KR20200030228A - Electronic pen system interlocked with artificial intelligent speaker - Google Patents
Electronic pen system interlocked with artificial intelligent speaker Download PDFInfo
- Publication number
- KR20200030228A KR20200030228A KR1020180108804A KR20180108804A KR20200030228A KR 20200030228 A KR20200030228 A KR 20200030228A KR 1020180108804 A KR1020180108804 A KR 1020180108804A KR 20180108804 A KR20180108804 A KR 20180108804A KR 20200030228 A KR20200030228 A KR 20200030228A
- Authority
- KR
- South Korea
- Prior art keywords
- electronic pen
- artificial intelligence
- data
- voice
- speaker
- Prior art date
Links
- 238000013473 artificial intelligence Methods 0.000 claims abstract description 221
- 238000000034 method Methods 0.000 claims description 6
- 230000002452 interceptive effect Effects 0.000 claims description 5
- 238000004891 communication Methods 0.000 description 23
- 238000006243 chemical reaction Methods 0.000 description 8
- 238000010586 diagram Methods 0.000 description 6
- 230000000007 visual effect Effects 0.000 description 5
- 238000013528 artificial neural network Methods 0.000 description 3
- 230000002093 peripheral effect Effects 0.000 description 3
- 230000001960 triggered effect Effects 0.000 description 3
- 230000008859 change Effects 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 238000012905 input function Methods 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 230000008901 benefit Effects 0.000 description 1
- 238000011982 device technology Methods 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 238000007639 printing Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
- G06F3/167—Audio in a user interface, e.g. using voice commands for navigating, audio feedback
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/16—Sound input; Sound output
- G06F3/162—Interface to dedicated audio devices, e.g. audio drivers, interface to CODECs
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/10—Services
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/26—Speech to text systems
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/41—Structure of client; Structure of client peripherals
- H04N21/422—Input-only peripherals, i.e. input devices connected to specially adapted client devices, e.g. global positioning system [GPS]
- H04N21/42203—Input-only peripherals, i.e. input devices connected to specially adapted client devices, e.g. global positioning system [GPS] sound input device, e.g. microphone
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/47—End-user applications
- H04N21/472—End-user interface for requesting content, additional data or services; End-user interface for interacting with content, e.g. for content reservation or setting reminders, for requesting event notification, for manipulating displayed content
- H04N21/47202—End-user interface for requesting content, additional data or services; End-user interface for interacting with content, e.g. for content reservation or setting reminders, for requesting event notification, for manipulating displayed content for requesting content on demand, e.g. video on demand
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/02—Casings; Cabinets ; Supports therefor; Mountings therein
- H04R1/028—Casings; Cabinets ; Supports therefor; Mountings therein associated with devices performing functions other than acoustics, e.g. electric candles
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/08—Mouthpieces; Microphones; Attachments therefor
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Multimedia (AREA)
- Health & Medical Sciences (AREA)
- Signal Processing (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Business, Economics & Management (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Engineering & Computer Science (AREA)
- Tourism & Hospitality (AREA)
- Computational Linguistics (AREA)
- Databases & Information Systems (AREA)
- Economics (AREA)
- Human Resources & Organizations (AREA)
- Marketing (AREA)
- Primary Health Care (AREA)
- Strategic Management (AREA)
- General Business, Economics & Management (AREA)
- User Interface Of Digital Computer (AREA)
Abstract
Description
본 실시예는 인공지능스피커와 연동되는 전자펜에 관한 것이다. This embodiment relates to an electronic pen interlocked with an artificial intelligence speaker.
매체에 인쇄된 표식을 인식하고 표식과 관련된 데이터를 출력하는 장치들이 있다.There are devices for recognizing the marks printed on the medium and outputting data related to the marks.
바코드 리더가 대표적인 장치인데, 바코드 리더는 매체에 인쇄된 바코드들을 읽어들인 후 대응되는 데이터를 디스플레이 장치 등에 출력한다.A barcode reader is a typical device, and the barcode reader reads barcodes printed on a medium and outputs corresponding data to a display device or the like.
최근에는 책과 같은 매체에 인쇄된 특정 코드를 인식하고 인식된 코드에 대응되는 음성을 출력하는 전자펜이 다수 개발되고 있다.Recently, many electronic pens have been developed to recognize a specific code printed on a medium such as a book and to output a voice corresponding to the recognized code.
이러한 전자펜은 코드 리더 장치를 포함하고 있으면서 책과 같은 매체에 인쇄된 특정 코드를 읽어들인 후 해당 코드에 대응되는 음성을 스피커 등을 통해 출력한다.The electronic pen includes a code reader device, reads a specific code printed on a medium such as a book, and outputs a voice corresponding to the code through a speaker.
통상적으로 책과 같은 인쇄매체에는 텍스트만 표시되기 때문에 독자에게 활자 정보만 제공하게 되는데, 이러한 전자펜을 이용하면 활자 정보 이외에 음성 정보도 함께 제공할 수 있기 때문에 독자의 사용자 경험이 강화되는 효과가 있다.Normally, only text is displayed on a print medium such as a book, so only the type information is provided to the reader. If the electronic pen is used, voice information in addition to the type information can also be provided, thus enhancing the reader's user experience. .
일반적으로 알려진 사용자 입력장치-키보드, 마우스 등-는 매체와 독립적으로 구성되어 있어서, 사용자가 매체와 입력장치를 별도로 인식해야 하는 단점이 있는데 반해, 전자펜을 이용한 사용자 입력은 매체를 통해 이루어지기 때문에 매체와 입력장치가 통합적으로 인식되고 직관적인 조작이 가능하다는 장점이 있다.In general, a user input device known as a keyboard, a mouse, and the like is configured independently of a medium, and thus has a disadvantage that a user must separately recognize a medium and an input device, whereas a user input using an electronic pen is performed through a medium. There is an advantage that the media and the input device are integrated and intuitive operation is possible.
한편, 일반적으로 알려진 사용자 입력장치-키보드, 마우스 등-보다 사용자 편의성을 더 갖춘 입력장치로서 인공지능스피커(일명, AI(artificial intelligent)스피커)가 개발되고 있다. 인공지능스피커는 사용자의 음성을 인식하고, 음성에 따른 기능을 수행하거나 음성에 대한 대답을 출력하는 장치로서, 사용자의 수작업 없이 사용자의 음성만으로 명령을 입력할 수 있다는 측면에서 종래의 입력장치보다 더 사용자 편의성을 가지고 있는 것으로 평가된다.On the other hand, an artificial intelligence speaker (also known as an artificial intelligence (AI) speaker) has been developed as an input device having more user convenience than a generally known user input device-a keyboard, a mouse, and the like. The artificial intelligence speaker is a device that recognizes a user's voice, performs a function according to the voice, or outputs an answer to the voice, which is more than a conventional input device in that a user can input a command only with the user's voice without manual intervention. It is evaluated as having user convenience.
하지만, 아직까지 인공지능스피커의 음성인식수준이나 음성이해수준이 높지 않아, 기능이 제한되어 있고 기능 수행에 있어서도 보다 많은 사용자 음성입력을 요구하고 있어서 인공지능스피커가 종래의 입력장치를 완벽하게 대체하지 못하고 있다.However, since the AI speaker's voice recognition level or voice understanding level is not yet high, the function is limited and the user's voice input is required to perform more functions, so the AI speaker does not completely replace the conventional input device. I can't.
이러한 배경에서, 본 실시예의 목적은, 인공지능스피커와 연동되는 전자펜을 통해 개선된 사용자 입력장치 기술을 제공하는 것이다.Against this background, the purpose of this embodiment is to provide improved user input device technology through an electronic pen interworking with an artificial intelligence speaker.
전술한 목적을 달성하기 위하여, 일 실시예는, 제1음성데이터를 분석하여 상기 제1음성데이터에 포함된 음성명령을 인식하고, 상기 음성명령에 대응되는 명령데이터를 명령수행장치로 송신하는 인공지능서버; 컨텐츠코드를 수신하고, 상기 컨텐츠코드에 대응되는 컨텐츠데이터를 컨텐츠출력장치로 송신하는 컨텐츠서버; 호출음성이 인식되면 명령대기상태로 진입하고, 상기 명령대기상태에서 인식되는 음성을 상기 제1음성데이터로 변환하여 상기 인공지능서버로 송신하는 인공지능스피커; 및 인쇄물에 시각적으로 인식되지 않는 크기로 인쇄된 패턴이미지를 촬영하고, 상기 패턴이미지에 대응되는 코드를 생성하며, 상기 코드 중 상기 컨텐츠코드를 상기 인공지능스피커를 경유하여 상기 컨텐츠서버로 송신하는 전자펜을 포함하고, 상기 인공지능서버는, 상기 음성명령 중 상기 전자펜을 호출하는 전자펜호출명령에 대응되는 제1명령데이터를 상기 인공지능스피커로 송신하고, 상기 인공지능스피커는, 상기 제1명령데이터를 수신하면 무선연결신호를 탐색하여 상기 전자펜과 무선연결하고 전자펜서비스상태로 진입하며, 상기 전자펜서비스상태에서 상기 컨텐츠코드를 상기 컨텐츠서버로 송신하고 상기 컨텐츠서버로부터 수신되는 상기 컨텐츠데이터 중 음성컨텐츠데이터를 내장스피커를 통해 출력하는 전자펜 시스템을 제공한다. In order to achieve the above object, an embodiment is to analyze the first voice data to recognize the voice command included in the first voice data, and transmits the command data corresponding to the voice command to the command execution device Intelligent server; A content server that receives a content code and transmits content data corresponding to the content code to a content output device; An artificial intelligence speaker that enters a command waiting state when the call voice is recognized, and converts the voice recognized in the command waiting state into the first voice data and transmits the voice to the artificial intelligence server; And an electronic device that shoots a pattern image printed in a size not visually recognized on the printed object, generates a code corresponding to the pattern image, and transmits the content code among the codes to the content server via the artificial intelligence speaker. The pen includes a pen, and the artificial intelligence server transmits first command data corresponding to an electronic pen calling command to call the electronic pen among the voice commands to the artificial intelligence speaker, and the artificial intelligence speaker comprises the first Upon receiving the command data, the wireless connection signal is searched for wireless connection with the electronic pen, the electronic pen service state is entered, the content code is transmitted from the electronic pen service state to the content server, and the content received from the content server It provides an electronic pen system that outputs voice content data from the data through the built-in speaker.
상기 전자펜 시스템에서, 상기 인공지능스피커는, TV(television)서비스상태에서 TV데이터를 수신하고 상기 TV데이터를 TV장치를 통해 출력하며, 상기 전자펜서비스상태에서 상기 컨텐츠데이터 중 영상컨텐츠데이터를 상기 TV장치를 통해 출력할 수 있다.In the electronic pen system, the artificial intelligence speaker receives TV data in a TV (television) service state and outputs the TV data through a TV device, and receives image content data among the content data in the electronic pen service state. It can be output through a TV device.
상기 전자펜 시스템에서, 상기 인공지능스피커는, 무선연결된 상기 전자펜으로부터 제품식별데이터를 수신하고 상기 제품식별데이터에 대응되는 상기 전자펜의 외관이미지를 별도의 영상출력장치를 통해 표시In the electronic pen system, the artificial intelligence speaker receives product identification data from the electronic pen wirelessly connected and displays an external image of the electronic pen corresponding to the product identification data through a separate image output device.
상기 전자펜 시스템에서, 상기 전자펜은, 펜스피커를 내장하고, 상기 인공지능스피커와 무선연결되면 상기 펜스피커의 기능을 턴오프할 수 있다.In the electronic pen system, the electronic pen may include a pen speaker and turn off the function of the pen speaker when wirelessly connected to the artificial intelligence speaker.
상기 전자펜 시스템에서, 상기 전자펜은, 복수의 조작버튼으로 구성되는 조작부를 포함하고, 상기 조작버튼에 대응되는 명령코드를 생성하여 상기 인공지능스피커로 송신하며, 상기 인공지능스피커는, 상기 명령코드에 대응되는 기능을 수행하여 음성의 출력이나 영상의 출력을 변경할 수 있다.In the electronic pen system, the electronic pen includes an operation unit composed of a plurality of operation buttons, generates a command code corresponding to the operation button, and transmits the command code to the AI speaker, wherein the AI speaker is the command By performing a function corresponding to the code, it is possible to change the output of audio or video.
상기 전자펜 시스템에서, 상기 컨텐츠서버는, 상기 인공지능스피커를 경유하여 상기 전자펜으로부터 수신되는 인터랙티브(interactive)코드에 대응되는 프로그램을 실행시키고, 상기 프로그램의 실행에 따른 영상출력데이터 및 음성출력데이터를 상기 인공지능스피커로 송신하며, 상기 전자펜으로부터 인공지능스피커를 경유하여 상기 전자펜으로부터 명령코드를 수신하여 상기 프로그램의 기능을 조작할 수 있다.In the electronic pen system, the content server executes a program corresponding to an interactive code received from the electronic pen via the artificial intelligence speaker, and outputs video and audio output data according to the execution of the program. Is transmitted to the artificial intelligence speaker, the command code is received from the electronic pen via the artificial intelligence speaker from the electronic pen, and the function of the program can be operated.
상기 전자펜 시스템에서, 상기 전자펜은, 마이크로폰을 더 포함하고 상기 마이크로폰을 통해 생성되는 제2음성데이터를 상기 인공지능스피커를 경유하여 상기 인공지능서버로 송신하고, 상기 인공지능서버는, 상기 제2음성데이터를 텍스트데이터로 변환하여 상기 컨텐츠서버로 송신하고, 상기 컨텐츠서버는, 상기 텍스트데이터의 적합도를 판단하고 판단결과를 상기 인공지능스피커를 통해 출력할 수 있다.In the electronic pen system, the electronic pen further includes a microphone and transmits second voice data generated through the microphone to the artificial intelligence server via the artificial intelligence speaker, and the artificial intelligence server comprises: 2 The audio data is converted into text data and transmitted to the content server, and the content server can determine the suitability of the text data and output the determination result through the artificial intelligence speaker.
그리고, 상기 전자펜은, 상기 제2음성데이터를 송신하기 전에 상기 컨텐츠서버로 제1회화문에 대응되는 일 컨텐츠코드를 상기 컨텐츠서버로 송신하고, 상기 컨텐츠서버는, 상기 제1회화문의 대답으로서 미리 설정된 제2회화문과 상기 텍스트데이터의 유사도를 판단하여 상기 판단결과를 생성할 수 있다.Then, the electronic pen, before transmitting the second voice data, transmits a content code corresponding to the first conversation message to the content server to the content server, and the content server is previously configured as an answer to the first conversation statement. The determination result may be generated by determining the similarity between the set second conversation text and the text data.
다른 실시예는, 제1음성데이터를 분석하여 상기 제1음성데이터에 포함된 음성명령을 인식하고, 상기 음성명령에 대응되는 명령데이터를 명령수행장치로 송신하는 인공지능서버; 복수의 좌표코드를 수신하고, 상기 복수의 좌표코드를 조합하여 텍스트를 생성하고 상기 텍스트, 상기 텍스트를 변환한 음성데이터 및 상기 텍스트에 대응되는 영상데이터 중 적어도 하나를 송신하는 텍스트서버; 호출음성이 인식되면 명령대기상태로 진입하고, 상기 명령대기상태에서 인식되는 음성을 상기 제1음성데이터로 변환하여 상기 인공지능서버로 송신하는 인공지능스피커; 및 인쇄물에 시각적으로 인식되지 않는 크기로 인쇄된 패턴이미지를 촬영하고, 상기 패턴이미지에 대응되는 코드를 생성하며, 상기 코드 중 상기 좌표코드를 상기 인공지능스피커를 경유하여 상기 텍스트서버로 송신하는 전자펜을 포함하고, 상기 인공지능서버는, 상기 음성명령 중 상기 전자펜을 호출하는 전자펜호출명령에 대응되는 제1명령데이터를 상기 인공지능스피커로 송신하고, 상기 인공지능스피커는, 상기 제1명령데이터를 수신하면 무선연결신호를 탐색하여 상기 전자펜과 무선연결하고 전자펜서비스상태로 진입하며, 상기 전자펜서비스상태에서 상기 좌표코드를 상기 텍스트서버로 송신하고 상기 텍스트를 변환한 음성데이터를 내장스피커를 통해 출력하거나 상기 텍스트를 미리 선택된 다른 서버로 송신하는 전자펜 시스템을 제공한다. Another embodiment includes an artificial intelligence server that analyzes first voice data to recognize voice commands included in the first voice data, and transmits command data corresponding to the voice commands to a command execution device; A text server that receives a plurality of coordinate codes, generates text by combining the plurality of coordinate codes, and transmits at least one of the text, voice data converted from the text, and image data corresponding to the text; An artificial intelligence speaker that enters a command waiting state when the call voice is recognized, and converts the voice recognized in the command waiting state into the first voice data and transmits the voice to the artificial intelligence server; And a pattern image printed in a size not visually recognized on the printed material, generating a code corresponding to the pattern image, and transmitting the coordinate code among the codes to the text server via the artificial intelligence speaker. The pen includes a pen, and the artificial intelligence server transmits first command data corresponding to an electronic pen calling command to call the electronic pen among the voice commands to the artificial intelligence speaker, and the artificial intelligence speaker comprises the first Upon receiving the command data, it searches for a wireless connection signal, wirelessly connects with the electronic pen, enters an electronic pen service state, transmits the coordinate code to the text server in the electronic pen service state, and converts the voice data converted from the text. Provided is an electronic pen system for outputting through the built-in speaker or transmitting the text to another preselected server. .
상기 다른 서버는, 날짜별로 메모를 기록하고, 상기 전자펜의 고유번호에 대응되는 저장공간에 상기 텍스트를 날짜별로 저장할 수 있다.The other server may record a memo by date and store the text by date in a storage space corresponding to a unique number of the electronic pen.
이상에서 설명한 바와 같이 본 실시예에 의하면, 인공지능스피커와 전자펜이 연동됨으로써, 종래에 비해 획기적으로 개선된 사용자 편의성을 가지는 입력장치를 제공할 수 있다.As described above, according to the present exemplary embodiment, the artificial intelligence speaker and the electronic pen are interlocked, thereby providing an input device having significantly improved user convenience compared to the prior art.
도 1은 일 실시예에 따른 전자펜 시스템의 구성을 나타내는 도면이다.
도 2는 일 실시예에 따른 인공지능스피커의 구성도이다.
도 3은 일 실시예에 따른 전자펜(120)의 구성도이다.
도 4는 일 실시예에 따른 전자펜 시스템에서 컨텐츠를 출력하는 방법의 흐름도이다.
도 5는 일 실시예에 따른 전자펜 시스템에서 각 구성 사이의 신호 흐름을 나타내는 도면이다.
도 6은 일 실시예에 따른 전자펜의 조작부를 나타내는 도면이다.
도 7은 일 실시예에 따른 전자펜 시스템에서 프로그램을 실행시키는 것을 나타내는 도면이다.
도 8은 일 실시예에 따른 전자펜 시스템에서 회화평가가 이루어지는 과정을 나타내는 도면이다.
도 9는 다른 실시예에 따른 전자펜 시스템의 구성을 나타내는 도면이다.
도 10은 다른 실시예에 따른 전자펜 시스템에 적용될 수 있는 인쇄물을 나타내는 도면이다.1 is a view showing the configuration of an electronic pen system according to an embodiment.
2 is a block diagram of an artificial intelligence speaker according to an embodiment.
3 is a block diagram of an
4 is a flowchart of a method of outputting content from an electronic pen system according to an embodiment.
5 is a view showing a signal flow between each component in the electronic pen system according to an embodiment.
6 is a view showing an operation portion of the electronic pen according to an embodiment.
7 is a diagram illustrating a program execution in an electronic pen system according to an embodiment.
8 is a view showing a process of conversation evaluation in an electronic pen system according to an embodiment.
9 is a view showing the configuration of an electronic pen system according to another embodiment.
10 is a view showing a printed material that can be applied to the electronic pen system according to another embodiment.
이하, 본 발명의 일부 실시예들을 예시적인 도면을 통해 상세하게 설명한다. 각 도면의 구성요소들에 참조부호를 부가함에 있어서, 동일한 구성요소들에 대해서는 비록 다른 도면상에 표시되더라도 가능한 한 동일한 부호를 가지도록 하고 있음에 유의해야 한다. 또한, 본 발명을 설명함에 있어, 관련된 공지 구성 또는 기능에 대한 구체적인 설명이 본 발명의 요지를 흐릴 수 있다고 판단되는 경우에는 그 상세한 설명은 생략한다.Hereinafter, some embodiments of the present invention will be described in detail through exemplary drawings. It should be noted that in adding reference numerals to the components of each drawing, the same components have the same reference numerals as possible even though they are displayed on different drawings. In addition, in describing the present invention, when it is determined that detailed descriptions of related well-known configurations or functions may obscure the subject matter of the present invention, detailed descriptions thereof will be omitted.
또한, 본 발명의 구성 요소를 설명하는 데 있어서, 제 1, 제 2, A, B, (a), (b) 등의 용어를 사용할 수 있다. 이러한 용어는 그 구성 요소를 다른 구성 요소와 구별하기 위한 것일 뿐, 그 용어에 의해 해당 구성 요소의 본질이나 차례 또는 순서 등이 한정되지 않는다. 어떤 구성 요소가 다른 구성요소에 "연결", "결합" 또는 "접속"된다고 기재된 경우, 그 구성 요소는 그 다른 구성요소에 직접적으로 연결되거나 또는 접속될 수 있지만, 각 구성 요소 사이에 또 다른 구성 요소가 "연결", "결합" 또는 "접속"될 수도 있다고 이해되어야 할 것이다.In addition, in describing the components of the present invention, terms such as first, second, A, B, (a), and (b) may be used. These terms are only for distinguishing the component from other components, and the nature, order, or order of the component is not limited by the term. When a component is described as being "connected", "coupled" or "connected" to another component, that component may be directly connected to or connected to the other component, but another component between each component It should be understood that elements may be "connected", "coupled" or "connected".
도 1은 일 실시예에 따른 전자펜 시스템의 구성을 나타내는 도면이다.1 is a view showing the configuration of an electronic pen system according to an embodiment.
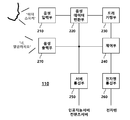
도 1을 참조하면, 전자펜 시스템(100)은 인공지능스피커(110), 전자펜(120), 인공지능서버(130), 컨텐츠서버(140) 등을 포함할 수 있다.Referring to FIG. 1, the
인공지능스피커(110)는 사용자(10)의 음성을 음성데이터로 변환하여 인공지능서버(130)로 송신할 수 있다. 그리고, 인공지능서버(130)는 음성데이터에 포함된 음성내용을 인식하고, 음성내용에 대응되는 기능을 수행할 수 있다.The
예를 들어, 인공지능서버(130)는 음성데이터에 포함된 음성명령을 인식하고, 음성명령에 대응되는 기능을 수행할 수 있다. 사용자(10)가 "라디오를 연결해 줘"라는 음성을 인공지능스피커(110)로 발화하면, 인공지능스피커(110)는 "라디오를 연결해 줘"라는 음성을 음성데이터-음성데이터는 아날로그신호은 음성을 디지털신호로 변환한 것임-로 변환하고, 변환된 음성데이터를 인공지능서버(130)로 송신할 수 있다. 인공지능서버(130)는 음성데이터에서 음성명령을 추출 혹은 분석하는 기능을 포함할 수 있다. 인공지능서버(130)는 학습된 신경지능망-예를 들어, 뉴럴네트워크 등-을 포함하고 있으면서, 신경지능망에 음성데이터를 입력하고 그 출력으로서 음성명령을 획득할 수 있다. 혹은 인공지능서버(130)는 음성데이터를 텍스트로 변환하는 기능을 포함하고 있고, 텍스트를 룰(rule)기반의 분류 프로그램에 대입시켜 텍스트가 지시하는 음성명령을 확인할 수 있다. 그리고, 인공지능서버(130)는 확인된 음성명령에 대응되는 기능-예를 들어, 라디오 서버에서 출력되는 음성데이터를 스트리밍형태로 인공지능스피커(110)로 송신하는 기능-을 수행할 수 있다.For example, the
사용자(10)의 음성에 대응되는 음성데이터에서 사용자(10)가 발화한 음성의 음성내용-예를 들어, 음성명령-을 인식하기 위해서는 고용량의 저장장치 및 고성능의 계산장치를 포함할 필요가 있다. 이에 따라, 소형 크기를 가지는 인공지능스피커(110)가 사용자(10)의 음성에서 바로 음성내용을 인식하는 기능을 내장하기는 어렵다. 이러한 난제에 따라, 일반적으로, 인공지능스피커(110)는 사용자(10)의 음성을 음성데이터로 변환하는 기능을 수행하고, 음성데이터로부터 음성내용을 인식하는 기능은 인공지능서버(130)에 의해 수행될 수 있다.It is necessary to include a high-capacity storage device and a high-performance computing device in order to recognize the voice content of the voice uttered by the user 10-for example, voice commands-from voice data corresponding to the
한편, 인공지능스피커(110)는 사용자(10)가 발화한 음성을 상시적으로 음성데이터로 변환하여 인공지능서버(130)로 송신하지는 않고 특정 상태에서만 사용자(10)의 음성에 대응되는 음성데이터를 인공지능서버(130)로 송신할 수 있다. 그렇지 않은 경우, 인공지능서버(130)가 사용자(10)의 일반적인 대화 내용에 반응하는 문제가 발생할 수 있다.On the other hand, the
인공지능스피커(110)는 호출대기상태를 유지하고 있다가 호출음성이 인식되면 명령대기상태로 진입할 수 있다. 호출대기상태에서 사용자(10)의 음성에 대응되는 음성데이터를 인공지능서버(130)로 송신하지 않기 때문에 인공지능스피커(110)는 사용자(10)의 음성에 대응되는 음성데이터가 호출음성에 대응되는지 자체적으로 판단할 수 있다. 후술하는 내용과 같이 인공지능스피커(110)는 내부에 트리거링모듈(triggering module)을 포함하고 있으면서 트리거링모듈을 통해 사용자(10)의 호출음성을 인식하고, 호출음성이 인식될 때, 명령대기상태로 진입할 수 있다.The
인공지능스피커(110)는 명령대기상태에서 인식되는 음성을 음성데이터로 변환하여 인공지능서버(130)로 송신할 수 있다. 명령대기상태에서 인식되는 음성을 이하에서는 제1음성데이터로 명명한다.The
인공지능서버(130)는 제1음성데이터를 분석하여 제1음성데이터에 포함된 음성명령을 인식할 수 있다. 인공지능서버(130)는 STT(speach to text)엔진을 포함하고 있으면서, 제1음성데이터를 텍스트로 변환하고 텍스트를 신경지능망 등의 분석모듈에 입력하여 그 출력으로서 음성명령을 인식할 수 있다. 그리고, 인공지능서버(130)는 음성명령에 대응되는 명령데이터를 명령수행장치로 송신할 수 있다. 예를 들어, 인공지능서버(130)는 "전등 꺼 줘"라는 음성명령을 인식하고 전등을 턴오프하는 명령데이터를 전등제어장치로 송신할 수 있다.The
인공지능서버(130)는 제1음성데이터에 포함된 음성명령 중 전자펜(120)을 호출하는 전자펜호출명령을 인식하면 전자펜호출명령에 대응되는 제1명령데이터를 인공지능스피커(110)로 송신할 수 있다. 예를 들어, 사용자(10)가 "세이펜 연결해 줘"라는 음성명령을 발화하면, 인공지능스피커(110)는 이에 대응되는 제1음성데이터를 인공지능서버(130)로 송신하고, 인공지능서버(130)는 제1음성데이터에서 전자펜호출명령을 인식하고 전자펜호출명령에 대응되는 제1명령데이터를 인공지능스피커(110)로 송신할 수 있다.The
인공지능스피커(110)는 제1명령데이터를 수신하면 무선연결신호를 탐색하여 전자펜(120)과 무선연결할 수 있다. 예를 들어, 인공지능스피커(110)와 전자펜(120)는 블루투스, 와이파이 등의 무선통신모듈을 포함하고 있으면서, 이러한 무선통신모듈을 통해 무선연결될 수 있다.When receiving the first command data, the
인공지능스피커(110)는 제1명령데이터를 통해 전자펜(120)과 무선연결되면 전자펜서비스상태로 진입할 수 있다.The
인공지능스피커(110)에서 전자펜서비스상태는 전자펜(120)으로부터 수신되는 각종 코드를 처리할 수 있는 상태로서, 인공지능스피커(110)의 음성을 통한 사용자 입력기능에 더해 전자펜(120)을 통한 사용자 입력기능이 부가된 상태로 이해될 수 있다.The electronic pen service state in the
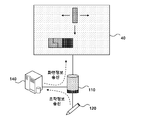
전자펜(120)은 OID(object identifier)모듈을 포함하고 있으면서, OID모듈을 통해 패턴이미지를 촬영할 수 있다. 패턴이미지는 인쇄물(20)에 시각적으로 인식되지 않는 크기로 인쇄된 이미지로서 OID모듈이 인식할 수 있는 패턴으로 구성된다. 인쇄물(20)에는 시각적으로 인식될 수 있는 크기의 시각이미지가 인쇄될 수 있다. 시각이미지로서 예를 들어, 글자, 도형, 사진 등이 인쇄물(20)에 인쇄될 수 있다. 이에 반해, 패턴이미지는 시각적으로 인식되지 않는 크기로 시각이미지와 중첩되도록 인쇄될 수 있다. 따라서, 사용자(10)는 인쇄물(20)에 인쇄된 시각이미지는 인식할 수 있으나 패턴이미지는 인식할 수 없게 된다. 반대로, 전자펜(120)은 촬영영역이 미세하기 때문에, 패턴이미지를 촬영하여 그에 대응되는 코드를 인식할 수 있으나, 넓은 영역에 인쇄되어 있는 시각이미지는 인식하지 못할 수 있다.The
전자펜(120)는 OID모듈을 통해 패턴이미지를 촬영하고, 패턴이미지에 대응되는 코드를 생성할 수 있다. 서로 다른 패턴을 가지는 복수의 패턴이미지들이 미리 정의될 수 있고, 전자펜(120)은 각각의 패턴이미지에 대응되는 코드들을 저장하고 있을 수 있다. 그리고, 전자펜(120)은 특정 패턴이미지가 촬영되면 해당 패턴이미지에 대응되는 코드를 생성할 수 있다.The
전자펜(120)는 생성되는 코드들을 인공지능스피커(110)로 송신할 수 있다. 그리고, 인공지능스피커(110)는 수신되는 코드 중 컨텐츠코드를 컨텐츠서버(140)로 송신할 수 있다.The
인공지능스피커(110)와 전자펜(120)은 무선통신을 통해 연결되고, 인공지능스피커(110)와 인공지능서버(130) 및 컨텐츠서버(140)는 네트워크(30)를 통해 연결될 수 있다. 인공지능스피커(110), 인공지능서버(130) 및 컨텐츠서버(140)는 IP(internet protocol)주소와 같은 네트워크식별아이디를 가지고 있으면서 네트워크식별아이디를 통해 네트워크(30)에 접속되어 있을 수 있다. 인공지능스피커(110), 인공지능서버(130) 및 컨텐츠서버(140)는 네트워크(30)를 통해 복수의 장치들과 연결되어 있을 수 있다. 예를 들어, 인공지능스피커(110)는 네트워크(30)를 통해 인공지능서버(130)와 정보를 주고 받을 수 있고, 컨텐츠서버(140)와 정보를 주고 받을 수 있다. 이에 반해, 전자펜(120)은 근접지에 위치하는 하나의 장치와 무선연결될 수 있다. 예를 들어, 전자펜(120)은 블루투스를 통해 인공지능스피커(110)와 연결될 수 있다. 전자펜(120)은 인공지능서버(130)와 컨텐츠서버(140)와 정보를 주고 받기 위해 인공지능스피커(110)를 이용할 수 있다. 예를 들어, 전자펜(120)은 인공지능스피커(110)를 통해 컨텐츠코드를 컨텐츠서버(140)로 송신할 수 있고, 인공지능스피커(110)를 통해 컨텐츠서버(140)로부터 정보를 수신할 수 있다.The
전자펜(120)는 코드 중 컨텐츠코드를 인공지능스피커(110)를 경유하여 컨텐츠서버(140)로 송신할 수 있다. 그리고, 컨텐츠서버(140)는 컨텐츠코드를 수신하고, 컨텐츠코드에 대응되는 컨텐츠데이터를 컨텐츠출력장치로 송신할 수 있다. 예를 들어, 전자페(120)이 특정 책의 1페이지에 해당되는 컨텐츠코드를 컨텐츠서버(140)로 송신하면, 컨텐츠서버(140)는 해당 페이지의 내용을 음성으로 녹음한 음성컨텐츠데이터 및 해당 페이지의 내용을 영상으로 각색한 영상컨텐츠데이터를 인공지능스피커(110)로 송신할 수 있다.The
인공지능스피커(110)는 컨텐츠서버(140)로부터 수신되는 컨텐츠데이터 중 음성컨텐츠데이터를 내장스피커를 통해 출력할 수 있다. 그리고, 인공지능스피커(110)는 컨텐츠서버(140)로부터 수신되는 컨텐츠데이터 중 영상컨텐츠데이터를 별도의 영상출력장치를 통해 표시할 수 있다.The
별도의 영상출력장치는 일 예로서, TV(television)장치(40)일 수 있다. 인공지능스피커(110)는 TV서비스상태에서 TV데이터를 수신하고 TV데이터를 TV장치(40)를 통해 출력할 수 있다. TV데이터를 출력하기 위해, 인공지능스피커(110) 내에 셋톱박스가 내장될 수 있다. 실시예에 따라서는 TV장치(40)에 셋톱박스가 부착되거나 셋톱박스가 내장될 수 있다.The separate image output device may be, for example, a TV (television)
인공지능스피커(110)는 전자펜서비스상태에서 컨텐츠데이터 중 영상컨텐츠데이터를 TV장치(40)를 통해 출력할 수 있다.The
전자펜(120)은 독자적인 기능 수행을 위해 스피커(펜스피커)를 내장할 수 있다. 그리고, 실시예에 따라서는, 음성컨텐츠데이터가 인공지능스피커(110)에서 출력될 수 있고, 전자펜(120)에서 출력될 수 있다. 인공지능스피커(110)에서 음성컨텐츠데이터가 출력되는 경우, 인공지능스피커(110)와 전자펜(120)이 무선연결되는 경우, 펜스피커의 기능은 턴오프될 수 있다.The
한편, 전자펜 시스템(100)에는 복수의 전자펜(120)이 포함될 수 있고, 인공지능스피커(110)는 무선연결신호를 통해 복수의 전자펜(120)에 대한 제품식별데이터를 수신하고, 각 제품식별데이터에 대응되는 전자펜(120)의 외관이미지를 별도의 영상출력장치-예를 들어, TV장치(40)-를 통해 표시할 수 있다. 그리고, 복수의 외관이미지 중 하나가 사용자(10)에 의해 선택되면 인공지능스피커(110)는 선택된 전자펜(120)과 무선연결되고 해당 전자펜(120)으로부터 수신된 제품식별데이터에 대응되는 전자펜(120)의 외관이미지를 영상출력장치를 통해 표시할 수 있다. 복수의 외관이미지 중 하나를 선택하는 것은 사용자(10)의 음성명령에 의해 이루어질 수 있다.Meanwhile, the
도 2는 일 실시예에 따른 인공지능스피커의 구성도이다.2 is a block diagram of an artificial intelligence speaker according to an embodiment.
도 2를 참조하면, 인공지능스피커(110)는 음성입력부(210), 음성데이터변환부(220), 트리거링부(230), 제어부(240), 서버통신부(250), 전자펜통신부(260), 음성출력부(270) 등을 포함할 수 있다.2, the
음성입력부(210)는 마이크로폰을 포함하고 있으면서, 사용자가 발화한 음성을 아날로그전기신호로 변환할 수 있다. 음성입력부(210)는 필요에 따라 필터를 더 포함하고 있으면서 사용자 주변의 노이즈를 제거하거나 기타 다른 소스에 의해 발생되는 노이즈를 제거할 수 있다.The
음성입력부(210)에서 변환된 아날로그전기신호는 음성데이터변환부(220)로 전달되고, 음성데이터변환부(220)는 아날로그전기신호를 디지털신호인 음성데이터로 변환할 수 있다.The analog electrical signal converted by the
트리거링부(230)는 트리거링모듈을 포함하고 있으면서 음성데이터를 미리 설정된 호출음성데이터와 비교하고, 음성데이터가 호출음성데이터와 유사한 경우, 사용자가 호출음성을 발화한 것으로 판단할 수 있다. 트리거링부(230)가 호출음성을 인식하면, 플래그 등을 통해 호출음성이 인식되었음을 제어부(240)로 알릴 수 있다.The triggering
제어부(240)는 호출대기상태에 있다가 트리거링부(230)로부터 호출음성이 인식되었다는 신호를 전달받으면 명령대기상태로 진입할 수 있다. 제어부(240)는 명령대기상태에 진입했음을 사용자에게 알리기 위해 명령대기상태음성을 음성출력부(270)를 통해 출력할 수 있다.When the
사용자 행위의 관점에서 설명하면, 사용자가 호출음성-예를 들어, "헤이, 스피커"-을 발화하면, 트리거링부(230)가 호출음성을 인식하고, 이에 대응하여, 제어부(240)가 명령대기상태음성-예를 들어, "네, 말씀하세요"-을 음성출력부(270)를 통해 출력할 수 있다.Explained in terms of user behavior, when the user utters a ringing voice-for example, "hey, speaker"-the triggering
음성출력부(270)는 스피커 및 DAC(digital-to-analog converter)를 포함하고 있으면서, 디지털신호인 음성데이터를 아날로그전기신호를 변환하고 아날로그전기신호를 음파로 변환하여 출력할 수 있다.The
명령대기상태에서 음성입력부(210)를 통해 입력되는 음성은 음성데이터변환부(220)를 통해 제1음성데이터로 변환된 후 서버통신부(250)를 통해 인공지능서버로 송신될 수 있다. 서버통신부(250)는 도 1을 참조하여 설명한 네트워크와 연결될 수 있으며, 네트워크르 통해 인공지능서버 혹은 컨텐츠서버와 정보를 주고 받을 수 있다. 그리고, 서버통신부(250)는 네트워크를 통해 다른 서버와도 정보를 송수신할 수 있는데, 예를 들어, 서버통신부(250)는 TV데이터서버를 통해 TV데이터를 수신할 수 있고, 스마트홈서버와 연결되면서 가정 내 전기기기를 제어하는 신호/데이터를 송수신할 수 있다.The voice input through the
인공지능서버는 서버통신부(250)를 통해 수신되는 제1음성데이터를 통해 전자펜호출명령을 인식할 수 있다. 그리고, 인공지능서버는 전자펜호출명령에 대응되는 제1명령데이터를 인공지능스피커-예를 들어, 서버통신부(250)-로 송신할 수 있다.The artificial intelligence server may recognize the electronic pen call command through the first voice data received through the
인공지능스피커-예를 들어, 제어부(240)-는 제1명령데이터를 수신한 후 전자페통신부(260)를 통해 무선연결신호를 탐색하여 전자펜과 무선연결할 수 있다. 이때, 전자펜통신부(260)와 전자펜이 무선연결될 수 있다.The artificial intelligence speaker-for example, the control unit 240-may receive the first command data and search for a wireless connection signal through the
전자펜통신부(260)와 전자펜이 무선연결되면 제어부(240)는 전자펜서비스상태로 진입할 수 있다. 그리고, 전자펜서비스상태에서, 전자펜통신부(260)는 전자펜으로부터 각종 코드르 수신할 수 있는데, 이러한 코드 중 컨텐츠코드는 서버통신부(250)를 통해 컨텐츠서버로 송신될 수 있다. 그리고, 컨텐츠서버로부터 수신되는 컨텐츠데이터 중 음성컨텐츠데이터는 음성출력부(270)를 통해 출력될 수 있다.When the electronic
도 3은 일 실시예에 따른 전자펜(120)의 구성도이다.3 is a block diagram of an
도 3을 참조하면, 전자펜(120)은 이미지센서(310), 프로세서(320), 통신부(330), 펜스피커(340), 마이크로폰(350) 및 조작부(360)를 포함할 수 있다.Referring to FIG. 3, the
이미지센서(310)는 광을 전기신호로 변환하는 광전소자를 포함하고 있으면서 광전소자를 이용하여 인쇄물에 시각적으로 인식되지 않는 크기로 인쇄된 패턴이미지를 촬영할 수 있다. 이미지센서(310)는 일종의 카메라로서, 국소영역을 정밀하게 촬영할 수 있는 고해상도/고정밀 카메라로 볼 수 있으며, OID(object identifier)모듈이라고 호칭되기도 한다.The
프로세서(320)는 코드변환부(322) 및 펜제어부(324)를 포함할 수 있다.The
코드변환부(322)는 이미지센서(310)에서 촬영된 패턴이미지의 패턴을 분석하고 해당 패턴에 대응되는 코드를 생성할 수 있다. 패턴은 예를 들어, 가상의 격자에서 점들이 배치되는 위치에 대한 것으로서, 코드변환부(322)는 촬영된 패턴이미지에서 인식되는 점들의 위치를 이용하여 코드를 생성할 수 있다.The
펜제어부(324)는 전자펜(120)의 제반 기능을 제어할 수 있는데, 특히, 코드변환부(322)로부터 수신되는 코드를 확인하고 각각의 코드에 대응되는 기능을 제어할 수 있다.The
코드는 여러 가지로 세분될 수 있는데, 예를 들어, 코드는 컨텐츠코드, 명령코드 등으로 세분될 수 있다. 컨텐츠코드는 컨텐츠와 매칭되어 있는 코드로서, 펜제어부(324)는 컨텐츠코드가 확인되면 해당 컨텐츠코드에 대응되는 컨텐츠가 사용자에게 표시될 수 있도록 전자펜(120) 혹은 그 주변 기기를 제어할 수 있다. 명령코드는 특정 기능과 매칭되어 있는 코드로서, 펜제어부(324)는 명령코드가 확인되면 해당 명령코드에 대응되는 기능이 수행되도록 전자펜(120) 혹은 그 주변 기기를 제어할 수 있다. 명령코드는 예를 들어, 볼륨업, 볼륨다운, 음소거, 녹음, 이전트랙재생, 이후트랙재생, 일시멈춤, 재생 등의 기능과 매칭될 수 있다.The code may be subdivided into various types, for example, the code may be subdivided into content codes, instruction codes, and the like. The content code is a code that matches the content, and when the content code is confirmed, the
통신부(330)는 주변 기기와 무선통신을 수행하는 모듈로서, 인공지능스피커 혹은 일반 스피커와 블루투스 등의 무선통신을 통해 연결될 수 있다.The
펜스피커(340)는 음성을 출력하는 장치로서, 컨텐츠코드에 대응되는 컨텐츠데이터 중 음성컨텐츠데이터가 출력될 수 있고, 펜제어부(324)의 제어에 따라 미리 설정된 음성이 출력될 수 있다.The
마이크로폰(350)은 ADC(analog-to-digital converter)를 포함하고 있으면서, 입력되는 음성을 디지털신호인 음성데이터로 변환하는 모듈이다. 마이크로폰(350)으로 입력되는 음성은 음성데이터로 변환된 후 펜스피커(340)를 통해 출력될 수 있다. 실시예에 따라서는, 프로세서(320)에 오디오믹서가 포함되어 있을 수 있고, 마이크로폰(350)에서 생성되는 음성데이터는 오디오믹서에서 음성컨텐츠데이터와 믹싱된 후 펜스피커(340)를 통해 출력될 수 있다.The
통신부(330)가 블루투스 등의 무선통신을 통해 외부 스피커 혹은 인공지능스피커와 무선연결되어 있는 경우, 펜스피커의 기능은 턴오프될 수 있다. 이때, 펜스피커(340)로 전달되는 음성데이터는 무선연결된 외부 스피커 혹은 인공지능스피커로 전달되어 출력될 수 있다. 오디오믹서에 의해 믹싱된 음성데이터도 마찬가지로 외부 스피커 혹은 인공지능스피커로 전달되어 출력될 수 있다.When the
조작부(360)는 사용자의 수조작을 인식할 수 있는 모듈이다. 조작부(360)는 복수의 조작버튼을 포함하고 있으면서, 각각의 조작버튼이 눌려졌을 때, 서로 다른 명령코드를 생성하여 펜제어부(324)로 전달할 수 있다. 예를 들어, 조작부(360)는 볼률업버튼, 볼륨다운버튼, 음소거버튼, 녹음버튼, 이적트랙재생버튼, 이후트랙재생버튼, 일시멈춤버튼, 재생버튼 등을 포함하고 있으면서, 각 버튼의 눌림에 따라 서로 다른 명령코드를 생성할 수 있다.The
도 4는 일 실시예에 따른 전자펜 시스템에서 컨텐츠를 출력하는 방법의 흐름도이다.4 is a flowchart of a method of outputting content from an electronic pen system according to an embodiment.
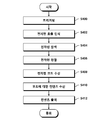
도 4를 참조하면, 인공지능스피커가 먼저 트리거링될 수 있다(S400). 인공지능스피커는 트리거링모듈을 이용하여 호출음성을 인식하면서 트리거링될 수 있다. 인공지능스피커는 트리거링된 후에 명령대기상태로 진입하여 사용자의 음성명령이 이루어질 때까지 대기할 수 있다.4, the artificial intelligence speaker may be triggered first (S400). The artificial intelligence speaker may be triggered while recognizing the call voice using the triggering module. The AI speaker may enter a command waiting state after being triggered and wait until a user's voice command is made.
명령대기상태로 진입한 후에 인공지능스피커는 전자펜을 호출하는 전자펜호출명령을 수신하고, 전자펜호출명령을 제1음성데이터로 변환하여 인공지능서버로 전송할 수 있다. 그리고, 인공지능서버는 수신되는 제1음성데이터에 대한 분석을 통해 전자펜호출명령을 인식할 수 있다(S402).After entering the command-waiting state, the AI speaker may receive an electronic pen call command to call the electronic pen, convert the electronic pen call command to first voice data, and transmit it to the AI server. Then, the artificial intelligence server may recognize the electronic pen call command through analysis of the received first voice data (S402).
전자펜호출명령이 인식되면, 인공지능서버는 전자펜호출명령에 대응되는 제1명령데이터를 인공지능스피커로 송신할 수 있다. 그리고, 인공지능스피커는 제1명령데이터를 수신한 후에, 무선연결신호를 탐색하여 전자펜과의 통신연결을 시도할 수 있다(S404). 그리고, 인공지능스피커는 무선연결가능상태에 있는 하나의 전자펜과 무선연결될 수 있다(S406).When the electronic pen calling command is recognized, the artificial intelligence server may transmit the first command data corresponding to the electronic pen calling command to the artificial intelligence speaker. Then, after receiving the first command data, the artificial intelligence speaker may search for a wireless connection signal and attempt communication connection with the electronic pen (S404). Then, the artificial intelligence speaker may be wirelessly connected to one electronic pen in a wireless connection enabled state (S406).
그리고, 인공지능스피커는 전자펜서비스상태로 진입하고, 전자펜서비스상태에서 전자펜으로부터 코드를 수신할 수 있다(S408).Then, the artificial intelligence speaker may enter the electronic pen service state and receive a code from the electronic pen in the electronic pen service state (S408).
인공지능스피커는 코드 중에서 컨텐츠코드가 수신되면, 컨텐츠코드를 컨텐츠서버로 송신하고, 컨텐츠서버로부터 컨텐츠데이터를 수신할 수 있다(S410).When the content code is received among the codes, the artificial intelligence speaker may transmit the content code to the content server and receive content data from the content server (S410).
컨텐츠데이터에는 영상컨텐츠데이터와 음성컨텐츠데이터가 포함될 수 있는데, 인공지능스피커는 영상컨텐츠데이터를 TV장치 등 별도의 영상출력장치를 이용하여 출력하고, 음성컨텐츠데이터를 내장스피커 등을 이용하여 출력할 수 있다(S412).The content data may include video content data and audio content data, and the artificial intelligence speaker may output video content data using a separate video output device such as a TV device, and output the audio content data using a built-in speaker. Yes (S412).
도 5는 일 실시예에 따른 전자펜 시스템에서 각 구성 사이의 신호 흐름을 나타내는 도면이다.5 is a view showing a signal flow between each component in the electronic pen system according to an embodiment.
도 5를 참조하면, 인공지능스피커(110)는 내장된 트리거링모듈을 이용하여 자체적으로 호출음성을 인식하고 트리거링될 수 있다(S400).Referring to FIG. 5, the
그리고, 인공지능스피커(110)는 사용자의 발화에 따른 음성명령을 입력받고(S502), 음성명령을 음성데이터로 변환한 후 인공지능서버(130)로 송신할 수 있다(S504).Then, the
인공지능서버(130)는 음성데이터를 분석하여 음성명령을 인식하고 음성명령에 대응되는 명령데이터를 명령수행장치로 송신할 수 있는데, 음성명령이 전자펜호출명령임을 인식하게 되면, 전자펜호출명령에 대응되는 제1명령데이터를 인공지능스피커(110)로 송신할 수 있다(S506).The
전자펜호출명령에 대응되는 제1명령데이터를 수신하면, 인공지능스피커(110)가 명령수행장치로서 기능하게 되는데, 인공지능스피커(110)는 명령수행장치로서 무선연결신호를 탐색하여 전자펜(120)과의 무선연결을 시도할 수 있다(S404).Upon receiving the first command data corresponding to the electronic pen call command, the
무선연결신호를 통해 인공지능스피커(110)와 하나의 전자펜(120)이 무선연결될 수 있다(S406). 그리고, 전자펜(120)은 패턴이미지를 촬영하고(S508), 패턴이미지에 대한 코드를 생성하여 인공지능스피커(110)로 송신할 수 있다(S408).The
그리고, 인공지능스피커(110)는 코드 중 컨텐츠코드를 컨텐츠서버(140)로 송신하고(S510), 컨텐츠서버(140)로부터 컨텐츠데이터를 수신할 수 있다(S512).Then, the
그리고, 인공지능스피커(110)는 컨텐츠데이터 중 음성컨텐츠데이터를 내장스피커 등을 이용하여 출력하고(S514), 영상컨텐츠데이터를 TV장치(40) 등 별도의 영상출력장치를 이용하여 출력할 수 있다(S516).In addition, the
도 6은 일 실시예에 따른 전자펜의 조작부를 나타내는 도면이다.6 is a view showing an operation portion of the electronic pen according to an embodiment.
도 6을 참조하면, 전자펜(120)은 복수의 조작버튼(621 ~ 625)으로 구성되는 조작부(620)를 포함할 수 있다. 그리고, 전자펜(120)은 조작버튼에 대응되는 명령코드를 생성하여 인공지능스피커로 송신할 수 있다. 그리고, 인공지능스피커는 명령코드에 대응되는 기능을 수행하여 음성의 출력이나 영상의 출력을 변경할 수 있다. 예를 들어, 일 예로, 전자펜(120)은 제2조작버튼(622)이 눌려질 때, 제2명령코드를 생성하여 인공지능스피커로 송신할 수 있고, 인공지능스피커는 제2명령코드에 대응하여 음성 혹은 영상의 출력을 일시멈춤할 수 있다. 다른 예로, 제1조작버튼(621)이 눌려질 때, 인공지능스피커는 음성 혹은 영상의 출력을 다시 시작할 수 있고, 제3조작버튼(623)이 눌려질 때, 인공지능스피커는 음성 혹은 영상의 출력을 중단할 수 있다. 또 다른 예로, 제4조작버튼(624)이 눌려질 때, 인공지능스피커는 이전트랙-혹은 이전에 재생된 컨텐츠-을 재생할 수 있고, 제5조작버튼(625)이 눌려질 때, 인공지능스피커는 이후트랙-혹은 다음에 재생될 컨텐츠-을 재생할 수 있다.Referring to FIG. 6, the
한편, 인공지능스피커에서는 프로그램이 실행될 수 있는데, 이러한 프로그램이 인공지능스피커에서 실행될 때, 조작부에 의해 생성되는 명령코드는 프로그램의 기능을 조작하는 것에 사용될 수 있다.Meanwhile, a program may be executed in the AI speaker. When such a program is executed in the AI speaker, the command code generated by the operation unit may be used to manipulate the function of the program.
도 7은 일 실시예에 따른 전자펜 시스템에서 프로그램을 실행시키는 것을 나타내는 도면이다.7 is a diagram illustrating a program execution in an electronic pen system according to an embodiment.
도 7을 참조하면, 인공지능스피커(110)는 전자펜(120)으로부터 인터랙티브(interactive)코드를 수신할 수 있다. 그리고, 인공지능스피커(110)는 인터랙티브코드를 컨텐츠서버(140)로 송신할 수 있는데, 컨텐츠서버(140)는 인터랙티브코드에 대응되는 프로그램을 실행시킬 수 있다. 프로그램은 인공지능스피커(110)에 다운로드된 후 인공지능스피커(110)에서 실행될 수도 있고, 컨텐츠서버(140)에서 실행되면서 실행의 결과로서의 영상출력데이터 및 음성출력데이터만 인공지능스피커(110)로 송신될 수 있다. 그리고, 인공지능스피커(110)는 영상출력데이터를 TV장치(40) 등의 별도의 영상출력장치를 통해 출력할 수 있고, 음성출력데이터를 내장스피커 등을 통해 출력할 수 있다.Referring to FIG. 7, the
한편, 프로그램에 대한 조작은 전자펜(120)에서 생성되는 명령코드에 의해 이루어질 수 있다. 전자펜(120)은 조작부에 배치되는 조작버튼의 눌림을 인식하고, 각 조작버튼에 대응되는 명령코드를 생성하여 인공지능스피커(110)로 송신할 수 있다. 인공지능스피커(110)에서 프로그램이 실행되는 경우, 인공지능스피커(110)는 조작버튼에 대응되는 명령코드를 인식하여 프로그램의 기능을 조작할 수 있다. 그리고, 컨텐츠서버(140)에서 프로그램이 실행되는 경우, 인공지능스피커(110)는 조작버튼에 대응되는 명령코드를 컨텐츠서버(140)로 송신하고, 컨텐츠서버(140)는 명령코드를 인식하여 프로그램의 기능을 조작할 수 있다.Meanwhile, manipulation of the program may be performed by a command code generated in the
도 8은 일 실시예에 따른 전자펜 시스템에서 회화평가가 이루어지는 과정을 나타내는 도면이다.8 is a view showing a process of conversation evaluation in an electronic pen system according to an embodiment.
도 8을 참조하면, 전자펜(120)은 마이크로폰을 통해 생성되는 제2음성데이터를 인공지능스피커(110)를 경유하여 인공지능서버(130)로 송신할 수 있다. 그리고, 인공지능서버(130)는 제2음성데이터를 텍스트데이터로 변환(STT: speech-to-text)하여 컨텐츠서버(140)로 송신할 수 있다. 그리고, 컨텐츠서버(140)는 텍스트데이터의 적합도를 판단하고, 판단결과를 인공지능스피커(110)를 통해 출력할 수 있다.Referring to FIG. 8, the
전자펜(120)은 제2음성데이터를 송신하기 전에 컨텐츠서버(140)로 제1회화문에 대응되는 일 컨텐츠코드를 컨텐츠서버(140)로 송신하고, 컨텐츠서버(140)는 제1회화문의 대답으로서 미리 설정된 제2회화문과 STT를 통해 변환된 텍스트데이터의 유사도를 판단하여 전술한 판단결과를 생성할 수 있다.The
인쇄물(20)에는 제1회화문이 시각적으로 인식될 수 있는 크기로 인쇄되어 있고, 제1회화문에 대응되는 패턴이미지가 시각적으로 인식되지 않는 크기로 인쇄되어 있을 수 있다. 그리고, 인쇄물(20)에는 제1회화문에 대응되는 대답부분이 빈칸으로 형성되어 있을 수 있다.The first conversational text may be visually recognized on the printed
사용자는 제1회화문을 확인하고 전자펜(120)으로 제1회화문을 지시할 수 있는데, 이때, 제1회화문에 대응되는 음성컨텐츠 및/혹은 영상컨텐츠가 인공지능스피커를 통해 출력될 수 있다. 그리고, 사용자는 제1회화문에 대한 대답으로서 특정 음성을 발화할 수 있는데, 이러한 음성은 인공지능스피커(110)에서 제2음성데이터로 변환된 후에 인공지능서버(130)로 송신될 수 있다.The user may check the first conversational sentence and instruct the
인공지능서버(130)는 제2음성데이터를 STT엔진을 이용하여 텍스트데이터로 변환하고, 텍스트데이터를 컨텐츠서버(140)로 송신할 수 있다. 이때, 인공지능서버(130)는 텍스트데이터를 인공지능스피커(110)를 경유하여 송신할 수 있는데, 인공지능서버(110)는 텍스트데이터를 인공지능스피커(110)로 송신하고, 인공지능스피커(110)는 텍스트데이터를 컨텐츠서버(140)로 송신할 수 있다.The
그리고, 컨텐츠서버(140)는 사용자의 대답이 적절한지를 판단하기 위해 수신되는 텍스트데이터와 미리 설정된 제2회화문의 유사도를 판단하고 판단결과를 인공지능스피커(110)로 송신할 수 있다. 이때, 제2회화문은 복수 개로 설정될 수 있고, 컨텐츠서버(140)는 복수의 제2회화문 각각과 텍스테이터의 유사도를 판단하고 유사도가 가장 높게 나온 것으로 판단결과를 생성할 수 있다.In addition, the
도 9는 다른 실시예에 따른 전자펜 시스템의 구성을 나타내는 도면이다.9 is a view showing the configuration of an electronic pen system according to another embodiment.
도 9를 참조하면, 전자펜 시스템(900)은 인공지능스피커(110), 전자펜(120), 인공지능서버(130) 및 텍스트서버(940) 등을 포함할 수 있다.Referring to FIG. 9, the
인쇄물(920)에는 사용자가 시각적으로 인식할 수 없는 크기로 인쇄된 패턴이미지가 포함될 수 있는데, 전자펜(120)은 이러한 패턴이미지를 촬영하고 패턴이미지에 대응되는 코드를 생성할 수 있다.The printed
다른 실시예에서 인쇄물(920)에 인쇄된 패턴이미지는 좌표코드에 대응되는 패턴이미지일 수 있다. 전자펜(120)은 이러한 패턴이미지를 촬영하고 좌표코드를 생성하여 인공지능스피커(110)로 송신할 수 있다. 그리고, 인공지능스피커(110)는 좌표코드를 텍스트서버(940)로 송신할 수 있다.In another embodiment, the pattern image printed on the printed
도 1을 참조하여 설명한 것과 같이, 호출음성이 인식되면, 인공지능스피커(110)는 명령대기상태로 진입하고, 명령대기상태에서 인식되는 음성을 제1음성데이터로 변환하여 인공지능서버(130)로 송신할 수 있다.As described with reference to FIG. 1, when the call voice is recognized, the
그리고, 인공지능서버(130)는 음성명령에 대응되는 명령데이터를 명령수행장치로 송신하는데, 음성명령 중에서 전자펜을 호출하는 전자펜호출명령을 인식하면 이에 대응되는 제1명령데이터를 인공지능스피커(110)로 송신할 수 있다.Then, the
인공지능스피커(110)는 제1명령데이터를 수신하면 무선연결신호를 탐색하여 전자펜(120)과 무선연결하고 전자펜서비스상태로 진입할 수 있다.When receiving the first command data, the
그리고, 인공지능스피커(110)는 전자펜서비스상태에서 전자펜(120)으로부터 좌표코드를 수신하고 좌표코드를 텍스트서버(940)로 송신할 수 있다.Then, the
전자펜(120)는 다수의 좌표코드를 연속하여 인공지능스피커(110)로 송신할 수 있고, 인공지능스피커(110)는 다수의 좌표코드를 텍스트서버(940)로 송신할 수 있다.The
텍스트서버(940)는 복수의 좌표코드를 수신하고, 복수의 좌표코드를 조합하여 텍스트를 생성할 수 있다. 그리고, 텍스트서버(940)는 텍스트를 변환한 음성데이터 및/또는 텍스트에 대응되는 영상데이터를 인공지능스피커(110)로 송신하고, 인공지능스피커(110)는 내장스피커를 이용하여 음성데이터를 출력할 수 있고, 텍스트를 미리 선택된 다른 서버로 송신할 수 있다.The
여기서, 다른 서버는 날짜 혹은 시간별로 메모를 기록하고, 전자펜(120) 혹은 인공지능스피커(110)의 고유번호에 대응되는 저장공간에 텍스트를 날짜 혹은 시간별로 저장할 수 있다.Here, another server may record the memo by date or time, and store the text by date or time in a storage space corresponding to a unique number of the
도 10은 다른 실시예에 따른 전자펜 시스템에 적용될 수 있는 인쇄물을 나타내는 도면이다.10 is a view showing a printed material that can be applied to the electronic pen system according to another embodiment.
도 10을 참조하면, 인쇄물에는 시각적으로 인식될 수 있는 크기의 격자들이 인쇄되고, 시각적으로 인식될 수 없는 크기의 패턴이미지가 위치별로 서로 다른 패턴으로 인쇄될 수 있다.Referring to FIG. 10, grids having a size visually recognizable are printed on a printed material, and pattern images having a size not visually recognizable may be printed in different patterns for each location.
전자펜(120)에는 잉크와 같은 쓰기 수단이 포함되어 있고, 사용자가 전자펜(120)을 인쇄물(920)에 접촉할 때, 인쇄물(920)에 잉크와 같은 쓰기 수단이 뭍어 나올 수 있다.The
사용자는 이러한 전자펜(120)의 쓰기 수단을 이용하여 인쇄물(920)에 글씨 혹은 그림을 그릴 수 있다. 전자펜(120)은 인쇄물(920)에 잉크와 같은 쓰기 수단을 뭍이면서 동시에 같은 위치를 OID모듈을 이용하여 촬영할 수 있다. 그리고, 전자펜(120)은 그 촬영된 패턴이미지에 대응되는 좌표코드를 인공지능스피커를 경유하여 텍스트서버로 송신할 수 있다. 그러면, 텍스트서버는 인쇄물(920)에 그려진 글씨 혹은 그림에 대응되는 좌표코드들을 수신할 수 있고, 사용자가 의도한 글씨를 텍스트로 변환할 수 있다.The user may draw letters or pictures on the printed
인쇄물(920)에는 별도의 고유번호가 있는데, 전술한 다른 서버는 이러한 고유번호에 대응되는 저장공간에 인식된 글씨 혹은 그림을 저장할 수 있다.The
이상에서 설명한 바와 같이 본 실시예에 의하면, 인공지능스피커와 전자펜이 연동됨으로써, 종래에 비해 획기적으로 개선된 사용자 편의성을 가지는 입력장치를 제공할 수 있다.As described above, according to the present exemplary embodiment, the artificial intelligence speaker and the electronic pen are interlocked, thereby providing an input device having significantly improved user convenience compared to the prior art.
이상에서 기재된 "포함하다", "구성하다" 또는 "가지다" 등의 용어는, 특별히 반대되는 기재가 없는 한, 해당 구성 요소가 내재될 수 있음을 의미하는 것이므로, 다른 구성 요소를 제외하는 것이 아니라 다른 구성 요소를 더 포함할 수 있는 것으로 해석되어야 한다. 기술적이거나 과학적인 용어를 포함한 모든 용어들은, 다르게 정의되지 않는 한, 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자에 의해 일반적으로 이해되는 것과 동일한 의미를 가진다. 사전에 정의된 용어와 같이 일반적으로 사용되는 용어들은 관련 기술의 문맥 상의 의미와 일치하는 것으로 해석되어야 하며, 본 발명에서 명백하게 정의하지 않는 한, 이상적이거나 과도하게 형식적인 의미로 해석되지 않는다.The terms "comprises", "composes" or "haves" as described above mean that the corresponding components can be inherent unless otherwise stated, and do not exclude other components. It should be interpreted that it may further include other components. All terms, including technical or scientific terms, unless otherwise defined, have the same meaning as commonly understood by a person skilled in the art to which the present invention pertains. Commonly used terms, such as predefined terms, should be interpreted as being consistent with the meaning in the context of the related art, and are not to be interpreted as ideal or excessively formal meanings unless explicitly defined in the present invention.
이상의 설명은 본 발명의 기술 사상을 예시적으로 설명한 것에 불과한 것으로서, 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자라면 본 발명의 본질적인 특성에서 벗어나지 않는 범위에서 다양한 수정 및 변형이 가능할 것이다. 따라서, 본 발명에 개시된 실시예들은 본 발명의 기술 사상을 한정하기 위한 것이 아니라 설명하기 위한 것이고, 이러한 실시예에 의하여 본 발명의 기술 사상의 범위가 한정되는 것은 아니다. 본 발명의 보호 범위는 아래의 청구범위에 의하여 해석되어야 하며, 그와 동등한 범위 내에 있는 모든 기술 사상은 본 발명의 권리범위에 포함되는 것으로 해석되어야 할 것이다.The above description is merely illustrative of the technical idea of the present invention, and those skilled in the art to which the present invention pertains may make various modifications and variations without departing from the essential characteristics of the present invention. Therefore, the embodiments disclosed in the present invention are not intended to limit the technical spirit of the present invention, but to explain, and the scope of the technical spirit of the present invention is not limited by these embodiments. The scope of protection of the present invention should be interpreted by the claims below, and all technical spirits within the scope equivalent thereto should be interpreted as being included in the scope of the present invention.
Claims (10)
컨텐츠코드를 수신하고, 상기 컨텐츠코드에 대응되는 컨텐츠데이터를 컨텐츠출력장치로 송신하는 컨텐츠서버;
호출음성이 인식되면 명령대기상태로 진입하고, 상기 명령대기상태에서 인식되는 음성을 상기 제1음성데이터로 변환하여 상기 인공지능서버로 송신하는 인공지능스피커; 및
인쇄물에 시각적으로 인식되지 않는 크기로 인쇄된 패턴이미지를 촬영하고, 상기 패턴이미지에 대응되는 코드를 생성하며, 상기 코드 중 상기 컨텐츠코드를 상기 인공지능스피커를 경유하여 상기 컨텐츠서버로 송신하는 전자펜을 포함하고,
상기 인공지능서버는,
상기 음성명령 중 상기 전자펜을 호출하는 전자펜호출명령에 대응되는 제1명령데이터를 상기 인공지능스피커로 송신하고,
상기 인공지능스피커는,
상기 제1명령데이터를 수신하면 무선연결신호를 탐색하여 상기 전자펜과 무선연결하고 전자펜서비스상태로 진입하며, 상기 전자펜서비스상태에서 상기 컨텐츠코드를 상기 컨텐츠서버로 송신하고 상기 컨텐츠서버로부터 수신되는 상기 컨텐츠데이터 중 음성컨텐츠데이터를 내장스피커를 통해 출력하는 전자펜 시스템.An artificial intelligence server that analyzes first voice data, recognizes voice commands included in the first voice data, and transmits command data corresponding to the voice commands to a command execution device;
A content server that receives a content code and transmits content data corresponding to the content code to a content output device;
An artificial intelligence speaker that enters a command waiting state when the call voice is recognized, and converts the speech recognized in the command waiting state into the first voice data and transmits the voice to the artificial intelligence server; And
An electronic pen that shoots a pattern image printed in a size that is not visually recognized on a print, generates a code corresponding to the pattern image, and transmits the content code among the codes to the content server via the artificial intelligence speaker. Including,
The artificial intelligence server,
The first command data corresponding to the electronic pen call command that calls the electronic pen among the voice commands is transmitted to the artificial intelligence speaker,
The artificial intelligence speaker,
Upon receiving the first command data, the wireless connection signal is searched for wireless connection with the electronic pen, the electronic pen service state is entered, and the content code is transmitted from the electronic pen service state to the content server and received from the content server. An electronic pen system that outputs voice content data from the contents data through a built-in speaker.
상기 인공지능스피커는,
TV(television)서비스상태에서 TV데이터를 수신하고 상기 TV데이터를 TV장치를 통해 출력하며, 상기 전자펜서비스상태에서 상기 컨텐츠데이터 중 영상컨텐츠데이터를 상기 TV장치를 통해 출력하는 전자펜 시스템.According to claim 1,
The artificial intelligence speaker,
An electronic pen system that receives TV data in a TV (television) service state, outputs the TV data through a TV device, and outputs video content data among the content data in the electronic pen service state through the TV device.
상기 인공지능스피커는,
무선연결된 상기 전자펜으로부터 제품식별데이터를 수신하고 상기 제품식별데이터에 대응되는 상기 전자펜의 외관이미지를 별도의 영상출력장치를 통해 표시하는 전자펜 시스템.According to claim 1,
The artificial intelligence speaker,
An electronic pen system that receives product identification data from the wirelessly connected electronic pen and displays an external image of the electronic pen corresponding to the product identification data through a separate image output device.
상기 전자펜은,
펜스피커를 내장하고, 상기 인공지능스피커와 무선연결되면 상기 펜스피커의 기능을 턴오프하는 전자펜 시스템.According to claim 1,
The electronic pen,
An electronic pen system incorporating a pen speaker and turning off the function of the pen speaker when wirelessly connected to the AI speaker.
상기 전자펜은,
복수의 조작버튼으로 구성되는 조작부를 포함하고, 상기 조작버튼에 대응되는 명령코드를 생성하여 상기 인공지능스피커로 송신하며,
상기 인공지능스피커는,
상기 명령코드에 대응되는 기능을 수행하여 음성의 출력이나 영상의 출력을 변경하는 전자펜 시스템.According to claim 1,
The electronic pen,
It includes an operation unit consisting of a plurality of operation buttons, generates a command code corresponding to the operation button and transmits it to the artificial intelligence speaker,
The artificial intelligence speaker,
An electronic pen system that changes a voice output or a video output by performing a function corresponding to the command code.
상기 컨텐츠서버는,
상기 인공지능스피커를 경유하여 상기 전자펜으로부터 수신되는 인터랙티브(interactive)코드에 대응되는 프로그램을 실행시키고, 상기 프로그램의 실행에 따른 영상출력데이터 및 음성출력데이터를 상기 인공지능스피커로 송신하며, 상기 전자펜으로부터 인공지능스피커를 경유하여 상기 전자펜으로부터 명령코드를 수신하여 상기 프로그램의 기능을 조작하는 전자펜 시스템.According to claim 1,
The content server,
The program corresponding to the interactive code received from the electronic pen is executed through the AI speaker, and image output data and audio output data according to the execution of the program are transmitted to the AI speaker, and the electronic An electronic pen system that receives a command code from the electronic pen via an artificial intelligence speaker from the pen and manipulates the functions of the program.
상기 전자펜은,
마이크로폰을 더 포함하고 상기 마이크로폰을 통해 생성되는 제2음성데이터를 상기 인공지능스피커를 경유하여 상기 인공지능서버로 송신하고,
상기 인공지능서버는,
상기 제2음성데이터를 텍스트데이터로 변환하여 상기 컨텐츠서버로 송신하고,
상기 컨텐츠서버는,
상기 텍스트데이터의 적합도를 판단하고 판단결과를 상기 인공지능스피커를 통해 출력하는 전자펜 시스템.According to claim 1,
The electronic pen,
It further includes a microphone and transmits the second voice data generated through the microphone to the AI server via the AI speaker,
The artificial intelligence server,
The second audio data is converted to text data and transmitted to the content server,
The content server,
An electronic pen system that determines the suitability of the text data and outputs the determination result through the artificial intelligence speaker.
상기 전자펜은,
상기 제2음성데이터를 송신하기 전에 상기 컨텐츠서버로 제1회화문에 대응되는 일 컨텐츠코드를 상기 컨텐츠서버로 송신하고,
상기 컨텐츠서버는,
상기 제1회화문의 대답으로서 미리 설정된 제2회화문과 상기 텍스트데이터의 유사도를 판단하여 상기 판단결과를 생성하는 전자펜 시스템.The method of claim 7,
The electronic pen,
Before transmitting the second voice data, one content code corresponding to the first conversation message is transmitted to the content server to the content server,
The content server,
An electronic pen system that determines the similarity between the second conversational text and the text data set in advance as an answer to the first conversational text to generate the determination result.
복수의 좌표코드를 수신하고, 상기 복수의 좌표코드를 조합하여 텍스트를 생성하고 상기 텍스트, 상기 텍스트를 변환한 음성데이터 및 상기 텍스트에 대응되는 영상데이터 중 적어도 하나를 송신하는 텍스트서버;
호출음성이 인식되면 명령대기상태로 진입하고, 상기 명령대기상태에서 인식되는 음성을 상기 제1음성데이터로 변환하여 상기 인공지능서버로 송신하는 인공지능스피커; 및
인쇄물에 시각적으로 인식되지 않는 크기로 인쇄된 패턴이미지를 촬영하고, 상기 패턴이미지에 대응되는 코드를 생성하며, 상기 코드 중 상기 좌표코드를 상기 인공지능스피커를 경유하여 상기 텍스트서버로 송신하는 전자펜을 포함하고,
상기 인공지능서버는,
상기 음성명령 중 상기 전자펜을 호출하는 전자펜호출명령에 대응되는 제1명령데이터를 상기 인공지능스피커로 송신하고,
상기 인공지능스피커는,
상기 제1명령데이터를 수신하면 무선연결신호를 탐색하여 상기 전자펜과 무선연결하고 전자펜서비스상태로 진입하며, 상기 전자펜서비스상태에서 상기 좌표코드를 상기 텍스트서버로 송신하고 상기 텍스트를 변환한 음성데이터를 내장스피커를 통해 출력하거나 상기 텍스트를 미리 선택된 다른 서버로 송신하는 전자펜 시스템.An artificial intelligence server that analyzes first voice data, recognizes voice commands included in the first voice data, and transmits command data corresponding to the voice commands to a command execution device;
A text server that receives a plurality of coordinate codes, generates text by combining the plurality of coordinate codes, and transmits at least one of the text, voice data converted from the text, and image data corresponding to the text;
An artificial intelligence speaker that enters a command waiting state when the call voice is recognized, and converts the voice recognized in the command waiting state into the first voice data and transmits the voice to the artificial intelligence server; And
An electronic pen that shoots a pattern image printed at a size that is not visually recognized on a print, generates a code corresponding to the pattern image, and transmits the coordinate code among the codes to the text server via the artificial intelligence speaker. Including,
The artificial intelligence server,
The first command data corresponding to the electronic pen call command that calls the electronic pen among the voice commands is transmitted to the artificial intelligence speaker,
The artificial intelligence speaker,
Upon receiving the first command data, the wireless connection signal is searched, wirelessly connected to the electronic pen, and entered into the electronic pen service state. In the electronic pen service state, the coordinate code is transmitted to the text server and the text is converted. An electronic pen system that outputs voice data through a built-in speaker or transmits the text to another preselected server.
상기 다른 서버는,
날짜별로 메모를 기록하고, 상기 전자펜의 고유번호에 대응되는 저장공간에 상기 텍스트를 날짜별로 저장하는 전자펜 시스템.The method of claim 9,
The other server,
An electronic pen system that records a memo by date and stores the text by date in a storage space corresponding to a unique number of the electronic pen.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020180108804A KR102156054B1 (en) | 2018-09-12 | 2018-09-12 | Electronic pen system interlocked with artificial intelligent speaker |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020180108804A KR102156054B1 (en) | 2018-09-12 | 2018-09-12 | Electronic pen system interlocked with artificial intelligent speaker |
Related Child Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020200055761A Division KR102156055B1 (en) | 2020-05-11 | 2020-05-11 | Electronic pen system for controlling interactive program in conjunction with artificial intelligent speaker |
| KR1020200055763A Division KR102164774B1 (en) | 2020-05-11 | 2020-05-11 | Electronic pen system for controlling function of artificial intelligent speaker |
| KR1020200055762A Division KR102164773B1 (en) | 2020-05-11 | 2020-05-11 | Electronic pen system interlocked with artificial intelligent speaker with microphone |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20200030228A true KR20200030228A (en) | 2020-03-20 |
| KR102156054B1 KR102156054B1 (en) | 2020-09-15 |
Family
ID=69958273
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020180108804A KR102156054B1 (en) | 2018-09-12 | 2018-09-12 | Electronic pen system interlocked with artificial intelligent speaker |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102156054B1 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20220358920A1 (en) * | 2019-07-19 | 2022-11-10 | Lg Electronics Inc. | Display device and artificial intelligence server which can control home appliance through user voice |
| CN116736994A (en) * | 2023-06-12 | 2023-09-12 | 星景科技有限公司 | Tool pen based on artificial intelligent interaction and operation method |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9619200B2 (en) * | 2012-05-29 | 2017-04-11 | Samsung Electronics Co., Ltd. | Method and apparatus for executing voice command in electronic device |
| KR20170129045A (en) * | 2017-03-31 | 2017-11-24 | 김철회 | Electronic pen for contents streaming service, system and method for providing contents streaming service using the electronic pen |
| KR20180008107A (en) * | 2016-07-15 | 2018-01-24 | 김철회 | Electronic pen for electronic data streaming service, system and method for electronic data streaming output using the electronic pen |
| KR20180017548A (en) * | 2016-08-10 | 2018-02-21 | 김철회 | Electronic pen and user authentication method of the electronic pen |
-
2018
- 2018-09-12 KR KR1020180108804A patent/KR102156054B1/en active IP Right Grant
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9619200B2 (en) * | 2012-05-29 | 2017-04-11 | Samsung Electronics Co., Ltd. | Method and apparatus for executing voice command in electronic device |
| KR20180008107A (en) * | 2016-07-15 | 2018-01-24 | 김철회 | Electronic pen for electronic data streaming service, system and method for electronic data streaming output using the electronic pen |
| KR20180017548A (en) * | 2016-08-10 | 2018-02-21 | 김철회 | Electronic pen and user authentication method of the electronic pen |
| KR20170129045A (en) * | 2017-03-31 | 2017-11-24 | 김철회 | Electronic pen for contents streaming service, system and method for providing contents streaming service using the electronic pen |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20220358920A1 (en) * | 2019-07-19 | 2022-11-10 | Lg Electronics Inc. | Display device and artificial intelligence server which can control home appliance through user voice |
| CN116736994A (en) * | 2023-06-12 | 2023-09-12 | 星景科技有限公司 | Tool pen based on artificial intelligent interaction and operation method |
Also Published As
| Publication number | Publication date |
|---|---|
| KR102156054B1 (en) | 2020-09-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8873722B2 (en) | Cradle for mobile telephone, videophone system, karaoke system, car navigation system, and emergency information notification system | |
| TW442772B (en) | Voice control input for portable capture devices | |
| CN108847214B (en) | Voice processing method, client, device, terminal, server and storage medium | |
| US20100268929A1 (en) | Electronic device and setting method thereof | |
| CN114464180A (en) | Intelligent device and intelligent voice interaction method | |
| JP7119615B2 (en) | Server, sound data evaluation method, program, communication system | |
| KR102156054B1 (en) | Electronic pen system interlocked with artificial intelligent speaker | |
| JP4268667B2 (en) | Audio information recording device | |
| CN107945806A (en) | User identification method and device based on sound characteristic | |
| US11978252B2 (en) | Communication system, display apparatus, and display control method | |
| KR102164773B1 (en) | Electronic pen system interlocked with artificial intelligent speaker with microphone | |
| KR102164774B1 (en) | Electronic pen system for controlling function of artificial intelligent speaker | |
| KR102156055B1 (en) | Electronic pen system for controlling interactive program in conjunction with artificial intelligent speaker | |
| JP2023131635A (en) | Display system, display method, imaging apparatus, and program | |
| KR20200056962A (en) | Electronic pen system for controlling tv in conjunction with artificial intelligence speaker | |
| KR20200056754A (en) | Apparatus and method for generating personalization lip reading model | |
| TWI771858B (en) | Smart language learning method and system thereof combining image recognition and speech recognition | |
| KR102112931B1 (en) | System for tv control | |
| CN114373464A (en) | Text display method and device, electronic equipment and storage medium | |
| US20230280961A1 (en) | Device management system, information processing system, information processing device, device management method, and non-transitory recording medium | |
| KR20200053748A (en) | Closed Interactive Multimedia Content Play Learning System Using Electronic Pen and Artificial Intelligent Speaker | |
| KR101318949B1 (en) | Pattern recognition unit, multimedia apparatus with pattern recognition and method for driving the same | |
| CN106601044A (en) | Click and learn method of click and learn device realized through utilizing wireless technology to transmit signal to electronic equipment | |
| CN107948696A (en) | A kind of set-top box text entry method, system and set-top box | |
| JP2017016484A (en) | Communication system, recording apparatus, terminal device, program, and information processing method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal | ||
| A107 | Divisional application of patent | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant |