KR20210010488A - 기계 학습 가능한 생물학적 중합체 어셈블리 - Google Patents
기계 학습 가능한 생물학적 중합체 어셈블리 Download PDFInfo
- Publication number
- KR20210010488A KR20210010488A KR1020207035288A KR20207035288A KR20210010488A KR 20210010488 A KR20210010488 A KR 20210010488A KR 1020207035288 A KR1020207035288 A KR 1020207035288A KR 20207035288 A KR20207035288 A KR 20207035288A KR 20210010488 A KR20210010488 A KR 20210010488A
- Authority
- KR
- South Korea
- Prior art keywords
- assembly
- nucleotide
- learning model
- locations
- location
- Prior art date
Links
- 229920000642 polymer Polymers 0.000 title claims abstract description 203
- 238000000034 method Methods 0.000 claims abstract description 201
- 238000012163 sequencing technique Methods 0.000 claims abstract description 191
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 74
- 229920002521 macromolecule Polymers 0.000 claims abstract description 66
- 102000004169 proteins and genes Human genes 0.000 claims abstract description 63
- 125000003275 alpha amino acid group Chemical group 0.000 claims abstract description 28
- 239000002773 nucleotide Substances 0.000 claims description 275
- 125000003729 nucleotide group Chemical group 0.000 claims description 275
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 161
- 238000013136 deep learning model Methods 0.000 claims description 100
- 150000001413 amino acids Chemical class 0.000 claims description 43
- 238000013527 convolutional neural network Methods 0.000 claims description 26
- 108020004707 nucleic acids Proteins 0.000 claims description 23
- 102000039446 nucleic acids Human genes 0.000 claims description 23
- 150000007523 nucleic acids Chemical class 0.000 claims description 23
- 108091035707 Consensus sequence Proteins 0.000 claims description 7
- 229920001222 biopolymer Polymers 0.000 claims description 6
- 238000010801 machine learning Methods 0.000 abstract description 208
- 230000000712 assembly Effects 0.000 abstract description 47
- 238000000429 assembly Methods 0.000 abstract description 47
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 48
- 230000008569 process Effects 0.000 description 42
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 40
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 35
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 24
- 229930024421 Adenine Natural products 0.000 description 24
- 229960000643 adenine Drugs 0.000 description 24
- 229940113082 thymine Drugs 0.000 description 24
- 239000000523 sample Substances 0.000 description 23
- 108020004414 DNA Proteins 0.000 description 22
- 229940104302 cytosine Drugs 0.000 description 20
- 230000006870 function Effects 0.000 description 16
- 238000013528 artificial neural network Methods 0.000 description 11
- 108090000765 processed proteins & peptides Proteins 0.000 description 9
- 230000004044 response Effects 0.000 description 9
- 239000011159 matrix material Substances 0.000 description 7
- 239000012472 biological sample Substances 0.000 description 6
- 239000003153 chemical reaction reagent Substances 0.000 description 6
- 238000004590 computer program Methods 0.000 description 5
- 239000012634 fragment Substances 0.000 description 5
- 238000012706 support-vector machine Methods 0.000 description 5
- 238000007671 third-generation sequencing Methods 0.000 description 4
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 3
- 230000004913 activation Effects 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 238000003064 k means clustering Methods 0.000 description 3
- 238000011176 pooling Methods 0.000 description 3
- 102000004196 processed proteins & peptides Human genes 0.000 description 3
- 238000000734 protein sequencing Methods 0.000 description 3
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 2
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 2
- 108010026552 Proteome Proteins 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 2
- 238000012300 Sequence Analysis Methods 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 238000005457 optimization Methods 0.000 description 2
- 230000000306 recurrent effect Effects 0.000 description 2
- 241000894006 Bacteria Species 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 238000003066 decision tree Methods 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 238000003062 neural network model Methods 0.000 description 1
- 238000007481 next generation sequencing Methods 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 230000000379 polymerizing effect Effects 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 238000012175 pyrosequencing Methods 0.000 description 1
- 238000007480 sanger sequencing Methods 0.000 description 1
- 238000007841 sequencing by ligation Methods 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 238000004885 tandem mass spectrometry Methods 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
Images













Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
- G16B40/20—Supervised data analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/0464—Convolutional networks [CNN, ConvNet]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B15/00—ICT specially adapted for analysing two-dimensional or three-dimensional molecular structures, e.g. structural or functional relations or structure alignment
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/10—Sequence alignment; Homology search
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/20—Sequence assembly
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B40/00—ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding
- G16B40/30—Unsupervised data analysis
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B50/00—ICT programming tools or database systems specially adapted for bioinformatics
Landscapes
- Physics & Mathematics (AREA)
- Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Theoretical Computer Science (AREA)
- Medical Informatics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Biotechnology (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Data Mining & Analysis (AREA)
- Chemical & Material Sciences (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Bioethics (AREA)
- Databases & Information Systems (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Analytical Chemistry (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Public Health (AREA)
- Epidemiology (AREA)
- Mathematical Physics (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Crystallography & Structural Chemistry (AREA)
- Biomedical Technology (AREA)
- Computational Linguistics (AREA)
- Molecular Biology (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Apparatus Associated With Microorganisms And Enzymes (AREA)
- Addition Polymer Or Copolymer, Post-Treatments, Or Chemical Modifications (AREA)
Abstract
거대분자들의 생물학적 중합체 어셈블리들을 생성하기 위한 기계 학습 기술들이 본 명세서에 설명된다. 예를 들어, 시스템은 기계 학습 기술들을 이용하여 유기체의 DNA의 게놈 어셈블리, 유기체의 DNA의 부분의 유전자 서열, 또는 단백질의 아미노산 서열을 생성할 수 있다. 시스템은 서열 분석 디바이스에 의해 생성된 생물학적 중합체 서열들 및 서열들로부터 생성된 어셈블리에 액세스할 수 있다. 시스템은 서열들 및 어셈블리를 이용하여 기계 학습 모델에 대한 입력을 생성할 수 있다. 시스템은 대응하는 출력을 획득하기 위해 기계 학습 모델에 입력을 제공할 수 있다. 시스템은 대응하는 출력을 이용하여 어셈블리에서의 위치들에서의 생물학적 중합체들을 식별하고, 이어서 어셈블리에서의 위치들에서의 식별된 생물학적 중합체들 표시하기 위해 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득할 수 있다.
Description
관련 출원들에 대한 상호 참조
본 출원은 2018년 5월 14일자로 출원된, "DEEP LEARNING MODEL TO IMPROVE SPEED AND ACCURACY OF GENOME ASSEMBLY"라는 명칭의 미국 가출원 제62/671,260호, 및 2018년 5월 15일자로 출원된, "DEEP LEARNING MODEL TO IMPROVE SPEED AND ACCURACY OF GENOME ASSEMBLY"라는 명칭의 미국 가출원 제62/671,884호에 대한 35 U.S.C. §119 하의 우선권을 주장하며, 이러한 가출원들 각각은 그 전체가 본 명세서에 참조로 포함된다.
본 개시는 거대분자(macromolecule)(예를 들어, 핵산(nucleic acid) 또는 단백질(protein))의 생물학적 중합체들(biological polymers)(예를 들어, 게놈 어셈블리(genome assembly), 뉴클레오티드 서열(nucleotide sequence), 또는 단백질 서열(protein sequence))의 어셈블리를 생성하는 것에 관한 것이다. 서열 분석 디바이스들(sequencing devices)은 어셈블리를 생성하는데 이용될 수 있는 서열 분석 데이터(sequencing data)를 생성할 수 있다. 예로서, 서열 분석 데이터는 (전체적으로 또는 부분적으로) 게놈을 조립하는데 이용될 수 있는 생물학적 샘플로부터의 DNA의 뉴클레오티드 서열들을 포함할 수 있다. 다른 예로서, 서열 분석 데이터는 (전체적으로 또는 부분적으로) 단백질 서열을 조립하는데 이용될 수 있는 아미노산 서열들(amino acid sequences)을 포함할 수 있다.
일 양태에 따르면, 거대분자의 생물학적 중합체 어셈블리를 생성하는 방법이 제공된다. 방법은 적어도 하나의 컴퓨터 하드웨어 프로세서를 이용하여, 복수의 생물학적 중합체 서열들 및 개개의 어셈블리 위치들에서 존재하는 생물학적 중합체들을 표시하는 어셈블리에 액세스하는 단계; 복수의 생물학적 중합체 서열들 및 어셈블리를 이용하여, 트레이닝된 심층 학습 모델(trained deep learning model)에 제공될 제1 입력을 생성하는 단계; 제1 입력을 트레이닝된 심층 학습 모델에 제공하여, 제1 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 생물학적 중합체들 각각이 그 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제1 출력을 획득하는 단계; 트레이닝된 심층 학습 모델의 제1 출력을 이용하여 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 단계; 및 제1 복수의 어셈블리 위치들에서의 식별된 생물학적 중합체들을 표시하도록 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득하는 단계를 수행하는 것을 포함한다.
일 실시예에 따르면, 거대분자는 단백질을 포함하고, 복수의 생물학적 중합체 서열들은 복수의 아미노산 서열들을 포함하고, 어셈블리는 개개의 어셈블리 위치들에서의 아미노산들을 표시한다.
일 실시예에 따르면, 거대분자는 핵산을 포함하고, 복수의 생물학적 중합체 서열들은 복수의 뉴클레오티드 서열들을 포함하고, 어셈블리는 개개의 어셈블리 위치들에서의 뉴클레오티드들을 표시한다.
일 실시예에 따르면, 어셈블리는 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 제1 뉴클레오티드를 표시하고; 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 단계는 제1 어셈블리 위치에서의 제2 뉴클레오티드를 식별하는 단계를 포함하고; 어셈블리를 업데이트하는 단계는 제1 어셈블리 위치에서의 제2 뉴클레오티드를 표시하기 위해 어셈블리를 업데이트하는 단계를 포함한다.
일 실시예에 따르면, 방법은 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득한 후에, 복수의 뉴클레오티드 서열들을 업데이트된 어셈블리에 정렬하는 단계; 복수의 뉴클레오티드 서열들 및 업데이트된 어셈블리를 이용하여, 트레이닝된 심층 학습 모델에 제공될 제2 입력을 생성하는 단계; 제2 입력을 트레이닝된 심층 학습 모델에 제공하여, 제2 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 뉴클레오티드들 각각이 그 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제2 출력을 획득하는 단계; 트레이닝된 심층 학습 모델의 제2 출력에 기초하여 제2 복수의 어셈블리 위치들에서의 뉴클레오티드들을 식별하는 단계; 및 제2 복수의 어셈블리 위치들에서의 식별된 뉴클레오티드들을 표시하도록 업데이트된 어셈블리를 업데이트하여 제2 업데이트된 어셈블리를 획득하는 단계를 더 포함한다.
일 실시예에 따르면, 방법은 복수의 뉴클레오티드 서열들을 어셈블리에 정렬하는 단계를 더 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들은 적어도 5개의 뉴클레오티드 서열들을 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들은 적어도 9개의 뉴클레오티드 서열들을 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들은 적어도 10개의 뉴클레오티드 서열들을 포함한다.
일 실시예에 따르면, 트레이닝된 심층 학습 모델에 대한 제1 입력을 생성하는 단계는, 제1 복수의 어셈블리 위치들을 선택하는 단계; 및 선택된 제1 복수의 어셈블리 위치들에 기초하여 제1 입력을 생성하는 단계를 포함한다. 일 실시예에 따르면, 어셈블리에서 제1 복수의 위치들을 선택하는 단계는, 어셈블리가 제1 복수의 어셈블리 위치들에서의 뉴클레오티드들을 부정확하게 표시할 가능성들을 결정하는 단계; 및 결정된 가능성들을 이용하여 제1 복수의 어셈블리 위치들을 선택하는 단계를 포함한다.
일 실시예에 따르면, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 단계는 복수의 뉴클레오티드 서열들 중의 개개의 뉴클레오티드 서열들을 어셈블리와 비교하는 단계를 포함한다. 일 실시예에 따르면, 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 식별하기 위해 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 단계는: 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치 각각에서의 다수의 뉴클레오티드들 각각에 대해: 뉴클레오티드가 그 위치에 있다는 것을 표시하는 복수의 뉴클레오티드 서열들의 수를 표시하는 카운트를 결정하는 단계; 어셈블리가 그 위치에서의 뉴클레오티드를 표시하는지에 기초하여 기준값(reference value)을 결정하는 단계; 카운트와 기준값 사이의 차이를 표시하는 에러값(error value)을 결정하는 단계; 및 기준값 및 에러값을 제1 입력에 포함하는 단계를 포함한다.
일 실시예에 따르면, 어셈블리가 그 위치에서의 뉴클레오티드를 표시하는지에 기초하여 기준값을 결정하는 단계는: 어셈블리가 그 위치에서의 뉴클레오티드를 표시할 때 기준값을 제1 값인 것으로 결정하는 단계; 및 어셈블리가 그 위치에서의 뉴클레오티드를 표시하지 않을 때 기준값을 제2 값인 것으로 결정하는 단계를 포함한다. 일 실시예에 따르면, 제1 값은 복수의 뉴클레오티드 서열들의 수이고; 제2 값은 0이다.
일 실시예에 따르면, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 단계는 열들(columns)을 갖는 데이터 구조에 값들을 배열하는 단계를 포함하고, 여기서: 제1 열은 제1 어셈블리 위치에서의 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유(hold)하고; 제2 열은 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치 중의 제2 어셈블리 위치에서의 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유한다. 일 실시예에 따르면, 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치는 제1 어셈블리 위치로부터 분리된 적어도 2개의 어셈블리 위치들을 포함한다.
일 실시예에 따르면, 하나 이상의 개개의 생물학적 중합체 각각이 어셈블리 위치에서 존재할 하나 이상의 가능성은, 다수의 뉴클레오티드들 각각에 대해, 뉴클레오티드가 어셈블리 위치에서 존재할 가능성을 포함하고; 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 단계는 제1 뉴클레오티드가 제1 위치에서 존재할 가능성이 다수의 뉴클레오티드들 중의 제2 뉴클레오티드가 제1 어셈블리 위치에서 존재할 가능성보다 크다고 결정함으로써, 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 다수의 뉴클레오티드들 중의 제1 뉴클레오티드인 것으로 식별하는 단계를 포함한다.
일 실시예에 따르면, 방법은 복수의 뉴클레오티드 서열들로부터 어셈블리를 생성하는 단계를 더 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들로부터 어셈블리를 생성하는 단계는 복수의 뉴클레오티드 서열들로부터의 컨센서스 서열(consensus sequence)을 어셈블리인 것으로 결정하는 단계를 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들로부터 어셈블리를 생성하는 단계는 중첩 레이아웃 컨센서스(overlap layout consensus)(OLC) 알고리즘을 복수의 뉴클레오티드 서열들에 적용하는 단계를 포함한다.
일 실시예에 따르면, 방법은 기준 거대분자를 서열 분석하는 것으로부터 획득된 생물학적 중합체 서열들 및 기준 거대분자의 미리 결정된 어셈블리를 포함하는 트레이닝 데이터에 액세스하는 단계; 및 트레이닝 데이터를 이용하여 심층 학습 모델을 트레이닝해서 트레이닝된 심층 학습 모델을 획득하는 단계를 더 포함한다. 일 실시예에 따르면, 기준 거대분자는 거대분자와 상이하다. 일 실시예에 따르면, 심층 학습 모델은 컨볼루션 신경망(convolutional neural network)(CNN)을 포함한다.
다른 양태에 따르면, 거대분자의 생물학적 중합체 어셈블리를 생성하기 위한 시스템이 제공된다. 시스템은: 적어도 하나의 컴퓨터 하드웨어 프로세서; 및 명령어들을 저장하는 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체를 포함하고, 명령어들은, 적어도 하나의 컴퓨터 하드웨어 프로세서에 의해 실행될 때, 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금: 복수의 생물학적 중합체 서열들 및 개개의 어셈블리 위치들에서 존재하는 생물학적 중합체들을 표시하는 어셈블리에 액세스하는 것; 복수의 생물학적 중합체 서열들 및 어셈블리를 이용하여, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 것; 제1 입력을 트레이닝된 심층 학습 모델에 제공하여, 제1 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 생물학적 중합체들 각각이 그 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제1 출력을 획득하는 것; 트레이닝된 심층 학습 모델의 제1 출력을 이용하여 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 것; 및 제1 복수의 어셈블리 위치들에서의 식별된 생물학적 중합체들을 표시하도록 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득하는 것을 수행하게 한다.
일 실시예에 따르면, 거대분자는 단백질을 포함하고, 복수의 생물학적 중합체 서열들은 복수의 아미노산 서열들을 포함하고, 어셈블리는 개개의 어셈블리 위치들에서의 아미노산들을 표시한다.
일 실시예에 따르면, 거대분자는 핵산을 포함하고, 복수의 생물학적 중합체 서열들은 복수의 뉴클레오티드 서열들을 포함하고, 어셈블리는 개개의 어셈블리 위치들에서의 뉴클레오티드들을 표시한다.
일 실시예에 따르면, 어셈블리는 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 제1 뉴클레오티드를 표시하고; 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 것은 제1 어셈블리 위치에서의 제2 뉴클레오티드를 식별하는 것을 포함하고; 어셈블리를 업데이트하는 것은 제1 어셈블리 위치에서의 제2 뉴클레오티드를 표시하기 위해 어셈블리를 업데이트하는 것을 포함한다.
일 실시예에 따르면, 명령어들은 또한, 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금, 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득한 후에, 복수의 뉴클레오티드 서열들을 업데이트된 어셈블리에 정렬하는 것; 복수의 뉴클레오티드 서열들 및 업데이트된 어셈블리를 이용하여, 트레이닝된 심층 학습 모델에 제공될 제2 입력을 생성하는 것; 제2 입력을 트레이닝된 심층 학습 모델에 제공하여, 제2 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 뉴클레오티드들 각각이 그 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제2 출력을 획득하는 것; 트레이닝된 심층 학습 모델의 제2 출력에 기초하여 제2 복수의 어셈블리 위치들에서의 뉴클레오티드들을 식별하는 것; 및 제2 복수의 어셈블리 위치들에서의 식별된 뉴클레오티드들을 표시하도록 업데이트된 어셈블리를 업데이트하여 제2 업데이트된 어셈블리를 획득하는 것을 수행하게 한다.
일 실시예에 따르면, 명령어들은 또한, 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금, 복수의 뉴클레오티드 서열들을 어셈블리에 정렬하는 것을 수행하게 한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들은 적어도 5개의 뉴클레오티드 서열들을 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들은 적어도 9개의 뉴클레오티드 서열들을 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들은 적어도 10개의 뉴클레오티드 서열들을 포함한다.
일 실시예에 따르면, 트레이닝된 심층 학습 모델에 대한 제1 입력을 생성하는 것은: 제1 복수의 어셈블리 위치들을 선택하는 것; 및 선택된 제1 복수의 어셈블리 위치들에 기초하여 제1 입력을 생성하는 것을 포함한다. 일 실시예에 따르면, 어셈블리에서 제1 복수의 위치들을 선택하는 것은: 어셈블리가 제1 복수의 어셈블리 위치들에서의 뉴클레오티드들을 부정확하게 표시할 가능성들을 결정하는 것; 및 결정된 가능성들을 이용하여 제1 복수의 어셈블리 위치들을 선택하는 것을 포함한다.
일 실시예에 따르면, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 것은 복수의 뉴클레오티드 서열들 중의 개개의 뉴클레오티드 서열들을 어셈블리와 비교하는 것을 포함한다. 일 실시예에 따르면, 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 식별하기 위해 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 것은: 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치 각각에서의 다수의 뉴클레오티드들 각각에 대해: 뉴클레오티드가 그 위치에 있다는 것을 표시하는 복수의 뉴클레오티드 서열들의 수를 표시하는 카운트를 결정하는 것; 어셈블리가 그 위치에서의 뉴클레오티드를 표시하는지에 기초하여 기준값을 결정하는 것; 카운트와 기준값 사이의 차이를 표시하는 에러값을 결정하는 것; 및 기준값 및 에러값을 제1 입력에 포함하는 것을 포함한다. 일 실시예에 따르면, 어셈블리가 그 위치에서의 뉴클레오티드를 표시하는지에 기초하여 기준값을 결정하는 것은: 어셈블리가 그 위치에서의 뉴클레오티드를 표시할 때 기준값을 제1 값인 것으로 결정하는 것: 및 어셈블리가 그 위치에서의 뉴클레오티드를 표시하지 않을 때 기준값을 제2 값인 것으로 결정하는 것을 포함한다. 일 실시예에 따르면, 제1 값은 복수의 뉴클레오티드 서열들의 수이고; 제2 값은 0이다. 일 실시예에 따르면, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 것은 열들을 갖는 데이터 구조에 값들을 배열하는 것을 포함하고, 여기서: 제1 열은 제1 어셈블리 위치에서의 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유하고; 제2 열은 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치 중의 제2 어셈블리 위치에서의 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유한다. 일 실시예에 따르면, 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치는 제1 어셈블리 위치로부터 분리된 적어도 2개의 어셈블리 위치들을 포함한다.
일 실시예에 따르면, 하나 이상의 개개의 생물학적 중합체 각각이 어셈블리 위치에서 존재할 하나 이상의 가능성은, 다수의 뉴클레오티드들 각각에 대해, 뉴클레오티드가 어셈블리 위치에서 존재할 가능성을 포함하고; 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 것은 제1 뉴클레오티드가 제1 위치에서 존재할 가능성이 다수의 뉴클레오티드들 중의 제2 뉴클레오티드가 제1 어셈블리 위치에서 존재할 가능성보다 크다고 결정함으로써, 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 다수의 뉴클레오티드들 중의 제1 뉴클레오티드인 것으로 식별하는 것을 포함한다.
일 실시예에 따르면, 명령어들은 또한, 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금, 복수의 뉴클레오티드 서열들로부터 어셈블리를 생성하는 것을 수행하게 한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들로부터 어셈블리를 생성하는 것은 복수의 뉴클레오티드 서열들로부터의 컨센서스 서열을 어셈블리인 것으로 결정하는 것을 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들로부터 어셈블리를 생성하는 것은 중첩 레이아웃 컨센서스(OLC) 알고리즘을 복수의 뉴클레오티드 서열들에 적용하는 것을 포함한다.
일 실시예에 따르면, 명령어들은 또한, 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금: 기준 거대분자를 서열 분석하는 것으로부터 획득된 생물학적 중합체 서열들 및 기준 거대분자의 미리 결정된 어셈블리를 포함하는 트레이닝 데이터에 액세스하는 것; 및 트레이닝 데이터를 이용하여 심층 학습 모델을 트레이닝해서 트레이닝된 심층 학습 모델을 획득하는 것을 수행하게 한다. 일 실시예에 따르면, 기준 거대분자는 거대분자와 상이하다. 일 실시예에 따르면, 심층 학습 모델은 컨볼루션 신경망(CNN)을 포함한다.
다른 양태에 따르면, 비일시적 컴퓨터 판독가능 저장 매체가 제공된다. 비일시적 컴퓨터 판독가능 저장 매체는 명령어들을 저장하고, 명령어들은, 적어도 하나의 컴퓨터 하드웨어 프로세서에 의해 실행될 때, 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금, 거대분자의 생물학적 중합체 어셈블리를 생성하는 방법을 수행하게 한다. 방법은: 복수의 생물학적 중합체 서열들 및 개개의 어셈블리 위치들에서 존재하는 생물학적 중합체들을 표시하는 어셈블리에 액세스하는 단계; 복수의 생물학적 중합체 서열들 및 어셈블리를 이용하여, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 단계; 제1 입력을 트레이닝된 심층 학습 모델에 제공하여, 제1 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 생물학적 중합체들 각각이 그 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제1 출력을 획득하는 단계; 트레이닝된 심층 학습 모델의 제1 출력을 이용하여 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 단계; 및 제1 복수의 어셈블리 위치들에서의 식별된 생물학적 중합체들을 표시하도록 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득하는 단계를 포함한다.
일 실시예에 따르면, 거대분자는 단백질을 포함하고, 복수의 생물학적 중합체 서열들은 복수의 아미노산 서열들을 포함하고, 어셈블리는 개개의 어셈블리 위치들에서의 아미노산들을 표시한다.
일 실시예에 따르면, 거대분자는 핵산을 포함하고, 복수의 생물학적 중합체 서열들은 복수의 뉴클레오티드 서열들을 포함하고, 어셈블리는 개개의 어셈블리 위치들에서의 뉴클레오티드들을 표시한다.
일 실시예에 따르면, 어셈블리는 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 제1 뉴클레오티드를 표시하고; 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 단계는 제1 어셈블리 위치에서의 제2 뉴클레오티드를 식별하는 단계를 포함하고; 어셈블리를 업데이트하는 단계는 제1 어셈블리 위치에서의 제2 뉴클레오티드를 표시하기 위해 어셈블리를 업데이트하는 단계를 포함한다.
일 실시예에 따르면, 방법은 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득한 후에: 복수의 뉴클레오티드 서열들을 업데이트된 어셈블리에 정렬하는 단계; 복수의 뉴클레오티드 서열들 및 업데이트된 어셈블리를 이용하여, 트레이닝된 심층 학습 모델에 제공될 제2 입력을 생성하는 단계; 제2 입력을 트레이닝된 심층 학습 모델에 제공하여, 제2 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 뉴클레오티드들 각각이 그 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제2 출력을 획득하는 단계; 트레이닝된 심층 학습 모델의 제2 출력에 기초하여 제2 복수의 어셈블리 위치들에서의 뉴클레오티드들을 식별하는 단계; 및 제2 복수의 어셈블리 위치들에서의 식별된 뉴클레오티드들을 표시하도록 업데이트된 어셈블리를 업데이트하여 제2 업데이트된 어셈블리를 획득하는 단계를 더 포함한다.
일 실시예에 따르면, 방법은 복수의 뉴클레오티드 서열들을 어셈블리에 정렬하는 단계를 더 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들은 적어도 5개의 뉴클레오티드 서열들을 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들은 적어도 9개의 뉴클레오티드 서열들을 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들은 적어도 10개의 뉴클레오티드 서열들을 포함한다.
일 실시예에 따르면, 트레이닝된 심층 학습 모델에 대한 제1 입력을 생성하는 단계는: 제1 복수의 어셈블리 위치들을 선택하는 단계; 및 선택된 제1 복수의 어셈블리 위치들에 기초하여 제1 입력을 생성하는 단계를 포함한다. 일 실시예에 따르면, 어셈블리에서 제1 복수의 위치들을 선택하는 단계는: 어셈블리가 제1 복수의 어셈블리 위치들에서의 뉴클레오티드들을 부정확하게 표시할 가능성들을 결정하는 단계; 및 결정된 가능성들을 이용하여 제1 복수의 어셈블리 위치들을 선택하는 단계를 포함한다.
일 실시예에 따르면, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 단계는 복수의 뉴클레오티드 서열들 중의 개개의 뉴클레오티드 서열들을 어셈블리와 비교하는 단계를 포함한다. 일 실시예에 따르면, 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 식별하기 위해 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 단계는: 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치 각각에서의 다수의 뉴클레오티드들 각각에 대해: 뉴클레오티드가 그 위치에 있다는 것을 표시하는 복수의 뉴클레오티드 서열들의 수를 표시하는 카운트를 결정하는 단계; 어셈블리가 위치에서의 뉴클레오티드를 표시하는지에 기초하여 기준값을 결정하는 단계; 카운트와 기준값 사이의 차이를 표시하는 에러값을 결정하는 단계; 및 기준값 및 에러값을 제1 입력에 포함하는 단계를 포함한다. 일 실시예에 따르면, 어셈블리가 그 위치에서의 뉴클레오티드를 표시하는지에 기초하여 기준값을 결정하는 단계는: 어셈블리가 그 위치에서의 뉴클레오티드를 표시할 때 기준값을 제1 값인 것으로 결정하는 단계; 및 어셈블리가 그 위치에서의 뉴클레오티드를 표시하지 않을 때 기준값을 제2 값인 것으로 결정하는 단계를 포함한다. 일 실시예에 따르면, 제1 값은 복수의 뉴클레오티드 서열들의 수이고; 제2 값은 0이다. 일 실시예에 따르면, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 단계는 열들을 갖는 데이터 구조에 값들을 배열하는 단계를 포함하고, 여기서: 제1 열은 제1 어셈블리 위치에서의 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유하고; 제2 열은 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치 중의 제2 어셈블리 위치에서의 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유한다. 일 실시예에 따르면, 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치는 제1 어셈블리 위치로부터 분리된 적어도 2개의 어셈블리 위치들을 포함한다.
일 실시예에 따르면, 하나 이상의 개개의 생물학적 중합체 각각이 어셈블리 위치에서 존재할 하나 이상의 가능성은, 다수의 뉴클레오티드들 각각에 대해, 뉴클레오티드가 어셈블리 위치에서 존재할 가능성을 포함하고; 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 단계는 제1 뉴클레오티드가 제1 위치에서 존재할 가능성이 다수의 뉴클레오티드들 중의 제2 뉴클레오티드가 제1 어셈블리 위치에서 존재할 가능성보다 크다고 결정함으로써, 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 다수의 뉴클레오티드들 중의 제1 뉴클레오티드인 것으로 식별하는 단계를 포함한다.
일 실시예에 따르면, 방법은 복수의 뉴클레오티드 서열들로부터 어셈블리를 생성하는 단계를 더 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들로부터 어셈블리를 생성하는 단계는 복수의 뉴클레오티드 서열들로부터의 컨센서스 서열을 어셈블리인 것으로 결정하는 단계를 포함한다. 일 실시예에 따르면, 복수의 뉴클레오티드 서열들로부터 어셈블리를 생성하는 단계는 중첩 레이아웃 컨센서스(OLC) 알고리즘을 복수의 뉴클레오티드 서열들에 적용하는 단계를 포함한다.
일 실시예에 따르면, 방법은: 기준 거대분자를 서열 분석하는 것으로부터 획득된 생물학적 중합체 서열들 및 기준 거대분자의 미리 결정된 어셈블리를 포함하는 트레이닝 데이터에 액세스하는 단계; 및 트레이닝 데이터를 이용하여 심층 학습 모델을 트레이닝해서 트레이닝된 심층 학습 모델을 획득하는 단계를 더 포함한다. 일 실시예에 따르면, 기준 거대분자는 거대분자와 상이하다. 일 실시예에 따르면, 심층 학습 모델은 컨볼루션 신경망(CNN)을 포함한다.
본 출원의 다양한 양태들 및 실시예들이 다음의 도면들을 참조하여 설명될 것이다. 도면들은 반드시 축척비율대로 그려진 것은 아니라는 점을 이해하여야 한다. 다수의 도면들에 출현하는 항목들은 그것들이 출현하는 모든 도면들에서 동일한 참조 번호에 의해 표시된다.
도 1a 내지 도 1c는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 본 명세서에 설명된 기술의 양태들이 구현될 수 있는 시스템들을 도시한다.
도 2a 내지 도 2d는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 조립 시스템의 실시예들을 도시한다.
도 3a는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 생물학적 중합체 어셈블리를 생성하기 위해 기계 학습 모델을 트레이닝하기 위한 예시적인 프로세스(300)이다.
도 3b는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 생물학적 중합체 어셈블리를 생성하기 위해 도 3a의 프로세스에 의해 획득된 기계 학습 모델을 이용하기 위한 예시적인 프로세스(310)이다.
도 4a 내지 도 4c는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 기계 학습 모델에 대한 입력을 생성하는 예를 도시한다.
도 5는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 생물학적 중합체 어셈블리를 업데이트하는 예를 도시한다.
도 6은 본 명세서에 설명된 기술의 일부 실시예들에 따른, 생물학적 중합체 어셈블리를 생성하기 위해 이용된 예시적인 컨볼루션 신경망(CNN) 모델의 구조를 도시한다.
도 7은 종래의 기술들에 대한, 본 명세서에 설명된 기술의 일부 실시예들에 따라 구현된 조립 기술들의 성능을 도시한다.
도 8은 본 명세서에 설명된 기술의 일부 실시예들을 구현하는데 이용될 수 있는 예시적인 컴퓨팅 디바이스(800)의 블록도이다.
도 1a 내지 도 1c는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 본 명세서에 설명된 기술의 양태들이 구현될 수 있는 시스템들을 도시한다.
도 2a 내지 도 2d는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 조립 시스템의 실시예들을 도시한다.
도 3a는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 생물학적 중합체 어셈블리를 생성하기 위해 기계 학습 모델을 트레이닝하기 위한 예시적인 프로세스(300)이다.
도 3b는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 생물학적 중합체 어셈블리를 생성하기 위해 도 3a의 프로세스에 의해 획득된 기계 학습 모델을 이용하기 위한 예시적인 프로세스(310)이다.
도 4a 내지 도 4c는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 기계 학습 모델에 대한 입력을 생성하는 예를 도시한다.
도 5는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 생물학적 중합체 어셈블리를 업데이트하는 예를 도시한다.
도 6은 본 명세서에 설명된 기술의 일부 실시예들에 따른, 생물학적 중합체 어셈블리를 생성하기 위해 이용된 예시적인 컨볼루션 신경망(CNN) 모델의 구조를 도시한다.
도 7은 종래의 기술들에 대한, 본 명세서에 설명된 기술의 일부 실시예들에 따라 구현된 조립 기술들의 성능을 도시한다.
도 8은 본 명세서에 설명된 기술의 일부 실시예들을 구현하는데 이용될 수 있는 예시적인 컴퓨팅 디바이스(800)의 블록도이다.
거대분자는 단백질 또는 단백질 단편, (임의의 타입의 DNA의) DNA 분자 또는 단편, 또는 (임의의 타입의 RNA의) RNA 분자 또는 단편일 수 있다. 생물학적 중합체는 (예를 들어, 거대분자가 단백질 또는 그것의 단편인 경우) 아미노산, 또는 (예를 들어, 거대분자가 DNA, RNA, 또는 그것의 단편인 경우) 뉴클레오티드일 수 있다.
본 발명자들은 거대분자들의 생물학적 중합체 어셈블리들을 생성하기 위해 기계 학습 기술들을 이용하는 시스템을 개발하였다. 예를 들어, 본 발명자들에 의해 개발된 시스템은 기계 학습 기술들을 이용하여, 유기체의 DNA의 게놈 어셈블리를 생성하도록 구성될 수 있다. 다른 예로서, 본 발명자들에 의해 개발된 시스템은 기계 학습 기술들을 이용하여, 단백질의 아미노산 서열을 생성하도록 구성될 수 있다.
일부 실시예들에서, 시스템은 (예를 들어, 서열 분석 디바이스에 의해 생성된) 하나 이상의 생물학적 중합체 서열 및 서열들로부터 생성된 초기 어셈블리에 액세스할 수 있다. 어셈블리는 개개의 어셈블리 위치들에서의 생물학적 중합체들(예를 들어, 뉴클레오티드들, 아미노산들)의 존재를 표시할 수 있다. 시스템은: (1) 서열들 및 초기 어셈블리를 이용하여 기계 학습 모델에 제공될 입력을 생성하고; (2) 입력을 트레이닝된 기계 학습 모델에 제공하여 대응하는 출력을 획득하고; (3) 기계 학습 모델로부터 획득된 출력을 이용하여 초기 어셈블리를 업데이트해서 업데이트된 어셈블리를 획득함으로써, 초기 어셈블리의 생물학적 중합체 표시들에서 에러들을 정정할 수 있다. 업데이트된 어셈블리는 초기 어셈블리보다, 생물학적 중합체 표시들에서 더 적은 에러들을 가질 수 있다.
일부 실시예들에서, 어셈블리는 개개의 위치들에서의 생물학적 중합체들(예를 들어, 뉴클레오티드들 또는 아미노산들)의 다수의 위치들 및 표시들을 포함할 수 있다. 예로서, 어셈블리는 유기체의 게놈에서의 위치들에서의 뉴클레오티드들을 표시하는 게놈 어셈블리일 수 있다. 다른 예로서, 어셈블리는 유기체의 DNA의 부분의 뉴클레오티드들의 서열을 표시하는 유전자 서열(gene sequence)일 수 있다. 다른 예로서, 어셈블리는 단백질의 아미노산 서열("단백질 서열"이라고도 지칭됨)일 수 있다. 생물학적 중합체는 뉴클레오티드, 아미노산, 또는 임의의 다른 타입의 생물학적 중합체일 수 있다. 생물학적 중합체 서열은 또한 본 명세서에서 "서열" 또는 "판독(read)"이라고 지칭될 수 있다.
일부 종래의 생물학적 중합체 조립 기술들은 서열 분석 기술을 이용하여 거대분자(예를 들어, DNA, RNA, 또는 단백질)의 생물학적 중합체 서열들을 생성하고, 생성된 서열들을 이용하여 거대분자의 어셈블리를 생성할 수 있다. 예를 들어, 서열 분석 디바이스는 유기체의 DNA 샘플들로부터 뉴클레오티드 서열들을 생성할 수 있고, 그 서열들은 이번에는 유기체의 DNA의 게놈 어셈블리를 생성하기 위해 이용될 수 있다. 다른 예로서, 서열 분석 디바이스는 단백질 샘플의 아미노산 서열들을 생성할 수 있고, 그 서열들은 이번에는 단백질에 대한 더 긴 아미노산 서열을 조립하기 위해 이용될 수 있다. 컴퓨팅 디바이스는 조립 알고리즘을 서열 분석 디바이스에 의해 생성된 서열들에 적용하여 어셈블리를 생성할 수 있다. 예를 들어, 컴퓨팅 디바이스는 중첩 레이아웃 컨센서스(OLC) 조립 알고리즘을 DNA 샘플의 뉴클레오티드 서열들에 적용하여 유기체의 게놈 어셈블리 또는 그것의 부분을 생성할 수 있다.
핵산 샘플로부터 뉴클레오티드 서열들을 생성하기 위해 이용된 한가지 타입의 서열 분석 기술은, 1000개 미만의 뉴클레오티드들(즉, "짧은 판독들(short reads)")의 뉴클레오티드 서열들을 생성하는 2세대 서열 분석("짧은-판독 서열 분석"이라고도 알려짐)이다. 서열 분석 기술은 이제, 1000개 이상의 뉴클레오티드들(즉, "긴 판독들(long reads)")의 뉴클레오티드 서열들을 생성하고, 2세대 서열 분석에 비해 어셈블리의 더 큰 부분들을 제공하는, 3세대 서열 분석("긴-판독 서열 분석"이라고도 알려짐)으로 진보하였다. 그러나, 본 발명자들은 3세대 서열 분석이 2세대 서열 분석보다 덜 정확하고, 그 결과, 긴 판독들로부터 생성된 어셈블리들이 짧은 판독들로부터 생성된 어셈블리들보다 덜 정확하다는 것을 인식하였다. 본 발명자들은 또한, 조립 정확도를 개선하기 위한 종래의 에러 정정 기술들이 계산적으로 비싸고 시간 소모적이라는 것을 인식하였다. 따라서, 본 발명자들은 어셈블리들에서 에러들을 정정하기 위한 기계 학습 기술들을 개발하였고, 이 기술들은 (1) 3세대 서열 분석으로부터 생성된 어셈블리들의 정확도를 개선하고; (2) 종래의 에러 정정 기술들보다 더 효율적이다.
본 명세서에 설명된 일부 실시예들은, 본 발명자들이 어셈블리들의 생성에 의해 인식한 전술한 문제들 모두를 해결한다. 그러나, 본 명세서에 설명된 모든 실시예가 이러한 문제들 모두를 해결하는 것은 아니라는 것을 이해해야 한다. 또한 본 명세서에서 설명된 기술의 실시예들은 생물학적 중합체 어셈블리의 전술한 문제들을 해결하는 것 이외의 목적들을 위해 이용될 수 있다는 것을 이해해야 한다. 일례로서, 본 명세서에 설명된 기술의 실시예들은 아미노산 서열들로부터 생성된 단백질 서열들의 정확도를 개선하기 위해 이용될 수 있다. 다른 예로서, 본 명세서에 설명된 기술의 실시예들은 짧은 판독들로부터 생성된 어셈블리들의 정확도를 개선하기 위해 이용될 수 있다.
일부 실시예들에서, 시스템은: (1) 개개의 어셈블리 위치들에서 존재하는 생물학적 중합체들을 표시하는 (예를 들어, 복수의 생물학적 중합체 서열들로부터 생성된) 어셈블리에 액세스하고; (2) 복수의 생물학적 중합체 서열들 및 어셈블리를 이용하여, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하고; (3) 제1 입력을 트레이닝된 심층 학습 모델에 제공하여, 제1 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 생물학적 중합체들 각각이 어셈블리 위치에서 존재할 하나 이상의 가능성(예를 들어, 확률)을 표시하는 대응하는 제1 출력을 획득하고; (4) 트레이닝된 심층 학습 모델의 제1 출력을 이용하여 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하고; (5) 제1 복수의 어셈블리 위치들에서의 식별된 생물학적 중합체들을 표시하도록 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 복수의 생물학적 중합체 서열들을 어셈블리에 정렬하도록 구성될 수 있다.
일부 실시예들에서, 거대분자는 단백질일 수 있고, 복수의 생물학적 중합체 서열은 복수의 아미노산 서열들일 수 있고, 어셈블리는 개개의 어셈블리 위치들에서의 아미노산들을 표시한다. 일부 실시예들에서, 거대분자는 핵산(예를 들어, DNA, RNA)일 수 있고, 복수의 생물학적 서열들은 뉴클레오티드 서열들일 수 있고, 어셈블리는 개개의 어셈블리 위치들에서의 뉴클레오티드들을 표시한다.
일부 실시예들에서, 어셈블리는 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 제1 뉴클레오티드(예를 들어, 아데닌(adenine))를 표시한다. 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 것은, 제1 뉴클레오티드와 상이한 제1 어셈블리 위치에서의 제2 뉴클레오티드(예를 들어, 티민(thymine))를 식별하는 것을 포함하고; 어셈블리를 업데이트하는 것은 제1 어셈블리 위치에서의 제2 뉴클레오티드(예를 들어, 티민)를 표시하기 위해 어셈블리를 업데이트하는 것을 포함한다.
일부 실시예들에서, 시스템은 다수의 업데이트 반복들을 수행하도록 구성될 수 있다. 시스템은, 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득한 후에: (1) 복수의 뉴클레오티드 서열들을 업데이트된 어셈블리에 정렬하고; (2) 복수의 뉴클레오티드 서열들 및 업데이트된 어셈블리를 이용하여, 트레이닝된 심층 학습 모델에 제공될 제2 입력을 생성하고; (3) 제2 입력을 트레이닝된 심층 학습 모델에 제공하여, 제2 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 뉴클레오티드들 각각이 어셈블리 위치에서 존재할 하나 이상의 가능성(예를 들어, 확률)을 표시하는 대응하는 제2 출력을 획득하고; (4) 트레이닝된 심층 학습 모델의 제2 출력에 기초하여 제2 복수의 어셈블리 위치들에서의 뉴클레오티드들을 식별하고; (5) 제2 복수의 어셈블리 위치들에서의 식별된 뉴클레오티드들을 표시하도록 업데이트된 어셈블리를 업데이트하여 제2 업데이트된 어셈블리를 획득하도록 구성될 수 있다.
일부 실시예들에서, 시스템은: (1) 제1 복수의 어셈블리 위치들을 선택하고; (2) 선택된 제1 복수의 어셈블리 위치들에 기초하여 제1 입력을 생성함으로써, 트레이닝된 심층 학습 모델에 대한 제1 입력을 생성하도록 구성될 수 있다. 일부 실시예들에서, 시스템은: (1) 어셈블리가 제1 복수의 어셈블리 위치들에서의 뉴클레오티드들을 부정확하게 표시할 가능성들을 결정하고; (2) 결정된 가능성들을 이용하여 제1 복수의 어셈블리 위치들을 선택함으로써, 제1 복수의 어셈블리 위치들을 선택하도록 구성될 수 있다.
일부 실시예들에서, 시스템은 (예를 들어, 하나 이상의 특징의 값을 결정하기 위해) 복수의 뉴클레오티드 서열들 중의 개개의 뉴클레오티드 서열들을 어셈블리와 비교함으로써, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치 각각에서의 다수의 뉴클레오티드들 각각에 대해: (1) 뉴클레오티드가 어셈블리 위치에 있는 것을 표시하는 복수의 뉴클레오티드 서열들의 수를 표시하는 카운트를 결정하고; (2) 어셈블리가 어셈블리 위치에서의 뉴클레오티드를 표시하는지에 기초하여 기준값을 결정하고; (3) 카운트와 기준값 사이의 차이를 표시하는 에러값을 결정하고; (4) 기준값 및 에러값을 제1 입력에 포함함으로써, 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 식별하기 위한 제1 입력을 생성하도록 구성될 수 있다. 일부 실시예들에서, 시스템은: (1) 어셈블리가 어셈블리 위치에서의 뉴클레오티드를 표시할 때 기준값이 제1 값(예를 들어, 복수의 뉴클레오티드 서열들의 수)인 것으로 결정하고; (2) 어셈블리가 어셈블리 위치에서의 뉴클레오티드를 표시하지 않을 때 기준값을 제2 값(예를 들어, 0)인 것으로 결정함으로써, 어셈블리가 어셈블리 위치에서의 뉴클레오티드를 표시하는지에 기초하여 기준값을 결정하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45 또는 50개의 위치들의 이웃을 이용하도록 구성될 수 있다.
일부 실시예들에서, 시스템은 행/열을 갖는 데이터 구조에 값들을 배열함으로써 제1 어셈블리 위치에서의 뉴클레오티드를 식별하기 위한 제1 입력을 생성하도록 구성될 수 있고, 여기서: (1) 제1 행/열은 제1 어셈블리 위치에서의 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유하고; (2) 제2 행/열은 제1 어셈블리 위치의 이웃에서의 제2 위치에서의 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유한다.
일부 실시예들에서, 하나 이상의 개개의 생물학적 중합체들 각각이 어셈블리 위치에서 존재할 하나 이상의 가능성은, 다수의 뉴클레오티드들 각각에 대해, 뉴클레오티드가 어셈블리 위치에서 존재할 가능성(예를 들어, 확률)을 포함한다. 시스템은 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 다수의 뉴클레오티드들 중의 제1 뉴클레오티드인 것으로 식별함으로써, 어셈블리에서의 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하도록 구성될 수 있다. 시스템은 제1 뉴클레오티드가 제1 어셈블리 위치에서 존재할 가능성이 다수의 뉴클레오티드들 중의 제2 뉴클레오티드가 제1 어셈블리 위치에서 존재할 가능성보다 크다고 결정함으로써, 제1 어셈블리 위치에서의 뉴클레오티드를 제1 뉴클레오티드인 것으로 식별할 수 있다.
일부 실시예들에서, 시스템은 복수의 뉴클레오티드 서열들로부터 어셈블리(예를 들어, 초기 어셈블리)를 생성하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 (예를 들어, 다수결 투표(majority vote)에 의해) 복수의 뉴클레오티드 서열들로부터의 컨센서스 서열을 어셈블리인 것으로 결정함으로써 어셈블리를 생성하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 중첩 레이아웃 컨센서스(OLC) 알고리즘을 복수의 뉴클레오티드 서열들에 적용함으로써 복수의 뉴클레오티드 서열들로부터 어셈블리를 생성하도록 구성될 수 있다. 일부 실시예들에서, 시스템은: (1) 기준 거대분자를 서열 분석하는 것으로부터 획득된 생물학적 중합체 서열들 및 기준 거대분자의 미리 결정된 생물학적 중합체 어셈블리를 포함하는 트레이닝 데이터에 액세스하고; (2) 트레이닝 데이터를 이용하여 심층 학습 모델(예를 들어, 컨볼루션 신경망 또는 순환 신경망(recurrent neural network))을 트레이닝해서 트레이닝된 심층 학습 모델을 획득하도록 구성될 수 있다. 일부 실시예들에서, 심층 학습 모델을 트레이닝하기 위해 이용된 기준 거대분자는 어셈블리가 생성되고 있는 거대분자와 상이할 수 있다.
위에서 소개되고 아래에서 더 상세히 설명되는 기술들은, 임의의 특정 구현 방식으로 제한되지 않으므로, 임의의 다양한 방식으로 구현될 수 있음을 이해해야 한다. 구현의 상세들의 예들은 단지 예시의 목적으로 본 명세서에 제공된다. 또한, 본 명세서에 개시된 기술들은, 본 명세서에 설명된 기술의 양태들이 임의의 특정한 기술 또는 기술들의 조합으로 제한되지 않으므로, 개별적으로 또는 임의의 적절한 조합으로 이용될 수 있다.
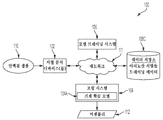
도 1a는 본 명세서에 설명된 기술의 양태들이 구현될 수 있는 시스템(100)을 도시한다. 시스템(100)은 하나 이상의 서열 분석 디바이스(102), 조립 시스템(104), 모델 트레이닝 시스템(106) 및 데이터 저장소(108A)를 포함하고, 이들 각각은 네트워크(111)에 접속된다.
일부 실시예들에서, 서열 분석 디바이스(들)(102)는 거대분자의 하나 이상의 샘플 시료(sample specimen)(110)의 서열 분석에 의해 서열 분석 데이터를 생성하도록 구성될 수 있다. 예를 들어, 샘플 시료(들)(110)는 핵산들(예를 들어, DNA 및/또는 RNA), 또는 단백질(예를 들어, 펩티드(peptide))을 함유하는 생물학적 샘플일 수 있다. 서열 분석 데이터는 샘플 시료(들)(110)의 생물학적 중합체 서열들을 포함할 수 있다. 생물학적 중합체 서열은 거대분자 샘플에서 존재하는 생물학적 중합체들의 순서 및 위치를 표시하는 영숫자 심볼들의 시퀀스로서 표현될 수 있다. 일부 실시예들에서, 생물학적 중합체 서열들은 생물학적 샘플을 서열 분석하는 것으로부터 생성된 뉴클레오티드 서열들일 수 있다. 예로서, 뉴클레오티드 서열은: (1) 아데닌을 표현하기 위해 "A"를; (2) 시토신(cytosine)을 표현하기 위해 "C"를; (3) 구아닌(guanine)을 표현하기 위해 "G"를; (4) 티민을 표현하기 위해 "T"를; (5) 우라실(Uracil)을 표현하기 위해 "U"를; (6) 서열에서의 위치에 어떠한 뉴클레오티드도 존재하지 않음을 표현하기 위해 "-"를 이용할 수 있다. 일부 실시예들에서, 생물학적 중합체 서열들은 단백질 샘플(예를 들어, 펩티드)을 서열 분석하는 것으로부터 생성된 아미노산 서열들일 수 있다. 예로서, 아미노산 서열은 단백질에 존재할 수 있는 개개의 상이한 아미노산들을 표현하기 위해 상이한 영숫자 문자들을 이용하는 영숫자 시퀀스일 수 있다.
일부 실시예들에서, 서열 분석 디바이스(들)(102)는 핵산 샘플(예를 들어, DNA 샘플)을 서열 분석하는 것으로부터 뉴클레오티드 서열들을 생성하도록 구성될 수 있다. 일부 실시예들에서, 서열 분석 디바이스(들)(102)는 합성에 의해 핵산 샘플을 서열 분석하도록 구성될 수 있다. 서열 분석 디바이스(들)(102)는 뉴클레오티드들이 서열 분석되는 핵산에 상보적인 핵산의 새롭게 합성된 가닥(strand) 내에 통합될 때에 뉴클레오티드들을 식별하도록 구성될 수 있다. 서열 분석 동안, 중합 효소(polymerizing enzyme)(예를 들어, DNA 폴리머라제(polymerase))는 타겟 핵산 분자의 프라이밍 위치(priming location)("프라이머(primer)"라고 지칭됨)에 결합(예를 들어, 부착)되고, 뉴클레오티드들을 중합 효소의 작용을 통해 프라이머에 통합할 수 있다. 서열 분석 디바이스(들)(102)는 통합되고 있는 각각의 뉴클레오티드를 검출하도록 구성될 수 있다. 일부 실시예들에서, 뉴클레오티드들은 여기(excitation)에 응답하여 광을 방출하는 개개의 발광 분자들(luminescent molecules)(예를 들어, 형광단(fluorophores))과 연관될 수 있다. 발광 분자가 연관되는 개개의 뉴클레오티드가 통합되고 있을 때 발광 분자가 여기될 수 있다. 서열 분석 디바이스(들)(102)는 광 방출들을 검출하기 위한 하나 이상의 센서를 포함할 수 있다. 각각의 타입의 뉴클레오티드는 개개의 타입의 발광 분자와 연관될 수 있다. 서열 분석 디바이스(들)(102)는 검출된 광 방출들에 기초하여 발광 분자의 타입을 식별함으로써 통합되는 뉴클레오티드를 식별할 수 있다. 예를 들어, 서열 분석 디바이스(들)(102)는 광 방출 강도, 수명, 파장들, 또는 다른 특성들을 이용하여 상이한 발광 분자들을 구별할 수 있다. 일부 실시예들에서, 서열 분석 디바이스(들)(102)는 통합되는 뉴클레오티드를 식별하기 위해 뉴클레오티드 통합 동안 생성된 전기 신호들을 검출하도록 구성될 수 있다. 서열 분석 디바이스(들)(102)는 전기 신호들을 검출하기 위한 센서(들)를 포함할 수 있고, 통합되는 뉴클레오티드들을 식별하기 위해 이들 신호들을 이용할 수 있다.
일부 실시예들에서, 서열 분석 디바이스(들)(102)는 본 명세서에 설명된 것들과 상이한 기술들을 이용하여 핵산을 서열 분석하도록 구성될 수 있다. 일부 실시예들은 본 명세서에 설명된 핵산 서열 분석의 임의의 특정 기술로 제한되지 않는다.
일부 실시예들에서, 서열 분석 디바이스(들)(102)는 단백질 샘플(예를 들어, 펩티드)을 서열 분석하는 것으로부터 아미노산 서열들을 생성하도록 구성될 수 있다. 일부 실시예들에서, 서열 분석 디바이스(들)(102)는 개개의 아미노산에 선택적으로 결합되는 시약들(reagents)을 이용하여 단백질 샘플을 서열 분석하도록 구성될 수 있다. 시약은 다른 타입의 아미노산들에 대해 하나 이상의 타입의 아미노산들에 선택적으로 결합될 수 있다. 일부 실시예들에서, 시약들은 개개의 발광 분자들과 연관될 수 있다. 발광 분자들은 발광 분자가 연관되는 시약과 아미노산 사이의 상호작용에 응답하여 여기될 수 있다. 일부 실시예들에서, 서열 분석 디바이스(들)(102)는 발광 분자들의 광 방출을 검출함으로써 아미노산들을 식별하도록 구성될 수 있다. 서열 분석 디바이스(들)(102)는 광 방출들을 검출하기 위한 하나 이상의 센서를 포함할 수 있다. 일부 실시예들에서, 각각의 타입의 아미노산은 개개의 타입의 발광 분자와 연관될 수 있다. 서열 분석 디바이스(들)(102)는 검출된 광 방출들에 기초하여 발광 분자의 타입을 식별함으로써 아미노산을 식별할 수 있다. 예로서, 서열 분석 디바이스(들)(102)는 광 방출 강도, 수명, 파장들, 또는 다른 특성들을 이용하여 상이한 발광 분자들을 구별할 수 있다. 일부 실시예들에서, 서열 분석 디바이스(들)(102)는 시약들과 아미노산들 사이의 결합 상호작용들 동안 생성된 전기 신호들을 검출하도록 구성될 수 있다. 서열 분석 디바이스(들)(102)는 전기 신호들을 검출하기 위한 센서(들)를 포함할 수 있고, 신호들을 이용하여 개개의 결합 상호작용들에 수반되는 아미노산들을 식별할 수 있다.
일부 실시예들에서, 서열 분석 디바이스(들)(102)는 본 명세서에 설명된 것들과 상이한 기술들을 이용하여 단백질을 서열 분석하도록 구성될 수 있다. 일부 실시예들은 본 명세서에 설명된 단백질 서열 분석의 임의의 특정 기술로 제한되지 않는다.
도 1a의 실시예에 도시된 바와 같이, 서열 분석 디바이스(들)(102)는 디바이스(들)(102)에 의해 생성된 서열 분석 데이터를, 저장을 위해 데이터 저장소(108A)에 송신하도록 구성될 수 있다. 서열 분석 데이터는 거대분자 샘플들의 서열 분석으로부터 생성된 서열들을 포함할 수 있다. 서열 분석 데이터는 하나 이상의 다른 시스템에 의해 이용될 수 있다. 예로서, 서열 분석 데이터는 조립 시스템(104)에 의해, 거대분자의 어셈블리를 생성하는데 이용될 수 있다. 다른 예로서, 서열 분석 데이터는 모델 트레이닝 시스템(106)에 의해, 조립 시스템(104)에 의한 이용을 위한 기계 학습 모델을 트레이닝하기 위한 트레이닝 데이터로서 이용될 수 있다. 서열 분석 데이터의 예시적인 이용들이 본 명세서에서 설명된다.
일부 실시예들에서, 조립 시스템(104)은 서열 분석 디바이스(들)(102)에 의해 생성된 서열 분석 데이터를 이용하여 어셈블리(112)를 생성하도록 구성된 컴퓨팅 디바이스일 수 있다. 조립 시스템(104)은 조립 시스템(104)이 어셈블리를 생성하기 위해 이용하는 기계 학습 모델(104A)을 포함한다. 일부 실시예들에서, 기계 학습 모델(104A)은 모델 트레이닝 시스템(106)으로부터 획득된 트레이닝된 기계 학습 모델일 수 있다. 조립 시스템(104)에 의해 이용될 수 있는 기계 학습 모델의 예들이 본 명세서에서 설명된다.
일부 실시예들에서, 조립 시스템(104)은 초기 어셈블리를 업데이트함으로써 어셈블리(112)를 생성하도록 구성될 수 있다. 초기 어셈블리는 서열 분석 데이터에 대한 종래의 조립 알고리즘의 적용으로부터 획득될 수 있다. 일부 실시예들에서, 조립 시스템(104)은 초기 어셈블리를 생성하도록 구성될 수 있다. 조립 시스템(104)은 서열 분석 디바이스(들)(102)로부터 획득된 서열 분석 데이터에 조립 알고리즘을 적용함으로써 초기 어셈블리를 생성하도록 구성될 수 있다. 예로서, 조립 시스템(104)은 데이터 저장소(108A)로부터의 서열 분석 데이터(예를 들어, 뉴클레오티드 서열들)에 중첩 레이아웃 컨센서스(OLC) 조립 또는 DBG(De Bruijn Graph) 조립을 적용하여 초기 어셈블리를 생성할 수 있다. 일부 실시예들에서, 조립 시스템(104)은 조립 시스템(104)으로부터 분리된 시스템에 의해 생성된 초기 어셈블리를 획득하도록 구성될 수 있다. 예로서, 조립 시스템(104)은 조립 알고리즘을 서열 분석 디바이스(들)(102)에 의해 생성된 서열 분석 데이터에 적용한 조립 시스템(104)으로부터 분리된 컴퓨팅 디바이스에 의해 생성된 초기 어셈블리를 수신할 수 있다.
일부 실시예들에서, 조립 시스템(104)은 트레이닝된 기계 학습 모델(104A)을 이용하여 어셈블리(예를 들어, 조립 알고리즘의 적용으로부터 획득된 초기 어셈블리)를 업데이트하거나 정제(refine)하도록 구성될 수 있다. 조립 시스템(104)은 어셈블리에서의 하나 이상의 에러를 정정하고/하거나 어셈블리에서의 생물학적 중합체 표시들을 확인함으로써, 어셈블리를 업데이트하도록 구성될 수 있다. 일부 실시예들에서, 조립 시스템(104)은: (1) 서열 분석 데이터 및 어셈블리를 이용하여 기계 학습 모델(104A)에 대한 입력을 생성하고; (2) 생성된 입력을 기계 학습 모델(104A)에 제공하여 대응하는 출력을 획득하고; (3) 기계 학습 모델(104A)로부터 획득된 출력을 이용하여 어셈블리를 업데이트함으로써, 어셈블리를 업데이트하도록 구성될 수 있다. 일부 실시예들에서, 기계 학습 모델(104A)의 출력은, 어셈블리에서의 다수의 위치들 각각에 대해, 하나 이상의 개개의 생물학적 중합체들(예를 들어, 뉴클레오티드들 또는 아미노산들) 각각이 어셈블리에서의 위치에서 존재할 하나 이상의 가능성을 표시할 수 있다. 예로서, 출력은, 위치들 각각에 대해, 개개의 뉴클레오티드들이 위치에서 존재할 확률들을 표시할 수 있다. 일부 실시예들에서, 조립 시스템(104)은: (1) 기계 학습 모델(104A)로부터 획득된 출력을 이용하여 어셈블리 위치들에서의 생물학적 중합체들(예를 들어, 뉴클레오티드들 또는 아미노산들)을 식별하고; (2) 위치들에서의 식별된 생물학적 중합체를 표시하도록 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득하도록 구성될 수 있다. 기계 학습 모델을 이용하여 어셈블리를 업데이트하기 위한 예시적인 기술들이 본 명세서에 설명된다.
일부 실시예들에서, 조립 시스템(104)은 업데이트(예를 들어, 정정 또는 확인)될 어셈블리에서의 위치들을 식별하도록 구성될 수 있다. 조립 시스템(104)은 선택된 위치들을 이용하여 기계 학습 모델(104A)에 대한 입력을 생성하도록 구성될 수 있다. 일부 실시예들에서, 조립 시스템(104)은: (1) 개개의 어셈블리 위치들에서의 생물학적 중합체들의 표시들이 부정확할 가능성들을 결정하고; (2) 결정된 가능성들에 기초하여 정정될 위치들을 선택함으로써, 업데이트될 위치들을 식별하도록 구성될 수 있다. 일부 실시예들에서, 조립 시스템(104)은 개개의 위치들에서 표시된 생물학적 중합체들이 부정확할 가능성들을 표시하는 수치 값들을 결정하고, 가능성 값들에 기초하여 업데이트될 위치들을 선택하도록 구성될 수 있다. 예로서, 조립 시스템(104)은 임계값보다 큰 부정확할 가능성을 갖는 위치들을 선택할 수 있다.
일부 실시예들에서, 조립 시스템(104)은 어셈블리에서의 위치들에 대한 특징 값들을 결정함으로써 기계 학습 모델(104A)에 대한 입력들을 생성하도록 구성될 수 있다. 조립 시스템(104)은 어셈블리 및 어셈블리가 생성되게 하였던 서열들을 이용하여 특징 값들을 결정하도록 구성될 수 있다. 예시적인 특징들이 본 명세서에서 설명된다. 일부 실시예들에서, 조립 시스템(104)은 다수의 위치들 각각에 대해 기계 학습 모델(104A)에 대한 입력들을 생성하도록 구성될 수 있다. 각각의 위치에 대해, 조립 시스템(104)은 특징 값들을 결정하고, 특징 값들을 기계 학습 모델(104A)에 입력으로서 제공하여 대응하는 출력을 획득하도록 구성될 수 있다. 조립 시스템(104)은 위치에서 표시된 생물학적 중합체를 정정하기 위해 위치에 대해 제공된 입력에 대응하는 출력을 이용하거나, 위치에서 표시된 생물학적 중합체가 정확한 것을 확인하도록 구성될 수 있다. 일부 실시예들에서, 다수의 위치들은 어셈블리에서의 모든 위치들일 수 있다. 일부 실시예들에서, 다수의 위치들은 어셈블리에서의 위치들의 서브세트일 수 있다.
위치들의 서브세트가 업데이트되는 실시예들에서, 조립 시스템(104)은 위치들의 서브세트를 선택하도록 구성될 수 있다. 조립 시스템(104)은: (1) 어셈블리가 다수의 위치들에서의 생물학적 중합체들을 부정확하게 표시할 가능성들을 결정하는 것; 및 (2) 가능성들을 이용하여 다수의 위치들로부터의 위치들의 서브세트를 선택하는 것을 포함하는 다수의 방식들로 위치들의 서브세트를 선택하도록 구성될 수 있다. 예를 들어, 조립 시스템(104)은: (1) 임계 가능성을 초과할 가능성을 갖는 위치들을 식별하고; (2) 식별된 위치들을 위치들의 서브세트인 것으로 선택할 수 있다.
일부 실시예들에서, 조립 시스템(104)은 위치의 이웃에서의 하나 이상의 위치에서 결정된 특징 값들을 이용하여 정정될 위치에 대한 입력을 생성하도록 구성될 수 있다. 선택된 위치에 대해, 기계 학습 모델(104A)은 어셈블리에서의 주변 위치들로부터의 컨텍스트 정보를 이용하여 선택된 위치에 대한 출력을 생성할 수 있다. 일부 실시예들에서, 위치의 이웃은: (1) 선택된 위치, 및 (2) 선택된 위치를 둘러싸는 위치들의 세트를 포함할 수 있다. 예로서, 이웃은 기계 학습 모델(104A)이 출력을 생성하는 선택된 위치에 중심을 둔 위치들의 윈도우일 수 있다. 조립 시스템(104)은 5개 위치, 10개 위치, 15개 위치, 20개 위치, 25개 위치, 30개 위치, 35개 위치, 40개 위치, 45개 위치, 및/또는 50개 위치의 윈도우를 이용할 수 있다.
일부 실시예들에서, 조립 시스템(104)은 최종 어셈블리(112)를 생성하기 위해 다수의 업데이트 반복들을 수행하도록 구성될 수 있다. 예로서, 조립 시스템(104)은: (1) 초기 어셈블리에 대해 제1 반복을 수행하여 제1 업데이트된 어셈블리를 획득하고; (2) 제1 업데이트된 어셈블리에 대해 제2 반복을 수행하여 제2 업데이트된 어셈블리를 획득할 수 있다. 일부 실시예들에서, 조립 시스템(104)은 업데이트들을 반복적으로 수행하도록 구성될 수 있다. 조립 시스템(104)은 조건이 충족될 때까지 업데이트 반복들을 수행하도록 구성될 수 있다. 예시적인 조건들이 본 명세서에서 설명된다.
일부 실시예들에서, 모델 트레이닝 시스템(106)은 데이터 저장소(108A)에 저장된 데이터에 액세스하고, 액세스된 데이터를 이용하여 어셈블리를 생성하는데 이용하기 위한 기계 학습 모델을 트레이닝하도록 구성된 컴퓨팅 디바이스일 수 있다. 일부 실시예들에서, 모델 트레이닝 시스템(106)은 상이한 조립 시스템들에 대해 별도의 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 개개의 조립 시스템에 대해 트레이닝된 기계 학습 모델은 조립 시스템의 고유 특성에 맞춰질 수 있다. 예로서, 모델 트레이닝 시스템(106)은: (1) 제1 조립 시스템에 대해 제1 기계 학습 모델을 트레이닝하고; (2) 제2 조립 시스템에 대해 제2 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 조립 시스템들 각각에 대한 별도의 기계 학습 모델은 개개의 조립 시스템들의 고유 에러 프로파일들에 맞춰질 수 있다. 예를 들어, 상이한 조립 시스템들은 초기 어셈블리를 생성하기 위해 상이한 조립 알고리즘들을 이용할 수 있고, 각각의 조립 시스템에 대해 트레이닝된 기계 학습 모델은 조립 알고리즘의 에러 프로파일에 맞춰질 수 있다.
일부 실시예들에서, 모델 트레이닝 시스템(106)은 단일의 트레이닝된 기계 학습 모델을 다수의 조립 시스템들에 제공하도록 구성될 수 있다. 예로서, 모델 트레이닝 시스템(106)은 다수의 조립 시스템들로부터의 어셈블리들을 집계(aggregate)하고, 단일의 기계 학습 모델을 트레이닝할 수 있다. 단일의 기계 학습 모델은 조립 시스템들에 의해 이용된 조립 기술들의 변화로부터 기인하는 모델 변화들을 완화하기 위해 다수의 조립 시스템들에 대해 정규화될 수 있다. 일부 실시예들에서, 모델 트레이닝 시스템(106)은 다수의 서열 분석 디바이스들에 대해 단일의 트레이닝된 기계 학습 모델을 제공하도록 구성될 수 있다. 예로서, 모델 트레이닝 시스템(106)은 다수의 서열 분석 디바이스로부터 서열 분석 데이터를 집계하고, 단일의 기계 학습 모델을 트레이닝할 수 있다. 단일의 기계 학습 모델은 디바이스 변화에 기인하는 모델 변화들을 완화하기 위해 다수의 서열 분석 디바이스들에 대해 정규화될 수 있다.
일부 실시예들에서, 모델 트레이닝 시스템(106)은: (1) 하나 이상의 기준 거대분자(예를 들어, DNA, RNA, 단백질)을 서열 분석하는 것으로부터 획득된 생물학적 중합체 서열들; 및 (2) 기준 거대분자(들)의 하나 이상의 미리 결정된 어셈블리를 포함하는 트레이닝 데이터를 이용함으로써, 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 일부 실시예들에서, 모델 트레이닝 시스템(106)은 미리 결정된 어셈블리들에서의 생물학적 중합체들의 표시들을 기계 학습 모델을 트레이닝하기 위한 표지들로서 이용하도록 구성될 수 있다. 표지들은 어셈블리 위치들에서의 정확한 또는 원하는 표시들을 나타낼 수 있다. 예로서, 트레이닝 데이터는 유기체의 서열 분석 DNA 샘플들로부터의 뉴클레오티드 서열들, 및 유기체의 미리 결정된 게놈 어셈블리를 포함할 수 있다. 이 예에서, 모델 트레이닝 시스템(106)은, 미리 결정된 게놈 어셈블리에서의 뉴클레오티드들의 표시들을 감독(supervised) 학습 알고리즘을 트레이닝 데이터에 적용하기 위한 표지들로서 이용할 수 있다.
일부 실시예들에서, 모델 트레이닝 시스템(106)은 외부 데이터베이스들로부터의 트레이닝 데이터에 액세스하도록 구성될 수 있다. 예로서, 모델 트레이닝 시스템(106)은: (1) Pacific Biosciences RS II (Pacbio) 데이터베이스 및/또는 Oxford Nanopore MiniION (ONT) 데이터베이스로부터의 서열 분석 데이터; 및 (2) 기준 게놈들의 NCBI(National Center for Biotechnology Information) 데이터베이스로부터의 미리 결정된 게놈 어셈블리들에 액세스할 수 있다. 다른 예로서, 모델 트레이닝 시스템(106)은 단백질 서열 분석 데이터, 및 UnitProt 데이터베이스 및/또는 HPP(Human Proteome Project) 데이터베이스로부터의 연관된 단백질체 어셈블리(proteome assembly)들에 액세스할 수 있다.
일부 실시예들에서, 모델 트레이닝 시스템(106)은 표지된 트레이닝 데이터를 이용하여 감독 학습 트레이닝 알고리즘을 적용함으로써 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 예로서, 모델 트레이닝 시스템(504)은 확률적 기울기 하강(stochastic gradient descent)을 이용함으로써 심층 학습 모델(예를 들어, 신경망)을 트레이닝할 수 있다. 다른 예로서, 모델 트레이닝 시스템(106)은 지원 벡터 기계(support vector machine)(SVM)를 트레이닝하여, 비용 함수를 최적화함으로써 SVM의 결정 경계들을 식별할 수 있다. 예로서, 모델 트레이닝 시스템(106)은: (1) 서열 분석 데이터 및 서열 분석 데이터에 대한 조립 알고리즘의 적용으로부터 생성된 어셈블리를 이용하여 기계 학습 모델에 대한 입력들을 생성하고; (2) (예를 들어, 공공 데이터베이스로부터의) 거대분자의 미리 결정된 어셈블리를 이용하여 입력들을 표지하고; 및 (3) 감독 트레이닝 알고리즘을 생성된 입력들 및 대응하는 표지들에 적용할 수 있다.
일부 실시예들에서, 모델 트레이닝 시스템(106)은 비감독(unsupervised) 학습 알고리즘을 트레이닝 데이터에 적용하기 위한 표지들로서 학습 알고리즘을 트레이닝 데이터에 적용함으로써 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 예로서, 모델 트레이닝 시스템(106)은 k-평균 클러스터링(k-means clustering)을 수행함으로써 클러스터링 모델의 클러스터들을 식별할 수 있다. 일부 실시예들에서, 모델 트레이닝 시스템(106)은: (1) 서열 분석 데이터 및 서열 분석 데이터에 대한 조립 알고리즘의 적용으로부터 생성된 어셈블리를 이용하여 기계 학습 모델에 대한 입력들을 생성하고; (2) 비감독 학습 알고리즘을 생성된 입력들에 적용하도록 구성될 수 있다. 예로서, 모델 트레이닝 시스템(106)은 모델의 각각의 클러스터가 개개의 뉴클레오티드를 나타내는 클러스터링 모델을 트레이닝할 수 있고, 클러스터 분류는 게놈 어셈블리 또는 유전자 서열에서의 위치에서의 뉴클레오티드를 표시할 수 있다. 다른 예로서, 모델 트레이닝 시스템(106)은 모델의 각각의 클러스터가 개개의 아미노산을 나타내는 클러스터링 모델을 트레이닝할 수 있고, 클러스터 분류는 단백질 서열에서의 위치에서의 아미노산을 표시할 수 있다.
일부 실시예들에서, 모델 트레이닝 시스템(106)은 반감독(semi-supervised) 학습 알고리즘을 트레이닝 데이터에 적용함으로써 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 일부 실시예들에서, 모델 트레이닝 시스템(106)은: (1) 비감독 학습 알고리즘(예를 들어, 클러스터링)을 트레이닝 데이터에 적용함으로써 표지되지 않은 트레이닝 데이터의 세트를 표지하고; (2) 감독 학습 알고리즘을 표지된 트레이닝 데이터에 적용함으로써, 반감독 학습 알고리즘을 트레이닝 데이터에 적용하도록 구성될 수 있다. 예로서, 모델 트레이닝 시스템(106)은: (1) 서열 분석 데이터 및 서열 분석 데이터에 대한 조립 알고리즘의 적용으로부터 생성된 어셈블리를 이용하여 기계 학습 모델에 대한 입력들을 생성하고; (2) 입력들을 표지하기 위해 비감독 학습 알고리즘을 생성된 입력들에 적용하고; (3) 감독 학습 알고리즘을 표지된 트레이닝 데이터에 적용할 수 있다.
일부 실시예들에서, 기계 학습 모델은 심층 학습 모델(예를 들어, 신경망)을 포함할 수 있다. 일부 실시예들에서, 심층 학습 모델은 컨볼루션 신경망(CNN)을 포함할 수 있다. 일부 실시예들에서, 심층 학습 모델은 순환 신경망(RNN), 다계층 퍼셉트론(multi-layer perceptron), 오토인코더(autoencoder) 및/또는 CTC-피팅된(fitted) 신경망 모델을 포함할 수 있다. 일부 실시예들에서, 기계 학습 모델은 클러스터링 모델을 포함할 수 있다. 예로서, 클러스터링 모델은 다수의 클러스터들을 포함할 수 있고, 클러스터들 각각은 생물학적 중합체(예를 들어, 뉴클레오티드들 또는 아미노산들)와 연관된다.
일부 실시예들에서, 모델 트레이닝 시스템(106)은 다수의 서열 분석 디바이스들 각각에 대해 별개의 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 개개의 서열 분석 디바이스에 대해 트레이닝된 기계 학습 모델은 서열 분석 디바이스의 고유 특성들에 맞춰질 수 있다. 예로서, 모델 트레이닝 시스템(106)은: (1) 제1 서열 분석 디바이스에 대해 제1 기계 학습 모델을 트레이닝하고; (2) 제2 서열 분석 디바이스에 대해 제2 기계 학습 모델을 트레이닝할 수 있다. 개개의 서열 분석 디바이스에 대해 트레이닝된 기계 학습 모델은 서열 분석 디바이스에 의해 생성된 서열 분석 데이터와 함께 이용하기 위해 최적화될 수 있다. 예를 들어, 기계 학습 모델은 서열 분석 디바이스에 의해 이용된 특정 서열 분석 기술(예를 들어, 3세대 서열 분석)에 대해 최적화될 수 있다.
일부 실시예들에서, 모델 트레이닝 시스템(106)은 이전에 트레이닝된 기계 학습 모델을 주기적으로 업데이트하도록 구성될 수 있다. 일부 실시예들에서, 모델 트레이닝 시스템(106)은 새로운 트레이닝 데이터를 이용하여 기계 학습 모델의 하나 이상의 파라미터의 값들을 업데이트함으로써 이전에 트레이닝된 모델을 업데이트하도록 구성될 수 있다. 일부 실시예들에서, 모델 트레이닝 시스템(106)은 이전에 획득된 트레이닝 데이터 및 새로운 트레이닝 데이터의 조합을 이용하여 새로운 기계 학습 모델을 트레이닝함으로써 기계 학습 모델을 업데이트하도록 구성될 수 있다.
일부 실시예들에서, 모델 트레이닝 시스템(106)은 상이한 타입들의 이벤트들 중 임의의 하나에 응답하여 기계 학습 모델을 업데이트하도록 구성될 수 있다. 예를 들어, 일부 실시예들에서, 모델 트레이닝 시스템(106)은 사용자 명령에 응답하여 기계 학습 모델을 업데이트하도록 구성될 수 있다. 예로서, 모델 트레이닝 시스템(106)은 사용자가 트레이닝 프로세스의 수행을 명령하게 할 수 있는 사용자 인터페이스를 제공할 수 있다. 일부 실시예들에서, 모델 트레이닝 시스템(106)은, 예를 들어, 소프트웨어 명령에 응답하여, 자동으로(즉, 사용자 명령에 응답하지 않고) 기계 학습 모델을 업데이트하도록 구성될 수 있다. 다른 예로서, 일부 실시예들에서, 모델 트레이닝 시스템(106)은 하나 이상의 조건을 검출하는 것에 응답하여 기계 학습 모델을 업데이트하도록 구성될 수 있다. 예를 들어, 모델 트레이닝 시스템(106)은 소정의 시간 기간의 만료를 검출하는 것에 응답하여 기계 학습 모델을 업데이트할 수 있다. 다른 예로서, 모델 트레이닝 시스템(106)은 새로운 트레이닝 데이터의 임계량(예를 들어, 서열들 및/또는 어셈블리들의 수)을 수신하는 것에 응답하여 기계 학습 모델을 업데이트할 수 있다.
도 1a에 도시된 예시적인 실시예에서, 모델 트레이닝 시스템(106)은 조립 시스템(104)으로부터 분리되지만, 일부 실시예들에서, 모델 트레이닝 시스템(106)은 조립 시스템(104)의 일부일 수 있다. 도 1a에 도시된 예시적인 실시예에서, 조립 시스템(104)은 서열 분석 디바이스(들)(102)로부터 분리되지만, 일부 실시예들에서, 조립 시스템(104)은 서열 분석 디바이스의 컴포넌트일 수 있다. 일부 실시예들에서, 서열 분석 디바이스(102), 모델 트레이닝 시스템(106), 및 조립 시스템(104)은 각각 단일 시스템의 컴포넌트들일 수 있다.
일부 실시예들에서, 데이터 저장소(108A)는 데이터를 저장하기 위한 시스템일 수 있다. 일부 실시예들에서, 데이터 저장소(108A)는 하나 이상의 컴퓨팅 디바이스(예를 들어, 서버)에 의해 호스팅된 하나 이상의 데이터베이스를 포함할 수 있다. 일부 실시예들에서, 데이터 저장소(108A)는 하나 이상의 물리적 저장 디바이스를 포함할 수 있다. 예로서, 물리적 저장 디바이스(들)는 하나 이상의 솔리드 스테이트 드라이브(solid state drive), 하드 디스크 드라이브, 플래시 드라이브, 및/또는 광학 드라이브를 포함할 수 있다. 일부 실시예들에서, 데이터 저장소(108A)는 데이터를 저장하는 하나 이상의 파일을 포함할 수 있다. 예로서, 데이터 저장소(108A)는 데이터를 저장하는 하나 이상의 텍스트 파일을 포함할 수 있다. 다른 예로서, 데이터 저장소(108A)는 하나 이상의 XML 파일을 포함할 수 있다. 일부 실시예들에서, 데이터 저장소(108A)는 컴퓨팅 디바이스의 저장소(예를 들어, 하드 드라이브)일 수 있다. 일부 실시예들에서, 데이터 저장소(108A)는 클라우드 저장 시스템일 수 있다.
일부 실시예들에서, 네트워크(111)는 무선 네트워크, 유선 네트워크, 또는 이들의 임의의 적절한 조합일 수 있다. 일례로서, 네트워크(111)는 인터넷과 같은 광역 네트워크(Wide Area Network)(WAN)일 수 있다. 일부 실시예들에서, 네트워크(111)는 근거리 네트워크(local area network)(LAN)일 수 있다. 근거리 네트워크는 서열 분석 디바이스(들)(102), 조립 시스템(104), 모델 트레이닝 시스템(106), 및 데이터 저장소(108A) 사이의 유선 및/또는 무선 접속들에 의해 형성될 수 있다. 일부 실시예들은 본 명세서에 설명된 임의의 특정 타입의 네트워크로 제한되지 않는다.
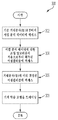
도 1b는 유전자 어셈블리를 생성하도록 구성될 때의 시스템(100)의 예를 도시한다. 유전자 어셈블리는 게놈 어셈블리 또는 유전자 서열일 수 있다. 예를 들어, 출력된 어셈블리(112)는 유전자 어셈블리일 수 있다. 서열 분석 디바이스(들)(102)는 뉴클레오티드 서열들을 생성하기 위해 핵산 샘플(110)을 서열 분석하도록 구성될 수 있다. 예로서, 서열 분석 디바이스(들)(102)는 유기체로부터 DNA 샘플을 서열 분석하여 뉴클레오티드 서열들을 생성할 수 있다. 서열 분석 디바이스(들)(102)에 의해 생성된 뉴클레오티드 서열들은 데이터 저장소(108B)에 저장될 수 있다. 조립 시스템(104)은 기계 학습 모델(104A)을 이용하여 유전자 어셈블리를 생성하도록 구성될 수 있다. 예로서, 조립 시스템(104)은: (1) 서열 분석 디바이스(들)(102)에 의해 생성된 뉴클레오티드 서열들에 조립 기술(예를 들어, OLC)을 적용함으로써 초기 유전자 어셈블리를 획득하고; (2) 기계 학습 모델(104A)을 이용하여 초기 유전자 어셈블리를 업데이트하여 유전자 어셈블리(112)를 획득할 수 있다.
도 1c는 단백질 서열을 생성하도록 구성될 때의 시스템(100)의 예를 도시한다. 예를 들어, 출력된 어셈블리(112)는 단백질 서열일 수 있다. 서열 분석 디바이스(들)(102)는 아미노산 서열들을 생성하기 위해 단백질 샘플(110)을 서열 분석하도록 구성될 수 있다. 예로서, 서열 분석 디바이스(들)(102)는 아미노산 서열들을 생성하기 위해 단백질로부터의 펩티드들을 서열 분석할 수 있다. 서열 분석 디바이스(들)(102)에 의해 생성된 아미노산 서열들은 데이터 저장소(108C)에 저장될 수 있다. 조립 시스템(104)은 기계 학습 모델(104A)을 이용하여 단백질 서열을 생성하도록 구성될 수 있다. 예로서, 단백질 서열 분석 시스템(104)은: (1) 서열 분석 디바이스(들)(102)에 의해 생성된 아미노산 서열들에 조립 알고리즘을 적용함으로써 단백질 서열을 획득하고; (2) 기계 학습 모델(104A)을 이용하여 단백질 서열을 업데이트하여 단백질 서열을 획득할 수 있다.
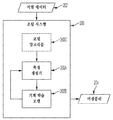
도 2a는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 어셈블리를 생성하기 위한 조립 시스템(200)을 도시한다. 조립 시스템(200)은 도 1a 내지 도 1c를 참조하여 전술한 조립 시스템(104)일 수 있다. 조립 시스템(200)은 서열 분석 데이터(202)를 이용하여 어셈블리(204)를 생성하도록 구성된 컴퓨팅 디바이스일 수 있다. 조립 시스템(200)은 특징 생성기(feature generator)(200A) 및 기계 학습 모델(200B)을 포함하는 다수의 컴포넌트들을 포함한다. 조립 시스템(200C)은 조립기(assembler)(200C)를 선택적으로 포함할 수 있다.
일부 실시예들에서, 특징 생성기(200A)는 기계 학습 모델에 입력으로서 제공될 수 있는 하나 이상의 특징의 값들을 결정하도록 구성될 수 있다. 특징 생성기(200A)는: (1) 서열 데이터(202); 및 (2) (예를 들어, 서열 데이터(202)에 대한 조립 알고리즘의 적용으로부터 획득된) 어셈블리로부터 특징(들)의 값들을 결정하도록 구성될 수 있다. 서열 데이터(202)는 어셈블리를 생성하기 위해 조립 알고리즘에 의해 이용되는 다수의 서열들을 포함할 수 있다. 일부 실시예들에서, 특징 생성기(200A)는 서열들 각각을 어셈블리와 비교함으로써 특징(들)의 값들을 결정하도록 구성될 수 있다. 일부 실시예들에서, 특징 생성기(200A)는 서열들을 어셈블리의 부분과 정렬하도록 구성될 수 있다. 예를 들어, 특징 생성기(200A)는 서열들을 어셈블리에서의 위치들의 세트와 정렬할 수 있고, 여기서, 어셈블리에서의 위치들의 세트에서의 생물학적 중합체 표시들은 정렬된 서열들로부터 결정된다. 특징 생성기(200A)는 정렬된 서열들을 어셈블리에서의 위치들의 세트에서 표시된 생물학적 중합체들(예를 들어, 뉴클레오티드들, 아미노산들)과 비교함으로써 특징(들)의 값들을 결정하도록 구성될 수 있다. 특징(들)의 값들을 결정하기 위한 예시적인 기술들이 도 4a 내지 도 4c를 참조하여 아래에 설명된다.
도 2a의 실시예에서 도시된 바와 같이, 특징 생성기(200A)는 기계 학습 모델(200B)에 제공될 입력을 생성하도록 구성될 수 있다. 일부 실시예들에서, 특징 생성기(200A)는 어셈블리에서 다수의 위치들 각각에 대한 입력을 생성하도록 구성될 수 있다. 일부 실시예들에서, 특징 생성기(200A)는 위치들을 선택하고, 선택된 위치들을 이용하여 입력을 생성하도록 구성될 수 있다. 일부 실시예들에서, 특징 생성기(200A)는 어셈블리가 그 위치들에서의 생물학적 중합체들을 부정확하게 표시할 가능성들을 결정하고, 결정된 가능성들을 이용하여 위치들을 선택함으로써, 위치들을 선택하도록 구성될 수 있다. 일부 실시예들에서, 특징 생성기(200A)는 어셈블리가 어셈블리에서 표시된 생물학적 중합체와 상이한 위치에서의 생물학적 중합체를 명시하는 위치와 정렬된 서열들의 수에 기초하여 위치에서의 생물학적 중합체를 부정확하게 표시할 가능성을 결정하도록 구성될 수 있다. 특징 생성기(200A)는 가능성이 임계 가능성을 초과하는 것으로 결정될 때 그 위치에 대한 입력을 생성하도록 구성될 수 있다.
일부 실시예들에서, 특징 생성기(200A)는: (1) 타겟 위치에서 식별된 생물학적 중합체; 및 (2) 타겟 위치의 이웃에서의 하나 이상의 다른 위치에서 식별된 생물학적 중합체를 이용하여, 어셈블리에서의 타겟 위치에 대한 기계 학습 모델(200B)에 제공될 입력을 생성하도록 구성될 수 있다. 일부 실시예들에서, 특징 생성기(200A)는 타겟 위치에서의 그리고 타겟 위치의 이웃에 있는 다른 위치(들)에서의 특징 값들을 결정하도록 구성될 수 있다. 이웃에서의 다른 위치(들)에서의 특징 값들은 기계 학습 모델(200A)에 컨텍스트 정보를 제공하여 타겟 위치에 대한 출력을 생성할 수 있다. 일부 실시예들에서, 이웃의 크기는 구성가능한 파라미터일 수 있다. 예를 들어, 이웃의 크기는 소프트웨어 애플리케이션에서의 사용자 입력에 의해 명시될 수 있다.
일부 실시예들에서, 특징 생성기(200A)는 타겟 위치의 이웃에서의 위치들에서 결정된 특징 값들을 포함하는 윈도우로서 입력을 생성하도록 구성될 수 있다. 타겟 위치의 이웃은 타겟 위치 및 타겟 위치의 윈도우에서의 하나 이상의 다른 위치를 포함할 수 있다. 일부 실시예들에서, 윈도우의 크기는 2개 위치, 3개 위치, 5개 위치, 10개 위치, 15개 위치, 20개 위치, 25개 위치, 30개 위치, 35개 위치, 40개 위치, 45개 위치, 또는 50개 위치일 수 있다. 일부 실시예들에서, 특징 생성기(200A)는 이웃 크기 60개 위치, 70개 위치, 80개 위치, 90개 위치, 또는 100개 위치를 이용하도록 구성될 수 있다. 일부 실시예들에서, 윈도우는 타겟 위치에 중심을 둘 수 있다.
일부 실시예들에서, 기계 학습 모델(200B)은 도 1a 내지 도 1c를 참조하여 전술한 기계 학습 모델(104A)일 수 있다. 도 1a의 실시예에서 도시된 바와 같이, 기계 학습 모델(200B)은 특징 생성기(200A)로부터 입력을 수신하도록 구성될 수 있다. 기계 학습 모델(200B)은 특징 생성기(200A)에 의해 제공된 개개의 입력에 대응하는 출력을 생성하도록 구성될 수 있다. 기계 학습 모델(200B)은 어셈블리에서의 위치들에서의 생물학적 중합체들(예를 들어, 뉴클레오티드들 또는 아미노산들)을 식별하기 위해 조립 시스템(200)에 의해 이용되는 출력을 생성하도록 구성될 수 있다. 일부 실시예들에서, 기계 학습 모델(200B)은 위치에 대해 다수의 생물학적 중합체들 각각이 위치에서 존재할 가능성들을 출력하도록 구성될 수 있다. 예로서, 기계 학습 모델(200B)은, 다수의 뉴클레오티드들 각각에 대해, 뉴클레오티드가 위치에서 존재할 확률을 출력할 수 있다. 다른 예로서, 기계 학습 모델(200B)은, 다수의 아미노산들 각각에 대해, 아미노산이 위치에서 존재할 확률을 출력할 수 있다. 일부 실시예들에서, 조립 시스템(200)은 어셈블리에서의 위치에서의 생물학적 중합체를, 기계 학습 모델(200B)의 출력에 의해 표시된 바와 같이 생물학적 중합체들의 위치에서 존재할 가장 큰 가능성을 갖는 생물학적 중합체인 것으로 식별하도록 구성될 수 있다. 예로서, 조립 시스템(200)은, 다수의 뉴클레오티드들 중에서, 위치에서 존재할 가장 큰 확률을 갖는 것을 선택할 수 있다. 다른 예로서, 조립 시스템(200)은, 다수의 아미노산들 중에서, 위치에서 존재할 가장 큰 확률을 갖는 것을 선택할 수 있다.
일부 실시예들에서, 조립 시스템(200)은 기계 학습 모델(200B)로부터 획득된 출력을 이용하여 출력 어셈블리(204)를 생성하도록 구성될 수 있다. 조립 시스템(200)은 기계 학습 모델(200B)로부터 획득된 출력으로부터 어셈블리에서의 위치들에서 식별된 생물학적 중합체들을 이용하여 어셈블리를 업데이트하도록 구성될 수 있다. 조립 시스템(200)은 어셈블리에서의 위치들에서의 식별된 생물학적 중합체들을 표시하도록 어셈블리를 업데이트하여 출력 어셈블리(204)를 획득하도록 구성될 수 있다. 일례로서, 어셈블리는 어셈블리에서의 제1 위치에서의 아데닌을, 그리고 어셈블리에서의 제2 위치에서의 구아닌을 표시할 수 있다. 이 예에서, 조립 시스템(200)은, (1) 기계 학습 모델(200B)로부터 획득된 출력을 이용하여, 제1 위치에서의 뉴클레오티드를 티민인 것으로, 제2 위치에서의 뉴클레오티드를 구아닌인 것으로 식별하고; (2) 티민을 표시하기 위해 어셈블리에서의 제1 위치를 업데이트하고, 출력 어셈블리(204)를 생성하기 위해 제2 위치에서 표시된 뉴클레오티드를 변경되지 않은 채로 남겨둘 수 있다. 상기의 예에 의해 예시된 바와 같이, 조립 시스템(200)은 다른 위치(들)에서의 생물학적 중합체 표시들을 변경되지 않은 채로 남겨두면서, 기계 학습 모델(200B)로부터 획득된 출력을 이용하여 어셈블리에서의 위치(들)에서의 생물학적 중합체 표시들을 수정할 수 있다. 예를 들어, 조립 시스템(200)은 어셈블리에서의 위치에서 식별된 생물학적 중합체가 어셈블리에서 표시된 생물학적 중합체와 매칭되는 것으로 결정하고, 위치에서의 표시를 업데이트된 어셈블리에서 변경되지 않은 채로 남겨둘 수 있다.
도 1a의 실시예에 도시된 바와 같이, 조립기(200C)는 어셈블리를 특징 생성기(200A)에 제공하도록 구성될 수 있다. 일부 실시예들에서, 조립기(200C)는 조립 알고리즘을 (예를 들어, 거대분자 샘플을 서열 분석하는 것으로부터 수신된) 서열 데이터(202)에 적용함으로써 특징 생성기(200A)에 제공될 어셈블리를 생성하도록 구성될 수 있다. 예로서, 조립기(200C)는 조립 알고리즘을 서열 데이터(202)에 포함된 뉴클레오티드 서열들에 적용하여 어셈블리를 생성하도록 구성될 수 있다. 이어서, 어셈블리를 특징 생성기(200A)에 제공하여 기계 학습 모델(200B)에 제공될 입력을 생성해서, 어셈블리에서의 위치들에서의 생물학적 중합체들을 식별하기 위한 출력을 획득할 수 있다. 조립기(200C)에 의해 생성된 어셈블리는 기계 학습 모델(200B)로부터 획득된 출력을 이용하여 조립 시스템(200)에 의해 업데이트되어 출력 어셈블리(204)를 생성할 수 있다.
일부 실시예들에서, 조립기(200C)는 중첩 레이아웃 컨센서스(OLC) 알고리즘을 서열 데이터(202)에 포함된 뉴클레오티드 서열들에 적용하여 어셈블리를 생성하도록 구성될 수 있다. 서열 분석 디바이스는 핵산(들)을 포함하는 생물학적 샘플의 다수의 카피들을 서열 분석할 수 있다. 그 결과, 서열 데이터(202)는, 어셈블리의 각각의 부분(예를 들어, 위치들의 세트)에 대해, 어셈블리의 부분에 정렬되는 다수의 서열들을 포함할 수 있다. 어셈블리에서의 위치를 커버하는 서열들의 평균 수는 서열들의 "커버리지(coverage)"로서 지칭될 수 있다. 조립기(200C)는: (1) 서열들의 중첩 영역들에 기초하여 중첩 그래프를 생성하고; (2) 중첩 그래프를 이용하여, 어셈블리의 개개의 부분들과 정렬되는 서열들("콘티그(contig)들"로서 또한 지칭됨)의 레이아웃을 생성하고; (3) 어셈블리의 부분에 정렬되는 서열들의 각각의 세트에 대해, 어셈블리의 부분을 생성하기 위해 세트에서의 서열들의 컨센서스를 취하는 것에 의해, 서열들에 OLC 알고리즘을 적용하도록 구성될 수 있다.
일부 실시예들에서, 조립기(200C)는 서열들의 쌍들을 비교함으로써 중첩 영역들을 갖는 서열들을 식별하여, 그들이 생물학적 중합체들(예를 들어, 뉴클레오티드들)의 하나 이상의 동일한 부서열들(subsequences)을 포함하는지를 결정하도록 구성될 수 있다. 일부 실시예들에서, 조립기(200C)는: (1) 적어도 임계 수(예를 들어, 3, 4, 5, 6, 8, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 200, 300, 400, 500)의 동일한 부서열(들)을 공유하는 서열들의 쌍들을 중첩하는 서열들인 것으로 식별하고; (2) 각각의 중첩 영역의 길이(즉, 뉴클레오티드들의 수)를 결정하고; (3) 중첩 영역들의 길이들 및 식별된 중첩 서열들에 기초하여 중첩 그래프를 생성하도록 구성될 수 있다. 중첩 그래프는 중첩하는 서열들의 개개의 쌍들을 접속하는 꼭지점들 및 에지들로서의 서열들을 포함할 수 있다. 결정된 길이들은 중첩 그래프에서 에지들의 표지들로서 이용될 수 있다.
일부 실시예들에서, 조립기(200C)는 중첩 그래프를 이용하여 서열들을 함께 연결함으로써 어셈블리의 개개의 부분들과 정렬된 서열들의 세트들의 레이아웃을 생성하도록 구성될 수 있다. 조립기(200C)는 서열들을 연결하기 위해 중첩 그래프를 통해 경로들을 찾도록 구성될 수 있다. 예로서, 조립기(200C)는 연결된 서열들을 획득하기 위해 뉴클레오티드들을 표현하는 영숫자 문자들의 세트를 연결할 수 있다. 일부 실시예들에서, 조립기(200C)는 연결된 서열들을 식별하기 위해 중첩 그래프에 그리디 알고리즘(greedy algorithm)을 적용할 수 있다. 예로서, 조립기(200C)는 가장 짧은 공통의 수퍼스트링(superstring)을 연결된 서열들로서 식별하기 위해 그리디 알고리즘을 적용할 수 있다.
일부 실시예들에서, 조립기(200C)는 레이아웃 서열들을 이용하여 어셈블리를 생성하도록 구성될 수 있다. 일부 실시예들에서, 조립기(200C)는 레이아웃 서열들의 다수의 세트들을 식별할 수 있으며, 여기서 각각의 세트는 어셈블리의 부분과 정렬된다. 조립기(200C)는 어셈블리의 부분과 정렬되는 레이아웃 서열들의 컨센서스를 취함으로써 어셈블리의 부분을 생성하도록 구성될 수 있다. 일부 실시예들에서, 조립기(200C)는 어셈블리의 부분에서의 위치에서의 생물학적 중합체(예를 들어, 뉴클레오티드)를 어셈블리의 부분에 정렬된 서열들의 대다수가 위치에 있는 생물학적 중합체인 것으로 결정함으로써 컨센서스를 취하도록 구성될 수 있다. 예로서, 조립기(200C)는 뉴클레오티드 서열들의 중첩 그래프를 생성하고, 어셈블리에서의 4개의 위치들의 세트에 대응하는 4개의 뉴클레오티드 서열들 "TAGA", "TAGA", "TAGT", "TAGA", 및 "TAGC"를 식별할 수 있다. 이 예에서, 조립기(200C)는 4개의 뉴클레오티드 서열들 전부가 처음 3개의 위치들을 "TAG"인 것으로 표시하고, 뉴클레오티드 서열들의 대부분은 네 번째 위치를 "A"인 것으로 표시하기 때문에, 4개의 뉴클레오티드 서열들 사이의 컨센서스는 "TAGA"인 것으로 결정할 수 있다.
일부 실시예들에서, 조립 시스템(200)은 기계 학습 기술들을 이용하여 OLC 알고리즘의 컨센서스 단계를 수행하도록 구성될 수 있다. 조립기(200C)가 어셈블리를 생성하기 위해 이용될 레이아웃을 생성한 경우, 시스템은 레이아웃 및 레이아웃으로부터 획득된 컨센서스 어셈블리를 이용하여 기계 학습 모델에 대한 입력을 생성하도록 구성될 수 있다. 일부 실시예들에서, 조립 시스템(200)은 출력 어셈블리(204)를 획득하기 위해 본 명세서에 설명된 기술들을 이용하여 컨센서스 어셈블리를 업데이트하도록 구성될 수 있다.
일부 실시예들에서, 조립기(200C)는 본 명세서에 의해 참고로 포함되는, 문헌(Genomics Volume 95, Issue 6, June 2010)에 발표된, "Assembly Algorithms for Next-Generation Sequencing Data"에 기술된 서열 데이터(202)에 알고리즘을 적용하도록 구성될 수 있다. 일부 실시예들에서, 조립기(200C)는 OLC 알고리즘 이외의 조립 알고리즘을 서열 데이터(202)에 적용하여 어셈블리를 생성하도록 구성될 수 있다. 일부 실시예들에서, 조립기(200C)는 서열 데이터(202)에 DBG(de Bruijn graph) 어셈블리를 적용하도록 구성될 수 있다. 일부 실시예들은 특정 타입의 조립 알고리즘으로 제한되지 않는다. 일부 실시예들에서, 조립기(200C)는 서열 데이터(202)를 이용하여 어셈블리를 생성하도록 구성된 소프트웨어 애플리케이션을 포함할 수 있다. 예로서, 시스템은 HGAP, Falcon, Canu, Hinge, Miniasm, 또는 Flye 조립기를 포함할 수 있다. 다른 예로서, 시스템은 SPAdes, Ray, ABySS, ALLPATHS-LG, 또는 Trinity 어셈블리 애플리케이션을 포함할 수 있다. 일부 실시예들은 특정 조립기로 제한되지 않는다.
도 2a에서 파선에 의해 표시된 바와 같이, 일부 실시예들에서, 조립기(200C)는 조립 시스템에 포함되지 않을 수 있다. 조립 시스템(200)은 별도의 시스템으로부터 어셈블리를 수신하고, 수신된 어셈블리를 업데이트하여 출력 어셈블리(204)를 생성하도록 구성될 수 있다. 예로서, 별도의 컴퓨팅 디바이스는 조립 알고리즘(예를 들어, OLC)을 서열 데이터(202)에 적용하여 어셈블리를 생성하고, 생성된 어셈블리를 조립 시스템(200)에 송신할 수 있다.
도 2b는 조립 시스템(200)이, 기계 학습 모델(200B)로부터 특징 생성기(200A)로의 피드백 화살표에 의해 표시된 바와 같이, 어셈블리에 대한 다수의 업데이트 반복들을 수행하도록 구성되는, 도 2a를 참조하여 전술한 조립 시스템(200)의 실시예를 도시한다. 일부 실시예들에서, 조립 시스템(200)은 제1 업데이트된 어셈블리를 획득한 후에 기계 학습 모델(200B)에 입력으로서 제공될 수 있는 하나 이상의 특징의 값들을 결정하도록 구성될 수 있다. 특징 생성기(200A)는: (1) 서열 데이터(202); 및 (2) 서열 데이터(202)에 대한 조립 알고리즘의 적용으로부터 획득된 초기 어셈블리를 업데이트하는 것으로부터 획득된 제1 업데이트된 어셈블리로부터 특징(들)의 값들을 결정하도록 구성될 수 있다. 특징 생성기(200A)는 특징(들)의 결정된 값들을 기계 학습 모델(200B)에 입력으로서 제공하여 출력을 획득하도록 구성될 수 있다. 조립 시스템(200)은 기계 학습 모델(200B)로부터의 출력을 이용하여: (1) 제1 업데이트된 어셈블리에서의 개개의 위치들에서의 생물학적 중합체들을 식별하고; (2) 개개의 위치들에서의 식별된 생물학적 중합체를 표시하도록 제1 업데이트된 어셈블리를 업데이트하여 제2 업데이트된 어셈블리를 획득하도록 구성될 수 있다. 제2 업데이트된 어셈블리는 조립 시스템(200)에 의해 출력된 어셈블리(204)일 수 있다.
일부 실시예들에서, 조립 시스템(200)은 조건이 충족될 때까지 업데이트 반복들을 수행하도록 구성될 수 있다. 일부 실시예들에서, 조립 시스템(104)은 임계 수의 반복들이 수행되었다고 시스템이 결정할 때까지 업데이트 반복들을 수행하도록 구성될 수 있다. 일부 실시예들에서, 임계 수의 반복들은 사용자 입력(예를 들어, 소프트웨어 명령, 또는 하드 코딩된 값)에 의해 설정될 수 있다. 일부 실시예들에서, 조립 시스템(104)은 임계 수의 반복들을 결정하도록 구성될 수 있다. 예로서, 조립 시스템(200)은 초기 어셈블리를 획득하기 위해 이용된 조립 기술의 타입에 기초하여 임계 수의 업데이트 반복들을 결정할 수 있다. 일부 실시예들에서, 조립 시스템(200)은 명시된 중지 기준이 만족되었을 때까지 어셈블리를 반복적으로 업데이트하도록 구성될 수 있다. 예로서, 조립 시스템(200)은: (1) 최신의 업데이트 반복으로부터 획득된 현재 어셈블리와 이전의 어셈블리 사이의 차이들의 수를 결정하고; (2) 차이들의 수가 임계 수의 차이들보다 작을 때 및/또는 차이들의 백분율이 임계 백분율보다 작을 때, 어셈블리를 반복적으로 업데이트하는 것을 중지하도록 결정할 수 있다.
도 2c는 조립 시스템(200)이, 특징 생성기(200A)로부터 기계 학습 모델(200B)로의 다수의 화살표들에 의해 표시된 바와 같이, 어셈블리의 다수의 위치들을 병렬로 정정하도록 구성되는, 도 2a를 참조하여 전술한 조립 시스템(200)의 실시예를 도시한다. 도 2a를 참조하여 설명된 바와 같이, 일부 실시예들에서, 특징 생성기(200A)는 다수의 위치들 각각에 대한 기계 학습 모델(200B)에 제공될 입력을 생성하도록 구성될 수 있다. 도 2c의 실시예에서, 조립 시스템(200)은 어셈블리의 다수의 위치들을 병렬로 업데이트하도록 구성될 수 있다. 조립 시스템(200)은: (1) 어셈블리에서의 제1 위치를 업데이트하고; (2) 어셈블리에서의 제1 위치의 업데이트를 완료하기 전에, 어셈블리에서의 제2 위치를 업데이트하기 시작하도록 구성될 수 있다. 일부 실시예들에서, 조립 시스템(200)은 다수의 개개의 위치들을 위해 생성된 다수의 입력들을 기계 학습 모델(200B)에 병렬로 생성 및/또는 제공함으로써 다수의 위치들을 병렬로 업데이트하도록 구성될 수 있다. 예로서, 특징 생성기(200A)는: (1) 제1 위치에 대한 제1 입력을 기계 학습 모델(200B)에 생성 및/또는 제공하고; (2) 제1 입력에 대응하는 기계 학습 모델(200B)로부터의 출력을 획득하기 전에, 제2 위치에 대한 제2 입력을 기계 학습 모델(200B)에 생성 및/또는 제공할 수 있다.
일부 실시예들에서, 도 2c의 조립 시스템(200)은 어셈블리의 다수의 위치들을 병렬로 업데이트하도록 구성된 다수의 프로세서들을 포함하는 컴퓨팅 디바이스일 수 있다. 일부 실시예들에서, 조립 시스템(200)은, 애플리케이션의 각각의 스레드(thread)가 하나 이상의 다른 스레드와 병렬로 어셈블리에서의 개개의 위치를 업데이트하도록 구성되는 멀티 스레드 애플리케이션을 이용하도록 구성될 수 있다.
도 2d는 도 2a를 참조하여 전술한 조립 시스템(200)의 실시예를 도시하며, 여기서 조립 시스템(200)은: (1) 기계 학습 모델(200B)로부터 특징 생성기(200A)로의 화살표에 의해 표시된 바와 같이, 다수의 업데이트 반복들을 수행하고; (2) 특징 생성기(200A)로부터 기계 학습 모델(200B)로의 다수의 화살표들에 의해 표시된 바와 같이, 어셈블리의 다수의 위치들을 병렬로 정정하도록 구성된다. 일부 실시예들에서, 조립 시스템(200)은 도 2b를 참조하여 전술한 바와 같이 다수의 업데이트 반복들을 수행하고, 각각의 업데이트 사이클 동안, 도 2c를 참조하여 전술한 바와 같이 어셈블리에서의 다수의 위치들을 병렬로 업데이트하도록 구성될 수 있다.
도 3a는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 생물학적 중합체 어셈블리를 생성하기 위한 기계 학습 모델을 트레이닝하기 위한 예시적인 프로세스(300)를 도시한다. 프로세스(300)는 임의의 적절한 컴퓨팅 디바이스(들)에 의해 수행될 수 있다. 예로서, 프로세스(300)는 도 1a 내지 도 1c를 참조하여 설명된 모델 트레이닝 시스템(106)에 의해 수행될 수 있다. 프로세스(300)는 본 명세서에 설명된 기계 학습 모델들을 트레이닝하기 위해 수행될 수 있다. 예로서, 프로세스(300)는 도 6을 참조하여 설명된 컨볼루션 신경망(CNN)(600)과 같은 심층 학습 모델을 트레이닝하기 위해 수행될 수 있다.
일부 실시예들에서, 기계 학습 모델은 심층 학습 모델일 수 있다. 일부 실시예들에서, 심층 학습 모델은 신경망일 수 있다. 예로서, 기계 학습 모델은 어셈블리에서의 위치들에서의 생물학적 중합체들(예를 들어, 뉴클레오티드들, 아미노산들)을 식별하는데 이용하기 위한 출력을 생성하는 컨볼루션 신경망(CNN)일 수 있다. 다른 예로서, 기계 학습 모델은 CTC-피팅된 신경망일 수 있다. 일부 실시예들에서, 심층 학습 모델의 부분들은 개별적으로 트레이닝될 수 있다. 예로서, 심층 학습 모델은 입력 데이터를 하나 이상의 특징의 값들로 인코딩하는 제1 부분, 및 하나 이상의 생물학적 중합체를 식별하는 출력을 생성하기 위해 입력으로서 특징(들)의 값들을 수신하는 제2 부분을 가질 수 있다.
일부 실시예들에서, 기계 학습 모델은 클러스터링 모델일 수 있다. 일부 실시예들에서, 모델의 각각의 클러스터는 생물학적 중합체와 연관될 수 있다. 예시적인 예로서, 클러스터링 모델은 5개의 클러스터를 포함할 수 있으며, 각각의 클러스터는 개개의 뉴클레오티드와 연관된다. 예를 들어, 제1 클러스터는 아데닌과 연관될 수 있고; 제2 클러스터는 시토신과 연관될 수 있고; 제3 클러스터는 구아닌과 연관될 수 있고; 제4 클러스터는 티민과 연관될 수 있고; 제5 클러스터는 (예를 들어, 어셈블리에서의 위치에서) 어떠한 뉴클레오티드도 존재하지 않음을 표시할 수 있다. 예시의 목적들을 위해 예시적인 수들의 클러스터들 및 연관된 생물학적 중합체들이 본 명세서에서 설명된다.
프로세스(300)는, 프로세스(300)를 실행하는 시스템이 하나 이상의 기준 거대분자(예를 들어, DNA, RNA, 또는 단백질)를 서열 분석하는 것으로부터의 서열 분석 데이터에 액세스하는 블록 302에서 시작한다. 일부 실시예들에서, 시스템은 데이터베이스로부터의 기준 거대분자들을 서열 분석하는 것으로부터의 서열 분석 데이터에 액세스하도록 구성될 수 있다. 예로서, 시스템은 ONG 데이터베이스로부터의 박테리아의 서열 분석으로부터 획득된 서열 분석 데이터에 액세스할 수 있다. 서열 분석 데이터는 거대분자의 하나 이상의 샘플을 서열 분석하는 것으로부터 획득될 수 있다. 예로서, 서열 분석 데이터는 효모(yeast)의 종(species)인 사카로마이세스 세레비시아에(Saccharomyces cerevisiae)의 생물학적 샘플들로부터 획득될 수 있다. 다른 예로서, 서열 분석 데이터는 단백질의 펩티드 샘플들을 서열 분석하는 것으로부터 획득될 수 있다. 일부 실시예들에서, 서열 분석 데이터는 핵산(예를 들어, DNA, RNA)을 포함하는 생물학적 샘플들을 서열 분석하는 것으로부터 획득된 뉴클레오티드 서열들을 포함할 수 있다. 일부 실시예들에서, 서열 분석 데이터는 단백질 샘플들(예를 들어, 단백질로부터의 펩티드들)을 서열 분석하는 것으로부터 획득된 아미노산 서열들을 포함할 수 있다.
일부 실시예들에서, 시스템은, 기계 학습 모델이 타겟 서열 분석 기술에 의해 생성된 데이터를 서열 분석하는 것으로부터 생성된 어셈블리들의 정확도를 개선시키게 트레이닝될 수 있도록, 타겟 서열 분석 기술로부터의 서열 분석 데이터에 액세스하도록 구성될 수 있다. 기계 학습 모델은 타겟 서열 분석 기술의 에러 프로파일에 대해 트레이닝되어, 기계 학습 모델이 타겟 서열 분석 기술의 에러들 특성을 정정하도록 최적화될 수 있게 한다. 일부 실시예들에서, 시스템은 3세대 서열 분석으로부터 획득된 데이터에 액세스하도록 구성될 수 있다. 일부 실시예들에서, 3세대 서열 분석은 단일 분자 실시간 서열 분석일 수 있다. 예로서, 시스템은 뉴클레오티드들과 연관된 발광 분자들에 의한 광 방출들을 검출함으로써 핵산 샘플들을 서열 분석하는 시스템으로부터 획득된 데이터에 액세스할 수 있다. 다른 예로서, 시스템은 아미노산들과 선택적으로 상호작용하는 시약들과 연관된 발광 분자들에 의한 광 방출들을 검출함으로써 펩티드들을 서열 분석하는 시스템으로부터 획득된 데이터에 액세스할 수 있다. 일부 실시예들에서, 시스템은 2세대 서열 분석으로부터 획득된 데이터에 액세스하도록 구성될 수 있다. 예로서, 시스템은 생어(Sanger) 서열 분석, 맥삼-길버트(Maxam-Gilbert) 서열 분석, 샷건(shotgun) 서열 분석, 파이로시퀀싱(pyrosequencing), 조합 프로브 앵커 합성(combinatorial probe anchor synthesis), 또는 라이게이션(ligation)에 의한 서열 분석으로부터 획득된 서열 분석 데이터에 액세스할 수 있다. 일부 실시예들에서, 시스템은 신생(de novo) 펩티드 서열 분석으로부터 획득된 데이터에 액세스하도록 구성될 수 있다. 예로서, 시스템은 탠덤 질량 분석법(tandem mass spectrometry)으로부터 획득된 아미노산 서열들에 액세스할 수 있다. 일부 실시예들은 특정 타겟 서열 분석 기술로 제한되지 않는다.
다음, 프로세스(300)는 시스템이 블록 302에서 획득된 서열 분석 데이터의 적어도 부분으로부터 생성된 어셈블리들에 액세스하는 블록 304로 진행한다. 일부 실시예들에서, 시스템은 서열 분석 데이터에 대한 조립 알고리즘(예를 들어, OLC 조립, DBG 조립)의 적용으로부터 획득된 어셈블리들에 액세스하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 조립 알고리즘을 서열 분석 데이터에 적용함으로써 어셈블리들에 액세스하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 서열 분석 데이터에 대한 하나 이상의 조립 알고리즘의 적용으로부터 생성된 미리 결정된 어셈블리들에 액세스하도록 구성될 수 있다. 예로서, 어셈블리들은 별도의 컴퓨팅 디바이스에 의해 이전에 수행되어 데이터베이스에 저장될 수 있다. 예를 들어, 서열 분석 데이터가 획득되게 하는 데이터베이스는 또한, 서열 분석 데이터에 대한 하나 이상의 조립 알고리즘의 적용으로부터 생성된 어셈블리들을 저장할 수 있다.
일부 실시예들에서, 시스템은 타겟 조립 기술로부터 생성된 어셈블리들에 액세스하도록 구성될 수 있고, 따라서 기계 학습 모델은 타겟 조립 기술에 특징적인 에러들을 정정하도록 트레이닝될 수 있다. 기계 학습 모델은 타겟 조립 기술의 에러 프로파일에 대해 트레이닝될 수 있고, 따라서 기계 학습 모델은 타겟 조립 기술에 특징적인 에러들을 정정하도록 최적화될 수 있다. 일부 실시예들에서, 시스템은 특정 조립 알고리즘 및/또는 소프트웨어 애플리케이션에 의해 생성된 어셈블리들에 액세스하도록 구성될 수 있다. 예로서, 시스템은 Canu, Miniasm, 또는 Flye 조립기에 의해 생성된 어셈블리들에 액세스할 수 있다. 일부 실시예들에서, 시스템은 조립기들의 클래스로부터 생성된 어셈블리들에 액세스하도록 구성될 수 있다. 예로서, 시스템은 그리디 알고리즘 조립기들 또는 그래프 방법 조립기들로부터 생성된 어셈블리들에 액세스할 수 있다. 일부 실시예들은 특정 조립 기술로 제한되지 않는다.
다음, 프로세스(300)는 시스템이 기준 거대분자(들)의 하나 이상의 미리 결정된 어셈블리에 액세스하는 블록 306으로 진행한다. 일부 실시예들에서, 기준 거대분자(들)의 미리 결정된 어셈블리들은 개개의 거대분자(들)에 대한 진정한(true) 또는 정확한(correct) 어셈블리들을 나타낼 수 있다. 그와 같이, 시스템은 트레이닝 데이터를 표지하기 위해 기준 거대분자(들)의 미리 결정된 어셈블리들을 이용하도록 구성될 수 있다. 예로서, 시스템은 NCBI 데이터베이스로부터 유기체의 DNA의 기준 게놈(reference genome)에 액세스할 수 있다. 이 예에서, 시스템은 게놈 어셈블리에서의 뉴클레오티드들을 식별하기 위해 기계 학습 모델을 트레이닝하도록 감독 학습을 수행하는데 이용하기 위한 표지들을 결정하기 위해 기준 게놈을 이용할 수 있다. 다른 예로서, 시스템은 UnitProt 데이터베이스로부터의 단백질의 기준 단백질 서열에 액세스할 수 있고, 기준 단백질 서열을 이용하여, 단백질 서열에서의 아미노산들을 식별하기 위해 기계 학습 모델을 트레이닝하도록 감독 학습을 수행하는데 이용하기 위한 표지를 결정할 수 있다.
다음, 프로세스(300)는 시스템이 블록들 302 내지 308에서 액세스된 데이터를 이용하여 기계 학습 모델을 트레이닝하는 블록 308로 진행한다. 일부 실시예들에서, 시스템은: (1) 블록 302에서 액세스된 서열 분석 데이터 및 블록 304에서 액세스된 어셈블리들을 이용하여 기계 학습 모델에 대한 입력들을 생성하고; (2) 블록 306에서 액세스된 미리 결정된 어셈블리들을 이용하여 생성된 입력들을 표지하고; (3) 감독 학습 알고리즘을 표지된 트레이닝 데이터에 적용하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 서열 분석 데이터를 이용하여 하나 이상의 특징의 값들을 생성함으로써 기계 학습 모델에 대한 입력들을 생성하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 어셈블리에서의 각각의 위치에 대한 특징(들)의 값들을 결정하도록 구성될 수 있다. 예로서, 시스템은: (1) 개개의 뉴클레오티드들에 대한 카운트들을 결정―각각의 카운트는 뉴클레오티드가 위치에서 존재하는 것을 표시하는 뉴클레오티드 서열들의 수를 표시함―하고; (2) 카운트들 이용하여 특징(들)의 값들을 결정함으로써, 위치에 대한 특징들의 값들을 결정할 수 있다. 입력들을 생성하고 입력들을 표지하기 위한 예시적인 기술들이 도 4a 내지 도 4c를 참조하여 본 명세서에 설명된다.
일부 실시예들에서, 시스템은 표지된 트레이닝 데이터를 이용하여 심층 학습 모델을 트레이닝하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 표지된 트레이닝 데이터를 이용하여 결정 트리 모델(decision tree model)을 트레이닝하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 표지된 트레이닝 데이터를 이용하여 지원 벡터 기계(SVM)를 트레이닝하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 표지된 트레이닝 데이터를 이용하여 NBC(Naive Bayes classifier)를 트레이닝하도록 구성될 수 있다.
일부 실시예들에서, 시스템은 확률적 기울기 하강을 이용함으로써 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 시스템은 트레이닝된 기계 학습 모델을 획득하기 위해 목적 함수(objective function)를 최적화하기 위해 기계 학습 모델의 파라미터들에 대한 변경들을 반복적으로 행할 수 있다. 예를 들어, 시스템은 컨볼루션 네트워크의 필터들 및/또는 신경망의 가중치들을 트레이닝하기 위해 확률적 기울기 하강을 이용할 수 있다.
일부 실시예들에서, 시스템은 표지된 트레이닝 데이터를 이용하여 감독 트레이닝을 수행하도록 구성될 수 있다. 일부 실시예들에서, 시스템은: (1) 대응하는 출력을 획득하기 위해 기계 학습 모델에 생성된 입력들을 제공하고; (2) 출력들을 이용하여 어셈블리에서의 위치들에서 존재하는 생물학적 중합체들을 식별하고; (3) 기준 어셈블리들에서의 위치들에서 표시된 생물학적 중합체들과 식별된 생물학적 중합체들 사이의 차이에 기초하여 기계 학습 모델을 트레이닝함으로써, 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 기준 어셈블리에서의 위치에서 표시된 생물학적 중합체는 개개의 입력에 대한 표지일 수 있다. 차이는 기계 학습 모델이 그의 현재 파라미터들의 세트로 구성될 때 표지를 재생(reproducing)하는데 얼마나 잘 수행되는지에 대한 척도(measure)를 제공할 수 있다. 예로서, 기계 학습 모델의 파라미터들은 확률적 기울기 하강 및/또는 모델을 트레이닝하기에 적합한 임의의 다른 반복적 최적화 기술을 이용하여 업데이트될 수 있다. 예로서, 시스템은 결정된 차이에 기초하여 모델의 하나 이상의 파라미터를 업데이트하도록 구성될 수 있다.
일부 실시예들에서, 시스템은 비감독 트레이닝 알고리즘들을 표지되지 않은 트레이닝 데이터의 세트에 적용할 수 있다. 도 3a의 실시예는 블록 306에서 기준 거대분자들의 미리 결정된 어셈블리들에 액세스하는 것을 포함하지만, 일부 실시예들에서, 시스템은 미리 결정된 어셈블리들에 액세스하지 않고 트레이닝을 수행하도록 구성될 수 있다. 이들 실시예들에서, 시스템은 기계 학습 모델을 트레이닝하기 위해 비감독 트레이닝 알고리즘을 트레이닝 데이터에 적용하도록 구성될 수 있다. 시스템은: (1) 서열 분석 데이터 및 서열 분석 데이터로부터 생성된 어셈블리들을 이용하여 모델에 대한 입력들을 생성하고; (2) 비감독 트레이닝 알고리즘을 생성된 입력들에 적용함으로써, 모델을 트레이닝하도록 구성될 수 있다. 일부 실시예들에서, 기계 학습 모델은 클러스터링 모델일 수 있고, 시스템은 비감독 학습 알고리즘을 트레이닝 데이터에 적용함으로써 클러스터링 모델의 클러스터들을 식별하도록 구성될 수 있다. 각각의 클러스터는 생물학적 중합체(예를 들어, 뉴클레오티드 또는 아미노산)와 연관될 수 있다. 예로서, 시스템은 트레이닝 데이터를 이용하여 클러스터들(예를 들어, 클러스터 중심들)을 식별하기 위해 k-평균 클러스터링을 수행할 수 있다.
일부 실시예들에서, 시스템은 반감독 학습 알고리즘을 트레이닝 데이터에 적용하도록 구성될 수 있다. 시스템은: (1) 비감독 학습 알고리즘(예를 들어, 클러스터링)을 트레이닝 데이터에 적용함으로써 표지되지 않은 트레이닝 데이터의 세트를 표지하고; (2) 감독 학습 알고리즘을 표지된 트레이닝 데이터에 적용할 수 있다. 예로서, 시스템은 k-평균 클러스터링을 서열 분석 데이터 및 서열 분석 데이터로부터 획득된 어셈블리들로부터 생성된 입력들에 적용하여 입력들을 클러스터링할 수 있다. 시스템은 이어서 각각의 입력을 클러스터 멤버쉽에 기초한 분류로 표지할 수 있다. 시스템은 이어서 확률적 기울기 하강 알고리즘 및/또는 임의의 다른 반복적 최적화 기술을 표지된 데이터에 적용함으로써 기계 학습 모델을 트레이닝할 수 있다.
블록 308에서 기계 학습 모델을 트레이닝한 후에, 프로세스(300)가 종료된다. 일부 실시예들에서, 시스템은 트레이닝된 기계 학습 모델을 저장하도록 구성될 수 있다. 시스템은 기계 학습 모델의 하나 이상의 트레이닝된 파라미터의 값(들)을 저장할 수 있다. 예로서, 기계 학습 모델은 하나 이상의 신경망을 포함할 수 있고, 시스템은 신경망(들)의 트레이닝된 가중치들의 값들을 저장할 수 있다. 다른 예로서, 기계 학습 모델은 컨볼루션 신경망을 포함하고, 시스템은 컨볼루션 신경망의 하나 이상의 트레이닝된 필터를 저장할 수 있다. 일부 실시예들에서, 시스템은 어셈블리(예를 들어, 게놈 어셈블리, 단백질 서열, 또는 그것의 부분)를 생성하는데 이용하기 위해 트레이닝된 기계 학습 모델을 (예를 들어, 조립 시스템(104)에서) 저장하도록 구성될 수 있다.
일부 실시예들에서, 시스템은 새로운 트레이닝 데이터를 이용하여 기계 학습 모델을 업데이트하기 위해 새로운 데이터를 획득하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 새로운 트레이닝 데이터를 이용하여 새로운 기계 학습 모델을 트레이닝함으로써 기계 학습 모델을 업데이트하도록 구성될 수 있다. 예로서, 시스템은 새로운 트레이닝 데이터를 이용하여 새로운 기계 학습 모델을 트레이닝할 수 있다. 일부 실시예들에서, 시스템은 기계 학습 모델의 하나 이상의 파라미터를 업데이트하기 위해 새로운 트레이닝 데이터를 이용하여 기계 학습 모델을 재트레이닝함으로써 기계 학습 모델을 업데이트하도록 구성될 수 있다. 예로서, 모델에 의해 생성된 출력(들) 및 대응하는 입력 데이터는 이전에 획득된 트레이닝 데이터와 함께 트레이닝 데이터로서 이용될 수 있다. 일부 실시예들에서, 시스템은 (예를 들어, 도 3b를 참조하여 후술되는 프로세스(310)를 수행하는 것으로부터 획득된) 아미노산들을 식별하는 데이터 및 출력들을 이용하여 트레이닝된 기계 학습 모델을 반복적으로 업데이트하도록 구성될 수 있다. 예로서, 시스템은 입력 데이터를 제1 트레이닝된 기계 학습 모델(예를 들어, 교사 모델(teacher model))에 제공하고, 하나 이상의 아미노산을 식별하는 출력을 획득하도록 구성될 수 있다. 그 다음, 시스템은 입력 데이터 및 대응하는 출력을 이용하여 기계 학습 모델을 재트레이닝하여 제2 트레이닝된 기계 학습 모델(예를 들어, 학생 모델(student model))을 획득할 수 있다.
일부 실시예들에서, 시스템은 다수의 서열 분석 기술들 각각에 대해 별개의 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 기계 학습 모델은 서열 분석 기술로부터 획득된 데이터를 이용하여 개개의 서열 분석 기술에 대해 트레이닝될 수 있다. 기계 학습 모델은 서열 분석 기술의 에러 프로파일에 대해 조정될 수 있다. 일부 실시예들에서, 시스템은 다수의 조립 기술들 각각에 대해 별도의 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 조립 기술로부터 획득된 어셈블리들을 이용하여 개개의 조립 기술에 대해 기계 학습 모델이 트레이닝될 수 있다. 기계 학습 모델은 조립 기술의 에러 프로파일에 대해 조정될 수 있다.
일부 실시예들에서, 시스템은 다수의 서열 분석 기술들에 이용될 일반화된 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 일반화된 기계 학습 모델은 다수의 서열 분석 기술들로부터 집계된 데이터를 이용하여 트레이닝될 수 있다. 일부 실시예들에서, 시스템은 다수의 조립 기술들에 이용될 일반화된 기계 학습 모델을 트레이닝하도록 구성될 수 있다. 일반화된 기계 학습 모델은 다수의 조립 기술들을 이용하여 생성된 어셈블리들을 이용하여 트레이닝될 수 있다.
도 3b는 본 명세서에 설명된 기술의 일부 실시예에 따른, 어셈블리(예를 들어, 게놈 어셈블리, 유전자 서열, 단백질 서열, 또는 그것의 부분)를 생성하기 위해 프로세스(300)로부터 획득된 트레이닝된 기계 학습 모델을 이용하기 위한 예시적인 프로세스(310)를 도시한다. 프로세스(310)는 임의의 적절한 컴퓨팅 디바이스에 의해 수행될 수 있다. 예로서, 프로세스(310)는 도 1a 내지 도 1c를 참조하여 전술한 조립 시스템(104)에 의해 수행될 수 있다.
프로세스(310)는 시스템이 어셈블리를 생성하기 위해 서열 분석 데이터에 대해 조립 알고리즘(예를 들어, OLC 조립 또는 DBG 조립)을 수행하는 블록 312에서 시작한다. 예로서, 시스템은 DNA 샘플의 서열 분석으로부터 생성된 뉴클레오티드 서열들에 조립 알고리즘을 적용할 수 있다. 다른 예로서, 시스템은 단백질로부터의 펩티드 샘플의 서열 분석으로부터 생성된 아미노산 서열들에 조립 알고리즘을 적용할 수 있다. 시스템은 도 2a 내지 도 2d의 조립기(200C)를 참조하여 전술한 바와 같이 조립 알고리즘을 적용할 수 있다. 일부 실시예들에서, 시스템은 조립 애플리케이션을 포함할 수 있다. 시스템은 조립 애플리케이션을 실행함으로써 어셈블리를 생성하도록 구성될 수 있다. 조립 애플리케이션들의 예들이 본 명세서에 설명된다.
블록 312 주위에 파선들로 도시된 바와 같이, 일부 실시예들에서, 시스템은 조립 알고리즘을 수행하지 않을 수 있다. 시스템은 별도의 시스템(예를 들어, 별도의 컴퓨팅 디바이스)에 의해 생성된 어셈블리를 획득하고, 획득된 어셈블리를 업데이트하기 위해 블록들 314 내지 322의 단계들을 수행할 수 있다.
다음, 프로세스(310)는 시스템이 서열 분석 데이터 및 어셈블리에 액세스하는 블록 312로 진행한다. 일부 실시예들에서, 시스템은 (예를 들어, 블록 312에서) 시스템에 의해 생성된 어셈블리에 액세스하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 별도의 시스템에 의해 생성된 어셈블리에 액세스하도록 구성될 수 있다. 예로서, 시스템은 시스템으로부터 분리된 컴퓨팅 디바이스 상에서 실행되는 소프트웨어 애플리케이션에 의해 생성된 어셈블리를 수신할 수 있다. 일부 실시예들에서, 시스템은 프로세스(300)에서 트레이닝된 기계 학습 모델이 (예를 들어, 에러를 정정하기 위해) 업데이트하도록 최적화된 타겟 조립 기술(예를 들어, 알고리즘 및/또는 소프트웨어 애플리케이션)로부터 생성된 서열 분석 데이터에 액세스하도록 구성될 수 있다. 예로서, 기계 학습 모델은 Canu 조립 애플리케이션으로부터 생성된 어셈블리들에 대해 트레이닝될 수 있고, 시스템은 Canu 조립 애플리케이션에 의해 생성된 어셈블리에 액세스할 수 있다.
일부 실시예들에서, 시스템은 액세스된 어셈블리를 생성하기 위해 이용된 생물학적 중합체 서열들을 포함하는 서열 분석 데이터에 액세스하도록 구성될 수 있다. 예로서, 액세스된 서열 분석 데이터는 게놈 어셈블리 또는 유전자 서열을 생성하기 위해 조립 알고리즘이 적용된 뉴클레오티드 서열들을 포함할 수 있다. 다른 예로서, 액세스된 서열 분석 데이터는 단백질 서열을 생성하기 위해 조립 알고리즘이 적용된 아미노산 서열들을 포함할 수 있다. 일부 실시예들에서, 시스템은 프로세스(300)에서 트레이닝된 기계 학습 모델이 업데이트되도록 최적화된 타겟 서열 분석 기술로부터 생성된 서열 분석 데이터에 액세스하도록 구성될 수 있다. 예로서, 기계 학습 모델은 3세대 서열 분석으로부터 생성된 서열 분석 데이터에 대해 트레이닝될 수 있고, 시스템은 3세대 서열 분석으로부터 생성된 서열 분석 데이터에 액세스할 수 있다.
다음, 프로세스(310)는 시스템이 서열 분석 데이터 및 어셈블리를 이용하여 기계 학습 모델에 제공될 입력을 생성하는 블록 316으로 진행한다. 일부 실시예들에서, 시스템은 어셈블리에서의 개개의 위치들에 대한 입력들을 생성하도록 구성될 수 있다. 시스템은: (1) 서열 분석 데이터로부터의 서열들을 어셈블리에서의 위치들의 세트에 정렬하고; (2) 정렬된 서열들의 생물학적 중합체들을 어셈블리에서의 위치들에서 표시된 생물학적 중합체들과 비교하여 하나 이상의 특징의 값들을 결정함으로써, 어셈블리에서의 위치들의 세트에 대한 입력들을 생성하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 어셈블리에서의 위치들의 세트에서의 생물학적 중합체들을 표시하는 서열 분석 데이터로부터의 서열들을 식별함으로써 서열들을 어셈블리에서의 위치들의 세트에 정렬하도록 구성될 수 있다. 예로서, 어셈블리는 1 내지 10,000으로 인덱싱되는 위치들을 포함할 수 있고, 시스템은 뉴클레오티드 서열들 "TAGGTC", "TAGTTC", "TAGGCC", "TAGGTC" 각각이 어셈블리의 5 내지 10으로 인덱싱된 위치들과 정렬되는 것으로 결정할 수 있다. 이 예에서, 시스템은 뉴클레오티드 서열들 각각을 어셈블리에서 5 내지 10으로 인덱싱된 위치들에서 표시된 생물학적 중합체들과 비교하여 특징(들)의 값들을 결정할 수 있다. 특징들, 및 특징들의 값들의 생성의 예들이 도 4a 내지 도 4c를 참조하여 설명된다.
일부 실시예들에서, 시스템은 어셈블리에서의 개개의 위치들에 대한 입력들을 생성하도록 구성될 수 있다. 시스템은 기계 학습 모델에 입력으로서 제공하기 위한 위치에 대한 입력을 생성하여, 어셈블리에서의 위치에서 존재하는 생물학적 중합체(예를 들어, 뉴클레오티드, 아미노산)를 식별하는데 이용될 수 있는 출력을 획득하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 위치에서의 생물학적 중합체 표시, 및 위치의 이웃에 있는 하나 이상의 다른 위치에서의 생물학적 중합체 표시들에 기초하여 어셈블리에서의 위치에 대한 입력을 생성하도록 구성될 수 있다. 입력은 모델이 대응하는 출력을 생성하기 위해 이용하는 어셈블리에서의 위치 주위의 컨텍스트 정보를 기계 학습 모델에 제공할 수 있다. 시스템은 위치에서의, 그리고 위치의 이웃에서의 다른 위치(들)에서의 특징(들)의 값들을 결정함으로써 위치의 이웃에서의 위치들에서의 생물학적 중합체 표시들에 기초하여 위치에 대한 입력을 생성하도록 구성될 수 있다. 예로서, 시스템은: (1) 위치를 선택하고; (2) 선택된 위치에 중심을 둔 위치들의 이웃을 식별하고; (3) 입력을 선택된 위치 및 위치들의 이웃의 각각에서의 특징(들)의 값들인 것으로 생성할 수 있다.
일부 실시예들에서, 시스템은 설정된 크기의 이웃을 이용하도록 구성될 수 있다. 예시적인 이웃 크기들이 본 명세서에서 설명된다. 일부 실시예들에서, 시스템에 의해 이용되는 이웃에서의 위치들의 수는 구성가능한 파라미터일 수 있다. 예를 들어, 시스템은 이용하기 위한 이웃 크기를 명시하는 (예를 들어, 소프트웨어 애플리케이션에서의) 사용자 입력을 수신할 수 있다. 일부 실시예들에서, 시스템은 이웃 크기를 결정하도록 구성될 수 있다. 예로서, 시스템은 서열 분석 데이터가 생성되게 하였던 서열 분석 기술 및/또는 어셈블리가 생성되게 하였던 조립 기술에 기초하여 이웃 크기를 결정할 수 있다.
일부 실시예들에서, 시스템은: (1) 어셈블리에서의 위치들을 선택하고; (2) 선택된 위치들에 대한 개개의 입력들을 생성함으로써, 기계 학습 모델에 제공될 입력을 생성하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 어셈블리가 어셈블리에서의 위치들에서의 생물학적 중합체들을 부정확하게 표시할 가능성들을 결정하고, 결정된 가능성들을 이용하여 입력을 생성할 위치들을 선택함으로써, 어셈블리에서의 위치들을 선택하도록 구성될 수 있다. 예로서, 시스템은 어셈블리가 위치에서의 생물학적 중합체를 부정확하게 표시할 가능성이 임계 가능성을 초과하는지를 결정하고, 가능성이 임계 가능성을 초과하는 경우 위치에 대한 입력을 생성할 수 있다. 일부 실시예들에서, 시스템은 생물학적 중합체가 위치에서 존재하는 것을 표시하는 정렬된 서열들의 수에 기초하여 위치가 생물학적 중합체를 부정확하게 표시할 가능성을 결정하도록 구성될 수 있다. 시스템은 그 가능성을 생물학적 중합체가 위치에 있는 것을 표시하는 서열들의 수와 서열들의 총 수 사이의 차이인 것으로 결정할 수 있다. 예로서, 어셈블리는 뉴클레오티드 서열들 중의 4개가 티민이 위치에서 존재하는 것을 표시하고, 뉴클레오티드 서열들 중의 2개가 구아닌이 위치에서 존재하는 것을 표시하고, 뉴클레오티드 서열들 중의 3개가 아데닌이 위치에서 존재하는 것을 표시하는, 9개의 뉴클레오티드 서열들의 세트로부터의 컨센서스에 기초하여 어셈블리에서의 위치에서의 티민을 표시할 수 있다. 이 예에서, 시스템은, 어셈블리가 어셈블리에서의 위치에서의 생물학적 중합체를 부정확하게 표시할 가능성을, 5의 값을 얻기 위한 티민을 표시하는 뉴클레오티드 서열들의 수(4)와 뉴클레오티드 서열들의 총 수(9) 사이의 차이인 것으로 결정할 수 있다. 시스템은 5가 임계 차이(예를 들어, 1, 2, 3, 4)보다 큰 것으로 결정할 수 있고, 그 결과, 위치에 대한 입력을 생성할 수 있다.
일부 실시예들에서, 시스템은 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10의 임계 차이를 이용하도록 구성될 수 있다. 일부 실시예들은 특정 임계 차이로 제한되지 않는다. 일부 실시예들에서, 임계 차이는 구성가능한 파라미터일 수 있다. 시스템에 의해 이용된 임계 가능성은 시스템이 모델에 제공될 입력을 생성하는 위치들의 수에 영향을 미칠 수 있다. 예로서, 시스템은 소프트웨어 애플리케이션에 대한 사용자 입력으로서 임계값의 값을 수신할 수 있다. 일부 실시예들에서, 시스템은 설정된 임계 가능성을 이용할 수 있다. 예로서, 임계 가능성의 값이 인코딩될 수 있다. 일부 실시예들에서, 시스템은 임계 가능성을 자동으로 결정하도록 구성될 수 있다. 예로서, 시스템은 어셈블리가 생성되게 한 조립 기술 및/또는 서열 분석 데이터가 생성되게 한 서열 분석 기술에 기초하여 임계 가능성을 결정할 수 있다.
일부 실시예들에서, 시스템은 위치에 대한 입력을 2-D 행렬로서 생성하도록 구성될 수 있다. 일부 실시예들에서, 행렬의 각각의 행/열은 어셈블리에서의 개개의 위치에서 결정된 특징(들)의 값들을 명시할 수 있다. 일부 실시예들에서, 시스템은 입력을 이미지로서 생성하도록 구성될 수 있으며, 이미지의 픽셀들은 특징(들)의 값들을 보유한다. 예로서, 이미지의 각각의 행/열은 어셈블리에서의 개개의 위치에서 결정된 특징(들)의 값들을 명시할 수 있다.
다음, 프로세스(310)는 시스템이 블록 316에서 생성된 입력을 기계 학습 모델에 제공하여 대응하는 출력을 획득하는 블록 318로 진행한다. 일부 실시예들에서, 시스템은 어셈블리에서의 개개의 위치들에 대해 생성된 입력들을 기계 학습 모델에 대한 개별 입력들로서 제공하도록 구성될 수 있다. 예로서, 시스템은 타겟 위치에 대한 대응하는 출력을 획득하기 위해 기계 학습 모델에 대한 입력으로서 위치들의 이웃에서의 위치들 및 타겟 위치에서 결정된 특징 값들의 세트를 제공할 수 있다. 일부 실시예들에서, 시스템은 (예를 들어, 도 2c 내지 도 2d를 참조하여 전술한 바와 같이) 다수의 위치들에 대해 생성된 입력들을 병렬로 제공하도록 구성될 수 있다. 예로서, 시스템은: (1) 제1 위치에 대해 생성된 제1 입력을 모델에 제공하고; (2) 제1 입력에 대응하는 제1 출력을 획득하기 전에, 제2 위치에 대해 생성된 제2 입력을 모델에 제공할 수 있다. 일부 실시예들에서, 시스템은 다수의 위치들에 대해 생성된 입력들을 순차적으로 제공하도록 구성될 수 있다. 예를 들어, 시스템은: (1) 대응하는 제1 출력을 획득하기 위해 제1 위치에 대해 생성된 제1 입력을 모델에 제공하고; (2) 제1 출력을 획득한 후에, 대응하는 제2 출력을 획득하기 위해 제2 위치에 대한 제2 입력을 제공할 수 있다.
일부 실시예들에서, 기계 학습 모델에 제공된 입력에 대응하는 출력은, 어셈블리에서의 다수의 위치들 각각에 대해, 하나 이상의 생물학적 중합체 각각이 위치에서 존재할 가능성을 표시할 수 있다. 예로서, 출력은 게놈 어셈블리에서의 다수의 위치들 각각에 대해, 하나 이상의 뉴클레오티드(예를 들어, 아데닌, 구아닌, 티민, 시토신) 각각이 위치에서 존재할 가능성(예를 들어, 확률)을 표시할 수 있다. 다른 예로서, 출력은, 단백질 서열에서의 다수의 위치들 각각에 대해, 하나 이상의 아미노산 각각이 위치에서 존재할 가능성을 표시할 수 있다. 일부 실시예들에서, 출력은 어떠한 생물학적 중합체도 어셈블리에서의 위치에서 존재하지 않을 가능성을 표시할 수 있다. 예로서, 시스템은 "-" 문자가 어셈블리에서의 위치에 있을 가능성을 표시할 수 있다.
일부 실시예들에서, 모델은 어셈블리에서의 개개의 위치들에 대응하는 출력들을 제공할 수 있다. 시스템은 어셈블리에서의 타겟 위치에 대해 생성된 입력을 제공하고, 하나 이상의 생물학적 중합체 각각이 타겟 위치에서 존재할 가능성들을 표시하는 대응하는 출력을 획득할 수 있다. 예로서, 시스템은 게놈 어셈블리에서의 위치에 대해 생성된 입력을 제공하고, 4개의 가능한 뉴클레오티드들(예를 들어, 아데닌, 구아닌, 티민, 시토신)의 세트 각각이 위치에서 존재할 가능성들을 표시하는 대응하는 출력을 획득할 수 있다. 예를 들어, 가능성은 각각의 뉴클레오티드가 위치에서 존재할 확률 값들일 수 있다.
다음, 프로세스(310)는 시스템이 모델로부터 획득된 출력을 이용하여 어셈블리에서의 위치들에서의 생물학적 중합체를 식별하는 블록 320으로 진행한다. 일부 실시예들에서, 시스템은 위치들 각각에 대해, 모델에 제공된 대응하는 입력에 응답하여 위치에 대해 획득된 출력을 이용하여 위치에서 존재하는 생물학적 중합체를 식별함으로써 어셈블리에서의 위치들에서의 생물학적 중합체들을 식별하도록 구성될 수 있다. 모델로부터의 출력은 개개의 위치들에 대응하는 출력 값들의 다수의 세트들을 포함할 수 있다. 출력 값들의 각각의 세트는 하나 이상의 생물학적 중합체 각각이 어셈블리에서의 개개의 위치에서 존재할 가능성들을 명시할 수 있다. 시스템은 개개의 위치에서의 생물학적 중합체를, 위치에서 존재할 가장 큰 가능성을 갖는 생물학적 중합체인 것으로 식별할 수 있다. 예로서, 어셈블리에서의 제1 위치에 대한 출력 값들의 세트는 위치에 대한 다음의 가능성들의 세트: 아데닌(A) 0.1, 시토신(C) 0.6, 구아닌(G) 0.1, 티민(T) 0.15, 및 블랭크(-) 0.05를 표시할 수 있다. 이 예에서, 시스템은 시토신(C)을 어셈블리에서의 위치에 있는 것으로 식별할 수 있다. 일부 실시예들에서, 위치에 대해 생성된 입력에 대응하는 모델로부터의 출력은 그 위치에서의 생물학적 중합체를 명시하는 분류일 수 있다. 예로서, 모델로부터의 출력은 아데닌(A), 시토신(C), 구아닌(G), 티민(T) 또는 블랭크(-)의 분류일 수 있다.
다음, 프로세스(310)는 시스템이 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득하는 블록 322로 진행한다. 시스템은 블록 320에서 식별된 생물학적 중합체들에 기초하여 어셈블리를 업데이트하도록 구성될 수 있다. 일부 실시예들에서, 시스템은 어셈블리에서의 위치들에서의 생물학적 중합체들의 표시들을 업데이트함으로써 어셈블리를 업데이트하도록 구성될 수 있다. 일부 경우들에서, 블록 320에서 위치에서 존재하는 것으로 식별된 생물학적 중합체는 어셈블리에서의 생물학적 중합체 표시와는 상이할 수 있다. 이러한 경우들에서, 시스템은 어셈블리에서의 위치에서의 생물학적 중합체 표시를 수정할 수 있다. 예로서, 시스템은: (1) 모델의 출력을 이용하여, 티민 "T"가 아데닌 "A"의 표시를 갖는 어셈블리에서의 제1 위치에서 존재하는 것으로 식별하고; (2) 아데닌 "A"의 이전 표시로부터 티민 "T"로 표시하기 위해 어셈블리에서의 제1 위치를 변경할 수 있다. 일부 경우들에서, 위치에서 존재하는 것으로 식별된 생물학적 중합체는 어셈블리에서의 위치에서의 생물학적 중합체 표시와 동일할 수 있다. 이러한 경우들에서, 시스템은 어셈블리에서의 위치에서의 생물학적 중합체 표시를 변경하지 않을 수 있다. 예로서, 시스템은: (1) 모델의 출력을 이용하여, 티민 "T"가 티민 "T"의 표시를 갖는 어셈블리에서의 제1 위치에서 존재하는 것으로 식별하고; (2) 제1 위치에서의 표시를 변경되지 않은 채로 남겨둘 수 있다.
일부 실시예들에서, 시스템은 어셈블리에서의 다수의 위치들을 병렬로 업데이트하도록 구성될 수 있다. 예로서, 시스템은: (1) 어셈블리에서의 제1 위치를 업데이트하기 시작하고; (2) 제1 위치에서의 업데이트를 완료하기 전에, 어셈블리에서의 제2 위치를 업데이트하기 시작할 수 있다. 일부 실시예들에서, 시스템은 어셈블리에서의 위치들을 순차적으로 업데이트하도록 구성될 수 있다. 예로서, 시스템은: (1) 어셈블리에서의 제1 위치를 업데이트하고; (2) 어셈블리에서의 제1 위치에서 업데이트를 완료한 후에, 어셈블리에서의 제2 위치를 업데이트할 수 있다.
일부 실시예들에서, 제1 업데이트된 어셈블리를 획득하기 위해 블록 322에서 어셈블리를 업데이트한 후에, 프로세스(310)는 블록 322로부터 블록 316으로의 파선에 의해 표시된 바와 같이 블록 316으로 복귀할 수 있다. 일부 실시예들에서, 시스템은 제1 업데이트된 어셈블리 및 서열 분석 데이터를 이용하여 기계 학습 모델에 대한 입력을 생성하도록 구성될 수 있다. 예로서, 시스템은 서열 분석 데이터의 뉴클레오티드 서열들의 세트 및 제1 업데이트된 어셈블리를 이용하여 모델에 대한 입력을 생성할 수 있다. 시스템은 전술한 바와 같이 기계 학습 모델에 대한 입력을 생성하기 위해 뉴클레오티드 서열들을 제1 업데이트된 어셈블리의 개개의 위치들에 정렬할 수 있다. 그 다음, 시스템은 제2 업데이트된 어셈블리를 획득하기 위해 블록 316 내지 322에서의 동작들을 수행할 수 있다. 일부 실시예들에서, 조립 시스템은 조건이 충족될 때까지 반복들을 수행하도록 구성될 수 있다.
일부 실시예들에서, 시스템은 임계 수의 반복들이 수행되었다고 시스템이 결정할 때까지 업데이트 반복들을 수행하도록 구성될 수 있다. 일부 실시예들에서, 임계 수의 반복들은 사용자 입력(예를 들어, 소프트웨어 명령, 또는 하드 코딩된 값)에 의해 설정될 수 있다. 일부 실시예들에서, 시스템은 임계 수의 반복들을 결정하도록 구성될 수 있다. 예로서, 시스템은 초기 어셈블리를 획득하기 위해 이용된 조립 기술의 타입에 기초하여 임계 수의 업데이트 반복들을 결정할 수 있다. 일부 실시예들에서, 시스템은 시스템이 어셈블리가 수렴한 것을 검출할 때까지 업데이트 반복들을 수행하도록 구성될 수 있다. 예로서, 조립 시스템은: (1) 최신의 반복으로부터 획득된 현재 어셈블리와 이전 어셈블리 사이의 차이들의 수를 결정하고; (2) 차이들의 수가 임계 수 또는 차이들의 백분율보다 작을 때 업데이트 반복들의 수행을 중지하도록 결정할 수 있다.
일부 실시예들에서, 시스템은 어셈블리에 대한 단일 업데이트를 수행하도록 구성될 수 있고, 프로세스(310)는 어셈블리에 대한 단일 업데이트를 수행한 후에 블록 322에서 종료할 수 있다. 업데이트된 어셈블리는 시스템에 의해 출력 어셈블리로서 출력될 수 있다. 예로서, 시스템은 출력 어셈블리가 블록 314에서 액세스된 초기 어셈블리보다 더 정확하도록 어셈블리에서의 에러들이 정정된 게놈 어셈블리를 출력할 수 있다. 다른 예로서, 시스템은 출력 단백질 서열이 블록 314에서 액세스된 초기 단백질 서열보다 더 정확하도록 에러들이 정정되었던 단백질 서열을 출력할 수 있다.
일부 실시예들에서, 시스템은 어셈블리의 제1 부분에 대한 제1 수의 업데이트 반복들 및 어셈블리의 제2 부분에 대한 제2 수의 업데이트 반복들을 수행하도록 구성될 수 있다. 예로서, 시스템은 (예를 들어, 블록들 316 내지 322에서의 동작들의 다수의 반복들을 수행함으로써) 게놈 어셈블리의 1 내지 100으로 인덱싱된 위치들을 다수회 업데이트하고, (예를 들어, 블록들 316 내지 322에서의 동작들을 한번 수행함으로써) 게놈 어셈블리의 101 내지 200으로 인덱싱된 위치들을 한번 업데이트할 수 있다. 시스템은 생물학적 중합체들을 부정확하게 표시할 수 있는 부분들에서의 위치들의 수에 기초하여 다수회 업데이트하기 위한 어셈블리의 부분들을 결정하도록 구성될 수 있다. 예로서, 시스템은: (1) 임계 가능성을 초과하는 부정확한 생물학적 중합체 표시들을 가질 가능성을 갖는 위치들의 윈도우에서의 위치들의 수(예를 들어, 25, 50, 75, 100 또는 1000개의 위치들)를 결정하고; (2) 그 수가 위치들의 임계 수를 초과할 때 위치들의 윈도우 상에서 업데이트 사이클을 수행하기로 결정할 수 있다.
도 4a 내지 도 4c는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 기계 학습 모델에 제공될 입력을 생성하는 예를 도시한다.
도 4a는 뉴클레오티드 서열(401)(도 4a에서 "파일업(Pileup)"으로 표지됨), 뉴클레오티드 서열(401)로부터 생성된 생물학적 중합체들의 어셈블리(402), 및 어셈블리에서의 개개의 위치들에 대한 생물학적 중합체들의 표지들(404)을 포함하는 어레이(400)를 도시한다. 예로서, 도 4a에 도시된 데이터는 기계 학습 모델을 트레이닝하기 위해 프로세스(300)를 수행하는 것으로부터 획득된 트레이닝 데이터일 수 있고, 여기서: (1) 서열 분석 데이터(401) 및 어셈블리(402)는 블록들 302 및 304에서 획득되고; (2) 표지들(404)은 블록 306에서 획득된다. 다른 예로서, 서열 분석 데이터(401) 및 어셈블리(402)는 트레이닝된 기계 학습 모델을 이용하여 어셈블리를 생성하기 위해 프로세스(310)의 블록들 312 및/또는 314에서 획득될 수 있다.
도 4a의 실시예에 도시된 바와 같이, 서열 분석 데이터(401)는 서열 분석 DNA로부터 생성된 뉴클레오티드 서열들을 포함한다. 서열 분석 데이터(401)의 각각의 행은 뉴클레오티드 서열이다. 도 4a의 예에 도시된 바와 같이, 뉴클레오티드 서열들은 영숫자 문자들의 시퀀스들로서 표현되고, 여기서 "A"는 아데닌을 나타내고, "C"는 시토신을 나타내고, "G" 구아닌을 나타내고, "T"는 티민을 나타내고, "-"는 그 위치에 어떠한 뉴클레오티드도 존재하지 않음을 나타낸다. 본 명세서에 설명된 예시적인 영숫자 문자들은, 일부 실시예들이 개개의 뉴클레오티드들 또는 그것의 결여를 나타내기 위한 영숫자 문자들의 특정 세트로 제한되지 않기 때문에, 예시적인 목적들을 위한 것이다.
도 4a의 실시예에서, 어셈블리(402)는 뉴클레오티드 서열들(401)로부터 생성된다. 일부 실시예들에서, 어셈블리(402)는 조립 알고리즘(예를 들어, OLC 조립)을 서열 분석 데이터(401)에 적용하는 것으로부터 획득될 수 있다. 도 4a의 실시예에서, 어셈블리(402)는 뉴클레오티드 서열들의 컨센서스를 취하는 것으로부터 획득된다. 컨센서스는 어셈블리(402)에서의 각각의 위치에 대한 뉴클레오티드 서열들의 다수결 투표에 의해 결정되고, 여기서 시스템은 가장 큰 수의 뉴클레오티드 서열들에 의해 위치에서 표시된 생물학적 중합체를 식별한다. 시스템은 다수의 뉴클레오티드 각각에 대해, (1) (예를 들어, 뉴클레오티드가 위치에서 존재하는 것을 표시함으로써) 뉴클레오티드를 투표하는 뉴클레오티드 서열들의 수를 결정하고; (2) 위치에 표시될 가장 큰 수의 투표들을 갖는 뉴클레오티드를 식별하도록 구성될 수 있다. 예로서, 강조된 열(406)의 위치에 대해, (1) 서열들 중 4개는 아데닌을 표시하고, 서열들 중 3개는 시토신을 표시하고, 서열들 중 2개는 구아닌을 표시하고; (2) 어셈블리(402)에서의 위치는 아데닌을 표시한다. 다른 예로서, 어셈블리(402)에서의 제1 위치에 대해, 모든 뉴클레오티드 서열들은 시토신을 표시하고, 따라서 어셈블리(402)는 제1 위치에서 시토신을 표시한다.
도 4a의 실시예에서, 표지들(404)은 어셈블리(402)에서의 위치들에 대한 원하는 생물학적 중합체를 표시할 수 있다. 일부 실시예들에서, 시스템은 기준 게놈으로부터 표지들을 결정하도록 구성될 수 있다. 예를 들어, 시스템은 유기체로부터의 DNA 샘플을 서열 분석하는 것으로부터 뉴클레오티드 서열들을 획득하고, 뉴클레오티드 서열들에 대한 조립 알고리즘의 적용으로부터 어셈블리(402)를 획득하고, (예를 들어, NCBI 데이터베이스로부터의) 유기체의 알려진 기준 게놈으로부터 표지들(404)을 획득할 수 있다. 표지들(404)은 감독 트레이닝을 위해 및/또는 생성된 어셈블리의 정확도를 결정하기 위해 이용될 각각의 위치에 대한 진정한 또는 정확한 생물학적 중합체 표시를 나타낼 수 있다.
도 4b는 도 4a에 도시된 데이터(400)로부터 결정된 값들의 어레이(410)를 도시한다. 어레이(410)는 어셈블리(402)에서의 열(406)의 위치에 대한 기계 학습 모델에 대한 입력을 생성하는 중간 단계를 도시한다. 어레이(410)는 도 4a의 뉴클레오티드 서열들을 나타내는 "파일업"으로 표지된 행들의 세트를 포함한다. 어셈블리에서의 각각의 위치에 대해, 시스템은 다수의 뉴클레오티드들 각각에 대한 카운트를 결정하고, 여기서 카운트는 뉴클레오티드가 어셈블리에서의 위치에 있음을 표시하는 뉴클레오티드 서열들의 수를 표시한다. 어레이(410)의 "파일업" 섹션에서의 각각의 엔트리는 뉴클레오티드에 대한 카운트를 보유한다. 예로서, 도 4b에서의 열(412)은 아데닌에 대해 4, 시토신에 대해 3, 구아닌에 대해 2, 티민에 대해 0, 및 뉴클레오티드 없음에 대해 0의 카운트를 갖는다. 다른 예로서, 어레이(410)의 제1 열은 아데닌에 대해 0, 시토신에 대해 9, 구아닌에 대해 0, 티민에 대해 0, 및 뉴클레오티드 없음에 대해 0의 카운트를 갖는다.
어레이(410)는 도 4b의 어셈블리(402)를 나타내는, 도 4b에서 "어셈블리"로 표지된 행들의 세트를 더 포함한다. 어셈블리(402)에서의 각각의 위치에 대해, 어레이(410)는 위치에서 표시된 뉴클레오티드로부터 결정된 값들의 열을 포함한다. 각각의 위치에 대해, 시스템은 다수의 뉴클레오티드들 각각에 기준값을 할당할 수 있고, 여기서 기준값은 뉴클레오티드가 어셈블리에서의 위치에 표시되는지를 표시한다. 일례로서, 도 4b의 412로 표지된 열에서, 어셈블리 섹션은: (1) 그것이 어셈블리(402)에서의 대응하는 위치에 표시된 뉴클레오티드이기 때문에 아데닌에 대해 9의 값을 갖고; (2) 그들이 어셈블리(402)에서의 대응하는 위치에서 표시되지 않기 때문에 다른 뉴클레오티드들 각각에 대해 0의 값을 갖는다. 다른 예로서, 어레이(410)의 제1 열에서, 어셈블리 섹션은: (1) 그것이 어셈블리(402)에서의 대응하는 위치에 표시된 뉴클레오티드이기 때문에 시토신에 대해 9의 값을 갖고; (2) 그들이 어셈블리(402)에서의 대응하는 위치에서 표시되지 않기 때문에 다른 뉴클레오티드들 각각에 대해 0의 값을 갖는다. 도 4b의 예에 도시된 바와 같이, 일부 실시예들에서, 뉴클레오티드가 어셈블리 위치에서 표시될 때, 어셈블리 위치에서의 뉴클레오티드에 할당된 기준값은 정렬된 뉴클레오티드 서열들의 수(예를 들어, 도 4a의 예에서 9)와 동일하다.
도 4c는 도 4b의 어레이(410)에서의 값들을 이용하여 생성된 특징 값들의 어레이(420)를 도시한다. 일부 실시예들에서, 어레이(420)는 대응하는 출력을 획득하기 위해 기계 학습 모델에 입력으로서 제공될 수 있다. 도 4c의 예에서, 어레이(420)는 열(422)에 대응하는 어셈블리에서의 위치에 대한 모델에 제공될 입력이다. 어레이(420)는 열(422)에 대응하는 타겟 위치에서 결정된 특징들의 값들, 및 타겟 위치의 이웃에서의 24개 위치들에 대해 결정된 특징들의 값들을 포함한다. 어레이(420)는 타겟 위치의 좌측에 대한 12개 위치들 및 타겟 위치의 우측에 대한 12개 위치들에 대한 특징들의 값들을 포함한다.
어레이(420)의 파일업 섹션에서, 각각의 열은 다수의 뉴클레오티드들 각각에 대한 에러값을 명시한다. 열에서의 뉴클레오티드에 대한 에러값은: (1) 뉴클레오티드가 열에 대응하는 어셈블리(402)에서의 위치에 있음을 표시하는 뉴클레오티드 서열들의 수와 (2) 어레이(420)의 어셈블리 섹션에서의 뉴클레오티드에 할당된 기준값 사이의 차이를 표시한다. 예로서, 도 4c의 열(422)에 대해, 값들은 다음과 같이 결정된다: (1) 아데닌은 4 - 9 = -5이고; (2) 시토신은 3 - 0 = 3이고; (3) 구아닌은 2 - 0 = 2이고; (4) 티민은 0 - 0 = 0이고; (5) 블랭크는 0 - 0 = 0이다. 어레이(420)의 어셈블리 섹션은 도 4b의 어레이(410)의 어셈블리 섹션과 동일할 수 있다.
일부 실시예들에서, 어레이(420)에서의 파일업의 값들은 어셈블리(402)가 위치에서의 뉴클레오티드를 부정확하게 식별할 가능성을 표시할 수 있다. 시스템은 값들을 이용하여 기계 학습 모델에 대한 입력을 생성할 위치들을 선택할 수 있다. 도 4c에 도시된 바와 같이, 파일업의 0이 아닌 값들이 강조된다. 일부 실시예들에서, 시스템은 위치에서의 파일업 값이 임계값을 초과할 때 위치에 대한 기계 학습 모델에 제공될 입력을 생성하도록 결정하게 구성될 수 있다. 예를 들어, 시스템은 아데닌에 대해 결정된 5의 차이가 4의 임계 차이를 초과하는 것으로 결정함으로써 열(422)에 대응하는 어셈블리(402)에서의 위치에 대한 입력을 생성하도록 결정할 수 있다. 예시적인 임계 차이들이 본 명세서에 설명된다.
일부 실시예들에서, 어레이(420)는 어셈블리에서의 위치(예를 들어, 열(422)에 대응하는 위치)를 업데이트하기 위해 기계 학습 모델에 입력으로서 제공될 수 있다. 시스템은 기계 학습 모델로부터 획득된 대응하는 출력을 이용하여 어셈블리에서의 위치에서 존재하는 뉴클레오티드를 식별하고, 그에 따라 어셈블리를 업데이트할 수 있다. 일부 실시예들에서, 어레이(420)는 모델을 트레이닝하는 것의 일부로서 기계 학습 모델에 제공된 다수의 입력들 중 하나일 수 있다. 시스템은 기계 학습 모델로부터 획득된 대응하는 출력들 및 표지들(404)을 이용하여 기계 학습 모델의 하나 이상의 파라미터에 대한 조정들을 결정할 수 있다. 예로서, 기계 학습 모델은 신경망일 수 있고, 시스템은 기계 학습 모델의 출력들로부터 식별된 뉴클레오티드들과 표지들 사이의 차이를 이용하여 신경망의 가중치들에 대한 하나 이상의 조정을 결정할 수 있다.
도 4a의 예시적인 실시예는 핵산들과 관련된 데이터를 보여주지만, 일부 실시예들에서, 데이터는 단백질과 관련될 수 있다. 예를 들어, 서열들(401)은 아미노산 서열들일 수 있고, 어셈블리(402)는 단백질 서열일 수 있고, 표지들(404)은 단백질 서열에서의 위치들 각각에 대한 기준 아미노산들일 수 있다. 시스템은 아미노산 서열들, 단백질 서열 및/또는 표지들에 기초하여 도 4b 내지 도 4c에 도시된 값들을 결정할 수 있다.
도 5는 본 명세서에 설명된 기술의 일부 실시예들에 따른, 어셈블리를 업데이트하는 프로세스를 도시한다. 도 5는 업데이트된 어셈블리(508)를 생성하기 위해 기계 학습 모델(502)에 제공될 어셈블리 데이터(500)로부터의 입력의 생성을 도시한다. 어셈블리 데이터(500)는, 예를 들어, 도 4c를 참조하여 전술한 데이터의 형태일 수 있다. 도시된 업데이트의 프로세스는 도 1a 내지 도 1c를 참조하여 전술한 조립 시스템(104)에 의해 수행될 수 있다.
도 5의 실시예에 도시된 바와 같이, 시스템은 업데이트될 어셈블리에서의 위치(504A 및 506A)를 선택한다. 예로서, 시스템은: (1) 어셈블리에서의 위치들에서의 생물학적 중합체(예를 들어, 뉴클레오티드, 아미노산)를 부정확하게 표시할 가능성들을 결정하고; (2) 위치(504A, 506A)에서의 가능성들 각각이 위치들(504A, 506A)을 선택할 임계 가능성을 초과하는 것으로 결정함으로써, 위치들(504A, 506A)을 선택할 수 있다. 시스템이 위치들(504A, 506A)을 선택할 때, 시스템은 기계 학습 모델(502)에 제공될 대응하는 입력들을 생성하도록 결정할 수 있다.
도 5의 실시예에 도시된 바와 같이, 시스템은 위치(504A)에 대응하는 제1 입력(504B) 및 위치(506A)에 대응하는 제2 입력(506B)을 생성한다. 시스템은 도 4a 내지 도 4c를 참조하여 전술한 바와 같이 입력들(504B, 506B) 각각을 생성할 수 있다. 예를 들어, 시스템은: (1) 위치에 중심을 둔 위치들의 이웃을 선택하고; (2) 이웃에서의 위치들 각각에서의 하나 이상의 특징들의 값들을 결정하고; (3) 특징(들)의 값들을 위치에 대한 입력으로서 이용함으로써, 입력들(504B, 506B) 각각을 생성할 수 있다. 일부 실시예들에서, 시스템은 데이터 구조에서의 특징(들)의 값들을 저장하도록 구성될 수 있다. 예로서, 시스템은 도 4c에 도시된 바와 같이 2차원 어레이 또는 이미지로 값들을 저장할 수 있다.
도 5의 실시예에 도시된 바와 같이, 시스템은 생성된 입력들(504B, 506B) 각각을 기계 학습 모델(502)에 입력으로서 제공하여 대응하는 출력들을 획득한다. 출력(504C)은 위치(504A)에 대해 생성된 입력(504B)에 대응하고, 출력(506C)은 위치(506A)로부터 생성된 입력(506B)에 대응한다. 일부 실시예들에서, 시스템은 입력들(504B, 506B)을 기계 학습 모델(502)에 순차적으로 제공하도록 구성될 수 있다. 예로서, 시스템은: (1) 대응하는 출력(504C)을 획득하기 위해 입력(504B)을 기계 학습 모델(502)에 제공하고; (2) 출력(504C)을 획득한 후에, 대응하는 출력(506C)을 획득하기 위해 입력(506B)을 기계 학습 모델(502)에 제공할 수 있다. 일부 실시예들에서, 시스템은 입력들(504B, 506B)을 기계 학습 모델(502)에 병렬로 제공하도록 구성될 수 있다. 예로서, 시스템은: (1) 입력(504B)을 기계 학습 모델(502)에 제공하고; (2) 입력(504B)에 대응하는 출력(504C)을 획득하기 전에, 입력(506B)을 기계 학습 모델(502)에 제공할 수 있다.
도 5의 실시예에 도시된 바와 같이, 출력들(504C, 506C) 각각은 하나 이상의 뉴클레오티드 각각이 어셈블리에서의 위치에서 존재할 가능성들을 표시한다. 도 5의 실시예에서, 가능성들은 확률들이다. 예로서, 출력(504C)은: (1) 4개의 상이한 뉴클레오티드들 각각에 대해, 뉴클레오티드가 위치(504A)에 존재할 확률; 및 (2) 뉴클레오티드가 위치(504A)에서 존재하지 않을 확률("-" 문자로 표현됨)을 명시한다. 출력(504C)에서, 아데닌은 0.2의 확률을 갖고, 시토신은 0.5의 확률이고, 구아닌은 0.1의 확률이고, 티민은 0.1의 확률이고, 뉴클레오티드가 위치(504A)에 있지 않을 0.1의 확률이 존재한다. 다른 예로서, 출력(506C)은: (1) 4개의 상이한 뉴클레오티드들 각각에 대해, 뉴클레오티드가 위치(506A)에서 존재할 확률; 및 (2) 뉴클레오티드가 위치(506A)에서 존재하지 않을 확률("-" 문자로 표현됨)을 명시한다. 이 예에서, 아데닌은 0.6의 확률을 갖고, 시토신은 0.1의 확률이고, 구아닌은 0.2의 확률이고, 티민은 0.05의 확률이고, 뉴클레오티드가 위치(504A)에 있지 않을 0.05의 확률이 존재한다.
도 5의 실시예에 도시된 바와 같이, 시스템은 기계 학습 모델(502)로부터 획득된 출력을 이용하여 어셈블리에서의 위치들을 업데이트해서 업데이트된 어셈블리(508)를 획득한다. 일부 실시예들에서, 시스템은: (1) 기계 학습 모델로부터 획득된 출력을 이용하여 위치들에서 존재하는 뉴클레오티드를 식별하고; (2) 식별된 뉴클레오티드들을 표시하도록 어셈블리에서의 위치들을 업데이트하여 업데이트된 어셈블리(508)를 획득함으로써, 어셈블리를 업데이트하도록 구성될 수 있다. 도 5의 예에 도시된 바와 같이, 시스템은: (1) 시토신이 출력(504C)을 이용하는 위치에서 존재할 가장 높은 가능성을 갖는다고 결정하고; (2) 업데이트된 어셈블리(508)에서의 대응하는 위치(508A)를 위치에서의 시토신 "C"를 표시하도록 설정함으로써, 초기 어셈블리에서의 위치(504A)를 업데이트한다. 다른 예로서, 시스템은: (1) 아데닌이 출력(506C)을 이용하는 위치에서 존재할 가장 높은 가능성을 갖는다고 결정하고; (2) 업데이트된 어셈블리(508)에서의 대응하는 위치(508B)를 아데닌 "A"를 표시하도록 설정함으로써, 초기 어셈블리에서의 위치(506A)를 업데이트한다. 일부 경우들에서, 시스템은: (1) 기계 학습 모델(502)로부터 획득된 출력을 이용한 위치에서 식별된 뉴클레오티드가 이미 위치에 표시될 수 있다고 결정하고; (2) 위치에서의 표시를 업데이트된 어셈블리(508)에서 변경하지 않은 채로 유지할 수 있다.
업데이트된 어셈블리(508)가 초기 어셈블리로부터 분리되어 도시되어 있지만, 일부 실시예들에서, 업데이트된 어셈블리(508)는 초기 어셈블리의 업데이트된 버전일 수 있다. 예를 들어, 시스템은 메모리에 초기 어셈블리를 저장하고, 메모리에서의 초기 어셈블리의 값들을 업데이트하여 업데이트된 어셈블리(508)를 획득할 수 있다. 일부 실시예들에서, 시스템은 초기 어셈블리보다 개별 어셈블리로서 업데이트된 어셈블리(508)를 생성할 수 있다. 예를 들어, 시스템은 제1 메모리 위치에 초기 어셈블리를 저장하고, 업데이트된 어셈블리(508)를 개별 어셈블리로서 제2 메모리 위치에 저장할 수 있다.
일부 실시예들에서, 시스템은 초기 어셈블리에서의 위치들에서의 업데이트들을 순차적으로 수행하도록 구성될 수 있다. 예로서, 시스템은: (1) 출력(504C)을 이용하여 업데이트된 어셈블리(508)에서의 위치(508A)를 업데이트하고; (2) 위치(508A)에서 업데이트를 완료한 후에, 출력(506C)을 이용하여 업데이트된 어셈블리(508)에서의 위치(508B)를 업데이트할 수 있다. 일부 실시예들에서, 시스템은 초기 어셈블리에서의 위치들에서 업데이트들을 병렬로 수행하도록 구성될 수 있다. 예로서, 시스템은: (1) 출력(504C)을 이용하여 위치(508A)를 업데이트하기 시작하고; (2) 위치(508A)에서 업데이트를 완료하기 전에, 출력(506C)을 이용하여 위치(508B)를 업데이트하기 시작할 수 있다.
일부 실시예들에서, 시스템은 어셈블리에서의 개개의 위치들에 대한 입력들을 생성하고, 기계 학습 모델(502)에 입력들을 제공하고, 기계 학습 모델로부터의 출력들을 이용하여 어셈블리에서의 위치들을 업데이트하는 프로세스를 병렬로 수행하도록 구성될 수 있다. 예로서, 시스템은: (1) 초기 어셈블리의 위치(504A)에 대한 입력의 생성을 시작하고; (2) 위치(504A)에서의 위치에 대한 업데이트를 완료하기 전에, 초기 어셈블리의 위치(506A)에 대한 입력의 생성을 시작할 수 있다. 어셈블리 업데이트들을 병렬화함으로써, 시스템은 (예를 들어, 더 적은 시간을 요구하는 것에 의해) 어셈블리를 더 효율적으로 생성하는 프로세스를 만든다. 시스템은 다수의 프로세서들을 이용하고/하거나 다수의 애플리케이션 스레드들을 이용함으로써 프로세스들을 병렬화할 수 있다.
도 5의 실시예는 게놈 어셈블리의 부분을 업데이트하는 것을 도시하지만, 일부 실시예들은 단백질 서열 또는 그것의 부분을 업데이트하도록, 예시된 프로세스를 구현할 수 있다. 예를 들어, 초기 어셈블리는 단백질 서열일 수 있다. 그 후, 시스템은 기계 학습 모델(502)에 제공하기 위해 단백질 서열에서의 위치들에 대한 입력들을 생성할 수 있다. 시스템은 다수의 아미노산들 각각이 위치에서 존재할 가능성들(예를 들어, 확률들)을 표시하는 출력을 획득할 수 있다. 시스템은 이어서 초기 단백질 서열을 업데이트하여 업데이트된 단백질 서열을 획득할 수 있다.
도 6은 본 명세서에 설명된 기술의 일부 실시예들에 따른, 어셈블리를 생성하기 위한 컨볼루션 신경망 모델(600)의 예를 도시한다. 일부 실시예들에서, 컨볼루션 신경망 모델(600)은 도 3a를 참조하여 전술한 프로세스(300)를 수행함으로써 트레이닝될 수 있다. 일부 실시예들에서, 프로세스(300)로부터 획득된 트레이닝된 컨볼루션 신경망 모델(600)은 도 3b를 참조하여 전술한 바와 같이 어셈블리를 생성하기 위해 프로세스(310)를 수행하는데 이용될 수 있다.
일부 실시예들에서, 모델(600)은 서열 분석 데이터로부터 생성된 입력, 및 서열 분석 데이터로부터 생성된 어셈블리를 수신하도록 구성된다. 예로서, 모델(600)은 도 1a 내지 도 1c를 참조하여 전술한 조립 시스템(104)에 의해 이용된 기계 학습 모델일 수 있다. 서열 분석 데이터는 생물학적 중합체 서열들(예를 들어, 뉴클레오티드 서열들 또는 아미노산 서열들)을 포함할 수 있다. 일부 실시예들에서, 시스템은 하나 이상의 특징의 값들을 결정하고, 결정된 값들을 모델(600)에 입력으로서 제공하도록 구성될 수 있다. 예로서, 시스템은 어셈블리에서의 위치들의 이웃에서의 특징들의 값들을 결정하고, 위치들의 이웃에서의 결정된 값들을 모델(600)에 입력으로서 제공할 수 있다. 예시적인 입력들 및 입력들을 생성하기 위한 기술들이 본 명세서에서 설명된다.
도 6의 예시적인 실시예에서, 모델(600)은 모델(600)에 제공된 입력을 수신하는 제1 컨볼루션 계층(602)을 포함한다. 제1 계층(602)에서, 시스템은 모델(600)에 제공된 입력을 3x5x64 행렬로서 표현된 64개의 3x5 필터들로 컨볼루션한다. 예를 들어, 시스템은 출력을 획득하기 위해 (예를 들어, 도 4c에 도시된 바와 같이) 10x25 입력 행렬을 3x5x64 행렬의 각각의 채널로 컨볼루션할 수 있다. 제1 계층(602)은 시스템이 컨볼루션으로부터의 출력에 적용하는 활성화 함수로서 ReLu 함수를 포함한다. 일부 실시예들에서, 제1 계층(602)은 컨볼루션의 출력의 크기를 감소시키기 위해 풀링 계층(pooling layer)을 또한 포함할 수 있다.
도 6의 예시적인 실시예에서, 모델은 제1 계층(602)의 출력을 수신하는 제2 컨볼루션 계층(604)을 포함한다. 제2 계층(604)에서, 시스템은 입력을 3x5x128 행렬로서 표현된 128개의 3x5 필터들의 세트로 컨볼루션한다. 시스템은 제1 컨볼루션 계층(602)으로부터의 출력을 3x5x128 필터 세트로 컨볼루션할 수 있다. 제2 컨볼루션 계층(604)은 시스템이 컨볼루션으로부터의 출력에 적용하는 활성화 함수로서의 ReLU 함수를 포함한다. 일부 실시예들에서, 제2 계층(604)은 컨볼루션의 출력의 크기를 감소시키기 위해 풀링 계층을 또한 포함할 수 있다. 이어서, 제2 컨볼루션 계층(604)의 출력은 제3 컨볼루션 계층(606)으로 전달된다. 제3 계층(606)에서, 시스템은 입력을 3x5x256 행렬로서 표현된 256개의 3x5 필터들의 세트로 컨볼루션한다. 그 후 시스템은 컨볼루션으로부터의 출력에 ReLu 활성화 함수를 적용한다. 일부 실시예들에서, 제3 계층(606)은 컨볼루션의 출력의 크기를 감소시키기 위해 풀링 계층을 또한 포함할 수 있다.
도 6의 예시적인 실시예에서, 모델(600)은 각각 256개의 입력 값들을 수신하는 5개의 완전 접속된 층들을 갖는 조밀 계층(dense layer)(608)을 포함한다. 시스템은 제3 컨볼루션 계층(606)으로부터 획득된 출력을 응축하여 조밀 계층(608)에 입력으로서 제공할 수 있다. 조밀 계층(608)은 다수의 값들을 출력할 수 있고, 여기서 각각의 값은 입력이 모델(600)에 제공되었던 위치에 개개의 생물학적 중합체(예를 들어, 뉴클레오티드 또는 아미노산)가 존재할 가능성을 표시한다. 예로서, 조밀 계층은 5개의 값들을 출력할 수 있으며, 여기서 각각의 값은 위치에 뉴클레오티드(예를 들어, 아데닌, 시토신, 구아닌, 티민, 및/또는 뉴클레오티드 없음)의 가능성을 표시한다. 시스템은 조밀 계층(608)의 출력에 softmax 함수를 적용하여 1로 합산된 확률 값들의 세트를 획득할 수 있다. 도 6의 예시적인 실시예에 도시된 바와 같이, 시스템은 조밀 계층(608)의 출력에 softmax 함수를 적용하여, 개개의 뉴클레오티드들이 어셈블리에서의 위치에서 존재할 확률들을 표시하는 5개의 확률들의 출력(610)을 획득한다. 출력(610)은 (예를 들어, 도 5를 참조하여 전술한 바와 같이) 어셈블리를 업데이트하는데 이용될 수 있다.
도 7은 본 명세서에 설명된 기술의 일부 실시예들에 따른 기술들의 성능 결과들을 도시한다. 도면들 각각은 종래의 기술들에 대한, 본 기술들에 의해 제공된 정확도에서의 개선들을 보여준다. 도 7에서, Canu 및 Miniasm은 2개의 종래의 조립 기술들이다. Miniasm+Racon은 Racon 에러 정정의 적용을 갖는 Miniasm을 나타낸다. Canu+Quorum은 Canu로부터 생성된 어셈블리를 정정하기 위한 본 명세서에 설명된 기술들의 구현이다. Miniasm+Quorum은 Miniasm으로부터 생성된 어셈블리를 정정하기 위한 본 명세서에 설명된 기술들의 구현이다.
도 7에 도시된 바와 같이, Miniasm+Quorum은 데이터의 샘플들 각각에 대해 Miniasm+Racon보다 상당히 더 적은 에러율들을 갖는다. 예로서, 30X Pacbio 데이터로부터의 이. 콜라이(E. coli)에 대해, (접속된 포인트들에 의해 표현된) Miniasm+Quorum의 각각의 반복은 100 에러들/100 킬로-염기(kilo-base)보다 작은 에러율들을 갖는 반면, Miniasm+Racon은 대략 200 에러들/100 킬로-염기의 최소 에러율을 갖는다. 다른 예로서, 30X ONT 데이터로부터의 이. 콜라이에 대해, Miniasm+Quorum의 각각의 반복은 대략 400 에러들/100 킬로-염기의 에러율을 갖는 반면, Miniasm+Racon은 대략 500 에러들/100 킬로-염기의 에러율들을 갖는다.
도 7에 도시된 바와 같이, Canu+Quorum은 Canu 단독으로부터의 결과들에 비해 개선된 정확도를 제공한다. Canu는 종래의 에러 정정 기술들을 포함하지만, 본 명세서에 설명된 기술들은 어셈블리 생성의 개선된 정확도를 제공한다. 예로서, 30X ONT 데이터로부터의 이. 콜라이에 대해, Canu는 500 에러들/100 킬로-염기보다 큰 에러율을 갖는 반면, Canu+Quorum의 각각의 반복은 350 에러들/100 킬로-염기보다 작은 에러율을 갖는다.
도 7에 도시된 바와 같이, 본 명세서에 설명된 기술들은 에러 정정을 수행하기 위해 실질적으로 많은 양의 계산 시간을 추가하지 않고 어셈블리들의 개선된 정확도를 제공할 수 있다. 예로서, Miniasm+Quorum은 실질적으로 동일한 수의 CPU 시간들에서 Miniasm+Racon보다 더 우수한 정확도를 달성한다. 다른 예로서, Canu+Quorum은 어셈블리를 정정하기 위해 CPU 시간들의 수를 실질적으로 증가시키지 않고 Canu 단독보다 더 우수한 정확도를 달성한다.
일부 실시예들에서, 본 명세서에 설명된 시스템들 및 기술들은 하나 이상의 컴퓨팅 디바이스를 이용하여 구현될 수 있다. 그러나, 실시예들은 임의의 특정 타입의 컴퓨팅 디바이스로 동작하는 것으로 제한되지 않는다. 추가의 예시로서, 도 8은 예시적인 컴퓨팅 디바이스(800)의 블록도이다. 컴퓨팅 디바이스(800)는 하나 이상의 프로세서(802) 및 하나 이상의 유형의(tangible) 비일시적 컴퓨터 판독가능 저장 매체(예를 들어, 메모리(804))를 포함할 수 있다. 메모리(804)는, 유형의 비일시적 컴퓨터 판독가능 매체에서, 실행될 때, 전술한 기능 중 임의의 것을 구현하는 컴퓨터 프로그램 명령어들을 저장할 수 있다. 프로세서(들)(802)는 메모리(804)에 결합될 수 있고, 그러한 컴퓨터 프로그램 명령어들을 실행하여 기능이 실현 및 수행되게 할 수 있다.
컴퓨팅 디바이스(800)는 또한, 컴퓨팅 디바이스가 (예를 들어, 네트워크를 통해) 다른 컴퓨팅 디바이스들과 통신할 수 있게 하는 네트워크 입력/출력(I/O) 인터페이스(806)를 포함할 수 있으며, 또한 컴퓨팅 디바이스가 사용자에게 출력을 제공하고 사용자로부터 입력을 수신할 수 있게 하는 하나 이상의 사용자 I/O 인터페이스(808)를 포함할 수 있다. 사용자 I/O 인터페이스들은 키보드, 마우스, 마이크로폰, 디스플레이 디바이스(예를 들어, 모니터 또는 터치 스크린), 스피커들, 카메라, 및/또는 다양한 다른 타입들의 I/O 디바이스들과 같은 디바이스들을 포함할 수 있다.
전술한 실시예들은 다양한 방식들 중 임의의 방식으로 구현될 수 있다. 예를 들어, 실시예는 하드웨어, 소프트웨어 또는 그들의 조합을 이용하여 구현될 수 있다. 소프트웨어로 구현될 때, 소프트웨어 코드는, 단일의 컴퓨팅 디바이스에 제공되거나 또는 다수의 컴퓨팅 디바이스들 사이에 분산되든지 간에, 임의의 적절한 프로세서(예를 들어, 마이크로프로세서) 또는 프로세스들의 모음 상에서 실행될 수 있다. 전술된 기능들을 수행하는 임의의 컴포넌트 또는 컴포넌트들의 모음은 위에서 논의된 기능들을 제어하는 하나 이상의 제어기로서 총칭적으로 간주될 수 있다는 것을 이해해야 한다. 하나 이상의 제어기는 다양한 방식으로, 예를 들어, 전용 하드웨어를 이용하여, 또는 위에 기재된 기능들을 수행하는 마이크로코드 또는 소프트웨어를 이용하여 프로그래밍되는 범용 하드웨어(예를 들어, 하나 이상의 프로세서)를 이용하여 구현될 수 있다.
이와 관련하여, 본 명세서에 설명된 실시예들의 하나의 구현은, 하나 이상의 프로세서 상에서 실행될 때, 하나 이상의 실시예의 상기에 논의된 기능들을 수행하는 컴퓨터 프로그램(즉, 복수의 실행가능 명령어들)으로 인코딩되는 적어도 하나의 컴퓨터 판독가능 저장 매체(예를 들어, RAM, ROM, EEPROM, 플래시 메모리 또는 다른 메모리 기술, CD-ROM, DVD(digital versatile disks) 또는 다른 광학 디스크 저장소, 자기 카세트들, 자기 테이프, 자기 디스크 저장소 또는 다른 자기 저장 디바이스들, 또는 다른 유형의 비일시적 컴퓨터 판독가능 저장 매체)를 포함한다는 것을 이해해야 한다. 컴퓨터 판독가능 매체는, 매체에 저장된 프로그램이 임의의 컴퓨팅 디바이스 상에 로딩되어 본 명세서에서 논의된 기술들의 양태들을 구현할 수 있도록 이송가능할(transportable) 수 있다. 또한, 실행될 때, 상기에 논의된 기능들 중 임의의 것을 수행하는 컴퓨터 프로그램에 대한 참조는, 호스트 컴퓨터 상에서 실행되는 애플리케이션 프로그램으로 제한되지 않는다는 것을 이해해야 한다. 오히려, 컴퓨터 프로그램 및 소프트웨어라는 용어들은, 본 명세서에서 논의된 기법들의 양태들을 구현하기 위해 하나 이상의 프로세서를 프로그래밍하도록 채용될 수 있는 임의의 타입의 컴퓨터 코드(예를 들어, 애플리케이션 소프트웨어, 펌웨어, 마이크로코드, 또는 임의의 다른 형태의 컴퓨터 명령어)를 참조하기 위해 일반적인 의미로 본 명세서에서 이용된다.
본 개시의 다양한 특징들 및 양태들은 단독으로, 2개 이상의 임의의 조합으로, 또는 상기에서 설명된 실시예들에서 구체적으로 논의되지 않은 다양한 배열들로 이용될 수 있고, 따라서, 그 응용에 있어서, 상기한 설명에서 개시되거나 도면들에서 도시된 컴포넌트들의 세부사항들 및 배열로 제한되지는 않는다. 예로서, 일 실시예에 설명된 양태들이 다른 실시예들에 설명된 양태들과 임의의 방식으로 결합될 수 있다.
"대략", "실질적으로" 및 "약"이라는 용어들은 일부 실시예들에서 타겟 값의 ±20% 이내, 일부 실시예들에서 타겟 값의 ±10% 이내, 일부 실시예들에서 타겟 값의 ±5% 이내, 일부 실시예들에서 타겟 값의 ±2% 이내를 의미하기 위해 이용될 수 있다. "대략" 및 "약"이라는 용어들은 타겟 값을 포함할 수 있다.
또한, 본 명세서에서 개시된 개념들은 그 예가 제공되었던 방법으로서 구체화될 수 있다. 방법의 일부로서 수행되는 동작들은 임의의 적절한 방식으로 순서가 정해질 수 있다. 따라서, 예시적인 실시예들에서는 순차적 동작들로서 도시되어 있더라도, 일부 동작들을 동시에 수행하는 것을 포함할 수 있는, 도시된 것과는 상이한 순서로 동작들이 수행되는 실시예들이 구성될 수 있다.
청구항 요소를 수식하기 위한 청구항들에서의 "제1", "제2", "제3" 등과 같은 서수 용어들의 이용은 그것만으로는 방법의 동작들이 수행되는 시간 순서 또는 하나의 청구항 요소의 다른 청구항 요소에 대한 임의의 우선순위, 선행(precedence), 또는 순서를 내포하는 것이 아니라, 청구항 요소들을 구별하기 위해, 특정 명칭을 갖는 하나의 청구항 요소를, (서수 용어를 이용한 것을 제외하고는) 동일한 명칭을 갖는 다른 요소로부터 구별하기 위한 표지들로서 단지 이용된다.
또한, 본 명세서에서 이용된 어법 및 용어는 설명의 목적을 위한 것이며, 제한적인 것으로 간주되어서는 안된다. 본 명세서에서 "포함하는(including)", "포함하는(comprising)", "갖는(having)", "함유하는(containing)", "수반하는(involving)" 및 이들의 변형들을 이용하는 것은, 그 앞에 열거되는 항목들 및 그의 등가물들 뿐만 아니라, 추가적인 항목들을 포괄함을 의미하는 것이다.
Claims (66)
- 거대분자의 생물학적 중합체 어셈블리를 생성하는 방법으로서,
적어도 하나의 컴퓨터 하드웨어 프로세서를 이용하여:
복수의 생물학적 중합체 서열들 및 개개의 어셈블리 위치들에서 존재하는 생물학적 중합체들을 표시하는 어셈블리에 액세스하는 단계;
상기 복수의 생물학적 중합체 서열들 및 상기 어셈블리를 이용하여, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 단계;
상기 제1 입력을 상기 트레이닝된 심층 학습 모델에 제공하여, 제1 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 생물학적 중합체들 각각이 상기 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제1 출력을 획득하는 단계;
상기 트레이닝된 심층 학습 모델의 상기 제1 출력을 이용하여 상기 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 단계; 및
상기 제1 복수의 어셈블리 위치들에서의 상기 식별된 생물학적 중합체들을 표시하도록 상기 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득하는 단계를 수행하는 것을 포함하는, 방법. - 제1항에 있어서,
상기 거대분자는 단백질을 포함하고, 상기 복수의 생물학적 중합체 서열들은 복수의 아미노산 서열들을 포함하고, 상기 어셈블리는 개개의 어셈블리 위치들에서의 아미노산들을 표시하는, 방법. - 제1항 또는 임의의 다른 선행하는 항에 있어서,
상기 거대분자는 핵산을 포함하고, 상기 복수의 생물학적 중합체 서열들은 복수의 뉴클레오티드 서열들을 포함하고, 상기 어셈블리는 개개의 어셈블리 위치들에서의 뉴클레오티드들을 표시하는, 방법. - 제3항 또는 임의의 다른 선행하는 항에 있어서,
상기 어셈블리는 상기 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 제1 뉴클레오티드를 표시하고;
상기 제1 복수의 어셈블리 위치들에서의 상기 생물학적 중합체들을 식별하는 단계는 상기 제1 어셈블리 위치에서의 제2 뉴클레오티드를 식별하는 단계를 포함하고;
상기 어셈블리를 업데이트하는 단계는 상기 제1 어셈블리 위치에서의 상기 제2 뉴클레오티드를 표시하기 위해 상기 어셈블리를 업데이트하는 단계를 포함하는, 방법. - 제3항 또는 임의의 다른 선행하는 항에 있어서,
상기 어셈블리를 업데이트하여 상기 업데이트된 어셈블리를 획득한 후에:
상기 복수의 뉴클레오티드 서열들을 상기 업데이트된 어셈블리에 정렬하는 단계;
상기 복수의 뉴클레오티드 서열들 및 상기 업데이트된 어셈블리를 이용하여, 상기 트레이닝된 심층 학습 모델에 제공될 제2 입력을 생성하는 단계;
상기 제2 입력을 상기 트레이닝된 심층 학습 모델에 제공하여, 제2 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 뉴클레오티드들 각각이 상기 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제2 출력을 획득하는 단계;
상기 트레이닝된 심층 학습 모델의 상기 제2 출력에 기초하여 상기 제2 복수의 어셈블리 위치들에서의 뉴클레오티드들을 식별하는 단계; 및
상기 제2 복수의 어셈블리 위치들에서의 상기 식별된 뉴클레오티드들을 표시하도록 상기 업데이트된 어셈블리를 업데이트하여 제2 업데이트된 어셈블리를 획득하는 단계를 더 포함하는, 방법. - 제3항 또는 임의의 다른 선행하는 항에 있어서,
상기 복수의 뉴클레오티드 서열들을 상기 어셈블리에 정렬하는 단계를 더 포함하는, 방법. - 제6항 또는 임의의 다른 선행하는 항에 있어서,
상기 복수의 뉴클레오티드 서열들은 적어도 9개의 뉴클레오티드 서열들을 포함하는, 방법. - 제3항 또는 임의의 다른 선행하는 항에 있어서,
상기 트레이닝된 심층 학습 모델에 대한 상기 제1 입력을 생성하는 단계는,
상기 제1 복수의 어셈블리 위치들을 선택하는 단계; 및
상기 선택된 제1 복수의 어셈블리 위치들에 기초하여 상기 제1 입력을 생성하는 단계를 포함하는, 방법. - 제8항 또는 임의의 다른 선행하는 항에 있어서,
상기 어셈블리에서 상기 제1 복수의 위치들을 선택하는 단계는,
상기 어셈블리가 상기 제1 복수의 어셈블리 위치들에서의 뉴클레오티드들을 부정확하게 표시할 가능성들을 결정하는 단계; 및
상기 결정된 가능성들을 이용하여 상기 제1 복수의 어셈블리 위치들을 선택하는 단계를 포함하는, 방법. - 제3항 또는 임의의 다른 선행하는 항에 있어서,
상기 트레이닝된 심층 학습 모델에 제공될 상기 제1 입력을 생성하는 단계는 상기 복수의 뉴클레오티드 서열들 중의 개개의 뉴클레오티드 서열들을 상기 어셈블리와 비교하는 단계를 포함하는, 방법. - 제3항 또는 임의의 다른 선행하는 항에 있어서,
상기 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 식별하기 위해 상기 트레이닝된 심층 학습 모델에 제공될 상기 제1 입력을 생성하는 단계는:
상기 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치 각각에서의 다수의 뉴클레오티드들 각각에 대해:
상기 뉴클레오티드가 상기 위치에 있다는 것을 표시하는 상기 복수의 뉴클레오티드 서열들의 수를 표시하는 카운트를 결정하는 단계;
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시하는지에 기초하여 기준값을 결정하는 단계;
상기 카운트와 상기 기준값 사이의 차이를 표시하는 에러값을 결정하는 단계; 및
상기 기준값 및 상기 에러값을 상기 제1 입력에 포함하는 단계를 포함하는, 방법. - 제11항 또는 임의의 다른 선행하는 항에 있어서,
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시하는지에 기초하여 상기 기준값을 결정하는 단계는:
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시할 때 상기 기준값을 제1 값인 것으로 결정하는 단계; 및
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시하지 않을 때 상기 기준값을 제2 값인 것으로 결정하는 단계를 포함하는, 방법. - 제12항 또는 임의의 다른 선행하는 항에 있어서,
상기 제1 값은 상기 복수의 뉴클레오티드 서열들의 수이고;
상기 제2 값은 0인, 방법. - 제11항 또는 임의의 다른 선행하는 항에 있어서,
상기 트레이닝된 심층 학습 모델에 제공될 상기 제1 입력을 생성하는 단계는 열들을 갖는 데이터 구조에 값들을 배열하는 단계를 포함하고,
제1 열은 상기 제1 어셈블리 위치에서의 상기 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유하고;
제2 열은 상기 제1 어셈블리 위치의 상기 이웃에서의 상기 하나 이상의 어셈블리 위치 중의 제2 어셈블리 위치에서의 상기 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유하는, 방법. - 제11항 또는 임의의 다른 선행하는 항에 있어서,
상기 제1 어셈블리 위치의 상기 이웃에서의 상기 하나 이상의 어셈블리 위치는 상기 제1 어셈블리 위치로부터 분리된 적어도 2개의 어셈블리 위치들을 포함하는, 방법. - 제3항 또는 임의의 다른 선행하는 항에 있어서,
상기 하나 이상의 개개의 생물학적 중합체 각각이 상기 어셈블리 위치에서 존재할 상기 하나 이상의 가능성은, 다수의 뉴클레오티드들 각각에 대해, 상기 뉴클레오티드가 상기 어셈블리 위치에서 존재할 가능성을 포함하고;
상기 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 단계는 상기 제1 뉴클레오티드가 상기 제1 위치에서 존재할 가능성이 상기 다수의 뉴클레오티드들 중의 제2 뉴클레오티드가 상기 제1 어셈블리 위치에서 존재할 가능성보다 크다고 결정함으로써, 상기 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 상기 다수의 뉴클레오티드들 중의 제1 뉴클레오티드인 것으로 식별하는 단계를 포함하는, 방법. - 제3항 또는 임의의 다른 선행하는 항에 있어서,
상기 복수의 뉴클레오티드 서열들로부터 상기 어셈블리를 생성하는 단계를 더 포함하는, 방법. - 제17항 또는 임의의 다른 선행하는 항에 있어서,
상기 복수의 뉴클레오티드 서열들로부터 상기 어셈블리를 생성하는 단계는 상기 복수의 뉴클레오티드 서열들로부터의 컨센서스 서열을 상기 어셈블리인 것으로 결정하는 단계를 포함하는, 방법. - 제17항 또는 임의의 다른 선행하는 항에 있어서,
상기 복수의 뉴클레오티드 서열들로부터 상기 어셈블리를 생성하는 단계는 중첩 레이아웃 컨센서스(OLC) 알고리즘을 상기 복수의 뉴클레오티드 서열들에 적용하는 단계를 포함하는, 방법. - 제1항 또는 임의의 다른 선행하는 항에 있어서,
기준 거대분자를 서열 분석하는 것으로부터 획득된 생물학적 중합체 서열들 및 상기 기준 거대분자의 미리 결정된 어셈블리를 포함하는 트레이닝 데이터에 액세스하는 단계; 및
상기 트레이닝 데이터를 이용하여 심층 학습 모델을 트레이닝해서 상기 트레이닝된 심층 학습 모델을 획득하는 단계를 더 포함하는, 방법. - 제20항 또는 임의의 다른 선행하는 항에 있어서,
상기 기준 거대분자는 상기 거대분자와 상이한, 방법. - 제1항 또는 임의의 다른 선행하는 항에 있어서,
상기 심층 학습 모델은 컨볼루션 신경망(CNN)을 포함하는, 방법. - 거대분자의 생물학적 중합체 어셈블리를 생성하기 위한 시스템으로서,
적어도 하나의 컴퓨터 하드웨어 프로세서; 및
명령어들을 저장하는 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체를 포함하고,
상기 명령어들은, 상기 적어도 하나의 컴퓨터 하드웨어 프로세서에 의해 실행될 때, 상기 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금:
복수의 생물학적 중합체 서열들 및 개개의 어셈블리 위치들에서 존재하는 생물학적 중합체들을 표시하는 어셈블리에 액세스하는 것;
상기 복수의 생물학적 중합체 서열들 및 상기 어셈블리를 이용하여, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 것;
상기 제1 입력을 상기 트레이닝된 심층 학습 모델에 제공하여, 제1 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 생물학적 중합체들 각각이 상기 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제1 출력을 획득하는 것;
상기 트레이닝된 심층 학습 모델의 상기 제1 출력을 이용하여 상기 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 것; 및
상기 제1 복수의 어셈블리 위치들에서의 상기 식별된 생물학적 중합체들을 표시하도록 상기 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득하는 것을 수행하게 하는, 시스템. - 제23항에 있어서,
상기 거대분자는 단백질을 포함하고, 상기 복수의 생물학적 중합체 서열들은 복수의 아미노산 서열들을 포함하고, 상기 어셈블리는 개개의 어셈블리 위치들에서의 아미노산들을 표시하는, 시스템. - 제23항 또는 임의의 다른 선행하는 항에 있어서,
상기 거대분자는 핵산을 포함하고, 상기 복수의 생물학적 중합체 서열들은 복수의 뉴클레오티드 서열들을 포함하고, 상기 어셈블리는 개개의 어셈블리 위치들에서의 뉴클레오티드들을 표시하는, 시스템. - 제25항 또는 임의의 다른 선행하는 항에 있어서,
상기 어셈블리는 상기 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 제1 뉴클레오티드를 표시하고;
상기 제1 복수의 어셈블리 위치들에서의 상기 생물학적 중합체들을 식별하는 것은 상기 제1 어셈블리 위치에서의 제2 뉴클레오티드를 식별하는 것을 포함하고;
상기 어셈블리를 업데이트하는 것은 상기 제1 어셈블리 위치에서의 상기 제2 뉴클레오티드를 표시하기 위해 상기 어셈블리를 업데이트하는 것을 포함하는, 시스템. - 제25항 또는 임의의 다른 선행하는 항에 있어서,
상기 명령어들은 또한, 상기 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금, 상기 어셈블리를 업데이트하여 상기 업데이트된 어셈블리를 획득한 후에:
상기 복수의 뉴클레오티드 서열들을 상기 업데이트된 어셈블리에 정렬하는 것;
상기 복수의 뉴클레오티드 서열들 및 상기 업데이트된 어셈블리를 이용하여, 상기 트레이닝된 심층 학습 모델에 제공될 제2 입력을 생성하는 것;
상기 제2 입력을 상기 트레이닝된 심층 학습 모델에 제공하여, 제2 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 뉴클레오티드들 각각이 상기 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제2 출력을 획득하는 것;
상기 트레이닝된 심층 학습 모델의 상기 제2 출력에 기초하여 상기 제2 복수의 어셈블리 위치들에서의 뉴클레오티드들을 식별하는 것; 및
상기 제2 복수의 어셈블리 위치들에서의 상기 식별된 뉴클레오티드들을 표시하도록 상기 업데이트된 어셈블리를 업데이트하여 제2 업데이트된 어셈블리를 획득하는 것을 수행하게 하는, 시스템. - 제25항 또는 임의의 다른 선행하는 항에 있어서,
상기 명령어들은 또한, 상기 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금, 상기 복수의 뉴클레오티드 서열들을 상기 어셈블리에 정렬하는 것을 수행하게 하는, 시스템. - 제28항 또는 임의의 다른 선행하는 항에 있어서,
상기 복수의 뉴클레오티드 서열들은 적어도 9개의 뉴클레오티드 서열들을 포함하는, 시스템. - 제25항 또는 임의의 다른 선행하는 항에 있어서,
상기 트레이닝된 심층 학습 모델에 대한 상기 제1 입력을 생성하는 것은:
상기 제1 복수의 어셈블리 위치들을 선택하는 것; 및
상기 선택된 제1 복수의 어셈블리 위치들에 기초하여 상기 제1 입력을 생성하는 것을 포함하는, 시스템. - 제30항 또는 임의의 다른 선행하는 항에 있어서,
상기 어셈블리에서 상기 제1 복수의 위치들을 선택하는 것은:
상기 어셈블리가 상기 제1 복수의 어셈블리 위치들에서의 뉴클레오티드들을 부정확하게 표시할 가능성들을 결정하는 것; 및
상기 결정된 가능성들을 이용하여 상기 제1 복수의 어셈블리 위치들을 선택하는 것을 포함하는, 시스템. - 제25항 또는 임의의 다른 선행하는 항에 있어서,
상기 트레이닝된 심층 학습 모델에 제공될 상기 제1 입력을 생성하는 것은 상기 복수의 뉴클레오티드 서열들 중의 개개의 뉴클레오티드 서열들을 상기 어셈블리와 비교하는 것을 포함하는, 시스템. - 제25항 또는 임의의 다른 선행하는 항에 있어서,
상기 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 식별하기 위해 상기 트레이닝된 심층 학습 모델에 제공될 상기 제1 입력을 생성하는 것은:
상기 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치 각각에서의 다수의 뉴클레오티드들 각각에 대해:
상기 뉴클레오티드가 상기 위치에 있다는 것을 표시하는 상기 복수의 뉴클레오티드 서열들의 수를 표시하는 카운트를 결정하는 것;
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시하는지에 기초하여 기준값을 결정하는 것;
상기 카운트와 상기 기준값 사이의 차이를 표시하는 에러값을 결정하는 것; 및
상기 기준값 및 상기 에러값을 상기 제1 입력에 포함하는 것을 포함하는, 시스템. - 제33항 또는 임의의 다른 선행하는 항에 있어서,
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시하는지에 기초하여 상기 기준값을 결정하는 것은:
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시할 때 상기 기준값을 제1 값인 것으로 결정하는 것: 및
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시하지 않을 때 상기 기준값을 제2 값인 것으로 결정하는 것을 포함하는, 시스템. - 제34항 또는 임의의 다른 선행하는 항에 있어서,
상기 제1 값은 상기 복수의 뉴클레오티드 서열들의 수이고;
상기 제2 값은 0인, 시스템. - 제33항 또는 임의의 다른 선행하는 항에 있어서,
상기 트레이닝된 심층 학습 모델에 제공될 상기 제1 입력을 생성하는 것은 열들을 갖는 데이터 구조에 값들을 배열하는 것을 포함하고,
제1 열은 상기 제1 어셈블리 위치에서의 상기 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유하고;
제2 열은 상기 제1 어셈블리 위치의 상기 이웃에서의 상기 하나 이상의 어셈블리 위치 중의 제2 어셈블리 위치에서의 상기 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유하는, 시스템. - 제33항 또는 임의의 다른 선행하는 항에 있어서,
상기 제1 어셈블리 위치의 상기 이웃에서의 상기 하나 이상의 어셈블리 위치는 상기 제1 어셈블리 위치로부터 분리된 적어도 2개의 어셈블리 위치들을 포함하는, 시스템. - 제25항 또는 임의의 다른 선행하는 항에 있어서,
상기 하나 이상의 개개의 생물학적 중합체 각각이 상기 어셈블리 위치에서 존재할 상기 하나 이상의 가능성은, 다수의 뉴클레오티드들 각각에 대해, 상기 뉴클레오티드가 상기 어셈블리 위치에서 존재할 가능성을 포함하고;
상기 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 것은 상기 제1 뉴클레오티드가 상기 제1 위치에서 존재할 가능성이 상기 다수의 뉴클레오티드들 중의 제2 뉴클레오티드가 상기 제1 어셈블리 위치에서 존재할 가능성보다 크다고 결정함으로써, 상기 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 상기 다수의 뉴클레오티드들 중의 제1 뉴클레오티드인 것으로 식별하는 것을 포함하는, 시스템. - 제25항 또는 임의의 다른 선행하는 항에 있어서,
상기 명령어들은 또한, 상기 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금, 상기 복수의 뉴클레오티드 서열들로부터 상기 어셈블리를 생성하는 것을 수행하게 하는, 시스템. - 제39항 또는 임의의 다른 선행하는 항에 있어서,
상기 복수의 뉴클레오티드 서열들로부터 상기 어셈블리를 생성하는 것은 상기 복수의 뉴클레오티드 서열들로부터의 컨센서스 서열을 상기 어셈블리인 것으로 결정하는 것을 포함하는, 시스템. - 제39항 또는 임의의 다른 선행하는 항에 있어서,
상기 복수의 뉴클레오티드 서열들로부터 상기 어셈블리를 생성하는 것은 중첩 레이아웃 컨센서스(OLC) 알고리즘을 상기 복수의 뉴클레오티드 서열들에 적용하는 것을 포함하는, 시스템. - 제23항 또는 임의의 다른 선행하는 항에 있어서,
상기 명령어들은 또한, 상기 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금:
기준 거대분자를 서열 분석하는 것으로부터 획득된 생물학적 중합체 서열들 및 상기 기준 거대분자의 미리 결정된 어셈블리를 포함하는 트레이닝 데이터에 액세스하는 것; 및
상기 트레이닝 데이터를 이용하여 심층 학습 모델을 트레이닝해서 상기 트레이닝된 심층 학습 모델을 획득하는 것을 수행하게 하는, 시스템. - 제42항 또는 임의의 다른 선행하는 항에 있어서,
상기 기준 거대분자는 상기 거대분자와 상이한, 시스템. - 제23항 또는 임의의 다른 선행하는 항에 있어서,
상기 심층 학습 모델은 컨볼루션 신경망(CNN)을 포함하는, 시스템. - 명령어들을 저장하는 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체로서,
상기 명령어들은, 적어도 하나의 컴퓨터 하드웨어 프로세서에 의해 실행될 때, 상기 적어도 하나의 컴퓨터 하드웨어 프로세서로 하여금, 거대분자의 생물학적 중합체 어셈블리를 생성하는 방법을 수행하게 하고, 상기 방법은:
복수의 생물학적 중합체 서열들 및 개개의 어셈블리 위치들에서 존재하는 생물학적 중합체들을 표시하는 어셈블리에 액세스하는 단계;
상기 복수의 생물학적 중합체 서열들 및 상기 어셈블리를 이용하여, 트레이닝된 심층 학습 모델에 제공될 제1 입력을 생성하는 단계;
상기 제1 입력을 상기 트레이닝된 심층 학습 모델에 제공하여, 제1 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 생물학적 중합체들 각각이 상기 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제1 출력을 획득하는 단계;
상기 트레이닝된 심층 학습 모델의 상기 제1 출력을 이용하여 상기 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 단계; 및
상기 제1 복수의 어셈블리 위치들에서의 상기 식별된 생물학적 중합체들을 표시하도록 상기 어셈블리를 업데이트하여 업데이트된 어셈블리를 획득하는 단계를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제45항에 있어서,
상기 거대분자는 단백질을 포함하고, 상기 복수의 생물학적 중합체 서열들은 복수의 아미노산 서열들을 포함하고, 상기 어셈블리는 개개의 어셈블리 위치들에서의 아미노산들을 표시하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제45항 또는 임의의 다른 선행하는 항에 있어서,
상기 거대분자는 핵산을 포함하고, 상기 복수의 생물학적 중합체 서열들은 복수의 뉴클레오티드 서열들을 포함하고, 상기 어셈블리는 개개의 어셈블리 위치들에서의 뉴클레오티드들을 표시하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제47항 또는 임의의 다른 선행하는 항에 있어서,
상기 어셈블리는 상기 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 제1 뉴클레오티드를 표시하고;
상기 제1 복수의 어셈블리 위치들에서의 상기 생물학적 중합체들을 식별하는 단계는 상기 제1 어셈블리 위치에서의 제2 뉴클레오티드를 식별하는 단계를 포함하고;
상기 어셈블리를 업데이트하는 단계는 상기 제1 어셈블리 위치에서의 상기 제2 뉴클레오티드를 표시하기 위해 상기 어셈블리를 업데이트하는 단계를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제47항 또는 임의의 다른 선행하는 항에 있어서,
상기 방법은, 상기 어셈블리를 업데이트하여 상기 업데이트된 어셈블리를 획득한 후에:
상기 복수의 뉴클레오티드 서열들을 상기 업데이트된 어셈블리에 정렬하는 단계;
상기 복수의 뉴클레오티드 서열들 및 상기 업데이트된 어셈블리를 이용하여, 상기 트레이닝된 심층 학습 모델에 제공될 제2 입력을 생성하는 단계;
상기 제2 입력을 상기 트레이닝된 심층 학습 모델에 제공하여, 제2 복수의 어셈블리 위치들 각각에 대해, 하나 이상의 개개의 뉴클레오티드들 각각이 상기 위치에서 존재할 하나 이상의 가능성을 표시하는 대응하는 제2 출력을 획득하는 단계;
상기 트레이닝된 심층 학습 모델의 상기 제2 출력에 기초하여 상기 제2 복수의 어셈블리 위치들에서의 뉴클레오티드들을 식별하는 단계; 및
상기 제2 복수의 어셈블리 위치들에서의 상기 식별된 뉴클레오티드들을 표시하도록 상기 업데이트된 어셈블리를 업데이트하여 제2 업데이트된 어셈블리를 획득하는 단계를 더 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제47항 또는 임의의 다른 선행하는 항에 있어서,
상기 방법은 상기 복수의 뉴클레오티드 서열들을 상기 어셈블리에 정렬하는 단계를 더 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제50항 또는 임의의 다른 선행하는 항에 있어서,
상기 복수의 뉴클레오티드 서열들은 적어도 9개의 뉴클레오티드 서열들을 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제47항 또는 임의의 다른 선행하는 항에 있어서,
상기 트레이닝된 심층 학습 모델에 대한 상기 제1 입력을 생성하는 단계는:
상기 제1 복수의 어셈블리 위치들을 선택하는 단계; 및
상기 선택된 제1 복수의 어셈블리 위치들에 기초하여 상기 제1 입력을 생성하는 단계를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제52항 또는 임의의 다른 선행하는 항에 있어서,
상기 어셈블리에서 상기 제1 복수의 위치들을 선택하는 단계는:
상기 어셈블리가 상기 제1 복수의 어셈블리 위치들에서의 뉴클레오티드들을 부정확하게 표시할 가능성들을 결정하는 단계; 및
상기 결정된 가능성들을 이용하여 상기 제1 복수의 어셈블리 위치들을 선택하는 단계를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제47항 또는 임의의 다른 선행하는 항에 있어서,
상기 트레이닝된 심층 학습 모델에 제공될 상기 제1 입력을 생성하는 단계는 상기 복수의 뉴클레오티드 서열들 중의 개개의 뉴클레오티드 서열들을 상기 어셈블리와 비교하는 단계를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제47항 또는 임의의 다른 선행하는 항에 있어서,
상기 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 식별하기 위해 상기 트레이닝된 심층 학습 모델에 제공될 상기 제1 입력을 생성하는 단계는:
상기 제1 어셈블리 위치의 이웃에서의 하나 이상의 어셈블리 위치 각각에서의 다수의 뉴클레오티드들 각각에 대해:
상기 뉴클레오티드가 상기 위치에 있다는 것을 표시하는 상기 복수의 뉴클레오티드 서열들의 수를 표시하는 카운트를 결정하는 단계;
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시하는지에 기초하여 기준값을 결정하는 단계;
상기 카운트와 상기 기준값 사이의 차이를 표시하는 에러값을 결정하는 단계; 및
상기 기준값 및 상기 에러값을 상기 제1 입력에 포함하는 단계를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제55항 또는 임의의 다른 선행하는 항에 있어서,
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시하는지에 기초하여 상기 기준값을 결정하는 단계는:
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시할 때 상기 기준값을 제1 값인 것으로 결정하는 단계; 및
상기 어셈블리가 상기 위치에서의 상기 뉴클레오티드를 표시하지 않을 때 상기 기준값을 제2 값인 것으로 결정하는 단계를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제56항 또는 임의의 다른 선행하는 항에 있어서,
상기 제1 값은 상기 복수의 뉴클레오티드 서열들의 수이고;
상기 제2 값은 0인, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제55항 또는 임의의 다른 선행하는 항에 있어서,
상기 트레이닝된 심층 학습 모델에 제공될 상기 제1 입력을 생성하는 단계는 열들을 갖는 데이터 구조에 값들을 배열하는 단계를 포함하고,
제1 열은 상기 제1 어셈블리 위치에서의 상기 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유하고;
제2 열은 상기 제1 어셈블리 위치의 상기 이웃에서의 상기 하나 이상의 어셈블리 위치 중의 제2 어셈블리 위치에서의 상기 다수의 뉴클레오티드들에 대해 결정된 기준값들 및 에러값들을 보유하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제55항 또는 임의의 다른 선행하는 항에 있어서,
상기 제1 어셈블리 위치의 상기 이웃에서의 상기 하나 이상의 어셈블리 위치는 상기 제1 어셈블리 위치로부터 분리된 적어도 2개의 어셈블리 위치들을 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제47항 또는 임의의 다른 선행하는 항에 있어서,
상기 하나 이상의 개개의 생물학적 중합체 각각이 상기 어셈블리 위치에서 존재할 상기 하나 이상의 가능성은, 다수의 뉴클레오티드들 각각에 대해, 상기 뉴클레오티드가 상기 어셈블리 위치에서 존재할 가능성을 포함하고;
상기 제1 복수의 어셈블리 위치들에서의 생물학적 중합체들을 식별하는 단계는 상기 제1 뉴클레오티드가 상기 제1 위치에서 존재할 가능성이 상기 다수의 뉴클레오티드들 중의 제2 뉴클레오티드가 상기 제1 어셈블리 위치에서 존재할 가능성보다 크다고 결정함으로써, 상기 제1 복수의 어셈블리 위치들 중의 제1 어셈블리 위치에서의 뉴클레오티드를 상기 다수의 뉴클레오티드들 중의 제1 뉴클레오티드인 것으로 식별하는 단계를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제47항 또는 임의의 다른 선행하는 항에 있어서,
상기 방법은 상기 복수의 뉴클레오티드 서열들로부터 상기 어셈블리를 생성하는 단계를 더 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제61항 또는 임의의 다른 선행하는 항에 있어서,
상기 복수의 뉴클레오티드 서열들로부터 상기 어셈블리를 생성하는 단계는 상기 복수의 뉴클레오티드 서열들로부터의 컨센서스 서열을 상기 어셈블리인 것으로 결정하는 단계를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제61항 또는 임의의 다른 선행하는 항에 있어서,
상기 복수의 뉴클레오티드 서열들로부터 상기 어셈블리를 생성하는 단계는 중첩 레이아웃 컨센서스(OLC) 알고리즘을 상기 복수의 뉴클레오티드 서열들에 적용하는 단계를 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제45항 또는 임의의 다른 선행하는 항에 있어서,
상기 방법은,
기준 거대분자를 서열 분석하는 것으로부터 획득된 생물학적 중합체 서열들 및 상기 기준 거대분자의 미리 결정된 어셈블리를 포함하는 트레이닝 데이터에 액세스하는 단계; 및
상기 트레이닝 데이터를 이용하여 심층 학습 모델을 트레이닝해서 상기 트레이닝된 심층 학습 모델을 획득하는 단계를 더 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제64항 또는 임의의 다른 선행하는 항에 있어서,
상기 기준 거대분자는 상기 거대분자와 상이한, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체. - 제45항 또는 임의의 다른 선행하는 항에 있어서,
상기 심층 학습 모델은 컨볼루션 신경망(CNN)을 포함하는, 적어도 하나의 비일시적 컴퓨터 판독가능 저장 매체.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862671260P | 2018-05-14 | 2018-05-14 | |
| US62/671,260 | 2018-05-14 | ||
| US201862671884P | 2018-05-15 | 2018-05-15 | |
| US62/671,884 | 2018-05-15 | ||
| PCT/US2019/032065 WO2019222120A1 (en) | 2018-05-14 | 2019-05-13 | Machine learning enabled biological polymer assembly |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210010488A true KR20210010488A (ko) | 2021-01-27 |
Family
ID=66669118
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020207035288A KR20210010488A (ko) | 2018-05-14 | 2019-05-13 | 기계 학습 가능한 생물학적 중합체 어셈블리 |
Country Status (10)
| Country | Link |
|---|---|
| US (1) | US20190348152A1 (ko) |
| EP (1) | EP3794596A1 (ko) |
| JP (1) | JP2021523479A (ko) |
| KR (1) | KR20210010488A (ko) |
| CN (1) | CN112437961A (ko) |
| AU (1) | AU2019270961A1 (ko) |
| BR (1) | BR112020022257A2 (ko) |
| CA (1) | CA3098876A1 (ko) |
| MX (1) | MX2020012278A (ko) |
| WO (1) | WO2019222120A1 (ko) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3624068A1 (en) * | 2018-09-14 | 2020-03-18 | Covestro Deutschland AG | Method for improving prediction relating to the production of a polymer-ic produc |
| US11664090B2 (en) * | 2020-06-11 | 2023-05-30 | Life Technologies Corporation | Basecaller with dilated convolutional neural network |
| CN116325001A (zh) | 2020-09-11 | 2023-06-23 | 弗哈夫曼拉罗切有限公司 | 用于从多个噪声序列生成共有序列的基于深度学习的技术 |
| CA3214755A1 (en) * | 2021-04-09 | 2022-10-13 | Natalie CASTELLANA | Method for antibody identification from protein mixtures |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DK2511843T3 (en) * | 2009-04-29 | 2017-03-27 | Complete Genomics Inc | METHOD AND SYSTEM FOR DETERMINING VARIATIONS IN A SAMPLE POLYNUCLEOTIDE SEQUENCE IN TERMS OF A REFERENCE POLYNUCLEOTIDE SEQUENCE |
| WO2012168815A2 (en) * | 2011-06-06 | 2012-12-13 | Koninklijke Philips Electronics N.V. | Method for assembly of nucleic acid sequence data |
| CN105980578B (zh) * | 2013-12-16 | 2020-02-14 | 深圳华大智造科技有限公司 | 用于使用机器学习进行dna测序的碱基判定器 |
| CA2894317C (en) * | 2015-06-15 | 2023-08-15 | Deep Genomics Incorporated | Systems and methods for classifying, prioritizing and interpreting genetic variants and therapies using a deep neural network |
-
2019
- 2019-05-13 JP JP2020564123A patent/JP2021523479A/ja active Pending
- 2019-05-13 EP EP19727233.9A patent/EP3794596A1/en active Pending
- 2019-05-13 BR BR112020022257-7A patent/BR112020022257A2/pt not_active IP Right Cessation
- 2019-05-13 CN CN201980047341.5A patent/CN112437961A/zh active Pending
- 2019-05-13 CA CA3098876A patent/CA3098876A1/en active Pending
- 2019-05-13 KR KR1020207035288A patent/KR20210010488A/ko not_active Application Discontinuation
- 2019-05-13 US US16/411,056 patent/US20190348152A1/en active Pending
- 2019-05-13 MX MX2020012278A patent/MX2020012278A/es unknown
- 2019-05-13 WO PCT/US2019/032065 patent/WO2019222120A1/en unknown
- 2019-05-13 AU AU2019270961A patent/AU2019270961A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| BR112020022257A2 (pt) | 2021-02-23 |
| CA3098876A1 (en) | 2019-11-21 |
| JP2021523479A (ja) | 2021-09-02 |
| MX2020012278A (es) | 2021-01-29 |
| US20190348152A1 (en) | 2019-11-14 |
| EP3794596A1 (en) | 2021-03-24 |
| CN112437961A (zh) | 2021-03-02 |
| AU2019270961A1 (en) | 2020-11-19 |
| WO2019222120A1 (en) | 2019-11-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102539188B1 (ko) | 심층 컨볼루션 신경망을 트레이닝하기 위한 심층 학습-기반 기술 | |
| US11817180B2 (en) | Systems and methods for analyzing nucleic acid sequences | |
| KR20210010488A (ko) | 기계 학습 가능한 생물학적 중합체 어셈블리 | |
| US20200176082A1 (en) | Analysis of nanopore signal using a machine-learning technique | |
| CN112837747A (zh) | 基于注意力孪生网络的蛋白质结合位点预测方法 | |
| US20240120027A1 (en) | Machine-learning model for refining structural variant calls | |
| Balvert et al. | Ogre: overlap graph-based metagenomic read clustEring | |
| Mørk et al. | Evaluating bacterial gene-finding HMM structures as probabilistic logic programs | |
| US10937523B2 (en) | Methods, systems and computer readable storage media for generating accurate nucleotide sequences | |
| Basha Gutierrez et al. | A genetic algorithm for motif finding based on statistical significance | |
| AU2022383192A1 (en) | Methods and systems for discovery of embedded target genes in biosynthetic gene clusters | |
| US20250069699A1 (en) | Methods and Systems for Discovery of Embedded Target Genes in Biosynthetic Gene Clusters | |
| Chin et al. | Optimized local protein structure with support vector machine to predict protein secondary structure | |
| JPWO2019222120A5 (ko) | ||
| WO2024079204A1 (en) | Pathogenicity prediction for protein mutations using amino acid score distributions | |
| Shaw | Prediction of Isoform Functions and Interactions with ncRNAs via Deep Learning | |
| Bravo et al. | The TELCoMB Protocol for High‐Sensitivity Detection of ARG‐MGE Colocalizations in Complex Microbial Communities | |
| Eraslan | Enriching the characterization of complex clinical and molecular phenotypes with deep learning | |
| Zheng | Deep learning predicts the impact of non-coding genetic variants in human traits and diseases | |
| Zhu et al. | Coral: a dual context-aware basecaller for nanopore direct RNA sequencing | |
| Hartmann | Regulatory motif discovery using PWMs and the architecture of eukaryotic core promoters | |
| WIJAYA | Integrative methods for discovering generic cis-regulatory motifs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20201208 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| PA0201 | Request for examination |
Patent event code: PA02012R01D Patent event date: 20220513 Comment text: Request for Examination of Application |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
Comment text: Notification of reason for refusal Patent event date: 20250115 Patent event code: PE09021S01D |