시각 주의 모델(
VISUAL
ATTENTION
MODELS
)
시각 주의 모델은 장면 내의 영역들이 시각 주의를 끌거나 안구 운동(eye movement)을 끌어낼 가능성과 관련하여 상이한 정도를 결정한다. 장면은 시각 주의 모델에 의해 평가될 수 있는 임의의 형태의 입력(예를 들어, 그래픽 이미지)이며, 예를 들어 디지털 사진, 가상 3D 장면, 웹 페이지, 문서, 또는 비디오일 수 있다.
시각 주의 모델의 객체에 대한 배치는 시각 주의의 모델이 장면 내의 객체의 상대적 현저성을 특성화하는 방법을 지칭한다. 예를 들어, 일부 시각 주의 모델은 예측되는 객체 주위에 트레이스 라인(trance line)을 겹쳐 놓을 것이다. 다른 시각 주의 모델은, 이미지 위에 겹쳐질 수 있거나 이미지와는 별개로 보일 수 있는 열 지도(heat map)를 생성할 것이다. 심지어 다른 것들은 상대적인 관점에서 그 객체의 현저성을 나타내는 값을 생성하여 그 값을 특정 객체 및/또는 영역에 할당할 수 있다. 트레이스 라인과 관련하여, 객체의 배치는 모델에 의해 "선택되는 것"(트레이스될 때) 또는 "선택되지 않는 것"으로 고려될 수 있다. 열 지도와 관련하여, 객체의 배치는 알고리즘이 그 객체를 선택한(또는 객체를 선택하지 않은) 정도이다. 또한, 현저성 수(saliency number)와 관련하여, 객체의 배치는 현저성 수 자체일 수 있다.
인간 시각 주의가 장면 내의 어느 곳에 할당될 것인지를 예측하는 많은 시각 주의 모델이 있다. 일반적으로, 이들 시각 주의 모델은 환경의 단일 이미지를 입력으로서 취하고, 주의가 그 장면 내의 어느 곳에 할당될 것인지에 관한 예측을 생성한다. 경험적 접근법(empirical approach)은 인간 주체(subject)를 장면에 노출시키고 그들의 안구 운동을 추적한다. 그러나, 이러한 경험적 접근법은 리소스 집중적(resource intensive)이어서, 장면의 적어도 부분적인 분석에 의해 주의를 예측하고자 하는 다수의 수학적 모델이 개발되었다. 즉, 경험적 접근법은 또한 본 명세서에 설명되는 시스템 및 방법의 일부로서 사용될 수 있고, 본 명세서에 사용되는 바와 같이 경험적 접근법은 일 타입의 시각 주의 모델링인 것으로 간주된다.
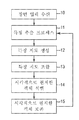
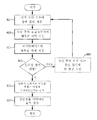
이들 모델 중 하나의 기본적 방법론이 도 1에 표현되어 있는데, 이는 잇티, 엘.(Itti, L.) 및 코흐, 씨.(Koch, C.)의 2000년도 문헌[A saliency-based search mechanism for overt and covert shifts of visual attention, Vision Research, vol. 40, pages 1489-1506]에 의해 제안된 것이다. 고 레벨에서, 도 1은, 시각 주의에 대한 예측이 인간 시력의 몇몇 양태를 조정하는 시각적 표현의 구축 블록(building block)으로서 역할하는, 컬러(color), 움직임(motion), 휘도, 에지 등과 같은 "상향식(bottom-up)" 특징들의 평가에 의해 어떻게 이루어지는지를 도시한다. 먼저, 디지털 사진 형태의 장면이 잇티 및 코흐 모델의 컴퓨터 구현 버전에 제공된다(단계 10). 다음, 특징 추출 프로세스가 컬러, 세기, 배향, 또는 기타 장면 큐(scene cue), 예컨대 움직임, 결합(junction), 종결부(terminators), 입체 부등(stereo disparity) 및 음영으로부터의 형상에 대해 디지털 사진을 분석한다(단계 11). 특징 추출 프로세스는 복수의 특징 지도를 생성하며(단계 12), 이들이 조합되어 현저성 지도를 생성한다(단계 13). 잇티 및 코흐 모델의 경우, 현저성 데이터는, 시각 주의가 다음에 할당될 것으로 모델이 예측했던 "가장 밝은" 객체를 갖는 원본 디지털 사진의 렌더링으로서 사용자에게 제공된다. 이러한 예측된 객체는 시각적으로 현저한 것(단계 14)으로 "승자독식(winner-take-all)" 타입 알고리즘으로 식별되며(단계 15), 프로세스는 그 후 복수의 객체가 모델에 의해 식별될 때까지 반복된다.
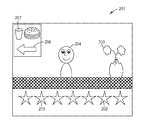
도 2는 잇티 및 코흐의 것과 같은 시각 주의 모델에 제공될 수 있는 장면(201)의 아티스트 렌더링(artist's rendering)이다. 이는 단지 예시의 목적으로 본 명세서에 포함된 단순화된 장면이며; 실제로 장면은 종종 실제 디지털 사진 또는 비디오이고, 더욱 더 복잡하다. 도 2는 별(202), 꽃(203), 얼굴(204), 별(205), 화살표(206) 및 컵(207)과 같은 장면 내의 다수의 객체를 포함한다.
도 3a는 잇티 및 코흐 모델로부터의 출력이 어떻게 표현될 수 있는지를 나타내는 아티스트 렌더링이다. 하이라이트된(그리고 이러한 대표적 예시에서 원으로 둘러싸인) 객체는 모델이 시각적으로 현저한 것으로 예측한 것들이다. 예를 들어, 별(202)은 이 도면에서 하이라이트 테두리(208) 내에 있고, 꽃(203)은 테두리(209) 내에 있으며, 얼굴(204)은 테두리(210) 내에 있고, 별(205)은 테두리(211) 내에 있으며, 화살표(206)는 테두리(212) 내에 있고, 컵(207)은 테두리(213) 내에 있다. 따라서, 이 경우의 모델은 다른 객체에 비해 시각적으로 더욱 현저한 6개의 객체를 결정하였다. 이러한 특정 모델은 또한 주의가 일부 시각적 현저성 임계치를 초과하는 것으로 결정된 객체들 간에서 어떻게 이동할 것인지를 예측한다. 예를 들어, 시각 주의 경로(301, 302, 303, 304, 305)는 예측된 시각 주의 경로를 도시한다.
도 3b는 잇티 및 코흐 모델로부터의 출력이 때때로 표현되는 다른 방식을 도시하는 제2 아티스트 렌더링이다. 도 3a에 도시된 것에 부가하여, 도 3b는 예측된 시각 주의의 시퀀스(sequence)를 포함한다. 예를 들어, 별(202)은 "1"(주의 시퀀스 번호 214)로 라벨링되고, 꽃(203)은 "2"(주의 시퀀스 번호 215)로 라벨링되는 등이다.
물론, 도 3a 및 도 3b는 단지 시각 주의 예측이 사용자에게 전달될 수 있는 한 가지 방식이며; 상이한 모델이 이러한 정보(또는 이의 일부 하위세트)를 상이한 방식으로 나타낸다. 예를 들어, 모든 모델이 예측된 주의 시퀀스를 결정하는 것은 아니지만, 이러한 주의 시퀀스는 최고 레벨의 시각적 현저성을 갖는 객체를 결정하고 이어서 그 객체를 제거하고 다음으로 가장 높은 것을 찾는 것 등에 의해 도달될 수 있다.
잇티 및 코흐의 모델은, 그것이 장면의 항목들의 분석에 기초하여 그의 예측안을 만든다는 점에서 "상향식" 시각 주의 모델을 대표한다. 다른 상향식 시각적 현저성 모델은 가오(Gao), 마하드반(Mahadevan) 및 베스콘셀로스(Vesconcelos)의 2008년도 문헌에 설명되어 있다.
상향식 모델 외에, 시각 주의의 "하향식(top down)" 모델로 지칭되는 다른 부류의 모델이 있다. 상향식 모델과 대조적으로, 이들 모델은, 명시적 태스크(예를 들어, 장애물을 회피하고 객체를 수집함) 또는 주의가 특정 검색 태스크 중에 할당되는 곳에 영향을 미칠 세계의 사전 지식(예를 들어, 의자는 천장에 있는 것이 아니라 바닥에 있기 마련임) 중 어느 하나와 장면으로 시작한다. 이러한 지식(태스크-기반 및 장면-기반 모두)은, 상향식 특징과 함께 사용되어 관찰된 장면 내의 객체로 주의를 향하게 한다. 몇몇 예시적인 하향식 모델은 로드코프, 씨.에이.(Rothkopf, C.A.), 발라드, 디.에이치.(Ballard, D.H.) 및 헤이호, 엠.엠.(Hayhoe, M.M.)의 2007년도 문헌[Task and context Determine Where You Look, Journal of Vision 7(14):16, 1-20] 및 토랄바, 에이.(Torralba, A.)의 문헌[Contextual Modulation of Target Saliency, Adv. in Neural Information Processing Systems 14 (NIPS), (2001) MIT Press, 2001]에 설명되어 있다. 예를 들어, 토랄바의 시각 주의 모델은, 특정 타입의 객체를 포함하는 특징 및 장면 내의 이들 객체의 절대적 및 상대적 위치에 관한 정보에 관한 사전 지식을 갖는다. 이 사전 지식은 장면 내의 특정 타깃의 검색에 "하향식" 영향을 제공한다.
본 분야는 상향식 및 하향식 디자인 둘다의 특징을 갖는 하이브리드 시각 주의 모델을 포함하도록 발전되어 왔고, 모델이 노출될 장면의 타입들에서의 차이(예를 들어, 비디오 대 스틸 이미지, 실외 이미지 대 웹 페이지 등)에 적응되어 왔다.
강건성(ROBUSTNESS)
강건성은 하기의 것들 중 어느 하나 또는 이들의 몇몇 조합에 대한 시각 주의 모델로부터의 예측 출력의 감도를 지칭한다:
(a) 예를 들어, 장면 내의 객체들의 배열, 객체들의 조명, 객체들의 컬러 등을 포함하는, 장면의 시각적 특성 내의 변경 및/또는 가변성("외적 가변성"으로 지칭됨); 또는
(b) 관찰자 또는 관찰의 모델 내의 변경 및/또는 가변성("내적 가변성"으로 지칭됨).
본 명세서에서 사용되는 바와 같은 객체라는 용어는 장면 내의 사물 또는 구역 또는 영역을 지칭하거나, 경우에 따라 시각 주의 모델에 의해 분석되는 장면 내의 영역들을 지칭할 수 있다. 객체라는 용어는 경우에 따라 "구역" 또는 "영역"과 상호 교환가능하게 사용된다.
2가지 타입의 변경 (a) 및 (b)는 집합적으로 내적 또는 외적, 또는 IE 변경으로 지칭되며, 그러한 변경을 도입하고 이어서 평가하는 다양한 방법이 이하 상세히 논의된다.
강건성 평가는 주의가 장면 내에서 어디에 할당될 것인지에 대한 IE 변경의 효과를 측정하는 방법이다. 그러면, 장면 내의 객체의 강건성은, 시각 주의 모델의 특정 객체의 예측된 배치가 변경되는 정도, 또는 IE 변경에도 불구하고 변경되지 않는 정도이다.
객체들의 그룹의 강건성은 하나 초과의 객체(객체들의 집합)에 대한 시각 주의 모델의 배치가 변경되거나 IE 변경에도 변경되지 않는 정도이다.
장면의 강건성은 장면에서 시각 주의 모델의 객체의 배치가 변경되거나, IE 변경에도 불구하고 변경되지 않는 정도이다. 예를 들어, 시각 주의 모델이 장면 내의 동일한 4개의 객체에 대해 주의 또는 고정성(fixation)이 만들어진다는 것을 예측하고, 이들 4개의 객체가 IE 변경에도 불구하고 시각 주의 모델에 의해 예측된 상태로 유지되는 경향이 있다면, 장면은 4개의 객체가 IE 변경에 따라 변경되었던 경우보다 더욱 강건한 경향이 있다.
시각 주의 강건성 평가 시스템(VISUAL ATTENTION ROBUSTNESS ASSESSMENT SYSTEM)
도 6은 장면의 강건성 또는 장면 내의 객체들의 강건성 또는 다수의 장면에 걸친 객체들의 강건성을 평가하기 위한 시스템인 시각 주의 강건성 평가 시스템(403)의 예시적인 기능 모듈들을 도시하는 다이어그램이다. 물론, 이들 방법은 또한 수동으로 실행될 수 있다. 시각 주의 강건성 평가 시스템은 도 6에 도시된 실시 형태에서 컴퓨터 시스템(408) 내에 있다. 컴퓨터 시스템(408)은 임의의 범용 또는 주문형(application-specific) 컴퓨터 또는 장치일 수 있다. 이는 독립형(stand-alone) 랩톱 컴퓨터 또는 복수의 네트워크화된 컴퓨터일 수 있다. 또한, 컴퓨터 시스템(408)은 핸드헬드 컴퓨터, 디지털 카메라, 또는 태블릿 PC, 또는 심지어 휴대 전화일 수 있다. 컴퓨터 시스템(408)은 일 실시 형태에서 운영 체제를 포함하는 다양한 기능 모듈(도 6에는 도시 안됨)을 갖는다. 그러한 운영 체제는 컴퓨터 시스템의 리소스로의 시각 주의 강건성 평가 시스템의 액세스를 용이하게 한다. 컴퓨터 시스템(408)은 프로세서와 메모리, 및 다양한 통상적인 입력/출력 인터페이스를 갖는다.
시각 주의 모듈(403)은 임의의 시각 주의 모델 또는 모델들의 조합의 임의의 실시 형태이다. 이전에 언급된 바와 같이, 상이한 타입의 시각 주의 모델이 있지만, 그들 모두는 어느 정도 시각 주의가 할당되는 경향이 있을 장면 내의 객체 또는 구역을 예측한다. 시각 주의 모듈(403)은 시각 주의 강건성 평가 시스템(402)의 일부로서 도 6에 도시되어 있지만, 다른 실시 형태에서의 시각 주의 모듈(403)은 독립형 컴퓨터 프로세스로서 동작하거나 심지어 원격 컴퓨터에서 (월드 와이드 웹과 같은) 임의의 타입의 컴퓨터 네트워크를 통해 제공되는 서비스로서 동작한다.
VAM 수정 모듈(404)은 시각 주의 모듈 수정 모듈이다. VAM 수정 모듈(404)은 시각 주의 모듈의 파라미터 또는 아키텍처의 양태들을 수정한다. 이 수정은 시각 주의 모듈(403)의 구현에 따라 많은 방식으로 달성될 수 있다. 예를 들어, 시각 주의 모듈(403)은 그 자체가 시각 주의 모듈이 어떻게 작용하는지에 대한 양태들을 수정하는 함수 호출들을 지원할 수 있다. 일 실시 형태에서, 시각 주의 모듈(403)은 장면의 소정 양태들(예를 들어, 밝기(brightness))에 주어지는 가중치를 수정하는 함수 호출을 지원할 수 있다. 다른 실시 형태에서, 시각 주의 모듈이 커맨드 라인을 통해 실행되면, 다양한 스위치가 시각 주의 모듈 내의 변수들을 변경하도록 채용될 수 있다. 대안적으로, 시각 주의 모듈(403)이 스크립트 또는 프로그래밍 코드로 구현되면, IE 수정 모듈이 스크립트 또는 프로그래밍 코드 자체를 수정할 수 있다. 다른 실시 형태에서, 전체 시각 주의 모델이 다른 시각 주의 모델에 의해 교체된다. VAM 수정 모듈(404)이 시각 주의 모듈(403)의 기본적인 시각 주의 모델(또는 이러한 모델의 장면으로의 적용)을 수정하는 특정 방식은 이하 상세히 논의되지만, 일례는 현저성 지도를 생성하는 데 사용되는 복수의 특징 지도와 연관된 가중치를 수정하는 것일 수 있다. 이는 이들 값을 허용가능한 값들의 분포에 기초하여 수정할 함수 호출을 통해 달성될 수 있다.
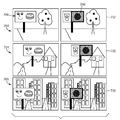
장면 수정 모듈(405)은 분석을 위해 시각 주의 모듈(403)에 제공될 장면을 수정한다. 장면 변경은 환경의 역동적 속성을 시뮬레이션하는 외적 환경과 연관된 변경이다. 그러한 외적 가변성은, 예를 들어 장면 내에서의 객체 이동(예를 들어, 보행자의 배치), 조명 방향의 변경으로 인한 음영의 변경, 또는 대기 조건의 변경(예를 들어, 공기 중의 먼지)을 포함할 수 있다. 이 가변성은 다수의 방식으로 발생할 수 있다. 한 가지 방법은 장면 내에 카메라를 배치하고 상이한 시간에 이미지를 포착하는 것이다. 이는 현실 장면의 자연적 가변성을 포착할 것이다. 다른 방법은 장면의 단일 이미지를 포착하고, 그 장면 내의 개별 요소들 및 객체들에 대해 이루어질 수 있는 가능한 변경을 명시하는 것이다. 이러한 기술의 예시가 도 7에 도시되어 있다. 장면(801)은 원본 장면의 표현이다. 장면(802)은 음영과 같은 장면 가변성 요소들로 교체된 장면(801)으로부터의 객체 및 다른 객체(예를 들어, 자동차 또는 새 - 장면 내에서 교체될 수 있는 임의의 객체)를 도시한다. 장면(803, 804, 805, 806)은 원본 장면(801)과 장면 가변성 요소들과의 여러 조합을 도시한다. 당업자는 미국 캘리포니아주 새너제이 소재의 어도비 시스템즈(Adobe Systems)에 의해 "포토샵(Photoshop)"이라는 상표명으로 시판되는 것과 같은 구매가능한 이미지 편집 소프트웨어를 사용하는 것과 같이, 장면을 수정하는 무수한 상이한 접근법이 있다는 것을 이해할 것이다. 본 명세서에서는 단지 몇 가지만이 비제한적인 예로서 제시되었다.
장면 수정 모듈(405)은 장면에 외적 가변성을 추가하며, 이는 이어서 다수의 버전의 장면 또는 장면 인스턴스(scene instance)들을 생성할 것이다. 장면 인스턴스들의 집합은 일 실시 형태에서 장면 내의 가변성을 포착한다. 객체의 강건성 또는 장면의 강건성을 측정하기 위해, 각각의 장면 인스턴스는 시각 주의가 각각의 장면 인스턴스 내에서 어디에 할당될 것인지(즉, 어떤 객체가 할당될 것인지)에 관한 예측을 생성하도록 시각 주의 모듈(403)에 제공된다. 각각의 런(run)에 관한 정보는 데이터베이스(407)에 저장되고, 그 후에 강건성 평가 모듈(409)이 데이터를 평가하여 주의가 이들 상이한 인스턴스에 걸쳐 할당될 것으로(그리고 이전에 더 상세히 설명된 바와 같이) 모델이 예측한 객체들에 기초하여 통계치를 생성한다.
그래픽 사용자 인터페이스 모듈(406)은 사용자(401)와의 상호 작용을 용이하게 한다. 그래픽 사용자 인터페이스 모듈(406)은, 예를 들어 그래픽 사용자 인터페이스를 구축하여 사용자(401)로부터의 입력을 권유할 것을 (컴퓨터 시스템(408)으로부터) 운영 체제 리소스로 요청할 수 있다. 일 실시 형태에서의 이러한 입력은 시각 주의 강건성 평가 시스템에 대한 다른 운영 파라미터뿐만 아니라 장면의 위치를 포함한다. 이 입력은 일 실시 형태에서 사용자(401)가 평가에 관심을 갖는 장면 내의 영역들 및/또는 위치들을 명시할 것이다. 이러한 위치들을 명시하는 것에 부가하여, 사용자(401)는 어떤 타입의 가변성이 시각 주의 모듈(403)에 의해 고려될 것인지를 명시할 수 있다. 이는 일반적 또는 특정 내적 가변성, 또는 일반적 또는 특정 외적 가변성을 포함할 수 있다. 예를 들어, 한 가지 특정 타입의 외적 가변성은 조명 방향의 변동으로 인해 이미지를 변경하는 것일 수 있다. 광이 변경됨에 따라, 생성된 음영이 변경될 것이다. 이는, 동적 객체, 대기 수차(atmospheric aberration) 등과 같은 다른 인자를 고려하지 않기 때문에 특정 타입의 외적 가변성이다. 일반적 내적 가변성의 예는 각각의 특징 지도에 대한 가중치가 독립적으로 변동하도록 허용되는 조건일 것이다. 특정 내적 가변성의 예는 특징 지도들의 하나의 세트의 가중치가 변동할 수 있지만(예를 들어, 밝기) 다른 것들은 변동하지 않는 경우이다. 그래픽 사용자 인터페이스 모듈(406)은 또한 장면의 이미지들이 어디에서 획득되어야 하는지에 관한 입력을, 가능하게는 사용자로부터, 용이하게 얻게 한다. 가능한 위치들은, 예를 들어 데이터베이스 또는 플랫 파일(flat file)을 포함한다.
강건성 평가 모듈(409)은 장면 내의 객체들의 강건성 또는 장면 자체의 강건성을 평가하기 위해 다른 모듈의 상호 작용을 제어한다. 예를 들어, 강건성 평가 모듈(409)은, VAM 수정 모듈(404) 및 장면 수정 모듈(405)뿐만 아니라 필요에 따라 시각 주의 모듈(403)을 실행시킨다. 강건성 평가 모듈(409)이 다양한 모듈을 실행시키는 방식은, 예를 들어 그래픽 사용자 인터페이스 모듈(406)을 통해 강건성 평가 모듈(409)에 제공되는, 사용자(401)로부터의 입력에 의해 수정될 수 있다. 강건성 평가 모듈(409)은 또한 다른 모듈에 의해 제공되는 데이터를 평가하며, 필요에 따라 리포트를 생성한다.
데이터베이스(407)는 시각 주의 강건성 평가 시스템(402)의 데이터 저장 요구를 처리한다. 특히, 데이터베이스(407)는 장면의 이미지들을 보유할 수 있다. 데이터베이스(407)는 임의의 컴퓨터 메모리일 수 있다. 이는 랜덤 액세스 메모리(random access memory), 또는 플랫 파일, 또는 하나 이상의 데이터베이스 서버를 실행시키는 하나 이상의 데이터베이스 관리 시스템(DBMS)일 수 있다. 데이터베이스 관리 시스템은 관계형(RDBMS), 계층형(HDBMS), 다차원형(MDBMS), 객체 지향형(ODBMS 또는 OODBMS), 또는 객체 관계형(ORDBMS) 데이터베이스 관리 시스템일 수 있다. 데이터베이스(407)는, 예를 들어 마이크로소프트 코포레이션(Microsoft Corporation)오로부터의 SQL 서버와 같은 단일 관계형 데이터베이스일 수 있다.
사용자(401)는 시각 주의 강건성 평가 시스템의 임의의 사용자이다. 몇몇 실시 형태에서, 시각 주의 강건성 평가 시스템(402)은 시각적 현저성 이론에 친숙하지 않은 사람이 시스템을 사용하여 객체, 영역 또는 장면의 강건성을 평가할 수 있도록 사용하기에 충분히 쉽다. 사용자(401)는 간판(sign) 및 비-간판(non-sign) 객체의 그들의 환경 내에서의 위치설정을 평가하기 위해 상업적 엔티티(commercial entity)에 의해 고용된 컨설턴트 또는 상업적 엔티티를 위해 일하는 피고용자일 수 있다. 사용자(401)는 또한 페이지의 시각적 특성이 변경될 수 있는 웹 페이지 상의 (광고와 같은) 디지털 객체의 디자인 및 배치를 평가하는 데 관심을 갖는 콘텐트 디자이너일 수 있다.
도 8은 웹 서버 모듈(501)을 추가로 포함하는 시각 주의 강건성 평가 시스템의 대안적인 실시 형태를 도시한다. 웹 서버 모듈(501)은, 편의상, 시각 주의 강건성 평가 시스템(402)의 일부로서 도시되어 있다. 그러나, 웹 서버 모듈은 컴퓨터 시스템(408)에서 구동하는 소프트웨어 모듈로서 별도의 메모리 공간에 구현될 수 있다. 또는, 웹 서버 모듈(501)은 네트워크를 통해 시각 주의 강건성 평가 시스템(402)에 결합된 별도의 컴퓨터 시스템 상에 있는 것일 수 있다.
웹 서버 모듈(501)은 사용자(401)가 클라이언트 컴퓨터(503) 및 네트워크(502)를 통해 시각 주의 강건성 평가 시스템(402)과 통신할 수 있게 하는 인터페이스를 제공한다. 하나의 구성에서, 웹 모듈(501)은 미국 워싱턴주 레드몬드 소재의 마이크로소프트 코포레이션으로부터의 인터넷 인포메이션 서버(Internet Information Server)와 같은 웹 서버 소프트웨어를 실행시킨다. 웹 서버 모듈(501)은, 예를 들어 액티브 서버 페이지(Active Server Page), 하이퍼텍스트 마크업 언어(hypertext markup language, HTML) 또는 동적 HTML로 작성된 웹 페이지, 액티브 X 모듈, 로터스 스크립트(Lotus script), 자바 스크립트(Java script), 자바 애플릿(Java Applet), 분산 구성요소 객체 모듈(Distributed Component Object Module, DCOM) 등의 사용을 통해 원격 사용자(401)와 상호 작용하기 위한 메커니즘을 제공한다.
컴퓨터 시스템(408)에 의해 제공되는 운영 환경 내에서 실행하는 "서버측" 소프트웨어 모듈로서 예시되어 있지만, 시각 주의 강건성 평가 시스템(402)을 포함하는 기능 모듈은, 사용자(401)에 의해 사용되는 바와 같이, 클라이언트 컴퓨터(503)와 같은 컴퓨팅 장치 상에서 실행시키는 "클라이언트측" 소프트웨어 모듈로서 용이하게 구현될 수 있다. 시각 주의 강건성 평가 시스템(402)은, 예를 들어 클라이언트 컴퓨터(503) 상에서 실행하는 웹 브라우저에 의해 실행되는 액티브 X 모듈로서 구현될 수 있다.
네트워크(502)는 임의의 종류의 네트워크, 즉 공공망 또는 사설망일 수 있다. 일 실시 형태에서, 네트워크(502)는 인터넷이다.
도 7 및 도 8의 사용자(401)는 인터넷의 임의의 사용자일 수 있다. 일 실시 형태에서, 사용자(401)는 라이센스(license)를 통해 시각 주의 강건성 평가 시스템의 기능성에 액세스하도록 사전 구성되었을 수 있다.
도 9는 시각 주의 강건성 평가 시스템(402)이 장면 내의 객체 또는 장면 자체의 강건성을 평가하도록 이용될 수 있는 프로세스의 일 실시 형태를 예시하는 고-레벨 흐름도이다. 먼저, 시각 주의 모듈이 실행되고 장면 입력을 제공받는다(단계 601). 이어서, 장면 내에서부터의 예측된 객체들이 시각 주의 모듈로부터 수신된다(단계 602). 다음, 모델이 높은 상대적 현저성을 갖는 것으로 예측하는 위치/객체/영역의 일부 표시가 데이터베이스에 저장된다(단계 603). 정확히 말해, 데이터베이스에 저장되는 것은, 단계 602에서 시각 주의 모듈로부터 수신되는 출력 타입에 크게 의존한다. 데이터베이스는, 일 실시 형태에서, 임계 현저성 값에 도달한 객체들에 관한 정보를 저장한다. 다른 실시 형태에서, 데이터베이스는 이미지에서 각각의 객체에 대해 하나씩 식별되는 값들의 매트릭스를 저장하고, 예를 들어 객체가 임계 현저성 값에 도달한 횟수를 저장한다. 다음, 프로세스가 완료되었는지를 알기 위한 검사가 이루어진다(단계 605). 일 실시 형태에서, 이 검사는 현재의 반복과정이 사용자(401)에 의해 초기에 설정된 반복과정의 횟수를 초과하는지를 결정할 수 있다. 다른 실시 형태에서, 반복과정의 횟수는 알고리즘에 의해 결정될 수 있다. 또 다른 실시 형태에서, 반복과정의 횟수는 장면의 특성에 의해 또는 강건성 척도에 관한 통계치에 의해 결정될 수 있다. 예를 들어, 2개의 광고 중 어떤 것이 특정 사이트에 더 좋을 것인지를 결정하고자 한다면, 2개의 광고의 강건성 값들 사이에 통계적으로 신뢰할 수 있는 효과가 있을 때까지 알고리즘을 구동할 수 있다.
강건성 평가가 완료되지 않았다면(단계 605에서 "아니오"), IE 변경이 시각 주의 모듈의 시각 주의 모델 또는 장면 입력 내에 도입될 것이다. IE 변경은 2개의 카테고리, 즉 구조적 및 랜덤으로 나뉠 수 있다. 랜덤 가변성은 상관되지 않는 가변성이다. 예를 들어, 장면에서의 랜덤 가변성은 개별 픽셀 컬러 및/또는 세기의 랜덤 변동을 포함할 수 있다. 이러한 경우, 픽셀 변동은 상관되지 않는다. 대조적으로, 구조적 가변성은 수정되는 요소들 사이에 상관성을 갖는다. 예를 들어, 장면 내의 객체의 움직임을 시뮬레이션하거나 장면 내의 개체를 추가 또는 제거함으로써 수정된 장면은 구조적 장면 가변성을 구성할 것이다. 이러한 경우, 픽셀 수정에서의 변경은 상관된다. 랜덤 내적 변동은 시각 주의 모듈에 의해 사용되는 주의 모델에서의 랜덤 변동을 포함할 수 있다. 반면, 구조적 가변성은 다른 부분보다 주의 지도의 한 부분에서의 주의를 위한 프로그램 바이어스(programmatic bias)일 수 있다. 가변성을 생성하는 타입의 방법이 표 1에 요약되어 있다. IE 변경을 도입하는 서브-프로세스는 이하 추가로 상술된다.
일단 IE 변경이 이루어지면, 프로세스는 단계 601로 되돌아간다.
일단 프로세스가 완료되면(단계 605에서 "예"), 시각 주의 모듈에 의해 예측되는 객체들이 연속적 반복과정에서 어떻게 그리고 어느 정도로 변경되었는지에 대한 분석이 이루어진다(단계 606). 이 분석은 이하 추가로 설명된다.
마지막으로, 강건성을 나타내는 출력이 생성된다(단계 607). 일 실시 형태에서, 이 출력은 그래픽 사용자 인터페이스 모듈(406)을 통해 사용자에게 제공된다. 그러나, 출력은 또한 다른 형태, 예를 들면 다른 프로그램 또는 호출 함수로 제공될 수 있다.
시각 주의 모델에 대한 변경(CHANGES TO THE VISUAL ATTENTION MODEL)
시각 주의 모델을 수정하는 일례(상기 논의된 도 9의 단계 604에서 도입될 수 있는 타입의 변경)는 장면 내의 특정 특징 또는 장면 내의 특정 구역을 향하는 바이어스를 프로그램적으로 도입하는 것이다. 시각 주의 모델에 대한 이러한 가변성은 주의가 할당 될 곳에 대해 영향을 미칠 것이고, 관찰자들 사이의 가변성 및/또는 시간에 따라 장면을 경험하는 인간 관찰자들 사이의 가변성을 시뮬레이션할 것이다. 일례로서, 장면의 시각 주의 강건성을 평가하는 데 잇티 및 코흐 상향식 시각적 현저성 모델을 사용할 수 있다. 이러한 모델을 이용하여, 현저성 "지도"는 상이한 시각적 특징 지도들로부터의 입력을 조합함으로써 생성된다. 예를 들어, 일부 사례에서, 3개의 특징 지도들, 즉 컬러에 민감한 첫 번째의 특징 지도, 방향에 민감한 두 번째의 특징 지도, 및 휘도와 연관된 세 번째의 특징 지도가 있다. 현저성 지도로의 입력은 이들 3개의 지도의 가중된 조합이다. 전형적으로, 이들 3개의 지도는 다른 타입에 비해 한 가지 타입의 특징에 대한 어떠한 바이어스도 없음을 나타내는 현저성 지도 내로 동일한 가중치들을 가지며, 가중화 벡터로서 표현(예를 들어, 3개의 특징 지도의 동일한 가중치에 대해 [1 1 1])될 수 있다. 관찰자의 바이어스에서의 가변성을 생성하는 한 가지 방법은 다른 특징보다 하나의 특징을 향해 바이어싱될 수 있는 뷰어(viewer)를 시뮬레이션하는 그러한 가중치들을 수정하는 것이다. 예를 들어, 가중치를 [0.5 0.5 2]로 설정함으로써 환경 내의 보다 밝은 아이템을 향해 모델을 바이어싱할 수 있다. 내적 가변성을 생성(또는 뷰어 가변성을 시뮬레이션)하는 한 가지 방법은 상이한 가중치 값들을 갖는 모델들의 집합을 생성하는 것이다. 이것은 각각의 모델에 대한 값들을 랜덤하게 설정함으로써 이루어질 수 있다.
다른 접근법은 모델의 내적 장면 표현을 랜덤하게 수정하는 것이다. 예를 들어, 인간 시각 체계의 뉴런은 그들의 활성화가 심지어 동일한 이미지의 표현에 따라서도 변동할 것이라는 점에서 다소 노이즈가 있다(noisy). 이 가변성을 시뮬레이션하는 것은 시각 주의 모델이 개발한 개별 특징 지도들과 연관된 값들의 내적 표현(예를 들어, 컬러, 형상, 배향, 밝기)을 장면에 대한 응답으로 섭동(perturb)시킴으로써 이루어질 수 있다.
다른 방법은 이미지에서 가장 현저한 영역들을 식별하는 데 사용되는 현저성 지도의 값들을 섭동시키는 것이다. 예를 들면, 각각의 고정성 계산에 이어 내적 표현을 섭동시키거나 장면이 제시될 때마다 값들을 독립적으로 섭동시킬 수 있다.
장면에 대한 변경(CHANGES TO THE SCENE)
장면은, 장면의 특성이 변동되는 기존의 장면에 기초하여, 그래픽 편집기(예컨대, 포토샵), 장면의 3D 표현(예를 들어, 가상 현실 모델), 또는 비디오(또한, 본 명세서에서 모두 집합적으로 "장면"으로 불림)를 사용하여 새로운 이미지를 생성함으로써 변경된다. 예를 들어, 이러한 변동된 특성은 시뮬레이션된(또는 실제의) 조명 변경, 또는 객체들(현실 또는 가상)의 신규 추가 또는 제거, 또는 픽셀 컬러의 랜덤 변화를 포함할 수 있다.
장면을 변경하기 위한 많은 상이한 방식이 있다. 이루어질 외적 변경을 결정하는 것은 상황에 따라 변할 수 있다. 장면에 이루어지는 변경의 타입을 결정하기 위한 한 가지 방법은, 장면 내에서 전형적으로 일어나고 그러한 변경들을 분석되는 이미지들에 도입하는 장면 가변성의 타입을 결정하는 것이다. 예를 들면, 호텔 로비에서, 사람들은 장면 전체에 걸쳐 움직이고 있을 것이다. 때로는 손님들이 카운터에 서 있을 것이고, 때로는 엘리베이터에 서 있을 것이며, 또는 한 장소에서 다른 장소로 걷고 있을 것이다. 이들 상황을 시뮬레이션하는 것은 실제 장면에서의 가변성을 포착하기 위한 방법을 제공한다.
외적 가변성이 장면에 추가되는 정도를 변동 및/또는 측정하기를 원할 수 있다. 외적 가변성의 정도를 정량화하는 한 가지 방법은 장면에서 조작되는 객체들의 수를 변동시키는 것이다. 예를 들어, 보행자가 있는 호텔 로비의 예로 되돌아가서, 장면에서 보행자의 수를 변동시킬 수 있다. 소수의 보행자는 작은 양의 가변성으로 변환될 것이고, 반면에 다수의 보행자는 큰 가변성으로 변환될 것이다. 가변성을 측정하기 위한 다른 방법은 생성되는 모든 이미지에 대한 픽셀 변동을 측정하는 것이다. 픽셀 가변성의 한 가지 예시적인 척도는 생성되는 이미지들의 세트에 대해 각각의 픽셀의 평균 분산을 측정하는 것이다. 일단 각각의 픽셀의 가변성이 계산되면, 모든 픽셀의 평균 분산을 계산함으로써 하나의 수가 생성될 수 있다. 또한, 이미지의 가변성이 증가함에 따라, 이 값이 또한 증가할 것이다.
변경을 생성하기 위한 한 가지 방법은 미국 새너제이 소재의 어도비 시스템즈 인크.에 의해 "포토샵"이라는 상표명으로 시판되는 것과 같은 구매가능한 이미지 편집 소프트웨어를 사용하여 이미지를 디지털 방식으로 수정함으로써 이미지에 대한 변경을 이루어 내는 것이다. 이 방법을 사용하여, 디지털 방식으로 객체들을 배치하거나, 객체들을 제거하거나, 조명 변경을 시뮬레이션함으로써 장면을 수정할 수 있다. 그러면, 이들 변경은 모델에 의해 판독 및 분석될 이미지들의 집합으로 변환될 것이다. 이들 변경은 또한 알고리즘적으로 레이어들을 이미지 상에 겹쳐 놓음으로써 이미지들에 자동으로 적용될 수 있다.
외적 구조적 가변성을 생성하기 위한 다른 방법은 장면의 가상 표현을 생성하는 것이다. 이 접근법을 사용하여, 객체들의 위치들, 객체 특성들 및 조명 조건들을 용이하게 수정할 수 있다. 이들 가상 표현으로부터, 객체들, 그들의 특성들, 그들의 자세들 및 조명 조건들이 변경된 이미지들이 생성될 수 있다.
지금까지, 장면을 변경하는 접근법들은 "합성(synthetic)"인 것으로 말할 수 있다 - 즉, 그들은 장면 자체보다는 장면의 표현에 대한 변경이다. 장면을 수정하는 다른 접근법은 실제 장면을 수정하는 것이다. 예를 들면, 일련의 시간-지연 이미지들(예를 들어, 정의된 주기 동안 매 300초마다 하나의 사진)을 취할 수 있다. 그러면, 이 일련의 사진들은 시각 주의 강건성 평가 시스템의 연속적 반복과정에 사용될 수 있다. 이러한 분석(시간에 걸친 다수의 이미지)은 외적 구조 가변성의 척도를 제공할 것이다. 또한, 이러한 가변성(예를 들어, 태양의 위치 변경으로 인한 조명 방향의 변경과 함께, 움직이는 사람 및 객체)이 주어지면, 주의가 전형적으로 환경 내에서 어디에 할당될 것인지를 분석할 수 있다.
외적 및 내적 가변성을 "맹목적으로(blindly)" 추가하는 것에 부가하여, 장면에서 상이한 객체들의 시각적 현저성에 의존하는 가변성을 또한 도입할 수 있다. 예를 들어, 주의가 할당되는 곳의 가변성의 정도를 감소시키고, 주의가 할당되지 않는 그러한 영역들에 대해 가변성의 정도를 증가시키기를 원할 수 있다.
강건성 평가(EVALUATING ROBUSTNESS)
"열 지도"의 그래픽 표현, 내적 엔트로피 값, 강건성 지수(index), 또는 강건성 값을 사용하는 것과 같은, 장면의 강건성을 특성화하는 다수의 방법이 있다. 각각의 반복과정에 대해 몇몇 타입의 IE 변경을 적용하면서, 시각 주의 모델을 장면에 반복적으로 적용하는 것으로부터의 통합 결과들을 요약하는 한 가지 기본적인 접근법은 장면의 표현 상에 오버레이되는 관련 값들 또는 영역들의 그래픽 표현을 생성하는 것이다. 이러한 접근법은 열 지도에 유사한 무엇인가를 산출하며, "보다 밝은" 객체들은 해당 가변성에 대해 더욱 강건하다.
시각 주의 모델이 예측한 객체들에 대한 노이즈의 효과를 평가하는 것에 부가하여, 강건성을 평가하기 위한 다른 방법은 모델의 장면의 내적 표현의 가변성을 측정하는 것이다. 예를 들어, 잇티 및 코흐 모델은 시각 주의가 할당될 위치들을 결정하는 데 내적 "현저성 지도" 표현을 사용한다. IE 변경들의 함수로서의 현저성 지도의 이러한 내적 표현에서는, 변경의 양 또는 엔트로피를 강건성에 대한 기준(metric)으로서 측정할 수 있다(그러나 유일한 방법은 아님). 또한, 개별 특징 지도들의 응답들, 또는 IE 변경들의 효과를 측정하도록 하는 시각 주의 모델의 다른 내적 표현을 살펴볼 수 있다.
강건성 기준을 생성하기 위한 다른 방법은 IE 변경들을 파라미터화하는 경우이다. 이는, 예를 들어 랜덤 휘도 노이즈를 장면에 추가(그에 따라, 이미지 내의 휘도 에너지에 대해 노이즈의 휘도 에너지를 수정함으로써 노이즈의 양을 변경)하는 경우일 것이다. 또는, 시각 주의 모델의 연결 가중치(connection weight)들의 가변성을 증가시키고 엔트로피의 측정치로서 변경 정도를 특성화시킬 수 있다. 객체, 객체들의 그룹, 또는 장면의 강건성을 특성화하기 위한 다른 방법은 이들 객체들이 그들의 시각적 현저성 계층을 유지하면서 허용할 수 있는 노이즈의 양을 결정하는 것이다. 이러한 기준을 위한 방법은 생성된 가변성의 양의 함수로서 객체가 주의될 가능성을 측정하는 것이다. 매우 강건한 이들 객체 및/또는 장면은, 주의가 노이즈 요소들에는 끌리기 시작하지만 객체들/영역들에는 그렇지 않게 되기 전에 다량의 노이즈를 허용할 것이다. 그 결과의 기준은, 주의가 객체로부터 노이즈를 향해 돌려지기 전에 객체가 허용할 수 있는 노이즈의 레벨일 것이다.
도 4는 객체에 주의할 확률 대 2개의 객체들, 즉 낮은 노이즈 허용오차(낮은 강건성 값)를 갖는 제1 객체(451) 및 높은 노이즈 허용오차(높은 강건성 값)를 갖는 제2 객체(452)에 대한 가변성 정도를 도시하는 그래프이다. 그래프는 주의가 각각 상이한 각자의 강건성 지수를 갖는 객체(451) 및 객체(452)에 할당될 것인지에 대한 가변성의 효과를 도시한다. 이러한 예에서, 작은 양의 가변성을 추가하는 것은, 주의가 객체(451)에 할당될 것이라고 모델이 예측할 확률에 현저하게 영향을 미친다. 이는 작은 양의 가변성만을 갖는 확률 저하에 의해 도 4에 예시된다. 대조적으로, 객체(452)는 작은 양의 가변성에 의해서는 영향받지 않는다. 이는 훨씬 큰 레벨의 가변성에 따라 일어날 "드롭-오프(Drop-off)" 지점에 의해 예시된다. 이러한 "드롭-오프" 지점을 측정함으로써, 강건성 지수와 관련하여, 장면 내의 상이한 객체들을 정량화할 수 있다.
바로 위에서 설명된 열 지도 접근법보다는, 또는 그에 부가하여, 때때로 장면 내의 특정 객체(또는 복수의 객체)의 강건성을 정량화하는 것은 유용할 수 있다. 이러한 정량화는 장면 내의 특정 객체의 현저성 정도를 감소시키기 시작하는 IE 변경들의 정도(또는 강건성 지수 값)를 결정하는 것과 같은 후속 분석을 허용할 수 있다.
또한, 장면 자체의 강건성을 평가 및/또는 정량화하는 것이 때때로 유용할 수 있다. 객체와 장면 강건성 사이의 이러한 구별은 많은 타입의 흥미로운 후속 분석에 대해 편의를 제공한다. 예를 들면, 장면이 낮은 강건성 값을 갖고(즉, 모델이 시각 주의를 받을 것으로 예측한 객체들의 세트가 IE 변경들의 함수로서 변동함), 반면에 그 장면 내의 객체는 높은 강건성 값을 갖는다는 것이 가능하다. "높은" 객체 강건성 값 및 "낮은" 장면 강건성 값의 예는, 예를 들어 타깃 객체가 항상 상측의 3개의 주의 고정성에 있지만, 고려되는 다른 객체들은 상당히 변동하는 경우일 것이다.
표 2는 타깃 객체가 낮은 강건성 값 및 높은 강건성 값을 갖는 장면들과 교차되는 높은 강건성 값 및 낮은 강건성 값을 갖는 예시적 데이터를 제공한다. 이 표에서는, 이하 강건성 값으로 불리는 표준화된 가능성 값이 각각의 객체에 대해 계산되는 하나의 가능한 강건성 기준이 도시되어 있다. 각각의 장면에 대해, 좌측 컬럼은 IE 변경들이 있을 때 객체가 처음 3개의 단속성(saccade)에 나타난 시간의 비율을 나타낸다. 표 2에 도시된 예에서, 장면 내에 14개의 객체들, 즉 하나의 타깃 객체와, 현저성을 갖는 비-타깃 객체들 또는 영역들인 13개의 주의 분산체(distractor)가 있다. 모델이 3개의 객체를 랜덤하게 선택하였다면, 각각의 객체는 21.42%의 선택 기회(3 x 1/14=0.2142)를 가질 것이다. 이는 객체 및/또는 장면의 강건성이 매우 적은 조건일 것이며, 그에 따라 그것은 장면의 강건성을 비교하게 하는 중요한 기준선(baseline)으로서 역할한다. 이는, 확률이 기회의 확률에 접근함에 따라 강건성이 하락하기 때문이다. 이러한 예에서, 강건성 값은 수학적으로 % 선택 기회로 나눈 % 주의이며, 따라서 4.6667 = 100%/21.42%의 제1 강건성 값이다. 장면에 대한 강건성 값을 계산하는 한 가지 방법은 상측 K개의 객체들에 대한 평균 강건성 값(주의 선택들의 수)을 계산하는 것이다. 하측에서, 표 2는 상측 3개의 객체에 대한 평균 강건성 값이다.
표 2는 객체들에 의해 주의가 할당되는 위치들을 분류하고 있다. 그러나, 이전에 언급된 바와 같이, 객체라는 용어는 이미지(또는 장면)에서 영역 또는 구역으로서 막연하게 정의된다. 그러나, 본 명세서에 설명되는 방법 및 시스템은 객체-기반 접근법으로 제한되지 않는다 - 다른 유사한 접근법들이 또한 작용할 것이다. 예를 들어, 동일한 크기 영역들의 그리드(grid)가 장면, 또는 인간 시각 체계의 특성(예를 들어, 뷰어의 중심와(fovea)의 크기)에 기초하여 정의된 장면의 영역들에 걸쳐 정의될 수 있다.
장면에 걸친 강건성 평가(ASSESSING ACROSS SCENE ROBUSTNESS)
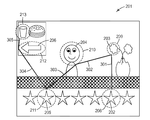
객체 또는 장면의 강건성을 평가하기 위한 상기의 방법이 주어지면, 다음에는, 다른 방식으로 강건성의 평가를 확장하는 것이 가능하다. 예를 들어, "장면에 걸친 강건성(across scene robustness)"은 객체(또는 객체들의 그룹)의 강건성이 상이한 장면들에 걸쳐 어떻게 변경되는지의 척도이다. 장면과는 별도로, (상기 논의된 바와 같이) 객체에 대한 강건성 기준을 제공함으로써, 상이한 장면들에서 특정 객체의 강건성을 평가할 수 있다. 예를 들어, 3개의 상이한 장면에 있는 3개의 상이한 게시판 간판(billboard sign) 상에 배치될 두 편의 상이한 광고 콘텐트 사이에서 광고주가 결정하고 있는 상황을 고려하자. 도 5는 이러한 시나리오의 예의 예시를 제공한다. 장면(703)은 게시판(700)을 포함한다. 게시판(700)은 장면(704, 705)에서 반복된다. 유사하게, 게시판(706)은 장면(707, 708, 709)에서 보인다.
앞서 설명된 방법을 사용하여(예를 들어, 장면의 그래픽 표현에서 광고 콘텐트를 겹쳐 놓음), 3개의 장면들 각각에서 각각의 게시판에 대한 강건성 값을 결정할 수 있다 - 6개의 상이한 객체 강건성 값을 생성할 수 있다. 그러면, 고객은 최고 평균 강건성 값(또는 강건성 값들의 집합에 기초한 다른 기준)을 갖는 광고(객체)를 선택할 수 있다.
또한, 객체들의 세트를 가질 때 유사한 분석을 이용할 수 있지만, 객체 또는 객체들을 배치할 장면들의 세트로부터 선택할 필요가 있다. 게시판 광고의 예로 계속하면, 고객은 그들이 3개의 상이한 장면 중 2개의 장면에 배치하기를 원하는 단일 광고를 가질 수 있다. 3개의 상이한 장면에서 각각의 광고에 대한 강건성 값을 생성하는 데 사용될 수 있는 디지털 이미지들을 생성하기 위해 전술된 기술을 채용할 수 있다. 장면 선택을 용이하게 하기 위해, 고객은 최고 강건성 값들을 갖는 2개의 장면을 (장면 내에서 겹쳐지는 광고와 함께) 선택할 수 있다.
장면들의 고정된 세트에 대한 객체들의 집합으로부터 단일 객체(예를 들어, 광고 게시판)를 선택하거나 단일 객체에 대한 (장면들의 집합으로부터의) 장면들의 세트를 선택하는 것에 부가하여, 강건성 값에 기초하여 객체들을 특정 장면들에 또한 할당할 수 있다. 예를 들어, 고객은 개선된 3개의 상이한 광고들(게시판 상에 배치되는 콘텐트) 및 이들 간판들이 배치될 수 있는 20개의 상이한 게시판을 가질 수 있다. 20개의 장면에 배치되는 3개의 광고 각각에 대한 강건성 값들을 생성함으로써, 고객은 이어서 각각의 개별 장면에 대한 최고 강건성 값을 갖는 광고를 사용할 것을 선택할 수 있다. 또한, 최상의 광고들을 최고 강건성 값을 갖는 10개의 장면에 할당할 수 있다.
이와 같은 예들은 게시판 및 광고와 관련하여 이루어지는 선택을 개선하는 데 강건성 기준이 어떻게 사용될 수 있는지를 예시하고 있지만, 강건성 기준의 이점은 이러한 영역(domain)으로 제한되지 않으며, 상점 또는 호텔 내의 디지털 간판, 정적 간판(static sign), 제품 간판, 제품 패키징 구성, 또는 웹 사이트와 같이, 이들 간에 선택할 콘텍스트들(장면들)의 집합 및 시각적 자극들(객체들)의 집합을 갖는 임의의 영역에서 사용될 수 있다.
본 명세서에 설명되는, 장면 내의 객체들의 강건성 또는 장면 자체의 강건성을 평가하기 위한 시스템 및 방법은 시각 주의를 결정하기 위해 임의의 특정 방법론에 의존하지 않는다는 것에 유의한다. 오히려, 이들은 일반적으로 시각 주의를 평가하기 위해 임의의 모델과 함께 사용될 수 있고, 일부 실시 형태에서는 다수의 상이한 시각 주의 모델이 객체 또는 장면의 강건성을 평가하는 데 사용될 수 있다.
강건성 및 주의 고정성 시퀀스(ROBUSTNESS AND ATTENTIONAL FIXATION SEQUENCE)
지금까지의 논의는, 주로 객체들이 주의되는 순서를 고려하지 않고 장면 내의 객체의 강건성 또는 그 장면 또는 그 장면 내의 객체들의 집합의 강건성에 중점을 두었다. 예를 들어, 주의가 객체에 할당되었는지 아닌지를 모델이 실제로 예측했는지의 여부만을 평가할 때까지 분석한다. 그러나, 요소들의 순서가 실제로 중요한 상황들이 있다. 예를 들어, 다중-객체 장면의 경우, 하나의 객체가 종종 어떻게 다른 객체 앞에 나타나는지 및 2개의 개별 객체로의 주의 사이에서 주의되는 개재하는 객체들(소위 개재 객체들)이 있는지를 알기 원할 수 있다.
가변성을 장면에 도입하는 것과 관련하여 전술된 방법들을 사용하여, 주의 고정성 시퀀스들의 집합이 이들에 이용가능하게 될 것이다. 이러한 데이터를 사용하여, 타깃 순서(예를 들어, 객체-B 앞의 객체-A에 주의함)가 얻어지는 모든 시퀀스를 식별할 수 있다. 시퀀스 강건성 분석은 시퀀스 타깃 강건성의 척도로서 타깃 시퀀스를 얻을 확률을 사용할 수 있다. 시퀀스 타깃 강건성을 측정하기 위한 한 가지 예시적인 방법은, 타깃 순서(즉, 객체-B 앞의 객체-A)가, 객체들을 랜덤하게 선택했다면 발생할 가능성을 계산하는 것이다. 시퀀스 타깃 강건성 값은 타깃 시퀀스가 얻어질 확률을 그것이 우연히 발생했을 가능성으로 나눈 것일 것이다. 이 기준 배후의 원리들은 전술된 강건성 값의 배후의 원리들과 유사하다.
주의의 상대적인 순서가 중요하지만 개재 객체들은 그렇지 않은 첫 번째 경우를 고려하자. 목적은, 예를 들면 회사가 레스토랑 근처에 있는 게시판 자체에 레스토랑의 저녁 특별 메뉴를 광고하고 있는 경우와 같이, 객체-B 앞의 객체-A로 주의가 끌리게 하는 것이다. 회사는 2개의 개별 광고에서 저녁 특별 메뉴를 고려하고 있을 수 있다. 목표는 지나는 사람들이 먼저 저녁 특별 메뉴에 주의를 기울이고 이어서 레스토랑 자체에 주의를 기울이게 하는 것이다. 전술된 방법(즉, 디지털 이미지에 디지털 방식으로 광고를 삽입하여, 그것들이 배치될 장면 내에 위치되는 바와 같이, 게시판에 있는 것처럼 나타나게 하는 것)을 사용하여 2개의 상이한 광고를 평가하고, 이어서 IE 변경들을 적용하면, 레스토랑 앞의 게시판이 얼마나 자주 시각 주의를 받는지를 계산할 수 있다. 표3 및 표 4는 객체-A 및 객체-B가 조금이라도 주의를 받았는지의 여부(객체-# 주의되지 않음)의 여부와 함께 객체-A 및 객체-B의 상대적 순서화를 나타내는 가능한 가능성을 제공한다. 이들 표로부터, 객체-B 앞의 객체-A는 광고 콘텐트-1을 갖는 시간의 65%를 점유하였지만 광고 콘텐트-2를 갖는 시간의 40%만을 점유하였다는 것을 알 수 있다. 따라서, 이러한 시퀀스가 중요했다면, 고객은 광고 콘텐트-1을 선택하도록 마음이 기울 수 있다.
강건성 및 다중-샘플 조건(ROBUSTNESS AND MULTI-SAMPLE CONDITIONS)
지금까지의 논의는 단일 위치로부터 객체를 관찰할 때에 중점에 두었다. 그러나, 세계는 매우 역동적이며, 때때로 관찰자는 공간 전체에 걸쳐 움직이고 있다. 관찰자가 공간 전체에 걸쳐 움직이고 있음에 따라, 관찰자는 특정 객체를 "처리"할 다수의 기회를 가질 수 있다. 그러나, 이러한 움직임은 객체가 가시적일 시간의 양 또는 고정성의 수가 변동할 수 있는 강건성 분석에 대한 다른 중요 양태를 생성한다. 이것을 가시성 지속기간 - 특정 장면 또는 객체가 관찰자에 의해 얼마나 오랫동안 가시적인가 - 이라고 지칭할 것이다. 가시성 지속기간을 포착하기 위한 한 가지 방법은 예측된 시퀀스의 시각 주의 위치들을 보고하는 모델을 사용하는 것에 의한 것이다. 이들 모델에 따라, 가시성 지속기간은 모델이 장면에 대한 강건성 평가를 고려하는 고정성의 수를 제한함으로써 명시될 수 있다(이는 또한 이하 논의되는 장면 최적화에 적용됨). 보다 긴 가시성 지속기간은 더 많은 고정성에 대응하며, 반면에 보다 짧은 가시성 지속기간은 더 적은 고정성에 대응할 것이다. 가시성 지속기간의 변경은 강건성 분석에 상당한 영향을 미칠 수 있다.
장면을 처리할 수 있는 고정성의 수가 제한될 때, 객체가 주의를 받을 것인지 아닌지의 여부는 그것이 시각 주의의 시퀀스에서 어디에 있는지에 의존할 것이다. 예를 들어, 고객은 호텔 내에 디지털 간판을 배치할 수 있다. 디지털 간판은 두 편의 콘텐트를 차례로 제시하고 있다. 한 편의 콘텐트는 3초 동안 제시되고 두 번째 것은 6초 동안 제시된다. 그 제한된 가시성 지속기간이 주어지면, 3초 분량 콘텐트는 6초 분량 콘텐트보다 더 빨리 주의의 시퀀스에 나타날 필요가 있다. 예를 들어, 사람이 초당 2회 고정성을 만들면, 모델은 주의가 처음 6회 고정성에서 객체에 끌릴 것을 예측해야 한다. 대조적으로, 6초 분량 콘텐트는 처음 12회 고정성에서 시각 주의를 받아야 한다. 이러한 역동성 및 이들과 유사한 기타의 사항들이 주어지면, 가시성 지속기간을 고려하지 않는 것은 장면에서 사람이 주의할 객체에 관한 부정확한 예측을 야기할 수 있다.
이를 예시하기 위해, 게시판 예를 확장할 것이다(그러나, 이 동일한 개념은 동적으로 변경되고 있는 임의의 디스플레이에 적용함). 도로를 따라 다수의 간판이 있는 긴 직선 도로를 고려하자. 또한, 도로는 평탄하고, 게시판 이외의 어떠한 다른 객체도 없다. 이러한 조건 하에서는, 모든 게시판이 동일한 가시성 지속기간을 가질 것이다. 즉, 시각 체계가 임의의 특정 게시판을 처리하는 시간의 양은 동일하며, 장면에서 자동차의 속도, 간판의 크기 및 임의의 대기 수차에 의해 결정될 것이다.
이제, 동일한 도로를 고려하되 이 도로 상에는 하나의 마지막 게시판 정면에 152.4 미터(500 피트)의 나무들의 열이 있다. 다른 모든 게시판은 동일한 가시성 지속기간을 가질 것이지만, 이 마지막 게시판은 보다 짧은 가시성 지속기간을 가질 것이다. 가시성 지속기간에서 이러한 변경이 주어지면, 모델이 강건성 평가를 고려할 고정성의 수를 제한하기 원할 것이다. 제1 세트의 게시판들은 매우 많은 수의 고정성을 가질 수 있지만, 마지막 게시판에 대한 지속기간을 고려할 때에는, 영화로부터의 보다 적은 프레임을 고려하거나 이미지에서의 보다 적은 고정성을 고려할 수 있다.
가시성 지속기간의 이러한 양태는, 장면 내에 다수의 객체가 있는 상황을 고려할 때 중요한 역할을 할 수 있다. 일부 조건 하에서, 객체들이 처리되기에(또는 주의를 포착하기에) 충분히 현저하지만 그들이 장면 내에서 다른 객체들에서 주의 분산될 정도로 현저하지는 않도록, 주의 포착 요소들을 분포시키기를 원할 수 있다. (주의: 이 개념은 또한 특정 목표를 달성하는 방식으로 장면을 수정하는 것과 관련되는 장면 최적화와도 관련된다. 장면 최적화는 이하 추가로 논의된다.) 이러한 조건이 주어지면, 객체, 객체들의 집합 또는 장면의 강건성을 분석할 때, 가시성 지속기간을 고려하길 원할 것이다. 예를 들어, 경로 상에서 짧은 가시성 지속기간을 갖는 객체의 경우, 현저성 요소들(예를 들어, 움직임, 밝기, 컬러 콘트라스트(contrast) 등)을 증가시켜 특정 객체가 그 짧은 가시성 지속기간 동안에 처리될 가능성을 증가시키기를 원할 수 있다. 그러나, 동일한 경로 상에서 가시적이지만 보다 긴 가시성 지속기간을 갖는 다른 객체의 경우, 그 객체를 처리할 보다 많은 기회가 있어서 그 객체에 보다 적은(또는 보다 약한) 현저성 요소들을 할당할 수 있다는 사실을 활용할 수 있다.
가시성 지속기간은 객체가 경로를 따라 어디에서든 시각 주의를 받았는지의 여부를 고려함으로써 강건성 분석에 대한 요인이 될 것이다. 이와 같이, 다른 것들보다 더 긴 가시성 지속기간을 갖는 특정 객체들은 그들과 연관된 더 많은 주의 고정성을 가질 것이며, 주의가 그 시퀀스를 따라 어디에서든 객체에 할당되었다면, "히트(hit)"로 간주될 것이다. 따라서, 보다 긴 가시성 지속기간을 갖는 객체들은 더 많은 샘플을 가질 것이며, 처리되는 보다 높은 가능성을 갖게 되어, 보다 낮은 레벨의 처리될 현저성을 요구할 수 있다. 보다 짧은 가시성 지속기간을 갖는 객체는 보다 적은 샘플을 가질 것이며, 따라서 보다 덜 주의되기 쉬워서, 그 더 짧은 시퀀스 동안에 검출될 보다 높은 레벨의 현저성 요소들을 요구할 수 있다.
장면 최적화(SCENE OPTIMIZATION)
지금까지, 개시 내용은 강건성에 중점을 두었다. 이제, 몇몇 실시 형태에서, 전술된 강건성 관련 방법 및 시스템으로부터 이점을 가질 수 있지만 반드시 강건성 평가를 요구하는 것은 아닌 다른 시각 주의 모델링 관련 개념을 생각한다. 한 가지 이러한 관련 개념은 장면의 최적화의 개념이다.
앞서 논의된 바와 같이, 주체가 장면 내에서 그의 또는 그녀의 시각 주의를 어디에 할당할 것인지를 예측할 수 있는 시각 주의 모델이 존재한다. 그러나, 이러한 모델은 장면이 어떻게 수정되어 특정한 시각적 목표(visual goal)를 달성할 수 있는지를 식별하기 위한 임의의 메커니즘을 제공하지 않는다. 인간의 시각 체계가 실제로는 장면의 볼 수 있는 전체 구역을 처리하지 않지만, 그 대신에 주의가 끌리는 그러한 영역들만을 처리하기 때문에, 많은 실제 상황에서는 사람들이 장면 내의 특정한 객체들을 '보게' 할 뿐만 아니라 그들을 특정한 객체들에 '주의'하게 하는 것이 바람직하다.
그러면, 시각적 목표는 주체가 장면 내에서 객체들에 주의할 바람직한 방식을 참조한다. 예를 들어, 시각적 목표는, 단순히 특정 객체들, 즉 중요하지 않거나 심지어 불리한 것으로 간주되는 객체들의 집합에 부가하여, (시각 주의 관점에서) 중요한 것으로 결정한 장면 내의 객체들의 집합에 주의된다는 요구일 수 있다. 또는, 그것은 특정 객체들이 특정 시퀀스 또는 특정 시간에 주의되게 하거나, 특정 객체들이 특정 뷰잉 포인트(viewing point)으로부터 주의되지만 반드시 그 외의 것들로부터는 주의되어야 하는 것은 아니라는 요구일 수 있다. 이 단락의 나머지 부분은 시각 주의의 계산 모델을 이용하여 시각적 목표를 달성하도록 장면을 최적화할 수 있는 방식을 논의한다. 논의될 방법들 중 일부는 앞서 논의된 바와 같이 강건성 평가를 이용하지만, 일부 방법은 그렇지 않다.
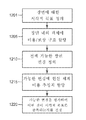
도 10을 참조하면, 일단 시각적 목표가 정의되었다면(단계 1201), 장면 최적화는 장면 내의 객체들 상에 명시적 비용/보상 구조(explicit cost/reward structure)를 할당함으로써 시작된다(단계 1205). 이러한 할당은 정량적으로 시각적 목표를 정의한다. 비용/보상 구조는 장면 내의 어떤 객체들이 높은 가치의 객체, 낮은 가치의 객체, 및 심지어 사용자에게 시각적 목표에 주의 분산을 야기하거나 불리한 것으로 보이는 객체인지를 정의한다. 사용자는 시각적 목표의 일부(긍정적 보상)인 것으로 간주되거나 불리한(부정적 비용) 각각의 객체들에게 "주의 효용(attention utility)" 값을 제기할 것이다. 또는, 사용자는 어떤 요소들이 다른 요소들보다 시각적 목표에 "더욱" 가치가 있는지를 명시하는 우선권을 제기할 수 있다.
다음, 다수의 가능한 장면 변경이 정의된다(단계 1210). 이러한 변경은 조명, 객체 컬러, 객체 위치설정 등과 같은 단순한 변경, 또는 로비 내의 어느 곳에 리셉션 구역이 건설되어야 하는지와 같은 보다 복잡한 디자인 변경일 수 있다. 물론, 이상적으로, 리셉션 구역의 위치설정만큼 근본적인 무엇인가를 평가할 시간은 호텔 로비를 건설하기 전에 충분히 이루어지며, 그에 따라 본 명세서에 설명되는 장면 최적화 방법의 한 가지 효용은 그러한 장면 내에서 합성적인 또는 부분적으로 합성적인 장면 및 디자인/레이아웃 선택을 평가하기 위한 것일 것으로 예상된다.
실제 현실 세계 "비용"(또는 추정치)은 각각의 가능한 장면 변경과 연관된다(단계1215). 예를 들어, 단골 고객을 특정 간판에 주의시키는 것이 목표인 호텔 로비의 경우, 간판의 컬러를 변경하는 것은 상대적으로 저렴한 것일 수 있지만($200의 추정된 변경 값을 할당받을 수 있음), 화강암 바닥의 컬러를 변경하는 것은 비싼 것일 것이다($20,000의 추정된 변경 값을 할당받을 수 있음). 현실 세계 비용 추정치를 할당하는 것은, 가격 액수를 복수의 변경과 연관시키는 것을 가능하게 한다. 예를 들어, 가능한 장면 변경의 범위가 고려될 수 있으며, 일부는 모든 목표를 충족시키고, 일부는 대부분의 목표를 충족시키며, 일부는 목표를 충족시키되 가장 저렴하게 그렇게 하고, 다른 것은 정의된 목표의 90%를 충족시키되, 나머지 10%의 목표를 달성하기 위해 과도한 자본 투자를 취한다는 것을 알 수 있다. 다시 말해, 현실 세계 비용을 가능한 변경과 연관시키는 것은, 일부 실시 형태에서, 옵션의 보다 더 유용한 평가를 가능하게 한다. 결국, 이 방법은 객체 특징 구성과 연관된 비용을 최소화하면서 주의 효용을 최대화하는 장면 구성을 제공한다(단계 1220).
현실 세계 비용은 특정 변경의 상대적 비용이 어떻게 공동 연관될 수 있는지의 단지 일례임에 유의한다 - 특정 변경에 대해 더 높은 비용을 관련시키는 보다 높은 점수 및 덜 비싼 변경인 보다 낮은 점수를 갖는 점수 시스템과 같은 다른 시스템이 마찬가지로 사용될 수 있다.
별개의 객체들을 추적하고 조작할 능력을 갖는 그래픽 편집기는 가능한 장면 변경을 정의하는 데 유용할 수 있다. 예를 들어, 그러한 그래픽 편집기 내에서 보이고 있는 장면의 간판이 식별(예를 들어, 마우스로 우측 클릭)될 수 있고, 사용자는 그 객체의 변경가능한 특성들을 선택할 수 있을 것이다. 이러한 변경가능한 특성들은 컬러, 조명, 레이어 내의 위치설정(예를 들어, 객체는 일부 다른 객체의 전방 또는 후방에 놓일 수 있음), 콘트라스트, 음영, 크기 등을 포함할 수 있다. 변경될 수 있는 개별 특성들을 선택하는 것에 부가하여, 사용자는 또한 변경의 허용된 범주 또는 다른 관련 파라미터들을 정의할 능력을 가질 수 있다. 예를 들어, 컬러와 관련하여, 클라이언트 또는 사용자가 장면 내에 있는 특정 벽에 대해 허용가능한 것으로 찾을 수 있는 유일한 컬러는 황갈색의 음영일 수 있다. 따라서, 컬러 속성은 오로지 특정된 스펙트럼 범위 내에서 변동되는 것으로 정의된다. 유사하게, 속성이 크기이면, 객체의 크기가 클라이언트 또는 사용자에게 허용될 수 없기 전에 그 특정 객체가 성장(또는 감소)될 수 있는 크기까지의 명백한 한계가 있을 수 있다. 전술된 바와 같이, 현실 세계 비용 추정치는 각각의 가능한 변경과 연관된다. 가능한 변경의 범위가 있는 경우, 사용자는 그 범위 내에서 예시적인 점수 비용을 정의할 수 있으며, 지원하는 컴퓨터 시스템(후술됨)은 예시적인 점수들에 대해 최적합 곡선을 외삽할 것이다. 사용자에게는 다수의 가능한 최적합 알고리즘들이 제시되어 어떤 것을 사용할 것인지를 선택하도록 질문받을 수 있다. 예를 들어, 사용자는 간판 크기에 대해 최소 허용가능한 간판 비용 $100 및 중간 간판의 비용이 이들 2개의 비용 점수 사이에서 선형적으로 (크기에 기초하여) 증가한다는 것을 단지 정의하기를 원할 수 있다.
정의된 목표(또는 복수의 목표), 목표에 대한 주의 효용, 가능한 장면 변경, 및 정의된 가능한 장면 변경의 비용에 따라, 다음 단계는, 가능한 장면 변경의 이득을 평가하고 단계 1201에서 정의된 시각적 목표를 달성하는 장면 구성을 찾아내고자 시도하는 것이다. 이것은, 일 실시 형태에서, 예상된 보상을 최대화시키는 장면의 특성, 또는 보상을 최대화하면서 비용을 최소화하는 장면 구성, 또는 최소 비용으로 정의된 목표를 간단히 충족시키는 장면 구성을 알고리즘적으로 수정함으로써 이루어진다. 예상된 보상은 특정 객체가 주의를 받을 가능성 및 그러한 객체들에 주의시키기 위한 보상/비용으로서 계산된다. 장면에서 위치에 주의시키기 위한 보상/비용에 부가하여, 최적화 루틴은 또한 특정 타입의 장면 변경(예를 들어, 장면 내의 객체의 컬러 및/또는 위치 변경)을 만들기 위한 비용/보상을 요인으로 포함한다. 객체가 주의를 받을 가능성을 계산하기 위한 한 가지 방법은 이전 단락에서 설명된 강건성 분석을 사용하여 결정될 수 있다.
수학식 1은 시각 주의의 계산 모델을 사용하여 효용 함수를 어떻게 정형화시키는지에 대한 일례를 제공한다.
F는 장면 내의 객체들에 대한 변경가능한 속성들의 세트이다. 예를 들어, 그것은, 장면 내의 각각의 객체들에 대한 컬러, 텍스처, 또는 위치를 포함할 것이다. A는 이러한 특징 구성 F가 주어지면 모델이 예측하는 주의 고정성들의 세트이다. R(Oxy)는 특징 세트 f를 갖는 위치(xy)에서 객체에 주의시키기 위한 (긍정적 및 부정적) 보상이다. a(xy)는 모델이 주의가 위치 xy에 할당될 것을 예측할 가능성이다. 일부 모델 및 시각 주의의 접근법의 경우에 a(xy)는 이진 값(주의가 위치에 할당될 것인지 아닌지의 여부를 나타내는 0 또는 1)일 수 있는 반면에, 다른 모델 및 접근법의 경우에는 이것은 주의가 이 위치(0…1)에 할당될 가능성일 수 있다. 어느 방식이든, 수학식의 이 부분은 현재 객체 특징 세트에 대한 주의의 할당을 위한 보상을 명시한다.
함수의 나머지 부분은 객체 o에 대한 특징 세트 f를 사용하기 위한 비용을 명시한다. R(Of)는 객체 o에서 특징 세트 f를 사용하기 위한 보상/비용을 명시한다. 일부 경우, 특정 특징에 대한 비용은 0.0일 수 있다(예를 들어, 이것은 객체 o에 대한 현재 특징 세트에 대한 경우일 수 있음). 그러나, 모델이 동일하게 어려운 모든 가능한 특징 조합들을 고려하기를 원할 수도 있다. 이 경우, 모든 특징에 대한 보상은 동일할 것이다(또 가장 쉽게는 0.0일 것임). 그러나, 일부 상황(예를 들어, 장면에서 카펫의 컬러를 변경하는 경우 대 화병을 옮기는 경우)에서는, 허용가능한 특징 구성에 대한 제약이 있을 것이다. 이러한 상황에서는, 객체(o) 및 특징(f)에 대한 비용/보상과 관련하여 그러한 값들을 명시하거나, 단순히 허용 불가능한 특징 구성을 허용가능한 변경으로 정의하지 않을 수 있다.
이 보상 함수를 이용하여, 기술된 보상 함수를 최적화하는 특징 구성을 위한 솔루션 공간이 조사된다. 일단 보상 함수가 명시되면 최적의 솔루션을 달성하기 위한 다수의 방법이 있다. 이러한 방법들은, 닫힌 형태 방정식(closed form equation), 몬테 카를로 시뮬레이션(Monte Carlo Simulation), 시뮬레이션된 어닐링(Simulated Annealing), 유전 알고리즘(Genetic Algorithm) 및 확률적 경사 하강(Stochastic Gradient Descent)을 포함하지만, 이에 제한되지 않는다. 이러한 근사화 접근법에 부가하여, 일부 시각 주의 모델의 경우, 닫힌 형태 분석을 구현할 수 있다.
그러면, 목표를 충족시키는 솔루션 공간으로부터의 솔루션 및 연관된 비용 정보가 평가되는 데 이용될 수 있다.
지금까지의 예들 중 대부분은 장면 내의 객체들의 시각적 현저성을 증가시킴으로써 그 장면을 최적화하는 데 중점을 둔다는 점에 유의한다. 그러나, 일부 시각적 목표는 다른 객체들로부터 시각 주의(또는 주의 분산)을 감소시킴으로써 달성될 수 있다는 점에 유의한다. 비용 모델이 어떻게 설정되었는지에 따라, 본 명세서에 설명되는 장면 최적화 방법은 장면의 양태를 약화시킬 수 있다(항상 객체들을 시각적으로 현저하게 만드는 것은 아님).
장면 최적화 및 주의 시퀀스(SCENE OPTIMIZATION AND ATTENTION SEQUENCE)
전술된 바와 같이, 일부 목표는 객체가 주의되는 순서를 고려하지 않을 수 있다. 이러한 조건 하에서, 객체에 주의시키기 위한 보상/비용은 시퀀스에서 그의 위치 및/또는 현재 주의 고정성 전후에 주의되는 객체들 중 어느 것에 의해서도 영향받지 않을 것이다. 그러나, 장면 내의 객체들의 주의 고정성 순서가 중요할 수 있는 상황들이 있다. 예를 들어, 순서는 주체가 특정 시퀀스의 명령을 따를 때 문제가 되기 쉽다.
이러한 더욱 복잡한 시각적 목표를 다루기 위해, 상기의 예상된 보상 함수(수학식 1)는 확장되어, 예상된 보상이 순서 의존적이도록 특징 구성을 최적화할 수 있다. 이것은, 단속성 수의 함수로서 가변 보상 구조를 이용함으로써 이루어질 수 있다. 수학식 1에서 객체에 주의시키기 위한 보상은 개별 주의 단속성에 의해 인덱싱(Ra)된다는 것에 유의한다. 단속성의 순차적 위치(α)에 기초하여 상이한 보상을 특정함으로써, 장면이 예측된 단속성 순서에 의해 최적화되게 하는 방법을 생성할 수 있다. 도 11은 2개의 보상 구조를 예시하는 그래프이다. 하나의 보상 구조는 단속성 위치에 따른 불변량에 의해 표현되며(라인 1225), 두 번째 것은 단속성 위치에 의존한다(라인 1230). 단속성 의존 보상 구조는 이 특정 객체에 주의시키기 위한 예상된 보상이 빨리 발생하는 경우에는 매우 높지만, 주의가 시퀀스에서 이후에 할당될 때는 감소한다는 것을 명시한다. 이러한 타입의 보상 구조는 건축 구역 장면에서의 보행자와 같은 "높은 가치"의 객체들과 연관될 수 있다.
(도 11이 예시하는 바와 같이) 객체가 주의 시퀀스에서 얼마나 빨리 주의되는지에 대한 보상에 기초하기보다는, 객체의 보상이 그것 전후에 주의를 받은 객체에 기초하는 경우, 보상을 시퀀스 기반 목표에 기초할 수 있다. 예를 들어, 호텔 소유주는 2개의 외부 간판을 갖출 수 있다. 하나는 그들의 레스토랑의 특별 메뉴를 광고하고, 두 번째 것은 그들의 호텔명 및 로고를 광고한다. 호텔 소유주는 광고용 특별 메뉴 간판이 호텔 간판 앞에 보여야 한다는 것이 중요하다고 결정한다. 이 시각적 목표가 주어지면, 분석은 "레스토랑 특별 메뉴" 간판이 호텔명에 앞서 주의될 때 매우 높은 보상을 둘 것이다. 또한, 호텔명이 "특별 메뉴 광고" 간판에 앞서 주의될 때에는 낮은 보상이 부여될 것이고, 하나의 간판이 다른 간판 없이 주의된다면 어떠한 보상도 제공되지 않을 수 있다. 시퀀스는 상대적인 시퀀스(앞 대 뒤)이거나 절대적 시퀀스(객체-A가 시각 주의를 받는 제1 객체로서 발생하지 않고 객체-B가 시각 주의를 받는 제2 객체가 아닌 한 객체-A 및 객체-B에 주의시키기 위한 보상이 없는 경우)일 수 있다. 물론, 당업자라면 이해하는 바와 같이, 보상 구조가 정형화될 수 있는 많은 다른 방식이 있다.
지금까지, 이 단락은 단속성의 위치 또는 단속성의 순서가 보상에 영향을 미치는 두 가지 가능한 보상 함수를 논의하였다. 당업자라면, 객체들의 세트 및 단속성들의 세트에 걸쳐 임의의 자의적인 순차적 보상 함수를 정의할 수 있음을 인식할 것이다. 보다 일반적으로, 해당 단속성 시퀀스의 길이인 M 차원 공간(각각의 객체에 대해 하나의 차원)을 정의함으로써 보상 구조의 이 순차적 구성요소를 정의할 수 있다.
최적화 루틴은 보상 구조가 주어지면 장면에 최상의 구성을 제공하도록 설정될 수 있지만, 최종 생성 장면 "추천"은 적절하지 않다는 것을 알 수 있다. 예를 들어, 한 객체의 컬러를 수정하여 그것이 더욱 눈에 잘 띄거나 덜 띄도록 수정했다면 주의 시퀀스가 어떻게 변경되는지를 이상하게 여길 수 있다. 하나의 객체가 더욱 눈에 띄게 만드는 것은 예측된 시퀀스에 불분명하고 비선형적 효과를 가질 수 있다. 이것은, 정의에 의해 주의 할당이 제로-섬 게임(zero-sum game)이라는 사실, 즉 하나의 객체에 주의를 할당하는 것은 반드시 주의가 다른 객체로부터 떨어져 할당되는 것을 의미할 것이라는 사실로 인한 것이다. 따라서, 하나의 객체의 특징을 수정하여 그것의 현저성을 증가시키는 것은, 이 객체가 주의를 받을 가능성(및 주의 시퀀스에서 그것이 주의를 받는 경우)을 변경할 뿐만 아니라 다른 객체들이 주의를 받을 가능성 및 주의 시퀀스에서 그러한 객체들이 주의를 받는 경우에도 영향을 미칠 것이다.
최적화 루틴에 대한 하나의 접근법이 다수의 특징 구성을 자동으로 고려하는 것이기 때문에, 솔루션 공간을 정의하는 가능한 구성의 대부분(또는 모두)이 조사될 것이다. 비-최적 솔루션은 사용자 또는 클라이언트에게 훌륭한 관심거리일 수 있다. 예를 들어, 어떤 컬러가 간판 위치를 이동시키게 하는지, 말하자면, 단속성 시퀀스에서 25번째 위치로부터 상측 5번째 위치로 그의 위치를 이동시키게 하는지 알기를 원할 수 있다. 시스템은 모든 다른 객체들의 특징들이 일정하게 유지되고 관심 객체가 상측 5개의 단속성에 포함되는 저장된 주의 시퀀스를 조사할 수 있다.
앞서 논의된 강건성이 또한 장면 최적화에 사용될 수 있다. 예를 들면, 그 이미지의 특성뿐만 아니라 하루 중 여러 시간에 나타날 수 있는 장면에 대해 또는 상이한 뷰어에 대해 장면을 최적화할 수 있다. 즉, 최적화 루틴은 장면이 경험할 수 있는 가변성에 대해 강건한 장면을 추천한다. 이전에, 입력 장면 및 모델에 대해 내적 및 외적 가변성을 포착하고 생성하는 방법을 설명하였다. 이들 접근법의 목표는 실제 장면의 예상된 변동을 시뮬레이션(또는 포착)하는 것이었다. 예를 들어, 관찰자의 가변성을 포착하기 위한 한 가지 방법은, 시각 주의 모델의 파라미터(예를 들면, 현저성을 계산하기 위한 개별 특징 지도들의 가중치)를 변동시키고 동일한 이미지 상에서 이들 모델을 구동하는 것이다. 다수 사례의 상이한 모델 파라미터들(내적 가변성)을 통해 각각의 장면 구성을 구동하는 것은 특정 장면 구성에 다중 스코어 - 각 모델에 대해 하나의 주의 시퀀스 - 를 부여할 것이다. 각각의 모델 구성에 대해 평균 스코어를 취함으로써, 주어진 가변성을 갖는 장면 구성에 대한 예상된 스코어를 생성할 수 있다. 최상의 평균 스코어를 제공하는 장면 구성을 추천할 수 있다.
또한, 강건성과 관련하여 시각적 목표를 정의할 수 있고, 이어서 특정 강건성 값에 대한 장면의 객체(또는 객체들)를 최적화할 수 있다.
가시성 지속기간(Visibility Duration)
강건성 논의와 관련하여 전술된 바와 같이, 상이한 객체들 또는 상이한 장면들은 상이한 가시성 지속기간을 가질 수 있다. 상기하면, 가시성 지속기간은 객체 및/또는 장면이 보일 기간을 지칭한다. 시간과 관련하여 명시될 수 있는 가시성 지속기간은 전형으로 최적화 루틴에서 고려될 예측된 주의 고정성(또는 현저성 영역들)의 수로 변환될 것이다. 가시성 지속기간은 다양한 장면들의 분석에 사용될 고정성들의 세트를 제한하는 데 사용될 것이다. 보다 구체적으로, 그것은 시각적 목표 분석에 사용될 것이다.
가시성 지속기간은 다수의 시각적 목표를 고려할 때 효과를 가질 수 있다. 예로서, 상이한 보상을 갖는 6가지 시각적 목표를 갖는 문서 또는 콘텐트를 가질 수 있다 - 즉, 보상 값은 1, 2, 3, 4, 5, 6이다. 콘텐트가 5초마다 디지털 간판에 디스플레이되고, 사람들이 초당 약 2회 고정성을 만든다면, 이것은 10회 고정성의 가시성 지속기간으로 변환한다. 가시성 지속기간이 10회 고정성이라면, 가시성 지속기간은 모든 시각적 목표를 포착할 정도로 충분히 길다. 이 조건 하에서, (장면 내에 다른 객체가 없고 변경을 위한 비용이 동일하다는 것을 가정하면) 모델은 6개 아이템의 현저성을 상대적으로 동일하게 만들 것이다. 가시성 지속기간을 갖는 최적화 루틴이 시각적 목표를 대략적으로 동일하게 만드는 이유는, 모델이 이 조건 하에서 모든 타깃에 주의시키기가 보다 쉽다는 것이다. 타깃들(즉, 최고 보상을 갖는 객체) 중 하나의 타깃의 현저성이 다른 객체들(즉, 최저 현저성을 갖는 객체) 중 하나의 객체의 현저성보다 상당히 높다면, 대부분의 시각 주의 모델은 먼저 가장 현저한 객체에 주의할 것이며, 그 다음에는 두 번째로 가장 현저한 객체에 주의할 것이지만, 결국은 전형적으로 가장 현저한 객체로 다시 되돌아갈 것이다. 이전 객체로 되돌아가기 위한 어떠한 추가 보상도 없다면, 이 주의 고정성은 전체 보상을 증가시키지 않을 것이다. 그러나, 객체를 현저성 면에서 상대적으로 동일하게 함으로써, 가시성 지속기간이 주어지면 모델은 모든 타깃 객체에 주의하기 쉽고, 그에 따라 시각적 목표 중 (전부는 아니더라도) 많은 것을 달성하기 쉽다. 최적화 루틴 및 가시성 지속기간의 이러한 양태는 객체의 현저성을 단순히 타깃 객체의 보상 또는 관련성과 관계되게 하는 것과는 매우 상이하다.
도 12는 장면 최적화 시스템(1255)의 고-레벨 다이어그램이다. 이 도면에서 동일한 명칭의 구성요소는 기능성 및 능력 면에서 앞서 논의된 모듈과 유사하다. 장면 최적화 시스템(1255)은, 컴퓨터(503)를 통해 네트워크(502)에 걸쳐 사용자(401)로부터 입력을 수신하여 가능한 장면 변경뿐만 아니라 장면에 대한 하나 이상의 시각적 목표를 정의하는 데이터베이스 그래픽 사용자 인터페이스(1245)를 포함한다. 장면에서 객체들에 대한 이러한 가능한 변경은 데이터베이스(1235)에 저장된다. 장면 최적화 모듈(1260)은 시각적 목표를 충족시키는 가능한 장면의 전체의 조사를 반복하고, 조사하며, 장면 수정 모듈(1240)이 사용자(401)에 의해 정의되는 가능한 변경에 부합하는 방식으로 장면 입력을 수정하도록 실행시킨다. 이는 시각 주의 모듈(403)에 제공되는 수정 장면을 생성하며, 이 시각 주의 모듈은 데이터베이스(1235)에 저장되는 시각 주의에 관계되는 출력을 제공한다. 장면 최적화 시스템(1255)은 (도 12에 도시된 바와 같이) 사용자(401)가 원격이라면, 웹 서버 모듈(1250)을 포함할 수 있다.
다중-시야 장면 분석(MULTI-PERSPECTIVE SCENE ANALYSIS)
지금까지, 설명은 주로 단일의 정적 이미지 또는 영화를 이용하여 주의가 이미지 또는 이미지들 내에서 어디에 할당될지를 예측하는 시각 주의 모델링에 중점을 두었다. 이러한 두 가지 접근법은 종종 많은 상황에 유용하지만, 그들이 실제에 있어서 복잡한 3차원 장면인 것의 단일 2차원 뷰(view)에서 동작한다는 점에서 제한적이다.
우리가 살고 있는 3D 세계에서, 시야(배향 및/또는 위치)에서의 작은 변경은 관찰자의 망막에 투영되는 이미지 상에 상당한 변경을 가질 수 있다. 하나의 시야로부터 가시적인 객체들은 다른 시야에서는 전혀 가시적이지 않을 수 있다. 또한, 객체들 사이의 공간적 관계(즉, 제2 객체에 대해 상대적으로 망막 상에 비치는 하나의 객체의 투영 이미지의 위치)는 시야에 따라 현저하게 변경될 수 있다. 시야의 변경이 망막에 투영되는 이미지에 큰 변동을 발생시킬 수 있기 때문에, 그것들은 또한 인간 시각 주의가 장면 내에서 할당될 곳에 대해서는 상당한 효과를 가질 것이다. 예를 들어, 도 13a는 뒤에 디지털 간판(1290)을 갖는 리셉션 데스크를 포함하는 호텔 로비 장면의 아티스트 렌더링이다. 장면은 도 13a에서 가장 주의를 끄는 2개의 객체가 디지털 간판(1290) 및 광고 카드(1285)라고 예측한 시각 주의 모델에 의해 분석되었다. 도 13b는 동일한 호텔 로비의 동일한 리셉션 구역이지만, 디지털 간판(1290)은 시각 주의 모델에 의해 식별된 여러 개의 객체들 사이에 있지 않다. 시각적 목표가 단골 고객을 디지털 간판(1290)에 주의시키는 것이고, 도 13a에 도시된 장면만이 분석된다면, 시각적 목표가 일관되게 충족되고 있다는 잘못된 안전감이 있을 것이다. 따라서, 3D 장면 내의 장면 콘텐트를 측정하고 평가하는 효율적인 방식을 가질 필요가 있다.
(본 명세서에서 다중-시야 장면 분석으로 지칭되는) 3D 장면 평가는 2D 시각 주의 분석을 영화 시퀀스와 같은 것으로 단순히 확장하는 것과 같지는 않다는 것에 유의한다. 이러한 접근법은 많은 시야로부터의 데이터를 제공할 수 있지만, 궁극적으로는, 그것이 공간 전체에 걸쳐 특정 움직임에 대한 주의의 할당을 분석할 능력을 제공하지만 그 공간을 통해 다른 경로 및/또는 움직임을 고려할 능력을 제공하지 않을 수 있다는 점에서 단일 이미지 접근법과 유사한 제한을 갖는다. 정적 장면의 시각 주의 분석 또는 복수의 연속적인 정적 장면(비디오) 중 어떠한 것도 이미지가 3D 환경으로부터 도출된다는 사실을 효과적으로 다루지는 않는다.
따라서, 그러면 3차원을 수용하는 다중-시야 시각 주의 모델링 프로세스 및 관찰자가 3차원인 지리학적 공간을 가로지를 수 있는 무수한 방식을 갖는 것이 유용할 수 있다.
도 15는 다중-시야 시각 주의 모델링 프로세스를 도시하는 흐름도이다. 프로세스는 분석하기를 원하는 3D 장면 내의 위치 및 객체를 결정하는 것으로 구성되는 사이트 계획(site planning)으로 시작한다(단계 1329). 실제로, 이것은 분석될 3D 장면의 플로어 계획(floor plan)을 획득하거나 개발하는 것, 및 사용자의 관찰 시야를 대표할 플로어 계획 내의 위치를 결정하는 것을 의미할 수 있다. 물론, 3D 장면의 플로어 계획이 없을 때에는, 사용자가 간단히 그 사이트로 가며, 관심이 있는 위치에 관하여 결정을 내리고 그러한 위치로부터 사진을 찍는 보다 덜 엄격한 접근법이 사용될 수 있다. 또한, 사용자는 이미지가 취해진 위치 및 배향을 기록할 수 있는데, 이는 보고 목적에 유용할 수 있다.
사진보다는, 프레임이 비디오 또는 비디오 시퀀스로부터 포착되는 비디오 기술이 또한 사용될 수 있다. 프레임(비디오로부터의 이미지) 또는 (예를 들어 디지털 카메라로부터의) 이미지가 사용될 때, 사용자는 또한 2개의 상이한 이미지 사이에 있는 뷰를 생성하는 데 뷰 보간(view interpolation) 기술을 사용할 수 있다. 전술된 바와 같이, 이미지는 실제 환경으로부터 생성되는 것으로 제한되는 것은 아니지만, 그것들은 합성(가상) 환경으로부터 또한 생성될 수 있다. 그러나, 양측 모두의 경우, 이미지가 취해지는 환경에서의 위치, 및 카메라의 시야(카메라가 가리키는 방향)를 기록하거나 사전 명시해야 한다. 간단한 접근법은, 위치를 명시하고, 이어서 각각의 연속적 이미지를 북쪽, 동쪽, 남쪽, 서쪽 축 주위에 90도 전진시킨 시야로부터 생성되게 하는 것이다(하기의 예에서 이루어짐). 그러나, 사전 명시한 위치 및 카메라 조준 프로토콜이 없다면, 카메라는 그 대신에 가능하게는 광학적 추적 기술과 조합하여 GPS 추적 기술을 사용하여 추적될 수 있다. 예를 들어, 기구 또는 기구들은 매시간 이미지가 취해지도록 카메라에 부착될 것이며, 시스템은 3개의 위치적 차원(X, Y, Z) 및 3개의 배향적 차원(요(yaw), 피치(pitch), 롤(roll))을 기록하여 이미지가 포착되는 뷰포인트의 명시적 표현을 제공할 것이다. 이러한 6개의 값은 메모리에 저장될 것이며, 그 시간에 포착된 이미지와 연관될 것이다. 물론, 카메라 위치 및 배향은 수동으로 기록될 수 있다.
3D 장면이 결정되면, 3D 환경으로부터 그 다음의 다수의 이미지가 수신되고, 다수의 이미지는 관찰자가 3D 환경을 통해 상호 작용하고 네비게이트함에 따라 관찰자가 경험할 수 있는 뷰들의 세트를 표현한다(단계 1330). 일 실시 형태에서, 이것은 (또한 호텔 로비와 같은) 3D 장면 내의 다수의 위치 및 배향으로부터 다수의 사진이 찍히게 함으로써 달성된다. 다른 실시 형태에서, 비디오는 관찰자가 있는 것으로 예상될 수 있는 다수의 대표적 구역으로부터 찍히는 샷을 갖는 3D 장면으로 구성된다. 또 다른 실시 형태에서, 가상 3D 모델이 사용되며, 뷰는 가상 카메라를 가상 3D 모델을 통해 이동시킴으로써 생성된다. 어떻게 생성되든, 결과는 3D 장면 내의 다양한 위치로부터의 복수의 2D 이미지이다. 사전 명시되지 않았다면, 3D 환경 내의 위치를 대표하는 데이터 및 카메라 배향이 또한 수집된다. 이 데이터는 관찰자가 3D 공간을 통해 취할 수 있는 많은 상이한 경로를 평가하는 것과 함께 많은 시야로부터의 장면을 평가하게 할 것이다.
일단 이미지가 수집되면, 관심 객체들에 대응하는 2차원 이미지의 영역들이 선택되고 식별된다(단계 1335). 이것은 이러한 객체들을 자동으로 추출하는 방법들, 수동적인 영역 선택, 또는 심지어 자동 및 수동 태깅(tagging) 및 라벨링(labeling) 기술 모두를 사용하는 하이브리드 접근법을 포함할 수 있는(그러나, 이에 제한되지 않음) 다수의 상이한 방법을 사용하여 달성될 수 있다. 이 프로세스를 달성하기 위한 (수동적인) 한 가지 방법의 그래픽 결과의 예시가 도 14a 및 도 14b에 도시되어 있다. 벽화(1310), 디지털 간판(1315) 및 꽃병(1320)과 같은 객체들은 모두 수동 선택 프로세스에 의해 식별되었다.
다음, 관심 객체를 포함하는 이미지는 시각 주의 모델을 사용하여 시각 주의 데이터를 생성하도록 처리된다(단계 1340). 전술된 바와 같이, 하나의 이러한 모델은 잇티 및 코흐에 의해 설명된 것(2001년도)이지만, 임의의 시각 주의 모델이 사용될 수 있다. 그러면, 관찰자가 각각의 뷰포인트에 있을 때 시각 주의가 할당될 것으로 모델이 예측하는 2차원 위치는 예를 들어 데이터베이스에 기록된다. 이후, 이러한 위치는 각각의 뷰포인트에 대해 태깅 및 라벨링된 영역에 비교되어, 가시적 구역 내의 어떤 객체들이 주의를 받을 것인지를 결정하게 한다.
각각의 개별 뷰포인트를 분석하고, 모델이 각각의 개별 뷰포인트에 대해 시각 주의를 끌 객체를 계산한 후, 어떤 객체가 어떤 위치로부터 주의될 것인지에 관한 데이터가 생성 및 저장된다. 그러면, 이 데이터는, 예를 들어 잠재적 관찰자가 3D 장면을 가로지름에 따라 특정 객체를 그 잠재적 관찰자가 (조금이라도) 보게 될 가능성; 사실상 3D 장면 내의 특정 객체를 관찰할 잠재적 관찰자의 비율; 객체가 (로비에 들어가는 것 대 로비를 나가는 것과 같은 특정 진행 경로에 관한 정보를 분석하는 데 유용할 수 있는) 특정 뷰들의 서브-세트에 대해 주의되는 가능성, 또는 객체가 보일 수 있을 때 그 객체가 주의될 가능성(일부 객체가 환경 내에서 가능한 뷰포인트의 대부분으로부터 눈에 띄지 않을 필요가 있을 수 있지만 객체가 보일 수 있는 뷰포인트에 대해서는 그것에 대해 주의가 끌릴 높은 정도의 확실성을 갖기를 원할 수 있음), 또는 객체가 가시적인(또는 그 객체가 주의될) 3D 장면 내의 뷰포인트를 결정하는 데 사용될 수 있다.
이 3D 시각 주의 모델링은 장면 최적화와 관련하여 상기 논의된 시스템 및 방법과 조합될 수 있다. 그러나, 3D 시각 주의 모델링과 관련하여 정의될 수 있는 시각적 목표들은 상이할 수 있다. 예를 들어, 시각적 목표는 사실상 잠재적 관찰자의 90%가 호텔 로비를 가로지르는 동안 몇몇 지점에서 특정 디지털 간판을 관찰하도록 정의될 수 있다.
장면 최적화와 조합되는 3D 시각 주의 모델링을 적용하는 예로서, 몇몇 뷰포인트로부터 관찰될 때에는 객체가 눈에 띄지 않고 남게 되지만 그 객체가 관련되게 되면 다른 뷰포인트로부터 눈에 띄기를 원할 수 있는 경우를 고려한다. 예를 들어, 호텔은 고객이 보고 그들의 방문 동안에 주의시키기를 원하는 세 가지 상이한 형태의 광고 콘텐트를 갖는다. 제1 콘텐트는 룸 업그레이드에 대한 특매품을 광고하고 있고; 제2 콘텐트는 룸 서비스에 대한 특매품을 광고하고 있으며; 제3 콘텐트는 호텔 볼룸(ballroom)에서 소지되는 활동 티켓을 광고하고 있다. 이러한 상이한 형태의 콘텐트는 고객의 방문 동안의 상이한 시간에서 관련된다. 룸 업그레이드는 고객이 호텔에 체크인하고 있을 때에는 관련되지만, 다른 시간에는 관련되지 않는다. 룸 서비스는 고객이 그들의 방에 들어가려 할 때에 관련되지만, 고객이 호텔을 떠나 있을 때에는 반드시 그러한 것은 아니다. 활동 티켓은 대조적으로 거의 항상 고객과 관련된다. 장면 최적화 기술과 조합되는 3D 시각 주의 모델링 기술(양측 기술 모두 전술됨)을 사용하면, 하기의 방식으로 그러한 광고 제재의 배치 및 콘텐트를 최적화할 수 있다. 먼저, 정보가 가장 관련이 깊을 호텔 로비에서의 위치를 결정할 수 있다. 예를 들어, 룸 업그레이드는 고객이 호텔에 체크인하고 있을 때 관련되는데, 통상적으로는 고객이 체크인 카운터의 전방에 서 있을 때 일어난다. 엘리베이터 옆의 구역은 (활동 티켓과 같은) 일반적인 광고에 가장 좋을 수 있다. 단지 호텔이 소정 태스크(예를 들어, 체크인 또는 룸으로 가는 일)에 대응하는 뷰포인트로부터 눈에 띄는 소정 간판을 원할 때, 호텔은 관련되지 않은 간판(예를 들어, 엘리베이터를 기다릴 때 룸 업그레이드)이 눈에 띄지 않기를 원할 것이다. 체크인 카운터에 서 있을 때에 있을 수 있는 위치 및 배향의 세트에 기초하여 광고 제재의 위치 및 콘텐트를 분석할 수 있다.
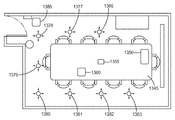
전술된 3D 시각 주의 모델링 및 장면 최적화 방법의 일 실시 형태를 시험하기 위해, 도 16에서 볼 수 있는 다이어그램인 표준 회의실을 시험 3D 장면으로서 취하였다. 회의실은 탁자(1345), 황색 간판(1350), 녹색 바스켓(1360), 전화기(1355), 자주색 간판(1365), 및 회의실에서 발견되는 것을 예상되는 다른 전형적인 물건(의자, 휴지통, 스크린)을 포함하였다. 관찰자가 룸을 볼 것으로 예상될 수 있는 대표 지점은 수동으로 결정되어, 8개의 대표적인 관찰 위치(관찰 위치 1366, 1377, 1378, 1379, 1380, 1381, 1382, 및 1383)를 생성하였다. 이 시험을 위해, 관찰 위치는 룸의 방해 없는 영역(가구가 없음) 전체에 걸쳐 대략 1.21 미터(4 피트) 이격되었다. 디지털 카메라를 사용하여, 4개의 이미지가 8개의 관찰 위치 각각으로부터 취해져 32개의 이미지를 생성하였다. 관찰 위치로부터 외향으로 연장하는 화살표는 디지털 카메라가 각각의 사진에 대해 조준된 전반적인 방향 - 각각의 관찰 위치에서 각각의 사진마다 약 90도의 배향 차이 - 을 나타낸다. 32개의 상이한 이미지 각각에 대한 위치 및 배향이 기록되었다.
이어서, 32개의 이미지 중 적어도 하나에서 발견된 12개의 상이한 객체들과 연관된 픽셀을 식별하고 태깅하였다. 이것은, 사용자가 32개의 각각의 이미지 상에서 관심 객체를 포함하는 2D 영역을 정의한 다각형 영역을 선택하게 함으로써 이루어졌다. 도 17a 및 도 17b는 32개의 이미지 중 2개의 이미지의 아티스트 렌터링을 도시하는데, 여기서 다각형은 녹색 바스켓(1360) 및 황색 간판(1350)과 같은 관심 객체를 둘러싸고 있다. "태깅"은 간단히 ("황색 간판"과 같은) 객체를 포함하는 영역을 명명하는 것을 지칭한다. 객체를 둘러싼 다각형은 태깅 소프트웨어의 목적을 나타내고; 근본적인 이미지는 실제로 다각형으로 수정되지 않으며; 일단 사용자에 의해 명시되면, 식별된 영역은 어떠한 방법으로도 원본 이미지 상에서 나타내어지지 않는다는 것에 유의한다.
이미지를 태깅 및 라벨링한 후, 이미지는 시각 주의가 할당될 것으로 모델이 예측하는 이미지 내의 위치를 수집하도록 시각 주의 모델에 보내졌다. 모든 이미지를 보낸 후, 컴퓨터는, 각각의 이미지에 대해 시각 주의가 할당될 것으로 모델이 예측한 x,y 좌표를 기록하였다. 컴퓨터는 또한 이들 주의 고정성 각각에 대해 그것이 사용자에 의해 태깅 및 라벨링된 이미지의 영역 내에 있는지의 여부를 계산하였다. 컴퓨터는 또한 주의를 받는 것으로 예측되지 않은 ("누락(miss)") 태깅 영역을 포함한 각각의 이미지를 기록하였다. 모든 데이터는 데이터베이스에 저장되었고, 이후에 장면 내에서 객체의 현저성에 관한 일련의 개요를 생성하는 데 사용되었다.
도 18은 회의실 내에서 태깅 및 라벨링된 12개의 객체(1400)에 대해 이루어진 세 가지의 상이한 예시적 분석을 예시하는 그래프(1395)를 도시한다. 제1 분석은 객체가 가시적이거나 보일 수 있는 가능성(p(Visible))이다. 이것은, 객체가 있는 이미지를 총 이미지 수로 나눈 비이다. 그러면, p(Visible)는 관심 객체가 환경 내에서 어떻게 잘 배치되는지의 일부 표시를 제공하는 기준이다. 결정되는 기준은, 객체가 가시적이었다면 그것이 주의되었을 가능성(p(Attended|Visible))으로서, 객체가 가시적이었던 모든 이미지를 취하고 시각 주의 모델이 특정 객체를 정의하는 영역에서 고정성이 발생할 것으로 예측했는지의 여부를 식별함으로써 계산되었다. 계산된 기준은 특정 객체가 조금이라도 주의될 가능성(p(Attended))이었는데, 이는 모델이 적어도 한번 객체로의 주의 할당을 예측했던 이미지의 수를 취하고 그 값을 총 이미지 수로 나눔으로써 계산된다.
다중-시야 장면 분석은 타깃 객체가 많은 상이한 경우로부터 보일 수 있다는 사실을 나타낸다. 예를 들어, 전술된 게시판 예를 고려한다. 길고 평탄한 도로를 운전하고 있을 때에는, 게시판에 주의하고 그에 따라 처리할 많은 기회가 있다. 대조적으로, 다른 게시판에 대해서는, 마지막 순간까지 간판을 보이지 않게 하고 있는 언덕 또는 일 군의 나무들이 있을 수 있다. 이러한 상이한 뷰포인트를 고려함으로써, 객체가 보일 수 있는 여러 뷰포인트로부터 시각 주의를 받을 가능성을 더욱 정확하게 분석할 수 있다. 다중-시야 없이 단일 뷰만을 사용하면, 객체는 객체가 주의될 수 있는 수의 시야가 주어지면 시각 주의를 받을 것인지 또는 받지 않을 것인지를 부정확하게 예측할 수 있다.
도 18은 전술된 분석으로부터 생성되는 데이터에서 실행할 수 있는 가능한 평가들의 서브세트를 도시한다. 데이터로부터 도출할 수 있는 다수의 결론이 있다. 먼저, 자주색 간판(PurpleSign) 객체는 스크린(Screen) 객체보다 종종 덜 가시적이다(그래프 상의 흰색 바)(즉, 그것은 환경 내에서 취해지는 이미지들 중 보다 적은 이미지에 있음)라는 점에 유의한다. 그러나, 이러한 2개의 객체에 대한 흑색 바를 찾아보면, 자주색 간판이 가시적일 때(즉, 그것이 이미지에 있을 때), 그것은 항상 주의되지만(p(Attended|Visible)=1.0), 스크린이 가시적일 때에는 결코 주의되지 않는다는 것을 알 수 있다. 이것은, 자주색 간판이 매우 흔하게 보이는 것은 아닌 장소에 위치한다 하더라도, 그것이 뷰에 있을 때, 주의가 그것에 할당될 것을 모델이 예측한다는 것을 암시한다.
그러면, 자주색 간판 객체는 호텔 로비의 상황에서 이전에 바람직한 것으로 논의되었던 타입의 특성을 생성하고 있다. 즉, 간판은 많은 위치로부터 가시적이지 않지만(눈에 띄지 않지만), 사람들은, 그것이 (체크인 카운터에 의해) 가시적인 위치에 있을 때, 거의 항상 그 객체에 주의할 것이다. 이것은, 자주색 간판 객체가 가시적일 확률(백색 바)이 약 15%라는 사실에 의해 예시된다. 그러나, 그것이 가시적일 때 주의가 자주색 간판에 의해 포착될 확률(흑색 바)은 1.0이다.
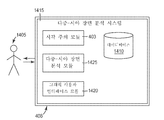
도 19는 다양한 실시 형태에서 도 15와 관련하여 설명된 다중-시야 시각 주의 모델링 프로세스를 수행할 수 있는 다중-시야 장면 분석 시스템(1415)을 포함하는 고-레벨 기능 모듈을 도시하는 블록 다이어그램이다. 그것은, 일 실시 형태에서, (운영 체제와 같은) 다수의 다른 기능 모듈, 및 메모리 또는 프로세서(둘 중 어느 것도 도 19에는 도시되지 않음)와 같은 하드웨어를 포함하는 컴퓨터 시스템(408)에 상주한다. 도 19에 단일 컴퓨터로 도시되어 있지만, 실제로, 기능성의 다양한 부분은 네트워크화된 구성에서 수 개 또는 다수의 컴퓨터 간에 분산될 수 있다. 다중-시야 장면 분석 시스템(1415)은 시각 주의 모듈(403)(상기 논의됨)을 포함한다. 그것은 또한 다중-시야 장면 분석 모듈(1425)을 포함하는데, 다중-시야 장면 분석 모듈은 필요에 따라 시각 주의 모듈(403)이 (도 15의 단계 1340과 관련하여 앞서 논의된) 관심 분석을 실행하고, 분석으로부터의 결과를 수신하게 하며(어떤 정의된 객체가 어떤 이미지에서 시각 주의 모듈에 의해 식별되었는지를 포함함), 그러한 결과 또는 그 결과의 개요를 데이터베이스(1410)에 저장하게 한다. 데이터베이스(1410)는 컴퓨터 플랫 파일, 컴퓨터 메모리, 또는 데이터베이스와 같은 임의의 데이터 저장 장치 또는 시스템이다. 다중-시야 장면 분석 시스템(1415)은 또한 그래픽 사용자 인터페이스 모듈(1420)을 포함하며, 이 그래픽 사용자 인터페이스 모듈은 (도 15의 단계 1330에서 획득된) 다수의 이미지의 입력을 용이하게 하며, 이어서, 이 실시 형태에서는 이미지 내의 관심 객체의 식별 및 태깅(도 15의 단계 1335)을 용이하게 한다.
사용자(1405)는 다중-시야 장면 분석 시스템과 상호 작용하는 데 관심이 있는 임의의 사람 또는 다른 컴퓨터 시스템이다. 일 실시 형태에서, 사용자(1405)는 회사에 의해 소유되거나 제어되는 3D 장면으로의 구성 변경을 분석 및 추천하도록 그 회사에 의해 고용된 컨설턴트이다.
종종, 뷰어는 합당한 기간 동안 동일한 위치에 남아 있을 것이다. 예를 들어, 누군가가 식료품점, 생활용품점 또는 호텔에서 계산하는 대기열에 있을 수 있다. 이 시간 동안, 개개인은 "시각적 채집(visible foraging)" 태스크에 참여할 수 있다. 시각적 채집은 관찰자가 특정한 무언가를 찾는 것이 아니라 관심이 있는 무언가에 대해 환경을 단순히 살펴보는 상황이다. 이러한 시각적 채집, 사람은 그의 눈을 움직임으로써 여러 가지의 정보들에 주의할 것이며, 그의 눈이 그 회전 축의 에지에 다다른 때 그 사람은 그의 머리를 움직일 것이다. 전형적으로, 그는 관심 아이템이 고정성 중심에 있도록 그의 머리 및 눈을 움직일 것이다. 현재의 최고 기술 수준은 이미지에 이러한 타입의 재중심설정하는(re-centering) 동작을 시뮬레이션하지 않는다. 그 대신, 이미지가 분석될 때, 이미지의 중심은 항상 고정되어 유지된다. 이것은, 고정성 지점이 이미지의 에지(또는 시계(visual field))에 있을 때에도 그러하다. 재중심설정 없이, 현재의 최고 기술 수준의 접근법은 단지 이미지의 에지에 고정시킬 수 있을 것이지만, 그 지점을 넘어서는 결코 고정시키지 못할 것이다. 대조적으로, 인간은 그들의 시계의 에지에 주의하고 그들의 머리를 회전시킬 것이어서, 그들의 눈이 시선 중앙으로 재정렬된다. 이것은, 시각 체계가 동일한 방향으로 다른 고정성을 만들게 할 것이다. 단일 이미지를 이용하면, 이미지의 에지에 더 이상의 정보가 없다는 사실로 인해 동일한 방향으로 고정성을 만들 수 없다.
본 명세서에 설명되는 시스템 및 방법은, 일부 실시 형태에서, 시각적 채집 동안에 눈의 재중심설정을 시뮬레이션하도록 장면의 다수 뷰 또는 단일 파노라마식 뷰를 사용할 수 있다. 이것은 하기와 같이 이루어질 수 있다:
1. 단일 뷰포인트로부터의 다수의 이미지의 생성. 이미지는 (수직 또는 다른) 뷰잉 축 둘레에서 회전되는 360도 파노라마식 카메라 또는 다수의 단일 이미지들을 사용함으로써 생성된다. 뷰들이 서로 "중첩(overlap)"하는 다수의 이미지가 취해질 수 있다. 뷰들의 배향은 또한 각각의 뷰에 할당될 것이다.
2. 초기 뷰("시작 뷰")가 시각 주의 모델에 주어진다. 뷰는 누군가가 그들의 가시적 채집을 시작하는 전형적인 뷰잉 배향에 의해 결정될 수 있다(예를 들어, 상점 라인에서, 그것은 출납원을 향해 "전방"을 보고 있을 수 있음). 또한 랜덤하게 선택된 배향으로 시작할 수 있다. 파노라마식 뷰의 경우, "시작" 뷰에 중심을 둔 파노라마 뷰의 "슬라이스(slice)"가 사용될 수 있다. 다수의 뷰/이미지의 경우, 시작 위치에 가장 가깝게 중심을 둔 이미지가 사용될 것이다.
3. "시작 뷰"는 시각 주의 모델로 분석된다. 초기 고정성은 모델에 의해 예측된다. 이 고정성의 배향이 계산될 것이다(이것은 삼각법(trigonometry)을 사용하여 이루어질 수 있음). 파노라마식 뷰가 사용되면, 이 새로운 고정성에 중심을 둔 파노라마식 뷰의 새로운 "슬라이스"가 만들어질 것이다. 다수의 이미지가 사용되면, 이 새로운 고정성에 가장 가깝게 중심을 둔 이미지가 사용될 것이다.
4. 새로운 뷰에 따라, 시스템은 다음 현저성 영역을 분석할 것이다.
a. 그러면, 프로세스는 반복된다(고정성을 결정하고, 이어서 뷰포인트에 중심을 둠).
실시예
전술된 시스템 및 방법이 어떻게 실용적으로 사용될 수 있는지를 나타내는 몇몇 비제한적 실시예가 이하 제공된다.
실시예 1: 외적 변동을 사용한 강건성 계산
배경: 호텔 소유주가 호텔 로비에 2개의 디지털 간판을 설치하기를 원한다. 그녀는 그것들이 고객에 의해 주목되기를 원하며, 그것들을 3개의 가능한 위치 중 임의의 위치에 놓아 2개의 디지털 간판의 3가지 가능한 구성을 형성할 수 있다(즉, 위치(1-2, 1-3 또는 2-3)의 간판). 강건성은 주목될 최상의 간판 위치를 추천하도록 계산된다.
1. 디지털 카메라를 사용하여 호텔 로비 이미지를 포착하고, 주의 모델을 구동할 수 있는 컴퓨터에 이미지를 다운로드한다. 컴퓨터는 (미국 매사추세츠주 나틱크 소재의 더 매스웍스(The MathWorks)로부터 입수가능한) 매트랩(Matlab™)과 함께 설치되는 시각 주의 모델링 소프트웨어(예를 들어, 코흐 및 잇티)를 구비한다.
2. 시뮬레이션된 디지털 간판을 포함하도록 이미지를 수정한다. 3개의 가능한 위치에서 2개의 간판의 모든 조합이 생성되도록 2개의 디지털 간판을 각각 시뮬레이션하는 3개의 수정된 이미지를 생성한다. (미국 캘리포니아주 새너제이 소재의 어도비 컴퍼니(Adobe Co.)로부터 입수가능한) 포토샵(Photoshop™)과 같은 표준 디지털 사진 조작 프로그램을 사용한다. 각각의 시뮬레이션된 디지털 간판은 적절히 스케일링되고, 호텔 로고 그래픽과 같은 시뮬레이션된 콘텐트를 갖는다. 컴퓨터 상의 파일에, 3개의 디지털 간판 위치 각각과 연관되며 픽셀 어드레스에 의해 정의되는 이미지 영역을 저장한다.
3. 주의 모델을 통해 수정된 이미지를 구동시킨다. 출력은 수정된 이미지의 예측된 현저성 영역을 포함할 것이다. 각각의 현저성 영역은 단계 2에서 저장된 디지털 간판 픽셀 어드레스에 비교된다. 현저성 영역이 저장된 픽셀 어드레스 내에 있거나 그와 중첩되면, 예측된 주의는 원하는 위치로 간다. 3개의 수정된 이미지 각각은 상측 10회 고정성에 있을 디지털 간판을 나타내어, 3개의 위치 중 임의의 위치가 양호한 후보라는 것을 확인한다.
4. 일련의 스틸 사진을 사용하거나 비디오를 사용하며, 비디오 스트림으로부터 이미지를 샘플링하여, 동일한 장면의 다수의 이미지를 포착한다. 이미지는 16시간 주기에 걸쳐 매 5분마다 취해지고, 그에 따라 다양한 조명 조건 및 보행자 움직임으로 인해 형성되는 장면 외적 가변성을 포착한다. 목표는 이러한 타입의 가변성(조명 및 보행자 움직임)에 대해 강건한 간판 위치를 갖는 것이다. 이러한 이미지를 컴퓨터로 로딩하고, 그것들을 단계 2에서 설명된 바와 같이 시뮬레이션된 디지털 간판을 이용하여 수정한다.
5. 단계 4로부터의 각각의 수정된 이미지는 주의 모델에 의해 분석되며, 단계 3에서 설명된 바와 같이 저장된 픽셀 어드레스에 비교된다. 간판 위치 1 및 위치 2와 연관된 일련의 수정된 이미지들은 예측된 고정성이 이미지들 중 20%의 이미지에서 양측의 디지털 간판 위치로 갔다는 것을 나타내었다. 유사하게, 위치 1 및 위치 3은 양측 간판 위치로 가는 35%의 고정성을 가졌고, 반면에 위치 2 및 위치 3은 양측 간판 위치로 가는 85%의 고정성을 가졌다. 간판이 위치 2 및 위치 3에 설치되게 하는 것은, 가장 강건한 구성이 되어 호텔에 최상의 솔루션을 제공한다. 이 솔루션을 호텔 소유주에게 추천한다.
실시예
2: 내적 변동을 사용한
강건성
계산
배경: 호텔 소유주가 호텔 로비에 2개의 디지털 간판을 설치하기를 원한다. 그녀는 그것들이 고객에 의해 주목되기를 원하며, 그것들을 3개의 가능한 위치 중 하나의 위치에 놓아 2개의 디지털 간판의 3가지 가능한 구성을 형성할 수 있다(즉, 위치(1-2, 1-3 또는 2-3)의 간판). 강건성은 주목될 최상의 간판 위치를 추천하도록 계산된다.
1. 디지털 카메라를 사용하여 호텔 로비 이미지를 포착하고, 주의 모델을 구동할 수 있는 범용 컴퓨터에 이미지를 다운로드한다. 컴퓨터는 (미국 매사추세츠주 나틱크 소재의 더 매스웍스로부터 입수가능한) 매트랩™과 함께 설치되는 시각 주의 모델링 소프트웨어(예를 들어, 코흐 및 잇티)를 구비한다.
2. 시뮬레이션된 디지털 간판을 포함하도록 이미지를 수정한다. 3개의 가능한 위치에서 2개의 간판의 모든 조합이 생성되도록 2개의 디지털 간판을 각각 시뮬레이션하는 3개의 수정된 이미지를 생성한다. (미국 캘리포니아주 새너제이 소재의 어도비 컴퍼니로부터 입수가능한) 포토샵™과 같은 표준 디지털 사진 조작 프로그램을 사용한다. 각각의 시뮬레이션된 디지털 간판은 적절히 스케일링되고, 호텔 로고 그래픽과 같은 시뮬레이션된 콘텐트를 갖는다. 컴퓨터 상의 파일에, 3개의 디지털 간판 위치 각각과 연관되며 픽셀 어드레스에 의해 정의되는 이미지 영역을 저장한다.
3. 주의 모델을 통해 수정된 이미지를 구동시킨다. 출력은 수정된 이미지의 예측된 현저성 영역을 포함할 것이다. 각각의 현저성 영역은 단계 2에서 저장된 디지털 간판 픽셀 어드레스에 비교된다. 현저성 영역이 저장된 픽셀 어드레스 내에 있거나 그와 중첩되면, 예측된 주의는 원하는 위치로 간다. 3개의 수정된 이미지 각각은 상측 10회 고정성에 있을 디지털 간판을 나타내어, 3개의 위치 중 임의의 위치가 양호한 후보라는 것을 확인한다.
4. 단계 1에서 명시된 바와 같은 코흐 및 잇티의 기본 시각 주의 모델로 시작한다. 수정된 이미지의 분석에 이용하기 위한 모델 변동의 수(예를 들어, 100개 모델 변동)를 명시한다. 각각의 시각 주의 모델은 3개의 상이한 특징 지도(컬러, 배향 및 휘도)를 가지며; 현저성 지도는 이러한 지도 각각의 가중된 조합으로서 계산된다. 기본 시각 주의 모델은 각각의 지도에 대한 가중 파라미터를 (1, 1, 1)로 동일하게 설정한다. 100개 모델 변동을 생성하기 위해, 각각의 모델에 대한 가중 벡터를 랜덤하게 설정한다. 이것은, 각각의 가중치를 랜덤하게 설정하고 가중치 합을 3(3*(RandWeights/sum(RandWeights))으로 표준화하는 알고리즘에 의해 완성된다.
5. 단계 2 및 단계 3에서 설명된 바와 같이, 각각의 이미지를 (100개의 랜덤 가중치 값에 의해 정의되는) 100개 시각 주의 모델 변동에 의해 분석하고, 그 결과를 저장된 픽셀 어드레스에 비교한다. 디지털 간판 위치 1 및 위치 2와 연관된 일련의 수정된 이미지는 예측된 고정성이 이미지들 중 20%의 이미지에서 양측 디지털 간판 위치로 간다는 것을 나타낸다. 유사하게, 위치 1 및 위치 3은 양측 간판 위치로 가는 35%의 고정성을 갖고, 반면에 위치 2 및 위치 3은 양측 간판 위치로 가는 85%의 고정성을 갖는다. 간판이 위치 2 및 위치 3에 설치되게 하는 것은 호텔에 대해 가장 강건한 구성이 될 것이다. 이 추천을 호텔 소유주에게 제공한다.
실시예 3: 장면 최적화
배경: 호텔 소유주는 2개의 디지털 간판 상에 디스플레이되는 콘텐트 및 호텔 로비를 시각적으로 최적화하기를 원한다. 그녀의 특정 시각적 목표는 고객이 4개의 타깃 객체, 즉 제1 및 제2 디지털 간판, 호텔 레스토랑을 광고하는 정적 그래픽 간판, 및 체크인 카운터 뒤의 스태프에 주목하는 것이다.
1. 최적화 옵션에 대한 스코어를 생성하기 위해, 타깃 객체에 주의를 끄는 변경에 대한 보상이 주어지며, 현실 세계 비용은 허용가능한 변경과 연관된다. 노동과 관련되는 달러 단위 추정 비용 및 공급 비용은 하기 사항이 고려되는 잠재적 변경에 할당된다:
체크인 카운터 뒤에 현재 위치하는 그림을 옮기는 비용: $100
레스토랑 간판 뒤의 조명을 변경하는 비용: $2500, 및
2개의 디지털 간판 상에 디스플레이되는 콘텐트를 재디자인하는 비용: 각각 $250.
시각적 목표를 달성하기 위해 할당되는 보상 값은 하기와 같다:
2개의 디지털 간판에 주의를 끄는 보상 값: 각각 $500
레스토랑 간판에 주의를 끄는 보상 값: $250, 및
체크인 카운터 뒤의 스태프에 주의를 끄는 보상 값: $150.
2. 디지털 카메라를 사용하여 기존 로비 이미지를 포착하고, 주의 모델을 구동할 수 있는 컴퓨터에 이미지를 다운로드한다. 컴퓨터는 매트랩™(미국 매사추세츠주 나틱크 소재의 더 매스웍스)과 함께 시각 주의 모델링 소프트웨어, 예를 들어 코흐 및 잇티를 구비한다.
3. 고려되는 변경을 반영하도록 이미지를 수정하여, 가능한 변경들의 모든 가능한 조합과 연관되는 복수의 이미지를 생성한다. 포토샵(미국 캘리포니아주 새너제이 소재의 어도비)과 같은 표준 디지털 사진 조작 프로그램을 사용한다. 고객의 시각적 목표와 연관된 타깃 객체들의 픽셀 어드레스가 또한 메모리에 명시 및 저장된다.
4. 주의 모델을 사용하여 단계 3으로부터의 각각의 이미지를 분석하고, 모델에 의해 예측되는 현저성 객체를 타깃 객체에 대한 저장된 픽셀 어드레스에 비교한다. 예측된 시각 주의와 타깃 객체에 대한 픽셀 어드레스의 중첩에 의해 나타내어지는 스코어는 수정된 이미지에서 시각적 목표를 달성하기 위한 보상 값으로부터 변경을 위한 비용을 감산함으로써 각각의 시뮬레이션된 구성에 대해 계산된다. 예를 들어, 주의가 레스토랑 간판에 할당될 때, 그림을 옮기는 변경을 사용하면, 스코어는 $250-$100 = $150이다. 모든 시뮬레이션된 이미지를 분석한 후, 발견된 가장 비용 효율적인 솔루션은 $100의 비용으로 그림을 옮기고 $250의 비용으로 여러 편의 콘텐트 중 하나의 콘텐트의 컬러를 수정하는 것이다(총 비용 $350). 이러한 변경은 모든 시각적 목표가 달성되게 하여, $1400의 보상 스코어 및 $1050의 총 스코어를 생성한다.
실시예
4: 다중-시야 장면 분석
배경: 실시예 3으로부터 계속하여, 추천된 변경이 이루어졌다. 호텔 소유주는 호텔 로비에서 다중 시야로부터 볼 때 각각의 타깃 객체의 시각적 현저성을 이해하고 싶을 것이다.
1. 로비 전체에 걸쳐 분포된 4개의 관심 위치가 식별되고, 4개의 디지털 사진은 카메라를 90도 증분으로 회전시킴으로써 각각의 위치로부터 취해져, 각각이 하나의 시야를 표현하는 총 16개의 이미지가 된다. 이미지는 디지털 카메라를 사용하여 취해진 사진이다. 이미지는 주의 모델을 구동할 수 있는 컴퓨터로 다운로드된다. 컴퓨터는 매트랩™(미국 매사추세츠주 나틱크 소재의 더 매스웍스)과 함께 시각 주의 모델링 소프트웨어, 예를 들어 코흐 및 잇티를 구비한다. 각각의 시야에 대해, 타깃 객체에 대한 픽셀 어드레스가 식별되고 컴퓨터의 메모리에 저장되며, 타깃 객체는 식별자로 태깅된다.
2. 단계 1로부터의 16개의 이미지 각각이 주의 모델을 사용하여 분석된다. 각각의 이미지에 대해, 그것은 시각 주의 모델에 의해 어떤 타깃 객체가 가시적인지 및 어떤 타깃 객체가 주의를 끌 것으로 예측되는지에 의해 결정된다.
3. 각각의 타깃 객체가 모든 이미지에 걸쳐서 가시적일 확률이 계산되고, 그것이 주의되는 확률이 또한 계산된다. 이 데이터는 호텔 소유주에게로의 보고서에 제시되어, 다양한 시야로부터 로비에서의 시각적 특징에 대한 보다 양호한 이해를 제공한다.
본 명세서에 설명되는 방법 및 시스템에 대한 예시적 응용은 논의된 특정 응용의 범위를 넘어서 광범위한 응용을 갖는다는 것에 유의한다. 예를 들어, 이들 응용은 소매(retail) 환경을 포함한다.