KR20150123902A - 콘텐츠 기반 잡음 억제 - Google Patents
콘텐츠 기반 잡음 억제 Download PDFInfo
- Publication number
- KR20150123902A KR20150123902A KR1020157026895A KR20157026895A KR20150123902A KR 20150123902 A KR20150123902 A KR 20150123902A KR 1020157026895 A KR1020157026895 A KR 1020157026895A KR 20157026895 A KR20157026895 A KR 20157026895A KR 20150123902 A KR20150123902 A KR 20150123902A
- Authority
- KR
- South Korea
- Prior art keywords
- signal
- audio signal
- noise
- noise signal
- content
- Prior art date
Links
- 230000001629 suppression Effects 0.000 title description 16
- 230000005236 sound signal Effects 0.000 claims abstract description 156
- 238000000034 method Methods 0.000 claims abstract description 82
- 238000004891 communication Methods 0.000 claims abstract description 42
- 230000002238 attenuated effect Effects 0.000 claims abstract description 12
- 230000003044 adaptive effect Effects 0.000 claims description 41
- 230000001360 synchronised effect Effects 0.000 claims description 20
- 230000004044 response Effects 0.000 claims description 6
- 238000004590 computer program Methods 0.000 claims description 2
- 238000012545 processing Methods 0.000 description 64
- 238000010586 diagram Methods 0.000 description 20
- 238000013500 data storage Methods 0.000 description 14
- 230000001934 delay Effects 0.000 description 9
- 230000006870 function Effects 0.000 description 9
- 230000000694 effects Effects 0.000 description 8
- 239000000872 buffer Substances 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 238000001914 filtration Methods 0.000 description 6
- 230000006978 adaptation Effects 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- 238000001514 detection method Methods 0.000 description 4
- 238000012805 post-processing Methods 0.000 description 4
- 230000008569 process Effects 0.000 description 4
- 230000003287 optical effect Effects 0.000 description 3
- 239000000758 substrate Substances 0.000 description 3
- 238000002592 echocardiography Methods 0.000 description 2
- 239000000284 extract Substances 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 239000000835 fiber Substances 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 230000003595 spectral effect Effects 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 240000001436 Antirrhinum majus Species 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 239000010979 ruby Substances 0.000 description 1
- 229910001750 ruby Inorganic materials 0.000 description 1
- 238000010845 search algorithm Methods 0.000 description 1
- 238000013179 statistical model Methods 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
Images





Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04M—TELEPHONIC COMMUNICATION
- H04M9/00—Arrangements for interconnection not involving centralised switching
- H04M9/08—Two-way loud-speaking telephone systems with means for conditioning the signal, e.g. for suppressing echoes for one or both directions of traffic
- H04M9/082—Two-way loud-speaking telephone systems with means for conditioning the signal, e.g. for suppressing echoes for one or both directions of traffic using echo cancellers
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10K—SOUND-PRODUCING DEVICES; METHODS OR DEVICES FOR PROTECTING AGAINST, OR FOR DAMPING, NOISE OR OTHER ACOUSTIC WAVES IN GENERAL; ACOUSTICS NOT OTHERWISE PROVIDED FOR
- G10K11/00—Methods or devices for transmitting, conducting or directing sound in general; Methods or devices for protecting against, or for damping, noise or other acoustic waves in general
- G10K11/16—Methods or devices for protecting against, or for damping, noise or other acoustic waves in general
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L2021/02082—Noise filtering the noise being echo, reverberation of the speech
Landscapes
- Engineering & Computer Science (AREA)
- Signal Processing (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Quality & Reliability (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Soundproofing, Sound Blocking, And Sound Damping (AREA)
- Circuit For Audible Band Transducer (AREA)
Abstract
오디오 잡음 감쇄를 위한 장치 및 방법들이 개시된다. 오디오 신호 분석기는 마이크로폰 디바이스로부터 수신된 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지 여부를 결정할 수 있다. 식별가능한 콘텐츠를 갖는 잡음 신호가 있다면, 콘텐츠 소스는 잡음 신호의 카피를 획득하기 위해 액세스된다. 오디오 캔슬러는 잡음 신호의 카피를 입력 오디오 신호와 비교하는 것에 기초하여 감쇄된 잡음 신호를 갖는 프로세싱된 오디오 신호를 생성할 수 있다. 추가적으로 또는 대안적으로, 데이터는, 별개의 미디어 디바이스로부터 잡음 신호의 카피의 적어도 부분을 수신하거나, 콘텐츠 소스에 대응하는 콘텐츠 식별 데이터를 수신하기 위해, 통신 채널 상에서 별개의 미디어 디바이스에 통신될 수도 있다.
Description
다음의 설명은 오디오 신호 프로세싱과 관련된다. 특히, 본 설명은 오디오 잡음 억제와 관련된다.
개인용 디바이스들은, 부분적으로는, 배터리, 프로세싱, 및 통신 기술들의 발전으로 인해 점차적으로 이동식이 되고, 강력해지며 접속적이 되었다. 이들 기술들이 발전함에 따라, 사용자들은 그들이 그들의 디바이스들을 이용하고 그들의 디바이스들과 상호작용할 수도 있는 방식들에 있어서 더 많은 가요성 (flexibility) 을 갖는다. 특히, 모바일 디바이스는 사용자들이 음성 커맨드들로 모바일 디바이스를 제어하는 것을 허용하기 위해 음성 인식을 이용할 수도 있다. 더욱이, 음성 인식은 물론 음성 텔레메트리 (telemetry) 를 위해, 사용자들은 음향적으로 거친 (acoustically-harsh) 환경들을 포함한 다양한 환경들에서 모바일 디바이스를 정상적으로 동작시키길 원한다.
다양한 잡음 억제 스킴들은 사용자가 모바일 디바이스와 상호작용하고 있을 때 배경 잡음의 부작용들을 감소 또는 완화시키는데 이용되었다. 예를 들어, 주파수 선택적 필터링은 소정의 주파수 대역들과 연관된 잡음들을 억제하는데 이용될 수 있다. 다른 잡음 억제 스킴들은 통계적 모델들을 이용하여 노이즈와 통계적으로 관련되거나 의도된 오디오 신호와 통계적으로 관련되지 않는 캡처된 오디오 신호의 소정의 양태들을 억제한다. 또 다른 잡음 억제 스킴들은 내부 신호들을 이용하여 모바일 디바이스에 의해 생성된 후 감지된 사운드로부터 발생하는 잡음 (예를 들어, 에코 잡음) 을 캔슬한다.
본 발명의 시스템들, 방법들, 및 디바이스들은 각각 여러 양태들을 가지며, 그 양태들 중 단일의 양태가 단독으로 그 바람직한 속성들을 담당하지 않는다. 다음에 오는 청구항들에 의해 표현한 바와 같이 본 발명의 범위를 제한하지 않고, 일부 특징들이 이제 간략하게 논의될 것이다. 이 논의를 고려한 후, 그리고 특히 "상세한 설명" 이란 제목의 섹션을 읽은 후, 본 발명의 특징들이 오디오 프로세싱을 개선시키기 위해 배경 잡음들을 감소시키는 것을 포함하는 이점들을 제공하는 방법을 이해할 것이다.
하나의 실시형태는 오디오 잡음을 감쇄시키기 위한 디바이스이다. 디바이스는 입력 오디오 신호를 수신하도록 구성된 마이크로폰을 포함할 수 있다. 디바이스는 또한, 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지를 결정하도록 구성된 오디오 신호 분석기를 포함할 수 있다. 식별가능한 콘텐츠를 갖는 잡음 신호가 있다면, 오디오 신호 분석기는 잡음 신호의 카피 (copy) 를 획득하기 위해 콘텐츠 소스에 액세스할 수 있다. 디바이스는 또한, 잡음 신호의 카피를 입력 오디오 신호와 비교하는 것에 기초하여 감쇄된 잡음 신호를 갖는 프로세싱된 오디오 신호를 생성하도록 구성된 오디오 캔슬러 (audio canceller) 를 포함할 수 있다.
다른 실시형태는 오디오 잡음을 감쇄시키기 위한 방법이다. 방법은 입력 오디오 신호를 수신하는 단계를 포함할 수 있다. 방법은 또한, 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지를 결정하는 단계를 포함할 수 있다. 식별가능한 콘텐츠를 갖는 잡음 신호가 있다면, 방법은 잡음 신호의 카피를 획득하기 위해 콘텐츠 소스에 액세스하는 단계를 포함할 수 있다. 방법은 잡음 신호의 카피를 입력 오디오 신호와 비교하는 것에 기초하여 감쇄된 잡음 신호를 갖는 프로세싱된 오디오 신호를 생성하는 단계를 더 포함할 수 있다.
또 다른 실시형태는, 실행될 때, 프로세서로 하여금, 방법을 수행하게 하는 명령들을 저장하는 비일시적 컴퓨터 판독가능 매체이다. 방법은 입력 오디오 신호를 수신하는 단계 및 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지를 결정하는 단계를 포함한다. 식별가능한 콘텐츠를 갖는 잡음 신호가 있다면, 방법은 잡음 신호의 카피를 획득하기 위해 콘텐츠 소스에 액세스하는 단계를 포함한다. 방법은 잡음 신호의 카피를 입력 오디오 신호와 비교하는 것에 기초하여 감쇄된 잡음 신호를 갖는 프로세싱된 오디오 신호를 생성하는 단계를 더 포함한다.
도 1 은 하나의 실시형태에 따른 하나 이상의 미디어 디바이스들로부터의 잡음을 억제하기 위한 모바일 폰을 포함하는 오디오 시스템의 블록 개략도이다.
도 2 는 오디오 잡음을 억제하기 위한 오디오 프로세싱 디바이스의 예시적인 실시형태의 블록도이다.
도 3 은 도 2 의 오디오 프로세싱 디바이스에 의해 구현된 오디오 신호 분석기의 특정 예시적인 실시형태의 블록도이다.
도 4 는 도 2 의 오디오 프로세싱 디바이스에 의해 구현된 오디오 캔슬러 시스템의 특정 예시적인 실시형태의 블록도이다.
도 5 는 도 2 의 오디오 프로세싱 디바이스에 의해 구현된 오디오 캔슬러 시스템의 다른 특정 예시적인 실시형태의 블록도이다.
도 6 은 다양한 실시형태들에 따른 오디오 잡음 억제의 방법의 플로우도이다.
도 7a 는 하나의 실시형태에 따른 오디오 입력 신호가 식별가능한 콘텐츠를 갖는 노이즈를 포함하는지를 결정하기 위한 예의 방법의 예시적인 플로우도이다.
도 7b 는 하나의 실시형태에 따른 소스 신호를 획득하기 위해 콘텐츠 소스에 액세스하기 위한 예의 방법의 예시적인 플로우도이다.
도 8 은 실시형태에 따른 오디오 잡음을 감쇄시키기 위한 예의 방법의 예시적인 플로우도이다.
도 9 는 실시형태에 따른 오디오 잡음 억제의 특정 예시적인 방법의 플로우도이다.
도 2 는 오디오 잡음을 억제하기 위한 오디오 프로세싱 디바이스의 예시적인 실시형태의 블록도이다.
도 3 은 도 2 의 오디오 프로세싱 디바이스에 의해 구현된 오디오 신호 분석기의 특정 예시적인 실시형태의 블록도이다.
도 4 는 도 2 의 오디오 프로세싱 디바이스에 의해 구현된 오디오 캔슬러 시스템의 특정 예시적인 실시형태의 블록도이다.
도 5 는 도 2 의 오디오 프로세싱 디바이스에 의해 구현된 오디오 캔슬러 시스템의 다른 특정 예시적인 실시형태의 블록도이다.
도 6 은 다양한 실시형태들에 따른 오디오 잡음 억제의 방법의 플로우도이다.
도 7a 는 하나의 실시형태에 따른 오디오 입력 신호가 식별가능한 콘텐츠를 갖는 노이즈를 포함하는지를 결정하기 위한 예의 방법의 예시적인 플로우도이다.
도 7b 는 하나의 실시형태에 따른 소스 신호를 획득하기 위해 콘텐츠 소스에 액세스하기 위한 예의 방법의 예시적인 플로우도이다.
도 8 은 실시형태에 따른 오디오 잡음을 감쇄시키기 위한 예의 방법의 예시적인 플로우도이다.
도 9 는 실시형태에 따른 오디오 잡음 억제의 특정 예시적인 방법의 플로우도이다.
상세한 설명
실시형태들은 전자 디바이스에 의해 수신된 오디오 신호에서 원하지 않는 오디오 잡음을 억제하기 위한 시스템들 및 방법들에 관한 것이다. 하나의 실시형태에서, 시스템은 배경으로 플레이되고 있는 유행가와 같은 식별가능한 미디어 콘텐츠를 표현하는 오디오 잡음을 억제한다. 시스템은 미디어 콘텐츠의 카피를 획득하고, 미디어 콘텐츠의 카피로부터 원하지 않는 오디오 잡음의 카피를 생성하며, 오디오 신호에서 원하지 않는 오디오 잡음을 제거할 수도 있다. 예를 들어, 동작에서, 시스템은 원하지 않는 오디오 잡음의 음향 패턴 또는 지문을 결정하고 그 패턴을 이용하여 오디오 잡음에 의해 표현된 미디어 콘텐츠 (예를 들어, 특정 노래) 를 식별한다. 아이덴티티는 식별된 노래의 디지털 레코딩과 같이, 미디어 콘텐츠 소스를 검색하는데 이용될 수 있다. 일단 노래가 식별되면, 그 노래의 카피가 전자 디바이스로 다운로드된 후 오디오 신호에서 그 노래를 차감하는데 이용될 수 있다. 하나의 실시형태에서, 시스템은 셀룰러 폰과 같은 휴대용 컴퓨팅 디바이스에 의해 구현될 수 있다. 예를 들어, 셀룰러 폰은 전화 통화 중 배경으로 플레이중인 노래들 또는 다른 미디어 콘텐츠를 억제할 수 있다.
하나의 특정 예에서, 시스템은 셀룰러 폰에 의해 구현될 수 있으며, 그 셀룰러 폰은 마이크로폰 및 그 폰의 메모리에 저장된 디지털 뮤직 라이브러리를 갖는다. 사람이 특정 노래를 플레이중인 라디오 근처에서 통화할 때, 시스템은 마이크로폰의 오디오 신호에서 오디오 특징 (audio feature) 들을 추출하여 그 노래의 음향 패턴 또는 지문을 디벨롭핑 (developing) 할 수 있다. 디벨롭핑된 패턴은 그 후 라디오가 플레이중인 노래를 찾기 위해 이러한 음향 패턴들에 의해 인덱싱된 노래 아이덴티티 (song identity) 들을 포함하는 데이터베이스를 검색하는데 이용될 수 있다. 노래 아이덴티티가 패턴과 매칭하면, 폰은 그 후 식별된 노래의 카피를 찾아 그것의 뮤직 라이브러리를 검색할 수 있다. 대안적으로, 폰은 네트워크 접속을 통해 서버로부터 식별된 노래의 카피를 요청할 수 있다. 일단 액세스되면, 노래의 카피는 수신된 오디오 신호에서 노래를 억제하기 위해 그 노래가 라디오 상에서 플레이될 때 그 노래의 시간 포지션 (temporal position) 에 동기화될 수 있다. 이 시스템을 갖는 폰은 다르게는 전화 통화하기에 너무 음향적으로 거친 영역들, 이를 테면 야외 공연장 또는 콘서트 홀에서 사용자가 폰을 동작시키는 것을 허용할 것이다.
다른 특정 예에서, 잡음 억제 시스템은 무선 통신 능력들을 갖는 텔레비전 (TV) 과 같은 별개의 미디어 디바이스를 제어하는 음성 제어 원격 제어기에 의해 구현될 수 있다. 그 제어기는 TV 로부터 직접 콘텐츠 정보를 수신할 수도 있다. 예를 들어, TV 는 디스플레이중인 액티브 채널을 원격지 (remote) 에 통신할 수 있고, 원격지는 그 정보를 이용하여 인터넷 접속을 통하여 채널의 오디오에 액세스할 수 있다. 대안적으로, TV 는 브로드캐스트의 카피를 원격지로 전송할 수 있다. 원격지는 차례로, 브로드캐스트의 카피를 이용하여 TV 에 의해 생성된 오디오를 상쇄시킬 수 있다. 이것은 음성 제어 전자 디바이스들이 오디오를 생성하는 미디어 디바이스들과 기능하는 것을 허용할 것이다.
개시된 방법들, 장치, 및 시스템들은 기존의 잡음 억제 기법들을 개선시키도록 기능할 수도 있다. 구체적으로, 일부 상황들에서, 오디오 잡음은 오디오 잡음의 콘텐츠를 추정 및/또는 식별한 후에 실질적으로 결정론적인 것으로 발견될 수 있다. 예시에 의해, 하나의 이러한 상황은 프리레코딩된 노래가 잡음 소스인 경우이다. 이 경우에, 노래가 어떤 특정 노래, 및 노래의 특정 타이밍을 플레이중이라는 것이 알려진다면, 그 노래는 실질적으로 결정론적일 수 있다. 상기 콘텐츠 관련 정보가 알려지거나 식별가능하다면, 그 노래 또는 오디오 신호의 카피가 그 노래에 대응하는 오디오 신호의 컴포넌트를 감쇄, 또는 상쇄시키는데 이용될 수 있다. 노래의 억제는 이렇게 하여 모바일 디바이스를 통한 음성 인식 또는 음성 통신의 품질을 개선시킬 수도 있다.
모바일 디바이스의 예들은 텔레비전, 라디오, 랩톱/넷북 컴퓨터, 태블릿 컴퓨터, 데스크톱 컴퓨터, 및 오디오 미디어 콘텐츠를 포함한 미디어 콘텐츠를 플레이하도록 구성된 유사한 전자 디바이스들을 포함한다. 오디오 미디어 콘텐츠의 예들은 뮤직, 비디오, 및 오디오를 갖는 다른 유사한 미디어를 표현하는 데이터 또는 신호들을 포함한다.
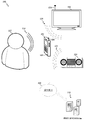
더욱 예시하기 위해, 도 1 은 하나 이상의 미디어 디바이스들로부터의 잡음을 억제하도록 구성되는 모바일 폰 (102) 을 포함하는 특정 오디오 구성 (100) 의 블록도를 도시한다. 특히, 모바일 폰 (102) 은 마이크로폰 (104) 및 안테나 (106) 를 갖는다. 모바일 폰 (102) 은 음성 및 데이터 신호들을 네트워크 (108) 또는 다른 전자 디바이스들에 통신할 수 있다. 네트워크 (108) 는 유선 또는 무선 네트워크일 수 있고, 뮤직 및 오디오-비디오 데이터 파일들과 같은 다양한 콘텐츠 소스들을 저장하는 하나 이상의 콘텐츠 데이터베이스들 (110) 에 대한 액세스를 제공할 수 있다. 하나의 실시형태에서, 네트워크는 인터넷이다.
동작에서, 사용자 (112) 는 예를 들어, 모바일 폰 (102) 을 제어하거나 모바일 폰 (102) 에 통신적으로 커플링된 다른 전자 디바이스들을 제어하기 위해, 음성 통신 및/또는 음성 인식을 위한 모바일 폰 (102) 의 마이크로폰 (104) 에 말한다. 모바일 폰 (102) 의 마이크로폰 (104) 은 사용자의 음성 커맨드들 (114) 을 캡처하여 입력 오디오 신호를 생성한다. 모바일 폰 (102) 은 일부 상황들에서, 네트워크 가능 (network-enabled) 텔레비전 (TV) (116) 또는 라디오 (118) 와 같은 별개의 미디어 디바이스들에 매우 근접하여 있을 수도 있다. 이들 디바이스들은 모바일 폰 (102) 의 동작에 대하여 원하지 않는 배경 오디오 잡음의 역할을 하는 배경 사운드들 (120, 122) 을 생성할 수도 있다.
예를 들어, 네트워크 가능 TV (116) 또는 라디오 (118) 는 저장된 또는 스트리밍 뮤직을 플레이중일 수 있다. 마이크로폰 (104) 은 네트워크 가능 TV (116) 또는 라디오 (118) 에 의해 생성된 배경 사운드들과 동시 발생적으로 사용자 (112) 로부터의 음성 커맨드들 (114) 을 캡처할 수도 있다. 이러한 사정으로, 네트워크 가능 TV (116) 또는 라디오 (118) 로부터의 사운드는 사용자의 음성 커맨드들 (114) 을 상당히 간섭하고 대화 또는 음성 인식을 사용자에게 어렵게 만들 수도 있다. 다양한 실시형태들은 입력 오디오 신호의 잡음 컴포넌트들을 억제하는 것과 관련된다.
모바일 폰 (102) 은 특히 잡음 신호의 콘텐츠가 식별될 수 있다면 잡음 신호를 더 많이 억제할 수 있다. 하나의 실시형태에서, 모바일 폰 (102) 은 입력 오디오 신호를 분석하여 그 입력 오디오 신호가 텔레비전 브로드캐스트로부터의 특정 노래 또는 오디오와 같은 식별가능한 콘텐츠를 갖는지 여부를 결정한다. 예를 들어, 하나의 실시형태는 입력 오디오 신호의 특징들을 추출하고, 그 후 콘텐츠 소스를 검색, 다운로딩, 스트리밍, 또는 다르게는 액세스함으로써 콘텐츠 식별 정보 (이를 테면 노래 타이틀, 앨범 네임, 아티스트 네임 등) 를 결정한다. 예를 들어, 도 1 을 참조하면, 모바일 폰 (102) 은 콘텐츠 소스에 액세스하기 위해 콘텐츠 데이터베이스들 (110) 을 검색할 수 있으며, 여기서 콘텐츠 소스는 소스 식별 정보와 매칭하는 것에 기초하여 결정된다. 콘텐츠 소스에 액세스하면, 모바일 폰 (102) 은 오디오 잡음 ("소스 신호") 의 카피를 획득할 수 있고, 이는 미디어 디바이스들에 의해 생성된 사운드에 대응하는 오디오 잡음을 특히 감쇄 또는 억제하는데 이용될 수 있다.
추가적으로 또는 대안적으로, 모바일 폰 (102) 은 직접 또는 네트워크 (108) 를 통해 중 어느 하나에 의해, 네트워크 가능 TV (116) 및/또는 라디오 (118) 와 통신하여 콘텐츠 소스를 식별할 수도 있다. 예를 들어, 모바일 폰 (102) 은 네트워크 가능 TV (116) 로부터 예를 들어 채널 정보를 요청가능할 수도 있으며, 여기서 네트워크 가능 TV (116) 는 그것의 통신 안테나 (124) 를 이용함으로써 통신할 수 있다. 수신된 채널 정보에 기초하여, 모바일 폰 (102) 은 콘텐츠 데이터베이스들 (110) 로부터의 콘텐츠 소스에 액세스할 수 있다. 다른 예로서, 모바일 폰 (102) 은 예를 들어, 식별된 채널로 튜닝함으로써 미디어 콘텐츠를 네트워크 가능 TV (116) 로 브로드캐스팅중인 디바이스 (미도시) 로부터의 콘텐츠 소스에 액세스할 수 있다. 또 다른 예로서, 모바일 폰 (102) 은 네트워크 가능 TV (116) 로부터의 콘텐츠 소스에 액세스할 수 있다. 즉, 네트워크 가능 TV (116) 는 모바일 폰 (102) 에 직접 콘텐츠 소스를 송신 또는 중계할 수 있다.
이제 도 2 로 돌아가면, 원하지 않는 오디오 잡음을 억제하도록 구성되는 오디오 프로세싱 디바이스 (202) 의 예시적인 실시형태의 블록도가 도시된다. 오디오 프로세싱 디바이스 (202) 는 버스 (214) 에 의해 상호접속되는 프로세서 (204), 마이크로폰 (206), 통신 인터페이스 (208), 데이터 스토리지 디바이스 (210), 및 메모리 (212) 를 포함한다. 더욱이, 메모리 (212) 는 오디오 신호 분석기 모듈 (216), 오디오 캔슬러 모듈 (218), 및 통신 모듈 (220) 을 포함할 수 있다. 오디오 프로세싱 디바이스 (202) 의 예들은 임의의 적용가능한 전자 디바이스, 이를 테면 모바일 컴퓨팅 디바이스, 셀룰러 폰, 범용 컴퓨터 등을 포함한다.
프로세서 (204) 는 메모리 (212) 로부터의 명령들을 실행하고 마이크로폰 (206), 통신 인터페이스 (208), 데이터 스토리지 디바이스 (210), 메모리 (212), 및 버스 (214) 를 제어 및 동작하도록 구성된, 마이크로프로세서 또는 마이크로제어기와 같은 회로부 (circuitry) 를 포함한다. 특히, 프로세서 (204) 는 범용 단일- 또는 다중-칩 마이크로프로세서 (예를 들어, ARM), 특수 목적 마이크로프로세서 (예를 들어, 디지털 신호 프로세서 (DSP)), 마이크로제어기, 프로그램가능 게이트 어레이 등일 수도 있다. 단지 단일의 프로세서만이 오디오 프로세싱 디바이스 (202) 내에 도시되지만, 대안의 구성에서는, 프로세서들 (예를 들어, ARM 및 DSP) 의 조합이 이용될 수 있다.
마이크로폰 (206) 은 메모리 (212) 로부터의 특정 명령들을 실행하는 프로세서 (204) 에 의해 제어한 바와 같이, 음향 사운드들을 캡처하고 응답으로 입력 오디오 신호를 생성하도록 구성된다. 마이크로폰 (206) 의 예들은 사운드를 전기 오디오 신호로 컨버팅하기 위한 임의의 적용가능한 센서 또는 트랜스듀서, 이를 테면 콘덴서 마이크로폰들, 다이내믹 마이크로폰들, 압전기 마이크로폰들 등을 포함한다. 일부 실시형태들에서, 마이크로폰 (206) 은 옵션적이며, 도 3 을 참조하여 이하 논의될 바와 같이, 입력 오디오 신호는 예를 들어 데이터 스토리지 디바이스 (210) 또는 메모리 (212) 로부터의 데이터로부터 생성되거나, 또는 통신 인터페이스 (208) 로부터 수신된다.
통신 인터페이스 (208) 는 오디오 프로세싱 디바이스 (202) 가 데이터, 이를 테면 콘텐츠 소스를 식별, 취출 또는 액세스하기 위한 데이터를 송신 및 수신하는 것을 허용하도록 구성된 전자장치 (electronics) 를 포함한다. 통신 인터페이스 (208) 는 무선 안테나, WLAN/LAN 및 다른 타입들의 라우터들 및 유사한 통신 디바이스들에 통신적으로 커플링될 수 있다.
데이터 스토리지 디바이스 (210) 및 메모리 (212) 는 화학, 자기, 전기, 광 또는 유사한 수단에 의해 정보를 저장하도록 구성된 메커니즘들을 포함한다. 예를 들어, 데이터 스토리지 디바이스 (210) 및 메모리 (212) 는 각각 불휘발성 메모리 디바이스, 이를 테면 플래시 메모리 또는 하드 디스크 드라이브, 또는 휘발성 메모리 디바이스, 이를 테면 동적 랜덤 액세스 메모리 (DRAM) 또는 정적 랜덤 액세스 메모리 (SRAM) 일 수 있다. 일부 실시형태들에서, 프로세서 (204) 는 데이터 스토리지 디바이스 (210) 의 콘텐츠 소스 데이터베이스에 액세스함으로써 콘텐츠 소스에 액세스할 수 있다. 도 2 는 데이터 스토리지 디바이스 (210) 를 오디오 프로세싱 디바이스 (202) 의 일부로서 도시한다. 다른 실시형태들에서, 데이터 스토리지 디바이스 (210) 는 별개의 디바이스 상에 위치하고 예를 들어 네트워크를 통해 통신 채널들에 의해 액세스될 수도 있다. 오디오 신호 분석기 모듈 (216) 은 도 3 과 관련하여 더욱 상세히 논의될 것이다.
메모리 (212) 내에는, 입력 오디오 신호의 콘텐츠의 식별을 개시하고, 대응하는 콘텐츠 소스에 대한 액세스를 제공하며, 및/또는 식별된 소스 신호를 수신하도록 프로세서 (204) 를 구성하는 명령들을 포함하는 오디오 신호 분석기 모듈 (216) 이 있다. 도 3 과 관련하여 더욱 상세히 논의될 바와 같이, 일부 실시형태들에서 특징들이 입력 오디오 신호로부터 추출된다. 추출된 특징들은 입력 오디오 신호에 의해 표현된 미디어 콘텐츠의 콘텐츠 아이덴티티를 결정하는데 이용될 수 있으며, 콘텐츠 아이덴티티는 콘텐츠 아이덴티티와 연관된 콘텐츠 소스에 액세스하는데 이용될 수 있다. 오디오 신호 분석기 모듈 (218) 은 도 4 및 도 5 와 관련하여 더욱 상세히 논의될 것이다.
메모리 (212) 내에는, 오디오 잡음을 감쇄시키기 위해 식별된 소스 신호로 입력 오디오 신호를 프로세싱하도록 프로세서 (204) 를 구성하는 명령들을 포함하는 오디오 캔슬러 모듈 (218) 이 있다. 특히, 입력 오디오 신호는 식별된 소스 신호와 비교된다. 하나의 실시형태에서, 식별된 소스 신호는 실내 음향학 (room acoustics) 을 설명하기 위해 필터링된다. 이것이 행해지는 한가지 이유는, 무엇보다도, 미디어 디바이스에 의해 생성된 사운드가, 부분적으로는, 전자 디바이스가 위치하는 음향 공간의 음향 효과들로 인해 식별된 소스 신호와 다를 수도 있기 때문이다. 음향 효과들은 음향 댐프닝 (acoustical dampening) 및 에코들을 포함할 수도 있다. 다른 실시형태에서, 입력 오디오 신호 및 식별된 소스 신호는 컴퓨테이션, 통신 및 음향 팩터들로부터 발생하는 다양한 지연들을 설명하기 위해 동기화된다. 오디오 캔슬러 모듈 (218) 은 도 4 및 도 5 와 관련하여 더욱 상세히 논의될 것이다.
메모리 (212) 내에는, 데이터를 송신 또는 수신하기 위해 통신 인터페이스 (208) 를 제어하도록 프로세서 (204) 를 구성하는 명령들을 포함하는 통신 모듈 (220) 이 있다. 일부 실시형태들에서, 통신은 이하 더 상세히 논의되는 바와 같이, 오디오 프로세싱 디바이스 (202) 와 별개의 미디어 디바이스, 이를 테면 도 1 의 네트워크 가능 TV (116) 간에 개시될 수 있다.
동작에서, 프로세서 (204) 는 마이크로폰 (206) 에 의해 캡처된 입력 오디오 신호를 수신하기 위해 메모리 (212) 로부터의 명령들을 실행할 수 있다. 입력 오디오 신호는 음성 신호 및 오디오 잡음 신호를 포함할 수도 있다. 예를 들어, 음성 신호는 사용자의 음성을 표현할 수도 있는 반면 오디오 잡음 신호는 인근의 미디어 디바이스들에 의해 생성된 사운드를 표현할 수도 있다. 프로세서 (204) 는 오디오 잡음 신호의 콘텐츠를 식별하기 위해 오디오 신호 분석기 모듈 (216) 로부터의 명령들을 실행할 수도 있다. 프로세서 (204) 는 그 후 식별된 콘텐츠와 연관된 콘텐츠 소스를 찾아 데이터 스토리지 디바이스 (210) 를 검색할 수도 있다. 추가적으로 또는 대안적으로, 프로세서 (204) 는 통신 인터페이스 (208) 를 경유하여 네트워크를 통해 데이터베이스들을 검색하기 위해 오디오 신호 분석기 및/또는 통신 모듈 (212) 로부터의 명령들을 실행할 수도 있다. 일단 오디오 프로세싱 디바이스 (202) 가 콘텐츠 소스에 액세스하고 대응하는 식별된 소스 신호를 갖는다면, 프로세서 (204) 는 잡음 신호 (예를 들어, 필터링된 또는 필터링되지 않은 식별된 소스 신호) 의 카피를 입력 오디오 신호와 비교함으로써 오디오 잡음 신호의 적어도 일부를 억제 또는 감쇄시키기 위해 오디오 캔슬러 모듈 (218) 로부터의 명령들을 실행할 수도 있다.
도 3 을 참조하면, 블록도는 도 2 의 오디오 프로세싱 디바이스 (202) 에 의해 구현된 오디오 신호 분석기 (300) 의 특정 예시적인 실시형태를 도시한다. 오디오 신호 분석기 (300) 는 프로세서 (204) 에 의해 실행되는, 오디오 신호 분석기 모듈 (216) 의 명령들과 같은 컴퓨터 실행가능 명령들로 구현될 수 있다. 도 3 의 오디오 신호 분석기 (300) 는 입력 오디오 신호를 수신하고 콘텐츠 식별 정보를 생성하도록 구성된 식별자 생성기 (302) 를 포함한다. 콘텐츠 식별 정보는 아티스트의 네임, 콘텐츠 타이틀 (노래, 영화, 오디오북 등의 네임), 식별 번호, 및 유사한 아이덴티티 표시 중 하나 이상을 포함할 수 있다. 오디오 신호 분석기 (300) 는 또한 콘텐츠 식별 정보를 수신하고 식별된 소스 신호를 생성하도록 구성되는 소스 매처 (source matcher) (304) 를 갖는다.
도 3 의 식별자 생성기 (302) 는 특징 추출기 (306), 콘텐츠 식별기 (308), 및 콘텐츠 아이덴티티 데이터베이스 (310) 를 갖는다. 특징 추출기 (306) 는 콘텐츠를 결정하기 위해 입력 오디오 신호의 특징 정보를 결정하도록 프로세서 (204) 를 구성하는 명령들을 포함하는 모듈에 의해 구현될 수 있다. 예를 들어, 동작에서 특징 추출기 (306) 는 입력 오디오 신호를 분석하여 입력 오디오 신호를 식별 또는 특징화할 수 있는 음향 패턴 또는 지문을 결정할 수 있다. 하나의 실시형태에서, 음향 패턴 또는 지문은 스펙트로그램 (예를 들어, 시간-주파수) 분석을 수행하는 것에 기초할 수 있다. 특징 추출을 위한 다른 적용가능한 방법들 및 시스템들, 이를 테면 MFC (Mel-frequency cepstral) 계수들 및/또는 지각 선형 예측 (예를 들어, 상대 스펙트럼 변환-지각 선형 예측) 에 기초한 오디오 프로세싱 기법들이 선택될 수 있다는 것이 인정될 것이다. 콘텐츠 식별을 위한 특징 추출 시스템들의 하나의 특정 비제한적인 예가 예를 들어, Wang 에 의한 페이퍼 "An industrial strength audio search algorithm" (Proc. Int. Conf. on Music Info. Retrieval ISMIR. Vol.3. 2003) 에서 발견될 수 있다. 예를 들어, Wang 에 의해 설명된 시스템은 배경 잡음에 대한 강인성 (robustness) 을 개선시키기 위해 스펙트로그램에서의 로컬 피크 패턴들을 활용한다.
콘텐츠 식별기 (308) 는 음향 패턴 또는 지문을 이용하여 음향 패턴 또는 지문의 콘텐츠 아이덴티티를 찾아 콘텐츠 아이덴티티 데이터베이스 (310) 를 검색하도록 프로세서 (204) 를 구성하는 명령들을 포함하는 모듈에 의해 구현될 수 있다. 예를 들어, 프로세서 (204) 는 음향 패턴 또는 지문에 대응하거나 대략 매칭하는 콘텐츠 식별 정보를 찾아 콘텐츠 아이덴티티 데이터베이스 (310) 를 검색할 수 있다. 식별자 생성기 (302) 는 콘텐츠 식별 정보를 소스 매처 (304) 에 제공한다.
도 3 의 소스 매처 (304) 는 소스 검색기 (312), 소스 데이터베이스 (314), 및 소스 송신기 (316) 를 포함한다. 소스 검색기 (312) 는 콘텐츠 식별 정보를 이용하여 콘텐츠 소스를 찾아 소스 데이터베이스 (314) 를 검색하도록 프로세서 (204) 를 구성하는 명령들을 포함하는 모듈에 의해 구현될 수 있다. 예를 들어, 프로세서 (204) 는 콘텐츠 식별 정보에 대응하거나 대략 매칭하는 노래의 MP3 파일과 같은 콘텐츠 소스를 찾아 데이터 스토리지 디바이스 (210) 상에 저장된 (또는 외부에 저장되고 통신 인터페이스 (208) 로 액세스된) 소스 데이터베이스 (314) 를 검색할 수 있다.
소스 송신기 (316) 는 소스 검색기 (312) 에 의해 식별된 콘텐츠 소스에 액세스할 수 있고 식별된 소스 신호를 생성할 수 있다. 소스 신호는 펄스 코드 변조 (PCM) 오디오 샘플들, 데이터 패킷들 (압축된 또는 코딩된 데이터를 포함), 또는 유사한 데이터 포맷들로서 송신될 수 있다. 이에 따라, 소스 송신기 (316) 는 오디오 프로세싱 디바이스 (202) 에 송신될 코딩된 오디오 데이터 패킷들을 생성하기 위해 보코더/인코더 (318) 를 옵션적으로 포함할 수도 있다. 즉, 소스 송신기 (316) 는 서버 컴퓨팅 디바이스에 위치할 수 있고, 소스 신호는 데이터 경로 또는 음성 경로 상에서 오디오 프로세싱 디바이스 (202) (이를 테면 도 1 의 모바일 폰 (102)) 로 전송될 수 있다.
오디오 신호 분석기 (300) 의 기능들 각각은 도 2 의 오디오 프로세싱 디바이스 (202) 에 의해 수행될 수 있다는 것이 인정될 것이다. 즉, 하나 이상의 기능들은 하나 이상의 서버 컴퓨팅 디바이스들 (이를 테면 콘텐츠 데이터베이스들 (110) 및 네트워크에 접속된 다른 디바이스들) 에 의해 수행된다. 예를 들어, 오디오 프로세싱 디바이스 (202) 는 통신 인터페이스 (208) 를 이용하여 네트워크를 통해 서버 컴퓨터와 통신할 수 있다. 식별된 소스 신호는 스트리밍 유사 방식 그대로, 또는 데이터 블록들에서, 다운로드 유사 방식으로 네트워크를 통해 제공될 수도 있다. 따라서, 오디오 프로세싱 디바이스 (202) 는 그것이 캔슬링을 위해 필요로 하기 전에 식별된 소스 신호의 부분들을 수신할 수도 있다. 이에 따라, 콘텐츠 아이덴티티 데이터베이스 (310) 및 소스 데이터베이스 (314) 각각은 오디오 프로세싱 디바이스 (202) 의 데이터 스토리지 디바이스 (210) 또는 메모리 (212) 상에 전자적으로 저장될 수 있고, 또는 오디오 프로세싱 디바이스 (202) 의 외부에 저장되고 네트워크를 통해 액세스될 수 있다.
도 4 는 도 2 의 오디오 프로세싱 디바이스 (202) 에 의해 구현된 오디오 캔슬러 시스템 (400) 의 특정 예시적인 실시형태의 블록도를 도시한다. 도시한 바와 같이, 오디오 캔슬러 시스템 (400) 은 다수의 오디오 잡음 소스들을 억제하는데 이용될 수 있다. 예를 들어, 오디오 캔슬러 시스템 (400) 은 n 개의 동기화 블록들 (402(1) 내지 402(n)) ("신호 동기화기들" 이라고도 불림) 및 n 개의 대응하는 오디오 캔슬러들 (404(1) 내지 404(n)), 뿐만 아니라 옵션적 포스트 프로세싱 (406), 보코더 (408), 및 음성 인식 (410) 블록들을 갖는다. 오디오 캔슬러 시스템 (400) 은 프로세서 (204) 에 의해 실행되는, 오디오 캔슬러 모듈 (218) 의 명령들과 같은 컴퓨터 실행가능 명령들로 구현될 수 있다.
동작에서, 오디오 캔슬러 시스템 (400) 은 입력 오디오 신호, 및 n 개의 식별된 소스 신호들을, 감쇄될 n 개의 가능한 오디오 잡음들 각각 당 하나씩 수신한다. 예를 들어, 도 1 을 참조하면, 오디오 잡음 1 은 네트워크 가능 TV (116) 로부터의 오디오 (120) 에 대응할 수 있고, 오디오 잡음 2 는 라디오 (118) 로부터의 오디오 (122) 에 대응할 수 있다. 더욱이, 각각의 식별된 소스 신호들은 예를 들어, 도 3 의 오디오 신호 분석기 (300) 에 의해 생성된 소스 신호에 대응할 수 있다. 동기화 블록 (402(1) 내지 402(n)) 및 오디오 캔슬러 블록 (404(1) 내지 404 (n)) 의 n 개의 쌍들은 오디오 잡음 1 이 먼저 억제되고, 결과의 프로세싱된 입력 오디오 신호가 오디오 잡음 2 를 억제하기 위해 오디오 캔슬러 2 에 공급되며 등등을 행하도록 직렬로 구성된다. 다른 적용가능한 구성들, 이를 테면 n 개의 병렬 오디오 캔슬러들 (404(1) 내지 404(n)) 이 선택될 수 있다는 것이 인정될 것이다.
서술한 바와 같이, n 개의 식별된 소스 신호들은 도 3 에 도시된 소스 송신기와 같은 n 개의 별개의 소스 송신기들에 의해 제공될 수 있다. 추가적으로 또는 대안적으로, n 개의 식별된 소스 신호들은 오디오 잡음을 생성하는 별개의 미디어 디바이스에 의해 생성될 수 있다. n 개의 식별된 소스 신호들 (뿐만 아니라 입력 오디오 신호) 은 각각 PCM 오디오 샘플들 또는 데이터 패킷들로서 제공될 수 있다. 예를 들어, 하나의 실시형태에서, n 개의 식별된 소스 신호들은 코딩된 음성 패킷들로서 송신되고 오디오 캔슬러 시스템 (400) 은 동기화 블록들 (402(1) 내지 402(n)) 에 신호들을 제공하기 전에 그 신호들을 디코딩하기 위한 옵션적 보코더들/디코더들 (미도시) 을 포함한다.
도 4 에 도시한 바와 같이, 오디오 캔슬러들 (404(1) 내지 404(n)) 각각은 동기화 블록 (402(1) 내지 402(n)) 과 각각 연관된다. 동기화 블록들 (402(1) 내지 402(n)) 각각은 입력 오디오 신호 (또는 이전의 오디오 캔슬러의 출력) 및 대응하는 식별된 소스 신호를 동기화할 수 있다. 동기화 블록들 (402(1) 내지 402(n)) 은 프로세싱, 통신, 및 유사한 지연들의 소스들로 인한 타이밍 차이들을 보상할 수 있다. 게다가, 동기화 블록들 (402(1) 내지 402(n)) 은 미디어 디바이스에 의해 플레이되고 있는 소스의 현재의 시간 로케이션을 결정 또는 추정하는데 있어서의 에러들을 보상하는데 이용될 수 있다. 동기화 블록들 (402(1) 내지 402(n)) 각각은 동기화를 위한 지연을 제공하기 위해, 대응하는 데이터 버퍼 (416(1) 내지 (416(n)) 를 각각 가질 수 있다. 지연은 일부 실시형태들에서는 튜너블일 수 있다. 동작에서, 튜너블 지연은 캘리브레이션 프로세스를 수행함으로써 결정될 수 있다. 지연들을 캘리브레이팅 및 튜닝하기 위한 프로세스들의 비제한적인 예들은 2012년 8월 9일자로 출원된 미국 가특허출원 제61/681,474호에서 발견될 수 있다.
n 개의 오디오 캔슬러들 (404(1) 내지 404(n)) 각각은 대응하는 소스 신호를 필터링하도록 구성된 하나 이상의 적응 필터들 (412(1) 내지 412(n)) 을 각각 가질 수 있다. 필터링은 캡처된 오디오 잡음과 소스 신호 간의 변화 (variation) 들을 설명하는데 이용될 수 있다. 즉, 마이크로폰 (206) 에 의해 캡처된 오디오 잡음은 음향 공간의 다이내믹스 (예를 들어, 에코들 및 음향 댐프닝, 이는 마이크로폰 (206) 및 미디어 디바이스 로케이션들에 따라 변할 수 있다), 스피커/마이크로폰의 다이내믹스, 콘텐츠 소스들 (예를 들어, 상이한 레코딩 품질들) 의 변화들 등을 포함한 다수의 팩터들 때문에 소스 신호와 다를 수도 있다.
이들 변화들을 보상하기 위해, 적응 필터들 (412(1) 내지 412(n)) 각각은 하나 이상의 튜너블 필터 파라미터들을 가질 수 있다. 일부 실시형태들에서, 필터 파라미터들은 입력 오디오 신호 및 소스 신호에 기초하여 이들 변화들을 모델링하기 위해 온라인 튜닝될 수 있다. 예를 들어, 입력 오디오 신호가 미디어 디바이스 1 에 의해 생성된 사운드를 아주 많이 포함할 때, 적응 필터 (412(1)) 의 출력 ("필터링된 소스 신호") 과 입력 오디오 신호 간의 에러가 그 신호들 간의 에러를 감소시키기 위한 방식으로 필터 파라미터들을 튜닝하는데 이용될 수 있다. 작은 에러는 적응 필터 (412(1)) 가 오디오 잡음 신호를 변형시키는 음향 효과들을 대략 모델링중임을 나타낼 수 있는 반면, 큰 에러는 적응 필터 (412(1)) 가 음향 효과들을 모델링중이 아님을 나타낸다. "적응 법칙들" 또는 "업데이트 규칙들" 과 같은 다양한 방법들이 필터 계수들을 조정하는데 이용될 수 있다. 예들은 튜너블 필터 파라미터들을 조정하여 필터링된 소스 신호와 입력 오디오 신호 간의 에러를 감소시키기 위해, 구배 방법 (gradient method) 에 기초한 적응 법칙들, 이를 테면 순간 또는 인테그랄 비용을 감소시키는 것에 기초한 적응 법칙들을 포함한다. 다른 예들은 최소 평균 제곱 방법, 리아프노프/안정성 방법, 및 스토캐스틱 방법들을 포함한다. 그러나, 임의의 적합한 재귀적, 비재귀적, 또는 배치 (btach) 적응 법칙이 튜너블 필터 파라미터들을 조정하는데 이용될 수 있다는 것이 인정될 것이다.
동작에서, 오디오 캔슬러 (404(1)) 는 식별된 소스 신호 1 및 입력 오디오 신호의 동기화된 카피들을 수신한다. 서술한 바와 같이, 식별된 소스 신호 1 은 오디오 잡음을 생성중인 스피커를 구동하는 오디오 신호를 근사화할 수 있다. 적응 필터 (412(1)) 는 음향 공간의 음향 다이내믹스를 설명하기 위해 식별된 소스 신호를 필터링하여, 마이크로폰 (206) 에 의해 캡처된 오디오 잡음 1 을 근사화하는 필터링된 소스 신호 1 을 생성할 수 있다. 오디오 캔슬러 (404(1)) 는 동기화된 입력 오디오 신호를 필터링된 소스 신호 1 과 비교하여 오디오 잡음 1 을 감쇄 또는 억제한다. 도시한 바와 같이, 오디오 캔슬러 (404(1)) 는 입력 오디오 신호에서 필터링된 소스 신호를 차감한다. 억제된 잡음 1 을 가진 오디오 신호는 그 후, n 개의 오디오 잡음들이 입력 오디오 신호로부터 억제될 때까지 오디오 잡음 2 를 억제하기 위해 제 2 동기화 블록에 공급되며 등등이다.
추가적으로, 각각의 적응 필터 (412(1) 내지 412(n)) 는 소정의 상황들 하에서 그 필터 파라미터의 조정을 중단 또는 인에이블하기 위해, 더블 토크 검출기 ("DTD") (414(1) 내지 414(n)) 를 각각 옵션적으로 가질 수 있다. 입력 오디오 신호 (또는 이전의 오디오 캔슬러의 출력) 가 대응하는 오디오 잡음에 더하여 다른 근단 신호들 (이를 테면 사용자의 음성 또는 다른 미디어 잡음들) 을 포함할 때, 대응하는 적응 필터 (412(n)) 는 적절히 적응하지 않을 수도 있다. 적응 필터 (412(n)) 가 오디오 잡음 이외의 추가적인 근단 신호들이 존재할 때 적응중일 수도 있기 때문에, 그 추가적인 근단 신호들은 적응 법칙에 대하여 강하게 비상관된 잡음의 역할을 할 수도 있다. 따라서, 추가적인 근단 신호들의 존재는 적응 필터 (412(n)) 를 분기하게 하고 비억제된 오디오 잡음을 허용할 수도 있다. 이에 따라, DTD들 (414(1) 내지 414(n)) 각각은 대응하는 적응 필터 (412(1) 내지 412(n)) 의 입력을 모니터링하고 추가적인 근단 신호들의 검출에 기초하여 적응을 중단 또는 인에이블하는데 이용될 수도 있다.
DTD들 (414(1) 내지 414(n)) 의 하나의 이러한 방법은 적응 필터 입력 신호가 추가적인 근단 신호들을 포함할 때를 결정하기 위해 더블 토크 검출 통계를 계산하는 단계를 수반할 수도 있다. 하나의 예의 더블 토크 검출 통계는 소스 신호 전력 대 대응하는 적응 필터 입력 신호의 비율에 의해 주어진다. 다른 적응가능한 더블 토크 검출 통계들이 선택될 수 있다. 더욱이, 더블 토크 통계는 시간 도메인에서 또는 주파수 도메인에서 컴퓨팅될 수도 있다.
도 4 에 도시한 바와 같이, 옵션적 비선형 포스트 프로세싱 블록 (406) 이 에코 캔슬러 (404(n)) 에 의해 제공된 신호에 대해 소정의 타입들의 프로세싱을 수행하기 위해 옵션적으로 포함될 수 있다. 예를 들어, 비선형 포스트 프로세싱 블록 (406) 은 에코 캔슬러 (404(n)) 를 떠난 신호에서 잔차 잡음 (예를 들어, 오디오 잡음 신호의 비선형 컴포넌트) 을 제거할 수도 있다. 일부 실시형태들에서, 비선형 잡음 컴포넌트는 입력 오디오 신호의 비선형 컴포넌트를 추정한 후 입력 오디오 신호에서 그 추정치를 (예를 들어, 스펙트럼 차감 기법들을 이용하는 것에 의해) 차감함으로써 제거 또는 감쇄될 수 있다. 비선형 포스트 프로세싱 블록은 DTD들 (414(1) 내지 414(n)) 로부터의 더블 토크 결정들에 기초하여 동작할 수도 있다. 따라서, 더블 토크 결정들은 비선형 포스트 프로세서 (204) 가 신호를 완전히 클립 또는 제거하기 전에 근단 신호와 잔차 오디오 잡음 간을 구별하게 돕는다.
억제된 잡음들 1, ..., n 을 가진 오디오 신호는 오디오 신호를 음성 패킷들로 인코딩하기 위해 보코더 (408) 에 제공될 수도 있다. 추가적으로 또는 대안적으로, 억제된 잡음들을 가진 오디오 신호는 추가 오디오 신호 프로세싱을 위해 음성 인식 블록 (410) 에 제공될 수도 있다.
오디오 캔슬러들 (404(1) 내지 404(n)) 의 수 (n) 는 예상된 잡음 환경들, 컴퓨팅 전력, 실시간 제약들, 메모리, 성능, 및/또는 유사한 고려사항들과 같은 다양한 고려사항들에 기초하여 선택될 수 있다. 그러나, 다른 적용가능한 팩터들이 고려될 수 있다는 것이 인정될 것이다. 마찬가지로, 오디오 캔슬러 시스템은 임의의 적용가능한 수의 동기화 블록들을 포함할 수 있다는 것이 인정될 것이다. 일부 실시형태들에서, 이들 컴포넌트들의 수는 도 5 와 관련하여 이하 논의한 바와 같이 식별된 잡음 컴포넌트들의 수에 대하여 동적으로 변할 수 있다.
도 5 는 도 2 의 오디오 프로세싱 디바이스 (202) 에 의해 구현된 오디오 캔슬러 시스템 (500) 의 다른 특정 예시적인 실시형태의 블록도를 도시한다. 도 4 및 도 5 의 시스템들 (400, 500) 에 공통인 엘리먼트들은 공통 기준 표시를 공유하고, 시스템들 (400, 500) 간의 차이들만이 간략화를 위해 본 명세서에 설명된다.
오디오 캔슬러 시스템 (500) 은 n 개의 동기화 블록들 (402(1) 내지 (402(n)), n 개의 오디오 캔슬러 블록들 (404(1) 내지 404(n)), 소스 식별자 검출기 (502), 및 재구성가능한 캔슬러 인에이블러 (504) 를 갖는다. 소스 식별자 검출기 (502) 는 n 개의 식별된 소스 신호들을 수신하여 식별된 소스 신호 경로들 중 어느 경로가 액티브인지를 결정한다. 예를 들어, 소스 식별자 검출기 (502) 는 신호의 존재 또는 그 경로 상의 대응하는 신호의 에너지의 레벨에 기초하여 액티브 소스 신호 경로들을 결정할 수 있다. 차례로, 재구성가능한 캔슬러 인에이블러 (504) 는 액티브 식별된 소스 신호 경로들에 대응하는 오디오 캔슬러 블록들 (404(1) 내지 404(n)) 을 활성화한다. 오디오 캔슬러 블록들 (404(1) 내지 404(n)) 의 각각의 액티브 오디오 캔슬러 블록은 도 4 와 관련하여 상기 설명한 바와 같이 동작할 수 있다. 오디오 캔슬러 블록들 (404(1) 내지 404(n)) 의 각각의 인액티브 오디오 캔슬러 블록은 예를 들어 패스-스루 필터로서 구성될 수 있다.
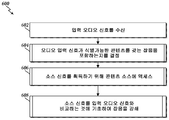
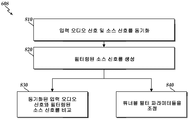
도 6 은 하나의 실시형태에 따른 오디오 잡음 억제의 방법 (600) 의 플로우도를 도시한다. 다음에 오는 방법들의 설명은 개인용 오디오 프로세싱 디바이스 (202), 이를 테면 모바일 폰, 개인용 오디오 플레이어 상의 구현에 초점을 맞추고 있지만, 다른 디바이스들이 방법 또는 그 변형을 수행하도록 구성될 수도 있다. 방법들은 오디오 프로세싱 디바이스 (202) 와 연관된 컴퓨팅 디바이스의 비일시적 컴퓨터 스토리지, 이를 테면 RAM, ROM, 하드 디스크 드라이브 등에 속하는 소프트웨어 모듈 또는 모듈들의 컬렉션으로서 구현될 수 있다. 컴퓨팅 디바이스의 하나 이상의 프로세서들은 소프트웨어 모듈을 실행할 수 있다.
블록 602 에서, 방법 (600) 은 입력 오디오 신호를 수신하는 단계를 포함한다. 예를 들어, 오디오 프로세싱 디바이스 (202) 는 오디오 프로세싱 디바이스 (202) 의 마이크로폰 (206) 으로부터, 데이터 스토리지 디바이스 (210) 또는 메모리 (212) 디바이스로부터, 또는 통신 인터페이스 (208) 에서 수신된 입력 오디오 신호를 수신할 수도 있다.
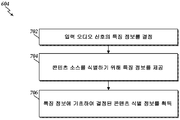
블록 602 에서 입력 오디오 신호가 수신된 후, 프로세서 (600) 는 오디오 입력 신호가 식별가능한 콘텐츠를 갖는 잡음을 포함하는지가 결정되는 블록 604 로 이동한다. 예를 들어, 하나의 실시형태에서, 오디오 프로세싱 디바이스 (202) 는 오디오 잡음의 콘텐츠를 식별하는데 이용될 수도 있는 오디오 입력 신호의 특징 정보를 결정하기 위해 오디오 신호 분석기 모듈 (216) 로부터의 명령들을 실행할 수도 있다. 특징 정보는 콘텐츠 식별 정보를 결정하기 위해 콘텐츠 식별자 (308) 에 의해 이용될 수 있다. 하나의 실시형태에서, 오디오 프로세싱 디바이스 (202) 는 특징 정보를 추가 프로세싱을 위해 네트워크를 통해 서버로 전송한 후 네트워크를 통해 콘텐츠 식별 정보를 수신할 수 있다. 다른 실시형태에서, 콘텐츠 식별기 (308) 및 소스 검색기 (312) 블록들의 기능들 중 하나 이상은 콘텐츠 식별 정보를 결정하기 위해 오디오 프로세싱 디바이스 (202) 상에서 수행될 수 있다. 블록 604 의 동작을 구현하기 위한 방법의 하나의 실시형태가 도 7a 와 관련하여 이하 설명된다.
다른 실시형태에서, 블록 (604) 의 동작은 별개의 미디어 디바이스와 통신하여 오디오 입력 신호가 식별가능한 콘텐츠를 갖는지를 결정하기 위해 오디오 신호 분석기 모듈 (216) 로부터의 실행 명령들에 의해 수행된다. 예를 들어, 오디오 프로세싱 디바이스 (202) 는 미디어 디바이스가 오디오 미디어를 플레이중인지 여부에 관하여 별개의 미디어 디바이스로부터 정보를 요?할 수 있고, 만약 그렇다면 콘텐츠 식별 정보를 요청할 수 있다. 응답으로, 오디오 프로세싱 디바이스 (202) 는 콘텐츠 식별 정보를 수신할 수도 있다.
일단 오디오 입력 신호가 식별가능한 콘텐츠를 갖는 배경 잡음을 포함한다고 결정되면, 방법 (600) 은 블록 606 으로 이동하여 소스 신호를 획득하기 위해 식별가능한 콘텐츠의 콘텐츠 소스에 액세스한다. 예를 들어, 하나의 실시형태에서, 오디오 프로세싱 디바이스 (202) 는 통신 인터페이스 (208) 를 통해 또는 메모리 (212) 또는 데이터 스토리지 디바이스 (210) 를 통해 콘텐츠 소스 또는 콘텐츠 소스 신호에 액세스할 수도 있다. 예를 들어, 블록 604 에서 획득된 콘텐츠 식별 정보는 콘텐츠 소스를 로케이팅 및 액세스하는데 이용될 수 있다. 콘텐츠 소스는 소스 신호를 생성하는데 이용될 수 있다. 블록 606 의 동작을 구현하기 위한 방법의 하나의 실시형태는 도 7b 와 관련하여 이하 설명된다.
소스 신호의 적어도 부분이 이용가능한 후, 방법 (600) 은 잡음이 소스 신호를 입력 오디오 신호와 비교하는 것에 기초하여 감쇄되는 블록 608 로 나아간다. 예를 들어, 하나의 실시형태에서, 오디오 프로세싱 디바이스 (202) 는 도 4 또는 도 5 에 도시된 오디오 캔슬러 시스템에 따라 오디오 잡음을 감쇄시키기 위해 메모리 (212) 내의 오디오 캔슬러 모듈 (218) 의 명령들을 실행한다.
이제 도 7a 로 돌아가면, 하나의 실시형태에 따른 오디오 입력 신호가 식별가능한 콘텐츠를 갖는 잡음을 포함하는지를 결정하기 위한 블록 604 에서 착수된 단계들의 예의 예시적인 플로우도가 도시된다. 블록 702 에서, 방법 (604) 은 입력 오디오 신호의 특징 정보를 결정한다. 예를 들어, 하나의 실시형태에서, 오디오 프로세싱 디바이스 (202) 는 도 3 에 도시된 특징 추출기 (306) 에 따라 특징들을 추출하기 위해 메모리 (212) 내의 오디오 신호 분석기 모듈 (216) 의 명령들을 실행한다. 일단 충분한 특징 정보가 결정되었다면, 프로세스 (604) 는 그 후 블록 704 로 이동하여 콘텐츠 소스를 식별하기 위해 특징 정보를 제공한다. 예를 들어, 하나의 실시형태에서, 오디오 프로세싱 디바이스 (202) 는 통신 인터페이스 (208) 로 하여금, 특징 정보를 서버 디바이스에 의한 프로세싱을 위해 네트워크를 통해 서버 디바이스에 송신하게 하기 위해 메모리 (212) 내의 오디오 신호 분석기 모듈 (216) 의 명령들을 실행한다.
특징 정보를 제공한 후, 방법 (604) 은 콘텐츠 식별 정보를 획득하기 위해 블록 706 으로 나아간다. 예를 들어, 오디오 프로세싱 디바이스 (202) 는 수행 블록 704 에서 특징 정보를 수신한 서버 디바이스로부터 콘텐츠 식별 정보를 수신할 수 있다. 대안적으로 또는 추가적으로, 일부 실시형태들에서, 오디오 프로세싱 디바이스 (202) 는 서버 디바이스와 통신하는 대신에 프로세싱 디바이스 (202) 에 대해 필요한 단계들을 수행함으로써 콘텐츠 식별 정보를 생성한다. 예를 들어, 오디오 프로세싱 디바이스 (202) 의 프로세서 (204) 는 도 3 의 오디오 신호 분석기 (300) 를 구현하기 위해 메모리 (212) 내의 오디오 신호 분석기 모듈 (216) 의 명령들을 실행할 수 있다.
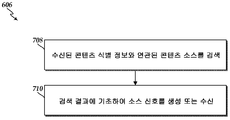
도 7b 는 하나의 실시형태에 따른 소스 신호를 획득하기 위해 콘텐츠 소스에 액세스하기 위한 예의 방법 (606) 의 예시적인 플로우도이다. 블록 708 에서, 방법 (606) 은 수신된 콘텐츠 식별 정보와 연관된 콘텐츠 소스를 검색하는 단계를 포함한다. 예를 들어, 하나의 실시형태에서, 오디오 프로세싱 디바이스 (202) 는 데이터 스토리지 디바이스 (210) 에 저장된 미디어 라이브러리를 검색하기 위해 메모리 (212) 내의 오디오 신호 분석기 모듈 (216) 의 명령들을 실행한다. 검색 후, 방법 (606) 은 검색 결과에 기초하여 소스 신호를 생성 또는 수신하기 위해 블록 710 으로 나아간다. 예를 들어, 콘텐츠 소스가 오디오 프로세싱 디바이스 (202) 상에서 로컬로 발견되면, 프로세서 (204) 는 콘텐츠 소스로부터 소스 신호를 생성하기 위해 명령들을 실행한다. 콘텐츠 소스가 디바이스 상에서 로컬로 발견되지 않으면, 하나의 실시형태에서, 오디오 프로세싱 디바이스 (202) 는 네트워크 (108) 를 통해 콘텐츠 데이터베이스들 (110) 로부터 식별된 소스 신호를 요청 및 수신하기 위해 메모리 (212) 내의 오디오 신호 분석기 모듈 (216) 의 명령들을 실행한다.
이제 도 8 로 돌아가면, 실시형태에 따른 오디오 잡음을 감쇄시키기 위한 블록 608 에서 착수된 단계들의 예의 예시적인 플로우도가 도시된다. 블록 810 에서, 입력 오디오 신호 및 소스 신호는 2 개의 신호들 간의 시간 지연들을 보상하기 위해 동기화된다. 동작에서, 신호들은 상이한 신호 및 컴퓨테이션 경로들을 이용하는 것으로부터 발생하는 다양한 지연들을 포함한 다양한 이유들로 동시에 이뤄지지 않게 될 수 있다. 신호들을 동기화하기 위해, 각각의 신호는 각각의 신호의 타이밍을 제어하기 위하여 가변 길이의 데이터 버퍼 (이를 테면 원형 버퍼) 에 저장될 수 있다. 예를 들어, 도 4 를 참조하면, 입력 오디오 신호 및 식별된 소스 신호는 제 1 동기화 블록 (402(1)) 에서 수신될 수도 있다. 동기화 블록 (402(1)) 은 버퍼 블록 (416(1)) 에 저장된 대응하는 원형 버퍼들 데이터 구조들 내에 신호들을 저장할 수 있으며, 여기서 원형 버퍼들의 길이들은 신호들을 동기화하기 위한 원하는 지연의 함수일 수 있다. 일부 실시형태들에서, 원하는 지연은 예를 들어 캘리브레이션 모드 동안 계산 또는 추정된다. 입력 오디오 신호가 n 개의 오디오 캔슬러들 (404(1) 내지 404(n)) 에 의해 프로세싱되기 때문에, 오디오 신호에서의 추가적인 지연들이 n 개의 오디오 캔슬러들 (404(1) 내지 404(n)) 각각에서 발생할 수 있다. 예를 들어, n 개의 적응 필터들 (412(1) 내지 412(n)) 에 의한 필터링은 지연들을 도입할 수 있다. 추가적으로, n 개의 식별된 소스 신호들은 예를 들어, 식별된 소스 신호들을 식별하고 궁극적으로 수신하는데 걸리는 시간으로 인해 다양한 지연들을 경험할 수 있다. 이에 따라, n 개의 동기화 블록들 (402(1) 내지 402(n)) 은 그 다양한 지연들을 보상하고 오디오 캔슬링 프로세싱 동안 동기화된 오디오 신호 및 식별된 소스 신호들을 유지하는데 이용될 수 있다.
오디오 입력 신호 및 식별된 소스 신호가 동기화된 후, 방법 (608) 은 블록 820 을 계속하여 오디오 잡음에 영향을 주는 음향 효과들, 이를 테면 음향 다이내믹스, 스피커 및 마이크로폰 다이내믹스 등을 설명하기 위해 식별된 소스 신호를 필터링한다. 필터링은 식별된 소스 신호가 마이크로폰 (206) 에 의해 캡처되는 오디오 잡음을 정확하게 표현하지 않을 수도 있기 때문에 행해진다. 식별된 소스 신호가 오디오 잡음과 실질적으로 다르다면, 오디오 억제는 효과적이지 않을 수도 있다. 잡음 억제를 개선시키기 위해, 이러한 팩터들의 효과들은 오디오 잡음과 밀접하게 매칭하거나 복제하는 식별된 소스 신호를 형상화하기 위하여 온라인 추정될 수 있다. 예를 들어, 이제 도 4 를 참조하면, 동기화된 오디오 입력 신호 및 동기화된 식별된 소스 신호 1 은 오디오 잡음 캔슬러 (404(1)) 에 그리고 적응 필터 (412(1)) 에 전달된다. 적응 필터 (412(1)) 는 그 후 오디오 잡음을 대략 복제하기 위한 기준 신호를 생성하기 위해 식별된 소스 신호 1 을 필터링 또는 형상화할 수 있다. 적응 필터 (412(1)) 는 필터가 식별된 소스 신호를 형상화하는 방법에 영향을 주는 하나 이상의 필터 파라미터들 (예를 들어, 무한 임펄스 응답 필터의 유한 임펄스 응답의 하나 이상의 필터 계수) 을 가질 수 있다. 일부 실시형태들은 광범위한 음향 효과들을 설명하기 위해 튜너블 파라미터들을 포함한다.
식별된 소스 신호를 동기화 및 필터링한 후, 방법 (608) 은 블록 830 으로 나아가 동기화된 오디오 입력과 필터링 소스 신호를 비교함으로써 프로세싱된 오디오 신호를 생성할 수 있다. 하나의 실시형태에서, 필터링된 소스 신호는 동기화된 오디오 입력 신호에서 차감된다. 예시하기 위해, 도 4 는 적응 필터 (412(1)) 의 출력이 억제된 잡음 1 을 가진 오디오 신호를 생성하기 위해 오디오 입력 신호에서 차감되는 것을 도시한다. 하나의 실시형태에서, 억제된 잡음 1 을 가진 오디오 신호는 통신 또는 음성 인식 애플리케이션들을 위해 프로세싱될 수 있다. 다른 실시형태에서, 억제된 잡음 1 을 가진 오디오 신호는 추가 잡음 억제를 위해 프로세싱될 수 있다. 예를 들어, 도 4 는 억제된 잡음 1 을 가진 프로세싱된 오디오 신호가 식별된 소스 신호들 2-n 을 가진 추가적인 잡음들 2-n 을 억제하기 위해 동기화 블록들 (402(2) 내지 402(n)) 및 오디오 캔슬러들 (404(2) 내지 404(n)) 에 제공될 수 있다는 것을 도시한다.
옵션적으로, 방법 (608) 은 블록 820 을 수행한 후 블록 840 으로 나아가 광범위한 음향 효과들에 대한 잡음 억제를 개선시키기 위해 적응 필터 (412(1)) 의 튜너블 필터 파라미터들을 조정할 수 있다. 하나의 실시형태에서, 튜너블 필터 파라미터들의 조정은 적응 법칙 또는 업데이트 법칙에 의해 좌우된다. 예를 들어, 도 4 를 참조하면, 적응 필터 (414(1)) 는 동기화된 오디오 입력 신호 및 식별된 소스 신호 양자를 수신한다. 적응 필터 (414(1)) 는 필터링된 소스 신호를 생성할 수 있다. "에러 신호" 또는 "리프레서 신호 (repressor signal)" 는 오디오 입력 신호와 필터링된 소스 신호를 비교함으로써 생성될 수 있다. 에러 신호는 적응 필터가 오디오 잡음을 얼마나 밀접하게 복제하고 있는지를 나타낼 수 있다. 예를 들어, 오디오 입력이 실질적으로 오디오 잡음으로 구성되면, 동기화된 오디오 입력 신호와 필터링된 소스 신호 간의 차이는 필터링된 식별된 소스 신호와 오디오 잡음 간의 미스매치 (mismatch) 의 양을 나타낸다. 즉, 작은 에러는 적응 필터가 실내 (room) 의 실제 음향 다이내믹스를 밀접하게 모델링중임을 나타낸다. 적응 법칙는 에러 신호를 감소시키는 방식으로 적응 필터 (412(1)) 의 튜너블 필터 파라미터들을 조정하기 위해 (예를 들어, 구배 또는 재귀적 최소 평균 제곱들, 또는 유사한 방법들에 기초하여) 선정될 수 있다.
그러나, 오디오 입력 신호가 실질적으로 식별된 소스 신호 1 에 대응하는 오디오 잡음으로 구성되지 않을 때, 적응 필터 (414(1)) 는 그것의 튜너블 파라미터들을 적절히 조정하지 않을 수도 있다. 예를 들어, 오디오 신호는 제 2 소스로부터의 오디오 잡음 또는 사용자의 음성 커맨드들을 포함할 수 있다. 이 상황에서, 에러 신호는 적응 필터가 예를 들어 오디오 잡음 1 에 대하여 실내 음향학에 얼마나 밀접하게 매칭중인지의 의미 있는 표시를 제공하지 않을 수도 있다. 이에 따라, DTD (414(1)) 블록은 도 4 와 관련하여 이전에 서술한 바와 같이 DTD 블록이 이러한 조건을 검출할 때 적응 필터의 조정을 턴 오프할 수도 있다.
서술한 바와 같이, 동기화 및 필터링의 단계들은 n 개의 오디오 잡음들을 캔슬하기 위해 n 개의 식별된 소스 신호들을 이용하여 수행될 수 있다. 도 4 를 참조하면, 특히, 오디오 잡음들은 순차적으로 캔슬된다. 그러나, 일부 실시형태들에서, 잡음들은 병렬로 캔슬될 수 있다.
도 9 는 실시형태에 따른 오디오 잡음 억제의 특정 예시적인 방법 (900) 의 플로우도이다. 블록 902 에서, 방법 (900) 은 입력 오디오 신호를 수신하는 단계를 포함한다. 블록 902 는 도 6 과 관련하여 설명한 바와 같이 수행될 수 있다. 오디오 입력 신호의 적어도 부분을 수신한 후, 방법 (900) 은 별개의 미디어 디바이스에 의해 생성된 잡음과 관련된 정보를 수신하기 위해 블록 904 로 나아간다. 예를 들어, 오디오 프로세싱 디바이스 (202) 는 도 2 와 관련하여 논의한 바와 같이, 오디오 신호 분석기 모듈 (216) 및 통신 모듈 (220) 로부터의 명령들을 실행함으로써 별개의 미디어 디바이스와 통신할 수 있다. 별개의 미디어 디바이스는 별개의 미디어 디바이스가 미디어 콘텐츠를 갖는 잡음을 생성중인지 여부의 표시를 오디오 프로세싱 디바이스 (202) 에 제공할 수도 있다. 추가적으로 또는 대안적으로, 별개의 미디어 디바이스는 오디오 프로세싱 디바이스 (202) 가 콘텐츠 소스를 검색하기 위해 이용할 수도 있는 콘텐츠 식별 정보를 통신할 수 있다. 콘텐츠 식별 정보의 예는 TV 채널, 무선 주파수, 및 유사한 미디어 브로드캐스트 선택 정보를 포함한다. 하나의 실시형태에서, 별개의 미디어 디바이스는 소스 신호를 오디오 프로세싱 디바이스 (202) 로 전송할 수도 있다.
오디오 프로세싱 디바이스 (202) 가 잡음과 관련된 정보를 수신한 후, 방법 (900) 은 별개의 미디어 디바이스에 의해 생성된 잡음과 관련된 수신된 정보에 기초하여 소스 신호를 수신하기 위해 블록 906 으로 나아간다. 예를 들어, 오디오 프로세싱 디바이스가 미디어 디바이스가 잡음을 생성중이라는 표시를 별개의 미디어 디바이스로부터 수신한다면, 또는 오디오 프로세싱 디바이스 (202) 가 콘텐츠 식별 정보를 수신한다면, 오디오 프로세싱 디바이스 (202) 는 상기 설명한 바와 같이 도 6, 도 7a 및 도 7b 의 방법들 (604 및 606) 을 수행함으로써 소스 신호를 수신할 수 있다. 일부 실시형태들에서, 오디오 프로세싱 디바이스 (202) 는 별개의 미디어 디바이스로부터 소스 신호를 수신한다. 예를 들어, 별개의 미디어 디바이스는 별개의 미디어 디바이스가 플레이중인 미디어의 카피를 송신할 수 있다.
소스 신호를 수신한 후, 방법 (900) 은 소스 신호를 입력 오디오 신호와 비교하는 것에 기초하여 잡음을 감쇄시키기 위해 블록 908 로 나아갈 수 있다. 예를 들어, 오디오 프로세싱 디바이스 (202) 는 상기 설명한 바와 같이 도 6 및 도 8 의 방법 (608) 을 수행함으로써 오디오 잡음을 감쇄시킨다.
기술은 다수의 다른 범용 또는 특수 목적 컴퓨팅 시스템 환경들 또는 구성들로 동작한다. 본 발명에의 이용에 적합할 수도 있는 잘 알려진 컴퓨팅 시스템들, 환경들 및/또는 구성들의 예들은 개인용 컴퓨터들, 서버 컴퓨터들, 핸드헬드 또는 랩톱 디바이스들, 멀티프로세서 시스템들, 프로세서 기반 시스템들, 프로그램가능한 가전 제품들, 네트워크 PC들, 미니컴퓨터들, 메인프레임 컴퓨터들, 상기 시스템들 또는 디바이스들 중 임의의 것을 포함하는 분산형 컴퓨팅 환경들 등을 포함하지만 이들에 제한되지 않는다.
본 명세서에 사용한 바와 같이, 명령들은 시스템에서 정보를 프로세싱하기 위한 컴퓨터 구현 단계들을 지칭한다. 명령들은 소프트웨어, 펌웨어 또는 하드웨어에서 구현되고 시스템의 컴포넌트들에 의해 착수되는 임의의 타입의 프로그램된 단계를 포함할 수 있다.
프로세서는 임의의 종래의 범용 단일- 또는 다중-칩 프로세서, 이를 테면 AMD® Athlon® Ⅱ 또는 Phenom® Ⅱ 프로세서, Intel® i3®/i5®/i7® 프로세서들, Intel Xeon® 프로세서, 또는 ARM® 프로세서의 임의의 조합일 수도 있다. 또한, 프로세서는 OMAP 프로세서들, Qualcomm® 프로세서들, 이를 테면 Snapdragon®, 또는 디지털 신호 프로세서 또는 그래픽스 프로세서를 포함하는 임의의 종래의 특수 목적 프로세서일 수도 있다. 프로세서는 통상 종래의 어드레스 라인들, 종래의 데이터 라인들, 및 하나 이상의 종래의 제어 라인들을 갖는다.
시스템은 상세히 논의한 바와 같이 다양한 모듈들로 구성된다. 당업자가 인정할 수 있는 바와 같이, 모듈들 각각은 다양한 서브 루틴들, 절차들, 정의를 내리는 스테이트먼트들 및 매크로들을 포함한다. 모듈들 각각은 통상 개별 컴파일링되며 단일 실행가능 프로그램에 링크된다. 따라서, 모듈들 각각의 설명은 바람직한 시스템의 기능성을 설명하기 위한 편의를 위해 이용된다. 따라서, 모듈들 각각에 의해 행해지는 프로세스들은 다른 모듈들 중 하나에 임의적으로 재분배되거나, 단일 모듈에 함께 조합되거나, 또는 예를 들어, 공유가능한 동적 링크 라이브러리에서 입수가능해질 수도 있다.
시스템은 임의의 종래의 프로그래밍 언어, 이를 테면 C#, C, C++, BASIC, Pascal, 또는 Java 로 기입되고, 종래의 오퍼레이팅 시스템 하에서 실행될 수도 있다. C#, C, C++, BASIC, Pascal, Java, 및 FORTRAN 은 많은 상업적 컴파일러들이 실행가능한 코드를 생성하는데 이용될 수 있는 산업 표준 프로그래밍 언어들이다. 시스템은 또한, Perl, Python 또는 Ruby 와 같은 인터프리팅된 언어들을 이용하여 기입될 수도 있다.
당업자들은 또한, 본원에서 개시된 실시형태들과 관련하여 설명된 다양한 예시적인 논리 블록들, 모듈들, 회로들, 및 알고리즘 단계들이 전자 하드웨어, 컴퓨터 소프트웨어, 또는 양자의 조합들로서 구현될 수도 있다는 것을 인정할 것이다. 하드웨어 및 소프트웨어의 이러한 상호교환가능성을 분명히 예시하기 위해, 다양한 예시적인 컴포넌트들, 블록들, 모듈들, 회로들, 및 단계들은 그들의 기능성의 관점에서 상기 설명되었다. 이러한 기능성이 하드웨어로서 구현되는지 또는 소프트웨어로서 구현되는지 여부는 특정 애플리케이션 및 전체 시스템에 부과되는 설계 제약들에 의존한다. 당업자들은 각각의 특정 애플리케이션에 대해 다양한 방식들로 설명된 기능성을 구현할 수도 있지만, 이러한 구현 결정들이 본 개시물의 범위로부터 벗어남을 야기하는 것으로 해석되어서는 안된다.
본원에서 개시된 실시형태들과 관련하여 설명된 다양한 예시적인 논리 블록들, 모듈들, 및 회로들은 범용 프로세서, 디지털 신호 프로세서 (digital signal processor; DSP), 주문형 집적 회로 (application specific integrated circuit; ASIC), 필드 프로그램가능 게이트 어레이 (field programmable gate array; FPGA) 또는 다른 프로그램가능 로직 디바이스, 별개의 게이트 또는 트랜지스터 로직, 별개의 하드웨어 컴포넌트들, 또는 본 명세서에 설명된 기능들을 수행하도록 설계된 이들의 임의의 조합으로 구현 또는 수행될 수도 있다. 범용 프로세서는 마이크로프로세서일 수도 있지만, 대안으로, 프로세서는 임의의 종래의 프로세서, 제어기, 마이크로제어기, 또는 상태 머신일 수도 있다. 프로세서는 또한 컴퓨팅 디바이스들의 조합, 예를 들면, DSP 와 마이크로프로세서의 조합, 복수의 마이크로프로세서들, DSP 코어와 결합된 하나 이상의 마이크로프로세서들, 또는 임의의 다른 이러한 구성으로서 구현될 수도 있다.
하나 이상의 예시적인 실시형태들에서, 설명된 기능들 및 방법들은 프로세서 상에서 실행되는 하드웨어, 소프트웨어, 또는 펌웨어, 또는 이들의 임의의 조합에서 구현될 수도 있다. 소프트웨어에서 구현되면, 그 기능들은 컴퓨터 판독가능 매체 상에 하나 이상의 명령들 또는 코드로서 저장되거나 또는 송신될 수도 있다. 컴퓨터 판독가능 매체들은 한 장소에서 다른 장소로 컴퓨터 프로그램의 전송을 용이하게 하는 임의의 매체를 포함하는 통신 매체들 및 컴퓨터 저장 매체들 양자를 포함한다. 저장 매체는 컴퓨터에 의해 액세스될 수 있는 임의의 이용가능한 매체들일 수도 있다. 제한이 아닌 일 예로, 이러한 컴퓨터 판독가능 매체들은 RAM, ROM, EEPROM, CD-ROM 또는 다른 광 디스크 저장, 자기 디스크 저장 또는 다른 자기 저장 디바이스들, 또는 원하는 프로그램 코드를 명령들 또는 데이터 구조들의 형태로 운반 또는 저장하는데 이용될 수 있고 컴퓨터에 의해 액세스될 수 있는 임의의 다른 매체를 포함할 수 있다. 또한, 임의의 접속이 컴퓨터 판독가능 매체라고 적절히 불린다. 예를 들면, 소프트웨어가 동축 케이블, 광섬유 케이블, 연선 (twisted pair), 디지털 가입자 회선 (DSL), 또는 적외선, 무선, 및 마이크로파와 같은 무선 기술들을 이용하여 웹사이트, 서버, 또는 다른 원격 소스로부터 송신되면, 동축 케이블, 광섬유 케이블, 연선, DSL, 또는 적외선, 무선, 및 마이크로파와 같은 무선 기술들이 매체의 정의 내에 포함된다. 디스크 (disk) 및 디스크 (disc) 는 본 명세서에 사용한 바와 같이, CD (compact disc), 레이저 디스크, 광 디스크, DVD (digital versatile disc), 플로피 디스크, 및 블루-레이 디스크를 포함하며, 여기서 디스크 (disk) 들은 보통 데이터를 자기적으로 재생하는 한편, 디스크 (disc) 들은 레이저들을 이용하여 데이터를 광학적으로 재생한다. 상기의 조합들이 또한 컴퓨터 판독가능 매체들의 범위 내에 포함되어야 한다.
전술한 설명은 본 명세서에 개시된 시스템들, 디바이스들, 및 방법들의 소정의 실시형태들을 상세화한다. 그러나, 전술한 것이 텍스트에서 아무리 상세화한 것으로 보일지라도, 시스템들, 디바이스들, 및 방법들은 많은 방식들로 실시될 수 있다는 것을 인정할 것이다. 또한 위에 서술한 바와 같이, 본 발명의 소정의 특징들 또는 양태들을 설명할 때의 특정 전문용어의 사용은 그 전문용어가 그 전문용어가 연관하는 기술의 특징들 또는 양태들의 임의의 특정 특성들을 포함하는 것으로 제한되도록 본 명세서에서 재정의되고 있음을 의미하게 되지 않아야 한다는 것에 주목해야 한다.
다양한 변형들 및 변경들이 설명된 기술의 범위로부터 벗어남 없이 행해질 수도 있다는 것이 당업자에 의해 인정될 것이다. 이러한 변형들 및 변경들은 실시형태들의 범위에 포함되도록 의도된다. 당업자는 또한, 일 실시형태에 포함된 부분들은 다른 실시형태들과 상호교환가능하며; 묘사된 실시형태로부터의 하나 이상의 부분들이 임의의 조합에 다른 묘사된 실시형태들과 함께 포함될 수 있음을 인정할 것이다. 예를 들어, 본 명세서에 설명되고/되거나 도면들에 묘사된 다양한 컴포넌트들 중 임의의 것은 다른 실시형태들과 조합되거나, 상호교환되거나, 또는 다른 실시형태들로부터 배제될 수도 있다.
본 명세서에서의 실질적으로 임의의 복수 및/또는 단수 용어들의 사용과 관련하여, 당업자라면, 맥락 및/또는 에플리케이션에 적절하게 복수에서 단수로 및/또는 단수에서 복수로 번역할 수 있다. 다양한 단수/복수 순열들이 명료함을 위해 본 명세서에 명확히 기재될 수도 있다.
일반적으로, 본 명세서에 사용된 용어들은 일반적으로, "열린" 용어들로서 의도된다는 것이 당업자에 의해 이해될 것이다 (예를 들면, 용어 "포함하는 것" 은 "포함하지만 제한되지 않는 것" 으로 해석되어야 하고, 용어 "갖는 것" 은 "적어도 갖는 것" 으로 해석되어야 하며, 용어 "포함한다" 는 "포함하지만 제한되지 않는다" 로 해석되어야 하며 등등이다). 특정 수의 도입된 청구항 기재가 의도되면, 이러한 의도는 청구항에서 명시적으로 인용될 것이며, 이러한 기재의 부재 시에는 이러한 의도가 존재하지 않는다는 것이 당업자에 의해 더욱 이해될 것이다. 예를 들어, 이해를 돕기 위한 것으로서, 다음의 첨부된 청구항들은, 청구항 기재를 도입하기 위해, 도입 어구들 "적어도 하나" 및 "하나 이상" 의 사용을 포함할 수도 있다. 그러나, 이러한 어구들의 사용은, 부정 관사 "a (본 번역문에서는 특별히 번역하지 않음)" 또는 "an (본 번역문에서는 특별히 번역하지 않음)"에 의한 청구항 기재의 도입이, 이러한 도입된 청구항 기재를 포함하는 임의의 특정 청구항을, 그 동일한 청구항이 도입 어구들 "하나 이상" 또는 "적어도 하나" 및 "a" 또는 "an" (예를 들어, "a" 및/또는 "an" 은 "적어도 하나" 또는 "하나 이상" 을 의미하도록 통상 해석되어야 한다) 과 같은 부정 관사들을 포함하는 경우라도, 단지 하나의 이러한 기재를 포함하는 실시형태들로 제한함을 의미하도록 해석되어서는 안되며; 청구항 기재들을 도입하기 위해 정관사를 사용하는 경우에도 마찬가지이다. 또한, 특정 수의 도입된 청구항 기재가 명시적으로 인용되더라도, 당업자는 이러한 기재가 통상 적어도 인용된 번호를 의미하도록 해석되어야 한다는 것을 인정할 것이다 (예를 들어, 다른 수정자들이 없는 "2 기재들" 의 순수한 기재는 통상적으로 적어도 2 기재들, 또는 2 이상의 기재들을 의미한다). 더욱이, "A, B 및 C 중 적어도 하나 등" 과 유사한 관례가 사용되는 그 경우들에서, 일반적으로 이러한 구성은 당업자가 그 관례를 이해할 것이라는 의미에서 의도된다 (예를 들면, "A, B, 및 C 중 적어도 하나를 갖는 시스템" 은, A 단독, B 단독, C 단독, A 와 B 를 함께, A 와 C 를 함께, B 와 C 를 함께, 및/또는 A, B, 및 C 를 함께 갖는 시스템들 등을 포함할 것이지만 이에 제한되지 않을 것이다). "A, B 또는 C 중 적어도 하나 등" 과 유사한 관례가 사용되는 경우들에서, 일반적으로 이러한 구성은 당업자가 그 관례를 이해할 것이라는 의미에서 의도된다 (예를 들면, "A, B, 또는 C 중 적어도 하나를 갖는 시스템" 은, A 단독, B 단독, C 단독, A 와 B 를 함께, A 와 C 를 함께, B 와 C 를 함께, 및/또는 A, B, 및 C 를 함께 갖는 시스템 등을 포함할 것이지만 이에 제한되는 않을 것이다). 상세한 설명, 청구항들, 또는 도면들 어디에서든, 2 개 이상의 대안적인 용어들을 제시하는 사실상 임의의 이접 단어 및/또는 어구는 용어들 중 하나, 용어들 중 어느 일방, 또는 용어들 양자 모두를 포함할 가능성들을 고려하는 것으로 이해되어야 한다는 것이 당업자에 의해 또한 이해될 것이다. 예를 들어, 어구 "A 또는 B" 는 "A" 또는 "B", 또는 "A 및 B" 의 가능성들을 포함하는 것으로 이해될 것이다.
다양한 양태들 및 실시형태들이 본 명세서에 개시되었지만, 다른 양태들 및 실시형태들이 당업자에게 명백할 것이다. 본 명세서에 개시된 다양한 양태들 및 실시형태들은 설명의 목적을 위한 것이지 제한하기 위한 것이 아니다.
Claims (20)
- 오디오 잡음을 감쇄시키기 위한 디바이스로서,
입력 오디오 신호를 수신하도록 구성된 마이크로폰;
상기 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지를 결정하도록 구성된 오디오 신호 분석기로서, 식별가능한 콘텐츠를 갖는 잡음 신호가 있다면, 상기 잡음 신호의 카피를 획득하기 위해 콘텐츠 소스에 액세스하는, 상기 오디오 신호 분석기; 및
상기 잡음 신호의 상기 카피를 상기 입력 오디오 신호와 비교하는 것에 기초하여 감쇄된 잡음 신호를 갖는 프로세싱된 오디오 신호를 생성하도록 구성된 오디오 캔슬러 (audio canceller) 를 포함하는, 오디오 잡음을 감쇄시키기 위한 디바이스. - 제 1 항에 있어서,
상기 오디오 신호 분석기는, 별개의 미디어 디바이스들에 의해 생성된 잡음 신호들에 대해 상기 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지 여부의 상기 결정을 수행하도록 구성되는, 오디오 잡음을 감쇄시키기 위한 디바이스. - 제 1 항에 있어서,
통신 인터페이스를 더 포함하며,
상기 오디오 신호 분석기는 또한 :
상기 입력 오디오 신호의 특징 정보를 결정하고;
상기 통신 인터페이스를 이용하여, 상기 특징 정보를 송신하며;
상기 통신 인터페이스를 이용하여, 상기 특징 정보를 송신하는 것에 적어도 기초하여 상기 잡음 신호의 상기 카피를 수신하도록 구성되는, 오디오 잡음을 감쇄시키기 위한 디바이스. - 제 3 항에 있어서,
상기 오디오 신호 분석기는 또한 :
상기 통신 인터페이스를 이용하여, 상기 특징 정보를 제공하는 것에 응답하여 콘텐츠 식별 정보를 수신하고;
수신된 상기 콘텐츠 식별 정보를 상기 콘텐츠 소스와 매칭시키는 것에 기초하여 상기 콘텐츠 소스를 찾아 상기 오디오 잡음을 감쇄시키기 위한 디바이스를 검색하며;
상기 검색이 상기 콘텐츠 소스와 매칭시키는 것을 초래한다면 상기 콘텐츠 소스로부터 상기 잡음 신호의 상기 카피를 생성하도록 구성되는, 오디오 잡음을 감쇄시키기 위한 디바이스. - 제 1 항에 있어서,
상기 오디오 신호 분석기는 :
상기 입력 오디오 신호의 특징 정보를 결정하도록 구성된 특징 추출기;
상기 특징 정보와 연관된 콘텐츠 식별 정보를 결정하도록 구성된 콘텐츠 식별기;
상기 콘텐츠 식별 정보를 상기 콘텐츠 소스와 매칭시키는 것에 기초하여 상기 콘텐츠 소스를 찾아 데이터베이스를 검색하도록 구성된 소스 검색기; 및
상기 검색이 상기 콘텐츠 소스를 로케이팅한다면 상기 콘텐츠 소스로부터 상기 잡음 신호의 상기 카피를 생성하도록 구성된 소스 송신기를 포함하는, 오디오 잡음을 감쇄시키기 위한 디바이스. - 제 1 항에 있어서,
상기 입력 오디오 신호 및 상기 잡음 신호의 상기 카피 중 적어도 하나를 지연시키도록 구성된 신호 동기화기를 더 포함하며,
상기 오디오 캔슬러는 :
튜너블 필터 파라미터를 갖는 적응 필터로서, 상기 적응 필터는 상기 잡음 신호의 동기화된 카피 및 상기 튜너블 필터 파라미터에 기초하여 필터링된 잡음 신호를 생성하도록 구성되며, 상기 적응 필터는 동기화된 입력 오디오 신호와 상기 잡음 신호의 상기 동기화된 카피를 비교하는 것에 기초하여 상기 튜너블 필터 파라미터를 조정하도록 구성된, 상기 적응 필터; 및
상기 적응 필터의 더블 토크 검출기로서, 상기 더블 토크 검출기가 상기 입력 오디오 신호가 상기 잡음 신호의 상기 카피에 더하여 다른 신호를 갖는다는 것을 검출할 때 상기 적응 필터의 상기 튜너블 필터 파라미터의 조정을 디스에이블하도록 구성된, 상기 더블 토크 검출기를 포함하며,
상기 오디오 캔슬러는 상기 필터링된 잡음 신호를 상기 동기화된 입력 오디오 신호와 비교함으로써 상기 잡음 신호의 상기 카피를 상기 입력 오디오 신호와 비교하는, 오디오 잡음을 감쇄시키기 위한 디바이스. - 제 1 항에 있어서,
상기 오디오 잡음을 감쇄시키기 위한 디바이스와 별개의 미디어 디바이스 간의 통신 채널 상에서 데이터를 통신하도록 구성된 통신 모듈을 더 포함하며,
상기 통신 모듈은 상기 별개의 미디어 디바이스로부터 상기 잡음 신호의 상기 카피의 적어도 부분을 수신하는, 오디오 잡음을 감쇄시키기 위한 디바이스. - 제 1 항에 있어서,
상기 오디오 잡음을 감쇄시키기 위한 디바이스와 별개의 미디어 디바이스 간의 통신 채널 상에서 데이터를 통신하도록 구성된 통신 모듈을 더 포함하며,
상기 소스 통신 모듈은 상기 콘텐츠 소스에 대응하는 콘텐츠 식별 데이터를 수신하는, 오디오 잡음을 감쇄시키기 위한 디바이스. - 오디오 잡음을 감쇄시키기 위한 방법으로서,
입력 오디오 신호를 수신하는 단계;
상기 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지를 결정하는 단계;
식별가능한 콘텐츠를 갖는 잡음 신호가 있다면, 상기 잡음 신호의 카피를 획득하기 위해 콘텐츠 소스에 액세스하는 단계; 및
상기 잡음 신호의 상기 카피를 상기 입력 오디오 신호와 비교하는 것에 기초하여 감쇄된 잡음 신호를 갖는 프로세싱된 오디오 신호를 생성하는 단계를 포함하는, 오디오 잡음을 감쇄시키기 위한 방법. - 제 9 항에 있어서,
상기 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지 여부를 결정하는 단계는, 상기 입력 오디오 신호가 별개의 미디어 디바이스에 의해 생성되고 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지 여부를 결정하는 단계를 포함하는, 오디오 잡음을 감쇄시키기 위한 방법. - 제 9 항에 있어서,
상기 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지 여부를 결정하는 단계는 :
상기 입력 오디오 신호의 특징 정보를 결정하는 단계; 및
상기 특징 정보를 송신하는 단계를 포함하며,
상기 잡음 신호의 상기 카피에 액세스하는 단계는, 상기 특징 정보를 송신하는 것에 적어도 기초하여 상기 잡음 신호의 상기 카피를 수신하는 단계를 포함하는, 오디오 잡음을 감쇄시키기 위한 방법. - 제 11 항에 있어서,
상기 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지 여부를 결정하는 단계는 :
상기 특징 정보를 제공하는 것에 응답하여 콘텐츠 식별 정보를 수신하는 단계;
수신된 상기 콘텐츠 식별 정보를 상기 콘텐츠 소스와 매칭시키는 것에 기초하여 상기 콘텐츠 소스를 찾아 디바이스를 검색하는 단계; 및
상기 검색이 상기 콘텐츠 소스와 매칭시키는 것을 초래한다면 상기 콘텐츠 소스로부터 상기 잡음 신호의 상기 카피를 생성하는 단계를 포함하는, 오디오 잡음을 감쇄시키기 위한 방법. - 제 9 항에 있어서,
상기 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지 여부를 결정하는 단계는 :
상기 입력 오디오 신호의 특징 정보를 결정하는 단계;
상기 특징 정보와 연관된 콘텐츠 식별 정보를 결정하는 단계;
상기 콘텐츠 식별 정보를 상기 콘텐츠 소스와 매칭시키는 것에 기초하여 상기 콘텐츠 소스를 찾아 데이터베이스를 검색하는 단계; 및
상기 검색이 상기 콘텐츠 소스를 로케이팅한다면 상기 콘텐츠 소스로부터 상기 잡음 신호의 상기 카피를 생성하는 단계를 포함하는, 오디오 잡음을 감쇄시키기 위한 방법. - 제 9 항에 있어서,
상기 입력 오디오 신호 및 상기 잡음 신호의 상기 카피를 동기화하기 위해 상기 입력 오디오 신호 및 상기 잡음 신호의 상기 카피 중 적어도 하나를 지연시키는 단계를 더 포함하며,
상기 프로세싱된 오디오 신호를 생성하는 단계는 :
튜너블 필터 파라미터를 갖는 적응 필터를 이용하여 상기 잡음 신호의 동기화된 상기 카피 및 상기 튜너블 필터 파라미터에 기초하여 필터링된 잡음 신호를 생성하는 단계;
동기화된 상기 입력 오디오 신호와 상기 잡음 신호의 동기화된 상기 카피를 비교하는 것에 기초하여 상기 튜너블 필터 파라미터를 선택적으로 조정하는 단계;
상기 입력 오디오 신호가 상기 잡음 신호에 더하여 다른 신호를 갖는지 여부를 결정하는 단계;
상기 입력 오디오 신호가 상기 잡음 신호에 더하여 다른 신호를 갖는다고 결정될 때 상기 적응 필터의 상기 튜너블 필터 파라미터의 조정을 디스에이블하는 단계를 포함하며,
상기 잡음 신호를 상기 입력 오디오 신호와 비교함으로써 상기 잡음 신호의 상기 카피를 상기 입력 오디오 신호와 비교하는 단계는, 상기 필터링된 잡음 신호를 동기화된 상기 입력 오디오 신호와 비교하는 단계를 포함하는, 오디오 잡음을 감쇄시키기 위한 방법. - 제 9 항에 있어서,
통신 채널 상에서 별개의 미디어 디바이스와 데이터를 통신하여 상기 별개의 미디어 디바이스로부터 상기 잡음 신호의 상기 카피의 적어도 부분을 수신하는 단계를 더 포함하는, 오디오 잡음을 감쇄시키기 위한 방법. - 제 9 항에 있어서,
통신 채널 상에서 별개의 미디어 디바이스에 데이터를 통신하여 상기 콘텐츠 소스에 대응하는 콘텐츠 식별 데이터를 수신하는 단계를 더 포함하는, 오디오 잡음을 감쇄시키기 위한 방법. - 명령들을 저장하는 비일시적 컴퓨터 판독가능 매체로서,
상기 명령들은, 실행될 때, 프로세서로 하여금 :
입력 오디오 신호를 수신하는 단계;
상기 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지를 결정하는 단계;
식별가능한 콘텐츠를 갖는 잡음 신호가 있다면, 상기 잡음 신호의 카피를 획득하기 위해 콘텐츠 소스에 액세스하는 단계; 및
상기 잡음 신호의 상기 카피를 상기 입력 오디오 신호와 비교하는 것에 기초하여 감쇄된 잡음 신호를 갖는 프로세싱된 오디오 신호를 생성하는 단계
를 포함하는 방법을 수행하게 하는, 비일시적 컴퓨터 판독가능 매체. - 제 17 항에 있어서,
상기 명령들은, 실행될 때 :
상기 입력 오디오 신호의 특징 정보를 결정하는 단계;
통신 인터페이스를 이용함으로써 상기 특징 정보를 송신하는 단계; 및
상기 통신 인터페이스를 이용함으로써 상기 특징 정보를 송신하는 것에 적어도 기초하여 상기 잡음 신호의 상기 카피를 수신하는 단계
를 더 포함하는 방법을 수행하는, 비일시적 컴퓨터 판독가능 매체. - 오디오 잡음을 감쇄시키기 위한 장치로서,
입력 오디오 신호를 수신하는 수단;
상기 입력 오디오 신호가 식별가능한 콘텐츠를 갖는 잡음 신호를 포함하는지를 결정하고, 식별가능한 콘텐츠를 갖는 잡음 신호가 있다면 상기 잡음 신호의 카피를 획득하기 위해 콘텐츠 소스에 선택적으로 액세스하는 수단; 및
상기 잡음 신호의 상기 카피를 상기 입력 오디오 신호와 비교하는 것에 기초하여 감쇄된 잡음 신호를 갖는 프로세싱된 오디오 신호를 생성하는 수단을 포함하는, 오디오 잡음을 감쇄시키기 위한 장치. - 제 19 항에 있어서,
상기 결정하는 수단은 :
상기 특징 정보와 연관된 콘텐츠 식별 정보를 결정하는 수단;
상기 콘텐츠 식별 정보를 상기 콘텐츠 소스와 매칭시키는 것에 기초하여 상기 콘텐츠 소스를 찾아 데이터베이스를 검색하는 수단; 및
상기 검색이 상기 콘텐츠 소스를 로케이팅한다면 상기 콘텐츠 소스로부터 상기 잡음 신호의 상기 카피를 생성하는 수단을 포함하는, 오디오 잡음을 감쇄시키기 위한 장치.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US13/787,605 US9275625B2 (en) | 2013-03-06 | 2013-03-06 | Content based noise suppression |
| US13/787,605 | 2013-03-06 | ||
| PCT/US2014/017381 WO2014137612A1 (en) | 2013-03-06 | 2014-02-20 | Content based noise suppression |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20150123902A true KR20150123902A (ko) | 2015-11-04 |
Family
ID=50236325
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020157026895A KR20150123902A (ko) | 2013-03-06 | 2014-02-20 | 콘텐츠 기반 잡음 억제 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US9275625B2 (ko) |
| EP (1) | EP2965496B1 (ko) |
| JP (1) | JP2016513816A (ko) |
| KR (1) | KR20150123902A (ko) |
| CN (1) | CN105027541B (ko) |
| WO (1) | WO2014137612A1 (ko) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018038379A1 (ko) * | 2016-08-26 | 2018-03-01 | 삼성전자 주식회사 | 음성 인식을 위한 전자 장치 및 이의 제어 방법 |
| KR20200006905A (ko) * | 2017-05-16 | 2020-01-21 | 소니 주식회사 | 방송 환경들에서의 스피치 인식 애플리케이션들에 대한 스피치 강화 |
| KR20200035118A (ko) * | 2017-08-07 | 2020-04-01 | 소노스 인코포레이티드 | 활성 단어 검출 억제 |
Families Citing this family (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9947333B1 (en) * | 2012-02-10 | 2018-04-17 | Amazon Technologies, Inc. | Voice interaction architecture with intelligent background noise cancellation |
| US9570087B2 (en) * | 2013-03-15 | 2017-02-14 | Broadcom Corporation | Single channel suppression of interfering sources |
| US9832299B2 (en) * | 2013-07-17 | 2017-11-28 | Empire Technology Development Llc | Background noise reduction in voice communication |
| US10149047B2 (en) * | 2014-06-18 | 2018-12-04 | Cirrus Logic Inc. | Multi-aural MMSE analysis techniques for clarifying audio signals |
| US10325591B1 (en) * | 2014-09-05 | 2019-06-18 | Amazon Technologies, Inc. | Identifying and suppressing interfering audio content |
| US9952095B1 (en) | 2014-09-29 | 2018-04-24 | Apple Inc. | Methods and systems for modulation and demodulation of optical signals |
| US9979955B1 (en) * | 2014-09-30 | 2018-05-22 | Apple Inc. | Calibration methods for near-field acoustic imaging systems |
| US9747488B2 (en) | 2014-09-30 | 2017-08-29 | Apple Inc. | Active sensing element for acoustic imaging systems |
| JP6322125B2 (ja) * | 2014-11-28 | 2018-05-09 | 日本電信電話株式会社 | 音声認識装置、音声認識方法および音声認識プログラム |
| CN105988049B (zh) * | 2015-02-28 | 2019-02-19 | 惠州市德赛西威汽车电子股份有限公司 | 一种噪声抑制的调试方法 |
| US9672821B2 (en) * | 2015-06-05 | 2017-06-06 | Apple Inc. | Robust speech recognition in the presence of echo and noise using multiple signals for discrimination |
| EP3317878B1 (de) * | 2015-06-30 | 2020-03-25 | Fraunhofer Gesellschaft zur Förderung der Angewand | Verfahren und vorrichtung zum erzeugen einer datenbank |
| US11048902B2 (en) | 2015-08-20 | 2021-06-29 | Appple Inc. | Acoustic imaging system architecture |
| CN105489215B (zh) * | 2015-11-18 | 2019-03-12 | 珠海格力电器股份有限公司 | 一种噪声源识别方法及系统 |
| US11277210B2 (en) * | 2015-11-19 | 2022-03-15 | The Hong Kong University Of Science And Technology | Method, system and storage medium for signal separation |
| DE112017001830B4 (de) * | 2016-05-06 | 2024-02-22 | Robert Bosch Gmbh | Sprachverbesserung und audioereignisdetektion für eine umgebung mit nichtstationären geräuschen |
| US9838815B1 (en) * | 2016-06-01 | 2017-12-05 | Qualcomm Incorporated | Suppressing or reducing effects of wind turbulence |
| US10554822B1 (en) * | 2017-02-28 | 2020-02-04 | SoliCall Ltd. | Noise removal in call centers |
| JP6545419B2 (ja) * | 2017-03-08 | 2019-07-17 | 三菱電機株式会社 | 音響信号処理装置、音響信号処理方法、及びハンズフリー通話装置 |
| US10313218B2 (en) * | 2017-08-11 | 2019-06-04 | 2236008 Ontario Inc. | Measuring and compensating for jitter on systems running latency-sensitive audio signal processing |
| EP3692530B1 (en) | 2017-10-02 | 2021-09-08 | Dolby Laboratories Licensing Corporation | Audio de-esser independent of absolute signal level |
| US10847178B2 (en) * | 2018-05-18 | 2020-11-24 | Sonos, Inc. | Linear filtering for noise-suppressed speech detection |
| US10297266B1 (en) | 2018-06-15 | 2019-05-21 | Cisco Technology, Inc. | Adaptive noise cancellation for multiple audio endpoints in a shared space |
| US10867615B2 (en) * | 2019-01-25 | 2020-12-15 | Comcast Cable Communications, Llc | Voice recognition with timing information for noise cancellation |
| EP3709194A1 (en) | 2019-03-15 | 2020-09-16 | Spotify AB | Ensemble-based data comparison |
| CN110047497B (zh) * | 2019-05-14 | 2021-06-11 | 腾讯科技(深圳)有限公司 | 背景音频信号滤除方法、装置及存储介质 |
| US11017792B2 (en) * | 2019-06-17 | 2021-05-25 | Bose Corporation | Modular echo cancellation unit |
| US11094319B2 (en) * | 2019-08-30 | 2021-08-17 | Spotify Ab | Systems and methods for generating a cleaned version of ambient sound |
| US11328722B2 (en) | 2020-02-11 | 2022-05-10 | Spotify Ab | Systems and methods for generating a singular voice audio stream |
| US11308959B2 (en) | 2020-02-11 | 2022-04-19 | Spotify Ab | Dynamic adjustment of wake word acceptance tolerance thresholds in voice-controlled devices |
| US11950512B2 (en) | 2020-03-23 | 2024-04-02 | Apple Inc. | Thin-film acoustic imaging system for imaging through an exterior surface of an electronic device housing |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7747002B1 (en) * | 2000-03-15 | 2010-06-29 | Broadcom Corporation | Method and system for stereo echo cancellation for VoIP communication systems |
| CN100538701C (zh) * | 2000-07-31 | 2009-09-09 | 兰德马克数字服务公司 | 用于从媒体样本辨认媒体实体的方法 |
| US6990453B2 (en) * | 2000-07-31 | 2006-01-24 | Landmark Digital Services Llc | System and methods for recognizing sound and music signals in high noise and distortion |
| EP1457889A1 (en) * | 2003-03-13 | 2004-09-15 | Koninklijke Philips Electronics N.V. | Improved fingerprint matching method and system |
| JP2005077865A (ja) * | 2003-09-02 | 2005-03-24 | Sony Corp | 音楽検索システムおよび方法、情報処理装置および方法、プログラム、並びに記録媒体 |
| CN1897054A (zh) | 2005-07-14 | 2007-01-17 | 松下电器产业株式会社 | 可根据声音种类发出警报的传输装置及方法 |
| US20090012786A1 (en) | 2007-07-06 | 2009-01-08 | Texas Instruments Incorporated | Adaptive Noise Cancellation |
| JP4431836B2 (ja) * | 2007-07-26 | 2010-03-17 | 株式会社カシオ日立モバイルコミュニケーションズ | 音声取得装置、雑音除去システム、及び、プログラム |
| US20090034750A1 (en) | 2007-07-31 | 2009-02-05 | Motorola, Inc. | System and method to evaluate an audio configuration |
| US9112989B2 (en) | 2010-04-08 | 2015-08-18 | Qualcomm Incorporated | System and method of smart audio logging for mobile devices |
| US9280598B2 (en) | 2010-05-04 | 2016-03-08 | Soundhound, Inc. | Systems and methods for sound recognition |
| US8812014B2 (en) | 2010-08-30 | 2014-08-19 | Qualcomm Incorporated | Audio-based environment awareness |
| JP5561195B2 (ja) * | 2011-02-07 | 2014-07-30 | 株式会社Jvcケンウッド | ノイズ除去装置およびノイズ除去方法 |
| US9384726B2 (en) | 2012-01-06 | 2016-07-05 | Texas Instruments Incorporated | Feedback microphones encoder modulators, signal generators, mixers, amplifiers, summing nodes |
-
2013
- 2013-03-06 US US13/787,605 patent/US9275625B2/en active Active
-
2014
- 2014-02-20 CN CN201480010777.4A patent/CN105027541B/zh active Active
- 2014-02-20 EP EP14708428.9A patent/EP2965496B1/en not_active Not-in-force
- 2014-02-20 JP JP2015561382A patent/JP2016513816A/ja active Pending
- 2014-02-20 WO PCT/US2014/017381 patent/WO2014137612A1/en active Application Filing
- 2014-02-20 KR KR1020157026895A patent/KR20150123902A/ko active IP Right Grant
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2018038379A1 (ko) * | 2016-08-26 | 2018-03-01 | 삼성전자 주식회사 | 음성 인식을 위한 전자 장치 및 이의 제어 방법 |
| KR20180023702A (ko) * | 2016-08-26 | 2018-03-07 | 삼성전자주식회사 | 음성 인식을 위한 전자 장치 및 그 제어 방법 |
| US11087755B2 (en) | 2016-08-26 | 2021-08-10 | Samsung Electronics Co., Ltd. | Electronic device for voice recognition, and control method therefor |
| KR20200006905A (ko) * | 2017-05-16 | 2020-01-21 | 소니 주식회사 | 방송 환경들에서의 스피치 인식 애플리케이션들에 대한 스피치 강화 |
| KR20200035118A (ko) * | 2017-08-07 | 2020-04-01 | 소노스 인코포레이티드 | 활성 단어 검출 억제 |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2965496B1 (en) | 2018-01-03 |
| WO2014137612A1 (en) | 2014-09-12 |
| CN105027541B (zh) | 2018-01-16 |
| CN105027541A (zh) | 2015-11-04 |
| US20140254816A1 (en) | 2014-09-11 |
| US9275625B2 (en) | 2016-03-01 |
| JP2016513816A (ja) | 2016-05-16 |
| EP2965496A1 (en) | 2016-01-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| EP2965496B1 (en) | Content based noise suppression | |
| US9704478B1 (en) | Audio output masking for improved automatic speech recognition | |
| US9913056B2 (en) | System and method to enhance speakers connected to devices with microphones | |
| RU2467406C2 (ru) | Способ и устройство для поддержки воспринимаемости речи в многоканальном звуковом сопровождении с минимальным влиянием на систему объемного звучания | |
| US9558755B1 (en) | Noise suppression assisted automatic speech recognition | |
| CN105814909B (zh) | 用于反馈检测的系统和方法 | |
| JP2018528479A (ja) | スーパー広帯域音楽のための適応雑音抑圧 | |
| US9286883B1 (en) | Acoustic echo cancellation and automatic speech recognition with random noise | |
| WO2020069190A1 (en) | Linear filtering for noise-suppressed speech detection via multiple network microphone devices | |
| JP2009518880A (ja) | エコー除去の構成 | |
| US9773510B1 (en) | Correcting clock drift via embedded sine waves | |
| US10325591B1 (en) | Identifying and suppressing interfering audio content | |
| US9076452B2 (en) | Apparatus and method for generating audio signal having sound enhancement effect | |
| GB2532041A (en) | Comfort noise generation | |
| US8582754B2 (en) | Method and system for echo cancellation in presence of streamed audio | |
| KR100633213B1 (ko) | 불가청 정보를 포함함으로써 적응형 필터 성능을개선시키는 방법 및 장치 | |
| US20130058496A1 (en) | Audio Noise Optimizer | |
| US11222647B2 (en) | Cascade echo cancellation for asymmetric references | |
| KR20230028725A (ko) | 음향 투과성을 위한 시스템들, 장치, 및 방법들 | |
| WO2018219459A1 (en) | A method and an apparatus for enhancing an audio signal captured in an indoor environment | |
| US9392365B1 (en) | Psychoacoustic hearing and masking thresholds-based noise compensator system | |
| GB2575873A (en) | Processing audio signals | |
| Eskimez et al. | Real-time joint personalized speech enhancement and acoustic echo cancellation with e3net | |
| KR102196519B1 (ko) | 소리 제거 시스템 및 이를 이용한 소리 제거 방법 | |
| KR100754558B1 (ko) | 주기 신호 향상 시스템 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| A302 | Request for accelerated examination | ||
| E701 | Decision to grant or registration of patent right |