KR20160044553A - Method and apparatus for utility-aware privacy preserving mapping through additive noise - Google Patents
Method and apparatus for utility-aware privacy preserving mapping through additive noise Download PDFInfo
- Publication number
- KR20160044553A KR20160044553A KR1020167007121A KR20167007121A KR20160044553A KR 20160044553 A KR20160044553 A KR 20160044553A KR 1020167007121 A KR1020167007121 A KR 1020167007121A KR 20167007121 A KR20167007121 A KR 20167007121A KR 20160044553 A KR20160044553 A KR 20160044553A
- Authority
- KR
- South Korea
- Prior art keywords
- data
- user
- noise
- eigenvectors
- release
- Prior art date
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/62—Protecting access to data via a platform, e.g. using keys or access control rules
- G06F21/6218—Protecting access to data via a platform, e.g. using keys or access control rules to a system of files or objects, e.g. local or distributed file system or database
- G06F21/6245—Protecting personal data, e.g. for financial or medical purposes
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
- G06F17/10—Complex mathematical operations
- G06F17/18—Complex mathematical operations for evaluating statistical data, e.g. average values, frequency distributions, probability functions, regression analysis
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/602—Providing cryptographic facilities or services
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Bioethics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Computer Hardware Design (AREA)
- Computer Security & Cryptography (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Analysis (AREA)
- Computational Mathematics (AREA)
- Mathematical Optimization (AREA)
- Pure & Applied Mathematics (AREA)
- Mathematical Physics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Evolutionary Biology (AREA)
- Storage Device Security (AREA)
- Operations Research (AREA)
- Probability & Statistics with Applications (AREA)
- Algebra (AREA)
Abstract
본 실시예들은 일부 유틸리티를 얻을 희망으로, (S로 표시된) 사적 데이터와 연관되는, (X로 표시된) 일부 공용 데이터를 분석가에게 릴리즈하기를 원하는 사용자가 마주치게 되는 프라이버시-유틸리티 트레이드오프에 초점이 맞추어져 있다. 잡음이 프라이버시 보호 메커니즘, 즉 Y=X+N으로서 추가되는 경우 -Y는 분석가에게 실제로 릴리즈되는 데이터이고 N은 잡음임- , 우리는 가우시안 잡음을 추가하는 것이 연속 데이터 X에 대한 1_2-노름 왜곡 하에서 최적이라는 것을 보여준다. 우리는 가우시안 메커니즘에 의해 최악의 경우의 정보 누설을 최소화하는 가우시안 잡음을 추가하는 메커니즘을 표시한다. 가우시안 메커니즘에 대한 파라미터들은 X의 공분산의 고유벡터들 및 고유값들에 기초하여 결정된다. 우리는 또한 이산 데이터 X에 대한 확률 프라이버시 보호 매핑 메커니즘을 전개하고, 여기서 랜덤 이산 잡음은 최대-엔트로피 분산을 따른다.These embodiments focus on the privacy-utility tradeoff encountered by a user who wishes to release to the analyst some public data (denoted by X) associated with private data (denoted by S) in the hope of obtaining some utility It is tailored. If noise is added as a privacy protection mechanism, i.e., Y = X + N, then -Y is the data actually released to the analyst and N is noise-we add that adding Gaussian noise It is optimal. We present a mechanism to add Gaussian noise that minimizes the worst case information leakage by Gaussian mechanism. The parameters for the Gaussian mechanism are determined based on the eigenvectors of the covariance of X and eigenvalues. We also develop a probability privacy protection mapping mechanism for discrete data X, where the random discrete noise follows a maximum-entropy variance.

Description
관련 출원들에 대한 상호 참조Cross reference to related applications
본원은 하기 미국 가출원의 출원일의 이익을 주장하며, 이는 모든 목적을 위해 그 전체가 참조로서 본 명세서에 포함된다: 2013년 8월 19일자로 출원되고, "Method and Apparatus for Utility-Aware Privacy Preserving Mapping through Additive Noise"라는 발명의 명칭의 일련번호 제61/867.546호.This application claims the benefit of the filing date of the following US Provisional Application, which is hereby incorporated by reference in its entirety for all purposes: "Method and Apparatus for Utility-Aware Privacy Preserving Mapping " filed August 19, Serial No. 61 / 867,546 entitled " through Additive Noise ".
본원은 2012년 8월 20일자로 출원되고, "A Framework for Privacy against Statistical Inference"라는 발명의 명칭의 미국 가특허 출원 제61/691,090호(이하 "Fawaz")에 관련된다. 이 가출원은 그 전체가 참조로서 본 명세서에 명시적으로 포함된다.This application is related to U.S. Provisional Patent Application No. 61 / 691,090 ("Fawaz"), filed on August 20, 2012 and entitled "A Framework for Privacy against Statistical Inference". This application is expressly incorporated herein by reference in its entirety.
또한, 본원은: (1) "Method and Apparatus for Utility-Aware Privacy Preserving Mapping against Inference Attacks"라는 명칭의 대리인 정리번호 PU130120, 및 (2) "Method and Apparatus for Utility-Aware Privacy Preserving Mapping in View of Collusion and Composition"이라는 명칭의 대리인 정리번호 PU130121에 관련되고, 이들은 함께 양도되고, 그 전체가 참조로서 포함되며, 본 명세서와 함께 제출되었다.(1) Attorney Docket No. PU130120, entitled " Method and Apparatus for Utility-Aware Privacy Preserving Mapping Against Inference Attacks, " and (2) "Method and Apparatus for Utility-Aware Privacy Preserving Mapping in View of Collusion and Composition ", assigned to the assignee of the present invention and assigned to Attorney Docket No. PU130121, both of which are incorporated herein by reference in their entireties.
본 발명은 프라이버시를 보호하기 위한 방법 및 장치에 관한 것으로, 특히 프라이버시를 보호하기 위해 사용자 데이터에 잡음을 추가하기 위한 방법 및 장치에 관한 것이다.The present invention relates to a method and apparatus for protecting privacy, and more particularly to a method and apparatus for adding noise to user data to protect privacy.
빅 데이터(Big Data)의 시대에, 사용자 데이터의 수집 및 마이닝(mining)은 복수의 사설 및 공공 기관에 의한 빠르게 성장하고 일반적인 실무가 되고 있다. 예를 들어, 기술 회사들은 사용자 데이터를 활용하여 그들의 고객들에게 개인맞춤화된 서비스들을 제공하거나, 정부 기관들은 데이터에 의존하여 다양한 과제들, 예로서 국가 보안, 국민 건강, 예산 및 기금 할당을 다루거나, 의료 기관들은 데이터를 분석하여 질병들에 대한 원인들 및 잠재적인 치료법들을 발견한다. 일부 예들에서, 사용자 데이터의 수집, 분석, 또는 제삼자들과의 공유는 사용자의 동의 또는 자각 없이 수행된다. 다른 예들에서, 사용자는 데이터를 특정 분석자에게 자발적으로 릴리즈하여 그에 대한 응답으로 서비스를 획득하는데, 예를 들어 제품 등급들을 릴리즈하여 추천들을 획득한다. 이러한 서비스, 또는 사용자가 사용자 데이터에 대한 액세스의 허용으로부터 얻는 다른 이익은 유틸리티로서 지칭될 수 있다. 어느 경우에나, 수집되는 데이터의 일부는 예를 들어 정치적 견해, 건강 상태, 수입 레벨과 같이 사용자에 의해 민감한 것으로 간주될 수 있거나, 예를 들어 제품 등급들과 같이 언뜻 보아서는 무해한 것으로 보이지만 그와 상관된 더 민감한 데이터의 추론을 유발할 수 있으므로, 프라이버시 위험들이 발생한다. 후자의 위험은 사적 데이터를 공개적으로 릴리즈된 데이터와의 그 상관을 이용하여 추론하는 기술인 추론 공격으로 지칭된다.In the era of Big Data, the collection and mining of user data has become a fast-growing and common practice by multiple private and public agencies. For example, technology companies can utilize user data to provide personalized services to their customers, or government agencies can rely on data to deal with a variety of challenges, such as national security, national health, budget and funding, Medical institutions analyze data to find causes and potential treatments for diseases. In some instances, the collection, analysis, or sharing of user data with third parties is performed without the user's consent or awareness. In other examples, the user voluntarily releases the data to a particular analyst and obtains the service in response thereto, for example by releasing product ratings to obtain recommendations. Such a service, or other benefit that a user derives from granting access to user data, may be referred to as a utility. In any case, some of the collected data may be regarded as sensitive by the user, for example, political views, health status, income levels, or seemingly innocuous at first glance, such as product ratings, Privacy risk may arise because it can lead to inferences of more sensitive data. The latter risk is referred to as an inference attack, which is a technique for inferring private data using its correlation with publicly released data.
본 원리들은 사용자를 위해 사용자 데이터를 처리하기 위한 방법을 제공하며, 이 방법은 사적 데이터와 공용 데이터를 포함하는 사용자 데이터에 액세스하는 단계 -사적 데이터는 제1 데이터 카테고리에 대응하고, 공용 데이터는 제2 데이터 카테고리에 대응함- ; 제1 데이터 카테고리의 공분산 행렬을 결정하는 단계; 공분산 행렬에 응답하여 가우시안 잡음을 생성하는 단계; 사용자의 공용 데이터에 생성된 가우시안 잡음을 추가함으로써 공용 데이터를 수정하는 단계; 및 후술되는 바와 같이 서비스 제공자와 데이터 수집 에이전시 중 적어도 하나에게 수정된 데이터를 릴리즈하는 단계를 포함한다. 본 원리들은 또한 이들 단계들을 수행하기 위한 장치를 제공한다.The present principles provide a method for processing user data for a user, the method comprising: accessing user data including private data and public data, wherein the private data corresponds to a first data category, Corresponding to 2 data categories; Determining a covariance matrix of the first data category; Generating Gaussian noise in response to a covariance matrix; Modifying the common data by adding the generated Gaussian noise to the public data of the user; And releasing the modified data to at least one of the service provider and the data collection agency as described below. These principles also provide an apparatus for performing these steps.
본 원리들은 또한 사용자를 위해 사용자 데이터를 처리하기 위한 방법을 제공하며, 이 방법은 사적 데이터와 공용 데이터를 포함하는 사용자 데이터에 액세스하는 단계; 유틸리티 D에 대한 제약에 액세스하는 단계 -유틸리티는 사용자의 공용 데이터 및 릴리즈 데이터에 응답함- ; 유틸리티 제약에 응답하여 랜덤 잡음 Z를 생성하는 단계 -랜덤 잡음은 유틸리티 제약 하에서 최대 엔트로피 확률 분포를 따름- ; 및 후술되는 바와 같이 사용자에 대한 릴리즈 데이터를 생성하기 위해 사용자의 공용 데이터에 생성된 잡음을 추가하는 단계를 포함한다. 본 원리들은 또한 이들 단계들을 수행하기 위한 장치를 제공한다.The principles also provide a method for processing user data for a user, the method comprising: accessing user data including private data and public data; Accessing the constraints on utility D - the utility responds to the user's public data and release data; Generating a random noise Z in response to a utility constraint; the random noise follows a maximum entropy probability distribution under a utility constraint; And adding the generated noise to the user ' s public data to generate release data for the user as described below. These principles also provide an apparatus for performing these steps.
또한, 본 원리들은 전술한 방법들에 따라 사용자를 위해 사용자 데이터를 처리하기 위한 명령어들이 저장되는 컴퓨터 판독가능 저장 매체를 제공한다.The present principles also provide a computer-readable storage medium having stored thereon instructions for processing user data for a user in accordance with the methods described above.
도 1은 본 원리들의 실시예에 따라, 연속적인 데이터에 가우시안 잡음을 추가함으로써 프라이버시를 보호하기 위한 예시적인 방법을 묘사한 흐름도이다.
도 2는 본 원리들의 실시예에 따라, 이산 데이터에 이산 잡음을 추가함으로써 프라이버시를 보호하기 위한 예시적인 방법을 묘사한 흐름도이다.
도 3은 본 원리들의 실시예에 따른, 예시적인 프라이버시 에이전트를 묘사한 블록도이다.
도 4는 본 원리들의 일 실시예에 따른, 다중 프라이버시 에이전트를 갖는 예시적인 시스템을 묘사한 블록도이다.1 is a flow diagram depicting an exemplary method for protecting privacy by adding Gaussian noise to continuous data, in accordance with an embodiment of the present principles.
Figure 2 is a flow diagram depicting an exemplary method for protecting privacy by adding discrete noise to discrete data, in accordance with embodiments of the present principles.
3 is a block diagram depicting an exemplary privacy agent, in accordance with an embodiment of the present principles.
4 is a block diagram depicting an exemplary system with multiple privacy agents, in accordance with an embodiment of the present principles.
우리는 Fawaz에서 기술된 설정을 고려하며, 여기서 사용자는 상관되는 2가지 종류의 데이터를 갖는다: 사적으로 남기고 싶은 일부 데이터와, 분석가에게 릴리즈할 의향이 있으며 일부 유틸리티를 파생시킬 수 있는 비-사적 데이터 예를 들어, 서비스 제공자에게의 미디어 선호의 릴리즈(release)는 보다 정확한 콘텐츠 추천들을 접수하기 위한 것이다.We take into account the settings described in Fawaz, where the user has two types of correlated data: some data that he wants to leave private, non-private data that is intended to be released to analysts and may derive some utilities For example, a release of media preference to a service provider is intended to receive more accurate content recommendations.
본 출원에서 사용되는 바와 같이, 예를 들어, 서비스 제공자의 시스템의 일부일 수 있는, 용어 분석가는 사용자에게 유틸리티를 제공하기 위해 표면상 데이터를 사용하는, 릴리즈 데이터의 수령인을 지칭한다. 분석가는 릴리즈 데이터의 합법적인 수령인이다. 그러나, 분석가는 또한 릴리즈 데이터를 위법으로 이용하고 사용자의 사적 데이터에 관한 일부 정보를 추론할 수 있다. 이것은 프라이버시와 유틸리티 요구 간의 갈등을 만든다. 유틸리티를 유지하는 동안 추론 위협을 감소시키기 위해, 사용자는 유틸리티 제약 하에서 설계된, "프라이버시 보호 매핑(privacy preserving mapping)"이라고 불리는 조건부 확률 매핑(conditional probabilistic mapping)에 따라 생성된, 데이터의 "왜곡된 버전"을 릴리즈할 수 있다.As used in this application, a terminology analyst, which may be part of a service provider's system, for example, refers to a recipient of release data that uses surface data to provide a utility to a user. The analyst is the legitimate recipient of the release data. However, the analyst may also illegally use the release data and infer some information about the user's private data. This creates a conflict between privacy and utility needs. In order to reduce the threat of speculation while maintaining the utility, the user has to create a "distorted version" of the data, generated according to a conditional probabilistic mapping, called a "privacy preserving mapping" "Can be released.
본 출원에서, 우리는 사용자가 "사적 데이터"로서 사적으로 남기고 싶은 데이터, 사용자가 "공용 데이터(public data)"로서 릴리즈할 의향이 있는 데이터, 및 사용자가 실제로 "릴리즈 데이터(released data)"로서 릴리즈한 데이터를 참조한다. 예를 들어, 사용자는 그의 정치적인 견해를 사적으로 유지하기를 원할 수 있고, 그의 TV 순위들을 수정하여 릴리즈할 의향이 있을 수 있다(예를 들어, 사용자의 프로그램의 실제 순위는 4이지만, 그는 순위를 3으로 릴리즈한다). 이 경우에, 사용자의 정치적인 견해는 이 사용자에 대한 사적 데이터인 것으로 간주되고, 텔레비전 순위들은 공용 데이터인 것으로 간주되며, 릴리즈된 수정된 TV 순위들은 릴리즈 데이터인 것으로 간주된다. 또 다른 사용자는 수정 없이 정치적인 견해와 TV 순위들 양쪽 모두를 릴리즈할 의향이 있을 수 있으며, 그에 따라 이 다른 사용자의 경우, 정치적인 견해와 TV 순위들만이 고려될 때, 사적 데이터, 공용 데이터 및 릴리즈 데이터 간에 차이가 없다는 것에 유의해야 한다. 많은 사람들이 정치적인 견해와 TV 순위들을 릴리즈하면, 분석가는 정치적인 견해와 TV 순위들 간의 상관을 유도해 낼 수 있기 때문에, 정치적인 견해를 사적으로 유지하기를 원하는 사용자의 정치적인 견해를 추론할 수 있다.In the present application, we have determined that the data that the user wants to leave private as "private data ", data that the user intends to release as" public data & Refer to released data. For example, a user may want to keep his political views private and may be willing to modify and release his TV rankings (e.g., the actual rank of the user's program is 4, 3). In this case, the user's political view is considered to be private data for this user, the television rankings are considered to be common data, and the released modified TV rankings are considered to be release data. Another user may be willing to release both political views and TV rankings without modification, so that for this other user, when only political views and TV rankings are considered, private data, public data, and release data It should be noted that there is no difference between the two. As many people release political views and TV rankings, analysts can derive correlations between political views and TV rankings, so they can infer the political views of users who want to maintain their political views privately.
사적 데이터에 관하여, 이것은 사용자가 공개적으로 릴리즈되지 않아야 하는 것을 나타내는 것을 물론이고 릴리즈한 다른 데이터로부터 추론되기를 원하지 않는다는 것을 나타내는 데이터를 지칭한다. 공용 데이터는 사용자가 프라이버시 에이전트로 하여금 사적 데이터의 추론을 방지하기 위해 아마도 왜곡된 방식으로 릴리즈하도록 허용한 데이터이다.With respect to private data, this refers to data indicating that the user does not want to be inferred from other data released, as well as to indicate that the user should not be released publicly. Public data is data that allows a user to release a privacy agent in a distorted way, perhaps to prevent inference of private data.
일 실시예에서, 공용 데이터는 서비스 제공자가 사용자에게 서비스를 제공하기 위해 사용자에게 요청한 데이터이다. 그러나, 사용자는 서비스 제공자에게 릴리즈하기 전에 왜곡할 것이다(즉, 수정할 것이다). 또 다른 실시예에서, 공용 데이터는 릴리즈(release)가 사적 데이터의 추론에 대항하여 보호하는 형태를 취하는 한 릴리즈되는 것을 꺼리지 않는다는 점에서 사용자가 "공용(public)"인 것으로 표시되는 데이터이다.In one embodiment, the common data is data that the service provider has requested the user to provide the service to the user. However, the user will distort (i.e., modify) it before releasing it to the service provider. In yet another embodiment, the public data is data that is marked as "public " by the user in that it does not mind releasing as long as the release takes the form of protecting against speculation of private data.
앞서 논의한 바와 같이, 데이터의 특정 카테고리가 사적 데이터 또는 공용 데이터로서 고려될지의 여부는 특정 사용자의 관점에 기초한다. 표기의 용이성을 위해, 우리는 현재 사용자의 관점에서 데이터의 특정 카테고리를 사적 데이터 또는 공용 데이터라고 칭한다. 예를 들어, 정치적인 사적 견해를 유지하기를 원하는 현재 사용자에 대한 프라이버시 보호 매핑을 설계하려고 할 때, 우리는 그의 정치적인 견해를 릴리즈할 의향이 있는 다른 사용자와 현재 사용자 양쪽 모두에 대해 정치적인 견해를 사적 데이터라고 칭한다.As discussed above, whether a particular category of data is to be considered private or public data is based on the particular user's perspective. For ease of representation, we refer to a particular category of data as private or public data from the perspective of the current user. For example, when attempting to design a privacy-protected mapping for the current user who wants to maintain a political, private view, we may use political views of both current and current users who are willing to release his political views, Quot;
본 원리에서, 우리는 릴리즈 데이터와 공용 데이터 간의 왜곡을 유틸리티의 척도로서 이용한다. 왜곡이 더 큰 경우, 릴리즈 데이터는 공용 데이터와 상당히 상이하고, 더 많은 프라이버시가 보호되지만, 왜곡 데이터로부터 파생된 유틸리티는 사용자에 대해 더 낮아질 수 있다. 한편, 왜곡이 더 작은 경우, 릴리즈 데이터는 공용 데이터의 보다 정확한 표현이고 사용자는 더 많은 유틸리티를 받을 수 있고, 예를 들어 보다 정확한 콘텐츠 추천을 받을 수 있다.In this principle, we use the distortion between release data and public data as a measure of utility. If the distortion is larger, the release data is significantly different from the public data and more privacy is protected, but the utility derived from the distortion data may be lower for the user. On the other hand, if the distortion is smaller, the release data is a more accurate representation of the public data and the user can receive more utilities, for example, more accurate content recommendations.
일 실시예에서, 통계적 추론에 대항하여 프라이버시를 보호하기 위해, 우리는 왜곡 제약에 종속되고, 사적 데이터와 릴리즈 데이터 간의 상호 정보(mutual information)량으로서 정의되는 정보 누설을 최소화하는 최적화 문제를 해결함으로써 사적-유틸리티 트레이드오프를 모델링하고 프라이버시 보호 매핑을 설계한다.In one embodiment, in order to protect privacy against statistical reasoning, we solve the optimization problem that is subject to distortion constraints and minimizes the information leakage defined as the amount of mutual information between private and release data Model private-utility tradeoffs and design privacy-protected mappings.
Fawaz에서, 프라이버시 보호 매핑을 찾는 것은, 사적 데이터와 릴리즈 데이터를 링크하는 사전 결합 분포(joint distribution)가 알려져 있고 최적화 문제에 대한 입력으로서 제공될 수 있다고 하는 기본적인 가정에 의존한다. 실제로, 참된 사전 분포는 알려져 있지 않지만, 일부 종래의 통계들은 관찰될 수 있는 한 세트의 샘플 데이터로부터 추정될 수 있다. 예를 들어, 사전 결합 분포는, 프라이버시에 대한 관심을 가지고 있지 않으며 또한 그들의 프라이버시에 관해 관심있는 사용자들에 의해 사적 또는 공용 데이터인 것으로 고려될 수 있는 상이한 데이터의 카테고리들을 공개적으로 릴리즈하는 한 세트의 사용자들로부터 추정될 수 있다. 대안적으로, 사적 데이터가 관찰될 수 없을 때, 릴리즈될 공용 데이터의 주변 분포, 또는 단순히 그것의 2차 순서 통계(order statistics)가, 단지 그들의 공용 데이터를 릴리즈한 한 세트의 사용자들로부터 추정될 수 있다. 다음으로, 이 샘플들의 세트에 기초하여 추정된 통계는 그들의 프라이버시에 대해 관심있는, 새로운 사용자들에게 적용되게 될 프라이버시 보호 매핑 메커니즘을 설계하는데 사용된다. 실제로, 예를 들어 적은 수의 관찰가능한 샘플들로 인해 또는 관찰가능한 데이터의 불완전성으로 인해, 추정된 사전 통계와 참된 사전 통계 간의 불일치가 존재할 수도 있다.In Fawaz, looking for a privacy-protected mapping relies on a basic assumption that a joint distribution linking private and release data is known and can be provided as input to the optimization problem. In practice, a true prior distribution is not known, but some conventional statistics can be estimated from a set of sample data that can be observed. For example, the pre-combined distribution may be a set of publicly releasing categories of different data that do not have an interest in privacy and may be considered private or public data by interested users about their privacy Can be estimated from users. Alternatively, when private data can not be observed, the distribution of the public data to be released, or simply its secondary order statistics, may be estimated from a set of users who have just released their public data . Next, the estimated statistics based on the set of these samples are used to design a privacy protection mapping mechanism that will be applied to new users interested in their privacy. In fact, there may be a discrepancy between the estimated dictionary and the true dictionary statistics, for example due to a small number of observable samples or due to the incompleteness of the observable data.
이 문제를 공식화하기 위해, 공용 데이터는 확률 분포 PX를 가진 랜덤 변수 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
다음에서, 우리는 첫번째로 프라이버시 개념을 정의하고나서, 정확도 개념을 정의한다.In the following, we first define the concept of privacy, then define the concept of accuracy.
정의 1. S→X→Y를 가정한다. 커널 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
우리는 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
정의 2. ![]()
![]()
![]()
![]()
![]()
![]()
프라이버시 보호 매핑의 누설 인수 ![]()
![]()
본 원리는 사전 부분적인 통계 지식만이 활용가능할 때 유틸리티-인식 프라이버시 보호 매핑을 설계하는 방법들을 제안한다. 보다 구체적으로, 본 원리는 가산성 잡음 메커니즘들의 클래스로 프라이버시 보호 매핑 메커니즘들을 제공하고, 여기서 잡음은 공용 데이터가 릴리즈되기 전에 공용 데이터에 추가된다. 분석시, 우리는 잡음의 평균값이 0이라고 가정한다. 메커니즘은 또한 평균이 제로가 아닐 경우에 적용될 수도 있다. 일례에서, 결과들은 엔트로피가 평균에 민감하지 않기 때문에 비-제로 평균의 경우에도 동일하다. 메커니즘들은 연속 데이터와 이산 데이터 양쪽 둘다에 대해 릴리즈될 데이터의 2차 모멘트들의 지식만을 필요로 한다.This principle suggests ways to design utility-aware privacy-protected mappings when only pre-local statistical knowledge is available. More specifically, the present principles provide privacy protection mapping mechanisms as classes of additive noise mechanisms, where noise is added to public data before public data is released. In the analysis, we assume that the mean value of the noise is zero. The mechanism may also be applied when the average is not zero. In one example, the results are the same for the non-zero mean as entropy is not averaged. The mechanisms need only knowledge of the second moments of the data to be released for both continuous data and discrete data.
가우시안Gaussian 메커니즘 mechanism
일 실시예에서, 우리는 연속 공용 데이터 X와 신호에 잡음을 부가함으로써, 즉 Y=X+N으로 달성될 수 있는 프라이버시 보호 매핑 방식들을 고려한다. 예시적인 연속 공용 데이터는 사용자의 키 또는 혈압일 수 있다. 매핑은 PX와 PS,X에 대한 지식없이, VAR(X)(또는 다차원 X인 경우에 공분산 행렬)을 알고 있음으로써 획득된다. 첫번째로, 우리는 잡음이 프라이버시를 보호하기 위해 공용 데이터에 추가될 때 모든 프라이버시 보호 매핑 메커니즘들 중에서, 가우시안 잡음을 추가하는 것이 최적이라는 것을 보일 것이다.In one embodiment, we consider privacy protection mapping schemes that can be achieved by adding consecutive common data X and noise to the signal, i.e., Y = X + N. Exemplary consecutive data may be the user's key or blood pressure. The mapping is obtained by knowing VAR (X) (or covariance matrix in the case of multidimensional X), without knowledge of P X and P S, X. First, we will show that it is optimal to add Gaussian noise among all the privacy protection mapping mechanisms when noise is added to the public data to protect privacy.
S→X→Y 이기 때문에, 우리는 I(S;Y)≤I(X;Y)를 갖는다. 정보 누설 I(S;Y)을 바운드(bound)하기 위해, 우리는 I(X;Y)로 바운드한다. ![]()
![]()
![]()
![]()
![]()
![]()
명제 2. PX는 프라이버시 보호 매핑의 설계시 알려져 있지 않았고 우리는 어떤 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
여기서, NG는 가우시안 잡음을 나타내고 N은 랜덤 변수이어서 ![]()
![]()
![]()
![]()
![]()
![]()
증명: 가우시안 안장점 정리를 이용하면, 우리는Proof: Using the Gaussian Intaglio Theorem, we

여기서 XG는 제로 평균과 분산 ![]()
![]()
![]()
![]()
이제 우리는 잡음이 프라이버시를 보호하기 위해 추가될 때, 가우시안 잡음을 추가하는 것이 ![]()
![]()
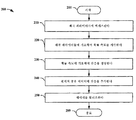
한가지 예시적 실시예에서, 주어진 CX와 왜곡 레벨 D에 대해, 가우시안 메커니즘은 도 1에 예시된 바와 같은 단계들에 의해 진행된다.In one exemplary embodiment, for a given C X and distortion level D, the Gaussian mechanism proceeds by the steps illustrated in FIG.
방법 100은 105에서 시작된다. 단계 110에서, 공용 데이터 또는 사적 데이터의 프라이버시에 관해 관심이 없는 사용자들에 의해 릴리즈된 데이터에 기초하여 통계 정보를 추정한다. 우리는 이들 사용자들을 "공용 사용자들"이라고 표시하고, 사적 데이터의 프라이버시에 관해 관심이 있는 사용자들을 "사적 사용자들"이라고 표시한다.
통계는 웹을 크롤링(crawling)하고 상이한 데이터베이스에 액세스함으로써 수집될 수 있거나, 데이터 집계기(data aggregator), 예를 들어 bluekai.com.에 의해 제공될 수 있다. 어느 통계 정보가 수집될 수 있는지는 공용 사용자들이 무엇을 릴리즈하는지에 의존한다. 주변 분포 PX를 특성화하는 것보다 분산을 특성화하기 위해 더 적은 데이터를 필요로 한다는 것에 유의해야 한다. 따라서, 우리는 우리가 분산을 추정할 수 있지만, 주변 분포를 정확하게 추정할 수 없는 상황에 있을 수 있다. 일 예에서, 우리는 단지 수집된 통계 정보에 기초하여 단계 120에서 공용 데이터의 평균과 분산(또는 공분산)을 얻을 수 있다.Statistics can be collected by crawling the web and accessing different databases, or by a data aggregator, such as bluekai.com. Which statistical information can be collected depends on what public users release it. It should be noted that it requires less data to characterize the dispersion than to characterize the perimeter distribution P X. Thus, we can be in a situation where we can estimate the variance, but can not accurately estimate the marginal distribution. In one example, we can obtain the mean and variance (or covariance) of the common data at
단계 130에서, 우리는 공분산 행렬 CX의 고유값 분해를 취한다. 가우시안 잡음 NG의 공분산 행렬은 CX의 고유벡터들과 동일하게 고유벡터들을 갖는다. 게다가, CN의 대응하는 고유값들은 하기 최적화 문제In

를 해결함으로써 주어지고Given by solving
여기서, ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
단계 140에서, 가우시안 잡음은 공용 데이터에 추가되는데, 즉 Y=X+NG이다. 다음으로, 왜곡 데이터가 예를 들어, 단계 150에서, 서비스 제공자 또는 데이터 수집 에이전시에게 릴리즈된다. 방법 100은 단계 199에서 종료된다.In
하기 정리에서, 우리는 제안된 가우시안 메커니즘이 ![]()
![]()
정리 3. ![]()
![]()
최적 잡음 NG의 공분산 행렬이 CX의 고유벡터들과 동일하게 고유 벡터들을 갖는다는 것을 충족한다. 또한, 고유값들은 (17)에서 주어진다.It is satisfied that the covariance matrix of the optimal noise N G has eigenvectors equal to the eigenvectors of C X. In addition, the eigenvalues are given in (17).
증명: 우리는 ![]()
![]()
여기서, 부등식은 2012년, 윌리-인터사이언스(Wiley-interscience), "Elements of information theory", 티.엠. 커버(T.M. Cover)와 제이.에이. 토마스(J.A. Thomas)에 의한 책의 정리 8.6.5로부터 유래한다. 우리가 X의 분산을 알지 못하기 때문에, 우리는 상계(upper bound) ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
보편성의 손실없이, ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
예 3. X는 S의 결정론적 실수치 함수이며, ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
주석 1. 이 분석은 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
예 5. 분산 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
이산 메커니즘(Discrete Mechanism)Discrete Mechanism
또 다른 실시예에서, 우리는 이산 랜덤 변수 X를 고려하며, 여기서 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
정의 5. 주어진 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
즉, 최적화 문제는 ![]()
![]()
![]()
![]()
![]()
![]()
다음으로, 우리는 ![]()
![]()
명제 3. 임의의 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
증명: ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
따라서, H(Z)≥H(W)이고 ![]()
![]()
![]()
![]()
우리는 이산 메커니즘에 의해 이산 공용 데이터에 잡음 ![]()
![]()
방법 200은 205에서 시작된다. 단계 210에서, 왜곡 측도를 정의하기 위해, 파라미터들, 예를 들어 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
단계 230에서, 잡음은 단계 240에서 이것이 공용 데이터에 추가되기 전에, 즉 Y=X+Z되기 전에 확률 측도에 따라 생성되며, 여기서 ![]()
![]()
![]()
![]()
다음으로, 우리는 상호 정보량 I(X;Y)을 분석한다. ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
가산성 잡음 기술의 장점은 이것이 S에 관한 정보는 물론이고, X의 통계에 관한 많은 정보를 요구하지 않을 뿐만 아니라, 우리가 설계하는데 필요한 모든 것이 풀 커널 ![]()
![]()
유리하게는, 결합 확률 분포 PS,X의 지식없이 그리고 공용 데이터 X의 1차 및 2차 모멘트들의 지식만을 가지고, 본 원리는 연속 및 이산 데이터 양쪽 둘다에 대해, 공용 데이터에 잡음을 추가함으로써 프라이버시를 보호하는 프라이버시 보호 매핑 메커니즘을 제공한다.Advantageously, only with knowledge of the joint probability distribution P S, X , and knowledge of the first and second moments of the common data X, this principle applies to both the continuous and discrete data, by adding noise to the common data, A privacy protection mapping mechanism is provided.
프라이버시 에이전트는 사용자에게 프라이버시 서비스를 제공하는 엔티티이다. 프라이버시 에이전트는 다음 중 어느 하나를 수행할 수 있다:A privacy agent is an entity that provides a privacy service to a user. The Privacy Agent may perform any of the following:
- 사용자로부터 그가 어떤 데이터를 사적인 것으로 간주하는지, 그가 어떤 데이터를 공용으로 간주하는지, 및 그가 어떤 레벨의 프라이버시를 원하는지를 수신하고;- receiving from the user what data he considers to be private, what data he regards as public, and what level of privacy he desires;
- 프라이버시 보호 매핑을 계산하고; - computing a privacy-protected mapping;
- 사용자를 위한 프라이버시 보호 매핑을 구현하고(즉, 매핑에 따라 그의 데이터를 왜곡하고); 및 Implement a privacy-protected mapping for the user (i.e., distort its data according to the mapping); And
- 왜곡 데이터를, 예를 들어 서비스 제공자 또는 데이터 수집 에이전시에게 릴리즈한다.- release the distorted data to a service provider or data collection agency, for example.
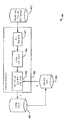
본 원리들은 사용자 데이터의 프라이버시를 보호하는 프라이버시 에이전트에서 사용될 수 있다. 도 3은 프라이버시 에이전트가 이용될 수 있는 예시적인 시스템(300)의 블록도를 나타낸다. 공용 사용자들(310)은 그들의 사적 데이터(S) 및/또는 공용 데이터(X)를 릴리즈한다. 앞서 논의한 바와 같이, 공용 사용자들은 공용 데이터를 그대로 릴리즈하는데, 즉, Y=X이다. 공용 사용자들에 의해 릴리즈된 정보는 프라이버시 에이전트에게 유용한 통계 정보가 된다.These principles may be used in a privacy agent that protects the privacy of user data. FIG. 3 shows a block diagram of an
프라이버시 에이전트(380)는 통계 수집 모듈(320), 가산성 잡음 생성기(330) 및 프라이버시 보호 모듈(340)을 포함한다. 통계 수집 모듈(320)은 공용 데이터의 공분산을 수집하는데 사용될 수 있다. 통계 수집 모듈(320)은 또한 bluekai.com과 같은 데이터 집계기들로부터 통계를 수신할 수 있다. 이용가능한 통계 정보에 따라, 가산성 잡음 생성기(330)는 예를 들어, 가우시안 메커니즘 또는 이산 메커니즘에 기초하여 잡음을 설계한다. 프라이버시 보호 모듈(340)은 생성된 잡음을 추가함으로써, 릴리즈되기 전에 사적 사용자(360)의 공용 데이터를 왜곡한다. 일 실시예에서, 통계 수집 모듈(320), 가산성 잡음 생성기(330) 및 프라이버시 보호 모듈(340)은 각각 방법 100에서의 단계들 110, 130 및 140을 수행하는데 사용될 수 있다.The
프라이버시 에이전트는 데이터 수집 모듈에서 수집된 전체 데이터에 대한 지식 없이 작업하기 위해 통계만을 필요로 한다는 점에 유의해야 한다. 따라서, 또 다른 실시예에서, 데이터 수집 모듈은 데이터를 수집하고나서 통계를 계산하는 독립형 모듈일 수 있으며, 프라이버시 에이전트의 일부일 필요가 없다. 데이터 수집 모듈은 프라이버시 에이전트와 통계를 공유한다. 일 실시예에서, 가산성 잡음 생성기(330)와 프라이버시 보호 모듈(340)은 각각 방법 200에서의 단계들 220 및 230을 수행하는데 사용될 수 있다.It should be noted that the privacy agent only needs statistics to work without knowledge of the entire data collected in the data collection module. Thus, in yet another embodiment, the data collection module may be a stand-alone module that collects data and then compiles statistics, and does not need to be part of the privacy agent. The data collection module shares statistics with the privacy agent. In one embodiment,
프라이버시 에이전트는 사용자와 사용자 데이터의 수령인(예를 들어, 서비스 제공자) 사이에 위치한다. 예를 들어, 프라이버시 에이전트는 사용자 디바이스, 예를 들어 컴퓨터 또는 셋톱 박스(STB)에 위치할 수 있다. 다른 예에서, 프라이버시 에이전트는 별개의 엔티티일 수 있다.The privacy agent is located between the user and the recipient of the user data (e.g., a service provider). For example, the privacy agent may be located in a user device, for example a computer or a set-top box (STB). In another example, the privacy agent may be a separate entity.
프라이버시 에이전트의 모든 모듈들은 하나의 디바이스에 위치할 수 있거나, 상이한 디바이스들에 걸쳐 분산될 수 있는데, 예를 들어 통계 수집 모듈(320)은 단지 통계를 모듈(330)에 릴리즈하는 데이터 집계기에 위치할 수 있고, 가산성 잡음 생성기(330)는 "프라이버시 서비스 제공자"에 또는 모듈(320)에 접속되는 사용자 디바이스 상의 사용자 단부에 위치할 수 있고, 프라이버시 보호 모듈(340)은 사용자와, 사용자가 데이터를 릴리즈하기를 원하는 대상인 서비스 제공자 사이에 매개물로서 작용하는 프라이버시 서비스 제공자에 또는 사용자 디바이스 상의 사용자 단부에 위치할 수 있다.All of the modules of the privacy agent may be located in one device or distributed across different devices, for example, the
프라이버시 에이전트는 릴리즈 데이터를 서비스 제공자, 예를 들어 컴캐스트(Comcast) 또는 넷플릭스(Netflix)에 제공할 수 있으며, 이에 따라 사적 사용자(360)는 릴리즈 데이터에 기초하여 수신 서비스를 개선할 수 있는데, 예를 들어 추천 시스템은 사용자에게 그의 릴리즈된 영화 순위들에 기초하여 영화 추천들을 제공한다.The privacy agent may provide the release data to a service provider, such as Comcast or Netflix, which allows the
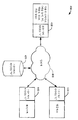
도 4에서, 우리는 시스템 내에 복수의 프라이버시 에이전트가 존재한다는 것을 나타낸다. 상이한 변형들에서는, 도처에 프라이버시 에이전트들이 존재할 필요가 없는데, 이는 프라이버시 시스템이 작동할 요건이 아니기 때문이다. 예를 들어, 사용자 디바이스에 또는 서비스 제공자에 또는 이들 양자에 하나의 프라이버시 에이전트만이 존재할 수 있다. 도 4에서, 우리는 넷플릭스(Netflix)와 페이스북(Facebook) 양자에 대해 동일 프라이버시 에이전트 "C"가 존재한다는 것을 나타낸다. 다른 실시예에서, 페이스북 및 넷플리스에 있는 프라이버시 에이전트들은 동일할 수 있지만, 반드시 그럴 필요는 없다.In Figure 4, we show that there are multiple privacy agents in the system. In different variants, there is no need for privacy agents to be present everywhere, since this is not a requirement for the privacy system to operate. For example, there may be only one privacy agent at the user device or at the service provider, or both. In Figure 4, we show that there is the same privacy agent "C " for both Netflix and Facebook. In another embodiment, the privacy agents in Facebook and Netfliess may be the same, but not necessarily.
본 명세서에서 기술되는 구현들은, 예를 들어 방법 또는 프로세스, 장치, 소프트웨어 프로그램, 데이터 스트림 또는 신호에 구현될 수 있다. 단일 형태의 구현의 맥락으로만 논의되는(예를 들어, 방법으로만 논의되는) 경우에도, 논의되는 특징들의 구현은 다른 형태들(예를 들어, 장치 또는 프로그램)로도 구현될 수 있다. 장치는 예를 들어, 적절한 하드웨어, 소프트웨어, 및 펌웨어로 구현될 수 있다. 방법들은 예를 들어, 일반적으로 예를 들어 컴퓨터, 마이크로프로세서, 집적 회로, 또는 프로그램가능 로직 디바이스를 포함하는 프로세싱 디바이스들을 지칭하는 예컨대 프로세서와 같은 장치에서 구현될 수 있다. 프로세서들은 또한 예를 들어 컴퓨터, 셀 폰, 휴대용/개인용 디지털 단말기("PDA"), 및 최종 사용자들 간의 정보의 통신을 용이하게 하는 다른 장치들과 같은 통신 장치들을 포함한다.Implementations described herein may be implemented in, for example, a method or process, an apparatus, a software program, a data stream, or a signal. Even when discussed only in the context of a single type of implementation (e.g., discussed only by way of example), the implementation of the features discussed may also be implemented in other forms (e.g., a device or a program). The device may be implemented with, for example, suitable hardware, software, and firmware. The methods may be implemented, for example, in an apparatus such as a processor, for example, generally referring to processing devices including, for example, a computer, microprocessor, integrated circuit, or programmable logic device. The processors also include communication devices such as, for example, computers, cell phones, portable / personal digital assistants ("PDAs"), and other devices that facilitate communication of information between end users.
본원의 원리들의 "일 실시예" 또는 "실시예" 또는 "하나의 구현" 또는 "구현"에 대한 참조뿐 아니라 그의 다른 변형들은, 실시예와 관련하여 설명되는 특정한 특징, 구조, 특성 등이 본원의 원리들의 적어도 일 실시예에 포함된다는 것을 의미한다. 따라서, 명세서 전체에 걸쳐서 다양한 곳에서 나타나는 "일 실시예에서" 또는 "실시예에서" 또는 "하나의 구현에서" 또는 "구현에서"라는 문구뿐 아니라 임의의 다른 변형들은 반드시 모두가 동일 실시예를 지칭하는 것은 아니다.Reference to "an embodiment" or "an embodiment" or "an embodiment" or "an implementation" of the principles of the present application as well as other modifications thereof, means that the particular features, Quot; is included in at least one embodiment of the principles of < / RTI > Thus, the appearances of the phrases "in one embodiment" or "in an embodiment" or "in one embodiment" or "in an implementation" appearing in various places throughout the specification are not necessarily all referring to the same embodiment It does not refer to it.
게다가, 본원, 또는 그의 청구항들은 다양한 정보들을 "결정하는 것"을 지칭할 수 있다. 정보를 결정하는 것은 예를 들어, 정보를 추정하는 것, 정보를 계산하는 것, 정보를 예측하는 것 또는 메모리로부터의 정보를 검색하는 것 중 하나 이상을 포함할 수 있다.Furthermore, the present application, or claims, may refer to "determining " various information. Determining the information may include, for example, one or more of estimating the information, calculating the information, predicting the information, or retrieving information from the memory.
또한, 본원, 또는 그의 청구항들은 다양한 정보들을 "액세스하는 것"을 지칭할 수 있다. 정보에 액세스하는 것은 예를 들어, 정보를 수신하는 것, (예를 들어, 메모리로부터의) 정보를 검색하는 것, 정보를 저장하는 것, 정보를 처리하는 것, 정보를 전송하는 것, 정보를 이동시키는 것, 정보를 복사하는 것, 정보를 소거하는 것, 정보를 계산하는 것, 정보를 결정하는 것, 정보를 예측하는 것, 또는 정보를 추정하는 것 중 하나 이상을 포함할 수 있다.Further, the subject matter, or claims thereof, may refer to "accessing " various information. Accessing information may include, for example, receiving information, retrieving information (e.g., from memory), storing information, processing information, transferring information, It may include one or more of moving, copying information, clearing information, calculating information, determining information, predicting information, or estimating information.
게다가, 본원, 또는 그의 청구항들은 다양한 정보의 "수신"을 지칭할 수 있다. 수신은 "액세스"와 같이 광범위한 용어인 것을 의도한다. 정보의 수신은 예를 들어, 정보에 액세스하는 것 또는 (예를 들어, 메모리로부터의) 정보를 검색하는 것 중 하나 이상을 포함할 수 있다. 또한, "수신"은 통상적으로 예를 들어, 정보를 저장하는 것, 정보를 처리하는 것, 정보를 전송하는 것, 정보를 이동시키는 것, 정보를 복사하는 것, 정보를 소거하는 것, 정보를 계산하는 것, 정보를 결정하는 것, 정보를 예측하는 것 또는 정보를 추정하는 것과 같은 동작들 동안 하나의 방식 또는 다른 방식으로 수반된다.Furthermore, the present application, or claims, may refer to "reception" of various information. Reception is intended to be a broad term such as "access ". Receipt of information may include, for example, one or more of accessing information or retrieving information (e.g., from memory). Also, "receiving" typically includes, for example, storing information, processing information, transferring information, moving information, copying information, deleting information, Computation, information determination, prediction of information, or estimation of information, in one way or another.
통상의 기술자에게 명백할 것인 바와 같이, 구현들은 예를 들어 저장 또는 전송될 수 있는 정보를 전달하도록 포맷팅되는 다양한 신호들을 생성할 수 있다. 정보는, 예를 들어 방법을 수행하기 위한 명령어들, 또는 설명되는 구현들 중 하나에 의해 생성되는 데이터를 포함할 수 있다. 예를 들어, 신호는 설명되는 실시예의 비트스트림을 전달하도록 포맷팅될 수 있다. 그러한 신호는, (예를 들어, 스펙트럼의 무선 주파수 부분을 이용하여) 예를 들어, 전자기파로서, 또는 기저대역 신호로서 포맷팅될 수 있다. 포맷팅은, 예를 들어 데이터 스트림을 인코딩하고, 인코딩된 데이터 스트림으로 반송파를 변조하는 것을 포함할 수 있다. 신호가 전달하는 정보는, 예를 들어 아날로그 또는 디지털 정보일 수 있다. 신호는 알려진 바와 같이, 각종 상이한 유선 또는 무선 링크들을 통해 전송될 수 있다. 신호는 프로세서 판독가능 매체 상에 저장될 수 있다.As will be apparent to those of ordinary skill in the art, implementations may generate various signals that are formatted, for example, to convey information that may be stored or transmitted. The information may include, for example, instructions for performing the method, or data generated by one of the described implementations. For example, the signal may be formatted to convey the bitstream of the described embodiment. Such a signal may be formatted (e.g., using a radio frequency portion of the spectrum), for example, as an electromagnetic wave, or as a baseband signal. Formatting may include, for example, encoding the data stream and modulating the carrier with the encoded data stream. The information that the signal carries may be, for example, analog or digital information. The signals may be transmitted over a variety of different wired or wireless links, as is known. The signal may be stored on the processor readable medium.
Claims (21)
사적 데이터와 공용 데이터를 포함하는 상기 사용자 데이터에 액세스하는 단계 -상기 사적 데이터는 제1 데이터 카테고리에 대응하고, 상기 공용 데이터는 제2 데이터 카테고리에 대응함- ;
상기 제1 데이터 카테고리의 공분산 행렬을 결정하는 단계(120);
상기 공분산 행렬에 응답하여 가우시안 잡음을 생성하는 단계(130);
상기 사용자의 공용 데이터에 상기 생성된 가우시안 잡음을 추가함으로써 상기 공용 데이터를 수정하는 단계(140); 및
서비스 제공자와 데이터 수집 에이전시 중 적어도 하나에게 상기 수정된 데이터를 릴리즈(release)하는 단계(150)
를 포함하는 방법.A method for processing user data for a user,
Accessing the user data including private data and public data, the private data corresponding to a first data category and the common data corresponding to a second data category;
Determining (120) a covariance matrix of the first data category;
Generating (130) Gaussian noise in response to the covariance matrix;
(140) modifying the common data by adding the generated Gaussian noise to the common data of the user; And
Releasing the modified data to at least one of a service provider and a data collection agency (150)
≪ / RTI >
상기 공용 데이터는 상기 사용자가 공개적으로 릴리즈될 수 있는 것으로 표시한 데이터를 포함하고, 상기 사적 데이터는 상기 사용자가 공개적으로 릴리즈되지 않도록 표시한 데이터를 포함하는 방법.The method according to claim 1,
Wherein the public data includes data indicating that the user is publicly releasable and the private data includes data indicating that the user is not publicly released.
상기 가우시안 잡음을 생성하는 단계는,
상기 공분산 행렬의 고유값들 및 고유벡터들을 결정하는 단계; 및
각각, 상기 결정된 고유값들 및 고유벡터들에 응답하여 또 다른 고유값들 및 고유벡터들을 결정하는 단계
를 포함하고,
상기 가우시안 잡음은 상기 또 다른 고유값들 및 고유벡터들에 응답하여 생성되는 방법.The method according to claim 1,
Wherein the generating the Gaussian noise comprises:
Determining eigenvalues and eigenvectors of the covariance matrix; And
Determining respective eigenvalues and eigenvectors in response to the determined eigenvalues and eigenvectors, respectively
Lt; / RTI >
Wherein the Gaussian noise is generated in response to the further eigenvalues and eigenvectors.
상기 결정된 또 다른 고유벡터들은 상기 공분산 행렬의 상기 결정된 고유벡터들과 실질적으로 동일한 방법.The method according to claim 1,
Wherein the determined other eigenvectors are substantially the same as the determined eigenvectors of the covariance matrix.
상기 가우시안 잡음을 생성하는 단계는 왜곡 제약에 추가로 응답하는 방법.The method according to claim 1,
Wherein generating the Gaussian noise is further responsive to distortion constraints.
상기 가우시안 잡음을 생성하는 단계는 상기 제2 데이터 카테고리의 정보와 독립적으로 생성하는 단계를 포함하는 방법.The method according to claim 1,
Wherein generating the Gaussian noise comprises generating independently of the information of the second data category.
상기 릴리즈 데이터에 기초하여 서비스를 수신하는 단계를 더 포함하는 방법.The method according to claim 1,
And receiving a service based on the release data.
사적 데이터와 공용 데이터를 포함하는 상기 사용자 데이터에 액세스하는 단계;
유틸리티 D에 대한 제약에 액세스하는 단계(220) -상기 유틸리티는 상기 사용자의 상기 공용 데이터 및 릴리즈 데이터에 응답함- ;
상기 유틸리티 제약에 응답하여 랜덤 잡음 Z를 생성하는 단계(230) -상기 랜덤 잡음은 상기 유틸리티 제약 하에서 최대 엔트로피 확률 분포를 따름- ;
상기 사용자에 대한 상기 릴리즈 데이터를 생성하기 위해 상기 사용자의 상기 공용 데이터에 상기 생성된 잡음을 추가하는 단계(140); 및
서비스 제공자와 데이터 수집 에이전시 중 적어도 하나에게 상기 릴리즈 데이터를 릴리즈하는 단계(150)
를 포함하는 방법.CLAIMS 1. A method for processing user data for a user,
Accessing the user data including private data and public data;
Accessing (220) constraints on utility D, the utility responding to the user's public data and release data;
Generating (230) random noise Z in response to the utility constraint, the random noise following a maximum entropy probability distribution under the utility constraint;
Adding (140) the generated noise to the public data of the user to generate the release data for the user; And
Releasing (150) the release data to at least one of a service provider and a data collection agency,
≪ / RTI >
상기 랜덤 잡음은 분포(distribution)
The random noise may be a distribution,
사적 데이터와 공용 데이터를 포함하는, 상기 사용자 데이터의 제1 데이터 카테고리의 공분산 행렬을 결정하도록 구성된 통계 수집 모듈(320) -상기 사적 데이터는 상기 제1 데이터 카테고리에 대응하고, 상기 공용 데이터는 제2 데이터 카테고리에 대응함- ;
상기 공분산 행렬에 응답하여 가우시안 잡음을 생성하도록 구성된 가산성 잡음 생성기(330); 및
상기 사용자의 상기 공용 데이터에 상기 생성된 가우시안 잡음을 추가함으로써 상기 공용 데이터를 수정하고, 및
서비스 제공자와 데이터 수집 에이전시 중 적어도 하나에게 상기 수정된 데이터를 릴리즈하도록 구성된 프라이버시 보호 모듈(340)
을 포함하는 장치. An apparatus for processing user data for a user,
A statistics collection module (320) configured to determine a covariance matrix of a first data category of the user data, including private data and public data, the private data corresponding to the first data category, Corresponds to data category -;
An additive noise generator (330) configured to generate Gaussian noise in response to the covariance matrix; And
Modifying the common data by adding the generated Gaussian noise to the common data of the user, and
A privacy protection module (340) configured to release the modified data to at least one of a service provider and a data collection agency,
/ RTI >
상기 공용 데이터는 상기 사용자가 공개적으로 릴리즈될 수 있는 것으로 표시한 데이터를 포함하고, 상기 사적 데이터는 상기 사용자가 공개적으로 릴리즈되지 않도록 표시한 데이터를 포함하는 장치.12. The method of claim 11,
Wherein the public data includes data indicating that the user is publicly releasable, and the private data includes data indicating that the user is not publicly released.
상기 가산성 잡음 생성기(330)는,
상기 공분산 행렬의 고유값들 및 고유벡터들을 결정하고,
각각, 상기 결정된 고유값들 및 고유벡터들에 응답하여 또 다른 고유값들 및 고유벡터들을 결정하도록 구성되고, 상기 가우시안 잡음은 상기 또 다른 고유값들 및 고유벡터들에 응답하여 생성되는 장치.12. The method of claim 11,
The additive noise generator 330 generates a noise-
Determining eigenvalues and eigenvectors of the covariance matrix,
And to determine further eigenvalues and eigenvectors in response to the determined eigenvalues and eigenvectors, respectively, and wherein the Gaussian noise is generated in response to the eigenvalues and eigenvectors.
상기 결정된 또 다른 고유벡터들은 상기 공분산 행렬의 상기 결정된 고유벡터들과 실질적으로 동일한 장치.12. The method of claim 11,
Wherein the determined other eigenvectors are substantially identical to the determined eigenvectors of the covariance matrix.
상기 가산성 잡음 생성기는 왜곡 제약에 응답하도록 구성되는 장치.12. The method of claim 11,
Wherein the additive noise generator is configured to respond to a distortion constraint.
상기 가산성 잡음 생성기는 상기 제2 데이터 카테고리의 정보와 독립적으로 상기 가우시안 잡음을 생성하는 장치.12. The method of claim 11,
Wherein the additive noise generator generates the Gaussian noise independently of the information of the second data category.
상기 릴리즈 데이터에 기초하여 서비스를 수신하도록 구성된 프로세서를 더 포함하는 장치.12. The method of claim 11,
And a processor configured to receive the service based on the release data.
유틸리티 D에 대한 제약에 액세스하도록 구성된 통계 수집 모듈(320) -상기 유틸리티는 상기 사용자의 공용 데이터 및 릴리즈 데이터에 응답함- ;
상기 유틸리티 제약에 응답하여 랜덤 잡음 Z를 생성하도록 구성된 가산성 잡음 생성기 -상기 랜덤 잡음은 상기 유틸리티 제약 하에서 최대 엔트로피 확률 분포를 따름- ; 및
사적 데이터 및 공용 데이터를 포함하는 상기 사용자 데이터에 액세스하고,
상기 사용자에 대한 릴리즈 데이터를 생성하기 위해 상기 사용자의 상기 공용 데이터에 상기 생성된 잡음을 추가하며, 및
서비스 제공자와 데이터 수집 에이전시 중 적어도 하나에게 상기 릴리즈 데이터를 릴리즈하도록 구성된 프라이버시 보호 모듈(340)
을 포함하는 장치.An apparatus for processing user data for a user,
A statistics gathering module (320) configured to access constraints on utility D, the utility responsive to the user's public data and release data;
An additive noise generator configured to generate a random noise Z in response to the utility constraint, the random noise following a maximum entropy probability distribution under the utility constraint; And
Accessing the user data including private data and public data,
Add the generated noise to the public data of the user to generate release data for the user, and
A privacy protection module (340) configured to release the release data to at least one of a service provider and a data collection agency,
/ RTI >
상기 랜덤 잡음은 분포
The random noise
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201361867546P | 2013-08-19 | 2013-08-19 | |
| US61/867,546 | 2013-08-19 | ||
| PCT/US2013/071290 WO2015026386A1 (en) | 2013-08-19 | 2013-11-21 | Method and apparatus for utility-aware privacy preserving mapping through additive noise |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20160044553A true KR20160044553A (en) | 2016-04-25 |
Family
ID=49880942
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020167007121A KR20160044553A (en) | 2013-08-19 | 2013-11-21 | Method and apparatus for utility-aware privacy preserving mapping through additive noise |
Country Status (5)
| Country | Link |
|---|---|
| EP (1) | EP3036679A1 (en) |
| JP (1) | JP2016531513A (en) |
| KR (1) | KR20160044553A (en) |
| CN (1) | CN105659249A (en) |
| WO (1) | WO2015026386A1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102055864B1 (en) * | 2019-05-08 | 2019-12-13 | 서강대학교 산학협력단 | Method for publish a differentially private time interval dataset |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108141460B (en) * | 2015-10-14 | 2020-12-04 | 三星电子株式会社 | System and method for privacy management of unlimited data streams |
| US10956603B2 (en) * | 2016-04-07 | 2021-03-23 | Samsung Electronics Co., Ltd. | Private dataaggregation framework for untrusted servers |
| CN106130675B (en) * | 2016-06-06 | 2018-11-09 | 联想(北京)有限公司 | One kind plus treating method and apparatus of making an uproar |
| US10333822B1 (en) | 2017-05-23 | 2019-06-25 | Cisco Technology, Inc. | Techniques for implementing loose hop service function chains price information |
| US11132453B2 (en) * | 2017-12-18 | 2021-09-28 | Mitsubishi Electric Research Laboratories, Inc. | Data-driven privacy-preserving communication |
| CN109543445B (en) * | 2018-10-29 | 2022-12-20 | 复旦大学 | Privacy protection data publishing method based on conditional probability distribution |
| CN111209531B (en) * | 2018-11-21 | 2023-08-08 | 百度在线网络技术(北京)有限公司 | Correlation degree processing method, device and storage medium |
| CN109753921A (en) * | 2018-12-29 | 2019-05-14 | 上海交通大学 | A kind of face feature vector secret protection recognition methods |
| US20220215116A1 (en) * | 2019-05-14 | 2022-07-07 | Telefonaktiebolaget Lm Ericsson (Publ) | Utility optimized differential privacy system |
| CN110648289B (en) * | 2019-08-29 | 2023-07-11 | 腾讯科技(深圳)有限公司 | Image noise adding processing method and device |
| SE2050534A1 (en) * | 2020-05-07 | 2021-11-08 | Dpella Ab | Estimating Accuracy of Privacy-Preserving Data Analyses |
| CN112231764B (en) * | 2020-09-21 | 2023-07-04 | 北京邮电大学 | Time sequence data privacy protection method and related equipment |
| CN112364372A (en) * | 2020-10-27 | 2021-02-12 | 重庆大学 | Privacy protection method with supervision matrix completion |
| CN113821577B (en) * | 2021-08-27 | 2024-02-02 | 同济大学 | Geographic indistinguishability-based position blurring method in indoor environment |
| CN116305292B (en) * | 2023-05-17 | 2023-08-08 | 中国电子科技集团公司第十五研究所 | Government affair data release method and system based on differential privacy protection |
| CN118053596B (en) * | 2024-03-04 | 2024-08-06 | 飞图云科技(山东)有限公司 | Intelligent medical platform data management method and system |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060069452A (en) * | 2003-08-08 | 2006-06-21 | 코닌클리케 필립스 일렉트로닉스 엔.브이. | System for processing data and method thereof |
| US7302420B2 (en) * | 2003-08-14 | 2007-11-27 | International Business Machines Corporation | Methods and apparatus for privacy preserving data mining using statistical condensing approach |
| US7363192B2 (en) * | 2005-12-09 | 2008-04-22 | Microsoft Corporation | Noisy histograms |
| US7853545B2 (en) * | 2007-02-26 | 2010-12-14 | International Business Machines Corporation | Preserving privacy of one-dimensional data streams using dynamic correlations |
| US8619984B2 (en) * | 2009-09-11 | 2013-12-31 | Microsoft Corporation | Differential privacy preserving recommendation |
-
2013
- 2013-11-21 CN CN201380078968.XA patent/CN105659249A/en active Pending
- 2013-11-21 JP JP2016536079A patent/JP2016531513A/en not_active Withdrawn
- 2013-11-21 WO PCT/US2013/071290 patent/WO2015026386A1/en active Application Filing
- 2013-11-21 KR KR1020167007121A patent/KR20160044553A/en not_active Application Discontinuation
- 2013-11-21 EP EP13812234.6A patent/EP3036679A1/en not_active Withdrawn
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102055864B1 (en) * | 2019-05-08 | 2019-12-13 | 서강대학교 산학협력단 | Method for publish a differentially private time interval dataset |
Also Published As
| Publication number | Publication date |
|---|---|
| EP3036679A1 (en) | 2016-06-29 |
| WO2015026386A1 (en) | 2015-02-26 |
| CN105659249A (en) | 2016-06-08 |
| JP2016531513A (en) | 2016-10-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20160044553A (en) | Method and apparatus for utility-aware privacy preserving mapping through additive noise | |
| US20160210463A1 (en) | Method and apparatus for utility-aware privacy preserving mapping through additive noise | |
| Li et al. | Privacy computing: concept, computing framework, and future development trends | |
| Wu et al. | An effective approach for the protection of user commodity viewing privacy in e-commerce website | |
| US20160203333A1 (en) | Method and apparatus for utility-aware privacy preserving mapping against inference attacks | |
| Ganti et al. | PoolView: stream privacy for grassroots participatory sensing | |
| US20160006700A1 (en) | Privacy against inference attacks under mismatched prior | |
| Shen et al. | Epicrec: Towards practical differentially private framework for personalized recommendation | |
| EP3036678A1 (en) | Method and apparatus for utility-aware privacy preserving mapping in view of collusion and composition | |
| US20150235051A1 (en) | Method And Apparatus For Privacy-Preserving Data Mapping Under A Privacy-Accuracy Trade-Off | |
| US20180181878A1 (en) | Privacy-preserving transformation of continuous data | |
| US20150339493A1 (en) | Privacy protection against curious recommenders | |
| EP3036677A1 (en) | Method and apparatus for utility-aware privacy preserving mapping against inference attacks | |
| EP4097618B1 (en) | Privacy preserving machine learning for content distribution and analysis | |
| CN111353554A (en) | Method and device for predicting missing user service attributes | |
| Bandoh et al. | Distributed secure sparse modeling based on random unitary transform | |
| US20160203334A1 (en) | Method and apparatus for utility-aware privacy preserving mapping in view of collusion and composition | |
| Ding et al. | On the privacy and utility properties of triple matrix-masking | |
| AU2013377887A1 (en) | Privacy protection against curious recommenders | |
| Yang et al. | SPoFC: A framework for stream data aggregation with local differential privacy | |
| Berg et al. | Benchmarked small area prediction | |
| Wang | Privacy preservation for linear and learning based inference systems | |
| CN111095235A (en) | Statistics-based multidimensional data cloning | |
| Yang | Improving privacy preserving in modern applications | |
| Zhang et al. | Towards Efficient and Privacy-Preserving Service QoS Prediction with Federated Learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| WITN | Withdrawal due to no request for examination |