KR20200044209A - Computer program and theminal for providing individual animal information based on the facial and nose pattern imanges of the animal - Google Patents
Computer program and theminal for providing individual animal information based on the facial and nose pattern imanges of the animal Download PDFInfo
- Publication number
- KR20200044209A KR20200044209A KR1020180121037A KR20180121037A KR20200044209A KR 20200044209 A KR20200044209 A KR 20200044209A KR 1020180121037 A KR1020180121037 A KR 1020180121037A KR 20180121037 A KR20180121037 A KR 20180121037A KR 20200044209 A KR20200044209 A KR 20200044209A
- Authority
- KR
- South Korea
- Prior art keywords
- image
- animal
- region
- information
- computer program
- Prior art date
Links
Images













Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
-
- G06K9/00362—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
-
- G06K9/3233—
-
- G06K9/627—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/24—Aligning, centring, orientation detection or correction of the image
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/25—Determination of region of interest [ROI] or a volume of interest [VOI]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/40—Extraction of image or video features
Abstract
Description
본 개시는 컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램 및 단말기에 관한 것으로서, 구체적으로 동물의 이미지에 기초하여 동물의 개체 정보를 제공하는 컴퓨터 판독가능 저장 매체에 저장된 프로그램 및 단말기에 관한 것이다.The present disclosure relates to a computer program and a terminal stored in a computer-readable storage medium, and more particularly, to a program and a terminal stored in a computer-readable storage medium that provides object information of an animal based on the image of the animal.
애완 동물에 대한 수요가 증가하고 있다. 그리고, 애완 동물의 수요가 증가함에 따라, 한 해 유기 및 유실 동물의 발생 건수 역시 증가하고 있다.The demand for pets is increasing. And, as the demand for pets increases, the number of organic and lost animals per year also increases.
이러한 문제를 해결하기 위해, 정부는 유기된 동물의 소유주를 쉽게 찾을 수 있도록 동물 등록제를 시행하고 있다. 동물 등록을 위해서, 애완 동물에 무선 식별 칩을 삽입하는 내장형과 무선 식별 칩이 부착된 인식표를 애완 동물의 목에 걸어주는 외장형으로 나뉜다.To solve this problem, the government is implementing an animal registration system to make it easier to find the owners of the abandoned animals. For animal registration, it is divided into a built-in type that inserts a wireless identification chip into a pet and an external type that hangs the identification tag with a wireless identification chip attached to the pet's neck.
내장형인 식별 칩은 동물의 체내에 주입한다는 특성에 의해 비인도적이며, 삽입 후 체내 부작용이 발생할 수 있는 문제가 있다. 그리고 외장형인 인식표는 분실될 염려가 있으며 의도적으로 인식표를 제거하여 유기한 경우에는 추적이 불가능한 문제가 있다.The identification chip, which is a built-in type, is inhuman due to the characteristic that it is injected into the body of an animal, and there is a problem that side effects may occur in the body after insertion. In addition, there is a fear that the external identification tag may be lost, and if the identification tag is intentionally removed and abandoned, there is a problem that tracking is impossible.
그리하여 최근에는, 개체를 촬영한 이미지를 이용하는 기술에 대한 연구가 활발히 진행되고 있다. 이중에서 비문은 동물의 코에서 발견할 수 있는 고유의 무늬로 사람의 지문과 같은 역할을 할 수 있다는 점에서 전술한 동물 등록제의 대안 기술로 요구되고 있다.Therefore, in recent years, research on technology using an image of an object has been actively conducted. Among them, the inscription is a unique pattern that can be found on the nose of an animal and can be used as a human fingerprint, so it is required as an alternative technique to the animal registration system described above.
한국 등록특허 10-1788272는 생체 인식을 통한 동물 인식 및 등록 관리 방법을 제공한다.Korean Patent Registration No. 10-1788272 provides a method for managing animal recognition and registration through biometric recognition.
본 개시는 전술한 배경기술에 대응하여 안출된 것으로, 동물의 이미지에 기초하여 동물의 개체 정보를 제공하는 컴퓨터 판독가능 저장 매체에 저장된 프로그램 및 단말기를 제공하고자 한다.The present disclosure has been devised in correspondence with the background art described above, and is intended to provide a program and a terminal stored in a computer-readable storage medium that provides individual information of an animal based on the image of the animal.
본 개시의 기술적 과제들은 이상에서 언급한 기술적 과제로 제한되지 않으며, 언급되지 않은 또 다른 기술적 과제들은 아래의 기재로부터 당업자에게 명확하게 이해될 수 있을 것이다.The technical problems of the present disclosure are not limited to the technical problems mentioned above, and other technical problems not mentioned will be clearly understood by those skilled in the art from the following description.
전술한 바와 같은 과제를 해결하기 위한 본 개시의 몇몇 실시예에 따라, 컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램이 개시된다. 상기 컴퓨터 프로그램은 사용자 단말기로 하여금 이하의 동작들을 수행하기 위한 명령들을 포함하며, 상기 동작들은: 사용자 단말기의 카메라로 촬영된 동물의 안면이 포함된 제 1 이미지를 획득하는 동작; 상기 제 1 이미지를 사전 학습된 종 분류 모델에 입력하여 상기 동물의 종에 대한 제 1 정보를 획득하는 동작; 상기 제 1 이미지 내에서 상기 동물의 코를 포함하는 제 1 영역의 위치를 인식하는 동작; 사전 설정된 조건을 만족된 경우 상기 제 1 영역 내에서 관심 영역(Region Of Interest)을 결정하는 동작; 상기 관심 영역이 결정된 경우, 상기 제 1 이미지 내에서 상기 관심 영역을 포함하는 제 2 이미지를 추출하는 동작; 및 상기 제 2 이미지가 추출된 경우, 상기 제 1 정보 및 상기 제 2 이미지를 서버에 전송하는 동작; 을 포함할 수 있다.In accordance with some embodiments of the present disclosure for solving the above-described problems, a computer program stored in a computer-readable storage medium is disclosed. The computer program includes instructions for causing the user terminal to perform the following operations, the operations comprising: obtaining a first image including a face of an animal photographed by a camera of the user terminal; Inputting the first image into a pre-trained species classification model to obtain first information about the animal species; Recognizing a position of a first region including the nose of the animal in the first image; Determining a region of interest within the first region when a preset condition is satisfied; When the region of interest is determined, extracting a second image including the region of interest from within the first image; And when the second image is extracted, transmitting the first information and the second image to a server. It may include.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 종 분류 모델을 학습시키기 위한 제 1 학습 데이터는, 동물의 안면이 포함된 이미지 데이터를 학습 데이터의 입력으로 하고, 상기 동물의 안면이 포함된 이미지 데이터에 동물의 종에 대한 제 1 분류 클래스를 라벨로 하여 생성될 수 있다. 그리고 상기 종 분류 모델은, 상기 제 1 학습 데이터를 포함하는 제 1 학습 데이터 세트를 이용하여 상기 동물의 안면과 매칭되는 상기 동물의 종에 대한 분류를 학습하고, 상기 제 1 이미지에 기초하여 상기 제 1 정보를 획득하도록 할 수 있다.In addition, in some embodiments of the present disclosure, the first learning data for training the species classification model uses image data including an animal's face as an input of learning data, and image data including the animal's face. Can be generated by labeling the first classification class for a species of animal. And the species classification model, using the first training data set including the first training data to learn the classification of the animal species that match the face of the animal, based on the first image, the first 1 You can get information.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 종 분류 모델은, 상기 제 1 이미지를 입력 노드로 입력 받으면, 상기 제 1 분류 클래스 각각에 대한 컨피던스 스코어(confidence score)를 출력 노드에서 출력하고, 상기 컨피던스 스코어 중 가장 높은 값을 가지는 상기 제 1 분류 클래스를 제 1 정보로 획득할 수 있다.In addition, in some embodiments of the present disclosure, the species classification model, when receiving the first image as an input node, outputs a confidence score for each of the first classification classes at an output node, and The first classification class having the highest value among the confidence scores may be obtained as first information.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 제 1 이미지 내에서 상기 동물의 코를 포함하는 제 1 영역의 위치를 인식하는 동작은, 상기 제 1 이미지를 사전 학습된 코 영역 인식 모델에 입력하여 상기 제 1 이미지 내에서 상기 제 1 영역의 위치를 인식하는 동작을 포함할 수 있다.In addition, in some embodiments of the present disclosure, the operation of recognizing the position of the first region including the animal's nose in the first image may include inputting the first image into a pre-trained nose region recognition model. And recognizing a position of the first region within the first image.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 코 영역 인식 모델은, 동물의 안면이 포함된 이미지 데이터를 포함하는 제 2 학습 데이터 세트 및 바운딩 박스(bounding box)에 대한 좌표를 이용하여 상기 동물의 안면의 이미지와 매칭되는 코 영역의 위치를 학습하고, 상기 제 1 이미지 내에서 상기 제 1 영역의 위치를 인식할 수 있다.In addition, in some embodiments of the present disclosure, the nose region recognition model uses the coordinates for a bounding box and a second training data set including image data including an animal's face. The location of the nose region matching the image of the face may be learned, and the location of the first region within the first image may be recognized.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 제 1 이미지 내에서 상기 동물의 코를 포함하는 제 1 영역의 위치를 인식하는 동작은, 상기 제 1 이미지 내에서 상기 동물의 눈을 포함하는 제 2 영역의 위치 및 상기 동물의 입을 포함하는 제 3 영역을 인식하는 동작; 및 상기 제 2 영역의 위치 및 상기 제 3 영역의 위치에 기초하여 상기 제 1 영역의 위치를 인식하는 동작; 을 포함할 수 있다.In addition, in some embodiments of the present disclosure, the operation of recognizing the position of the first region including the nose of the animal in the first image may include: a second including the animal's eye in the first image. Recognizing a location of the region and a third region including the animal's mouth; And recognizing the position of the first area based on the position of the second area and the position of the third area. It may include.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 사전 설정된 조건을 만족된 경우 상기 제 1 영역 내에서 관심 영역(Region Of Interest)을 결정하는 동작은, 상기 제 1 영역 내에서 상기 동물의 우측 콧구멍(nostril) 및 좌측 콧구멍을 인식하는 동작; 상기 우측 콧구멍 및 상기 좌측 콧구멍의 원형성(circularity) 및 상기 콧구멍의 관성률(Inertia ratio) 중 적어도 하나에 기초하여 상기 동물이 촬영된 포즈(pose)를 인식하는 동작; 및 상기 포즈가 기 설정된 포즈에 매칭되는 경우 상기 사전 설정된 조건이 만족되었다고 인식하는 동작;을 포함할 수 있다.In addition, in some embodiments of the present disclosure, when the preset condition is satisfied, the operation of determining a region of interest in the first region may include: right nostril of the animal within the first region (nostril) and left nostril recognition; Recognizing a pose in which the animal is photographed based on at least one of a circularity of the right nostril and the left nostril and an inertia ratio of the nostril; And when the pose matches a preset pose, recognizing that the preset condition is satisfied.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 제 1 영역 내에서 사전 설정된 조건을 만족하는 관심 영역(Region Of Interest)을 결정하는 동작은, 상기 사전 설정된 조건을 만족되는 경우, 상기 우측 콧구멍 및 상기 좌측 콧구멍 간의 거리를 산출하는 동작; 상기 거리에 기초하여 상기 관심 영역의 크기 및 상기 관심 영역의 위치를 결정하는 동작;을 포함할 수 있다.In addition, in some embodiments of the present disclosure, the operation of determining a region of interest that satisfies a preset condition within the first region may include, when the preset condition is satisfied, the right nostril and Calculating a distance between the left nostrils; And determining the size of the region of interest and the location of the region of interest based on the distance.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 제 1 영역 내에서 사전 설정된 조건을 만족하는 관심 영역(Region Of Interest)을 결정하는 동작은, 상기 사전 설정된 조건이 만족되지 않은 경우, 상기 사전 설정된 조건을 만족하는 제 1 이미지가 획득되도록 재촬영을 요구하는 인디케이터를 디스플레이하도록 디스플레이부를 제어하는 동작;을 더 포함할 수 있다.In addition, in some embodiments of the present disclosure, the operation of determining a region of interest that satisfies a preset condition in the first region may be performed when the preset condition is not satisfied. The control may further include controlling the display unit to display an indicator requiring re-shooting so that a first image that satisfies.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 제 1 영역 내에서 사전 설정된 조건을 만족하는 관심 영역(Region Of Interest)을 결정하는 동작은, 상기 사전 설정된 조건을 만족하지 못하는 경우에, 상기 제 1 이미지를 정면화(Frontalization)하여 상기 포즈가 상기 기 설정된 포즈에 매칭되도록 만드는 동작;을 더 포함할 수 있다.In addition, in some embodiments of the present disclosure, the operation of determining a region of interest that satisfies a preset condition within the first region may be performed when the region of interest is not satisfied. It may further include an operation of making the pose match the preset pose by frontalizing the image.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 제 1 이미지를 정면화하여 상기 포즈가 상기 기 설정된 포즈에 매칭되도록 만드는 동작은, 상기 제 1 영역의 이미지 상에서 콧구멍들의 특징점을 추출하는 동작; 및 상기 추출한 콧구멍들의 특징점이 메모리에 사전 저장된 동물을 정면에서 촬영한 이미지 상에서 콧구멍들의 특징점과 매칭되도록 상기 제 1 이미지를 보정하는 동작;을 더 포함할 수 있다.In addition, in some embodiments of the present disclosure, the operation of frontizing the first image so that the pose matches the preset pose includes: extracting feature points of nostrils on the image of the first region; And correcting the first image such that the extracted feature points of the nostrils match the feature points of the nostrils on an image photographed from the front of the animal pre-stored in the memory.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 제 1 정보 및 상기 제 2 이미지를 상기 서버에 전송한 후, 상기 서버로부터 상기 전송된 제 1 정보 및 상기 제 2 이미지에 대응하는 상기 동물의 개체 정보를 수신하는 동작; 및 상기 개체 정보를 디스플레이하는 동작;을 더 포함할 수 있다.In addition, in some embodiments of the present disclosure, after transmitting the first information and the second image to the server, the transmitted first information from the server and the individual information of the animal corresponding to the second image Receiving an operation; And displaying the entity information.
또한, 본 개시의 몇몇 실시예에 있어서, 상기 개체 정보는, 상기 제 2 이미지를 상기 서버에서 로컬 히스토그램(local histogram)에 기초하여 전처리한 제 2 이미지에 매칭되는 제 1 비문 이미지에 맵핑(mapping)된 개체 정보이고, 상기 제 1 비문 이미지는, 상기 서버에 저장되어 있는 복수의 비문 이미지 중 하나일 수 있다.In addition, in some embodiments of the present disclosure, the entity information is mapped to a first inscription image matching the second image pre-processed based on a local histogram at the server. The object information, and the first inscription image may be one of a plurality of inscription images stored in the server.
한편, 본 개시의 다른 몇몇 실시예에 따른, 컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램이 개시된다. 상기 컴퓨터 프로그램은 서버로 하여금 이하의 동작들을 수행하기 위한 명령들을 포함하며, 상기 동작들은: 사용자 단말기로부터 상기 사용자 단말기의 카메라로 촬영된 동물의 안면이 포함된 제 1 이미지로부터 획득한 상기 동물의 종에 대한 제 1 정보 및 상기 제 1 이미지 내에서 상기 동물의 코를 포함하는 제 1 영역 내에서 관심 영역을 포함하는 제 2 이미지를 수신하는 동작; 상기 제 2 이미지를 로컬 히스토그램에 기초하여 전처리하는 동작; 상기 서버의 메모리에 저장된 복수의 비문 이미지에서 상기 전처리한 제 2 이미지에 매칭되는 제 1 비문 이미지를 검색하는 동작; 및 상기 전처리한 제 2 이미지에 매칭되는 제 1 비문 이미지 및 상기 제 1 비문 이미지에 맵핑된 개체 정보 중 적어도 하나를 획득하는 동작; 및 상기 제 1 비문 이미지 및 상기 개체 정보 중 적어도 하나를 상기 사용자 단말기에 전송하는 동작;을 포함할 수 있다.Meanwhile, a computer program stored in a computer readable storage medium according to some other embodiments of the present disclosure is disclosed. The computer program includes instructions for causing the server to perform the following operations, the operations being: a species of the animal obtained from a first image including a face of an animal captured by the camera of the user terminal from a user terminal. Receiving first information about and a second image including a region of interest within a first region including the nose of the animal within the first image; Pre-processing the second image based on a local histogram; Retrieving a first inscription image matching the preprocessed second image from a plurality of inscription images stored in the memory of the server; And obtaining at least one of a first inscription image matching the pre-processed second image and object information mapped to the first inscription image; And transmitting at least one of the first inscription image and the object information to the user terminal.
또한, 본 개시의 다른 몇몇 실시예에 있어서, 상기 복수의 비문 이미지 중 상기 제 1 특징점에 대응하는 제 2 특징점에서 상기 제 1 정보에 대응하는 코 주름에 대한 제 2 정보를 갖는 상기 제 1 비문 이미지를 검색하는 동작은, 상기 제 1 특징점과 상기 제 2 특징점의 위치가 어긋나는 경우, 상기 제 1 특징점의 위치를 이동시키기 위해 상기 제 2 이미지를 보정하는 동작; 및 상기 보정한 제 2 이미지를 이용하여 상기 제 1 비문 이미지를 검색하는 동작; 을 더 포함할 수 있다.In addition, in some other embodiments of the present disclosure, the first inscription image having second information about a nose wrinkle corresponding to the first information at a second characteristic point corresponding to the first characteristic point among the plurality of inscription images The searching may include correcting the second image to move the position of the first feature point when the first feature point and the second feature point are misaligned; And retrieving the first inscription image using the corrected second image. It may further include.
또한, 본 개시의 다른 몇몇 실시예에 있어서, 상기 제 1 특징점과 상기 제 2 특징점의 위치가 어긋나는 경우, 상기 제 1 특징점의 위치를 이동시키기 위해 상기 제 2 이미지를 보정하는 동작은, 상기 제 1 특징점과 상기 제 2 특징점의 위치가 일치하도록 상기 제 2 이미지를 종횡 이동시키거나 상기 제 2 이미지를 회전 이동 시키는 동작; 을 더 포함할 수 있다.In addition, in some other embodiments of the present disclosure, when the first feature point and the second feature point are misaligned, the operation of correcting the second image to move the position of the first feature point may include: Moving the second image vertically or horizontally or rotating the second image so that the location of the feature point and the second feature point coincide; It may further include.
본 개시에서 얻을 수 있는 기술적 해결 수단은 이상에서 언급한 해결 수단들로 제한되지 않으며, 언급하지 않은 또 다른 해결 수단들은 아래의 기재로부터 본 개시가 속하는 기술분야에서 통상의 지식을 가진 자에게 명확하게 이해될 수 있을 것이다.The technical solutions that can be obtained in the present disclosure are not limited to the above-mentioned solutions, and other solutions that are not mentioned are clearly understood by those skilled in the art from the description below. Will be understandable.
본 개시는 동물의 이미지에 기초하여 동물의 개체 정보를 제공하는 컴퓨터 판독가능 저장 매체에 저장된 프로그램 및 단말기를 제공할 수 있다.The present disclosure can provide programs and terminals stored in a computer-readable storage medium that provides animal information based on an animal image.
본 개시에서 얻을 수 있는 효과는 이상에서 언급한 효과로 제한되지 않으며, 언급하지 않은 또 다른 효과들은 아래의 기재로부터 본 개시가 속하는 기술분야에서 통상의 지식을 가진 자에게 명확하게 이해될 수 있을 것이다.The effects obtainable in the present disclosure are not limited to the above-mentioned effects, and other effects not mentioned may be clearly understood by those skilled in the art from the following description. .
다양한 양상들이 이제 도면들을 참조로 기재되며, 여기서 유사한 참조 번호들은 총괄적으로 유사한 구성요소들을 지칭하는데 이용된다. 이하의 실시예에서, 설명 목적을 위해, 다수의 특정 세부사항들이 하나 이상의 양상들의 총체적 이해를 제공하기 위해 제시된다. 그러나, 그러한 양상(들)이 이러한 구체적인 세부사항들 없이 실시될 수 있음은 명백할 것이다.
도 1은 본 개시의 몇몇 실시예에 따른 사용자 단말기 및 서버를 개략적으로 나타낸 도면이다.
도 2는 본 개시의 몇몇 실시예에 따른 사용자 단말기의 블록도이다.
도 3은 본 개시의 몇몇 실시예에 따른 동물의 제 1 정보 및 제 2 이미지를 서버에 전송하는 동작을 나타내는 흐름도이다.
도 4는 본 개시의 몇몇 실시예에 따른 컨벌루셔널 뉴럴 네트워크(Convolutional neural network)를 나타내는 개략도이다.
도 5는 본 개시의 몇몇 실시예에 따른 종 분류 모델을 개략적으로 설명하기 위한 도면이다.
도 6은 본 개시의 몇몇 실시예에 따라 종 분류 모델을 이용하여 동물의 종에 대한 정보를 획득하는 방법의 일례를 설명하기 위한 도면이다.
도 7은 본 개시의 몇몇 실시예에 따른 동물의 코를 포함하는 제 1 영역을 인식하는 방법을 설명하기 위한 도면이다.
도 8은 본 개시의 몇몇 실시예에 따른 동물의 코를 포함하는 제 1 영역을 인식하는 방법을 설명하기 위한 도면이다.
도 9는 본 개시의 몇몇 실시예에 따른 사전 설정된 조건이 만족되는지 인식하는 동작을 나타내는 흐름도이다.
도 10은 본 개시의 몇몇 실시예에 따른 콧구멍을 인식하는 동작의 예시를 나타내는 도면이다.
도 11은 본 개시의 몇몇 실시예에 따른 콧구멍의 원형성 측정하는 방법의 일례를 설명하기 위한 도면이다.
도 12는 본 개시의 몇몇 실시예에 따른 콧구멍의 관성률을 측정하는 방법의 일례를 설명하기 위한 도면이다.
도 13은 본 개시의 몇몇 실시예에 따른 제 1 영역 내에서 관심 영역을 결정하는 방법의 일례를 설명하기 위한 흐름도이다.
도 14는 본 개시의 몇몇 실시예에 따른 사용자 단말기에 동물의 개체 정보가 제공되는 방법의 일례를 설명하기 위한 흐름도이다.
도 15은 본 개시의 몇몇 실시예에 따른 제 2 이미지를 전처리한 예시를 나타낸 도면이다.Various aspects are now described with reference to the figures, in which like reference numerals are used collectively to refer to similar elements. In the following embodiments, for illustrative purposes, a number of specific details are presented to provide a holistic understanding of one or more aspects. However, it will be apparent that such aspect (s) may be practiced without these specific details.
1 is a schematic diagram of a user terminal and a server according to some embodiments of the present disclosure.
2 is a block diagram of a user terminal in accordance with some embodiments of the present disclosure.
3 is a flowchart illustrating an operation of transmitting first information and second images of animals to a server according to some embodiments of the present disclosure.
4 is a schematic diagram illustrating a convolutional neural network according to some embodiments of the present disclosure.
5 is a diagram for schematically describing a species classification model according to some embodiments of the present disclosure.
6 is a view for explaining an example of a method for obtaining information about a species of an animal using a species classification model according to some embodiments of the present disclosure.
7 is a diagram for describing a method of recognizing a first region including a nose of an animal according to some embodiments of the present disclosure.
8 is a diagram for describing a method of recognizing a first region including a nose of an animal according to some embodiments of the present disclosure.
9 is a flowchart illustrating an operation of recognizing whether a preset condition is satisfied according to some embodiments of the present disclosure.
10 is a diagram illustrating an example of an operation of recognizing a nostril according to some embodiments of the present disclosure.
11 is a view for explaining an example of a method for measuring the circularity of the nostrils according to some embodiments of the present disclosure.
12 is a view for explaining an example of a method for measuring the inertia of the nostrils according to some embodiments of the present disclosure.
13 is a flowchart illustrating an example of a method for determining a region of interest within a first region according to some embodiments of the present disclosure.
14 is a flowchart for explaining an example of a method in which animal information of an animal is provided to a user terminal according to some embodiments of the present disclosure.
15 is a diagram illustrating an example of preprocessing a second image according to some embodiments of the present disclosure.
다양한 실시예들 및/또는 양상들이 이제 도면들을 참조하여 개시된다. 하기 설명에서는 설명을 목적으로, 하나 이상의 양상들의 전반적 이해를 돕기 위해 다수의 구체적인 세부사항들이 개시된다. 그러나, 이러한 양상(들)은 이러한 구체적인 세부사항들 없이도 실행될 수 있다는 점 또한 본 개시의 기술 분야에서 통상의 지식을 가진 자에게 감지될 수 있을 것이다. 이후의 기재 및 첨부된 도면들은 하나 이상의 양상들의 특정한 예시적인 양상들을 상세하게 기술한다. 하지만, 이러한 양상들은 예시적인 것이고 다양한 양상들의 원리들에서의 다양한 방법들 중 일부가 이용될 수 있으며, 기술되는 설명들은 그러한 양상들 및 그들의 균등물들을 모두 포함하고자 하는 의도이다. 구체적으로, 본 명세서에서 사용되는 "실시예", "예", "양상", "예시" 등은 기술되는 임의의 양상 또는 설계가 다른 양상 또는 설계들보다 양호하다거나, 이점이 있는 것으로 해석되지 않을 수도 있다.Various embodiments and / or aspects are now disclosed with reference to the drawings. In the following description, for purposes of explanation, a number of specific details are disclosed to assist in the overall understanding of one or more aspects. However, it will also be appreciated by those skilled in the art of this disclosure that this aspect (s) can be practiced without these specific details. The following description and the annexed drawings set forth in detail certain illustrative aspects of the one or more aspects. However, these aspects are exemplary and some of the various methods in the principles of the various aspects may be used, and the descriptions described are intended to include all such aspects and their equivalents. Specifically, as used herein, "an embodiment", "yes", "a good", "an example", and the like, any aspect or design described is not to be construed as being advantageous or advantageous over other aspects or designs. It may not.
이하, 도면 부호에 관계없이 동일하거나 유사한 구성 요소는 동일한 참조 번호를 부여하고 이에 대한 중복되는 설명은 생략한다. 또한, 본 명세서에 개시된 실시예를 설명함에 있어서 관련된 공지 기술에 대한 구체적인 설명이 본 명세서에 개시된 실시예의 요지를 흐릴 수 있다고 판단되는 경우 그 상세한 설명을 생략한다. 또한, 첨부된 도면은 본 명세서에 개시된 실시예를 쉽게 이해할 수 있도록 하기 위한 것일 뿐, 첨부된 도면에 의해 본 명세서에 개시된 기술적 사상이 제한되지 않는다.Hereinafter, the same or similar components are assigned the same reference numbers regardless of reference numerals, and overlapping descriptions thereof are omitted. In addition, in describing the embodiments disclosed in this specification, detailed descriptions of related well-known technologies are omitted when it is determined that the gist of the embodiments disclosed in this specification may be obscured. In addition, the accompanying drawings are only for easy understanding of the embodiments disclosed herein, and the technical spirit disclosed herein is not limited by the accompanying drawings.
본 명세서에서 사용된 용어는 실시예들을 설명하기 위한 것이며 본 개시를 제한하고자 하는 것은 아니다. 본 명세서에서, 단수형은 문구에서 특별히 언급하지 않는 한 복수형도 포함한다. 명세서에서 사용되는 "포함한다(comprises)" 및/또는 "포함하는(comprising)"은 언급된 구성요소 외에 하나 이상의 다른 구성요소의 존재 또는 추가를 배제하지 않는다.The terminology used herein is for describing the embodiments and is not intended to limit the present disclosure. In this specification, the singular form also includes the plural form unless otherwise specified in the phrase. As used herein, “comprises” and / or “comprising” does not exclude the presence or addition of one or more other components other than the components mentioned.
비록 제1, 제2 등이 다양한 소자나 구성요소들을 서술하기 위해서 사용되나, 이들 소자나 구성요소들은 이들 용어에 의해 제한되지 않음은 물론이다. 이들 용어들은 단지 하나의 소자나 구성요소를 다른 소자나 구성요소와 구별하기 위하여 사용하는 것이다. 따라서, 이하에서 언급되는 제1 소자나 구성요소는 본 개시의 기술적 사상 내에서 제2 소자나 구성요소 일 수도 있음은 물론이다.Although the first, second, etc. are used to describe various elements or components, it goes without saying that these elements or components are not limited by these terms. These terms are only used to distinguish one element or component from another element or component. Therefore, it goes without saying that the first element or component mentioned below may be the second element or component within the technical spirit of the present disclosure.
다른 정의가 없다면, 본 명세서에서 사용되는 모든 용어(기술 및 과학적 용어를 포함)는 본 개시가 속하는 기술분야에서 통상의 지식을 가진 자에게 공통적으로 이해될 수 있는 의미로 사용될 수 있을 것이다. 또 일반적으로 사용되는 사전에 정의되어 있는 용어들은 명백하게 특별히 정의되어 있지 않는 한 이상적으로 또는 과도하게 해석되지 않는다.Unless otherwise defined, all terms (including technical and scientific terms) used in the present specification may be used as meanings commonly understood by those skilled in the art to which the present disclosure pertains. In addition, terms defined in the commonly used dictionary are not ideally or excessively interpreted unless specifically defined.
더불어, 용어 "또는"은 배타적 "또는"이 아니라 내포적 "또는"을 의미하는 것으로 의도된다. 즉, 달리 특정되지 않거나 문맥상 명확하지 않은 경우에, "X는 A 또는 B를 이용한다"는 자연적인 내포적 치환 중 하나를 의미하는 것으로 의도된다. 즉, X가 A를 이용하거나; X가 B를 이용하거나; 또는 X가 A 및 B 모두를 이용하는 경우, "X는 A 또는 B를 이용한다"가 이들 경우들 어느 것으로도 적용될 수 있다. 또한, 본 명세서에 사용된 "및/또는"이라는 용어는 열거된 관련 아이템들 중 하나 이상의 아이템의 가능한 모든 조합을 지칭하고 포함하는 것으로 이해되어야 한다. In addition, the term “or” is intended to mean an inclusive “or” rather than an exclusive “or”. That is, unless specified otherwise or unclear in context, "X uses A or B" is intended to mean one of the natural inclusive substitutions. That is, X uses A; X uses B; Or, if X uses both A and B, "X uses A or B" can be applied in either of these cases. It should also be understood that the term “and / or” as used herein refers to and includes all possible combinations of one or more of the listed related items.
더불어, 본 명세서에서 사용되는 용어 "정보" 및 "데이터"는 종종 서로 상호교환 가능하도록 사용될 수 있다.In addition, the terms "information" and "data" as used herein can often be used interchangeably with each other.
이하의 설명에서 사용되는 구성 요소에 대한 접미사 "모듈" 및 "부"는 명세서 작성의 용이함만이 고려되어 부여되거나 혼용되는 것으로서 그 자체로 서로 구별되는 의미 또는 역할을 갖는 것은 아니다.The suffixes "modules" and "parts" for components used in the following description are given or mixed only considering the ease of writing the specification, and do not have a meaning or a role distinguished from each other.
본 개시의 목적 및 효과, 그리고 그것들을 달성하기 위한 기술적 구성들은 첨부되는 도면과 함께 상세하게 후술되어 있는 실시예들을 참조하면 명확해질 것이다. 본 개시를 설명하는데 있어서 공지 기능 또는 구성에 대한 구체적인 설명이 본 개시의 요지를 불필요하게 흐릴 수 있다고 판단되는 경우에는 그 상세한 설명을 생략할 것이다. 그리고 후술되는 용어들은 본 개시에서의 기능을 고려하여 정의된 용어들로서 이는 사용자, 운용자의 의도 또는 관례 등에 따라 달라질 수 있다.The objectives and effects of the present disclosure, and technical configurations for achieving them, will be apparent with reference to embodiments described below in detail together with the accompanying drawings. In describing the present disclosure, when it is determined that a detailed description of a known function or configuration may unnecessarily obscure the subject matter of the present disclosure, the detailed description will be omitted. In addition, terms to be described later are terms defined in consideration of functions in the present disclosure, which may vary according to a user's or operator's intention or practice.
그러나 본 개시는 이하에서 개시되는 실시예들에 한정되는 것이 아니라 서로 다른 다양한 형태로 구현될 수 있다. 단지 본 실시예들은 본 개시가 완전하도록 하고, 본 개시가 속하는 기술분야에서 통상의 지식을 가진 자에게 개시의 범주를 완전하게 알려주기 위해 제공되는 것이며, 본 개시는 청구항의 범주에 의해 정의될 뿐이다. 그러므로 그 정의는 본 명세서 전반에 걸친 내용을 토대로 내려져야 할 것이다.However, the present disclosure is not limited to the embodiments disclosed below, and may be implemented in various different forms. Only the present embodiments are provided to make the present disclosure complete, and to fully inform the person of ordinary skill in the art to which the present disclosure belongs, and the present disclosure is only defined by the scope of the claims. . Therefore, the definition should be made based on the contents throughout this specification.
도 1은 본 개시의 몇몇 실시예에 따른 사용자 단말기 및 서버를 개략적으로 나타낸 도면이다.1 is a schematic diagram of a user terminal and a server according to some embodiments of the present disclosure.
도 1에 도시된 바와 같이, 사용자 단말기(100)는 네트워크(300)를 통해 서버(200)와 유/무선으로 연결될 수 있다.As illustrated in FIG. 1, the
본 개시의 실시예에 따르면, 사용자 단말기(100)는 카메라부(110)로 촬영한 동물의 안면이 포함된 제 1 이미지를 획득할 수 있다. 사용자 단말기(100)는 제 1 이미지로부터 촬영한 동물의 종에 대한 제 1 정보 및 제 1 이미지 내의 관심 영역을 포함하는 제 2 이미지를 획득할 수 있다. 사용자 단말기(100)는 획득한 제 1 정보 및 제 2 이미지를 네트워크(300)를 통해 서버(200)에 전송할 수 있다. 사용자 단말기(100)는 서버(200)에 전송한 제 1 정보 및 제 2 이미지에 기초하여 서버(200)로부터 상기 촬영한 동물의 개체 정보를 수신할 수 있다. 사용자 단말기(100)는 수신한 동물의 개체 정보를 디스플레이할 수 있다. 여기서 동물의 개체 정보는 동물의 종, 성별, 특이점 중 적어도 어느 하나를 포함할 수 있다. 또한, 동물의 개체 정보는 동물의 주인의 이름, 연락처, 주소 중 적어도 어느 하나를 포함할 수 있다. 이러한 동물의 개체 정보는 촬영한 동물의 주인을 확인하는데 사용될 수 있다. 전술한 동물의 개체 정보는 예시일 뿐이며, 본 개시는 이에 제한되지 않는다.According to an embodiment of the present disclosure, the
전술한 사용자 단말기(100)의 제 1 정보 및 제 2 이미지를 서버(200)에 송신하고 서버(200)로부터 동물의 개체 정보를 수신하는 구체적인 설명은 이하 도 2 내지 도 13에서 자세히 설명한다.A detailed description of transmitting the first information and the second image of the
다음으로, 본 개시의 몇몇 실시예에 따른 서버(200)는 사용자 단말기(100)로부터 상기 제 1 정보 및 상기 제 2 이미지를 수신할 수 있다. 서버(200)는 제 1 정보 및 제 2 이미지에 기초하여 서버(200)의 메모리에 저장된 제 1 비문 이미지를 검색할 수 있다. 서버(200)는 검색한 비문 이미지에 맵핑(mapping)된 개체 정보를 획득할 수 있다. 서버(200)는 맵핑된 개체 정보를 네트워크(300)를 통해 사용자 단말기(100)에 송신할 수 있다. 전술한 서버(200)가 제 1 정보 및 제 2 이미지에 기초하여 동물의 개체 정보를 사용자 단말기(100)에 송신하는 방법은 예시일 뿐이며, 본 개시는 이제 제한되지 않는다.Next, the
전술한 서버(200)가 동물의 개체 정보를 사용자 단말기(100)에 송신하는 구체적인 동작은 이하 도 14 내지 도 15에서 자세히 설명한다.The detailed operation of the above-described
도면에 개시되지는 않았지만, 서버(200)는 제어부, 네트워크부 및 메모리를 포함할 수 있다. 상술한 서버(200)의 각 구성요소들은 후술할 사용자 단말기(100)에 포함된 구성 요소들과 유사한 바 이에 대한 자세한 설명은 생략한다. 다만, 이에 한정되는 것은 아니고 서버(200)는 상술한 구성 요소들보다 많거나 적은 구성요소를 포함할 수 있다.Although not shown in the drawings, the
본 개시의 몇몇 실시예에 따르면 서버(200)의 메모리는 후술할 본 개시의 몇몇 실시예에 따른 서버(200)의 동작들을 수행하기 위한 컴퓨터 프로그램을 저장할 수 있다. 서버(200)의 메모리에 저장된 컴퓨터 프로그램은 서버(200)의 제어부에 의해 판독되어 구동될 수 있다. 또한, 서버(200)의 메모리는 서버(200)의 제어부의 동작을 위한 프로그램을 저장할 수 있다. According to some embodiments of the present disclosure, the memory of the
다음으로, 본 개시의 몇몇 실시예에 따른 네트워크(300)는 공중전화 교환망(PSTN: Public Switched Telephone Network), xDSL(x Digital Subscriber Line), RADSL(Rate Adaptive DSL), MDSL(Multi Rate DSL), VDSL(Very High Speed DSL), UADSL(Universal Asymmetric DSL), HDSL(High Bit Rate DSL) 및 근거리 통신망(LAN) 등과 같은 다양한 유선 통신 시스템들을 사용할 수 있다.Next, the
또한, 여기서 제시되는 네트워크(300)는 CDMA(Code Division Multi Access), TDMA(Time Division Multi Access), FDMA(Frequency Division Multi Access), OFDMA(Orthogonal Frequency Division Multi Access), SCFDMA(Single Carrier-FDMA) 및 다른 시스템들과 같은 다양한 무선 통신 시스템들을 사용할 수 있다.In addition, the
그 외에도, WLAN(Wireless LAN), Wi-Fi(Wireless-Fidelity), Wi-Fi(Wireless Fidelity) Direct, DLNA(Digital Living Network Alliance), WiBro(Wireless Broadband), WiMAX(World Interoperability for Microwave Access), HSDPA(High Speed Downlink Packet Access), HSUPA(High Speed Uplink Packet Access), LTE(Long Term Evolution), LTE-A(Long Term Evolution-Advanced) 등 이 사용자 단말기(100) 및 서버(200)와의 통신 등에 이용될 수 있다.In addition, Wireless LAN (WLAN), Wireless-Fidelity (Wi-Fi), Wireless Fidelity (Wi-Fi) Direct, Digital Living Network Alliance (DLNA), Wireless Broadband (WiBro), World Interoperability for Microwave Access (WiMAX), HSDPA (High Speed Downlink Packet Access), HSUPA (High Speed Uplink Packet Access), LTE (Long Term Evolution), LTE-A (Long Term Evolution-Advanced), etc., communication with the
본 명세서에서 설명된 기술들은 위에서 언급된 네트워크들뿐만 아니라, 다른 네트워크들에서도 사용될 수 있다.The techniques described herein can be used in the networks mentioned above, as well as other networks.
도 2는 본 개시의 몇몇 실시예에 따른 사용자 단말기의 블록도이다.2 is a block diagram of a user terminal in accordance with some embodiments of the present disclosure.
본 개시의 몇몇 실시예에 따르면, 사용자 단말기(100)는 카메라부(110), 메모리(120), 제어부(130), 네트워크부(140) 및 디스플레이부(150)를 포함할 수 있다. 다만, 전술한 구성 요소들은 사용자 단말기(100)를 구현하는데 있어서 필수적인 것은 아니어서, 사용자 단말기(100)는 위에서 열거된 구성요소들 보다 많거나, 또는 적은 구성요소들을 가질 수 있다. 여기서, 각각의 구성 요소들은 별개의 칩이나 모듈이나 장치로 구성될 수 있고, 하나의 장치 내에 포함될 수도 있다.According to some embodiments of the present disclosure, the
본 개시의 몇몇 실시예에 따른 사용자 단말기(100)는 PC(personal computer), 노트북(note book), 모바일 단말기(mobile terminal), 스마트 폰(smart phone), 태블릿 PC(tablet pc) 등일 수 있다. 다만, 이에 한정되는 것은 아니며, 사용자 단말기(100)는 영상을 촬영할 수 있는 카메라부(110)가 구비된 모든 종류의 단말기일 수 있다. The
사용자 단말기(100)는 영상 정보의 입력을 위하여, 하나 또는 복수의 카메라부(110)를 구비할 수 있다. 카메라부(110)는 촬영 모드에서 이미지 센서에 의해 얻어지는 정지영상 또는 동영상 등의 화상 프레임을 처리할 수 있다. 처리된 화상 프레임은 디스플레이부(150)에 표시되거나 메모리(120)에 저장될 수 있다. The
한편, 사용자 단말기(100)에 구비되는 복수의 카메라부(110)는 매트릭스 구조를 이루도록 배치될 수 있으며, 이와 같이 매트릭스 구조를 이루는 카메라부(110)를 통하여, 사용자 단말기(100)에는 다양한 각도 또는 초점을 갖는 복수의 영상정보가 입력될 수 있다. Meanwhile, the plurality of
본 개시의 몇몇 실시예에 따른 카메라부(110)는 동물의 안면이 포함된 제 1 이미지를 획득할 수 있다. 여기서 제 1 이미지는 영상 이미지 또는 프리뷰 이미지일 수 있다. 전술한 제 1 이미지는 예시일 뿐이며, 본 개시는 이제 제한되지 않는다. The
제 1 이미지는 사용자가 사용자 단말기(100)로 촬영한 동물의 종에 대한 제 1 정보를 획득하기 위해 이용될 수 있다. 또한, 상기 제 1 이미지는 촬영된 동물의 코를 포함하는 제 1 영역 내에서 관심 영역을 포함하는 제 2 이미지를 추출하기 위해 이용될 수 있다. The first image may be used by a user to obtain first information about a species of animal photographed by the
카메라부(110)가 획득한 제 1 이미지는 메모리(120)에 저장될 수 있다. 또한, 상기 제 1 이미지는 네트워크부(140)를 통해 서버(200)에 전송될 수도 있다. The first image acquired by the
메모리(120)는 사용자 단말기(100)의 다양한 기능을 지원하는 데이터를 저장할 수 있다. 메모리(120)는 사용자 단말기(100)에서 구동되는 다수의 응용 프로그램(application program 또는 애플리케이션(application)), 사용자 단말기(100)의 동작을 위한 데이터들, 명령어들을 저장할 수 있다. 이러한 응용 프로그램 중 적어도 일부는, 무선 통신을 통해 외부 서버로부터 다운로드 될 수 있다. 또한 이러한 응용 프로그램 중 적어도 일부는, 사용자 단말기(100)의 기본적인 기능을 위하여 출고 당시부터 사용자 단말기(100) 상에 존재할 수 있다. 한편, 응용 프로그램은, 메모리(120)에 저장되고, 사용자 단말기(100) 상에 설치되어, 제어부(130)에 의하여 사용자 단말기(100)의 동작(또는 기능)을 수행하도록 구동될 수 있다.The
메모리(120)는 플래시 메모리 타입(flash memory type), 하드디스크 타입(hard disk type), SSD 타입(Solid State Disk type), SDD 타입(Silicon Disk Drive type), 멀티미디어 카드 마이크로 타입(multimedia card micro type), 카드 타입의 메모리(예를 들어 SD 또는 XD 메모리 등), 램(random access memory; RAM), SRAM(static random access memory), 롬(read-only memory; ROM), EEPROM(electrically erasable programmable read-only memory), PROM(programmable read-only memory), 자기 메모리, 자기 디스크 및 광디스크 중 적어도 하나의 타입의 저장매체를 포함할 수 있다. 사용자 단말기(100)는 인터넷(internet)상에서 상기 메모리(170)의 저장 기능을 수행하는 웹 스토리지(web storage)와 관련되어 동작될 수도 있다.The
본 개시의 몇몇 실시예에 따른 메모리(120)는 제 1 정보를 획득 및 제 2 이미지를 추출하여 서버(200)에 상기 제 1 정보 및 제 2 이미지를 전송하는 동작을 수행하기 위한 컴퓨터 프로그램을 저장할 수 있다. 메모리(120)에 저장된 컴퓨터 프로그램은 제어부(130)에 의해 판독되어 구동될 수 있다. 또한, 메모리(120)는 제어부(130)의 동작을 위한 프로그램을 저장할 수 있고, 입/출력되는 데이터들(예를 들어, 동물의 안면이 포함된 제 1 이미지, 동물의 종에 대한 제 1 정보, 관심 영역을 포함하는 제 2 이미지 및 동물의 개체 정보 등)을 임시 또는 영구 저장할 수도 있다. 메모리(120)는 디스플레이 및 음향에 관한 데이터를 저장할 수 있다. The
제어부(130)는 하나 이상의 코어로 구성될 수 있으며, 컴퓨팅 장치의 중앙 처리 장치(CPU: central processing unit), 범용 그래픽 처리 장치 (GPGPU: general purpose graphics processing unit), 텐서 처리 장치(TPU: tensor processing unit) 등의 데이터 분석, 딥 러닝을 위한 프로세서를 포함할 수 있다.The
본 개시의 몇몇 실시예에 따른 제어부(130)는 메모리(120)에 저장된 컴퓨터 프로그램을 판독하여 제 1 이미지로부터 사용자가 촬영한 동물의 종에 대한 제 1 정보 및 제 1 이미지 내에서 관심 영역을 포함하는 제 2 이미지를 추출할 수 있다.The
본 개시의 몇몇 실시예에 따라 제어부(130)는 신경망의 학습을 위한 계산을 수행할 수 있다. 제어부(130)는 딥 러닝(DN: deep learning)에서 학습을 위한 입력 데이터의 처리, 입력 데이터에서의 피쳐(feature) 추출, 오차 계산, 역전파(backpropagation)를 이용한 신경망의 가중치 업데이트 등의 신경망의 학습을 위한 계산을 수행할 수 있다.According to some embodiments of the present disclosure, the
제어부(130)의 CPU, GPGPU, 및 TPU 중 적어도 하나가 모델의 학습을 처리할 수 있다. 예를 들어, CPU 와 GPGPU가 함께 모델의 학습, 모델을 이용하여 촬영한 동물의 종에 대한 제 1 정보의 획득 및 제 1 이미지 내에서 관심 영역을 포함하는 제 2 이미지의 추출에 대한 연산을 처리할 수 있다. 또한, 본 개시의 몇몇 실시예에서 복수의 컴퓨팅 장치의 프로세서를 함께 사용하여 모델의 학습, 모델을 통한 상기 제 1 정보의 획득 및 상기 제 2 이미지의 추출 중 적어도 하나에 대한 연산을 처리할 수 있다. 또한, 본 개시의 몇몇 실시예에 따른 컴퓨팅 장치에서 수행되는 컴퓨터 프로그램은 CPU, GPGPU 또는 TPU 실행가능 프로그램일 수 있다.At least one of the CPU, GPGPU, and TPU of the
본 개시의 몇몇 실시예에서 사용자 단말기(100)는 CPU, GPGPU, 및 TPU 중 적어도 하나를 이용하여 모델을 분산하여 처리할 수 있다. 또한 본 개시의 몇몇 실시예에서 사용자 단말기(100)는 다른 컴퓨팅 장치와 함께 모델을 분산하여 처리할 수 있다.In some embodiments of the present disclosure, the
네트워크부(140)는 사용자 단말기(100)와 무선 통신 시스템 사이, 사용자 단말기(100)와 다른 단말기(미도시) 사이, 또는 사용자 단말기(100)와 서버(200) 사이의 무선 통신을 가능하게 하는 하나 이상의 모듈을 포함할 수 있다. 또한, 네트워크부(140)는 사용자 단말기(100)를 하나 이상의 네트워크에 연결하는 하나 이상의 모듈을 포함할 수 있다.The
무선 인터넷 기술로는, 예를 들어 WLAN(Wireless LAN), Wi-Fi(Wireless-Fidelity), Wi-Fi(Wireless Fidelity) Direct, DLNA(Digital Living Network Alliance), WiBro(Wireless Broadband), WiMAX(World Interoperability for Microwave Access), HSDPA(High Speed Downlink Packet Access), HSUPA(High Speed Uplink Packet Access), LTE(Long Term Evolution), LTE-A(Long Term Evolution-Advanced) 등이 있으며, 상기 무선 인터넷 접속을 위한 모듈은 상기에서 나열되지 않은 인터넷 기술까지 포함한 범위에서 적어도 하나의 무선 인터넷 기술에 따라 데이터를 송수신할 수 있다.Wireless Internet technologies include, for example, WLAN (Wireless LAN), Wi-Fi (Wireless-Fidelity), Wi-Fi (Wireless Fidelity) Direct, DLNA (Digital Living Network Alliance), WiBro (Wireless Broadband), WiMAX (World) Interoperability for Microwave Access (HSDPA), High Speed Downlink Packet Access (HSDPA), High Speed Uplink Packet Access (HSUPA), Long Term Evolution (LTE), Long Term Evolution-Advanced (LTE-A), etc. The module for transmitting and receiving data according to at least one wireless Internet technology in a range including the Internet technology not listed above.
디스플레이부(150)는 사용자 단말기(100)에서 처리되는 정보를 표시(출력)한다. 예를 들어, 디스플레이부(150)는 사용자 단말기(100)에서 구동되는 응용 프로그램의 실행화면 정보, 또는 이러한 실행화면 정보에 따른 UI(User Interface), GUI(Graphic User Interface) 정보를 표시할 수 있다.The
디스플레이부(150)는 액정 디스플레이(liquid crystal display, LCD), 박막 트랜지스터 액정 디스플레이(thin film transistor-liquid crystal display, TFT LCD), 유기 발광 다이오드(organic light-emitting diode, OLED), 플렉서블 디스플레이(flexible display), 3차원 디스플레이(3D display), 전자잉크 디스플레이(e-ink display) 중에서 적어도 하나를 포함할 수 있다.The
이하에서 도 3 내지 도 13을 참조하여, 본 개시의 몇몇 실시예에 따른 사용자 단말기(100)의 동작을 제어하는 제어부(130)에 대해 자세히 설명한다.Hereinafter, a
도 3은 본 개시의 몇몇 실시예에 따른 동물의 제 1 정보 및 제 2 이미지를 서버에 전송하는 동작을 나타내는 흐름도이다.3 is a flowchart illustrating an operation of transmitting first information and second images of animals to a server according to some embodiments of the present disclosure.
본 개시의 몇몇 실시예에 따라 제어부(130)는 카메라부(110)로부터 촬영된 동물의 안면이 포함된 제 1 이미지를 획득할 수 있다(S210).According to some embodiments of the present disclosure, the
구체적으로, 제어부(130)는 이미지 촬영 명령에 기초하여 카메라부(110)로부터 촬영된 동물의 안면이 포함된 제 1 이미지를 획득할 수 있다. 예를 들어, 사용자가 사용자 단말기(100)의 카메라부(110)로 동물을 촬영하는 경우에, 제어부(130)는 동물의 안면이 모두 포함되도록(예를 들어, 사용자가 촬영하는 동물의 눈, 코, 입 및 귀가 모두 포함되는)하는 촬영 명령을 나타내는 사용자 인터페이스를 디스플레이부(150)를 통해 디스플레이할 수 있다. 여기서 제 1 이미지는 영상 이미지 또는 프리뷰 이미지일 수도 있다. Specifically, the
다음으로, 제어부(130)는 제 1 이미지를 사전 학습된 종 분류 모델에 입력하여 촬영된 동물의 종에 대한 제 1 정보를 획득할 수 있다(S220).Next, the
이하에서 도 4 내지 도 6을 참조하여, 본 개시의 몇몇 실시예에 따른 제 1 정보를 획득하는 방법에 대해 자세히 설명한다.Hereinafter, a method of obtaining first information according to some embodiments of the present disclosure will be described in detail with reference to FIGS. 4 to 6.
도 4는 본 개시의 몇몇 실시예에 따른 컨벌루셔널 뉴럴 네트워크(Convolutional neural network)를 나타내는 개략도이다.4 is a schematic diagram illustrating a convolutional neural network according to some embodiments of the present disclosure.
본 명세서에 걸쳐, 신경망, 네트워크 함수, 뉴럴 네트워크(neural network)는 동일한 의미로 사용될 수 있다. 딥 뉴럴 네트워크(DNN: deep neural network, 심층신경망)는 입력 레이어와 출력 레이어 외에 복수의 히든 레이어를 포함하는 신경망을 의미할 수 있다. 딥 뉴럴 네트워크를 이용하면 데이터의 잠재적인 구조(latent structures)를 파악할 수 있다. 즉, 사진, 글, 비디오, 음성, 음악의 잠재적인 구조(예를 들어, 어떤 물체가 사진에 있는지, 글의 내용과 감정이 무엇인지, 음성의 내용과 감정이 무엇인지 등)를 파악할 수 있다. 딥 뉴럴 네트워크는 컨벌루셔널 뉴럴 네트워크 (CNN: convolutional neural network), 리커런트 뉴럴 네트워크(RNN: recurrent neural network), 제한 볼츠만 머신(RBM: restricted boltzmann machine), 심층 신뢰 네트워크(DBN: deep belief network), Q 네트워크, U 네트워크, 샴 네트워크 등 을 포함할 수 있다.Throughout this specification, neural networks, network functions, and neural networks may be used in the same sense. A deep neural network (DNN) may mean a neural network including a plurality of hidden layers in addition to an input layer and an output layer. Deep neural networks can be used to identify potential latent structures in data. In other words, it is possible to grasp the potential structure of photos, text, video, voice, and music (for example, what objects are in the picture, what the content and emotions of the text are, what the content and emotions of the speech, etc.) . Deep neural networks include convolutional neural networks (CNNs), recurrent neural networks (RNNs), restricted boltzmann machines (RBMs), and deep belief networks (DBNs). , Q network, U network, Siam network, and the like.
도 4에 도시된 컨벌루셔널 뉴럴 네트워크는 딥 뉴럴 네트워크의 일종으로서, 컨벌루셔널 레이어를 포함하는 신경망을 포함한다. 컨벌루셔널 뉴럴 네트워크는 최소한의 전처리(preprocess)를 사용하도록 설계된 다계층 퍼셉트론(multilayer perceptorns)의 한 종류이다. CNN은 하나 또는 여러 개의 컨벌루셔널 레이어와 이와 결합된 인공 신경망 계층들로 구성될 수 있다. CNN은 가중치와 풀링 레이어(pooling layer)들을 추가로 활용할 수 있다. 이러한 구조 덕분에 CNN은 2 차원 구조의 입력 데이터를 충분히 활용할 수 있다. 컨벌루셔널 뉴럴 네트워크는 이미지에서 오브젝트를 인식하기 위하여 사용될 수 있다. 컨벌루셔널 뉴럴 네트워크는 이미지 데이터를 차원을 가진 행렬로 나타내어 처리할 수 있다. 예를 들어 RGB(red-green-blue)로 인코딩 된 이미지 데이터의 경우, R, G, B 색상별로 각각 2차원(예를 들어, 2 차원 이미지 인 경우) 행렬로 나타내 질 수 있다. 즉, 이미지 데이터의 각 픽셀의 색상 값이 행렬의 성분이 될 수 있으며 행렬의 크기는 이미지의 크기와 같을 수 있다. 따라서 이미지 데이터는 3개의 2차원 행렬로(3차원의 데이터 어레이)로 나타내질 수 있다.The convolutional neural network illustrated in FIG. 4 is a type of deep neural network and includes a neural network including a convolutional layer. Convolutional neural networks are a type of multilayer perceptorns designed to use minimal preprocessing. The CNN may consist of one or several convolutional layers and artificial neural network layers combined with it. CNN may additionally utilize weights and pooling layers. Thanks to this structure, CNN can fully utilize the input data of the two-dimensional structure. Convolutional neural networks can be used to recognize objects in an image. The convolutional neural network can process image data as a matrix with dimensions. For example, in the case of red-green-blue (RGB) -encoded image data, each of R, G, and B colors may be represented as a two-dimensional (for example, two-dimensional image) matrix. That is, the color value of each pixel of the image data may be a component of the matrix, and the size of the matrix may be the same as the size of the image. Therefore, the image data can be represented by three two-dimensional matrices (three-dimensional data array).
컨벌루셔널 뉴럴 네트워크에서 컨벌루셔널 필터를 이동해가며 컨벌루셔널 필터와 이미지의 각 위치에서의 행렬 성분끼리 곱하는 것으로 컨벌루셔널 과정(컨벌루셔널 레이어의 입출력)을 수행할 수 있다. 컨벌루셔널 필터는 n*n 형태의 행렬로 구성될 수 있다. 컨벌루셔널 필터는 일반적으로 이미지의 전체 픽셀의 수보다 작은 고정된 형태의 필터로 구성될 수 있다. 즉, m*m 이미지를 컨벌루셔널 레이어(예를 들어, 컨벌루셔널 필터의 사이즈가 n*n인 컨벌루셔널 레이어)입력시키는 경우, 이미지의 각 픽셀을 포함하는 n*n 픽셀을 나타내는 행렬이 컨벌루셔널 필터와 성분 곱 (즉, 행렬의 각 성분끼리의 곱) 될 수 있다. 컨벌루셔널 필터와의 곱에 의하여 이 미지에서 컨벌루셔널 필터와 매칭되는 성분이 추출될 수 있다. 예를 들어, 이미지에서 상하 직선 성분을 추출하기 위한 3*3 컨벌루셔널 필터는 [[0,1,0], [0,1,0], [0,1,0]] 와 같이 구성될 수 있다. 이미지에서 상하 직선 성분을 추출하기 위한 3*3 컨벌루셔널 필터가 입력 이미지에 적용되면 이미지에서 컨벌루셔널 필터와 매칭되는 상하 직선 성분이 추출되어 출력될 수 있다. 컨벌루셔널 레이어는 이미지를 나타낸 각각의 채널에 대한 각각의 행렬(즉, R, G, B 코딩 이미지의 경우, R, G, B 색상)에 컨벌루셔널 필터를 적용할 수 있다. 컨벌루셔널 레이어는 입력 이미지에 컨벌루셔널 필터를 적용하여 입력 이미지에서 컨벌루셔널 필터와 매칭되는 피쳐를 추출할 수 있다. 컨벌루셔널 필터의 필터 값(즉, 행렬의 각 성분의 값)은 컨벌루셔널 뉴럴 네트워크의 학습 과정에서 역전파에 의하여 업데이트 될 수 있다.A convolutional process (input / output of a convolutional layer) can be performed by moving a convolutional filter in a convolutional neural network and multiplying the convolutional filter and matrix components at each position of the image. The convolutional filter may be configured as an n * n matrix. The convolutional filter may generally consist of a fixed type filter smaller than the total number of pixels in the image. That is, when an m * m image is input to a convolutional layer (for example, a convolutional layer having a convolutional filter size of n * n), a matrix representing n * n pixels including each pixel of the image It can be multiplied by this convolutional filter (ie, the product of each component of the matrix). A component matching the convolutional filter in the image may be extracted by multiplication with the convolutional filter. For example, a 3 * 3 convolutional filter for extracting a vertical line component from an image may be configured as [[0,1,0], [0,1,0], [0,1,0]] You can. When a 3 * 3 convolutional filter for extracting vertical components from the image is applied to the input image, vertical components that match the convolutional filter from the image may be extracted and output. The convolutional layer may apply a convolutional filter to each matrix for each channel representing an image (ie, R, G, and B colors in the case of R, G, and B coded images). The convolutional layer may extract a feature matching the convolutional filter from the input image by applying a convolutional filter to the input image. The filter value of the convolutional filter (that is, the value of each component of the matrix) may be updated by backpropagation in the learning process of the convolutional neural network.
컨벌루셔널 레이어의 출력에는 서브샘플링 레이어가 연결되어 컨벌루셔널 레이어의 출력을 단순화하여 메모리 사용량과 연산량을 줄일 수 있다. 예를 들어, 2*2 맥스 풀링 필터를 가지는 풀링 레이어에 컨벌루셔널 레이어의 출력을 입력시키는 경우, 이미지의 각 픽셀에서 2*2 패치마다 각 패치에 포함되는 최대값을 출력하여 이미지를 압축할 수 있다. 전술한 풀링은 패치에서 최소값을 출력하거나, 패치의 평균값을 출력하는 방식일 수도 있으며 임의의 풀링 방식이 본 개시에 포함될 수 있다.A subsampling layer is connected to the output of the convolutional layer, thereby simplifying the output of the convolutional layer to reduce memory usage and computation. For example, if the output of a convolutional layer is input to a pooling layer having a 2 * 2 max pooling filter, the maximum value included in each patch is output for each 2 * 2 patch in each pixel of the image to compress the image. You can. The aforementioned pooling may be a method of outputting a minimum value in a patch or outputting an average value of patches, and any pooling method may be included in the present disclosure.
컨벌루셔널 뉴럴 네트워크는 하나 이상의 컨벌루셔널 레이어, 서브 샘플링 레이어를 포함할 수 있다. 컨벌루셔널 뉴럴 네트워크는 컨벌루셔널 과정과 서브샘플링 과정(예를 들어, 전술한 맥스 풀링 등)을 반복적으로 수행하여 이미지에서 피쳐를 추출할 수 있다. 반복적인 컨벌루션널 과정과 서브샘플링 과정을 통해 뉴럴 네트워크는 이미지의 글로벌 피쳐를 추출할 수 있다.The convolutional neural network may include one or more convolutional layers and sub-sampling layers. The convolutional neural network can extract features from an image by repeatedly performing a convolutional process and a subsampling process (for example, the Max pooling described above). Through the iterative convolutional and subsampling process, the neural network can extract global features of the image.
컨벌루셔널 레이어 또는 서브샘플링 레이어의 출력은 풀 커넥티드 레이어(fully connected layer)에 입력될 수 있다. 풀 커넥티드 레이어는 하나의 레이어에 있는 모든 뉴런과 이웃한 레이어에 있는 모든 뉴런이 연결되는 레이어이다. 풀 커넥티드 레이어는 뉴럴 네트워크에서 각 레이어의 모든 노드가 다른 레이어의 모든 노드에 연결된 구조를 의미할 수 있다.The output of the convolutional layer or subsampling layer may be input to a fully connected layer. A full connected layer is a layer in which all neurons in one layer are connected to all neurons in a neighboring layer. The full connected layer may refer to a structure in which all nodes of each layer are connected to all nodes of the other layer in the neural network.
본 개시의 몇몇 실시예에서 이미지 데이터의 세그먼테이션(segmentation)을 수행하기 위하여 뉴럴 네트워크는 디컨벌루셔널 뉴럴 네트워크(DCNN: deconvolutional neural network)를 포함할 수 있다. 디컨벌루셔널 뉴럴 네트워크는 컨벌루셔널 뉴럴 네트워크를 역방향으로 계산시킨 것과 유사한 동작을 수행한다. 디컨벌루셔널 뉴럴 네트워크는 컨벌루셔널 뉴럴 네트워크에서 추출된 피쳐를 원본 데이터와 관련된 피쳐맵으로 출력할 수 있다. 컨벌루셔널 뉴럴 네트워크에 대한 구체적인 구성에 관한 설명은 본 출원에서 전체가 참조로서 통합되는 미국 등록 특허 US9870768B2에서 보다 구체적으로 논의된다.In some embodiments of the present disclosure, the neural network may include a deconvolutional neural network (DCNN) to perform segmentation of image data. The deconvolutional neural network performs an operation similar to that of calculating the convolutional neural network in the reverse direction. The deconvolutional neural network may output features extracted from the convolutional neural network as a feature map related to original data. Descriptions of specific configurations for the convolutional neural network are discussed in more detail in US patent US9870768B2, which is incorporated herein by reference in its entirety.
본 개시의 몇몇 실시예에 따르면, 사전 학습된 종 분류 모델은 컨벌루셔널 뉴럴 네트워크에 해당하며, 제어부(130)는 상술한 컨벌루션 뉴럴 네트워크를 이용하여 촬영된 동물의 종을 인식할 수 있다. According to some embodiments of the present disclosure, the pre-trained species classification model corresponds to a convolutional neural network, and the
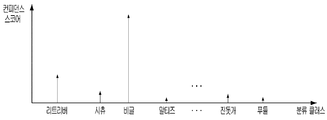
도 5는 본 개시의 몇몇 실시예에 따른 종 분류 모델을 개략적으로 설명하기 위한 도면이다. 도 6은 본 개시의 몇몇 실시예에 따라 종 분류 모델을 이용하여 동물의 종에 대한 정보를 획득하는 방법의 일례를 설명하기 위한 도면이다.5 is a diagram for schematically describing a species classification model according to some embodiments of the present disclosure. 6 is a view for explaining an example of a method for obtaining information about a species of an animal using a species classification model according to some embodiments of the present disclosure.
도 5를 참조하면, 본 개시의 사전 학습된 종 분류 모델은 사전 학습된 네트워크 함수(520)로서 이는 교사 학습(supervised learning), 비 교사 학습(unsupervised learning) 및 반교사학습(semi supervised learning) 중 적어도 하나의 방식으로 학습될 수 있다. Referring to FIG. 5, the pre-trained species classification model of the present disclosure is a
네트워크 함수의 학습은 출력의 오류를 최소화하기 위한 것이다. 네트워크 함수의 학습에서 반복적으로 학습 데이터를 네트워크 함수에 입력시킨다. 네트워크 함수의 학습에서 학습 데이터에 대한 네트워크 함수의 출력과 타겟의 에러를 계산한다. 네트워크 함수의 학습에서 에러를 줄이기 위한 방향으로 네트워크 함수의 에러를 네트워크 함수의 출력 레이어에서부터 입력 레이어 방향으로 역전파하여 네트워크 함수의 각 노드의 가중치를 업데이트 할 수 있다. Learning network functions is intended to minimize errors in the output. In the learning of the network function, learning data is repeatedly input to the network function. In the training of the network function, the output of the network function for the training data and the error of the target are calculated. The weight of each node of the network function can be updated by back propagating the error of the network function from the output layer of the network function to the input layer in the direction of reducing errors in the learning of the network function.
본 개시의 몇몇 실시예에 있어서 종 분류 모델은 전술한 네트워크 함수(520)일 수 있다.In some embodiments of the present disclosure, the species classification model may be the
본 개시의 몇몇 실시예에 있어서 종 분류 모델을 학습시키기 위한 제 1 학습 데이터는 동물의 안면이 포함된 이미지 데이터를 학습 데이터의 입력으로 하고, 동물의 안면이 포함된 이미지 데이터에 동물의 종에 대한 제 1 분류 클래스를 라벨로 하여 생성될 수 있다.In some embodiments of the present disclosure, the first learning data for training the species classification model includes image data including an animal's face as an input of training data, and image data including an animal's face for an animal species. It can be created by labeling the first classification class.
본 개시의 몇몇 실시예에 있어서, 종 분류 모델은 제 1 학습 데이터를 포함하는 제 1 학습 데이터 세트를 이용하여 동물의 안면과 매칭되는 동물의 종에 대한 분류를 학습하고, 제 1 이미지에 기초하여 동물의 종에 대한 제 1 정보가 획득되도록 생성될 수 있다.In some embodiments of the present disclosure, the species classification model uses the first training data set including the first training data to learn classification for the animal species that matches the animal's face, and based on the first image. It can be generated to obtain first information about the species of the animal.
여기서 종 분류 모델은 외부 서버 또는 다른 컴퓨팅 장치로부터 생성될 수 있다. 그리고, 외부 서버 또는 다른 컴퓨팅 장치는 웹 크롤링(Web Crawling)을 수행하여 동물의 안면이 포함된 이미지 데이터를 획득할 수 있다. 이미지 데이터는 종 분류 모델을 학습시키기 위한 제 1 학습 데이터 세트에 이용될 수 있다. 또한, 외부 서버 또는 다른 컴퓨팅 장치는 사용자 단말기(100) 또는 다른 사용자 단말기로부터 동물 안면이 포함된 이미지 데이터를 획득할 수 있다. 전술한 이미지 데이터를 획득하는 방법은 예시일 뿐, 본 개시는 이제 제한되지 않는다. Here, the species classification model may be generated from an external server or other computing device. In addition, the external server or other computing device may perform web crawling to acquire image data including an animal's face. The image data can be used in the first set of training data for training the species classification model. In addition, the external server or other computing device may acquire image data including an animal face from the
본 개시의 몇몇 실시예에 따른 사용자 단말기(100)는 외부에서 생성된 종 분류 모델을 획득하여 메모리(120)에 저장할 수 있다. 한편, 본 개시의 다른 몇몇 실시예에 따르면, 사용자 단말기(100)가 종 분류 모델을 생성할 수도 있다.The
예를 들어, 개의 종에 따라 눈, 코, 입 및 귀 각각의 크기, 모양 및 위치가 상이할 수 있다. 이러한 개의 종에 따른 특징에 기초하여 개의 종을 구별할 수 있다. 외부 서버 또는 다른 컴퓨팅 장치는 전술한 방법으로 동물의 안면이 포함된 이미지 데이터를 획득할 수 있다. 외부 서버 또는 다른 컴퓨팅 장치는 상기 획득한 이미지 데이터에 상기 동물의 종을 구별할 수 있는 특징에 기초하여 동물의 종에 정보를 라벨링하여 제 1 학습 데이터를 생성할 수 있다. 외부 서버 또는 다른 컴퓨팅 장치는 제 1 학습 데이터를 포함하는 제 1 학습 데이터 세트를 이용하여 네트워크 함수에 동물의 안면과 매칭되는 동물의 종에 대한 분류를 학습시켜 종 분류 모델을 생성할 수 있다. 한편, 전술한 종 분류 모델을 생성하는 방법은 예시일 뿐이며, 본 개시는 이에 제한되지 않고 사용자 단말기(100)가 직접 종 분류 모델을 생성할 수도 있다. For example, the size, shape, and location of each of the eyes, nose, mouth, and ears may differ depending on the species of dog. The dog species can be distinguished based on the characteristics of the dog species. An external server or other computing device may acquire image data including the animal's face in the manner described above. The external server or other computing device may generate the first learning data by labeling information on the animal species based on the characteristic that can distinguish the animal species from the acquired image data. The external server or other computing device may generate a species classification model by learning the classification of the animal species that matches the animal's face in the network function using the first training data set including the first training data. Meanwhile, the method for generating the above-described species classification model is only an example, and the present disclosure is not limited thereto, and the
본 개시의 몇몇 실시예에 따른 제어부(130)는 상기 생성된 종 분류 모델을 제 1 이미지에 입력하여 제 1 이미지에 포함된 동물의 종에 대한 정보를 획득할 수 있다.The
구체적으로 제어부(130)는 종 분류 모델에 동물의 안면이 포함된 제 1 이미지를 입력하여 연산할 수 있다. 제어부(130)는 종 분류 모델을 이용하여 동물의 종에 대한 제 1 분류 클래스 각각에 대한 컨피던스 스코어(confidence score)를 출력 노드(530)에서 출력할 수 있다. 제어부(130)는 출력된 컨피던스 스코어에 기초하여 컨피던스 스코어 중 가장 높은 값을 가지는 제 1 분류 클래스를 제 1 정보로 획득할 수 있다. 전술한 제 1 정보를 획득하는 방법은 예시일 뿐이며, 본 개시는 이에 제한되지 않는다.Specifically, the
예를 들어, 도 6을 참조하면, 제어부(130)는 종 분류 모델에 동물이 촬영된 이미지를 입력하여 컨피던스 스코어를 연산할 수 있다. 제어부(130)는 눈, 코, 입 및 귀 각각의 모양, 크기 및 위치 등과 같은 특징에 기초하여 이미지에 포함된 동물(예를 들어, 개)의 종류 별로 분류된 제 1 분류 클래스 각각의 컨피던스 스코어를 종 분류 모델을 이용하여 연산할 수 있다. For example, referring to FIG. 6, the
사용자 단말기(100)에서 종 분류 모델에 입력된 이미지가 비글의 이미지인 경우, 도 6과 같이 연산된 컨피던스 스코어 중 비글에 대한 컨피던스 스코어가 가장 높은 값을 가질 수 있다. 이 경우, 제어부(130)는 제 1 이미지로부터 촬영된 동물의 종을 비글로 인식하여 제 1 정보를 획득할 수 있다. 전술한 제 1정보를 획득하는 방법은 예시일 뿐이며, 본 개시는 이제 제한되지 않는다.When the image input to the species classification model in the
한편, 도 3을 다시 참조하면, 제어부(130)는 단계(S220)에서 동물의 종에 대한 제 1 정보를 획득한 경우, 제 1 이미지 내에서 촬영된 동물의 코를 포함하는 제 1 영역의 위치를 인식할 수 있다(S230).Meanwhile, referring to FIG. 3 again, when the
이하 도 7 및 도 8에서 본 개시의 몇몇 실시예에 따른 제어부(130)가 동물의 제 1 영역의 위치를 인식하는 방법에 대해 자세히 설명한다.Hereinafter, a method of recognizing the position of the first region of the animal by the
도 7 및 도 8은 본 개시의 몇몇 실시예에 따른 동물의 코를 포함하는 제 1 영역을 인식하는 방법을 설명하기 위한 도면들이다. 7 and 8 are diagrams for describing a method of recognizing a first region including a nose of an animal according to some embodiments of the present disclosure.
본 개시의 몇몇 실시예에 따르면, 제어부(130)는 제 1 이미지를 사전 학습된 코 영역 인식 모델에 입력하여 제 1 이미지 내에서 촬영된 동물의 코를 포함하는 제 1 영역의 위치를 인식할 수 있다. 코 인식 모델은 YOLO(You Only Look Once) 알고리즘을 이용하는 모델일 수 있다. YOLO 알고리즘을 이용하는 모델에 대한 구체적인 구성에 대해서는 본 출원의 전체가 참조로서 통합되는 논문 "Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi; The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779-788"에서 구체적으로 논의된다 According to some embodiments of the present disclosure, the
여기서 코 영역 인식 모델은 외부 서버 또는 다른 컴퓨팅 장치로부터 생성될 수 있다. 코 영역 인식 모델을 학습시키기 위한 이미지 데이터는 전술한 종 분류 모델을 학습시키기 위한 이미지 데이터를 이용할 수 있다. 또한, 외부 서버 또는 다른 컴퓨팅 장치는 전술한 이미지 데이터를 획득하기 위한 방법으로 코 영역을 학습시키기 위한 이미지 데이터를 획득할 수 있다. 전술한 코 영역 인식 모델을 학습시키기 위한 이미지 데이터를 획득하는 방법은 예시일 뿐, 본 개시는 이제 제한되지 않는다. Here, the nose region recognition model may be generated from an external server or other computing device. As image data for training the nose region recognition model, image data for training the above-described species classification model may be used. In addition, an external server or other computing device may acquire image data for learning the nose region as a method for obtaining the image data described above. The method of obtaining image data for training the nose region recognition model described above is merely an example, and the present disclosure is not limited.
사용자 단말기(100)는 외부에서 생성된 코 영역 인식 모델을 획득하여 메모리(120)에 저장할 수 있다. 한편, 본 개시의 다른 몇몇 실시예에 따르면, 사용자 단말기(100)가 코 영역 인식 모델을 생성할 수도 있다.The
코 영역 인식 모델은 동물의 안면이 포함된 이미지 데이터를 포함하는 제 2 학습 데이터 세트 및 바운딩 박스(bounding box)에 대한 좌표를 이용하여 동물의 안면의 이미지와 매칭되는 코 영역의 위치를 학습할 수 있다.The nose region recognition model can learn the location of the nose region that matches the image of the animal's face using coordinates for a bounding box and a second training data set that includes image data that includes the animal's face. have.
예를 들어 외부 서버 또는 다른 컴퓨팅 장치는 동물의 안면이 포함된 이미지 데이터에서 코를 포함하는 제 1 영역의 위치에 대한 제 2 정보를 라벨링 하여 제 2 학습 데이터를 생성할 수 있다. 여기서 제 2 정보는 동물의 안면 이미지 내에서 다른 객체(예를 들어, 눈, 입, 귀 등)와 식별하기 위한 동물의 코의 모양, 위치 및 크기에 대한 정보를 포함할 수 있다. 라벨링된 학습 데이터는 사용자가 직접 동물 안면이 포함된 이미지의 내에서 제 2 정보를 라벨링한 것일 수 있다. 라벨링된 학습 데이터는 다른 네트워크 함수 모델을 이용하여 동물 안면이 포함된 이미지 데이터에 제 2 정보를 라벨링한 것일 수 있다. 예를 들어 동물 안면이 포함된 이미지 내에서 코를 포함하는 제 1 영역의 위치에 제 2 정보를 라벨링할 수 있다. 외부 서버 또는 다른 컴퓨팅 장치는 라벨링된 제 2 학습 데이터 세트에 포함된 제 2 학습 데이터 각각을 코 영역 인식 모델을 이용하여 연산하여 코를 포함하는 제 1 영역의 위치에 대한 제 2 정보를 획득할 수 있다.For example, an external server or other computing device may generate the second learning data by labeling the second information about the location of the first area including the nose in the image data including the face of the animal. Here, the second information may include information about the shape, position, and size of the animal's nose for identification with other objects (eg, eyes, mouth, ears, etc.) in the face image of the animal. The labeled learning data may be that the user directly labels the second information within the image containing the animal face. The labeled learning data may be labeling second information on image data including an animal face using another network function model. For example, the second information may be labeled at the position of the first region including the nose in the image including the animal face. An external server or other computing device may obtain second information about the location of the first region including the nose by calculating each of the second training data included in the labeled second training data set using a nose region recognition model. have.
외부 서버 또는 다른 컴퓨팅 장치는 코 영역 인식 모델을 이용하여 연산하여 획득한 제 1 영역의 위치에 대한 정보와 제 2 학습 데이터의 라벨링 된 제 2 정보를 비교하여 오차를 계산할 수 있다. 외부 서버 또는 다른 컴퓨팅 장치는 영역이 겹쳐지는 정도에 기초하여 오차를 연산할 수 있다. 외부 서버 또는 다른 컴퓨팅 장치는 학습 데이터의 라벨링된 제 2 정보의 바운딩 박스와 코 영역 인식 모델을 이용하여 연산하여 획득한 제 1 영역의 위치에 대한 정보의 바운딩 박스의 영역이 겹쳐지는 정도에 기초하여 오차를 연산할 수 있다. 오차는, 라벨링된 제 2 정보의 바운딩 박스와 코 영역 인식 모델을 이용하여 연산한 제 1 영역의 위치에 대한 정보의 바운딩 박스의 교집합을 합집합으로 나눈 것일 수 있다. 외부 서버 또는 다른 컴퓨팅 장치는 역방향인, 코 영역 인식 모델의 출력 레이어에서 입력 레이어 방향으로 계산된 오차를 역전파할 수 있다. 외부 서버 또는 다른 컴퓨팅 장치는 출력 레이어에서 입력 레이어 방향으로 오차를 역전파하여 역전파에 따라 각 레이어의 각 노드들의 연결 가중치를 업데이트할 수 있다. 업데이트 되는 각 노드의 연결 가중치는 학습률(learning rate)에 따라 변화량이 결정될 수 있다. 입력 데이터인 제 1 이미지 대한 코 영역 인식 모델의 계산과 에러의 역전파는 학습 사이클을 구성할 수 있다. 학습률은 네트워크 함수의 학습 사이클의 반복 횟수에 따라 상이하게 적용될 수 있다. 예를 들어, 네트워크 함수의 학습 초기에는 높은 학습률을 사용하여 네트워크 함수가 빠르게 일정 수준의 성능을 확보하도록 하여 효율성을 높일 수 있다. 예를 들어, 네트워크 함수의 학습 후기에는 낮은 학습률을 사용하여 정확도를 높일 수 있다. 예를 들어, 외부 서버 또는 다른 컴퓨팅 장치는 코 영역 인식 모델의 학습에 대한 학습률을 0.001에서 0.1로 에폭 마다 상승시킬 수 있다. 예를 들어, 외부 서버 또는 다른 컴퓨팅 장치는 코 영역 인식 모델의 학습에 대하여 마지막 30 에폭 동안의 학습률을 0.0001로 하여 코 영역 인식 모델을 학습시킬 수 있다. 외부 서버 또는 다른 컴퓨팅 장치는 코 영역 인식 모델의 학습에서 과적합 (overfitting)을 방지하기 위하여 히든 노드의 출력의 일부가 다음 히든 노드에 전달되지 못하도록 드롭 아웃(drop out)을 설정할 수 있다. 예를 들어, 제어부(130)는 코 영역 인식 모델의 드롭 아웃률을 0.5로 설정하여 코 영역 인식 모델의 학습을 수행할 수 있다. 전술한 코 영역 인식 모델을 생성하는 방법에 대한 기재는 예시일 뿐이며 본 개시는 이에 제한되지 않는다. 전술한 외부 서버 또는 다른 컴퓨팅 장치가 코 영역 인식 모델을 생성하는 방법으로 사용자 단말기(100)는 코 영역 인식 모델을 생성할 수도 있다.The external server or other computing device may calculate an error by comparing information about the location of the first region obtained by calculating using the nose region recognition model and labeled second information of the second training data. The external server or other computing device can calculate the error based on the degree of overlap of regions. The external server or other computing device is based on the degree of overlap of the bounding box of the information about the location of the first area obtained by calculating using the nose area recognition model and the bounding box of the second labeled information of the learning data. The error can be calculated. The error may be obtained by dividing the intersection of the bounding box of the information on the position of the first region calculated using the bounding box of the labeled second information and the nose region recognition model by the union. The external server or other computing device may back propagate the error calculated in the direction of the input layer from the output layer of the nose region recognition model, which is the reverse direction. The external server or other computing device may reverse the error from the output layer to the input layer to update the connection weight of each node of each layer according to the back propagation. The connection weight of each node to be updated may be determined according to a learning rate. The calculation of the nose region recognition model for the first image, which is the input data, and the back propagation of errors may constitute a learning cycle. The learning rate may be applied differently according to the number of iterations of the learning cycle of the network function. For example, in the early stages of learning a network function, a high learning rate may be used to rapidly increase the efficiency of the network function by ensuring a certain level of performance. For example, a low learning rate can be used to increase accuracy in a later learning period of a network function. For example, an external server or other computing device may increase the learning rate for learning the nose region recognition model from 0.001 to 0.1 per epoch. For example, an external server or other computing device may train the nose region recognition model by setting the learning rate during the last 30 epochs to 0.0001 for training the nose region recognition model. An external server or other computing device may set drop out so that a part of the output of the hidden node is not delivered to the next hidden node in order to prevent overfitting in learning the nose region recognition model. For example, the
도 7을 참조하면, 제어부(130)는 상술한 코 인식 모델인 YOLO 알고리즘에 제 1 이미지, 제 1 이미지에 포함된 동물의 종에 대한 제 1 정보 및 제 2 분류 클래스 각각에 대한 스코어링 값에 기초하여 코를 포함하는 제 1 영역의 위치(710)에 대한 제 2 정보를 결정할 수 있다. 제 2 분류 클래스는 코 영역을 포함하는 제 1 영역의 위치를 인식하기 위한 것일 수 있다.Referring to FIG. 7, the
본 개시의 다른 몇몇 실시예에 따르면, 제어부(130)는 동물의 눈과 동물의 입의 위치에 기초하여 동물의 코를 포함하는 제 1 영역의 위치(710)를 인식할 수도 있다.According to some other embodiments of the present disclosure, the
구체적으로, 도 8을 참조하면, 제어부(130)는 제 1 이미지 내에서 상기 동물의 눈을 포함하는 제 2 영역의 위치 및 상기 동물의 입을 포함하는 제 3 영역을 인식할 수 있다(S231).Specifically, referring to FIG. 8, the
예를 들어, 제어부(130)는 동물의 눈을 포함하는 제 2 영역의 위치와 동물의 입을 포함하는 제 3 영역의 위치를 메모리(120)에 저장된 눈 영역 인식 모델 및 입 영역 인식 모델을 이용하여 인식할 수 있다. 여기서, 눈 영역 인식 모델(또는 입 영역 인식 모델)은 상술한 코 영역 인식 모델과 같은 방식으로 눈 영역(또는 입 영역)을 인식할 수 있으므로, 이에 대한 자세한 설명은 생략한다. 다만, 이에 한정되는 것은 아니고 제어부(130)는 다양한 방법으로, 동물의 눈을 포함하는 제 2 영역의 위치 및 동물의 입을 포함하는 제 3 영역의 위치를 인식할 수 있다. For example, the
그리고 제어부(130)는 상기 제 2 영역의 위치 및 상기 제 3 영역의 위치에 기초하여 제 1 이미지 내에서 촬영된 동물의 코를 포함하는 제 1 영역의 위치를 인식할 있다(S232).Then, the
구체적으로, 메모리(120)에는 눈의 위치 및 입의 위치에 기초하여 코의 위치를 인식하는 코 위치 인식 모델이 저장될 수 있다. 따라서, 제어부(130)는 단계(S231)에서 획득한 제 2 영역의 위치, 단계(S231)에서 획득한 제 3 영역의 위치를 상기 메모리에 저장된 코 위치 인식 모델에 입력하여 동물의 코를 포함하는 제 1 영역의 위치를 인식할 수 있다. 이 경우, 코 위치 인식 모델은 동물의 종에 대한 정보도 추가로 입력 받아 코 위치를 인식할 수도 있다. Specifically, the nose position recognition model for recognizing the position of the nose based on the position of the eye and the position of the mouth may be stored in the
전술한 동물의 코를 포함하는 제 1 영역의 위치를 인식하는 방법은 예시일 뿐, 본 개시는 이에 제한되지 않는다.The method of recognizing the position of the first region including the nose of the animal described above is merely an example, and the present disclosure is not limited thereto.
한편, 도 3을 다시 참조하면, 단계(S230)에서 제 1 이미지 내에서 동물의 코를 포함하는 제 1 영역의 위치를 인식한 경우, 제어부(130)는 사전 설정된 조건을 만족되는지 여부를 결정할 수 있다(S240).Meanwhile, referring to FIG. 3 again, if the position of the first region including the nose of the animal is recognized in the first image in step S230, the
이하에서 도 9 내지 도 12를 참조하여 사전 설정된 조건이 만족되는지 인식하는 동작에 대해 자세히 설명을 한다.Hereinafter, an operation of recognizing whether a preset condition is satisfied will be described in detail with reference to FIGS. 9 to 12.
도 9는 본 개시의 몇몇 실시예에 따른 사전 설정된 조건이 만족되는지 여부를 인식하는 방법을 설명하기 위한 흐름도이다. 도 10은 본 개시의 몇몇 실시예에 따른 콧구멍을 인식하는 동작의 예시를 나타내는 도면이다. 도 11은 본 개시의 몇몇 실시예에 따른 콧구멍의 원형성 측정하는 방법의 일례를 설명하기 위한 도면이다. 도 12는 본 개시의 몇몇 실시예에 따른 콧구멍의 관성률을 측정하는 방법의 일례를 설명하기 위한 나타내는 도면이다.9 is a flowchart illustrating a method of recognizing whether a preset condition is satisfied according to some embodiments of the present disclosure. 10 is a diagram illustrating an example of an operation of recognizing a nostril according to some embodiments of the present disclosure. 11 is a view for explaining an example of a method for measuring the circularity of the nostrils according to some embodiments of the present disclosure. 12 is a view for explaining an example of a method for measuring the inertia of the nostrils according to some embodiments of the present disclosure.
본 개시의 몇몇 실시예에 따른 제어부(130)는 제 1 영역 내에서 상기 동물의 우측 콧구멍(nostril) 및 좌측 콧구멍을 인식할 수 있다(S241). The
구체적으로, 도 10을 참조하면, 제어부(130)는 특징점 추출(feature extraction) 알고리즘을 이용하여 제 1 영역 내에서 동물의 우측 콧구멍 및 좌측 콧구멍을 인식할 있다. Specifically, referring to FIG. 10, the
예를 들어, 제 1 이미지의 제 1 영역 내에서 콧구멍이 위치하는 영역이 가장 어두울 수 있다. 따라서, 제 1 영역 내의 이미지 상에서 콧구멍이 위치하는 영역의 픽셀들의 명도 값과 콧구멍의 가장자리에 위치하는 코 영역 픽셀들의 명도 값의 차이가 최대 값을 가질 수 있다. 이 때 명도 값은 제 1 이미지 데이터의 화소 깊이에 따라 달라질 수 있다. 제어부(130)는 제 1 영역의 이미지의 픽셀들의 명도 값을 추출하고, 인접하는 영역들 사이의 픽셀들의 명도 값의 차이가 최대 값을 가지는 영역을 콧구멍의 가장자리로 인식할 수 있다. 그리고 제어부(130)는 명도 값의 차이가 최대 값을 가지는 영역의 픽셀들을 콧구멍의 특징점들로 추출할 수 있다. 전술한 콧구멍을 인식하는 방법은 예시일 뿐이며, 본 개시는 이에 제한되지 않는다. For example, the region where the nostril is located in the first region of the first image may be the darkest. Accordingly, a difference between the brightness value of pixels in the nostril region on the image in the first region and the brightness value of pixels in the nostril region located at the edge of the nostril may have a maximum value. In this case, the brightness value may vary depending on the pixel depth of the first image data. The
한편, 도 9를 다시 참조하면, 제어부(130)는 우측 콧구멍 및 상기 좌측 콧구멍의 원형성(circularity) 및 상기 콧구멍의 관성률(Inertia ratio) 중 적어도 하나에 기초하여 상기 동물이 촬영된 포즈(pose)를 인식할 수 있다(S242). 여기서, 동물이 촬영된 포즈는 사용자가 동물의 안면을 어느 쪽에서 촬영했는지를 나타내는 정보일 수 있다. Meanwhile, referring to FIG. 9 again, the
본 개시의 몇몇 실시예에 따라, 제어부(130)가 우측 콧구멍 및 상기 좌측 콧구멍의 원형성(circularity)에 기초하여 동물이 촬영된 포즈를 인식하는 방법은 다음과 같다. 여기서, 원형성은 이미지에 포함된 동물의 콧구멍의 상/하/좌/우측에 존재하는 특징점에서의 콧구멍의 곡률이 메모리(120)에 저장된 동물의 종에 대응하는 콧구멍의 상/하/좌/우측에 존재하는 특징점에서의 콧구멍의 곡률과 유사한 정도를 의미할 수 있다. According to some embodiments of the present disclosure, a method in which the
제어부(130)는 제 1 이미지로부터 획득한 동물의 종에 대한 제 1 정보 및 메모리(120)에 저장된 동물의 종에 따른 원형성에 기초하여 상기 동물이 촬영된 포즈(pose)를 인식할 수 있다. The
예를 들어, 도 11을 참조하면, 제어부(130)는 카메라부(110)로 촬영하여 획득한 동물의 안면이 포함된 제 1 이미지에 포함된 동물의 콧구멍의 상/하/좌/우측에 존재하는 특징점들(P1, P2, P3, P4) 각각에서 측정한 콧구멍의 곡률과 메모리(120)에 저장된 상/하/좌/우측에 존재하는 특징점들 각각에서 측정되는 콧구멍의 곡률간의 차이 값을 산출할 수 있다. 제어부(130)는 산출된 차이 값이 기 설정된 임계 값보다 적은 경우에 상기 동물의 포즈가 정면이라고 인식할 수 있다. 여기서, 메모리(120)에 저장된 상/하/좌/우측에 존재하는 특징점들 각각에서 측정되는 콧구멍의 곡률은 동물의 안면이 정면으로 촬영된 경우, 동물의 종에 따른 콧구멍의 상/하/좌/우측에 존재하는 특징점 각각에서 측정된 콧구멍의 곡률일 수 있다.For example, referring to FIG. 11, the
한편, 사용자가 사용자 단말기(100)를 이용하여 동물의 안면을 정면보다 우측면(또는 좌측면)에서 촬영한 경우에는, 동물의 콧구멍의 중심으로부터 좌측에 존재하는 특징점(P4)에서의 콧구멍의 곡률과 우측에 존재하는 특징점(P2)에서의 콧구멍의 곡률은 메모리에 저장된 좌측 및 우측에 존재하는 특징점의 곡률 보다 작을 수 있다. 그리고 콧구멍의 상측에 존재하는 특징점(P1)에서의 곡률과 콧구멍의 하측에 존재하는 특징점(P3)에서의 곡률은 메모리에 저장된 상측 및 하측에 존재하는 특징점의 곡률 보다 클 수 있다. 이 경우, 제어부(130)는 동물이 촬영된 포즈가 우측(또는 좌측)이라고 인식할 수 있다. On the other hand, when the user uses the
본 개시의 다른 몇몇 실시예에 따라, 제어부(130)가 우측 콧구멍 및 상기 좌측 콧구멍의 관성률에 기초하여 동물이 촬영된 포즈를 인식하는 방법은 다음과 같다. 여기서, 관성률은 콧구멍의 중심에서 가로축의 길이(a)와 세로축의 길이(b)의 비율을 의미한다.According to some other embodiments of the present disclosure, a method in which the
도 12를 참조하면, 제어부(130)는 상기 콧구멍의 특징점들 중 콧구멍의 중심으로부터 가로축에 위치하는 2개의 콧구멍의 특징점들 간의 제 1 길이(a)를 측정할 수 있다. 그리고 제어부(130)는 상기 콧구멍의 중심으로부터 세로축에 위치하는 2개의 콧구멍의 특징점들 간의 제 2 길이(b)를 측정할 수 있다. 제어부(130)는 제 1 길이(a) 및 제 2 길이(b)의 비율에 기초하여 콧구멍의 관성률을 측정할 수 있다. Referring to FIG. 12, the
제어부(130)는 제 1 이미지로부터 획득한 동물의 종에 대한 제 1 정보, 메모리에 저장된 제 1 정보에 대응하는 관성률 및 제 1 이미지에 의해 측정된 관성률에 기초하여 상기 동물이 촬영된 포즈를 인식할 수 있다. The
한편, 동물의 종에 따른 관성률이 메모리(120)에 저장될 수 있다. 제어부(130)는 제 1 이미지로부터 측정된 관성률과 메모리에 저장된 동물의 종에 대한 제 1 정보에 맵핑된 관성률의 차이 값에 기초하여 상기 동물이 촬영된 포즈를 인식할 수 있다. 여기서, 메모리(120)에 저장된 관성률은 해당 종의 동물이 정면에서 촬영된 경우에 가질 수 있는 관성률일 수 있다. Meanwhile, the inertia rate according to the animal species may be stored in the
예를 들어, 제어부(130)는 카메라부(110)로 촬영하여 획득한 동물의 안면이 포함된 제 1 이미지에 포함된 동물의 콧구멍의 관성률과 메모리(120)에 저장된 관성률의 차이값을 산출할 수 있다. 제어부(130)는 산출된 차이 값이 기 설정된 임계 값보다 적은 경우에 상기 동물의 포즈가 정면이라고 인식할 수 있다. 여기서, 메모리(120)에 저장된 관성률은 동물의 안면이 정면에서 촬영된 경우의 관성률일 수 있다.For example, the
한편, 사용자가 사용자 단말기(100)를 이용하여 동물의 안면을 정면보다 우측면에서 촬영한 경우에는, 동물의 우측 콧구멍에 위치하는 가로축의 길이(a)는 메모리(120)에 저장된 우측 콧구멍의 가로축의 길이 보다 길고 세로축의 길이(b)는 동일하게 측정될 수 있다. 반면에 사용자가 사용자 단말기(100)를 이용하여 동물의 안면을 정면보다 우측면에서 촬영한 경우에는, 동물의 좌측 콧구멍에 위치하는 가로축의 길이(a)는 메모리(120)에 저장된 좌측 콧구멍의 가로축의 길이보다 짧고 세로축의 길이는 동일하게 측정될 수 있다. 따라서, 제어부(130)는 포즈가 우측면인 경우, 제 1 이미지를 통해 인식된 관성률과 메모리(120)에 저장된 관성률을 비교하여 포즈가 우측면이라고 인식할 수 있다. On the other hand, when the user uses the
한편, 도 9를 다시 참조하면, 제어부(130)는 촬영된 포즈가 기 설정된 포즈에 매칭되는 경우 상기 사전 설정된 조건이 만족되었다고 인식할 수 있다(S243).On the other hand, referring back to FIG. 9, when the photographed pose matches the preset pose, the
구체적으로, 제어부(130)는 단계(S242)에서 촬영된 동물의 포즈를 인식하면, 제어부(130)는 촬영된 동물의 포즈가 기 설정된 포즈에 매칭되는 경우에 사전 설정된 조건이 만족되었다고 인식할 수 있다. 여기서, 기 설정된 포즈는 동물이 정면에서 촬영된 모습를 의미한다.Specifically, when the
예를 들어, 제어부(130)는 단계(S243)에서 인식된 포즈가 정면이라고 인식한 경우 기 설정된 조건이 만족되었다고 인식할 수 있다. 반면에 제어부(130)는 단계(S243)에서 인식된 포즈가 정면이 아니라고 인식한 경우 기 설정된 조건에 만족되지 않는다고 인식할 수 있다. For example, when it is recognized that the pose recognized in step S243 is front, the
한편, 도 3을 다시 참조하면, 제어부(130)는 단계(S240)에서 사전 설정된 조건이 만족되는 경우에 제 1 영역 내에서 관심 영역(Region Of Interest)을 결정할 수 있다(S250).Meanwhile, referring back to FIG. 3, the
본 개시의 몇몇 실시예에 따른 제 1 영역 내에서 관심 영역은 동물의 코에서 발견할 수 있는 고유한 무늬인 비문이 포함된 영역일 수 있다. 동물이 코를 벌렁거리는 경우에 동물의 콧구멍의 바깥쪽의 코의 크기 확장되거나 축소되고, 동물의 콧구멍의 바깥쪽에 위치하는 비문의 모양이 변형될 수 있다. 그러나 동물이 코를 벌렁거리는 경우에 좌/우 콧구멍 사이는 콧구멍의 바깥쪽보다 크기의 변화가 적고, 좌/우 콧구멍 사이에 위치하는 비문의 모양도 역시 콧구멍의 바깥쪽에 위치하는 비문의 모양보다 변형이 작게 일어날 수 있다. 따라서, 좌/우 콧구멍 사이를 관심 영역으로 결정하는 것이 바람직하다.The region of interest within the first region according to some embodiments of the present disclosure may be a region containing an inscription, which is a unique pattern found in the nose of an animal. When the animal is swollen, the size of the nose outside the animal's nostrils expands or contracts, and the shape of the inscription located outside the animal's nostrils can be altered. However, when the animal has a nostril, the size between the left and right nostrils changes less than the outside of the nostrils, and the shape of the inscription located between the left and right nostrils is also located outside the nostrils. Deformation may occur smaller than the shape of. Therefore, it is desirable to determine the region of interest between the left and right nostrils.
도 13은 본 개시의 몇몇 실시예에 따른 제 1 영역 내에서 관심 영역을 결정하는 방법의 일례를 설명하기 위한 흐름도이다.13 is a flowchart illustrating an example of a method for determining a region of interest within a first region according to some embodiments of the present disclosure.
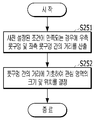
도 13을 참조하면, 제어부(130)는 도 9의 단계(S243)에서 사전 설정된 조건이 만족되는 경우에 우측 콧구멍 및 좌측 콧구멍 간의 거리를 산출할 수 있다(S251).Referring to FIG. 13, when the preset condition is satisfied in step S243 of FIG. 9, the
예를 들어, 제어부(130)는 전술한 단계(S241)에서 제 1 영역 내의 이미지 상에서 좌/우측 콧구멍의 특징점을 추출하여 좌/우측 콧구멍을 인식할 수 있다. 그리고 제어부(130) 우측 콧구멍 및 좌측 콧구멍 간의 거리를 산출할 수 있다. For example, the
다음으로, 제어부(130)는 콧구멍 간의 거리에 기초하여 관심 영역의 크기 및 위치를 결정할 수 있다(S252)Next, the
제어부(130)는 단계(S251)에서 산출된 좌/우측 콧구멍 간의 거리가 길면 관심 영역의 크기를 크게 결정할 수 있다. 반면에 제어부(130)는 산출된 좌/우측 콧구멍 간의 거리가 짧으면 관심 영역의 크기를 작게 결정할 수 있다. 그리고 제어부(130)는 좌/우측 콧구멍의 간의 거리의 중심이 되는 위치를 관심 영역의 위치로 결정할 수 있다. 전술한 바와 같이 좌/우측 콧구멍의 간의 거리의 중심이 되는 위치가 콧구멍의 움직임에 따라 모양의 변화가 가장 적은 위치이기 때문이다.If the distance between the left and right nostrils calculated in step S251 is long, the
반면에, 본 개시의 몇몇 실시예에 따라 제어부(130)는 사전 설정된 조건이 만족되지 않는 경우에 사전 설정된 조건을 만족하는 제 1 이미지가 획득되도록 재촬영을 요구하는 인디케이터를 디스플레이하도록 디스플레이부(150)를 제어할 수 있다.On the other hand, according to some embodiments of the present disclosure, the
예를 들어, 제어부(130) 단계(S240)에서 촬영된 포즈가 우측면에서 촬영한 것으로 인식하는 경우에 기 설정된 조건에 만족되지 않는다고 인식할 수 있다. 제어부(130)는 기 설정된 조건에 만족되도록 카메라부(110)를 동물의 안면의 좌측면으로 이동시켜 재촬영을 요구하는 인디케이터를 디스플레이하도록 디스플레이부(150)를 제어할 수 있다. 제어부(130)는 재촬영된 제 1 이미지가 기 설정된 조건을 만족하는지 다시 판단할 수 있다. 전술한 제 1 이미지를 재촬영하는 인디케이터 방법은 예시일 뿐이며, 본 개시는 이제 제한되지 않는다.For example, when it is recognized that the pose taken in step S240 of the
또한, 본 개시의 몇몇 실시예에 따라 제어부(130)는 사전 설정된 조건이 만족되지 않는 경우에 제 1 이미지를 정면화(Frontalization)하여 상기 사전 설정된 조건을 만족하도록할 수 있다.In addition, according to some embodiments of the present disclosure, when the preset condition is not satisfied, the
구체적으로, 제어부(130)는 전술한 단계(S241)에서 제 1 영역 내의 이미지 상에서 좌/우측 콧구멍의 특징점을 추출할 수 있다. 메모리(120)에는 동물의 안면을 정면으로 촬영된 이미지에 기초하여 좌/우측 콧구멍들의 특징점들의 위치에 관한 정보가 저장될 수 있다. 제어부(130)는 메모리(120)에 저장된 콧구멍들의 특징점들의 위치에 관한 정보에 기초하여 제 1 영역 내의 이미지 상에서 추출한 콧구멍들의 특징점들을 상기 저장된 특징점들에 매칭되도록 제 1 이미지를 보정할 수 있다. 예를 들어, 사용자가 동물을 우측에서 촬영한 경우에, 제 1 이미지 상에서 우측 콧구멍이 위치하는 영역의 이미지는 실제 동물의 우측 콧구멍의 위치하는 영역보다 넓게 획득되고, 반면에 좌측 콧구멍이 위치하는 영역의 이미지는 실제 동물의 좌측 콧구멍이 위치하는 영역보다 좁게 획득된다. 제어부(130)는 제 1 이미지 상에서 동물의 안면이 우측에서 촬영된 것을 판단할 수 있다. 제어부(130)는 제 1 이미지의 우측에 위치하는 픽셀들의 크기를 보다 감소시키거나 좌측으로 위치를 이동시키는 보정을 할 수 있다. 그리고 제 1 이미지의 좌측에 위치하는 픽셀들의 크기를 보다 증가시키거나 우측으로 이동시키는 보정을 할 수 있다. 제어부(130)는 보정된 제 1 이미지 상에서 좌/우측 콧구멍의 특징점을 다시 추출할 수 있다. 제어부(130)는 다시 추출된 좌/우측 콧구멍들의 특징점과 상기 저장된 특징점들에 매칭되면 상기 사전 설정된 조건이 만족하는 것을 인식할 수 있다. 전술한, 제 1 이미지를 보정하여 정면화하는 방법은 예시일 뿐이며, 본 개시는 이에 제한되지 않는다.Specifically, the
한편, 도 3을 다시 참조하면, 제어부(130)는 관심 영역이 결정된 경우, 제 1 이미지 내에서 관심 영역을 포함하는 제 2 이미지를 추출할 수 있다(S260).Meanwhile, referring to FIG. 3 again, when the region of interest is determined, the
본 개시의 몇몇 실시예에 따라 제어부(130)는 제 1 이미지 내에서 관심 영역을 포함하는 제 2 이미지 데이터를 생성할 수 있다. 제 2 이미지는 서버에 전송되고 촬영한 동물의 개체 정보를 획득하는데 이용될 수 있다.According to some embodiments of the present disclosure, the
다음으로, 제어부(130)는 단계(S260)에서 제 2 이미지가 추출된 경우, 제 1 정보 및 제 2 이미지를 서버에 전송하도록 네트워크부(140)를 제어할 수 있다. Next, the
서버(200)의 제어부는 수신된 제 1 정보 및 제 2 이미지에 기초하여 사용자 단말기(100)가 촬영한 동물의 개체 정보를 획득하고, 사용자 단말기(100)에게 전송하도록 서버(200)의 네트워크부를 제어할 수 있다. The control unit of the
한편, 사용자 단말기(100)가 서버(200)로부터 동물의 개체 정보를 네트워크부(140)를 통해 수신하는 경우에, 제어부(130)는 디스플레이부(150)를 통해 동물의 개체 정보를 디스플레이하도록 디스플레이부(150)를 제어할 수 있다. On the other hand, when the
여기서 동물의 개체 정보는 동물의 종, 성별, 특이점 중 적어도 어느 하나를 포함할 수 있다. 또한, 동물의 개체 정보는 동물의 소유자의 이름, 연락처, 주소 중 적어도 어느 하나를 포함할 수 있다. 이러한 동물의 개체 정보는 촬영한 동물의 소유자를 확인하는데 사용될 수 있다. 전술한 동물의 개체 정보는 예시일 뿐이며, 본 개시는 이에 제한되지 않는다.Here, the individual information of the animal may include at least one of animal species, gender, and singularity. Further, the animal's individual information may include at least one of the animal's owner's name, contact information, and address. The individual information of the animal can be used to identify the owner of the photographed animal. The above-mentioned animal information is only examples, and the present disclosure is not limited thereto.
제어부(130)는 상기 응용 프로그램과 관련된 동작 외에도, 통상적으로 사용자 단말기(100)의 전반적인 동작을 제어할 수 있다. 제어부(130)는 위에서 살펴본 구성요소들을 통해 입력 또는 출력되는 신호, 데이터, 정보 등을 처리하거나 메모리(120)에 저장된 응용 프로그램을 구동함으로써, 사용자에게 적절한 정보 또는 기능을 제공 또는 처리할 수 있다.The
또한, 제어부(130)는 메모리(120)에 저장된 응용 프로그램을 구동하기 위하여, 도 2와 함께 살펴본 구성요소들 중 적어도 일부를 제어할 수 있다. 나아가, 제어부(130)는 상기 응용 프로그램의 구동을 위하여, 사용자 단말기(100)에 포함된 구성요소들 중 적어도 둘 이상을 서로 조합하여 동작 시킬 수 있다.In addition, the
도 14는 본 개시의 몇몇 실시예에 따른 사용자 단말기에 동물의 개체 정보가 제공되는 방법의 일례를 설명하기 위한 흐름도이다. 도 15은 본 개시의 몇몇 실시예에 따른 제 2 이미지를 전처리한 예시를 나타낸 도면이다.14 is a flowchart for explaining an example of a method in which animal information of an animal is provided to a user terminal according to some embodiments of the present disclosure. 15 is a diagram illustrating an example of preprocessing a second image according to some embodiments of the present disclosure.
도 14를 참조하면, 사용자 단말기(100)의 제어부(130)는 카메라부(110)를 통해 획득된 제 1 이미지에 기초하여 제 1 정보 및 제 2 이미지를 추출할 수 있다(S310). 이는, 도 3 내지 도 13에서 상술한바 자세한 설명은 생략한다. Referring to FIG. 14, the
전술한 바와 같이 제 1 정보는 촬영한 동물의 종에 대한 정보를 포함할 수 있다. 그리고 제 2 이미지는 촬영한 동물의 개체 정보를 확인할 수 있는 동물의 비문 이미지를 포함할 수 있다.As described above, the first information may include information on the species of the photographed animal. In addition, the second image may include an inscription image of the animal that can confirm the object information of the photographed animal.
사용자 단말기(100)의 제어부(130)는 네트워크부(140)를 통해 제 1 정보 및 제 2 이미지를 서버(200)에 전송하도록 네트워크부(140)를 제어할 수 있다(S320).The
서버(200)의 제어부는 로컬 히스토그램(local histogram)에 기초하여 수신한 제 2 이미지를 전처리할 수 있다(S330).The control unit of the
사용자가 사용자 단말기(100)를 이용하여 동물의 안면을 촬영하여 제 1 이미지를 획득함에 있어서, 사용자가 동물을 촬영하는 환경에 따라 제 1 이미지의 품질이 차이가 발생할 수 있다. 예를 들어, 사용자 단말기(100)의 기종에 따라 제 1 이미지의 품질이 상이할 수 있다. 또는, 동물의 코에 이물질(예를 들어, 동물의 땀), 사용자 단말기(100)의 카메라부(110)의 반사광 등 기타 노이즈가 제 1 이미지에 포함될 수 있다. 따라서, 노이즈를 포함할 수 있는 제 1 이미지에 기초하여 추출한 제 2 이미지에도 노이즈가 포함될 수 있다.When the user acquires the first image by photographing the face of the animal using the
도 15를 참조하면, 본 개시의 몇몇 실시예에 따른 서버(200)의 제어부는 이미지 처리 알고리즘을 포함하는 로컬 히스토그램에 기초하여 노이즈가 포함된 제 2 이미지(1510)를 전처리할 수 있다.Referring to FIG. 15, the control unit of the
한편, 몇몇 실시예에 따르면, 서버(200)의 이미지 처리 알고리즘은 캐니 엣지 디텍션(canny edge detection), 해리스 코너 디텍션(harris corner detection)등을 포함할 수도 있으나, 본개시는 이에 제한되지 않는다. Meanwhile, according to some embodiments, the image processing algorithm of the
예를 들어, 캐니 엣지 디텍션을 통해 서버(200)는 제 2 이미지(1510)를 블러링(blurring) 처리하여 노이즈를 제거하고, 마스크 엣지를 이용하여 동물의 코 무늬(비문)들의 엣지를 검출하고, Non-Maximum Value를 제거하고, Double Threshold로 크기를 구분하여 엣지를 연결함으로써 엣지를 추출할 수 있다. 그리고, 서버(200)는 제 2 이미지의 픽셀들의 넓이와 깊이를 측정할 수 있다. 서버(200)는 엣지, 픽셀들의 넓이와 깊이에 기초하여 제 2 이미지(1510)를 전처리 할 수 있다. 서버(200)에 의해 제 2 이미지(1510)가 전처리되면, 전처리된 제 2 이미지(1520) 상의 패턴들의 명암 차이가 증가할 수 있다. 전술한 제 2 이미지를 전처리하는 방법은 예시일 뿐이며, 본 개시는 이제 제한되지 않는다.For example, through the canny edge detection, the
서버(200)가 제 2 이미지(1510)를 전처리하면, 전처리된 제 2 이미지(1520)는 사용자 단말기(100)의 기종에 따른 제 2 이미지(1510)의 품질 차이를 줄일 수 있다. 또한, 전처리 전 제 2 이미지(1510)에 포함된 노이즈(예를 들어, 동물의 코에 묻은 이물질에 의한 노이즈 또는 카메라의 반사광에 의한 노이즈)를 줄일 수 있다. 또한, 전처리된 제 2 이미지(1520) 내에서 코 무늬의 형상 및 코 무늬의 갈라짐이 보다 선명해 질 수 있다. 이를 통해, 후술하는 바와 같이 전처리한 제 2 이미지(1520)와 매칭되는 제 1 비문 이미지를 보다 정확하게 검색할 수 있다. When the
한편, 도 14을 다시 참조하면, 서버(200)는 서버(200)의 메모리에 저장된 복수의 비문 이미지에서 전처리한 제 2 이미지에 매칭되는 제 1 비문 이미지를 검색할 수 있다(S340).Meanwhile, referring to FIG. 14 again, the
서버(200)의 메모리에 복수의 비문 이미지들이 동물의 종에 따라 분류하여 저장될 수 있다. 서버(200)의 제어부는 분류된 동물의 비문 이미지 내에서 촬영된 동물의 종류에 대한 제 1 정보에 기초하여 제 2 이미지에 매칭되는 제 1 비문 이미지를 검색할 수 있다. 서버(200)의 메모리에 동물의 종에 따라 분류되어 비문 이미지들이 저장되어 있어 제 2 이미지에 매칭되는 제 1 비문 이미지를 검색하는 속도를 향상시킬 수 있다. 전술한 제 1 비문 이미지를 검색하는 방법은 예시일 뿐이며, 본 개시는 이제 제한되지 않는다.A plurality of inscription images may be classified and stored according to animal species in the memory of the
단계(S340)에서 제 1 비문 이미지를 검색하는 방법은 다음과 같다. The method for searching for the first inscription image in step S340 is as follows.
서버(200)의 제어부는 전처리한 제 2 이미지에서 제 1 특징점을 인식할 수 있다. The control unit of the
서버(200)의 제어부는 특징점 추출(feature extraction) 알고리즘을 이용하여 전처리한 제 2 이미지에서 제 1 특징점을 인식할 수 있다. 여기서 제 1 특징점은 제 2 이미지 내에서 코 주름의 골(valley)들(예를 들어, 제 2 이미지 내에서 어두운 부분)이 만나는 지점을 의미한다. 따라서, 전처리한 제 2 이미지 내에서 제 1 특징점이 위치하는 픽셀들의 명도 값은 제 2 이미지 내에서 패턴들(예를 들어, 제 2 이미지 내에서 밝은 부분)이 위치하는 픽셀들의 명도 값보다 높은 값을 가질 수 있다. 이 때 명도 값은 전처리한 제 2 이미지의 화소 깊이에 따라 달라질 수 있다. 서버(200)의 제어부는 전처리된 제 2 이미지의 픽셀들의 명도 값을 추출할 수 있다. 추출된 명도 값이 서버(200)의 메모리에 저장된 화소의 깊이에 따라 기 설정된 명도 값을 초과하는 경우에, 서버(200)의 제어부는 기 설정된 명도 값을 초과하는 명도 값을 가지는 픽셀들의 위치를 제 2 이미지 내에서 제 1 특징점으로 인식할 수 있다. 전술한 제 1 특징점을 인식하는 방법은 예시일 뿐이며, 본 개시는 이에 제한되지 않는다.The control unit of the
서버(200)의 제어부는 제 1 특징점에서 코 주름에 대한 제 1 정보를 인식할 수 있다. 여기서 코 주름에 대한 제 1 정보는 특징점에서 코 주름이 향한 방향에 대한 정보, 코 주름이 갈라지는 개수에 대한 정보 등을 포함할 수 있다. 전술한 코 주름에 대한 제 1 정보는 예시일 뿐이며, 본 개시는 이에 제한되지 않는다.The control unit of the
서버(200)의 제어부는 복수의 비문 이미지 중 제 1 특징점에 대응하는 제 2 특징점에서 코 주름에 대한 제 1 정보에 대응하는 코 주름에 대한 제 2 정보를 갖는 제 1 비문 이미지를 검색할 수 있다. The control unit of the
구체적으로, 서버(200)의 메모리에는 복수의 비문 이미지 각각에 포함된 복수의 특징점 각각에서의 코 주름에 대한 정보가 저장되어 있을 수 있다. 서버(200)의 제어부는 제 1 특징점에서 코 주름이 향한 방향에 대한 정보, 코 주름이 갈라지는 개수에 대한 정보와 대응되는 정보를 포함하는 코 주름에 대한 정보를 메모리에서 검색하여 상술한 제 1 비문 이미지로 인식할 수 있다. 즉, 서버(200)의 제어부는 같은 특징점에서 같은 코 주름에 대한 정보를 갖는 비문 이미지를 서버(200)의 메모리에 저장된 복수의 비문 이미지 중에서 검색할 수 있다. Specifically, information about the nose wrinkles at each of the plurality of feature points included in each of the plurality of inscription images may be stored in the memory of the
한편, 서버(200)의 제어부는 제 1 특징점과 제 2 특징점의 위치가 어긋나는 경우에는 제 1 특징점의 위치를 이동시키기 위한 제 2 이미지를 보정할 수 있다. 여기서, 서버(200)의 제어부는 제 1 특징점의 좌표와 제 2 특징점의 좌표가 서로 상이하거나 제 1 특징점에서의 코 주름이 향한 방향이 제 2 특징점에서 코 주름이 향한 방향과 상이한 경우 제 1 특징점과 제 2 특징점의 위치가 어긋났다고 인식할 수 있다. Meanwhile, the control unit of the
구체적으로, 서버(200)의 제어부는 제 2 이미지 내의 제 1 특징점과 제 1 비문 이미지 내의 제 2 특징점의 위치가 일치하도록 제 2 이미지를 종횡 이동시키거나 또는 제 2 이미지를 회전 이동시키는 보정을 할 수 있다. Specifically, the control unit of the
한편, 서버(200)의 제어부는 제 2 이미지에 매칭되는 제 1 비문 이미지에 맵핑된 개체 정보를 획득할 수 있다(S350). 다만, 이에 한정되는 것은 아니고 서버(200)의 제어부는 제 2 이미지에 매칭되는 제1 비문 이미지 및 상기 제 1 비문 이미지에 맵핑된 개체 정보 중 적어도 하나를 획득할 수도 있다. Meanwhile, the control unit of the
서버(200)의 제어부는 단계(S350)에서 획득된 개체 정보를 사용자 단말기에 전송할 수 있다(S360). 다만, 이에 한정되는 것은 아니고, 서버(200)의 제어부는 개체 정보 및 제 1 비문 이미지 중 적어도 하나를 사용자 단말기(100)에 전송할 수도 있다.The control unit of the
사용자 단말기(100)의 제어부(130)는 서버(200)로부터 수신된 개체 정보를 디스플레이하도록 디스플레이부(150)를 제어할 수 있다(S370). 다만, 이에 한정되는 것은 아니고, 개체 정보 및 제 1 비문 이미지 중 적어도 하나를 디스플레이할 수 있다.The
여기서 동물의 개체 정보는 동물의 종, 성별, 특이점 중 적어도 어느 하나를 포함할 수 있다. 또한, 동물의 개체 정보는 동물의 소유자의 이름, 연락처, 주소 중 적어도 어느 하나를 포함할 수 있다. 이러한 동물의 개체 정보는 촬영한 동물의 소유자를 확인하는데 사용될 수 있다. 전술한 동물의 개체 정보는 예시일 뿐이며, 본 개시는 이에 제한되지 않는다.Here, the individual information of the animal may include at least one of animal species, gender, and singularity. Further, the animal's individual information may include at least one of the animal's owner's name, contact information, and address. The individual information of the animal can be used to identify the owner of the photographed animal. The above-mentioned animal information is only examples, and the present disclosure is not limited thereto.
제시된 실시예들에 대한 설명은 임의의 본 개시의 기술 분야에서 통상의 지식을 가진 자가 본 개시를 이용하거나 또는 실시할 수 있도록 제공된다. 이러한 실시예들에 대한 다양한 변형들은 본 개시의 기술 분야에서 통상의 지식을 가진 자에게 명백할 것이며, 여기에 정의된 일반적인 원리들은 본 개시의 범위를 벗어남이 없이 다른 실시예들에 적용될 수 있다. 그리하여, 본 개시는 여기에 제시된 실시예들로 한정되는 것이 아니라, 여기에 제시된 원리들 및 신규한 특징들과 일관되는 최광의의 범위에서 해석되어야 할 것이다.Descriptions of the presented embodiments are provided to enable any person of ordinary skill in the art to use or practice the present disclosure. Various modifications to these embodiments will be apparent to those skilled in the art of the present disclosure, and the general principles defined herein can be applied to other embodiments without departing from the scope of the present disclosure. Thus, the present disclosure should not be limited to the embodiments presented herein, but should be interpreted in the broadest scope consistent with the principles and novel features presented herein.
Claims (17)
상기 컴퓨터 프로그램은 사용자 단말기로 하여금 이하의 동작들을 수행하기 위한 명령들을 포함하며, 상기 동작들은:
상기 사용자 단말기의 카메라로 촬영된 동물의 안면이 포함된 제 1 이미지를 획득하는 동작;
상기 제 1 이미지를 사전 학습된 종 분류 모델에 입력하여 상기 동물의 종에 대한 제 1 정보를 획득하는 동작;
상기 제 1 이미지 내에서 상기 동물의 코를 포함하는 제 1 영역의 위치를 인식하는 동작;
사전 설정된 조건을 만족된 경우 상기 제 1 영역 내에서 관심 영역(Region Of Interest)을 결정하는 동작;
상기 관심 영역이 결정된 경우, 상기 제 1 이미지 내에서 상기 관심 영역을 포함하는 제 2 이미지를 추출하는 동작; 및
상기 제 2 이미지가 추출된 경우, 상기 제 1 정보 및 상기 제 2 이미지를 서버에 전송하는 동작;
을 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
A computer program stored in a computer-readable storage medium,
The computer program includes instructions for a user terminal to perform the following operations, which include:
Acquiring a first image including a face of an animal photographed by a camera of the user terminal;
Inputting the first image into a pre-trained species classification model to obtain first information about the animal species;
Recognizing a position of a first region including the nose of the animal in the first image;
Determining a region of interest within the first region when a preset condition is satisfied;
When the region of interest is determined, extracting a second image including the region of interest from within the first image; And
When the second image is extracted, transmitting the first information and the second image to a server;
Containing,
A computer program stored on a computer readable storage medium.
상기 종 분류 모델을 학습시키기 위한 제 1 학습 데이터는,
동물의 안면이 포함된 이미지 데이터를 학습 데이터의 입력으로 하고, 상기 동물의 안면이 포함된 이미지 데이터에 동물의 종에 대한 제 1 분류 클래스를 라벨로 하여 생성되고, 그리고
상기 종 분류 모델은,
상기 제 1 학습 데이터를 포함하는 제 1 학습 데이터 세트를 이용하여 상기 동물의 안면과 매칭되는 상기 동물의 종에 대한 분류를 학습하고, 상기 제 1 이미지에 기초하여 상기 제 1 정보를 획득하도록 하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
According to claim 1,
The first training data for training the species classification model,
The image data including the face of the animal is used as input of learning data, and the image data including the face of the animal is generated by labeling the first classification class for the animal species, and
The species classification model,
Learning to classify the species of the animal that matches the face of the animal by using the first set of learning data including the first learning data, and to obtain the first information based on the first image,
A computer program stored on a computer readable storage medium.
상기 종 분류 모델은,
상기 제 1 이미지를 입력 노드로 입력 받으면, 상기 제 1 분류 클래스 각각에 대한 컨피던스 스코어(confidence score)를 출력 노드에서 출력하고, 상기 컨피던스 스코어 중 가장 높은 값을 가지는 상기 제 1 분류 클래스를 제 1 정보로 획득하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
According to claim 2,
The species classification model,
When the first image is received as an input node, a confidence score for each of the first classification classes is output from an output node, and the first classification class having the highest value among the confidence scores is first information. Acquired by,
A computer program stored on a computer readable storage medium.
상기 제 1 이미지 내에서 상기 동물의 코를 포함하는 제 1 영역의 위치를 인식하는 동작은,
상기 제 1 이미지를 사전 학습된 코 영역 인식 모델에 입력하여 상기 제 1 이미지 내에서 상기 제 1 영역의 위치를 인식하는 동작을 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
According to claim 1,
Recognizing the position of the first region including the nose of the animal in the first image,
And inputting the first image into a pre-trained nose region recognition model to recognize the location of the first region within the first image,
A computer program stored on a computer readable storage medium.
상기 코 영역 인식 모델은,
동물의 안면이 포함된 이미지 데이터를 포함하는 제 2 학습 데이터 세트 및 바운딩 박스(bounding box)에 대한 좌표를 이용하여 상기 동물의 안면의 이미지와 매칭되는 코 영역의 위치를 학습하고, 상기 제 1 이미지 내에서 상기 제 1 영역의 위치를 인식하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
The method of claim 4,
The nose region recognition model,
A second learning data set including image data including an animal's face and coordinates for a bounding box are used to learn the location of the nose region matching the image of the animal's face, and the first image Recognizing the position of the first region within,
A computer program stored on a computer readable storage medium.
상기 제 1 이미지 내에서 상기 동물의 코를 포함하는 제 1 영역의 위치를 인식하는 동작은,
상기 제 1 이미지 내에서 상기 동물의 눈을 포함하는 제 2 영역의 위치 및 상기 동물의 입을 포함하는 제 3 영역을 인식하는 동작; 및
상기 제 2 영역의 위치 및 상기 제 3 영역의 위치에 기초하여 상기 제 1 영역의 위치를 인식하는 동작;
을 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
The method of claim 4,
Recognizing the position of the first region including the nose of the animal in the first image,
Recognizing a position of a second area including the animal's eye and a third area including the animal's mouth within the first image; And
Recognizing the position of the first area based on the position of the second area and the position of the third area;
Containing,
A computer program stored on a computer readable storage medium.
상기 사전 설정된 조건을 만족된 경우 상기 제 1 영역 내에서 관심 영역(Region Of Interest)을 결정하는 동작은,
상기 제 1 영역 내에서 상기 동물의 우측 콧구멍(nostril) 및 좌측 콧구멍을 인식하는 동작;
상기 우측 콧구멍 및 상기 좌측 콧구멍의 원형성(circularity) 및 상기 콧구멍의 관성률(Inertia ratio)에 기초하여 상기 동물이 촬영된 포즈(pose)를 인식하는 동작; 및
상기 포즈가 기 설정된 포즈에 매칭되는 경우 상기 사전 설정된 조건이 만족되었다고 인식하는 동작;
을 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
According to claim 1,
When the predetermined condition is satisfied, the operation of determining a region of interest within the first region may include:
Recognizing a nostril and a left nostril of the animal within the first region;
Recognizing a pose in which the animal is photographed based on circularity of the right nostril and the left nostril and inertia ratio of the nostril; And
Recognizing that the preset condition is satisfied when the pose matches a preset pose;
Containing,
A computer program stored on a computer readable storage medium.
상기 제 1 영역 내에서 사전 설정된 조건을 만족하는 관심 영역(Region Of Interest)을 결정하는 동작은,
상기 사전 설정된 조건을 만족되는 경우, 상기 우측 콧구멍 및 상기 좌측 콧구멍 간의 거리를 산출하는 동작; 및
상기 거리에 기초하여 상기 관심 영역의 크기 및 상기 관심 영역의 위치를 결정하는 동작;
을 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
The method of claim 7,
The operation of determining a region of interest that satisfies a preset condition in the first region may include:
Calculating a distance between the right nostril and the left nostril when the preset condition is satisfied; And
Determining a size of the region of interest and a location of the region of interest based on the distance;
Containing,
A computer program stored on a computer readable storage medium.
상기 제 1 영역 내에서 사전 설정된 조건을 만족하는 관심 영역(Region Of Interest)을 결정하는 동작은,
상기 사전 설정된 조건이 만족되지 않은 경우, 상기 사전 설정된 조건을 만족하는 제 1 이미지가 획득되도록 재촬영을 요구하는 인디케이터를 디스플레이하도록 디스플레이부를 제어하는 동작;
을 더 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
The method of claim 7,
The operation of determining a region of interest that satisfies a preset condition in the first region may include:
Controlling the display unit to display an indicator requesting re-shooting so that a first image satisfying the preset condition is obtained when the preset condition is not satisfied;
Containing more,
A computer program stored on a computer readable storage medium.
상기 제 1 영역 내에서 사전 설정된 조건을 만족하는 관심 영역(Region Of Interest)을 결정하는 동작은,
상기 사전 설정된 조건을 만족하지 못하는 경우에, 상기 제 1 이미지를 정면화(Frontalization)하여 상기 포즈가 상기 기 설정된 포즈에 매칭되도록 만드는 동작;
을 더 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
The method of claim 7,
The operation of determining a region of interest that satisfies a preset condition in the first region may include:
If the preset condition is not satisfied, frontalizing the first image to make the pose match the preset pose;
Containing more,
A computer program stored on a computer readable storage medium.
상기 제 1 이미지를 정면화하여 상기 포즈가 상기 기 설정된 포즈에 매칭되도록 만드는 동작은,
상기 제 1 영역의 이미지 상에서 콧구멍들의 특징점을 추출하는 동작; 및
상기 추출한 콧구멍들의 특징점이 메모리에 사전 저장된 동물을 정면에서 촬영한 이미지 상에서 콧구멍들의 특징점과 매칭되도록 상기 제 1 이미지를 보정하는 동작;
을 더 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
The method of claim 10,
The operation of making the pose match the preset pose by frontalizing the first image,
Extracting feature points of nostrils on the image of the first region; And
Correcting the first image so that the feature points of the extracted nostrils match the feature points of nostrils on an image photographed from the front of an animal pre-stored in memory;
Containing more,
A computer program stored on a computer readable storage medium.
상기 제 1 정보 및 상기 제 2 이미지를 상기 서버에 전송한 후, 상기 서버로부터 상기 전송된 제 1 정보 및 상기 제 2 이미지에 대응하는 상기 동물의 개체 정보 및 제 1 비문 이미지 중 적어도 어느 하나를 수신하는 동작; 및
상기 개체 정보 및 제 1 비문 이미지 중 적어도 어느 하나를 디스플레이하는 동작;
을 더 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
According to claim 1,
After transmitting the first information and the second image to the server, the server receives at least one of the first information and the animal information corresponding to the second image and the first inscription image from the server. To do; And
Displaying at least one of the object information and the first inscription image;
Containing more,
A computer program stored on a computer readable storage medium.
상기 개체 정보는,
상기 제 2 이미지를 상기 서버에서 로컬 히스토그램(local histogram)에 기초하여 전처리한 제 2 이미지에 매칭되는 제 1 비문 이미지에 맵핑(mapping)된 개체 정보이고,
상기 제 1 비문 이미지는,
상기 서버에 저장되어 있는 복수의 비문 이미지 중 하나인,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
The method of claim 12,
The individual information,
The second image is object information mapped to a first inscription image matching the second image pre-processed based on a local histogram at the server,
The first inscription image,
One of a plurality of inscription images stored in the server,
A computer program stored on a computer readable storage medium.
상기 컴퓨터 프로그램은 서버로 하여금 이하의 동작들을 수행하기 위한 명령들을 포함하며, 상기 동작들은:
사용자 단말기로부터 상기 사용자 단말기의 카메라로 촬영된 동물의 안면이 포함된 제 1 이미지로부터 획득한 상기 동물의 종에 대한 제 1 정보 및 상기 제 1 이미지 내에서 상기 동물의 코를 포함하는 제 1 영역 내에서 관심 영역을 포함하는 제 2 이미지를 수신하는 동작;
상기 제 2 이미지를 로컬 히스토그램에 기초하여 전처리하는 동작;
상기 서버의 메모리에 저장된 복수의 비문 이미지에서 상기 전처리한 제 2 이미지에 매칭되는 제 1 비문 이미지를 검색하는 동작; 및
상기 전처리한 제 2 이미지에 매칭되는 제 1 비문 이미지 및 상기 제 1 비문 이미지에 맵핑된 개체 정보 중 적어도 하나를 획득하는 동작; 및 상기 제 1 비문 이미지 및 상기 개체 정보 중 적어도 하나를 상기 사용자 단말기에 전송하는 동작;
을 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
A computer program stored in a computer-readable storage medium,
The computer program includes instructions for the server to perform the following actions, which include:
In the first area including the nose of the animal in the first image and the first information about the species of the animal obtained from the first image containing the face of the animal photographed by the camera of the user terminal from the user terminal Receiving a second image including the region of interest in the;
Pre-processing the second image based on a local histogram;
Retrieving a first inscription image matching the preprocessed second image from a plurality of inscription images stored in the memory of the server; And
Obtaining at least one of a first inscription image matching the pre-processed second image and object information mapped to the first inscription image; And transmitting at least one of the first inscription image and the object information to the user terminal.
Containing,
A computer program stored on a computer readable storage medium.
상기 서버의 메모리에 저장된 복수의 비문 이미지에서 상기 전처리한 제 2 이미지에 매칭되는 제 1 비문 이미지를 검색하는 동작은,
상기 전처리한 제 2 이미지에서 제 1 특징점을 인식하는 동작;
상기 제 2 이미지의 상기 제 1 특징점에서 코 주름에 대한 제 1 정보를 인식하는 동작;
상기 복수의 비문 이미지 중 상기 제 1 특징점에 대응하는 제 2 특징점에서 상기 제 1 정보에 대응하는 코 주름에 대한 제 2 정보를 갖는 상기 제 1 비문 이미지를 검색하는 동작;
을 더 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
The method of claim 14,
Searching for a first inscription image matching the second pre-processed image from a plurality of inscription images stored in the memory of the server,
Recognizing a first feature point from the pre-processed second image;
Recognizing first information about nose wrinkles at the first feature point of the second image;
Retrieving the first inscription image having second information about a nose wrinkle corresponding to the first information at a second characteristic point corresponding to the first characteristic point among the plurality of inscription images;
Containing more,
A computer program stored on a computer readable storage medium.
상기 복수의 비문 이미지 중 상기 제 1 특징점에 대응하는 제 2 특징점에서 상기 제 1 정보에 대응하는 코 주름에 대한 제 2 정보를 갖는 상기 제 1 비문 이미지를 검색하는 동작은,
상기 제 1 특징점과 상기 제 2 특징점의 위치가 어긋나는 경우, 상기 제 1 특징점의 위치를 이동시키기 위해 상기 제 2 이미지를 보정하는 동작; 및
상기 보정한 제 2 이미지를 이용하여 상기 제 1 비문 이미지를 검색하는 동작;
을 더 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
The method of claim 15,
The operation of retrieving the first inscription image having the second information on the nose wrinkle corresponding to the first information from the second characteristic point corresponding to the first characteristic point among the plurality of inscription images may include:
Correcting the second image to move the position of the first feature point when the positions of the first feature point and the second feature point are shifted; And
Retrieving the first inscription image using the corrected second image;
Containing more,
A computer program stored on a computer readable storage medium.
상기 제 1 특징점과 상기 제 2 특징점의 위치가 어긋나는 경우, 상기 제 1 특징점의 위치를 이동시키기 위해 상기 제 2 이미지를 보정하는 동작은,
상기 제 1 특징점과 상기 제 2 특징점의 위치가 일치하도록 상기 제 2 이미지를 종횡 이동시키거나 상기 제 2 이미지를 회전 이동 시키는 동작;
을 더 포함하는,
컴퓨터 판독가능 저장 매체에 저장된 컴퓨터 프로그램.
The method of claim 16,
When the position of the first feature point and the second feature point are misaligned, the operation of correcting the second image to move the position of the first feature point may include:
Moving the second image vertically or horizontally to rotate the second image so that the positions of the first feature point and the second feature point coincide;
Containing more,
A computer program stored on a computer readable storage medium.
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020180121037A KR102117860B1 (en) | 2018-10-11 | 2018-10-11 | Computer program and theminal for providing individual animal information based on the facial and nose pattern imanges of the animal |
| PCT/KR2018/012008 WO2020075888A1 (en) | 2018-10-11 | 2018-10-12 | Computer program and terminal for providing information about individual animals on basis of animal face and noseprint images |
| KR1020200028977A KR102487825B1 (en) | 2018-10-11 | 2020-03-09 | Computer program and theminal for providing individual animal information based on the facial and nose pattern imanges of the animal |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020180121037A KR102117860B1 (en) | 2018-10-11 | 2018-10-11 | Computer program and theminal for providing individual animal information based on the facial and nose pattern imanges of the animal |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020200028977A Division KR102487825B1 (en) | 2018-10-11 | 2020-03-09 | Computer program and theminal for providing individual animal information based on the facial and nose pattern imanges of the animal |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200044209A true KR20200044209A (en) | 2020-04-29 |
| KR102117860B1 KR102117860B1 (en) | 2020-06-02 |
Family
ID=70165027
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020180121037A KR102117860B1 (en) | 2018-10-11 | 2018-10-11 | Computer program and theminal for providing individual animal information based on the facial and nose pattern imanges of the animal |
Country Status (2)
| Country | Link |
|---|---|
| KR (1) | KR102117860B1 (en) |
| WO (1) | WO2020075888A1 (en) |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102158799B1 (en) * | 2020-05-06 | 2020-09-22 | 호서대학교 산학협력단 | Method, computer program and apparatus for recognition of building by using deep neural network model |
| KR102176934B1 (en) * | 2020-09-24 | 2020-11-10 | 주식회사 디랩스 | System for providing pet total care service using face recognition |
| KR102246471B1 (en) * | 2020-05-13 | 2021-04-30 | 주식회사 파이리코 | Apparatus for detecting nose of animal in image and method thereof |
| WO2021230680A1 (en) * | 2020-05-13 | 2021-11-18 | Pireco Co,. Ltd. | Method and device for detecting object in image |
| KR102344718B1 (en) * | 2020-10-30 | 2021-12-30 | 주식회사 아이싸이랩 | Method for clustering acquired animal images to perform at least one of identifying and authenticating animals |
| KR102444928B1 (en) * | 2021-06-28 | 2022-09-21 | 주식회사 펫나우 | Method for detecting object for identifying animal and apparatus thereof |
| KR102444929B1 (en) * | 2021-06-28 | 2022-09-21 | 주식회사 펫나우 | Method for processing image of object for identifying animal and apparatus thereof |
| KR102452192B1 (en) * | 2021-06-28 | 2022-10-11 | 주식회사 펫나우 | Method for filtering image of object for identifying animal and apparatus thereof |
| KR102453695B1 (en) * | 2021-06-28 | 2022-10-12 | 주식회사 펫나우 | Method for capturing object for identifying animal and apparatus thereof |
| KR102459723B1 (en) | 2022-03-21 | 2022-10-27 | 주식회사 타이로스코프 | Method for verification of image, diagnostic system performing the same and computer-readable recording medium on which the method of performing the same |
| WO2023277473A1 (en) * | 2021-06-28 | 2023-01-05 | 주식회사 펫나우 | Method for photographing object for identifying companion animal, and electronic device |
| US11972603B2 (en) | 2022-03-21 | 2024-04-30 | Thyroscope Inc. | Image verification method, diagnostic system performing same, and computer-readable recording medium having the method recorded thereon |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GR1010102B (en) * | 2021-03-26 | 2021-10-15 | Breed Ike, | Animal's face recognition system |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007135501A (en) * | 2005-11-21 | 2007-06-07 | Atom System:Kk | Nose characteristic information-producing apparatus and nose characteristic information-producing program |
| KR20140137149A (en) * | 2013-05-22 | 2014-12-02 | 주식회사 아이싸이랩 | Apparatus and Method of an Animal Recognition System using nose patterns |
| KR101732815B1 (en) * | 2015-11-05 | 2017-05-04 | 한양대학교 산학협력단 | Method and apparatus for extracting feature point of entity, system for identifying entity using the method and apparatus |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100414606B1 (en) * | 2001-02-13 | 2004-01-07 | 박현종 | System for network-based identification of the dog using a nose pattern |
| KR101494717B1 (en) * | 2014-10-31 | 2015-02-26 | 주식회사 아이싸이랩 | Apparatus of Animal Recognition System using nose patterns |
| KR101788272B1 (en) * | 2016-11-01 | 2017-10-19 | 오승호 | Animal Identification and Registration Method based on Biometrics |
| KR101903377B1 (en) * | 2017-09-26 | 2018-10-02 | (주)인투씨엔에스 | Clinical entity specific system using integrated management of animal information related to animal insurance and entity identification means |
-
2018
- 2018-10-11 KR KR1020180121037A patent/KR102117860B1/en active IP Right Grant
- 2018-10-12 WO PCT/KR2018/012008 patent/WO2020075888A1/en active Application Filing
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007135501A (en) * | 2005-11-21 | 2007-06-07 | Atom System:Kk | Nose characteristic information-producing apparatus and nose characteristic information-producing program |
| KR20140137149A (en) * | 2013-05-22 | 2014-12-02 | 주식회사 아이싸이랩 | Apparatus and Method of an Animal Recognition System using nose patterns |
| KR101732815B1 (en) * | 2015-11-05 | 2017-05-04 | 한양대학교 산학협력단 | Method and apparatus for extracting feature point of entity, system for identifying entity using the method and apparatus |
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102158799B1 (en) * | 2020-05-06 | 2020-09-22 | 호서대학교 산학협력단 | Method, computer program and apparatus for recognition of building by using deep neural network model |
| KR102246471B1 (en) * | 2020-05-13 | 2021-04-30 | 주식회사 파이리코 | Apparatus for detecting nose of animal in image and method thereof |
| WO2021230680A1 (en) * | 2020-05-13 | 2021-11-18 | Pireco Co,. Ltd. | Method and device for detecting object in image |
| KR102176934B1 (en) * | 2020-09-24 | 2020-11-10 | 주식회사 디랩스 | System for providing pet total care service using face recognition |
| KR102344718B1 (en) * | 2020-10-30 | 2021-12-30 | 주식회사 아이싸이랩 | Method for clustering acquired animal images to perform at least one of identifying and authenticating animals |
| KR102444929B1 (en) * | 2021-06-28 | 2022-09-21 | 주식회사 펫나우 | Method for processing image of object for identifying animal and apparatus thereof |
| KR102444928B1 (en) * | 2021-06-28 | 2022-09-21 | 주식회사 펫나우 | Method for detecting object for identifying animal and apparatus thereof |
| KR102452192B1 (en) * | 2021-06-28 | 2022-10-11 | 주식회사 펫나우 | Method for filtering image of object for identifying animal and apparatus thereof |
| KR102453695B1 (en) * | 2021-06-28 | 2022-10-12 | 주식회사 펫나우 | Method for capturing object for identifying animal and apparatus thereof |
| WO2023277472A1 (en) * | 2021-06-28 | 2023-01-05 | 주식회사 펫나우 | Method and electronic device for capturing image of object for identifying companion animal |
| WO2023277473A1 (en) * | 2021-06-28 | 2023-01-05 | 주식회사 펫나우 | Method for photographing object for identifying companion animal, and electronic device |
| KR102459723B1 (en) | 2022-03-21 | 2022-10-27 | 주식회사 타이로스코프 | Method for verification of image, diagnostic system performing the same and computer-readable recording medium on which the method of performing the same |
| WO2023182727A1 (en) * | 2022-03-21 | 2023-09-28 | Thyroscope Inc. | Image verification method, diagnostic system performing same, and computer-readable recording medium having the method recorded thereon |
| US11972603B2 (en) | 2022-03-21 | 2024-04-30 | Thyroscope Inc. | Image verification method, diagnostic system performing same, and computer-readable recording medium having the method recorded thereon |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2020075888A1 (en) | 2020-04-16 |
| KR102117860B1 (en) | 2020-06-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102117860B1 (en) | Computer program and theminal for providing individual animal information based on the facial and nose pattern imanges of the animal | |
| KR102487825B1 (en) | Computer program and theminal for providing individual animal information based on the facial and nose pattern imanges of the animal | |
| CN109492643B (en) | Certificate identification method and device based on OCR, computer equipment and storage medium | |
| US11176393B2 (en) | Living body recognition method, storage medium, and computer device | |
| US10019655B2 (en) | Deep-learning network architecture for object detection | |
| US9953425B2 (en) | Learning image categorization using related attributes | |
| US9767381B2 (en) | Similarity-based detection of prominent objects using deep CNN pooling layers as features | |
| US20200242422A1 (en) | Method and electronic device for retrieving an image and computer readable storage medium | |
| WO2019100724A1 (en) | Method and device for training multi-label classification model | |
| CN110647829A (en) | Bill text recognition method and system | |
| TWI754887B (en) | Method, device and electronic equipment for living detection and storage medium thereof | |
| US20160035078A1 (en) | Image assessment using deep convolutional neural networks | |
| CN113743384B (en) | Stomach picture identification method and device | |
| US11676390B2 (en) | Machine-learning model, methods and systems for removal of unwanted people from photographs | |
| CN110569844B (en) | Ship recognition method and system based on deep learning | |
| Abinaya et al. | Naive Bayesian fusion based deep learning networks for multisegmented classification of fishes in aquaculture industries | |
| US11854116B2 (en) | Task-based image masking | |
| US11417007B2 (en) | Electronic apparatus and method for controlling thereof | |
| US20230104262A1 (en) | Panoptic segmentation refinement network | |
| CN113011450B (en) | Training method, training device, recognition method and recognition system for glaucoma recognition | |
| CN112418327A (en) | Training method and device of image classification model, electronic equipment and storage medium | |
| US20210312200A1 (en) | Systems and methods for video surveillance | |
| US20210326595A1 (en) | Systems and methods for stream recognition | |
| CN112613471A (en) | Face living body detection method and device and computer readable storage medium | |
| CN114913339B (en) | Training method and device for feature map extraction model |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A107 | Divisional application of patent | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant |