KR20200090355A - 실시간 번역 기반 멀티 채널 방송 시스템 및 이를 이용하는 방법 - Google Patents
실시간 번역 기반 멀티 채널 방송 시스템 및 이를 이용하는 방법 Download PDFInfo
- Publication number
- KR20200090355A KR20200090355A KR1020190007277A KR20190007277A KR20200090355A KR 20200090355 A KR20200090355 A KR 20200090355A KR 1020190007277 A KR1020190007277 A KR 1020190007277A KR 20190007277 A KR20190007277 A KR 20190007277A KR 20200090355 A KR20200090355 A KR 20200090355A
- Authority
- KR
- South Korea
- Prior art keywords
- video
- information
- user terminal
- unit
- translation
- Prior art date
Links
Images




Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/47—End-user applications
- H04N21/488—Data services, e.g. news ticker
- H04N21/4884—Data services, e.g. news ticker for displaying subtitles
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/58—Use of machine translation, e.g. for multi-lingual retrieval, for server-side translation for client devices or for real-time translation
-
- G06K9/00268—
-
- G06K9/00335—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/168—Feature extraction; Face representation
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/20—Movements or behaviour, e.g. gesture recognition
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/24—Speech recognition using non-acoustical features
- G10L15/25—Speech recognition using non-acoustical features using position of the lips, movement of the lips or face analysis
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/21—Server components or server architectures
- H04N21/218—Source of audio or video content, e.g. local disk arrays
- H04N21/21805—Source of audio or video content, e.g. local disk arrays enabling multiple viewpoints, e.g. using a plurality of cameras
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N5/00—Details of television systems
- H04N5/222—Studio circuitry; Studio devices; Studio equipment
- H04N5/262—Studio circuits, e.g. for mixing, switching-over, change of character of image, other special effects ; Cameras specially adapted for the electronic generation of special effects
- H04N5/278—Subtitling
Abstract
본 발명은 실시간 번역 기반 멀티 채널 방송 시스템 및 이를 이용하는 방법에 관한 것으로, 보다 상세하게는 복수개의 사용자 단말기로 전송되는 멀티미디어 콘텐츠의 실시간 스트리밍 등의 방송 등에서 활용 가능한 실시간 번역을 지원 기능을 포함한 멀티 채널 시스템 및 이를 이용하는 방법에 관한 발명으로, 특히 MCN 시스템을 기반으로 카메라를 통해 입력되는 영상과 마이크를 통해 입력되는 음성을 포함하는 입력영상으로부터 BJ 등 발화자의 입술 영역을 추출하고, 입술의 움직임을 기반으로 하여 음성으로부터 텍스트를 추출하고, 추출된 텍스트를 특정 언어로 번역한 후, 입력영상에 번역된 텍스트를 자막으로 추가하여 제공하는 동영상 번역 시스템 및 방법에 관한 것이다.
Description
본 발명은 실시간 번역 기반 멀티 채널 방송 시스템 및 방법에 관한 것으로, 보다 상세하게는 하나의 방송 콘텐츠를 촬상하는 복수개의 카메라가 생성하는 영상신호를 시청자가 선택하여 시청할 수 있도록 하며, 시청자가 리모트 콘트롤러를 이용하여 타 카메라의 영상신호를 선택할 수 있도록 하는 멀티채널 방송(MCN) 시스템을 기반으로, 특히 MCN 시스템을 기반으로 개인 방송을 진행하는 BJ(Broadcasting Jockey)의 카메라를 통해 입력되는 영상과 마이크를 통해 입력되는 음성을 포함하는 입력영상으로부터 BJ 등 발화자의 입술 영역을 추출하고, 입술의 움직임을 기반으로 하여 음성으로부터 텍스트를 추출하고, 추출된 텍스트를 특정 언어로 번역한 후, 입력영상에 번역된 텍스트를 자막으로 추가하여 제공할 수 있도록 지원하는 기능을 포함하는 실시간 번역 기반 멀티 채널 방송 시스템 및 방법에 관한 것이다.
MCN 시스템을 기반으로 다양한 기업과 BJ 등이 다양한 주제(게임, 뉴스, 음악, 디지털 방송 등)에 대해 동영상 콘텐츠 등을 기반으로 실시간 또는 녹음된 방송을 진행하고, 전 세계의 다양한 연령층의 사람들에 의해 소비되고 있는 추세가 증가하고 있다.
또한 최근에는 MCN 시스템을 기반으로 많은 개인화된 방송 서비스(BJ 등이 운영)가 네트워크를 통해 제공되고 있으며, 이에 따라 기존의 대형 방송국이 아니더라도, 많은 사용자들이 직접 멀티미디어 콘텐츠를 생성하기도 하고, 다른 사용자들이 생성된 멀티미디어 콘텐츠를 소비하는 멀티미디어 콘텐츠 소비 구조가 형성되고 있기도 하다. 또한 MCN 시스템의 고도화로 전 세계에서 생성된 다양한 콘텐츠에 대한 접근성 역시 쉬워지게 되어, 콘텐츠 소비에 대한 니즈 역시 증대하고 있기도 하다.
그러나, 외국어를 사용하는 콘텐츠 제작자에 으해 생성, 유통되는 방송 콘텐츠의 경우, 추가적으로 콘텐츠 이해를 위한 번역이 필요한 경우가 많이 존재하며, 특히 BJ에 의해 진행되는 실시간 진행되는 방송 콘텐츠의 경우 실시간 번역 제공이 어렵거나 불가능한 경우가 다수 존재하여 온 것이 사실이다. 이러한 문제점은 단순히 국내 콘텐츠 소비자에게만 해당되지 않고, 외국에서 최근 소비 추세가 증대하고 있는 K-POP과 같은 한류의 영향에 따라 한국 BJ가 생성 및 MCN 시스템을 통해 유통하는 한국어 콘텐츠의 해외 소비에도 적지 않은 장벽이 되고 있는 것이 현실이기도 하다.
이에 따라, 다양한 동영상 콘텐츠가 생성되고 유통되는 MCN 시스템과 생태계 내에서 실시간으로 콘텐츠 소비자의 언어 환경에 일치하는 화자(BJ 등)의 입술 이미지를 인식하여 입술의 움직임에 따라 정확한 음성을 인식하는 기술 개발이 요구되어 왔다.
본 발명이 이루고자 하는 기술적 과제는, 복수개의 카메라를 통해 입력되는 영상과 마이크를 통해 입력되는 음성을 포함하여 생성된 입력영상(동영상 콘텐츠 등)이 복수개 채널들을 통해 데이터를 통신할 수 있도록 지원하는 MCN 시스템에 있어서, 통신되는 입력영상 내 BJ 등 발화자의 입술 영역을 추출하고, 입술의 움직임을 기반으로 하여 음성으로부터 텍스트를 추출하고, 추출된 텍스트를 특정 언어로 번역한 후, 입력영상에 번역된 텍스트를 자막으로 추가하여 제공하는 동영상 번역 시스템 및 방법을 제공하는 것이다.
다만, 본 발명이 이루고자 하는 기술적 과제는 이상에서 언급한 기술적 과제로 제한되지 않으며, 언급되지 않은 또 다른 기술적 과제들은 아래의 기재로부터 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자에게 명확하게 이해될 수 있을 것이다.
전술한 본 발명의 목적은 MCN 시스템 기반의 멀티미디어 콘텐츠 제공을 위한 실시간 번역 기반 멀티 채널 방송 시스템에 있어서, 상기 실시간 번역 기반 멀티 채널 방송 시스템은, 멀티미디어 콘텐츠 제공을 위해 동영상 및 동영상 정보를 입력받고, 요청에 따라 선택된 동영상 및 동영상 정보를 전송하는 동영상 번역 시스템; 및 상기 동영상 번역 시스템과 네트워크를 통해 연결되어 동영상을 선택하고 선택된 동영상의 전송을 요청할 수 있는 사용자 단말기를 포함하되, 상기 동영상 번역 시스템은, 영상과 음성을 포함하는 동영상과 동영상 카테고리 정보를 입력 받는 동영상 입력부; 입력 받은 동영상의 프레임에서 입술 영역을 추출하고, 추출된 입술 영역으로부터 입술의 특징점을 추출하여 동영상 내의 음성을 텍스트로 추출하는 입술인식부; 추출된 텍스트를 특정 언어로 번역하여 자막 정보를 생성하는 번역부; 상기 입력된 동영상과 상기 자막 정보를 동기화하여 출력영상을 생성하는 출력영상생성부; 및 생성된 출력영상을 사용자 단말기로 전송하는 통신부;를 포함하되, 상기 입술인식부는, 상기 동영상 카테고리 정보를 기반으로 하여 동영상 내의 음성을 텍스트로 추출하며, 상기 입술인식부는, 입력 받은 동영상의 프레임에서 얼굴 영역을 추출하고, 추출된 얼굴 영역에서 얼굴의 특징점 정보를 추출하고, 상기 입술 영역은 추출된 얼굴의 특징점 정보 중의 하나인 것을 특징으로 하는 실시간 번역 기반 멀티 채널 방송 시스템의 제공을 통해 달성 가능하게 된다.
또한 전술한 본 발명의 목적 달성을 위해 본 발명의 일 실시예에 따른 상기 번역부는, 상기 추출된 텍스트를 상기 사용자 단말기로부터 요청받은 특정 언어로 번역하여 자막 정보를 생성하고, 상기 사용자 단말기로부터 번역하고자 하는 언어에 대한 요청이 없을 경우, 사용자 단말기의 위치 정보를 이용하여 번역하고자 하는 언어를 결정하고 상기 추출된 텍스트를 번역하여 자막 정보를 생성하는 것을 특징으로 하는 동영상 번역 시스템으로도 고려 가능하다.
또한 본 발명에 따른 상기 출력영상생성부는, 상기 입력된 동영상과 두 개 이상의 다른 언어로 된 자막 정보를 동기화하여 출력영상을 생성하는 것을 특징으로 하는 동영상 번역 시스템으로 제공될 수도 있다.
전술한 본 발명의 목적 달성을 위해, 영상과 음성을 포함하는 동영상과 동영상 카테고리 정보를 입력 받는 정보 입력 단계; 사용자 단말기로부터 동영상에 대한 전송을 요청받는 요청 수신 단계; 및 상기 사용자 단말기로 선택된 동영상을 전송하는 콘텐츠 전송 단계를 포함하는 실시간 번역 기반 멀티 채널 방송 방법에 있어서, 상기 정보 입력 단계는, 영상과 음성을 포함하는 동영상과 동영상 카테고리 정보를 입력 받는 단계; 입력 받은 동영상의 프레임에서 입술 영역을 추출하고, 추출된 입술 영역으로부터 입술의 특징점을 추출하는 단계; 상기 동영상 카테고리 정보를 기반으로 하여 동영상 내의 음성을 텍스트로 추출하는 단계; 및 추출된 텍스트를 특정 언어로 번역하여 자막 정보를 생성하고 저장하는 단계를 포함하고, 상기 콘텐츠 전송 단계는, 상기 입력된 동영상과 상기 자막 정보를 동기화하여 출력영상을 생성하는 단계; 및 생성된 출력영상을 사용자 단말기로 전송하는 단계;를 포함하는 것을 특징으로 하는 실시간 번역 기반 멀티 채널 방송 방법이 고려될 수 있다.
또한 추가적으로 상기 입술 영역을 추출하는 단계는, 입력 받은 동영상의 프레임에서 얼굴 영역을 추출하고, 추출된 얼굴 영역에서 얼굴의 특징점 정보를 추출하는 단계를 포함하고, 상기 입술 영역은 추출된 얼굴의 특징점 정보 중의 하나인 것을 특징으로 하는 동영상 번역 방법이거나 상기 자막 정보를 생성하는 단계는, 상기 추출된 텍스트를 사용자 단말기로부터 요청받은 특정 언어로 번역하여 자막 정보를 생성하고, 사용자 단말기로부터 번역하고자 하는 언어에 대한 요청이 없을 경우, 사용자 단말기의 위치 정보를 이용하여 번역하고자 하는 언어를 결정하고 상기 추출된 텍스트를 번역하여 자막 정보를 생성하는 것을 특징으로 하는 동영상 번역 방법의 제공을 통해서도 전술한 본 발명의 목적 달성이 가능하게 된다.
또한 상기 출력영상을 생성하는 단계는, 상기 입력된 동영상과 두 개 이상의 다른 언어로 된 자막 정보를 동기화하여 출력영상을 생성하는 것을 특징으로 하는 동영상 번역 방법 역시 고려 가능하다.
추가적으로 본 발명에 따른 동영상 재생 단말기에 있어서, 상기 동영상 재생 단말기의 위치 정보를 생성하는 센싱부; 동영상의 자막과 관련된 언어를 설정하는 제어부; 상기 위치 정보와 동영상 재생 요청 신호를 동영상 제공 서버로 전송하고, 상기 동영상 제공 서버로부터 출력영상을 수신하는 통신부; 및 상기 동영상 제공 서버로부터 수신된 상기 출력영상을 재생하는 디스플레이부;를 포함하고, 상기 동영상 제공 서버는, 영상과 음성을 포함하는 동영상과 동영상 카테고리 정보를 입력 받는 동영상 입력부; 입력 받은 동영상의 프레임에서 입술 영역을 추출하고, 추출된 입술 영역으로부터 입술의 특징점을 추출하여 동영상 내의 음성을 텍스트로 추출하는 입술인식부; 추출된 텍스트를 상기 자막 언어로 번역하여 자막 정보를 생성하는 번역부; 상기 입력된 동영상과 상기 자막 정보를 동기화하여 출력영상을 생성하는 출력영상생성부; 및 생성된 출력영상을 사용자 단말기로 전송하는 네트워크부;를 포함하여, 상기 동영상 재생 요청 신호는 자막 언어와 동영상의 해상도 정보를 포함하는 것을 특징으로 하는 동영상 재생 단말기의 제공을 통해서도 전순한 본 발명의 목적 달성은 가능하게 된다.
본 발명의 일 실시예에 따른 실시간 번역 기반 멀티 채널 방송 시스템 및 이를 이용하는 방법은 MCN 시스템을 기반으로 사용자가 선택한 동영상 콘텐츠를 소비할 수 있도록 지원할 수 있는 동시에, BJ 등 발화자의 입술 움직임을 추출하여 음성 인식을 제공함으로써, BJ 등 발화자 주변 잡음에 의하여 인식이 불가능한 음성을 입술의 움직임으로 추출된 음성으로 제공할 수 있다.
또한, 본 발명에 의하면 발화자의 입술의 움직임으로부터 음성 텍스트를 추출하는 과정에서 발화자의 얼굴을 인식하고 입술을 인식함에 따라 입술의 인식 확률을 높일 수 있다
또한, 본 발명에 의하면 발화자의 이야기 카테고리 정보를 이용하여, 발화자의 입술의 움직임으로부터 추출된 음성 텍스트에서 카테고리와 유사한 단어를 추출함으로써, 음성 텍스트 추출의 정확도를 높일 수 있다.
또한, 본 발명에 의하면 사용자의 원하는 언어로 동영상에 대한 번역 자막을 제공함으로써, 다른 언어를 사용하는 다양한 시청자를 확보하여 콘텐츠의 활용 범위를 넓힐 수 있다.
도 1은 본 발명의 일 실시예에 따른 실시간 번역 기반 멀티 채널 방송 시스템의 개요도이다.
도 2은 본 발명의 일 실시예에 따른 동영상 번역 시스템을 설명하기 위한 블럭도이다.
도 3는 본 발명과 관련된 사용자 단말기를 설명하기 위한 블럭도이다.
도 4은 본 발명의 일 실시예에 따른 동영상 번역 방법을 설명하기 위한 도면이다.
도 5는 본 발명의 일 실시예에 따른 입술의 특징점 추출 방법을 설명하기 위한 도면이다.
도 6는 본 발명의 일 실시예에 따른 입술 이미지로부터 음성 인식 방법을 설명하기 위한 도면이다.
도 7은 본 발명의 일 실시예에 따른 동영상의 카테고리를 이용하여 입술 이미지로부터 음성 인식 방법을 설명하기 위한 도면이다.
도 8은 본 발명의 일 실시예에 따른 동영상과 번역 자막을 재생하는 방법을 설명하기 위한 도면이다.
도 2은 본 발명의 일 실시예에 따른 동영상 번역 시스템을 설명하기 위한 블럭도이다.
도 3는 본 발명과 관련된 사용자 단말기를 설명하기 위한 블럭도이다.
도 4은 본 발명의 일 실시예에 따른 동영상 번역 방법을 설명하기 위한 도면이다.
도 5는 본 발명의 일 실시예에 따른 입술의 특징점 추출 방법을 설명하기 위한 도면이다.
도 6는 본 발명의 일 실시예에 따른 입술 이미지로부터 음성 인식 방법을 설명하기 위한 도면이다.
도 7은 본 발명의 일 실시예에 따른 동영상의 카테고리를 이용하여 입술 이미지로부터 음성 인식 방법을 설명하기 위한 도면이다.
도 8은 본 발명의 일 실시예에 따른 동영상과 번역 자막을 재생하는 방법을 설명하기 위한 도면이다.
이하에서는 첨부한 도면을 참조하여 본 발명을 설명하기로 한다. 그러나 본 발명은 여러 가지 상이한 형태로 구현될 수 있으며, 따라서 여기에서 설명하는 실시예로 한정되는 것은 아니다. 그리고 도면에서 본 발명을 명확하게 설명하기 위해서 설명과 관계없는 부분은 생략하였으며, 명세서 전체를 통하여 유사한 부분에 대해서는 유사한 도면 부호를 붙였다.
명세서 전체에서, 어떤 부분이 다른 부분과 "연결(접속, 접촉, 결합)"되어 있다고 할 때, 이는 "직접적으로 연결"되어 있는 경우뿐 아니라, 그 중간에 다른 부재를 사이에 두고 "간접적으로 연결"되어 있는 경우도 포함한다. 또한, 어떤 부분이 어떤 구성요소를 "포함"한다고 할 때, 이는 특별히 반대되는 기재가 없는 한 다른 구성요소를 제외하는 것이 아니라 다른 구성요소를 더 구비할 수 있다는 것을 의미한다.
본 명세서에서 사용한 용어는 단지 특정한 실시예를 설명하기 위해 사용된 것으로, 본 발명을 한정하려는 의도가 아니다. 단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수의 표현을 포함한다. 본 명세서에서, "포함하다" 또는 "가지다" 등의 용어는 명세서 상에 기재된 특징, 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것이 존재함을 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다.
이하에서는 도 1을 참조하여, 본 발명의 일 실시예에 따른 실시간 번역 기반 멀티 채널 방송 시스템(10) 및 이를 기반으로 하는 실시간 번역 기반 멀티 채널 방송 방법에 대해 기술한다.
도 1은 본 발명의 일 실시예에 따른 실시간 번역 기반 멀티 채널 방송 시스템(10)의 개요도이다.
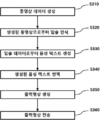
도 1에 도시된 바와 같이, 본 발명에 따른 실시간 번역 기반 멀티 채널 방송 시스템(10)은 실시간으로 멀티미디어 콘텐츠 제공을 위해 동영상 및 동영상 정보를 입력받고, 요청에 따라 선택된 동영상 및 동영상 정보를 전송하는 동영상 번역 시스템(100) 및 동영상 번역 시스템(100)과 네트워크를 통해 연결되어 동영상을 선택하고 선택된 동영상의 실시간 전송을 요청할 수 있는 사용자 단말기(200)를 포함할 수 있다. 이 경우 본 발명에 따른 실시간 번역 기반 멀티 채널 방송 시스템(10) 이용 방법은 영상과 음성을 포함하는 동영상과 동영상 카테고리 정보를 입력 받는 정보 입력 단계(S10; 사용자 단말기로부터 동영상에 대한 전송을 요청받는 요청 수신 단계(S20); 및 상기 사용자 단말기로 선택된 동영상을 전송하는 콘텐츠 전송 단계(S30)를 포함하는 실시간 번역 기반 멀티 채널 방송 방법으로 구성될 수 있다.
또한 이하 후술할 내용을 참고로, 본 발명에 따른 시스템(10)의 이용 방법은 다시, 정보 입력 단계(S10)가 영상과 음성을 포함하는 동영상과 동영상 카테고리 정보를 입력 받는 단계(S310); 입력 받은 동영상의 프레임에서 입술 영역을 추출하고, 추출된 입술 영역으로부터 입술의 특징점을 추출하는 단계(S320); 상기 동영상 카테고리 정보를 기반으로 하여 동영상 내의 음성을 텍스트로 추출하는 단계(S330); 및 추출된 텍스트를 특정 언어로 번역하여 자막 정보를 생성하고 저장하는 단계(S340, 도 4 참조)를 포함하고, 콘텐츠 전송 단계(S30)는, 상기 입력된 동영상과 상기 자막 정보를 동기화하여 출력영상을 생성하는 단계(S350); 및 생성된 출력영상을 사용자 단말기로 전송하는 단계(360);를 포함하는 것을 특징으로 하는 실시간 번역 기반 멀티 채널 방송 방법의 형태로 제공될 수도 있다.
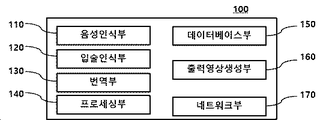
이를 위해 본 발명에 따른 실시간 번역 기반 멀티 채널 방송 시스템(10)은 동영상 및 음성 등이 포함된 멀티미디어 콘텐츠 정보를 기반으로 사용자 요청 멀티미디어 콘텐츠를 제공할 수 있는 데이터베이스부(150, 도 2 참조), 복수의 사용자 단말기(200)와 통신이 가능한 네트워크부(170), 네트워크부(170)와 연결된 프로세싱부(140)를 포함할 수 있다. 이 경우 본 발명에 따른 프로세싱부(140)는 사용자 단말기(200)로부터 멀티미디어 콘텐츠 서비스 어플리케이션에 대한 요청을 수신하고, 직접적으로 또는 별도의 중계 서버를 통해 사용자 단말기(200)에 요청받은 멀티미디어 콘텐츠 서비스 채널 정보 및 콘텐츠의 실시간 스트리밍 데이터를 전송하도록 할 수 있다.
또한 실시간 번역 기반 멀티 채널 방송 시스템(10)은 사용자 단말기(200, 도 3 참조)의 사용자입력부(260) 및/또는 인터페이스부(270)를 통해 요청된 멀티미디어 콘텐츠를 요청한 사용자에게 제공(스트리밍 등의 방식)하되, 동시에 필요한 번역 기능을 추가적으로 제공할 수 있다. 이를 위해 본 발명에 따른 실시간 번역 기반 멀티 채널 방송 시스템(10)은 동영상 번역 시스템(100)을 더 포함할 수 있다.
이하에서는 본 발명에 따른 동영상 번역 시스템(100)에 대해 보다 자세히 설명하기로 한다.
도 2은 본 발명의 일 실시예에 따른 동영상 번역 시스템을 설명하기 위한 블럭도이다.
도 2에 도시된 바와 같이, 동영상 번역 시스템(100)은 음성인식부(110), 입술인식부(120), 번역부(130), 프로세싱부(140), 데이터베이스부(150), 출력영상생성부(160) 및 네트워크부(170)를 포함할 수 있다. 도 2에 도시된 구성요소들은 동영상 번역 시스템(100)을 구현하는데 있어서 필수적인 것은 아니어서, 본 명세서 상에서 설명되는 동영상 번역 시스템(100)은 위에서 열거된 구성요소들 보다 많거나, 또는 적은 구성요소들을 가질 수 있다.
참고적으로 본 발명에 따른 동영상 번역 시스템(100)은 동영상 입력부(미도시)를 추가로 포함할 수 있으며, 이 경우 동영상 입력부는 영상과 음성을 포함하는 동영상과 동영상 카테고리 정보 등을 사용자(또는 서비스 제공자)로부터 입력 받을 수 있다. 동영상 입력부는 발화자가 발화한 음성 신호를 수신하는 마이크 등과 같은 음성 수신 장치와 정해진 초당 프레임 단위로 영상을 촬영하는 카메라 등과 같은 촬상장치를 포함할 수 있다.
음성인식부(110)는 마이크(미도시)를 통해 수신된 음향신호로부터 잡음을 제거하고, BJ 등 발화자의 음성을 검출할 수 있다. 또한, 음성인식부(110)는 검출된 음성의 특징을 추출하여 음성모델 데이터베이스와 비교하여 음성을 인식하고, 단어나 문장으로 이루어진 텍스트 정보로 변환하여 출력할 수 있다. 이때, 음성인식부(110)는 음성인식의 확률을 높이기 위해 언어를 지정하여 음성을 인식하고 텍스트로 변환할 수 있다. 예를 들어, 한국어로 설정한 경우, 음성을 한국어로 인식하고 한국어 텍스트로 변환할 수 있다.
마이크는 발화자가 발화한 음성 신호를 수신할 수 있다. 그리고, A/D 변환기를 통해 아날로그 음성 신호를 디지털 신호로 변환할 수 있다. 이때, 마이크는 동영상 번역 시스템(100)의 외부에 별도의 마이크로 구현될 수 있으나, 이는 일 실시예에 불과할 뿐, 동영상 번역 시스템(100) 내부에 구현될 수 있다.
입술인식부(120)는 촬영 장치를 통해 촬영되고 있는 발화자 얼굴에서 발화자의 입술 이미지를 검출하고, 검출된 입술 이미지의 움직임을 파악하여 음성을 텍스트로 변환할 수 있다. 입술인식부(120)는 카메라를 통해 정해진 초당 프레임 단위로 촬영된 동영상으로부터 입술 이미지를 프레임 단위로 추출할 수 있다. 여기서, 초당 프레임은 초당 30 또는 60, 120프레임일 수 있다. 입술 이미지를 검출하기 위하여, 먼저 발화자의 얼굴을 인식하고, 인식된 얼굴의 형상 내에서 입술 영역을 검출한 후, 입술 이미지를 검출하는 방식으로 입술 이미지의 검출 확률을 높일 수 있다.
얼굴을 인식하는 과정은 입력 영상에서 사람의 얼굴을 검출하고, 검출된 얼굴을 정렬하고, 얼굴의 특징을 추출하는 과정을 포함할 수 있다. 입력 영상에서 사람의 얼굴을 검출하는 과정은 사람의 얼굴을 찾아 그 위치 정보를 추출하는 과정일 수 있다. 검출된 얼굴들은 다양한 조명과 회전으로 인해 인식기에 바로 입력할 경우 인식률이 매우 낮아지게 되므로, 조명의 영향을 줄이고, 영상의 잡음을 제거한 후, 얼굴의 회전, 크기 등을 보정하는 얼굴 정렬과정을 수행할 수 있다. 정렬된 얼굴 영상에서 사람의 얼굴을 잘 표현하는 특징을 추출할 수 있다. 얼굴의 특징은 눈, 코, 입, 입술, 눈썹 등의 특징점과 특징점들 사이의 거리 정보를 포함할 수 있다.
입술인식부(120)는 얼굴인식과정에서 추출된 입술 이미지로부터 프레임 단위로 입술 이미지의 특징점을 추출할 수 있다. 여기서 입술 특징점은 양쪽 입꼬리의 끝점, 윗입술의 중간 지점, 아랫입술의 중간 지점, 윗입술의 중간 지점과 입꼬리의 중간 지점, 아랫입술의 중간 지점과 입꼬리의 중간 지점, 입술의 전체적인 형상 정보를 포함할 수 있다. 추출된 입술의 특징점들의 프레임 간의 움직임을 추적하여 발화자가 발화하는 음성 구간에 발화자의 입술 이미지의 변화를 추적할 수 있다. 이때, 입술인식부(120)는 입술 이미지의 변화에 따라 입술 이미지의 특징점을 추출할 수 있다. 특징점의 움직임 데이터를 이용하여 발화자의 음성을 인식하고 텍스트로 추출할 수 있다.
입술인식부(120)는 입술의 움직임으로부터 음성인식하는 확률을 높이기 위해 발화자별로 입술 움직임에 따라 발음하는 자음과 모음 데이터를 이용하여 발화자의 음성으로부터 텍스트를 추출할 수 있다.
번역부(130)는 입술 움직임 데이터로부터 생성된 텍스트 정보를 특정 언어로 번역하여 자막 데이터를 생성할 수 있다. 여기서, 특정언어는 사용자 단말기(200)의 현재 위치에 지정된 언어이거나 사용자 단말기(200)에서 요청한 언어일 수 있다. 사용자 단말기(200)로부터 번역하고자 하는 언어에 대한 요청이 없을 경우, 사용자 단말기(200)의 위치 정보를 이용하여 번역하고자 하는 언어를 결정하고 번역하여 자막 데이터를 생성할 수 있다.
사용자 단말기(200)가 위치한 장소를 확인하고, 위치한 장소가 해당하는 국가의 주사용 언어로 번역을 진행할 수 있다. 사용자 단말기(200)의 위치한 장소는 GPS센서의 위치 정보나 사용자 단말기(200)의 IP 주소를 통해 확인할 수 있다. 사용자 단말기(200)에서 자막으로 재생되기를 원하는 언어를 설정하여 동영상 재생 요청을 할 때 설정된 언어 정보를 동영상 번역 시스템(100)으로 자막 재생 언어 정보를 전송할 수 있다. 따라서 번역부(130)는 입술 움직임 데이터로부터 생성된 텍스트 정보로부터 정해진 언어로 번역하여 자막 데이터를 생성할 수 있다. 또한, 번역부(130)는 동시에 여러 개의 언어로 자막을 생성할 수 있다.
프로세싱부(140)는 동영상 번역 시스템(100)의 전반적인 동작을 제어할 수 있다. 예를 들어, 프로세싱부(140)는 데이터베이스부(150)에 저장된 프로그램들을 실행하여, 음성인식부(110), 입술인식부(120), 번역부(130), 데이터베이스부(150), 출력영상생성부(160) 및 네트워크부(170)를 등을 제어할 수 있다.
프로세싱부(140)는 입술인식부(120)에 의해 발화자의 음성으로부터 생성된 텍스트를 출력영상생성부(160)를 통해 동영상에 자막 형태로 추가하여 출력영상을 생성할 수 있도록 할 수 있다. 또한, 프로세싱부(140)는 사용자 단말기(200)로부터 수신한 동영상 재생 관련 부가 정보를 반영하여 출력영상을 생성하도록 할 수 있다. 여기서 동영상 재생 관련 부가 정보는 자막 언어, 동영상 크기, 동영상 프레임수, 동영상 재생 속도 등을 포함할 수 있다.
프로세싱부(140)는 음성인식부(110)에 의해 인식된 발화자의 음성과 입술인식부(120)에 의해 생성된 입술 움직임 데이터를 이용하여 발화자의 입술 움직임에 따른 발화자의 음성 데이터를 생성하여 데이터베이스부(150)에 저장할 수 있다. 프로세싱부(140)는 카메라와 마이크로부터 입력되는 특정 프레임 구간에서의 음성으로부터 추출된 텍스트와 입술 움직임으로부터 추출된 데이터를 비교하여 정확한 발음을 검증하여 입술의 움직임에 따른 발음되는 음소나 단어를 저장하거나 사용자입력부(260)로부터 입술의 움직임에 따른 발음되는 음소나 단어를 입력 받아서 데이터베이스부(150)에 저장할 수 있다. 예를 들어, 발화자가 '오'발음을 하는 경우, 음성인식부(110)에 의해 '오'라고 인식을 하고, 입술인식부(120)에 의해 '우'라고 인식하였을 때, '오'라고 발음하는 프레임 구간의 입술 특징점의 움직임을 '오'라고 인식하도록 해당 입술 움직임 데이터를 '오'라고 데이터베이스부(150)에 저장할 수 있다. 따라서 이후에 동일한 입술 움직임 데이터가 추출되면 데이터베이스부(150)에 저장된 입술 움직임 데이터와 비교하여 '오'로 인식할 수 있다.
프로세싱부(140)는 동영상 번역 시스템(100)에서 카메라 등의 촬영장치로부터 입력되는 영상과 마이크 등의 입력 장치로 입력되는 음성을 동기화하여 출력영상이 생성되도록 하고, 번역부(130)에서 생성된 자막 정보도 영상과 음성에 동기화시켜서 디스플레이 상에 오버레이 형태로 출력영상에 추가되도록 할 수 있다. 영상과 음성, 자막의 동기화를 위하여 입술인식부(120)에서 입술 움직임 데이터로부터 텍스트 정보를 추출하고 번역부(130)에 의해 자막 정보로 생성되는 시간 동안, 실시간으로 입력되는 영상과 음성에 시간 지연을 추가하여 자막 정보와 동기화되어 출력영상이 생성되도록 할 수 있다.
데이터베이스부(150)는 동영상 번역 시스템(100)에서 실행되는 동작과 관련된 프로그램을 저장할 수 있다. 데이터베이스부(150)는 음성인식 알고리즘, 이술인식 알고리즘, 번역 알고리즘, 발화자별 입술 움직임 데이터와 텍스트 정보 등을 저장할 수 있다.
데이터베이스부(150)는 BJ 등 발화자의 입술 움직임에 따른 발화자의 음성 데이터를 생성하여 저장할 수 있다. 데이터베이스부(150)는 발화자별로 동영상의 특정 프레임 구간의 입술의 움직임 데이터를 특정 음소나 음절, 단어, 문장으로 저장할 수 있다. 또한 데이터베이스부(150)는 동영상의 카테고리별로 동영상의 특정 프레임 구간의 입술의 움직임 데이터를 특정 음소나 음절, 단어, 문장으로 저장할 수 있다.
데이터베이스부(150)는 플래시 메모리 타입, 하드디스크 타입, 멀티미디어 카드 마이크로 타입 및 카드 타입의 메모리, RAM, SRAM, ROM, EEPROM, PROM, 자기메모리, 자기 디스크, 광디스크 중 적어도 하나의 타입의 저장매체를 포함할 수 있다. 또한, 디바이스는 인터넷 상에서 메모리의 저장 기능을 수행하는 웹 스토리지 또는 클라우드 서버를 운영할 수도 있다.
네트워크부(170)는 동영상 번역 시스템(100)이 서버나 다른 기기와 데이터 등을 송신 또는 수신할 수 있는 연결을 구성해 줄 수 있다. 또한 네트워크부(170)는 출력데이터를 서버나 다른 기기로 송신하거나 서버나 다른 기기로부터의 입력데이터를 수신할 수 있도록 할 수 있다.
네트워크부(170)는 사용자 단말기(200)로부터 동영상 재생요청을 받아서 프로세싱부(140)로 전달하고, 동영상 번역 시스템(100)에서 생성된 출력영상을 사용자 단말기(200)로 전송할 수 있다. 또한 네트워크부(170)는 사용자 단말기(200)로부터 동영상 재생과 관련된 부가 정보를 수신하여 프로세싱부(140)로 전달할 수 있다.
네트워크부(170)는 블루투스, NFC(Near Field Communication), WLAN(Wireless LAN), Wi-Fi(Wireless-Fidelity), Zigbee, IrDA(infrared Data Association), WFD(Wi-Fi Direct), UWB(ultra wideband), Wireless USB(Wireless Universal Serial Bus), Ant+ 등의 근거리 네트워크나 3G, LTE, LTE-A, 5G 등의 이동 통신 네트워크를 지원할 수 있다.
도 3는 본 발명과 관련된 사용자 단말기를 설명하기 위한 블럭도이다.
도 3를 참조하면, 본 발명의 일 실시예에 따른 사용자 단말기(200)는 센싱부(210), 제어부(220), 통신부(230), 전원부(240), 출력부(250), 사용자입력부(260), 인터페이스부(270)를 포함할 수 있다. 도 3에 도시된 구성요소들은 사용자 단말기(200)를 구현하는데 있어서 필수적인 것은 아니어서, 본 명세서 상에서 설명되는 사용자 단말기(200)는 위에서 열거된 구성요소들 보다 많거나, 또는 적은 구성요소들을 가질 수 있다.
각 구성요소에 대해 구체적으로 살펴보면, 센싱부(210)는 사용자 단말기(200)의 주변 환경 정보 및 사용자 정보 중 적어도 하나를 센싱하기 위한 하나 이상의 센서를 포함할 수 있다.
센싱부(210)는 자이로 센서(gyro sensor), 가속도 센서(acceleration sensor), 자기 센서(magnetic sensor), 거리측정 센서(예를 들어, 레이저 센서, 초음파 센서, 적외선 센서, 라이다(LIDAR) 센서, 레이더(RADAR) 센서, 카메라 센서 등), 근접센서(proximity sensor), 조도 센서(illumination sensor), 터치 센서(touch sensor), 중력 센서(G-sensor), 모션 센서(motion sensor), RGB 센서, 적외선 센서(IR 센서: infrared sensor), 지문인식 센서(finger scan sensor), 초음파 센서(ultrasonic sensor), 광 센서(optical sensor), 배터리 게이지(battery gauge), 환경 센서, 화학 센서 중 적어도 하나를 포함할 수 있다. 한편, 본 명세서에 개시된 사용자 단말기(200)는, 이러한 센서들 중 적어도 둘 이상의 센서에서 센싱되는 정보들을 조합하여 활용할 수 있다.
터치 센서는 저항막 방식, 정전용량 방식, 적외선 방식, 초음파 방식, 자기장 방식 등 여러 가지 터치방식 중 적어도 하나를 이용하여 터치 스크린(또는 디스플레이부(251))에 가해지는 터치(또는 터치입력)을 감지할 수 있다.
일 예로서, 터치 센서는, 터치 스크린의 특정 부위에 가해진 압력 또는 특정 부위에 발생하는 정전 용량 등의 변화를 전기적인 입력신호로 변환하도록 구성될 수 있다. 터치 센서는, 터치 스크린 상에 터치를 가하는 터치 대상체가 터치 센서 상에 터치 되는 위치, 면적, 터치 시의 압력, 터치 시의 정전 용량 등을 검출할 수 있도록 구성될 수 있다. 여기에서, 터치 대상체는 상기 터치 센서에 터치를 인가하는 물체로서, 예를 들어, 손가락, 터치펜 또는 스타일러스 펜(Stylus pen), 포인터 등이 될 수 있다.
이와 같이, 터치 센서에 대한 터치 입력이 있는 경우, 그에 대응하는 신호(들)는 터치 제어기로 보내질 수 있다. 터치 제어기는 그 신호(들)를 처리한 다음 대응하는 데이터를 제어부(220)로 전송할 수 있다. 이로써, 제어부(220)는 디스플레이부(251)의 어느 영역이 터치 되었는지 여부 등을 알 수 있게 된다. 여기에서, 터치 제어기는, 제어부(220)와 별도의 구성요소일 수 있고, 제어부(220) 자체일 수 있다.
제어부(220)는 사용자 단말기(200)의 전반적인 동작을 제어한다. 예를 들어, 제어부(220)는 저장부(미도시)에 저장된 프로그램들을 실행함으로써, 센싱부(210), 통신부(230), 저장부, 전원부(240), 출력부(250), 사용자입력부(260) 등을 제어할 수 있다.
제어부(220)는 센싱부(210)에 의해 발생된 센싱 신호에 기초하여, 사용자 단말기(200)의 구동 또는 동작을 제어하거나, 사용자 단말기(200)에 설치된 응용 프로그램과 관련된 데이터 처리, 기능 또는 동작을 수행할 수 있다.
예를 들어, 제어부(220)는 사용자입력부(260)에 의해 입력된 정보에 의해 동영상 재생과 자막 제공 요청을 받고, 동영상 번역 시스템(100)으로부터 동영상과 함께 자막 정보를 제공받아서 디스플레이부(251)에 제공할 수 있다.
통신부(230)는 사용자 단말기(200)가 동영상 번역 시스템(100)이나 다른 기기와 데이터 등을 송신 또는 수신할 수 있는 연결을 구성해 줄 수 있다. 또한 통신부(230)는 사용자 단말기(200)의 출력데이터를 동영상 번역 시스템(100)이나 다른 기기로 송신하거나 동영상 번역 시스템(100)이나 다른 기기로부터의 입력데이터를 수신할 수 있도록 한다.
통신부(230)는 블루투스, NFC(Near Field Communication), WLAN(Wireless LAN), Wi-Fi(Wireless-Fidelity), Zigbee, IrDA(infrared Data Association), WFD(Wi-Fi Direct), UWB(ultra wideband), Wireless USB(Wireless Universal Serial Bus), Ant+ 등의 근거리 네트워크나 3G, LTE, LTE-A, 5G 등의 이동 통신 네트워크를 지원할 수 있다.
전원부(240)는 제어부(220)의 제어 하에서, 외부의 전원, 내부의 전원을 인가받아 사용자 단말기(200)에 포함된 각 구성요소들에 전원을 공급한다. 이러한 전원부(240)는 배터리를 포함하며, 상기 배터리는 내장형 배터리 또는 교체가능한 형태의 배터리가 될 수 있다.
또한, 전원부(240)는 연결포트를 구비할 수 있으며, 연결포트는 배터리의 충전을 위하여 전원을 공급하는 외부 충전기가 전기적으로 연결되는 인터페이스의 일 예로서 구성될 수 있다.
다른 예로서, 전원부(240)는 상기 연결포트를 이용하지 않고 무선방식으로 배터리를 충전하도록 이루어질 수 있다. 이 경우에, 전원부(240)는 외부의 무선 전력 전송장치로부터 자기 유도 현상에 기초한 유도 결합(Inductive Coupling) 방식이나 전자기적 공진 현상에 기초한 공진 결합(Magnetic Resonance Coupling) 방식 중 하나 이상을 이용하여 전력을 전달받을 수 있다.
출력부(250)는 오디오 신호 또는 비디오 신호 또는 진동 신호의 출력을 위한 것으로, 이에는 디스플레이부(251)와 음향출력부(미도시) 등이 포함될 수 있다.
디스플레이부(251)는 동영상 번역 시스템(100)에서 처리되는 정보를 표시할 수 있다.
예를 들어, 디스플레이부(251)는 동영상 번역 시스템(100)에서 카메라 등의 촬영장치로부터 입력되는 영상과 마이크 등의 입력 장치로 입력되는 음성을 통신부(230)를 통해 수신 받아서 디스플레이로 출력하고, 추가로, 동영상 번역 시스템(100)에서 생성된 텍스트 정보를 통신부(230)를 통해 수신 받아서 디스플레이 상에 자막 형태로 출력할 수 있다.
또한, 디스플레이부(251)는 사용자 단말기(200)에서 구동되는 응용 프로그램의 실행화면 정보, 또는 이러한 실행화면 정보에 따른 UI(User Interface), GUI(Graphic User Interface) 정보를 표시할 수 있다.
한편, 디스플레이부(251)와 터치패드가 레이어 구조를 이루어 터치 스크린으로 구성되는 경우, 디스플레이부(251)는 출력 장치 이외에 입력 장치로도 사용될 수 있다. 디스플레이부(251)는 액정 디스플레이(liquid crystal display), 박막 트랜지스터 액정 디스플레이(thin film transistor-liquid crystal display), 유기 발광 다이오드(organic light-emitting diode), 플렉시블 디스플레이(flexible display), 3차원 디스플레이(3D display), 전기영동 디스플레이(electrophoretic display) 중에서 적어도 하나를 포함할 수 있다. 그리고 디바이스의 구현 형태에 따라 동영상 번역 시스템(100)은 디스플레이부(251)를 2개 이상 포함할 수도 있다
음향출력부는 마이크로부터 수신되거나 저장부에 저장된 오디오 데이터를 출력할 수 있다. 또한, 음향출력부는 사용자 단말기(200)에서 수행되는 기능과 관련된 음향 신호를 출력할 수 있다. 이러한 음향출력부에는 스피커(speaker), 버저(Buzzer) 등이 포함될 수 있다.
사용자입력부(260)는 사용자로부터 정보를 입력받기 위한 것으로서, 사용자입력부(260)를 통해 정보가 입력되면, 제어부(220)는 입력된 정보에 대응되도록 사용자 단말기(200)의 동작을 제어할 수 있다. 이러한, 사용자입력부(260)는 기계식 (mechanical) 입력수단(또는, 메커니컬 키, 예를 들어, 동영상 번역 시스템(100)의 전·후면 또는 측면에 위치하는 버튼, 돔 스위치 (dome switch), 조그 휠, 조그 스위치 등) 및 터치식 입력수단을 포함할 수 있다. 일 예로서, 터치식 입력수단은, 소프트웨어적인 처리를 통해 터치스크린에 표시되는 가상 키(virtual key), 소프트 키(soft key) 또는 비주얼 키(visual key)로 이루어지거나, 상기 터치스크린 이외의 부분에 배치되는 터치 키(touch key)로 이루어질 수 있다. 한편, 상기 가상키 또는 비주얼 키는, 다양한 형태를 가지면서 터치스크린 상에 표시되는 것이 가능하며, 예를 들어, 그래픽(graphic), 텍스트(text), 아이콘(icon), 비디오(video) 또는 이들의 조합으로 이루어질 수 있다.
인터페이스부(270)는 사용자 단말기(200)에 연결되는 모든 외부 기기와의 통로 역할을 할 수 있다. 인터페이스부(270)는 외부 기기로부터 데이터를 전송받거나, 전원을 공급받아 사용자 단말기(200) 내부의 각 구성요소에 전달하거나, 사용자 단말기(200) 내부의 데이터가 외부 기기로 전송되도록 한다. 예를 들어, 유/무선 헤드셋 포트(port), 외부 충전기 포트(port), 유/무선 데이터 포트(port), 메모리 카드(memory card) 포트(port), 식별 모듈이 구비된 장치를 연결하는 포트(port), 오디오 I/O(Input/Output) 포트(port), 비디오 I/O(Input/Output) 포트(port), 이어폰 포트(port) 등이 인터페이스부(270)에 포함될 수 있다.
도 4은 본 발명의 일 실시예에 따른 동영상 번역 방법을 설명하기 위한 도면이다.
도 4을 참조하면, 본 발명의 일 실시예에 따른 동영상 번역 방법은 동영상 데이터를 생성하는 단계(S310); 생성된 동영상으로부터 입술을 인식하는 단계(S320); 인식된 입술 데이터로부터 음성 텍스트를 생성하는 단계(S330); 생성된 음성 텍스트를 번역하는 단계(S340); 번역된 음성 텍스트를 동영상 데이터에 추가하여 출력영상을 생성하는 단계(S350)로 이루어질 수 있다. 추가로 생성된 출력영상을 사용자 단말기(200)로 전송하는 단계(S360)을 더 포함할 수 있다.
S310단계는 카메라와 같은 촬영 장치로부터 영상을 촬영하고, 마이크를 통해 음향을 수신하여 입력영상을 생성하는 과정일 수 있다. 입력영상은 초당 정해진 프레임 단위로 정해진 비디오 코딩 방식에 따라 저장될 수 있다. 여기서, 초당 프레임은 초당 30 또는 60, 120프레임일 수 있고, 촬영 장치의 설정값에 따라 달라질 수 있다. 음성은 정해진 오디오 코딩 방식에 따라 코딩되어 저장될 수 있다. 촬영된 동영상은 2개 이상의 카메라와 마이크에 의해 촬영된 3D 비디오와 3D오디오를 포함할 수 있다.
S320단계는 입력영상으로부터 입술 이미지를 추출하여 입술의 움직임 데이터를 생성하는 과정일 수 있다. 입술 이미지를 검출하기 위하여, 먼저 발화자의 얼굴을 인식하고, 인식된 얼굴의 형상 내에서 입술 영역을 검출한 후, 입술 이미지를 검출하여 입술의 특징점을 검출할 수 있다.
얼굴을 인식하기 위해서, 입력영상으로부터 사람의 얼굴을 검출하고, 검출된 얼굴을 정렬한 후, 얼굴의 특징을 추출하는 과정을 수행할 수 있다. 입력영상에서 사람의 얼굴을 찾아 그 위치 정보를 추출하여 사람의 얼굴을 검출할 수 있다. 검출된 얼굴의 인식률을 높이기 위해, 조명의 영향을 줄이고, 영상의 잡음을 제거한 후, 얼굴의 회전, 크기 등을 보정하는 얼굴 정렬과정을 수행할 수 있다. 정렬된 얼굴 영상에서 눈, 코, 입, 입술, 눈썹 등의 특징점과 특징점들 사이의 거리 정보와 같은 얼굴을 잘 표현하는 특징을 추출할 수 있다. 발화자별로 얼굴의 특징으로부터 데이터베이스부(150)에 저장하고, 추출된 얼굴의 특징을 이용하여 특정 발화자를 인식할 수 있다.
추출된 얼굴의 특징 중에서 입술 이미지를 검출하여 프레임 단위로 입술 이미지의 특징점과 위치 좌표를 추출하여 입술 움직임 데이터를 생성할 수 있다. 여기서 입술 특징점은 양쪽 입꼬리의 끝점, 윗입술의 중간 지점, 아랫입술의 중간 지점, 윗입술의 중간 지점과 입꼬리의 중간 지점, 아랫입술의 중간 지점과 입꼬리의 중간 지점, 입술의 전체적인 형상 정보를 포함할 수 있다. 추출된 입술의 특징점들의 프레임 간의 위치 좌표 변화를 추적하여 발화자가 발화하는 음성 구간에 발화자의 입술 이미지의 변화를 추적할 수 있다. 입술의 움직임 데이터는 각 프레임에서의 입술의 특정점의 위치 데이터일 수 있고, 특정점 중 하나를 기준점으로 하는 다른 특정점의 상대적 거리와 방향을 나타내는 벡터 데이터일 수 있다.
S330단계는 생성된 입술 움직임 데이터로부터 발화자의 음성을 텍스트로 변환하는 과정일 수 있다. 입력영상의 특정 프레임 구간에서의 입술 움직임 데이터로부터 발화자가 발음하는 음소 또는 음절, 단어, 문장 등을 추출하여 텍스트로 변환할 수 있다.
발화자별로 발음하는 입모양에 달라질 수 있기 때문에 입력영상을 생성하기 전에 발화자의 입술 움직임과 발음하는 음소 또는 음절, 단어, 문장을 데이터베이스화하여 데이터베이스부(150)에 저장할 수 있다.
발화자별로 동영상의 특정 프레임 구간의 입술의 움직임 데이터를 특정 음소나 음절, 단어, 문장으로 저장할 수 있다. 예를 들어, 발화자 A가 '아' 발음을 하는 경우, 입술 특징점 각각의 이동 방향과 이동 크기를 데이터베이스부(150)에 저장할 수 있다. 발화자 A가 '아' 발음을 하는 경우, 동영상 번역 시스템(100)의 음성인식부(110)에서 인식하는 발음과 입술인식부(120)에서 인식하는 발음이 동일하면, 입술 특징점 각각의 이동 방향과 이동 크기를 데이터베이스부(150)에 저장할 수 있다. 발화자 A가 '아' 발음을 하는 경우, '아' 발음에 대한 입술 움직임 데이터로 입술 특징점 각각의 이동 방향과 이동 크기를 데이터베이스부(150)에 저장할 수 있다.
입력영상으로부터 얼굴을 인식하여 발화자를 인식하거나 기 설정된 발화자정보로부터 발화자를 인식하여, 입력영상의 특정 프레임 구간에서의 입술 움직임 데이터를 동영상 번역 시스템(100)의 데이터베이스부(150)에 저장된 발화자의 입술 움직임 데이터와 비교하여 발화자가 발음하는 음소 또는 음절, 단어, 문장 등을 추출하여 텍스트로 변환할 수 있다.
S340단계는 발화자의 음성에 해당하는 텍스트 정보를 특정 언어의 문장으로 변환하는 번역 과정일 수 있다. 번역되고자 하는 특정언어는 사용자 단말기(200)에서 요청된 언어이거나 사용자 단말기(200)의 현재 위치 정보로부터 설정된 언어일 수 있다. 사용자 단말기(200)의 영상 재생을 위한 플레이어에 설정된 자막 언어 설정 정보가, 영상 재생 요청 시에 동영상 번역 시스템(100)으로 전송되어, 사용자 단말기(200)의 요청 언어로 확인될 수 있다. 사용자 단말기(200)의 현재 위치 정보로부터 설정하기 위하여, 사용자 단말기(200)가 위치한 장소를 확인하고, 위치한 장소가 해당하는 국가의 주사용 언어로 번역을 진행할 수 있다. 사용자 단말기(200)의 위치한 장소는 GPS센서의 위치 정보나 사용자 단말기(200)의 IP 주소를 통해 확인할 수 있다.
또한 동영상 번역 시스템(100)에 기본으로 설정되거나 사용자 단말기(200)의 요청에 의해 설정된 문체(예를 들어, 구어체, 문어체, 간결체, 만연체, 강건체, 우유체, 화려체, 건조체, 산문체, 운문체)로 문장을 생성할 수 있다. 사용자 단말기(200)의 사용자의 성별 나이에 따라 문체를 설정하여 문장을 생성할 수 있다.
S350단계는 입력영상과 번역된 자막 정보를 이용하여 출력영상를 생성하는 과정일 수 있다. 출력영상은 촬영된 영상과 음성을 자막 정보와 동기화하여 영상과 음성, 자막으로 이루어진 정보일 수 있다. 이와 같이 별도의 자막 정보가 사용자 단말기(200)로 전송되는 경우, 사용자 단말기(200)에서 자막의 출력 위치와 폰트 크기를 설정하여 출력할 수 있다. 출력영상은 촬영된 영상에 영상과 동기화된 자막를 추가하여 새로운 영상으로 생성하여 영상과 음성으로 이루어진 정보일 수 있다.
동영상 번역 시스템(100)은 입력되는 영상에 생성된 자막 정보를 동기화시켜서 디스플레이 상에 오버레이 형태로 출력영상에 추가할 수 있다. 출력영상에서 영상과 음성, 자막의 동기화를 위하여, 입술 움직임 데이터로부터 텍스트 정보를 추출하고 특정언어로 번역된 자막 정보를 생성하기 위해 소요되는 시간만큼, 실시간으로 입력되는 영상과 음성에 시간 지연으로 추가하여, 자막 정보와 동기화되어 출력영상이 생성할 수 있다.
S360단계는 생성된 출력영상을 사용자 단말기(200)로 전송하는 과정일 수 있다. 생성된 출력영상을 동영상 번역 시스템(100)의 네트워크부(170)와 사용자 단말기(200)의 통신부(230)를 통해 사용자 단말기(200)로 전송할 수 있다. 동영상 번역 시스템(100)에 기본으로 설정되거나 사용자 단말기(200)의 요청에 의해 설정된 동영상의 해상도 및 재생 속도로 출력영상을 생성하거나 변환하여 사용자 단말기(200)로 전송할 수 있다.
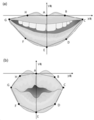
도 5는 본 발명의 일 실시예에 따른 입술의 특징점 추출 방법을 설명하기 위한 도면이다.
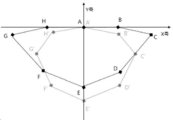
도 5를 참조하면, 발화자의 얼굴에서 추출된 입술 이미지로부터 노이즈를 제거하고, 일정한 크기로 입술을 정렬한 후 입술에서 특징점을 추출할 수 있다. 카메라를 바라보는 얼굴의 방향이나 기울기에 따라서 입술의 모양과 크기가 달라지므로, 표준화된 입술 영역을 얻기 위하여, 얼굴을 일정한 방향으로 정렬하고, 동일한 얼굴 크기로 변환한 후 입술 영역을 검출할 수 있다. 입술 영역에서 입술의 특징점의 입술의 외곽 영역을 기준으로 추출될 수 있다. 입술 특징점은 양쪽 입꼬리의 끝점(C, G), 윗입술의 중간 지점(A), 아랫입술의 중간 지점(E), 윗입술의 중간 지점과 입꼬리의 중간 지점(B, H), 아랫입술의 중간 지점과 입꼬리의 중간 지점(D, F), 입술의 전체적인 형상 정보를 포함할 수 있다. 입술의 특징점 정보는 XY축의 위치정보로 저장될 수 있다. 입술의 특징점 중의 하나를 기준점으로 하여 나머지 좌표를 결정할 수 있다. 기준점의 좌표는 (0, 0)으로 표시할 수 있고, 기준점을 윗입술의 중간 지점(A)으로 설정할 수 있다. 윗입술의 중간 지점(A)과 아랫입술의 중간 지점(E)을 연결한 선을 X축으로 설정하고, X축에 직교하고 윗입술의 중간 지점(A)를 지나는 선을 Y축으로 설정할 수 있다.
도 6는 본 발명의 일 실시예에 따른 입술 이미지로부터 음성 인식 방법을 설명하기 위한 도면이다.
도 6를 참조하면, 발화자의 입술 이미지로부터 추출된 특징점의 위치의 움직임을 인식하여 발화자가 발음하는 음소 또는 음절, 단어, 문장 등을 추출할 수 있다. 동영상의 첫번째 프레임에서 입술의 특징점인 A, B, C, D, E, F, G, H를 추출하고, 기준점을 윗입술의 중간 지점에 해당하는 A 점으로 설정하고, 좌표값을 (0, 0)으로 설정할 수 있다. 그리고 동영상의 두번째 프레임으로부터 입술의 특징점인 A', B', C', D', E', F', G', H'을 추축하고, 기준점을 윗입술의 중간 지점에 해당하는 A' 점으로 설정하고, 좌표값을 (0, 0)으로 설정할 수 있다. 첫번째 프레임의 특징점 좌표에서 두번째 프레임의 특징점 좌표로 이동한 특징점의 위치좌표를 이용하여 이동크기와 방향을 추출할 수 있다. 특징점 좌표의 이동 방향은 원점을 기준으로 Y축의 정방향을 0도로 하고, X축 정방향을 90도, Y축 부방향을 180도, X축 부방향을 270도로 설정할 수 있고, 특징점 좌표의 이동 크기는 첫번째 프레임의 특징점 좌표와 두번째 프레임의 특징점 좌표의 직선거리로 나타낼 수 있다.
예를 들어, 첫번째 프레임의 B좌표가 (5, 0)이고, 두번째 프레임의 B'좌표가 (5, 1)이라고 하면, B좌표는 Y축 방향으로 -1만큼 이동한 것을 알 수 있다. 하여 B좌표의 이동 방향은 180도이고, B좌표의 이동 크기는 1인 것을 알 수 있다.
기준점에 해당하는A와 A'좌표를 제외한 나머지 특징점 좌표의 이동 방향과 크기를 추출하여 특정 음소나 음절, 단어, 문장을 추출할 수 있다. 특정 음소나 음절, 단어, 문장을 추출하기 위하여, 두개의 프레임 간의 특징점 좌표의 이동 방향과 크기를 이용할 수 있고, 두개 이상의 프레임에서 특징점 좌표의 이동 방향과 크기의 패턴을 추출할 수 있다. 프레임 간의 특징점 좌표의 이동 방향과 크기 또는 이동 방향과 크기의 패턴을 저장된 이동 방향과 크기 또는 이동 방향과 크기의 패턴과 비교하여 특정 음소나 음절, 단어, 문장을 추출할 수 있다. 또한, 프레임 간의 특징점 좌표의 이동 방향과 크기 또는 이동 방향과 크기의 패턴을 사용자별로 저장된 이동 방향과 크기 또는 이동 방향과 크기의 패턴과 비교하여 특정 음소나 음절, 단어, 문장을 추출할 수 있다.
도 7은 본 발명의 일 실시예에 따른 동영상의 카테고리를 이용하여 입술 이미지로부터 음성 인식 방법을 설명하기 위한 도면이다.
도 7을 참조하면, 발화자가 이야기하는 카테고리 정보를 이용하여 발화자의 입술 이미지로부터 음성을 인식하여 음성 인식 확률을 높일 수 있다. 발화자가 이야기하는 카테고리에 대한 정보를 동영상 촬영단계에서 입력하여 유사한 단어에 대하여 카테고리와 동일한 단어를 선택하도록 하여 음성 인식 확률을 높일 수 있다. 발화자의 이야기 카테고리는 음식, 의류, 애완동물, 스포츠, 연예, 정치, 경제 등의 다양한 카테고리로 설정할 수 있다. 설정된 카테고리별로 자주 사용되는 단어를 데이터베이스부(150)에 저장하고, 음성 인식 단계에서 해당 카테고리별 데이터 베이스에서 우선적으로 유사한 특정 음소나 음절, 단어, 문장을 추출하고, 해당 카테고리별 데이터 베이스에서 특정 음소나 음절, 단어, 문장을 찾을 수 없을 경우, 사용자별 데이터 베이스를 검색하여 유사한 특정 음소나 음절, 단어, 문장을 추출할 수 있다.
도 8은 본 발명의 일 실시예에 따른 동영상과 번역 자막을 재생하는 방법을 설명하기 위한 도면이다.
도 8을 참조하면, 발화자의 입술 정보를 추출하여 발화자의 음성을 말하고 있는 언어로 추출하여 도 8(a)와 같이 텍스트 정보를 추출할 수 있다. 사용자 단말기(200)에서 요청하는 언어나 동영상 번역 시스템(100)에서 제공하는 기본 언어로 번역하여 자막을 제공할 수 있다. 동영상 재생 도중에 사용자 단말기(200)로부터 자막 언어에 대한 변경 요청이 있을 경우, 발화자의 음성으로부터 추출된 텍스트 정보를 요청한 언어로 번역하여 자막을 생성하여 사용자 단말기(200)에 제공할 수 있다. 사용자 단말기(200)에서 발화자의 음성을 번역된 자막과 동일한 언어로 변경을 요청할 경우, 자막 정보를 이용하여 요청한 언어로 음성을 생성하여 오디오 정보로 제공할 수 있다. 발화자가 실제 말하고 있는 언어와 다른 언어로 번역된 자막과 함께 발화자의 언어와 자막의 언어와 다른 제3의 언어로 음성을 생성하여 동영상과 함께 제공할 수 있다. 또한, 동시에 여러 개의 언어로 번역된 자막을 제공하여 다양한 언어로 소통이 가능하도록 할 수 있다.
본 발명의 일 실시예에 따른 방법은 다양한 컴퓨터 수단을 통하여 수행될 수 있는 프로그램 명령 형태로 구현되어 컴퓨터 판독 가능 매체에 기록될 수 있다. 컴퓨터 판독 가능 매체는 프로그램 명령, 데이터 파일, 데이터 구조 등을 단독으로 또는 조합하여 포함할 수 있다. 매체에 기록되는 프로그램 명령은 본 발명을 위하여 특별히 설계되고 구성된 것들이거나 컴퓨터 소프트웨어 당업자에게 공지되어 사용 가능한 것일 수도 있다. 컴퓨터 판독 가능 기록 매체의 예에는 하드 디스크, 플로피 디스크 및 자기 테이프와 같은 자기 매체(magnetic media), CD-ROM, DVD와 같은 광기록 매체(optical media), 플롭티컬 디스크(floptical disk)와 같은 자기-광 매체(magneto-optical media), 및 롬(ROM), 램(RAM), 플래시 메모리 등과 같은 프로그램 명령을 저장하고 수행하도록 특별히 구성된 하드웨어 장치가 포함된다. 프로그램 명령의 예에는 컴파일러에 의해 만들어지는 것과 같은 기계어 코드뿐만 아니라 인터프리터 등을 사용해서 컴퓨터에 의해서 실행될 수 있는 고급 언어 코드를 포함한다. 상기된 하드웨어 장치는 본 발명의 동작을 수행하기 위해 하나 이상의 소프트웨어 모듈로서 작동하도록 구성될 수 있으며, 그 역도 마찬가지이다.
전술한 본 발명의 설명은 예시를 위한 것이며, 본 발명이 속하는 기술분야의 통상의 지식을 가진 자는 본 발명의 기술적 사상이나 필수적인 특징을 변경하지 않고서 다른 구체적인 형태로 쉽게 변형이 가능하다는 것을 이해할 수 있을 것이다. 그러므로 이상에서 기술한 실시예들은 모든 면에서 예시적인 것이며 한정적이 아닌 것으로 이해해야만 한다. 예를 들어, 단일형으로 설명되어 있는 각 구성 요소는 분산되어 실시될 수도 있으며, 마찬가지로 분산된 것으로 설명되어 있는 구성 요소들도 결합된 형태로 실시될 수 있다.
본 발명의 범위는 후술하는 특허청구범위에 의하여 나타내어지며, 특허청구범위의 의미 및 범위 그리고 그 균등 개념으로부터 도출되는 모든 변경 또는 변형된 형태가 본 발명의 범위에 포함되는 것으로 해석되어야 한다.
100: 동영상 번역 시스템
110: 음성인식부
120: 입술인식부
130 번역부
140: 프로세싱부
150: 데이터베이스부
160: 출력영상생성부
170: 네트워크부
200: 사용자 단말기
210: 센싱부
220: 제어부
230: 통신부
240: 전원부
250: 출력부
251: 디스플레이부
260: 사용자입력부
270: 인터페이스부
110: 음성인식부
120: 입술인식부
130 번역부
140: 프로세싱부
150: 데이터베이스부
160: 출력영상생성부
170: 네트워크부
200: 사용자 단말기
210: 센싱부
220: 제어부
230: 통신부
240: 전원부
250: 출력부
251: 디스플레이부
260: 사용자입력부
270: 인터페이스부
Claims (6)
- MCN 시스템 기반의 멀티미디어 콘텐츠 제공을 위한 실시간 번역 기반 멀티 채널 방송 시스템에 있어서,
상기 실시간 번역 기반 멀티 채널 방송 시스템은,
실시간으로 멀티미디어 콘텐츠 제공을 위해 동영상 및 동영상 정보를 입력받고, 요청에 따라 선택된 동영상 및 동영상 정보를 전송하는 동영상 번역 시스템; 및
상기 동영상 번역 시스템과 네트워크를 통해 연결되어 동영상을 선택하고 선택된 동영상의 실시간 전송을 요청할 수 있는 사용자 단말기를 포함하되,
상기 동영상 번역 시스템은,
영상과 음성을 포함하는 동영상과 동영상 카테고리 정보를 입력 받는 동영상 입력부;
입력 받은 동영상의 프레임에서 입술 영역을 추출하고, 추출된 입술 영역으로부터 입술의 특징점을 추출하여 동영상 내의 음성을 텍스트로 추출하는 입술인식부;
추출된 텍스트를 특정 언어로 번역하여 자막 정보를 생성하는 번역부;
상기 입력된 동영상과 상기 자막 정보를 동기화하여 출력영상을 생성하는 출력영상생성부; 및
생성된 출력영상을 사용자 단말기로 전송하는 통신부;를 포함하되,
상기 입술인식부는,
상기 동영상 카테고리 정보를 기반으로 하여 동영상 내의 음성을 텍스트로 추출하며,
상기 입술인식부는,
입력 받은 동영상의 프레임에서 얼굴 영역을 추출하고, 추출된 얼굴 영역에서 얼굴의 특징점 정보를 추출하고,
상기 입술 영역은 추출된 얼굴의 특징점 정보 중의 하나인 것을 특징으로 하는 실시간 번역 기반 멀티 채널 방송 시스템.
- 제1항에 있어서,
상기 번역부는,
상기 추출된 텍스트를 상기 사용자 단말기로부터 요청받은 특정 언어로 번역하여 자막 정보를 생성하고,
상기 사용자 단말기로부터 번역하고자 하는 언어에 대한 요청이 없을 경우, 사용자 단말기의 위치 정보를 이용하여 번역하고자 하는 언어를 결정하고 상기 추출된 텍스트를 번역하여 자막 정보를 생성하는 것을 특징으로 하는 동영상 번역 시스템.
- 제1항에 있어서,
상기 출력영상생성부는,
상기 입력된 동영상과 두 개 이상의 다른 언어로 된 자막 정보를 동기화하여 출력영상을 생성하는 것을 특징으로 하는 동영상 번역 시스템.
- 영상과 음성을 포함하는 동영상과 동영상 카테고리 정보를 입력 받는 정보 입력 단계;
사용자 단말기로부터 동영상에 대한 전송을 요청받는 요청 수신 단계; 및
상기 사용자 단말기로 선택된 동영상을 전송하는 콘텐츠 전송 단계를 포함하는 실시간 번역 기반 멀티 채널 방송 방법에 있어서,
상기 정보 입력 단계는,
영상과 음성을 포함하는 동영상과 동영상 카테고리 정보를 입력 받는 단계;
입력 받은 동영상의 프레임에서 입술 영역을 추출하고, 추출된 입술 영역으로부터 입술의 특징점을 추출하는 단계;
상기 동영상 카테고리 정보를 기반으로 하여 동영상 내의 음성을 텍스트로 추출하는 단계; 및
추출된 텍스트를 특정 언어로 번역하여 자막 정보를 생성하고 저장하는 단계를 포함하고,
상기 콘텐츠 전송 단계는,
상기 입력된 동영상과 상기 자막 정보를 동기화하여 출력영상을 생성하는 단계; 및
생성된 출력영상을 사용자 단말기로 전송하는 단계;를 포함하는 것을 특징으로 하는 실시간 번역 기반 멀티 채널 방송 방법.
- 제4항에 있어서,
상기 자막 정보를 생성하는 단계는,
상기 추출된 텍스트를 사용자 단말기로부터 요청받은 특정 언어로 번역하여 자막 정보를 생성하고, 사용자 단말기로부터 번역하고자 하는 언어에 대한 요청이 없을 경우, 사용자 단말기의 위치 정보를 이용하여 번역하고자 하는 언어를 결정하고 상기 추출된 텍스트를 번역하여 자막 정보를 생성하는 것을 특징으로 하는 동영상 번역 방법.
- 제4항에 있어서,
상기 출력영상을 생성하는 단계는,
상기 입력된 동영상과 두 개 이상의 다른 언어로 된 자막 정보를 동기화하여 출력영상을 생성하는 것을 특징으로 하는 동영상 번역 방법.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190007277A KR20200090355A (ko) | 2019-01-21 | 2019-01-21 | 실시간 번역 기반 멀티 채널 방송 시스템 및 이를 이용하는 방법 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190007277A KR20200090355A (ko) | 2019-01-21 | 2019-01-21 | 실시간 번역 기반 멀티 채널 방송 시스템 및 이를 이용하는 방법 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200090355A true KR20200090355A (ko) | 2020-07-29 |
Family
ID=71893501
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020190007277A KR20200090355A (ko) | 2019-01-21 | 2019-01-21 | 실시간 번역 기반 멀티 채널 방송 시스템 및 이를 이용하는 방법 |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR20200090355A (ko) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20220043144A1 (en) * | 2020-08-07 | 2022-02-10 | Tdk Corporation | Acoustic multipath correction |
| CN115880737A (zh) * | 2021-09-26 | 2023-03-31 | 天翼爱音乐文化科技有限公司 | 一种基于降噪自学习的字幕生成方法、系统、设备及介质 |
| US11626099B2 (en) | 2016-05-10 | 2023-04-11 | Invensense, Inc. | Transmit beamforming of a two-dimensional array of ultrasonic transducers |
| US11651611B2 (en) | 2016-05-04 | 2023-05-16 | Invensense, Inc. | Device mountable packaging of ultrasonic transducers |
| US11673165B2 (en) | 2016-05-10 | 2023-06-13 | Invensense, Inc. | Ultrasonic transducer operable in a surface acoustic wave (SAW) mode |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101055908B1 (ko) | 2004-03-09 | 2011-08-09 | 톰슨 라이센싱 | 다채널 자격 관리 및 제어를 통한 안전한 데이터 전송 |
| KR101187600B1 (ko) | 2011-02-09 | 2012-10-08 | 한국과학기술연구원 | 스테레오 카메라 기반의 3차원 실시간 입술 특징점 추출을 이용한 음성 인식 장치 및 음성 인식 방법 |
| KR101869332B1 (ko) | 2016-12-07 | 2018-07-20 | 정우주 | 사용자 맞춤형 멀티미디어 컨텐츠를 제공하는 방법 및 장치 |
-
2019
- 2019-01-21 KR KR1020190007277A patent/KR20200090355A/ko unknown
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101055908B1 (ko) | 2004-03-09 | 2011-08-09 | 톰슨 라이센싱 | 다채널 자격 관리 및 제어를 통한 안전한 데이터 전송 |
| KR101187600B1 (ko) | 2011-02-09 | 2012-10-08 | 한국과학기술연구원 | 스테레오 카메라 기반의 3차원 실시간 입술 특징점 추출을 이용한 음성 인식 장치 및 음성 인식 방법 |
| KR101869332B1 (ko) | 2016-12-07 | 2018-07-20 | 정우주 | 사용자 맞춤형 멀티미디어 컨텐츠를 제공하는 방법 및 장치 |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11651611B2 (en) | 2016-05-04 | 2023-05-16 | Invensense, Inc. | Device mountable packaging of ultrasonic transducers |
| US11626099B2 (en) | 2016-05-10 | 2023-04-11 | Invensense, Inc. | Transmit beamforming of a two-dimensional array of ultrasonic transducers |
| US11673165B2 (en) | 2016-05-10 | 2023-06-13 | Invensense, Inc. | Ultrasonic transducer operable in a surface acoustic wave (SAW) mode |
| US20220043144A1 (en) * | 2020-08-07 | 2022-02-10 | Tdk Corporation | Acoustic multipath correction |
| CN115880737A (zh) * | 2021-09-26 | 2023-03-31 | 天翼爱音乐文化科技有限公司 | 一种基于降噪自学习的字幕生成方法、系统、设备及介质 |
| CN115880737B (zh) * | 2021-09-26 | 2024-04-19 | 天翼爱音乐文化科技有限公司 | 一种基于降噪自学习的字幕生成方法、系统、设备及介质 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11423909B2 (en) | Word flow annotation | |
| CN110288077B (zh) | 一种基于人工智能的合成说话表情的方法和相关装置 | |
| KR20200090355A (ko) | 실시간 번역 기반 멀티 채널 방송 시스템 및 이를 이용하는 방법 | |
| WO2021036644A1 (zh) | 一种基于人工智能的语音驱动动画方法和装置 | |
| US10276154B2 (en) | Processing natural language user inputs using context data | |
| CN113454708A (zh) | 语言学风格匹配代理 | |
| US10089974B2 (en) | Speech recognition and text-to-speech learning system | |
| EP3824462B1 (en) | Electronic apparatus for processing user utterance and controlling method thereof | |
| US20140036022A1 (en) | Providing a conversational video experience | |
| JP2018106148A (ja) | 多重話者音声認識修正システム | |
| CN110322760B (zh) | 语音数据生成方法、装置、终端及存储介质 | |
| US9749582B2 (en) | Display apparatus and method for performing videotelephony using the same | |
| US10388325B1 (en) | Non-disruptive NUI command | |
| JP2019533181A (ja) | 通訳装置及び方法(device and method of translating a language) | |
| Ivanko et al. | Multimodal speech recognition: increasing accuracy using high speed video data | |
| KR20220037819A (ko) | 복수의 기동어를 인식하는 인공 지능 장치 및 그 방법 | |
| JP2000207170A (ja) | 情報処理装置および情報処理方法 | |
| CN113205569A (zh) | 图像绘制方法及装置、计算机可读介质和电子设备 | |
| CN113409770A (zh) | 发音特征处理方法、装置、服务器及介质 | |
| WO2019150708A1 (ja) | 情報処理装置、情報処理システム、および情報処理方法、並びにプログラム | |
| KR20200056754A (ko) | 개인화 립 리딩 모델 생성 방법 및 장치 | |
| CN112742024A (zh) | 虚拟对象的控制方法、装置、设备及存储介质 | |
| CN111212323A (zh) | 音视频合成的方法、装置、电子设备及介质 | |
| KR20200003529A (ko) | 음성 인식이 가능한 디지털 디바이스 및 그 제어 방법 | |
| US20240119930A1 (en) | Artificial intelligence device and operating method thereof |