KR20220116660A - 인공지능 스피커 기능을 탑재한 텀블러 장치 - Google Patents
인공지능 스피커 기능을 탑재한 텀블러 장치 Download PDFInfo
- Publication number
- KR20220116660A KR20220116660A KR1020210019766A KR20210019766A KR20220116660A KR 20220116660 A KR20220116660 A KR 20220116660A KR 1020210019766 A KR1020210019766 A KR 1020210019766A KR 20210019766 A KR20210019766 A KR 20210019766A KR 20220116660 A KR20220116660 A KR 20220116660A
- Authority
- KR
- South Korea
- Prior art keywords
- voice
- module
- speech
- tts
- user
- Prior art date
Links
Images



Classifications
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B65—CONVEYING; PACKING; STORING; HANDLING THIN OR FILAMENTARY MATERIAL
- B65D—CONTAINERS FOR STORAGE OR TRANSPORT OF ARTICLES OR MATERIALS, e.g. BAGS, BARRELS, BOTTLES, BOXES, CANS, CARTONS, CRATES, DRUMS, JARS, TANKS, HOPPERS, FORWARDING CONTAINERS; ACCESSORIES, CLOSURES, OR FITTINGS THEREFOR; PACKAGING ELEMENTS; PACKAGES
- B65D81/00—Containers, packaging elements, or packages, for contents presenting particular transport or storage problems, or adapted to be used for non-packaging purposes after removal of contents
- B65D81/38—Containers, packaging elements, or packages, for contents presenting particular transport or storage problems, or adapted to be used for non-packaging purposes after removal of contents with thermal insulation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/02—Casings; Cabinets ; Supports therefor; Mountings therein
- H04R1/028—Casings; Cabinets ; Supports therefor; Mountings therein associated with devices performing functions other than acoustics, e.g. electric candles
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/225—Feedback of the input speech
Abstract
인공지능 스피커 기능을 탑재한 텀블러 장치를 제공한다. 본 명세서는, 텀블러의 하우징; 상기 하우징의 상단부 일 영역에서 상기 하우징의 외형을 따라 둘러싸도록 구비되는 스피커; 음성 명령을 수신하는 마이크; 및 상기 마이크를 통해 사용자의 음성 명령을 수신하여 음성 인식을 수행하고, 상기 음성 명령에 따른 응답을 생성하기 위한 음성 합성을 수행하여 상기 스피커를 통해 상기 응답을 출력하도록 준비하는 음성 처리부;를 포함한다.
Description
본 명세서는 인공지능 스피커 기능을 탑재한 텀블러 장치에 관한 것이다.
스마트 스피커(smart speaker)는 무선 스피커의 일종으로서, 하나 이상의 인상적인 말(hot word)의 도움을 받아 상호작용 동작과 핸즈프리 활성화를 제공하는 가상 비서가 내장된 보이스 커맨드 디바이스이다.
일부 스마트 스피커들은 와이파이를 이용하는 스마트 장치의 역할을 할 수 있으며 블루투스와 기타 무선 프로토콜 표준을 사용하여 스마트홈 장치를 통제하기 위한 목적 등으로 오디오 재생의 이용 범위를 넓힐 수 있다. 이는 수많은 서비스와 플랫폼을 경유하는 호환성, 메시 네트워크를 통한 P2P 연결, 지능형 가상 비서와 같은 기능 등을 포함할 수 있으나 반드시 이에 국한된 것은 아니다. 각각의 스마트 스피커는 저마다 독창적인 인터페이스와 기능을 갖추고 있으며 애플리케이션이나 스마트 홈 소프트웨어를 통해 시작되거나 통제되는 것이 보통이다.
본 발명이 이루고자 하는 기술적 과제들은 이상에서 언급한 기술적 과제들로 제한되지 않으며, 언급되지 않은 또 다른 기술적 과제들은 이하의 발명의 상세한 설명으로부터 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자에게 명확하게 이해될 수 있을 것이다.
본 명세서의 일 실시예에 따른 인공지능 스피커 기능을 탑재한 텀블러는 텀블러 하우징; 상기 하우징의 상단부 일 영역에서 상기 하우징의 외형을 따라 둘러싸도록 구비되는 스피커; 음성 명령을 수신하는 마이크; 및 상기 마이크를 통해 사용자의 음성 명령을 수신하여 음성 인식을 수행하고, 상기 음성 명령에 따른 응답을 생성하기 위한 음성 합성을 수행하여 상기 스피커를 통해 상기 응답을 출력하도록 준비하는 음성 처리부;를 포함한다.
상기 차량 좌석은 등받이부, 착석부, 팔걸이부를 포함하고, 상기 진동 출력부는 상기 팔걸이부에 구비되는 것을 특징으로 하는 목적지 알람수단을 구비한다.
본 명세서의 일 실시예에 따르면, 인공지능 스피커 기능을 탑재한 텀블러를 제공할 수 있다.
본 발명에서 얻을 수 있는 효과는 이상에서 언급한 효과로 제한되지 않으며, 언급하지 않은 또 다른 효과들은 아래의 기재로부터 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자에게 명확하게 이해될 수 있을 것이다.
본 명세서에 관한 이해를 돕기 위해 상세한 설명의 일부로 포함되는, 첨부 도면은 본 명세서에 대한 실시예를 제공하고, 상세한 설명과 함께 본 명세서의 기술적 특징을 설명한다.
도 1은 본 명세서의 일 실시예에 따라 인공지능 스피커 기능을 탑재한 텀블러를 설명하기 위한 도면이다.
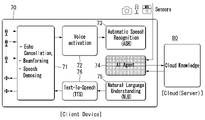
도 2는 본 발명의 일 실시예에 따른 인공지능 스피커 기능을 구비하는 텀블러 장치의 개략적인 블럭도를 도시한다.
도 3은 본 발명의 다른 실시예에 따른 인공지능 스피커 기능을 구비한 텀블러의 개략적인 블럭도를 도시한다.
도 4는 본 명세서의 인공지능 스피커 기능을 구비한 텀블러를 구현할 수 있는 지능형 에이전트의 개략적인 블럭도를 도시한다.
도 5는 본 발명의 일 실시예에 따라 인공지능 스피커 기능을 구비한 텀블러의 다른 블럭도이다.
본 발명에 관한 이해를 돕기 위해 상세한 설명의 일부로 포함되는, 첨부 도면은 본 발명에 대한 실시예를 제공하고, 상세한 설명과 함께 본 발명의 기술적 특징을 설명한다.
이하, 첨부된 도면을 참조하여 본 명세서에 개시된 실시예를 상세히 설명하되, 도면 부호에 관계없이 동일하거나 유사한 구성요소는 동일한 참조 번호를 부여하고 이에 대한 중복되는 설명은 생략하기로 한다. 이하의 설명에서 사용되는 구성요소에 대한 접미사 "모듈" 및 "부"는 명세서 작성의 용이함만이 고려되어 부여되거나 혼용되는 것으로서, 그 자체로 서로 구별되는 의미 또는 역할을 갖는 것은 아니다. 또한, 본 명세서에 개시된 실시예를 설명함에 있어서 관련된 공지 기술에 대한 구체적인 설명이 본 명세서에 개시된 실시예의 요지를 흐릴 수 있다고 판단되는 경우 그 상세한 설명을 생략한다. 또한, 첨부된 도면은 본 명세서에 개시된 실시예를 쉽게 이해할 수 있도록 하기 위한 것일 뿐, 첨부된 도면에 의해 본 명세서에 개시된 기술적 사상이 제한되지 않으며, 본 발명의 사상 및 기술 범위에 포함되는 모든 변경, 균등물 내지 대체물을 포함하는 것으로 이해되어야 한다.
제1, 제2 등과 같이 서수를 포함하는 용어는 다양한 구성요소들을 설명하는데 사용될 수 있지만, 상기 구성요소들은 상기 용어들에 의해 한정되지는 않는다. 상기 용어들은 하나의 구성요소를 다른 구성요소로부터 구별하는 목적으로만 사용된다.
어떤 구성요소가 다른 구성요소에 "연결되어" 있다거나 "접속되어" 있다고 언급된 때에는, 그 다른 구성요소에 직접적으로 연결되어 있거나 또는 접속되어 있을 수도 있지만, 중간에 다른 구성요소가 존재할 수도 있다고 이해되어야 할 것이다. 반면에, 어떤 구성요소가 다른 구성요소에 "직접 연결되어" 있다거나 "직접 접속되어" 있다고 언급된 때에는, 중간에 다른 구성요소가 존재하지 않는 것으로 이해되어야 할 것이다.
단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수의 표현을 포함한다.
본 출원에서, "포함한다" 또는 "가지다" 등의 용어는 명세서상에 기재된 특징, 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것이 존재함을 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다.
도 1은 본 명세서의 일 실시예에 따라 인공지능 스피커 기능을 탑재한 텀블러를 설명하기 위한 도면이다.
도 1을 참조하면, 인공지능 스피커 기능을 탑재한 텀블러는 텀블러 하우징(C), 상기 하우징의 상단부 일 영역에서 상기 하우징의 외형을 따라 둘러싸도록 구비되는 스피커(B); 음성 명령을 수신하는 마이크를 포함할 수 있다.
상기 텀블러는 상기 마이크를 통해 사용자의 음성 명령을 수신하여 음성 인식을 수행하고, 상기 음성 명령에 따른 응답을 생성하기 위한 음성 합성을 수행하여 상기 스피커를 통해 상기 응답을 출력하도록 준비하는 음성 처리부를 더 포함한다.
상기 음성 처리부는 인공 지능을 통한 음성 처리를 위해 음성 인식 모듈과 음성 합성 모듈을 구비할 수 있다. 상기 텀블러는 무선 통신부를 더 구비하고 상기 무선 통신부를 통해 마이크에서 수신한 사용자의 음성 명령을 서버로 전송하고 서버에서 음성 인식 동작을 수행한 후, 그 결과값을 통신부를 통해 전달받을 수도 있다. 상기 서버로 전달된 음성 인식 결과에 기초하여 음성 합성 과정을 수행하고 스피커를 통해 음성 합성 결과를 출력할 수 있다.
이하, 음성 처리기능에 대항 보다 상세하게 설명한다.
도 2는 본 발명의 일 실시예에 따른 인공지능 스피커 기능을 구비하는 텀블러 장치의 개략적인 블럭도를 도시한다.
엔드 투 엔드(end-to-end) 음성 UI 환경에서 음성 이벤트를 처리하기 위해서는 다양한 구성요소가 필요하다. 음성 이벤트를 처리하는 시퀀스는 음성 신호를 수집하여(Signal acquisition and playback), 음성 사전 처리(Speech Pre Processing), 음성 활성화(Voice Activation), 음성 인식(Speech Recognition), 자연어 이해(Natural Language Processing) 및 최종적으로 장치가 사용자에게 응답하는 음성 합성(Speech Synthesis) 과정을 수행한다.
클라이언트 디바이스(50)는 입력 모듈을 포함할 수 있다. 상기 입력 모듈은 사용자로부터 사용자 입력을 수신할 있다. 예를 들어, 입력 모듈은 연결된 외부 장치(예를 들어, 키보드, 헤드셋) 으로부터 사용자 입력을 수신할 수 있다. 또한 예를 들어, 입력 모듈은 터치 스크린을 포함할 수 있다. 또한 예를 들어, 입력 모듈은 사용자 단말에 위치한 하드웨어 키를 포함할 수 있다.
일 실시예에 의하면, 상기 입력 모듈은 사용자의 발화를 음성 신호로 수신할 수 있는 적어도 하나의 마이크를 포함할 수 있다. 상기 입력 모듈은 발화 입력 시스템(speech input system)을 포함하고, 상기 발화 입력 시스템을 통해 사용자의 발화를 음성 신호로 수신할 수 있다. 상기 적어도 하나의 마이크는 오디오 입력을 위한 입력 신호를 생성함으로써, 유저의 발화에 대한 디지털 입력 신호를 결정할 수 있다. 일 실시예에 의하면, 복수의 마이크가 어레이로 구현될 수 있다. 어레이는 기하학적 패턴, 예를 들어, 선형 기하학적 형태, 원형 기하학적 형태 또는 임의의 다른 구성으로 배열될 수 있다. 예를 들어, 소정 지점에 대하여, 네 개의 센서들의 어레이는 네 개의 방향들로부터 사운드를 수신하기 위해 90도로 구분되어 원형의 패턴으로 배치될 수 있다. 일부 구현들에서, 상기 마이크는 데이터 통신 내 공간적으로 서로 다른 어레이의 센서들을 포함할 수 있는데, 센서들의 네트워크화된 어레이가 포함될 수 있다. 마이크는 무지향성(omnidirectional), 방향성(directional, 예를 들어, 샷건(shotgun) 마이크)등을 포함할 수 있다.
클라이언트 디바이스(50)는 상기 입력 모듈(예를 들어, 마이크)을 통해 수신된 사용자 입력(음성 신호)를 전처리할 수 있는 전처리 모듈(pre-processing module)(51)을 포함할 수 있다.
상기 전처리 모듈(51)은 적응 반향 제거(adaptive echo canceller, AEC) 기능을 포함함으로써, 상기 마이크를 통해 입력된 사용자 음성 신호에 포함된 에코(echo)를 제거할 수 있다. 상기 전처리 모듈(51)은 노이즈 억제(noise suppression, NS) 기능을 포함함으로써, 사용자 입력에 포함된 배경 잡음을 제거할 수 있다. 상기 전처리 모듈(51)은 종점 검출(end-point detect, EPD) 기능을 포함함으로써, 사용자 음성의 종점을 검출하여 사용자의 음성이 존재하는 부분을 찾을 수 있다. 또한, 상기 전처리 모듈(51)은 자동 이득 제어(automatic gain control, AGC) 기능을 포함함으로써, 상기 사용자 입력을 인식하여 처리하기 적합하도록 상기 사용자 입력의 음량을 조절할 수 있다.
클라이언트 디바이스(50)는 음성 인식 활성화(voice activation) 모듈(52)을 포함할 수 있다. 상기 음성인식 활성화 모듈(52)은 사용자의 호출을 인식하는 웨이크업(wake up) 명령을 인식할 수 있다. 상기 음성인식 활성화 모듈(52)은 전처리 과정을 거친 사용자 입력으로부터 소정의 키워드(ex, Hi LG)를 디텍트할 수 있다. 상기 음성인식 활성화 모듈(52)은 대기 상태로 존재하여 올 웨이즈 온 키워드 디텍트(Always-on keyword detection) 기능을 수행할 수 있다.
클라이언트 디바이스(50)는 사용자 음성입력을 클라우드 서버로 전송할 수 있다. 사용자 음성을 처리하기 위한 핵심 구성인 자동 음성 인식(ASR), 자연어 이해(NLU) 동작은 컴퓨팅, 저장, 전원 제약 등으로 인해 전통적으로 클라우드에서 실행되고 있는 것이 일반적이다. 상기 클라우드는 클라이언트로부터 전송된 사용자 입력을 처리하는 클라우드 디바이스(60)를 포함할 수 있다. 상기 클라우드 디바이스(60)는 서버 형태로 존재할 수 있다.
클라우드 디바이스(60)는 자동 음성 인식(Auto Speech Recognition, ASR) 모듈(61), 지능형 에이전트(Artificial Intelligent Agent)(62), 자연어 이해(Natural Language Understanding, NLU) 모듈(63), 텍스트 음성 변환(Text-to-Speech, TTS) 모듈(64)과, 서비스 매니저(65)를 포함할 수 있다.
ASR 모듈(61)은 클라이언트 디바이스(50)로부터 수신된 사용자 음성 입력을 텍스트 데이터로 변환할 수 있다.
ASR 모듈(61)은 프론트-엔드 스피치 프리프로세서(front-end speech pre-processor)를 포함한다. 프론트-엔드 스피치 프리프로세서는 스피치 입력으로부터 대표적인 특징을 추출한다. 예를 들어, 프론트-엔드 스피치 프리프로세서는 스피치 입력을 푸리에 변환을 수행하여 대표적인 다차원 벡터의 시퀀스로서 스피치 입력을 특징짓는 스펙트럼 특징을 추출한다. 또한, ASR 모듈(61)은 하나 이상의 스피치 인식 모델(예컨대, 음향 모델 및/또는 언어 모델)을 포함하고, 하나 이상의 스피치 인식 엔진을 구현할 수 있다. 스피치 인식 모델의 예는 은닉 마르코프 모델(hidden Markov models), 가우시안 혼합 모델(Gaussian-Mixture Models), 딥 신경망 모델(Deep Neural Network Models), n-gram 언어 모델, 및 기타 통계 모델을 포함한다. 스피치 인식 엔진의 예는 동적 시간 왜곡 기반 엔진 및 가중치 유한 상태 변환기(WFST) 기반 엔진을 포함한다. 하나 이상의 스피치 인식 모델 및 하나 이상의 스피치 인식 엔진은 중간 인식 결과들(예를 들어, 음소, 음소 문자열, 및 하위 단어들), 및 궁극적으로 텍스트 인식 결과들(예컨대, 단어, 단어 문자열, 또는 토큰들의 시퀀스)을 생성하기 위해 프론트-엔드 스피치 프리프로세서의 추출된 대표 특징들을 처리하는 데 사용될 수 있다.
ASR 모듈(61)이 텍스트 문자열(예를 들어, 단어들, 또는 단어들의 시퀀스, 또는 토큰들의 시퀀스)을 포함하는 인식 결과를 생성하면, 인식 결과는 의도 추론을 위해 자연 언어 처리 모듈(732)로 전달된다. 일부 예들에서, ASR 모듈(730)은 스피치 입력의 다수의 후보 텍스트 표현들을 생성한다. 각각의 후보 텍스트 표현은 스피치 입력에 대응하는 단어들 또는 토큰들의 시퀀스이다.
NLU 모듈(63)은 문법적 분석(Syntactic analyze) 또는 의미적 분석(Semantic analyze)을 수행하여 사용자 의도를 파악할 수 있다. 상기 문법적 분석은 문법 단위(예를 들어, 단어, 구, 형태소 등)를 나누고, 나누어진 단위가 어떠한 문법적인 요소를 갖는지 파악할 수 있다. 상기 의미적 분석은 의미(semantic) 매칭, 룰(rule) 매칭, 포뮬러(formula) 매칭 등을 이용하여 수행할 수 있다. 이에 따라, NUL 모듈(63)은 사용자 입력이 어느 도메인(domain), 의도(intent) 또는 상기 의도를 표현하는데 필요한 파라미터(parameter)를 획득할 수 있다.
상기 NLU 모듈(63)은 도메인, 의도 및 상기 의도를 파악하는데 필요한 파라미터로 나누어진 매핑 규칙을 이용하여 사용자의 의도 및 파라미터를 결정할 수 있다. 예를 들어, 하나의 도메인(예를 들어, 알람)은 복수의 의도(예를 들어, 알람 설정, 알람 해제)를 포함할 수 있고, 하나의 의도는 복수의 파라미터(예를 들어, 시간, 반복 횟수, 알람음 등)을 포함할 수 있다. 복수의 룰은, 예를 들어, 하나 이상의 필수 요소 파라미터를 포함할 수 있다. 상기 매칭 규칙은 자연어 이해 데이터 베이스(Natural Language Understanding Database)에 저장될 수 있다.
상기 NLU 모듈(63)은 형태소, 구 등의 언어적 특징(예를 들어, 문법적 요소)을 이용하여 사용자 입력으로부터 추출된 단어의 의미를 파악하고, 상기 파악된 단어의 의미를 도메인 및 의도에 매칭시켜 사용자의 의도를 결정한다. 예를 들어, NLU 모듈(63)은 각각의 도메인 및 의도에 사용자 입력에서 추출된 단어가 얼마나 포함되어 있는지를 계산하여 사용자 의도를 결정할 수 있다. 일 실시예에 따르면, NLU 모듈(63)은 상기 의도를 파악하는데 기초가된 단어를 이용하여 사용자 입력의 파라미터를 결정할 수 있다. 일 실시예에 따르면, NLU 모듈(63)은 사용자 입력의 의도를 파악하기 위한 언어적 특징이 저장된 자연어 인식 데이터 베이스를 이용하여 사용자의 의도를 결정할 수 있다. 또한 일 실시예에 따르면, NLU 모듈(63)은 개인화 언어 모델(personal language model, PLM)을 이용하여 사용자의 의도를 결정할 수 있다. 예를 들어, NLU 모듈(63)은 개인화된 정보(예를 들어, 연락처 리스트, 음악 리스트, 스케줄 정보, 소셜 네트워크 정보 등)을 이용하여 사용자의 의도를 결정할 수 있다. 상기 개인화 언어 모델은, 예를 들어, 자연어 인식 데이터 베이스에 저장될 수 있다. 일 실시예에 따르면, NLU 모듈(63) 뿐 아니라 ASR 모듈(61)도 자연어 인식 데이터 베이스에 저장된 개인화 언어 모델을 참고하여 사용자 음성을 인식할 수 있다.
NLU 모듈(63)은 자연어 생성 모듈(미도시)을 더 포함할 수 있다. 상기 자연어 생성 모듈은 지정된 정보를 텍스트 형태로 변경할 수 있다. 상기 텍스트 형태로 변경된 정보는 자연어 발화의 형태일 수 있다. 상기 지정된 정보는 예를 들어, 추가 입력에 대한 정보, 사용자 입력에 대응되는 동작의 완료를 안내하는 정보 또는 사용자의 추가 입력을 안내하는 정보 등을 포함할 수 있다. 상기 텍스트 형태로 변경된 정보는 클라이언트 디바이스로 전송되어 디스플레이에 표시되거나, TTS 모듈로 전송되어 음성 형태로 변경될 수 있다.
음성 합성 모듈(TTS 모듈, 64)은 텍스트 형태의 정보를 음성 형태의 정보로 변경할 수 있다. TTS 모듈(64)은 NLU 모듈(63)의 자연어 생성 모듈로부터 텍스트 형태의 정보를 수신하고, 상기 텍스트 형태의 정보를 음성 형태의 정보로 변경하여 클라이언트 디바이스(50)로 전송할 수 있다. 상기 클라이언트 디바이스(50)는 상기 음성 형태의 정보를 스피커를 통해 출력할 수 있다.
음성 합성 모듈(64)은 제공된 텍스트에 기초하여 스피치 출력을 합성한다. 예를 들어, 음성 인식 모듈(ASR)(61)에서 생성된 결과는 텍스트 문자열의 형태이다. 음성 합성 모듈(64)은 텍스트 문자열을 가청 스피치 출력으로 변환한다. 음성 합성 모듈(64)은, 텍스트로부터의 스피치 출력을 생성하기 위하여 임의의 적절한 스피치 합성 기법을 사용하는데, 이는 편집 합성(concatenative synthesis), 단위 선택 합성(unit selection synthesis), 다이폰 합성, 도메인-특정 합성, 포먼트 합성(Formant synthesis), 조음 합성(Articulatory synthesis), HMM(hidden Markov model) 기반 합성, 및 정현파 합성(sinewave synthesis)을 포함하지만 이로 한정되지 않는다.
일부 예들에서, 음성 합성 모듈(64)은 단어들에 대응하는 음소 문자열에 기초하여 개별 단어들을 합성하도록 구성된다. 예를 들어, 음소 문자열은 생성된 텍스트 문자열의 단어와 연관된다. 음소 문자열은 단어와 연관된 메타데이터에 저장된다. 음성 합성 모듈(64)은 스피치 형태의 단어를 합성하기 위해 메타데이터 내의 음소 문자열을 직접 프로세싱하도록 구성된다.
클라우드 환경은 일반적으로 클라이언트 디바이스보다 많은 처리 능력 또는 리소스를 갖기때문에, 클라이언트 측 합성에서 실제보다 높은 품질의 스피치 출력을 획득하는 것이 가능하다. 그러나, 본 발명은 이에 한정되지 않으며, 실제로 음성 합성 과정이 클라이언트 측에서 이루어질 수 있음은 물론이다.
한편, 본 발명의 일 실시예에 따라 클라우드 환경에는 지능형 에이전트(Artificial Intelligence Agent, AI 에이전트)(62)를 더 포함할 수 있다. 상기 지능형 에이전트(62)는 전술한 ASR 모듈(61), NLU 모듈(62) 및/또는 TTS 모듈(64)이 수행하는 기능 중 적어도 일부의 기능을 수행하도록 설계될 수 있다. 또한 상기 지능형 에이전트 모듈(62)은 ASR 모듈(61), NLU 모듈(62) 및/또는 TTS 모듈(64) 각각의 독립적인 기능을 수행하는데 기여할 수 있다.
상기 지능형 에이전트 모듈(62)은 심층학습(딥러닝)을 통해 전술한 기능들을 수행할 수 있다. 상기 심층학습은 어떠한 데이터가 있을 때 이를 컴퓨터가 알아 들을 수 있는 형태(예를 들어 이미지의 경우는 픽셀정보를 열벡터로 표현하는 등)로 표현(representation)하고 이를 학습에 적용하기 위해 많은 연구(어떻게 하면 더 좋은 표현기법을 만들고 또 어떻게 이것들을 학습할 모델을 만들지에 대한)가 진행되고 있으며, 이러한 노력의 결과로 심층 신경망(DNN, deep neural networks), 합성곱 신경망(CNN, convolutional deep neural networks), 순환 신경망(RNN, Recurrent Boltzmann Machine), 제한 볼츠만 머신(RBM, Restricted Boltzmann Machine), 심층 신뢰 신경망(DBN, deep belief networks), 심층 Q-네트워크(Deep Q-Network)와 같은 다양한 딥 러닝 기법들이 컴퓨터비젼, 음성인식, 자연어처리, 음성/신호처리 등의 분야에 적용될 수 있다.
현재 모든 주요 상업 음성인식 시스템(MS 코타나, 스카이프 번역기, 구글 나우, 애플 시리 등등)이 딥 러닝 기법에 기반하고있다.
특히, 지능형 에이전트 모듈(62)은 자연어 처리 분야에서 심층 인공신경망 구조를 이용하여 자동 번역(machine translation), 감정 분석(emotion analysis), 정보 검색(information retrieval)을 비롯한 다양한 자연언어처리 과정을 수행할 수 있다.
한편, 상기 클라우드 환경은 다양한 개인화된 정보를 수집하여 상기 지능형 에이전트(62)의 기능을 지원할 수 있는 서비스 매니저(service manager)(65)를 포함할 수 있다. 상기 서비스 매니저를 통해 획득되는 개인화된 정보는, 클라이언트 디바이스(50)가 클라우드 환경을 통해 이용하는 적어도 하나의 데이터(캘린더 애플리케이션, 메시징 서비스, 뮤직 애플리케이션 사용 등), 상기 클라이언트 디바이스(50) 및/또는 클라우드(60)가 수집하는 적어도 하나의 센싱 데이터들(카메라, 마이크로폰, 온도, 습도, 자이로 센서, C-V2X, 펄스(pulse), 조도(Ambient light), 홍채 인식(Iris scan) 등), 상기 클라이언트 디바이스(50)와 직접적으로 관련 없는 오프 디바이스 데이터들을 포함할 수 있다. 예를 들어, 상기 개인화된 정보는, 맵(maps), SMS, News, Music, Stock, Weather, wikipedia 정보를 포함할 수 있다.
상기 지능형 에이전트(62)은 설명의 편의를 위해 ASR 모듈(61), NLU 모듈(63) 및 TTS 모듈(64)과 구분되도록 별도의 블럭으로 표현하였으나, 상기 지능형 에이전트(62)는 상기 각 모듈(61,62,64)의 적어도 일부 또는 전부의 기능을 수행할 수도 있다.
이상, 도 2에서는 상기 지능형 에이전트(62)가 컴퓨팅 연산, 저장 및 전원 제약 등으로 인해 클라우드 환경에서 구현되는 예를 설명하였으나, 본 발명은 이에 한정되는 것은 아니다.
예를 들어, 도 3은 상기 지능형 에이전트(AI agent)가 클라이언트 디바이스에 포함되어 있는 경우를 제외하고는 도 4에 도시된 바와 동일하다.
도 3은 본 발명의 다른 실시예에 따른 인공지능 스피커 기능을 구비한 텀블러의 개략적인 블럭도를 도시한다. 도 3에 도시된 클라이언트 디바이스(70) 및 클라우드 환경(80)은 도 2에서 언급한 클라이언트 디바이스(50) 및 클라우드 환경(60)에 일부 구성 및 기능에 있어서 차이가 있을 뿐 대응될 수 있다. 이에 따라 대응되는 블럭의 구체적인 기능에 대해서는 도 4를 참조할 수 있다.
도 3를 참조하면, 클라이언트 디바이스(70)는 전처리 모듈(51), 음성 인식 활성화(voice activation) 모듈(72), ASR 모듈(73), 지능형 에이전트(74), NLU 모듈(75), TTS 모듈(76)을 포함할 수 있다. 또한, 클라이언트 디바이스(50)는 입력 모듈(적어도 하나의 마이크로 폰)과, 적어도 하나의 출력 모듈을 포함할 수 있다.
또한, 클라우드 환경은 개인화된 정보를 지식(knowledge) 형태로 저장하는 클라우드 지식(Cloud Knowledge)(80)을 포함할 수 있다.
도 3에 도시된 각 모듈의 기능은 도 2를 참조할 수 있다. 다만, ASR 모듈(73), NLU 모듈(75) 및 TTS 모듈(76)이 클라이언트 디바이스(70)에 포함되어 있어서 음성 인식 및 음성 합성 등의 음성 처리 과정을 위해 클라우드와의 통신이 필요없을 수 있으며, 이에 따라 즉각적이고 실시간 음성 처리처리 동작이 가능하게 된다.
도 2 및 도 3에 도시된 각 모듈은 음성 처리 과정을 설명하기 위한 예시일 뿐이며, 도 2 및 도 3에 도시된 모듈보다 더 많거나 더 적은 모듈을 가질 수 있다. 또한, 둘 이상의 모듈을 조합할 수 있거나 또는 상이한 모듈 또는 상이한 배열의 모듈을 가질 수 있다는 것에 유의해야 한다. 도 2 및 도 3에 도시된 다양한 모듈들은 하나 이상의 신호 프로세싱 및/또는 주문형 직접 회로, 하드웨어, 하나 이상의 프로세서에 의한 실행을 위한 소프트웨어 명령어들, 펌웨어 또는 이들의 조합으로 구현될 수 있다.
도 4는 본 명세서의 인공지능 스피커 기능을 구비한 텀블러를 구현할 수 있는 지능형 에이전트의 개략적인 블럭도를 도시한다.
도 4를 참조하면, 상기 지능형 에이전트(74)는 도 2 및 도 3을 통해 설명한 음성 처리 과정에서 ASR 동작, NLU 동작 및 TTS 동작을 수행하는 것 외에, 사용자와 상호 작용(interactive operation)을 지원할 수 있다. 또는 상기 지능형 에이전트(74)는 컨텍스트 정보를 이용하여, NLU 모듈(63)이 ASR 모듈(61)로부터 수신된 텍스트 표현들에 포함된 정보를 보다 명확하게 하고, 보완하거나 추가적으로 정의하는 동작을 수행하는데 기여할 수 있다.
여기서, 컨텍스트 정보는, 클라이언트 디바이스 사용자의 선호도, 클라이언트 디바이스의 하드웨어 및/또는 소프트웨어 상태들, 사용자 입력 전, 입력 중, 또는 입력 직후에 수집되는 다양한 센서 정보, 상기 지능형 에이전트와 사용자 사이의 이전 상호 작용들(예를 들어, 대화) 등을 포함할 수 있다. 본 문서에서 컨텍스트 정보는 동적이고, 시간, 위치, 대화의 내용 및 기타 요소들에 따라 가변되는 특징임을 물론이다.
지능형 에이전트(74)는 컨텍스트 퓨전 및 학습 모듈(91), 로컬 지식(92), 다이얼로그 매니지먼트(93)를 더 포함할 수 있다.
컨텍스트 퓨전 및 학습모듈(91)은 적어도 하나의 데이터에 기초하여 사용자의 의도를 학습할 수 있다. 상기 적어도 하나의 데이터는 클라이언트 디바이스 또는 클라우드 환경에서 획득되는 적어도 하나의 센싱 데이터를 포함할 수 있다. 또한, 상기 적어도 하나의 데이터는 화자 식별(speaker identification), 음향 사건 인지(Acoustic event detection), 화자의 개인 정보(성별 및 나이)(Gender and age detection), 음성 활성도 검출(VAD, voice activity detection), 감정 정보(Emotion Classification) 을 포함할 수 있다.
상기 화자 식별은, 발화 하는 사람을 음성에 의해 등록된 대화군 속에서 특정하는 것을 의미할 수 있다. 상기 화자 식별은 기 등록된 화자를 식별하거나, 새로운 화자로 등록하는 과정을 포함할 수 있다. 음향 사건 인지(Acoustic event detection)는 음성 인식 기술을 넘어서 음향 자체를 인식함으로써, 소리의 종류, 소리의 발생 장소를 인지할 수 있다. 음성 활성도 검출(VAD)은 음악, 잡음 또는 다른 사운드를 포함할 수 있는 오디오 신호에서 인간의 스피치(음성)의 존재 또는 부재가 검출되는 스피치 프로세싱 기술이다. 일 예에 따라 지능형 에이전트(74)는 상기 입력된 오디오 신호로부터 스피치의 존재 여부를 확인할 수 있다. 일 예에 따라 지능형 에이전트(74)는 심층 신경망(DNN, deep neural networks) 모델을 이용하여 스피치 데이터(speech data)와 비 스피치 데이터(non-speech data)를 구분할 수 있다.
상기 컨텍스트 퓨전 및 학습 모듈(91)은 전술한 동작을 수행하기 위해 DNN 모델을 포함할 수 있으며, 상기 DNN 모델 및 클라이언트 디바이스 또는 클라우드 환경에서 수집되는 센싱 정보에 기초하여 사용자 입력의 의도를 확인할 수 있다.
상기 적어도 하나의 데이터는 예시적인 것에 불과하며 음성 처리 과정에서 사용자의 의도를 확인하는데 참조될수 있는 어떠한 데이터도 포함될 수 있음은 물론이다. 상기 적어도 하나의 데이터는, 전술한 DNN 모델을 통해 획득할 수 있음은 물론이다.
지능형 에이전트(74)는 로컬 지식(Local Knowledge)(92)을 포함할 수 있다. 상기 로컬 지식(92)은 사용자 데이터를 포함할 수 있다. 상기 사용자 데이터는 사용자의 선호도, 사용자 주소, 사용자의 초기 설정 언어, 사용자의 연락처 목록 등을 포함할 수 있다. 일 예에 따르면, 지능형 에이전트(74)는 사용자의 특정 정보를 이용하여 사용자의 음성 입력에 포함된 정보를 보완하여 사용자 의도를 추가적으로 정의할 수 있다. 예를 들어, "내 생일 파티에 내 친구들을 초대해주세요" 라는 사용자의 요청에 응답하여, 지능형 에이전트(74)는 "친구들"이 누구인지, "생일 파티"가 언제, 어디서 열리지를 결정하기 위해 사용자에게 보다 명확한 정보를 제공하도록 요구하지 않고, 상기 로컬 지식(92)을 이용할 수 있다.
지능형 에이전트(74)는 다이얼로그 관리(Dialog Management)(93)를 더 포함할 수 있다. 상기 지능형 에이전트(74)는 사용자와의 음성 대화가 가능하도록 다이얼로그 인터페이스를 제공할 수 있다. 상기 다이얼로그 인터페이스는 사용자의 음성 입력에 응답을 디스플레이 또는 스피커를 통해 출력하는 과정을 의미할 수 있다. 여기서 상기 다이얼로그 인터페이스를 통해 출력하는 최종 결과물은 전술한 ASR 동작, NLU 동작 및 TTS 동작에 기초할 수 있다.
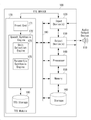
도 5는 본 발명의 일 실시예에 따라 인공지능 스피커 기능을 구비한 텀블러의 다른 블럭도이다.
도 5에 도시된 음성 합성 장치(TTS Device, 100)는, TTS 장치(100) 또는 다른 장치에 의해 처리된 음성을 출력하기 위한 오디오 출력 장치(110)를 포함할 수 있다.
도 5는 음성 합성을 수행하기 위한 음성 합성 장치(TTS Device, 100)를 개시한다. 본 명세서의 일 실시예는 상기 TTS 장치(100)에 포함될 수 있는 컴퓨터 판독 가능한 및 컴퓨터 실행 가능한 명령들을 포함할 수 있다. 도 5는 상기 TTS 장치(100)에 포함된 복수의 구성 요소들을 개시하지만, 상기 개시되지 않은 구성요소들이 상기 TTS 장치(100)에 포함될 수도 있음은 물론이다.
한편, 상기 TTS 장치(100)에 개시된 몇몇 구성요소들은 단일 구성요소로서, 하나의 장치에서 여러번 나타날 수 있다. 예를 들어, 상기 TTS 장치(100)는 복수의 입력 장치(120), 출력 장치(130) 또는 복수의 컨트롤러/프로세서(140)를 포함할 수 있다.
복수의 TTS 장치가 하나의 음성 합성 장치에 적용될 수도 있다. 그러한 다중 장치 시스템에서 상기 TTS 장치는 음성 합성 처리의 다양한 측면들을 수행하기 위한 서로 다른 구성요소들을 포함할 수 있다. 도 5에 도시된 TTS 장치(100)는 예시적인 것이며, 독립된 장치일 수 있으며, 보다 큰 장치 또는 시스템의 일 구성요소로 구현될 수도 있다.
본 발명의 일 실시예는 복수의 서로 다른 장치 및 컴퓨터 시스템 예를 들어, 범용 컴퓨팅 시스템, 서버-클라이언트 컴퓨팅 시스템, 전화(telephone) 컴퓨팅 시스템, 랩탑 컴퓨터, 휴대용 단말기, PDA, 테블릿 컴퓨터 등에 적용될 수 있다. 상기 TTS 장치(100)는 자동 입출금기(ATMs), 키오스크(kiosks), 글로벌 위치 시스템(GPS), 홈 어플라이언스(예를 들어, 냉장고, 오븐, 세탁기 등), 차량(vehicles), 전자 책 리더(ebook readers) 등의 음성 인식 기능을 제공하는 다른 장치 또는 시스템의 일 구성요소로 적용될 수도 있다.
도 5를 참조하면, 상기 TTS 장치(100)는 상기 TTS 장치(100) 또는 다른 장치에 의해 처리된 음성을 출력하기 위한 음성 출력 장치(110)를 포함할 수 있다. 상기 음성 출력 장치(110)는 스피커(speaker), 헤드폰(headphone) 또는 음성을 전파하는 다른 적절한 구성요소를 포함할 수 있다. 상기 음성 출력 장치(110)는 상기 TTS 장치(100)에 통합되거나, 상기 TTS 장치(100)와 분리되어 구현될 수도 있다.
상기 TTS 장치(100)는 상기 TTS 장치(100)의 구성요소들 사이에 데이터를 전달하기 위한 어드레스/데이터 버스(224)를 포함할 수 있다. 상기 TTS 장치(100) 내의 각 구성요소들은 상기 버스(224)를 통해 다른 구성요소들과 직접적으로 연결될 수 있다. 한편, 상기 TTS 장치(100) 내의 각 구성요소들은 TTS 모듈(170)과 직접적으로 연결될 수도 있다.
TTS 장치(100)는 제어부(프로세서)(140)를 포함할 수 있다. 상기 프로세서(208)는 데이터를 처리하기 위한 CPU, 데이터를 처리하는 컴퓨터 판독 가능한 명령 및 데이터 및 명령들을 저장하기 위한 메모리에 대응될 수 있다. 상기 메모리(150)는 휘발성 RAM, 비휘발성 ROM 또는 다른 타입의 메모리를 포함할 수 있다.
TTS 장치(100)는 데이터 및 명령을 저장하기 위한 스토리지(160)를 포함할 수 있다. 스토리지(160)는 마그네틱 스토리지, 광학식 스토리지, 고체 상태(solid-state) 스토리지 타입 등을 포함할 수 있다.
TTS 장치(100)는 입력 장치(120) 또는 출력 장치(130)를 통해 착탈식 또는 외장 메모리(예를 들어, 분리형 메모리 카드, 메모리 키 드라이브, 네트워크 스토리지 등)에 접속될 수 있다.
TTS 장치(100) 및 다양한 구성요소들을 동작시키기 위한 프로세서(140)에서 처리될 컴퓨터 명령(computer instructions)은, 프로세서(140)에 의해 실행될 수 있고, 메모리(150), 스토리지(160), 외부 디바이스 또는 후술할 TTS 모듈(170)에 포함된 메모리나 스토리지에 저장될 수 있다. 대안적으로, 실행 가능한 명령의 전부 또는 일부는 소프트웨어에 추가하여 하드웨어 또는 펌웨어에 내장될 수도 있다. 본 발명의 일 실시예는 예를 들어, 소프트웨어, 펌웨어 및/또는 하드웨어의 다양한 조합으로 구현될 수 있다.
TTS 장치(100)는 입력 장치(120), 출력 장치(130)를 포함한다. 예를 들어, 상기 입력 장치(120)는 마이크로폰, 터치 입력 장치, 키보드, 마우스, 스타일러스 또는 다른 입력 장치와 같은 오디오 출력 장치(110)를 포함할 수 있다. 상기 출력 장치(130)는 디스플레이(visual display or tactile display), 오디오 스피커, 헤드폰, 프린터 또는 기타 출력 장치가 포함될 수 있다. 입력 장치(120) 및/또는 출력 장치(130)는 또한 USB(Universal Serial Bus), FireWire, Thunderbolt 또는 다른 연결 프로토콜과 같은 외부 주변 장치 연결용 인터페이스를 포함할 수 있다. 입력 장치(120) 및/또는 출력 장치(130)는 또한 이더넷 포트, 모뎀 등과 같은 네트워크 연결을 포함할 수 있다. 무선 주파수(RF), 적외선(infrared), 블루투스(Bluetooth), 무선 근거리 통신망(WLAN)(WiFi 등)과 같은 무선 통신 장치 또는 5G 네트워크, LTE(Long Term Evolution) 네트워크, WiMAN 네트워크, 3G 네트워크와 같은 무선 네트워크 무선 장치를 포함할 수 있다. TTS 장치(100)는 입력 장치(120) 및/또는 출력 장치(130)를 통해 인터넷 또는 분산 컴퓨팅 환경(distributed computing environment)을 포함할 수도 있다.
TTS 장치(100)는 텍스트 데이터를 음성을 포함하는 오디오 파형을 처리하기 위한 TTS 모듈(170)을 포함할 수 있다.
TTS 모듈(170)은 버스(224), 입력 장치(120), 출력 장치(130), 오디오 출력 장치(110), 프로세서(140) 및/또는 TTS 장치(100)의 다른 구성요소에 접속될 수 있다.
텍스트 데이터(textual data)의 출처는 TTS 장치(100)의 내부 구성요소에 의해 생성된 것일 수 있다. 또한, 상기 텍스트 데이터의 출처는 키보드와 같이 입력 장치로부터 수신되거나, 네트워크 연결을 통해 TTS 장치(100)로 전송될 것일 수 있다. 텍스트는 TTS 모듈(170)에 의해 스피치로 변환하기 위한 텍스트, 숫자 및/또는 문장 부호(punctuation)를 포함하는 문장의 형태 일 수있다. 입력 텍스트는 또한 TTS 모듈(170)에 의한 처리를 위하여, 특수 주석(special annotation)을 포함할 수 있으며, 상기 특수 주석을 통해 특정 텍스트가 어떻게 발음되어야 하는지를 지시 할 수 있다. 텍스트 데이터는 실시간으로 처리되거나 나중에 저장 및 처리 될 수 있다.
TTS 모듈(170)은 전처리부(Front End)(171), 음성 합성 엔진(Speech Synthesis Engine)(172) 및 TTS 저장부(180)를 포함할 수 있다. 전처리부(171)는 입력 테스트 데이터를 음성 합성 엔진(172)에 의한 처리를 위해 기호 언어 표현(symbolic linguistic representation)으로 변환할 수 있다. 음성 합성 엔진(172)은 주석된 음성 단위 모델(annotated phonetic units models)과 TTS 저장부(180)에 저장된 정보를 비교하여 입력 텍스트를 음성으로 변환할 수 있다. 전처리부(171) 및 음성 합성 엔진(172)은 임베디드된 내부 프로세서 또는 메모리를 포함할 수 있거나, TTS 장치(100)에 포함된 프로세서(1400) 및 메모리(150)를 이용할 수 있다. 전처리부(171) 및 음성 합성 엔진(172)을 동작시키기 위한 명령들은 TTS 모듈(170), TTS 장치(100)의 메모리(150) 및 스토리지(160) 또는 외부 장치 내에 포함될 수도 있다.
TTS 모듈(170)로의 텍스트 입력은 프로세싱을 위해 전처리부(171)로 전송될 수 있다. 전처리부(1710)는 텍스트 정규화(text normalization), 언어 분석( linguistic analysis), 언어 운율 생성(linguistic prosody generation)을 수행하기 위한 모듈을 포함할 수 있다.
전처리부(171)는 텍스트 정규화 동작을 수행하는 동안, 텍스트 입력을 처리하고 표준 텍스트(standard text)를 생성하여, 숫자(numbers), 약어(abbreviations), 기호(symbols)를 쓰여진 것과 동일하게 변환한다.
전처리부(171)는 언어 분석 동작을 수행하는 동안, 정규화된 텍스트의 언어를 분석하여 입력 텍스트에 대응하는 일련의 음성학적 단위(phonetic units)를 생성할 수 있다. 이와 같은 과정은 발음 표기(phonetic transcription)로 호칭될 수 있다. 음성 단위(phonetic units)는 최종적으로 결합되어 음성(speech)으로서 TTS 장치(100)에 의해 출력되는 사운드 단위(sound units)의 심볼 표현을 포함한다. 다양한 사운드 유닛들이 음성 합성을 위해 텍스트를 분할하는데 사용될 수 있다. TTS 모듈(170)은 음소(phonemes, 개별 음향), 하프-음소(half-phonemes), 다이폰(di-phones, 인접한 음소의 전반과 결합된 하나의 음소의 마지막 절반), 바이폰(bi-phones, 두 개의 연속적인 음속), 음절(syllables), 단어(words), 문구(phrases), 문장(sentences), 또는 기타 단위들에 기초하여 음성을 처리할 수 있다. 각 단어는 하나 이상의 음성 단위(phonetic units)에 매핑될 수 있다. 이와 같은 매핑은 TTS 장치(100)에 저장된 언어 사전(language dictionary)을 이용하여 수행될 수 있다.
전처리부(171)에 의해 수행되는 언어 분석은 또한 접두사(prefixes), 접미사(suffixes), 구(phrases), 구두점(punctuation), 구문론 경계(syntactic boundaries)와 같은 서로 다른 문법적 요소들 확인하는 과정을 포함할 수 있다. 이와 같은 문법적 구성요소는 TTS 모듈(1700)에 의해 자연스러운 오디오 파형 출력을 만드는데 사용될 수 있다. 상기 언어 사전은 또한 TTS 모듈(170)에 의해 발생할 수 있는 이전에 확인되지 않은 단어 또는 문자 조합을 발음하는데 사용될 수 있는 문자 대 소리 규칙(letter-to-sound rules) 및 다른 도구들을 포함할 수 있다. 일반적으로 언어 사전에 포함된 정보들이 많을 수록 고 품질의 음성 출력을 보장할 수 있다.
상기 언어 분석에 기초하여, 전처리부(171)는 음성 단위(phonetic units)에 최종 음향 단위가 최종 출력 음성에서 어떻게 발음되어야 하는지를 나타내는 운율 특성(prosodic characteristics)으로 주석 처리된 언어 운율 생성을 수행할 수 있다.
상기 운율 특성은 음향 특징(acoustic features)으로도 호칭될 수 있다. 이 단계의 동작을 수행하는 동안, 전처리부(171)는 텍스트 입력을 수반하는 임의의 운율 주석(prosodic annotations)을 고려하여 TTS 모듈(170)에 통합할 수 있다. 이와 같은 음향 특징(acoustic features)은 피치(pitch), 에너지(energy), 지속 시간(duration) 등을 포함할 수 있다. 음향 특징의 적용은 TTS 모듈(170)이 이용할 수 있는 운율 모델(prosodic models)에 기초할 수 있다. 이러한 운율 모델은 특정 상황에서 음성 단위(phonetic units)가 어떻게 발음되어야 하는지를 나타낸다. 예를 들어, 운율 모델은 음절에서 음소의 위치(a phoneme's position in a syllable), 단어에서 음절의 위치(a syllable's position in a word), 문장 또는 구문에서 단어의 위치(a word's position in a sentence or phrase), 인접한 음운 단위(neighboring phonetic units) 등을 고려할 수 있다. 언어 사전과 마찬가지로, 운율 정보(prosodic model)의 정보가 많을수록 고품질의 음성 출력이 보장될 수 있다.
전처리부(171)의 출력은, 운율 특성(prosodic characteristics)으로 주석 처리된 일련의 음성 단위를 포함할 수 있다. 상기 전처리부(171)의 출력은 기호식 언어 표현(symbolic linguistic representation)으로 호칭될 수 있다. 상기 심볼릭 언어 표현은 음성 합성 엔진(172)에 전송될 수 있다. 상기 음성 합성 엔진(172)은 오디오 출력 장치(110)를 통해 사용자에게 출력하기 위해 스피치(speech)를 오디오 파형(audio waveform)으로의 변환 과정을 수행한다. 음성 합성 엔진(172)은 입력 텍스트를 효율적인 방식으로 고품질의 자연스러운 음성으로 변환하도록 구성될 수 있다. 이러한 고품질의 스피치는 가능한 한 화자(human speaker)와 유사하게 발음되도록 구성될 수 있다.
음성 합성 엔진(172)은 적어도 하나 이상의 다른 방법을 이용하여 음성 합성을 수행할 수 있다.
유닛 선택 엔진(Unit Selection Engine)(173)은 녹음된 스피치 데이터 베이스(recorded speech database)를, 상기 전처리부(171)에 의해 생성된 기호식 언어 표현(symbolic linguistic representation)과 대조한다. 유닛 선택 엔진(173)은 상기 심볼 언어 표현과 스피치 데이터베이스의 음성 오디오 유닛을 매칭한다. 음성 출력(speech output)을 형성하기 위해 매칭 유닛이 선택되고, 선택된 매칭 유닛들이 함께 연결될 수 있다. 각 유닛은 .wav 파일(피치, 에너지 등)과 연관된 다양한 음향 특성들의 설명(description)과 함께, 특정 사운드의 짧은 ,wav 파일과 같은 음성 유닛(phonetic unit)에 대응하는 오디오 파형(audio waveform) 뿐 아니라, 상기 음성 유닛이 단어, 문장 또는 문구, 이웃 음성 유닛에 표시되는 위치와 같은 다른 정보들을 포함할 수 있다.
유닛 선택 엔진(173)은 자연스러운 파형을 생성하기 위하여 유닛 데이터 베이스 내의 모든 정보를 이용하여 입력 텍스트를 매칭시킬 수 있다. 유닛 데이터 베이스는 유닛들을 스피치로 연결하기 위해 서로 다른 옵션들을 TTS 장치(100)에 제공하는 다수의 음성 유닛들의 예시를 포함할 수 있다. 유닛 선택의 장점 중 하나는, 데이터 베이스의 크기에 따라 자연스러운 자연스러운 음성 출력이 생성될 수 있다는 것이다. 또한, 유닛 데이터 베이스가 클수록 TTS 장치(100)는 자연스러운 음성을 구성할 수 있게 된다.
한편, 음성 합성은 전술한 유닛 선택 합성 외에 파라미터 합성 방법이 존재한다. 파라미터 합성은 인공적인 음성 파형을 생성하기 위해 주파수, 볼륨, 잡음과 같은 합성 파라미터들이 파라미터 합성 엔진(175), 디지털 신호 프로세서, 또는 다른 오디오 생성 장치에 의해 변형될 수 있다.
파라미터 합성은, 음향 모델 및 다양한 통계 기법을 사용하여 기호식 언어 표현(symbolic linguistic representation) 원하는 출력 음성 파라미터와 일치시킬 수 있다. 파라미터 합성에는 유닛 선택과 관련된 대용량의 데이터베이스 없이도 음성을 처리할 수 있을 뿐 아니라, 높은 처리 속도로 정확한 처리가 가능하다. 유닛 선택 합성 방법 및 파라미터 합성 방법은 개별적으로 수행되거나 결합되어 수행되어 음성 오디오 출력을 생성할 수 있다.
파라미터 음성 합성은 다음과 같이 수행될 수 있다. TTS 모듈(170)은 오디오 신호 조작에 기초하여 기호식 언어 표현(symbolic linguistic representation)을 텍스트 입력의 합성 음향 파형(synthetic acoustic waveform)으로 변환이 가능한 음향 모델(acoustic model)을 포함할 수 있다. 상기 음향 모델은, 입력 음성 단위 및/또는 운율 주석(prosodic annotations)에 특정 오디오 파형 파라미터(specific audio waveform parameters)를 할당하기 위해 파라미터 합성 엔진(175)에 의해 사용될 수 있는 규칙(rules)을 포함할 수 있다. 상기 규칙은 특정 오디오 출력 파라미터(주파수, 볼륨 등)가 전처리부(171)로부터의 입력 기호식 언어 표현의 부분에 대응할 가능성을 나타내는 스코어를 계산하는데 이용될 수 있다.
파라미터 합성 엔진(175)은 합성될 음성을 입력 음성 유닛 및/또는 운율 주석과 매칭시키기 위해 복수의 기술들이 적용될 수 있다. 일반적인 기술 중 하나는 HMM(Hidden Markov Model)을 사용한다, HMM은 오디오 출력이 텍스트 입력과 일치해야 하는 확률을 결정하는데 이용될 수 있다. HMM은 원하는 음성을 인공적으로 합성하기 위해, 언어 및 음향 공간의 파라미터들을 보코더(디지털 보이스 인코더)에 의해 사용될 파라미터들로 전환시키는데 이용될 수 있다.
TTS 장치(100)는 유닛 선택에 사용하기 위한 음성 유닛 데이터베이스를 포함할 수 있다.
상기 음성 유닛 데이터 베이스는 TTS 스토리지(180), 스토리지(160) 또는 다른 스토리지 구성에 저장될 수 있다. 상기 음성 유닛 데이터 베이스는 레코딩된 스피치 발성을 포함할 수 있다. 상기 스피치 발성은 발화 내용에 대응되는 텍스트일 수 있다. 또한, 음성 유닛 데이터 베이스는 TTS 장치(100)에서 상당한 저장 공간을 차지하는 녹음된 음성(오디오 파형, 특징 벡터 또는 다른 포맷의 형태)을 포함할 수 있다. 음성 유닛 데이터베이스의 유닛 샘플들은 음성 단위(음소, 다이폰, 단어 등), 언어적 운율 레이블, 음향 특징 시퀀스, 화자 아이덴티티 등을 포함하는 다양한 방법으로 분류될 수 있다. 샘플 발화(sample utterance)는 특정 음성 유닛에 대한 원하는 오디오 출력에 대응하는 수학적 모델을 생성하는데 사용될 수 있다.
음성 합성 엔진(172)은 기호화된 언어 표현을 매칭할 때, 입력 텍스트(음성 단위 및 운율 기호 주석 모두를 포함)와 가장 근접하게 일치하는 음성 유닛 데이터베이스 내의 유닛을 선택할 수 있다. 일반적으로 음성 유닛 데이터 베이스가 클 수록 선택 가능한 유닛 샘플 수가 많아서 정확한 스피치 출력이 가능하게 된다.
TTS 모듈(213)로부터 음성 출력을 포함하는 오디오 파형(audio waveforms)은 사용자에게 출력하기 위해 오디오 출력 장치(110)로 전송될 수 있다. 음성을 포함하는 오디오 파형은 일련의 특징 벡터(feature vectors), 비 압축 오디오 데이터(uncompressed audio data) 또는 압축 오디오 데이터와 같은 복수의 상이한 포맷으로 저장될 수 있다. 예를 들어, 음성 출력은 상기 전송 전에 인코더/디코더에 의해 인코딩 및/또는 압축될 수 있다. 인코더/디코더는 디지털화된 오디오 데이터, 특징 벡터 등과 같은 오디오 데이터를 인코딩 및 디코딩할 수 있다. 또한 인코더/디코더의 기능은 별도의 컴포넌트 내에 위치될 수 있거나, 프로세서(140), TTS 모듈(170)에 의해 수행될 수도 있음은 물론이다.
한편, 상기 TTS 스토리지(180)는 음성 인식(speech recognition)을 위해 다른 정보들을 저장할 수 있다.
TTS 스토리지(180)의 컨텐츠는 일반적인 TTS 사용을 위해 준비될 수도 있고, 특정 애플리케이션에서 사용될 가능성이 있는 소리 및 단어를 포함하도록 맞춤화될 수 있다. 예를 들어, GPS 장치에 의해 TTS 처리를 위해 TTS 스토리지(180)는 위치 및 내비게이션에 특화된 맞춤형 음성을 포함할 수 있다.
또한 예를 들어, TTS 스토리지(180)는 개인화된 원하는 음성 출력에 기초하여 사용자에게 커스터마이징될 수도 있다. 예를 들어, 사용자는 출력되는 보이스가 특정 성별, 특정 억양, 특정 속도, 특정 감정(예를 들어, 행복한 음성)을 선호할 수 있다. 음성 합성 엔진(172)은 이와 같은 사용자 선호도를 설명하기 위하여 특수 데이터 베이스 또는 모델(specialized database or model)을 포함할 수 있다.
TTS 장치(100)는 또한 다중 언어로 TTS 처리를 수행하도록 구성될 수 있다. 각 언어에 대해, TTS 모듈(170)은 원하는 언어로 음성을 합성하기 위해 특별히 구성된 데이터, 명령 및/또는 구성 요소를 포함할 수 있다.
성능 향상을 위해 TTS 모듈(213)은 TTS 처리 결과에 대한 피드백에 기초하여 TTS 스토리지(180)의 내용을 수정하거나 갱신할 수 있으므로, TTS 모듈(170)이 훈련 코퍼스(training corpus)에서 제공되는 능력 이상으로 음성 인식을 향상시킬 수 있다.
TTS 장치(100)의 처리 능력이 향상됨에 따라, 입력 텍스트가 갖는 감정 속성을 반영하여 음성 출력이 가능하다. 또는 TTS 장치(100)는 상기 입력 텍스트에 감정 속성에 포함되어 있지 않더라도, 입력 텍스트를 작성한 사용자의 의도(감정 정보)를 반영하여 음성 출력이 가능하다.
실제로 TTS 처리를 수행하는 TTS 모듈에 통합될 모델이 구축될 때 TTS 시스템은, 위에서 언급한 다양한 구성요소와 다른 구성요소를 통합할 수 있다. 일 예로, TTS 장치(100)는 음성에 감정 요소를 삽입할 수 있다.
전술한 본 발명은, 프로그램이 기록된 매체에 컴퓨터가 읽을 수 있는 코드로서 구현하는 것이 가능하다. 컴퓨터가 읽을 수 있는 매체는, 컴퓨터 시스템에 의하여 읽혀질 수 있는 데이터가 저장되는 모든 종류의 기록장치를 포함한다. 컴퓨터가 읽을 수 있는 매체의 예로는, HDD(Hard Disk Drive), SSD(Solid State Disk), SDD(Silicon Disk Drive), ROM, RAM, CD-ROM, 자기 테이프, 플로피 디스크, 광 데이터 저장 장치 등이 있으며, 또한 캐리어 웨이브(예를 들어, 인터넷을 통한 전송)의 형태로 구현되는 것도 포함한다. 따라서, 상기의 상세한 설명은 모든 면에서 제한적으로 해석되어서는 아니되고 예시적인 것으로 고려되어야 한다. 본 발명의 범위는 첨부된 청구항의 합리적 해석에 의해 결정되어야 하고, 본 발명의 등가적 범위 내에서의 모든 변경은 본 발명의 범위에 포함된다.
Claims (1)
- 텀블러의 하우징;상기 하우징의 상단부 일 영역에서 상기 하우징의 외형을 따라 둘러싸도록 구비되는 스피커;음성 명령을 수신하는 마이크; 및상기 마이크를 통해 사용자의 음성 명령을 수신하여 음성 인식을 수행하고, 상기 음성 명령에 따른 응답을 생성하기 위한 음성 합성을 수행하여 상기 스피커를 통해 상기 응답을 출력하도록 준비하는 음성 처리부;를 포함하는 인공지능 스피커 기능을 탑재한 텀블러.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210019766A KR20220116660A (ko) | 2021-02-15 | 2021-02-15 | 인공지능 스피커 기능을 탑재한 텀블러 장치 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210019766A KR20220116660A (ko) | 2021-02-15 | 2021-02-15 | 인공지능 스피커 기능을 탑재한 텀블러 장치 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220116660A true KR20220116660A (ko) | 2022-08-23 |
Family
ID=83092871
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020210019766A KR20220116660A (ko) | 2021-02-15 | 2021-02-15 | 인공지능 스피커 기능을 탑재한 텀블러 장치 |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR20220116660A (ko) |
-
2021
- 2021-02-15 KR KR1020210019766A patent/KR20220116660A/ko unknown
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11514886B2 (en) | Emotion classification information-based text-to-speech (TTS) method and apparatus | |
| US20230012984A1 (en) | Generation of automated message responses | |
| US10027662B1 (en) | Dynamic user authentication | |
| US10140973B1 (en) | Text-to-speech processing using previously speech processed data | |
| US10163436B1 (en) | Training a speech processing system using spoken utterances | |
| US11798556B2 (en) | Configurable output data formats | |
| EP3387646B1 (en) | Text-to-speech processing system and method | |
| US11450313B2 (en) | Determining phonetic relationships | |
| US10176809B1 (en) | Customized compression and decompression of audio data | |
| US20140303958A1 (en) | Control method of interpretation apparatus, control method of interpretation server, control method of interpretation system and user terminal | |
| US11837225B1 (en) | Multi-portion spoken command framework | |
| US11676572B2 (en) | Instantaneous learning in text-to-speech during dialog | |
| CN104899192B (zh) | 用于自动通译的设备和方法 | |
| US11355112B1 (en) | Speech-processing system | |
| KR20230158603A (ko) | 신경 텍스트-투-스피치 변환을 위한 음소 및 자소 | |
| CN116601702A (zh) | 一种用于多说话者和多语言语音合成的端到端神经系统 | |
| CN115176309A (zh) | 语音处理系统 | |
| US20220375469A1 (en) | Intelligent voice recognition method and apparatus | |
| KR20220116660A (ko) | 인공지능 스피커 기능을 탑재한 텀블러 장치 | |
| US11393451B1 (en) | Linked content in voice user interface | |
| US20190019497A1 (en) | Expressive control of text-to-speech content | |
| KR20220096129A (ko) | 감정톤을 자동조절하는 음성합성 시스템 | |
| Motyka et al. | Information Technology of Transcribing Ukrainian-Language Content Based on Deep Learning |