KR20220024912A - 루마 및 크로마 신호를 처리하기 위한 방법 및 시스템 - Google Patents
루마 및 크로마 신호를 처리하기 위한 방법 및 시스템 Download PDFInfo
- Publication number
- KR20220024912A KR20220024912A KR1020227002429A KR20227002429A KR20220024912A KR 20220024912 A KR20220024912 A KR 20220024912A KR 1020227002429 A KR1020227002429 A KR 1020227002429A KR 20227002429 A KR20227002429 A KR 20227002429A KR 20220024912 A KR20220024912 A KR 20220024912A
- Authority
- KR
- South Korea
- Prior art keywords
- block
- chroma
- luma
- picture
- boundary
- Prior art date
Links
Images























Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/186—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being a colour or a chrominance component
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/105—Selection of the reference unit for prediction within a chosen coding or prediction mode, e.g. adaptive choice of position and number of pixels used for prediction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/132—Sampling, masking or truncation of coding units, e.g. adaptive resampling, frame skipping, frame interpolation or high-frequency transform coefficient masking
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/136—Incoming video signal characteristics or properties
- H04N19/14—Coding unit complexity, e.g. amount of activity or edge presence estimation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/70—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by syntax aspects related to video coding, e.g. related to compression standards
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
본 발명은 비디오 컨텐츠를 처리하기 위한 시스템 및 방법을 제공한다. 상기 방법은, 픽처에서 제1 블록 및 제2 블록을 나타내는 데이터를 수신하는 단계이며, 상기 데이터는 상기 제1 블록과 관련된 복수의 크로마 샘플 및 상기 제2 블록과 관련된 복수의 루마 샘플을 포함하는, 상기 단계; 상기 제2 블록과 관련된 복수의 루마 샘플의 평균값을 결정하는 단계; 상기 평균값에 기초하여, 상기 제1 블록에 대한 크로마 스케일링 인자를 결정하는 단계; 및 상기 크로마 스케일링 인자를 사용하여 상기 제1 블록과 관련된 복수의 크로마 샘플을 처리하는 단계를 포함한다.
Description
관련 출원에 대한 상호 참조
본 출원은, 2019년 6월 24일자로 출원되고, 전체적으로 본 명세서에 참고로 포함되는 미국 가출원 제62/865,815호에 대한 우선권의 이익을 주장한다.
본 발명은 일반적으로, 비디오 처리, 더욱 구체적으로는 크로마 스케일링을 사용한 루마 맵핑을 수행하기 위한 방법 및 시스템에 관한 것이다.
비디오는 시각적 정보를 포착하는 일련의 정적 픽처(또는 "프레임")이다. 저장 메모리 및 전송 대역폭을 저감시키기 위해, 비디오는 저장 또는 전송 전에 압축될 수 있고, 디스플레이 전에 압축해제될 수 있다. 압축 과정은 통상 인코딩으로 언급되고, 압축해제 과정은 통상 디코딩으로 언급된다. 가장 흔하게는 예측, 변환, 양자화(quantization), 엔트로피 코딩 및 인-루프 필터링(in-loop filtering)에 기초한 표준화된 비디오 코딩 기술을 사용하는 다양한 비디오 코딩 포맷이 있다. 특정 비디오 코딩 포맷을 명시하는 고효율 비디오 코딩(HEVC/H.265) 표준 및 다용도 비디오 코딩(VVC/H.266) 표준 AVS 표준과 같은 비디오 코딩 표준은 표준화 기구에 의해 개발된다. 비디오 표준에 점점 더 발전된 비디오 코딩 기술이 채택되면서, 새로운 비디오 코딩 표준의 코딩 효율은 점점 더 높아지고 있다.
본 발명의 실시예는 크로마 스케일링(chroma scaling) 및 교차 구성요소 선형 모델(cross component linear model)을 사용한 인-루프 루마 맵핑을 수행하기 위한 방법 및 시스템을 제공한다.
예시적인 일 실시예에서, 상기 방법은, 픽처에서 제1 블록 및 제2 블록을 나타내는 데이터를 수신하는 단계이며, 상기 데이터는 제1 블록과 관련된 복수의 크로마 샘플 및 제2 블록과 관련된 복수의 루마 샘플을 포함하는, 상기 단계; 제2 블록과 관련된 복수의 루마 샘플의 평균값을 결정하는 단계; 상기 평균값에 기초하여 제1 블록에 대한 크로마 스케일링 인자를 결정하는 단계; 및 크로마 스케일링 인자를 사용하여 제1 블록과 관련된 복수의 크로마 샘플을 처리하는 단계를 포함한다.
일부 실시예에서, 상기 시스템은, 일련의 명령을 저장하기 위한 메모리; 및 적어도 하나의 프로세서를 포함하고, 상기 적어도 하나의 프로세서는 상기 시스템이, 픽처에서 제1 블록 및 제2 블록을 나타내는 데이터를 수신하는 단계이며, 상기 데이터는 제1 블록과 관련된 복수의 크로마 샘플 및 제2 블록과 관련된 복수의 루마 샘플을 포함하는, 상기 단계; 제2 블록과 관련된 복수의 루마 샘플의 평균값을 결정하는 단계; 상기 평균값에 기초하여 제1 블록에 대한 크로마 스케일링 인자를 결정하는 단계; 및 크로마 스케일링 인자를 사용하여 제1 블록과 관련된 복수의 크로마 샘플을 처리하는 단계를 수행하도록 상기 일련의 명령을 실행하도록 구성된다.
본 발명의 실시예 및 다양한 양태가 이하의 상세한 설명 및 첨부 도면에 예시된다. 도면에 도시된 다양한 특징은 일정한 비율로 도시되어 있지 않다.
도 1은 본 발명의 일부 실시예에 따른 예시적 비디오 시퀀스의 구조를 예시한다.
도 2a는 본 발명의 일부 실시예에 따른 예시적 인코딩 과정의 개략적인 다이어그램을 예시한다.
도 2b는 본 발명의 일부 실시예에 따른 다른 예시적 인코딩 과정의 개략적인 다이어그램을 예시한다.
도 3a는 본 발명의 일부 실시예에 따른 예시적 디코딩 과정의 개략적인 다이어그램을 예시한다.
도 3b는 본 발명의 일부 실시예에 따른 다른 예시적 디코딩 과정의 개략적인 다이어그램을 예시한다.
도 4는 본 발명의 일부 실시예에 따른 비디오를 인코딩 또는 디코딩하기 위한 예시적 장치의 블록도를 예시한다.
도 5는 본 발명의 일부 실시예에 따른 예시적인 크로마 스케일링을 사용한 루마 맵핑(LMCS) 과정의 개략적인 다이어그램을 예시한다.
도 6은 본 발명의 일부 실시예에 따른 LMCS용 타일 그룹 레벨 신택스 테이블이다.
도 7은 본 발명의 일부 실시예에 따른 LMCS용 신택스 테이블이다.
도 8은 본 발명의 일부 실시예에 따른 LMCS용 슬라이스 레벨 신택스 테이블이다.
도 9는 본 발명의 일부 실시예에 따른 LMCS 구분적 선형 모델용 신택스 테이블이다.
도 10은 본 발명의 일부 실시예에 따른 α 및 β의 도출용으로 사용된 샘플의 위치의 일 예를 예시한다.
도 11은 본 발명의 일부 실시예에 따른 CCLM이 활성화될 때, 루마 모드로부터의 크로마 예측 모드의 도출용 테이블이다.
도 12는 본 발명의 일부 실시예에 따른 예시적 코딩 트리 유닛 신택스 구조이다.
도 13은 본 발명의 일부 실시예에 따른 예시적 듀얼 트리 파티션 신택스 구조이다.
도 14는 본 발명의 일부 실시예에 따른 예시적 코딩 트리 유닛 신택스 구조이다.
도 15는 본 발명의 일부 실시예에 따른 예시적 듀얼 트리 파티션 신택스 구조이다.
도 16a는 본 발명의 일부 실시예에 따른 예시적 크로마 트리 파티션을 예시한다.
도 16b는 본 발명의 일부 실시예에 따른 예시적 루마 트리 파티션을 예시한다.
도 17은 본 발명의 일부 실시예에 따른 평균화 작업의 예시적 단순화를 예시한다.
도 18은 본 발명의 일부 실시예에 따른 크로마 스케일링 인자를 도출하기 위해, 평균 계산에 사용된 샘플의 예를 예시한다.
도 19는 본 발명의 일부 실시예에 따른 픽처 우측 또는 하단 경계에서의 블록에 대한 크로마 스케일링 인자 도출의 일 예를 예시한다.
도 20은 본 발명의 일부 실시예에 따른 예시적 코딩 트리 유닛 신택스 구조이다.
도 21은 본 발명의 일부 실시예에 따른 다른 예시적 코딩 트리 유닛 신택스 구조이다.
도 22는 본 발명의 일부 실시예에 따른 슬라이스 레벨의 LMCS 구분적 선형 모델의 예시적인 수정된 시그널링이다.
도 23은 본 발명의 일부 실시예에 따른 비디오 컨텐츠를 처리하기 위한 예시적 방법의 흐름도이다.
도 1은 본 발명의 일부 실시예에 따른 예시적 비디오 시퀀스의 구조를 예시한다.
도 2a는 본 발명의 일부 실시예에 따른 예시적 인코딩 과정의 개략적인 다이어그램을 예시한다.
도 2b는 본 발명의 일부 실시예에 따른 다른 예시적 인코딩 과정의 개략적인 다이어그램을 예시한다.
도 3a는 본 발명의 일부 실시예에 따른 예시적 디코딩 과정의 개략적인 다이어그램을 예시한다.
도 3b는 본 발명의 일부 실시예에 따른 다른 예시적 디코딩 과정의 개략적인 다이어그램을 예시한다.
도 4는 본 발명의 일부 실시예에 따른 비디오를 인코딩 또는 디코딩하기 위한 예시적 장치의 블록도를 예시한다.
도 5는 본 발명의 일부 실시예에 따른 예시적인 크로마 스케일링을 사용한 루마 맵핑(LMCS) 과정의 개략적인 다이어그램을 예시한다.
도 6은 본 발명의 일부 실시예에 따른 LMCS용 타일 그룹 레벨 신택스 테이블이다.
도 7은 본 발명의 일부 실시예에 따른 LMCS용 신택스 테이블이다.
도 8은 본 발명의 일부 실시예에 따른 LMCS용 슬라이스 레벨 신택스 테이블이다.
도 9는 본 발명의 일부 실시예에 따른 LMCS 구분적 선형 모델용 신택스 테이블이다.
도 10은 본 발명의 일부 실시예에 따른 α 및 β의 도출용으로 사용된 샘플의 위치의 일 예를 예시한다.
도 11은 본 발명의 일부 실시예에 따른 CCLM이 활성화될 때, 루마 모드로부터의 크로마 예측 모드의 도출용 테이블이다.
도 12는 본 발명의 일부 실시예에 따른 예시적 코딩 트리 유닛 신택스 구조이다.
도 13은 본 발명의 일부 실시예에 따른 예시적 듀얼 트리 파티션 신택스 구조이다.
도 14는 본 발명의 일부 실시예에 따른 예시적 코딩 트리 유닛 신택스 구조이다.
도 15는 본 발명의 일부 실시예에 따른 예시적 듀얼 트리 파티션 신택스 구조이다.
도 16a는 본 발명의 일부 실시예에 따른 예시적 크로마 트리 파티션을 예시한다.
도 16b는 본 발명의 일부 실시예에 따른 예시적 루마 트리 파티션을 예시한다.
도 17은 본 발명의 일부 실시예에 따른 평균화 작업의 예시적 단순화를 예시한다.
도 18은 본 발명의 일부 실시예에 따른 크로마 스케일링 인자를 도출하기 위해, 평균 계산에 사용된 샘플의 예를 예시한다.
도 19는 본 발명의 일부 실시예에 따른 픽처 우측 또는 하단 경계에서의 블록에 대한 크로마 스케일링 인자 도출의 일 예를 예시한다.
도 20은 본 발명의 일부 실시예에 따른 예시적 코딩 트리 유닛 신택스 구조이다.
도 21은 본 발명의 일부 실시예에 따른 다른 예시적 코딩 트리 유닛 신택스 구조이다.
도 22는 본 발명의 일부 실시예에 따른 슬라이스 레벨의 LMCS 구분적 선형 모델의 예시적인 수정된 시그널링이다.
도 23은 본 발명의 일부 실시예에 따른 비디오 컨텐츠를 처리하기 위한 예시적 방법의 흐름도이다.
예들이 첨부 도면에 예시되어 있는 예시적인 실시예에 대해 이제 상세히 참조할 것이다. 이하의 기술 내용은, 상이한 도면에 있어서 동일한 도면부호가 달리 표시되지 않는 한 동일하거나 유사한 요소를 나타내는 첨부 도면을 참고한다. 예시적인 실시예의 이하의 설명에 개시된 실행예들은 본 발명에 부합하는 모든 실행예를 나타내는 것은 아니다. 대신, 실행예들은 첨부된 청구범위에 인용된 바와 같은 본 발명에 관련된 양태에 부합하는 장치 및 방법에 대한 예에 불과하다. 명확하게 달리 언급되지 않는 한, 용어 "또는"은 실행 불가능한 경우를 제외하고, 모든 가능한 조합을 포함한다. 예를 들어, 구성요소가 A 또는 B를 포함할 수 있다고 언급되는 경우라면, 명확하게 달리 언급되거나 실행 불가능한 경우가 아닌 한, 구성요소는 A, 또는 B, 또는 A 및 B를 포함할 수 있다. 제2 예로서, 구성요소가 A, B 또는 C를 포함할 수 있다고 언급되는 경우라면, 명확하게 달리 언급되거나 실행 불가능한 경우가 아닌 한, 구성요소는 A, 또는 B, 또는 C, 또는 A 및 B, 또는 A 및 C, 또는 B 및 C, 또는 A 및 B 및 C를 포함할 수 있다.
비디오는 시각적 정보를 저장하기 위해 시간적 시퀀스(temporal sequence)로 배열된 일련의 정적 픽처(또는 "프레임")이다. 비디오 포착 장치(예를 들어, 카메라)는 시간적 시퀀스로 이들 픽처를 포착 및 저장하는데 사용될 수 있고, 비디오 재생 장치(예를 들어, 텔레비전, 컴퓨터, 스마트폰, 테블릿 컴퓨터, 비디오 플레이어, 또는 디스플레이 기능을 갖는 임의의 최종 사용자 단말기)는 시간적 시퀀스로 이러한 픽처를 디스플레이하는데 사용될 수 있다. 또한, 일부 적용예에서, 비디오 포착 장치는 예를 들어 모니터링, 회의 또는 생방송을 위해, 포착된 비디오를 실시간으로 비디오 재생 장치(예를 들어, 모니터를 갖춘 컴퓨터)로 전송할 수 있다.
이러한 적용예에 의해 요구되는 저장 공간 및 전송 대역폭의 저감을 위해, 비디오는 저장 및 전송 전에 압축될 수 있고, 디스플레이 전에 압축해제될 수 있다. 압축 및 압축해제는 프로세서(예를 들어, 일반 컴퓨터의 프로세서) 또는 특화된 하드웨어에 의해 수행되는 소프트웨어에 의해 실행될 수 있다. 압축용 모듈은 일반적으로 "인코더"로 언급되고, 압축해제용 모듈은 일반적으로 "디코더"로 언급된다. 인코더 및 디코더는 총체적으로 "코덱"으로 언급될 수 있다. 인코더 및 디코더는 여러 적합한 하드웨어, 소프트웨어 또는 이들의 조합 중 어느 하나로서 실행될 수 있다. 예를 들어, 인코더 및 디코더의 하드웨어 실행은 하나 이상의 마이크로프로세서, 디지털 신호 프로세서(DSP), 주문형 반도체(ASIC), 현장-프로그래머블 게이트 어레이(FPGA), 이산 논리, 또는 이들의 임의의 조합과 같은 회로를 포함할 수 있다. 인코더 및 디코더의 소프트웨어 실행은 프로그램-코드, 컴퓨터-수행 가능한 명령, 펌웨어, 또는 임의의 적합한 컴퓨터-실행 알고리즘 또는 컴퓨터-판독 가능한 매체에 고정된 프로세스를 포함할 수 있다. 비디오 압축 및 압축해제는 MPEG- 1, MPEG-2, MPEG-4, H.26x 시리즈 등과 같은 다양한 알고리즘 또는 표준에 의해 실행될 수 있다. 일부 적용예에서, 코덱이 "트랜스코더"로 언급될 수 있는 경우에, 코덱은 제1 코딩 표준으로부터 비디오를 압축해제할 수 있고, 제2 코딩 표준을 사용하여 압축해제된 비디오를 재압축할 수 있다.
비디오 인코딩 과정은 픽처를 복원하는데 사용될 수 있는 유용한 정보를 확인 및 유지하고, 복원을 위해 중요하지 않은 정보를 무시할 수 있다. 무시된 중요하지 않은 정보가 완전히 복원될 수 없다면, 이러한 인코딩 과정은 "손실성(lossy)"으로 언급될 수 있다. 그렇지 않으면, "무손실성(lossless)"으로 언급될 수 있다. 대부분의 인코딩 과정은 손실성이며, 이는 요구되는 저장 공간 및 전송 대역폭을 저감하기 위한 반대급부(tradeoff)이다.
인코딩되는 픽처("현재의 픽처"로 언급됨)의 유용한 정보는 참조 픽처(예를 들어, 앞서 인코딩 및 복원된 픽처)에 대한 변화를 포함한다. 이러한 변화는 픽셀의 위치 변화, 광도 변화 또는 색상 변화를 포함할 수 있으며, 이들 중 위치 변화가 주요 관심 대상이다. 물체를 나타내는 픽셀 그룹의 위치 변화는 물체의 참조 픽처와 현재의 픽처 사이의 움직임을 반영할 수 있다.
다른 픽처를 참조하지 않고 코딩된 픽처(즉, 자신의 참조 픽처임)는 "I-픽처"로 언급된다. 참조 픽처로서 이전 픽처를 사용하여 코딩된 픽처는 "P-픽처"로 언급된다. 참조 픽처로서 이전 픽처와 향후 픽처 둘 모두를 사용(즉, 참조는 "양방향성"임)하여 코딩된 픽처는 "B-픽처"로 언급된다.
앞서 언급된 바와 같이, 새로운 비디오 코딩 기술을 개발하는 목적 중 하나는 코딩 효율을 개선하는 것, 즉 더 적은 코딩된 데이터를 사용하여 동일한 픽처 품질을 나타내는 것이다. 본 발명은 크로마 스케일링을 사용한 루마 맵핑을 수행하기 위한 방법 및 시스템을 제공한다. 루마 맵핑은 루프 필터에서 사용할 루마 샘플을 맵핑하기 위한 과정이고, 크로마 스케일링은 크로마 잔여 값을 스케일링하기 위한 루마-의존성 과정이다. 절반의 대역폭을 사용하는 HEVC/H.265와 동일한 주관적 품질 LMCS는 2개의 주요 구성요소, 즉 1) 입력 루마 코드값을 코딩 루프 내에서의 사용을 위한 새로운 일련의 코드값으로 맵핑하는 과정; 및 2) 크로마 잔여 값을 스케일링하는 루마-의존성 과정을 갖는다. 루마 맵핑 과정은 명시된 비트 심도에서 허용된 루마 코드값 범위의 사용을 보다 우수하게 함으로써, 표준 및 높은 동적 범위 비디오 신호에 대한 코딩 효율을 개선한다.
도 1은 본 발명의 일부 실시예에 따른 비디오 코딩에서 사용하는 예시적 비디오 시퀀스(100)의 구조를 예시한다. 비디오 시퀀스(100)는 생중계 비디오 또는 포착 및 보관 중인 비디오일 수 있다. 비디오(100)는 실제 비디오, 컴퓨터-생성 비디오(예를 들어, 컴퓨터 게임 비디오), 또는 이들의 조합(예를 들어, 증강-현실 효과가 있는 실제 비디오)일 수 있다. 비디오 시퀀스(100)는 비디오 포착 장치(예를 들어, 카메라), 앞서 포착된 비디오를 포함하는 비디오 아카이브(예를 들어, 저장 장치에 저장된 비디오 파일), 또는 비디오 컨텐츠 공급자로부터 비디오를 수신하기 위한 비디오 피드 인터페이스(예를 들어, 비디오 브로드캐스트 송수신기)로부터 입력될 수 있다.
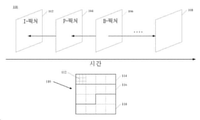
도 1에 도시된 바와 같이, 비디오 시퀀스(100)는 픽처(102, 104, 106 및 108)를 포함하는, 시간선을 따라 시간적으로 배열된 일련의 픽처를 포함할 수 있다. 픽처(102 내지 106)는 연속적이고, 픽처(106)와 픽처(108) 사이에 더 많은 픽처가 있다. 도 1에서, 픽처(102)는 I-픽처이고, 이의 참조 픽처는 픽처(102) 자신이다. 픽처(104)는 P-픽처이고, 이의 참조 픽처는 화살표로 표시된 바와 같이 픽처(102)이다. 픽처(106)는 B-픽처이고, 이의 참조 픽처는 화살표로 표시된 바와 같이 픽처(104 및 108)이다. 일부 실시예에서, 픽처(예를 들어, 픽처(104))의 참조 픽처는 상기 픽처 직전 또는 직후가 아닐 수 있다. 예를 들어, 픽처(104)의 참조 픽처는 픽처(102)에 선행하는 픽처일 수 있다. 픽처(102 내지 106)의 참조 픽처는 단지 예이며, 본 발명은 도 1에 도시된 예로서 참조 픽처의 실시예를 한정하지 않는다는 것에 유의해야 한다.
전형적으로, 비디오 코덱은 이러한 태스크(task)의 연산 복잡성으로 인해 픽처 전체를 동시에 인코딩 또는 디코딩하지 않는다. 오히려, 상기 코덱은 픽처를 기본 세그먼트로 분할할 수 있고, 세그먼트별로 픽처를 인코딩 또는 디코딩할 수 있다. 이러한 기본 세그먼트는 본 발명에서는 기본 처리 유닛("BPU")으로 언급된다. 예를 들어, 도 1의 구조(110)는 비디오 시퀀스(100)의 픽처(픽처(102 내지 108) 중 임의의 픽처)의 예시적 구조를 도시한다. 구조(110)에서, 픽처는 4×4 기본 처리 유닛으로 분할되고, 상기 유닛의 경계는 점선으로 도시되어 있다. 일부 실시예에서, 기본 처리 유닛은 일부 비디오 코딩 표준(예를 들어, MPEG 패밀리, H.261, H.263, 또는 H.264/AVC)에서 "매크로블록"으로 언급될 수 있거나, 일부 다른 비디오 코딩 표준(예를 들어, H.265/HEVC 또는 H.266/VVC)에서 "코딩 트리 유닛"("CTU")으로 언급될 수 있다. 기본 처리 유닛은 128×128, 64×64, 32×32, 16×16, 4×8, 16×32와 같은 픽처에 있어서의 가변적 크기, 또는 픽셀의 임의의 형상 및 크기를 가질 수 있다. 기본 처리 유닛의 크기 및 형상은 기본 처리 유닛에서 유지될 상세의 레벨과 코딩 효율의 균형에 기초하여 픽처에 대해 선택될 수 있다.
기본 처리 유닛은 컴퓨터 메모리(예를 들어, 비디오 프레임 버퍼)에 저장된 상이한 유형의 비디오 데이터의 그룹을 포함할 수 있는 논리적 유닛일 수 있다. 예를 들어, 컬러 픽처의 기본 처리 유닛은 무채색 밝기 정보를 나타내는 루마 구성요소(Y), 색상 정보를 나타내는 하나 이상의 크로마 구성요소(예를 들어, Cb 및 Cr) 및 관련 신택스 요소를 포함할 수 있고, 루마 및 크로마 구성요소는 동일한 크기의 기본 처리 유닛을 가질 수 있다. 루마 및 크로마 구성요소는 일부 비디오 코딩 표준(예를 들어, H.265/HEVC 또는 H.266/VVC)에서 "코딩 트리 블록"("CTB")으로 언급될 수 있다. 기본 처리 유닛에 대해 수행된 임의의 작업은 루마 및 크로마 구성요소 각각에 대해 반복적으로 수행될 수 있다.
비디오 코딩은 다수의 작업 단계를 가지며, 이의 예가 도 2a-2b 및 3a-3b에 열거될 것이다. 각각의 단계에 대해, 기본 처리 유닛의 크기는 처리하기에 여전히 클 수 있으며, 따라서 본 발명에서 "기본 처리 서브-유닛"으로 언급되는 세그먼트로 추가로 분할될 수 있다. 일부 실시예에서, 기본 처리 서브-유닛은 일부 비디오 코딩 표준(예를 들어, MPEG 패밀리, H.261, H.263, 또는 H.264/AVC)에서 "블록"으로 언급될 수 있거나, 일부 다른 비디오 코딩 표준(예를 들어, H.265/HEVC 또는 H.266/VVC)에서 "코딩 유닛"("CU")으로 언급될 수 있다. 기본 처리 서브-유닛은 기본 처리 유닛과 동일하거나 작은 크기를 가질 수 있다. 기본 처리 유닛과 유사하게, 기본 처리 서브-유닛도 컴퓨터 메모리(예를 들어, 비디오 프레임 버퍼)에 저장된 상이한 유형의 비디오 데이터(예를 들어, Y, Cb, Cr 및 관련 신택스 요소)의 그룹을 포함할 수 있는 논리적 유닛이다. 기본 처리 서브-유닛에 대해 수행된 임의의 작업은 루마 및 크로마 구성요소 각각에 대해 반복적으로 수행될 수 있다. 이러한 분할은 처리 요구에 따라 추가적인 레벨로 수행될 수 있다는 것에 유의해야 한다. 또한, 상이한 단계가 상이한 체계를 사용하여 기본 처리 유닛을 분할할 수 있다는 것에 유의해야 한다.
예를 들어, 모드 결정 단계(그 일 예가 도 2b에 열거됨)에서, 인코더는 기본 처리 유닛에 사용할 예측 모드(예를 들어, 인트라-픽처 예측 또는 인터-픽처 예측)가 무엇일지 결정할 수 있는데, 이는 이러한 결정을 하기엔 너무 클 수 있다. 인코더는 기본 처리 유닛을 다수의 기본 처리 서브-유닛(예를 들어, H.265/HEVC 또는 H.266/VVC에서와 같이 CU)으로 분할할 수 있으며, 각각의 개별 기본 처리 서브-유닛에 대해 예측 유형을 결정할 수 있다.
다른 예에 대해, 예측 단계(그 일 예가 도 2a에 열거됨)에서, 인코더는 기본 처리 서브-유닛(예를 들어, CU)의 레벨에서 예측 작업을 수행할 수 있다. 그러나, 일부 경우에 있어서, 기본 처리 서브-유닛은 처리하기에 여전히 너무 클 수 있다. 인코더는 기본 처리 서브-유닛을 더 작은 세그먼트(예를 들어, H.265/HEVC 또는 H.266/VVC에서 "PB" 또는 "예측 블록"으로 언급됨)로 추가로 분할할 수 있는데, 이 레벨에서 예측 작업이 실행될 수 있다.
다른 예에 대해, 변환 단계(그 일 예가 도 2a에 열거됨)에서, 인코더는 잔여 기본 처리 서브-유닛(예를 들어, CU)에 대한 변환 작업을 수행할 수 있다. 그러나, 일부 경우에 있어서, 기본 처리 서브-유닛은 처리하기에 여전히 너무 클 수 있다. 인코더는 기본 처리 서브-유닛을 더 작은 세그먼트(예를 들어, H.265/HEVC 또는 H.266/VVC에서 "TB" 또는 "변환 블록"으로 언급됨)로 추가로 분할할 수 있는데, 이 레벨에서 변환 작업이 실행될 수 있다. 동일한 기본 처리 서브-유닛의 분할 체계는 예측 단계 및 변환 단계에서 상이할 수 있다는 것에 유의해야 한다. 예를 들어, H.265/HEVC 또는 H.266/VVC에서, 동일한 CU의 예측 블록 및 변환 블록은 상이한 크기 및 개수를 가질 수 있다.
도 1의 구조(110)에서, 기본 처리 유닛(112)은 경계가 점선으로 도시되어 있는 3×3 기본 처리 서브-유닛으로 추가로 분할된다. 동일한 픽처의 상이한 기본 처리 유닛이 상이한 체계에서 기본 처리 서브-유닛으로 분할될 수 있다.
일부 실행에 있어서, 비디오 인코딩 및 디코딩에 대한 오류 복원력 및 병렬 처리 능력을 제공하기 위해, 픽처는 처리를 위한 영역으로 분할될 수 있으며, 이에 따라 픽처의 한 영역에 대해, 인코딩 또는 디코딩 과정은 픽처의 임의의 다른 영역으로부터의 정보에 의존하지 않도록 할 수 있다. 다시 말해, 픽처의 각각의 영역은 독립적으로 처리될 수 있다. 이렇게 함으로써, 코덱은 픽처의 상이한 영역을 병렬로 처리할 수 있으며, 이로 인해 코딩 효율이 증가한다. 또한, 어떤 영역의 데이터가 처리 시 오류가 발생하거나, 네트워크 전송 시 손실될 때, 코덱은 오류가 발생하거나 손실된 데이터에 대해 의존하지 않고서 동일한 픽처의 다른 영역을 바르게 인코딩 또는 디코딩할 수 있는데, 이에 의해 오류 복원력을 제공한다. 일부 비디오 코딩 표준에서, 픽처는 상이한 유형의 영역으로 분할될 수 있다. 예를 들어, H.265/HEVC 및 H.266/VVC는 2가지 유형의 영역: "슬라이스" 및 "타일"을 제공한다. 또한, 비디오 시퀀스(100)의 상이한 픽처가 픽처를 영역들로 분할하기 위한 상이한 파티션 체계를 가질 수 있다는 것에 유의해야 한다.
예를 들어, 도 1에서, 구조(110)는 경계가 구조(110) 내에서 실선으로 도시된 3개의 영역(114, 116 및 118)으로 분할된다. 영역(114)은 4개의 기본 처리 유닛을 포함한다. 영역(116 및 118) 각각은 6개의 기본 처리 유닛을 포함한다. 도 1의 구조(110)의 기본 처리 유닛, 기본 처리 서브-유닛 및 영역들은 단지 예이며, 본 발명은 이의 실시예로 한정되지 않는다는 것에 유의해야 한다.
도 2a는 본 발명의 일부 실시예에 따른 예시적 인코딩 과정(200A)의 개략적인 다이어그램을 예시한다. 인코더는 과정(200A)에 따라 비디오 시퀀스(202)를 비디오 비트스트림(228)으로 인코딩할 수 있다. 도 1의 비디오 시퀀스(100)와 유사하게, 비디오 시퀀스(202)는 시간적 순서로 배열된 일련의 픽처("원본 픽처"로 언급됨)를 포함할 수 있다. 도 1의 구조(110)와 유사하게, 비디오 시퀀스(202)의 각각의 원본 픽처는 인코더에 의해 기본 처리 유닛, 기본 처리 서브-유닛 또는 처리용 영역으로 분할될 수 있다. 일부 실시예에서, 인코더는 비디오 시퀀스(202)의 각각의 원본 픽처에 대한 기본 처리 유닛의 레벨에서 과정(200A)을 수행할 수 있다. 예를 들어, 인코더는 반복하는 방식으로 과정(200A)을 수행할 수 있으며, 이 방식에서 인코더는 과정(200A)의 일회 반복으로 기본 처리 유닛을 인코딩할 수 있다. 일부 실시예에서, 인코더는 비디오 시퀀스(202)의 각각의 원본 픽처의 영역(예를 들어, 영역(114-118))에 대해 병렬로 과정(200A)을 수행할 수 있다.
도 2a에서, 인코더는 비디오 시퀀스(202)의 원본 픽처의 기본 처리 유닛("원본 BPU"로 언급됨)을 예측 단계(204)로 공급하여 예측 데이터(206) 및 예측된 BPU(208)를 생성할 수 있다. 인코더는 원본 BPU로부터 예측된 BPU(208)를 차감함으로써 잔여 BPU(210)를 생성할 수 있다. 인코더는 잔여 BPU(210)를 변환 단계(212) 및 양자화 단계(214)에 공급하여 양자화된 변환 계수(216)를 생성할 수 있다. 인코더는 예측 데이터(206) 및 양자화된 변환 계수(216)를 이진 코딩 단계(226)에 공급하여 비디오 비트스트림(228)을 생성할 수 있다. 구성요소(202, 204, 206, 208, 210, 212, 214, 216, 226 및 228)는 "전진 경로"로서 언급될 수 있다. 과정(200A) 동안, 양자화 단계(214) 후에, 인코더는 양자화된 변환 계수(216)를 역양자화 단계(218) 및 역변환 단계(220)에 공급하여 복원된 잔여 BPU(222)를 생성할 수 있다. 인코더는 복원된 잔여 BPU(222)를 예측된 BPU(208)에 추가하여, 과정(200A)의 다음 반복을 위해 예측 단계(204)에서 사용되는 예측 참조(224)를 생성할 수 있다. 과정(200A)의 구성요소(218, 220, 222 및 224)는 "복원 경로"로서 언급될 수 있다. 복원 경로는 인코더 및 디코더 둘 모두가 예측을 위해 동일한 참조를 사용하는 것을 보장하도록 사용될 수 있다.
인코더는 (전진 경로에 있어서의) 원본 픽처의 각각의 원본 BPU를 인코딩하고, (복원 경로에 있어서의) 원본 픽처의 다음 원본 BPU를 인코딩하기 위한 예측된 참조(224)를 생성하기 위해 과정(200A)을 반복적으로 수행할 수 있다. 원본 픽처의 모든 원본 BPU를 인코딩한 후에, 인코더는 비디오 시퀀스(202)에서 다음 픽처를 인코딩하도록 진행할 수 있다.
과정(200A)을 참고하면, 인코더는 비디오 포착 장치(예를 들어, 카메라)에 의해 생성되는 비디오 시퀀스(202)를 수신할 수 있다. 본 명세서에서 사용되는 용어 "수신하다"는 수신하고, 입력하고, 획득하고, 검색하고, 얻고, 판독하고, 접속하고, 또는 데이터를 입력하기 위한 임의의 방식의 임의의 행위를 나타낼 수 있다.
예측 단계(204)에서, 현재의 반복에서, 인코더는 원본 BPU 및 예측 참조(224)를 수신할 수 있고, 예측 작업을 수행하여 예측 데이터(206) 및 예측된 BPU(208)를 생성할 수 있다. 예측 참조(224)는 과정(200A)의 이전 반복의 복원 경로로부터 생성될 수 있다. 예측 단계(204)의 목적은, 예측 데이터(206) 및 예측 참조(224)로부터 원본 BPU를 예측된 BPU(208)로서 복원하는데 사용될 수 있는 예측 데이터(206)를 추출함으로써 정보 과잉을 저감하는 것이다.
이상적으로는, 예측된 BPU(208)는 원본 BPU와 동일할 수 있다. 그러나, 비-이상적 예측 및 복원 작업으로 인해, 예측된 BPU(208)는 일반적으로 원본 BPU와는 약간 상이하다. 이러한 차이를 기록하기 위해, 예측된 BPU(208) 생성 후, 인코더는 상기 예측된 BPU를 원본 BPU로부터 차감하여 잔여 BPU(210)를 생성할 수 있다. 예를 들어, 인코더는 원본 BPU의 대응하는 픽셀의 값으로부터 예측된 BPU(208)의 픽셀의 값(예를 들어, 그레이스케일 값 또는 RGB 값)을 차감할 수 있다. 잔여 BPU(210)의 각각의 픽셀은 예측된 BPU(208) 및 원본 BPU의 대응하는 픽셀 사이에서 이러한 차감의 결과로서 잔여 값을 가질 수 있다. 원본 BPU와 비교하여, 예측 데이터(206) 및 잔여 BPU(210)는 더 적은 수의 비트를 가질 수 있지만, 이들은 현저한 품질 저하 없이 원본 BPU를 복원하는데 사용될 수 있다. 이에 따라, 원본 BPU가 압축된다.
잔여 BPU(210)를 추가로 압축하기 위해, 변환 단계(212)에서, 인코더는 각각의 기본 패턴이 "변환 계수"와 관련되어 있는 일련의 2차원 "기본 패턴"으로 잔여 BPU(210)를 분해함으로써, 잔여 BPU의 공간적 과잉을 저감할 수 있다. 기본 패턴은 동일한 크기(예를 들어, 잔여 BPU(210)의 크기)를 가질 수 있다. 각각의 기본 패턴은 잔여 BPU(210)의 변화 주파수(예를 들어, 밝기 변화의 주파수) 구성요소를 나타낼 수 있다. 기본 패턴 중 어느 패턴도 임의의 다른 기본 패턴의 임의의 조합(예를 들어, 선형 조합)으로부터 재생될 수 없다. 다시 말해, 분해는 주파수 도메인으로의 잔여 BPU(210)의 변화를 분해할 수 있다. 이러한 분해는 기본 패턴이 이산 푸리에 변환의 기본 함수(예를 들어, 삼각 함수)와 유사하고 변환 계수는 기본 함수와 관련된 계수와 유사하다는 함수의 이산 푸리에 변환과 유사하다.
상이한 변환 알고리즘이 상이한 기본 패턴을 사용할 수 있다. 다양한 변환 알고리즘은 예를 들어, 이산 코사인 변환, 이산 사인 변환 등과 같은 변환 단계(212)에서 사용될 수 있다. 변환 단계(212)에서의 변환은 가역적이다. 즉, 인코더는 변환의 역작업("역변환"으로 언급됨)에 의해 잔여 BPU(210)를 복원할 수 있다. 예를 들어, 잔여 BPU(210)의 픽셀을 복원하기 위해, 역변환은 기본 패턴의 대응하는 픽셀의 값에 각각의 관련 계수를 곱하고, 그 결과값을 더하여 가중치 합을 산출하는 것일 수 있다. 비디오 코딩 표준에 대해, 인코더 및 디코더 둘 모두는 동일한 변환 알고리즘(이에 따라, 동일한 기본 패턴)을 사용할 수 있다. 따라서, 인코더는 변환 계수만 기록할 수 있으며, 이로부터 디코더는 인코더로부터 기본 패턴을 수신함이 없이, 잔여 BPU(210)를 복원할 수 있다. 잔여 BPU(210)와 비교하여, 변환 계수는 더 적은 수의 비트를 가질 수 있지만, 이들은 현저한 품질 저하 없이 잔여 BPU(210)를 복원하는데 사용될 수 있다. 이에 따라, 잔여 BPU(210)가 추가로 압축된다.
인코더는 양자화 단계(214)에서 변환 계수를 추가로 압축할 수 있다. 변환 과정에서, 상이한 기본 패턴이 상이한 변화 주파수(예를 들어, 밝기 변화 주파수)를 나타낼 수 있다. 인간의 눈은 일반적으로 저주파수 변화를 더 잘 인식하기 때문에, 인코더는 디코딩 시 현저한 품질 저하를 초래하지 않고 고주파수 변화의 정보를 무시할 수 있다. 예를 들어, 양자화 단계(214)에서, 인코더는 각각의 변환 계수를 정수값("양자화 파라미터"라고 언급됨)으로 나누고, 몫을 가장 가까운 정수로 반올림함으로써, 양자화된 변환 계수(216)를 생성할 수 있다. 이러한 작업 후에, 고주파수 기본 패턴의 일부 변환 계수는 0으로 변환될 수 있고, 저주파수 기본 패턴의 변환 계수는 보다 작은 정수로 변환될 수 있다. 인코더는 0-값 양자화된 변환 계수(216)를 무시할 수 있으며, 이에 의해 변환 계수는 추가로 압축된다. 또한, 양자화 과정은 가역적이고, 여기서 양자화된 변환 계수(216)는 양자화의 역작업("역양자화"로 언급됨)에서 변환 계수로 복원될 수 있다.
인코더가 반올림 작업에서 이러한 나누기의 나머지를 무시하기 때문에, 양자화 단계(214)는 손실성일 수 있다. 전형적으로, 양자화 단계(214)는 과정(200A)에서 최대 정보 손실에 기여할 수 있다. 정보 손실이 크면 클수록, 양자화된 변환 계수(216)가 더 적은 비트를 요구할 수 있다. 상이한 레벨의 정보 손실을 획득하기 위해, 인코더는 양자화 파라미터 또는 양자화 과정의 임의의 다른 파라미터의 상이한 값을 사용할 수 있다.
이진 코딩 단계(226)에서, 인코더는 예를 들어, 엔트로피 코딩, 가변 길이 코딩, 산술 코딩, 호프만 코딩, 컨텍스트 어댑티브 이진 산술 코딩 또는 임의의 다른 무손실 또는 손실 압축 알고리즘과 같은 이진 코딩 기술을 사용하여 예측 데이터(206) 및 양자화된 변환 계수(216)를 인코딩할 수 있다. 일부 실시예에서, 예측 데이터(206) 및 양자화된 변환 계수(216) 외에, 인코더는 예를 들어, 예측 단계(204)에서 사용되는 예측 모드, 예측 작업의 파라미터, 변환 단계(212)에서의 변환 유형, 양자화 과정의 파라미터(예를 들어, 양자화 파라미터), 인코더 제어 파라미터(예를 들어, 비트전송속도 제어 파라미터) 등과 같은 이진 코딩 단계(226)에서의 다른 정보를 인코딩할 수 있다. 인코더는 이진 코딩 단계(226)의 출력 데이터를 사용하여 비디오 비트스트림(228)을 생성할 수 있다. 일부 실시예에서, 비디오 비트스트림(228)은 네트워크 전송을 위해 추가로 패킷화될 수 있다.
과정(200A)의 복원 경로를 참고하면, 역양자화 단계(218)에서, 인코더는 양자화된 변환 계수(216)에 역양자화를 수행하여 복원된 변환 계수를 생성할 수 있다. 역변환 단계(220)에서, 인코더는 복원된 변환 계수에 기초하여, 복원된 잔여 BPU(222)를 생성할 수 있다. 인코더는 복원된 잔여 BPU(222)를 예측된 BPU(208)에 추가하여 과정(200A)의 다음 반복에서 사용될 예측 참조(224)를 생성할 수 있다.
과정(200A)의 다른 변화는 비디오 시퀀스(202)를 인코딩하는데 사용될 수 있다는 것에 유의해야 한다. 일부 실시예에서, 과정(200A)의 단계는 인코더에 의해 상이한 순서로 수행될 수 있다. 일부 실시예에서, 과정(200A)의 하나 이상의 단계는 단일 단계로 결합될 수 있다. 일부 실시예에서, 과정(200A)의 단일 단계는 다수의 단계로 분할될 수 있다. 예를 들어, 변환 단계(212) 및 양자화 단계(214)가 단일 단계로 결합될 수 있다. 일부 실시예에서, 과정(200A)은 추가적인 단계를 포함할 수 있다. 일부 실시예에서, 과정(200A)은 도 2a에 있어서 하나 이상의 단계를 생략할 수 있다.
도 2b는 본 발명의 일부 실시예에 따른 다른 예시적인 인코딩 과정(200B)의 개략적인 다이어그램을 예시한다. 과정(200B)은 과정(200A)으로부터 수정될 수 있다. 예를 들어, 과정(200B)은 하이브리드 비디오 코딩 표준(예를 들어, H.26x 시리즈)에 부합하는 인코더에 의해 사용될 수 있다. 과정(200A)에 비해, 과정(200B)의 전진 경로는 모드 결정 단계(230)를 추가로 포함하고, 예측 단계(204)를 공간적 예측 단계(2042) 및 시간적 예측 단계(2044)로 분할한다. 과정(200B)의 복원 경로는 루프 필터 단계(232) 및 버퍼(234)를 추가로 포함한다.
일반적으로, 예측 기술은 2가지 유형: 공간적 예측 및 시간적 예측으로 범주화될 수 있다. 공간적 예측(예를 들어, 인트라-픽처 예측 또는 "인트라 예측")은 현재의 BPU를 예측하기 위해, 동일한 픽처에서 하나 이상의 이미 코딩된 이웃하는 BPU로부터의 픽셀을 사용할 수 있다. 즉, 공간적 예측에서의 예측 참조(224)는 이웃하는 BPU를 포함할 수 있다. 공간적 예측은 픽처의 내재적인 공간적 과잉을 저감할 수 있다. 시간적 예측(예를 들어, 인터-픽처 예측 또는 "인터 예측")은 현재의 BPU를 예측하기 위해 하나 이상의 이미 코딩된 픽처로부터의 영역을 사용할 수 있다. 즉, 시간적 예측에서의 예측 참조(224)는 코딩된 픽처를 포함할 수 있다. 시간적 예측은 픽처의 내재적인 시간적 과잉을 저감할 수 있다.
과정(200B)을 참고하면, 전진 경로에서, 인코더는 공간적 예측 단계(2042) 및 시간적 예측 단계(2044)에서 예측 작업을 수행한다. 예를 들어, 공간적 예측 단계(2042)에서, 인코더는 인트라 예측을 수행할 수 있다. 인코딩되는 픽처의 원본 BPU에 대해, 예측 참조(224)는 동일한 픽처에서 (전진 경로에서) 인코딩되고 (복원 경로에서) 복원된 하나 이상의 이웃하는 BPU를 포함할 수 있다. 인코더는 이웃하는 BPU를 외삽함으로써 예측된 BPU(208)를 생성할 수 있다. 외삽 기법은 예를 들어, 선형 외삽 또는 내삽, 다항식 외삽 또는 내삽 등을 포함할 수 있다. 일부 실시예에서, 인코더는 예를 들어, 예측된 BPU(208)의 각각의 픽셀에 대해 대응하는 픽셀의 값을 외삽함으로써, 픽셀 레벨에서 외삽을 수행할 수 있다. 외삽용으로 사용된 이웃하는 BPU는 수직 방향(예를 들어, 원본 BPU의 상단), 수평 방향(예를 들어, 원본 BPU의 좌측), 대각선 방향(예를 들어, 원본 BPU의 아래서 좌측, 아래서 우측, 상부에서 좌측 또는 상부에서 우측), 또는 사용된 비디오 코딩 표준에서 규정된 임의의 방향에서와 같은 다양한 방향으로부터 원본 BPU에 대해 위치될 수 있다. 인트라 예측에 대해, 예측 데이터(206)는 예를 들어, 사용된 이웃하는 BPU의 위치(예를 들어, 좌표), 사용된 이웃하는 BPU의 크기, 외삽의 파라미터, 원본 BPU에 대한 사용된 이웃하는 BPU의 방향 등을 포함할 수 있다.
다른 예에 대해, 시간적 예측 단계(2044)에서, 인코더는 인터 예측을 수행할 수 있다. 현재의 픽처의 원본 BPU에 대해, 예측 참조(224)는 (전진 경로에서) 인코딩되고 (복원된 경로에서) 복원된 하나 이상의 픽처("참조 픽처"로 언급됨)를 포함할 수 있다. 일부 실시예에서, 참조 픽처는 BPU별로 인코딩되고 복원될 수 있다. 예를 들어, 인코더는 복원된 잔여 BPU(222)를 예측된 BPU(208)에 추가하여 복원된 BPU를 생성할 수 있다. 동일한 픽처의 복원된 모든 BPU가 생성된 때, 인코더는 복원된 픽처를 참조 픽처로서 생성할 수 있다. 인코더는 참조 픽처의 범주("검색창"으로 언급됨)에서 매칭 영역을 검색하기 위해, "움직임 추정"의 작업을 수행할 수 있다. 참조 픽처에 있어서 검색창의 위치는 현재의 픽처에서 원본 BPU의 위치에 기초하여 결정될 수 있다. 예를 들어, 검색창은 현재의 픽처에서 원본 BPU로서 참조 픽처에 있어서 동일한 좌표를 갖는 위치에 중심설정될 수 있고, 미리 결정된 거리에 대해 연장될 수 있다. 인코더가 검색창에서 원본 BPU와 유사한 영역을 (예를 들어, 펠-리커시브(pel-recursive) 알고리즘, 블록-매칭 알고리즘 등을 사용하여) 확인할 때, 인코더는 이러한 영역을 매칭 영역으로서 결정할 수 있다. 매칭 영역은 원본 BPU와 상이한 치수(예를 들어, 보다 작은, 동일한, 보다 큰 또는 상이한 형상으로)를 가질 수 있다. 참조 픽처 및 현재의 픽처가 (예를 들어, 도 1에 도시된 바와 같이) 시간선에서 시간적으로 분리되어 있기 때문에, 시간이 지남에 따라, 매칭 영역이 원본 BPU의 위치로 "움직이는" 것으로 여겨질 수 있다. 인코더는 "움직임 벡터"로서 이러한 움직임의 방향 및 거리를 기록할 수 있다. (예를 들어, 도 1의 픽처(106)와 같이) 다수의 참조 픽처가 사용될 때, 인코더는 매칭 영역을 검색하고, 각각의 참조 픽처에 대해 관련된 움직임 벡터를 결정할 수 있다. 일부 실시예에서, 인코더는 각각의 매칭 참조 픽처의 매칭 영역의 픽셀값에 대해 가중치를 부여할 수 있다.
움직임 추정은 예를 들어, 병진(translation), 회전, 주밍(zooming) 등과 같은 다양한 유형의 움직임을 확인하는데 사용될 수 있다. 인터 예측에 대해, 예측 데이터(206)는 예를 들어, 매칭 영역의 위치(예를 들어, 좌표), 매칭 영역과 관련된 움직임 벡터, 참조 픽처의 개수, 참조 픽처와 관련된 가중치 등을 포함할 수 있다.
예측된 BPU(208)를 생성하기 위해, 인코더는 "움직임 보상"의 작업을 수행할 수 있다. 움직임 보상은 예측 데이터(206)(예를 들어, 움직임 벡터) 및 예측 참조(224)에 기초하여 예측된 BPU(208)를 복원하는데 사용될 수 있다. 예를 들어, 인코더는 움직임 벡터에 따라 참조 픽처의 매칭 영역을 이동시킬 수 있으며, 인코더는 현재의 픽처의 원본 BPU를 예측할 수 있다. 다수의 참조 픽처가 (도 1의 픽처(106)로서) 사용될 때, 인코더는 매칭 영역의 평균 픽셀값 및 움직임 벡터 각각에 따라 참조 픽처의 매칭 영역을 이동시킬 수 있다. 일부 실시예에서, 인코더가 각각의 매칭 참조 픽처의 매칭 영역의 픽셀값에 가중치를 부여한 경우, 인코더는 이동된 매칭 영역의 픽셀값의 가중치 합을 추가할 수 있다.
일부 실시예에서, 인터 예측은 단방향성 또는 양방향성일 수 있다. 단방향성 인터 예측은 현재의 픽처에 대해 동일한 시간적 방향으로 하나 이상의 참조 픽처를 사용할 수 있다. 예를 들어, 도 1의 픽처(104)는 참조 픽처(즉, 픽처(102))가 픽처(104)에 선행하는 단방향성 인터-예측된 픽처이다. 양방향성 인터 예측은 현재의 픽처에 대해 시간적 방향 둘 모두에서 하나 이상의 참조 픽처를 사용할 수 있다. 예를 들어, 도 1의 픽처(106)는 참조 픽처(즉, 픽처(104 및 108))가 픽처(104)에 대해 시간적 방향 둘 모두에 있는 양방향성 인터-예측된 픽처이다.
과정(200B)의 전진 경로를 다시 참고하면, 공간적 예측 단계(2042) 및 시간적 예측 단계(2044) 후에, 모드 결정 단계(230)에서, 인코더는 과정(200B)의 현재의 반복에 대해 예측 모드(예를 들어, 인트라 예측 또는 인터 예측 중 하나)를 선택할 수 있다. 예를 들어, 인코더는 레이트-왜곡 최적화 기술(rate-distortion optimization technique)을 수행할 수 있으며, 인코더는 후보 예측 모드의 비트율 및 후보 예측 모드하에서 복원된 참조 픽처의 왜곡에 따라 비용 함수의 값을 최소화하기 위해 예측 모드를 선택할 수 있다. 선택된 예측 모드에 따라, 인코더는 대응하는 예측된 BPU(208) 및 예측된 데이터(206)를 생성할 수 있다.
과정(200B)의 복원 경로에 있어서, 인트라 예측 모드가 전진 경로에서 선택된 경우에, 예측 참조(224)(예를 들어, 현재의 픽처에서 인코딩되고 복원된 현재의 BPU)를 생성한 후, 인코더는 차후 사용을 위해(예를 들어, 현재의 픽처의 다음 BPU의 외삽을 위해), 예측 참조(224)를 공간적 예측 단계(2042)로 바로 공급할 수 있다. 전진 경로에서 인터 예측 모드가 선택된 경우에, 예측 참조(224)(예를 들어, 모든 BPU가 인코딩되고 복원된 현재의 픽처)를 생성한 후, 인코더는 인터 예측에 의해 도입된 왜곡(예를 들어, 블록화 아티팩트)을 감소시키거나 제거하기 위해 예측 참조(224)에 루프 필터를 적용할 수 있는 루프 필터 단계(232)에 예측 참조(224)를 공급할 수 있다. 인코더는 예를 들어, 블록화해제(deblocking), 샘플 어댑티브 오프셋, 어댑티브 루프 필터 등과 같은 루프 필터 단계(232)에 다양한 루프 필터 기술을 적용할 수 있다. 루프-필터링된 참조 픽처는 차후 사용을 위해(예를 들어, 비디오 시퀀스(202)의 향후 픽처에 대한 인터-예측 참조 픽처로서 사용되기 위해) 버퍼(234)(또는 "디코딩된 픽처 버퍼")에 저장될 수 있다. 인코더는 시간적 예측 단계(2044)에서 사용되도록 버퍼(234)에 하나 이상의 참조 픽처를 저장할 수 있다. 일부 실시예에서, 인코더는 양자화된 변환 계수(216), 예측 데이터(206) 및 다른 정보와 함께, 이진 코딩 단계(226)에서 루프 필터의 파라미터(예를 들어, 루프 필터 강도)를 인코딩할 수 있다.
도 3a는 본 발명의 일부 실시예에 따른 예시적 디코딩 과정(300A)의 개략적인 다이어그램을 예시한다. 과정(300A)은 도 2a의 압축 과정(200A)에 대응하는 압축해제 과정일 수 있다. 일부 실시예에서, 과정(300A)은 과정(200A)의 복원 경로와 유사할 수 있다. 디코더는 과정(300A)에 따라 비디오 비트스트림(228)을 비디오 스트림(304)으로 디코딩할 수 있다. 비디오 스트림(304)은 비디오 시퀀스(202)와 매우 유사할 수 있다. 그러나, 압축 및 압축해제 과정(예를 들어, 도 2a-2b에 있어서 양자화 단계(214))에서의 정보 손실로 인해, 일반적으로 비디오 스트림(304)은 비디오 시퀀스(202)와 동일하지 않다. 도 2a-2b에서의 과정(200A 및 200B)과 유사하게, 디코더는 비디오 비트스트림(228)에서 인코딩되는 각각의 픽처에 대해 기본 처리 유닛(BPU)의 레벨에서 과정(300A)을 수행할 수 있다. 예를 들어, 디코더는 상기 디코더가 과정(300A)의 일회 반복으로 기본 처리 유닛을 디코딩할 수 있는 반복 방식으로 과정(300A)을 수행할 수 있다. 일부 실시예에서, 디코더는 비디오 비트스트림(228)에서 인코딩되는 각각의 픽처의 영역(예를 들어, 영역(114 내지 118))에 대해 병렬로 과정(300A)을 수행할 수 있다.
도 3a에서, 디코더는 인코딩된 픽처의 기본 처리 유닛("인코딩된 BPU"로 언급됨)과 관련된 비디오 비트스트림(228)의 일부를 이진 디코딩 단계(302)로 공급할 수 있다. 이진 디코딩 단계(302)에서, 디코더는 상기 일부를 예측 데이터(206) 및 양자화된 변환 계수(216)로 디코딩할 수 있다. 디코더는 양자화된 변환 계수(216)를 역양자화 단계(218) 및 역변환 단계(220)에 공급하여 복원된 잔여 BPU(222)를 생성할 수 있다. 디코더는 예측 데이터(206)를 예측 단계(204)로 공급하여 예측된 BPU(208)를 생성할 수 있다. 디코더는 복원된 잔여 BPU(222)를 예측된 BPU(208)에 추가하여 예측된 참조(224)를 생성할 수 있다. 일부 실시예에서, 예측된 참조(224)는 버퍼(예를 들어, 컴퓨터 메모리에서 디코딩된 픽처 버퍼)에 저장될 수 있다. 디코더는 과정(300A)의 다음 반복에서 예측 작업을 수행하기 위해, 예측된 참조(224)를 예측 단계(204)에 공급할 수 있다.
디코더는 인코딩된 픽처의 각각의 인코딩된 BPU를 디코딩하고, 인코딩된 픽처의 다음 인코딩된 BPU를 인코딩하기 위해 예측된 참조(224)를 생성하도록, 과정(300A)을 반복적으로 수행할 수 있다. 인코딩된 픽처의 모든 인코딩된 BPU를 디코딩한 후에, 디코더는 디스플레이를 위해 픽처를 비디오 스트림(304)에 출력하고, 비디오 비트스트림(228)에서 다음 인코딩된 픽처를 디코딩하도록 진행할 수 있다.
이진 디코딩 단계(302)에서, 디코더는 인코더에 의해 사용된 이진 코딩 기술(예를 들어, 엔트로피 코딩, 가변 길이 코딩, 산술 코딩, 호프만 코딩, 컨텍스트 어댑티브 이진 산술 코딩 또는 임의의 다른 무손실 압축 알고리즘)의 역작업을 수행할 수 있다. 일부 실시예에서, 예측 데이터(206) 및 양자화된 변환 계수(216) 외에, 디코더는 예를 들어, 예측 모드, 예측 작업의 파라미터, 변환 유형, 양자화 과정의 파라미터(예를 들어, 양자화 파라미터), 인코더 제어 파라미터(예를 들어, 비트전송속도 제어 파라미터) 등과 같은 이진 디코딩 단계(302)에서의 다른 정보를 디코딩할 수 있다. 일부 실시예에서, 비디오 비트스트림(228)이 패킷으로 네트워크를 통해 전송되면, 디코더는 이를 이진 디코딩 단계(302)에 공급하기 전에, 비디오 비트스트림(228)을 디페커타이징할 수 있다.
도 3b는 본 발명의 일부 실시예에 따른 다른 예시적인 디코딩 과정(300B)의 개략적인 다이어그램을 예시한다. 과정(300B)은 과정(300A)으로부터 수정될 수 있다. 예를 들어, 과정(300B)은 하이브리드 비디오 코딩 표준(예를 들어, H.26x 시리즈)에 부합하는 디코더에 의해 사용될 수 있다. 과정(300A)과 비교하여, 과정(300B)은 추가적으로 예측 단계(204)를 공간적 예측 단계(2042) 및 시간적 예측 단계(2044)로 분할하고, 추가적으로 루프 필터 단계(232) 및 버퍼(234)를 포함한다.
과정(300B)에서, 디코딩되는 인코딩된 픽처("현재의 픽처"로 언급됨)의 인코딩된 기본 처리 유닛("현재의 BPU"로 언급됨)에 대해, 디코더에 의해 이진 디코딩 단계(302)로부터 디코딩된 예측 데이터(206)는 예측 모드가 인코더에 의해 현재의 BPU를 인코딩하는데 사용된 것에 따라, 다양한 유형의 데이터를 포함할 수 있다. 예를 들어, 현재의 BPU를 인코딩하기 위해, 인코더에 의해 인트라 예측이 사용되는 경우에, 예측 데이터(206)는 인트라 예측을 나타내는 예측 모드 지표(예를 들어, 플래그 값), 인트라 예측 작업의 파라미터 등을 포함할 수 있다. 인트라 예측 작업의 파라미터는 예를 들어, 참조로서 사용된 하나 이상의 이웃하는 BPU의 위치(예를 들어, 좌표), 이웃하는 BPU의 크기, 외삽의 파라미터, 원본 BPU에 대한 이웃하는 BPU의 방향 등을 포함할 수 있다. 다른 예에 대해, 현재의 BPU를 인코딩하기 위해, 인코더에 의해 인터 예측이 사용되는 경우에, 예측 데이터(206)는 인터 예측을 나타내는 예측 모드 지표(예를 들어, 플래그 값), 인터 예측 작업의 파라미터 등을 포함할 수 있다. 인터 예측 작업의 파라미터는 예를 들어, 현재의 BPU와 관련된 참조 픽처의 개수, 각각 참조 픽처와 관련된 가중치, 각각의 참조 픽처에서의 하나 이상의 매칭 영역의 위치(예를 들어, 좌표), 각각 매칭 영역과 관련된 하나 이상의 움직임 벡터 등을 포함할 수 있다.
예측 모드 지표에 기초하여, 디코더는 공간적 예측 단계(2042)에서 공간적 예측(예를 들어, 인트라 예측)을 수행할지, 또는 시간적 예측 단계(2044)에서 시간적 예측(예를 들어, 인터 예측)을 수행할지를 결정할 수 있다. 이러한 공간적 예측 또는 시간적 예측의 수행에 대한 상세가 도 2b에 묘사되고, 이하에서는 반복되지 않을 것이다. 이러한 공간적 예측 또는 시간적 예측을 수행한 후, 디코더는 예측된 BPU(208)를 생성할 수 있다. 도 3a에 묘사된 바와 같이, 디코더는 예측된 BPU(208) 및 복원된 잔여 BPU(222)를 합하여 예측 참조(224)를 생성할 수 있다.
과정(300B)에서, 디코더는 과정(300B)의 다음 반복에서의 예측 작업을 수행하기 위해, 예측된 참조(224)를 공간적 예측 단계(2042) 또는 시간적 예측 단계(2044)에 공급할 수 있다. 예를 들어, 현재의 BPU가 공간적 예측 단계(2042)에서 인트라 예측을 사용하여 디코딩되는 경우, 예측 참조(224)(예를 들어, 디코딩된 현재의 BPU) 생성 후, 디코더는 차후 사용을 위해(예를 들어, 현재의 픽처의 다음 BPU의 외삽을 위해) 예측 참조(224)를 공간적 예측 단계(2042)에 직접 공급할 수 있다. 현재의 BPU가 시간적 예측 단계(2044)에서 인터 예측을 사용하여 디코딩되는 경우, 예측 참조(224)(예를 들어, 모든 BPU가 디코딩된 참조 픽처)를 생성한 후, 인코더는 왜곡(예를 들어, 블록화 아티팩트)을 감소시키거나 제거하기 위해, 예측 참조(224)를 루프 필터 단계(232)에 공급할 수 있다. 도 2b에 묘사되어 있는 바와 같은 방식으로, 디코더는 루프 필터를 예측 참조(224)에 적용할 수 있다. 루프 필터링된 참조 픽처는 차후 사용을 위해(예를 들어, 비디오 비트스트림(228)의 향후 인코딩된 픽처에 대한 인터-예측 참조 픽처로서 사용되기 위해) 버퍼(234)(예를 들어, 컴퓨터 메모리의 디코딩된 픽처 버퍼)에 저장될 수 있다. 디코더는 시간적 예측 단계(2044)에서 사용되도록 버퍼(234)에 하나 이상의 참조 픽처를 저장할 수 있다. 일부 실시예에서, 예측 데이터(206)의 예측 모드 지표가, 인터 예측이 현재의 BPU를 인코딩하는데 사용된 것을 가리킬 때, 예측 데이터는 루프 필터의 파라미터(예를 들어, 루프 필터 강도)를 추가로 포함할 수 있다.
도 4는 본 발명의 일부 실시예에 따른 비디오의 인코딩 또는 디코딩을 위한 예시적 장치(400)의 블록도이다. 도 4에 도시된 바와 같이, 장치(400)는 프로세서(402)를 포함할 수 있다. 프로세서(402)가 본 명세서에 기술된 명령을 실행할 때, 장치(400)는 비디오 인코딩 또는 디코딩을 위한 특화된 기계가 될 수 있다. 프로세서(402)는 정보를 조작 또는 처리할 수 있는 임의의 유형의 회로일 수 있다. 예를 들어, 프로세서(402)는 중앙 처리 장치(또는 "CPU"), 그래픽 처리 장치(또는 "GPU"), 신경 처리 장치("NPU"), 마이크로컨트롤러 장치("MCU"), 광학 프로세서, 프로그래머블 로직 컨트롤러, 마이크로컨트롤러, 마이크로프로세서, 디지털 신호 프로세서, 지적 재산권(IP) 코어, 프로그래머블 로직 어레이(PLA), 프로그래머블 어레이 로직(PAL), 일반 어레이 로직(GAL), 복합 프로그래머블 논리 소자(CPLD), 현장 프로그래머블 게이트 어레이(FPGA), 시스템 온 칩(SoC), 주문형 반도체(ASIC) 등의 임의의 개수의 임의의 조합을 포함할 수 있다. 일부 실시예에서, 프로세서(402)는 또한, 단일 로직 구성요소로서 그룹화되는 일련의 프로세서일 수 있다. 예를 들어, 도 4에 도시된 바와 같이, 프로세서(402)는 프로세서(402a), 프로세서(402b) 및 프로세서(402n)를 포함한 다수의 프로세서를 포함할 수 있다.
장치(400)는 또한, 데이터(예를 들어, 일련의 명령, 컴퓨터 코드, 중간 데이터 등)를 저장하도록 구성되는 메모리(404)를 포함할 수 있다. 예를 들어, 도 4에 도시된 바와 같이, 저장된 데이터는 프로그램 명령(예를 들어, 과정(200A, 200B, 300A 또는 3OOB)에서의 단계를 수행하기 위한 프로그램 명령) 및 처리용 데이터(예를 들어, 비디오 시퀀스(202), 비디오 비트스트림(228) 또는 비디오 스트림(304))를 포함할 수 있다. 프로세서(402)는 프로그램 명령 및 처리용 데이터에 (예를 들어, 버스(410)를 통해) 접속할 수 있고, 처리용 데이터에 대한 작업 또는 조작을 수행하기 위해 프로그램 명령을 실행할 수 있다. 메모리(404)는 고속 랜덤 액세스 저장 장치 또는 비-휘발성 저장 장치를 포함할 수 있다. 일부 실시예에서, 메모리(404)는 랜덤-액세스 메모리(RAM), 리드-온리 메모리(ROM), 광학 디스크, 자기 디스크, 하드 드라이브, 솔리드-스테이트 드라이브, 플래시 드라이브, 보안 디지털(SD) 카드, 메모리 스틱, 콤팩트 플래시(CF) 카드 등의 임의의 개수의 임의의 조합을 포함할 수 있다. 메모리(404)는 또한, 단일 로직 구성요소로서 그룹화되는 메모리의 그룹(도 4에 도시되지 않음)일 수 있다.
버스(410)는 내부 버스(예를 들어, CPU-메모리 버스), 외부 버스(예를 들어, 유니버설 시리얼 버스 포트, 주변 구성요소 상호연결 고속 포트) 등과 같은, 장치(400) 내 구성요소들 사이에서 데이터를 이동시키는 통신 장치일 수 있다.
모호성을 야기하지 않고 설명하기 위해, 프로세서(402) 및 다른 데이터 처리 회로는 본 발명에서, 총체적으로 "데이터 처리 회로"로 언급된다. 데이터 처리 회로는 전체적으로 하드웨어로 또는 소프트웨어, 하드웨어 또는 펌웨어의 조합으로 실행될 수 있다. 또한, 데이터 처리 회로는 단일 독립 모듈이거나 장치(400)의 임의의 다른 구성요소로 전체적으로 또는 부분적으로 결합될 수 있다.
장치(400)는 네트워크(예를 들어, 인터넷, 인트라넷, 단거리 통신망, 모바일 통신 네트워크 등)와의 유선 또는 무선 통신을 제공하기 위해 네트워크 인터페이스(406)를 추가로 포함할 수 있다. 일부 실시예에서, 네트워크 인터페이스(406)는 네트워크 인터페이스 컨트롤러(NIC), 무선 주파수(RF) 모듈, 트랜스폰더, 트랜스시버, 모뎀, 라우터, 게이트웨이, 유선 네트워크 어댑터, 무선 네트워크 어댑터, 블루투스 어댑터, 적외선 어댑터, 근거리 통신("NFC") 어댑터, 셀룰러 네트워크 칩 등의 임의의 개수의 임의의 조합을 포함할 수 있다.
일부 실시예에서, 선택적으로, 장치(400)는 하나 이상의 주변 장치에 대한 연결을 제공하기 위해 주변 인터페이스(408)를 추가로 포함할 수 있다. 도 4에 도시된 바와 같이, 주변 장치는 커서 제어 장치(예를 들어, 마우스, 터치패드 또는 터치스크린), 키보드, 디스플레이(예를 들어, 음극선관 디스플레이, 액정 디스플레이 또는 광선 다이오드 디스플레이), 비디오 입력 장치(예를 들어, 카메라 또는 비디오 아카이브에 결합된 입력 인터페이스) 등을 포함할 수 있지만, 이에 한정되지 않는다.
비디오 코덱(예를 들어, 과정(200A, 200B, 300A 또는 300B)을 수행하는 코덱)이 장치(400)에 있어서 임의의 소프트웨어 또는 하드웨어 모듈의 임의의 조합으로 실행될 수 있다는 것에 유의해야 한다. 예를 들어, 과정(200A, 200B, 300A 또는 300B)의 일부 또는 전체 단계는 메모리(404)에 로딩될 수 있는 프로그램 명령과 같은 장치(400)의 하나 이상의 소프트웨어 모듈로서 실행될 수 있다. 다른 예에 대해, 과정(200A, 200B, 300A 또는 300B)의 일부 또는 전체 단계는 특화된 데이터 처리 회로(예를 들어, FPGA, ASIC, NPU 등)와 같은 장치(400)의 하나 이상의 하드웨어 모듈로서 실행될 수 있다.
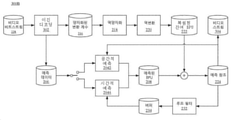
도 5는 본 발명의 일부 실시예에 따른 예시적인 크로마 스케일링을 사용한 루마 맵핑(LMCS) 과정(500)의 개략적인 다이어그램을 예시한다. 예를 들어, 과정(500)은 하이브리드 비디오 코딩 표준(예를 들어, H.26x 시리즈)에 부합하는 디코더에 의해 사용될 수 있다. LMCS는 도 2b의 루프 필터(232)에 앞서 적용된 새로운 처리 블록이다. LMCS는 또한 재구성기(reshaper)로 언급될 수 있다.
LMCS 과정(500)은 어댑티브 구분적 선형 모델 및 크로마 구성요소의 루마-의존성 크로마 잔여 스케일링에 기초한 루마 구성요소 값의 인-루핑 맵핑(in-looping mapping)을 포함할 수 있다.
도 5에 도시된 바와 같이, 어댑티브 구분적 선형 모델에 기초한 루마 구성요소 값의 인-루핑 맵핑은 전진 맵핑 단계(518) 및 역맵핑 단계(508)를 포함할 수 있다. 크로마 구성요소의 루마-의존성 크로마 잔여 스케일링은 크로마 스케일링(520)을 포함할 수 있다.
맵핑 전 또는 역맵핑 후의 샘플값은 원본 도메인에서의 샘플로 언급될 수 있으며, 맵핑 후 또는 역맵핑 전의 샘플값은 맵핑된 도메인에서의 샘플로 언급될 수 있다. 과정(500)에 있어서의 일부 단계는 LMCS가 활성화된 때, 원본 도메인 대신 맵핑된 도메인에서 수행될 수 있다. 전진 맵핑 단계(518) 및 역맵핑 단계(508)가 SPS 플래그를 사용하여 시퀀스 레벨에서 활성화/비활성화될 수 있다는 것을 인지해야 한다.
도 5에 도시된 바와 같이, Q-1&T-1 단계(504), 복원(506), 인트라 예측(514)은 맵핑된 도메인에서 수행된다. 예를 들어, Q-1&T-1 단계(504)는 역양자화 및 역변환을 포함할 수 있고, 복원(506)은 루마 예측 및 루마 잔여의 추가를 포함할 수 있으며, 인트라 예측(508)은 루마 인트라 예측을 포함할 수 있다.
루프 필터(510), 움직임 보상 단계(516 및 530), 인트라 예측 단계(528), 복원 단계(522) 및 디코딩된 픽처 버퍼(DPB)(512 및 526)는 원본(즉, 비-맵핑된) 도메인에서 수행된다. 일부 실시예에서, 루프 필터(510)는 블록화해제, 어댑티브 루프 필터(ALF) 및 샘플 어댑티브 오프셋(SAO)을 포함할 수 있고, 복원 단계(522)는 크로마 잔여와 함께 크로마 예측의 추가를 포함할 수 있으며, DPB(512 및 526)는 디코딩된 픽처를 참조 픽처로서 저장할 수 있다.
일부 실시예에서, 구분적 선형 모델에 의한 루마 맵핑을 사용하여 비디오 컨텐츠를 처리하기 위한 방법이 적용될 수 있다.
루마 구성요소의 인-루프 맵핑은 압축 효율을 개선하기 위해, 동적 범위에 걸쳐 코드워드를 재배포함으로써 입력 비디오의 신호 통계를 조정할 수 있다. 루마 맵핑은 전진 맵핑 함수("FwdMap") 및 대응하는 역맵핑 함수("InvMap")를 사용한다. "FwdMap" 함수는 16개의 동일한 조각(piece)을 가진 구분적 선형 모델을 사용하여 시그널링된다. "InvMap" 함수는 시그널링될 필요가 없으며, 대신 "FwdMap" 함수로부터 도출된다.
구분적 선형 모델의 시그널링이 도 6의 테이블 1 및 도 7의 테이블 2에 도시되고, 후에 VVC 드래프트 5에서, 구분적 선형 모델의 시그널링은 도 8의 테이블 3 및 도 9의 테이블 4에서처럼 변경된다. 테이블 1 및 테이블 3은 타일 그룹 헤더 및 슬라이스 헤더의 신택스 구조를 도시한다. 먼저, 재구성기 모델 파라미터 존재 플래그는 루마 맵핑 모델이 타깃 타일 그룹 또는 타깃 슬라이스에 존재하는지 여부를 나타내도록 시그널링될 수 있다. 루마 맵핑 모델이 현재의 타일 그룹/슬라이스에 존재하는 경우, 타깃 타일 그룹 또는 타깃 슬라이스에 대응하는 구분적 선형 모델 파라미터는 도 7의 테이블 2 및 도 9의 테이블 4에 도시된 신택스 요소를 사용하여, tile_group_reshaper_model()/lmcs_data()으로 시그널링될 수 있다. 구분적 선형 모델은 입력 신호의 동적 범위를 16개의 동일한 조각으로 분할한다. 각각의 조각에 대해, 그 선형 맵핑 파라미터는 조각에 부여된 다수의 코드워드를 사용하여 표현될 수 있다. 10-비트 입력의 일 예에서, 입력의 16개 조각의 각각은 디폴트로서 조각에 부여되는 64개의 코드워드를 가질 수 있다. 다수의 시그널링된 코드워드는 스케일링 인자를 계산하고 이에 따라 조각에 대한 맵핑 함수를 조정하는데 사용될 수 있다. 도 7의 테이블 2 및 도 9의 테이블 4는 또한, 통틀어 테이블 2에서와 같이 "reshaper_model_min_bin_idx" 및 "reshaper_model_delta_max_bin_idx", 테이블 4에서와 같이 "lmcs_min_bin_idx" 및 "lmcs_delta_max_bin_idx"과 같은 시그널링된 코드워드의 개수 중에서 최소 인덱스와 최대 인덱스를 규정한다. 조각 인덱스가 "reshaper_model_min_bin_idx" 또는 "lmcs_min_bin_idx"보다 작거나, "15-reshaper_model_max_bin_idx" 또는 "15-lmcs_delta_max_bin_idx,"보다 크다면, 상기 조각에 대한 코드워드의 개수는 시그널링되지 않고, 0인 것으로 추론된다. 다시 말해, 어떠한 코드워드도 부여되지 않으며, 어떠한 맵핑/스케일링도 조각에 적용되지 않는다.
타일 그룹 헤더 레벨 또는 슬라이스 헤더 레벨에 있어서, 다른 재구성기 인에이블 플래그(예를 들어, "tile_group_reshaper_enable_flag" 또는 "slice_lmcs_enabled_flag")는 도 5에 묘사된 것 같은 LMCS 과정이 타깃 타일 그룹 또는 타깃 슬라이스에 적용되는지 여부를 나타내도록 시그널링될 수 있다. 재구성기가 타깃 타일 그룹 또는 타깃 슬라이스에 대해 활성화되는 경우와 타깃 타일 그룹 또는 타깃 슬라이스가 듀얼 트리 파티션을 사용하지 않는 경우라면, 추가적인 크로마 스케일링 인에이블 플래그가 크로마 스케일링이 타깃 타일 그룹 또는 타깃 슬라이스에 대해 활성화되는지 여부를 나타내도록 시그널링될 수 있다. 듀얼 트리 파티션이 크로마 분리 트리로도 언급될 수 있다는 것을 인지해야 한다. 이하에서, 본 발명은 듀얼 트리 파티션을 보다 상세하게 설명할 것이다.
구분적 선형 모델은 다음과 같이 테이블 2 또는 테이블 4의 시그널링된 신택스 요소에 기초하여 구성될 수 있다. "FwdMap" 구분적 선형 모델의 i-번째 조각(i = 0 ... 15)은 2개의 입력 피벗 포인트(InputPivot[]) 및 2개의 맵핑된 피벗 포인트(MappedPivot[])에 의해 규정될 수 있다. 맵핑된 피벗 포인트(MappedPivot[])는 "FwdMap" 구분적 선형 모델의 출력일 수 있다. InputPivot[] 및 MappedPivot[]는 예시적 입력 비디오의 비트 심도를 10-비트로 가정하여, 다음과 같은 시그널링된 신택스에 기초하여 산출될 수 있다. 비트 심도는 10-비트와 다를 수 있다는 것을 인지해야 한다.
a) 테이블 2의 신택스 요소 사용:

b) 테이블 4의 신택스 요소 사용:

역맵핑 함수("InvMap")도 InputPivot[] 및 MappedPivot[]에 의해 규정된다. "FwdMap"와 달리, "InvMap" 구분적 선형 모델에 대해, 각각의 조각의 2개의 입력 피벗 포인트는 MappedPivot[]에 의해 규정되고, 2개의 출력 피벗 포인트는 InputPivot[]에 의해 규정된다. 이러한 방식으로, "FwdMap"의 입력은 동일한 조각으로 분할되지만, "InvMap"의 입력은 동일한 조각으로 분할된다고 보장 받지 못한다.
도 5에 도시된 바와 같이, 인터-코딩된 블록에 대해, 움직임 보상된 예측은 맵핑된 도메인에서 수행될 수 있다. 다시 말해, 움직임-보상된 예측(516) 후,  은 DPB에서 참조 신호에 기초하여 계산되고, "FwdMap" 함수(518)는 원본 도메인의 루마 예측 블록을 맵핑된 도메인에 맵핑하는데 적용될 수 있다(
은 DPB에서 참조 신호에 기초하여 계산되고, "FwdMap" 함수(518)는 원본 도메인의 루마 예측 블록을 맵핑된 도메인에 맵핑하는데 적용될 수 있다(  ). 인트라-코딩된 블록에 대해, "FwdMap" 함수는 인트라 예측에서 사용된 참조 샘플이 이미 맵핑된 도메인에 있기 때문에 적용되지 않는다. 복원된 블록(506) 후에,
). 인트라-코딩된 블록에 대해, "FwdMap" 함수는 인트라 예측에서 사용된 참조 샘플이 이미 맵핑된 도메인에 있기 때문에 적용되지 않는다. 복원된 블록(506) 후에,  이 계산될 수 있다. "InvMap" 함수(508)는 맵핑된 도메인의 복원된 루마값을 원본 도메인의 복원된 루마값으로 다시 변환시키도록 적용될 수 있다(
이 계산될 수 있다. "InvMap" 함수(508)는 맵핑된 도메인의 복원된 루마값을 원본 도메인의 복원된 루마값으로 다시 변환시키도록 적용될 수 있다( ). "InvMap" 함수(508)는 인트라- 및 인터-코딩된 루마 블록 둘 모두에 적용될 수 있다.
). "InvMap" 함수(508)는 인트라- 및 인터-코딩된 루마 블록 둘 모두에 적용될 수 있다.
루마 맵핑 과정(전진 또는 역맵핑)은 룩-업-테이블(LUT)을 사용하거나 즉석 산출(on-the-fly computation)을 사용하여 실행될 수 있다. LUT가 사용된다면, 테이블("FwdMapLUT[]" 및 "InvMapLUT[]")은 타일 그룹 레벨 또는 슬라이스 레벨에서의 사용을 위해 사전-계산 및 사전-저장될 수 있으며, 전진 및 역맵핑은 각각,  및
및  으로서 간단하게 실행될 수 있다.
으로서 간단하게 실행될 수 있다.
대안적으로, 즉석 산출이 사용될 수 있다. 일 예로서, 전진 맵핑 함수("FwdMap")를 취한다. 루마 샘플이 속하는 조각을 결정하기 위해, 샘플값이 6비트(10-비트 비디오를 가정하여 16개의 동일한 조각에 대응함)만큼 우측으로 이동하여 조각 인덱스를 획득할 수 있다. 그 후, 상기 조각에 대해 선형 모델 파라미터가 즉석에서 검색 및 적용되어 맵핑된 루마값을 산출한다. "FwdMap" 함수는 다음과 같이 평가된다:
여기서, "i"는 조각 인덱스이고, a1은 InputPivot[i]이고, a2는 InputPivot[i+1]이고, b1은 MappedPivot[i]이고, b2는 MappedPivot[i+1]이다.
"InvMap" 함수는, 맵핑된 도메인의 조각은 동일한 크기가 보장되지 않기 때문에, 샘플값이 속한 조각을 파악할 때 간단한 우측 비트-이동 대신 조건부 검사를 적용할 필요가 있다는 점을 제외하면 유사한 방식으로 즉석에서 산출될 수 있다.
일부 실시예에서, 루마-의존성 크로마 잔여 스케일링을 사용하여 비디오 컨텐츠를 처리하기 위한 방법이 제공될 수 있다.
크로마 잔여 스케일링은 루마 신호와 루마 신호에 대응하는 크로마 신호 사이의 상호작용에 대해 보상하기 위해 사용될 수 있다. 크로마 잔여 스케일링이 활성화되어 있는지 여부 또한, 타일 그룹 레벨 또는 슬라이스 레벨에서 시그널링될 수 있다. 도 6의 테이블 1 및 도 8의 테이블 3에 도시된 바와 같이, 루마 맵핑이 활성화되는 경우, 그리고 듀얼 트리 파티션이 현재의 타일 그룹에 적용되지 않는 경우, 추가적인 플래그(예를 들어, "tile_group_reshaper_chroma_residual_scale_flag" 또는 "slice_chroma_residual_scale_flag")는 루마-의존성 크로마 잔여 스케일링이 활성화되었는지 여부를 나타내도록 시그널링될 수 있다. 타깃 타일 그룹(또는 타깃 슬라이스)에서 듀얼 트리 파티션이 사용되거나, 루마 맵핑이 사용되지 않을 때, 이에 따라 루마-의존성 크로마 잔여 스케일링이 비활성화될 수 있다. 또한, 루마-의존성 크로마 잔여 스케일링은 그 영역이 4 이하인 크로마 블록에 대해 비활성화될 수 있다.
크로마 잔여 스케일링은 크로마 신호에 대응하는 루마 예측 블록(인트라- 및 인터-코딩된 블록 둘 모두에 대한)의 평균값에 따른다. 루마 예측 블록의 평균(" ")은 이하의 식을 사용하여 결정될 수 있다.
")은 이하의 식을 사용하여 결정될 수 있다.

크로마 잔여 스케일링에 대한 크로마 스케일링 인자의 값(" ")은 아래와 같은 단계를 사용하여 결정될 수 있다.
")은 아래와 같은 단계를 사용하여 결정될 수 있다.
1) InvMap 함수에 기초하여,  이 속하는 구분적 선형 모델의 인덱스(
이 속하는 구분적 선형 모델의 인덱스( )를 찾는다.
)를 찾는다.
2)  = cScaleInv[
= cScaleInv[ ], 여기서, cScaleInv[]는 예를 들어, 16 조각을 갖는 사전-산출된 LUT.
], 여기서, cScaleInv[]는 예를 들어, 16 조각을 갖는 사전-산출된 LUT.
일부 실시예에서, LMCS 방법에 있어서, i의 범위가 0 내지 15인 사전-산출된 LUT("cScaleInv[i]")는 아래와 같이, 64-엔트리 정적 LUT("ChromaResidualScaleLut") 및 시그널링된 코드워드("SignaledCW[i]") 값에 기초하여 도출될 수 있다.

일 예로서, 입력이 10-비트라고 가정하면, 정적 LUT("ChromaResidualScaleLut[]")는 64 엔트리를 포함하고, 시그널링된 코드워드("SignaledCW[]")는 [0, 128]의 범위에 있다. 따라서, 2에 의한 분할(또는 1만큼 우측 이동)은 크로마 스케일링 인자 LUT("cScaleInv []")를 구성하는데 사용된다. LUT("cScaleInv []")는 타일 그룹(또는 슬라이스 레벨)에서 구성될 수 있다.
현재의 블록이 인트라, CIIP 또는 인트라 블록 카피(IBC) 모드를 사용하여 코딩될 수 있다면,  는 인트라-, CIIP- 또는 IBC-예측된 루마값의 평균으로서 결정될 수 있다. 그렇지 않으면, 전진 맵핑된 인터 예측된 루마값(즉, 도 3의
는 인트라-, CIIP- 또는 IBC-예측된 루마값의 평균으로서 결정될 수 있다. 그렇지 않으면, 전진 맵핑된 인터 예측된 루마값(즉, 도 3의  )의 평균으로서 산출된다. 또한, IBC는 현재의 픽처 참조(CPR) 모드로서 언급될 수도 있다. 샘플 베이시스 상에서 수행되는 루마 맵핑과는 달리, "
)의 평균으로서 산출된다. 또한, IBC는 현재의 픽처 참조(CPR) 모드로서 언급될 수도 있다. 샘플 베이시스 상에서 수행되는 루마 맵핑과는 달리, " "는 전체 크로마 블록에 대한 상수값이다. "
"는 전체 크로마 블록에 대한 상수값이다. " "의 경우, 크로마 잔여 스케일링은 다음과 같이 디코더 측에 적용될 수 있다:
"의 경우, 크로마 잔여 스케일링은 다음과 같이 디코더 측에 적용될 수 있다:

여기서,  은 현재의 블록의 복원된 크로마 잔여다. 인코더 측에서, 전진 크로마 잔여 스케일링(변환 및 양자화되기 전)은 다음과 같이 수행된다: 인코더측:
은 현재의 블록의 복원된 크로마 잔여다. 인코더 측에서, 전진 크로마 잔여 스케일링(변환 및 양자화되기 전)은 다음과 같이 수행된다: 인코더측:  .
.
일부 실시예에서, 교차-구성요소 선형 모델 예측을 사용하여 비디오 컨텐츠를 처리하기 위한 방법이 제공될 수 있다.
교차-구성요소 과잉을 저감하기 위해, 교차-구성요소 선형 모델(CCLM) 예측 모드가 사용될 수 있다. CCLM에서, 크로마 샘플은 아래와 같은 선형 모델을 사용함으로써 동일한 코딩 유닛(CU)의 복원된 루마 샘플에 기초하여 예측된다:
여기서,  은 CU에 있어서 예측된 크로마 샘플을 나타내고,
은 CU에 있어서 예측된 크로마 샘플을 나타내고,  은 동일한 CU의 다운샘플링된 복원된 루마 샘플을 나타낸다.
은 동일한 CU의 다운샘플링된 복원된 루마 샘플을 나타낸다.
선형 모델 파라미터(α 및 β)는 2개의 샘플 위치로부터의 루마값과 크로마값 사이의 관계에 기초하여 도출된다. 2개의 샘플 위치는 일련의 다운샘플링된 이웃하는 루마 샘플 중에서 최대 루마 샘플값을 갖는 제1 루마 샘플 위치 및 최소 루마 샘플값을 갖는 제2 루마 샘플 위치, 및 이들의 대응하는 크로마 샘플을 포함할 수 있다. 선형 모델 파라미터(α 및 β)는 이하의 식에 따라 획득된다.
여기서, Ya 및 Xa는 각각 제1 루마 샘플 위치의 루마값 및 크로마값을 나타낸다. 그리고, Xb 및 Yb는 각각 제2 루마 샘플 위치의 루마값 및 크로마값을 나타낸다.
도 10은 본 발명의 일부 실시예에 따른 CCLM 모드에 수반되는 샘플 위치의 일 예를 예시한다.
파라미터(α)의 계산은 룩-업 테이블로 실행될 수 있다. 테이블 저장에 요구되는 메모리를 줄이기 위해, diff 값(최댓값과 최솟값 간의 차이) 및 파라미터(α)는 지수 표기법에 의해 표현된다. 예를 들어, diff는 4-비트 유효 부분과 지수로 근사화된다. 결과적으로, 1/diff에 대한 테이블은 다음과 같이 16개의 유효값에 대해 16개의 요소로 감소된다:

테이블("DivTable []")은 계산의 복잡성을 감소시킬 수 있고, 또한 필요한 테이블을 저장하기 위해 필요한 메모리 크기를 감소시킬 수 있다.
상단 위치 및 좌측 위치가 함께 선형 모델 계수를 계산하는데 사용될 수 있는 것 외에, 이들은 대안적으로, LM_A 및 LM_L 모드라고 하는 다른 2개의 LM 모드에서도 사용할 수 있다.
LM_A 모드에서는, 상단 위치의 샘플만이 선형 모델 계수를 계산하는데 사용된다. 더 많은 샘플을 획득하기 위해, 상단 위치는 (W+H) 샘플을 커버하도록 확장될 수 있다. LM_L 모드에서는, 좌측 위치의 샘플만이 선형 모델 계수를 계산하는데 사용된다. 더 많은 샘플을 얻기 위해, 좌측 위치는 (H+W) 샘플을 커버하도록 확장될 수 있다.
비-정사각형 블록에 대해, 위의 템플릿은 W+W로 확장되고, 좌측 템플릿은 H+H로 확장된다.
4:2:0 비디오 시퀀스에 대해 크로마 샘플 위치를 매칭하기 위해, 2가지 유형의 다운샘플링 필터가 루마 샘플에 적용되어 수평 방향과 수직 방향 둘 모두에서 2 대 1의 다운샘플링비를 얻을 수 있다. 다운샘플링 필터의 선택은 SPS 레벨 플래그에 의해 명시될 수 있다. 각각 "type-0" 및 "type-2" 컨텐츠에 대응하는 2개의 다운샘플링 필터는 다음과 같다.

하나의 루마 라인(인트라 예측에 있어서의 일반적 라인 버퍼)만이 상부 참조 라인이 CTU 경계에 있을 때 다운샘플링된 루마 샘플을 산출하는데 사용된다는 것이 인식된다.
이러한 파라미터 산출은 디코딩 과정의 일부로서 수행될 수 있으며, 단순히 인코더 검색 작업인 것은 아니다. 결과적으로, α 및 β 값을 디코더에 운반하는데 어떠한 신택스도 사용되지 않는다. α 및 β 파라미터는 별도로 각각의 크로마 구성요소에 대해 산출된다.
크로마 인트라 모드 코딩에 대해, 총 8개의 인트라 모드가 허용될 수 있다. 이들 모드는 5개의 전통적인 인트라 모드와 3개의 교차-구성요소 선형 모델 모드(예를 들어, CCLM, LM_A 및 LM_L)를 포함한다. CCLM이 활성화될 때, 크로마 모드를 시그널링하고 도출하기 위한 과정이 도 9의 테이블 5에 도시된다. 크로마 블록의 크로마 모드 코딩은 크로마 블록에 대응하는 루마 블록의 인트라 예측 모드에 따를 수 있다. 루마 및 크로마 구성요소에 대한 별도의 블록 분할 구조가 I 슬라이스(후술됨)에서 활성화되기 때문에, 하나의 크로마 블록이 다수의 루마 블록에 대응할 수 있다. 따라서, 크로마 도출된 모드(DM)에 대해, 현재의 크로마 블록의 중심 위치를 커버하는 대응하는 루마 블록의 인트라 예측 모드가 상속된다.
일부 실시예에서, 듀얼 트리 파티션을 사용하여 비디오 컨텐츠를 처리하기 위한 방법이 제공될 수 있다.
VVC 드래프트에서, 코딩 트리 체계는 루마 및 크로마가 별도의 블록 트리 파티션을 갖는 능력을 지원한다. 이는 듀얼 트리 파티션으로 언급되기도 한다. VVC 드래프트에서, 듀얼 트리 파티션의 시그널링이 도 12의 테이블 6 및 도 13의 테이블 7에 도시된다. 그리고 후에 VVC 드래프트 5에서, 듀얼 트리 파티션은 도 14의 테이블 8 및 도 15의 테이블 9에서와 같이 시그널링된다. SPS에서 시그널링된 시퀀스 레벨 제어 플래그(예를 들어, "qtbtt_dual_tree_intra_flag")가 작동되고(turn on), 타깃 타일 그룹(또는 타깃 슬라이스)이 인트라 코딩될 때, 블록 파티션 정보는 먼저 루마에 대해 그리고 그 후에 크로마에 대해 별도로 시그널링될 수 있다. 인터 코딩된 타일 그룹/슬라이스(예를 들어, P 및 B 타일 그룹/슬라이스)에 대해, 듀얼 트리 파티션은 허용되지 않는다. 도 13의 테이블 7에 도시된 바와 같이, 별도의 블록 트리 모드가 적용될 때, 루마 코딩 트리 블록(CTB)은 제1 코딩 트리 구조에 의해 CU로 분할되고, 크로마 CTB는 제2 코딩 트리 구조에 의해 크로마 CU로 분할된다.
루마 및 크로마 블록이 상이한 파티션을 갖도록 허용될 때, 문제는 상이한 색상 구성요소들 사이의 의존성을 갖는 코딩 툴에 대해 발생할 수 있다. 예를 들어, LMCS가 적용될 때, 타깃 크로마 블록에 대응하는 루마 블록의 평균값은 타깃 크로마 블록에 적용될 스케일링 인자를 결정하는데 사용될 수 있다. 듀얼 트리 파티션이 사용될 때, 루마 블록의 평균값의 결정은 전체 CTU의 대기 시간(latency)을 생성할 수 있다. 예를 들어, CTU의 루마 블록이 수직으로 일회 분할되고, CTU의 크로마 블록이 수평으로 일회 분할되면, CTU의 루마 블록들 둘 모두는 CTU의 제1 크로마 블록이 디코딩될 수 있기 전에, 평균값을 계산하기 위해 디코딩된다. VVC에서, CTU는 128×128의 루마 샘플 단위만큼 클 수 있으므로, 크로마 블록을 디코딩하는 대기 시간이 크게 증가한다. 따라서, VVC 드래프트 4 및 드래프트 5는 듀얼 트리 파티션 및 루마-의존성 크로마 스케일링의 결합을 억제할 수 있다. 듀얼 트리 파티션이 타깃 타일 그룹(또는 타깃 슬라이스)에 대해 활성화될 때, 크로마 스케일링이 강제로 해제될 수 있다. LMCS의 루마 맵핑부는 루마 구성요소에서만 작동하고 교차 색상 구성요소 의존성 문제가 없기 때문에, 여전히 듀얼 트리 파티션에서 허용된다는 것에 유의해야 한다.
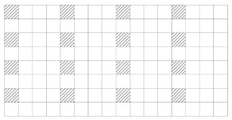
보다 우수한 코딩 효율을 얻기 위해 색상 구성요소들 사이의 의존성에 의존하는 코딩 툴의 다른 예는 전술된 교차 구성요소 선형 모델(CCLM)로 불린다. CCLM에서, 이웃하는 루마 및 크로마 복원된 샘플이 교차 구성요소 파라미터를 도출하는데 사용될 수 있다. 그리고 교차 구성요소 파라미터는 크로마 구성요소에 대한 예측 변수를 도출하기 위해 타깃 크로마 블록의 대응하는 복원된 루마 샘플에 적용될 수 있다. 듀얼 트리 파티션이 사용되는 경우, 루마 및 크로마 파티션은 정렬되는 것이 보장되지 않는다. 따라서, CCLM은 CCLM에 사용되는 샘플을 포함하는 대응하는 루마 블록 전체가 복원될 때까지 크로마 블록에 대해 개시될 수 없다.
도 16a-16b는 본 발명의 일부 실시예에 따른 예시적인 크로마 트리 파티션 및 예시적인 루마 트리 파티션을 예시한다. 도 16a는 크로마 블록(1600)의 예시적인 분할 구조를 예시한다. 그리고, 도 16b는 도 16의 크로마 블록(1600)에 대응하는 루마 블록(1610)의 예시적인 분할 구조를 예시한다. 도 16a에서, 크로마 블록(1600)은 4개의 서브-블록으로 4분할되고, 좌측 하단의 서브-블록은 4개의 서브-블록으로 다시 4분할되며, 격자 패턴을 갖는 블록이 예측될 현재의 블록이다. 도 16b에서, 루마 블록(1610)은 2개의 서브-블록으로 수평 방향으로 2분할되며, 격자 패턴을 갖는 영역이 예측될 타깃 크로마 블록에 대응하는 영역이다. CCLM 파라미터를 도출하기 위해, 빈 원형으로 표시되는 이웃하는 복원된 샘플값이 요구된다. 따라서, 타깃 크로마 블록의 예측은 긴 대기 시간을 가져오는 하단 루마 블록 복원이 마칠 때까지 개시될 수 없다.
일부 실시예에서, 가상의 파이프라인 데이터 유닛을 사용하여 비디오 컨텐츠를 처리하기 위한 방법이 제공될 수 있다.
VVC 표준화에 있어서, 가상의 파이프라인 데이터 유닛(VPDU)의 개념은 보다 친숙한 하드웨어 실행을 위해 도입된다. VPDU는 픽처에 있어서 비-중첩 M×M-루마(L)/N×N-크로마(C) 유닛으로서 규정된다. 하드웨어 디코더에 있어서, 연속적인 VPDU는 동시에 다수의 파이프라인 단계에 의해 처리된다. 상이한 단계는 상이한 VPDU를 동시에 처리한다. VPDU 크기는 대부분의 파이프라인 단계에서 버퍼 크기에 대략적으로 비례하며, 이에 따라 VPDU 크기를 작게 유지하는 것이 중요하다. VVC에서, VPDU의 크기는 64×64 샘플로 설정된다. 따라서, VVC에 채택된 모든 코딩 툴은 VDPU 제약을 어길 수 없다. 예를 들어, 최대 변환 크기는, 전체 변환 블록이 동일한 파이프라인 단계에서 작동될 필요가 있기 때문에, 단지 64×64일 수 있다. VPDU 제약으로 인해, 인트라 예측 블록은 또한, 64×64보다 크지 않아야 한다. 따라서, 인트라 코딩된 타일 그룹/슬라이스(예를 들어, I 타일 그룹/슬라이스)에 있어서, CTU는 4개의 64×64 블록(CTU가 64×64보다 큰 경우)으로 강제적으로 분할되고, 각각의 64×64 블록은 듀얼 트리 구조로 추가로 분할될 수 있다. 따라서, 듀얼 트리가 활성화된 때, 루마 분할 트리와 크로마 분할 트리의 공통 루트는 64x64 블록 크기이다.
LMCS 및 CCLM의 현재의 디자인에 있어서는 몇몇 문제가 있다.
첫째로, 예를 들어, 타일 그룹 레벨 크로마 스케일링 인자 LUT의 도출("cScaleInv[]")은 쉽게 확장가능하지 않다. 도출 과정은 현재 64개의 엔트리가 있는 상수 크로마 LUT("ChromaResidualScaleLut")에 의존한다. 16 조각을 갖는 10-비트 비디오에 대해, 2에 의한 분할의 추가 단계가 적용되어야 한다. 조각의 개수가 변화될 때(예를 들어, 16 조각 대신 8 조각이 사용되는 경우), 도출 과정은 2 대신 4에 의한 분할을 적용하도록 변화되어야 한다. 이러한 추가 단계는 정확성 손실을 야기할 수 있다.
둘째로, 예를 들어, 크로마 스케일링 인자를 획득하는데 사용되는  를 계산하기 위해, 전체 루마 블록의 평균값이 사용된다. 최대 CTU 크기 128×128을 고려하여, 평균 루마값은 복잡한 16384 (128×128) 루마 샘플에 기초하여 계산될 수 있다. 또한, 루마 블록 파티션 128×128이 인코더에 의해 선택되는 경우, 상기 블록은 동종의 컨텐츠를 포함할 가능성이 더 높다. 따라서, 블록에 있어서 루마 샘플의 서브세트가 루마 평균을 계산하기에 충분할 수 있다.
를 계산하기 위해, 전체 루마 블록의 평균값이 사용된다. 최대 CTU 크기 128×128을 고려하여, 평균 루마값은 복잡한 16384 (128×128) 루마 샘플에 기초하여 계산될 수 있다. 또한, 루마 블록 파티션 128×128이 인코더에 의해 선택되는 경우, 상기 블록은 동종의 컨텐츠를 포함할 가능성이 더 높다. 따라서, 블록에 있어서 루마 샘플의 서브세트가 루마 평균을 계산하기에 충분할 수 있다.
셋째로, 듀얼 트리 파티션 동안, 크로마 스케일링은 하드웨어 디코더에 대한 잠재적인 파이프라인 문제를 회피하기 위해 꺼지도록 설정된다. 그러나, (크로마 스케일링 인자를 도출하기 위해 대응하는 루마 샘플을 사용하는 대신) 적용될 크로마 스케일링 인자를 나타내기 위해 명시적 시그널링이 사용되는 경우 이러한 의존성이 회피될 수 있다. 인트라 코딩된 타일 그룹/슬라이스에 있어서 크로마 스케일링을 활성화하는 것은 코딩 효율을 추가로 개선할 수 있다.
넷째로, 종래적으로, 델타 코드워드 값은 16 조각 각각에 대해 시그널링된다. 종종 제한된 개수의 상이한 코드워드만이 16 조각에 대해 사용되는 것으로 관찰되었다. 따라서, 시그널링 오버헤드가 추가로 감소될 수 있다.
다섯째로, CCLM의 파라미터는 타깃 크로마 블록의 인과적 이웃인 블록으로부터 루마 및 크로마 복원된 샘플로 도출된다. 듀얼 트리 파티션에 있어서, 루마 및 크로마 블록 파티션은 반드시 정렬되지는 않는다. 따라서, 하나를 초과하는 개수의 루마 블록 또는 타깃 크로마 블록보다 큰 영역을 갖는 루마 블록은 타깃 크로마 블록에 대응할 수 있다. 타깃 크로마 블록의 CCLM 파라미터를 도출하기 위해, 대응하는 모든 루마 블록은 도 16a-16b에 도시된 바와 같이 먼저 복원되어야 한다. 이는 파이프라인 실행에 있어서의 대기 시간을 발생시키고, 하드웨어 디코더의 처리량을 감소시킨다.
위의 문제를 해결하기 위해, 본 발명의 실시예들이 이하에 제공된다.
본 발명의 실시예들은 크로마 스케일링 LUT을 제거함으로써, 비디오 컨텐츠를 처리하기 위한 방법을 제공한다.
전술한 바와 같이, 64개의 엔트리의 크로마 LUT는 쉽게 확장가능하지 않으며, 다른 구분적 선형 모델이 사용될 때(예를 들어, 8 조각, 4 조각, 64 조각 등)의 문제를 야기할 수 있다. 또한, 크로마 스케일링 인자가 대응하는 조각의 루마 스케일링 인자와 동일하게 설정될 수 있기 때문에, 동일한 코딩 효율을 얻는 것이 불필요하다. 본 발명의 일부 실시예에서,  은 현재의 크로마 블록의 조각 인덱스로 표시되고, 크로마 스케일링 인자를 결정하기 위해 이하의 단계들이 사용된다:
은 현재의 크로마 블록의 조각 인덱스로 표시되고, 크로마 스케일링 인자를 결정하기 위해 이하의 단계들이 사용된다:
●  > reshaper_model_max_bin_idx이거나,
> reshaper_model_max_bin_idx이거나,  < reshaper_model_min_bin_idx이면, 또는 SignaledCW[
< reshaper_model_min_bin_idx이면, 또는 SignaledCW[ ] = 0이면, chroma_scaling을 디폴트로 설정(chroma_scaling = 1.0), 즉 어떠한 스케일링도 적용되지 않는다.
] = 0이면, chroma_scaling을 디폴트로 설정(chroma_scaling = 1.0), 즉 어떠한 스케일링도 적용되지 않는다.
● 그렇지 않으면, chroma_scaling을 SignaledCW[ ]/OrgCW으로 설정.
]/OrgCW으로 설정.
위에서 도출된 크로마 스케일링 인자는 프랙쇼널 정확성(fractional precision)을 갖는다. 하드웨어/소프트웨어 플랫폼에 대한 의존성을 회피하기 위해, 고정점 근사가 적용될 수 있다. 또한, 디코더 측에서, 역크로마 스케일링이 수행될 필요가 있다. 이러한 나눗셈은 곱하기와 이에 이은 우향 자리 이동을 사용하여 고정점 연산에 의해 수행될 수 있다. 고정점 근사에 있어서의 비트의 개수를 CSCALE_FP_PREC로서 나타낸다. 아래는 고정점 정확성에 있어서 역크로마 스케일링 인자를 결정하는데 사용될 수 있다:

여기서, luma_bit_depth은 루마 비트 심도이고, TOTAL_NUMBER_PIECES은 VVC 드래프트 4에서 16으로 설정되는 구분적 선형 모델에 있어서의 조각의 총수이다. inverse_chroma_scaling 값은 단지 타일 그룹/슬라이스당 일회 계산될 필요가 있을 수 있으며, 위에 있어서의 나눗셈은 정수 나눗셈 작업이다.
추가적인 양자화는 크로마 스케일링 및 역스케일링 인자를 도출하는데 적용될 수 있다. 예를 들어, SignaledCW의 모든 짝수(2×m) 값을 위해 역크로마 스케일링 인자가 계산될 수 있으며, SignaledCW의 홀수(2×m+1) 값은 이웃하는 짝수 값의 스케일링 인자의 크로마 스케일링 인자를 재사용한다. 다시 말해, 아래가 사용될 수 있다:

크로마 스케일링 인자를 양자화하는 위의 실시예들은 추가로 일반화될 수 있는데, 예를 들어, SignaledCW의 모든 n번째 값에 대해 역크로마 스케일링 인자가 계산되고, 이웃하는 모든 다른 값에 동일한 크로마 스케일링 인자가 공유될 수 있다. 예를 들어, "n"은 4로 설정될 수 있는데, 이는 4개의 이웃하는 코드워드 값마다 동일한 역크로마 스케일링 인자 값을 공유한다는 의미이다. "n"의 값이 2의 거듭 제곱이 되는 것이 바람직하며, 이는 시프팅(shifting)이 나눗셈을 계산하는데 사용될 수 있게 한다. log2(n)의 값을 LOG2_n으로 나타내면, 위의 사항은 다음과 같이 수정될 수 있다: tempCW = SignaledCW[ ] >> LOG2_n)<<LOG2_n.
] >> LOG2_n)<<LOG2_n.
마지막으로, LOG2_n의 값은 구분적 선형 모델에 사용되는 조각의 개수의 함수일 수 있다. 보다 적은 개수의 조각이 사용된다면 보다 큰 LOG2_n을 사용하는 것이 유리하다. 예를 들어, TOTAL_NUMBER_PIECES의 값이 16 이하라면, LOG2_n은 1+(4 - log2(TOTAL_NUMBER_PIECES))으로 설정될 수 있다. TOTAL_NUMBER_PIECES이 16보다 크다면, LOG2_n은 0으로 설정될 수 있다.
본 발명의 실시예는 루마 예측 블록의 평균화를 단순화함으로써 비디오 컨텐츠를 처리하기 위한 방법을 제공한다.
전술한 바와 같이, 현재의 크로마 블록의 조각 인덱스(" ")를 결정하기 위해, 대응하는 루마 블록의 평균값이 사용될 수 있다. 그러나, 큰 블록 크기에 대해서는, 평균화 과정은 다수의 루마 샘플을 수반할 수 있다. 최악의 경우, 128×128 루마 샘플이 평균화 과정에 수반될 수 있다.
")를 결정하기 위해, 대응하는 루마 블록의 평균값이 사용될 수 있다. 그러나, 큰 블록 크기에 대해서는, 평균화 과정은 다수의 루마 샘플을 수반할 수 있다. 최악의 경우, 128×128 루마 샘플이 평균화 과정에 수반될 수 있다.
본 발명의 실시예는 단순화된 평균화 과정을 제공하여 N×N 루마 샘플(N은 2의 거듭 제곱)을 사용하는 것만으로 최악의 경우를 감소시킨다.
일부 실시예에서, 2차원 루마 블록의 양 차원 모두가 미리 설정된 임계값 N 이하에 해당하는 것은 아닌 경우(다시 말해, 2개의 차원 중 적어도 하나는 N보다 큰 경우), "다운샘플링(downsampling)"은 상기 차원에 있어서 N 위치만 사용하는데 적용될 수 있다. 일반성을 잃지 않고, 수평 차원을 일 예로서 다루어 본다. 폭이 N보다 큰 경우라면, 위치(x)(x = i×(width >> log2(N)), i = 0,... N-1)에서의 샘플만이 평균화에 사용된다.
도 17은 본 발명의 일부 실시예에 따른 평균화 작업의 예시적인 단순화를 예시한다. 본 예에서, N은 4로 설정되고, 블록 내 16개의 루마 샘플(음영 처리된 샘플)만이 평균화에 사용된다. N의 값은 4로 한정되지 않는다는 것을 인지해야 한다. 예를 들어, N은 2의 거듭 제곱인 임의의 값으로 설정될 수 있다. 다시 말해, N은 1, 2, 4, 8 등일 수 있다.
일부 실시예에서, 상이한 N의 값이 수평적 및 수직적 차원으로 적용될 수 있다. 다시 말해, 평균화 작업의 최악의 경우는 N×M 샘플을 사용하는 것일 수 있다. 일부 실시예에서, 샘플의 개수는 치수에 상관 없이 평균화 과정에서 제한될 수 있다. 예를 들어, 최대 16개의 샘플이 사용될 수 있다. 16개의 샘플은 1×16, 16×1, 2×8, 8×2, 4×4의 형태 또는 타깃 블록의 형상에 맞춘 형태로 수평적 또는 수직적 차원으로 분배될 수 있다. 예를 들어, 2×8은 블록이 가늘고 긴 경우에 사용되고, 8×2는 블록이 넓고 짧은 경우에 사용되며, 4×4는 블록이 정사각형인 경우에 사용된다.
비록, 이러한 단순화로 인해 평균값이 전체 루마 블록의 진짜 평균과는 상이하게 될 수 있지만, 임의의 이러한 차이는 작을 것이다. 이는 큰 블록 크기가 선택될 때, 블록 내 컨텐츠는 더 동질화하는 경향이 있기 때문이다.
또한, 디코더-측 움직임 벡터 미세화(decoder-side motion vector refinement)(DMVR) 모드는 VVC 표준에서, 특히 디코더에 대해 복잡한 과정이다. 이는 DMVR은 움직임 보상이 적용될 수 있기 전에, 디코더가 움직임 벡터를 도출하기 위해 움직임 검색을 수행할 것을 요구하기 때문이다. VVC 표준에 있어서 양방향성 시각적 유동(BDOF) 모드는 상황을 더욱 복잡하게 할 수 있는데, 이는 BDOF가 루마 예측 블록을 획득하기 위해, DMVR 이후에 적용될 필요가 있는 추가적인 순차적 과정이기 때문이다. 크로마 스케일링이 대응하는 루마 예측 블록의 평균값을 요구하기 때문에, DMVR 및 BDOF는 평균값이 계산될 수 있기 전에 적용될 수 있어 대기 시간 문제를 야기한다.
이러한 대기 시간 문제를 해결하기 위해, 본 발명의 일부 실시예에서, 루마 예측 블록은 평균 루마값을 계산하기 위해 DMVR 및 BDOF에 앞서 사용되며, 평균 루마값이 크로마 스케일링 인자를 획득하기 위해 사용된다. 이는 크로마 스케일링이 DMVR 및 BDOF 과정에 병렬로 적용될 수 있도록 하며, 이에 따라 대기 시간을 현저하게 감소시킬 수 있다.
본 발명과 일관되도록, 대기 시간 감소에 대한 변화가 고려될 수 있다. 일부 실시예에서, 이러한 대기 시간 감소는 평균 루마값을 계산하기 위해 루마 예측 블록의 일부만을 사용하는 전술한 단순화된 평균화 과정과 결합될 수도 있다. 일부 실시예에서, 루마 예측 블록은 DMVR 과정 이후 및 BDOF 과정 이전에 사용되어, 평균 루마값을 계산할 수 있다. 그 후, 평균 루마값은 크로마 스케일링 인자를 획득하는데 사용된다. 이러한 디자인은 크로마 스케일링 인자를 결정하는 정확성을 유지하면서도, 크로마 스케일링이 BDOF 과정에 병렬로 적용될 수 있도록 한다. DMVR 과정은 움직임 벡터를 미세화할 수 있으며, 이에 따라 DMVR 과정 이후 미세화된 움직임 벡터를 갖는 예측 샘플을 사용하는 것은 DMVR 과정 이전 움직임 벡터를 갖는 예측 샘플을 사용하는 것보다 더 정확할 수 있다.
또한, VVC 표준에 있어서, CU 신택스 구조(예를 들어, coding_unit())는 타깃 CU에 있어서 임의의 0이 아닌 잔여 계수가 있는지 여부를 나타내는 신택스 요소("cu_cbf")를 포함할 수 있다. TU 레벨에서, TU 신택스 구조(transform_unit())는 타깃 TU에 있어서 임의의 0이 아닌 크로마(Cb 또는 Cr) 잔여 계수가 있는지 여부를 나타내는 신택스 요소(tu_cbf_cb and tu_cbf_cr)를 포함한다. VVC 드래프트 4에서, 대응하는 루마 블록의 평균화는 크로마 스케일링이 타일 그룹 레벨 또는 슬라이스 레벨에서 활성화되는 경우에 적용될 수 있다. 본 발명은 또한, 루마 평균화 과정을 우회하는(bypass) 방법을 제공한다. 개시된 실시예들과 일관되도록, 크로마 스케일링 과정이 잔여 크로마 계수에 적용되기 때문에, 루마 평균화 과정은 0이 아닌 크로마 계수가 존재하지 않는 경우에 우회될 수 있다. 이는 이하의 조건에 기초하여 결정될 수 있다:
조건 1: cu_cbf는 0과 같다
조건 2: tu_cbf_cr 및 tu_cbf_cb는 둘 모두 0과 같다
조건 1 또는 조건 2가 충족되는 경우, 루마 평균화 과정은 우회될 수 있다.
위 실시예에 있어서, 예측 블록의 N×N 샘플만이 평균값을 도출하는데 사용되는데, 이로 인해 평균화 과정이 단순화된다. 예를 들어, N이 1과 동일할 때, 예측 블록의 상단 좌측 샘플만이 사용될 수 있다. 그러나, 이러한 단순화된 경우에도 먼저 예측 블록을 생성해야 하기 때문에, 대기 시간이 발생하게 된다. 따라서, 일부 실시예에서, 참조 루마 샘플이 크로마 스케일링 인자를 직접 도출하는데 사용될 수 있는 것이 고려된다. 이는 디코더가 루마 예측 과정에 병렬로 크로마 스케일링 인자를 도출할 수 있도록 하며, 이이 따라 대기 시간을 감소시킨다. 다시 말해, 인트라 예측 및 인터 예측이 별도로 처리된다.
인트라 예측의 경우에, 동일한 픽처에 있어서 이미 디코딩된 이웃하는 샘플들이 예측 블록을 생성하기 위해 참조 샘플로서 사용될 수 있다. 이들 참조 샘플은 타깃 블록의 상단 상의, 타깃 블록의 좌측에 대한, 그리고 타깃 블록의 상단 좌측에 대한 샘플을 포함한다. 이러한 참조 샘플 모두의 평균이 크로마 스케일링 인자를 도출하는데 사용될 수 있다. 대안적으로, 이들 참조 샘플의 일부만의 평균이 사용될 수 있다. 예를 들어, 타깃 블록의 상단 좌측 위치에 가장 가까운 M 참조 샘플(예를 들어, M=3)만이 평균화될 수 있다.
다른 예로서, 도 18에서와 같이, 크로마 스케일링 인자를 도출하기 위해 평균화되는 M 참조 샘플은 상단 좌측 위치에 가장 가깝지 않지만, 타깃 블록의 상단 경계 및 좌측 경계를 따라 분포된다. 도 18은 크로마 스케일링 인자를 도출하기 위해 평균 계산에 사용되는 예시적인 샘플을 예시한다. 도 18에 도시된 바와 같이, 예시적인 샘플은 실선 박스로 표시된다. 1, 2, 3, 4, 5, 6 및 8개의 샘플이 도 18에 도시된 예시적 블록(1801-1807)의 각각에서 평균화된다. 본 발명에서 평균 계산은 상이한 샘플들이 평균 계산에서 상이한 가중치를 가질 수 있는 가중 평균으로 대체될 수 있다. 예를 들어, 가중치의 합은 평균 계산에서의 나눗셈 연산을 회피하기 위해 2의 거듭 제곱일 수 있다.
인터 예측의 경우에, 시간적 참조 픽처로부터의 참조 샘플은 예측 블록을 생성하는데 사용될 수 있다. 이들 참조 샘플은 참조 픽처 인덱스 및 움직임 벡터에 의해 확인된다. 움직임 벡터가 프랙쇼널 정확성을 갖는 경우, 내삽(interpolation)이 적용될 수 있다. 참조 샘플의 평균을 계산하기 위해, 내삽 이후의 참조 샘플이 사용될 수 있으며, 또는 내삽 이전의 참조 샘플(즉, 정수 정확도로 클리핑되는 움직임 벡터)이 사용될 수도 있다. 개시된 실시예들과 일관되도록, 모든 참조 샘플이 평균을 계산하는데 사용될 수 있다. 대안적으로, 참조 샘플의 일부(예를 들어, 타깃 블록의 상단 좌측 위치에 대응하는 참조 샘플)만이 평균을 계산하는데 사용될 수 있다.
도 5에 도시된 바와 같이, 인트라 예측은 재구성된 도메인에서 수행되는 반면, 인터 예측은 원본 도메인에서 수행된다. 따라서, 인터 예측에 대해, 전진 맵핑이 예측 블록 상에 적용되고, 전진 맵핑 후 루마 예측 블록이 루마 블록의 평균값을 계산하는데 사용된다. 대기 시간을 감소시키기 위해, 평균값은 전진 맵핑 전 루마 예측 블록을 사용하여 계산될 수 있다. 예를 들어, 전진 맵핑 전 전체 루마 블록, 또는 전진 맵핑 전 루마 블록의 N×N 부분, 또는 전진 맵핑 전 루마 블록의 상단 좌측 샘플이 사용될 수 있다.
본 발명의 실시예는 추가로, 듀얼-트리 파티션에 대한 크로마 스케일링을 사용하여 비디오 컨텐츠를 처리하기 위한 방법을 제공한다.
루마 블록에 대한 의존성으로 인해 하드웨어 디자인 복잡성이 야기될 수 있기 때문에, 크로마 스케일링은 듀얼-트리 파티션을 활성화하는 인트라-코딩된 타일 그룹/슬라이스에 대해 꺼져 있을 수 있다. 그러나, 이러한 제약은 코딩 효율 손실을 야기할 수 있다.
CTU가 루마 코딩 트리 및 크로마 코딩 트리 둘 모두의 공통 루트이기 때문에, CTU 레벨 상에서 크로마 스케일링 인자를 도출하는 것은 듀얼 트리 파티션에 있어서 크로마와 루마 사이의 의존성을 제거할 수 있다. 예를 들어, CTU 이웃하는 복원된 루마 샘플 또는 크로마 샘플은 크로마 스케일링 인자를 도출하는데 사용된다. 그 후, 이러한 크로마 스케일링 인자는 CTU 내 모든 크로마 샘플에 대해 사용될 수 있다. 이러한 예에서, 위의 참조 샘플을 평균화하는 방법은 CTU 이웃하는 복원된 샘플을 평균화하는데 적용될 수 있다. 이들 참조 샘플 모두의 평균이 크로마 스케일링 인자를 도출하는데 사용될 수 있다. 또는, 이들 참조 샘플의 일부만의 평균값이 사용될 수 있다. 예를 들어, 타깃 블록의 상단 좌측 위치에 가장 가까운 M 참조 샘플(예를 들어, M=4, 8, 16, 32 또는 64)만이 평균화 될 수 있다.
그러나, 픽처 하단 또는 우측 경계 상의 CTU에 대해, 도 19에서 회색 CTU처럼, CTU의 샘플 모두가 픽처 경계 내에 존재하지는 않을 수 있다. 이러한 경우에, 픽처 경계 내 CTU 경계 상의 이웃하는 복원된 샘플(도 19의 회색 샘플)만이 크로마 스케일링 인자를 도출하는데 사용될 수 있다. 그러나, 평균 계산에 있어서 샘플의 가변 개수는 하드웨어 실행에 있어서 바람직하지 않은 나눗셈 연산을 요구한다. 따라서, 본 발명의 실시예는 평균 계산에 있어서 나눗셈 연산을 회피할 수 있도록, 2의 거듭 제곱인 고정수에 픽처 경계 샘플을 패딩처리하는(padding) 방법을 제공한다. 예를 들어, 도 19에 도시된 바와 같이, 픽처 하단 경계 밖의 패딩처리된 샘플(도 19에서 흰색 샘플)은 픽처 하단 경계 상의 모든 샘플들 중에서 패딩처리된 샘플에 가장 가까운 샘플인 샘플(1905)로부터 생성된다. CTU 레벨 크로마 스케일링 인자 도출에 더해, 크로마 스케일링 인자는 고정 격자 상에서 도출될 수 있다. 파이프라인 단계에 의해 처리된 데이터 유닛으로서 규정되는 가상의 파이프라인 데이터 유닛(VPDU)을 고려하여, 크로마 스케일링 인자는 VPDU 레벨에서 도출될 수 있다. VVC 드래프트 5에서, VPDU는 루마 샘플 격자 상의 64×64 블록으로서 규정된다. 따라서, 64×64 블록의 입상에서의 크로마 스케일링 인자 도출이 본 발명의 실시예에 제공된다. VVC 드래프트 6에서, VPDU는 루마 샘플 격자 상의 M×M 블록으로서 규정되고, 여기서 M이 CTU의 크기 및 64 중 더 작은 것이다. 전술된 CTU 레벨 도출 방법은 VPDU 레벨에서도 사용될 수 있다.
일부 실시예에서, 격자 크기가 CTU보다 작은 고정 격자 상에서 크로마 스케일링 인자를 도출하는 것 외에, 상기 인자는 CTU당 일회만 도출되고, CTU 내에서 모든 격자 유닛(예를 들어, VPDU)에 대해 사용된다. 예를 들어, CTU의 제1 VPDU 상에서 크로마 스케일링 인자를 도출하고, 상기 인자는 CTU 내에서 모든 VPDU에 대해 사용된다. VPDU 레벨에서의 방법은 도출에 있어서 제한된 개수의 이웃하는 샘플을 사용하는(예를 들어, CTU에서 제1 VPDU에 대응하는 이웃하는 샘플만을 사용하는) CTU 레벨 도출과 동등하다는 것을 인지해야 한다.
CTU 레벨에서, VPDU 레벨에서, 또는 임의의 다른 고정-크기 블록 유닛 레벨에서,  를 계산하기 위해 대응하는 루마 블록의 샘플값을 평균화하는 것, 조각 인덱스(
를 계산하기 위해 대응하는 루마 블록의 샘플값을 평균화하는 것, 조각 인덱스( )를 결정하는 것, 그리고 크로마 스케일링 인자(inverse_chroma_scaling[
)를 결정하는 것, 그리고 크로마 스케일링 인자(inverse_chroma_scaling[ ])를 획득하는 것 대신, 크로마 스케일링 인자는 듀얼 트리 파티션의 경우에 루마에 대한 의존성을 회피하기 위해 비트스트림에서 명확하게 시그널링될 수도 있다.
])를 획득하는 것 대신, 크로마 스케일링 인자는 듀얼 트리 파티션의 경우에 루마에 대한 의존성을 회피하기 위해 비트스트림에서 명확하게 시그널링될 수도 있다.
크로마 스케일링 인덱스는 복수의 레벨에서 시그널링될 수 있다. 예를 들어, 크로마 스케일링 인덱스는 도 20의 테이블 10 및 도 21의 테이블 11에서 도시된 바와 같이, 크로마 예측 모드와 함께 코딩 유닛(CU) 레벨에서 시그널링될 수 있다. 신택스 요소(lmcs_scaling_factor_idx)(도 20의 요소(2002) 및 도 21의 요소(2102))는 타깃 크로마 블록에 대한 크로마 스케일링 인자를 결정하는데 사용된다. 존재하지 않는 경우, 타깃 크로마 블록에 대한 크로마 스케일링 인자는 부동점 정확성(floating point precision)에서 1.0과 같거나 고정점 정확성(fixed point precision)에서 동등하게(1<<CSCALE_FP_PREC) 추론된다. lmcs_chroma_scaling_idx에 대한 허용값의 범위는 타일 그룹 레벨 또는 슬라이스 레벨에서 결정될 수 있으며, 후술될 것이다.
lmcs_chroma_scaling_idx의 가능한 값에 따라, 그 시그널링 비용이 너무 높을 수 있으며, 특히 작은 블록에 대한 비용이 너무 높을 수 있다. 따라서, 본 발명의 일부 실시예에서, 도 20의 테이블 10의 시그널링 조건은 추가적으로, 블록 크기 조건을 포함할 수 있다. 예를 들어, 타깃 블록이 N개를 초과하는 크로마 샘플을 포함하거나, 타깃 블록이 소정의 폭(W)보다 큰 폭 및/또는 소정의 높이(H)보다 높은 높이를 갖는 경우에, 이 신택스 요소 "lmcs_chroma_scaling_idx" (도 20의 요소(2002))만 시그널링된다. 보다 작은 블록에 대해, lmcs_chroma_scaling_idx이 시그널링되지 않는다면, 그 크로마 스케일링 인자는 디코더 측에서 결정될 수 있다. 일 예로서, 크로마 스케일링 인자는 부동점 정확성으로 1.0으로 설정될 수 있다. 일부 실시예에서, 디폴트 lmcs_chroma_scaling_idx 값은 타일 그룹 헤더 레벨 또는 슬라이스 헤더 레벨(도 10의 테이블 1)에서 추가될 수 있다. 시그널링 되지 않은 lmcs_chroma_scaling_idx를 갖는 블록(예를 들어, 작은 블록)은 블록에 대응하는 크로마 스케일링 인자를 도출하기 위해 타일 그룹/슬라이스 레벨 디폴트 인덱스를 사용할 수 있다. 일부 실시예에서, 작은 블록의 크로마 스케일링 인자는 명확하게 시그널링된 스케일링 인자를 갖는 작은 블록의 이웃요소(예를 들어, 상단 또는 좌측 이웃요소)로부터 상속될 수 있다.
CTU 레벨에서 이러한 "lmcs_chroma_scaling_idx"의 신택스 요소를 시그널링하는 것 외에, 상기 신택스 요소는 CTU 레벨에서도 시그널링될 수 있다. 그러나, VVC에서 최대 CTU 크기가 128×128인 경우, CTU 레벨에서 "lmcs_chroma_scaling_idx"의 시그널링된 신택스 요소에 따른 크로마 스케일링은 너무 거칠 수 있다. 따라서, 본 발명의 일부 실시예에서, "lmcs_chroma_scaling_idx"의 이러한 신택스 요소는 고정 입상을 사용하여 시그널링될 수 있다. 예를 들어, 16×16 샘플을 갖는 영역(또는 VPDU에 대해 64×64 샘플을 갖는 영역)에 대해, 하나의 lmcs_chroma_scaling_idx가 시그널링될 수 있고, 16×16 샘플을 갖는 영역(또는 64×64 샘플을 갖는 영역)의 샘플에 적용될 수 있다.
타깃 타일 그룹/슬라이스에 대한 lmcs_chroma_scaling_idx의 범위는 얼마나 많은 크로마 스케일링 인자값이 타깃 타일 그룹/슬라이스에서 허용되는냐에 달려 있다. lmcs_chroma_scaling_idx의 범위는 전술한 바와 같이 64-엔트리 크로마 LUT에 의존하는 VVC에서의 기존 방법에 의해 결정될 수 있다. 대안적으로, 전술한 크로마 스케일링 인자 계산을 사용하여 결정될 수도 있다.
일 예로서, LOG2_n의 값은 전술한 "양자화" 방법에 대해 2로 설정(즉, "n"은 4로 설정)되고, 타깃 타일 그룹/슬라이스의 구분적 선형 모델에 있어서의 각각의 조각의 코드워드 배정은 다음과 같이 설정된다: {0, 65, 66, 64, 67, 62, 62, 64, 64, 64, 67, 64, 64, 62, 61, 0}. 그러면, 64 내지 67로부터의 임의의 코드워드 값이 동일한 스케일링 인자값(예를 들어, 프랙쇼널 정확성에서 1.0)을 가질 수 있고, 60 내지 63으로부터의 임의의 코드워드 값이 동일한 스케일링 인자값(예를 들어, 프랙쇼널 정확성에서 60/64 = 0.9375)을 가질 수 있기 때문에, 전체 타일 그룹에 대해 단 2개의 가능한 스케일링 인자값이 존재한다. 어떠한 코드워드도 부여되지 않은 2개의 엔드 조각에 대해, 크로마 스케일링 인자는 디폴트로 1.0이 설정될 수 있다. 따라서, 본 예에서, 타깃 슬라이스에서의 블록에 대해 lmcs_chroma_scaling_idx을 시그널링을 위해 하나의 비트면 충분하다. 블록은 크로마 스케일링 인자 시그널링 레벨에 따라 CU, CTU 또는 고정 영역을 포함할 수 있다.
구분적 선형 모델을 사용하여 가능한 크로마 스케일링 인자값의 개수를 도출하는 것 외에, 일부 실시예에서, 인코더는 타일 그룹/슬라이스 헤더에서 일련의 크로마 스케일링 인자값을 시그널링할 수 있다. 그 후, 블록 레벨에서, 크로마 스케일링 인자값은 상기 블록에 대해 lmcs_chroma_scaling_idx 값 및 상기 일련의 크로마 스케일링 인자값을 사용하여 결정될 수 있다.
대안적으로, 시그널링 비용을 절감하기 위해, 크로마 스케일링 인자는 이웃하는 블록으로부터 예측될 수 있다. 예를 들어, 플래그는 타깃 블록의 크로마 스케일링 인자가 타깃 블록의 이웃하는 블록의 인자와 동일하다는 것을 나타내는데 사용될 수 있다. 이웃하는 블록은 상단 또는 좌측의 이웃하는 블록일 수 있다. 따라서, 최대 2 비트가 타깃 블록용으로 시그널링될 수 있다. 예를 들어, 2 비트에 있어서, 제1 비트는 타깃 블록의 크로마 스케일링 인자가 타깃 블록의 좌측 이웃요소의 인자와 동일한지 여부를 나타낼 수 있고, 제2 비트는 타깃 블록의 크로마 스케일링 인자가 타깃 블록의 상측 이웃요소의 인자와 동일한지 여부를 나타낼 수 있다. 어떤 비트의 값도 타깃 블록의 크로마 스케일링 인자가 상단 이웃요소 또는 좌측 이웃요소와 동일함을 나타내지 않는다면, lmcs_chroma_scaling_idx 신택스가 시그널링될 수 있다.
"lmcs_chroma_scaling_idx"의 상이한 값의 확률에 따라, 가변 길이 코드워드는 평균 코드 길이를 감소시키기 위해 "code lmcs_chroma_scaling_idx"에 사용될 수 있다.
컨텍스트-기반 어댑티브 이진 산술 코딩(CABAC)은 타깃 블록의 "lmcs_chroma_scaling_idx"을 코딩하는데 적용될 수 있다. 타깃 블록과 관련된 CABAC 컨텍스트는 타깃 블록의 이웃하는 블록의 "lmcs_chroma_scaling_idx"에 따를 수 있다. 예를 들어, 좌측 이웃하는 블록 또는 상단 이웃하는 블록은 CABAC 컨텍스트를 형성하는데 사용될 수 있다. "lmcs_chroma_scaling_idx"의 이진화 측면에서, 잘린 라이스 이진화(truncated Rice binarization)가 "lmcs_chroma_scaling_idx"를 이진화하는데 사용될 수 있다.
"lmcs_chroma_scaling_idx"를 시그널링함으로써, 인코더는 레이트 왜곡 비용 측면에서 어댑티브 lmcs_chroma_scaling_idx를 선택할 수 있다. 따라서, 코딩 효율을 개선하기 위해 레이트 왜곡 최적화를 사용하여 lmcs_chroma_scaling_idx이 선택될 수 있으며, 이는 시그널링 비용 상승을 상쇄하는데 도움이 될 수 있다.
본 발명의 실시예는 LMCS 구분적 선형 모델을 시그널링하여 비디오 컨텐츠를 처리하기 위한 방법을 추가로 제공한다.
비록, VVC 드래프트 4에서 LMCS 방법이 16개의 조각을 갖는 구분적 선형 모델을 사용하지만, 타일 그룹/슬라이스에 있어서 SignaledCW[i]의 다수의 고유값은 16보다 훨씬 적은 경향이 있다. 예를 들어, 16개의 조각 중 일부가 디폴트 수의 코드워드("OrgCW")를 사용하고, 16개의 조각의 일부가 서로 동일한 수의 코드워드를 가질 수 있다. 따라서, LMCS 구분적 선형 모델을 시그널링함에 있어서, 다수의 고유 코드워드가 "listUniqueCW[]"의 형태로 시그널링될 수 있고, 그 후에 LMCS 구분적 선형 모델의 각각의 조각에 대해, listUniqueCW[]의 인덱스가 타깃 조각에 대한 코드워드를 선택하기 위해 발송될 수 있다.
수정된 신택스 테이블이 도 22의 테이블 12에 제공되며, 이탤릭체로 표시된 신택스 요소(2202 및 2204)는 본 실시예에 따라 변경된다.
개시된 시그널링 방법의 의미론은 다음과 같으며, 여기서 변경된 부분은 밑줄 처리된다:
reshaper_model_min_bin_idx는 재구성기 구성 과정에서 사용될 최소 빈(또는 조각) 인덱스를 명시한다. reshape_model_min_bin_idx의 값은 0 내지 MaxBinIdx(포함)의 범위에 있어야 한다. MaxBinIdx의 값은 15와 동일해야 한다.
reshaper_model_delta_max_bin_idx는 재구성기 구성 과정에서 사용될 최대 허용 빈(또는 조각) 인덱스(MaxBinIdx) 빼기 최대 빈 인덱스를 명시한다. reshape_model_max_bin_idx의 값은 MaxBinIdx - reshape_model_delta_max_bin_idx와 동일하게 설정된다.
reshaper_model_bin_delta_abs_cw_prec_minus1 더하기 1은 신택스 reshape_model_bin_delta_abs_CW[ i ]의 표현을 위해 사용되는 비트의 수를 명시한다.
reshaper_model_bin_num_unique_cw_minus1
더하기 1은 코드워드 어레이(listUniqueCW)의 크기를 명시한다
.
reshaper_model_bin_delta_abs_CW[ i ]은 i-번째 빈에 대한 절대 델타 코드워드 값을 명시한다.
reshaper_model_bin_delta_sign_CW_flag[ i ]은 다음과 같이 reshape_model_bin_delta_abs_CW[ i ]의 부호를 명시한다:
- reshape_model_bin_delta_sign_CW_flag[ i ]이 0과 동일한 경우, 대응하는 변수 RspDeltaCW[ i ]은 양의 값이다.
- 그렇지 않은 경우(reshape_model_bin_delta_sign_CW_flag[ i ]이 0과 동일하지 않은 경우), 대응하는 변수 RspDeltaCW[ i ]은 음의 값이다.
reshape_model_bin_delta_sign_CW_flag[ i ]이 존재하지 않을 때, 이는 0과 동일한 것으로 추론된다.
변수 RspDeltaCW[ i ]이 RspDeltaCW[ i ] = (1 -- 2*reshape_model_bin_delta_sign_CW [ i ]) * reshape_model_bin_delta_abs_CW [ i ]으로서 도출된다
변수 listUniqueCW[ 0 ]이 OrgCW와 동일하게 설정된다. 변수 listUniqueCW[ i ] with i = 1 ... reshaper_model_bin_num_unique_cw_minus1, inclusive이 다음과 같이 도출된다:
- 변수 OrgCW는 (1 << BitDepthY ) / ( MaxBinIdx + 1)와 동일하게 설정된다.
- listUniqueCW [ i ] = OrgCW + RspDeltaCW[ i - 1 ]
reshaper_model_bin_cw_idx
[ i ]는 RspCW [ i ]를 도출하는데 사용되는 어레이 listUniqueCW[]의 인덱스를 명시한다. reshaper_model_bin_cw_idx [ i ]의 값은 0 내지 (reshaper_model_bin_num_unique_cw_minus1 + 1)(포함)의 범위에 있어야 한다.
RspCW[ i ]은 다음과 같이 도출된다:
- reshaper_model_min_bin_idx < = i <= reshaper_model_max_bin_idx이면, RspCW[ i ] = listUniqueCW[ reshaper_model_bin_cw_idx [ i ] ].
- 그렇지 않으면, RspCW[ i ] = 0.
RspCW [ i ]의 값은 BitDepthY의 값이 10과 동일하다면, 32 내지 2 * OrgCW - 1의 범위에 있을 수 있다.
본 발명의 실시예는 블록 레벨에서 조건부 크로마 스케일링을 사용하여 비디오 컨텐츠를 처리하기 위한 방법을 제공한다.
도 6의 테이블 1에 도시된 바와 같이, 크로마 스케일링이 적용되는지 여부는 타일 그룹/슬라이스 레벨에서 시그널링된 tile_group_reshaper_chroma_residual_scale_flag에 의해 결정될 수 있다. 그러나, 블록 레벨에서 크로마 스케일링을 적용하는지 여부를 결정하는 것이 유리할 수 있다. 예를 들어, 일부 실시예에서, CU 레벨 플래그는 크로마 스케일링이 타깃 블록에 적용되는지 여부를 나타내도록 시그널링될 수 있다. CU 레벨 플래그의 존재는 타일 그룹 레벨 플래그 "tile_group_reshaper_chroma_residual_scale_flag"에 따라 조정될 수 있다. 다시 말해, CU 레벨 플래그는 크로마 스케일링이 타일 그룹/슬라이스 레벨에서 허용되는지 여부만 시그널링될 수 있다. CU 레벨 플래그가 인코더로 하여금 크로마 스케일링이 타깃 블록에 대해 유리한지 여부에 따라 크로마 스케일링을 사용할지 여부를 선택할 수 있도록 할 수 있지만, 이는 또한 시그널링 오버헤드를 발생시킬 수 있다.
개시된 실시예와 일관되게, 위의 시그널링 오버헤드를 회피하기 위해, 크로마 스케일링이 블록에 적용되는지 여부는 타깃 블록의 예측 모드에 따라 조정될 수 있다. 예를 들어, 타깃 블록이 인터 예측되는 경우, 예측 신호는 특히, 참조 픽처가 시간적 거리에 있어 더욱 가까운 경우에 우수한 경향이 있다. 이러한 경우에, 잔여가 매우 적은 것으로 예상되기 때문에, 크로마 스케일링은 우회될 수 있다. 예를 들어, 보다 높은 시간적 레벨에 있어서의 픽처가 시간적 거리에 있어서 가까운 참조 픽처를 갖는 경향이 있으며, 인근의 참조 픽처를 사용하는 이들 픽처에 있어서의 블록에 대해, 크로마 스케일링이 비활성화될 수 있다. 타깃 픽처와 타깃 블록의 참조 픽처 사이의 픽처 순서 카운트(POC) 차이는 이러한 조건이 만족되는지 여부를 결정하는데 사용될 수 있다.
일부 실시예에서, 크로마 스케일링은 인터 코딩된 모든 블록에 대해 비활성화될 수 있다. 일부 실시예에서, 크로마 스케일링은 인트라 코딩된 모든 블록에 대해 비활성화될 수 있다. 일부 실시예에서, 크로마 스케일링은 VVC 표준에서 규정되는 결합된 인트라/인터 예측(CIIP) 모드에 대해 비활성화될 수 있다.
VVC 표준에서, CU 신택스 구조("coding_unit()")는 타깃 CU에 있어서 임의의 0이 아닌 잔여 계수가 존재하는지 여부를 나타내기 위해 신택스 요소("cu_cbf")를 포함할 수 있다. TU 레벨에서, TU 신택스 구조("transform_unit()")는 타깃 TU에 있어서 임의의 0이 아닌 크로마(Cb 또는 Cr) 잔여 계수가 존재하는지 여부를 나타내기 위해 신택스 요소("tu_cbf_cb" and "tu_cbf_cr")를 포함할 수 있다. 크로마 스케일링 과정은 이들 플래그에 따라 조정될 수 있다. 전술한 바와 같이, 대응하는 루마 크로마 스케일링 과정의 평균화는 0이 아닌 잔여 계수가 존재하지 않는 경우에 크로마 스케일링 과정이 우회될 수 있는 것으로 언급되며, 본 발명은 루마 평균화 과정을 우회하는 방법을 제공한다.
본 발명의 실시예는 CCLM 파라미터 도출을 사용하여 비디오 컨텐츠를 처리하기 위한 방법을 제공한다.
앞서 설명된 바와 같이, VVC 5에서, 타깃 크로마 블록의 예측을 위한 CCLM의 파라미터는 이웃하는 블록으로부터 루마 및 크로마 복원된 샘플로 도출된다. 듀얼 트리의 경우에, 루마 블록 파티션 및 크로마 블록 파티션은 정렬되지 않을 수 있다. 다시 말해, 하나의 N×M 크로마 블록에 대해 CCLM 파라미터를 도출하기 위해, 다수의 이웃하는 루마 블록 또는 크기가 2N×2M보다 큰 루마 블록(컬러 포맷 4:2:0의 경우에)이 복원될 수 있으며, 이에 의해 대기 시간이 발생한다.
대기 시간을 감소시키기 위해, 일 예로서, CCLM 파라미터는 CTU/VPDU 레벨에서 도출된다. 이웃하는 CTU/VPDU로부터의 복원된 루마 및 크로마 샘플이 CCLM 파라미터를 도출하는데 사용될 수 있다. 그리고 도출된 파라미터는 CTU/VPDU 내 모든 블록에 적용될 수 있다. 예를 들어, 교차-구성요소 선형 모델 예측에서 설명된 식은 Xa 및 Ya가 각각 CTU/VPDU 이웃하는 루마 샘플 중 최대 루마 샘플값을 갖는 루마 샘플 위치의 루마 값 및 크로마 값인 파라미터를 도출하는데 사용될 수 있다. Xb 및 Yb는 각각 CTU/VPDU 이웃하는 루마 샘플 중 최소 루마 샘플을 갖는 루마 샘플 위치의 루마 값 및 크로마 값을 나타낸다. 이 기술이 속하는 분야의 통상의 지식을 가진 자에게, 임의의 다른 도출 과정이 본 명세서에서 제안된 CTU/VPDU 레벨 파라미터 도출 개념과 결합하여 사용될 수 있다.
CTU/VPDU 레벨 CCLM 파라미터 도출 외에, 이러한 도출 과정은 고정 루마 격자 상에서 수행될 수 있다. VVC 드래프트 5에서, 듀얼 트리 분할이 사용될 때, 별도의 루마 및 크로마 파티션은 64×64 루마 격자로부터 개시될 수 있다. 다시 말해, 128×128 CTU로부터 64×64 CU까지의 분할이 루마 및 크로마에 대해 별도가 아닌 함께 수행될 수 있다. 따라서, 다른 예로서, CCLM 파라미터는 64×64 루마 격자 상에 도출될 수 있다. 64×64 격자 유닛의 이웃하는 복원된 루마 및 크로마 샘플은 64×64 격자 유닛 내 모든 크로마 블록에 대해 CCLM 파라미터를 도출하는데 사용될 수 있다. 루마 샘플에 있어서 최대 128×128일 수 있는 CTU 레벨 도출에 비해, 64×64 유닛 레벨 도출은 보다 정확할 수 있고, 여전히 현재의 VVC 드래프트 5에서와 같이 파이프라인 대기 시간 문제를 갖지 않는다. 본 예 외에, CCLM 파라미터 도출은 일부 격자에 대한 도출을 생략함으로써 더 단순화될 수 있다. 예를 들어, CCLM 파라미터는 CTU 내 제1 64×64 블록 상에서만 도출되며, 동일한 CTU 내 후속하는 64×64 블록에 대한 도출은 생략된다. 제1 64×64 블록에 기초하여 도출되는 파라미터는 CTU 내 모든 블록에 대해 사용될 수 있다.
도 23은 본 발명의 일부 실시예에 따른 비디오 컨텐츠를 처리하기 위한 예시적인 방법(2300)의 흐름도를 예시한다. 일부 실시예에서, 방법(2300)은 코덱(예를 들어, 도 2a-2b의 인코더 또는 도 3a-3b의 디코더)에 의해 수행될 수 있다. 예를 들어, 코덱은 비디오 시퀀스를 인코딩 또는 트랜스코딩하기 위한 장치(예를 들어, 장치(400))의 하나 이상의 소프트웨어 또는 하드웨어 구성요소로서 실현될 수 있다. 일부 실시예에서, 비디오 시퀀스는 압축해제된 비디오 시퀀스(예를 들어, 비디오 시퀀스(202)) 또는 디코딩되는 압축된 비디오 시퀀스(예를 들어, 비디오 스트림(304))일 수 있다. 일부 실시예에서, 비디오 시퀀스는 상기 장치의 프로세서(예를 들어, 프로세서(402))와 관련된 모니터링 장치(예를 들어, 도 4의 비디오 입력 장치)에 의해 포착될 수 있는 모니터링 비디오 시퀀스일 수 있다. 비디오 시퀀스는 다수의 픽처를 포함할 수 있다. 상기 장치는 픽처의 레벨에서 방법(2300)을 수행할 수 있다. 예를 들어, 상기 장치는 방법(2300)에서 하나의 픽처를 동시에 처리할 수 있다. 다른 예에 대해, 상기 장치는 방법(2300)에서 복수의 픽처를 동시에 처리할 수 있다. 방법(2300)은 아래와 같은 단계들을 포함할 수 있다.
단계(2302)에서, 픽처에서 제1 블록 및 제2 블록을 나타내는 데이터가 수신될 수 있다. 복수의 블록은 제1 블록 및 제2 블록을 포함할 수 있다. 일부 실시예에서, 제1 블록은 타깃 크로마 블록(예를 들어, 도 16a의 크로마 블록(1600))일 수 있고, 제2 블록은 코딩 트리 블록(CTB), 변환 유닛(TU) 또는 가상의 파이프라인 데이터 유닛(VPDU)일 수 있다. 가상의 파이프라인 데이터 유닛은 픽처에 대한 코딩 트리 유닛의 크기 이하인 크기를 갖는 픽처에 있어서의 비-중첩 유닛이다. 예를 들어, CTU의 크기가 128×128 픽셀일 때, VPDU는 CTU의 크기보다 작은 크기를 가질 수 있으며, VPDU의 크기(예를 들어, 64×64 픽셀)는 하드웨어(예를 들어, 하드웨어 디코더)의 대부분의 파이프라인 단계에 있어서의 버퍼 크기에 비례할 수 있다.
일부 실시예에서, 코딩 트리 블록은 타깃 크로마 블록에 대응하는 루마 블록(예를 들어, 도 16b의 루마 블록(1610))일 수 있다. 따라서, 데이터는 제1 블록과 관련된 복수의 크로마 샘플 및 제2 블록과 관련된 복수의 루마 샘플을 포함할 수 있다. 제1 블록과 관련된 복수의 크로마 샘플은, 제1 블록 내 복수의 크로마 잔여 샘플을 포함한다.
단계(2304)에서, 제2 블록과 관련된 복수의 루마 샘플의 평균값이 결정될 수 있다. 복수의 루마 샘플은 도 18-19에 관해 기술된 샘플을 포함할 수 있다. 일 예로서, 도 19에 도시된 바와 같이, 복수의 루마 샘플은 제2 블록(예를 들어, "1902")의 좌측 경계(1901) 상에 또는 제2 블록의 상단 경계 상에 복수의 복원된 루마 샘플(예를 들어, 음영처리된 샘플(1905) 및 패딩처리된 샘플(1903))을 포함할 수 있다. 복수의 복원된 루마 샘플은 이웃하는 복원된 루마 블록(예를 들어, "1904")에 속할 수 있다는 것을 인식해야 한다.
방법(2300)은 제2 블록과 관련된 복수의 루마 샘플 중에서, 제1 루마 샘플이 픽처의 경계를 벗어나 있는지 여부를 결정하는 단계; 및 상기 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있다는 결정에 응답하여, 상기 제1 루마 샘플의 값을 상기 복수의 루마 샘플 중 상기 픽처의 경계 내에 있는 제2 루마 샘플의 값으로 설정하는 단계를 추가로 포함할 수 있다. 픽처의 경계는 픽처의 우측 경계 및 픽처의 하단 경계 중 하나를 포함할 수 있다. 예를 들어, 패딩처리된 샘플(1903)이 픽처 하단 경계를 벗어나 있는 것으로 결정될 수 있으며, 이에 따라 패딩처리된 샘플(1903)의 값은 픽처 하단 경계 상의 모든 샘플 중에서 패딩처리된 샘플(1903)에 가장 가까운 샘플인 음영처리된 샘플(1905)의 값으로 되도록 설정된다.
제2 블록(예를 들어, "1902")이 픽처의 경계를 가로지를 때, 패딩처리된 샘플(예를 들어, 패딩처리된 샘플(1903))이 생성될 수 있으며, 이에 의해 여러 복수의 루마 샘플은 나눗셈 작업을 회피하기 위해 통상 2의 거듭 제곱인 고정수일 수 있다는 것은 인지해야 한다.
단계(2306)에서, 제1 블록에 대한 크로마 스케일링 인자는 평균값에 기초하여 결정될 수 있다. 도 18에 관하여 전술한 바와 같이, 인트라 예측에서, 동일한 픽처의 이웃하는 블록에 있어서의 디코딩된 샘플이 예측 블록을 생성하기 위해 참조 샘플로서 사용될 수 있다. 예를 들어, 이웃하는 블록에 있어서의 샘플의 평균값은 타깃 블록(예를 들어, 본 예에 있어서 제1 블록)의 크로마 스케일링 인자를 결정하기 위한 루마 평균값으로서 사용될 수 있으며, 제1 블록에 대한 크로마 스케일링 인자는 제2 블록의 루마 평균값을 사용하여 결정될 수 있다.
단계(2308)에서, 제1 블록과 관련된 복수의 크로마 샘플은 크로마 스케일링 인자를 사용하여 처리될 수 있다. 도 5와 관련하여 전술된 바와 같이, 복수의 크로마 스케일링 인자는 타일 그룹 레벨에서 크로마 스케일링 인자(LUT)를 구성할 수 있으며, 타깃 블록의 복원된 크로마 잔여 상에서 디코더 측에 적용될 수 있다. 유사하게, 크로마 스케일링 인자도 인코더 측에 적용될 수 있다.
일부 실시예에서, 또한, 명령을 포함하는 비-일시적 컴퓨터 판독 가능한 저장 매체가 제공되며, 상기 명령은 전술한 방법을 수행하기 위해, (개시된 인코더 및 디코더와 같은) 장치에 의해 실행될 수 있다. 비-일시적 매체의 통상적인 형태에는 예를 들어, 플로피 디스크, 가요성 디스크, 하드 디스크, 고체 드라이브, 자기 테이프 또는 임의의 다른 자기 데이터 저장 매체, CD-ROM, 임의의 다른 광학 데이터 저장 매체, 홀 패턴을 갖는 임의의 물리적 매체, RAM, PROM 및 EPROM, FLASH-EPROM 또는 임의의 다른 플래시 메모리, NVRAM, 캐쉬, 레지스터, 임의의 다른 메모리 칩 또는 카트리지 및 동일한 네트워크 버전이 포함된다. 상기 장치는 하나 이상의 프로세서(CPU), 입력/출력 인터페이스, 네트워크 인터페이스 및/또는 메모리를 포함할 수 있다.
실시예는 이하의 항목을 사용하여 추가로 기술될 수 있다:
1. 비디오 컨텐츠를 처리하기 위한 컴퓨터-실행 방법으로서,
픽처(picture)에서 제1 블록 및 제2 블록을 나타내는 데이터를 수신하는 단계이며, 상기 데이터는 상기 제1 블록과 관련된 복수의 크로마 샘플(chroma samples) 및 상기 제2 블록과 관련된 복수의 루마 샘플(luma samples)을 포함하는, 상기 단계;
상기 제2 블록과 관련된 상기 복수의 루마 샘플의 평균값을 결정하는 단계;
상기 평균값에 기초하여, 상기 제1 블록에 대한 크로마 스케일링 인자(chroma scaling factor)를 결정하는 단계; 및
상기 크로마 스케일링 인자를 사용하여 상기 제1 블록과 관련된 상기 복수의 크로마 샘플을 처리하는 단계
를 포함하는 방법.
2. 항목 1에 있어서, 상기 제2 블록과 관련된 복수의 루마 샘플은, 상기 제2 블록의 좌측 경계 상에 또는 상기 제2 블록의 상단 경계 상에 복수의 복원된(reconstructed) 루마 샘플을 포함하는 방법.
3. 항목 2에 있어서,
상기 제2 블록과 관련된 복수의 루마 샘플 중에서, 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있는지 여부를 결정하는 단계; 및
상기 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있다는 결정에 응답하여, 상기 제1 루마 샘플의 값을 상기 복수의 루마 샘플 중 상기 픽처의 경계 내에 있는 제2 루마 샘플의 값으로 설정하는 단계를 추가로 포함하는 방법.
4. 항목 3에 있어서,
상기 제2 블록과 관련된 복수의 루마 샘플 중에서, 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있는지 여부를 결정하는 단계; 및
상기 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있다는 결정에 응답하여, 상기 제1 루마 샘플의 값을 상기 복수의 루마 샘플 중 상기 픽처의 경계 상에 있는 제2 루마 샘플의 값으로 설정하는 단계를 추가로 포함하는 방법.
5. 항목 4에 있어서, 상기 픽처의 경계는 상기 픽처의 우측 경계 및 상기 픽처의 하단 경계 중 하나인 방법.
6. 항목 1 내지 항목 5 중 어느 한 항목에 있어서, 상기 제2 블록은 코딩 트리 블록, 변환 유닛 또는 가상의 파이프라인 데이터 유닛이고, 상기 가상의 파이프라인 데이터 유닛의 크기는 상기 픽처에 대한 코딩 트리 유닛의 크기 이하인 방법.
7. 항목 6에 있어서, 상기 가상의 파이프라인 데이터 유닛은 픽처 내 비-중첩 유닛(non-overlapping unit)인 방법.
8. 항목 1 내지 항목 7 중 어느 한 항목에 있어서, 상기 제1 블록과 관련된 복수의 크로마 샘플은, 상기 제1 블록 내 복수의 크로마 잔여 샘플(residual sample)을 포함하는 방법.
9. 항목 1 내지 항목 8 중 어느 한 항목에 있어서, 상기 제1 블록은 타깃 크로마 블록이고, 상기 제2 블록은 상기 타깃 크로마 블록에 대응하는 루마 블록인 방법.
10. 비디오 컨텐츠를 처리하기 위한 시스템으로서,
명령의 세트를 저장하기 위한 메모리; 및
상기 시스템이,
픽처에서 제1 블록 및 제2 블록을 나타내는 데이터를 수신하는 단계이며, 상기 데이터는 상기 제1 블록과 관련된 복수의 크로마 샘플 및 상기 제2 블록과 관련된 복수의 루마 샘플을 포함하는, 상기 단계;
상기 제2 블록과 관련된 복수의 루마 샘플의 평균값을 결정하는 단계;
상기 평균값에 기초하여, 상기 제1 블록에 대한 크로마 스케일링 인자를 결정하는 단계; 및
상기 크로마 스케일링 인자를 사용하여 상기 제1 블록과 관련된 복수의 크로마 샘플을 처리하는 단계
를 수행하게 하는 상기 명령의 세트를 실행하도록 구성되는 적어도 하나의 프로세서
를 포함하는 시스템.
11. 항목 10에 있어서, 상기 제2 블록과 관련된 복수의 루마 샘플은, 상기 제2 블록의 좌측 경계 상에 또는 상기 제2 블록의 상단 경계 상에 복수의 복원된 루마 샘플을 포함하는 시스템.
12. 항목 11에 있어서, 상기 적어도 하나의 프로세서는 상기 시스템이,
상기 제2 블록과 관련된 복수의 루마 샘플 중에서, 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있는지 여부를 결정하는 단계; 및
상기 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있다는 결정에 응답하여, 상기 제1 루마 샘플의 값을 상기 복수의 루마 샘플 중 상기 픽처의 경계 내에 있는 제2 루마 샘플의 값으로 설정하는 단계
를 추가로 수행할 수 있게 상기 일련의 명령을 실행하도록 구성되는 시스템.
13. 항목 12에 있어서, 상기 제2 루마 샘플은 상기 픽처의 경계 상에 있는 시스템.
14. 항목 13에 있어서, 상기 픽처의 경계는 상기 픽처의 우측 경계 및 상기 픽처의 하단 경계 중 하나인 시스템.
15. 항목 10 내지 항목 14 중 어느 한 항목에 있어서, 상기 제2 블록은 코딩 트리 블록, 변환 유닛 또는 가상의 파이프라인 데이터 유닛이고, 상기 가상의 파이프라인 데이터 유닛의 크기는 상기 픽처에 대한 코딩 트리 유닛의 크기 이하인 시스템.
16. 항목 15에 있어서, 상기 가상의 파이프라인 데이터 유닛은 픽처 내 비-중첩 유닛인 시스템.
17. 항목 10 내지 항목 16 중 어느 한 항목에 있어서, 상기 제1 블록과 관련된 복수의 크로마 샘플은, 상기 제1 블록 내 복수의 크로마 잔여 샘플을 포함하는 시스템.
18. 항목 10 내지 항목 17 중 어느 한 항목에 있어서, 상기 제1 블록은 타깃 크로마 블록이고, 상기 제2 블록은 상기 타깃 크로마 블록에 대응하는 루마 블록인 시스템.
19. 컴퓨터 시스템이 비디오 컨텐츠를 처리하기 위한 방법을 수행하게 하는 상기 컴퓨터 시스템의 적어도 하나의 프로세서에 의해 실행 가능한 명령의 세트를 저장하는 비-일시적 컴퓨터 판독 가능한 매체로서, 상기 방법은,
픽처에서 제1 블록 및 제2 블록을 나타내는 데이터를 수신하는 단계이며, 상기 데이터는 상기 제1 블록과 관련된 복수의 크로마 샘플 및 상기 제2 블록과 관련된 복수의 루마 샘플을 포함하는, 상기 단계;
상기 제2 블록과 관련된 복수의 루마 샘플의 평균값을 결정하는 단계;
상기 평균값에 기초하여, 상기 제1 블록에 대한 크로마 스케일링 인자를 결정하는 단계; 및
상기 크로마 스케일링 인자를 사용하여 상기 제1 블록과 관련된 복수의 크로마 샘플을 처리하는 단계를 포함하는 비-일시적 컴퓨터 판독 가능한 매체.
20. 항목 19에 있어서, 상기 제2 블록과 관련된 복수의 루마 샘플은, 상기 제2 블록의 좌측 경계 상에 또는 상기 제2 블록의 상단 경계 상에 복수의 복원된 루마 샘플을 포함하는 비-일시적 컴퓨터 판독 가능한 매체.
본 명세서에서 "제1(첫째)" 및 "제2(둘째)"와 같은 관계형 용어는 개체나 작업을 다른 개체나 작업과 구별하기 위해서만 사용되고, 이러한 개체나 작업 간의 임의의 실제 관계나 순서를 요구하거나 암시하지 않는다는 점에 유의해야 한다. 또한, 단어 "~ 포함하는"("comprising", "containing" and "including"), "~ 갖는" 및 다른 유사한 형태는 의미가 동일하며, 이들 단어 중 임의의 하나에 선행하는 항목 또는 항목들이 해당 항목 또는 항목들의 전체 목록을 의미하는 것이 아니거나, 나열된 항목 또는 항목들로만 제한되는 것을 의미하는 것이 아니라는 점에서 비제한적인 것이다.
본 명세서에 사용된 바와 같이, 명확하게 달리 언급되지 않는 한, 용어 "또는"은 실행 불가능한 경우를 제외하고, 모든 가능한 조합을 포함한다. 예를 들어, 데이터베이스가 A 또는 B를 포함할 수 있다고 언급되는 경우라면, 명확하게 달리 언급되거나 실행 불가능한 경우가 아니라면, 데이터베이스는 A, 또는 B, 또는 A 및 B를 포함할 수 있다. 제2 예로서, 데이터베이스 A, B 또는 C를 포함할 수 있다고 언급되는 경우라면, 명확하게 달리 언급되거나 실행 불가능한 경우가 아니라면, 데이터베이스는 A, 또는 B, 또는 C, 또는 A 및 B, 또는 A 및 C, 또는 B 및 C, 또는 A 및 B 및 C를 포함할 수 있다.
전술한 실시예가 하드웨어, 또는 소프트웨어(프로그램 코드), 또는 하드웨어와 소프트웨어의 조합에 의해 실현될 수 있다는 것이 인식된다. 소프트웨어에 의해 실현되는 경우, 전술한 컴퓨터-판독 가능한 매체에 저장될 수 있다. 프로세서에 의해 수행될 때, 소프트웨어는 개시된 방법을 수행할 수 있다. 연산 유닛 및 본 명세서에 개시된 다른 기능성 유닛이 하드웨어, 또는 소프트웨어, 또는 하드웨어와 소프트웨어의 조합에 의해 실현될 수 있다. 이 기술이 속하는 분야의 통상의 지식을 가진 자는 또한, 전술한 모듈/유닛 중 다수의 모듈 또는 유닛이 하나의 모듈/유닛으로서 결합될 수 있으며, 전술한 모듈/유닛 각각이 복수의 서브-모듈/서브-유닛으로 추가로 분할될 수 있다는 것을 이해할 것이다.
앞서의 명세서에 있어서, 실시예들은 실행 간에 변경될 수 있는 다수의 특정 상세를 참고하여 설명되었다. 기술된 실시예들의 소정의 조정 및 수정이 이루어질 수 있다. 다른 실시예는 본 명세서에 개시된 본 발명의 사양 및 실행을 고려하여 이 기술이 속하는 분야의 통상의 지식을 가진 자에게 명백할 수 있다. 사양 및 예들은 예시로서만 고려되어야 하며, 본 발명의 진정한 범위 및 사상은 이하의 청구범위에 의해 시사되어야 한다. 또한, 도면에 도시된 단계들의 순서는 단지 예시적인 목적을 위한 것이며, 단계들의 임의의 특정 순서로 한정하고자 하는 것이 아니다. 이처럼, 이 기술이 속하는 분야의 통상의 지식을 가진 자는 이들 단계들이 동일한 방법을 실행하는 동안 상이한 순서로 수행될 수 있다는 것을 인식할 수 있다.
도면 및 명세서에서, 예시적인 실시예들이 개시되었다. 그러나, 많은 변형 및 수정이 이들 실시예에 이루어질 수 있다. 따라서, 비록 특정 용어가 채용되더라도, 이들 용어는 일반적이고 서술적인 의미로만 사용되며 제한의 목적은 아니다.
Claims (20)
- 비디오 컨텐츠를 처리하기 위한 컴퓨터-실행 방법으로서,
픽처(picture)에서 제1 블록 및 제2 블록을 나타내는 데이터를 수신하는 단계이며, 상기 데이터는 상기 제1 블록과 관련된 복수의 크로마 샘플(chroma samples) 및 상기 제2 블록과 관련된 복수의 루마 샘플(luma samples)을 포함하는, 상기 단계;
상기 제2 블록과 관련된 상기 복수의 루마 샘플의 평균값을 결정하는 단계;
상기 평균값에 기초하여, 상기 제1 블록에 대한 크로마 스케일링 인자(chroma scaling factor)를 결정하는 단계; 및
상기 크로마 스케일링 인자를 사용하여 상기 제1 블록과 관련된 상기 복수의 크로마 샘플을 처리하는 단계
를 포함하는 방법. - 제1항에 있어서, 상기 제2 블록과 관련된 상기 복수의 루마 샘플은,
상기 제2 블록의 좌측 경계 상에 또는 상기 제2 블록의 상단 경계 상에 복수의 복원된(reconstructed) 루마 샘플을 포함하는 방법. - 제2항에 있어서,
상기 제2 블록과 관련된 상기 복수의 루마 샘플 중에서, 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있는지 여부를 결정하는 단계; 및
상기 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있다는 결정에 응답하여, 상기 제1 루마 샘플의 값을 상기 복수의 루마 샘플 중 상기 픽처의 경계 내에 있는 제2 루마 샘플의 값으로 설정하는 단계를 추가로 포함하는 방법. - 제3항에 있어서,
상기 제2 블록과 관련된 상기 복수의 루마 샘플 중에서, 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있는지 여부를 결정하는 단계; 및
상기 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있다는 결정에 응답하여, 상기 제1 루마 샘플의 값을 상기 복수의 루마 샘플 중 상기 픽처의 경계 상에 있는 제2 루마 샘플의 값으로 설정하는 단계를 추가로 포함하는 방법. - 제4항에 있어서, 상기 픽처의 경계는 상기 픽처의 우측 경계 및 상기 픽처의 하단 경계 중 하나인 방법.
- 제1항에 있어서, 상기 제2 블록은 코딩 트리 블록, 변환 유닛 또는 가상의 파이프라인 데이터 유닛이고, 상기 가상의 파이프라인 데이터 유닛의 크기는 상기 픽처에 대한 코딩 트리 유닛의 크기 이하인 방법.
- 제6항에 있어서, 상기 가상의 파이프라인 데이터 유닛은 상기 픽처 내 비-중첩 유닛(non-overlapping unit)인 방법.
- 제1항에 있어서, 상기 제1 블록과 관련된 상기 복수의 크로마 샘플은, 상기 제1 블록 내 복수의 크로마 잔여 샘플(residual samples)을 포함하는 방법.
- 제1항에 있어서, 상기 제1 블록은 타깃 크로마 블록이고, 상기 제2 블록은 상기 타깃 크로마 블록에 대응하는 루마 블록인 방법.
- 비디오 컨텐츠를 처리하기 위한 시스템으로서,
명령의 세트를 저장하기 위한 메모리; 및
상기 시스템이,
픽처에서 제1 블록 및 제2 블록을 나타내는 데이터를 수신하는 단계이며, 상기 데이터는 상기 제1 블록과 관련된 복수의 크로마 샘플 및 상기 제2 블록과 관련된 복수의 루마 샘플을 포함하는, 상기 단계;
상기 제2 블록과 관련된 상기 복수의 루마 샘플의 평균값을 결정하는 단계;
상기 평균값에 기초하여, 상기 제1 블록에 대한 크로마 스케일링 인자를 결정하는 단계; 및
상기 크로마 스케일링 인자를 사용하여 상기 제1 블록과 관련된 상기 복수의 크로마 샘플을 처리하는 단계
를 수행하게 하는 상기 명령의 세트를 실행하도록 구성되는 적어도 하나의 프로세서
를 포함하는 시스템. - 제10항에 있어서, 상기 제2 블록과 관련된 상기 복수의 루마 샘플은,
상기 제2 블록의 좌측 경계 상에 또는 상기 제2 블록의 상단 경계 상에 복수의 복원된 루마 샘플을 포함하는 시스템. - 제11항에 있어서, 상기 적어도 하나의 프로세서는 상기 시스템이,
상기 제2 블록과 관련된 상기 복수의 루마 샘플 중에서, 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있는지 여부를 결정하는 단계; 및
상기 제1 루마 샘플이 상기 픽처의 경계를 벗어나 있다는 결정에 응답하여, 상기 제1 루마 샘플의 값을 상기 복수의 루마 샘플 중 상기 픽처의 경계 내에 있는 제2 루마 샘플의 값으로 설정하는 단계
를 추가로 수행하게 하는 상기 명령의 세트를 실행하도록 구성되는 시스템. - 제12항에 있어서, 상기 제2 루마 샘플은 상기 픽처의 경계 상에 있는 시스템.
- 제13항에 있어서, 상기 픽처의 경계는 상기 픽처의 우측 경계 및 상기 픽처의 하단 경계 중 하나인 시스템.
- 제10항에 있어서, 상기 제2 블록은 코딩 트리 블록, 변환 유닛 또는 가상의 파이프라인 데이터 유닛이고, 상기 가상의 파이프라인 데이터 유닛의 크기는 상기 픽처에 대한 코딩 트리 유닛의 크기 이하인 시스템.
- 제15항에 있어서, 상기 가상의 파이프라인 데이터 유닛은 상기 픽처 내 비-중첩 유닛인 시스템.
- 제10항에 있어서, 상기 제1 블록과 관련된 복수의 크로마 샘플은, 상기 제1 블록 내 복수의 크로마 잔여 샘플을 포함하는 시스템.
- 제10항에 있어서, 상기 제1 블록은 타깃 크로마 블록이고, 상기 제2 블록은 상기 타깃 크로마 블록에 대응하는 루마 블록인 시스템.
- 컴퓨터 시스템이 비디오 컨텐츠를 처리하기 위한 방법을 수행하게 하는 상기 컴퓨터 시스템의 적어도 하나의 프로세서에 의해 실행 가능한 명령의 세트를 저장하는 비-일시적 컴퓨터 판독 가능한 매체로서, 상기 방법은,
픽처에서 제1 블록 및 제2 블록을 나타내는 데이터를 수신하는 단계이며, 상기 데이터는 상기 제1 블록과 관련된 복수의 크로마 샘플 및 상기 제2 블록과 관련된 복수의 루마 샘플을 포함하는, 상기 단계;
상기 제2 블록과 관련된 상기 복수의 루마 샘플의 평균값을 결정하는 단계;
상기 평균값에 기초하여, 상기 제1 블록에 대한 크로마 스케일링 인자를 결정하는 단계; 및
상기 크로마 스케일링 인자를 사용하여 상기 제1 블록과 관련된 상기 복수의 크로마 샘플을 처리하는 단계를 포함하는 비-일시적 컴퓨터 판독 가능한 매체. - 제19항에 있어서, 상기 제2 블록과 관련된 상기 복수의 루마 샘플은,
상기 제2 블록의 좌측 경계 상에 또는 상기 제2 블록의 상단 경계 상에 복수의 복원된 루마 샘플을 포함하는 비-일시적 컴퓨터 판독 가능한 매체.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201962865815P | 2019-06-24 | 2019-06-24 | |
| US62/865,815 | 2019-06-24 | ||
| PCT/US2020/035049 WO2020263493A1 (en) | 2019-06-24 | 2020-05-29 | Method and system for processing luma and chroma signals |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20220024912A true KR20220024912A (ko) | 2022-03-03 |
Family
ID=74038645
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020227002429A KR20220024912A (ko) | 2019-06-24 | 2020-05-29 | 루마 및 크로마 신호를 처리하기 위한 방법 및 시스템 |
Country Status (6)
| Country | Link |
|---|---|
| US (3) | US11051022B2 (ko) |
| EP (1) | EP3977737A4 (ko) |
| JP (1) | JP2022538747A (ko) |
| KR (1) | KR20220024912A (ko) |
| CN (1) | CN114375582A (ko) |
| WO (1) | WO2020263493A1 (ko) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP4029265A4 (en) * | 2019-09-29 | 2023-11-08 | HFI Innovation Inc. | METHOD AND APPARATUS FOR COMBINED INTER AND INTRA PREDICTION WITH DIFFERENT CHROMA FORMATS FOR VIDEO CODING |
| CN115299051A (zh) | 2020-03-11 | 2022-11-04 | 抖音视界有限公司 | 视频编解码的一致性窗口参数 |
| US11601657B2 (en) * | 2020-04-02 | 2023-03-07 | Qualcomm Incorporated | LUMA mapping with chroma scaling (LMCS) in video coding |
| US11330266B2 (en) * | 2020-05-18 | 2022-05-10 | Tencent America LLC | Signaling method for chroma intra prediction mode |
| CN115699753A (zh) * | 2020-05-31 | 2023-02-03 | 抖音视界有限公司 | 具有本地双树模式类型定义的调色板模式 |
| US11800102B2 (en) * | 2021-08-27 | 2023-10-24 | Mediatek Inc. | Low-latency video coding methods and apparatuses for chroma separated tree |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8761531B2 (en) | 2009-07-09 | 2014-06-24 | Qualcomm Incorporated | Image data compression involving sub-sampling of luma and chroma values |
| CN103650512B (zh) | 2011-07-12 | 2017-04-19 | 英特尔公司 | 基于亮度的色度帧内预测 |
| WO2013102293A1 (en) | 2012-01-04 | 2013-07-11 | Mediatek Singapore Pte. Ltd. | Improvements of luma-based chroma intra prediction |
| US9686561B2 (en) * | 2013-06-17 | 2017-06-20 | Qualcomm Incorporated | Inter-component filtering |
| US9648330B2 (en) * | 2013-07-15 | 2017-05-09 | Qualcomm Incorporated | Inter-color component residual prediction |
| US10397607B2 (en) * | 2013-11-01 | 2019-08-27 | Qualcomm Incorporated | Color residual prediction for video coding |
| SG11201706978TA (en) * | 2015-03-02 | 2017-09-28 | Hfi Innovation Inc | Method and apparatus for intrabc mode with fractional-pel block vector resolution in video coding |
| EP3354019A4 (en) | 2015-09-23 | 2019-05-22 | Telefonaktiebolaget LM Ericsson (publ) | DETERMINATION OF QUANTIZATION PARAMETER VALUES |
| US10484712B2 (en) * | 2016-06-08 | 2019-11-19 | Qualcomm Incorporated | Implicit coding of reference line index used in intra prediction |
| CN113452999B (zh) * | 2016-07-22 | 2023-12-05 | 夏普株式会社 | 使用自适应分量缩放对视频数据进行编码的系统和方法 |
| US10778978B2 (en) * | 2017-08-21 | 2020-09-15 | Qualcomm Incorporated | System and method of cross-component dynamic range adjustment (CC-DRA) in video coding |
| US20200288159A1 (en) * | 2019-03-08 | 2020-09-10 | Qualcomm Incorporated | Combined residual coding in video coding |
| US20200288126A1 (en) * | 2019-03-08 | 2020-09-10 | Qualcomm Incorporated | Reshaping filter average calculation for video coding |
| US11451826B2 (en) * | 2019-04-15 | 2022-09-20 | Tencent America LLC | Lossless coding mode and switchable residual coding |
-
2020
- 2020-05-29 WO PCT/US2020/035049 patent/WO2020263493A1/en unknown
- 2020-05-29 EP EP20831392.4A patent/EP3977737A4/en active Pending
- 2020-05-29 US US16/887,048 patent/US11051022B2/en active Active
- 2020-05-29 JP JP2021570780A patent/JP2022538747A/ja active Pending
- 2020-05-29 KR KR1020227002429A patent/KR20220024912A/ko unknown
- 2020-05-29 CN CN202080043294.XA patent/CN114375582A/zh active Pending
-
2021
- 2021-06-28 US US17/360,625 patent/US11711517B2/en active Active
-
2023
- 2023-06-09 US US18/332,244 patent/US20230353745A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| JP2022538747A (ja) | 2022-09-06 |
| US20200404278A1 (en) | 2020-12-24 |
| US11051022B2 (en) | 2021-06-29 |
| US20220132130A1 (en) | 2022-04-28 |
| WO2020263493A1 (en) | 2020-12-30 |
| EP3977737A1 (en) | 2022-04-06 |
| US11711517B2 (en) | 2023-07-25 |
| EP3977737A4 (en) | 2022-08-03 |
| CN114375582A (zh) | 2022-04-19 |
| US20230353745A1 (en) | 2023-11-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11902581B2 (en) | Method and system for processing video content | |
| US11711517B2 (en) | Method and system for processing luma and chroma signals | |
| US11323711B2 (en) | Method and system for signaling chroma quantization parameter offset | |
| US11889091B2 (en) | Methods for processing chroma signals | |
| US20220417511A1 (en) | Methods and systems for performing combined inter and intra prediction | |
| US11638019B2 (en) | Methods and systems for prediction from multiple cross-components | |
| US20210306623A1 (en) | Sign data hiding of video recording | |
| US20240048772A1 (en) | METHOD AND APPARATUS FOR PROCESSING VIDEO CONTENT WITH ALF and CCALF | |
| KR20220160019A (ko) | 루프 필터의 높은 레벨 신택스 제어 | |
| KR20220115984A (ko) | 팔레트 모드에서 비디오 데이터를 코딩하기 위한 방법 및 장치 | |
| WO2023131208A1 (en) | Fusion of video prediction modes | |
| US20230090025A1 (en) | Methods and systems for performing combined inter and intra prediction | |
| US20220141459A1 (en) | Offset-based refinement of intra prediction (orip) of video coding | |
| KR20220143870A (ko) | 최대 변환 크기 및 잔차 코딩 방법의 시그널링 | |
| KR20220063272A (ko) | 비디오 코딩을 위한 움직임 보상 방법 | |
| US11711528B2 (en) | Systems and methods for liner model derivation | |
| US11606577B2 (en) | Method for processing adaptive color transform and low-frequency non-separable transform in video coding | |
| US20230007245A1 (en) | Methods and systems for cross-component adaptive loop filter | |
| KR20240072191A (ko) | 결합된 인터 및 인트라 예측을 수행하기 위한 방법들 및 시스템들 |