KR20170119152A - Ensemble of Jointly Trained Deep Neural Network-based Acoustic Models for Reverberant Speech Recognition and Method for Recognizing Speech using the same - Google Patents
Ensemble of Jointly Trained Deep Neural Network-based Acoustic Models for Reverberant Speech Recognition and Method for Recognizing Speech using the same Download PDFInfo
- Publication number
- KR20170119152A KR20170119152A KR1020160046952A KR20160046952A KR20170119152A KR 20170119152 A KR20170119152 A KR 20170119152A KR 1020160046952 A KR1020160046952 A KR 1020160046952A KR 20160046952 A KR20160046952 A KR 20160046952A KR 20170119152 A KR20170119152 A KR 20170119152A
- Authority
- KR
- South Korea
- Prior art keywords
- neural network
- reverberation
- ensemble
- speech recognition
- acoustic model
- Prior art date
Links
Images





Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/16—Speech classification or search using artificial neural networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L17/00—Speaker identification or verification
- G10L17/04—Training, enrolment or model building
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
- G10L19/032—Quantisation or dequantisation of spectral components
- G10L19/035—Scalar quantisation
Abstract
잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법이 제시된다. 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법에 있어서, 입력되는 음성 신호로부터 특징 벡터를 추출하는 단계; 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합하는 단계; 및 음소를 분류하여 음성을 인식하는 단계를 포함하고, 상기 미리 학습된 심화신경망 앙상블 기반의 음향 모델은, 다수의 잔향 환경에서 각각의 잔향 환경에 대해 음소 확률을 추정할 수 있다. A combined deep - learning neural network ensemble - based acoustic model for speech recognition in reverberant environments and a speech recognition method using it are presented. A speech recognition method using an acoustic model of a deep-learning neural network ensemble for speech recognition in a reverberant environment, the method comprising: extracting a feature vector from an input speech signal; Combining the feature vectors using an ensemble of acoustic models based on the deepened neural network ensembles previously learned for each reverberation environment; And recognizing speech by classifying the phonemes, wherein the pre-learned deepening neural network ensemble-based acoustic model can estimate a phoneme probability for each reverberation environment in a plurality of reverberation environments.
Description
아래의 실시예들은 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법에 관한 것이다. The following embodiments relate to a combined learned deep-fired neural network ensemble-based acoustic model for speech recognition in reverberation environments and a speech recognition method using the same.
음성 인식(Speech recognition) 기술은 자동적 수단에 의하여 음성으로부터 언어적 의미 내용을 식별하는 것으로, 음성파형을 입력하여 단어나 단어열을 식별하고 의미를 추출하는 처리 과정이며, 크게 음성 분석, 음소 인식, 단어 인식, 문장 해석, 의미 추출의 5 가지로 분류된다. Speech recognition technology identifies verbally meaningful contents from speech by automatic means. It is a process of recognizing words and word sequences by inputting speech waveforms and extracting meaning. It is widely used in speech analysis, phoneme recognition, Word recognition, sentence analysis, and semantic extraction.
최근의 음성 인식 기술은 HMM(Hidden Markov Model)을 기반으로 구현되고 있다. HMM 기반의 음성 인식 기술은 각 HMM 상태의 가우시안 성분(Gaussian mixture component) 중 확률적 분포가 가장 유사한 두 개의 가우시안 성분들을 점진적으로 통합하여 이진 트리를 구성한 뒤, 구성된 이진 트리를 적정 수준에서 가지치기하여 최적의 음향 모델을 생성하고, 생성된 음향 모델을 기반으로 음성 인식을 수행한다.Recently, speech recognition technology is implemented based on HMM (Hidden Markov Model). The HMM-based speech recognition technology consists of two Gaussian components with the most probable distribution among the Gaussian mixture components of each HMM state, and then constructs a binary tree. Then, the constructed binary tree is pruned at an appropriate level Generates an optimal acoustic model, and performs speech recognition based on the generated acoustic model.
그런데 최근 음성 인식 기술의 응용 분야가 점차 확대되면서 음성 인식시스템이 적용되는 환경이 다양해지고 있다. 이렇게 주변 환경이 변경될 경우, 주변 잡음의 크기 및 종류, 그리고 음성 파형이 달라질 수 있기 때문에 적용되는 환경에 맞추어 음향 모델을 재 학습하는 과정이 필요하다. Recently, as the application field of speech recognition technology has been expanded, the environment in which the speech recognition system is applied is diversified. If the surrounding environment is changed, the magnitude and type of the ambient noise and the sound waveform may be changed. Thus, it is necessary to re-learn the acoustic model according to the applied environment.
종래의 심화신경망 기법을 이용한 음향 모델은 단순한 구조를 적용하였기 때문에 다양한 실제 환경에 대해 효과적으로 모델링되지 않는다. 또한 다양한 환경의 음성 신호 데이터를 사용하더라도 한계가 존재하고, 학습 데이터와 테스트 환경이 다를 경우 인식성능 저하를 초래할 수 있다.The acoustic model using the conventional deepening neural network technique is not effectively modeled on various real environments since it is a simple structure. In addition, even if voice signal data of various environments are used, there is a limit, and if the learning data and the test environment are different, the recognition performance may deteriorate.
한국공개특허 10-2016-0015005호는 이러한 클래스 기반 음향 모델의 변별 학습 방법 및 장치, 그리고 이를 이용한 음성 인식 장치에 관한 기술을 기재하고 있다. Korean Patent Laid-Open No. 10-2016-0015005 describes a method and apparatus for discriminating learning of class-based acoustic models and a technique for speech recognition apparatus using the same.
실시예들은 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법에 관하여 기술하며, 보다 구체적으로 다양한 잔향 환경의 음성 신호를 효과적으로 모델링하기 위해서 잔향 시간 추정을 이용한 음향 모델 앙상블 구조와 결합 학습된 심화신경망 모델의 앙상블 구조를 이용하는 기술을 제공한다. Embodiments describe a combined learning deepened neural network ensemble based acoustic model for speech recognition in reverberation environment and a speech recognition method using the same. More specifically, in order to effectively model speech signals of various reverberation environments, And a technique using an ensemble structure of a learned deepened neural network model.
실시예들은 심화신경망 앙상블 구조를 기반으로 테스트 환경에 최적화된 음향 모델의 음소 확률을 추정함으로써, 다양한 잔향 환경에서 우수한 인식성능을 가지는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법을 제공하는데 있다. Embodiments are based on the deepening neural network ensemble structure, and by estimating the phoneme probability of the acoustic model optimized for the test environment, the combined learning deepened neural network ensembles based on the speech recognition in the reverberation environment having excellent recognition performance in various reverberation environments And a speech recognition method using the same.
또한, 실시예들은 결합 학습된 심화신경망 모델을 앙상블에 이용하여 잔향 제거와 음향 모델이 통합된 하나의 심화신경망을 생성함으로써, 잔향 환경에 더욱 효과적인 음향 모델 및 이를 이용한 음성인식 방법을 제공하는데 있다.Embodiments also provide an acoustic model that is more effective in a reverberation environment and a speech recognition method using the same, by generating a deepening neural network in which a reverberation elimination and an acoustic model are integrated by using a combined deepened neural network model in an ensemble.
일 실시예에 따른 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법에 있어서, 입력되는 음성 신호로부터 특징 벡터를 추출하는 단계; 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합하는 단계; 및 음소를 분류하여 음성을 인식하는 단계를 포함하고, 상기 미리 학습된 심화신경망 앙상블 기반의 음향 모델은, 다수의 잔향 환경에서 각각의 잔향 환경에 대해 음소 확률을 추정할 수 있다. A method of recognizing speech using an acoustic model of a deep-learning neural network based ensemble for speech recognition in a reverberation environment, the method comprising: extracting a feature vector from an input speech signal; Combining the feature vectors using an ensemble of acoustic models based on the deepened neural network ensembles previously learned for each reverberation environment; And recognizing speech by classifying the phonemes, wherein the pre-learned deepening neural network ensemble-based acoustic model can estimate a phoneme probability for each reverberation environment in a plurality of reverberation environments.
상기 음성 신호로부터 잔향 시간을 추정하는 단계; 및 상기 잔향 시간을 기반으로 가중치를 산출하는 단계를 더 포함하고, 상기 음소를 분류하여 음성을 인식하는 단계는, 산출된 상기 가중치를 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델의 앙상블 결합에 적용하는 단계를 포함할 수 있다.Estimating a reverberation time from the voice signal; And calculating a weight based on the reverberation time, wherein the step of classifying the phonemes and recognizing the speech comprises: applying the calculated weight to an ensemble combination of the learned neural network ensemble-based acoustic model .
상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합하는 단계는, 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델에 기반한 앙상블 모델을 통과시켜 음소 확률을 추정할 수 있다.Wherein combining the feature vectors using an ensemble of deepened neural network ensemble-based acoustic models previously learned for each reverberation environment comprises coupling the feature vectors to a deep- The phoneme probability can be estimated by passing the model-based ensemble model.
상기 음소를 분류하여 음성을 인식하는 단계는, 상기 음소 확률과 상기 가중치를 이용하여 상기 심화신경망 앙상블 기반의 음향 모델의 사후 확률(posterior probability)을 산출하여 상기 음소를 분류할 수 있다.The step of recognizing speech by classifying the phonemes may classify the phonemes by calculating a posterior probability of the deepening ensemble-based acoustic model using the phoneme probability and the weight.
상기 음성 신호로부터 잔향 시간을 추정하는 단계는, 상기 심화신경망 앙상블 기반의 음향 모델 중 우도비가 가장 큰 두 개의 음향 모델을 선택하여 최대 우도법(maximum likelihood)을 통한 상기 잔향 시간을 추정할 수 있다.The estimating of the reverberation time from the voice signal may include estimating the reverberation time through a maximum likelihood by selecting two acoustic models having the greatest likelihood ratios among the deepening neural network ensemble based acoustic models.
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계를 더 포함하고, 상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계는, 학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 단계; 추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 단계; 및 추출된 상기 특징 벡터를 심화신경망을 통하여 각각의 상기 잔향 환경에 대해 학습시키는 단계를 포함할 수 있다.Learning the ensemble-based acoustic model based on the deepened neural network ensemble based acoustic model, wherein the step of learning the deepened neural network ensemble-based acoustic model comprises the steps of: receiving a speech signal in a plurality of reverberation environments and extracting a feature vector; ; Separating characteristics of the reverberation environment of the extracted feature vector; And learning the extracted feature vector for each reverberation environment through a deepening neural network.
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계를 더 포함하고, 상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계는, 학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 단계; 추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 단계; 추출된 상기 특징 벡터를 잔향이 없는 음성 특징으로 맵핑(mapping)시키는 상기 특징 맵핑 심화신경망을 통과시키는 단계; 상기 특징 맵핑 심화신경망의 출력을 이용하여 상기 음향 모델링 심화신경망을 학습시키는 단계; 및 상기 음향 모델링 심화신경망은 상기 특징 맵핑 심화신경망 위에 바로 쌓이고, 결합된 상기 심화신경망 앙상블 기반의 음향 모델은 연결되어 재학습되는 단계를 포함할 수 있다.Learning the ensemble-based acoustic model based on the deepened neural network ensemble based acoustic model, wherein the step of learning the deepened neural network ensemble-based acoustic model comprises the steps of: receiving a speech signal in a plurality of reverberation environments and extracting a feature vector; ; Separating characteristics of the reverberation environment of the extracted feature vector; Passing the feature mapping enrichment neural network to map the extracted feature vector to a reverberant voice feature; Learning the acoustic modeling deepening neural network using the output of the feature mapping deepening neural network; And the acoustic modeling enrichment neural network may be stacked directly on the feature mapping enrichment neural network and the combined deepening neural network ensemble based acoustic model may be linked and re-learned.
다른 실시예에 따른 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델에 있어서, 입력되는 음성 신호로부터 특징 벡터를 추출하는 특징 벡터 추출부; 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합하는 앙상블 모델; 및 음소를 분류하여 음성을 인식하는 음소 분류부를 포함하고, 상기 미리 학습된 심화신경망 앙상블 기반의 음향 모델은, 다수의 잔향 환경에서 각각의 잔향 환경에 대해 음소 확률을 추정할 수 있다.A combined neural network ensemble-based acoustic model for speech recognition in a reverberation environment according to another embodiment includes: a feature vector extractor for extracting a feature vector from an input speech signal; An ensemble model that combines the feature vectors using an ensemble of acoustic models based on deepened neural network ensembles previously learned for each reverberation environment; And a phoneme classifier for classifying the phonemes and recognizing the phonemes, and the pre-learned deepen network ensemble-based acoustic model can estimate a phoneme probability for each reverberation environment in a plurality of reverberation environments.
상기 음성 신호로부터 잔향 시간을 추정하는 잔향 시간 예측부; 및 상기 잔향 시간을 기반으로 가중치를 산출하는 가중치 결정부를 더 포함하고, 상기 음소 분류부는, 산출된 상기 가중치를 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델의 앙상블 결합에 적용할 수 있다.A reverberation time predicting unit for estimating a reverberation time from the voice signal; And a weight determining unit for calculating a weight based on the reverberation time, and the phoneme classifying unit may apply the calculated weight to the ensemble combination of the deepened neural network ensemble-based acoustic model previously learned.
상기 앙상블 모델은, 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델에 기반한 앙상블 모델을 통과시켜 음소 확률을 추정할 수 있다.The ensemble model may estimate the phoneme probability by passing the feature vector through an ensemble model based on the deepened neural network ensemble-based acoustic model previously learned for each reverberation environment.
상기 음소 분류부는, 상기 음소 확률과 상기 가중치를 이용하여 상기 심화신경망 앙상블 기반의 음향 모델의 사후 확률(posterior probability)을 산출하여 상기 음소를 분류할 수 있다.The phoneme classifier may classify the phoneme by calculating a posterior probability of the deepening neural network ensemble-based acoustic model using the phoneme probability and the weight.
상기 잔향 시간 예측부는, 상기 심화신경망 앙상블 기반의 음향 모델 중 우도비가 가장 큰 두 개의 음향 모델을 선택하여 최대 우도법(maximum likelihood)을 통한 상기 잔향 시간을 추정할 수 있다.The reverberation time predicting unit may estimate the reverberation time through a maximum likelihood by selecting two acoustic models having the greatest likelihood ratios among the deepening neural network ensemble based acoustic models.
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 학습부를 더 포함하고, 상기 학습부는, 학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 특징 벡터 추출부; 추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 잔향 특징 분류부; 및 추출된 상기 특징 벡터를 심화신경망을 통하여 각각의 상기 잔향 환경에 대해 학습시키는 다중 심화신경망 학습부를 포함할 수 있다.Wherein the learning unit further comprises a feature vector extraction unit for extracting a feature vector by receiving speech signals in a plurality of reverberation environments in a learning step; A reverberation feature classifier for classifying a feature of a reverberation environment of the extracted feature vector; And a multi-depth neural network learning unit for learning the extracted feature vectors for each of the reverberation environments through a deepening neural network.
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 학습부를 더 포함하고, 상기 학습부는, 잔향이 없는 음성 특징으로 맵핑(mapping)시키는 특징 맵핑 심화신경망과 음향 모델링 심화신경망을 결합하는 구조를 이용하여, 서로 다른 잔향 환경에 대해 학습된 음향 모델을 구성할 수 있다.And a learning unit for learning the deepened neural network ensemble-based acoustic model, wherein the learning unit uses a structure that combines a feature mapping deepening neural network and an acoustic modeling deepening neural network that maps the reverberation- It is possible to construct a learned acoustic model for another reverberation environment.
상기 학습부는, 학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 특징 벡터 추출부; 추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 잔향 특징 분류부; 추출된 상기 특징 벡터를 잔향이 없는 음성 특징으로 맵핑(mapping)시키는 상기 특징 맵핑 심화신경망; 및 상기 특징 맵핑 심화신경망의 출력을 이용하여 학습시키는 상기 음향 모델링 심화신경망을 포함하고, 상기 음향 모델링 심화신경망은 상기 특징 맵핑 심화신경망 위에 바로 쌓이고, 결합된 상기 심화신경망 앙상블 기반의 음향 모델은 연결되어 재학습될 수 있다. Wherein the learning unit comprises: a feature vector extracting unit that receives a speech signal in a plurality of reverberation environments and extracts a feature vector in a learning step; A reverberation feature classifier for classifying a feature of a reverberation environment of the extracted feature vector; The feature mapping enrichment neural network mapping the extracted feature vector to a reverberant voice feature; And the acoustic modeling enrichment neural network for learning using the output of the feature mapping enrichment neural network, wherein the acoustic modeling enrichment neural network is stacked directly on the feature mapping enrichment neural network and the combined deepening neural network ensemble based acoustic model is connected Can be re-learned.
실시예들에 따르면 심화신경망 앙상블 구조를 기반으로 테스트 환경에 최적화된 음향 모델의 음소 확률을 추정함으로써, 다양한 잔향 환경에서 우수한 인식성능을 가지는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법을 제공할 수 있다. According to the embodiments, by estimating the phoneme probability of the acoustic model optimized for the test environment based on the deepened neural network ensemble structure, the combined learned deepened neural network ensembles for speech recognition in reverberation environments having excellent recognition performance in various reverberation environments And a speech recognition method using the same.
또한, 실시예들에 따르면 결합 학습된 심화신경망 모델을 앙상블에 이용하여 잔향 제거와 음향 모델이 통합된 하나의 심화신경망을 생성함으로써, 잔향 환경에 더욱 효과적인 음향 모델 및 이를 이용한 음성인식 방법을 제공할 수 있다. In addition, according to the embodiments, an acoustic model and a speech recognition method using the deep-reverberated neural network model can be more effective in a reverberation environment by using the combined deep-learning neural network model as an ensemble to generate one deep- .
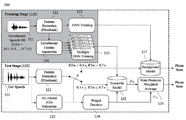
도 1은 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템을 개략적으로 나타내는 블록도이다.
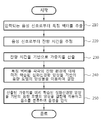
도 2는 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법을 나타내는 흐름도이다.
도 3은 다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템을 개략적으로 나타내는 블록도이다.
도 4는 다른 실시예에 따른 특징 맵핑 심화신경망의 입력과 출력을 설명하기 위한 도면이다.
도 5는 일 실시예에 따른 잔향 시뮬레이션 환경을 나타내는 도면이다.
도 6은 일 실시예에 따른 다양한 잔향 환경에서 종래의 배경 모델과 제안된 앙상블 모델의 단어 오인지율의 비교를 나타내는 그래프이다.
도 7은 일 실시예에 따른 잔향 환경에서의 음성에 대해 추정된 잔향 시간에 대한 최대 우도비 그래프를 나타낸다. FIG. 1 is a block diagram schematically illustrating a speech recognition system using an acoustic model based on a deepening neural network ensemble according to an embodiment.
FIG. 2 is a flowchart illustrating a speech recognition method using a deepening neural network ensemble-based acoustic model according to an exemplary embodiment.
FIG. 3 is a block diagram schematically illustrating a speech recognition system using an enhanced-neural network ensemble-based acoustic model of a combined learning structure according to another embodiment.
4 is a diagram for explaining input and output of a feature mapping deepening network according to another embodiment.
5 is a diagram illustrating a reverberation simulation environment in accordance with one embodiment.
FIG. 6 is a graph illustrating a comparison of the word-false-recognition rate between the conventional background model and the proposed ensemble model in various reverberation environments according to an embodiment.
7 shows a maximum likelihood ratio graph for reverberation time estimated for speech in a reverberation environment according to an embodiment.
이하, 첨부된 도면을 참조하여 실시예들을 설명한다. 그러나, 기술되는 실시예들은 여러 가지 다른 형태로 변형될 수 있으며, 본 발명의 범위가 이하 설명되는 실시예들에 의하여 한정되는 것은 아니다. 또한, 여러 실시예들은 당해 기술분야에서 평균적인 지식을 가진 자에게 본 발명을 더욱 완전하게 설명하기 위해서 제공되는 것이다. 도면에서 요소들의 형상 및 크기 등은 보다 명확한 설명을 위해 과장될 수 있다.
Hereinafter, embodiments will be described with reference to the accompanying drawings. However, the embodiments described may be modified in various other forms, and the scope of the present invention is not limited by the embodiments described below. In addition, various embodiments are provided to more fully describe the present invention to those skilled in the art. The shape and size of elements in the drawings may be exaggerated for clarity.
아래의 실시예들은 결합 학습된 심화신경망 앙상블 음향 모델을 이용한 잔향 환경에서의 음성인식 방법에 관한 것으로서, 다양한 잔향 환경의 음성 신호를 효과적으로 모델링하기 위해서 잔향 시간 추정을 이용한 음향 모델 앙상블 구조와 결합 학습된 심화신경망 모델의 앙상블 구조를 이용한다.The following embodiments relate to a speech recognition method in a reverberation environment using a combined deepened neural network ensemble acoustic model. In order to effectively model speech signals of various reverberation environments, an acoustic model ensemble structure using reverberation time estimation and a combined learning method The ensemble structure of the deepening neural network model is used.
여기에서, 음향 모델(Acoustic Model)이란 음성 신호를 음소 데이터로 분류하는 기술로 음성인식의 필수적인 요소이다. 예를 들어, 음향 모델은 음성인식을 이용하여 편리한 기기 조작, 화자의 고유 정보 전달을 가능하게 하여 편의성을 증대시키며 보안, 금융, 의료 등 개인별 서비스 제공을 가능하게 하는 역할을 한다. 또한 음향 모델은 번역기 및 검색 서비스의 경우 음성인식 시스템을 이용하여 효율적인 실시간 정보 처리를 할 수 있다. 잔향 환경에 적합한 음향 모델은 실제 환경에서의 음성인식 성능을 향상시킬 수 있기 때문에 널리 연구되고 있다. 잔향에 의해 왜곡된 입력신호들은 단순한 심화신경망 구조 기반의 음향 모델로 충분히 모델링하는데 한계가 존재한다.Here, the acoustic model (Acoustic Model) is a technique for classifying a speech signal into phoneme data, and is an essential element of speech recognition. For example, the acoustic model uses voice recognition to facilitate convenient device manipulation, to allow the speaker to transmit unique information, to increase convenience, and to provide personalized services such as security, finance, and medical services. In the case of the translator and the search service, the acoustic model can perform efficient real-time information processing using the speech recognition system. The acoustic model suitable for the reverberant environment is widely studied because it can improve speech recognition performance in a real environment. The input signals distorted by the reverberation are limited enough to be modeled as a simple deepening neural network based acoustic model.
이에 따라 실시예들은 입력신호들로부터 추출한 음성 특징들의 왜곡을 제거하는 특징 매핑 심화신경망과 음향 모델링 심화신경망을 통합하는 결합 학습 구조를 이용하여 각각의 잔향 환경에 대한 모델들의 음소 확률을 추정하고, 계산된 각 모델의 음소 확률의 앙상블을 이용하여 결합함으로써 음소를 분류할 수 있다.Accordingly, the embodiments can estimate the phoneme probability of the models for each reverberation environment using the combined learning deepening neural network, which eliminates the distortion of the voice characteristics extracted from the input signals, and the combined learning structure that integrates the acoustic modeling deepening neural network, The phoneme can be classified by combining using the ensemble of the phoneme probability of each model.
실시예들에 따르면 음성 신호로부터 추출한 특징 벡터들을 결합 구조 심화신경망을 통하여 각각의 잔향 환경에 대해 모델링하고, 이를 기반으로 테스트 환경에서의 최대 우도법(maximum likelihood)을 통한 잔향 시간 추정을 이용하여 음소 확률을 앙상블함으로써, 다양한 잔향 환경에서도 우수한 성능의 음성인식이 가능하다.
According to the embodiments, the feature vectors extracted from the speech signal are modeled for each reverberation environment through the combined structure deepening neural network, and based on the model, the reverberation time estimation using the maximum likelihood in the test environment is used, By ensembling probability, it is possible to perform speech recognition with excellent performance even in various reverberation environments.
아래에서 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델의 앙상블에 대해 설명한다. The ensemble of the deepening neural network ensemble-based acoustic model according to an embodiment will be described below.
도 1은 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템을 개략적으로 나타내는 블록도이다. FIG. 1 is a block diagram schematically illustrating a speech recognition system using an acoustic model based on a deepening neural network ensemble according to an embodiment.
일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템은 다양한 잔향 환경의 음성 신호를 효과적으로 모델링하기 위해서 잔향 시간 추정을 이용한 음향 모델 앙상블 구조를 이용할 수 있다. 이러한 심화신경망 앙상블 기반의 음향 모델을 기반으로 테스트 환경에 최적화된 음향 모델의 음소 확률을 추정함으로써, 다양한 잔향 환경에서 우수한 인식성능을 가지는 음성인식 방법을 제공할 수 있다.The speech recognition system using the deepened neural network ensemble-based acoustic model according to an embodiment can utilize an acoustic model ensemble structure using reverberation time estimation to effectively model speech signals of various reverberation environments. By estimating the phoneme probability of the acoustic model optimized for the test environment based on the deepened neural network ensemble based acoustic model, it is possible to provide a speech recognition method having excellent recognition performance in various reverberation environments.
특히, 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템은 최대 우도법을 이용한 실제 잔향 환경 추정을 기반으로 상이한 가중치를 산출하고, 이를 각각의 잔향 환경에 대해 학습된 음향 모델의 결합에 적용하는 앙상블 모델을 이용할 수 있다. In particular, the speech recognition system using the deepened neural network ensemble-based acoustic model according to an exemplary embodiment calculates different weights based on the actual reverberation environment estimation using the maximum likelihood method, and calculates different weights using the learned acoustic model for each reverberation environment An ensemble model to be applied to combining can be used.
도 1을 참조하면, 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템(100)은 학습부(110) 및 테스트부(120)를 포함하여 이루어질 수 있다. Referring to FIG. 1, the
학습부(110)는 상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 것으로, 특징 벡터 추출부(112), 잔향 특징 분류부(114), 및 다중 심화신경망 학습부(115)를 포함하여 이루어질 수 있다. 또한 실시예에 따라 학습부(110)는 음성 입력부(111) 및 심화신경망 학습부(113)를 더 포함하여 이루어질 수 있다. The
특징 벡터 추출부(112)는 학습 단계에서 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출할 수 있다. The feature
잔향 특징 분류부(114)는 학습 단계에서 추출된 상기 특징 벡터의 잔향 환경의 특징을 분리시킬 수 있다. The reverberation
다중 심화신경망 학습부(115)는 학습 단계에서 추출된 상기 특징 벡터를 심화신경망을 통하여 각각의 상기 잔향 환경에 대해 학습시킬 수 있다. The multiple enrichment neural
테스트부(120)는 학습부(110)에서 미리 학습된 심화신경망 앙상블 기반의 음향 모델을 기반으로 최적화된 음향 모델의 음소 확률을 추정함으로써, 다양한 잔향 환경에서 우수한 인식성능을 가지는 음성인식 방법을 제공할 수 있다. 이러한 테스트부(120)는 특징 벡터 추출부(122), 잔향 시간 예측부(123), 가중치 결정부(124), 앙상블 모델(125), 및 음소 분류부(126)를 포함하여 이루어질 수 있다. 또한 실시예에 따라 테스트부(120)는 음성 입력부(121) 및 배경 모델(127)을 더 포함하여 이루어질 수 있다. The
특징 벡터 추출부(122)는 입력되는 음성 신호로부터 특징 벡터를 추출할 수 있다. The feature
잔향 시간 예측부(123)는 음성 신호로부터 잔향 시간을 추정할 수 있으며, 상기 심화신경망 앙상블 기반의 음향 모델 중 우도비가 가장 큰 두 개의 음향 모델을 선택하여 최대 우도법(maximum likelihood)을 통한 상기 잔향 시간을 추정할 수 있다.The reverberation
가중치 결정부(124)는 잔향 시간을 기반으로 가중치를 산출할 수 있다. The
앙상블 모델(125)은 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합할 수 있다. The
여기에서 미리 학습된 심화신경망 앙상블 기반의 음향 모델은 다수의 잔향 환경에서 각각의 잔향 환경에 대해 음소 확률을 추정할 수 있다.Here, the deepened neural network ensemble-based acoustic model that has been learned in advance can estimate the phoneme probability for each reverberation environment in a plurality of reverberation environments.
앙상블 모델(125)은 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델에 기반한 앙상블 모델을 통과시켜 음소 확률을 추정할 수 있다. The
음소 분류부(126)는 음소를 분류하여 음성을 인식할 수 있으며, 음소 분류부(126)는 가중치 결정부(124)에서 산출된 상기 가중치를 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델의 앙상블 결합에 적용할 수 있다.The
이러한 음소 분류부(126)는 상기 음소 확률과 상기 가중치를 이용하여 상기 심화신경망 앙상블 기반의 음향 모델의 사후 확률(posterior probability)을 산출하여 상기 음소를 분류할 수 있다. The
아래에서 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델에 대해 하나의 예를 들어 더 구체적으로 설명한다.
An example of a deepening neural network ensemble based acoustic model according to an embodiment will be described in more detail below.
도 2는 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법을 나타내는 흐름도이다. FIG. 2 is a flowchart illustrating a speech recognition method using a deepening neural network ensemble-based acoustic model according to an exemplary embodiment.
일 실시예에 따른 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법은 입력되는 음성 신호로부터 특징 벡터를 추출하는 단계(210), 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합하는 단계(240), 및 음소를 분류하여 음성을 인식하는 단계(250)를 포함하여 이루어질 수 있다. 여기에서 미리 학습된 심화신경망 앙상블 기반의 음향 모델은 다수의 잔향 환경에서 각각의 잔향 환경에 대해 음소 확률을 추정할 수 있다. The method of extracting feature vectors from an input speech signal includes a step 210 of extracting a feature vector from an input speech signal, a step of extracting a feature vector from each of the feature vectors, (240) using an ensemble of acoustic models based on the deepened neural network ensemble based on the reverberation environment, and classifying the phonemes and recognizing the speech (250). Here, the deepened neural network ensemble-based acoustic model that has been learned in advance can estimate the phoneme probability for each reverberation environment in a plurality of reverberation environments.
그리고, 일 실시예에 따른 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법은 상기 음성 신호로부터 잔향 시간을 추정하는 단계(220) 및 상기 잔향 시간을 기반으로 가중치를 산출하는 단계(230)를 더 포함하여 이루어질 수 있다. In addition, a speech recognition method using a deep-learning neural network ensemble-based acoustic model for speech recognition in a reverberation environment according to an exemplary embodiment includes a
이때, 상기 음소를 분류하여 음성을 인식하기 위해서 산출된 상기 가중치를 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델의 앙상블 결합에 적용할 수 있다. At this time, the phonemes can be classified and the calculated weight values for recognizing speech can be applied to the ensemble combination of the learned deepened neural network ensemble-based acoustic model.
이와 같이 실시예들은 심화신경망 앙상블 구조를 기반으로 테스트 환경에 최적화된 음향 모델의 음소 확률을 추정함으로써, 다양한 잔향 환경에서 우수한 인식성능을 가지는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법을 제공하는데 있다.
In this manner, the embodiments can estimate the phoneme probability of the acoustic model optimized for the test environment based on the deepened neural network ensemble structure, and thereby provide a combined deepened neural network ensemble based on speech recognition in reverberation environments having excellent recognition performance in various reverberation environments And a speech recognition method using the same.
아래에서는 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법의 각 단계에 대해 상세히 설명하기로 한다. 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법은 도 1에서 설명한 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템을 이용하여 더 구체적으로 설명할 수 있다. Each step of the speech recognition method using an acoustic model based on the deepening neural network ensemble will be described in detail below. The speech recognition method using the deepened neural network ensemble-based acoustic model according to an embodiment can be more specifically explained using the speech recognition system using the deepened neural network ensemble-based acoustic model according to the embodiment described in FIG.
일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템(100)은 학습부(110) 및 테스트부(120)를 포함하여 이루어질 수 있다. The
여기에서 학습부(110)는 상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 것으로, 특징 벡터 추출부(112), 잔향 특징 분류부(114), 및 다중 심화신경망 학습부(115)를 포함하여 이루어질 수 있다. 또한 실시예에 따라 학습부(110)는 음성 입력부(111) 및 심화신경망 학습부(113)를 더 포함하여 이루어질 수 있다. The
테스트부(120)는 학습부(110)에서 미리 학습된 심화신경망 앙상블 기반의 음향 모델을 기반으로 최적화된 음향 모델의 음소 확률을 추정하는 것으로, 특징 벡터 추출부(122), 잔향 시간 예측부(123), 가중치 결정부(124), 앙상블 모델(125), 및 음소 분류부(126)를 포함하여 이루어질 수 있다. 또한 실시예에 따라 테스트부(120)는 음성 입력부(121) 및 배경 모델(127)을 더 포함하여 이루어질 수 있다. The
먼저, 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법은 상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계를 포함하여 이루어질 수 있다. First, the speech recognition method using the deepening neural network ensemble-based acoustic model according to an embodiment may include the step of learning the deepening neural network ensemble-based acoustic model.
학습 단계에서, 특징 벡터 추출부(112)는 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출할 수 있으며, 잔향 특징 분류부(114)는 추출된 상기 특징 벡터의 잔향 환경의 특징을 분리시킬 수 있다. 이후, 다중 심화신경망 학습부(115)는 추출된 상기 특징 벡터를 심화신경망을 통하여 각각의 상기 잔향 환경에 대해 학습시킬 수 있다. In the learning step, the feature
일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법은 다양한 잔향 환경의 음성 신호를 효과적으로 모델링하기 위해서 잔향 시간 추정을 이용한 음향 모델 앙상블 구조를 이용할 수 있다. 이후, 이러한 심화신경망 앙상블 기반의 음향 모델을 기반으로 테스트 환경에 최적화된 음향 모델의 음소 확률을 추정함으로써, 다양한 잔향 환경에서 우수한 인식성능을 가지는 음성인식 방법을 제공할 수 있다.The speech recognition method using the deepened neural network ensemble-based acoustic model according to an exemplary embodiment can use an acoustic model ensemble structure using reverberation time estimation to effectively model speech signals of various reverberation environments. Then, by estimating the phoneme probability of the acoustic model optimized for the test environment based on the deepened neural network ensemble-based acoustic model, a speech recognition method having excellent recognition performance in various reverberation environments can be provided.
단계(210)에서, 테스트부(120)의 특징 벡터 추출부(122)는 입력되는 음성 신호로부터 특징 벡터를 추출할 수 있다. In step 210, the feature
한편, 단계(220)에서 잔향 시간 예측부(123)는 음성 신호로부터 잔향 시간을 추정할 수 있다. 더 구체적으로 잔향 시간 예측부(123)는 심화신경망 앙상블 기반의 음향 모델 중 우도비가 가장 큰 두 개의 음향 모델을 선택하여 최대 우도법(maximum likelihood)을 통한 상기 잔향 시간을 추정할 수 있다.Meanwhile, in
또한 단계(230)에서 가중치 결정부(124)는 잔향 시간을 기반으로 가중치를 산출할 수 있다. Also, in
단계(240)에서 앙상블 모델(125)은 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합할 수 있다. In
여기에서 미리 학습된 심화신경망 앙상블 기반의 음향 모델은 다수의 잔향 환경에서 각각의 잔향 환경에 대해 음소 확률을 추정할 수 있다.Here, the deepened neural network ensemble-based acoustic model that has been learned in advance can estimate the phoneme probability for each reverberation environment in a plurality of reverberation environments.
앙상블 모델(125)은 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델에 기반한 앙상블 모델을 통과시켜 음소 확률을 추정할 수 있다. The
단계(250)에서 음소 분류부(126)는 음소를 분류하여 음성을 인식할 수 있으며, 더 구체적으로 음소 분류부(126)는 가중치 결정부(124)에서 산출된 상기 가중치를 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델의 앙상블 결합에 적용할 수 있다.More specifically, the
이러한 음소 분류부(126)는 상기 음소 확률과 상기 가중치를 이용하여 상기 심화신경망 앙상블 기반의 음향 모델의 사후 확률(posterior probability)을 산출하여 상기 음소를 분류할 수 있다. The
서로 다른 잔향 환경에 대해 각각 학습된 ![]()
![]()
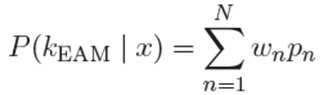
여기에서 n 은 음향 모델 인덱스, k 는 히든 마르코브 모델(Hidden Markov Model, HMM) 상태(state), x 는 음성 특징 벡터 인덱스를 각각 나타낼 수 있다. ![]()
![]()
![]()
![]()
![]()
![]()
잔향은 수학식 2와 같이 간단한 잡음 감소 곡선(noise decay curve)으로 수학적으로 모델링 가능하다.The reverberation can be mathematically modeled by a simple noise reduction curve as shown in Equation (2).
![]()
![]()
여기에서 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
그리고 ![]()
![]()
![]()
![]()
![]()
![]()
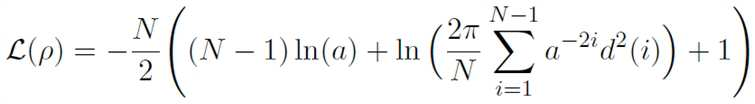
이 때, ![]()
![]()
![]()
![]()

여기에서 ![]()
![]()

이에 따라 서로 다른 잔향 환경에 대해 학습된 N 개의 음향 모델 중 우도비가 가장 큰 두 개의 음향 모델 ![]()
![]()
![]()
![]()

여기에서 ![]()
![]()
![]()
![]()
![]()
From here ![]()
![]()
![]()
![]()
![]()
아래에서 다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델의 앙상블에 대해 설명한다. The ensemble of the deepening neural network ensemble-based acoustic model of the combined learning structure according to another embodiment will be described below.
도 3은 다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템을 개략적으로 나타내는 블록도이다. FIG. 3 is a block diagram schematically illustrating a speech recognition system using an enhanced-neural network ensemble-based acoustic model of a combined learning structure according to another embodiment.
다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템은 다양한 잔향 환경의 음성 신호를 효과적으로 모델링하기 위해서 잔향 시간 추정을 이용한 결합 학습된 심화신경망 모델의 앙상블 구조를 이용할 수 있다. 이러한 결합 학습된 심화신경망 모델을 앙상블에 이용하여 잔향 제거와 음향 모델이 통합된 하나의 심화신경망을 생성함으로써, 잔향 환경에 더욱 효과적인 모델을 구성할 수 있다. Deepening of the Combined Learning Structure According to Another Embodiment The speech recognition system using the neural network ensemble-based acoustic model can use an ensemble structure of a deeply-enriched deepened neural network model using reverberation time estimation to effectively model the voice signals of various reverberation environments have. By using the combined deepened neural network model as an ensemble to generate one deepened neural network that integrates reverberation and acoustic models, a more effective model can be constructed for the reverberant environment.
특히, 다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템은 최대 우도법을 이용한 실제 잔향 환경 추정을 기반으로 상이한 가중치를 산출하고 이를 각각의 잔향 환경에 대해 결합 학습된 모델의 결합에 적용하는 앙상블 결합 모델을 이용할 수 있다. In particular, the speech recognition system using the deepening neural network ensemble-based acoustic model of the combined learning structure according to another embodiment calculates the different weights based on the actual reverberation environment estimation using the maximum likelihood method, An ensemble combining model can be used that applies to the combination of the two models.
도 3을 참조하면, 다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템은 서로 다른 잔향 환경에 대해 학습된 ![]()
![]()
다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템(300)은 학습부(310) 및 테스트부(320)를 포함하여 이루어질 수 있다. Deepening of the Combined Learning Structure According to Another Embodiment The
학습부(310)는 상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 것으로, 특징 벡터 추출부(312), 잔향 특징 분류부(314), 및 다중 결합 학습부(315)를 포함하여 이루어질 수 있다. 또한 실시예에 따라 학습부(310)는 음성 입력부(311) 및 결합 학습부(313)를 더 포함하여 이루어질 수 있다. 결합 학습부(313)는 하나의 특징 맵핑 심화신경망과 음향 모델링 심화신경망을 포함하여 이루어질 수 있다. The
이러한 학습부(310)는 잔향이 없는 음성 특징으로 맵핑(mapping)시키는 특징 맵핑 심화신경망과 음향 모델링 심화신경망을 결합하는 구조를 이용하여, 서로 다른 잔향 환경에 대해 학습된 음향 모델을 구성할 수 있다. The
특징 벡터 추출부(312)는 학습 단계에서 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출할 수 있다. The
잔향 특징 분류부(314)는 학습 단계에서 추출된 상기 특징 벡터의 잔향 환경의 특징을 분리시킬 수 있다. The reverberation
다중 결합 학습부(315)는 특징 맵핑 심화신경망(315a)과 음향 모델링 심화신경망(315b)을 포함하여 이루어질 수 있다. The multiple
특징 맵핑 심화신경망(315a)은 추출된 상기 특징 벡터를 잔향이 없는 음성 특징으로 맵핑(mapping)시킬 수 있다. 그리고 음향 모델링 심화신경망(315b)은 특징 맵핑 심화신경망(315a)의 출력을 이용하여 학습시킬 수 있다. Feature mapping deepening neural network 315a may map the extracted feature vectors to reverberation-free voice features. And the acoustic modeling deepening neural network 315b can be learned using the output of the feature mapping deepening neural network 315a.
음향 모델링 심화신경망(315b)은 특징 맵핑 심화신경망(315a) 위에 바로 쌓이고, 결합된 상기 심화신경망 앙상블 기반의 음향 모델은 연결되어 재학습될 수 있다. The acoustic modeling deepening neural network 315b is stacked directly on the feature mapping deepening neural network 315a and the combined deepening neural network ensemble based acoustic models can be re-learned.
테스트부(320)는 학습부(310)에서 미리 학습된 심화신경망 앙상블 기반의 음향 모델을 기반으로 최적화된 음향 모델의 음소 확률을 추정함으로써, 다양한 잔향 환경에서 우수한 인식성능을 가지는 음성인식 방법을 제공할 수 있다. 이러한 테스트부(320)는 특징 벡터 추출부(322), 잔향 시간 예측부(323), 가중치 결정부(324), 앙상블 모델(325), 및 음소 분류부(326)를 포함하여 이루어질 수 있다. 또한 실시예에 따라 테스트부(320)는 음성 입력부(321) 및 배경 모델(327)을 더 포함하여 이루어질 수 있다. The
특징 벡터 추출부(322)는 입력되는 음성 신호로부터 특징 벡터를 추출할 수 있다. The feature
잔향 시간 예측부(323)는 음성 신호로부터 잔향 시간을 추정할 수 있으며, 상기 심화신경망 앙상블 기반의 음향 모델 중 우도비가 가장 큰 두 개의 음향 모델을 선택하여 최대 우도법(maximum likelihood)을 통한 상기 잔향 시간을 추정할 수 있다.The reverberation
가중치 결정부(324)는 잔향 시간을 기반으로 가중치를 산출할 수 있다. The
앙상블 모델(325)은 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합할 수 있다. The
여기에서 미리 학습된 심화신경망 앙상블 기반의 음향 모델은 다수의 잔향 환경에서 각각의 잔향 환경에 대해 음소 확률을 추정할 수 있다.Here, the deepened neural network ensemble-based acoustic model that has been learned in advance can estimate the phoneme probability for each reverberation environment in a plurality of reverberation environments.
앙상블 모델(325)은 상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델에 기반한 앙상블 모델을 통과시켜 음소 확률을 추정할 수 있다. The
음소 분류부(326)는 음소를 분류하여 음성을 인식할 수 있으며, 음소 분류부(326)는 가중치 결정부(324)에서 산출된 상기 가중치를 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델의 앙상블 결합에 적용할 수 있다.The
이러한 음소 분류부(326)는 상기 음소 확률과 상기 가중치를 이용하여 상기 심화신경망 앙상블 기반의 음향 모델의 사후 확률(posterior probability)을 산출하여 상기 음소를 분류할 수 있다. The
이와 같이 최대 우도법을 이용한 잔향 시간 추정을 통해 다양한 잔향 환경에 대해 학습된 모델들을 가중치를 두어 결합하는 앙상블 구조와 이를 확장하여 종래의 음향 모델 학습법 대신 결합 학습법을 적용하여 학습시킨 모델들을 결합하는 결합 앙상블 구조를 이용하여 음성인식 성능을 확인할 수 있다.The reverberation time estimation using maximum likelihood method is used to combine learned models of various reverberation environments by weights and an ensemble structure that combines learned models by applying combined learning method instead of conventional acoustic model learning method The ensemble structure can be used to verify speech recognition performance.
한편, 다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법은 다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템을 이용하여 수행될 수 있다. 다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법은 도 2에서 설명한 일 실시예에 따른 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법과 유사하므로, 차이점을 중심으로 설명하기로 한다. Meanwhile, the speech recognition method using the deepening neural network ensemble-based acoustic model of the combined learning structure according to another embodiment may be performed using the speech recognition system using the deepening neural network ensemble-based acoustic model of the combined learning structure according to another embodiment . Deepening of the Combined Learning Structure According to Another Embodiment The speech recognition method using the neural network ensemble based acoustic model is similar to the speech recognition method using the deepened neural network ensemble based acoustic model according to the embodiment described in FIG. 2, .
다른 실시예에 따른 결합 학습 구조의 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법은 상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계를 포함하여 이루어질 수 있다. The method of recognizing speech using the deepening neural network ensemble-based acoustic model according to another embodiment may include the step of learning the deepening neural network ensemble-based acoustic model.
학습 단계에서, 특징 벡터 추출부(312)는 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출할 수 있으며, 잔향 특징 분류부(314)는 추출된 상기 특징 벡터의 잔향 환경의 특징을 분리시킬 수 있다. In the learning step, the feature
이후, 특징 맵핑 심화신경망(315a)은 추출된 상기 특징 벡터를 잔향이 없는 음성 특징으로 맵핑(mapping)시킬 수 있다. 그리고 음향 모델링 심화신경망(315b)은 특징 맵핑 심화신경망(315a)의 출력을 이용하여 학습시킬 수 있다. Thereafter, the feature mapping deepening neural network 315a may map the extracted feature vectors to reverberation-free speech features. And the acoustic modeling deepening neural network 315b can be learned using the output of the feature mapping deepening neural network 315a.
이러한 음향 모델링 심화신경망(315b)은 특징 맵핑 심화신경망(315a) 위에 바로 쌓이고, 결합된 상기 심화신경망 앙상블 기반의 음향 모델은 연결되어 재학습될 수 있다. 이때 다중 결합 학습부(315)는 특징 맵핑 심화신경망(315a)과 음향 모델링 심화신경망(315b)을 포함하여 이루어질 수 있다.
This acoustic modeling deepening neural network 315b is stacked directly on the feature mapping deepening neural network 315a, and the combined deepening neural network ensemble based acoustic models can be linked and re-learned. At this time, the multiple
도 4는 다른 실시예에 따른 특징 맵핑 심화신경망의 입력과 출력을 설명하기 위한 도면이다. 4 is a diagram for explaining input and output of a feature mapping deepening network according to another embodiment.
도 4를 참조하면, (a) 잔향이 없는 음성의 특징, (b) 잔향 시간이 0.3 s인 음성의 특징, (c) 잔향 시간이 0.5 s인 음성의 특징, (d) 잔향 시간이 0.7 s인 음성의 특징, (e) 잔향 시간이 0.3 s인 음성의 특징 맵핑 심화신경망 출력, (f) 잔향 시간이 0.5 s인 음성의 특징 맵핑 심화신경망 출력, 및 (g) 잔향 시간이 0.7 s인 음성의 특징 맵핑 심화신경망 출력을 나타내는 것을 확인할 수 있다. (C) a characteristic of a voice having a reverberation time of 0.5 s; (d) a characteristic of a reverberation time of 0.7 s (E) a feature mapping deepening neural network output with a reverberation time of 0.3 s, (f) a feature deepening neural network output with a reverberation time of 0.5 s, and (g) a voice with a reverberation time of 0.7 s Of-feature deepening neural network output.
모든 잔향 환경에서 특징 맵핑 층을 통과하면서 잔향에 의해 발생한 번짐이 감소하고, 프레임간의 경계가 회복될 수 있다. The blur caused by reverberation while passing through the feature mapping layer in all reverberation environments is reduced and the boundary between frames can be restored.
다음으로, 특징 맵핑 층의 출력을 이용하여 음향 모델링 층을 학습시킬 수 있다. 음향 모델링 심화신경망은 특징 맵핑 심화신경망 위에 바로 쌓이고, 결합된 심화신경망은 연결되어 재학습될 수 있다. 이렇게 결합 학습법을 이용하여 학습된 ![]()
![]()

여기에서 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
그리고 결합 학습된 앙상블 모델의 최종 사후 확률은 수학식 8과 같이 표현될 수 있으며, 이러한 최종 사후 확률은 음소 구분에 사용할 수 있다. The final posterior probability of the jointly learned ensemble model can be expressed as

여기에서 n 은 음향 모델 인덱스, k 는 히든 마르코브 모델(Hidden Markov Model, HMM) 상태(state), x 는 음성 특징 벡터 인덱스를 각각 나타낼 수 있다. ![]()
![]()
![]()
Where n is the acoustic model index, k is the Hidden Markov Model (HMM) state, and x is the voice feature vector index. ![]()
![]()
![]()
본 실시예의 구조의 성능을 검증하기 위해 다양한 잔향 환경에서 실험을 진행할 수 있다. Experiments can be conducted in various reverberation environments to verify the performance of the structure of this embodiment.
도 5는 일 실시예에 따른 잔향 시뮬레이션 환경을 나타내는 도면이다.5 is a diagram illustrating a reverberation simulation environment in accordance with one embodiment.
도 5를 참조하면, 훈련을 위해 5 가지의 잔향 시간 0.3 s, 0.4 s, 0.5 s, 0.6 s, 0.7 s에서 각각의 환경마다 3,320개의 발화를 이용하고, 타당성 확인을 위해 동일한 5 가지 잔향 시간에 대해 각각 376개의 발화를 이용할 수 있다. 실험을 위해서는 잔향 시간 0.3 s부터 0.7 s까지 0.01 s 간격으로 50 가지의 잔향 환경에 대해 각각 192개의 발화를 이용할 수 있다. 특징 벡터로 72 차원(dimension) 필터뱅크(filterbank) 특징을 사용하고, 프레임 길이는 25 ms, 프레임 이동은 10 ms를 사용할 수 있다. 또한 2,021개의 tied-state triphone HMM을 이용할 수 있다. 음성 인식 성능 실험은 칼디(Kaldi)를 사용할 수 있다.Referring to FIG. 5, for training, 3,320 utterances are used for each environment at five reverberation times of 0.3 s, 0.4 s, 0.5 s, 0.6 s, and 0.7 s, and the same five reverberation times 376 utterances are available for each. For the experiment, we can use 192 utterances for each 50 reverberation environments at intervals of 0.01 s from 0.3 s to 0.7 s of reverberation time. As a feature vector, a 72-dimensional filterbank feature can be used, with a frame length of 25 ms and a frame shift of 10 ms. In addition, 2,021 tied-state triphone HMMs are available. The speech recognition performance test can use Kaldi.
표 1은 다양한 잔향 환경에서 단일 모델과 기본 모델의 단어 오인지율 비교를 나타내는 것이다. Table 1 shows the word error rate comparisons of the single model and the base model in various reverberation environments.
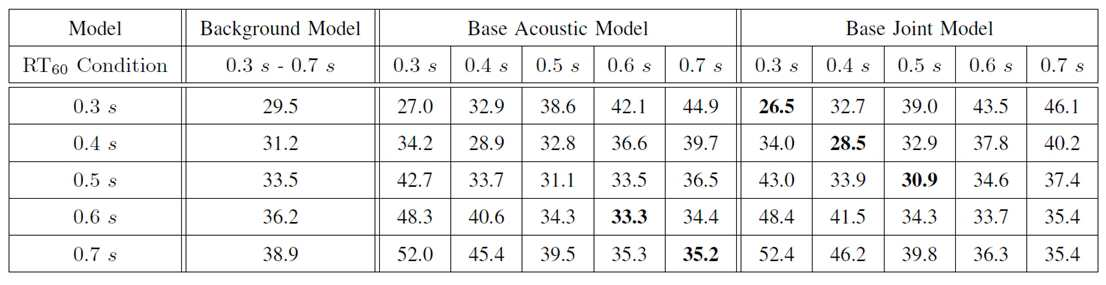
표 1을 참조하면, 다양한 잔향 환경에서 기존 단일 음향 모델과 각 잔향 환경에 대한 기본 모델들의 단어 오인지율(word error rate)(%) 성능을 비교할 수 있다. Referring to Table 1, it is possible to compare the word error rate (%) performance of the basic models for each reverberation environment with the existing single acoustic model in various reverberation environments.
배경 모델(background model)은 기존의 단일 음향 모델이고, 기본 음향 모델(base acoustic model)은 각각의 잔향 환경에 대한 음향 모델이며, 기본 결합 모델(base joint model)은 결합 학습법을 이용하여 각각의 잔향 환경에 대해 학습시킨 모델을 의미한다. 표 1에서 가장 뛰어난 성능을 보이는 경우는 진하게 표시되었다. The background model is a conventional single acoustic model, the base acoustic model is an acoustic model for each reverberation environment, and the base joint model is an acoustic model for each reverberation environment, It means a model learned about the environment. In Table 1, the best performance was shown in bold.
배경 모델과 각각의 기본 음향 모델은 7개의 은닉층과 1개의 소프트맥스(softmax) 층으로 구성되어 있으며, 각 은닉층은 2,048개의 노드로 이루어질 수 있다. The background model and each basic acoustic model are composed of seven hidden layers and one softmax layer, and each hidden layer can be composed of 2,048 nodes.
기본 결합 모델은 2,048개의 노드로 이루어진 3개의 은닉층으로 구성된 특징 맵핑 층, 2,048개의 노드로 이루어진 7개의 은닉층, 1개의 소프트맥스(softmax) 층으로 구성될 수 있다. The basic combining model can be composed of a feature mapping layer composed of 3 hidden layers made up of 2,048 nodes, seven hidden layers made up of 2,048 nodes, and one softmax layer.
모든 잔향 환경에서 종래의 단일 음향 모델에 비해 각각의 잔향 환경에 대해 구성한 기본 모델들의 성능이 뛰어나다는 것을 알 수 있으며, 그 중에서도 특히 일반적인 잔향 환경에서 결합 학습된 모델의 성능이 뛰어남을 확인할 수 있다.
It can be seen that the performance of the basic models constructed for each reverberation environment is superior to that of the conventional single acoustic model in all reverberation environments. In particular, it can be seen that the performance of the combined learning model is excellent in general reverberation environments.
도 6은 일 실시예에 따른 다양한 잔향 환경에서 종래의 배경 모델과 제안된 앙상블 모델의 단어 오인지율의 비교를 나타내는 그래프이다. FIG. 6 is a graph illustrating a comparison of the word-false-recognition rate between the conventional background model and the proposed ensemble model in various reverberation environments according to an embodiment.
도 6을 참조하면, 기존의 단일 음향 모델과 제안하는 앙상블 음향 모델, 결합 학습된 앙상블 모델에 대한 단어 오인지율 비교할 수 있다. 이 그래프는 단어 오인지율과 잔향 시간을 각각 y축과 x축으로 하여, 보다 그래프가 낮을수록 높은 인식 정확도를 나타낼 수 있다. Referring to FIG. 6, the word error rate can be compared with the existing single acoustic model, the proposed ensemble acoustic model, and the combined learned ensemble model. The graph shows the word recognition rate and the reverberation time as the y-axis and the x-axis, respectively, and the lower the graph, the higher the recognition accuracy.
본래의 배경 모델(original background model)은 기존의 단일 음향 모델을 나타내며, 깊은 배경 모델(deep background model)은 앙상블 모델과 연산량을 맞추기 위해 3,390개의 노드와 10개의 은닉층으로 증가시킨 단일 음향 모델을 나타내고, 앙상블 모델(ensemble model)은 기본 음향 모델들의 앙상블 구조를 나타내며, 앙상블 결합 모델(ensemble joint model)은 결합 학습된 모델들의 앙상블 구조를 의미할 수 있다. The original background model represents the existing single acoustic model and the deep background model represents the single acoustic model increased to 3,390 nodes and 10 hidden layers to match the ensemble model and computational complexity, An ensemble model represents an ensemble structure of basic acoustic models, and an ensemble joint model represents an ensemble structure of combined learning models.
모든 잡음 상황에서 제안한 앙상블 모델과 결합 학습된 앙상블 모델이 뛰어난 성능을 나타내는 것을 확인할 수 있다. 같은 연산량에도 불구하고 깊은 배경 모델에 비해 앙상블 모델의 인식 성능이 더 뛰어났고, 앙상블 구조에 결합 학습법을 적용함으로써 일반적인 잔향 환경에서의 성능을 더욱 향상시킬 수 있다.
The proposed ensemble model and the combined ensemble model in all noise situations show excellent performance. Despite the same amount of computation, the recognition performance of the ensemble model is superior to that of the deep background model, and the performance in the general reverberation environment can be further improved by applying the joint learning method to the ensemble structure.
도 7은 일 실시예에 따른 잔향 환경에서의 음성에 대해 추정된 잔향 시간에 대한 최대 우도비 그래프를 나타낸다. 7 shows a maximum likelihood ratio graph for reverberation time estimated for speech in a reverberation environment according to an embodiment.
도 7을 참조하면, 잔향 환경에서의 음성에 대해 추정된 잔향 시간에 대한 최대 우도비 그래프는 최대 우도비와 잔향 시간을 각각 y축과 x축으로 하여, 보다 그래프가 위에 위치할수록 높은 확률을 의미할 수 있다. Referring to FIG. 7, the maximum likelihood ratio graph for the estimated reverberation time for the voice in the reverberant environment has a higher probability that the maximum likelihood ratio and the reverberation time are located on the y axis and the x axis, respectively, can do.
그래프는 5 가지의 잔향 시간에 대한 각각의 최대 우도비를 나타내며, (a) 잔향 시간이 0.61 s인 음성에 대한 최대 우도비, (b) 잔향 시간이 0.63 s인 음성에 대한 최대 우도비, (c) 잔향 시간이 0.67 s인 음성에 대한 최대 우도비를 보인다.The graph shows the maximum likelihood ratios for each of the five reverberation times, (a) the maximum likelihood ratio for speech with a reverberation time of 0.61 s, (b) the maximum likelihood ratio for speech with a reverberation time of 0.63 s, c) Maximum likelihood ratio for speech with reverberation time of 0.67 s.
모든 그래프에서 5가지 잔향 시간 중에서 잔향 시간이 0.6 s일 확률과 0.7 s일 확률이 가장 높다. 잔향 시간이 0.61 s인 음성과 0.63 s인 음성에서는 0.6 s일 확률이 더 높고, 0.67 s인 음성에서는 0.7 s일 확률이 더 높다. 잔향 환경 추정은 일반적으로 정확하므로 이를 앙상블 가중치로 사용할 수 있다.In all graphs, the probability of a reverberation time of 0.6 s and the probability of 0.7 s is the highest among five reverberation times. The probability of 0.6 s is higher for a voice with a reverberation time of 0.61 s and 0.63 s, and 0.7 s for a voice with a reverberation time of 0.61 s. The reverberation environment estimate is generally accurate and can be used as an ensemble weight.
기존 단일 음향 모델 구조는 학습에 사용하지 않은 잔향 환경에서 음성인식성능을 저하시킨다. 실시예들은 앙상블 구조와 결합 학습법을 적용함으로써 보다 다양한 잔향 환경에 강인하게 함으로써 다양한 기기 및 시스템에 적용하여 음성인식의 정확도를 높일 수 있을 것이다.The existing single acoustic model structure degrades speech recognition performance in reverberation environments not used for learning. Embodiments can enhance the accuracy of speech recognition by applying the ensemble structure and the combining learning method to various devices and systems by making them robust to various reverberation environments.
음향 모델은 음성인식에 적용되어 실제 잔향 및 잡음이 존재하는 환경에서의 인식성능을 향상시키는 역할을 할 수 있다. 또한 여러 기기들과 시스템에 적용되어 다양한 환경에서 음성인식을 이용한 편리한 조작과 서비스 제공이 가능하다.The acoustic model can be applied to speech recognition, which can improve recognition performance in the presence of real reverberation and noise. In addition, it can be applied to various devices and systems to provide convenient operation and service using voice recognition in various environments.
따라서, 실시예들에 따른 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델 및 이를 이용한 음성인식 방법은 휴대폰 단말기, 무선통신사업자, 카카오톡 등의 음성통화 서비스, 구글 보이스, 시리 등의 음성인식 서비스뿐만 아니라 다양한 실제 환경에서의 음성 신호처리 분야에 적용되어 보다 우수한 성능을 도출할 수 있다.
Therefore, the combined neural network ensemble-based acoustic model for speech recognition in reverberation environments and speech recognition method using the deep-neural network ensemble-based acoustic model for voice recognition in reverberation environments can be applied to mobile phone terminals, wireless communication companies, voice call services such as KakaoTalk, It can be applied to speech signal processing service in various practical environments as well as speech recognition service such as speech recognition,
이상에서 설명된 장치는 하드웨어 구성요소, 소프트웨어 구성요소, 및/또는 하드웨어 구성요소 및 소프트웨어 구성요소의 조합으로 구현될 수 있다. 예를 들어, 실시예들에서 설명된 장치 및 구성요소는, 예를 들어, 프로세서, 컨트롤러, ALU(arithmetic logic unit), 디지털 신호 프로세서(digital signal processor), 마이크로컴퓨터, FPA(field programmable array), PLU(programmable logic unit), 마이크로프로세서, 또는 명령(instruction)을 실행하고 응답할 수 있는 다른 어떠한 장치와 같이, 하나 이상의 범용 컴퓨터 또는 특수 목적 컴퓨터를 이용하여 구현될 수 있다. 처리 장치는 운영 체제(OS) 및 상기 운영 체제 상에서 수행되는 하나 이상의 소프트웨어 애플리케이션을 수행할 수 있다. 또한, 처리 장치는 소프트웨어의 실행에 응답하여, 데이터를 접근, 저장, 조작, 처리 및 생성할 수도 있다. 이해의 편의를 위하여, 처리 장치는 하나가 사용되는 것으로 설명된 경우도 있지만, 해당 기술분야에서 통상의 지식을 가진 자는, 처리 장치가 복수 개의 처리 요소(processing element) 및/또는 복수 유형의 처리 요소를 포함할 수 있음을 알 수 있다. 예를 들어, 처리 장치는 복수 개의 프로세서 또는 하나의 프로세서 및 하나의 컨트롤러를 포함할 수 있다. 또한, 병렬 프로세서(parallel processor)와 같은, 다른 처리 구성(processing configuration)도 가능하다.The apparatus described above may be implemented as a hardware component, a software component, and / or a combination of hardware components and software components. For example, the apparatus and components described in the embodiments may be implemented within a computer system, such as, for example, a processor, controller, arithmetic logic unit (ALU), digital signal processor, microcomputer, field programmable array (FPA) A programmable logic unit (PLU), a microprocessor, or any other device capable of executing and responding to instructions. The processing device may execute an operating system (OS) and one or more software applications running on the operating system. The processing device may also access, store, manipulate, process, and generate data in response to execution of the software. For ease of understanding, the processing apparatus may be described as being used singly, but those skilled in the art will recognize that the processing apparatus may have a plurality of processing elements and / As shown in FIG. For example, the processing apparatus may comprise a plurality of processors or one processor and one controller. Other processing configurations are also possible, such as a parallel processor.
소프트웨어는 컴퓨터 프로그램(computer program), 코드(code), 명령(instruction), 또는 이들 중 하나 이상의 조합을 포함할 수 있으며, 원하는 대로 동작하도록 처리 장치를 구성하거나 독립적으로 또는 결합적으로(collectively) 처리 장치를 명령할 수 있다. 소프트웨어 및/또는 데이터는, 처리 장치에 의하여 해석되거나 처리 장치에 명령 또는 데이터를 제공하기 위하여, 어떤 유형의 기계, 구성요소(component), 물리적 장치, 가상 장치(virtual equipment), 컴퓨터 저장 매체 또는 장치, 또는 전송되는 신호 파(signal wave)에 영구적으로, 또는 일시적으로 구체화(embody)될 수 있다. 소프트웨어는 네트워크로 연결된 컴퓨터 시스템 상에 분산되어서, 분산된 방법으로 저장되거나 실행될 수도 있다. 소프트웨어 및 데이터는 하나 이상의 컴퓨터 판독 가능 기록 매체에 저장될 수 있다.The software may include a computer program, code, instructions, or a combination of one or more of the foregoing, and may be configured to configure the processing device to operate as desired or to process it collectively or collectively Device can be commanded. The software and / or data may be in the form of any type of machine, component, physical device, virtual equipment, computer storage media, or device , Or may be permanently or temporarily embodied in a transmitted signal wave. The software may be distributed over a networked computer system and stored or executed in a distributed manner. The software and data may be stored on one or more computer readable recording media.
실시예에 따른 방법은 다양한 컴퓨터 수단을 통하여 수행될 수 있는 프로그램 명령 형태로 구현되어 컴퓨터 판독 가능 매체에 기록될 수 있다. 상기 컴퓨터 판독 가능 매체는 프로그램 명령, 데이터 파일, 데이터 구조 등을 단독으로 또는 조합하여 포함할 수 있다. 상기 매체에 기록되는 프로그램 명령은 실시예를 위하여 특별히 설계되고 구성된 것들이거나 컴퓨터 소프트웨어 당업자에게 공지되어 사용 가능한 것일 수도 있다. 컴퓨터 판독 가능 기록 매체의 예에는 하드 디스크, 플로피 디스크 및 자기 테이프와 같은 자기 매체(magnetic media), CD-ROM, DVD와 같은 광기록 매체(optical media), 플롭티컬 디스크(floptical disk)와 같은 자기-광 매체(magneto-optical media), 및 롬(ROM), 램(RAM), 플래시 메모리 등과 같은 프로그램 명령을 저장하고 수행하도록 특별히 구성된 하드웨어 장치가 포함된다. 프로그램 명령의 예에는 컴파일러에 의해 만들어지는 것과 같은 기계어 코드뿐만 아니라 인터프리터 등을 사용해서 컴퓨터에 의해서 실행될 수 있는 고급 언어 코드를 포함한다. 상기된 하드웨어 장치는 실시예의 동작을 수행하기 위해 하나 이상의 소프트웨어 모듈로서 작동하도록 구성될 수 있으며, 그 역도 마찬가지이다.The method according to an embodiment may be implemented in the form of a program command that can be executed through various computer means and recorded in a computer-readable medium. The computer-readable medium may include program instructions, data files, data structures, and the like, alone or in combination. The program instructions to be recorded on the medium may be those specially designed and configured for the embodiments or may be available to those skilled in the art of computer software. Examples of computer-readable media include magnetic media such as hard disks, floppy disks and magnetic tape; optical media such as CD-ROMs and DVDs; magnetic media such as floppy disks; Magneto-optical media, and hardware devices specifically configured to store and execute program instructions such as ROM, RAM, flash memory, and the like. Examples of program instructions include machine language code such as those produced by a compiler, as well as high-level language code that can be executed by a computer using an interpreter or the like. The hardware devices described above may be configured to operate as one or more software modules to perform the operations of the embodiments, and vice versa.
이상과 같이 실시예들이 비록 한정된 실시예와 도면에 의해 설명되었으나, 해당 기술분야에서 통상의 지식을 가진 자라면 상기의 기재로부터 다양한 수정 및 변형이 가능하다. 예를 들어, 설명된 기술들이 설명된 방법과 다른 순서로 수행되거나, 및/또는 설명된 시스템, 구조, 장치, 회로 등의 구성요소들이 설명된 방법과 다른 형태로 결합 또는 조합되거나, 다른 구성요소 또는 균등물에 의하여 대치되거나 치환되더라도 적절한 결과가 달성될 수 있다.While the present invention has been particularly shown and described with reference to exemplary embodiments thereof, it is to be understood that the invention is not limited to the disclosed exemplary embodiments. For example, it is to be understood that the techniques described may be performed in a different order than the described methods, and / or that components of the described systems, structures, devices, circuits, Lt; / RTI > or equivalents, even if it is replaced or replaced.
그러므로, 다른 구현들, 다른 실시예들 및 특허청구범위와 균등한 것들도 후술하는 특허청구범위의 범위에 속한다.Therefore, other implementations, other embodiments, and equivalents to the claims are also within the scope of the following claims.
Claims (15)
입력되는 음성 신호로부터 특징 벡터를 추출하는 단계;
상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합하는 단계; 및
음소를 분류하여 음성을 인식하는 단계
를 포함하고,
상기 미리 학습된 심화신경망 앙상블 기반의 음향 모델은,
다수의 잔향 환경에서 각각의 잔향 환경에 대해 음소 확률을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법.A speech recognition method using an acoustic model based on a coupled deepened neural network ensemble for speech recognition in a reverberant environment,
Extracting a feature vector from an input speech signal;
Combining the feature vectors using an ensemble of acoustic models based on the deepened neural network ensembles previously learned for each reverberation environment; And
Recognizing speech by classifying phonemes
Lt; / RTI >
Wherein the pre-learned deepening neural network ensemble-
Estimating phoneme probability for each reverberation environment in multiple reverberant environments
A method for speech recognition using an acoustic model based on a combined deepened neural network ensemble for speech recognition in a reverberant environment.
상기 음성 신호로부터 잔향 시간을 추정하는 단계; 및
상기 잔향 시간을 기반으로 가중치를 산출하는 단계
를 더 포함하고,
상기 음소를 분류하여 음성을 인식하는 단계는,
산출된 상기 가중치를 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델의 앙상블 결합에 적용하는 단계
를 포함하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법.The method according to claim 1,
Estimating a reverberation time from the voice signal; And
Calculating a weight based on the reverberation time
Further comprising:
The step of recognizing speech by classifying the phonemes comprises:
And applying the calculated weight to the ensemble combination of the learned deepened neural network ensemble-based acoustic model
A method of speech recognition using an acoustic model based on combined deepened neural network ensembles for speech recognition in reverberation environments.
상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합하는 단계는,
상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델에 기반한 앙상블 모델을 통과시켜 음소 확률을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법.3. The method of claim 2,
Combining the feature vectors using an ensemble of acoustic models based on the deepened neural network ensembles previously learned for each reverberation environment,
And estimating the phoneme probability by passing the feature vector through an ensemble model based on the deepened neural network ensemble-based acoustic model previously learned for each reverberation environment
A method for speech recognition using an acoustic model based on a combined deepened neural network ensemble for speech recognition in a reverberant environment.
상기 음소를 분류하여 음성을 인식하는 단계는,
상기 음소 확률과 상기 가중치를 이용하여 상기 심화신경망 앙상블 기반의 음향 모델의 사후 확률(posterior probability)을 산출하여 상기 음소를 분류하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법.The method of claim 3,
The step of recognizing speech by classifying the phonemes comprises:
And classifying the phoneme by calculating a posterior probability of the deepening neural network ensemble based acoustic model using the phoneme probability and the weight value
A method for speech recognition using an acoustic model based on a combined deepened neural network ensemble for speech recognition in a reverberant environment.
상기 음성 신호로부터 잔향 시간을 추정하는 단계는,
상기 심화신경망 앙상블 기반의 음향 모델 중 우도비가 가장 큰 두 개의 음향 모델을 선택하여 최대 우도법(maximum likelihood)을 통한 상기 잔향 시간을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법.3. The method of claim 2,
Estimating a reverberation time from the speech signal,
Selecting two acoustic models having the greatest likelihood ratios among the acoustic models based on the deepening neural network ensemble and estimating the reverberation time through maximum likelihood
A method for speech recognition using an acoustic model based on a combined deepened neural network ensemble for speech recognition in a reverberant environment.
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계
를 더 포함하고,
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계는,
학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 단계;
추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 단계; 및
추출된 상기 특징 벡터를 심화신경망을 통하여 각각의 상기 잔향 환경에 대해 학습시키는 단계
를 포함하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법.The method according to claim 1,
A step of learning an acoustic model based on the deepened neural network ensemble
Further comprising:
The step of learning the deepened neural network ensemble-
Extracting a feature vector by receiving speech signals in a plurality of reverberation environments in a learning step;
Separating characteristics of the reverberation environment of the extracted feature vector; And
Learning the extracted feature vectors for each of the reverberation environments through the deepening neural network
A method of speech recognition using an acoustic model based on combined deepened neural network ensembles for speech recognition in reverberation environments.
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계
를 더 포함하고,
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 단계는,
학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 단계;
추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 단계;
추출된 상기 특징 벡터를 잔향이 없는 음성 특징으로 맵핑(mapping)시키는 상기 특징 맵핑 심화신경망을 통과시키는 단계;
상기 특징 맵핑 심화신경망의 출력을 이용하여 상기 음향 모델링 심화신경망을 학습시키는 단계; 및
상기 음향 모델링 심화신경망은 상기 특징 맵핑 심화신경망 위에 바로 쌓이고, 결합된 상기 심화신경망 앙상블 기반의 음향 모델은 연결되어 재학습되는 단계
를 포함하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 방법.The method according to claim 1,
A step of learning an acoustic model based on the deepened neural network ensemble
Further comprising:
The step of learning the deepened neural network ensemble-
Extracting a feature vector by receiving speech signals in a plurality of reverberation environments in a learning step;
Separating characteristics of the reverberation environment of the extracted feature vector;
Passing the feature mapping enrichment neural network to map the extracted feature vector to a reverberant voice feature;
Learning the acoustic modeling deepening neural network using the output of the feature mapping deepening neural network; And
Wherein the acoustic modeling enrichment neural network is stacked directly on the feature mapping enrichment neural network and the combined deepening neural network ensemble based acoustic model is re-
A method of speech recognition using an acoustic model based on combined deepened neural network ensembles for speech recognition in reverberation environments.
입력되는 음성 신호로부터 특징 벡터를 추출하는 특징 벡터 추출부;
상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 심화신경망 앙상블 기반의 음향 모델의 앙상블을 이용하여 결합하는 앙상블 모델; 및
음소를 분류하여 음성을 인식하는 음소 분류부
를 포함하고,
상기 미리 학습된 심화신경망 앙상블 기반의 음향 모델은,
다수의 잔향 환경에서 각각의 잔향 환경에 대해 음소 확률을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템.A speech recognition system using a combined deepened neural network ensemble based acoustic model for speech recognition in a reverberant environment,
A feature vector extracting unit for extracting a feature vector from an input speech signal;
An ensemble model that combines the feature vectors using an ensemble of acoustic models based on deepened neural network ensembles previously learned for each reverberation environment; And
A phoneme classifier for classifying phonemes and recognizing speech
Lt; / RTI >
Wherein the pre-learned deepening neural network ensemble-
Estimating phoneme probability for each reverberation environment in multiple reverberant environments
A Speech Recognition System Using Combined Learned Neural Network Ensemble Based Acoustic Model for Speech Recognition in Reverberation Environment.
상기 음성 신호로부터 잔향 시간을 추정하는 잔향 시간 예측부; 및
상기 잔향 시간을 기반으로 가중치를 산출하는 가중치 결정부
를 더 포함하고,
상기 음소 분류부는,
산출된 상기 가중치를 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델의 앙상블 결합에 적용하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템.9. The method of claim 8,
A reverberation time predicting unit for estimating a reverberation time from the voice signal; And
A weight determining unit for calculating a weight based on the reverberation time,
Further comprising:
Wherein the phoneme classifying unit comprises:
And applying the calculated weight to the ensemble combination of the learned deepened neural network ensemble-based acoustic model
A Speech Recognition System Using Combined Learned Neural Network Ensemble Based Acoustic Model for Speech Recognition in Reverberation Environment.
상기 앙상블 모델은,
상기 특징 벡터를 각각의 잔향 환경에 대해 미리 학습된 상기 심화신경망 앙상블 기반의 음향 모델에 기반한 앙상블 모델을 통과시켜 음소 확률을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템.10. The method of claim 9,
In the ensemble model,
And estimating the phoneme probability by passing the feature vector through an ensemble model based on the deepened neural network ensemble-based acoustic model previously learned for each reverberation environment
A Speech Recognition System Using Combined Learned Neural Network Ensemble Based Acoustic Model for Speech Recognition in Reverberation Environment.
상기 음소 분류부는,
상기 음소 확률과 상기 가중치를 이용하여 상기 심화신경망 앙상블 기반의 음향 모델의 사후 확률(posterior probability)을 산출하여 상기 음소를 분류하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템.11. The method of claim 10,
Wherein the phoneme classifying unit comprises:
And classifying the phoneme by calculating a posterior probability of the deepening neural network ensemble based acoustic model using the phoneme probability and the weight value
A Speech Recognition System Using Combined Learned Neural Network Ensemble Based Acoustic Model for Speech Recognition in Reverberation Environment.
상기 잔향 시간 예측부는,
상기 심화신경망 앙상블 기반의 음향 모델 중 우도비가 가장 큰 두 개의 음향 모델을 선택하여 최대 우도법(maximum likelihood)을 통한 상기 잔향 시간을 추정하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템.10. The method of claim 9,
Wherein the reverberation time predicting unit comprises:
Selecting two acoustic models having the greatest likelihood ratios among the acoustic models based on the deepening neural network ensemble and estimating the reverberation time through maximum likelihood
A Speech Recognition System Using Combined Learned Neural Network Ensemble Based Acoustic Model for Speech Recognition in Reverberation Environment.
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 학습부
를 더 포함하고,
상기 학습부는,
학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 특징 벡터 추출부;
추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 잔향 특징 분류부; 및
추출된 상기 특징 벡터를 심화신경망을 통하여 각각의 상기 잔향 환경에 대해 학습시키는 다중 심화신경망 학습부
를 포함하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템.9. The method of claim 8,
A learning unit for learning the deepening neural network ensemble-based acoustic model;
Further comprising:
Wherein,
A feature vector extractor for extracting a feature vector by receiving speech signals in a plurality of reverberation environments in a learning step;
A reverberation feature classifier for classifying a feature of a reverberation environment of the extracted feature vector; And
And a multi-depth neural network learning unit for learning the extracted feature vectors for each of the reverberation environments through a deep-
A Speech Recognition System Using Combined Learned Neural Network Ensemble Based Acoustic Model for Speech Recognition in Reverberation Environment.
상기 심화신경망 앙상블 기반의 음향 모델을 학습시키는 학습부
를 더 포함하고,
상기 학습부는,
잔향이 없는 음성 특징으로 맵핑(mapping)시키는 특징 맵핑 심화신경망과 음향 모델링 심화신경망을 결합하는 구조를 이용하여, 서로 다른 잔향 환경에 대해 학습된 음향 모델을 구성하는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템.9. The method of claim 8,
A learning unit for learning the deepening neural network ensemble-based acoustic model;
Further comprising:
Wherein,
Feature Mapping to Reverberation-Free Speech Feature Deepening Neural Network and Acoustic Modeling Deepening By constructing a learned acoustic model for different reverberation environments using a structure that combines neural networks
A Speech Recognition System Using Combined Learned Neural Network Ensemble Based Acoustic Model for Speech Recognition in Reverberation Environment.
상기 학습부는,
학습 단계에서, 다수의 잔향 환경에서의 음성 신호를 입력 받아 특징 벡터를 추출하는 특징 벡터 추출부;
추출된 상기 특징 벡터의 잔향 환경의 특징을 분리하는 잔향 특징 분류부;
추출된 상기 특징 벡터를 잔향이 없는 음성 특징으로 맵핑(mapping)시키는 상기 특징 맵핑 심화신경망; 및
상기 특징 맵핑 심화신경망의 출력을 이용하여 학습시키는 상기 음향 모델링 심화신경망
을 포함하고,
상기 음향 모델링 심화신경망은 상기 특징 맵핑 심화신경망 위에 바로 쌓이고, 결합된 상기 심화신경망 앙상블 기반의 음향 모델은 연결되어 재학습되는 것
을 특징으로 하는 잔향 환경에서의 음성인식을 위한 결합 학습된 심화신경망 앙상블 기반의 음향 모델을 이용한 음성인식 시스템.15. The method of claim 14,
Wherein,
A feature vector extractor for extracting a feature vector by receiving speech signals in a plurality of reverberation environments in a learning step;
A reverberation feature classifier for classifying a feature of a reverberation environment of the extracted feature vector;
The feature mapping enrichment neural network mapping the extracted feature vector to a reverberant voice feature; And
Wherein the acoustic modeling enrichment neural network
/ RTI >
Wherein the acoustic modeling enrichment neural network is stacked directly on the feature mapping enrichment neural network and the combined deepening neural network ensemble based acoustic model is re-learned
A Speech Recognition System Using Combined Learned Neural Network Ensemble Based Acoustic Model for Speech Recognition in Reverberation Environment.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020160046952A KR101807948B1 (en) | 2016-04-18 | 2016-04-18 | Ensemble of Jointly Trained Deep Neural Network-based Acoustic Models for Reverberant Speech Recognition and Method for Recognizing Speech using the same |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020160046952A KR101807948B1 (en) | 2016-04-18 | 2016-04-18 | Ensemble of Jointly Trained Deep Neural Network-based Acoustic Models for Reverberant Speech Recognition and Method for Recognizing Speech using the same |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20170119152A true KR20170119152A (en) | 2017-10-26 |
| KR101807948B1 KR101807948B1 (en) | 2017-12-11 |
Family
ID=60300764
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020160046952A KR101807948B1 (en) | 2016-04-18 | 2016-04-18 | Ensemble of Jointly Trained Deep Neural Network-based Acoustic Models for Reverberant Speech Recognition and Method for Recognizing Speech using the same |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR101807948B1 (en) |
Cited By (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190060028A (en) * | 2017-11-23 | 2019-06-03 | 삼성전자주식회사 | Neural network device for speaker recognition, and operation method of the same |
| KR20190108711A (en) * | 2018-03-15 | 2019-09-25 | 한양대학교 산학협력단 | Method and apparatus for estimating direction of ensemble sound source based on deepening neural network for estimating direction of sound source robust to reverberation environment |
| WO2020130687A1 (en) * | 2018-12-19 | 2020-06-25 | Samsung Electronics Co., Ltd. | System and method for automated execution of user-specified commands |
| WO2020204525A1 (en) * | 2019-04-01 | 2020-10-08 | 한양대학교 산학협력단 | Combined learning method and device using transformed loss function and feature enhancement based on deep neural network for speaker recognition that is robust in noisy environment |
| KR102201198B1 (en) * | 2020-05-22 | 2021-01-11 | 서울시립대학교 산학협력단 | Apparatus and method for classifying data by using machine learning and ensemble method |
| US10930268B2 (en) | 2018-05-31 | 2021-02-23 | Samsung Electronics Co., Ltd. | Speech recognition method and apparatus |
| WO2020256257A3 (en) * | 2019-06-21 | 2021-03-11 | 한양대학교 산학협력단 | Combined learning method and device using transformed loss function and feature enhancement based on deep neural network for speaker recognition that is robust to noisy environment |
| KR20210123554A (en) * | 2020-04-03 | 2021-10-14 | 서울시립대학교 산학협력단 | Apparatus and method for enhancing speaker feature based on deep neural network that selectively compensates for distant utterances |
| CN113593560A (en) * | 2021-07-29 | 2021-11-02 | 普强时代(珠海横琴)信息技术有限公司 | Customizable low-delay command word recognition method and device |
| WO2021251627A1 (en) * | 2020-06-11 | 2021-12-16 | 한양대학교 산학협력단 | Method and apparatus for combined training of deep neural network-based reverberation removal, beamforming, and acoustic recognition models using multi-channel acoustic signal |
| WO2023068552A1 (en) * | 2021-10-21 | 2023-04-27 | 삼성전자주식회사 | Electronic device for voice recognition, and control method therefor |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102550598B1 (en) * | 2018-03-21 | 2023-07-04 | 현대모비스 주식회사 | Apparatus for recognizing voice speaker and method the same |
-
2016
- 2016-04-18 KR KR1020160046952A patent/KR101807948B1/en active IP Right Grant
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190060028A (en) * | 2017-11-23 | 2019-06-03 | 삼성전자주식회사 | Neural network device for speaker recognition, and operation method of the same |
| KR20190108711A (en) * | 2018-03-15 | 2019-09-25 | 한양대학교 산학협력단 | Method and apparatus for estimating direction of ensemble sound source based on deepening neural network for estimating direction of sound source robust to reverberation environment |
| US10930268B2 (en) | 2018-05-31 | 2021-02-23 | Samsung Electronics Co., Ltd. | Speech recognition method and apparatus |
| WO2020130687A1 (en) * | 2018-12-19 | 2020-06-25 | Samsung Electronics Co., Ltd. | System and method for automated execution of user-specified commands |
| WO2020204525A1 (en) * | 2019-04-01 | 2020-10-08 | 한양대학교 산학협력단 | Combined learning method and device using transformed loss function and feature enhancement based on deep neural network for speaker recognition that is robust in noisy environment |
| KR20200116225A (en) * | 2019-04-01 | 2020-10-12 | 한양대학교 산학협력단 | Combined learning method and apparatus using deepening neural network based feature enhancement and modified loss function for speaker recognition robust to noisy environments |
| WO2020256257A3 (en) * | 2019-06-21 | 2021-03-11 | 한양대학교 산학협력단 | Combined learning method and device using transformed loss function and feature enhancement based on deep neural network for speaker recognition that is robust to noisy environment |
| US11854554B2 (en) | 2019-06-21 | 2023-12-26 | Iucf-Hyu (Industry-University Cooperation Foundation Hanyang University) | Method and apparatus for combined learning using feature enhancement based on deep neural network and modified loss function for speaker recognition robust to noisy environments |
| KR20210123554A (en) * | 2020-04-03 | 2021-10-14 | 서울시립대학교 산학협력단 | Apparatus and method for enhancing speaker feature based on deep neural network that selectively compensates for distant utterances |
| KR102201198B1 (en) * | 2020-05-22 | 2021-01-11 | 서울시립대학교 산학협력단 | Apparatus and method for classifying data by using machine learning and ensemble method |
| WO2021251627A1 (en) * | 2020-06-11 | 2021-12-16 | 한양대학교 산학협력단 | Method and apparatus for combined training of deep neural network-based reverberation removal, beamforming, and acoustic recognition models using multi-channel acoustic signal |
| CN113593560A (en) * | 2021-07-29 | 2021-11-02 | 普强时代(珠海横琴)信息技术有限公司 | Customizable low-delay command word recognition method and device |
| CN113593560B (en) * | 2021-07-29 | 2024-04-16 | 普强时代(珠海横琴)信息技术有限公司 | Customizable low-delay command word recognition method and device |
| WO2023068552A1 (en) * | 2021-10-21 | 2023-04-27 | 삼성전자주식회사 | Electronic device for voice recognition, and control method therefor |
Also Published As
| Publication number | Publication date |
|---|---|
| KR101807948B1 (en) | 2017-12-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101807948B1 (en) | Ensemble of Jointly Trained Deep Neural Network-based Acoustic Models for Reverberant Speech Recognition and Method for Recognizing Speech using the same | |
| KR102167719B1 (en) | Method and apparatus for training language model, method and apparatus for recognizing speech | |
| JP4548646B2 (en) | Noise model noise adaptation system, noise adaptation method, and speech recognition noise adaptation program | |
| JP5423670B2 (en) | Acoustic model learning device and speech recognition device | |
| US8428950B2 (en) | Recognizer weight learning apparatus, speech recognition apparatus, and system | |
| KR101704926B1 (en) | Statistical Model-based Voice Activity Detection with Ensemble of Deep Neural Network Using Acoustic Environment Classification and Voice Activity Detection Method thereof | |
| KR102294638B1 (en) | Combined learning method and apparatus using deepening neural network based feature enhancement and modified loss function for speaker recognition robust to noisy environments | |
| EP4028953A1 (en) | Convolutional neural network with phonetic attention for speaker verification | |
| Kim et al. | Environmental noise embeddings for robust speech recognition | |
| EP1465154B1 (en) | Method of speech recognition using variational inference with switching state space models | |
| KR101618512B1 (en) | Gaussian mixture model based speaker recognition system and the selection method of additional training utterance | |
| JP7176627B2 (en) | Signal extraction system, signal extraction learning method and signal extraction learning program | |
| Ismail et al. | Mfcc-vq approach for qalqalahtajweed rule checking | |
| KR102406512B1 (en) | Method and apparatus for voice recognition | |
| CN113674733A (en) | Method and apparatus for speaking time estimation | |
| KR102305672B1 (en) | Method and apparatus for speech end-point detection using acoustic and language modeling knowledge for robust speech recognition | |
| Hadjahmadi et al. | Robust feature extraction and uncertainty estimation based on attractor dynamics in cyclic deep denoising autoencoders | |
| KR19990083632A (en) | Speaker and environment adaptation based on eigenvoices imcluding maximum likelihood method | |
| Hwang et al. | End-to-end speech endpoint detection utilizing acoustic and language modeling knowledge for online low-latency speech recognition | |
| CN102237082B (en) | Self-adaption method of speech recognition system | |
| JP4233831B2 (en) | Noise model noise adaptation system, noise adaptation method, and speech recognition noise adaptation program | |
| Nicolson et al. | Sum-product networks for robust automatic speaker identification | |
| KR20200120595A (en) | Method and apparatus for training language model, method and apparatus for recognizing speech | |
| CN112489678A (en) | Scene recognition method and device based on channel characteristics | |
| Nahar et al. | Effect of data augmentation on dnn-based vad for automatic speech recognition in noisy environment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| GRNT | Written decision to grant |