType>
<InlineType Name=”Type2” BaseType=”Another.AnotherType”>
…
</InlineType>
</Schema>
3.1.1 Правила именования
Все наименования типа, отношения и набора таблиц должны подчиняться правилам CLR для наименований типов. Наименования также должны подчиняться руководящим принципам именования типов каркаса .Net.
Наименования типов и отношений должны быть уникальными. То есть, тип и отношение не могут иметь одинаковое полностью уточненное наименование, и никакие два типа или два отношения не могут иметь одинаковое полностью уточненное наименование.
Все наименования наборов таблиц должны быть уникальными (никакие два набора таблиц не могут иметь одинаковое полностью уточненное наименование), но набор таблиц может иметь такое же наименование, как тип или отношение.
3.2 Простые типы
Простой тип представляет одиночное значение без какой-либо внутренней структуры, видимой в модели данных.
Типы значений CLR используются в качестве простых типов в общей модели данных. Некоторое количество типов значения, определенных в пространстве имен CLR System, System.Storage и System.Data.SqlTypes, изначально поддерживаются для использования в модели данных. Этими типами являются:
| System.Data.SqlTypes.SqlString | System.String | System.Storage.ByteCollection |
| System.Data.SqlTypes.SqlBinary | System.Boolean | System.Storage.StorageStreamReference |
| System.Data.SqlTypes.SqlBoolean | System.Byte | System.Storage.StorageXmlReference |
| System.Data.SqlTypes.SqlByte | System.Int16 | |
| System.Data.SqlTypes.SqlInt16 | System.Int32 | |
| System.Data.SqlTypes.SqlInt32 | System.Int64 | |
| System.Data.SqlTypes.SqlInt64 | System.Single | |
| System.Data.SqlTypes.SqlSingle | System.Double | |
| System.Data.SqlTypes.SqlDouble | System.Decimal | |
| System.Data.SqlTypes.SqlDecimal | System.DateTime | |
| System.Data.SqlTypes.SqlDateTime | System.Guid | |
| System.Data.SqlTypes.SqlGuid | System.Uri | |
| (TODO: полный перечень) | System.TimeSpan |
| Любой тип значения, который удовлетворяет набору требований, также мог бы быть способен использоваться в качестве простого типа в модели данных. Условия, которым такому типу необходимо удовлетворять, либо будут предоставлять ему возможность быть сохраненным и использованным прямо в запросе (к примеру, UDT), или будут снабжать метаданными, необходимыми, чтобы обеспечивать преобразования хранилища и запроса, через CLR-атрибуты. |
3.2.1 Ограничения простого типа
Является возможным ограничивать значения простого типа с использованием одного из ограничительных элементов, определенных ниже. Эти элементы могут быть вложенными внутри различных элементов, которые ссылаются на простые типы (например, элемент <Property> в элементе <EntityType> или <InlineType>).
3.2.1.1 Length
Ограничительный элемент <Length> может быть применен к типам System.String, System.Storage.ByCollection и System.Data.SqlTypes.String, чтобы ограничить длину значения. Этот элемент может содержать следующие атрибуты:
• Minimum (минимум) - Минимальная длина значения. Значение по умолчанию - нуль.
• Maximum (максимум) - максимальная длина значения. Значение “unbounded” («неограниченный») указывает, что никакого заданного максимума нет. Значением по умолчанию является “unbounded”.
Чтобы быть совместимым с ограничением, заданным в базовом типе, значение, заданное для Minimum (минимума), должно быть равным или большим, чем прежнее значение, а значение, заданное для Maximum (максимума), должно быть равным или меньшим, чем прежнее значение.
3.2.1.2 Decimal
Ограничительный элемент <Decimal> может быть применен к типам System.Decimal и System.SqlDecimal, чтобы ограничивать точность и шкалу допустимых значений. Этот элемент может содержать следующие атрибуты:
• Precision (точность) - TODO.
• Scale (шкала) - TODO.
Должен быть совместимым с ограничением, заданным в базовом типе… TODO.
3.2.1.3 Default
Ограничительный элемент <Default> может быть применен к любому простому типу, чтобы задавать значение по умолчанию, которое должно быть использовано для свойства. Этот элемент может содержать следующие атрибуты:
Value (значение) - обязательный. Значение по умолчанию для свойства. Значение этого атрибута должно быть конвертируемым в значение собственного типа. Смотрите раздел о наборах таблиц (TableSets), приведенный ниже.
Заметим, что элемент <Default> фактически не задает ограничение. Любое значение является совместимым со значением, заданным в базовом типе.
3.2.1.4 Check
Ограничительный элемент <Check> может содержать в себе булево выражение запроса. Чтобы значение свойства было действительным, это выражение должно обращаться в истинное значение. Выражение не должно иметь никаких побочных эффектов. Смотрите раздел 3.17, приведенный ниже.
Когда ограничение проверки задано и в базовом, и порожденном типах, оба ограничения проверяются на действительность.
3.3 Перечислимые типы
Перечислимый тип определяет набор наименований, которые представляют уникальные значения. Тип лежащих в основе значений, но не сами хранимые значения, является видимым в общей модели данных. Когда используются заказные преобразования хранилища, лежащий в основе тип определяется этим преобразованием. Для проскриптивного хранилища, лежащий в основе тип будет выбран автоматически или мог бы быть предоставлен посредством специфичной хранилищу рекомендации.
Перечислимый тип объявляется с использованием элемента <EnumerationType>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование перечислимого типа.
• Extensible (расширяемый) - необязательный. Значение “true” («истинно») указывает, что перечислимый тип может быть расширен с использованием элемента <EnumerationExtension> (см. ниже). Значение “false” указывает, что никакие расширения не разрешены. Значение по умолчанию - "false" (никаких расширений не разрешено).
Элемент <EnumerationType> может содержать 0 или более элементов <EnumerationMember>. Эти элементы могут содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование используется, чтобы представлять специфичное перечислению значение. Это наименование должно быть уникальным внутри объявляющего элемента <EnumerationType>.
При ссылке на член перечисления, это наименование всегда уточняется наименованием типа перечисления.
• AliasesMember (определяет псевдоним члена) - необязательный. Содержит наименование другого члена перечисления. Указывает, что этот член перечисления является псевдонимом для именованного члена (т.е. оба наименования представляют одно и то же значение).
Примерное перечисление определено ниже:
<Schema Name=”MyCompany.MySchema”>
<EnumerationType Name=”A”>
<EnumerationMember Name=”P” />
<EnumerationMember Name=”Q” />
<EnumerationMember Name=”R” AliasesMember=”Q”/>
</EnumerationType>
</Schema>
Отметим, что перечисления в стиле «битового флажка» не могут быть описаны с использованием перечислимого типа. Взамен, необходимо использовать массив перечислимого типа.
3.3.1 Расширяемые перечисления
Когда элемент <EnumerationType> задает Extensible=”true”, является возможным расширять перечисление дополнительными значениями. Свойство перечислимого типа может содержать в себе любое из значений, заданных в <EnumerationType> или в любом расширении такого типа.
Значения, определенные в каждом расширении, являются обособленными от значений, определенных в базовом перечислимом типе и всех других расширениях. Это предоставляет перечислимому типу возможность быть независимо расширенным многочисленными разработчиками без возможности конфликтов.
Тип расширения перечисления определяется с использованием элемента <EnumerationExtensionType>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование типа расширения перечисления.
• ExtendsType (расширяет тип) - обязательный. Наименование перечислимого типа, который является расширяемым. Не допускается расширять тип расширения перечисления.
Элемент <EnumerationExtensionType> может содержать в себе нуль или более элементов <EnumerationMember>. Эти элементы могут содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование используется, чтобы представлять специфичное перечислению значение. Это наименование должно быть уникальным внутри объявляющего элемента <EnumerationExtensionType>.
Наименование, однако, может дублировать наименование в типе расширения перечисления. В таких случаях значение, определенное в расширении, по-прежнему является отдельным от значения, определенного в расширенном перечислении.
При осуществлении ссылки на члена перечисления это наименование всегда уточняется наименованием типа расширения перечисления.
• AliasesMember (определяет псевдоним члена) - необязательный. Содержит полное наименование (enumeration-type-name.enumeration-member-name (перечисление-тип-наименование.перечисление-член-наименование)) другого члена перечисления, в одном из этого расширения, другого расширения к тому же самому перечислимому типу, или самом расширяемом перечислимом типе. Указывает, что этот член перечисления является псевдонимом для именованного члена (т.е. оба наименования представляют одно и то же значение).
Примерное перечисление определено ниже:
<Schema Name=”MyCompany.MySchema”>
<!--
Сочетание перечислимого типа C и типов D и E расширения определяют следующие отдельные значения, которые могут быть сохранены в свойстве типа C: C.P, C.Q, D.Q, D.S, E.T, и E.U. Перечислимые члены C.R, D.T, и E.U все являются псевдонимами для C.Q и, поэтому не представляют уникальных значений.
-->
<EnumerationType Name=”C” Extensible=”true”>
<EnumerationMember Name=”P”/>
<EnumerationMember Name=”Q”/>
<EnumerationMember Name=”R” AliasesMember=”Q”/>
</EnumerationType>
<EnumerationExtensionType Name=”D” ExtendsType=”C”>
<EnumerationMember Name=”Q”/>
<EnumerationMember Name=”S”/>
<EnumerationMember Name=”T” AliasesMember=”C.R”/>
</EumerationExtension>
<EnumerationExtension Name=”E” ExtendsType=”C”>
<EnumerationMember Name=”T”/>
<EnumerationMember Name=”U” AliasesMember=”D.T”/>
</EnumerationExtension>
</Schema>
3.4 Типы массива
Экземпляры типов массива могут хранить многочисленные экземпляры заданного типа: простого, встроенного, перечислимого, ссылки объектной сущности или ссылки таблицы (массивы массивов не разрешены). Эти экземпляры являются элементами массива. Порядок элементов фиксируется и может поддерживаться приложением явным образом. Приложения могут вставлять элементы в массив и удалять элементы из массива.
Типы массива задаются с использованием синтаксиса:
Array (element-type)
где element-type - наименование типа элемента.
3.4.1 Ограничения типа массива
Является возможным ограничивать значения типа массива с использованием одного из ограничительных элементов, определенных ниже. Эти элементы могут быть вложенными внутри различных элементов, которые ссылаются на типы массива (например, элемент <Property> в элементе <EntityType> или <InlineType>).
3.4.1.1 ElementConstraint
Ограничительный элемент <ElementConstraint> может быть использован, чтобы накладывать ограничения на элементы в массиве. Любой ограничительный элемент, который является действительным для типа элемента, может быть задан внутри элемента <ElementConstraint>.
3.4.1.2 Occurs
Ограничительный элемент <Occurs> может быть использован, чтобы ограничивать количество элементов в массиве. Этот элемент может содержать следующие атрибуты:
• Minimum (минимум) - необязательный. Задает минимальное количество компонент в массиве. Значением по умолчанию является нуль.
• Maximum (максимум) - необязательный. Задает максимальное количество компонент в массиве. Значение “unbounded” (“не ограничено”) означает, что ограничений нет. Значением по умолчанию является “unbounded”.
Чтобы быть совместимым с ограничением, заданным в базовом типе, значение, заданное для Minimum (минимума), должно быть равным или большим, чем прежнее значение, а значение, заданное для Maximum (максимума), должно быть равным или меньшим, чем прежнее значение.
3.4.1.3 Unique
Ограничительный элемент <Unique> может быть использован, чтобы задавать свойство или свойства типа элемента, который должен содержать уникальное значение в массиве. Этот элемент может содержать следующие атрибуты:
• Properties (свойства) - обязательный. Разделенный запятыми список наименований свойств элемента.
3.4.1.4 Check
Ограничительный элемент <Check> содержит в себе булево выражение запроса. Чтобы значение свойства было действительным, это выражение должно обращаться в истинное значение. Выражение не должно иметь никаких побочных эффектов. Смотрите раздел 3.17, изложенный ниже для описания языка запросов.
Когда ограничение проверки задано и в базовом, и порожденном типах, оба ограничения проверяются на действительность.
Отметим, что ограничение проверки по свойству массива применяется к свойству как целому. Например, оно может быть использовано, чтобы проверить, что сумма свойства элемента является меньшей, чем некоторое предельное значение. В качестве альтернативы ограничение проверки, помещенное внутри элемента <ElementConstraint>, могло бы применяться к каждому значению индивидуально.
3.5 Табличные типы
Экземпляры табличных типов могут хранить неупорядоченную коллекцию экземпляров заданного типа объектной сущности.
Заданный тип объектной сущности, или тип в иерархии его базового типа, должен задавать ключевые свойства. Заметим, что это не обязательно означает, что тип объектной сущности не может быть абстрактным типом. Ключевые свойства типа объектной сущности, сохраненные во вложенной таблице, должны быть уникальными в любом экземпляре таблицы.
Таблица может удерживать любую объектную сущность заданного типа, или типа, порожденного от такого типа. Приложения могут вставлять объектные сущности в таблицу и удалять объектные сущности из таблицы.
Табличные типы задаются с использованием синтаксиса:
Table(entity-type)
Типы объектной сущности (и только типы объектной сущности) могут определять свойства табличных типов. Такие свойства представляют вложенные таблицы. Вложенные таблицы определяют ячейку хранилища, которая является зависимой от экземпляра содержащей объектной сущности. Объектные сущности, сохраненные во вложенной таблице, считаются частью образующего единое целое блока данных, определенного содержащей объектной сущностью (например, они удаляются, когда удаляется содержащая объектная сущность). Однако отсутствует гарантия устойчивости касательно превращений в контейнер и содержащиеся объектные сущности, ожидаемых в качестве явным образом управляемых через приложение с использованием транзакций.
Является ошибкой определять рекурсивные таблицы. То есть, объектная сущность не может определять таблицу своего типа, своих надтипов или своих подтипов, также объектная сущность не может объявлять таблицу некоторого другого типа объектной сущности, содержащего таблицу ее типа.
Типизированные табличным типом свойства определяют отношения композиции между двумя объектными сущностями (родительской объектной сущностью со свойством и дочерними объектными сущностями, содержащимися в таблице). Смотрите раздел 3.14, изложенный ниже, для дополнительных сведений о композициях.
3.6 Типы ссылки объектной сущности
Экземпляры ссылочных типов хранят ссылки на объектную сущность заданного типа. Ссылка инкапсулирует ссылку на таблицу, которая содержит в себе объектную сущность и значения ключевого свойства объектной сущности.
Ссылка может быть разрешена в объектную сущность, которая является целевым объектом ссылки. Ссылочные типы задаются с использованием синтаксиса:
Ref(entity-type)
Типы объектной сущности и подставляемые типы могут определять свойства ссылочных типов.
Типизированные ссылочным типом свойства определяют отношения ассоциации между двумя объектными сущностями (исходной объектной сущностью со свойством и целевой объектной сущностью, указанной ссылкой свойством). Смотрите 3.6, приведенный ниже.
3.7 Типы ссылки таблицы
Экземпляры типов ссылки таблицы хранят ссылку на таблицу. Целевая таблица могла бы быть таблицей, «самой высокоуровневой» в наборе таблиц, или вложенной таблицей.
Ссылка может быть разрешена в таблицу, которая является целевым объектом ссылки.
Типы ссылки таблицы задаются с использованием синтаксиса:
TableRef(entity-type)
Типы объектной сущности и подставляемые типы могут определять свойства ссылочных типов.
3.8 Свойства
Свойства используются в типах объектной сущности и подставляемых, чтобы выделять хранилище. Свойство определяется с использованием элемента <Property>. В дополнение к общим элементам члена, определенным выше, этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование члена. Наименование должно быть уникальным в области определяющего типа. Наименование должно соблюдать CLR-правила для наименований членов класса и должно следовать руководящим принципам именования каркаса .Net.
• DuplicateName (дублировать наименование) - необязательный. Наименования членов также должны быть уникальными по всей иерархии базового типа, если не предусмотрен атрибут DuplicateName или не обладает значением “true”. Значение “false”, устанавливаемое по умолчанию, указывает, что наименование члена предполагается уникальным.
Роль этого атрибута заключается в том, чтобы а) документировать тот факт, что наименование члена дублирует свойство в базовом типе, и b) принуждает разработчика схемы предпочитать дублировать наименование целенаправленно (т.е. он играет такую же роль, как ключевое слово new в С#).
• Type (тип) - обязательный. Тип свойства. Это может быть любой тип: простой, подставляемый, массива, ссылки объектной сущности или ссылки таблицы. Для свойств, определенных в объектных сущностях, табличные типы также разрешены.
• Nullable (обнуляемый) - обязателен для свойств всех типов, за исключением массивов и вложенных таблиц, не разрешен для свойств с типами массива и вложенной таблицы. Значение “true” означает, что свойство может хранить нулевое значение. Значение “false” означает, что свойство не может хранить нулевое значение.
• Association (ассоциация) - обязателен, если тип свойства является ссылочным или массивом ссылочного типа. Задает наименование ассоциации, в которой это свойство участвует. Дополнительно смотрите Ассоциации.
• Composition (композиция) - обязателен, если тип свойства является табличным типом. Задает наименование ассоциации или композиции, в которой это свойство участвует. Дополнительно смотрите Композиции.
• Role (роль) - задает роль ассоциации, в которой это свойство участвует. Смотри раздел по ассоциациям для описания того, когда этот атрибут обязателен.
Некоторые примерные определения свойства показаны ниже:
<Schema Namespace=”MyCompany.MySchema”>
<Using Namespace=”System”/>
<InlineType Name=”A”>
<Property Name=”One” Type=”Int32”/>
</InlineType>
<InlineType Name=”B” BaseType=”A”>
<Property Name=”One” Type=”String” DuplicateName=”true”/>
<Property Name=”Two” Type=”Int32”/>
</InlineType>
</Schema>
3.8.1 Ограничения свойства
Значение, которое может быть сохранено в свойстве, может быть ограничено с использованием ограничительного элемента внутри элемента <Property>. Набор разрешенных ограничительных элементов является зависимым от типа свойства и определяется так, как каждый тип, который обсужден.
В дополнение, свойство может быть дополнительно ограничено в порожденном типе посредством размещения ограничительных элементов внутри элемента <PropertyConstraint>. Этот элемент может содержать следующие атрибуты:
• Property (свойство) - обязательный. Наименование ограниченного свойства. В случаях, когда существуют дубликатные наименования свойства, это наименование может быть уточнено с использованием наименования типа. Если наименование дублировано и не уточнено, предполагается свойство в наиболее производном типе.
• Type (тип) - необязательный. Тип, которым ограничено свойство. Тип может быть задан, только если исходным типом свойства был Array(T), Table(T), Ref(T) или TableRef(T). В таких случаях новый тип должен быть Array(S), Table(S), Ref(S) или TableRef(S), соответственно, а S должен быть подтипом T.
При использовании элемента <PropertyConstraint> необходимо, чтобы заданные ограничения были совместимы с любыми ограничениями, определенными в базовом типе. Определение каждого ограничительного элемента включает в себя описание того, что влечет за собой совместимость.
Некоторые простые примеры показаны ниже:
<Schema Namespace=”MyCompany.MySchema”>
<Using Namespace=”System”/>
<InlineType Name=”A”>
<Property Name=”X” Type=”Int32”>
<Range Minimum=”10” Maximum=”1000”/>
</Property>
<Property Name=”Y” Type=”String”>
<Length Maximum=”100”/>
</Property>
</InlineType>
<InlineType Name=”B” BaseType=”A”>
<PropertyConstraint Property=”Y”>
<Length Maximum=”50”/>
</PropertyConstraint>
</InlineType>
</Schema>
3.8.2 Наложение ограничений на целевые типы
При порождении типа от типа, который содержит ссылочное свойство, является допустимым дополнительно ограничивать тип объектной сущности, который может быть задан. Это делается с использованием элемента внутри элемента <PropertyConstraint> и заданием значения для атрибута Type, как в разделе 3.8.1, приведенном выше.
Например:
<Schema Namespace=”MyCompany.MySchema>
<EntityType Name=”A” Key=”ID”>
<Property Name=”ID” Type=”Int32”/>
</EntityType>
<EntityType Name=”B” BaseType=”A”>
</EntityType>
<InlineType Name=”C”>
<Property Name=”ARef” Type=”Ref(A)”/>
</InlineType>
<InlineType Name=”D” BaseType=”C”>
<PropertyConstraint Property=”ARef” Type=”Ref(B)”/>
</InlineType>
</Schema>
3.9 Расчетные свойства
Расчетные свойства используются в типах объектной сущности и подставляемых типах, чтобы представлять, скорее, рассчитываемое, чем хранимое, значение. Алгоритм, используемый для вычисления значения свойства, не рассматривается частью модели данных.
| Может быть описано свойство, которое возвращает запрос в качестве части модели данных. |
Расчетное свойство объявляется с использованием элемента <ComputedProperty>. В дополнение к общим атрибутам члена, определенным выше, этот элемент может содержать следующие атрибуты:
• ReadOnly (только для чтения) - необязательный. Указывает, когда свойство только для чтения. Значением по умолчанию является “true”,означающее, что свойство только для чтения и не может быть использовано при обновлениях.
• Static (статический) - необязательный. Указывает, является ли свойство статическим или свойством экземпляра. Значением по умолчанию является “false”, указывающее, что это - свойство экземпляра.
Пример, приведенный ниже, объявляет расчетное свойство, именованное «X», с типом «Int32»:
<Schema Namespace=”MyCompany.MySchema”>
<InlineType Name=”A”>
<ComputedProperty Name=”X” Type=”Int32”/>
</InlineType>
</Schema>
3.9.1 Ограничения расчетных свойств
Значения, которые могут быть сохранены в свойстве, могут быть ограничены с использованием ограничительного элемента внутри элемента <ComputedProperty>. Набор разрешенных ограничительных элементов является зависимым от типа свойства и определяется так, как каждый тип, который рассматривается.
| В одной из реализаций элементы <PropertyConstraint> также работают с расчетными свойствами. |
3.10 Методы
Методы используются в подставляемых типах и типах объектной сущности, чтобы представлять операцию, которая может быть выполнена. Алгоритм, используемый для реализации метода, не рассматривается частью модели данных.
| В одной из реализаций как часть модели данных может быть описан метод, который принимает запрос в качестве входных данных и возвращает запрос в качестве выходных данных. Ассоциации, по существу, определяют такие методы. |
Метод объявляется с использованием элемента <Method>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование члена. Наименование должно быть уникальным в области определяющего типа. Наименование должно соблюдать CLR-правила для наименований членов класса и должно следовать руководящим принципам именования каркаса .Net.
• DuplicateName (дублировать наименование) - необязательный. Наименования членов также должны быть уникальными по всей иерархии базового типа, если не предусмотрен атрибут DuplicateName или не обладает значением “true”. Значение “false”, устанавливаемое по умолчанию, указывает, что наименование члена предполагается уникальным.
Роль этого атрибута заключается в том, чтобы а) документировать тот факт, что наименование члена дублирует свойство в базовом типе, и b) принуждает разработчика схемы предпочитать дублировать наименование целенаправленно (т.е. он играет такую же роль, как ключевое слово new в С#).
• ReturnType (возвращаемый тип) - обязательный. Тип значения, возвращаемого методом. Это может быть тип: простой, подставляемый, массива, ссылки объектной сущности, ссылки таблицы или табличный, или он может быть пустой строкой, указывающей, что не возвращается никаких значений.
• Static (статический) - необязательный. Указывает, является ли метод статическим или методом экземпляра. Значением по умолчанию является “false”, указывающее, что это - метод экземпляра.
• Association (ассоциация) - обязателен, если возвращаемый тип является ссылочным или массивом ссылочного типа. Задает наименование ассоциации, в которой этот метод участвует. Дополнительно смотрите раздел по ассоциациям.
• Composition (композиция) - обязателен, если возвращаемый тип является табличным типом. Задает наименование ассоциации или композиции, в которой этот метод участвует. Дополнительно смотрите раздел по композициям.
• Role (роль) - Задает роль ассоциации, в которой этот метод участвует. Смотрите раздел по ассоциациям для описания того, когда этот атрибут обязателен.
Элемент <ReturnTypeConstraints> может быть вложенным внутри элемента <Method>. Ограничительные элементы, которые применяются к возвращаемому типу метода, могут быть вложенными внутри элемента <ReturnTypeConstraints>.
Элемент <Method> может содержать нуль или более вложенных элементов <Parameter> для задания параметров, принимаемых методом. Элемент <Parameter>может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование параметра.
• Type (тип) - обязательный. Тип параметра.
• Out (выходной) - необязательный. Значение “true”, если это выходной параметр, или “false”, значение по умолчанию, если это входной параметр.
Ограничительные элементы, которые применяются к типу параметра, могут быть вложенными внутри элемента <Parameter>.
Пример, приведенный ниже, объявляет расчетное свойство, именованное “X” с типом “Int32” и методом, именованным “Y”, с параметром, именованным “a” типа “Int32”, и который возвращает значение типа “Int32”.
<Schema Namespace=”MyCompany.MySchema”>
<InlineType Name=”Foo”>
<Method Name=”Y” Type=”Int32”>
<Parameter Name=”a” Type=”String”>
<Length Maximum=”100”/>
</Parameter>
</Method>
</InlineType>
</Schema>
3.11 Подставляемые типы
Экземпляры подставляемых типов могут быть сделаны устойчивыми только в качестве компонентов одного и только одного экземпляра объектной сущности. Экземпляры подставляемых типов не обладают явно заданной идентичностью (идентичность неявно выражена в том, каким образом он расположен внутри своей содержащей объектные сущности). Невозможно хранить долговременную ссылку на экземпляр подставляемого типа.
Объектные сущности подставляемых типов подразумеваются частью образующего единое целое блока данных, определенного содержащей объектной сущностью (например, они удаляются, когда удаляется содержащая объектная сущность). Также есть гарантия, что непротиворечивость по всем подставляемым данным, которые являются частью объектной сущности, будет обеспечиваться без каких-либо явных действий приложения. Заметим, что это не устраняет признаки, подобные единицам изменения и синхронизации WinFS, от снабжения разработчика схемы более изящным разветвленным контролем над непротиворечивостью.
Разработчик схемы может определять новые подставляемые типы со структурой, состоящей из набора свойств. Такой подставляемый тип может быть порожден от отдельного подставляемого базового типа. Такие типы определяются с использованием элемента <InlineType> внутри элемента <Schema> (вложенные подставляемые типы не разрешены). Элемент <InlineType> может содержать следующие атрибуты:
• Name (наименование) - обязательный. Задает наименование типа.
• BaseType (базовый тип) - необязательный. Описывает подставляемый тип, типизированный этим типом как подтип. Если никакой базовый тип не задан, предполагается анонимный абстрактный базовый тип, который не определяет никаких свойств.
• Abstract (абстрактный) - необязательный, “true” - если тип является абстрактным, “false” - если он является конкретным. Экземпляры только неабстрактных типов могут быть созданы. Значением по умолчанию является “false”.
• Sealed (изолированный) - необязательный, “true” - если тип является изолированным, “false” - если не является, или “external” - если изолирован только при использованиях, внешних по отношению к определяющей схеме. Значением по умолчанию является “false”.
• FriendSchemas (дружественные схемы) - необязательный. Разделенный запятыми список пространств имен схем, которые считаются “друзьями” определяющего типа. Эти схемы не подвергаются ограничениям, наложенным значением атрибута Sealed=”external” (однако, они подвергаются ограничению Sealed=”true”).
Некоторыми примерными описаниями подставляемого (Inline) типа являются
<Schema Namespace=”MyCompany.MySchema”>
<InlineType Name=”A” Abstract=”true”>
<Property Name=”One” Type=”Int32”/>
</InlineType>
<InlineType Name=”B” BaseType=”A”>
<Property Name=”Two” Type=”Int32”/>
</InlineType>
<InlineType Name=”C” BaseType=”B”>
<Property Name=”Three” Type=”Int32”/>
</InlineType>
</Schema>
Эти типы могут быть проиллюстрированы с использованием UML, как изложено ниже:

3.11.1 Ограничения подставляемых типов
Экземпляры подставляемого типа могут быть ограничены с использованием следующих ограничительных элементов. Эти элементы могут быть вложенными внутри различных элементов, которые ссылаются на подставляемые типы (например, элемент <Property> в элементе <EntityType> или <InlineType>).
3.11.1.1 Check
Ограничительный элемент <Check> может содержать в себе булево выражение запроса. Чтобы значение свойства было действительным, это выражение должно обращаться в истинное значение. Выражение не должно иметь никаких побочных эффектов. Смотрите раздел 3.17, приведенный ниже.
Когда ограничение проверки задано и в базовом, и порожденном типах, оба ограничения проверяются на действительность.
3.12 Типы объектной сущности
Тип объектной сущности определяет образующий единое целое блок данных. Экземпляры типов объектной сущности могут быть сделаны устойчивыми в одной и только одной таблице. Экземпляры типов объектной сущности обладают явно заданной идентичностью. Является возможным сохранять долговременную ссылку на экземпляр типа объектной сущности с использованием ссылочного типа.
Разработчик схемы может определять новые типы объектной сущности со структурой, состоящей из набора свойств. Тип объектной сущности может быть порожден от одиночного базового типа объектной сущности. Такие типы объявляются с использованием элемента <EntityType> внутри элемента <Schema> (вложенные типы объектной сущности не разрешены). Элемент <EntityType> может содержать следующие атрибуты:
• Name (наименование) - обязательный. Задает наименование типа. Наименование должно быть уникальным среди всех наименований типа (оба наименования, подставляемого типа и типа объектной сущности), определенных в объемлющей схеме.
• BaseType (базовый тип) - необязательный. Определяет тип объектной сущности, типизированный этим типом как подтип. Если никакой базовый тип не задан, предполагается анонимный абстрактный базовый тип, который не определяет никаких свойств.
• Abstract (абстрактный) - необязательный, “true” - если тип является абстрактным, “false” - если он является конкретным. Экземпляры только неабстрактных типов могут быть созданы. Значением по умолчанию является “false”.
• Sealed (изолированный) - необязательный, “true” - если тип является изолированным, “false” - если не является, или “external” - если изолирован только при использованиях, внешних по отношению к определяющей схеме. Значением по умолчанию является “false”.
• FriendSchemas (дружественные схемы) - необязательный. Разделенный запятыми список пространств имен схем, которые считаются “друзьями” определяющего типа. Эти схемы не подвергаются ограничениям, наложенным посредством lnternal="true" или Sealed=”external” (однако, они подвергаются ограничению Sealed=”true”).
• Table (таблица) - необязательный. Задает наименование одной и только одной самой высокоуровневой или вложенной таблицы, которая будет содержать в себе экземпляры этого типа объектной сущности, с использованием синтаксиса entity-type-name.table-property-name (объектная сущность-тип-наименование.таблица-свойство-наименование). Установленным по умолчанию является то, что любое количество таблиц может быть определено, чтобы содержать экземпляры типа объектной сущности.
• Extensible (расширяемый) - необязательный. Значение “true”, значение по умолчанию, указывает, что объектная сущность может быть расширена с использованием элементов <EntityExtensionType>, как описано ниже. Значение “false” указывает, что объектная сущность не может быть расширена.
• Association (ассоциация) - если объектная сущность обладает ролью объектной сущности ассоциации в описании ассоциации, этот атрибут обязателен и должен задавать наименование ассоциации. В ином случае, этот атрибут не может быть представлен.
• Key (ключ) - разделенный запятыми список одного или более наименований свойств, определенных в типе объектной сущности или базовом типе. Только один тип в иерархии типа объектной сущности может задавать ключевой (Key) атрибут. Все типы в иерархии базового типа такого типа должны быть абстрактными типами. Заданные свойства могут быть взяты из типа или его базовых типов.
Заданные свойства устанавливают часть идентичности объектной сущности. Остаток идентичности неявным образом принимается от родителя объектной сущности (т.е. экземпляра объектной сущности, который определяет табличное свойство, в котором находится дочерняя объектная сущность).
Только свойства с подставляемым необнуляемым типом, исключая массивы, могут быть заданы в качестве ключевого свойства. Если свойство определяемого пользователем подставляемого типа, все свойства этого типа рассматриваются ключевыми свойствами и все должны быть однозначными и необнуляемыми.
Вложенные свойства (свойства у свойства составного типа) также могут быть заданы в качестве ключевых свойств.
Некоторыми примерными определениями типа объектной сущности являются:
<Schema Namespace=”MyCompany.MySchema”>
<EntityType Name=”A” Abstract=”true”>
<Property Name=”One” Type=”Int32”/>
</EntityType>
<EntityType Name=”B” BaseType=”A” Key=”Two”>
<Property Name=”Two” Type=”Int32”/>
</EntityType>
<EntityType Name=”C” BaseType=”B”>
<Property Name=”Three” Type=”Int32”/>
</EntityType>
<InlineType Name=”D”>
<Property Name=”X” Type=”Int32”/>
<Property Name=”Y” Type=”Int32”/>
</InlineType>
<EntityType Name=”E” Key=”D”>
<Property Name=”D” Type=”D”/>
</EntityType>
<EntityType Name=”F” Key=”D.X”>
<Property Name=”D” Type=”D”/>
</EntityType>
</Schema>
Эти типы могут быть описаны с использованием UML, как изложено ниже:
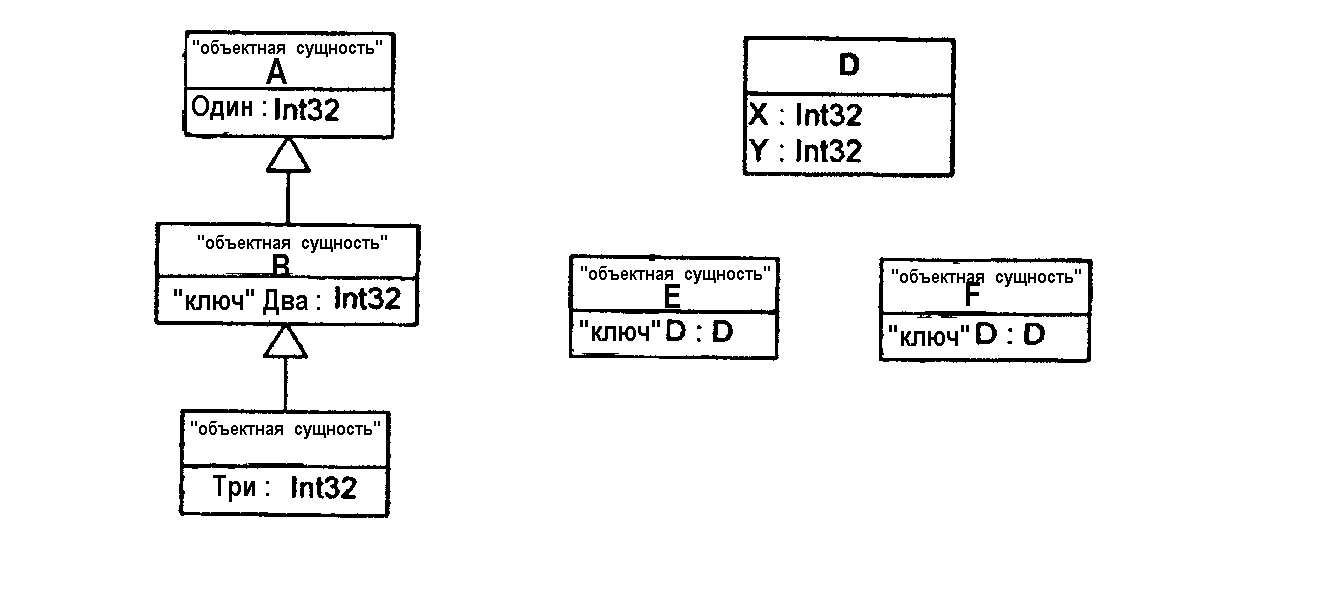
3.12.1 Ограничения типа объектной сущности
Экземпляры типа объектной сущности могут быть ограничены с использованием следующих ограничительных элементов. Эти элементы могут быть вложенными внутри различных элементов, которые ссылаются на типы объектной сущности (например, элемент <Property> в элементе <EntityType>).
3.12.1.1 Check
Ограничительный элемент <Check> может содержать в себе булево выражение запроса. Чтобы значение свойства было действительным, это выражение должно обращаться в истинное значение. Выражение не должно иметь никаких побочных эффектов. Смотрите раздел 3.17, приведенный ниже.
Когда ограничение проверки задано и в базовом, и порожденном типах, оба ограничения проверяются на действительность.
3.12.2 Типы расширения объектной сущности
Чтобы обращаться к сценариям WinFS и MBF, должно быть возможным расширять данный набор типов, фактически не модифицируя схемы, где такие типы были описаны. Хотя это может быть выполнено заимствованием одного из некоторого количества шаблонов (к примеру, снабжением базового класса таблицей типа объектной сущности расширения (Extension)), желательно сделать такую концепцию первоклассной частью модели данных. Это предоставляет специальным API-шаблонам возможность быть сформированными для расширений и является более простым для разработчика типа для понимания и использования.
Только типы объектной сущности, которые задают атрибут Extensible="true", могут быть расширены. Расширение объектной сущности объявляется с использованием элемента <EntityExtensionType> внутри элемента <Schema>. Элемент <EntityExtensionType> может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование типа расширения.
• ExtendsType (расширяет тип) - обязательный. Наименование типа объектной сущности, являющегося расширяемым.
• InstanceManagement (управление экземплярами) - обязательный. Значение “Implicit” указывает, что экземпляры расширения добавляются и удаляются в/из расширенной объектной сущности неявным образом. Значение “Explicit” указывает, что экземпляры расширения должны быть добавлены и удалены приложением явным образом.
• Table (таблица) - необязательный. Задает таблицу, в которой следует сохранять расширения.
Могло бы не быть возможным порождать один тип расширения от другого типа расширения.
Элемент <EntityExtensionType> может содержать в себе любой элемент, который может быть помещен внутри элемента <EntityType>. Типично это включает в себя элементы <Property>. Не является необходимым для наименований свойств быть уникальными по всем расширениям или даже по свойствам расширенного типа.
Если InstanceManagement=”Implicit”, все из свойств, определенных в расширении, должны быть обнуляемыми, или задавать значение по умолчанию, либо иметь тип массива, коллекции или табличный с минимальным ограничением вхождения нуля. Заметим, что типизированное одноэлементным подставляемым типом свойство не может задавать значение по умолчанию, а значит, обязано быть обнуляемым. Это предоставляет запросам возможность быть выполненными по отношению к расширению, как если бы оно всегда присутствовало.
Если InstanceManagement=”Explicit”, приложения должны явным образом добавлять и удалять расширение в/из экземпляра объектной сущности с использованием TBD операций, описанных на языке запросов для общей модели данных (смотрите раздел 3.17, приведенный ниже). Средство для проверки наличия расширения также предусмотрено.
Экземпляры расширения объектной сущности подразумеваются частью образующего единое целое блока данных, определенного содержащей объектной сущностью (например, они удаляются, когда удаляется содержащая объектная сущность). Однако нет гарантии устойчивости касательно изменений по отношению к объектной сущности и расширению, предполагаемых в качестве явным образом управляемых через приложение с использованием транзакций.
Все расширения объектной сущности (EntityExtension) содержат свойство по умолчанию, именованное “Entity” типа Ref(T), где T - значение типа ExtendsType, которое указывает на экземпляр объектной сущности, с которым ассоциативно связано расширение.
Примерные тип и расширение объектной сущности показаны ниже:
<Schema Namespace=”MyCompany.MySchema”>
<EntityType Name=”A” Key=”ID”>
<Property Name=”ID” Type=”Int32”/>
<Property Name=”X” Type=”Int32”/>
</EntityType>
<EntityExtension Name=”B” ExtendsType=”A”
InstanceManagement=”Implicit”>
<Property Name=”X” Type=”String”/>
<Property Name=”Y” Type=”Int32”/>
</EntityExtension>
</Schema>
3.13. Ассоциация
Ассоциация предоставляет возможность двум или более объектным сущностям, объектным сущностям сторон, быть соотнесенными друг с другом. Каждая из сторон на понятийном уровне остается независимой от других.
Ассоциации изображаются с использованием элемента <Association>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование ассоциации.
• Scope (область) - необязательный. Задает наименование типа объектной сущности. Ассоциация ограничена по области экземпляром объектной сущности заданного типа и ее действительность может быть проверена относительно экземпляра.
Элемент <Association> имеет два или более вложенных элемента <End>, каждый описывает одну из сторон ассоциации. Заметим, что более чем два элемента <End> могут быть заданы, только если также задан элемент <AssociationEntity>. Элемент <End> может содержать следующие атрибуты:
• Role (роль) - обязательный. Именует роль, которую эта сторона играет в ассоциации.
• PluralRole (множественная роль) - необязательный. Предусматривает множественную форму наименования роли. Это наименование используется в модели запроса и каноническом объектном преобразовании. Если не задан, взамен используется наименование вида roleEntities (ролевые объектные сущности).
• Type (тип) - обязательный. Тип объектной сущности представлен стороной.
• Multiplicity (кратность) - необязательный. Кратность этой стороны ассоциации, которая устанавливает нижнее и верхнее граничное значение касательно мощности множества. Она задается в качестве целочисленного диапазона вида <lower_bound>..<upper_bound> (<нижнее_граничное значение>..<верхнее_граничное значение>), или в качестве одиночного целочисленного значения, если нижнее и верхнее граничные значения являются одинаковыми. Верхним граничным значением может быть “*”, которое указывает неограниченное значение. Взятое в отдельности “*” является синонимичным с “0..*”. Значения по умолчанию и правила касательно того, могут ли подменяться эти значения по умолчанию, зависят от вида ассоциации.
• Ссылка: “*” на указывающей ссылкой стороне, “0..1” на указываемой ссылкой стороне
• Композиция: “1” на родительской стороне (фиксированное), “*” на дочерней стороне
• Условие и общее значение: “*” на обеих сторонах (фиксированное)
• Объектная сущность ассоциации: “*” на обеих сторонах
Кратность, большая, чем 1, является допустимой, но также может интерпретироваться как * в целях принудительного применения.
• Table - обязательный для целевого объекта основанной на ссылке ассоциации, в ином случае - необязательный. Задает табличное свойство типа объектной сущности, заданного Type (типом), или одним из предков типа (Type). Сторона ограничивается из условия, что ассоциативно связанная объектная сущность появляется в заданной таблице. Синтаксис задает путь, который начинается типом объектной сущности и заканчивается табличным свойством собственного типа. Каждый сегмент пути приводится к типу объектной сущности одним из двух способов:
1. Он задает ссылочное или табличное свойство по типу объектной сущности (либо приводит к лежащему в основе типу объектной сущности). Этот синтаксис имеет вид: <entity-type>/<property-name>. Если использовано ссылочное свойство, то его соответствующая сторона ассоциации должна содержать заданное наименование таблицы.
2. Он задает роль в ассоциации или композиции (либо приводит к типу стороны). Этот синтаксис имеет вид: <entity-type>/<relationship-name>.<role-name>. Если используется ассоциация, то сторона, заданная наименованием роли, должна содержать заданное наименование таблицы.
На основанной на ссылке ассоциации может присутствовать ””, указывающее, что ссылка может быть в любой таблице корректного типа. Если был задан атрибут Scope (область), то путь может начинаться с указанного типа объектной сущности. Если атрибут Table (таблица) задан в описании Type (типа), то этот путь должен быть с ним совместим.
• Scoped (ограничен областью) - необязательный. Указывает, ограничена ли область этой стороны экземпляром этой объектной сущности, указанной в атрибуте Scope элемента <Association>. По умолчанию является истинным значением.
• OnDelete (по удалении) - необязательный. Задает действие, которое должно быть предпринято, когда удаляется объектная сущность в пределах этой роли. Может быть задано, только когда эта сторона перечислена в элементе <Reference> или <CommonValue>. Возможными значениями являются:
• Restrict (ограничить) - предохраняет объектную сущность от удаления. Это значение по умолчанию.
• Cascade (каскадировать) - служит причиной того, чтобы были удалены объектные сущности в ролях других сторон.
• CascadeToAssociationEntity (каскадировать до объектной сущности ассоциации) - служит причиной того, чтобы была удалена только объектная сущность ассоциации.
• SetNull (установить в нуль) - служит причиной того, чтобы было установлено в нуль свойство на другой стороне ассоциации. В тех случаях, когда свойство является коллекцией ссылок, ссылки удаляются из коллекции. Нижнее граничное значение кратности на другой стороне ассоциации должно быть нулевым. Допускает задание, только если эта сторона перечислена в одном из свойств элемента <CommonValue> или ToRole элемента <Reference>.
• OnUpdate (по обновлению) - необязательный. Задает действие, которое должно быть предпринято, когда обновляется свойство общего значения объектной сущности в роли стороны. Может быть задано, только когда эта сторона перечислена в элементе <CommonValue>. Когда OnUpdate не задано, то обновление свойства на одной стороне не оказывает никакого влияния на свойство на другой стороне. Возможными значениями являются:
• Restrict (ограничить) - предохраняет объектную сущность от обновления.
• Cascade (каскадировать) - служит причиной того, чтобы свойство общего значения объектной сущности в другой роли стороны было обновлено тем же самым значением.
• SetNull (установить в нуль) - служит причиной того, чтобы было установлено в нуль свойство общего значения объектной сущности в роли другой стороны. Нижнее граничное значение кратности на другой стороне ассоциации должно быть нулевым.
3.13.1 Виды ассоциаций
Вид ассоциации указывает, каким образом связаны стороны. Каждая ассоциация является одним из четырех видов, указанных вложенностью одного из следующих элементов под элементом <Association>.
• <Reference> - две стороны связаны с использованием ссылочного свойства на одной из сторон.
• <Condition> - две стороны связаны посредством произвольного соединения на сторонах.
• <CommonValue> - две стороны связаны посредством объединения эквивалентностью по свойству с каждой стороны.
• <AssociationEntity> - две или более сторон связаны с использованием дополнительной объектной сущности. Только когда использован этот элемент, могут быть заданы более чем два элемента <End>.
Элемент <Reference> описывает ассоциацию ссылочного вида. Элемент может содержать следующие атрибуты:
• FromRole (исходная роль) - обязательный. Наименование роли, которая содержит типизированное ссылочным типом свойство. Для объектных сущностей ассоциации это должно быть наименование роли объектной сущности ассоциации.
• ToRole (целевая роль) - обязательный. Наименование роли, на которую нацелено ссылочное свойство. Идентифицированная роль не должна задавать атрибут OnUpdate (по обновлению).
• Property (свойство) - обязательный. Наименование свойства ссылки в объектной сущности FromRole (исходной роли). Элемент <Property>, определяющий это свойство, должен иметь атрибут Role, задающий содержащую ассоциацию. Если верхним граничным значением кратности является единица, то тип свойства должен быть ссылкой, и такая ссылка должна быть обнуляемой, если нижним граничным значением является нуль. Если больше, чем единица, типом свойства должен быть массив ссылок.
Ниже показан пример ссылочной ассоциации “AtoB” («A к B»), соотносящей объектной сущности А и В.
<EntityType Name="A" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="BRef" Type="Ref(B)" Association = "AtoB"/>
</EntityType>
<EntityType Name="B" Key="ID">
<Property Name="ID" Type="Int32">
</EntityType>
<Association Name="AtoB">
<End Role="ARole" Type="A"/>
<End Role="BRole" Type="B"/>
<Reference FromRole="ARole" ToRole="BRole" Property="BRef"/>
</Association>
Элемент <CommonValue> описывает ассоциацию вида общего значения. Элемент может содержать следующие атрибуты:
• Property1 (свойство1) - обязательный. Идентифицирует свойство на одной из сторон с использованием строки с форматом role-name.property-name (роль-наименование.свойство-наименование).
• Property2 (свойство2) - обязательный. Идентифицирует свойство на одной из сторон с использованием строки с форматом role-name.property-name (роль-наименование.свойство-наименование).
Для объектной сущности ассоциации, одно из Property1 (свойство1) и Property2 (свойство2) задает роль объектной сущности ассоциации, а другое - задает роль стороны. Заданная сторона может содержать атрибут OnUpdate (по обновлению) и/или OnDelete (по удалении).
Ниже показан пример ассоциации “AtoB” («A к B») общего значения, соотносящей объектной сущности А и В.
<EntityType Name="A" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="X" Type="String"/>
</EntityType>
<EntityType Name="B" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="Y" Type="String"/>
</EntityType>
<Association Name="AtoB">
<End Role="ARole" Type="A"/>
<End Role="BRole" Type="B"/>
<CommonValue Property1="ARole.X" Property2="BRole.Y"/>
</Association>
Элемент <Condition> описывает ассоциацию, основанную на произвольном соединении между двумя сторонами. Элемент должен содержать выражение, которое обращается в истинное для соотнесенных объектных сущностей. Наименования ролей, заданные в элементах <End> и <Using>, могут быть использованы в этом выражении.
Если элемент <Association> содержит элемент <Condition>, он также может содержать нуль или более элементов <Using>. Эти элементы описывают дополнительные объектные сущности, которые используются для определения отношения между сторонами. Элементы <Using> могут содержать следующие атрибуты:
• Role (роль) - обязательный. Именует роль стороны, используемой в отношении.
• Type (тип) - обязательный. Тип объектной сущности, используемой в отношении.
• Table (таблица) - смотрите описание атрибута по элементу <End> ассоциации.
С использованием элементов <End>, <Using> и <Condition> конструируется полный запрос. Этот запрос имеет вид:
SELECT end-role-1, end-role-2
FROM end-table-1 AS end-role-1, end-table-2 AS end-role-2, using-
table-n AS using-role-n, …
WHERE condition
Следующий пример показывает две объектные сущности А и В, соотнесенные с использованием выражения, включающего в себя третью объектную сущность С.
<EntityType Name="A" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="X" Type="String"/>
</EntityType>
<EntityType Name="B" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="Y" Type="String"/>
</EntityType>
<EntityType Name="C" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="Z1" Type="String"/>
<Property Name="Z2" Type="String"/>
</EntityType>
<Association Name="AtoB">
<End Role="ARole" Type="A"/>
<End Role="BRole" Type="B"/>
<Using Role="CRole" Type="C" Table="CTable"/>
<Condition>
ARole.X=CRole.Z1 AND BRole.Y=CRole.Z2
</Condition>
</Association>
Элемент <AssociationEntity> указывает, что стороны ассоциации связаны посредством объектной сущности ассоциации. Элемент <AssociationEntity> может содержать следующие атрибуты:
• Role (роль) - обязательный. Именует роль, которую объектная сущность ассоциации играет в ассоциации.
• PluralRole (множественная роль) - необязательный. Предусматривает множественную форму наименования роли. Это наименование используется в модели запроса и каноническом объектном преобразовании. Если не задан, взамен используется наименование вида roleEntities (ролевые объектные сущности).
• Type (тип) - обязательный. Тип объектной сущности ассоциации. Элемент <EntityType>, который определяет этот тип, должен задавать атрибут Association (ассоциация), который идентифицирует охватывающий элемент <Association>.
• Table (таблица) - смотрите описание атрибута по элементу <End> ассоциации.
Элемент <AssociationEntity> содержит один вложенный элемент <End>. Объектная сущность ассоциации определяет ассоциацию между этим элементом <End> и каждым из элементов <End>, вложенных под элементом <Association>. Вид этих ассоциаций описывается элементом <Reference>, <Condition> или <CommonValue>. Одна из ассоциаций взамен может быть описана элементом <Composition>:
• <Composition> - объектная сущность ассоциации является потомком одной из сторон композиции.
Role (роль) по каждому <End> элемента <Association> должна быть указана ссылкой одной из двух ролей в одном из этих элементов вида; другая роль ссылается на <End> элемента <AssociationEntity>.
Элемент <Composition> вписывает композицию объектной сущности ассоциации в одну из ролей сторон. Он должен быть вложенным внутри <AssociationEntity>. Элемент <Composition> содержит следующие атрибуты:
• ParentRole (родительская роль) - обязательный. Наименование роли стороны, которая содержит в себе вложенную таблицу типа объектной сущности ассоциации. Это не должно быть ролью объектной сущности ассоциации. Атрибут OnDelete (по удалении) в элементе <End>, указываемый ссылкой этой ролью, должен задавать Cascade (каскадировать) или CascadeToAssocationEntity (каскадировать до объектной сущности ассоциации). Атрибут OnUpdate (по обновлению) не может быть задан.
• ChildRole (дочерняя роль) - обязательный. Наименование роли, которая содержится в родительской объектной сущности. Это должно быть ролью <End> объектной сущности ассоциации.
• Property (свойство) - обязательный. Наименование табличного свойства в родительской объектной сущности. Элемент <Property>, который определяет это свойство, должен содержать атрибут Association (ассоциация), который задает вмещающую ассоциацию.
Элемент <Condition> должен содержать следующий атрибут, когда он вложен под элементом <AssociationEntity>:
• JoinedRoles (объединенные роли) - обязательный. Общий разделенный перечень из двух или более наименований ролей. Этот перечень должен включать в себя наименование роли <End> из <AssociationEntity> и одно из наименований ролей сторон. Перечисленные роли не должны задавать атрибут OnDelete (по удалении) или OnUpdate (по обновлению).
Следующий пример показывает ассоциацию "AtoB" («A к B») объектной сущности, соотносящую А и В и использующую объектную сущность С ассоциации, где С скомпонована в А и содержит ссылку на В.
<EntityType Name="A" Key="ID">
<Property Name="ID" Type="Int32">
<Property Name="CTable" Type="Table(C)"/>
</EntityType>
<EntityType Name="B" Key="ID">
<Property Name="ID" Type="Int32">
</EntityType>
<EntityType Name="C" Key="ARef, BRef" Association="AtoB">
<Property Name="BRef" Type="Ref(B)" Role="BRole"/>
</EntityType>
<Association Name="AtoB">
<AssociationEntity Type="C">
<End Role="CRole" Type="C"/>
<Composition ParentRole="ARole" ChildRole="CRole"
Property="CTable"/>
<Reference FromRole="CRole" ToRole="BRole"
Property="BRef"/>
</AssociationEntity>
<End Role="ARole" Type="A"/>
<End Role="BRole" Type="B"/>
</Association>
3.14 Композиция
Каждая вложенная таблица определяет композицию между объектными сущностями двух типов: типом объектной сущности, который содержит типизированное табличным типом свойство, и типом объектной сущности, который содержится таблицей. Композиция описывается с использованием элемента <Composition>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование композиции.
Элемент <Composition> должен содержать элемент <ParentEnd>. Этот элемент может содержать следующие атрибуты:
• Role (роль) - обязательный. Именует роль родительской объектной сущности.
• Type (тип) - обязательный. Задает тип родительской объектной сущности.
• Property (свойство) - обязательный. Задает свойство в родительской объектной сущности, которое определяет композицию.
• PluralRole (множественная роль) - необязательный. Предусматривает множественную форму наименования роли. Это наименование используется в модели запроса и каноническом объектном преобразовании. Если не задан, взамен используется наименование вида roleEntities (ролевые объектные сущности).
Элемент <Composition> также должен содержать элемент <ChildEnd>. Этот элемент может содержать следующие атрибуты:
• Role (роль) - обязательный. Именует роль дочерней объектной сущности.
• Type (тип) - обязательный. Задает тип дочерней объектной сущности.
• Multiplicity (кратность) - необязательный. Кратность потомка (дочерней объектной сущности) в композиции. Смотрите также атрибут Multiplicity (кратность) элемента <End> ассоциации.
• PluralRole (множественная роль) - необязательный. Предусматривает множественную форму наименования роли. Это наименование используется в модели запроса и каноническом объектном преобразовании. Если не задан, взамен используется наименование вида roleEntities (ролевые объектные сущности).
Схема, приведенная ниже, определяет две независимых вложенных таблицы, которые могут содержать экземпляры А: В.АTable (таблица В.А) и С.АTable (таблица С.А). Также есть вложенная таблица, которая может содержать экземпляры В, D.BTable (таблицу D.B), и вложенная таблица, которая может содержать экземпляры С, D.CTable (таблицу D.С). Экземпляры D содержатся в самой высокоуровневой таблице, названной DTable (таблицей D).
<Schema Namespace=”MyCompany.MySchema”>
<EntityType Name=”A” Key=”AID”>
<Property Name=”AID” Type=”String”>
<Length Maximum=”2”/>
</Property>
</EntityType>
<EntityType Name=”B” Key=”BID”>
<Property Name=”BID” Type=”String”>
<Length Maximum=”2”/>
</Property>
<Property Name=”TableA” Type="Table(A)" Composition=”BA”/>
</EntityType>
<Composition Name=”BA”>
<ParentEnd Role=”RoleB” Type="B" Property="TableA"/>
<ChildEnd Role=”RoleA” Type="A"/>
</Composition>
<EntityType Name=C” Key=CID”>
<Property Name=”CID” Type=”String”>
<Length Maximum=”2”/>
</Property>
<Property Name=”TableA” Type=”Table(A)” Composition=”CA”/>
</EntityType>
<Composition Name=”CA”>
<ParentEnd Role=”RoleC” Type="C" Property="TableA"/>
<ChildEnd Role=”RoleA” Type="A"/>
</Composition>
<EntityType Name=”D” Key=”DID”>
<Property Name=”DID” Type=”String”>
<Length Maximum=”2”/>
</Property>
<Property Name=”TableB” Type=”Table(B)” Composition=”DB”/>
<Property Name=”TableC” Type=”Table(C)” Composition=”DC”/>
</EntityType>
<Composition Name=”DB”>
<ParentEnd Role=”RoleD” Type="D" Property="TableB"/>
<ChildEnd Role=”RoleB” Type="B"/>
</Composition>
<Composition Name=”DC”>
<ParentEnd Role=”RoleD” Type="D" Property="TableC"/>
<ChildEnd Role=”RoleC” Type="C"/>
</Composition>
<TableSet Name=”TS”>
<Table Name=”TableD” Type=”D”/>
</TableSet>
</Schema>
Те же самые типы описываются с использованием UML:

Экземпляр D в TS.TableD может быть визуализирован, как показано ниже:

Концептуально, SQL-таблицы, соответствующие этим таблицам объектных сущностей, могли бы обладать структурой и значениями, показанными ниже. Столбец BID внешних ключей в таблице D_TableB_B_TableA мог бы быть ограничен столбцом BID первичных ключей в таблице D_TableB. Подобным образом для других столбцов внешних и первичных ключей. Локальный контекст мог бы быть установлен посредством фильтрации, основанной на идентификаторе (ID) родительской объектной сущности.

3.14.1 Ограничения типа вложенной таблицы
Является допустимым ограничивать значения типа коллекции и массива с использованием одного из ограничительных элементов, определенных ниже. Эти элементы могут быть вложенными внутри различных элементов, которые ссылаются на табличные типы (например, элемент <Property> в элементе <EntityType> или <InlineType>).
3.14.1.1 EntityConstraint
Ограничительный элемент <EntityConstraint> может быть использован, чтобы размещать ограничения по объектным сущностям в таблице. Любой ограничительный элемент, который является действительным для типа объектной сущности, может быть задан внутри элемента <EntityConstraint>.
3.14.1.2 Occurs
Ограничительный элемент <Occurs> может быть использован, чтобы ограничивать количество объектных сущностей в таблице. Этот элемент может содержать следующие атрибуты:
• Minimum (минимум) - необязательный. Задает минимальное количество вхождений в таблице. Значением по умолчанию является нуль.
• Maximum (максимум) - необязательный. Задает максимальное количество таблицы вхождений. Значение “unbounded” (“не ограничено”) означает, что ограничений нет. Значением по умолчанию является “unbounded”.
Чтобы быть совместимым с ограничением, заданным в базовом типе, значение, заданное для Minimum (минимума), должно быть равным или большим, чем прежнее значение, а значение, заданное для Maximum (максимума), должно быть равным или меньшим, чем прежнее значение.
3.14.1.3 Unique
Ограничительный элемент <Unique> может быть использован, чтобы задавать свойство или свойства типа объектной сущности, которые должны содержать уникальное значение в таблице. Этот элемент может содержать следующие атрибуты:
• Properties (свойства) - обязательный. Разделенный запятыми список наименований свойств объектной сущности.
3.14.1.4 Check
Ограничительный элемент <Check> может содержать булево выражение запроса. Для таблицы, которая должна быть действительной, это выражение должно обращаться в истинное значение. Выражение не должно иметь никаких побочных эффектов. Смотрите раздел 3.17, приведенный ниже.
Когда ограничение проверки задано и в базовом, и производном типах, оба ограничения проверяются на действительность.
Заметим, что ограничение проверки по таблице применяется к свойству как единому целому. Например, оно могло бы быть использовано, чтобы проверять, что сумма значения конкретного свойства является меньшей, чем некоторое предельное значение. В качестве альтернативы, ограничение проверки, помещенное внутри элемента <EntityConstraint>, могло бы применяться к каждому значению индивидуально.
3.15 Свойства навигации
Свойство навигации по выбору может быть размещено в объектной сущности, заданной любой стороной отношения. Это свойство предоставляет средство навигации от одной стороны до другой стороны отношения.
Свойства навигации представлены с использованием элемента <NavigationProperty> в пределах описания <Entity>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование члена. Наименование должно быть уникальным в области определяющего типа. Наименование должно соблюдать CLR-правила для наименований членов класса и должно следовать руководящим принципам именования каркаса .Net.
• DuplicateName (дублировать наименование) - необязательный. Наименования членов также должны быть уникальными по всей иерархии базового типа, если атрибут DuplicateName не предусмотрен или не обладает значением “true”. Значение “false”, устанавливаемое по умолчанию, указывает, что наименование члена предполагается уникальным.
Роль этого атрибута заключается в том, чтобы а) документировать тот факт, что наименование члена дублирует свойство в базовом типе, и b) принудить разработчика схемы предпочитать дублировать наименование целенаправленно (т.е. он играет такую же роль, как ключевое слово new в С#).
• Association (ассоциация) - должен присутствовать атрибут либо Association (ассоциации), либо Composition (композиции). Задает наименование ассоциации, олицетворенной этим свойством.
• Composition (композиция) - должен присутствовать атрибут либо Association (ассоциации), либо атрибут Composition (композиции). Задает наименование композиции, олицетворенной этим свойством.
• FromRole (исходная роль) - обязательный. Роль стороны, представленной этой объектной сущностью со свойством навигации.
• ToRole (целевая роль) - обязательный. Роль стороны, представленной свойством.
3.16 Псевдонимы типа
Псевдоним типа дает уникальное наименование типу: простому, коллекции, массива, табличному или ссылочному, и набор ограничений. Псевдоним типа определяется с использованием элемента <TypeAlias>, который допускает следующие атрибуты:
• Name (наименование) - обязательный, наименование псевдонима.
• AliasedType (именуемый псевдонимом тип) - обязательный. Наименование именуемого псевдонимом типа. Это должен быть тип: простой, коллекции, массива, табличный или ссылочный.
Элемент <TypeAlias> может содержать любой ограничительный элемент, разрешенный для именованного псевдонимом типа.
Определенное наименование псевдонима может быть использовано везде, где может быть использовано наименование именованного псевдонимом типа.
Некоторые примерные псевдонимы показаны ниже:
<Schema Namespace=”MyCompany.MySchema”>
<TypeAlias Name=”Name” AliasedType=”String”>
<Length Maximum=”1000”/>
</TypeAlias>
<TypeAlias Name=”PersonRef” BaseType=”Ref(PersonItem)”>
</TypeAlias>
<TypeAlias Name=”Keywords” AliasedType=”Collection(String)”>
<Length Maximum=”100”/>
<Occurs Minimum=”0” Maximum=”unbounded”/>
</TypeAlias>
</Schema>
3.17 Наборы таблиц и типы набора таблиц
3.17.1 Типы набора таблиц
Тип набора таблиц является ограниченной формой типа объектной сущности. Тип набора таблиц определяется с использованием элемента <TableSetType>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование типа набора таблиц. Это наименование должно быть уникальным среди всех типов и отношений в определяющей схеме.
• DefaultTableSet (набор таблиц по умолчанию) - необязательный. Задает набор таблиц по умолчанию типа набора таблиц. Если не задан, то значения по умолчанию нет.
Элементы <TableSetType> могут содержать элементы <Property>, которые задают ссылочные и табличные типы. Ссылочное свойство может задавать только типы набора таблиц. Элементы <TableSetType> также могут содержать элементы <ComputedProperty> и <Method>.
3.17.2 Экземпляры набора таблиц
Набор таблиц является экземпляром типа набора таблиц. Наборы таблиц образуют “высший уровень” модели данных. Вся память хранилища прямым или косвенным образом выделяется посредством создания набора таблиц.
Набор таблиц описывается с использованием элемента <TableSet>. Этот элемент может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование набора таблиц. Это наименование должно быть уникальным среди всех наборов таблиц в определяющей схеме.
• Type (тип) - обязательный. Наименование типа набора таблиц.
3.17.3 Объединение наборов таблиц
Элемент <TableSet> должен содержать элемент <AggregatedTableSet> для каждого типизированного ссылочным типом свойства в заданном типе объектной сущности. Это предоставляет предварительно определенным наборам таблиц возможность быть соединенными в новый набор таблиц. Это полезно, при комбинировании данных из двух раздельных приложений в единое приложение. Элемент <AggregatedTableSet> может содержать следующие атрибуты:
• Property (свойство) - обязательный. Наименование заданного ссылочным типом свойства.
• TableSet (набор таблиц) - обязательный. Наименование набора таблиц, который будет указан ссылкой посредством свойства.
Пример, приведенный ниже, иллюстрирует это:
Из Sales Schema (схемы продаж)
<TableSetType Name="SalesData">
…
</TableSetType>
<TableSet Name="Sales" Type="SalesData"/>
Из схемы WinFS (файловой системы Windows)
<TableSetType Name="WinFSData" DefaultTableSet="WinFS">
…
</TableSetType>
<TableSet Name="WinFS" Type="WinFSData"/>
Из Third Schema (третьей схемы)
<TableSetType Name="ThirdAppData">
<Property Name="Sales" Type="Ref(SalesData)" …/>
<Property Name="WinFS" Type="Ref(WinFSData)" …/>
…
</TableSetType>
<TableSet Name="ThirdApp" Type="ThirdAppData">
<AggregatedTableSet Property="WinFS" TableSet="WinFS"/>
<AggregatedTableSet Property="Sales" TableSet="Sales"/>
</TableSet>
4. ОБЩЕДОСТУПНЫЕ РЕЗУЛЬТАТЫ
Последующие признаки общей модели данных попадают под всестороннее исследование:
• Язык запросов, используемый в документах схем. Раздел 4.1.1, приведенный ниже, предоставляет текущие рассуждения об языке запросов.
• Интерфейсы. Раздел 4.1.2, приведенный ниже, обрисовывает исходные суждения об интерфейсах.
• Участие расчетных свойств и методов в отношениях.
• Порождение новых типов объектной сущности ассоциации от базовых типов объектной сущности ассоциации и синтаксис, используемый для описания результирующих ассоциаций.
• Ассоциации, которые вовлекают стороны, которые являются подставляемыми типами.
4.1.1 Язык запросов
| Для общей модели данных может быть специфицирован язык запросов. Язык запросов основан на SQL-нацеливании CDM-понятий, подобных объектным сущностям и отношениям. |
4.1.1.1 Использование композиций в запросах
Композиция делает следующие функции доступными для использования в запросе:
| Эти шаблоны работают при определении набора таблиц, на котором основана введенная таблица. |
• Table( parent-type ) composition.Get parent-role-p(Table(child-type) ) - возвращает родителей введенных потомков.
• parent-type composition.Getparent-role-s(child-type) - родитель введенного потомка.
• Table( parent-type ) composition.Filter parent-role-p(Table(parent-type) , Table( child-type )) - возвращает набор родителей, отфильтрованных по наличию потомка во введенном наборе потомков.
• Table( child-type ) composition.Get child-role-p (Table( parent-type )) - возвращает потомков введенных родителей.
• Table( child-type ) composition.Get child-role-p(parent-type) - возвращает потомков введенных родителей.
• Table( child-type ) composition.Filter child-role-p(Table(child-type) , Table( parent-type )) - возвращает набор потомков, отфильтрованный по наличию потомка во введенном наборе родителей.
Где:
• сomposition представляет наименование композиции
• parent-role-s представляет форму единственного числа наименования родительской роли
• parent-role-p представляет форму множественного числа наименования родительской роли
• child-role-s представляет форму единственного числа наименования дочерней роли
• child-role-p представляет форму множественного числа наименования дочерней роли
• parent-type представляет тип родительской объектной сущности
• child-type представляет тип дочерней объектной сущности
• Table(type) представляет запрос по таблице конкретного типа
4.1.1.2 Использование ассоциаций в запросах
Ассоциация делает следующие функции доступными для использования в запросе:
| Эти шаблоны работают при определении набора таблиц, на котором основана введенная таблица. |
• Table( end-1-type ) association.Get end-1-role-p(Table(end-2-type) ) - возвращает объектные сущности end-1, ассоциативно связанные с заданными объектными сущностями end-2.
• Table( end-1-type ) association.Get end-1-role-p(end-2-type) - возвращает объектные сущности end-1, ассоциативно связанные с заданной объектной сущностью end-2.
• Table( end-1-type ) association.Filter end-1-role-p(Table(end-1-type) , Table( end-2-type )) - возвращает набор объектных сущностей end-1, отфильтрованных по наличию ассоциативно связанной объектной сущности end-2 во введенном наборе объектных сущностей end-2.
• Вышеприведенные методы повторяются для всех сочетаний сторон, в том числе объектной сущности ассоциации, если присутствует.
Где:
• association представляет наименование ассоциации
• end-1-role-s представляет форму единственного числа наименования роли стороны
• end-1-role-p представляет форму множественного числа наименования роли стороны
• end-2-role-s представляет форму единственного числа наименования роли стороны
• end-2-role-p представляет форму множественного числа наименования роли стороны
• end-1-type представляет тип исходной объектной сущности
• end-2-type представляет тип целевой объектной сущности
• Table(type) представляет запрос по таблице конкретного типа
4.1.2 Интерфейс
Тема интерфейсов не была обсуждена подробно. Они описываются, чтобы спровоцировать ответную реакцию. Они могут быть интегрированы в общую модель данных в будущем.
Интерфейсы предусматривают CLR-подобные интерфейсы для типов объектных сущностей и подставляемых типов. Они могут быть использованы для решения большинства из тех же самых проблем, которые интерфейсы решают в объектных системах типов.
Интерфейс объявляется с использованием элемента <Interface>. Элемент <Interface> может содержать следующие атрибуты:
• Name (наименование) - обязательный. Наименование интерфейса. Должно быть уникальным среди всех типов и самых высокоуровневых таблиц, определенных в схеме.
• BaseInterfaces (базовые интерфейсы) - необязательный. Разделенный запятыми список интерфейсов, от которых порожден этот интерфейс.
Элемент <EntityType> или <InlineType> может использовать атрибут ImplementedInterfaces (реализованные интерфейсы) для того, чтобы задавать разделенный запятыми список интерфейсов, которые он реализует. Каждое из свойств, определенных в перечисленном интерфейсе, должно быть определено в типе.
Как с интерфейсом в С#, свойство, определенное в интерфейсе, реализуется неявным образом в типе простым объявлением свойства с таким же наименованием и типом. Ограничения по свойству могут быть сужены, когда оно объявлено.
Свойство также может быть реализовано неявным образом. Это достигается включением наименования типа интерфейса в наименование свойства (в точности, как для С#). Это предоставляет разным ограничениям возможность быть примененными к свойствам, которые имеют одну и ту же сигнатуру, но унаследованы от разных интерфейсов.
Например:
<Schema Namespace=”MyCompany.MySchema”>
<Interface Name=”IA”>
<Property Name=”X” Type=”Int32”/>
<Property Name=”Y” Type=”Int32”/>
</Interface>
<Interface Name=”IB”>
<Property Name=”X” Type=”Int32”/>
<Property Name=”Y” Type=”Int32”/>
</Interface>
<EntityType Name=”C” ImplementedInterfaces=”IA, IB” Key=”ID”>
<Property Name=”ID” Type=”Int32”/>
<Property Name=”X” Type=”Int32”/>
<Proреrty Name=”IA.Y” Type=”Int32”>
<RangeConstraint Maximum=”100”/>
</Proреrty>
<Property Name=”IB.Y” Type=”Int32”>
<RangeConstraint Maximum=”10”/>
</Property>
</EntityType>
</Schema>
5. ПРИЛОЖЕНИЯ
5.1 Завершенная примерная схема
Пример, приведенный ниже, определяет типы объектной сущности Customer (потребителя), Order (заказа), OrderLine (товара заказа), Product (продукта) и Supplier (поставщика) вместе с ассоциациями, описывающими, каким образом соотнесены эти объектные сущности.
<Schema Namespace="MyLOB">
<InlineType Name="Address">
<Property Name="Line1" Type="String" Nullable="false">
<Length Maximum="100"/>
</Property>
<Property Name="Line2" Type="String" Nullable="true">
<Length Maximum="100"/>
</Property>
<Property Name="City" Type="String" Nullable="false">
<Length Maximum="50"/>
</Property>
<Property Name="State" Type="String" Nullable="false">
<Length Minimum="2" Maximum="2"/>
</Property>
<Property Name="ZipCode" Type="String" Nullable="false">
<Length Minimum="5" Maximum="5"/>
</Property>
</InlineType>
<EntityType Name="Customer" Key="CustomerId">
<Property Name="CustomerId" Type="String" Nullable="false">
<Length Minimum="10" Maximum="10"/>
</Property>
<Property Name="Name" Type="String" Nullable="false">
<Length Maximum="200"/>
</Property>
<Property Name="Addresses" Type="Array(Address)">
<Occurs Minimum="1" Maximum="3"/>
</Property>
<NavigationProperty Name="Orders" Association="OrderCustomer"
FromRole="Customer" ToRole="Orders"/>
</EntityType>
<EntityType Name="Order" Key="OrderId">
<Property Name="OrderId" Type="String" Nullable="false">
<Length Minimum="10" Maximum="10"/>
</Property>
<Property Name="Date" Type="DateTime" Nullable="false"/>
<Property Name="Customer" Type="Ref(Customer)"
Association="OrderCustomer"/>
<Property Name="Lines" Type="Table(OrderLine)"
Composition="OrderOrderLine"/>
<Property Name="ShippingAddress" Type="Address" Nullable="false"/>
</EntityType>
<Composition Name="OrderOrderLine">
<ParentEnd Role="Order" Type="Order" PluralRole="Orders" Property="Lines"/>
<ChildEnd Role="OrderLine" Type="OrderLine"
PluralRole="OrderLines" Multiplicity="100"/>
</Composition>
<Association Name="OrderCustomer">
<End Role="Order" Type="Order" PluralRole="Orders"/>
<End Role="Customer" Type="Customer" PluralRole="Customers"
OnDelete="Cascade" Table=""/>
</Association>
<EntityType Name="OrderLine" Key="LineId">
<Property Name="LineId" Type="Byte" Nullable="false"/>
<Property Name="Product" Type="Ref(Product)" Nullable="false"
Association="OrderLineProduct"/>
<Property Name="Quantity" Type="Int16" Nullable="false">
<Range Minimum="1" Maximum="100"/>
</Property>
<Property Name="Price" Type="Decimal" Nullable="false">
<Decimal Precision="6" Scale="2"/>
</Property>
<NavigationProperty Name="Order" Composition="OrderOrderLine"
FromRole="Line" ToRole="Order"/>
</EntityType>
<Association Name="OrderLineProduct">
<End Role="OrderLine" PluralRole="OrderLines"/>
<End Role="Product" Type="Product" PluralRole="Products"
Table=""/>
<Reference FromRole="OrderLine" ToRole="Product"
Property="Product"/>
</Association>
<EntityType Name="Product" Key="ProductId">
<Property Name="ProductId" Type="Guid" Nullable="false"/>
<Property Name="Title" Type="String" Nullable="false">
<Length Maximum="100"/>
</Property>
<Property name="Description" Type="String" Nullable="false">
<Length Maxumum="1000"/>
</Property>
</EntityType>
<Association Name="CustomerProduct">
<End Role=="Customer" PluralRole=="Customers" Type=="Customer"/>
<End Role="Product" PluralRole="Products" Type="Product"/>
<Uses Role="Order" Type="Order"/>
<Uses Role="Line" Type="Lines"/>
<Condition>
Order.Customer = Customer AND OrderLine.Product = Product
</Condition>
</Association>
<EntityType Name="Supplier" Key="SupplierId">
<Property Name="SupplierId" Type="String" Nullable="false">
<Length Minimum="10" Maximum="10"/>
</Property>
<Property Name="Name" Type="String" Nullable="false">
<Length Maximum="200"/>
</Property>
<Property Name="Addresses" Type="Array(Address)">
<Occurs Minimum="1" Maximum="3"/>
</Property>
<NavigationProperty Name="Products" Association="ProductSupplier"
FromRole="Supplier" ToRole="Product"/>
</EntityType>
<EntityType Name="ProductSupplierLink" Key="Product, Supplier"
Association="ProductSupplier">
<Property Name="Product" Type="Ref(Product)" Nullable="false"
Role="Product"/>
<Property Name="Supplier" Type="Ref(Supplier)" Nullable="false"
Role="Supplier"/>
<Property Name="Price" Type="Decimal" Nullable="false">
<Decimal Precision="6" Scale="2"/>
</Property>
</EntityType>
<Association Name="ProductSupplier">
<AssociationEntity Type="ProductSupplierLink">
<End Role="Link" Type="ProductSupplierLink"/>
<Reference FromRole="Link" ToRole="Product"
Property="Product"/>
<Reference FromRole="Link" ToRole="Supplier"
Property="Supplier"/>
</AssociationEntity>
<End Role="Product" Type="Product" PluralRole="Products"
Table="" />
<End Role="Supplier" Type="Supplier" PluralRole="Suppliers"
Table="" />
</Association>
<TableSetType Name="LOBData">
<Property Name="Orders" Type="Table(Order)"/>
<Property Name="Customers" Type="Table(Customer)"/>
<Property Name="Products" Type="Table(Product)"/>
<Property Name="Suppliers" Type="Table(Supplier)"/>
<Property Name="PSLinks" Type="Table(ProductSupplierLink)"/>
</TableSetType>
<TableSet Name="LOB" Type="TableSetType"/>
</Schema>
5.2 SQL 99 и Общая модель данных
SQL 99 определяет несколько объектных расширений по отношению к основной реляционной модели данных (SQL 92). Ключевыми понятиями SQL 99 являются:
1. Определяемые пользователем типы
а. Индивидуальные типы
b. Структурированные типы
2. Методы (поведения)
3. Типизированные таблицы
4. Ссылки
Задача для SQL 99 заключалась в том, чтобы определять полную систему типов, замкнутую в пределах SQL-модели данных. Несмотря на то, что объекты в языках программирования могут быть преобразованы в SQL-объекты, определять сильную связь с языком программирования (например, Java, C#) не является задачей SQL 99. Например, методы в SQL 99 лучше описываются на процедурном языке SQL, чем на стандартном языке программирования. Целью для общей модели данных является задавать точное согласование как с SQL, так и с CLR. Мы полагаем, что предложенная модель достигает этой цели.
5.2.1 Определяемые пользователем типы
Типы, простые и составные, в общей модели данных соответствуют почти один к одному определяемым пользователем типам в SQL 99. Простые типы и псевдонимы простых типов соответствуют скалярным типам и индивидуальным типам SQL 99, составные (Complex) типы соответствуют структурированному типу данных SQL 99. Главным различием между структурированным типом SQL и составным типом является разграничение между подставляемыми (Inline) типами и типами объектной сущности (Entity). В общей модели данных понятие идентичности/ключа определяется во время описания типа. В SQL 99 идентичность определяется, когда тип используется для определения типизированной таблицы. Поэтому в SQL 99 не было необходимости проводить различие между типами с и без идентичности, следовательно, была поддержка повторного использования типа для описания как таблицы (допускающих ссылку объектов), так и столбца (не пригодных для ссылки, подставленных объектов). Такое повторное использование типа действует именно на хранение, так как идентичность может быть определена во время описания таблицы. Однако один и тот же тип не может быть приведен в соответствие подставленному классу так же, как пригодному для указания ссылкой классу. Так как целью общей модели данных является предоставить объектный каркас и каркас устойчивости приложения, разграничение между подставляемыми типами и типами объектной сущности является важным.
5.2.2 Методы/Поведения
В общей модели данных поведения определяются с использованием каркаса CLR. SQL99 определяет свой собственный каркас методов/поведений. Несмотря на то, что он является близким к большинству современных (объектно-ориентированных) OO-языков, он по-прежнему является иным и не предусматривает подходящей среды программирования для приложений. Типично, приложения (или серверы приложений) преодолевают пробел между средой программирования и средой баз данных. Мы представляем себе общую модель данных предусматривающей более унифицированный каркас программирования и устойчивости.
5.2.3 Типизированные таблицы против таблиц объектных сущностей
Таблицы объектных сущностей в общей модели данных подобны типизированным таблицам SQL 99. Однако экстент (непрерывная область резервируемого хранилища) является логическим - он является логической коллекцией объектов. Физическое хранилище, ассоциативно связанное с экстентом, отсутствует. Таблица типов является SQL-таблицей со всеми атрибутами хранилища, разрешенными в таблицах. Мы представляем себе непрерывные области памяти приведенными в соответствие одной или более физическим таблицам.
5.2.4 Ссылки
Ссылки в общей модели данных и в SQL 99 очень похожи. В общей модели данных ссылке задается область посредством задания непрерывной области памяти для ссылки; в SQL 99 ссылке задается область посредством задания таблицы типов в качестве целевого объекта для ссылки. В обоих случаях ссылка разрешается в объект.
5.2.5 Примерная простая LOB-схема
Раздел представляет простую LOB-схему из предыдущего раздела на SQL 99 и Oracle 9i SQL. Так как понятия, подобные вложенным таблицам (Nested Tables), не являются частью SQL 99, мы использовали синтаксис Oracle 9i SQL для VARRAY-массивов и NESTED TABLES.
Так как ассоциация не является формальным понятием в SQL 99 или в SQL какого бы то ни было производителя, в SQL нет декларативного способа задания семантики отношения. Отсутствие ассоциаций является весьма наглядным, когда она доходит до описания свойств навигации (Navigation Properties), которые предусматривают более простую модель программирования для отношений между объектными сущностями.
CREATE SCHEMA SimpleLOB
CREATE TYPE VarrayOfAddresses VARRAY(Address);
CREATE TYPE Customer AS (
| CustomerID | INTEGER, |
| Name | VARCHAR(128), |
| Addresses | VarrayOfAddresses |
);
CREATE TYPE Address AS (
| Name | VARCHAR(128), |
| City | VARCHAR(128), |
| State | CHAR(2) |
);
CREATE TYPE Product AS (
| ProductID | INTEGER, |
| Description | VARCHAR(100) |
};
CREATE TYPE Order AS (
| OrderID | INTEGER, |
| Date | DATE, |
| CustomerRef | REF(Customer), |
| Details | OrderDetailNestedTableTyp |
};
CREATE TYPE OrderDetail AS (
| DetailID | INTEGER, |
| ProductRef | Ref(Product), |
| Quantity | INTEGER, |
| Price | DECIMAL |
};
CREATE TYPE OrderDetailNestedTableTyp AS TABLE OF OrderDetail;
| CREATE | TABLE Customers OF Customer ( |
| REF | CustomerID IS USER DEFINED |
);
| CREATE | TABLE Products OF Product ( |
| REF | ProductID IS USER DEFINED |
);
CREATE TABLE Orders OF Order (
CustomerRef WITH OPTIONS SCOPE Customers ON DELETE CASCADE,
NESTED TABLE Details STORE AS OrderDetailTable (
PRIMARY KEY (NESTED_TABLE_ID, DetailID),
ProductRef WITH OPTIONS SCOPE Products,
CHECK (Quantity*Price < 100)
),
REF OrderID IS USER DEFINED
);
CREATE TYPE AccountManager AS (
| AccountManagerID | INTEGER, |
| Name VARCHAR(128) | VARCHAR(128) |
);
CREATE TABLE AccountManagers OF AccountManager;
CREAYE TYPE CustomerAccountManagerLink AS (
| CustomerRef | Ref(Customer) NOT NULL, |
| AccountManagerRef | Ref(AccountManager) NOT NULL |
);
CREATE TABLE CustomerAccountManagerLinkTable OF
CustomerAccountManagerLink (
REF (CustomerRef, AccountManagerRef) IS USER DEFINED,
CustomerRef WITH OPTIONS SCOPE Customer ON DELETE CASCADE,
AccountManagerRef WITH OPTIONS SCOPE AccountManager ON DELETE
CASCADE
);
END SCHEMA SimpleLOB
5.3 Структурная семантика
Этот раздел предоставляет фрагменты метамодели, которые проясняют семантические отношения между элементами модели.
Каждый из классов на диаграмме является элементом модели или схемы. Те, которые в зеленом цвете, могут быть объявлены пользователями. Те, которые в белом цвете, являются любыми из структурных элементов, неявно структурированных элементов (таких как ссылочные типы) или встроенных элементов (таких как простые типы, которые расширяются импортированием CLR-типов, а не через прямое объявление).
5.3.1 Типы

Комментарии и дополнительные ограничения:
• Объявление типа объектной сущности неявным образом определяет тип таблицы объектных сущностей (EntityTableType) и ссылочный тип (ReferenceType). На практике, эти типы могли бы быть реализованы групповыми признаками, такими как Ref<T> или Table<T>.
• Свойства могут быть объявлены только в объявлениях подставляемого типа и типа объектной сущности.
• typeof(ArrayType.ElementType) != ArrayType
5.3.2 Свойства

Комментарии и дополнительные ограничения:
• Свойства ссылочного или табличного типа являются свойствами ассоциации, каковое буквально означает, что они включают в себя лежащий в основе тип объектной сущности.
• Свойства навигации возвращают запрос.
2420-135044RU/051
Приложение B
ОБЗОР АРХИТЕКТУРЫ ОбщЕЙ ПЛАТФОРМЫ ДАННЫХ
| Содержание | |
| 1. ВВЕДЕНИЕ | 4 |
| 1.1 Потребность в платформе данных | 4 |
| 1.2 Почему не DBMS? | 8 |
| 1.3 Почему не WinFS? | 12 |
| 1.3.1 Новые соглашения касательно переориентации Longhorn | 12 |
| 1.3.2 Архитектурные проблемы, касающиеся использования WinFS, “как есть” | 13 |
| 1.4 Уровневая архитектура для CDP | 15 |
| 1.4.1 Является ли CDP сервером приложений? | 16 |
| 1.5 Что такое единое хранилище или интегрированное хранилище? | 17 |
| 2. ОБЗОР ОБЩЕЙ ИНФОРМАЦИОННОЙ ПЛАТФОРМЫ | 18 |
| 2.1 Признаки CDP | 18 |
| 2.2 Функциональная архитектура | 21 |
| 2.3 Гибкая реализация | 23 |
| 2.4 Поток данных/управления | 24 |
| 3. ДЕТАЛИЗАЦИЯ ПРИЗНАКОВ CDP | 29 |
| 3.1 Общая модель данных | 30 |
| 3.1.1 Основные понятия CDM | 31 |
| 3.1.2 Схемы и наборы таблиц | 32 |
| 3.1.3 Объектные сущности | 33 |
| 3.1.4 Ссылки объектной сущности | 35 |
| 3.1.5 Отношения | 35 |
| 3.2 Объектно-реляционные преобразования | 39 |
| 3.3 Плоскость программирования | 41 |
| 3.3.1 Инструментальные средства среды проектирования | 41 |
| 3.3.2 API CDP | 43 |
| 3.3.3 Query | 44 |
| 3.3.4 Отношение между типами CDM и плоскостью программирования | 46 |
| 3.4 Ограничения | 47 |
| 3.5 Безопасность | 49 |
| 3.6 Кэш | 50 |
| 3.7 Курсоры | 50 |
| 3.8 CDP-каркасы | 52 |
| 3.9 Ведущий узел бизнес-логики (BL) | 56 |
| 3.9.1 Ограничения | 57 |
| 3.9.2 Обработчики событий | 57 |
| 3.9.3 Статические/экземплярные методы | 58 |
| 3.9.4 Связываемые поведения | 59 |
| 3.9.5 Статические служебные методы | 59 |
| 3.10 На каких хранилищах реализован CDP? | 60 |
| 4. СОВМЕСТНОЕ ИСПОЛЬЗОВАНИЕ/ФУНКЦИОНАЛЬНАЯ СОВМЕСТИМОСТЬ ДАННЫХ, СЦЕНАРИИ «ЕДИНОГО ХРАНИЛИЩА» | 60 |
| 4.1 Сценарии “единого хранилища” | 61 |
| 4.2 Прозрачность данных | 61 |
| 4.3 Совместное использование/функциональная совместимость данных | 63 |
| 4.3.1 Многочисленные приложения, одиночный каркас | 63 |
| 4.3.2 Одиночное приложение, многочисленные каркасы | 64 |
| 4.3.3 Многочисленные приложения, многочисленные каркасы | 65 |
| 4.3.4 Совместное использование вместе с “отличными от CDP” хранилищами | 68 |
| 5. РАЗВЕРТЫВАНИЕ КОМПОНЕНТОВ CDP ПО ЯРУСАМ | 68 |
| 5.1 Двухъярусное развертывание | 68 |
| 5.1.1 Двухъярусное развертывание с совместно используемыми данными | 69 |
| 5.1.2 Двухъярусное развертывание с закрытыми данными | 71 |
| 5.1.3 Прямой доступ к хранилищу | 73 |
| 5.2 Трехъярусное развертывание | 76 |
| 5.2.1 Функционирование логики приложения на среднем ярусе (“Веб-служба”) | 77 |
| 5.2.1.1 Сервис-ориентированная архитектура для удаленного взаимодействия | 79 |
| 5.2.1.2 Поток данных/управления через ярусы | 81 |
| 5.2.2 Функционирование логики приложения на обоих, клиентском и промежуточном, ярусах | 85 |
| 5.2.2.1 Поток данных/управления через ярусы | 85 |
| 5.2.2.2 Применение «локального хранилища» | 87 |
| 5.2.3 Автономный режим | 88 |
| 5.3 CDP-хранилища | 92 |
| 5.4 Именование и обнаружение | 93 |
| 5.4.1 Именование | 93 |
| 5.4.2 Обнаружение | 95 |
| 6. CDP-СЛУЖБЫ | 95 |
| 6.1 Служба наблюдателя/уведомления | 95 |
| 6.2 Службы синхронизации | 96 |
| 6.3 Службы явного кэша | 98 |
| 6.4 Вспомогательные операции | 99 |
| 7. WinFS ПОВЕРХ CDP: UAF | 99 |
| 7.1 Что такое UAF? | 99 |
| 7.2 Разделение WinFS между CDP и UAF | 101 |
| 8. MBF ПОВЕРХ CDP: КАРКАС LOB | 103 |
| 8.1 Обзор MBF (каркас построения бизнеса Microsoft) | 103 |
| 8.1.1 Доступ к данным | 106 |
| 8.1.2 SOA и удаленное взаимодействие | 107 |
| 8.2 Реализация MBF с использованием CDP | 107 |
| 9. БИБЛИОГРАФИЧЕСКИЙ СПИСОК | 110 |
1. ВВЕДЕНИЕ
Этот раздел исследует потребность в общей платформе данных и предусматривает изложение мотивов, почему такая платформа данных должна быть построена с использованием уровневой архитектуры.
1.1 Потребность в платформе данных
Данные стали важным ресурсом почти в каждом приложении, является ли оно отраслевым промышленным приложением, осуществляющим поиск продуктов и вырабатывающим заказы, или приложением управления персональной информацией, планирующим встречу между людьми. Приложения выполняют операции как доступа/манипулирования данными, так и управления данными, над данными приложения. Типичное приложение запрашивает набор данных, извлекает результирующий набор, приводит в исполнение некоторую логику приложения, которая изменяет состояние данных, и, наконец, делает устойчивыми (сохраняет) данные. Традиционно, клиент-серверные приложения низводили действия запроса и осуществления устойчивости до систем управления базами данных (DBMS), развернутыми на информационном ярусе. Если есть логика с централизованными данными, она кодируется в виде хранимых процедур в системе базы данных. Система базы данных оперировала данными в терминах таблиц и строк, а приложение, на прикладном ярусе, оперировало данными в терминах объектов языка программирования (например, классов и структур). Несоответствие в службах (и механизмах) манипулирования данными на прикладном и информационном ярусах было приемлимым в клиент-серверных системах. Однако, с пришествием веб-технологии (и (ориентированных на обслуживание) сервис-ориентированных архитектур) и с более широким признанием серверов приложений, приложения становятся многоярусными, и что более важно, данные теперь присутствуют на каждом ярусе. В таких многоярусных архитектурах приложений данные подвергаются манипуляциям на многочисленных ярусах. Кроме того, с продвижениями аппаратных средств в адресуемости и запоминающих устройствах большой емкости большее количество данных существует резидентно в памяти. Приложения к тому же имеют дело с различными типами данных - объектами, файлами и XML-данными.
В таких аппаратных и программных средах возрастает потребность в наполненных широкими возможностями службах доступа и манипулирования данными, хорошо интегрированных со средами программирования. Последующее является некоторыми из ключевых требований по механизмам доступа и манипулирования данными для построения приложений с широкими возможностями:
• Моделирование сложных объектов
○ Сложные структуры
○ Наследование
○ Неструктурированных, XML и структурированнх данных
• Обогащенные отношения (например, UML-вида)
○ Ассоциации
○ Композиции
○ Объектные сущности ассоциации
○ Обогащенный язык запросов
• Разделение логической и физической абстракций данных
○ Возможность приводить обогащенную логическую абстракцию данных в соответствие разным концепциям физического хранения данных, например, преобразование классов C# в реляционные строки
• Концепции запроса обогащенной модели данных
○ Хорошо интегрированные со средой (программирования) приложений
○ Общие по разным типам данных - объектам, XML и
файловым
• Обогащенный анализ данных и процессов
• Гранулярные операции
○ Копировать (Copy), переместить (Move),
резервировать/восстановить (Backup/Restore), защитить
(Security) над объектами приложения
• Активные уведомления
• Синхронизация данных (и действий)
• Интегрированная информационная логика
○ Логика, хорошо интегрированная с приложением
○ Оптимистическое управление параллельным доступом
• Поддержка для сервис-ориентированных архитектур (SOA)
○ Возможность манипулировать данными, независимо, на каждом уровне обслуживания
• Лучшая интеграция со среднеярусной инфраструктурой
○ Обогащенное моделирование, преобразование и запрашивание в пределах серверов приложений
○ Тесная интеграция с языками программирования
○ Кэширование и запрашивание
○ Встроенные DB-возможности (баз данных)
Платформа данных является платформой, которая предоставляет коллекцию служб (механизмов) для приложения для осуществления доступа, манипулирования и управления данными, которая тесно интегрирована со средой программирования приложения. Платформа данных должна направлять усилия на вышеприведенные требования приложений к данным. Платформа данных к тому же должна быть размещаемой на многочисленных ярусах.
Общая платформа данных (CDP) является платформой, которая предполагается для предоставления информационных служб, которые являются общими по всему многообразию каркасов приложений (например, PIM-каркасу, LOB-каркасу). Эти службы и механизмы включают в себя Общую модель данных, Общий язык запросов (CQL) (например, операторы последовательности C#, ОPath), интерфейсы доступа к данным (например, транзакции, результирующие наборы), кэширование, обработку запросов и другие службы, подобные защите объектного уровня, отслеживанию изменений, уведомлениям и операциям (копировать (Copy), импортировать/экспортировать (Import/Export), и т.д.)
1.2 Почему не DBMS?
Как только мы осознаем потребность в общей платформе данных, следующим логичным вопросом является: Мог бы DBMS послужить этой роли?
Находящиеся в обращении базы данных обеспечивают богатые возможности управления данными (подобные производительности, масштабируемости, большому количеству пользователей, безопасности и так далее), но они оказываются недостаточными при обеспечении обогащенных информационных моделей приложения для моделирования структуры и поведения. Приложения по своему существу являются более близкими к языковым средам программирования, а абстракции моделирования данных не обязательно соответствуют прикладным абстракциям. Системы баз данных не стали успешными в предложении абстракций для моделирования объектов приложения так же, как и его бизнес-логики.
Можно было бы привести доводы, что система базы данных (SQL Server) могла бы быть улучшена для осуществления поддержки обогащенных абстракций данных (скажем, расширениями SQL 99), чтобы стать платформой данных для разработки приложений. Но даже с этими усовершенствованиями система базы данных не удовлетворяет требованиям приложений (описанным выше), в частности, ведению логики приложения и ее интеграция со средами прикладного программирования. Несмотря на то, что система базы данных является допускающей исполнение кода (например, хранимых процедур), она не пригодна для ведения общей логики приложения. Конкретный аспект ведения логики приложения служит отличительным признаком серверов приложений от систем баз данных. Сложными задачами ведения логики приложения являются следующие:
• Приложения требуют, чтобы логика велась на многочисленных ярусах - клиентском, среднем ярусе (прикладном ярусе) и ярусе данных. Развертывание системы базы данных на каждом ярусе является непрактичным подходом, особенно в ракурсе масштабируемости и управляемости приложения.
• Типичное, управляемое моделью, основанное на SOA приложение разрабатывается с использованием многообразия технологий серверов приложений и веб-служб (например, ASP (активных серверных страниц), WinOE (встраивания объектов Windows), Indigo), размещенных в экземпляре процесса (исполняемого процесса OS (ОС, операционной системы)). Служба платформы данных должна сосуществовать с другими механизмами исполнения приложения. Предъявление требований к системам баз данных размещать технологии, подобные ASP и Indigo, в приложении является нежелательным в ракурсе развертывания.
• В серверах приложений приложение работает на одном или более серверах приложений, и необходимые данные доставляются приложению, для выполнения операций. На сервере приложений почти совсем нет устойчивого состояния. Данные на прикладном ярусе имеют тенденцию быть ссылочными данными (не аутентичной копией) и не обладают такими же требованиями к управлению данными, как в системе базы данных. Сервер приложений главным образом сосредотачивается на управлении приложением.
• В системах баз данных данные существуют на сервере, а приложение (в качестве некоторой разновидности хранимых процедур) должно быть вытолкнуто в базу данных, чтобы оперировать данными. Системы баз данных, главным образом, сосредотачиваются на управлении состоянием (данными). Управление приложением является вторичным (или нецелевым). Ортогональность признака базы данных является решающей для сделанных устойчивыми данных, чтобы гарантировать непротиворечивость данных, тем самым увеличивая сложность управления данными.
Подтверждено, что подход сервера приложений является подходящим для лучшего масштабирования. Есть обоснованные доказательства рынка, что масштабирование базы данных является дорогостоящим предложением, в сравнении с масштабированием сервера приложений, последнее предусматривает развертывания гибких приложений. Поставщики баз данных (Oracle и IBM) привели доводы и попытались позиционировать системы управления базами данных в качестве серверов приложений, но не достигли цели. И Oracle, и IBM, которые имели значительную долю рынка баз данных, имеют серьезные предложения серверов приложений (Oracle Application Server и IBM Websphere, соответственно) для размещения и управления приложением.
В дополнение, в то время как базы данных стали критическими в управлении данными предприятия, программное обеспечение DBMS также стало слишком громоздким и слишком сложным. Большинство коммерческих DBMS-продуктов являются весьма сложными, с миллионами строк кода. Так как системы баз данных увеличиваются по возможностям, они становятся более трудными для управления. К тому же, системы баз данных стали более монолитными, без должного компонентного представления. Следовательно, добавление или удаление функциональных возможностей базы данных стало значительно дорогостоящим. Недостаток компонентного представления или разделения на уровни также делает их трудными для использования возможностей базы данных на других ярусах без потребности в цельном гигантском пространстве запоминающего устройства базы данных. Сложность базы данных также делает ее трудной для направления усилий на вопросы масштабирования, производительности и надежности базы данных.
Мы полагаем, что проблемы разработки приложений могут быть лучше решены, скорее, посредством применения хорошо проверенных технологий баз данных в контексте серверов приложений или приложений, чем требования от приложений размещаться в базе данных. Например, системы баз данных могут экспортировать определенные технологии (например, запрос) в серверы приложений так, чтобы данные могли лучше запрашиваться близко к приложению. Это является согласующимся с современной тенденцией в промышленности содержать некоторую разновидность процессора запросов в процессе сервера приложений. Например, IBM WebSphere может вести Cloudscape (базу данных Java) в пределах своего процесса, тем самым предусматривая обогащенное запрашивание Java-объектов. Подобным образом, кэширование является еще одной технологией, которую базы данных могут привнести в сферу серверов приложений.
1.3 Почему не WinFS?
В дни юности проекта WinFS видение состояло в том, чтобы построить платформу данных, которая предусматривала бы обогащенные возможности моделирования для всех типов данных и к тому же преодолевала импедансное несоответствие между структурами хранения и абстракциями языка программирования. Поскольку проект развивался, он становился все более и более согласующимся только с одной стороной своего более широкого видения: быть файловой системой для Longhorn. Имеющими к этому отношение были требования со стороны командного интерфейса, которые даже еще больше подтолкнули архитектуру в направлении исключительной цели моделирования пользовательских/PIM-данных и развертыванию в двухъярусной архитектуре.
1.3.1 Новые соглашения касательно переориентации Longhorn
Переориентация в приоритетах Longhorn привела к следующим новым соглашениям:
• Больше нет необходимости сосредотачиваться исключительно на создании большого хранилища для файловой системы, командной оболочки, и PIM
• Выпуск VI WinFS согласован с выпуском Katmai SQL Server, который предусматривает благоприятные возможности для сосуществования WinFS и отличных от WinFS данных
• В дополнение к клиентским сценариям WinFS должны быть рассмотрены следующие сценарии:
○ Требования LOB/MBF/сервера приложений, особенно
учитывающие многоярусное развертывание недирективные O-R-преобразования
○ WinFS Server
Одним из способов направить усилия на эти новые сценарии является построение многочисленных больших хранилищ, одного для каждой области определения. Однако это не является долгосрочной масштабируемой моделью; она также ограничивает гибкость платформы.
1.3.2. Архитектурные проблемы, касающиеся использования WinFS, “как есть”
Фиг.1 показывает текущую архитектуру WinFS.

Фиг.1 WinFS сегодня
WinFS построена в виде монолитного большого хранилища данных. Это приводит к следующим проблемам:
1. Записи и подтипы WinFS не являются уместным уровнем абстракции для моделирования и взаимодействия с отличными от WinFS данными
2. API не является достаточно обобщенным для новых требований
3. Распределение хранилища является негибким: в особенности, есть необходимость в недирективном O-R-преобразовании
4. Функциональная совместимость между LOB и WinFS является маловразумительной
5. Модель многоярусного развертывания является негибкой.
| Заметим, что они не являются проблемами, связанными с проектом WinFS; проект был замечательным касательно того, что имела намерением делать WinFS, каковая должна была быть нацелена на требования Windows-клиента. Проблемы возникают, когда проект пытается достичь нового набора требований LOB. |
1.4 Уровневая архитектура для CDP
Целью платформы данных является поддержать быструю разработку приложений посредством разрешения поддержки многообразия каркасов приложений (например, LOB, конечного пользователя, управления системой). Мы представляем себе приложения, использующие в своих интересах каркасы приложений, платформу данных, и лежащие в основе хранилища для разработки приложений с широкими возможностями. Мы назначаем уровневый подход технической стратегии и следующий чертеж иллюстрирует такое иерархическое представляение для разработки приложений:

Фиг.2: Многоуровневая архитектура
для платформы данных
Уровень хранилища (Store) предусматривает поддержку для основных возможностей (например, масштабируемости, производительности, доступности и безопасности) управления данными; уровень общей платформы данных (CDP) поддерживает обогащенные механизмы модели данных, преобразования, запрашивания и доступа к данным для каркасов приложений; механизмы платформы данных являются расширяемыми так, что многочисленные каркасы приложений могут быть построены на платформе данных; каркасы приложений являются дополнительными моделями и механизмами, специфичными для прикладных областей (например, WinFS для приложений конечного пользователя; MBF для LOB-приложений).
Многоуровневый архитектурный подход имеет некоторые преимущества:
• Предусматривает для каждого уровня возможность независимого и быстрого введения изменений и развертывания
• Уровень платформы данных может быть более гибким, иметь больше свободы для нововведений и может вводить изменения более часто, чем уровень хранилища
• Согласует уровень платформы данных со стратегией компании
• Уровень хранилища может сосредоточиться на основных возможностях управления данными, совместимых со стратегией
1.4.1 Является ли CDP сервером приложений?
Нет, CDP не является сервером приложений. CDP является набором компоновочных узлов платформы данных, которые могут быть размещены на многочисленных ярусах, включающих в себя сервер приложений. CDP, сама по себе, не обеспечивает размещение и среду исполнения для приложений. Она действует в среде размещения, поставляемой приложением, либо сервером приложений, либо сервером базы данных. Мы полагаем, что CDP следует предоставлять службы данных (хранения) и кэша для сервера приложений. CDP с помощью ее тесной интеграции со средой программирования будет предоставлять платформу для разработки логики доступа и манипулирования данными на сервере приложения.
1.5 Что такое единое хранилище или интегрированное хранилище?
Основанная на CDP стратегия описывает уровень платформы данных для разработки приложений. Движущий механизм SQL-сервера и BL-серверы обеспечивают основные возможности управления данными, тогда как уровень UAF (WinFS) предлагает функциональные возможности конечного пользователя/файловой системы. Но до сих пор остается открытым вопрос “что такое единое хранилище или интегрированное хранилище?" Каким образом мы реализуем видение унифицированного хранилища?
Мы полагаем, что совокупность продуктов и механизмов в разделенной на уровни архитектуре, которая описана выше, формирует видение интегрированного хранилища. Движущий механизм SQL Server является ядром интегрированного хранилища (Integrated Store). Вокруг этого ядра выстраиваются другие платформы и каркасы например, BL-серверы, общая платформа данных и WinFS. Ядро SQL Server, наряду с другими платформами и каркасами, формирует интегрированное хранилище.
Вместо построения интегрированного хранилища в монолитном стиле (посредством вталкивания платформы данных и других каркасов в движущий механизм SQL Server) мы предполагаем многоуровневую архитектуру, как описано выше. Многоуровневый подход к интегрированному хранилищу не только привносит архитектурные преимущества, он также обладает некоторыми преимуществами исполнения.
2. ОБЗОР ОБЩЕЙ ПЛАТФОРМЫ ДАННЫХ
2.1 Признаки CDP
Первичная задача CDP заключается в том, чтобы предоставить общую платформу разработки приложений (постольку поскольку рассматриваются осведомленные о данных приложения) по разным прикладным областям - WinFS, LOB и т.д. Чтобы быть эффективной платформой данных, CDP должна обладать признаками, такими как интеграция языка программирования, обогащенное моделирование данных, каркас устойчивости, службы и так далее. Быть агностическим по отношению к области определения подразумевает, что платформа должна делать абсолютный минимум предположений о природе и конфигурации данных, а также семантических ограничениях, требуемых по ним. Для этой цели CDP предусматривает следующие признаки:
1. Общая модель данных: В центре CDP находится общая модель данных (CDM). Цель CDM состоит в том, чтобы факторизовать концепции моделирования, общие по многочисленным прикладным областям, от приложений, работающих главным образом с пользовательскими данными (PIM, документами и т.д.), до данных LOB и предприятия.
2. Интеграция языков программирования, включающая в себя язык запросов: Основные признаки CDP - сеансы, транзакции, запрос, устойчивость, курсоры и т.д. - инкапсулированы в несколько «исполняемых» классов, имеющихся в распоряжении в API (например, StorageContext (контекста хранения)) CDP.
На основании типов, созданных в CDM, инструментальные средства среды разработки CDP формируют строго типизированные CLR-классы. CDP определяет язык запросов (названный общим языком запросов или CQL) над системой типов CDM. CQL дает возможность обогащенных запросов в отношении объектных структур, с которыми работает программист. Задача состоит в том, чтобы согласовать CQL с работой операторов последовательности (Sequence Operators), создаваемых группой C# (выбранной на время действия Orcas).
Эти признаки эффективно предоставляют строго типизированную, основанную на объектах абстракцию в отношении данных, хранимых в RDBMS (или любом другом задействованном CDP хранилище).
Более того, CDP-каркас устойчивости может быть использован, чтобы делать долговременно устойчивыми и запрашивать обычные прежние CLR-объекты (POCO).
3. Объектно-реляционные преобразования. Так как CDP предусматривает основанную на объектах абстракцию поверх реляционного (табличного) хранения, ей требуется предусмотреть компонент O-R-преобразования. CDP поддерживает как директивные преобразования (CDP решает, каким образом происходит преобразование), так и недирективные преобразования (разрабочик типов задает преобразования).
Заметим, что WinFS-реализация в наши дни использует директивные преобразования, в то время как обычные O-R-каркасы устойчивости (например, SlimOS) нуждаются в недирективных преобразованиях.
4. Ограничения: CDP предоставляет разработчику типов возможность декларативно создавать ограничения. Эти ограничения выполняются в хранилище. Типично, область ограничений CDP охватывает понятия, такие как длина, точность, шкала, значение по умолчанию, проверка и так далее. Эти ограничения принудительно применяются механизмом ограничения CDP во время выполнения.
5. Безопасность: уровень CDP предусматривает модель безопасности для контроля доступа к объектным сущностям в CDP. Она поддерживает аутентификацию Windows-пользователей, авторизацию на уровне объектных сущностей (с раздельными полномочиями для чтения и обновления).
6. Кэширование: CDP-среда исполнения поддерживает в рабочем состоянии кэш результатов запроса (курсоров) и незаверенных обновлений. Мы это называем кэшем сеансов. CDP также предусматривает явный кэш, который дает приложению возможность работать в автономном режиме (разъединения). CDP предусматривает различные гарантии непротиворичивости для данных в явном кэше.
7. Процессор запросов: При осуществлении запроса по отношению к хранилищу, CQL-запросы приводятся в соответствие SQL; однако при осуществлении действий по отношению к явному кэшу CQL-запросы обрабатываются QP-компонентом.
8. Курсоры: CDP предусматривает как однонаправленные, так и прокручиваемые курсоры. Курсоры поддерживают уведомления, многоуровневое группирование с состоянием расширения/сжатия, динамическую сортировку и фильтрацию.
9. Ведущий узел бизнес-логики: CDP предоставляет среду исполнения, чтобы вести бизнес-логику по типам/экземплярам и по операциям.
10. Службы: CDP предоставляет основной набор служб, которые доступны всем CDP-клиентам. Эти службы включают в себя правила, отслеживание изменений, обнаружение конфликтов, формирование событий и уведомления.
Взятые вместе, эти признаки обеспечивают мощную платформу для разработки информационно-централизованных приложений и логики, которые могут быть гибко развернуты на разных ярусах.
2.2 Функциональная архитектура
Фиг.3 показывает архитектурные компоненты общей платформы данных.
| Примечание: Расположение блоков на этой диаграмме не подразумевает (и не обязательно не допускает) любое конкретное развертывание за пределами границ процесса/машины. Оно является схематичной диаграммой, используемой, чтобы показать функциональные компоненты. Смотрите раздел 5 “Развертывание компонентов CDP по ярусам” для вариантов развертывания этих компонентов вне границ процесса и машины. |
CDP состоит из 3 основных компонентов:
1) API CDP: Это предоставляет интерфейс программирования для приложений, использующих CDP, в виде общедоступных классов, интерфейсов и статических вспомогательных функций. Примерами являются: StorageContext (контекст хранения), StorageSearcher (искатель хранения), Entity (объектная сущность), Entity (объектная сущность), TableSet (набор таблиц), Table (таблица), EntityReference (ссылка объектной сущности), TableReference (ссылка таблицы). Интеграция языков программирования баз данных (например, операторов последовательности C#) также являются частью этого уровня.
2) Среда исполнения CDP: Этот уровень реализует различные признаки (смотрите раздел 2.1 “Признаки CDP”), раскрываемые на уровне общедоступного API. Он реализует общую модель данных (CDM) посредством предоставления O-R и запросных преобразований, принудительного применения ограничений модели данных, и т.д. Более точно:
a) Реализацию CDM
b) Процессор запросов
c) Сеансы и транзакции
d) Кэш объектов: кэш сеанса (незаверенных обновлений) и явный кэш
e) Службы
f) Курсоры
g) Ведение бизнес-логики
h) Механизм устойчивости и запросов: Предоставляет основные службы устойчивости и запросов. Неотъемлемыми для служб устойчивости и запросов являются объектно-реляционные преобразования, включающие в себя преобразования запросов/обновлений.
3) Механизм ограничений/безопасности

Фиг.3: Компоненты CDP
2.3 Гибкая реализация
Одним из ключевых преимуществ архитектуры CDP является то, что она обеспечивает гибкость в реализации. Это означает две вещи:
1) Некоторые из компонентов, показанных на фиг.3, являются «мобильными» в том смысле, что они могут существовать в разных процессах/ярусах. Более точно, механизм ограничений/безопасности типично существует в процессе хранилища.
2) Не всем компонентам, показанным на фиг.3, требуется быть реализованными для того, чтобы иметь в распоряжении полностью функционирующую платформу данных. Более точно, мы полагаем, что:
a) Наиболее вероятно, кэш объектов будет состоять только из кэша сеанса во временном интервале 07. Будущие усовершенствования будут включать в себя явный кэш, который будет синхронизирован с хранилищем.
b) Процессор запросов, который будет оперировать объектами в кэше объектов, может не быть реализованным во временном интервале 07.
c) Выпуск 07 может выпускаться с неполным набором служб; будущие выпуски будут добавлять дополнительные службы.
2.4 Поток данных/управления
Является поучительным исследовать взаимодействие различных компонентов в ответ на вызовы методов приложением. Мы будем использовать следующий пример, который автор заимствовал из [WFS-API].

Этот пример добавляет изделие в сделанную устойчивой корзину для покупок. Представьте, что этот метод активизирован в качестве части обработки веб-страницы ASP .NET.
Фиг.4 показывает поток данных в пределах различных компонентов CDP.
Строка 3: Создание контекста хранения
Приложение (1) выполняет этот вызов; API (2) открывает для воздействия класс StorageContext. Код конструктора является частью (3.с). (3.с) открывает соединение с хранилищем (5), выполняет работу, необходимую, чтобы начать сеанс и создать контекст транзакции. Устанавливается (4) контекст безопасности. В заключение, экземпляр StorageContext (контекста хранилища) возвращается API-интерфейсом (2) в (1).
| Вопрос для группы по разработке клиента с расширенными возможностями: В 2-ярусном случае ясно, что получение StorageContext имеет результатом присоединение к хранилищу. 3-ярусное развертывание может потребовать иной ориентации. |
Строка 5: Запрос
Правая сторона выражения в строке 5 является запросом OPath (пути объекта). Механизм устойчивости и запросов (3.g) открывает для воздействия рудиментарный интерфейс, названный IQuery, с методами для извлечения объектов, основанными на запросе CDM. Реализация (3.а) CDM вызывает метод IQuery вместе с заданным OPath. (3.g) преобразует запрос в SQL и отправляет его по сети в виде полезной нагрузки TDS. (4) гарантирует, что безопасность применяется должным образом и что приложение/пользователь видит только те данные, которые им разрешено видеть. (5) выполняет запрос и возвращает результаты обратно в (3). (3.a) и (3.g) совместно работают, чтобы собрать объекты из TDS-результатов, и эти объекты помещаются в кэш (он мог быть размещен в кэше сеанса) (3.b) объектов. Результат всего этого состоит в том, что (2) возвращает объект ShoppingCart (корзины для покупок) в (1).
Строка 7: Запрос
Подобная последовательность операции как в строке 5.
Ни этот запрос, ни предыдущий не привели к созданию какого бы то ни было курсора (они были запросами FindOne() (найти один)). Однако, если запрос требовал, чтобы был создан курсор, то (3.d) должен бы был зафиксировать эти действия.

Фиг.4: Поток данных в пределах CDP-компонентов
Строка 9: Обновление
Объект ShoppingCart (корзины для покупок) в кэше объектов (3.b) обновляется определенным Product (продуктом).
Строка 10: Вырезать изменения
Высший уровень реализации SaveChanges() (сохранить изменения) находится в ведущем узле (3.f) бизнес-логики. На понятийном уровне, это вовлекает следующие этапы:
1. Запускается код проверки действительности; этот код привязывается к событию, определенному API-интерфейсом CDP.
| Примечание: Другая возможность здесь состоит в том, что код проверки действительности мог бы быть привязанным к установщику для объекта. |
2. Запускает код предварительного сохранения, этот код привязывается к событию, определенному API-интерфейсом CDP.
3. Фактически записывает изменения в хранилище. Сначала (3.f) работает с (3.b), чтобы получить вектор изменений, который содержит все изменения, сделанные в пределах этого контекста хранения. Механизм (3.g) устойчивости открывает для воздействия интерфейс, названный IPersist. Это рудиментарный интерфейс с методами, такими как Write(<changeVector>) (Записать<вектор изменений>), и т.д. (3.f) получает IPersist от (3.g) и вызывает IPersist.Write() с вектором изменений. (3.g) преобразует запрос записи в соответствующее SQL-обновление (либо фактический оператор UPDATE, либо вызов хранимой процедуры) и использует это, чтобы записать изменения в хранилище. Во время этой последовательности операций (4) гарантирует, что выполнено соответствующее принудительное применение защиты. Он к тому же запускает всякую ограничительную логику.
4. Запускается код после сохранения, этот код привязан к событию, определенному API-интерфейсом CDP.
| Примечания 1. Заметим, что запуск бизнес-логики может иметь результатом изменения касательно объектов в кэше. Эти изменения делаются устойчивыми в хранилище вызовом myStorageContext.SaveChanges(), который гарантирует, что бизнес-логика не игнорируется. 2. Многочисленные ISV могут пожелать запускать логику по изменениям данных, в каковом случае они привязывают свои обработчики к событию, а обработчики вызываются CLR в порядке FIFO («первым пришел - первым обслужен»). |
3. ДЕТАЛИЗАЦИЯ ПРИЗНАКОВ CDP
В этом разделе мы рассмотрим более подробно некоторые признаки/компоненты в CDP. Заметим, что интерпретация в этом разделе, наряду с большей глубиной, не является исчерпывающей. Где применимо, мы предоставили ссылки на документы, которые обеспечивают исчерпывающую интерпретацию данной темы. Однако, во многих случаях мы ожидаем, что отдельные группы разработчиков конкретизируют детали на основе скелета, представленного здесь (и они будут указаны явным образом).
3.1 Общая модель данных
| Примечание: Дополнительный материал может быть найден в [CDM-REFERENCE]. |
В центре CDP находится общая модель данных (CDM). Цель CDM состоит в том, чтобы факторизовать концепции моделирования, общие по многочисленным прикладным областям, от приложений, работающих главным образом с пользовательскими данными (PIM, документами и т.д.), до данных LOB и предприятия. Вообще, есть два способа становления этого:
1. Моделировать понятия, специфичные для каждой потенциальной (или потенциально важной) области определения. Например, точно определять, что означает "Customer" («Потребитель») (из области определения LOB) и что означает "Person" («Действующее лицо») (из пользовательской области определения), и так далее.
2. Предоставить гибкую основу, поверх которой разработчики приложений могут создавать свои собственные, специфичные области определения типы, ограничения, отношения.
CDM избирает второй подход. Она предоставляет базовый набор типов и определяет гибкий каркас для создания новых типов. В этом смысле, CDM является как моделью данных (т.е. она в действительности описывает определенные типы и их семантику), и так и информационной мета-моделью (т.е она делает возможным специфицирование других моделей).
Ключевые признаки CDM:
1. Модель данных категоризирует реляционную модель данных. Это означает, что понятия таблиц, строк, запросов и обновлений в таблицах раскрываются в CDM.
2. Определяет более богатую объектную абстракцию для данных, чем таблицы и строки. В частности, она делает возможным моделирование артефактов реального мира, таких как объектные сущности, отношения между объектными сущностями, их наследование, включение и коллекции.
3. Минимизирует угрозу несоответствия между структурами приложения и структурами хранения посредством согласования системы типов языка программирования с прикладными абстракциями, моделируемыми в CDM.
4. Поддерживает поведения (например, методы, функции) приложений и гибкое развертывание поведений, чтобы сделать возможными двухъярусные и многоярусные приложения.
5. Фиксирует семантику устойчивости независимо от лежащего в основе физического хранилища.
• Дает возможность CDM быть реализованной посредством
широкого разнообразия хранилищ.
3.1.1 Основные понятия CDM
Сердцевиной общей модели данных являются 4 понятия:
1. Тип объектной сущности (Entity Type): Спецификация разработчика приложений ради группирования свойств и методов. Объектная сущность (Entity) является экземпляром типа объектной сущности. Типы объектной сущности могут быть организованы в иерархии наследования.
2. Таблица (Table) - набор объектных сущностей, которая (потенциально) является свойствами других объектных сущностей. Используя объектные сущности, наследование и таблицы, приложения могут рекурсивно определять иерархии данных. Таблица является строго типизированной в том смысле, что данная таблица может содержать только объектные сущности заданного типа или его подтипов.
3. Набор таблиц (Table set) - объектная сущность, чьими свойствами являются таблицы. Это является основным случаем для рекурсивной иерархии данных, определенной с использованием таблиц и объектных сущностей. Он подобен понятию базы данных.
4. Отношения (Relationships) выражают семантику связей между объектными сущностями. Она может быть расширена, чтобы определять ассоциативные объединения, включения и т.д.
Легко увидеть, каким образом метамодель, вытекающая из этих фундаментальных понятий, может быть использована для разработки специфичных области определения моделей данных.
3.1.2 Схемы и наборы таблиц
Все описания объектной сущности, отношения и набора таблиц присходят в контексте схемы. Основным назначением схемы является определять пространство имен для задания области наименований содержимого, описанного в схеме.
Наборы таблиц образуют “высший уровень” модели данных. Вся память хранилища прямым или косвенным образом выделяется посредством создания набора таблиц. Вот пример:

3.1.3 Объектные сущности
Тип объектной сущности (Entity) содержит свойства и методы. Для задания типов для свойств, параметров методов и возвращаемых методами значений CDM предусматривает несколько встроенных типов:
• Простые типы: Int32 (целочисленный 32-битный), string (строковый), другие CLR-типы значений
• Перечислимые (Enumeration) типы: эквивалентны перечислениям (enums) CLR
• Ссылочные (Reference) типы (обсуждены позже)
• Типы массива (Array): упорядоченная коллекция подставляемых типов (смотрите далее).
Свойства этих встроенных типов могут быть сгруппированы, чтобы сформировать подставляемый тип (Inline Type); подставляемый тип может содержать членов других подставляемых типов. Вот пример:

Объектная сущность построена с использованием встроенных типов и/или подставляемых типов, вот так:

Всякая объектная сущность (за исключением набора таблиц) всегда содержится в пределах таблицы (так как наборы таблиц являются самыми высокоуровневыми организационными единицами, и набор таблиц является состоящим из таблиц). В пределах области таблицы, каждая объектная сущность содержит уникальное ключевое значение. В пределах области в масштабе всего хранилища, каждая объектная сущность обладает уникальной идентичностью - ее ключевое значение рекурентно сцеплено с идентичностью ее таблицы.
Объектная сущность является наименьшей единицей в CDM, пригодной для указания ссылкой по ключу или идентичности. Большинство операций хранения нацеливаются на объектную сущность: сделать устойчивой, сохранить, переместить, скопировать, удалить, переименовать, резервировать, восстановить и т.д. С другой стороны, экземпляр подставляемого типа всецело используется в контексте содержащей объектной сущности.
CDM определяет понятия абстрактного типа объектной сущности, которые подобны абстрактным классам в CLR - они не могут быть непосредственно конкретизированы; от них можно только осуществлять порождение, чтобы создавать другие конкретизируемые типы.
3.1.4 Ссылки объектной сущности
Ссылка объектной сущности является долговременной, устойчивой ссылкой на объектные сущности. Значения ссылок изменяются в пределах идентичностей объектных сущностей. Косвенное указание объектной сущности возвращает ее ссылку; разыменование ссылки возвращает экземпляр объектной сущности.
Основной целью ссылок является сделать возможным совместное использование объектной сущности: например, все заказы для одного и того же потребителя могли бы иметь одно и то же значение для свойства Ref(Customer), поэтому говорится, объектные сущности заказов совместно используют объектную сущность потребителя (смотрите для примера строку 6 кодового примера в следующем разделе).
3.1.5 Отношения
«Отсутствие глубины является островом» («отсутствие информации - тоже информация»)
Любой показательный набор данных реального мира всегда содержит отношения между его составными частями. Это понятие на столько всеобъемлющее, что оно отражено даже в способе, которым мы говорим о данных. Например:
Документ имеет одного или более авторов; сообщение электронной почты имеет набор получателей; деловой контакт содержит 0 или более фотографий, ассоциативно связанных с ним; заказ содержит детализацию заказа; и так далее.
В этом высказывании мы показали данные курсивом и подчеркнули отношения между ними.
Ясно, что понятие отношений является неотъемлемым для любой попытки информационного моделирования. Реляционная модель не поддерживает отношения явным образом; PK/FK/ссылочная целостность предоставляет инструментальные средства для реализации отношений ограниченным образом.
CDM поддерживает явно заданное концептуальное отношение с использованием ассоциаций и композиций. Мы используем следующий пример, чтобы понять их возможности:

Ассоциации
Ассоциации изображают равноправные отношения между объектными сущностями. В вышеприведенном примере заказ связан с потребителем посредством ассоциации. В вышеприведенном примере строка 6 показывает, что каждый заказ имеет ассоциативно связанного потребителя (который задан ссылочным свойством Customer (потребителя)). Природа ассоциации определяется в строках 12-15: они говорят, что ассоциация OrderCustomer (заказ потребителя) является ассоциацией от заказа (Order) к потребителю (Customer) (строка 15); они также говорят, что для каждого потребителя (Customer) (Multiplicity = “1” в строке 14), могут иметь место многочисленные заказы (Orders) (Multiplicity="*" в строке 13).
Тип ассоциации, показанной выше, называется ссылочной ассоциацией, по очевидным причинам. CDM определяет два других типа ассоциаций: Ассоциации значения (Value Associations) и ассоциацию посредством объектных сущностей ассоциации (Association Entities).
Ассоциации значения делают возможным выражение отношений через любое свойство, не только через ссылку идентичности. Например, свойство Document.Author относится к Contact.Name через условие равенства.
Объектные сущности ассоциации делают возможным моделирование отношений, где само отношение несет некоторые данные, например, трудовые отношения между компанией и лицом, могли бы нести свойства, подобные периоду трудоустройства или положению и званию лица в рамках компании.
Композиции
Композиции олицетворяют отношения родитель-потомок или отношения включения. Рассмотрим заказы (Orders) и товары заказов (OrderLines) (например, Order (заказ) является итоговой суммой того, что вы положили в карзину для покупок на сайте amazon.com; OrderLine (товар заказа) является каждым индивидуальным изделием в корзине - книгой, DVD и т.п.). Каждый заказ (OrderLine) имеет смысл только в контексте заказа (Order). Он не обладает и не должен обладать независимым существованием вне содержащего заказа (Order). Другими словами, товар заказа (OrderLine) содержится в заказе (Order), и время его существования определено временем существования заказа (Order).
Такие отношения моделируются с использованием композиций (Composition). Строка 8 показывает пример композиции. Свойство Lines (товары) и композиция OrderOrderLines (строки 18-22) выражают то, что заказ полностью контролирует свои товары и что товары полностью зависят от заказа, который их вмещает. Заказ является родителем, а товары - потомками.
До какой степени композиции отличаются от подставляемых типов? Основным отличием является то, что композиции включают в себя объектные сущности. Это означает, что (в нашем примере) будет допустимым для OrderLine (товара заказа) быть целевым объектом ссылки, тогда как подставляемый тип не может быть.
Свойства навигации
Одно из преимуществ явного моделирования отношений CDM состоит в том, что оно обеспечивает поддержку метаданных для запроса. Мы видели, как ассоциативно связать каждый заказ с соответствующим потребителем с использованием отношений. Но как мы можем решить противоположную задачу: при данном потребителе найти все заказы (без обязанности хранить явные обратные указатели)? Свойство навигации (NavigationProperty) является инструментом CDM для содействия таким восходящим запросам. Это показано в строке 28 кодового фрагмента в разделе 3.1.3, “Entities” (“объектные сущности”) воспроизведены ниже для удобства:

Наша интерпретация отношений была очень краткой. [CDM-REFERENCE] содержит дополнительные подробности.
3.2 Объектно-реляционные преобразования
Абстракции моделирования, доступа и запроса, предоставленные посредством CDP (через CDM, APIG-классы и CQL), являются основанными на объектах. Основной технологией хранения, используемой CDP, является Yukon (или Katmai или SQL 2000 - суть в том, что они все реляционные).
Таким образом, ключевым признаком, предоставленным CDP-платформой, являются O-R-преобразования. Этот компонент приводит классы языка в соответствие лежащему в основе табличному представлению. При рассмотрении O-R-преобразований возможны два случая:
1. Директивные O-R-преобразования: преобразование между CDP-типами и их реляционным представлениям закодировано в CDP жестко. Разработчик типов не имеет в распоряжении гибкости при выборе компоновки лежащих в основе таблиц.
Это в наши дни является реализацией WinFS.
2. Недирективные O-R-преобразования: разработчик имеет в распоряжении переменные степени гибкости, чтобы избирать, каким образом CLR-классы приводятся в соответствие лежащим в основе структурам хранения. Есть два подварианта, которые здесь должны быть рассмотрены:
а. Экспонирование существующей реляционной схемы как объектов. Разработчик типов использует высокоуровневый язык спецификаций, чтобы разрабатывать CDM-типы, инструментальные средства, чтобы вырабатывать классы, основанные на них, и гибкость, чтобы задавать, каким образом типы приводятся в соответствие таблицам.
Этот сценарий происходит, когда CDP-приложения применяются параллельно (в смысле использования одних и тех же данных) с существующими реляционными приложениями. Например, отдел IT (информационных технологий) компании Ford Motor Company имеет в распоряжении LOB-приложение; ему требуется написать CDP-приложение, которое действует на фоне тех же самых данных (вероятно, в качестве части стратегии поэтапного перехода). Но требование заключается в том, чтобы оба, LOB-приложение и новое CDP-приложение, работали вместе по отношению к тем же самым данным.
b. Устойчивость коллекции классов в реляционную схему. Разработчик не использует вырабатываемые классы; предпочтительнее, он использует классы своей собственной разработки. Он желает приводить эти классы в соответствие реляционной схеме.
Есть много разных сценариев, которые формируют это требование. Смотрите [POCO-SCEN] для детального охвата.
Заметим, что к этой категории относятся требования и сценарии SlimOS.
CDP будет обеспечивать директивные и недирективные преобразования.
| Границы недирективного преобразования могут включать в себя, в одной крайности, систему, где разработчик предоставляет некоторые указания во время разработки типа; CDP будет использовать эти указания по своему усмотрению. В другой крайности, разработчик будет явно задавать соответствие между классами/свойствами и таблицами/столбцами. |
3.3 Плоскость программирования
Этот раздел описывает все аспекты плоскости программирования, доступные разработчикам CDP-приложений и программистам. Мы разбиваем эту плоскость на три главные области:
1. Инструментальные средства среды проектирования: Инструментальные средства, чтобы позволить разработчикам типов создавать CDM-типы и их ограничения, вырабатывать CLR-классы из этих типов и добавлять поведение к этим типам.
2. API: Классы и методы для написания CDP-приложений.
3. Query: Язык для запрашивания CDM-объектов (т.е. экземпляров объектных сущностей).
Эти компоненты плоскости программирования работают синергическим образом, чтобы предоставлять строго типизированную, основанную на объектах абстракцию по отношению к лежащим в основе данным хранилища.
3.3.1 Инструментальные средства среды проектирования
CDP обеспечивает декларативный общий язык описания схем (CSDL), аналогичный языку описания данных SQL или описаниям классов C#, для описания типов объектной сущности, отношений между типами объектной сущности и ограничений. Три основных компонента среды проектирования.
1. Генератор API. Разработчик приложения разрабатывает CDM-типы и отношения с использованием CSDL и применяет инструментальное средство среды проектирования CDP, названное APIG (произносится эй-пиг), который вырабатывает частичные CLR-классы, соответствующие этим типам и отношениям. Сформированные APIG классы доступны прикладным программистам в виде сборок и могут быть указаны ссылкой их прикладной программой с помощью C#-оператора using.
Классы, выработанные посредством APIG, до известной степени, являются каноническими классами; они являются непосредственным представлением CDM-типов в пределах прикладной программы. Иногда прикладные классы ограничиваются в их описании - так, как, например, когда приложение использует классы из предварительно написанной библиотеки классов (графического пакета, математического пакета и т.д.). Приложение по-прежнему должно быть способным использовать каркас устойчивости объектов CDP, чтобы долговременно хранить в устойчивом состоянии и запрашивать экземпляры этих классов в хранилище. Мы ссылаемся на такие объекты, как обычные старые CLR-объекты, или POCO. CDP также поддерживает POCO-сценарии.
2. Объектно-реляционное преобразование. Этот компонент CSDL помогает разработчикам приложений объявлять точные, недирективные преобразования между понятиями хранилища, такими как таблицы и разрезы, и CLR-классами. Он также может задавать, каким образом ограничение, определенное в терминах CDM, могло бы быть преобразовано в описательное ограничение, триггер или хранимую процедуру SQL.
3. Поведения. CSDL дает возможность разработчикам приложений определять, какая часть бизнес-логики реализована в виде экземплярных методов, в виде статических функций, в виде хранимых процедур. Он также определяет ярус, где логика может выполняться (например, среда исполнения CDP в противоположность хранилищу).
3.3.2 API CDP
Это является частью плоскости программирования, вплоть до которой пишутся приложения. Он состоит из трех подчастей:
1. Групповой доступ к CDP-данным. Это часть API, которая открывает для воздействия хранилища, сеансы, транзакции (например, StorageContext), службы запросов (например, StorageSearcher), и CRUD-службы (например, SaveChanges).
2. Классы данных CDM. Это набор канонических, независимых от приложения классов, раскрывающих CDM-понятия, такие как объектная сущность (Entity), отношение (Relationship), расширение (Extension) и т.д.
3. Классы данных области определения. Таковыми являются специфичные приложению/каркасу классы, такие как Contact (деловой контакт), Message (сообщение), PurchaseOrderes (заказы на покупку), которые соответствуют CDM, но раскрывают свойства и поведения, специфичные для области определения.
| ● “tables” ("таблицы") могут быть раскрыты через CDP или непосредственно раскрыты как SQL, или раскрыты через упаковщик таблиц объектных сущностей. Это определяет отношение между API CDP и API ADO.NET. ● В одной из реализаций привязка данных может быть частью классов данных области определения. ● В одной из реализаций шаблоны асинхронного CLR-кодирования являются частью плоскости программирования CDM (либо через CDM, либо классы данных области определения). |
3.3.3 Query
CDM также определяет язык запросов, названный Общий язык запросов (CQL). CQL разрабатывается, чтобы сделать возможными обогащенные запросы по отношению к объектным структурам, с которыми работает программист. Мы идентифицировали 3 кандидата в качестве основы для формальной системы CQL:
1. OPath: Язык OPath имеет свои корни в SQL и XPath и был разработан, чтобы быть объектной CLR-версией XPath. Проектирование строится на XPath-понятии выражений пути, чтобы один за другим раскрывать метод разыменования свойств объектов. Проектирование основано на одном простом принципе: разработчики ожидают увидеть коллекции объектов, в качестве основной “структурной” конструкции, в объектно-ориентированном API.
OPath - это формальная POR-система запросов для WinFS.
2. Объектный SQL: Этот подход расширяет язык запросов SQL, чтобы манипулировать номограммами и коллекциями CDM-объектов. Язык запросов Windows (WinQL), SQL-вариант, предназначенный для запрашивания и манипулирования номограммами CLR-объектов, является проектом-кандидатом для расширений, необходимых в SQL.
3. Операторы последовательности C#: Это набор расширений C# для строго типизированного, проверяемого во время компиляции запроса и набора операций, которые могут быть применены к обширному классу переходных или устойчивых коллекций CLR-объектов (например, посредством объектно-реляционных преобразований).
Стратегически подход операторов последовательности C# имеет наибольший смысл для становления каркаса для CQL. Тактически, неясно, могут ли быть доставлены последовательности C# во временной интервал 07.
CQL является языком запросов, а не языком описания данных или обновлений. Создания, обновления, удаления выполняются как объектные операции (оператор new, установщик свойств и т.д.). Компонент O-R-преобразования преобразует эти операции в лежащие в основе DML-операции на SQL.
| В одной из реализаций CQL будет развиваться в последовательности C# неунаследованным образом. Богатая семантика, зафиксированная CDM (например, отношений), может быть усилена посредством CQL. Независимо от того, какая формальная система будет избрана для CQL, CQL-запросы в отношении устойчивых данных, в конечном счете, будут преобразованы в SQL-запросы. Это означает, что CQL и компоненты O-R-преобразования взаимодействуют, чтобы создавать SQL-запрос в отношении хранилища. При последнем, реализуется автономный кэш, CQL может целиком выполняться в CDP. В этом сценарии CDP будет реализовывать ограниченную форму процессора запросов. Динамические запросы (приложения «поздно связанных» запросов, такие как генераторы отчетов) поддерживаются CQL. |
3.3.4 Отношение между типами CDM и плоскостью программирования
(Последующая изящная таксономия более подробно описана в [WINFS-API]).
Понятие “типа” в CDM может быть рассмотрено на 3 разных уровнях:
1. Пространство схемы: Описание типа в CDM-схеме. Они являются исключительно абстрактными типами, в том смысле, что они не материализованы явным образом в пределах любого компонента стека среды исполнения (от приложения, весь путь вниз, до хранилища).
2. Пространство приложения: Представление типов в качестве CLR-классов в пределах API CDP. Всегда есть соответствие 1-1 (один к одному) между типами объектной сущности/подставляемыми в пространстве схемы и классами данных в пространстве приложения. Другими словами, каждый тип объектной сущности и подставляемый тип в CDM-схеме имеет результатом CLR-класс. Часто эти классы автоматически формируются посредством APIG; однако, в случае POCO, разработчик будет явным образом задавать преобразование между CLR-классами и типами в пространстве схемы. Пространство приложения также содержит классы отношений в дополнение к классам для типов объектной сущности и подставляемых типов.
3. Пространство хранения: Формат устойчивости типа в лежащем в основе хранилище. Если хранилище является реляционным хранилищем, то эти типы являются SQL-типами таблиц/UDT/основными. Компонент O-R-преобразования CDP поддерживает схему преобразования, которая предоставляет типам в схеме возможность быть преобразованными в типы в пространстве хранения, например, тип объектной сущности заказа на покупку (Purchase Order) может быть преобразован в таблицу PurchaseOrder в SQL Server.
Язык запросов CDP нацелен на пространство приложения. Это имеет смысл, поскольку разработчик желает осуществлять запрос с использованием тех же самых абстракций, которые он использует для других операций, т.е. объектов и коллекций. Однако, семантика CQL описывается с использованием CDM-абстракций (пространство схемы).
3.4 Ограничения
Почти все данные, когда рассматриваются в пределах большего их семантического контекста, будут ограничены областью определения своего типа в той или иной форме. Таким образом, является очень важным для CDP предусмотреть способ для разработчиков типов и приложений, чтобы выражать эти ограничения.
CSDL может быть использован для создания ограничений декларативно во время разработки типа. Примеры ограничений включают в себя
● Ограничения простого типа, такие как длина, точность, шкала, значение по умолчанию и проверка.
● Ограничения типа массива, такие как ограничения элементов, количество появлений, уникальность и проверка.
● Ограничения свойств
● и т.п.
Эти ограничения принудительно применяются механизмом ограничений CDP во время выполнения.
Заметим, что именно это действие приспосабливания к общей модели данных подразумевает набор ограничений, когда рассматривается с уровня лежащего в основе реляционного хранилища. Например, CDM требует, что "каждая объектная сущность ДОЛЖНА обладать уникальным ключом в пределах области содержащей ее таблицы”. Это транслируется в ограничение уникального ключа на уровне хранилища. Есть несколько других примеров таких ограничений. Особенность здесь в том, что механизм ограничений CDP принудительно применяет два типа ограничений: те, что подразумеваются (и требуются для приспосабливания к) CDM, и те, что созданы разработчиком типа.
В дополнение к декларативным ограничениям, созданным на CSDL, ограничения также могут быть написаны с использованием хранимых процедур SQL Server. Этот способ делает возможным выражение более сложных ограничений, чем допустимые декларативным языком.
3.5 Безопасность
Уровень CDP предусматривает модель безопасности для контроля доступа к объектным сущностям в CDP. Модель безопасности для CDP должна удовлетворять, по меньшей мере, следующим сценариям:
Аутентификация: Модель безопасности должна поддерживать аутентификацию Windows-пользователей. Это включает в себя пользователей в домене, рабочей группе или автономной клиентской машине. Это также включает в себя поддержку аутентификации, основанной как на NTLM, так и на Kerberos.
Авторизация: Модель безопасности CDP должна поддерживать авторизацию безопасности, по меньшей мере, на уровне объектной сущности. Она также должна делать возможным управление раздельными полномочиями для чтения и обновления объектной сущности.
Как минимум, CDP предусматривает, чтобы “свойство” (или набор свойств) объектной сущности рассматривалось в качестве идентификатора защиты объектной сущности. Права доступа объектной сущности определяются функцией, ассоциативно связанной с таблицей, которая принимает идентификатор защиты в качестве параметра. CDP также должна делать возможной раздельную инициализацию пользователей, которые могут изменять идентификатор защиты от пользователей, которые могут изменять остальную часть объектной сущности.
Мы бы предпочли CDP, которая будет поддерживать более общую основанную на ролях модель, которая делает возможными иные полномочия, кроме просто чтения и записи.
3.6 КЭШ
Среда исполнения CDP поддерживает в рабочем состоянии кэш результатов запроса (курсоры) и незаверенных обновлений. Мы называем это кэшем сеанса потому, что он привязан к сеансу - он начинает существовать, когда сеанс создается, и перестает, когда сеанс завершается. Сеанс CDP инкапсулирован в пределах объекта StorageContext. Приложение может конкретизировать различные экземпляры StorageContext, тем самым инициируя многочисленные сеансы, а следовательно, многочисленные кэши сеансов.
CDP также открывает для воздействия другой вид кэша, названный явным кэшем. Явный кэш предоставляет кэш данных из одного или более запросов. Как только данные материализованы в явном кэше, обеспечиваются различные гарантии непротиворечивости данных:
- Только чтение, неаутентично
- Сквозная запись, аутентична
- Автоматическая регенерация посредством внешних уведомлений
Модель программирования и запросов в отношении явного кэша является такой же, как по данным хранилища.
3.7 Курсоры
Курсор является механизмом, который предоставляют набору объектных сущностей данных (здесь мы используем термин «объектная сущность» в обычном смысле этого слова на английском языке, а не в смысле формата CDM), возвращенных из СQL, возможность быть обработанными по одному за раз. Приложение всегда может создавать курсор на результирующем наборе посредством простого копирования полного результирующего набора результатов в память и наложения шаблона прокрутки поверх этой структуры памяти. Однако, повсеместность этого требования и сложность, которая иногда вовлекается в реализацию курсора (особенно, когда учитываются обновления, страничная организация и т.п.), означает, что любая платформа данных, по своей сути, должна предусматривать модель указывания курсором.
CDP предусматривает как однонаправленный курсор, так и курсор прокрутки (значения этих терминов должны быть очевидными, не требуя дополнительного пояснения). В дополнение к базовым функциональным возможностям поиска и прокрутки CDP-курсоры предусматривают следующие признаки:
● нешние уведомления и сопровождение
● Многоуровневое группирование с состоянием расширения/сжатия
● Динамическую сортировку и фильтрацию (также известную под названием “пост-обработки”)
Заметим, что курсоры не являются иным механизмом для задания результирующего набора; результирующие наборы задаются запросами, а курсоры находятся поверх этих запросов.
| В одной из реализаций CDP предусматривает страничную организацию. Автономный курсор (также известный под названием курсор стороны клиента): В этой модели результаты запроса локально сохраняются в кэше (возможно устойчивом); последующие операции над результирующим набором, в том числе, работа с курсором, разбиение на страницы и т.д., выполняются над локальным кэшем. Изменения отправляются в хранилище посредством операции выравнивания. Обогащенные прикладные разрезы данных и виртуальная коллекция записей разреза данных (VVRC). В одной из реализаций это могут быть признаки CDP или признаки UAF (=WinFS). В другой реализации настоящий признак WinFS делится на сегменты по CDP и UAF. |
3.8 CDP-каркасы
CDP является платформой данных, которая предназначена, чтобы быть пригодной для применения по различным специализированным вертикальным областям определения, таким как пользовательские данные, LOB-данные и т.п. CDM обеспечивает агностическую информационную модель области определения, которая является достаточно богатой, чтобы выражать специфические для области определения конструкции и семантику, но в то же время является достаточно общей, чтобы быть пригодной для использования по разным областям определения. Различные признаки CDP основаны на CDM, а следовательно, имеются в распоряжении по приложениям всех областей определения.
Универсум всех приложений, написанных, опираясь на CDP, может быть разделен на 3 класса:
1. Каркасы: Каркас использует механизмы расширяемости, предусмотренные CDP, для того чтобы настраивать CDP для конкретной области определения. Каркас добавляет значение к CDP вместе конкретизацией типов и дополнительными службами. Однако модель программирования, открытая приложению, является CDP-моделью программирования; в частности, приложения по-прежнему используют классы данных, контекст хранения (StorageContext), искатель хранения (StorageSearcher) и CQL. WinFS является примером каркаса поверх CDP, который настроен для области определения пользовательских данных.
2. Вертикальные платформы: Отдельный уровень поверх CDP со своими собственными API-интерфейсами, абстракциями и моделью данных. Он скрывает CDP и открывает полностью разную модель программирования приложениям. Например, приложение, подобное Outlook, могло бы использовать CDP, но открывает модель Outlook-объектов (Outlook Object Model) для своих пользователей (мы не говорим, что Outlook должен быть написан этим способом, а только - что он может).
3. “Обычные” приложения: Как раз CDP-приложение предназначалось для выполнения специального набора задач. Оно не специализируется на каком-либо CDP-типе, и не открывает для воздействия модель программирования, и не использует какой бы то ни было каркас или вертикальную платформу.
Вертикальные платформы и “обычные” приложения являются просто кодами; они могут использовать CDP любым образом, в котором нуждаются без пристрастия и предубеждения. Каркасы являются несколько различными; так как они добавляют значение к CDP без сокрытия его от приложения, они должны придерживаться определенных правил:
1. Модель данных каркаса является идентичной CDM, или является простой, хорошо документированной специализацией CDM. Она может определять новые типы, но эти типы приводятся к окончательному супертипу объектной сущностью (Entity).
2. Каркас может определять дополнительные ограничения по существующему CDM-типу и/или создать новые ограничения с использованием CSDL. Другими словами, ограничения могут выражаться посредством использования методологии CDM для описаний ограничений.
3. Каркасы обычно не раскрывают свой собственный язык запросов; даже если они это делают, он должен быть в дополнение к, а не вместо, CQL.
4. Каркасы обычно не раскрывают своей собственной модели программирования; даже если они это делают, она должна быть в дополнение к, а не вместо, CQL.
5. Каркасы обеспечивают дополнительные специализированные службы сверх CDP. Эти службы могут быть реализованы в качестве бизнес-логики CDP или в качестве дополнительных классов и методов вспомогательного механизма.
Все эти правила имеют намерением гарантировать, что данные, сохраненные в CDP данным каркасом, должны быть доступными всем приложениям, независимо от того, является приложение использующим этот каркас или нет. Фиг.5, приведенная ниже, показывает использование CDP/каркасов разными приложениями:

Фиг.5: CDP-каркасы
Этот чертеж показывает поверх CDP 3 каркаса: UAF (WinFS), совмещенный каркас (такой как WSS) и MBF (LOB-каркас). Данные, принадлежащие к каждому каркасу, показаны тем же цветом, что и прямоугольник (если вы печатаете черным по белому: Item, Contact = UAF, Doc Lib = Collab, Order = MBF) каркаса. Заметим, что все они типизированы конечным супертипом объектной сущности (Entity).
Фиг.5 также показывает 3 приложения: приложение управления деловыми контактами, совмещенное приложение (такое как Outlook) и CRM-приложение. Приложение управления деловыми связями целиком работает с данными из UAF; CRM-приложение работает с данными как из UAF, так и из LOB; и совмещенное приложение работает с данными из всех трех каркасов.
3.9 Ведущий узел бизнес-логики (BL)
Когда многочисленные приложения манипулируют одними и теми же данными, ключевое требование состоит в том, чтобы гарантировать, что данные остаются достоверными, то есть, гарантировании того, что данные соответствуют различным правилам верификации, бизнес-правилам и любым другим системам проверки и баланса, введенным разработчиком типа и/или владельцем данных. Является хорошим для установления допущением, что приложения вообще не являются заслуживающими доверия. Из глупости, злого умысла или просто острой необходимости непредусмотренного использования шаблонов, они пытаются сохранять данные, которые являются недействительными (пример: пользователь вводит 292 в качестве междугородного телефонного кода и приложение сохраняет это. Но 292 является недействительным междугородным телефонным кодом и, следовательно, значение в поле телефонного номера больше не олицетворяет телефонный номер. Другими словами, ему не может быть оказано “доверие” быть телефонным номером). Обычный способ предотвратить это состоит в том, чтобы создавать доверительную границу: некоторую форму из декларативных правил/кода верификации/и т.п. (часто указываемые ссылкой как бизнес-логика) выполняются в отдельном процессе и всегда проверяют каждое изменение данных, сделанное приложением, чтобы “одобрить” изменение. Затем, и только затем, она сохраняет эти изменения в хранилище. Во многих случаях бизнес-логика делает больше, чем проверка-и-одобрение; она также принудительно применяет бизнес-правила, заставляет происходить документооборот, и т.п. (например, когда внесен новый потребитель, сообщение электронной почты должно быть отправлено в отдел проверки кредитов, чтобы гарантировать кредитоспособность).
CDP предусматривает несколько механизмов для создания BL. Эти механизмы могут быть разделены на следующие 5 категорий: ограничения, обработчики событий, статические/экземплярные методы, связываемые поведения, статические служебные методы.
3.9.1 Ограничения
Ими являются декларативные и процедурные ограничения, описанные ранее, в разделе 3.4 «Ограничения». Эти ограничения выполняются в хранилище, прямо возле данных. Таким образом, они находятся в пределах доверительной границы. Ограничения создаются разработчиком типа.
3.9.2 Обработчики событий
Программный API CDP провоцирует некоторые события по операциям изменения данных. Авторы BL могут осуществлять привязку к этим событиям посредством кода обработчика. Например, рассмотрим приложение управления заказами. Каждый раз, когда поступает новый заказ, приложению необходимо убедиться, что стоимость заказа яляется меньшей, чем кредитный лимит, разрешенный для этого потребителя. Эта логика может быть частью кода обработчика событий, который запускается перед тем, как заказ помещается в хранилище.
Вообще говоря, мы различаем 3 типа событий:
1. Верификация: Эти события обеспечивают возможность для заинтересованной стороны проверять предлагаемое значение и подтвердить его действительность.
2. Перед сохранением: Это событие провоцируется только перед сохранением изменений в хранилище. Это является подобным по назначению и поведению триггеру "BEFORE" в SQL Server.
3. После сохранения: Это событие провоцируется после сохранения изменений в хранилище. Это является аналогичным по назначению и поведению триггеру "AFTER " в SQL Server.
Этот тип бизнес-логики работает в CDP и, следовательно, может быть запущен на любом ярусе, на котором развернута CDP. Таким образом, когда она запускается на клиентском ярусе, она может быть обойдена другими приложениями (то есть, она не работает в пределах доверительной границы).
3.9.3 Статические/экземплярные методы
Классы, автоматически сформированные для CDM-типов, являются частичными классами. Разработчик типов может завершить эти частичные классы добавлением к ним дополнительных методов, типично, чтобы реализовать логику, которая имеет смысл для конкретного типа или набора типов. Примеры: person.GetOnlineStatus(), где person (лицо) - экземпляр типа действующего лица (Person); emailAddr.IsValidAddress(), где emailAddr (адрес электронной почты) - экземпляр типа SMTPEmailAddress; и так далее.
По самой своей природе, этот вид BL не является принудительно применимым; например, она находится в зависимости от приложения, чтобы вызывать IsValidAddress(), для гарантирования действительности. Она выполняется на любом ярусе, на котором развернута CDP. Таким образом, она не работает в пределах доверительной границы, когда CDP находится на клиентском ярусе.
3.9.4 Связываемые поведения:
Этот шаблон кодирования предоставляет разработчикам типов возможность создавать точки подключения для сторонних расширений. Классическим примером является тип для сообщения электронной почты. Разные программы электронной почты могут быть запущены на данной машине. Каждой программе требуется использовать общий тип Message, но каждой программе необходимо также настраивать поведение метода SendMessage (отправить сообщение). Разработчик типов совершает это посредством определения базового поведения для метода SendMessage и предоставления третьим сторонам возможности добавить указатель на реализацию.
Связываемые поведения также работают на любом ярусе, на котором развернута CDP. Таким образом, они не работают в пределах доверительной границы, когда CDP находится на клиентском ярусе.
3.9.5 Статические служебные методы
BL, написанная и развернутая на среднем ярусе и вынесенная на клиентский ярус с использованием Indigo - то есть, BL работает как веб-служба на среднем ярусе. Например, рассмотрим службу управления календарем (Calendar Management Service), которая предоставляет такие услуги, как Create Appointment() (создать время встречи), GetFreeBusy() (получить незанятое время) и т.п. Эти службы (“статические служебные методы”) реализованы с использованием CDP, а веб-служба развернута на среднем ярусе. Клиентский ярус содержит модуль доступа веб-службы, который используется приложением, чтобы активизировать эти службы с использованием канала Indigo. (Смотрите раздел 5.2.1 «Выполнение логики приложения на среднем ярусе («веб-служба»)» для подробного разбора).
Эта разновидность BL целиком выполняется на среднем ярусе, и, следовательно, в пределах доверительной границы.
3.10 На каких хранилищах реализован CDP?
Компонентная архитектура делает для CDP возможным оставлять хранилище агностическим до некоторой степени. Признаки CDP, такие как кэш объектов, курсоры, сеансы, транзакции и т.д., используют абстракции уровня CDP. Приведение в соответствие лежащим в основе абстракциям хранения происходит на уровне O-R-преобразования и устойчивости. Посредством перезаписи логики преобразования CDP может быть реализован на различных хранилищах.
CDP начинает реализовыватся поверх SQL Server 2005 (Yukon) и SQL Server Katmai.
4. СОВМЕСТНОЕ ИСПОЛЬЗОВАНИЕ/ВЗАИМОСОВМЕСТИМОСТЬ ДАННЫХ, СЦЕНАРИИ “ЕДИНОГО ХРАНИЛИЩА”
Видение CDP должно быть единственной платформой данных для Windows, которая используется в своих интересах всеми приложениями. Есть много преимуществ по отношению к этой модели: обогащенное моделирование, прозрачность данных и совместное использование данных. В этом разделе мы будем подробно исследовать эти сценарии.
4.1 Сценарии “единого хранилища”
CDM предоставляет гибкую среду моделирования, которая может быть использована, чтобы описывать типы, требуемые разнотипными наборами приложений и сценариев. Например, пользовательские данные (документы, файлы, фотографии, музыка…), LOB-данные (потребители (Customers), заказы (Orders), детализация заказа (Order Details)…), PIM-данные (деловые контакты, сообщения электронной почты, календарь, задания…), все могут быть промоделированы с использованием CDM.
Этот вид обогащенного моделирования, который охватывает структурированные, частично структурированные и неструктурированные данные, а также охватывает вертикальные области определения, делает для одиночного приложения допустимым работать с разными видами данных, используя общие абстракции и язык запросов. Другими словами, CDP может быть использована в качестве «Единого Хранилища».
4.2 Прозрачность данных
Как только мы получили в распоряжение единую платформу данных, которая используется в собственных интересах всеми приложениями (т.е. CDP), данные, сохраненные с использованием CDP, теперь становятся доступными всем приложениям, чтобы оперировать ими (конечно, при условии политик безопасности). Это может показаться приятным для восприятия очевидным утверждением, но есть тонкости, заключенные в нем, которые несут в себе более глубокое толкование.
Рассмотрим ситуацию в наши дни: каждое приложение сохраняет данные в формате, который является непрозрачным любому, кроме самого приложения. Следует привести только два примера: содержимое почтового ящика Outlook является непрозрачным для всех других приложений, кроме Outlook; CRM-приложение имеет замысловатый набор схем, который оно накладывает поверх таблиц, чтобы создать такие абстракции как потребитель (Customer), обстоятельство (Case) и так далее, таким образом делая понятие “Customer” непрозрачным для всех других приложений (разве только они не знают схему, использованную CRM-приложением).
Ясно, что в Outlook есть данные, которые на понятийном уровне являются подобными данным, сохраненным CRM-приложением - очевидным примером является информация делового контакта (Contact). Поскольку говорится о пользователе, Contact является деловым контактом; с его ракурса трудно понять, почему та же самая информация делового контакта (Contact) сохраняется дважды, один раз в CRM и один раз - в почтовом ящике Outlook. Проблемами здесь являются не просто избыточное сохранение, но и все аномалии, которые это предполагают: осуществление обновлений, происходящих в обоих местах, согласование удалений, и гарантирование вставок в обоих местах, и так далее.
Рассмотрим, что происходит, когда оба, Outlook и CRM, надстроены над CDP-хранилищем. С использованием CDM, тип Contact (делового контакта) может быть выведен из типа Entity (объектной сущности), и его структура становится прозрачной и для Outlook, и для CRM. Таким образом, до тех пор пока они договариваются о схеме для типа, разные приложения могут использовать данные друг друга, даже будучи неосведомленными о существовании друг друга. Так как CDP предлагает общую модель запросов, CRM-приложение (для примера) может запрашивать данные делового контакта (Contact) независимо от того, «принадлежит» ему конкретный экземпляр Contact или нет.
4.3 Совместное использование/взаимосовместимость данных
Сочетание обогащенного моделирования, прозрачности данных и архитектуры платформы-каркаса делает возможными многие сценарии совместного использования/взаимосовместимости данных, вовлекающие комбинации многочисленных приложений и каркасов.
| Термин “Совместное использование”, как он здесь используется, означает следующее: приложение может использовать данные, пока они хранятся в CDP, независимо от того, какое именно приложение их сохранило и/или какой именно каркас был использован для их сохранения. |
4.3.1 Многочисленные приложения, одиночный каркас
Фиг.6 показывает общий сценарий WinFS, где многочисленные приложения совместно используют данные, которые, в этом случае, являются набором UAF-типов, производных от Item (изделия) (которое, в свою очередь, является производным от Entity (объектной сущности)).

Фиг.6. Совместное использование: Многочисленные приложения, использующие одиночный каркас
Не делается никаких заявлений, также не налагается никаких ограничений, относительно яруса, на котором находится приложение/CDP/UAF. Например, одно из приложений на вышеприведенном изображении могло бы быть WSS, которое типично могло бы работать на среднем ярусе.
4.3.2 Одиночное приложение, многочисленные каркасы
Фиг.7 показывает CRM-приложение, которое изначально написано посредством LOB-каркаса, но использует данные делового контакта (Contact) из UAF-каркаса. CRM-приложение, при использовании данных UAF, использует абстракции уровня CDP. Это не является необходимым для использования методов UAF.

Фиг.7. Совместное использование:
одиночное приложение использует многочисленные каркасы
Хотя мы показали CRM-приложение (которое типично размещается на среднем ярусе), приложение может находиться на любом ярусе.
4.3.3 Многочисленные приложения, многочисленные каркасы
Это обобщение двух случаев, приведенных выше. Фиг.8 показывает 3 каркаса поверх CDP и 3 приложения, которые используют сочетание программирования уровня каркаса и уровня CDP.
Пронумерованные стрелки на чертеже показывают разные пути, по которым эти приложения взаимодействуют с данными:
(1) Приложение управления деловыми контактами использует CQL, чтобы запрашивать Contact (деловой контакт); оно использует методы UAF, такие как Item Level Move (перемещение уровня изделия), Copy (копирования), contact.GetBestEAddress(), и т.д. Оно также использует основные классы среды исполнения CDP - StorageContext, StorageSearcher и классы данных CDP (класс Contact и ассоциативно связанные получатели и установщики).
(2, 3, 4) Совмещенное (Collab) приложение использует CQL, чтобы запрашивать деловые контакты (Contact), любые документы в библиотеке документов (Doc Library) и даже возможно заказы (Order). Нет необходимости знать о существовании UAF или MBF, чтобы произвести эти запросы - они создаются исключительно на уровне CDP без использования какого-либо специального кода, записанного согласно другим каркасам. Оно использует операции, специфичные каркасу Collab, чтобы манипулировать библиотекой документов (Doc Library) (такой, как /Add/Document>ToDocLib(<document>, <docLib>), и т.д.).
Оно также использует классы уровня CDP, такие как StorageContext (контекст хранения), StorageSearcher (искатель хранения), Contact (деловой контакт), Order (заказ), DocLibrary (библиотека документов) и ассоциативно связанные получатели и установщики.

Фиг.8. Совместное использование:
многочисленные приложения, многочисленные каркасы
(5, 6) CRM-приложение использует CQL, чтобы запрашивать все заказы (Order) по данному деловому контакту (Contact); отметим, что можно сделать этот запрос без какого-либо знания, что деловой контакт (Contact) фактически был создан с использованием UAF. Оно манипулирует заказами (Order), используя методы и службы, предусмотренные MBF (такие, как FindShipSfatus(<order>) (найти состояние отгрузки (<заказа>))). Оно также использует классы уровня CDP, такие как StorageContext (контекст хранения), StorageSearcher (искатель хранилища), Contact (деловой контакт), Order (заказ), и ассоциированные получатели и установщики.
4.3.4 Совместное использование с отличными от CDP хранилищами
CDP не содействует модели поставщика, вследствие чего произвольные источники данных могут могут появляться в качестве хранилищ CDP. Когда приложению CDP/каркаса требуется работать с данными в отличном от CDP хранилище, оно имеет два варианта выбора:
1. Использовать архитектуру Sync Adapter (которая является частью UAF), чтобы синхронизировать эти данные в хранилище CDP.
2. Построить заказную логику для интеграции с отличным от CDP хранилищем (иначе называемом «вы - на вашем собственном»).
5. РАЗВЕРТЫВАНИЕ CDP-КОМПОНЕНТОВ ПО ЯРУСАМ
Различные компоненты, которые содержит CDP, являются, до известной степени, мобильными. С определенными ограничениями, они могут быть развернуты вне разных границ процессов и машин, имея в результате 2-ярусную, 3-ярусную и n-ярусную конфигурации.
5.1 Двухъярусное развертывание
В этой конфигурации API CDP и среда исполнения CDP - обе в процессе приложения. Механизм ограничения и хранилище находятся в разных процессах и/или разных машинах. Это показано на фиг.9.

Фиг.9. Двухъярусное развертывание
Заметим, что модуль «ограничений/безопасности» размещен в процессе хранилища, в то время как остальные компоненты CDP находятся в процессе клиента. Это то, что мы имели в виду ранее, когда говорили, что CDP-компоненты могут рассматриваться мобильными.
5.1.1 Двухъярусное развертывание с совместно используемыми данными
С базовой моделью процесса, показанного на фиг.9, мы можем представить себе три типа двухъярусных конфигураций. Первая конфигурация, обсужденная в этом разделе, имеет место, когда многочисленные приложения совместно используют одни и те же данные. Это не означает, что приложение должно совместно использовать данные; скорее, оно говорит, что любые данные приложений доступны другим приложениям. Заметим также, что мы говорим о приложениях, а не пользователях, поскольку это отлично от понятия мандата пользователя. Модуль безопасности среды исполнения CDP (4 на фиг.4) будет обрабатывать это независимо от приложения.
Эта конфигурация показана ниже, на фиг.10.

Фиг.10. Двухъярусное развертывание,
совместное использование данных
Эта конфигурация очень важна во многих пользовательских сценариях; например, это краеугольный камень в видении WinFS схематизированных данных пользователя, которые могут быть использованы в своих интересах ISV-поставщиками, чтобы построить интеллектуальное, сведущее в данных приложение. Проект М (иначе называемый Milk-shake (Молочный коктейль)), известный также под названием The New Shell (новая командная оболочка), полагается на это, чтобы завершить свое видение существования универсальной канвы для всех данных пользователя.
Это первичная конфигурация, поддерживаемая CDF. Текущая реализация WinFS следует этой модели.
5.1.2 Двухъярусное развертывание с закрытыми данными
Вторая конфигурация - когда приложение содержит приватные (закрытые) данные, просмотра которых другими приложениями оно не желает. Это показано на фиг.11.
Есть много пользовательских сценариев и сценариев ISV, которые требуют понятие приватных данных приложения. Например, если приложение решает сохранить свои конфигурационные данные (имеем в виду эквиваленты файла инициализации) в WinFS, является очень желательным для таковых быть приватными для приложения. Часто, есть требования по частичной приватности - чтения разрешены, но записи - нет.
Например, Outlook мог бы не обращать внимание на Shell (Проект М), являющийся способным отображать его почтовый ящик, но мог бы только сам желать иметь право осуществлять модификацию почтового ящика.
В 2-ярусном развертывании CDP имеет ограниченную поддержку для этой конфигурации. Нет рациональной поддержки для безопасности уровня приложения в хранилище SQL Server; следовательно, нет способа, чтобы отметить часть данных как приватные для данного приложения, в буквальном смысле предотвращения доступа к данным. Однако эта ситуация может быть частично обеспечена следующими способами:
• Приложение использует свои собственные типы и помещает свои типы в отдельное пространство имен и создает приватные сборки для классов данных, происходящих от таких типов. Поскольку весь доступ уровня CDP к данным экземпляра, принадлежащим этой схеме, происходит через эти сборки, другие приложения не будут иметь доступа к соответствующим классам.
• Приложение создает свое собственное приватное CDP-хранилище (хотя мы не определили понятие “объем CDP”, должно быть ясно из контекста, что мы имели в виду: набор объектных сущностей в CDP, по которым может быть создан StorageContext (контекст хранения)), чье наименование не публикуется для других приложений.
• Посредством документирования.
Приложение может избрать некоторые или все способы, чтобы обладать приватными данными.
| Важно отметить, что архитектура CDP сама по себе не создает препятствие в направлении реализации истинного понятия частных данных. Таким образом, является возможным, что когда безопасность уровня приложения становится доступной в лежащей в основе платформе, CDP может легко открыть ее для использования. |
Заметим, что во многих случаях «требование приватных данных» возникает не из-за истинной необходимости ограничить область, но из-за необходимости принудительно применять специфичную приложению бизнес-логику к данным. Например, локальные почтовые ящики, созданные посредством Outlook, имеют папку Calendar (календарь); правило заключается в том, что только элементы календаря могут быть размещены в этой папке. Outlook не заботится о том, может другое приложение (такое как Eudora) видеть/изменять его почтовый ящик или нет, до тех пор пока принудительно применяется это правило. Архитектура CDP обеспечивает принудительное применение всей бизнес-логики, пока все приложения проходят уровень CDP.

Фиг.11. Двухъярусное развертывание, приватные данные
| Примечание: Приватные данные приложения поддерживаются в 3-ярусном развертывании, потому что это может осуществлять средний ярус. |
5.1.3 Прямой доступ к хранилищу
Третья конфигурация из интересующих имеет место в случае, когда другое приложение осуществляет доступ непосредственно к хранилищу. Это показано ниже, на фиг.12. Приложение 2 осуществляет доступ непосредственно к SQL-хранилищу, возможно, через ADO.NET, или другой API доступа к данным (мы, несомненно, имеем в распоряжении достаточное их количество для того, чтобы появиться списку некоторого размера!)
Это важный сценарий, и для CDP желательно быть построенной так, чтобы делать его возможным. Например, является маловероятным, чтобы крупные IT-магазины, которые содержат сложившиеся SQL-приложения, отбросили их и двинулись всей массой к основанному на CDP приложению. Скорее, они будут мигрировать к CDP на постепенной основе. До тех пор пока отсутствие времени простоя и стабильность являются ключевыми вопросами в производственной среде, вероятно, что CDP-приложения будут продолжать работать рядом с SQL-приложениями в течение некоторого времени. Так как CDP предлагает гибкое, недирективное O-R-преобразование, CDP-приложение может быть использовано поверх сложившейся схемы.
Архитектура CDP, естественно, делает возможным прямой SQL-доступ. Это происходит потому, что “Данные Приложения 1” являются просто набором таблиц и нет ничего, чтобы устранить Приложение 2 от доступа к ним непосредственным образом до тех пор, пока оно имеет надлежащие полномочия.

Фиг.12. Двухъярусное развертывание,
прямой доступ к хранилищу
Отметим следующие последствия для приложения 2:
1) Оно не имеет доступа к CDP-службам (или любым службам, построенным посредством каркаса поверх CDP).
2) А именно, оно не имеет в распоряжении преимущества CDP - значит, оно должно вычислять табличное представление и выдавать запросы/обновления прямо на этом уровне.
Отметим следующие последствия для приложения 1:
1) Бизнес-логика в BL-службе(ах) фактически обойдена приложением 2.
2) Некоторые ограничения - т.е. те, которые не реализованы в качестве тригеров/DRI (декларативной целостности ссылочных данных), также обойдены приложением 2.
В этом конкретном развертывании ответственность разработчиков приложения/администраторов внедрения - убедиться, что приложение 2 имеет свою собственную логику, чтобы принудительно применять ограничения, и т.д., с тем, чтобы происходили правильные вещи.
5.2 Трехъярусное развертывание
Компоненты CDP могут быть развернуты в 3-ярусной конфигурации. В этой конфигурации среда исполнения CDP представлена на обоих, клиентском и среднем, ярусах. Приложение располагается на клиентском ярусе, а хранилище располагается на серверном ярусе. Логика (есть два претендента на термин «логика приложения» на фиг.7: Первым является прямоугольник, помеченный «Клиент» - прямоугольник 1. Вторым являются оранжевые прямоугольники (7, 8, и окружности внутри 3.f). Несмотря на то, что "Клиент", несомненно, является приложением и поэтому логика, содержащаяся в нем, может быть обоснованно названа как «Логика приложения», это не является тем, на что мы ссылаемся. Взамен, мы ссылаемся на логику, содержащуюся внутри оранжевых прямоугольников. Это код, написанный ISV-поставщиком, и предназначен, чтобы быть развернутым на среднем ярусе, таким образом, в весьма действительном смысле, это - среднеярусное «приложение») приложения может находиться на обоих, клиентском и среднем, ярусах. В зависимости от того, где работает логика приложения, есть несколько возможных сценариев, которые мы будем рассматривать ниже.
До перехода к рассмотрению сценариев мы отметим, что тема многоярусного развертывания тесно связана со способами, которыми действия приложений подвергаются удаленному взаимодействию через ярусы. Мы используем термин «удаленное взаимодействие», чтобы охватить следующие три общих подхода к удаленному взаимодействию операций уровня приложения или уровня CDP-службы через ярусы:
1. Удаленное взаимодействие уровня приложения посредством веб-служб: в этом сценарии логика приложения находится в среднем ярусе и открыта клиенту в качестве удаленных статических методов. Это обсуждено в подробно в разделе 5.2.1 «Функционирование логики приложения на среднем ярусе («Веб-служба»)».
2. Неявное удаленное взаимодействие вызова CDP-службы: Вызовы API CDP такие, как FindAll(), FindOne(), SaveChanges(), неявно отправляются на средний ярус через агента удаленного взаимодействия и компоненты службы удаленного взаимодействия. Эта архитектура описана в разделе 5.2.1.1 «Сервис-ориентированная архитектура для удаленного взаимодействия». Дальнейшие разделы содержат примеры, которые описывают, как это работает.
3. Явно заданное автономное удаленное взаимодействие: API CDP определяет программный шаблон, посредством которого приложение явно определяет, когда должны происходить пересекающие ярусы операции. Если эта операция имеет результатом извлечение данных, то возвращенные данные кэшируются на клиентском ярусе. Этот образец обычно упоминается, как «автономный режим». Это описано в разделе 5.2.3 «Режим разъединения».
5.2.1 Функционирование логики приложения на среднем ярусе («Веб-служба»)
Первичный сценарий для среднеярусного развертывания является случаем, где логика приложения запускается исключительно на среднем ярусе, клиент активизирует эту логику посредством механизма веб-службы. Это показано далее, на фиг.13.

Фиг.13. Трехъярусное развертывание
| Хотя мы показали механизм безопасности (порт у (4) на серверном ярусе в нижней части фиг.13), он может вестись на среднем ярусе CDP-процесса. |
5.2.1.1 Сервис-ориентированная архитектура для удаленного взаимодействия
В 2-ярусном развертывании вызовы CDP были обработаны средой исполнения CDP в пределах клиентского процесса; среда исполнения осуществляла связь с сервером при необходимости. В 3-ярусном развертывании это больше не является вариантом выбора. Некоторые вызовы CDP обрабатываются локально (Клиентский ярус), а некоторые обрабатываются удаленно (Средний ярус). А оставшиеся остальные обрабатываются в обоих местах. Таким образом, является существенным для 3-ярусного развертывания определять способ для удаленного взаимодействия соответствующих вызовов.
Это делается посредством определения компонента Агента удаленного взаимодействия (Remoting Agent) в клиенте. Этот компонент использует канал Indigo, чтобы упаковывать и отправлять запросы в CDP на среднем ярусе (это реальное действие вызова удаленной процедуры). На среднем ярусе находится Служба удаленного взаимодействия (Remoting Service), которая, достаточно уместно, обслуживает эти запросы. Этот шаблон является частью того, что обычно известно как Сервис-ориентированная архитектура (SOA). Ключевой характеристикой SOA является то, что разные ярусы взаимодействуют друг с другом посредством обмена сообщениями. CDP использует инфраструктуру Indigo для этой цели.
Служба удаленного взаимодействия предоставляет очень простой набор ориентированных на данные служб - такой, как «выполнить запрос», «вставить», «удалить», «обновить», «создать», «сохранить», «получить Объект, заданный ключом», «получить корневой ключ». В поддержание парадигмы SOA, эти операции являются вербальными командами в пределах SOAP-сообщения. Любое действие, которое клиентскому ярусу требуется иметь выполненным в среднем ярусе, выражено в терминах этих простых вербальных команд. Эти основные вербальные команды передачи сообщений абстрагированы в методы на 2 интерфейса с использованием возможностей, обеспечиваемых Indigo; фактически, есть интерфейсы IPersist и IQuery, с которыми мы встречались ранее в разделе 2.4 «Поток данных/управления». Так, агент удаленного взаимодействия и служба удаленного взаимодействия совместно действуют в качестве конечных точек в канале Indigo, чтобы осуществлять удаленное взаимодействие методов интерфейсов IPersist и IQuery.
Примечание: Методы в IQuery и IPersist являются «грубыми» в следующем смысле: они могут быть использованы, чтобы осуществлять запрос или выполнять операцию над большим набором объектов. Например: в ответ на метод SaveChanges() (сохранить изменения), агент удаленного взаимодействия однократно выдает IPersist.Write() службе удаленного взаимодействия с полным набором помеченных флажком изменения объектов. Таким образом, интерфейс между клиентом и средним ярусом является ориентированным на большие объемы и не склонным к детализации.
5.2.1.2 Поток данных/управления через ярусы
Мы будем использовать следующий пример кода, чтобы изучить поток данных/управления через разные модули, показанные на фиг.13, в ответ на вызовы метода. Мы будем использовать следующий кодовый фрагмент в качестве основы для этого изучения:

В этом примере приложение запрашивает совместно используемый календарь для Анила Нори в интранет (локальной сети, основанной на технологях сети Интернет), чтобы получить календарную запись на 29 октября 2004 года, 9 утра. Таковые представлены объектом ScheduleEntry (запись расписания), который является типом, производным от Entity (ScheduleEntry является частью PIM-схемы WinFS и представляет пункт пользовательского расписания) (объектной сущности). Он модифицирует ScheduleEntry - прилагает текст "[important, please come!]" [важно, пожалуйста, зайди!] к заголовку предписания. Затем он активизирует метод CreateAppointment (создать предписание) в веб-службе (называемой ScheduleService (служба расписания)), чтобы поместить этот измененный ScheduleEntry в совместно используемый календарь Pedro Celis.
Этот кодовый фрагмент иллюстрирует несколько ключевых моментов при 3-ярусном развертывании:
1. Клиент использует локальную среду исполнения CDP, чтобы запросить объектные сущности хранилища. Запросы выполняются на среднем ярусе.
2. Результаты запроса находятся в кэше сеанса клиентского яруса CDP.
3. Полная «логика приложения», в том числе бизнес-логика, верификация и т.д., выполняется в среднем ярусе посредством веб-службы и CDP-механизмом ведения BL. Эта обработка запускается вызовом метода CreateAppointment().
Далее мы изучим поток данных/управления более подробно.
Строка 1: Создание контекста хранения
Клиент (1) производит этот вызов; API (2 на клиентском ярусе) открывает для воздействия класс StorageContext. Код конструктора является частью (3 на клиентском ярусе).
| Открытие StorageContext может иметь результатом любые вызовы в Средний ярус или серверные ярусы. Если, однако, это не происходит, то это может означать, что аутентичный контекст безопасности не устанавливается до тех пор, пока не выполнен первый запрос (или другая «пересекающая ярусы операция»). |
Строка 2: Запрос
Правая сторона выражения в строке 2 является OPath-запросом. Запрос возвращается самое большее с одним объектом ScheduleEntry - первой (допустим, что существует точное описание «первой записи» ([OPATH] дает дополнительные подробности касательно этого)) записью на 9 утра 10/29/04. Среда исполнения CDP (3 на клиентском ярусе) получает интерфейс IQuery у агента удаленного взаимодействия (3.а на клиентском ярусе) и вызывает ExecuteQuery(<Opath>) в нем. (3.a) использует канал Indigo и отправляет этот запрос службе удаленного взаимодействия (9 на среднем ярусе). Запрос преобразуется и выполняется точно так же, как в двухъярусном случае, а результаты возвращаются на клиентский ярус. Здесь есть две возможности:
1. Результаты TDS-строки возвращаются со среднего яруса на клиентский ярус без выделения объектов. (3 на клиентском ярусе) затем выделяет объекты.
1. Если эти объекты уже существуют в кэше объектов (3.b среднего яруса), выделенные объекты возвращаются на клиентский ярус.
| Немногословный интерфейс: Заметим, что полный OPath-запрос отправляется через канал Indigo. Например, если запрос был «Найти все объекты типа ScheduleEntry» (то есть, активизацией метода FindAll()), то этот полный запрос будет отправлен в (6 на среднем ярусе) в одном SOAP-сообщении - а не по одному сообщению на каждый объект. |
Строка 3: Манипулирование кэшем объектов клиентского яруса
Как только объект ScheduleEntry возвращен на клиентский ярус, он доступен для дополнительных манипуляций в пределах кэша сеанса (3 на клиентском ярусе). Когда (1) изменяет свойство DisplayName объекта ScheduleEntry, это обрабатывается полностью посредством (3 на клиентском ярусе).
Строка 4: Выполнение операции New над модулем доступа веб-службы на клиентском ярусе
Предположительно (1) уже добавил ссылку к соответствующему asmx (или эквиваленту Indigo) во время периода проектирования. Строка 4 просто создает экземпляр объекта модуля доступа службы веб в клиенте. Этот вызов полностью обслуживается модулем доступа веб-службы (7).
Строка 5: Вызов метода веб-службы
CreateAppointment() - один из методов, подвергнутых удаленному взаимодействию веб-службой (8 на среднем ярусе). Этот метод принимает объект ScheduleEntry и строку связи CDP; он использует эту информацию, чтобы создать объект ScheduleEntry в пределах StorageContext, определенного строкой связи. Неотъемлемой в пределах этой операции записи является работа соответствующей бизнес-логики и логики верификации.
Этот метод упакован модулем доступа веб-службы (7) и отправлен посредством SOAP-сообщения через канал Indigo веб-службе (8) на среднем ярусе. Веб-служба реализует этот метод посредством вызовов API CDP ((2) на среднем ярусе) точно так же, как если бы она была любым другим приложением. Ключевым моментом, который следует здесь отметить, является то, что полная логика для CreateAppointment() работает на среднем ярусе.
5.2.2 Функционирование логики приложения на обоих, клиентском и среднем, ярусах
Фиг.13 показывает 3-ярусное использование, где логика приложения была запущена полностью на среднем ярусе. Иногда желательно запускать логику приложения на обоих, клиентском и среднем, ярусах. Фиг.14 - пример этого развертывания.
5.2.2.1 Поток данных/управления через ярусы
Мы изучим поток данных/управления через разные компоненты и ярусы в ответ на вызовы методов. Мы будем использовать тот же самый пример, как мы делали в разделе 2.4 «Поток данных/управления», который мы воспроизвели ниже в целях удобства.

Line 3: Создание контекста хранения
Строка 5, Строка 7: Запрос
Строка 9: Обновление
Поток данных/управления для этих 3 строк идентичен тому, что описан в разделе 5.2.1.2 «Поток данных/управления через ярусы».
Строка 10: Вырезать изменения
Мы должны рассмотреть здесь две возможности:
1. BL запущен на обоих, клиентском ярусе и среднем ярусе: В этом случае ведущий узел (3.f) бизнес-логики на клиентском ярусе запускает логику верификации и предварительного сохранения и вызывает агента (3.h) удаленного взаимодействия на клиентском ярусе с IPersist.Write(<change vector>). (3.h) отправляет вызов cлужбе удаленного взаимодействия (6) на среднем ярусе. (6) метит флажком кэш (3.b) объектов на среднем ярусе и вызывает SaveChanges(). Таковой запускает этапы BL и устойчивости, как описано выше, и осуществляет возврат в (6); (6) затем осуществляет возврат в (3.h) на клиентском ярусе, который, в свою очередь, осуществляет возврат обратно в (3.f). Логика после сохранения клиентской стороны посредством (3.f) не выполняется.
2. BL работает только на среднем ярусе. В этом случае (3.f) немедленно пересылает вызов в (3.h), который, в свою очередь, пересылает его в (6). Обработка происходит на среднем ярусе, как описано выше.
Преимущество выполнения BL на обоих ярусах заключается в том, что в случае ошибок в логике верификации предварительного сохранения они могут быть перехвачены на клиентском ярусе без необходимости проходить через затраты присоединения к среднему ярусу.
5.2.2.2 Применение «локального хранилища»
Впечатление однородности автономного режима является одной из целей WinFS. Это требует локального хранилища, которое синхронизирует данные с удаленным хранилищем. Прямоугольник справа на фиг.14 показывает это «локальное хранилище». В этом случае локальное хранилище находится на той же машине, но в другом процессе (который, по нашему определению, является еще 2-ярусным развертыванием). Так как модель программирования для 3-ярусного и 2-ярусного развертывания симметричны, для такой синхронизации обслуживания является легким выполнять операции между локальным хранилищем и средним ярусом и поддерживать данные в синхронизме.

Фиг.14. Трехъярусное развертывание с логикой
на клиенте и средних ярусах
5.2.3 Автономный режим
Рассмотрим строку 2 в примере кода, показанного в разделе 5.2.1.2 «Поток данных/управления через ярусы». Запрос имел результатом пересекающую ярусы операцию. В этом конкретном примере был только один возвращенный объект (объект ScheduleEntry). Вообще, однако, он может потенциально возвращать очень большой результирующий набор. Подобные комментарии применяются к строке 5 примера кода в разделе 5.2.2.1. Есть два вопроса, которые должны быть здесь рассмотрены, которые особенно уместны при 3-ярусном развертывании.
• Пересечение яруса является потенциально дорогостоящим, а следовательно, не должно происходить неявно: Нет явно заданного указания в строке 2, что это будет иметь результатом операцию пересечения яруса - другими словами, привлечено «волшебство». «Волшебство» использовано здесь в том смысле, что что-то происходит без извещения меня (приложения) об этом или наличия возможности управлять его происхождением. Очень часто волшебство является добро; действительно, целью большей части программного обеспечения является скрыть лежащую в основе сложность и сделать вещи происходящими «как будто по волшебству». Однако, в этом конкретном случае, долгий опыт показал, что составители приложений волей-неволей отправляют огромные запросы, полагая, что код снизу каким-то образом вернет большое количество данных без засорения сети и нагрузки на сервер. Является испытанной парадигма разработки, что любое волшебство пресечения яруса должно быть сделано явным образом для приложения, тем самым поощряя благоразумные правила кодирования (мне ДЕЙСТВИТЕЛЬНО нужно «выбирать* из <таблицы-в-миллион-строк>»)? Может быть, я могу использовать оператор ГДЕ (WHERE)…)
• Кэширование на стороне клиента и операция без состояния: Вопреки попыткам в разумном кодировании, есть моменты, когда приложению нужно работать с (потенциально большим) набором данных; часто, ему известно, чем является этот набор данных. Чтобы оптимизировать доступ к данным в таких случаях, приложение должно иметь возможность запускать запрос, выбирать (потенциально большой) набор данных и помещать его локально в кэш. Дополнительные запросы/сортировка/фильтрация/изменения производятся с локальной копией данных. В заключение, операция вырезки записывает изменения обратно в хранилище.
Работа с локальным кэшем означает, что средний ярус обслуживает самое минимальное (или никакое) состояние, таким образом делая его более масштабируемым.
Решением является обеспечить явно заданную автономную модель. Это характеризуется следующим шаблоном:
1. Приложение задает значение локальному кэшу вот так:
LocalContext 1c = new LocalContext();
2. Локальный кэш будет содержать результаты одного или более запросов, заданных вот так:
lc.QueryCollection.Add ("<query1>");
lc.QueryCollection.Add("<query2>");
//etc
3. Приложение «заполняет» локальный контекст
lc.Fill();
4. Оно работает с локальным контекстом точно так же, как оно работало бы с любым контекстом хранения. Например:
ScheduleEntry s =
lc.Entities.FilterByType<ScheduleEntry>().Filter(
"StartTime > @0", new DateTime(
2004, 10, 29, 9, 0, 0)}.GetFirst();
s.DisplayName = s.DisplayName + "[important, please come!]";
5. В заключение, оно отправляет изменения всей массой в хранилище вот так:
// sc - StorageContext
lc.SaveChanges(sc);
Отметим, каким образом приложение всегда является откровенным в том, когда оно желает, чтобы произошла операция пересечения яруса - Ic.Fill() на этапе 3 - так что нет волшебства, запущенного наивным кодом. Отметим также, что все последующие операции происходят над локальным кэшем и, следовательно, пересечение ярусов минимизировано (наряду с сопутствующим обслуживанием состояния на среднем ярусе).
CDP предусматривает автономную модель
Если связанная модель не оптимальна для 3-ярусного развертывания, то должно ли оно быть позволено полностью? Другими словами, должна CDP навязывать правило, что связанные запросы не работают в 3-ярусном развертывании? Очевидным преимуществом этого является то, что «плохо написанные» приложениям не разрешено действовать, таким образом, делая взятое в целом развертывание очень удачным местом, где были «хорошо написанные» приложения. Недостатком является то, что модель программирования больше не является симметричной между 2-ярусной и 3-ярусной. 2-ярусное приложение не может быть использовано в 3-ярусной среде, пока не является истинным одно из следующего: (a) оно использует только автономную модель программирования или (b) оно является переписанным, чтобы использовать автономную модель программирования.
CDP выбирает подход предоставления обеих, связанной и автономно, моделей программирования в 3-ярусных развертываниях. Приложениям будет дана директива, что если «они предполагаются развернутыми в 3-ярусной среде, то должны использовать автономный кэш».
5.3 CDP-хранилища
Чтобы упрочить контекст для этого раздела, мы заметим, что универсум данных SQL Server разделена на следующие 4 уровня иерархии: экземпляр, база данных, схема, таблица. Связываемой единицей является экземпляр; база данных является контейнером, на котором определены резервирование, восстановление и реплицирование. Сочетание базы данных и схемы обеспечивает контекст для запросов.
CDP использует 3-уровневую иерархию: хранилище, схема, тип. Хранилище CDP является связываемой единицей; схема обеспечивает контекст для запросов. Данная схема может вестись многочисленными CDP-хранилищами (это не означает, что некоторые данные находятся в ведении 2-х CDP-хранилищ; скорее, это означает, что набор типов (CRM-схема) может быть развернута в двух разных экземплярах CDP. Если желательно «единообразие», то должны использоваться механизмы вне CDP (реплицирование, массовое копирование)). Данное CDP-хранилище может содержать многочисленные схемы, развернутые на нем, такие как HRсхема (людских ресурсов), схема Accounting (бухгалтерского учета), и т.д.
| В одной из реализаций CQL работает по многочисленным схемам и транзакциям. В одной из реализаций CQL работает по многочисленным хранилищам. |
5.4 Именование и обнаружение
Рассмотрим строку 3 кодового фрагмента из раздела 2.4 «Поток данных/управления», воспроизведенный ниже:
using (StorageContext sc =
new StorageContext(@"\\corp001\defaultstore"))
Есть два вопроса, которые возникают при пристальном рассмотрении этой части кода:
1. Именование: Каким образом приложение идентифицирует CDP-хранилище, по которому желателен StorageContext? То есть, что является аргументом для ктора StorageContext?
2. Обнаружение: Каким образом приложение обнаруживает имеющиеся в распоряжении CDP-хранилища?
5.4.1 Именование
До ответа на вопрос об именовании CDP-хранилища мы должны сначала выяснить, что CDP-хранилище означает. Есть две возможности:
1. Оно является реально физическим хранилищем - базой данных Yukon/Katmai/ и т.п. на реальном сервере.
2. Оно является логическим хранилищем - аргумент для ктора идентифицирует логический контейнер экземпляров объектной сущности. В действительности, это могло бы быть использовано в качестве фермы реплицированных физических хранилищ, и интерфейсный сервер работает со стабилизатором нагрузки, чтобы выбрать реальное физическое хранилище, которое формирует контекст для этого конкретного сеанса.
В модели CDP контекст хранения идентифицирует логическое хранилище, а не физическое хранилище. CDP не задает, каким образом механизмы реплицирования, резервирования/восстановления работают на уровне физического хранилища.
Следующим вопросом является: каков формат аргумента ктора? Другими словами, как выглядит «строка связи»? Вообще, это - универсальный идентификатор ресурса, или URI (смотри [URI-SYNTAX] для дополнительной информации).
Индивидуальные каркасы могут определять альтернативный формат именования для использования своими приложениями. Например, UAF может избрать позволить этим приложениям создавать контекст хранения заданием UNC-наименования (\\server\share). Фактически, это то, что показано во всех примерах в этом документе.
Однако, всегда должно быть возможным присоединиться к хранилищу CDP посредством URI; другими словами, любые альтернативные наименования, используемые каркасом, должны иметь в распоряжении хорошо определенное преобразование в соответствующий уровень URI CDP.
5.4.2 Обнаружение
CDP не задает, каким образом хранилища могут быть обнаружены. Ожидается, что приложения будут использовать существующие механизмы и репозитарии (например, UDDI) для этих целей. В дополнение, каркас может задавать свои собственные методы для обнаружения.
6. CDP-СЛУЖБЫ
В этом разделе мы описываем дополнительные CDP-службы, которыми приложения могут воспользоваться. Эти службы включают в себя:
• Службы наблюдателя/уведомления
• Службы синхронизации
• Службы явного кэша
• Вспомогательные операции
Мы кратко опишем каждую из этих служб ниже. Этот раздел должен рассматриваться, как описательный, а не архитектурный. Мы ожидаем, что отдельные рабочие группы (например, рабочая группа по синхронизации CDP, рабочая группа по CDP-операциям) предоставят необходимые архитектурные подробности.
6.1 Служба наблюдателя/уведомления
Уведомления (иначе называемые наблюдателями) обеспечивают возможность провоцировать асинхронные уведомления об изменениях по отношению к объектным сущностям (данным), сделанных устойчивыми в лежащем в основе хранилище. Приложение (или любой другой компонент) может использовать эту службу, чтобы наблюдать за изменениями в сделанных устойчивыми объектных сущностях. Приложение будет обладать полным контролем за тем, что наблюдает и как часто желает быть уведомлено. Например, уведомления об обогащенных прикладных разрезах (RAV) построено с использованием наблиюдателей; приложение просмотра стороны клиента может использовать RAV-уведомления, чтобы активно реагировать на изменения данных, используя эти уведомления.
Модель программирования CDP поддерживает класс Watcher (наблюдатель), то есть является допускающей наблюдение изменений в объектных сущностях. Механизм наблюдателя объектной сущности эффективен для каркасов и приложений для построения высокоуровневых абстракций наблюдателя. Например, WinFS может построить абстракции Item (запись), Item Extension (расширение записи) и Link (связь) на основе абстракции (заметим, что объектная сущность является наиболее гранулярной порцией данных, которая может наблюдаться) наблюдателя объектной сущности.
Каждое уведомление, сообщенное наблюдателем, сопровождается данными состояния наблюдателя. Приложения могут сохранить эти данные состояния в CDP или некотором другом хранилище данных и позднее извлекать сделанное устойчивым состояние, чтобы начать прием уведомлений для изменений, которые произошли после того, как состояние было сформировано. Модель программирования наблюдателя CDP будет поддерживать богатый набор классов и методов, чтобы управлять наблюдателем и данными состояния наблюдателя.
6.2 Службы синхронизации
Приложения, написанные для CDP, а также каркасов поверх него, будут извлекать пользу следующих относящихся к синхронизации служб:
1) Аннотации схемы для отслеживания изменений. Разработчики схемы могут обозначать границы единицы изменения для своих типов объектной сущности. Спецификации единицы изменения управляют функционированием службы Отслеживания изменений.
2) Отслеживание изменений. В значительной степени незаметно для приложений, она поддерживает версии для единиц изменения во время всех CDP-операций, а также регистрирует критические операции, такие как удаления объектных сущностей. Отслеживание изменений функционирует корректно, даже если существующие приложения продолжают проводить изменения, в обход среды исполнения CDP.
3) Подсчет изменений. Предоставляет CDP-приложению возможность извлекать набор объектных сущностей и их единицы изменения, которые были модифицированы со времени определенной скрытой маркировки. Изменения возвращаются в качестве объектных сущностей и наборов строк (RowSets) CDP. Набор служб предусмотрен для обслуживания скрытой маркировки вопреки отказам, резервированиям и восстановлениям, и сложных топологий синхронизации.
4) Обнаружение конфликтов. Предоставляет CDP-приложению возможность определять, будет ли операция CDP (такая как обновление) конфликтовать с операцией, которая уже была выполнена (вновь, на основании скрытой маркировки).
Используя эти основные функциональные возможности, каркасы могут строить дополнительные, высокоуровневые службы синхронизации.
6.3 Службы явного кэша
Служба явного кэша в CDP обеспечивает улучшенное выполнение/масштабируемость приложения, поддержку для автономной модели (заметим, что автономная модель программирования может быть реализована без преимущества явного кэша с полным набором признаков) программирования и поддержку для переходных данных.
Мы представляем себе следующие признаки в явном кэше:
• Помещение в кэш разных типов данных (например, объектных сущностей, неструктурированных и XML-данных).
• Разные режимы доступа к кэшу (например, только на чтение (Read Only), чтение-запись (Read-Write), совместно используемый (Shared), и т.д.).
• Когерентность кэша с сохраненными данными (например, для данных, сохраненных в SQL Server).
• Когерентность кэша (определенного типа данных, например, данных контекста сеанса) по многочисленным кэшам CDP касательно перехвата управления приложением.
Плоскость программирования для явного кэша будет открывать для воздействия:
• Создание кэшей
• Заполнение кэшей
• Задание устойчивости кэшей (части данных) для лежащих в основе хранилищ
• Запрос и обновление через кэшированные данные
Мы не ожидаем, что первоначальная реализации CDP будет содержать явный кэш.
6.4 Вспомогательные операции
CDP обеспечивает поддержку для многообразия административных и вспомогательных операций над объектными сущностями и наборами объектных сущностей. Выборка таких операций включает в себя
• Копирование
• Перемещение
• Сериализация/Десериализация
• Резервирование/Восстановление
7. WinFS ПОВЕРХ CDP: UAF
Реализация WinFS охватывает аспекты как CDP, так и UAF. Очень важно отметить, что архитектура CDP не означает переписывание WinFS, а всего лишь повторную сегментацию компонентов WinFS. В этом разделе мы сперва определим каркас пользовательского приолжения (UAF) и затем исследуем, каким образом разные компоненты WinFS могут быть сегментированы в UAF и CDP.
7.1 Что такое UAF?
UAF является CDP-каркасом, который имеет отношение к моделированию «пользовательских» данных. Пользовательские данные указывают ссылкой на общеизвестные каждодневные данные, которые имеют отношение к типичному конечному пользователю, таким как документ, фотография, музыка, деловой контакт, и т.д.
К основной инфраструктуре CDP UAF добавляет
• Базовый тип элемента данных (Item) (и имеющие отношение типы)
• Реальные типы для моделирования пользовательских данных
• Ограничения, к примеру, управления временем существования, включения, и т.д.
• Действия, которые пользователь может делать с элементами данных: перемещение, копирование, переименование, сериализация…
• Организационные конструкции для элементов данных (Item): контейнеры, списки, автоматические списки, аннотации, категории
• Абстракции программирования конечного пользователя по элементам данных (такие, как правила создания)
• Заметим, что для разработчиков приложения CDP является моделью программирования UAF. Понятие элемента данных в UAF на самом деле порождено от нескольких объектных сущностей, как показано на фиг.15, приведенной ниже:

Фиг.15. Моделирование элемента данных
с использованием объектных сущностей (Entities)
Так как UAF надстроен поверх CDP, он использует CDP-механизм расширяемости для реализации дополнительных функциональных возможностей. Это показано ниже, на фиг.16:

Фиг.16. Построение UAF на CDP
UAF использует механизм ограничения CDP, чтобы принудительно применять семантику элемента данных (и другую семантику типа). Она создается с использованием CSDL, а генератор схемы создает ограничения уровня хранилища для нее. Поведение Элемента, такое как перемещение (Move), сериализация (Serialize) и т.д., реализованы с использованием CDP-механизмов BL. Типы UAF могут иметь связываемые поведения, ассоциированные с ними. Эти поведения создаются разработчиком UAF-приложения после того, как разработаны и развернуты типы. Другие UAF-службы, такие как синхронизации, обработки метаданных и т.д., реализованы как обычный код CDP. Взятые вместе, эти отдельные части логики, работающие на разных уровнях CDP, формируют UAF.
7.2 Разделение WinFS между CDP и UAF
Следующие возможности в WinFS находятся на уровне CDP:
1. O-R-преобразование - преобразование объектных сущностей в таблицы. Отметим, что WinFS в настоящее время поддерживает только директивное O-R-преобразование; CDP также необходимо недирективное преобразование, чтобы обрабатывать сценарии POCO и сценарии сервера WinFS.
Это также включает в себя преобразование обновления, обеспечение основных операций CUD по отношению к типам объектной сущности (и производным).
2. Преобразование OPath-запроса
3. Реализация типов объектной сущности (Entity) и других основных типов CDM
4. Контекст хранения (StorageContext) и искатель контекста (StorageSearcher) наряду с управлением сеансом и транзакцией
5. Кэш сеанса, логика вырезания кэша (сохранение изменений (SaveChanges))
6. Отслеживание изменений
7. Наблюдатели по типам объектной сущности
8. Службы курсора, в том числе RAV
9. Механизмы принудительного применения безопасности уровня элемента данных (безопасность уровня строки, предикаты безопасности включают в себя разрезы типа)
Следующие возможности в WinFS находятся на ярусе UAF:
1. Связываемое, поэкземплярное поведение
2. Метаданные API WinFS (классы клиента и поведения выражены как метаданные CLR)
3. Методы уровня элемента данных (копирование, перемещение, преобразование в последовательную форму, переименование)
4. Синхронизация, области синхронизации, подсчет изменений
5. Наблюдатели по контейнерам
6. Таблица путей для эффективного вычисления наименования пути и областей определения элементов данных
7. Обработчики метаданных
8. Пространство имен WinFS
9. Код для приведения в жизнь целостности элементов данных WinFS (контейнер, части элемента данных, связи, файловые потоки, управление временем существования и т.д.).
8. MBF ПОВЕРХ CDP: КАРКАС LOB
MBF, Бизнес-структура Microsoft, является примером структуры LOB (сферы деятельности). В этом разделе мы коротко описываем требования каркаса LOB и каким образом они могут быть поддержаны общей платформой данных.
8.1 Обзор MBF (каркаса построения бизнеса Microsoft)
Отделению бизнес-решений Microsoft (MBS) даны привилегии по выпуску решений, которые стимулируют преобразования в способе, которым ведется бизнес, посредством предоставления бизнес-связей и самообслуживания по сети Интернет. Гораздо большие, чем "тонкий" клиент обозревателя, эти приложения имеют в центре бизнес-процессы и могут персонифицироваться и настраиваться по специальным требованиям для нужд бизнеса потребителя. Видение продукта бизнес-решений Microsoft должно создать экосистему бизнес-приложения вокруг бизнес-платформы .NET, которая состоит из бизнес-решений .NET Microsoft, бизнес-компонентов .NET, каркаса бизнеса Microsoft и Microsoft .NET.
Сегодня отделение бизнес-решений Microsoft (MBS) продает линейки продуктов по трем горизонтальным сегментам рынка:
• Малый бизнес: Small Business Manager, bCentral Commerce Manager и Navision XAL
• Средний рынок: Dynamics, Solomon IV и Navision Attain для среднего рынка
• Среднее предприятие: eEnterprise и Navision Axapta.
MBS также предпринял усилие построить перспективный, управляемый моделью, процесс-центрированный комплект бизнес-приложений, известный как Project Green. MBS Green представляет комплект бизнес-приложений, подобных Financials, Order Management и управлению Supply Chain.
Основной набор признаков для бизнес-приложений упакован в виде совместно используемых бизнес-компонентов. Группы этих компонентов управляют разными бизнес-функциями. Они могут простираться от главной бухгалтерской книги (General Ledger) в Financials до служб автоматизации продавцов (Sales Force Automation Services) в CRM. Ключевым признаком является то, что эти компоненты обезличены, наращиваемы и могут использоваться, чтобы обслуживать нужды многочисленных рынков в зависимости от того, какой уровень функциональных возможностей и сложности используется.
Каркас построения бизнеса Microsoft (MBF) используется разработчиками бизнес-компонентов по всей экосистеме. Они состоят из каркаса бизнес-решений (Business Solutions Framework) и каркаса бизнес-приложений (Business Application Framework).
Каркас бизнес-решений обеспечивает функциональные возможности, полезные для построения большинства бизнес-приложений. Это включает в себя фундаментальные типы бизнес-данных, такие как деньги (Money) и количество (Quantity); объектные сущности большого семейства бизнес-приложений, такие как клиент, бизнес-единица, многопоточная информация и сроки платежей; строительные блоки для реализации общих бизнес-шаблонов, к примеру, бизнес-транзакции (Business Transaction) и бюджета (Account); и общие шаблоны бизнес-процессов, таких как для переноса в гроссбух записи бизнес-транзакции.
Каркас решений написан с использованием каркаса бизнес-приложений, который поддерживает компоненты записи, предлагая службы с широкими возможностями для доступа к данным, защиты, пользовательского интерфейса, документооборота, модели программирования компонентов и гораздо больше. Если модель и бизнес-правила, определенные каркасом решений, не являются подходящими приложению, то они могут быть обойдены, и разработчик приложения может использовать каркас приложения непосредственно.
Каркас бизнес-приложения обеспечивает директивную модель программирования, которая принимает каркас. NET и фокусирует его возможности в направлении бизнес-приложений. Будучи вполне расширяемым, он создает некоторое количество решений для разработчика приложений, чего не могли бы более общие решения, увеличивая производительность и непротиворечивость в реализации и структуре для всех приложений в экосистеме, которые его используют.
Каркас бизнес-приложения предусматривает модель программирования и службы для написания веб-ориентированных, распределенных OLTP-приложений (с оперативной обработкой транзакций). Он не содержит бизнес-логики, частной для некоторых продуктов, и таким образом пригоден для создания не только бизнес-приложений, но также любых других приложений, настраивающих свой основной профиль. Он предоставляет набор служб, которые обеспечивают поддержку для доступа к данным, обмена сообщениями (такого, как использование SOAP и других протоколов), документооборота, посредничеству событиям, активизации экземпляров, диагностики, конфигурирования, управления метаданными (отображение), защиты компонентов приложения, глобализации, командной бизнес-оболочки рабочего места и более того.
Требования по CDP в основном происходят от части каркаса бизнес-приложения MBF, особенно в областях доступа к данным и удаленного взаимодействия информационной логики.
8.1.1 Доступ к данным
Устойчивость объектной сущности (Entity Persistence, EP), подсистема доступа к данным в каркасе построения бизнеса Microsoft поддерживает обогащенную модель данных, основанную на практичном каркасе объектно-реляционного преобразования. Она является объектно-реляционной по той причине, что разработчик имеет дело с объектами (C#), которые приводятся в соответствие реляционным строкам. Основными понятиями моделирования данных являются объектные сущности и отношения между объектными сущностями. Общая информационная модель (CDM), по существу, поддерживает требования моделирования данных доступа к данным MBF.
EP MBF требует поддержки для следующих действий доступа к данным:
• Создать, чтение, обновление и удаление объектной сущности
• Специализированные запросы, которые возвращают набор данных (DataSet)
• Основанные на наборах операции, которые исполняются в базе данных
8.1.2 SOA и удаленное взаимодействие
MBF предписывает каркас агента/службы для поддержки распределенных, сервис-ориентированных конфигураций. При заданной некоторой части функциональных возможностей бизнеса агент работает настолько близко к пользователю функциональных возможностей, насколько возможно, а служба работает настолько близко, насколько возможно, к данным. «Настолько близко, насколько возможно» отличается при каждом сценарии развертывания и видом пользователя. Шаблон агента/службы обеспечивает гибкость развертывания от 2-ярусного (клиент-сервер) до многоярусного развертывания. В таких применениях службы предоставляют интерфейсы, которые могут быть активизированы вне границ службы; агенты типично выбирают данные, близкие клиенту (пользователю), воздействуют ими на них и транслируют изменения службе.
8.2 Реализация MBF с использованием CDP
Фиг.17 показывает, каким образом каркас/приложение LOB может воспользоваться CDP.

Фиг.17. Построение каркаса LOB на CDP
На этом чертеже каркас (и приложение, построенное с использованием каркаса) размещен на сервере приложений на среднем ярусе. Он предоставляет стандартные LOB-службы, такие как технологический маршрут, обмен сообщениями, бизнес-процессы, и т.д. в виде интерфейса веб-служб для клиентского приложения. Он использует CDP, чтобы создавать ограничения хранилища и имеющую в центре данные бизнес-логику.
Клиентское приложение активизирует метод веб-служб через канал Indigo, в дополнение, оно может также воспользоваться CDP на клиентском ярусе для своих нужд устойчивости объектов/доступа к данным.
Чтобы сделать фиг.17 реальностью, есть несколько требований, которые должны быть удовлетворены CDP:
• Управление сеансом
• CRUD
• Поддержка общей модели данных (CDM)
- Абстракция объектной сущности
- Расширение объектной сущности
• Запрос
- Специализированный
- Объектная сущность
• Запуск кэша объектов (неявного)
• Управление взаимосовместимостью
- Оптимистическое, с уровнями изоляции, обнаружением
конфликтов, т.д.
• Бизнес-логика
- В методе
- Верификация/задание значений по умолчанию
- Шаблоны свойств
- События
• Расширение безопасности
• Преобразование (запроса, схемы)
- Поставщики
• Реляционные
• WinFS
• Возможность расширять метаданные (поддерживает другие
использования объектной сущности)
• Операции наборов
• Возможность вызывать хранимые процедуры
• N-ярусное развертывание
Устойчивость объектной сущности MBF является естественной, приспособленной для общей платформы данных. Большинство требований устойчивости MBF полностью поддерживается CDP. Некоторые из требований SOA также решены CDP. Однако полная поддержка для модели агента/службы, бизнес-операций и процессов MBF лежит вне сферы применения CDP. Эти возможности MBF должны быть построены поверх CDP в качестве каркаса LOB. Структура бизнес-решений MBF также наслоена поверх CDP.
9. БИБЛИОГРАФИЧЕСКИЙ СПИСОК
[CDM-REFERENCE]
WinFS Common Data Model Draft 6: BBeckman, Editor.
[C#-SEQUENCES]
Sequence Operators: Adding Query and Set Operations to
C#, PowerPoint presentation by AndersH.
[OPATH]
WinFS API OPath Language: RameshN, MikeDeem, Authors.
[WFS-API]
Svstem.Storage API Architecture: DaleWo.
[POCO-SCEN]
Basic POCO Scenarios: DineshKu.
[URI-SYNTAX]
Uniform Resource Identifiers (URI): Generic Syntax. T.Berners-Lee, R. Fielding, L. Masinter, Authors.
2420-135044/051
Приложение С
ОБЩАЯ МОДЕЛЬ ДАННЫХ
Claims (15)
1. Система для определения отношения между первой и второй объектными сущностями данных, содержащая
компьютерный процессор для выполнения компьютерно-выполняемых инструкций и обработки данных, хранящихся в памяти,
память, соединенную с процессором, хранящую компоненты объектной сущности и компоненты отношения, причем:
первый компонент объектной сущности и второй компонент объектной сущности, предоставляют первую объектную сущность данных и вторую объектную сущность данных, причем каждая объектная сущность данных обладает унифицированной идентичностью на большом количестве разнородных приложений, при этом каждая объектная сущность данных приводится в соответствие к лежащим в основе данным в хранилище данных, и при этом каждая унифицированная идентичность уникальна для каждой объектной сущности данных, пополнена значениями ключей объектной сущности и является основой для формирования ссылки на каждую объектную сущность; и
компонент отношения явным образом определяет отношение между первой и второй объектными сущностями данных, причем отношение представляет собой ассоциацию, содержащую две стороны, так что первая сторона представляет первую объектную сущность данных, а вторая сторона представляет вторую объектную сущность данных, при этом первая объектная сущность данных независима от второй объектной сущности данных в ассоциации, и Свойство Навигации используется для запрашивания по первой и второй объектным сущностям данных, относящимся посредством ассоциации при помощи указания пути навигации от первой объектной сущности данных к ассоциированной второй объектной сущности данных, причем ассоциация допускает первую кратность в первой стороне и вторую кратность во второй стороне, причем первая кратность имеет значения кратности, отличные от второй кратности, и при этом первая кратность представляет собой первое ограничение, указывающее первое количество экземпляров объектной сущности данных, вовлеченных в ассоциацию на первой стороне, а вторая кратность представляет собой второе ограничение, указывающее второе количество экземпляров объектной сущности данных, вовлеченных в ассоциацию на второй стороне, при этом ассоциация включает в себя операционное поведение для отношения между первой и второй объектными сущностями данных, причем первая сторона содержит атрибут удаление со значением каскадировать для указания того, что вторая объектная сущность данных будет удалена при удалении первой объектной сущности данных.
компьютерный процессор для выполнения компьютерно-выполняемых инструкций и обработки данных, хранящихся в памяти,
память, соединенную с процессором, хранящую компоненты объектной сущности и компоненты отношения, причем:
первый компонент объектной сущности и второй компонент объектной сущности, предоставляют первую объектную сущность данных и вторую объектную сущность данных, причем каждая объектная сущность данных обладает унифицированной идентичностью на большом количестве разнородных приложений, при этом каждая объектная сущность данных приводится в соответствие к лежащим в основе данным в хранилище данных, и при этом каждая унифицированная идентичность уникальна для каждой объектной сущности данных, пополнена значениями ключей объектной сущности и является основой для формирования ссылки на каждую объектную сущность; и
компонент отношения явным образом определяет отношение между первой и второй объектными сущностями данных, причем отношение представляет собой ассоциацию, содержащую две стороны, так что первая сторона представляет первую объектную сущность данных, а вторая сторона представляет вторую объектную сущность данных, при этом первая объектная сущность данных независима от второй объектной сущности данных в ассоциации, и Свойство Навигации используется для запрашивания по первой и второй объектным сущностям данных, относящимся посредством ассоциации при помощи указания пути навигации от первой объектной сущности данных к ассоциированной второй объектной сущности данных, причем ассоциация допускает первую кратность в первой стороне и вторую кратность во второй стороне, причем первая кратность имеет значения кратности, отличные от второй кратности, и при этом первая кратность представляет собой первое ограничение, указывающее первое количество экземпляров объектной сущности данных, вовлеченных в ассоциацию на первой стороне, а вторая кратность представляет собой второе ограничение, указывающее второе количество экземпляров объектной сущности данных, вовлеченных в ассоциацию на второй стороне, при этом ассоциация включает в себя операционное поведение для отношения между первой и второй объектными сущностями данных, причем первая сторона содержит атрибут удаление со значением каскадировать для указания того, что вторая объектная сущность данных будет удалена при удалении первой объектной сущности данных.
2. Система по п.1, в которой объектная сущность данных включает в себя тип объектной сущности, в котором определено свойство.
3. Система по п.2, в которой тип объектной сущности содержит данные идентичности.
4. Система по п.1, в которой первая и вторая объектные сущности связаны вместе объектной сущностью ассоциации.
5. Система по п.1, в которой каждая объектная сущность данных сделана устойчивой, будучи добавленной в таблицу объектных сущностей, причем таблица объектных сущностей является типизированной коллекцией объектных сущностей.
6. Система по п.1, в которой каждая объектная сущность данных включает в себя член, который имеет тип, который является одним из подставляемого типа, типа объектной сущности, табличного типа, перечисляемого типа и типа массива.
7. Система по п.6, в которой подставляемый тип не имеет идентичности сверх наложенной конкретной объектной сущностью, в которой он находится.
8. Система по п.1, в которой каждый компонент объектной сущности включает в себя членов объектной сущности, которые содержат расчетное свойство.
9. Система по п.1, в которой ассоциация может быть задана область для применения только к конкретной таблице.
10. Машиночитаемый носитель, содержащий выполняемые компьютером инструкции, сохраненные на нем, для обеспечения реализуемого компьютером способа определения отношения между первой и второй объектными сущностями данных, содержащего этапы, на которых
предоставляют первую объектную сущность и вторую объектную сущность, причем каждая объектная сущность является отдельной идентичностью связанных данных, при этом первая и вторая объектные сущности приводятся в соответствие к лежащим в основе данным, при этом первая и вторая объектные сущности являются уникально идентифицируемыми, причем уникальные идентификаторы пополняются значениями ключей объектной сущности и формируют ссылки на соответствующие первую и вторую объектную сущности;
идентифицируют структуру каждой из первой объектной сущности и второй объектной сущности в качестве свойств; и
определяют отношение между первой и второй объектными сущностями с использованием явных отношений, включающих в себя ассоциацию, содержащую две стороны, так что первая сторона представляет первую объектную сущность, а вторая сторона представляет вторую объектную сущность, при этом первая объектная сущность независима от второй объектной сущности в ассоциации, и Свойство Навигации используется для запрашивания по первой и второй объектным сущностям, относящимся посредством ассоциации при помощи указания пути навигации от первой объектной сущности к ассоциированной второй объектной сущности, причем ассоциация допускает первую кратность в первой стороне и вторую кратность во второй стороне, причем первая кратность имеет значения кратности, отличные от второй кратности, и при этом первая кратность представляет собой первое ограничение, указывающее первое количество экземпляров объектной сущности, вовлеченных в ассоциацию на первой стороне, а вторая кратность представляет собой второе ограничение, указывающее второе количество экземпляров объектной сущности, вовлеченных в ассоциацию на второй стороне, при этом ассоциация включает в себя операционное поведение для отношения между первой и второй объектными сущностями, причем первая сторона содержит атрибут удаление со значением каскадировать для указания того, что вторая объектная сущность будет удалена при удалении первой объектной сущности данных.
предоставляют первую объектную сущность и вторую объектную сущность, причем каждая объектная сущность является отдельной идентичностью связанных данных, при этом первая и вторая объектные сущности приводятся в соответствие к лежащим в основе данным, при этом первая и вторая объектные сущности являются уникально идентифицируемыми, причем уникальные идентификаторы пополняются значениями ключей объектной сущности и формируют ссылки на соответствующие первую и вторую объектную сущности;
идентифицируют структуру каждой из первой объектной сущности и второй объектной сущности в качестве свойств; и
определяют отношение между первой и второй объектными сущностями с использованием явных отношений, включающих в себя ассоциацию, содержащую две стороны, так что первая сторона представляет первую объектную сущность, а вторая сторона представляет вторую объектную сущность, при этом первая объектная сущность независима от второй объектной сущности в ассоциации, и Свойство Навигации используется для запрашивания по первой и второй объектным сущностям, относящимся посредством ассоциации при помощи указания пути навигации от первой объектной сущности к ассоциированной второй объектной сущности, причем ассоциация допускает первую кратность в первой стороне и вторую кратность во второй стороне, причем первая кратность имеет значения кратности, отличные от второй кратности, и при этом первая кратность представляет собой первое ограничение, указывающее первое количество экземпляров объектной сущности, вовлеченных в ассоциацию на первой стороне, а вторая кратность представляет собой второе ограничение, указывающее второе количество экземпляров объектной сущности, вовлеченных в ассоциацию на второй стороне, при этом ассоциация включает в себя операционное поведение для отношения между первой и второй объектными сущностями, причем первая сторона содержит атрибут удаление со значением каскадировать для указания того, что вторая объектная сущность будет удалена при удалении первой объектной сущности данных.
11. Машиночитаемый носитель по п.10, в котором каждая объектная сущность составлена из члена объектной сущности, который осуществляет одно из: выделения хранилища для экземпляра конкретного типа, является свойством, которое вычисляется, и представления операции, которая может быть выполнена.
12. Машиночитаемый носитель по п.11, в котором член объектной сущности для каждой объектной сущности включает в себя тип.
13. Машиночитаемый носитель по п.11, в котором член объектной сущности включает в себя подставляемый тип, чьи данные сохранены внутри объектной сущности.
14. Машиночитаемый носитель по п.11, в котором член объектной сущности включает в себя табличный тип, который является неупорядоченной коллекцией экземпляров заданного типа объектной сущности.
15. Устройство для определения отношения между первой и второй объектными сущностями данных, содержащее
компьютерный процессор для выполнения компьютерно-выполняемых инструкций; и по меньшей мере один машиночитаемый носитель, хранящий компьютерно-выполняемые инструкции, которые при их выполнении компьютерным процессором обеспечивают выполнение этапов, на которых
сохраняют связанные данные;
предоставляют первую объектную сущность и вторую объектную сущность, причем каждая объектная сущность является отдельной идентичностью связанных данных и является уникально идентифицируемой, причем уникальная идентичность для каждой из первой и второй объектной сущности пополняются значениями ключей объектной сущности и формируют ссылки на соответствующие объектные сущности;
идентифицируют структуру каждой объектной сущности в качестве свойств; и
определяют отношение между первой и второй объектными сущностями при помощи ассоциации, содержащей две стороны, так что первая сторона представляет первую объектную сущность, а вторая сторона представляет вторую объектную сущность, при этом первая объектная сущность независима от второй объектной сущности в ассоциации, и Свойство Навигации используется для запрашивания по первой и второй объектным сущностям, относящимся посредством ассоциации при помощи указания пути навигации от первой объектной сущности к ассоциированной второй объектной сущности, причем ассоциация допускает первую кратность в первой стороне и вторую кратность во второй стороне, причем первая кратность имеет значения кратности, отличные от второй кратности, и при этом первая кратность представляет собой первое ограничение, указывающее первое количество экземпляров объектной сущности, вовлеченных в ассоциацию на первой стороне, а вторая кратность представляет собой второе ограничение, указывающее второе количество экземпляров объектной сущности, вовлеченных в ассоциацию на второй стороне, при этом ассоциация включает в себя операционное поведение для отношения между первой и второй объектными сущностями, причем первая сторона содержит атрибут удаление со значением каскадировать для указания того, что вторая объектная сущность будет удалена при удалении первой объектной сущности данных.
компьютерный процессор для выполнения компьютерно-выполняемых инструкций; и по меньшей мере один машиночитаемый носитель, хранящий компьютерно-выполняемые инструкции, которые при их выполнении компьютерным процессором обеспечивают выполнение этапов, на которых
сохраняют связанные данные;
предоставляют первую объектную сущность и вторую объектную сущность, причем каждая объектная сущность является отдельной идентичностью связанных данных и является уникально идентифицируемой, причем уникальная идентичность для каждой из первой и второй объектной сущности пополняются значениями ключей объектной сущности и формируют ссылки на соответствующие объектные сущности;
идентифицируют структуру каждой объектной сущности в качестве свойств; и
определяют отношение между первой и второй объектными сущностями при помощи ассоциации, содержащей две стороны, так что первая сторона представляет первую объектную сущность, а вторая сторона представляет вторую объектную сущность, при этом первая объектная сущность независима от второй объектной сущности в ассоциации, и Свойство Навигации используется для запрашивания по первой и второй объектным сущностям, относящимся посредством ассоциации при помощи указания пути навигации от первой объектной сущности к ассоциированной второй объектной сущности, причем ассоциация допускает первую кратность в первой стороне и вторую кратность во второй стороне, причем первая кратность имеет значения кратности, отличные от второй кратности, и при этом первая кратность представляет собой первое ограничение, указывающее первое количество экземпляров объектной сущности, вовлеченных в ассоциацию на первой стороне, а вторая кратность представляет собой второе ограничение, указывающее второе количество экземпляров объектной сущности, вовлеченных в ассоциацию на второй стороне, при этом ассоциация включает в себя операционное поведение для отношения между первой и второй объектными сущностями, причем первая сторона содержит атрибут удаление со значением каскадировать для указания того, что вторая объектная сущность будет удалена при удалении первой объектной сущности данных.
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US65729505P | 2005-02-28 | 2005-02-28 | |
| US60/657,295 | 2005-02-28 | ||
| US11/228,731 | 2005-09-16 | ||
| US11/228,731 US20060195460A1 (en) | 2005-02-28 | 2005-09-16 | Data model for object-relational data |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| RU2006102530A RU2006102530A (ru) | 2007-08-10 |
| RU2421798C2 true RU2421798C2 (ru) | 2011-06-20 |
Family
ID=36384459
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| RU2006102530/08A RU2421798C2 (ru) | 2005-02-28 | 2006-01-27 | Модель данных для объектно-реляционных данных |
Country Status (9)
| Country | Link |
|---|---|
| US (1) | US20060195460A1 (ru) |
| EP (1) | EP1696348A3 (ru) |
| JP (1) | JP2006244498A (ru) |
| KR (1) | KR20060095452A (ru) |
| AU (1) | AU2006200227A1 (ru) |
| BR (1) | BRPI0600122A (ru) |
| CA (1) | CA2534260A1 (ru) |
| MX (1) | MXPA06001209A (ru) |
| RU (1) | RU2421798C2 (ru) |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013048273A1 (ru) * | 2011-09-26 | 2013-04-04 | Gorishniy Sergey Anatolievich | Система и метод хранения, извлечения и управления данными в объектной форме |
| RU2515565C1 (ru) * | 2012-10-22 | 2014-05-10 | Закрытое акционерное общество Научно-производственное предприятие "Реляционные экспертные системы" | Способ обновления структурированных данных в системе управления реляционными базами данных |
| RU2601198C2 (ru) * | 2011-08-11 | 2016-10-27 | МАЙКРОСОФТ ТЕКНОЛОДЖИ ЛАЙСЕНСИНГ, ЭлЭлСи | Система среды выполнения |
| WO2016183564A1 (en) * | 2015-05-14 | 2016-11-17 | Walleye Software, LLC | Data store access permission system with interleaved application of deferred access control filters |
| RU2607977C1 (ru) * | 2015-06-30 | 2017-01-11 | Александр Игоревич Колотыгин | Способ создания модели объекта |
| RU2621185C2 (ru) * | 2015-11-10 | 2017-05-31 | Акционерное общество "Центральный научно-исследовательский институт экономики, информатики и систем управления" (АО "ЦНИИ ЭИСУ") | Система для определения отношения между первой и второй объектными сущностями данных |
| US10002154B1 (en) | 2017-08-24 | 2018-06-19 | Illumon Llc | Computer data system data source having an update propagation graph with feedback cyclicality |
| RU2702977C2 (ru) * | 2014-06-02 | 2019-10-14 | МАЙКРОСОФТ ТЕКНОЛОДЖИ ЛАЙСЕНСИНГ, ЭлЭлСи | Фильтрация данных в корпоративной системе |
| US10635504B2 (en) | 2014-10-16 | 2020-04-28 | Microsoft Technology Licensing, Llc | API versioning independent of product releases |
Families Citing this family (113)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7523128B1 (en) | 2003-03-18 | 2009-04-21 | Troux Technologies | Method and system for discovering relationships |
| US7590643B2 (en) * | 2003-08-21 | 2009-09-15 | Microsoft Corporation | Systems and methods for extensions and inheritance for units of information manageable by a hardware/software interface system |
| US7853961B2 (en) * | 2005-02-28 | 2010-12-14 | Microsoft Corporation | Platform for data services across disparate application frameworks |
| US7996443B2 (en) * | 2005-02-28 | 2011-08-09 | Microsoft Corporation | Schema grammar and compilation |
| US7685561B2 (en) * | 2005-02-28 | 2010-03-23 | Microsoft Corporation | Storage API for a common data platform |
| US7890545B1 (en) * | 2005-03-31 | 2011-02-15 | Troux Technologies | Method and system for a reference model for an enterprise architecture |
| US8234223B1 (en) | 2005-04-28 | 2012-07-31 | Troux Technologies, Inc. | Method and system for calculating cost of an asset using a data model |
| US7603352B1 (en) | 2005-05-19 | 2009-10-13 | Ning, Inc. | Advertisement selection in an electronic application system |
| US8346950B1 (en) | 2005-05-19 | 2013-01-01 | Glam Media, Inc. | Hosted application server |
| US7630784B2 (en) * | 2005-07-22 | 2009-12-08 | International Business Machines Corporation | Method and apparatus for independent deployment of roles |
| US7756945B1 (en) * | 2005-08-02 | 2010-07-13 | Ning, Inc. | Interacting with a shared data model |
| US7664712B1 (en) | 2005-08-05 | 2010-02-16 | Troux Technologies | Method and system for impact analysis using a data model |
| US7788651B2 (en) * | 2005-09-02 | 2010-08-31 | Microsoft Corporation | Anonymous types |
| US7676493B2 (en) * | 2005-09-07 | 2010-03-09 | Microsoft Corporation | Incremental approach to an object-relational solution |
| US7818344B2 (en) | 2005-09-26 | 2010-10-19 | Bea Systems, Inc. | System and method for providing nested types for content management |
| US7917537B2 (en) * | 2005-09-26 | 2011-03-29 | Oracle International Corporation | System and method for providing link property types for content management |
| US20070073663A1 (en) * | 2005-09-26 | 2007-03-29 | Bea Systems, Inc. | System and method for providing full-text searching of managed content |
| US20070136254A1 (en) * | 2005-12-08 | 2007-06-14 | Hyun-Hwa Choi | System and method for processing integrated queries against input data stream and data stored in database using trigger |
| US7761850B2 (en) * | 2005-12-22 | 2010-07-20 | Sap Ag | Items on workplaces |
| US7512907B2 (en) * | 2006-02-01 | 2009-03-31 | International Business Machines Corporation | Generating rules for nets that cross package boundaries |
| US7756828B2 (en) * | 2006-02-28 | 2010-07-13 | Microsoft Corporation | Configuration management database state model |
| US7680767B2 (en) * | 2006-03-23 | 2010-03-16 | Microsoft Corporation | Mapping architecture with incremental view maintenance |
| US7647298B2 (en) * | 2006-03-23 | 2010-01-12 | Microsoft Corporation | Generation of query and update views for object relational mapping |
| US7984416B2 (en) * | 2006-03-24 | 2011-07-19 | The Mathworks, Inc. | System and method for providing class definitions in a dynamically typed array-based language |
| US8966456B2 (en) * | 2006-03-24 | 2015-02-24 | The Mathworks, Inc. | System and method for providing and using meta-data in a dynamically typed array-based language |
| US7725495B2 (en) * | 2006-04-11 | 2010-05-25 | Microsoft Corporation | Implementing referential integrity in a database hosting service |
| US7979475B2 (en) * | 2006-04-26 | 2011-07-12 | Robert Mack | Coherent data identification method and apparatus for database table development |
| US8086998B2 (en) * | 2006-04-27 | 2011-12-27 | International Business Machines Corporation | transforming meta object facility specifications into relational data definition language structures and JAVA classes |
| US7526501B2 (en) * | 2006-05-09 | 2009-04-28 | Microsoft Corporation | State transition logic for a persistent object graph |
| US20070266041A1 (en) * | 2006-05-11 | 2007-11-15 | Microsoft Corporation | Concept of relationshipsets in entity data model (edm) |
| US7577909B2 (en) * | 2006-05-16 | 2009-08-18 | Microsoft Corporation | Flexible management user interface from management models |
| US8214877B1 (en) | 2006-05-22 | 2012-07-03 | Troux Technologies | System and method for the implementation of policies |
| US7822710B1 (en) | 2006-05-24 | 2010-10-26 | Troux Technologies | System and method for data collection |
| US7895241B2 (en) | 2006-10-16 | 2011-02-22 | Schlumberger Technology Corp. | Method and apparatus for oilfield data repository |
| US7801926B2 (en) * | 2006-11-22 | 2010-09-21 | Microsoft Corporation | Programmable logic and constraints for a dynamically typed storage system |
| US8930890B2 (en) * | 2006-12-05 | 2015-01-06 | International Business Machines Corporation | Software model skinning |
| US8756561B2 (en) * | 2006-12-05 | 2014-06-17 | International Business Machines Corporation | Software model normalization and mediation |
| US20080162526A1 (en) * | 2006-12-28 | 2008-07-03 | Uma Kant Singh | Method and system for managing unstructured data in a structured data environment |
| US20080168352A1 (en) * | 2007-01-05 | 2008-07-10 | Microsoft Corporation | System and Method for Displaying Related Entity Information |
| JP4632056B2 (ja) * | 2007-01-15 | 2011-02-16 | 日本電気株式会社 | マッピングシステム、マッピング方法及びプログラム |
| US20080201338A1 (en) * | 2007-02-16 | 2008-08-21 | Microsoft Corporation | Rest for entities |
| WO2008106351A1 (en) * | 2007-02-28 | 2008-09-04 | Wms Gaming, Inc. | System for validating wagering game data |
| US9430552B2 (en) | 2007-03-16 | 2016-08-30 | Microsoft Technology Licensing, Llc | View maintenance rules for an update pipeline of an object-relational mapping (ORM) platform |
| US7664779B1 (en) * | 2007-06-29 | 2010-02-16 | Emc Corporation | Processing of a generalized directed object graph for storage in a relational database |
| US20090037700A1 (en) * | 2007-07-30 | 2009-02-05 | Clear Falls Pty Ltd | Method and system for reactively assigning computational threads of control between processors |
| US20090049064A1 (en) * | 2007-08-15 | 2009-02-19 | Lori Alquier | Data and application model for configurable tracking and reporting system |
| BRPI0817507B1 (pt) | 2007-09-28 | 2021-03-23 | International Business Machines Corporation | Método para análise de um sistema para associação de registro de dados, mídia de armazenamento legível por computador e sistema computacional para análise de um centro de identidade |
| US8713434B2 (en) * | 2007-09-28 | 2014-04-29 | International Business Machines Corporation | Indexing, relating and managing information about entities |
| US8027956B1 (en) | 2007-10-30 | 2011-09-27 | Troux Technologies | System and method for planning or monitoring system transformations |
| US8027445B2 (en) | 2007-11-07 | 2011-09-27 | At&T Intellectual Property I, L.P. | Method and system to provision emergency contact services in a communication network |
| US7957373B2 (en) * | 2007-12-12 | 2011-06-07 | At&T Intellectual Property I, L.P. | Method and system to provide contact services in a communication network |
| US8165116B2 (en) * | 2007-12-12 | 2012-04-24 | At&T Intellectual Property I, L.P. | Method and system to provide contact services in a communication network |
| CN101499003A (zh) * | 2008-01-31 | 2009-08-05 | 国际商业机器公司 | 生成关于模型的约束表达式的方法以及约束语言编辑器 |
| US20090228428A1 (en) * | 2008-03-07 | 2009-09-10 | International Business Machines Corporation | Solution for augmenting a master data model with relevant data elements extracted from unstructured data sources |
| US8745127B2 (en) * | 2008-05-13 | 2014-06-03 | Microsoft Corporation | Blending single-master and multi-master data synchronization techniques |
| US20090300649A1 (en) * | 2008-05-30 | 2009-12-03 | Microsoft Corporation | Sharing An Object Among Multiple Applications |
| US8010512B2 (en) * | 2008-06-16 | 2011-08-30 | International Business Machines Corporation | System and method for model-driven object store |
| US20090313212A1 (en) * | 2008-06-17 | 2009-12-17 | Microsoft Corporation | Relational database with compound identifier |
| US8762420B2 (en) * | 2008-06-20 | 2014-06-24 | Microsoft Corporation | Aggregation of data stored in multiple data stores |
| DE102008047915B4 (de) * | 2008-09-19 | 2010-05-12 | Continental Automotive Gmbh | Infotainmentsystem und Computerprogrammprodukt |
| US8413119B2 (en) * | 2008-10-03 | 2013-04-02 | Microsoft Corporation | Semantic subtyping for declarative data scripting language by calling a prover |
| US8255373B2 (en) * | 2008-10-24 | 2012-08-28 | Microsoft Corporation | Atomic multiple modification of data in a distributed storage system |
| US8719308B2 (en) * | 2009-02-16 | 2014-05-06 | Business Objects, S.A. | Method and system to process unstructured data |
| US8150882B2 (en) * | 2009-03-03 | 2012-04-03 | Microsoft Corporation | Mapping from objects to data model |
| US20100274823A1 (en) * | 2009-04-23 | 2010-10-28 | Sailesh Sathish | Method, apparatus and computer program product for providing an adaptive context model framework |
| US8554801B2 (en) | 2009-07-10 | 2013-10-08 | Robert Mack | Method and apparatus for converting heterogeneous databases into standardized homogeneous databases |
| US8732146B2 (en) * | 2010-02-01 | 2014-05-20 | Microsoft Corporation | Database integrated viewer |
| US8364675B1 (en) * | 2010-06-30 | 2013-01-29 | Google Inc | Recursive algorithm for in-place search for an n:th element in an unsorted array |
| US8825745B2 (en) | 2010-07-11 | 2014-09-02 | Microsoft Corporation | URL-facilitated access to spreadsheet elements |
| US8635592B1 (en) | 2011-02-08 | 2014-01-21 | Troux Technologies, Inc. | Method and system for tailoring software functionality |
| JP5721056B2 (ja) * | 2011-05-10 | 2015-05-20 | 日本電気株式会社 | トランザクション処理装置、トランザクション処理方法およびトランザクション処理プログラム |
| US8965879B2 (en) * | 2011-06-03 | 2015-02-24 | Microsoft Technology Licensing, Llc | Unique join data caching method |
| US10417263B2 (en) * | 2011-06-03 | 2019-09-17 | Robert Mack | Method and apparatus for implementing a set of integrated data systems |
| US8892585B2 (en) * | 2011-07-05 | 2014-11-18 | Microsoft Corporation | Metadata driven flexible user interface for business applications |
| US9164751B2 (en) * | 2011-09-30 | 2015-10-20 | Emc Corporation | System and method of rolling upgrades of data traits |
| US8612405B1 (en) | 2011-09-30 | 2013-12-17 | Emc Corporation | System and method of dynamic data object upgrades |
| US8620963B2 (en) * | 2012-03-08 | 2013-12-31 | eBizprise Inc. | Large-scale data processing system, method, and non-transitory tangible machine-readable medium thereof |
| US8751505B2 (en) * | 2012-03-11 | 2014-06-10 | International Business Machines Corporation | Indexing and searching entity-relationship data |
| US8676788B2 (en) * | 2012-03-13 | 2014-03-18 | International Business Machines Corporation | Structured large object (LOB) data |
| CN103324635A (zh) * | 2012-03-23 | 2013-09-25 | 富泰华工业(深圳)有限公司 | 数据源控件转换系统和方法 |
| US9251180B2 (en) | 2012-05-29 | 2016-02-02 | International Business Machines Corporation | Supplementing structured information about entities with information from unstructured data sources |
| US9530115B2 (en) * | 2013-01-07 | 2016-12-27 | Sap Se | Message evaluation tool |
| US10545932B2 (en) * | 2013-02-07 | 2020-01-28 | Qatar Foundation | Methods and systems for data cleaning |
| US9128962B2 (en) | 2013-03-11 | 2015-09-08 | Sap Se | View based table replacement for applications |
| US9280581B1 (en) | 2013-03-12 | 2016-03-08 | Troux Technologies, Inc. | Method and system for determination of data completeness for analytic data calculations |
| US10296618B1 (en) | 2013-05-20 | 2019-05-21 | EMC IP Holding Company LLC | Storage system query mechanism and techniques |
| US9361407B2 (en) | 2013-09-06 | 2016-06-07 | Sap Se | SQL extended with transient fields for calculation expressions in enhanced data models |
| US9619552B2 (en) | 2013-09-06 | 2017-04-11 | Sap Se | Core data services extensibility for entity-relationship models |
| US9442977B2 (en) | 2013-09-06 | 2016-09-13 | Sap Se | Database language extended to accommodate entity-relationship models |
| US9176801B2 (en) | 2013-09-06 | 2015-11-03 | Sap Se | Advanced data models containing declarative and programmatic constraints |
| US9354948B2 (en) | 2013-09-06 | 2016-05-31 | Sap Se | Data models containing host language embedded constraints |
| US9430523B2 (en) | 2013-09-06 | 2016-08-30 | Sap Se | Entity-relationship model extensions using annotations |
| US9639572B2 (en) | 2013-09-06 | 2017-05-02 | Sap Se | SQL enhancements simplifying database querying |
| US9575819B2 (en) | 2013-09-06 | 2017-02-21 | Sap Se | Local buffers for event handlers |
| CN103617167B (zh) * | 2013-10-22 | 2017-05-31 | 芜湖大学科技园发展有限公司 | 一种通用的元数据/关系映射框架 |
| US9607415B2 (en) * | 2013-12-26 | 2017-03-28 | International Business Machines Corporation | Obscured relationship data within a graph |
| US11288290B2 (en) * | 2014-12-18 | 2022-03-29 | Ab Initio Technology Llc | Building reports |
| RU2693682C2 (ru) | 2014-12-19 | 2019-07-03 | Сергей Анатольевич Горишний | Система и способ управления функционально связанными данными |
| US10579354B2 (en) * | 2015-03-10 | 2020-03-03 | Kordata, Llc | Method and system for rapid deployment and execution of customized functionality across multiple distinct platforms |
| US9886270B2 (en) * | 2015-04-17 | 2018-02-06 | Sap Se | Layered business configuration |
| US20160335544A1 (en) * | 2015-05-12 | 2016-11-17 | Claudia Bretschneider | Method and Apparatus for Generating a Knowledge Data Model |
| US10671636B2 (en) * | 2016-05-18 | 2020-06-02 | Korea Electronics Technology Institute | In-memory DB connection support type scheduling method and system for real-time big data analysis in distributed computing environment |
| US10776352B2 (en) | 2016-11-30 | 2020-09-15 | Hewlett Packard Enterprise Development Lp | Generic query language for data stores |
| US10534765B2 (en) * | 2017-04-07 | 2020-01-14 | Micro Focus Llc | Assigning segments of a shared database storage to nodes |
| US10430606B1 (en) * | 2018-04-30 | 2019-10-01 | Aras Corporation | System and method for implementing domain based access control on queries of a self-describing data system |
| CN111241053B (zh) * | 2018-11-29 | 2022-08-23 | 中国移动通信集团四川有限公司 | 数据表创建方法、装置、设备及存储介质 |
| US11302327B2 (en) * | 2020-06-22 | 2022-04-12 | Bank Of America Corporation | Priori knowledge, canonical data forms, and preliminary entrentropy reduction for IVR |
| US11392573B1 (en) | 2020-11-11 | 2022-07-19 | Wells Fargo Bank, N.A. | Systems and methods for generating and maintaining data objects |
| US11640565B1 (en) * | 2020-11-11 | 2023-05-02 | Wells Fargo Bank, N.A. | Systems and methods for relationship mapping |
| CN112394927B (zh) * | 2020-12-08 | 2024-07-19 | 上海数设科技有限公司 | 一种产品模型的增维形态和模型定义方法 |
| US20220269702A1 (en) * | 2021-02-19 | 2022-08-25 | Sap Se | Intelligent annotation of entity-relationship data models |
| US20240119030A1 (en) * | 2022-10-11 | 2024-04-11 | Caret Holdings, Inc. | Managing and providing a rule independent data model |
| US20240241865A1 (en) * | 2023-01-12 | 2024-07-18 | Sap Se | Automatic enforcement of standardized data model mapping |
Family Cites Families (62)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US15488A (en) * | 1856-08-05 | Improvement in corn and cob mills | ||
| US15814A (en) * | 1856-09-30 | Machine eob | ||
| US15489A (en) * | 1856-08-05 | Joseph m | ||
| US15474A (en) * | 1856-08-05 | William s | ||
| US15509A (en) * | 1856-08-12 | Odometeb | ||
| US5449293A (en) * | 1992-06-02 | 1995-09-12 | Alberta Research Council | Recognition training system |
| US5579471A (en) * | 1992-11-09 | 1996-11-26 | International Business Machines Corporation | Image query system and method |
| US5576954A (en) * | 1993-11-05 | 1996-11-19 | University Of Central Florida | Process for determination of text relevancy |
| US5560005A (en) * | 1994-02-25 | 1996-09-24 | Actamed Corp. | Methods and systems for object-based relational distributed databases |
| US5627979A (en) * | 1994-07-18 | 1997-05-06 | International Business Machines Corporation | System and method for providing a graphical user interface for mapping and accessing objects in data stores |
| US5799309A (en) * | 1994-12-29 | 1998-08-25 | International Business Machines Corporation | Generating an optimized set of relational queries fetching data in an object-relational database |
| US5717913A (en) * | 1995-01-03 | 1998-02-10 | University Of Central Florida | Method for detecting and extracting text data using database schemas |
| US6128624A (en) * | 1997-11-12 | 2000-10-03 | Ncr Corporation | Collection and integration of internet and electronic commerce data in a database during web browsing |
| US6385618B1 (en) * | 1997-12-22 | 2002-05-07 | Sun Microsystems, Inc. | Integrating both modifications to an object model and modifications to a database into source code by an object-relational mapping tool |
| US6175837B1 (en) * | 1998-06-29 | 2001-01-16 | Sun Microsystems, Inc. | Object-relational mapping toll that processes views |
| WO1999064970A1 (en) * | 1998-06-11 | 1999-12-16 | Boardwalk Ag | System, method, and computer program product for providing relational patterns between entities |
| US6735593B1 (en) * | 1998-11-12 | 2004-05-11 | Simon Guy Williams | Systems and methods for storing data |
| US6341277B1 (en) * | 1998-11-17 | 2002-01-22 | International Business Machines Corporation | System and method for performance complex heterogeneous database queries using a single SQL expression |
| US6341289B1 (en) * | 1999-05-06 | 2002-01-22 | International Business Machines Corporation | Object identity and partitioning for user defined extents |
| US6847980B1 (en) * | 1999-07-03 | 2005-01-25 | Ana B. Benitez | Fundamental entity-relationship models for the generic audio visual data signal description |
| US6556983B1 (en) * | 2000-01-12 | 2003-04-29 | Microsoft Corporation | Methods and apparatus for finding semantic information, such as usage logs, similar to a query using a pattern lattice data space |
| US20010047372A1 (en) * | 2000-02-11 | 2001-11-29 | Alexander Gorelik | Nested relational data model |
| US6591275B1 (en) * | 2000-06-02 | 2003-07-08 | Sun Microsystems, Inc. | Object-relational mapping for tables without primary keys |
| US20030105732A1 (en) * | 2000-11-17 | 2003-06-05 | Kagalwala Raxit A. | Database schema for structure query language (SQL) server |
| US6957230B2 (en) * | 2000-11-30 | 2005-10-18 | Microsoft Corporation | Dynamically generating multiple hierarchies of inter-object relationships based on object attribute values |
| US7043481B2 (en) * | 2001-06-01 | 2006-05-09 | Thought, Inc. | System, method and software for creating, maintaining, navigating or manipulating complex data objects and their data relationships |
| US20030005019A1 (en) * | 2001-06-27 | 2003-01-02 | Kuldipsingh Pabla | Application frameworks for mobile devices |
| US20030046266A1 (en) * | 2001-07-26 | 2003-03-06 | Ward Mullins | System, method and software for creating or maintaining distributed transparent persistence of complex data objects and their data relationships |
| US6907433B2 (en) * | 2001-08-01 | 2005-06-14 | Oracle International Corp. | System and method for managing object to relational one-to-many mapping |
| US7158994B1 (en) * | 2001-09-28 | 2007-01-02 | Oracle International Corporation | Object-oriented materialized views |
| GB2381153B (en) * | 2001-10-15 | 2004-10-20 | Jacobs Rimell Ltd | Policy server |
| US6836777B2 (en) * | 2001-11-15 | 2004-12-28 | Ncr Corporation | System and method for constructing generic analytical database applications |
| WO2003046694A2 (en) * | 2001-11-28 | 2003-06-05 | Bow Street Software, Inc. | Method and apparatus for creating software objects |
| US7162721B2 (en) * | 2001-12-03 | 2007-01-09 | Sun Microsystems, Inc. | Application-independent API for distributed component collaboration |
| US7062502B1 (en) * | 2001-12-28 | 2006-06-13 | Kesler John N | Automated generation of dynamic data entry user interface for relational database management systems |
| US7058655B2 (en) * | 2002-01-11 | 2006-06-06 | Sun Microsystems, Inc. | Determining object graph and object graph projection |
| AU2003224753A1 (en) * | 2002-03-22 | 2003-10-13 | Thought, Inc. | Micro edition dynamic object- driven database manipulation and mapping system |
| US7069260B2 (en) * | 2002-05-15 | 2006-06-27 | Motorola, Inc. | QOS framework system |
| US6910032B2 (en) * | 2002-06-07 | 2005-06-21 | International Business Machines Corporation | Parallel database query processing for non-uniform data sources via buffered access |
| US7096216B2 (en) * | 2002-07-20 | 2006-08-22 | Microsoft Corporation | Performing operations on a set of objects in a database system |
| US7412436B2 (en) * | 2002-07-20 | 2008-08-12 | Microsoft Corporation | System and interface for manipulating a database |
| US7162469B2 (en) * | 2002-07-20 | 2007-01-09 | Microsoft Corporation | Querying an object for properties |
| US7191182B2 (en) * | 2002-07-20 | 2007-03-13 | Microsoft Corporation | Containment hierarchy in a database system |
| US7130856B2 (en) * | 2002-07-20 | 2006-10-31 | Microsoft Corporation | Map and data location provider |
| US7711675B2 (en) * | 2002-07-22 | 2010-05-04 | Microsoft Corporation | Database simulation of data types |
| US7730446B2 (en) * | 2003-03-12 | 2010-06-01 | Microsoft Corporation | Software business process model |
| US7054877B2 (en) * | 2003-03-31 | 2006-05-30 | International Business Machines Corporation | Dealing with composite data through data model entities |
| US7412569B2 (en) * | 2003-04-10 | 2008-08-12 | Intel Corporation | System and method to track changes in memory |
| AU2003901968A0 (en) * | 2003-04-23 | 2003-05-15 | Wolfgang Flatow | A universal database schema |
| EP1482418A1 (en) * | 2003-05-28 | 2004-12-01 | Sap Ag | A data processing method and system |
| EP1482419A1 (en) * | 2003-05-28 | 2004-12-01 | Sap Ag | Data processing system and method for application programs in a data warehouse |
| FI115676B (fi) * | 2003-07-28 | 2005-06-15 | Nolics Oy | Menetelmä relaatiotyyppisen tiedon oliomuotoiseksi käsittelemiseksi |
| US8131739B2 (en) * | 2003-08-21 | 2012-03-06 | Microsoft Corporation | Systems and methods for interfacing application programs with an item-based storage platform |
| US7599948B2 (en) * | 2003-10-10 | 2009-10-06 | Oracle International Corporation | Object relational mapping layer |
| US7454428B2 (en) * | 2003-10-29 | 2008-11-18 | Oracle International Corp. | Network data model for relational database management system |
| US8200684B2 (en) * | 2003-12-08 | 2012-06-12 | Ebay Inc. | Method and system for dynamic templatized query language in software |
| US7219102B2 (en) * | 2003-12-22 | 2007-05-15 | International Business Machines Corporation | Method, computer program product, and system converting relational data into hierarchical data structure based upon tagging trees |
| US7660805B2 (en) * | 2003-12-23 | 2010-02-09 | Canon Kabushiki Kaisha | Method of generating data servers for heterogeneous data sources |
| US7536409B2 (en) * | 2005-02-15 | 2009-05-19 | International Business Machines Corporation | Having a single set of object relational mappings across different instances of the same schemas |
| US7685561B2 (en) * | 2005-02-28 | 2010-03-23 | Microsoft Corporation | Storage API for a common data platform |
| US7853961B2 (en) * | 2005-02-28 | 2010-12-14 | Microsoft Corporation | Platform for data services across disparate application frameworks |
| US20070266041A1 (en) * | 2006-05-11 | 2007-11-15 | Microsoft Corporation | Concept of relationshipsets in entity data model (edm) |
-
2005
- 2005-09-16 US US11/228,731 patent/US20060195460A1/en not_active Abandoned
-
2006
- 2006-01-09 KR KR1020060002291A patent/KR20060095452A/ko not_active Application Discontinuation
- 2006-01-19 AU AU2006200227A patent/AU2006200227A1/en not_active Abandoned
- 2006-01-24 EP EP06100768A patent/EP1696348A3/en not_active Withdrawn
- 2006-01-26 CA CA002534260A patent/CA2534260A1/en not_active Abandoned
- 2006-01-27 RU RU2006102530/08A patent/RU2421798C2/ru not_active IP Right Cessation
- 2006-01-30 MX MXPA06001209A patent/MXPA06001209A/es active IP Right Grant
- 2006-01-31 BR BRPI0600122-0A patent/BRPI0600122A/pt not_active IP Right Cessation
- 2006-02-28 JP JP2006053434A patent/JP2006244498A/ja not_active Ceased
Cited By (73)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2601198C2 (ru) * | 2011-08-11 | 2016-10-27 | МАЙКРОСОФТ ТЕКНОЛОДЖИ ЛАЙСЕНСИНГ, ЭлЭлСи | Система среды выполнения |
| US9563487B2 (en) | 2011-08-11 | 2017-02-07 | Microsoft Technology Licensing, Llc. | Runtime system |
| WO2013048273A1 (ru) * | 2011-09-26 | 2013-04-04 | Gorishniy Sergey Anatolievich | Система и метод хранения, извлечения и управления данными в объектной форме |
| RU2515565C1 (ru) * | 2012-10-22 | 2014-05-10 | Закрытое акционерное общество Научно-производственное предприятие "Реляционные экспертные системы" | Способ обновления структурированных данных в системе управления реляционными базами данных |
| RU2702977C2 (ru) * | 2014-06-02 | 2019-10-14 | МАЙКРОСОФТ ТЕКНОЛОДЖИ ЛАЙСЕНСИНГ, ЭлЭлСи | Фильтрация данных в корпоративной системе |
| US10635504B2 (en) | 2014-10-16 | 2020-04-28 | Microsoft Technology Licensing, Llc | API versioning independent of product releases |
| US10242040B2 (en) | 2015-05-14 | 2019-03-26 | Deephaven Data Labs Llc | Parsing and compiling data system queries |
| US9898496B2 (en) | 2015-05-14 | 2018-02-20 | Illumon Llc | Dynamic code loading |
| US9619210B2 (en) | 2015-05-14 | 2017-04-11 | Walleye Software, LLC | Parsing and compiling data system queries |
| US9639570B2 (en) | 2015-05-14 | 2017-05-02 | Walleye Software, LLC | Data store access permission system with interleaved application of deferred access control filters |
| US9672238B2 (en) | 2015-05-14 | 2017-06-06 | Walleye Software, LLC | Dynamic filter processing |
| US9679006B2 (en) | 2015-05-14 | 2017-06-13 | Walleye Software, LLC | Dynamic join processing using real time merged notification listener |
| US9690821B2 (en) | 2015-05-14 | 2017-06-27 | Walleye Software, LLC | Computer data system position-index mapping |
| US10353893B2 (en) | 2015-05-14 | 2019-07-16 | Deephaven Data Labs Llc | Data partitioning and ordering |
| US9760591B2 (en) | 2015-05-14 | 2017-09-12 | Walleye Software, LLC | Dynamic code loading |
| US9805084B2 (en) | 2015-05-14 | 2017-10-31 | Walleye Software, LLC | Computer data system data source refreshing using an update propagation graph |
| US9836494B2 (en) | 2015-05-14 | 2017-12-05 | Illumon Llc | Importation, presentation, and persistent storage of data |
| US9836495B2 (en) | 2015-05-14 | 2017-12-05 | Illumon Llc | Computer assisted completion of hyperlink command segments |
| US9886469B2 (en) | 2015-05-14 | 2018-02-06 | Walleye Software, LLC | System performance logging of complex remote query processor query operations |
| US9613018B2 (en) | 2015-05-14 | 2017-04-04 | Walleye Software, LLC | Applying a GUI display effect formula in a hidden column to a section of data |
| US10003673B2 (en) | 2015-05-14 | 2018-06-19 | Illumon Llc | Computer data distribution architecture |
| US10002153B2 (en) | 2015-05-14 | 2018-06-19 | Illumon Llc | Remote data object publishing/subscribing system having a multicast key-value protocol |
| US10002155B1 (en) | 2015-05-14 | 2018-06-19 | Illumon Llc | Dynamic code loading |
| US10452649B2 (en) | 2015-05-14 | 2019-10-22 | Deephaven Data Labs Llc | Computer data distribution architecture |
| US11687529B2 (en) | 2015-05-14 | 2023-06-27 | Deephaven Data Labs Llc | Single input graphical user interface control element and method |
| US10019138B2 (en) | 2015-05-14 | 2018-07-10 | Illumon Llc | Applying a GUI display effect formula in a hidden column to a section of data |
| US10069943B2 (en) | 2015-05-14 | 2018-09-04 | Illumon Llc | Query dispatch and execution architecture |
| US10176211B2 (en) | 2015-05-14 | 2019-01-08 | Deephaven Data Labs Llc | Dynamic table index mapping |
| US10198466B2 (en) | 2015-05-14 | 2019-02-05 | Deephaven Data Labs Llc | Data store access permission system with interleaved application of deferred access control filters |
| US10198465B2 (en) | 2015-05-14 | 2019-02-05 | Deephaven Data Labs Llc | Computer data system current row position query language construct and array processing query language constructs |
| US11663208B2 (en) | 2015-05-14 | 2023-05-30 | Deephaven Data Labs Llc | Computer data system current row position query language construct and array processing query language constructs |
| US11556528B2 (en) | 2015-05-14 | 2023-01-17 | Deephaven Data Labs Llc | Dynamic updating of query result displays |
| US10212257B2 (en) | 2015-05-14 | 2019-02-19 | Deephaven Data Labs Llc | Persistent query dispatch and execution architecture |
| US10241960B2 (en) | 2015-05-14 | 2019-03-26 | Deephaven Data Labs Llc | Historical data replay utilizing a computer system |
| US11514037B2 (en) | 2015-05-14 | 2022-11-29 | Deephaven Data Labs Llc | Remote data object publishing/subscribing system having a multicast key-value protocol |
| US10242041B2 (en) | 2015-05-14 | 2019-03-26 | Deephaven Data Labs Llc | Dynamic filter processing |
| US9612959B2 (en) | 2015-05-14 | 2017-04-04 | Walleye Software, LLC | Distributed and optimized garbage collection of remote and exported table handle links to update propagation graph nodes |
| US10346394B2 (en) | 2015-05-14 | 2019-07-09 | Deephaven Data Labs Llc | Importation, presentation, and persistent storage of data |
| US9710511B2 (en) | 2015-05-14 | 2017-07-18 | Walleye Software, LLC | Dynamic table index mapping |
| US9613109B2 (en) | 2015-05-14 | 2017-04-04 | Walleye Software, LLC | Query task processing based on memory allocation and performance criteria |
| US11263211B2 (en) | 2015-05-14 | 2022-03-01 | Deephaven Data Labs, LLC | Data partitioning and ordering |
| US10496639B2 (en) | 2015-05-14 | 2019-12-03 | Deephaven Data Labs Llc | Computer data distribution architecture |
| US10540351B2 (en) | 2015-05-14 | 2020-01-21 | Deephaven Data Labs Llc | Query dispatch and execution architecture |
| US10552412B2 (en) | 2015-05-14 | 2020-02-04 | Deephaven Data Labs Llc | Query task processing based on memory allocation and performance criteria |
| US10565194B2 (en) | 2015-05-14 | 2020-02-18 | Deephaven Data Labs Llc | Computer system for join processing |
| US10565206B2 (en) | 2015-05-14 | 2020-02-18 | Deephaven Data Labs Llc | Query task processing based on memory allocation and performance criteria |
| US10572474B2 (en) | 2015-05-14 | 2020-02-25 | Deephaven Data Labs Llc | Computer data system data source refreshing using an update propagation graph |
| US10621168B2 (en) | 2015-05-14 | 2020-04-14 | Deephaven Data Labs Llc | Dynamic join processing using real time merged notification listener |
| WO2016183564A1 (en) * | 2015-05-14 | 2016-11-17 | Walleye Software, LLC | Data store access permission system with interleaved application of deferred access control filters |
| US10642829B2 (en) | 2015-05-14 | 2020-05-05 | Deephaven Data Labs Llc | Distributed and optimized garbage collection of exported data objects |
| US11249994B2 (en) | 2015-05-14 | 2022-02-15 | Deephaven Data Labs Llc | Query task processing based on memory allocation and performance criteria |
| US10678787B2 (en) | 2015-05-14 | 2020-06-09 | Deephaven Data Labs Llc | Computer assisted completion of hyperlink command segments |
| US10691686B2 (en) | 2015-05-14 | 2020-06-23 | Deephaven Data Labs Llc | Computer data system position-index mapping |
| US11238036B2 (en) | 2015-05-14 | 2022-02-01 | Deephaven Data Labs, LLC | System performance logging of complex remote query processor query operations |
| US11151133B2 (en) | 2015-05-14 | 2021-10-19 | Deephaven Data Labs, LLC | Computer data distribution architecture |
| US11023462B2 (en) | 2015-05-14 | 2021-06-01 | Deephaven Data Labs, LLC | Single input graphical user interface control element and method |
| US10915526B2 (en) | 2015-05-14 | 2021-02-09 | Deephaven Data Labs Llc | Historical data replay utilizing a computer system |
| US10922311B2 (en) | 2015-05-14 | 2021-02-16 | Deephaven Data Labs Llc | Dynamic updating of query result displays |
| US10929394B2 (en) | 2015-05-14 | 2021-02-23 | Deephaven Data Labs Llc | Persistent query dispatch and execution architecture |
| RU2607977C1 (ru) * | 2015-06-30 | 2017-01-11 | Александр Игоревич Колотыгин | Способ создания модели объекта |
| RU2621185C2 (ru) * | 2015-11-10 | 2017-05-31 | Акционерное общество "Центральный научно-исследовательский институт экономики, информатики и систем управления" (АО "ЦНИИ ЭИСУ") | Система для определения отношения между первой и второй объектными сущностями данных |
| US10241965B1 (en) | 2017-08-24 | 2019-03-26 | Deephaven Data Labs Llc | Computer data distribution architecture connecting an update propagation graph through multiple remote query processors |
| US10783191B1 (en) | 2017-08-24 | 2020-09-22 | Deephaven Data Labs Llc | Computer data distribution architecture for efficient distribution and synchronization of plotting processing and data |
| US10657184B2 (en) | 2017-08-24 | 2020-05-19 | Deephaven Data Labs Llc | Computer data system data source having an update propagation graph with feedback cyclicality |
| US10909183B2 (en) | 2017-08-24 | 2021-02-02 | Deephaven Data Labs Llc | Computer data system data source refreshing using an update propagation graph having a merged join listener |
| US11449557B2 (en) | 2017-08-24 | 2022-09-20 | Deephaven Data Labs Llc | Computer data distribution architecture for efficient distribution and synchronization of plotting processing and data |
| US10866943B1 (en) | 2017-08-24 | 2020-12-15 | Deephaven Data Labs Llc | Keyed row selection |
| US10198469B1 (en) | 2017-08-24 | 2019-02-05 | Deephaven Data Labs Llc | Computer data system data source refreshing using an update propagation graph having a merged join listener |
| US11574018B2 (en) | 2017-08-24 | 2023-02-07 | Deephaven Data Labs Llc | Computer data distribution architecture connecting an update propagation graph through multiple remote query processing |
| US10002154B1 (en) | 2017-08-24 | 2018-06-19 | Illumon Llc | Computer data system data source having an update propagation graph with feedback cyclicality |
| US11126662B2 (en) | 2017-08-24 | 2021-09-21 | Deephaven Data Labs Llc | Computer data distribution architecture connecting an update propagation graph through multiple remote query processors |
| US11860948B2 (en) | 2017-08-24 | 2024-01-02 | Deephaven Data Labs Llc | Keyed row selection |
| US11941060B2 (en) | 2017-08-24 | 2024-03-26 | Deephaven Data Labs Llc | Computer data distribution architecture for efficient distribution and synchronization of plotting processing and data |
Also Published As
| Publication number | Publication date |
|---|---|
| EP1696348A3 (en) | 2007-04-18 |
| CA2534260A1 (en) | 2006-08-28 |
| EP1696348A2 (en) | 2006-08-30 |
| BRPI0600122A (pt) | 2006-10-24 |
| US20060195460A1 (en) | 2006-08-31 |
| RU2006102530A (ru) | 2007-08-10 |
| JP2006244498A (ja) | 2006-09-14 |
| AU2006200227A1 (en) | 2006-09-14 |
| MXPA06001209A (es) | 2006-09-19 |
| KR20060095452A (ko) | 2006-08-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| RU2421798C2 (ru) | Модель данных для объектно-реляционных данных | |
| US7853961B2 (en) | Platform for data services across disparate application frameworks | |
| US7673282B2 (en) | Enterprise information unification | |
| Elmasri | Fundamentals of database systems seventh edition | |
| US20070219976A1 (en) | Extensible query language with support for rich data types | |
| US8392464B2 (en) | Easily queriable software repositories | |
| US20030179228A1 (en) | Instance browser for ontology | |
| US20040181544A1 (en) | Schema server object model | |
| US8438141B2 (en) | System and method for providing secure access to data with user defined table functions | |
| JP2006528800A (ja) | 自己記述型ビジネスオブジェクト | |
| MXPA06001984A (es) | Sistemas y metodos para conectar con una interfase programas de aplicacion una plataforma de almacenamiento basada en elementos. | |
| JP2006528801A (ja) | サービス指向ビジネスフレームワークのサービス管理 | |
| Dietrich et al. | Fundamentals of object databases: Object-oriented and object-relational design | |
| Reese | Java Database Best Practices: Persistence Models and Techniques for Java Database Programming | |
| EP1274018A2 (en) | Instance browser for ontology | |
| Roantree | Engineering Federated Information Systems: Proceedings of the 3rd Workshop, EFIS 2000, June 19-20, 2000, Dublin (Ireland) | |
| Rahayu et al. | Object-oriented oracle | |
| Lin | Object-oriented database systems: A survey | |
| Pu et al. | The DIOM Approach to Large-scale Interoperable Database Systems | |
| de Wouters | Principles of Database Management | |
| Lavariega-Jarquin | Object-oriented query processing in a multidatabase environment: Integrating structural and operational approaches | |
| Draheim et al. | Data Modeling | |
| Woliso | Lecture Notes ON | |
| DELDICQUE | IST Project IST-1999-11009 Commission of the European Communities | |
| Dayal | The Role of Object-Oriented Database Technology in Distributed Information Systems |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| MM4A | The patent is invalid due to non-payment of fees |
Effective date: 20150128 |