KR20140104882A - Method for processing query based on hadoop - Google Patents
Method for processing query based on hadoop Download PDFInfo
- Publication number
- KR20140104882A KR20140104882A KR1020130066978A KR20130066978A KR20140104882A KR 20140104882 A KR20140104882 A KR 20140104882A KR 1020130066978 A KR1020130066978 A KR 1020130066978A KR 20130066978 A KR20130066978 A KR 20130066978A KR 20140104882 A KR20140104882 A KR 20140104882A
- Authority
- KR
- South Korea
- Prior art keywords
- query
- database
- result corresponding
- stored
- hive
- Prior art date
Links
Images





Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/903—Querying
- G06F16/9038—Presentation of query results
Abstract
Description
본 발명은 질의 처리 방법 및 장치에 관한 것으로, 더욱 상세하게는 빅 데이터를 처리하기 위해 사용되는 하둡을 기초로 하여 사용자의 질의를 신속하게 처리하기 위한 질의 처리 방법 및 장치에 관한 것이다.The present invention relates to a query processing method and apparatus, and more particularly, to a query processing method and apparatus for quickly processing a user query based on Hadoop used for processing big data.
하둡(hadoop)은 빅 데이터(big data)를 처리하기 위해 사용되는 기술 중 하나로, 크게 하둡 분산 파일 시스템(hadoop distributed file system, HDFS)과 맵 리듀스(map reduce)로 구성된다.Hadoop is one of the technologies used to handle big data, and it consists largely of the Hadoop distributed file system (HDFS) and the map reduce.
맵 리듀스는 실제 빅 데이터를 처리하는 프로그램으로서, 맵 단계와 리듀스 단계로 구분할 수 있다. 맵 단계에서는 입력 데이터를 키-값(key-value)으로 매핑(mapping)하며, 특정 키에 대한 값들을 병합하여 중간 데이터로 출력한다. 리듀스 단계에서는 맵 단계를 통해 생성된 중간 데이터를 입력으로 받아 사용자가 원하는 방향으로 최종 분석, 처리하여 그 결과를 출력한다.Map Reduce is a program that processes actual big data, and can be divided into a map step and a reduction step. In the map step, the input data is mapped to a key-value, and the values for a specific key are merged and output as intermediate data. In the redesing step, the intermediate data generated through the map step is received as an input, and finally analyzed and processed in a direction desired by the user, and the result is outputted.
맵 리듀스 프로그램은 일반적으로 자바(java) 프로그래밍 언어를 통해 개발된다. 즉, 빅 데이터를 분석 및 처리하기 위해 사용자는 자바 프로그래밍 언어를 다룰줄 알아야 하며, 이는 기존의 SQL(structured query language)을 통해 데이터를 분석하던 사용자의 입장에서 큰 진입 장벽이 된다.MapReduce programs are generally developed through the Java programming language. In other words, to analyze and process big data, users need to know how to handle Java programming language, which is a big entry barriers for users who analyze data through existing SQL (structured query language).
이러한 문제점을 해결하기 위해 하이브(hive)가 개발되었으며, 하이브는 HiveQL(hive query language)라고 불리는 SQL과 상당이 유사한 인터페이스(interface)를 제공한다. 빅 데이터를 분석 및 처리하기 위해 HiveQL로 작성된 질의는 내부적으로 낮은-레벨(low-level)에서 맵 리듀스 잡(job)으로 변환되어 동작하게 된다. 이로 인해, 실제 빅 데이터의 사용자는 자바 프로그래밍 언어를 사용하여 맵 리듀스 잡을 작성할 필요 없이 HiveQL과 같은 질의 자체에만 집중할 수 있다.To solve this problem, a hive has been developed, and the hive provides a similar interface to SQL called HiveQL (hive query language). In order to analyze and process big data, queries written in HiveQL are internally converted from low-level to a map reduction job. This allows users of real Big Data to focus solely on queries such as HiveQL without having to write a MapReduce job using the Java programming language.
이러한 하이브를 사용함으로써 맵 리듀스 프로그램에 대한 접근성이 향상되었으나, 하이브를 사용하는 경우에도 질의를 처리하기 위해 맵 리듀스 프로그램을 수행해야 하므로, 실질적으로 빅 데이터의 분석 및 처리 성능이 향상되지 못하는 문제점이 있다.The use of such a hive improves accessibility to the map reduction program. However, even if a hive is used, the map reduction program must be executed in order to process the query. Therefore, the analysis and processing performance of the big data can not be substantially improved .
상기와 같은 문제점을 해결하기 위한 본 발명의 목적은, 관계형 데이터베이스를 통해 사용자의 질의를 신속히 처리하기 위한 질의 처리 방법을 제공하는 데 있다.An object of the present invention is to provide a query processing method for quickly processing a query of a user through a relational database.
상기와 같은 문제점을 해결하기 위한 본 발명의 다른 목적은, 관계형 데이터베이스를 통해 사용자의 질의를 신속히 처리하기 위한 질의 처리 장치를 제공하는 데 있다.Another object of the present invention is to provide a query processing apparatus for quickly processing a query of a user through a relational database.
상기 목적을 달성하기 위한 본 발명의 일 실시예에 따른 질의 처리 방법은, 사용자 단말로부터 질의를 수신하는 단계, 상기 질의에 대응된 결과가 상기 질의 처리 장치 내의 데이터베이스에 저장되어 있는지 판단하는 단계 및 상기 질의에 대응된 결과가 상기 데이터베이스에 저장되어 있는 경우, 저장된 상기 질의에 대응된 결과를 상기 사용자 단말에 제공하는 단계를 포함한다.According to another aspect of the present invention, there is provided a query processing method including receiving a query from a user terminal, determining whether a result corresponding to the query is stored in a database in the query processing apparatus, And providing a result corresponding to the stored query to the user terminal if a result corresponding to the query is stored in the database.
여기서, 상기 질의 처리 방법은, 상기 질의에 대응된 결과가 상기 데이터베이스에 저장되어 있지 않은 경우, 상기 질의를 하이브에 제공하는 단계, 상기 하이브를 통해 처리된 상기 질의에 대응된 결과를 획득하는 단계 및 상기 질의에 대응된 결과를 상기 사용자 단말에 제공하는 단계를 더 포함할 수 있다.Wherein the query processing method further comprises the steps of providing the query to the hive if a result corresponding to the query is not stored in the database, obtaining a result corresponding to the query processed through the hive, And providing a result corresponding to the query to the user terminal.
여기서, 상기 질의 처리 방법은, 상기 하이브를 통해 처리된 상기 질의에 대응된 결과를 상기 데이터베이스에 저장하는 단계를 더 포함할 수 있다.Here, the query processing method may further include storing the result corresponding to the query processed through the hive in the database.
여기서, 상기 질의 처리 방법은, 상기 데이터베이스에 저장된 임의의 질의에 대응된 결과가 미리 설정된 시간 동안 사용되지 않는 경우, 상기 임의의 질의에 대응된 결과를 삭제할 수 있다.Here, the query processing method may delete a result corresponding to the arbitrary query if a result corresponding to an arbitrary query stored in the database is not used for a predetermined time.
여기서, 상기 질의 처리 방법은, 임의의 질의에 대응된 결과가 상기 데이터베이스에 저장된 시점부터 미리 설정된 시간이 지난 경우, 상기 임의의 질의에 대응된 결과를 갱신할 수 있다.Here, the query processing method may update a result corresponding to the arbitrary query when a predetermined time has elapsed since a result corresponding to an arbitrary query was stored in the database.
여기서, 상기 데이터베이스는, 상기 질의와 상기 질의에 대응된 결과를 기반으로 생성된 관계형 데이터베이스일 수 있다.Here, the database may be a relational database generated based on the query and a result corresponding to the query.
상기 다른 목적을 달성하기 위한 본 발명의 일 실시예에 따른 질의 처리 장치는, 사용자 단말로부터 수신한 질의를 분석하여 상기 질의에 대응된 결과가 데이터베이스에 저장되어 있는지 판단하고, 상기 질의에 대응된 결과가 상기 데이터베이스에 저장되어 있는 경우 상기 질의에 대응된 결과를 상기 사용자 단말에 제공하는 프로세서, 및 질의 및 질의에 대응된 결과를 저장하는 상기 데이터베이스를 포함한다.According to another aspect of the present invention, there is provided a query processing apparatus for analyzing a query received from a user terminal to determine whether a result corresponding to the query is stored in a database, A processor for providing a result corresponding to the query to the user terminal if the query is stored in the database, and a database for storing a result corresponding to the query and the query.
여기서, 상기 프로세서는, 상기 질의에 대응된 결과가 상기 데이터베이스에 저장되어 있지 않은 경우 상기 질의를 하이브에 제공하고, 상기 하이브를 통해 처리된 상기 질의에 대응된 결과를 획득하고, 상기 질의에 대응된 결과를 상기 사용자 단말에 제공할 수 있다.Wherein the processor is configured to: provide the query to a hive if a result corresponding to the query is not stored in the database; obtain a result corresponding to the query processed through the hive; And provide the result to the user terminal.
여기서, 상기 데이터베이스는, 상기 하이브를 통해 처리된 상기 질의에 대응된 결과를 저장할 수 있다.Here, the database may store a result corresponding to the query processed through the hive.
여기서, 상기 프로세서는, 상기 데이터베이스에 저장된 임의의 질의에 대응된 결과가 미리 설정된 시간 동안 사용되지 않는 경우, 상기 임의의 질의에 대응된 결과를 삭제할 수 있다.Here, the processor may delete a result corresponding to the arbitrary query if a result corresponding to any query stored in the database is not used for a predetermined time.
여기서, 상기 프로세서는, 임의의 질의에 대응된 결과가 상기 데이터베이스에 저장된 시점부터 미리 설정된 시간이 지난 경우, 상기 임의의 질의에 대응된 결과를 갱신할 수 있다.Here, the processor may update the result corresponding to the arbitrary query if a predetermined time has elapsed since the result corresponding to the arbitrary query was stored in the database.
여기서, 상기 데이터베이스는, 상기 질의와 상기 질의에 대응된 결과를 기반으로 생성된 관계형 데이터베이스일 수 있다.Here, the database may be a relational database generated based on the query and a result corresponding to the query.
본 발명에 의하면, 맵 리듀스 과정을 통해 처리된 질의에 대한 정보를 포함한 관계형 데이터베이스를 구축할 수 있고, 추후 동일하거나 유사한 질의에 대해서는 맵 리듀스 과정을 거치지 않고 관계형 데이터베이스를 사용하여 처리할 수 있으므로, 사용자의 질의를 신속하게 처리할 수 있다.According to the present invention, it is possible to construct a relational database including information on a query processed through a map reduction process, and to process the same or similar queries later using a relational database without performing a map reduction process , The user's query can be processed quickly.
도 1은 하둡 기반의 질의 처리 시스템을 도시한 블록도이다.
도 2는 본 발명의 일 실시예에 따른 질의 처리 방법을 도시한 흐름도이다.
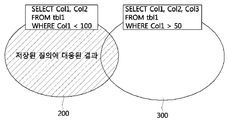
도 3은 완전 부분 질의에 대한 일 실시예를 도시한 개념도이다.
도 4는 불완전 부분 질의에 대한 일 실시예를 도시한 개념도이다.
도 5는 관계형 데이터베이스와 하이브의 관계를 도시한 개념도이다.
도 6은 본 발명의 일 실시예에 따른 질의 처리 장치를 도시한 블록도이다.
도 7은 본 발명의 일 실시예에 따른 프로세서의 구성을 도시한 블록도이다.
도 8은 본 발명의 일 실시예에 따른 질의 처리 장치가 적용된 하둡 기반의 질의 처리 시스템을 도시한 블록도이다.1 is a block diagram illustrating a Hadoop-based query processing system.
2 is a flowchart illustrating a query processing method according to an embodiment of the present invention.
3 is a conceptual diagram showing an embodiment of a perfect partial query.
4 is a conceptual diagram showing an embodiment of an incomplete partial query.
5 is a conceptual diagram showing the relationship between a relational database and a hive.
6 is a block diagram illustrating a query processing apparatus according to an embodiment of the present invention.
7 is a block diagram illustrating a configuration of a processor according to an embodiment of the present invention.
8 is a block diagram illustrating a Hadoop-based query processing system to which a query processing apparatus according to an embodiment of the present invention is applied.
본 발명은 다양한 변경을 가할 수 있고 여러 가지 실시예를 가질 수 있는 바, 특정 실시예들을 도면에 예시하고 상세하게 설명하고자 한다.While the invention is susceptible to various modifications and alternative forms, specific embodiments thereof are shown by way of example in the drawings and will herein be described in detail.
그러나, 이는 본 발명을 특정한 실시 형태에 대해 한정하려는 것이 아니며, 본 발명의 사상 및 기술 범위에 포함되는 모든 변경, 균등물 내지 대체물을 포함하는 것으로 이해되어야 한다.It should be understood, however, that the invention is not intended to be limited to the particular embodiments, but includes all modifications, equivalents, and alternatives falling within the spirit and scope of the invention.
제1, 제2 등의 용어는 다양한 구성요소들을 설명하는데 사용될 수 있지만, 상기 구성요소들은 상기 용어들에 의해 한정되어서는 안 된다. 상기 용어들은 하나의 구성요소를 다른 구성요소로부터 구별하는 목적으로만 사용된다. 예를 들어, 본 발명의 권리 범위를 벗어나지 않으면서 제1 구성요소는 제2 구성요소로 명명될 수 있고, 유사하게 제2 구성요소도 제1 구성요소로 명명될 수 있다. 및/또는 이라는 용어는 복수의 관련된 기재된 항목들의 조합 또는 복수의 관련된 기재된 항목들 중의 어느 항목을 포함한다.The terms first, second, etc. may be used to describe various components, but the components should not be limited by the terms. The terms are used only for the purpose of distinguishing one component from another. For example, without departing from the scope of the present invention, the first component may be referred to as a second component, and similarly, the second component may also be referred to as a first component. And / or < / RTI > includes any combination of a plurality of related listed items or any of a plurality of related listed items.
어떤 구성요소가 다른 구성요소에 "연결되어" 있다거나 "접속되어" 있다고 언급된 때에는, 그 다른 구성요소에 직접적으로 연결되어 있거나 또는 접속되어 있을 수도 있지만, 중간에 다른 구성요소가 존재할 수도 있다고 이해되어야 할 것이다. 반면에, 어떤 구성요소가 다른 구성요소에 "직접 연결되어" 있다거나 "직접 접속되어" 있다고 언급된 때에는, 중간에 다른 구성요소가 존재하지 않는 것으로 이해되어야 할 것이다.It is to be understood that when an element is referred to as being "connected" or "connected" to another element, it may be directly connected or connected to the other element, . On the other hand, when an element is referred to as being "directly connected" or "directly connected" to another element, it should be understood that there are no other elements in between.
본 출원에서 사용한 용어는 단지 특정한 실시예를 설명하기 위해 사용된 것으로, 본 발명을 한정하려는 의도가 아니다. 단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수의 표현을 포함한다. 본 출원에서, "포함하다" 또는 "가지다" 등의 용어는 명세서상에 기재된 특징, 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것이 존재함을 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다.The terminology used in this application is used only to describe a specific embodiment and is not intended to limit the invention. The singular expressions include plural expressions unless the context clearly dictates otherwise. In the present application, the terms "comprises" or "having" and the like are used to specify that there is a feature, a number, a step, an operation, an element, a component or a combination thereof described in the specification, But do not preclude the presence or addition of one or more other features, integers, steps, operations, elements, components, or combinations thereof.
다르게 정의되지 않는 한, 기술적이거나 과학적인 용어를 포함해서 여기서 사용되는 모든 용어들은 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자에 의해 일반적으로 이해되는 것과 동일한 의미를 가지고 있다. 일반적으로 사용되는 사전에 정의되어 있는 것과 같은 용어들은 관련 기술의 문맥 상 가지는 의미와 일치하는 의미를 가진 것으로 해석되어야 하며, 본 출원에서 명백하게 정의하지 않는 한, 이상적이거나 과도하게 형식적인 의미로 해석되지 않는다.Unless defined otherwise, all terms used herein, including technical or scientific terms, have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs. Terms such as those defined in commonly used dictionaries should be interpreted as having a meaning consistent with the meaning in the context of the relevant art and are to be interpreted in an ideal or overly formal sense unless explicitly defined in the present application Do not.
이하, 첨부한 도면들을 참조하여, 본 발명의 바람직한 실시예를 보다 상세하게 설명하고자 한다. 본 발명을 설명함에 있어 전체적인 이해를 용이하게 하기 위하여 도면상의 동일한 구성요소에 대해서는 동일한 참조부호를 사용하고 동일한 구성요소에 대해서 중복된 설명은 생략한다.
Hereinafter, preferred embodiments of the present invention will be described in detail with reference to the accompanying drawings. In order to facilitate the understanding of the present invention, the same reference numerals are used for the same constituent elements in the drawings and redundant explanations for the same constituent elements are omitted.
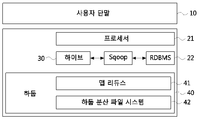
도 1은 하둡(hadoop) 기반의 질의 처리 시스템을 도시한 블록도이다.1 is a block diagram illustrating a Hadoop-based query processing system.
도 1을 참조하면, 사용자 단말(10)은 질의(query)를 질의 처리 장치(20)에 제공할 수 있다. 사용자 단말(10)은 데스크탑 컴퓨터(Desktop Computer), 랩탑 컴퓨터(Laptop Computer), 태블릿(Tablet) PC 등을 의미할 수 있다. Referring to FIG. 1, the
질의 처리 장치(20)는 사용자 단말(10)로부터 수신한 질의에 대응된 결과가 질의 처리 장치(20) 내에 저장되어 있는 경우, 저장된 질의에 대응된 결과를 사용자 단말(10)에 제공할 수 있다. 한편, 사용자 단말(10)로부터 수신한 질의에 대응된 결과가 질의 처리 장치(20) 내에 저장되어 있지 않은 경우, 질의 처리 장치(20)는 질의를 하이브(hive)(30)에 제공할 수 있다. 질의 처리 장치(20)의 구체적인 구성 및 각 구성의 기능에 대해서는 도 6을 참조하여 후술하도록 한다.The
하이브(30)는 질의 처리 장치(20)로부터 수신한 질의에 대응된 결과가 하이브(30) 내에 저장되어 있는 경우, 저장된 질의에 대응된 결과를 질의 처리 장치(20)에 제공할 수 있다. 한편, 질의 처리 장치(20)로부터 수신한 질의에 대응된 결과가 하이브(30) 내에 저장되어 있지 않은 경우, 하이브(30)는 하둡(40)을 기초로 하여 질의를 처리할 수 있다.The
하이브(30)는 SQL(structured query language)와 유사한 HiveQL(hive query language) 기반의 인터페이스(interface)를 제공하며, 빅 데이터를 분석 및 처리하기 위해 HiveQL로 작성된 질의는 내부적으로 낮은-레벨(low-level)에서 맵 리듀스(map reduce) 잡으로 변환되어 동작하게 된다.The
하둡(40)은 크게 하둡 분산 파일 시스템(hadoop distributed file system, HDFS)과 맵 리듀스로 구성된다. 하둡(40)은 하이브(30)로부터 수신된 질의를 맵 리듀스를 기반으로 처리할 수 있고, 처리된 결과를 하이브(30)에 제공할 수 있다.
Hadoop (40) consists largely of the Hadoop distributed file system (HDFS) and map redess. The Hadoop 40 can process the query received from the
도 2는 본 발명의 일 실시예에 따른 질의 처리 방법을 도시한 흐름도이다.2 is a flowchart illustrating a query processing method according to an embodiment of the present invention.
도 2를 참조하면, 하둡 기반의 질의 처리 방법은, 사용자 단말로부터 질의를 수신하는 단계(S100), 질의에 대응된 결과가 데이터베이스(database)에 저장되어 있는지 판단하는 단계(S110) 및 질의에 대응된 결과가 데이터베이스에 저장되어 있는 경우, 저장된 질의에 대응된 결과를 사용자 단말에 제공하는 단계(S120)를 포함한다.Referring to FIG. 2, a Hadoop-based query processing method includes receiving a query from a user terminal (S100), determining whether a result corresponding to the query is stored in a database (S110) And providing the result corresponding to the stored query to the user terminal (S120) if the result is stored in the database.
또한, 하둡 기반의 질의 처리 방법은, 질의에 대응된 결과가 데이터베이스에 저장되어 있지 않은 경우 질의를 하이브에 제공하는 단계(S130), 하이브를 통해 처리된 질의에 대응된 결과를 획득하는 단계(S140) 및 질의에 대응된 결과를 사용자 단말에 제공하는 단계(S150)를 포함할 수 있다.In addition, the Hadoop-based query processing method includes a step of providing a query to a hive if the result corresponding to the query is not stored in the database (S130), obtaining a result corresponding to the query processed through the hive (S140 And providing a result corresponding to the query to the user terminal (S150).
하둡 기반의 질의 처리 방법은 도 6에 도시된 질의 처리 장치(20)에서 수행될 수 있으며, 질의 처리 장치(20)는 프로세서(processor)(21) 및 데이터베이스(22)를 포함한다.The Hadoop-based query processing method can be performed in the
단계 S100에서, 질의 처리 장치는 사용자 단말로부터 질의를 수신할 수 있다. 사용자 단말은 질의에 대응된 결과를 요청하기 위해 사용자가 사용하는 것으로, 데스크탑 컴퓨터, 랩탑 컴퓨터, 태블릿 PC 등을 의미할 수 있다.In step S100, the query processing device may receive a query from the user terminal. A user terminal may be a desktop computer, a laptop computer, a tablet PC, or the like, used by a user to request a result corresponding to a query.
단계 S110에서, 질의 처리 장치는 사용자 단말로부터 수신된 질의에 대응된 결과가 질의 처리 장치 내의 데이터베이스에 저장되어 있는지 판단할 수 있다. 예를 들어, 사용자 단말로부터 수신된 질의가 'SELECT year, month FROM airline_delay WHERE year=2013' 인 경우, 질의 처리 장치는 SELECT 구문, FROM 구문, WHERE 구문별로 질의에 대응된 결과가 질의 처리 장치 내의 데이터베이스에 저장되어 있는지 판단할 수 있다.In step S110, the query processing device can determine whether the result corresponding to the query received from the user terminal is stored in the database in the query processing device. For example, if the query received from the user terminal is 'SELECT year, month FROM airline_delay WHERE year = 2013', then the query processing device determines that the result corresponding to the query by the SELECT, FROM, It is possible to judge whether or not it is stored.
사용자 단말로부터 수신한 질의가 질의 처리 장치 내의 데이터베이스에 저장된 질의에 포함되는 경우(즉, 완전 부분 질의), 질의 처리 장치는 사용자 단말로부터 수신된 질의에 대응된 결과가 자신의 데이터베이스에 모두 저장되어 있는 것으로 판단할 수 있다.
When the query received from the user terminal is included in the query stored in the database in the query processing device (that is, the query is a complete partial query), the query processing apparatus stores the results corresponding to the query received from the user terminal in its database .
도 3은 완전 부분 질의에 대한 일 실시예를 도시한 개념도이다.3 is a conceptual diagram showing an embodiment of a perfect partial query.
도 3을 참조하면, 사용자 단말로부터 수신한 질의(300)가 'SELECT Col1, Col2', 'FROM tbl1', 'WHERE Col1>100'이고 질의 처리 장치 내의 데이터베이스에 저장된 질의(200)가 'SELECT Col1, Col2, Col3', 'FROM tbl1'인 경우, 사용자 단말로부터 수신한 질의(300)는 질의 처리 장치 내의 데이터베이스에 저장된 질의(200)에 포함되므로(즉, 완전 부분 질의), 질의 처리 장치는 사용자 단말로부터 수신된 질의에 대응된 결과가 자신의 데이터베이스에 모두 저장되어 있는 것으로 판단할 수 있다. 따라서, 이와 같은 경우 질의 처리 장치는 다음 단계로 S120을 수행할 수 있다.3, if the
한편, 사용자 단말로부터 수신한 질의가 질의 처리 장치 내의 데이터베이스에 저장된 질의의 일부인 경우(즉, 불완전 부분 질의), 질의 처리 장치는 사용자 단말로부터 수신된 질의에 대응된 결과가 자신의 데이터베이스에 일부 저장되어 있는 것으로 판단할 수 있다.On the other hand, when the query received from the user terminal is a part of the query stored in the database in the query processing device (that is, incomplete partial query), the query processing device stores part of the results corresponding to the query received from the user terminal in its database .
도 4는 불완전 부분 질의에 대한 일 실시예를 도시한 개념도이다.4 is a conceptual diagram showing an embodiment of an incomplete partial query.
도 4를 참조하면, 사용자 단말로부터 수신한 질의(300)가 'SELECT Col1, Col2, Col3', 'FROM tbl1', 'WHERE Col1>50'이고 질의 처리 장치 내의 데이터베이스에 저장된 질의(200)가 'SELECT Col1, Col2', 'FROM tbl1', 'WHERE Col1<100'인 경우, 사용자 단말로부터 수신한 질의(300)는 질의 처리 장치 내의 데이터베이스에 저장된 질의(200)에 일부 포함되므로(즉, 불완전 부분 질의), 질의 처리 장치는 사용자 단말로부터 수신된 질의에 대응된 결과가 자신의 데이터베이스에 일부 저장되어 있는 것으로 판단할 수 있다.4, when the
이와 같은 경우, 질의 처리 장치는 자신의 데이터베이스에 저장된 질의에 대해서는 단계 S120을 통해 처리(즉, 자신의 데이터베이스를 사용하여 처리)할 수 있고, 자신의 데이터베이스에 저장되지 않은 질의에 대해서는 단계 S130, 단계 S140, 단계 S150을 통해 처리(즉, 하이브를 통해 처리)할 수 있다.
In this case, the query processing apparatus can process the query stored in its own database through step S120 (i.e., process it using its own database), and for the query not stored in its database in step S130, (I.e., processing through the hive) through steps S140 and S150.
다시 도 2를 참조하면, 단계 S120에서 질의 처리 장치는 자신의 데이터베이스에 저장된 질의에 대응된 결과를 사용자 단말에 제공할 수 있다. 즉, 질의 처리 장치는 사용자 단말로부터 수신한 질의에 대응한 질의를 자신의 데이터베이스 내에서 검색하고, 검색된 질의에 대응된 결과를 사용자 단말에 제공할 수 있다.Referring again to FIG. 2, in step S120, the query processing device may provide a result corresponding to the query stored in its database to the user terminal. That is, the query processing apparatus searches the database for the query corresponding to the query received from the user terminal, and provides a result corresponding to the retrieved query to the user terminal.
단계 S130에서, 질의 처리 장치는 자신의 데이터베이스에 저장되지 않은 질의를 하이브에 제공할 수 있다. 하이브는 자신의 스토리지(storage) 내에 질의 처리 장치로부터 수신한 질의에 대응된 결과가 저장되어 있는 경우, 저장된 질의에 대응된 결과를 질의 처리 장치에 제공할 수 있다. 한편, 자신의 스토리지 내에 질의 처리 장치로부터 수신한 질의에 대응된 결과가 저장되어 있지 않은 경우, 하이브는 맵 리듀스를 사용하여 질의에 대응된 결과를 생성할 수 있고, 생성된 질의에 대응된 결과를 질의 처리 장치에 제공할 수 있다.In step S130, the query processing device may provide a query to the hive that is not stored in its database. The hive can provide the query processing apparatus with a result corresponding to the stored query if the result corresponding to the query received from the query processing apparatus is stored in its storage. On the other hand, when the result corresponding to the query received from the query processing device is not stored in the storage, the hive can generate the result corresponding to the query using the map reduction, and the result corresponding to the generated query To the query processing apparatus.
단계 S140에서, 질의 처리 장치는 하이브에서 처리된 질의에 대응된 결과를 획득할 수 있다. 예를 들어, 질의 처리 장치는 하이브에서 처리된 질의에 대응된 결과를 오픈 소스(open source)인 스쿱(sqoop)을 사용하여 데이터베이스로 캐싱(caching)할 수 있다. 즉, 질의 처리 장치는 하이브에서 처리된 질의에 대응된 결과를 데이터베이스에 저장할 수 있다.In step S140, the query processing device can obtain a result corresponding to the query processed in the hive. For example, the query processing device can cach the results corresponding to the query processed in the hive to the database using an open source (sqoop). That is, the query processing device can store the result corresponding to the query processed in the hive in the database.
단계 S150에서, 질의 처리 장치는 하이브로부터 획득된 질의에 대응된 결과를 사용자 단말에 제공할 수 있다.
In step S150, the query processing device may provide the user terminal with a result corresponding to the query obtained from the hive.
여기서, 데이터베이스는 질의 처리 장치에 포함된 하나의 구성으로, 관계형 데이터베이스(relational database)를 의미할 수 있다. 데이터베이스는 하이브에서 처리된 결과를 기반으로 미리 구축될 수 있다. 즉, 질의 처리 장치는 하이브를 통해 처리된 질의, 질의에 대응된 결과를 저장하여 데이터베이스를 구축할 수 있다.Here, the database may be a configuration included in the query processing apparatus, and may refer to a relational database. The database can be pre-built based on the results processed in the hive. That is, the query processing device can build a database by storing the results corresponding to the queries and queries processed through the hive.
도 5는 관계형 데이터베이스와 하이브의 관계를 도시한 개념도이다.5 is a conceptual diagram showing the relationship between a relational database and a hive.
도 5를 참조하면, 관계형 데이터베이스(22)와 하이브(30)는 논리적으로 계층적 구조를 가질 수 있다. 즉, 관계형 데이터베이스(22)는 논리적으로 하이브(30)의 상부에 위치할 수 있다. 관계형 데이터베이스(22)는 하이브(30)보다 빠른 데이터 입출력 속도를 가지는 스토리지를 의미할 수 있고, 하이브(30)는 관계형 데이터베이스(22)보다 느린 데이터 입출력 속도를 가지는 스토리지를 의미할 수 있다. 하이브(30)에 저장된 질의에 대응된 결과들 중에서 자주 사용되는 질의에 대응된 결과는 관계형 데이터베이스(22)에 저장(즉, 캐시(cache))될 수 있으며, 이러한 캐싱 과정은 도 6에 도시된 질의 처리 장치에 의해 수행될 수 있다.Referring to FIG. 5, the
이와 같이 관계형 데이터베이스를 구축함으로써, 질의 처리 장치는 사용자 단말로부터 수신한 질의를 먼저 관계형 데이터베이스(22)를 통해 처리할 수 있고, 관계형 데이터베이스(22)를 통해 처리할 수 없는 경우(즉, 질의에 대응된 결과가 관계형 데이터베이스(22)에 저장되어 있지 않은 경우) 하이브(30)를 통해 질의를 처리할 수 있다.
By constructing the relational database in this manner, the query processing apparatus can process the query received from the user terminal first through the
다시 도 2를 참조하면, 하둡 기반의 질의 처리 방법은 미리 설정된 제1 시간이 지난 경우 질의 처리 장치 내의 데이터베이스에 저장된 질의에 대응된 결과를 갱신하는 단계(S160)를 더 포함할 수 있다. 예를 들어, 제1 질의에 대응된 결과가 질의 처리 장치 내의 데이터베이스에 저장된 시점부터 미리 설정된 제1 시간이 지난 경우, 질의 처리 장치는 제1 질의와 대응된 질의를 하이브에서 검색할 수 있고, 검색된 질의에 대응된 결과를 하이브로부터 캐싱할 수 있다. 이때, 질의 처리 장치는 하이브에서 검색된 질의에 대응된 결과와 자신의 데이터베이스에 저장된 제1 질의에 대응된 결과가 다른 경우 검색된 질의에 대응된 결과를 하이브로부터 캐싱할 수 있으며, 하이브에서 검색된 질의에 대응된 결과와 자신의 데이터베이스에 저장된 제1 질의에 대응된 결과가 동일한 경우 캐싱 과정을 수행하지 않을 수 있다. 미리 설정된 제1 시간은 사용자의 요구에 따라 다양하게 설정될 수 있다.Referring again to FIG. 2, the Hadoop-based query processing method may further include a step (S160) of updating the result corresponding to the query stored in the database in the query processing apparatus after a predetermined first time has elapsed. For example, when the first time is longer than the first predetermined time from the time when the result corresponding to the first query is stored in the database in the query processing device, the query processing device can search the hive for the query corresponding to the first query, The results corresponding to the query can be cached from the hive. At this time, the query processing apparatus can cache results corresponding to the retrieved query from the hive if the results corresponding to the query retrieved from the hive are different from those corresponding to the first query stored in the database, and correspond to the query retrieved from the hive And the result corresponding to the first query stored in the database is the same, the caching process may not be performed. The preset first time may be set variously according to the demand of the user.
이와 같은 갱신 과정을 수행함으로써, 질의 처리 장치는 자신의 데이터베이스에 저장된 정보를 최신의 정보로 유지할 수 있다.By performing such an updating process, the query processing apparatus can keep the information stored in its own database as the latest information.
하둡 기반의 질의 처리 방법은 질의 처리 장치 내의 데이터베이스에 저장된 질의에 대응된 결과가 미리 설정된 제2 시간 동안 사용되지 않는 경우 질의에 대응된 결과를 삭제하는 단계(S170)를 더 포함할 수 있다. 예를 들어, 제1 질의에 대응된 결과가 질의 처리 장치 내의 데이터베이스에 저장된 시점(또는, 제1 질의에 대응된 결과가 이전에 사용된 시점)부터 미리 설정된 제2 시간 동안 사용되지 않은 경우, 질의 처리 장치는 자신의 데이터베이스에 저장된 제1 질의에 대응된 결과를 삭제할 수 있다. 미리 설정된 제2 시간은 사용자의 요구에 따라 다양하게 설정될 수 있으며, 미리 설정된 제2 시간은 미리 설정된 제1 시간보다 길게 설정될 수 있다.The Hadoop-based query processing method may further include a step (S170) of deleting the result corresponding to the query if the result corresponding to the query stored in the database in the query processing device is not used for the second predetermined time. For example, when the result corresponding to the first query is not used for the second predetermined time from the time when the result is stored in the database in the query processing device (or the result corresponding to the first query has been used previously) The processing apparatus can delete the result corresponding to the first query stored in its database. The preset second time may be set variously according to the request of the user, and the preset second time may be set longer than the preset first time.
이와 같은 삭제 과정을 수행함으로써, 질의 처리 장치는 불필요한 정보가 데이터베이스에 저장되는 것을 방지할 수 있다.
By performing this deletion process, the query processing apparatus can prevent unnecessary information from being stored in the database.
본 발명에 따른 질의 처리 방법들은 다양한 컴퓨터 수단을 통해 수행될 수 있는 프로그램 명령 형태로 구현되어 컴퓨터 판독 가능 매체에 기록될 수 있다. 컴퓨터 판독 가능 매체는 프로그램 명령, 데이터 파일, 데이터 구조 등을 단독으로 또는 조합하여 포함할 수 있다. 컴퓨터 판독 가능 매체에 기록되는 프로그램 명령은 본 발명을 위해 특별히 설계되고 구성된 것들이거나 컴퓨터 소프트웨어 당업자에게 공지되어 사용 가능한 것일 수도 있다.The query processing methods according to the present invention may be implemented in the form of program instructions that can be executed through various computer means and recorded in a computer-readable medium. The computer readable medium may include program instructions, data files, data structures, and the like, alone or in combination. The program instructions recorded on the computer readable medium may be those specially designed and constructed for the present invention or may be available to those skilled in the computer software.
컴퓨터 판독 가능 매체의 예에는 롬(rom), 램(ram), 플래시 메모리(flash memory) 등과 같이 프로그램 명령을 저장하고 수행하도록 특별히 구성된 하드웨어 장치가 포함된다. 프로그램 명령의 예에는 컴파일러(compiler)에 의해 만들어지는 것과 같은 기계어 코드뿐만 아니라 인터프리터(interpreter) 등을 사용해서 컴퓨터에 의해 실행될 수 있는 고급 언어 코드를 포함한다. 상술한 하드웨어 장치는 본 발명의 동작을 수행하기 위해 적어도 하나의 소프트웨어 모듈로 작동하도록 구성될 수 있으며, 그 역도 마찬가지이다.
Examples of computer readable media include hardware devices that are specially configured to store and execute program instructions, such as ROM, RAM, flash memory, and the like. Examples of program instructions include machine language code such as those generated by a compiler, as well as high-level language code that can be executed by a computer using an interpreter or the like. The hardware devices described above may be configured to operate with at least one software module to perform the operations of the present invention, and vice versa.
도 6은 본 발명의 일 실시예에 따른 질의 처리 장치를 도시한 블록도이다.6 is a block diagram illustrating a query processing apparatus according to an embodiment of the present invention.
도 6을 참조하면, 질의 처리 장치(20)는 프로세서(21) 및 데이터베이스(22)를 포함한다. 프로세서(21)는 사용자 단말로부터 수신한 질의를 분석하여 질의에 대응된 결과가 데이터베이스(22)에 저장되어 있는지 판단할 수 있고, 질의에 대응된 결과가 데이터베이스(22)에 저장되어 있는 경우 질의에 대응된 결과를 상기 사용자 단말에 제공할 수 있다.Referring to FIG. 6, the
프로세서(21)는 사용자 단말로부터 질의를 수신할 수 있다. 사용자 단말은 질의에 대응된 결과를 요청하기 위해 사용자가 사용하는 것으로, 데스크탑 컴퓨터, 랩탑 컴퓨터, 태블릿 PC 등을 의미할 수 있다.
프로세서(21)는 사용자 단말로부터 수신된 질의에 대응된 결과가 데이터베이스(22)에 저장되어 있는지 판단할 수 있다. 예를 들어, 사용자 단말로부터 수신된 질의가 'SELECT year, month FROM airline_delay WHERE year=2013' 인 경우, 프로세서(21)는 SELECT 구문, FROM 구문, WHERE 구문별로 질의에 대응된 결과가 데이터베이스(22)에 저장되어 있는지 판단할 수 있다.The
사용자 단말로부터 수신한 질의가 데이터베이스(22)에 저장된 질의에 포함되는 경우(즉, 완전 부분 질의), 프로세서(21)는 사용자 단말로부터 수신된 질의에 대응된 결과가 데이터베이스(22)에 모두 저장되어 있는 것으로 판단할 수 있다. 예를 들어, 앞서 설명한 도 3에 도시된 경우에서, 프로세서(21)는 사용자 단말로부터 수신된 질의에 대응된 결과가 데이터베이스(22)에 모두 저장되어 있는 것으로 판단할 수 있다. When the query received from the user terminal is included in the query stored in the database 22 (i.e., a full partial query), the
한편, 사용자 단말로부터 수신한 질의가 데이터베이스(22)에 저장된 질의의 일부인 경우(즉, 불완전 부분 질의), 프로세서(21)는 사용자 단말로부터 수신된 질의에 대응된 결과가 데이터베이스(22)에 일부 저장되어 있는 것으로 판단할 수 있다. 예를 들어, 앞서 설명한 도 4에 도시된 경우에서, 프로세서(21)는 사용자 단말로부터 수신된 질의에 대응된 결과가 데이터베이스(22)에 일부 저장되어 있는 것으로 판단할 수 있다.On the other hand, when the query received from the user terminal is part of the query stored in the database 22 (i.e., incomplete partial query), the
이와 같은 경우, 프로세서(21)는 데이터베이스(22)에 저장된 질의에 대해서는 데이터베이스(22)를 사용하여 처리할 수 있고, 데이터베이스(22)에 저장되지 않은 질의에 대해서는 하이브를 통해 처리할 수 있다.
In such a case, the
질의에 대응된 결과가 데이터베이스(22)에 저장되어 있는 경우, 프로세서(21)는 데이터베이스(22)에 저장된 질의에 대응된 결과를 사용자 단말에 제공할 수 있다. 즉, 프로세서(21)는 사용자 단말로부터 수신한 질의에 대응한 질의를 데이터베이스(22) 내에서 검색하고, 검색된 질의에 대응된 결과를 사용자 단말에 제공할 수 있다.When the result corresponding to the query is stored in the
한편 질의에 대응된 결과가 데이터베이스(22)에 저장되어 있지 않은 경우, 프로세서(21)는 질의를 하이브에 제공할 수 있다. 하이브는 자신의 스토리지 내에 프로세서(21)로부터 수신한 질의에 대응된 결과가 저장되어 있는 경우, 저장된 질의에 대응된 결과를 프로세서(21)에 제공할 수 있다. 한편, 자신의 스토리지 내에 프로세서(21)로부터 수신한 질의에 대응된 결과가 저장되어 있지 않은 경우, 하이브는 맵 리듀스를 사용하여 질의에 대응된 결과를 생성할 수 있고, 생성된 질의에 대응된 결과를 프로세서(21)에 제공할 수 있다.If, on the other hand, the result corresponding to the query is not stored in the
프로세서(21)는 하이브에서 처리된 질의에 대응된 결과를 획득할 수 있다. 예를 들어, 프로세서(21)는 하이브에서 처리된 질의에 대응된 결과를 오픈 소스인 스쿱을 사용하여 데이터베이스(22)로 캐싱할 수 있다. 즉, 프로세서(21)는 하이브에서 처리된 질의에 대응된 결과를 데이터베이스(22)에 저장할 수 있다. 프로세서(21)는 하이브로부터 획득된 질의에 대응된 결과를 사용자 단말에 제공할 수 있다.The
프로세서(21)는 미리 설정된 제1 시간이 지난 경우 데이터베이스(22)에 저장된 질의에 대응된 결과를 갱신할 수 있다. 예를 들어, 제1 질의에 대응된 결과가 데이터베이스(22)에 저장된 시점부터 미리 설정된 제1 시간이 지난 경우, 프로세서(21)는 제1 질의와 대응된 질의를 하이브에서 검색할 수 있고, 검색된 질의에 대응된 결과를 하이브로부터 캐싱할 수 있다. 이때, 프로세서(21)는 하이브에서 검색된 질의에 대응된 결과와 데이터베이스(22)에 저장된 제1 질의에 대응된 결과가 다른 경우 검색된 질의에 대응된 결과를 하이브로부터 캐싱할 수 있으며, 하이브에서 검색된 질의에 대응된 결과와 데이터베이스(22)에 저장된 제1 질의에 대응된 결과가 동일한 경우 캐싱 과정을 수행하지 않을 수 있다. 미리 설정된 제1 시간은 사용자의 요구에 따라 다양하게 설정될 수 있다.The
프로세서(21)는 데이터베이스(22)에 저장된 질의에 대응된 결과가 미리 설정된 제2 시간 동안 사용되지 않는 경우 질의에 대응된 결과를 삭제할 수 있다. 예를 들어, 제1 질의에 대응된 결과가 데이터베이스(22)에 저장된 시점(또는, 제1 질의에 대응된 결과가 이전에 사용된 시점)부터 미리 설정된 제2 시간 동안 사용되지 않은 경우, 프로세서(21)는 데이터베이스(22)에 저장된 제1 질의에 대응된 결과를 삭제할 수 있다. 미리 설정된 제2 시간은 사용자의 요구에 따라 다양하게 설정될 수 있으며, 미리 설정된 제2 시간은 미리 설정된 제1 시간보다 길게 설정될 수 있다.
The
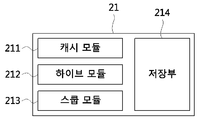
도 7은 본 발명의 일 실시예에 따른 프로세서의 구성을 도시한 블록도이다.7 is a block diagram illustrating a configuration of a processor according to an embodiment of the present invention.
도 7을 참조하면, 프로세서(21)는 캐시 모듈(211), 하이브 모듈(212), 스쿱 모듈(213) 및 저장부(214)를 포함한다. 여기서, 프로세서(21)는 도 6에 도시된 질의 처리 장치의 프로세서를 의미한다.Referring to FIG. 7, the
캐시 모듈(211)은 질의에 대응된 결과가 질의 처리 장치 내의 데이터베이스에 저장되어 있는지 판단하는 과정을 수행할 수 있다. 하이브 모듈(212)은 질의가 하이브에서 처리되도록 제어할 수 있다. 스쿱 모듈(213)은 하이브에서 처리된 결과를 질의 처리 장치 내의 데이터베이스에 캐싱하는 과정을 수행할 수 있다. 저장부(214)는 캐시 모듈(211), 하이브 모듈(212) 및 스쿱 모듈(213)을 통해 처리되는 결과와 처리된 결과를 저장할 수 있다.
The
다시 도 6을 참조하면, 데이터베이스(21)는 질의 및 질의에 대응된 결과를 저장할 수 있으며, 하이브를 통해 처리된 질의에 대응된 결과도 저장할 수 있다. 데이터베이스(21)는 질의와 질의에 대응된 결과를 기반으로 생성된 관계형 데이터베이스를 의미할 수 있다.
Referring again to FIG. 6, the
도 8은 본 발명의 일 실시예에 따른 질의 처리 장치가 적용된 하둡 기반의 질의 처리 시스템을 도시한 블록도이다.8 is a block diagram illustrating a Hadoop-based query processing system to which a query processing apparatus according to an embodiment of the present invention is applied.
도 8을 참조하면, 프로세서(21)는 도 6에 도시된 질의 처리 장치의 프로세서를 의미하고, RDBMS(relational database management system)(22)는 도 6에 도시된 질의 처리 장치의 데이터베이스를 의미한다.Referring to FIG. 8, the
프로세서(21)는 사용자 단말(10)로부터 질의를 수신할 수 있고, 수신된 질의에 대응된 결과가 RDBMS(22)에 저장되어 있는 경우 저장된 질의에 대응된 결과를 사용자 단말(10)에 제공할 수 있다. 한편, 사용자 단말(10)로부터 수신된 질의에 대응된 결과가 RDBMS(22)에 저장되어 있지 않은 경우, 프로세서(21)는 하이브(30)에 질의를 제공할 수 있다. 하이브(30)는 하둡(40)을 기초로 하여 질의에 대응된 결과를 생성할 수 있고, 생성된 질의에 대응된 결과를 프로세서(21)에 제공할 수 있다. 즉, 프로세서(21)는 하이브(30)에 의해 생성된 질의에 대응된 결과를 오픈 소스인 스쿱을 사용하여 캐싱할 수 있다. 프로세서(21)는 하이브(30)로부터 캐싱된 질의에 대응된 결과를 RDBMS(22)에 저장할 수 있고, 질의에 대응된 결과를 사용자 단말(10)에 제공할 수 있다.
The
이상 실시예를 참조하여 설명하였지만, 해당 기술 분야의 숙련된 당업자는 하기의 특허 청구의 범위에 기재된 본 발명의 사상 및 영역으로부터 벗어나지 않는 범위 내에서 본 발명을 다양하게 수정 및 변경시킬 수 있음을 이해할 수 있을 것이다.It will be understood by those skilled in the art that various changes in form and details may be made therein without departing from the spirit and scope of the invention as defined in the appended claims. It will be possible.
20: 질의 처리 장치
21: 프로세서
22: 데이터베이스20: Query processing device
21: Processor
22: Database
Claims (12)
사용자 단말로부터 질의(query)를 수신하는 단계;
상기 질의에 대응된 결과가 상기 질의 처리 장치 내의 데이터베이스(database)에 저장되어 있는지 판단하는 단계; 및
상기 질의에 대응된 결과가 상기 데이터베이스에 저장되어 있는 경우, 저장된 상기 질의에 대응된 결과를 상기 사용자 단말에 제공하는 단계를 포함하는 것을 특징으로 하는 질의 처리 방법.A query processing method performed in a Hadoop based query processing apparatus,
Receiving a query from a user terminal;
Determining whether a result corresponding to the query is stored in a database in the query processing apparatus; And
And providing a result corresponding to the stored query to the user terminal if a result corresponding to the query is stored in the database.
상기 질의 처리 방법은,
상기 질의에 대응된 결과가 상기 데이터베이스에 저장되어 있지 않은 경우, 상기 질의를 하이브(hive)에 제공하는 단계;
상기 하이브를 통해 처리된 상기 질의에 대응된 결과를 획득하는 단계; 및
상기 질의에 대응된 결과를 상기 사용자 단말에 제공하는 단계를 더 포함하는 것을 특징으로 하는 질의 처리 방법.The method according to claim 1,
The query processing method includes:
Providing the query to the hive if the result corresponding to the query is not stored in the database;
Obtaining a result corresponding to the query processed through the hive; And
And providing a result corresponding to the query to the user terminal.
상기 질의 처리 방법은,
상기 하이브를 통해 처리된 상기 질의에 대응된 결과를 상기 데이터베이스에 저장하는 단계를 더 포함하는 것을 특징으로 하는 질의 처리 방법.The method of claim 2,
The query processing method includes:
And storing the result corresponding to the query processed through the hive in the database.
상기 질의 처리 방법은,
상기 데이터베이스에 저장된 임의의 질의에 대응된 결과가 미리 설정된 시간 동안 사용되지 않는 경우, 상기 임의의 질의에 대응된 결과를 삭제하는 것을 특징으로 하는 질의 처리 방법.The method according to claim 1,
The query processing method includes:
And deletes the result corresponding to the arbitrary query if the result corresponding to the arbitrary query stored in the database is not used for a predetermined period of time.
상기 질의 처리 방법은,
임의의 질의에 대응된 결과가 상기 데이터베이스에 저장된 시점부터 미리 설정된 시간이 지난 경우, 상기 임의의 질의에 대응된 결과를 갱신하는 것을 특징으로 하는 질의 처리 방법.The method according to claim 1,
The query processing method includes:
And updates the result corresponding to the arbitrary query if a predetermined time has elapsed since the result corresponding to the arbitrary query was stored in the database.
상기 데이터베이스는,
상기 질의와 상기 질의에 대응된 결과를 기반으로 생성된 관계형 데이터베이스(relational database)인 것을 특징으로 하는 질의 처리 방법.The method according to claim 1,
The database includes:
Wherein the query is a relational database generated based on the query and a result corresponding to the query.
사용자 단말로부터 수신한 질의를 분석하여 상기 질의에 대응된 결과가 데이터베이스(database)에 저장되어 있는지 판단하고, 상기 질의에 대응된 결과가 상기 데이터베이스에 저장되어 있는 경우 상기 질의에 대응된 결과를 상기 사용자 단말에 제공하는 프로세서(processor); 및
질의 및 질의에 대응된 결과를 저장하는 상기 데이터베이스를 포함하는 것을 특징으로 하는 질의 처리 장치.In a Hadoop-based query processing apparatus,
The method includes analyzing a query received from a user terminal to determine whether a result corresponding to the query is stored in a database, and when a result corresponding to the query is stored in the database, A processor for providing the terminal with information; And
And the database storing results corresponding to the query and the query.
상기 프로세서는,
상기 질의에 대응된 결과가 상기 데이터베이스에 저장되어 있지 않은 경우 상기 질의를 하이브(hive)에 제공하고, 상기 하이브를 통해 처리된 상기 질의에 대응된 결과를 획득하고, 상기 질의에 대응된 결과를 상기 사용자 단말에 제공하는 것을 특징으로 하는 질의 처리 장치.The method of claim 7,
The processor comprising:
Providing a query to a hive when a result corresponding to the query is not stored in the database, obtaining a result corresponding to the query processed through the hive, To the user terminal.
상기 데이터베이스는,
상기 하이브를 통해 처리된 상기 질의에 대응된 결과를 저장하는 것을 특징으로 하는 질의 처리 장치.The method of claim 8,
The database includes:
And stores a result corresponding to the query processed through the hive.
상기 프로세서는,
상기 데이터베이스에 저장된 임의의 질의에 대응된 결과가 미리 설정된 시간 동안 사용되지 않는 경우, 상기 임의의 질의에 대응된 결과를 삭제하는 것을 특징으로 하는 질의 처리 장치.The method of claim 7,
The processor comprising:
And deletes a result corresponding to the arbitrary query if a result corresponding to the arbitrary query stored in the database is not used for a predetermined period of time.
상기 프로세서는,
임의의 질의에 대응된 결과가 상기 데이터베이스에 저장된 시점부터 미리 설정된 시간이 지난 경우, 상기 임의의 질의에 대응된 결과를 갱신하는 것을 특징으로 하는 질의 처리 장치.The method of claim 7,
The processor comprising:
And updates the result corresponding to the arbitrary query if a predetermined time has elapsed since a result corresponding to an arbitrary query was stored in the database.
상기 데이터베이스는,
상기 질의와 상기 질의에 대응된 결과를 기반으로 생성된 관계형 데이터베이스(relational database)인 것을 특징으로 하는 질의 처리 장치.The method of claim 7,
The database includes:
Wherein the query processing unit is a relational database generated based on the query and a result corresponding to the query.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR20130016699 | 2013-02-18 | ||
| KR1020130016699 | 2013-02-18 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20140104882A true KR20140104882A (en) | 2014-08-29 |
| KR101542299B1 KR101542299B1 (en) | 2015-08-07 |
Family
ID=51748556
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020130066978A KR101542299B1 (en) | 2013-02-18 | 2013-06-12 | Method for processing query based on hadoop |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR101542299B1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20160067289A (en) | 2014-12-03 | 2016-06-14 | 충북대학교 산학협력단 | Cache Management System for Enhancing the Accessibility of Small Files in Distributed File System |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101083563B1 (en) * | 2009-04-24 | 2011-11-14 | 엔에이치엔비즈니스플랫폼 주식회사 | Method and System for Managing Database |
| JP5351746B2 (en) | 2009-12-22 | 2013-11-27 | ヤフー株式会社 | Data processing apparatus and method |
| JP5276639B2 (en) | 2010-10-01 | 2013-08-28 | 日本電信電話株式会社 | Distributed database management apparatus and distributed database management program |
-
2013
- 2013-06-12 KR KR1020130066978A patent/KR101542299B1/en active IP Right Grant
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20160067289A (en) | 2014-12-03 | 2016-06-14 | 충북대학교 산학협력단 | Cache Management System for Enhancing the Accessibility of Small Files in Distributed File System |
Also Published As
| Publication number | Publication date |
|---|---|
| KR101542299B1 (en) | 2015-08-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9639567B2 (en) | For all entries processing | |
| US10585876B2 (en) | Providing snapshot isolation to a database management system | |
| US9910877B2 (en) | Query handling in a columnar database | |
| US9811577B2 (en) | Asynchronous data replication using an external buffer table | |
| US10528341B2 (en) | User-configurable database artifacts | |
| US9507816B2 (en) | Partitioned database model to increase the scalability of an information system | |
| US9110601B2 (en) | Backup lifecycle management | |
| US8620924B2 (en) | Refreshing a full-text search index in a partitioned database | |
| WO2016041480A1 (en) | Method and system for adaptively building and updating column store database from row store database based on query demands | |
| US10007548B2 (en) | Transaction system | |
| US10261950B2 (en) | Table as query language parameter | |
| US9519673B2 (en) | Management of I/O and log size for columnar database | |
| US11249968B2 (en) | Large object containers with size criteria for storing mid-sized large objects | |
| CN114817320A (en) | Cache processing method and device | |
| JP7006013B2 (en) | Data provision program, data provision method, and data provision device | |
| JP7030767B2 (en) | Non-uniform pagination of columnar data | |
| US8200673B2 (en) | System and method for on-demand indexing | |
| US10140337B2 (en) | Fuzzy join key | |
| KR101542299B1 (en) | Method for processing query based on hadoop | |
| US10489374B2 (en) | In-place updates with concurrent reads in a decomposed state | |
| US11327961B2 (en) | Action queue for hierarchy maintenance | |
| US10042942B2 (en) | Transforms using column dictionaries | |
| US20180075118A1 (en) | Replication queue handling | |
| US20230359605A1 (en) | Autonomous Refactoring System for Database | |
| US11487755B2 (en) | Parallel query execution |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| FPAY | Annual fee payment |
Payment date: 20180702 Year of fee payment: 4 |
|
| FPAY | Annual fee payment |
Payment date: 20190717 Year of fee payment: 5 |