KR20160045673A - 정량적 f0 패턴 생성 장치 및 방법, 그리고 f0 패턴 생성을 위한 모델 학습 장치 및 방법 - Google Patents
정량적 f0 패턴 생성 장치 및 방법, 그리고 f0 패턴 생성을 위한 모델 학습 장치 및 방법 Download PDFInfo
- Publication number
- KR20160045673A KR20160045673A KR1020167001355A KR20167001355A KR20160045673A KR 20160045673 A KR20160045673 A KR 20160045673A KR 1020167001355 A KR1020167001355 A KR 1020167001355A KR 20167001355 A KR20167001355 A KR 20167001355A KR 20160045673 A KR20160045673 A KR 20160045673A
- Authority
- KR
- South Korea
- Prior art keywords
- component
- pattern
- accent
- generating
- phrase
- Prior art date
Links
Images








Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
- G10L13/10—Prosody rules derived from text; Stress or intonation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/06—Elementary speech units used in speech synthesisers; Concatenation rules
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
- G10L13/086—Detection of language
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/02—Feature extraction for speech recognition; Selection of recognition unit
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/04—Segmentation; Word boundary detection
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Processing of the speech or voice signal to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0316—Speech enhancement, e.g. noise reduction or echo cancellation by changing the amplitude
- G10L21/0364—Speech enhancement, e.g. noise reduction or echo cancellation by changing the amplitude for improving intelligibility
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/18—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being spectral information of each sub-band
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/02—Methods for producing synthetic speech; Speech synthesisers
- G10L13/027—Concept to speech synthesisers; Generation of natural phrases from machine-based concepts
Abstract
[과제] 정확도를 유지하면서 언어학적 정보와 F0 패턴의 대응이 명확해지는 통계적 모델에 의한 F0 패턴의 합성 장치를 제공한다.
[해결수단] HMM 학습 장치는 연속 F0 패턴(132)에 피팅하는 F0 패턴(133)을 프레이즈 성분과 악센트 성분의 합으로서 나타내고, 그것들의 타깃 포인트를 추정하는 파라미터 추정부와, 피팅 후의 F0 패턴을 학습 데이터로 해서 HMM(139)의 학습을 행하는 HMM 학습 수단을 포함한다. 연속 F0 패턴(132)을 악센트 성분(134), 프레이즈 성분(136), 및 마이크로 프로소디 성분(138)으로 분리하여 개별의 HMM(140, 142 및 144)의 HMM을 학습해도 좋다. 텍스트 해석의 결과를 이용하여 악센트 성분, 프레이즈 성분, 및 마이크로 프로소디 성분을 개별로 HMM(140, 142 및 144)으로부터 생성해서 합성하여 F0 패턴을 얻는다.
[해결수단] HMM 학습 장치는 연속 F0 패턴(132)에 피팅하는 F0 패턴(133)을 프레이즈 성분과 악센트 성분의 합으로서 나타내고, 그것들의 타깃 포인트를 추정하는 파라미터 추정부와, 피팅 후의 F0 패턴을 학습 데이터로 해서 HMM(139)의 학습을 행하는 HMM 학습 수단을 포함한다. 연속 F0 패턴(132)을 악센트 성분(134), 프레이즈 성분(136), 및 마이크로 프로소디 성분(138)으로 분리하여 개별의 HMM(140, 142 및 144)의 HMM을 학습해도 좋다. 텍스트 해석의 결과를 이용하여 악센트 성분, 프레이즈 성분, 및 마이크로 프로소디 성분을 개별로 HMM(140, 142 및 144)으로부터 생성해서 합성하여 F0 패턴을 얻는다.
Description
본 발명은 음성 합성 기술에 관한 것이고, 특히 음성 합성시의 기본 주파수 패턴의 합성 기술에 관한 것이다.
음성의 기본 주파수의 시간 변화 패턴(이하, 「F0 패턴」이라고 부른다.)은 문장의 구분을 명확하게 하거나 악센트 위치를 표현하거나 단어를 구별하거나 하는데 도움이 된다. F0 패턴은 또한, 발화에 따른 감정 등 비언어적인 정보를 전하는데 있어서도 큰 역할을 한다. 또한, 발화의 자연스러움에도 F0 패턴이 큰 영향을 준다. 특히, 발화 중의 초점의 위치를 분명하게 하고, 문장의 구조를 명확하게 하기 위해서는 문장을 적절한 인토네이션으로 발화할 필요가 있다. F0 패턴이 적절하지 않으면, 합성 음성의 양해성이 손상되어 버린다. 따라서, 음성 합성에 있어서 어떻게 해서 소망의 F0 패턴을 합성할지는 큰 문제가 된다.
F0 패턴의 합성 방법으로서, 뒤에 나타내는 비특허문헌 1에 개시된 후지사키 모델이라고 불리는 방법이 있다.
후지사키 모델은 소수의 파라미터에 의해서 F0 패턴을 정량적으로 기술하는 F0 패턴 생성 과정 모델이다. 도 1을 참조해서, 이 F0 패턴 생성 과정 모델(30)은 F0 패턴을 프레이즈 성분과 악센트 성분과 기저 성분(Fb)의 합으로서 표현한 것이다.
프레이즈 성분이란, 발화 중 1개의 프레이즈의 개시 직후에 상승하는 피크를 갖고, 프레이즈의 끝까지 완만하게 하강하도록 변화되는 성분인 것을 가리킨다. 악센트 성분이란 단어에 대응한 국소적인 요철로 나타내어지는 성분을 가리킨다.
도 1의 좌측을 참조해서, 후지사키 모델에서는 프레이즈 성분을 프레이즈의 선두에서 발생되는 임펄스 상의 프레이즈 커맨드(40)에 대한 프레이즈 제어 기구(42)의 응답으로 나타낸다. 한편, 악센트 성분은 마찬가지로 스텝 형상의 악센트 커맨드(44)에 대한 악센트 제어 기구(46)의 응답으로 나타낸다. 이들 프레이즈 성분과 악센트 성분과 기저 성분(Fb)의 대수 logeFb를 가산기(48)에 의해 가산함으로써 F0 패턴(50)의 대수 표현 logeF0(t)이 얻어진다.
이 모델에서는 악센트 성분 및 프레이즈 성분과, 발화의 언어학적 정보 및 파라 언어학적 정보 사이의 대응관계가 명확하다. 또한, 모델 파라미터를 변화시키는 것만으로 용이하게 문장의 초점을 정할 수 있다고 하는 특징도 있다.
그러나, 이 모델에서는 적절한 파라미터를 결정하는 것이 곤란하다고 하는 문제가 있다. 최근의 음성 기술에서는 컴퓨터의 발달과 함께 대량으로 수집한 음성 데이터로부터 모델을 구축한다고 하는 방법이 주류이다. 후지사키 모델에서는 음성 말뭉치에서 관측된 F0 패턴으로부터 모델 파라미터를 자동적으로 얻는 것이 어렵다.
한편, 대량으로 수집한 음성 데이터로부터 모델을 구축하는 방법의 전형적인 것으로서, 뒤에 나타내는 비특허문헌 2에 기재된 음성 말뭉치에서 관측된 F0 패턴에 의해 HMM(Hidden Marcov Model)을 구축하는 방법이 있다. 이 방법은 다양한 발화 콘텍스트에 있어서의 F0 패턴을 음성 말뭉치로부터 얻어서 모델화할 수 있기 때문에 합성 음성의 자연스러움 및 정보 전달 기능을 실현하는데 있어서 매우 중요하다.
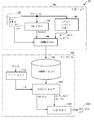
도 2를 참조해서, 이 방법에 따른 종래의 음성 합성 시스템(70)은 음성 말뭉치로부터 F0 패턴 합성용의 HMM 모델의 학습을 행하는 모델 학습부(80)와, 입력된 텍스트에 대응하는 합성 음성 신호(118)를 학습에 의해 얻은 HMM을 이용하여 얻어진 F0 패턴에 따라서 합성하는 음성 합성부(82)를 포함한다.
모델 학습부(80)는 음소의 콘텍스트 라벨이 부착된 음성 말뭉치를 기억하는 음성 말뭉치 기억 장치(90)와, 음성 말뭉치 기억 장치(90)에 기억된 음성 말뭉치 내의 각 발화의 음성 신호로부터 F0을 추출하는 F0 추출부(92)와, 마찬가지로 각 발화로부터 스펙트럼 파라미터로서 멜 켑스트럼 파라미터를 추출하는 스펙트럼 파라미터 추출부(94)와, F0 추출부(92)에 의해 추출된 F0 패턴, 음성 말뭉치 기억 장치(90)로부터 얻어지는 F0 패턴에 대응하는 발화 중의 각 음소의 라벨 및 스펙트럼 파라미터 추출부(94)로부터 주어지는 멜 켑스트럼 파라미터를 이용하여 각 프레임의 특성 벡터를 생성하고, 생성 대상이 되는 음소의 콘텍스트 라벨로 이루어지는 라벨열이 주어지면, 그 프레임에서 각 F0 주파수와 멜 켑스트럼 파라미터의 세트가 출력되는 확률을 출력하도록 HMM의 통계적인 학습을 행하는 HMM 학습부(96)를 포함한다. 여기서, 콘텍스트 라벨이란 음성 합성용의 제어 기호로서, 상기 음소에 대하여 그 음소 환경 등의 각종 언어 정보(콘텍스트)를 부여한 라벨이다.
음성 합성부(82)는 HMM 학습부(96)에 의한 학습이 행해진 HMM의 파라미터를 기억하는 HMM 기억 장치(110)와, 음성 합성의 대상이 되는 텍스트가 주어지면 그 텍스트에 대하여 텍스트 해석을 하고, 발화 중의 단어 및 그 음소의 특정, 악센트의 결정, 포즈의 삽입 위치의 결정, 및 문장의 종류의 결정 등을 행하여 발화를 나타내는 라벨열을 출력하는 텍스트 해석부(112)와, 텍스트 해석부(112)로부터 라벨열을 받으면 HMM 기억 장치(110)에 기억된 HMM과 이 라벨열을 비교하여 원래의 텍스트를 발화할 때의 F0 패턴 및 멜 켑스트럼열의 조합으로서 가장 확률이 높은 조합을 생성하여 출력하는 파라미터 생성부(114)와, 파라미터 생성부(114)로부터 주어진 F0 패턴에 따라서 파라미터 생성부(114)로부터 주어진 멜 켑스트럼 파라미터에 의해 나타내어지는 음성을 합성하여 합성 음성 신호(118)로서 출력하는 음성 합성기(116)를 포함한다.
이 음성 합성 시스템(70)에 의하면, 대량의 음성 데이터에 의거해서 광범위한 콘텍스트에 의해 다채로운 F0 패턴을 출력할 수 있다고 하는 효과를 얻을 수 있다.
Fujisaki, H., and Hirose, K.(1984), "Analysis of voice fundamental frequency contours for declarative sentences of Japanese," J. Acoust. Soc. Jpn., 5, 233-242.
Tokuda, K., Masuko, T., Miyazaki, N., and Kobayashi, T.(1999), "Hidden Markov models based on multi-space probability distribution for pitch pattern modeling," Proc. of ICASSP1999, 229-232.
Ni, J. and Nakamura, S.(2007), "Use of Poisson processes to generate fundamental frequency contours", Proc. of ICASSP2007, 825-828.
Ni, J, Shiga, Y., Kawai, H., and Kashioka, H.(2012), "Resonance-based spectral deformation in HMM-based speech synthesis," Proc. of ISCSLP2012, 88-92.
실제의 발화에서는 음소의 경계 등에 있어서 발화 방법의 변화 등에 따라 음성의 피치에 미세한 변동이 생긴다. 이것을 마이크로 프로소디라 부른다. 특히 유성/무성 구간의 경계 등에서는 F0이 급격히 변화된다. 이러한 변화는 음성을 처리함으로써 관측은 되지만, 청각 상은 그다지 의미를 갖지 않는다. 상기 HMM을 이용한 음성 합성 시스템(70)(도 2 참조)의 경우, 이러한 마이크로 프로소디의 영향을 받아서 F0 패턴의 오차가 커진다고 하는 문제가 있다. 또한, 비교적 긴 구간에 걸친 F0의 변화 패턴에 추종하는 능력이 낮다고 하는 문제도 있다. 이것들에 추가하여 또한, 합성되는 F0 패턴과 언어학적 정보 사이의 관계가 불명료한 것, 및 문장의 초점(콘텍스트에 의존하지 않는 F0의 변동)을 설정하는 것이 곤란하다고 하는 문제도 있다.
그러므로 본 발명은, 통계적 모델에 의해 F0 패턴을 생성할 때에, 정확도를 유지하면서 언어학적 정보와 F0 패턴의 대응이 명확해지는 F0 패턴의 합성 장치 및 방법을 제공하는 것을 목적으로 한다.
본 발명의 다른 목적은 통계적 모델에 의해 F0 패턴을 생성할 때에 정확도를 유지하면서 언어학적 정보와 F0 패턴의 대응이 명확하고, 또한 문장의 초점을 용이하게 설정할 수 있는 장치 및 방법을 제공하는 것을 목적으로 한다.
본 발명의 제 1 국면에 의한 정량적 F0 패턴 생성 장치는 텍스트 해석에 의해 얻어진 발화의 악센트구에 대하여 소여의 수의 타깃 포인트를 이용하여 F0 패턴의 악센트 성분을 생성하는 수단과, 발화의 구조를 포함하는 언어 정보에 따라서 발화를 1개 이상의 악센트구를 포함하는 그룹으로 나눔으로써 한정된 수의 타깃 포인트를 이용하여 F0 패턴의 프레이즈 성분을 생성하는 수단과, 악센트 성분과 프레이즈 성분에 의거해서 F0 패턴을 생성하는 수단을 포함한다.
각 악센트구는 3개 또는 4개의 타깃 포인트에 의해 기술된다. 4개의 점 중 2개는 악센트구의 F0 패턴 중 주파수가 낮은 부분을 나타내는 저타깃, 나머지 1개 또는 2개의 점은 F0 패턴 중 주파수가 높은 부분을 나타내는 고타깃이다. 고타깃이 2개인 경우, 그 강도는 같아도 좋다.
F0 패턴을 생성하는 수단은 연속된 F0 패턴을 생성한다.
본 발명의 제 2 국면에 의한 정량적 F0 패턴의 생성 방법은 텍스트 해석에 의해 얻어진 발화의 악센트구에 대하여 소여의 수의 타깃 포인트를 이용하여 F0 패턴의 악센트 성분을 생성하는 스텝과, 발화의 구조를 포함하는 언어 정보에 따라서 발화를 1개 이상의 악센트구를 포함하는 그룹으로 나눔으로써 한정된 수의 타깃 포인트를 이용하여 F0 패턴의 프레이즈 성분을 생성하는 스텝과, 악센트 성분과 상기 프레이즈 성분에 의거해서 F0 패턴을 생성하는 스텝을 포함한다.
본 발명의 제 3 국면에 의한 정량적 F0 패턴 생성 장치는 F0 패턴의 프레이즈 성분의 타깃 파라미터 생성용의 생성 모델과 F0 패턴의 악센트 성분의 타깃 파라미터 생성용의 생성 모델의 파라미터를 기억하는 모델 기억 수단과, 음성 합성의 대상이 되는 텍스트의 입력을 받아서 텍스트 해석하고 음성 합성용의 제어 기호열을 출력하는 텍스트 해석 수단과, 텍스트 해석 수단이 출력하는 제어 기호열을 프레이즈 성분 생성용의 생성 모델과 비교함으로써 F0 패턴의 프레이즈 성분을 생성하는 프레이즈 성분 생성 수단과, 텍스트 해석 수단이 출력하는 제어 기호열을 악센트 성분 생성용의 생성 모델과 비교함으로써 F0 패턴의 악센트 성분을 생성하는 악센트 성분 생성 수단과, 프레이즈 성분 생성 수단에 의해 생성된 프레이즈 성분 및 악센트 성분 생성 수단에 의해 생성된 악센트 성분을 합성함으로써 F0 패턴을 생성하는 F0 패턴 합성 수단을 포함한다.
모델 기억 수단은 또한, F0 패턴의 마이크로 프로소디 성분 추정용의 생성 모델의 파라미터를 기억해도 좋다. 이 경우, F0 패턴 생성 장치는 또한, 텍스트 해석 수단이 출력하는 제어 기호열을 마이크로 프로소디 성분 생성용의 생성 모델과 비교함으로써 F0 패턴의 마이크로 프로소디 성분을 출력하는 마이크로 프로소디 성분 출력 수단을 포함한다. F0 패턴 생성 수단은 프레이즈 성분 생성 수단에 의해 생성된 프레이즈 성분, 악센트 성분 생성 수단에 의해 생성된 악센트 성분, 및 마이크로 프로소디 성분을 합성함으로써 F0 패턴을 생성하는 수단을 포함한다.
본 발명의 제 4 국면에 의한 정량적 F0 패턴 생성 방법은 F0 패턴의 프레이즈 성분의 타깃 파라미터 생성용의 생성 모델과 F0 패턴의 악센트 성분의 타깃 파라미터 생성용의 생성 모델의 파라미터를 기억한 모델 기억 수단을 이용하는 정량적 F0 패턴 생성 방법으로서, 음성 합성의 대상이 되는 텍스트의 입력을 받아서 텍스트 해석하고 음성 합성용의 제어 기호열을 출력하는 텍스트 해석 스텝과, 텍스트 해석에 있어서 출력되는 제어 기호열을 기억 수단에 기억된 프레이즈 성분 생성용의 생성 모델과 비교함으로써 F0 패턴의 프레이즈 성분을 생성하는 프레이즈 성분 생성 수단과, 텍스트 해석 스텝에 있어서 출력되는 제어 기호열을 기억 수단에 기억된 악센트 성분 생성용의 생성 모델과 비교함으로써 F0 패턴의 악센트 성분을 생성하는 악센트 성분 생성 스텝과, 프레이즈 성분 생성 스텝에 있어서 생성된 프레이즈 성분 및 악센트 성분 생성 스텝에 있어서 생성된 악센트 성분을 합성함으로써 F0 패턴을 생성하는 F0 패턴 생성 스텝을 포함한다.
본 발명의 제 5 국면에 의한 F0 패턴 생성을 위한 모델 학습 장치는 음성 데이터 신호로부터 F0 패턴을 추출하는 F0 패턴 추출 수단과, 추출된 F0 패턴에 피팅하는 F0 패턴을 프레이즈 성분과 악센트 성분의 중첩에 의해 나타내기 위해서, 프레이즈 성분을 나타내는 타깃 파라미터와 악센트 성분을 나타내는 타깃 파라미터를 추정하는 파라미터 추정 수단과, 파라미터 추정 수단에 의해 추정된 프레이즈 성분의 타깃 파라미터 및 악센트 성분의 타깃 파라미터에 의해 나타내어지는 연속적인 F0 패턴을 학습 데이터로 해서 F0 생성 모델의 학습을 행하는 모델 학습 수단을 포함한다.
F0 생성 모델은 프레이즈 성분 생성용의 생성 모델과 악센트 성분 생성용의 생성 모델을 포함해도 좋다. 모델 학습 수단은 파라미터 추정 수단에 의해 추정된 프레이즈 성분의 타깃 파라미터에 의해서 나타내어지는 프레이즈 성분의 시간 변화 패턴과 악센트 성분의 타깃 파라미터에 의해 나타내어지는 악센트 성분의 시간 변화 패턴을 학습 데이터로 해서, 프레이즈 성분 생성용의 생성 모델과 악센트 성분 생성용의 생성 모델의 학습을 행하는 제 1 모델 학습 수단을 포함한다.
상기한 모델 학습 장치는 또한, F0 패턴 추출 수단에 의해서 추출된 F0 패턴으로부터 마이크로 프로소디 성분을 분리하고, 상기 마이크로 프로소디 성분을 학습 데이터로 해서 마이크로 프로소디 성분 생성용의 생성 모델의 학습을 행하는 제 2 모델 학습 수단을 포함해도 좋다.
본 발명의 제 6 국면에 의한 F0 패턴 생성을 위한 모델 학습 방법은 음성 데이터 신호로부터 F0 패턴을 추출하는 F0 패턴 추출 스텝과, F0 패턴 추출 스텝에 있어서 추출된 F0 패턴에 피팅하는 F0 패턴을 프레이즈 성분과 악센트 성분의 중첩에 의해 나타내기 위해서, 프레이즈 성분을 나타내는 타깃 파라미터와 악센트 성분을 나타내는 타깃 파라미터를 추정하는 파라미터 추정 스텝과, 파라미터 추정 스텝에 있어서 추정된 프레이즈 성분의 타깃 파라미터 및 악센트 성분의 타깃 파라미터에 의해 나타내어지는 연속적인 F0 패턴을 학습 데이터로 해서 F0 생성 모델의 학습을 행하는 모델 학습 스텝을 포함한다.
F0 생성 모델은 프레이즈 성분 생성용의 생성 모델과 악센트 성분 생성용의 생성 모델을 포함해도 좋다. 모델 학습 스텝은 파라미터 추정 스텝에 있어서 추정된 프레이즈 성분의 타깃 파라미터에 의해서 나타내어지는 프레이즈 성분의 시간 변화 패턴과 악센트 성분의 타깃 파라미터에 의해 나타내어지는 악센트 성분의 시간 변화 패턴을 학습 데이터로 해서, 프레이즈 성분 생성용의 생성 모델과 악센트 성분 생성용의 생성 모델의 학습을 행하는 스텝을 포함한다.
도 1은 비특허문헌 1에 의한 F0 패턴 생성 과정 모델의 개념을 나타내는 모식도이다.
도 2는 비특허문헌 2에 의한 음성 합성 시스템의 구성을 나타내는 블록도이다.
도 3은 본 발명의 제 1 및 제 2 실시형태에 있어서의 F0 패턴의 생성 과정을 모식적으로 나타내는 블록도이다.
도 4는 F0 패턴의 악센트 성분과 프레이즈 성분을 각각 타깃 포인트로 나타내고, 그것들을 합성하여 F0 패턴을 생성하는 방법을 나타내는 모식도이다.
도 5는 악센트 성분 및 프레이즈 성분의 타깃 포인트를 결정하기 위한 프로그램의 제어 구조를 나타내는 플로우차트이다.
도 6은 관측된 불연속 F0 패턴과, 이 패턴에 피팅시킨 연속 F0 패턴과 그것들을 나타내는 프레이즈 성분 및 악센트 성분을 나타내는 그래프이다.
도 7은 본 발명의 제 1 실시형태에 의한 음성 합성 시스템의 구성을 나타내는 블록도이다.
도 8은 생성된 F0 패턴에 대한 주관적 평가 테스트의 결과를 설명하기 위한 도면이다.
도 9는 본 발명의 제 2 실시형태에 의한 음성 합성 시스템의 구성의 블록도이다.
도 10은 본 발명의 실시형태를 실현하기 위한 컴퓨터 시스템의 외관도이다.
도 11은 도 10에 외관을 나타내는 컴퓨터 시스템의 컴퓨터의 하드웨어 구성을 나타내는 블록도이다.
도 2는 비특허문헌 2에 의한 음성 합성 시스템의 구성을 나타내는 블록도이다.
도 3은 본 발명의 제 1 및 제 2 실시형태에 있어서의 F0 패턴의 생성 과정을 모식적으로 나타내는 블록도이다.
도 4는 F0 패턴의 악센트 성분과 프레이즈 성분을 각각 타깃 포인트로 나타내고, 그것들을 합성하여 F0 패턴을 생성하는 방법을 나타내는 모식도이다.
도 5는 악센트 성분 및 프레이즈 성분의 타깃 포인트를 결정하기 위한 프로그램의 제어 구조를 나타내는 플로우차트이다.
도 6은 관측된 불연속 F0 패턴과, 이 패턴에 피팅시킨 연속 F0 패턴과 그것들을 나타내는 프레이즈 성분 및 악센트 성분을 나타내는 그래프이다.
도 7은 본 발명의 제 1 실시형태에 의한 음성 합성 시스템의 구성을 나타내는 블록도이다.
도 8은 생성된 F0 패턴에 대한 주관적 평가 테스트의 결과를 설명하기 위한 도면이다.
도 9는 본 발명의 제 2 실시형태에 의한 음성 합성 시스템의 구성의 블록도이다.
도 10은 본 발명의 실시형태를 실현하기 위한 컴퓨터 시스템의 외관도이다.
도 11은 도 10에 외관을 나타내는 컴퓨터 시스템의 컴퓨터의 하드웨어 구성을 나타내는 블록도이다.
이하의 설명 및 도면에서는 동일한 부품에는 동일한 참조번호를 붙이고 있다. 따라서, 그것들에 대한 상세한 설명은 반복되지 않는다. 또한, 이하의 실시형태에서는 F0 패턴 생성 모델로서 HMM을 이용하지만 모델은 HMM에만 한정되는 것은 아니다. 예를 들면, CART(Classification and Regression Tree) 모델링(L.Breiman, J.H.Friedman, R.A. Olshen and C.J.Stone, "Classification and Regression Trees", Wadsworth(1984)), Simulated annealing(어닐링법)에 의거한 모델링(S. Kirkpatrick, C.D. Gellatt, Jr., and M.P. Vecchi "Optimization by simulated annealing," IBM Thomas J. Watson Research Center, Yorktown Heights, NY, 1982.) 등을 이용할 수도 있다.
[기본적 개념]
도 3을 참조해서, 본원 발명의 기본적 개념은 이하와 같다. 최초로, 음성 말뭉치로부터 F0 패턴을 추출하여 관측 F0 패턴(130)을 작성한다. 이 관측 F0 패턴은 통상은 불연속이다. 이 불연속한 F0 패턴을 연속화·평활화시켜 연속 F0 패턴(132)을 생성한다. 여기까지는 선행기술을 이용하여 실현할 수 있다.
제 1 실시형태에서는 이 연속 F0 패턴(132)을 프레이즈 성분과 악센트 성분의 합성에 의해 피팅하고, 피팅 후의 F0 패턴(133)을 추정한다. 이 피팅 후의 F0 패턴(133)을 학습 데이터로 해서 비특허문헌 2와 마찬가지의 방법에 의해 HMM의 학습을 행하여 학습 후의 HMM 파라미터를 HMM 기억 장치(139)에 격납한다. F0 패턴(145)의 추정은 비특허문헌 2의 방법과 마찬가지로 행할 수 있다. 특성 벡터는, 여기에서는 0차를 포함하는 40개의 멜 켑스트럼 파라미터 및 F0의 대수, 그리고 그것들의 델타 및 델타 델타를 요소로서 포함한다.
한편, 제 2 실시형태에서는 얻어진 연속 F0 패턴(132)을 악센트 성분(134), 프레이즈 성분(136), 및 마이크로 프로소디 성분(이하, 「마이크로 성분」이라고도 부른다.)(138)으로 분해한다. 그리고, 이것들에 대하여 각각 HMM(140, 142 및 144)의 학습을 행한다. 단, 이때 이들 3개의 성분으로 시간 정보를 공유할 필요가 있다. 따라서, 후술하는 바와 같이 HMM(140, 142 및 144)의 학습에는 특성 벡터를 이들 3개의 HMM을 위한 멀티 스트림 형식으로 1개로 정리한 것을 사용한다. 사용하는 특성 벡터의 구성은 제 1 실시형태와 마찬가지이다.
음성 합성시에는 텍스트 해석의 결과를 이용하고, 악센트 성분의 HMM(140), 프레이즈 성분의 HMM(142), 및 마이크로 성분의 HMM(144)을 이용하여 개별적으로 F0 패턴의 악센트 성분(146), 프레이즈 성분(148), 및 마이크로 성분(150)을 생성한다. 이것들을 가산기(152)에 의해 가산함으로써 최종적인 F0 패턴(154)을 생성한다.
이 경우, 연속 F0 패턴을 악센트 성분, 및 프레이즈 성분, 또한 마이크로 성분으로 표현할 필요가 있다. 무엇보다도, 마이크로 성분은 F0 패턴으로부터 악센트 성분 및 프레이즈 성분을 제거한 것으로 생각할 수 있다. 따라서, 어떻게 해서 악센트 성분과 프레이즈 성분을 얻는지가 문제가 된다.
이 경우, 이러한 특징을 타깃 포인트라고 불리는 것으로 기술하는 것이 직절적으로 알기쉽다. 악센트 성분 및 프레이즈 성분 중 어느 경우에나 타깃 포인트에서의 기술이란 1개의 악센트 또는 프레이즈를 3개 또는 4개의 점으로 기술하는 방법이다. 4개의 점 중 2개는 저타깃, 나머지 1개 또는 2개의 점은 고타깃을 나타낸다. 이것들을 타깃 포인트라고 부른다. 고타깃이 2개인 경우, 모두 그 강도는 동일한 것으로 한다.
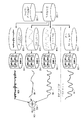
도 4를 참조해서, 예를 들면 관측 F0 패턴(170)으로부터 연속 F0 패턴(174)을 생성한다. 또한, 이 연속 F0 패턴(174)을 프레이즈 성분(220, 222)과 악센트 성분(200, 202, 204, 206, 208)으로 분할하고, 각각을 타깃 포인트로 기술한다. 이하, 악센트를 위한 타깃 포인트를 악센트 타깃이라고 부르고, 프레이즈를 위한 타깃 포인트를 프레이즈 타깃이라고 부른다. 연속 F0 패턴(174)은 프레이즈 성분(172) 상에 악센트 성분이 올려진 형태로 나타내어진다.
이와 같이 타깃 포인트로 악센트 성분 및 프레이즈 성분을 기술하는 것은 악센트 성분과 프레이즈 성분 사이의 비선형인 상호작용을 서로를 관계시켜서 정의함으로써 적절하게 처리하기 때문이다. 타깃 포인트를 F0 패턴으로부터 찾아내는 것은 비교적 용이하다. 타깃 포인트 사이의 F0의 전이는 푸아송 프로세스(비특허문헌 3)에 따른 내삽으로 나타낼 수 있다.
단, 악센트 성분과 프레이즈 성분 사이의 비선형인 상호작용을 처리하기 위해서는, 또한 이것들을 보다 높은 레벨에서 처리할 필요가 있다. 따라서, 여기에서는 F0 패턴을 2레벨의 기구에 의해 모델화한다. 제 1 레벨에서는 푸아송 프로세스를 이용한 기구에 의해 악센트 성분 및 프레이즈 성분을 생성한다. 또한, 제 2 레벨에서는 레저넌스를 이용한 기구에 의해 이것들을 합성하여 F0 패턴을 생성한다. 또한, 마이크로 성분은 최초로 얻어진 연속 F0 패턴으로부터 악센트 성분 및 프레이즈 성분을 제거한 것으로서 얻어진다.
<레저넌스를 이용한 F0 패턴의 분해>
F0은 성대의 진동으로부터 발생된다. F0 패턴을 조작하는데 있어서, 레저넌스 기구를 사용하는 것이 유효한 것이 알려져 있다. 여기에서는, 레저넌스를 이용한 매핑(비특허문헌 4)을 적용하고, 악센트 성분과 프레이즈 성분 사이의 잠재적 간섭을 토폴로지의 변환의 일종으로서 취급함으로써 처리한다.
λ(주파수비의 제곱)와 α(감쇠율에 관련된 각도) 사이의 레저넌스를 이용한 매핑(이하, λ=f(α)로 쓴다.)은 다음의 식(1)에 의해 정의된다.

이것은 레저넌스의 변환을 나타낸다. 설명을 간명하게 하기 위해서, α=f-1(λ)를 상기 매핑의 역매핑으로 한다. λ가 0 내지 1로 변화될 때, α의 값은 1/3 내지 0으로 감소한다.
최저 주파수(f0b)와 최고 주파수(f0t) 사이의 음성 주파수 범위의 임의의 F0을 f0로 한다. f0을 [0,1]의 구간으로 정규화한다.

그리고, 비특허문헌 4에 기재되어 있는 바와 같은 정육면체와 구 사이의 토폴로지적 변환을 f0에 적용한다. 구체적으로는 이하와 같다.

식 4는 lnf0의 시간축 상에서의 분해를 나타낸다. 보다 구체적으로는 αf0r은 프레이즈 성분(기준치로서 취급한다.)를 나타내고 φf0 | f0r은 악센트 성분을 나타낸다. 악센트 성분을 φf0 | f0r로 나타내고 프레이즈 성분을 αf0r로 나타내면, lnf0은 이하의 식(5)에 의해 계산할 수 있다.

따라서, 레저넌스를 이용한 기구를 사용하여 악센트 성분과 프레이즈 성분 사이의 비선형인 간섭을 처리하고, 통합하여 F0 패턴을 얻을 수 있다.
<레저넌스를 이용한 F0 중첩 모델>
F0 패턴을 시간(t)의 함수로서 나타내는 모델은 대수 표현에서는 레저넌스에 의한 프레이즈 성분 Cp(t) 상으로의 악센트 성분 Ca(t)의 중첩으로서 표현할 수 있다.


발화의 F0 패턴을 나타내는 모델 파라미터는 이하와 같다.

식(7) 중에 「10」이라고 하는 정수 계수가 있지만, 이것은 Ca(t)의 값을 α의 영역(0, 1/3) 내에 포함되도록 하기 위한 것이다.
프레이즈 타깃 γpi는 대수 표현에서 [f0b, f0t]의 범위의 F0에 의해 정의된다. 악센트 타깃 γai는 0.5를 제로점으로 해서 (0, 1.5)의 범위로 나타내어진다. 악센트 타깃 γai<0.5이면 악센트 성분은 프레이즈 성분에 파고들어(프레이즈 성분의 일부를 제거하고), 자연 발화에서 관측되는 바와 같이 F0 패턴의 말미를 끌어내린다. 즉, 악센트 성분은 프레이즈 성분에 중첩되지만, 그 때 악센트 성분에 의해 프레이즈 성분의 일부가 제거되는 것이 허용된다.
<F0 중첩 모델의 모델 파라미터의 추정>
악센트적 프레이즈 경계에 관한 정보가 주어진 것으로서, 일본어의 발화에 대하여 관측된 F0 패턴으로부터 타깃 포인트의 파라미터(타깃 파라미터)를 추정하기 위한 알고리즘을 개발했다. 파라미터(f0b 및 f0t)를 관측된 F0 패턴의 집합의 F0 범위와 일치시킨다. 일본어에서는 악센트적 프레이즈는 악센트(악센트 타입 0, 1, 2, ...)를 갖는다. 이 알고리즘은 이하와 같은 것이다.
도 5는 플로우차트 형식으로 나타낸 제어 구조의 프로그램이며, 도 3에 나타내는 관측 F0 패턴(130)으로부터 F0 패턴을 추출하는 처리, 추출된 F0 패턴을 평활화·연속화해서 연속 F0 패턴(132)을 생성하는 처리, 연속 F0 패턴(132)을 모두 타깃 포인트로 나타낸 프레이즈 성분 및 악센트 성분의 합으로 나타내기 위한 타깃 파라미터의 추정과, 추정된 타깃 파라미터에 의해 연속 F0 패턴(132)에 피팅한 F0 패턴(133)의 생성을 실행하는 처리를 행하는 기능을 갖는다.
도 5를 참조해서, 이 프로그램은 관측된 불연속한 F0 패턴을 평활화하고, 연속화해서 연속 F0 패턴을 출력하는 스텝(340)과, 스텝(340)에서 출력된 연속 F0 패턴을 N개의 그룹으로 분할하는 스텝(342)을 포함한다. 여기서, N은 미리 지정되는 임의의 양의 정수(예를 들면, N=2, N=3 등)이다. 분할되는 그룹의 각각은 호기 단락에 상당한다. 이하에 설명하는 실시형태에서는 긴 윈도우 폭을 이용하여 연속 F0 패턴을 평활화하고, F0 패턴이 곡부가 되는 개소를 지정된 개수만큼 검출하고, 거기에서 F0 패턴을 분할한다.
이 프로그램은 또한, 반복 제어 변수 k에 0을 대입하는 스텝(344)과, 프레이즈 성분 P를 초기화하는 스텝(346)과, 프레이즈 성분 P 및 악센트 성분 A와 연속 F0 패턴의 오차를 최소화하도록 악센트 성분 A의 타깃 파라미터 및 프레이즈 성분 P의 타깃 파라미터를 추정하는 스텝(348)과, 스텝(348) 후 반복 제어 변수 k에 1을 가산하는 스텝(354)과, 변수 k의 값이 미리 정해진 반복수 n보다 작은지의 여부를 판정하고, 판정이 YES인 경우에 제어의 흐름을 스텝(346)으로 되돌리는 스텝(356)과, 스텝(356)의 판정이 NO인 경우에 스텝(346)~스텝(356)의 반복에 의해 얻은 악센트의 타깃 파라미터를 최적화하고, 최적화 후의 악센트 타깃 및 프레이즈 타깃을 출력하는 스텝(358)을 포함한다. 이것들에 의해 나타내어지는 F0 패턴과 원래의 연속 F0 패턴의 오차가 마이크로 프로소디 성분에 상당한다.
스텝(348)은 악센트의 타깃 파라미터를 추정하는 스텝(350)과, 스텝(350)에서 추정된 악센트의 타깃 파라미터를 이용하여 프레이즈 성분 P의 타깃 파라미터를 추정하는 스텝(352)을 포함한다.
상기한 알고리즘의 상세는 이하와 같은 것이다. 도 5를 참조하면서 설명한다.
(A) 전처리
F0 패턴을 f0r=f0b로 해서 φf0|f0r로 변환하고, 2개의 윈도우 사이즈(단기: 10포인트, 장기: 80포인트)로 함께 평활화하고(스텝(340)), 전체적인 상승-(플랫)-하강이라고 하는 일본어 악센트의 특징을 고려하여 마이크로 프로소디의 영향을 제거한다(음소 세그먼트를 이용하여 F0을 변경한다). 평활화된 F0 패턴을 파라미터 추출을 위해서 식(5)을 이용하여 F0으로 되돌린다.
(B) 파라미터 추출
포즈 사이의 세그먼트에서 0.3초보다 긴 것을 호기 단락으로 간주하고, 호기 단락을 또한 장기 윈도우에서 평활화한 F0 패턴을 이용하여 N개의 단락으로 분할한다(스텝(342)). 이하의 처리를 각 그룹에 대하여 적용한다. 이 때, F0 오차의 절대값을 최소화한다고 하는 기준을 이용한다. 이하, 스텝(348)을 반복해서 실행하기 위하여 반복해서 제어 변수 k를 0으로 설정한다(스텝(344)). (a) 초기값으로서 2개의 저타깃 포인트와 1개의 고타깃 포인트를 갖는 3타깃 포인트의 프레이즈 성분 P를 준비한다(스텝(346)). 이 프레이즈 성분 P는, 예를 들면 도 4의 최하부에 있는 프레이즈 성분 P의 그래프의 좌반분과 마찬가지의 형상이다. 이 고타깃 포인트의 타이밍을 제 2 모라의 개시시에 맞춰서 1번째의 저타깃 포인트를 0.3초만큼 빠르게 앞당긴다. 또한, 2번째의 저타깃 포인트의 타이밍을 호기 단락의 말미에 일치시킨다. 프레이즈 타깃의 강도 γpi의 초기값은 장기 윈도우를 이용하여 평활화한 F0 패턴을 이용하여 결정한다.
다음의 스텝(348)에서는 (b) 식(4)에 의해서 평활화된 F0 패턴과 현재의 프레이즈 성분 P를 이용하여 악센트 성분 A을 계산한다. 또한, 현재의 악센트 성분 A로부터 악센트의 타깃 포인트를 추정한다. (c) γai를 모든 고타깃 포인트에 대하여 [0.9, 1.1]의 범위로 되도록, 모든 저타깃 포인트에 대하여 [0.4, 0.6]의 범위로 되도록 조정하고, 조정된 타깃 포인트를 이용하여 악센트 성분 A를 재계산한다(스텝(350)). (d) 현재의 악센트 성분 A를 계산에 넣어서 프레이즈 타깃을 다시 추정한다(스텝(352)). (e) 미리 정해진 횟수에 도달할 때까지 (b)로 되돌리는 것을 반복하기 위해서, 변수 k에 1을 가산한다(스텝(354). (f) 고프레이즈 타깃 포인트를 삽입함으로써 생성된 F0 패턴과 평활화된 F0 패턴 사이의 오차의 감소량이 소정 임계값보다 커진다면, 고프레이즈 타깃 포인트를 삽입하고 (b)로 되돌아간다. 상기 (b)로 되돌아가야하는지의 여부를 판정하기 위해서 스텝(354)에서 변수 k에 1을 가산한다. 변수 k의 값이 n에 도달하고 있지 않으면 제어를 스텝(346)으로 되돌린다. 이 처리에 의해, 예를 들면 도 4 하단의 우반분과 같은 프레이즈 성분 P가 얻어진다. 변수 k의 값이 n에 도달하고 있으면, 스텝(358)에서 악센트 파라미터의 최적화가 행해진다.
(C) 파라미터의 최적화(스텝(358))
추정된 프레이즈 성분 P를 전제로 생성된 F0 패턴과 관측된 F0 패턴 사이의 오차를 최소화하도록 악센트의 타깃 포인트를 최적화한다. 이 결과, 평활화된 F0 패턴에 피팅하는 바와 같은 F0 패턴을 생성할 수 있는 프레이즈 성분 P 및 악센트 성분 A의 타깃 포인트가 얻어진다.
이미 상술한 바와 같이, 평활화된 F0 패턴과 프레이즈 성분 P 및 악센트 성분 A로부터 생성된 F0 패턴의 차에 상당하는 부분으로부터 마이크로 프로소디 성분 M이 얻어진다.
도 6에, 텍스트를 해석한 결과에 따라서 프레이즈 성분 P와 악센트 성분 A를 합성하여 관측된 F0 패턴에 F0 패턴을 피팅시키는 예를 나타낸다. 도 6에는 2개의 케이스를 겹쳐서 나타내고 있다. 도 6에 있어서, 목표가 되는 F0 패턴(240)(관측된 F0 패턴)을 기호 「+」의 열로 나타내고 있다.
도 6에 나타내는 제 1 케이스는 파선으로 나타내어지는 프레이즈 성분(242)에 마찬가지로 파선으로 나타내어지는 악센트 성분(250)을 합성함으로써 피팅된 F0 패턴(246)을 얻는 것이다. 제 2 케이스는 세선으로 나타내어지는 프레이즈 성분(244)에 마찬가지로 세선으로 나타내어지는 악센트 성분(252)을 합성함으로써 F0 패턴(246)을 얻는 것이다.
도 6에 나타내는 바와 같이, 악센트 성분(250)과 악센트 성분(252)은 거의 일치하고 있지만, 최초의 악센트 요소의 고타깃 포인트와 후방측의 저타깃 포인트의 위치가 악센트 성분(252)에 비해서 낮아져 있다.
프레이즈 성분(242)과 악센트 성분(250)을 조합하는 경우와, 프레이즈 성분(244)과 악센트 성분(252)을 조합하는 경우의 상위는 주로 텍스트 해석의 결과에 따른다. 텍스트 해석의 결과, 호기 단락이 2개로 된 경우에는 프레이즈 성분으로서 2개의 프레이즈로 이루어지는 프레이즈 성분(242)을 채용하고, 일본어의 악센트 패턴에 의해 얻은 악센트 성분(252)과 합성한다. 텍스트 해석의 결과, 호기 단락이 3개로 된 경우에는 프레이즈 성분(244)과 악센트 성분(250)을 합성한다.
도 6에 나타내는 예에서는 프레이즈 성분(242)도 프레이즈 성분(244)도 3개째의 악센트 요소와 4개째의 악센트 요소 사이에 프레이즈 경계가 있다. 한편, 텍스트 해석의 결과, 세로선(254)으로 나타내어지는 위치에 3번째의 프레이즈 경계가 있는 것으로 한다. 이 경우에는 프레이즈 성분(244)이 채용된다. 또한, 세로선(254)으로 나타내어지는 위치에서의 F0 패턴의 곡부를 나타내기 위해서, 악센트 성분(250)과 같이 이 위치의 직전에 위치하는 악센트 요소의 고타깃 포인트와 후방측의 저타깃 포인트를 끌어내린다. 이렇게 함으로써, 텍스트 해석의 결과 3개의 프레이즈가 존재하는 경우라도, F0 패턴을 정확도 좋게 텍스트 해석의 결과에 맞추어 피팅할 수 있다. 이것은 이 알고리즘에 의하면, 발화의 구성과 악센트 타입에 의해 발화의 기초를 이루는 언어학적 정보가 나타내어지고, 또한 언어학적 정보와 F0 패턴의 대응관계가 명확해지게 된다.
[제 1 실시형태]
<구성>
도 7을 참조해서, 제 1 실시형태에 의한 F0 패턴 합성부(359)는 음성 말뭉치에 포함되는 다수의 음성 신호의 각각으로부터 관측된 관측 F0 패턴(130)을 평활화·연속화해서 얻은 연속 F0 패턴(132)에 대하여 소여의 악센트 경계에 의거해서 상기한 원리에 따라 프레이즈 성분 P를 규정하는 타깃 포인트 및 악센트 성분 A를 규정하는 타깃 파라미터를 추정하는 파라미터 추정부(366)와, 파라미터 추정부(366)에 의해 추정된 프레이즈 성분 P와 악센트 성분 A를 합성함으로써 연속 F0 패턴에 피팅한 피팅 후의 F0 패턴을 생성하는 F0 패턴 피팅부(368)와, 피팅 후의 F0 패턴을 이용하여 종래와 마찬가지로 HMM의 학습을 행하는 HMM 학습부(369)와, 학습 후의 HMM 파라미터를 기억하는 HMM 기억 장치(370)를 포함한다. HMM 기억 장치(370)에 기억된 HMM을 이용하여 F0 패턴(372)을 합성하는 처리는 도 2에 나타내는 음성 합성부(82)와 마찬가지의 장치에 의해 실현할 수 있다.
<동작>
도 7을 참조해서, 제 1 실시형태의 시스템은 이하와 같이 동작한다. 관측 F0 패턴(130)의 각각에 대하여 평활화·연속화함으로써 연속 F0 패턴(132)을 얻는다. 파라미터 추정부(366)는 이 연속 F0 패턴(132)을 프레이즈 성분 P와 악센트 성분 A로 분해하고, 각각의 타깃 파라미터를 상기한 방법으로 추정한다. F0 패턴 피팅부(368)는 추정된 타깃 파라미터에 의해 표현되는 프레이즈 성분 P와 악센트 성분 A를 합성하여 관측 F0 패턴에 피팅한 피팅 후의 F0 패턴을 얻는다. 이 시스템은 이러한 동작을 관측 F0 패턴(130)의 각각에 대하여 행한다.
HMM 학습부(369)는 이렇게 얻어진 다수의 피팅 후의 F0 패턴을 이용하여 종래와 마찬가지의 방법에 의해 HMM의 학습을 행한다. HMM 기억 장치(370)는 학습 후의 HMM의 파라미터를 기억한다. HMM의 학습이 종료된 후에는 종래와 마찬가지로 텍스트가 주어지면, 이 텍스트를 해석하고 그 결과에 따라서 HMM 기억 장치(370)에 기억된 HMM을 이용하여 F0 패턴(372)을 합성한다. 이 F0 패턴(372)과 텍스트의 음소에 맞추어서 선택된 멜 켑스트럼 등의 음성 파라미터열을 사용함으로써 종래와 마찬가지의 방법으로 음성 신호를 얻을 수 있다.
<제 1 실시형태의 효과>
상기 제 1 실시형태에 의해 HMM의 학습을 행하고, 학습 후의 HMM을 사용하여 합성한 F0 패턴을 이용하여 합성한 음성에 대하여 주관적인 평가(선호 평가) 테스트를 행했다.
이 평가 테스트의 실험은 출원인이 작성하고, 공개한 음성 말뭉치 ATR503set에 포함되는 503 발화를 이용하여 행했다. 503 발화 중, 490 발화를 HMM의 학습에 이용하고, 나머지를 테스트에 사용했다. 발화 신호는 16kHz의 샘플링 레이트로 샘플링하고, 5밀리초의 프레임 시프트에 따른 STRAIGHT 분석에서 스펙트럼 포락을 추출했다. 특성 벡터는 제 0차를 포함하는 40개의 멜 켑스트럼 파라미터, logF0, 및 그것들의 델타 및 델타 델타로 이루어진다. 5스테이트의 왼쪽에서부터 오른쪽으로의 일방향 HMM 모델 토폴로지를 사용했다.
HMM 학습을 위해서, 이하의 4개의 F0 패턴을 준비했다.
(1) 음성 파형으로부터 얻은 F0 패턴(오리지널)
(2) 실시형태 1에 의해 생성된 F0 패턴(Proposed)
(3) 유성 부분은 오리지널, 무성 부분은 실시형태 1의 방법에 의해 생성된 F0 패턴(Prop.+MP(Micro-prosody))
(4) 유성 부분은 오리지널, 무성 부분은 스플라인에 의한 내삽을 사용한 F0 패턴(Spl+MP)
상기한 4개의 패턴 중, (2)~(4)는 연속 F0 패턴이다. (2)는 마이크로 프로소디도 포함하고 F0 추출 오차도 포함하지만, (3) 및 (4)는 양자를 포함하는 점에 주의가 필요하다.
오리지널은 종래의 기술과 마찬가지로, MSD-HMM을 이용하여 학습했다. (2)~(4)는 연속 F0 패턴(및 그 델타 및 델타 델타)을 5번째의 스트림에 추가하고, 그 무게를 0으로 해서 MSD-HMM의 학습을 행했다. 따라서, (2)~(4)에 대해서는 모두 연속 F0 패턴이 얻어졌다.
음성 합성시에는 최초에 연속 F0 패턴 HMM을 이용하여 연속 F0 패턴을 합성하고, 또한 MSD-HMM을 이용하여 유성·무성의 판정을 행했다.
선호 평가 테스트에서는, 위와 같이 해서 얻어진 4개의 F0 패턴에서부터 F0 패턴의 조합 등을 4가지 선택하고, 그것들에 의해 생성된 음성 신호 중 어느 것이 보다 자연스러운지를 5인의 피험자에 의해 판정시켰다. 이들 피험자는 모두 일본어를 모국어로 한다. 4개의 패턴쌍은 이하와 같다.
(1) Proposed 대 오리지널
(2) Proposed 대 Prop+MP
(3) Proposed 대 Spl+MP
(4) Prop+MP 대 Spl+MP
학습에 사용하지 않았던 9문장을 이용하여 각 피험자에 의한 평가를 행했다. 9개의 wave 파일의 쌍을 복제하고, 각각의 버전에서 각 쌍의 Wave 파일의 순서를 교체했다. 이렇게 해서 얻은 72쌍(4×9×2)의 wave 파일쌍을 각 피험자에 대하여 랜덤한 순서로 제시하고, 어느 쪽을 선호하는지, 또는 어느 쪽도 선호하지 않는지를 대답하게 했다.
이 피험자에 의한 평가의 결과를 도 8에 나타낸다. 도 8로부터 명확한 바와 같이 Proposed 방법에 의해 합성된 F0 패턴을 사용한 합성 음성은 관측된 F0 패턴을 사용한 합성 음성보다 바람직했다(Proposed 대 오리지널). Proposed에 마이크로 프로소디를 추가해도, 발화의 자연스러움에 개선은 얻어지지 않는다(Proposed 대 Prop+MP). 스플라인 내삽에 의해 얻은 연속 F0 패턴에 의한 합성 음성과 비교해도 Proposed의 음성이 좋아지는 빈도가 높다(Proposed 대 Spl +MP). 최후의 2개의 결과는 Prop+MP 대 Spl+MP의 결과로부터도 확인할 수 있었다.
[제 2 실시형태]
제 1 실시형태에서는 프레이즈 성분 P 및 악센트 성분 A를 타깃 포인트로 나타내고, 그것들을 합성함으로써 F0 패턴을 피팅하고 있다. 그러나, 타깃 포인트를 사용하는 아이디어는 이 제 1 실시형태에 한정되는 것은 아니다. 제 2 실시형태는 위에 설명한 방법에 의해서 관측된 F0 패턴을 프레이즈 성분 P, 악센트 성분 A 및 마이크로 프로소디 성분 M으로 분리하고, 그것들의 시간 변화 패턴에 대하여 각각 HMM 학습을 행한다. F0 생성시에는 학습 완료의 HMM을 이용하여 프레이즈 성분 P, 악센트 성분 A 및 마이크로 프로소디 성분 M의 시간 변화 패턴을 얻고, 또한 그것들을 합성함으로써 F0 패턴을 추정한다.
<구성>
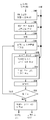
도 9를 참조해서, 이 실시형태에 의한 음성 합성 시스템(270)은 음성 합성을 위한 HMM의 학습을 행하는 모델 학습부(280)와, 모델 학습부(280)에 의해서 학습을 행했던 HMM을 이용하여 텍스트가 입력되면 그 음성을 합성하여 합성 음성 신호(284)로서 출력하는 음성 합성부(282)를 포함한다.
모델 학습부(280)는 도 2에 나타내는 종래의 음성 합성 시스템(70)의 모델 학습부(80)와 마찬가지로, 음성 말뭉치 기억 장치(90), F0 추출부(92), 및 스펙트럼 파라미터 추출부(94)를 갖는다. 단, 모델 학습부(280)는 모델 학습부(80)의 HMM 학습부(96) 대신에 F0 추출부(92)가 출력하는 불연속한 F0 패턴(93)을 평활화하고, 연속화해서 연속 F0 패턴(291)을 출력하는 F0 평활화부(290)와, F0 평활화부(290)가 출력하는 연속한 F0 패턴을 프레이즈 성분 P, 악센트 성분 A, 및 마이크로 프로소디 성분 M으로 분리하고, 각 성분 각각의 시간 변화 패턴을 생성하여 유성/무성 정보를 포함하는 불연속한 F0 패턴(93)과 함께 출력하는 F0 분리부(292)를 갖는다. 또한, 모델 학습부(280)는 스펙트럼 파라미터 추출부(94)가 출력하는 멜 켑스트럼 파라미터(95)와, F0 분리부(292)의 출력으로 이루어지는 멀티 스트림 형식의 HMM 학습 데이터 벡터(293)(0차를 포함하는 40개의 멜 켑스트럼 파라미터 및 상기 F0의 3성분의 시간 변화 패턴, 및 그것들의 델타 및 델타 델타)로부터 음성 말뭉치 기억 장치(90)로부터 판독된 학습 데이터 벡터(293)에 대응하는 음소의 콘텍스트 라벨에 의거해서 HMM의 통계적인 학습을 행하는 HMM 학습부(294)를 포함한다.
음성 합성부(282)는 HMM 학습부(294)에 의해 학습이 행해진 HMM을 기억하는 HMM 기억 장치(310)와, 도 2에 나타내는 것과 같은 텍스트 해석부(112)와, 텍스트 해석부(112)로부터 주어진 콘텍스트 라벨열에 대하여, HMM 기억 장치(310)에 기억된 HMM을 이용하여 가장 적절한(라벨열의 시초가 된 음성일 확률이 높다) 프레이즈 성분 P, 악센트 성분 A, 및 마이크로 프로소디 성분 M의 시간 변화 패턴, 및 멜 켑스트럼 파라미터를 추정하여 출력하는 파라미터 생성부(312)와, 파라미터 생성부(312)에 의해 출력된 프레이즈 성분 P, 악센트 성분 A, 및 마이크로 프로소디 성분 M의 시간 변화 패턴을 합성함으로써 F0 패턴을 생성하여 출력하는 F0 패턴 합성부(314)와, 파라미터 생성부(312)가 출력하는 멜 켑스트럼 파라미터와, F0 패턴 합성부(314)가 출력하는 F0 패턴으로부터 음성을 합성하는 도 2에 나타내는 것과 같은 음성 합성기(116)를 포함한다.
도 9에 나타내는 F0 평활화부(290), F0 분리부(292) 및 HMM 학습부(294)를 실현하기 위한 컴퓨터 프로그램의 제어 구조는 도 5에 나타낸 것과 마찬가지이다.
<동작>
음성 합성 시스템(270)은 이하와 같이 동작한다. 음성 말뭉치 기억 장치(90)에는 대량의 발화 신호가 기억되어 있다. 발화 신호는 프레임 단위로 기억되어 있으며, 각 음소에 대하여 음소의 콘텍스트 라벨이 부착되어 있다. F0 추출부(92)는 각 발화의 발화 신호로부터 불연속한 F0 패턴(93)을 출력한다. F0 평활화부(290)는 불연속한 F0 패턴(93)을 평활화하고, 연속 F0 패턴(291)을 출력한다. F0 분리부(292)는 연속 F0 패턴(291)과 F0 추출부(92)가 출력하는 불연속한 F0 패턴(93)을 받아서, 상술한 방법에 따라서 각 프레임에 대하여 프레이즈 성분 P의 시간 변화 패턴, 악센트 성분 A의 시간 변화 패턴, 마이크로 프로소디 성분 M의 시간 변화 패턴, 불연속한 F0 패턴(93)으로부터 얻어지는, 각 프레임이 유성 구간인지 무성 구간인지를 나타내는 정보 F0(U/V) 및 스펙트럼 파라미터 추출부(94)가 각 발화의 음성 신호의 각 프레임에 대하여 산출한 멜 켑스트럼 파라미터로 이루어지는 학습 데이터 벡터(293)를 HMM 학습부(294)에 준다.
HMM 학습부(294)는 각 발화의 음성 신호의 각 프레임에 대하여, 음성 말뭉치 기억 장치(90)로부터 판독한 라벨과, F0 분리부(292)로부터 주어지는 학습 데이터 벡터(293)와, 스펙트럼 파라미터 추출부(94)로부터의 멜 켑스트럼 파라미터로부터, 상술한 구성의 특성 벡터를 학습 데이터로 하고, 추정 대상의 프레임의 콘텍스트 라벨이 주어지면 그 프레임의 프레이즈 성분 P, 악센트 성분 A, 및 마이크로 프로소디 성분 M의 시간 변화 패턴과 멜 켑스트럼 파라미터의 값의 확률을 출력하도록 통계적인 HMM의 학습을 행한다. 음성 말뭉치 기억 장치(90)의 모든 발화에 대하여 HMM의 학습이 완료되면, 그 HMM의 파라미터는 HMM 기억 장치(310)에 격납된다.
음성 합성의 대상이 되는 텍스트가 부여되면 음성 합성부(282)는 이하와 같이 동작한다. 텍스트 해석부(112)는 주어진 텍스트를 해석하고, 합성해야할 음성을 나타내는 콘텍스트 라벨열을 생성하고, 파라미터 생성부(312)에 준다. 파라미터 생성부(312)는 이 라벨열에 포함되는 라벨의 각각에 대하여, HMM 기억 장치(310)를 참조함으로써, 그 라벨열에 대하여 그러한 라벨열을 생성하는 음성일 확률이 가장 높은 파라미터열(프레이즈 성분 P, 악센트 성분 A, 및 마이크로 프로소디 성분 M의 시간 변화 패턴, 및 멜 켑스트럼 파라미터)을 생성하고, 프레이즈 성분 P, 악센트 성분 A, 및 마이크로 프로소디 성분 M은 F0 패턴 합성부(314)에, 멜 켑스트럼 파라미터는 음성 합성기(116)에 각각 준다.
F0 패턴 합성부(314)는 프레이즈 성분 P, 악센트 성분 A, 마이크로 프로소디 성분 M의 시간 변화 패턴을 합성하여 F0 패턴으로서 음성 합성기(116)에 준다. 또한, 본 실시형태에서는 HMM의 학습시에는 프레이즈 성분 P, 악센트 성분 A, 및 마이크로 프로소디 성분 M은 모두 대수로 표현하고 있다. 따라서, F0 패턴 합성부(314)의 합성에서는 이것들을 대수 표현으로부터 통상의 주파수 성분으로 변환한 후, 서로 가산하면 된다. 이 때, 학습시에 각 성분의 제로점을 이동시키고 있으므로 제로점을 원래대로 되돌리는 조작도 필요하다.
음성 합성기(116)는 F0 패턴 합성부(314)로부터 출력되는 F0 패턴에 따른 음성 신호를 합성하고, 또한 그것을 파라미터 생성부(312)로부터 주어지는 멜 켑스트럼 파라미터에 따라서 변조하는 것에 상당하는 신호 처리를 행하여 합성 음성 신호(284)를 출력한다.
<제 2 실시형태의 효과>
이 제 2 실시형태에서는 F0 패턴을 프레이즈 성분 P, 악센트 성분 A, 및 마이크로 프로소디 성분 M으로 분해하고, 그것들을 이용하여 각각의 HMM의 학습을 행한다. 음성 합성시에는 텍스트 해석의 결과에 의거해, 이것들 HMM을 이용하여 프레이즈 성분 P, 악센트 성분 A, 및 마이크로 프로소디 성분 M를 각각 생성한다. 또한, 생성된 프레이즈 성분 P, 악센트 성분 A, 및 마이크로 프로소디 성분 M을 합성함으로써 F0 패턴을 생성할 수 있다. 이렇게 해서 얻어진 F0 패턴을 이용하면 제 1 실시형태와 마찬가지로 자연적인 발화를 얻을 수 있다. 또한, 악센트 성분 A와 F0 패턴의 대응관계가 명확하므로, 특정의 단어에 대하여 악센트 성분 A의 범위를 크게 함으로써, 상기 단어에 초점을 두거나 하는 것이 용이하게 행해진다. 이것은, 예를 들면 도 6의 악센트 성분(250)에 있어서 세로선(254)의 직전의 성분에 관해서 주파수를 내리는 조작, 및 도 6의 악센트 성분(250 및 252)에 있어서 말미의 F0 패턴의 주파수를 떨어뜨리는 조작으로부터도 알 수 있다.
[컴퓨터에 의해 실현]
상기 제 1 실시형태 및 제 2 실시형태에 의한 F0 패턴 합성부는 모두 컴퓨터 하드웨어와 그 컴퓨터 하드웨어 상에서 실행되는 컴퓨터 프로그램에 의해 실현할 수 있다. 도 10은 이 컴퓨터 시스템(530)의 외관을 나타내고, 도 11은 컴퓨터 시스템(530)의 내부 구성을 나타낸다.
도 10을 참조해서, 이 컴퓨터 시스템(530)은 메모리 포트(552) 및 DVD(Digital Versatile Disc) 드라이브(550)를 갖는 컴퓨터(540)와, 키보드(546)와, 마우스(548)와, 모니터(542)를 포함한다.
도 11을 참조해서, 컴퓨터(540)는 메모리 포트(552) 및 DVD 드라이브(550)에 추가하여, CPU(중앙 처리 장치)(556)와, CPU(556), 메모리 포트(552) 및 DVD 드라이브(550)에 접속된 버스(566)와, 부트 프로그램 등을 기억하는 판독 전용 메모리(ROM)(558)와, 버스(566)에 접속되고, 프로그램 명령, 시스템 프로그램 및 작업 데이터 등을 기억하는 랜덤 액세스 메모리(RAM)(560)와, 하드 디스크(554)를 포함한다. 컴퓨터 시스템(530)은 또한, 다른 단말과의 통신을 가능하게 하는 네트워크(568)로의 접속을 제공하는 네트워크 인터페이스(I/F)(544)를 포함한다.
컴퓨터 시스템(530)을 상기한 실시형태에 의한 F0 패턴 생성 합성부의 각 기능부로서 기능시키기 위한 컴퓨터 프로그램은 DVD 드라이브(550) 또는 메모리 포트(552)에 장착되는 DVD(562) 또는 리무버블 메모리(564)에 기억되고, 또한 하드 디스크(554)에 전송된다. 또는, 프로그램은 네트워크(568)를 통해서 컴퓨터(540)에 송신되어 하드 디스크(554)에 기억되어도 좋다. 프로그램은 실행시에 RAM(560)에 로드된다. DVD(562)로부터, 리무버블 메모리(564)로부터 또는 네트워크(568)를 통해서 직접 RAM(560)에 프로그램을 로딩해도 좋다.
이 프로그램은 컴퓨터(540)를 상기 실시형태에 의한 F0 패턴 합성부의 각 기능부로서 기능시키기 위한 복수의 명령으로 이루어지는 명령열을 포함한다. 컴퓨터(540)에 이 동작을 행하게 하는데에 필요한 기본적 기능 중 일부는 컴퓨터(540) 상에서 동작하는 오퍼레이팅 시스템 또는 써드 파티의 프로그램, 또는 컴퓨터(540)에 설치되는 각종 프로그래밍 툴 키트 또는 프로그래밍 라이브러리에 의해 제공된다. 따라서, 이 프로그램 자체는 이 실시형태의 시스템 및 방법을 실현하는데 필요한 기능 모두를 반드시 포함하지 않아도 된다. 이 프로그램은 명령 중, 소망의 결과가 얻어지도록 제어된 방식으로 적절한 기능 또는 프로그래밍 툴 키트 또는 프로그램 라이브러리 내의 적절한 프로그램을 실행시에 동적으로 호출함으로써, 상기한 시스템으로서의 기능을 실현하는 명령만을 포함하고 있으면 된다. 물론, 프로그램만으로 필요한 기능을 모두 제공하도록 해도 좋다.
금회 개시된 실시형태는 단지 예시로서, 본 발명은 상기한 실시형태에만 제한되는 것은 아니다. 본 발명의 범위는 발명의 상세한 설명의 기재를 참작하면서 청구의 범위의 각 청구항에 의해서 나타내어지고, 그것에 기재된 문언과 균등의 의미 및 범위 내에서의 모든 변경을 포함한다.
(산업상 이용가능성)
본 발명은 음성 합성을 이용한 서비스의 제공, 및 음성 합성을 이용한 장치의 제조에 이용할 수 있다.
30: F0 패턴 생성 과정 모델
40: 프레이즈 커맨드
42: 프레이즈 제어 기구
44: 악센트 커맨드
46: 악센트 제어 기구
48, 152: 가산기
50: F0 패턴
70, 270: 음성 합성 시스템
80, 280: 모델 학습부
82, 282: 음성 합성부
90: 음성 말뭉치 기억 장치
92: F0 추출부
93: 불연속한 F0 패턴
94: 스펙트럼 파라미터 추출부
95: 멜 켑스트럼 파라미터
96, 294, 369: HMM 학습부
110, 310, 139, 370: HMM 기억 장치
112: 텍스트 해석부
114: 파라미터 생성부
116: 음성 합성기
130, 170: 관측 F0 패턴
132, 174, 291: 연속 F0 패턴
134, 146, 200, 202, 204, 206, 208, 250, 252: 악센트 성분
136, 148, 220, 222, 242, 244: 프레이즈 성분
138, 150: 마이크로 프로소디 성분
140, 142, 144: HMM
48, 152: 가산기
154, 240, 246: F0 패턴
172: 프레이즈 성분
290: F0 평활화부
292: F0 분리부
293: 학습 데이터 벡터
312: 파라미터 생성부
314, 359: F0 패턴 합성부
366: 파라미터 추정부
368: F0 패턴 피팅부
40: 프레이즈 커맨드
42: 프레이즈 제어 기구
44: 악센트 커맨드
46: 악센트 제어 기구
48, 152: 가산기
50: F0 패턴
70, 270: 음성 합성 시스템
80, 280: 모델 학습부
82, 282: 음성 합성부
90: 음성 말뭉치 기억 장치
92: F0 추출부
93: 불연속한 F0 패턴
94: 스펙트럼 파라미터 추출부
95: 멜 켑스트럼 파라미터
96, 294, 369: HMM 학습부
110, 310, 139, 370: HMM 기억 장치
112: 텍스트 해석부
114: 파라미터 생성부
116: 음성 합성기
130, 170: 관측 F0 패턴
132, 174, 291: 연속 F0 패턴
134, 146, 200, 202, 204, 206, 208, 250, 252: 악센트 성분
136, 148, 220, 222, 242, 244: 프레이즈 성분
138, 150: 마이크로 프로소디 성분
140, 142, 144: HMM
48, 152: 가산기
154, 240, 246: F0 패턴
172: 프레이즈 성분
290: F0 평활화부
292: F0 분리부
293: 학습 데이터 벡터
312: 파라미터 생성부
314, 359: F0 패턴 합성부
366: 파라미터 추정부
368: F0 패턴 피팅부
Claims (8)
- 텍스트 해석에 의해 얻어진 발화의 악센트구에 대하여, 소여의 수의 타깃 포인트를 이용하여 F0 패턴의 악센트 성분을 생성하는 수단과,
발화의 구조를 포함하는 언어 정보에 따라서 발화를 1개 이상의 악센트구를 포함하는 그룹으로 나눔으로써, 한정된 수의 타깃 포인트를 이용하여 F0 패턴의 프레이즈 성분을 생성하는 수단과,
상기 악센트 성분과 상기 프레이즈 성분에 의거해서 F0 패턴을 생성하는 수단을 포함하는 것을 특징으로 하는 정량적 F0 패턴 생성 장치. - 텍스트 해석에 의해 얻어진 발화의 악센트구에 대하여, 소여의 수의 타깃 포인트를 이용하여 F0 패턴의 악센트 성분을 생성하는 스텝과,
발화의 구조를 포함하는 언어 정보에 따라서 발화를 1개 이상의 악센트구를 포함하는 그룹으로 나눔으로써, 한정된 수의 타깃 포인트를 이용하여 F0 패턴의 프레이즈 성분을 생성하는 스텝과,
상기 악센트 성분과 상기 프레이즈 성분에 의거해서 F0 패턴을 생성하는 스텝을 포함하는 것을 특징으로 하는 정량적 F0 패턴 생성 방법. - F0 패턴의 프레이즈 성분의 타깃 파라미터 생성용의 생성 모델과 F0 패턴의 악센트 성분의 타깃 파라미터 생성용의 생성 모델의 파라미터를 기억하는 모델 기억 수단과,
음성 합성의 대상이 되는 텍스트의 입력을 받아서 텍스트 해석하고, 음성 합성용의 제어 기호열을 출력하는 텍스트 해석 수단과,
상기 텍스트 해석 수단이 출력하는 제어 기호열을 상기 프레이즈 성분 생성용의 생성 모델과 비교함으로써 F0 패턴의 프레이즈 성분을 생성하는 프레이즈 성분 생성 수단과,
상기 텍스트 해석 수단이 출력하는 제어 기호열을 상기 악센트 성분 생성용의 생성 모델과 비교함으로써 F0 패턴의 악센트 성분을 생성하는 악센트 성분 생성 수단과,
상기 프레이즈 성분 생성 수단에 의해 생성된 프레이즈 성분 및 상기 악센트 성분 생성 수단에 의해 생성된 악센트 성분을 합성함으로써, F0 패턴을 생성하는 F0 패턴 생성 수단을 포함하는 것을 특징으로 하는 정량적 F0 패턴 생성 장치. - F0 패턴의 프레이즈 성분의 타깃 파라미터 생성용의 생성 모델과 F0 패턴의 악센트 성분의 타깃 파라미터 생성용의 생성 모델의 파라미터를 기억한 모델 기억 수단을 이용하는 정량적 F0 패턴 생성 방법으로서,
음성 합성의 대상이 되는 텍스트의 입력을 받아서 텍스트 해석하고, 음성 합성용의 제어 기호열을 출력하는 텍스트 해석 스텝과,
상기 텍스트 해석에 있어서 출력되는 제어 기호열을 상기 기억 수단에 기억된 상기 프레이즈 성분 생성용의 생성 모델과 비교함으로써 F0 패턴의 프레이즈 성분을 생성하는 프레이즈 성분 생성 수단과,
상기 텍스트 해석 스텝에 있어서 출력되는 제어 기호열을 상기 기억 수단에 기억된 상기 악센트 성분 생성용의 생성 모델과 비교함으로써 F0 패턴의 악센트 성분을 생성하는 악센트 성분 생성 스텝과,
상기 프레이즈 성분 생성 스텝에 있어서 생성된 프레이즈 성분 및 상기 악센트 성분 생성 스텝에 있어서 생성된 악센트 성분을 합성함으로써, F0 패턴을 생성하는 F0 패턴 생성 스텝을 포함하는 것을 특징으로 하는 정량적 F0 패턴 생성 방법. - 음성 데이터 신호로부터 F0 패턴을 추출하는 F0 패턴 추출 수단과,
추출된 F0 패턴에 피팅하는 F0 패턴을 프레이즈 성분과 악센트 성분의 중첩에 의해 나타내기 위해서, 프레이즈 성분을 나타내는 타깃 파라미터와 악센트 성분을 나타내는 타깃 파라미터를 추정하는 파라미터 추정 수단과,
상기 파라미터 추정 수단에 의해 추정된 프레이즈 성분의 타깃 파라미터 및 악센트 성분의 타깃 파라미터에 의해 나타내어지는 연속적인 F0 패턴을 학습 데이터로 해서 F0 생성 모델의 학습을 행하는 모델 학습 수단을 포함하는 것을 특징으로 하는 F0 패턴 생성을 위한 모델 학습 장치. - 제 5 항에 있어서,
상기 F0 생성 모델은 프레이즈 성분 생성용의 생성 모델과 악센트 성분 생성용의 생성 모델을 포함하고,
상기 모델 학습 수단은 상기 파라미터 추정 수단에 의해 추정된 프레이즈 성분의 타깃 파라미터에 의해서 나타내어지는 프레이즈 성분의 시간 변화 패턴과, 악센트 성분의 타깃 파라미터에 의해 나타내어지는 악센트 성분의 시간 변화 패턴을 각각 학습 데이터로 해서, 상기 프레이즈 성분 생성용의 생성 모델과 상기 악센트 성분 생성용의 생성 모델의 학습을 행하는 수단을 포함하는 것을 특징으로 하는 F0 패턴 생성을 위한 모델 학습 장치. - 음성 데이터 신호로부터 F0 패턴을 추출하는 F0 패턴 추출 스텝과,
상기 F0 패턴 추출 스텝에 있어서 추출된 F0 패턴에 피팅하는 F0 패턴을 프레이즈 성분과 악센트 성분의 중첩에 의해 나타내기 위해서, 프레이즈 성분을 나타내는 타깃 파라미터와 악센트 성분을 나타내는 타깃 파라미터를 추정하는 파라미터 추정 스텝과,
상기 파라미터 추정 스텝에 있어서 추정된 프레이즈 성분의 타깃 파라미터 및 악센트 성분의 타깃 파라미터에 의해 나타내어지는 연속적인 F0 패턴을 학습 데이터로 해서 F0 생성 모델의 학습을 행하는 모델 학습 스텝을 포함하는 것을 특징으로 하는 F0 패턴 생성을 위한 모델 학습 방법. - 제 7 항에 있어서,
상기 F0 생성 모델은 프레이즈 성분 생성용의 생성 모델과 악센트 성분 생성용의 생성 모델을 포함하고,
상기 모델 학습 스텝은 상기 파라미터 추정 스텝에 있어서 추정된 프레이즈 성분의 타깃 파라미터에 의해서 나타내어지는 프레이즈 성분의 시간 변화 패턴과, 악센트 성분의 타깃 파라미터에 의해 나타내어지는 악센트 성분의 시간 변화 패턴을 학습 데이터로 해서, 프레이즈 성분 생성용의 생성 모델과 악센트 성분 생성용의 생성 모델의 학습을 행하는 스텝을 포함하는 것을 특징으로 하는 F0 패턴 생성을 위한 모델 학습 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013173634A JP5807921B2 (ja) | 2013-08-23 | 2013-08-23 | 定量的f0パターン生成装置及び方法、f0パターン生成のためのモデル学習装置、並びにコンピュータプログラム |
| JPJP-P-2013-173634 | 2013-08-23 | ||
| PCT/JP2014/071392 WO2015025788A1 (ja) | 2013-08-23 | 2014-08-13 | 定量的f0パターン生成装置及び方法、並びにf0パターン生成のためのモデル学習装置及び方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20160045673A true KR20160045673A (ko) | 2016-04-27 |
Family
ID=52483564
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020167001355A KR20160045673A (ko) | 2013-08-23 | 2014-08-13 | 정량적 f0 패턴 생성 장치 및 방법, 그리고 f0 패턴 생성을 위한 모델 학습 장치 및 방법 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20160189705A1 (ko) |
| EP (1) | EP3038103A4 (ko) |
| JP (1) | JP5807921B2 (ko) |
| KR (1) | KR20160045673A (ko) |
| CN (1) | CN105474307A (ko) |
| WO (1) | WO2015025788A1 (ko) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6472005B2 (ja) * | 2016-02-23 | 2019-02-20 | 日本電信電話株式会社 | 基本周波数パターン予測装置、方法、及びプログラム |
| JP6468519B2 (ja) * | 2016-02-23 | 2019-02-13 | 日本電信電話株式会社 | 基本周波数パターン予測装置、方法、及びプログラム |
| JP6468518B2 (ja) * | 2016-02-23 | 2019-02-13 | 日本電信電話株式会社 | 基本周波数パターン予測装置、方法、及びプログラム |
| JP6876641B2 (ja) * | 2018-02-20 | 2021-05-26 | 日本電信電話株式会社 | 音声変換学習装置、音声変換装置、方法、及びプログラム |
| CN112530213B (zh) * | 2020-12-25 | 2022-06-03 | 方湘 | 一种汉语音调学习方法及系统 |
Family Cites Families (61)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3704345A (en) * | 1971-03-19 | 1972-11-28 | Bell Telephone Labor Inc | Conversion of printed text into synthetic speech |
| JP3077981B2 (ja) * | 1988-10-22 | 2000-08-21 | 博也 藤崎 | 基本周波数パタン生成装置 |
| US5475796A (en) * | 1991-12-20 | 1995-12-12 | Nec Corporation | Pitch pattern generation apparatus |
| JPH06332490A (ja) * | 1993-05-20 | 1994-12-02 | Meidensha Corp | 音声合成装置のアクセント成分基本テーブルの作成方法 |
| JP2880433B2 (ja) * | 1995-09-20 | 1999-04-12 | 株式会社エイ・ティ・アール音声翻訳通信研究所 | 音声合成装置 |
| JPH09198073A (ja) * | 1996-01-11 | 1997-07-31 | Secom Co Ltd | 音声合成装置 |
| EP1100072A4 (en) * | 1999-03-25 | 2005-08-03 | Matsushita Electric Ind Co Ltd | LANGUAGE SYNTHETIZATION SYSTEM AND METHOD |
| CN1207664C (zh) * | 1999-07-27 | 2005-06-22 | 国际商业机器公司 | 对语音识别结果中的错误进行校正的方法和语音识别系统 |
| CN1160699C (zh) * | 1999-11-11 | 2004-08-04 | 皇家菲利浦电子有限公司 | 语音识别系统 |
| US6810379B1 (en) * | 2000-04-24 | 2004-10-26 | Sensory, Inc. | Client/server architecture for text-to-speech synthesis |
| US20080147404A1 (en) * | 2000-05-15 | 2008-06-19 | Nusuara Technologies Sdn Bhd | System and methods for accent classification and adaptation |
| US6856958B2 (en) * | 2000-09-05 | 2005-02-15 | Lucent Technologies Inc. | Methods and apparatus for text to speech processing using language independent prosody markup |
| CN1187693C (zh) * | 2000-09-30 | 2005-02-02 | 英特尔公司 | 以自底向上方式将声调集成到汉语连续语音识别系统中的方法和系统 |
| US7263488B2 (en) * | 2000-12-04 | 2007-08-28 | Microsoft Corporation | Method and apparatus for identifying prosodic word boundaries |
| US6845358B2 (en) * | 2001-01-05 | 2005-01-18 | Matsushita Electric Industrial Co., Ltd. | Prosody template matching for text-to-speech systems |
| WO2002073595A1 (fr) * | 2001-03-08 | 2002-09-19 | Matsushita Electric Industrial Co., Ltd. | Dispositif generateur de prosodie, procede de generation de prosodie, et programme |
| US7035794B2 (en) * | 2001-03-30 | 2006-04-25 | Intel Corporation | Compressing and using a concatenative speech database in text-to-speech systems |
| US20030055640A1 (en) * | 2001-05-01 | 2003-03-20 | Ramot University Authority For Applied Research & Industrial Development Ltd. | System and method for parameter estimation for pattern recognition |
| JP4680429B2 (ja) * | 2001-06-26 | 2011-05-11 | Okiセミコンダクタ株式会社 | テキスト音声変換装置における高速読上げ制御方法 |
| WO2003019528A1 (fr) * | 2001-08-22 | 2003-03-06 | International Business Machines Corporation | Procede de production d'intonation, dispositif de synthese de signaux vocaux fonctionnant selon ledit procede et serveur vocal |
| US7136802B2 (en) * | 2002-01-16 | 2006-11-14 | Intel Corporation | Method and apparatus for detecting prosodic phrase break in a text to speech (TTS) system |
| US7136816B1 (en) * | 2002-04-05 | 2006-11-14 | At&T Corp. | System and method for predicting prosodic parameters |
| US20030191645A1 (en) * | 2002-04-05 | 2003-10-09 | Guojun Zhou | Statistical pronunciation model for text to speech |
| US7136818B1 (en) * | 2002-05-16 | 2006-11-14 | At&T Corp. | System and method of providing conversational visual prosody for talking heads |
| US7219059B2 (en) * | 2002-07-03 | 2007-05-15 | Lucent Technologies Inc. | Automatic pronunciation scoring for language learning |
| US20040030555A1 (en) * | 2002-08-12 | 2004-02-12 | Oregon Health & Science University | System and method for concatenating acoustic contours for speech synthesis |
| US7467087B1 (en) * | 2002-10-10 | 2008-12-16 | Gillick Laurence S | Training and using pronunciation guessers in speech recognition |
| US8768701B2 (en) * | 2003-01-24 | 2014-07-01 | Nuance Communications, Inc. | Prosodic mimic method and apparatus |
| US20050086052A1 (en) * | 2003-10-16 | 2005-04-21 | Hsuan-Huei Shih | Humming transcription system and methodology |
| US7315811B2 (en) * | 2003-12-31 | 2008-01-01 | Dictaphone Corporation | System and method for accented modification of a language model |
| US20050187772A1 (en) * | 2004-02-25 | 2005-08-25 | Fuji Xerox Co., Ltd. | Systems and methods for synthesizing speech using discourse function level prosodic features |
| US20060229877A1 (en) * | 2005-04-06 | 2006-10-12 | Jilei Tian | Memory usage in a text-to-speech system |
| US20060259303A1 (en) * | 2005-05-12 | 2006-11-16 | Raimo Bakis | Systems and methods for pitch smoothing for text-to-speech synthesis |
| CN101176146B (zh) * | 2005-05-18 | 2011-05-18 | 松下电器产业株式会社 | 声音合成装置 |
| CN1945693B (zh) * | 2005-10-09 | 2010-10-13 | 株式会社东芝 | 训练韵律统计模型、韵律切分和语音合成的方法及装置 |
| JP4559950B2 (ja) * | 2005-10-20 | 2010-10-13 | 株式会社東芝 | 韻律制御規則生成方法、音声合成方法、韻律制御規則生成装置、音声合成装置、韻律制御規則生成プログラム及び音声合成プログラム |
| US7996222B2 (en) * | 2006-09-29 | 2011-08-09 | Nokia Corporation | Prosody conversion |
| JP4787769B2 (ja) * | 2007-02-07 | 2011-10-05 | 日本電信電話株式会社 | F0値時系列生成装置、その方法、そのプログラム、及びその記録媒体 |
| JP4455610B2 (ja) * | 2007-03-28 | 2010-04-21 | 株式会社東芝 | 韻律パタン生成装置、音声合成装置、プログラムおよび韻律パタン生成方法 |
| JP2009047957A (ja) * | 2007-08-21 | 2009-03-05 | Toshiba Corp | ピッチパターン生成方法及びその装置 |
| JP5238205B2 (ja) * | 2007-09-07 | 2013-07-17 | ニュアンス コミュニケーションズ,インコーポレイテッド | 音声合成システム、プログラム及び方法 |
| US7996214B2 (en) * | 2007-11-01 | 2011-08-09 | At&T Intellectual Property I, L.P. | System and method of exploiting prosodic features for dialog act tagging in a discriminative modeling framework |
| JP5025550B2 (ja) * | 2008-04-01 | 2012-09-12 | 株式会社東芝 | 音声処理装置、音声処理方法及びプログラム |
| US8374873B2 (en) * | 2008-08-12 | 2013-02-12 | Morphism, Llc | Training and applying prosody models |
| US8571849B2 (en) * | 2008-09-30 | 2013-10-29 | At&T Intellectual Property I, L.P. | System and method for enriching spoken language translation with prosodic information |
| US8321225B1 (en) * | 2008-11-14 | 2012-11-27 | Google Inc. | Generating prosodic contours for synthesized speech |
| US8296141B2 (en) * | 2008-11-19 | 2012-10-23 | At&T Intellectual Property I, L.P. | System and method for discriminative pronunciation modeling for voice search |
| JP5471858B2 (ja) * | 2009-07-02 | 2014-04-16 | ヤマハ株式会社 | 歌唱合成用データベース生成装置、およびピッチカーブ生成装置 |
| JP5293460B2 (ja) * | 2009-07-02 | 2013-09-18 | ヤマハ株式会社 | 歌唱合成用データベース生成装置、およびピッチカーブ生成装置 |
| CN101996628A (zh) * | 2009-08-21 | 2011-03-30 | 索尼株式会社 | 提取语音信号的韵律特征的方法和装置 |
| JP5747562B2 (ja) * | 2010-10-28 | 2015-07-15 | ヤマハ株式会社 | 音響処理装置 |
| US9286886B2 (en) * | 2011-01-24 | 2016-03-15 | Nuance Communications, Inc. | Methods and apparatus for predicting prosody in speech synthesis |
| US9087519B2 (en) * | 2011-03-25 | 2015-07-21 | Educational Testing Service | Computer-implemented systems and methods for evaluating prosodic features of speech |
| JP5929909B2 (ja) * | 2011-05-30 | 2016-06-08 | 日本電気株式会社 | 韻律生成装置、音声合成装置、韻律生成方法および韻律生成プログラム |
| US10453479B2 (en) * | 2011-09-23 | 2019-10-22 | Lessac Technologies, Inc. | Methods for aligning expressive speech utterances with text and systems therefor |
| JP2014038282A (ja) * | 2012-08-20 | 2014-02-27 | Toshiba Corp | 韻律編集装置、方法およびプログラム |
| US9135231B1 (en) * | 2012-10-04 | 2015-09-15 | Google Inc. | Training punctuation models |
| US9224387B1 (en) * | 2012-12-04 | 2015-12-29 | Amazon Technologies, Inc. | Targeted detection of regions in speech processing data streams |
| US9495955B1 (en) * | 2013-01-02 | 2016-11-15 | Amazon Technologies, Inc. | Acoustic model training |
| US9292489B1 (en) * | 2013-01-16 | 2016-03-22 | Google Inc. | Sub-lexical language models with word level pronunciation lexicons |
| US9761247B2 (en) * | 2013-01-31 | 2017-09-12 | Microsoft Technology Licensing, Llc | Prosodic and lexical addressee detection |
-
2013
- 2013-08-23 JP JP2013173634A patent/JP5807921B2/ja active Active
-
2014
- 2014-08-13 US US14/911,189 patent/US20160189705A1/en not_active Abandoned
- 2014-08-13 EP EP14837587.6A patent/EP3038103A4/en not_active Ceased
- 2014-08-13 KR KR1020167001355A patent/KR20160045673A/ko not_active Application Discontinuation
- 2014-08-13 WO PCT/JP2014/071392 patent/WO2015025788A1/ja active Application Filing
- 2014-08-13 CN CN201480045803.7A patent/CN105474307A/zh active Pending
Non-Patent Citations (4)
| Title |
|---|
| Fujisaki, H., and Hirose, K.(1984), "Analysis of voice fundamental frequency contours for declarative sentences of Japanese," J. Acoust. Soc. Jpn., 5, 233-242. |
| Ni, J, Shiga, Y., Kawai, H., and Kashioka, H.(2012), "Resonance-based spectral deformation in HMM-based speech synthesis," Proc. of ISCSLP2012, 88-92. |
| Ni, J. and Nakamura, S.(2007), "Use of Poisson processes to generate fundamental frequency contours", Proc. of ICASSP2007, 825-828. |
| Tokuda, K., Masuko, T., Miyazaki, N., and Kobayashi, T.(1999), "Hidden Markov models based on multi-space probability distribution for pitch pattern modeling," Proc. of ICASSP1999, 229-232. |
Also Published As
| Publication number | Publication date |
|---|---|
| US20160189705A1 (en) | 2016-06-30 |
| JP5807921B2 (ja) | 2015-11-10 |
| CN105474307A (zh) | 2016-04-06 |
| JP2015041081A (ja) | 2015-03-02 |
| EP3038103A4 (en) | 2017-05-31 |
| WO2015025788A1 (ja) | 2015-02-26 |
| EP3038103A1 (en) | 2016-06-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6777768B2 (ja) | 単語ベクトル化モデル学習装置、単語ベクトル化装置、音声合成装置、それらの方法、及びプログラム | |
| JP3933750B2 (ja) | 連続密度ヒドンマルコフモデルを用いた音声認識方法及び装置 | |
| CN107924686B (zh) | 语音处理装置、语音处理方法以及存储介质 | |
| JP5631915B2 (ja) | 音声合成装置、音声合成方法、音声合成プログラムならびに学習装置 | |
| JP4455610B2 (ja) | 韻律パタン生成装置、音声合成装置、プログラムおよび韻律パタン生成方法 | |
| JP6392012B2 (ja) | 音声合成辞書作成装置、音声合成装置、音声合成辞書作成方法及び音声合成辞書作成プログラム | |
| Hashimoto et al. | Trajectory training considering global variance for speech synthesis based on neural networks | |
| KR20160045673A (ko) | 정량적 f0 패턴 생성 장치 및 방법, 그리고 f0 패턴 생성을 위한 모델 학습 장치 및 방법 | |
| EP4266306A1 (en) | A speech processing system and a method of processing a speech signal | |
| KR20210059586A (ko) | 텍스트 음성 변환과 함께 멀티태스크 학습을 사용한 감정적 음성 변환 방법 및 장치 | |
| JP7124373B2 (ja) | 学習装置、音響生成装置、方法及びプログラム | |
| KR102528019B1 (ko) | 인공지능 기술에 기반한 음성 합성 시스템 | |
| US10157608B2 (en) | Device for predicting voice conversion model, method of predicting voice conversion model, and computer program product | |
| Chen et al. | The USTC System for Voice Conversion Challenge 2016: Neural Network Based Approaches for Spectrum, Aperiodicity and F0 Conversion. | |
| JPWO2016103652A1 (ja) | 音声処理装置、音声処理方法、およびプログラム | |
| JP2009069179A (ja) | 基本周波数パターン生成装置、基本周波数パターン生成方法及びプログラム | |
| JP6137708B2 (ja) | 定量的f0パターン生成装置、f0パターン生成のためのモデル学習装置、並びにコンピュータプログラム | |
| Yamagishi et al. | Improved average-voice-based speech synthesis using gender-mixed modeling and a parameter generation algorithm considering GV | |
| JP4177751B2 (ja) | 声質モデル生成方法、声質変換方法、並びにそれらのためのコンピュータプログラム、当該プログラムを記録した記録媒体、及び当該プログラムによりプログラムされたコンピュータ | |
| JP4417892B2 (ja) | 音声情報処理装置、音声情報処理方法および音声情報処理プログラム | |
| JP6442982B2 (ja) | 基本周波数調整装置、方法及びプログラム、並びに、音声合成装置、方法及びプログラム | |
| JP7469015B2 (ja) | 学習装置、音声合成装置及びプログラム | |
| KR102532253B1 (ko) | 스펙트로그램에 대응하는 어텐션 얼라인먼트의 디코더 스코어를 연산하는 방법 및 음성 합성 시스템 | |
| KR102503066B1 (ko) | 어텐션 얼라인먼트의 스코어를 이용하여 스펙트로그램의 품질을 평가하는 방법 및 음성 합성 시스템 | |
| KR20240014250A (ko) | 스펙트로그램에 대응하는 어텐션 얼라인먼트의 인코더 스코어를 연산하는 방법 및 음성 합성 시스템 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WITN | Withdrawal due to no request for examination |