KR20230136121A - 인공 신경망을 사용한 프로그래시브 데이터 압축 - Google Patents
인공 신경망을 사용한 프로그래시브 데이터 압축 Download PDFInfo
- Publication number
- KR20230136121A KR20230136121A KR1020237024615A KR20237024615A KR20230136121A KR 20230136121 A KR20230136121 A KR 20230136121A KR 1020237024615 A KR1020237024615 A KR 1020237024615A KR 20237024615 A KR20237024615 A KR 20237024615A KR 20230136121 A KR20230136121 A KR 20230136121A
- Authority
- KR
- South Korea
- Prior art keywords
- content
- quantization
- quantization bin
- encoded
- compression
- Prior art date
Links
Images

Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/124—Quantisation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/084—Backpropagation, e.g. using gradient descent
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G06N3/088—Non-supervised learning, e.g. competitive learning
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/3059—Digital compression and data reduction techniques where the original information is represented by a subset or similar information, e.g. lossy compression
-
- H—ELECTRICITY
- H03—ELECTRONIC CIRCUITRY
- H03M—CODING; DECODING; CODE CONVERSION IN GENERAL
- H03M7/00—Conversion of a code where information is represented by a given sequence or number of digits to a code where the same, similar or subset of information is represented by a different sequence or number of digits
- H03M7/30—Compression; Expansion; Suppression of unnecessary data, e.g. redundancy reduction
- H03M7/3082—Vector coding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/112—Selection of coding mode or of prediction mode according to a given display mode, e.g. for interlaced or progressive display mode
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/119—Adaptive subdivision aspects, e.g. subdivision of a picture into rectangular or non-rectangular coding blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/124—Quantisation
- H04N19/126—Details of normalisation or weighting functions, e.g. normalisation matrices or variable uniform quantisers
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/146—Data rate or code amount at the encoder output
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/146—Data rate or code amount at the encoder output
- H04N19/147—Data rate or code amount at the encoder output according to rate distortion criteria
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Data Mining & Analysis (AREA)
- Computing Systems (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
Abstract
본 개시의 특정 양태들은 신경망을 사용하여 컨텐츠를 압축하기 위한 기법을 제공한다. 예시적인 방법은 일반적으로 압축을 위한 컨텐츠를 수신하는 단계를 포함한다. 컨텐츠는 컨텐츠의 잠재 코드 공간 표현을 생성하도록 트레이닝된 인공 신경망에 의해 구현되는 인코더를 통하여 제 1 잠재 코드 공간으로 인코딩된다. 인코딩된 컨텐츠의 제 1 압축된 버전은 양자화 빈 사이즈들의 시리즈 중 제 1 양자화 빈 사이즈를 사용하여 생성된다. 인코딩된 컨텐츠의 리파이닝된 압축된 버전은 적어도 인코딩된 컨텐츠의 제 1 압축된 버전의 값에 대해 컨디셔닝되어, 인코딩된 컨텐츠의 제 1 압축된 버전을 제 1 양자화 빈 사이즈보다 더 작은 하나 이상의 제 2 양자화 빈 사이즈들로 스케일링하는 것에 의해 생성된다. 인코딩된 컨텐츠의 리파이닝된 압축된 버전이 송신을 위하여 출력된다.
Description
관련 출원들에 대한 상호 참조
이 출원은 2022년 1월 24일자로 출원된 미국 출원 제 17/648,808 호를 우선권으로 주장하며, 이는 2021년 1월 25일자로 출원되고 발명의 명칭이 "Progressive Data Compression Using Artificial Neural Networks"이고 본 출원의 양수인에게 양도된 미국 가특허 출원 제 63/141,322 호를 우선권으로 주장하며, 이들 각각의 전체 내용은 본 명세서에서 그 전체가 참조로서 포함된다.
기술 분야
본 개시의 양태들은 머신 러닝에 관한 것이고 보다 구체적으로, 데이터, 이를 테면, 비디오 컨텐츠를 압축하기 위해 인공 신경망을 사용하는 것에 관한 것이다.
데이터 압축 기법들은 저장 및 송신의 효율을 개선하고 의도된 용도 (예를 들어, 디바이스의 디스플레이의 사이즈에 대한 데이터의 적절한 해상도) 를 매칭시키는 것을 포함하는 다양한 이유들로 컨텐츠의 사이즈를 감소시키기 위해 사용될 수 있다. 데이터 압축은 데이터의 압축해제된 버전이 압축된 원본 데이터의 근사치이도록 손실 기법을 사용하여 또는 데이터의 압축해제된 버전이 원본 데이터와 동등하게 되는 무손실 기법을 사용하여 수행될 수도 있다.
일반적으로, 무손실 압축은 압축에서, 이를 테면, 파일들의 아카이브들을 압축하는 데 있어서, 데이터가 손실되지 않아야 하는 무손실 압축이 사용될 수도 있다. 이와 대조적으로, 손실 압축은 원본 데이터의 정확한 재생이 필요하지 않는 경우 (예를 들어, 스틸 이미지, 비디오 또는 오디오를 압축하는데 있어서, 일부 데이터 손실, 이를 테면, 오디오 스펙트럼의 극단부에서의 오디오 주파수들에서 또는 컬러 데이터의 미세도에서의 손실들이 허용될 수 있는 경우) 사용될 수도 있다.
데이터 압축 방식들은 종종 정의되거나 고정된 압축 레이트 (예를 들어, 단일 비트 레이트) 에 기초할 수 있으며, 이는 이들 압축 방식들을 다양한 데이터 타입들 및 압축 요구들에 유연하지 않게 한다. 즉, 임의의 주어진 압축 방식에 대해, 데이터는 일반적으로 데이터가 더 높은 또는 더 낮은 압축 비트레이트로 수정가능한지 여부에 관계없이 특정 비트레이트로 압축된다. 예를 들어, 미세한 디테일을 포함하지 않는 이미지들에서, 고정 비트레이트 압축 방식은 이미지들에서 정보를 표현하기 위해 필요한 것보다 많은 비트들을 사용하여 이들 이미지들을 압축할 수 있지만, 이미지들은 손실 압축 방식들 (및 그에 대응하여 더 낮은 비트레이트들) 을 사용하여 압축할 수 있다. 이와 유사하게, 보다 상세한 이미지는 너무 낮은 비트레이트로 압축되어 충분히 재생될 수 없다. 따라서, 종래의 방식들은 종종 동적이고 적응가능하지 않은 고정 압축 방식의 설계에 절충을 수반한다.
이에 따라, 적응적으로 컨텐츠를 압축하기 위한 개선된 기법이 요구된다.
특정 양태들은 신경망을 사용하여 컨텐츠를 압축하기 위한 방법을 제공한다. 예시적인 방법은 일반적으로 압축을 위한 컨텐츠를 수신하는 단계를 포함한다. 컨텐츠는 인공 신경망에 의해 구현되는 인코더를 통해 제 1 잠재 코드 공간으로 인코딩된다. 인코딩된 컨텐츠의 제 1 압축된 버전은 양자화 빈 사이즈들의 시리즈 중 제 1 양자화 빈 사이즈를 사용하여 생성된다. 인코딩된 컨텐츠의 리파이닝된 압축된 버전은 적어도 인코딩된 컨텐츠의 제 1 압축된 버전의 값에 대해 컨디셔닝되어, 인코딩된 컨텐츠의 제 1 압축된 버전을 제 1 양자화 빈 사이즈보다 더 작은 하나 이상의 제 2 양자화 빈 사이즈들로 스케일링하는 것에 의해 생성한다. 인코딩된 컨텐츠의 리파이닝된 압축된 버전이 출력된다.
특정 양태들은 신경망을 사용하여 압축된 컨텐츠를 압축해제하기 위한 방법을 제공한다. 예시적인 방법은 일반적으로 압축해제를 위한 인코딩된 컨텐츠를 수신하는 단계를 포함한다. 잠재 코드 공간에서의 값의 근사치는 양자화 빈 사이즈들의 시리즈로부터 코드들을 복구하는 것에 의해 수신된 인코딩된 컨텐츠로부터 복구되고, 여기서, 양자화 빈 사이즈들의 시리즈는 제 1 양자화 빈 사이즈 및 제 1 양자화 빈 사이즈보다 더 작은 하나 이상의 제 2 양자화 빈 사이즈들을 포함한다. 인코딩된 컨텐츠의 압축해제된 버전은 인공 신경망에 의해 구현되는 디코더를 통해 잠재 코드 공간 내의 값의 근사치를 디코딩하는 것에 의해 생성된다. 인코딩된 컨텐츠의 압축해제된 버전이 출력된다.
다른 양태들은 전술한 방법 및 여기에 설명된 것들을 수행하도록 구성된 프로세싱 시스템; 프로세싱 시스템의 하나 이상의 프로세서에 의해 실행될 때, 프로세싱 시스템으로 하여금 전술한 방법 및 여기에 설명된 것들을 수행하게 하는 명령들을 포함하는 비일시적 컴퓨터 판독 가능 매체; 전술한 방법 및 여기에 추가로 설명된 것들을 수행하기 위한 코드를 포함하는 컴퓨터 판독 가능 저장 매체에 구체화된 컴퓨터 프로그램 제품; 및 전술한 방법 및 여기에 추가로 설명된 것들을 수행하는 수단을 포함하는 프로세싱 시스템을 제공한다.
다음의 설명 및 관련 도면들은 하나 이상의 양태들의 소정의 예시적인 특징들을 상세히 제시한다.
첨부된 도면은 하나 이상의 양태 중 소정 양태를 도시하고 따라서 본 개시의 범위를 제한하는 것으로 간주되어서는 안된다.
도 1 은 일 예의 신경망-기반 데이터 압축 파이프라인을 도시한다.
도 2 는 인공 신경망들 및 압축 비트레이트의 연속적인 스케일링으로서 구현되는 인코더들 및 디코더들을 사용하여 컨텐츠를 압축 및 압축해제하기 위한 일 예의 파이프라인 을 예시한다.
도 3 은 본 개시의 양태들에 따라, 압축 비트레이트의 연속적인 제어에서의 양자화 폭의 잠재적 스케일링의 일 예를 예시한다.
도 4a 는 본 개시의 양태들에 따라, 상이한 압축 비트레이트들을 달성하기 위해 사용되는 양자화 빈 사이즈들의 일 예를 예시한다.
도 4b 는 본 개시의 양태들에 따른, 양자화 빈 사이즈 레벨들에서의 빈들이 불균일한 사이즈들을 갖는 상이한 압축 비트레이트들을 달성하기 위해 사용되는 양자화 빈 사이즈 레벨들의 일 예를 예시한다.
도 5 는 본 개시의 양태들에 따라, 더 거친 양자화 빈 사이즈들에서의 양자화된 코드들에 대해 컨디셔닝된 더 미세한 양자화 빈 사이즈들에서의 양자화된 코드들에 기초한 네스트된 양자화의 일 예를 예시한다.
도 6 은 본 개시의 양태들에 따라, 프로그래시브 코딩을 사용하여 압축 파이프라인을 통해 수신된 컨텐츠를 압축하기 위한 일 예의 동작들을 예시한다.
도 7 은 본 개시의 양태들에 따른, 인코딩된 컨텐츠를 압축해제하기 위한 일 예의 동작들을 예시한다.
도 8 은 본 개시의 양태들에 따라, 상이한 채널들에 대한 상이한 비트레이트들을 사용하여 채널-와이즈 프로그래시브 코딩의 일 예를 예시한다.
도 9 는 본 개시의 양태들에 따른, 프로그래시브 코딩을 위한 유효 양자화 그리드를 예시한다.
도 10 은 본 개시의 양태들에 따른, 가장 미세한 양자화 그리드에 대한 정렬을 갖는 프로그래시브 코딩을 위한 양자화 그리드를 예시한다.
도 11 은 본 개시의 양태들에 따라, 프로그래시브 코딩을 사용한 데이터 압축의 일 예의 결과들을 예시한다.
도 12 는 본 개시의 양태들에 따라, 코딩 유닛들의 상이한 오더링들에 기초하여 데이터 압축의 일 예의 결과들을 예시한다.
도 13 은 본 개시의 양태들에 따라, 코딩 유닛들의 프로그래시브 코딩 및 상이한 오더링들을 사용하여 데이터 압축의 일 예의 결과들을 예시한다.
도 14 는 본 개시의 양태들에 따라, 사이드 정보가 데이터를 압축해제하는데 사용되는 일 예의 신경망-기반 데이터 압축 파이프라인을 예시한다.
도 15 는 본 개시의 양태들에 따라, 컨텐츠의 프로그래시브 코딩 및 디코딩이 수행될 수 있는 프로세싱 시스템의 일 예의 구현을 예시한다.
이해를 용이하게 하기 위하여, 가능한 경우, 도면들에 공통되는 동일한 요소들을 나타내는 데 동일한 도면 부호들을 사용하였다. 일 양태의 엘리먼트들 및 피처들은 추가 기재없이도 다른 양태들에 유익하게 통합될 수도 있음이 고려된다.
도 1 은 일 예의 신경망-기반 데이터 압축 파이프라인을 도시한다.
도 2 는 인공 신경망들 및 압축 비트레이트의 연속적인 스케일링으로서 구현되는 인코더들 및 디코더들을 사용하여 컨텐츠를 압축 및 압축해제하기 위한 일 예의 파이프라인 을 예시한다.
도 3 은 본 개시의 양태들에 따라, 압축 비트레이트의 연속적인 제어에서의 양자화 폭의 잠재적 스케일링의 일 예를 예시한다.
도 4a 는 본 개시의 양태들에 따라, 상이한 압축 비트레이트들을 달성하기 위해 사용되는 양자화 빈 사이즈들의 일 예를 예시한다.
도 4b 는 본 개시의 양태들에 따른, 양자화 빈 사이즈 레벨들에서의 빈들이 불균일한 사이즈들을 갖는 상이한 압축 비트레이트들을 달성하기 위해 사용되는 양자화 빈 사이즈 레벨들의 일 예를 예시한다.
도 5 는 본 개시의 양태들에 따라, 더 거친 양자화 빈 사이즈들에서의 양자화된 코드들에 대해 컨디셔닝된 더 미세한 양자화 빈 사이즈들에서의 양자화된 코드들에 기초한 네스트된 양자화의 일 예를 예시한다.
도 6 은 본 개시의 양태들에 따라, 프로그래시브 코딩을 사용하여 압축 파이프라인을 통해 수신된 컨텐츠를 압축하기 위한 일 예의 동작들을 예시한다.
도 7 은 본 개시의 양태들에 따른, 인코딩된 컨텐츠를 압축해제하기 위한 일 예의 동작들을 예시한다.
도 8 은 본 개시의 양태들에 따라, 상이한 채널들에 대한 상이한 비트레이트들을 사용하여 채널-와이즈 프로그래시브 코딩의 일 예를 예시한다.
도 9 는 본 개시의 양태들에 따른, 프로그래시브 코딩을 위한 유효 양자화 그리드를 예시한다.
도 10 은 본 개시의 양태들에 따른, 가장 미세한 양자화 그리드에 대한 정렬을 갖는 프로그래시브 코딩을 위한 양자화 그리드를 예시한다.
도 11 은 본 개시의 양태들에 따라, 프로그래시브 코딩을 사용한 데이터 압축의 일 예의 결과들을 예시한다.
도 12 는 본 개시의 양태들에 따라, 코딩 유닛들의 상이한 오더링들에 기초하여 데이터 압축의 일 예의 결과들을 예시한다.
도 13 은 본 개시의 양태들에 따라, 코딩 유닛들의 프로그래시브 코딩 및 상이한 오더링들을 사용하여 데이터 압축의 일 예의 결과들을 예시한다.
도 14 는 본 개시의 양태들에 따라, 사이드 정보가 데이터를 압축해제하는데 사용되는 일 예의 신경망-기반 데이터 압축 파이프라인을 예시한다.
도 15 는 본 개시의 양태들에 따라, 컨텐츠의 프로그래시브 코딩 및 디코딩이 수행될 수 있는 프로세싱 시스템의 일 예의 구현을 예시한다.
이해를 용이하게 하기 위하여, 가능한 경우, 도면들에 공통되는 동일한 요소들을 나타내는 데 동일한 도면 부호들을 사용하였다. 일 양태의 엘리먼트들 및 피처들은 추가 기재없이도 다른 양태들에 유익하게 통합될 수도 있음이 고려된다.
본 개시의 양태들은 단일 모델이 가변 비트레이트 또는 품질 레벨들에서 컨텐츠를 인코딩하는데 사용될 수 있도록 인공 신경망들을 사용하여 컨텐츠를 프로그래시브하게 압축하기 위한 기법들을 제공한다.
신경망-기반 데이터 압축 시스템들은 다양한 유형들의 데이터를 압축하는데 사용될 수 있다. 예를 들어, 신경망-기반 데이터 압축은 압축에 순응하는 다양한 유형의 컨텐츠를 압축하는데 사용될 수 있다. 이 컨텐츠는 예를 들어, 비디오 컨텐츠, 이미지 컨텐츠, 오디오 컨텐츠, 센서 컨텐츠, 및 압축에 순응하는 다른 유형의 데이터를 포함할 수 있다. 일반적으로, 신경망-기반 데이터 압축은 인코딩된 컨텐츠의 사이즈와 왜곡 사이의 트레이드오프 (원본 컨텐츠와 압축해제된 컨텐츠 사이의 차이) 에 기초하여 선험적으로 결정되는 비트레이트를 사용하여 컨텐츠를 압축할 수도 있다. 많은 데이터 압축 시스템들에서, 더 높은 비트레이트들 (예를 들어, 압축될 컨텐츠를 표현하기 위해 사용되는 더 많은 수의 비트들) 은 더 낮은 왜곡과 연관될 수 있는 반면, 더 작은 비트레이트들은 더 높은 왜곡과 연관될 수 있다. 왜곡 (D) 과 비트레이트 (R) 사이의 트레이드오프는 식 에 의해 표현될 수 있으며, 여기서 θ 는 (예를 들어, 확률적 기울기 하강 방법들을 사용하여) 엔드-투-엔드로부터 최적화되는 오토-인코더에서의 파라미터들을 나타내고, β 는 비트레이트 R 에 적용되는 가중치를 나타낸다.
그러나, 통상적인 신경망-기반 데이터 압축은 다양한 이유들로 대규모 배치에 적합하지 않을 수도 있다. 예를 들어, 많은 머신 러닝-기반 압축 방식들에서, 모델들은 상이한 비트레이트들을 지원하기 위하여 트레이닝될 필요가 있을 수 있다. 즉, 제 1 모델은 낮은 (베이스라인) 비트레이트에 대해 트레이닝될 수 있고, 제 2 모델은 베이스라인 비트레이트보다 높은 제 2 비트레이트에 대해 트레이닝될 수 있고, 제 3 모델은 제 2 모델의 비트레이트보다 높은 제 3 비트레이트에 대해 트레이닝될 수 있는 등이다. 다른 머신-러닝-기반 압축 방식들에서, 인코더 및 디코더 네트워크는 단일 모델이 상이한 레이트-왜곡 트레이드오프들에 적응할 수 있도록 β 파라미터에 의존할 수 있다. 다른 머신-러닝-기반 압축 방식들은 생성된 잠재들의 양자화 스텝 사이즈들을 조정하도록 학습할 수 있다. 그러나, 이러한 모델들은 컨텐츠의 가변 코딩을 허용하는 압축 방식을 효과적으로 학습하지 못할 수도 있다. 이 가변 코딩은 프로그래시브 코딩 방식, 또는 특정 데이터가 더 낮은 비트레이트를 사용하여 인코딩 및 디코딩될 수 있도록 다수의 비트레이트들을 사용하여 데이터가 압축되는 것을 허용하는 인코딩 방식을 통하여 실현될 수 있고 다른 데이터 (예를 들어, 디코딩될 때 이러한 디테일의 보다실패적인 복원을 가져오는 보다 높은 디테일을 가는 이미지의 부분) 는 압축 중에 있는 데이터에서의 차이들을 동적으로 고려하기 위해 더 높은 비트레이트들을 사용하여 인코딩 및 디코딩될 수 있다.
본 개시의 양태들은 단일 모델을 사용하여 컨텐츠의 프로그래시브 코딩 (및 압축) 을 허용하는 기법들을 제공한다. 컨텐츠의 프로그래시브 코딩에서, 더 높은 비트레이트 코드들이 더 낮은 비트레이트 코드들에 기초하여 생성될 수 있어, 입력 데이터의 인코딩된, 압축된 버전은 다수의 모델들을 사용하여 입력 데이터를 압축할 필요 없이 복수의 비트레이트들을 사용하여 프로그래시브으로 압축된다. 그 다음, 압축된 데이터는 여러 고려요건들, 이를 테면, 데이터를 압축해제하는 디바이스의 프로세싱 능력들, 압축해제된 데이터에 필요한 디테일의 양 등에 따라 복수의 비트레이트들의 어느 것을 사용하여 복구될 수 있다. 또한, 프로그래시브로 압축된 데이터는 단일 파일 대 다수의 버전들로 저장될 수도 있고, 이들 각각은 상이한 비트레이트로 압축되며, 이는 압축된 데이터에 대한 저장 및 송신 효율을 개선시킬 수 있다.
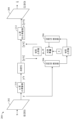
일 예의 신경망-기반 데이터 압축 파이프라인
도 1 은 본 개시의 양태들에 따른 일 예의 신경망-기반 데이터 압축 파이프라인 (100) 을 예시한다. 예시된 바와 같이, 파이프라인 (100) 은 압축을 위해 컨텐츠 x (111) 를 수신하고 압축된 비트스트림을 생성하도록 구성되며, 압축된 비트스트림으로부터 컨텐츠 x (111) 의 근사치 ()(127) 가 복구될 수 있다. 일반적으로, 파이프라인 (100) 의 인코딩 측 (110) 은 잠재 코드 공간에서 컨텐츠 x (111) 를 코드 y (113) 에 맵핑하는 컨볼루션 신경망-기반 비선형 변환 계층 (ga)(112), 잠재 코드 공간에서 코드 y (113) 를 압축하는 학습된 양자화 방식 (Q) (114), 및 컨텐츠의 압축된 (양자화된) 버전을 표현하는 비트스트림을 생성하는 엔티티 코더 (116) 를 포함한다. 잠재 코드 공간은 컨텐츠가 맵핑될 수 있는 신경망의 은닉된 계층의 압축된 공간일 수도 있고 그 계층 내에 컨텐츠가 맵핑될 수 있다. 잠재 코드 공간에서의 코드들은 일반적으로, 다차원들로 존재할 수도 있는 입력 데이터의 피처들이 더 콤팩트한 표현으로 감소되도록 이들 코드들이 맵핑되는 입력 데이터의 무손실 압축된 버전들을 표현한다.
파이프라인 (100) 의 디코딩 측 (120) 에서, 엔티티 디코더 (122) 는 컨텐츠의 양자화된 버전을 복구하고, 역 양자화 스킴 (Q-1)(124) 은 근사화된 코드 () 를 복구한다. 그 후, 컨볼루션 기반 비선형 변환 계층 (gs)(126) 은 근사화된 코드 () 로부터 컨텐츠 x 의 근사치 () 를 생성하고, (예를 들어, 사용자 디바이스 상의 디스플레이를 위하여 또는 압축된 컨텐츠가 사용자 디바이스로의 송신을 위하여 취출될 수도 있는 지속적인 데이터 기억부로의 저장을 위하여) 컨텐츠 x 의 근사치 () 를 출력할 수도 있다.
신경망-기반 데이터 압축에 수반되는 트레이닝 손실들은 (예를 들어, 컨텐츠 x (111) 와 컨텐츠 x (111) 의 근사치 ()(127) 사이에 계산되는) 왜곡의 양과 레이트 파라미터 β 의 합으로서 표현될 수 있으며, 이는 일반적으로 압축 비트레이트를 표현한다. 위에 설명된 바와 같이, β 를 증가시키는 것은 일반적으로 증가된 품질 및 감소된 압축량을 초래한다. 압축 비트레이트가 증가되면, 입력 데이터의 결과적인 압축된 버전은 압축 비트레이트가 더 작은 경우보다 더 큰 사이즈를 가질 수 있다. 따라서, 송신할 더 많은 데이터가 있을 것이고, 이는 데이터를 수신하고 압축해제하는데 필요한 전력의 양, 입력 데이터의 압축된 버전을 송신하는데 사용되는 더 많은 네트워크 용량, 입력 데이터의 압축된 버전을 저장하는데 필요한 더 많은 스토리지, 입력 데이터의 압축된 버전을 압축해제하는데 필요한 더 많은 프로세싱 전력 등을 증가시킬 수 있다.
일반적으로, 독립 모델들은 컨텐츠를 압축하기 위한 상이한 비트레이트 옵션들을 획득하도록 트레이닝될 수 있다. 그러나, 이러한 독립 모델들은 개별적으로 트레이닝되고 어떠한 관계도 없기 때문에 컨텐츠의 프로그래시브 인코딩이 가능하지 않다. 따라서, 이들 독립 모델들은 단일 인코더-디코더가 사용되는 비-프로그래시브 모델들이고, 다양한 파라미터들이 독립 모델들의 레이트-왜곡 트레이드오프를 조정하는데 사용될 수 있다. 또한, 가변 비트 레이트 솔루션들은 상이한 품질 레벨들에서 입력의 인코딩된 버전들의 다수의 사본들의 생성, 송신, 및/또는 저장을 수반할 수 있으며, 이는 데이터 압축 동작들에서 생성, 송신, 및 저장되는 데이터의 양을 증가시킬 수 있다.
본 개시의 양태들은 단일 인코더-디코더 모델을 사용하여 데이터의 프로그래시브 압축을 제공한다. 일반적으로, 데이터의 압축은 데이터를 더 컴팩트한 표현들로 인코딩하는 코딩 기법들을 사용하여 실현될 수 있다. 본 명세서에서 프로그래시브 코딩으로 지칭되지만, 임베디드 코딩 또는 스케일러블 코딩으로도 알려진 이들 코딩 기법은, 복수의 비트레이트의 각각이 임베딩되는, 컨텐츠가 한번 인코딩되는 것을 허용한다. 복수의 비트레이트가 임베딩된 컨텐츠를 한번 인코딩하는 것에 의해, 압축 비트레이트의 동적 제어는 데이터의 다수의 인코딩된 버전들이 상이한 압축 비트레이트들 (그리고 따라서, 상이한 레벨들의 압축 품질 보존) 을 지원하기 위해 생성될 필요가 없도록 단순화될 수 있다.
예를 들어, 브로드캐스트 컨텐츠의 비트레이트들은 (예를 들어, 이용가능한 스루풋, 레이턴시, 컨텐츠의 복잡성 및 이 컨텐츠를 압축할 때 보존될 디테일의 양 등에 응답하여) 동적으로 적응될 수 있다. 또한, 컨텐츠의 프로그래시브 코딩은 복수의 지원되는 비트레이트들 각각에 대해 생성된 압축된 컨텐츠의 다수의 버전들 대신에 다양한 비트레이트들을 사용하여 디코딩될 수 있는 압축된 컨텐츠의 단일 버전을 제공하는 것에 의해 송신 및 저장 비용들의 감소를 허용할 수 있다.
복수의 비트레이트들 각각이 임베딩되어 컨텐츠가 한번 인코딩되도록 컨텐츠의 프로그래시브 코딩을 허용하기 위해, 컨텐츠 x 를 표현하는 잠재 코드 공간 코드 y 는 더 미세한 양자화 레벨들 (및 대응적으로, 더 높은 비트레이트 압축) 과 연관된 코드들이 더 거친 양자화 레벨들 (및 대응적으로, 더 낮은 비트레이트 압축) 과 연관된 코드들에 임베딩되는 네스트된 양자화 모델을 사용하여 인코딩될 수 있다. 본 명세서에서 보다 자세하게 추가로 논의된 바와 같이, 네스트된 양자화는 더 미세한 양자화 레벨들과 연관된 코드들이 더 거친 양자화 레벨들과 연관된 코드들에 대해 컨디셔닝되도록 허용할 수 있어, 데이터가 더 미세한 양자화 레벨들로 프로그래시브하게 인코딩될 수 있고, 압축해제된 데이터의 품질 및 비트레이트에서의 대응적으로 프로그래시브한 증가들을 가져온다.
네스트된 양자화 모델에서, 높은 비트레이트 모델로 시작하여, 양자화 빈 사이즈들의 시리즈가 학습될 수 있다. 시리즈 중 각각의 양자화 빈 사이즈는 특정 파라미터 (예를 들어, β 의 값) 와 연관될 수도 있다. 가장 거친 양자화 빈 (즉, 최저 비트레이트와 연관된 양자화 빈) 으로부터 시작하여, 컨텐츠 x 를 나타내는 잠재 코드 공간 코드 y 는 더 미세한 양자화 빈들로 프로그래시브로 코딩될 수도 있다. 본 명세서에서 더 상세히 논의되는 바와 같이, 특정 양자화 빈에 대한 비트들은 양자화된 확률들의 체인 규칙에 따라 특정 양자화 빈까지 가장 거친 양자화 빈에 대한 비트들 및 각각의 프로그래시브하게 더 미세한 양자화 빈에 대한 비트들의 합으로서 표현될 수도 있다. 일반적으로, 네스트된 양자화 모델의 각각의 양자화 레벨에서, 확률은 가능한 코드들의 유니버스의 각각의 코드와 연관될 수 있고, 가장 높은 확률을 갖는 코드는 그 양자화 레벨에서 데이터가 압축되는 코드로서 선택될 수 있다. 체인 룰에 기초하여, 데이터가 임의의 주어진 양자화 레벨 (N) 에서 압축되는 코드는 데이터가 N 보다 더 낮은 양자화 레벨들로 (즉, 더 거친 양자화 빈들과 연관된 양자화 레벨에서) 압축되는 코드들의 함수로서 표현될 수 있음을 알 수 있다. 예를 들어, 가장 미세한 양자화 빈 (즉, N 개의 양자화 빈들 중 N번째) 에 대한 비트들은 하기 식에 의해 표현될 수도 있다:
식에서, P(yN) 은 압축된 입력 데이터와 연관된 코드가 N번째 양자화 빈에 위치되는 분포 곡선 하에서의 확률 질량이고 P(yN|yN-1) 는 입력 데이터와 연관된 코드가 N번째 양자화 빈에 위치되어, N-1번째 양자화 빈에서의 입력 데이터와 연관된 코드에 대해 컨디셔닝되는 분포 곡선 하에서의 확률 질량이다. 즉, 가장 미세한 양자화 빈의 비트들 (즉, ) 은 가장 거친 양자화 빈에 대한 비트들 (즉, ), 가장 거친 양자화 빈에 대해 컨디셔닝된 제 2 양자화 빈에 대한 비트들 (즉, ), 가장 거친 양자화 빈 및 제 2 양자화 빈에 대해 컨디셔닝된 제 3 양자화 빈에 대한 비트들 (즉, ) 등의 합으로서 표현될 수도 있다.
또한, 아래에서 추가로 상세히 논의되는 바와 같이, 프로그래시브 코딩은 채널-기반 잠재 오더링 오더링에서 사용될 수 있다. 채널-기반 잠재 오더링에서, 양자화 빈 사이즈들은 압축될 데이터 내의 상이한 채널들에 걸쳐 프로그래시브로 리파이닝될 수 있다.
예를 들어, 휘도 (Y), 청색 차이 (Pb), 및 적색 차이 (Pr) 채널들에 의해 표현되는 비디오 컨텐츠에서, 상이한 빈 사이즈들이 Y, Pb, 및 Pr 채널들에 대해 사용될 수 있다. 다른 예에서, 크로미넌스 채널들 (예를 들어, 적색 (R), 녹색 (G) 및 청색 (B) 컬러 채널들) 에 의해 표현되는 시각적 컨텐츠에 대해, 상이한 빈 사이즈들이 R, G 및 B 컬러 채널들에 대해 사용될 수 있다. 이들 채널들의 오더링은 더 높은 압축이 상당히 더 많은 왜곡을 초래하지 않는 채널들에 대해 더 거친 양자화 빈들이 사용되고 더 높은 압축이 상당히 더 많은 왜곡을 초래하는 채널들에 대해 더 미세한 양자화 빈들이 사용되도록 각각의 채널에 대해 계산된 왜곡 차이 및 레이트 차이의 비율에 기초하여 채널들을 분류하는 것에 의해 정의될 수 있다. 따라서, 채널들을 오더링하고, 채널들이 오더링되는 순서에 따라 상이한 양자화 비트들을 사용하여 채널들을 인코딩하는 것에 의해, 결과적인 압축해제된 데이터의 품질에 최대 영향을 갖는 채널들이 최고 품질 압축을 사용하여 압축될 수도 있고 결과적인 압축해제된 데이터의 품질에 대해 더 적은 영향을 갖는 채널들은 더 낮은 품질 압축을 사용하여 압축될 수 있도록 멀티-채널 컨텐츠가 인코딩될 수도 있다. 이는 입력 데이터의 결과적으로 압축된 표현의 사이즈를 감소시킬 수도 있고, 이는 이어서 압축된 데이터에 대한 저장 및 송신 비용들을 감소시킬 수도 있다.
도 2 는 인공 신경망들 및 압축 비트레이트의 연속적인 스케일링으로서 구현되는 인코더들 및 디코더들을 사용하여 (예를 들어, 도 1 에 예시된 바와 같이) 컨텐츠를 압축 및 압축해제하기 위한 일 예의 파이프라인의 추가의 세부사항들을 예시한다.
파이프라인 (200) 에서, 인코더 (202) 는 입력 x 를 잠재 코드 공간 코드 y 로 인코딩한다. 잠재 비트레이트를 연속적으로 제어하기 위해, 잠재 코드 공간 코드 y 는 하이퍼인코더 (204) 를 통하여 프로세싱될 수 있고, 하이퍼인코더는 인코더 신경망에서 가중치들을 제어하는데 사용되는 입력들을 표현하는 하이퍼 잠재성을 생성하기 위해, 인코더 신경망에 대한 가중치를 생성하는데 사용되는 다른 네트워크일 수도 있다. 하이퍼 잠재성은 데이터에서의 공간 종속성들을 캡처하는 정보로서 사용될 수 있고, y 를 [y] 로 지정된 y 의 라운딩된 (양자화된) 표현으로 라운딩 (또는 양자화) 하는데 사용될 수 있다 (s = 1 이도록 스케일링 팩터가 적용되지 않을 때, 양자화의 간략화된 버전; 이러한 경우, ). 사전 모델은 y 를 [y] 로 양자화하기 위해 사용되는 확률 분포 (도시되지 않음) 를 특성화할 수 있으며, 여기서 [y] 는 확률 분포에서 가장 높은 확률과 연관된 주어진 양자화 레벨에서의 양자화된 값에 대응한다.
디코더 측에서, 디코더 신경망에 대한 가중치들을 생성하는데 사용되는 네트워크일 수 있는 하이퍼디코더 (206) 는 라운드형 (양자화된) 잠재 코드 공간 코드 [y] 를 코딩하는데 사용되는 엔트로피 모델을 결정하기 위해 하이퍼잠재성을 디코딩한다. 엔트로피 모델은 예를 들어, y 를 코드 [y] 로 인코딩하기 위해 파이프라인 (200) 의 인코더 측에 대해 사용되는 확률 분포를 생성하는데 사용되는 확률 모델일 수도 있다. 엔트로피 모델에 기초하여, 디코더 (208) 는 [y] 로부터 x 를 복구하고, 그리고 x 가 (예를 들어, 디스플레이 디바이스로의 디스플레이, 송신 등을 위하여) 출력될 수도 있다.
일부 경우들에서, 스케일링 팩터는 컨텐츠 x 의 압축된 버전을 생성할 때 적용되는 압축의 양 및 비트레이트에 영향을 주기 위해 파이프라인 (200) 에 적용될 수 있다. 이 경우, 스케일링 파라미터 s 는 양자화 이전에 스케일러 (210) 에서 적용될 수 있고 (y 를 양자화된 값으로 라운딩함), 압축해제 이전에 리스케일러 (212) 에서 적용될 수 있고; 따라서, 컨텐츠 x 를 나타내는 잠재적 공간 코드 y 의 양자화되고 스케일링된 버전은 y/s로서 표현될 수 있다. 스케일링 팩터 (s) 에 의해 y를 스케일링하는 것에 의해, y 를 라운드 (양자화) 하는데 사용되는 양자화 빈 사이즈는 기본 값 (예를 들어, 1) 으로부터 양자화의 더 미세한 또는 더 거친 정도 그리고 이에 따라 압축의 더 미세한 또는 더 거친 정도에 대응하는 상이한 값으로 변경될 수 있다. 이는 모델이 양자화 빈 사이즈에 대해 트레이닝될 수 있게 하고, 상이한 왜곡-레이트 트레이드오프들의 사용을 허용한다.
데이터의 프로그래시브 코딩에서의 양자화 폭의 일 예의 스케일링
도 3 은 압축 비트레이트의 연속적인 제어에서 양자화 폭의 잠재적 스케일링의 일 예를 예시한다. 예시된 바와 같이, s 로 스케일링하기 이전에, 주어진 값 y 에 대해, y 의 양자화는 가장 가까운 이산 포인트 [y](306) 로의 라운딩을 초래한다. y 를 [y] (306) 로 양자화하고 엔트로피 코딩을 통해 전송하기 위해, 시스템은 y가 놓여 있는 양자화 빈(304)의 상한치와 하한치 사이의 확률 분포 (300) 내의 확률 질량 (302) 을 계산할 수 있다. 확률 질량은 하기 식으로 표현될 수 있다:
식에서, pdf(a)da 는 양자화 빈 (304) 의 상한 및 하한 사이의 확률 분포 함수의 값이고, CDF 는 확률 분포 (300) 를 따라 주어진 값에서의 누적 분포 함수의 값이다. 확률 질량은 따라서, 양자화 빈의 상한치의 누적 분포 함수와 양자화 빈의 하한치의 누적 분포 함수 사이의 차이로서 표현될 수도 있다. 확률 질량은 y 를 [y] 로 양자화하는 데 필요한 비트들의 수를 나타낼 수 있으며, 이는 확률 분포 (300) 아래에 예시된 복수의 도트들 중 하나일 수 있다.
스케일링이 적용될 때, 양자화 빈 사이즈는 상이한 값으로 변경될 수 있다. 예를 들어, 스케줄링된 확률 분포 (310) 에서 예시된 바와 같이, 2 의 스케일링 팩터는 (즉, 확률 분포 (310) 아래의 복수의 도트들에 의해 예시되는 바와 같이) 양자화 빈 사이즈의 폭을 두배로 할 수도 있고 y 가 코딩될 수 있는 가능한 값들의 수를 반으로 할 수도 있다. s 로 스케일링한 후에, y 의 주어진 값에 대해, y 의 양자화는 가장 가까운 이산 포인트 2[y/2] (316) 로의 라운딩을 초래한다. y 를 2[y/2] 로 양자화 및 스케일링하기 위해 그리고 엔트로피 코딩을 통해 전송하기 위해, 시스템은 y가 놓여 있는 스케일링된 양자화 빈 (314) 의 상한치와 하한치 사이의 스케일링된 확률 분포 (310) 내의 확률 질량 (312) 을 계산할 수 있다. 확률 질량은 하기 식으로 표현될 수 있다:
이는 확률 분포 (300) 에 예시된 것보다 더 큰 양자화 간격 및 더 적은 수의 비트들에 대응한다.
양자화해제된 잠재성은 식: 에 따라 y/s 가 양자화되는 양자화 빈 후에 s 를 곱하는 것에 의해 획득될 수 있으며, 여기서 μ 는 하이퍼코더에 의해 학습된 추정된 평균을 표현한다. 압축된 컨텐츠의 비트스트림 표현을 엔트로피 코딩하고 생성하는데 사용되는 (y/s) 의 사전 확률은 변수들의 변화 식을 통하여 원래의 사전 밀도로부터 도출될 수도 있다:
식에서 및 는 각각 유효 양자화 빈의 상한치 및 하한치를 나타낸다
도 4a 및 4b 는 본 개시의 양태들에 따라, 상이한 압축 비트레이트들을 달성하기 위해 사용되는 양자화 빈 사이즈들의 예들을 예시한다.
특히, 도 4a 는 잠재 코드 y 가 맵핑될 수 있는 빈 사이즈들 s1 및 s2를 갖는 양자화 레벨들의 시리즈 (400A) 를 예시한다. s1 및 s2 는 상이한 빈 사이즈들이기 때문에, 각각의 양자화 레벨은 값들이 양자화되거나 라운딩될 수 있는 상이한 중간점들 및 상이한 수의 상이하게 사이징된 빈들을 가질 수도 있다. 따라서, 빈 사이즈 (s1) 와 연관된 양자화 레벨은 빈 사이즈 (s2) 와 연관된 양자화 레벨보다 더 낮은 유효 비트레이트를 가질 수도 있다. 따라서, 양자화 레벨 (s1) 을 사용하여 압축된 데이터는 양자화 레벨 (s2) 을 사용하여 압축되는 데이터보다 더 작을 수도 있지만 압축해제될 때 더 낮은 품질을 가질 수도 있다.
보다 일반적으로, 양자화 빈 사이즈들의 시리즈에서 수 N 개의 양자화 빈 사이즈들에 대해, 제 1 양자화 빈 사이즈 (s1) 는 가장 큰 양자화 빈 사이즈에 대응하고, 연속적인 양자화 빈 사이즈들은 sN 의 양자화 빈 사이즈를 향해 감소하며, 양자화 빈 사이즈들은 에 따라 표현될 수 있다. 대응적으로, 양자화 빈 사이즈들에 대한 비트레이트는 에 따라 표현될 수 있다.
일부 양태들에서, 양자화 레벨들의 세트 {1, 2, ..., N} 에서의 양자화의 임의의 레벨 n 에 대한 빈 사이즈들은 양자화의 레벨 전체에 걸쳐 일관될 필요가 없다. 예를 들어, 도 4b 는 상이한 양자화 빈 사이즈들을 갖는 양자화 레벨들 (402, 404, 406, 408) 의 시리즈 (400B) 를 예시한다. 예시된 바와 같이, 양자화 레벨 (402) 은 가장 거친 양자화 빈 사이즈를 가질 수 있고, 양자화 레벨 (404) 은 제 1 중간 양자화 빈 사이즈를 가질 수 있고, 양자화 레벨 (406) 은 양자화 레벨 (404) 의 빈 사이즈보다 더 미세한 제 2 중간 양자화 빈 사이즈, 및 양자화 레벨 (408) 의 가장 미세한 양자화 빈 사이즈를 가질 수 있다.
또한, 도 4b 는 양자화 빈 사이즈들이 양자화 레벨 내에서도 상이할 수 있음을 도시한다. 예를 들어, 양자화 레벨 (406) 에서, 중심 빈 (416) 은 다른 빈들과 상이한 사이즈를 가질 수도 있다. 양자화 레벨 (404) 은 다른 빈들과 상이한 사이즈를 갖는 단일 빈을 예시하지만, 양자화 레벨은 다양한 사이즈들의 그리고 다양한 위치들의 빈들을 포함할 수 있다는 것을 유의해야 한다. 예를 들어, 양자화 레벨은 큰 중심 빈 및 중심 점의 어느 측에 대해 프로그래시브하게 더 작은 빈들을 가질 수도 있다 (예를 들어, 더 작은 비-중심 빈들 및 더 큰 중심 빈). 다른 예들에서, 양자화 레벨은 더 작은 빈들 사이에 개재된 큰 빈들을 가질 수도 있다. 일반적으로, 가우시안 분포에서, 확률 분포 (300) 하에서의 대부분의 확률 질량은확률 분포의 중심점 주변에서 센터링될 수도 있기 때문에 더 큰 중심 빈 선택을 사용하는 것은 압축 성능을 개선할 수도 있다 (예를 들어, 이미지의 원래 버전에 대하여 왜곡을 감소시키는 것에 의해 압축해제된 이미지의 품질을 개선할 수도 있다). 따라서, 확률 분포의 중심점 주변의 빈 사이즈를 증가시키는 것은 비중심 빈들에 대하여 빈 사이즈를 증가시키는 것보다 레이트 감소에 대하여 더 큰 영향을 가질 수도 있다 (예를 들어, 레이트는 식 : 에 따라 정의됨)
도 5 는 일 예의 네스트된 양자화 (500) 를 예시한다. 일반적으로, 네스트된 양자화는 더 거친 양자화 빈 사이즈들에서의 양자화된 코드들에 대해 컨디셔닝되는 것으로서 정의될 더 미세한 양자화 빈 사이즈들을 사용하여 데이터의 양자화를 허용할 수도 있다. 위에서 논의된 바와 같이, 양자화 빈 사이즈 (s1) 를 사용하는 잠재 코드 공간 코드 y 의 양자화는 일반적으로 더 작은 양자화 빈 사이즈 (s2) 를 사용하는 잠재 코드 공간 코드 y 의 양자화보다 더 낮은 비트레이트를 초래한다. 이 경우, 잠재 코드 공간 코드 y 가 주어지면, y 는 양자화 빈 사이즈가 s1 인 양자화 레벨에 대한 상한치 및 하한치 를 갖는 값 y1로 양자화될 수 있음을 알 수 있다. 이에 대응하여, 양자화 빈 사이즈 (s2) 를 갖는 양자화 레벨에 대하여, y 는 양자화 빈 사이즈 (s2) 를 갖는 양자화 레벨에서 양자화 빈의 중심점인 값 (y2) 으로 양자화될 수 있다. 따라서, 결과적인 유효 양자화 빈은 y 가 양자화되는 양자화 빈들의 바운더리들의 교차부에 기초하여 상한치 및 하한치 를 가질 수도 있다. 이 예에서, 유효 양자화 빈은 y2 가 놓여 있는 양자화 빈의 상한치 및 y1 이 놓여 있는 양자화 빈의 하한치를 가질 수도 있다.
보다 일반적으로, y 를 임의의 양자화 레벨 i 로 스케일링하기 위해, yi 는 식: 에 의해 정의될 수도 있으며, 여기서 라운드 함수는 를 가장 가까운 값 (예를 들어, 주어진 양자화 레벨에서 정의된 양자화된 값들 중 하나) 로 라운딩한다. yi 의 확률 질량은 하기 식으로 표현될 수 있다:
식에서, 는 yi 가 양자화 그리드에 놓여 있는 빈의 상한치를 나타내고 은 yi 가 양자화 그리드에 놓여 있는 빈의 하한치를 나타낸다.
네스트된 양자화에서, 최저 양자화 레벨에서 양자화된 y 의 확률 질량 (및 이에 따른 최대 양자화 빈 사이즈) 은 컨텐츠 x 가 압축되기 위해 잠재 코드 공간 코드 y 의 초기 양자화를 표현할 수도 있다. 즉, y 의 확률 질량은 y 가 맵핑되는 최저 양자화 레벨에서의 코드들 중 하나와 연관된 확률 질량에 대응한다. 더 높은 양자화 레벨들로의 y의 후속 양자화 (및 따라서, 더 작은 양자화 빈 사이즈들 및 더 높은 비트레이트들) 는 더 거친 양자화된 값에 대해 컨디셔닝된 조건적 확률 질량으로서 계산될 수 있다. 예를 들어, 제 2 양자화 빈 사이즈 s2를 사용하여 y를 양자화하기 위해, y1에 컨디셔닝된 양자화된 값 y2 의 확률 질량은 하기 식으로 표현될 수도 있다:
(예를 들어, 최소의 빈 사이즈 및 이에 따라 최대 빈 레이트를 갖는 양자화 레벨에 대해) 가장 미세적인 양자화 빈을 사용하여 압축된 데이터를 표현하는데 사용된 비트들의 수는 식 에 따라 표현될 수도 있다. 비트 할당은 가장 미세한 양자화 빈으로 양자화되는 값에 대한 비트 할당이 이전 양자화 빈들에 의해 컨디셔닝되는 다른 양자화 빈들에 대한 조건적 확률의 합산에 의해 표현될 수도 있도록 조건적 확률의 체인으로 분해될 수도 있다. 따라서, 가장 미세한 양자화 빈에 대한 비트 할당은 하기 식으로 표현될 수도 있다:
즉, 임의의 주어진 양자화 빈 사이즈에 대해, 그 양자화 빈 사이즈에 대한 조건적 화률은 그 양자화 빈 사이즈보다 더 큰 양자화 빈 사이즈에 대해 계산되는 조건적 확률들에 대해 컨디셔닝될 수도 있다. 임의의 주어진 양자화 빈 사이즈에서의 양자화된 코드 [y] 의 조건적 확률이 더 큰 양자화 빈 사이즈들에서 코드들의 조건적 확률들에 대해 컨디셔닝될 수도 있기 때문에, 임의의 주어진 양자화 빈 사이즈에서의 코드는 더 큰 양자화 빈 사이즈들에서 생성된 코드들을 사용한 체인 룰에 기초하여 도출될 수도 있다. 따라서, 단일 모델은 압축된 컨텐츠에 임베딩된 복수의 지원되는 압축 비트레이트들로, 임의의 압축 비트레이트에서 컨텐츠를 인코딩 및 압축하는 데 사용될 수 있다. 또한, 압축된 컨텐츠는 임의의 주어진 압축 비트레이트로부터 압축해제될 수 있으며, 이는 디바이스들이 예를 들어, 각각의 디바이스의 컴퓨팅 능력들에 기초하여 데이터를 압축해제하게 할 수 있다.
일반적으로, 네스트된 양자화에서, 인코딩은 N 스테이지들에서 발생할 수 있다 (여기서 N 은 y 가 인코딩될 수 있는 양자화 레벨들의 수를 나타낸다). 일반적으로, y 는 가장 거친 양자화 빈과 연관된 양자화 레벨을 사용하여 초기에 양자화될 수도 있고, y 의 양자화는 프로그래시브하게 더 미세한 양자화 빈 사이즈들을 사용하여 반복적으로 리파이닝될 수도 있다. 일반적으로, 더 미세한 양자화 빈 사이즈를 갖는 양자화 레벨로 y 를 양자화하는 것으로부터 초래되는 여분의 정보는 조건적 확률 식에 의해 표현될 수도 있다:
여기서, 및 In+1 은 양자화 빈들: (여기서, )의 상호작용 교차부로서 정의된다.
일부 양태들에서, 나이브 접근법은 (아래에서 더 상세히 논의되는 바와 같이) 증가된 복잡성 및 가장 미세한 양자화 레벨에서 생성된 코드워드 길이보다 클 수 있는 코드워드 길이를 초래할 수 있다. 예를 들어, 나이브 접근법을 취하면, N 개의 스테이지들에 의해 생성된 코드는 N개의 상이한 비트레이트들의 데이터에 데이터를 임베딩하는 비트스트림을 형성하고, 비트스트림의 총 길이는 다음 식으로 표현될 수도 있다:
식에서 는 가장 거친 양자화 빈에 대한 코드워드 길이를 표현하고 는 N번째 양자화 빈 (예를 들어 가장 미세한 양자화 빈) 까지 더 미세한 양자화 빈들로부터 리파이닝된 정보에 대하여 코드워드 길이를 표현한다. 이 경우에, 위에 논의된 조건적 확률 식은 교차된 양자화 바운더리들의 추적을 수반할 수도 있고 코드워드 길이의 합 () 은 식 에 의해 표현되는 가장 미세한 양자화 레벨에 대하여 코드워드 길이보다 클 수도 있다.
복잡성을 감소시키기 위해, 아래 논의된 바와 같이, 완전히 네스트된 양자화 레벨들의 세트는, 더 거친 양자화 레벨에서의 양자화 빈들의 중심 점들이 더 미세한 양자화 레벨에서 양자화 빈들의 중심 점들의 서브세트이도록 정의될 수도 있다. 완전히 네스트된 양자화 레벨들을 사용하여, 더 거친 양자화 빈 내의 그리드 포인트들의 세트는 더 미세한 양자화 빈 내의 포인트들의 서브세트일 수 있다. 즉, 양자화는 하기 식에 따라 정의될 수도 있다:
이는 간단하게 다음 식으로 위에 논의된 비트스트림 길이 식일 수도 있다:
완전히 네스트된 양자화 레벨들의 세트를 사용하는 것에 의해, 데이터를 압축하는 프로세스를 단순화하면서 코딩 모델에서의 최고 비트 레이트 모델의 성능이 보존될 수 있다.
일부 양태들에서, 스케일링 팩터들의 선택들은 다양한 타입들의 압축을 효과적으로 구현할 수 있다. 예를 들어, si-1= 2si일 때, 결과적인 압축 방식은 이진 비트 평면 코딩일 수 있다. si-1 이 si의 정수배일 때, 양자화 빈의 상한치 및 하한치를 계산하는 것은 간단한 계산일 수 있고, 따라서 데이터의 덜 프로세서 집약적인 압축 및 압축해제를 허용할 수 있다.
데이터 압축을 위한 데이터의 프로그래시브 코딩을 위한 일 예의 방법들
도 6 은 프로그래시브 코딩을 사용하여, 도 1 또는 도 2 에 예시된 파이프라인들 (100 또는 200) 과 같은 압축 파이프라인을 통해 수신된 컨텐츠를 압축하기 위해 시스템에 의해 수행될 수 있는 일 예의 동작들 (600) 을 예시한다. 동작들 (600) 은 학습된 네스트된 양자화 방식을 구현하는 양자화기 및 신경망-기반 인코더를 포함하는 압축 파이프라인을 구현하는, 도 12 의 시스템 (1200) 과 같은 하나 이상의 프로세서들을 갖는 시스템에 의해 수행될 수 있다.
예시된 바와 같이, 동작들 (600) 은 블록 (610) 에서 압축을 위한 컨텐츠를 수신하는 것으로 시작할 수 있다. 수신된 컨텐츠는 데이터의 스트림과 같은 단일 채널 컨텐츠, 또는 상이한 채널들이 독립적으로 압축될 수 있는 멀티-채널 컨텐츠 (즉, 다수의 데이터 채널들을 갖는 컨텐츠) 일 수 있다. 멀티-채널 컨텐츠는, 예를 들어, 복수의 공간 채널들 (좌측/우측 스테레오, 서라운드 사운드 컨텐츠 등) 을 포함하는 오디오 컨텐츠, 루미넌스 및/또는 크로미넌스 채널들 (YPbPr, RGB 등) 을 포함하는 비디오 컨텐츠, 독립적인 시각적 채널들 및 오디오 채널들을 포함하는 시청각 컨텐츠 등을 포함할 수 있다.
블록 (620) 에서, 컨텐츠는 (예를 들어, 도 1 에 예시된 인코더 (112)(ga) 를 통해) 잠재 코드 공간으로 인코딩된다. 컨텐츠를 잠재 코드 공간으로 인코딩하기 위해, 컨텐츠의 잠재 코드 공간 표현을 생성하도록 트레이닝되는 인공 신경망에 의해 구현되는 인코더가 사용될 수 있다. 일부 양태들에서, 잠재 코드 공간에서 코드 y 로의 수신된 컨텐츠 x 의 인코딩은 코드 y 로의 수신된 컨텐츠 x 의 무손실 맵핑일 수도 있다. 원래의 수신된 컨텐츠 x에 대한 압축 및 결과적인 손실 (또는 왜곡) 은 코드 y 를 양자화하는 것에 의해 달성될 수 있다.
블록 (630) 에서, 인코딩된 컨텐츠의 제 1 압축된 버전이 (예를 들어, 도 1 에 예시된 양자화기 (114)(Q) 를 통해) 생성된다. 인코딩된 컨텐츠의 제 1 압축된 버전을 생성하기 위해, 컨텐츠가 인코딩되는 코드 y 는, 제 1 비트레이트와 연관되는 양자화 빈 사이즈들의 세트의 제 1 양자화 빈 사이즈를 사용하여 양자화될 수 있다. 예를 들어, 제 1 양자화 빈 사이즈는 양자화 빈 사이즈들의 세트에서 복수의 양자화 빈 사이즈들 중 가장 거친 양자화 빈 사이즈일 수 있고, 복수의 양자화 빈 사이즈들과 연관된 비트레이트들의 최저 비트레이트에서의 압축을 초래할 수 있다.
블록 (640) 에서, 인코딩된 컨텐츠의 리파이닝된 압축된 버전이 (예를 들어, 도 1 에 예시된 양자화기 (114)(Q) 를 통해) 생성된다. 일 예에서, 인코딩된 컨텐츠의 리파이닝된 압축된 버전을 생성하기 위해, 인코딩된 컨텐츠의 제 1 압축된 버전은 적어도 인코딩된 컨텐츠의 값에 따라 컨디셔닝되어 제 1 양자화 빈 사이즈보다 작은 하나 이상의 제 2 양자화 빈 사이즈들로 스케일링된다. 일반적으로, 하나 이상의 제 2 양자화 빈 사이즈들의 각각의 개별 양자화 빈 사이즈는 제 1 비트레이트보다 높은 비트레이트에 대응한다. 즉, 하나 이상의 제 2 양자화 빈 사이즈들의 각각의 개별적인 양자화 빈 사이즈는 제 1 양자화 빈 사이즈보다 더 작을 수도 있다.
블록 (650) 에서, 인코딩된 컨텐츠의 리파이닝된 압축된 버전은 송신을 위하여 (예를 들어, 도 1 에 예시된 엔티티 코더 (116) (EC) 를 통하여) 출력된다.
도 7 은 인코딩된 컨텐츠를 압축해제하기 위해 시스템에 의해 수행될 수도 있는 일 예의 동작들 (700) 을 예시한다. 동작들 (700) 은 학습된 네스트된 양자화 방식을 구현하는 양자화기 및 신경망-기반 인코더를 포함하는 압축 파이프라인, 이를 테면, 도 1 또는 2 에 예시된 파이프라인들 (100 또는 200) 을 구현하는, 도 12 의 시스템 (1200) 과 같은 하나 이상의 프로세서들을 갖는 시스템에 의해 수행될 수 있다.
예시된 바와 같이, 동작들 (700) 은 블록 (710) 에서 시작하며, 여기서 인코딩된 컨텐츠는 압축해제를 위하여 수신된다.
블록 (720) 에서, 잠재 코드 공간 내의 코드의 근사치가 수신된 인코딩된 컨텐츠로부터 복구된다.
일부 경우들에서, 코드의 근사치 () 가 양자화 빈 사이즈들의 시리즈로부터 코드들을 복구하는 것에 의해 복구될 수도 있다. 코드의 근사치 () 는 예를 들어, 도 1 에 도시된 역 양자화기 (124)(Q-1) 에 의해 복구될 수 있다. 양자화 빈 사이즈들의 시리즈는 제 1 비트레이트와 연관된 제 1 양자화 빈 사이즈 및 제 1 양자화 빈 사이즈보다 더 작은 하나 이상의 제 2 양자화 빈 사이즈들을 포함할 수도 있다.
일반적으로, 양자화 빈 사이즈들의 시리즈는 인코딩된 컨텐츠의 압축해제된 버전에서 허용가능한 왜곡의 양에 기초하여 임의의 비트레이트에 대한 단일 모델을 사용한 컨텐츠의 압축 해제를 허용할 수도 있다. 위에 논의된 바와 같이, 압축된 데이터를 표현하는 코드들은 체인 룰을 사용한 임의의 양자화 레벨로부터 복구될 수도 있고, 여기서 주어진 양자화 레벨에서의 코드는 더 낮은 양자화 레벨 (예를 들어, 주어진 양자화 레벨에서의 것보다 더 낮은 양자화 빈 사이즈들을 갖는 양자화 레벨들) 에서 획득된 코드들에 대하여 컨디셔닝된 코드들로서 정의될 수도 있다. 인코딩된 컨텐츠의 압축해제된 버전에서의 왜곡의 양은 코드의 근사치를 복구하는데 사용되는 가장 작은 양자화 빈 사이즈와 연관된 비트레이트에 반비례할 수 있다. 즉, 양자화 빈 사이즈들의 시리즈의 가장 큰 양자화 빈 사이즈와 연관된 가장 낮은 비트레이트는 가장 높은 양의 왜곡을 가질 수 있고, 연속적으로 더 작은 양자화 빈 사이즈들이 코드의 근사치를 복원하는 데 사용됨에 따라 왜곡이 감소할 수 있다.
블록 (730) 에서, 인코딩된 컨텐츠의 압축해제된 버전은 인공 신경망에 의해 구현되는 디코더, 이를 테면, 도 1 에 예시된 디코더 (126) (gs) 를 통하여 잠재 코드 공간 내의 값의 근사치를 디코딩하는 것에 의해 생성된다. 인공 신경망에 의해 구현되는 디코더는, 예를 들어, 인공 신경망에 의해 구현되는 인코더에 상보적일 수 있고, 도 6 과 관련하여 위에서 논의된 바와 같이 잠재 코드 공간으로 컨텐츠를 인코딩하는데 사용될 수 있다.
블록 (740) 에서, 인코딩된 컨텐츠의 압축해제된 버전이 출력된다. 일부 양태들에서, 인코딩된 컨텐츠의 압축해제된 버전은 디바이스의 사용자에게 재생하기 위해 시스템에 연결되거나 통합된 디스플레이 또는 오디오 디바이스와 같은 하나 이상의 출력 디바이스에 출력될 수 있다. 일부 양태들에서, 인코딩된 컨텐츠의 압축해제된 버전은 이들 컴퓨팅 시스템들의 사용자들에게 출력하기 위해 하나 이상의 다른 컴퓨팅 시스템들에 출력될 수 있다.
일부 양태들에서, 프로그래시브 코딩은 멀티-채널 데이터에서의 각각의 채널에 대해 상이한 레벨들의 압축을 사용하여 (따라서, 상이한 레벨들의 왜곡을 달성하여) 멀티-채널 데이터를 압축하는데 사용될 수도 있다. 논의된 바와 같이, 멀티 채널 데이터에서의 채널들은 시각적 컨텐츠에서의 루미넌스 및/또는 크로미넌스 채널들, 멀티 채널 오디오에서의 공간 사운드 정보 등을 포함할 수 있다. 각각의 채널은 압축해제될 때 컨텐츠의 최종 오디오 비주얼 레디션 (rendition) 에 대해 상이한 양의 데이터 또는 상이한 영향을 가질 수 있고, 따라서 상이한 양의 압축을 사용하여 각각의 채널을 인코딩 (압축) 하는 것이 유용할 수 있다. 데이터를 압축하거나 압축해제하는 데 사용할 비트레이트의 선택은 예를 들어 네트워크 스택 내의 애플리케이션 계층에 의해 제어되는 혼잡 제어 또는 대역폭 적응 기능들에 기초하여 이루어질 수 있다. 예를 들어, 컨텐츠 서버가 컨텐츠 서버와 요청 디바이스 사이의 낮은 대역폭을 검출하면 컨텐츠 서버는 더 낮은 비트레이트들을 선택 (예를 들어, 더 큰 양자화 빈 사이즈들을 사용하는 압축) 할 수 있고; 이와 유사하게, 컨텐츠 서버가 컨텐츠 서버와 요청 디바이스 사이의 높은 대역폭을 검출하면 컨텐츠 서버가 더 높은 비트레이트들을 선택 (예를 들어, 더 작은 양자화 빈 사이즈들을 사용하는 압축) 할 수 있다.
(즉, 루미넌스 채널 및 두 개의 컬러 채널들을 갖는) YPbPr 공간에서의 멀티-채널 비디오 데이터에서, 예를 들어, 루미넌스 채널이 멀티-채널 비디오 데이터에서 대부분의 비쥬얼 정보를 반송하기 때문에, 루미넌스 채널은 가장 중요한 채널로서 고려될 수도 있다. 따라서, 비디오 컨텐츠에 적용되는 압축의 양과 품질의 균형을 맞추기 위해, 최고 비트레이트를 사용하여 휘도 채널을 인코딩하고, 더 낮은 비트레이트들을 사용하여 컬러 채널들을 인코딩하는 것이 바람직할 수도 있다. 따라서, YPbPr 공간에서 멀티 채널 비디오 데이터를 인코딩함에 있어서, 신경망은 Y, Pb, 및 Pr 채널들 각각을 상이한 잠재 코드 공간 코드들 yY, yPb, 및 yPr로 독립적으로 인코딩할 수 있고, 이들 잠재 코드 공간 코드들 각각은 독립적으로 인코딩될 수 있다.
다른 예에서, 다수의 컬러 데이터 채널들에서 (예를 들어, RGB 크로미넌스 컬러 공간들에서) 반송되는 이미지 데이터에서, 일부 컬러 데이터는 다른 컬러 데이터보다 압축해제된 컨텐츠의 시각적 레디션에 더 큰 영향을 미칠 수 있다. 예를 들어, 상이한 컬러들에 대한 선험적으로 알려진 민감도에 기초하여, 하나의 컬러 채널은 다른 채널들보다 더 높은 비트레이트 압축을 사용하여 인코딩될 수 있다. 예를 들어, RGB 데이터의 경우, 사람의 눈이 다른 컬러 데이터보다 녹색 컬러 데이터에 더 민감한 것으로 알려질 수 있기 때문에, 녹색 컬러 채널은 적색 및 청색 컬러 채널들에 대해 사용되는 것보다 더 높은 비트레이트를 사용하여 압축될 수 있다.
채널별 프로그래시브 코딩을 수행하기 위해서는 각각의 채널에 적용할 압축량에 따라 채널을 오더링할 수 있다. 오더링은 왜곡의 차이 ΔD 및 비트레이트의 차이 ΔR에 기초하여 결정될 수 있다. 예를 들어, 오더링는 각각의 채널에 대해 계산된 비율 에 기초할 수 있으며, 이는 각각의 채널과 연관된 압축 우선순위에 대응할 수 있다. 채널에 대한 왜곡 (ΔD) 의 차이를 결정하기 위해, 시스템은 인코딩된 입력을 두번 디코딩할 수 있다, 즉 채널을 포함하여 한번, 그리고 채널을 배제하여 한번 디코딩할 수 있다. 따라서, 압축해제에 대해 계산된 왜곡의 양은 주어진 비트레이트에서 압축해제로부터 채널을 배제하는 것에 의해 초래될 왜곡의 양을 나타낼 수 있다. 비트레이트 (ΔR) 의 차이를 결정하기 위해, 시스템은 제 1 비트레이트에서의 압축 및 제 2 비트레이트에서의 압축을 위해 생성된 비트들의 수의 차이를 계산할 수 있다.
일 예의 채널-와이즈 프로그래시브 코딩
도 8 은 상이한 채널들에 대해 상이한 비트레이트들을 사용하는 채널-와이즈 프로그래시브 코딩 (800) 의 일 예를 예시한다.
예시된 바와 같이, 코딩 (800) 에서, 비트스트림은 C 개의 채널들 각각에 대해 생성될 수도 있다. 이들 채널들 1 내지 C 에서, 주어진 비트레이트 b 에서 채널 c 의 각각에 대해 생성된 코드에 대한 양자화 빈 사이즈는 로서 표현될 수 있다. C개의 채널들은, 위에서 논의된 바와 같이, 각각의 채널 c를 표현하기 위해 사용될 압축의 증가 또는 감소량들에 따라 (즉, 각각의 채널에 대해 계산된 에 기초하여) 오더링될 수 있다. 도 3 내지 도 5 에 대해 위에서 논의된 바와 같이, 채널에 대한 코딩은 상이한 양자화 빈 사이즈들의 시퀀스를 갖는 네스트된 양자화로서 표현될 수도 있다. 도시된 예에서, 는 복수의 양자화 빈 사이즈들 중 거친 양자화 빈 사이즈에 대응하고, 는 점진적으로 더 미세한 양자화 빈 사이즈들에 대응할 수도 있다.
각각의 채널에 대해, 채널의 잠재 코드 공간 표현에서의 코드 yc는 가장 거친 양자화 빈 사이즈로 압축되고 송신을 위해 출력될 수 있다. 각각의 채널에 대해 네스트된 양자화를 달성하기 위해, 코드 yc 는 더 미세한 양자화 빈 사이즈들에서 압축되고, 더 거친 빈 사이즈들에서 y의 양자화된 값에 컨디셔닝되고, 송신을 위해 출력될 수 있다. 더 미세한 양자화 빈 사이즈들에 대한 추가 코드 정보 yc 를 출력하는 것에 의해, 압축된 컨텐츠의 품질은 가장 거친 양자화 빈 사이즈에서의 압축에 대응하는 압축의 베이스라인 양으로부터 프로그래시브으로 개선될 수 있고, 개선량은 송신을 위해 출력된 추가 코드들 yc 의 양에 기초하여 제어될 (즉, 프로그래시브하게 더 미세한 양자화 빈 사이즈들에 대해 생성될) 수 있다.
일부 경우들에서, 추가적인 프로그래시브 코딩은 C 개의 채널들의 세트 내의 채널들 (c) 중 일부 에 대한 추가적인 양자화 정보를 출력하는 것에 의해 달성될 수 있다.
예를 들어, 채널들 c 각각은 가장 거친 양자화 빈 사이즈로 압축되고 송신을 위해 출력될 수 있다. 압축해제된 데이터의 결과적인 품질에 더 큰 영향을 미치는 채널들에 대해, 점진적으로 더 미세한 양자화 빈 사이즈들에 대해 생성된 추가적인 코드들 yc 이 (예를 들어, 채널들 (c) 의 서브세트에 대해) 출력될 수 있다. 가장 거친 양자화 빈 사이즈와 연관된 레벨을 넘어서는 임의의 양자화 레벨에 대해, 코드들이 C 개의 채널들의 서브세트에 대해 생성될 수도 있어, 압축해제된 데이터의 결과적인 품질에 작은 영향들을 갖는 채널들에 대해 추가적인 압축이 수행되지 않는다. 임의의 양자화 레벨 N에 대해 생성된 C 개의 채널들의 서브세트는, 예를 들어 그리디 기법 (greedy technique)(예를 들어, 양자화 레벨의 각각의 1-레벨 증가에 대해, 증가된 양자화 레벨을 사용하여 인코딩된 채널들의 수를 1만큼 감소시킴) 을 사용하거나, 또는 각각의 채널에 대해 계산된 에 기초하여, 증가된 양자화 레벨 (및 대응하여 감소된 양자화 빈 사이즈) 을 사용하여 어느 채널들 (y) 이 생성될지를 결정하기 위해 임계화 기법을 적용하는 것에 의해 선택될 수 있다. 이러한 방식으로 컨텐츠를 압축하는 것에 의해, 프로그래시브 코딩은 채널별 및 양자화 레벨별 기반으로 달성될 수 있다.
도 8 에서, 코딩 (800) 에 예시된 각각의 레벨은 C 개의 채널들을 압축하는데 사용되는 상이한 양자화 레벨 및 대응하는 비트레이트를 나타낸다. 예시된 바와 같이, C 개의 채널들 각각은 최저 양자화 레벨을 사용하여 인코딩 및 압축될 수도 있다 (예를 들어, 양자화 레벨 1, 이 레벨에 대해, 값은 식 () 에 의해 표현될 수도 있음, 여기서 n 은 C 개의 채널들 중 하나를 표현될 수도 있음). 채널들이 중요도에서 증가함에 따라, 이들 채널들은 더 낮은 양자화 레벨들에서의 코드들 (예를 들어, 양자화 레벨들 1 내지 n-1에서의 코드들) 에 의해 컨디셔닝되어, n 번째 양자화 레벨에서의 확률 분포에 의해 코드의 값이 표현되는 식들에 의해 표현되는 더 높은 양자화 레벨들을 사용하여 인코딩 및 압축될 수도 있다. 예를 들어, 코딩 (800) 에서 쉐이딩은 채널들 1 및 2 이 값이 식 에 의해 표현될 수도 있는 제 2 양자화 레벨에서 인코딩 및 압축되지만, 다른 채널들은 이 양자화 레벨에서 인코딩 및 압축되지 않는다.
데이터 압축에서의 프로그래시브 코딩을 위한 일 예의 양자화 그리드들
도 9 는 컨텐츠의 프로그래시브 코딩을 위한 효과적인 양자화 그리드 (900) 의 일 예를 예시한다. 도시된 바와 같이, 컨텐츠 x 를 나타내는 잠재 코드 공간 코드 y를 양자화하기 위해 3개의 양자화 레벨이 사용된다. 제 1 양자화 레벨은 양자화 빈 사이즈 (s1) 와 연관되고, 제 2 양자화 레벨은 양자화 빈 사이즈 (s2) 와 연관되고, 제 3 양자화 레벨은 양자화 빈 사이즈 (s3) 와 연관된다. 코드 y1 가 양자화 레벨들의 세트에서 가장 거친 양자화 레벨을 사용하여 생성되었기 때문에 양자화 빈 사이즈 (s1) 와 연관된 양자화 레벨에서 y 를 양자화하는 것에 의해 생성된 코드 y1 에 대해, 송신될 비트들의 수는 식 () 에 따라 표현될 수도 있다. 다음 레벨에서, y 는 y1 이 위치되는 양자화 빈의 상한치와 y2가 위치되는 양자화 빈의 하한치의 교차부 (902) 에 의해 표현될 수 있다. 따라서, 제 2 양자화 레벨에서의 유효 양자화 빈은 제 2 양자화 레벨에서의 양자화 빈 사이즈보다 작을 수도 있다. 제 2 양자화 레벨에서 네스트된 양자화를 달성하기 위해 송신할 추가 비트들의 수는 하기 식으로 표현될 수도 있다:
추가적인 양자화 레벨에서, 코드 y3은 y3 이 위치하는 빈의 상한치와 y2 의 하한치의 교차부 (904) 에 의해 표현될 수 있고, 하기 식에 의해 표현될 수 있다:
따라서, 유효 양자화 빈 사이즈는 컨텐츠를 압축하는데 사용되는 가장 미세한 빈보다 더 미세할 수 있다. 송신된 비트들의 합은 따라서, 식 () 에 의해 표현될 수도 있고, 식에서, intersectionOfBins 는 n번째 양자화 빈을 선행할 수도 있는 n-1 번째 양자화 빈의 바운더리에 의해 형성된 n번째 양자화 빈의 바운더리에 의해 형성된 최저 유효 양자화 빈 (906) 을 표현한다.
네스트된 양자화를 순수하게 적용할 때 데이터의 압축에서의 성능 저하가 있을 수 있는데, 그 이유는 유효 양자화 빈이 컨텐츠 x 의 잠재 코드 공간 표현들 y 를 양자화하기 위해 실제로 사용되는 가장 미세한 빈보다 더 작을 수도 있기 때문이다. 성능 저하는 유효 압축 비트레이트들을 증가시키기 위해 피크 신호-대-잡음비 (PSNR) 에 의해 측정되는 품질의 감소된 증가들에서 보여질 수 있다. 네스트된 양자화를 순전히 적용하는 것으로부터 성능 저하를 완화하기 위해, 프로그래시브 코딩을 위한 양자화 그리드 (1000) 는 도 10 에 예시된 바와 같이 가장 미세한 양자화 그리드 (1002) 에 정렬될 수도 있다.
양자화 그리드 (1004) 를 가장 정밀한 양자화 그리드 사이즈에 대한 그리드 (1002) 에 정렬하기 위해, 멀티-패스 양자화는 가장 정밀한 양자화 빈 사이즈에 기초하여 복수의 더 거친 양자화 빈들을 양자화하는데 사용될 수도 있다. 멀티-패스 양자화를 적용하는 것에 의해, 더 작은 양자화 빔들의 교점이 식별됨에 따라 (예를 들어, 유효 양자화 빈 (906) 이 식별됨에 따라), 유효 양자화 빈 사이즈는 프로세싱을 단순화하고 가변 유효 양자화 빈 사이즈들의 사용으로부터 성능 저하를 회피하기 위해 최상의 양자화 빈 사이즈보다 더 작지 않다. 양자화 그리드 (1000) 의 중간점 (1006) 은 양자화 레벨들 각각에 대한 그리드들 내의 중간 양자화 빈의 중간점에 그리고 유효 양자화 그리드 (1004) 내의 중간 양자화 빈의 중간점에 있을 수 있다.
도 11 은 프로그래시브 코딩을 이용한 데이터 압축의 일 예의 결과들을 예시한다.
그래프들 (1100A-1100F) 은 샘플 이미지를 압축하는데 사용되는 다양한 압축 기법들에 대한 비트레이트와 픽셀 당 PSNR 사이의 관계들을 예시한다. 그래프 (1100A) 에 예시된 바와 같이, 본 명세서에 설명된 프로그래시브 코딩 기법들을 사용하는 압축은 샘플 이미지를 압축하는데 사용되는 픽셀 당 0.11 비트들의 낮은 비트레이트에서 26.59 dB의 PSNR 을 제공할 수 있다. 그래프 (1100B) 는 본 명세서에 설명된 프로그래시브 코딩 기법이, 샘플 이미지를 압축하는데 사용되는 픽셀 당 0.34 비트들의 비트레이트에서 31.02 dB의 PSNR 을 제공할 수 있음을 예시한다. 그래프 (1100C) 는 본 명세서에 설명된 프로그래시브 코딩 기법이, 샘플 이미지를 압축하는데 사용되는 픽셀 당 0.60 비트들의 비트레이트에서 33.52 dB의 PSNR 을 제공할 수 있음을 예시한다. 그래프 (1100D) 는 본 명세서에 설명된 프로그래시브 코딩 기법이, 샘플 이미지를 압축하는데 사용되는 픽셀 당 0.90 비트들의 비트레이트에서 35.99 dB의 PSNR 을 제공할 수 있음을 예시한다. 그래프 (1100E) 는 본 명세서에 설명된 프로그래시브 코딩 기법이, 샘플 이미지를 압축하는데 사용되는 픽셀 당 1.21 비트들의 비트레이트에서 37.70 dB의 PSNR 을 제공할 수 있음을 예시한다. 마지막으로, 그래프 (1100F) 는 본 명세서에 설명된 프로그래시브 코딩 기법이, 샘플 이미지를 압축하는데 사용되는 픽셀 당 1.48 비트들의 비트레이트에서 39.69 dB의 PSNR 을 제공할 수 있음을 예시한다. 이들 예들에서, 네스트된 드롭아웃 프로그래시브 코딩에 비해, 압축된 이미지의 품질 (압축된 이미지에 대한 PSNR 측정에 의해 표현됨) 은 각각의 유효 비트레이트에 대해 더 높다는 것을 알 수 있다. 또한, 각각의 유효 비트레이트에 대해, 압축된 이미지의 품질은 데이터를 압축하는데 사용되는 각각의 비트레이트에 대해 선험적으로 정의된 모델들이 사용되는 다양한 비프로그래시브 코딩 방식들을 사용하여 생성된 압축된 이미지들의 품질에 접근할 수 있다.
프로그래시브 데이터 압축을 위한 일 예의 코딩 유닛 오더링
일부 양태들에서, 본 명세서에 설명된 기법들을 사용하여 압축되는 데이터는 다수의 코딩 유닛들로 분할될 수 있으며, 각각의 코딩 유닛은 독립적으로 압축될 수 있다. 코딩 유닛은, 예를 들어, 채널, 이미지 내의 픽셀 (예를 들어, 이미지 또는 비디오 컨텐츠 내의 특정 위치에서의 복수의 채널들 각각에 대한 데이터), 데이터의 블록들 (예를 들어, 이미지 또는 비디오 컨텐츠 내의 n x m 픽셀 블록에 대한 하나 이상의 채널들), 또는 단일 엘리먼트 (예를 들어, 이미지 또는 비디오 컨텐츠 내의 특정 위치에서의 단일 채널에 대한 데이터) 일 수 있다. 프로그래시브 코딩을 용이하게 하고 각각의 코딩 유닛이 압축 손실에 대한 상이한 민감도 및 상이한 양의 정보를 가질 수도 있음을 반영하기 위해, 각각의 코딩 유닛은 점진적으로 독립적으로 리파이닝될 수도 있다. 프로그래시브 코딩은 두 단계로 구분될 수 있다. 제 1 단계는 가장 큰 양자화 빈 (예를 들어, 가장 낮은 양자화 레벨) 으로부터 가장 작은 양자화 빈 (예를 들어, 가장 높은 양자화 빈) 까지 잠재 변수들 (예를 들어, 인공 신경망-기반 인코더에 의해 생성된 입력 x를 나타내는 코드 y) 을 인코딩한다. 제 2 단계에서, 인접한 양자화 레벨들 사이의 개선들은 코딩 유닛들 사이의 경계들을 나타내는 결과적인 임베디드 비트스트림 내의 각각의 절단 포인트가 양자화 레벨에서의 증분 변화와 연관되도록 코딩 유닛 단위로 증분적으로 이루어질 수 있다.
동작적으로, 연속적인 잠재 변수는 잠재 변수가 각각 주어진 중심점 값으로 양자화되도록 무한히 큰 양자화 빈으로부터 인코딩될 수 있다. 그 결과, 디코더로 전달될 역양자화된 잠재성은 사전 평균일 수 있다. 정교화를 위한 코딩 유닛 오더링 (ordering) 은, 현재의 양자화 빈에서의 코딩 유닛이 적절한 양자화 빈에서 디코딩될 수도 있도록 사전 양자화로부터 발견될 수도 있다. 코딩 유닛 오더링에 기초하여, 코딩 유닛들은 가장 큰 양자화 빈으로부터 가장 작은 양자화 빈으로 리파이닝될 수도 있다. 프로세싱을 단순화하기 위해, 가장 높은 양자화 레벨들 (및 대응하는 가장 큰 양자화 빈 사이즈들) 을 사용하여 인코딩된 코딩 유닛들이 먼저 코딩되고, 더 낮은 양자화 레벨들 (및 대응하는 더 작은 양자화 빈 사이즈들) 을 사용하여 인코딩된 코딩 유닛들이 가장 높은 양자화 레벨들을 사용하여 코딩 유닛들 이후에 인코딩되도록 코딩이 오더링될 수 있다.
프로그래시브 코딩 방식에서는 잠재 코드 공간 (latent space) 내의 텐서 (tensor) 일 수 있는 코드 y 가 N개의 코딩 단위 {y1,...,yN} 로 분할될 수 있다. 코딩 유닛 내의 요소들은 함께 리파이닝될 수 있고, 절단 포인트 (truncation point), 또는 최저 왜곡 (예를 들어, 압축 손실) 을 달성하는 공간 내의 포인트에 대응할 수 있다. 형상 (C, H, W)4를 갖는 잠재 코드 공간의 텐서에 대해, 다양한 코딩들이 정의될 수 있다. 단일 채널 코딩은 사이즈 (1, H, W) 를 갖는 잠재 슬라이스에 대응할 수도 있고; 단일 픽셀 코딩은 사이즈 (C, 1, 1) 를 갖는 잠재 슬라이스에 대응할 수도 있으며; 단일 엘리먼트 코딩은 사이즈 (1, 1, 1) 를 갖는 잠재 슬라이스에 대응할 수도 있다.
주어진 압축 차수 ρ=(ρ1,…,ρN) 에 대해, 오더링된 코딩 유닛들 yρ = (yρ1,..., yρN) 은 sn 의 스케일링 팩터로부터 sn-1 의 스케일링 팩터로 개별적으로 스케일링될 수도 있다. 평균 공간 하이퍼사전 모델 (mean space hyperprior model) 에서, 잠재 엘리먼들의 우선 순위는 하이퍼잠재성 (hyper latent) 상에서 조정될 수 있다. 본 명세서에 설명된 스케일링으로 t번째 코딩 유닛 (ΔR) 을 개선하는 비트레이트 증가는 하기 식에 따라 정의될 수도 있고:
그리고 하이퍼사전 모델의 하이퍼잠재성이 계산되면 병렬로 계산될 수 있다.
왜곡의 감소 (ΔD) 는 또한 계산될 수 있고, 다른 오더링된 코딩 유닛들에 의존할 수 있다. 왜곡의 감소 (ΔD) 는 다음 식으로 표현될 수 있다:
여기서 이고 이며 이는 코드 y 에 대한 왜곡을 나타낸다. 따라서, 압축 오더 ρ 를 사용하여 오더링된 잠재성을 리파이닝하는 것은 하기 식에 의해 정의된 레이트-왜곡 (R-D) 포인트들의 세트를 초래할 수 있다:
일반적으로, ρ 의 최적 오더는 H(ρ) 의 컨벡스 헐 (convex hull) 이 ρ의 다른 오더들의 것보다 더 양호한 오더일 수도 있다 (예를 들어, 이는 Pareto 최적의 압축 오더이다).
도 12 는 서로 다른 오더를 사용하여 컨텐츠를 인코딩하는 데 수반되는 코딩 손실의 양 사이의 관계를 예시한다. 그래프 (1200) 에서, 간략화를 위해, 2 개의 코딩 유닛들 (y1 및 y2) 이 예시되지만; 인코딩될 데이터가 임의의 수의 코딩 유닛들을 가질 수도 있다는 것이 이해되어야 한다. 예시된 바와 같이, y1 은 의 왜곡-대-레이트-변화비를 갖고, y2 는 를 갖고, y1 에 대한 왜곡-대-레이트-변화비는 y2 에 대한 왜곡-대-레이트-변화비보다 크다.
왜곡 라인 (1202) 은 y2 가 y1 이전에 인코딩되고 y2가 y1 보다 더 높은 레이트를 사용하여 인코딩되는 코딩 손실을 예시한다. 이와 대조적으로, 왜곡 라인 (1204) 은 y1 이 y2 이전에 인코딩되고 y1 이 y2 보다 더 높은 레이트를 사용하여 인코딩되는 코딩 손실을 예시한다. (y1, y2) 또는 (y2, y1) 의 오더링을 사용하는 압축의 경우, 총 왜곡/레이트 손실은 동일할 수 있다. 그러나, y2 는 y1 보다 압축 레이트의 변화들에 덜 민감하기 때문에 (즉, y2 에 대한 압축 레이트의 임의의 주어진 증가에 대한 왜곡의 감소가 y1에 대한 것보다 작기 때문에), 왜곡 라인 (1202) 보다 낮은 왜곡 라인 (1204) 에 의해 예시된 바와 같이, y2 를 인코딩하기 전에 y1 을 인코딩하는 것이 더 효율적일 수 있다.
따라서, 컨텐츠가 최적으로 인코딩되도록 프로그래시브 컨텐츠를 압축하기 위해서, 코딩 유닛들은 이들 개별적인 왜곡-대-레이트-변화율들의 내림차순으로 분류될 수도 있다. 왜곡 손실의 양이, 유닛들이 코딩되는 순서에 종속적일 수도 있기 때문에, 코딩 유닛들이 신경망-기반 인코더, 이를 테면, 도 1 에 예시된 인코더 (112) 에 의해 생성되는 경우 추가적인 복잡도가 도입될 수도 있다. 그러나, 격리된 각각의 코딩 유닛에 대해 계산된 왜곡-대-레이트-변화 비율은 프로그래시브 코딩을 위한 코딩 유닛들을 오더링하기 위한 근사치로서 처리될 수 있다.
도 13 은 코딩 유닛들의 프로그래시브 코딩 및 상이한 오더링들을 사용하여 데이터 압축의 일 예의 결과들을 예시한다.
그래프 (1300) 는 상이한 코딩 유닛들 및 정렬 기준들에 기초하여 데이터의 프로그래시브 압축을 위한 픽셀 당 피크 신호-대-잡음비 (PSNR) 와 비트레이트 사이의 관계들을 예시한다.
논의된 바와 같이, 코딩 유닛들은 데이터의 다양한 세분화도들에 대해 정의될 수도 있다. 채널들의 수 (C), 높이 치수 (H), 및 폭 치수 (W) 에 의해 정의된 형상을 갖는 잠재성 (예를 들어, 복수의 컬러 공간 채널들 및 공간 치수들로서 정의된 스틸 이미지 또는 비디오 프레임) 에 대해, 코딩 유닛은 C 개의 채널들 중 하나, 단일 픽셀, C 채널들 중 하나에 대한 픽셀들의 블록, 또는 잠재성 내의 단일 엘리먼트 (예를 들어, 이미지 내의 특정 위치에서의 C 개의 채널들 중 한 채널의 값) 일 수도 있다. 그래프 (1300) 에 예시된 분류 기준은 각각의 코딩 블록에 대한 왜곡-대-레이트 변화율 (), 레이트 차이 (ΔR) 및 사전 표준 편차 (σ) 에 의해 표현되는 레이트-왜곡 중요도를 포함한다.
예시된 바와 같이, 엘리먼트 당 기반의 잠재성 오더링 및 압축은 채널당 기반의 잠재성 오더링 및 압축보다 주어진 압축 레이트에서 더 높은 PSNR 을 실현할 수도 있고, 픽셀당 기반의 잠재성 오더링 및 압축은 더 높은 압축 비트레이트를 제외하고는, 상당히 더 낮은 PSNR들을 실현할 수도 있다. 채널 기반 코딩 유닛들의 분류를 사용하는 압축의 경우, 사전 표준 편차, 레이트 차이, 또는 레이트-왜곡 중요도에 의한 분류에 대해 압축 성능이 유사할 수도 있다. 그러나, 엘리먼트-기반 코딩 유닛들 또는 픽셀-기반 코딩 유닛들의 분류를 사용하는 압축의 경우, 압축 성능이 상이한 타입들의 오더링 사이에서 발산함을 알 수 있다. 예를 들어, 엘리먼트-기반 코딩 유닛들의 분류를 사용하여 압축하기 위해, 레이트 차이 메트릭에 기초한 오더링은 사전 표준 편차에 기초한 분류보다 더 양호한 압축 성능 (예를 들어, 주어진 비트 레이트에 대해 더 높은 PSNR) 을 달성할 수 있다는 것을 알 수 있다.
오더링 코딩 유닛들은 압축 및 압축해제를 위해 일부 오버헤드를 부과할 수 있다. 예를 들어, 사전 표준 편차에 의해 코딩 유닛들을 오더링하는 것은, 하이퍼잠재성이 디코딩되면 사전 표준 편차가 디코더에 알려질 수 있기 때문에, 압축된 데이터를 복원하기 위해 추가적인 정보를 필요로 하지 않고 압축이 수행되는 것을 허용할 수 있다. 그러나, 레이트 차이 메트릭 또는 레이트-왜곡 중요도 메트릭에 의해 코딩 유닛들을 오더링하는 것은, 코딩 유닛들이 인코딩되는 순서를 전달하기 위한 비트레이트 오버헤드를 부과하는 것을 희생하면서, 코딩 유닛들의 더 정확한 오더링를 허용할 수도 있다. 일부 양태들에서, 코딩 유닛들이 인코딩되는 순서가 부가 정보로서 정렬 정보를 디코더에 전달하는 추가적인 오버헤드를 수용하기에 충분히 중요한 것으로 간주되는 경우, 다양한 최적화들은 이 오더링 정보를 디코더에 전달하는 데 수반되는 오버헤드를 감소시키기 위해 사용될 수 있다. 예를 들어, 스틸 이미지 내의 개개의 픽셀들보다는 픽셀들의 블록들과 같은 더 큰 코딩 유닛들이 데이터를 압축하기 위해 사용될 수 있으며, 이는 전달될 부가 정보의 양을 감소시킬 수 있다. 다른 양태에서, 예상 순서는 트레이닝 데이터로부터 머신 학습 모델에 의해 학습될 수 있고, 트레이닝된 머신 학습 모델에 의해 생성된 예상 순서는 디코더에 전달될 수 있다. 또 다른 양태들에서, 오더링은 더 큰 양자화 빈 사이즈를 사용하여 이미 디코딩된 잠재성으로부터와 같은 다른 이용가능한 정보로부터 학습될 수도 있다.
도 14 는 사이드 정보가 데이터를 압축해제하는데 사용되는 일 예의 신경망-기반 데이터 압축 파이프라인 (1400) 을 예시한다.
예시된 바와 같이, 압축 파이프라인은 도 1 에 예시되고 위에 논의되는 엘리먼트들 뿐만 아니라, 압축된 비트스트림으로부터 원래의 컨텐츠 x 의 근사치 () 를 생성하는데 사용될 수도 있는 사이드 채널 (예를 들어, 하이퍼 잠재성 z) 에 대한 정보를 생성하고 인코딩하는데 사용되는 추가적인 정보를 포함할 수도 있다.
컨텐츠 x를 나타내는 잠재 코드 공간 코드 y의 압축된 버전을 디코딩하는데 사용될 수 있는 사이드 채널에 대한 정보를 생성하기 위해, 하이퍼 분석 변환 (1402)(ha) 은 하이퍼 잠재성 (z) 을 생성할 수 있으며, 이는 양자화기 (1404) 에 의해 양자화되고 엔트로피 코더 (1406) 에 의해 하이퍼사전 으로 인코딩될 수 있다. 하이퍼사전은 잠재 코드 공간 코드 y의 압축된 버전과 함께 송신되고 엔트로피 디코더 (1408) 를 사용하여 디코딩되고, 하이퍼잠재성 (z) 의 근사치 () 를 복구하기 위해 역양자화기 (1410) 를 사용하여 양자화해제될 수 있다. 근사치 () 는, 사전 표준 편차 σ 및 사전 평균 μ를 복구하기 위해, 각각, 하이퍼합성 변환 (1412 (hs) 및 1414 (hm)) 을 통해 프로세싱될 수 있다.
사전 표준 편차 σ 및 평균 μ는 엔트로피 코더 (116) 및 엔트로피 디코더 (122) 에 의해 코드 y 의 양자화된 버전을 인코딩하고, 코드 y 의 인코딩된 양자화된 버전을 나타내는 비트스트림으로부터 코드 y 의 양자화된 버전을 복구하는데 사용될 수 있다. 사전 평균 μ 는 한편으로, y 를 양자화하고 엔트로피 디코더 (122) 에 의해 복구되는 비트스트림을 양자화해제하기 위한 파라미터로서 사용되어, 컨텐츠 x 가 맵핑되는 잠재 코드 공간 코드 y 의 근사치 () 를 복구할 수도 있다.
프로그래시브 데이터 압축을 위한 예의 프로세싱 시스템
도 15 는 예를 들어 도 6-7 과 관련하여 본 명세서에 설명된 바와 같은 컨볼루션 신경망 프로세싱을 수행하기 위한 일 예의 프로세싱 시스템 (1500) 을 예시한다.
프로세싱 시스템 (1200) 은 일부 예에서 멀티 코어 CPU일 수도 있는 중앙 프로세싱 유닛 (CPU) (1502) 을 포함한다. CPU (1502) 에서 실행되는 명령들은 예를 들어 CPU (1502) 와 연관된 프로그램 메모리로부터 로딩될 수도 있거나, 또는 메모리 파티션 (1524) 으로부터 로딩될 수도 있다.
프로세싱 시스템 (1500) 은 또한 특정 기능들에 맞추어지는 추가적인 프로세싱 컴포넌트들, 이를 테면, 그래픽 프로세싱 유닛 (GPU)(1504), 디지털 신호 프로세서 (DSP)(1506), 뉴럴 프로세싱 유닛 (NPU)(1508), 멀티미디어 프로세싱 유닛 (1510), 멀티미디어 프로세싱 유닛 (1510), 및 무선 접속성 컴포넌트 (1512) 를 포함한다.
1508 과 같은 NPU 는 일반적으로 인공 신경망 (ANN), 심층 신경망 (DNN), 랜덤 포레스트 (RF) 등과 같은 머신 러닝 알고리즘을 실행하기 위한 모든 필요한 제어 및 산술 로직을 구현하도록 구성된 전문적인 회로이다. NPU 는 때때로 대안적으로 신경 신호 프로세서 (NSP), 텐서 프로세싱 유닛 (TPU), 신경망 프로세서 (NNP), 지능 프로세싱 유닛 (IPU), 비전 프로세싱 유닛 (VPU) 또는 그래프 프로세싱 유닛으로 지칭될 수 있다.
1508 과 같은 NPU는 이미지 분류, 기계 번역, 객체 검출 및 기타 다양한 예측 모델과 같은 일반적인 기계 학습 작업의 성능을 가속화하도록 구성된다. 일부 예에서, 복수의 NPU는 SoC (system on chip) 와 같은 단일 칩에서 인스턴스화될 수 있는 반면, 다른 예에서는 전용 신경망 가속기의 일부일 수 있다.
NPU 는 훈련 또는 추론에 최적화되거나 또는 일부 경우에 둘 사이의 성능을 균형잡도록 구성될 수 있다. 훈련과 추론 양자 모두를 수행할 수 있는 NPU의 경우, 두 작업은 여전히 일반적으로 독립적으로 수행될 수 있다.
훈련을 가속화하도록 설계된 NPU 는 일반적으로, 새로운 모델의 최적화를 가속화하도록 구성되고, 이는 기존 데이터 세트 (종종 레이블화 또는 태그화됨) 를 입력하고, 데이터 세트에 대해 반복한 다음, 모델 성능을 향상시키기 위해 가중치 (weight) 와 바이어스 (bias) 와 같은 모델 파라미터를 조정하는 것을 수반하는 고도로 계산 집약적인 작업이다. 일반적으로, 잘못된 예측을 기반으로 하는 최적화에는 모델의 레이어를 통해 다시 전파하고 예측 에러를 줄이기 위해 기울기를 결정하는 것을 수반한다.
추론을 가속화하도록 설계된 NPU는 일반적으로 완전한 모델 상에서 작동하도록 구성된다. 따라서 이러한 NPU 는 새로운 데이터 조각을 입력하고 이를 이미 훈련된 모델을 통해 빠르게 처리하여 모델 출력 (예: 추론) 을 생성하도록 구성될 수 있다.
일 구현에서, NPU (1508) 는 CPU (1502), GPU (1504), 및/또는 DSP (1506) 중 하나 이상의 일부이다.
일부 실시예에서, 무선 접속성 구성 요소 (1512) 은 예를 들어, 3세대(3G) 접속성, 4세대(4G) 접속성(예를 들어, 4G LTE), 5세대 접속성(예를 들어, 5G 또는 NR), Wi-Fi 접속성, Bluetooth 접속성 및 기타 무선 데이터 송신 표준을 위한 하위 구성 요소를 포함할 수 있다. 무선 접속성 처리 구성 요소 (1512) 는 하나 이상의 안테나 (1514) 에 추가로 접속된다.
처리 시스템 (1500) 은 또한 임의의 방식의 센서와 연관된 하나 이상의 센서 프로세서 (1516), 임의의 방식의 이미지 센서와 연관된 하나 이상의 이미지 신호 프로세서 (ISP) (1518), 및/또는 위성 기반 포지셔닝 시스템 구성 요소 (예: GPS 또는 GLONASS) 및 관성 포지셔닝 시스템 구성 요소를 포함할 수 있는 내비게이션 프로세서 (1520) 를 포함할 수 있다.
프로세싱 시스템 (1500) 은 또한, 스크린들, 터치 감응형 표면들 (터치 감응형 디스플레이들을 포함함), 물리적 버튼들, 스피커들, 마이크로폰들 등과 같은 하나 이상의 입력 및/또는 출력 디바이스들 (1522) 을 포함할 수도 있다.
일부 예들에서, 프로세싱 시스템 (1500) 의 프로세서들 중 하나 이상은 ARM 또는 RISC-V 명령 세트에 기반할 수도 있다.
프로세싱 시스템 (1500) 은 또한 동적 랜덤 액세스 메모리, 플래시 기반 정적 메모리 등과 같은 하나 이상의 정적 및/또는 동적 메모리를 나타내는 메모리 (1524) 를 포함한다. 이 예에서, 메모리 (1524) 는 처리 시스템 (1500) 의 전술한 프로세서들 중 하나 이상에 의해 실행될 수 있는 컴퓨터 실행 가능 컴포넌트들을 포함한다.
구체적으로, 이 예에서, 메모리 (1524) 는 잠재 코드 공간 인코딩 컴포넌트 (1524A), 프로그래시브 코딩 컴포넌트 (1524B), 프로그래시브 코드 복구 컴포넌트 (1524C) 및 잠재 코드 공간 디코딩 컴포넌트 (1524D) 를 포함한다. 도시된 컴포넌트 및 도시되지 않은 다른 것들은 본원에 설명된 방법의 다양한 양태를 수행하도록 구성될 수 있다.
일반적으로, 프로세싱 시스템(1500) 및/또는 그의 컴포넌트는 본 명세서에 기재된 방법을 수행하도록 구성될 수도 있다.
특히, 다른 양태에서, 처리 시스템 (1500) 이 서버 컴퓨터 등인 경우와 같은, 처리 시스템 (1500) 의 양태는 생략될 수 있다. 예를 들어, 멀티미디어 컴포넌트 (1510), 무선 접속성 (1512), 센서 (1516), ISP (1518), 및/또는 내비게이션 컴포넌트 (1520) 는 다른 양태들에서 생략될 수도 있다. 또한, 프로세싱 시스템 (1500) 의 양태들은 모델을 훈련하고 모델을 사용하여 사용자 확인 예측과 같은 추론을 생성하는 것과 같이 분산될 수도 있다.
예시적인 항들
항 1: 신경망을 사용하여 컨텐츠를 압축하는 방법은: 압축을 위한 컨텐츠를 수신하는 단계; 컨텐츠를 인공 신경망에 의해 구현되는 인코더를 통해 제 1 잠재 코드 공간으로 인코딩하는 단계; 양자화 빈 사이즈들의 시리즈 중 제 1 양자화 빈 사이즈를 사용하여 인코딩된 컨텐츠의 제 1 압축된 버전을 생성하는 단계; 적어도 인코딩된 컨텐츠의 제 1 압축된 버전의 값에 대해 컨디셔닝되어, 인코딩된 컨텐츠의 제 1 압축된 버전을 제 1 양자화 빈 사이즈보다 더 작은 하나 이상의 제 2 양자화 빈 사이즈들로 스케일링하는 것에 의해 인코딩된 컨텐츠의 리파이닝된 압축된 버전을 생성하는 단계; 및 인코딩된 컨텐츠의 리파이닝된 압축된 버전을 출력하는 단계를 포함한다.
항 2: 항 1 의 방법에서, 인코딩된 컨텐츠의 리파이닝된 압축된 버전을 생성하는 단계는: 인코딩된 컨텐츠의 제 1 압축된 버전의 값에 대해 컨디셔닝되어, 인코딩된 컨텐츠의 제 1 압축된 버전을 제 1 의 더 미세한 양자화 빈 사이즈로 스케일링하는 것에 의해 인코딩된 컨텐츠의 제 1 리파이닝된 압축된 버전을 생성하는 단계; 및 인코딩된 컨텐츠의 제 1 리파이닝된 압축된 버전 및 인코딩된 컨텐츠의 제 1 압축된 버전의 값에 대해 컨디셔닝되어, 인코딩된 컨텐츠의 제 1 리파이닝된 압축된 버전을 제 2 의 더 미세한 양자화 빈 사이즈로 스케일링하는 것에 의해 인코딩된 컨텐츠의 제 2 리파이닝된 압축된 버전을 생성하는 단계 - 제 2 의 더 미세한 양자화 빈 사이즈는 제 1 의 미세한 양자화 빈 사이즈보다 더 작음 - 을 포함한다.
항 3: 항 1 또는 2 의 방법에서, 양자화 빈 사이즈들의 시리즈의 각각의 개별적인 양자화 빈 사이즈의 사이즈는 제 1 양자화 빈 사이즈의 정수배이다.
항 4: 항들 1 내지 3 의 어느 하나의 방법에서, 양자화 빈 사이즈들의 시리즈의 양자화 빈 사이즈에 대한 중심 빈은 양자화 빈 사이즈에서의 비-중심 빈들보다 더 큰 빈 사이즈를 갖는다.
항 5: 항들 1 내지 4 의 어느 하나의 방법에서, 인코딩된 컨텐츠의 리파이닝된 압축된 버전을 생성하는 단계는 조건적 확률의 체인에 기초하여 비트스트림을 생성하는 단계를 포함하고, 조건적 확률들의 체인에서의 각각의 조건적 확률은 가장 미세한 양자화 빈 사이즈이외의 양자화 빈 사이즈들의 시리즈에서의 개별적인 양자화 빈 사이즈와 연관되고 개별적인 양자화 빈 사이즈보다 더 큰 양자화 빈 사이즈들에 대해 계산된 조건적 확률들에 대해 컨디셔닝된다.
항 6: 항들 1 내지 5 의 어느 하나의 방법에서, 인코딩된 컨텐츠의 리파이닝된 압축된 버전을 생성하는 단계는 양자화 빈 사이즈들의 시리즈의 각각의 양자화 빈 사이즈에 대해, 인코딩된 컨텐츠가 위치되는 각각의 양자화 빈의 상한치 및 하한치의 누적 분포 함수에 기초하여 인코딩된 컨텐츠의 확률 질량을 생성하는 단계를 포함한다.
항 7: 항 6 의 방법은, 양자화 빈 사이즈들의 시리즈의 각각의 개별적인 양자화 빈 사이즈에 대한 확률 질량은 개별적인 양자화 빈 사이즈보다 더 큰 양자화 빈 사이즈들의 시리즈에서의 양자화 빈 사이즈들의 확률 질량에 대해 컨디셔닝된다.
항 8: 항들 1 내지 7 의 어느 하나의 방법에서, 수신된 컨텐츠는 다수의 데이터 채널들을 갖는 컨텐츠를 포함한다.
항 9: 항 8 의 방법에서, 다수의 데이터 채널들의 각각의 개별적인 데이터 채널은 개별적인 데이터 채널을 압축하는데 사용될 압축의 양에 대응하는 압축 우선순위와 연관된다.
항 10: 항 9 의 방법에서, 다수의 데이터 채널들은 비주얼 컨텐츠에서 루미넌스 채널 및 복수의 크로미넌스 채널들을 포함하고 루미넌스 채널은 복수의 크로미넌스 채널들과 연관된 압축 우선순위들보다 더 낮은 양의 압축과 연관된 압축 우선순위와 연관된다.
항 11: 항 9 의 방법에서, 수신된 컨텐츠는 압축될 비주얼 컨텐츠를 포함하고, 다수의 데이터 채널들은 비주얼 컨텐츠 내의 복수의 컬러 데이터 채널들을 포함하고, 그리고 인코딩된 컨텐츠의 압축된 버전의 품질에 대해 최고 영향을 미치는 복수의 컬러 데이터 채널들의 제 1 컬러 데이터 채널은 제 1 컬러 데이터 채널 이외의 컬러 데이터 채널들과 연관된 압축 우선순위들보다 낮은 양의 압축과 연관된 압축 우선순위와 연관된다.
항 12: 항 11 의 방법은: 복수의 컬러 데이터 채널들 각각에 포함된 루미넌스 데이터의 양에 기초하여 제 1 컬러 데이터 채널을 식별하는 단계를 더 포함한다.
항 13: 항들 9 내지 12 의 어느 하나의 방법은: 다수의 데이터 채널들의 각각의 개별적인 데이터 채널과 연관된 압축 우선순위가, 개별적인 데이터 채널이 양자화 빈 사이즈들의 시리즈에서의 각각의 양자화 빈 사이즈와 연관된 복수의 비트레이트들 각각에 대하여 인코딩될 때, 디코딩 후의 왜곡에서의 감소를 계산하는 것, 및 비트레이트에서의 증가를 계산하는 것에 기초한다고 결정하는 단계를 더 포함한다.
항 14: 항 13 의 방법에서, 각각의 개별적인 데이터 채널에 대한 왜곡에서의 감소를 계산하는 단계는 개별적인 데이터 채널을 포함하는 제 1 시간에 인코딩된 컨텐츠를 디코딩하는 것에 의해 생성된 왜곡과 개별적인 데이터 채널을 배제한 제 2 시간에 인코딩된 컨텐츠를 디코딩하는 것에 의해 생성된 왜곡 사이의 차이를 계산하는 단계를 포함한다.
항 15: 항들 1 내지 14 의 어느 하나의 방법은: 수신된 컨텐츠를 복수의 코딩 유닛들로 분할하는 단계; 및 압축 메트릭에 기초하여 복수의 코딩 유닛들을 오더링하는 단계를 더 포함하고, 인코딩된 컨텐츠의 리파이닝된 압축된 버전들을 생성하는 단계는 복수의 코딩 유닛들의 각각이 상이한 양자화 레벨을 사용하여 압축되고, 더 높은 압축 메트릭들을 갖는 코딩 유닛은 더 낮은 압축 메트릭들을 갖는 코딩 유닛들보다 더 낮은 양의 압축을 사용하여 압축되도록 복수의 코딩 유닛들의 각각을 리파이닝하는 단계를 포함한다.
항 16: 항 15 의 방법에서, 수신된 컨텐츠를 복수의 코딩 유닛들로 분할하는 것은 수신된 컨텐츠를 복수의 엘리먼트들로 분할하는 단계를 포함하고, 각각의 엘리먼트는 수신된 컨텐츠 내에서 특정 위치에 복수의 채널들 중 하나에 대한 데이터를 표현한다.
항 17: 항 15 의 방법에서, 수신된 컨텐츠를 복수의 코딩 유닛들로 분할하는 것은 수신된 컨텐츠를 복수의 블록들로 분할하는 단계를 포함하고, 각각의 블록은 수신된 컨텐츠 내에서 위치의 특정 범위에서 복수의 채널들 중 하나에 대한 데이터를 표현한다.
항 18: 항 15 의 방법에서, 수신된 컨텐츠를 복수의 코딩 유닛들로 분할하는 단계는 수신된 컨텐츠를 복수의 채널들로 분할하는 단계를 포함한다.
항 19: 항 15 의 방법에서, 수신된 컨텐츠를 복수의 코딩 유닛들로 분할하는 것은 수신된 컨텐츠를 복수의 픽셀들로 분할하는 단계를 포함하고, 각각의 픽셀은 수신된 컨텐츠 내에서 특정 위치에 복수의 채널들에 대한 데이터를 표현한다.
항 20: 항 15 의 방법에서, 압축 메트릭은 하이퍼잠재에서 인코딩되는 사전 표준 편차를 포함하고, 하이퍼잠재는 인코딩된 컨텐츠의 리파이닝된 압축된 버전의 초기 부분을 포함한다.
항 21: 항 15 의 방법에서, 압축 메트릭은 왜곡-대-레이트 비를 포함하고, 인코딩된 컨텐츠의 리파이닝된 압축된 버전은 최고 왜곡-대-레이트 비로부터 최저 왜곡-대-레이트 비까지 복수의 코딩 유닛들에 대한 오더링 정보를 포함하는 것을 포함한다.
항 22: 항 15 의 방법에서, 압축 메트릭은 레이트 메트릭에서의 변화를 포함하고, 인코딩된 컨텐츠의 리파이닝된 압축된 버전은 최고 레이트 메트릭로부터 최저 레이트 메트릭까지 복수의 코딩 유닛들에 대한 오더링 정보를 포함하는 것을 포함한다.
항 23: 항들 1 내지 22 의 어느 하나의 방법에서, 제 1 양자화 빈 사이즈는 제 1 비트레이트와 연관되고, 하나 이상의 제 2 양자화 빈 사이즈들의 각각의 개별 양자화 빈 사이즈는 제 1 비트레이트보다 높은 비트레이트에 대응한다.
항 24: 신경망을 사용하여 컨텐츠를 압축해제하는 방법은: 압축해제를 위한 인코딩된 컨텐츠를 수신하는 단계; 양자화 빈 사이즈들의 시리즈로부터 코드들을 복구하는 것에 의해 수신된 인코딩된 컨텐츠로부터 잠재 코드 공간에서의 값의 근사치를 복구하는 단계 - 양자화 빈 사이즈들의 시리즈는 제 1 양자화 빈 사이즈 및 제 1 양자화 빈 사이즈보다 더 작은 하나 이상의 제 2 양자화 빈 사이즈들을 포함함 -; 인공 신경망에 의해 구현되는 디코더를 통해 잠재 코드 공간 내의 값의 근사치를 디코딩하는 것에 의해 인코딩된 컨텐츠의 압축해제된 버전을 생성하는 단계; 및 인코딩된 컨텐츠의 압축해제된 버전을 출력하는 단계를 포함한다.
항 25: 항 24 의 방법에서, 양자화 빈 사이즈들의 시리즈의 각각의 개별적인 양자화 빈 사이즈의 사이즈는 제 1 양자화 빈 사이즈의 정수배이다.
항 26: 항 24 또는 25 의 방법에서, 양자화 빈 사이즈들의 시리즈의 양자화 빈 사이즈에 대한 중심 빈은 양자화 빈 사이즈에서의 비-중심 빈들보다 더 큰 빈 사이즈를 갖는다.
항 27: 항들 24 내지 26 의 어느 하나의 방법에서, 잠재 코드 공간에서의 값의 근사치를 복구하는 단계는 인코딩된 컨텐츠를 표현하는 비트스트림으로부터 조건적 확률들의 체인에 기초하여 코드를 복구하는 단계를 포함하고, 조건적 확률들의 체인에서의 각각의 조건적 확률은 가장 미세한 양자화 빈 사이즈이외의 양자화 빈 사이즈들의 시리즈에서의 개별적인 양자화 빈 사이즈와 연관되고 개별적인 양자화 빈 사이즈보다 더 큰 양자화 빈 사이즈들에 대해 계산된 조건적 확률들에 대해 컨디셔닝된다.
항 28: 항들 24 내지 27 의 어느 하나의 방법에서, 잠재 코드 공간에서의 값의 근사치를 복구하는 단계는 양자화 빈 사이즈들의 시리즈의 각각의 양자화 빈 사이즈로부터, 인코딩된 컨텐츠가 위치되는 각각의 양자화 빈의 상한치 및 하한치의 누적 분포 함수에 기초하여 인코딩된 컨텐츠의 확률 질량을 식별하는 단계를 포함한다.
항 29: 항 28 의 방법에서, 양자화 빈 사이즈들의 시리즈의 각각의 개별적인 양자화 빈 사이즈에 대한 확률 질량은 개별적인 양자화 빈 사이즈보다 더 큰 양자화 빈 사이즈들의 시리즈에서의 양자화 빈 사이즈들의 확률 질량에 대해 컨디셔닝된다.
항 30: 항들 24 내지 29 의 어느 하나의 방법에서, 수신된 인코딩된 컨텐츠는 다수의 데이터 채널들을 갖는 컨텐츠를 포함한다.
항 31: 항 30 의 방법에서, 다수의 데이터 채널들의 각각의 개별적인 데이터 채널은 개별적인 데이터 채널을 압축하는데 사용될 압축의 양에 대응하는 압축 우선순위와 연관된다.
항 32: 항 31 의 방법에서, 다수의 데이터 채널들은 비주얼 컨텐츠에서 루미넌스 채널 및 복수의 크로미넌스 채널들을 포함하고 루미넌스 채널은 복수의 크로미넌스 채널들과 연관된 압축 우선순위들보다 더 낮은 양의 압축과 연관된 압축 우선순위와 연관된다.
항 33: 항 31 의 방법에서, 수신된 인코딩된 컨텐츠는 압축해제될 비주얼 컨텐츠를 포함하고, 다수의 데이터 채널들은 비주얼 컨텐츠 내의 복수의 컬러 데이터 채널들을 포함하고, 그리고 인코딩된 컨텐츠의 압축해제된 버전의 품질에 대해 최고 영향을 미치는 복수의 컬러 데이터 채널들의 제 1 컬러 데이터 채널은 제 1 컬러 데이터 채널 이외의 컬러 데이터 채널들과 연관된 압축 우선순위들보다 낮은 양의 압축과 연관된 압축 우선순위와 연관된다.
항 34: 항 33 의 방법은: 복수의 컬러 데이터 채널들 각각에 포함된 루미넌스 데이터의 양에 기초하여 제 1 컬러 데이터 채널을 식별하는 단계를 더 포함한다.
항 35: 항들 24 내지 34 의 어느 하나의 방법에서, 인코딩된 컨텐츠는 복수의 인코딩된 코딩 유닛들을 포함하고, 수신된 인코딩된 컨텐츠로부터의 잠재 코드 공간 내의 값의 근사치를 복구하는 단계는 복수의 인코딩된 코딩 유닛들 각각과 연관된 잠재 코드 공간 내의 코드를 복구하는 단계를 포함한다.
항 36: 항 35 의 방법에서, 복수의 코딩 유닛들은 복수의 엘리먼트들을 포함하고, 각각의 엘리먼트는 수신된 컨텐츠 내에서 특정 위치에 복수의 채널들 중 하나에 대한 데이터를 표현한다.
항 37: 항 35 의 방법에서, 복수의 코딩 유닛들은 복수의 블록들을 포함하고, 각각의 블록은 수신된 컨텐츠 내에서 특정 위치 범위에 복수의 채널들 중 하나에 대한 데이터를 표현한다.
항 38: 항 35 의 방법에서, 복수의 코딩 유닛들은 복수의 채널들을 포함한다.
항 39: 항 35 의 방법에서, 복수의 코딩 유닛들은 복수의 픽셀들을 포함하고, 각각의 픽셀은 수신된 컨텐츠 내에서 특정 위치에 복수의 채널들 중 하나에 대한 데이터를 표현한다.
항 40: 항 35 의 방법에서, 잠재 코드 공간에서 값의 근사치를 복구하는 단계는 하이퍼잠재에 인코딩되는 사전 표준 편차를 복구하는 단계를 포함하고, 하이퍼잠재는 인코딩된 컨텐츠의 초기 부분을 포함한다.
항 41: 항 35 의 방법에서, 잠재 코드 공간에서의 값의 근사치를 복구하는 단계는 복수의 코딩 유닛들이 압축해제되었던 순서를 복구하는 단계를 포함하고, 순서는 인코딩된 컨텐츠와 연관된 사이드 정보로서 포함된다.
항 42: 항들 24 내지 42 의 어느 하나의 방법에서, 제 1 양자화 빈 사이즈는 제 1 비트레이트와 연관되고, 하나 이상의 제 2 양자화 빈 사이즈들의 각각의 개별 양자화 빈 사이즈는 제 1 비트레이트보다 높은 비트레이트에 대응한다.
항 43: 프로세싱 시스템은 컴퓨터 실행가능 명령들을 포함하는 메모리; 및 컴퓨터 실행가능 명령들을 실행하고 프로세싱 시스템으로 하여금 항 1-42 중 어느 하나에 따른 방법을 수행하게 하도록 구성된 하나 이상의 프로세서들을 포함한다.
항 44: 프로세싱 시스템은 항 1-42 중 어느 하나에 따른 방법을 수행하기 위한 수단을 포함한다.
항 45: 컴퓨터 실행가능 명령들을 포함하는 비일시적 컴퓨터 판독가능 매체로서, 컴퓨터 실행가능 명령들은, 프로세싱 시스템의 하나 이상의 프로세서들에 의해 실행될 경우, 프로세싱 시스템으로 하여금 항들 1-42 중 어느 하나에 따른 방법을 수행하게 한다.
항 46: 컴퓨터 판독가능 저장 매체 상에 수록된 컴퓨터 프로그램 제품은 항들 1-42 중 어느 하나에 따른 방법을 수행하기 위한 코드를 포함한다.
추가적인 고려사항들
이전의 설명은 당업자가 본 명세서에서 설명된 다양한 양태들을 실시하는 것을 가능하게 하기 위해 제공된다.본 명세서에서 논의된 예들은 청구항들에 기재된 범위, 적용가능성, 또는 양태들을 한정하는 것은 아니다. 이들 양태들에 대한 다양한 수정들은 당업자에게 용이하게 자명할 것이며, 본 명세서에서 정의된 일반적인 원리들은 다른 양태들에 적용될 수도 있다. 예를 들어, 본 개시의 범위로부터 일탈함없이 논의된 엘리먼트들의 기능 및 배열에 있어서 변경들이 행해질 수도 있다. 다양한 예들은 다양한 절차들 또는 컴포넌트들을 적절하게 생략, 치환, 또는 추가할 수도 있다. 예를 들어, 설명된 방법들은 설명된 것과는 상이한 순서로 수행될 수도 있고, 다양한 단계들이 추가, 생략, 또는 결합될 수도 있다. 또한, 일부 예들에 관하여 설명된 특징들은 기타 예들에서 결합될 수도 있다. 예를 들어, 본 명세서에 기술된 임의의 수의 양태들을 이용하여 장치가 구현될 수도 있거나 또는 방법이 실시될 수도 있다. 또한, 본 개시의 범위는 여기에 제시된 본 개시의 다양한 양태들 외에 또는 이에 추가하여 다른 구조, 기능성, 또는 구조 및 기능성을 이용하여 실시되는 그러한 장치 또는 방법을 커버하도록 의도된다. 본 명세서에 개시된 개시의 임의의 양태는 청구항의 하나 이상의 엘리먼트에 의해 구체화될 수도 있다는 것이 이해되어야 한다.
본 명세서에서 사용된 바와 같이, 단어 "예시적인" 은 예, 예증, 또는 예시로서 작용함을 의미하도록 사용된다. 본 명세서에서 "예시적인" 으로서 설명된 임의의 양태가 반드시 다른 양태들에 비해 유리하거나 또는 바람직한 것으로서 해석되어야 하는 것은 아니다.
본원에 사용된, 항목들의 리스트 "중 적어도 하나" 를 나타내는 어구는, 단일 멤버들을 포함한 그러한 아이템들의 임의의 조합을 나타낸다. 일 예로서, "a, b, 또는 c 중 적어도 하나" 는 a, b, c, a-b, a-c, b-c, 및 a-b-c 뿐 아니라 동일한 엘리먼트의 배수들과의 임의의 조합 (예컨대, a-a, a-a-a, a-a-b, a-a-c, a-b-b, a-c-c, b-b, b-b-b, b-b-c, c-c, 및 c-c-c 또는 a, b, 및 c 의 임의의 다른 오더링) 을 커버하도록 의도된다.
본원에서 이용되는 바와 같이, 용어 "결정하는" 은 매우 다양한 액션들을 망라한다. 예를 들어, "결정하는 것" 은 계산하는 것, 컴퓨팅하는 것, 프로세싱하는 것, 도출하는 것, 조사하는 것, 룩업하는 것 (예를 들어, 표, 데이터베이스 또는 다른 데이터 구조에서 룩업하는 것), 확인하는 것 등을 포함할 수도 있다. 또한, "결정하는 것" 은 수신하는 것 (예를 들어, 정보를 수신하는 것), 액세스하는 것 (예를 들어, 메모리 내 데이터에 액세스하는 것) 등을 포함할 수도 있다. 또한, "결정하는 것" 은 해결하는 것, 선택하는 것, 선출하는 것, 확립하는 것 등을 포함할 수도 있다.
본 명세서에 개시된 방법들은 그 방법들을 달성하기 위한 하나 이상의 단계 또는 액션들을 포함한다. 그 방법 단계들 및/또는 액션들은 청구항들의 범위로부터 일탈함 없이 서로 상호교환될 수도 있다. 즉, 단계들 또는 액션들의 특정 순서가 명시되지 않으면, 특정 단계들 및/또는 액션들의 순서 및/또는 사용은 청구항들의 범위로부터 일탈함이 없이 수정될 수도 있다. 또한, 설명된 다양한 방법 동작들은 대응하는 기능들을 수행 가능한 임의의 적합한 수단에 의해 수행될 수도 있다. 그 수단은, 회로, 주문형 집적 회로 (ASIC), 또는 프로세서를 포함하지만 이들에 제한되지는 않는 다양한 하드웨어 및/또는 소프트웨어 컴포넌트(들) 및/또는 모듈(들)을 포함할 수도 있다. 일반적으로, 도면들에 예시된 동작들이 있는 경우에, 그 동작들은 유사한 넘버링을 가진 대응하는 상대의 기능식 (means-plus-function) 컴포넌트들을 가질 수도 있다.
다음의 청구항들은 본 명세서에 나타낸 양태들로 한정되도록 의도되지 않지만, 청구항들의 언어와 부합하는 전체 범위를 부여받아야 한다. 청구항 내에서, 단수로의 엘리먼트에 대한 언급은, 구체적으로 그렇게 서술되지 않는 한 "하나 및 오직 하나" 를 의미하도록 의도되지 않고 오히려 "하나 이상" 을 의미하도록 의도된다. 명확하게 달리 서술되지 않으면, 용어 "일부" 는 하나 이상을 지칭한다. 어떠한 청구항 엘리먼트도 그 엘리먼트가 어구 "~하는 수단" 을 사용하여 명백하게 기재되지 않는다면, 또는 방법 청구항의 경우, 그 엘리먼트가 어구 "~하는 단계" 를 사용하여 기재되지 않는다면, 35 U.S.C.§112(f) 의 규정 하에서 해석되지 않아야 한다. 당업자에게 공지되거나 나중에 공지되게 될 본 개시 전반에 걸쳐 설명된 다양한 양태들의 엘리먼트들에 대한 모든 구조적 및 기능적 균등물들은 본 명세서에 참조에 의해 명백히 통합되며 청구항들에 의해 포괄되도록 의도된다. 더욱이, 본 명세서에 개시된 어떤 것도, 그러한 개시가 청구항들에 명시적으로 기재되는지 여부와 무관하게 공중에 전용되도록 의도되지 않는다.
Claims (30)
- 신경망을 사용하여 컨텐츠를 압축하는 방법으로서,
압축을 위한 컨텐츠를 수신하는 단계;
상기 컨텐츠를 인공 신경망에 의해 구현되는 인코더를 통해 제 1 잠재 코드 공간으로 인코딩하는 단계;
양자화 빈 사이즈들의 시리즈 중 제 1 양자화 빈 사이즈를 사용하여 인코딩된 컨텐츠의 제 1 압축된 버전을 생성하는 단계;
적어도 상기 인코딩된 컨텐츠의 상기 제 1 압축된 버전의 값에 대해 컨디셔닝되어, 상기 인코딩된 컨텐츠의 상기 제 1 압축된 버전을 상기 제 1 양자화 빈 사이즈보다 더 작은 상기 양자화 빈 사이즈들의 시리즈에서의 하나 이상의 제 2 양자화 빈 사이즈들로 스케일링하는 것에 의해 상기 인코딩된 컨텐츠의 리파이닝된 압축된 버전을 생성하는 단계; 및
상기 인코딩된 컨텐츠의 상기 리파이닝된 압축된 버전을 출력하는 단계를 포함하는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 1 항에 있어서,
상기 인코딩된 컨텐츠의 상기 리파이닝된 압축된 버전을 생성하는 단계는:
상기 인코딩된 컨텐츠의 상기 제 1 압축된 버전의 값에 대해 컨디셔닝되어, 상기 인코딩된 컨텐츠의 제 1 압축된 버전을 제 1 의 더 미세한 양자화 빈 사이즈로 스케일링하는 것에 의해 상기 인코딩된 컨텐츠의 제 1 리파이닝된 압축된 버전을 생성하는 단계; 및
상기 인코딩된 컨텐츠의 상기 제 1 리파이닝된 압축된 버전 및 상기 인코딩된 컨텐츠의 상기 제 1 압축된 버전의 값에 대해 컨디셔닝되어, 상기 인코딩된 컨텐츠의 상기 제 1 리파이닝된 압축된 버전을 제 2 의 더 미세한 양자화 빈 사이즈로 스케일링하는 것에 의해 상기 인코딩된 컨텐츠의 제 2 리파이닝된 압축된 버전을 생성하는 단계로서, 상기 제 2 의 더 미세한 양자화 빈 사이즈는 상기 제 1 의 미세한 양자화 빈 사이즈보다 더 작은, 상기 인코딩된 컨텐츠의 제 2 리파이닝된 압축된 버전을 생성하는 단계를 포함하는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 1 항에 있어서,
상기 양자화 빈 사이즈들의 시리즈의 각각의 개별적인 양자화 빈 사이즈의 사이즈는 상기 제 1 양자화 빈 사이즈의 정수배인, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 1 항에 있어서,
상기 양자화 빈 사이즈들의 시리즈의 양자화 빈 사이즈에 대한 중심 빈은 상기 양자화 빈 사이즈에서의 비-중심 빈들보다 더 큰 빈 사이즈를 갖는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 1 항에 있어서,
상기 인코딩된 컨텐츠의 상기 리파이닝된 압축된 버전을 생성하는 단계는 조건적 확률들의 체인에 기초하여 비트스트림을 생성하는 단계를 포함하고,
상기 조건적 확률들의 체인에서의 각각의 조건적 확률은 가장 미세한 양자화 빈 사이즈이외의 양자화 빈 사이즈들의 시리즈에서의 개별적인 양자화 빈 사이즈와 연관되고 개별적인 양자화 빈 사이즈보다 더 큰 양자화 빈 사이즈들에 대해 계산된 조건적 확률들에 대해 컨디셔닝되는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 1 항에 있어서,
상기 인코딩된 컨텐츠의 상기 리파이닝된 압축된 버전을 생성하는 단계는:
상기 양자화 빈 사이즈들의 시리즈의 각각의 양자화 빈 사이즈에 대해, 상기 인코딩된 컨텐츠가 위치되는 각각의 양자화 빈의 상한치 및 하한치의 누적 분포 함수에 기초하여 상기 인코딩된 컨텐츠의 확률 질량을 생성하는 단계를 포함하고, 그리고
상기 양자화 빈 사이즈들의 시리즈의 각각의 개별적인 양자화 빈 사이즈에 대한 상기 확률 질량은 개별적인 양자화 빈 사이즈보다 더 큰 양자화 빈 사이즈들의 시리즈에서의 양자화 빈 사이즈들의 확률 질량에 대해 컨디셔닝되는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 1 항에 있어서,
상기 인코딩된 컨텐츠는 다수의 데이터 채널들을 갖는 컨텐츠를 포함하고,
상기 다수의 데이터 채널들의 각각의 개별적인 데이터 채널은 상기 개별적인 데이터 채널을 압축하는데 사용될 압축의 양에 대응하는 압축 우선순위와 연관되는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 7 항에 있어서,
상기 다수의 데이터 채널들의 각각의 개별적인 데이터 채널과 연관된 압축 우선순위가, 상기 개별적인 데이터 채널이 양자화 빈 사이즈들의 시리즈에서의 각각의 양자화 빈 사이즈와 연관된 복수의 비트레이트들 각각에 대하여 인코딩될 때, 디코딩 후의 왜곡에서의 감소를 계산하는 것, 및 비트레이트에서의 증가를 계산하는 것에 기초한다고 결정하는 단계를 더 포함하는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 8 항에 있어서,
각각의 개별적인 데이터 채널에 대한 왜곡에서의 감소를 계산하는 것은 개별적인 데이터 채널을 포함하는 제 1 시간에 인코딩된 컨텐츠를 디코딩하는 것에 의해 생성된 왜곡과 개별적인 데이터 채널을 배제한 제 2 시간에 인코딩된 컨텐츠를 디코딩하는 것에 의해 생성된 왜곡 사이의 차이를 계산하는 것을 포함하는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 1 항에 있어서,
상기 수신된 컨텐츠를 복수의 코딩 유닛들로 분할하는 단계; 및
압축 메트릭에 기초하여 상기 복수의 코딩 유닛들을 오더링하는 단계를 더 포함하고;
상기 인코딩된 컨텐츠의 상기 리파이닝된 압축된 버전을 생성하는 단계는:
상기 복수의 코딩 유닛들의 각각이 상이한 양자화 레벨을 사용하여 압축되고, 더 높은 압축 메트릭들을 갖는 코딩 유닛이 더 낮은 압축 메트릭들을 갖는 코딩 유닛들보다 더 낮은 양의 압축을 사용하여 압축되도록 상기 복수의 코딩 유닛들의 각각을 리파이닝하는 단계를 포함하는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 10 항에 있어서,
상기 수신된 컨텐츠를 상기 복수의 코딩 유닛들로 분할하는 단계는, 상기 수신된 컨텐츠를 복수의 엘리먼트들로 분할하는 단계를 포함하고, 각각의 엘리먼트는 상기 수신된 컨텐츠 내에서 특정 위치에 복수의 채널들 중 하나에 대한 데이터를 표현하는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 10 항에 있어서,
상기 수신된 컨텐츠를 상기 복수의 코딩 유닛들로 분할하는 단계는 상기 수신된 컨텐츠를 복수의 블록들로 분할하는 단계를 포함하고, 각각의 블록은 상기 수신된 컨텐츠 내에서 특정 위치 범위에서 복수의 채널들 중 하나에 대한 데이터를 표현하는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 10 항에 있어서,
상기 수신된 컨텐츠를 상기 복수의 코딩 유닛들로 분할하는 단계는 상기 수신된 컨텐츠를 복수의 채널들로 분할하는 단계를 포함하는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 10 항에 있어서,
상기 수신된 컨텐츠를 상기 복수의 코딩 유닛들로 분할하는 단계는 상기 수신된 컨텐츠를 복수의 픽셀들로 분할하는 단계를 포함하고, 각각의 픽셀은 수신된 컨텐츠 내에서 특정 위치에 복수의 채널들에 대한 데이터를 표현하는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 10 항에 있어서,
상기 압축 메트릭은:
하이퍼잠재 (hyperlatent) 에서 인코딩되는 사전 표준 편차로서, 상기 하이퍼잠재는 상기 인코딩된 컨텐츠의 리파이닝된 압축된 버전의 초기 부분을 포함하는, 상기 사전 표준 편차;
왜곡-대-레이트 비로서, 상기 인코딩된 컨텐츠의 상기 리파이닝된 압축된 버전은 최고 왜곡-대-레이트 비로부터 최저 왜곡-대-레이트 비까지 상기 복수의 코딩 유닛들에 대한 오더링 정보를 포함하는, 상기 왜곡-대-레이트 비; 또는
레이트 메트릭에서의 변화로서, 상기 인코딩된 컨텐츠의 상기 리파이닝된 압축된 버전은 최고 레이트 메트릭로부터 최저 레이트 메트릭까지 복수의 코딩 유닛들에 대한 오더링 정보를 포함하는, 상기 레이트 메트릭에서의 변화
중 하나 이상을 포함하는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 제 1 항에 있어서,
상기 제 1 양자화 빈 사이즈는 제 1 비트레이트와 연관되고, 상기 하나 이상의 제 2 양자화 빈 사이즈들의 각각의 개별적인 양자화 빈 사이즈는 제 1 비트레이트보다 높은 비트레이트에 대응하는, 신경망을 사용하여 컨텐츠를 압축하는 방법. - 신경망을 사용하여 컨텐츠를 압축해제하는 방법으로서,
압축해제를 위한 인코딩된 컨텐츠를 수신하는 단계;
양자화 빈 사이즈들의 시리즈로부터 코드들을 복구하는 것에 의해 수신된 상기 인코딩된 컨텐츠로부터 잠재 코드 공간에서의 값의 근사치를 복구하는 단계로서, 상기 양자화 빈 사이즈들의 시리즈는 제 1 양자화 빈 사이즈 및 제 1 양자화 빈 사이즈보다 더 작은 하나 이상의 제 2 양자화 빈 사이즈들을 포함하는, 상기 잠재 코드 공간에서의 값의 근사치를 복구하는 단계;
인공 신경망에 의해 구현되는 디코더를 통해 잠재 코드 공간 내의 값의 근사치를 디코딩하는 것에 의해 인코딩된 컨텐츠의 압축해제된 버전을 생성하는 단계; 및
상기 인코딩된 컨텐츠의 압축해제된 버전을 출력하는 단계를 포함하는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 제 17 항에 있어서,
상기 양자화 빈 사이즈들의 시리즈의 각각의 개별적인 양자화 빈 사이즈의 사이즈는 상기 제 1 양자화 빈 사이즈의 정수배이고,
상기 잠재 코드 공간에서의 값의 근사치를 복구하는 단계는 인코딩된 컨텐츠를 표현하는 비트스트림으로부터 조건적 확률들의 체인에 기초하여 코드를 복구하는 단계를 포함하고,
상기 조건적 확률들의 체인에서의 각각의 조건적 확률은 가장 미세한 양자화 빈 사이즈이외의 양자화 빈 사이즈들의 시리즈에서의 개별적인 양자화 빈 사이즈와 연관되고 개별적인 양자화 빈 사이즈보다 더 큰 양자화 빈 사이즈들에 대해 계산된 조건적 확률들에 대해 컨디셔닝되는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 제 17 항에 있어서,
상기 잠재 코드 공간에서의 값의 근사치를 복구하는 단계는 양자화 빈 사이즈들의 시리즈의 각각의 양자화 빈 사이즈로부터, 상기 인코딩된 컨텐츠가 위치되는 각각의 양자화 빈의 상한치 및 하한치의 누적 분포 함수에 기초하여 인코딩된 컨텐츠의 확률 질량을 식별하는 단계를 포함하고,
상기 양자화 빈 사이즈들의 시리즈의 각각의 개별적인 양자화 빈 사이즈에 대한 상기 확률 질량은 개별적인 양자화 빈 사이즈보다 더 큰 양자화 빈 사이즈들의 시리즈에서의 양자화 빈 사이즈들의 확률 질량에 대해 컨디셔닝되는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 제 17 항에 있어서,
상기 수신된 인코딩된 컨텐츠는 다수의 데이터 채널들을 갖는 컨텐츠를 포함하고,
상기 다수의 데이터 채널들의 각각의 개별적인 데이터 채널은 상기 개별적인 데이터 채널을 압축하는데 사용될 압축의 양에 대응하는 압축 우선순위와 연관되는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 제 17 항에 있어서,
상기 인코딩된 컨텐츠는 복수의 인코딩된 코딩 유닛들을 포함하고,
상기 수신된 인코딩된 컨텐츠로부터의 잠재 코드 공간 내의 값의 근사치를 복구하는 단계는 상기 복수의 인코딩된 코딩 유닛들 각각과 연관된 상기 잠재 코드 공간 내의 코드를 복구하는 단계를 포함하는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 제 21 항에 있어서,
상기 복수의 코딩 유닛들은 복수의 엘리먼트들을 포함하고, 각각의 엘리먼트는 수신된 컨텐츠 내에서 특정 위치에 복수의 채널들 중 하나에 대한 데이터를 표현하는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 제 21 항에 있어서,
상기 복수의 코딩 유닛들은 복수의 블록들을 포함하고, 각각의 블록은 수신된 컨텐츠 내에서 특정 위치 범위에서 복수의 채널들 중 하나에 대한 데이터를 표현하는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 제 21 항에 있어서,
상기 복수의 코딩 유닛들은 복수의 채널들을 포함하는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 제 21 항에 있어서,
상기 복수의 코딩 유닛들은 복수의 픽셀들을 포함하고, 각각의 픽셀은 수신된 컨텐츠 내에서 특정 위치에 복수의 채널들 중 하나에 대한 데이터를 표현하는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 제 21 항에 있어서,
상기 잠재 코드 공간에서 값의 근사치를 복구하는 단계는 하이퍼잠재에 인코딩되는 사전 표준 편차를 복구하는 단계를 포함하고, 상기 하이퍼잠재는 인코딩된 컨텐츠의 초기 부분을 포함하는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 제 21 항에 있어서,
상기 잠재 코드 공간에서의 값의 근사치를 복구하는 단계는 복수의 코딩 유닛들이 압축해제되었던 순서를 복구하는 단계를 포함하고, 상기 순서는 상기 인코딩된 컨텐츠와 연관된 사이드 정보로서 포함되는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 제 17 항에 있어서,
상기 제 1 양자화 빈 사이즈는 제 1 비트레이트와 연관되고, 상기 하나 이상의 제 2 양자화 빈 사이즈들의 각각의 개별 양자화 빈 사이즈는 상기 제 1 비트레이트보다 높은 비트레이트에 대응하는, 신경망을 사용하여 컨텐츠를 압축해제하는 방법. - 시스템으로서,
실행가능 명령들이 저장된 메모리; 및
상기 실행가능 명령들을 실행하도록 구성되는 프로세서를 포함하고,
상기 실행가능 명령들은 상기 시스템으로 하여금:
압축을 위한 컨텐츠를 수신하게 하고;
상기 컨텐츠를 인공 신경망에 의해 구현되는 인코더를 통해 제 1 잠재 코드 공간으로 인코딩하게 하고;
양자화 빈 사이즈들의 시리즈 중 제 1 양자화 빈 사이즈를 사용하여 인코딩된 컨텐츠의 제 1 압축된 버전을 생성하게 하고;
적어도 상기 인코딩된 컨텐츠의 상기 제 1 압축된 버전의 값에 대해 컨디셔닝되어, 상기 인코딩된 컨텐츠의 상기 제 1 압축된 버전을 제 1 양자화 빈 사이즈보다 더 작은 상기 양자화 빈 사이즈들의 시리즈에서의 하나 이상의 제 2 양자화 빈 사이즈들로 스케일링하는 것에 의해 상기 인코딩된 컨텐츠의 리파이닝된 압축된 버전을 생성하게 하고; 그리고
상기 인코딩된 컨텐츠의 상기 리파이닝된 압축된 버전을 출력하게 하는, 시스템. - 시스템으로서,
실행가능한 명령들이 저장된 메모리; 및
상기 실행가능 명령들을 실행하도록 구성되는 프로세서를 포함하고,
상기 실행가능 명령들은 상기 시스템으로 하여금:
압축해제를 위한 인코딩된 컨텐츠를 수신하게 하고;
양자화 빈 사이즈들의 시리즈로부터 코드들을 복구하는 것에 의해 수신된 인코딩된 컨텐츠로부터 잠재 코드 공간에서의 값의 근사치를 복구하게 하는 것으로서, 양자화 빈 사이즈들의 시리즈는 제 1 양자화 빈 사이즈 및 상기 제 1 양자화 빈 사이즈보다 더 작은 하나 이상의 제 2 양자화 빈 사이즈들을 포함하는, 상기 잠재 코드 공간에서의 값의 근사치를 복구하게 하고;
인공 신경망에 의해 구현되는 디코더를 통해 잠재 코드 공간 내의 값의 근사치를 디코딩하는 것에 의해 인코딩된 컨텐츠의 압축해제된 버전을 생성하게 하고; 그리고
상기 인코딩된 컨텐츠의 압축해제된 버전을 출력하게 하는, 시스템.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202163141322P | 2021-01-25 | 2021-01-25 | |
| US63/141,322 | 2021-01-25 | ||
| US17/648,808 US20220237740A1 (en) | 2021-01-25 | 2022-01-24 | Progressive data compression using artificial neural networks |
| US17/648,808 | 2022-01-24 | ||
| PCT/US2022/013723 WO2022159897A1 (en) | 2021-01-25 | 2022-01-25 | Progressive data compression using artificial neural networks |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230136121A true KR20230136121A (ko) | 2023-09-26 |
Family
ID=80284798
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237024615A KR20230136121A (ko) | 2021-01-25 | 2022-01-25 | 인공 신경망을 사용한 프로그래시브 데이터 압축 |
Country Status (5)
| Country | Link |
|---|---|
| EP (1) | EP4282076A1 (ko) |
| JP (1) | JP2024504315A (ko) |
| KR (1) | KR20230136121A (ko) |
| BR (1) | BR112023013954A2 (ko) |
| WO (1) | WO2022159897A1 (ko) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116260969B (zh) * | 2023-05-15 | 2023-08-18 | 鹏城实验室 | 一种自适应的通道渐进式编解码方法、装置、终端及介质 |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10886943B2 (en) * | 2019-03-18 | 2021-01-05 | Samsung Electronics Co., Ltd | Method and apparatus for variable rate compression with a conditional autoencoder |
-
2022
- 2022-01-25 JP JP2023543424A patent/JP2024504315A/ja active Pending
- 2022-01-25 EP EP22703810.6A patent/EP4282076A1/en active Pending
- 2022-01-25 BR BR112023013954A patent/BR112023013954A2/pt unknown
- 2022-01-25 WO PCT/US2022/013723 patent/WO2022159897A1/en active Application Filing
- 2022-01-25 KR KR1020237024615A patent/KR20230136121A/ko unknown
Also Published As
| Publication number | Publication date |
|---|---|
| BR112023013954A2 (pt) | 2023-11-07 |
| JP2024504315A (ja) | 2024-01-31 |
| EP4282076A1 (en) | 2023-11-29 |
| WO2022159897A1 (en) | 2022-07-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11062211B2 (en) | Deep learning based adaptive arithmetic coding and codelength regularization | |
| KR102285738B1 (ko) | 영상의 주관적 품질을 평가하는 방법 및 장치 | |
| JP5957559B2 (ja) | 大きいサイズの変換単位を用いた映像符号化、復号化方法及び装置 | |
| US10594338B1 (en) | Adaptive quantization | |
| US20220237740A1 (en) | Progressive data compression using artificial neural networks | |
| US20220191521A1 (en) | Processing of residulas in video coding | |
| US11893762B2 (en) | Method and data processing system for lossy image or video encoding, transmission and decoding | |
| CN110383835B (zh) | 使用用于gcli熵编码的子带相关预测适应进行编码或解码的装置和方法 | |
| KR102312337B1 (ko) | Ai 부호화 장치 및 그 동작방법, 및 ai 복호화 장치 및 그 동작방법 | |
| Fu et al. | Improved hybrid layered image compression using deep learning and traditional codecs | |
| US20030081852A1 (en) | Encoding method and arrangement | |
| KR20230136121A (ko) | 인공 신경망을 사용한 프로그래시브 데이터 압축 | |
| Kabir et al. | Edge-based transformation and entropy coding for lossless image compression | |
| KR102312338B1 (ko) | Ai 부호화 장치 및 그 동작방법, 및 ai 복호화 장치 및 그 동작방법 | |
| US20240155132A1 (en) | Processing of residuals in video coding | |
| CN116746066A (zh) | 使用人工神经网络的渐进式数据压缩 | |
| US20220321879A1 (en) | Processing image data | |
| CN116723333B (zh) | 基于语义信息的可分层视频编码方法、装置及产品 | |
| WO2022229495A1 (en) | A method, an apparatus and a computer program product for video encoding and video decoding | |
| EA045392B1 (ru) | Обработка остатков при кодировании видео |