KR20200028856A - 인트라 예측을 이용한 영상 부호화/복호화 방법 및 장치 - Google Patents
인트라 예측을 이용한 영상 부호화/복호화 방법 및 장치 Download PDFInfo
- Publication number
- KR20200028856A KR20200028856A KR1020190110217A KR20190110217A KR20200028856A KR 20200028856 A KR20200028856 A KR 20200028856A KR 1020190110217 A KR1020190110217 A KR 1020190110217A KR 20190110217 A KR20190110217 A KR 20190110217A KR 20200028856 A KR20200028856 A KR 20200028856A
- Authority
- KR
- South Korea
- Prior art keywords
- block
- sample
- current block
- prediction
- intra prediction
- Prior art date
Links
Images







Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/124—Quantisation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/103—Selection of coding mode or of prediction mode
- H04N19/105—Selection of the reference unit for prediction within a chosen coding or prediction mode, e.g. adaptive choice of position and number of pixels used for prediction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/119—Adaptive subdivision aspects, e.g. subdivision of a picture into rectangular or non-rectangular coding blocks
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/12—Selection from among a plurality of transforms or standards, e.g. selection between discrete cosine transform [DCT] and sub-band transform or selection between H.263 and H.264
- H04N19/122—Selection of transform size, e.g. 8x8 or 2x4x8 DCT; Selection of sub-band transforms of varying structure or type
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/102—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or selection affected or controlled by the adaptive coding
- H04N19/132—Sampling, masking or truncation of coding units, e.g. adaptive resampling, frame skipping, frame interpolation or high-frequency transform coefficient masking
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/134—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the element, parameter or criterion affecting or controlling the adaptive coding
- H04N19/157—Assigned coding mode, i.e. the coding mode being predefined or preselected to be further used for selection of another element or parameter
- H04N19/159—Prediction type, e.g. intra-frame, inter-frame or bidirectional frame prediction
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/10—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding
- H04N19/169—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding
- H04N19/17—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object
- H04N19/176—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using adaptive coding characterised by the coding unit, i.e. the structural portion or semantic portion of the video signal being the object or the subject of the adaptive coding the unit being an image region, e.g. an object the region being a block, e.g. a macroblock
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/593—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding involving spatial prediction techniques
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/90—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using coding techniques not provided for in groups H04N19/10-H04N19/85, e.g. fractals
- H04N19/96—Tree coding, e.g. quad-tree coding
Abstract
본 발명에 따른 비디오 신호 처리 방법 및 장치는, 현재 블록의 인트라 예측 모드를 결정하고, 상기 현재 블록의 인트라 예측을 위한 참조 샘플을 결정하며, 상기 인트라 예측 모드를 기반으로, 소정의 매트릭스를 결정하고, 상기 참조 샘플 및 매트릭스를 기반으로, 상기 현재 블록을 예측할 수 있다.
Description
본 발명은 영상 부호화/복호화 방법 및 장치에 관한 것이다.
인터넷과 휴대 단말의 보급과 정보 통신 기술의 발전에 따라 멀티미디어 데이터에 대한 이용이 급증하고 있다. 따라서, 각종 시스템에서 영상 예측을 통해 다양한 서비스나 작업을 수행하기 위하여 영상 처리 시스템의 성능 및 효율 개선에 대한 필요성이 상당히 증가하고 있으나, 이러한 분위기에 호응할 수 있는 연구 개발 결과가 미흡한 실정이다.
이와 같이, 종래 기술의 영상 부호화 복호화 방법 및 장치에서는 영상 처리 특히 영상 부호화 또는 영상 복호화에 대한 성능 개선이 요구되고 있는 실정이다.
본 발명은, 적응적인 블록 분할을 통해서 부호화/복호화 효율을 향상시키고자 한다.
본 발명은, 매트릭스 기반 인트라 예측을 통해서 부호화/복호화 효율을 향상시키고자 한다.
본 발명은, 매트릭스 기반 인트라 예측을 위한 참조 샘플 및 매트릭스를 결정하는 방법 및 장치를 제공한다.
본 발명은, 매트릭스 기반 인트라 예측을 위한 다운샘플링 및 업샘플링의 방법 및 장치를 제공한다.
본 발명에 따른 비디오 신호 처리 방법 및 장치는, 현재 블록의 인트라 예측 모드를 결정하고, 상기 현재 블록의 인트라 예측을 위한 참조 샘플을 결정하며, 상기 인트라 예측 모드를 기반으로, 소정의 매트릭스를 결정하고, 상기 참조 샘플 및 매트릭스를 기반으로, 상기 현재 블록을 예측할 수 있다.
본 발명에 따른 비디오 신호 처리 방법 및 장치에 있어서, 상기 참조 샘플을 결정하는 단계는, 상기 현재 블록의 주변 영역을 결정하는 단계 및 상기 결정된 주변 영역을 다운샘플링하는 단계를 포함할 수 있다.
본 발명에 따른 비디오 신호 처리 방법 및 장치에 있어서, 상기 주변 영역은 복수의 샘플 그룹으로 구분되고, 상기 샘플 그룹은 하나 또는 그 이상의 샘플로 구성되며, 상기 샘플 그룹의 대표값이 상기 참조 샘플로 결정되고, 상기 대표값은 평균값, 최소값, 최대값, 최빈값, 또는 중간값 중 어느 하나일 수 있다.
본 발명에 따른 비디오 신호 처리 방법 및 장치에 있어서, 상기 매트릭스는, 상기 현재 블록의 부호화 정보를 더 고려하여 결정되고, 상기 부호화 정보는, 상기 현재 블록의 크기, 형태, 인트라 예측 모드의 각도 또는 방향성을 포함할 수 있다.
본 발명에 따른 비디오 신호 처리 방법 및 장치에 있어서, 상기 현재 블록을 예측하는 단계는, 상기 참조 샘플에 상기 매트릭스를 적용하여 예측 블록을 생성하는 단계를 포함할 수 있다.
본 발명에 따른 비디오 신호 처리 방법 및 장치에 있어서, 상기 현재 블록을 예측하는 단계는, 상기 생성된 예측 블록의 예측 샘플 전부 또는 일부를 재배열하는 단계를 더 포함할 수 있다.
본 발명에 따른 비디오 신호 처리 방법 및 장치에 있어서, 상기 현재 블록을 예측하는 단계는, 상기 예측 블록 또는 상기 현재 블록에 인접한 기-복원된 샘플 중 적어도 하나를 기반으로, 상기 현재 블록을 보간하는 단계를 더 포함할 수 있다.
본 발명에 따르면, 트리구조의 블록 분할을 통해 부호화/복호화 효율을 향상시킬 수 있다.
본 발명에 따르면, 매트릭스 기반 인트라 예측을 통해 부호화/복호화 효율을 향상시킬 수 있다.
본 발명에 따르면, 매트릭스 기반 인트라 예측을 위한 다운샘플링 또는 업샘플링을 통해 부호화/복호화 효율을 향상시킬 수 있다.
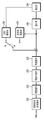
도 1은 본 발명의 일실시예로서, 부호화 장치의 개략적인 블록도를 도시한 것이다.
도 2는 본 발명의 일실시예로서, 복호화 장치의 개략적인 블록도를 도시한 것이다.
도 3은 본 발명이 적용되는 일실시예로서, 블록 분할 타입을 도시한 것이다.
도 4는 본 발명이 적용되는 일실시예로서, 트리 구조 기반의 블록 분할 방법을 도시한 것이다.
도 5는 본 발명의 일실시예로서, 매트릭스 기반으로 현재 블록에 대한 인트라 예측을 하는 과정을 도시한 것이다.
도 6은 본 발명이 적용되는 일실시예로서, 주변 영역을 다운샘플링하여 참조 샘플을 결정하는 방법을 도시한 것이다.
도 7은 본 발명이 적용되는 일실시예로서, 가중 평균에 기반한 다운샘플링 방법을 도시한다.
도 8은 본 발명이 적용되는 일실시예로서, 제1 예측 샘플의 할당 및 나머지 영역에 대한 보간 방법을 도시한 것이다.
도 9는 본 발명이 적용되는 일실시예로서, 보간 단계에서 거리에 대한 가중치를 부여하는 것을 도시한 것이다.
도 10은 본 발명이 적용되는 일실시예로서, 보간 단계의 순서를 도시한 것이다.
도 2는 본 발명의 일실시예로서, 복호화 장치의 개략적인 블록도를 도시한 것이다.
도 3은 본 발명이 적용되는 일실시예로서, 블록 분할 타입을 도시한 것이다.
도 4는 본 발명이 적용되는 일실시예로서, 트리 구조 기반의 블록 분할 방법을 도시한 것이다.
도 5는 본 발명의 일실시예로서, 매트릭스 기반으로 현재 블록에 대한 인트라 예측을 하는 과정을 도시한 것이다.
도 6은 본 발명이 적용되는 일실시예로서, 주변 영역을 다운샘플링하여 참조 샘플을 결정하는 방법을 도시한 것이다.
도 7은 본 발명이 적용되는 일실시예로서, 가중 평균에 기반한 다운샘플링 방법을 도시한다.
도 8은 본 발명이 적용되는 일실시예로서, 제1 예측 샘플의 할당 및 나머지 영역에 대한 보간 방법을 도시한 것이다.
도 9는 본 발명이 적용되는 일실시예로서, 보간 단계에서 거리에 대한 가중치를 부여하는 것을 도시한 것이다.
도 10은 본 발명이 적용되는 일실시예로서, 보간 단계의 순서를 도시한 것이다.
본 발명은 다양한 변경을 가할 수 있고 여러 가지 실시예를 가질 수 있는 바, 특정 실시예들을 도면에 예시하고 상세한 설명에 상세하게 설명하고자 한다. 그러나, 이는 본 발명을 특정한 실시 형태에 대해 한정하려는 것이 아니며, 본 발명의 사상 및 기술 범위에 포함되는 모든 변경, 균등물 내지 대체물을 포함하는 것으로 이해되어야 한다. 각 도면을 설명하면서 유사한 참조부호를 유사한 구성요소에 대해 사용하였다.
제1, 제2 등의 용어는 다양한 구성요소들을 설명하는데 사용될 수 있지만, 상기 구성요소들은 상기 용어들에 의해 한정되어서는 안 된다. 상기 용어들은 하나의 구성요소를 다른 구성요소로부터 구별하는 목적으로만 사용된다. 예를 들어, 본 발명의 권리 범위를 벗어나지 않으면서 제1 구성요소는 제2 구성요소로 명명될 수 있고, 유사하게 제2 구성요소도 제1 구성요소로 명명될 수 있다. 및/또는 이라는 용어는 복수의 관련된 기재된 항목들의 조합 또는 복수의 관련된 기재된 항목들 중의 어느 항목을 포함한다.
어떤 구성요소가 다른 구성요소에 "연결되어" 있다거나 "접속되어"있다고 언급된 때에는, 그 다른 구성요소에 직접적으로 연결되어 있거나 또는 접속되어 있을 수도 있지만, 중간에 다른 구성요소가 존재할 수도 있다고 이해되어야 할 것이다. 반면에, 어떤 구성요소가 다른 구성요소에 "직접 연결되어"있다거나 "직접 접속되어"있다고 언급된 때에는, 중간에 다른 구성요소가 존재하지 않는 것으로 이해되어야 할 것이다.
본 출원에서 사용한 용어는 단지 특정한 실시예를 설명하기 위해 사용된 것으로, 본 발명을 한정하려는 의도가 아니다. 단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수의 표현을 포함한다. 본 출원에서, "포함하다" 또는 "가지다" 등의 용어는 명세서상에 기재된 특징, 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것이 존재함을 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다.
다르게 정의되지 않는 한, 기술적이거나 과학적인 용어를 포함해서 여기서 사용되는 모든 용어들은 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자에 의해 일반적으로 이해되는 것과 동일한 것을 의미한다. 일반적으로 사용되는 사전에 정의되어 있는 것과 같은 용어들은 관련 기술의 문맥상 가지는 의미와 일치하는 것으로 해석되어야 하며, 본 출원에서 명백하게 정의하지 않는 한, 이상적이거나 과도하게 형식적인 의미로 해석되지 않는다.
이하, 첨부한 도면들을 참조하여, 본 발명의 바람직한 실시예를 보다 상세하게 설명하고자 한다. 이하, 도면상의 동일한 구성요소에 대해서는 동일한 참조부호를 사용하고 동일한 구성요소에 대해서 중복된 설명은 생략한다.
도 1은 본 발명의 일실시예로서, 부호화 장치의 개략적인 블록도를 도시한 것이다.
도 1을 참조하면, 부호화 장치(100)는 픽쳐 분할부(110), 예측부(120, 125), 변환부(130), 양자화부(135), 재정렬부(160), 엔트로피 부호화부(165), 역양자화부(140), 역변환부(145), 필터부(150) 및 메모리(155)를 포함할 수 있다.
도 1에 나타난 각 구성부들은 영상 부호화 장치에서 서로 다른 특징적인 기능들을 나타내기 위해 독립적으로 도시한 것으로, 각 구성부들이 분리된 하드웨어로 이루어짐을 의미할 수 있다. 다만, 각 구성부는 설명의 편의상 각각의 구성부로 나열하여 포함한 것으로, 각 구성부 중 적어도 두 개의 구성부가 합쳐져 하나의 구성부로 이루어지거나, 하나의 구성부가 복수개의 구성부로 나뉘어져 기능을 수행할 수 있고, 이러한 각 구성부의 통합된 실시예 및 분리된 실시예도 본 발명의 본질에서 벗어나지 않는 한 본 발명의 권리범위에 포함된다.
또한, 일부의 구성 요소는 본 발명에서 본질적인 기능을 수행하는 필수적인 구성 요소는 아니고 단지 성능을 향상시키기 위한 선택적 구성 요소일 수 있다. 본 발명은 단지 성능 향상을 위해 사용되는 구성 요소를 제외한 본 발명의 본질을 구현하는데 필수적인 구성부만을 포함하여 구현될 수 있고, 단지 성능 향상을 위해 사용되는 선택적 구성 요소를 제외한 필수 구성 요소만을 포함한 구조도 본 발명의 권리범위에 포함된다.
픽쳐 분할부(110)는 입력된 픽쳐를 적어도 하나의 블록으로 분할할 수 있다. 이때, 블록은 부호화 단위(CU), 예측 단위(PU) 또는 변환 단위(TU)를 의미할 수 있다. 상기 분할은 쿼드 트리(Quadtree), 바이너리 트리(Biniary tree), 터너리 트리(Ternary tree) 중 적어도 하나에 기반하여 수행될 수 있다. 쿼드 트리는 상위 블록을 너비와 높이가 상위 블록의 절반인 하위 블록으로 사분할하는 방식이다. 바이너리 트리는 상위 블록을 너비 또는 높이 중 어느 하나가 상위 블록의 절반인 하위 블록으로 이분할하는 방식이다. 바이너리 트리에서는 상위 블록이 높이가 절반이 전술한 바이너리 트리 기반의 분할을 통해, 블록은 정방형뿐만 아니라 비정방형의 형태를 가질 수 있다.
이하, 본 발명의 실시예에서는 부호화 단위는 부호화를 수행하는 단위의 의미로 사용할 수도 있고, 복호화를 수행하는 단위의 의미로 사용할 수도 있다.
예측부(120, 125)는 인터 예측을 수행하는 인터 예측부(120)와 인트라 예측을 수행하는 인트라 예측부(125)를 포함할 수 있다. 예측 단위에 대해 인터 예측을 사용할 것인지 또는 인트라 예측을 수행할 것인지를 결정하고, 각 예측 방법에 따른 구체적인 정보(예컨대, 인트라 예측 모드, 움직임 벡터, 참조 픽쳐 등)를 결정할 수 있다. 이때, 예측이 수행되는 처리 단위와 예측 방법 및 구체적인 내용이 정해지는 처리 단위는 다를 수 있다. 예컨대, 예측의 방법과 예측 모드 등은 예측 단위로 결정되고, 예측의 수행은 변환 단위로 수행될 수도 있다. 생성된 예측 블록과 원본 블록 사이의 잔차값(잔차 블록)은 변환부(130)로 입력될 수 있다. 또한, 예측을 위해 사용한 예측 모드 정보, 움직임 벡터 정보 등은 잔차값과 함께 엔트로피 부호화부(165)에서 부호화되어 복호화 장치에 전달될 수 있다. 특정한 부호화 모드를 사용할 경우, 예측부(120, 125)를 통해 예측 블록을 생성하지 않고, 원본 블록을 그대로 부호화하여 복호화부에 전송하는 것도 가능하다.
인터 예측부(120)는 현재 픽쳐의 이전 픽쳐 또는 이후 픽쳐 중 적어도 하나의 픽쳐의 정보를 기초로 예측 단위를 예측할 수도 있고, 경우에 따라서는 현재 픽쳐 내의 부호화가 완료된 일부 영역의 정보를 기초로 예측 단위를 예측할 수도 있다. 인터 예측부(120)는 참조 픽쳐 보간부, 움직임 예측부, 움직임 보상부를 포함할 수 있다.
참조 픽쳐 보간부에서는 메모리(155)로부터 참조 픽쳐 정보를 제공받고 참조 픽쳐에서 정수 화소 이하의 화소 정보를 생성할 수 있다. 휘도 화소의 경우, 1/4 화소 단위로 정수 화소 이하의 화소 정보를 생성하기 위해 필터 계수를 달리하는 DCT 기반의 8탭 보간 필터(DCT-based Interpolation Filter)가 사용될 수 있다. 색차 신호의 경우 1/8 화소 단위로 정수 화소 이하의 화소 정보를 생성하기 위해 필터 계수를 달리하는 DCT 기반의 4탭 보간 필터(DCT-based Interpolation Filter)가 사용될 수 있다.
움직임 예측부는 참조 픽쳐 보간부에 의해 보간된 참조 픽쳐를 기초로 움직임 예측을 수행할 수 있다. 움직임 벡터를 산출하기 위한 방법으로 FBMA(Full search-based Block Matching Algorithm), TSS(Three Step Search), NTS(New Three-Step Search Algorithm) 등 다양한 방법이 사용될 수 있다. 움직임 벡터는 보간된 화소를 기초로 1/2 또는 1/4 화소 단위의 움직임 벡터값을 가질 수 있다. 움직임 예측부에서는 움직임 예측 방법을 다르게 하여 현재 예측 단위를 예측할 수 있다. 움직임 예측 방법으로 스킵(Skip) 방법, 머지(Merge) 방법, AMVP(Advanced Motion Vector Prediction) 방법 등 다양한 방법이 사용될 수 있다.
인트라 예측부(125)는 현재 픽쳐 내의 화소 정보인 현재 블록 주변의 참조 화소 정보를 기초로 예측 단위를 생성할 수 있다. 현재 예측 단위의 주변 블록이 인터 예측을 수행한 블록이어서, 참조 화소가 인터 예측을 수행한 화소일 경우, 인터 예측을 수행한 블록에 포함되는 참조 화소를 주변의 인트라 예측을 수행한 블록의 참조 화소 정보로 대체하여 사용할 수 있다. 즉, 참조 화소가 가용하지 않는 경우, 가용하지 않은 참조 화소 정보를 가용한 참조 화소 중 적어도 하나의 참조 화소로 대체하여 사용할 수 있다.
인트라 예측에서 예측 모드는 참조 화소 정보를 예측 방향에 따라 사용하는 방향성 예측 모드와 예측을 수행시 방향성 정보를 사용하지 않는 비방향성 모드를 가질 수 있다. 휘도 성분을 예측하기 위한 모드와 색차 성분을 예측하기 위한 모드가 상이할 수 있고, 휘도 성분을 예측하기 위해 사용된 인트라 예측 모드 또는 예측/복원된 휘도 성분을 이용하여 색차 성분을 예측할 수 있다.
인트라 예측 방법은 인트라 예측 모드에 따라 참조 화소에 AIS(Adaptive Intra Smoothing) 필터를 적용한 후 예측 블록을 생성할 수 있다. 참조 화소에 적용되는 AIS 필터의 종류는 상이할 수 있다. 인트라 예측 방법을 수행하기 위해 현재 예측 단위의 인트라 예측 모드는 현재 예측 단위의 주변에 존재하는 예측 단위의 인트라 예측 모드로부터 예측할 수 있다. 주변 예측 단위로부터 예측된 모드 정보를 이용하여 현재 예측 단위의 예측 모드를 예측하는 경우, 현재 예측 단위와 주변 예측 단위의 인트라 예측 모드가 동일하면 소정의 플래그 정보를 이용하여 현재 예측 단위와 주변 예측 단위의 인트라 예측 모드가 동일하다는 정보를 전송할 수 있고, 만약 현재 예측 단위와 주변 예측 단위의 인트라 예측 모드가 서로 상이하면 엔트로피 부호화를 수행하여 현재 블록의 인트라 예측 모드 정보를 부호화할 수 있다.
또한, 예측부(120, 125)에서 생성된 예측 단위와 원본 블록 간의 차이값인 잔차값(Residual) 정보를 포함하는 잔차 블록이 생성될 수 있다. 생성된 잔차 블록은 변환부(130)로 입력될 수 있다.
변환부(130)에서는 잔차 데이터를 포함한 잔차 블록을 DCT, DST 등과 같은 변환 타입을 사용하여 변환시킬 수 있다. 이때, 변환 타입은 잔차 블록을 생성하기 위해 사용된 예측 단위의 인트라 예측 모드에 기반하여 결정될 수 있다.
양자화부(135)는 변환부(130)에서 주파수 영역으로 변환된 값들을 양자화할 수 있다. 블록에 따라 또는 영상의 중요도에 따라 양자화 계수는 변할 수 있다. 양자화부(135)에서 산출된 값은 역양자화부(140)와 재정렬부(160)에 제공될 수 있다.
재정렬부(160)는 양자화된 잔차 블록에 대해 계수값의 재정렬을 수행할 수 있다. 재정렬부(160)는 계수 스캐닝(Coefficient Scanning) 방법을 통해 2차원의 블록 형태의 계수를 1차원의 벡터 형태로 변경할 수 있다. 예를 들어, 재정렬부(160)에서는 소정의 스캔 타입을 이용하여 DC 계수부터 고주파수 영역의 계수까지 스캔하여 1차원 벡터 형태로 변경시킬 수 있다.
엔트로피 부호화부(165)는 재정렬부(160)에 의해 산출된 값들을 기초로 엔트로피 부호화를 수행할 수 있다. 엔트로피 부호화는 예를 들어, 지수 골롬(Exponential Golomb), CAVLC(Context-Adaptive Variable Length Coding), CABAC(Context-Adaptive Binary Arithmetic Coding)과 같은 다양한 부호화 방법을 사용할 수 있다.
엔트로피 부호화부(165)는 재정렬부(160) 및 예측부(120, 125)로부터 부호화 단위의 잔차 계수 정보 및 블록 타입 정보, 예측 모드 정보, 분할 단위 정보, 예측 단위 정보 및 전송 단위 정보, 움직임 벡터 정보, 참조 프레임 정보, 블록의 보간 정보, 필터링 정보 등 다양한 정보를 부호화할 수 있다.
엔트로피 부호화부(165)에서는 재정렬부(160)에서 입력된 부호화 단위의 계수값을 엔트로피 부호화할 수 있다.
역양자화부(140) 및 역변환부(145)에서는 양자화부(135)에서 양자화된 값들을 역양자화하고 변환부(130)에서 변환된 값들을 역변환한다. 역양자화부(140) 및 역변환부(145)에서 생성된 잔차값(Residual)은 예측부(120, 125)에 포함된 움직임 추정부, 움직임 보상부 및 인트라 예측부를 통해서 예측된 예측 단위와 합쳐져 복원 블록(Reconstructed Block)을 생성할 수 있다.
필터부(150)는 디블록킹 필터, 오프셋 보정부, ALF(Adaptive Loop Filter)중 적어도 하나를 포함할 수 있다.
디블록킹 필터는 복원된 픽쳐에서 블록간의 경계로 인해 생긴 블록 왜곡을 제거할 수 있다. 디블록킹을 수행할지 여부를 판단하기 위해 블록에 포함된 몇 개의 열 또는 행에 포함된 화소를 기초로 현재 블록에 디블록킹 필터 적용할지 여부를 판단할 수 있다. 블록에 디블록킹 필터를 적용하는 경우 필요한 디블록킹 필터링 강도에 따라 강한 필터(Strong Filter) 또는 약한 필터(Weak Filter)를 적용할 수 있다. 또한 디블록킹 필터를 적용함에 있어 수직 필터링 및 수평 필터링 수행시 수평 방향 필터링 및 수직 방향 필터링이 병행 처리되도록 할 수 있다.
오프셋 보정부는 디블록킹을 수행한 영상에 대해 화소 단위로 원본 영상과의 오프셋을 보정할 수 있다. 특정 픽쳐에 대한 오프셋 보정을 수행하기 위해 영상에 포함된 화소를 일정한 수의 영역으로 구분한 후 오프셋을 수행할 영역을 결정하고 해당 영역에 오프셋을 적용하는 방법 또는 각 화소의 에지 정보를 고려하여 오프셋을 적용하는 방법을 사용할 수 있다.
ALF(Adaptive Loop Filtering)는 필터링한 복원 영상과 원래의 영상을 비교한 값을 기초로 수행될 수 있다. 영상에 포함된 화소를 소정의 그룹으로 나눈 후 해당 그룹에 적용될 하나의 필터를 결정하여 그룹마다 차별적으로 필터링을 수행할 수 있다. ALF를 적용할지 여부에 관련된 정보는 휘도 신호는 부호화 단위(Coding Unit, CU) 별로 전송될 수 있고, 각각의 블록에 따라 적용될 ALF 필터의 모양 및 필터 계수는 달라질 수 있다. 또한, 적용 대상 블록의 특성에 상관없이 동일한 형태(고정된 형태)의 ALF 필터가 적용될 수도 있다.
메모리(155)는 필터부(150)를 통해 산출된 복원 블록 또는 픽쳐를 저장할 수 있고, 저장된 복원 블록 또는 픽쳐는 인터 예측을 수행 시 예측부(120, 125)에 제공될 수 있다.
도 2는 본 발명의 일실시예로서, 복호화 장치의 개략적인 블록도를 도시한것이다.
도 2를 참조하면, 복호화 장치(200)는 엔트로피 복호화부(210), 재정렬부(215), 역양자화부(220), 역변환부(225), 예측부(230, 235), 필터부(240), 메모리(245)가 포함될 수 있다.
도 2에 나타난 각 구성부들은 복호화 장치에서 서로 다른 특징적인 기능들을 나타내기 위해 독립적으로 도시한 것으로, 각 구성부들이 분리된 하드웨어로 이루짐을 의미할 수 있다. 다만, 각 구성부는 설명의 편의상 각각의 구성부로 나열하여 포함한 것으로 각 구성부 중 적어도 두 개의 구성부가 합쳐져 하나의 구성부로 이루어지거나, 하나의 구성부가 복수개의 구성부로 나뉘어져 기능을 수행할 수 있고, 이러한 각 구성부의 통합된 실시예 및 분리된 실시예도 본 발명의 본질에서 벗어나지 않는 한 본 발명의 권리범위에 포함된다.
엔트로피 복호화부(210)는 입력 비트스트림에 대해 엔트로피 복호화를 수행할 수 있다. 예를 들어, 엔트로피 복호화를 위해, 지수 골롬(Exponential Golomb), CAVLC(Context-Adaptive Variable Length Coding), CABAC(Context-Adaptive Binary Arithmetic Coding)과 같은 다양한 방법이 적용될 수 있다.
엔트로피 복호화부(210)에서는 부호화 장치에서 수행된 인트라 예측 및 인터 예측에 관련된 정보를 복호화할 수 있다.
재정렬부(215)는 엔트로피 복호화부(210)에서 엔트로피 복호화된 비트스트림에 대해 재정렬을 수행할 수 있다. 1차원 벡터 형태로 표현된 계수들을 다시 2차원의 블록 형태의 계수로 복원하여 재정렬할 수 있다. 재정렬부(215)에서는 부호화 장치에서 수행된 계수 스캐닝에 관련된 정보를 제공받고, 해당 부호화 장치에서 수행된 스캐닝 순서에 기초하여 역으로 스캐닝하는 방법을 통해 재정렬을 수행할 수 있다.
역양자화부(220)는 양자화 파라미터와 재정렬된 블록의 계수값을 기초로 역양자화를 수행할 수 있다.
역변환부(225)는 역양자화된 변환 계수를 소정의 변환 타입으로 역변환을 수행할 수 있다. 이때, 변환 타입은, 예측 모드(인터/인트라 예측), 블록의 크기/형태, 인트라 예측 모드, 성분 타입(휘도/색차 성분), 분할 타입(QT, BT, TT 등) 등에 관한 정보 중 적어도 하나를 기반으로 결정될 수 있다.
예측부(230, 235)는 엔트로피 복호화부(210)에서 제공된 예측 블록 생성 관련 정보와 메모리(245)에서 제공된 이전에 복호화된 블록 또는 픽쳐 정보를 기초로 예측 블록을 생성할 수 있다.
예측부(230, 235)는 예측 단위 판별부, 인터 예측부 및 인트라 예측부를 포함할 수 있다. 예측 단위 판별부는 엔트로피 복호화부(210)에서 입력되는 예측 단위 정보, 인트라 예측 방법의 인트라 예측 모드 관련 정보, 인터 예측 방법의 움직임 예측 관련 정보 등 다양한 정보를 입력 받고, 현재 부호화 단위(CU)에서 예측 단위를 구분하고, 예측 단위가 인터 예측을 수행하는지 아니면 인트라 예측을 수행하는지 여부를 판별할 수 있다. 인터 예측부(230)는 부호화 장치에서 제공된 현재 예측 단위의 인터 예측에 필요한 정보를 이용하여, 현재 예측 단위가 포함된 현재 픽쳐의 이전 픽쳐 또는 이후 픽쳐 중 적어도 하나의 픽쳐에 포함된 정보를 기초로 현재 예측 단위에 대한 인터 예측을 수행할 수 있다. 또는, 현재 예측 단위가 포함된 현재 픽쳐 내에서 기-복원된 일부 영역의 정보를 기초로 인터 예측을 수행할 수도 있다. 이를 위해, 상기 기-복원된 일부 영역이 참조 픽쳐 리스트에 추가될 수 있다.
인터 예측을 수행하기 위해 부호화 단위를 기준으로, 해당 부호화 단위에 포함된 예측 단위의 움직임 예측 방법이 스킵 모드(Skip Mode), 머지 모드(Merge 모드), AMVP 모드(AMVP Mode), 현재 픽쳐 참조 모드 중 어떠한 방법인지 여부를 판단할 수 있다.
인트라 예측부(235)는 현재 픽쳐 내의 화소 정보를 기초로 예측 블록을 생성할 수 있다. 예측 단위가 인트라 예측을 수행한 예측 단위인 경우, 부호화 장치에서 제공된 예측 단위의 인트라 예측 모드 정보를 기초로, 인트라 예측을 수행할 수 있다. 인트라 예측부(235)에는 AIS(Adaptive Intra Smoothing) 필터, 참조 화소 보간부, DC 필터를 포함할 수 있다. AIS 필터는 현재 블록의 참조 화소에 필터링을 수행하는 부분으로서, 현재 예측 단위의 예측 모드에 따라 필터의 적용 여부를 결정하여 적용할 수 있다. 부호화 장치에서 제공된 예측 단위의 예측 모드 및 AIS 필터 정보를 이용하여, 현재 블록의 참조 화소에 AIS 필터링을 수행할 수 있다. 현재 블록의 예측 모드가 AIS 필터링을 수행하지 않는 모드일 경우, AIS 필터는 적용되지 않을 수 있다.
참조 화소 보간부는 예측 단위의 예측 모드가 참조 화소를 보간한 화소값을 기초로 인트라 예측을 수행하는 예측 단위일 경우, 참조 화소를 보간하여 정수값 이하의 화소 단위의 참조 화소를 생성할 수 있다. 현재 예측 단위의 예측 모드가 참조 화소를 보간하지 않고 예측 블록을 생성하는 예측 모드일 경우, 참조 화소는 보간되지 않을 수 있다. DC 필터는 현재 블록의 예측 모드가 DC 모드일 경우 필터링을 통해서 예측 블록을 생성할 수 있다.
복원된 블록 또는 픽쳐는 필터부(240)로 제공될 수 있다. 필터부(240)는 디블록킹 필터, 오프셋 보정부, ALF를 포함할 수 있다.
부호화 장치로부터 해당 블록 또는 픽쳐에 디블록킹 필터를 적용하였는지 여부에 대한 정보 및 디블록킹 필터를 적용하였을 경우, 강한 필터를 적용하였는지 또는 약한 필터를 적용하였는지에 대한 정보를 제공받을 수 있다. 복호화 장치의 디블록킹 필터에서는 부호화 장치에서 제공된 디블록킹 필터 관련 정보를 제공받고, 복호화 장치에서 해당 블록에 대한 디블록킹 필터링을 수행할 수 있다.
오프셋 보정부는 부호화시 영상에 적용된 오프셋 보정의 종류 및 오프셋 값 정보 등을 기초로 복원된 영상에 오프셋 보정을 수행할 수 있다.
ALF는 부호화기로부터 제공된 ALF 적용 여부 정보, ALF 계수 정보 등을 기초로 부호화 단위에 적용될 수 있다. 이러한 ALF 정보는 특정한 파라메터 셋에 포함되어 제공될 수 있다.
메모리(245)는 복원된 픽쳐 또는 블록을 저장하여 참조 픽쳐 또는 참조 블록으로 사용할 수 있도록 할 수 있고 또한 복원된 픽쳐를 출력부로 제공할 수 있다.
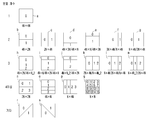
도 3은 본 발명이 적용되는 일실시예로서, 블록 분할 타입을 도시한 것이다.
도 3을 참조하면, 분할 설정, 분할 방식에 따라 a 내지 s의 블록을 획득할 수 있으며, 도시되지 않은 추가적인 블록 형태 또한 가능할 수 있다.
일 예(1)로, 트리 기반의 분할에 비대칭 분할을 허용할 수 있다. 예를 들어, 바이너리 트리의 경우 b, c와 같은 블록이 가능할 수 있거나 또는 b ~ g와 같은 블록이 가능할 수 있다. 비대칭 분할을 허용하는 플래그가 부/복호화 설정에 따라 명시적 또는 묵시적으로 비활성화될 경우 획득 가능한 후보 블록은 b 또는 c일 수 있고, 비대칭 분할을 허용하는 플래그가 활성화될 경우 획득 가능한 후보 블록은 b, d, e(본 예에서 가로 분할)일 수 있거나 c, f, g(본 예에서 세로 분할)일 수 있다.
상기 예에서 비대칭 분할의 좌:우 또는 상:하의 길이 비율은 1:3 또는 3:1인 경우를 가정하여 설명하나 이에 한정하지 않고 그 외의 비율을 갖는 후보군(예를 들어, 1:2, 1:4, 2:3, 2:5, 3:5 등)을 갖는 것도 부호화 설정에 따라 가능할 수 있다.
다음은 바이너리 트리 분할(본 예에서 1:1, 1:3, 3:1의 후보군)에서 발생하는 분할 정보에 대한 다양한 예를 나타낸다.
예를 들어, 분할 여부를 나타내는 플래그, 분할 방향을 나타내는 플래그에 추가적으로 분할 형태를 나타내는 플래그가 발생할 수 있다. 이때, 분할 형태는 대칭 또는 비대칭 분할을 의미할 수 있다. 이 중 비대칭 분할이 분할 형태로 결정되는 경우에는 분할 비율을 나타내는 플래그가 발생할 수 있으며, 기 설정된 후보군에 따라 인덱스가 할당될 수 있다. 만약 1:3 또는 3:1의 분할 비율이 후보군으로 지원될 경우 1비트 플래그를 통해 분할 비율을 선택할 수 있다.
또는, 분할 여부를 나타내는 플래그, 분할 방향을 나타내는 플래그에 추가적으로 분할 비율을 나타내는 플래그가 발생할 수 있다. 본 예에서 분할 비율에 대한 후보군으로 1:1의 대칭 비율을 갖는 후보가 포함되어 구성될 수 있다.
본 발명에서는 (비대칭 분할을 허용하는 플래그가 활성화될 경우) 바이너리 트리 분할에서 전자의 예와 같은 구성을 갖는 경우를 가정하며, 특별한 설명이 없는 한 바이너리 트리는 대칭 바이너리 트리를 의미한다.
일 예(2)로, 트리 기반의 분할에 추가적인 트리 분할을 허용할 수 있다. 예를 들어, 터너리 트리(Ternary Tree), 쿼드 타입 트리(Quad Type Tree), 옥타 트리(Octa Tree) 등의 분할이 가능할 수 있으며, 이를 통해 n개의 분할 블록(본 예에서 3, 4, 8. n은 정수)을 획득할 수 있다. 터너리 트리의 경우 지원되는 블록(본 예에서 복수의 블록으로 분할된 경우)은 h ~ m일 수 있고, 쿼드 타입 트리의 경우 지원되는 블록은 n ~ p일 수 있고, 옥타 트리의 경우 지원되는 블록은 q일 수 있다. 상기 트리 기반의 분할의 지원 여부는 부/복호화 설정에 따라 묵시적으로 정해지거나 또는 명시적으로 관련 정보가 생성될 수 있다. 또한, 부/복호화 설정에 따라 단독으로 사용되거나 또는 바이너리 트리, 쿼드 트리 분할 등과 혼합 사용될 수 있다.
예를 들어, 바이너리 트리의 경우 b, c와 같은 블록이 가능할 수 있고, 바이너리 트리와 터너리 트리가 혼합 사용되는 경우(본 예는 바이너리 트리의 사용 범위와 터너리 트리의 사용 범위가 일부 중복되는 경우라 가정) b, c, i, l와 같은 블록이 가능할 수 있다. 기존 트리 외의 추가 분할을 허용하는 플래그가 부/복호화 설정에 따라 명시적 또는 묵시적으로 비활성화될 경우 획득 가능한 후보 블록은 b 또는 c일 수 있고, 활성화될 경우 획득 가능한 후보 블록은 b, i 또는 b, h, i, j(본 예에서 가로 분할)일 수 있거나 c, l 또는 c, k, l, m(본 예에서 세로 분할)일 수 있다.
상기 예에서 터너리 트리 분할의 좌:중:우 또는 상:중:하의 길이 비율은 2:1:1 또는 1:2:1 또는 1:1:2 인 경우를 가정하여 설명하나 이에 한정하지 않고 그 외의 비율을 갖는 것도 부호화 설정에 따라 가능할 수 있다.
다음은 터너리 트리 분할(본 예에서 1:2:1 인 후보)에서 발생하는 분할 정보에 대한 예를 나타낸다.
예를 들어, 분할 여부를 나타내는 플래그, 분할 방향을 나타내는 플래그에 추가적으로 분할 종류를 나타내는 플래그가 발생할 수 있다. 이때, 분할 종류는 바이너리 트리 또는 터너리 트리 분할을 의미할 수 있다.
본 발명에서는 분할 방식에 따라 적응적인 부/복호화 설정을 적용할 수 있다.
일 예로, 블록의 종류에 따라 분할 방식이 정해질 수 있다. 예를 들어, 부호화 블록과 변환 블록은 쿼드 트리 분할을, 예측 블록은 쿼드 트리와 바이너리 트리(또는 터너리 트리 등) 분할 방식을 사용할 수 있다.
일 예로, 블록의 크기에 따라 분할 방식이 정해질 수 있다. 예를 들어, 블록의 최대값과 최소값 사이에서 일부 범위(예를 들어, a×b ~ c×d. 후자가 더 큰 크기인 경우)에는 쿼드 트리 분할을, 일부 범위(예를 들어, e×f ~ g×h)에는 바이너리 트리(또는 터너리 트리 등) 분할이 가능할 수 있다. 이때, 분할 방식에 따른 범위 정보가 명시적으로 생성될 수 있거나 묵시적으로 정해질 수 있으며, 상기 범위는 중첩되는 경우 또한 가능하다.
일 예로, 블록(또는 분할 전 블록)의 형태에 따라 분할 방식이 정해질 수 있다. 예를 들어, 블록의 형태가 정사각일 경우 쿼드 트리와 바이너리 트리(또는 터너리 트리 등) 분할이 가능할 수 있다. 또는, 블록의 형태가 직사각일 경우에 바이너리 트리(또는 터너리 트리 등) 기반의 분할이 가능할 수 있다.
일 예로, 블록의 종류에 따라 분할 설정이 정해질 수 있다. 예를 들어, 트리 기반의 분할에서 부호화 블록과 예측 블록은 쿼드 트리, 변환 블록은 바이너리 트리 분할을 사용할 수 있다. 또는, 부호화 블록의 경우 분할 허용 깊이는 m, 예측 블록의 경우 분할 허용 깊이는 n, 변환 블록의 경우 분할 허용 깊이는 o로 설정할 수 있으며, m과 n과 o는 동일하거나 동일하지 않을 수 있다.
일 예로, 블록의 크기에 따라 분할 설정이 정해질 수 있다. 예를 들어, 블록의 일부 범위(예를 들어, a×b ~ c×d)에는 쿼드 트리 분할을, 일부 범위(예를 들어, e×f ~ g×h. 본 예에서 c×d는 g×h보다 크다고 가정)에는 바이너리 트리 분할을, 일부 범위(예를 들어, i×j ~ k×l. 본 예에서 g×h은 k×l보다 크거나 같다고 가정)에는 터너리 트리 분할이 가능할 수 있다. 이때, 상기 범위로 블록의 최대값과 최소값 사이의 모든 범위를 포함할 수 있고, 상기 범위는 서로 중첩되지 않은 설정을 갖거나 중첩되는 설정을 가질 수 있다. 예를 들어, 일부 범위의 최소값은 일부 범위의 최대값과 동일하거나 또는 일부 범위의 최소값은 일부 범위의 최대값보다 작을 수 있다. 중첩되는 범위를 가질 경우 더 높은 최대값을 갖는 분할 방식이 우선 순위를 가질 수 있거나 어떤 분할 방식을 사용할 지에 대한 정보가 명시적으로 발생할 수 있다. 즉, 우선 순위를 갖는 분할 방식에서 분할 결과에 따라 후순위를 갖는 분할 방식의 수행 여부가 정해질 수 있거나 분할 방식 선택 정보에 따라 어떤 분할 방식을 사용할 지가 정해질 수 있다.
일 예로, 블록의 형태에 따라 분할 설정이 정해질 수 있다. 예를 들어, 블록의 형태가 정사각일 경우 쿼드 트리 분할이 가능할 수 있다. 또는, 블록의 형태가 직사각일 경우에 바이너리 트리 또는 터너리 트리 분할이 가능할 수 있다.
일 예로, 부/복호화 정보(예를 들어, 슬라이스 타입, 컬러 성분, 부호화 모드 등)에 따라 분할 설정이 정해질 수 있다. 예를 들어, 슬라이스 타입이 I일 경우 쿼드 트리(또는 바이너리 트리, 터너리 트리) 분할은 일부 범위(예를 들어, a×b ~ c×d), P일 경우 일부 범위(예를 들어, e×f ~ g×h), B일 경우 일부 범위(예를 들어, i×j ~ k×l)에서 가능할 수 있다. 또한, 슬라이스 타입이 I일 경우 쿼드 트리(또는 바이너리 트리, 터너리 트리 분할) 분할의 분할 허용 깊이 m, P일 경우 분할 허용 깊이 n, B일 경우 분할 허용 깊이 o으로 설정할 수 있으며, m과 n과 o는 동일하거나 동일하지 않을 수 있다. 일부 슬라이스 타입의 경우 다른 슬라이스(예를 들어, P와 B 슬라이스)와 동일한 설정을 가질 수 있다.
다른 예로, 컬러 성분이 휘도 성분일 경우 쿼드 트리(또는 바이너리 트리, 터너리 트리) 분할 허용 깊이를 m, 색차 성분일 경우 n으로 설정할 수 있으며, m과 n은 동일하거나 동일하지 않을 수 있다. 또한, 컬러 성분이 휘도 성분일 경우 쿼드 트리(또는 바이너리 트리, 터너리 트리) 분할의 범위(예를 들어, a×b ~ c×d)와 색차 성분일 경우 쿼드 트리(또는 바이너리 트리, 터너리 트리) 분할의 범위(예를 들어, e×f ~ g×h)는 동일하거나 동일하지 않을 수 있다.
다른 예로, 부호화 모드가 Intra일 경우 쿼드 트리(또는 바이너리 트리, 터너리 트리) 분할 허용 깊이가 m, Inter일 경우 n(본 예에서 n은 m보다 크다고 가정)일 수 있으며, m과 n은 동일하거나 동일하지 않을 수 있다. 또한, 부호화 모드가 Intra일 경우 쿼드 트리(또는 바이너리 트리, 터너리 트리) 분할의 범위와 부호화 모드가 Inter일 경우 쿼드 트리(또는 바이너리 트리, 터너리 트리) 분할의 범위는 동일하거나 동일하지 않을 수 있다.
상기 예의 경우 부/복호화 정보에 따른 적응적인 분할 후보군 구성 지원 여부에 대한 정보가 명시적으로 생성될 수 있거나 묵시적으로 정해질 수 있다.
상기 예를 통해 부/복호화 설정에 따라 분할 방식과 분할 설정이 정해지는 경우를 설명하였다. 상기 예는 각 요소에 따른 일부 경우를 나타내며, 다른 경우로의 변형 또한 가능할 수 있다. 또한, 복수의 요소에 의한 조합에 따라 분할 방식과 분할 설정이 정해질 수도 있다. 예를 들어, 블록의 종류, 크기, 형태, 부/복호화 정보 등에 의해 분할 방식과 분할 설정이 정해질 수 있다.
또한, 상기 예에서 분할 방식, 설정 등에 관여하는 요소들은 묵시적으로 정해지거나 또는 명시적으로 정보를 생성하여 상기 예와 같은 적응적인 경우의 허용 여부를 정할 수 있다.
상기 분할 설정 중 분할 깊이는 초기 블록을 기준으로 공간적으로 분할한 횟수(본 예에서 초기 블록의 분할 깊이는 0)를 의미하며, 분할 깊이가 증가할수록 더 작은 블록으로 분할될 수 있다. 이는 분할 방식에 따라 깊이 관련 설정을 달리할 수 있다. 예를 들어, 트리 기반의 분할을 수행하는 방식 중 바이너리 트리의 분할 깊이와 터너리 트리의 분할 깊이는 공통되는 하나의 깊이를 사용할 수 있고, 쿼드 트리의 분할 깊이와 바이너리 트리의 분할 깊이는 다른 깊이를 사용하는 등 트리의 종류에 따른 개별적인 깊이를 사용할 수 있다.
상기 예에서 트리의 종류에 따라 개별적인 분할 깊이를 사용하는 경우 트리의 분할 시작 위치(본 예에서 분할을 수행하기 전 블록)에서 분할 깊이 0으로 설정할 수 있다. 각 트리의 분할 범위(본 예에서 최대값)에 기반하지 않고 분할이 시작되는 위치를 중심으로 분할 깊이가 계산될 수 있다.
도 4는 본 발명이 적용되는 일실시예로서, 트리 구조 기반의 블록 분할 방법을 도시한 것이다.
그림에서 굵은 실선은 기본 부호화 블록, 굵은 점선은 쿼드 트리 분할 경계, 이중 실선은 대칭 바이너리 트리 분할 경계, 실선은 터너리 트리 분할 경계, 얇은 점선은 비대칭 바이너리 트리 분할 경계를 의미한다. 굵은 실선을 제외하고는 각 분할 방법에 따라 구획되는 경계를 의미한다. 다음에서 설명하는 분할 설정(예를 들어, 분할 종류, 분할 정보, 분할 정보 구성 순서 등)은 해당 예의 경우에만 한정되지 않으며, 다양한 변형의 예가 가능할 수 있다.
설명의 편의를 위해 기본 부호화 블록(2N x 2N. 128 x 128)을 기준으로 좌상, 우상, 좌하, 우하 블록(N x N. 64 x 64)에 개별적인 블록 분할 설정을 갖는 경우를 가정하여 설명한다. 우선, 초기 블록에서 한 번의 분할 동작(분할 깊이 0 -> 1. 즉, 분할 깊이 1 증가)으로 인해 4개의 서브 블록이 획득된 상태이며, 쿼드 트리에 관한 분할 설정으로 최대 부호화 블록은 128 x 128, 최소 부호화 블록은 8 x 8이며 최대 분할 깊이는 4인 경우로 이는 각 블록에 공통 적용되는 설정임을 가정한다.
(1번. 좌상 블록. A1 ~ A6)
본 예는 단일 트리 방식의 분할(본 예에서 쿼드 트리)이 지원되는 경우로, 최대 부호화 블록, 최소 부호화 블록, 분할 깊이 등과 같은 하나의 블록 분할 설정을 통해 획득 가능한 블록의 크기 및 형태가 정해질 수 있다. 본 예에서는 분할에 따라 획득 가능한 블록이 하나인 경우(가로와 세로를 각각 2분할)로 한 번의 분할 동작(분할 전 블록 4M x 4N 기준. 분할 깊이 1 증가)에 요구되는 분할 정보는 분할 여부를 나타내는 플래그(본 예에서 0이면 분할 x. 1이면 분할 o)이며 획득 가능한 후보는 4M x 4N과 2M x 2N일 수 있다.
(2번. 우상 블록. A7 ~ A11)
본 예는 다중 트리 방식의 분할(본 예에서 쿼드 트리, 바이너리 트리)이 지원되는 경우로, 복수의 블록 분할 설정을 통해 획득 가능한 블록의 크기 및 형태가 정해질 수 있다. 본 예에서 바이너리 트리의 경우 최대 부호화 블록은 64 x 64, 최소 부호화 블록은 한 쪽 길이가 4이고 최대 분할 깊이가 4인 경우라 가정한다.
본 예에서는 분할에 따라 획득 가능한 블록은 2개 이상인 경우(본 예에서 2 또는 4개)라 한 번의 분할 동작(쿼드 트리 분할 깊이 1 증가)에 요구되는 분할 정보는 분할 여부를 나타내는 플래그, 분할 종류를 나타내는 플래그, 분할 형태를 나타내는 플래그, 분할 방향을 나타내는 플래그이며 획득 가능한 후보는 4M x 4N, 4M x 2N, 2M x 4N, 4M x N/4M x 3N, 4M x 3N/4M x N, M x 4N/3M x 4N, 3M x 4N/M x 4N일 수 있다.
만약 쿼드 트리와 바이너리 트리 분할 범위가 중첩(즉, 현재 단계에서 쿼드 트리 분할과 바이너리 트리 분할이 모두 가능한 범위)되며 현재 블록(아직 분할 하기 전 상태)이 쿼드 트리 분할에 의해 획득된 블록(부모 블록<분할 깊이가 현재보다 1적은 경우>에서 쿼드 트리 분할에 의해 획득된 블록)일 경우에 분할 정보는 다음과 같은 경우로 구분되어 구성될 수 있다. 즉, 각 분할 설정에 따라 지원되는 블록이 복수의 분할 방법에 의해 획득 가능한 경우에는 다음과 같은 과정으로 분류하여 분할 정보가 발생 가능하다.
(1) 쿼드 트리 분할과 바이너리 트리 분할이 중첩되는 경우
[표 1]

위의 표에서 a는 쿼드 트리 분할 여부를 나타내는 플래그를 의미하며, 1이면 쿼드 트리 분할(QT)을 수행한다. 상기 플래그가 0이면 바이너리 트리 분할 여부를 나타내는 플래그인 b를 확인한다. b가 0이면 해당 블록에서 더 이상의 분할은 수행하지 않고(No Split), 1이면 바이너리 트리 분할을 수행한다.
c는 분할 방향을 나타내는 플래그로 0이면 가로 분할(hor), 1이면 세로 분할(ver)을 의미하고, d는 분할 형태를 나타내는 플래그로 0이면 대칭 분할(SBT. Symmetric Binary Tree), 1이면 비대칭 분할(ABT. Asymmetric Binary Tree)을 의미한다. d가 1일때만 비대칭 분할에서의 세부 분할 비율에 대한 정보(1/4 or 3/4)를 확인하며, 0일 때는 좌/우 또는 상/하 블록에서 좌와 상 블록이 1/4의 비율을 갖고 우와 하 블록이 3/4의 비율을 가지며, 1이면 반대의 비율을 갖는다.
(2) 바이너리 트리 분할만 가능한 경우
위의 표에서 a를 제외한 b 내지 e의 플래그로 분할 정보에 대한 표현이 가능하다.
도 4에서 A7 블록의 경우 분할 전 블록(A7 ~ A11)에서 쿼드 트리 분할이 가능한 경우(즉, 쿼드 트리 분할이 가능했지만 쿼드 트리 분할이 아닌 바이너리 트리 분할이 된 경우)였으므로 (1)에서의 분할 정보가 생성되는 경우에 해당한다.
반면, A8 내지 A11의 경우 분할 전 블록(A8 ~ A11)에서 이미 쿼드 트리 분할이 수행되지 않고 바이너리 트리 분할이 된 경우(즉, 더 이상 해당 블록<A8 ~ A11>에서는 쿼드 트리 분할이 불가능한 경우)라 (2)에서의 분할 정보가 생성되는 경우에 해당한다.
(3번. 좌하 블록. A12 ~ A15)
본 예는 다중 트리 방식의 분할(본 예에서 쿼드 트리, 바이너리 트리, 터너리 트리)이 지원되는 경우로, 복수의 블록 분할 설정을 통해 획득 가능한 블록의 크기 및 형태가 정해질 수 있다. 본 예에서 바이너리 트리/터너리의 경우 최대 부호화 블록은 64 x 64, 최소 부호화 블록은 한 쪽 길이가 4이고 최대 분할 깊이가 4인 경우라 가정한다.
본 예에서는 분할에 따라 획득 가능한 블록은 2개 이상인 경우(본 예에서 2, 3, 4개)라 한 번의 분할 동작에 요구되는 분할 정보는 분할 여부를 나타내는 플래그, 분할 종류를 나타내는 플래그, 분할 방향을 나타내는 플래그이며 획득 가능한 후보는 4M x 4N, 4M x 2N, 2M x 4N, 4M x N/4M x 2N/4M x N, M x 4N/2M x 4N/M x 4N일 수 있다.
만약 쿼드 트리와 바이너리 트리/터너리 트리 분할 범위가 중첩되며 현재 블록이 쿼드 트리 분할에 의해 획득된 블록일 경우에 분할 정보는 다음과 같은 경우로 구분되어 구성될 수 있다.
(1) 쿼드 트리 분할과 바이너리 트리/터너리 트리 분할이 중첩되는 경우
[표 2]

위의 표에서 a는 쿼드 트리 분할 여부를 나타내는 플래그이고, 1이면 쿼드 트리 분할을 수행한다. 상기 플래그가 0이면 바이너리 트리 또는 터너리 트리 분할 여부를 나타내는 플래그인 b를 확인한다. b가 0이면 해당 블록에서 더 이상의 분할은 수행하지 않고, 1이면 바이너리 트리 또는 터너리 트리 분할을 수행한다.
c는 분할 방향을 나타내는 플래그로 0이면 가로 분할, 1이면 세로 분할을 의미하고, d는 분할 종류를 나타내는 플래그로 0이면 바이너리 트리 분할(BT), 1이면 터너리 트리 분할(TT)을 의미한다.
(2) 바이너리 트리/터너리 트리 분할만 가능한 경우
위의 표에서 a를 제외한 b 내지 d의 플래그로 분할 정보에 대한 표현이 가능하다.
도 4에서 A12, A15 블록의 경우 분할 전 블록(A12 ~ A15)에서 쿼드 트리 분할이 가능한 경우였으므로 (1)에서의 분할 정보가 생성되는 경우에 해당한다.
반면, A13와 A14는 분할 전 블록(A13, A14)에서 이미 쿼드 트리로 분할이 수행되지 않고 터너리 트리로 분할이 된 경우라 (2)에서의 분할 정보가 생성되는 경우에 해당한다.
(4번. 좌하 블록. A16 ~ A20)
본 예는 다중 트리 방식의 분할(본 예에서 쿼드 트리, 바이너리 트리, 터너리 트리)이 지원되는 경우로, 복수의 블록 분할 설정을 통해 획득 가능한 블록의 크기 및 형태가 정해질 수 있다. 본 예에서 바이너리 트리/터너리 트리의 경우 최대 부호화 블록은 64 x 64, 최소 부호화 블록은 한 쪽 길이가 4이고 최대 분할 깊이가 4인 경우라 가정한다.
본 예에서는 분할에 따라 획득 가능한 블록은 2개 이상인 경우(본 예에서 2, 3, 4개)라 한 번의 분할 동작에 요구되는 분할 정보로 분할 여부를 나타내는 플래그, 분할 종류를 나타내는 플래그, 분할 형태를 나타내는 플래그, 분할 방향을 나타내는 플래그이며 획득 가능한 후보는 4M x 4N, 4M x 2N, 2M x 4N, 4M x N/4M x 3N, 4M x 3N/4M x N, M x 4N/3M x 4N, 3M x 4N/M x 4N, 4M x N/4M x 2N/4M x N, M x 4N/2M x 4N/M x 4N일 수 있다.
만약 쿼드 트리와 바이너리 트리/터너리 트리 분할 범위가 중첩되며 현재 블록이 쿼드 트리 분할에 의해 획득된 블록일 경우에 분할 정보는 다음과 같은 경우로 구분되어 구성될 수 있다.
(1) 쿼드 트리 분할과 바이너리 트리/터너리 분할이 중첩되는 경우
[표 3]

위의 표에서 a는 쿼드 트리 분할 여부를 나타내는 플래그를 의미하며, 1이면 쿼드 트리 분할을 수행한다. 상기 플래그가 0이면 바이너리 트리 분할 여부를 나타내는 플래그인 b를 확인한다. b가 0이면 해당 블록에서 더 이상의 분할은 수행하지 않고, 1이면 바이너리 트리 또는 터너리 트리 분할을 수행한다.
c는 분할 방향을 나타내는 플래그로 0이면 가로 분할, 1이면 세로 분할을 의미하고, d는 분할 종류를 나타내는 플래그로 0이면 터너리 분할, 1이면 바이너리 트리 분할을 의미한다. d가 1일 때는 분할 형태에 대한 플래그인 e를 확인하여 e가 0일 때는 대칭 분할을, 1일 때는 비대칭 분할을 수행한다. e가 1일 ?는 비대칭 분할에서의 세부 분할 비율에 대한 정보를 확인하며 이는 이전 예에서와 동일하다.
(2) 바이너리 트리/터너리 트리 분할만 가능한 경우
위의 표에서 a를 제외한 b 내지 f의 플래그로 분할 정보에 대한 표현이 가능하다.
도 4에서 A20 블록은 분할 전 블록(A16 ~ A19)에서 쿼드 트리 분할이 가능한 경우였으므로 (1)에서의 분할 정보가 생성되는 경우에 해당한다.
반면, A16 내지 A19의 경우 분할 전 블록(A16 ~ A19)에서 이미 쿼드 트리 분할이 수행되지 않고 바이너리 트리 분할이 된 경우라 (2)에서의 분할 정보가 생성되는 경우에 해당한다.
도 5는 본 발명의 일실시예로서, 매트릭스 기반으로 현재 블록에 대한 인트라 예측을 수행하는 과정을 도시한 것이다.
도 5를 참조하면, 현재 블록의 인트라 예측을 위한 인트라 예측 모드를 결정할 수 있다(S500).
부호화/복호화 장치는, 현재 블록의 인트라 예측을 함에 있어서, 인트라 예측 모드를 결정할 수 있다. 상기 현재 블록은 코딩 블록(CU), 예측 블록(PU), 변환 블록(TU), 또는 이들의 서브블록 중 어느 하나일 수 있다.
(실시예 1) 상기 인트라 예측 모드는, 시그날링되는 정보에 기초하여 결정될 수 있다. 상기 정보는, 부호화/복호화 장치에 기-정의된 N개의 인트라 예측 모드 중 어느 하나를 특정할 수 있다. 상기 기-정의된 인트라 예측 모드는, 현재 블록이 이용 가능한 전체 인트라 예측 모드를 의미하고, N은 67보다 작거나 같고, 11보다 크거나 같은 자연수(e.g, 67, 35, 11)일 수 있다. 또한, N 값은 현재 블록의 크기에 기초하여 결정될 수 있다. 예를 들어, 현재 블록이 8x8보다 작은 경우, N은 35로 결정되고, 그렇지 않은 경우, N은 19 또는 11 중 어느 하나로 결정될 수 있다.
(실시예 2) 상기 인트라 예측 모드는, 부호화/복호화 장치에 기-약속된 고정된 모드 또는 인덱스로 결정될 수도 있다. 상기 고정된 모드는, Planar mode(인덱스 0), DC 모드(인덱스 1), 수평 모드(인덱스 18), 수직 모드(인덱스 50), 대각선 모드(인덱스 2, 34, 66) 중 적어도 하나일 수 있다. 여기서, 인덱스는 기-정의된 인트라 예측 모드가 67개인 경우에 대응되고, 상기 N 값에 따라 모드 별 인덱스는 상이하게 할당될 수 있다.
(실시예 3) 상기 인트라 예측 모드는, 부호화 정보에 기초하여 가변적으로 결정될 수도 있다. 여기서, 부호화 정보는 부호화 장치에서 부호화 되어 시그날링되는 정보뿐만 아니라, 복호화 장치에서 시그날링되는 정보에 기초하여 유도되는 정보까지 포함할 수 있다. 상기 부호화 정보는, 현재 블록 또는 주변 블록 중 적어도 하나에 관한 것일 수 있다. 주변 블록은, 현재 블록의 공간적 및/또는 시간적 주변 블록을 포함하고, 공간적 주변 블록은 현재 블록의 좌측, 상단, 좌상단, 좌하단 또는 우상단 중 적어도 하나에 인접한 블록을 의미할 수 있다.
상기 부호화 정보는 블록 크기/형태, 블록의 가용성, 분할 타입, 분할 횟수, 성분 타입, 예측 모드, 인트라 예측 모드에 관한 정보, 인터 모드, 움직임 정보, 변환 타입, 변환 스킵 모드, 넌-제로 잔차 계수에 관한 정보, 스캔 순서, 칼라 포맷, 인-루프 필터 정보 등을 포함할 수 있다. 상기 블록 크기는 너비 또는 높이 중 어느 하나, 너비와 높이 중 최소값/최대값, 너비와 높이의 합, 블록에 속한 샘플의 개수 등으로 표현될 수 있다. 상기 블록의 가용성은 블록 위치, 병렬 처리 영역의 범위, 복호화 순서 등을 고려하여 판단될 수 있다. 상기 예측 모드는 인트라 모드 또는 인터 모드를 나타내는 정보를 의미할 수 있다. 상기 인트라 예측 모드에 관한 정보는 인트라 예측 모드가 비방향성 모드인지 여부, 인트라 예측 모드가 수직/수평 모드인지 여부, 인트라 예측 모드의 방향성, 부호화/복호화 장치에 기-정의된 인트라 예측 모드의 개수 등에 관한 정보를 포함할 수 있다. 상기 인터 모드는 머지/스킵 모드, AMVP 모드 또는 현재 픽쳐 참조 모드를 나타내는 정보를 의미할 수 있다. 상기 현재 픽쳐 참조 모드는 현재 픽쳐의 기-복원된 영역을 이용하여 현재 블록을 예측하는 방법을 의미한다. 상기 현재 픽쳐는 상기 현재 블록이 속한 픽쳐일 수 있다. 상기 현재 픽쳐는 인터 예측을 위한 참조 픽쳐 리스트에 추가될 수 있으며, 상기 현재 픽쳐는 참조 픽쳐 리스트 내에서 근거리(short-term) 참조 픽쳐 또는 장거리(long-term) 참조 픽쳐 다음에 배열될 수 있다. 상기 움직임 정보는 예측 방향 플래그, 움직임 벡터, 참조 픽쳐 인덱스 등을 포함할 수 있다.
(실시예 4) 상기 인트라 예측 모드는, MPM 리스트 및 MPM 인덱스에 기초하여 유도될 수도 있다. 상기 MPM 리스트는 복수의 MPM을 포함하고, MPM은 현재 블록의 공간적/시간적 주변 블록의 인트라 예측 모드에 기초하여 결정될 수 있다. MPM의 개수는 x개이며, x는 3, 4, 5, 6, 또는 그 이상의 정수일 수 있다.
예를 들어, MPM 리스트는, 주변 블록의 인트라 예측 모드 modeA, (modeA-n), (modeA+n) 또는 디폴트 모드 중 적어도 하나를 포함할 수 있다. 상기 n 값은 1, 2, 3, 4 또는 그 이상의 정수일 수 있다. 상기 주변 블록은, 현재 블록의 좌측 및/또는 상단에 인접한 블록을 의미할 수 있다. 디폴트 모드는, Planar 모드, DC 모드, 또는 소정의 방향성 모드 중 적어도 하나일 수 있다. 소정의 방향성 모드는, 수평 모드(modeV), 수직 모드(modeH), (modeV-k), (modeV+k), (modeH-k) 또는 (modeH+k) 중 적어도 하나를 포함할 수 있다.
상기 MPM 인덱스는, MPM 리스트의 MPM 중에서, 현재 블록의 인트라 예측 모드와 동일한 MPM을 특정할 수 있다. 즉, MPM 인덱스에 의해 특정된 MPM이 현재 블록의 인트라 예측 모드로 설정될 수 있다.
전술한 실시예 1 내지 4 중 어느 하나를 선택적으로 이용하여 현재 블록의 인트라 예측 모드가 결정될 수도 있고, 실시예 1 내지 4 중 적어도 2개의 조합에 기초하여 현재 블록의 인트라 예측 모드가 결정될 수도 있다. 상기 선택을 위해 소정의 플래그가 이용될 수 있고, 이때 플래그는 부호화 장치에서 부호화되어 시그날링될 수 있다.
도 5를 참조하면, 현재 블록의 인트라 예측을 위한 참조 샘플을 결정할 수 있다(S510).
상기 참조 샘플은 현재 블록의 주변 영역으로부터 유도될 수 있다. 상기 현재 블록의 주변 영역은 상기 현재 블록의 좌측, 우측, 상단, 좌하단, 좌상단, 우하단, 또는 우상단 중 적어도 어느 하나를 포함할 수 있다.
상기 주변 영역은 하나 또는 그 이상의 샘플 라인을 포함할 수 있다. 구체적으로, 주변 영역에 속한 샘플 라인의 개수는 k개이며, 여기서 k는 1, 2, 3, 4, 또는 그 이상의 자연수일 수 있다. k 값은 부호화/복호화 장치에 기-약속된 고정된 값일 수도 있고, 전술한 부호화 정보에 기초하여 가변적으로 결정될 수도 있다. 예를 들어, 현재 블록이 제1 크기(e.g., 4x4, 4x8, 8x4)인 경우, 주변 영역은 1개의 샘플 라인으로 구성되고, 현재 블록이 제2 크기(e.g., 8x8, 16x16 등)인 경우, 주변 영역은 2개의 샘플 라인으로 구성될 수 있다. 상기 샘플 라인은 주변 영역의 위치에 따라 수직 방향 또는 수평 방향으로 결정될 수 있다. 또한, 상기 샘플 라인은 현재 블록에 접해 있을 수도 있고, 현재 블록을 기준으로 수직 및/또는 수평 방향으로 소정의 거리만큼 떨어져 있을 수도 있다
상기 복수개의 샘플 라인들은, 현재 블록을 기준으로 수직 및/또는 수평 방향으로 연속적으로 위치하거나, 상호 소정의 거리만큼 떨어져 위치할 수도 있다. 일실시예로서, 현재 블록의 상단에 2개의 샘플 라인이 있는 경우, 상기 2개의 라인들 중 가장 하단의 샘플 라인부터 위쪽 방향으로 각각 제1, 제2 샘플 라인이라고 명명한다. 이 경우, 제1 샘플 라인과 제2 샘플 라인은 서로 접해 있거나, 소정의 거리만큼 떨어져 위치할 수도 있다. 여기서, 소정의 거리는 i개의 라인 길이(즉, 너비 또는 높이)로 표현될 수 있다. 여기서, i는 0, 1, 2, 3 또는 그 이상의 자연수일 수 있다. 일실시예로서, 현재 블록의 상단에 3개의 샘플 라인이 있는 경우, 상기 복수개의 샘플 라인들 중 가장 하단의 샘플 라인부터 위쪽 방향으로 각각 제1, 제2, 제3 샘플 라인이라 명명한다. 이 경우, 제1 샘플 라인과 제2 샘플 라인은 서로 접하고, 제2 샘플 라인과 제3 샘플 라인은 서로 접할 수 있다. 또는, 제1 내지 제3 샘플 라인은 전술한 소정의 거리만큼 떨어져 위치할 수도 있다. 이때, 제1 및 제2 샘플 라인 사이의 간격(d1)과 제2 및 제3 샘플 라인 사이의 간격(d2)이 동일한 간격을 가질 수 있다. 또는, d1은 d2보다 크도록 설정될 수 있고, 반대로 d1은 d2보다 작도록 설정될 수도 있다. 일실시예로서, 현재 블록의 상단에 4개 이상의 샘플 라인이 있는 경우, 상기 4개의 샘플 라인은 상기 3개의 샘플 라인의 경우와 같은 방법으로 결정될 수 있다. 또한, 본 실시예는 상단에 위치한 샘플 라인뿐만 아니라 좌측에 위치한 샘플 라인에도 동일하게 적용될 수 있으며, 자세한 설명은 생략하기로 한다.
상기 참조 샘플은, 주변 영역에 속한 샘플 전부 또는 일부를 이용하여 유도될 수 있다.
(실시예 1) 상기 주변 영역의 일부 샘플은, 부호화/복호화 장치에 기-약속된 위치의 샘플일 수 있다. 상기 기-약속된 위치는, 상단 샘플 라인의 최좌측 샘플, 최우측 샘플 또는 중앙 샘플 중 적어도 하나를 포함할 수 있다. 상기 기-약속된 위치는, 좌측 샘플 라인의 최상단 샘플, 최하단 샘플 또는 중앙 샘플 중 적어도 하나를 포함할 수 있다. 또는, 기-약속된 위치는, 상단 및/또는 좌측 샘플 라인의 짝수번째 샘플 중 적어도 하나를 포함하거나, 홀수번째 샘플 중 적어도 하나를 포함할 수 있다. 또는, 기-약속된 위치는, 상단 샘플 라인의 샘플 중 j배수의 x 좌표를 가진 샘플을 포함하거나, 좌측 샘플 라인의 샘플 중 j배수의 y 좌표를 가진 샘플을 포함할 수도 있다. 여기서, j는 2, 3, 4 또는 그 이상의 자연수일 수 있다.
(실시예 2) 상기 주변 영역의 일부 샘플은, 부호화 정보에 기초하여 가변적으로 결정될 수도 있다. 여기서, 부호화 정보는 전술한 바와 같으며, 자세한 설명은 생략하기로 한다.
상기 실시예 1 또는 2 중 어느 하나가 선택적으로 이용될 수도 있고, 실시예 1 및 2의 조합에 기초하여 일부 샘플이 특정될 수도 있다. 이때, 전술한 바와 같이, 일부 샘플들 간의 간격이 균등하게 설정될 수 있으나, 이에 한정되지 아니하며, 일부 샘플들 간의 간격이 균등하지 않게 설정될 수도 있다.
상기 일부 샘플의 개수는, 부호화/복호화 장치에 기-정의된 1개, 2개, 3개, 4개 또는 그 이상일 수 있다. 또한, 일부 샘플의 개수는, 현재 블록의 좌측 주변 영역과 상단 주변 영역에 대해서 각각 상이하게 정의될 수 있다. 예를 들어, 현재 블록의 너비가 높이보다 큰 경우, 상단 주변 영역에 속한 일부 샘플의 개수(numSamA)는 좌측 주변 영역에 속한 일부 샘플의 개수(numSamL)보다 클 수 있다. 반대로, 현재 블록의 너비가 높이보다 작은 경우, numSamA는 numSamL보다 작을 수 있다. 또는, 일부 샘플의 개수는 전술한 부호화 정보에 기초하여 가변적으로 결정될 수도 있다.
상기 주변 영역의 샘플은 예측 샘플 또는 복원 샘플일 수 있다. 상기 예측 샘플은 인트라 예측 또는 인터 예측을 통해 획득될 수 있다. 상기 복원 샘플은 인-루프 필터가 적용되기 전 복원 샘플일 수도 있고, 인-루프 필터가 적용된 복원 샘플일 수도 있다.
한편, 참조 샘플은 주변 영역의 샘플로 그대로 유도되거나(CASE 1), 주변 영역의 샘플을 다운샘플링하여 유도될 수 있다(CASE 2). 상기 CASE 1과 2 중 어느 하나가 선택적으로 이용될 수 있다. 상기 선택은, 전술한 부호화 정보에 기초하여 수행될 수 있다. 예를 들어, 현재 블록의 크기가 소정의 문턱값보다 작은 경우, CASE 1에 기초하여 참조 샘플이 유도되고, 그렇지 않은 경우, CASE 2에 기초하여 참조 샘플이 유도될 수 있다. 여기서, 크기는 현재 블록의 너비, 높이, 너비와 높이의 최대값/최소값, 너비와 높이의 비율 또는 너비와 높이의 곱 중 어느 하나로 표현될 수 있다. 일예로, 현재 블록이 8x8보다 작은 경우, 참조 샘플은 주변 영역의 샘플로 유도되고, 그렇지 않은 경우, 참조 샘플은 주변 영역의 샘플을 다운샘플링하여 유도될 수 있다. 상기 다운샘플링 방법에 대해서는 도 6 및 도 7을 참조하여 자세히 살펴보도록 한다.
도 5를 참조하면, 매트릭스 기반 인트라 예측을 위한 매트릭스를 결정할 수 있다(S520).
상기 매트릭스는, S500에서 결정된 인트라 예측 모드 또는 현재 블록의 크기 중 적어도 하나에 기초하여 결정될 수 있다. 또는, 상기 매트릭스는, 현재 블록의 인트라 예측 모드만을 고려하여 결정되거나, 현재 블록의 크기만을 고려하여 결정되도록 제한될 수도 있다. 상기 크기는, 너비 또는 높이 중 어느 하나, 너비와 높이 중 최소값/최대값, 너비와 높이의 합, 현재 블록에 속한 샘플의 개수 등으로 표현될 수 있다. 다만, 이에 한정되지 아니하며, 상기 매트릭스는, 현재 블록에 관한 부호화 정보를 더 고려하여 결정될 수 있다. 여기서, 부호화 정보는 전술한 바와 같으며, 자세한 설명은 생략하기로 한다.
구체적으로, 부호화/복호화 장치에 기-약속된 매트릭스는 복수의 매트릭스 그룹으로 그룹핑될 수 있다. 상기 복수의 매트릭스 그룹은, 제1 매트릭스 그룹, 제2 매트릭스 그룹, ?, 제m 매트릭스 그룹으로 구성될 수 있다. 여기서, m은 2, 3, 4, 5 또는 그 이상의 자연수일 수 있다. 현재 블록의 크기에 기초하여, 현재 블록은 복수의 매트릭스 그룹 중 어느 하나를 선택적으로 이용할 수 있다. 예를 들면, 현재 블록의 크기가 4x4인 경우에 제1 매트릭스 그룹이 이용되고, 현재 블록의 크기가 8x4, 4x8, 및 8x8인 경우에 제2 매트릭스 그룹이 이용되며, 그리고 그 외의 경우에 제3 매트릭스 그룹이 이용될 수 있다. 현재 블록의 크기에 기초하여 선택된 매트릭스 그룹은, 하나 또는 그 이상의 매트릭스 후보를 포함할 수 있다. 복수의 매트릭스 후보 중 어느 하나가 현재 블록의 매트릭스로 결정될 수 있다. 상기 결정은, 전술한 현재 블록의 부호화 정보(e.g., 인트라 예측 모드)에 기초하여 수행될 수 있다.
상기 기-약속된 매트릭스의 개수는 전술한 기-정의된 인트라 예측 모드의 개수와 동일할 수 있다. 또한, 상기 기-약속된 매트릭스의 개수는 상기 기-정의된 인트라 예측 모드의 개수보다 적을 수 있다. 이 경우, 하나의 매트릭스에 복수개의 인트라 예측 모드가 매칭될 수 있다. 예를 들면, 하나의 매트릭스가 2개의 인트라 예측 모드와 매칭될 수 있다. 이 경우, 상기 기-약속된 매트릭스의 개수는 기-정의된 인트라 예측 모드의 개수의 1/2배 값을 가질 수 있다. 다만, 이에 한정되지 아니하며, 하나의 매트릭스에 매칭되는 인트라 예측 모드의 개수는 3개, 4개, 5개, 6개 또는 그 이상일 수 있다.
일실시예로서, 상기 매칭은, 인트라 예측 모드의 방향성 및/또는 대칭성을 고려하여 결정될 수 있다.
기-정의된 인트라 예측 모드는 소정의 각도를 가진 방향성 모드를 포함할 수 있다. 방향성 모드는 수평 방향성을 가진 제1 모드 그룹과 수직 방향성을 가진 제2 모드 그룹으로 구분될 수 있다. 방향성 모드의 개수가 65개인 경우를 가정하면, 상기 제1 모드 그룹은 인덱스 2 내지 인덱스 34 사이에 속하는 모드로 구성되고, 상기 제2 모드 그룹은 인덱스 34 내지 인덱스 66 사이에 속하는 모드로 구성될 수 있다.
부호화/복호화 장치는, 제1 모드 그룹에 대한 매트릭스만을 정의하고, 제2 모드 그룹은 제1 모드 그룹에 대해 정의된 매트릭스를 동일하게 이용할 수 있다. 반대로, 부호화/복호화 장치는, 제2 모드 그룹에 대한 매트릭스만을 정의하고, 제1 모드 그룹은 제2 모드 그룹에 대해 정의된 매트릭스를 동일하게 이용할 수 있다. 이 경우, 기-약속된 매트릭스의 개수는 기-정의된 인트라 예측 모드 개수의 1/2배 값을 가질 수 있다. 일실시예로서, 상기 대칭성을 가지는 모드 그룹이 x개인 경우, 상기 기-약속된 매트릭스의 개수는 기-정의된 인트라 예측 모드 개수의 1/x배 값을 가질 수 있다. 여기서 x는 3,4 또는 그 이상일 수 있다.
상기 대칭성은, 각도 -45°를 가진 인트라 예측 모드를 기준으로, 수직 방향성을 가진 모드와 수평 방향성을 가진 모드 간의 예측 각도의 대칭성을 포함할 수 있다. 여기서, 방향성을 가진 인트라 예측 모드는 각 방향성에 따른 예측 각도(PredAngle)를 가진다. 여기서, 수직 방향성을 가진 모드는, 상기 각도가 -45°인 인트라 예측 모드를 기준으로, 해당 모드와 해당 모드부터 x축 방향으로 -45°<(PredAngle)≤45°의 각도를 가지는 모드들은 포함할 수 있다. 여기서, 수평 방향성 가진 모드는, 상기 각도가 -45°인 인트라 예측 모드를 기준으로, 해당 모드를 제외하고 해당 모드로부터 y축 방향으로 -45°<(PredAngle)≤45°의 각도를 가지는 모드들을 포함할 수 있다.
도 5를 참조하면, 참조 샘플 및 매트릭스를 기반으로 현재 블록을 예측할 수 있다(S530).
S510에서 참조 샘플이 결정되고, S520에서 매트릭스가 결정되면, 부호화/복호화 장치는 상기 참조 샘플 및 매트릭스를 기반으로 현재 블록을 예측할 수 있다.
상기 현재 블록을 예측하는 단계는 상기 참조 샘플에 상기 매트릭스를 적용하여 DS 블록의 예측 샘플(이하, 제1 예측 샘플이라 함)을 획득하는 단계를 포함할 수 있다. 상기 DS 블록은 현재 블록을 의미할 수도 있고, 다운샘플링된 현재 블록을 의미할 수도 있다. 즉, DS 블록은 현재 블록과 동일한 크기를 가질 수도 있고, 현재 블록의 크기(너비 또는 높이 중 적어도 하나)의 1/2, 1/4, 1/8 또는 1/16인 크기를 가질 수도 있다. 예를 들어, 현재 블록이 4x4, 4x8 또는 8x4 블록인 경우, DS 블록은 4x4 블록일 수 있다. 또는, 현재 블록이 8x8, 8x16 또는 16x8 블록인 경우, DS 블록은 4x4 또는 8x8 블록일 수 있다. 또는, 현재 블록이 16x16보다 크거나 같은 경우, DS 블록은 8x8 또는 16x16 블록일 수 있다. 다만, DS 블록은 정방형 블록에 한하지 않으며, 비정방형 블록일 수도 있다. 또는, DS 블록은 정방형 블록으로 제한될 수도 있다. 여기서, 상기 매트릭스의 적용은 상기 참조 샘플에 상기 매트릭스로부터 얻는 가중치를 곱하는 것을 포함할 수 있다.
상기 제1 예측 샘플을 얻는 단계는 offset 값을 더하는 단계 또는 필터링 단계 중 적어도 하나를 포함할 수 있다.
상기 제1 예측 샘플을 얻는 단계는, 제1 예측 샘플을 재배열하는 단계를 더 포함할 수도 있다. 상기 재배열은, 하나의 매트릭스에 복수개의 인트라 예측 모드가 매칭되는 경우에 한하여 수행될 수 있다.
또는, 상기 재배열은, 현재 블록의 인트라 예측 모드가 수평 방향성을 가진 제1 모드 그룹에 속하는 경우에 한하여 수행될 수 있다. 예를 들어, 현재 블록의 인트라 예측 모드가 수평 방향성을 가진 제1 모드 그룹에 속하는 경우, DS 블록의 제1 예측 샘플에 대한 재배열을 수행하고, 현재 블록의 인트라 예측 모드가 수직 방향성을 가진 제2 모드 그룹에 속하는 경우, DS 블록의 제1 예측 샘플에 대한 재배열을 수행하지 않을 수 있다.
반대로, 상기 재배열은, 현재 블록의 인트라 예측 모드가 수직 방향성을 가진 제2 모드 그룹에 속하는 경우에 한하여 수행될 수 있다. 예를 들어, 현재 블록의 인트라 예측 모드가 수평 방향성을 가진 제1 모드 그룹에 속하는 경우, DS 블록의 제1 예측 샘플에 대한 재배열을 수행하지 않고, 현재 블록의 인트라 예측 모드가 수직 방향성을 가진 제2 모드 그룹에 속하는 경우, DS 블록의 제1 예측 샘플에 대한 재배열을 수행할 수 있다.
상기 재배열은, 다음 수학식 1과 같이 수행될 수 있다. 여기서, x는 x축 좌표값, y는 y축 좌표 값을 의미할 수 있다. 즉, 상기 재배열은 (x,y) 좌표의 제1 예측 샘플을 (y,x) 좌표에 할당하는 과정을 의미할 수 있다.
[수학식 1]
제1_예측_샘플[x][y] = 제1_예측_샘플[y][x]
또는, 본 발명에 따른 재배열은, 제1 예측 샘플로 구성된 DS 블록은 소정의 각도로 회전하는 과정을 의미할 수도 있다. 여기서, 소정의 각도는, 시계 방향으로 90도 또는 180도를 의미할 수도 있고, 반시계 방향으로 90도 또는 180도를 의미할 수도 있다.
상기 현재 블록을 예측하는 단계는, 상기 현재 블록에 인접한 기-복원된 샘플 또는 상기 제1 예측 샘플 중 적어도 하나를 기반으로 업샘플링을 수행하여 제2 예측 샘플을 획득하는 단계를 더 포함할 수 있다.
상기 업샘플링에 있어서, 상기 업샘플링의 수행 여부 또는 상기 업샘플링의 방법 중 적어도 하나는 현재 블록의 부호화 정보에 기초하여 결정될 수 있다. 예를 들어, 상기 업샘플링의 수행 여부 또는 상기 업샘플링의 방법 중 적어도 하나는, 상기 제1 예측 샘플로 구성된 DS 블록의 크기와 현재 블록의 크기를 기반으로 결정될 수 있다. 상기 블록 크기는, 너비 또는 높이 중 어느 하나, 너비와 높이 중 최소값/최대값, 너비와 높이의 합, 블록에 속한 샘플의 개수 등으로 표현될 수 있다.
상기 업샘플링 수행 여부는 상기 제1 예측 샘플로 구성된 DS 블록의 크기가 상기 현재 블록의 크기보다 작은 경우에만 수행되도록 결정될 수 있다.
상기 업샘플링 수행 방법은 상기 제1 예측 샘플로 구성된 DS 블록의 크기와 상기 현재 블록의 크기의 비율을 이용하여 상기 제1 예측 샘플을 상기 현재 블록 내의 소정의 위치에 할당하는 단계와, 상기 현재 블록 내 나머지 영역을 보간하는 단계를 포함할 수 있다. 상기 나머지 영역은, 현재 블록 내에서 상기 제1 예측 샘플이 할당된 영역을 제외한 영역을 의미할 수 있다. 상기 제1 예측 샘플의 할당 및 나머지 영역에 대한 보간 방법에 대해서는 도 8 내지 도 10을 참조하여 자세히 살펴보기로 한다.
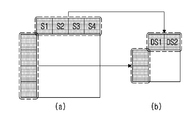
도 6은 본 발명이 적용되는 일실시예로서, 주변 영역을 다운샘플링하여 참조 샘플을 결정하는 방법을 도시한 것이다.
도 6을 참조하면, 도 6-(a)는 인트라 예측을 위한 주변 영역이 현재 블록의 좌측 및 상단에 위치하는 경우를 도시한다. 또한, 일실시예로서, 현재 블록의 좌측에 위치한 샘플 라인은 현재 블록에 접해있고, 수직 방향의 1개 샘플 라인으로 구성된다. 현재 블록의 상단에 위치한 샘플 라인은 현재 블록에 접해있고, 수평 방향의 1개 샘플 라인으로 구성된다.
상기 참조 샘플은 상기 현재 블록의 주변 영역을 다운샘플링하여 형성된 다운샘플링된 영역을 포함할 수 있다.
상기 다운샘플링된 영역은 상기 주변 영역에 속한 전체 또는 일부 샘플의 평균값, 최대값, 최소값, 최빈값, 또는 필터링된 값으로 유도될 수 있다.
상기 평균값으로 유도되는 경우, 상기 다운샘플링된 영역은 서로 다른 N개의 샘플들의 평균값을 다운샘플링된 영역의 샘플에 할당하는 방법으로 형성될 수 있다.
상기 서로 다른 N개의 샘플은 연속적으로 배열된 샘플이거나, 일정 간격을 두고 상호 떨어져 있을 수 있다. 상기 일정 간격은 하나 또는 그 이상의 샘플 크기의 간격이다. 상기 간격이 복수개인 경우, 상기 복수개의 간격들은 균등하거나 불균등할 수 있다. (여기서, N은 2이상이고, 상기 주변 영역에 속한 샘플들의 총 개수'이하이다.) 또한, 상기 서로 다른 N개의 샘플들의 집합을 샘플 그룹이라고 부르기로 한다. 이때, 제1 샘플 그룹과 제2 샘플 그룹은 겹칠 수도 있고, 겹치지 않을 수도 있다.
일실시예로서, 도 6은, N이 2이고, 2개의 샘플 그룹이 서로 겹지치 않으며, 각 샘플 그룹에 속하는 2개의 샘플들의 평균값을 다운샘플링된 영역 내 1개의 샘플에 각각 할당하여 다운샘플링 하는 것을 도시한다.
또는, 연속적인 3개의 샘플(S1, S2, S3)로 제1 샘플 그룹이 구성될 수 있고, 제1 샘플 그룹에 속한 3개의 샘플의 평균값을 다운샘플링된 영역의 샘플(DS1)에 할당할 수 있다. 연속적인 3개의 샘플(S2, S3, S4)로 제2 샘플 그룹이 구성될 수 있고, 제2 샘플 그룹에 속한 3개의 샘플의 평균값을 다운샘플링된 영역의 샘플(DS2)에 할당할 수 있다.
또는, 제1 샘플 그룹에 속한 2개의 샘플(S1, S2) 중 최소값 또는 최대값을 결정하고, 이를 다운샘플된 영역의 샘플(DS1)에 할당할 수 있다. 마찬가지로, 제2 샘플 그룹에 속한 2개의 샘플(S3, S4) 중 최소값 또는 최대값을 결정하고, 이를 다운샘플된 영역의 샘플(DS2)에 할당할 수 있다. 이는, 제1/제2 샘플 그룹이 3개의 샘플로 구성된 경우에도 동일하게 이용될 수 있다.
또는, 상단 주변 영역에 있어서, 제1 샘플 그룹에 속한 복수의 샘플 중 기-정의된 위치의 샘플이 다운샘플링된 영역의 샘플(DS1)에 할당되고, 제2 샘플 그룹에 속한 복수의 샘플 중 기-정의된 위치의 샘플이 다운샘플링된 영역의 샘플(DS2)에 할당될 수 있다. 상기 기-정의된 위치는, 부호화/복호화 장치에 기-약속된 고정된 위치를 의미하며, 일예로 최좌측, 최우측 또는 중앙 위치 중 어느 하나일 수 있다. 좌측 주변 영역에서도, 각 샘플 그룹에 속한 복수의 샘플 중 기-정의된 위치의 샘플이 다운샘플링된 영역의 샘플에 각각 할당될 수 있다. 이때, 기-정의된 위치는, 최상단, 최하단 또는 중앙 위치 중 어느 하나일 수 있다.
도 7은 본 발명이 적용되는 일실시예로서, 가중 평균에 기반한 다운샘플링 방법을 도시한다.
본 실시예에서, 평균값은  (이하, 제1 평균식)으로 계산되거나,
(이하, 제1 평균식)으로 계산되거나,  (이하, 제2 평균식)으로 계산될 수 있다.
(이하, 제2 평균식)으로 계산될 수 있다.
도 7-(a)은, 전술한 샘플 그룹이 3개의 샘플로 구성된 경우이다. 이 경우, 3개의 샘플에 적용되는 가중치는 1:2:1의 비율로 결정될 수 있다. 도 7-(b)와 같이 샘플 그룹이 5개의 샘플로 구성된 경우, 상기 가중치는 1:1:4:1:1의 비율로 걸정될 수 있다. 도 7-(c)와 같이 샘플 그룹이 6개의 샘플로 구성된 경우, 상기 가중치는, 좌측 상단을 시작점으로 하여, Z방향으로, 1:2:1:2:2:1 또는 1:2:2:1:2:1의 비율로 결정될 수 있다. 또한, 상기 도 7-(a)와 (c)는 상단 주변 영역에 적용되는 가중치를 도시하고 있으나, 이는 좌측 주변 영역에도 동일하게 적용될 수 있다.
상기 평균값은, 상기 제1 평균식 또는 제2 평균식으로 계산된 복수개의 평균값들에 소정의 연산을 적용하여 나온 결과값을 포함할 수도 있다. 여기서, 소정의 연산은 전술한 제1 평균식 또는 제2 평균식일 수 있다. 예를 들면, 샘플 그룹에 3개의 샘플(즉, 제1 내지 제3 샘플)이 속한 경우, 제1 샘플과 제2 샘플 간의 평균값(제1 값), 그리고 제2 샘플과 제3 샘플 간의 평균값(제2 값)을 각각 산출할 수 있다. 상기 평균값은, 산출된 제1 값 및 제2 값 간의 평균값으로 유도될 수 있다.
전술한 다운샘플링 방법은, 상단 주변 영역에 대해서만 적용될 수도 있고, 반대로 좌측 주변 영역에 대해서만 적용될 수도 있다. 또는, 도 6에 따른 다운샘플링 방법(이하, 제1 방법이라 함)은 상단 또는 좌측 주변 영역 중 어느 하나에 적용되고, 도 7에 따른 다운샘플링 방법(이하 제2 방법이라 함)은 상단 또는 좌측 주변 영역 중 다른 하나에 적용될 수 있다.
또한, 현재 블록의 크기/형태를 고려하여, 제1 방법 또는 제2 방법 중 적어도 하나를 선택적으로 이용할 수 있다. 예를 들어, 현재 블록의 너비가 소정의 문턱값보다 큰 경우, 현재 블록의 상단 주변 영역에는 제1 방법이 적용되고, 그렇지 않은 경우, 제2 방법이 적용될 수 있다. 현재 블록의 높이도 동일한 방식으로 다운샘플링이 수행될 수 있다. 또는, 현재 블록이 비정방향인 경우, 상단 또는 좌측 주변 영역 중 어느 하나에는 제1 방법이 적용되고, 다른 하나에는 제2 방법이 적용될 수 있다. 이때, 현재 블록의 너비가 높이보다 큰 경우, 상단 주변 영역에 제1 방법이, 좌측 주변 영역에 제2 방법이 각각 적용될 수 있다. 반대로, 현재 블록의 너비가 높이보다 작은 경우, 상단 주변 영역에 제2 방법이, 좌측 주변 영역에 제1 방법이 각각 적용될 수 있다. 현재 블록의 정방형인 경우, 상단 및 좌측 주변 영역에 동일한 다운샘플링 방법이 적용될 수 있으며, 여기서 다운샘플링 방법은 상기 제1 방법으로 제한될 수도 있다.
도 8은 본 발명이 적용되는 일실시예로서, 제1 예측 샘플의 할당 및 나머지 영역에 대한 보간 방법을 도시한 것이다.
도 8-(a) 를 참조하면, DS 블록의 예측 샘플은, 현재 블록 내 소정의 위치의 예측 샘플에 할당될 수 있다. 여기서, 소정의 위치는, 현재 블록과 DS 블록 간의 크기 비율을 고려하여 결정될 수 있다. 예를 들어, DS 블록과 현재 블록 간 예측 샘플의 대응 관계는 다음 수학식 2와 같이 정의될 수 있다.
[수학식 2]
여기서, r은 현재 블록과 DS 블록 간의 크기 비율을 의미하고,, x,y는 각각 DS 블록 내 제1 예측 샘플의 x축,y축 좌표이다. 제1 예측_샘플_curBLK은 현재 블록 내 제1 예측 샘플의 위치를 의미하고, 제1_예측_샘플_dsBLK는 DS 블록 내 제1 예측 샘플의 위치를 의미할 수 있다.
상기 보간 단계는, 도 8-(b)를 참조하면, 현재 블록 내에서 상기 제1 예측 샘플이 할당되지 않은 샘플(이하, 보간 대상 샘플)은, 현재 블록에 할당된 상기 제1 예측 샘플 또는 상기 현재 블록에 인접한 기-복원된 샘플 중 적어도 하나(이하, 보간 참조 샘플)를 이용하여 유도될 수 있다. 또한, 상기 보간 참조 샘플은, 현재 보간 대상 샘플 이전에 보간을 통해 생성된 예측 샘플(즉, 이전 보간 대상 샘플)을 더 포함할 수도 있다.
상기 현재 블록에 인접한 기-복원된 샘플의 위치 및 범위는, 전술한 참조 샘플과 동일하므로 자세한 설명은 생략한다.
보간 대상 샘플의 위치에 따라서, 상기 보간 참조 샘플은 복수의 제1 예측 샘플로 구성될 수도 있고, 적어도 하나의 제1 예측 샘플과 적어도 하나의 기-복원된 주변 샘플로 구성될 수도 있다. 상기 기-복원된 주변 샘플은, 보간 대상 샘플과 동일한 x 좌표 또는 y 좌표를 가진 샘플 중 어느 하나가 선택적으로 이용될 수도 있고, 보간 대상 샘플과 동일한 x 좌표 또는 y 좌표 중 적어도 하나가 동일한 복수의 샘플을 이용할 수도 있다. 상기 선택은, 보간 대상 샘플의 위치에 기반하여 수행될 수 있다. 예를 들어, 보간 대상 샘플이 제1 예측 샘플과 동일한 x 좌표를 가진 경우, 기-복원된 주변 샘플은 보간 대상 샘플과 동일한 x 좌표를 가진 샘플만이 포함할 수 있다. 반대로, 보간 대상 샘플이 제1 예측 샘플과 동일한 y 좌표를 가진 경우, 기-복원된 주변 샘플은 보간 대상 샘플과 동일한 y 좌표를 가진 샘플만을 포함할 수 있다. 또는, 기-복원된 주변 샘플은, 보간 대상 샘플과 동일한 수평 및 수직 라인에 위치한 복수의 샘플을 포함할 수도 있다.
상기 보간 대상 샘플은, 복수의 보간 참조 샘플의 대표값으로 유도될 수 있으며, 여기서, 대표값은 평균값, 최소값, 최대값, 최빈값, 또는 중간값 중 적어도 하나를 포함할 수 있다.
상기 평균값은  (이하, 제1 평균식)으로 계산되거나,
(이하, 제1 평균식)으로 계산되거나,  (이하, 제2 평균식)으로 계산될 수 있다. 제2 평균식에 따른 가중치는, 보간 대상 샘플과 보간 참조 샘플 간의 상대적/절대적 거리에 기초하여 결정될 수 있으며, 이는 도 9를 참조하여 자세히 살펴 보기로 한다.
(이하, 제2 평균식)으로 계산될 수 있다. 제2 평균식에 따른 가중치는, 보간 대상 샘플과 보간 참조 샘플 간의 상대적/절대적 거리에 기초하여 결정될 수 있으며, 이는 도 9를 참조하여 자세히 살펴 보기로 한다.
도 9는 본 발명이 적용되는 일실시예로서, 보간 단계에서 거리에 대한 가중치를 부여하는 것을 도시한 것이다.
본 발명에 따른 가중치는 보간 대상 샘플으로부터 보간 참조 샘플까지의 거리를 기반으로 결정되는 가중치를 포함할 수 있다. 일실시예로, 도 9를 참조하면, 제1 보간 대상 블록(910)을 보간하는 경우, 제1 보간 대상 샘플(910)로부터 제1 보간 참조 샘플(911)과 제2 보간 참조 샘플(912)의 각각의 거리의 비는 3:1이므로, 제1 보간 참조 샘플(911)과 제2 보간 참조 샘플에 적용되는 가중치는 비는 1:3일 수 있다. 제2 보간 대상 샘플(920)을 보간하는 경우, 제2 보간 대상 샘플(920)로부터 제1 보간 참조 샘플(921)과 제2 보간 참조 샘플(922)의 각각의 거리의 비는 1:1이므로, 제1 및 제2 보간 참조 블록(921, 922)에 적용되는 가중치의 비는 1:1일 수 있다.
또한, 본 발명에 따른 보간 필터는 방향성을 가질 수 있다. 상기 방향성은 수직, 수평, 지그재그, 대각선 등의 방향을 포함할 수 있다.
상기 보간 단계는, 소정의 우선 순서에 기초하여 수행될 수 있다. 상기 우선 순서는 수직 방향으로 보간 후 수평 방향으로 보간하는 경우(제1 순서) 또는 수평 방향으로 보간 후 수직 방향으로 보간하는 경우(제2 순서) 중 어느 하나일 수 있다. 또는 수직 방향 및 수평 방향을 병행하여 보간(제3 순서)이 수행될 수도 있다.
현재 블록은 전술한 제1 순서 내지 제3 순서 중 어느 하나만을 이용하여 보간될 수도 있고, 제1 순서 내지 제3 순서 중 적어도 2개의 조합을 이용하여 보간될 수도 있다. 보간 순서에 대해서는 도 10을 참조하여 자세히 살펴 보도록 한다.
도 10은 본 발명이 적용되는 일실시예로서, 보간 단계의 순서를 도시한 것이다.
도 10-(a)는, 도 9에서의 제1 순서에 관한 것이다. 구체적으로, 제1 예측 샘플이 속한 수직 라인을 먼저 보간하고, 보간된 라인과 현재 블록 좌측의 보간 참조 샘플을 기반으로, 수평 라인을 보간할 수 있다.
도 10-(b)는, 도 9에서의 제2 순서에 관한 것이다. 구체적으로, 제1 예측 블록이 속한 수평 라인을 먼저 보간하고, 보간된 라인과 현재 블록 상단의 보간 참조 샘플을 기반으로, 수직 라인을 보간할 수 있다.
도 10-(c)는 도 9에서의 제3 순서에 관한 것이다. 먼저, 제1 예측 샘플이 속한 수직 및 수평 라인을 보간할 수 있다. 그런 다음, 보간되지 않은 남은 샘플에 대해서 보간을 수행하며, 이때 보간은 수직 라인으로만 수행되거나, 수평 라인으로만 수행되거나, 또는 수직 및 수평 라인으로 수행될 수 있다. 상기 수직 및 수평 라인으로 보간하는 경우, 하나의 보간 대상 샘플은 수직 라인으로의 제1 보간 값 및 수평 라인으로의 제2 보간 값을 모두 가질 수 있다. 이 경우, 제1 보간 값과 제2 보간 값 간의 대표값을 상기 보간 대상 샘플에 할당할 수 있다. 여기서, 대표값은 평균값, 최소값, 최대값, 최빈값, 또는 중간값으로 유도될 수 있다.
상기 보간 순서는, 부호화/복호화 장치에 기-약속된 순서일 수도 있고, 현재 블록의 부호화 정보에 기초하여 선택적으로 결정될 수도 있다. 여기서, 부호화 정보는 전술한 바와 같은바, 여기서 자세한 설명은 생략하기로 한다.
상기 순서는 블록 크기에 기반하여 결정될 수 있다. 상기 블록 크기는 너비 또는 높이 중 어느 하나, 너비와 높이 중 최소값/최대값, 너비와 높이의 합, 블록에 속한 샘플의 개수 등으로 표현될 수 있다.
예를 들면, 현재 블록의 크기가 소정의 문턱값보다 큰 경우에는 상기 제1 보간을 수행할 수 있고, 그렇지 않은 경우에는 상기 제2 보간을 수행할 수 있다. 이와 달리, 현재 블록의 크기가 소정의 문턱값보다 큰 경우에는 상기 제2 보간을 수행할 수 있고, 그렇지 않은 경우에는 상기 제1 보간을 수행할 수 있다. 상기 문턱값은, 8, 16, 32 또는 그 이상의 자연수일 수 있다.
Claims (7)
- 현재 블록의 인트라 예측 모드를 결정하는 단계;
상기 현재 블록의 인트라 예측을 위한 참조 샘플을 결정하는 단계;
상기 인트라 예측 모드를 기반으로, 소정의 매트릭스를 결정하는 단계; 및
상기 참조 샘플 및 매트릭스를 기반으로, 상기 현재 블록을 예측하는 단계를 포함하는, 비디오 신호 처리 방법. - 제1항에 있어서,
상기 참조 샘플을 결정하는 단계는,
상기 현재 블록의 주변 영역을 결정하는 단계; 및
상기 결정된 주변 영역을 다운샘플링하는 단계를 포함하는, 비디오 신호 처리 방법. - 제2항에 있어서,
상기 주변 영역은 복수의 샘플 그룹으로 구분되고,
상기 샘플 그룹은 하나 또는 그 이상의 샘플로 구성되며,
상기 샘플 그룹의 대표값이 상기 참조 샘플로 결정되고,
상기 대표값은 평균값, 최소값, 최대값, 최빈값, 또는 중간값 중 어느 하나인, 비디오 신호 처리 방법. - 제1항에 있어서,
상기 매트릭스는, 상기 현재 블록의 부호화 정보를 더 고려하여 결정되고,
상기 부호화 정보는, 상기 현재 블록의 크기, 형태, 인트라 예측 모드의 각도 또는 방향성을 포함하는, 비디오 신호 처리 방법. - 제1항에 있어서,
상기 현재 블록을 예측하는 단계는,
상기 참조 샘플에 상기 매트릭스를 적용하여 예측 블록을 생성하는 단계를 포함하는, 비디오 신호 처리 방법. - 제5항에 있어서,
상기 현재 블록을 예측하는 단계는,
상기 생성된 예측 블록의 예측 샘플 전부 또는 일부를 재배열하는 단계를 더 포함하는, 비디오 신호 처리 방법. - 제5항에 있어서,
상기 현재 블록을 예측하는 단계는,
상기 예측 블록 또는 상기 현재 블록에 인접한 기-복원된 샘플 중 적어도 하나를 기반으로, 상기 현재 블록을 보간하는 단계를 더 포함하는, 비디오 신호 처리 방법.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR20180107255 | 2018-09-07 | ||
| KR1020180107255 | 2018-09-07 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20200028856A true KR20200028856A (ko) | 2020-03-17 |
Family
ID=69722959
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020190110217A KR20200028856A (ko) | 2018-09-07 | 2019-09-05 | 인트라 예측을 이용한 영상 부호화/복호화 방법 및 장치 |
Country Status (15)
| Country | Link |
|---|---|
| US (5) | US11477439B2 (ko) |
| EP (1) | EP3833021A4 (ko) |
| JP (1) | JP7448526B2 (ko) |
| KR (1) | KR20200028856A (ko) |
| CN (4) | CN113225557B (ko) |
| AU (1) | AU2019336038A1 (ko) |
| BR (1) | BR112021004024A2 (ko) |
| CA (1) | CA3111982C (ko) |
| CL (1) | CL2021000527A1 (ko) |
| IL (1) | IL281221A (ko) |
| MX (1) | MX2021002608A (ko) |
| PH (1) | PH12021550480A1 (ko) |
| SG (1) | SG11202102238SA (ko) |
| WO (1) | WO2020050684A1 (ko) |
| ZA (1) | ZA202101569B (ko) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022186620A1 (ko) * | 2021-03-04 | 2022-09-09 | 현대자동차주식회사 | 인트라 예측의 예측 신호를 개선하는 비디오 코딩방법 및 장치 |
| WO2023204624A1 (ko) * | 2022-04-20 | 2023-10-26 | 엘지전자 주식회사 | Cccm(convolutional cross-component model) 예측에 기반한 영상 부호화/복호화 방법, 장치 및 비트스트림을 저장하는 기록 매체 |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IL281625B2 (en) | 2018-09-21 | 2024-03-01 | Guangdong Oppo Mobile Telecommunications Corp Ltd | A method for encoding/decoding image signals and a device therefor |
| SG11202102788YA (en) | 2018-09-21 | 2021-04-29 | Guangdong Oppo Mobile Telecommunications Corp Ltd | Image signal encoding/decoding method and device therefor |
| WO2020117010A1 (ko) | 2018-12-07 | 2020-06-11 | 삼성전자 주식회사 | 비디오 복호화 방법 및 장치, 비디오 부호화 방법 및 장치 |
| CA3113787C (en) | 2018-12-25 | 2024-02-13 | Guangdong Oppo Mobile Telecommunications Corp., Ltd. | Decoding prediction method, apparatus and computer storage medium which use reference samples adjacent to at least one side of decoding block |
| JP7299342B2 (ja) | 2019-04-12 | 2023-06-27 | 北京字節跳動網絡技術有限公司 | ビデオ処理方法、装置、記憶媒体、及び記憶方法 |
| JP7403555B2 (ja) | 2019-04-16 | 2023-12-22 | 北京字節跳動網絡技術有限公司 | イントラコーディングモードにおけるマトリクスの導出 |
| CN113812150B (zh) | 2019-05-01 | 2023-11-28 | 北京字节跳动网络技术有限公司 | 使用滤波的基于矩阵的帧内预测 |
| CN113728647B (zh) | 2019-05-01 | 2023-09-05 | 北京字节跳动网络技术有限公司 | 基于矩阵的帧内预测的上下文编码 |
| JP2022533190A (ja) | 2019-05-22 | 2022-07-21 | 北京字節跳動網絡技術有限公司 | アップサンプリングを使用した行列ベースのイントラ予測 |
| KR20220013939A (ko) | 2019-05-31 | 2022-02-04 | 베이징 바이트댄스 네트워크 테크놀로지 컴퍼니, 리미티드 | 행렬 기반 인트라 예측에서의 제한된 업샘플링 프로세스 |
| KR20210138115A (ko) * | 2019-06-03 | 2021-11-18 | 엘지전자 주식회사 | 매트릭스 기반 인트라 예측 장치 및 방법 |
| CN113950836B (zh) | 2019-06-05 | 2024-01-12 | 北京字节跳动网络技术有限公司 | 基于矩阵的帧内预测的上下文确定 |
| KR20220082847A (ko) | 2019-10-28 | 2022-06-17 | 베이징 바이트댄스 네트워크 테크놀로지 컴퍼니, 리미티드 | 색상 성분에 기초한 신택스 시그널링 및 파싱 |
| CN117426088A (zh) * | 2021-09-17 | 2024-01-19 | Oppo广东移动通信有限公司 | 视频编解码方法、设备、系统、及存储介质 |
Family Cites Families (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20080082143A (ko) * | 2007-03-07 | 2008-09-11 | 삼성전자주식회사 | 영상 부호화 방법 및 장치, 복호화 방법 및 장치 |
| US8705619B2 (en) * | 2010-04-09 | 2014-04-22 | Sony Corporation | Directional discrete wavelet transform (DDWT) for video compression applications |
| CN102972028B (zh) * | 2010-05-17 | 2015-08-12 | Lg电子株式会社 | 新的帧内预测模式 |
| US9258573B2 (en) | 2010-12-07 | 2016-02-09 | Panasonic Intellectual Property Corporation Of America | Pixel adaptive intra smoothing |
| US10992958B2 (en) * | 2010-12-29 | 2021-04-27 | Qualcomm Incorporated | Video coding using mapped transforms and scanning modes |
| US20120218432A1 (en) | 2011-02-28 | 2012-08-30 | Sony Corporation | Recursive adaptive intra smoothing for video coding |
| US20130336398A1 (en) * | 2011-03-10 | 2013-12-19 | Electronics And Telecommunications Research Institute | Method and device for intra-prediction |
| US8861593B2 (en) * | 2011-03-15 | 2014-10-14 | Sony Corporation | Context adaptation within video coding modules |
| KR20120140181A (ko) * | 2011-06-20 | 2012-12-28 | 한국전자통신연구원 | 화면내 예측 블록 경계 필터링을 이용한 부호화/복호화 방법 및 그 장치 |
| CN104954805B (zh) * | 2011-06-28 | 2019-01-04 | 三星电子株式会社 | 用于使用帧内预测进行图像编码和解码的方法和设备 |
| KR102173630B1 (ko) | 2011-09-15 | 2020-11-03 | 브이아이디 스케일, 인크. | 공간 예측을 위한 시스템들 및 방법들 |
| KR20130037161A (ko) * | 2011-10-05 | 2013-04-15 | 한국전자통신연구원 | 스케일러블 비디오 코딩을 위한 향상된 계층간 움직임 정보 예측 방법 및 그 장치 |
| US9036704B2 (en) | 2011-10-24 | 2015-05-19 | Infobridge Pte. Ltd. | Image decoding method using intra prediction mode |
| WO2015182342A1 (ja) * | 2014-05-26 | 2015-12-03 | シャープ株式会社 | 画像復号装置、および、画像符号化装置 |
| GB2557809B (en) * | 2015-08-28 | 2021-12-01 | Kt Corp | Method and device for processing video signal |
| JPWO2017068856A1 (ja) * | 2015-10-21 | 2018-08-09 | シャープ株式会社 | 予測画像生成装置、画像復号装置および画像符号化装置 |
| CN108370441B (zh) * | 2015-11-12 | 2022-07-12 | Lg 电子株式会社 | 在图像编译系统中用于系数引起的帧内预测的方法和装置 |
| US10812807B2 (en) * | 2016-06-03 | 2020-10-20 | Lg Electronics Inc. | Intra-prediction method and apparatus in image coding system |
| US10484712B2 (en) * | 2016-06-08 | 2019-11-19 | Qualcomm Incorporated | Implicit coding of reference line index used in intra prediction |
| CN117221602A (zh) | 2016-06-22 | 2023-12-12 | Lx 半导体科技有限公司 | 图像编码/解码设备以及传输图像数据的设备 |
| PL3477951T3 (pl) | 2016-06-24 | 2022-05-02 | Kt Corporation | Adaptacyjne filtrowanie pikseli referencyjnych dla predykcji wewnątrzobrazowej z wykorzystaniem oddalonych linii pikseli |
| KR102383104B1 (ko) * | 2016-06-24 | 2022-04-06 | 주식회사 케이티 | 비디오 신호 처리 방법 및 장치 |
| US10477240B2 (en) * | 2016-12-19 | 2019-11-12 | Qualcomm Incorporated | Linear model prediction mode with sample accessing for video coding |
| CA3065922A1 (en) * | 2017-09-08 | 2019-03-14 | Kt Corporation | Method and device for processing video signal |
| CN111373755A (zh) * | 2017-11-16 | 2020-07-03 | 韩国电子通信研究院 | 图像编码/解码方法和装置以及存储比特流的记录介质 |
| KR20230008911A (ko) * | 2017-12-15 | 2023-01-16 | 엘지전자 주식회사 | 변환에 기반한 영상 코딩 방법 및 그 장치 |
| BR122021019686B1 (pt) * | 2017-12-21 | 2022-05-24 | Lg Electronics Inc | Método de decodificação/codificação de imagem realizado por um aparelho de decodificação/ codificação, aparelho de decodificação/codificação para decodificação / codificação de imagem, método e aparelho de transmissão de dados que compreende um fluxo de bits para uma imagem e mídia de armazenamento digital legível por computador não transitória |
| GB2587982B (en) * | 2018-06-08 | 2023-01-04 | Kt Corp | Method and apparatus for processing video signal |
| WO2020005045A1 (ko) | 2018-06-30 | 2020-01-02 | 김기백 | 머지 모드 기반의 인터 예측 방법 및 장치 |
| US10404980B1 (en) * | 2018-07-10 | 2019-09-03 | Tencent America LLC | Intra prediction with wide angle mode in video coding |
-
2019
- 2019-09-05 KR KR1020190110217A patent/KR20200028856A/ko active Search and Examination
- 2019-09-06 WO PCT/KR2019/011554 patent/WO2020050684A1/ko unknown
- 2019-09-06 CN CN202110462138.3A patent/CN113225557B/zh active Active
- 2019-09-06 CA CA3111982A patent/CA3111982C/en active Active
- 2019-09-06 CN CN201980056309.3A patent/CN112806001A/zh active Pending
- 2019-09-06 JP JP2021512701A patent/JP7448526B2/ja active Active
- 2019-09-06 EP EP19858139.9A patent/EP3833021A4/en active Pending
- 2019-09-06 SG SG11202102238SA patent/SG11202102238SA/en unknown
- 2019-09-06 MX MX2021002608A patent/MX2021002608A/es unknown
- 2019-09-06 BR BR112021004024-2A patent/BR112021004024A2/pt unknown
- 2019-09-06 CN CN202310429492.5A patent/CN116389742A/zh active Pending
- 2019-09-06 AU AU2019336038A patent/AU2019336038A1/en active Pending
- 2019-09-06 CN CN202310426208.9A patent/CN116405679A/zh active Pending
-
2021
- 2021-03-03 IL IL281221A patent/IL281221A/en unknown
- 2021-03-03 CL CL2021000527A patent/CL2021000527A1/es unknown
- 2021-03-04 US US17/192,733 patent/US11477439B2/en active Active
- 2021-03-05 PH PH12021550480A patent/PH12021550480A1/en unknown
- 2021-03-08 ZA ZA2021/01569A patent/ZA202101569B/en unknown
-
2022
- 2022-09-15 US US17/932,627 patent/US20230024256A1/en active Pending
- 2022-09-15 US US17/932,632 patent/US20230024482A1/en active Pending
- 2022-09-15 US US17/932,585 patent/US20230026401A1/en active Pending
- 2022-09-15 US US17/932,636 patent/US20230026704A1/en active Pending
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022186620A1 (ko) * | 2021-03-04 | 2022-09-09 | 현대자동차주식회사 | 인트라 예측의 예측 신호를 개선하는 비디오 코딩방법 및 장치 |
| WO2023204624A1 (ko) * | 2022-04-20 | 2023-10-26 | 엘지전자 주식회사 | Cccm(convolutional cross-component model) 예측에 기반한 영상 부호화/복호화 방법, 장치 및 비트스트림을 저장하는 기록 매체 |
Also Published As
| Publication number | Publication date |
|---|---|
| SG11202102238SA (en) | 2021-04-29 |
| CN116405679A (zh) | 2023-07-07 |
| WO2020050684A1 (ko) | 2020-03-12 |
| JP2022501881A (ja) | 2022-01-06 |
| US11477439B2 (en) | 2022-10-18 |
| CL2021000527A1 (es) | 2021-08-20 |
| CA3111982C (en) | 2024-02-27 |
| AU2019336038A1 (en) | 2021-04-01 |
| ZA202101569B (en) | 2022-08-31 |
| IL281221A (en) | 2021-04-29 |
| US20230026401A1 (en) | 2023-01-26 |
| MX2021002608A (es) | 2021-05-12 |
| US20210195176A1 (en) | 2021-06-24 |
| CN113225557A (zh) | 2021-08-06 |
| EP3833021A1 (en) | 2021-06-09 |
| JP7448526B2 (ja) | 2024-03-12 |
| CN112806001A (zh) | 2021-05-14 |
| CN113225557B (zh) | 2023-06-20 |
| US20230024482A1 (en) | 2023-01-26 |
| US20230024256A1 (en) | 2023-01-26 |
| CA3111982A1 (en) | 2020-03-12 |
| US20230026704A1 (en) | 2023-01-26 |
| CN116389742A (zh) | 2023-07-04 |
| EP3833021A4 (en) | 2021-10-06 |
| BR112021004024A2 (pt) | 2021-05-25 |
| PH12021550480A1 (en) | 2021-10-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20200028856A (ko) | 인트라 예측을 이용한 영상 부호화/복호화 방법 및 장치 | |
| CN109417633B (zh) | 用于编码/解码视频信号的方法和装置 | |
| US11818354B2 (en) | Method and an apparatus for encoding/decoding residual coefficient | |
| CN109644281B (zh) | 用于处理视频信号的方法和设备 | |
| KR20240037910A (ko) | 영상 부호화/복호화 방법 및 장치 | |
| CN112262575A (zh) | 用于基于量化参数对残差块进行编码/解码的方法和装置 | |
| CN112262576A (zh) | 残差系数编码/解码方法和装置 | |
| RU2801823C2 (ru) | Способ и устройство для кодирования/декодирования изображений с использованием внутреннего предсказания | |
| RU2808540C2 (ru) | Способ и устройство для кодирования/декодирования изображений с использованием внутреннего предсказания | |
| KR102512179B1 (ko) | 잔차 계수 부호화/복호화 방법 및 장치 | |
| RU2809077C2 (ru) | Способ и устройство для кодирования/декодирования изображений с использованием внутреннего предсказания | |
| KR102390731B1 (ko) | 잔차 계수 부호화/복호화 방법 및 장치 | |
| KR20240019183A (ko) | 영상 부호화/복호화 방법 및 장치 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| N231 | Notification of change of applicant | ||
| A201 | Request for examination |