KR20170140808A - 단어 사이의 불확실성에 따른 단어 공백의 비대칭 포맷팅을 위한 시스템 및 방법 - Google Patents
단어 사이의 불확실성에 따른 단어 공백의 비대칭 포맷팅을 위한 시스템 및 방법 Download PDFInfo
- Publication number
- KR20170140808A KR20170140808A KR1020177028553A KR20177028553A KR20170140808A KR 20170140808 A KR20170140808 A KR 20170140808A KR 1020177028553 A KR1020177028553 A KR 1020177028553A KR 20177028553 A KR20177028553 A KR 20177028553A KR 20170140808 A KR20170140808 A KR 20170140808A
- Authority
- KR
- South Korea
- Prior art keywords
- word
- text
- blank
- key
- lexical
- Prior art date
Links
Images




















Classifications
-
- G06F17/2294—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/163—Handling of whitespace
-
- G06F17/217—
-
- G06F17/218—
-
- G06F17/2247—
-
- G06F17/271—
-
- G06F17/277—
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/103—Formatting, i.e. changing of presentation of documents
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/103—Formatting, i.e. changing of presentation of documents
- G06F40/106—Display of layout of documents; Previewing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/103—Formatting, i.e. changing of presentation of documents
- G06F40/114—Pagination
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/103—Formatting, i.e. changing of presentation of documents
- G06F40/117—Tagging; Marking up; Designating a block; Setting of attributes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/10—Text processing
- G06F40/12—Use of codes for handling textual entities
- G06F40/14—Tree-structured documents
- G06F40/143—Markup, e.g. Standard Generalized Markup Language [SGML] or Document Type Definition [DTD]
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G06F40/211—Syntactic parsing, e.g. based on context-free grammar [CFG] or unification grammars
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/284—Lexical analysis, e.g. tokenisation or collocates
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Document Processing Apparatus (AREA)
- Machine Translation (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Circuits Of Receivers In General (AREA)
Abstract
단어 사이의 불확실성에 따라 단어 공백의 비대칭 포맷팅은 초기 필터링 프로세스 및 후속 텍스트 포맷팅 프로세스를 포함한다. 애매도 필터는 코퍼스 또는 단어 시퀀스 빈도 데이터(입력)로부터 키 및 값(출력)의 매핑을 생성한다. 값을 사용하여 키에 인접한 공백의 폭을 비대칭으로 조정하는 텍스트 포맷팅 프로세스를 포함한다. 키 및 값의 매핑을 생성하는 필터링 프로세스는 코퍼스를 분석하기 위해 한 번 수행되며, 일단 생성되면, 키-값 매핑은 후속 텍스트 처리 프로세스에 의해 여러 번 사용될 수 있다.
Description
관련 출원에 대한 상호 참조
본 출원은 2015년 3월 10일에 출원되고, 명칭이 "Systems And Methods For Asymmetrical Formatting Of Word Spaces According To The Uncertainty Between Words"인 미국 가출원 제62/131,187호의 우선권을 주장하며, 이는 그 전체가 참고로 본 명세서에 통합된다.
기술분야
본 발명은 독서 경험을 향상시키기 위해 단어 사이의 불확실성에 따른 텍스트 프리젠테이션(text presentation)에서 단어 간 공백(between-word space)의 폭을 비대칭적으로 포맷팅하는 것에 관한 것이다.
구문 포맷팅(phrase-formatting)은 종종 단어 공백을 구문 사이에서 더 크게 만들고, 구문 내에서는 단어 공백을 더 작게 만들어 문장 내의 구문이 강조되는 독서 경험을 향상시키기 위한 타이포그래피 기술(typographic technique)이다. 이러한 비대칭 단어 공백 사이징(sizing)은 독자가 의미 단위를 청킹(chunking)하는데 도움을 주기 위해 텍스트에 시각적 단서(visual cues)를 제공한다. 이러한 기술의 수동, 반자동 및 자동 사용은 독해력, 속도 및 즐거움을 향상시키는 것으로 입증되었다.
하나의 구문 포맷팅 시스템 및 방법(Bever and Robbart, 2006)은 3개의 계층 연결 모델: 입력 계층, "숨겨진(hidden)" 계층 및 출력 계층을 가진 인공 신경망을 사용한다. 이러한 인공 신경망은 텍스트 입력 데이터에 대해 교육하고, 구문 끊김(phrase break)의 가능성과 같은 패턴을 추출하며, 라이브러리에 저장된 모델 단위에 대한 가중치 및 연결 파일을 작성한다. 인공 신경망은 구두점 및 기능 단어의 라이브러리를 시작 데이터로서 사용하고, 텍스트 입력에 걸친 3개의 단어 시퀀스의 슬라이딩 윈도우를 검사하여 파서(parser)로부터의 텍스트를 분석한다.
이러한 교육 분석(training analysis) 중에, 세 단어 시퀀스의 제2 단어가 문장의 끝에 있을 가능성을 분류하는 방법을 학습한다. 구두점이나 관사 또는 기능 단어를 발견하면, 제1 단어 및 제3 단어를 기록하고, 라이브러리의 데이터 모델에 정보를 부가한다. 그렇지 않으면, 저장된 데이터 모델을 검사한다. 그 다음, 세 단어 시퀀스의 검사 결과에 기초하여, 신경망은 단어가 단어 사이의 공백에 구문의 시작 또는 끝이라는 우도(likelihood) 값을 할당한다.
텍스트의 코퍼스(corpus)에 대해 교육을 받으면, 신경망은 텍스트를 포맷팅하는데 사용될 수 있다. 포맷팅될 텍스트를 입력한 후, 신경망은 0 내지 3의 범위의 "C" 값을 결정하기 위해 실행되며, "3"은 구문 구두점의 끝을 나타내고, "2"는 큰 구문 끊김을 나타내고, "1"은 작은 구문 끊김을 나타내며, "0"은 모든 다른 끊김에 할당된다. 이러한 구문 경계가 설정되면, 텍스트 여백은 역 라인 순서로 한 라인씩 포맷팅된다. 그 다음, 각각의 라인의 이용 가능한 공백이 결정된 다음, 구문 경계 값과 이용 가능한 공백을 사용하여, 상대 공백 값이 할당된다.
다른 시스템 및 방법(Bever et al., 2012)은 문자 프로미넌스(character prominence)를 조정하기 위해 어휘 항목(단어)에 인접한 (구두점 및 공백과 같은) 어휘 이외의 정보의 정보성을 계산한다. 이러한 방법에서, 단어의 시작 또는 끝에 있는 공백의 정보성은 공백이 아닌 구두점 문자의 빈도(frequency)에 대한 공백 문자의 빈도에 비례한다. Bever et al.(2012)는 또한 어휘 단위 이후의 구두점의 예측 가능성과 다음 어휘 단위 이전의 구두점의 예측 가능성을 사용하여 구두점의 정보성이 계산되는 제2 방법을 설명한다:
(1) 단어가 구문의 시작 또는 끝이라는 가능성을 결정하거나, (2) 인공 신경망을 사용하거나, (3) 구문의 끝을 결정하거나 정보성을 계산하기 위해 구두점을 사용하지 않고 단어 간 공백의 폭을 비대칭으로 포맷팅하기 위한 시스템 및 방법을 갖는 것이 바람직하다.
참고 문헌


일 실시예는 초기 필터링 프로세스 및 후속 텍스트 포맷팅 프로세스를 포함한다. 제1 프로세스의 실시예는 코퍼스 또는 단어 시퀀스 빈도 데이터(입력)로부터의 키 및 값(출력)의 매핑을 생성하는 애매도 필터(equivocation filter)를 포함한다. 제2 프로세스의 실시예는 값을 사용하여 키에 인접한 공백의 폭을 비대칭적으로 조정하기 위한 텍스트 포맷팅 프로세스를 포함한다. 키와 값의 매핑을 생성하는 필터링 프로세스는 코퍼스를 분석하기 위해 한 번만 수행될 필요가 있을 뿐이지만, 일단 생성되면, 키-값(key-value) 매핑은 후속 텍스트 처리 프로세스에 의해 여러 번 사용될 수 있다.
일 실시예에서, 필터링 프로세스는 언어의 통계적 모델링을 포함하고, 지각 스팬 비대칭, 전략적으로 불확정 입력 데이터 및 정보 이론(perceptual span asymmetry, strategically indeterminate input data, and information theory)으로부터의 원리를 사용하여 단어 공백에 걸친 불확실성의 측정을 포함한다. 실시예에서, 필터에 대한 입력은 단어 시퀀스 빈도 카운트(n-gram)와 같은 파생어(derivatives)로 구성된다. 다른 실시예에서, 필터에 대한 입력은 단어 시퀀스 빈도 카운트(n-gram)가 생성될 수 있는 원시(raw) 코퍼스이다. 실시예에서, 필터링 프로세스는 공백 이후의 단어의 특성이 공백 이전의 단어의 특성에 의존할 수 있는 판독의 비대칭 특성을 포함한다. 후속 단어는 (1) 알려진 단어와 (2) 불완전하지만 다음의 단어에 대한 유용한 파라포빌(parafoveal) 정보의 문맥에 기초하여 부분적으로 예측할 수 있다. 실시예에서, 필터링 프로세스는 기능 단어 및 내용 단어 전이에 관해 전략적으로 불확정한 의사 구문(pseudo-syntactic) 정보로 구성되도록 어휘 빈도 입력의 부분적 합성(partial conflation)을 포함한다. 부분적 합성은 부족한 구문 정보(내용 단어)가 하나 이상의 와일드카드(wildcard)(" ")로 대체된(합성된) 자신의 동일성(identity)를 갖는 어휘 항목을 가지면서 구문 정보(기능 단어)가 자신의 동일성을 유지하는 어휘 항목을 가짐으로써 달성된다. 실시예에서, 필터링 프로세스는 단어 사이의 정보 비대칭을 정량화하기 위해 단어 공백에 걸쳐 또한 애매도(equivocation)라고 불리고 H(y|x)로 기록된 조건부 엔트로피(conditional entropy)의 계산을 포함한다. 이것은 알려진 제1 단어 또는 와일드카드(x)의 가변성이 주어지면 알려지지 않은 제2 단어 또는 와일드카드(y)의 가변성의 양을 측정한다. 실시예에서, 와일드카드는 단어의 음성 카테고리의 일부이다. 실시예에서, 와일드카드는 단어의 개방 클래스 상태(open-class status)(즉, 내용 단어)이다. 실시예에서, 필터의 출력은 언어(예를 들어,
")로 대체된(합성된) 자신의 동일성(identity)를 갖는 어휘 항목을 가지면서 구문 정보(기능 단어)가 자신의 동일성을 유지하는 어휘 항목을 가짐으로써 달성된다. 실시예에서, 필터링 프로세스는 단어 사이의 정보 비대칭을 정량화하기 위해 단어 공백에 걸쳐 또한 애매도(equivocation)라고 불리고 H(y|x)로 기록된 조건부 엔트로피(conditional entropy)의 계산을 포함한다. 이것은 알려진 제1 단어 또는 와일드카드(x)의 가변성이 주어지면 알려지지 않은 제2 단어 또는 와일드카드(y)의 가변성의 양을 측정한다. 실시예에서, 와일드카드는 단어의 음성 카테고리의 일부이다. 실시예에서, 와일드카드는 단어의 개방 클래스 상태(open-class status)(즉, 내용 단어)이다. 실시예에서, 필터의 출력은 언어(예를 들어, 
 등)의 둘 이상의 어휘 항목 하이브리드 시퀀스에 대한 키 및 값의 매핑이다.
등)의 둘 이상의 어휘 항목 하이브리드 시퀀스에 대한 키 및 값의 매핑이다.
실시예에서, 텍스트 포맷팅 프로세스는 키 및 값의 애매도 필터 매핑으로부터의 값을 사용하여 키에 인접한 공백의 폭을 비대칭적으로 조정한다. 실시예에서, 각각의 텍스트 데이터 블록에 대해, 프로세스는 공백-종료 단어 토큰(token)("잉크(ink)")가 뒤따르는 공백에 대한 데이터를 스캔한다. 발견되면, 이전 파싱된(parsed) 토큰 다음에 현재 토큰이 각각 Token A 및 Token B로 표시된다. 실시예에서, 각각의 토큰은 선행(leading) 및/또는 후행(trailing) 구두점에 대해 검사되어 Core A 및 Core B 토큰을 생성하며, 이는 부분 합성을 사용하여 의사 구문 와일드카드로 대체된다. 실시예에서, 이러한 의사 구문 코어 토큰은 선택적으로 있다면 Key A 및 Key B를 생성하기 위해 후행 구두점과 연접된다. 다른 실시예에서, 코어 토큰은 키를 직접 생성하는데 사용된다. 다른 실시예에서, 키는 공백에 인접한 후행(Key A) 및/또는 선행(Key B) 구두점과 조합하여 코어 토큰으로부터 생성된다. 실시예에서, 프로세스는 하나 이상의 키를 사용하여 애매도 필터 프로세스의 기록된 출력으로부터 조정 값을 검색한다. 일 실시예에서, 키는 키 쌍(Key A, Key B)으로부터 도출된다. 대안적 실시예에서, 키는 구두점, 와일드카드, 하위 분류된(sub-classed) 와일드카드, 품사(part of speech), 또는 기능 단어 중 하나 이상과 같은 어휘 정보의 복합 세그먼트로 이루어진다. 추가의 실시예에서, 키는 연결된 문자열, 튜플, 사전 또는 유사한 데이터 구조로 표현된 단일 키 또는 다수의 키 중 어느 하나로 이루어진다. 실시예에서, 프로세스는 Token A와 Token B 사이의 공백에 비례 조정을 적용하며, 공백 폭의 비례 변경치는 조정 값과 동일하다.
도 1은 애매도 필터 및 텍스트 포맷팅 프로세스로부터의 데이터를 사용하여 단어 사이의 불확실성에 따른 단어 공백의 비대칭 포맷팅을 위한 예시적인 방법을 도시하는 흐름도;
도 2는 애매도 필터 프로세스로 키 및 값의 매핑을 생성하기 위한 예시적인 방법을 도시하는 흐름도;
도 3은 영어에 대한 단어 및 구두점 시퀀스 데이터(바이그램(bigram) 및 유니그램(unigram) 및 이들 각각의 빈도 카운트)의 선택된 예를 갖는 애매도 필터에 대한 입력을 도시하는 다이어그램;
도 4는 스페인어에 대한 단어 시퀀스 데이터(바이그램 및 유니그램 및 이들 각각의 빈도 카운트)의 선택된 예를 갖는 애매도 필터에 대한 입력을 도시하는 다이어그램;
도 5는 영어에 대한 하이브리드( 은 와일드카드, 즉 임의의 내용 단어를 나타냄)로 부분적 합성 후에 단어 시퀀스 데이터의 선택된 예를 갖는 애매도 필터에서의 중간 단계를 도시하는 다이어그램;
은 와일드카드, 즉 임의의 내용 단어를 나타냄)로 부분적 합성 후에 단어 시퀀스 데이터의 선택된 예를 갖는 애매도 필터에서의 중간 단계를 도시하는 다이어그램;
도 6은 하이브리드( 은 와일드카드, 즉 임의의 내용 단어를 나타냄) 및 스페인어에 대한 기능 의사 카테고리(#는 의사 와일드카드, 즉 모든 아라비아 숫자를 나타냄)로 부분적 합성 후에 단어 시퀀스 데이터의 선택된 예를 갖는 애매도 필터에서의 중간 단계를 도시하는 다이어그램;
은 와일드카드, 즉 임의의 내용 단어를 나타냄) 및 스페인어에 대한 기능 의사 카테고리(#는 의사 와일드카드, 즉 모든 아라비아 숫자를 나타냄)로 부분적 합성 후에 단어 시퀀스 데이터의 선택된 예를 갖는 애매도 필터에서의 중간 단계를 도시하는 다이어그램;
도 7은 애매도 필터로부터의 출력의 선택된 영어 예, 3개의 예시적인 값에 대한 예: 원시 애매도 점수, 정규화 후의 애매도 점수, 및 상대 조정 값을 생성하기 위해 (범위=1의 스케일링 인수를 이용하여) 미학적으로 다시 스케일링한 후에 정규 애매도 점수에 의한 키 및 값의 매핑을 도시하는 다이어그램;
도 8은 애매도 필터로부터의 출력의 선택된 스페인어 예, 3개의 예시적인 값에 대한 예: 원시 애매도 점수, 정규화 후의 애매도 점수, 및 상대 조정 값을 생성하기 위해 (범위=1의 스케일링 인수를 이용하여) 미학적으로 다시 스케일링한 후에 정규 애매도 점수에 의한 키 및 값의 매핑을 도시하는 다이어그램;
도 9는 애매도 필터로부터의 키 및 값의 데이터 매핑을 사용하는 텍스트 포맷팅 프로세스에 대한 예시적인 방법을 도시하는 흐름도;
도 10은 텍스트 포맷팅 프로세스를 적용하기 전의 HTML 문서를 도시하는 다이어그램;
도 11은 텍스트 포맷팅 프로세스를 적용한 후 HTML 문서의 헤드를 도시하고, CSS 스팬 태그로서 구현된 비대칭 단어 공백을 도시하는 다이어그램;
도 12는 텍스트 포맷팅 프로세스를 적용한 후 HTML 문서의 몸체(body)를 도시하고, CSS 스팬 태그로서 구현된 비대칭 단어 공백을 도시하는 다이어그램;
도 13은 텍스트 포맷팅 프로세스를 적용하기 전에 영어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 14는 텍스트 포맷팅 프로세스를 적용한 후 영어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 15는 와일드카드와 단어 "of" 사이의 확장된 공백을 강조하는 텍스트 포맷팅 프로세스를 적용한 후 영어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 16은 단어 "the"와 와일드카드 사이의 응축된 공백(condensed space)을 강조하는 텍스트 포맷팅 프로세스를 적용한 후 영어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 17은 텍스트 포맷팅 프로세스를 적용하기 전에 스페인어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 18은 텍스트 포맷팅 프로세스를 적용한 후에 스페인어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 19는 텍스트 포맷팅 프로세스를 적용하기 전에 독일어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 20은 텍스트 포맷팅 프로세스를 적용한 후에 독일어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 21은 마크업 언어 문서(.idml)에 적용된 애매도 필터로부터의 키 및 값의 데이터 매핑을 사용하는 텍스트 포맷팅 프로세스에 대한 예시적인 방법을 도시하고, 선택적으로 마크업 언어 문서의 소스가 인쇄용 데스크톱 출판 문서(.indd)인 경우에 단락 길이에 대한 임의의 변경을 위해 정정하는 흐름도;
도 22는 시스템의 실시예가 구현될 수 있는 클라이언트-서버 시스템 및 네트워크의 블록도;
도 23은 시스템의 실시예에서 사용될 수 있는 클라이언트 또는 컴퓨터의 일례에 대한 보다 상세한 다이어그램; 및
도 24는 클라이언트 컴퓨터 시스템의 시스템 블록도.
도 2는 애매도 필터 프로세스로 키 및 값의 매핑을 생성하기 위한 예시적인 방법을 도시하는 흐름도;
도 3은 영어에 대한 단어 및 구두점 시퀀스 데이터(바이그램(bigram) 및 유니그램(unigram) 및 이들 각각의 빈도 카운트)의 선택된 예를 갖는 애매도 필터에 대한 입력을 도시하는 다이어그램;
도 4는 스페인어에 대한 단어 시퀀스 데이터(바이그램 및 유니그램 및 이들 각각의 빈도 카운트)의 선택된 예를 갖는 애매도 필터에 대한 입력을 도시하는 다이어그램;
도 5는 영어에 대한 하이브리드(
도 6은 하이브리드(
도 7은 애매도 필터로부터의 출력의 선택된 영어 예, 3개의 예시적인 값에 대한 예: 원시 애매도 점수, 정규화 후의 애매도 점수, 및 상대 조정 값을 생성하기 위해 (범위=1의 스케일링 인수를 이용하여) 미학적으로 다시 스케일링한 후에 정규 애매도 점수에 의한 키 및 값의 매핑을 도시하는 다이어그램;
도 8은 애매도 필터로부터의 출력의 선택된 스페인어 예, 3개의 예시적인 값에 대한 예: 원시 애매도 점수, 정규화 후의 애매도 점수, 및 상대 조정 값을 생성하기 위해 (범위=1의 스케일링 인수를 이용하여) 미학적으로 다시 스케일링한 후에 정규 애매도 점수에 의한 키 및 값의 매핑을 도시하는 다이어그램;
도 9는 애매도 필터로부터의 키 및 값의 데이터 매핑을 사용하는 텍스트 포맷팅 프로세스에 대한 예시적인 방법을 도시하는 흐름도;
도 10은 텍스트 포맷팅 프로세스를 적용하기 전의 HTML 문서를 도시하는 다이어그램;
도 11은 텍스트 포맷팅 프로세스를 적용한 후 HTML 문서의 헤드를 도시하고, CSS 스팬 태그로서 구현된 비대칭 단어 공백을 도시하는 다이어그램;
도 12는 텍스트 포맷팅 프로세스를 적용한 후 HTML 문서의 몸체(body)를 도시하고, CSS 스팬 태그로서 구현된 비대칭 단어 공백을 도시하는 다이어그램;
도 13은 텍스트 포맷팅 프로세스를 적용하기 전에 영어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 14는 텍스트 포맷팅 프로세스를 적용한 후 영어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 15는 와일드카드와 단어 "of" 사이의 확장된 공백을 강조하는 텍스트 포맷팅 프로세스를 적용한 후 영어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 16은 단어 "the"와 와일드카드 사이의 응축된 공백(condensed space)을 강조하는 텍스트 포맷팅 프로세스를 적용한 후 영어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 17은 텍스트 포맷팅 프로세스를 적용하기 전에 스페인어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 18은 텍스트 포맷팅 프로세스를 적용한 후에 스페인어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 19는 텍스트 포맷팅 프로세스를 적용하기 전에 독일어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 20은 텍스트 포맷팅 프로세스를 적용한 후에 독일어 HTML 문서를 렌더링하는 웹 브라우저를 도시하는 다이어그램;
도 21은 마크업 언어 문서(.idml)에 적용된 애매도 필터로부터의 키 및 값의 데이터 매핑을 사용하는 텍스트 포맷팅 프로세스에 대한 예시적인 방법을 도시하고, 선택적으로 마크업 언어 문서의 소스가 인쇄용 데스크톱 출판 문서(.indd)인 경우에 단락 길이에 대한 임의의 변경을 위해 정정하는 흐름도;
도 22는 시스템의 실시예가 구현될 수 있는 클라이언트-서버 시스템 및 네트워크의 블록도;
도 23은 시스템의 실시예에서 사용될 수 있는 클라이언트 또는 컴퓨터의 일례에 대한 보다 상세한 다이어그램; 및
도 24는 클라이언트 컴퓨터 시스템의 시스템 블록도.
컴퓨터 구현 시스템 및 방법은 독서 경험을 향상시키기 위해 단어 사이의 불확실성에 따른 텍스트 프리젠테이션에서 단어 간 공백의 폭을 비대칭적으로 포맷팅하기 위해 개시된다.
단어 공백의 폭을 비대칭적으로 조정하는 것은 먼저 언어의 의사 구문 구조를 분석하는 필터링 프로세스, 및 이러한 분석 결과를 텍스트를 포함하는 주어진 문서에 적용하는 제2 텍스트 포맷팅 프로세스를 필요로 한다. 도 1에 도시된 바와 같이, 필터링 프로세스는 적어도 하나의 코퍼스 또는 단어 시퀀스 빈도 데이터(입력)로부터 키 및 값(120)(출력)의 매핑을 생성하기 위해 애매도 필터(110)를 사용한다. 텍스트 포맷팅 프로세스(130)는 이러한 값을 사용하여 키에 인접한 공백의 폭을 비대칭적으로 조정한다. 텍스트 포맷팅 프로세스는 입력 문서(140)를 수신하고, 처리된 문서(150)를 출력으로서 생성하기 위해 텍스트 포맷팅 프로세스(130)를 적용한다.
필터링 프로세스는 기능 단어의 데이터베이스가 제공될 경우 의미론적 역할보다는 주로 구문론적 역할을 갖는 폐쇄된 클래스 단어(closed-class word)를 조작한다. 데이터베이스는 하나 이상의 어휘 카테고리: 보조 동사, 한정사, 접속사, 전치사 및 대명사 단어 클래스; 및 선택적으로 아라비아 숫자, 로마 숫자 또는 적절한 이름과 같은 기능 단어 카테고리; 또는 예를 들어, 영어에서 선택적 구두점 문자의 리스트로부터의 단어 또는 단어 시퀀스를 포함한다:
. ? ! , ; : ( ) 등.
필터링 프로세스는 언어의 통계적 모델링을 포함하고, 지각 스팬 비대칭, 전략적으로 불확정 입력 데이터 및 정보 이론(perceptual span asymmetry, strategically indeterminate input data, and information theory)으로부터의 원리를 사용하여 단어 공백에 걸친 불확실성의 측정을 포함한다.
독자가 단어에 대한 유용한 정보를 얻는 지각 스팬(perceptual span)은 크기가 제한되며, 길이가 비대칭이며: 고정(fixation) 뒤에 약 3 내지 4 문자, 고정 앞에 약 14 내지 15 문자이다. 지각 스팬은 쓰기 스크립트(writing script)의 읽기(reading) 방향에 의해 영향을 받으며, 시력 요인(visual acuity factor)보다는 주의력으로 인한 것이다. 읽기는 본질적으로 고정되어 있는 단어가 알려지기 때문에 비대칭이며, 후속 단어는 아직 알려지지 않지만, 그것은 알려진 단어의 문맥과, 다음의 단어에 대해 불완전하지만 여전히 유용한 파라포빌 정보에 기초하여 부분적으로 예측 가능할 수 있다.
도 2를 참조하면, 흐름도의 실시예는 애매도 필터 프로세스로 키 및 값의 매핑을 생성하는 방법에 대해 도시된다. 필터에 대한 원시 입력은 n-gram 빈도 카운트(220) 또는 이들이 생성될 수 있는 선택적인 코퍼스(210)와 같은 파생어다. 먼저, 부분 합성 필터(230)를 사용하여 원시 단어 시퀀스 빈도 데이터를 하이브리드 구조로 다시 분류함으로써 이러한 입력은 전략적으로 불확실하게 만들어진다. 이러한 필터링 프로세스에서, 구문 정보를 지닌 어휘 항목(폐쇄 클래스 또는 기능 단어)은 자신의 동일성을 유지하지만; 구문 정보가 없는 어휘 항목(개방 클래스 또는 내용 단어)은 어휘 항목의 카테고리인 하나 이상의 와일드카드 로 대체된 자신의 동일성(합성)을 갖는다. 이러한 부분적 합성 하이브리드는 기능 단어와 내용 단어 사이(또는 폐쇄 클래스와 개방 클래스 단어 사이)에서 전이에 대한 의사 구문 정보를 포함한다. 결정적으로, 이러한 하이브리드화 단계는 자신의 어휘 동일성로서 취급되는 일부 단어와 카테고리로 취급되는 일부 단어를 사용하여 하나 이상의 추상화 수준에서 특징 분석을 필요로 한다. 부분 합성의 일례에서, 단어 am, are, was, was, were 등은 모든 굴절된 단어 형식(inflected word form)을 포함하는 어휘(어근(root word)) "to be"로서 취급된다. 다른 예에서, to be, to do, 및 to have와 같은 다수의 어휘로부터의 is, are, did, has 등과 같은 단어는 어휘 카테고리(단어 클래스 또는 품사) "보조 동사"로서 취급된다. 다른 예에서, 시간(time)과 같은 명사, 말했다(said)와 같은 어떤 동사, 새로운(new)과 같은 형용사, 및 최근에(recently)와 같은 부사는 카테고리 "내용 단어"로서 취급될 수 있다. 그 다음, 이러한 하이브리드에서, 고유 항목 및 항목 시퀀스에 대한 빈도 카운트는 생성되고(240), 애매도 값을 계산하는데(250) 사용된다. 최종적으로, 키 및 값(120)의 매핑으로서 출력되기 전에, 애매도 값은 정규화되고(260), 원하는 상대 조정 값으로 리스케일링되며(270), 선택적으로 절대 조정 값으로 리스케일링된다(280).
로 대체된 자신의 동일성(합성)을 갖는다. 이러한 부분적 합성 하이브리드는 기능 단어와 내용 단어 사이(또는 폐쇄 클래스와 개방 클래스 단어 사이)에서 전이에 대한 의사 구문 정보를 포함한다. 결정적으로, 이러한 하이브리드화 단계는 자신의 어휘 동일성로서 취급되는 일부 단어와 카테고리로 취급되는 일부 단어를 사용하여 하나 이상의 추상화 수준에서 특징 분석을 필요로 한다. 부분 합성의 일례에서, 단어 am, are, was, was, were 등은 모든 굴절된 단어 형식(inflected word form)을 포함하는 어휘(어근(root word)) "to be"로서 취급된다. 다른 예에서, to be, to do, 및 to have와 같은 다수의 어휘로부터의 is, are, did, has 등과 같은 단어는 어휘 카테고리(단어 클래스 또는 품사) "보조 동사"로서 취급된다. 다른 예에서, 시간(time)과 같은 명사, 말했다(said)와 같은 어떤 동사, 새로운(new)과 같은 형용사, 및 최근에(recently)와 같은 부사는 카테고리 "내용 단어"로서 취급될 수 있다. 그 다음, 이러한 하이브리드에서, 고유 항목 및 항목 시퀀스에 대한 빈도 카운트는 생성되고(240), 애매도 값을 계산하는데(250) 사용된다. 최종적으로, 키 및 값(120)의 매핑으로서 출력되기 전에, 애매도 값은 정규화되고(260), 원하는 상대 조정 값으로 리스케일링되며(270), 선택적으로 절대 조정 값으로 리스케일링된다(280).
정보 이론(information theory)의 원리로부터, 엔트로피(entropy)는 무작위 변수를 예측할 때의 불확실성의 양의 측정치이다. 보다 구체적으로, 단어 공백에 걸쳐 또한 애매도(equivocation)라고 불리고 H(y|x)로 기록된 조건부 엔트로피(conditional entropy)는 단어 사이의 정보 비대칭을 정량화하기 위한 방법이다. 이것은 알려진 제1 단어(x)의 가변성이 주어지면 알려지지 않은 제2 단어(y)의 가변성의 양을 측정치이다. 애매도는 공백을 뒤따르는 단어가 공백 앞의 단어에 대한 지식을 얼마나 불확실하게 하는지에 대한 효과적인 비대칭 측정치이다. 애매도는 이벤트가 발생하는 정도, 즉 이벤트 모호성의 측정치를 반영한다. 이는 알려진 이벤트(x)의 관찰을 제1 이벤트(x)와 제2 이벤트(y)의 교차점(x, y)의 관찰에 관련시키는 측정치이다. 중요하게는, 부분 합성(230) 후에, 이벤트(x 및 y)는 상이한 타입(예를 들어, 어휘 동일성: x = the, 하나 이상의 카테고리: 예를 들어, y = 내용 단어(content word))이거나 동일한 타입(예를 들어, x = of, y = the; or x = pronoun, y = auxiliary verb)일 수 있다.
기능적으로 애매도(조건부 엔트로피)와 등가인 다른 조건부 확률 통계(예를 들어, 전이 확률, 상호 정보, 상관)가 있다. 이것은 개개의 이벤트의 전체 빈도만큼 동시 발생 빈도를 정규화한다. 역방향 전이 확률(Y가 주어진 X의 확률)을 포함하여 이러한 조건부 확률 통계의 어느 하나는 전이에서 분할에 대한 정보를 제공한다.
불확실성을 측정하기 위한 부분 합성 하이브리드를 사용하면 방법으로 하여금 모델이 익숙하지 않은 새로운 내용 단어를 견고하게 처리하도록 한다. 부분적 합성 하이브리드를 사용하면 애매도가 단어 사이의 의미론적 및 구문론적 중첩 정도와 이러한 단어가 실제로 언어에서 어떻게 사용되는지를 측정하도록 한다. 의미론적 및 구문론적 중첩 정도는 단어 사이의 의사 구문 거리의 연속 측정치이다. 이것은 의미론(내용) 단어와 구문론(기능) 단어가 언어로 언어에서 서로 어떻게 전이하는지의 간단한 일차원 측정치이다.
애매도 필터 프로세스
일 실시예에 따르면, 코퍼스 내의 각각의 문서에 대해: 첫째로, 영어에 대한 도 3 및 스페인어에 대한 도 4에 도시된 바와 같이, 문서는 공백 분리된 토큰의 리스트 또는 n-grams(220)로 분리되고; 둘째로, 영어에 대한 도 5 및 스페인어에 대한 도 6에 도시된 바와 같이, 이러한 토큰 리스트는 의사 구문 하이브리드(230)의 유니그램 및 바이그램 빈도(240)를 카운트하는 것을 통해 반복되며; 셋째로, 영어에 대한 도 7 및 스페인어에 대한 도 8에 도시된 바와 같이, 유니그램 및 바이그램 빈도 카운트는 각각의 문서(250)에 대한 각각의 하이브리드에 대한 애매도(조건부 엔트로피) 점수를 계산하고 출력하는데 사용된다. 실시예에서, 필터링된 의사 구문 하이브리드에 대한 애매도 점수는 키-값 매핑(120)에서의 값(250)으로서 직접 사용될 수 있다. 다른 실시예에서, 애매도 점수는 정규화될 수 있고(260), 원하는 미학적 범위로 리스케일링된 다음, 값(270)으로서 사용될 수 있다. 실시예에서, 필터(110)의 출력은 언어(예를 들어, 
 등), 키(510) 및 값(520)의 리스트의 둘 이상의 어휘 항목 하이브리드 시퀀스에 대한 키 및 값의 매핑(120)이다.
등), 키(510) 및 값(520)의 리스트의 둘 이상의 어휘 항목 하이브리드 시퀀스에 대한 키 및 값의 매핑(120)이다.
부분 합성(230) 및 부분 합성 하이브리드(240)의 빈도 카운트의 실시예에서, 토큰 리스트를 통한 반복 동안, 2개의 토큰 윈도우는 리스트 내의 주어진 위치 n에서 생성되고, Token A는 n-1 위치에 설정되지만, Token B는 n 위치에 설정된다. 그 다음, Token A의 임의의 선행 및 후행 구두점은 Core A 토큰에서 분리된다. Core A가 아라비아 또는 로마 숫자의 형식이면, 그것은 의사 와일드카드 토큰으로 대체된다. 그렇지 않으면, Core A가 기능 단어의 데이터베이스 내에 없으면, Core A는 와일드카드 토큰으로 대체된다. 검색 키 "Key A"가 작성되며, 이러한 키는 (순서대로) Token A로부터의 임의의 선행 구두점, Core A, 및 Token A로부터의 임의의 후행 구두점을 연결한다. 그런 다음, Key A에 대한 유니그램 카운터는 증가된다.
다음으로, Token B의 임의의 선행 및 후행 구두점은 Core B 토큰에서 분리된다. Core B가 아라비아 숫자 또는 로마 숫자의 형식이면, 그것은 의사 와일드카드 토큰으로 대체된다. 그렇지 않으면, Core B가 기능 단어의 데이터베이스에 없으면, Core B는 와일드카드 토큰으로 대체된다. 검색 키 "Key B"가 작성되며, 이러한 키는 (순서대로) Token B로부터의 임의의 선행 구두점, Core B, 및 Token B로부터의 임의의 후행 구두점을 연결한다. 그런 다음, (Key A, Key B)에 대한 바이그램 카운터는 증가된다.
문서를 통한 반복이 완료되면, 의사 구문 하이브리드의 유니그램 및 바이그램 빈도 카운트는 애매도 점수를 계산하는데 사용된다. 실시예에서, 각각의 기록된 바이그램(Key A, Key B)에 대해, Key A의 기록된 유니그램 빈도, 기록된 바이그램(Key A, Key B) 빈도, 및 총(합) 유니그램 및 바이그램 빈도가 주어지면, 애매도 (조건부 엔트로피) 점수(250)는 다음을 사용하여 계산된다:

바람직한 실시예에서, 각각의 문서에 대해, 애매도 점수는 표준화되고(260)(예를 들어, 표준 점수로 변환된 후), 각각의 문서에 대한 이러한 정규화된 값은 코퍼스에 걸쳐 평균화된다(즉, 문서의 수에 의해 더해지고 나누어진다). 대안적 실시예에서, 다중 문서 코퍼스는 애매도 점수를 계산(및 정규화)할 때 하나의 큰 문서로서 취급된다. 실시예에서, 애매도 점수는 다음을 사용하여 계산된 표준 점수(z-점수)(260)를 사용하여 정규화된다:
여기서, h는 각각의 기록된 애매도 점수, H(y|x)이다. 추가의 실시예에서, 정규화된 애매도 점수는 원하는 미학적 범위(즉, 증가 및 감소하는 단어 공백 폭에 대한 최대 범위)로 리스케일링된다. 예를 들어, 정규화된 애매도 점수의 미학적 리스케일링(270)은 다음과 같은 변환을 사용한다:
상대 조정 값 = z × r/(최대(z)-최소(z))
여기서 r은 조정 값이 변할 수 있는 범위(상한 및 하한)를 설명하는 스케일링 인수이고(예를 들어, r = 1), z는 정규화된 애매도 점수이다.
실시예에서, 상대 조정(270)은 값으로서 직접 사용되거나, (선택적으로) 절대 스케일링 조정이 요구되는 경우, 절대 비율 값(280)으로 변환될 수 있다:
절대 조정 값 = 상대 조정 값 × 100+100
실시예에서, 각각의 바이그램 및 이의 상대 또는 절대 조정 값 중 어느 하나의 이러한 매핑은 키(510) 및 값(520)으로서 출력된다. 실시예에서, 값(520)은 정규화되어 원하는 미학적 변형(270)으로 리스케일링되었다. 이러한 조정 값(270)은 증가된 폭(550), 감소된 폭(555), 또는 원래의 폭을 유지하는 예외를 포함하는 가변 공백 폭을 지정한다. 대안적 실시예에서, 애매도(조건부 엔트로피) 점수(250) 또는 포스트-정규화된 점수(260)는 매핑 입력에서의 값으로서 사용되며, 정규화 및/또는 미학적 리스케일링은 텍스트 포맷팅 프로세스(130) 동안 수행된다. 이러한 실시예에서, 미학적 리스케일링은 미리 결정된 디폴트를 사용하거나, 텍스트 포맷팅 시에 사용자에 의해 결정될 수 있다. 이러한 값이 키(130)에 의해 나타내어진 텍스트에서 단어 공백 사이의 포맷팅을 조정하기 위해 적용될 때, 텍스트의 타이포그래피 구조는 제1 단어의 지식이 주어지면 제2 단어의 구문론적/비구문론적 불확실성에 따라 포맷팅된다
분배 방법
다음의 것은 문서의 공백의 폭을 비대칭적으로 조정하기 위해 필터링 프로세스로부터의 출력의 적용의 비제한적 예이다. 이러한 예에서, 문서는 HTML 문서이지만, 동일한 원리가 텍스트를 포함하는 다른 타입의 문서에 적용하도록 적응될 수 있다. 도 9를 참조하면, 애매도 필터(120)로부터의 키 및 값의 데이터 매핑을 사용하는 텍스트 포맷팅 프로세스(130)를 위한 방법에 대한 흐름도의 실시예가 도시된다.
텍스트 처리
도 9을 참조하면, 텍스트(140)의 각각의 블록에 대해, 블록(610)은 공백-종료 단어 토큰("잉크")이 뒤따르는 공백에 대해 반복적으로 스캔된다. 이전에 파싱된 토큰(또는 데이터 블록의 시작 부분에 있는 경우 제1 토큰)과 현재 파싱된 토큰은 Token A 및 Token B로 지정되고, 각각 640이다. 각각의 토큰(A 및 B)에 대해, 임의의 선행 및 후행 구두점(토큰 별 왼쪽 구두점 및 오른쪽 구두점)이, 존재한다면, Core 토큰에서 분리된다.
실시예에서, Core A 또는 Core B 토큰이 아라비아 또는 로마 숫자인 경우, Core A 및 Core B는 대응하는 의사 와일드카드로 대체되며; 그렇지 않으면, 키 "Key A" 및 "Key B"는 각각 (순서대로): 각각 Token A 또는 Token B로부터의 임의의 선행 구두점; 각각 Core A 또는 Core B; 및 각각 Token A 또는 Token B로부터의 임의의 후행 구두점을 연결하여 생성된다(650).
실시예에서, Key A는 Core A만으로부터의 임의의 후행 구두점이 되고, 그렇지 않으면, Key A는 Core A가 된다. 실시예에서, 키는 단어를 포함하고, 선택적 구두점이 뒤따르며, 이러한 구두점에 의해 진행되는 잉크의 스트링(string)을 포함한다. 제2 실시예에서, Key A는 단어 및 잉크 스트링의 최종 구두점만을 포함하고, Key B는 단어 및 잉크 스트링의 초기 구두점만을 포함한다. 제3 실시예에서, 키는 단어(Core A 또는 Core B)만을 포함한다.
다음에, 애매도 필터로부터의 출력으로서 기록된 조정 값은 키(Key A, Key B)(660)를 이용하여 검색된다.
이러한 조정 값은 목적지 매체(예를 들어, HTML, IDML, PDF 등) 내에 적용된 공백 조정을 알리기 위해(670) (직접 또는 수정되어) 사용될 수 있다.
이러한 프로세스는 임의의 나머지 토큰(630) 및 데이터 블록(620)에 걸쳐 반복한다. 일단 모든 토큰 및 데이터 블록이 처리되었으면, 문서는 처리된 문서로서 방출된다(150).
HTML 처리
텍스트를 포함하는 주어진 HTML 문서에 대해, 텍스트 포맷팅 프로세스는, 있다면, 텍스트 요소가 문서의 다른 부분과의 계층적 관계, 또는 HTML 요소가 표시되어야 하는 방법을 포함하는 사용자가 볼 수 있는 내용("데이터")을 마크업(markup)에서 격리하기 위해 HTML을 파싱(parsing)하는 단계를 포함한다. 그 후, 표시 가능한 텍스트의 각각의 섹션은 "텍스트 처리(Text Processing)"에서와 같이 처리된다.
실시예에서, 도 10의 140과 같은 텍스트 및 HTML을 포함하는 주어진 문서에 대해, 텍스트 포맷팅 프로세스는, 있다면, 텍스트 요소가 문서의 다른 부분과의 계층적 관계, 또는 텍스트 요소가 표시되어야 하는 방법을 포함하는 사용자가 볼 수 있는 내용("데이터")(160)을 마크업에서 격리하기 위해 HTML을 파싱하는 단계를 포함한다.
도 10은 도 9에 도시되어 있지만, HTML에 적용되는 "텍스트 처리"(130)의 일반적인 방법에 대한 예시적인 입력 파일(140)을 도시한다. 도 11 및 도 12는 처리된 문서(150)로서 방출된 후의 각각 HTML의 헤드 및 몸체의 예를 도시한다. 도 13 및 도 14는 영어에서 사용자가 볼 수 있는 내용에 대해 공백 조정이 각각 적용되기 전과 후에 사용자가 볼 수 있는 내용의 브라우저 렌더링을 도시한다. 도 15는 조정 값에 따라 키에 의해 나타내어진 공백을 확장하기 위해(550) 적용된 비대칭 공백의 예로 공백 조정이 적용된 후에 사용자가 볼 수 있는 내용의 브라우저 렌더링을 도시한다. 도 16은 조정 값에 따라 키에 의해 나타내어진 공백을 압축하기 위해(555) 적용된 비대칭 공백의 예로 공백 조정이 적용된 후에 사용자가 볼 수 있는 내용의 브라우저 렌더링을 도시한다. 도 10-16에서, 예의 텍스트는 영어이다.
도 17 및 도 18은 공백 조정이 스페인어로 사용자가 볼 수 있는 내용에 각각 적용되기 전과 후에 사용자가 볼 수 있는 내용의 브라우저 렌더링을 도시한다. 도 19 및 도 20은 공백 조정이 독일어로 사용자가 볼 수 있는 내용에 각각 적용되기 전과 후에 사용자가 볼 수 있는 내용의 브라우저 렌더링을 도시한다.
실시예에서, 단어 공백 분리된 키 및 대응하는 조정 값이 주어지면, 공백의 조정된 크기는 em의 단위이다. em은 타이포그래피의 분야에서 현재 지정된 포인트 크기와 동일한 단위이다. 따라서, 16 포인트 서체(typeface)에서의 하나의 em은 16 포인트이다. 따라서, 이러한 단위는 주어진 포인트 크기에서 모든 서체에 대해 동일하다. 조정된 크기는 디폴트 크기(예를 들어, 0.25 em)에 조정 값을 곱한 값을 사용하여 계산될 수 있다. 예를 들어, 0.10(+ 10%)의 조정 값 및 0.25 em의 디폴트 공백 크기는 공백의 크기가 0.275 em로 다시 정해진다. 추가의 실시예에서, 프로세스는 이미 0.275 em의 조정을 적용했는지를 체크한다. 그렇지 않으면, 그것은 새로운 공백 폭을 지정하는 새로운 고유 SPAN 클래스에 대한 CSS 사양을 작성한 다음 새로운 SPAN 클래스를 스타일시트, 예를 들어, "adjustment1"로 방출한다. Key A와 Key B 사이의 공백은 위에 정의된 클래스를 사용하여 SPAN 사양으로 둘러싸인다. 예를 들어:
<span class="adjustment1"> </span>
프로세스가 이미 주어진 크기의 조정을 적용하였다면, 그것은 이전에 정의된 SPAN 클래스(예를 들어, "adjustment1")를 검색한다. Key A와 Key B 사이의 공백은 이전에 정의된 클래스를 사용하여 SPAN 사양으로 둘러싸이며, 예를 들어:
<span class="adjustment1"> </span>
바람직한 실시예에서, 단어 공백의 겉보기 크기(apparent size)에 영향을 주도록 조정된 파라미터는 문자 공백이다. 다른 실시예에서, 수평 스케일링, 커닝(kerning), 수평 오프셋, 패딩, 좌측 여백 또는 우측 여백 중 하나 이상을 포함하는 다른 파라미터가 조정된다.
다른 실시예에서, 이전에 참조된 조정은 렌더링시에 문서 객체 모델 내의 각각의 ID 또는 클래스 식별자를 사용하여 SPAN에 조정을 적용하는 생성된 입력을 갖는 생성된 JavaScript 또는 고정된 JavaScript로부터의 <SPAN> 태그에 적용될 수 있다. 다른 실시예에서, 조정은 하나 이상의 공백을 증가시키거나 대체하기 위해 텍스트에 따라 배치될 수 있는 정적 공백 구조(예를 들어, <IMG> 및 <SPACER> HTML 엔티티)를 삽입함으로써 구현될 수 있다.
임의 파일 포맷 처리
실시예에서, 마크업 언어(예를 들어, XML, HTML, XHTML 또는 IDML)를 포함하는 텍스트를 포함하는 임의의 파일 포맷은 "텍스트 처리"에서 설명된 방법과 유사하게 처리된다. 텍스트 세그먼트는 "텍스트 처리"에서와 같이 추출되고 처리된다. 공백은 네이티브 마크업 언어 사양(native markup language specification)을 사용하여 문서 내에서 조정되고, 처리된 문서(또는 지정된 서브세트)는 출력으로서 생성된다. 도 21을 참조하면, InDesign Markup Language(.idml) 파일에 적용된 텍스트 포맷팅 프로세스(130)의 방법에 대한 흐름도의 실시예가 도시된다. InDesign 문서(,indd)(1140)는 각각의 텍스트 블록(1145)에 대한 초기 단락 길이를 측정하고 기록한 다음, idml 파일, XML(140)의 타입으로 내보내진다. 이러한 입력 파일은 처리되고(130), 출력 파일(150)은 현재 단락 길이(1155)를 재측정하는데 사용되는 처리된 indd 문서(1150)로 변환된다. 현재 길이가 모든 단락에 대해 초기 길이(1160)와 대략 동일하면, 처리는 완료되고 문서는 (PDF 파일로) 내보내진다(1170). 그렇지 않으면, 공백은 길이 패리티가 달성될 때까지 동적으로 재조정될 수 있다(1180).
서버를 통한 텍스트
실시예에서, 선택적인 폰트 사양을 갖는 텍스트의 세그먼트는 서버(로컬 또는 원격)에 제출되며, 이는 "텍스트 처리"에서 설명된 방법을 텍스트에 적용한다. 제출된 데이터의 포맷은 텍스트이거나, JSON, BSON, HTML, XHTML, XML, 또는 다른 캡슐화 방법으로 캡슐화될 수 있다. 공백 조정은 공백을 <ASYM=N>으로 대체함으로써 반환(return)되며, 여기서 N은 "텍스트 처리"로부터 계산된 조정이다. 다른 실시예에서, 조정 값의 데이터베이스가 반환된다. 각각의 데이터베이스 엔트리는 소스 텍스트 내의 하나 이상의 공백에 해당한다. 다른 실시예에서, "텍스트 처리"의 로직은 브라우저, 브라우저 확장 또는 애플리케이션 플러그-인(예를 들어, NSAPI)에 내장된다. 텍스트는 로컬 또는 원격 서버로 송신되는 대신에 이러한 내장된 프로그램에 제출된다.
서버를 통한 HTML
"HTML 처리"의 방법, 여기서 HTML은 "HTML 처리"를 텍스트에 적용하는 서버(로컬 또는 원격)에 선택적 폰트 사양과 함께 제출된다. 제출된 데이터의 포맷은 JSON, BSON, XHTML, XML 또는 다른 데이터 포맷으로서 캡슐화될 수 있다. 일 실시예에서, HTML은 HTML에 자동으로 삽입된 <STYLE> CSS 스타일 시트와 함께 반환된다. 다른 실시예에서, 스타일 시트는 별개의 데이터의 항목으로서 반환된다. 다른 실시예에서, "HTML 처리"의 논리는 브라우저, 브라우저 확장 또는 애플리케이션 플러그-인(예를 들어, NSAPI)에 내장된다. HTML은 로컬 또는 원격 서버로 송신되는 대신에 이러한 내장된 프로세서에 제출된다.
확장
실시예에서, 텍스트는 브라우저의 DOM(Document Object Model) 상에서 동작하는 프로그램을 구현하는 브라우저 애드온(add-on) 또는 확장을 통해 파싱되고 조정된다. 확장은 렌더링된 웹 페이지의 DOM을 파싱하여, 사용자에게 표시되거나 표시될 수 있는 텍스트를 추출한다. 그 후, 텍스트 블록과 선택적 블록별 폰트 사양은 "서버를 통한 텍스트"에 따라 제출된다.
DOM 처리
일 실시예에서, 반환된 공백 조정 값은 공백을 대체하는 공백 조정에 의해 알려진 크기의 새로운 DOM 요소로 변환된다. 다른 실시예에서, 공백은 "HTML 처리"에서와 같이 공백을 조정하기 위해 부가적인 DOM 요소로 증가된다.
텍스트 처리에 대한 HTML(HTML to Text Processing)
다른 실시예에서, 웹 페이지의 HTML은 DOM으로부터 추출되고, "서버를 통한 HTML"에서와 같이 내보내고, 웹 페이지로 다시 불러오며, 그 후 웹 페이지는 내용을 업데이트하도록 리프레시된다. 다른 실시예에서, 웹 페이지의 HTML은 DOM으로부터 추출되고, "서버를 통한 HTML"에서와 같이 내보내진다. 그 후, 응답은 보통의 텍스트 섹션으로 분리되어 DOM 요소의 내용에 직접 적용된다.
다른 실시예에서, 선택적인 폰트 사양을 갖는 표시 가능한 텍스트 세그먼트는 DOM으로부터 파싱되어, "서버를 통한 텍스트"에서와 같이 제출된다. 그 후, 반환된 공백 조정은 "DOM 처리"에서와 같이 DOM에 적용된다.
다른 실시예에서, 선택적인 폰트 사양을 갖는 표시 가능한 텍스트 세그먼트는 DOM으로부터 파싱되어 "서버를 통한 텍스트"에서와 같이 제출된다. 그 후, 반환된 HTML은 예를 들어 DOM 요소 innerHTML을 통해 '텍스트 처리에 대한 HTML(HTML to Text Processing)'에서와 같이 DOM에 적용된다.
다른 실시예에서, 웹 페이지 상의 표시 가능한 텍스트 세그먼트는 고유 단어 쌍으로 나누어진다. 그 후, 이러한 단어 쌍은 "서버를 통한 텍스트"에서와 같이 하나 이상의 텍스트 블록으로 제출된다. 반환된 조정은 데이터베이스에 저장된다. 웹 페이지 상의 표시 가능한 텍스트 세그먼트는 단어 쌍에 대해 다시 파싱되며, 해당 단어 쌍에 대해 데이터베이스에 저장된 임의의 조정이 적용된다. 다른 실시예에서, 표시 가능한 텍스트는 데이터베이스 내의 각각의 단어 쌍에 대해 검색되고, 공백 조정이 적용된다. 다른 실시예에서, 임의의 소스로부터의 텍스트의 블록은 상술한 바와 같이 제출되어, 공백 조정을 생성한다.
다른 실시예에서, 웹 브라우저 NSAPI(또는 다른 네이티브) 플러그인은 브라우저 <EMBED> 태그에서 웹 페이지를 렌더링하고, "서버를 통한 텍스트" 또는 "서버를 통한 HTML"로부터 반환된 공백을 적용하고, 웹 페이지의 텍스트를 표시하는데 사용된다.
애플리케이션
일 실시예에서, 컴퓨터 애플리케이션 프로그램(또는 컴퓨터 애플리케이션 프로그램 플러그인, 확장 등)은 전술한 방법 중 하나 이상으로부터의 출력을 수용하고, 주어진 포맷에 고유한 포맷팅 메커니즘을 사용하여 조정되는 처리된 텍스트 및 공백으로 새로운 문서를 작성한다. 예시적인 파일 포맷은 PDF, HTML, ePUB, IDML, INDD, DOC 및 DOCX를 포함하지만, 이에 한정되지 않는다. 다른 실시예에서, 이러한 새로운 문서는 선택적으로 메모리에 렌더링되고, 판독을 위해 사용자에게 표시된다. 이러한 타입의 애플리케이션은 웹 브라우저, 텍스트 편집기, 단어 프로세서, 데스크톱 게시 애플리케이션 및 전자 북 판독기를 포함한다.
정의:
"단어 공백에 걸친 불확실성"은 제1 알려진 단어(공백 전)가 주어진 제2 알려지지 않은 단어(공백 후)의 가변성의 측정치이다.
"어휘 불확실성을 계산하기 위한 필터"는 구문 정보를 가진 어휘 항목(폐쇄 클래스 또는 기능 단어)이 자신의 동일성을 유지하지만; 구문 정보가 없는 어휘 항목(개방 클래스 또는 내용 단어)이 하나 이상의 와일드카드 로 대체된 자신의 동일성(합성)을 갖는 프로세스이다.
로 대체된 자신의 동일성(합성)을 갖는 프로세스이다.
"와일드카드"는 그룹, 예를 들어 어휘 카테고리(보조 동사, 대명사, 숫자 등) 또는 내용 단어로서 카운트된 다수의 어휘 항목을 가진 카테고리이다.
"기능 단어"는 어휘적 의미가 거의 없고, 문장 내의 다른 단어와 문법적 또는 구문론적 관계를 표현하거나, 화자의 태도 또는 분위기(attitude or mood of a speaker)를 지정하는 단어이다. 기능 단어는 일반적으로 의미가 희박하다.
"내용 단어"는 명사, 대부분의(전부는 아님) 동사, 형용사 및 부사와 같은 단어이며, 이는 일부 객체, 동작 또는 특징을 지칭한다. 내용 단어는 일반적으로 의미가 풍부한다(의미론적).
"N-gram 빈도 카운트"는 주어진 텍스트의 시퀀스로부터 n개 항목의 인접한 시퀀스에서 이벤트가 발생하는 횟수이다. n-gram의 예는 1 항목(유니그램), 2 항목(바이그램), 3 항목(트라이그램) 등이다.
"의사 구문 하이브리드"는 기능 단어 및 내용 단어 전이에 대한 의사 구문 정보를 포함하고, 선택적으로 기능 단어와 다른 기능 단어 사이의 부분 합성 하이브리드이다. 부분 합성은 일부 단어 클래스의 단어가 합성된다는 (카테고리로 조합된다는) 것을 의미한다. 어떤 단어는 그 자체로 취급될 수 있으며(어휘의 동일성을 유지함), 카테고리로 조합되지 않는다. 다른 단어는 카테고리로서 취급될 수 있다. 예를 들어, am, are, was, was, were 등은 어휘(모든 어형 변화된 단어 형식을 포함하는 어근 단어(root word) "to be")로서 취급될 수 있다. 다른 예에서는, 어휘 카테고리(to be, to do, 및 to have와 같은 다수의 어휘를 포함하는 "보조 동사"). 또는 예를 들어, 시간(time)과 같은 명사, 말했다(said)와 같은 어떤 동사, 새로운(new)과 같은 형용사, 및 최근에(recently)와 같은 부사는 카테고리 "내용 단어"로서 취급될 수 있다.
"어휘(Lexeme)"는 그것이 가질 수 있는 굴절 어미(inflectional ending) 또는 그것이 포함할 수 있는 단어의 수에 관계없이 존재하는 어휘적 의미의 단위이다. 어휘는 단일 단어로 취해진 형식의 세트에 대략적으로 상응하는 카테고리이다.
"어휘 항목"은 단일 단어, 단어의 일부 또는 언어 어휘집(어휘)의 기본 요소를 형성하는 단어의 체인(chain)이다.
"어휘 동일성"은 단어 자체이다.
"어휘 카테고리"는 단어 클래스(때때로 어휘 클래스 또는 음성의 일부라고 함)이다. 일반적인 어휘 카테고리의 예는 명사, 동사, 형용사, 부사, 대명사, 전치사, 접속사, 숫자, 관사 및 한정사를 포함한다.
"폐쇄 클래스"는 새로운 항목을 수용하지 않거나 거의 수용하지 않는 단어 클래스이다. 폐쇄 클래스 카테고리의 예는 접속사, 한정사, 대명사 및 전치사를 포함한다. 일반적으로, 설명한 폐쇄 클래스는 주로 문법적이고, 기능적인 역할을 하며, 의미가 희박한 단어를 포함하는 구문 카테고리이다.
"개방 클래스"는 많은 단어를 포함하고, 새로운 단어의 부가를 수용하는 단어 클래스이다. 예는 명사, 동사, 형용사, 부사 및 감탄사를 포함한다. 일반적으로, 개방 클래스는 주로 의미론적이고, 내용을 가지며, 의미가 풍부한 단어를 포함하는 어휘 카테고리이다.
"코퍼스"는 서면 텍스트의 모음이다.
"키 및 값"은 키-값 데이터베이스, 관련 어레이, 사전 또는 해시 테이블로서도 알려져 있는 키-값 저장부의 요소이다. 각각의 키는 관련 값을 참조하고, 관련 값에 대한 액세스를 제공하는 고유 식별자이다. 값은 간단한 데이터 포인트이거나 레코드, 어레이 또는 사전과 같은 복합 데이터 타입일 수 있는 데이터를 나타낸다.
"키 및 값의 매핑 입력"은 키 및 이의 값의 별개의 세트이다.
"HTML 문서"는 HTML 표준에 의해 정의된 바와 같이 0개 이상의 구문 요소를 포함하는 텍스트 또는 데이터의 블록이다. 이러한 문서는 일반적으로 웹 브라우저 내에서 보여질 수 있도록 의도된다.
"HTML 태그"는 HTML 문서의 내용과 포맷팅을 정의하는 코드이다. HTML 태그는 '<' 및 '>' 문자로 묶인다. HTML 문서 내의 인접한 공백의 폭은 HTML 태그를 삽입하여 조정될 수 있다.
"XML 문서"는 XML 표준에 의해 정의된 바와 같이 0개 이상의 구문 요소를 포함하는 텍스트 또는 데이터의 블록이다. 이러한 문서는 일반적으로 웹 브라우저 내에서 보여지도록 의도된다. XML 문서 내의 인접한 공백의 폭은 공백의 폭을 지정하는 XML 태그로 표시될 수 있다.
"XML 태그"는 HTML 문서의 내용과 포맷팅을 정의하는 코드이다. XML 태그는 '<' 및 '>' 문자로 묶인다.
"XHTML 문서"는 XHTML 표준에 의해 정의된 바와 같이 0개 이상의 구문 요소를 포함하는 텍스트 또는 데이터의 블록이다. 이러한 문서는 일반적으로 웹 브라우저 내에서 보여지도록 의도된다. XHTML 문서 내의 인접한 공백의 폭은 XHTML 태그를 삽입하여 조정될 수 있다.
"XHTML 태그"는 XHTML 문서의 내용과 포맷팅을 정의하는 코드이다. XHTML 태그는 '<' 및 '>' 문자로 묶인다.
"절대 공백 크기"는 주어진 화이트스페이스(whitespace)의 영역의 별개의 크기 측정치이다. 예시적인 절대 공백 크기는 0.25이다.
"상대 공백 크기"는 기존의 절대 공백 크기에 비례하는 양수 또는 음수 조정치이다. 예시적인 상대 공백 크기는 +0.1 또는 -0.2이며, 이는 초기 크기로부터의 공백의 크기가 각각 10%씩 증가하거나 20%씩 감소한다.
"선간 텍스트 밀도"는 잉크가 라인에서 라인까지 얼마나 작고 느슨한지를 나타낸다. 예를 들어, 텍스트 한 줄당 평균 문자 또는 단어의 양이다.
"공백 문자"는 단어를 분리하고, 일반적으로 화이트스페이스를 도입하기 위해 텍스트의 디지털 표현(digital representation)에 사용되는 표준 공백 문자이다. 공백 문자는 보통 ASCII 테이블에서 32로서 식별되지만, 또한 ASCII 코드 160 또는 HTML 엔터티 & nbsp; (줄 바꿈 없는 공백(non-breaking space)), 또는 유니코드 표준에서 정의된 바와 같이 (U+0020, U+00A0, U+1680, U+180E, U+2000 내지 U+200B, U+202F, U+205F, U+3000, U+FEFF를 포함하는) 임의의 공백 문자로서 나타내어질 수 있다.
"유니코드 개인용 영역 공백 문자(unicode private use area space character)"는 U+E000 내지 E+F8FF의 범위 내에서 유니코드 표준에 의해 정의된 바와 같은 문자이다. 이러한 범위 내의 문자의 시각적 표현은 상이한 화이트스페이스의 크기를 나타내는 폰트의 사용을 포함하는 어떠한 목적에 맞도록 수정될 수 있다.
"CSS 스타일시트"는 시각적 요소가 텍스트 또는 다른 내용의 페이지 상에 어떻게 나타내야 하는지를 결정하기 위해 CSS 언어의 요소를 이용하는 코드의 블록이다. HTML 또는 XHTML 문서 내의 인접한 공백의 폭은 CSS 스타일시트로부터 하나 이상의 스타일을 참조하는 HTML 또는 XHTML 태그를 사용하여 조정될 수 있다.
일반적인 고려 사항
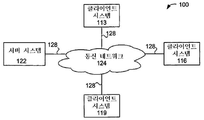
도 22는 분산형 컴퓨터 네트워크(100)의 단순화된 블록도이다. 컴퓨터 네트워크(100)는 다수의 클라이언트 시스템(113, 116 및 119), 및 복수의 통신 링크(128)를 통해 통신 네트워크(124)에 결합된 서버 시스템(122)을 포함한다. 시스템에는 다수의 클라이언트 및 서버가 있을 수 있다. 통신 네트워크(124)는 분산형 네트워크(100)의 다양한 구성 요소가 서로 통신하고 정보를 교환하도록 허용하기 위한 메커니즘을 제공한다.
통신 네트워크(124)는 그 자체로 많은 상호 연결된 컴퓨터 시스템 및 통신 링크로 구성될 수 있다. 통신 링크(128)는 하드와이어 링크, 광 링크, 위성 또는 다른 무선 통신 링크, 파동 전파 링크, 또는 정보의 통신을 위한 임의의 다른 메커니즘일 수 있다. 다양한 통신 프로토콜은 도 22에 도시된 다양한 시스템 간의 통신을 용이하게 하는데 사용될 수 있다. 이러한 통신 프로토콜은 TCP/IP, HTTP 프로토콜, 무선 애플리케이션 프로토콜(wireless application protocol; WAP), 벤더 특정(vendor-specific) 프로토콜, 맞춤형 프로토콜 등을 포함할 수 있다. 일 실시예에서, 통신 네트워크(124)는 인터넷이지만, 다른 실시예에서, 통신 네트워크(124)는 근거리 통신망(local area network; LAN), 광역 통신망(wide area network; WAN), 무선 네트워크, 인트라넷, 사설 네트워크, 공중 네트워크, 교환 네트워크 및 이의 조합 등을 포함하는 임의의 적절한 통신 네트워크일 수 있다.
도 22의 분산형 컴퓨터 네트워크(100)는 단지 실시예를 예시하기 위한 것이며, 청구 범위에 설명된 바와 같은 본 발명의 범위를 제한하려는 것은 아니다. 당업자는 다른 변형, 수정 및 대안을 인식할 것이다. 예를 들어, 하나 이상의 서버 시스템(122)은 통신 네트워크(124)에 연결될 수 있다. 다른 예로서, 다수의 클라이언트 시스템(113, 116 및 119)은 액세스 제공자(도시되지 않음) 또는 일부 다른 서버 시스템을 통해 통신 네트워크(124)에 결합될 수 있다.
클라이언트 시스템(113, 116 및 119)은 통상적으로 정보를 제공하는 서버 시스템으로부터 정보를 요청한다. 이러한 이유로, 서버 시스템은 통상적으로 클라이언트 시스템보다 더 많은 컴퓨팅 및 저장 용량을 갖는다. 그러나, 특정 컴퓨터 시스템은 컴퓨터 시스템이 정보를 요구하는지 또는 제공하는지에 따라 클라이언트 또는 서버 둘 다의 역할을 할 수 있다. 부가적으로, 시스템의 양태가 클라이언트-서버 환경을 사용하여 설명되었지만, 시스템은 또한 독립형 컴퓨터 시스템에서 구현될 수 있다는 것이 명백해야 한다. 시스템의 양태는 클라이언트-서버 환경 또는 클라우드-컴퓨팅 환경을 사용하여 구현될 수 있다.
서버(122)는 클라이언트 시스템(113, 116 및 119)으로부터 정보 요청을 수신하고, 요청을 만족시키는데 필요한 처리를 수행하며, 요청에 대응하는 결과를 요청 클라이언트 시스템으로 다시 전송할 책임이 있다. 요청을 만족시키는데 필요한 처리는 서버 시스템(122)에 의해 수행될 수 있거나, 대안적으로 통신 네트워크(124)에 연결된 다른 서버로 위임될 수 있다.
클라이언트 시스템(113,116 및 119)은 사용자가 서버 시스템(122)에 의해 저장된 정보에 액세스하여 질의하도록 할 수 있다. 특정 실시예에서, 클라이언트 시스템상에서 실행되는 "웹 브라우저" 애플리케이션은 사용자가 서버 시스템(122)에 의해 저장된 정보를 선택, 액세스, 검색 또는 질의하도록 할 수 있다. 웹 브라우저의 예는 마이크로소프트사(Microsoft Corporation)에 의해 제공된 인터넷 익스플로러(Internet Explorer) 브라우저 프로그램, 구글사(Google)에 의해 제공된 구글 크롬(Google Chrome), 애플사(Apple Inc.)에 의해 제공된 사파리(Safari) 및 모질라 파운데이션(Mozilla Foundation)에 의해 제공된 파이어폭스(Firefox) 브라우저 등을 포함한다.
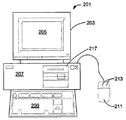
도 23은 예시적인 클라이언트 또는 서버 시스템을 도시한다. 실시예에서, 사용자는 도 23에 도시된 바와 같은 컴퓨터 워크스테이션 시스템을 통해 시스템과 인터페이스한다. 도 23은 모니터(203), 스크린(205), 캐비닛(207), 키보드(209) 및 마우스(211)를 포함하는 컴퓨터 시스템(201)을 도시한다. 마우스(211)는 마우스 버튼(213)과 같은 하나 이상의 버튼을 가질 수 있다. 캐비닛(207)은 프로세서, 메모리, 대용량 저장 디바이스(217) 등과 같이 친숙한 컴퓨터 구성 요소를 수용하며, 이의 일부는 도시되지 않는다.
대용량 저장 디바이스(217)는 대용량 디스크 드라이브, 플로피 디스크, 자기 디스크, 광학 디스크, 광 자기 디스크, 고정 디스크, 하드 디스크, CD-ROM, 기록 가능한 CD, DVD, 기록 가능한 DVD(예를 들어, DVD-R, DVD+R, DVD-RW, DVD+RW, HD-DVD, 또는 블루-레이 디스크(Blu-ray Disc)), 플래시 및 다른 비휘발성 고체 상태 저장 디바이스(예를 들어, USB 플래시 드라이브), 배터리 백업 휘발성 메모리, 테이프 스토리지, 판독기, 및 다른 유사한 매체 및 이의 조합을 포함할 수 있다.
시스템의 컴퓨터 구현 또는 컴퓨터 실행 가능 버전은 컴퓨터 판독 가능한 매체 또는 비일시적 컴퓨터 판독 가능한 매체를 사용하여 구현되거나, 저장되거나 관련될 수 있다. 컴퓨터 판독 가능한 매체는 실행을 위해 하나 이상의 프로세서에 명령어를 제공하는데 참여하는 임의의 매체를 포함할 수 있다. 이러한 매체는 비휘발성 및 휘발성 매체를 포함하지만, 이에 한정되지 않는 많은 형태를 취할 수 있다. 비휘발성 매체는 예를 들어 플래시 메모리 또는 광학 또는 자기 디스크를 포함한다. 휘발성 매체는 캐시 메모리 또는 RAM과 같은 정적 또는 동적 메모리를 포함한다.
예를 들어, 본 시스템의 소프트웨어의 이진 머신 실행 가능한 버전은 RAM 또는 캐시 메모리, 또는 대용량 저장 디바이스(217)에 저장되거나 상주할 수 있다. 소프트웨어의 소스 코드는 또한 대용량 저장 디바이스(217)(예를 들어, 하드 디스크, 자기 디스크, 테이프 또는 CD-ROM)에 저장되거나 상주할 수 있다. 추가의 예로서, 코드는 유선, 또는 인터넷과 같은 네트워크를 통해 송신될 수 있다.
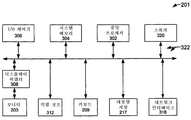
도 24는 컴퓨터 시스템(201)의 시스템 블록도를 도시한다. 도 23에서와 같이, 컴퓨터 시스템(201)은 모니터(203), 키보드(209) 및 대용량 저장 디바이스(217)를 포함한다. 컴퓨터 시스템(201)은 중앙 프로세서(302), 시스템 메모리(304), 입출력(I/O) 제어기(306), 디스플레이 어댑터(308), 직렬 또는 범용 직렬 버스(universal serial bus; USB) 포트(312), 네트워크 인터페이스(318) 및 스피커(320)를 더 포함한다. 실시예에서, 컴퓨터 시스템은 부가적 또는 더 적은 서브시스템을 포함한다. 예를 들어, 컴퓨터 시스템은 하나 이상의 프로세서(302)(즉, 멀티프로세서 시스템)를 포함할 수 있거나 시스템은 캐시 메모리를 포함할 수 있다.
322와 같은 화살표는 컴퓨터 시스템(201)의 시스템 버스 아키텍처를 나타낸다. 그러나, 이러한 화살표는 서브시스템을 링크하는 역할을 하는 임의의 상호 연결 방식을 예시한다. 예를 들어, 스피커(320)는 포트를 통해 다른 서브시스템에 연결되거나 중앙 프로세서(302)에 대한 내부 직접 연결부를 가질 수 있다. 프로세서는 정보의 병렬 처리를 허용할 수 있는 다중 프로세서 또는 멀티 코어 프로세서를 포함할 수 있다. 도 23에 도시된 컴퓨터 시스템(201)은 적절한 컴퓨터 시스템의 일례일 뿐이다. 사용하기에 적합한 서브시스템의 다른 구성은 당업자에게 쉽게 명백해질 것이다.
컴퓨터 소프트웨어 제품은 C, C++, C#, 파스칼(Pascal), 포트란(Fortran), Perl, (매트웍스사(MathWorks)로부터의) 매트랩(Matlab), SAS, SPSS, 자바스크립트(JavaScript), AJAX, 자바(Java), SQL 및 XQuery와 같은 다양한 적절한 프로그래밍 언어 중 어느 하나의 언어(XML 파일 또는 XML, HTML 또는 둘 다로서 보여질 수 있는 임의의 데이터 소스로부터의 데이터를 처리하도록 설계되는 질의(query) 언어)로 작성될 수 있다. 컴퓨터 소프트웨어 제품은 데이터 입력 모듈 및 데이터 디스플레이 모듈을 가진 독립 애플리케이션일 수 있다. 대안으로, 컴퓨터 소프트웨어 제품은 분산형 객체로서 인스턴스화될 수 있는 클래스일 수 있다. 컴퓨터 소프트웨어 제품은 또한 (오라클사(Oracle Corporation)로부터의) 자바 빈스(Java Beans) 또는 엔터프라이즈 자바 빈스(Enterprise Java Beans)(오라클사로부터의 EJB)와 같은 컴포넌트 소프트웨어일 수 있다. 특정 실시예에서, 본 시스템은 설명된 프로세스 또는 기술 중 어느 하나를 수행하도록 컴퓨터를 프로그램하는 컴퓨터 코드와 같은 명령어를 저장하는 컴퓨터 프로그램 제품을 제공한다.
시스템용 운영 체제는 운영 체제의 마이크로소프트 윈도우즈(Microsoft Windows)® 계열(예를 들어, Windows NT, Windows 2000, Windows XP, Windows XP x64판, Windows Vista, Windows 7, Windows CE, Windows Mobile, Windows 8), 리눅스(Linux), HP-UX, TRU64, 유닉스(UNIX), Sun OS, 솔라리스(Solaris) SPARC 및 x64, Mac OS X, Alpha OS, AIX, IRIX32 또는 IRIX64 중 하나일 수 있다. 다른 운영 체제가 또한 사용되거나 대신 사용될 수 있다. 마이크로소프트 윈도우즈는 마이크로소프트사의 상표이다.
더욱이, 컴퓨터는 네트워크에 연결될 수 있고, 이러한 네트워크를 사용하여 다른 컴퓨터에 인터페이스할 수 있다. 네트워크는 인트라넷, 인터넷(internet) 또는 특히 인터넷(Internet)일 수 있다. 네트워크는 (예를 들어, 구리를 사용하는) 유선 네트워크, 전화 네트워크, 패킷 네트워크, (예를 들어, 광섬유를 사용하는) 광학 네트워크, 또는 무선 네트워크, 또는 이의 임의의 조합일 수 있다. 예를 들어, 와이-파이(Wi-Fi)(몇 가지 예를 들자면, IEEE 표준 802.11, 802.11a, 802.11b, 802.11e, 802.11g, 802.11i 및 802.11n)와 같은 프로토콜을 사용하는 무선 네트워크를 사용하여 시스템의 컴퓨터와 구성 요소(또는 단계) 간에 데이터 및 다른 정보가 전달될 수 있다. 예를 들어, 컴퓨터로부터의 신호는 적어도 부분적으로 무선으로 구성 요소 또는 다른 컴퓨터로 전송될 수 있다.
실시예에서, 컴퓨터 워크스테이션 시스템상에서 실행되는 웹 브라우저를 사용하여, 사용자는 인터넷과 같은 네트워크를 통해 WWW(World Wide Web) 상의 시스템에 액세스한다. 웹 브라우저는 HTML, XML, 텍스트, PDF 및 포스트스크립트를 포함한 다양한 포맷의 웹 페이지 또는 다른 콘텐츠를 다운로드하는 데 사용되며, 시스템의 다른 부분에 정보를 업로드하는 데 사용될 수 있다. 웹 브라우저는 URL(uniform resource identifier)을 사용하여 웹 상에서 파일을 전송할 때 웹 상의 자원 및 HTTP(Hypertext Transfer Protocol)를 식별할 수 있다.
청구된 주제(subject matter)에 대한 완전한 이해를 제공하기 위해 다수의 특정 세부 사항이 본 명세서에 설명된다. 그러나, 당업자는 청구된 주제가 이러한 특정 세부 사항 없이 실시될 수 있다는 것을 이해할 것이다. 다른 경우에, 당업자에 의해 알려진 방법, 장치 또는 시스템은 청구된 주제를 모호하게 하지 않기 위해 상세히 설명되지 않았다.
달리 구체적으로 언급되지 않으면, 본 명세서 전반에 걸쳐, "처리", "컴퓨팅", "계산", "결정" 및 "식별" 등과 같은 용어를 이용하는 논의는 메모리, 레지스터 또는 다른 정보 저장 디바이스, 송신 디바이스, 또는 컴퓨팅 플랫폼의 디스플레이 디바이스 내의 물리적 전자 또는 자기적 수량으로 나타내어진 데이터를 조작하거나 변환하는 하나 이상의 컴퓨터 또는 유사한 전자 컴퓨팅 디바이스 또는 디바이스들과 같은 컴퓨팅 장치의 동작 또는 프로세스를 지칭한다는 것이 이해될 것이다.
본 명세서에서 논의된 시스템 또는 시스템들은 임의의 특정 하드웨어 아키텍처 또는 구성으로 제한되지 않는다. 컴퓨팅 장치는 하나 이상의 입력 상에서 조절된(conditioned) 결과를 제공하는 임의의 적절한 구성 요소의 배치를 포함할 수 있다. 적절한 컴퓨팅 디바이스는 범용 컴퓨팅 장치로부터 본 주제의 하나 이상의 실시예를 구현하는 전문화된 컴퓨팅 장치로 컴퓨팅 시스템을 프로그래밍하거나 구성하는 저장된 소프트웨어에 액세스하는 다목적 마이크로 프로세서 기반 컴퓨터 시스템을 포함한다. 임의의 적절한 프로그래밍, 스크립팅, 또는 다른 타입의 언어 또는 언어의 조합은 컴퓨팅 장치를 프로그래밍하거나 구성하는데 사용되는 소프트웨어에서 본 명세서에 포함된 교시를 구현하는데 사용될 수 있다.
본 명세서에 개시된 방법의 실시예는 이러한 컴퓨팅 장치의 동작에서 수행될 수 있다. 위의 예에서 제시된 블록의 순서는 변경될 수 있으며, 예를 들어, 블록은 서브 블록으로 재순서, 조합 및/또는 분리될 수 있다. 어떤 블록 또는 프로세스는 병렬로 수행될 수 있다.
본 명세서에서 "적응된(adapted to)" 또는 "구성된(configured to)"을 사용한다는 것은 부가적인 태스크 또는 단계를 수행하도록 적응되거나 구성된 디바이스를 방해하지 않는 개방적이고 포괄적인 언어를 의미한다. 부가적으로, 하나 이상의 열거된 조건 또는 값에 "기반한" 프로세스, 단계, 계산 또는 다른 동작이 실제로 열거한 것 이상의 부가적인 조건 또는 값에 기초할 수 있다는 점에서 "기반(based on)"의 사용은 개방적이고 포괄적임을 의미한다. 본 명세서에 포함된 표제, 리스트 및 넘버링은 설명의 편의를 위한 것이며, 제한하는 것으로 의미되지 않는다.
본 주제는 이의 특정 실시예와 관련하여 상세히 설명되었지만, 당업자는 전술한 내용을 이해할 때 이러한 실시예에 대한 변경, 변형 및 균등물을 용이하게 생성할 수 있음을 알 것이다. 따라서, 본 개시 내용은 제한이 아닌 예시를 위해 제시되었으며, 당업자에게는 쉽게 명백하듯이 본 주제에 대한 이러한 수정, 변형 및/또는 부가의 포함을 배제하지 않는 것으로 이해되어야 한다.
Claims (22)
- 텍스트 내의 단어 공백에 걸친 불확실성을 결정하는 방법으로서,
a) 텍스트 입력을 제공하는 단계;
b) 기능 단어의 데이터베이스를 제공하는 단계;
d) 상기 텍스트 입력의 복수의 단어를 검사하는 단계;
e) 상기 복수의 단어의 각각을 상기 데이터베이스의 상기 기능 단어 중 하나로서 식별하거나, 식별되는 단어가 상기 데이터베이스에 없는 경우에는 내용 단어로서 식별하는 단계;
f) 각각의 고유 의사 구문 하이브리드에 대한 n-gram 빈도 카운트를 생성하는 단계로서, 상기 고유 의사 구문 하이브리드의 각각은 어휘 동일성, 어휘, 어휘 카테고리 및 개방 클래스 단어 중 적어도 하나로 구성된 n-gram인, 상기 생성하는 단계;
h) 종료 텍스트 입력이 도달될 때까지 다음의 복수의 단어에 대해 단계 d-f를 반복하는 단계; 및
g) 상기 고유 의사 구문 하이브리드의 각각에 대한 불확실성을 계산하기 위해 상기 n-gram 빈도 카운트를 사용하는 단계를 포함하되;
상기 어휘 동일성은 단어이고, 상기 어휘는 단어가 취할 수 있는 형식의 세트이고, 상기 어휘 카테고리는 상기 단어의 일부이고, 상기 개방 클래스 단어는 구문 정보가 없는 내용 단어인, 단어 공백에 걸친 불확실성을 결정하는 방법. - 제1항에 있어서, 상기 텍스트 입력은 텍스트를 포함하는 문서인, 단어 공백에 걸친 불확실성을 결정하는 방법.
- 제1항에 있어서, 상기 텍스트 입력은 상기 n-gram 빈도 카운트가 코퍼스로부터 생성되는 것인, 단어 공백에 걸친 불확실성을 결정하는 방법.
- 텍스트 내의 단어 공백에 걸친 불확실성을 결정하는 시스템으로서,
기능 단어의 데이터베이스;
각각의 고유 의사 구문 하이브리드에 대한 빈도 카운트를 생성하기 위한 카운터로서, 의사 구문 하이브리드는 어휘 동일성, 어휘, 어휘 카테고리 및 개방 클래스 단어 중 적어도 하나로 구성되는, 상기 카운터; 및
생성된 빈도 카운트를 사용하여 의사 구문 하이브리드의 상기 단어 공백에 걸친 어휘 불확실성을 계산하기 위한 필터를 포함하되;
상기 어휘 동일성은 단어이고, 상기 어휘는 단어가 취할 수 있는 형식의 세트이고, 상기 어휘 카테고리는 상기 단어의 일부이고, 상기 어휘 항목의 상기 개방 클래스 상태는 구문 정보가 없는 내용 단어인, 단어 공백에 걸친 불확실성을 결정하는 시스템. - 제4항에 있어서, 상기 불확실성을 계산하면 키 및 값의 입력 맵을 제공하고, 상기 키의 각각은 적어도 하나의 의사 구문 하이브리드를 나타내고, 상기 값은 상기 키에 인접한 상기 단어 공백에 걸친 불확실성을 나타내는, 단어 공백에 걸친 불확실성을 결정하는 시스템.
- 텍스트를 포맷팅하는 방법으로서,
텍스트 입력을 제공하는 단계;
키 및 값의 매핑 입력을 제공하는 단계로서, 상기 키의 각각은 고유 의사 구문 하이브리드 중 적어도 하나를 나타내고, 상기 값은 상기 키에 인접한 단어 공백에 걸친 불확실성을 나타내는, 상기 매핑 입력을 제공하는 단계; 및
상기 매핑 입력에서 상기 키를 찾기 위해 상기 텍스트 입력을 검사하고, 상기 검사의 결과에 기초하여 상기 텍스트 입력의 인접한 공백의 폭을 포맷팅하는 단계로서, 상기 텍스트 입력의 인접한 공백의 폭의 포맷팅은 상기 값에 의해 결정되는, 상기 공백의 폭을 포맷팅하는 단계를 포함하는, 텍스트를 포맷팅하는 방법. - 제6항에 있어서, 상기 인접한 공백의 폭은 공백 문자, 선행 문자 또는 후행 문자의 다음의 문자 속성: 문자 공백, 수평 스케일링, 커닝, 수평 오프셋, 패딩, 왼쪽 여백 또는 오른쪽 여백 중 적어도 하나를 변경하여 조정되는, 텍스트를 포맷팅하는 방법.
- 제6항에 있어서, 상기 인접한 공백의 폭은 HTML 문서 내에 HTML 태그를 삽입함으로써 조정되는, 텍스트를 포맷팅하는 방법.
- 제6항에 있어서, 상기 인접한 공백의 폭은 XML 문서 내에 XML 태그를 삽입함으로써 조정되는, 텍스트를 포맷팅하는 방법.
- 제6항에 있어서, 상기 인접한 공백의 폭은 XHTML 문서 내에 XHTML 태그를 삽입함으로써 조정되는, 텍스트를 포맷팅하는 방법.
- 제6항에 있어서, 상기 매핑 입력으로부터의 값 중 하나는 절대 공백 크기를 나타내는, 텍스트를 포맷팅하는 방법.
- 제6항에 있어서, 상기 인접한 공백의 폭은 상기 매핑 입력으로부터의 값과 매칭되는 지정된 폭을 갖는 적어도 하나의 유니코드 개인용 영역 공백 문자로 공백 문자를 대체함으로써 조정되는, 텍스트를 포맷팅하는 방법.
- 제6항에 있어서, 상기 매핑 입력으로부터의 값 중 하나는 상기 인접한 공백의 폭으로서 적용될 절대 공백 크기로 변환되는 상대 공백 크기를 나타내는, 텍스트를 포맷팅하는 방법.
- 제13항에 있어서, 상기 키에 걸친 상기 상대 공백 크기의 분포 및 상기 매핑 입력의 값은 유지되지만, 절대 공백 크기는 동적으로 조정되는, 텍스트를 포맷팅하는 방법.
- 제14항에 있어서, HTML 태그는 상기 절대 공백 크기를 동적으로 조정하는 데 사용되는, 텍스트를 포맷팅하는 방법.
- 제14항에 있어서, HTML 태그는 상기 HTML 태그에 의해 적용되는 상기 절대 공백 크기의 조정을 제공하는 CSS 스타일시트를 지칭하는, 텍스트를 포맷팅하는 방법.
- 제6항에 있어서, 상기 인접한 공백의 폭의 포맷팅은 공백 문자 전후에 하나 이상의 픽셀 또는 서브 픽셀을 삽입함으로써 조정되는, 텍스트를 포맷팅하는 방법.
- 제6항에 있어서, 상기 인접한 공백의 폭의 포맷팅은 웹 브라우저 또는 웹 문서를 렌더링하는 웹 브라우저 플러그인에 의해 조정되는, 텍스트를 포맷팅하는 방법.
- 제6항에 있어서, 상기 키는 어휘 동일성, 어휘 카테고리, 어휘 항목의 개방 클래스 상태 및 상기 어휘 항목의 폐쇄 클래스 상태 중 적어도 하나로 구성되는 하나 이상의 항목의 리스트를 나타내고, 상기 어휘 동일성은 단어이고, 상기 어휘는 단어가 취할 수 있는 형식의 세트이고, 상기 어휘 카테고리는 상기 단어의 일부이고, 상기 어휘 항목의 상기 개방 클래스 상태는 구문 정보가 없는 내용 단어이며, 상기 어휘 항목의 상기 폐쇄 클래스 상태는 새로운 항목을 수용하지 않는 단어의 클래스인, 텍스트를 포맷팅하는 방법.
- 제19항에 있어서, 상기 단어 공백에 걸친 불확실성은 조건부 엔트로피의 측정에 의해 결정되는, 텍스트를 포맷팅하는 방법.
- 텍스트를 포맷팅하는 컴퓨터 프로그램 제품으로서,
상기 컴퓨터 프로그램 제품은 컴퓨터 판독 가능한 프로그램 코드 부분을 저장하는 비일시적 컴퓨터 판독 가능한 저장 매체를 포함하되, 상기 컴퓨터 판독 가능한 프로그램 코드 부분은,
텍스트를 제공하도록 구성된 제1 부분;
키 및 값의 매핑 입력을 제공하도록 구성된 제2 부분으로서, 상기 키의 각각은 적어도 하나의 의사 구문 하이브리드를 나타내고, 상기 값의 각각은 상기 키에 인접한 단어 공백에 걸친 불확실성을 나타내는, 상기 제2 부분; 및
상기 매핑 입력에서 상기 키를 찾기 위해 상기 텍스트 입력을 검사하고, 상기 검사의 결과에 기초하는 상기 텍스트 입력의 단어 간 공백의 폭을 포맷팅하도록 구성된 제3 실행 가능한 부분으로서, 상기 단어 간 공백의 폭의 포맷팅은 상기 값에 의해 결정되는, 상기 제3 실행 가능한 부분을 포함하는, 텍스트를 포맷팅하는 컴퓨터 프로그램 제품. - 디스플레이를 갖는 컴퓨터 시스템에서, 텍스트를 디스플레이하는 방법으로서,
a) 단어의 모든 경우의 리스트를 생성하는 단계로서; 상기 단어 앞의 문자는 공백, 단어의 시작, 라인의 시작, 단락의 시작, 문서의 시작, 탭, 들여 쓰기 또는 구두점 문자 중 적어도 하나를 포함하는, 상기 리스트를 생성하는 단계;
b) 단계 a로부터의 리스트 내의 단어 각각에 대해, 조정 점수 라이브러리에서 단어(n) 및 단어(n) 바로 다음에 오는 후속 단어(n+1)를 검색하는 단계로서, 상기 단어 및 뒤따르는 후속 단어는 공백 문자에 의해 분리되는, 상기 검색하는 단계;
c) 조정 라이브러리에서 발견되면, 상기 조정 라이브러리의 단어 및 후속 단어의 단어 바이그램(bigram)에 대해 발견된 조정 점수를 사용하여 상기 공백 문자의 폭을 조정하는 단계;
d) n을 n+1로 설정하는 단계; 및
e) 단계 a에서 생성된 상기 리스트의 모든 항목에 대해 단계 b 내지 d를 반복하는 단계를 포함하는, 텍스트를 디스플레이하는 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562131187P | 2015-03-10 | 2015-03-10 | |
| US62/131,187 | 2015-03-10 | ||
| PCT/US2016/021381 WO2016144963A1 (en) | 2015-03-10 | 2016-03-08 | Systems and methods for asymmetrical formatting of word spaces according to the uncertainty between words |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20170140808A true KR20170140808A (ko) | 2017-12-21 |
Family
ID=56879374
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020177028553A KR20170140808A (ko) | 2015-03-10 | 2016-03-08 | 단어 사이의 불확실성에 따른 단어 공백의 비대칭 포맷팅을 위한 시스템 및 방법 |
Country Status (9)
| Country | Link |
|---|---|
| US (2) | US10157168B2 (ko) |
| EP (1) | EP3268872A4 (ko) |
| JP (1) | JP2018513453A (ko) |
| KR (1) | KR20170140808A (ko) |
| CN (1) | CN107615268B (ko) |
| AU (1) | AU2016229923B2 (ko) |
| BR (1) | BR112017017612A2 (ko) |
| MX (1) | MX2017011452A (ko) |
| WO (1) | WO2016144963A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102209133B1 (ko) * | 2020-04-27 | 2021-01-28 | 주식회사 뉴로라인즈 | 물질안전보건자료를 위한 판독 및 처리 시스템 및 이를 위한 동작 방법 |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109190124B (zh) * | 2018-09-14 | 2019-11-26 | 北京字节跳动网络技术有限公司 | 用于分词的方法和装置 |
| CN111261162B (zh) * | 2020-03-09 | 2023-04-18 | 北京达佳互联信息技术有限公司 | 语音识别方法、语音识别装置及存储介质 |
| CN112016322B (zh) * | 2020-08-28 | 2023-06-27 | 沈阳雅译网络技术有限公司 | 一种英文粘连词错误的还原方法 |
Family Cites Families (52)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5146405A (en) * | 1988-02-05 | 1992-09-08 | At&T Bell Laboratories | Methods for part-of-speech determination and usage |
| US20020052903A1 (en) * | 1993-05-31 | 2002-05-02 | Mitsuhiro Aida | Text input method |
| US5579466A (en) * | 1994-09-01 | 1996-11-26 | Microsoft Corporation | Method and system for editing and formatting data in a dialog window |
| WO1996041281A1 (en) * | 1995-06-07 | 1996-12-19 | International Language Engineering Corporation | Machine assisted translation tools |
| US5857212A (en) * | 1995-07-06 | 1999-01-05 | Sun Microsystems, Inc. | System and method for horizontal alignment of tokens in a structural representation program editor |
| US5801679A (en) * | 1996-11-26 | 1998-09-01 | Novell, Inc. | Method and system for determining a cursor location with respect to a plurality of character locations |
| US6240430B1 (en) * | 1996-12-13 | 2001-05-29 | International Business Machines Corporation | Method of multiple text selection and manipulation |
| US20020116196A1 (en) * | 1998-11-12 | 2002-08-22 | Tran Bao Q. | Speech recognizer |
| WO2000073936A1 (en) * | 1999-05-28 | 2000-12-07 | Sehda, Inc. | Phrase-based dialogue modeling with particular application to creating recognition grammars for voice-controlled user interfaces |
| US7069508B1 (en) * | 2000-07-13 | 2006-06-27 | Language Technologies, Inc. | System and method for formatting text according to linguistic, visual and psychological variables |
| US7346489B1 (en) * | 1999-07-16 | 2008-03-18 | Language Technologies, Inc. | System and method of determining phrasing in text |
| US6282327B1 (en) * | 1999-07-30 | 2001-08-28 | Microsoft Corporation | Maintaining advance widths of existing characters that have been resolution enhanced |
| US6477488B1 (en) * | 2000-03-10 | 2002-11-05 | Apple Computer, Inc. | Method for dynamic context scope selection in hybrid n-gram+LSA language modeling |
| US7093240B1 (en) * | 2001-12-20 | 2006-08-15 | Unisys Corporation | Efficient timing chart creation and manipulation |
| US7385606B2 (en) * | 2002-12-18 | 2008-06-10 | Microsoft Corporation | International font measurement system and method |
| US7516404B1 (en) * | 2003-06-02 | 2009-04-07 | Colby Steven M | Text correction |
| US20040253568A1 (en) * | 2003-06-16 | 2004-12-16 | Shaver-Troup Bonnie S. | Method of improving reading of a text |
| US7773248B2 (en) * | 2003-09-30 | 2010-08-10 | Brother Kogyo Kabushiki Kaisha | Device information management system |
| US7292244B2 (en) * | 2004-10-18 | 2007-11-06 | Microsoft Corporation | System and method for automatic label placement on charts |
| US9465852B1 (en) * | 2007-08-02 | 2016-10-11 | Amazon Technologies, Inc. | Data format for processing information |
| US8306356B1 (en) * | 2007-09-28 | 2012-11-06 | Language Technologies, Inc. | System, plug-in, and method for improving text composition by modifying character prominence according to assigned character information measures |
| US8996682B2 (en) * | 2007-10-12 | 2015-03-31 | Microsoft Technology Licensing, Llc | Automatically instrumenting a set of web documents |
| US8417713B1 (en) * | 2007-12-05 | 2013-04-09 | Google Inc. | Sentiment detection as a ranking signal for reviewable entities |
| US9529974B2 (en) * | 2008-02-25 | 2016-12-27 | Georgetown University | System and method for detecting, collecting, analyzing, and communicating event-related information |
| US20110231755A1 (en) * | 2008-07-14 | 2011-09-22 | Daniel Herzner | Method of formatting text in an electronic document to increase reading speed |
| JP5226425B2 (ja) * | 2008-08-13 | 2013-07-03 | インターナショナル・ビジネス・マシーンズ・コーポレーション | 情報処理装置、情報処理方法およびプログラム |
| US20100146444A1 (en) * | 2008-12-05 | 2010-06-10 | Microsoft Corporation | Motion Adaptive User Interface Service |
| US8819541B2 (en) * | 2009-02-13 | 2014-08-26 | Language Technologies, Inc. | System and method for converting the digital typesetting documents used in publishing to a device-specfic format for electronic publishing |
| US8306819B2 (en) * | 2009-03-09 | 2012-11-06 | Microsoft Corporation | Enhanced automatic speech recognition using mapping between unsupervised and supervised speech model parameters trained on same acoustic training data |
| US8712774B2 (en) * | 2009-03-30 | 2014-04-29 | Nuance Communications, Inc. | Systems and methods for generating a hybrid text string from two or more text strings generated by multiple automated speech recognition systems |
| US8543914B2 (en) * | 2009-05-22 | 2013-09-24 | Blackberry Limited | Method and device for proportional setting of font attributes |
| EP2517156A4 (en) * | 2009-12-24 | 2018-02-14 | Moodwire, Inc. | System and method for determining sentiment expressed in documents |
| US9026907B2 (en) * | 2010-02-12 | 2015-05-05 | Nicholas Lum | Indicators of text continuity |
| US8959427B1 (en) * | 2011-08-05 | 2015-02-17 | Google Inc. | System and method for JavaScript based HTML website layouts |
| US8862602B1 (en) * | 2011-10-25 | 2014-10-14 | Google Inc. | Systems and methods for improved readability of URLs |
| US9116654B1 (en) * | 2011-12-01 | 2015-08-25 | Amazon Technologies, Inc. | Controlling the rendering of supplemental content related to electronic books |
| CN103106227A (zh) * | 2012-08-03 | 2013-05-15 | 人民搜索网络股份公司 | 一种基于网页文本的新词查找系统及方法 |
| JP2016035607A (ja) * | 2012-12-27 | 2016-03-17 | パナソニック株式会社 | ダイジェストを生成するための装置、方法、及びプログラム |
| JP2014130445A (ja) * | 2012-12-28 | 2014-07-10 | Toshiba Corp | 情報抽出サーバ、情報抽出クライアント、情報抽出方法、及び、情報抽出プログラム |
| IN2013CH00469A (ko) * | 2013-01-21 | 2015-07-31 | Keypoint Technologies India Pvt Ltd | |
| CN104063387B (zh) * | 2013-03-19 | 2017-07-28 | 三星电子(中国)研发中心 | 在文本中抽取关键词的装置和方法 |
| JP6136568B2 (ja) * | 2013-05-23 | 2017-05-31 | 富士通株式会社 | 情報処理装置および入力制御プログラム |
| EP2824586A1 (en) * | 2013-07-09 | 2015-01-14 | Universiteit Twente | Method and computer server system for receiving and presenting information to a user in a computer network |
| US20160301828A1 (en) * | 2014-06-18 | 2016-10-13 | Sarfaraz K. Niazi | Visual axis optimization for enhanced readability and comprehension |
| US20150371120A1 (en) * | 2014-06-18 | 2015-12-24 | Sarfaraz K. Niazi | Visual axis optimization for enhanced readability and comprehension |
| WO2016125177A1 (en) * | 2015-02-05 | 2016-08-11 | Hewlett-Packard Development Company, L.P. | Character spacing adjustment of text columns |
| US10891699B2 (en) * | 2015-02-09 | 2021-01-12 | Legalogic Ltd. | System and method in support of digital document analysis |
| CN104915446B (zh) * | 2015-06-29 | 2019-01-29 | 华南理工大学 | 基于新闻的事件演化关系自动提取方法及其系统 |
| CN105373614B (zh) * | 2015-11-24 | 2018-09-28 | 中国科学院深圳先进技术研究院 | 一种基于用户账号的子用户识别方法及系统 |
| US10235348B2 (en) * | 2016-04-12 | 2019-03-19 | Microsoft Technology Licensing, Llc | Assistive graphical user interface for preserving document layout while improving the document readability |
| US10552217B2 (en) * | 2016-08-15 | 2020-02-04 | International Business Machines Corporation | Workload placement in a hybrid cloud environment |
| US10467241B2 (en) * | 2017-03-24 | 2019-11-05 | Ca, Inc. | Dynamically provisioning instances of a single-tenant application for multi-tenant use |
-
2016
- 2016-03-08 US US15/063,794 patent/US10157168B2/en active Active
- 2016-03-08 AU AU2016229923A patent/AU2016229923B2/en not_active Ceased
- 2016-03-08 KR KR1020177028553A patent/KR20170140808A/ko not_active Application Discontinuation
- 2016-03-08 US US15/549,509 patent/US10599748B2/en active Active
- 2016-03-08 CN CN201680027497.3A patent/CN107615268B/zh active Active
- 2016-03-08 MX MX2017011452A patent/MX2017011452A/es unknown
- 2016-03-08 EP EP16762347.9A patent/EP3268872A4/en not_active Withdrawn
- 2016-03-08 WO PCT/US2016/021381 patent/WO2016144963A1/en active Application Filing
- 2016-03-08 BR BR112017017612A patent/BR112017017612A2/pt not_active Application Discontinuation
- 2016-03-08 JP JP2017545541A patent/JP2018513453A/ja active Pending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102209133B1 (ko) * | 2020-04-27 | 2021-01-28 | 주식회사 뉴로라인즈 | 물질안전보건자료를 위한 판독 및 처리 시스템 및 이를 위한 동작 방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3268872A4 (en) | 2018-11-21 |
| US20180039617A1 (en) | 2018-02-08 |
| CN107615268B (zh) | 2021-08-24 |
| AU2016229923A1 (en) | 2017-09-07 |
| CN107615268A (zh) | 2018-01-19 |
| JP2018513453A (ja) | 2018-05-24 |
| US20170185566A1 (en) | 2017-06-29 |
| WO2016144963A1 (en) | 2016-09-15 |
| AU2016229923B2 (en) | 2021-01-21 |
| MX2017011452A (es) | 2018-06-15 |
| US10157168B2 (en) | 2018-12-18 |
| EP3268872A1 (en) | 2018-01-17 |
| US10599748B2 (en) | 2020-03-24 |
| BR112017017612A2 (pt) | 2018-05-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Pasha et al. | Madamira: A fast, comprehensive tool for morphological analysis and disambiguation of arabic. | |
| US7469251B2 (en) | Extraction of information from documents | |
| US9817814B2 (en) | Input entity identification from natural language text information | |
| US7627562B2 (en) | Obfuscating document stylometry | |
| US9268749B2 (en) | Incremental computation of repeats | |
| Schofield et al. | Quantifying the effects of text duplication on semantic models | |
| US20120290288A1 (en) | Parsing of text using linguistic and non-linguistic list properties | |
| KR20170140808A (ko) | 단어 사이의 불확실성에 따른 단어 공백의 비대칭 포맷팅을 위한 시스템 및 방법 | |
| US7757161B2 (en) | Apparatus and method for automatically sizing fields within reports | |
| Klahold et al. | Computer aided writing | |
| CN111199151A (zh) | 数据处理方法、及数据处理装置 | |
| JP2018513453A5 (ko) | ||
| US11861305B2 (en) | Word processing system and word processing method | |
| JPH05158401A (ja) | 文書速読支援表示方式並びに文書処理装置及び文書検索装置 | |
| Rakholia et al. | The design and implementation of diacritic extraction technique for Gujarati written script using Unicode Transformation Format | |
| Llorens et al. | Deep level lexical features for cross-lingual authorship attribution | |
| JP2009265770A (ja) | 重要文提示システム | |
| Kouroupetroglou et al. | DocEmoX: a system for the typography-derived emotional annotation of documents | |
| KR20070067058A (ko) | 웹 문서 제목 추출 방법 및 그 장치 | |
| Unger | What linguistic units do Chinese characters represent? | |
| KR20070095506A (ko) | 웹 문서 제목 추출 방법 및 그 장치 | |
| Lučanský et al. | Improving relevance of keyword extraction from the web utilizing visual style information | |
| Gajdoš | A Syntactic Object in Chinese—A Corpus Analysis | |
| CN107403002B (zh) | 一种基于词汇关键度的网络论坛正文提取方法、装置 | |
| CN115017885A (zh) | 一种从电力领域的文本中抽取实体关系的方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal |