KR20220163364A - 텍스처 기반 몰입형 비디오 코딩 - Google Patents
텍스처 기반 몰입형 비디오 코딩 Download PDFInfo
- Publication number
- KR20220163364A KR20220163364A KR1020227031516A KR20227031516A KR20220163364A KR 20220163364 A KR20220163364 A KR 20220163364A KR 1020227031516 A KR1020227031516 A KR 1020227031516A KR 20227031516 A KR20227031516 A KR 20227031516A KR 20220163364 A KR20220163364 A KR 20220163364A
- Authority
- KR
- South Korea
- Prior art keywords
- pixels
- view
- patch
- patches
- atlas
- Prior art date
Links
Images


















Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/70—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by syntax aspects related to video coding, e.g. related to compression standards
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/50—Depth or shape recovery
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
- G06V10/54—Extraction of image or video features relating to texture
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/74—Image or video pattern matching; Proximity measures in feature spaces
- G06V10/761—Proximity, similarity or dissimilarity measures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/167—Position within a video image, e.g. region of interest [ROI]
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/182—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being a pixel
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/20—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using video object coding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/46—Embedding additional information in the video signal during the compression process
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/597—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding specially adapted for multi-view video sequence encoding
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Databases & Information Systems (AREA)
- Evolutionary Computation (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Testing, Inspecting, Measuring Of Stereoscopic Televisions And Televisions (AREA)
Abstract
텍스처 기반 몰입형 비디오 코딩을 위한 방법들, 장치들, 시스템들 및 제조 물품들이 개시된다. 예시적인 장치는 (i) 제1 뷰의 복수의 픽셀들에 포함된 제1 고유한 픽셀들 및 제1 대응하는 픽셀들을 식별하고 (ii) 제2 뷰의 복수의 픽셀들에 포함된 제2 고유한 픽셀들 및 제2 대응하는 픽셀들을 식별하기 위한 대응 관계 라벨러; (i) 제1 뷰에서의 인접한 픽셀들을 비교하고, (ii) 인접한 픽셀들의 비교 및 대응 관계들에 기초하여 고유한 픽셀들의 제1 패치 및 대응하는 픽셀들의 제2 패치를 식별하기 위한 대응 관계 패치 패커 - 대응하는 픽셀들의 제2 패치는 제2 뷰에서의 대응하는 패치들을 식별해 주는 대응 관계 리스트로 태깅됨 -; 및 인코딩된 비디오 데이터에 포함시킬 적어도 하나의 아틀라스를 생성하기 위한 아틀라스 생성기 - 인코딩된 비디오 데이터는 깊이 맵들을 포함하지 않음 - 를 포함한다.
Description
관련 출원
이 특허는 2020년 4월 13일에 제출된 미국 가특허 출원 제63/009,356호의 이익을 주장한다. 미국 가특허 출원 제63/009,356호는 이로써 참조에 의해 그 전체가 본 명세서에 포함된다. 이로써 미국 특허 출원 제63/009,356호에 대한 우선권이 주장된다.
개시내용의 분야
본 개시내용은 일반적으로 비디오 코딩에 관한 것으로, 더 상세하게는 텍스처 기반 몰입형 비디오 코딩에 관한 것이다.
압축/압축해제(코덱) 시스템들에서, 압축 효율과 비디오 품질은 중요한 성능 기준들이다. 예를 들어, 시각적 품질은 많은 비디오 응용들에서 사용자 경험의 중요한 측면이며, 압축 효율은 비디오 파일들을 저장하는 데 필요한 메모리 저장소의 양 및/또는 비디오 콘텐츠를 전송 및/또는 스트리밍하는 데 필요한 대역폭의 양에 영향을 미친다. 비디오 인코더는 더 많은 정보가 주어진 대역폭을 통해 전송되거나 주어진 메모리 공간 등에 저장될 수 있도록 비디오 정보를 압축한다. 압축된 신호 또는 데이터는 이어서 사용자에게 디스플레이하기 위해 신호 또는 데이터를 디코딩하거나 압축해제하는 디코더에 의해 디코딩된다. 많은 구현들에서, 더 큰 압축과 함께 더 높은 시각적 품질이 바람직하다.
현재, MPEG(Moving Picture Experts Group) 몰입형 비디오 코딩을 포함하여, 몰입형 비디오 코딩에 대한 표준들이 개발되고 있다. 그러한 표준들은 몰입형 비디오 및 포인트 클라우드 코딩의 맥락에서 압축 효율과 재구성 품질을 설정하고 개선시키려고 한다.
도 1은 예시적인 MPEG 몰입형 비디오(MIV) 인코더의 블록 다이어그램이다.
도 2는 선택된 입력 뷰들로부터의 예시적인 패치 형성을 예시한다.
도 3은 예시적인 MIV 디코더의 블록 다이어그램이다.
도 4는 아틀라스 패치들로부터의 프루닝된 뷰들의 예시적인 재구성을 예시한다.
도 5는 본 개시내용의 교시에 따른 예시적인 텍스처 기반 MIV 인코더의 블록 다이어그램이다.
도 6은 도 5의 텍스처 기반 MIV 인코더에서 입력 뷰들로부터의 예시적인 아틀라스 생성을 예시한다.
도 7은 본 개시내용의 교시에 따른 예시적인 텍스처 기반 MIV 디코더의 블록 다이어그램이다.
도 8은 도 7의 텍스처 기반 MIV 디코더에 의해 구현되는 예시적인 렌더링 프로세스의 블록 다이어그램이다.
도 9는 도 7의 텍스처 기반 MIV 디코더에서의 예시적인 아틀라스 뷰 재구성을 예시한다.
도 10은 MIV 확장들을 갖는 예시적인 V3C(Video-Based Volumetric Video Coding) 샘플 스트림을 예시한다.
도 11은 도 5의 텍스처 기반 MIV 인코더를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다.
도 12는 도 5의 텍스처 기반 MIV 인코더에 포함된 예시적인 대응 관계 라벨러(correspondence labeler)를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다.
도 13은 도 5의 텍스처 기반 MIV 인코더에 포함된 예시적인 대응 관계 프루너(correspondence pruner)를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다.
도 14은 도 5의 텍스처 기반 MIV 인코더에 포함된 예시적인 대응 관계 패치 패커(correspondence patch packer)를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다.
도 15는 도 7의 텍스처 기반 MIV 디코더를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다.
도 16은 본 개시내용의 적어도 일부 구현들에 따른 예시적인 시스템의 예시적인 다이어그램이다.
도 17은 본 개시내용의 적어도 일부 구현들에 따라 모두가 배열되어 있는, 예시적인 디바이스를 예시한다.
도 18은 도 5의 텍스처 기반 MIV 인코더를 구현하기 위해 도 11, 도 12, 도 13, 및 도 14의 명령어들을 실행하도록 구성된 예시적인 프로세싱 플랫폼의 블록 다이어그램이다.
도 19는 도 7의 텍스처 기반 MIV 디코더를 구현하기 위해 도 15의 명령어들을 실행하도록 구성된 예시적인 프로세싱 플랫폼의 블록 다이어그램이다.
도 20은 소프트웨어(예를 들면, 도 11, 도 12, 도 13, 도 14, 및 도 15의 예시적인 컴퓨터 판독 가능 명령어들에 대응하는 소프트웨어)를 소비자들(예를 들면, 라이선스, 판매 및/또는 사용을 위해), 소매업체들(예를 들면, 판매, 재판매, 라이선스 및/또는 서브 라이선스를 위해), 및/또는 OEM들(original equipment manufacturers)(예를 들면, 예를 들어, 소매업체들 및/또는 직접 구매 고객들에 배포될 제품들에 포함시키기 위해)과 같은 클라이언트 디바이스들에게 배포하기 위한 예시적인 소프트웨어 배포 플랫폼의 블록 다이어그램이다,
도면들은 일정한 축척으로 되어 있지 않다. 일반적으로, 동일한 또는 유사한 부분들을 지칭하기 위해 도면(들) 및 첨부된 서면 설명 전반에 걸쳐 동일한 참조 번호들이 사용될 것이다.
달리 구체적으로 언급되지 않는 한, "제1", "제2", "제3" 등과 같은 기술어들은 우선순위, 물리적 순서, 리스트에서의 배열, 및/또는 순서의 어떠한 의미도 결코 전가하지 않거나 달리 나타내지 않고 본 명세서에서 사용되지만, 개시된 예들의 이해의 편의를 위해 요소들을 구별하기 위한 라벨들 및/또는 임의적인 이름들로서만 사용된다. 일부 예들에서, 기술어 "제1"은 상세한 설명에서 요소를 지칭하는 데 사용될 수 있는 반면, 동일한 요소가 청구항에서는 "제2" 또는 "제3"과 같은 상이한 기술어를 사용하여 지칭될 수 있다. 그러한 경우에, 그러한 기술어들이, 예를 들어, 동일한 이름을 다른 방식으로 공유할 수 있는 해당 요소들을 뚜렷하게 식별하기 위해서만 사용된다는 것이 이해되어야 한다. 본 명세서에 사용되는 바와 같이, "대략" 및 "약"은 제조 공차들 및/또는 다른 현실 세계 불완전성들로 인해 정확하지 않을 수 있는 치수들을 지칭한다. 본 명세서에서 사용되는 바와 같이, "실질적으로 실시간"은, 계산 시간, 전송 등에 대해 현실 세계 지연들이 있을 수 있다는 것을 인식하여, 거의 즉각적인 방식으로 발생하는 것을 지칭한다. 따라서, 달리 명시되지 않는 한, "실질적으로 실시간"은 실시간 +/- 1초를 지칭한다.
도 2는 선택된 입력 뷰들로부터의 예시적인 패치 형성을 예시한다.
도 3은 예시적인 MIV 디코더의 블록 다이어그램이다.
도 4는 아틀라스 패치들로부터의 프루닝된 뷰들의 예시적인 재구성을 예시한다.
도 5는 본 개시내용의 교시에 따른 예시적인 텍스처 기반 MIV 인코더의 블록 다이어그램이다.
도 6은 도 5의 텍스처 기반 MIV 인코더에서 입력 뷰들로부터의 예시적인 아틀라스 생성을 예시한다.
도 7은 본 개시내용의 교시에 따른 예시적인 텍스처 기반 MIV 디코더의 블록 다이어그램이다.
도 8은 도 7의 텍스처 기반 MIV 디코더에 의해 구현되는 예시적인 렌더링 프로세스의 블록 다이어그램이다.
도 9는 도 7의 텍스처 기반 MIV 디코더에서의 예시적인 아틀라스 뷰 재구성을 예시한다.
도 10은 MIV 확장들을 갖는 예시적인 V3C(Video-Based Volumetric Video Coding) 샘플 스트림을 예시한다.
도 11은 도 5의 텍스처 기반 MIV 인코더를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다.
도 12는 도 5의 텍스처 기반 MIV 인코더에 포함된 예시적인 대응 관계 라벨러(correspondence labeler)를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다.
도 13은 도 5의 텍스처 기반 MIV 인코더에 포함된 예시적인 대응 관계 프루너(correspondence pruner)를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다.
도 14은 도 5의 텍스처 기반 MIV 인코더에 포함된 예시적인 대응 관계 패치 패커(correspondence patch packer)를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다.
도 15는 도 7의 텍스처 기반 MIV 디코더를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다.
도 16은 본 개시내용의 적어도 일부 구현들에 따른 예시적인 시스템의 예시적인 다이어그램이다.
도 17은 본 개시내용의 적어도 일부 구현들에 따라 모두가 배열되어 있는, 예시적인 디바이스를 예시한다.
도 18은 도 5의 텍스처 기반 MIV 인코더를 구현하기 위해 도 11, 도 12, 도 13, 및 도 14의 명령어들을 실행하도록 구성된 예시적인 프로세싱 플랫폼의 블록 다이어그램이다.
도 19는 도 7의 텍스처 기반 MIV 디코더를 구현하기 위해 도 15의 명령어들을 실행하도록 구성된 예시적인 프로세싱 플랫폼의 블록 다이어그램이다.
도 20은 소프트웨어(예를 들면, 도 11, 도 12, 도 13, 도 14, 및 도 15의 예시적인 컴퓨터 판독 가능 명령어들에 대응하는 소프트웨어)를 소비자들(예를 들면, 라이선스, 판매 및/또는 사용을 위해), 소매업체들(예를 들면, 판매, 재판매, 라이선스 및/또는 서브 라이선스를 위해), 및/또는 OEM들(original equipment manufacturers)(예를 들면, 예를 들어, 소매업체들 및/또는 직접 구매 고객들에 배포될 제품들에 포함시키기 위해)과 같은 클라이언트 디바이스들에게 배포하기 위한 예시적인 소프트웨어 배포 플랫폼의 블록 다이어그램이다,
도면들은 일정한 축척으로 되어 있지 않다. 일반적으로, 동일한 또는 유사한 부분들을 지칭하기 위해 도면(들) 및 첨부된 서면 설명 전반에 걸쳐 동일한 참조 번호들이 사용될 것이다.
달리 구체적으로 언급되지 않는 한, "제1", "제2", "제3" 등과 같은 기술어들은 우선순위, 물리적 순서, 리스트에서의 배열, 및/또는 순서의 어떠한 의미도 결코 전가하지 않거나 달리 나타내지 않고 본 명세서에서 사용되지만, 개시된 예들의 이해의 편의를 위해 요소들을 구별하기 위한 라벨들 및/또는 임의적인 이름들로서만 사용된다. 일부 예들에서, 기술어 "제1"은 상세한 설명에서 요소를 지칭하는 데 사용될 수 있는 반면, 동일한 요소가 청구항에서는 "제2" 또는 "제3"과 같은 상이한 기술어를 사용하여 지칭될 수 있다. 그러한 경우에, 그러한 기술어들이, 예를 들어, 동일한 이름을 다른 방식으로 공유할 수 있는 해당 요소들을 뚜렷하게 식별하기 위해서만 사용된다는 것이 이해되어야 한다. 본 명세서에 사용되는 바와 같이, "대략" 및 "약"은 제조 공차들 및/또는 다른 현실 세계 불완전성들로 인해 정확하지 않을 수 있는 치수들을 지칭한다. 본 명세서에서 사용되는 바와 같이, "실질적으로 실시간"은, 계산 시간, 전송 등에 대해 현실 세계 지연들이 있을 수 있다는 것을 인식하여, 거의 즉각적인 방식으로 발생하는 것을 지칭한다. 따라서, 달리 명시되지 않는 한, "실질적으로 실시간"은 실시간 +/- 1초를 지칭한다.
하나 이상의 실시예 또는 구현이 첨부 도면들을 참조하여 이제 설명된다. 특정 구성들 및 배열들이 논의되지만, 이것이 예시 목적으로만 행해진다는 것을 이해되어야 한다. 관련 기술의 통상의 기술자는 본 설명의 사상 및 범위를 벗어나지 않으면서 다른 구성들 및 배열들이 이용될 수 있다는 것을 인식할 것이다. 본 명세서에서 설명되는 기술들 및/또는 배열들이 또한 본 명세서에서 설명되는 것 이외의 다양한 다른 시스템들 및 응용들에서 이용될 수 있다는 것이 관련 기술의 통상의 기술자에게 명백할 것이다.
이하의 설명이, 예를 들어, SoC(system-on-a-chip) 아키텍처들과 같은 아키텍처들에서 나타날 수 있는 다양한 구현들을 제시하지만, 본 명세서에서 설명되는 기술들 및/또는 배열들의 구현이 특정 아키텍처들 및/또는 컴퓨팅 시스템들로 제한되지 않고, 유사한 목적들을 위해 임의의 아키텍처 및/또는 컴퓨팅 시스템에 의해 구현될 수 있다. 예를 들어, 다수의 집적 회로(IC) 칩들 및/또는 패키지들, 및/또는 셋톱 박스들, 스마트 폰들 등과 같은 다양한 컴퓨팅 디바이스들 및/또는 소비자 전자(CE) 디바이스들을 이용하는 다양한 아키텍처들이 본 명세서에서 설명된 기술들 및/또는 배열들을 구현될 수 있다. 게다가, 이하의 설명이 시스템 컴포넌트들의 로직 구현들, 유형들 및 상호관계들, 로직 파티셔닝/통합 선택 사항들 등과 같은 수많은 특정 세부 사항들을 제시할 수 있지만, 청구된 주제는 그러한 특정 세부 사항들이 없어도 실시될 수 있다. 다른 경우에, 예를 들어, 제어 구조들 및 전체 소프트웨어 명령어 시퀀스들과 같은 일부 내용은 본 명세서에서 개시되는 내용을 모호하게 하지 않기 위해 상세하게 제시되지 않을 수 있다.
"일 구현", "구현", "예시적인 구현" 등에 대한 본 명세서에서의 언급들은 설명되는 구현이 특정 특징, 구조, 또는 특성을 포함할 수 있지만, 모든 실시예가 특정 특징, 구조, 또는 특성을 반드시 포함하는 것은 아닐 수 있다는 것을 나타낸다. 더욱이, 그러한 문구들이 반드시 동일한 구현을 지칭하는 것은 아니다. 게다가, 특정 특징, 구조, 또는 특성이 실시예와 관련하여 설명될 때, 본 명세서에서 명시적으로 설명되어 있는지에 관계없이 그러한 특징, 구조, 또는 특성을 다른 구현들과 관련하여 실시하는 것을 본 기술 분야의 통상의 기술자가 알고 있다고 여겨진다.
"실질적으로(substantially)", "~에 가까운(close)", "대략(approximately)", "거의(near)" 및 "약(about)"이라는 용어들은 일반적으로 목표 값의 +/- 10% 내에 있는 것을 지칭한다. 예를 들어, "실질적으로 동일한(substantially equal)", "거의 동일한(about equal)" 및 "대략 동일한(approximately equal)"이라는 용어들은, 이들의 사용의 명시적 맥락에서 달리 명시되지 않는 한, 그렇게 설명된 것들 사이에 부수적인 변화만이 있음을 의미한다. 본 기술 분야에서, 그러한 변화는 전형적으로 미리 결정된 목표 값의 +/- 10% 이하이다.
디지털 미디어 기술의 발전은 새로운 미디어 포맷들을 사용하여 마음을 사로잡는 몰입형 경험들을 전달하는 것을 가능하게 하고 있다. MPEG(Moving Picture Experts Group)은 몰입형 미디어 액세스 및 전달을 지원하기 위한 표준들을 개발하는 하나의 표준화 그룹이다. 예를 들어, 몰입형 미디어의 코딩된 표현(MPEG-I)은, 파노라마 360° 비디오, 체적 포인트 클라우드들, 및 몰입형 비디오와 같은, 몰입형 미디어 포맷들에 관한 일단의 몰입형 미디어 산업 표준들이다.
MPEG는 MPEG 몰입형 비디오(MIV)라는 몰입형 비디오 코딩 표준을 개발하고 있다. 본 명세서에서 "몰입형 비디오 코딩 표준들"이라고 지칭되는, MIV 표준(J. Boyce, R.  , V. Kumar Malamal Vadakital (Eds.), "Working Draft 4 of Immersive Video", ISO/IEC JTC1/SC29/WG11 MPEG/N19001, Jan. 2020, Brussels, Belgium) 및 몰입형 비디오에 대한 테스트 모델(TMIV)(B. Salahieh, B. Kroon, J. Jong, M. Domanski (Eds.), "Test Model 4 for Immersive Video", ISO/IEC JTC1/SC29/WG11 MPEG/N19002, Jan. 2020, Brussels, Belgium)을 참조한다. MIV 표준은 몰입형 비디오에 대한 비트스트림 포맷 및 디코딩 프로세스를 지정한다. 몰입형 비디오에 대한 테스트 모델은 참조 인코딩 프로세스 및 렌더링 프로세스에 대해 논의하지만; 이러한 프로세스들이 MIV 표준에 규범적이지 않다.
, V. Kumar Malamal Vadakital (Eds.), "Working Draft 4 of Immersive Video", ISO/IEC JTC1/SC29/WG11 MPEG/N19001, Jan. 2020, Brussels, Belgium) 및 몰입형 비디오에 대한 테스트 모델(TMIV)(B. Salahieh, B. Kroon, J. Jong, M. Domanski (Eds.), "Test Model 4 for Immersive Video", ISO/IEC JTC1/SC29/WG11 MPEG/N19002, Jan. 2020, Brussels, Belgium)을 참조한다. MIV 표준은 몰입형 비디오에 대한 비트스트림 포맷 및 디코딩 프로세스를 지정한다. 몰입형 비디오에 대한 테스트 모델은 참조 인코딩 프로세스 및 렌더링 프로세스에 대해 논의하지만; 이러한 프로세스들이 MIV 표준에 규범적이지 않다.
MIV 초안 표준은 고효율 비디오 코딩(HEVC) 비디오 코덱을 사용하여, 각각이 특정 위치 및 배향에 있는, 다수의 입력 뷰들에 대한 텍스처 및 깊이 비디오를 코딩한다. MIV 표준은 참조 렌더러를 지정하지 않지만 필요한 메타데이터 및 디코딩된 스트림들을 지정한다. 참조 렌더러의 의도된 출력은 텍스처의 투시 뷰포트이며, 뷰포트는 뷰어의 위치 및 배향에 기초하여 선택되고 몰입형 미디어 디코더의 출력들을 사용하여 생성된다. MIV 표준은 뷰어가 6 자유도(6DoF)로 동적으로 이동하고, (예를 들면, 헤드 마운티드 디스플레이, 예들로서 위치 입력들을 갖는 2차원(2D) 모니터 등에 의해 지원되는 바와 같은) 제한된 범위 내에서 위치(x, y, z) 및 배향(요, 피치, 롤)을 조정할 수 있게 한다.
MIV 표준에서, 깊이 정보(지오메트리(geometry)라고도 함)는 몰입형 비디오 코딩을 위해 비트스트림의 일부로서 요구될 수 있으며, 이는 텍스처 콘텐츠와 함께 스트리밍되는 경우 추가 대역폭을 필요로 할 수 있다. 추가적으로, 프루닝, 클러스터링, 및 패킹과 같은, MIV의 테스트 모델에서 구현되는 인코딩 동작들은 텍스처 정보를 고려하지 않고 깊이에만 의존하며, 따라서 중요한 몰입 신호들(immersive cues)(예를 들면, 경면반사성들, 투명성들, 상이한 카메라들로부터의 캡처된 뷰들에 대한 다양한 조명 조건들)이 추출된 패치들(즉, 뷰들로부터의 직사각형 영역들)에서 누락된다. 게다가, 깊이 맵들이 직접 캡처/제공되지 않는 경우 깊이 맵들을 추정하는 것은 비용이 많이 드는 동작일 수 있으며, 깊이 추정 알고리즘들의 국부적 특성으로 인해 자연 콘텐츠에 대해 모든 카메라들에 걸쳐 깊이 일관성을 유지하기 어려울 수 있다. 따라서, 일부 서비스들은 깊이를 사용하지 않기로 하고 MIV에 의해 현재 지원되지 않는다. 현재, 다양한 캡처 카메라로부터의 텍스처 콘텐츠는 고효율 비디오 코딩(HEVC)과 같은 표준 비디오 코덱들을 사용하여 별도로 인코딩 및 전송될 수 있거나 MV-HEVC와 같은 비디오 코덱들의 멀티뷰 확장(Multi-View Extension)을 사용하여 예측적으로 인코딩될 수 있다. 이어서, 디코딩된 텍스처 콘텐츠 및 뷰포트 정보(즉, 목표 뷰잉 위치 및 배향)에 기초하여 원하는 뷰포트를 렌더링하기 위해 뷰 합성 기술들이 적용될 수 있다. 그러한 뷰 합성은 투영들을 적절하게 수행하기 위해 디코딩된 텍스처에 대한 깊이 추정(또는 다른 유형의 시차(disparity) 정보) 프리프로세싱 단계를 요구할 수 있다. 그렇지만, 그러한 접근 방식들은 개별적인 뷰들의 동시 인코딩이 인코딩에서의 중복성을 결과하기 때문에 상이한 뷰들에 걸친 각도 중복성(angular redundancy)을 충분히 활용하지 못한다. MV-HEVC에서, 뷰 간 예측(inter-view prediction)은 종래의 프레임 간 시간 예측(inter-frame temporal prediction)과 유사하지만 블록 모션 모델에서의 수평 이동들만이 지원되며, 이는 MIV에서 이용되는 뷰 간 상관(inter-view correlation)을 활용하는 재투영 기반 접근 방식과 비교하여 비효율적인 대역폭 활용을 초래한다.
텍스처 기반 몰입형 비디오 코딩을 위한 방법들, 장치들, 및 시스템들이 본 명세서에서 개시된다. 본 명세서에서 개시되는 예시적인 인코딩 기술들 및 메타데이터 시그널링 기술들은 대응 관계 인코딩 동작들을 지원하고 MIV 비트스트림으로부터 깊이를 배제하는 것을 가능하게 하기 위해 개별적으로 시그널링되는 깊이 맵(선택적임) 및 점유 맵을 갖는다. 일부 개시된 예시적인 인코딩 기술들에서, 입력 뷰마다 깊이 정보를 필요로 하지 않고, 입력 뷰마다 텍스처 정보만이 활용된다. 카메라 파라미터들이 또한 활용되지만 텍스처 콘텐츠로부터 추정/추론될 수도 있다. 개시된 예시적인 인코딩 기술들은 중복적인 텍스처 정보를 제거하기 위해 이용 가능한 입력 뷰들에 걸쳐 텍스처 콘텐츠에서 대응 관계 패치들을 식별하는 것을 포함한다. 개시된 예시적인 인코딩 기술들은 인코딩된 비트스트림에서 텍스처 콘텐츠를 식별된 대응 관계 패치들과 함께 전송한다. 개시된 예시적인 기술들은 더 많은 몰입 신호들이 전달될 수 있게 하는 대역폭의 추가 절감(깊이가 인코딩된 비트스트림의 일부로 인코딩되지 않기 때문임)을 제공하고, 더 넓은 범위의 몰입형 응용들을 지원한다.
본 명세서에서 개시되는 예시적인 디코딩 기술들은, 코딩된 텍스처 비디오들, 코딩된 점유 비디오들, 및 메타데이터를 포함하는, 입력 비트스트림을 수신한다. 개시된 예시적인 디코딩 기술들은 코딩된 텍스처 비디오들로부터 깊이 정보를 추론한다. 개시된 예시적인 디코딩 기술들은 코딩된 텍스처 비디오들에서 대응 관계 정보를 획득한다. 개시된 예시적인 디코딩 기술들은 비디오 데이터에서 깊이 정보를 추론하기 위해 텍스처 패치들 및 다른 뷰들로부터의 대응하는 텍스처 패치들을 사용한다. 개시된 예시적인 디코딩 기술들은 메타데이터 및 원하는 뷰잉 위치 및 배향과 함께 텍스처 패치들 및 대응하는 텍스처 패치들에 기초하여 뷰포트를 합성하는 것을 더 포함한다.
도 1은 예시적인 몰입형 비디오(MIV) 인코더(100)의 블록 다이어그램이다. 예시적인 MIV 인코더(100)는 예시적인 뷰 최적화기(102), 예시적인 아틀라스 구성기(atlas constructor)(104), 예시적인 깊이/점유 코더(120), 예시적인 지오메트리 스케일러(122), 예시적인 비디오 인코더(132), 및 예시적인 비디오 인코더(134)를 포함한다. 예시적인 MIV 인코더(100)는 예시적인 소스 뷰들(101)을 수신한다. 예를 들어, 소스 뷰들(101)은 캡처된 장면의 텍스처 데이터(예를 들면, 텍스처 비트스트림들) 및 깊이 데이터(예를 들면, 깊이 비트스트림들)를 포함한다. 본 명세서에서 사용되는 바와 같이, "텍스처"와 "어트리뷰트(attribute)"는 상호 교환 가능하게 사용되고 픽셀의 색상 성분(예를 들면, 적색-녹색-청색(RGB) 성분들)과 같은 픽셀의 가시적 측면들을 지칭한다. 본 명세서에서 사용되는 바와 같이, "깊이" 및 "지오메트리"는 달리 언급되지 않는 한 상호 교환 가능하게 사용되는데, 그 이유는 픽셀의 지오메트리가 전형적으로 참조 평면으로부터의 픽셀의 거리를 지칭하는 픽셀의 깊이를 포함하기 때문이다. 예를 들어, 소스 뷰들(101)은 비디오 캡처기들에 의해 생성되는 소스 뷰들, 컴퓨터에 의해 생성되는 가상 뷰들 등일 수 있다. 예시된 예에서, 소스 뷰들(101)은 비디오 시퀀스로서 표현된다. 예시적인 MIV 인코더(100)는 예시적인 소스 카메라 파라미터 리스트(103)을 더 수신한다. 예를 들어, 소스 카메라 파라미터 리스트(103)는 소스 카메라들이 어디에 위치되는지, 소스 카메라들의 각도 등을 포함할 수 있다.
예시적인 뷰 최적화기(102)는 인코딩할 뷰들을 선택한다. 예를 들어, 뷰 최적화기(102)는 소스 뷰들(101)을 분석하고 어느 뷰들을 인코딩할지를 선택한다. 일부 예들에서, 뷰 최적화기(102)는 소스 뷰들(101)의 뷰들을 기본 뷰(basic view) 또는 추가 뷰(additional view)로서 라벨링한다. 본 명세서에서 사용되는 바와 같이, 기본 뷰는 단일 패치로서 아틀라스에 패킹될 입력 뷰이다. 본 명세서에서 사용되는 바와 같이, 추가 뷰는 프루닝되어 하나 이상의 패치에 패킹될 입력 뷰이다. 예를 들어, 뷰 최적화기(102)는 픽셀률(pixel rate) 제약들, 입력 뷰당 샘플 카운트 등과 같은 기준들에 기초하여 입력 뷰들에 몇 개의 기본 뷰가 있을 수 있는지를 결정할 수 있다.
예시적인 아틀라스 구성기(104)는 예시적인 뷰 최적화기(102)에 의해 결정되는 기본 뷰 및/또는 추가 뷰를 수신한다. 아틀라스 구성기(104)는, 프루닝 및 클러스터링을 사용하여, 선택된 뷰들(예를 들면, 기본 뷰 및/또는 추가 뷰)로부터 패치들을 형성하여 하나 이상의 아틀라스에 패킹하며, 도 2와 관련하여 예시된 바와 같이, 아틀라스들 각각은 선택적인 텍스처 성분 및 필수적인 깊이 성분을 포함한다. 예시적인 아틀라스 구성기(104)는 예시적인 프루너(106), 예시적인 마스크 집계기(108), 예시적인 패치 패커(110), 및 예시적인 아틀라스 생성기(112)를 포함한다. 예시적인 프루너(106)는 추가 뷰들을 프루닝한다. 예를 들어, 프루너(106)는 비중복적인 폐색된 영역들을 추출하기 위해 기본 뷰들의 깊이 및/또는 텍스처 데이터를 추가 뷰들 및/또는 이전에 프루닝된 뷰들의 각자의 깊이 및/또는 텍스처 데이터 상으로 투영한다.
예시적인 마스크 집계기(108)는 패치들을 생성하기 위해 예시적인 프루너(106)에 의해 생성되는 프루닝 결과들을 집계한다. 예를 들어, 마스크 집계기(108)는 모션을 고려하기 위해 인트라 기간(intra-period)(예를 들면, 미리 결정된 프레임 집합체)에 걸쳐 프루닝 결과들(예를 들면, 프루닝 마스크들)을 누적한다. 예시적인 패치 패커(110)는 패치들를 하나 이상의 예시적인 아틀라스(116)에 패킹한다. 예를 들어, 패치 패커(110)는 직사각형 패치들을 추출하여 아틀라스들에 패킹하기 위해 클러스터링(예를 들면, 프루닝 마스크에서의 픽셀들을 결합하여 패치들을 형성하는 것)을 수행한다. 일부 예들에서, 패치 패커(110)는 프로세싱된 인트라 기간에 걸쳐 프레임마다 콘텐츠를 업데이트한다.
패치 패커(110)는 패치를 패치 식별자(예를 들면, 패치 ID)로 태깅한다. 패치 ID는 패치 인덱스를 식별해 준다. 예를 들어, 패치 ID들은 0 내지 생성된 패치 수 - 1의 범위일 수 있다. 패치 패커(110)는 블록 대 패치 맵(block to patch map)(예를 들면, 패치 ID 맵)을 생성할 수 있다. 블록 대 패치 맵은 하나 이상의 픽셀의 주어진 블록과 연관된 패치 ID를 나타내는 2D 어레이(예를 들면, 아틀라스에서의 포인트 위치들(positions)/장소들(locations)을 나타냄)이다. 패치 패커(110)는 예시적인 데이터(114)(블록 대 패치 맵 및 패치 ID 데이터를 포함함)를 깊이/점유 코더(120)에 제공한다. 아틀라스 생성기(112)는 패치 패커(110)로부터의 패치 데이터를 사용하여 깊이/점유 성분(118)을 갖는 아틀라스들 및 선택적인 텍스처 성분을 갖는 아틀라스들(116)을 생성한다. 아틀라스 생성기(112)는 깊이/점유 성분(118)을 갖는 아틀라스들을 깊이/점유 코더(120)에 제공한다. 아틀라스 생성기(112)는 선택적인 텍스처 컴포넌트를 갖는 아틀라스들(116)을 어트리뷰트(텍스처) 비디오 데이터(128)로서 예시적인 비디오 인코더(134)에 제공한다.
깊이/점유 코더(120)는 패치의 픽셀이 점유되어 있는지(예를 들면, 유효한지) 점유되어 있지 않은지(예를 들면, 유효하지 않은지)를 나타내기 위해 점유 맵을 생성한다. 일부 예들에서, 점유 맵은 이진 맵이다. 일부 그러한 예들에서, 점유 맵은 픽셀이 점유되어 있음을 나타내는 1의 값 및 픽셀이 점유되어 있지 않음을 나타내는 0의 값을 갖는다. 깊이/점유 코더(120)는 패치 패커(110)로부터의 데이터(114)에 포함된 블록 대 패치 맵 및 패치 ID 데이터에 기초하여 그리고 아틀라스 생성기(112)로부터의 깊이/점유 성분(118)을 갖는 아틀라스들의 데이터에 기초하여 점유 맵을 생성한다. 깊이/점유 코더(120)는 점유 맵, 블록 대 패치 맵, 및 패치 ID 데이터를 예시적인 MIV 데이터 비트스트림(130)에 포함시킨다. 예시된 예에서, MIV 데이터 비트스트림(130)은 패치들을 뷰들과 아틀라스들 사이에 매핑하기 위한 패치 파라미터들, 나중에 블록 대 패치 맵들을 검색하는 데 필요한 중첩된 패치들을 나타내기 위한 패킹 순서, V-PCC(Video-based Point Cloud Compression) 파라미터 세트, 및 적응 파라미터 세트(뷰 파라미터들을 포함함), 및 비디오 코딩된 데이터로부터의 임의의 다른 메타데이터를 포함한다.
지오메트리 스케일러(122)는 깊이/점유 코더(120)로부터 아틀라스들의 깊이(지오메트리) 데이터를 획득한다. 지오메트리 스케일러(122)는 깊이 데이터를 포함하는 아틀라스마다 지오메트리 비디오 데이터의 양자화 및 스케일링을 수행한다. 지오메트리 스케일러(122)는 깊이(지오메트리) 성분(124)을 갖는 아틀라스들을 깊이(지오메트리) 비디오 데이터(126)로서 예시적인 비디오 인코더(132)에 제공한다.
예시적인 비디오 인코더(132)는 깊이(지오메트리) 비디오 데이터(126)로부터 인코딩된 아틀라스들을 생성한다. 예시적인 비디오 인코더(134)는 어트리뷰트(텍스처) 비디오 데이터(128)로부터 인코딩된 아틀라스들을 생성한다. 예를 들어, 비디오 인코더(132)는 예시적인 깊이(지오메트리) 비디오 데이터(126)(아틀라스들을 포함함)를 수신하고 HEVC 비디오 인코더를 사용하여 깊이 성분을 예시적인 HEVC 비트스트림(136)에 인코딩한다. 추가적으로, 비디오 인코더(134)는 예시적인 어트리뷰트(텍스처) 비디오 데이터(128)(아틀라스들을 포함함)를 수신하고 HEVC 비디오 인코더를 사용하여 텍스처 성분을 예시적인 HEVC 비트스트림(138)에 인코딩한다. 그렇지만, 예시적인 비디오 인코더(132) 및 예시적인 비디오 인코더(134)는 추가적으로 또는 대안적으로 고급 비디오 코딩(AVC) 비디오 인코더 등을 사용할 수 있다. 예시적인 HEVC 비트스트림(136) 및 예시적인 HEVC 비트스트림(138)은 패치들을 뷰들과 아틀라스들 사이에 매핑하기 위한 패치 파라미터들, 깊이(지오메트리) 비디오 데이터(126) 및 어트리뷰트(텍스처) 비디오 데이터(128)에, 제각기, 관련된 블록 대 패치 맵들을 나중에 검색하는 데 필요한 중첩된 패치들을 나타내기 위한 패킹 순서 등을 포함할 수 있다.
도 2는 선택된 입력 뷰들로부터의 예시적인 패치 형성을 예시한다. 입력 뷰들은 예시적인 제1 뷰(202), 예시적인 제2 뷰(204), 및 예시적인 제3 뷰(206)를 포함한다. 예를 들어, 제1 뷰(202)는 뷰 0이고, 제2 뷰(204)는 뷰 1이며, 제3 뷰(206)는 뷰 2이다. 예를 들어, 뷰들(202, 204, 206)은 뷰 표현들(208)(예를 들면, 어트리뷰트(텍스처) 맵들, 지오메트리(깊이) 맵들, 엔티티(객체) 맵들)을 포함한다. 도 2의 예시된 예에서, 뷰들(202, 204, 206)의 뷰 표현들(208)은 3명의 사람을 포함한다. 즉, 3명의 사람과 관련하여 3개의 상이한 각도에서 3개의 상이한 카메라로부터 뷰들(202, 204, 206)이 캡처된다.
예시적인 프루너(106)(도 1)는 패치들을 생성하기 위해 뷰들(202, 204, 206)을 프루닝한다. 예를 들어, 제1 뷰(202)는 예시적인 제1 패치(210) 및 예시적인 제2 패치(212)를 포함하고, 제2 뷰(204)는 예시적인 제3 패치(214)를 포함하며, 제3 뷰(206)는 예시적인 제4 패치(216) 및 예시적인 제5 패치(218)를 포함한다. 일부 예들에서, 각각의 패치는 하나의 각자의 엔티티(객체)에 대응한다. 예를 들어, 제1 패치(210)는 제1 사람의 머리에 대응하고, 제2 패치(212)는 제2 사람의 머리에 대응하며, 제3 패치(214)는 제2 사람의 팔에 대응하고, 제4 패치(216)는 제3 사람의 머리에 대응하며, 제5 패치(218)는 제2 사람의 다리에 대응한다.
일부 예들에서, 패치 패커(110)(도 1)는 패치들을 패치 ID들로 태깅한다. 예를 들어, 패치 패커(110)는 제1 패치(210)를 2의 패치 ID로 태깅하고, 제2 패치(212)를 5의 패치 ID로 태깅하며, 제3 패치(214)를 8의 패치 ID로 태깅하고, 제4 패치(216)를 3의 패치 ID로 태깅하며, 제5 패치(218)를 7의 패치 ID로 태깅한다.
예시적인 아틀라스 생성기(112)(도 1)는 예시적인 제1 아틀라스(220) 및 예시적인 제2 아틀라스(222)를 생성한다. 아틀라스들(220, 222)은 텍스처(어트리뷰트) 맵과 깊이(지오메트리) 맵을 포함한다. 예시된 예에서, 제1 아틀라스(220)는 예시적인 제1 패치(210), 예시적인 제2 패치(212), 및 예시적인 제3 패치(214)를 포함한다. 예시된 예에서, 제2 아틀라스(222)는 예시적인 제4 패치(216) 및 예시적인 제5 패치(218)를 포함한다.
도 3은 예시적인 몰입형 비디오(MIV) 디코더(300)의 블록 다이어그램이다. 예시적인 MIV 디코더(300)는 예시적인 비디오 디코더(308), 예시적인 비디오 디코더(312), 예시적인 블록 대 패치 맵 디코더(318), 예시적인 MIV 디코더 및 파서(316), 예시적인 지오메트리 스케일러(326), 예시적인 컬러(culler)(328), 및 예시적인 렌더러(330)를 포함한다. 예시적인 렌더러(330)는 예시적인 제어기(332), 예시적인 합성기(334), 및 예시적인 인페인터(inpainter)(336)를 포함한다. 도 3의 예시된 예에서, MIV 디코더(300)는 지오메트리 성분들 및 선택적으로 텍스처 어트리뷰트들에 대한 비디오 서브스트림들 각각에 대한 코딩된 비디오 시퀀스(CVS)를 수신한다. 일부 예들에서, MIV 디코더(300)는 예시적인 MIV 인코더(100)(도 1)로부터 예시적인 MIV 데이터 비트스트림(130), 예시적인 HEVC 비트스트림(136), 및 예시적인 HEVC 비트스트림(138)을 수신한다.
도 3의 예시된 예에서, 비디오 디코더(308)는 HEVC 비트스트림(138)을 수신한다. HEVC 비트스트림(138)은 어트리뷰트(텍스처) 비디오 데이터에 관련된 패치 파라미터들을 포함한다. 그러한 파라미터들의 예들은 뷰들과 아틀라스들 사이의 패치들의 맵, 나중에 블록 대 패치 맵들을 검색하는 데 활용되는 중첩된 패치들을 나타내기 위한 패킹 순서 등을 포함한다. 비디오 디코더(308)는 디코딩된 텍스처 픽처들(310)의 시퀀스를 생성한다. 비디오 디코더(312)는 HEVC 비트스트림(136)을 수신한다. HEVC 비트스트림(136)은 깊이(지오메트리) 비디오 데이터에 관련된 패치 파라미터들을 포함한다. 그러한 파라미터들의 예들은 뷰들과 아틀라스들 사이의 패치들의 맵, 나중에 블록 대 패치 맵들을 검색하는 데 활용되는 중첩된 패치들을 나타내기 위한 패킹 순서 등을 포함한다. 비디오 디코더(308)는 디코딩된 깊이 픽처들(314)의 시퀀스를 생성한다. 비디오 디코더(308) 및 비디오 디코더(312)는 디코딩된 텍스처 픽처들(310)과 디코딩된 깊이 픽처들(314)의 디코딩된 픽처 쌍들의 시퀀스들을 생성한다. 일부 예들에서, 디코딩된 텍스처 픽처들(310) 및 디코딩된 깊이 픽처들(314)은 동일한 또는 상이한 해상도들을 가질 수 있다. 예시된 예에서, 예시적인 디코딩된 텍스처 픽처들(310) 및 예시적인 디코딩된 깊이 픽처들(314)은 예시적인 아틀라스를 나타낸다. 일부 예들에서, 비디오 디코더(308) 및 비디오 디코더(312)는 HEVC 디코더들일 수 있다. 도 3의 예시된 예에서, 비디오 디코더(308)는 디코딩된 텍스처 픽처들(310)을 렌더러(330)에 제공한다. 비디오 디코더(312)는 디코딩된 깊이 픽처들(314)을 지오메트리 스케일러(326) 및 블록 대 패치 맵 디코더(318)에 제공한다.
MIV 디코더 및 파서(316)는 MIV 데이터 비트스트림(130)을 수신한다. 예시적인 MIV 디코더 및 파서(316)는 예시적인 아틀라스 데이터(320) 및 예시적인 V-PCC(Video-based Point Cloud Compression) 및 시점 파라미터 세트(322)를 생성하기 위해 MIV 데이터 비트스트림(130)을 파싱한다. 예를 들어, MIV 디코더 및 파서(316)는 예시적인 패치 리스트, 카메라 파라미터 리스트 등에 대해 인코딩된 MIV 데이터 비트스트림(130)을 파싱한다. MIV 디코더 및 파서(316)는 아틀라스 데이터(320) 및 V-PCC 및 시점 파라미터 세트(322)를 예시적인 블록 대 패치 맵 디코더(318), 예시적인 컬러(328), 및 예시적인 렌더러(330)에 제공한다.
블록 대 패치 맵 디코더(318)는 비디오 디코더(312)로부터 디코딩된 깊이 픽처들(314)을 수신하고 예시적인 MIV 디코더 및 파서(316)로부터 아틀라스 데이터(320)(패치 리스트 및 카메라 파라미터들 리스트를 포함함) 및 V-PCC 및 시점 파라미터 세트(322)를 수신한다. 블록 대 패치 맵 디코더(318)는 디코딩된 깊이 픽처들(314)의 아틀라스(들)에서의 포인트 위치들/장소들을 결정하기 위해 블록 대 패치 맵(324)을 디코딩한다. 예시된 예에서, 블록 대 패치 맵(324)은 디코딩된 깊이 픽처들(314)의 하나 이상의 픽셀의 주어진 블록과 연관된 패치 ID를 나타내는 2D 어레이(예를 들면, 아틀라스에서의 포인트 위치들/장소들을 나타냄)이다. 블록 대 패치 맵 디코더(318)는 블록 대 패치 맵(324)을 예시적인 지오메트리 스케일러(326)에 제공한다. 도 3의 예시된 예에서, 지오메트리 스케일러(326)는 디코딩된 깊이 픽처들(314)에 포함된 아틀라스마다 지오메트리 비디오 데이터의 업스케일링을 수행한다. 지오메트리 스케일러(326)는 디코딩된 깊이 픽처들(314)에 포함된 아틀라스마다 업스케일링된 지오메트리 비디오 데이터를 예시적인 컬러(328) 및 예시적인 렌더러(330)에 제공한다.
예시적인 컬러(328)는 지오메트리 스케일러(326)로부터 지오메트리 스케일링된 블록 대 패치 맵(324)을 수신하고, 또한 예시적인 MIV 디코더 및 파서(316)로부터 아틀라스 데이터(320)(패치 리스트 및 카메라 파라미터들 리스트를 포함함) 및 V-PCC 및 시점 파라미터 세트(322)를 수신한다. 컬러(328)는 예시적인 뷰잉 위치 및 뷰잉 배향(340)(예를 들면, 타깃 뷰)에 기초하여 패치 컬링(patch culling)을 수행한다. 컬러(328)는 사용자로부터 뷰잉 위치 및 뷰잉 배향(340)을 수신할 수 있다. 컬러(328)는 타깃 뷰잉 위치 및 뷰잉 배향(340)에 기초하여 보이지 않는 블록들을 아틀라스 데이터(320)로부터 필터링 제거하기 위해 블록 대 패치 맵(324)을 사용한다.
예시적인 렌더러(330)는 예시적인 뷰포트(338)를 생성한다. 예를 들어, 렌더러(330)는 디코딩된 텍스처 픽처들(310) 및 디코딩된 깊이 픽처들(314)로부터의 디코딩된 아틀라스들, 아틀라스 데이터(320)(예를 들면, 아틀라스 파라미터들 리스트, 카메라 파라미터들 리스트, 아틀라스 패치 점유 맵), 및 뷰어 위치 및 배향(342) 중 하나 이상에 액세스한다. 즉, 예시적인 렌더러(330)는, 예시적인 뷰어 위치 및 배향(342)에 기초하여 선택되는, 텍스처 이미지들의 투시 뷰포트를 출력한다. 본 명세서에서 개시되는 예들에서, 뷰어는 6 자유도(6DoF)로 동적으로 이동하여(예를 들면, 뷰어 위치 및 배향(342)을 조정하여), (예를 들면, 헤드 마운티드 디스플레이 또는 위치 입력들을 갖는 2D 모니터 등에 의해 지원되는 바와 같은) 제한된 범위 내에서 위치(x, y, z) 및 배향(요, 피치, 롤)을 조정할 수 있다. 렌더러(330)는 필수적인 깊이 성분들(디코딩된 깊이 픽처들(314)) 및 선택적인 텍스처 성분들(디코딩된 텍스처 픽처들(310))이 패치들, 뷰들, 또는 아틀라스들을 포함하는지 여부에 관계없이 이들 양쪽 모두에 기초하여 예시적인 뷰포트(338)를 생성한다.
도 3의 예시된 예에서, 렌더러(330)는 제어기(332), 합성기(334), 및 인페인터(336)를 포함한다. 예시적인 제어기(332)는, 디코딩된 깊이 픽처들(314) 또는 디코딩된 텍스처 픽처들(310)에서의 아틀라스의 픽셀이 뷰어 위치 및 배향(342)에서 점유되는지 여부를 나타내는, 아틀라스 데이터(320)로부터의 아틀라스 패치 점유 맵에 액세스한다. 제어기(332)는, 도 4와 관련하여 아래에서 더 상세히 설명되는, 블록 대 패치 맵들을 사용하여 디코딩된 텍스처 픽처들(310) 및 디코딩된 깊이 픽처들(314)의 아틀라스들에서의 패치들로부터 프루닝된 뷰들을 재구성한다. 본 명세서에서 개시되는 예들에서, 프루닝된 뷰는, 디코딩된 텍스처 픽처들(310) 및 디코딩된 깊이 픽처들(314)의 아틀라스들 내에서 운반되는 패치들에 의해 점유되는, 인코더 측(예를 들면, 도 1의 MIV 인코더(100))에서의 소스(입력) 뷰의 부분 뷰 표현이다. 제어기(332)는 뷰어 위치 및 배향(342)에 속하는 프루닝된 뷰들을 재구성한다. 일부 예들에서, 뷰어 위치 및 배향(342)에 속하는 프루닝된 뷰들은 다른 프루닝된 또는 완성된 뷰에 그들의 콘텐츠가 존재하는 것으로 인해 구멍들을 포함할 수 있다. 합성기(334)는 아틀라스 패치 점유 맵 및 제어기(332)로부터의 재구성된 프루닝된 뷰들 및 뷰어 위치 및 배향(342)에 기초하여 뷰 합성을 수행한다. 본 명세서에서 개시되는 예들에서, 인페인터(336)는 재구성된 프루닝된 뷰들에서 임의의 누락된 픽셀들을 매칭 값들로 채운다.
도 4는 아틀라스 패치들로부터의 프루닝된 뷰들의 예시적인 재구성(400)을 예시한다. 도 4에 도시된 바와 같이, 아틀라스들(406)은 아틀라스(402) 및 아틀라스(404)를 포함한다. 일부 예들에서, 비디오 디코더(308)(도 3) 및 비디오 디코더(312)(도 3)는 아틀라스들(402, 404)을 디코딩한다. 도 4의 예시된 예에서, 아틀라스들(402, 404)은 텍스처 맵 및 깊이 맵을 포함한다. 아틀라스(402)는 예시적인 제1 패치(410), 예시적인 제2 패치(412), 및 예시적인 제3 패치(414)를 포함한다. 아틀라스(404)는 예시적인 제4 패치(416) 및 예시적인 제5 패치(418)를 포함한다. 일부 예들에서, 패치들은 예시적인 패치 패커(110)(도 1)에 의해 결정되는 패치 ID들을 포함한다. 예를 들어, 제1 패치(410)는 2의 패치 ID를 포함하고, 제2 패치(412)는 5의 패치 ID를 포함하며, 제3 패치(414)는 8의 패치 ID를 포함하고, 제4 패치(416)는 3의 패치 ID를 포함하며, 제5 패치(418)는 7의 패치 ID를 포함한다.
일부 예들에서, 블록 대 패치 맵 디코더(318)(도 3)는 블록 대 패치 맵들을 사용하여 제1 패치(410), 제2 패치(412), 제3 패치(414), 제4 패치(416), 및 제5 패치(418)를 뷰 표현들(408)에 포함된 이용 가능한 뷰들(420, 424, 426)에 매칭시킨다. 블록 대 패치 맵 디코더(318)는 이용 가능한 뷰들(420, 424, 426)을 적어도 부분적으로 재구성하기 위해 패치들을 이용 가능한 뷰에 매칭시킨다. 예를 들어, 블록 대 패치 맵 디코더(318)는 제1 패치(410) 및 제2 패치(412)를 제1 이용 가능한 뷰(420)에 매칭시키고, 제3 패치(414)를 제2 이용 가능한 뷰(424)에 매칭시키며, 제4 패치(416) 및 제5 패치(418)를 제3 이용 가능한 뷰(426)에 매칭시킨다.
일부 예들에서, 각각의 패치는 이용 가능한 뷰들(예를 들면, 제1 이용 가능한 뷰(420), 제2 이용 가능한 뷰(424), 및 제3 이용 가능한 뷰(426))에서의 하나의 각자의 엔티티(객체)에 대응한다. 예를 들어, 제1 이용 가능한 뷰(420)에서 제1 패치(410)는 제1 사람의 머리에 대응하고 제2 패치(412)는 제2 사람의 머리에 대응하며, 제2 이용 가능 뷰(424)에서 제3 패치(414)는 제2 사람 팔에 대응하고, 제3 이용 가능한 뷰(426)에서 제4 패치(416)는 제3 사람의 머리에 대응하고 제5 패치(418)는 제2 사람의 다리에 대응한다.
도 5는 본 개시내용의 교시에 따른 예시적인 텍스처 기반 몰입형 비디오(MIV) 인코더(500)의 블록 다이어그램이다. 예시된 예의 텍스처 기반 MIV 인코더(500)에서, 어트리뷰트들(예를 들면, 텍스처, 엔티티들, 반사율 등)만이 뷰마다 입력되고, 깊이는 뷰마다 제공되지 않는다(또는 선택적임). 일부 실시예들에서 카메라 파라미터들이 이용(예를 들면, 인코딩)될 수 있다. 일부 예들에서, 그러한 카메라 파라미터들은 (예를 들면, 디코더에서) 텍스처 콘텐츠로부터 추정/추론될 수 있다. 도 5의 예시된 예시에서, 예시적인 텍스처 기반 MIV 인코더(500)는 예시적인 뷰 최적화기(502), 예시적인 깊이 추론기(504), 예시적인 대응 관계 아틀라스 구성기(506), 예시적인 점유 패커(524), 예시적인 비디오 인코더(534), 및 예시적인 비디오 인코더(536)를 포함한다. 예시적인 대응 관계 아틀라스 구성기(506)는 예시적인 대응 관계 라벨러(508), 예시적인 대응 관계 프루너(510), 예시적인 마스크 집계기(512), 예시적인 대응 관계 패치 패커(514), 및 예시적인 아틀라스 생성기(516)를 포함한다.
예시된 예에서, 예시적인 텍스처 기반 MIV 인코더(500)는 예시적인 소스 뷰들(501)을 수신한다. 예를 들어, 소스 뷰들(501)은 캡처된 장면의 텍스처 데이터(예를 들면, 텍스처 비트스트림들), 및 어쩌면 깊이 데이터(예를 들면, 깊이 비트스트림들)를 포함한다. 예를 들어, 소스 뷰들(501)은 비디오 캡처기들에 의해 생성되는 소스 뷰들, 컴퓨터에 의해 생성되는 가상 뷰들 등일 수 있다. 추가적으로 또는 대안적으로, 소스 뷰들(501)은 다른 어트리뷰트들(예를 들면, 엔티티들, 반사율 등)을 포함한다. 예시된 예에서, 소스 뷰들(501)은 비디오 시퀀스로서 표현된다. 예시적인 텍스처 기반 MIV 인코더(500)는 예시적인 소스 카메라 파라미터 리스트(503)를 추가로 수신한다. 예를 들어, 소스 카메라 파라미터 리스트(503)는 소스 카메라들이 어디에 위치되는지, 소스 카메라들의 각도 등을 포함할 수 있다.
예시적인 뷰 최적화기(502)는 인코딩할 뷰들을 식별하기 위해 카메라 파라미터 리스트(503)로부터의 카메라 파라미터들을 사용한다. 예를 들어, 뷰 최적화기(502)는 소스 뷰들(501)을 분석하고 어느 뷰들을 인코딩할지를 선택한다. 일부 예들에서, 뷰 최적화기(502)는 소스 뷰들(501)의 뷰들을 기본 뷰 또는 추가 뷰로서 라벨링한다. 본 명세서에서 사용되는 바와 같이, 기본 뷰는 단일 패치로서 아틀라스에 패킹될 입력 뷰이다. 본 명세서에서 사용되는 바와 같이, 추가 뷰는 프루닝되어 하나 이상의 패치에 패킹될 입력 뷰이다. 본 명세서에서 개시되는 예들에서, 뷰 최적화기는 소스 뷰들(501)에 뷰 ID들(identifications)을 라벨링한다.
예시적인 깊이 추론기(504)는 소스 뷰들(501)로부터 깊이 정보를 검색하기 위해 선택적인 깊이 추론 프로세스를 수행한다. 예를 들어, 깊이 추론기(504)는 소스 뷰들(501)에 대한 실제 깊이 맵들을 추정하고, 광학 흐름과 같은 기술들을 사용하여 소스 뷰들(501)의 시차 표현을 계산하며, 뷰들에 걸쳐 모션 기반 구조(structure from motion) 기술들을 사용하여 뷰마다 포인트 클라우드 표현을 찾는 등을 할 수 있다. 본 명세서에서 개시되는 예들에서, 깊이 추론기(504)는 임의의 깊이 정보가 소스 뷰들(501)에 포함되어 있는지를 결정한다. 깊이 추론기(504)가 어떠한 깊이 정보도 결정하지 않거나 깊이 추론기(504)가 예시적인 구현으로부터 생략되는 경우, 텍스처 기반 MIV 인코더(500)는 소스 뷰들(501)에 포함된 텍스처 정보만으로 진행한다.
대응 관계 아틀라스 구성기(506)는 예시적인 뷰 최적화기(102)에 의해 결정되는 기본 뷰 및/또는 추가 뷰를 수신한다. 대응 관계 아틀라스 구성기(506)는 소스 뷰마다 고유한 텍스처 정보를 식별하고 고유한 텍스처 정보를 패치들로서 추출하기 위해 기본 뷰 및/또는 추가 뷰에서 텍스처 콘텐츠/정보를 평가한다. 추가적으로 또는 대안적으로, 대응 관계 아틀라스 구성기(506)는 소스 뷰마다 고유한 어트리뷰트 정보를 식별하고 고유한 어트리뷰트 정보를 패치들로서 추출하기 위해 기본 뷰 및/또는 추가 뷰에서 다른 어트리뷰트 콘텐츠/정보(예를 들면, 엔티티들, 반사율 등)를 평가한다. 일부 예들에서, 대응 관계 아틀라스 구성기(506)는 깊이 추론기(504)로부터의 선택적인 깊이 정보(이용 가능한 경우)를 평가한다. 대응 관계 아틀라스 구성기(506)는 패치들을 결정하기 위해 라벨링, 프루닝, 및 클러스터링을 사용하여 선택된 뷰들(예를 들면, 기본 뷰 및/또는 추가 뷰)로부터 패치들을 형성한다. 대응 관계 아틀라스 구성기(506)는 대응 관계 라벨러(508), 대응 관계 프루너(510), 마스크 집계기(512), 대응 관계 패치 패커(514), 및 아틀라스 생성기(516)를 포함한다.
대응 관계 라벨러(508)는 모든 뷰들(예를 들면, 기본 뷰 및/또는 추가 뷰)에 걸쳐 대응하는 픽셀들을 식별하고 텍스처 콘텐츠(및/또는 다른 어트리뷰트 콘텐츠) 및 이용 가능한 경우 깊이 정보에 기초하여 이들을 라벨링한다. 그에 따라, 대응 관계 라벨러(508)는 고유한 픽셀들 및 대응하는 픽셀들을 식별하기 위한 수단의 예이다. 본 명세서에서 개시되는 예들에서, 제1 뷰로부터 3D 세계로의 제1 픽셀의 역투영 및 제2 뷰로의 제1 픽셀의 후속 재투영이 제1 픽셀을 제2 뷰로부터의 제2 픽셀과 동일한 위치에 배치하는 경우 제1 픽셀과 제2 픽셀(제1 뷰로부터의 제1 픽셀과 제2 뷰로부터의 제2 픽셀)은 대응하는 픽셀들로 간주된다. 본 명세서에서 개시되는 예들에서, 제1 뷰 및 제2 뷰는 기본 뷰들, 추가 뷰들, 및/또는 기본 뷰와 추가 뷰의 조합일 수 있다. 일부 예들에서, 대응 관계 라벨러(508)는 유사한 멀티뷰 콘텐츠에 대해 트레이닝된 후에 모든 뷰들에 걸쳐 매칭된 픽셀들을 식별하고 라벨링하기 위해 멀티뷰 특징 추출 및 패턴 인식 기술들(예를 들면, 종래의 또는 AI 기반)을 사용할 수 있다.
예시된 예에서, 대응 관계 라벨러(508)는 픽셀들을 고유한 것으로서 또는 대응하는 것으로서 라벨링하며 이에 의해 뷰 최적화기(502)로부터의 모든 소스 뷰들에 걸쳐 대응하는 픽셀들을 식별한다. 대응 관계 라벨러(508)는 다른 이용 가능한 뷰들에서 대응하는 픽셀들을 갖지 않는 픽셀들을 임의의 뷰로부터의 해당 픽셀들에 대해 "고유한" 것으로서 라벨링한다. 예를 들어, 단말 카메라들의 가장자리 영역들에 또는 특정 뷰에서만 볼 수 있는 폐색된 영역들에 위치하는 픽셀들은 전형적으로 "고유한" 픽셀들로서 라벨링된다. 대응 관계 라벨러(508)는 다른 이용 가능한 뷰들에서의 하나 이상의 대응하는 픽셀을 갖는 픽셀들을 임의의 뷰로부터의 해당 픽셀들에 대해 "대응하는" 것으로서 라벨링한다. 2개 이상의 대응하는 픽셀의 각각의 그룹에 대해, 대응 관계 라벨러(508)는 해당 그룹 내의 대응하는 픽셀들이 유사한 텍스처 콘텐츠를 갖는지를 결정한다. 예를 들어, 대응 관계 라벨러(508)는 2개의 대응하는 픽셀 사이에서 텍스처 콘텐츠를 비교하고 텍스처 콘텐츠의 차이를 임계값과 비교한다. 일부 예들에서, 임계값은 색상 성분들(예를 들면, 적색-녹색-청색(RGB) 성분들)의 차이일 수 있다. 예를 들어, 임계값은 색상 성분들 중 임의의 것 사이의 5(또는 어떤 다른 값)의 차이일 수 있다. 대응 관계 라벨러(508)는 텍스처 콘텐츠의 차이가 임계값 미만일 때 대응하는 픽셀들이 유사한 텍스처 콘텐츠를 갖는다고 결정한다. 대응 관계 라벨러(508)는 대응하는 픽셀들을 "유사한 텍스처"로서 라벨링하고 대응하는 픽셀들의 좌표(예를 들면, x, y) 위치들과 함께 대응하는 픽셀들을 포함하는 소스 뷰들의 뷰 ID들을 대응 관계 리스트에 저장한다. 예를 들어, 대응 관계 리스트는 엔트리들: { (4, 27, 33), (7, 450, 270) }을 포함할 수 있다. 이 예에서, 2개의 대응하는 유사한 텍스처 픽셀이 있다(하나는 이미지 좌표 (27,33)에서 뷰 ID 4를 갖는 소스 뷰에 위치하고 다른 하나는 이미지 좌표 (450, 270)에서 뷰 ID 7을 갖는 소스 뷰에 위치한다).
일부 예들에서, 대응 관계 라벨러(508)는 텍스처 콘텐츠의 차이가 임계값 초과일 때 대응하는 픽셀들이 상이한 텍스처 콘텐츠를 갖는다고 결정한다(그러나 이들은 대응하는 투영된 위치들을 갖고 따라서 대응하는 픽셀들로 분류된다). 일부 예들에서, 대응하는 픽셀들은 상이한 경면반사 정보, 상이한 일루미네이션(illumination)/조명 정보, 상이한 카메라 설정들로 인한 색상 불일치들 등에 기초하여 상이한 텍스처 콘텐츠를 갖는 것으로 결정될 수 있다. 대응 관계 라벨러(508)는 대응하는 픽셀들을 "상이한 텍스처"로서 라벨링하고 대응하는 픽셀들의 좌표(예를 들면, x, y) 위치들과 함께 대응하는 픽셀들을 포함하는 소스 뷰들의 뷰 ID들을 대응 관계 리스트에 저장한다. 본 명세서에서 개시되는 예들에서, 대응 관계 라벨러(508)는 대응하는 픽셀들에 대한 추가 라벨들 "유사한 텍스처" 및 "상이한 텍스처"를 포함시켜 대응 관계 프루너(510)가 그러한 정보를 사용하여 중복성들을 감소시키고 이에 의해 비중복적인 정보를 출력할 수 있게 한다. 일부 예들에서, 대응 관계 라벨러는, 이용 가능한 경우, 텍스처 이외의 어트리뷰트들에서 대응하는 픽셀들의 차이들를 나타내기 위해 픽셀들에 대해 "유사한 텍스처" 및 "상이한 텍스처" 라벨들, 및/또는 추가 라벨들을 위해 다른 이름들/식별자들을 사용할 수 있다. 예를 들어, 추가 라벨들은 투명성들, 반사율, 모션 등의 차이들을 식별해 줄 수 있다. 대응 관계 라벨러(508)는 대응 관계 경우들에 수반되는 뷰들에 대한 대응 관계 라벨링 맵들 및 인덱싱된(예를 들면, corresponding_id) 픽셀 단위 대응 관계 리스트들을 출력한다.
대응 관계 프루너(510)는 미리 결정되거나 구성 가능하거나 등등 할 수 있는 하나 이상의 기준(예를 들면, 뷰들 사이의 중첩된 정보, 캡처 카메라들 사이의 거리 등)에 따라 프루닝 순서를 결정한다. 본 명세서에서 개시되는 예들에서, 기본 뷰들은 프루닝 동안 먼저 정렬된다. 일부 예들에서, (예를 들면, 하나 이상의 기준에 기초하여 선택되는) 기본 뷰들 중 제1 기본 뷰는 프루닝되지 않은 상태로 유지되고, 소스 뷰들(501)에 포함된 임의의 다른 기본 뷰들 및 추가 뷰들은 프루닝될 수 있다. 본 명세서에서 개시되는 예들에서, 대응 관계 프루너(510)는 소스 뷰들을 프루닝하고 뷰 내의 픽셀이 유지되어야 하는지(예를 들면, 프루닝 마스크 픽셀이 "1"로 설정되어야 하는지) 또는 제거되어야 하는지(예를 들면, 프루닝 마스크 픽셀이 "0"으로 설정되어야 하는지)를 나타내는 이진 프루닝 마스크들을 (뷰마다 하나씩) 출력한다. 대응 관계 프루너(510)는 대응 관계 라벨러(508)로부터의 라벨링된 픽셀들을 사용하여 소스 뷰들을 프루닝한다.
일부 예들에서, 대응 관계 프루너(510)는 프루닝 마스크들의 픽셀들을 0(또는 어떤 다른 초기 값)으로 초기화한다. 일부 예들에서, 대응 관계 프루너는 제1(또는 유일한) 기본 뷰의 픽셀들 중 어느 것도 프루닝되지 않는다는 것을 나타내기 위해 제1 기본 뷰에 대응하는 프루닝 마스크 내의 모든 픽셀들을 1(또는 초기 값과 상이한 어떤 다른 값)로 설정한다. 대응 관계 프루너(510)는 다른 뷰들 각각에 대해 대응 관계 라벨러(508)에 의해 "고유한" 것으로 및 "대응하는, 상이한 텍스처"로서 라벨링된 픽셀들을 식별하고 해당 뷰들에 대한 대응하는 프루닝 마스크들 내의 픽셀들을 값 1로 설정한다. 일부 예들에서, 대체로 중첩되는 뷰들에 속하는 픽셀들이 프루닝되고 서로 멀리 떨어진 뷰들이 유지되도록, 대응 관계 프루너(510)는 "대응하는, 상이한 텍스처" 픽셀들에 대한 가중 방식을 설정하기로 선택할 수 있다. 예를 들어, 뷰들의 소스들(예를 들면, 카메라들) 사이의 거리가 임계값(예를 들면, 10 피트 이격, 20 피트 이격 등)을 충족시킬 때 뷰들은 서로 멀리 있는 것으로 간주될 수 있다.
대응 관계 프루너(510)는 다른 뷰들에 대해 대응 관계 리스트들을 탐색하고 다른 뷰들 각각에 대해 대응 관계 라벨러(508)에 의해 "대응하는, 유사한 텍스처"로서 라벨링된 픽셀들을 식별한다. 일부 예들에서, 대응 관계 리스트에 포함된 픽셀들 중 적어도 2개가 2개의 이전에 프루닝된 뷰에 속하는 경우, 대응 관계 프루너(510)는 연관된 프루닝 마스크 내의 픽셀들을 0(예를 들면, 픽셀들이 프루닝되어야 한다는 것을 나타내는, 초기 값)으로 유지한다. 그렇지 않은 경우, 대응 관계 프루너(510)는 연관된 프루닝 마스크 내의 픽셀들을 1(예를 들면, 픽셀들이 프루닝되지 않아야 한다는 것을 나타내는, 초기 값 이외의 값)으로 설정한다. 일부 예들에서, 2개의 프루닝 뷰에서 "대응하는, 유사한 텍스처"로서 라벨링된 적어도 2개의 픽셀이 선택되고, 깊이 정보를 추론하기 위해 예시적인 디코더에 의해 사용될 연관된 프루닝 마스크들에서 1로 설정된다.
본 명세서에서 개시되는 예들에서, 대응 관계 프루너(510)는 모든 뷰들에 걸친 모든 픽셀들이 뷰마다 프루닝 마스크들을 식별하도록 프로세싱될 때까지 프루닝을 반복한다. 추가적으로 또는 대안적으로, 대응 관계 프루너(510)는 다른 어트리뷰트 콘텐츠/정보(예를 들면, 엔티티들, 반사율 등)를 사용하여 프루닝을 완료할 수 있다. 그에 따라, 대응 관계 프루너(510)는 프루닝 마스크를 생성하기 위한 수단의 예이다. 대응 관계 프루너(510)는 텍스처 기반 MIV 인코더(500)에는 없는 깊이 정보를 결정하기 위해 예시적인 디코더에 의해 사용될 수 있는 중요한 정보를 전달하기 위해 상이한 텍스처 정보 또는 최소한의 대응 관계 정보를 대응하는 픽셀들이 갖는 경우 인코딩된 비트스트림에 대응하는 픽셀들을 유지한다.
예시적인 마스크 집계기(512)는 예시적인 대응 관계 프루너(510)에 의해 생성되는 프루닝 결과들을 집계하여 패치들을 생성한다. 예를 들어, 마스크 집계기(108)는 모션을 고려하기 위해 인트라 기간(예를 들면, 미리 결정된 프레임 집합체)에 걸쳐 프루닝 결과들(예를 들면, 프루닝 마스크들)을 누적한다. 그에 따라, 마스크 집계기(512)는 프루닝 마스크들을 집계하기 위한 수단의 예이다. 예시적인 대응 관계 패치 패커(514)는 마스크 집계기(512)로부터의 집계된 프루닝 마스크들에 대해 클러스터링을 수행한다.
일부 예들에서, 대응 관계 패치 패커(514)는 대응하는 패치들을 식별해 주는 패치 ID(identification)(patch_ids)를 포함하는 각자의 패치별 대응 관계 리스트들로 태깅될 수 있는 패치들을 추출한다. 대응 관계 패치 패커(514)는 대응 관계를 갖지 않는 주어진 집계된 프루닝된 마스크에서 인접한 픽셀들을 식별하고(예를 들면, 인접한 픽셀들은 양쪽 모두 "고유한" 것으로서 라벨링됨) 인접한 픽셀들을 하나의 패치로 그룹화한다. 본 명세서에서 개시되는 예들에서, 인접한 픽셀들이 그룹화되는 패치는 비어 있는 패치별 대응 관계 리스트와 연관된다.
일부 예들에서, 대응 관계 패치 패커(514)는 "대응하는, 유사한 텍스처" 또는 "대응하는, 상이한 텍스처"로서 라벨링되는 주어진 집계된 프루닝된 마스크에서 인접한 픽셀들을 다른 집계된 프루닝된 마스크들의 픽셀들과 함께 식별하고, 대응 관계 패치 패커(514)는 이러한 인접한 픽셀들을 하나의 패치로 패킹한다. 대응 관계 패치 패커(514)는 또한 모든 다른 집계된 프루닝된 마스크들 내의 연관된 픽셀들을 뷰마다 하나의 패치로 함께 그룹화하며, 이는 다수의 대응 관계 패치들을 결과한다. 대응 관계 패치 패커(514)는 주어진 집계된 프루닝된 마스크 내의 패치 및 모든 다른 집계된 프루닝된 마스크들 내의 패치들을 대응 관계 패치들의 patch_ids를 나타내는 패치별 대응 관계 리스트들로 태깅한다. 본 명세서에서 개시되는 예들에서, 대응 관계 패치들은 상이한 뷰들에 속해야 한다(예를 들면, 각각은 고유한 view_id를 갖는다). 예를 들어, 동일한 뷰에 속하는(예를 들면, 동일한 view_id를 갖는) 2개의 패치는 대응하는 패치들일 수 없다. 대응 관계 패치 패커(514)는 집계된 프루닝된 마스크들 내의 모든 픽셀들이 연관된 대응 관계 정보를 사용하여 클러스터링되고 패치들에서 추출될 때까지 이 클러스터링을 반복한다. 그에 따라, 대응 관계 패치 패커(514)는 패치들을 결정하기 위한 수단의 예이다. 본 명세서에서 개시되는 예들에서, 대응 관계 패치 패커(514)는 다른 이용 가능한 뷰들 내의 패치들과의 대응 관계를 설정하기 위해 제1 기본 뷰의 모든 정보를 다수의 패치들(예를 들면, 전체 단일 패치가 아님)로 클러스터링한다.
본 명세서에서 개시되는 예들에서, 각각의 뷰 내의 각각의 패치에 대한 패치별 대응 관계 리스트들을 시그널링할 때 사용되는 비트들을 절감하기 위해, 순환 방식으로 각각의 패치마다 하나의 대응하는 패치만을 나타내는 것이 가능하다. 예를 들어, 제각기, patch_id 2, 5, 8의 3개의 대응하는 패치를 가정할 때, 각각의 패치의 패치 파라미터들에 pdu_corresponding_id가 도입될 수 있다. 그러한 예들에서, patch_id = 2의 패치는 pdu_corresponding_id = 5 또는 전체 리스트 pdu_corresponding_list = [5,8]을 갖고, patch_id = 5의 패치는 pdu_corresponding_id = 8 또는 전체 리스트 pdu_corresponding_list = [2,8]을 가지며, patch_id = 8의 패치는 pdu_corresponding_id = 2 또는 전체 리스트 pdu_corresponding_list = [2,5]를 갖는다.
일단 패치들의 클러스터링 및 추출이 완료되면, 대응 관계 패치 패커(514)는 블록 대 패치 맵(예를 들면, 패치 ID 맵)을 생성할 수 있다. 블록 대 패치 맵은 하나 이상의 픽셀의 주어진 블록과 연관된 패치 ID를 나타내는 2D 어레이(예를 들면, 아틀라스에서의 포인트 위치들/장소들을 나타냄)이다.
아틀라스 생성기(516)는 텍스처 패치들을 텍스처 전용 아틀라스들(520)에 기입한다(왜냐하면 텍스처 기반 MIV 인코더(500)에 아틀라스들에 대한 깊이 성분이 존재하지 않기 때문임). 아틀라스 생성기(516)는 텍스처 전용 아틀라스들(520)을 예시적인 어트리뷰트(텍스처) 비디오 데이터(530)로서 예시적인 비디오 인코더(536)에 출력한다. 그에 따라, 아틀라스 생성기(516)는 아틀라스를 생성하기 위한 수단의 예이다. 아틀라스 생성기(516)는 또한 연관된 아틀라스들과 동일한 크기의 이진 점유 맵들(522)(아틀라스당 하나씩)을 예시적인 점유 패커(524)에 출력한다. 아틀라스 생성기(516)는 뷰 파라미터들 및 다른 시퀀스 정보에 더하여 아틀라스들 간에 패치들가 어떻게 매핑되는지를 전달하는 메타데이터를 생성하고 메타데이터(518)를 예시적인 점유 패커(524) 및 예시적인 비디오 인코더(536)에 출력한다.
점유 패커(524)는 아틀라스 생성기(516)로부터 점유 맵들(522)을 수신한다. 일부 예에서, 점유 패커(524)는 매 X 개의 이진 픽셀(비트)를 하나의 컴포넌트(예를 들면, X는 8 비트, 10 비트 등일 수 있음)로서 패킹하고, 이는 픽셀률을 절감하기 위해 명시적으로 시그널링되는 점유 맵의 크기의 감소를 결과한다. 일부 예들에서, 점유 패커(524)는 무손실 방식으로 반복 패턴들을 압축하기 위해 런 렝스 코딩(run length coding) 기술들을 사용한다. 일부 예들에서, 점유 패커(524)는 패킹된 점유 맵들(526), 블록 대 패치 맵, 및 패치 ID 데이터를 예시적인 MIV 데이터 비트스트림(532)에 포함시킨다. 예시된 예에서, MIV 데이터 비트스트림(532)은 패치들을 뷰들과 아틀라스들 사이에 매핑하기 위한 패치 파라미터들, 나중에 블록 대 패치 맵들을 검색하는 데 필요한 중첩된 패치들을 나타내기 위한 패킹 순서, V-PCC(Video-based Point Cloud Compression) 파라미터 세트, 및 적응 파라미터 세트(뷰 파라미터들을 포함함), 및 비디오 코딩된 데이터로부터의 임의의 다른 메타데이터를 포함한다. 일부 예들에서, MIV 데이터 비트스트림(532)은 인코딩된 비디오 데이터가 뷰들/아틀라스들에서의 지오메트리(깊이) 정보를 포함하지 않는다는 것을 식별해 주기 위한 플래그(또는 비트)를 포함한다.
예시적인 비디오 인코더(534)는 점유 비디오 데이터(528)로부터 인코딩된 아틀라스들을 생성한다. 예시적인 비디오 인코더(536)는 어트리뷰트(텍스처) 비디오 데이터(530)로부터 인코딩된 아틀라스들을 생성한다. 예를 들어, 비디오 인코더(534)는 예시적인 점유 비디오 데이터(528)를 수신하고, HEVC 비디오 인코더를 사용하여 패킹된 점유 맵(526)을 예시적인 HEVC 비트스트림(538)에 인코딩한다. 추가적으로, 비디오 인코더(536)는 예시적인 어트리뷰트(텍스처) 비디오 데이터(530)(아틀라스들을 포함함)를 수신하고 HEVC 비디오 인코더를 사용하여 텍스처 성분을 예시적인 HEVC 비트스트림(540)에 인코딩한다. 그렇지만, 예시적인 비디오 인코더(534) 및 예시적인 비디오 인코더(536)는 추가적으로 또는 대안적으로 고급 비디오 코딩(AVC) 비디오 인코더 등을 사용할 수 있다. 예시적인 HEVC 비트스트림(538) 및 예시적인 HEVC 비트스트림(540)은 패치들을 뷰들과 아틀라스들 사이에 매핑하기 위한 패치 파라미터들, 점유 비디오 데이터(528) 및 어트리뷰트(텍스처) 비디오 데이터(530)에, 제각기, 관련된 블록 대 패치 맵들을 나중에 검색하는 데 필요한 중첩된 패치들을 나타내기 위한 패킹 순서 등을 포함할 수 있다. 본 명세서에서 개시되는 예들에서, 점유 비디오 데이터(528) 및 어트리뷰트(텍스처) 비디오 데이터(530)에서의 패킹된 점유 맵들은 비디오 코딩되고 MIV 데이터 비트스트림(532)에 포함된 메타데이터와 함께 다중화되며, 이는 디코더(예를 들면, 도 7의 예시적인 텍스처 기반 MIV 디코더(700))로 전송될 수 있고/있거나 디코딩하여 사용자에게 제시하기 위해 저장 및 임의의 수의 디코더들로의 최종적인 전송을 위해 메모리 디바이스로 전송될 수 있다.
도 6은 도 5의 텍스처 기반 MIV 인코더(500)에서 입력 뷰들로부터의 예시적인 아틀라스 생성을 예시한다. 입력 뷰들은 예시적인 제1 뷰(602), 예시적인 제2 뷰(604), 및 예시적인 제3 뷰(606)를 포함한다. 예시된 예에서, 제1 뷰(602)는 또한 뷰 0으로서 라벨링되고, 제2 뷰(604)는 또한 뷰 1로서 라벨링되며, 제3 뷰(606)는 또한 뷰 2로서 라벨링된다. 예시된 예에서, 뷰들(602, 604, 606)은 뷰 표현들(608)(예를 들면, 어트리뷰트(텍스처) 맵들)을 포함한다. 도 6의 예시된 예에서, 뷰들(602, 604, 606)의 뷰 표현들(608)은 3명의 사람을 포함한다. 즉, 3명의 사람과 관련하여 3개의 상이한 각도에서 3개의 상이한 카메라로부터 뷰들(602, 604, 606)이 캡처된다.
예시적인 대응 관계 프루너(510)(도 5)는 패치들을 생성하기 위해 뷰들(602, 604, 606)을 프루닝한다. 예를 들어, 제1 뷰(602)는 예시적인 제1 패치(610) 및 예시적인 제2 패치(612)를 포함하고, 제2 뷰(604)는 예시적인 제3 패치(616)를 포함하며, 제3 뷰(606)는 예시적인 제4 패치(624) 및 예시적인 제5 패치(626)를 포함한다. 일부 예들에서, 각각의 패치는 하나의 각자의 엔티티(객체)에 대응한다. 예를 들어, 제1 패치(210)는 제1 사람의 머리에 대응하고, 제2 패치(212)는 제2 사람의 머리에 대응하며, 제3 패치(214)는 제2 사람의 팔에 대응하고, 제4 패치(216)는 제3 사람의 머리에 대응하며, 제5 패치(218)는 제2 사람의 다리에 대응한다.
예시적인 대응 관계 프루너(510)는 대응 관계 패치들을 생성하기 위해 뷰들(602, 604, 606)을 프루닝한다. 예를 들어, 제1 뷰(602)는 예시적인 제1 대응 관계 패치(614)를 포함하고, 제2 뷰(604)는 예시적인 제2 대응 관계 패치(618), 예시적인 제3 대응 관계 패치(620), 및 예시적인 제4 대응 관계 패치(622)를 포함하고, 제3 뷰(606)는 예시적인 제5 대응 관계 패치(628)를 포함한다. 본 명세서에서 개시되는 예들에서, 대응 관계 프루너(510)는 대응 관계 패치들(614, 618, 620, 622, 628)을 식별하기 위해 예시적인 대응 관계 라벨러(508)(도 5)로부터의 라벨링된 픽셀들(예를 들면, 대응하는, 유사한 텍스처, 상이한 텍스처 등)을 사용한다. 예시된 예에서, 제1 뷰(602)의 제1 대응 관계 패치(614)는 제2 뷰(604)의 제3 패치(616)에 대응하고, 제2 뷰(604)의 제2 대응 관계 패치(618)는 제1 뷰(602)의 제1 패치(610)에 대응하며, 제2 뷰(604)의 제3 대응 관계 패치(620)는 제3 뷰(606)의 제4 패치(624)에 대응하고, 제2 뷰(604)의 제4 대응 관계 패치(622)는 제3 뷰(606)의 제5 패치(626)에 대응하며, 제3 뷰(606)의 제5 대응 관계 패치(628)는 제1 뷰(602)의 제2 패치(612)에 대응한다. 일부 실시예들에서, 대응하는 픽셀들을 결정하기 위한 임계값은 (도 5와 관련하여 위에서 논의된 바와 같이) 더 많은 픽셀들이 "유사한" 것보다 "상이한" 것으로 간주될 수 있도록 조정될 수 있으며, 이는 예시적인 디코더가 패치들로부터 깊이 정보를 검색할 수 있기에 충분한 정보를 전송하도록 중복성을 증가시킨다. 예를 들어, 대응 관계 프루너(510)는 더 많은 대응하는 픽셀들을 대응 관계 패치들에 포함시킨다.
일부 예들에서, 대응 관계 패치 패커(514)(도 5)는 패치들을 패치 ID들로 태깅하고 대응 관계 패치들을 대응하는 패치 ID들로 태깅한다. 예를 들어, 대응 관계 패치 패커(514)는 제1 패치(610)를 2의 패치 ID로 태깅하고, 제2 패치(612)를 5의 패치 ID로 태깅하며, 제3 패치(616)를 8의 패치 ID로 태깅하고, 제4 패치(624)를 3의 패치 ID로 태깅하며, 제5 패치(626)를 7의 패치 ID로 태깅한다. 대응 관계 패치 패커(514)는 제1 대응 관계 패치(614)를 18의 패치 ID로 태깅하고, 제2 대응 관계 패치(618)를 12의 패치 ID로 태깅하며, 제3 대응 관계 패치(620)를 13의 패치 ID로 태깅하고, 제4 대응 관계 패치(622)를 17의 패치 ID로 태깅하며, 제5 대응 관계 패치(628)를 15의 패치 ID로 태깅한다.
예시적인 아틀라스 생성기(516)(도 5)는 예시적인 제1 아틀라스(630) 및 예시적인 제2 아틀라스(632)를 생성한다. 아틀라스들(630, 632)은 텍스처(어트리뷰트) 맵(예를 들면, 텍스처 #0 및 텍스처 #1)을 포함한다. 예시적인 제1 아틀라스(630)는 제1 패치(610), 제2 패치(612), 제3 패치(616), 제3 대응 관계 패치(620), 및 제5 대응 관계 패치(628)를 포함한다. 예시적인 제2 아틀라스(632)는 제4 패치(624), 제5 패치(626), 제1 대응 관계 패치(614), 제2 대응 관계 패치(618), 및 제4 대응 관계 패치(622)를 포함한다. 일부 예들에서, 대응 관계 패치 패커(514)는 제1 아틀라스(630) 및 제2 아틀라스(632)와 연관된 대응 관계 리스트들을 생성한다. 대응 관계 리스트들은 대응하는 픽셀들의 좌표(예를 들면, x, y) 위치들과 함께 대응하는 픽셀들을 포함하는 소스 뷰들의 뷰 ID들을 저장한다. 예를 들어, 대응 관계 패치 패커(514)는 제1 대응 관계 패치(614)에 포함된 픽셀들을 식별하고, 대응하는 픽셀들을 포함하는 소스 뷰(예를 들면, 제1 뷰(602))의 뷰 ID를 제1 대응 관계 패치(614)에서의 대응하는 픽셀들의 좌표(예를 들면, x, y) 위치들과 함께 저장한다. 아틀라스 생성기(516)는 대응하는 패치들(예를 들면, 제1 대응 관계 패치(614), 제2 대응 관계 패치(618), 제3 대응 관계 패치(620), 제4 대응 관계 패치(622), 및 제5 대응 관계 패치(628))을 식별하기 위해 제1 아틀라스(630) 및 제2 아틀라스(632)를 각자의 대응 관계 리스트들로 태깅한다.
도 7은 본 개시내용의 교시에 따른 예시적인 텍스처 기반 몰입형 비디오(MIV) 디코더(700)의 블록 다이어그램이다. 예시적인 텍스처 기반 MIV 디코더(700)는 예시적인 비디오 디코더(708), 예시적인 비디오 디코더(712), 예시적인 점유 언패커(occupancy unpacker)(714), 예시적인 MIV 디코더 및 파서(718), 예시적인 블록 대 패치 맵 디코더(720), 예시적인 컬러(728), 및 예시적인 렌더러(730)를 포함한다. 예시적인 렌더러(730)는 예시적인 제어기(732), 예시적인 깊이 추론기(734), 예시적인 합성기(736), 및 예시적인 인페인터(738)를 포함한다. 도 7에 예시된 바와 같이, 텍스처 기반 MIV 디코더(700)에 대한 입력 비트스트림(예를 들면, 도 5의 텍스처 기반 MIV 인코더(500)로부터 수신됨)은 코딩된 텍스처 비디오들, 코딩된 점유 비디오들, 및 메타데이터를 포함한다. 일부 예들에서, 텍스처 기반 MIV 디코더(700)는 예시적인 텍스처 기반 MIV 인코더(500)(도 5)로부터 예시적인 HEVC 비트스트림(540), 예시적인 HEVC 비트스트림(538), 및 예시적인 MIV 데이터 비트스트림(532)을 수신한다.
도 7의 예시된 예에서, 비디오 디코더(708)는 HEVC 비트스트림(540)을 수신한다. HEVC 비트스트림(540)은 어트리뷰트(텍스처) 비디오 데이터에 관련된 패치 파라미터들을 포함한다. 그러한 파라미터들의 예들은 뷰들과 아틀라스들 사이의 패치들의 맵, 나중에 블록 대 패치 맵들을 검색하는 데 활용되는 중첩된 패치들을 나타내기 위한 패킹 순서 등을 포함한다. 비디오 디코더(708)는 디코딩된 텍스처 픽처들(710)의 시퀀스를 생성한다. 비디오 디코더(712)는 HEVC 비트스트림(538)을 수신한다. HEVC 비트스트림(538)은 디코딩된 점유 비디오 데이터에 관련된 패치 파라미터들을 포함한다. 그러한 파라미터들의 예들은 뷰들과 아틀라스들 사이의 패치들의 맵, 나중에 블록 대 패치 맵들을 검색하는 데 활용되는 중첩된 패치들을 나타내기 위한 패킹 순서, 점유 맵 등을 포함한다. 비디오 디코더(712)는 디코딩된 점유 비디오 데이터를 예시적인 점유 언패커(714)에 제공한다. 예시된 예에서, 예시적인 디코딩된 텍스처 픽처들(710)은 예시적인 아틀라스를 나타낸다. 일부 예들에서, 비디오 디코더(708) 및 비디오 디코더(712)는 HEVC 디코더들일 수 있다. 그에 따라, 비디오 디코더(708) 및 비디오 디코더(712)는 인코딩된 비디오 데이터(예를 들면, HEVC 비트스트림(538) 및 HEVC 비트스트림(540))를 디코딩하기 위한 수단의 예이다. 도 7의 예시된 예에서, 비디오 디코더(708)는 디코딩된 텍스처 픽처들(710)을 렌더러(730)에 제공한다.
예시적인 점유 언패커(714)는 디코딩된 텍스처 픽처들(710)의 텍스처 아틀라스들과 동일한 크기의 점유 맵들(716)을 검색하기 위해 패킹 프로세스를 반대로 한다. 일부 예들에서, 점유 콘텐츠가 런 렝스 인코딩 기술을 사용하여 인코딩되는 경우, 비디오 디코더(712) 및 점유에 대한 점유 언패커(714)는 인코딩 프로세스를 반대로 하고 이진 점유 맵들을 재구성하기 위해 런 렝스 디코더로 대체된다. 본 명세서에서 개시되는 예들에서, 점유 언패커(714)는 점유 맵들(716)을 렌더러(730) 및 블록 대 패치 맵 디코더(720)에 제공한다.
MIV 디코더 및 파서(718)는 MIV 데이터 비트스트림(532)을 수신한다. 예시적인 MIV 디코더 및 파서(718)는 예시적인 아틀라스 데이터(722) 및 예시적인 V-PCC(Video-based Point Cloud Compression) 및 시점 파라미터 세트(724)를 생성하기 위해 MIV 데이터 비트스트림(532)을 파싱한다. 예를 들어, MIV 디코더 및 파서(718)는 예시적인 패치 리스트, 카메라 파라미터 리스트 등에 대해 인코딩된 MIV 데이터 비트스트림(532)을 파싱한다. 예시된 예에서, MIV 디코더 및 파서(718)는 플래그(또는 비트)가 인코딩된 비디오 데이터가 지오메트리(깊이) 정보를 포함하지 않음을 나타내도록 설정되어 있는지를 식별하기 위해 MIV 데이터 비트스트림(532)을 파싱한다. 그에 따라, MIV 디코더 및 파서(718)는 인코딩된 비디오 데이터(예를 들면, MIV 데이터 비트스트림(532))에서 플래그를 식별하기 위한 수단의 예이다. MIV 디코더 및 파서(718)는 아틀라스 데이터(722) 및 V-PCC 및 시점 파라미터 세트(724)를 예시적인 블록 대 패치 맵 디코더(720), 예시적인 컬러(728), 및 예시적인 렌더러(730)에 제공한다.
블록 대 패치 맵 디코더(720)는 비디오 디코더(712)로부터 점유 맵들(716)을 수신하고 예시적인 MIV 디코더 및 파서(718)로부터 아틀라스 데이터(722)(패치 리스트 및 카메라 파라미터들 리스트를 포함함) 및 V-PCC 및 시점 파라미터 세트(724)를 수신한다. 블록 대 패치 맵 디코더(720)는 텍스처 아틀라스들 및 점유 맵들(716)에서 포인트 위치들/장소들을 결정하기 위해 블록 대 패치 맵(726)을 디코딩한다. 예시된 예에서, 블록 대 패치 맵(726)은 텍스처 아틀라스들의 하나 이상의 픽셀의 주어진 블록과 연관된 패치 ID를 나타내는 2D 어레이(예를 들면, 아틀라스에서의 포인트 위치들/장소들을 나타냄)이다. 블록 대 패치 맵 디코더(720)는 블록 대 패치 맵(726)을 예시적인 컬러(728)에 제공한다. 본 명세서에서 논의되는 텍스처 기반 기술들에서, 비트스트림에 코딩된 깊이(지오메트리)가 없으며, 따라서 지오메트리 스케일러가 제거된다는 점에 유의한다.
예시적인 컬러(728)는 블록 대 패치 맵 디코더(729)로부터 블록 대 패치 맵(726)을 수신하고 예시적인 MIV 디코더 및 파서(718)로부터 아틀라스 데이터(722)(패치 리스트 및 카메라 파라미터들 리스트를 포함함) 및 V-PCC 및 시점 파라미터 세트(724)를 수신한다. 컬러(728)는 예시적인 뷰잉 위치 및 뷰잉 배향(742)(예를 들면, 타깃 뷰)에 기초하여 패치 컬링을 수행한다. 컬러(728)는 사용자로부터 뷰잉 위치 및 뷰잉 배향(742)을 수신할 수 있다. 컬러(728)는 타깃 뷰잉 위치 및 뷰잉 배향(742)에 기초하여 보이지 않는 블록들을 블록 대 패치 맵(726)에 기초하여 아틀라스 데이터(722)로부터 필터링 제거한다.
예시적인 렌더러(730)는 예시적인 뷰포트(740)를 생성한다. 예를 들어, 렌더러(730)는 디코딩된 텍스처 픽처들(310) 및 점유 맵들(716)로부터의 디코딩된 아틀라스들, 아틀라스 데이터(722)(예를 들면, 아틀라스 파라미터들 리스트, 카메라 파라미터들 리스트, 아틀라스 패치 점유 맵), V-PCC 및 시점 파라미터 세트(724), 및 뷰어 위치 및 배향(744) 중 하나 이상에 액세스한다. 즉, 예시적인 렌더러(730)는, 예시적인 뷰어 위치 및 배향(744)에 기초하여 선택되는, 텍스처 이미지들의 투시 뷰포트를 출력한다. 본 명세서에서 개시되는 예들에서, 뷰어는 6 자유도(6DoF)로 동적으로 이동하여(예를 들면, 뷰어 위치 및 배향(744)을 조정하여), (예를 들면, 헤드 마운티드 디스플레이 또는 위치 입력들을 갖는 2D 모니터 등에 의해 지원되는 바와 같은) 제한된 범위 내에서 위치(x, y, z) 및 배향(요, 피치, 롤)을 조정할 수 있다. 그에 따라, 렌더러(730)는 타깃 뷰를 생성하기 위한 수단의 예이다. 렌더러(730)는 텍스처 성분들(디코딩된 텍스처 픽처들(310)) 및 대응 관계 텍스처 성분들에 기초하여 추론된 깊이 성분들 양쪽 모두에 기초하여 예시적인 뷰포트(740)를 생성한다.
도 7의 예시된 예에서, 렌더러(730)는 제어기(732), 깊이 추론기(734), 합성기(736), 및 인페인터(738)를 포함한다. 예시적인 제어기(732)는 디코딩된 텍스처 픽처들(710)에서의 아틀라스의 픽셀이 뷰어 위치 및 배향(744)에서 점유되는지 여부를 나타내는 아틀라스 패치 점유 맵들(716)에 액세스한다. 본 명세서에서 개시되는 예들에서, 디코딩된 텍스처 픽처들(710)의 디코딩된 아틀라스들은 필요에 따라 깊이 추론을 가능하게 하기에 충분한 정보를 포함한다. 일부 예들에서, 제어기(732)는 디코딩된 텍스처 픽처들(710)에서의 아틀라스들 내의 패치들을 대체하기 위해 블록 대 패치 맵들을 사용한다. 제어기(732)는 블록 대 패치 맵들을 사용하여 디코딩된 텍스처 픽처들(710)의 아틀라스들 내의 패치들로부터 프루닝된 뷰들을 재구성한다. 본 명세서에서 개시되는 예들에서, 프루닝된 뷰는, 디코딩된 텍스처 픽처들(710)의 아틀라스들 내에서 운반되는 패치들에 의해 점유되는, 인코더 측(예를 들면, 도 5의 텍스처 기반 MIV 인코더(500))에서의 소스(입력) 뷰의 부분 뷰 표현이다. 제어기(732)는 뷰어 위치 및 배향(744)에 속하는 프루닝된 뷰들을 재구성한다. 일부 예들에서, 뷰어 위치 및 배향(744)에 속하는 프루닝된 뷰들은 다른 프루닝된 또는 완성된 뷰에 그들의 콘텐츠가 존재하는 것으로 인해 구멍들을 포함할 수 있다.
예시된 예에서, 깊이 추론기(734)는 프루닝된 뷰들로부터 깊이 정보를 추론한다. 각각의 뷰에서의 각각의 재매핑된 패치가 상이한 프루닝된 뷰로부터의 적어도 하나의 대응 관계 패치를 갖기 때문에(인코딩 스테이지 동안 그의 픽셀들이 "고유한" 것으로서 라벨링되지 않는 한), 깊이 추론기(734)는 디코딩된 텍스처 픽처들(710)의 아틀라스들로부터 깊이 정보를 결정(예를 들면, 추론/추정)하기 위해 대응 관계 패치들을 사용한다. 일부 예들에서, 깊이 추론기(734)는 디코딩된 텍스처 픽처들(710) 내에서 이용 가능한(또는 관련 SEI 메시지에서 보충되는) pdu_correspondence_id(또는 pdu_correspondence_list)를 사용하여 대응 관계 패치들을 식별한다. pdu_correspondence_id(또는 pdu_correspondence_list)에서 대응하는 패치들을 식별하는 것은 깊이 추론기(734)가, 예를 들어, 제한된 윈도 내에서 대응하는 픽셀들을 효율적으로 탐색할 수 있게 하며(왜냐하면 대응하는 패치들의 정확한 위치들이 알려져 있기 때문임), 이에 의해 종래의 스테레오 기반 깊이 추정 기술들에서 보통 배포되는 비용이 많이 드는 탐색 및 블록 매칭 동작들의 필요성을 제거한다. 일부 예들에서, 깊이 추론기(734)는 추정 품질을 개선시키기 위해 (예를 들면, "대응하는, 상이한 텍스처"로서 라벨링된 대응하는 패치들 또는 2개 초과의 대응하는 패치를 가능하게 하는 허용오차로 "대응하는, 유사한 텍스처"로서 라벨링된 대응하는 패치들에 대해) 프루닝된 뷰들 내에서 이용 가능한 경우 2개 초과의 대응하는 패치를 사용할 수 있다. 깊이 추론기(734)는 뷰어 모션과 상호작용적으로 실시간 수행을 제공한다.
도 7의 예시된 예에서, 합성기(736)는 아틀라스 패치 점유 맵 및 제어기(732)로부터의 재구성된 프루닝된 뷰들 및 뷰어 위치 및 배향(744)에 기초하여 뷰 합성을 수행한다. 본 명세서에서 개시되는 예들에서, 인페인터(738)는 재구성된 프루닝된 뷰들에서 임의의 누락된 픽셀들을 매칭 값들로 채운다.
도 8은 도 7의 텍스처 기반 MIV 디코더(700)에 의해 구현되는 예시적인 렌더링 프로세스의 블록 다이어그램이다. 예시적인 렌더링 프로세스(800)는 예시적인 디코딩된 지오메트리(깊이) 아틀라스들(802), 예시적인 디코딩된 점유 아틀라스들(804), 예시적인 디코딩된 텍스처 어트리뷰트 아틀라스들(806), 예시적인 아틀라스 정보(808), 예시적인 뷰 정보(810), 예시적인 지오메트리 비디오 스케일링 프로세스(812), 예시적인 점유 비디오 재구성 프로세스(814), 예시적인 엔티티 필터링 프로세스(816), 예시적인 소스 뷰들 재구성 프로세스(818), 예시적인 깊이 디코딩 프로세스(820), 예시적인 깊이 추정 프로세스(822), 예시적인 재구성된 뷰들 대 뷰포트 투영 프로세스(824), 및 예시적인 블렌딩 및 인페인팅 프로세스(826)를 포함한다. 예시된 예에서, 아틀라스 정보(808)는 아틀라스 파라미터들 및 패치 리스트를 포함하고, 뷰 정보(810)는 뷰 파라미터들을 포함한다. 예시적인 렌더링 프로세스(800)는 깊이 정보가 이용 가능하거나 이용 가능하지 않을 때 텍스처 기반 MIV 디코더(700)(도 7)의 렌더링 프로세스를 예시한다.
예시된 예에서, 엔티티 필터링 프로세스(816)는 깊이(지오메트리) 아틀라스들이 비트스트림에 포함되는지를 식별해 주는 비트스트림 표시자들(예를 들면, 플래그들, 비트들 등)을 식별하기 위해 아틀라스 정보(808)를 파싱한다. 예를 들어, 아틀라스 정보(808)는 깊이 정보가 아틀라스에 포함되는지를 식별해 주기 위한 아틀라스에 대한 플래그(예를 들면, vps_geometry_video_present_flag[ j ] 여기서 j는 0 또는 1의 이진 값을 나타냄)를 포함할 수 있다. 일부 예들에서, 아틀라스 정보(808)가 깊이 정보가 존재한다는 것을 나타내는 경우, 예시적인 지오메트리 비디오 스케일링 프로세스(812)는 디코딩된 지오메트리(깊이) 아틀라스들(802)로부터 지오메트리(깊이) 정보를 디코딩하도록 진행한다. 예시된 예에서, 점유 비디오 재구성 프로세스(814)는 디코딩된 점유 아틀라스들(804) 및 디코딩된 텍스처 어트리뷰트 아틀라스들(806)에 대한 점유 맵들을 재구성한다.
아틀라스 정보(808)가 깊이 정보가 존재한다는 것을 나타내는 일부 예들에서, 예시적인 렌더링 프로세스는 디코딩된 지오메트리(깊이) 아틀라스들(802), 디코딩된 점유 아틀라스들(804), 디코딩된 텍스처 어트리뷰트 아틀라스들(806), 아틀라스 정보(808), 및 뷰 정보(810)를 사용하여 텍스처 및 지오메트리 이미지들의 투시 뷰포트를 결정 및 출력하기 위해 예시적인 소스 뷰들 재구성 프로세스(818), 예시적인 깊이 디코딩 프로세스(820), 및 예시적인 재구성된 뷰들 대 뷰포트 투영 프로세스(824)를 수행한다. 아틀라스 정보(808)가 깊이 정보가 존재하지 않는다는 것을 나타내는 예들에서, 예시적인 렌더링 프로세스(800)는 예시적인 깊이 디코딩 프로세스(820)를 수행하지 않고, 그 대신에, 깊이 추정 프로세스(822)를 수행한다. 그러한 예들에서, 깊이 추정 프로세스(822)는 디코딩된 점유 아틀라스들(804), 디코딩된 텍스처 어트리뷰트 아틀라스들(806), 아틀라스 정보(808), 및 뷰 정보(810)를 사용하여 텍스처 어트리뷰트 아틀라스들(806) 각각으로부터 깊이 값들을 결정(예를 들면, 추론/추정)한다. 도 8의 예시된 예에서, 렌더링 프로세스(800)는 제공된 깊이 아틀라스들(예를 들면, 디코딩된 지오메트리(깊이) 아틀라스들(802))로부터 또는 제공된 점유 맵들 및 텍스처 아틀라스들(예를 들면, 디코딩된 점유 아틀라스들(804) 및 디코딩된 텍스처 어트리뷰트 아틀라스들(806)))로부터 깊이를 추론하는 것으로부터 깊이 정보를 결정할 수 있다. 본 명세서에서 개시되는 예들에서, 아틀라스 정보(808)에 포함된 표시자는 투시 뷰포트에 대한 깊이 정보를 결정하기 위해 어느 프로세스(예를 들면, 예시적인 깊이 디코딩 프로세스(820) 또는 예시적인 깊이 추정 프로세스(822))가 수행되는지를 결정한다.
도 9는 도 7의 텍스처 기반 MIV 디코더(700)에서의 예시적인 아틀라스 뷰 재구성(900)을 예시한다. 도 9에 도시된 바와 같이, 아틀라스들(906)은 아틀라스(902) 및 아틀라스(904)를 포함한다. 일부 예들에서, 비디오 디코더(708)(도 7) 및 비디오 디코더(712)(도 7)는 아틀라스들(902, 904)을 디코딩한다. 도 9의 예시된 예에서, 아틀라스들(902, 904)은 텍스처 맵(예를 들면, 텍스처 #0 및 텍스처 #1)을 포함한다. 아틀라스(902)는 예시적인 제1 패치(910), 예시적인 제2 패치(912), 예시적인 제3 패치(914), 예시적인 제1 대응 관계 패치(916), 및 예시적인 제2 대응 관계 패치(918)를 포함한다. 예시적인 아틀라스(904)는 예시적인 제4 패치(920), 예시적인 제5 패치(922), 예시적인 제3 대응 관계 패치(924), 예시적인 제4 대응 관계 패치(926), 및 예시적인 제5 대응 관계 패치(928)를 포함한다. 일부 예들에서, 패치들은 패치 ID들을 포함하고 대응 관계 패치는 예시적인 대응 관계 패치 패커(514)(도 5)에 의해 결정되는 대응하는 패치 ID들을 포함한다. 예를 들어, 제1 패치(910)는 2의 패치 ID를 포함하고, 제2 패치(912)는 5의 패치 ID를 포함하며, 제3 패치(914)는 8의 패치 ID를 포함하고, 제4 패치(920)는 3의 패치 ID를 포함하며, 제5 패치(922)는 7의 패치 ID를 포함한다. 13의 패치 ID를 갖는 제1 대응 관계 패치(916), 15의 패치 ID를 갖는 제2 대응 관계 패치(918), 12의 패치 ID를 갖는 제3 대응 관계 패치(924), 17의 패치 ID를 갖는 제4 대응 관계 패치(622), 및 18의 패치 ID를 갖는 제5 대응 관계 패치(928).
일부 예들에서, 블록 대 패치 맵 디코더(720)(도 7)는 블록 대 패치 맵들을 사용하여 제1 패치(910), 제2 패치(912), 제3 패치(914), 제1 대응 관계 패치(916), 제2 대응 관계 패치(918), 제4 패치(920), 제5 패치(922), 제3 대응 관계 패치(924), 제4 대응 관계 패치(926), 및 제5 대응 관계 패치(928)를 예시적인 뷰 표현들(908)에 포함된 이용 가능한 뷰들(930, 934, 936)에 매칭시킨다. 블록 대 패치 맵 디코더(720)는 이용 가능한 뷰들(930, 934, 936)을 적어도 부분적으로 재구성하기 위해 패치들 및 대응 관계 패치들을 이용 가능한 뷰에 매칭시킨다. 예를 들어, 블록 대 패치 맵 디코더(720)는 제1 패치(910), 제2 패치(912), 및 제5 대응 관계 패치(928)를 제1 이용 가능한 뷰(930)에 매칭시키고, 제3 패치(914), 제1 대응 관계 패치(916), 제3 대응 관계 패치(924), 및 제4 대응 관계 패치(926)를 제2 이용 가능한 뷰(934)에 매칭시키며, 제4 패치(920), 제5 패치(922), 제2 대응 관계 패치(918)를 제3 이용 가능한 뷰(936)에 매칭시킨다.
일부 예들에서, 각각의 패치 및 대응 관계 패치는 이용 가능한 뷰들(예를 들면, 제1 이용 가능한 뷰(930), 제2 이용 가능한 뷰(934), 및 제3 이용 가능한 뷰(936))에서의 하나의 각자의 엔티티(객체)에 대응한다. 예를 들어, 제1 이용 가능한 뷰(930)에서의 제1 패치(910) 및 제2 이용 가능한 뷰(934)에서의 제3 대응 관계 패치(924)는 제1 사람의 머리에 대응하고, 제1 이용 가능한 뷰(930)에서의 제2 패치(912) 및 제2 대응 관계 패치(918)는 제3 사람의 머리에 대응하며, 제2 이용 가능한 뷰(934)에서의 제3 패치(914) 및 제1 이용 가능한 뷰(930)에서의 제5 대응 관계 패치(928)는 제3 사람의 팔에 대응하고, 제3 이용 가능한 뷰(936)에서의 제4 패치(920) 및 제2 이용 가능한 뷰(934)에서의 제1 대응 관계 패치(916)는 제2 사람의 머리에 대응하며, 제5 패치(922) 및 제4 대응 관계 패치(926)는 제3 사람의 다리에 대응한다. 본 명세서에서 개시되는 예들에서, 아틀라스들(예를 들면, 아틀라스(902) 및 아틀라스(904))에서 제공되지 않는 깊이 정보를 결정하도록 텍스처 맵들로부터의 추가 텍스처 정보를 제공하기 위해 개별적인 이용 가능한 뷰들에서 패치들(예를 들면, 제1 패치(910), 제2 패치(912), 제3 패치(914), 제4 패치(920), 및 제5 패치(922))이 대응 관계 패치들(예를 들면, 제1 대응 관계 패치(916), 제2 대응 관계 패치(918), 제3 대응 관계 패치(924), 제4 대응 관계 패치(926), 및 제5 대응 관계 패치(928))에 매칭된다. 일부 예들에서, 예시적인 비디오 디코더(708)(도 7)는 도 5의 예시적인 텍스처 기반 MIV 인코더(500)로부터의 아틀라스들(902, 904) 및 각자의 대응 관계 리스트들을 식별하기 위해 예시적인 HEVC 비트스트림(540)(도 7)을 디코딩한다. 아틀라스들(902, 904)에 대한 대응 관계 리스트들은 소스 뷰의 뷰 ID 및 패치들과 연관된 대응 관계 패치들 각각에 대한 대응하는 픽셀들의 좌표(예를 들면, x, y) 위치들을 식별해 준다. 예를 들어, 아틀라스(902)에 대한 대응 관계 리스트는 제1 대응 관계 패치(916)의 소스 뷰(제1 이용 가능한 뷰(930)) 및 제1 대응 관계 패치(916)에 포함된 대응하는 픽셀들의 좌표(예를 들면, x, y) 위치들을 제4 패치(920)와 연관되는(예를 들면, 제4 패치(920)에 매칭되는) 것으로서 식별해 준다.
도 10은 MIV 확장들을 갖는 예시적인 V3C 샘플 스트림(예를 들면, 예시적인 V3C 샘플 스트림(1000))을 예시한다. 예를 들어, 텍스처 기반 MIV 인코더(500)는 V3C 샘플 스트림(1000)을 생성한다. 예시적인 V3C 샘플 스트림(1000)은 예시적인 V3C 파라미터 세트(1002), 예시적인 공통 아틀라스 데이터(1004), 예시적인 아틀라스 데이터(1006), 예시적인 지오메트리 비디오 데이터(1008), 예시적인 어트리뷰트 비디오 데이터(1010), 및 예시적인 점유 비디오 데이터(1011)를 포함한다.
예를 들어, V3C 파라미터 세트(1002)는 예시적인 IV 액세스 유닛 파라미터들 및 예시적인 IV 시퀀스 파라미터들을 포함한다. 예시적인 공통 아틀라스 데이터(1004)는 예시적인 뷰 파라미터들 리스트(1012)를 포함한다. 예를 들어, 공통 아틀라스 데이터(1004)는 아틀라스 서브 비트스트림을 포함하지만, 주요 네트워크 추상화 계층(NAL) 유닛은 뷰 파라미터들 리스트(1012) 또는 그의 업데이트들을 포함하는 공통 아틀라스 프레임(CAF)이다. 예시적인 아틀라스 데이터(1006)는 예시적인 SEI 메시지들을 포함하는 NAL 샘플 스트림이다. 예를 들어, 아틀라스 데이터(1006)는 패치 데이터 유닛들(PDU)의 리스트를 운반하는 아틀라스 타일 계층(ATL)을 포함한다. 본 명세서에서 개시되는 예들에서, 각각의 PDU는 아틀라스에서의 패치와 가상 입력 뷰에서의 동일한 패치 사이의 관계를 설명한다. 예시적인 아틀라스 데이터(1006)는 예시적인 아틀라스 타일 계층들(1014)(예를 들면, 패치 데이터(1014))을 포함한다. 예를 들어, 패치 데이터(1014)는 예시적인 인트라 기간들(1016) 동안만(예를 들면, 인트라 기간(1016)당 1회) 송신된다. 일부 예들에서, 프레임 순서 카운트 NAL 유닛은 한 번에 모든 인터프레임들을 스킵하는 데 사용된다.
본 명세서에서 개시되는 예들에서, (공통 아틀라스 데이터(1004)에 포함된) 적응 가능한 파라미터 세트는 텍스처 기반 시그널링 옵션들을 포함한다. 일부 예들에서, MIV 동작 모드들은 표 1에서 다음과 같이 적응 파라미터 세트에서의 전용 메타데이터 신택스 요소(예를 들면, aps_operation_mode)에 의해 표시된다.
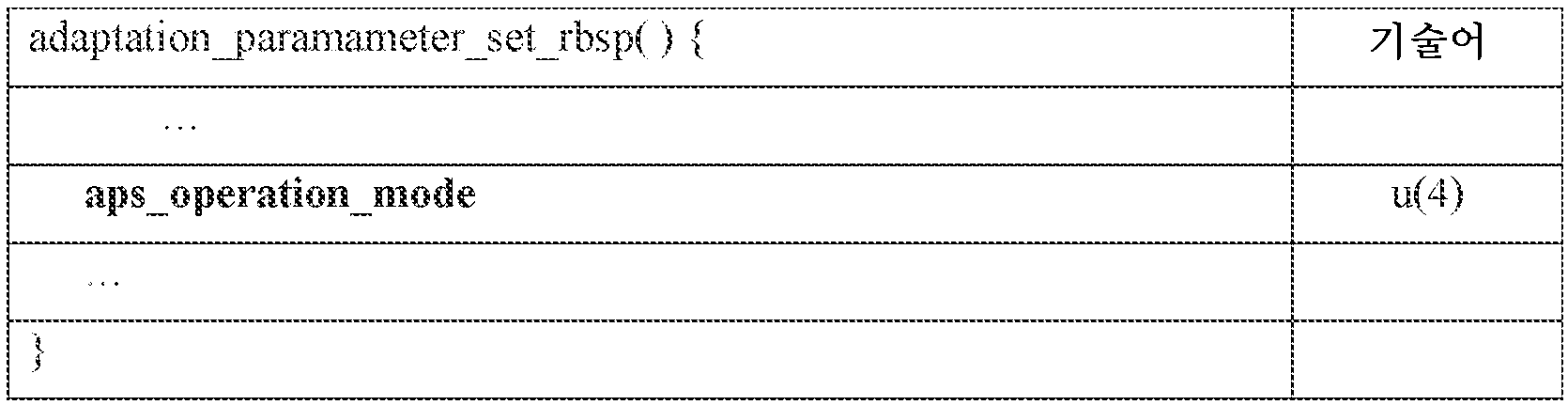
일부 실시예들에서, aps_operation_mode는 표 2에서 다음과 같이 정의된 바와 같이 MIV 동작 모드들을 지정한다.

본 명세서에서 개시되는 예들에서, V3C 파라미터 세트(1002)는 예시적인 표시자(vps_geometry_video_present_flag[ j ])를 포함하고, 여기서 표시자의 인덱스(j)는 지오메트리가 존재하지 않음을 나타내기 위해 0과 동일하게 설정된다.
일부 예들에서, 표 3과 관련하여 아래에서 정의되는 바와 같이, 점유가 지오메트리에 포함되어 있지 않음을 나타내기 위해 vme_embedded_occupancy_flag가 vps_miv_extension()에 추가된다.

일부 예들에서, 아틀라스당 일정한 깊이 패치 기능을 지원하기 위해, 표시자(플래그)(예를 들면, asme_patch_constant_depth_flag)가 asps_miv_extension()에 추가된다. 일부 예들에서, 이 표시자가 설정될 때, 아틀라스에 대한 지오메트리 비디오가 존재하지 않으며, 그의 값은 pdu_depth_start[ p ] 신택스 요소에 의해 직접 결정된다.

위의 예시적인 표 4에서, asme_patch_constant_depth_flag가 1과 동일하게 설정되는 것은, vps_geometry_video_present_flag[ atlasIdx ]가 0과 동일할 때, 디코딩된 깊이가 본 명세서에서 개시되는 바와 같이 도출된다는 것을 지정한다. 일부 예들에서, asme_patch_constant_depth_flag가 0과 동일하게 설정되는 것은, vps_geometry_video_present_flag[ atlasIdx ]가 0과 동일할 때, 깊이가 외부 수단에 의해 결정된다는 것을 지정한다.
점유 맵들의 시그널링이 깊이 내에 묵시적으로 포함되는지 또는 서브 비트스트림에 명시적으로 존재하는지(그리고 점유 서브 비트스트림 비디오에 대해 성분당 몇 비트가 패킹되는지)는 표 5에서 다음과 같이 아틀라스 데이터(1006)에서 설정된 아틀라스 시퀀스 파라미터들을 사용하여 아틀라스마다 결정될 수 있다.

예를 들어, 신택스 요소 masp_occupancy_subbitstream_present_flag가 1과 동일한 것은 VPCC_OVD vpcc 유닛들이 3VC 시퀀스에 존재할 수 있다는 것을 지정한다. masp_occupancy_subbitstream_present_flag가 0과 동일한 것은 VPCC_OVD vpcc 유닛들이 3VC 시퀀스에 존재하지 않는다는 것을 지정한다. 존재하지 않을 때, masp_occupancy_subbitstream_present_flag의 값은 0과 동일한 것으로 추론된다.
신택스 요소 masp_occupancy_num_packed_bits는 몇 개의 연속적인 점유 값들이 하나의 샘플로서 함께 패킹되는지를 지정한다. 점유 맵들의 크기는 (AspsFrameFrameWidth[ a ] / masp_occupancy_num_packed_bits) x AspsFrameFrameHeight[ a ]가 되도록 감소된다.
게다가, 패치별 대응 관계 정보는 표 6에서 다음과 같이 정의될 수 있다.

예를 들어, 신택스 요소 pdu_correspondence_id는 patchIdx와 동일한 인덱스를 갖는 패치와 연관된 대응하는 패치 id를 지정한다. pdu_correspondence_id가 존재하지 않는 경우, 이는 0xFFFF(예를 들면, 유효하지 않음)인 것으로 추론되며, 이는 patchIdx와 동일한 인덱스를 갖는 패치에 대한 대응하는 패치가 없다는 것을 의미한다. 일부 실시예들에서, 대응 관계 정보는, 추가적으로 또는 대안적으로, 아틀라스마다 패치마다 전용 SEI 메시지 내에서 시그널링된다.
텍스처 기반 MIV 인코더(500)를 구현하는 예시적인 방식이 도 5에 예시되어 있지만, 도 5에 예시된 요소들, 프로세스들 및/또는 디바이스들 중 하나 이상이 임의의 다른 방식으로 조합, 분할, 재배열, 생략, 제거 및/또는 구현될 수 있다. 게다가, 예시적인 뷰 최적화기(502), 예시적인 깊이 추론기(504), 예시적인 대응 관계 아틀라스 구성기(506), 예시적인 대응 관계 라벨러(508), 예시적인 대응 관계 프루너(510), 예시적인 마스크 집계기(512), 예시적인 대응 관계 패치 패커(514), 예시적인 아틀라스 생성기(516), 예시적인 점유 패커(524), 예시적인 비디오 인코더(534), 예시적인 비디오 인코더(536) 및/또는, 더 일반적으로, 도 5의 예시적인 텍스처 기반 MIV 인코더(500)는 하드웨어, 소프트웨어, 펌웨어 및/또는 하드웨어, 소프트웨어 및/또는 펌웨어의 임의의 조합에 의해 구현될 수 있다. 따라서, 예를 들어, 예시적인 뷰 최적화기(502), 예시적인 깊이 추론기(504), 예시적인 대응 관계 아틀라스 구성기(506), 예시적인 대응 관계 라벨러(508), 예시적인 대응 관계 프루너(510), 예시적인 마스크 집계기(512), 예시적인 대응 관계 패치 패커(514), 예시적인 아틀라스 생성기(516), 예시적인 점유 패커(524), 예시적인 비디오 인코더(534), 예시적인 비디오 인코더(536) 및/또는, 더 일반적으로, 예시적인 텍스처 기반 MIV 인코더(500) 중 임의의 것은 하나 이상의 아날로그 또는 디지털 회로(들), 로직 회로들, 프로그래밍 가능 프로세서(들), 프로그래밍 가능 제어기(들), 그래픽 프로세싱 유닛(들)(GPU(들)), 디지털 신호 프로세서(들)(DSP(들)), 주문형 집적 회로(들) (ASIC(들)), 프로그래머블 로직 디바이스(들)(PLD(들)) 및/또는 필드 프로그래머블 로직 디바이스(들)(FPLD(들))에 의해 구현될 수 있다. 순수한 소프트웨어 및/또는 펌웨어 구현을 커버하기 위해 이 특허의 장치 또는 시스템 청구항들 중 임의의 것을 읽을 때, 예시적인 뷰 최적화기(502), 예시적인 깊이 추론기(504), 예시적인 대응 관계 아틀라스 구성기(506), 예시적인 대응 관계 라벨러(508), 예시적인 대응 관계 프루너(510), 예시적인 마스크 집계기(512), 예시적인 대응 관계 패치 패커(514), 예시적인 아틀라스 생성기(516), 예시적인 점유 패커(524), 예시적인 비디오 인코더(534), 및/또는 예시적인 비디오 인코더(536) 중 적어도 하나는 이로써 소프트웨어 및/또는 펌웨어를 포함하는 메모리, DVD(digital versatile disk), CD(compact disk), 블루레이 디스크 등과 같은 비일시적 컴퓨터 판독 가능 저장 디바이스 또는 저장 디스크를 포함하도록 명시적으로 정의된다. 게다가, 도 5의 예시적인 텍스처 기반 MIV 인코더(500)는 도 5에 예시된 것들 외에도 또는 그 대신에 하나 이상의 요소, 프로세스 및/또는 디바이스를 포함할 수 있고/있거나 예시된 요소들, 프로세스들 및 디바이스들 중 일부 또는 전부 중 하나 초과를 포함할 수 있다. 본 명세서에서 사용되는 바와 같이, "통신하는"이라는 문구는, 그의 변형들을 포함하여, 직접 통신 및/또는 하나 이상의 중간 컴포넌트를 통한 간접 통신을 포괄하며, 직접적인 물리적(예컨대, 유선) 통신 및/또는 상시 통신을 요구하지는 않지만, 오히려 주기적인 간격, 스케줄링된 간격, 비주기적인 간격, 및/또는 일회성 이벤트로 있는 선택적인 통신을 추가적으로 포함한다.
텍스처 기반 MIV 디코더(700)를 구현하는 예시적인 방식이 도 7에 예시되어 있지만, 도 7에 예시된 요소들, 프로세스들 및/또는 디바이스들 중 하나 이상이 임의의 다른 방식으로 조합, 분할, 재배열, 생략, 제거 및/또는 구현될 수 있다. 게다가, 예시적인 비디오 디코더(708), 예시적인 비디오 디코더(712), 예시적인 점유 언패커(714), 예시적인 MIV 디코더 및 파서(718), 예시적인 블록 대 패치 맵 디코더(720), 예시적인 컬러(728), 예시적인 렌더러(730), 예시적인 제어기(732), 예시적인 깊이 추론기(734), 예시적인 합성기(736), 예시적인 인페인터(738) 및/또는, 더 일반적으로, 도 7의 예시적인 텍스처 기반 MIV 디코더(700)는 하드웨어, 소프트웨어, 펌웨어 및/또는 하드웨어, 소프트웨어 및/또는 펌웨어의 임의의 조합에 의해 구현될 수 있다. 따라서, 예를 들어, 예시적인 비디오 디코더(708), 예시적인 비디오 디코더(712), 예시적인 점유 언패커(714), 예시적인 MIV 디코더 및 파서(718), 예시적인 블록 대 패치 맵 디코더(720), 예시적인 컬러(728), 예시적인 렌더러(730), 예시적인 제어기(732), 예시적인 깊이 추론기(734), 예시적인 합성기(736), 예시적인 인페인터(738) 및/또는, 더 일반적으로, 예시적인 텍스처 기반 MIV 디코더(700) 중 임의의 것은 하나 이상의 아날로그 또는 디지털 회로(들), 로직 회로들, 프로그래밍 가능 프로세서(들), 프로그래밍 가능 제어기(들), 그래픽 프로세싱 유닛(들)(GPU(들)), 디지털 신호 프로세서(들)(DSP(들)), 주문형 집적 회로(들)(ASIC(들)), 프로그래머블 로직 디바이스(들)(PLD(들)) 및/또는 필드 프로그래머블 로직 디바이스(들)(FPLD(들))에 의해 구현될 수 있다. 순수한 소프트웨어 및/또는 펌웨어 구현을 커버하기 위해 이 특허의 장치 또는 시스템 청구항들 중 임의의 것을 읽을 때, 예시적인 비디오 디코더(708), 예시적인 비디오 디코더(712), 예시적인 점유 언패커(714), 예시적인 MIV 디코더 및 파서(718), 예시적인 블록 대 패치 맵 디코더(720), 예시적인 컬러(728), 예시적인 렌더러(730), 예시적인 제어기(732), 예시적인 깊이 추론기(734), 예시적인 합성기(736), 및/또는 예시적인 인페인터(738) 중 적어도 하나는 이로써 소프트웨어 및/또는 펌웨어를 포함하는 메모리, DVD(digital versatile disk), CD(compact disk), 블루레이 디스크 등과 같은 비일시적 컴퓨터 판독 가능 저장 디바이스 또는 저장 디스크를 포함하도록 명시적으로 정의된다. 게다가, 도 7의 예시적인 텍스처 기반 MIV 디코더(700)는 도 7에 예시된 것들 외에도 또는 그 대신에 하나 이상의 요소, 프로세스 및/또는 디바이스를 포함할 수 있고/있거나 예시된 요소들, 프로세스들 및 디바이스들 중 일부 또는 전부 중 하나 초과를 포함할 수 있다. 본 명세서에서 사용되는 바와 같이, "통신하는"이라는 문구는, 그의 변형들을 포함하여, 직접 통신 및/또는 하나 이상의 중간 컴포넌트를 통한 간접 통신을 포괄하며, 직접적인 물리적(예컨대, 유선) 통신 및/또는 상시 통신을 요구하지는 않지만, 오히려 주기적인 간격, 스케줄링된 간격, 비주기적인 간격, 및/또는 일회성 이벤트로 있는 선택적인 통신을 추가적으로 포함한다.
도 5의 텍스처 기반 MIV 인코더(500)를 구현하기 위한 예시적인 하드웨어 로직, 머신 판독 가능 명령어들, 하드웨어 구현 상태 머신들, 및/또는 이들의 임의의 조합을 표현하는 플로차트들이 도 11 내지 도 14에 도시되어 있다. 머신 판독 가능 명령어들은 도 18과 관련하여 아래에서 논의되는 예시적인 프로세서 플랫폼(1800)에 도시된 프로세서(1812)와 같은 컴퓨터 프로세서 및/또는 프로세서 회로에 의해 실행하기 위한 하나 이상의 실행 가능 프로그램 또는 실행 가능 프로그램의 하나 이상의 부분(들)일 수 있다. 프로그램은 프로세서(1812)와 연관된 CD-ROM, 플로피 디스크, 하드 드라이브, DVD, 블루레이 디스크, 또는 메모리와 같은 비일시적 컴퓨터 판독 가능 저장 매체 상에 저장된 소프트웨어로 구체화될 수 있지만, 전체 프로그램 및/또는 그 일부들은 대안적으로 프로세서(1812) 이외의 디바이스에 의해 실행될 수 있고/있거나 펌웨어 또는 전용 하드웨어로 구체화될 수 있다. 게다가, 예시적인 프로그램이 도 4에 예시된 플로차트를 참조하여 설명되지만, 예시적인 텍스처 기반 MIV 인코더(500)를 구현하는 많은 다른 방법들이 대안적으로 사용될 수 있다. 예를 들어, 블록들의 실행 순서가 변경될 수 있고/있거나 설명된 블록들 중 일부가 변경, 제거, 또는 조합될 수 있다. 추가적으로 또는 대안적으로, 블록들 중 일부 또는 전부는 소프트웨어 또는 펌웨어를 실행함이 없이 대응하는 동작을 수행하도록 구성된 하나 이상의 하드웨어 회로(예를 들면, 이산 및/또는 통합 아날로그 및/또는 디지털 회로, FPGA, ASIC, 비교기, 연산 증폭기(op-amp), 로직 회로 등)에 의해 구현될 수 있다. 프로세서 회로는 상이한 네트워크 위치들에 분산되고/되거나 하나 이상의 디바이스에 로컬일 수 있다(예를 들면, 단일 머신 내의 멀티코어 프로세서, 서버 랙에 걸쳐 분산된 다수의 프로세서들 등).
도 7의 텍스처 기반 MIV 디코더(700)를 구현하기 위한 예시적인 하드웨어 로직, 머신 판독 가능 명령어들, 하드웨어 구현 상태 머신들, 및/또는 이들의 임의의 조합을 표현하는 플로차트가 도 15에 도시되어 있다. 머신 판독 가능 명령어들은 도 19와 관련하여 아래에서 논의되는 예시적인 프로세서 플랫폼(1900)에 도시된 프로세서(1912)와 같은 컴퓨터 프로세서 및/또는 프로세서 회로에 의해 실행하기 위한 하나 이상의 실행 가능 프로그램 또는 실행 가능 프로그램의 하나 이상의 부분(들)일 수 있다. 프로그램은 프로세서(1912)와 연관된 CD-ROM, 플로피 디스크, 하드 드라이브, DVD, 블루레이 디스크, 또는 메모리와 같은 비일시적 컴퓨터 판독 가능 저장 매체 상에 저장된 소프트웨어로 구체화될 수 있지만, 전체 프로그램 및/또는 그 일부들은 대안적으로 프로세서(1912) 이외의 디바이스에 의해 실행될 수 있고/있거나 펌웨어 또는 전용 하드웨어로 구체화될 수 있다. 게다가, 예시적인 프로그램이 도 4에 예시된 플로차트를 참조하여 설명되지만, 예시적인 텍스처 기반 MIV 디코더(700)를 구현하는 많은 다른 방법들이 대안적으로 사용될 수 있다. 예를 들어, 블록들의 실행 순서가 변경될 수 있고/있거나 설명된 블록들 중 일부가 변경, 제거, 또는 조합될 수 있다. 추가적으로 또는 대안적으로, 블록들 중 일부 또는 전부는 소프트웨어 또는 펌웨어를 실행함이 없이 대응하는 동작을 수행하도록 구성된 하나 이상의 하드웨어 회로(예를 들면, 이산 및/또는 통합 아날로그 및/또는 디지털 회로, FPGA, ASIC, 비교기, 연산 증폭기(op-amp), 로직 회로 등)에 의해 구현될 수 있다. 프로세서 회로는 상이한 네트워크 위치들에 분산되고/되거나 하나 이상의 디바이스에 로컬일 수 있다(예를 들면, 단일 머신 내의 멀티코어 프로세서, 서버 랙에 걸쳐 분산된 다수의 프로세서들 등).
본 명세서에서 설명되는 머신 판독 가능 명령어들은 압축된 포맷, 암호화된 포맷, 단편화된 포맷, 컴파일된 포맷, 실행 가능한 포맷, 패키징된 포맷 등 중 하나 이상으로 저장될 수 있다. 본 명세서에서 설명되는 바와 같은 머신 판독 가능 명령어들은 머신 실행 가능 명령어들을 제작, 제조, 및/또는 생성하는 데 활용될 수 있는 데이터 또는 데이터 구조(예를 들면, 명령어들의 부분들, 코드, 코드 표현들 등)로서 저장될 수 있다. 예를 들어, 머신 판독 가능 명령어들은 단편화되어, 네트워크 또는 네트워크들의 집합체의 동일한 또는 상이한 위치들에(예를 들면, 클라우드에, 에지 디바이스들 등에) 위치하는 하나 이상의 저장 디바이스 및/또는 컴퓨팅 디바이스(예를 들면, 서버)에 저장될 수 있다. 머신 판독 가능 명령어들은 이들을 컴퓨팅 디바이스 및/또는 다른 머신에 의해 직접 판독 가능하게, 인터프리트 가능하게, 및/또는 실행 가능하게 만들기 위해 설치, 수정, 적응, 업데이트, 결합, 보완, 구성, 복호화, 압축해제, 언패킹, 분배, 재할당, 컴파일 등 중 하나 이상을 요구할 수 있다. 예를 들어, 머신 판독 가능 명령어들은, 개별적으로 압축되고, 암호화되어, 개별적인 컴퓨팅 디바이스들에 저장되는, 다수의 부분들로 저장될 수 있으며, 여기서 부분들은, 복호화되고, 압축해제되며, 결합될 때, 본 명세서에서 설명된 것과 같은 프로그램을 함께 형성할 수 있는 하나 이상의 기능을 구현하는 실행 가능 명령어들의 세트를 형성한다.
다른 예에서, 머신 판독 가능 명령어들은 이들이 프로세서 회로에 의해 판독될 수 있는 상태로 저장될 수 있지만, 특정 컴퓨팅 디바이스 또는 다른 디바이스 상에서 명령어들을 실행하기 위해 라이브러리(예를 들면, 동적 링크 라이브러리(DLL)), 소프트웨어 개발 키트(SDK), 애플리케이션 프로그래밍 인터페이스(API) 등의 추가를 요구할 수 있다. 다른 예에서, 머신 판독 가능 명령어들 및/또는 대응하는 프로그램(들)이 전체적으로 또는 부분적으로 실행될 수 있기 전에 머신 판독 가능 명령어들이 구성될(예컨대, 설정들이 저장되고, 데이터가 입력되며, 네트워크 어드레스들이 기록되는 등) 필요가 있을 수 있다. 따라서, 머신 판독 가능 매체는, 본 명세서에서 사용되는 바와 같이, 저장되거나 다른 방식으로 보관 중이거나 운송 중일 때의 머신 판독 가능 명령어들 및/또는 프로그램(들)의 특정 포맷 또는 상태에 관계없이 머신 판독 가능 명령어들 및/또는 프로그램(들)을 포함할 수 있다.
본 명세서에서 설명되는 머신 판독 가능 명령어들은 임의의 과거, 현재 또는 미래의 명령어 언어, 스크립팅 언어, 프로그래밍 언어 등에 의해 표현될 수 있다. 예를 들어, 머신 판독 가능 명령어들은 다음 언어들 중 임의의 것을 사용하여 표현될 수 있다: C, C++, Java, C#, Perl, Python, JavaScript, HTML(HyperText Markup Language), SQL(Structured Query Language), Swift 등
위에서 언급된 바와 같이, 도 11 내지 도 15의 예시적인 프로세스들은 정보가 임의의 지속기간 동안(예를 들면, 연장된 시간 기간들 동안, 영구적으로, 짧은 순간들 동안, 일시적으로 버퍼링하기 위해, 및/또는 정보의 캐싱을 위해) 저장되는 하드 디스크 드라이브, 플래시 메모리, 판독 전용 메모리, 콤팩트 디스크, 디지털 다기능 디스크, 캐시, 랜덤 액세스 메모리 및/또는 임의의 다른 저장 디바이스 또는 저장 디스크와 같은 비일시적 컴퓨터 및/또는 머신 판독 가능 매체에 저장되는 실행 가능 명령어들(예를 들면, 컴퓨터 및/또는 머신 판독 가능 명령어들)을 사용하여 구현될 수 있다. 본 명세서에서 사용되는 바와 같이, 비일시적 컴퓨터 판독 가능 매체라는 용어는 임의의 유형의 컴퓨터 판독 가능 저장 디바이스 및/또는 저장 디스크를 포함하도록 그리고 전파 신호들을 배제하도록 그리고 전송 매체들을 배제하도록 명확하게 정의된다.
"포함하는(Including)" 및 "포함하는(comprising)"(및 이들의 모든 형태들 및 시제들)은 본 명세서에서 개방형 용어(open ended term)이도록 사용된다. 따라서, 청구항이 전제부로서 또는 임의의 종류의 청구항 기재(claim recitation) 내에서 임의의 형태의 "포함하다(include)" 또는 "포함하다(comprise)"(예를 들면, 포함한다(comprises), 포함한다(includes), 포함하는(comprising), 포함하는(including), 가지는(having) 등)를 이용할 때마다, 대응하는 청구항 또는 기재의 범위를 벗어나지 않으면서 추가 요소들, 용어들 등이 존재할 수 있음이 이해되어야 한다. 본 명세서에서 사용되는 바와 같이, "적어도"라는 문구가, 예를 들어, 청구항의 전제부에서 이행구(transition term)로서 사용될 때, 이는 "포함하는(comprising)" 및 "포함하는(including)"이라는 용어가 개방형인 것과 동일한 방식으로 개방형이다. 예를 들어, A, B, 및/또는 C와 같은 형태로 사용될 때의 용어 "및/또는"은 (1) A 단독, (2) B 단독, (3) C 단독, (4) A와 B, (5) A와 C, (6) B와 C, (7) A와 B와 C와 같은 A, B, C의 임의의 조합 또는 서브세트를 지칭한다. 구조들, 컴포넌트들, 항목들, 객체들 및/또는 사물들을 설명하는 맥락에서 본 명세서에서 사용되는 바와 같이, "A 및 B 중 적어도 하나"라는 문구는 (1) 적어도 하나의 A, (2) 적어도 하나의 B, 및 (3) 적어도 하나의 A와 적어도 하나의 B 중 임의의 것을 포함한 구현들을 지칭하는 것으로 의도된다. 유사하게, 구조들, 컴포넌트들, 항목들, 객체들 및/또는 사물들을 설명하는 맥락에서 본 명세서에서 사용되는 바와 같이, "A 또는 B 중 적어도 하나"라는 문구는 (1) 적어도 하나의 A, (2) 적어도 하나의 B, 및 (3) 적어도 하나의 A와 적어도 하나의 B 중 임의의 것을 포함한 구현들을 지칭하는 것으로 의도된다. 프로세스들, 명령어들, 액션들, 활동들 및/또는 단계들의 수행 또는 실행을 설명하는 맥락에서 본 명세서에서 사용되는 바와 같이, "A 및 B 중 적어도 하나"라는 문구는 (1) 적어도 하나의 A, (2) 적어도 하나의 B, 및 (3) 적어도 하나의 A와 적어도 하나의 B 중 임의의 것을 포함한 구현들을 지칭하는 것으로 의도된다. 유사하게, 프로세스들, 명령어들, 액션들, 활동들 및/또는 단계들의 수행 또는 실행을 설명하는 맥락에서 본 명세서에서 사용되는 바와 같이, "A 또는 B 중 적어도 하나"라는 문구는 (1) 적어도 하나의 A, (2) 적어도 하나의 B, 및 (3) 적어도 하나의 A와 적어도 하나의 B 중 임의의 것을 포함한 구현들을 지칭하는 것으로 의도된다.
본 명세서에서 사용되는 바와 같이, 단수 참조들(예를 들면, "한", "어떤", "제1", "제2" 등)는 복수를 배제하지 않는다. 용어 "한" 또는 "어떤" 엔티티는, 본 명세서에서 사용되는 바와 같이, 하나 이상의 해당 엔티티를 지칭한다. 용어 "한"(또는 "어떤"), "하나 이상", 및 "적어도 하나"는 본 명세서에서 상호 교환 가능하게 사용될 수 있다. 게다가, 개별적으로 나열되지만, 복수의 수단들, 요소들 또는 방법 액션들은, 예를 들면, 단일 유닛 또는 프로세서에 의해 구현될 수 있다. 추가적으로, 개별 특징들이 상이한 예들 또는 청구항들에 포함될 수 있지만, 이들은 어쩌면 조합될 수 있으며, 상이한 예들 또는 청구항들에 포함된 것이 특징들의 조합이 실현 가능하지 않고/않거나 유리하지 않다는 것을 암시하지는 않는다.
도 11은 도 5의 텍스처 기반 MIV 인코더(500)를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다. 도 11의 프로그램(1100)은 예시적인 뷰 최적화기(502)(도 5)가 장면의 비디오 데이터를 수신하는 블록(1102)에서 실행을 시작한다. 예를 들어, 뷰 최적화기(502)는 텍스처 맵들을 포함하는 입력 뷰들(예를 들면, 도 5의 소스 뷰들(501))을 수신한다. 블록(1104)에서, 예시적인 대응 관계 라벨러(508)(도 5)는 이용 가능한 입력 뷰들의 대응하는 픽셀들을 식별, 합성, 및 라벨링한다. 예를 들어, 대응 관계 라벨러(508)는 모든 뷰들(예를 들면, 기본 뷰 및/또는 추가 뷰)에 걸쳐 대응하는 픽셀들을 식별하고 텍스처 콘텐츠에 기초하여 이들을 라벨링한다. 아래에서 더 상세히 설명되는 바와 같이, 도 12의 예시적인 플로차트(1104)는 이용 가능한 입력 뷰들의 대응하는 픽셀들을 식별, 합성, 및 라벨링하도록 구현될 수 있는 예시적인 머신 판독 가능 명령어들을 나타낸다.
블록(1106)에서, 예시적인 대응 관계 프루너(510)(도 5)는 기본 뷰 및 추가 뷰(들)에 대해 대응 관계 프루닝을 수행한다. 예를 들어, 대응 관계 프루너(510)는 대응 관계 라벨러(508)로부터의 라벨링된 픽셀들에 기초하여 기본 뷰 및 추가 뷰(들)를 프루닝한다. 아래에서 더 자세히 설명되는 바와 같이, 도 13의 예시적인 플로차트(1106)는 기본 뷰 및 추가 뷰(들)에 대해 대응 관계 프루닝을 수행하도록 구현될 수 있는 예시적인 머신 판독 가능 명령어를 나타낸다. 블록(1108)에서, 예시적인 대응 관계 프루너(510)는 대응 관계 프루닝 마스크들을 결정한다. 예를 들어, 대응 관계 프루너(510)는 뷰 내의 픽셀이 유지되어야 하는지(예를 들면, 프루닝 마스크 픽셀이 "1"로 설정되어야 하는지) 또는 제거되어야 하는지(예를 들면, 프루닝 마스크 픽셀이 "0"으로 설정되어야 하는지)를 나타내는 이진 프루닝 마스크들을 (뷰마다 하나씩) 출력한다.
블록(1110)에서, 예시적인 대응 관계 패치 패커(514)(도 5)는 대응 관계 패치(들)를 생성한다. 예를 들어, 대응 관계 패치 패커(514)는 대응하는 패치들을 식별해 주는 패치 ID(identification)(patch_ids)를 포함하는 각자의 패치별 대응 관계 리스트들로 태깅될 수 있는 패치들을 추출한다. 아래에서 더 상세히 설명되는 바와 같이, 도 14의 예시적인 플로차트(1110)는 대응 관계 패치(들)를 생성하도록 구현될 수 있는 예시적인 머신 판독 가능 명령어를 나타낸다. 블록(1112)에서, 예시적인 아틀라스 생성기(516)(도 5)는 아틀라스(들)를 생성한다. 예를 들어, 아틀라스 생성기(516)는 대응 관계 패치 패커(514)로부터의 텍스처 패치들을 텍스처 전용 아틀라스들에 기입한다(왜냐하면 텍스처 기반 MIV 인코더(500)에 아틀라스들에 대한 깊이 성분이 존재하지 않기 때문임).
블록(1114)에서, 예시적인 텍스처 기반 MIV 인코더(500)는 인코딩된 비트스트림을 생성한다. 예를 들어, 비디오 인코더(534) 및 비디오 인코더(536)는, 제각기, 점유 비디오 데이터(528)(도 5) 및 어트리뷰트(텍스처) 비디오 데이터(530)(도 5)로부터 인코딩된 아틀라스들을 생성한다. 비디오 인코더(534)는 예시적인 점유 비디오 데이터(528)를 수신하고 점유 맵들을 예시적인 HEVC 비트스트림(538)(도 5)에 인코딩한다. 비디오 인코더(536)는 예시적인 어트리뷰트(텍스처) 비디오 데이터(530)(아틀라스들을 포함함)를 수신하고 텍스처 성분들을 예시적인 HEVC 비트스트림(540)(도 5)에 인코딩한다. 예시적인 HEVC 비트스트림(538)은 디코딩된 점유 비디오 데이터에 관련된 패치 파라미터들을 포함한다. 그러한 파라미터들의 예들은 뷰들과 아틀라스들 사이의 패치들의 맵, 나중에 블록 대 패치 맵들을 검색하는 데 활용되는 중첩된 패치들을 나타내기 위한 패킹 순서, 점유 맵 등을 포함한다. 예시적인 HEVC 비트스트림(540)은 어트리뷰트(텍스처) 비디오 데이터에 관련된 패치 파라미터들을 포함한다. 그러한 파라미터들의 예들은 뷰들과 아틀라스들 사이의 패치들의 맵, 나중에 블록 대 패치 맵들을 검색하는 데 활용되는 중첩된 패치들을 나타내기 위한 패킹 순서 등을 포함한다. 일부 예들에서, MIV 데이터 비트스트림(532)은 인코딩된 비디오 데이터(예를 들면, HEVC 비트스트림(538) 및 HEVC 비트스트림(540))가 뷰들/아틀라스들에서의 지오메트리(깊이) 정보를 포함하지 않는다는 것을 식별해 주기 위한 플래그(또는 비트)를 포함한다. 본 명세서에서 개시되는 예들에서, 점유 비디오 데이터(528) 및 어트리뷰트(텍스처) 비디오 데이터(530)에서의 패킹된 점유 맵들은 비디오 코딩되고 MIV 데이터 비트스트림(532)에 포함된 메타데이터와 함께 다중화되며, 이는 디코더(예를 들면, 도 7의 예시적인 텍스처 기반 MIV 디코더(700))로 전송될 수 있고/있거나 디코딩하여 사용자에게 제시하기 위해 저장 및 임의의 수의 디코더들로의 최종적인 전송을 위해 메모리 디바이스로 전송될 수 있다. 블록(1114) 후에, 프로그램(1100)이 종료된다.
도 12는 도 5의 텍스처 기반 MIV 인코더(500)에 포함된 예시적인 대응 관계 라벨러(508)(도 5)를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다. 도 12의 프로그램(1104)은 예시적인 대응 관계 라벨러(508)가 제1 이용 가능한 입력 뷰로부터 제1 픽셀을 선택하는 블록(1202)에서 실행을 시작한다. 블록(1204)에서, 예시적인 대응 관계 라벨러(508)는 제2 이용 가능한 입력 뷰로부터 제2 픽셀을 선택한다. 예를 들어, 대응 관계 라벨러(508)는 임의의 이용 가능한 입력 뷰들(예를 들면, 기본 뷰 및/또는 추가 뷰)로부터 제1 픽셀 및 제2 픽셀(제1 이용 가능한 뷰로부터의 제1 픽셀 및 제2 이용 가능한 뷰로부터의 제2 픽셀)을 선택하고, 이용 가능한 경우 텍스처 콘텐츠 및 깊이 정보에 기초하여 이들을 라벨링한다.
블록(1206)에서, 예시적인 대응 관계 라벨러(508)는 3D 세계로의 제1 픽셀의 역투영을 결정한다. 블록(1208)에서, 예시적인 대응 관계 라벨러(508)는 제2 이용 가능한 입력 뷰로의 제1 픽셀의 재투영을 결정한다. 블록(1210)에서, 예시적인 대응 관계 라벨러(508)는 제1 픽셀이 제2 픽셀과 동일한 위치에 있는지를 결정한다. 예시적인 대응 관계 라벨러(508)가 제1 픽셀이 제2 픽셀과 동일한 위치에 있다고 결정하는 경우, 블록(1212)에서, 예시적인 대응 관계 라벨러(508)는 제1 픽셀과 제2 픽셀을 대응하는 픽셀들로서 라벨링한다. 본 명세서에서 개시되는 예들에서, 제1 이용 가능한 입력 뷰로부터 3D 세계로의 제1 픽셀의 역투영 및 제2 이용 가능한 입력 뷰로의 제1 픽셀의 후속 재투영이 제1 픽셀을 제2 이용 가능한 입력 뷰로부터의 제2 픽셀과 동일한 위치에 배치하는 경우 제1 픽셀과 제2 픽셀은 대응하는 픽셀들로 간주된다. 블록(1210)으로 돌아가서, 예시적인 대응 관계 라벨러(508)가 제1 픽셀이 제2 픽셀과 동일한 위치에 있지 않다고 결정하는 경우, 블록(1214)에서, 예시적인 대응 관계 라벨러(508)는 제1 픽셀과 제2 픽셀을 고유한 픽셀들로서 라벨링한다. 대응 관계 라벨러(508)는 임의의 이용 가능한 입력 뷰로부터의 픽셀들이 다른 이용 가능한 입력 뷰들에 대응하는 픽셀들을 갖지 않는 경우 픽셀들을 "고유한" 것으로서 라벨링한다. 예를 들어, 단말 카메라들의 가장자리 영역들에 또는 특정 뷰에서만 볼 수 있는 폐색된 영역들에 위치하는 픽셀들은 전형적으로 "고유한" 픽셀들로서 라벨링된다.
블록(1216)에서, 예시적인 대응 관계 라벨러(508)는 추가 픽셀들이 있는지를 결정한다. 예시적인 대응 관계 라벨러(508)가 추가 픽셀들이 있다고 결정하는 경우, 프로그램(1104)은 예시적인 대응 관계 라벨러(508)가 제1 이용 가능한 입력 뷰로부터 상이한 픽셀을 선택하는 블록(1202)으로 복귀한다. 블록(1216)으로 돌아가서, 예시적인 대응 관계 라벨러(508)가 추가 픽셀들이 없다고 결정하는 경우, 블록(1218)에서, 예시적인 대응 관계 라벨러(508)는 추가의 이용 가능한 입력 뷰들이 있는지를 결정한다. 예시적인 대응 관계 라벨러(508)가 추가의 이용 가능한 입력 뷰가 있다고 결정하는 경우, 프로그램(1104)은 예시적인 대응 관계 라벨러(508)가 상이한 이용 가능한 입력 뷰로부터 제1 픽셀을 선택하는 블록(1202)으로 복귀한다. 블록(1218)으로 돌아가서, 예시적인 대응 관계 라벨러(508)가 추가의 이용 가능한 입력 뷰들이 없다고 결정하는 경우, 블록(1212)에서, 예시적인 대응 관계 라벨러(508)는 모든 이용 가능한 입력 뷰들로부터 대응하는 픽셀들을 선택한다.
블록(1222)에서, 예시적인 대응 관계 라벨러(508)는 2개의 대응하는 픽셀 사이에서 텍스처 콘텐츠를 비교한다. 예를 들어, 대응하는 픽셀들의 각각에 대해, 대응 관계 라벨러(508)는 대응하는 픽셀들이 유사한 텍스처 콘텐츠를 갖는지를 결정한다. 블록(1224)에서, 예시적인 대응 관계 라벨러(508)는 텍스처 콘텐츠의 차이가 임계값을 충족시키는지를 결정한다. 예를 들어, 대응 관계 라벨러(508)는 2개의 대응하는 픽셀 사이에서 텍스처 콘텐츠를 비교하고 텍스처 콘텐츠의 차이를 임계값과 비교한다. 일부 예들에서, 임계값은 색상 성분들(예를 들면, 적색-녹색-청색(RGB) 성분들)의 차이일 수 있다. 예를 들어, 임계값은 색상 성분들 중 임의의 것 사이의 5(또는 어떤 다른 값)의 차이일 수 있다. 예시적인 대응 관계 라벨러(508)가 텍스처 콘텐츠의 차이가 임계값을 충족시킨다고 결정하는 경우, 블록(1226)에서, 예시적인 대응 관계 라벨러(508)는 대응하는 픽셀들을 유사한 것으로서 라벨링한다. 대응 관계 라벨러(508)는 텍스처 콘텐츠의 차이가 임계값 미만일 때 대응하는 픽셀들이 유사한 텍스처 콘텐츠를 갖는다고 결정한다. 대응 관계 라벨러(508)는 대응하는 픽셀들을 "유사한 텍스처"로서 라벨링하고 대응하는 픽셀들의 좌표(예를 들면, x, y) 위치들과 함께 대응하는 픽셀들을 포함하는 소스 뷰들의 뷰 ID들을 대응 관계 리스트에 저장한다.
블록(1224)으로 돌아가서, 예시적인 대응 관계 라벨러(508)가 텍스처 콘텐츠의 차이가 임계값을 충족시키지 않는다고 결정하는 경우, 블록(1228)에서, 예시적인 대응 관계 라벨러(508)는 대응하는 픽셀들을 상이한 것으로서 라벨링한다. 대응 관계 라벨러(508)는 텍스처 콘텐츠의 차이가 임계값 초과일 때 2개의 대응하는 픽셀이 상이한 텍스처 콘텐츠를 갖는다고 결정한다. 일부 예들에서, 대응하는 픽셀들은 상이한 경면반사 정보, 상이한 일루미네이션/조명 정보, 상이한 카메라 설정들로 인한 색상 불일치들 등에 기초하여 상이한 텍스처 콘텐츠를 갖는 것으로 결정될 수 있다. 대응 관계 라벨러(508)는 대응하는 픽셀들을 "상이한 텍스처"로서 라벨링하고 대응하는 픽셀들의 좌표(예를 들면, x, y) 위치들과 함께 대응하는 픽셀들을 포함하는 소스 뷰들의 뷰 ID들을 대응 관계 리스트에 저장한다.
블록(1230)에서, 예시적인 대응 관계 라벨러(508)는 추가의 대응하는 픽셀들이 있는지를 결정한다. 예시적인 대응 관계 라벨러(508)가 추가의 대응하는 픽셀들이 있다고 결정하는 경우, 프로그램(1104)은 예시적인 대응 관계 라벨러(508)가 2개의 상이한 대응하는 픽셀 사이에서 텍스처 콘텐츠를 비교하는 블록(1220)으로 복귀한다. 블록(1230)으로 돌아가서, 예시적인 대응 관계 라벨러(508)가 추가의 대응하는 픽셀들이 없다고 결정하는 경우, 프로그램(1104)은 완료되고 도 11의 프로그램(1100)으로 복귀한다.
도 13은 도 5의 텍스처 기반 MIV 인코더(500)에 포함된 예시적인 대응 관계 프루너(510)(도 5)를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다. 도 13의 프로그램(1106)은 예시적인 대응 관계 프루너(510)가 기본 뷰의 프루닝 마스크에 대해 모든 픽셀들을 1로 설정하는 블록(1302)에서 실행을 시작한다. 대응 관계 프루너(510)는 미리 결정되거나 구성 가능하거나 등등 할 수 있는 주어진 기준들(예를 들면, 뷰들 사이의 중첩된 정보, 캡처 카메라들 사이의 거리 등)에 따라 프루닝 순서를 결정한다. 본 명세서에서 개시되는 예들에서, 기본 뷰들은 프루닝 동안 먼저 정렬된다. 예를 들어, (예를 들면, 하나 이상의 기준에 기초하여 선택되는) 기본 뷰들 중 제1 기본 뷰는 프루닝되지 않은 상태로 유지되고, 소스 뷰들(501)(도 5)에 포함된 임의의 다른 기본 뷰들 및 추가 뷰들은 프루닝될 수 있다.
블록(1304)에서, 예시적인 대응 관계 프루너(510)는 추가 뷰를 선택한다. 예를 들어, 대응 관계 프루너(510)는 소스 비디오들(501)로부터 추가 뷰를 선택한다. 블록(1306)에서, 예시적인 대응 관계 프루너(510)는 고유한 것으로서 라벨링된 뷰 픽셀(들)에 대응하는 픽셀 마스크의 픽셀(들)을 (예를 들면, 픽셀들이 프루닝되어서는 안 된다는 것을 나타내기 위해) 1로 설정한다. 블록(1308)에서, 예시적인 대응 관계 프루너(510)는 대응하는, 상이한 것으로서 라벨링된 뷰 픽셀(들)에 대응하는 픽셀 마스크의 픽셀(들)을 (예를 들면, 픽셀들이 프루닝되어서는 안 된다는 것을 나타내기 위해) 1로 설정한다. 대응 관계 프루너(510)는 다른 뷰들 각각에 대해 대응 관계 라벨러(508)에 의해 "고유한" 것으로 및 "대응하는, 상이한 텍스처"로서 라벨링된 픽셀들을 식별하고 해당 뷰들에 대한 대응하는 프루닝 마스크들 내의 픽셀들을 값 1로 설정한다. 일부 예들에서, 대체로 중첩되는 뷰들에 속하는 픽셀들이 프루닝되고 서로 멀리 떨어진 뷰들이 유지되도록, 대응 관계 프루너(510)는 "대응하는, 상이한 텍스처" 픽셀들에 대한 가중 방식을 설정하기로 선택할 수 있다. 예를 들어, 뷰들의 소스들(예를 들면, 카메라들) 사이의 거리가 임계값(예를 들면, 10 피트 이격, 20 피트 이격 등)을 충족시킬 때 뷰들은 서로 멀리 있는 것으로 간주될 수 있다.
블록(1310)에서, 예시적인 대응 관계 프루너(510)는 대응하는, 유사한 것으로서 라벨링된 현재 프루닝된 뷰에서의 픽셀이 2개의 이전에 프루닝된 뷰에 포함되는지를 결정한다. 대응 관계 프루너(510)는 다른 뷰들에 대해 대응 관계 리스트들을 탐색하고 다른 뷰들 각각에 대해 대응 관계 라벨러(508)에 의해 "대응하는, 유사한 텍스처"로서 라벨링된 픽셀들을 식별한다. 예시적인 대응 관계 프루너(510)가 대응하는, 유사한 것으로서 라벨링된 현재 프루닝된 뷰에서의 픽셀이 2개의 이전에 프루닝된 뷰에 포함된다고(예를 들면, 2개의 이전에 프루닝된 뷰에서의 픽셀이 1로 설정되어 있다)고 결정하는 경우, 블록(1312)에서, 예시적인 대응 관계 프루너(510)는 대응하는, 유사한 것으로서 라벨링된 픽셀을 (예를 들면, 픽셀들이 프루닝되어야 한다는 것을 나타내기 위해) 0으로 설정한다. 일부 예들에서, 대응 관계 리스트에 포함된 픽셀들 중 적어도 2개가 이전에 프루닝된 뷰에 속하는 경우, 대응 관계 프루너(510)는 연관된 프루닝 마스크 내의 픽셀들을 0으로 유지한다. 블록(1310)으로 돌아가서, 예시적인 대응 관계 프루너(510)가 대응하는, 유사한 것으로서 라벨링된 현재 프루닝된 뷰에서의 픽셀이 2개의 이전에 프루닝된 뷰에 포함되지 않는다고(예를 들면, 2개의 이전에 프루닝된 뷰 중 적어도 하나가 픽셀을 포함하지 않거나 2개의 이전에 프루닝된 뷰 중 적어도 하나에서의 픽셀이 0으로 설정되어 있다)고 결정하는 경우, 블록(1314)에서, 예시적인 대응 관계 프루너(510)는 대응하는, 유사한 것으로서 라벨링된 픽셀을 (예를 들면, 픽셀들이 프루닝되어서는 안 된다는 것을 나타내기 위해) 1로 설정한다. 일부 예들에서, "대응하는, 유사한 텍스처"로서 라벨링된 적어도 2개의 픽셀이 선택되고, 깊이 정보를 추론하기 위해 예시적인 디코더에 의해 사용될 연관된 프루닝 마스크에서 1로 설정된다.
블록(1316)에서, 예시적인 대응 관계 프루너(510)는 현재 프루닝된 뷰에 대응하는, 유사한 것으로서 라벨링된 추가 픽셀들이 있는지를 결정한다. 예시적인 대응 관계 프루너(510)가 현재 프루닝된 뷰에 대응하는, 유사한 것으로서 라벨링된 추가 픽셀들이 있다고 결정하는 경우, 프로그램(1106)은 예시적인 대응 관계 프루너(510)가 대응하는, 유사한 것으로서 라벨링된 현재 프루닝된 뷰에서의 픽셀이 2개의 이전에 프루닝된 뷰에 포함되는지를 결정하는 블록(1310)으로 돌아간다. 블록(1316)으로 돌아가서, 예시적인 대응 관계 프루너(510)가 현재 프루닝된 뷰에 대응하는, 유사한 것으로서 라벨링된 추가 픽셀들이 없다고 결정하는 경우, 블록(1318)에서, 예시적인 대응 관계 프루너(510)는 추가 뷰들이 있는지를 결정한다. 예시적인 대응 관계 프루너(510)가 추가 뷰들이 있다고 결정하는 경우, 프로그램(1106)은 예시적인 대응 관계 프루너(510)가 대응하는, 유사한 것으로서 라벨링된 현재 프루닝된 뷰에서의 픽셀이 2개의 이전에 프루닝된 뷰에 포함되는지를 결정하는 블록(1310)으로 돌아간다. 블록(1318)으로 돌아가서, 예시적인 대응 관계 프루너(510)가 추가 뷰들이 없다고 결정하는 경우, 프로그램(1106)은 완료되고 도 11의 프로그램(1100)으로 복귀한다.
도 14은 도 5의 텍스처 기반 MIV 인코더(500)에 포함된 예시적인 대응 관계 패치 패커(514)(도 5)를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다. 도 14의 프로그램(1110)은 예시적인 대응 관계 패치 패커(514)가 예시적인 대응 관계 프루너(510)(도 5)로부터 프루닝된 대응 관계 마스크들을 획득하는 블록(1402)에서 실행을 시작한다.
블록(1404)에서, 예시적인 대응 관계 패치 패커(514)는 프루닝된 대응 관계 마스크들에서의 인접한 픽셀들을 비교한다. 예를 들어, 대응 관계 패치 패커(514)는 프루닝된 대응 관계 마스크들에서의 인접한 픽셀들의 라벨들을 비교한다. 블록(1406)에서, 예시적인 대응 관계 패치 패커(514)는 인접한 픽셀들이 고유한 것으로서 라벨링되어 있는지를 결정한다. 예를 들어, 대응 관계 패치 패커(514)는 대응 관계를 갖지 않는 주어진 집계된 프루닝된 마스크에서 인접한 픽셀들을 식별한다(예를 들면, 인접한 픽셀들은 양쪽 모두 프루닝된 대응 관계 마스크에서"고유한" 것으로서 라벨링되어 있다). 예시적인 대응 관계 패치 패커(514)가 인접한 픽셀들이 고유한 것으로서 라벨링되어 있다고 결정하는 경우, 블록(1408)에서, 예시적인 대응 관계 패치 패커(514)는 대응 관계 리스트를 사용하지 않고 인접한 픽셀들을 하나의 패치로 함께 그룹화한다. 예를 들어, 대응 관계 패치 패커(514)는 대응 관계를 갖지 않는(예를 들면, 인접한 픽셀들 양쪽 모두가 "고유한" 것으로서 라벨링됨) 주어진 집계된 프루닝된 대응 관계 마스크에서의 인접한 픽셀들을 하나의 패치로 그룹화하고, 패치는 비어 있는 패치별 대응 관계 리스트와 연관된다.
블록(1406)으로 돌아가서, 예시적인 대응 관계 패치 패커(514)가 인접한 픽셀들이 고유한 것으로서 라벨링되어 있지 않다고 결정하는 경우, 블록(1410)에서, 예시적인 대응 관계 패치 패커(514)는 인접한 픽셀들이 대응하는 것으로서(유사한 것으로서 또는 상이한 것으로서) 라벨링되어 있는지를 결정한다. 예를 들어, 대응 관계 패치 패커(514)는 "대응하는, 유사한 텍스처" 또는 "대응하는, 상이한 텍스처"로서 라벨링되어 있는 주어진 집계된 프루닝된 마스크에서의 인접한 픽셀들을 식별한다. 예시적인 대응 관계 패치 패커(514)가 인접한 픽셀들이 대응하는 것으로서(유사한 것으로서 또는 상이한 것으로서) 라벨링되어 있다고 결정하는 경우, 블록(1412)에서, 예시적인 대응 관계 패치 패커(514)는 인접한 픽셀들을 제2 패치로 함께 그룹화한다. 블록(1410)으로 돌아가서, 예시적인 대응 관계 패치 패커(514)가 인접한 픽셀들이 대응하는 것으로서(유사한 것으로서 또는 상이한 것으로서) 라벨링되어 있지 않다고 결정하는 경우, 블록(1416)에서, 예시적인 대응 관계 패치 패커(514)는 프루닝된 대응 관계 마스크들에 추가 픽셀들이 있는지를 결정한다.
블록(1414)에서, 예시적인 대응 관계 패치 패커(514)는 대응하는 패치들을 식별해 주는 대응 관계 리스트로 제2 패치를 태깅한다. 예를 들어, 대응 관계 패치 패커(514)는 대응하는 패치들의 patch_ids를 나타내는 패치별 대응 관계 리스트로 주어진 집계된 프루닝된 대응 관계 마스크에서의 제2 패치를 태깅한다. 대응 관계 패치 패커(514)는 또한 모든 다른 집계된 프루닝된 대응 관계 마스크들 내의 연관된 픽셀들을 뷰마다 하나의 패치(예를 들면, 제2 패치)로 함께 그룹화하며, 이는 다수의 대응 관계 패치들을 결과한다.
블록(1416)에서, 예시적인 대응 관계 패치 패커(514)는 프루닝된 대응 관계 마스크들에 추가 픽셀들이 있는지를 결정한다. 예시적인 대응 관계 패치 패커(514)가 프루닝된 대응 관계 마스크들에 추가 픽셀들이 있다고 결정하는 경우, 프로그램(1110)은 예시적인 대응 관계 패치 패커(514)가 프루닝된 대응 관계 마스크들에서 상이한 인접한 픽셀들을 비교하는 블록(1404)으로 복귀한다. 블록(1416)으로 돌아가서, 예시적인 대응 관계 패치 패커(514)가 프루닝된 대응 관계 마스크들에 추가 픽셀들이 없다고 결정하는 경우, 프로그램(1110)은 완료되고 도 11의 프로그램(1100)으로 복귀한다.
도 15는 도 7의 텍스처 기반 MIV 디코더(700)를 구현하기 위해 실행될 수 있는 머신 판독 가능 명령어들을 나타내는 플로차트이다. 도 15의 프로그램(1500)은 예시적인 텍스처 기반 MIV 디코더(700)(도 7)가 인코딩된 데이터를 수신하는 블록(1502)에서 실행을 시작한다. 예를 들어, 텍스처 기반 MIV 디코더(700)는 예시적인 텍스처 기반 MIV 인코더(500)(도 5)에 의해 생성되는 예시적인 HEVC 비트스트림(540), 예시적인 HEVC 비트스트림(538), 및 예시적인 MIV 데이터 비트스트림(532)을 수신한다. 블록(1504)에서, 예시적인 텍스처 기반 MIV 디코더(700)는 인코딩된 데이터를 역다중화하고 디코딩한다. 예를 들어, 비디오 디코더(708)(도 7) 및 비디오 디코더(712)(도 7)는 텍스처 및 점유 데이터를 포함하는 디코딩된 아틀라스들을 생성하기 위해 인코딩된 아틀라스들을 디코딩한다. 일부 예들에서, HEVC 비트스트림(540)은 어트리뷰트(텍스처) 비디오 데이터에 관련된 패치 파라미터들을 포함한다. 그러한 파라미터들의 예들은 뷰들과 아틀라스들 사이의 패치들의 맵, 나중에 블록 대 패치 맵들을 검색하는 데 활용되는 중첩된 패치들을 나타내기 위한 패킹 순서 등을 포함한다. 비디오 디코더(708)는 디코딩된 텍스처 아틀라스들의 시퀀스(예를 들면, 디코딩된 텍스처 픽처들(710))를 생성한다. 일부 예들에서, HEVC 비트스트림(538)은 디코딩된 점유 비디오 데이터에 관련된 패치 파라미터들을 포함한다. 그러한 파라미터들의 예들은 뷰들과 아틀라스들 사이의 패치들의 맵, 나중에 블록 대 패치 맵들을 검색하는 데 활용되는 중첩된 패치들을 나타내기 위한 패킹 순서, 점유 맵 등을 포함한다. 비디오 디코더(712)는 점유 아틀라스들을 디코딩한다.
블록(1506)에서, 예시적인 MIV 디코더 및 파서(718)는 파라미터 리스트들을 결정한다. 예를 들어, MIV 디코더 및 파서(718)(도 7)는 MIV 데이터 비트스트림(532)을 수신한다. 예시적인 MIV 디코더 및 파서(718)는 예시적인 아틀라스 데이터(722)(도 7) 및 예시적인 V-PCC(Video-based Point Cloud Compression) 및 시점 파라미터 세트(724)(도 7)를 생성하기 위해 MIV 데이터 비트스트림(532)을 파싱한다. 예를 들어, MIV 디코더 및 파서(718)는 예시적인 패치 리스트, 카메라 파라미터 리스트 등에 대해 인코딩된 MIV 데이터 비트스트림(532)을 파싱한다. 블록(1508)에서, 예시적인 점유 언패커(714)(도 7)는 아틀라스 패치 점유 맵을 언패킹한다. 예를 들어, 점유 언패커(714)는 디코딩된 텍스처 픽처들(710)(도 7)의 텍스처 아틀라스들과 동일한 크기의 점유 맵들(716)(도 7)을 검색하기 위해 패킹 프로세스를 반대로 한다.
블록(1510)에서, 예시적인 MIV 디코더 및 파서(718)는 깊이 정보가 인코딩된 비트스트림들에 포함되어 있는지를 결정한다. 예를 들어, MIV 디코더 및 파서(718)는 깊이 정보가 인코딩된 비트스트림들(예를 들면, HEVC 비트스트림(540), HEVC 비트스트림(538), 및 MIV 데이터 비트스트림(532))에 포함되어 있는지를 나타내는 표시자(예를 들면, 플래그, 비트 등)를 아틀라스 데이터(722)(도 7)가 포함하는지를 결정한다. 예시적인 MIV 디코더 및 파서(718)가 깊이 정보가 포함되어 있다고 결정하는 경우, 블록(1514)에서, 예시적인 렌더러(730)는 뷰를 합성한다. 예를 들어, 합성기(736)(도 7)는 아틀라스들(텍스처 및 깊이), 점유 맵, 및/또는 파라미터들에 기초하여 장면을 합성한다. 블록(1514) 후에, 프로그램(1500)이 종료된다.
블록(1510)으로 돌아가서, 예시적인 MIV 디코더 및 파서(718)가 깊이 정보가 포함되어 있지 않다고 결정하는 경우, 블록(1512)에서, 예시적인 렌더러(730)는 대응 관계 패치들로부터 깊이 정보를 결정한다. 예를 들어, 깊이 추론기(734)는 텍스처 아틀라스들의 대응 관계 패치들을 사용하여 깊이 정보를 추론한다. 블록(1512) 후에, 프로그램(1500)은 예시적인 렌더러(730)가 뷰를 합성하는 블록(1514)으로 계속된다. 예를 들어, 합성기(736)는 텍스처 아틀라스들, 점유 맵, 추론된 깊이 정보, 및/또는 파라미터들에 기초하여 장면을 합성한다. 블록(1514) 후에, 프로그램(1500)이 종료된다.
도 16 및 도 17은 논의된 기술들, 인코더들(예를 들면, 도 1의 MIV 인코더(100), 도 5의 텍스처 기반 MIV 인코더(500) 등), 및 디코더들(예를 들면, 도 3의 MIV 디코더(300), 도 7의 텍스처 기반 MIV 디코더(700))을 구현하기 위한 예시적인 시스템들 및 디바이스들을 예시한다. 예를 들어, 본 명세서에서 논의되는 임의의 인코더(인코더 시스템), 디코더(디코더 시스템), 또는 비트스트림 추출기는 도 16에 예시된 시스템 및/또는 도 17에 구현된 디바이스를 통해 구현될 수 있다. 일부 예들에서, 논의된 기술들, 인코더들(예를 들면, 도 1의 MIV 인코더(100), 도 5의 텍스처 기반 MIV 인코더(500) 등), 및 디코더들(예를 들면, 도 3의 MIV 디코더(300), 도 7의 텍스처 기반 MIV 디코더(700))은 개인용 컴퓨터, 랩톱 컴퓨터, 태블릿, 패블릿, 스마트 폰, 디지털 카메라, 게이밍 콘솔, 웨어러블 디바이스, 디스플레이 디바이스, 올인원(all-in-one) 디바이스, 투인원(two-in-one) 디바이스 등과 같은 본 명세서에서 논의된 임의의 적합한 디바이스 또는 플랫폼을 통해 구현될 수 있다.
본 명세서에서 설명되는 시스템들의 다양한 컴포넌트들은 소프트웨어, 펌웨어, 및/또는 하드웨어 및/또는 이들의 임의의 조합으로 구현될 수 있다. 예를 들어, 본 명세서에서 논의되는 디바이스들 또는 시스템들의 다양한 컴포넌트들은, 예를 들어, 스마트 폰과 같은 컴퓨팅 시스템에서 발견될 수 있는 것과 같은 컴퓨팅 SoC(System-on-a-Chip)의 하드웨어에 의해, 적어도 부분적으로, 제공될 수 있다. 본 기술 분야의 통상의 기술자는 본 명세서에서 설명되는 시스템들이 대응하는 도면들에 묘사되지 않은 추가 컴포넌트들을 포함할 수 있음을 인식할 수 있다. 예를 들어, 본 명세서에서 논의되는 시스템들은 명확성을 위해 묘사되지 않은 추가 컴포넌트들을 포함할 수 있다.
본 명세서에서 논의되는 예시적인 프로세스들의 구현이 예시된 순서로 제시된 모든 동작들의 수행을 포함할 수 있지만, 본 개시내용은 이 점에서 제한되지 않으며, 다양한 예들에서, 본 명세서에서의 예시적인 프로세스들의 구현은 제시된 동작들의 서브세트만, 예시된 것과 상이한 순서로 수행되는 동작들, 또는 추가 동작들을 포함할 수 있다.
추가적으로, 본 명세서에서 논의되는 동작들 중 임의의 하나 이상의 동작은 하나 이상의 컴퓨터 프로그램 제품에 의해 제공되는 명령어들에 응답하여 수행될 수 있다. 그러한 프로그램 제품들은, 예를 들어, 프로세서에 의해 실행될 때, 본 명세서에서 설명되는 기능을 제공할 수 있는 명령어들을 제공하는 신호 전달 매체(signal bearing media)를 포함할 수 있다. 컴퓨터 프로그램 제품들은 임의의 형태의 하나 이상의 머신 판독 가능 매체로 제공될 수 있다. 따라서, 예를 들어, 하나 이상의 그래픽 프로세싱 유닛(들) 또는 프로세서 코어(들)를 포함하는 프로세서는 하나 이상의 머신 판독 가능 매체에 의해 프로세서에 전달되는 프로그램 코드 및/또는 명령어들 또는 명령어 세트들에 응답하여 본 명세서에서의 예시적인 프로세스들의 블록들 중 하나 이상의 블록을 수행할 수 있다. 일반적으로, 머신 판독 가능 매체는 본 명세서에서 설명되는 디바이스들 및/또는 시스템들 중 임의의 것으로 하여금 디바이스들 또는 시스템들의 적어도 부분들, 또는 본 명세서에서 논의되는 바와 같은 임의의 다른 모듈 또는 컴포넌트를 구현하게 할 수 있는 프로그램 코드 및/또는 명령어들 또는 명령어 세트들의 형태로 소프트웨어를 전달할 수 있다.
본 명세서에서 사용되는 바와 같이, 용어 "모듈"은 본 명세서에서 설명되는 기능을 제공하도록 구성된 소프트웨어 로직, 펌웨어 로직, 하드웨어 로직, 및/또는 회로의 임의의 조합을 지칭한다. 소프트웨어는 소프트웨어 패키지, 코드 및/또는 명령어 세트 또는 명령어들로서 구체화될 수 있으며, "하드웨어"는, 본 명세서에서 사용되는 바와 같이, 예를 들어, 단독으로 또는 임의의 조합으로, 고정 배선 회로, 프로그래밍 가능한 회로, 상태 머신 회로, 고정 기능 회로, 실행 유닛 회로, 및/또는 프로그래밍 가능한 회로에 의해 실행되는 명령어들을 저장하는 펌웨어를 포함할 수 있다. 모듈은, 집합적으로 또는 개별적으로, 더 큰 시스템의 일부를 형성하는 회로, 예를 들어, 집적 회로(IC), SoC(system on-chip) 등으로서 구현될 수 있다.
도 16은 본 개시내용의 적어도 일부 구현들에 따라 배열된, 예시적인 시스템(1600)의 예시적인 다이어그램이다. 일부 예들에서, 시스템(1600)은 모바일 디바이스 시스템일 수 있지만 시스템(1600)은 이러한 맥락으로 제한되지 않는다. 예를 들어, 시스템(1600)은 개인용 컴퓨터(PC), 랩톱 컴퓨터, 울트라 랩톱 컴퓨터, 태블릿, 터치 패드, 휴대용 컴퓨터, 핸드헬드 컴퓨터, 팜톱 컴퓨터, 개인 휴대 정보 단말(PDA), 셀룰러 전화, 겸용 셀룰러 전화/PDA, 텔레비전, 스마트 디바이스(예를 들면, 스마트 폰, 스마트 태블릿 또는 스마트 텔레비전), 모바일 인터넷 디바이스(MID), 메시징 디바이스, 데이터 통신 디바이스, 카메라들(예를 들면, 포인트 앤 슈트(point-and-shoot) 카메라들, 슈퍼 줌 카메라들, DSLR(digital single-lens reflex) 카메라들), 감시 카메라, 카메라를 포함하는 감시 시스템 등에 통합될 수 있다.
일부 예들에서, 시스템(1600)은 디스플레이(1620)에 결합된 플랫폼(1602)을 포함한다. 플랫폼(1602)은 콘텐츠 서비스들 디바이스(들)(1630) 또는 콘텐츠 전달 디바이스(들)(1640)와 같은 콘텐츠 디바이스 또는 이미지 센서들(1619)과 같은 다른 콘텐츠 소스로부터 콘텐츠를 수신할 수 있다. 예를 들어, 플랫폼(1602)은 이미지 센서들(1619) 또는 임의의 다른 콘텐츠 소스로부터 본 명세서에서 논의된 바와 같은 이미지 데이터를 수신할 수 있다. 하나 이상의 탐색(navigation) 특징부를 포함하는 탐색 제어기(1650)는, 예를 들어, 플랫폼(1602) 및/또는 디스플레이(1620)와 상호작용하는 데 사용될 수 있다. 이러한 컴포넌트들 각각은 아래에 더 상세히 설명된다.
일부 예들에서, 플랫폼(1602)은 칩세트(1605), 프로세서(1610), 메모리(1612), 안테나(1613), 저장소(1614), 그래픽 서브시스템(1615), 애플리케이션들(1616), 이미지 신호 프로세서(1617) 및/또는 무선기(1618)의 임의의 조합을 포함할 수 있다. 칩세트(1605)는 프로세서(1610), 메모리(1612), 저장소(1614), 그래픽 서브시스템(1615), 애플리케이션들(1616), 이미지 신호 프로세서(1617) 및/또는 무선기(1618) 간의 상호통신을 제공할 수 있다. 예를 들어, 칩세트(1605)는 저장소(1614)와의 상호통신을 제공할 수 있는 저장소 어댑터(도시되지 않음)를 포함할 수 있다.
프로세서(1610)는 CISC(Complex Instruction Set Computer) 또는 RISC(Reduced Instruction Set Computer) 프로세서들, x86 명령어 세트 호환 프로세서들, 멀티코어, 또는 임의의 다른 마이크로프로세서 또는 중앙 프로세싱 유닛(CPU)으로서 구현될 수 있다. 일부 예들에서, 프로세서(1610)는 듀얼 코어 프로세서(들), 듀얼 코어 모바일 프로세서(들) 등일 수 있다.
메모리(1612)는 RAM(Random Access Memory), DRAM(Dynamic Random Access Memory) 또는 SRAM(Static RAM)과 같은, 그러나 이에 제한되지는 않는 휘발성 메모리 디바이스로서 구현될 수 있다.
저장소(1614)는 자기 디스크 드라이브, 광학 디스크 드라이브, 테이프 드라이브, 내부 저장 디바이스, 부착형 저장 디바이스, 플래시 메모리, 배터리 백업 SDRAM(동기 DRAM), 및/또는 네트워크 액세스 가능한 저장 디바이스와 같은, 그러나 이에 제한되지는 않는 비휘발성 저장 디바이스로서 구현될 수 있다. 일부 예들에서, 저장소(1614)는, 예를 들어, 다수의 하드 드라이브들이 포함될 때 귀중한 디지털 미디어에 대한 저장 성능 강화 보호(storage performance enhanced protection)를 증대시키는 기술을 포함할 수 있다.
이미지 신호 프로세서(1617)는 이미지 프로세싱에 사용되는 특수 디지털 신호 프로세서 등으로서 구현될 수 있다. 일부 예들에서, 이미지 신호 프로세서(1617)는 단일 명령어 다중 데이터(single instruction multiple data) 또는 다중 명령어 다중 데이터(multiple instruction multiple data) 아키텍처 등에 기초하여 구현될 수 있다. 일부 예들에서, 이미지 신호 프로세서(1617)는 미디어 프로세서라고 할 수 있다. 본 명세서에서 논의되는 바와 같이, 이미지 신호 프로세서(1617)는 시스템 온 칩 아키텍처에 기초하여 및/또는 멀티코어 아키텍처에 기초하여 구현될 수 있다.
그래픽 서브시스템(1615)은 디스플레이하기 위한 스틸(still) 또는 비디오와 같은 이미지들의 프로세싱을 수행할 수 있다. 그래픽 서브시스템(1615)은, 예를 들어, 그래픽 프로세싱 유닛(GPU) 또는 비주얼 프로세싱 유닛(VPU)일 수 있다. 아날로그 또는 디지털 인터페이스는 그래픽 서브시스템(1615)과 디스플레이(1620)를 통신 가능하게 결합시키는 데 사용될 수 있다. 예를 들어, 인터페이스는 고화질 멀티미디어 인터페이스, DisplayPort, 무선 HDMI 및/또는 무선 HD 호환 기술들 중 임의의 것일 수 있다. 그래픽 서브시스템(1615)은 프로세서(1610) 또는 칩세트(1605)에 통합될 수 있다. 일부 구현들에서, 그래픽 서브시스템(1615)은 칩세트(1605)에 통신 가능하게 결합된 독립형 디바이스일 수 있다.
본 명세서에서 설명되는 그래픽 및/또는 비디오 프로세싱 기술들은 다양한 하드웨어 아키텍처들로 구현될 수 있다. 예를 들어, 그래픽 및/또는 비디오 기능은 칩세트 내에 통합될 수 있다. 대안적으로, 개별 그래픽 및/또는 비디오 프로세서가 사용될 수 있다. 또 다른 구현으로서, 그래픽 및/또는 비디오 기능들은 멀티코어 프로세서를 포함하는 범용 프로세서에 의해 제공될 수 있다. 추가 실시예들에서, 기능들은 소비자 전자 디바이스에서 구현될 수 있다.
무선기(1618)는 다양한 적합한 무선 통신 기술들을 사용하여 신호들을 전송 및 수신할 수 있는 하나 이상의 무선기를 포함할 수 있다. 그러한 기술들은 하나 이상의 무선 네트워크를 통한 통신을 수반할 수 있다. 예시적인 무선 네트워크들은 무선 로컬 영역 네트워크들(WLAN들), 무선 개인 영역 네트워크들(WPAN들), 무선 대도시 영역 네트워트들(WMAN들), 셀룰러 네트워크들, 및 위성 네트워크들을 포함한다(그러나 이에 제한되지 않는다). 그러한 네트워크들을 통한 통신에서, 무선기(1618)는 임의의 버전에서 하나 이상의 적용 가능한 표준에 따라 작동할 수 있다.
일부 예들에서, 디스플레이(1620)는 임의의 텔레비전 유형 모니터 또는 디스플레이를 포함할 수 있다. 디스플레이(1620)는, 예를 들어, 컴퓨터 디스플레이 스크린, 터치 스크린 디스플레이, 비디오 모니터, 텔레비전과 같은 디바이스, 및/또는 텔레비전을 포함할 수 있다. 디스플레이(1620)는 디지털 및/또는 아날로그일 수 있다. 일부 예들에서, 디스플레이(1620)는 홀로그래픽 디스플레이일 수 있다. 또한, 디스플레이(1620)는 시각적 투영(visual projection)을 수용할 수 있는 투명한 표면일 수 있다. 그러한 투영들은 다양한 형태들의 정보, 이미지들, 및/또는 객체들을 전달할 수 있다. 예를 들어, 그러한 투영들은 모바일 증강 현실(MAR) 응용에 대한 시각적 오버레이(visual overlay)일 수 있다. 하나 이상의 소프트웨어 애플리케이션(1616)의 제어 하에서, 플랫폼(1602)은 디스플레이(1620) 상에 사용자 인터페이스(1622)를 디스플레이할 수 있다.
일부 예들에서, 콘텐츠 서비스들 디바이스(들)(1630)는 임의의 국내, 국제 및/또는 독립 서비스에 의해 호스팅될 수 있고 따라서, 예를 들어, 인터넷을 통해 플랫폼(1602)에 액세스 가능할 수 있다. 콘텐츠 서비스들 디바이스(들)(1630)는 플랫폼(1602) 및/또는 디스플레이(1620)에 결합될 수 있다. 플랫폼(1602) 및/또는 콘텐츠 서비스들 디바이스(들)(1630)는 미디어 정보를 네트워크(1660)로 및 네트워크(1660)로부터 통신(예를 들면, 송신 및/또는 수신)하기 위해 네트워크(1660)에 결합될 수 있다. 콘텐츠 전달 디바이스(들)(1640)는 또한 플랫폼(1602) 및/또는 디스플레이(1620)에 결합될 수 있다.
이미지 센서들(1619)은 장면에 기초하여 이미지 데이터를 제공할 수 있는 임의의 적합한 이미지 센서들을 포함할 수 있다. 예를 들어, 이미지 센서들(1619)은 반도체 CCD(charge coupled device) 기반 센서, CMOS(complimentary metal-oxide-semiconductor) 기반 센서, NMOS(N-type metal-oxide-semiconductor) 기반 센서 등을 포함할 수 있다. 예를 들어, 이미지 센서들(1619)은 이미지 데이터를 생성하기 위해 장면의 정보를 검출할 수 있는 임의의 디바이스를 포함할 수 있다.
일부 예들에서, 콘텐츠 서비스들 디바이스(들)(1630)는, 네트워크(1660)를 통해 또는 직접적으로, 디지털 정보 및/또는 콘텐츠를 전달할 수 있는 케이블 텔레비전 박스, 개인용 컴퓨터, 네트워크, 전화, 인터넷 가능 디바이스들 또는 기기, 및 콘텐츠 제공자들과 플랫폼(1602) 및/디스플레이(1620) 사이에서 단방향으로 또는 양방향으로 콘텐츠를 통신할 수 있는 임의의 다른 유사한 디바이스를 포함할 수 있다. 콘텐츠가 네트워크(1660)를 통해 콘텐츠 제공자 및 시스템(1600) 내의 컴포넌트들 중 임의의 것으로 및 그로부터 단방향으로 및/또는 양방향으로 통신될 수 있다는 것이 이해될 것이다. 콘텐츠의 예들은, 예를 들어, 비디오, 음악, 의료 및 게이밍 정보 등을 포함하는 임의의 미디어 정보를 포함할 수 있다.
콘텐츠 서비스들 디바이스(들)(1630)는 미디어 정보, 디지털 정보, 및/또는 다른 콘텐츠를 포함하는 케이블 텔레비전 프로그래밍과 같은 콘텐츠를 수신할 수 있다. 콘텐츠 제공자들의 예들은 임의의 케이블 또는 위성 텔레비전 또는 라디오 또는 인터넷 콘텐츠 제공자들을 포함할 수 있다. 제공된 예들은 어떤 식으로든 본 개시내용에 따른 구현들을 제한하는 것으로 의도되지 않는다.
일부 예들에서, 플랫폼(1602)은 하나 이상의 탐색 특징부를 갖는 탐색 제어기(1650)로부터 제어 신호들을 수신할 수 있다. 탐색 제어기(1650)의 탐색 특징부들은, 예를 들어, 사용자 인터페이스(1622)와 상호작용하는 데 사용될 수 있다. 다양한 실시예들에서, 탐색 제어기(1650)는 사용자가 공간적(예를 들면, 연속적인 다차원) 데이터를 컴퓨터에 입력할 수 있게 하는 컴퓨터 하드웨어 컴포넌트(구체적으로, 휴먼 인터페이스 디바이스)일 수 있는 포인팅 디바이스일 수 있다. 그래픽 사용자 인터페이스들(GUI), 및 텔레비전들 및 모니터들과 같은 많은 시스템들은 사용자가 신체 제스처들을 사용하여 컴퓨터 또는 텔레비전을 제어하고 그에 데이터를 제공할 수 있게 한다.
탐색 제어기(1650)의 탐색 특징부들의 움직임들은 포인터, 커서, 포커스 링(focus ring), 또는 디스플레이 상에 디스플레이되는 다른 시각적 표시자들의 움직임들에 의해 디스플레이(예를 들면, 디스플레이(1620)) 상에 재현(replicate)될 수 있다. 예를 들어, 소프트웨어 애플리케이션들(1616)의 제어 하에서, 탐색 제어기(1650) 상에 위치하는 탐색 특징부들은, 예를 들어, 사용자 인터페이스(1622) 상에 디스플레이되는 가상 탐색 특징부들에 매핑될 수 있다. 다양한 실시예들에서, 탐색 제어기(1650)는 별도의 컴포넌트가 아닐 수 있고 플랫폼(1602) 및/또는 디스플레이(1620)에 통합될 수 있다. 그렇지만, 본 개시내용은 본 명세서에 도시되거나 설명되는 요소들로 또는 문맥으로 제한되지 않는다.
일부 예들에서, 드라이버들(도시되지 않음)은, 예를 들어, 인에이블될 때, 초기 부팅 후에 사용자들이 버튼을 터치하여 텔레비전과 같은 플랫폼(1602)을 즉시 켜고 끌 수 있도록 하는 기술을 포함할 수 있다. 프로그램 로직은 플랫폼이 "꺼져" 있을 때에도 플랫폼(1602)이 콘텐츠를 미디어 어댑터들 또는 다른 콘텐츠 서비스들 디바이스(들)(1630) 또는 콘텐츠 전달 디바이스(들)(1640)로 스트리밍하도록 할 수 있다. 추가적으로, 칩세트(1605)는, 예를 들어, 5.1 서라운드 사운드 오디오 및/또는 고화질 7.1 서라운드 사운드 오디오를 위한 하드웨어 및/또는 소프트웨어 지원을 포함할 수 있다. 드라이버들은 통합 그래픽 플랫폼들을 위한 그래픽 드라이버를 포함할 수 있다. 다양한 실시예들에서, 그래픽 드라이버는 PCI(peripheral component interconnect) Express 그래픽 카드를 포함할 수 있다.
일부 예들에서, 시스템(1600)에 도시된 컴포넌트들 중 임의의 하나 이상이 통합될 수 있다. 예를 들어, 플랫폼(1602)과 콘텐츠 서비스들 디바이스(들)(1630)가 통합될 수 있거나, 플랫폼(1602)과 콘텐츠 전달 디바이스(들)(1640)가 통합될 수 있거나, 또는 플랫폼(1602), 콘텐츠 서비스들 디바이스(들)(1630), 및 콘텐츠 전달 디바이스(들)(1640)가, 예를 들어, 통합될 수 있다. 다양한 실시예들에서, 플랫폼(1602)과 디스플레이(1620)는 통합된 유닛일 수 있다. 예를 들어, 디스플레이(1620)와 콘텐츠 서비스들 디바이스(들)(1630)가 통합될 수 있거나, 또는 디스플레이(1620)와 콘텐츠 전달 디바이스(들)(1640)가 통합될 수 있다. 이들 예는 본 개시내용을 제한하는 것으로 의도되지 않는다.
다양한 실시예들에서, 시스템(1600)은 무선 시스템, 유선 시스템, 또는 이 둘의 조합으로서 구현될 수 있다. 무선 시스템으로서 구현될 때, 시스템(1600)은, 하나 이상의 안테나, 송신기, 수신기, 트랜시버, 증폭기, 필터, 제어 로직 등과 같은, 무선 공유 매체를 통해 통신하기에 적합한 컴포넌트들 및 인터페이스들을 포함할 수 있다. 무선 공유 매체의 예는, RF 스펙트럼 등과 같은, 무선 스펙트럼의 부분들을 포함할 수 있다. 유선 시스템으로서 구현될 때, 시스템(1600)은, 입출력(I/O) 어댑터들, I/O 어댑터를 대응하는 유선 통신 매체와 연결시키는 물리적 커넥터들, 네트워크 인터페이스 카드(NIC), 디스크 제어기, 비디오 제어기, 오디오 제어기 등과 같은, 유선 통신 매체를 통해 통신하기에 적합한 컴포넌트들 및 인터페이스들을 포함할 수 있다. 유선 통신 매체의 예들은 와이어, 케이블, 금속 리드들, 인쇄 회로 기판(PCB), 백플레인, 스위치 패브릭, 반도체 재료, 연선 와이어(twisted-pair wire), 동축 케이블, 광섬유 등을 포함할 수 있다.
플랫폼(1602)은 정보를 통신하기 위해 하나 이상의 논리적 또는 물리적 채널을 설정할 수 있다. 정보는 미디어 정보 및 제어 정보를 포함할 수 있다. 미디어 정보는 사용자를 위해 의도된 콘텐츠를 나타내는 임의의 데이터를 지칭할 수 있다. 콘텐츠의 예들은, 예를 들어, 음성 대화, 화상 회의, 스트리밍 비디오, 전자 메일("이메일") 메시지, 음성 메일 메시지, 영숫자 심벌들, 그래픽, 이미지, 비디오, 텍스트 등으로부터의 데이터를 포함할 수 있다. 음성 대화로부터의 데이터는, 예를 들어, 음성 정보, 묵음 기간, 배경 소음, 통신 소음(comfort noise), 톤 등일 수 있다. 제어 정보는 자동화 시스템을 위해 의도된 커맨드들, 명령어들 또는 제어 단어들을 나타내는 임의의 데이터를 지칭할 수 있다. 예를 들어, 제어 정보는 시스템을 통해 미디어 정보를 라우팅하는 데 사용되거나, 노드에 미리 결정된 방식으로 미디어 정보를 프로세싱하도록 지시하는 데 사용될 수 있다. 그렇지만, 실시예들은 도 16에 도시되거나 설명된 요소들 또는 문맥으로 제한되지 않는다.
위에서 설명된 바와 같이, 시스템(1600)은 다양한 물리적 스타일들 또는 폼 팩터들로 구체화될 수 있다. 도 17은 본 개시내용의 적어도 일부 구현들에 따라 배열된, 예시적인 소형 폼 팩터 디바이스(1700)를 예시한다. 일부 예들에서, 시스템(1600)은 디바이스(1700)를 통해 구현될 수 있다. 다른 예들에서, 본 명세서에서 논의된 다른 시스템들, 컴포넌트들, 또는 모듈들 또는 그의 부분들이 디바이스(1700)를 통해 구현될 수 있다. 다양한 실시예들에서, 예를 들어, 디바이스(1700)는 무선 능력들을 갖는 모바일 컴퓨팅 디바이스로서 구현될 수 있다. 모바일 컴퓨팅 디바이스는, 예를 들어, 하나 이상의 배터리와 같은, 모바일 전원 또는 전력 공급 장치 및 프로세싱 시스템을 갖는 임의의 디바이스를 지칭할 수 있다.
모바일 컴퓨팅 디바이스의 예들은 개인용 컴퓨터(PC), 랩톱 컴퓨터, 울트라 랩톱 컴퓨터, 태블릿, 터치 패드, 휴대용 컴퓨터, 핸드헬드 컴퓨터, 팜톱 컴퓨터, 개인 휴대 정보 단말(PDA), 셀룰러 전화, 겸용 셀룰러 전화/PDA, 스마트 디바이스(예를 들면, 스마트폰, 스마트 태블릿 또는 스마트 모바일 텔레비전), 모바일 인터넷 디바이스(MID), 메시징 디바이스, 데이터 통신 디바이스, 카메라들(예를 들면, 포인트 앤 슈트 카메라들, 슈퍼 줌 카메라들, DSLR(digital single-lens reflex) 카메라들) 등을 포함할 수 있다.
모바일 컴퓨팅 디바이스의 예들은 또한 자동차 또는 로봇에 의해 구현되거나 사람이 착용하도록 배열된 컴퓨터들, 예컨대, 손목 컴퓨터, 손가락 컴퓨터, 반지 컴퓨터, 안경 컴퓨터, 벨트 클립 컴퓨터, 팔걸이 컴퓨터, 신발 컴퓨터, 의류 컴퓨터 및 다른 웨어러블 컴퓨터를 포함할 수 있다. 다양한 실시예들에서, 예를 들어, 모바일 컴퓨팅 디바이스는 컴퓨터 애플리케이션들을 실행할 수 있는 것은 물론 음성 통신 및/또는 데이터 통신을 할 수 있는 스마트폰으로서 구현될 수 있다. 일부 실시예들이 예로서 스마트폰으로서 구현되는 모바일 컴퓨팅 디바이스를 사용하여 설명될 수 있지만, 다른 실시예들이 다른 무선 모바일 컴퓨팅 디바이스들도 사용하여 구현될 수 있다는 것이 이해될 수 있다. 실시예들이 이와 관련하여 제한되지 않는다.
도 17에 도시된 바와 같이, 디바이스(1700)는 전면(1701) 및 후면(1702)을 갖는 하우징을 포함할 수 있다. 디바이스(1700)는 디스플레이(1704), 입출력(I/O) 디바이스(1706), 컬러 카메라(1721), 컬러 카메라(1722), 및 통합 안테나(1708)를 포함한다. 일부 실시예들에서, 컬러 카메라(1721) 및 컬러 카메라(1722)는 본 명세서에서 논의된 바와 같이 평면 이미지들을 획득한다. 일부 실시예들에서, 디바이스(1700)는 컬러 카메라(1721 및 1722)를 포함하지 않고 디바이스(1700)는 다른 디바이스로부터 입력 이미지 데이터(예를 들면, 본 명세서에서 논의된 임의의 입력 이미지 데이터)를 획득한다. 디바이스(1700)는 또한 탐색 특징부들(1712)을 포함할 수 있다. I/O 디바이스(1706)는 모바일 컴퓨팅 디바이스에 정보를 입력하기 위한 임의의 적합한 I/O 디바이스를 포함할 수 있다. I/O 디바이스(1706)에 대한 예들은 영숫자 키보드, 숫자 키패드, 터치 패드, 입력 키들, 버튼들, 스위치들, 마이크로폰들, 스피커들, 음성 인식 디바이스 및 소프트웨어 등을 포함할 수 있다. 정보는 또한 마이크로폰(도시되지 않음)을 통해 디바이스(1700)에 입력될 수 있거나 음성 인식 디바이스에 의해 디지털화될 수 있다. 도시된 바와 같이, 디바이스(1700)는 컬러 카메라들(1721, 1722), 및 디바이스(1700)의 후면(1702)(또는 다른 곳)에 통합된 플래시(1710)를 포함할 수 있다. 다른 예들에서, 컬러 카메라들(1721, 1722) 및 플래시(1710)는 디바이스(1700)의 전면(1701)에 통합될 수 있거나 전면 카메라 세트 및 후면 카메라 세트 양쪽 모두가 제공될 수 있다. 컬러 카메라들(1721, 1722) 및 플래시(1710)는 디스플레이(1704)로 출력되고/되거나, 예를 들어, 안테나(1708)를 통해 디바이스(1700)로부터 원격으로 통신되는 이미지 또는 스트리밍 비디오로 프로세싱될 수 있는 IR 텍스처 보정을 갖는 컬러 이미지 데이터를 생성하는 카메라 모듈의 컴포넌트들일 수 있다.
예시적인 실시예들은 하드웨어 요소들, 소프트웨어 요소들, 또는 이 둘의 조합을 사용하여 구현될 수 있다. 하드웨어 요소들의 예들은 프로세서, 마이크로프로세서, 회로, 회로 요소(예를 들어, 트랜지스터, 저항기, 커패시터, 인덕터 등), 집적 회로, ASIC(application specific integrated circuit), PLD(programmable logic device), DSP(digital signal processor), FPGA(field programmable gate array), 로직 게이트, 레지스터, 반도체 디바이스, 칩, 마이크로칩, 칩세트 등을 포함할 수 있다. 소프트웨어의 예들은 소프트웨어 컴포넌트, 프로그램, 애플리케이션, 컴퓨터 프로그램, 애플리케이션 프로그램, 시스템 프로그램, 머신 프로그램, 운영 체제 소프트웨어, 미들웨어, 펌웨어, 소프트웨어 모듈, 루틴, 서브루틴, 함수, 메소드, 프로시저, 소프트웨어 인터페이스, API(application program interface), 명령어 세트, 컴퓨팅 코드, 컴퓨터 코드, 코드 세그먼트, 컴퓨터 코드 세그먼트, 워드, 값, 심벌, 또는 이들의 임의의 조합을 포함할 수 있다. 일 실시예가 하드웨어 요소들 및/또는 소프트웨어 요소들을 사용하여 구현되는지 여부를 결정하는 것은, 원하는 계산 속도, 전력 레벨, 열 허용오차, 프로세싱 사이클 버짓, 입력 데이터 속도, 출력 데이터 속도, 메모리 자원, 데이터 버스 속도 및 다른 설계 또는 성능 제약들과 같은, 임의의 수의 인자들에 따라 달라질 수 있다.
일부 예들에서, 적어도 하나의 실시예의 하나 이상의 양상은, 머신에 의해 판독될 때, 머신으로 하여금 본 명세서에서 설명된 기술들을 수행하는 로직을 제조하게 하는, 프로세서 내의 다양한 로직을 표현하는 머신 판독 가능 매체에 저장된 대표적인 명령어들에 의해 구현될 수 있다. IP 코어라고 알려진, 그러한 표현은 유형적(tangible) 머신 판독 가능 매체에 저장될 수 있고, 로직 또는 프로세서를 실제로 제조하는 제조 머신들에 로딩하기 위해, 다양한 고객들 또는 제조 시설들에 공급될 수 있다.
도 18은 도 5의 텍스처 기반 MIV 인코더(500)를 구현하기 위해 도 11 내지 도 14의 명령어들을 실행하도록 구성된 예시적인 프로세서 플랫폼(1800)의 블록 다이어그램이다. 프로세서 플랫폼(1800)은, 예를 들어, 서버, 개인용 컴퓨터, 워크스테이션, 자가 학습 머신(예를 들면, 신경 네트워크), 모바일 디바이스(예를 들면, 셀 폰, 스마트 폰, iPadTM와 같은 태블릿), 개인 휴대 정보 단말(PDA), 인터넷 기기, DVD 플레이어, CD 플레이어, 디지털 비디오 레코더, 블루레이 플레이어, 게이밍 콘솔, 개인 비디오 레코더, 셋톱 박스, 헤드셋 또는 다른 웨어러블 디바이스, 또는 임의의 다른 유형의 컴퓨팅 디바이스일 수 있다.
예시된 예의 프로세서 플랫폼(1800)은 프로세서(1812)를 포함한다. 예시된 예의 프로세서(1812)는 하드웨어이다. 예를 들어, 프로세서(1812)는 임의의 원하는 패밀리 또는 제조업체로부터의 하나 이상의 집적 회로, 로직 회로, 마이크로프로세서, GPU, DSP, 또는 제어기에 의해 구현될 수 있다. 하드웨어 프로세서는 반도체 기반(예를 들면, 실리콘 기반) 디바이스일 수 있다. 이 예에서, 프로세서는 뷰 최적화기(502), 예시적인 깊이 추론기(504), 예시적인 대응 관계 아틀라스 구성기(506), 예시적인 대응 관계 라벨러(508), 예시적인 대응 관계 프루너(510), 예시적인 마스크 집계기(512), 예시적인 대응 관계 패치 패커(514), 예시적인 아틀라스 생성기(516), 예시적인 점유 패커(524), 예시적인 비디오 인코더(534), 및 예시적인 비디오 인코더(536)를 구현한다.
예시된 예의 프로세서(1812)는 로컬 메모리(1813)(예를 들면, 캐시)를 포함한다. 예시된 예의 프로세서(1812)는 버스(1818)를 통해 휘발성 메모리(1814) 및 비휘발성 메모리(1816)를 포함하는 메인 메모리와 통신한다. 휘발성 메모리(1814)는 SDRAM(Synchronous Dynamic Random Access Memory), DRAM(Dynamic Random Access Memory), RDRAM®(RAMBUS® Dynamic Random Access Memory), 및/또는 임의의 다른 유형의 랜덤 액세스 메모리 디바이스에 의해 구현될 수 있다. 비휘발성 메모리(1816)는 플래시 메모리 및/또는 임의의 다른 원하는 유형의 메모리 디바이스에 의해 구현될 수 있다. 메인 메모리(1814, 1816)에 대한 액세스는 메모리 제어기에 의해 제어된다.
예시된 예의 프로세서 플랫폼(1800)은 인터페이스 회로(1820)를 또한 포함한다. 인터페이스 회로(1820)는, 이더넷 인터페이스, USB(universal serial bus), 블루투스® 인터페이스, NFC(near field communication) 인터페이스, 및/또는 PCI express 인터페이스와 같은, 임의의 유형의 인터페이스 표준에 의해 구현될 수 있다.
예시된 예에서, 하나 이상의 입력 디바이스(1822)가 인터페이스 회로(1820)에 연결된다. 입력 디바이스(들)(1822)는 사용자가 데이터 및/또는 커맨드들을 프로세서(1812)에 입력할 수 있게 한다. 입력 디바이스(들)는, 예를 들어, 오디오 센서, 마이크로폰, 카메라(스틸 또는 비디오), 키보드, 버튼, 마우스, 터치스크린, 트랙 패드, 트랙볼, 아이소포인트(isopoint) 및/또는 음성 인식 시스템에 의해 구현될 수 있다.
하나 이상의 출력 디바이스(1824)가 또한 예시된 예의 인터페이스 회로(1820)에 연결된다. 출력 디바이스들(1824)은, 예를 들어, 디스플레이 디바이스들(예를 들면, LED(light emitting diode), OLED(organic light emitting diode), LCD(liquid crystal display), CRT(cathode ray tube) 디스플레이, IPS(in-place switching) 디스플레이, 터치스크린 등), 촉각 출력 디바이스, 프린터 및/또는 스피커에 의해 구현될 수 있다. 예시된 예의 인터페이스 회로(1820)는, 따라서, 전형적으로 그래픽 드라이버 카드, 그래픽 드라이버 칩 및/또는 그래픽 드라이버 프로세서를 포함한다.
예시된 예의 인터페이스 회로(1820)는 네트워크(1826)를 통한 외부 머신들(예를 들면, 임의의 종류의 컴퓨팅 디바이스들)과의 데이터 교환을 용이하게 하기 위해 송신기, 수신기, 트랜시버, 모뎀, 주택용 게이트웨이, 무선 액세스 포인트, 및/또는 네트워크 인터페이스와 같은 통신 디바이스를 또한 포함한다. 통신은, 예를 들어, 이더넷 연결, DSL(digital subscriber line) 연결, 전화선 연결, 동축 케이블 시스템, 위성 시스템, 가시선 무선 시스템, 셀룰러 전화 시스템 등을 통할 수 있다.
예시된 예의 프로세서 플랫폼(1800)은 소프트웨어 및/또는 데이터를 저장하기 위한 하나 이상의 대용량 저장 디바이스(1828)를 또한 포함한다. 그러한 대용량 저장 디바이스들(1828)의 예들은 플로피 디스크 드라이브, 하드 드라이브 디스크, 콤팩트 디스크 드라이브, 블루레이 디스크 드라이브, RAID(redundant array of independent disks) 시스템, 및 DVD(digital versatile disk) 드라이브를 포함한다.
도 11 내지 도 14의 머신 실행 가능 명령어들(1832)은 대용량 저장 디바이스(1828)에, 휘발성 메모리(1814)에, 비휘발성 메모리(1816)에, 및/또는 CD 또는 DVD와 같은 이동식 비일시적 컴퓨터 판독 가능 저장 매체에 저장될 수 있다.
도 19는 도 7의 텍스처 기반 MIV 디코더(700)를 구현하기 위해 도 15의 명령어들을 실행하도록 구성된 예시적인 프로세서 플랫폼(1900)의 블록 다이어그램이다. 프로세서 플랫폼(1900)은, 예를 들어, 서버, 개인용 컴퓨터, 워크스테이션, 자가 학습 머신(예를 들면, 신경 네트워크), 모바일 디바이스(예를 들면, 셀 폰, 스마트 폰, iPadTM와 같은 태블릿), 개인 휴대 정보 단말(PDA), 인터넷 기기, DVD 플레이어, CD 플레이어, 디지털 비디오 레코더, 블루레이 플레이어, 게이밍 콘솔, 개인 비디오 레코더, 셋톱 박스, 헤드셋 또는 다른 웨어러블 디바이스, 또는 임의의 다른 유형의 컴퓨팅 디바이스일 수 있다.
예시된 예의 프로세서 플랫폼(1900)은 프로세서(1912)를 포함한다. 예시된 예의 프로세서(1912)는 하드웨어이다. 예를 들어, 프로세서(1912)는 임의의 원하는 패밀리 또는 제조업체로부터의 하나 이상의 집적 회로, 로직 회로, 마이크로프로세서, GPU, DSP, 또는 제어기에 의해 구현될 수 있다. 하드웨어 프로세서는 반도체 기반(예를 들면, 실리콘 기반) 디바이스일 수 있다. 이 예에서, 프로세서는 비디오 디코더(708), 예시적인 비디오 디코더(712), 예시적인 점유 언패커(714), 예시적인 MIV 디코더 및 파서(718), 예시적인 블록 대 패치 맵 디코더(720), 예시적인 컬러(728), 예시적인 렌더러(730), 예시적인 제어기(732), 예시적인 깊이 추론기(734), 예시적인 합성기(736), 및 예시적인 인페인터(738)를 구현한다.
예시된 예의 프로세서(1912)는 로컬 메모리(1913)(예를 들면, 캐시)를 포함한다. 예시된 예의 프로세서(1912)는 버스(1918)를 통해 휘발성 메모리(1914) 및 비휘발성 메모리(1916)를 포함하는 메인 메모리와 통신한다. 휘발성 메모리(1914)는 SDRAM(Synchronous Dynamic Random Access Memory), DRAM(Dynamic Random Access Memory), RDRAM®(RAMBUS® Dynamic Random Access Memory), 및/또는 임의의 다른 유형의 랜덤 액세스 메모리 디바이스에 의해 구현될 수 있다. 비휘발성 메모리(1916)는 플래시 메모리 및/또는 임의의 다른 원하는 유형의 메모리 디바이스에 의해 구현될 수 있다. 메인 메모리(1914, 1916)에 대한 액세스는 메모리 제어기에 의해 제어된다.
예시된 예의 프로세서 플랫폼(1900)은 인터페이스 회로(1920)를 또한 포함한다. 인터페이스 회로(1920)는, 이더넷 인터페이스, USB(universal serial bus), 블루투스® 인터페이스, NFC(near field communication) 인터페이스, 및/또는 PCI express 인터페이스와 같은, 임의의 유형의 인터페이스 표준에 의해 구현될 수 있다.
예시된 예에서, 하나 이상의 입력 디바이스(1922)가 인터페이스 회로(1920)에 연결된다. 입력 디바이스(들)(1922)는 사용자가 데이터 및/또는 커맨드들을 프로세서(1912)에 입력할 수 있게 한다. 입력 디바이스(들)는, 예를 들어, 오디오 센서, 마이크로폰, 카메라(스틸 또는 비디오), 키보드, 버튼, 마우스, 터치스크린, 트랙 패드, 트랙볼, 아이소포인트(isopoint) 및/또는 음성 인식 시스템에 의해 구현될 수 있다.
하나 이상의 출력 디바이스(1924)가 또한 예시된 예의 인터페이스 회로(1920)에 연결된다. 출력 디바이스들(1924)은, 예를 들어, 디스플레이 디바이스들(예를 들면, LED(light emitting diode), OLED(organic light emitting diode), LCD(liquid crystal display), CRT(cathode ray tube) 디스플레이, IPS(in-place switching) 디스플레이, 터치스크린 등), 촉각 출력 디바이스, 프린터 및/또는 스피커에 의해 구현될 수 있다. 예시된 예의 인터페이스 회로(1920)는, 따라서, 전형적으로 그래픽 드라이버 카드, 그래픽 드라이버 칩 및/또는 그래픽 드라이버 프로세서를 포함한다.
예시된 예의 인터페이스 회로(1920)는 네트워크(1926)를 통한 외부 머신들(예를 들면, 임의의 종류의 컴퓨팅 디바이스들)과의 데이터 교환을 용이하게 하기 위해 송신기, 수신기, 트랜시버, 모뎀, 주택용 게이트웨이, 무선 액세스 포인트, 및/또는 네트워크 인터페이스와 같은 통신 디바이스를 또한 포함한다. 통신은, 예를 들어, 이더넷 연결, DSL(digital subscriber line) 연결, 전화선 연결, 동축 케이블 시스템, 위성 시스템, 가시선 무선 시스템, 셀룰러 전화 시스템 등을 통할 수 있다.
예시된 예의 프로세서 플랫폼(1900)은 소프트웨어 및/또는 데이터를 저장하기 위한 하나 이상의 대용량 저장 디바이스(1928)를 또한 포함한다. 그러한 대용량 저장 디바이스들(1928)의 예들은 플로피 디스크 드라이브, 하드 드라이브 디스크, 콤팩트 디스크 드라이브, 블루레이 디스크 드라이브, RAID(redundant array of independent disks) 시스템, 및 DVD(digital versatile disk) 드라이브를 포함한다.
도 15의 머신 실행 가능 명령어들(1932)은 대용량 저장 디바이스(1928)에, 휘발성 메모리(1914)에, 비휘발성 메모리(1916)에, 및/또는 CD 또는 DVD와 같은 이동식 비일시적 컴퓨터 판독 가능 저장 매체에 저장될 수 있다.
도 18의 예시적인 컴퓨터 판독 가능 명령어들(1832) 및/또는 도 19의 예시적인 컴퓨터 판독 가능 명령어들(1932)과 같은 소프트웨어를 제3자에게 배포하기 위한 예시적인 소프트웨어 배포 플랫폼(2005)을 예시하는 블록 다이어그램이 도 20에 예시되어 있다. 예시적인 소프트웨어 배포 플랫폼(2005)은 소프트웨어를 저장하고 다른 컴퓨팅 디바이스들로 전송할 수 있는 임의의 컴퓨터 서버, 데이터 설비, 클라우드 서비스 등에 의해 구현될 수 있다. 제3자는 소프트웨어 배포 플랫폼을 소유 및/또는 운영하는 엔티티의 고객일 수 있다. 예를 들어, 소프트웨어 배포 플랫폼을 소유 및/또는 운영하는 엔티티는 도 18의 예시적인 컴퓨터 판독 가능 명령어들(1832) 및/또는 도 19의 예시적인 컴퓨터 판독 가능 명령어들(1932)와 같은 소프트웨어의 개발자, 판매자 및/또는 라이선스 제공자(licensor)일 수 있다. 제3자는 사용 및/또는 재판매 및/또는 재라이선싱(sub-licensing)을 위해 소프트웨어를 구매 및/또는 라이선싱하는 소비자, 사용자, 소매업체, OEM 등일 수 있다. 예시된 예에서, 소프트웨어 배포 플랫폼(2005)은 하나 이상의 서버 및 하나 이상의 저장 디바이스를 포함한다. 저장 디바이스는, 위에서 설명된 바와 같이, 도 18의 예시적인 컴퓨터 판독 가능 명령어들(1832) 및/또는 도 19의 예시적인 컴퓨터 판독 가능 명령어들(1932)에 대응할 수 있는, 컴퓨터 판독 가능 명령어들(1832 및/또는 1932)을 저장한다. 예시적인 소프트웨어 배포 플랫폼(2005)의 하나 이상의 서버는, 위에서 설명된 예시적인 네트워크들(1826, 1926) 중 임의의 것 및/또는 인터넷 중 임의의 하나 이상에 대응할 수 있는, 네트워크(2010)와 통신한다. 일부 예들에서, 하나 이상의 서버는 상거래의 일부로서 요청 당사자에게 소프트웨어를 전송하라는 요청에 응답한다. 소프트웨어의 전달, 판매 및/또는 라이선스에 대한 지불은 소프트웨어 배포 플랫폼의 하나 이상의 서버에 의해 및/또는 제3자 결제 엔티티를 통해 처리될 수 있다. 서버들은 구매자 및/또는 라이선스 제공자가 소프트웨어 배포 플랫폼(2005)으로부터 컴퓨터 판독 가능 명령어들(1832 및/또는 1932)을 다운로드할 수 있게 한다. 예를 들어, 도 18의 예시적인 컴퓨터 판독 가능 명령어들(1832)에 대응할 수 있는 소프트웨어는 예시적인 프로세서 플랫폼(1800)으로 다운로드될 수 있으며, 이 프로세서 플랫폼(1800)은 도 5의 텍스처 기반 MIV 인코더(500)를 구현하기 위해 컴퓨터 판독 가능 명령어들(1832)을 실행한다. 예를 들어, 도 19의 예시적인 컴퓨터 판독 가능 명령어들(1932)에 대응할 수 있는 소프트웨어는 예시적인 프로세서 플랫폼(1900)으로 다운로드될 수 있으며, 이 프로세서 플랫폼(1900)은 도 7의 텍스처 기반 MIV 디코더(700)를 구현하기 위해 컴퓨터 판독 가능 명령어들(1932)을 실행한다. 일부 예에서, 소프트웨어 배포 플랫폼(2005)의 하나 이상의 서버는 개선 사항, 패치, 업데이트 등이 최종 사용자 디바이스들에서의 소프트웨어에 배포되고 적용되도록 보장하기 위해 소프트웨어(예를 들면, 도 18의 예시적인 컴퓨터 판독 가능 명령어들(1832) 및/또는 도 19의 예시적인 컴퓨터 판독 가능 명령어들(1932))에 대한 업데이트들을 주기적으로 제공, 전송 및/또는 강제한다.
전술한 것으로부터, 텍스처 기반 몰입형 비디오 코딩을 가능하게 하는 예시적인 방법들, 장치들 및 제조 물품들이 개시되었다는 것이 이해될 것이다. 개시된 방법들, 장치들 및 제조 물품들은 대응 관계 리스트에서 대응하는 패치들을 결정하고 할당하는 것에 의해 컴퓨팅 디바이스를 사용하는 효율성을 개선시킨다. 예를 들어, 텍스처 기반 인코더는 대응하는 패치들의 리스트를 아틀라스에 저장한다. 텍스처 기반 인코더는 뷰들 사이의 상이한 텍스처 정보로부터 깊이 정보를 추론하기 위해 대응하는 패치들을 식별한다. 텍스처 기반 인코더가 어떠한 깊이 아틀라스들도 전송하지 않기 때문에 텍스처 기반 인코더는 인코딩된 비트스트림들을 전송하는 데 더 적은 대역폭을 필요로 한다. 텍스처 기반 디코더는 텍스처 기반 인코더로부터의 아틀라스(들)에 포함된 대응하는 패치들의 리스트로 인해 대응하는 관심 패치들을 식별하는 데 상대적으로 낮은 대역폭을 필요로 한다. 개시된 방법들, 장치들 및 제조 물품들은 그에 따라 컴퓨터의 기능에서의 하나 이상의 개선 사항(들)에 관한 것이다.
텍스처 기반 몰입형 비디오 코딩을 위한 예시적인 방법들, 장치들, 시스템들, 및 제조 물품들이 본 명세서에서 개시된다. 추가의 예들 및 이들의 조합들은 다음과 같은 것들을 포함한다:
예 1은 비디오 인코더를 포함하며, 이 비디오 인코더는 (i) 제1 뷰의 복수의 픽셀들에 포함된 제1 고유한 픽셀들 및 제1 대응하는 픽셀들을 식별하고 (ii) 제2 뷰의 복수의 픽셀들에 포함된 제2 고유한 픽셀들 및 제2 대응하는 픽셀들을 식별하기 위한 대응 관계 라벨러 - 제1 대응하는 픽셀들 하나하나는 제2 대응하는 픽셀들 하나하나와 각자의 대응 관계들을 갖고, 제1 대응하는 픽셀들 중 제1의 것 및 제2 대응하는 픽셀들 중 제2의 것은 유사한 텍스처 정보 또는 상이한 텍스처 정보 중 적어도 하나를 갖는 것으로 분류됨 -, (i) 제1 뷰에서의 인접한 픽셀들을 비교하고, (ii) 인접한 픽셀들의 비교 및 대응 관계들에 기초하여 고유한 픽셀들의 제1 패치 및 대응하는 픽셀들의 제2 패치를 식별하기 위한 대응 관계 패치 패커 - 제2 패치는 제2 뷰에서의 대응하는 패치들을 식별해 주는 대응 관계 리스트로 태깅됨 -, 및 인코딩된 비디오 데이터에 포함시킬 적어도 하나의 아틀라스를 생성하기 위한 아틀라스 생성기 - 적어도 하나의 아틀라스는 고유한 픽셀들의 제1 패치 및 대응하는 픽셀들의 제2 패치를 포함하고, 인코딩된 비디오 데이터는 깊이 맵들을 포함하지 않음 - 를 포함한다.
예 2는 예 1의 비디오 인코더를 포함하며, 제1 뷰에 대한 제1 프루닝 마스크를 생성하기 위한 대응 관계 프루너 - 제1 프루닝 마스크는 제1 고유한 픽셀들 및 제1 대응하는 픽셀들로부터의 텍스처 정보에 기초함 - 를 더 포함한다.
예 3은 예 2의 비디오 인코더를 포함하며, 여기서 제1 대응하는 픽셀들은 이전 프루닝된 뷰에 포함된 대응하는 픽셀들을 포함하지 않는다.
예 4는 예 2 또는 예 3 중 어느 한 예의 비디오 인코더를 포함하며, 여기서 대응 관계 프루너는 제2 뷰에 대한 제2 프루닝 마스크를 생성하며, 제2 프루닝 마스크는 제2 고유한 픽셀들 및 제2 대응하는 픽셀들로부터의 텍스처 정보에 기초한다.
예 5는 예 4의 비디오 인코더를 포함하며, 여기서 제2 대응하는 픽셀들은 제1 뷰의 제1 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함한다.
예 6은 예 4 또는 예 5 중 어느 한 예의 비디오 인코더를 포함하며, 대응 관계 프루너는 제3 뷰에 대한 제3 프루닝 마스크를 생성하고, 제3 프루닝 마스크는 제3 고유한 픽셀들 및 제3 대응하는 픽셀들로부터의 텍스처 정보에 기초하며, 제3 대응하는 픽셀들은 제1 뷰의 제1 대응하는 픽셀들 및 제2 뷰의 제2 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함한다.
예 7은 예 6의 비디오 인코더를 포함하며, 대응 관계 프루너는 유지될 제1 복수의 픽셀들, 제2 복수의 픽셀들, 및 제3 복수의 픽셀들을 식별해 주기 위한 제1 값들 및 프루닝될 제4 복수의 픽셀들을 식별해 주기 위한 제2 값들을 포함할 제1 프루닝 마스크, 제2 프루닝 마스크, 및 제3 프루닝 마스크를 생성하고, 제4 복수의 픽셀들은 제1 뷰의 제1 대응하는 픽셀들 및 제2 뷰의 제2 대응하는 픽셀들에 포함된 제3 대응하는 픽셀들을 포함한다.
예 8은 예 7의 비디오 인코더를 포함하며, 제1 프루닝 마스크, 제2 프루닝 마스크, 및 제3 프루닝 마스크를 집계하기 위한 마스크 집계기를 더 포함한다.
예 9는 예 1의 비디오 인코더를 포함하며, 여기서 대응 관계 라벨러는, 제2 뷰 상에 재투영될 때, 제2 뷰의 복수의 픽셀들 하나하나의 위치들에 투영되지 않는 제1 뷰의 복수의 픽셀들 하나하나일 제1 고유한 픽셀들을 식별한다.
예 10은 예 1의 비디오 인코더를 포함하며, 여기서 대응 관계 라벨러는, 제2 뷰 상에 재투영될 때, 제2 뷰의 제2 대응하는 픽셀들 하나하나 각자의 위치들에 투영되는 제1 뷰의 복수의 픽셀들 하나하나일 제1 대응하는 픽셀들을 식별한다.
예 11은 예 10의 비디오 인코더를 포함하며, 대응 관계 라벨러는 제1 뷰와 제2 뷰에서의 그 각자의 텍스처 콘텐츠 사이의 차이가 임계값을 충족시킬 때 제1 대응하는 픽셀들 중 제1의 것과 제2 대응하는 픽셀들 중 제2의 것을 유사한 것으로서 식별한다.
예 12는 예 1의 비디오 인코더를 포함하며, 여기서 적어도 하나의 아틀라스는 어트리뷰트 맵들 또는 점유 맵들 중 적어도 하나를 포함한다.
예 13은 예 1의 비디오 인코더를 포함하며, 여기서 입력 뷰들은 어트리뷰트 맵들을 포함한다.
예 14는 예 1의 비디오 인코더를 포함하며, 인코딩된 비디오 데이터는 적어도 하나의 아틀라스가 깊이 맵들을 포함하지 않는다는 것을 식별해 주기 위한 플래그를 포함한다.
예 15는 명령어들을 포함하는 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 명령어들은, 실행될 때, 하나 이상의 프로세서로 하여금, 적어도 제1 뷰의 복수의 픽셀들에 포함된 제1 고유한 픽셀들 및 제1 대응하는 픽셀들을 식별하게 하고, 제2 뷰의 복수의 픽셀들에 포함된 제2 고유한 픽셀들 및 제2 대응하는 픽셀들을 식별하게 하며 - 제1 대응하는 픽셀들 하나하나는 제2 대응하는 픽셀들 하나하나와 각자의 대응 관계들을 갖고, 제1 대응하는 픽셀들 중 제1의 것 및 제2 대응하는 픽셀들 중 제2의 것은 유사한 텍스처 정보 또는 상이한 텍스처 정보 중 적어도 하나를 갖는 것으로 분류됨 -, 제1 뷰에서의 인접한 픽셀들을 비교하게 하고, 인접한 픽셀들의 비교 및 대응 관계들에 기초하여 고유한 픽셀들의 제1 패치 및 대응하는 픽셀들의 제2 패치를 식별하게 하며 - 제2 패치는 제2 뷰에서의 대응하는 패치들을 식별해 주는 대응 관계 리스트로 태깅됨 -, 인코딩된 비디오 데이터에 포함시킬 적어도 하나의 아틀라스를 생성하게 - 적어도 하나의 아틀라스는 고유한 픽셀들의 제1 패치 및 대응하는 픽셀들의 제2 패치를 포함하고, 인코딩된 비디오 데이터는 깊이 맵들을 포함하지 않음 - 한다.
예 16은 예 15의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 명령어들은 하나 이상의 프로세서로 하여금 제1 뷰에 대한 제1 프루닝 마스크를 생성하게 하고, 제1 프루닝 마스크는 제1 고유한 픽셀들 및 제1 대응하는 픽셀들로부터의 텍스처 정보에 기초한다.
예 17은 예 16의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 제1 대응하는 픽셀들은 이전 프루닝된 뷰에 포함된 대응하는 픽셀들을 포함하지 않는다.
예 18은 예 16 또는 예 17 중 어느 한 예의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 명령어들은 하나 이상의 프로세서로 하여금 제2 뷰에 대한 제2 프루닝 마스크를 생성하게 하고, 제2 프루닝 마스크는 제2 고유한 픽셀들 및 제2 대응하는 픽셀들로부터의 텍스처 정보에 기초한다.
예 19는 예 18의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 제2 대응하는 픽셀들은 제1 뷰의 제1 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함한다.
예 20은 예 18 또는 예 19 중 어느 한 예의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 명령어들은 하나 이상의 프로세서로 하여금 제3 뷰에 대한 제3 프루닝 마스크를 생성하게 하고, 제3 프루닝 마스크는 제3 고유한 픽셀들 및 제3 대응하는 픽셀들로부터의 텍스처 정보에 기초하며, 제3 대응하는 픽셀들은 제1 뷰의 제1 대응하는 픽셀들 및 제2 뷰의 제2 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함한다.
예 21은 예 20의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 명령어들은 하나 이상의 프로세서로 하여금 유지될 제1 복수의 픽셀들, 제2 복수의 픽셀들, 및 제3 복수의 픽셀들을 식별해 주기 위한 제1 값들 및 프루닝될 제4 복수의 픽셀들을 식별해 주기 위한 제2 값들을 포함할 제1 프루닝 마스크, 제2 프루닝 마스크, 및 제3 프루닝 마스크를 생성하게 하고, 제4 복수의 픽셀들은 제1 뷰의 제1 대응하는 픽셀들 및 제2 뷰의 제2 대응하는 픽셀들에 포함된 제3 대응하는 픽셀들을 포함한다.
예 22는 예 21의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 명령어들은 하나 이상의 프로세서로 하여금 제1 프루닝 마스크, 제2 프루닝 마스크, 및 제3 프루닝 마스크를 집계하게 한다.
예 23은 예 15의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 명령어들은 하나 이상의 프로세서로 하여금, 제2 뷰 상에 재투영될 때, 제2 뷰의 복수의 픽셀들 하나하나의 위치들에 투영되지 않는 제1 뷰의 복수의 픽셀들 하나하나일 제1 고유한 픽셀들을 식별하게 한다.
예 24는 예 15의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 명령어들은 하나 이상의 프로세서로 하여금, 제2 뷰 상에 재투영될 때, 제2 뷰의 제2 대응하는 픽셀들 하나하나 각자의 위치들에 투영되는 제1 뷰의 복수의 픽셀들 하나하나일 제1 대응하는 픽셀들을 식별하게 한다.
예 25는 예 24의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 명령어들은 하나 이상의 프로세서로 하여금 제1 뷰와 제2 뷰에서의 그 각자의 텍스처 콘텐츠 사이의 차이가 임계값을 충족시킬 때 제1 대응하는 픽셀들 중 제1의 것과 제2 대응하는 픽셀들 중 제2의 것을 유사한 것으로서 식별하게 한다.
예 26은 예 15의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 적어도 하나의 아틀라스는 어트리뷰트 맵들 또는 점유 맵들 중 적어도 하나를 포함한다.
예 27은 예 15의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 인코딩된 비디오 데이터는 적어도 하나의 아틀라스가 깊이 맵들을 포함하지 않는다는 것을 식별해 주기 위한 플래그를 포함한다.
예 28은 방법을 포함하며, 이 방법은 제1 뷰의 복수의 픽셀들에 포함된 제1 고유한 픽셀들 및 제1 대응하는 픽셀들을 식별하는 단계, 제2 뷰의 복수의 픽셀들에 포함된 제2 고유한 픽셀들 및 제2 대응하는 픽셀들을 식별하는 단계 - 제1 대응하는 픽셀들 하나하나는 제2 대응하는 픽셀들 하나하나와 각자의 대응 관계들을 갖고, 제1 대응하는 픽셀들 중 제1의 것 및 제2 대응하는 픽셀들 중 제2의 것은 유사한 텍스처 정보 또는 상이한 텍스처 정보 중 적어도 하나를 갖는 것으로 분류됨 -, 제1 뷰에서의 인접한 픽셀들을 비교하는 단계, 인접한 픽셀들의 비교 및 대응 관계들에 기초하여 고유한 픽셀들의 제1 패치 및 대응하는 픽셀들의 제2 패치를 식별하는 단계 - 제2 패치는 제2 뷰에서의 대응하는 패치들을 식별해 주는 대응 관계 리스트로 태깅됨 -, 인코딩된 비디오 데이터에 포함시킬 적어도 하나의 아틀라스를 생성하는 단계 - 적어도 하나의 아틀라스는 고유한 픽셀들의 제1 패치 및 대응하는 픽셀들의 제2 패치를 포함하고, 인코딩된 비디오 데이터는 깊이 맵들을 포함하지 않음 - 를 포함한다.
예 29는 예 28의 방법을 포함하며, 제1 뷰에 대한 제1 프루닝 마스크를 생성하는 단계 - 제1 프루닝 마스크는 제1 고유한 픽셀들 및 제1 대응하는 픽셀들로부터의 텍스처 정보에 기초함 - 를 더 포함한다.
예 30은 예 29의 방법을 포함하며, 여기서 제1 대응하는 픽셀들은 이전 프루닝된 뷰에 포함된 대응하는 픽셀들을 포함하지 않는다.
예 31은 예 29 또는 예 30 중 어느 한 예의 방법을 포함하며, 제2 뷰에 대한 제2 프루닝 마스크를 생성하는 단계 - 제2 프루닝 마스크는 제2 고유한 픽셀들 및 제2 대응하는 픽셀들로부터의 텍스처 정보에 기초함 - 를 더 포함한다.
예 32는 예 31의 방법을 포함하며, 여기서 제2 대응하는 픽셀들은 제1 뷰의 제1 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함한다.
예 33은 예 31 또는 예 32 중 어느 한 예의 방법을 포함하며, 제3 뷰에 대한 제3 프루닝 마스크를 생성하는 단계 - 제3 프루닝 마스크는 제3 고유한 픽셀들 및 제3 대응하는 픽셀들로부터의 텍스처 정보에 기초하며, 제3 대응하는 픽셀들은 제1 뷰의 제1 대응하는 픽셀들 및 제2 뷰의 제2 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함함 - 를 더 포함한다.
예 34는 예 33의 방법을 포함하며, 유지될 제1 복수의 픽셀들, 제2 복수의 픽셀들, 및 제3 복수의 픽셀들을 식별해 주기 위한 제1 값들 및 프루닝될 제4 복수의 픽셀들을 식별해 주기 위한 제2 값들을 포함할 제1 프루닝 마스크, 제2 프루닝 마스크, 및 제3 프루닝 마스크를 생성하는 단계 - 제4 복수의 픽셀들은 제1 뷰의 제1 대응하는 픽셀들 및 제2 뷰의 제2 대응하는 픽셀들에 포함된 제3 대응하는 픽셀들을 포함함 - 를 더 포함한다.
예 35는 예 34의 방법을 포함하며, 제1 프루닝 마스크, 제2 프루닝 마스크, 및 제3 프루닝 마스크를 집계하는 단계를 더 포함한다.
예 36은 예 28의 방법을 포함하며, 제2 뷰 상에 재투영될 때, 제2 뷰의 복수의 픽셀들 하나하나의 위치들에 투영되지 않는 제1 뷰의 복수의 픽셀들 하나하나일 제1 고유한 픽셀들을 식별하는 단계를 더 포함한다.
예 37은 예 28의 방법을 포함하며, 제2 뷰 상에 재투영될 때, 제2 뷰의 제2 대응하는 픽셀들 하나하나 각자의 위치들에 투영되는 제1 뷰의 복수의 픽셀들 하나하나일 제1 대응하는 픽셀들을 식별하는 단계를 더 포함한다.
예 38은 예 37의 방법을 포함하며, 제1 뷰와 제2 뷰에서의 그 각자의 텍스처 콘텐츠 사이의 차이가 임계값을 충족시킬 때 제1 대응하는 픽셀들 중 제1의 것과 제2 대응하는 픽셀들 중 제2의 것을 유사한 것으로서 식별하는 단계를 더 포함한다.
예 39는 예 28의 방법을 포함하며, 여기서 적어도 하나의 아틀라스는 어트리뷰트 맵들 또는 점유 맵들 중 적어도 하나를 포함한다.
예 40은 예 28의 방법을 포함하며, 인코딩된 비디오 데이터는 적어도 하나의 아틀라스가 깊이 맵들을 포함하지 않는다는 것을 식별해 주기 위한 플래그를 포함한다.
예 41은 비디오 디코더를 포함하며, 이 비디오 디코더는 비트스트림 디코더 및 렌더러를 포함하며, 비트스트림 디코더는 인코딩된 비디오 데이터에서 플래그를 식별하고 - 이 플래그는 깊이 맵들을 포함하지 않는 제1 아틀라스 및 제2 아틀라스를 식별해 줌 -, (i) 제1 뷰의 제1 메타데이터 및 (ii) 제2 뷰의 제2 메타데이터를 획득하기 위해 인코딩된 비디오 데이터를 디코딩하며, 여기서 제1 뷰 및 제2 뷰로부터의 패치들은 동일한 아틀라스에 속하거나 상이한 아틀라스들에 걸쳐 분포되고, 제1 뷰는 제1 아틀라스 내의 제1 패치들을 포함하고, 제2 뷰는 대응 관계 리스트로 태깅된 제2 아틀라스 또는 제1 아틀라스 내의 대응하는 제2 패치들을 포함하며, 렌더러는 제1 패치들에 포함된 픽셀들과 대응하는 제2 패치들에 포함된 대응하는 픽셀들의 비교에 기초하여 깊이 정보를 결정하고 결정된 깊이 정보로부터 타깃 뷰를 합성한다.
예 42는 예 41의 비디오 디코더를 포함하며, 여기서 제1 메타데이터는 제1 뷰에서의 픽셀 블록들을 제1 뷰에 포함된 제1 패치들에 매핑하는 제1 맵을 포함하고, 제2 메타데이터는 제2 뷰에서의 픽셀 블록들을 제2 뷰에 포함된 대응하는 제2 패치들에 매핑하는 제2 맵을 포함한다.
예 43은 예 42의 비디오 디코더를 포함하며, 여기서 렌더러는 제2 맵에 기초하여 대응하는 제2 패치들을 재구성한다.
예 44는 예 41의 비디오 디코더를 포함하며, 여기서 렌더러는 인코딩된 비디오 데이터로부터의 대응 관계 리스트에 기초하여 대응하는 제2 패치들에서 대응하는 픽셀들을 식별한다.
예 45는 예 41 또는 예 44 중 어느 한 예의 비디오 디코더를 포함하며, 여기서 렌더러는 제1 뷰로부터의 제1 패치들 중 제1의 것 및 제1 패치들 중 제1의 것에 대응하는 것으로 결정되는 제2 뷰로부터의 대응하는 제2 패치들의 각자의 것에 기초하여 깊이 정보를 결정하며, 대응하는 제2 패치들의 각자의 것은 제1 패치들 중 제1의 것과 상이한 텍스처 정보 또는 제1 패치들 중 제1의 것과 유사한 텍스처 정보를 갖는다.
예 46은 명령어들을 포함하는 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 명령어들은, 실행될 때, 하나 이상의 프로세서로 하여금, 적어도 인코딩된 비디오 데이터에서 플래그를 식별하게 하고 - 이 플래그는 깊이 맵들을 포함하지 않는 제1 아틀라스 및 제2 아틀라스를 식별해 줌 -, (i) 제1 뷰의 제1 메타데이터 및 (ii) 제2 뷰의 제2 메타데이터를 획득하기 위해 인코딩된 비디오 데이터를 디코딩하게 하며 - 제1 뷰 및 제2 뷰로부터의 패치들은 동일한 아틀라스에 속하거나 상이한 아틀라스들에 걸쳐 분포되고, 제1 뷰는 제1 아틀라스 내의 제1 패치들을 포함하고, 제2 뷰는 대응 관계 리스트로 태깅된 제2 아틀라스 또는 제1 아틀라스 내의 대응하는 제2 패치들을 포함함 -, 제1 패치들에 포함된 픽셀들과 대응하는 제2 패치들에 포함된 대응하는 제2 픽셀들의 비교에 기초하여 깊이 정보를 결정하게 하고, 결정된 깊이 정보로부터 타깃 뷰를 합성하게 한다.
예 47은 예 46의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 제1 메타데이터는 제1 뷰에서의 픽셀 블록들을 제1 뷰에 포함된 제1 패치들에 매핑하는 제1 맵을 포함하고, 제2 메타데이터는 제2 뷰에서의 픽셀 블록들을 제2 뷰에 포함된 대응하는 제2 패치들에 매핑하는 제2 맵을 포함한다.
예 48은 예 47의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 명령어들은 하나 이상의 프로세서로 하여금 제2 맵에 기초하여 대응하는 제2 패치들을 재구성하게 한다.
예 49는 예 46의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 명령어들은 하나 이상의 프로세서로 하여금 인코딩된 비디오 데이터로부터의 대응 관계 리스트에 기초하여 대응하는 제2 패치들에서 대응하는 제2 픽셀들을 식별하게 한다.
예 50은 예 46 또는 예 49 중 어느 한 예의 적어도 하나의 비일시적 컴퓨터 판독 가능 매체를 포함하며, 여기서 명령어들은 하나 이상의 프로세서로 하여금 제1 뷰로부터의 제1 패치들 중 제1의 것 및 제1 패치들 중 제1의 것에 대응하는 것으로 결정되는 제2 뷰로부터의 대응하는 제2 패치들의 각자의 것에 기초하여 깊이 정보를 결정하게 하며, 여기서 대응하는 제2 패치들의 각자의 것은 제1 패치들 중 제1의 것과 상이한 텍스처 정보 또는 제1 패치들 중 제1의 것과 유사한 텍스처 정보를 갖는다.
예 51은 방법을 포함하고, 이 방법은 인코딩된 비디오 데이터에서 플래그를 식별하는 단계 - 이 플래그는 깊이 맵들을 포함하지 않는 제1 아틀라스 및 제2 아틀라스를 식별해 줌 -, (i) 제1 뷰의 제1 메타데이터 및 (ii) 제2 뷰의 제2 메타데이터를 획득하기 위해 인코딩된 비디오 데이터를 디코딩하는 단계 - 제1 뷰 및 제2 뷰로부터의 패치들은 동일한 아틀라스에 속하거나 상이한 아틀라스들에 걸쳐 분포되고, 제1 뷰는 제1 아틀라스 내의 제1 패치들을 포함하고, 제2 뷰는 대응 관계 리스트로 태깅된 제2 아틀라스 또는 제1 아틀라스 내의 대응하는 제2 패치들을 포함함 -, 제1 패치들에 포함된 픽셀들과 대응하는 제2 패치들에 포함된 대응하는 제2 픽셀들의 비교에 기초하여 깊이 정보를 결정하는 단계, 및 결정된 깊이 정보로부터 타깃 뷰를 합성하는 단계를 포함한다.
예 52는 예 51의 방법을 포함하며, 여기서 제1 메타데이터는 제1 뷰에서의 픽셀 블록들을 제1 뷰에 포함된 제1 패치들에 매핑하는 제1 맵을 포함하고, 제2 메타데이터는 제2 뷰에서의 픽셀 블록들을 제2 뷰에 포함된 대응하는 제2 패치들에 매핑하는 제2 맵을 포함한다.
예 53은 예 52의 방법을 포함하며, 제2 맵에 기초하여 대응하는 제2 패치들을 재구성하는 단계를 더 포함한다.
예 54는 예 51의 방법을 포함하며, 인코딩된 비디오 데이터로부터의 대응 관계 리스트에 기초하여 대응하는 제2 패치들에서 대응하는 제2 픽셀들을 식별하는 단계를 더 포함한다.
예 55는 예 51 또는 예 54 중 어느 한 예의 방법을 포함하며, 제1 뷰로부터의 제1 패치들 중 제1의 것 및 제1 패치들 중 제1의 것에 대응하는 것으로 결정되는 제2 뷰로부터의 대응하는 제2 패치들의 각자의 것에 기초하여 깊이 정보를 결정하는 단계를 더 포함하며, 여기서 대응하는 제2 패치들의 각자의 것은 제1 패치들 중 제1의 것과 상이한 텍스처 정보 또는 제1 패치들 중 제1의 것과 유사한 텍스처 정보를 갖는다.
특정 예시적인 방법들, 장치들 및 제조 물품들이 본 명세서에서 개시되었지만, 본 특허의 보호 범위는 이에 제한되지 않는다. 반대로, 본 특허는 본 특허의 청구항들의 범위 내에 명백히 속하는 모든 방법들, 장치들 및 제조 물품들을 커버한다.
이하의 청구항들은 이로써 이 참조에 의해 이 발명을 실시하기 위한 구체적인 내용에 포함되며, 각각의 청구항은 본 개시내용의 개별 실시예로서 독립해 있다.
Claims (55)
- 비디오 인코더로서,
(i) 제1 뷰의 복수의 픽셀들에 포함된 제1 고유한 픽셀들 및 제1 대응하는 픽셀들을 식별하고 (ii) 제2 뷰의 복수의 픽셀들에 포함된 제2 고유한 픽셀들 및 제2 대응하는 픽셀들을 식별하기 위한 대응 관계 라벨러 - 상기 제1 대응하는 픽셀들 하나하나는 상기 제2 대응하는 픽셀들 하나하나와 각자의 대응 관계들을 갖고, 상기 제1 대응하는 픽셀들 중 제1의 것 및 상기 제2 대응하는 픽셀들 중 제2의 것은 유사한 텍스처 정보 또는 상이한 텍스처 정보 중 적어도 하나를 갖는 것으로 분류됨 -;
(i) 상기 제1 뷰에서의 인접한 픽셀들을 비교하고, (ii) 상기 인접한 픽셀들의 상기 비교 및 상기 대응 관계들에 기초하여 고유한 픽셀들의 제1 패치 및 대응하는 픽셀들의 제2 패치를 식별하기 위한 대응 관계 패치 패커 - 상기 제2 패치는 상기 제2 뷰에서의 대응하는 패치들을 식별해 주는 대응 관계 리스트로 태깅됨 -; 및
인코딩된 비디오 데이터에 포함시킬 적어도 하나의 아틀라스를 생성하기 위한 아틀라스 생성기 - 상기 적어도 하나의 아틀라스는 상기 고유한 픽셀들의 제1 패치 및 상기 대응하는 픽셀들의 제2 패치를 포함하고, 상기 인코딩된 비디오 데이터는 깊이 맵들을 포함하지 않음 -
를 포함하는, 비디오 인코더. - 제1항에 있어서, 상기 제1 뷰에 대한 제1 프루닝 마스크를 생성하기 위한 대응 관계 프루너 - 상기 제1 프루닝 마스크는 상기 제1 고유한 픽셀들 및 상기 제1 대응하는 픽셀들로부터의 텍스처 정보에 기초함 -
를 더 포함하는, 비디오 인코더. - 제2항에 있어서, 상기 제1 대응하는 픽셀들은 이전 프루닝된 뷰에 포함된 대응하는 픽셀들을 포함하지 않는, 비디오 인코더.
- 제2항에 있어서, 상기 대응 관계 프루너는 상기 제2 뷰에 대한 제2 프루닝 마스크를 생성하며, 상기 제2 프루닝 마스크는 상기 제2 고유한 픽셀들 및 상기 제2 대응하는 픽셀들로부터의 텍스처 정보에 기초하는, 비디오 인코더.
- 제4항에 있어서, 상기 제2 대응하는 픽셀들은 상기 제1 뷰의 상기 제1 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함하는, 비디오 인코더.
- 제4항에 있어서, 상기 대응 관계 프루너는 제3 뷰에 대한 제3 프루닝 마스크를 생성하고, 상기 제3 프루닝 마스크는 제3 고유한 픽셀들 및 제3 대응하는 픽셀들로부터의 텍스처 정보에 기초하며, 상기 제3 대응하는 픽셀들은 상기 제1 뷰의 상기 제1 대응하는 픽셀들 및 상기 제2 뷰의 상기 제2 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함하는, 비디오 인코더.
- 제6항에 있어서, 상기 대응 관계 프루너는 유지될 제1 복수의 픽셀들, 제2 복수의 픽셀들, 및 제3 복수의 픽셀들을 식별해 주기 위한 제1 값들 및 프루닝될 제4 복수의 픽셀들을 식별해 주기 위한 제2 값들을 포함할 상기 제1 프루닝 마스크, 상기 제2 프루닝 마스크, 및 상기 제3 프루닝 마스크를 생성하고, 상기 제4 복수의 픽셀들은 상기 제1 뷰의 상기 제1 대응하는 픽셀들 및 상기 제2 뷰의 상기 제2 대응하는 픽셀들에 포함된 상기 제3 대응하는 픽셀들을 포함하는, 비디오 인코더.
- 제7항에 있어서, 상기 제1 프루닝 마스크, 상기 제2 프루닝 마스크, 및 상기 제3 프루닝 마스크를 집계하기 위한 마스크 집계기
를 더 포함하는, 비디오 인코더. - 제1항에 있어서, 상기 대응 관계 라벨러는, 상기 제2 뷰 상에 재투영될 때, 상기 제2 뷰의 상기 복수의 픽셀들 하나하나의 위치들에 투영되지 않는 상기 제1 뷰의 상기 복수의 픽셀들 하나하나일 상기 제1 고유한 픽셀들을 식별하는, 비디오 인코더.
- 제1항에 있어서, 상기 대응 관계 라벨러는, 상기 제2 뷰 상에 재투영될 때, 상기 제2 뷰의 상기 제2 대응하는 픽셀들 하나하나 각자의 위치들에 투영되는 상기 제1 뷰의 상기 복수의 픽셀들 하나하나일 상기 제1 대응하는 픽셀들을 식별하는, 비디오 인코더.
- 제10항에 있어서, 상기 대응 관계 라벨러는 상기 제1 뷰와 상기 제2 뷰에서의 그 각자의 텍스처 콘텐츠 사이의 차이가 임계값을 충족시킬 때 상기 제1 대응하는 픽셀들 중 상기 제1의 것과 상기 제2 대응하는 픽셀들 중 상기 제2의 것을 유사한 것으로서 식별하는, 비디오 인코더.
- 제1항에 있어서, 상기 적어도 하나의 아틀라스는 어트리뷰트 맵들 또는 점유 맵들 중 적어도 하나를 포함하는, 비디오 인코더.
- 제1항에 있어서, 입력 뷰들은 어트리뷰트 맵들을 포함하는, 비디오 인코더.
- 제1항에 있어서, 상기 인코딩된 비디오 데이터는 상기 적어도 하나의 아틀라스가 깊이 맵들을 포함하지 않는다는 것을 식별해 주기 위한 플래그를 포함하는, 비디오 인코더.
- 명령어들을 포함하는 적어도 하나의 비일시적 컴퓨터 판독 가능 매체로서, 상기 명령어들은, 실행될 때, 하나 이상의 프로세서로 하여금, 적어도:
제1 뷰의 복수의 픽셀들에 포함된 제1 고유한 픽셀들 및 제1 대응하는 픽셀들을 식별하게 하고,
제2 뷰의 복수의 픽셀들에 포함된 제2 고유한 픽셀들 및 제2 대응하는 픽셀들을 식별하게 하며 - 상기 제1 대응하는 픽셀들 하나하나는 상기 제2 대응하는 픽셀들 하나하나와 각자의 대응 관계들을 갖고, 상기 제1 대응하는 픽셀들 중 제1의 것 및 상기 제2 대응하는 픽셀들 중 제2의 것은 유사한 텍스처 정보 또는 상이한 텍스처 정보 중 적어도 하나를 갖는 것으로 분류됨 -;
상기 제1 뷰에서의 인접한 픽셀들을 비교하게 하고;
상기 인접한 픽셀들의 상기 비교 및 상기 대응 관계들에 기초하여 고유한 픽셀들의 제1 패치 및 대응하는 픽셀들의 제2 패치를 식별하게 하며 - 상기 제2 패치는 상기 제2 뷰에서의 대응하는 패치들을 식별해 주는 대응 관계 리스트로 태깅됨 -;
인코딩된 비디오 데이터에 포함시킬 적어도 하나의 아틀라스를 생성하게 - 상기 적어도 하나의 아틀라스는 상기 고유한 픽셀들의 제1 패치 및 상기 대응하는 픽셀들의 제2 패치를 포함하고, 상기 인코딩된 비디오 데이터는 깊이 맵들을 포함하지 않음 - 하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체. - 제15항에 있어서, 상기 명령어들은 상기 하나 이상의 프로세서로 하여금 상기 제1 뷰에 대한 제1 프루닝 마스크를 생성하게 하고, 상기 제1 프루닝 마스크는 상기 제1 고유한 픽셀들 및 상기 제1 대응하는 픽셀들로부터의 텍스처 정보에 기초하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제16항에 있어서, 상기 제1 대응하는 픽셀들은 이전 프루닝된 뷰에 포함된 대응하는 픽셀들을 포함하지 않는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제16항에 있어서, 상기 명령어들은 상기 하나 이상의 프로세서로 하여금 상기 제2 뷰에 대한 제2 프루닝 마스크를 생성하게 하고, 상기 제2 프루닝 마스크는 상기 제2 고유한 픽셀들 및 상기 제2 대응하는 픽셀들로부터의 텍스처 정보에 기초하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제18항에 있어서, 상기 제2 대응하는 픽셀들은 상기 제1 뷰의 상기 제1 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제18항에 있어서, 상기 명령어들은 상기 하나 이상의 프로세서로 하여금 제3 뷰에 대한 제3 프루닝 마스크를 생성하게 하고, 상기 제3 프루닝 마스크는 제3 고유한 픽셀들 및 제3 대응하는 픽셀들로부터의 텍스처 정보에 기초하며, 상기 제3 대응하는 픽셀들은 상기 제1 뷰의 상기 제1 대응하는 픽셀들 및 상기 제2 뷰의 상기 제2 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제20항에 있어서, 상기 명령어들은 상기 하나 이상의 프로세서로 하여금 유지될 제1 복수의 픽셀들, 제2 복수의 픽셀들, 및 제3 복수의 픽셀들을 식별해 주기 위한 제1 값들 및 프루닝될 제4 복수의 픽셀들을 식별해 주기 위한 제2 값들을 포함할 상기 제1 프루닝 마스크, 상기 제2 프루닝 마스크, 및 상기 제3 프루닝 마스크를 생성하게 하고, 상기 제4 복수의 픽셀들은 상기 제1 뷰의 상기 제1 대응하는 픽셀들 및 상기 제2 뷰의 상기 제2 대응하는 픽셀들에 포함된 상기 제3 대응하는 픽셀들을 포함하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제21항에 있어서, 상기 명령어들은 상기 하나 이상의 프로세서로 하여금 상기 제1 프루닝 마스크, 상기 제2 프루닝 마스크, 및 상기 제3 프루닝 마스크를 집계하게 하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제15항에 있어서, 상기 명령어들은 상기 하나 이상의 프로세서로 하여금, 상기 제2 뷰 상에 재투영될 때, 상기 제2 뷰의 상기 복수의 픽셀들 하나하나의 위치들에 투영되지 않는 상기 제1 뷰의 상기 복수의 픽셀들 하나하나일 상기 제1 고유한 픽셀들을 식별하게 하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제15항에 있어서, 상기 명령어들은 상기 하나 이상의 프로세서로 하여금, 상기 제2 뷰 상에 재투영될 때, 상기 제2 뷰의 상기 제2 대응하는 픽셀들 하나하나 각자의 위치들에 투영되는 상기 제1 뷰의 상기 복수의 픽셀들 하나하나일 상기 제1 대응하는 픽셀들을 식별하게 하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제24항에 있어서, 상기 명령어들은 상기 하나 이상의 프로세서로 하여금, 상기 제1 뷰와 상기 제2 뷰에서의 그 각자의 텍스처 콘텐츠 사이의 차이가 임계값을 충족시킬 때 상기 제1 대응하는 픽셀들 중 상기 제1의 것과 상기 제2 대응하는 픽셀들 중 상기 제2의 것을 유사한 것으로서 식별하게 하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제15항에 있어서, 상기 적어도 하나의 아틀라스는 어트리뷰트 맵들 또는 점유 맵들 중 적어도 하나를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제15항에 있어서, 상기 인코딩된 비디오 데이터는 상기 적어도 하나의 아틀라스가 깊이 맵들을 포함하지 않는다는 것을 식별해 주기 위한 플래그를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 방법으로서,
제1 뷰의 복수의 픽셀들에 포함된 제1 고유한 픽셀들 및 제1 대응하는 픽셀들을 식별하는 단계;
제2 뷰의 복수의 픽셀들에 포함된 제2 고유한 픽셀들 및 제2 대응하는 픽셀들을 식별하는 단계 - 상기 제1 대응하는 픽셀들 하나하나는 상기 제2 대응하는 픽셀들 하나하나와 각자의 대응 관계들을 갖고, 상기 제1 대응하는 픽셀들 중 제1의 것 및 상기 제2 대응하는 픽셀들 중 제2의 것은 유사한 텍스처 정보 또는 상이한 텍스처 정보 중 적어도 하나를 갖는 것으로 분류됨 -;
상기 제1 뷰에서의 인접한 픽셀들을 비교하는 단계;
상기 인접한 픽셀들의 상기 비교 및 상기 대응 관계들에 기초하여 고유한 픽셀들의 제1 패치 및 대응하는 픽셀들의 제2 패치를 식별하는 단계 - 상기 제2 패치는 상기 제2 뷰에서의 대응하는 패치들을 식별해 주는 대응 관계 리스트로 태깅됨 -; 및
인코딩된 비디오 데이터에 포함시킬 적어도 하나의 아틀라스를 생성하는 단계 - 상기 적어도 하나의 아틀라스는 상기 고유한 픽셀들의 제1 패치 및 상기 대응하는 픽셀들의 제2 패치를 포함하고, 상기 인코딩된 비디오 데이터는 깊이 맵들을 포함하지 않음 -
를 포함하는, 방법. - 제28항에 있어서, 상기 제1 뷰에 대한 제1 프루닝 마스크를 생성하는 단계 - 상기 제1 프루닝 마스크는 상기 제1 고유한 픽셀들 및 상기 제1 대응하는 픽셀들로부터의 텍스처 정보에 기초함 -
를 더 포함하는, 방법. - 제29항에 있어서, 상기 제1 대응하는 픽셀들은 이전 프루닝된 뷰에 포함된 대응하는 픽셀들을 포함하지 않는, 방법.
- 제29항에 있어서, 상기 제2 뷰에 대한 제2 프루닝 마스크를 생성하는 단계 - 상기 제2 프루닝 마스크는 상기 제2 고유한 픽셀들 및 상기 제2 대응하는 픽셀들로부터의 텍스처 정보에 기초함 -
를 더 포함하는, 방법. - 제31항에 있어서, 상기 제2 대응하는 픽셀들은 상기 제1 뷰의 상기 제1 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함하는, 방법.
- 제31항에 있어서, 제3 뷰에 대한 제3 프루닝 마스크를 생성하는 단계 - 상기 제3 프루닝 마스크는 제3 고유한 픽셀들 및 제3 대응하는 픽셀들로부터의 텍스처 정보에 기초하며, 상기 제3 대응하는 픽셀들은 상기 제1 뷰의 상기 제1 대응하는 픽셀들 및 상기 제2 뷰의 상기 제2 대응하는 픽셀들에 포함된 대응하는 픽셀들을 포함함 -
를 더 포함하는, 방법. - 제33항에 있어서, 유지될 제1 복수의 픽셀들, 제2 복수의 픽셀들, 및 제3 복수의 픽셀들을 식별해 주기 위한 제1 값들 및 프루닝될 제4 복수의 픽셀들을 식별해 주기 위한 제2 값들을 포함할 상기 제1 프루닝 마스크, 상기 제2 프루닝 마스크, 및 상기 제3 프루닝 마스크를 생성하는 단계 - 상기 제4 복수의 픽셀들은 상기 제1 뷰의 상기 제1 대응하는 픽셀들 및 상기 제2 뷰의 상기 제2 대응하는 픽셀들에 포함된 상기 제3 대응하는 픽셀들을 포함함 -
를 더 포함하는, 방법. - 제34항에 있어서, 상기 제1 프루닝 마스크, 상기 제2 프루닝 마스크, 및 상기 제3 프루닝 마스크를 집계하는 단계
를 더 포함하는, 방법. - 제28항에 있어서, 상기 제2 뷰 상에 재투영될 때, 상기 제2 뷰의 상기 복수의 픽셀들 하나하나의 위치들에 투영되지 않는 상기 제1 뷰의 상기 복수의 픽셀들 하나하나일 상기 제1 고유한 픽셀들을 식별하는 단계
를 더 포함하는, 방법. - 제28항에 있어서, 상기 제2 뷰 상에 재투영될 때, 상기 제2 뷰의 상기 제2 대응하는 픽셀들 하나하나 각자의 위치들에 투영되는 상기 제1 뷰의 상기 복수의 픽셀들 하나하나일 상기 제1 대응하는 픽셀들을 식별하는 단계
를 더 포함하는, 방법. - 제37항에 있어서, 상기 제1 뷰와 상기 제2 뷰에서의 그 각자의 텍스처 콘텐츠 사이의 차이가 임계값을 충족시킬 때 상기 제1 대응하는 픽셀들 중 상기 제1의 것과 상기 제2 대응하는 픽셀들 중 상기 제2의 것을 유사한 것으로서 식별하는 단계
를 더 포함하는, 방법. - 제28항에 있어서, 상기 적어도 하나의 아틀라스는 어트리뷰트 맵들 또는 점유 맵들 중 적어도 하나를 포함하는, 방법.
- 제28항에 있어서, 상기 인코딩된 비디오 데이터는 상기 적어도 하나의 아틀라스가 깊이 맵들을 포함하지 않는다는 것을 식별해 주기 위한 플래그를 포함하는, 방법.
- 비디오 디코더로서, 비트스트림 디코더 및 렌더러를 포함하며,
상기 비트스트림 디코더는:
인코딩된 비디오 데이터에서 플래그를 식별하고 - 상기 플래그는 깊이 맵들을 포함하지 않는 제1 아틀라스 및 제2 아틀라스를 식별해 줌 -;
(i) 제1 뷰의 제1 메타데이터 및 (ii) 제2 뷰의 제2 메타데이터를 획득하기 위해 상기 인코딩된 비디오 데이터를 디코딩하며 - 상기 제1 뷰 및 상기 제2 뷰로부터의 패치들은 동일한 아틀라스에 속하거나 상이한 아틀라스들에 걸쳐 분포되고, 상기 제1 뷰는 제1 아틀라스 내의 제1 패치들을 포함하고, 상기 제2 뷰는 대응 관계 리스트로 태깅된 제2 아틀라스 또는 제1 아틀라스 내의 대응하는 제2 패치들을 포함함 -;
상기 렌더러는:
상기 제1 패치들에 포함된 픽셀들과 상기 대응하는 제2 패치들에 포함된 대응하는 픽셀들의 비교에 기초하여 깊이 정보를 결정하고;
상기 결정된 깊이 정보로부터 타깃 뷰를 합성하는, 비디오 디코더. - 제41항에 있어서, 상기 제1 메타데이터는 상기 제1 뷰에서의 픽셀 블록들을 상기 제1 뷰에 포함된 상기 제1 패치들에 매핑하는 제1 맵을 포함하고, 상기 제2 메타데이터는 상기 제2 뷰에서의 픽셀 블록들을 상기 제2 뷰에 포함된 상기 대응하는 제2 패치들에 매핑하는 제2 맵을 포함하는, 비디오 디코더.
- 제42항에 있어서, 상기 렌더러는 상기 제2 맵에 기초하여 상기 대응하는 제2 패치들을 재구성하는, 비디오 디코더.
- 제41항에 있어서, 상기 렌더러는 상기 인코딩된 비디오 데이터로부터의 상기 대응 관계 리스트에 기초하여 상기 대응하는 제2 패치들에서 상기 대응하는 픽셀들을 식별하는, 비디오 디코더.
- 제41항에 있어서, 상기 렌더러는 상기 제1 뷰로부터의 상기 제1 패치들 중 제1의 것 및 상기 제1 패치들 중 상기 제1의 것에 대응하는 것으로 결정되는 상기 제2 뷰로부터의 상기 대응하는 제2 패치들의 각자의 것에 기초하여 상기 깊이 정보를 결정하며, 상기 대응하는 제2 패치들의 상기 각자의 것은 상기 제1 패치들 중 상기 제1의 것과 상이한 텍스처 정보 또는 상기 제1 패치들 중 상기 제1의 것과 유사한 텍스처 정보를 갖는, 비디오 디코더.
- 명령어들을 포함하는 적어도 하나의 비일시적 컴퓨터 판독 가능 매체로서, 상기 명령어들은, 실행될 때, 하나 이상의 프로세서로 하여금, 적어도:
인코딩된 비디오 데이터에서 플래그를 식별하게 하고 - 상기 플래그는 깊이 맵들을 포함하지 않는 제1 아틀라스 및 제2 아틀라스를 식별해 줌 -;
(i) 제1 뷰의 제1 메타데이터 및 (ii) 제2 뷰의 제2 메타데이터를 획득하기 위해 상기 인코딩된 비디오 데이터를 디코딩하게 하며 - 상기 제1 뷰 및 상기 제2 뷰로부터의 패치들은 동일한 아틀라스에 속하거나 상이한 아틀라스들에 걸쳐 분포되고, 상기 제1 뷰는 제1 아틀라스 내의 제1 패치들을 포함하고, 상기 제2 뷰는 대응 관계 리스트로 태깅된 제2 아틀라스 또는 제1 아틀라스 내의 대응하는 제2 패치들을 포함함 -;
상기 제1 패치들에 포함된 픽셀들과 상기 대응하는 제2 패치들에 포함된 대응하는 제2 픽셀들의 비교에 기초하여 깊이 정보를 결정하게 하고;
상기 결정된 깊이 정보로부터 타깃 뷰를 합성하게 하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체. - 제46항에 있어서, 상기 제1 메타데이터는 상기 제1 뷰에서의 픽셀 블록들을 상기 제1 뷰에 포함된 상기 제1 패치들에 매핑하는 제1 맵을 포함하고, 상기 제2 메타데이터는 상기 제2 뷰에서의 픽셀 블록들을 상기 제2 뷰에 포함된 상기 대응하는 제2 패치들에 매핑하는 제2 맵을 포함하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제47항에 있어서, 상기 명령어들은 상기 하나 이상의 프로세서로 하여금 상기 제2 맵에 기초하여 상기 대응하는 제2 패치들을 재구성하게 하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제46항에 있어서, 상기 명령어들은 상기 하나 이상의 프로세서로 하여금 상기 인코딩된 비디오 데이터로부터의 상기 대응 관계 리스트에 기초하여 상기 대응하는 제2 패치들에서 상기 대응하는 제2 픽셀들을 식별하게 하는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 제46항에 있어서, 상기 명령어들은 상기 하나 이상의 프로세서로 하여금 상기 제1 뷰로부터의 상기 제1 패치들 중 제1의 것 및 상기 제1 패치들 중 상기 제1의 것에 대응하는 것으로 결정되는 상기 제2 뷰로부터의 상기 대응하는 제2 패치들의 각자의 것에 기초하여 상기 깊이 정보를 결정하게 하며, 상기 대응하는 제2 패치들의 상기 각자의 것은 상기 제1 패치들 중 상기 제1의 것과 상이한 텍스처 정보 또는 상기 제1 패치들 중 상기 제1의 것과 유사한 텍스처 정보를 갖는, 적어도 하나의 비일시적 컴퓨터 판독 가능 매체.
- 방법으로서,
인코딩된 비디오 데이터에서 플래그를 식별하는 단계 - 상기 플래그는 깊이 맵들을 포함하지 않는 제1 아틀라스 및 제2 아틀라스를 식별해 줌 -;
(i) 제1 뷰의 제1 메타데이터 및 (ii) 제2 뷰의 제2 메타데이터를 획득하기 위해 상기 인코딩된 비디오 데이터를 디코딩하는 단계 - 상기 제1 뷰 및 상기 제2 뷰로부터의 패치들은 동일한 아틀라스에 속하거나 상이한 아틀라스들에 걸쳐 분포되고, 상기 제1 뷰는 제1 아틀라스 내의 제1 패치들을 포함하고, 상기 제2 뷰는 대응 관계 리스트로 태깅된 제2 아틀라스 또는 제1 아틀라스 내의 대응하는 제2 패치들을 포함함 -;
상기 제1 패치들에 포함된 픽셀들과 상기 대응하는 제2 패치들에 포함된 대응하는 제2 픽셀들의 비교에 기초하여 깊이 정보를 결정하는 단계; 및
상기 결정된 깊이 정보로부터 타깃 뷰를 합성하는 단계
를 포함하는, 방법. - 제51항에 있어서, 상기 제1 메타데이터는 상기 제1 뷰에서의 픽셀 블록들을 상기 제1 뷰에 포함된 상기 제1 패치들에 매핑하는 제1 맵을 포함하고, 상기 제2 메타데이터는 상기 제2 뷰에서의 픽셀 블록들을 상기 제2 뷰에 포함된 상기 대응하는 제2 패치들에 매핑하는 제2 맵을 포함하는, 방법.
- 제52항에 있어서, 상기 제2 맵에 기초하여 상기 대응하는 제2 패치들을 재구성하는 단계
를 더 포함하는, 방법. - 제51항에 있어서, 상기 인코딩된 비디오 데이터로부터의 상기 대응 관계 리스트에 기초하여 상기 대응하는 제2 패치들에서 상기 대응하는 제2 픽셀들을 식별하는 단계
를 더 포함하는, 방법. - 제51항에 있어서, 상기 제1 뷰로부터의 상기 제1 패치들 중 제1의 것 및 상기 제1 패치들 중 상기 제1의 것에 대응하는 것으로 결정되는 상기 제2 뷰로부터의 상기 대응하는 제2 패치들의 각자의 것에 기초하여 상기 깊이 정보를 결정하는 단계
를 더 포함하며, 상기 대응하는 제2 패치들의 상기 각자의 것은 상기 제1 패치들 중 상기 제1의 것과 상이한 텍스처 정보 또는 상기 제1 패치들 중 상기 제1의 것과 유사한 텍스처 정보를 갖는, 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063009356P | 2020-04-13 | 2020-04-13 | |
| US63/009,356 | 2020-04-13 | ||
| PCT/US2020/066944 WO2021211173A1 (en) | 2020-04-13 | 2020-12-23 | Texture based immersive video coding |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220163364A true KR20220163364A (ko) | 2022-12-09 |
Family
ID=78083803
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227031516A KR20220163364A (ko) | 2020-04-13 | 2020-12-23 | 텍스처 기반 몰입형 비디오 코딩 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20230247222A1 (ko) |
| EP (1) | EP4136845A4 (ko) |
| JP (1) | JP2023521287A (ko) |
| KR (1) | KR20220163364A (ko) |
| CN (1) | CN115336269A (ko) |
| WO (1) | WO2021211173A1 (ko) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023148730A1 (en) * | 2022-02-06 | 2023-08-10 | Yoom.Com Ltd | Material segmentation |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102726044B (zh) * | 2010-01-22 | 2016-08-10 | 汤姆逊许可证公司 | 使用基于示例的超分辨率的用于视频压缩的数据剪切 |
| EP3481067A1 (en) * | 2017-11-07 | 2019-05-08 | Thomson Licensing | Method, apparatus and stream for encoding/decoding volumetric video |
| KR102459853B1 (ko) * | 2017-11-23 | 2022-10-27 | 삼성전자주식회사 | 디스패리티 추정 장치 및 방법 |
| KR102138536B1 (ko) * | 2018-06-08 | 2020-07-28 | 엘지전자 주식회사 | 360 비디오 시스템에서 오버레이 처리 방법 및 그 장치 |
| US20220138990A1 (en) * | 2018-07-13 | 2022-05-05 | Interdigital Vc Holdings, Inc. | Methods and devices for encoding and decoding three degrees of freedom and volumetric compatible video stream |
| US10887574B2 (en) * | 2018-07-31 | 2021-01-05 | Intel Corporation | Selective packing of patches for immersive video |
-
2020
- 2020-12-23 EP EP20931480.6A patent/EP4136845A4/en active Pending
- 2020-12-23 JP JP2022554297A patent/JP2023521287A/ja active Pending
- 2020-12-23 WO PCT/US2020/066944 patent/WO2021211173A1/en unknown
- 2020-12-23 US US17/918,859 patent/US20230247222A1/en active Pending
- 2020-12-23 CN CN202080098970.3A patent/CN115336269A/zh active Pending
- 2020-12-23 KR KR1020227031516A patent/KR20220163364A/ko unknown
Also Published As
| Publication number | Publication date |
|---|---|
| WO2021211173A1 (en) | 2021-10-21 |
| EP4136845A1 (en) | 2023-02-22 |
| EP4136845A4 (en) | 2024-04-17 |
| CN115336269A (zh) | 2022-11-11 |
| JP2023521287A (ja) | 2023-05-24 |
| US20230247222A1 (en) | 2023-08-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102658657B1 (ko) | 향상된 비디오 코딩을 위한 참조 프레임 재투영 | |
| CN112399178A (zh) | 视觉质量优化的视频压缩 | |
| US20140092439A1 (en) | Encoding images using a 3d mesh of polygons and corresponding textures | |
| US10075689B2 (en) | Region-of-interest based 3D video coding | |
| EP3970361A1 (en) | Immersive video coding techniques for three degree of freedom plus/metadata for immersive video (3dof+/miv) and video-point cloud coding (v-pcc) | |
| US10708627B2 (en) | Volumetric video compression with motion history | |
| US20220262041A1 (en) | Object-based volumetric video coding | |
| US10165267B2 (en) | Multiview video coding schemes | |
| US20150163499A1 (en) | Inter-layer residual prediction | |
| US11902540B2 (en) | Immersive video coding using object metadata | |
| US20230067541A1 (en) | Patch based video coding for machines | |
| US11991376B2 (en) | Switchable scalable and multiple description immersive video codec | |
| US20230247222A1 (en) | Texture based immersive video coding | |
| KR20210130148A (ko) | 몰입형 비디오 코딩을 위한 고 수준 구문 | |
| US20230370636A1 (en) | Image processing device and method | |
| US20240007668A1 (en) | Image processing device and method | |
| US20220329857A1 (en) | Mpeg media transport (mmt) signaling of visual volumetric video-based coding (v3c) content | |
| US20230032599A1 (en) | Methods and apparatuses for encoding, decoding and rendering 6dof content from 3dof+ composed elements |