KR20140005195A - 얼굴 등록 방법 - Google Patents
얼굴 등록 방법 Download PDFInfo
- Publication number
- KR20140005195A KR20140005195A KR1020137016826A KR20137016826A KR20140005195A KR 20140005195 A KR20140005195 A KR 20140005195A KR 1020137016826 A KR1020137016826 A KR 1020137016826A KR 20137016826 A KR20137016826 A KR 20137016826A KR 20140005195 A KR20140005195 A KR 20140005195A
- Authority
- KR
- South Korea
- Prior art keywords
- images
- user
- distance metric
- users
- constraints
- Prior art date
Links
Images






Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/41—Structure of client; Structure of client peripherals
- H04N21/422—Input-only peripherals, i.e. input devices connected to specially adapted client devices, e.g. global positioning system [GPS]
- H04N21/4223—Cameras
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/23—Clustering techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F3/00—Input arrangements for transferring data to be processed into a form capable of being handled by the computer; Output arrangements for transferring data from processing unit to output unit, e.g. interface arrangements
- G06F3/01—Input arrangements or combined input and output arrangements for interaction between user and computer
- G06F3/048—Interaction techniques based on graphical user interfaces [GUI]
- G06F3/0487—Interaction techniques based on graphical user interfaces [GUI] using specific features provided by the input device, e.g. functions controlled by the rotation of a mouse with dual sensing arrangements, or of the nature of the input device, e.g. tap gestures based on pressure sensed by a digitiser
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/74—Image or video pattern matching; Proximity measures in feature spaces
- G06V10/761—Proximity, similarity or dissimilarity measures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/762—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using clustering, e.g. of similar faces in social networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/161—Detection; Localisation; Normalisation
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/41—Structure of client; Structure of client peripherals
- H04N21/422—Input-only peripherals, i.e. input devices connected to specially adapted client devices, e.g. global positioning system [GPS]
- H04N21/42204—User interfaces specially adapted for controlling a client device through a remote control device; Remote control devices therefor
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/44—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream, rendering scenes according to MPEG-4 scene graphs
- H04N21/44008—Processing of video elementary streams, e.g. splicing a video clip retrieved from local storage with an incoming video stream, rendering scenes according to MPEG-4 scene graphs involving operations for analysing video streams, e.g. detecting features or characteristics in the video stream
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/45—Management operations performed by the client for facilitating the reception of or the interaction with the content or administrating data related to the end-user or to the client device itself, e.g. learning user preferences for recommending movies, resolving scheduling conflicts
- H04N21/4508—Management of client data or end-user data
- H04N21/4532—Management of client data or end-user data involving end-user characteristics, e.g. viewer profile, preferences
Abstract
사용자가 자신의 이미지를 검출하고, 사용자 이미지 데이터베이스를 매칭시킴으로써, 시스템과 상호 작용할 때, 사용자 인터페이스는 사용자의 선호도를 자동으로 검색한다. 이미지 데이터베이스는 시스템의 사용자들을 구분할 수 있는 시스템의 사용자들의 물리적 특징들을 저장한다. 사용자 등록 방법은 사용자 이미지들로부터의 학습된 디스턴스 메트릭을 이용한 클러스터링을 통해, 사용자를 이미지 데이터베이스에 투명하게 등록시킨다. 디스턴스 메트릭을 학습하는 방법은 데이터 포인트들로부터 쌍의 제약들(pair-wise constraints)을 식별하고, 쌍들의 제1 집합과 쌍들의 제2 집합의 디스턴스들 사이의 마진을 최대화하며, 이는 세미-포지티브 데피니트 프로그래밍(semi-positive definite programming)을 통해 더 해결될 수 있다.
Description
본 발명은 얼굴 인식 및 메트릭 학습(metric learning)의 분야에 관한 것이며, 특히 얼굴 등록의 기술에 관련된다.
가전 제품들과 같은 가정 내의 시스템들을 제어하는 종래의 방법은 시스템을 원하는 모드로 수동 설정하는 것에 의한다. 사용자들이 인터페이스하는 시스템들이 자동 제어된다면, 매력적일 것이다. TV들과 같은 시스템들에 있어서, 사용자는 자신이 주로 시청한 TV 프로그램들의 유형 또는 TV 채널들에 대한 사용자의 선호도를 학습하는 메커니즘을 갖는 것을 선호할 것이다. 그리고 나서, 사용자가 TV 앞에 나타나면, 상응하는 설정들이 자동으로 로딩된다.
사용자 인식은 얼굴 인식, 제스쳐 인식 등과 같이, 지난 수십 년간 컴퓨터 기술의 열띤 영역이었다. 얼굴 인식을 예시로 들면, 보통 종래의 등록 프로세스는 복잡하다. 사용자들은 자신들의 ID를 입력할 필요가 있으며, 그동안에 많은 얼굴 이미지들은 특정 조명 환경 및 고정된 얼굴의 시야각들과 같은 미리-정의된 조건들 하에 촬영된다.
모든 사용자 이미지는 고 차원적 공간의 벡터이다. 유클리디안 메트릭(Euclidean metric)에 따라 이들을 직접 클러스터링하는 것은 원하지 않는 결과들을 가져올 수 있는데, 그 이유는 한 사람에 대한 사용자 이미지들의 분배는 구 모양(spherical)이 아닌, 엷은 판 모양(lamellar)이기 때문이다. 상이한 조건들 하에서 동일인에 대한 두 개의 이미지들 사이의 디스턴스는 동일한 조건 하에서 상이한 사람들 사이의 디스턴스보다 더 클 것이다. 이러한 문제를 해결하기 위해, 적절한 메트릭을 학습하는 것이 중요해지고 있다.
비디오 소스에 있어서, 이미지들의 일부 유용한 쌍의 제약들(pair-wise constraints)이 존재하며, 이는 시스템이 메트릭을 학습하도록 훈련시키는 것을 도울 수 있다. 예를 들면, 두 개의 근접한 프레임들로부터 캡쳐된 두 개의 사용자 이미지들은 동일인에 속하며, 하나의 프레임으로부터 캡쳐된 두 개의 사용자 이미지들은 상이한 사람들에 속한다. 이러한 두 가지 유형의 쌍의 제약들은 유사 쌍 제약들과 비 유사 쌍 제약들로 정의된다. 쌍의 제약들 하에서 메트릭을 학습하는 것에 대한 문제는 준-지도 메트릭 학습(semi-supervised metric learning)이라 불리운다. 종래의 준-지도 메트릭 학습의 주요 개념은 유사 샘플 쌍들의 디스턴스들을 최소화시키는 것이며, 비 유사 샘플 쌍들의 디스턴스들은 엄격히 제약을 받는다. 유사 및 비 유사 샘플 쌍들의 처리(treatments)는 불안정하기 때문에, 이 방법은 제약들의 개수에 대해 강하지 않다. 예를 들어, 비 유사 쌍들의 개수가 유사 쌍들의 개수보다 훨씬 큰 경우, 비 유사 샘플 쌍들의 제약들은 너무 느슨해져서 충분한 차이를 만들 수 없으며, 이 방법은 양호한 메트릭을 발견할 수 없다. 또 다른 디스턴스 메트릭 학습 방법에서, 최대화될 실제 대상(real object)은 디스턴스들에 대한 두 개의 클래스들의 인터페이스 값이며, 이는 마진의 폭보다 작은 디스턴스 값들을 갖는 클래스의 최대 디스턴스와, 마진의 폭보다 큰 디스턴스 값들을 갖는 다른 클래스의 최소 디스턴스의 중간 값이며, 상기 마진은 두 개의 클래스들에 대한 상기 최대 디스턴스와 상기 최소 디스턴스 간의 차이이다. 따라서, 본 시스템들은 강하지 않다.
본 발명은, 사용자 이미지를 등록하여, 검출된 사용자 이미지에 기초하여 사용자의 선호도를 분석함으로써, 사용자가 원하는 설정을 자동으로 검색해서 로딩할 수 있는, 사용자 얼굴 등록 방법 및 이에 관련된 사용자 인터페이스를 제공하고자 한다.
본 발명은 시스템과 상호 작용하며 사용자의 선호도를 분석할 수 있는, 그리고 사용자가 시스템과 상호 작용하고 사용자의 이미지가 검출되어 사용자 이미지 데이터베이스에 매칭되면, 사용자의 선호도를 자동 검색할 수 있는 사용자 인터페이스를 설명한다. 이는 시스템의 사용자들의 물리적 특징들에 상응하는 이미지들의 데이터베이스를 포함한다. 사용자들의 물리적 특징들은 시스템의 사용자들을 구분한다. 사용자가 시스템과 인터페이스할 때, 사용자 이미지들을 캡쳐하기 위해 비디오 디바이스가 사용된다. 선호도 분석기는 시스템과의 사용자 상호 작용에 기초하여 시스템의 사용자 선호도들을 수집하고, 시스템의 각 사용자들에 상응하는 개별 사용자 선호도들의 집합을 생성하기 위해 선호도들을 분리한다. 분리된 사용자 선호도들은 선호도 데이터베이스에 저장되고, 이미지들의 데이터베이스 내의 이미지들에 기초하여 상관기를 통해 시스템의 사용자들과 상관된다. 상관기는 사용자가 시스템과 인터페이스할 때, 비디오 디바이스에 의해 캡쳐된 시스템의 특정 사용자에 관한 개별 사용자 선호도들을 적용한다.
본 발명은 사용자를 이미지 데이터베이스에 등록하기 위한 사용자 등록 방법을 더 포함한다. 본 발명의 한 실시예에서, 사용자들에 대한 화상들의 시퀀스가 액세스되며, 이로부터 사용자들을 구분하는 사용자들의 물리적 특징들에 상응하는 이미지들이 검출된다. 디스턴스 메트릭은 상기 검출에 의해 검출된 이미지들을 사용하여 결정되고, 상기 이미지들은 상기 디스턴스 메트릭을 이용하여 계산된 디스턴스들에 기초하여 클러스터링된다. 클러스터링의 결과들은 사용자들을 등록하기 위해 사용된다.
본 발명의 다른 실시예는 사용자 등록을 업데이트하기 위한 방법을 제공하며, 이는 사용자들에 대한 화상들의 시퀀스에 액세스하는 단계; 상기 화상들의 시퀀스로부터 이미지들을 검출하는 단계로서, 상기 이미지들은 사용자들을 구분하는 사용자들의 물리적 특징들에 상응하는, 검출 단계; 검출된 이미지들 사이의 제약들을 식별하는 단계; 기존의 디스턴스 메트릭을 이용하여 계산된 디스턴스들에 기초하여 상기 이미지들을 클러스터링하는 단계; 상기 식별하는 단계에 의해 식별된 제약들을 통해 상기 클러스터링의 결과들을 검증하는 단계; 및 상기 클러스터링의 결과들 및 검증 결과들에 기초하여 사용자 등록을 업데이트하는 단계를 포함한다.
본 발명의 또 다른 실시예는 디스턴스 메트릭 A를 결정하는 방법을 제공하며: 포인트들 사이의 디스턴스를 갖는 복수의 포인트들 쌍 (xi, xj)을 식별하는 단계로서, 상기 디스턴스 dA는,
본 발명의 상기 특징들은 첨부된 도면들을 참조하여 이들의 예시적인 실시예들을 상세하게 설명함으로써 보다 명백해질 것이다.
본 발명을 통해, 서비스들은 사용자들을 구분할 수 있는 얼굴, 제스쳐 등과 같은 물리적 특징 인식 및 등록 메커니즘들에 기초하여 사용자들의 선호도들에 따라 사용자들에 맞춤화될 수 있다.
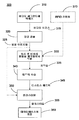
도 1은 본 발명에 따라 사용자 인터페이스를 도시하는 블록도.
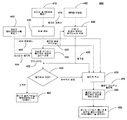
도 2는 본 발명에 따라 얼굴 등록 프로세스를 도시하는 흐름도.
도 3은 입력 비디오 세그먼트들에 기초하여 얼굴 이미지 데이터베이스를 구축하는 프로세스를 도시하는 흐름도.
도 4는 입력 비디오 세그먼트들에 기초하여 얼굴 이미지 데이터베이스를 업데이트하는 프로세스를 도시하는 흐름도.
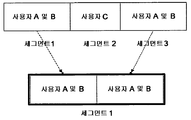
도 5는 본 발명에 따라 RFID 라벨들을 이용한 비디오 세그먼트들의 병합(merging)을 도시하는 도면.
도 6은 RFID 라벨들이 이용 가능할 때의 얼굴 등록 프로세스를 도시하는 흐름도.
도 7은 본 발명의 선호되는 실시예에 따라 얼굴 등록 프로세스를 도시하는 흐름도.
도 8은 발명된 MMML 메트릭 학습 방법의 성능을 도시하는 결과.
도 2는 본 발명에 따라 얼굴 등록 프로세스를 도시하는 흐름도.
도 3은 입력 비디오 세그먼트들에 기초하여 얼굴 이미지 데이터베이스를 구축하는 프로세스를 도시하는 흐름도.
도 4는 입력 비디오 세그먼트들에 기초하여 얼굴 이미지 데이터베이스를 업데이트하는 프로세스를 도시하는 흐름도.
도 5는 본 발명에 따라 RFID 라벨들을 이용한 비디오 세그먼트들의 병합(merging)을 도시하는 도면.
도 6은 RFID 라벨들이 이용 가능할 때의 얼굴 등록 프로세스를 도시하는 흐름도.
도 7은 본 발명의 선호되는 실시예에 따라 얼굴 등록 프로세스를 도시하는 흐름도.
도 8은 발명된 MMML 메트릭 학습 방법의 성능을 도시하는 결과.
본 발명은 사용자들을 구분할 수 있는 얼굴, 제스쳐 등과 같은 물리적 특징 인식 및 등록 메커니즘들에 기초하여 사용자들의 선호도들에 따라 서비스들을 사용자들(10)에 맞춤화하는 시스템이다. 맞춤화는 바람직하게도 아래에 설명되는 바와 같이 투명하게(transparently) 수행된다. 도 1은 사용자(10)가 인터페이스할 시스템의 예시로서 TV를 이용하고, 물리적 특징의 예시로서 얼굴을 이용하는 시스템을 도시한다. 카메라와 같은 비디오 디바이스(30)는, 카메라(30)에 대한 사용자들의 위치 또는 이들의 각도 등과 같은 사용자들에 대한 제한 없이, 사용자들이 시스템과 인터페이스할 때, 사용자들의 이미지들을 캡쳐하기 위해, 거실 내에 있는 TV 세트(20)의 위와 같은 작업 환경에 설치된다. 각 사용자에 대한 얼굴 이미지들은 비디오로부터 추출되고, 사용자들의 이미지 데이터베이스(40)를 구축하기 위해 각 사용자에 대해 등록된다. 선호도 분석기(90)는, 사용자가 시스템과 인터페이스할 때, 사용자가 가장 좋아하는 채널들, 선호되는 영화들의 장르와 같은 시스템에 대한 사용자 선호도들을 수집하고, 시스템의 사용자들 각각에 상응하는 개별 사용자 선호도들의 집합을 생성하기 위해 선호도들을 분리한다. 수집된 사용자 선호도들은 선호도 데이터베이스(50)에 저장된다. 상관기(60)는 각 개별 사용자에 대한 이미지를 사용자의 상응하는 선호도 집합에 맵핑시킴으로써, 사용자 선호도 데이터베이스(50) 및 이미지 데이터베이스(40)를 링크시킨다. 새로 캡쳐된 사용자의 이미지가 들어오면, 이것은 이미지 데이터베이스(40)에 등록되고, 이후 상관기(60)는 상응하는 사용자의 선호도 데이터를 검색하도록 트리거되며, 이후 이 선호도 데이터는 자동 설치를 위해 시스템에 전송된다. 메트릭 학습 모듈(70)은 등록 프로세스와 데이터베이스 구축 프로세스를 용이하게 하도록 사용된다. 캡쳐된 사용자 이미지가 이미지 데이터베이스에 대해 새로운 것, 즉 새로운 사용자일 경우, 사용자의 선호도를 구축하고 이를 선호도 데이터베이스(50)에 저장하기 위해, 업데이터(80)는 이미지 데이터베이스를 업데이트하고, 선호도 분석기(90)를 초기화한다. 상관기(60)는 선호도 프로파일을 사용자와 링크시키도록 사용된다.
도 2는 예시 특징으로서 얼굴을 이용하는 특징 등록(200)의 방법에 대한 한 실시예를 도시한다. 프로세스는 얼굴로 제한되지 않으며, 임의의 다른 특징들에도 마찬가지로 적용될 수 있음이 당업자에 의해 이해될 것이다. 본 발명의 장점은 특징 등록 프로세스가 사용자들에 대해 투명하다는 것이다. 종래의 얼굴 등록 프로세스와는 다르게, 사용자들은 이들의 ID를 입력할 필요가 있으며, 조명 및 얼굴의 시야각과 같은 특정 조건들 하에서 많은 얼굴 이미지들이 촬영되고, 한 선호되는 실시예는 비디오 소스로부터 직접 얼굴 이미지들을 추출하고, 추출된 얼굴 이미지들에 기초하여 등록을 실행한다. 이러한 프로세스를 용이하게 하기 위해, 비디오 소스는 바람직하게도 우선적으로 프로세싱된다. 한 선호되는 실시예에서, 비디오는 세그먼트들로 나누어진다. 각 세그먼트는, 예컨대 동일한 사용자들에 대해, 그리고 유사한 조건들 하에서 유사한 연속 프레임들로 구성된다. 비디오를 세그먼팅함으로써, 한 세그먼트에 나타나는 사용자들은 매우 관련성이 있으며, 이는 추후에 도시될 이미지들의 유사 및 비 유사 쌍들을 식별하는 프로세스를 경감시키는 것이 보장된다. 등록 프로세스가 사용자들에게 투명하기 때문에, 세그먼테이션은 자동으로 수행될 것이다. 따라서, 장면 검출(scene detection)과 같은 방법들은 세그먼테이션 프로세스에서 사용될 수 있다. 동일인 또는 상이한 사람들에 속하는 두 개의 이미지들과 같은 사용자들 사이의 관계가 본 실시예의 한 세그먼트 내에서만 보장될 수 있기 때문에, 등록 프로세스는 세그먼트 단위로 수행된다. 시스템이 작동을 시작하면, 이미지 데이터베이스는 비어있다. 따라서, 데이터베이스를 구축하는 프로세스가 수행된다. 이후에, 임의의 들어오는 비디오 시퀀스들에 대해서만, 데이터베이스 업데이트가 요구된다.
입력 비디오 시퀀스들은, 예컨대 비디오 디바이스(30)로부터 비디오 액세스 단계(210)에서 획득되며, 예컨대 장면 컷에 따라 비디오 세그먼테이션 단계(220)에서 세그먼트들로 나누어져서, 각 비디오 세그먼트는 적어도 한 사람의 얼굴을 포함하는 연속 프레임들로 구성된다. 단계(230)에서 검색된 세그먼트들 각각에 대해, 데이터베이스가 비어있는지의 여부에 대한 조건(235)이 검증된다. 조건(235)이 충족되는 경우, 즉 현재의 세그먼트가 프로세싱되는 순간에 이미지 데이터베이스가 비어있는 경우, 이미지 데이터베이스는 단계(250)에 따라 현재의 세그먼트에 기초하여 구축되며; 그렇지 않은 경우, 데이터베이스는 다음 단계(240)에서 업데이트된다. 단계들(235, 240, 및 250)은 조건(255)이 충족될 때까지, 즉 더 이상 비디오 세그먼트들이 존재하지 않을 때까지, 반복된다. 등록 프로세스는 단계(260)에서 중단된다.
이미지 데이터베이스(250)를 구축하는 단계는 도 3에 보다 상세하게 도시된다. 입력 비디오 세그먼트에 대해, 얼굴 추출이 수행된다. 추출된 얼굴 이미지들로부터, 쌍의 제약들이 식별된다. 한 선호되는 실시예에서, 유사 쌍 제약들과 비 유사 쌍 제약들이 사용된다. 유사 쌍 제약은 동일인의 두 개의 얼굴 이미지들로서 식별되며; 비 유사 쌍 제약은 상이한 2인의 두 개의 얼굴 이미지들로서 식별된다. 단계(220)가 비디오를 일관된 연속 프레임들로 세그먼팅했기 때문에, 한 세그먼트는 동일인들의 그룹을 포함할 것이다. 따라서, 유사 및 비 유사 제약들은 비교적 쉽게 식별될 수 있다. 예를 들어, 한 프레임에 속하는 두 개의 얼굴 이미지들은 비 유사 쌍들로서 식별되는데, 그 이유는 이들이 상이한 사람들에 속해야 하기 때문이다. 일반적으로 동일인의 얼굴 이미지들은 한 프레임에서부터 다음 프레임까지 너무 크게 이동하지 않을 것이기 때문에, 두 개의 연속 프레임들에 있어서 유사한 위치들에 존재하는 얼굴 이미지들은 유사 쌍으로서 식별된다. 얼굴 이미지들이 이러한 메트릭을 사용하여 각 사용자에 상응하는 각 클래스를 갖는 클래스들로 클러스터링될 수 있도록, 얼굴 이미지들과 함께 식별된 제약들은 메트릭을 획득하기 위해 메트릭 학습 메커니즘에 공급된다. 메트릭 학습이 여기서 사용되는 이유는 하나의 시나리오에서 클러스터링을 위해 사용된 하나의 메트릭이 상이한 시나리오에서 만족될 수 없다는 것이다. 예를 들어, 한 사람에 대한 얼굴 이미지들의 분배는 구 모양이 아니라 엷은 판 모양이다. 유클리디안 디스턴스가 사용되는 경우, 상이한 조건 하에서 동일인의 두 이미지들 사이의 디스턴스는 동일한 조건 하에서 상이한 사람들 사이의 디스턴스보다 클 것이다. 이러한 문제를 극복하기 위해, 적절한 메트릭을 학습하는 것이 중요해진다. 다양한 메트릭 학습 방법들은 이 단계에서 사용될 수 있다. 본 발명의 한 선호되는 실시예에서, 최대 마진 메트릭 학습(MMML) 방법이 사용된다. MMML에 대한 세부 사항들은 아래에 논의될 것이다. 일단 학습 메트릭이 획득되면, 클러스터들을 생성하기 위해 클러스터링이 수행될 수 있으며, 각 클러스터는 데이터베이스 내의 각 사용자의 식별로 표기된다.
도 3에서, 비디오 시퀀스(315)를 획득하기 위해, 비디오 세그먼트 액세스 단계(310)가 우선적으로 수행된다. 비디오 세그먼트(315)로부터 얼굴 이미지들(325)을 검출하기 위해, 얼굴 검출 단계(320)가 사용된다. 전형적인 얼굴 검출 방법은 Paul Viola와 Michael Jones, "강력한 실시간 얼굴 검출(Robust Real-Time Face Detection)", International Journal of Computer Vision, Vol.57, pp.137-154, 2004에서 발견될 수 있다. 검출된 얼굴 이미지들(325)로부터, 얼굴 이미지들의 유사 쌍들 및 얼굴 이미지들의 비 유사 쌍들은 단계(330)에서 제약들(335)로서 식별된다. 얼굴 이미지들(335)의 유사 쌍들 및 비 유사 쌍들에 대한 식별된 제약들은 이후 디스턴스 메트릭을 획득하기 위해 메트릭 학습 단계(340)로 공급된다. 디스턴스 메트릭(345)을 획득하자마자, 각각 한 사람을 나타내며 이로써 입력 비디오 내에서 개별 사용자를 각각 식별하는 몇몇의 클러스터들로 얼굴 이미지들을 그룹화시키도록 얼굴 이미지들(325)에 대한 클러스터링을 수행하기 위한 클러스터링 단계(350)가 사용된다. 얼굴 이미지들, 클러스터링의 결과들, 디스턴스 메트릭, 및 다른 필수 정보는 단계(360)에서 데이터베이스 내에 저장된다.
도 4는 새로운 입력 비디오 세그먼트에 기초하여 기존의 데이터베이스를 업데이트하는 프로세스(400)를 도시한다. 비디오 시퀀스(415)가 획득된 이후에, 비디오 시퀀스(415) 내의 얼굴 이미지들을 생성하기 위한 얼굴 검출 단계(420)가 시작된다. 바람직하게도, 기존의 데이터베이스는 이전의 비디오 세그먼트들로부터 학습된 자신의 디스턴스 메트릭을 이미 가지고 있다. 이러한 시나리오에서, 검출된 얼굴 이미지들에 대한 클러스터링을 수행하기 위해 메트릭이 우선적으로 사용된다. 즉, 검출된 얼굴 이미지들(425)은 기존의 데이터베이스로부터의 디스턴스 메트릭(444)에 기초하여 클러스터링 단계(450)에 입력된다. 메트릭은 본 시스템이 직면한 이전 비디오 세그먼트들로부터 학습되기 때문에, 이는 기존의 메트릭 학습이 고려하지 않는 새로운 양상들/제약들을 도입할 수 있는 현재의 세그먼트에 대해서는 유효하지 않을 수 있다. 따라서, 생성된 클러스터들(452)은 조건 검사기(455)에 입력된다. 검증될 조건들은 현재의 세그먼트에 대한 이미지들의 유사 및 비 유사 쌍들로서 단계(430)에서 식별된 제약들(435)이다. 단계(455)에서 조건들이 충족된 경우, 새로운 클러스터들은 데이터베이스 내에서 업데이트되고, 프로세스는 단계(460)에서 종료된다. 그렇지 않은 경우, 기존의 메트릭은 현재의 비디오 세그먼트의 특성들을 캡쳐하지 않고, 업데이트될 필요가 없다. 따라서, 식별된 제약들(435), 데이터베이스로부터의 기존의 제약들, 기존의 데이터베이스로부터의 얼굴 이미지들(442), 및 새로운 얼굴 이미지들(425)에 기초하여, 메트릭을 재학습하기 위한 메트릭 학습 단계(470)가 시작된다. 단계(470)로부터 학습된 새로운 디스턴스 메트릭(475)은 이후 클러스터링(480)을 수행하도록 사용되며, 상기 클러스터링(480)의 결과들은 새로운 디스턴스 메트릭과 함께 데이터베이스 내에서 업데이트된다. 한 선호되는 실시예에서, MMML 메트릭 학습 방법이 사용되며, 이에 대한 세부 사항들은 추후에 개시된다.
다른 실시예에서, 예컨대 가정 환경에서, 사용자들은 RFID 디바이스들 또는 다른 무선 커넥터들을 실행(carry)할 수 있으며, 이로써 캡쳐된 비디오는 이와 결합된 RFID 라벨들을 검출하였는데, 즉 특정 RFID 또는 다수의 RFID들이 검출되고, 특정 시간 주기 내의 프레임들에 결합된다. RFID 라벨들은 단계(220)에서 생성된 세그먼트들을 결합시키는 것에 있어서 유용할 수 있다. 세그먼트들 각각은 연속하는 프레임들의 일관된 집합이다. 하지만, 상이한 세그먼트들 사이에서, 이러한 관계는 보장되지 않으며, 식별되기에 어렵지만, 존재할 수 있다. 결과로서, 추출된 제약들은 분리되며(isolated), 메트릭 학습에 대한 열등한 성능의 원인이 될 수 있다. 이들 세그먼트들을 결합시키고, 제약들을 함께 링크시킴으로써, 메트릭 학습 정확도는 개선될 수 있다. RFID 라벨들은 세그먼트들을 결합시키기 위한 메커니즘을 제공한다. 예를 들어, 비디오 시퀀스는 도 5a에 도시된 바와 같이, 장면들에 기초하여 3개의 세그먼트들로 세그먼팅되는데, 여기서 세그먼트 1 및 3은 존재하는 사용자 A 및 B를 갖는 프레임들이지만, 세그먼트 2는 사용자 C만을 포함한다. RFID 라벨들이 세그먼트들 1 및 3 내에서 사용자 A 및 사용자 B를 위해 존재하는 경우, 두 세그먼트들이 사용자 A 및 사용자 B를 포함한다는 것과, 이들은 매우 관련성이 있다는 것이 RFID 검출로부터 알려지기 때문에, 세그먼트 1 및 3을 새로운 세그먼트 1로 병합하는 것이 가능하다. 유사하게도, 도 5B에서 도시되는 바와 같이, 캡쳐 동안 조명 조건 변화로 인해 두 개의 세그먼트들로 세그먼팅된 비디오 시퀀스는 RFID 라벨 정보를 사용함으로써 하나의 세그먼트로서 식별될 것이다. RFID 라벨 정보는 세그먼트들의 개수를 감소시키고, 이에 따라 도 2의 루프들의 개수를 감소시키며, 보다 신속한 얼굴 등록 프로세스를 제공한다. 본 시스템에서, RFID 라벨들은 단지 세그먼트들을 결합시키기 위한 브릿지의 역할을 한다. 전체의 비디오 캡쳐링 주기 동안, 사용자들이 RFID 카드들을 실행(carry)하는 것은 요구되지 않는다.
RFID 라벨 정보는 또한 단계(330 및 430)에서 식별된 유사 쌍 및 비 유사 쌍 제약들을 개선하도록 사용될 수 있다. 이전에 언급된 자동적인 방법을 사용하는 식별 프로세스의 선호되는 실시예에서, 유사 쌍들로서 표기되는 이들 얼굴 이미지들에 대해, 쌍의 한 얼굴 이미지가 다른 얼굴 이미지와는 상이한 RFID 라벨을 갖는 경우, 쌍은 비 유사 쌍으로서 재표기된다. 유사하게도, 비 유사 쌍의 두 개의 얼굴 이미지들이 동일한 RFID 라벨을 갖는 경우, 이 쌍은 유사 쌍으로서 재표기될 것이다. 모든 사용자들이 RFID 디바이스들을 실행시키는 경우가 아니라면, RFID 라벨들은 상응하는 사용자들과 결합될 필요가 있다. 얼굴 이미지들의 개수의 변화에 대한 정보는 이러한 목표를 성취하도록 사용될 수 있다. 예를 들어, 한 프레임 내에 두 개의 얼굴들이 존재하고, 하나의 RFID 카드만이 검출되는 경우, 이는 한 명의 사용자만이 이 RFID 카드를 실행시키는 것을 보여준다. 게다가, 다음 프레임에서 하나의 얼굴만이 검출되는 경우, 현재의 하나의 얼굴이 RFID 카드 검출의 결과에 기초하여 RFID 카드와 결합되는지의 여부가 결정된다. RFID 카드가 여전히 검출될 수 있는 경우, 현재의 얼굴은 RFID 카드와 결합된다. 그렇지 않은 경우, 이전 프레임의 다른 얼굴이 RFID 카드와 결합된다. 한 선호되는 실시예에 따르면, 이것은 피드백 링크로서 나타내어진다. 이러한 유형의 링크는 본 시스템이 유사 쌍 및 비 유사 쌍 제약들의 지식에 대한 수집을 개선하는 것을 도울 수 있다.
얼굴 등록 프로세스(600)의 수정된 흐름도는 도 6에 도시된다. RFID 라벨들에 대한 정보 및 비디오 프레임들에 대한 이것의 상응(correspondence)을 획득하기 위한 RFID 검출 및 결합 단계(630)가 수행된다. RFID 라벨 정보(635)를 통해, 비디오 세그먼트들의 병합 단계(640)는 보다 큰 비디오 세그먼트들에 관련된 비디오 세그먼트들을 결합시키도록 수행된다. 이후 등록 시스템은 결합된 비디오 세그먼트에 기초하여 세그먼트 단위로 프로세스한다. RFID 라벨들(635)는 또한 데이터베이스 구축 단계(670) 및 업데이트 단계(660)에서 사용되며, 여기서 RFID 라벨들(370 및 490)은 유사 및 비 유사 제약들 식별 프로세스(330 및 430)을 용이하게 하도록 사용된다.
본 발명의 다른 실시예에서, 비디오 시퀀스를 통한 얼굴 등록 프로세스는 도 7에 따라 수행되며, 비디오 세그먼트들을 통한 루프는 얼굴 검출(760)과 제약 식별(770)만을 포함한다. 얼굴 이미지들 및 제약들이 모든 비디오 세그먼트들로부터 수집된 이후에, 데이터베이스 구축 단계(790) 및 데이터베이스 업데이트 단계(780)는 데이터베이스가 비어있는지 여부의 조건에 기초하여 초기화된다. 본 실시예는 디스턴스 메트릭에 대한 학습과 클러스터링에 대한 반복의 개수를 제거하고, 이로써 보다 효율적인 솔루션을 제공한다. 업데이트 단계(780)는 얼굴 검출 단계(420)와 제약 식별 단계(430)가 빠진 것을 제외하면, 도 4에 도시된 것과 동일할 것이다. 유사하게도, 데이터베이스 구축 단계(790)는 얼굴 검출 단계(320)와 제약 식별 단계(330)가 빠진 것을 제외하면, 도 3에 도시된 것과 동일할 것이다. RFID 라벨들이 이용 가능할 때, 프로세스(700)는 루프 이전에, 관련된 세그먼트들을 보다 큰, 그리고 보다 적은 세그먼트들로 결합시키기 위한 세그먼트 병합(740)을 수행하도록 RFID 정보를 사용할 것이다. 제약 식별 단계(770)는 또한 이용 가능하다면, RFID 라벨 정보를 사용한다.
최대 마진 메트릭 학습(
Maximum
Margin
Metric
Learning
)
모든 이미지는 고 차원적 공간의 벡터이다. 유클리디안 메트릭에 따라 이들을 직접 클러스터링하는 것은 원하지 않는 결과들을 가져올 수 있는데, 그 이유는 한 사람에 대한 얼굴 이미지들의 분배는 구 모양이 아니라, 엷은 판 모양이기 때문이다. 동일인이지만 상이한 조건의 두 이미지들 사이의 디스턴스는 동일한 조건 하에서 상이한 사람들 사이의 디스턴스보다 클 것이다. 이러한 문제를 해결하기 위해, 적절한 메트릭을 학습하는 것은 중요해진다.
본 명세서에 설명된 준-지도 메트릭 학습(semi-supervised metric learning)의 프레임워크(framework)는 최대 마진 메트릭 학습(MMML)이라 불리운다. 주요 개념은 유사 샘플 쌍들의 디스턴스와 비 유사 샘플 쌍들의 디스턴스 사이의 마진을 최대화하는 것이다. 이는 세미-포지티브 데피니트 프로그래밍을 통해 해결될 수 있다. 상기 규칙들에 따라 학습된 메트릭은 유클리디안 메트릭에 비해 얼굴 이미지들과 같은 이미지들을 클러스터링하기에 보다 적절한데, 그 이유는 유사 쌍들의 디스턴스들이 비 유사 쌍들의 디스턴스들보다 작은 것을 보장하기 때문이다.
여기서, n은 입력 데이터 집합 샘플들의 개수이다. 각  는 d 차원의 열 벡터(column vector)이다. S는 유사 샘플 쌍들의 집합이고, D는 비 유사 샘플 쌍들의 집합이다. 쌍의 제약들은 규칙들 또는 어플리케이션 배경에 따른 사전 지식에 기초하여 식별될 수 있다.
는 d 차원의 열 벡터(column vector)이다. S는 유사 샘플 쌍들의 집합이고, D는 비 유사 샘플 쌍들의 집합이다. 쌍의 제약들은 규칙들 또는 어플리케이션 배경에 따른 사전 지식에 기초하여 식별될 수 있다.
디스턴스 메트릭은  로 나타내어진다. 이러한 디스턴스 메트릭을 이용하여 두 개의 샘플들 xi 및 xj 사이의 디스턴스는 다음과 같이 정의된다:
로 나타내어진다. 이러한 디스턴스 메트릭을 이용하여 두 개의 샘플들 xi 및 xj 사이의 디스턴스는 다음과 같이 정의된다:

공간  내의 모든 포인트들 쌍의 디스턴스가 비-네거티브라는 것을 보장하기 위해, 디스턴스 메트릭 A는 포지티브 세미-데피니트, 즉
내의 모든 포인트들 쌍의 디스턴스가 비-네거티브라는 것을 보장하기 위해, 디스턴스 메트릭 A는 포지티브 세미-데피니트, 즉  이어야 한다. 사실, A는 Mahalanobis 디스턴스 메트릭을 나타내며, I가 단위 행렬(identity matrix)인 경우, A=I이면, 디스턴스는 유클리디안 디스턴스로 퇴보된다.
이어야 한다. 사실, A는 Mahalanobis 디스턴스 메트릭을 나타내며, I가 단위 행렬(identity matrix)인 경우, A=I이면, 디스턴스는 유클리디안 디스턴스로 퇴보된다.
클러스터링을 용이하게 하기 위해, 비 유사 쌍들 사이의 디스턴스를 최대화하고, 유사 쌍들의 디스턴스를 최소화하는 메트릭이 학습된다. 이러한 목표를 성취하기 위해, 유사 및 비 유사 쌍들의 디스턴스들 사이의 마진이 확대된다. 다른 말로, 메트릭이 구해질 것인데, 이는 실수 축(real axis) 상의 디스턴스의 최대 공백 구간(maximum blank interval)을 제공하는데, 임의의 샘플 쌍들의 디스턴스는 상기 최대 공백 구간에 속하지 않으며, 유사 샘플 쌍들의 디스턴스들은 상기 최대 공백 구간의 한 측면에 속하지만, 비 유사 샘플 쌍들의 디스턴스들은 다른 측면에 속한다.
디스턴스 메트릭 학습의 프레임워크는 다음과 같이 공식화된다:

이러한 최적화 문제의 제약들은, 유사 쌍들의 디스턴스들이 b0-d보다 작다는 것과, 비 유사 쌍들의 디스턴스들이 b0+d보다 크다는 것을 보장한다. 따라서, 2d는 최대화할 공백 마진의 폭이다. Ω(A)는 A에 대해 정의된 조정자인데, 이는 A에 대한 함수이며, Ω(λA)가 스칼라 λ와 포지티브 상관되는 성질(property)을 가지며, Ω(A)≠Ω(λA)(λ≠1)임을 보장한다. 제약 Ω(A0)=1은 필수적이다. 그렇지 않다면, 임의의 d는 A0에 λ>0을 단지 곱함으로써 획득될 수 있다. 한 실시예에서, A의 Frobenius Norm은  로서 정의되는 조정자 Ω(A)로서 사용된다.
로서 정의되는 조정자 Ω(A)로서 사용된다.  이고,
이고,  에 포지티브 상관되기 때문에,
에 포지티브 상관되기 때문에,  과
과  로 나타내어지며, max d의 최적화 결과는 minΩ(A)와 등가이다. 따라서, 프레임워크는 아래와 등가이다.
로 나타내어지며, max d의 최적화 결과는 minΩ(A)와 등가이다. 따라서, 프레임워크는 아래와 등가이다.

현실-세계 응용에 있어서, 대부분의 데이터는 분리될 수 없으며(non-separable), 즉 상기의 모든 제약들을 충족시키는 마진은 발견될 수 없으며, 이에 따라 상기 문제는 이러한 경우에 어떠한 솔루션도 갖지 못한다. 이는 상기 제안된 방법을 적용 가능하지 않게 한다. 이러한 유형의 문제를 다루기 위해, 슬랙 변수들이 프레임워크에 도입된다:


여기서, λ는 오버 피팅(over fitting)을 제한하기 위한 포지티브 파라미터이고, α는 퍼니쉬먼트(punishment)의 웨이트(weight)를 제어하는 포지티브 파라미터이다.
프레임워크를 간소화하기 위해, yij는 다음과 같이 소개된다:

이후 프레임워크는 아래와 같이 기재될 수 있다.

이는 큰 마진 메트릭 학습(Large Margin Metric Learning)의 프레임워크의 주요 형식이다. 이는 컨벡스 최적화 문제(convex optimization problem)이다. 디스턴스 메트릭 A의 세미-데피니트 제약은 이 문제가 세미-데피니트 최적화 문제가 되는 것을 제한한다. 이러한 유형의 문제들을 해결할 수 있는 예시 툴들(example tools)은  , "Yalmip: MATLAB에서의 모델링 및 최적화를 위한 툴박스", in Proceedings of the CACSD Conference, Taipei, Taiwan, 2004에서 발견될 수 있다.
, "Yalmip: MATLAB에서의 모델링 및 최적화를 위한 툴박스", in Proceedings of the CACSD Conference, Taipei, Taiwan, 2004에서 발견될 수 있다.
온라인 학습 알고리즘(
Online
Learning
Algorithm
)
온라인 알고리즘은 Shai Shalev-Shwartz, Yoram Singer, 및 Nathan Srebro의 확률론적 기울기 하강 방법(stochastic gradient descent method)의 개념을 사용하여 본 방법의 효율을 개선시키도록 더 도출된다. "Pegasos: Primal estimated sub-gradient solver for svm". In ICML, pages 807-814, 2007. 기울기(gradient)를 풀어내는 계산을 간소화하기 위해, 상기 프레임워크는 다음과 같은 손실 함수(loss function) 형태로 재표현될 수 있다:

여기서,  은 α 힌쥐 손실 함수(hinge loss function)이고, α는 포지티브 파라미터이다. α=1일 때, 손실 함수는 힌쥐 손실 함수이다. α>1로 설정하면, 손실 함수는 평탄(smooth)해진다. 특히, α=2이면, 이는 스퀘어 힌지 손실 함수(squares hinge loss function)라고 불리우며, 힌지 손실과 스퀘어 손실 사이의 트레이드-오프(trade-off)로서 확인될 수 있다. α가 커지면, 함수는 큰 에러들에 보다 민감해진다. 적절한 손실 함수는 파라미터 α를 조정함으로써 쉽게 선택될 수 있다. 게다가, α<1일 때, α가 작아지면, 이는 마진에 근접하여 보다 민감해진다.
은 α 힌쥐 손실 함수(hinge loss function)이고, α는 포지티브 파라미터이다. α=1일 때, 손실 함수는 힌쥐 손실 함수이다. α>1로 설정하면, 손실 함수는 평탄(smooth)해진다. 특히, α=2이면, 이는 스퀘어 힌지 손실 함수(squares hinge loss function)라고 불리우며, 힌지 손실과 스퀘어 손실 사이의 트레이드-오프(trade-off)로서 확인될 수 있다. α가 커지면, 함수는 큰 에러들에 보다 민감해진다. 적절한 손실 함수는 파라미터 α를 조정함으로써 쉽게 선택될 수 있다. 게다가, α<1일 때, α가 작아지면, 이는 마진에 근접하여 보다 민감해진다.
f(A, b)는 상기 프레임워크의 목적 함수(objective function)로 지정되고, A와 b에 대해 f(A, b)의 기울기들은 다음과 같이 주어진다:

온라인 학습 알고리즘은 하나의 루프 내에서 하나의 제약만을 고려하며, 이로써 기울기의 합산 함수(summation function)에는 하나의 항(term)만이 존재한다. 알고리즘은 알고리즘 1로 표현된다.
알고리즘 1
최대 마진 메트릭 학습을 위한 온라인 학습 알고리즘
입력:
쌍의 제약들
 및 시간 t=1...T에서의
및 시간 t=1...T에서의
 ;
;
출력:
 ;
;
for
t=1...T
do
상기 공식으로
기울기
▽
A
f
(A)와 ▽
b
f
(A)에 대해 풀어냄


알고리즘에서, αt는 적절한 하강의 단계 길이이다. 이는 현재의 반복 시간들의 함수일 수 있거나, 또는 다른 규칙들에 따라 계산될 수 있다. A를 포지티브 세미-데피니트 콘에 투영시키는 공통적인 방법은 A의 모든 네거티브 고유값들을 0으로 설정하는 것이다. 특징들(features) d의 개수가 클 때, 모든 고유값들을 계산하는 것은 많은 시간을 소비할 것이다. 본 알고리즘은 이러한 문제로 난관을 겪지 않으며, 이는 아래에서 확인될 수 있다.
전제 1  가 세미-데피니트 행렬
가 세미-데피니트 행렬  이라면,
이라면,  의 네거티브 고유값들의 최대 개수는 1이다.
의 네거티브 고유값들의 최대 개수는 1이다.
하강 이후에 A의 네거티브 고유값들의 최대 개수가 1이라서, 최소 고유값과 이것의 고유 벡터만이 발견될 필요가 있음은 전제 1로부터 추론될 수 있다. e를 네거티브 고유값  의 고유 벡터라고 해본다. A를 포지티브 세미-데피니트 콘에 투영시키는 것은
의 고유 벡터라고 해본다. A를 포지티브 세미-데피니트 콘에 투영시키는 것은  로 설정함으로써 성취될 수 있다.
로 설정함으로써 성취될 수 있다.
예시
얼굴 이미지 데이터 집합에 대한 디스턴스 메트릭을 획득하기 위해, 본 MMML 메트릭 학습 방법을 이용하는 예시는 아래에 나와 있다. 본 예시에서, ORL 데이터 집합은 입력 얼굴 이미지들로 선택되고, 얼굴 이미지 벡터의 차원은 주성분 분석(PCA: Principle Component Analysis) 방법을 사용함으로써 30으로 감소된다. 쌍의 제약들은 데이터 집합 내에 이미 주어진 라벨 정보에 따라 생성된다. 데이터 집합 내에 주어진 라벨 정보는 얼굴 이미지들의 클래스들에 대한 지상 검증 자료(ground truth)이며, 클래스 라벨이라 불리운다. 이후 얼굴 이미지 데이터와 함께 식별된 제약들은 발명된 MMML 방법에 따라 디스턴스 메트릭을 학습하도록 사용된다. 쌍의 제약들 하에서 학습된 디스턴스 메트릭의 성능을 평가하기 위해, 획득된 디스턴스 메트릭은 K-평균(K-means) 방법에 의해 샘플들을 클러스터링하도록 사용되고, 클러스터링된 결과들은 클러스터 라벨들이라 불리운다. 따라서, 얼굴 이미지에 대해, 두 개의 라벨들: 지상 검증 자료 클래스인 클래스 라벨 및 학습된 디스턴스 메트릭을 이용한 클러스터링을 통해 획득된 클러스터인 클러스터 라벨을 가지고 있다. 클러스터링의 결과는 메트릭의 성능을 보여주기 위해 사용된다. 클러스터링 결과들을 양적으로 평가하기 위해 두 가지의 성능 측정들이 다음과 같이 채택된다.
1. 클러스터링 정확도.
클러스터링 정확도는 클러스터들과 클래스들 사이의 일대일 관계를 발견하고, 각 클러스터가 상응하는 클래스로부터의 데이터 포인트들을 포함하는 정도를 측정한다. 클러스터링 정확도는 다음과 같이 정의된다:

여기서, n은 얼굴 이미지들의 총 개수이고; ri는 얼굴 이미지 xi의 클러스터 라벨을 나타내며; li는 xi의 트루 클래스 라벨을 나타내고; δ(a, b)는, a=b일 경우에는 1과 동일하고, 그렇지 않을 경우에는 0과 동일한 델타 함수이며, map(ri)는 각 클러스터 라벨 ri를, 데이터 집합으로부터의 상응하는 클래스 라벨에 맵핑시키는 맵핑 함수이다.
2. 정상화된 상호 정보(Normalized Mutual Information)
제2 측정은 정상화된 상호 정보(NMI)이며, 클러스터들의 품질을 결정하기 위해 사용된다. 클러스터링 결과가 주어지면, NMI는  에 의해 추정되며, ni는 클러스터 Ri, i=1,...,c에 포함된 데이터 샘플들(즉, 얼굴 이미지들)의 개수를 나타내고, c는 클러스터들의 총 개수이다.
에 의해 추정되며, ni는 클러스터 Ri, i=1,...,c에 포함된 데이터 샘플들(즉, 얼굴 이미지들)의 개수를 나타내고, c는 클러스터들의 총 개수이다.  는 클래스 Lj, j=1,...,c에 속한 데이터 샘플들(즉, 얼굴 이미지들)의 개수이며, nij는 클러스터 Ri와 클래스 Lj 사이에서 교차하는 데이터의 개수를 나타낸다. NMI가 크면 클수록, 보다 양호한 클러스터링 결과가 획득된다.
는 클래스 Lj, j=1,...,c에 속한 데이터 샘플들(즉, 얼굴 이미지들)의 개수이며, nij는 클러스터 Ri와 클래스 Lj 사이에서 교차하는 데이터의 개수를 나타낸다. NMI가 크면 클수록, 보다 양호한 클러스터링 결과가 획득된다.
실험의 결과들은 도 8에 도시된다. 수평 축은, 이용 가능한 제약들의 최대 개수에 대한, 생성되어 사용된 제약들의 개수의 비율을 나타낸다. 실선은 Acc와 NMI에 관한 MMML의 결과들을 도시하며, 점선은 유클리디안 메트릭을 사용한 결과들을 나타낸다. 다른 두 개의 선들은 2개의 종래 기술의 결과들이다. 수치는 MMML 방법이 다른 것들에 비해 ORL 얼굴 데이터 집합에 있어서 훨씬 더 양호하게 수행하는 것을 도시한다. 이는 보다 양호한 얼굴 등록의 결과를 얻게 해줄 수 있다.
본 발명의 선호되는 실시예들이 본 명세서에 상세하게 설명되었을지라도, 본 발명은 이들 실시예들을 제한하지 않는다는 것과, 다른 수정들 및 변형들은 첨부된 청구항들에 의해 한정되는 바와 같이 본 발명의 사상과 범주로부터 벗어나지 않고 당업자에 의해 실행될 수 있다는 것이 이해될 것이다.
10 : 사용자 20 : TV 세트
30 : 비디오 디바이스 또는 카메라 40 : 이미지 데이터베이스
50 : 선호도 데이터베이스 60 : 상관기
70 : 메트릭 학습 모듈 80 : 업데이터
90 : 선호도 분석기
30 : 비디오 디바이스 또는 카메라 40 : 이미지 데이터베이스
50 : 선호도 데이터베이스 60 : 상관기
70 : 메트릭 학습 모듈 80 : 업데이터
90 : 선호도 분석기
Claims (25)
- 사용자 인터페이스로서,
시스템의 사용자들의 물리적 특징들에 상응하는 이미지들의 데이터베이스로서, 사용자들의 물리적 특징들은 시스템의 사용자들을 구분하는, 이미지들의 데이터베이스;
사용자가 시스템과 인터페이스할 때, 사용자 이미지들을 캡쳐하기 위한 비디오 디바이스;
시스템의 각 사용자들에 상응하는 개별 사용자 선호도들의 집합을 생성하기 위해, 시스템과의 사용자 상호 작용에 기초하여 시스템의 사용자 선호도들을 수집하고, 선호도들을 분리하기 위한 선호도 분석기;
시스템의 사용에 관한 개별 사용자 선호도들을 저장하는 선호도 데이터베이스; 및
이미지들의 데이터베이스 내의 이미지들에 기초하여 시스템의 사용자들을 상관시키고, 사용자가 시스템과 인터페이스할 때, 비디오 디바이스에 의해 캡쳐된 시스템의 특정 사용자에 관한 개별 사용자 선호도들을 적용하는 상관기;를 포함하는,
사용자 인터페이스. - 제1항에 있어서,
이미지들의 데이터베이스는 얼굴 이미지들의 데이터베이스인,
사용자 인터페이스. - 제1항에 있어서,
시스템은 TV 세트이고, 사용자 선호도들은 사용자가 가장 좋아하는 채널들, 선호되는 영화 장르, 및 TV 프로그램들을 포함하는,
사용자 인터페이스. - 사용자 등록 방법으로서,
사용자들에 대한 화상들의 시퀀스에 액세스하는 단계;
화상들의 상기 시퀀스로부터 이미지들을 검출하는 단계로서, 이미지들은 사용자들을 구분하는 사용자들의 물리적 특징들에 상응하는, 검출 단계;
상기 검출된 이미지들을 이용하여 디스턴스 메트릭(distance metric)을 결정하는 단계;
상기 디스턴스 메트릭을 이용하여 계산된 디스턴스들에 기초하여 상기 이미지들을 클러스터링하는 단계; 및
클러스터링의 결과들에 기초하여 사용자들을 등록하는 단계;를 포함하는,
사용자 등록 방법. - 제4항에 있어서,
검출된 이미지들은 얼굴 이미지들인,
사용자 등록 방법. - 제4항에 있어서,
디스턴스 메트릭을 결정하는 단계는 검출된 이미지들 사이의 제약들(constraints)을 식별하는 단계; 및 식별된 제약들에 기초하여 디스턴스 메트릭을 학습하는 단계;를 더 포함하는,
사용자 등록 방법. - 제6항에 있어서,
식별된 제약들은 검출된 이미지들의 유사 쌍들과 검출된 이미지들의 비 유사 쌍들을 포함하는,
사용자 등록 방법. - 제7항에 있어서,
검출된 이미지들의 유사 쌍은 동일인에 대한 두 개의 검출된 이미지들로 구성되는,
사용자 등록 방법. - 제7항에 있어서,
검출된 이미지들의 비 유사 쌍은 상이한 2인들에 대한 두 개의 검출된 이미지들로 구성되는,
사용자 등록 방법. - 사용자 등록을 업데이트하기 위한 방법으로서,
사용자들에 대한 화상들의 시퀀스에 액세스하는 단계;
화상들의 상기 시퀀스로부터 이미지들을 검출하는 단계로서, 이미지들은 사용자들을 구분하는 사용자들의 물리적 특징들에 상응하는, 검출 단계;
검출된 이미지들 사이의 제약들을 식별하는 단계;
기존의 디스턴스 메트릭을 이용하여 계산된 디스턴스들에 기초하여 상기 이미지들을 클러스터링하는 단계;
상기 식별된 제약들을 통해 상기 클러스터링의 결과들을 검증하는 단계; 및
상기 클러스터링의 결과들과 검증 결과들에 기초하여 사용자 등록을 업데이트하는 단계;를 포함하는,
사용자 등록을 업데이트하기 위한 방법. - 제10항에 있어서,
검출된 이미지들은 얼굴 이미지들인,
사용자 등록을 업데이트하기 위한 방법. - 제10항에 있어서,
제약들을 식별하는 단계는 검출된 이미지들의 유사 쌍들과 검출된 이미지들의 비 유사 쌍들을 식별하는 단계를 포함하는,
사용자 등록을 업데이트하기 위한 방법. - 제12항에 있어서,
검출된 이미지들의 유사 쌍은 동일인에 대한 두 개의 검출된 이미지들로 구성되는,
사용자 등록을 업데이트하기 위한 방법. - 제12항에 있어서,
검출된 이미지들의 비 유사 쌍은 상이한 2인들에 대한 두 개의 검출된 이미지들로 구성되는,
사용자 등록을 업데이트하기 위한 방법. - 제10항에 있어서,
상기 제약들이 검증하는 단계에서 충족되는 경우, 업데이트하는 단계는 새로 클러스터링된 이미지들을 추가함으로써, 사용자 등록을 업데이트하는 단계를 더 포함하는,
사용자 등록을 업데이트하기 위한 방법. - 제10항에 있어서,
상기 제약들이 검증하는 단계에서 충족되지 않는 경우, 업데이트하는 단계는,
상기 식별된 제약들을 추가함으로써, 디스턴스 메트릭을 학습하는 단계;
상기 학습된 디스턴스 메트릭을 이용하여 계산된 디스턴스들에 기초하여 상기 이미지들과 기존의 이미지들을 재 클러스터링하는 단계;
상기 재 클러스터링의 결과들과 상기 학습된 디스턴스 메트릭을 이용하여 사용자 등록을 업데이트하는 단계;를 더 포함하는,
사용자 등록을 업데이트하기 위한 방법. - 디스턴스 메트릭 A를 결정하는 방법으로서,
포인트들 사이의 디스턴스를 갖는 복수의 포인트들 쌍을 식별하는 단계로서, 한 쌍의 포인트들 (xi, xj) 사이의 디스턴스 dA(xi, xj)는,
로서
디스턴스 메트릭 A에 기초하여 정의되는, 식별 단계;
디스턴스 메트릭 A의 조정자(regularizer)를 선택하는 단계;
상기 조정자의 제1 값을 획득하기 위해, 상기 복수의 포인트들 쌍 사이의 디스턴스들 dA에 대한 제약들의 집합에 따라 상기 조정자를 최소화시키는 단계;
상기 제1 값 이하인 상기 조정자의 값을 획득하는 디스턴스 메트릭을 찾음으로써, 디스턴스 메트릭 A를 결정하는 단계;를 포함하는,
디스턴스 메트릭 A를 결정하는 방법. - 제17항에 있어서,
디스턴스 메트릭의 조정자는 Frobenius Norm인,
디스턴스 메트릭 A를 결정하는 방법. - 제17항에 있어서,
포인트들은 얼굴 이미지들인,
디스턴스 메트릭 A를 결정하는 방법. - 제17항에 있어서,
상기 조정자의 제1 값은 최소 값인,
디스턴스 메트릭 A를 결정하는 방법. - 제17항에 있어서,
포인트들의 유사 쌍들과 포인트들의 비 유사 쌍들을 식별하는 단계를 더 포함하는,
디스턴스 메트릭 A를 결정하는 방법. - 제21항에 있어서,
제약들의 집합은:
세미-데피니트(semi-definite)인 디스턴스 메트릭; 및 제1 비-네거티브 값 이하인 상기 식별된 유사 쌍들의 디스턴스들과, 제2 비-네거티브 값 이상인 상기 식별된 비 유사 쌍들의 디스턴스들을 포함하는,
디스턴스 메트릭 A를 결정하는 방법. - 제17항에 있어서,
최소화 단계에서 최소화되는 결합 함수를 통해 조정자와 결합되는 슬랙 변수들(slack variables)의 집합을 선택하는 단계를 더 포함하는,
디스턴스 메트릭 A를 결정하는 방법. - 제23항에 있어서,
포인트들의 유사 쌍들과 포인트들의 비 유사 쌍들을 식별하는 단계를 더 포함하는,
디스턴스 메트릭 A를 결정하는 방법. - 제24항에 있어서,
제약들의 집합은:
세미-데피니트인 디스턴스 메트릭; 비-네거티브인 슬랙 변수들; 및 제1 비-네거티브 값 이하인 상기 식별된 유사 쌍들의 디스턴스들과, 제2 비-네커티브 값 이상인 상기 식별된 비 유사 쌍들의 디스턴스들을 포함하는,
디스턴스 메트릭 A를 결정하는 방법.
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/CN2010/002192 WO2012088627A1 (en) | 2010-12-29 | 2010-12-29 | Method for face registration |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20140005195A true KR20140005195A (ko) | 2014-01-14 |
Family
ID=46382147
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020137016826A KR20140005195A (ko) | 2010-12-29 | 2010-12-29 | 얼굴 등록 방법 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20130250181A1 (ko) |
| EP (1) | EP2659434A1 (ko) |
| JP (1) | JP5792320B2 (ko) |
| KR (1) | KR20140005195A (ko) |
| CN (1) | CN103415859A (ko) |
| WO (1) | WO2012088627A1 (ko) |
Families Citing this family (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8904289B2 (en) * | 2011-04-21 | 2014-12-02 | Touchstream Technologies, Inc. | Play control of content on a display device |
| US9767195B2 (en) | 2011-04-21 | 2017-09-19 | Touchstream Technologies, Inc. | Virtualized hosting and displaying of content using a swappable media player |
| JP2013003631A (ja) * | 2011-06-13 | 2013-01-07 | Sony Corp | 情報処理装置、情報処理方法、情報処理システム、及びプログラム |
| KR20130078676A (ko) * | 2011-12-30 | 2013-07-10 | 삼성전자주식회사 | 디스플레이장치 및 그 제어방법 |
| WO2014094284A1 (en) * | 2012-12-20 | 2014-06-26 | Thomson Licensing | Learning an adaptive threshold and correcting tracking error for face registration |
| US9471847B2 (en) * | 2013-10-29 | 2016-10-18 | Nec Corporation | Efficient distance metric learning for fine-grained visual categorization |
| US9953217B2 (en) * | 2015-11-30 | 2018-04-24 | International Business Machines Corporation | System and method for pose-aware feature learning |
| KR102476756B1 (ko) | 2017-06-20 | 2022-12-09 | 삼성전자주식회사 | 사용자 인증을 위한 등록 데이터베이스의 적응적 갱신 방법 및 장치 |
| US10387749B2 (en) * | 2017-08-30 | 2019-08-20 | Google Llc | Distance metric learning using proxies |
| KR102564854B1 (ko) | 2017-12-29 | 2023-08-08 | 삼성전자주식회사 | 정규화된 표현력에 기초한 표정 인식 방법, 표정 인식 장치 및 표정 인식을 위한 학습 방법 |
| US10460330B1 (en) * | 2018-08-09 | 2019-10-29 | Capital One Services, Llc | Intelligent face identification |
| JP7340992B2 (ja) | 2019-08-26 | 2023-09-08 | 日本放送協会 | 画像管理装置およびプログラム |
| CN111126470B (zh) * | 2019-12-18 | 2023-05-02 | 创新奇智(青岛)科技有限公司 | 基于深度度量学习的图片数据迭代聚类分析方法 |
| CN113269282A (zh) * | 2021-07-21 | 2021-08-17 | 领伟创新智能系统(浙江)有限公司 | 一种基于自动编码器的无监督图像分类方法 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002032136A2 (en) * | 2000-10-10 | 2002-04-18 | Koninklijke Philips Electronics N.V. | Device control via image-based recognition |
| JP4384366B2 (ja) * | 2001-01-12 | 2009-12-16 | 富士通株式会社 | 画像照合処理システムおよび画像照合方法 |
| US20030120630A1 (en) * | 2001-12-20 | 2003-06-26 | Daniel Tunkelang | Method and system for similarity search and clustering |
| JP4187494B2 (ja) * | 2002-09-27 | 2008-11-26 | グローリー株式会社 | 画像認識装置、画像認識方法およびその方法をコンピュータに実行させるプログラム |
| JP4314016B2 (ja) * | 2002-11-01 | 2009-08-12 | 株式会社東芝 | 人物認識装置および通行制御装置 |
| CN100414558C (zh) * | 2002-12-06 | 2008-08-27 | 中国科学院自动化研究所 | 基于模板学习的自动指纹识别系统和方法 |
| US7519200B2 (en) * | 2005-05-09 | 2009-04-14 | Like.Com | System and method for enabling the use of captured images through recognition |
| US8244063B2 (en) * | 2006-04-11 | 2012-08-14 | Yeda Research & Development Co. Ltd. At The Weizmann Institute Of Science | Space-time behavior based correlation |
| WO2007127296A2 (en) * | 2006-04-25 | 2007-11-08 | Data Relation Ltd. | System and method to work with multiple pair-wise related entities |
| US20080101705A1 (en) * | 2006-10-31 | 2008-05-01 | Motorola, Inc. | System for pattern recognition with q-metrics |
| JP4508283B2 (ja) * | 2007-03-09 | 2010-07-21 | オムロン株式会社 | 認識処理方法およびこの方法を用いた画像処理装置 |
| US8266083B2 (en) * | 2008-02-07 | 2012-09-11 | Nec Laboratories America, Inc. | Large scale manifold transduction that predicts class labels with a neural network and uses a mean of the class labels |
-
2010
- 2010-12-29 JP JP2013546541A patent/JP5792320B2/ja not_active Expired - Fee Related
- 2010-12-29 KR KR1020137016826A patent/KR20140005195A/ko not_active Application Discontinuation
- 2010-12-29 CN CN2010800710195A patent/CN103415859A/zh active Pending
- 2010-12-29 EP EP10861396.9A patent/EP2659434A1/en not_active Withdrawn
- 2010-12-29 WO PCT/CN2010/002192 patent/WO2012088627A1/en active Application Filing
- 2010-12-29 US US13/989,983 patent/US20130250181A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| US20130250181A1 (en) | 2013-09-26 |
| JP2014507705A (ja) | 2014-03-27 |
| CN103415859A (zh) | 2013-11-27 |
| JP5792320B2 (ja) | 2015-10-07 |
| WO2012088627A1 (en) | 2012-07-05 |
| EP2659434A1 (en) | 2013-11-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR20140005195A (ko) | 얼굴 등록 방법 | |
| CN109961051B (zh) | 一种基于聚类和分块特征提取的行人重识别方法 | |
| De Geest et al. | Online action detection | |
| Ding et al. | Violence detection in video by using 3D convolutional neural networks | |
| JP6853379B2 (ja) | 対象人物の検索方法および装置、機器、プログラム製品ならびに媒体 | |
| Li et al. | Probabilistic multi-task learning for visual saliency estimation in video | |
| KR102554724B1 (ko) | 이미지 내 객체를 식별하기 위한 방법 및 상기 방법을 실행하기 위한 모바일 디바이스 | |
| US9639747B2 (en) | Online learning method for people detection and counting for retail stores | |
| CN110517293A (zh) | 目标跟踪方法、装置、系统和计算机可读存储介质 | |
| JP2021101384A (ja) | 画像処理装置、画像処理方法およびプログラム | |
| CN107408119B (zh) | 图像检索装置、系统以及方法 | |
| US10957055B2 (en) | Methods and systems of searching for an object in a video stream | |
| US10043103B2 (en) | System and method for object matching | |
| CN106056590B (zh) | 基于Manifold Ranking和结合前景背景特征的显著性检测方法 | |
| WO2017181892A1 (zh) | 前景分割方法及装置 | |
| Ta et al. | Recognizing and localizing individual activities through graph matching | |
| JP2015187759A (ja) | 画像検索装置、画像検索方法 | |
| JP2008077536A (ja) | 画像処理装置および方法、並びにプログラム | |
| CN111209818A (zh) | 视频个体识别方法、系统、设备及可读存储介质 | |
| Sapkota et al. | Large scale unconstrained open set face database | |
| KR20200060942A (ko) | 연속된 촬영 영상에서의 궤적기반 얼굴 분류 방법 | |
| Panda et al. | Adaptation of person re-identification models for on-boarding new camera (s) | |
| Atmosukarto et al. | Recognizing team formation in American football | |
| Deotale et al. | Optimized hybrid RNN model for human activity recognition in untrimmed video | |
| Chakraborty et al. | Person reidentification using multiple egocentric views |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal |